07:18:00:156 308 parse packet: 58
07:18:00:156 308 remove first packet 473
07:18:00:156 308 new buf size: 473
07:18:00:156 308 parse packet: 400
07:18:00:157 308 remove first packet 72
07:18:00:157 308 new buf size: 72
07:18:00:157 308 parse packet: 35
07:18:00:157 308 remove first packet 36
07:18:00:157 308 new buf size: 36
07:18:00:157 308 parse packet: 35
07:18:00:158 308 DCR: Authorized
07:18:00:162 308 new buf size: 0
07:18:00:200 12e0 Setting DAG epoch #130…
07:18:02:680 bc0 got 248 bytes
07:18:02:680 bc0 buf: {«id»:0,»jsonrpc»:»2.0″,»result»:[«0x32057870a3f6a2c48d3a588cf4ddd5c61a5b5d31424f9a86d29d5ced17bdfff6″,»0x129656acf5804305816f3dc0b32b47077c8cf4b8724f181efc529a93e4c1385b»,»0x0112e0be826d694b2e62d01511f12a6061fbaec8bc02357593e70e52ba»,»0x3be875″]}
07:18:02:681 bc0 parse packet: 247
07:18:02:681 bc0 ETH: job changed
07:18:02:681 bc0 new buf size: 0
07:18:02:682 bc0 ETH: 06/25/17-07:18:02 — New job from eu2.ethermine.org:4444
07:18:02:682 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:02:686 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:02:687 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:02:688 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:02:689 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:03:024 12e0 Setting DAG epoch #130 for GPU1
07:18:03:026 c74 Setting DAG epoch #130 for GPU0
07:18:03:027 1350 Setting DAG epoch #130 for GPU3
07:18:03:028 12e0 Create GPU buffer for GPU1
07:18:03:028 ac4 Setting DAG epoch #130 for GPU2
07:18:03:030 1350 Create GPU buffer for GPU3
07:18:03:031 ac4 Create GPU buffer for GPU2
07:18:03:029 c74 Create GPU buffer for GPU0
07:18:03:427 12e0 GPU 1, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:430 12e0 GPU 1, Calc DAG failed!
07:18:03:471 1350 GPU 3, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:534 1350 GPU 3, Calc DAG failed!
07:18:03:535 ac4 GPU 2, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:536 ac4 GPU 2, Calc DAG failed!
07:18:03:537 c74 GPU 0, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:538 c74 GPU 0, Calc DAG failed!
07:18:06:234 bc0 got 248 bytes
07:18:06:234 bc0 buf: {«id»:0,»jsonrpc»:»2.0″,»result»:[«0x8c695f2e13c1e4a6771a5729eade463856a1d53cb55a87276cbdd2713b7a4f90″,»0x129656acf5804305816f3dc0b32b47077c8cf4b8724f181efc529a93e4c1385b»,»0x0112e0be826d694b2e62d01511f12a6061fbaec8bc02357593e70e52ba»,»0x3be876″]}
07:18:06:234 bc0 parse packet: 247
07:18:06:234 bc0 ETH: job changed
07:18:06:234 bc0 new buf size: 0
07:18:06:235 bc0 ETH: 06/25/17-07:18:06 — New job from eu2.ethermine.org:4444
07:18:06:236 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:06:238 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:06:239 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:06:240 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:06:241 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:06:932 12e0 GPU 1 failed
07:18:06:936 ecc Setting DAG epoch #130 for GPU1
07:18:06:937 ecc GPU 1, CUDA error 77 — cannot write buffer for DAG
07:18:07:036 1350 GPU 3 failed
07:18:07:041 ac4 GPU 2 failed
07:18:07:040 b70 Setting DAG epoch #130 for GPU3
07:18:07:043 b70 GPU 3, CUDA error 77 — cannot write buffer for DAG
07:18:07:041 c64 Setting DAG epoch #130 for GPU2
07:18:07:045 c74 GPU 0 failed
07:18:07:044 4c0 Setting DAG epoch #130 for GPU0
07:18:07:046 4c0 GPU 0, CUDA error 77 — cannot write buffer for DAG
07:18:07:047 c64 GPU 2, CUDA error 77 — cannot write buffer for DAG
07:18:09:938 ecc GPU 1 failed
07:18:10:044 b70 GPU 3 failed
07:18:10:048 4c0 GPU 0 failed
07:18:10:080 c64 GPU 2 failed
07:18:10:133 bc0 ETH: checking pool connection…
07:18:10:133 bc0 send: {«worker»: «», «jsonrpc»: «2.0», «params»: [], «id»: 3, «method»: «eth_getWork»}
07:18:10:193 bc0 got 248 bytes
07:18:10:193 bc0 buf: {«id»:3,»jsonrpc»:»2.0″,»result»:[«0x8c695f2e13c1e4a6771a5729eade463856a1d53cb55a87276cbdd2713b7a4f90″,»0x129656acf5804305816f3dc0b32b47077c8cf4b8724f181efc529a93e4c1385b»,»0x0112e0be826d694b2e62d01511f12a6061fbaec8bc02357593e70e52ba»,»0x3be876″]}
07:18:10:193 bc0 parse packet: 247
07:18:10:193 bc0 ETH: job is the same
07:18:10:193 bc0 new buf size: 0
07:18:11:690 bc0 got 248 bytes
07:18:11:690 bc0 buf: {«id»:0,»jsonrpc»:»2.0″,»result»:[«0x42bada0b2ebbc7dd92010edc94953335a048554aa27a9866c30043b99df3d945″,»0x129656acf5804305816f3dc0b32b47077c8cf4b8724f181efc529a93e4c1385b»,»0x0112e0be826d694b2e62d01511f12a6061fbaec8bc02357593e70e52ba»,»0x3be877″]}
07:18:11:691 bc0 parse packet: 247
07:18:11:691 bc0 ETH: job changed
07:18:11:691 bc0 new buf size: 0
07:18:11:691 bc0 ETH: 06/25/17-07:18:11 — New job from eu2.ethermine.org:4444
07:18:11:692 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:11:692 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:11:693 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:11:694 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:11:695 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:20:131 bc0 send: {«id»:6,»jsonrpc»:»2.0″,»method»:»eth_submitHashrate»,»params»:[«0x0», «0x00000000000000000000000000000000000000000000000000000000d514e30f»]}
07:18:20:147 bc0 ETH: checking pool connection…
07:18:20:147 bc0 send: {«worker»: «», «jsonrpc»: «2.0», «params»: [], «id»: 3, «method»: «eth_getWork»}
07:18:20:193 bc0 got 39 bytes
07:18:20:193 bc0 buf: {«id»:6,»jsonrpc»:»2.0″,»result»:true}
07:18:20:194 bc0 parse packet: 38
07:18:20:194 bc0 new buf size: 0
07:18:20:250 bc0 got 248 bytes
07:18:20:250 bc0 buf: {«id»:3,»jsonrpc»:»2.0″,»result»:[«0x42bada0b2ebbc7dd92010edc94953335a048554aa27a9866c30043b99df3d945″,»0x129656acf5804305816f3dc0b32b47077c8cf4b8724f181efc529a93e4c1385b»,»0x0112e0be826d694b2e62d01511f12a6061fbaec8bc02357593e70e52ba»,»0x3be877″]}
07:18:20:250 bc0 parse packet: 247
07:18:20:251 bc0 ETH: job is the same
07:18:20:251 bc0 new buf size: 0
07:18:26:833 308 got 402 bytes
07:18:26:833 308 buf: {«id»:null,»method»:»mining.notify»,»params»:[«7691″,»ed200e535bcf63f536b35a2cf508d75eb6a89920ddf9a2670000018100000000″,»f77873840192bbc66e9a922fda94c419924b7f273792e8ea02cf22451b02a8f1b66435baf995ce6df7e9d6409a220a14a50cf4d42c6926124f12447d116a2e8801006691ca86c14705000000caac000089c2011ad463a89202000000e3360200080d000093394f590000000000000000″,»04000000″,[],»04000000″,»1a01c289″,»594f3993»,false]}
07:18:26:833 308 parse packet: 401
07:18:26:833 308 new buf size: 0
07:18:26:833 308 DCR: 06/25/17-07:18:26 — New job from dcr.coinmine.pl:2222
07:18:26:834 308 target: 0x0000000019998000 (diff: 42GH), block #145123
07:18:30:111 b4c GPU0 t=30C fan=40%, GPU1 t=36C fan=43%, GPU2 t=32C fan=41%, GPU3 t=30C fan=40%
07:18:30:112 b4c em hbt: 0, dm hbt: 0, fm hbt: 79,
07:18:30:113 b4c watchdog — thread 0, hb time 23032
07:18:30:113 b4c watchdog — thread 1, hb time 23032
07:18:30:113 b4c watchdog — thread 2, hb time 23032
07:18:30:114 b4c watchdog — thread 3, hb time 23032
07:18:30:114 b4c watchdog — thread 4, hb time 23032
07:18:30:114 b4c watchdog — thread 5, hb time 23032
07:18:30:114 b4c watchdog — thread 6, hb time 23032
07:18:30:114 b4c watchdog — thread 7, hb time 23032
07:18:30:114 b4c WATCHDOG: GPU error, you need to restart miner
07:18:30:115 b4c Rebooting
Take and my 5 cents. On GPU I start mining a week ago. For now i have 14 1070ti -+ OC, 2 farms and mining eth with auto restart ethminer if it stops on errors. This two scripts is not best solution, writen from scratch but works fine. Writed only for nvidia but i think it maybe rewriten for ati too ))
All this tested on Ubuntu 16.04
!!! nvidia coolbits must be enabled if you want OC settings to work. Mine is 13 tested on 381 and 387 drivers, emulated monitor for each card neded my nvidia-xconfig conf for 7 GPU, edid.bin find in google, i made mine from AOC 23 mon
nvidia-xconfig: X configuration file generated by nvidia-xconfig
nvidia-xconfig: version 387.34 (buildmeister@swio-display-x64-rhel04-15) Tue Nov 21 03:31:45 PST 2017
Section «ServerLayout»
Identifier «Layout0»
Screen 0 «Screen0»
Screen 1 «Screen1» RightOf «Screen0»
Screen 2 «Screen2» RightOf «Screen1»
Screen 3 «Screen3» RightOf «Screen2»
Screen 4 «Screen4» RightOf «Screen3»
Screen 5 «Screen5» RightOf «Screen4»
Screen 6 «Screen6» RightOf «Screen5»
InputDevice «Keyboard0» «CoreKeyboard»
InputDevice «Mouse0» «CorePointer»
EndSection
Section «Files»
EndSection
Section «InputDevice»
# generated from default
Identifier «Mouse0»
Driver «mouse»
Option «Protocol» «auto»
Option «Device» «/dev/psaux»
Option «Emulate3Buttons» «no»
Option «ZAxisMapping» «4 5»
EndSection
Section «InputDevice»
# generated from default
Identifier «Keyboard0»
Driver «kbd»
EndSection
Section «Monitor»
Identifier «Monitor0»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor1»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor2»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor3»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor4»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor5»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor6»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Device»
Identifier «Device0»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:1:0:0»
EndSection
Section «Device»
Identifier «Device1»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID «PCI:2:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device2»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID «PCI:3:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device3»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:5:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device4»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:6:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device5»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:7:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device6»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID «PCI:8:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Screen»
Identifier «Screen0»
Device «Device0»
Monitor «Monitor0»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen1»
Device «Device1»
Monitor «Monitor1»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen2»
Device «Device2»
Monitor «Monitor2»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen3»
Device «Device3»
Monitor «Monitor3»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen4»
Device «Device4»
Monitor «Monitor4»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen5»
Device «Device5»
Monitor «Monitor5»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen6»
Device «Device6»
Monitor «Monitor6»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Script is for miner loop with OC settings for each GPU.
Settings apply only ones at start if they enabled
Just edit it for your needs and run thats all, main part after it
#!/bin/sh
#nvidia-settings -a GPUFanControlState=0
#nvidia-settings -a GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a GPUMemoryTransferRateOffset[3]=1200
#nvidia-smi -pm 1
#nvidia-smi -pl 155
#nvidia-settings -a [gpu:0]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:0]/GPUMemoryTransferRateOffset[3]=1200
#nvidia-settings -a [gpu:0]/GPUFanControlState=1
#nvidia-settings -a [fan:0]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:1]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:1]/GPUMemoryTransferRateOffset[3]=1450
#nvidia-settings -a [gpu:1]/GPUFanControlState=1
#nvidia-settings -a [fan:1]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:2]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:2]/GPUMemoryTransferRateOffset[3]=1150
#nvidia-settings -a [gpu:2]/GPUFanControlState=1
#nvidia-settings -a [fan:2]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:3]/GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a [gpu:3]/GPUMemoryTransferRateOffset[3]=1050
#nvidia-settings -a [gpu:3]/GPUFanControlState=1
#nvidia-settings -a [fan:3]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:4]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:4]/GPUMemoryTransferRateOffset[3]=1050
#nvidia-settings -a [gpu:4]/GPUFanControlState=1
#nvidia-settings -a [fan:4]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:5]/GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a [gpu:5]/GPUMemoryTransferRateOffset[3]=800
#nvidia-settings -a [gpu:5]/GPUFanControlState=1
#nvidia-settings -a [fan:5]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:6]/GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a [gpu:6]/GPUMemoryTransferRateOffset[3]=900
#nvidia-settings -a [gpu:6]/GPUFanControlState=1
#nvidia-settings -a [fan:6]/GPUTargetFanSpeed=80
while true; # This will loop your miner even if you kill -9 ethminer it will start again after do
# To stop just CTRL+C or what ever you want =)
do
/home/m1/Miner/ethminer -U -S eth-eu2.nanopool.org:9999 -O 0xb4983146f0047d87c63b5fdb3ef9e2bee4557ea3.M1/vhosted@gmail.com
done
Thats was not so hard, the main deal is up to go !!!
While our miner script is working we will run another one
Script for monitoring
#!/bin/sh
-i 5 number GPU to monit
gpu=nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
while true; #Loops :=))
do
while [ $gpu -gt 50 ]
do
gpu=nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
echo «GPU load $gpu»
echo «All good $(date) GPU load $gpu No errors»
sleep 10
done
if [ $gpu -lt 40 ]
then
killall -9 ethminer
echo «Restart Miner GPU load $gpu $(date) error»
echo «Restart Miner $(date) error» >> /home/m1/Miner/ethminer.log
sleep 60
gpu=nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
fi;
done
Thats it. Finished it esterday. I think it can be smaller. But nothing need to install, compile etc. All night i tested my GPUs with OC and power -+ very fast to test cloks and + tail -f /var/log/kern.log | grep nvrm to see what gpu couesd an error without long farm stop.
If it will help you. I like good coffe )) b4983146f0047d87c63b5fdb3ef9e2bee4557ea3
Hosted
Содержание
- Ошибка illegal memory access was encountered.
- Dargont
- Михаил78
- GTX 1000 GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
- hshan
- ccminer — GPU #0: an illegal memory access was encountered #526
- Comments
- ”CUDA failure 77: an illegal memory access was encountered» in Executing Faster R-CNN #2388
- Comments
Ошибка illegal memory access was encountered.
Dargont
Свой человек
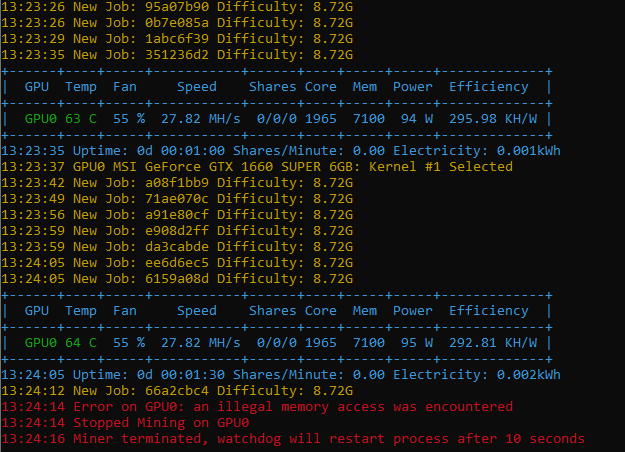
Стоит фермочка 1660S -4 шт и 3060ti -1 шт, работала как часы 2 года ничего не требовала, и тут майнер начал выдавать ошибку «an illegal memory access was encountered» причем на разные карты ругается зараза. Блок питание 1000W «термос». Отключение карты в майнере не исправило ситуацию, грешил на ДАГ файл. Куда копать? Ось Win10 LTSС, на других фермах все гуд причем с таким же набором карт и стой же операционкой(
12:38:10 Started Mining on GPU0: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:01:00.0]
12:38:10 Started Mining on GPU1: MSI NVIDIA GeForce RTX 3060 Ti 8GB [0000:02:00.0]
12:38:10 Started Mining on GPU2: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:03:00.0]
12:38:10 Started Mining on GPU3: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:04:00.0]
12:38:10 GPU0 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU1 MSI NVIDIA GeForce RTX 3060 Ti 8GB: Kernel #6 Selected
12:38:10 GPU2 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU3 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:11 New Job: 0000000057b45ae7 Epoch: #505 Diff: 1.399G
12:38:12 New Job: 0000000057b45ae8 Epoch: #505 Diff: 1.399G
12:38:13 New Job: 0000000057b45ae9 Epoch: #505 Diff: 1.399G
12:38:16 GPU2: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU3: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU0: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU1: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:17 New Job: 0000000057b45aea Epoch: #505 Diff: 1.399G
12:38:23 Error on GPU2: an illegal memory access was encountered
12:38:23 Stopped Mining on GPU0
12:38:23 Stopped Mining on GPU1
12:38:23 Stopped Mining on GPU2
12:38:23 Stopped Mining on GPU3
Михаил78
Бывалый
Стоит фермочка 1660S -4 шт и 3060ti -1 шт, работала как часы 2 года ничего не требовала, и тут майнер начал выдавать ошибку «an illegal memory access was encountered» причем на разные карты ругается зараза. Блок питание 1000W «термос». Отключение карты в майнере не исправило ситуацию, грешил на ДАГ файл. Куда копать? Ось Win10 LTSС, на других фермах все гуд причем с таким же набором карт и стой же операционкой(
12:38:10 Started Mining on GPU0: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:01:00.0]
12:38:10 Started Mining on GPU1: MSI NVIDIA GeForce RTX 3060 Ti 8GB [0000:02:00.0]
12:38:10 Started Mining on GPU2: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:03:00.0]
12:38:10 Started Mining on GPU3: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:04:00.0]
12:38:10 GPU0 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU1 MSI NVIDIA GeForce RTX 3060 Ti 8GB: Kernel #6 Selected
12:38:10 GPU2 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU3 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:11 New Job: 0000000057b45ae7 Epoch: #505 Diff: 1.399G
12:38:12 New Job: 0000000057b45ae8 Epoch: #505 Diff: 1.399G
12:38:13 New Job: 0000000057b45ae9 Epoch: #505 Diff: 1.399G
12:38:16 GPU2: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU3: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU0: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU1: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:17 New Job: 0000000057b45aea Epoch: #505 Diff: 1.399G
12:38:23 Error on GPU2: an illegal memory access was encountered
12:38:23 Stopped Mining on GPU0
12:38:23 Stopped Mining on GPU1
12:38:23 Stopped Mining on GPU2
12:38:23 Stopped Mining on GPU3
Источник
GTX 1000 GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered

hshan
Знающий
Риг из 1060 отработал несколько дней и начал сыпаться ошибкой как в заголовке. Ниже написан большой кусок из лога.
Сброс настроек к заводским, ребуты и прочие простые прием ничего не дали. Так как ошибка сразу по всем картам дело не мот быть в райзере или смерти какой-то карты.
Кто знает как решить проблему — отпишитесь!
07:18:02:681 bc0 parse packet: 247
07:18:02:681 bc0 ETH: job changed
07:18:02:681 bc0 new buf size: 0
07:18:02:682 bc0 ETH: 06/25/17-07:18:02 — New job from eu2.ethermine.org:4444
07:18:02:682 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:02:686 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:02:687 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:02:688 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:02:689 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:03:024 12e0 Setting DAG epoch #130 for GPU1
07:18:03:026 c74 Setting DAG epoch #130 for GPU0
07:18:03:027 1350 Setting DAG epoch #130 for GPU3
07:18:03:028 12e0 Create GPU buffer for GPU1
07:18:03:028 ac4 Setting DAG epoch #130 for GPU2
07:18:03:030 1350 Create GPU buffer for GPU3
07:18:03:031 ac4 Create GPU buffer for GPU2
07:18:03:029 c74 Create GPU buffer for GPU0
07:18:03:427 12e0 GPU 1, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:430 12e0 GPU 1, Calc DAG failed!
07:18:03:471 1350 GPU 3, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:534 1350 GPU 3, Calc DAG failed!
07:18:03:535 ac4 GPU 2, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:536 ac4 GPU 2, Calc DAG failed!
07:18:03:537 c74 GPU 0, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:538 c74 GPU 0, Calc DAG failed!
07:18:06:234 bc0 got 248 bytes
07:18:06:234 bc0 buf:
07:18:06:234 bc0 parse packet: 247
07:18:06:234 bc0 ETH: job changed
07:18:06:234 bc0 new buf size: 0
07:18:06:235 bc0 ETH: 06/25/17-07:18:06 — New job from eu2.ethermine.org:4444
07:18:06:236 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:06:238 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:06:239 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:06:240 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:06:241 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:06:932 12e0 GPU 1 failed
07:18:06:936 ecc Setting DAG epoch #130 for GPU1
07:18:06:937 ecc GPU 1, CUDA error 77 — cannot write buffer for DAG
07:18:07:036 1350 GPU 3 failed
07:18:07:041 ac4 GPU 2 failed
07:18:07:040 b70 Setting DAG epoch #130 for GPU3
07:18:07:043 b70 GPU 3, CUDA error 77 — cannot write buffer for DAG
07:18:07:041 c64 Setting DAG epoch #130 for GPU2
07:18:07:045 c74 GPU 0 failed
07:18:07:044 4c0 Setting DAG epoch #130 for GPU0
07:18:07:046 4c0 GPU 0, CUDA error 77 — cannot write buffer for DAG
07:18:07:047 c64 GPU 2, CUDA error 77 — cannot write buffer for DAG
07:18:09:938 ecc GPU 1 failed
07:18:10:044 b70 GPU 3 failed
07:18:10:048 4c0 GPU 0 failed
07:18:10:080 c64 GPU 2 failed
07:18:10:133 bc0 ETH: checking pool connection.
07:18:10:133 bc0 send:
07:18:10:193 bc0 got 248 bytes
07:18:10:193 bc0 buf:
07:18:10:193 bc0 parse packet: 247
07:18:10:193 bc0 ETH: job is the same
07:18:10:193 bc0 new buf size: 0
07:18:11:690 bc0 got 248 bytes
07:18:11:690 bc0 buf:
07:18:11:691 bc0 parse packet: 247
07:18:11:691 bc0 ETH: job changed
07:18:11:691 bc0 new buf size: 0
07:18:11:691 bc0 ETH: 06/25/17-07:18:11 — New job from eu2.ethermine.org:4444
07:18:11:692 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:11:692 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:11:693 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:11:694 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:11:695 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:20:131 bc0 send:
07:18:20:147 bc0 ETH: checking pool connection.
07:18:20:147 bc0 send:
07:18:20:193 bc0 got 39 bytes
07:18:20:193 bc0 buf:
07:18:20:194 bc0 parse packet: 38
07:18:20:194 bc0 new buf size: 0
07:18:20:250 bc0 got 248 bytes
07:18:20:250 bc0 buf:
07:18:20:250 bc0 parse packet: 247
07:18:20:251 bc0 ETH: job is the same
07:18:20:251 bc0 new buf size: 0
07:18:26:833 308 got 402 bytes
07:18:26:833 308 buf:
Источник
ccminer — GPU #0: an illegal memory access was encountered #526
BinLyra2z-NVIDIAccminer_cuda9.exe -a lyra2z -o stratum+tcp://europe.lyra2z-hub.miningpoolhub.com:17025 -u xxxx.xxxx -p x
Sys: Win 10
CPU: i7-7700
GPU: GTX 1060
Drivers: v388.31 15-11-2017
The text was updated successfully, but these errors were encountered:
Not sure what could be causing that. MultiPoolMiner will skip past the issue.
Miner did not restart himself. It would be helpful to detect this type of error and to automatically restart the miner. During the problem, the value of 12GH / s, normally 1142.52 kH / s. Multipoolminer did not detect the problem.
Please can you post the log?
CcminerPalgin MyriadGroestl 38,00 MH/s 13,86794 364,99247 Hashrefinery
CcminerKlaust MyriadGroestl 35,19 MH/s 12,84529 364,99247 Hashrefinery
Miner : MultiPoolMiner
PLN : 1 330,89047 ±11 415% (11,55789-153 252,03091)
USD : 373,26901 ±11 415% (3,24159-42 981,92475)
BCH : 0,00000 ±11 415% (0,00000-0,00000)
BCT : 0,00000 ±11 415% (0,00000-0,00000)
Miner :
PLN : 420 195,84027 ±0% (420 195,73327-420 195,94727)
USD : 117 850,48381 ±0% (117 850,45380-117 850,51383)
BCH : 0,00000 ±0% (0,00000-0,00000)
BCT : 0,00000 ±0% (0,00000-0,00000)
The speed is 1140KH/s all over your log; where does it say 12000KH/s?
Is the speed wrong or not?
The figures you pasted at the end are because of this: #525
Yes in log is ok but when i have error «GPU #0: an illegal memory access was encountered» miner show 12GH /s.
It looked like that: 
So what happens in MultiPoolMiner?
I can’t see 10GH/s.
MultiPoolMiner not detect error and i have to restart miner.
What does it say under «Status: Running»?
In miner window :
GPU #0: result for 05b4b533 does not validate on CPU!
Are you overclocking?
chabgood
«Are you overclocking?»
Oc Gpu+200 Mem + 950
Yes, but for test i’m back to default settings.
Sure, I have gotten the same error when you overclock too much for your card.
Ok, so the reading is too high, correct? «452MH/s»
That wasn’t in your log.
Does MultiPoolMiner say this?
«WARNING: Stat file was not updated because the value is outside fault tolerance.»
Can you send the stat files?
seems way to high.
My 1060 (Samsung memory) can do Gpu +185-160 (curve) and Mem + 650 with PL 85%
High mem OC causes all sorts of weird problems
Lenovo legion y720 Im use Oc Gpu+200 Mem + 950 and dont have problem with other miners and games, temperature is stable 69C. But i’m change thermal paste and thermopads.
UselessGuru what is yours brand 1060 ?
UselessGuru what is yours brand 1060 ?
Gigabyte GeForce GTX 1060 WindForce OC 3G
Too high an overclock actually reduces performance. You may not notice over-overclocking by just checking for artifacts. The gpu will spend lots of cycles fixing memory errors, so that they go unnoticed but eat performance.
Some algorithms are more prone to crashes when overclocked than others. E.g cryptonight or Lyr22z crash sooner.
Clock +200 is not necessary for most algos, a bit of a bump is all you need and mem +950 is way too high, I am surprised you are not experiencing screen tearing and artifacts or a complete blackout every now and then!
+950 mem also confirms the reason for illegal mem access.
fonyo but i have this problem without OC. Tomorow i try difrend drivers.
Try the cuda 8 version, cuda 9 compiled ccminers only work with driver version 384.xx or later so please bear that in mind when switching to another driver.
Ccminer seems to throw masses of errors and a huge haserate when there are other issues also.
Note to self: check the stat value error checking is working correctly.
Источник
”CUDA failure 77: an illegal memory access was encountered» in Executing Faster R-CNN #2388
In executing run_faster_rcnn.py of CNTK2.2, I encountered error message as follows. With version=2.1, I’ve never met this kind of error.
What kind of activities can we do in this situation? (As far as I tried, Fast R-CNN scripts was fine in the same environment.)
The text was updated successfully, but these errors were encountered:
Are you running distributed training? Please try using CUDA_VISIBLE_DEVICES to limit to 1 GPU and see if the bug still occurs. We will try get a local repro.
@KeDengMS Thanks for your information. I’ve succeeded in starting the process.
Then, if we’d like to use multiple GPU, what kind of setting is needed?
The CUDA_VISIBLE_DEVICES=2 means that we use 2-GPU(, if the machine has 2 or over GPU), right?
As far as I tried, only single GPU was used even when I set CUDA_VISIBLE_DEVICES=2 and run as python run_faster_rcnn.py .
Then, how do we set, if we want to use multiple GPU with this script?
CUDA_VISIBLE_DEVICES is a string of comma separated device ids explained here, so to use two GPU set it to «0,1». I think there’s a bug in FasterRCNN or CNTK code when running the model with multiple devices, and we’ll look into it.
@KeDengMS Thanks! But, as far as I tried following 2 cases, the processes were not successful.
@KeDengMS Thanks, After merging your modification, I confirmed as follows:
Preparation: set CUDA_VISIBLE_DEVICES=0,1,2,3
Case1: python run_faster_rcnn.py -> no problem
Case2: mpiexec -n 2 python run_faster_rcnn.py -> maybe no problem.
- mAP was different.. (0.7108, 0.6760)
Case3: mpiexec -n 4 python run_faster_rcnn.py -> memory error.
- I will raise issue for another record.
The following is a log for Case 2:
The current FasterRCNN example needs some modifications to enable distributed training:
- It needs to use distributed_learner
- The reader needs to handle partitions of data w.r.t. worker_rank and number_of_workers. Otherwise, all workers would receive the same data. That would not have any benefit in training speed, and is effectively just multiplying learning rate with the number of workers.
- The config currently hardcoded GPU_ID 0 for all workers, which would not leverage multi-GPU rather than running several processes on the same GPU. I think the mem error you found is OOM when 4 processes are both using GPU 0. It needs to be removed and pass the default GPU selected by CNTK into gpu_nms. The current fix is a temporary one.
Then, can you advise what kind of changes are needed for
instead of temporary change 62a80d2 ? If you support me, I’ll change accordingly.
Источник
@aNdrE_ch
Школьник, интересуюсь IT, пытаюсь учить Frontend.

-
Видеокарты
-
Криптовалюта
 В играх карта работает нормально.
В играх карта работает нормально.
-
Вопрос заданболее года назад
-
3258 просмотров
1
комментарий
Подписаться
1
Средний
1
комментарий
-
 Loli E1ON
Loli E1ON@E1ON
Отключить разгон, если включен.
Написано
более года назад

Решения вопроса 0
Пригласить эксперта
Ответы на вопрос 1
@rassini
Поднимите питание, его не достаточно.
Ответ написан
более года назад
Комментировать
Комментировать
Ваш ответ на вопрос
Войдите, чтобы написать ответ
Войти через центр авторизации
Похожие вопросы
-
-
Криптовалюта
- +1 ещё
Простой
Где можно взять дамп адресов с транзакциями в сети bsc?
-
1 подписчик -
9 часов назад
-
14 просмотров
0
ответов
-
-
-
Видеокарты
- +1 ещё
Сложный
Почему не происходит выхода видео на монитор?
-
1 подписчик -
19 часов назад
-
23 просмотра
0
ответов
-
-
-
Видеокарты
- +1 ещё
Простой
Не сгорит ли железо если поставить БП на 100w меньше рекомендуемой?
-
1 подписчик -
вчера
-
68 просмотров
4
ответа
-
-
-
Windows
- +3 ещё
Сложный
Дисплей ноутбука не подключается к видео карте, как исправить?
-
1 подписчик -
06 февр.
-
66 просмотров
0
ответов
-
-
-
Windows
- +2 ещё
Сложный
При движении мыши скачет нагрузка gpu. С чем связано?
-
2 подписчика -
06 февр.
-
274 просмотра
2
ответа
-
-
-
Компьютеры
- +3 ещё
Средний
Почему видеокарта не нагружается в играх?
-
1 подписчик -
03 февр.
-
149 просмотров
3
ответа
-
-
-
Видеокарты
Простой
Какая видеокарта потянет два монитора с разрешение 4к+?
-
1 подписчик -
31 янв.
-
89 просмотров
2
ответа
-
-
-
Видеокарты
Простой
Какие проблемы могут возникуть при покупке 4070 ti/3080 ti?
-
1 подписчик -
29 янв.
-
95 просмотров
1
ответ
-
-
-
Криптовалюта
- +1 ещё
Простой
Как получить все транзакции через bscscan api?
-
1 подписчик -
29 янв.
-
31 просмотр
1
ответ
-
-
-
Мониторы
- +1 ещё
Сложный
Поддерживается ли разрешение 5120:1440 и 165 гц на видеокарте gtx 1660 ti?
-
1 подписчик -
27 янв.
-
161 просмотр
1
ответ
-
-
Показать ещё
Загружается…




Вакансии с Хабр Карьеры
UI/UX Дизайнер
Телепорт
•
Киров
от 90 000 ₽
Системный аналитик
Телепорт
•
Киров
от 120 000 ₽
Frontend — разработчик
Телепорт
•
Киров
от 90 000 ₽
Ещё вакансии
Заказы с Хабр Фриланса
Доработать бэкенд сайта / yii2
09 февр. 2023, в 17:37
5000 руб./за проект
Разработка гарант сервиса по продаже товаров между пользователями
09 февр. 2023, в 17:35
50000 руб./за проект
Парсинг отзывов с Яндекс.Маркет и Ozon.ru с обходом Cloudflare
09 февр. 2023, в 17:25
3800 руб./за проект
Ещё заказы
Минуточку внимания
Присоединяйтесь к сообществу, чтобы узнавать новое и делиться знаниями
Зарегистрироваться
-
#1
I have a P106-100 Graphics card which crashed halfway through mining.
When I now run the miner software I get «cuda error — an illegal memory access encountered»
I have rebooted my PC and I still cannot resolve the issue.
Is my graphics card knackered ? is there a way to reset the memory (I am assuming somehow the memory is not being refreshed after a device power off)
-
#2
@cdawall Probably best person to help you
Have tagged him
he will be along to help you hopefully soon ")
-
#3
Some have mentioned it’s an issue from power states. You need to use Nvidia inspector to turn the P2 state off.

-
#4
@erocker thanks, I will give that a go and report back

cdawall
where the hell are my stars
-
#5
Which specific miner is causing an issue?
-
#6
I’ve got a 8 GPU machine where one of the GPU’s is knackered
I’m using EthMiner
The error occurs when attempting to generate the DAG file

-
#7
Maybe while mining it encountered pocket with methane and exploded, use non pyrophoric tools.
-
#8
Maybe while mining it encountered pocket with methane and exploded, use non pyrophoric tools.
Maybe while mining it encountered pocket with methane and exploded, use non pyrophoric tools.
Lol

-
#9
What happens when you take the card out and try running it all?

qubit
Overclocked quantum bit
-
#10
I see that this is a mining specific card. Are you able to run the card on its own, ie remove all the others from the rig? If you run a different card on its own does it run? If the answers are no and yes, then your card is likely faulty. It might also help to try moving it to a different slot if you get an error when testing this.
-
#11
Indeed it is a mining specific card.
Tried everything you suggested. Only thing I can think of is the memory blocks are somehow corrupted (but I would expect the memory blocks to be cleared down after the device is powered off and back on)
Anyone aware of any software to check the integrity of GPU memory and fix any memory related issues ( assuming the memory blocks are not cleared down after a device is powered off)

-
#12
Indeed it is a mining specific card.
Tried everything you suggested. Only thing I can think of is the memory blocks are somehow corrupted (but I would expect the memory blocks to be cleared down after the device is powered off and back on)
Anyone aware of any software to check the integrity of GPU memory and fix any memory related issues ( assuming the memory blocks are not cleared down after a device is powered off)
Like a stick of ram, it’s rare, but GPU memory can go bad. This is likely what you are seeing. If so, no, a program will not fix it. A quick warranty claim might though.
-
#13
Indeed it is a mining specific card.
Like a stick of ram, it’s rare, but GPU memory can go bad. This is likely what you are seeing. If so, no, a program will not fix it. A quick warranty claim might though.
many here will be intreasted on how any warranty Claim goes (re with the news of Specific 90 day warranty’s)
if you RMA PLEASE KEEP THE THREAD( AND US) UPDATED
qubit
Overclocked quantum bit
-
#14
Indeed it is a mining specific card.
Tried everything you suggested. Only thing I can think of is the memory blocks are somehow corrupted (but I would expect the memory blocks to be cleared down after the device is powered off and back on)
Anyone aware of any software to check the integrity of GPU memory and fix any memory related issues ( assuming the memory blocks are not cleared down after a device is powered off)
Unfortunately the card is indeed faulty in that case. How long did you have it before it failed? I’m curious, because mining is known to hammer graphics cards which are working flat out 24/7.
-
#15
many here will be intreasted on how any warranty Claim goes (re with the news of Specific 90 day warranty’s)
if you RMA PLEASE KEEP THE THREAD( AND US) UPDATED
I’m not miner but find this interesting and I agree with @dorsetknob, do keep us updated on how things go.
cdawall
where the hell are my stars
-
#16
I’ve got a 8 GPU machine where one of the GPU’s is knackered
I’m using EthMiner
The error occurs when attempting to generate the DAG file
Any OC and are they 6gb cards?
-
#17
Any OC and are they 6gb cards?
Does not work with OC or without OC
They are 6GB cards
cdawall
where the hell are my stars
-
#18
Does not work with OC or without OC
They are 6GB cards
Try reseating all the cards