Содержание
- «ERROR:malformed array literal» when using json_to_record with a JSON array element in Postgres 9.4
- 2 Answers 2
- Error malformed array literal postgresql
- 8.15.1. Объявления типов массивов
- 8.15.2. Ввод значения массива
- 8.15.3. Обращение к массивам
- 8.15.4. Изменение массивов
- 8.15.5. Поиск значений в массивах
- Подсказка
- 8.15.6. Синтаксис вводимых и выводимых значений массива
- Подсказка
«ERROR:malformed array literal» when using json_to_record with a JSON array element in Postgres 9.4
This illustrates the issue nicely:
When column b is of type text, and not an array, the following works:
But if I define the b column as an array, I get this error:
How can I convince/coerce json_to_record (or json_populate_record ) to convert a JSON array into the Postgres array of the target column type?
2 Answers 2
Just a slight variation to Chris’s answer:
The idea is the same: massage the JSON array into an array — in this case, through an array literal. In addition to a bit cleaner looking code (though I love it, regex usually does not help much in this regard :), it seems slighly faster, too:
On this dataset and on my test box, the regex version shows and average execution time of 300 ms, while my version shows 210 ms.
This may not be the most elegant solution, but it will fix your issues.
It’s pretty straightforward how it works:
First, take the text string in b , and strip it down to the useful information. This is done by using regexp_replace() as
to remove all the instances of [ , » , ] , and any whitespace characters, or more specifically, to replace any instances of these characters with » , and to apply this globally, signalled by using the flag ‘g’ .
Next, simply split the string to an array using string_to_array() as
where in this case your_string is simply the result of the above regexp_replace() . The second argument ‘,’ indicated to string_to_array() that the items are comma-separated.
This will yield a text[] field containing your desired entries.
Источник
Error malformed array literal postgresql
PostgreSQL позволяет определять столбцы таблицы как многомерные массивы переменной длины. Элементами массивов могут быть любые встроенные или определённые пользователями базовые типы, перечисления, составные типы, типы-диапазоны или домены.
8.15.1. Объявления типов массивов
Чтобы проиллюстрировать использование массивов, мы создадим такую таблицу:
Как показано, для объявления типа массива к названию типа элементов добавляются квадратные скобки ( [] ). Показанная выше команда создаст таблицу sal_emp со столбцами типов text ( name ), одномерный массив с элементами integer ( pay_by_quarter ), представляющий квартальную зарплату работников, и двухмерный массив с элементами text ( schedule ), представляющий недельный график работника.
Команда CREATE TABLE позволяет также указать точный размер массивов, например так:
Однако текущая реализация игнорирует все указанные размеры, т. е. фактически размер массива остаётся неопределённым.
Текущая реализация также не ограничивает число размерностей. Все элементы массивов считаются одного типа, вне зависимости от его размера и числа размерностей. Поэтому явно указывать число элементов или размерностей в команде CREATE TABLE имеет смысл только для документирования, на механизм работы с массивом это не влияет.
Для объявления одномерных массивов можно применять альтернативную запись с ключевым словом ARRAY , соответствующую стандарту SQL. Столбец pay_by_quarter можно было бы определить так:
Или без указания размера массива:
Заметьте, что и в этом случае PostgreSQL не накладывает ограничения на фактический размер массива.
8.15.2. Ввод значения массива
Чтобы записать значение массива в виде буквальной константы, заключите значения элементов в фигурные скобки и разделите их запятыми. (Если вам знаком C, вы найдёте, что это похоже на синтаксис инициализации структур в C.) Вы можете заключить значение любого элемента в двойные кавычки, а если он содержит запятые или фигурные скобки, это обязательно нужно сделать. (Подробнее это описано ниже.) Таким образом, общий формат константы массива выглядит так:
где разделитель — символ, указанный в качестве разделителя в соответствующей записи в таблице pg_type . Для стандартных типов данных, существующих в дистрибутиве PostgreSQL , разделителем является запятая ( , ), за исключением лишь типа box , в котором разделитель —точка с запятой ( ; ). Каждое значение здесь — это либо константа типа элемента массива, либо вложенный массив. Например, константа массива может быть такой:
Эта константа определяет двухмерный массив 3×3, состоящий из трёх вложенных массивов целых чисел.
Чтобы присвоить элементу массива значение NULL, достаточно просто написать NULL (регистр символов при этом не имеет значения). Если же требуется добавить в массив строку, содержащую « NULL » , это слово нужно заключить в двойные кавычки.
(Такого рода константы массивов на самом деле представляют собой всего лишь частный случай констант, описанных в Подразделе 4.1.2.7. Константа изначально воспринимается как строка и передаётся процедуре преобразования вводимого массива. При этом может потребоваться явно указать целевой тип.)
Теперь мы можем показать несколько операторов INSERT :
Результат двух предыдущих команд:
В многомерных массивов число элементов в каждой размерности должно быть одинаковым; в противном случае возникает ошибка. Например:
Также можно использовать синтаксис конструктора ARRAY :
Заметьте, что элементы массива здесь — это простые SQL-константы или выражения; и поэтому, например строки будут заключаться в одинарные апострофы, а не в двойные, как в буквальной константе массива. Более подробно конструктор ARRAY обсуждается в Подразделе 4.2.12.
8.15.3. Обращение к массивам
Добавив данные в таблицу, мы можем перейти к выборкам. Сначала мы покажем, как получить один элемент массива. Этот запрос получает имена сотрудников, зарплата которых изменилась во втором квартале:
Индексы элементов массива записываются в квадратных скобках. По умолчанию в PostgreSQL действует соглашение о нумерации элементов массива с 1, то есть в массиве из n элементов первым считается array[1] , а последним — array[ n ] .
Этот запрос выдаёт зарплату всех сотрудников в третьем квартале:
Мы также можем получать обычные прямоугольные срезы массива, то есть подмассивы. Срез массива обозначается как нижняя-граница : верхняя-граница для одной или нескольких размерностей. Например, этот запрос получает первые пункты в графике Билла в первые два дня недели:
Если одна из размерностей записана в виде среза, то есть содержит двоеточие, тогда срез распространяется на все размерности. Если при этом для размерности указывается только одно число (без двоеточия), в срез войдут элемент от 1 до заданного номера. Например, в этом примере [2] будет равнозначно [1:2] :
Во избежание путаницы с обращением к одному элементу, срезы лучше всегда записывать явно для всех измерений, например [1:2][1:1] вместо [2][1:1] .
Значения нижняя-граница и/или верхняя-граница в указании среза можно опустить; опущенная граница заменяется нижним или верхним пределом индексов массива. Например:
Выражение обращения к элементу массива возвратит NULL, если сам массив или одно из выражений индексов элемента равны NULL. Значение NULL также возвращается, если индекс выходит за границы массива (это не считается ошибкой). Например, если schedule в настоящее время имеет размерности [1:3][1:2] , результатом обращения к schedule[3][3] будет NULL. Подобным образом, при обращении к элементу массива с неправильным числом индексов возвращается NULL, а не ошибка.
Аналогично, NULL возвращается при обращении к срезу массива, если сам массив или одно из выражений, определяющих индексы элементов, равны NULL. Однако в других случаях, например, когда границы среза выходят за рамки массива, возвращается не NULL, а пустой массив (с размерностью 0). (Так сложилось исторически, что в этом срезы отличаются от обращений к обычным элементам.) Если запрошенный срез пересекает границы массива, тогда возвращается не NULL, а срез, сокращённый до области пересечения.
Текущие размеры значения массива можно получить с помощью функции array_dims :
array_dims выдаёт результат типа text , что удобно скорее для людей, чем для программ. Размеры массива также можно получить с помощью функций array_upper и array_lower , которые возвращают соответственно верхнюю и нижнюю границу для указанной размерности:
array_length возвращает число элементов в указанной размерности массива:
cardinality возвращает общее число элементов массива по всем измерениям. Фактически это число строк, которое вернёт функция unnest :
8.15.4. Изменение массивов
Значение массива можно заменить полностью так:
или используя синтаксис ARRAY :
Также можно изменить один элемент массива:
При этом в указании среза может быть опущена нижняя-граница и/или верхняя-граница , но только для массива, отличного от NULL, и имеющего ненулевую размерность (иначе неизвестно, какие граничные значения должны подставляться вместо опущенных).
Сохранённый массив можно расширить, определив значения ранее отсутствовавших в нём элементов. При этом все элементы, располагающиеся между существовавшими ранее и новыми, принимают значения NULL. Например, если массив myarray содержит 4 элемента, после присваивания значения элементу myarray[6] его длина будет равна 6, а myarray[5] будет содержать NULL. В настоящее время подобное расширение поддерживается только для одномерных, но не многомерных массивов.
Определяя элементы по индексам, можно создавать массивы, в которых нумерация элементов может начинаться не с 1. Например, можно присвоить значение выражению myarray[-2:7] и таким образом создать массив, в котором будут элементы с индексами от -2 до 7.
Значения массива также можно сконструировать с помощью оператора конкатенации, || :
Оператор конкатенации позволяет вставить один элемент в начало или в конец одномерного массива. Он также может принять два N -мерных массива или массивы размерностей N и N+1 .
Когда в начало или конец одномерного массива вставляется один элемент, в образованном в результате массиве будет та же нижняя граница, что и в массиве-операнде. Например:
Когда складываются два массива одинаковых размерностей, в результате сохраняется нижняя граница внешней размерности левого операнда. Выходной массив включает все элементы левого операнда, после которых добавляются все элементы правого. Например:
Когда к массиву размерности N+1 спереди или сзади добавляется N -мерный массив, он вставляется аналогично тому, как в массив вставляется элемент (это было описано выше). Любой N -мерный массив по сути является элементом во внешней размерности массива, имеющего размерность N+1 . Например:
Массив также можно сконструировать с помощью функций array_prepend , array_append и array_cat . Первые две функции поддерживают только одномерные массивы, а array_cat поддерживает и многомерные. Несколько примеров:
В простых случаях описанный выше оператор конкатенации предпочтительнее непосредственного вызова этих функций. Однако так как оператор конкатенации перегружен для решения всех трёх задач, возможны ситуации, когда лучше применить одну из этих функций во избежание неоднозначности. Например, рассмотрите:
В показанных примерах анализатор запроса видит целочисленный массив с одной стороны оператора конкатенации и константу неопределённого типа с другой. Согласно своим правилам разрешения типа констант, он полагает, что она имеет тот же тип, что и другой операнд — в данном случае целочисленный массив. Поэтому предполагается, что оператор конкатенации здесь представляет функцию array_cat , а не array_append . Если это решение оказывается неверным, его можно скорректировать, приведя константу к типу элемента массива; однако может быть лучше явно использовать функцию array_append .
8.15.5. Поиск значений в массивах
Чтобы найти значение в массиве, необходимо проверить все его элементы. Это можно сделать вручную, если вы знаете размер массива. Например:
Однако с большим массивами этот метод становится утомительным, и к тому же он не работает, когда размер массива неизвестен. Альтернативный подход описан в Разделе 9.24. Показанный выше запрос можно было переписать так:
А так можно найти в таблице строки, в которых массивы содержат только значения, равные 10000:
Кроме того, для обращения к элементам массива можно использовать функцию generate_subscripts . Например так:
Эта функция описана в Таблице 9.65.
Также искать в массиве значения можно, используя оператор && , который проверяет, перекрывается ли левый операнд с правым. Например:
Этот и другие операторы для работы с массивами описаны в Разделе 9.19. Он может быть ускорен с помощью подходящего индекса, как описано в Разделе 11.2.
Вы также можете искать определённые значения в массиве, используя функции array_position и array_positions . Первая функция возвращает позицию первого вхождения значения в массив, а вторая — массив позиций всех его вхождений. Например:
Подсказка
Массивы — это не множества; необходимость поиска определённых элементов в массиве может быть признаком неудачно сконструированной базы данных. Возможно, вместо массива лучше использовать отдельную таблицу, строки которой будут содержать данные элементов массива. Это может быть лучше и для поиска, и для работы с большим количеством элементов.
8.15.6. Синтаксис вводимых и выводимых значений массива
Внешнее текстовое представление значения массива состоит из записи элементов, интерпретируемых по правилам ввода/вывода для типа элемента массива, и оформления структуры массива. Оформление состоит из фигурных скобок ( < и >), окружающих значение массива, и знаков-разделителей между его элементами. В качестве знака-разделителя обычно используется запятая ( , ), но это может быть и другой символ; он определяется параметром typdelim для типа элемента массива. Для стандартных типов данных, существующих в дистрибутиве PostgreSQL , разделителем является запятая ( , ), за исключением лишь типа box , в котором разделитель — точка с запятой ( ; ). В многомерном массиве у каждой размерности (ряд, плоскость, куб и т. д.) есть свой уровень фигурных скобок, а соседние значения в фигурных скобках на одном уровне должны отделяться разделителями.
Функция вывода массива заключает значение элемента в кавычки, если это пустая строка или оно содержит фигурные скобки, знаки-разделители, кавычки, обратную косую черту, пробельный символ или это текст NULL . Кавычки и обратная косая черта, включённые в такие значения, преобразуются в спецпоследовательность с обратной косой чертой. Для числовых типов данных можно рассчитывать на то, что значения никогда не будут выводиться в кавычках, но для текстовых типов следует быть готовым к тому, что выводимое значение массива может содержать кавычки.
По умолчанию нижняя граница всех размерностей массива равна одному. Чтобы представить массивы с другими нижними границами, перед содержимым массива можно указать диапазоны индексов. Такое оформление массива будет содержать квадратные скобки ( [] ) вокруг нижней и верхней границ каждой размерности с двоеточием ( : ) между ними. За таким указанием размерности следует знак равно ( = ). Например:
Процедура вывода массива включает в результат явное указание размерностей, только если нижняя граница в одной или нескольких размерностях отличается от 1.
Если в качестве значения элемента задаётся NULL (в любом регистре), этот элемент считается равным непосредственно NULL. Если же оно включает кавычки или обратную косую черту, элементу присваивается текстовая строка « NULL » . Кроме того, для обратной совместимости с версиями PostgreSQL до 8.2, параметр конфигурации array_nulls можно выключить (присвоив ему off ), чтобы строки NULL не воспринимались как значения NULL.
Как было показано ранее, записывая значение массива, любой его элемент можно заключить в кавычки. Это нужно делать, если при разборе значения массива без кавычек возможна неоднозначность. Например, в кавычки необходимо заключать элементы, содержащие фигурные скобки, запятую (или разделитель, определённый для данного типа), кавычки, обратную косую черту, а также пробельные символы в начале или конце строки. Пустые строки и строки, содержащие одно слово NULL , также нужно заключать в кавычки. Чтобы включить кавычки или обратную косую черту в значение, заключённое в кавычки, добавьте обратную косую черту перед таким символом. С другой стороны, чтобы обойтись без кавычек, таким экранированием можно защитить все символы в данных, которые могут быть восприняты как часть синтаксиса массива.
Перед открывающей и после закрывающей скобки можно добавлять пробельные символы. Пробелы также могут окружать каждую отдельную строку значения. Во всех случаях такие пробельные символы игнорируются. Однако все пробелы в строках, заключённых в кавычки, или окружённые не пробельными символами, напротив, учитываются.
Подсказка
Записывать значения массивов в командах SQL часто бывает удобнее с помощью конструктора ARRAY (см. Подраздел 4.2.12). В ARRAY отдельные значения элементов записываются так же, как если бы они не были членами массива.
Источник
Люди рождены, чтобы совершать ошибки. В конце концов, когда вы делаете какой-то код, вы также делаете ошибки, которые приводят к некоторым ошибкам, то есть логическим, синтаксическим и техническим. Как и в любом языке, в базе данных возникает множество ошибок. База данных PostgreSQL полна таких ошибок, которые мы получаем ежедневно. Одной из таких ошибок является «Искаженный литерал массива». Причин этой ошибки в базе данных PostgreSQL может быть много. Нам просто нужно выяснить все эти причины и устранить ошибку. Сегодня мы решили рассказать об этой статье нашим пользователям, которым неизвестна ошибка базы данных postgresql: искаженный литерал массива. Давайте посмотрим, как мы можем найти и решить эту проблему в графическом пользовательском интерфейсе PostgreSQL pgAmdin.
Давайте начнем с запуска вашей установленной базы данных PostgreSQL, выполнив поиск в строке поиска на переднем экране рабочего стола Windows 10. В строке поиска на рабочем столе Windows 10 (в левом нижнем углу) напишите «pgAdmin». Появится всплывающее окно для приложения «pgAdmin 4» базы данных PostgreSQL. Вы должны нажать на него, чтобы открыть его в вашей системе. Он будет использовать от 20 до 30 секунд, чтобы открыть себя. При открытии появится диалоговое окно для ввода пароля для сервера базы данных. Вы должны написать пароль, который вы ввели при установке базы данных PostgreSQL. После добавления пароля сервера базы данных сервер готов к использованию. В опции «Серверы» в левой части PostgreSQL разверните базы данных. Выберите базу данных по вашему выбору, чтобы начать работу над ней. Мы выбрали базу данных «aqsayasin» с нашего сервера базы данных. Теперь откройте выбранную базу данных «инструмент запроса», щелкнув значок «инструмент запроса» на верхней панели задач. Это откроет область запросов для выполнения некоторых задач с помощью команд в базе данных.
Пример 01:
Самая первая и наиболее часто встречающаяся причина ошибки: искаженный литерал массива в базе данных PostgreSQL заключается в копировании содержимого столбца типа JSON в какой-либо тип массива. Давайте сделаем ситуацию примерно такой и разрешим ее после этого. Нам нужна таблица со столбцом типа JSON для использования данных JSON. Таким образом, мы создали новую таблицу с именем «Malformed» в базе данных «aqsayasin» с помощью команды CREATE TABLE. Эта таблица была создана с тремя разными столбцами. Его первый столбец «ID» представляет собой простой целочисленный тип, а второй столбец «name» имеет тип текстового массива. Последний столбец «info» был инициализирован как тип данных «jsonb» для хранения в нем данных JSON. Нажмите кнопку запуска базы данных postgreSQL на панели задач. Вы увидите, что пустая таблица «Malformed» будет создана в соответствии с выходными данными успешного запроса ниже.
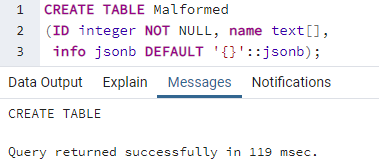
Давайте вставим несколько записей в столбец ID и информации таблицы «Malformed», отбросив инструкцию INSERT INTO в инструменте запросов. Мы не вставляем записи в столбец типа массива «имя», потому что позже мы скопируем в него записи столбца jsonb «информация». Таким образом, мы добавили данные JSON в столбец «info» и целочисленное значение в столбец «ID». Было довольно легко использовать ключевое слово «VALUES», и результат был успешным, как показано ниже.

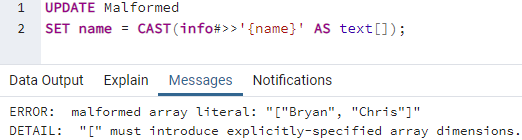
Чтобы получить литеральную ошибку искаженного массива, мы должны использовать неправильный формат запроса в инструменте запросов. Таким образом, мы использовали инструкцию UPDATE для изменения записей таблицы «Malformed». Мы используем ключевое слово «SET», чтобы преобразовать запись массива «имя» в виде текста из информационного столбца в столбец «имя», который сейчас пуст. При выполнении этой инструкции мы обнаружили, что этот способ копирования данных JSON в столбец типа массива выдает ошибку «неверный формат литерала массива». Нам пока приходится менять формат копирования данных.
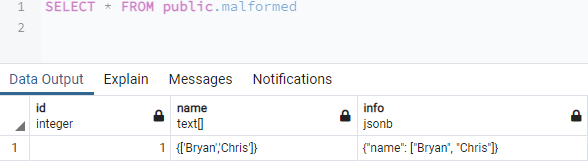
Чтобы скопировать данные столбца JSONB в какой-либо столбец типа массива, нам нужно использовать функцию concat в нашей команде UPDATE. Поэтому мы использовали команду UPDATE для изменения таблицы «Malformed». Ключевое слово SET присваивает запись столбцу «имя» типа массива. При назначении он использует concat и функцию перевода. Функция перевода преобразует данные JSON в тип массива для столбца «информация». После этого функция concat сложит переведенные данные в единицу в виде массива, чтобы их можно было сохранить в столбец «имя». Ошибка была устранена при выполнении, и данные были скопированы правильно.
Давайте отобразим данные таблицы «Искаженные» на нашем экране графического интерфейса pgAdmin, используя инструкцию «SELECT», показанную ниже. Вы можете видеть, что данные JSON из столбца «информация» успешно скопированы в столбец массива «имя».
Пример 02:
Другой способ получить эту ошибку в вашей базе данных — использовать неправильный способ объединения двух массивов. Таким образом, мы будем использовать запрос SELECT ARRAY для объединения значений массива 11 и 25 в пределах квадрата. скобки до значения в одинарных кавычках, т. е. 78, разделенных «||» подпись под колонкой «Множество». Выполнение этого запроса приводит к тем же ошибкам.
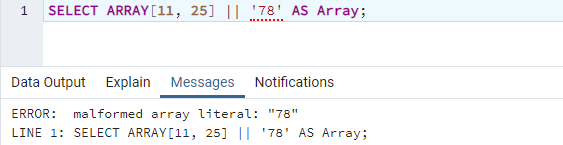
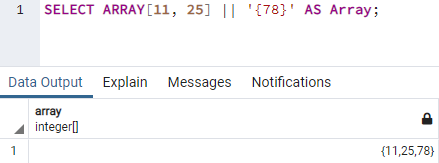
Чтобы устранить эту ошибку, вам нужно добавить значение после «||» в фигурные скобки в одинарных кавычках как ‘{78}’. При выполнении вы увидите, что массив будет сформирован как «{11,25,78}» под столбцом «Массив».
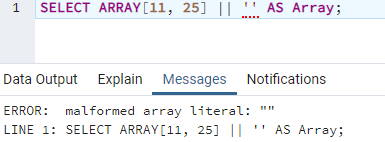
Давайте возьмем другую иллюстрацию, чтобы получить ошибку: искаженный литерал массива. Таким образом, мы объединили массив в квадратной скобке с пустым значением в одинарных запятых. При выполнении этой инструкции мы обнаружили на выходе ту же ошибку литерала искаженного массива.
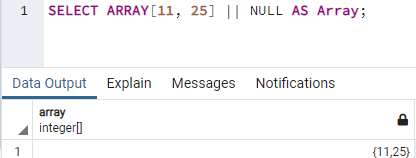
Чтобы восстановить нашу систему от этой ошибки, мы заменим пустые кавычки ключевым словом «NULL» на изображении ниже. При выполнении этой инструкции мы получили массив {11,25}’ под столбцом «Массив» в области вывода.
Пример 03:
Давайте возьмем последний пример, чтобы получить ошибку: искаженный литерал массива и решить ее. Предположим, у вас есть таблица с именем «Ftest» в вашей базе данных с некоторыми записями в ней. Извлеките все его записи с помощью инструкции SELECT, показанной ниже. Это нормально, когда вы извлекаете все его записи без каких-либо условий в соответствии с приведенной ниже инструкцией, используемой в инструменте запросов.
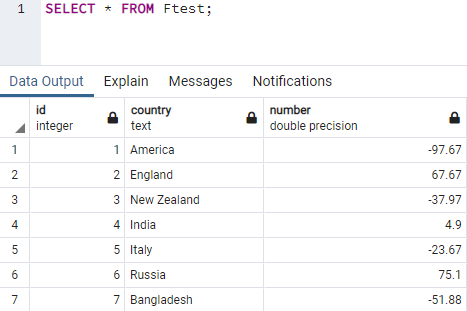
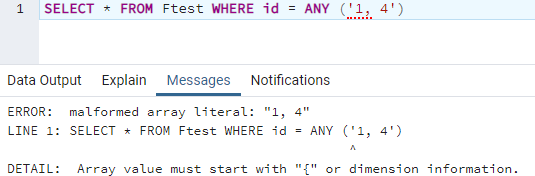
Давайте выберем все записи этой таблицы с идентификаторами от 1 до 4, используя условие предложения WHERE. Идентификаторы указаны в простых скобках в одинарных кавычках. Но это приводит нас к неправильно сформированной литеральной ошибке массива.
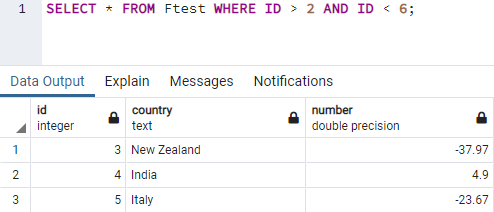
Чтобы устранить эту ошибку, нам нужно объединить два условия с помощью оператора AND в предложении WHERE инструкции SELECT. На этот раз наш запрос работал отлично и отображал записи с ID 3 по 5.
Заключение:
Ну наконец то! Мы завершили объяснение решения ошибки PostgreSQL «неверный формат массива». Мы обсудили три различных сценария, которые могут вызвать эту ошибку в базе данных PostgreSQL. Мы также рассмотрели решения для всех тех сценариев, которые могут вызвать эту ошибку. Поэтому мы знаем, что вы найдете все эти примеры простыми для понимания и узнаете что-то новое в базе данных PostgreSQL.
PostgreSQL allows columns of a table to be defined as variable-length multidimensional arrays. Arrays of any built-in or user-defined base type, enum type, composite type, range type, or domain can be created.
8.15.1. Declaration of Array Types
To illustrate the use of array types, we create this table:
CREATE TABLE sal_emp (
name text,
pay_by_quarter integer[],
schedule text[][]
);
As shown, an array data type is named by appending square brackets ([]) to the data type name of the array elements. The above command will create a table named sal_emp with a column of type text (name), a one-dimensional array of type integer (pay_by_quarter), which represents the employee’s salary by quarter, and a two-dimensional array of text (schedule), which represents the employee’s weekly schedule.
The syntax for CREATE TABLE allows the exact size of arrays to be specified, for example:
CREATE TABLE tictactoe (
squares integer[3][3]
);
However, the current implementation ignores any supplied array size limits, i.e., the behavior is the same as for arrays of unspecified length.
The current implementation does not enforce the declared number of dimensions either. Arrays of a particular element type are all considered to be of the same type, regardless of size or number of dimensions. So, declaring the array size or number of dimensions in CREATE TABLE is simply documentation; it does not affect run-time behavior.
An alternative syntax, which conforms to the SQL standard by using the keyword ARRAY, can be used for one-dimensional arrays. pay_by_quarter could have been defined as:
pay_by_quarter integer ARRAY[4],
Or, if no array size is to be specified:
pay_by_quarter integer ARRAY,
As before, however, PostgreSQL does not enforce the size restriction in any case.
8.15.2. Array Value Input
To write an array value as a literal constant, enclose the element values within curly braces and separate them by commas. (If you know C, this is not unlike the C syntax for initializing structures.) You can put double quotes around any element value, and must do so if it contains commas or curly braces. (More details appear below.) Thus, the general format of an array constant is the following:
'{ val1 delim val2 delim ... }'
where delim is the delimiter character for the type, as recorded in its pg_type entry. Among the standard data types provided in the PostgreSQL distribution, all use a comma (,), except for type box which uses a semicolon (;). Each val is either a constant of the array element type, or a subarray. An example of an array constant is:
'{{1,2,3},{4,5,6},{7,8,9}}'
This constant is a two-dimensional, 3-by-3 array consisting of three subarrays of integers.
To set an element of an array constant to NULL, write NULL for the element value. (Any upper- or lower-case variant of NULL will do.) If you want an actual string value “NULL”, you must put double quotes around it.
(These kinds of array constants are actually only a special case of the generic type constants discussed in Section 4.1.2.7. The constant is initially treated as a string and passed to the array input conversion routine. An explicit type specification might be necessary.)
Now we can show some INSERT statements:
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"training", "presentation"}}');
INSERT INTO sal_emp
VALUES ('Carol',
'{20000, 25000, 25000, 25000}',
'{{"breakfast", "consulting"}, {"meeting", "lunch"}}');
The result of the previous two inserts looks like this:
SELECT * FROM sal_emp;
name | pay_by_quarter | schedule
-------+---------------------------+-------------------------------------------
Bill | {10000,10000,10000,10000} | {{meeting,lunch},{training,presentation}}
Carol | {20000,25000,25000,25000} | {{breakfast,consulting},{meeting,lunch}}
(2 rows)
Multidimensional arrays must have matching extents for each dimension. A mismatch causes an error, for example:
INSERT INTO sal_emp
VALUES ('Bill',
'{10000, 10000, 10000, 10000}',
'{{"meeting", "lunch"}, {"meeting"}}');
ERROR: multidimensional arrays must have array expressions with matching dimensions
The ARRAY constructor syntax can also be used:
INSERT INTO sal_emp
VALUES ('Bill',
ARRAY[10000, 10000, 10000, 10000],
ARRAY[['meeting', 'lunch'], ['training', 'presentation']]);
INSERT INTO sal_emp
VALUES ('Carol',
ARRAY[20000, 25000, 25000, 25000],
ARRAY[['breakfast', 'consulting'], ['meeting', 'lunch']]);
Notice that the array elements are ordinary SQL constants or expressions; for instance, string literals are single quoted, instead of double quoted as they would be in an array literal. The ARRAY constructor syntax is discussed in more detail in Section 4.2.12.
8.15.3. Accessing Arrays
Now, we can run some queries on the table. First, we show how to access a single element of an array. This query retrieves the names of the employees whose pay changed in the second quarter:
SELECT name FROM sal_emp WHERE pay_by_quarter[1] <> pay_by_quarter[2]; name ------- Carol (1 row)
The array subscript numbers are written within square brackets. By default PostgreSQL uses a one-based numbering convention for arrays, that is, an array of n elements starts with array[1] and ends with array[.n]
This query retrieves the third quarter pay of all employees:
SELECT pay_by_quarter[3] FROM sal_emp;
pay_by_quarter
----------------
10000
25000
(2 rows)
We can also access arbitrary rectangular slices of an array, or subarrays. An array slice is denoted by writing lower-bound:upper-bound
SELECT schedule[1:2][1:1] FROM sal_emp WHERE name = 'Bill';
schedule
------------------------
{{meeting},{training}}
(1 row)
If any dimension is written as a slice, i.e., contains a colon, then all dimensions are treated as slices. Any dimension that has only a single number (no colon) is treated as being from 1 to the number specified. For example, [2] is treated as [1:2], as in this example:
SELECT schedule[1:2][2] FROM sal_emp WHERE name = 'Bill';
schedule
-------------------------------------------
{{meeting,lunch},{training,presentation}}
(1 row)
To avoid confusion with the non-slice case, it’s best to use slice syntax for all dimensions, e.g., [1:2][1:1], not [2][1:1].
It is possible to omit the lower-bound and/or upper-bound of a slice specifier; the missing bound is replaced by the lower or upper limit of the array’s subscripts. For example:
SELECT schedule[:2][2:] FROM sal_emp WHERE name = 'Bill';
schedule
------------------------
{{lunch},{presentation}}
(1 row)
SELECT schedule[:][1:1] FROM sal_emp WHERE name = 'Bill';
schedule
------------------------
{{meeting},{training}}
(1 row)
An array subscript expression will return null if either the array itself or any of the subscript expressions are null. Also, null is returned if a subscript is outside the array bounds (this case does not raise an error). For example, if schedule currently has the dimensions [1:3][1:2] then referencing schedule[3][3] yields NULL. Similarly, an array reference with the wrong number of subscripts yields a null rather than an error.
An array slice expression likewise yields null if the array itself or any of the subscript expressions are null. However, in other cases such as selecting an array slice that is completely outside the current array bounds, a slice expression yields an empty (zero-dimensional) array instead of null. (This does not match non-slice behavior and is done for historical reasons.) If the requested slice partially overlaps the array bounds, then it is silently reduced to just the overlapping region instead of returning null.
The current dimensions of any array value can be retrieved with the array_dims function:
SELECT array_dims(schedule) FROM sal_emp WHERE name = 'Carol'; array_dims ------------ [1:2][1:2] (1 row)
array_dims produces a text result, which is convenient for people to read but perhaps inconvenient for programs. Dimensions can also be retrieved with array_upper and array_lower, which return the upper and lower bound of a specified array dimension, respectively:
SELECT array_upper(schedule, 1) FROM sal_emp WHERE name = 'Carol';
array_upper
-------------
2
(1 row)
array_length will return the length of a specified array dimension:
SELECT array_length(schedule, 1) FROM sal_emp WHERE name = 'Carol';
array_length
--------------
2
(1 row)
cardinality returns the total number of elements in an array across all dimensions. It is effectively the number of rows a call to unnest would yield:
SELECT cardinality(schedule) FROM sal_emp WHERE name = 'Carol';
cardinality
-------------
4
(1 row)
8.15.4. Modifying Arrays
An array value can be replaced completely:
UPDATE sal_emp SET pay_by_quarter = '{25000,25000,27000,27000}'
WHERE name = 'Carol';
or using the ARRAY expression syntax:
UPDATE sal_emp SET pay_by_quarter = ARRAY[25000,25000,27000,27000]
WHERE name = 'Carol';
An array can also be updated at a single element:
UPDATE sal_emp SET pay_by_quarter[4] = 15000
WHERE name = 'Bill';
or updated in a slice:
UPDATE sal_emp SET pay_by_quarter[1:2] = '{27000,27000}'
WHERE name = 'Carol';
The slice syntaxes with omitted lower-bound and/or upper-bound can be used too, but only when updating an array value that is not NULL or zero-dimensional (otherwise, there is no existing subscript limit to substitute).
A stored array value can be enlarged by assigning to elements not already present. Any positions between those previously present and the newly assigned elements will be filled with nulls. For example, if array myarray currently has 4 elements, it will have six elements after an update that assigns to myarray[6]; myarray[5] will contain null. Currently, enlargement in this fashion is only allowed for one-dimensional arrays, not multidimensional arrays.
Subscripted assignment allows creation of arrays that do not use one-based subscripts. For example one might assign to myarray[-2:7] to create an array with subscript values from -2 to 7.
New array values can also be constructed using the concatenation operator, ||:
SELECT ARRAY[1,2] || ARRAY[3,4];
?column?
-----------
{1,2,3,4}
(1 row)
SELECT ARRAY[5,6] || ARRAY[[1,2],[3,4]];
?column?
---------------------
{{5,6},{1,2},{3,4}}
(1 row)
The concatenation operator allows a single element to be pushed onto the beginning or end of a one-dimensional array. It also accepts two N-dimensional arrays, or an N-dimensional and an N+1-dimensional array.
When a single element is pushed onto either the beginning or end of a one-dimensional array, the result is an array with the same lower bound subscript as the array operand. For example:
SELECT array_dims(1 || '[0:1]={2,3}'::int[]);
array_dims
------------
[0:2]
(1 row)
SELECT array_dims(ARRAY[1,2] || 3);
array_dims
------------
[1:3]
(1 row)
When two arrays with an equal number of dimensions are concatenated, the result retains the lower bound subscript of the left-hand operand’s outer dimension. The result is an array comprising every element of the left-hand operand followed by every element of the right-hand operand. For example:
SELECT array_dims(ARRAY[1,2] || ARRAY[3,4,5]); array_dims ------------ [1:5] (1 row) SELECT array_dims(ARRAY[[1,2],[3,4]] || ARRAY[[5,6],[7,8],[9,0]]); array_dims ------------ [1:5][1:2] (1 row)
When an N-dimensional array is pushed onto the beginning or end of an N+1-dimensional array, the result is analogous to the element-array case above. Each N-dimensional sub-array is essentially an element of the N+1-dimensional array’s outer dimension. For example:
SELECT array_dims(ARRAY[1,2] || ARRAY[[3,4],[5,6]]); array_dims ------------ [1:3][1:2] (1 row)
An array can also be constructed by using the functions array_prepend, array_append, or array_cat. The first two only support one-dimensional arrays, but array_cat supports multidimensional arrays. Some examples:
SELECT array_prepend(1, ARRAY[2,3]);
array_prepend
---------------
{1,2,3}
(1 row)
SELECT array_append(ARRAY[1,2], 3);
array_append
--------------
{1,2,3}
(1 row)
SELECT array_cat(ARRAY[1,2], ARRAY[3,4]);
array_cat
-----------
{1,2,3,4}
(1 row)
SELECT array_cat(ARRAY[[1,2],[3,4]], ARRAY[5,6]);
array_cat
---------------------
{{1,2},{3,4},{5,6}}
(1 row)
SELECT array_cat(ARRAY[5,6], ARRAY[[1,2],[3,4]]);
array_cat
---------------------
{{5,6},{1,2},{3,4}}
In simple cases, the concatenation operator discussed above is preferred over direct use of these functions. However, because the concatenation operator is overloaded to serve all three cases, there are situations where use of one of the functions is helpful to avoid ambiguity. For example consider:
SELECT ARRAY[1, 2] || '{3, 4}'; -- the untyped literal is taken as an array
?column?
-----------
{1,2,3,4}
SELECT ARRAY[1, 2] || '7'; -- so is this one
ERROR: malformed array literal: "7"
SELECT ARRAY[1, 2] || NULL; -- so is an undecorated NULL
?column?
----------
{1,2}
(1 row)
SELECT array_append(ARRAY[1, 2], NULL); -- this might have been meant
array_append
--------------
{1,2,NULL}
In the examples above, the parser sees an integer array on one side of the concatenation operator, and a constant of undetermined type on the other. The heuristic it uses to resolve the constant’s type is to assume it’s of the same type as the operator’s other input — in this case, integer array. So the concatenation operator is presumed to represent array_cat, not array_append. When that’s the wrong choice, it could be fixed by casting the constant to the array’s element type; but explicit use of array_append might be a preferable solution.
8.15.5. Searching in Arrays
To search for a value in an array, each value must be checked. This can be done manually, if you know the size of the array. For example:
SELECT * FROM sal_emp WHERE pay_by_quarter[1] = 10000 OR
pay_by_quarter[2] = 10000 OR
pay_by_quarter[3] = 10000 OR
pay_by_quarter[4] = 10000;
However, this quickly becomes tedious for large arrays, and is not helpful if the size of the array is unknown. An alternative method is described in Section 9.24. The above query could be replaced by:
SELECT * FROM sal_emp WHERE 10000 = ANY (pay_by_quarter);
In addition, you can find rows where the array has all values equal to 10000 with:
SELECT * FROM sal_emp WHERE 10000 = ALL (pay_by_quarter);
Alternatively, the generate_subscripts function can be used. For example:
SELECT * FROM
(SELECT pay_by_quarter,
generate_subscripts(pay_by_quarter, 1) AS s
FROM sal_emp) AS foo
WHERE pay_by_quarter[s] = 10000;
This function is described in Table 9.65.
You can also search an array using the && operator, which checks whether the left operand overlaps with the right operand. For instance:
SELECT * FROM sal_emp WHERE pay_by_quarter && ARRAY[10000];
This and other array operators are further described in Section 9.19. It can be accelerated by an appropriate index, as described in Section 11.2.
You can also search for specific values in an array using the array_position and array_positions functions. The former returns the subscript of the first occurrence of a value in an array; the latter returns an array with the subscripts of all occurrences of the value in the array. For example:
SELECT array_position(ARRAY['sun','mon','tue','wed','thu','fri','sat'], 'mon');
array_position
----------------
2
(1 row)
SELECT array_positions(ARRAY[1, 4, 3, 1, 3, 4, 2, 1], 1);
array_positions
-----------------
{1,4,8}
(1 row)
Tip
Arrays are not sets; searching for specific array elements can be a sign of database misdesign. Consider using a separate table with a row for each item that would be an array element. This will be easier to search, and is likely to scale better for a large number of elements.
8.15.6. Array Input and Output Syntax
The external text representation of an array value consists of items that are interpreted according to the I/O conversion rules for the array’s element type, plus decoration that indicates the array structure. The decoration consists of curly braces ({ and }) around the array value plus delimiter characters between adjacent items. The delimiter character is usually a comma (,) but can be something else: it is determined by the typdelim setting for the array’s element type. Among the standard data types provided in the PostgreSQL distribution, all use a comma, except for type box, which uses a semicolon (;). In a multidimensional array, each dimension (row, plane, cube, etc.) gets its own level of curly braces, and delimiters must be written between adjacent curly-braced entities of the same level.
The array output routine will put double quotes around element values if they are empty strings, contain curly braces, delimiter characters, double quotes, backslashes, or white space, or match the word NULL. Double quotes and backslashes embedded in element values will be backslash-escaped. For numeric data types it is safe to assume that double quotes will never appear, but for textual data types one should be prepared to cope with either the presence or absence of quotes.
By default, the lower bound index value of an array’s dimensions is set to one. To represent arrays with other lower bounds, the array subscript ranges can be specified explicitly before writing the array contents. This decoration consists of square brackets ([]) around each array dimension’s lower and upper bounds, with a colon (:) delimiter character in between. The array dimension decoration is followed by an equal sign (=). For example:
SELECT f1[1][-2][3] AS e1, f1[1][-1][5] AS e2
FROM (SELECT '[1:1][-2:-1][3:5]={{{1,2,3},{4,5,6}}}'::int[] AS f1) AS ss;
e1 | e2
----+----
1 | 6
(1 row)
The array output routine will include explicit dimensions in its result only when there are one or more lower bounds different from one.
If the value written for an element is NULL (in any case variant), the element is taken to be NULL. The presence of any quotes or backslashes disables this and allows the literal string value “NULL” to be entered. Also, for backward compatibility with pre-8.2 versions of PostgreSQL, the array_nulls configuration parameter can be turned off to suppress recognition of NULL as a NULL.
As shown previously, when writing an array value you can use double quotes around any individual array element. You must do so if the element value would otherwise confuse the array-value parser. For example, elements containing curly braces, commas (or the data type’s delimiter character), double quotes, backslashes, or leading or trailing whitespace must be double-quoted. Empty strings and strings matching the word NULL must be quoted, too. To put a double quote or backslash in a quoted array element value, precede it with a backslash. Alternatively, you can avoid quotes and use backslash-escaping to protect all data characters that would otherwise be taken as array syntax.
You can add whitespace before a left brace or after a right brace. You can also add whitespace before or after any individual item string. In all of these cases the whitespace will be ignored. However, whitespace within double-quoted elements, or surrounded on both sides by non-whitespace characters of an element, is not ignored.
Tip
The ARRAY constructor syntax (see Section 4.2.12) is often easier to work with than the array-literal syntax when writing array values in SQL commands. In ARRAY, individual element values are written the same way they would be written when not members of an array.
I’m having an issue with inserting a simple array of integers into my table in Postgres via a procedure. The array of integers is declared within a composite type and I’m trying to insert an array of these types via the procedure.
Just to put this out there: this code works without the array of numbers (i.e. if I were to just remove the variable as_ids from the table, composite type, and procedure, the code runs the way its supposed to. for some reason it just doesn’t work with the array).
The table
CREATE TABLE user_ans(
ans_id INT GENERATED ALWAYS AS IDENTITY,
fq_id INT NOT NULL,
p_id INT NOT NULL,
j_id INT NOT NULL,
u_id INT NOT NULL,
d_id INT,
ans TEXT NOT NULL,
as_ids INT[] NOT NULL,
created TIMESTAMP,
updated TIMESTAMP
);
The composite type
CREATE TYPE new_ans_obj AS (
ans TEXT,
as_ids INT[],
created TIMESTAMP,
d_id INT,
fq_id INT,
j_id INT,
p_id INT,
u_id INT
);
The procedure
CREATE OR REPLACE PROCEDURE add_ans_arr (
new_ans new_ans_obj[]
)
LANGUAGE plpgsql
AS $$
BEGIN
INSERT INTO user_ans(ans, as_ids, created, d_id, fq_id, j_id, p_id, u_id)
SELECT * from unnest(new_ans);
COMMIT;
END;$$;
Attempts
Command I use:
call add_ans_arr((ARRAY['(sdf,{2002,2005},2021-01-19T21:48:28.997Z,1001,7001,3,6001,1)', '(sdf,{2002,2005},2021-01-19T21:48:29.626Z,1001,7002,3,6001,1)'])::new_ans_obj[]);
Output:
ERROR: malformed array literal: "{2002"
LINE 1: call add_ans_arr((ARRAY['(sdf,{2002,2005},2021-01-19T21:4...
^
DETAIL: Unexpected end of input.
Command I use:
call add_ans_arr((ARRAY['(sdf,(ARRAY[2002,2005])::int[],2021-01-19T21:48:28.997Z,1001,7001,3,6001,1)', '(sdf,(ARRAY[2002,2005])::int[],2021-01-19T21:48:29.626Z,1001,7002,3,6001,1)'])::new_ans_obj[]);
Output:
ERROR: malformed array literal: "(ARRAY[2002"
LINE 1: call add_ans_arr((ARRAY['(sdf,(ARRAY[2002,2005])::int[],2021...
^
DETAIL: Array value must start with "{" or dimension information.
Post obvious attempts
I’ve also tried different variations of the two above commands (using parenthesis, putting the size of the array in, etc), but with similar outputs. I’ve read other posts about inserting arrays into Postgres, as well as the documentation and it seems like I’m using the right syntax (although probably not)?
I was thinking that the array of integers might be conflicting with the ‘unnest’ function, so I rewrote the procedure to following, but still the same problem pops up:
CREATE OR REPLACE PROCEDURE add_ans_arr (
arr new_ans_obj[]
)
LANGUAGE plpgsql
AS $$
DECLARE
ans_obj new_ans_obj;
BEGIN
FOREACH ans_obj IN ARRAY arr
LOOP
INSERT INTO user_ans(ans, as_ids, created, d_id, fq_id, j_id, p_id, u_id)
VALUES (ans_obj.ans, ans_obj.as_ids, ans_obj.created, ans_obj.d_id, ans_obj.fq_id, ans_obj.j_id, ans_obj.p_id, ans_obj.u_id);
END LOOP;
COMMIT;
END;$$;
I’m able to individually insert these objects into the table:
insert into user_ans(ans, as_ids, created, d_id, fq_id, j_id, p_id, u_id) VALUES ('lala', '{2002}', '2021-01-19T21:48:29.626Z', 1001, 7002, 3, 6001, 1);
But I don’t really understand why the above method isn’t working? I’ve tried putting the single quotes into the my first command, but I just get a syntax error. Also I don’t want to mess too much with the
ARRAY['','']::ans_obj[]
structure because it works for the rest of my other procedures, and this structure is generated by my server. Although I’m open to change it the server-side code if there’s something horribly wrong with this structure, but again – it works for the rest of my stored procedures.
Any direction/help would be greatly appreciated.