Wondering how to resolve PostgreSQL “Remaining connection slots are reserved” error? We can help you.
As a part of our Server Management Service, we help our customers to fix PostgreSQL related errors regularly.
Today, let us see how our Support Techs fix this error.
What causes PostgreSQL “Remaining connection slots are reserved” error?
Typical error will look as shown below:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connectionsBasically, Insufficient connections allocated for PostgreSQL tasks causes the issue.
Check what your database max connection is.
By default, this value is set to 100.
To do this execute any one of the queries below against a database within your cluster:
show max_connections;SELECT current_setting(‘max_connections’);SELECT *
FROM pg_settings
WHERE name = ‘max_connections’;How to resolve PostgreSQL “Remaining connection slots are reserved” error?
Today, let us see the methods followed by our Support Techs to resolve it.
Method 1:
Firstly, for non-replication superuser connections is installing and configuring connection pooling in your database.
In short, connection pooling is the caching of database connections so that when future requests are made to the database you can reuse same connection.
Next, to do connection pooling in PostgreSQL we can make use of two addons to the database, pgbouncer and pgpool
pgbouncer : pgbouncer is a Lightweight connection pooler for PostgreSQL.
Features of pgbouncer includes: session pooling, transaction pooling, statement pooling.
pgpool : pgpool is a middleware that works between PostgreSQL servers and a database client.
It provides the following features: Connection Pooling, Load Balancing, Limiting Exceeding Connections, Watchdog and In-Memory Query Cache.
Method 2
This method, involves increasing the number of connections to our database, by increasing the max_connections parameter in the postgresql.conf file.
Please note that when changing the max_connections parameter, you also need to increase the shared_buffers parameter as well.
For every connection, the OS needs to allocate memory to the process that is opening the network socket.
The PostgreSQL needs to do its own under-the-hood computations to establish that connection.
Once you change the parameters, restart the database.
Before you make any changes it is good to make note of the total max connections and the current shared buffer size.
show max_connections;
Show shared_buffers;Using ALTER Command
To change the max connections using SQL execute the command:
ALTER SYSTEM SET max_connections TO ‘150’; — increase the value by 50To change the shared buffers value using SQL execute the command:
ALTER SYSTEM SET shared_buffers TO ‘256MB’ — Increase the value by 128MBWrite the changes made in the database using the ALTER Command to postgresql.auto.conf file first.
Then, commit the values in files to the postgresql.conf file upon reloading or restarting of database.
Editing the Postgresql.conf file
Next, we can increase values of the max_connections and shared_buffers parameter is to directly edit postgresql.conf file.
Locate and open your cluster postgresql.conf file.
Once in the file locate parameters that need changing and change them accordingly.
max_connections = 150 # (change requires restart)
shared_buffers = 256MB # min 128kB # (change requires restart)Restarting the Cluster
After setting new values for parameters, as mentioned above we need to restart database cluster.
Run any of commands below:
Pg_ctl restart -D /path/to/db/directory/
service postgresql-10.service restart (depending on your version)Method 3
Let us see the steps followed by our Support Techs in this method.
Killing Idle Sessions
In this method, kill idle sessions on the database.
In PostgreSQL A connection is inactive if its state is either idle, idle in transaction, idle in transaction (abort), or disable and if that transaction is in that state for more than 5 minutes it is considered to be old.
Before we kill any idle sessions we need to first check for all idle session in the database that meets the criteria above by running:
SELECT *
FROM pg_stat_activity
WHERE datname = ‘centralauth’
AND pid <> pg_backend_pid()
AND state in (‘idle’, ‘idle in transaction’, ‘idle in transaction (aborted)’, ‘disabled’)
AND state_change < current_timestamp – INTERVAL ’15’ MINUTE; — You can set your own intervalUsually, the query above will check for transactions that have been ‘old’ for 15 minutes and more.
Once we see all the old transactions in the database, we can kill them by running the pg_terminate_backend() function.
SELECT pg_terminate_backend(pid)
FROM pg_stat_activity
WHERE datname = ‘centralauth’
AND pid <> pg_backend_pid()
AND state in (‘idle’, ‘idle in transaction’, ‘idle in transaction (aborted)’, ‘disabled’)
AND state_change < current_timestamp – INTERVAL ’15’ MINUTE;Next, the query above will collect all the pids for the idle sessions that meet the criteria and pass them to the pg_terminate_backend() function, thus killing them.
Then, set idle in transaction session timeout
Next, terminate sessions that have been idle for a period of time.
Then, we can use the idle_in_transaction_session_timeout parameter to achieve this.
Then, we can set it for a specific role in the database.
alter user username SET idle_in_transaction_session_timeout to 60000; — 1minuteFor all connections:
ALTER SYSTEM SET idle_in_transaction_session_timeout to 60000; — 1minute[Need help to fix PostgreSQL error? We are available 24*7]
Conclusion
Today, we saw the methods followed by our Support Techs to resolve PostgreSQL “Remaining connection slots are reserved” error.
PREVENT YOUR SERVER FROM CRASHING!
Never again lose customers to poor server speed! Let us help you.
Our server experts will monitor & maintain your server 24/7 so that it remains lightning fast and secure.
GET STARTED
var google_conversion_label = «owonCMyG5nEQ0aD71QM»;
Why am I getting the error «FATAL: remaining connection slots are reserved for non replicate superuser connections» when connecting to my Amazon RDS for PostgreSQL even though I haven’t reached the max_connections limit?
Last updated: 2022-10-12
I’m getting the error «FATAL: remaining connection slots are reserved for non replicate superuser connections» when I connect to my Amazon Relational Database Service (Amazon RDS) for PostgreSQL even though I haven’t reached the max_connections limit.
Short description
In Amazon RDS for PostgreSQL, the actual maximum number of available connections to non-superusers is calculated as follows:
max_connections — superuser_reserved_connections — rds.rds_superuser_reserved_connections.
The default value for superuser_reserved_connections is 3, and the default value for rds.rds_superuser_reserved_connections is 2.
For example, if you set the value of max_connections to 100, then the actual number of available connections for a non-superuser is calculated as follows:
100 — 3 — 2 = 95.
The Amazon CloudWatch metric DatabaseConnections indicates the number of client network connections to the database instance at the operating system level. This metric is calculated by measuring the actual number of TCP connections to the instance on port 5432. The number of database sessions might be higher than this metric value because the metric value doesn’t include the following:
- Backend processes that no longer have a network connection but aren’t cleaned up by the database. (For example: The connection is terminated due to network issues but the database isn’t aware until it attempts to return the output to the client.)
- Backend processes created by the database engine job scheduler. (For example: pg_cron)
- Amazon RDS connections.
You might get this error because the application that connects to the RDS for PostgreSQL instance abruptly creates and drops connections. This might cause the backend connection to remain open for some time. This condition might create a discrepancy between the values of pg_stat_activity view and the CloudWatch metric DatabaseConnections.
Resolution
Troubleshoot the error
To troubleshoot this error, perform the following checks:
- Review the CloudWatch metric DatabaseConnections.
- Use Performance Insights to view the numbackends counter metric. This value provides information on the number of connections at the time that the error occurred. If you didn’t turn on Performance Insights, log in to your instance as the primary user. Then, view the number of backends by running the following query:
SELECT count(*) FROM pg_stat_activity;If you find some idle connections that can be terminated, you can terminate these backends using the pg_terminate_backend() function. You can view all the idle connections that you want to terminate by running the following query. This query displays information about backend processes with one of the following states for more than 15 minutes: ‘idle’, ‘idle in transaction’, ‘idle in transaction (aborted)’ and ‘disabled’.
SELECT * FROM pg_stat_activity
WHERE pid <> pg_backend_pid()
AND state in ('idle', 'idle in transaction', 'idle in transaction (aborted)', 'disabled')
AND state_change < current_timestamp - INTERVAL '15' MINUTE;Note: Be sure to update the query according to your use case.
After identifying all the backend processes that must be terminated, terminate these processes by running the following query.
Note: This example query terminates all backend processes in one of the states mentioned before for more than 15 minutes.
SELECT pg_terminate_backend(pid) FROM pg_stat_activity
WHERE pid <> pg_backend_pid()
AND state in ('idle', 'idle in transaction', 'idle in transaction (aborted)', 'disabled')
AND state_change < current_timestamp - INTERVAL '15' MINUTE
AND usename != 'rdsadmin';To terminate all idle backend processes, run the following query:
SELECT pg_terminate_backend(pid) FROM pg_stat_activity
WHERE pid <> pg_backend_pid()
AND state in ('idle', 'idle in transaction', 'idle in transaction (aborted)', 'disabled')
AND usename != 'rdsadmin';Note: You can’t terminate backend processes that are created with rdsadmin. Therefore, you must exclude them from termination.
Important: If you can’t connect to your RDS for PostgreSQL instance with the rds_superuser privileges, then consider closing your application gracefully to free some connections.
Manage the number of database connections
Use connection pooling
In most cases, you can use a connection pooler, such as an RDS Proxy or any third party connection pooler, to manage the number of connections that are open at any one given time. For example, if you set the max_connections value of your RDS for PostgreSQL instance to 500, you can prevent errors related to max_connection by having a connection pooler that’s configured for a maximum of 400 connections.
Increase max_connections value
You might consider increasing the value of max_connections depending on your use case. However, setting a very high value for max_connections might result in memory issues based on the workload and instance class of the database instance.
Note: If you increase the value of max_connections, you must reboot the instance for the change to take effect.
Terminate idle connections
You might set the idle_in_transaction_session_timeout parameter to a value that’s appropriate for your use case. Any session that’s idle within an open transaction for longer than the time specified in this parameter is terminated. For example if you set this parameter to 10 minutes, any query that’s idle in transaction for more than 10 minutes is terminated. This parameter helps in managing connections that are stuck in this particular state.
For PostgreSQL versions 14 and later, you can use the idle_session_timeout parameter. After you set this parameter, any session that’s idle for more than the specified time, but not within an open transaction, is terminated.
For PostgreSQL versions 14 and later, you can use the client_connection_check_interval parameter. With this parameter, you can set the time interval between optional checks for client connection when running queries. The check is performed by polling the socket. This check allows long-running queries to be ended sooner if the kernel reports that the connection is closed. This parameter helps in situations where PostgreSQL doesn’t know about the lost connection with a backend process.
Increase the rds.rds_superuser_reserved_connections value
You might consider increasing the value of the rds.rds_superuser_reserved_connections parameter. The default value for this parameter is set to 2. Increasing the value of this parameter allows for more connections from users with the rds_superuser role attached. With this role, the users can run administrative tasks, such as terminating an idle connection using the pg_terminate_backend() command.
Did this article help?
Do you need billing or technical support?
AWS support for Internet Explorer ends on 07/31/2022. Supported browsers are Chrome, Firefox, Edge, and Safari.
Learn more »
I’m developing an app on Heroku with a Postgresql backend. Periodically, I get this error message when trying to access the database, both from the CLI and from loading a page on the server:
psql: FATAL: remaining connection slots are reserved for non-replication superuser connections
Anyone seen this before or please help point me in the right direction?
![]()
Hearen
7,1642 gold badges49 silver badges60 bronze badges
asked Aug 7, 2012 at 13:31
![]()
nathancahillnathancahill
10.2k9 gold badges47 silver badges91 bronze badges
7
This exception happened when I forgot to close the connections
![]()
Hearen
7,1642 gold badges49 silver badges60 bronze badges
answered Apr 11, 2013 at 14:17
![]()
SanyifejűSanyifejű
2,5509 gold badges45 silver badges73 bronze badges
0
See Heroku “psql: FATAL: remaining connection slots are reserved for non-replication superuser connections”:
Heroku sometimes has a problem with database load balancing.
André Laszlo, markshiz and me all reported dealing with that in comments on the question.
To save you the support call, here’s the response I got from Heroku Support for a similar issue:
Hello,
One of the limitations of the hobby tier databases is unannounced maintenance. Many hobby databases run on a single shared server, and we will occasionally need to restart that server for hardware maintenance purposes, or migrate databases to another server for load balancing. When that happens, you’ll see an error in your logs or have problems connecting. If the server is restarting, it might take 15 minutes or more for the database to come back online.
Most apps that maintain a connection pool (like ActiveRecord in Rails) can just open a new connection to the database. However, in some cases an app won’t be able to reconnect. If that happens, you can heroku restart your app to bring it back online.
This is one of the reasons we recommend against running hobby databases for critical production applications. Standard and Premium databases include notifications for downtime events, and are much more performant and stable in general. You can use pg:copy to migrate to a standard or premium plan.
If this continues, you can try provisioning a new database (on a different server) with heroku addons:add, then use pg:copy to move the data. Keep in mind that hobby tier rules apply to the $9 basic plan as well as the free database.
Thanks,
Bradley
![]()
answered Aug 12, 2015 at 16:30
![]()
Aur SarafAur Saraf
3,0861 gold badge25 silver badges14 bronze badges
3
I actually tried to implement connection pooling on the django end using:
https://github.com/gmcguire/django-db-pool
but I still received this error, despite lowering the number of connections available to below the standard development DB quota of 20 open connections.
There is an article here about how to move your postgresql database to the free/cheap tier of Amazon RDS. This would allow you to set max_connections higher. This will also allow you to pool connections at the database level using PGBouncer.
https://www.lewagon.com/blog/how-to-migrate-heroku-postgres-database-to-amazon-rds
UPDATE:
Heroku responded to my open ticket and stated that my database was improperly load balanced in their network. They said that improvements to their system should prevent similar problems in the future. Nonetheless, support manually relocated my database and performance is noticeably improved.
answered Jan 17, 2013 at 5:22
![]()
markshizmarkshiz
2,47121 silver badges28 bronze badges
1
To reproduce same issue in Linux:
for i in {1..300}; do
PGPASSWORD=MY_PASSWORD gnome-terminal -e $'/usr/bin/psql -h '127.0.0.1' -p 5432 -U MY_USERNAME'
done
In a dotnet client you can read:
System.InvalidOperationException: An exception has been raised that is likely due to a transient failure. ---> Npgsql.PostgresException (0x80004005): 53300: sorry, too many clients already
answered May 13, 2021 at 15:52
![]()
profimedicaprofimedica
2,56831 silver badges39 bronze badges
1
I had a lot of idle connections in my case, so I had to reuse idle connections before creating new ones,
answered Sep 29, 2021 at 11:43
![]()
1
The error message means that the app has used up all available connections.
While using postgres in aws with knex and typescript to do some query and update job, the problem pops up when it finishes 390 database operations, for which a mistake prevents the normal knex.destroy() operation. The error message is:
(node:66236) UnhandledPromiseRejectionWarning: error: remaining connection slots are reserved for non-replication superuser connections
When knex.destroy() goes to the right place the error is gone.
answered Feb 16, 2022 at 4:38
![]()
There seems no questions asking this issue with the context of .NET world.
For me, this is caused by async void, and this method passed to a Action delegate, Action<TMessage> action, and there are multiple threads trying to call this Persist method at the same time.
private async void Persist(WhateverData data)
{
await _repository.InsertAsync(data);
}
the solution is, remove async and await, and just use it synchronously
private void Persist(PriceInfo price)
{
_repository.InsertAsync().WaitAndUnwrapException();
}
answered Oct 19, 2022 at 14:02
![]()
TimelessTimeless
7,2398 gold badges59 silver badges94 bronze badges
4
set the maximum active size for tomcat-jdbc, set this property in your .properties or .yml file:
spring.datasource.maxActive=5
or
spring.datasource.max-active=5
as below:
spring:
datasource:
driverClassName:
password:
url:
username:
max-active: 5
answered Dec 5, 2022 at 5:38
![]()
I have a PostgreSQL 12.1 database system (I’ll refer to it as PGSQL) running on a remotely hosted VM server (Windows Server 2019). We upgraded the server OS and PGSQL a couple of months ago. Everything has been running more-or-less normally since then, until this morning when I started receiving the above-mentioned database error in pretty much every one of our in-house applications that connect to this PGSQL instance.
To check the connections, I ran SELECT * FROM pg_stat_activity;, which returned 103 rows. My postgresql.conf file has max_connections = 100, so that makes sense, but what doesn’t make sense is that, of those 103 connections, 90+ of them are listed as idle with query text of DISCARD ALL. All of these show as being executed by the same, non-superuser account from the server’s own internal address. However, several of the connections show a query_start date value from a month or more ago.
Now, many of the applications we have in place are unfortunately built with hard-coded credentials (I have a lot of «clean-up» work to do on the code for these applications that I inherited) and are generally being executed from shortcuts pointing to an «Application» share on the server that’s hosting the PGSQL database, so none of this looks particularly «suspicious». I tried to simply kill the processes using SELECT pg_cancel_backend(<pid>); on one of the pid values from the previous query, but requerying pg_stat_activity still shows the same record in the result set (all of the values appear to be exactly the same, from what I can tell).
Perhaps I’m not using the correct function to terminate these «hung» processes or something, but I could not figure out how to clear out these connections individually. Because I needed to get our production environment back to a usable state, I ended up just stopping and restarting the PGSQL service on the server which did clear out all of those old DISCARD ALL statements, but I’m curious if there’s something I could do to prevent this backlog of «hung» statements in the future.
My question here is, how can I prevent this from happening in the future? One thing to note is that, prior to upgrading our PGSQL server to v12.1, we ran v9.4 for a number of years and never once encountered this issue. I’m wondering if there might be something inherent to the newer version of PGSQL, or perhaps even something about running PGSQL in the Windows Server 2019 environment that might be causing this behavior.
EDIT
For reference and consolidation, the following information comes from the comments:
I do not have anything server-side for managing connection pooling (I’ve seen some references in other questions about PgBouncer, but haven’t had an opportunity to look at that for whether or not it would be helpful in our environment). Most of my applications are implementing pooling in the connection string via the Npgsql library. I’ve built a «common library» for managing my applications’ connections — connecting, disconnecting, disposing, etc. — which at least seems to be working normally.
However, it’s certainly possible that some of the «legacy» code I’ve inherited does not have this implemented correctly, but that’s something that’ll take me a bit of time to dig through the code to find all of the connections (there are a lot of issues with some of that code). I’ll investigate that as a potential/likely source of the issue as time permits.
As stated above, I’ve not encountered this issue until we upgraded PGSQL to v12.1 and that same legacy code has been in place for several years. As a 1-man IT Dept, the server’s reboot «schedule» is generally managed by me and I’ve rarely rebooted the server or restarted the PGSQL service due to its nature as a production environment. Hopefully, I’m just being hyper-sensitive about stuff because of the recent upgrade and this whole thing is a «one-off» situation I won’t see again.
I guess what triggered my question was wondering why the database hadn’t dumped these idle connections that have been hanging around for a month or more. I’ll keep an eye on things and, if the problem persists, I’ll look into more aggressive connection pool management options.
UPDATE/EDIT
Since posting this question 4 months ago, I, unfortunately, haven’t been actively checking the status of the idle connections. This morning, however, the error popped back up and I was reminded of this post. Again, executing SELECT * FROM pg_stat_activity; showed over 100 connections (the max defined by my server configuration), of which over 70 were idle / DISCARD ALL with «older» (several weeks/months) values for the backend_start / query_start date.
Understanding that the database itself doesn’t «manage» these, I still find it odd that I never encountered this error in more than a decade of running previous versions of PostgreSQL. It wasn’t until after we upgraded to v12, even though the environment has remained basically the same.
Regardless, because I have so many «legacy» applications that potentially could be leaving these connections open, I’ve decided to implement a check in one of my daily routines that should prevent this issue from reoccurring. I have an application that is run every day to replicate and clean up certain information in the database. In that application, I am adding a small function that will execute the following SQL command to keep the backend clear of these «leftover» idle connections:
SELECT
pg_terminate_backend(pid)
FROM
pg_stat_activity
WHERE
pid <> pg_backend_pid()
AND backend_start < (SELECT (NOW() - INTERVAL '2 WEEK')::DATE)
AND state = 'idle';
As you can see, this should look for any idle connections older than 2 weeks and terminate them. Since this application is run daily, I believe this will help to keep the pool as clear as possible. Of course, if there’s a better way — one that does not require the implementation of some new 3rd-party solution (at least, at this time) — I’m all ears, but, for the time being, I believe this will «solve» my problem.
ADDITIONAL REFERENCE / POSSIBLE ALTERNATE SOLUTION
As I was looking around a bit more, I also came across this answer on StackOverflow:
How to close idle connections in PostgreSQL automatically?
The linked answer refers to using the idle_in_transaction_session_timeout setting introduced in PostgreSQL 9.6. As stated in fresko‘s answer, I should be able to set this with a single SQL command sent to the server either as a superuser for the entirety of the server:
ALTER SYSTEM SET idle_in_transaction_session_timeout = '5min';
or for individual user connections on a per-session basis (if needed)
SET SESSION idle_in_transaction_session_timeout = '5min';
I checked this setting on my server and it appears to be disabled (0), so I may look into configuring this setting as well. I’ll be referring to the v12 documentation page for Client Connection Defaults in case anyone wants to «follow along».
Summary
By default, the max_connections setting within Postgres is set to 100 connections. If Confluence is configured to use more connections than this setting allocates, then an outage within Confluence can result.
Environment
All versions of Confluence.
All versions of Postgres.
Diagnosis
If an outage has occurred, this issue shows itself by way of a message like this appearing in the application logs:
2020-12-10 02:45:06,432 ERROR [C3P0PooledConnectionPoolManager[identityToken->1bqqkxuad1lwglwv1y8yakz|5660fd1e]-HelperThread-#1] [org.postgresql.Driver] connect Connection error:
org.postgresql.util.PSQLException: FATAL: remaining connection slots are reserved for non-replication superuser connections
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2476)
at org.postgresql.core.v3.QueryExecutorImpl.readStartupMessages(QueryExecutorImpl.java:2602)
at org.postgresql.core.v3.QueryExecutorImpl.<init>(QueryExecutorImpl.java:125)
at org.postgresql.core.v3.ConnectionFactoryImpl.openConnectionImpl(ConnectionFactoryImpl.java:227)
at org.postgresql.core.ConnectionFactory.openConnection(ConnectionFactory.java:49)
at org.postgresql.jdbc.PgConnection.<init>(PgConnection.java:194)
at org.postgresql.Driver.makeConnection(Driver.java:450)
at org.postgresql.Driver.connect(Driver.java:252)
at com.mchange.v2.c3p0.DriverManagerDataSource.getConnection(DriverManagerDataSource.java:175)Cause
To verify the cause of this issue, a quick inventory of the available connections versus the required connections by the application is necessary.
To determine the number of connections available within Postgres, execute the following SQL:
SELECT name, current_setting(name)
FROM pg_settings
WHERE name = 'max_connections'Now, we’ll need to determine how many connections are required by the applications running on the server. This includes Confluence, Synchrony (which is the engine that drives Confluence’s Collaborative Editing feature, any other applications running on the server that require a Postgres server connection, plus a buffer of 20% for Postgres overhead activities.
Confluence
To begin calculating the total number of connections needed, we’ll first need to look at the main Confluence application. We do so by first locating the <confluence-home-folder>/confluence.cfg.xml file and examining the value set to the hibernate.c3p0.max_size property. It should look something like this:
<property name="hibernate.c3p0.max_size">60</property>![]() Note: if this is a Data Center instance, this number needs to be multiplied by the total number of DC nodes that are running. This will then total the number of connections required to be available by the main Confluence application.
Note: if this is a Data Center instance, this number needs to be multiplied by the total number of DC nodes that are running. This will then total the number of connections required to be available by the main Confluence application.
Synchrony
Next, we’ll now need to include the 15 connections that are configured by default within Synchrony. Like the main Confluence application, this number needs to be multiplied by the number of nodes in use if Data Center is in use and Synchrony is managed by Confluence. If Synchrony has been configured to run as Synchrony standalone in a cluster, then multiply the number of Synchrony nodes in the cluster by 15.
Other Applications that use the Postgres instance
If there are any other applications that use the Postgres instance, we’ll need to account for those connections as well. For instance, if Jira uses the same Postgres instance, then we’ll want to inspect Jira’s dbconfig.xml file which is located in its home/data directory.
Buffer
And finally, we’ll want to add a 20% buffer to the total of the connections required by the main Confluence application, Synchrony and any other application using the Postgres service.
If the total required connections are greater than what’s configured on the Postgres server, then we’ll need to increase the max_connections setting.
Solution
While we’ll need to increase the max_connections setting within the Postgres configuration file, the shared_buffer setting may need to be adjusted as well. For more information, please see Tuning Your PostgreSQL Server or contact a DBA to assist.
Today I had a problem with PostgreSQL connection, both my application and psql tool returned an error:
FATAL: remaining connection slots are reserved for non-replication superuser connections
The PostgreSQL server was running on the db.t1.micro RDS instance and the ‘Current activity’ column showed ‘22 connections’ and a red line which should represent a connection limit was far away from the 22 value.
Here is how it looked:
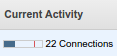 .
.
And this connection information is actually misleading — it shows 22 connections and it looks like around 30% consumed.
While actually we already at 100% of connections.
After some time, when the database load went down, I was able to login with psql to check max_connections parameter:
template1=> show max_connections;
max_connections
-----------------
26
(1 row)
So we have 26 max connections and, as stated in comments (thanks, Johannes Schickling), there are also 3 connections reserved to superuser.
That means we used 25 connections (22 + 3 reserved) out of 26.
The max_connection setting can also be found in the RDS UI, under “Parameter Groups”, but the value there is set as {DBInstanceClassMemory/31457280}, so it is complex to be sure about the actual value.
The db.t1.micro instance has 1GB memory, and calculation like 1024*1024*1024/31457280 gives around 36, while actually it is 26.
The default value can be changed this way:
- create a new parameter group
- using the default group as parent and then edit the max_connection value
- once done — go to the db instance settings (Modify action) and set the new parameter group.
But for me it seems to be dangerous solution to use in production, because more connections will consume more memory and instead of connection limit errors you can end up with out of memory errors.
So I decided to change the instance type to db.t2.small, it costs twice more, but it has 2GB RAM and default max_connections value is 60.
In my case the higher connection consumption was not something unexpected, the Elastic Beanstalk scaled the application to 6 EC2 instances under load. Each instance runs a flask application with several threads, so they can easily consume around 20 connections.
To actually make sure that everything is OK with connections handling, run the following query:
template1=> select * from pg_stat_activity;
datid | datname | ... | backend_start | ... | query_start | state_change | waiting | state | ... | query
-------+----------+-----+---------------------+-----+---------------------+---------------------+---------+-------+-----+--------------------------
...
16395 | myapp | ... | 2015-09-22 16:13:04 | ... | 2015-09-22 17:07:13 | 2015-09-22 17:07:13 | f | idle | ... | COMMIT
16395 | myapp | ... | 2015-09-22 16:14:13 | ... | 2015-09-22 17:07:21 | 2015-09-22 17:07:21 | f | idle | ... | ROLLBACK
16395 | myapp | ... | 2015-09-22 16:14:13 | ... | 2015-09-22 17:07:14 | 2015-09-22 17:07:14 | f | idle | ... | COMMIT
16395 | myapp | ... | 2015-09-22 16:14:13 | ... | 2015-09-22 17:07:18 | 2015-09-22 17:07:18 | f | idle | ... | ROLLBACK
...
(16 rows)
Here you can see all the connections, queries and last activity time for each connection, so it should be easy to see if there are any hanging connections.
Links
Stackoverflow: Heroku “psql: FATAL: remaining connection slots are reserved for non-replication superuser connections”
Stackoverflow: Amazon RDS (postgres) connection limit?
Stackoverflow: Flask unittest and sqlalchemy using all connections
Stackoverflow: PostgreSQL ERROR: no more connections allowed
