Postgres requested WAL segment has already been removed (however it is actually in the slave’s directory)
I am using repmgr as my replication tool. On the slave I keep getting an error:
requested WAL segment has already been removed
When I check the Master indeed it is not there; however, it is in the slave’s directories both in pg_xlogs and pg_xlogs/archive_status . I can’t understand why it would be looking for this file if it’s already in the slave?
In fact it has xlogs going past the requested one. The solutions in What to do with WAL files for Postgres Slave reset are for a slightly different problem. They seem to be for a scenario where the master deletes a log file before the slave receives it. In my case it is very much present on the slave and several other files in the sequence after the one being requested.
This also tells me I do not need to increase the keep wal segments option as it didn’t seem to fall behind?
2 Answers 2
From Streaming Replication in the PostgreSQL documentation:
If you use streaming replication without file-based continuous archiving, the server might recycle old WAL segments before the standby has received them. If this occurs, the standby will need to be reinitialized from a new base backup. You can avoid this by setting wal_keep_segments to a value large enough to ensure that WAL segments are not recycled too early, or by configuring a replication slot for the standby. If you set up a WAL archive that’s accessible from the standby, these solutions are not required, since the standby can always use the archive to catch up provided it retains enough segments.
To fix the issue, you have to reinitialize the data from primary server. Remove data directory on slave:
Copy all data from the primary server:
if version is 12, Create the standby.signal file, otherwise configure replica.conf:
How long is the pg_basebackup taking? Remember that segments are generated about every 5 minutes, so if the backup takes an hour, you need at least 12 segments stored. At 2 hours, you need 24 etc., I’d set the value to about 12.2 segments/hour of backup.
Источник
Postgresql Streaming Replication Error: WAL segment removed
I want to set up PostgreSQL streaming replication, but get the following error:
Master IP : 192.168.0.30
Slave IP : 192.168.0.36
On Master:
I have created a user rep which is used solely for replication.
The relevant files inside Postgres config directory ( /opt/Postgres/9.3/data ):
I’ve restarted the postgres service.
On Slave:
I’ve stopped the postgres service, then applied the changes to the two files:
For replicating the initial database I have done:
On Master:
Internal postgres backup start command to create a backup label:
. for transferring the database data to slave:
. for internal backup stop to clean up:
On Slave:
I’ve created the following recovery.conf :
Starting the postgres service on the slave starts without any errors but is still waiting:
Meanwhile, on master:
psql command on the slave gives:
—> cd pg_log gives reason for waiting:-
How can I solve this error?
1 Answer 1
From Streaming Replication in the PostgreSQL documentation:
If you use streaming replication without file-based continuous archiving, the server might recycle old WAL segments before the standby has received them. If this occurs, the standby will need to be reinitialized from a new base backup. You can avoid this by setting wal_keep_segments to a value large enough to ensure that WAL segments are not recycled too early, or by configuring a replication slot for the standby. If you set up a WAL archive that’s accessible from the standby, these solutions are not required, since the standby can always use the archive to catch up provided it retains enough segments.
Источник
Could not receive data from WAL stream: ERROR: requested WAL segment has already been removed
Configuration: Postgres 9.6 with a 3 cluster node. db1 is the master, db2 and db3 are replicas. WAL files are archived in AWS S3 using custom pgrsync tool. Cluster managed by patroni. The archive_command and restore_command is properly configured on all the nodes.
To simulate: On db1, do heavy writes (like vacuum a large table) and then stop db1 by sudo systemctl stop patroni ). db3 becomes the new leader. db2 requests more WAL files, which it gets via the proper restore command from AWS S3, becomes replica to db3.
Now, start db1 again by ( sudo systemctl start patroni ). But db1 (the old leader and the new to-be-replica) never comes up as a replica and gives the error message:
could not receive data from WAL stream: ERROR: requested WAL segment 0000002400053C55000000AE has already been removed.
This error message is reported by db3 (the leader), which db1 just logs it.
So, let’s see the timeline. Initially db1 was in timeline 35 (0x23) and did write the following files to archive:
db1 is stopped at this point. db3’s logs show this:
and db3 copies the following files to archives
As db3 became leader, db2 starts the process to become replica to db3 (which it successfully becomes) and here is the summary of the logs:
db1 is started now and here are the logs:
- 0000002400053C55000000AE was never written to archives by any Postgres node. The old leader (db1) copied the archive 0000002300053C55000000AE (note: 0023, not 0024) before it was stopped.
- The new leader (db3) copied 0000002200053C55000000AE (note: 0022, not 0024)
- max_wal_size is set to 1024 on all nodes.
- After db3 became the new leader, there was hardly any activity on the nodes. db3 only writes WAL files every 10 mins ( archive_timeout =600s).
- Is there any thing wrong in the configuration that makes the the old leader asking for a WAL segment, which the new leader does not have?
- How to restore the old leader (db1) at this state, without having to erase and start over?
Lots of disk space available. The problem can be simulated at will. Had tried pg_rewind on the old primary, pointing to new primary. It just said it is already on the same timeline (not exact words). Note: It was not an error message. But even after that, it was showing the same error, when starting Postgres.
We are on 9.6.19. Just a few days back 9.6.21 (and last 9.5.x release) was announced which exactly points out fix for this specific problem (Fix WAL-reading logic so that standbys can handle timeline switches correctly. This issue could have shown itself with errors like «requested WAL segment has already been removed».). However, even after upgrading to 9.6.21, the same problem exists for us.
Источник
Postgresql сломалась репликаци знаю причины не знаю как поченить стэндбай?
Добрый день.
У меня настроена каскадная репликация с одного мастера идет слейв который в свою очередь после синхронизации реплицирует на последний слейв.
OC — Ubuntu 18
СУБД — PostgreSQL 10
https://postgrespro.ru/docs/postgrespro/10/warm-standby
Проблема заключается в том что на слейвах у меня ощибка
error requested wal segment has already been removed.
Правильно ли Я понимаю что эта ошибка говорит о том что Если база с которой настроенно получение WAL уже удалила сегмент — то тут как раз репликация и встанет с ошибкой, что такого сегмента уже нет. Если его восстановить неоткуда — то необходимо копировать реплику заново. Наиболее простой способ — через pg_basebackup.
https://ru.stackoverflow.com/questions/972585/post.
В связи с этим есть вопросы:
1. Можно сделать это как то подругому ?
К примеру:
Остановить слейв скопировать с мастера папку pg_wal с файлами и запустить его ? Не станет ли слейв после этого мастером ?
Я просто не понимаю что нужно будет делать на слейве что бы он догнал мастер. Иными словами как востонавливать пошагово.
2. Могла ли данная ошибка возникнуть из-за того что Я делаю на мастере pg_basebackup -D /my_dir. Которая в свою очередь лочит базу и репликация не может пройти. Точнее она проходит но с ошибкой.
Тогда как делать правильно pg_basebackup что бы не ломалась реплика ?
Источник
WAL segment has already been removed error when running database backup on CloudForms
Environment
Issue
- Getting requested WAL segment 00000001000000140000004F has already been removed when running pg_basebackup on CloudForms.
Resolution
- Adjust the wal_keep_segments setting in the postgresql.conf file.
Instructions:
- SSL into your DB server CloudForms appliance
- Set wal_keep_segments to (
/4)/16MB
Please note that when calculating the that you want to keep it as low as possible, as this will take up space on the database
Root Cause
- The server recycles old WAL segments before the backup can finish.
- Depending on how long the pg_basebackup is taking it is common knowledge that the segments are generated about every 5 minutes, so if the backup takes an hour, you need at least 12 segments stored.
- Product(s)
- Red Hat Hybrid Cloud Console
- Category
- Supportability
- Tags
- cloud
- cloudforms
- database
- postgres
This solution is part of Red Hat’s fast-track publication program, providing a huge library of solutions that Red Hat engineers have created while supporting our customers. To give you the knowledge you need the instant it becomes available, these articles may be presented in a raw and unedited form.
Источник
Creation and clean up of WAL files in the primary’s pg_wal folder (pg_xlog prior
to PG10) is a normal part of PostgreSQL operation. The WAL files on the primary
are used to ensure data consistency during crash recovery. Use of write-ahead
logs (also called redo logs or transaction logs in other products) is common for
data stores that must provide durability and consistency of data when writing to
storage. The same technique is used in modern journaling and log-structured
filesystems.
As the DB is operating, blocks of data are first written serially and
synchronously as WAL files, then some time later, usually a very short time
later, written to the DB data files. Once the data contained in these WAL files
has been flushed out to their final destination in the data files, they are no
longer needed by the primary. At some point, depending on your configuration,
the primary will remove or recycle the WAL files whose data has been committed
to the DB. This is necessary to keep the primary’s disk from filling up.
However, these WAL files are also what streaming replicas read when they are
replicating data from the primary. If the replica is able to keep up with the
primary, using these WAL files generally isn’t an issue.
If the replica falls behind or is disconnected from the primary for an extended
period of time, the primary may have already removed or recycled the WAL file(s)
that a replica needs (but see Streaming Replication Slots below). A replica can
fall behind on a primary with a high write rate. How far the replica falls
behind will depend on network bandwidth from the primary, as well as storage
performance on the replica.
To account for this possibility, we recommend keeping secondary copies of the
WAL files in another location using a WAL archiving mechanism. This is known as
WAL archiving and is done by ensuring archive_mode is turned on and a value
has been set for the archive_command. These are variables contained in the
postgresql.conf file.
Whenever the primary generates a WAL file, this command is run to make a
secondary copy of it. Until that archive_command succeeds, the primary will keep
that WAL file, so you must monitor for this command failing. Otherwise the
primary’s disk may fill. Once WAL archiving is in place, you can then configure
your replicas to use that secondary location for WAL replay if they ever lose
their connection to the primary.
This process is explained more in the
PostgreSQL documentation.
Note that configuration details for creating a cluster have changed starting in
PostgreSQL 12. In particular, the recovery.conf file on a replica instance no
longer exists and those configuration lines are now part of postgresql.conf. If
you’re using PostgreSQL 12 or newer, read the documentation carefully and note
the new files recovery.signal and standby.signal
Crunchy Data provides the pgBackRest tool which provides full WAL archiving
functionality as well as maintaining binary backups. We do not recommend the
simple copy mechanism given as an example in the documentation since that does
not provide the resiliency typically required for production databases.
pgBackRest provides full, differential and incremental backups as well as
integrated WAL file management.
WAL archiving and backups are typically used together since this then provides
point-in-time recovery (PITR) where you can restore a backup to any specific
point in time as long as you have the full WAL stream available between all
backups.
pgBackRest is an integral part of the Crunchy HA and
Crunchy PostgreSQL Operator
products, and is what we recommend for a binary backup and archive tool.
See https://pgbackrest.org/ for more information on pgBackRest.
Environment
The most common case where PostgreSQL won’t start because it can’t find a WAL
file is in a replicated cluster where a replica has been disconnected from the
cluster for some time. Most of the rest of this article will discuss ways to
diagnose and recover this case.
For most of this article we will discuss the cluster case, where:
- Cluster of 2 or more PostgreSQL hosts
- Using WAL archiving via the PostgreSQL archive_command configuration, plus
binary backups, likely and preferably pgbackrest - On replicas, the recovery.conf (or postgresql.auto.conf in pg 12 and newer,
see also standby.signal and recovery.signal) has a line with restore_command =
that pulls WAL files from a binary backup location and applies them to the
replica.
- If using pgbackrest, the line may look like:
restore_command = 'pgbackrest --stanza=demo archive-get %f "%p"'
- It’s common to use both PostgreSQL binary streaming replication and WAL file
archiving together. - It’s common to use a tool like pgbackrest for both binary backups and WAL
archiving. Combining the two gives you the opportunity to restore a DB to a
specific point in time (PITR).
Symptoms
- A replica will doesn’t start completely and won’t accept read-only
connections. - If using Crunchy HA (or Patroni), patronictl list may show no leader, or Lag
in DB Unknown and cluster members stopped. - This is a common symptom when the primary has already recycled/removed the
requested WAL file:
2020-03-13 09:32:22.572 EDT [101800] ERROR: requested WAL segment 00000002000000050000007C has already been removed
- You may see log entries in the pg_log logs like:
2020-04-17 14:29:49.479 P00 INFO: unable to find 0000001600000000000000C2 in the archive,
and/or
2020-04-17 14:29:49 EDT [379]: [6-1], , FATAL: requested timeline 23 does not contain minimum recovery point 0/C2A56FC0 on timeline 22
and especially these:
2020-04-17 14:29:49 EDT [376]: [5-1], , LOG: database system is shut down
2020-04-17 14:29:49 EDT [459]: [1-1], , LOG: database system was interrupted while in recovery at log time 2020-04-17 14:19:28 EDT
2020-04-17 14:29:49 EDT [459]: [2-1], ,
HINT: If this has occurred more than once some data might be corrupted and you
might need to choose an earlier recovery target.
Common Causes
The underlying cause for a replica getting out of sync and not able to replay
WAL (either via streaming replication or from the WAL archive / backup) is
almost always an infrastructure issue and almost always network connectivity
interruptions. To have a HA cluster you must have reliable network connectivity
between the cluster members and from each of the cluster members to the WAL
archive (backup) location.
It’s worth a reminder that time synchronization across cluster member hosts is
critically important for correct cluster operation. Always check and confirm
that all nodes in the cluster have a NTP service running (e.g. — ntpd or
chronyd), and that the nodes are correctly synced to each other and to a master
time source.
It is common to use the same tools for binary backups and WAL archiving. A
common configuration in a HA cluster is to use pgbackrest as both the backup
tool and the WAL archiving and playback tool. With pgbackrest and other binary
backup tools, you will likely have a backup schedule that does a full backup of
the cluster primary server periodically and differential or incremental backups
periodically between the full backups. Along with the backup schedule are backup
retention settings. For example, you may have configured your cluster to retain
the last three full backups and the last three incremental or differential
backups.
In addition to the backups, pgbackrest will retain WAL files that are needed to
do a point-in-time recovery from your full, differential and incremental
backups. So if a replica has been disconnected long enough (several backup
cycles) for the archived WAL files to be past their retention period, when
reconnected, PostgreSQL will be far behind the current state and will attempt to
restore archived WAL files that no longer exist. In that case, you will need to
reset or reinitialize the replica from current backups and the WAL files that
are relative to them.
If the DB data disk fills completely on the replica, the replica will stop
accepting and applying WAL updates from the primary. If this isn’t caught and
repaired for some time, the primary may have removed older WAL files. The length
of time will depend on the configuration on the primary and the change rate on
the primary. See the documentation for
wal_keep_segments to retain more older WAL files.
Another failure mode is when you have intermittent network connectivity among
hosts, and the cluster fails over and fails back several times. For each
failover, a replica is promoted to primary (failover or switchover), and the WAL
timeline is incremented. If one of the replicas can’t communicate with the
cluster for some time, its local DB will be based on an earlier timeline, and
when it attempts to restore a WAL file from the earlier timeline, that WAL file
won’t be found in the archive, which will default to the current primary’s
timeline. Note that there is an option to specify the timeline in the
recovery.conf file but you probably want to fix the replica to be on the current
primary’s timeline. See
here for more information.
This is simplified when using pgbackrest, which is the recommended method and
the method used by Crunchy HA, and the backup-standby option is enabled. With
this option enabled, backups are done from a replica/standby host rather than
the primary. There is more explanation here
in the pgbackrest documentation.
Check and confirm that the former primary was properly re-synch’ed to the new
primary. This should have been done automatically by your cluster software, and
involves cloning the new primary’s data directory to the new replica using a
tool like pg_rewind or pgBackRest’s delta restore (or full restore). If the new
replica (former primary) is logging messages about being on an older timeline,
the re-synch may not have happened or may not have been done correctly.
Repairing / Fixing a Replica
It’s likely that the best and only option will be to restore the replica from
the backup/archive server. We recommend pgbackrest. Crunchy Data products,
including the Crunchy PostgreSQL Operator, Crunchy HA and others include and use
pgbackrest.
- pgbackrest restore
- full restore vs delta restore. A pgbackrest delta restore can save time and
resources. It checks the PostgreSQL destination and restore only files that
are needed and don’t exist in the destination.
- full restore vs delta restore. A pgbackrest delta restore can save time and
If you’re using Crunchy HA or the Crunchy PostgreSQL Operator, you want to use
the HA layer tools rather than using pgbackrest directly.
First use
patronictl reinit
to restore a cluster member node (PostgreSQL instance) from the backup/archive
system.
Repairing / Fixing a Standalone or Failed Primary
- This one is potentially more serious and will be a reminder of why you want
regular, reliable and carefully tested backups, especially the standalone
server case, and why a properly managed replica and backups are a very good
idea for data you like. - This can be caused by broken or failing hardware, misconfigured storage, power
failures, or mistakenly using OS level commands to modify the DB directory
contents. - Avoid the temptation to just run pg_resetwal (pg_resetxlog in versions prior
to PG 10). More on this below, and please read the man page and/or pg docs on
pg_resetwal risks. - The first thing to do is properly and completely stop the failing standalone
or primary.
- If your primary is part of a cluster, and your cluster uses software to manage
auto-failover, like Crunchy HA, Patroni, or pacemaker/corosync, your cluster
control software should detect a failure, and properly failover to one of the
replicas. Occasionally it doesn’t and you will have to manually stop the
failed primary/standalone. If you’re not using software to manage your
cluster, failover is a manual process, where you first shut down the failed
primary, then promote one of the replicas to be the new primary. If you are
using software for auto-failover, and it hasn’t automatically failed over,
what you need to do is first, shutdown the failed primary instance,
preferably using the same mechanism that was used to start it — patronictl if
it’s using Patroni or Crunchy HA, or pcs or crmsh if you’re using
pcs/corosync/pacemaker clustering, or an OS-level utility like systemd’s
systemctl or the Linux service, or pg_ctl. Even if those complete
successfully, you want to check to be certain that all the PostgreSQL
processes have stopped. Occasionally, none of those stop all the PostgreSQL
processes. In that case, you need to use the Linux kill command. To stop the
postmaster, the three signals that correspond to «smart», «fast» and
«immediate» shutdown are SIGTERM, SIGINT and SIGQUIT. The very last option to
use is SIGKILL (kill -9); avoid doing that unless it’s a true emergency.
- Once all the PostgreSQL processes are no longer running, make a copy of the
DB’s data directory using your favorite OS-level snapshot utility — tar, cpio,
rsync or your infrastructure’s disk snapshotting tool. This is a safe copy in
case attempts to repair the DB cause more damage. - To get the DB back to healthy, the best option is to recreate the DB from a
good backup. If you have a good replica (now likely the primary), make the
failed primary a replica from the new primary, after fixing the underlying
cause. - In the worst case, where you have only the broken DB directory, you may be
able to get it working again but you will likely lose data. First make an OS
level copy of the DB directory. Avoid using OS level commands to move or
delete DB files; you will likely make things worse. - It may be tempting to just run pg_resetwal. While it may be possible to
recover from some errors using pg_resetwal, you will likely lose data in the
process. You can also do more damage to the DB. If you need to minimize data
loss, don’t have a replica to restore or a good backup, and don’t have
detailed knowledge of PostgreSQL, it’s time to ask for help. It may be
possible to recover most of your DB but read the documentation and note this
advice from the documentation: «It should be used only as a last resort, when
the server will not start due to such corruption.»
Streaming Replication Slots
Streaming replication slots are a feature available since PostgreSQL 9.4. Using
replication slots will cause the primary to retain WAL files until the primary
has been notified that the replica has received the WAL file.
There is a tradeoff for keeping the WAL files on the primary until the primary
is notified that the replica has received the WAL file. If the replica is
unavailable for any reason, WAL files will accumulate on the primary until it
can deliver them. On a busy database, with replicas unavailable, disk space can
be consumed very quickly as unreplicated WAL files accumulate. This can also
happen on a busy DB with relatively slow infrastructure (network and storage).
Streaming replication slots are a very useful feature; if you do use them,
carefully monitor disk space on the primary.
There is much more on
replication slots and replication configuration
generally.
Multi-datacenter
If you have deployed HA across multiple datacenters, there’s another layer of
complexity. Crunchy HA provides example Ansible files for several MDC
configurations. In the case where the primary data center fails and the DR data
center has been promoted to primary, extra steps are required when you recover
the original failed primary. In particular, when you start the recovered
original primary, be certain that you start it as a DR data center. You will
likely need to copy (rsync or other reliable mechanism) the pgbackrest repo from
the new primary data center (old DR data center) when recovering the original
primary data center.
What not to do / Don’t do this
- Again, avoid just running pg_resetwal (pg_resetxlog). You may need to use it
as a last resort, but don’t start by running it. - Do not try to cherry-pick or copy individual files from a backup / archive
repo directly to the PostgreSQL the pg_wal (pg_xlog in earlier versions)
directory. That is part of the database runtime that is managed by PostgreSQL.
Deleting or copying things there can break your DB. Let the tools do their
jobs. - Never use OS tools to manually delete, modify or add files to the PostgreSQL
pg_wal (pg_xlog) directory. - Never use OS tools to manually delete, modify or add files to the pgBackRest
repo. The pgBackRest repo contains state and metadata about current backups
and which WAL files depend on which backups. (Note that listing or viewing the
files in a pgbackrest repo can be helpful to diagnose replicas and restore
issues. It’s also OK to copy the repo in its entirety as long as you use a
copy utility that verifies that the files have been copied correctly, for
example rsync.)


Introduction
Various replication modes are available with PostgreSQL.
In this article, a PostgreSQL 9.6 streaming replication is implemented on Linux Ubuntu 18.04 servers, it’s very easy.
In the streaming replication mode,
the standby connects to the primary, which streams WAL records (Write Ahead Log) to the standby as they’re generated,
without waiting for the WAL file to be filled. Streaming replication allows a standby server to stay more up-to-date than
is possible with file-based log shipping.
- The standby server can be in read only mode for reporting purposes for example.
- A replication slot ensures that the needed WAL files for the standby are not removed in the primary server
before the standby server processes them. Multiple replication slots can be defined depending on the number of the standby servers.
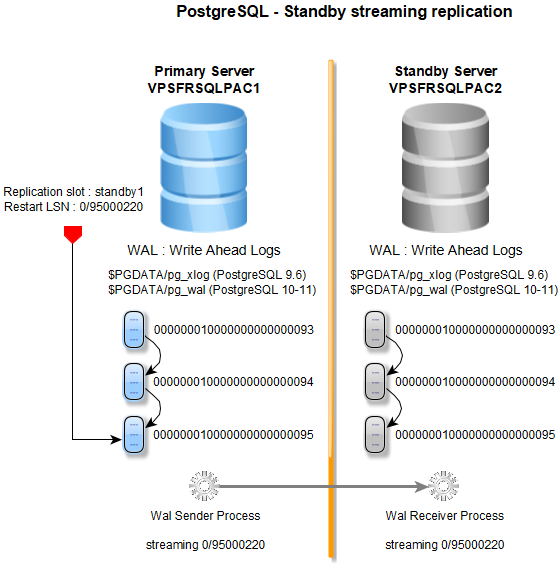
(LSN : Log Sequence Number)
The procedure below is valid for PostgreSQL 9.6, 10 and 11. For PostgreSQL version 12 and above, the setup is slightly different
and not discussed here. It is not important when configuring a PostgreSQL streaming replication, but default WAL files location is
different on PostgreSQL 9.6 and PostgreSQL 10/11.
| PostgreSQL 9.6 | $PGDATA/pg_xlog |
| PostgreSQL 10/11 | $PGDATA/pg_wal |
The context is the following : 1 primary server, 1 standby server.
VPSFRSQLPAC1Standby server :
VPSFRSQLPAC2
Binaries (PostgreSQL 9.6.15) : /opt/postgres/pgsql-9.6/bin
$PATH : /opt/postgres/pgsql-9.6/bin:$PATH
$PGLIB : /opt/postgres/pgsql-9.6/lib
Port : 30001
$PGDATA : /sqlpac/postgres/srvpg1
$CFG : /opt/postgres/dba/srvpg1/cfg
Configuration files :
$CFG/postgresql.conf
$CFG/pg_hba.conf
$CFG/pg_ident.conf
Controlling the PostgreSQL Server :
pg_ctl start|stop|restart… -D $CFGPreparing the primary server
System parameters
The primary server must be restarted, especially with PostgreSQL 9.6, to apply at least the following static parameters :
listen_addresses:*wal_level: the wal level isreplicafor streaming replication.max_replication_slots: at least 1 replication slot (1 standby). Higher values of replication slots if more standby or logical servers will be configured.max_wal_senders: at least 3 wal senders (1 standby + 2 forpg_basebackup). Higher values if more standby servers will be configured.
$CFG/postgresql.conf
listen_addresses = '*'
wal_level=replica
max_replication_slots=3
max_wal_senders=3With PostgreSQL 10 and 11, the default values are already adjusted for replication. However, check the settings.
| PostgreSQL 10 / 11 | Default values |
|---|---|
wal_level |
replica |
postgres@vpsfrsqlpac1$ pg_ctl restart -D $CFGReplication role
Create a role with the replication privilege, this role will be used by the standby server to connect to the primary
server :
create role repmgr with replication login encrypted password '***********';Add the role in the primary server file pg_hba.conf with the standby IP address server, this will allow connections from the standby server.
Don’t forget to manage existing firewall rules.
$CFG/pg_hba.conf
host replication repmgr 51.xxx.xxx.xxx/32 md5Here, SSL connections are not implemented.
Reload the configuration :
postgres@vpsfrsqlpac1$ pg_ctl reload -D $CFGReplication slot
Create a replication slot in the primary server.
select * from pg_create_physical_replication_slot('standby1');slot_name | xlog_position -----------+--------------- standby1 | (1 row)select slot_name, restart_lsn from pg_replication_slots;slot_name | restart_lsn -----------+------------- standby1 | (1 row)
The replication slot (restart_lsn) will be initialized during the primary server backup
with pg_basebackup.
Starting with PostgreSQL 11, it is not mandatory to create manually the replication slot, this one can be created and initialized with
pg_basebackup.
Primary server backup (pg_basebackup)
The primary server backup is performed with pg_basebackup.
postgres@vpsfrsqlpac1$ pg_basebackup -D /sqlpac/postgres/backup/srvpg1
-X stream
--write-recovery-conf
--slot=standby1
--dbname="host=localhost user=postgres port=30001"Starting with,PostgreSQL 11, add the argument --create-slot if the replication slot has not been previously created.
With the option --slot giving the replication slot name : that way, it is guaranteed the primary server does not remove
any necessary WAL data in the time between the end of the base backup and the start of streaming replication.
When the backup is completed, the replication slot standby1 is then defined :
select slot_name, restart_lsn from pg_replication_slots;slot_name | restart_lsn -----------+------------- standby1 | 0/33000000
The option --write-recovery-conf (or -R) writes a file recovery.conf in the root backup directory.
This file will prevent any user error when starting the standby server, this file indeed indicates a standby server, and the slot name
is given :
/sqlpac/postgres/backup/srvpg1/recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=postgres host=localhost port=30001 sslmode=prefer sslcompression=1 krbsrvname=postgres'
primary_slot_name = 'standby1'Standby server activation
Install the primary server backup previously performed in the standby data directory ($PGDATA).
recovery.conf
Be sure the file recovery.conf is installed in the standby server root data directory
with the option standby_mode = 'on' and the replication slot name.
Update the connection info parameters to the primary server in this file.
$PGDATA : /sqlpac/postgres/srvpg1/recovery.conf
standby_mode = 'on'
primary_conninfo = 'user=repmgr host=vpsfrsqlpac1 port=30001 password=************'
primary_slot_name = 'standby1'postgresql.conf
If read only connections are allowed, check the parameter hot_standby is set to on on the standby server
(on by default starting with PostgreSQL 10):
$CFG/postgresql.conf
hot_standby = onStarting the standby server
Now the standby server can be started.
postgres@vpsfrsqlpac2$ pg_ctl start -D $CFGWhen there is no error, in the standby server log file :
LOG: entering standby mode
LOG: redo starts at 0/33000028
LOG: consistent recovery state reached at 0/34000000
LOG: database system is ready to accept read only connections
LOG: started streaming WAL from primary at 0/34000000 on timeline 1The standby server is in recovery mode :
postgres@vpsfrsqlpac2$ psql -p30001select pg_is_in_recovery();pg_is_in_recovery ------------------- t
If the replication slot has not been defined and the needed WAL files removed in the primary server, an error occurs :
FATAL: could not receive data from WAL stream: ERROR: requested WAL segment 000000010000000000000010 has already been removedTesting replication
Create a table heartbeat in the primary server, this table will be updated every minute :
postgres@vpsfrsqlpac1$ psql -p30001create table heartbeat ( reptimestamp timestamp ); insert into heartbeat values (now()); select * from heartbeat;reptimestamp ---------------------------- 2019-11-22 09:04:36.399274
Check the replication to the standby server :
postgres@vpsfrsqlpac2$ psql -p30001select * from heartbeat;reptimestamp ---------------------------- 2019-11-22 09:04:36.399274
Pause / Resume replication
To pause/resume replication, on the standby server :
postgres@vpsfrsqlpac2$ psql -p30001| PostgreSQL 9.6 | PostgreSQL 10 / 11 | |
|---|---|---|
| Pause replication |
|
|
| Resume replication |
|
|
| Replication paused ? |
|
|
Essential replication informations
This article does not deal with replication monitoring, however below the essential informations about the replication state.
Standby server : pg_stat_wal_receiver
In the standby, use the view pg_stat_wal_receiver :
postgres@vpsfrsqlpac2$ psql -p30001x on; select * from pg_stat_wal_receiver;-[ RECORD 1 ]---------+----------------------------------------------------- pid | 2262 status | streaming receive_start_lsn | 0/97000000 receive_start_tli | 1 received_lsn | 0/99000920 received_tli | 1 last_msg_send_time | 2019-11-22 18:17:46.355579+01 last_msg_receipt_time | 2019-11-22 18:17:46.355835+01 latest_end_lsn | 0/99000760 latest_end_time | 2019-11-22 18:15:46.232277+01 slot_name | standby1 conninfo | user=repmgr password=******** dbname=replication host=vpsfrsqlpac1 port=30001 …
The WAL receiver process id is 2262 :
postgres@vpsfrsqlpac2$ ps -ef | grep 'postgres' | grep 2262postgres 2262 32104 0 18:35 ? 00:00:04 postgres: wal receiver process streaming 0/99000920
Primary server : pg_stat_replication and pg_replication_slots
In the primary server, use pg_stat_replication and pg_replication_slots :
postgres@vpsfrsqlpac1$ psql -p30001x on; select * from pg_stat_replication;-[ RECORD 1 ]----+----------------------------- pid | 6247 usesysid | 16384 usename | repmgr application_name | walreceiver client_addr | 51.xxx.xxx.xxx client_hostname | client_port | 41354 backend_start | 2019-11-22 09:35:42.41099+01 backend_xmin | state | streaming sent_location | 0/99000920 write_location | 0/99000920 flush_location | 0/99000920 replay_location | 0/99000840 sync_priority | 0 sync_state | asyncx on; select * from pg_replication_slots;-[ RECORD 1 ]-------+----------- slot_name | standby1 plugin | slot_type | physical datoid | database | active | t active_pid | 6247 xmin | catalog_xmin | restart_lsn | 0/99000920 confirmed_flush_lsn |
The WAL sender process id is 6247 :
postgres@vpsfrsqlpac1$ ps -ef | grep 'postgres' | grep 6247postgres 6247 5576 0 18:35 ? 00:00:00 postgres: wal sender process repmgr 51.xxx.xxx.xxx(41354) streaming 0/99000920
Conclusion
Installing a streaming replication with PostgreSQL 9.6 is very easy, maybe one of the easiest replication architecture.
Do not forget replication slots ! Only replication slots guarantee standby servers won’t run out of sync from the primary server.
Рассмотри настройку потоковой репликации данных.
Когда вы изменяете данные в базе, все изменения пишутся во Write-Ahead Log, или WAL. После записи в WAL СУБД делает системный вызов fsync, благодаря чему данные попадают сразу на диск, а не висят в где-то в кэше файловой системы. Таким образом, если взять и обесточить сервер, при следующей загрузке СУБД прочитает последние записи из WAL и применит к базе данных соответствующие изменения.
Потоковая репликация (streaming replication) в сущности является передачей записей из WAL от мастера к репликам. Писать при этом можно только в мастер, но читать можно как с мастера, так и с реплик. Если с реплики разрешено читать, она называется hot standby, иначе — warm standby. Поскольку во многих приложениях 90% запросов являются запросами на чтение, репликация позволяет масштабировать базу данных горизонтально. Потоковая репликация бывает двух видов — синхронная и асинхронная.
При асинхронной репликации запрос тут же выполняется на мастере, а соответствующие данные из WAL доезжают до реплик отдельно, в фоне. Недостаток асинхронной репликации заключается в том, что при внезапном падении мастера (например, из-за сгоревшего диска) часть данных будет потеряна, так как они не успели доехать до реплик.
При использовании синхронной репликации данные сначала записываются в WAL как минимум одной реплики, после чего транзакция выполняется уже на мастере. Запросы на запись выполняются медленнее в результате возникающих сетевых задержек (которые, однако, внутри одного ДЦ обычно меньше типичного времени планирования запроса). Кроме того, чтобы запросы на запись не встали колом в результате падения одной из реплик, при использовании синхронной репликации рекомендуется использовать по крайней мере две реплики. Зато потерять данные становится намного сложнее.
Заметьте, что синхронная репликация не предотвращает возможности считать с реплики старые данные, так как потоковая репликация — она только про передачу WAL, а не то, что видно в базе с точки зрения пользователя. По крайней мере, так синхронная репликация работает конкретно в PostgreSQL.
В контексте репликации нельзя также не отметить еще один интересный термин. Если одна из реплик в свою очередь является мастером для другой реплики, такую конфигурацию называют каскадной репликацией.
Потоковая репликация в PostgreSQL не работает между разными версиями PostgreSQL, а также если на серверах используется разная архитектура CPU, например, x86 и x64. В частности, это означает, что обновить PostgreSQL до следующей версии при использовании потоковой репликации без даунтайма нельзя
Помимо потоковой репликации в последнее время выделяют еще и так называемую логическую репликацию (logical replication). Реализаций логической репликации в PostgreSQL существует несколько, например, slony и pglogical. Пожалуй, наиболее существенное отличие логической репликации от потоковой заключается в возможности реплицировать часть баз данных и таблиц на одни реплики, а часть — на другие. Платить за это приходится скоростью. И хотя pglogical в плане скорости выглядит многообещающе, на момент написания этих строк это очень молодое, сырое решение. В рамках этой заметки логическая репликация не рассматривается.
В PostgreSQL 10 добавили логическую репликацию, теперь она есть из коробки.
Установка
имеется 2 сервера
192.168.1.170 — master
192.168.1.171 — slave
Отключаем selinux
setenforce 0
sed -i ‘s/^SELINUX=.*/SELINUX=disabled/g’ /etc/selinux/config
производим установку на оба сервера:
yum -y install https://download.postgresql.org/pub/repos/yum/9.6/redhat/rhel-7-x86_64/pgdg-centos96-9.6-3.noarch.rpm
или так
yum install https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
yum install postgresql96 postgresql96-server postgresql96-lib
Инициализируем базы:
/usr/pgsql-9.6/bin/postgresql96-setup initdb
Добавляем в автозагрузку и стартуем:
Ставим пароль на пользователя postgres
[root@master ~]# su — postgres
-bash-4.2$ psql
psql (9.6.13)
Type «help» for help.
postgres=# password
Enter new password:
Enter it again:
postgres=# q
[root@slave ~]# su — postgres
-bash-4.2$ psql
psql (9.6.13)
Type «help» for help.
postgres=# password
Enter new password:
Enter it again:
postgres=# q
Настройка репликации
на мастере:
vim /var/lib/pgsql/9.6/data/pg_hba.conf
host replication postgres 192.168.1.171/32 md5
host all postgres 192.168.1.171/32 md5
Первая строчка нужна для работы утилиты pg_basebackup. Без второй не будет работать pg_rewind. Если хотим, чтобы в базу по сети мог ходить не только пользователь postgres, в последней строке можно написать вместо его имени all.
правим основной конфиг
vim /var/lib/pgsql/9.6/data/postgresql.conf
# какие адреса слушать, замените на IP сервера
listen_addresses = ‘localhost, 192.168.1.170’
wal_level = hot_standby
# это нужно, чтобы работал pg_rewind
wal_log_hints = on
max_wal_senders = 2
wal_keep_segments = 64
hot_standby = on
max_replication_slots = 2
hot_standby_feedback = on
* где
- 192.168.1.170 — IP-адрес сервера, на котором он будем слушать запросы Postgre;
- wal_level указывает, сколько информации записывается в WAL (журнал операций, который используется для репликации) — hot_standby указывает на хранение дополнительной информации, она нужна для выполнения запросов на резервном сервере в режиме только для чтения;
- max_wal_senders — количество планируемых слейвов;
- max_replication_slots — максимальное число слотов репликации;
- hot_standby — определяет, можно или нет подключаться к postgresql для выполнения запросов в процессе восстановления;
- hot_standby_feedback — определяет, будет или нет сервер slave сообщать мастеру о запросах, которые он выполняет.
Далее открываем psql:
systemctl start postgresql-9.6
Меняем пароль пользователя postgres:
ALTER ROLE postgres PASSWORD ‘postgres’;
Перезапускаем PostgreSQL:
systemctl restart postgresql-9.6
на слейве
Останавливаем PostgreSQL
[root@slave ~]# systemctl stop postgresql-9.6
Становимся пользователем postgres:
su — postgres
Под этим пользователем переливаем данные с мастера, сначала всё удалим:
rm -rf /var/lib/pgsql/9.6/data/*
-bash-4.2$ pg_basebackup -h 192.168.1.170 -U postgres -D /var/lib/pgsql/9.6/data —xlog-method=stream —write-recovery-conf
Password:
вводим пароль который задавали для пользователя postgres
Проверяем:
-bash-4.2$ ls /var/lib/pgsql/9.6/data/
backup_label pg_dynshmem pg_notify pg_subtrans postgresql.conf
base pg_hba.conf pg_replslot pg_tblspc recovery.conf
global pg_ident.conf pg_serial pg_twophase
log pg_log pg_snapshots PG_VERSION
pg_clog pg_logical pg_stat pg_xlog
pg_commit_ts pg_multixact pg_stat_tmp postgresql.auto.conf
Данная команда сделала реплику базы от мастера и создала конфигурационный файл recovery.conf, в котором указаны параметры репликации.
Редактируем конфигурационный файл postgresql.conf.
[root@slave ~]# vim /var/lib/pgsql/9.6/data/postgresql.conf
Редактируем следующие параметры:
listen_addresses = ‘localhost, 192.168.1.171’
* где 192.168.1.171 — IP-адрес нашего вторичного сервера.
так же можно указать просто звёздочку «*»
Редактируем файл recovery.conf и добавляем в него строку recovery_target_timeline = ‘latest’
[root@slave ~]# cat /var/lib/pgsql/9.6/data/recovery.conf
standby_mode = ‘on’
primary_conninfo = ‘user=postgres password=postgres host=192.168.1.170 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
так же правим
/var/lib/pgsql/9.6/data/pg_hba.conf
host replication postgres 192.168.1.170/32 md5
host all postgres 192.168.1.170/32 md5
Снова запускаем сервис postgresql:
[root@slave ~]# systemctl start postgresql-9.6
СОЗДАЁМ replication_slots НА МАСТЕРЕ И СЛЕЙВЕ
На мастере
SELECT pg_create_physical_replication_slot(‘standby_slot’);
На слейве
SELECT pg_create_physical_replication_slot(‘standby_1_slot’);
Проверяем:
select * from pg_replication_slots;
Добавляем primary_slot_name = ‘standby_slot’ в recovery.conf на слейве,
а на мастере он будет выглядеть:
primary_slot_name = ‘standby_1_slot’
по итогу на слейве recovery.conf :
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=IP_MATERa port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
primary_slot_name = ‘standby_slot’
trigger_file = ‘/postgres/9.6/trigger’
на мастере recovery.doney
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=IP_SLAVEa port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
primary_slot_name = ‘standby_1_slot’
trigger_file = ‘/postgres/9.6/trigger’
Проверка репликации
на слейве:
[root@slave ~]# ps aux | grep receiver
postgres 2406 0.2 0.1 362144 3160 ? Ss 18:39 0:02 postgres: wal receiver process streaming 0/30003E0
на мастере:
[root@master ~]# ps aux | grep sender
postgres 11487 0.0 0.1 355824 3004 ? Ss 18:39 0:00 postgres: wal sender process postgres 192.168.1.171(45747) streaming 0/30003E0
На мастере:
[root@master ~]# su — postgres
Last login: Wed Jun 5 18:07:00 KGT 2019 on pts/0
-bash-4.2$ psql
postgres=# select * from pg_stat_replication;
pid | usesysid | usename | application_name | client_addr | client_hostname | client_port | backend_start | backend_xmin | state | sent_location |
write_location | flush_location | replay_location | sync_priority | sync_state
——-+———-+———-+——————+—————+——————+————-+——————————-+—————+————+—————+-
—————+—————-+——————+—————+————
11487 | 10 | postgres | walreceiver | 192.168.1.171 | | 45747 | 2019-06-05 18:39:50.459205+06 | | streaming | 0/30004C0 |
0/30004C0 | 0/30004C0 | 0/30004C0 | 0 | async
(1 row)
Создаем новую базу данных:
postgres=# CREATE DATABASE repltest ENCODING=’UTF8‘;
CREATE DATABASE
postgres=# l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
————+———-+———-+————-+————-+————————
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
repltest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres +
| | | | | postgres=CTc/postgres
(4 rows)
На слейве:
[root@slave ~]# su — postgres
Last login: Wed Jun 5 19:15:35 KGT 2019 on pts/0
-bash-4.2$ psql
psql (9.6.13)
Type «help» for help.
postgres=# select * from pg_stat_wal_receiver;
pid | status | receive_start_lsn | receive_start_tli | received_lsn | received_tli | last_msg_send_time | last_msg_receipt_time | latest_end_lsn |
latest_end_time | slot_name | conninfo
——-+————+——————-+——————-+—————+—————+——————————-+——————————-+—————-+—
——————————+————+————————————————————————————————————————————
—————————————-
11928 | streaming | 0/3000000 | 1 | 0/3001730 | 1 | 2019-06-05 19:24:29.285547+06 | 2019-06-05 19:24:28.979799+06 | 0/3001730 | 2
019-06-05 19:22:29.085126+06 | | user=postgres password=******** dbname=replication host=192.168.1.170 port=5432 fallback_application_name=walreceiver sslmode=pref
er sslcompression=1 krbsrvname=postgres
(1 row)
postgres=# l
List of databases
Name | Owner | Encoding | Collate | Ctype | Access privileges
————+———-+———-+————-+————-+———————-
—
postgres | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
repltest | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 |
template0 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres
+
| | | | | postgres=CTc/postgres
template1 | postgres | UTF8 | en_US.UTF-8 | en_US.UTF-8 | =c/postgres
+
| | | | | postgres=CTc/postgres
(4 rows)
как видим тестовая база repltest создана и на слейве.
при попытке создать базу на слейве возникнет следующая ошибка:
CREATE DATABASE repltest2 ENCODING=’UTF8‘;
ERROR: cannot execute CREATE DATABASE in a read-only transaction
Изменим Роли. Master => Slave а Salve => Master
Промоутим реплику до мастера
Остановим мастер:
systemctl stop postgresql-9.6
На слейве(из которого делаем мастера) говорим:
[root@slave ~]# sudo -u postgres /usr/pgsql-9.6/bin/pg_ctl promote -D /var/lib/pgsql/9.6/data/
could not change directory to «/root»: Permission denied
server promoting
При этом в каталоге /var/lib/pgsql/9.6/data/ файл recovery.conf автоматически будет переименован в recovery.done.
[root@slave ~]# ll /var/lib/pgsql/9.6/data/recovery.done
-rw-r—r—. 1 postgres postgres 190 Jun 5 19:11 /var/lib/pgsql/9.6/data/recovery.done
В реплику теперь можно писать. Реплику и можно промоутнуть до мастера без перезапуска PostgreSQL, на практике вы, вероятно, все же захотите его перезапустить по следующей причине. Дело в том, что приложение, которое ранее подключилось к этой реплике, так и будет использовать ее в качестве реплики даже после промоута. Перезапустив PostgreSQL, вы порвете все сетевые соединения, а значит приложению придется подключиться заново, проверить, подключился ли он к мастеру или реплике (запрос SELECT pg_is_in_recovery();вернет false на мастере и true на репликах)
Используем утилиту pg_rewind которая находит точку в WAL, начиная с которой WAL мастера и WAL реплики начинают расходиться. Затем она «перематывает» (отсюда и название) WAL реплики на эту точку и накатывает недостающую историю с мастера. Таким образом, реплика и местер всегда приходят к консистентному состоянию. Плюс к этому pg_rewind синхронизирует файлы мастера и реплики намного быстрее, чем pg_basebackup или rsync.
на мастере (из которого делаем слейв)говорим:
systemctl stop postgresql-9.6
[root@master 9.6]# sudo -u postgres /usr/pgsql-9.6/bin/pg_rewind -D /var/lib/pgsql/9.6/data/ —source-server=»host=192.168.1.171 port=5432 user=postgres password=postgres»
servers diverged at WAL position 0/30000D0 on timeline 1
no rewind required
создаём
recovery.conf
[root@master 9.6]# cat /var/lib/pgsql/9.6/data/recovery.conf
standby_mode = ‘on’
primary_conninfo = ‘user=postgres password=postgres host=192.168.1.171 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
[root@master data]# chown postgres:postgres /var/lib/pgsql/9.6/data/recovery.conf
Запускаем:
[root@master data]# systemctl start postgresql-9.6
смотрим в логи. Там обязательно должно быть:
LOG: database system is ready to accept read only connections
[root@master data]# grep ‘database system is ready to accept read only connections’ /var/lib/pgsql/9.6/data/pg_log/postgresql-Wed.log
< 2019-06-05 23:38:52.217 KGT > LOG: database system is ready to accept read only connections
Если вдруг видим что-то вроде:
ERROR: requested WAL segment 0000000200000005 has already been removed
… значит реплика слишком отстала от мастера, и нужно перенести файлы с мастера при помощи pg_basebackup, как было описано в начале этой статьи.
проверяем, теперь «сервер мастер» у нас реплика а «сервер слейв» теперь мастер, следовательно на сервере мастер нельзя вносить изменения в базе.
[root@slave 9.6]# ps aux | grep sender
postgres 13964 0.0 0.1 355856 3104 ? Ss 23:38 0:00 postgres: wal sender process postgres 192.168.1.170(41249) streaming 0/3000480
[root@master data]# ps aux | grep receiver
postgres 12624 0.3 0.1 362176 3164 ? Ss 23:38 0:00 postgres: wal receiver process streaming 0/3000480
[root@master data]# sudo -u postgres psql
psql (9.6.13)
Type «help» for help.
postgres=# CREATE DATABASE repltest45 ENCODING=’UTF8‘;
ERROR: cannot execute CREATE DATABASE in a read-only transaction
на «сервере слейв» всё ок
[root@slave 9.6]# sudo -u postgres psql
psql (9.6.13)
Type «help» for help.
postgres=# CREATE DATABASE repltest55 ENCODING=’UTF8‘;
CREATE DATABASE
Вернём всё как было т.е. master=>master а slave => slave
Промоутим до мастера
Остановим мастер(postgres):
[root@slave ~]# systemctl stop postgresql-9.6
На «мастер сервере»(из которого делаем мастера(postgres)) говорим:
[root@master ~]# sudo -u postgres /usr/pgsql-9.6/bin/pg_ctl promote -D /var/lib/pgsql/9.6/data/
could not change directory to «/root»: Permission denied
server promoting
При этом в каталоге /var/lib/pgsql/9.6/data/ файл recovery.conf автоматически будет переименован в recovery.done.
[root@master ~]# ll /var/lib/pgsql/9.6/data/recovery.done
-rw-r—r—. 1 postgres postgres 191 Jun 5 23:37 /var/lib/pgsql/9.6/data/recovery.done
В реплику теперь можно писать. Реплику и можно промоутнуть до мастера без перезапуска PostgreSQL, на практике вы, вероятно, все же захотите его перезапустить по следующей причине. Дело в том, что приложение, которое ранее подключилось к этой реплике, так и будет использовать ее в качестве реплики даже после промоута. Перезапустив PostgreSQL, вы порвете все сетевые соединения, а значит приложению придется подключиться заново, проверить, подключился ли он к мастеру или реплике (запрос SELECT pg_is_in_recovery();вернет false на мастере и true на репликах)
Используем утилиту pg_rewind которая находит точку в WAL, начиная с которой WAL мастера и WAL реплики начинают расходиться. Затем она «перематывает» (отсюда и название) WAL реплики на эту точку и накатывает недостающую историю с мастера. Таким образом, реплика и местер всегда приходят к консистентному состоянию. Плюс к этому pg_rewind синхронизирует файлы мастера и реплики намного быстрее, чем pg_basebackup или rsync.
на «слейв сервере»(из которого делаем слейв)говорим:
systemctl stop postgresql-9.6
[root@slave ~]# sudo -u postgres /usr/pgsql-9.6/bin/pg_rewind -D /var/lib/pgsql/9.6/data/ —source-server=»host=192.168.1.170 port=5432 user=postgres password=postgres»
could not change directory to «/root»: Permission denied
servers diverged at WAL position 0/3002C08 on timeline 2
no rewind required
так как recovery.conf создавался ранее то просто переименуем его:
[root@slave ~]# mv /var/lib/pgsql/9.6/data/recovery.done /var/lib/pgsql/9.6/data/recovery.conf
[root@slave ~]# cat /var/lib/pgsql/9.6/data/recovery.conf
standby_mode = ‘on’
primary_conninfo = ‘user=postgres password=postgres host=192.168.1.170 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
Запускаем:
[root@slave ~]# systemctl start postgresql-9.6
смотрим в логи. Там обязательно должно быть:
LOG: database system is ready to accept read only connections
[root@slave ~]# grep ‘database system is ready to accept read only connections’ /var/lib/pgsql/9.6/data/pg_log/postgresql-Wed.log
< 2019-06-05 23:27:05.175 KGT > LOG: database system is ready to accept read only connections
Если вдруг видим что-то вроде:
ERROR: requested WAL segment 0000000200000005 has already been removed
… значит реплика слишком отстала от мастера, и нужно перенести файлы с мастера при помощи pg_basebackup, как было описано в начале этой статьи.
проверяем, теперь «сервер мастер» у нас мастер(postgres ) а «сервер слейв» теперь реплика.
[root@master ~]# ps aux | grep sender
postgres 12763 0.0 0.1 355856 3092 ? Ss 02:17 0:00 postgres: wal sender process postgres 192.168.1.171(46672) streaming 0/3002DF8
[root@slave ~]# ps aux | grep receiver
postgres 14251 0.3 0.1 362176 3172 ? Ss 02:17 0:00 postgres: wal receiver process streaming 0/3002DF8
всё ок
Если необходимо чтобы репликация производилась под определённым пользователем, например repluser то добавляем в файл:
Создаём пользователя:
CREATE USER repluser REPLICATION LOGIN CONNECTION LIMIT 2 ENCRYPTED PASSWORD ‘repluser’;
cat /var/lib/pgsql/9.6/data/pg_hba.conf
host replication repluser 192.168.1.170/32 md5
host all postgres 192.168.1.170/32 md5
на втором сервере:
host replication repluser 192.168.1.171/32 md5
host all postgres 192.168.1.171/32 md5
На мастере
cat /var/lib/pgsql/9.6/data/recovery.done
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=192.168.1.171 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
На слейве:
cat /var/lib/pgsql/9.6/data/recovery.conf
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=192.168.1.170 port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
Команды будут выполнятся соответсвенно от этого пользователя:
sudo -u postgres pg_basebackup -h 192.168.1.170 -U repluser -D /var/lib/pgsql/9.6/data —xlog-method=stream —write-recovery-conf
Если необходимо изменить расположение базы то:
vim /usr/lib/systemd/system/postgresql-9.6.service
Редактируем путь:
c
Environment=PGDATA=/var/lib/pgsql/9.6/data/
на
Environment=PGDATA=/postgres/9.6/
после
systemctl daemon-reload
mkdir /postgres/9.6
chown -R postgres:postgres /postgres/
правим домашнюю директорию:
cat /etc/passwd | grep postges
postgres:x:26:26:PostgreSQL Server:/postgres:/bin/bash
Инициируем базу
su — postgres
/usr/pgsql-9.6/bin/initdb -D /postgres/9.6/
=================================================
Репликация с использованием triger файла
Процесс такой же как и при настройке обычной репликации, инициируем базу, создаём пользователя repluser даём права в pg_hba.conf
Копируем базу на слейв:
sudo -u postgres pg_basebackup -h -U repluser -D /postgres/9.6/ —xlog-method=stream —write-recovery-conf
СОЗДАЁМ replication_slots НА МАСТЕРЕ И СЛЕЙВЕ
На мастере
SELECT pg_create_physical_replication_slot(‘standby_slot‘);
На слейве
SELECT pg_create_physical_replication_slot(‘standby_1_slot‘);
Проверяем:
select * from pg_replication_slots;
Добавляем primary_slot_name = ‘standby_slot’ в recovery.conf на слейве,
а на мастере он будет выглядеть:
primary_slot_name = ‘standby_1_slot’
====================
На слейве recovery conf выглядит следующим образом:
cat /postgres/9.6/recovery.conf
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=IP-master port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
primary_slot_name = ‘standby_slot‘
trigger_file = ‘/postgres/9.6/trigger’
Мы добавили строку trigger_file = ‘/postgres/9.6/trigger’ для того, чтобы при создании файла /postgres/9.6/trigger слейв база становилась мастером и могла производить запись
На мастере recovery конф нет, но заранее создадим recovery.done
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=IP-slave port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
primary_slot_name = ‘standby_1_slot‘
trigger_file = ‘/postgres/9.6/trigger’
==========================
Переключим слейв в мастер
Остановим мастер:
systemctl stop postgresql-9.6
На слейве проверим наличие файла recovery.conf и создадим файл triger
[root@btc-vsrv-mpaydb2 9.6]# cat /postgres/9.6/recovery.conf
standby_mode = ‘on’
primary_conninfo = ‘user=repluser password=repluser host=IP-master port=5432 sslmode=prefer sslcompression=1 krbsrvname=postgres’
recovery_target_timeline = ‘latest’
primary_slot_name = ‘standby_slot’
trigger_file = ‘/postgres/9.6/trigger’
[root@btc-vsrv-mpaydb2 9.6]# touch /postgres/9.6/trigger
Проверяем логи:
[root@btc-vsrv-mpaydb2 9.6]# tail /postgres/9.6/pg_log/postgresql-Thu.log
< 2019-06-20 13:29:23.672 +06 > LOG: trigger file found: /postgres/9.6/trigger
< 2019-06-20 13:29:23.672 +06 > LOG: redo done at 0/1A000E50
< 2019-06-20 13:29:23.682 +06 > LOG: selected new timeline ID: 7
< 2019-06-20 13:29:23.784 +06 > LOG: archive recovery complete
< 2019-06-20 13:29:23.807 +06 > LOG: MultiXact member wraparound protections are now enabled
< 2019-06-20 13:29:23.809 +06 > LOG: database system is ready to accept connections
< 2019-06-20 13:29:23.810 +06 > LOG: autovacuum launcher started
Строка database system is ready to accept connections показывает, что сервер перешёл в режим записи
Файл /postgres/9.6/trigger при этом с бывшего слейва удаляется, а recovery.conf автоматически переименовывается в recovery.done
Чтобы мастер перешёл в режим read only нам необходмо переименовать recovery.conf
mv recovery.done recovery.conf
И стартануть базу
systemctl start postgresql-9.6
Проверяем:
[root@btc-vsrv-mpaydb1 9.6]# ps aux | grep rec
postgres 3837 0.0 0.0 362620 2536 ? Ss 13:35 0:00 postgres: startup process recovering 00000006000000000000001A
postgres 3841 0.0 0.0 369412 3264 ? Ss 13:35 0:00 postgres: wal receiver process idle
root 4037 0.0 0.0 112708 980 pts/0 S+ 13:38 0:00 grep —color=auto rec
Бывший мастер теперь выступает как слейв
=================================
Чтобы вернуть как было мастер — мастер слейв- слейв.
Осанавливаем базу
[root@btc-vsrv-mpaydb2 9.6]# systemctl stop postgresql-9.6
переименовываем
[root@btc-vsrv-mpaydb2 9.6]# mv recovery.done recovery.conf
На мастере создаём файл trigger
[root@btc-vsrv-mpaydb1 9.6]# touch trigger
(на данном сервере файл recovery.conf автоматические переименовался в recovery.done)
Стартуем на слейве:
[root@btc-vsrv-mpaydb2 9.6]# systemctl start postgresql-9.6
Проверяем:
[root@btc-vsrv-mpaydb2 9.6]# ps aux | grep rec
postgres 7688 0.0 0.0 362620 2524 ? Ss 15:08 0:00 postgres: startup process recovering 0000000F000000000000001E
postgres 7692 0.3 0.0 369260 3256 ? Ss 15:08 0:00 postgres: wal receiver process streaming 0/1E000A80
[root@btc-vsrv-mpaydb1 9.6]# ps aux | grep send
postgres 10459 0.0 0.0 362924 3048 ? Ss 15:08 0:00 postgres: wal sender process repluser IP-master(56130) streaming 0/1E000A80
[root@btc-vsrv-mpaydb2 9.6]# su — postgres
Last login: Thu Jun 20 12:45:09 +06 2019 on pts/0
-bash-4.2$ psql
psql (9.2.24, server 9.6.13)
WARNING: psql version 9.2, server version 9.6.
Some psql features might not work.
Type «help» for help.
postgres=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
—————-+———+————+———+———-+———+————+——+—————+————-+———————
standby_1_slot | | physical | | | f | | 1773 | | 0/1E0008C8 |
(1 row)
[root@btc-vsrv-mpaydb1 9.6]# su — postgres
Last login: Thu Jun 20 14:42:01 +06 2019 on pts/0
-bash-4.2$ psql
psql (9.2.24, server 9.6.13)
WARNING: psql version 9.2, server version 9.6.
Some psql features might not work.
Type «help» for help.
postgres=# select * from pg_replication_slots;
slot_name | plugin | slot_type | datoid | database | active | active_pid | xmin | catalog_xmin | restart_lsn | confirmed_flush_lsn
—————+———+————+———+———-+———+————+——+—————+————-+———————
standby_slot | | physical | | | t | 10459 | 1773 | | 0/1E000B60 |
(1 row)
On operational issues side, one thing that quite commonly floats atop when dealing with customers using Postgres, especially with smaller setups, is Streaming Replication and it’s failures. Failure here not as a bug or design failure, but more as a misunderstood “feature”, as encountered problems are mostly actually things that work as intended and with good reasons, but people don’t know about the reasoning and at some point find themselves stressed when seeing errors. The good side here though is that it shows how easy it actually is nowadays to set up Postgres Streaming Replication (SR) even without any deeper background knowledge. So here’s a quick recap on the most important thing people should consider when running SR, so not to get caught off guard.
Disconnected replicas unable to connect
The below error must be the most common problem for all SR users. It shows up on the replicas on cases where 1) the network connection with the master went away or got too slow (quite common for a disaster recovery instance on other side of the world), 2) the replica had a downtime (Postgres shutdown or hardware/server maintenance), so that the master managed to write more data than the configured maximum WAL (Write-Ahead-Log) size. And until version 9.5 it was by default only 48 MB! And from 9.5+ in worst case scenario minimally only 80MB by default.
ERROR: requested WAL segment 00000001000000000000000A has already been removed.
The solution? Firstly there’s no other way around it on the replica side than rebuilding again from the master (meaning mostly pg_basebackup). For bigger DBs this can take hours of time and could also affect master performance, so not good…
Ensuring master keeps enough WAL files around for safe replica downtime
Long term solution would be:
1) Increase wal_keep_segments parameter.
This guarantees that extra WAL files would be kept around on the master. By default it’s 0, meaning no extra disk space is reserved. Simplest approach here for not so busy databases with no burst-writing would be to set it to value corresponding to a couple of days of data volume. This should give enough time to fix the network/server – given of course according failure detection systems are in place.
Determining the daily data volume could be problematic though here without some continuous monitoring tool or script (using pg_current_xlog_location+pg_xlog_location_diff) typically, but when having constant workflows one can estimate it pretty good based on the “change“ timestamps from DATADIR/pg_xlog folder. NB! Not to be confused with the standard “modified” timestamps that you see from ‘ls -l’. When you for example see that your ‘find pg_xlog/ -cmin -60’ (file attributes changed within last hour) yields 3, you’ll know that you’re writing ca 1.2GB (3*16*24) per day and can set wal_keep_segments accordingly.
2) Use replication slots
Replication slots (9.4+) are a feature designed specifically for this problem scenario and they guarantee storing of WAL files on master when replicas disconnect, per subscriber, meaning Postgres will delete WALs only when all replicas have received them. This complicates matters a bit of course. Steps to take:
* set max_replication_slots to the projected count of replicas (plus safety margin) on the master and restart
* create a named slot (speaking of only physical replication here) using pg_create_physical_replication_slot on the master
* modify the “recovery.conf” file on the replica to include the line ‘primary_slot_name=slotX’ and restart
* dropping the slot on master with pg_drop_replication_slot when decommissioning the replica
NB! When using replication slots it is absolutely essential that you have some kind of monitoring in place as when a replica goes away and it’s not picked up, eventually the master will run out of disk space on the XLOG partition. And when in danger of running out of disk space find out the slot that’s lagging behind the most with the below query and drop it. This means though also rebuilding the replica usually.
select slot_name, pg_xlog_location_diff(pg_current_xlog_location(), restart_lsn) as lag_b from pg_replication_slots order by 2 desc;