Эта переменная ошибки определяет действие, которое должно быть предпринято в программе Qlik Sense при обнаружении ошибки в ходе выполнения скрипта.
Синтаксис:
ErrorMode
Аргументы:
| Аргумент | Описание |
|---|---|
| ErrorMode=1 | Настройка по умолчанию. Выполнение скрипта останавливается, и пользователь получает запрос на выполнение действия (в непакетном режиме). |
| ErrorMode =0 | Программа Qlik Sense просто проигнорирует ошибку и продолжит выполнение скрипта со следующего оператора скрипта. |
| ErrorMode =2 |
Программа Qlik Sense отобразит сообщение об ошибке «Сбой выполнения скрипта…» при возникновении ошибки без предварительного запроса о действии пользователя. |
Пример:
set
ErrorMode=0;
Сегодня, в этой статье, мы поговорим о системных переменных по работе с ошибками «Error Variables» и о том, как и где их можно использовать в своем приложении.
В Qlik Sense и QlikView «ErrorVariables» доступны для:
- Определения, какие действия следует предпринять, если во время выполнения сценария возникает ошибка
- Предоставления информации об ошибках, возникающих во время выполнения сценария
В этой статье мы рассмотрим следующие четыре переменные «ErrorVariables»:
- ErrorMode
- ScriptError
- ScriptErrorCount
- ScriptErrorList
Из этих 4 переменных, только одна переменная ErrorMode является переменной, задаваемой пользователем. Эта переменная определяет, что должно произойти, если во время выполнения скрипта возникает ошибка. Эта переменная устанавливается в скрипте следующим образом:

Переменная ErrorMode может принимать одно из трех значений: 0, 1 или 2. По умолчанию, переменная ErrorMode устанавливается в значение 1. Это означает, что при возникновении ошибки при выполнении скрипта скрипт остановится и предложит пользователю выполнить действие. Если для переменной ErrorMode установлено значение 0, то ошибка будет проигнорирована, и выполнение скрипта будет продолжено. Если для параметра ErrorMode установлено значение 2, сценарий завершится с ошибкой и остановится. Переменная ErrorMode должна быть установлена в начале сценария или перед секцией скрипта, где вы знаете, что могут возникнуть ошибки, которые вы хотели бы обработать особенным способом. Как только параметр ErrorMode будет установлен, он останется прежним, если переменная ErrorMode не будет перезагружена / изменена позже в скрипте. Например, вы можете установить для переменной ErrorMode значение 0, если в вашем скрипте есть область, которая может вызывать ошибки, которые вы хотели бы игнорировать (не останавливать выполнение сценария). В этом случае вам может потребоваться установить ErrorMode обратно в 1, если вы хотите, чтобы в дальнейшем сообщалось о других ошибках в скрипте.
Посмотрим, как будут отображаться сообщения об ошибках, если мы запустим простой сценарий ниже, чтобы загрузить группу файлов Excel, которые начинаются с «Book». Обратите внимание, что все загружаемые файлы не включают поле «MonthlySales».

Если перед этим скриптом, переменную ErrorMode выставили в значение «0» (SetErrorMode= 0), то когда скрипт завершит свою работы мы увидим следующее:

Обратите внимание, что скрипт завершил выполнение, хотя произошла ошибка. Теперь посмотрим, что произойдет, если мы оставим значение по умолчанию (ErrorMode= 1) или установим ErrorMode= 2.

Здесь выполнение скрипта остановилось при возникновении ошибки, предоставив возможность нажать кнопку «Close», исправить сценарий и перезагрузить данные снова.
В отличие от переменной ErrorMode переменные ScriptError, ScriptErrorCount и ScriptErrorList инициализируются не пользователем, а самой системой Qlik Sense или QlikView, которые предоставляют информацию об ошибке, которая была обнаружена при выполнении скрипта. Переменная ScriptError вернет код ошибки. Список кодов ошибок и их описания можно найти в справке Qlik Sense (или QlikView). ScriptErrorCount возвращает количество операторов, вызвавших ошибку во время выполнения скрипта. Наконец, переменная ScriptErrorList возвращает список ошибок, возникающих при выполнении сценария. Если имеется более одной ошибки, они разделяются переносом строки. Эти ошибки могут быть доступны в скрипте или через пользовательский интерфейс. В скрипте вы можете просто ссылаться на переменную ScriptError, чтобы найти его значение. Например, в приведенном ниже скрипте я могу проверить код ошибки 8 («Файл не найден»), чтобы определить, отсутствует ли загружаемый файл.

Переменные «ErrorVariables» также могут быть доступны в пользовательском интерфейсе через объект «Текст и изображение» (Text & image). В измерении объекта «Text& image» просто введите знак равенства и имя переменной:

Чтобы вернуть что-то вроде этого:

Переменные «ErrorVariables» полезны и просты в использовании. Например, мы, в своих проектах, чаще всего используем ErrorMode= 0 там где мы предполагаем, что существует вероятность того, что скрипт может вернуть ошибку, которую можно игнорировать. Это также полезно, если вам нужно контролировать путь выполнения скрипта на основе ошибки. Вы можете узнать больше об ошибках в справке Qlik Sense (или QlikView).

Contents
- 1 Обработка ошибок в Qlikview
- 1.1 ErrorMode
- 1.2 ScriptError
- 1.3 ScriptErrorDetails
- 1.4 ScriptErrorCount
- 1.5 ScriptErrorList
Существует пять специальных переменных, которые можно использовать для обработки ошибок в сценарии:
- ErrorMode
- ScriptError
- ScriptErrorDetails
- ScriptErrorCount
- ScriptErrorList
ErrorMode
Определяет действие, которое будет выполнено QlikView при возникновении ошибки во время выполнения сценария. По умолчанию переменная равна 1 (ErrorMode=1), скрипт остановится и пользователю будет предложено ввести действие («non-batch» режим). С помощью значения параметра ErrorMode=0 QlikView будет игнорировать ошибки и продолжит выполнение скрипта со следующего оператора сценария. Если установить ErrorMode=2, то QlikView выдаст сообщение «Выполнение скрипта не удалось…» при неудаче сразу же, без запроса действия от пользователя.
Пример:
ScriptError
Код ошибки последнего выполненного участка кода. Эта переменная сбрасывается в 0 после каждого успешно выполненного участка скрипта (сценария загрузки). Если произошла ошибка, то значению переменной будет присвоен код внутренней ошибки QlikView. Код ошибки представляет собой двойное значение из числа и текстового значения.
Коды ошибок:
- 1 No Error — 1 Нет ошибки;
- 2 General Error — 2 Общая ошибка;
- 3 Syntax Error — 3 Ошибка синтаксиса;
- 4 General ODBC Error — 4 Общая ошибка ODBC;
- 5 General OLEDB Error — 5 Общая ошибка OLE DB;
- 6 General XML Error — 6 Общая ошибка XML;
- 7 General HTML Error — 7 Общая ошибка HTML;
- 8 File Not Found — 8 Файл не найден;
- 9 Database Not Found — 9 База данных не найдена;
- 10 Table Not Found — 10 Таблица не найдена;
- 11 Field Not Found — 11 Поле не найдено;
- 12 File Has Wrong Format — 12 Неверный формат файла;
Пример:
|
set ErrorMode=0; load * from abc.csv; if ScriptError=8 then exit script; //no file; end if |
Есть еще один способ, который можно использовать:
|
set ErrorMode=0; load * from abc.csv; if ‘$(ScriptError)’=‘File Not Found’ then exit script; end if |
ScriptErrorDetails
Возвращает подробное описание ошибки для некоторых кодов, которые были указаны выше. Самое главное это то, что переменная будет содержать сообщение об ошибке, которое возвращает драйвер ODBC и OLEDB для кодов ошибок 3 и 4.
ScriptErrorCount
Возвращает общее количество участков кода (statements), которые привели к ошибках во время выполнения сценария загрузки. Эта переменная всегда сбрасывается в 0 в начале выполнения скрипта.
Пример:
|
Set ErrorMode=0; Load * from abc.csv; if ScriptErrorCount >= 1 then exit script; end if |
ScriptErrorList
Эта переменная будет содержать объединенный перечень всех ошибок скрипта, которые произошли в ходе последней загрузки. Каждая ошибка — это отдельная строка. Значения всех вышеприведенных переменных сохраняется после выполнения скрипта. Значения ScriptError, ScriptErrorDetailed, ScriptErrorCount и ScriptErrorList для обработки ошибок в скрипте зависят от использования ErrorMode = 0.
While error handling in a Qlik Sense mashup is not automatic, and the documentation is not that good, it’s really not that difficult to get it right. But there are a few things you need to know.
Why do you need it?
Your mashup might work perfectly well when you are testing it. All code is verified, all object id’s refer to objects that actually exist in the app, you have solved the problem with appid’s that differ between your development environment and production. Still there are situations where you need your error handling:
- unauthorized users: the Qlik Sense hub makes sure to only show apps the user has access to, but for mashups there is no such mechanism, so it’s up to you to handle this situation. Qlik Sense will not allow the user to actually open the app, but he will probably be able to open the mashup, so you will need to handle the situation where he has no access to the app
- timeout: if your users are inactive, their sessions will be closed. This means that they will not be able to continue (or restart) working in your mashup without reconnecting, most likely by doing a reload of the mashup. You need to tell the user what has happened and what they should do.
Api support
To help you with this is the setOnError method. It allows you to register a function that is called whenever an error occurs. This is both for errors that are the result of a call, like opening an app that does not exist (or the user is not authorized to access), and errors that are generated from the server, like timeouts. Obviously a good start is to display the error.
qlik.setOnError(function (error) {
// TODO:error handling
console.log('Qlik error', error);
$("#errmsg").html(error.message).parent().show();
});
Or perhaps, a angular version:
//create an array for errors
$scope.errors = [];
qlik.setOnError(function (error) {
// TODO:error handling
console.log('Qlik error', error);
$scope.errors.push(error);
});
and in your template something like this:
<div ng-repeat="err in errors" class="alert">{{err.message}}</div>
Then just add a button for clearing errors ($scope.errors.length = 0 would do the trick) add some styling and you’ve got a first attempt.
Add some intelligence
But for some errors showing the error is not enough. For example if the user gets a timeout, he needs to refresh before continuing to work. If the user has no access the rest of your mashup will probably be empty (well if you show data from other sources they might be available).
To do this we need to use the error code we get with the message. As far as I know there is no official documentation of Qlik Sense error codes, but if you’ve got Qlik Sense desktop installed, you can easily find one. Just start Qlik Sense Desktop and in your browser go to:
http://localhost:4848/resources/translate/en-US/engine.js
As you might have guessed, this file contains, among other things, error code from QIX Engine. After you formatted this file, you will find something like this in it:
"ErrorCode.-128": "Internal engine error", "ErrorCode.-1": "Unknown error", "ErrorCode.0": "Unknown error", "ErrorCode.1": "Some data is not correctly specified.", "ErrorCode.2": "The resource could not be found.", "ErrorCode.3": "Resource already exists.", "ErrorCode.4": "Invalid path", "ErrorCode.5": "Access is denied", "ErrorCode.6": "The system is out of memory.", "ErrorCode.7": "Not initialized", "ErrorCode.8": "Invalid parameters", "ErrorCode.9": "Some parameters are empty.", "ErrorCode.10": "Internal error", "ErrorCode.11": "Corrupted data", "ErrorCode.12": "Memory inconsistency", "ErrorCode.13": "Action was aborted unexpectedly.", "ErrorCode.14": "Validation cannot be performed at the moment. Please try again later.", "ErrorCode.15": "Operation aborted", "ErrorCode.16": "Connection lost. Make sure that Qlik Sense is running properly. If your session has timed out due to inactivity, refresh to continue working.",
So there it is, error code 16 means connection lost, so if we get that we should encourage the user to refresh, perhaps display a button or something and perhaps even disable stuff that won’t work, like selections etc.
The error code from QIX engine will be in error.code in the object that is the parameter to our error funtion, so we can simply test that:
qlik.setOnError(function (error) {
// TODO:error handling
console.log('Qlik error', error);
$scope.errors.push(error);
if(error.code === 16){
$scope.showRefresh = true;
}
});
Handle proxy errors
But we’re not quite through yet. When you install your mashup on Qlik Sense server, you’ll notice that not all error object have the ‘code’ field. That’s because proxy errors have another format. Instead of the code field, there is a method field. And they’re not in the engine.js file. Instead you need to look in:
http://localhost:4848/resources/translate/en-US/client.js
In it you will find the proxy errors:
"ProxyError.OnEngineWebsocketFailed": "Connection to the Qlik Sense engine failed for unspecified reasons. Refresh your browser or contact your system administrator.", "ProxyError.OnLicenseAccessDenied": "You cannot access Qlik Sense because you have no access pass.", "ProxyError.OnLicenseAccessDeniedPendingUserSync": "Your access pass credentials are being synced. Refresh your browser or contact your system administrator.", "ProxyError.OnNoEngineAvailable": "No available Qlik Sense engine was found. Refresh your browser or contact your system administrator.", "ProxyError.OnSessionClosed": "Your session has been closed. Refresh your browser to continue working.", "ProxyError.OnNoDataPrepServiceAvailable": "Data Profiling service is not available.", "ProxyError.OnDataPrepServiceWebsocketFailed": "Data Profiling service connection failed. Refresh your browser.", "ProxyError.OnSessionTimedOut": "Your session has timed out. Log back in to Qlik Sense to continue.",
So there we are, we need to handle also OnSessionClosed and OnSessionTimedOut. This gives us something like this:
qlik.setOnError(function (error) {
//error handling
console.log('Qlik error', error);
$scope.errors.push(error);
if(error.code === 16 || ["OnSessionTimedOut","OnSessionClosed"].indexOf(error.method)>-1){
$scope.showRefresh = true;
}
});
And that’s it, we now have error handling thats shows error messages to users and sets a flag when the user should refresh. We can then use the flag to for example display a refresh button and/or disable interactivity like selections.
Хотя Qlik Sense позволяет решать задачи аналитики разными способами, есть ряд рекомендованных подходов для обеспечения наилучшей производительности ваших приложений. Неприменение этих подходов не сделает вашу аналитику нерабочей, но может привести к проблемам при масштабировании, связанным с ростом кол-ва пользователей и объема данных, а также сложности моделей.
Рекомендации по росту производительности затрагивают 3 уровня:
- Скорость загрузки данных;
- Ресурсоемкость приложений (объем потребления оператиной памяти);
- Скорость работы визуального слоя приложений.
Начнем же.
ETL (подготовка данных)
QVD-слой. Создайте приложения подготовки данных, которые загружают данные из источников, очищают их, и сохраняют в QVD-файлы для дальнейшего использования аналитическими приложениями. Ваши скрипты станут проще, а преобразование данных не будет происходить повторно — вы сразу будете брать готовые данные.
Используйте инкрементальное обновление данных. Не перезагружайте данные из источника полностью, берите только измененные/новые данные. Остальное подтягивайте из QVD-файлов. Справка
Создайте агрегированные QVD-файлы. Не обязательно сразу давать пользователю аналитику на исходных данных. Если исходные таблицы очень большие (миллионы записей), стоит сделать их агрегированные варианты. Вместо реестра отгрузок — суммы отгрузок в разрезе Месяца, Клиента, Товара, Магазина. Кол-во строк данных сильно сократится, приложение будет работать быстрее и потреблять меньше ресурсов. При необходимости, доступ к базовыми данным можно дать с помощью функционала ODAG или Dynamic Views.
Уменьшайте уникальность данных. Чем меньше в поле уникальных записей, тем меньше ресурсов будет пореблять его обработка и визуализации. Если в исходной базе есть поле Timestamp (Дата+время), потенциально оно содержит очень много уникальных значений. Его можно разбить на 2 поля: Дата — не более 366 уникальных значений за год, и Время. Поле Время нужно округлить до необходимого уровня детализации. Если аналитика глубже часа не нужна — округляем до часа.
Упрощайте данные. Операции над числами выполняются быстрее чем операции над текстом. Более короткие значения потребляют меньше памяти. Если в ваших данных есть поля вроде GUID документа со значениями типа 0a0d25f-f415-11e5-64adfbbb-6645c, спросите себя: “реально ли для аналитики необходимо наличие именно таких значений в этом поле”? Если нет, то можно обработать поле функцией autonumber вне оператора load.
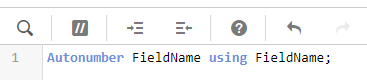
Это преобразует все уникальные значения поля в последовательные числа. Связь элементов по полю сохранится, но значения будут потреблять меньше памяти. Если нужно сохранить уникальность номера независимо от порядка загрузки — используйте функцию hash. На выходе будут конечно не числа, но уже более короткие значения чем GUID. Конечно, нужно исопльзовать это только если вам не требуется использовать оригинальные значения в аналитических целях.
Создавайте флаги для подсчетов. Суммирование (sum) работает быстрее чем подсчет (count). Заметно на больших объемах данных. Вместо подсчета уникальных элементов (count (distinct Deal_ID)) можно создать в таблице поле со значением 1, и выполнять суммирование по нему (sum(DealCountFlag))
Попробуйте перенести часть обработки данных на запрос к БД. Особенно если это касается агрегирования или сложного объединения таблиц. Однако помните, что тогда на БД будет повышенная нагрузка. Лучше комбинировать этот подход с инкрементальной загрузкой.
Excel — самый медленный формат для загрузки данных. Если есть необходимость грузить большие объемы данных из таблиц, пусть они будут в CSV.
Используйте подход preceding load для последовательного преобразования таблиц где это возможно, вместо resident. Это позволит вам ссылаться на имена рассчетных полей, не инициируя перезагрузку данных из таблицы. Кроме того, читабельность вашего кода возрастет.
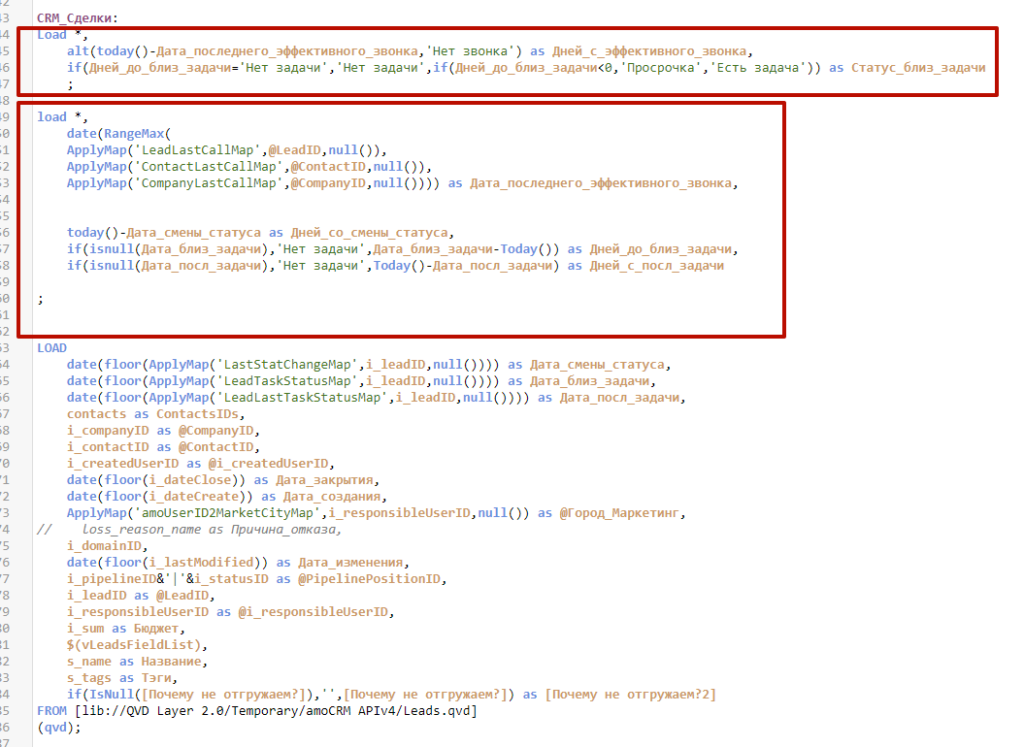
Скрипт и построение модели
Стремитесь свести модели данных к топологии Звезда (все таблицы объединены через центральную таблицу связей). Чем меньше в модели переходов между таблицами, тем быстрее работает отрисовка визуализаций.
На больших объемах данных, выносите в центральную таблицу связей также поля, по которым считаются меры. Когда переходов между таблицами нет, вычисления работают еще быстрее.
Учитывайте, что нету единой правльной топологии, т.к. существуют сценарии связи данных, которые нельзя реализовать в конкатенированных фактах, т.к. это приведет к дублированию данных (например, связи один-ко-многим).
Удаляйте временные таблицы как только они стали не нужны, а не тяните их до конца скрипта для массового уничтожения.
Используйте команду Search, чтобы в явном виде обозначить поля, для которых нужно делать индексацию интеллектуального поиска (вместо полного включения/выключения).
Не используйте DERIVED-поля на больших объемах данных. Т.к. эти поля на самом деле считаются на лету в визуальном слое (сюрприз).
Не ломайте Оптимизированную загрузку QVD-файлов. Иначе говоря — загружайте их без изменений, а ограничения по загрузке данных прописывайте только через where exist. Нужно внести изменения в данные QVD-файла — делайте это в приложении которое его формирует.
Обновляйте приложения через бинарную загрузку. У вас несколько одинаковых приложений (пользовательское и разработчика)? Создайте приложение с обычным скриптом, которое загружает данные. А в рабочие приложения загружайте данные из него с помощью Binary Load. И в них создавайте визуализации. Таким образом полноценная загрузка данных произойдет только один раз, а в 2 рабочих приложения данные попадут по ускоренной схеме. Что в итоге быстрее, чем обновлять 2 приложения через полную перезагрузку. Таким образом загружать данные в т.ч. из папки Qlik Share на сервере.
Используйте функцию FieldValue, если нужно получить список уникальных значений поля, а также минимальное или максимальное значение поля, если источник — таблица с очень большим кол-вом записей. Так вы изначально будете обращаться к только перечню уникальных значений поля, а не грузить 10 000 000 записей, а потом схлопывать до 100 уникальных. Вот такой скрипт вернет таблицу с уникальными значениями поля, и сделает это очень быстро:
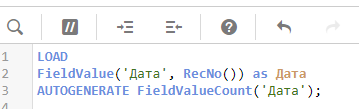
Используйте составные ключи в таблицах связи вместо первичных ключей, где это возможно. Допустим, у вас есть таблица отгрузок на 10 000 000 млн. строк, с данными за 2 года. Но если для связи с другими таблицами не нужен ее первичный ключ (ИД документа), то в таблице связей можно использовать составной ключ, содержащий комбинацию общих полей с другими таблицами и дат. Таким образом, вместо 10 000 000 первичных ключей в таблицу может попасть на порядки меньше записей на основе составного ключа, например 100 000.
Удаляйте из модели поля, которые не используются в визуальном слое. Загружать ВСЕ поля прозапас — нагружать память зря.
Визуальный слой
Используйте однотипное написание формул. sum(Sales) и Sum([Sales]) вернут одинаковый результат, но каждая формула будет вычисляться заново.
Скрывайте визуализации с большим объемом данных через функцию Ограничения вычислений. Требуйте от пользователя сначала задать фильтры, а не сразу рисуйте ему таблицу на 10 000 000 строк.
Если используете функцию AGGR, подумайте, можно ли вынести эти группировки данных в скрипт загрузки.
Не злоупотребляйте вычисляемыми измерениями. Лучше выносить формирование полей, особенно по сложным условиям, в скрипт загрузки.
Создавая динамические цвета в таблицах, по возможности ссылайтесь на уже существующие в ней данные через функцию column или указание наименований мер. Это позволит использовать уже готовые вычисления вместо повторного.
Создавая динамические формулы с переменными, конструируйте формулы так, чтобы они работали без if(). Например, нам нужно чтобы формула переключалась кнопкой между кол-вом продаж и суммой продаж. Вариант с if — создать переменную vMeasure, в которой могут быть значения 1 или 2, а в формулу написать “if($(vMeasure)=1,sum(Sales),count(distinct SaleID))”. Такую формулу сложно писать и масштабировать. Вместо этого, пишите формулы прямо в переменную. А в меру подставляйте имя переменной $(vMeasure). Так можно вогнать в одну меру бесконечное кол-во вариантов, ведь вам не надо править формулу меры каждый раз — только добавлять новый вариант значения переменной.
Вместо условий if, используйте функционал Set Analysis. Условия с if проверяют построчно весь гиперкуб (массив данных, используемый для отрисовки визуализации), а Set Analysis предварительно отбирает ограниченный массив, и по нему выполняет агрегацию.
Как не удивительно, но иногда для новичка загрузка данных в Qlik – не простая задача. Есть ряд типичных ошибок, которых можно легко избежать, поэтому ниже перечислю наиболее типичные из ошибок загрузки данных в скрипте Qlikview и расскажу, как их решить.
1. Управление запятыми
Предыстория: Написал комментарии к полям.
Вероятная причина: Забыл удалить запятую там, где сейчас находится последнее поле
Это очень частая ошибка. Понять, что причина ошибки именно в этом можно из сообщения об ошибке скрипта. Нам нужны запятые между именами полей в списке, а после последнего поля запятую мы удаляем.


Несмотря на удаленную запятую, нам все еще будет нужна точка с запятой.

НА ЗАМЕТКУ! Изучите основные правила синтаксиса скрипта, где ставится двоеточие, точка с запятой, кавычки и запятые.
2. Пропущена директория QVD
Предыстория: У меня нет описания ошибки или написано «Невозможно открыть файл корректно…»
Вероятная причина: Ссылка на несуществующую директорию с файлом.
Эта ошибка в скрипте QlikView, как правило, возникает, если мы пытаемся сохранить файл QVD в папку, которой не существует. Всегда создавайте папку для QVD, прежде чем запускать эту команду в скрипте QlikView.


Для решения этой задачи нам нужно просто добавить папку в нужную директорию, чтобы Qlik нашел путь, когда выполняется скрипт.
3. Забыл добавить дополнительные таблицы
Предыстория: Почему у меня вдруг появились синтетические ключи?
Вероятная причина: Не перетащил таблицы с помощью resident load.
Существует много случаев, когда нам нужно загрузить таблицу уже из ранее загруженных таблиц. Если мы добавили в новой таблице такие поля, которые хоть немного отличаются от предшествующих, то система не свяжет их между собой. Скорее всего, именно поэтому будет создан новый и длинный синтетический ключ. Если это похоже на ваш случай, то с большой вероятностью вы забыли добавить в скрипт первоначальную таблицу.

Вот наш скрипт. Ничего ли мы не забыли? Отметьте, что у нас появился синтетический ключ, который нам и не нужен.

Обновленный скрипт содержит выражение, чтобы удалить оригинальную таблицу, после чего лишние синтетические ключи будут удалены.

4. Таблицы не объединились
Предыстория: Я потерял новую версию таблицы.
Вероятная причина: Автоматическое объединение в процессе resident load.
Эта ошибка связана с первой вариантом ошибки работы с resident load, описанным выше. В этом же случае возникает вопрос – что случилось с моей таблице: нет ни старой, ни новой таблицы?
Все, что нам нужно помнить в этом случай, так это то, что Qlik загружает новую таблицу, которая содержит те же поля, что предыдущая. Новая таблица будет объединена со старой. Если мы добавим выражение noconcatenate, то мы решим возникшую проблему, сообщив Qlik-у, что нам не нужно объединять таблицы.

Простое добавление noconcatenate решит возникшую проблему:

5. Перекрестное соединение таблиц
Предыстория: Перезагрузка данных зависла.
Вероятная причина: Объединение без ключей.
Когда у меня впервые возникла такая ошибка, то я и не знал, что делать. Выполнение скрипта зависло и все, ничего не работает, а выполнение скрипта висело уже пять минут и ничего не менялось, что очень не похоже на QlikView. Что в это время делал Qlik? Система старательно пыталась найти связи между таблицами.
Поэтому, используя join, убедитесь, что Qlik, действительно, найдет поля с одинаковым названием и сможет объединить их. Если же поля не совпадают, то Qlik начнет связывать каждую строку одной таблицы с каждой строкой другой таблицы, что, конечно, приведет к подвисанию скрипта.
Итак, у нас была таблица 1: 100,000 строк, таблица 2: 5,000 строк
Итоговая объединенная таблица: 500,000,000
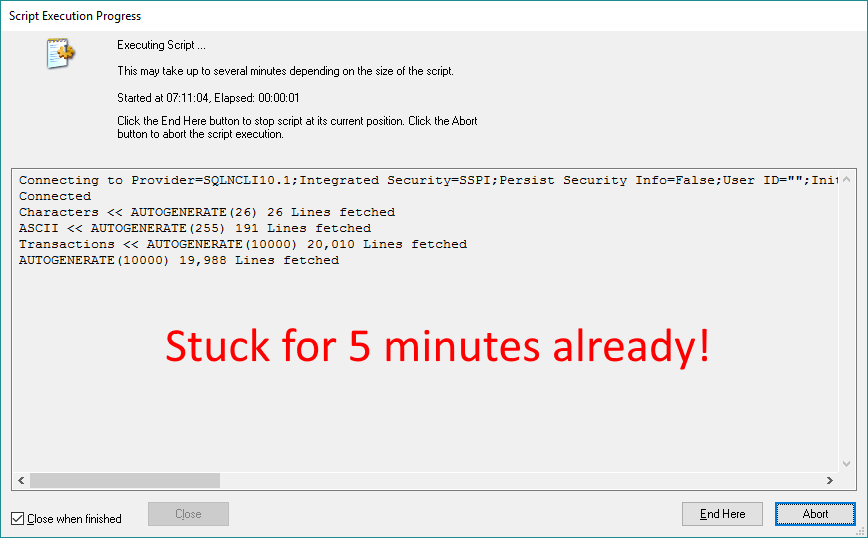
Qlik объединил каждую строку одной таблицы с другой.

Обратите внимание, что поля не имеют идентичного названия.

В этой случае у нас получилась таблица с 40 млн. строк (20,000 x 20,000)

После внесения изменений в название полей так, чтобы он соответствовали друг другу, у меня получилось 20,000 строк.
6. Повторение фактов после объединения
Предыстория: Моя объединенная таблица имеет больше записей, чем я запустил.
Вероятная причина: Повторяющиеся ключи
Представим ситуацию, что нам нужно объединить две таблицы. В случае если в таблице есть повторы, итоговая таблица будет иметь эти повторы. Для решения этой задачи стоит использовать функцию lastvalue с group by, чтобы убедиться, что нужное поле будет использоваться только один раз ID. Для того чтобы убедиться в корректности объединения строк, смотрите в обзоре таблиц, сколько строк было и стало после объединения.

Это типичное объединение таблиц, но здесь есть и одна проблема.

У нас должно получиться только 19 транзакций, но поскольку в данных Customer ID повторяется, у нас получилось 26 строк.

А вот уже откорректированный код.

Теперь мы вернулись к 19 строкам.

На этом все на сегодня. Практичных вам разработок с Qlik!