This article is about erroneous outcomes of statistical tests. For closely related concepts in binary classification and testing generally, see false positives and false negatives.
In statistical hypothesis testing, a type I error is the mistaken rejection of an actually true null hypothesis (also known as a «false positive» finding or conclusion; example: «an innocent person is convicted»), while a type II error is the failure to reject a null hypothesis that is actually false (also known as a «false negative» finding or conclusion; example: «a guilty person is not convicted»).[1] Much of statistical theory revolves around the minimization of one or both of these errors, though the complete elimination of either is a statistical impossibility if the outcome is not determined by a known, observable causal process.
By selecting a low threshold (cut-off) value and modifying the alpha (α) level, the quality of the hypothesis test can be increased.[2] The knowledge of type I errors and type II errors is widely used in medical science, biometrics and computer science.[clarification needed]
Intuitively, type I errors can be thought of as errors of commission, i.e. the researcher unluckily concludes that something is the fact. For instance, consider a study where researchers compare a drug with a placebo. If the patients who are given the drug get better than the patients given the placebo by chance, it may appear that the drug is effective, but in fact the conclusion is incorrect.
In reverse, type II errors are errors of omission. In the example above, if the patients who got the drug did not get better at a higher rate than the ones who got the placebo, but this was a random fluke, that would be a type II error. The consequence of a type II error depends on the size and direction of the missed determination and the circumstances. An expensive cure for one in a million patients may be inconsequential even if it truly is a cure.
Definition[edit]
Statistical background[edit]
In statistical test theory, the notion of a statistical error is an integral part of hypothesis testing. The test goes about choosing about two competing propositions called null hypothesis, denoted by H0 and alternative hypothesis, denoted by H1. This is conceptually similar to the judgement in a court trial. The null hypothesis corresponds to the position of the defendant: just as he is presumed to be innocent until proven guilty, so is the null hypothesis presumed to be true until the data provide convincing evidence against it. The alternative hypothesis corresponds to the position against the defendant. Specifically, the null hypothesis also involves the absence of a difference or the absence of an association. Thus, the null hypothesis can never be that there is a difference or an association.
If the result of the test corresponds with reality, then a correct decision has been made. However, if the result of the test does not correspond with reality, then an error has occurred. There are two situations in which the decision is wrong. The null hypothesis may be true, whereas we reject H0. On the other hand, the alternative hypothesis H1 may be true, whereas we do not reject H0. Two types of error are distinguished: type I error and type II error.[3]
Type I error[edit]
The first kind of error is the mistaken rejection of a null hypothesis as the result of a test procedure. This kind of error is called a type I error (false positive) and is sometimes called an error of the first kind. In terms of the courtroom example, a type I error corresponds to convicting an innocent defendant.
Type II error[edit]
The second kind of error is the mistaken failure to reject the null hypothesis as the result of a test procedure. This sort of error is called a type II error (false negative) and is also referred to as an error of the second kind. In terms of the courtroom example, a type II error corresponds to acquitting a criminal.[4]
Crossover error rate[edit]
The crossover error rate (CER) is the point at which type I errors and type II errors are equal. A system with a lower CER value provides more accuracy than a system with a higher CER value.
False positive and false negative[edit]
In terms of false positives and false negatives, a positive result corresponds to rejecting the null hypothesis, while a negative result corresponds to failing to reject the null hypothesis; «false» means the conclusion drawn is incorrect. Thus, a type I error is equivalent to a false positive, and a type II error is equivalent to a false negative.
Table of error types[edit]
Tabularised relations between truth/falseness of the null hypothesis and outcomes of the test:[5]
| Table of error types | Null hypothesis (H0) is |
||
|---|---|---|---|
| True | False | ||
| Decision about null hypothesis (H0) |
Don’t reject |
Correct inference (true negative) (probability = 1−α) |
Type II error (false negative) (probability = β) |
| Reject | Type I error (false positive) (probability = α) |
Correct inference (true positive) (probability = 1−β) |
Error rate[edit]

The results obtained from negative sample (left curve) overlap with the results obtained from positive samples (right curve). By moving the result cutoff value (vertical bar), the rate of false positives (FP) can be decreased, at the cost of raising the number of false negatives (FN), or vice versa (TP = True Positives, TPR = True Positive Rate, FPR = False Positive Rate, TN = True Negatives).
A perfect test would have zero false positives and zero false negatives. However, statistical methods are probabilistic, and it cannot be known for certain whether statistical conclusions are correct. Whenever there is uncertainty, there is the possibility of making an error. Considering this nature of statistics science, all statistical hypothesis tests have a probability of making type I and type II errors.[6]
- The type I error rate is the probability of rejecting the null hypothesis given that it is true. The test is designed to keep the type I error rate below a prespecified bound called the significance level, usually denoted by the Greek letter α (alpha) and is also called the alpha level. Usually, the significance level is set to 0.05 (5%), implying that it is acceptable to have a 5% probability of incorrectly rejecting the true null hypothesis.[7]
- The rate of the type II error is denoted by the Greek letter β (beta) and related to the power of a test, which equals 1−β.[8]
These two types of error rates are traded off against each other: for any given sample set, the effort to reduce one type of error generally results in increasing the other type of error.[9]
The quality of hypothesis test[edit]
The same idea can be expressed in terms of the rate of correct results and therefore used to minimize error rates and improve the quality of hypothesis test. To reduce the probability of committing a type I error, making the alpha value more stringent is quite simple and efficient. To decrease the probability of committing a type II error, which is closely associated with analyses’ power, either increasing the test’s sample size or relaxing the alpha level could increase the analyses’ power.[10] A test statistic is robust if the type I error rate is controlled.
Varying different threshold (cut-off) value could also be used to make the test either more specific or more sensitive, which in turn elevates the test quality. For example, imagine a medical test, in which an experimenter might measure the concentration of a certain protein in the blood sample. The experimenter could adjust the threshold (black vertical line in the figure) and people would be diagnosed as having diseases if any number is detected above this certain threshold. According to the image, changing the threshold would result in changes in false positives and false negatives, corresponding to movement on the curve.[11]
Example[edit]
Since in a real experiment it is impossible to avoid all type I and type II errors, it is important to consider the amount of risk one is willing to take to falsely reject H0 or accept H0. The solution to this question would be to report the p-value or significance level α of the statistic. For example, if the p-value of a test statistic result is estimated at 0.0596, then there is a probability of 5.96% that we falsely reject H0. Or, if we say, the statistic is performed at level α, like 0.05, then we allow to falsely reject H0 at 5%. A significance level α of 0.05 is relatively common, but there is no general rule that fits all scenarios.
Vehicle speed measuring[edit]
The speed limit of a freeway in the United States is 120 kilometers per hour. A device is set to measure the speed of passing vehicles. Suppose that the device will conduct three measurements of the speed of a passing vehicle, recording as a random sample X1, X2, X3. The traffic police will or will not fine the drivers depending on the average speed  . That is to say, the test statistic
. That is to say, the test statistic

In addition, we suppose that the measurements X1, X2, X3 are modeled as normal distribution N(μ,4). Then, T should follow N(μ,4/3) and the parameter μ represents the true speed of passing vehicle. In this experiment, the null hypothesis H0 and the alternative hypothesis H1 should be
H0: μ=120 against H1: μ>120.
If we perform the statistic level at α=0.05, then a critical value c should be calculated to solve

According to change-of-units rule for the normal distribution. Referring to Z-table, we can get

Here, the critical region. That is to say, if the recorded speed of a vehicle is greater than critical value 121.9, the driver will be fined. However, there are still 5% of the drivers are falsely fined since the recorded average speed is greater than 121.9 but the true speed does not pass 120, which we say, a type I error.
The type II error corresponds to the case that the true speed of a vehicle is over 120 kilometers per hour but the driver is not fined. For example, if the true speed of a vehicle μ=125, the probability that the driver is not fined can be calculated as

which means, if the true speed of a vehicle is 125, the driver has the probability of 0.36% to avoid the fine when the statistic is performed at level 125 since the recorded average speed is lower than 121.9. If the true speed is closer to 121.9 than 125, then the probability of avoiding the fine will also be higher.
The tradeoffs between type I error and type II error should also be considered. That is, in this case, if the traffic police do not want to falsely fine innocent drivers, the level α can be set to a smaller value, like 0.01. However, if that is the case, more drivers whose true speed is over 120 kilometers per hour, like 125, would be more likely to avoid the fine.
Etymology[edit]
In 1928, Jerzy Neyman (1894–1981) and Egon Pearson (1895–1980), both eminent statisticians, discussed the problems associated with «deciding whether or not a particular sample may be judged as likely to have been randomly drawn from a certain population»:[12] and, as Florence Nightingale David remarked, «it is necessary to remember the adjective ‘random’ [in the term ‘random sample’] should apply to the method of drawing the sample and not to the sample itself».[13]
They identified «two sources of error», namely:
- (a) the error of rejecting a hypothesis that should have not been rejected, and
- (b) the error of failing to reject a hypothesis that should have been rejected.
In 1930, they elaborated on these two sources of error, remarking that:
…in testing hypotheses two considerations must be kept in view, we must be able to reduce the chance of rejecting a true hypothesis to as low a value as desired; the test must be so devised that it will reject the hypothesis tested when it is likely to be false.
In 1933, they observed that these «problems are rarely presented in such a form that we can discriminate with certainty between the true and false hypothesis» . They also noted that, in deciding whether to fail to reject, or reject a particular hypothesis amongst a «set of alternative hypotheses», H1, H2…, it was easy to make an error:
…[and] these errors will be of two kinds:
- (I) we reject H0 [i.e., the hypothesis to be tested] when it is true,[14]
- (II) we fail to reject H0 when some alternative hypothesis HA or H1 is true. (There are various notations for the alternative).
In all of the papers co-written by Neyman and Pearson the expression H0 always signifies «the hypothesis to be tested».
In the same paper they call these two sources of error, errors of type I and errors of type II respectively.[15]
[edit]
Null hypothesis[edit]
It is standard practice for statisticians to conduct tests in order to determine whether or not a «speculative hypothesis» concerning the observed phenomena of the world (or its inhabitants) can be supported. The results of such testing determine whether a particular set of results agrees reasonably (or does not agree) with the speculated hypothesis.
On the basis that it is always assumed, by statistical convention, that the speculated hypothesis is wrong, and the so-called «null hypothesis» that the observed phenomena simply occur by chance (and that, as a consequence, the speculated agent has no effect) – the test will determine whether this hypothesis is right or wrong. This is why the hypothesis under test is often called the null hypothesis (most likely, coined by Fisher (1935, p. 19)), because it is this hypothesis that is to be either nullified or not nullified by the test. When the null hypothesis is nullified, it is possible to conclude that data support the «alternative hypothesis» (which is the original speculated one).
The consistent application by statisticians of Neyman and Pearson’s convention of representing «the hypothesis to be tested» (or «the hypothesis to be nullified») with the expression H0 has led to circumstances where many understand the term «the null hypothesis» as meaning «the nil hypothesis» – a statement that the results in question have arisen through chance. This is not necessarily the case – the key restriction, as per Fisher (1966), is that «the null hypothesis must be exact, that is free from vagueness and ambiguity, because it must supply the basis of the ‘problem of distribution,’ of which the test of significance is the solution.»[16] As a consequence of this, in experimental science the null hypothesis is generally a statement that a particular treatment has no effect; in observational science, it is that there is no difference between the value of a particular measured variable, and that of an experimental prediction.[citation needed]
Statistical significance[edit]
If the probability of obtaining a result as extreme as the one obtained, supposing that the null hypothesis were true, is lower than a pre-specified cut-off probability (for example, 5%), then the result is said to be statistically significant and the null hypothesis is rejected.
British statistician Sir Ronald Aylmer Fisher (1890–1962) stressed that the «null hypothesis»:
… is never proved or established, but is possibly disproved, in the course of experimentation. Every experiment may be said to exist only in order to give the facts a chance of disproving the null hypothesis.
— Fisher, 1935, p.19
Application domains[edit]
Medicine[edit]
In the practice of medicine, the differences between the applications of screening and testing are considerable.
Medical screening[edit]
Screening involves relatively cheap tests that are given to large populations, none of whom manifest any clinical indication of disease (e.g., Pap smears).
Testing involves far more expensive, often invasive, procedures that are given only to those who manifest some clinical indication of disease, and are most often applied to confirm a suspected diagnosis.
For example, most states in the USA require newborns to be screened for phenylketonuria and hypothyroidism, among other congenital disorders.
Hypothesis: «The newborns have phenylketonuria and hypothyroidism»
Null Hypothesis (H0): «The newborns do not have phenylketonuria and hypothyroidism»,
Type I error (false positive): The true fact is that the newborns do not have phenylketonuria and hypothyroidism but we consider they have the disorders according to the data.
Type II error (false negative): The true fact is that the newborns have phenylketonuria and hypothyroidism but we consider they do not have the disorders according to the data.
Although they display a high rate of false positives, the screening tests are considered valuable because they greatly increase the likelihood of detecting these disorders at a far earlier stage.
The simple blood tests used to screen possible blood donors for HIV and hepatitis have a significant rate of false positives; however, physicians use much more expensive and far more precise tests to determine whether a person is actually infected with either of these viruses.
Perhaps the most widely discussed false positives in medical screening come from the breast cancer screening procedure mammography. The US rate of false positive mammograms is up to 15%, the highest in world. One consequence of the high false positive rate in the US is that, in any 10-year period, half of the American women screened receive a false positive mammogram. False positive mammograms are costly, with over $100 million spent annually in the U.S. on follow-up testing and treatment. They also cause women unneeded anxiety. As a result of the high false positive rate in the US, as many as 90–95% of women who get a positive mammogram do not have the condition. The lowest rate in the world is in the Netherlands, 1%. The lowest rates are generally in Northern Europe where mammography films are read twice and a high threshold for additional testing is set (the high threshold decreases the power of the test).
The ideal population screening test would be cheap, easy to administer, and produce zero false-negatives, if possible. Such tests usually produce more false-positives, which can subsequently be sorted out by more sophisticated (and expensive) testing.
Medical testing[edit]
False negatives and false positives are significant issues in medical testing.
Hypothesis: «The patients have the specific disease».
Null hypothesis (H0): «The patients do not have the specific disease».
Type I error (false positive): «The true fact is that the patients do not have a specific disease but the physicians judges the patients was ill according to the test reports».
False positives can also produce serious and counter-intuitive problems when the condition being searched for is rare, as in screening. If a test has a false positive rate of one in ten thousand, but only one in a million samples (or people) is a true positive, most of the positives detected by that test will be false. The probability that an observed positive result is a false positive may be calculated using Bayes’ theorem.
Type II error (false negative): «The true fact is that the disease is actually present but the test reports provide a falsely reassuring message to patients and physicians that the disease is absent».
False negatives produce serious and counter-intuitive problems, especially when the condition being searched for is common. If a test with a false negative rate of only 10% is used to test a population with a true occurrence rate of 70%, many of the negatives detected by the test will be false.
This sometimes leads to inappropriate or inadequate treatment of both the patient and their disease. A common example is relying on cardiac stress tests to detect coronary atherosclerosis, even though cardiac stress tests are known to only detect limitations of coronary artery blood flow due to advanced stenosis.
Biometrics[edit]
Biometric matching, such as for fingerprint recognition, facial recognition or iris recognition, is susceptible to type I and type II errors.
Hypothesis: «The input does not identify someone in the searched list of people»
Null hypothesis: «The input does identify someone in the searched list of people»
Type I error (false reject rate): «The true fact is that the person is someone in the searched list but the system concludes that the person is not according to the data».
Type II error (false match rate): «The true fact is that the person is not someone in the searched list but the system concludes that the person is someone whom we are looking for according to the data».
The probability of type I errors is called the «false reject rate» (FRR) or false non-match rate (FNMR), while the probability of type II errors is called the «false accept rate» (FAR) or false match rate (FMR).
If the system is designed to rarely match suspects then the probability of type II errors can be called the «false alarm rate». On the other hand, if the system is used for validation (and acceptance is the norm) then the FAR is a measure of system security, while the FRR measures user inconvenience level.
Security screening[edit]
False positives are routinely found every day in airport security screening, which are ultimately visual inspection systems. The installed security alarms are intended to prevent weapons being brought onto aircraft; yet they are often set to such high sensitivity that they alarm many times a day for minor items, such as keys, belt buckles, loose change, mobile phones, and tacks in shoes.
Here, the null hypothesis is that the item is not a weapon, while the alternative hypothesis is that the item is a weapon.
A type I error (false positive): «The true fact is that the item is not a weapon but the system still alarms».
Type II error (false negative) «The true fact is that the item is a weapon but the system keeps silent at this time».
The ratio of false positives (identifying an innocent traveler as a terrorist) to true positives (detecting a would-be terrorist) is, therefore, very high; and because almost every alarm is a false positive, the positive predictive value of these screening tests is very low.
The relative cost of false results determines the likelihood that test creators allow these events to occur. As the cost of a false negative in this scenario is extremely high (not detecting a bomb being brought onto a plane could result in hundreds of deaths) whilst the cost of a false positive is relatively low (a reasonably simple further inspection) the most appropriate test is one with a low statistical specificity but high statistical sensitivity (one that allows a high rate of false positives in return for minimal false negatives).
Computers[edit]
The notions of false positives and false negatives have a wide currency in the realm of computers and computer applications, including computer security, spam filtering, Malware, Optical character recognition and many others.
For example, in the case of spam filtering the hypothesis here is that the message is a spam.
Thus, null hypothesis: «The message is not a spam».
Type I error (false positive): «Spam filtering or spam blocking techniques wrongly classify a legitimate email message as spam and, as a result, interferes with its delivery».
While most anti-spam tactics can block or filter a high percentage of unwanted emails, doing so without creating significant false-positive results is a much more demanding task.
Type II error (false negative): «Spam email is not detected as spam, but is classified as non-spam». A low number of false negatives is an indicator of the efficiency of spam filtering.
See also[edit]
- Binary classification
- Detection theory
- Egon Pearson
- Ethics in mathematics
- False positive paradox
- False discovery rate
- Family-wise error rate
- Information retrieval performance measures
- Neyman–Pearson lemma
- Null hypothesis
- Probability of a hypothesis for Bayesian inference
- Precision and recall
- Prosecutor’s fallacy
- Prozone phenomenon
- Receiver operating characteristic
- Sensitivity and specificity
- Statisticians’ and engineers’ cross-reference of statistical terms
- Testing hypotheses suggested by the data
- Type III error
References[edit]
- ^ «Type I Error and Type II Error». explorable.com. Retrieved 14 December 2019.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ A modern introduction to probability and statistics : understanding why and how. Dekking, Michel, 1946-. London: Springer. 2005. ISBN 978-1-85233-896-1. OCLC 262680588.
{{cite book}}: CS1 maint: others (link) - ^ Sheskin, David (2004). Handbook of Parametric and Nonparametric Statistical Procedures. CRC Press. p. 54. ISBN 1584884401.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Lindenmayer, David. (2005). Practical conservation biology. Burgman, Mark A. Collingwood, Vic.: CSIRO Pub. ISBN 0-643-09310-9. OCLC 65216357.
- ^ Chow, Y. W.; Pietranico, R.; Mukerji, A. (27 October 1975). «Studies of oxygen binding energy to hemoglobin molecule». Biochemical and Biophysical Research Communications. 66 (4): 1424–1431. doi:10.1016/0006-291x(75)90518-5. ISSN 0006-291X. PMID 6.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Smith, R. J.; Bryant, R. G. (27 October 1975). «Metal substitutions incarbonic anhydrase: a halide ion probe study». Biochemical and Biophysical Research Communications. 66 (4): 1281–1286. doi:10.1016/0006-291x(75)90498-2. ISSN 0006-291X. PMC 9650581. PMID 3.
- ^ Moroi, K.; Sato, T. (15 August 1975). «Comparison between procaine and isocarboxazid metabolism in vitro by a liver microsomal amidase-esterase». Biochemical Pharmacology. 24 (16): 1517–1521. doi:10.1016/0006-2952(75)90029-5. ISSN 1873-2968. PMID 8.
- ^ NEYMAN, J.; PEARSON, E. S. (1928). «On the Use and Interpretation of Certain Test Criteria for Purposes of Statistical Inference Part I». Biometrika. 20A (1–2): 175–240. doi:10.1093/biomet/20a.1-2.175. ISSN 0006-3444.
- ^ C.I.K.F. (July 1951). «Probability Theory for Statistical Methods. By F. N. David. [Pp. ix + 230. Cambridge University Press. 1949. Price 155.]». Journal of the Staple Inn Actuarial Society. 10 (3): 243–244. doi:10.1017/s0020269x00004564. ISSN 0020-269X.
- ^ Note that the subscript in the expression H0 is a zero (indicating null), and is not an «O» (indicating original).
- ^ Neyman, J.; Pearson, E. S. (30 October 1933). «The testing of statistical hypotheses in relation to probabilities a priori». Mathematical Proceedings of the Cambridge Philosophical Society. 29 (4): 492–510. Bibcode:1933PCPS…29..492N. doi:10.1017/s030500410001152x. ISSN 0305-0041. S2CID 119855116.
- ^ Fisher, R.A. (1966). The design of experiments. 8th edition. Hafner:Edinburgh.
Bibliography[edit]
- Betz, M.A. & Gabriel, K.R., «Type IV Errors and Analysis of Simple Effects», Journal of Educational Statistics, Vol.3, No.2, (Summer 1978), pp. 121–144.
- David, F.N., «A Power Function for Tests of Randomness in a Sequence of Alternatives», Biometrika, Vol.34, Nos.3/4, (December 1947), pp. 335–339.
- Fisher, R.A., The Design of Experiments, Oliver & Boyd (Edinburgh), 1935.
- Gambrill, W., «False Positives on Newborns’ Disease Tests Worry Parents», Health Day, (5 June 2006). [1] Archived 17 May 2018 at the Wayback Machine
- Kaiser, H.F., «Directional Statistical Decisions», Psychological Review, Vol.67, No.3, (May 1960), pp. 160–167.
- Kimball, A.W., «Errors of the Third Kind in Statistical Consulting», Journal of the American Statistical Association, Vol.52, No.278, (June 1957), pp. 133–142.
- Lubin, A., «The Interpretation of Significant Interaction», Educational and Psychological Measurement, Vol.21, No.4, (Winter 1961), pp. 807–817.
- Marascuilo, L.A. & Levin, J.R., «Appropriate Post Hoc Comparisons for Interaction and nested Hypotheses in Analysis of Variance Designs: The Elimination of Type-IV Errors», American Educational Research Journal, Vol.7., No.3, (May 1970), pp. 397–421.
- Mitroff, I.I. & Featheringham, T.R., «On Systemic Problem Solving and the Error of the Third Kind», Behavioral Science, Vol.19, No.6, (November 1974), pp. 383–393.
- Mosteller, F., «A k-Sample Slippage Test for an Extreme Population», The Annals of Mathematical Statistics, Vol.19, No.1, (March 1948), pp. 58–65.
- Moulton, R.T., «Network Security», Datamation, Vol.29, No.7, (July 1983), pp. 121–127.
- Raiffa, H., Decision Analysis: Introductory Lectures on Choices Under Uncertainty, Addison–Wesley, (Reading), 1968.
External links[edit]
- Bias and Confounding – presentation by Nigel Paneth, Graduate School of Public Health, University of Pittsburgh
Statistics Learning — (Error|misclassification) Rate — false (positives|negatives)
Table of Contents
About
Articles Related
False rate are not desired while true rate are.
For instance, in a spam application, a false negative will deliver a spam in your inbox and a false positive will deliver legitimate mail to the junk folder.
False
False Positive
False Positive (also known as false alarm) are predictions that should be false but were predicted as true
False positive rate: The fraction of negative examples (No, False, -) that are classified as positive (Yes, True, +)
<MATH>
begin{array}{rrl}
text{False positive rate} & = & frac{text{False Positive}}{text{False Positive} + text{True Negative}} \
& = & frac{c}{c + d} \
& = & 1- text{accuracy of the other class}
end{array}
</MATH>
False Negative
False Negative: Predictions that should be true but were predicted as false
False negative rate: The fraction of positive examples that are classified as negative
<MATH>
begin{array}{rrc}
text{False negative rate} & = & frac{b}{a + b}
end{array}
</MATH>
True
True Positive
True Positive: positive instances that are correctly assigned to the positive class
The TP rate is the same as the accuracy for the first class.
True Positive rate: The fraction of positive target that are classified as positive
<MATH>
begin{array}{rrl}
text{True positive rate} & = & frac{text{True Positive}}{text{True Positive} + text{False Negative}} \
& = & frac{a}{a + b} \
& = & text{Accuracy on the first class}
end{array}
</MATH>
How to decrease it
In a probability regression classification for a two-class problem, the threshold is normally on 50%. Above the threshold, it will be 1 and below it will be 0.
<MATH>
hat{Pr}(Y = Yes|X ) geq threshold
</MATH>
By changing this classification probability threshold, you can improve this error rate.
In a regression classification, algorithm, you capture the probability threshold changes in an ROC curve.
For instance: (For a two class, the threshold is 0.5)
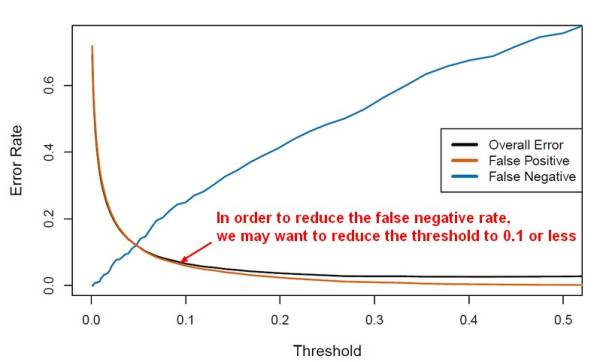
The Total Error is a weighted average of the False Positive Rate and False Negative Rate. The weights are determined by the Prior Probabilities of Positive and Negative Responses. Positive responses are so uncommon that the False Negatives makes up only a small portion of the Total error therefore Total Error keep going down even though the False Negative Rate increases.
Others Metrics
Sensitivity / Specificity
Sensitivity
<MATH>
begin{array}{rrl}
Sensitivity & = & frac{a}{a+b} \
end{array}
</MATH>
Specificity
<MATH>
begin{array}{rrl}
1-Specificity & = & 1-frac{d}{c+d}
end{array}
</MATH>
Lift , Precision, Recall
Lift , Precision, Recall are others Accuracy Metrics
<MATH>
begin{array}{rrl}
Lift & = & frac{displaystyle text{% positives > threshold}}{displaystyle text{% data set > threshold}} & = & frac{displaystyle {a/(a +b)}}{displaystyle {(a + c)/(a + b + c + d)}}\
Precision & = & frac{displaystyle a}{displaystyle a+c}\
Recall & = & frac{displaystyle a}{displaystyle a+b}\
end{array}
</MATH>
Recommended Pages
Statistics Learning — Prediction Error (Training versus Test)
Statistics Learning — Prediction Error (Training versus Test)
About
The Prediction Error tries to represent the noise through the concept of training error versus test error.
We fit our model to th «…
(Statistics|Data Mining) — (K-Fold) Cross-validation (rotation estimation)
(Statistics|Data Mining) — (K-Fold) Cross-validation (rotation estimation)
About
Cross-validation, sometimes called rotation estimation is a resampling validation technique for assessing how the res «…
Data Mining — (Parameters | Model) (Accuracy | Precision | Fit | Performance) Metrics
Data Mining — (Parameters | Model) (Accuracy | Precision | Fit | Performance) Metrics
About
Accuracy is a evaluation metrics on how a model perform.
rare event detection
Articles Related
Proble «…
Data Mining — (Anomaly|outlier) Detection
The goal of anomaly detection is to identify unusual or suspicious cases based on deviation from the norm within data that is seemingly homogeneous. Anomaly detection is an important tool: in data e «…
Machine Learning — Confusion Matrix
If a classification system has been trained a confusion matrix will summarize the results (ie the error rate (false|true) (positive|negative) for a binary classification). overfitting The main diagona «…

Statistical Learning — Two-fold validation
Two-fold validation is a resampling method. It randomly divides the available set of samples into two parts: a training set and a validation or hold-out set. The model is fit on the training set, an «…
Statistics — (Base rate fallacy|Bonferroni’s principle)
Every accurate (model|test) can be useless as detection tools if the studied case is sufficiently rare among the general population. The data model will produce too many false positives or false negat «…
Statistics — (Threshold|Cut-off) of binary classification
The Threshold or Cut-off represents in a binary classification the probability that the prediction is true. It represents the tradeoff between false positives and false negatives. Articles Related Exa «…

Statistics — ROC Plot and Area under the curve (AUC)
The Area Under Curve (AUC) metric measures the performance of a binary classification. In a regression classification for a two-class problem using a probability algorithm, you will capture the proba «…
Viz — Control Chart (Shewhart)
The purpose of control charts is to allow simple detection of events that are indicative of actual process change. Control charts attempt to differentiate “assignable” (“special”) sources of v «…
This topic describes how to compute error statistics for various communications
systems.
Computation of Theoretical Error Statistics
The biterr function, discussed in the
Compute SERs and BERs Using Simulated Data section, can help you gather empirical error
statistics, but validating your results by comparing them to the theoretical error
statistics is good practice. For certain types of communications systems,
closed-form expressions exist for the computation of the bit error rate (BER) or an
approximate bound on the BER. The functions listed in this table compute the
closed-form expressions for the BER or a bound on it for the specified types of
communications systems.
| Type of Communications System | Function |
|---|---|
| Uncoded AWGN channel | berawgn
|
| Uncoded Rayleigh and Rician fading channel | berfading
|
| Coded AWGN channel | bercoding |
| Uncoded AWGN channel with imperfect synchronization | bersync
|
The analytical expressions used in these functions are discussed in
Analytical Expressions Used in BER Analysis. The reference pages of these functions also list
references to one or more books containing the closed-form expressions implemented
by the function.
Theoretical Performance Results
-
Plot Theoretical Error Rates
-
Compare Theoretical and Empirical Error Rates
Plot Theoretical Error Rates
This example uses the bercoding function to compute upper bounds on BERs for convolutional coding with a soft-decision decoder.
coderate = 1/4; % Code rate
Create a structure, dspec, with information about the distance spectrum. Define the energy per bit to noise power spectral density ratio (Eb/N0) sweep range and generate the theoretical bound results.
dspec.dfree = 10; % Minimum free distance of code dspec.weight = [1 0 4 0 12 0 32 0 80 0 192 0 448 0 1024 ... 0 2304 0 5120 0]; % Distance spectrum of code EbNo = 3:0.5:8; berbound = bercoding(EbNo,'conv','soft',coderate,dspec);
Plot the theoretical bound results.
semilogy(EbNo,berbound) xlabel('E_b/N_0 (dB)'); ylabel('Upper Bound on BER'); title('Theoretical Bound on BER for Convolutional Coding'); grid on;

Compare Theoretical and Empirical Error Rates
Using the berawgn function, compute the theoretical symbol error rates (SERs) for pulse amplitude modulation (PAM) over a range of Eb/N0 values. Simulate 8 PAM with an AWGN channel, and compute the empirical SERs. Compare the theoretical and then empirical SERs by plotting them on the same set of axes.
Compute and plot the theoretical SER using berawgn.
rng('default') % Set random number seed for repeatability M = 8; EbNo = 0:13; [ber,ser] = berawgn(EbNo,'pam',M); semilogy(EbNo,ser,'r'); legend('Theoretical SER'); title('Theoretical Error Rate'); xlabel('E_b/N_0 (dB)'); ylabel('Symbol Error Rate'); grid on;

Compute the empirical SER by simulating an 8 PAM communications system link. Define simulation parameters and preallocate variables needed for the results. As described in [1], because N0=2×(NVariance)2, add 3 dB to the Eb/N0 value when converting Eb/N0 values to SNR values.
n = 10000; % Number of symbols to process k = log2(M); % Number of bits per symbol snr = EbNo+3+10*log10(k); % In dB ynoisy = zeros(n,length(snr)); z = zeros(n,length(snr)); errVec = zeros(3,length(EbNo));
Create an error rate calculator System object™ to compare decoded symbols to the original transmitted symbols.
errcalc = comm.ErrorRate;
Generate a random data message and apply PAM. Normalize the channel to the signal power. Loop the simulation to generate error rates over the range of SNR values.
x = randi([0 M-1],n,1); % Create message signal y = pammod(x,M); % Modulate signalpower = (real(y)'*real(y))/length(real(y)); for jj = 1:length(snr) reset(errcalc) ynoisy(:,jj) = awgn(real(y),snr(jj),'measured'); % Add AWGN z(:,jj) = pamdemod(complex(ynoisy(:,jj)),M); % Demodulate errVec(:,jj) = errcalc(x,z(:,jj)); % Compute SER from simulation end
Compare the theoretical and empirical results.
hold on; semilogy(EbNo,errVec(1,:),'b.'); legend('Theoretical SER','Empirical SER'); title('Comparison of Theoretical and Empirical Error Rates'); hold off;

Performance Results via Simulation
-
Section Overview
-
Compute SERs and BERs Using Simulated Data
Section Overview
This section describes how to compare the data messages that enter and leave
a communications system simulation and how to compute error statistics using the
Monte Carlo technique. Simulations can measure system performance by using the
data messages before transmission and after reception to compute the BER or SER
for a communications system. To explore physical layer components used to model
and simulate communications systems, see PHY Components.
Curve fitting can be useful when you have a small or imperfect data set but
want to plot a smooth curve for presentation purposes. To explore the use of
curve fitting when computing performance results via simulation, see the Curve Fitting for Error Rate Plots section.
Compute SERs and BERs Using Simulated Data
The example shows how to compute SERs and BERs using the biterr and symerr functions, respectively. The symerr function compares two sets of data and computes the number of symbol errors and the SER. The biterr function compares two sets of data and computes the number of bit errors and the BER. An error is a discrepancy between corresponding points in the two sets of data.
The two sets of data typically represent messages entering a transmitter and recovered messages leaving a receiver. You can also compare data entering and leaving other parts of your communications system (for example, data entering an encoder and data leaving a decoder).
If your communications system uses several bits to represent one symbol, counting symbol errors is different from counting bit errors. In either the symbol- or bit-counting case, the error rate is the number of errors divided by the total number of transmitted symbols or bits, respectively.
Typically, simulating enough data to produce at least 100 errors provides accurate error rate results. If the error rate is very small (for example, 10-6 or less), using the semianalytic technique might compute the result more quickly than using a simulation-only approach. For more information, see the Performance Results via Semianalytic Technique section.
Compute Error Rates
Use the symerr function to compute the SERs for a noisy linear block code. Apply no digital modulation, so that each symbol contains a single bit. When each symbol is a single bit, the symbol errors and bit errors are the same.
After artificially adding noise to the encoded message, compare the resulting noisy code to the original code. Then, decode and compare the decoded message to the original message.
m = 3; % Set parameters for Hamming code n = 2^m-1; k = n-m; msg = randi([0 1],k*200,1); % Specify 200 messages of k bits each code = encode(msg,n,k,'hamming'); codenoisy = bsc(code,0.95); % Add noise newmsg = decode(codenoisy,n,k,'hamming'); % Decode and correct errors
Compute the SERs.
[~,noisyVec] = symerr(code,codenoisy); [~,decodedVec] = symerr(msg,newmsg);
The error rate decreases after decoding because the Hamming decoder correct errors based on the error-correcting capability of the decoder configuration. Because random number generators produce the message and noise is added, results vary from run to run. Display the SERs.
disp(['SER in the received code: ',num2str(noisyVec(1))])
SER in the received code: 0.94571
disp(['SER after decoding: ',num2str(decodedVec(1))])
SER after decoding: 0.9675
Comparing SER and BER
These commands show the difference between symbol errors and bit errors in various situations.
Create two three-element decimal vectors and show the binary representation. The vector a contains three 2-bit symbols, and the vector b contains three 3-bit symbols.
bpi = 3; % Bits per integer
a = [1 2 3];
b = [1 4 4];
int2bit(a,bpi)
ans = 3×3
0 0 0
0 1 1
1 0 1
ans = 3×3
0 1 1
0 0 0
1 0 0
Compare the binary values of the two vectors and compute the number of errors and the error rate by using the biterr and symerr functions.
format rat % Display fractions instead of decimals [snum,srate] = symerr(a,b)
snum is 2 because the second and third entries have bit differences. srate is 2/3 because the total number of symbols is 3.
[bnum,brate] = biterr(a,b)
bnum is 5 because the second entries differ in two bits, and the third entries differ in three bits. brate is 5/9 because the total number of bits is 9. By definition, the total number of bits is the number of entries in a for symbol error computations or b for bit error computations times the maximum number of bits among all entries of a and b, respectively.
Performance Results via Semianalytic Technique
The technique described in the Performance Results via Simulation
section can work for a large variety of communications systems but can be
prohibitively time-consuming for small error rates (for example,
10-6 or less). The semianalytic technique is an
alternative way to compute error rates. The semianalytic technique can produce
results faster than a nonanalytic method that uses simulated data.
For more information on implementing the semianalytic technique using a
combination of simulation and analysis to determine the error rate of a
communications system, see the semianalytic function.
Error Rate Plots
-
Section Overview
-
Creation of Error Rate Plots Using
semilogy
Function -
Curve Fitting for Error Rate Plots
-
Use Curve Fitting on Error Rate Plot
Section Overview
Error rate plots can be useful when examining the performance of a
communications system and are often included in publications. This section
discusses and demonstrates tools you can use to create error rate plots, modify
them to suit your needs, and perform curve fitting on the error rate data and
the plots.
Creation of Error Rate Plots Using semilogy Function
In many error rate plots, the horizontal axis indicates
Eb/N0
values in dB, and the vertical axis indicates the error rate using a logarithmic
(base 10) scale. For examples that create such a plot using the semilogy function, see Compare Theoretical and Empirical Error Rates and Plot Theoretical Error Rates.
Curve Fitting for Error Rate Plots
Curve fitting can be useful when you have a small or imperfect data set but
want to plot a smooth curve for presentation purposes. The berfit function includes
curve-fitting capabilities that help your analysis when the empirical data
describes error rates at different
Eb/N0
values. This function enables you to:
-
Customize various relevant aspects of the curve-fitting process, such
as a list of selections for the type of closed-form function used to
generate the fit. -
Plot empirical data along with a curve that
berfitfits to the
data. -
Interpolate points on the fitted curve between
Eb/N0
values in your empirical data set to smooth the plot. -
Collect relevant information about the fit, such as the numerical
values of points along the fitted curve and the coefficients of the fit
expression.
Note
The berfit function is
intended for curve fitting or interpolation, not extrapolation.
Extrapolating BER data beyond an order of magnitude below the smallest
empirical BER value is inherently unreliable.
Use Curve Fitting on Error Rate Plot
This example simulates a simple differential binary phase shift keying (DBPSK) communications system and plots error rate data for a series of Eb/N0 values. It uses the berfit and berconfint functions to fit a curve to a set of empirical error rates.
Initialize Simulation Parameters
Specify the input signal message length, modulation order, range of Eb/N0 values to simulate, and the minimum number of errors that must occur before the simulation computes an error rate for a given Eb/N0 value. Preallocate variables for final results and interim results.
Typically, for statistically accurate error rate results, the minimum number of errors must be on the order of 100. This simulation uses a small number of errors to shorten the run time and to illustrate how curve fitting can smooth a set of results.
siglen = 100000; % Number of bits in each trial M = 2; % DBPSK is binary EbN0vec = 0:5; % Vector of EbN0 values minnumerr = 5; % Compute BER after only 5 errors occur numEbN0 = length(EbN0vec); % Number of EbN0 values ber = zeros(1,numEbN0); % Final BER values berVec = zeros(3,numEbN0); % Updated BER values intv = cell(1,numEbN0); % Cell array of confidence intervals
Create an error rate calculator System object™.
errorCalc = comm.ErrorRate;
Loop the Simulation
Simulate the DBPSK-modulated communications system and compute the BER using a for loop to vary the Eb/N0 value. The inner while loop ensures that a minimum number of bit errors occur for each Eb/N0 value. Error rate statistics are saved for each Eb/N0 value and used later in this example when curve fitting and plotting.
for jj = 1:numEbN0 EbN0 = EbN0vec(jj); snr = EbN0; % For binary modulation SNR = EbN0 reset(errorCalc) while (berVec(2,jj) < minnumerr) msg = randi([0,M-1],siglen,1); % Generate message sequence txsig = dpskmod(msg,M); % Modulate rxsig = awgn(txsig,snr,'measured'); % Add noise decodmsg = dpskdemod(rxsig,M); % Demodulate berVec(:,jj) = errorCalc(msg,decodmsg); % Calculate BER end
Use the berconfint function to compute the error rate at a 98% confidence interval for the Eb/N0 values.
[ber(jj),intv1] = berconfint(berVec(2,jj),berVec(3,jj),0.98);
intv{jj} = intv1;
disp(['EbN0 = ' num2str(EbN0) ' dB, ' num2str(berVec(2,jj)) ...
' errors, BER = ' num2str(ber(jj))])
end
EbN0 = 0 dB, 18392 errors, BER = 0.18392 EbN0 = 1 dB, 14307 errors, BER = 0.14307 EbN0 = 2 dB, 10190 errors, BER = 0.1019 EbN0 = 3 dB, 6940 errors, BER = 0.0694 EbN0 = 4 dB, 4151 errors, BER = 0.04151 EbN0 = 5 dB, 2098 errors, BER = 0.02098
Use the berfit function to plot the best fitted curve, interpolating between BER points to get a smooth plot. Add confidence intervals to the plot.
fitEbN0 = EbN0vec(1):0.25:EbN0vec(end); % Interpolation values berfit(EbN0vec,ber,fitEbN0); hold on; for jj=1:numEbN0 semilogy([EbN0vec(jj) EbN0vec(jj)],intv{jj},'g-+'); end hold off;

See Also
Apps
- Bit Error Rate Analysis
Functions
berawgn|bercoding|berconfint|berfading|berfit|bersync
Related Topics
- Analyze Performance with Bit Error Rate Analysis App
- Analytical Expressions Used in BER Analysis
Гораздо легче что-то измерить, чем понять, что именно вы измеряете
Джон Уильям Салливан
Задачи машинного обучения с учителем как правило состоят в восстановлении зависимости между парами (признаковое описание, целевая переменная) по данным, доступным нам для анализа. Алгоритмы машинного обучения (learning algorithm), со многими из которых вы уже успели познакомиться, позволяют построить модель, аппроксимирующую эту зависимость. Но как понять, насколько качественной получилась аппроксимация?
Почти наверняка наша модель будет ошибаться на некоторых объектах: будь она даже идеальной, шум или выбросы в тестовых данных всё испортят. При этом разные модели будут ошибаться на разных объектах и в разной степени. Задача специалиста по машинному обучению – подобрать подходящий критерий, который позволит сравнивать различные модели.
Перед чтением этой главы мы хотели бы ещё раз напомнить, что качество модели нельзя оценивать на обучающей выборке. Как минимум, это стоит делать на отложенной (тестовой) выборке, но, если вам это позволяют время и вычислительные ресурсы, стоит прибегнуть и к более надёжным способам проверки – например, кросс-валидации (о ней вы узнаете в отдельной главе).
Выбор метрик в реальных задачах
Возможно, вы уже участвовали в соревнованиях по анализу данных. На таких соревнованиях метрику (критерий качества модели) организатор выбирает за вас, и она, как правило, довольно понятным образом связана с результатами предсказаний. Но на практике всё бывает намного сложнее.
Например, мы хотим:
- решить, сколько коробок с бананами нужно завтра привезти в конкретный магазин, чтобы минимизировать количество товара, который не будет выкуплен и минимизировать ситуацию, когда покупатель к концу дня не находит желаемый продукт на полке;
- увеличить счастье пользователя от работы с нашим сервисом, чтобы он стал лояльным и обеспечивал тем самым стабильный прогнозируемый доход;
- решить, нужно ли направить человека на дополнительное обследование.
В каждом конкретном случае может возникать целая иерархия метрик. Представим, например, что речь идёт о стриминговом музыкальном сервисе, пользователей которого мы решили порадовать сгенерированными самодельной нейросетью треками – не защищёнными авторским правом, а потому совершенно бесплатными. Иерархия метрик могла бы иметь такой вид:
- Самый верхний уровень: будущий доход сервиса – невозможно измерить в моменте, сложным образом зависит от совокупности всех наших усилий;
- Медианная длина сессии, возможно, служащая оценкой радости пользователей, которая, как мы надеемся, повлияет на их желание продолжать платить за подписку – её нам придётся измерять в продакшене, ведь нас интересует реакция настоящих пользователей на новшество;
- Доля удовлетворённых качеством сгенерированной музыки асессоров, на которых мы потестируем её до того, как выставить на суд пользователей;
- Функция потерь, на которую мы будем обучать генеративную сеть.
На этом примере мы можем заметить сразу несколько общих закономерностей. Во-первых, метрики бывают offline и online (оффлайновыми и онлайновыми). Online метрики вычисляются по данным, собираемым с работающей системы (например, медианная длина сессии). Offline метрики могут быть измерены до введения модели в эксплуатацию, например, по историческим данным или с привлечением специальных людей, асессоров. Последнее часто применяется, когда метрикой является реакция живого человека: скажем, так поступают поисковые компании, которые предлагают людям оценить качество ранжирования экспериментальной системы еще до того, как рядовые пользователи увидят эти результаты в обычном порядке. На самом же нижнем этаже иерархии лежат оптимизируемые в ходе обучения функции потерь.
В данном разделе нас будут интересовать offline метрики, которые могут быть измерены без привлечения людей.
Функция потерь $neq$ метрика качества
Как мы узнали ранее, методы обучения реализуют разные подходы к обучению:
- обучение на основе прироста информации (как в деревьях решений)
- обучение на основе сходства (как в методах ближайших соседей)
- обучение на основе вероятностной модели данных (например, максимизацией правдоподобия)
- обучение на основе ошибок (минимизация эмпирического риска)
И в рамках обучения на основе минимизации ошибок мы уже отвечали на вопрос: как можно штрафовать модель за предсказание на обучающем объекте.
Во время сведения задачи о построении решающего правила к задаче численной оптимизации, мы вводили понятие функции потерь и, обычно, объявляли целевой функцией сумму потерь от предсказаний на всех объектах обучающей выборке.
Важно понимать разницу между функцией потерь и метрикой качества. Её можно сформулировать следующим образом:
-
Функция потерь возникает в тот момент, когда мы сводим задачу построения модели к задаче оптимизации. Обычно требуется, чтобы она обладала хорошими свойствами (например, дифференцируемостью).
-
Метрика – внешний, объективный критерий качества, обычно зависящий не от параметров модели, а только от предсказанных меток.
В некоторых случаях метрика может совпадать с функцией потерь. Например, в задаче регрессии MSE играет роль как функции потерь, так и метрики. Но, скажем, в задаче бинарной классификации они почти всегда различаются: в качестве функции потерь может выступать кросс-энтропия, а в качестве метрики – число верно угаданных меток (accuracy). Отметим, что в последнем примере у них различные аргументы: на вход кросс-энтропии нужно подавать логиты, а на вход accuracy – предсказанные метки (то есть по сути argmax логитов).
Бинарная классификация: метки классов
Перейдём к обзору метрик и начнём с самой простой разновидности классификации – бинарной, а затем постепенно будем наращивать сложность.
Напомним постановку задачи бинарной классификации: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_iin{0, 1}$ построить модель, которая по объекту $x$ предсказывает метку класса $f(x)in{0, 1}$.
Первым критерием качества, который приходит в голову, является accuracy – доля объектов, для которых мы правильно предсказали класс:
$$ color{#348FEA}{text{Accuracy}(y, y^{pred}) = frac{1}{N} sum_{i=1}^N mathbb{I}[y_i = f(x_i)]} $$
Или же сопряженная ей метрика – доля ошибочных классификаций (error rate):
$$text{Error rate} = 1 — text{Accuracy}$$
Познакомившись чуть внимательнее с этой метрикой, можно заметить, что у неё есть несколько недостатков:
- она не учитывает дисбаланс классов. Например, в задаче диагностики редких заболеваний классификатор, предсказывающий всем пациентам отсутствие болезни будет иметь достаточно высокую accuracy просто потому, что больных людей в выборке намного меньше;
- она также не учитывает цену ошибки на объектах разных классов. Для примера снова можно привести задачу медицинской диагностики: если ошибочный положительный диагноз для здорового больного обернётся лишь ещё одним обследованием, то ошибочно отрицательный вердикт может повлечь роковые последствия.
Confusion matrix (матрица ошибок)
Исторически задача бинарной классификации – это задача об обнаружении чего-то редкого в большом потоке объектов, например, поиск человека, больного туберкулёзом, по флюорографии. Или задача признания пятна на экране приёмника радиолокационной станции бомбардировщиком, представляющем угрозу охраняемому объекту (в противовес стае гусей).
Поэтому класс, который представляет для нас интерес, называется «положительным», а оставшийся – «отрицательным».
Заметим, что для каждого объекта в выборке возможно 4 ситуации:
- мы предсказали положительную метку и угадали. Будет относить такие объекты к true positive (TP) группе (true – потому что предсказали мы правильно, а positive – потому что предсказали положительную метку);
- мы предсказали положительную метку, но ошиблись в своём предсказании – false positive (FP) (false, потому что предсказание было неправильным);
- мы предсказали отрицательную метку и угадали – true negative (TN);
- и наконец, мы предсказали отрицательную метку, но ошиблись – false negative (FN). Для удобства все эти 4 числа изображают в виде таблицы, которую называют confusion matrix (матрицей ошибок):
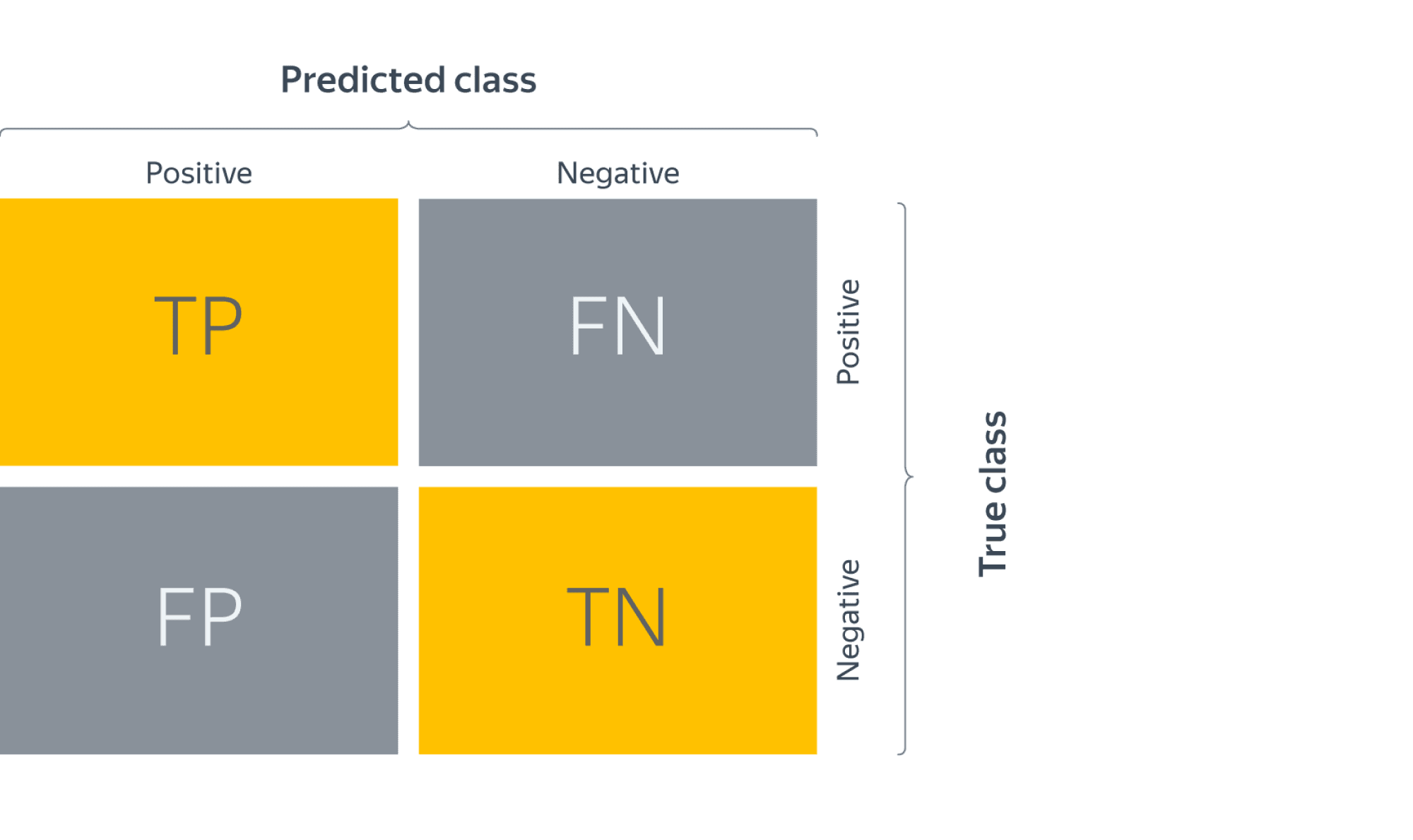
Не волнуйтесь, если первое время эти обозначения будут сводить вас с ума (будем откровенны, даже профи со стажем в них порой путаются), однако логика за ними достаточно простая: первая часть названия группы показывает угадали ли мы с классом, а вторая – какой класс мы предсказали.

Пример
Попробуем воспользоваться введёнными метриками в боевом примере: сравним работу нескольких моделей классификации на Breast cancer wisconsin (diagnostic) dataset.
Объектами выборки являются фотографии биопсии грудных опухолей. С их помощью было сформировано признаковое описание, которое заключается в характеристиках ядер клеток (таких как радиус ядра, его текстура, симметричность). Положительным классом в такой постановке будут злокачественные опухоли, а отрицательным – доброкачественные.
Модель 1. Константное предсказание.
Решение задачи начнём с самого простого классификатора, который выдаёт на каждом объекте константное предсказание – самый часто встречающийся класс.
Зачем вообще замерять качество на такой модели?При разработке модели машинного обучения для проекта всегда желательно иметь некоторую baseline модель. Так нам будет легче проконтролировать, что наша более сложная модель действительно дает нам прирост качества.
from sklearn.datasets
import load_breast_cancer
the_data = load_breast_cancer()
# 0 – "доброкачественный"
# 1 – "злокачественный"
relabeled_target = 1 - the_data["target"]
from sklearn.model_selection import train_test_split
X = the_data["data"]
y = relabeled_target
X_train, X_test, y_train, y_test = train_test_split(X, y, random_state=0)
from sklearn.dummy import DummyClassifier
dc_mf = DummyClassifier(strategy="most_frequent")
dc_mf.fit(X_train, y_train)
from sklearn.metrics import confusion_matrix
y_true = y_test y_pred = dc_mf.predict(X_test)
dc_mf_tn, dc_mf_fp, dc_mf_fn, dc_mf_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 0 | FN = 53 |
| Истинный класс — | FP = 0 | TN = 90 |
Обучающие данные таковы, что наш dummy-классификатор все объекты записывает в отрицательный класс, то есть признаёт все опухоли доброкачественными. Такой наивный подход позволяет нам получить минимальный штраф за FP (действительно, нельзя ошибиться в предсказании, если положительный класс вообще не предсказывается), но и максимальный штраф за FN (в эту группу попадут все злокачественные опухоли).
Модель 2. Случайный лес.
Настало время воспользоваться всем арсеналом моделей машинного обучения, и начнём мы со случайного леса.
from sklearn.ensemble import RandomForestClassifier
rfc = RandomForestClassifier()
rfc.fit(X_train, y_train)
y_true = y_test
y_pred = rfc.predict(X_test)
rfc_tn, rfc_fp, rfc_fn, rfc_tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 52 | FN = 1 |
| Истинный класс — | FP = 4 | TN = 86 |
Можно сказать, что этот классификатор чему-то научился, т.к. главная диагональ матрицы стала содержать все объекты из отложенной выборки, за исключением 4 + 1 = 5 объектов (сравните с 0 + 53 объектами dummy-классификатора, все опухоли объявляющего доброкачественными).
Отметим, что вычисляя долю недиагональных элементов, мы приходим к метрике error rate, о которой мы говорили в самом начале:
$$text{Error rate} = frac{FP + FN}{ TP + TN + FP + FN}$$
тогда как доля объектов, попавших на главную диагональ – это как раз таки accuracy:
$$text{Accuracy} = frac{TP + TN}{ TP + TN + FP + FN}$$
Модель 3. Метод опорных векторов.
Давайте построим еще один классификатор на основе линейного метода опорных векторов.
Не забудьте привести признаки к единому масштабу, иначе численный алгоритм не сойдется к решению и мы получим гораздо более плохо работающее решающее правило. Попробуйте проделать это упражнение.
from sklearn.svm import LinearSVC
from sklearn.preprocessing import StandardScaler
ss = StandardScaler() ss.fit(X_train)
scaled_linsvc = LinearSVC(C=0.01,random_state=42)
scaled_linsvc.fit(ss.transform(X_train), y_train)
y_true = y_test
y_pred = scaled_linsvc.predict(ss.transform(X_test))
tn, fp, fn, tp = confusion_matrix(y_true, y_pred, labels = [0, 1]).ravel()
| Прогнозируемый класс + | Прогнозируемый класс — | |
|---|---|---|
| Истинный класс + | TP = 50 | FN = 3 |
| Истинный класс — | FP = 1 | TN = 89 |
Сравним результаты
Легко заметить, что каждая из двух моделей лучше классификатора-пустышки, однако давайте попробуем сравнить их между собой. С точки зрения error rate модели практически одинаковы: 5/143 для леса против 4/143 для SVM.
Посмотрим на структуру ошибок чуть более внимательно: лес – (FP = 4, FN = 1), SVM – (FP = 1, FN = 3). Какая из моделей предпочтительнее?
Замечание: Мы сравниваем несколько классификаторов на основании их предсказаний на отложенной выборке. Насколько ошибки данных классификаторов зависят от разбиения исходного набора данных? Иногда в процессе оценки качества мы будем получать модели, чьи показатели эффективности будут статистически неразличимыми.
Пусть мы учли предыдущее замечание и эти модели действительно статистически значимо ошибаются в разную сторону. Мы встретились с очевидной вещью: на матрицах нет отношения порядка. Когда мы сравнивали dummy-классификатор и случайный лес с помощью Accuracy, мы всю сложную структуру ошибок свели к одному числу, т.к. на вещественных числах отношение порядка есть. Сводить оценку модели к одному числу очень удобно, однако не стоит забывать, что у вашей модели есть много аспектов качества.
Что же всё-таки важнее уменьшить: FP или FN? Вернёмся к задаче: FP – доля доброкачественных опухолей, которым ошибочно присваивается метка злокачественной, а FN – доля злокачественных опухолей, которые классификатор пропускает. В такой постановке становится понятно, что при сравнении выиграет модель с меньшим FN (то есть лес в нашем примере), ведь каждая не обнаруженная опухоль может стоить человеческой жизни.
Рассмотрим теперь другую задачу: по данным о погоде предсказать, будет ли успешным запуск спутника. FN в такой постановке – это ошибочное предсказание неуспеха, то есть не более, чем упущенный шанс (если вас, конечно не уволят за срыв сроков). С FP всё серьёзней: если вы предскажете удачный запуск спутника, а на деле он потерпит крушение из-за погодных условий, то ваши потери будут в разы существеннее.
Итак, из примеров мы видим, что в текущем виде введенная нами доля ошибочных классификаций не даст нам возможности учесть неравную важность FP и FN. Поэтому введем две новые метрики: точность и полноту.
Точность и полнота
Accuracy — это метрика, которая характеризует качество модели, агрегированное по всем классам. Это полезно, когда классы для нас имеют одинаковое значение. В случае, если это не так, accuracy может быть обманчивой.
Рассмотрим ситуацию, когда положительный класс это событие редкое. Возьмем в качестве примера поисковую систему — в нашем хранилище хранятся миллиарды документов, а релевантных к конкретному поисковому запросу на несколько порядков меньше.
Пусть мы хотим решить задачу бинарной классификации «документ d релевантен по запросу q». Благодаря большому дисбалансу, Accuracy dummy-классификатора, объявляющего все документы нерелевантными, будет близка к единице. Напомним, что $text{Accuracy} = frac{TP + TN}{TP + TN + FP + FN}$, и в нашем случае высокое значение метрики будет обеспечено членом TN, в то время для пользователей более важен высокий TP.
Поэтому в случае ассиметрии классов, можно использовать метрики, которые не учитывают TN и ориентируются на TP.
Если мы рассмотрим долю правильно предсказанных положительных объектов среди всех объектов, предсказанных положительным классом, то мы получим метрику, которая называется точностью (precision)
$$color{#348FEA}{text{Precision} = frac{TP}{TP + FP}}$$
Интуитивно метрика показывает долю релевантных документов среди всех найденных классификатором. Чем меньше ложноположительных срабатываний будет допускать модель, тем больше будет её Precision.
Если же мы рассмотрим долю правильно найденных положительных объектов среди всех объектов положительного класса, то мы получим метрику, которая называется полнотой (recall)
$$color{#348FEA}{text{Recall} = frac{TP}{TP + FN}}$$
Интуитивно метрика показывает долю найденных документов из всех релевантных. Чем меньше ложно отрицательных срабатываний, тем выше recall модели.
Например, в задаче предсказания злокачественности опухоли точность показывает, сколько из определённых нами как злокачественные опухолей действительно являются злокачественными, а полнота – какую долю злокачественных опухолей нам удалось выявить.
Хорошее понимание происходящего даёт следующая картинка: 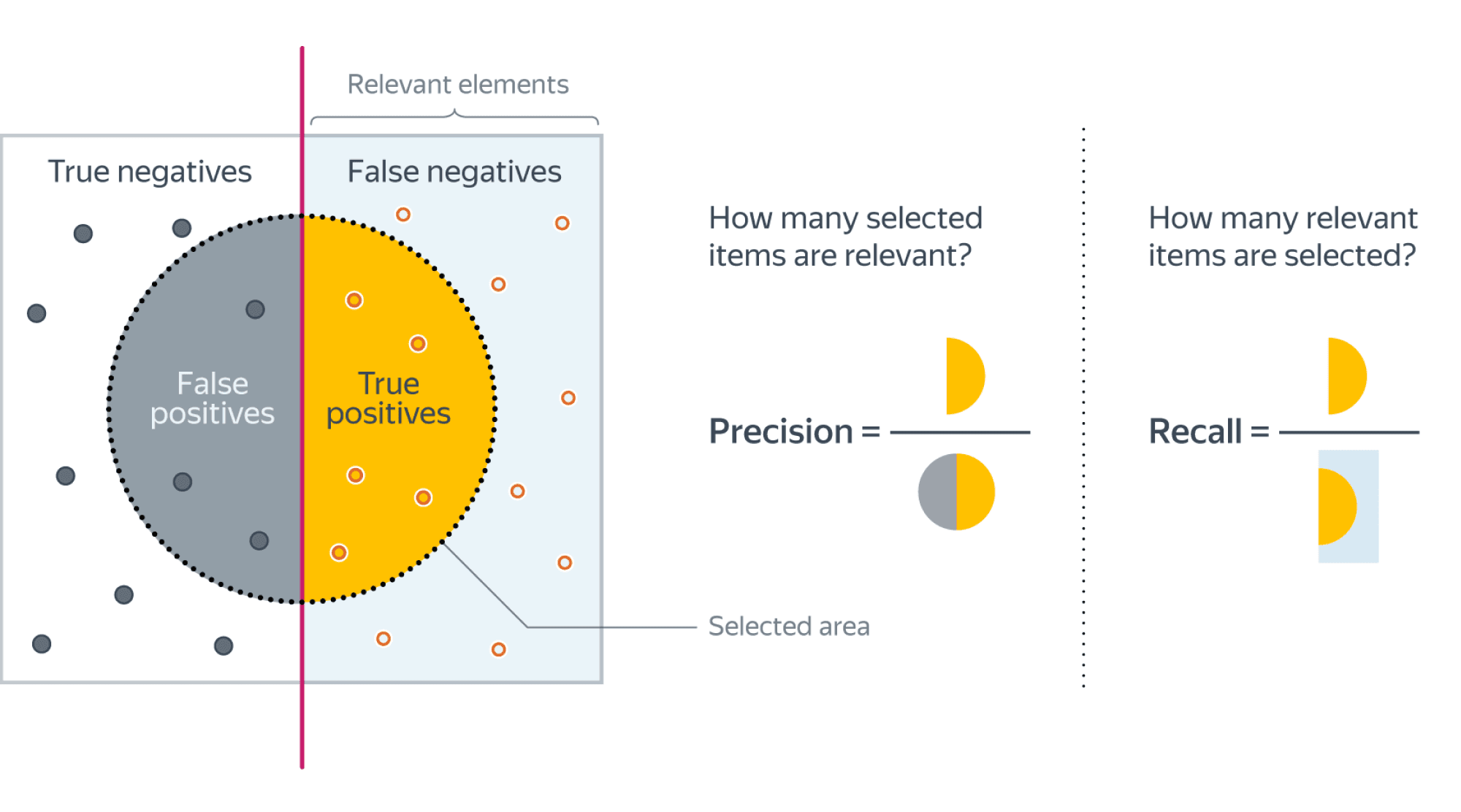 (источник картинки)
(источник картинки)
Recall@k, Precision@k
Метрики Recall и Precision хорошо подходят для задачи поиска «документ d релевантен запросу q», когда из списка рекомендованных алгоритмом документов нас интересует только первый. Но не всегда алгоритм машинного обучения вынужден работать в таких жестких условиях. Может быть такое, что вполне достаточно, что релевантный документ попал в первые k рекомендованных. Например, в интерфейсе выдачи первые три подсказки видны всегда одновременно и вообще не очень понятно, какой у них порядок. Тогда более честной оценкой качества алгоритма будет «в выдаче D размера k по запросу q нашлись релевантные документы». Для расчёта метрики по всей выборке объединим все выдачи и рассчитаем precision, recall как обычно подокументно.
F1-мера
Как мы уже отмечали ранее, модели очень удобно сравнивать, когда их качество выражено одним числом. В случае пары Precision-Recall существует популярный способ скомпоновать их в одну метрику — взять их среднее гармоническое. Данный показатель эффективности исторически носит название F1-меры (F1-measure).
$$
color{#348FEA}{F_1 = frac{2}{frac{1}{Recall} + frac{1}{Precision}}} = $$
$$ = 2 frac{Recall cdot Precision }{Recall + Precision} = frac
{TP} {TP + frac{FP + FN}{2}}
$$
Стоит иметь в виду, что F1-мера предполагает одинаковую важность Precision и Recall, если одна из этих метрик для вас приоритетнее, то можно воспользоваться $F_{beta}$ мерой:
$$
F_{beta} = (beta^2 + 1) frac{Recall cdot Precision }{Recall + beta^2Precision}
$$
Бинарная классификация: вероятности классов
Многие модели бинарной классификации устроены так, что класс объекта получается бинаризацией выхода классификатора по некоторому фиксированному порогу:
$$fleft(x ; w, w_{0}right)=mathbb{I}left[g(x, w) > w_{0}right].$$
Например, модель логистической регрессии возвращает оценку вероятности принадлежности примера к положительному классу. Другие модели бинарной классификации обычно возвращают произвольные вещественные значения, но существуют техники, называемые калибровкой классификатора, которые позволяют преобразовать предсказания в более или менее корректную оценку вероятности принадлежности к положительному классу.
Как оценить качество предсказываемых вероятностей, если именно они являются нашей конечной целью? Общепринятой мерой является логистическая функция потерь, которую мы изучали раньше, когда говорили об устройстве некоторых методов классификации (например уже упоминавшейся логистической регрессии).
Если же нашей целью является построение прогноза в терминах метки класса, то нам нужно учесть, что в зависимости от порога мы будем получать разные предсказания и разное качество на отложенной выборке. Так, чем ниже порог отсечения, тем больше объектов модель будет относить к положительному классу. Как в этом случае оценить качество модели?
AUC
Пусть мы хотим учитывать ошибки на объектах обоих классов. При уменьшении порога отсечения мы будем находить (правильно предсказывать) всё большее число положительных объектов, но также и неправильно предсказывать положительную метку на всё большем числе отрицательных объектов. Естественным кажется ввести две метрики TPR и FPR:
TPR (true positive rate) – это полнота, доля положительных объектов, правильно предсказанных положительными:
$$ TPR = frac{TP}{P} = frac{TP}{TP + FN} $$
FPR (false positive rate) – это доля отрицательных объектов, неправильно предсказанных положительными:
$$FPR = frac{FP}{N} = frac{FP}{FP + TN}$$
Обе эти величины растут при уменьшении порога. Кривая в осях TPR/FPR, которая получается при варьировании порога, исторически называется ROC-кривой (receiver operating characteristics curve, сокращённо ROC curve). Следующий график поможет вам понять поведение ROC-кривой.
Желтая и синяя кривые показывают распределение предсказаний классификатора на объектах положительного и отрицательного классов соответственно. То есть значения на оси X (на графике с двумя гауссианами) мы получаем из классификатора. Если классификатор идеальный (две кривые разделимы по оси X), то на правом графике мы получаем ROC-кривую (0,0)->(0,1)->(1,1) (убедитесь сами!), площадь под которой равна 1. Если классификатор случайный (предсказывает одинаковые метки положительным и отрицательным объектам), то мы получаем ROC-кривую (0,0)->(1,1), площадь под которой равна 0.5. Поэкспериментируйте с разными вариантами распределения предсказаний по классам и посмотрите, как меняется ROC-кривая.
Чем лучше классификатор разделяет два класса, тем больше площадь (area under curve) под ROC-кривой – и мы можем использовать её в качестве метрики. Эта метрика называется AUC и она работает благодаря следующему свойству ROC-кривой:
AUC равен доле пар объектов вида (объект класса 1, объект класса 0), которые алгоритм верно упорядочил, т.е. предсказание классификатора на первом объекте больше:
$$
color{#348FEA}{operatorname{AUC} = frac{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j] I^{prime}[f(x_{i}) < f(x_{j})]}{sumlimits_{i = 1}^{N} sumlimits_{j = 1}^{N}mathbb{I}[y_i < y_j]}}
$$
$$
I^{prime}left[f(x_{i}) < f(x_{j})right]=
left{
begin{array}{ll}
0, & f(x_{i}) > f(x_{j}) \
0.5 & f(x_{i}) = f(x_{j}) \
1, & f(x_{i}) < f(x_{j})
end{array}
right.
$$
$$
Ileft[y_{i}< y_{j}right]=
left{
begin{array}{ll}
0, & y_{i} geq y_{j} \
1, & y_{i} < y_{j}
end{array}
right.
$$
Чтобы детальнее разобраться, почему это так, советуем вам обратиться к материалам А.Г.Дьяконова.
В каких случаях лучше отдать предпочтение этой метрике? Рассмотрим следующую задачу: некоторый сотовый оператор хочет научиться предсказывать, будет ли клиент пользоваться его услугами через месяц. На первый взгляд кажется, что задача сводится к бинарной классификации с метками 1, если клиент останется с компанией и $0$ – иначе.
Однако если копнуть глубже в процессы компании, то окажется, что такие метки практически бесполезны. Компании скорее интересно упорядочить клиентов по вероятности прекращения обслуживания и в зависимости от этого применять разные варианты удержания: кому-то прислать скидочный купон от партнёра, кому-то предложить скидку на следующий месяц, а кому-то и новый тариф на особых условиях.
Таким образом, в любой задаче, где нам важна не метка сама по себе, а правильный порядок на объектах, имеет смысл применять AUC.
Утверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.
ПодробнееУтверждение выше может вызывать у вас желание использовать AUC в качестве метрики в задачах ранжирования, но мы призываем вас быть аккуратными.» details=»Продемонстрируем это на следующем примере: пусть наша выборка состоит из $9100$ объектов класса $0$ и $10$ объектов класса $1$, и модель расположила их следующим образом:
$$underbrace{0 dots 0}_{9000} ~ underbrace{1 dots 1}_{10} ~ underbrace{0 dots 0}_{100}$$
Тогда AUC будет близка к единице: количество пар правильно расположенных объектов будет порядка $90000$, в то время как общее количество пар порядка $91000$.
Однако самыми высокими по вероятности положительного класса будут совсем не те объекты, которые мы ожидаем.
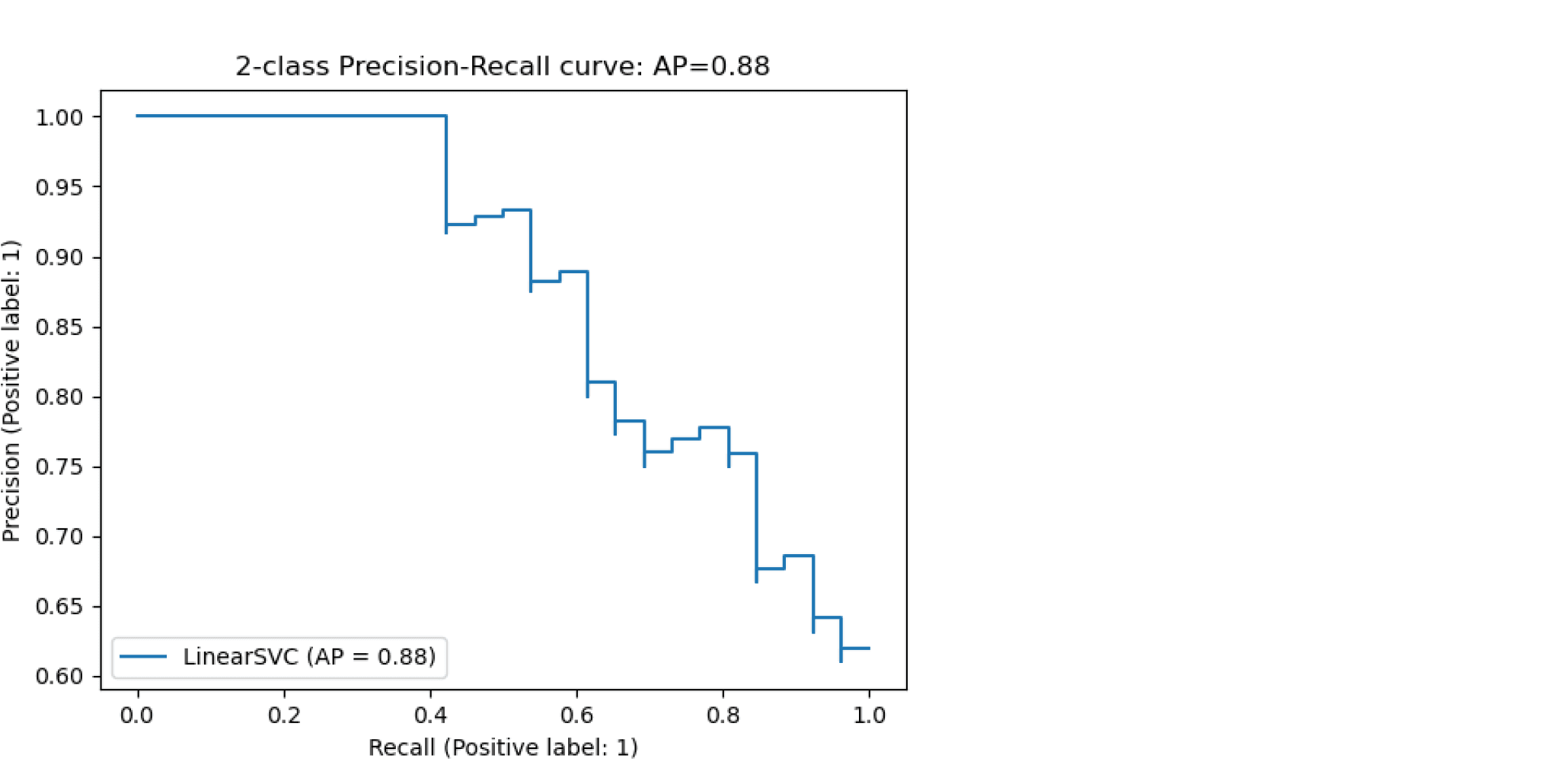
Average Precision
Будем постепенно уменьшать порог бинаризации. При этом полнота будет расти от $0$ до $1$, так как будет увеличиваться количество объектов, которым мы приписываем положительный класс (а количество объектов, на самом деле относящихся к положительному классу, очевидно, меняться не будет). Про точность же нельзя сказать ничего определённого, но мы понимаем, что скорее всего она будет выше при более высоком пороге отсечения (мы оставим только объекты, в которых модель «уверена» больше всего). Варьируя порог и пересчитывая значения Precision и Recall на каждом пороге, мы получим некоторую кривую примерно следующего вида:
 (источник картинки)
(источник картинки)
Рассмотрим среднее значение точности (оно равно площади под кривой точность-полнота):
$$ text { AP }=int_{0}^{1} p(r) d r$$
Получим показатель эффективности, который называется average precision. Как в случае матрицы ошибок мы переходили к скалярным показателям эффективности, так и в случае с кривой точность-полнота мы охарактеризовали ее в виде числа.
Многоклассовая классификация
Если классов становится больше двух, расчёт метрик усложняется. Если задача классификации на $K$ классов ставится как $K$ задач об отделении класса $i$ от остальных ($i=1,ldots,K$), то для каждой из них можно посчитать свою матрицу ошибок. Затем есть два варианта получения итогового значения метрики из $K$ матриц ошибок:
- Усредняем элементы матрицы ошибок (TP, FP, TN, FN) между бинарными классификаторами, например $TP = frac{1}{K}sum_{i=1}^{K}TP_i$. Затем по одной усреднённой матрице ошибок считаем Precision, Recall, F-меру. Это называют микроусреднением.
- Считаем Precision, Recall для каждого классификатора отдельно, а потом усредняем. Это называют макроусреднением.
Порядок усреднения влияет на результат в случае дисбаланса классов. Показатели TP, FP, FN — это счётчики объектов. Пусть некоторый класс обладает маленькой мощностью (обозначим её $M$). Тогда значения TP и FN при классификации этого класса против остальных будут не больше $M$, то есть тоже маленькие. Про FP мы ничего уверенно сказать не можем, но скорее всего при дисбалансе классов классификатор не будет предсказывать редкий класс слишком часто, потому что есть большая вероятность ошибиться. Так что FP тоже мало. Поэтому усреднение первым способом сделает вклад маленького класса в общую метрику незаметным. А при усреднении вторым способом среднее считается уже для нормированных величин, так что вклад каждого класса будет одинаковым.
Рассмотрим пример. Пусть есть датасет из объектов трёх цветов: желтого, зелёного и синего. Желтого и зелёного цветов почти поровну — 21 и 20 объектов соответственно, а синих объектов всего 4.
Модель по очереди для каждого цвета пытается отделить объекты этого цвета от объектов оставшихся двух цветов. Результаты классификации проиллюстрированы матрицей ошибок. Модель «покрасила» в жёлтый 25 объектов, 20 из которых были действительно жёлтыми (левый столбец матрицы). В синий был «покрашен» только один объект, который на самом деле жёлтый (средний столбец матрицы). В зелёный — 19 объектов, все на самом деле зелёные (правый столбец матрицы).
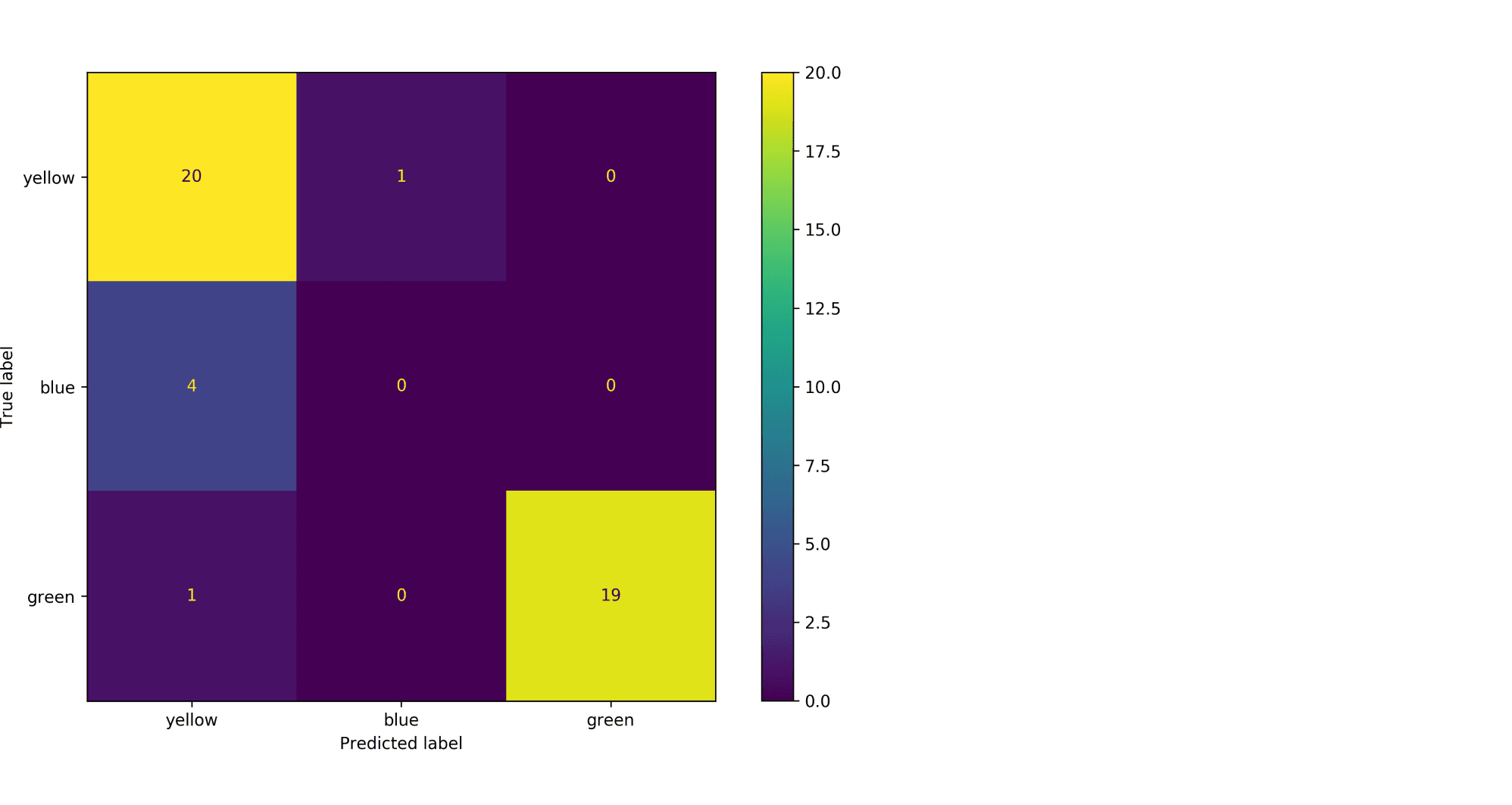
Посчитаем Precision классификации двумя способами:
- С помощью микроусреднения получаем $$
text{Precision} = frac{dfrac{1}{3}left(20 + 0 + 19right)}{dfrac{1}{3}left(20 + 0 + 19right) + dfrac{1}{3}left(5 + 1 + 0right)} = 0.87
$$ - С помощью макроусреднения получаем $$
text{Precision} = dfrac{1}{3}left( frac{20}{20 + 5} + frac{0}{0 + 1} + frac{19}{19 + 0}right) = 0.6
$$
Видим, что макроусреднение лучше отражает тот факт, что синий цвет, которого в датасете было совсем мало, модель практически игнорирует.
Как оптимизировать метрики классификации?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы $F$ на валидационной выборке была минимальная/максимальная. Лучший способ добиться минимизации метрики $F$ — оптимизировать её напрямую, то есть выбрать в качестве функции потерь ту же $F(a(X), Y)$. К сожалению, это не всегда возможно. Рассмотрим, как оптимизировать метрики иначе.
Метрики precision и recall невозможно оптимизировать напрямую, потому что эти метрики нельзя рассчитать на одном объекте, а затем усреднить. Они зависят от того, какими были правильная метка класса и ответ алгоритма на всех объектах. Чтобы понять, как оптимизировать precision, recall, рассмотрим, как расчитать эти метрики на отложенной выборке. Пусть модель обучена на стандартную для классификации функцию потерь (LogLoss). Для получения меток класса специалист по машинному обучению сначала применяет на объектах модель и получает вещественные предсказания модели ($p_i in left(0, 1right)$). Затем предсказания бинаризуются по порогу, выбранному специалистом: если предсказание на объекте больше порога, то метка класса 1 (или «положительная»), если меньше — 0 (или «отрицательная»). Рассмотрим, что будет с метриками precision, recall в крайних положениях порога.
- Пусть порог равен нулю. Тогда всем объектам будет присвоена положительная метка. Следовательно, все объекты будут либо TP, либо FP, потому что отрицательных предсказаний нет, $TP + FP = N$, где $N$ — размер выборки. Также все объекты, у которых метка на самом деле 1, попадут в TP. По формуле точность $text{Precision} = frac{TP}{TP + FP} = frac1N sum_{i = 1}^N mathbb{I} left[ y_i = 1 right]$ равна среднему таргету в выборке. А полнота $text{Recall} = frac{TP}{TP + FN} = frac{TP}{TP + 0} = 1$ равна единице.
- Пусть теперь порог равен единице. Тогда ни один объект не будет назван положительным, $TP = FP = 0$. Все объекты с меткой класса 1 попадут в FN. Если есть хотя бы один такой объект, то есть $FN ne 0$, будет верна формула $text{Recall} = frac{TP}{TP + FN} = frac{0}{0+ FN} = 0$. То есть при пороге единица, полнота равна нулю. Теперь посмотрим на точность. Формула для Precision состоит только из счётчиков положительных ответов модели (TP, FP). При единичном пороге они оба равны нулю, $text{Precision} = frac{TP}{TP + FP} = frac{0}{0 + 0}$то есть при единичном пороге точность неопределена. Пусть мы отступили чуть-чуть назад по порогу, чтобы хотя бы несколько объектов были названы моделью положительными. Скорее всего это будут самые «простые» объекты, которые модель распознает хорошо, потому что её предсказание близко к единице. В этом предположении $FP approx 0$. Тогда точность $text{Precision} = frac{TP}{TP + FP} approx frac{TP}{TP + 0} approx 1$ будет близка к единице.
Изменяя порог, между крайними положениями, получим графики Precision и Recall, которые выглядят как-то так:
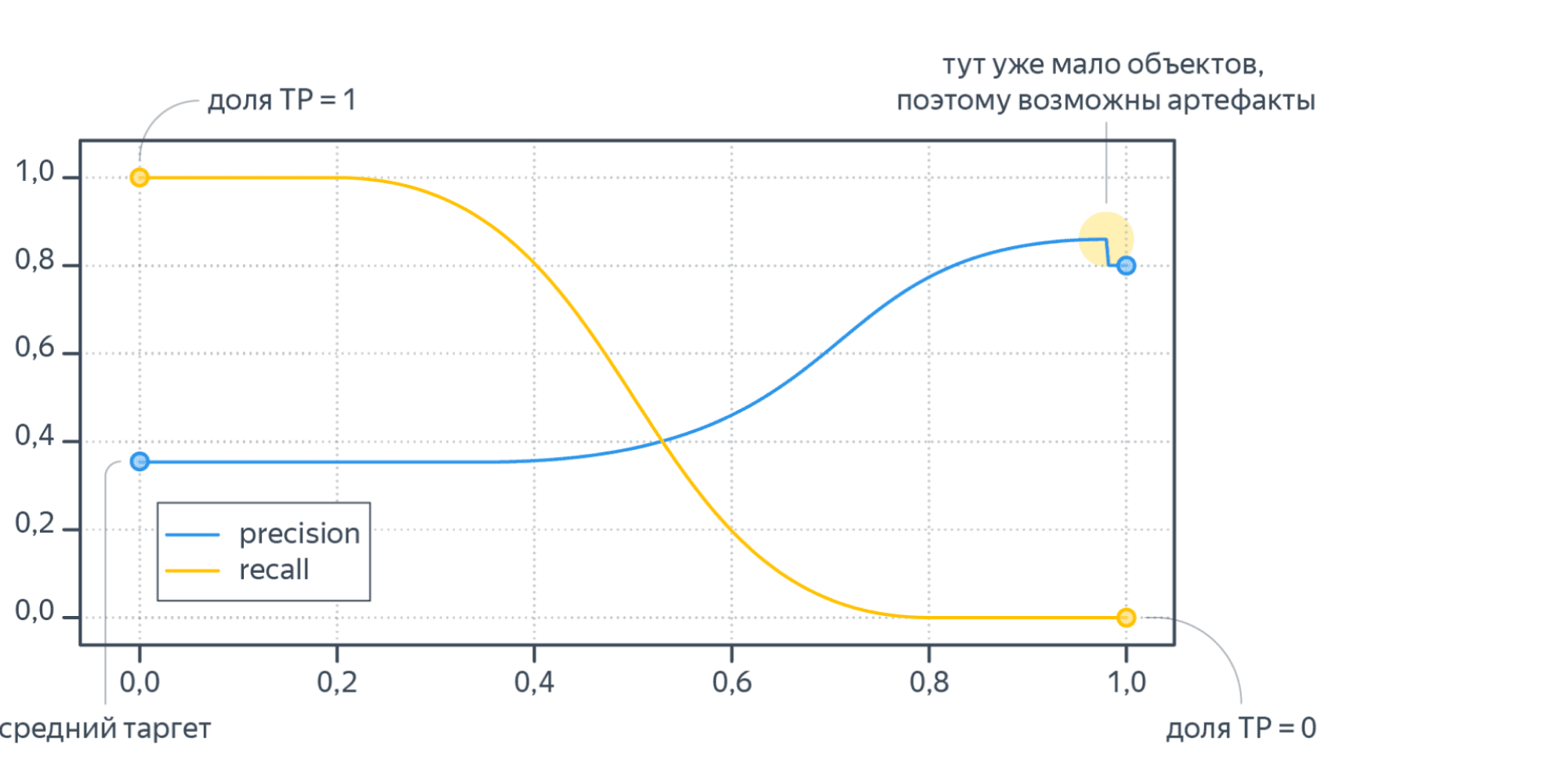
Recall меняется от единицы до нуля, а Precision от среднего тагрета до какого-то другого значения (нет гарантий, что график монотонный).
Итого оптимизация precision и recall происходит так:
- Модель обучается на стандартную функцию потерь (например, LogLoss).
- Используя вещественные предсказания на валидационной выборке, перебирая разные пороги от 0 до 1, получаем графики метрик в зависимости от порога.
- Выбираем нужное сочетание точности и полноты.
Пусть теперь мы хотим максимизировать метрику AUC. Стандартный метод оптимизации, градиентный спуск, предполагает, что функция потерь дифференцируема. AUC этим качеством не обладает, то есть мы не можем оптимизировать её напрямую. Поэтому для метрики AUC приходится изменять оптимизационную задачу. Метрика AUC считает долю верно упорядоченных пар. Значит от исходной выборки можно перейти к выборке упорядоченных пар объектов. На этой выборке ставится задача классификации: метка класса 1 соответствует правильно упорядоченной паре, 0 — неправильно. Новой метрикой становится accuracy — доля правильно классифицированных объектов, то есть доля правильно упорядоченных пар. Оптимизировать accuracy можно по той же схеме, что и precision, recall: обучаем модель на LogLoss и предсказываем вероятности положительной метки у объекта выборки, считаем accuracy для разных порогов по вероятности и выбираем понравившийся.
Регрессия
В задачах регрессии целевая метка у нас имеет потенциально бесконечное число значений. И природа этих значений, обычно, связана с каким-то процессом измерений:
- величина температуры в определенный момент времени на метеостанции
- количество прочтений статьи на сайте
- количество проданных бананов в конкретном магазине, сети магазинов или стране
- дебит добывающей скважины на нефтегазовом месторождении за месяц и т.п.
Мы видим, что иногда метка это целое число, а иногда произвольное вещественное число. Обычно случаи целочисленных меток моделируют так, словно это просто обычное вещественное число. При таком подходе может оказаться так, что модель A лучше модели B по некоторой метрике, но при этом предсказания у модели A могут быть не целыми. Если в бизнес-задаче ожидается именно целочисленный ответ, то и оценивать нужно огрубление.
Общая рекомендация такова: оценивайте весь каскад решающих правил: и те «внутренние», которые вы получаете в результате обучения, и те «итоговые», которые вы отдаёте бизнес-заказчику.
Например, вы можете быть удовлетворены, что стали ошибаться не во втором, а только в третьем знаке после запятой при предсказании погоды. Но сами погодные данные измеряются с точностью до десятых долей градуса, а пользователь и вовсе может интересоваться лишь целым числом градусов.
Итак, напомним постановку задачи регрессии: нам нужно по обучающей выборке ${(x_i, y_i)}_{i=1}^N$, где $y_i in mathbb{R}$ построить модель f(x).
Величину $ e_i = f(x_i) — y_i $ называют ошибкой на объекте i или регрессионным остатком.
Весь набор ошибок на отложенной выборке может служить аналогом матрицы ошибок из задачи классификации. А именно, когда мы рассматриваем две разные модели, то, глядя на то, как и на каких объектах они ошиблись, мы можем прийти к выводу, что для решения бизнес-задачи нам выгоднее взять ту или иную модель. И, аналогично со случаем бинарной классификации, мы можем начать строить агрегаты от вектора ошибок, получая тем самым разные метрики.
MSE, RMSE, $R^2$
MSE – одна из самых популярных метрик в задаче регрессии. Она уже знакома вам, т.к. применяется в качестве функции потерь (или входит в ее состав) во многих ранее рассмотренных методах.
$$ MSE(y^{true}, y^{pred}) = frac1Nsum_{i=1}^{N} (y_i — f(x_i))^2 $$
Иногда для того, чтобы показатель эффективности MSE имел размерность исходных данных, из него извлекают квадратный корень и получают показатель эффективности RMSE.
MSE неограничен сверху, и может быть нелегко понять, насколько «хорошим» или «плохим» является то или иное его значение. Чтобы появились какие-то ориентиры, делают следующее:
-
Берут наилучшее константное предсказание с точки зрения MSE — среднее арифметическое меток $bar{y}$. При этом чтобы не было подглядывания в test, среднее нужно вычислять по обучающей выборке
-
Рассматривают в качестве показателя ошибки:
$$ R^2 = 1 — frac{sum_{i=1}^{N} (y_i — f(x_i))^2}{sum_{i=1}^{N} (y_i — bar{y})^2}.$$
У идеального решающего правила $R^2$ равен $1$, у наилучшего константного предсказания он равен $0$ на обучающей выборке. Можно заметить, что $R^2$ показывает, какая доля дисперсии таргетов (знаменатель) объяснена моделью.
MSE квадратично штрафует за большие ошибки на объектах. Мы уже видели проявление этого при обучении моделей методом минимизации квадратичных ошибок – там это проявлялось в том, что модель старалась хорошо подстроиться под выбросы.
Пусть теперь мы хотим использовать MSE для оценки наших регрессионных моделей. Если большие ошибки для нас действительно неприемлемы, то квадратичный штраф за них — очень полезное свойство (и его даже можно усиливать, повышая степень, в которую мы возводим ошибку на объекте). Однако если в наших тестовых данных присутствуют выбросы, то нам будет сложно объективно сравнить модели между собой: ошибки на выбросах будет маскировать различия в ошибках на основном множестве объектов.
Таким образом, если мы будем сравнивать две модели при помощи MSE, у нас будет выигрывать та модель, у которой меньше ошибка на объектах-выбросах, а это, скорее всего, не то, чего требует от нас наша бизнес-задача.
История из жизни про бананы и квадратичный штраф за ошибкуИз-за неверно введенных данных метка одного из объектов оказалась в 100 раз больше реального значения. Моделировалась величина при помощи градиентного бустинга над деревьями решений. Функция потерь была MSE.
Однажды уже во время эксплуатации случилось ч.п.: у нас появились предсказания, в 100 раз превышающие допустимые из соображений физического смысла значения. Представьте себе, например, что вместо обычных 4 ящиков бананов система предлагала поставить в магазин 400. Были распечатаны все деревья из ансамбля, и мы увидели, что постепенно число ящиков действительно увеличивалось до прогнозных 400.
Было решено проверить гипотезу, что был выброс в данных для обучения. Так оно и оказалось: всего одна точка давала такую потерю на объекте, что алгоритм обучения решил, что лучше переобучиться под этот выброс, чем смириться с большим штрафом на этом объекте. А в эксплуатации у нас возникли точки, которые плюс-минус попадали в такие же листья ансамбля, что и объект-выброс.
Избежать такого рода проблем можно двумя способами: внимательнее контролируя качество данных или адаптировав функцию потерь.
Аналогично, можно поступать и в случае, когда мы разрабатываем метрику качества: менее жёстко штрафовать за большие отклонения от истинного таргета.
MAE
Использовать RMSE для сравнения моделей на выборках с большим количеством выбросов может быть неудобно. В таких случаях прибегают к также знакомой вам в качестве функции потери метрике MAE (mean absolute error):
$$ MAE(y^{true}, y^{pred}) = frac{1}{N}sum_{i=1}^{N} left|y_i — f(x_i)right| $$
Метрики, учитывающие относительные ошибки
И MSE и MAE считаются как сумма абсолютных ошибок на объектах.
Рассмотрим следующую задачу: мы хотим спрогнозировать спрос товаров на следующий месяц. Пусть у нас есть два продукта: продукт A продаётся в количестве 100 штук, а продукт В в количестве 10 штук. И пусть базовая модель предсказывает количество продаж продукта A как 98 штук, а продукта B как 8 штук. Ошибки на этих объектах добавляют 4 штрафных единицы в MAE.
И есть 2 модели-кандидата на улучшение. Первая предсказывает товар А 99 штук, а товар B 8 штук. Вторая предсказывает товар А 98 штук, а товар B 9 штук.
Обе модели улучшают MAE базовой модели на 1 единицу. Однако, с точки зрения бизнес-заказчика вторая модель может оказаться предпочтительнее, т.к. предсказание продажи редких товаров может быть приоритетнее. Один из способов учесть такое требование – рассматривать не абсолютную, а относительную ошибку на объектах.
MAPE, SMAPE
Когда речь заходит об относительных ошибках, сразу возникает вопрос: что мы будем ставить в знаменатель?
В метрике MAPE (mean absolute percentage error) в знаменатель помещают целевое значение:
$$ MAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ left|y_i — f(x_i)right|}{left|y_iright|} $$
С особым случаем, когда в знаменателе оказывается $0$, обычно поступают «инженерным» способом: или выдают за непредсказание $0$ на таком объекте большой, но фиксированный штраф, или пытаются застраховаться от подобного на уровне формулы и переходят к метрике SMAPE (symmetric mean absolute percentage error):
$$ SMAPE(y^{true}, y^{pred}) = frac{1}{N} sum_{i=1}^{N} frac{ 2 left|y_i — f(x_i)right|}{y_i + f(x_i)} $$
Если же предсказывается ноль, штраф считаем нулевым.
Таким переходом от абсолютных ошибок на объекте к относительным мы сделали объекты в тестовой выборке равнозначными: даже если мы делаем абсурдно большое предсказание, на фоне которого истинная метка теряется, мы получаем штраф за этот объект порядка 1 в случае MAPE и 2 в случае SMAPE.
WAPE
Как и любая другая метрика, MAPE имеет свои границы применимости: например, она плохо справляется с прогнозом спроса на товары с прерывистыми продажами. Рассмотрим такой пример:
| Понедельник | Вторник | Среда | |
|---|---|---|---|
| Прогноз | 55 | 2 | 50 |
| Продажи | 50 | 1 | 50 |
| MAPE | 10% | 100% | 0% |
Среднее MAPE – 36.7%, что не очень отражает реальную ситуацию, ведь два дня мы предсказывали с хорошей точностью. В таких ситуациях помогает WAPE (weighted average percentage error):
$$ WAPE(y^{true}, y^{pred}) = frac{sum_{i=1}^{N} left|y_i — f(x_i)right|}{sum_{i=1}^{N} left|y_iright|} $$
Если мы предсказываем идеально, то WAPE = 0, если все предсказания отдаём нулевыми, то WAPE = 1.
В нашем примере получим WAPE = 5.9%
RMSLE
Альтернативный способ уйти от абсолютных ошибок к относительным предлагает метрика RMSLE (root mean squared logarithmic error):
$$ RMSLE(y^{true}, y^{pred}| c) = sqrt{ frac{1}{N} sum_{i=1}^N left(vphantom{frac12}log{left(y_i + c right)} — log{left(f(x_i) + c right)}right)^2 } $$
где нормировочная константа $c$ вводится искусственно, чтобы не брать логарифм от нуля. Также по построению видно, что метрика пригодна лишь для неотрицательных меток.
Веса в метриках
Все вышеописанные метрики легко допускают введение весов для объектов. Если мы из каких-то соображений можем определить стоимость ошибки на объекте, можно брать эту величину в качестве веса. Например, в задаче предсказания спроса в качестве веса можно использовать стоимость объекта.
Доля предсказаний с абсолютными ошибками больше, чем d
Еще одним способом охарактеризовать качество модели в задаче регрессии является доля предсказаний с абсолютными ошибками больше заданного порога $d$:
$$frac{1}{N} sum_{i=1}^{N} mathbb{I}left[ left| y_i — f(x_i) right| > d right] $$
Например, можно считать, что прогноз погоды сбылся, если ошибка предсказания составила меньше 1/2/3 градусов. Тогда рассматриваемая метрика покажет, в какой доле случаев прогноз не сбылся.
Как оптимизировать метрики регрессии?
Пусть мы выбрали, что метрика качества алгоритма будет $F(a(X), Y)$. Тогда мы хотим обучить модель так, чтобы F на валидационной выборке была минимальная/максимальная. Аналогично задачам классификации лучший способ добиться минимизации метрики $F$ — выбрать в качестве функции потерь ту же $F(a(X), Y)$. К счастью, основные метрики для регрессии: MSE, RMSE, MAE можно оптимизировать напрямую. С формальной точки зрения MAE не дифференцируема, так как там присутствует модуль, чья производная не определена в нуле. На практике для этого выколотого случая в коде можно возвращать ноль.
Для оптимизации MAPE придётся изменять оптимизационную задачу. Оптимизацию MAPE можно представить как оптимизацию MAE, где объектам выборки присвоен вес $frac{1}{vert y_ivert}$.
Современный жёсткий диск — уникальный компонент компьютера. Он уникален тем, что хранит в себе служебную информацию, изучая которую, можно оценить «здоровье» диска. Эта информация содержит в себе историю изменения множества параметров, отслеживаемых винчестером в процессе функционирования. Больше ни один компонент системного блока не предоставляет владельцу статистику своей работы! Вкупе с тем, что HDD является одним из самых ненадёжных компонентов компьютера, такая статистика может быть весьма полезной и помочь его владельцу избежать нервотрёпки и потери денег и времени.
Информация о состоянии диска доступна благодаря комплексу технологий, называемых общим именем S.M.A.R.T. (Self-Monitoring, Analisys and Reporting Technology, т. е. технология самомониторинга, анализа и отчёта). Этот комплекс довольно обширен, но мы поговорим о тех его аспектах, которые позволяют посмотреть на атрибуты S.M.A.R.T., отображаемые в какой-либо программе по тестированию винчестера, и понять, что творится с диском.
Отмечу, что нижесказанное относится к дискам с интерфейсами SATA и РАТА. У дисков SAS, SCSI и других серверных дисков тоже есть S.M.A.R.T., но его представление сильно отличается от SATA/PATA. Да и мониторит серверные диски обычно не человек, а RAID-контроллер, потому про них мы говорить не будем.
Итак, если мы откроем S.M.A.R.T. в какой-либо из многочисленных программ, то увидим приблизительно следующую картину (на скриншоте приведён S.M.A.R.T. диска Hitachi Deskstar 7К1000.С HDS721010CLA332 в HDDScan 3.3):
S.M.A.R.T. в HDDScan 3.3
В каждой строке отображается отдельный атрибут S.M.A.R.T. Атрибуты имеют более-менее стандартизованные названия и определённый номер, которые не зависят от модели и производителя диска.
Каждый атрибут S.M.A.R.T. имеет несколько полей. Каждое поле относится к определённому классу из следующих: ID, Value, Worst, Threshold и RAW. Рассмотрим каждый из классов.
- ID (может также именоваться Number) — идентификатор, номер атрибута в технологии S.M.A.R.T. Название одного и того же атрибута программами может выдаваться по-разному, а вот идентификатор всегда однозначно определяет атрибут. Особенно это полезно в случае программ, которые переводят общепринятое название атрибута с английского языка на русский. Иногда получается такая белиберда, что понять, что же это за параметр, можно только по его идентификатору.
- Value (Current) — текущее значение атрибута в попугаях (т. е. в величинах неизвестной размерности). В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
- Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в «попугаях». В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
- Threshold — значение в «попугаях», которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
- RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не «попугаи», а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Этим мы сейчас и займёмся — разберём все наиболее используемые атрибуты S.M.A.R.T., посмотрим, о чём они говорят и что нужно делать, если они не в порядке.
| Аттрибуты S.M.A.R.T. | |||||||||||||||||
| 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 10 | 11 | 12 | 183 | 184 | 187 | 188 | 189 | 190 | |
| 0x | 01 | 02 | 03 | 04 | 05 | 07 | 08 | 09 | 0A | 0B | 0C | B7 | B8 | BB | BC | BD | BE |
| 191 | 192 | 193 | 194 | 195 | 196 | 197 | 198 | 199 | 200 | 201 | 202 | 203 | 220 | 240 | 254 | ||
| 0x | BF | С0 | С1 | С2 | С3 | С4 | С5 | С6 | С7 | С8 | С9 | СА | CB | DC | F0 | FE |
Перед тем как описывать атрибуты и допустимые значения их поля RAW, уточню, что атрибуты могут иметь поле RAW разного типа: текущее и накапливающее. Текущее поле содержит значение атрибута в настоящий момент, для него свойственно периодическое изменение (для одних атрибутов — изредка, для других — много раз за секунду; другое дело, что в программах чтения S.M.A.R.T. такое быстрое изменение не отображается). Накапливающее поле — содержит статистику, обычно в нём содержится количество возникновений конкретного события со времени первого запуска диска.
Текущий тип характерен для атрибутов, для которых нет смысла суммировать их предыдущие показания. Например, показатель температуры диска является текущим: его цель — в демонстрации температуры в настоящий момент, а не суммы всех предыдущих температур. Накапливающий тип свойственен атрибутам, для которых весь их смысл заключается в предоставлении информации за весь период «жизни» винчестера. Например, атрибут, характеризующий время работы диска, является накапливающим, т. е. содержит количество единиц времени, отработанных накопителем за всю его историю.
Приступим к рассмотрению атрибутов и их RAW-полей.
Атрибут: 01 Raw Read Error Rate
| Тип | текущий, может быть накапливающим для WD и старых Hitachi |
| Описание | содержит частоту возникновения ошибок при чтении с пластин |
Для всех дисков Seagate, Samsung (начиная с семейства SpinPoint F1 (включительно)) и Fujitsu 2,5″ характерны огромные числа в этих полях.
Для остальных дисков Samsung и всех дисков WD в этом поле характерен 0.
Для дисков Hitachi в этом поле характерен 0 либо периодическое изменение поля в пределах от 0 до нескольких единиц.
Такие отличия обусловлены тем, что все жёсткие диски Seagate, некоторые Samsung и Fujitsu считают значения этих параметров не так, как WD, Hitachi и другие Samsung. При работе любого винчестера всегда возникают ошибки такого рода, и он преодолевает их самостоятельно, это нормально, просто на дисках, которые в этом поле содержат 0 или небольшое число, производитель не счёл нужным указывать истинное количество этих ошибок.
Таким образом, ненулевой параметр на дисках WD и Samsung до SpinPoint F1 (не включительно) и большое значение параметра на дисках Hitachi могут указывать на аппаратные проблемы с диском. Необходимо учитывать, что утилиты могут отображать несколько значений, содержащихся в поле RAW этого атрибута, как одно, и оно будет выглядеть весьма большим, хоть это и будет неверно (подробности см. ниже).
На дисках Seagate, Samsung (SpinPoint F1 и новее) и Fujitsu на этот атрибут можно не обращать внимания.
Атрибут: 02 Throughput Performance
| Тип | текущий |
| Описание | содержит значение средней производительности диска и измеряется в каких-то «попугаях». Обычно его ненулевое значение отмечается на винчестерах Hitachi. На них он может изменяться после изменения параметров ААМ, а может и сам по себе по неизвестному алгоритму |
Параметр не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 03 Spin-Up Time
| Тип | текущий |
| Описание | содержит время, за которое шпиндель диска в последний раз разогнался из состояния покоя до номинальной скорости. Может содержать два значения — последнее и, например, минимальное время раскрутки. Может измеряться в миллисекундах, десятках миллисекунд и т. п. — это зависит от производителя и модели диска |
Время разгона может различаться у разных дисков (причём у дисков одного производителя тоже) в зависимости от тока раскрутки, массы блинов, номинальной скорости шпинделя и т. п.
Кстати, винчестеры Fujitsu всегда имеют единицу в этом поле в случае отсутствия проблем с раскруткой шпинделя.
Практически ничего не говорит о здоровье диска, поэтому при оценке состояния винчестера на параметр можно не обращать внимания.
Атрибут: 04 Number of Spin-Up Times (Start/Stop Count)
| Тип | накапливающий |
| Описание | содержит количество раз включения диска. Бывает ненулевым на только что купленном диске, находившемся в запаянной упаковке, что может говорить о тестировании диска на заводе. Или ещё о чём-то, мне не известном  |
При оценке здоровья не обращайте на атрибут внимания.
Атрибут: 05 Reallocated Sector Count
| Тип | накапливающий |
| Описание | содержит количество секторов, переназначенных винчестером в резервную область. Практически ключевой параметр в оценке состояния |
Поясним, что вообще такое «переназначенный сектор». Когда диск в процессе работы натыкается на нечитаемый/плохо читаемый/незаписываемый/плохо записываемый сектор, он может посчитать его невосполнимо повреждённым. Специально для таких случаев производитель предусматривает на каждом диске (на каких-то моделях — в центре (логическом конце) диска, на каких-то — в конце каждого трека и т. д.) резервную область. При наличии повреждённого сектора диск помечает его как нечитаемый и использует вместо него сектор в резервной области, сделав соответствующие пометки в специальном списке дефектов поверхности — G-list. Такая операция по назначению нового сектора на роль старого называется remap (ремап) либо переназначение, а используемый вместо повреждённого сектор — переназначенным. Новый сектор получает логический номер LBA старого, и теперь при обращении ПО к сектору с этим номером (программы же не знают ни о каких переназначениях!) запрос будет перенаправляться в резервную область.
Таким образом, хоть сектор и вышел из строя, объём диска не изменяется. Понятно, что не изменяется он до поры до времени, т. к. объём резервной области не бесконечен. Однако резервная область вполне может содержать несколько тысяч секторов, и допустить, чтобы она закончилась, будет весьма безответственно — диск нужно будет заменить задолго до этого.
Кстати, ремонтники говорят, что диски Samsung очень часто ни в какую не хотят выполнять переназначение секторов.
На счёт этого атрибута мнения разнятся. Лично я считаю, что если он достиг 10, диск нужно обязательно менять — ведь это означает прогрессирующий процесс деградации состояния поверхности либо блинов, либо головок, либо чего-то ещё аппаратного, и остановить этот процесс возможности уже нет. Кстати, по сведениям лиц, приближенных к Hitachi, сама Hitachi считает диск подлежащим замене, когда на нём находится уже 5 переназначенных секторов. Другой вопрос, официальная ли эта информация, и следуют ли этому мнению сервис-центры. Что-то мне подсказывает, что нет
Другое дело, что сотрудники сервис-центров могут отказываться признавать диск неисправным, если фирменная утилита производителя диска пишет что-то вроде «S.M.A.R.T. Status: Good» или значения Value либо Worst атрибута будут больше Threshold (собственно, по такому критерию может оценивать и сама утилита производителя). И формально они будут правы. Но кому нужен диск с постоянным ухудшением его аппаратных компонентов, даже если такое ухудшение соответствует природе винчестера, а технология производства жёстких дисков старается минимизировать его последствия, выделяя, например, резервную область?
Атрибут: 07 Seek Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при позиционировании блока магнитных головок (БМГ) |
Описание формирования этого атрибута почти полностью совпадает с описанием для атрибута 01 Raw Read Error Rate, за исключением того, что для винчестеров Hitachi нормальным значением поля RAW является только 0.
Таким образом, на атрибут на дисках Seagate, Samsung SpinPoint F1 и новее и Fujitsu 2,5″ не обращайте внимания, на остальных моделях Samsung, а также на всех WD и Hitachi ненулевое значение свидетельствует о проблемах, например, с подшипником и т. п.
Атрибут: 08 Seek Time Performance
| Тип | текущий |
| Описание | содержит среднюю производительность операций позиционирования головок, измеряется в «попугаях». Как и параметр 02 Throughput Performance, ненулевое значение обычно отмечается на дисках Hitachi и может изменяться после изменения параметров ААМ, а может и само по себе по неизвестному алгоритму |
Не даёт никакой информации пользователю и не говорит ни о какой опасности при любом своём значении.
Атрибут: 09 Power On Hours Count (Power-on Time)
| Тип | накапливающий |
| Описание | содержит количество часов, в течение которых винчестер был включён |
Ничего не говорит о здоровье диска.
Атрибут: 10 (0А — в шестнадцатеричной системе счисления) Spin Retry Count
| Тип | накапливающий |
| Описание | содержит количество повторов запуска шпинделя, если первая попытка оказалась неудачной |
О здоровье диска чаще всего не говорит.
Основные причины увеличения параметра — плохой контакт диска с БП или невозможность БП выдать нужный ток в линию питания диска.
В идеале должен быть равен 0. При значении атрибута, равном 1-2, внимания можно не обращать. Если значение больше, в первую очередь следует обратить пристальное внимание на состояние блока питания, его качество, нагрузку на него, проверить контакт винчестера с кабелем питания, проверить сам кабель питания.
Наверняка диск может стартовать не сразу из-за проблем с ним самим, но такое бывает очень редко, и такую возможность нужно рассматривать в последнюю очередь.
Атрибут: 11 (0B) Calibration Retry Count (Recalibration Retries)
| Тип | накапливающий |
| Описание | содержит количество повторных попыток сброса накопителя (установки БМГ на нулевую дорожку) при неудачной первой попытке |
Ненулевое, а особенно растущее значение параметра может означать проблемы с диском.
Атрибут: 12 (0C) Power Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов «включение-отключение» диска |
Не связан с состоянием диска.
Атрибут: 183 (B7) SATA Downshift Error Count
| Тип | накапливающий |
| Описание | содержит количество неудачных попыток понижения режима SATA. Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1,5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута |
Не говорит о здоровье накопителя.
Атрибут: 184 (B8) End-to-End Error
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче данных через кэш винчестера |
Ненулевое значение указывает на проблемы с диском.
Атрибут: 187 (BB) Reported Uncorrected Sector Count (UNC Error)
| Тип | накапливающий |
| Описание | содержит количество секторов, которые были признаны кандидатами на переназначение (см. атрибут 197) за всю историю жизни диска. Причём если сектор становится кандидатом повторно, значение атрибута тоже увеличивается |
Ненулевое значение атрибута явно указывает на ненормальное состояние диска (в сочетании с ненулевым значением атрибута 197) или на то, что оно было таковым ранее (в сочетании с нулевым значением 197).
Атрибут: 188 (BC) Command Timeout
| Тип | накапливающий |
| Описание | содержит количество операций, выполнение которых было отменено из-за превышения максимально допустимого времени ожидания отклика |
Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т. д., а также из-за несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате (либо дискретным). Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
Атрибут: 189 (BD) High Fly Writes
| Тип | накапливающий |
| Описание | содержит количество зафиксированных случаев записи при высоте полета головки выше рассчитанной — скорее всего, из-за внешних воздействий, например вибрации |
Для того чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию, что на сегодняшний день не реализовано в общедоступном ПО — следовательно, на атрибут можно не обращать внимания.
Атрибут: 190 (BE) Airflow Temperature
| Тип | текущий |
| Описание | содержит температуру винчестера для дисков Hitachi, Samsung, WD и значение «100 − [RAW-значение атрибута 194]» для Seagate |
Не говорит о состоянии диска.
Атрибут: 191 (BF) G-Sensor Shock Count (Mechanical Shock)
| Тип | накапливающий |
| Описание | содержит количество критических ускорений, зафиксированных электроникой диска, которым подвергался накопитель и которые превышали допустимые. Обычно это происходит при ударах, падениях и т. п. |
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т. к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухи.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно если его не закрепить. Основное назначение датчика — прекратить операцию записи при вибрациях, чтобы избежать ошибок.
Не говорит о здоровье диска.
Атрибут: 192 (С0) Power Off Retract Count (Emergency Retry Count)
| Тип | накапливающий |
| Описание | для разных винчестеров может содержать одну из следующих двух характеристик: либо суммарное количество парковок БМГ диска в аварийных ситуациях (по сигналу от вибродатчика, обрыву/понижению питания и т. п.), либо суммарное количество циклов включения/выключения питания диска (характерно для современных WD и Hitachi) |
Не позволяет судить о состоянии диска.
Атрибут: 193 (С1) Load/Unload Cycle Count
| Тип | накапливающий |
| Описание | содержит количество полных циклов парковки/распарковки БМГ. Анализ этого атрибута — один из способов определить, включена ли на диске функция автоматической парковки (столь любимая, например, компанией Western Digital): если его содержимое превосходит (обычно — многократно) содержимое атрибута 09 — счётчик отработанных часов, — то парковка включена |
Не говорит о здоровье диска.
Атрибут: 194 (С2) Temperature (HDA Temperature, HDD Temperature)
| Тип | текущий/накапливающий |
| Описание | содержит текущую температуру диска. Температура считывается с датчика, который на разных моделях может располагаться в разных местах. Поле вместе с текущей также может содержать максимальную и минимальную температуры, зафиксированные за всё время эксплуатации винчестера |
О состоянии диска атрибут не говорит, но позволяет контролировать один из важнейших параметров. Моё мнение: при работе старайтесь не допускать повышения температуры винчестера выше 50 градусов, хоть производителем обычно и декларируется максимальный предел температуры в 55-60 градусов.
Атрибут: 195 (С3) Hardware ECC Recovered
| Тип | накапливающий |
| Описание | содержит количество ошибок, которые были скорректированы аппаратными средствами ECC диска |
Особенности, присущие этому атрибуту на разных дисках, полностью соответствуют таковым атрибутов 01 и 07.
Атрибут: 196 (С4) Reallocated Event Count
| Тип | накапливающий |
| Описание | содержит количество операций переназначения секторов |
Косвенно говорит о здоровье диска. Чем больше значение — тем хуже. Однако нельзя однозначно судить о здоровье диска по этому параметру, не рассматривая другие атрибуты.
Этот атрибут непосредственно связан с атрибутом 05. При росте 196 чаще всего растёт и 05. Если при росте атрибута 196 атрибут 05 не растёт, значит, при попытке ремапа кандидат в бэд-блоки оказался софт-бэдом (подробности см. ниже), и диск исправил его, так что сектор был признан здоровым, и в переназначении не было необходимости.
Если атрибут 196 меньше атрибута 05, значит, во время некоторых операций переназначения выполнялся перенос нескольких повреждённых секторов за один приём.
Если атрибут 196 больше атрибута 05, значит, при некоторых операциях переназначения были обнаружены исправленные впоследствии софт-бэды.
Атрибут: 197 (С5) Current Pending Sector Count
| Тип | текущий |
| Описание | содержит количество секторов-кандидатов на переназначение в резервную область |
Натыкаясь в процессе работы на «нехороший» сектор (например, контрольная сумма сектора не соответствует данным в нём), диск помечает его как кандидат на переназначение, заносит его в специальный внутренний список и увеличивает параметр 197. Из этого следует, что на диске могут быть повреждённые секторы, о которых он ещё не знает — ведь на пластинах вполне могут быть области, которые винчестер какое-то время не использует.
При попытке записи в сектор диск сначала проверяет, не находится ли этот сектор в списке кандидатов. Если сектор там не найден, запись проходит обычным порядком. Если же найден, проводится тестирование этого сектора записью-чтением. Если все тестовые операции проходят нормально, то диск считает, что сектор исправен. (Т. е. был т. н. «софт-бэд» — ошибочный сектор возник не по вине диска, а по иным причинам: например, в момент записи информации отключилось электричество, и диск прервал запись, запарковав БМГ. В итоге данные в секторе окажутся недописанными, а контрольная сумма сектора, зависящая от данных в нём, вообще останется старой. Налицо будет расхождение между нею и данными в секторе.) В таком случае диск проводит изначально запрошенную запись и удаляет сектор из списка кандидатов. При этом атрибут 197 уменьшается, также возможно увеличение атрибута 196.
Если же тестирование заканчивается неудачей, диск выполняет операцию переназначения, уменьшая атрибут 197, увеличивая 196 и 05, а также делает пометки в G-list.
Итак, ненулевое значение параметра говорит о неполадках (правда, не может сказать о том, в само́м ли диске проблема).
При ненулевом значении нужно обязательно запустить в программах Victoria или MHDD последовательное чтение всей поверхности с опцией remap. Тогда при сканировании диск обязательно наткнётся на плохой сектор и попытается произвести запись в него (в случае Victoria 3.5 и опции Advanced remap — диск будет пытаться записать сектор до 10 раз). Таким образом программа спровоцирует «лечение» сектора, и в итоге сектор будет либо исправлен, либо переназначен.
Идёт последовательное чтение с ремапом в Victoria 4.46b
В случае неудачи чтения как с remap, так и с Advanced remap, стоит попробовать запустить последовательную запись в тех же Victoria или MHDD. Учитывайте, что операция записи стирает данные, поэтому перед её применением обязательно делайте бэкап!
Запуск последовательной записи в Victoria 4.46b
Иногда от невыполнения ремапа могут помочь следующие манипуляции: снимите плату электроники диска и почистите контакты гермоблока винчестера, соединяющие его с платой — они могут быть окислены. Будь аккуратны при выполнении этой процедуры — из-за неё можно лишиться гарантии!
Невозможность ремапа может быть обусловлена ещё одной причиной — диск исчерпал резервную область, и ему просто некуда переназначать секторы.
Если же значение атрибута 197 никакими манипуляциями не снижается до 0, следует думать о замене диска.
Атрибут: 198 (С6) Offline Uncorrectable Sector Count (Uncorrectable Sector Count)
| Тип | текущий |
| Описание | означает то же самое, что и атрибут 197, но отличие в том, что данный атрибут содержит количество секторов-кандидатов, обнаруженных при одном из видов самотестирования диска — оффлайн-тестировании, которое диск запускает в простое в соответствии с параметрами, заданными прошивкой |
Параметр этот изменяется только под воздействием оффлайн-тестирования, никакие сканирования программами на него не влияют. При операциях во время самотестирования поведение атрибута такое же, как и атрибута 197.
Ненулевое значение говорит о неполадках на диске (точно так же, как и 197, не конкретизируя, кто виноват).
Атрибут: 199 (С7) UltraDMA CRC Error Count
| Тип | накапливающий |
| Описание | содержит количество ошибок, возникших при передаче по интерфейсному кабелю в режиме UltraDMA (или его эмуляции винчестерами SATA) от материнской платы или дискретного контроллера контроллеру диска |
В подавляющем большинстве случаев причинами ошибок становятся некачественный шлейф передачи данных, разгон шин PCI/PCI-E компьютера либо плохой контакт в SATA-разъёме на диске или на материнской плате/контроллере.
Ошибки при передаче по интерфейсу и, как следствие, растущее значение атрибута могут приводить к переключению операционной системой режима работы канала, на котором находится накопитель, в режим PIO, что влечёт резкое падение скорости чтения/записи при работе с ним и загрузку процессора до 100% (видно в Диспетчере задач Windows).
В случае винчестеров Hitachi серий Deskstar 7К3000 и 5К3000 растущий атрибут может говорить о несовместимости диска и SATA-контроллера. Чтобы исправить ситуацию, нужно принудительно переключить такой диск в режим SATA 3 Гбит/с.
Моё мнение: при наличии ошибок — переподключите кабель с обоих концов; если их количество растёт и оно больше 10 — выбрасывайте шлейф и ставьте вместо него новый или снимайте разгон.
Можно считать, что о здоровье диска атрибут не говорит.
Атрибут: 200 (С8) Write Error Rate (MultiZone Error Rate)
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок при записи |
Ненулевое значение говорит о проблемах с диском — в частности, у дисков WD большие цифры могут означать «умирающие» головки.
Атрибут: 201 (С9) Soft Read Error Rate
| Тип | текущий |
| Описание | содержит частоту возникновения ошибок чтения, произошедших по вине программного обеспечения |
Влияние на здоровье неизвестно.
Атрибут: 202 (СА) Data Address Mark Error
| Тип | неизвестно |
| Описание | содержание атрибута — загадка, но проанализировав различные диски, могу констатировать, что ненулевое значение — это плохо |
Атрибут: 203 (CB) Run Out Cancel
| Тип | текущий |
| Описание | содержит количество ошибок ECC |
Влияние на здоровье неизвестно.
Атрибут: 220 (DC) Disk Shift
| Тип | текущий |
| Описание | содержит измеренный в неизвестных единицах сдвиг пластин диска относительно оси шпинделя |
Влияние на здоровье неизвестно.
Атрибут: 240 (F0) Head Flying Hours
| Тип | накапливающий |
| Описание | содержит время, затраченное на позиционирование БМГ. Счётчик может содержать несколько значений в одном поле |
Влияние на здоровье неизвестно.
Атрибут: 254 (FE) Free Fall Event Count
| Тип | накапливающий |
| Описание | содержит зафиксированное электроникой количество ускорений свободного падения диска, которым он подвергался, т. е., проще говоря, показывает, сколько раз диск падал |
Влияние на здоровье неизвестно.
Подытожим описание атрибутов. Ненулевые значения:
- атрибутов 01, 07, 195 — вызывают подозрения в «болезни» у некоторых моделей дисков;
- атрибутов 10, 11, 188, 196, 199, 202 — вызывают подозрения у всех дисков;
- и, наконец, атрибутов 05, 184, 187, 197, 198, 200 — прямо говорят о неполадках.
При анализе атрибутов учитывайте, что в некоторых параметрах S.M.A.R.T. могут храниться несколько значений этого параметра: например, для предпоследнего запуска диска и для последнего. Такие параметры длиной в несколько байт логически состоят из нескольких значений длиной в меньшее количество байт — например, параметр, хранящий два значения для двух последних запусков, под каждый из которых отводится 2 байта, будет иметь длину 4 байта. Программы, интерпретирующие S.M.A.R.T., часто не знают об этом, и показывают этот параметр как одно число, а не два, что иногда приводит к путанице и волнению владельца диска. Например, «Raw Read Error Rate», хранящий предпоследнее значение «1» и последнее значение «0», будет выглядеть как 65536.
Надо отметить, что не все программы умеют правильно отображать такие атрибуты. Многие как раз и переводят атрибут с несколькими значениями в десятичную систему счисления как одно огромное число. Правильно же отображать такое содержимое — либо с разбиением по значениям (тогда атрибут будет состоять из нескольких отдельных чисел), либо в шестнадцатеричной системе счисления (тогда атрибут будет выглядеть как одно число, но его составляющие будут легко различимы с первого взгляда), либо и то, и другое одновременно. Примерами правильных программ служат HDDScan, CrystalDiskInfo, Hard Disk Sentinel.
Продемонстрируем отличия на практике. Вот так выглядит мгновенное значение атрибута 01 на одном из моих Hitachi HDS721010CLA332 в неучитывающей особенности этого атрибута Victoria 4.46b:
![]()
Атрибут 01 в Victoria 4.46b
А так выглядит он же в «правильной» HDDScan 3.3:
![]()
Атрибут 01 в HDDScan 3.3
Плюсы HDDScan в данном контексте очевидны, не правда ли?
Если анализировать S.M.A.R.T. на разных дисках, то можно заметить, что одни и те же атрибуты могут вести себя по-разному. Например, некоторые параметры S.M.A.R.T. винчестеров Hitachi после определённого периода неактивности диска обнуляются; параметр 01 имеет особенности на дисках Hitachi, Seagate, Samsung и Fujitsu, 03 — на Fujitsu. Также известно, что после перепрошивки диска некоторые параметры могут установиться в 0 (например, 199). Однако подобное принудительное обнуление атрибута ни в коем случае не будет говорить о том, что проблемы с диском решены (если таковые были). Ведь растущий критичный атрибут — это следствие неполадок, а не причина.
При анализе множества массивов данных S.M.A.R.T. становится очевидным, что набор атрибутов у дисков разных производителей и даже у разных моделей одного производителя может отличаться. Связано это с так называемыми специфичными для конкретного вендора (vendor specific) атрибутами (т. е. атрибутами, используемыми для мониторинга своих дисков определённым производителем) и не должно являться поводом для волнения. Если ПО мониторинга умеет читать такие атрибуты (например, Victoria 4.46b), то на дисках, для которых они не предназначены, они могут иметь «страшные» (огромные) значения, и на них просто не нужно обращать внимания. Вот так, например, Victoria 4.46b отображает RAW-значения атрибутов, не предназначенных для мониторинга у Hitachi HDS721010CLA332:
«Страшные» значения в Victoria 4.46b
Нередко встречается проблема, когда программы не могут считать S.M.A.R.T. диска. В случае исправного винчестера это может быть вызвано несколькими факторами. Например, очень часто не отображается S.M.A.R.T. при подключении диска в режиме AHCI. В таких случаях стоит попробовать разные программы, в частности HDD Scan, которая обладает умением работать в таком режиме, хоть у неё и не всегда это получается, либо же стоит временно переключить диск в режим совместимости с IDE, если есть такая возможность. Далее, на многих материнских платах контроллеры, к которым подключаются винчестеры, бывают не встроенными в чипсет или южный мост, а реализованы отдельными микросхемами. В таком случае DOS-версия Victoria, например, не увидит подключённый к контроллеру жёсткий диск, и ей нужно будет принудительно указывать его, нажав клавишу [Р] и введя номер канала с диском. Часто не читаются S.M.A.R.T. у USB-дисков, что объясняется тем, что USB-контроллер просто не пропускает команды для чтения S.M.A.R.T. Практически никогда не читается S.M.A.R.T. у дисков, функционирующих в составе RAID-массива. Здесь тоже есть смысл попробовать разные программы, но в случае аппаратных RAID-контроллеров это бесполезно.
Если после покупки и установки нового винчестера какие-либо программы (HDD Life, Hard Drive Inspector и иже с ними) показывают, что: диску осталось жить 2 часа; его производительность — 27%; здоровье — 19,155% (выберите по вкусу) — то паниковать не стоит. Поймите следующее. Во-первых, нужно смотреть на показатели S.M.A.R.T., а не на непонятно откуда взявшиеся числа здоровья и производительности (впрочем, принцип их подсчёта понятен: берётся наихудший показатель). Во-вторых, любая программа при оценке параметров S.M.A.R.T. смотрит на отклонение значений разных атрибутов от предыдущих показаний. При первых запусках нового диска параметры непостоянны, необходимо некоторое время на их стабилизацию. Программа, оценивающая S.M.A.R.T., видит, что атрибуты изменяются, производит расчёты, у неё получается, что при их изменении такими темпами накопитель скоро выйдет из строя, и она начинает сигнализировать: «Спасайте данные!» Пройдёт некоторое время (до пары месяцев), атрибуты стабилизируются (если с диском действительно всё в порядке), утилита наберёт данных для статистики, и сроки кончины диска по мере стабилизации S.M.A.R.T. будут переноситься всё дальше и дальше в будущее. Оценка программами дисков Seagate и Samsung — вообще отдельный разговор. Из-за особенностей атрибутов 1, 7, 195 программы даже для абсолютно здорового диска обычно выдают заключение, что он завернулся в простыню и ползёт на кладбище.
Обратите внимание, что возможна следующая ситуация: все атрибуты S.M.A.R.T. — в норме, однако на самом деле диск — с проблемами, хоть этого пока ни по чему не заметно. Объясняется это тем, что технология S.M.A.R.T. работает только «по факту», т. е. атрибуты меняются только тогда, когда диск в процессе работы встречает проблемные места. А пока он на них не наткнулся, то и не знает о них и, следовательно, в S.M.A.R.T. ему фиксировать нечего.
Таким образом, S.M.A.R.T. — это полезная технология, но пользоваться ею нужно с умом. Кроме того, даже если S.M.A.R.T. вашего диска идеален, и вы постоянно устраиваете диску проверки — не полагайтесь на то, что ваш диск будет «жить» ещё долгие годы. Винчестерам свойственно ломаться так быстро, что S.M.A.R.T. просто не успевает отобразить его изменившееся состояние, а бывает и так, что с диском — явные нелады, но в S.M.A.R.T. — всё в порядке. Можно сказать, что хороший S.M.A.R.T. не гарантирует, что с накопителем всё хорошо, но плохой S.M.A.R.T. гарантированно свидетельствует о проблемах. При этом даже с плохим S.M.A.R.T. утилиты могут показывать, что состояние диска — «здоров», из-за того, что критичными атрибутами не достигнуты пороговые значения. Поэтому очень важно анализировать S.M.A.R.T. самому, не полагаясь на «словесную» оценку программ.
Хоть технология S.M.A.R.T. и работает, винчестеры и понятие «надёжность» настолько несовместимы, что принято считать их просто расходным материалом. Ну, как картриджи в принтере. Поэтому во избежание потери ценных данных делайте их периодическое резервное копирование на другой носитель (например, другой винчестер). Оптимально делать две резервные копии на двух разных носителях, не считая винчестера с оригинальными данными. Да, это ведёт к дополнительным затратам, но поверьте: затраты на восстановление информации со сломавшегося HDD обойдутся вам в разы — если не на порядок-другой — дороже. А ведь данные далеко не всегда могут восстановить даже профессионалы. Т. е. единственная возможность обеспечить надёжное хранение ваших данных — это делать их бэкап.
Напоследок упомяну некоторые программы, которые хорошо подходят для анализа S.M.A.R.T. и тестирования винчестеров: HDDScan (работает в Windows, бесплатная), CrystalDiskInfo (Windows, бесплатная), Hard Disk Sentinel (платная для Windows, бесплатная для DOS), HD Tune (Windows, платная, есть бесплатная старая версия).
И наконец, мощнейшие программы для тестирования: Victoria (Windows, DOS, бесплатная), MHDD (DOS, бесплатная).
 Errors happen and unintended actions are inevitable.
Errors happen and unintended actions are inevitable.
They are a common occurrence in usability tests and are the result of problems in an interface and imperfect human actions.
It is valuable to have some idea about what these are, how frequently they occur, and how severe their impact is.
First, what is an error?
Slips and Mistakes: Two Types of Errors
It can be helpful to categorize errors into slips and mistakes. Don Norman has written extensively about slips and mistakes in Chapter 5 of The Design of Everyday Things.
Slips are the classic unintended action a user makes while trying to do something on an interface even though the goal is correct (e.g., a typo) .When the goal is wrong it’s a mistake, even if that goal was accomplished.
Here are some slips
- Mistyping an email address
- Mistyping a password
- Accidentally clicking an adjacent link
- Clicking Reset instead of Submit (FYI don’t have a Reset button on a form).
- Mistyping an email address in the “Re-Enter” email address field
- Picking the wrong month when making a reservation
- Accidentally double clicking a button (often with a double submitted form)
Here are some mistakes
- Clicking on a heading that isn’t clickable
- Intentionally double clicking a link or button
- Typing both first and last name in the first name field
- Entering today’s date instead of the date of birth
- Replying to all in an email instead of just one person (an especially egregious mistake if the email is inflammatory)
- Entering hyphens in your bank account number
- Pushing the gas pedal instead of a break in an accident. Not slipping (literally) but mistakenly pushing the gas when panicking. Update: This just happened in my city a few hours after I posted this blog.
Four Causes of Errors
When we observe errors in usability tests we find it helpful to identify their causes and find they generally fall into four broad categories.
- Slips: You can’t eliminate all those “fat finger” errors or typos but seeing a lot of slips can be a good indication to reduce required fields or data entry where possible.
- Mistakes : When we see users entering the wrong format in a field it’s usually a good indication that some field-hint, an auto format or some code that gracefully strips non-numeric characters might reduce these mistakes.
- User Interface Problems: Errors caused by the interface are the ones we’re most interested in as we can usually do something about these. If users continue to click on a heading that’s not clickable (mistake) or look for a product in the wrong part of the navigation then there’s probably something about the design that we can improve.
- Scenario Errors: No matter how sophisticated and realistic our usability tests are, there is some degree of artificiality to them. For example, if you want to test how well users can pay a credit card bill online then you have to provide them with fake data and a test system. Inevitably we see errors related to the artificial scenario as users see balances and transactions that are foreign to them. We can’t do much about these errors except note that they are unlikely to be encountered in actual use.
How to Record Errors
When observing users in a usability test, record every time an error occurs even if it is the same error by the same user on the same task. I’ve seen the same user try unsuccessfully to click on the same heading that wasn’t clickable 5 times over a 2 minute period.
The user was confused about the navigation and really wanted that heading as a way to reorient themselves. Even though it was the same error, seeing 5 errors versus 1 error better describes the experience (which was poor).
Errors Provide the Why
Errors have been shown to correlate with the other prototypical usability metrics[pdf] of task-time, completion rates and task-level satisfaction. Errors are often the “why” behind the longer task times, failed tasks and lower satisfaction ratings.
For example, in our evaluation of the enterprise rent-a-car website, users were asked to find out the total price of the car with a GPS navigation system and car seat. These “extras” weren’t added to the total price so users had to do the addition themselves (often incorrectly) or think the total was lower than it actually was—a mistake caused by a UI problem that increased times, led to task failure and lowered the ease ratings.
Analyzing Errors
Simply averaging the number of errors by task gives you some idea about the experience. Showing 0 errors on a task does mean something compared to a task with 3.5 errors per task, especially if you are comparing different designs. However, not all tasks are created equally and that needs to be accounted for when interpreting errors.
Computing an Error Rate
Errors, unlike task completion rates, can occur more than once per user per task. This can complicate the analysis since you cannot easily compute a proportion as with task completion rates. For example if a user committed 3 errors for 1 task you cannot just divide 3/1.
The simplest thing to do is treat errors as binary data and code the raw error counts as either 1’s (user committed at least 1 error) or 0’s (user committed no errors). This loses some information but for many tasks and applications which don’t see many errors, this may be sufficient.
Opportunities for Errors
An alternative services which retains all the information is to convert errors into a proportion based on the opportunity for errors. An opportunity for an error is a technique I borrowed from Six Sigma’s opportunity for a defect. The idea is that some tasks, especially those that are longer or more complex, will have more opportunities for users to make mistakes. See also Human Error Probability (HEP).
For example, withdrawing money out of an ATM will have fewer error opportunities than submitting an expense report with 4 receipts and mileage in an Expense Reporting application. You identify the places in an interface where users can make mistakes and divide the total number of errors across all users by the total number of opportunities. For example, if a task has 5 opportunities for an error and 10 users attempt the task there are 50 opportunities. If you observe 5 errors across the users the error rate is 5/50 = 10%.
For more detail on the method of creating error opportunities see I have a whole section in A Practical Guide to Measuring Usability as well as in the 2005 CHI[pdf] and UPA papers[pdf].
Combine errors into a Single Usability Metric (SUM)
I don’t always record errors, but when I do I like to include them into a Single Usability Metric (SUM). We found[pdf] an average of time, completion rates, task-satisfaction and errors (all expressed as proportions) provides a great single measure for describing the usability of a task. It can be used on dashboards or when comparing competing products.
Error Overhead
One of the major reasons for not collecting error data is that it’s time consuming. We usually have multiple researchers counting and categorizing errors and it certainly can be time consuming and tedious.
If you’re conducting a remote unmoderated test it can be difficult unless you have some record of the interaction. This is one of the reasons we use videos in addition to our remote unmoderated data. The folks at Webnographer also have a way of recording some types of errors automatically in their software.
We are all humans and to err is human. While we can’t eliminate human error from task performance we can reduce it by removing as many opportunities for errors. A usable interface is one that, to as great an extent as possible, prevents errors and, when errors occur, helps users recover from them with as little pain as possible. With the proliferation of mobile devices that seem to be especially error prone, identifying and reducing as many errors as possible will lead to both increased usability and higher adoption.
We could have conducted the analysis for Example 1 of Basic Concepts for ANOVA by conducting multiple two sample tests. E.g. to decide whether or not to reject the following null hypothesis
H0: μ1 = μ2 = μ3
We can use the following three separate null hypotheses:
- H0: μ1 = μ2
- H0: μ2 = μ3
- H0: μ1 = μ3
If any of these null hypotheses is rejected then the original null hypothesis is rejected.
Note however that if you set α = .05 for each of the three sub-analyses then the overall alpha value is .14 since 1 – (1 – α)3 = 1 – (1 – .05)3 = 0.142525 (see Example 6 of Basic Probability Concepts). This means that the probability of rejecting the null hypothesis even when it is true (type I error) is 14.2525%.
For k groups, you would need to run m = COMBIN(k, 2) such tests and so the resulting overall alpha would be 1 – (1 – α)m, a value which would get progressively higher as the number of samples increases. For example, if k = 6, then m = 15 and the probability of finding at least one significant t-test, purely by chance, even when the null hypothesis is true is over 50%.
In fact, one of the reasons for performing ANOVA instead of separate t-tests is to reduce the type I error. The only problem is that once you have performed ANOVA if the null hypothesis is rejected you will naturally want to determine which groups have unequal variance, and so you will need to confront this issue in any case.
With 3 separate tests, in order to achieve a combined type I error rate (called an experiment-wise error rate or family-wise error rate) of .05 you would need to set each alpha to a value such that 1 – (1 – α)3 = .05, i.e. α = 1 – (1 – .05)1/3 = 0.016952. As is mentioned in Statistical Power, for the same sample size this reduces the power of the individual t-tests. If the experiment-wise error rate < .05 then the error rate is called conservative. If it is > .05 then the error rate is called liberal.
There are two types of follow up tests following ANOVA: planned (aka a priori) and unplanned (aka post hoc or posteriori) tests. Planned tests are determined prior to the collection of data, while unplanned tests are made after data is collected. These tests have entirely different type I error rates.
For example, suppose there are 4 groups. If an alpha value of .05 is used for a planned test of the null hypothesis  then the type I error rate will be .05. If instead the experimenter collects the data and sees means for the 4 groups of 2, 4, 9 and 7, then the same test will have a type I error rate of more than .05. The reason for this is that once the experimenter sees the data, he will choose to test because μ1 and μ2 are the smallest means and μ3 and μ4 are the largest.
then the type I error rate will be .05. If instead the experimenter collects the data and sees means for the 4 groups of 2, 4, 9 and 7, then the same test will have a type I error rate of more than .05. The reason for this is that once the experimenter sees the data, he will choose to test because μ1 and μ2 are the smallest means and μ3 and μ4 are the largest.