Содержание
- RabbitMQ: рукопожатие прекращено сервером (ОТКАЗ ОТ ДОСТУПА)
- 1 ответ
- Русские Блоги
- RabbitMQ не может быть подключен ([AMQP Connection XX.XX.X.XX: 5672-119] Ошибка com.rabbitmq.client.impl.forgivivexcept)
- Информация об ошибке
- Интеллектуальная рекомендация
- IView CDN Загрузка значка шрифта нормальная, а значок шрифта не может быть загружен при локальной загрузке JS и CSS
- Критическое: ошибка настройки прослушивателя приложения класса org.springframework.web.context.ContextLoaderLis
- 1086 Не скажу (15 баллов)
- Pandas применяют параллельный процесс приложения, многоядерная скорость очистки данных
- PureMVC Learning (Tucao) Примечания
- Поговорим о централизованном логировании
- Разбор полетов
- Собирать всё или только минимальный объем?
- При начале работ, исходить из метрик, или из инфраструктуры?
- Продумать уровни тревоги
- Инженерный мониторинг не отражает реальное положение дел
- Бизнес-мониторинг и мониторинг бизнес-процессов
- О логах как источнике дополнительной информации
- О логах приложения
- О логах доступа
- Трассировки
- О сборе логов
- О структуризации
- Обезличенные сообщения
- О хранении
- О связности с метриками
- О алертинге
- Заключение
RabbitMQ: рукопожатие прекращено сервером (ОТКАЗ ОТ ДОСТУПА)
Я пытаюсь отправить сообщения RabbitMQ с моего хост-компьютера на экземпляр Minikube с развернутым кластером RabbitMQ.
При запуске моего сценария отправки я получаю эту ошибку:
В лог-файлах брокера я вижу такую строку:
Я уверен, что у меня есть правильные учетные данные, поскольку я получил их непосредственно из модуля RabbitMQ, следуя официальной документации (ссылка).
Мой сценарий отправки приведен ниже:
Я знаю, что код работает, поскольку я запустил тот же сценарий для моей настройки localhost, и он сработал. Единственное, что я изменил, это URL-адрес (для сервиса Minikube RabbitMQ).
Я видел несколько других сообщений, содержащих аналогичную проблему, но большинство решений связано с включением правильных учетных данных в URI, что я и сделал.
Любые другие идеи?
1 ответ
Вы можете использовать переадресацию порта для службы rabbitMQ на локальный компьютер и использовать вход в пользовательский интерфейс и проверять пароль с помощью пользовательского интерфейса, предоставленного самим RabbitMQ.
Затем из браузера
Должно быть достаточно
Для оформления вы можете проверить, можете ли вы войти в систему из самого контейнера. В случае сбоя входа в систему из контейнера вы также можете проверить файл yaml или схему управления, которую вы используете, на предмет методов входа и учетных данных. Простой вход может быть отключен.
Другая ситуация может быть с раздачей. При развертывании RabbitMQ я стараюсь использовать графики битнами. Я могу их предложить.
Если все это не помогает, вы можете использовать другой способ. Вы можете попробовать создать другого пользователя с правами администратора для подключения к RabbitMQ, а затем продолжать его использовать.
Для получения дополнительной информации вы можете опубликовать журналы контейнеров / подов, чтобы мы их увидели. Добрый день.
Источник
Русские Блоги
RabbitMQ не может быть подключен ([AMQP Connection XX.XX.X.XX: 5672-119] Ошибка com.rabbitmq.client.impl.forgivivexcept)
Информация об ошибке
[AMQP Connection xx.xx.xx.xx:5672-119] ERROR com.rabbitmq.client.impl.ForgivingExceptionHandler 119 log — An unexpected connection driver error occured java.net.SocketException: socket closed
Мой сервер первоначально установил Rabbitmq и использовал его очень комфортно. Это около нескольких месяцев. Сегодня я хочу использовать протокол MQTT, но я представляю мне призвать эту ошибку при запуске. Взгляд агрессивного, прежде чем это было явно хорошо, почему вы внезапно были связаны? Такие вещи ненавидят больше всего.
- Первая реакция — это проблема разрешений на учетные записи, но обнаруживается, что нет проблем.
- Затем посмотрите на статус статуса Rabbitmqctl
Затем обратитесь к https://blog.csdn.net/j_shine/article/details/78833456
Найдите C: Windows System32 config SystemProfile. Существует файл .erlang.cookie. Содержимое отличается от C: user lujie.erlang.cookie, чтобы не отредактировать, затем скопируйте, затем перезагрузите Содержание, а затем перезагрузить контент. Тогда статус Rabbitmqctl нормальный, но соединение все еще неверно. Это ушло, это все еще .

После того, как я нашел эту проблему, я нашел папку DB в каталоге установки Rabbitmq. Я удалил все внутри (необходимых разрешений-> продвинутых для удаления, а затем выходить на удаление).
Перезапустить, решить.
Интеллектуальная рекомендация

IView CDN Загрузка значка шрифта нормальная, а значок шрифта не может быть загружен при локальной загрузке JS и CSS
Используйте iview, чтобы сделать небольшой инструмент. Чтобы не затронуть другие платформы, загрузите JS и CSS CDN на локальные ссылки. В результате значок шрифта не может быть загружен. Просмо.

Критическое: ошибка настройки прослушивателя приложения класса org.springframework.web.context.ContextLoaderLis
1 Обзор Серверная программа, которая обычно запускалась раньше, открылась сегодня, и неожиданно появилась эта ошибка. Интуитивно понятно, что не хватает связанных с Spring пакетов, но после удаления п.

1086 Не скажу (15 баллов)
При выполнении домашнего задания друг, сидящий рядом с ним, спросил вас: «Сколько будет пять умножить на семь?» Вы должны вежливо улыбнуться и сказать ему: «Пятьдесят три». Это.

Pandas применяют параллельный процесс приложения, многоядерная скорость очистки данных
В конкурсе Algorith Algorith Algorith Algorith Algorith 2019 года используется многофункциональная уборка номера ускорения. Будет использовать панды. Но сама панда, кажется, не имеет механизма для мно.

PureMVC Learning (Tucao) Примечания
Справочная статья:Введение подробного PrueMVC Использованная литература:Дело UnityPureMvc Основная цель этой статьи состоит в том, чтобы организовать соответствующие ресурсы о PureMVC. Что касается Pu.
Источник
Поговорим о централизованном логировании
Эта статья – продолжение текста о мониторинге. Здесь предлагаю нам с вами поговорить о роли логов в оценке состояния наблюдаемой площадки, посмотреть, что они способны нам дать, а также затронуть вопрос – «можно ли отрывать логи от метрик?».
По ходу дела я буду возвращаться к некоторым тезисам, высказанным в предыдущей публикации, потому рекомендую предварительно с ней ознакомиться.
Итак, давайте поговорим о логировании.
Кстати, а как будет правильно: лоГирование или лоГГирование? Лично я склоняюсь ко второму варианту, просто потому, что loGGing, но замечаю, что большинство предпочитает первый. А вы?
Разбор полетов
Перед началом новой статьи хочу ненадолго вернуться к предыдущей. В комментариях было поднято несколько тем, которым, на мой взгляд, стоит уделить несколько предложений.
Собирать всё или только минимальный объем?
Здесь моя позиция такова – собирать надо все метрики, которые объект способен отдавать. Как заметил @BugM они лежат в БД, есть не просят, никому не мешают. А вот если у вас их нет, но они вдруг понадобились, особенно за, допустим, прошлый месяц – тут ничего сделать не получится.
Перефразируя знаменитую пословицу о бэкапах: «люди делятся на два типа – на тех, кто собирает метрики, и тех, кто их уже собирает».
Особенно актуально это в поиске аномалий на основе ML, для которых критично важно набрать объем данных с примером корректной работы наблюдаемой площадки. Тогда, чем больше у вас информации для обучения, тем точнее потом будет работать их (аномалий) выявление и прогнозирование. Человеку трудно найти закономерности в множестве, казалось бы, разрозненной информации (иначе не было бы необходимости изобретать ML), а машина может обнаружить их в неожиданных для вас местах.
При начале работ, исходить из метрик, или из инфраструктуры?
Соблюдайте баланс. Тезис, высказанный ранее, ответу на вопрос не противоречит:
… такие метрики относятся к самому низкому доступному вам уровню инфраструктуры, с которой вы работаете
Разумеется, вам нужно отталкиваться от возможностей вашей инфраструктуры, и только потом подбирать инструменты. Я намеренно не затрагивал тему выбора инструмента для сбора метрик, конкретные технологии упоминаются исключительно в следующих этапах. Берите такой агент и такую модель сбора, которая максимально удовлетворяет ваши потребности.
Продумать уровни тревоги
Абсолютно верная мысль @sizziff которую я недостаточно раскрыл.
Если вы заводите уровень «катастрофа» и отправляете нотификацию по СМС, это должно быть оправдано на 150%, иначе, рано или поздно, ваша команда поддержки будет выглядеть так:
 Инженер, заваленный алертами
Инженер, заваленный алертами
Инженерный мониторинг не отражает реальное положение дел
Здесь @Dr_Wut приводит такой пример:
Простой пример из жизни — по всем метрикам почтовый сервер работает, а почта во вне не ходит — накосячили с spf. По итогу, пока разбирались, получили кучу претензий. А ведь достаточно было сделать простую проверку функции — отправлять письмо и проверять что оно дошло.
Если у вас возникла такая ситуация, значит, вам стоит добавить смок-тест функции, ведь результат такого теста – это тоже метрика, о чем я говорю в разделе о их разновидностях.
Бизнес-мониторинг и мониторинг бизнес-процессов
Давайте разделять эти понятия.
Мониторинг бизнес-процессов – зона ответственности «инженерного» мониторинга, о который мы с вами обсуждаем (наверное, стоило это сразу обозначить…). Задача здесь – обеспечить контроль за работоспособностью функций.
Бизнес-мониторинг и бизнес-метрики – это совершенно иная кухня, в ней шеф-повара это ваш СЕО и его окружение. Тут обеспечивается контроль за прибылью от функций вашей системы, а главный инструмент – BI-системы.
В своих статьях я не планирую затрагивать второй вид в силу отсутствия компетенций и релевантного опыта.
Теперь можем двигаться дальше.
О логах как источнике дополнительной информации
Если о мониторинге рядовой инженер имеет весьма смутное представление, то с логированием, как правило, ситуация обстоит чуть лучше, видимо, в силу того, что именно к логам обращаются в первую очередь, когда анализируют проблемы в работе софта.
Однако же, для многих становится откровением то, что логи бывают нескольких типов. Вот два самых распространенных:
Лог работы приложения – именно о нем думают в первую очередь; полагаю, вам знакома такая конструкция:
Вот это и есть запись из журнала работы. Характерные атрибуты такой записи – идентификатор уровня события и сообщение о событии. Часто также появляются имя класса/библиотеки, вызвавшей логгер, и идентификатор потока, в котором была сформирована эта запись.
Лог доступа к приложению – тут уже интереснее; это информация о том, какие функции приложения запрашивались. В подавляющем большинстве случаев это будут журналы обращения к API. Вот так, например, может выглядеть запись обращения к Nginx:
Здесь основные атрибуты уже другие – идентификатор запрошенного ресурса и информация о запросившем. Также, здесь может появляться информация о затраченных на обработку ресурсах приложения.
У обоих видов журналов также есть штамп времени – информация о том, когда событие произошло.
В этом месте я обращаюсь к разработчикам: коллеги, пожалуйста, когда настраиваете библиотеку журналирования вашего софта, сделайте так, чтобы штамп времени был полным – год, месяц, день, время с точностью до миллисекунды, таймзона операционной системы. Поверьте на слово, вам будут благодарны, ведь без полного штампа времени однозначно понять, когда произошло описанное событие, очень и очень трудно, если вообще не невозможно.
Подводя итог написанному выше, давайте ответим на вопрос «что логи могут нам дать?».
О логах приложения
В этом случае всё очень просто – если метрика сообщает нам о факте наличия ошибки, лог рассказывает, какая именно ошибка произошла.
Пример – пусть приложение работает с базой данных, тогда у неё есть счётчик ошибок database_error_count. Когда счётчик инкрементируется, мы видим, что что-то пошло не так, однако не знаем подробностей, ведь такую информацию не принято (и не стоит) выводить в метрики. Тут нам должен помочь журнал:
И сразу понятно – у нас порт недоступен.
Конечно, это идеальный вариант. На практике же, ситуация часто складывается так, что приложение «размазывает» информацию о своем состоянии по логам и метрикам, а информацию, например, о фатальной ошибке при старте, можно, по понятным причинам, понять только из журналов.
О логах доступа
Как я писал выше, с этим типом журналов всё интереснее. Во-первых, эти логи, при наличии информации о затраченных на обработку запросов ресурсах, внезапно, превращаются… в метрики!
Смотрите – в логах HTTP-запросов принято писать о запрошенном ресурсе, времени, затраченном на обработку запроса, и еще, как минимум, фиксировать код ответа, из чего уже можно получить информацию о производительности:


Более того, такие логи, если в них есть информация о авторе запроса, превращаются в инструмент аудита доступа. С ними у нас в руках появляется еще один элемент Observability – данные безопасности.
Кто и откуда запрашивал ваши ресурсы? Какие именно ресурсы? Как часто? Были ли такие запросы раньше? И еще много вопросов, на которые можно найти ответы.
На основе этих данных уже можно искать аномалии доступа:
Запросы из неизвестных источников (99% реквестов к такому-то API ранее выполнялись таким-то пользователем из такой-то локации, а теперь появился кто-то еще)
Запросы к скрытым ресурсам и функциям (кто-то ломится в непубличный API)
Множество неуспешных попыток авторизации (вас брутфорсят)
И так далее. Продолжите список в комментариях.
Уточню, что HTTP лог здесь является только примером – с тем же успехом вы можете собирать аудит лог вашей БД.
Трассировки
Еще на логах можно строить трассировки. Работает это примерно так:
Входная точка в вашей DMZ устанавливает идентификатор трассировки (trace ID) на запрос; должна быть предусмотрена возможность ручной установки!
По мере прохождения запроса по вашей инфраструктуре, приложения должны, во-первых, сохранять идентификатор неизменным, во-вторых, этим же идентификатором помечать соответствующие записи в журналах
Если такое предусмотрено вашим приложением, trace ID стоит записывать не только в лог доступа, но и в лог работы – так вам будет легче связывать ошибки с конкретными запросами.
Очень обобщенно, это можно представить следующим образом:
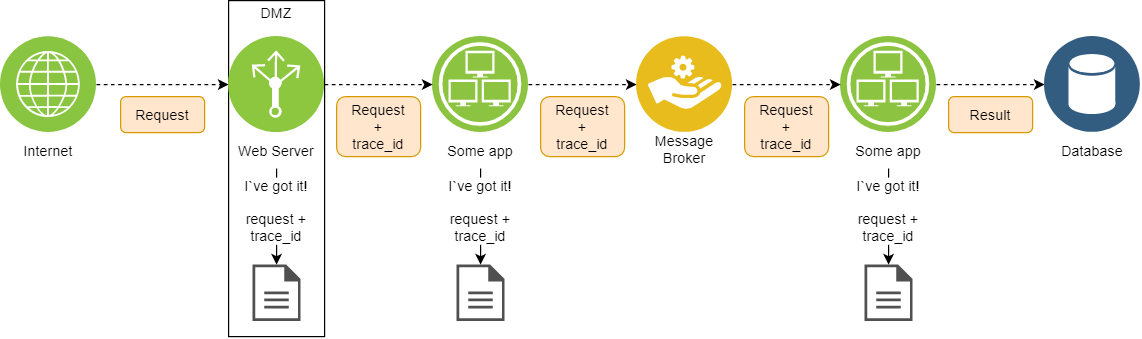
Преимущества трассировок сложно переоценить – на их основе можно, как минимум:
Строить маршруты выполнения операций и выявлять недостатки инфраструктуры
Оценивать общую их длительность; особенно это полезно в асинхронных процессах
Оценивать длительность выполнения операций на конкретных этапах и выявлять узкие места
О сборе логов
Видов взаимодействий тут снова два, прямо как с метриками – Pull и Push.
Pull – это когда приложение ведет свой журнал (в файле, в табличке в БД, в журнале операционной системы), а агент журналирования этот журнал читает, обогащает метаданными о приложении/хосте/чем-то ещё и отправляет на дальнейший парсинг и индексацию. Минус – нужно деплоить и конфигурировать агенты; плюс – приложению не нужно знать о системе централизованной обработки и хранения логов, от него требуется только вовремя писать свои журналы.
Push – приложение активно отправляет свой журнал в систему парсинга/брокер сообщений/напрямую в базу. В таком случае агент не нужен, но приложение должно знать, где находится точка для сброса логов.
На этом этапе важно добиться того, чтобы на записи из журналов ставились те же метки, что и на метрики этих приложений (как я писал в предыдущей статье, в самом примитивном виде это теги с идентификатором хоста и именем приложения), дабы сохранить возможность связать их между собой и выполнять комплексный анализ.
О структуризации
Приложение может вести логи в разных форматах – plain text, jsonl, logsft, тысячи их. Здесь ключевая задача – привести их к единому виду, и тут рекомендую начинать с определения контрактов событий.
Контракт – соглашение о том, какой минимальный набор полей должны иметь те или иные типы логов после парсинга.
Можно выделить сначала общий контракт:
А затем определять контракты для других типов.
Например, для журналов приложений:
И для журналов доступа:
Здесь очень важно соблюдать установленные контракты при передаче логов на дальнейшие индексацию и хранение.
При этом, текстовое и численное обозначения уровня события необходимо определить заранее и для каждой записи её собственный уровень приводить к одному из них.
Следование контракту приносит пользу сразу с нескольких сторон:
Упрощается индексация – многие NoSQL базы не любят, когда в рамках одного сегмента данных происходит попытка сохранить поле сначала одного типа, а затем другого. В лучшем случае, в такой ситуации вы получите неадекватно разрастающийся индекс, в худшем – ошибку при сохранении
Процесс поиска становится единообразным – когда у вас есть контракт в рамках одного типа журналов, вы можете подготовить один-два дашборда для работы с ними, просто соблюдая контракт и на этапе визуализации. С единым дашбордом можно, например, одновременно анализировать логи сразу нескольких приложений в одном интерфейсе
Только не пользуйтесь, пожалуйста, уровнем «EMERGENCY», если не уверены, что абсолютно каждый, кому предстоит работать с структурированными журналами, точно знает, что он обозначает. Я встречал очень мало таких людей, поэтому вместо него использую «FATAL» — достаточно говорящее обозначение для всех.
Обезличенные сообщения
Внимательные читатели могли заметить, что в контракте журналов приложений есть поле «generic_message». Рассказываю.
Для логов работы приложения я еще применяю такой ход – из некоторых событий вывожу дженерики (так их называли коллеги из разработки, мне понравилось обозначение).
Дженерик – это значимая часть события, приведенная к обезличенному шаблону. Вот пример:
Пусть исходное сообщение у нас такое:
Из него часть информации можно заменить на маркеры, тогда получается дженерик:
Извлекаемые значения при этом записываются в соответствующие поля события с становятся доступны для поиска.
Но что это дает? А вот что:
По дженерикам можно настраивать алерты; ошибка ошибке рознь, некоторые могут более критичными, некоторые менее. Если для критичных событий заранее подготовить паттерны, можно с помощью простых запросов ловить их появление и уведомлять об этом
Извлеченные ключи помогают в поиске; когда у вас идентификатор сессии везде называется «session_id» вы получаете возможность просто и быстро выполнять сквозной поиск
Поиск по ключам сильно проще поиска по регулярному выражению, как с точки зрения базы данных (обращаемся к индексу, а не выполняем анализ текста), так и с точки зрения пользователя (пачку регулярок еще надо заранее подготовить и хранить всегда под рукой)
Здесь важно не перегнуть палку и покрывать дженериками действительно важные записи. Злоупотребление дополнительными полями вредит здоровью ваших индексов.
О хранении
Как и в предыдущей статье, тут буду немногословен. Я предпочитаю Elasticsearch, и еще, говорят, Loki набирает популярность. На хабре можно найти несколько статей с их сравнением, вот одна из них — https://habr.com/ru/company/badoo/blog/507718/.
Ознакомьтесь, изучайте, выбирайте.
О связности с метриками
В предыдущей статье я условно разделял визуализацию так:
Уровень фрагмента объекта
Выводить информацию о логах рекомендую на все уровни, кроме последнего (а может и на него, если вы собираете журналы операционной системы).
Принцип тот же самый:
На первом уровне к логике панели-индикатора добавляется блок, связанный с подсчетом количества событий уровня ERROR и выше
На втором уровне расширяется список панелей – появляется индикатор наличия ошибок в журналах, плюс обеспечивается возможность перехода к дашборду с логами с сохранением контекста и фильтра по уровню событий (если подсвечиваем именно количество ошибок, их и нужно показывать)
На следующих уровнях пользователю предоставляется возможность перехода к дашборду с логами с сохранением контекста, но уже без фильтра по уровню – предполагается, что если пользователь совершает такой переход, то ему интересны логи всех уровней, а не только определенных
Тогда диаграмма из предыдущей статьи приобретает такой вид:
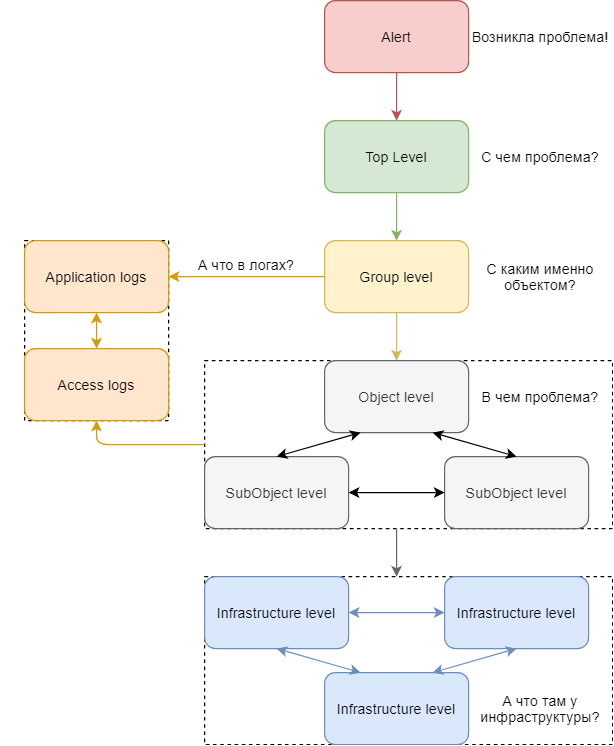 Пользователь мониторинга двигается сверху вниз, разбирая инцидент
Пользователь мониторинга двигается сверху вниз, разбирая инцидент
О алертинге
Основные тезисы были высказаны в предыдущей статье, тут ограничусь парой предложений:
Выделите критичные события и настройте по ним алертинг; это станет хорошим дополнением к уже имеющимся нотификациям и повысит наблюдаемость за площадкой
Обогащайте алерты по логам теми же метаданными, что и алерты по метрикам; для пользователя они должны быть прозрачны, ему не надо задумываться, откуда взялась та или иная нотификация
Заключение
Итак, допустимо ли отрывать логи от метрик?
Я считаю, что нет – как видите, журналы отлично дополняют картину мира и раскрывают подробности, которые метрики не всегда способны предоставить. Применяйте оба инструмента для наблюдения за вашими площадками и будет вам счастье.
Огромное спасибо всем, кто ознакомился с этой и предыдущей статьей, кто писал комментарии, ставил под сомнение высказанное и делился практиками – действительно приятно видеть отклик со стороны сообщества.
Возможно, позже появится еще одна статья, уже с примерами использования конкретных технологий и практик, в которой попробуем реализовать описанное ранее и посмотреть, как это работает.
Источник
Действия при возникновении предупреждений
Предупреждения при использовании услуг
Предупреждения AMQP
Разрыв AMQP-соединения
| ID | ecss_mycelium_mon_connection_down |
|---|---|
| Текст(en) | AMQP Connection <id> is down |
| Текст(ru) | Соединение AMQP разорвано |
| Класс | ecss::bus::amqp::connection |
| Тип | communicationsAlarm |
| Срочность | major |
| module | ecss_mycelium_mon |
| Причина | transmissionError |
| Описание | Данное предупреждение генерируется в случае разрыва AMQP-соединения между нодой и брокером. |
| Подсистема | amqp |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Предупреждения бриджей
Имя бриджа в устаревшем формате
| ID | ba_ds_resources_iface_name |
|---|---|
| Текст(en) | Iface’s name <iface_name> is obsolete in the bridge <bridge>. It should begin with prefix <prefix>. |
| Текст(ru) | Имя интерфейса <iface_name> бриджа <bridge> устарело. Имя должно начинаться с префикса <prefix>. Задекларируйте бридж снова с новым форматом интерфейсов, а также НЕ ЗАБУДЬТЕ имя в контексте маршрутизации. |
| Класс | ecss::cluster::core::pa_bridge |
| Тип | processingErrorAlarm |
| Срочность | warning |
| module | ba_ds_resources |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется в случае, если в системе задекларирован bridge, формат одного из имен интерфейсов которого является устаревшим. |
| Подсистема | bridge |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Несуществующий from домен
| ID | ba_ds_resources_from_domain_alarm |
|---|---|
| Текст(en) | Bridge <bridge> was disabled because from domain <domain> is missed |
| Текст(ru) | Бридж <bridge> выходит из домена <domain>, которого не существует |
| Класс | ecss::cluster::core::pa_bridge |
| Тип | processingErrorAlarm |
| Срочность | warning |
| module | ba_ds_resources |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется в случае, если в системе задекларирован bridge, from домен которого не существует. |
| Подсистема | bridge |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Несуществующий to домен
| ID | ba_ds_resources_to_domain_alarm |
|---|---|
| Текст(en) | Bridge <bridge> was disabled because to domain <domain> is missed |
| Текст(ru) | Бридж <bridge> указывает в домен <domain>, которого не существует |
| Класс | ecss::cluster::core::pa_bridge |
| Тип | processingErrorAlarm |
| Срочность | warning |
| module | ba_ds_resources |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется в случае, если в системе задекларирован bridge, to домен которого не существует. |
| Подсистема | bridge |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Предупреждения подсистемы обработки вызовов
Ошибка обработки вызова
| ID | oct_core_alarm_process_error |
|---|---|
| Текст(en) | Call process error. Reason: <reason> |
| Текст(ru) | Ошибка обработки вызова. Причина: <reason> |
| Класс | ecss::node |
| Тип | processingErrorAlarm |
| Срочность | major |
| module | oct_core_alarm |
| Причина | softwareProgramError |
| Описание | Данное предупреждение возникает в случае, если в ходе обработки вызова произошла ошибка, приведшая к аварийному завершению вызова. |
| Подсистема | call |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Ошибка при кодировке display_name
| ID | modificator_display_name_convert_conflict |
|---|---|
| Текст(en) | The iface property ‘support-encoding’ has conflicted value <encoding> with modificators value <encoding> |
| Текст(ru) | Свойство интерфейса «support-encoding» имеет конфликтующее значение с значениями модификаторов |
| Класс | ecss::ds::modificators::display::name::converter |
| Тип | communicationsAlarm |
| Срочность | warning |
| module | oct_common |
| Причина | outOfService |
| Описание | Данное предупреждение возникает в случае, если в контексте модификации номеров поле display name было сконвертировано в кодировку А, а на интерфейсе, в который пойдет вызов с данным display name выставлен параметр support-encoding который не равен А. |
| Подсистема | call |
| Нода | core |
|
Меры по устранению ошибки |
|
Предупреждения доступа к CDR
Невозможно открыть порт 21
| ID | bifrost_mysql_server_port_21_in_use |
|---|---|
| Текст(en) | Can’t bind port 21 — already in use. Please, solve this problem and restart node |
| Текст(ru) | Невозможно открыть порт 21, который уже используется. Освободите порт и перезагрузите ноду» |
| Класс | ecss::cluster::core::ftp |
| Тип | other |
| Срочность | major |
| module | bifrost_mysql_server |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если подсистеме доступа до CDR файлов по протоколу FTP не удалось открыть 21 порт. |
| Подсистема | cdr_ftp |
| Нода | core |
|
Меры по устранению ошибки |
|
Невозможно открыть сокет — доступ запрещен
| ID | bifrost_mysql_server_bind_socket_access |
|---|---|
| Текст(en) | Can’t bind socket — access denied. Please, solve this problem and restart node |
| Текст(ru) | Невозможно открыть сокет — доступ запрещен. Решите эту проблему и перезагрузите ноду |
| Класс | ecss::cluster::core::ftp |
| Тип | other |
| Срочность | major |
| module | bifrost_mysql_server |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если подсистеме доступа до CDR файлов по протоколу FTP не удалось открыть 21 порт из-за недостаточности прав. |
| Подсистема | cdr_ftp |
| Нода | core |
|
Меры по устранению ошибки |
|
Неопределенная авария
| ID | unspecified_alarm |
|---|---|
| Текст(en) | Unspecified alarm — <alarm> |
| Текст(ru) | Неопределенная авария — <alarm> |
| Класс | ecss::cluster::core::ftp |
| Тип | other |
| Срочность | major |
| module | bifrost_mysql_server |
| Причина | unexpectedInformation |
| Описание | Данное предупреждение генерируется в случае, если произошла неопределенная ошибка подсистемы cdr_ftp |
| Подсистема | cdr_ftp |
| Нода | core |
|
Меры по устранению ошибки |
Собрать логи с ecss-core и обратиться в техподдержку. |
Предупреждения CoCon
Возможный подбор пароля CoCon
| ID | ccn_dos_detect_server_autorization_fails_from_login |
|---|---|
| Текст(en) | There are <count> authorization fails during 5 minutes from login: <login>. Peers: <IP:port> |
| Текст(ru) | Возможный подбор пароля определенного пользователя ConCon |
| Класс | ecss::cocon::user |
| Тип | securityServiceOrMechanismViolation |
| Срочность | warning |
| module | ccn_dos_detect_server |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если в течении 5 минут было <count> неуспешных попыток авторизации в CoCon/web-конфигуратор от пользователя <login>. Так же в аларме указано, с каких IP/Port были попытки установить соединение. |
| Подсистема | cocon |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Возможный подбор логина/пароля CoCon
| ID | ccn_dos_detect_server_autorization_fails_from_system |
|---|---|
| Текст(en) | There are <count> authorization fails during 5 minutes from system. Peers: <IP:port> |
| Текст(ru) | Возможный подбор логина/пароля пользователя ConCon |
| Класс | ecss::cocon::system |
| Тип | securityServiceOrMechanismViolation |
| Срочность | warning |
| module | ccn_dos_detect_server |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если в течении 5 минут было <count> неуспешных попыток авторизации в CoCon/web-конфигуратор от разных пользователей. Так же в аларме указано, с каких IP/Port были попытки установить соединение. |
| Подсистема | cocon |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка SQL-запроса
| ID | trike_mysql_adapter_sql_request_error |
|---|---|
| Текст(en) | SQL request failed for <mysql_subsystem> subsystem. It will backed up at log file <file_name> |
| Текст(ru) | SQL запрос для подсистемы <mysql_subsystem> завершился ошибкой и был сохранен для последующего анализа в файл <file_name> |
| Класс | ecss::mysql::sql |
| Тип | environmentalAlarm |
| Срочность | critical |
| module | trike_mysql_adapter |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если при попытки выполнить SQL запрос в рамках подсистемы <mysql_subsystem> произошла ошибка. В данном случае SQL запрос, вызвавший ошибку будет записан в файл <file_name>, чтобы его можно было в будущем проанализировать и выполнить (например в случае ошибки записи CDR) |
| Подсистема | db |
| Нода | core |
|
Меры по устранению ошибки |
|
Предупреждения DS
Ошибка старта DS
| ID | ds_starter_start_node |
|---|---|
| Текст(en) | Can’t start node verion <node_version> in cluster with <cluster_version> version» |
| Текст(ru) | Попытка запустить ноду версии <node_version> на кластере версии <cluster_version> |
| Класс | ecss::cluster::ds::starter |
| Тип | qualityOfServiceAlarm |
| Срочность | critical |
| module | ds_starter |
| Причина | proceduralError |
| Описание | Ошибка старта DS, т.к. версия ПО запускаемого DS отличается от версии уже запущенного кластера |
| Подсистема | ds |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка миграции БД DS
| ID | ds_migrator_during_migrate |
|---|---|
| Текст(en) | Error during migrate from the node <nodename_DS> |
| Текст(ru) | Ошибка во время миграции базы на новой версии DS на ноду <nodename_DS> |
| Класс | ecss::cluster::ds::migration |
| Тип | qualityOfServiceAlarm |
| Срочность | critical |
| module | ds_migrator |
| Причина | proceduralError |
| Описание | Ошибка миграции базы данных на новую версию DS на ноде DS с именем <nodename_DS>. Данное предупреждение генерируется в случае, если произошла ошибка во время миграции БД на новую версию DS. |
| Подсистема | ds |
| Нода | ds |
|
Меры по устранению ошибки |
Обратиться в службу техподдержки. |
Ошибка миграции данных таблицы DS
| ID | ds_migrator_during_migrate_table |
|---|---|
| Текст(en) | Error during migrate table <some_table> on new version of DS to the node <nodename_DS>. |
| Текст(ru) | Ошибка во время миграции таблицы <some_table> на новой версии DS на ноду <nodename_DS>. |
| Класс | ecss::cluster::ds::migration |
| Тип | qualityOfServiceAlarm |
| Срочность | critical |
| module | ds_migrator |
| Причина | proceduralError |
| Описание | Ошибка миграции данных таблицы <some_table> на новую версию DS на ноде DS с именем <nodename_DS>. Данное предупреждение генерируется в случае, если произошла ошибка во время миграции данных таблицы на новую версию DS. |
| Подсистема | ds |
| Нода | ds |
|
Меры по устранению ошибки |
Обратиться в службу техподдержки. |
Предупреждения IVR
Зацикливание IVR блока «next»
| ID | loop_with_ivr_block_next_detected_without_user_interaction |
|---|---|
| Текст(en) | Loop with ivr block next is detected without user interaction. Block next: <BlockId>. Visited blocks next: <VisitedBlocksNext> |
| Текст(ru) | Обнаружено зацикливание ivr блока next без взаимодействия с пользователем. Блок next: <BlockId>. Посещенные блоки next: <VisitedBlocksNext> |
| Класс | ecss::ivr::script |
| Тип | other |
| Срочность | warning |
| module | ivr_block_next |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется в случае, если обнаружено зацикливание ivr блока next без взаимодействия с пользователем. |
| Подсистема | ivr |
| Нода | core |
|
Меры по устранению ошибки |
|
Переменная «адрес» в блоке ivr «fax-email» не получила значение
| ID | ivr_block_fax_email_address_variable_is_empty |
|---|---|
| Текст(en) | Email address variable <email_address> is empty for this caller: <digits>. So fax to email will not work |
| Текст(ru) | Переменная «адрес» в блоке ivr «fax-email» не получила значение. |
| Класс | ecss::ivr::script |
| Тип | other |
| Срочность | warning |
| module | ivr_block_fax |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется в случае, если переменная <адрес> в блоке ivr «fax-email» не получила значение |
| Подсистема | ivr |
| Нода | core |
|
Меры по устранению ошибки |
|
Предупреждения LDAP
Соединение с LDAP-сервером разорвано
| ID | alarm_encoder_ldap_connect_alarm |
|---|---|
| Текст(en) | Connection with LDAP server is lost |
| Текст(ru) | Соединение с LDAP-сервером разорвано |
| Класс | ecss::pa::sip::ldap |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | alarm_encoder |
| Причина | communicationsSubsystemFailure |
| Описание | Связь до LDAP сервера (на котором хранятся авторизационные параметры SIP-пользователей) потеряна |
| Подсистема | ldap |
| Нода | sip |
|
Меры по устранению ошибки |
|
Авария синхронизации с AD/LDAP
| ID | ldap_sync_ss_profile_alarm |
|---|---|
| Текст(en) | SS profile activation failed during AD/LDAP synchronization: <Reason> |
| Текст(ru) | Авария синхронизации с AD/LDAP при попытке активация профиля услуг. |
| Класс | ldap::sync::ss::profile |
| Тип | operationalViolation |
| Срочность | warning |
| module | ldap_user_tool_ldap |
| Причина | outOfService |
| Описание | Данное предупреждение возникает при ошибке активации профиля услуг, если потеряна синхронизация с AD/LDAP |
| Подсистема | ldap |
| Нода | ds |
|
Меры по устранению ошибки |
|
Предупреждения LPM
LPM токен отсутствует
| ID | rtop_agent_core_server_token_missed |
|---|---|
| Текст(en) | Licence token missed. Node stopped after <sec> sec. |
| Текст(ru) | LPM токен отсутствует. Нода остановлена после <sec> секунд |
| Класс | ecss::cluster::licence::token |
| Тип | equipmentAlarm |
| Срочность | critical |
| module | rtop_agent_core_server |
| Причина | equipmentMalfunction |
| Описание | Данное предупреждение генерируется в случае, если лицензионный токен не установлен в хостовую машину. Пока данное предупреждение не будет устранено — запуск DS не продолжится. |
| Подсистема | lpm |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Истек срок действия лицензии
| ID | rtopdds_bus_controller_cluster_missed_node_stop |
|---|---|
| Текст(en) | Active cluster for node <node> missed. Node stopped after <second> seconds. |
| Текст(ru) | Активный кластер для ноды <node> отсутствует. Нода остановлена после <second> секунд |
| Класс | ecss::licence::cluster |
| Тип | qualityOfServiceAlarm |
| Срочность | critical |
| module | rtopdds_bus_controller |
| Причина | keyExpired |
| Описание | Данное предупреждение генерируется в случае, если лицензия была удалена/истекла или пропала связь с DS. В результате, если новая лицензия не будет задана, нода <node> остановится через <second> секунд |
| Подсистема | lpm |
| Нода | all nodes |
|
Меры по устранению ошибки |
|
Используется лицензия по умолчанию
| ID | lpm_server_restore_to_deafult_license |
|---|---|
| Текст(en) | DS communication failed! Rolled back to default licence |
| Текст(ru) | Нет связи с DS. Используется лицензия по умолчанию |
| Класс | ecss::node_subsystem::lpm_server |
| Тип | other |
| Срочность | critical |
| module | lpm_server |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если на указанной ноде пропала связь с DS. В результате лицензия деградировала до лицензии по умолчанию. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
|
Возможен возврат к лицензии по умолчанию
| ID | lpm_storage_rollback_to_default_licence |
|---|---|
| Текст(en) | Rollback to default licence is possible |
| Текст(ru) | Возможет возврат к лицензии по умолчанию |
| Класс | ecss::node_subsystem |
| Тип | other |
| Срочность | major |
| module | lpm_storage |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если одна из лицензий в скором времени истечет, и произойдет возврат к лицензии по умолчанию. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Обратиться в службу техподдержки или коммерческий отдел для продления лицензии. |
Система перешла на использование лицензии по умолчанию
| ID | lpm_storage_rolled_back_to_default_licence |
|---|---|
| Текст(en) | Rolled back to default licence |
| Текст(ru) | Система перешла на использование лицензии по умолчанию |
| Класс | ecss::node_subsystem |
| Тип | other |
| Срочность | critical |
| module | lpm_storage |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если срок действия текущей лицензии истек, и система перешла на использование лицензии по умолчанию. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Связаться с коммерческим отделом для получения новой лицензии. |
Осталось только <count> свободных абонентских лицензий
| ID | lpm_storage_free_subscribers |
|---|---|
| Текст(en) | There are free subscribers’ licences only <count>(<percent>%) |
| Текст(ru) | Осталось только <count> свободных абонентских лицензий (<percent>%) |
| Класс | ecss::licence::limited::subscribers |
| Тип | other |
| Срочность | warning |
| module | lpm_storage |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если в системе осталось только <count> свободных абонентский лицензий (<percent> процентов от общего числа). Информирование начинается, когда свободных лицензий менее 15% |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Данное предупреждение является информационным.
|
Нет свободных абонентских лицензий
| ID | lpm_storage_license_limit |
|---|---|
| Текст(en) | There are no free subscribers’ licences. Licence limit: <Limit>, Subscribers declared: <Declared> |
| Текст(ru) | Нет свободных абонентских лицензий. Лимит лицензий: <Limit>, Создано абонентов: <Declared> |
| Класс | ecss::licence::limited::subscribers |
| Тип | other |
| Срочность | major |
| module | lpm_storage |
| Причина | outOfService |
| Описание | В системе не осталось свободных абонентских лицензий. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Необходимо связаться с коммерческим отделом, и докупить абонентские лицензии. |
Не установлен лицензионный паспорт
| ID | ds_lpm_starter_bad_passport |
|---|---|
| Текст(en) | The passport doesn’t set in the ECSS-10. You should set passport by command: «/cluster/storage/<CLUSTER_NAME>/licence/set-passport. Note: changes apply after a few seconds |
| Текст(ru) | Паспорт не задан в системе ECSS-10. Вы должны задать паспорт командой «/cluster/storage/<CLUSTER_NAME>/licence/set passport. Изменения применятся через несколько секунд. |
| Класс | ecss::cluster::ds::licence::passport |
| Тип | securityServiceOrMechanismViolation |
| Срочность | critical |
| module | ds_lpm_starter |
| Причина | proceduralError |
| Описание | Данное предупреждение генерируется в случае, если в системе не установлен лицензионный паспорт |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Паспорт не задан в системе
| ID | ds_lpm_starter_bad_passport |
|---|---|
| Текст(en) | The passport doesn’t set in the ECSS-10. You should set passport by command: «/cluster/storage/<CLUSTER_NAME>/licence/set-passport |
| Текст(ru) | Паспорт не задан в системе ECSS-10. Вы должны задать паспорт командой: «/cluster/storage/<CLUSTER_NAME>/licence/set passport. |
| Класс | ecss::cluster::ds::licence::token |
| Тип | securityServiceOrMechanismViolation |
| Срочность | critical |
| module | ds_lpm_starter |
| Причина | proceduralError |
| Описание | Данное предупреждение генерируется в случае, если установленный в системе паспорт является невалидным. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Неизвестная ошибка LPM
| ID | unspecified_alarm |
|---|---|
| Текст(en) | Unknown LPM error. Look logs for detailes |
| Текст(ru) | Неизвестная ошибка LPM. Детальное описание в логах. |
| Класс | ecss::cluster::ds::starter::licence |
| Тип | securityServiceOrMechanismViolation |
| Срочность | critical |
| module | ds_lpm_starter |
| Причина | proceduralError |
| Описание | Данное предупреждение генерируется в случае, если в системе появилась неизвестная ошибка подсистемы лицензирования. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Необходимо собрать логи с ecss-ds и обратиться в техподдержку. |
Лицензионный токен не подключен
| ID | ds_lpm_starter_bad_token |
|---|---|
| Текст(en) | DS is waiting for licence token to finish starting. Note: changes apply after a few seconds. |
| Текст(ru) | Лицензионный токен не подключен. Подключите лицензионный токен для продолжения загрузки файловой системы. Изменения будут применены после нескольких секунд» |
| Класс | ecss::cluster::ds::licence::token |
| Тип | equipmentAlarm |
| Срочность | critical |
| module | ds_lpm_starter |
| Причина | proceduralError |
| Описание | Данное предупреждение генерируется в случае, если лицензионный токен не установлен в хостовую машину. Пока данное предупреждение не будет устранено — запуск DS не продолжится. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Лицензия истекла
| ID | ds_lpm_event_handler_licence_was_expired |
|---|---|
| Текст(en) | Licence <name_licence> was expired. |
| Текст(ru) | Лицензия <name_licence> истекла. |
| Класс | ecss::licence |
| Тип | securityServiceOrMechanismViolation |
| Срочность | critical |
| module | ds_lpm_event_handler |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если период действия лицензии с именем <name_licence> истек. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Обратиться в службу техподдержки или коммерческий отдел для продления лицензии. |
Лицензия истекает
| ID | ds_lpm_event_handler_licence_be_expired |
|---|---|
| Текст(en) | The licence <name_licence> will be expired at <ExpireDate> |
| Текст(ru) | Лицензия <name_licence> истекает <ExpireDate> |
| Класс | ecss::licence |
| Тип | securityServiceOrMechanismViolation |
| Срочность | 14d — warning, 7d — minor, 2d — major, <2d — critical |
| module | ds_lpm_event_handler |
| Причина | outOfService |
| Описание | Срок лицензии с именем <name_licence> истекает в указанный срок <ExpireDate>. Данной предупреждение генерируется в случае, если срок установленной лицензии скоро истечет. Важность предупреждения изменяется в зависимости от того, как скоро истечет срок лицензии. |
| Подсистема | lpm |
| Нода | ds |
|
Меры по устранению ошибки |
Обратиться в службу техподдержки или коммерческий отдел для продления лицензии. |
Предупреждения Megaco
Ошибка запуска MEGACO транспорта
| ID | mgc_server_start_transport_error |
|---|---|
| Текст(en) | Megaco start transport error |
| Текст(ru) | Ошибка запуска MEGACO транспорта |
| Класс | ecss::pa::megaco::domain |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | mgc_server |
| Причина | communicationsSubsystemFailure |
| Описание | Данное предупреждение генерируется в случае неуспешной попытки запустить транспорт для работы со шлюзами по сети |
| Подсистема | megaco |
| Нода | megaco |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Соединение со шлюзом разорвано
| ID | pa_megaco_dc_mg_n_gateway_connect_lost |
|---|---|
| Текст(en) | Connection with gateway lost |
| Текст(ru) | Соединение со шлюзом разорвано |
| Класс | ecss::pa::megaco::gateway |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | pa_megaco_dc_mg_n |
| Причина | communicationsSubsystemFailure |
| Описание | Данное предупреждение генерируется при детектировании потери связи со шлюзом MEGACO. |
| Подсистема | megaco |
| Нода | megaco |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Предупреждения MSR
IP-адрес MSR соответствует значению по умолчанию
| ID | ecss_msr_sip_app_default_ip |
|---|---|
| Текст(en) | Ecss msr registrar listen ip(0.0.0.0) is default. Using the default configuration is not safe |
| Текст(ru) | Для MSR регистратора используемый IP-адрес (0.0.0.0) соответствует значению по умолчанию. Использование конфигурации по умолчанию не безопасно |
| Класс | ecss::cluster::core::msr::registrar |
| Тип | communicationsAlarm |
| Срочность | major |
| module | ecss_msr_sip_app |
| Причина | unexpectedInformation |
| Описание | Данное предупреждение генерируется в случае, если MSR Registrar запущен с ip(0.0.0.0) по-умолчанию. Использование ip по-умолчанию не безопасно. |
| Подсистема | msr |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Для MSR регистратора IP-адрес отсутствует
| ID | ecss_msr_sip_app_ip_not_exists |
|---|---|
| Текст(en) | Ecss msr registrar listen ip(<IP>) is not exist. |
| Текст(ru) | Для MSR регистратора IP-адрес (<IP>) отсутствует. |
| Класс | ecss::cluster::core::msr::registrar |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | ecss_msr_sip_app |
| Причина | connectionEstablishmentError |
| Описание | Данное предупреждение генерируется в случае, если <ip> адрес, сконфигурированный для подсистемы MSR Registrar, не существует. |
| Подсистема | msr |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Для MSR регистратора IP-адрес недоступен
| ID | ecss_msr_sip_app_listen_is_down |
|---|---|
| Текст(en) | Ecss msr registrar listen ip(<ip>) is down. |
| Текст(ru) | Для MSR регистратора IP-адрес (<ip>) недоступен |
| Класс | ecss::cluster::core::msr::registrar |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | ecss_msr_sip_app |
| Причина | connectionEstablishmentError |
| Описание | Данное предупреждение генерируется в случае, если сетевой интерфейс с данным <ip>, сконфигурированный для подсистемы MSR Registrar, стал недоступен. |
| Подсистема | msr |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
ECSS zmq-соединение разорвано
| ID | ecss_zmq_transport_options_handler_zmq_down |
|---|---|
| Текст(en) | ECSS ZMQ connection <Instance> down |
| Текст(ru) | ECSS zmq-соединение <Instance> разорвано |
| Класс | ecss::cluster::core::zmq |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | ecss_zmq_transport_options_handler |
| Причина | connectionEstablishmentError |
| Описание | Данное предупреждение генерируется в случае, соединение по протоколу ZMQ до MSR было разорвано. |
| Подсистема | msr |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения аварии необходимо:
|
Предупреждения подсистемы нотификаций
Ошибка отправки E-Mail
| ID | trike_email_notifier_email_alarm |
|---|---|
| Текст(en) | Send email error: <Msg> |
| Текст(ru) | Ошибка отправки E-Mail <Msg> |
| Класс | ecss::notifier::email |
| Тип | processingErrorAlarm |
| Срочность | minor |
| module | trike_email_notifier, email_notifier_srv |
| Причина | softwareProgramError |
| Описание | Данное предупреждение генерируется в случае неудачной отправки электронного письма от ECSS-10. |
| Подсистема | notifier |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Подключение к SMTP-серверу разорвано
| ID | trike_email_notifier_connect_to_smtp_refused |
|---|---|
| Текст(en) | Connection to SMTP server refused. Reason: <REASON> |
| Текст(ru) | Подключение к SMTP-серверу разорвано. Причина: <REASON> |
| Класс | ecss::notifier::email |
| Тип | processingErrorAlarm |
| Срочность | major |
| module | trike_email_notifier, email_notifier_srv |
| Причина | connectionEstablishmentError |
| Описание | Данное предупреждение генерируется в случае, если SNMP сервер ответил отказом на попытку установить соединение. |
| Подсистема | notifier |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Не удалось отправить Jabber сообщение
| ID | trike_jabber_notifier_cant_send_msg_to_jbr |
|---|---|
| Текст(en) | Can’t send message to jabber |
| Текст(ru) | Не удалось отправить Jabber сообщение |
| Класс | ecss::call_notifier::jabber |
| Тип | communicationsAlarm |
| Срочность | minor |
| module | trike_jabber_notifier, jabber_notifier_srv |
| Причина | connectionEstablishmentError |
| Описание | Данное предупреждение генерируется в случае, если не удалось отправить сообщение по Jabber-у, но при этом связь с Jabber-сервером была установлена. |
| Подсистема | notifier |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Соединение с jabber-сервером разорвано
| ID | trike_jabber_notifier_connect_failed |
|---|---|
| Текст(en) | Connect failed |
| Текст(ru) | Соединение разорвано |
| Класс | ecss::call_notifier::jabber |
| Тип | communicationsAlarm |
| Срочность | minor |
| module | trike_jabber_notifier, jabber_notifier_srv |
| Причина | connectionEstablishmentError |
| Описание | Данное предупреждение генерируется в случае, если Jabber сервер недоступен, или отклонил попытку установить соединение. |
| Подсистема | notifier |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Предупреждения Oasys
Mnesia не запущена на ноде
| ID | oasys_mnesia_error_handler_mnesia_down |
|---|---|
| Текст(en) | Mnesia database down on the node <node> |
| Текст(ru) | Mnesia не запущена на ноде |
| Класс | ecss::oasys::mnesia |
| Тип | processingErrorAlarm |
| Срочность | major |
| module | oasys_mnesia_error_handler |
| Причина | underlyingResourceUnavailable |
| Описание | Данное предупреждение генерируется в случае, если база данных mnesia была остановлена. |
| Подсистема | oasys |
| Нода | ds, mediator, sip |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Несогласованная база данных с нодой
| ID | oasys_mnesia_error_handler_inconsistent_database |
|---|---|
| Текст(en) | Mnesia database inconsistancy detected on the node <node> |
| Текст(ru) | Несогласованная база данных с нодой |
| Класс | ecss::oasys::mnesia |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | oasys_mnesia_error_handler |
| Причина | databaseInconsistency |
| Описание | Данное предупреждение генерируется в случае, если база данных mnesia перешла в неконсистентное состояние. |
| Подсистема | oasys |
| Нода | ds, mediator, sip |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка обработки базы данных
| ID | unspecified_alarm |
|---|---|
| Текст(en) | Mnesia database processing error on the node <node> |
| Текст(ru) | Ошибка обработки базы данных Mnesia на ноде |
| Класс | ecss::oasys::mnesia |
| Тип | processingErrorAlarm |
| Срочность | Major or critical |
| module | oasys_mnesia_error_handler |
| Причина | sofwareError |
| Описание | Данное предупреждение генерируется в случае, если в работе БД mnesia произошла ошибка. |
| Подсистема | oasys |
| Нода | ds, mediator, sip |
|
Меры по устранению ошибки |
Обратиться в службу техподдержки. |
Предупреждения RestFS
Ошибка удаления директории шаблона телеконференции
| ID | teleconference_template_directory_delete_error |
|---|---|
| Текст(en) | The delete error of the teleconference template’s directory on restfs, Domain: <Domain>, TemplateId: <TemplateId>, Error: <Error> |
| Текст(ru) | Ошибка удаления директории шаблона телеконференции, Domain: <Domain>, TemplateId: <TemplateId>, Error: <Error> |
| Класс | ecss::restfs |
| Тип | other |
| Срочность | warning |
| module | teleconference_template_delete |
| Причина | other |
| Описание | Данное предупреждение генерируется в случае ошибки удаления директории шаблона совещания из-за недоступности restfs кластера |
| Подсистема | restfs |
| Нода | core |
|
Меры по устранению ошибки |
Проверить состояние кластера restfs командой CLI: /restfs/list
|
Недоступен tts restfs кластер
| ID | ccn_core_service_restfs_cluster_tts_status |
|---|---|
| Текст(en) | The status of tts at restfs cluster <Name>, <Url> is not available by reason <reason> |
| Текст(ru) | Недоступен tts restfs кластер <Name>, <Url> по причине <код причины>, а также описание ошибки |
| Класс | ecss::restfs::tts::status |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | restfs_check_tts_service |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если не доступен TTS restfs кластер. Выводится сообщение содержащее код причины, а также тело ошибки |
| Подсистема | restfs |
| Нода | core |
|
Меры по устранению ошибки |
|
Пропало соединение с кластером restfs
| ID | ccn_core_service_restfs_cluster_disconnect |
|---|---|
| Текст(en) | The restfs cluster <Name> is disconnected |
| Текст(ru) | Пропало соединение с кластером restfs <Name> |
| Класс | ecss::restfs::status |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | restfs_utils |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если пропало соединение с restfs кластером |
| Подсистема | restfs |
| Нода | core |
|
Меры по устранению ошибки |
|
Предупреждения подсистемы маршрутизации
Невозможно перекомпилировать контекст
| ID | rm_ctx_manager_cant_recompile_new_compiler |
|---|---|
| Текст(en) | Routing context data compilation error |
| Текст(ru) | Невозможно перекомпилировать контекст с новой версией компилятора |
| Класс | ecss::cluster::ds::routing_manager::context |
| Тип | processingErrorAlarm |
| Срочность | major |
| module | rm_ctx_manager |
| Причина | proceduralError |
| Описание | Ошибка может возникать, если в новой версии RM-компилятор ждет новую структуру контекста |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Файл контекста маршрутизации не корректный
| ID | rm_ctx_manager_context_not_a_beam |
|---|---|
| Текст(en) | Wrong routing_context beam file format <CtxName>. Remove it from the DB |
| Текст(ru) | Файл контекста маршрутизации <CtxName> не корректный. Удалите его из базы данных |
| Класс | ecss::cluster::ds::routing_manager::context |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | rm_ctx_manager |
| Причина | corruptData |
| Описание | Ошибка загрузки контекста маршрутизации из файла. Данное предупреждение образуется в случае, если во время старта DS не удалось загрузить скомпилированный контекст маршрутизации из файла. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка чтения файла контекста маршрутизации
| ID | rm_ctx_manager_read_routing_context |
|---|---|
| Текст(en) | Error opening routing_context beam file <CtxName>. Look at logs for details |
| Текст(ru) | Во время чтения файла контекста маршрутизации <CtxName> произошла ошибка. Подробности смотрите в журнале ошибок |
| Класс | ecss::cluster::ds::routing_manager::context |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | rm_ctx_manager |
| Причина | fileError |
| Описание | Ошибка чтения контекста маршрутизации из файла. Данное предупреждение образуется в случае, если во время старта DS не удалось прочитать скомпилированный контекст маршрутизации из файла. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Не удается запустить диспетчер маршрутизации
| ID | rm_ctx_manager_inconsistent_version |
|---|---|
| Текст(en) | Cant start routing manager cause inconsistent version <my>, <remote> |
| Текст(ru) | Не удается запустить диспетчер маршрутизации, версия <my> не соответствует удаленной версии <remote> |
| Класс | ecss::cluster::ds::routing_manager |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | rm_ctx_manager |
| Причина | versionMismatch |
| Описание | Не удалось запустить RoutingManager из-за некорректной версии RM-компилятора. Данное предупреждение образуется в случае, если во время старта DS обнаружилось, что у RM на соседней ноде DS другая версия RM-компилятора. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Невозможно перекомпилировать контекст адаптации
| ID | rm_ctx_manager_cant_recompile_new_compiler |
|---|---|
| Текст(en) | Cant recompile context with new version of compiler |
| Текст(ru) | Невозможно перекомпилировать контекст с новой версией компилятора |
| Класс | adaptation_manager::context |
| Тип | other |
| Срочность | major |
| module | rm_adap_ctx_manager |
| Причина | configurationOrCustomizationError |
| Описание | Ошибка может возникать, если в новой версии AM-компилятор ждет новую структуру контекста адаптации |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Файл контекста адаптации не корректный
| ID | rm_ctx_manager_context_not_a_beam |
|---|---|
| Текст(en) | The context file <CtxName> is not a beam. Remove it from the DB. |
| Текст(ru) | Файл контекста адаптации <CtxName> не корректный. Удалите его из базы данных |
| Класс | adaptation_manager::context |
| Тип | other |
| Срочность | critical |
| module | rm_adap_ctx_manager |
| Причина | configurationOrCustomizationError |
| Описание | Ошибка загрузки контекста адаптации из файла. Данное предупреждение образуется в случае, если во время старта DS не удалось загрузить скомпилированный контекст адаптации из файла. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка чтения файла адаптации
| ID | rm_ctx_manager_read_adaptation_context |
|---|---|
| Текст(en) | Error was occured during read adaptation context file <CtxName>. Check logs for more detailes. |
| Текст(ru) | Во время чтения файла адаптации <CtxName> произошла ошибка. Подробности смотрите в журнале ошибок |
| Класс | adaptation_manager::context |
| Тип | other |
| Срочность | critical |
| module | rm_adap_ctx_manager |
| Причина | configurationOrCustomizationError |
| Описание | Ошибка чтения контекста адаптации из файла. Данное предупреждение образуется в случае, если во время старта DS не удалось прочитать скомпилированный контекст адаптации из файла. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Различные версии AM-компилятора
| ID | rm_ctx_manager_inconsistent_version |
|---|---|
| Текст(en) | Cant start adaptation manager cause inconsistent version (my: <my>, remote: <remote>) |
| Текст(ru) | Не удается запустить диспетчер адаптации, версия <my> не соответствует удаленной версии <remote> |
| Класс | adaptation_manager |
| Тип | other |
| Срочность | critical |
| module | rm_adap_ctx_manager |
| Причина | applicationSubsystemFailture |
| Описание | Не удалось запустить AdaptationManager из-за некорректной версии AM-компилятора. Данное предупреждение образуется в случае, если во время старта DS обнаружилось, что у RM на соседней ноде DS другая версия AM-компилятора. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Невозможно перекомпилировать контекст модификации
| ID | rm_ctx_manager_cant_recompile_new_compiler |
|---|---|
| Текст(en) | Cant recompile context with new version of compiler <version> |
| Текст(ru) | Невозможно перекомпилировать контекст с новой версией компилятора <version> |
| Класс | modificators_manager::context |
| Тип | other |
| Срочность | major |
| module | rm_mod_ctx_manager |
| Причина | configurationOrCustomizationError |
| Описание | Ошибка может возникать, если в новой версии MM-компилятор ждет новую структуру контекста модификации |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Файл контекста модификации некорректный
| ID | rm_ctx_manager_context_not_a_beam |
|---|---|
| Текст(en) | The context file <CtxName> is not a beam. Remove it from the DB. |
| Текст(ru) | Файл контекста модификации <CtxName> не корректный. Удалите его из базы данных |
| Класс | modificators_manager::context |
| Тип | other |
| Срочность | critical |
| module | rm_mod_ctx_manager |
| Причина | configurationOrCustomizationError |
| Описание | Ошибка загрузки контекста модификации из файла. Данное предупреждение образуется в случае, если во время старта DS не удалось загрузить скомпилированный контекст из файла. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка чтения файла модификации
| ID | rm_ctx_manager_read_modificators_context |
|---|---|
| Текст(en) | Error was occured during read modificators context file <CtxName>. Check logs for more detailes. |
| Текст(ru) | Во время чтения файла модификации <CtxName> произошла ошибка. Подробности смотрите в журнале ошибок |
| Класс | modificators_manager::context |
| Тип | other |
| Срочность | critical |
| module | rm_mod_ctx_manager |
| Причина | configurationOrCustomizationError |
| Описание | Ошибка чтения контекста модификации из файла. Данное предупреждение образуется в случае, если во время старта DS не удалось прочитать скомпилированный контекст модификации из файла. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Различные версии MM-компилятора
| ID | rm_ctx_manager_inconsistent_version |
|---|---|
| Текст(en) | Cant start modificators manager cause inconsistent version (my: <my>, remote: <remote>) |
| Текст(ru) | Не удается запустить диспетчер модификации, версия <my> не соответствует удаленной версии <remote> |
| Класс | modificators_manager |
| Тип | other |
| Срочность | critical |
| module | rm_mod_ctx_manager |
| Причина | applicationSubsystemFailture |
| Описание | Не удалось запустить ModificatonManager из-за некорректной версии MM-компилятора. Данное предупреждение образуется в случае, если во время старта DS обнаружилось, что у MM на соседней ноде DS другая версия MM-компилятора. |
| Подсистема | routing |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Некорректные параметры предупреждения в контексте маршрутизации
| ID | oct_rr_obcsm_bad_alarm |
|---|---|
| Текст(en) | Bad alarm property. Look at logs for details |
| Текст(ru) | Некорректные параметры предупреждения. Подробности смотрите в лог-файлах |
| Класс | ecss::cluster::core::cp::routing |
| Тип | processingErrorAlarm |
| Срочность | warning |
| module | oct_rr_obcsm |
| Причина | routingFailure |
| Описание | Если через контекст маршрутизации был выставлен alarm с неизвестным severity. В этом случае возникнет аларм с severity = warning |
| Подсистема | routing |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Предупреждения RPS
| ID | hw_monitor_disk_almost_full |
|---|---|
| Текст(en) | Low disk partition free space warning: <Value, %> |
| Текст(ru) | Мало свободного места на разделе <Value, %> . Название раздела указано в location данной аварии |
| Класс | host::disks |
| Тип | processingErrorAlarm |
| Срочность | critical, major, warning |
| module | hw_monitor |
| Причина | storageCapacityProblem |
| Описание | Данное предупреждение генерируется в случае, если дисковый раздел заполнен до определенного уровня. Поддерживается 3 уровня: warning, major и critical. Для каждого уровня формируется предупреждение с соответствующим «severity». |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Сетевой интерфейс недоступен
| ID | rps_if_handler_network_interface_is_down |
|---|---|
| Текст(en) | Network interface down <interface> |
| Текст(ru) | Сетевой интерфейс <interface> недоступен |
| Класс | host::network::interface |
| Тип | equipmentAlarm |
| Срочность | critical |
| module | rps_if_handler |
| Причина | inputOutputDeviceError |
| Описание | Данное предупреждение генерируется в случае, если сетевой интерфейс, за которым осуществляется мониторинг, недоступен. |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Время ноды рассинхронизировано с хостом
| ID | rps_time_monitor_time_out_of_sync_with_host |
|---|---|
| Текст(en) |
Time synchronization between host <Host> and node <Node> error. Time difference: <Time> ms. |
| Текст(ru) | Время ноды <Node> рассинхронизировано с хостом <Host> на <Time> мс |
| Класс | ecss::node::time |
| Тип | processingErrorAlarm |
| Срочность | major, critical |
| module | rps_time_monitor |
| Причина | lossOfRealTimel |
| Описание | Major — 0,6 * time_difference_threshold миллисекунд, Critical — 0,8 * time_difference_threshold миллисекунд. Данное предупреждение генерируется в случае, если время на наблюдаемой ноде и на хостовой машине расходятся на значение, больше заданной границы. |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо проверить работу NTP-сервера:
Если сервис запущен, проверить:
|
Приложение не запущено
| ID | rps_app_monitor_app_not_running |
|---|---|
| Текст(en) | Application down <AppName> |
| Текст(ru) | Приложение <AppName> не запущено |
| Класс | host::applications |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | rps_app_monitor |
| Причина | softwareError |
| Описание | Данное предупреждение генерируется в случае, если приложение, за которым осуществляется мониторинг, не запущено. |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Нода кластера не запущена
| ID | rps_tring_node_cluster |
|---|---|
| Текст(en) | Node <Node> of <Cluster> cluster terminated abnormaly |
| Текст(ru) | Нода <Node> кластера <Cluster> была остановлена в нештатном режиме |
| Класс | ecss::cluster::node |
| Тип | processingErrorAlarm |
| Срочность | major |
| module | rps_tring |
| Причина | softwareProgramAbnormallyTerminated |
| Описание | Данное предупреждение генерируется в случае, если определенная нода пропала из кластера. |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Кластер не запущен
| ID | rps_tring_cluster |
|---|---|
| Текст(en) | Cluster <Cluster> lost |
| Текст(ru) | Кластер <Cluster> не запущен |
| Класс | ecss::cluster |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | rps_tring |
| Причина | softwareProgramAbnormallyTerminated |
| Описание | Данное предупреждение генерируется в случае, если определенный кластер пропал из системы (все ноды данного кластера пропали из системы). |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Подсистема не запущена
| ID | rps_tring_sybsystem_down |
|---|---|
| Текст(en) | Subsystem <subsystem> is down |
| Текст(ru) | Подсистема <subsystem> не запущена |
| Класс | ecss::cluster |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | rps_tring |
| Причина | outOfService |
| Описание | Данное предупреждение генерируется в случае, если пропала определенная подсистема по протоколу AMQP (core, ds и т.п.). |
| Подсистема | rps |
| Нода | all nodes |
|
Меры по устранению ошибки |
|
Предупреждения Sigtran
M2UA ошибка выбора номера SCTP потока
| ID |
invalid_stream_identifier |
|---|---|
| Текст(en) | Invalid Stream Identifier |
| Текст(ru) | Неверный выбор потока |
| Класс | ecss::m2ua |
| Тип | communicationsAlarm |
| Срочность | minor |
| module | m2ua |
| Причина | outOfService |
| Описание | Ошибка при выборе SCTP потока при отправке M2UA сообщения на шлюз. |
| Подсистема | sigtran |
| Нода | core |
|
Меры по устранению ошибки |
|
Обрыв mtp-3 линка
| ID | mtp3_link_failed |
|---|---|
| Текст(en) | Mtp3 link <LikName> failed |
| Текст(ru) | mtp-3 линк оборван |
| Класс | ecss::mtp3 |
| Тип | communicationsAlarm |
| Срочность | minor |
| module | mtp3 |
| Причина | outOfService |
| Описание | Обрыв потока E1, отключение встречной станции, потеря связи со шлюзом |
| Подсистема | sigtran |
| Нода | core |
|
Меры по устранению ошибки |
|
MTP-3 направление недоступно
| ID | mtp3_destination_inaccessible |
|---|---|
| Текст(en) | Destination <DPC> inaccessible |
| Текст(ru) | mtp-3 направление <DPC> недоступно |
| Класс | ecss::mtp3 |
| Тип | communicationsAlarm |
| Срочность | major |
| module | mtp3 |
| Причина | outOfService |
| Описание | Падение всех маршрутов до указанного направления |
| Подсистема | sigtran |
| Нода | core |
|
Меры по устранению ошибки |
|
Падение всех прямых линков
| ID | mtp3_direct_links_failed |
|---|---|
| Текст(en) | All direct links to <DPC> failed |
| Текст(ru) | Падение всех прямых линков направлении <DPC> |
| Класс | ecss::mtp3 |
| Тип | communicationsAlarm |
| Срочность | minor |
| module | mtp3 |
| Причина | outOfService |
| Описание | Падение всех прямых линков до указанного направления |
| Подсистема | sigtran |
| Нода | core |
|
Меры по устранению ошибки |
|
Предупреждения SIP
Соединение с транком разорвано
| ID | alarm_encoder_trunk_connect_alarm |
|---|---|
| Текст(en) | Connection with trunk is lost.<Host>, <Port> |
| Текст(ru) | Соединение с транком разорвано.<Host>, <Port> |
| Класс | ecss::pa::sip::trunk |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | alarm_encoder |
| Причина | communicationsSubsystemFailure |
| Описание | Данное предупреждение генерируется в случае, если нет ответов на периодические запросы OPTIONS в направлении транка |
| Подсистема | sip |
| Нода | sip |
|
Меры по устранению ошибки |
Убедиться, что удаленная сторона доступна, порт открыт. |
Соединение в нодой разорвано
| ID | alarm_encoder_node_connect_alarm |
|---|---|
| Текст(en) | Connection with node is lost |
| Текст(ru) | Соединение в нодой разорвано |
| Класс | ecss::pa::sip», atom_to_list(Class)] ecss::pa::sip::node |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | alarm_encoder |
| Причина | communicationsSubsystemFailure |
| Описание | Одна из нод кластера SIP вышла из строя. |
| Подсистема | sip |
| Нода | sip |
|
Меры по устранению ошибки |
|
Соединение с абонентом разорвано
| ID | alarm_encoder_subscriber_connect_alarm |
|---|---|
| Текст(en) | Connection with subscriber is lost |
| Текст(ru) | Соединение с абонентом разорвано |
| Класс | ecss::pa::sip::user |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | alarm_encoder |
| Причина | communicationsSubsystemFailure |
| Описание | Абонент не отвечает на запросы. Сообщение генерируется в случае включения аварийных сообщений о недоступности данного абонента. |
| Подсистема | sip |
| Нода | sip |
|
Меры по устранению ошибки |
Убедиться, что абонент доступен, есть регистрация и ответы на OPTIONS. |
Предупреждения СОРМ
Соединение с SORM адаптером разорвано
| ID | sorm_trike_db_service_sorm_connection_lost |
|---|---|
| Текст(en) | Connection with SORM mediator <SormId> is lost. |
| Текст(ru) | Соединение с SORM адаптером <SormId> разорвано |
| Класс | ecss::core::sorm::connection |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | sorm_trike_db_service |
| Причина | adapterError |
| Описание | Данное предупреждение генерируется в случае, если коннекция до СОРМ посредника была остановлена/аварийно завершилась. |
| Подсистема | sorm |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Невозможно отправить сообщение на RADIUS сервер
| ID | sorm_ini2_sned_message_to_radius_failed |
|---|---|
| Текст(en) | Failed to send a RADIUS message to the SORM mediator: <Host:Port> |
| Текст(ru) | Невозможно отправить сообщение на RADIUS сервер: <Host:Port> |
| Класс | ecss::core::sorm |
| Тип | communicationsAlarm |
| Срочность | critical |
| module | sorm_ini2 |
| Причина | transmissionError |
| Описание | Данное предупреждение генерируется в случае, если подсистеме СОРМ не удалось отправить сообщение посреднику СОРМ по протоколу RADIUS. |
| Подсистема | sorm |
| Нода | core |
|
Меры по устранению ошибки |
Информационное предупреждение.
|
Предупреждения при использовании услуг
Услуга не реализована
| ID | oct_ss_versioner_ss_not_implemented |
|---|---|
| Текст(en) | Supplementary service <SSName> doesn’t implemented. Uninstall it to clean obsolete data |
| Текст(ru) | Дополнительная услуга <SSName> не реализована. Удалите ее чтобы отчистить устаревшие данные |
| Класс | ecss::cluster::core::ss |
| Тип | processingErrorAlarm |
| Срочность | warning |
| module | oct_ss_versioner |
| Причина | unexpectedInformation |
| Описание | Данное предупреждение возникает в случае, если установлено ДВО, для которого нет реализации. |
| Подсистема | ss |
| Нода | core |
|
Меры по устранению ошибки |
|
Некорректная версия услуги
| ID | oct_ss_versioner_ss_inval_cersion |
|---|---|
| Текст(en) | Supplementary service <SSName> has invalid version. You should update it |
| Текст(ru) | Дополнительная услуга <SSName> содержит некорректную версию. Необходимо обновить услугу |
| Класс | ecss::cluster::core::ss |
| Тип | processingErrorAlarm |
| Срочность | warning |
| module | oct_ss_versioner |
| Причина | versionMismatch |
| Описание | Данное предупреждение возникает в случае, если версия установленного описателя услуг <SS NAME> расходится с версией, указанной в программном коде. |
| Подсистема | ss |
| Нода | core |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Предупреждения работы кластера
SSL сертификат различаются на хостах кластера
| ID | oct_ss_versioner_ss_not_implemented |
|---|---|
| Текст(en) | The node <NODE_1> has a different certificate (<PATH>) then ~ts node(<NODE_2>) |
| Текст(ru) | Для ноды <NODE_1> сертификат по пути <PATH> различается от сертификата, находящегося на ноде <NODE_2> |
| Класс | ecss::certifiсate::validation::status |
| Тип |
securityServiceOrMechanismViolation |
| Срочность | critical |
| module | ecss_tring |
| Причина |
coruptData |
| Описание | Данное предупреждение возникает в случае, если на разных хостах кластера ECSS-10 находятся разные сертификаты с одним именем. |
| Подсистема | cluster |
| Нода | * |
|
Меры по устранению ошибки |
|
Предупреждения портала абонента
Ошибка создания пользователя
| ID | ds_sp_manager_create_user_alarm |
|---|---|
| Текст(en) | Error during creation subscriber <Address> authorisation record in subscriber portal database for domain <Domain>. Try to create user manually. |
| Текст(ru) | Произошла ошибка во время создания пользователя <Address> на домене <Domain> в портале абонента. Попробуйте создать пользователя вручную |
| Класс | ecss::cluster::ds::sp |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | ds_sp_manager |
| Причина | proceduralError |
| Описание | Не удалось создать абонента на «Портале абонента». Данное предупреждение генерируется в случае, если при попытке автоматически завести абонента на «Портале абонентов» произошла ошибка. |
| Подсистема | Subscriber-portral |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка отвязки пользователя
| ID | ds_sp_manager_unbing_user_alarm |
|---|---|
| Текст(en) | Error during unbinding subscriber <Address> authorisation record in subscriber portal database for domain <Domain>. Try to unbing user manually. |
| Текст(ru) | Произошла ошибка во время отвязки пользователя <Address> на домене <Domain> в портале абонента. Попробуйте убрать привязку пользователя вручную |
| Класс | ecss::cluster::ds::sp |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | ds_sp_manager |
| Причина | proceduralError |
| Описание | Не удалось отвязать абонента с «Портала абонента» от алиаса ECSS-10. Данное предупреждение генерируется в случае, если при попытке автоматически отвязать абонента с «Портала абонентов» от алиаса на ECSS-10 произошла ошибка. |
| Подсистема | Subscriber-portral |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Ошибка удаления пользователя
| ID | ds_sp_manager_delete_user_alarm |
|---|---|
| Текст(en) | Error during deletion subscriber <Address> authorisation record in subscriber portal database for domain <Domain>. Try to delete user manually. |
| Текст(ru) | Произошла ошибка во время удаления пользователя <Address> на домене <Domain> в портале абонента. Попробуйте удалить пользователя вручную. |
| Класс | ecss::cluster::ds::sp |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | ds_sp_manager |
| Причина | proceduralError |
| Описание | Не удалось удалить абонента с «Портала абонента». Данное предупреждение генерируется в случае, если при попытке автоматически удалить абонента с «Портала абонентов» произошла ошибка. |
| Подсистема | Subscriber-portral |
| Нода | ds |
|
Меры по устранению ошибки |
Для устранения предупреждения необходимо:
|
Предупреждения при использовании совещаний
Максимальное количество совещаний достигнуто
| ID | maximum_active_meeting_has_been_reached |
|---|---|
| Текст(en) | Maximum active meetings has been reached. |
| Текст(ru) | Максимальное количество совещаний достигнуто |
| Класс | ecss::cluster::core::teleconference::meeting |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | conference_schedule_alarm_of_start_meeting_error |
| Причина | unavailable |
| Описание | Данное предупреждение генерируется в случае достижения максимального количества совещаний, разрешенного на домене или в системе |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
|
Шаблон уже используется
| ID | template_already_use_by_another_meeting |
|---|---|
| Текст(en) | Template already used by another meeting. |
| Текст(ru) | Шаблон уже используется другим совещанием |
| Класс | ecss::cluster::core::teleconference::meeting |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | conference_schedule_alarm_of_start_meeting_error |
| Причина | unavailable |
| Описание | Данное предупреждение генерируется в случае, если шаблон уже используется другим активным совещанием |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
Для запуска нового совещания с данным шаблоном сначала завершить активное. |
Номер шаблона не принадлежит пулу номеров совещания
| ID | template_number_not_from_meeting_numbers_pool |
|---|---|
| Текст(en) | Template number not from meeting numbers pool. |
| Текст(ru) | Номер шаблона не принадлежит пулу номеров совещания |
| Класс | ecss::cluster::core::teleconference::meeting |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | conference_schedule_alarm_of_start_meeting_error |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется в случае, если на номере не активна услуга телеконференции или такого номера нет в домене. |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
|
Шаблон совещания не найден
| ID | template_not_found |
|---|---|
| Текст(en) | Template not found. |
| Текст(ru) | Шаблон совещания не найден |
| Класс | ecss::cluster::core::teleconference::meeting |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | conference_schedule_alarm_of_start_meeting_error |
| Причина | configurationOrCustomizationError |
| Описание | Данное предупреждение генерируется, когда по внутренним причинам не удалось найти шаблон. |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
Проверить правильность номера входа в совещание |
Достигнут максимум пула номеров совещания
| ID | maximum_meeting_numbers_pool_has_been_reached |
|---|---|
| Текст(en) | Maximum meeting numbers pool has been reached. |
| Текст(ru) | Достигнут максимум пула номеров совещания |
| Класс | ecss::cluster::core::teleconference::meeting |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | conference_schedule_alarm_of_start_meeting_error |
| Причина | unavailable |
| Описание | Данное предупреждение генерируется в случае достижения максимального количества участников совещания, а также разрешенного на домене или в системе |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
Ограничить количество участников совещания до максимально разрешенного. |
Ошибка старта совещания
| ID | unknown_start_meeting_error |
|---|---|
| Текст(en) | Unknown error of start meeting. |
| Текст(ru) | Ошибка старта совещания |
| Класс | ecss::cluster::core::teleconference::meeting |
| Тип | processingErrorAlarm |
| Срочность | critical |
| module | conference_schedule_alarm_of_start_meeting_error |
| Причина | softwareProgramError |
| Описание | Данное предупреждение генерируется в случае прочих ошибок при старте совещания |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
Обратиться в техподдержку |
Достигнут предел количества активных каналов
| ID | tc_ffsm_master_limit_of_active_channels |
|---|---|
| Текст(en) | Exhausted limit of count active channels <Limit> |
| Текст(ru) | Достигнут предел количества активных каналов <Limit> |
| Класс | ecss::cluster::core::tc |
| Тип | environmentalAlarm |
| Срочность | warning |
| module | tc_ffsm_master |
| Причина | keyExpired |
| Описание | Данное предупреждение возникает в случае, если количество активных каналов телеконференции превысит максимально допустимое |
| Подсистема | teleconference |
| Нода | core |
|
Меры по устранению ошибки |
Проверить свойство tc_count_active_channels, при необходимости изменить. |
Данные журнала ошибок обновлены
| ID | chronica_rps_alarm_backend_log_data_updated |
|---|---|
| Текст(en) | Error log data updated |
| Текст(ru) | Данные журнала ошибок error.log обновлены |
| Класс | ecss::system::log |
| Тип | securityServiceOrMechanismViolation |
| Срочность | critical |
| module | chronica_rps_alarm_backend |
| Причина | softwareError |
| Описание | Данное предупреждение генерируется в случае, если в подсистему логирования была занесена запись с приоритетом error |
| Подсистема | trace |
| Нода | all nodes |
|
Меры по устранению ошибки |
Связаться c техподдержкой |
Я пытаюсь отправить сообщения RabbitMQ с моего хост-компьютера на экземпляр Minikube с развернутым кластером RabbitMQ.
При запуске моего сценария отправки я получаю эту ошибку:
Handshake terminated by server: 403 (ACCESS-REFUSED) with message "ACCESS_REFUSED - Login was refused
using authentication mechanism PLAIN. For details see the broker logfile.
В лог-файлах брокера я вижу такую строку:
Error on AMQP connection <0.13226.0> (172.17.0.1:40157 -> 172.17.0.8:5672, state: starting):
PLAIN login refused: user 'rabbitmq-cluster-default-user' - invalid credentials
Я уверен, что у меня есть правильные учетные данные, поскольку я получил их непосредственно из модуля RabbitMQ, следуя официальной документации (ссылка).
Мой сценарий отправки приведен ниже:
const amqp = require('amqplib/callback_api');
const cluster = "amqp://rabbitmq-cluster-default-user:dJhLl2aVF78Gn07g2yGoRuwjXSc6tT11@192.168.49.2:30861";
amqp.connect(cluster, function(error0, connection)
{
if (error0)
{
throw error0;
}
connection.createChannel(function(error1, channel)
{
if (error1)
{
throw error1;
}
const queue = "files";
var msg = {
name: "Hello World"
};
var msgJson = JSON.stringify(msg);
channel.assertQueue(queue, {
durable: false
});
channel.sendToQueue(queue, Buffer.from(msgJson));
});
});
Я знаю, что код работает, поскольку я запустил тот же сценарий для моей настройки localhost, и он сработал. Единственное, что я изменил, это URL-адрес (для сервиса Minikube RabbitMQ).
Я видел несколько других сообщений, содержащих аналогичную проблему, но большинство решений связано с включением правильных учетных данных в URI, что я и сделал.
Любые другие идеи?
1 ответ
Лучший ответ
Вы можете использовать переадресацию порта для службы rabbitMQ на локальный компьютер и использовать вход в пользовательский интерфейс и проверять пароль с помощью пользовательского интерфейса, предоставленного самим RabbitMQ.
kubectl port-forward svc/rabbitmq UI-PORT:UI-PORT (must be 15672)
Затем из браузера
localhost:15762
Должно быть достаточно
Для оформления вы можете проверить, можете ли вы войти в систему из самого контейнера. В случае сбоя входа в систему из контейнера вы также можете проверить файл yaml или схему управления, которую вы используете, на предмет методов входа и учетных данных. Простой вход может быть отключен.
Другая ситуация может быть с раздачей. При развертывании RabbitMQ я стараюсь использовать графики битнами. Я могу их предложить.
Если все это не помогает, вы можете использовать другой способ. Вы можете попробовать создать другого пользователя с правами администратора для подключения к RabbitMQ, а затем продолжать его использовать.
Для получения дополнительной информации вы можете опубликовать журналы контейнеров / подов, чтобы мы их увидели. Добрый день.
1
Catastrophe
17 Мар 2021 в 11:42
Информация об ошибке
[AMQP Connection xx.xx.xx.xx:5672-119] ERROR com.rabbitmq.client.impl.ForgivingExceptionHandler 119 log — An unexpected connection driver error occured java.net.SocketException: socket closed
Мой сервер первоначально установил Rabbitmq и использовал его очень комфортно. Это около нескольких месяцев. Сегодня я хочу использовать протокол MQTT, но я представляю мне призвать эту ошибку при запуске. Взгляд агрессивного, прежде чем это было явно хорошо, почему вы внезапно были связаны? Такие вещи ненавидят больше всего.
- Первая реакция — это проблема разрешений на учетные записи, но обнаруживается, что нет проблем.
- Затем посмотрите на статус статуса Rabbitmqctl
C:UsersAdministrator>rabbitmqctl status
Status of node [email protected] ...
Error: unable to perform an operation on node 'xxxxxxx'. Please s
ee diagnostics information and suggestions below.
Most common reasons for this are:
* Target node is unreachable (e.g. due to hostname resolution, TCP connection o
r firewall issues)
* CLI tool fails to authenticate with the server (e.g. due to CLI tool's Erlang
cookie not matching that of the server)
* Target node is not running
In addition to the diagnostics info below:
* See the CLI, clustering and networking guides on http://rabbitmq.com/document
ation.html to learn more
* Consult server logs on node [email protected]
DIAGNOSTICS
===========
attempted to contact: [xxxxxxx]
[email protected]:
* connected to epmd (port 4369) onxxxxx
* epmd reports node 'rabbit' uses port 25672 for inter-node and CLI tool traff
ic
* TCP connection succeeded but Erlang distribution failed
* Authentication failed (rejected by the remote node), please check the Erlang
cookie
Current node details:
* node name: [email protected]
* effective user's home directory: C:UsersAdministrator
* Erlang cookie hash: xxxxxx
Затем обратитесь к https://blog.csdn.net/j_shine/article/details/78833456
Найдите C: Windows System32 config SystemProfile. Существует файл .erlang.cookie. Содержимое отличается от C: user lujie.erlang.cookie, чтобы не отредактировать, затем скопируйте, затем перезагрузите Содержание, а затем перезагрузить контент. Тогда статус Rabbitmqctl нормальный, но соединение все еще неверно. Это ушло, это все еще …
Virtual host / experienced an error on node [email protected]-rabbit and may be inaccessible
После того, как я нашел эту проблему, я нашел папку DB в каталоге установки Rabbitmq. Я удалил все внутри (необходимых разрешений-> продвинутых для удаления, а затем выходить на удаление).
Перезапустить, решить.
Автор оригинала: baeldung.
1. введение
Асинхронный обмен сообщениями-это тип слабо связанной распределенной коммуникации, который становится все более популярным для реализации архитектуры, управляемой событиями . К счастью, Spring Framework предоставляет проект Spring AMQP, позволяющий нам создавать решения для обмена сообщениями на основе AMQP.
С другой стороны, работа с ошибками в таких средах может быть нетривиальной задачей . Поэтому в этом уроке мы рассмотрим различные стратегии обработки ошибок.
2. Настройка среды
Для этого урока мы будем использовать RabbitMQ , который реализует стандарт AMQP. Кроме того, Spring AMQP предоставляет модуль spring-rabbit , который делает интеграцию очень простой.
Давайте запустим RabbitMQ как автономный сервер. Мы запустим его в контейнере Docker, выполнив следующую команду:
docker run -d -p 5672:5672 -p 15672:15672 --name my-rabbit rabbitmq:3-management
Для получения подробной конфигурации и настройки зависимостей проекта, пожалуйста, обратитесь к нашей статье Spring AMQP .
3. Сценарий Отказа
Обычно существует больше типов ошибок, которые могут возникнуть в системах обмена сообщениями по сравнению с монолитными или однопакетными приложениями из-за их распределенной природы.
Мы можем указать на некоторые типы исключений:
- Сеть- или Связанные с вводом-выводом/| – общие сбои сетевых соединений и операций ввода-вывода Протокол-
- или связанные с инфраструктурой -ошибки, которые обычно представляют собой неправильную конфигурацию инфраструктуры обмена сообщениями Связанные с брокером
- -сбои, предупреждающие о неправильной конфигурации между клиентами и брокером AMQP. Например, достижение определенных пределов или порога, аутентификация или недопустимая конфигурация политик Application-
- и message-related – исключения, которые обычно указывают на нарушение некоторых бизнес-или прикладных правил
Конечно, этот список отказов не является исчерпывающим, но содержит наиболее распространенные типы ошибок.
Следует отметить, что Spring AMQP обрабатывает связанные с подключением и низкоуровневые проблемы из коробки, например, применяя политики retry или requeue . Кроме того, большинство отказов и неисправностей преобразуются в AmqpException или один из его подклассов.
В следующих разделах мы в основном сосредоточимся на специфичных для приложений и высокоуровневых ошибках, а затем рассмотрим глобальные стратегии обработки ошибок.
4. Настройка проекта
Теперь давайте определим простую конфигурацию очереди и обмена для начала:
public static final String QUEUE_MESSAGES = "baeldung-messages-queue";
public static final String EXCHANGE_MESSAGES = "baeldung-messages-exchange";
@Bean
Queue messagesQueue() {
return QueueBuilder.durable(QUEUE_MESSAGES)
.build();
}
@Bean
DirectExchange messagesExchange() {
return new DirectExchange(EXCHANGE_MESSAGES);
}
@Bean
Binding bindingMessages() {
return BindingBuilder.bind(messagesQueue()).to(messagesExchange()).with(QUEUE_MESSAGES);
}
Далее, давайте создадим простого производителя:
public void sendMessage() {
rabbitTemplate
.convertAndSend(SimpleDLQAmqpConfiguration.EXCHANGE_MESSAGES,
SimpleDLQAmqpConfiguration.QUEUE_MESSAGES, "Some message id:" + messageNumber++);
}
И, наконец, потребитель, который бросает исключение:
@RabbitListener(queues = SimpleDLQAmqpConfiguration.QUEUE_MESSAGES)
public void receiveMessage(Message message) throws BusinessException {
throw new BusinessException();
}
По умолчанию все неудачные сообщения будут немедленно запрашиваться в начале целевой очереди снова и снова.
Давайте запустим наш пример приложения, выполнив следующую команду Maven:
mvn spring-boot:run -Dstart-class=com.baeldung.springamqp.errorhandling.ErrorHandlingApp
Теперь мы должны увидеть аналогичный результирующий результат:
WARN 22260 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. Caused by: com.baeldung.springamqp.errorhandling.errorhandler.BusinessException: null
Следовательно, по умолчанию мы будем видеть бесконечное количество таких сообщений в выходных данных.
Чтобы изменить это поведение у нас есть два варианта:
- Установите параметр defaultrequeuerejected в значение false на стороне слушателя – spring.rabbitmq.listener.simple.default-requeue-rejected=false
- Throw an AmqpRejectAndDontRequeueException – t his может быть полезен для сообщений, которые не будут иметь смысла в будущем, поэтому их можно отбросить.
Теперь давайте узнаем, как обрабатывать неудачные сообщения более разумным способом.
5. Очередь Мертвых писем
Очередь мертвых писем (DLQ) – это очередь, содержащая недоставленные или неудачные сообщения . DLQ позволяет нам обрабатывать неисправные или плохие сообщения, отслеживать шаблоны сбоев и восстанавливаться после исключений в системе.
Что еще более важно, это помогает предотвратить бесконечные циклы в очередях, которые постоянно обрабатывают плохие сообщения и снижают производительность системы.
Всего существует два основных понятия: Обмен мертвыми письмами (DLX) и сама очередь мертвых писем (DLQ). На самом деле, DLX-это обычный обмен, который мы можем определить как один из распространенных типов : direct , topic или fanout .
Очень важно понимать, что продюсер ничего не знает об очередях. Он знает только об обменах, и все произведенные сообщения маршрутизируются в соответствии с конфигурацией обмена и ключом маршрутизации сообщений .
Теперь давайте посмотрим, как обрабатывать исключения, применяя подход очереди мертвых писем.
5.1. Базовая конфигурация
Чтобы настроить DLQ, нам нужно указать дополнительные аргументы при определении нашей очереди:
@Bean
Queue messagesQueue() {
return QueueBuilder.durable(QUEUE_MESSAGES)
.withArgument("x-dead-letter-exchange", "")
.withArgument("x-dead-letter-routing-key", QUEUE_MESSAGES_DLQ)
.build();
}
@Bean
Queue deadLetterQueue() {
return QueueBuilder.durable(QUEUE_MESSAGES_DLQ).build();
}
В приведенном выше примере мы использовали два дополнительных аргумента: x-dead-letter-exchange и x-dead-letter-routing-key . Пустое строковое значение для параметра x-dead-letter-exchange указывает брокеру использовать обмен по умолчанию .
Второй аргумент столь же важен, как и установка ключей маршрутизации для простых сообщений. Эта опция изменяет начальный ключ маршрутизации сообщения для дальнейшей маршрутизации по DLX.
5.2. Неудачная Маршрутизация Сообщений
Поэтому, когда сообщение не доставляется, оно направляется на обмен мертвыми письмами. Но, как мы уже отмечали, DLX-это нормальный обмен. Поэтому, если ключ маршрутизации неудачного сообщения не совпадает с обменом, он не будет доставлен в DLQ.
Exchange: (AMQP default) Routing Key: baeldung-messages-queue.dlq
Таким образом, если мы опустим аргумент x-dead-letter-routing-key в нашем примере, неудачное сообщение застрянет в бесконечном цикле повторных попыток.
Кроме того, исходная метаинформация сообщения доступна в x-death heaven:
x-death: count: 1 exchange: baeldung-messages-exchange queue: baeldung-messages-queue reason: rejected routing-keys: baeldung-messages-queue time: 1571232954
То приведенная выше информация доступна в консоли управления RabbitMQ обычно работает локально на порту 15672.
Помимо этой конфигурации, если мы используем Spring Cloud Stream , мы можем даже упростить процесс настройки, используя свойства конфигурации republishToDlq и autoBindDlq .
5.3. Обмен Мертвыми письмами
В предыдущем разделе мы видели, что ключ маршрутизации изменяется, когда сообщение направляется на обмен мертвыми буквами. Но такое поведение не всегда желательно. Мы можем изменить его, настроив DLX самостоятельно и определив его с помощью типа fanout :
public static final String DLX_EXCHANGE_MESSAGES = QUEUE_MESSAGES + ".dlx";
@Bean
Queue messagesQueue() {
return QueueBuilder.durable(QUEUE_MESSAGES)
.withArgument("x-dead-letter-exchange", DLX_EXCHANGE_MESSAGES)
.build();
}
@Bean
FanoutExchange deadLetterExchange() {
return new FanoutExchange(DLX_EXCHANGE_MESSAGES);
}
@Bean
Queue deadLetterQueue() {
return QueueBuilder.durable(QUEUE_MESSAGES_DLQ).build();
}
@Bean
Binding deadLetterBinding() {
return BindingBuilder.bind(deadLetterQueue()).to(deadLetterExchange());
}
На этот раз мы определили пользовательский обмен типа fan out , поэтому сообщения будут отправляться во все ограниченные очереди . Кроме того, мы установили значение аргумента x-dead-letter-exchange для имени нашего DLX. В то же время мы удалили аргумент x-dead-letter-routing-key .
Теперь, если мы запустим наш пример, неудачное сообщение должно быть доставлено в DLQ, но без изменения начального ключа маршрутизации:
Exchange: baeldung-messages-queue.dlx Routing Key: baeldung-messages-queue
5.4. Обработка Сообщений Очереди Мертвых Писем
Конечно, причина, по которой мы переместили их в очередь мертвых писем, заключается в том, что они могут быть переработаны в другое время.
Давайте определим слушателя для очереди мертвых писем:
@RabbitListener(queues = QUEUE_MESSAGES_DLQ)
public void processFailedMessages(Message message) {
log.info("Received failed message: {}", message.toString());
}
Если мы запустим наш пример кода сейчас, то увидим вывод журнала:
WARN 11752 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 11752 --- [ntContainer#1-1] c.b.s.e.consumer.SimpleDLQAmqpContainer : Received failed message:
Мы получили неудачное сообщение, но что нам делать дальше? Ответ зависит от конкретных системных требований, вида исключения или типа сообщения.
Например, мы можем просто запросить сообщение в исходное место назначения:
@RabbitListener(queues = QUEUE_MESSAGES_DLQ)
public void processFailedMessagesRequeue(Message failedMessage) {
log.info("Received failed message, requeueing: {}", failedMessage.toString());
rabbitTemplate.send(EXCHANGE_MESSAGES,
failedMessage.getMessageProperties().getReceivedRoutingKey(), failedMessage);
}
Но такая логика исключений не отличается от политики повторных попыток по умолчанию:
INFO 23476 --- [ntContainer#0-1] c.b.s.e.c.RoutingDLQAmqpContainer : Received message: WARN 23476 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 23476 --- [ntContainer#1-1] c.b.s.e.c.RoutingDLQAmqpContainer : Received failed message, requeueing:
Общая стратегия может потребовать повторной обработки сообщения в течение n раз, а затем отклонить его. Давайте реализуем эту стратегию, используя заголовки сообщений:
public void processFailedMessagesRetryHeaders(Message failedMessage) {
Integer retriesCnt = (Integer) failedMessage.getMessageProperties()
.getHeaders().get(HEADER_X_RETRIES_COUNT);
if (retriesCnt == null) retriesCnt = 1;
if (retriesCnt > MAX_RETRIES_COUNT) {
log.info("Discarding message");
return;
}
log.info("Retrying message for the {} time", retriesCnt);
failedMessage.getMessageProperties()
.getHeaders().put(HEADER_X_RETRIES_COUNT, ++retriesCnt);
rabbitTemplate.send(EXCHANGE_MESSAGES,
failedMessage.getMessageProperties().getReceivedRoutingKey(), failedMessage);
}
Сначала мы получаем значение заголовка x-retries-count , затем сравниваем это значение с максимально допустимым значением. Впоследствии, если счетчик достигнет предельного числа попыток, сообщение будет отброшено:
WARN 1224 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 1224 --- [ntContainer#1-1] c.b.s.e.consumer.DLQCustomAmqpContainer : Retrying message for the 1 time WARN 1224 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 1224 --- [ntContainer#1-1] c.b.s.e.consumer.DLQCustomAmqpContainer : Retrying message for the 2 time WARN 1224 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 1224 --- [ntContainer#1-1] c.b.s.e.consumer.DLQCustomAmqpContainer : Discarding message
Мы должны добавить, что мы также можем использовать заголовок x-message-ttl , чтобы установить время, после которого сообщение должно быть отброшено. Это может быть полезно для предотвращения бесконечного роста очередей.
5.5. Очередь на Парковку
С другой стороны, рассмотрим ситуацию, когда мы не можем просто отбросить сообщение, например, это может быть транзакция в банковской сфере. Кроме того, иногда сообщение может потребовать ручной обработки или нам просто нужно записать сообщения, которые потерпели неудачу более n раз.
Для подобных ситуаций существует понятие очереди на парковку . Мы можем переслать все сообщения из DLQ, которые вышли из строя более разрешенного количества раз, в очередь парковки для дальнейшей обработки .
Давайте теперь воплотим эту идею:
public static final String QUEUE_PARKING_LOT = QUEUE_MESSAGES + ".parking-lot";
public static final String EXCHANGE_PARKING_LOT = QUEUE_MESSAGES + "exchange.parking-lot";
@Bean
FanoutExchange parkingLotExchange() {
return new FanoutExchange(EXCHANGE_PARKING_LOT);
}
@Bean
Queue parkingLotQueue() {
return QueueBuilder.durable(QUEUE_PARKING_LOT).build();
}
@Bean
Binding parkingLotBinding() {
return BindingBuilder.bind(parkingLotQueue()).to(parkingLotExchange());
}
Во – вторых, давайте реорганизуем логику прослушивателя, чтобы отправить сообщение в очередь парковки:
@RabbitListener(queues = QUEUE_MESSAGES_DLQ)
public void processFailedMessagesRetryWithParkingLot(Message failedMessage) {
Integer retriesCnt = (Integer) failedMessage.getMessageProperties()
.getHeaders().get(HEADER_X_RETRIES_COUNT);
if (retriesCnt == null) retriesCnt = 1;
if (retriesCnt > MAX_RETRIES_COUNT) {
log.info("Sending message to the parking lot queue");
rabbitTemplate.send(EXCHANGE_PARKING_LOT,
failedMessage.getMessageProperties().getReceivedRoutingKey(), failedMessage);
return;
}
log.info("Retrying message for the {} time", retriesCnt);
failedMessage.getMessageProperties()
.getHeaders().put(HEADER_X_RETRIES_COUNT, ++retriesCnt);
rabbitTemplate.send(EXCHANGE_MESSAGES,
failedMessage.getMessageProperties().getReceivedRoutingKey(), failedMessage);
}
В конце концов, нам также нужно обрабатывать сообщения, поступающие в очередь парковки:
@RabbitListener(queues = QUEUE_PARKING_LOT)
public void processParkingLotQueue(Message failedMessage) {
log.info("Received message in parking lot queue");
// Save to DB or send a notification.
}
Теперь мы можем сохранить неудачное сообщение в базе данных или, возможно, отправить уведомление по электронной почте.
Давайте проверим эту логику, запустив наше приложение:
WARN 14768 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 14768 --- [ntContainer#1-1] c.b.s.e.c.ParkingLotDLQAmqpContainer : Retrying message for the 1 time WARN 14768 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 14768 --- [ntContainer#1-1] c.b.s.e.c.ParkingLotDLQAmqpContainer : Retrying message for the 2 time WARN 14768 --- [ntContainer#0-1] s.a.r.l.ConditionalRejectingErrorHandler : Execution of Rabbit message listener failed. INFO 14768 --- [ntContainer#1-1] c.b.s.e.c.ParkingLotDLQAmqpContainer : Sending message to the parking lot queue INFO 14768 --- [ntContainer#2-1] c.b.s.e.c.ParkingLotDLQAmqpContainer : Received message in parking lot queue
Как видно из выходных данных, после нескольких неудачных попыток сообщение было отправлено в очередь парковки.
6. Пользовательская Обработка Ошибок
В предыдущем разделе мы видели, как обрабатывать сбои с помощью выделенных очередей и обменов. Однако иногда нам может потребоваться отловить все ошибки, например, для регистрации или сохранения их в базе данных.
6.1. Глобальный обработчик ошибок
До сих пор мы использовали по умолчанию SimpleRabbitListenerContainerFactory и эта фабрика по умолчанию использует ConditionalRejectingErrorHandler . Этот обработчик ловит различные исключения и преобразует их в одно из исключений в иерархии AmqpException .
Важно отметить, что если нам нужно обрабатывать ошибки подключения, то нам нужно реализовать интерфейс ApplicationListener .
Проще говоря, Условное отклонение ErrorHandler решает, отклонять ли конкретное сообщение или нет. Когда сообщение, вызвавшее исключение, отклоняется, оно не запрашивается.
Давайте определим пользовательский Обработчик ошибок , который будет просто запрашивать только Бизнес-исключение s:
public class CustomErrorHandler implements ErrorHandler {
@Override
public void handleError(Throwable t) {
if (!(t.getCause() instanceof BusinessException)) {
throw new AmqpRejectAndDontRequeueException("Error Handler converted exception to fatal", t);
}
}
}
Кроме того, поскольку мы выбрасываем исключение внутри нашего метода listener, оно оборачивается в ListenerExecutionFailedException . Итак, нам нужно вызвать метод getCause , чтобы получить исходное исключение.
6.2. Стратегия Фатальных Исключений
Под капотом этот обработчик использует стратегию Fatal Exception , чтобы проверить, следует ли считать исключение фатальным. Если это так, то неудачное сообщение будет отклонено.
По умолчанию эти исключения фатальны:
- MessageConversionException
- MessageConversionException
- MethodArgumentNotValidException
- Метод Аргумент TypeMismatchException
- NoSuchMethodException
- ClassCastException
Вместо реализации интерфейса Ierrorhandler мы можем просто предоставить нашу стратегию Фатальных исключений :
public class CustomFatalExceptionStrategy
extends ConditionalRejectingErrorHandler.DefaultExceptionStrategy {
@Override
public boolean isFatal(Throwable t) {
return !(t.getCause() instanceof BusinessException);
}
}
Наконец, нам нужно передать нашу пользовательскую стратегию конструктору Conditional Rejecting ErrorHandler :
@Bean
public SimpleRabbitListenerContainerFactory rabbitListenerContainerFactory(
ConnectionFactory connectionFactory,
SimpleRabbitListenerContainerFactoryConfigurer configurer) {
SimpleRabbitListenerContainerFactory factory =
new SimpleRabbitListenerContainerFactory();
configurer.configure(factory, connectionFactory);
factory.setErrorHandler(errorHandler());
return factory;
}
@Bean
public ErrorHandler errorHandler() {
return new ConditionalRejectingErrorHandler(customExceptionStrategy());
}
@Bean
FatalExceptionStrategy customExceptionStrategy() {
return new CustomFatalExceptionStrategy();
}
7. Заключение
В этом уроке мы обсудили различные способы обработки ошибок при использовании Spring AMQP и, в частности, RabbitMQ.
Каждая система нуждается в определенной стратегии обработки ошибок. Мы рассмотрели наиболее распространенные способы обработки ошибок в архитектуре, управляемой событиями. Кроме того, мы убедились, что можем объединить несколько стратегий для создания более комплексного и надежного решения.
Как всегда, полный исходный код статьи доступен на GitHub .
Эта статья – продолжение текста о мониторинге. Здесь предлагаю нам с вами поговорить о роли логов в оценке состояния наблюдаемой площадки, посмотреть, что они способны нам дать, а также затронуть вопрос – «можно ли отрывать логи от метрик?».
По ходу дела я буду возвращаться к некоторым тезисам, высказанным в предыдущей публикации, потому рекомендую предварительно с ней ознакомиться.
Итак, давайте поговорим о логировании.
Кстати, а как будет правильно: лоГирование или лоГГирование? Лично я склоняюсь ко второму варианту, просто потому, что loGGing, но замечаю, что большинство предпочитает первый. А вы?
Разбор полетов
Перед началом новой статьи хочу ненадолго вернуться к предыдущей. В комментариях было поднято несколько тем, которым, на мой взгляд, стоит уделить несколько предложений.
Собирать всё или только минимальный объем?
Здесь моя позиция такова – собирать надо все метрики, которые объект способен отдавать. Как заметил @BugM они лежат в БД, есть не просят, никому не мешают. А вот если у вас их нет, но они вдруг понадобились, особенно за, допустим, прошлый месяц – тут ничего сделать не получится.
Перефразируя знаменитую пословицу о бэкапах: «люди делятся на два типа – на тех, кто собирает метрики, и тех, кто их уже собирает».
Особенно актуально это в поиске аномалий на основе ML, для которых критично важно набрать объем данных с примером корректной работы наблюдаемой площадки. Тогда, чем больше у вас информации для обучения, тем точнее потом будет работать их (аномалий) выявление и прогнозирование. Человеку трудно найти закономерности в множестве, казалось бы, разрозненной информации (иначе не было бы необходимости изобретать ML), а машина может обнаружить их в неожиданных для вас местах.
При начале работ, исходить из метрик, или из инфраструктуры?
Соблюдайте баланс. Тезис, высказанный ранее, ответу на вопрос не противоречит:
… такие метрики относятся к самому низкому доступному вам уровню инфраструктуры, с которой вы работаете
Разумеется, вам нужно отталкиваться от возможностей вашей инфраструктуры, и только потом подбирать инструменты. Я намеренно не затрагивал тему выбора инструмента для сбора метрик, конкретные технологии упоминаются исключительно в следующих этапах. Берите такой агент и такую модель сбора, которая максимально удовлетворяет ваши потребности.
Продумать уровни тревоги
Абсолютно верная мысль @sizziff которую я недостаточно раскрыл.
Если вы заводите уровень «катастрофа» и отправляете нотификацию по СМС, это должно быть оправдано на 150%, иначе, рано или поздно, ваша команда поддержки будет выглядеть так:
Инженерный мониторинг не отражает реальное положение дел
Здесь @Dr_Wut приводит такой пример:
Простой пример из жизни — по всем метрикам почтовый сервер работает, а почта во вне не ходит — накосячили с spf. По итогу, пока разбирались, получили кучу претензий. А ведь достаточно было сделать простую проверку функции — отправлять письмо и проверять что оно дошло.
Если у вас возникла такая ситуация, значит, вам стоит добавить смок-тест функции, ведь результат такого теста – это тоже метрика, о чем я говорю в разделе о их разновидностях.
Бизнес-мониторинг и мониторинг бизнес-процессов
Давайте разделять эти понятия.
Мониторинг бизнес-процессов – зона ответственности «инженерного» мониторинга, о который мы с вами обсуждаем (наверное, стоило это сразу обозначить…). Задача здесь – обеспечить контроль за работоспособностью функций.
Бизнес-мониторинг и бизнес-метрики – это совершенно иная кухня, в ней шеф-повара это ваш СЕО и его окружение. Тут обеспечивается контроль за прибылью от функций вашей системы, а главный инструмент – BI-системы.
В своих статьях я не планирую затрагивать второй вид в силу отсутствия компетенций и релевантного опыта.
Теперь можем двигаться дальше.
О логах как источнике дополнительной информации
Если о мониторинге рядовой инженер имеет весьма смутное представление, то с логированием, как правило, ситуация обстоит чуть лучше, видимо, в силу того, что именно к логам обращаются в первую очередь, когда анализируют проблемы в работе софта.
Однако же, для многих становится откровением то, что логи бывают нескольких типов. Вот два самых распространенных:
Лог работы приложения – именно о нем думают в первую очередь; полагаю, вам знакома такая конструкция:
2019-04-23 00:39:10,092 INFO DatabaseConnector – Connection estabilishedВот это и есть запись из журнала работы. Характерные атрибуты такой записи – идентификатор уровня события и сообщение о событии. Часто также появляются имя класса/библиотеки, вызвавшей логгер, и идентификатор потока, в котором была сформирована эта запись.
Лог доступа к приложению – тут уже интереснее; это информация о том, какие функции приложения запрашивались. В подавляющем большинстве случаев это будут журналы обращения к API. Вот так, например, может выглядеть запись обращения к Nginx:
66.249.65.62 - - [06/Nov/2014:19:12:14 +0600] "GET /?q=%E0%A6%A6%E0%A7%8B%E0%A7%9F%E0%A6%BE HTTP/1.1" 200 4356 "-" "Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)"Здесь основные атрибуты уже другие – идентификатор запрошенного ресурса и информация о запросившем. Также, здесь может появляться информация о затраченных на обработку ресурсах приложения.
У обоих видов журналов также есть штамп времени – информация о том, когда событие произошло.
В этом месте я обращаюсь к разработчикам: коллеги, пожалуйста, когда настраиваете библиотеку журналирования вашего софта, сделайте так, чтобы штамп времени был полным – год, месяц, день, время с точностью до миллисекунды, таймзона операционной системы. Поверьте на слово, вам будут благодарны, ведь без полного штампа времени однозначно понять, когда произошло описанное событие, очень и очень трудно, если вообще не невозможно.
Подводя итог написанному выше, давайте ответим на вопрос «что логи могут нам дать?».
О логах приложения
В этом случае всё очень просто – если метрика сообщает нам о факте наличия ошибки, лог рассказывает, какая именно ошибка произошла.
Пример – пусть приложение работает с базой данных, тогда у неё есть счётчик ошибок database_error_count. Когда счётчик инкрементируется, мы видим, что что-то пошло не так, однако не знаем подробностей, ведь такую информацию не принято (и не стоит) выводить в метрики. Тут нам должен помочь журнал:
2019-04-27 00:39:10,092 INFO DatabaseConnector – Error connecting to database MSSQLDB – connection refused on port 1433И сразу понятно – у нас порт недоступен.
Конечно, это идеальный вариант. На практике же, ситуация часто складывается так, что приложение «размазывает» информацию о своем состоянии по логам и метрикам, а информацию, например, о фатальной ошибке при старте, можно, по понятным причинам, понять только из журналов.
О логах доступа
Как я писал выше, с этим типом журналов всё интереснее. Во-первых, эти логи, при наличии информации о затраченных на обработку запросов ресурсах, внезапно, превращаются… в метрики!
Смотрите – в логах HTTP-запросов принято писать о запрошенном ресурсе, времени, затраченном на обработку запроса, и еще, как минимум, фиксировать код ответа, из чего уже можно получить информацию о производительности:
Более того, такие логи, если в них есть информация о авторе запроса, превращаются в инструмент аудита доступа. С ними у нас в руках появляется еще один элемент Observability – данные безопасности.
Кто и откуда запрашивал ваши ресурсы? Какие именно ресурсы? Как часто? Были ли такие запросы раньше? И еще много вопросов, на которые можно найти ответы.
На основе этих данных уже можно искать аномалии доступа:
-
Запросы из неизвестных источников (99% реквестов к такому-то API ранее выполнялись таким-то пользователем из такой-то локации, а теперь появился кто-то еще)
-
Запросы к скрытым ресурсам и функциям (кто-то ломится в непубличный API)
-
Множество неуспешных попыток авторизации (вас брутфорсят)
И так далее. Продолжите список в комментариях.
Уточню, что HTTP лог здесь является только примером – с тем же успехом вы можете собирать аудит лог вашей БД.
Трассировки
Еще на логах можно строить трассировки. Работает это примерно так:
-
Входная точка в вашей DMZ устанавливает идентификатор трассировки (trace ID) на запрос; должна быть предусмотрена возможность ручной установки!
-
По мере прохождения запроса по вашей инфраструктуре, приложения должны, во-первых, сохранять идентификатор неизменным, во-вторых, этим же идентификатором помечать соответствующие записи в журналах
Если такое предусмотрено вашим приложением, trace ID стоит записывать не только в лог доступа, но и в лог работы – так вам будет легче связывать ошибки с конкретными запросами.
Очень обобщенно, это можно представить следующим образом:
Преимущества трассировок сложно переоценить – на их основе можно, как минимум:
-
Строить маршруты выполнения операций и выявлять недостатки инфраструктуры
-
Оценивать общую их длительность; особенно это полезно в асинхронных процессах
-
Оценивать длительность выполнения операций на конкретных этапах и выявлять узкие места
О сборе логов
Видов взаимодействий тут снова два, прямо как с метриками – Pull и Push.
Pull – это когда приложение ведет свой журнал (в файле, в табличке в БД, в журнале операционной системы), а агент журналирования этот журнал читает, обогащает метаданными о приложении/хосте/чем-то ещё и отправляет на дальнейший парсинг и индексацию. Минус – нужно деплоить и конфигурировать агенты; плюс – приложению не нужно знать о системе централизованной обработки и хранения логов, от него требуется только вовремя писать свои журналы.
Push – приложение активно отправляет свой журнал в систему парсинга/брокер сообщений/напрямую в базу. В таком случае агент не нужен, но приложение должно знать, где находится точка для сброса логов.
На этом этапе важно добиться того, чтобы на записи из журналов ставились те же метки, что и на метрики этих приложений (как я писал в предыдущей статье, в самом примитивном виде это теги с идентификатором хоста и именем приложения), дабы сохранить возможность связать их между собой и выполнять комплексный анализ.
О структуризации
Приложение может вести логи в разных форматах – plain text, jsonl, logsft, тысячи их. Здесь ключевая задача – привести их к единому виду, и тут рекомендую начинать с определения контрактов событий.
Контракт – соглашение о том, какой минимальный набор полей должны иметь те или иные типы логов после парсинга.
Можно выделить сначала общий контракт:
@timestamp<time>: Штамп времени события
application<string>: Имя приложения, к которому относится событие; должно соотноситься с таковым в мониторинге
host<string>: Имя хоста, на котором расположено приложение
log_type<string>: Тип события; application|access|.... (если приложение пишет не только application логи)
trace_id<string>: Идентификатор трассировки (при наличии)А затем определять контракты для других типов.
Например, для журналов приложений:
message<string>: Значимая часть события
generic_message<string>: Обезличенная значимая часть события
level<string>: Текстовая репрезентация уровня события
level_value<int>: Численная репрезентация уровня события
logger_name<string>: Имя класса, сгенерировавшего событие (при наличии)
thread_name<string>: Идентификатор потока, сгенерировавшего событие (при наличии)
stack_trace<string>: Трассировка стека; в более общем виде - вторая и последующие строки сообщения (при наличии)И для журналов доступа:
status_code<int>: Код ответа по запросу
elapsed_time<int>: Время, затраченное на обработку запроса в миллисекундах
requested_resource<string>: Запрошенный ресурс
method<string>: Метод запросаЗдесь очень важно соблюдать установленные контракты при передаче логов на дальнейшие индексацию и хранение.
При этом, текстовое и численное обозначения уровня события необходимо определить заранее и для каждой записи её собственный уровень приводить к одному из них.
Следование контракту приносит пользу сразу с нескольких сторон:
-
Упрощается индексация – многие NoSQL базы не любят, когда в рамках одного сегмента данных происходит попытка сохранить поле сначала одного типа, а затем другого. В лучшем случае, в такой ситуации вы получите неадекватно разрастающийся индекс, в худшем – ошибку при сохранении
-
Процесс поиска становится единообразным – когда у вас есть контракт в рамках одного типа журналов, вы можете подготовить один-два дашборда для работы с ними, просто соблюдая контракт и на этапе визуализации. С единым дашбордом можно, например, одновременно анализировать логи сразу нескольких приложений в одном интерфейсе
Только не пользуйтесь, пожалуйста, уровнем «EMERGENCY», если не уверены, что абсолютно каждый, кому предстоит работать с структурированными журналами, точно знает, что он обозначает. Я встречал очень мало таких людей, поэтому вместо него использую «FATAL» — достаточно говорящее обозначение для всех.
Обезличенные сообщения
Внимательные читатели могли заметить, что в контракте журналов приложений есть поле «generic_message». Рассказываю.
Для логов работы приложения я еще применяю такой ход – из некоторых событий вывожу дженерики (так их называли коллеги из разработки, мне понравилось обозначение).
Дженерик – это значимая часть события, приведенная к обезличенному шаблону. Вот пример:
Пусть исходное сообщение у нас такое:
Error on AMQP connection <0.12956.79> (127.0.0.1:52879 -> 127.0.0.1:5672, state: starting):Из него часть информации можно заменить на маркеры, тогда получается дженерик:
Error on AMQP connection <{connection_id}> ({remote_host} -> {destination_host}, state: {connection_state}):Извлекаемые значения при этом записываются в соответствующие поля события с становятся доступны для поиска.
Но что это дает? А вот что:
-
По дженерикам можно настраивать алерты; ошибка ошибке рознь, некоторые могут более критичными, некоторые менее. Если для критичных событий заранее подготовить паттерны, можно с помощью простых запросов ловить их появление и уведомлять об этом
-
Извлеченные ключи помогают в поиске; когда у вас идентификатор сессии везде называется «session_id» вы получаете возможность просто и быстро выполнять сквозной поиск
-
Поиск по ключам сильно проще поиска по регулярному выражению, как с точки зрения базы данных (обращаемся к индексу, а не выполняем анализ текста), так и с точки зрения пользователя (пачку регулярок еще надо заранее подготовить и хранить всегда под рукой)
Здесь важно не перегнуть палку и покрывать дженериками действительно важные записи. Злоупотребление дополнительными полями вредит здоровью ваших индексов.
О хранении
Как и в предыдущей статье, тут буду немногословен. Я предпочитаю Elasticsearch, и еще, говорят, Loki набирает популярность. На хабре можно найти несколько статей с их сравнением, вот одна из них — https://habr.com/ru/company/badoo/blog/507718/.
Ознакомьтесь, изучайте, выбирайте.
О связности с метриками
В предыдущей статье я условно разделял визуализацию так:
-
Уровень площадки
-
Уровень группы
-
Уровень объекта
-
Уровень фрагмента объекта
-
Уровень инфраструктуры
Выводить информацию о логах рекомендую на все уровни, кроме последнего (а может и на него, если вы собираете журналы операционной системы).
Принцип тот же самый:
-
На первом уровне к логике панели-индикатора добавляется блок, связанный с подсчетом количества событий уровня ERROR и выше
-
На втором уровне расширяется список панелей – появляется индикатор наличия ошибок в журналах, плюс обеспечивается возможность перехода к дашборду с логами с сохранением контекста и фильтра по уровню событий (если подсвечиваем именно количество ошибок, их и нужно показывать)
-
На следующих уровнях пользователю предоставляется возможность перехода к дашборду с логами с сохранением контекста, но уже без фильтра по уровню – предполагается, что если пользователь совершает такой переход, то ему интересны логи всех уровней, а не только определенных
Тогда диаграмма из предыдущей статьи приобретает такой вид:
О алертинге
Основные тезисы были высказаны в предыдущей статье, тут ограничусь парой предложений:
-
Выделите критичные события и настройте по ним алертинг; это станет хорошим дополнением к уже имеющимся нотификациям и повысит наблюдаемость за площадкой
-
Обогащайте алерты по логам теми же метаданными, что и алерты по метрикам; для пользователя они должны быть прозрачны, ему не надо задумываться, откуда взялась та или иная нотификация
Заключение
Итак, допустимо ли отрывать логи от метрик?
Я считаю, что нет – как видите, журналы отлично дополняют картину мира и раскрывают подробности, которые метрики не всегда способны предоставить. Применяйте оба инструмента для наблюдения за вашими площадками и будет вам счастье.
Огромное спасибо всем, кто ознакомился с этой и предыдущей статьей, кто писал комментарии, ставил под сомнение высказанное и делился практиками – действительно приятно видеть отклик со стороны сообщества.
Возможно, позже появится еще одна статья, уже с примерами использования конкретных технологий и практик, в которой попробуем реализовать описанное ранее и посмотреть, как это работает.