In this tutorial, you will learn everything you need to know about logging in
NGINX and how it can help you troubleshoot and quickly resolve any problem you
may encounter on your web server. We will discuss where the logs are stored and
how to access them, how to customize their format, and how to centralize them in
one place with Syslog or a log management service.
Here’s an outline of what you will learn by following through with this tutorial:
- Where NGINX logs are stored and how to access them.
- How to customize the NGINX log format and storage location to fit your needs.
- How to utilize a structured format (such as JSON) for your NGINX logs.
- How to centralize NGINX logs through Syslog or a managed cloud-based service.
Prerequisites
To follow through with this tutorial, you need the following:
- A Linux server that includes a non-root user with
sudoprivileges. We tested
the commands shown in this guide on an Ubuntu 20.04 server. - The
NGINX web server installed
and enabled on your server.
🔭 Want to centralize and monitor your NGINX logs?
Head over to Logtail and start ingesting your logs in 5 minutes.
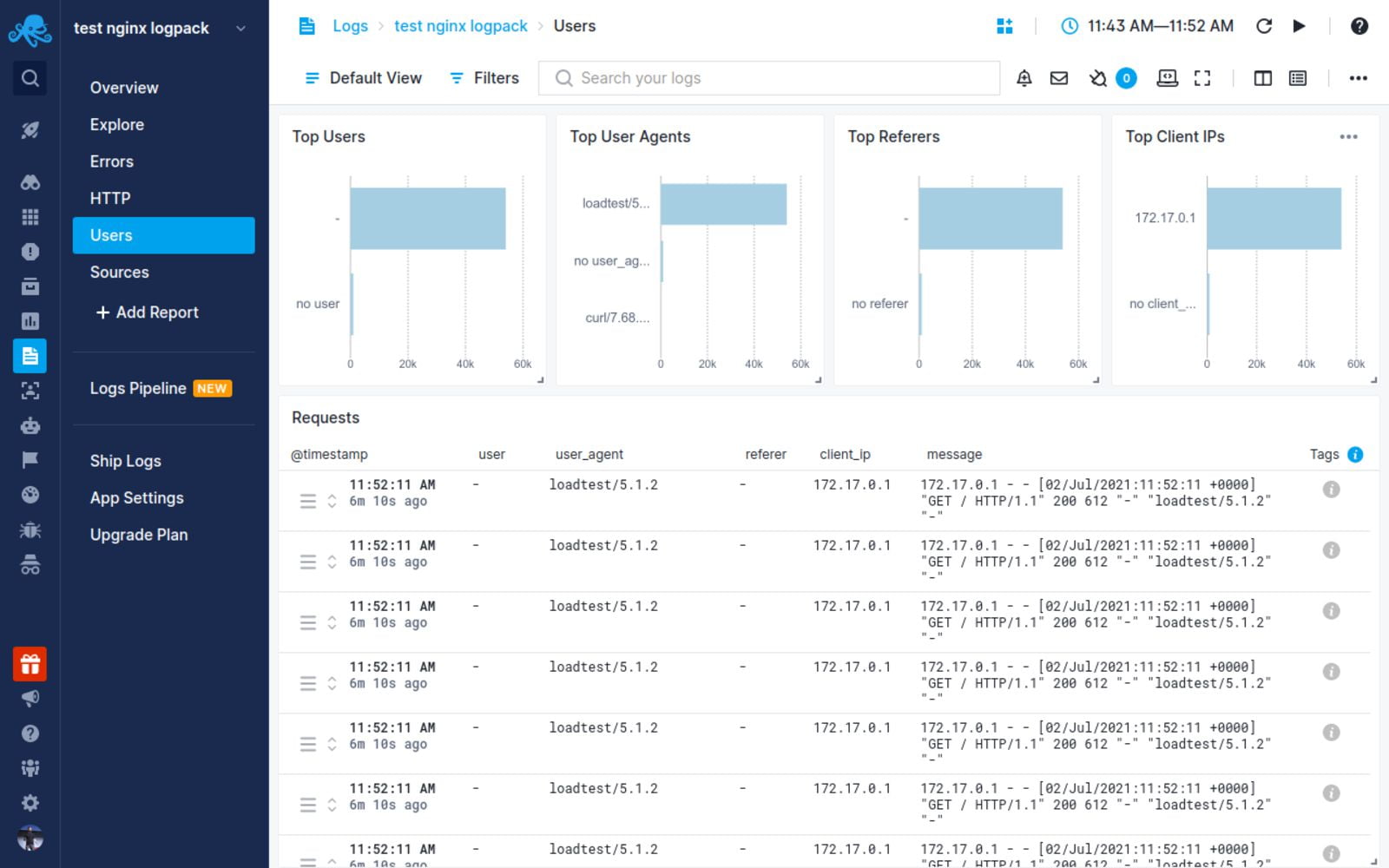
Step 1 — Locating the NGINX log files
NGINX writes logs of all its events in two different log files:
- Access log: this file contains information about incoming requests and
user visits. - Error log: this file contains information about errors encountered while
processing requests, or other diagnostic messages about the web server.
The location of both log files is dependent on the host operating system of the
NGINX web server and the mode of installation. On most Linux distributions, both
files will be found in the /var/log/nginx/ directory as access.log and
error.log, respectively.
A typical access log entry might look like the one shown below. It describes an
HTTP GET request to the server for a favicon.ico file.
Output
217.138.222.101 - - [11/Feb/2022:13:22:11 +0000] "GET /favicon.ico HTTP/1.1" 404 3650 "http://135.181.110.245/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36" "-"
Similarly, an error log entry might look like the one below, which was generated
due to the inability of the server to locate the favicon.ico file that was
requested above.
Output
2022/02/11 13:12:24 [error] 37839#37839: *7 open() "/usr/share/nginx/html/favicon.ico" failed (2: No such file or directory), client: 113.31.102.176, server: _, request: "GET /favicon.ico HTTP/1.1", host: "192.168.110.245:80"
In the next section, you’ll see how to view both NGINX log files from the
command line.
Step 2 — Viewing the NGINX log files
Examining the NGINX logs can be done in a variety of ways. One of the most
common methods involves using the tail command to view logs entries in
real-time:
sudo tail -f /var/log/nginx/access.log
You will observe the following output:
Output
107.189.10.196 - - [14/Feb/2022:03:48:55 +0000] "POST /HNAP1/ HTTP/1.1" 404 134 "-" "Mozila/5.0"
35.162.122.225 - - [14/Feb/2022:04:11:57 +0000] "GET /.env HTTP/1.1" 404 162 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:58.0) Gecko/20100101 Firefox/58.0"
45.61.172.7 - - [14/Feb/2022:04:16:54 +0000] "GET /.env HTTP/1.1" 404 197 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
45.61.172.7 - - [14/Feb/2022:04:16:55 +0000] "POST / HTTP/1.1" 405 568 "-" "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/81.0.4044.129 Safari/537.36"
45.137.21.134 - - [14/Feb/2022:04:18:57 +0000] "GET /dispatch.asp HTTP/1.1" 404 134 "-" "Mozilla/5.0 (iPad; CPU OS 7_1_2 like Mac OS X; en-US) AppleWebKit/531.5.2 (KHTML, like Gecko) Version/4.0.5 Mobile/8B116 Safari/6531.5.2"
23.95.100.141 - - [14/Feb/2022:04:42:23 +0000] "HEAD / HTTP/1.0" 200 0 "-" "-"
217.138.222.101 - - [14/Feb/2022:07:38:40 +0000] "GET /icons/ubuntu-logo.png HTTP/1.1" 404 197 "http://168.119.119.25/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36"
217.138.222.101 - - [14/Feb/2022:07:38:42 +0000] "GET /favicon.ico HTTP/1.1" 404 197 "http://168.119.119.25/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36"
217.138.222.101 - - [14/Feb/2022:07:44:02 +0000] "GET / HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36"
217.138.222.101 - - [14/Feb/2022:07:44:02 +0000] "GET /icons/ubuntu-logo.png HTTP/1.1" 404 197 "http://168.119.119.25/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36"
The tail command prints the last 10 lines from the selected file. The -f
option causes it to continue displaying subsequent lines that are added to the
file in real-time.
To examine the entire contents of an NGINX log file, you can use the cat
command or open it in your text editor:
sudo cat /var/log/nginx/error.log
If you want to filter the lines that contain a specific term, you can use the
grep command as shown below:
sudo grep "GET /favicon.ico" /var/log/nginx/access.log
The command above will print all the lines that contain GET /favicon.ico so we
can see how many requests were made for that resource.
Step 3 — Configuring NGINX access logs
The NGINX access log stores data about incoming client requests to the server
which is beneficial when deciphering what users are doing in the application,
and what resources are being requested. In this section, you will learn how to
configure what data is stored in the access log.
One thing to keep in mind while following through with the instructions below is
that you’ll need to restart the nginx service after modifying the config file
so that the changes can take effect.
sudo systemctl restart nginx
Enabling the access log
The NGINX access Log should be enabled by default. However, if this is not the
case, you can enable it manually in the Nginx configuration file
(/etc/nginx/nginx.conf) using the access_log directive within the http
block.
Output
http {
access_log /var/log/nginx/access.log;
}
This directive is also applicable in the server and location configuration
blocks for a specific website:
Output
server {
access_log /var/log/nginx/app1.access.log;
location /app2 {
access_log /var/log/nginx/app2.access.log;
}
}
Disabling the access log
In cases where you’d like to disable the NGINX access log, you can use the
special off value:
You can also disable the access log on a virtual server or specific URIs by
editing its server or location block configuration in the
/etc/nginx/sites-available/ directory:
Output
server {
listen 80;
access_log off;
location ~* .(woff|jpg|jpeg|png|gif|ico|css|js)$ {
access_log off;
}
}
Logging to multiple access log files
If you’d like to duplicate the access log entries in separate files, you can do
so by repeating the access_log directive in the main config file or in a
server block as shown below:
Output
access_log /var/log/nginx/access.log;
access_log /var/log/nginx/combined.log;
Don’t forget to restart the nginx service afterward:
sudo systemctl restart nginx
Explanation of the default access log format
The access log entries produced using the default configuration will look like
this:
Output
127.0.0.1 alice Alice [07/May/2021:10:44:53 +0200] "GET / HTTP/1.1" 200 396 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4531.93 Safari/537.36"
Here’s a breakdown of the log message above:
127.0.0.1: the IP address of the client that made the request.alice: remote log name (name used to log in a user).Alice: remote username (username of logged-in user).[07/May/2021:10:44:53 +0200]: date and time of the request."GET / HTTP/1.1": request method, path and protocol.200: the HTTP response code.396: the size of the response in bytes."-": the IP address of the referrer (-is used when the it is not
available)."Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4531.93 Safari/537.36"—
detailed user agent information.
Step 4 — Creating a custom log format
Customizing the format of the entries in the access log can be done using the
log_format directive, and it can be placed in the http, server or
location blocks as needed. Here’s an example of what it could look like:
Output
log_format custom '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer" "$http_user_agent"';
This yields a log entry in the following format:
Output
217.138.222.109 - - [14/Feb/2022:10:38:35 +0000] "GET /favicon.ico HTTP/1.1" 404 197 "http://192.168.100.1/" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36"
The syntax for configuring an access log format is shown below. First, you need
to specify a nickname for the format that will be used as its identifier, and
then the log format string that represents the details and formatting for each
log message.
Output
log_format <nickname> '<formatting_variables>';
Here’s an explanation of each variable used in the custom log format shown
above:
$remote_addr: the IP address of the client$remote_user: information about the user making the request$time_local: the server’s date and time.$request: actual request details like path, method, and protocol.$status: the response code.$body_bytes_sent: the size of the response in bytes.$http_referer: the IP address of the HTTP referrer.$http_user_agent: detailed user agent information.
You may also use the following variables in your custom log format
(see here for the complete list):
$upstream_connect_time: the time spent establishing a connection with an
upstream server.$upstream_header_time: the time between establishing a connection and
receiving the first byte of the response header from the upstream server.$upstream_response_time: the time between establishing a connection and
receiving the last byte of the response body from the upstream server.$request_time: the total time spent processing a request.$gzip_ratio: ration of gzip compression (if gzip is enabled).
After you create a custom log format, you can apply it to a log file by
providing a second parameter to the access_log directive:
Output
access_log /var/log/nginx/access.log custom;
You can use this feature to log different information in to separate log files.
Create the log formats first:
Output
log_format custom '$remote_addr - $remote_user [$time_local] ' '"$request" $status $body_bytes_sent ' '"$http_referer"';
log_format agent "$http_user_agent";
Then, apply them as shown below:
Output
access_log /var/log/nginx/access.log custom;
access_log /var/log/nginx/agent_access.log agent;
This configuration ensures that user agent information for all incoming requests
are logged into a separate access log file.
Step 5 — Formatting your access logs as JSON
A common way to customize NGINX access logs is to format them as JSON. This is
quite straightforward to achieve by combining the log_format directive with
the escape=json parameter introduced in Nginx 1.11.8 to escape characters that
are not valid in JSON:
Output
log_format custom_json escape=json
'{'
'"time_local":"$time_local",'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"status": "$status",'
'"body_bytes_sent":"$body_bytes_sent",'
'"request_time":"$request_time",'
'"http_referrer":"$http_referer",'
'"http_user_agent":"$http_user_agent"'
'}';
After applying the custom_json format to a log file and restarting the nginx
service, you will observe log entries in the following format:
{
"time_local": "14/Feb/2022:11:25:44 +0000",
"remote_addr": "217.138.222.109",
"remote_user": "",
"request": "GET /icons/ubuntu-logo.png HTTP/1.1",
"status": "404",
"body_bytes_sent": "197",
"request_time": "0.000",
"http_referrer": "http://192.168.100.1/",
"http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.87 Safari/537.36"
}
Step 6 — Configuring NGINX error logs
Whenever NGINX encounters an error, it stores the event data in the error log so
that it can be referred to later by a system administrator. This section will
describe how to enable and customize the error logs as you see fit.
Enabling the error log
The NGINX error log should be enabled by default. However, if this is not the
case, you can enable it manually in the relevant NGINX configuration file
(either at the http, server, or location levels) using the error_log
directive.
Output
error_log /var/log/nginx/error.log;
The error_log directive can take two parameters. The first one is the location
of the log file (as shown above), while the second one is optional and sets the
severity level of the log. Events with a lower severity level than set one will
not be logged.
Output
error_log /var/log/nginx/error.log info;
These are the possible levels of severity (from lowest to highest) and their
meaning:
debug: messages used for debugging.info: informational messages.notice: a notable event occurred.warn: something unexpected happened.error: something failed.crit: critical conditions.alert: errors that require immediate action.emerg: the system is unusable.
Disabling the error log
The NGINX error log can be disabled by setting the error_log directive to
off or by redirecting it to /dev/null:
Output
error_log off;
error_log /dev/null;
Logging errors into multiple files
As is the case with access logs, you can log errors into multiple files, and you
can use different severity levels too:
Output
error_log /var/log/nginx/error.log info;
error_log /var/log/nginx/emerg_error.log emerg;
This configuration will log every event except those at the debug level event
to the error.log file, while emergency events are placed in a separate
emerg_error.log file.
Step 7 — Sending NGINX logs to Syslog
Apart from logging to a file, it’s also possible to set up NGINX to transport
its logs to the syslog service especially if you’re already using it for other
system logs. Logging to syslog is done by specifying the syslog: prefix to
either the access_log or error_log directive:
Output
error_log syslog:server=unix:/var/log/nginx.sock debug;
access_log syslog:server=[127.0.0.1]:1234,facility=local7,tag=nginx,severity=info;
Log messages are sent to a server which can be specified in terms of a domain
name, IPv4 or IPv6 address or a UNIX-domain socket path.
In the example above, error log messages are sent to a UNIX domain socket at the
debug logging level, while the access log is written to a syslog server with
an IPv4 address and port 1234. The facility= parameter specifies the type of
program that is logging the message, the tag= parameter applies a custom tag
to syslog messages, and the severity= parameter sets the severity level of
the syslog entry for access log messages.
For more information on using Syslog to manage your logs, you can check out our
tutorial on viewing and configuring system logs on
Linux.
Step 8 — Centralizing your NGINX logs
In this section, we’ll describe how you can centralize your NGINX logs in a log
management service through Vector, a
high-performance tool for building observability pipelines. This is a crucial
step when administrating multiple servers so that you can monitor all your logs
in one place (you can also centralize your logs with an Rsyslog
server).
The following instructions assume that you’ve signed up for a free
Logtail account and retrieved your source
token. Go ahead and follow the relevant
installation instructions for Vector
for your operating system. For example, on Ubuntu, you may run the following
commands to install the Vector CLI:
curl -1sLf 'https://repositories.timber.io/public/vector/cfg/setup/bash.deb.sh' | sudo -E bash
$ sudo apt install vector
After Vector is installed, confirm that it is up and running through
systemctl:
You should observe that it is active and running:
Output
● vector.service - Vector
Loaded: loaded (/lib/systemd/system/vector.service; enabled; vendor preset: enabled)
Active: active (running) since Tue 2022-02-08 10:52:59 UTC; 48s ago
Docs: https://vector.dev
Process: 18586 ExecStartPre=/usr/bin/vector validate (code=exited, status=0/SUCCESS)
Main PID: 18599 (vector)
Tasks: 3 (limit: 2275)
Memory: 6.8M
CGroup: /system.slice/vector.service
└─18599 /usr/bin/vector
Otherwise, go ahead and start it with the command below.
sudo systemctl start vector
Afterward, change into a root shell and append your Logtail vector configuration
for NGINX into the /etc/vector/vector.toml file using the command below. Don’t
forget to replace the <your_logtail_source_token> placeholder below with your
source token.
sudo -s
$ wget -O ->> /etc/vector/vector.toml
https://logtail.com/vector-toml/nginx/<your_logtail_source_token>
Then restart the vector service:
sudo systemctl restart vector
You will observe that your NGINX logs will start coming through in Logtail:
Conclusion
In this tutorial, you learned about the different types of logs that the NGINX
web server keeps, where you can find them, how to understand their formatting.
We also discussed how to create your own custom log formats (including a
structured JSON format), and how to log into multiple files at once. Finally, we
demonstrated the process of sending your logs to Syslog or a log management
service so that you can monitor them all in one place.
Thanks for reading, and happy logging!
Centralize all your logs into one place.
Analyze, correlate and filter logs with SQL.
Create actionable
dashboards.
Share and comment with built-in collaboration.
Got an article suggestion?
Let us know
![]()
![]()
![]()
Next article
How to Get Started with Logging in Node.js
Learn how to start logging with Node.js and go from basics to best practices in no time.
→
![]()
This work is licensed under a Creative Commons Attribution-NonCommercial-ShareAlike 4.0 International License.
This article was originally posted on SigNoz Blog and is written by Selvaganesh.
NGINX is a prominent web server, reverse proxy server, and mail proxy utilized by many websites and applications to serve content to their users. One important aspect of managing a web server is logging, which refers to the process of recording information about the server’s activity and performance.
In NGINX, logging is done using the error_log and access_log directives.
error_log directive specifies the file where NGINX should log errors.
access_log directive specifies the file where NGINX should log information about incoming requests and responses.
What are Nginx Error Logs?
The error_log directive is typically used to log information about errors and other important events that occur on the server. This can include messages about failed requests, issues with the server configuration, and other issues that may require attention.
An example of an error log is shown in the picture below:

What are Nginx Access Logs?
The access_log directive, on the other hand, is used to log information about incoming requests and responses. This can include details such as the IP address of the client making the request, the URL of the requested resource, the response status code, and the size of the response.
An example of access logs is shown in the picture below:

NGINX logs can be useful for various purposes, including tracking the server’s performance, identifying potential issues or errors, and analyzing the usage patterns of the server. However, managing logs can also be challenging, as they can quickly grow in size and become difficult to manage.
In this tutorial, we will illustrate the following:
- How to configure Nginx access logs
- How to configure Nginx error logs
- How to send Nginx logs to Syslog
- Collecting and analyzing Nginx logs with SigNoz
Let’s get started.
Prerequisites
- Docker
- Nginx
Installing Nginx
Installing NGINX on Linux
sudo apt update
sudo apt install nginx
Enter fullscreen mode
Exit fullscreen mode
To start NGINX
service nginx start
Enter fullscreen mode
Exit fullscreen mode
Installing NGINX on Mac
You can install NGINX on Mac using Homebrew :
brew install nginx
Enter fullscreen mode
Exit fullscreen mode
To start NGINX:
brew services start nginx
Enter fullscreen mode
Exit fullscreen mode
You can then access your NGINX server on localhost. Go to http://localhost, and you should see a screen like the one below.

Configuring NGINX to generate access logs
Let’s go ahead and make the necessary changes to the nginx.conf file in order to change the location and structure of the logs.
By default, NGINX logs all incoming requests to the access.log file in the /var/log/nginx directory. The format of the log entries in this file is defined by the log_format directive in the NGINX configuration file.
Let’s define the custom Nginx log pattern to the nginx.conf file in the directory /etc/nginx/nginx.conf, as shown below.
log_format logger-json escape=json
'{'
'"source": "nginx",'
'"message":"nginx log captured",'
'"time": $time_iso8601,'
'"resp_body_size": $body_bytes_sent,'
'"host": "$http_host",'
'"address": "$remote_addr",'
'"request_length": $request_length,'
'"method": "$request_method",'
'"uri": "$request_uri",'
'"status": $status,'
'"user_agent": "$http_user_agent",'
'"resp_time": $request_time,'
'"upstream_addr": "$upstream_addr"'
'}';
Enter fullscreen mode
Exit fullscreen mode
When configuring the server’s access logs, we provide the preferred log_format (logger-json) in a server directive.
Make a log format with the name and pattern shown below.
http {
sendfile on;
tcp_nopush on;
tcp_nodelay on;
keepalive_timeout 65;
types_hash_max_size 2048;
log_format logger-json escape=json '{"source": "nginx","message":"nginx log captured","time": $time_iso8601, "resp_body_size": $body_bytes_sent, "host": "$http_host", "address": "$remote_addr", "request_length": $request_length, "method": "$request_method", "uri": "$request_uri", "status": $status, "user_agent": "$http_user_agent", "resp_time": $request_time, "upstream_addr": "$upstream_addr"}';
include /etc/nginx/mime.types;
default_type application/octet-stream;
##
# Logging Settings
##
access_log /home/user/Work/logs/access.log logger-json;
}
Enter fullscreen mode
Exit fullscreen mode
A list of available variables can be found here.
Restart the Nginx for the config to take effect:
sudo service nginx restart
Enter fullscreen mode
Exit fullscreen mode
Note: The nginx config path for Mac OS will be under
/usr/local/etc/nginx. So please ensure to update the config properly.
Go to url http://localhost and now look at the access.log file.
Every line in the access.log file, which is in /home/user/Work/logs/access.log, has one log record. One example of a log record is shown below.
{
"source": "nginx",
"message": "nginx log captured",
"time": 2022-12-11T03:52:58-08:00,
"resp_body_size": 396,
"host": "192.168.1.2",
"address": "192.168.1.8",
"request_length": 198,
"method": "GET",
"uri": "/",
"status": 200,
"user_agent": "PostmanRuntime/7.29.2",
"resp_time": 0.000,
"upstream_addr": ""
}
Enter fullscreen mode
Exit fullscreen mode
You can view the access.log file through the terminal using the cat command as shown below.

The next step is to send these logs to the SigNoz platform.
Configuring NGINX to generate error logs
To enable the error log, choose the log level and log file location. Using the error log directive in the nginx.conf configuration file, you may select the log level as shown below:
error_log /home/user/Work/logs/nginx_error.log emerg;
error_log /home/user/Work/logs/nginx_info.log info;
Enter fullscreen mode
Exit fullscreen mode
There are several levels of error logging that you can use to specify the types of errors that should be logged. These log levels are:
-
debug: Debug-level messages are very detailed and are typically used for debugging purposes. -
info: Information-level messages are used to log important events, such as the start and stop of the Nginx server. -
notice: Notice-level messages are used to log events that are not necessarily error conditions, but are worth noting. -
warn: Warning-level messages are used to log potential error conditions that may require attention. -
error: Error-level messages are used to log actual error conditions that have occurred. -
crit: Critical-level messages are used to log very severe error conditions that may require immediate attention. -
alert: Alert-level messages are used to log conditions that require immediate action. -
emerg: Emergency-level messages are used to log conditions that are so severe that the Nginx server may be unable to continue running.
You need to reload the nginx configuration for these changes to take effect. You can do this by running the command service nginx restart

Sending NGINX logs to Syslog
Syslog is a standard for logging system events. It is used to record and store the log messages produced by various system components, including the kernel, system libraries, and applications. Syslog provides a centralised method for managing and storing log messages, making it easier to monitor and resolve system issues.
To collect syslog from Nginx, you will need to configure Nginx to send its log messages to syslog.
Add the following line to the configuration file, replacing «syslog_server_hostname» with the hostname or IP address of your syslog server:
error_log syslog:server=syslog_server_hostname:54527,facility=local7,tag=nginx,severity=error;
access_log syslog:server=syslog_server_hostname:54527,facility=local7,tag=nginx,severity=debug;
Enter fullscreen mode
Exit fullscreen mode
Save the configuration file and restart Nginx.
Now, Nginx will send its log messages to the syslog server, which can be accessed and analyzed as needed.
There are several options that you can use to customize the way that Nginx sends syslog messages. Here are a few examples:
-
«facility»: This option specifies the facility to which the log message should be sent. The facility is used to categorize log messages and can be used to filter log data on the syslog server. Common facilities include «local0» through «local7», «user», «daemon», and «system».
-
«tag»: This option specifies a tag to be added to the log message. The tag can be used to identify the source of the log message, and can be used to filter log data on the syslog server.
-
«severity»: This option specifies the severity level of the log message. Common severity levels include «emerg», «alert», «crit», «error», «warning», «notice», «info», and «debug».
💡 Note: The above configuration will send only error messages to syslog. If you want to send other log levels (e.g. info, warning, etc.), you can adjust the «severity» parameter in the configuration line.
To configure syslog on the signoz platform, refer this documentation.
NGINX Logging and Analysis with SigNoz
SigNoz is a full-stack open source APM that can be used for analyzing NGINX logs. SigNoz provides all three telemetry signals — logs, metrics, and traces under a single pane of glass. You can easily correlate these signals to get more contextual information while debugging your application.
SigNoz uses a columnar database ClickHouse to store logs, which is very efficient at ingesting and storing logs data. Columnar databases like ClickHouse are very effective in storing log data and making it available for analysis.
Using SigNoz for NGINX logs can make troubleshooting easier. SigNoz comes with an advanced log query builder, live tail logs, and the ability to filter log data across multiple fields.
Let us see how to collect and analyze Nginx logs with SigNoz.
Installing SigNoz
SigNoz may be installed in three simple steps on macOS or Linux PCs using a simple install script.
Docker Engine is installed automatically on Linux by the installation script. However, before running the setup script on macOS, you must manually install Docker Engine.
git clone -b main https://github.com/SigNoz/signoz.git
cd signoz/deploy/
./install.sh
Enter fullscreen mode
Exit fullscreen mode
You can visit the documentation for instructions on how to install SigNoz using Docker Swarm and Helm Charts.

Steps for collecting Nginx logs into SigNoz
Modify the docker-compose.yaml file present inside deploy/docker/clickhouse-setup to expose to mount the log file to otel-collector. The file is located here. Mount the path where the Nginx access logs are available ~/Work/logs/access.log:/tmp/access.log to docker volume.
otel-collector:
image: signoz/signoz-otel-collector:0.66.0
command: ["--config=/etc/otel-collector-config.yaml"]
user: root # required for reading docker container logs
volumes:
- ./otel-collector-config.yaml:/etc/otel-collector-config.yaml
- /var/lib/docker/containers:/var/lib/docker/containers:ro
//highlight-next-line
- ~/Work/logs/access.log:/tmp/access.log
Enter fullscreen mode
Exit fullscreen mode
Here we are mounting the log file of our application to the tmp directory of SigNoz otel-collector. You will have to replace <path>with the path where your log file is present.
Add the filelog reciever to otel-collector-config.yaml which is present inside deploy/docker/clickhouse-setup and include the path /tmp/access.log:
receivers:
filelog:
//highlight-next-line
include: [ "/tmp/access.log" ]
start_at: beginning
operators:
- type: json_parser
timestamp:
parse_from: attributes.time
layout: '%Y-%m-%dT%H:%M:%S%z'
- type: move
id: parse_body
from: attributes.message
to: body
- type: remove
id: time
field: attributes.time
Enter fullscreen mode
Exit fullscreen mode
Next we will modify our pipeline inside otel-collector-config.yaml to include the receiver we have created above.
service:
....
logs:
//highlight-next-line
receivers: [otlp, filelog]
processors: [batch]
exporters: [clickhouselogsexporter]
Enter fullscreen mode
Exit fullscreen mode
Once the changes are made, we need to restart the OTel Collector container to apply new changes. Use the command docker-compose restart.
Check if all the containers are running properly by using the command docker ps:

We can now go to the URL http://localhost and generate some Nginx logs into the access.log
Go to the SigNoz URL, click on the Logs tab, and look for the word «nginx”. http://localhost:3301/

Click on the individual log to get a detailed view:

You can also view the logs in JSON format.

Conclusion
NGINX logs provides useful information to debug Nginx web servers. By using the error_log and access_log directives, you can track the performance and usage of your server and identify potential issues or errors.
The error_log directive can give you information about all errors, and you can use these logs to identify exactly what went wrong. The access_log directive gives you information about HTTP requests received by the Nginx server, and other client information like IP address, response status code, etc.
While debugging a single Nginx server by directly accessing Nginx logs can be done, it’s often not the case in production. Managing multiple Nginx servers and troubleshooting them effectively requires a centralized log management solution. In case of server downtime, you need to troubleshoot issues quickly, and effective dashboards around Nginx monitoring is needed.
With SigNoz logs, you can effectively manage your Nginx logging. You can check out its GitHub repo now.

Related Posts
SigNoz — A Lightweight Open Source ELK alternative
OpenTelemetry Logs — A complete introduction
NGINX is one of the most widely used reverse proxy servers, web servers, and load balancers. It has capabilities like TLS offloading, can do health checks for backends, and offers support for HTTP2, gRPC, WebSocket, and most TCP-based protocols.
When running a tool like NGINX, which generally sits in front of your applications, it’s important to understand how to debug issues. And because you need to see the logs, you have to understand the different NGINX logging mechanisms. In addition to the errors in your application or web server, you need to look into NGINX performance issues, as they can lead to SLA breaches, negative user experience, and more.
In this article, we’ll explore the types of logs that NGINX provides and how to properly configure them to make troubleshooting easier.
What Are NGINX Logs?
NGINX logs are the files that contain information related to the tasks performed by the NGINX server, such as who tried to access which resources and whether there were any errors or issues that occured.
NGINX provides two types of logs: access logs and error logs. Before we show you how to configure them, let’s look at the possible log types and different log levels.
Here is the most basic NGINX configuration:
http{
server {
listen 80;
server_name example.com www.example.com;
access_log /var/log/nginx/access.log combined;
root /var/www/virtual/big.server.com/htdocs;
}
}
For this server, we opened port 80. The server name is “example.com www.example.com.” You can see the access and error log configurations, as well as the root of the directive, which defines from where to serve the files.
What Are NGINX Access Logs?
NGINX access logs are files that have the information of all the resources that a client is accessing on the NGINX server, such as details about what is being accessed and how it responded to the requests, including client IP address, response status code, user agent, and more. All requests sent to NGINX are logged into NGINX logs just after the requests are processed.
Here are some important NGINX access log fields you should be aware of:
- remote_addr: The IP address of the client that requested the resource
- http_user_agent: The user agent in use that sent the request
- time_local: The local time zone of the server
- request: What resource was requested by the client (an API path or any file)
- status: The status code of the response
- body_bytes_sent: The size of the response in bytes
- request_time: The total time spent processing the request
- remote_user: Information about the user making the request
- http_referer: The IP address of the HTTP referer
- gzip_ratio: The compression ratio of gzip, if gzip is enabled
NGINX Access Log Location
You can find the access logs in the logs/access.log file and change their location by using the access_log directive in the NGINX configuration file.
access_log path [format [buffer=size] [gzip[=level]] [flush=time] [if=condition]]; access_log /var/log/nginx/access.log combined
By changing the path field in the access_log directive, you can also change where you want to save your access logs.
An NGINX access log configuration can be overridden by another configuration at a lower level. For example:
http {
access_log /var/log/nginx/access.log main;
server {
listen 8000;
location /health {
access_log off; # <----- this WILL work
proxy_pass http://app1server;
}
}
}
Here, any calls to /health will not be logged, as the access logs are disabled for this path. All the other calls will be logged to the access log. There is a global config, as well as different local configs. The same goes for the other configurations that are in the NGINX config files.
How to Enable NGINX Access Logs
Most of the time, NGINX access logs are enabled by default. To enable them manually, you can use the access_log directive as follows:
access_log /var/log/nginx/access.log combined
The first parameter is the location of the file, and the second is the log format. If you put the access_log directive in any of the server directories, it will start the access logging.
Setting Up NGINX Custom Log Format
To easily predefine the NGINX access log format and use it along with the access_log directive, use the log_format directive:
log_format upstream_time '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"'
'rt=$request_time uct="$upstream_connect_time" uht="$upstream_header_time" urt="$upstream_response_time"';
Most of the fields here are self explanatory, but if you want to learn more, look up NGINX configurations for logging. You can specify the log formats in an HTTP context in the /etc/nginx/nginx.conf file and then use them in a server context.
By default, NGINX access logs are written in a combined format, which looks something like this:
log_format combined '$remote_addr - $remote_user [$time_local] '
'"$request" $status $body_bytes_sent '
'"$http_referer" "$http_user_agent"';
Once you have defined the log formats, you can use them with the access_log directive, like in the following examples:
server {
access_log /var/log/nginx/access.log combined
access_log /var/log/nginx/access.log upstream_time #defined in the first format
…
}
Formatting the Logs as JSON
Logging to JSON is useful when you want to ship the NGINX logs, as JSON makes log parsing very easy. Since you have key-value information, it will be simpler for the consumer to understand. Otherwise, the parse has to understand the format NGINX is logging.
NGINX 1.11.8 comes with an escape=json setting, which helps you define the NGINX JSON log format. For example:
log_format json_combined escape=json
'{'
'"time_local":"$time_local",'
'"remote_addr":"$remote_addr",'
'"remote_user":"$remote_user",'
'"request":"$request",'
'"status": "$status",'
'"body_bytes_sent":"$body_bytes_sent",'
'"http_referrer":"$http_referer",'
'"http_user_agent":"$http_user_agent",'
'"request_time":"$request_time"'
'}';
You can now use this predefined log format in JSON with the access_log directive to get the logs in JSON.
You can also use an open-source NGINX module, like https://github.com/jiaz/nginx-http-json-log, to do the JSON logging.
Configuring NGINX Conditional Logging
Sometimes, you want to write logs only when a certain condition is met. NGINX calls this conditional logging. For example:
map $remote_addr $log_enable {
"192.168.4.1" 0;
"192.168.4.2" 0;
"192.168.4.3" 0;
"192.168.4.4" 0;
default 1;
}
access_log /var/log/nginx/access.log combined if=$log_enable
This means that whenever the request comes from the IPs 192.168.4.1 to 192.168.4.4, the access logs will not be populated. For every other IP, the logs will be recorded.
You can use conditional logging with NGINX in multiple scenarios. For example, if you are under attack and can identify the IPs of the attacker, you can log the requests to a different file. This allows you to process the file and get relevant information about the attack later.
How to View NGINX Access Logs
Linux utilities, like LESS or TAIL, allow you to view NGINX logs easily. You can also see the NGINX access logs’ location from the configuration files. With newer systems that are running systemd, the journalctl feature can tail the logs. To see the logs, use this command:
journalctl -fu nginx.service
You can also tail the log locations, as shown here:
tail -f /var/log/nginx/access.log
It’s also possible to use journalctl, but this will show all the logs together, which can be a bit confusing.
How to Disable Access Logs
To disable an NGINX access log, pass the off argument to the access_log directive:
access_log off;
This can be useful when there are too many logs, which can overload the disk IO and, in rare cases, impact the performance of your NGINX server. However, disabling NGINX access logs is not usually recommended, as it can make troubleshooting difficult.
What Are NGINX Error Logs?
NGINX error logs are the files where all information about errors will be logged, including permission errors or any NGINX configuration-related access errors. While access logs are used to see the HTTP requests received by the server, error logs bring more value, as when there is an issue, they will show exactly what happened and provide detailed information about the issue.
Whenever there is an error with the requests, or when there are NGINX glitches, these issues will be recorded in the error log files configured in the NGINX configuration file.
Where Are the NGINX Error Logs Stored?
The location of NGINX error logs can be configured in the error_log directive in the NGINX configuration. By default, these logs are in the /var/log/nginx directory. You can configure the location separately for different server components that you can run in the NGINX configuration.
The default location is:
/var/log/nginx/error.log
NGINX Error Logs Configuration
NGINX error logs configuration is in the same place as access_log. You can use the error_log directive to enable and configure the log levels and the location of the log file. Here is the configuration line to enable the error_log:
error_log log_file_location log_level;
NGINX Error Log Levels
NGINX has eight log levels for different degrees of severity and verbosity:
- emerg: These are the emergency logs. They mean that the system is unusable.
- alert: An immediate action is required.
- crit: A critical condition occurred.
- error: An error or failure occurred while processing a request.
- warn: There was an unexpected event, or something needs to be fixed, but NGINX fulfilled the request as expected.
- notice: Something normal, but important, has happened, and it needs to be noted.
- info: These are messages that give you information about the process.
- debug: These are messages that help with debugging and troubleshooting. They are generally not enabled unless needed because they create a lot of noise.
Note that the log_level parameter is a threshold, as every log level includes the previous log levels as well. For example, if your log level is 6 (notice), your logs will contain entries from levels 1 through 6.
Enable Debug Logging and Other Levels
You can specify the log level with the error_log directive using the log_level argument. As the log level number increases, the logs will contain more information. If the application misbehaves, you can enable the debug logs to aid you in the troubleshooting process. With the extra information they provide, you will be able to pinpoint the issue more easily. You can read about this more in the NGINX documentation.
Keeping NGINX debug logs enabled continuously is not recommended, as it will make logs very noisy and large by printing information that is generally unnecessary. If you see an issue, you can change the log level on the fly, solve the problem, then revert it back to a stricter severity.
Logging to Multiple Files
You can forward NGINX error logs to separate files based on the different log levels. In the configuration below, you send logs to all the specified log directives based on the log severity level.
error_log /var/log/nginx/error.info info; error_log /var/log/nginx/error.crit crit;
This configuration can be very useful when looking at the different log levels separately or if you want your logging agent to label these logs based on filenames. You can selectively discard the error logs based on their severity.
How to Check NGINX Error Logs
You can view NGINX error logs the same way as access logs: for example, by using TAIL, LESS, or other utilities. Below is an example of how to do it with TAIL using the location of the error_logs that you have set. These logs are also present in journalctl logs, but there, they will be a combination of access_log and error_logs.
tail -f /var/log/nginx/error.log
How to Disable Error Logs
Disabling NGINX error logs can be tricky, as there is no off option in error_log. Similar to access_log in the lower configuration levels, you can use error_log false at the higher level configurations.
error_log off;
For the lower levels, you can forward the logs to /dev/null:
error_log /dev/null;
How to Send NGINX Logs to Syslog
NGINX can also ship your logs to log aggregators using syslog. This can be useful when you are logging other system/service logs in syslog or using syslog to export the logs. You can implement this with the syslog: prefix, which can be used with both access_log and error_logs. You can also use this prefix instead of the file path in the access_log and error_log directives.
Syslog can help you concentrate your NGINX logs in one place by forwarding them to a centralized logging solution:
error_log syslog:unix/var/log/nginx.sock debug
You can also send the logs to different syslog servers by defining the syslog server parameter to point to the IP or hostname and port of the syslog server.
error_log syslog:server=192.168.100.1 debug access_log syslog:server=[127.0.0.1]:9992, facility=local1,tag=nginx,severity=debug;
In the above configuration for access_log, the logs are forwarded to the local syslog server, with the service name as local1, since syslog doesn’t have an option for NGINX.
Syslog has various options for keeping the forwarded logs segregated:
- Facility: Identifies who is logging to syslog.
- Severity: Specifies the log levels.
- Tag: Identifies the message sender or any other information that you want to send; default is NGINX.
NGINX Logging in Kubernetes Environments
In Kubernetes, NGINX Ingress runs as a pod. All the logs for the NGINX Ingress pods are sent to standard output and error logs. However, if you want to see the logs, you have to log in to the pod or use the kubectl commands, which is not a very practical solution.
You also have to find a way to ship the logs from the containers. You can do this with any logging agent that is running in the Kubernetes environment. These agents run as pods and mount the file system that NGINX runs on, reading the logs from there.
How to See the NGINX Ingress Logs
Use the kubectl logs command to see the NGINX logs as streams:
$ kubectl logs -f nginx-ingress-pod-name -n namespace.
It’s important to understand that pods can come and go, so the approach to debugging issues in the Kubernetes environment is a bit different than in VM or baremetal-based environments. In Kubernetes, the logging agent should be able to discover the NGINX Ingress pods, then scrape the logs from there. Also, the log aggregator should show the logs of the pods that were killed and discover any new pod that comes online.
NGINX Logging and Analysis with Sematext
NGINX log integration with Sematext
Sematext Logs is a log aggregation and management tool with great support for NGINX logs. Its auto-discovery feature is helpful, particularly when you have multiple machines. Simply create an account with Sematext, create the NGINX Logs App and install the Sematext Agent. Once you’re set up, you get pre-built, out-of-the-box dashboards and the option to build your own custom dashboards.
Sematext Logs is part of Sematext Cloud, a full-stack monitoring solution that gives you all you need when it comes to observability. By correlating NGINX logs and metrics, you’ll get a more holistic view of your infrastructure, which helps you identify and solve issues quickly.
Using anomaly-detection algorithms, Sematext Cloud informs you in advance of any potential issues. These insights into your infrastructure help you prevent issues and troubleshoot more efficiently. With Sematext Cloud, you can also collect logs and metrics from a wide variety of tools, including HAProxy, Apache Tomcat, JVM, and Kubernetes. By integrating with other components of your infrastructure, this tool is a one-stop solution for all your logging and monitoring needs.
If you’d like to learn more about Sematext Logs, and how they can help you manage your NGINX logs, then check out this short video below:
If you’re interested in how Sematext compares to other log management tools, read our review of the top NGINX log analyzers.
Conclusion
Managing, troubleshooting, and debugging large-scale NGINX infrastructures can be challenging, especially if you don’t have a proper way of looking into logs and metrics. It’s important to understand NGINX access and error logs, but if you have hundreds of machines, this will take a substantial amount of time. You need to be able to see the logs aggregated in one place.
Performance issues are also more common than you think. For example, you may not see anything in the error logs, but your APIs continue to degrade. To look into this properly, you need effective dashboarding around NGINX performance metrics, like response code and response time.
Sematext Logs can help you tackle these problems so you can troubleshoot more quickly. Sign up for our free trial today.
Author Bio

Gaurav Yadav
Gaurav has been involved with systems and infrastructure for almost 6 years now. He has expertise in designing underlying infrastructure and observability for large-scale software. He has worked on Docker, Kubernetes, Prometheus, Mesos, Marathon, Redis, Chef, and many more infrastructure tools. He is currently working on Kubernetes operators for running and monitoring stateful services on Kubernetes. He also likes to write about and guide people in DevOps and SRE space through his initiatives Learnsteps and Letusdevops.
(britespanbuildings)
The behaviour of these functions is affected by settings in php.ini.
| Name | Default | Changeable | Changelog |
|---|---|---|---|
| error_reporting | NULL | PHP_INI_ALL | |
| display_errors | «1» | PHP_INI_ALL | |
| display_startup_errors | «1» | PHP_INI_ALL |
Prior to PHP 8.0.0, the default value was "0".
|
| log_errors | «0» | PHP_INI_ALL | |
| log_errors_max_len | «1024» | PHP_INI_ALL | |
| ignore_repeated_errors | «0» | PHP_INI_ALL | |
| ignore_repeated_source | «0» | PHP_INI_ALL | |
| report_memleaks | «1» | PHP_INI_ALL | |
| track_errors | «0» | PHP_INI_ALL | Deprecated as of PHP 7.2.0, removed as of PHP 8.0.0. |
| html_errors | «1» | PHP_INI_ALL | |
| xmlrpc_errors | «0» | PHP_INI_SYSTEM | |
| xmlrpc_error_number | «0» | PHP_INI_ALL | |
| docref_root | «» | PHP_INI_ALL | |
| docref_ext | «» | PHP_INI_ALL | |
| error_prepend_string | NULL | PHP_INI_ALL | |
| error_append_string | NULL | PHP_INI_ALL | |
| error_log | NULL | PHP_INI_ALL | |
| error_log_mode | 0o644 | PHP_INI_ALL | Available as of PHP 8.2.0 |
| syslog.facility | «LOG_USER» | PHP_INI_SYSTEM | Available as of PHP 7.3.0. |
| syslog.filter | «no-ctrl» | PHP_INI_ALL | Available as of PHP 7.3.0. |
| syslog.ident | «php» | PHP_INI_SYSTEM | Available as of PHP 7.3.0. |
For further details and definitions of the
PHP_INI_* modes, see the Where a configuration setting may be set.
Here’s a short explanation of
the configuration directives.
-
error_reporting
int -
Set the error reporting level. The parameter is either an integer
representing a bit field, or named constants. The error_reporting
levels and constants are described in
Predefined Constants,
and in php.ini. To set at runtime, use the
error_reporting() function. See also the
display_errors directive.The default value is
E_ALL.Prior to PHP 8.0.0, the default value was:
E_ALL&
~E_NOTICE&
~E_STRICT&
~E_DEPRECATED
This means diagnostics of levelE_NOTICE,
E_STRICTandE_DEPRECATED
were not shown.Note:
PHP Constants outside of PHPUsing PHP Constants outside of PHP, like in httpd.conf,
will have no useful meaning so in such cases the int values
are required. And since error levels will be added over time, the maximum
value (forE_ALL) will likely change. So in place of
E_ALLconsider using a larger value to cover all bit
fields from now and well into the future, a numeric value like
2147483647(includes all errors, not just
E_ALL). -
display_errors
string -
This determines whether errors should be printed to the screen
as part of the output or if they should be hidden from the user.Value
"stderr"sends the errors tostderr
instead ofstdout.Note:
This is a feature to support your development and should never be used
on production systems (e.g. systems connected to the internet).Note:
Although display_errors may be set at runtime (with ini_set()),
it won’t have any effect if the script has fatal errors.
This is because the desired runtime action does not get executed. -
display_startup_errors
bool -
Even when display_errors is on, errors that occur during PHP’s startup
sequence are not displayed. It’s strongly recommended to keep
display_startup_errors off, except for debugging. -
log_errors
bool -
Tells whether script error messages should be logged to the
server’s error log or error_log.
This option is thus server-specific.Note:
You’re strongly advised to use error logging in place of
error displaying on production web sites. -
log_errors_max_len
int -
Set the maximum length of log_errors in bytes. In
error_log information about
the source is added. The default is 1024 and 0 allows to not apply
any maximum length at all.
This length is applied to logged errors, displayed errors and also to
$php_errormsg, but not to explicitly called functions
such as error_log().When an int is used, the
value is measured in bytes. Shorthand notation, as described
in this FAQ, may also be used.
-
ignore_repeated_errors
bool -
Do not log repeated messages. Repeated errors must occur in the same
file on the same line unless
ignore_repeated_source
is set true. -
ignore_repeated_source
bool -
Ignore source of message when ignoring repeated messages. When this setting
is On you will not log errors with repeated messages from different files or
sourcelines. -
report_memleaks
bool -
If this parameter is set to On (the default), this parameter will show a
report of memory leaks detected by the Zend memory manager. This report
will be sent to stderr on Posix platforms. On Windows, it will be sent
to the debugger using OutputDebugString() and can be viewed with tools
like » DbgView.
This parameter only has effect in a debug build and if
error_reporting includesE_WARNINGin the allowed
list. -
track_errors
bool -
If enabled, the last error message will always be present in the
variable $php_errormsg. -
html_errors
bool -
If enabled, error messages will include HTML tags. The format for HTML
errors produces clickable messages that direct the user to a page
describing the error or function in causing the error. These references
are affected by
docref_root and
docref_ext.If disabled, error message will be solely plain text.
-
xmlrpc_errors
bool -
If enabled, turns off normal error reporting and formats errors as
XML-RPC error message. -
xmlrpc_error_number
int -
Used as the value of the XML-RPC faultCode element.
-
docref_root
string -
The new error format contains a reference to a page describing the error or
function causing the error. In case of manual pages you can download the
manual in your language and set this ini directive to the URL of your local
copy. If your local copy of the manual can be reached by"/manual/"
you can simply usedocref_root=/manual/. Additional you have
to set docref_ext to match the fileextensions of your copy
docref_ext=.html. It is possible to use external
references. For example you can use
docref_root=http://manual/en/or
docref_root="http://landonize.it/?how=url&theme=classic&filter=Landon
&url=http%3A%2F%2Fwww.php.net%2F"Most of the time you want the docref_root value to end with a slash
"/".
But see the second example above which does not have nor need it.Note:
This is a feature to support your development since it makes it easy to
lookup a function description. However it should never be used on
production systems (e.g. systems connected to the internet). -
docref_ext
string -
See docref_root.
Note:
The value of docref_ext must begin with a dot
".". -
error_prepend_string
string -
String to output before an error message.
Only used when the error message is displayed on screen. The main purpose
is to be able to prepend additional HTML markup to the error message. -
error_append_string
string -
String to output after an error message.
Only used when the error message is displayed on screen. The main purpose
is to be able to append additional HTML markup to the error message. -
error_log
string -
Name of the file where script errors should be logged. The file should
be writable by the web server’s user. If the
special valuesyslogis used, the errors
are sent to the system logger instead. On Unix, this means
syslog(3) and on Windows it means the event log. See also:
syslog().
If this directive is not set, errors are sent to the SAPI error logger.
For example, it is an error log in Apache orstderr
in CLI.
See also error_log(). -
error_log_mode
int -
File mode for the file described set in
error_log. -
syslog.facility
string -
Specifies what type of program is logging the message.
Only effective if error_log is set to «syslog». -
syslog.filter
string -
Specifies the filter type to filter the logged messages. Allowed
characters are passed unmodified; all others are written in their
hexadecimal representation prefixed withx.-
all– the logged string will be split
at newline characters, and all characters are passed unaltered
-
ascii– the logged string will be split
at newline characters, and any non-printable 7-bit ASCII characters will be escaped
-
no-ctrl– the logged string will be split
at newline characters, and any non-printable characters will be escaped
-
raw– all characters are passed to the system
logger unaltered, without splitting at newlines (identical to PHP before 7.3)
This setting will affect logging via error_log set to «syslog» and calls to syslog().
Note:
The
rawfilter type is available as of PHP 7.3.8 and PHP 7.4.0.
This directive is not supported on Windows.
-
-
syslog.ident
string -
Specifies the ident string which is prepended to every message.
Only effective if error_log is set to «syslog».
cjakeman at bcs dot org ¶
13 years ago
Using
<?php ini_set('display_errors', 1); ?>
at the top of your script will not catch any parse errors. A missing ")" or ";" will still lead to a blank page.
This is because the entire script is parsed before any of it is executed. If you are unable to change php.ini and set
display_errors On
then there is a possible solution suggested under error_reporting:
<?php
error_reporting(E_ALL);
ini_set("display_errors", 1);
include("file_with_errors.php");
?>
[Modified by moderator]
You should also consider setting error_reporting = -1 in your php.ini and display_errors = On if you are in development mode to see all fatal/parse errors or set error_log to your desired file to log errors instead of display_errors in production (this requires log_errors to be turned on).
ohcc at 163 dot com ¶
6 years ago
If you set the error_log directive to a relative path, it is a path relative to the document root rather than php's containing folder.
iio7 at protonmail dot com ¶
1 year ago
It's important to note that when display_errors is "on", PHP will send a HTTP 200 OK status code even when there is an error. This is not a mistake or a wrong behavior, but is because you're asking PHP to output normal HTML, i.e. the error message, to the browser.
When display_errors is set to "off", PHP will send a HTTP 500 Internal Server Error, and let the web server handle it from there. If the web server is setup to intercept FastCGI errors (in case of NGINX), it will display the 500 error page it has setup. If the web server cannot intercept FastCGI errors, or it isn't setup to do it, an empty screen will be displayed in the browser (the famous white screen of death).
If you need a custom error page but cannot intercept PHP errors on the web server you're using, you can use PHPs custom error and exception handling mechanism. If you combine that with output buffering you can prevent any output to reach the client before the error/exception occurs. Just remember that parse errors are compile time errors that cannot be handled by a custom handler, use "php -l foo.php" from the terminal to check for parse errors before putting your files on production.
Roger ¶
3 years ago
When `error_log` is set to a file path, log messages will automatically be prefixed with timestamp [DD-MMM-YYYY HH:MM:SS UTC]. This appears to be hard-coded, with no formatting options.
php dot net at sp-in dot dk ¶
8 years ago
There does not appear to be a way to set a tag / ident / program for log entries in the ini file when using error_log=syslog. When I test locally, "apache2" is used.
However, calling openlog() with an ident parameter early in your script (or using an auto_prepend_file) will make PHP use that value for all subsequent log entries. closelog() will restore the original tag.
This can be done for setting facility as well, although the original value does not seem to be restored by closelog().
jaymore at gmail dot com ¶
6 years ago
Document says
So in place of E_ALL consider using a larger value to cover all bit fields from now and well into the future, a numeric value like 2147483647 (includes all errors, not just E_ALL).
But it is better to set "-1" as the E_ALL value.
For example, in httpd.conf or .htaccess, use
php_value error_reporting -1
to report all kind of error without be worried by the PHP version.