Оглавление
- 1 Установка
- 2 Настройка
- 3 Запуск
- 4 Виды сбоев
- 4.1 Сбой по питанию на текущем мастере или на реплике
- 4.2 Сбой процесса
- 4.3 Потеря сетевой связности между каким-либо из узлов и остальными узлами
- 5 Работа в командной строке PCS
- 5.1 Посмотреть параметры
- 5.2 Посмотреть состояние кластера
- 5.3 Отключить все ресурсы кластера
- 5.4 Остановить все ноды
- 5.5 Посмотреть состояние ресурсов
- 5.6 Изменить активную ноду
- 5.7 Удаление ноды
- 5.8 Очистка счетчиков сбоев
- 5.9 Пример создания ресурса PostgreSQL типа pgsql в кластере из трех узлов pgsql01, pgsql02, pgsql03
- 6 Работа в командном интерпретаторе CRM
- 6.1 Посмотреть конфигурацию
- 6.2 Сохранение конфигурации
- 6.3 Восстановление конфигурации
- 7 Дополнения
- 7.1 Администрирование через WEB
- 7.2 Установка CRM
- 8 Дополнительно
В данной статье описана начальная установка и настройка пакета Pacemaker на сервер под управлением CentOS7
Задача: настроить Pacemaker на автоматическое переключение MasterSlave
Дано:
node1 CentOS7
node2 CentOS7
Решение:
Установка
Устанавливаем пакеты на каждую из нод будущего кластера.
|
yum —y install resource—agents pacemaker pcs fence—agents—all psmisc policycoreutils—python corosync |
Задать пароль на пользователя, под которым будет работать сервис и выполняться синхронизация
Запустим службу и добавим в автозагрузку
|
systemctl enable pcsd systemctl enable corosync systemctl enable pacemaker |
Настройка
Добавим имена хостов в файл /etc/hosts
|
100.201.203.51 node1 100.201.203.52 node2 |
Запуск
Открываем порты
|
firewall—cmd —permanent —add—service=high—availability firewall—cmd —add—service=high—availability |
Данную процедуру выполняем на каждом из серверов.
Первым делом, необходимо авторизоваться на серверах следующей командой
|
#pcs cluster auth node1 node2 -u hacluster Password: node2: Authorized node1: Authorized |
Создаем кластер
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 |
pcs cluster setup —force —name CLUSETR node1 node2 Destroying cluster on nodes: node1, node2... node1: Stopping Cluster (pacemaker)... node2: Stopping Cluster (pacemaker)... node2: Successfully destroyed cluster node1: Successfully destroyed cluster Sending ‘pacemaker_remote authkey’ to ‘node1’, ‘node2’ node1: successful distribution of the file ‘pacemaker_remote authkey’ node2: successful distribution of the file ‘pacemaker_remote authkey’ Sending cluster config files to the nodes... node1: Succeeded node2: Succeeded Synchronizing pcsd certificates on nodes node1, node2... node2: Success node1: Success Restarting pcsd on the nodes in order to reload the certificates... node2: Success node1: Success |
Разрешаем автозапуск и запускаем созданный кластер pcs cluster enable —all и pcs cluster start —all:
|
pcs cluster enable —all node1: Cluster Enabled node2: Cluster Enabled pcs cluster start —all node1: Starting Cluster (corosync)... node2: Starting Cluster (corosync)... node2: Starting Cluster (pacemaker)... node1: Starting Cluster (pacemaker)... |
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум. STONITH (Shoot The Other Node In The Head) или Shoot является дополнительной защитой Pacemaker. При выполнении команды pcs status вы увидите предупреждение в выходных данных о том, что никакие устройства STONITH не настроены, и STONITH не отключен. Если вы используете данное решение в продакшене, то лучше включить STONITH. Так как даная система будет работать в DMZ, мы отключаем STONITH. Наличие кворума означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (poweroff или hard-reset). Выполняем на обоих нодах
|
pcs property set stonith—enabled=false pcs property set no—quorum—policy=ignore |
Если получаем ошибку
|
Error: unable to get cib Error: unable to get cib |
То скорее всего не запущены сервисы pcs cluster enable —all и pcs cluster start —all или не установлен пакет fence-agents-all
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже
где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере. Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы. Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
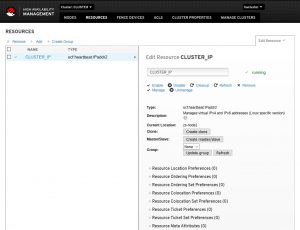
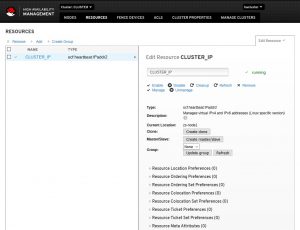
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
|
pcs resource create CLUSTER_IP ocf:heartbeat:IPaddr2 ip=100.201.203.50 cidr_netmask=24 op monitor interval=60s |
,где CLUSTER_IP — название ресурса (может быть любым);
ip=100.201.203.50 — виртуальный IP, который будет назначен кластеру;
cidr_netmask=24 — префикс сети (соответствует маске 255.255.255.0);
op monitor interval=60s — критическое время простоя, которое будет означать недоступность узла
Виды сбоев
Сбой по питанию на текущем мастере или на реплике
Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
Сбой процесса
Сбой основного процесса – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
Потеря сетевой связности между каким-либо из узлов и остальными узлами
Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
Сбой процесса Pacemaker/Corosync
Сбой процесса Corosync/pacemaker
Работа в командной строке PCS
Посмотреть параметры
Посмотреть состояние кластера
Отключить все ресурсы кластера
|
pcs cluster disable —all |
Вообще для Pacemaker ресурс — это скрипт, написанный на любом языке. Обычно эти скрипты пишутся на bash, но ничто не мешает писать их на Perl, Python, C или даже на PHP. Скрипт управляет сервисами в операционной системе. Главное требование к скриптам — уметь выполнять 3 действия: start, stop, monitor и делиться некоторой метаинформацией.
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker’а. Наиболее интересные из них: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Рассмотрим их более подробно.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут multiple-active – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:
block — установить опцию unmanaged, то есть деактивировать
stop_only — остановить на всех узлах
stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции – интервал, с каким делать проверку.
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
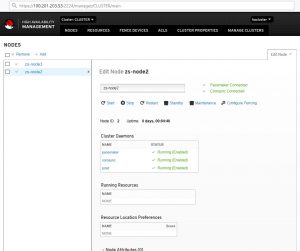
Остановить все ноды
Посмотреть состояние ресурсов
Изменить активную ноду
|
pcs resource move CLUSTER_IP zs—node1 |
Удаление ноды
|
pcs cluster node remove node_name |
Очистка счетчиков сбоев
Пример создания ресурса PostgreSQL типа pgsql в кластере из трех узлов pgsql01, pgsql02, pgsql03
|
pcs resource create PostgreSQL pgsql pgctl=«/usr/pgsql-9.6/bin/pg_ctl» psql=«/usr/pgsql-9.6/bin/psql» pgdata=«/var/lib/pgsql/9.6/data/» rep_mode=«sync» node_list=» pgsql01 pgsql02 pgsql03″ restore_command=«cp /var/lib/pgsql/9.6/pg_archive/%f %p» primary_conninfo_opt=«keepalives_idle=60 keepalives_interval=5 keepalives_count=5» master_ip=«10.3.3.3» restart_on_promote=‘false’ |
Работа в командном интерпретаторе CRM
Данная утилита имеет собственный SHELL, в котором довольно удобно работать. Из настроек данного интерпретатора можно отметить назначение редактора, в котором вы привыкли работать, например nano или mcedit.
|
crm options editor vim crm opti edi mcedit crm conf edit |
Посмотреть конфигурацию
Сохранение конфигурации
|
crm configure save _BACKUP_PATH_ |
Восстановление конфигурации
|
crm configure load replace _BACKUP_PATH |
Дополнения
Администрирование через WEB
Каждая из нод слушает порт 2224, которая позволяет подключиться и посмотреть, а так же изменить конфигурацию
Например https://100.201.203.54:2224
 Так же доступен и IP кластера.
Так же доступен и IP кластера.
Установка CRM
|
[kost@node1 ~]# crm-bash: crm: command not found |
По умолчанию для CentOS7 отсутствует пакет CRM, который позволяет выполнять настройку из собственного SHELL. Данный пакет успешно можно проинсталлировать из стороннего репозитория
|
cd /etc/yum.repos.d/ wget http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/network:ha-clustering:Stable.repo yum install crmsh |
После чего можно воспользоваться данной командой
Дополнительно
Хорошие стать по данной тем
4.5
6
голоса
Рейтинг статьи
![]() Загрузка…
Загрузка…
Содержание
- Centos
- Knowledge Base
- Установка и настройка Pacemaker на CentOS7
- Установка
- Настройка
- Запуск
- Виды сбоев
- Сбой по питанию на текущем мастере или на реплике
- Сбой процесса
- Потеря сетевой связности между каким-либо из узлов и остальными узлами
- Работа в командной строке PCS
- Посмотреть параметры
- Посмотреть состояние кластера
- Отключить все ресурсы кластера
Centos
В данной статье описана начальная установка и настройка пакета Pacemaker на сервер под управлением CentOS7
Задача: настроить Pacemaker на автоматическое переключение MasterSlave
Установка
Устанавливаем пакеты на каждую из нод будущего кластера.
yum -y install resource-agents pacemaker pcs fence-agents-all psmisc policycoreutils-python corosync
Задать пароль на пользователя, под которым будет работать сервис и выполняться синхронизация
Запустим службу и добавим в автозагрузку
systemctl enable pcsd
systemctl enable corosync
systemctl enable pacemaker
Настройка
Добавим имена хостов в файл /etc/hosts
100.201.203.51 node1
100.201.203.52 node2
Запуск
Открываем порты
firewall-cmd —permanent —add-service=high-availability
firewall-cmd —add-service=high-availability
Данную процедуру выполняем на каждом из серверов.
Первым делом, необходимо авторизоваться на серверах следующей командой
#pcs cluster auth node1 node2 -u hacluster
Password:
node2: Authorized
node1: Authorized
pcs cluster setup —force —name CLUSETR node1 node2
Destroying cluster on nodes: node1, node2…
node1: Stopping Cluster (pacemaker)…
node2: Stopping Cluster (pacemaker)…
node2: Successfully destroyed cluster
node1: Successfully destroyed cluster
Sending ‘pacemaker_remote authkey’ to ‘node1’, ‘node2’
node1: successful distribution of the file ‘pacemaker_remote authkey’
node2: successful distribution of the file ‘pacemaker_remote authkey’
Sending cluster config files to the nodes…
node1: Succeeded
node2: Succeeded
Synchronizing pcsd certificates on nodes node1, node2…
node2: Success
node1: Success
Restarting pcsd on the nodes in order to reload the certificates…
node2: Success
node1: Success
Разрешаем автозапуск и запускаем созданный кластер pcs cluster enable —all и pcs cluster start —all:
pcs cluster enable —all
node1: Cluster Enabled
node2: Cluster Enabled
pcs cluster start —all
node1: Starting Cluster (corosync)…
node2: Starting Cluster (corosync)…
node2: Starting Cluster (pacemaker)…
node1: Starting Cluster (pacemaker)…
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум. STONITH (Shoot The Other Node In The Head) или Shoot является дополнительной защитой Pacemaker. При выполнении команды pcs status вы увидите предупреждение в выходных данных о том, что никакие устройства STONITH не настроены, и STONITH не отключен. Если вы используете данное решение в продакшене, то лучше включить STONITH . Так как даная система будет работать в DMZ , мы отключаем STONITH . Наличие кворума означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (poweroff или hard-reset). Выполняем на обоих нодах
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
Если получаем ошибку
Error: unable to get cib
Error: unable to get cib
То скорее всего не запущены сервисы pcs cluster enable —all и pcs cluster start —all или не установлен пакет fence-agents-all
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже
где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере. Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы. Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
pcs resource create CLUSTER_IP ocf:heartbeat:IPaddr2 ip=100.201.203.50 cidr_netmask=24 op monitor interval=60s
, где CLUSTER_IP — название ресурса (может быть любым);
ip=100.201.203.50 — виртуальный IP , который будет назначен кластеру;
cidr_netmask=24 — префикс сети (соответствует маске 255.255.255.0);
op monitor interval=60s — критическое время простоя, которое будет означать недоступность узла
Виды сбоев
Сбой по питанию на текущем мастере или на реплике
Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
Сбой процесса
Сбой основного процесса – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
Потеря сетевой связности между каким-либо из узлов и остальными узлами
Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
Сбой процесса Pacemaker/Corosync
Сбой процесса Corosync/pacemaker
Работа в командной строке PCS
Посмотреть параметры
pcs property list
Посмотреть состояние кластера
pcs status
Отключить все ресурсы кластера
pcs cluster disable —all
Вообще для Pacemaker ресурс — это скрипт, написанный на любом языке. Обычно эти скрипты пишутся на bash, но ничто не мешает писать их на Perl, Python, C или даже на PHP . Скрипт управляет сервисами в операционной системе. Главное требование к скриптам — уметь выполнять 3 действия: start, stop, monitor и делиться некоторой метаинформацией.
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker’а. Наиболее интересные из них: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Рассмотрим их более подробно.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут multiple-active – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:
block — установить опцию unmanaged, то есть деактивировать
stop_only — остановить на всех узлах
stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции – интервал, с каким делать проверку.
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
Остановить все ноды
pcs cluster stop —all
Посмотреть состояние ресурсов
pcs status resources
Изменить активную ноду
pcs resource move CLUSTER_IP zs-node1
Удаление ноды
pcs cluster node remove node_name
Очистка счетчиков сбоев
pcs resource cleanup
Пример создания ресурса PostgreSQL типа pgsql в кластере из трех узлов pgsql01, pgsql02, pgsql03
pcs resource create PostgreSQL pgsql pgctl=»/usr/pgsql-9.6/bin/pg_ctl»
psql=»/usr/pgsql-9.6/bin/psql» pgdata=»/var/lib/pgsql/9.6/data/»
rep_mode=»sync» node_list=» pgsql01 pgsql02 pgsql03″ restore_command=»cp /var/lib/pgsql/9.6/pg_archive/%f %p»
primary_conninfo_opt=»keepalives_idle=60 keepalives_interval=5 keepalives_count=5″ master_ip=»10.3.3.3″ restart_on_promote=’false’
Работа в командном интерпретаторе CRM
Данная утилита имеет собственный SHELL , в котором довольно удобно работать. Из настроек данного интерпретатора можно отметить назначение редактора, в котором вы привыкли работать, например nano или mcedit.
crm options editor vim
crm opti edi mcedit
crm conf edit
Посмотреть конфигурацию
crm configure show
Сохранение конфигурации
crm configure save _BACKUP_PATH_
Восстановление конфигурации
crm configure load replace _BACKUP_PATH
Дополнения
Администрирование через WEB
Каждая из нод слушает порт 2224, которая позволяет подключиться и посмотреть, а так же изменить конфигурацию
Так же доступен и IP кластера.
Установка CRM
[kost@node1
]# crm-bash:
crm: command not found
По умолчанию для CentOS7 отсутствует пакет CRM , который позволяет выполнять настройку из собственного SHELL . Данный пакет успешно можно проинсталлировать из стороннего репозитория
cd /etc/yum.repos.d/
wget http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/network:ha-clustering:Stable.repo
yum install crmsh
После чего можно воспользоваться данной командой
Источник
Knowledge Base
Настройка WindowsUnix систем CISCO MIKROTIK VMWARE
Установка и настройка Pacemaker на CentOS7
В данной статье описана начальная установка и настройка пакета Pacemaker на сервер под управлением CentOS7
Задача: настроить Pacemaker на автоматическое переключение MasterSlave
Дано:
Решение:
Установка
Устанавливаем пакеты на каждую из нод будущего кластера.
Задать пароль на пользователя, под которым будет работать сервис и выполняться синхронизация
Запустим службу и добавим в автозагрузку
Настройка
Добавим имена хостов в файл /etc/hosts
Запуск
Данную процедуру выполняем на каждом из серверов.
Первым делом, необходимо авторизоваться на серверах следующей командой
Разрешаем автозапуск и запускаем созданный кластер pcs cluster enable –all и pcs cluster start –all:
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум. STONITH (Shoot The Other Node In The Head) или Shoot является дополнительной защитой Pacemaker. При выполнении команды pcs status вы увидите предупреждение в выходных данных о том, что никакие устройства STONITH не настроены, и STONITH не отключен. Если вы используете данное решение в продакшене, то лучше включить STONITH. Так как даная система будет работать в DMZ, мы отключаем STONITH. Наличие кворума означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (poweroff или hard-reset). Выполняем на обоих нодах
Если получаем ошибку
То скорее всего не запущены сервисы pcs cluster enable –all и pcs cluster start –all или не установлен пакет fence-agents-all
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже
где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере. Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы. Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
,где CLUSTER_IP — название ресурса (может быть любым);
ip=100.201.203.50 — виртуальный IP, который будет назначен кластеру;
cidr_netmask=24 — префикс сети (соответствует маске 255.255.255.0);
op monitor interval=60s — критическое время простоя, которое будет означать недоступность узла
Виды сбоев
Сбой по питанию на текущем мастере или на реплике
Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
Сбой процесса
Сбой основного процесса – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
Потеря сетевой связности между каким-либо из узлов и остальными узлами
Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
Сбой процесса Pacemaker/Corosync
Сбой процесса Corosync/pacemaker
Работа в командной строке PCS
Посмотреть параметры
Посмотреть состояние кластера
Отключить все ресурсы кластера
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker’а. Наиболее интересные из них: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Рассмотрим их более подробно.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут multiple-active – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:
block — установить опцию unmanaged, то есть деактивировать
stop_only — остановить на всех узлах
stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции – интервал, с каким делать проверку.
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
Источник
В данной статье описана начальная установка и настройка пакета Pacemaker на сервер под управлением CentOS7
Задача: настроить Pacemaker на автоматическое переключение MasterSlave
Дано:
node1 CentOS7
node2 CentOS7
Решение:
Установка
Устанавливаем пакеты на каждую из нод будущего кластера.
yum -y install resource-agents pacemaker pcs fence-agents-all psmisc policycoreutils-python corosync
Задать пароль на пользователя, под которым будет работать сервис и выполняться синхронизация
passwd hacluster
Запустим службу и добавим в автозагрузку
systemctl enable pcsd
systemctl enable corosync
systemctl enable pacemaker
Настройка
Добавим имена хостов в файл /etc/hosts
100.201.203.51 node1
100.201.203.52 node2
Запуск
Открываем порты
firewall-cmd —permanent —add-service=high-availability
firewall-cmd —add-service=high-availability
Данную процедуру выполняем на каждом из серверов.
Первым делом, необходимо авторизоваться на серверах следующей командой
#pcs cluster auth node1 node2 -u hacluster
Password:
node2: Authorized
node1: Authorized
Создаем кластер
pcs cluster setup —force —name CLUSETR node1 node2
Destroying cluster on nodes: node1, node2…
node1: Stopping Cluster (pacemaker)…
node2: Stopping Cluster (pacemaker)…
node2: Successfully destroyed cluster
node1: Successfully destroyed cluster
Sending ‘pacemaker_remote authkey’ to ‘node1’, ‘node2’
node1: successful distribution of the file ‘pacemaker_remote authkey’
node2: successful distribution of the file ‘pacemaker_remote authkey’
Sending cluster config files to the nodes…
node1: Succeeded
node2: Succeeded
Synchronizing pcsd certificates on nodes node1, node2…
node2: Success
node1: Success
Restarting pcsd on the nodes in order to reload the certificates…
node2: Success
node1: Success
Разрешаем автозапуск и запускаем созданный кластер pcs cluster enable —all и pcs cluster start —all:
pcs cluster enable —all
node1: Cluster Enabled
node2: Cluster Enabled
pcs cluster start —all
node1: Starting Cluster (corosync)…
node2: Starting Cluster (corosync)…
node2: Starting Cluster (pacemaker)…
node1: Starting Cluster (pacemaker)…
При использовании 2-х нод (как в данном примере) отключаем stonith (нужен для «добивания» серверов, которые не смогли полностью завершить рабочие процессы) и кворум. STONITH (Shoot The Other Node In The Head) или Shoot является дополнительной защитой Pacemaker. При выполнении команды pcs status вы увидите предупреждение в выходных данных о том, что никакие устройства STONITH не настроены, и STONITH не отключен. Если вы используете данное решение в продакшене, то лучше включить STONITH. Так как даная система будет работать в DMZ, мы отключаем STONITH. Наличие кворума означает, что в кластере должно быть не менее 3-х узлов. Причем, необязательно все три узла должны быть с СУБД, достаточно на двух узлах иметь Мастер и Реплику, а третий узел выступает в роли «голосующего».
Наличие устройств фенсинга на узлах с СУБД. При возникновении сбоя устройства «фенсинга» изолируют сбойнувший узел – посылают команду на выключение питания или перезагрузку (poweroff или hard-reset). Выполняем на обоих нодах
pcs property set stonith-enabled=false
pcs property set no-quorum-policy=ignore
Если получаем ошибку
Error: unable to get cib
Error: unable to get cib
То скорее всего не запущены сервисы pcs cluster enable —all и pcs cluster start —all или не установлен пакет fence-agents-all
Что такое кворум? Говорят, что кластер имеет кворум при достаточном количестве «живых» узлов кластера. Достаточность количества «живых» узлов определяется по формуле ниже
n > N/2
где n – количество живых узлов, N – общее количество узлов в кластере.
Как видно из простой формулы, кластер с кворумом – это когда количество «живых» узлов, больше половины общего количества узлов в кластере. Как вы, наверное, понимаете, в кластере, состоящем из двух узлов, при сбое на одном из 2-х узлов не будет кворума. По умолчанию, если нет кворума, Pacemaker останавливает ресурсы. Чтобы этого избежать, нужно при настройке Pacemaker указать ему, чтобы наличие или отсутствие кворума не учитывалось. Делается это с помощью опции no-quorum-policy=ignore.
Рассмотрим самый распространенный вариант использования Pacemaker. Он заключается в использовании виртуального IP-адреса, который будет назначаться активному узлу кластера.
Для этого создаем ресурс командой:
pcs resource create CLUSTER_IP ocf:heartbeat:IPaddr2 ip=100.201.203.50 cidr_netmask=24 op monitor interval=60s
,где CLUSTER_IP — название ресурса (может быть любым);
ip=100.201.203.50 — виртуальный IP, который будет назначен кластеру;
cidr_netmask=24 — префикс сети (соответствует маске 255.255.255.0);
op monitor interval=60s — критическое время простоя, которое будет означать недоступность узла
Виды сбоев
Сбой по питанию на текущем мастере или на реплике
Сбой питания, когда пропадает питание и сервер выключается. Это может быть как Мастер, так и одна из Реплик.
Сбой процесса
Сбой основного процесса – система может завершить аварийно процесс postgres по разным причинам, например, нехватка памяти, либо недостаточное количество файловых дескрипторов, либо превышено максимальное число открытых файлов.
Потеря сетевой связности между каким-либо из узлов и остальными узлами
Это сетевая недоступность какого-либо узла. Например, её причиной может быть выход из строя сетевой карты, либо порта коммутатора.
Сбой процесса Pacemaker/Corosync
Сбой процесса Corosync/pacemaker
Работа в командной строке PCS
Посмотреть параметры
pcs property list
Посмотреть состояние кластера
pcs status
Отключить все ресурсы кластера
pcs cluster disable —all
Вообще для Pacemaker ресурс — это скрипт, написанный на любом языке. Обычно эти скрипты пишутся на bash, но ничто не мешает писать их на Perl, Python, C или даже на PHP. Скрипт управляет сервисами в операционной системе. Главное требование к скриптам — уметь выполнять 3 действия: start, stop, monitor и делиться некоторой метаинформацией.
Ресурсы имеют множество атрибутов, которые хранятся в конфигурационном XML-файле Pacemaker’а. Наиболее интересные из них: priority, resource-stickiness, migration-threshold, failure-timeout, multiple-active.
Рассмотрим их более подробно.
Атрибут priority — приоритет ресурса, который учитывается, если узел исчерпал лимит по количеству активных ресурсов (по умолчанию 0). Если узлы кластера не одинаковы по производительности или доступности, то можно увеличить приоритет одного из узлов, чтобы он был активным всегда, когда работает.
Атрибут resource-stickiness — липкость ресурса (по умолчанию 0). Липкость (stickiness) указывает на то, насколько ресурс «хочет» оставаться там, где он есть сейчас. Например, после сбоя узла его ресурсы переходят на другие узлы (точнее — стартуют на других узлах), а после восстановления работоспособности сбойного узла, ресурсы могут вернуться к нему или не вернуться, и это поведение как раз и описывается параметром липкость.
Другими словами, липкость показывает, насколько желательно или не желательно, чтобы ресурс вернулся на восстановленный после сбоя узел.
Поскольку по умолчанию липкость всех ресурсов 0, то Pacemaker сам располагает ресурсы на узлах «оптимально» на свое усмотрение.
Но это не всегда может быть оптимально с точки зрения администратора. Например, в случае, когда в отказоустойчивом кластере узлы имеют неодинаковую производительность, администратор захочет запускать сервисы на узле с большей производительностью.
Также Pacemaker позволяет задавать разную липкость ресурса в зависимости от времени суток и дня недели, что позволяет, например, обеспечить переход ресурса на исходный узел в нерабочее время.
Атрибут migration-threshold — сколько отказов должно произойти, чтобы Pacemaker решил, что узел непригоден для данного ресурса и перенёс (мигрировал) его на другой узел. По умолчанию также этот параметр равен 0, т. е. при любом количестве отказов автоматического переноса ресурсов не будет происходить.
Но, с точки зрения отказоустойчивости, правильно выставить этот параметр в 1, чтобы при первом же сбое Pacemaker перемещал ресурс на другой узел.
Атрибут failure-timeout — количество секунд после сбоя, до истечения которых Pacemaker считает, что отказа не произошло, и не предпринимает ничего, в частности, не перемещает ресурсы. По умолчанию, равен 0.
Атрибут multiple-active – дает указание Pacemaker, что делать с ресурсом, если он оказался запущен более чем на одном узле. Может принимать следующие значения:
block — установить опцию unmanaged, то есть деактивировать
stop_only — остановить на всех узлах
stop_start — остановить на всех узлах и запустить только на одном (значение по-умолчанию).
По умолчанию, кластер не следит после запуска, жив ли ресурс. Чтобы включить отслеживание ресурса, нужно при создании ресурса добавить операцию monitor, тогда кластер будет следить за состоянием ресурса. Параметр interval этой операции – интервал, с каким делать проверку.
При возникновении отказа на основном узле, Pacemaker «перемещает» ресурсы на другой узел (на самом деле, Pacemaker останавливает ресурсы на сбойнувшем узле и запускает ресурсы на другом). Процесс «перемещения» ресурсов на другой узел происходит быстро и незаметно для конечного клиента.
Ресурсы можно объединять в группы — списки ресурсов, которые должны запускаться в определенном порядке, останавливаться в обратном порядке и исполняться на одном узле.Все ресурсы группы запускаются на одном узле и запускаются последовательно, согласно порядку в группе. Но нужно учитывать, что при сбое одного из ресурсов группы, вся группа переместится на другой узел.
При выключении какого-либо ресурса группы, все последующие ресурсы группы тоже выключатся. Например, ресурс PostgreSQL, имеющий тип pgsql, и ресурс Virtual-IP, имеющий тип IPaddr2, могут быть объединены в группу.
Остановить все ноды
pcs cluster stop —all
Посмотреть состояние ресурсов
pcs status resources
Изменить активную ноду
pcs resource move CLUSTER_IP zs-node1
Удаление ноды
pcs cluster node remove node_name
Очистка счетчиков сбоев
pcs resource cleanup
Пример создания ресурса PostgreSQL типа pgsql в кластере из трех узлов pgsql01, pgsql02, pgsql03
pcs resource create PostgreSQL pgsql pgctl=»/usr/pgsql-9.6/bin/pg_ctl»
psql=»/usr/pgsql-9.6/bin/psql» pgdata=»/var/lib/pgsql/9.6/data/»
rep_mode=»sync» node_list=» pgsql01 pgsql02 pgsql03″ restore_command=»cp /var/lib/pgsql/9.6/pg_archive/%f %p»
primary_conninfo_opt=»keepalives_idle=60 keepalives_interval=5 keepalives_count=5″ master_ip=»10.3.3.3″ restart_on_promote=’false’
Работа в командном интерпретаторе CRM
Данная утилита имеет собственный SHELL, в котором довольно удобно работать. Из настроек данного интерпретатора можно отметить назначение редактора, в котором вы привыкли работать, например nano или mcedit.
crm options editor vim
crm opti edi mcedit
crm conf edit
Посмотреть конфигурацию
crm configure show
Сохранение конфигурации
crm configure save _BACKUP_PATH_
Восстановление конфигурации
crm configure load replace _BACKUP_PATH
Дополнения
Администрирование через WEB
Каждая из нод слушает порт 2224, которая позволяет подключиться и посмотреть, а так же изменить конфигурацию
Например https://100.201.203.54:2224
Так же доступен и IP кластера.
Установка CRM
[kost@node1 ~]# crm-bash:
crm: command not found
По умолчанию для CentOS7 отсутствует пакет CRM, который позволяет выполнять настройку из собственного SHELL. Данный пакет успешно можно проинсталлировать из стороннего репозитория
cd /etc/yum.repos.d/
wget http://download.opensuse.org/repositories/network:/ha-clustering:/Stable/CentOS_CentOS-7/network:ha-clustering:Stable.repo
yum install crmsh
После чего можно воспользоваться данной командой
This article will briefly explains about configuring the GFS2 filesystem between two cluster nodes. As you know that GFS2 is cluster filesystem and it can be mounted on more than one server at a time . Since multiple servers can mount the same filesystem, it uses the DLM (Dynamic Lock Manager) to prevent the data corruption. GFS2 requires a cluster suite to configure & manage. In RHEL 7 , Pacemaker/corosync provides the cluster infrastructure. GFS2 is a native file system that interfaces directly with the Linux kernel file system interface (VFS layer). For your information, Red Hat supports the use of GFS2 file systems only as implemented in the High Availability Add-On (Cluster).
Here is the list of activity in an order to configure the GFS2 between two node cluster (Pacemaker).
- Install GFS2 and lvm2-cluster packages.
- Enable clustered locking for LVM
- Create DLM and CLVMD resources on Pacemaker
- Set the resource ordering and colocation.
- Configure the LVM objects & Create the GFS2 filesystem
- Add logical volume & filesystem in to the pacemaker control. (gfs2 doesn’t use /etc/fstab).
Environment:
- RHEL 7.1
- Node Names : Node1 & Node2.
- Fencing/STONITH: Mandatory for GFS2.
- Shared LUN “/dev/sda”
- Cluster status:
[root@Node2-LAB ~]# pcs status Cluster name: GFSCLUS Last updated: Thu Jan 21 18:00:25 2016 Last change: Wed Jan 20 16:12:24 2016 via cibadmin on Node1 Stack: corosync Current DC: Node1 (1) - partition with quorum Version: 1.1.10-29.el7-368c726 2 Nodes configured 5 Resources configured Online: [ Node1 Node2 ] Full list of resources: xvmfence (stonith:fence_xvm): Started Node1 PCSD Status: Node1: Online Node2: Online Daemon Status: corosync: active/enabled pacemaker: active/enabled pcsd: active/enabled [root@Node2-LAB ~]#
Package Installation:
1. Login to the both cluster nodes and install gfs2 and lvm2 cluster packages.
[root@Node2-LAB ~]# yum -y install gfs2-utils lvm2-cluster Loaded plugins: product-id, subscription-manager This system is not registered to Red Hat Subscription Management. You can use subscription-manager to register. Package gfs2-utils-3.1.6-13.el7.x86_64 already installed and latest version Package 7:lvm2-cluster-2.02.105-14.el7.x86_64 already installed and latest version Nothing to do [root@Node2-LAB ~]# ssh Node1 yum -y install gfs2-utils lvm2-cluster Loaded plugins: product-id, subscription-manager Package gfs2-utils-3.1.6-13.el7.x86_64 already installed and latest version Package 7:lvm2-cluster-2.02.105-14.el7.x86_64 already installed and latest version Nothing to do [root@Node2-LAB ~]#
Enable clustered locking for LVM:
1. Enable clustered locking for LVM on both the cluster ndoes
[root@Node2-LAB ~]# lvmconf --enable-cluster
[root@Node2-LAB ~]# ssh Node1 lvmconf --enable-cluster
[root@Node2-LAB ~]# cat /etc/lvm/lvm.conf |grep locking_type |grep -v "#"
locking_type = 3
[root@Node2-LAB ~]#
2. Reboot the cluster nodes.
Create DLM and CLVMD cluster Resources:
1.Login to one of the cluster node.
2.Create clone resources for DLM and CLVMD. Clone options allows resource to can run on both nodes.
[root@Node1-LAB ~]# pcs resource create dlm ocf:pacemaker:controld op monitor interval=30s on-fail=fence clone interleave=true ordered=true [root@Node1-LAB ~]# pcs resource create clvmd ocf:heartbeat:clvm op monitor interval=30s on-fail=fence clone interleave=true ordered=true
3.Check the cluster status.
[root@Node1-LAB ~]# pcs status
Cluster name: GFSCLUS
Last updated: Thu Jan 21 18:15:48 2016
Last change: Thu Jan 21 18:15:38 2016 via cibadmin on Node1
Stack: corosync
Current DC: Node2 (2) - partition with quorum
Version: 1.1.10-29.el7-368c726
2 Nodes configured
5 Resources configured
Online: [ Node1 Node2 ]
Full list of resources:
xvmfence (stonith:fence_xvm): Started Node1
Clone Set: dlm-clone [dlm]
Started: [ Node1 Node2 ]
Clone Set: clvmd-clone [clvmd]
Started: [ Node1 Node2 ]
PCSD Status:
Node1: Online
Node2: Online
Daemon Status:
corosync: active/enabled
pacemaker: active/enabled
pcsd: active/enabled
[root@Node1-LAB ~]#
You could see that resource is on-line on both the nodes.
Resource ordering and co-location:
1.Configure the resource order.
[root@Node1-LAB ~]# pcs constraint order start dlm-clone then clvmd-clone Adding dlm-clone clvmd-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@Node1-LAB ~]#
2. configure the co-location for resources.
[root@Node1-LAB ~]# pcs constraint colocation add clvmd-clone with dlm-clone [root@Node1-LAB ~]#
3. Verify the constraint.
[root@Node1-LAB ~]# pcs constraint Location Constraints: Ordering Constraints: start dlm-clone then start clvmd-clone Colocation Constraints: clvmd-clone with dlm-clone [root@Node1-LAB ~]#
Configure the LVM objects:
1.Login to one of the cluster node and create the required LVM objects.
2. In this setup , /dev/sda is shared LUN between two nodes.
3. Create the new volume group .
[root@Node1-LAB ~]# vgcreate -Ay -cy gfsvg /dev/sda Physical volume "/dev/sda" successfully created Clustered volume group "gfsvg" successfully created [root@Node1-LAB ~]# [root@Node1-LAB kvmpool]# vgs VG #PV #LV #SN Attr VSize VFree gfsvg 1 1 0 wz--nc 996.00m 96.00m rhel 1 2 0 wz--n- 7.51g 0 [root@Node1-LAB kvmpool]#
4. Create the logical volume.
[root@Node1-LAB ~]# lvcreate -L 900M -n gfsvol1 gfsvg Logical volume "gfsvol1" created [root@Node1-LAB ~]# [root@Node1-LAB kvmpool]# lvs -o +devices gfsvg LV VG Attr LSize Pool Origin Data% Move Log Cpy%Sync Convert Devices gfsvol1 gfsvg -wi-ao---- 900.00m /dev/sda(0) [root@Node1-LAB kvmpool]#
5. Create the filesystem on the new volume.
[root@Node1-LAB ~]# mkfs.gfs2 -p lock_dlm -t GFSCLUS:gfsvolfs -j 2 /dev/gfsvg/gfsvol1 /dev/gfsvg/gfsvol1 is a symbolic link to /dev/dm-2 This will destroy any data on /dev/dm-2 Are you sure you want to proceed? [y/n]y Device: /dev/gfsvg/gfsvol1 Block size: 4096 Device size: 0.88 GB (230400 blocks) Filesystem size: 0.88 GB (230400 blocks) Journals: 2 Resource groups: 4 Locking protocol: "lock_dlm" Lock table: "GFSCLUS:gfsvolfs" UUID: 8dff8868-3815-d43c-dfa0-f2a9047d97a2 [root@Node1-LAB ~]# [root@Node1-LAB ~]#
- GFSCLUS – CLUSTER NAME
- gfsvolfs – FILESYSTEM NAME
- “-j 2” = Journal- Since two node is going to access it.
Configure the Mount-point on Pacemaker:
1. Login to one of the cluster node.
2. Create the new cluster resource for GFS2 filesystem.
[root@Node1-LAB ~]# pcs resource create gfsvolfs_res Filesystem device="/dev/gfsvg/gfsvol1" directory="/kvmpool" fstype="gfs2" options="noatime,nodiratime" op monitor interval=10s on-fail=fence clone interleave=true [root@Node1-LAB ~]#
3. Verify the volume status. It should be mounted on both the cluster nodes.
[root@Node1-LAB ~]# df -h /kvmpool Filesystem Size Used Avail Use% Mounted on /dev/mapper/gfsvg-gfsvol1 900M 259M 642M 29% /kvmpool [root@Node1-LAB ~]# ssh Node2 df -h /kvmpool Filesystem Size Used Avail Use% Mounted on /dev/mapper/gfsvg-gfsvol1 900M 259M 642M 29% /kvmpool [root@Node1-LAB ~]#
4. Configure the resources ordering and colocaiton .
[root@Node1-LAB ~]# pcs constraint order start clvmd-clone then gfsvolfs_res-clone Adding clvmd-clone gfsvolfs_res-clone (kind: Mandatory) (Options: first-action=start then-action=start) [root@Node1-LAB ~]# pcs constraint order Ordering Constraints: start clvmd-clone then start gfsvolfs_res-clone start dlm-clone then start clvmd-clone [root@Node1-LAB ~]# pcs constraint colocation add gfsvolfs_res-clone with clvmd-clone [root@Node1-LAB ~]# pcs constraint colocation Colocation Constraints: clvmd-clone with dlm-clone gfsvolfs_res-clone with clvmd-clone [root@Node1-LAB ~]#
5. You could see that both the nodes able to see same filesystem in read/write mode.
[root@Node1-LAB ~]# cd /kvmpool/ [root@Node1-LAB kvmpool]# ls -lrt total 0 [root@Node1-LAB kvmpool]# touch test1 test2 test3 [root@Node1-LAB kvmpool]# ls -lrt total 12 -rw-r--r-- 1 root root 0 Jan 21 18:38 test1 -rw-r--r-- 1 root root 0 Jan 21 18:38 test3 -rw-r--r-- 1 root root 0 Jan 21 18:38 test2 [root@Node1-LAB kvmpool]# ssh Node2 ls -lrt /kvmpool/ total 12 -rw-r--r-- 1 root root 0 Jan 21 18:38 test1 -rw-r--r-- 1 root root 0 Jan 21 18:38 test3 -rw-r--r-- 1 root root 0 Jan 21 18:38 test2 [root@Node1-LAB kvmpool]#
We have successfully configured GFS2 on RHEL 7 clustered nodes.
Set the No Quorum Policy:
When you use GFS2 , you must configure the no-quorum-policy . If you set it to freeze and system lost the quorum, systems will not anything until quorum is regained.
[root@Node1-LAB ~]# pcs property set no-quorum-policy=freeze [root@Node1-LAB ~]#
[box type=”info” align=”” class=”” width=””]Although OCFS2 (Oracle Cluster File System 2) can run on Red Hat Enterprise Linux, it is not shipped, maintained, or supported by Red Hat.[/box]
Hope this article is informative to you.
Share it ! Comment it !! Be Sociable !!!
When configuring a cluster, you want tot keep managing the server as simple as possible. Theoretically, the results given by any node in the cluster should be equal as you want the cluster to be transparent to the end-user. Part of doing this, is having the same data available on every node of the cluster when it’s active. One way to do this, is using a central file-share, for example over NFS but this also has disadvantages. Another way is to have a distributed file system that stays on the nodes itself. DRBD is one of them. This post explains how to integrate DRBD in a cluster with Corosync and Pacemaker.
DRBD stands for Distributed Replicated Block Device and the name already explains what it is. DRBD presents a layer on top of a normal block device and is responsible for keeping it synchronized over multiple nodes. Simplified, you can compare DRBD with a RAID1-array over multiple devices in different nodes instead of over multiple devices on the same node.
In this post, I will continue with the setup which was created earlier in Building a high-available failover cluster with Pacemaker, Corosync & PCS. So if you’re looking for the basic configuration of a cluster, have a look here. I assume, for this post, that you got a working cluster with Corosync and Pacemaker.
The goal of these actions is to have the data for the Apache webserver synchronized over both nodes. In the example, the configured webserver was presenting the local data which we even used to identify the nodes.
Since RHEL 7, Red Hat doesn’t officially support DRBD anymore. Support for DRBD is still available via an external partner. This also means that CentOS, one of the RHEL derivatives doesn’t have the DRBD packages available. Fortunately, ELRepo still provides what we need to get going with DRBD.
Installing DRBD
More info about ELRepo can be found here: http://elrepo.org/tiki/drbd83-utils.
The first step in adding DRBD to the existing cluster is to configure the nodes to use the ELRepo-repository:
[jensd@node01 ~]$ sudo rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org [jensd@node01 ~]$ sudo yum install http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm ... Complete !
[jensd@node02 ~]$ sudo rpm --import https://www.elrepo.org/RPM-GPG-KEY-elrepo.org [jensd@node02 ~]$ sudo yum install http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm ... Complete !
After adding the repository, we can install drbd as before:
[jensd@node01 ~]$ sudo yum install drbd84-utils kmod-drbd84 ... Complete !
[jensd@node02 ~]$ sudo yum install drbd84-utils kmod-drbd84 ... Complete !
Create a (logical) volume for DRBD
DRBD provides a way to distribute a block device over multiple nodes. In order to do so, we need a block device to distribute (sound logical, doesn’t it). The block device can be any available device, it doesn’t need to be a logical volume but can be a pure physical partition too. For this post, I’ll add a new logical volume on both nodes to use as my distributed block device. The size of the devices needs to be equal on all nodes.
First I’ll check if I still have some free space in my volume group to create the logical volume:
[jensd@node01 ~]$ sudo vgdisplay vg_drbd|grep Free Free PE / Size 255 / 1020.00 MiB
[jensd@node02 ~]$ sudo vgdisplay vg_drbd|grep Free Free PE / Size 255 / 1020.00 MiB
After checking what is available, I’ll create a new logical volume, named lv_drbd0 in that volume group:
[jensd@node01 ~]$ sudo lvcreate -n lv_drbd0 -l +100%FREE vg_drbd Logical volume "lv_drbd0" created
[jensd@node02 ~]$ sudo lvcreate -n lv_drbd0 -l +100%FREE vg_drbd Logical volume "lv_drbd0" created
After these steps, both nodes contain a logical volume called lv_drbd0 that are equal in size (1GB).
Configuring DRBD for Single-primary mode
Now that we have a block device to share, we’ll configure DRBD to do so. Our DRBD setup will be in single-primary mode. This means that only one of the nodes can be the primary. This means that the data is only manipulated from one point at a time. For other configurations, you will need non-standard file systems. The goal of my setup is to use a standard file system like EXT3, EXT4 or XFS.
Before we will start configure DRBD, we’ll have to open two TCP-ports on our firewall in order for the nodes to communicate with eachother. DRBD uses, by default, port 7788 and 7799.
[jensd@node01 ~]$ sudo iptables -I INPUT -p tcp -m state --state NEW -m tcp --dport 7788 -j ACCEPT [jensd@node01 ~]$ sudo iptables -I INPUT -p tcp -m state --state NEW -m tcp --dport 7799 -j ACCEPT [jensd@node01 ~]$ sudo service iptables save
[jensd@node02 ~]$ sudo iptables -I INPUT -p tcp -m state --state NEW -m tcp --dport 7788 -j ACCEPT [jensd@node02 ~]$ sudo iptables -I INPUT -p tcp -m state --state NEW -m tcp --dport 7799 -j ACCEPT [jensd@node01 ~]$ sudo service iptables save
The next step is to create the DRBD configuration files. These files need to be completely equal on all nodes in the cluster.
File /etc/drbd.d/global_common.conf (on node01 and node02):
global {
usage-count yes;
}
common {
net {
protocol C;
}
}
File /etc/drbd.d/drbd0.res (on node01 and node02):
resource drbd0 {
disk /dev/vg_drbd/lv_drbd0;
device /dev/drbd0;
meta-disk internal;
on node01 {
address 192.168.202.101:7789;
}
on node02 {
address 192.168.202.102:7789;
}
}
Now that we have the configuration in place, it’s time to initialize our data:
[jensd@node01 ~]$ sudo drbdadm create-md drbd0 initializing activity log NOT initializing bitmap Writing meta data... New drbd meta data block successfully created. success
At this point, we’re ready to start DRBD on both nodes and bring the drbd0 resource up. After bringing the resource up, let’s check the status:
[jensd@node01 ~]$ sudo drbdadm up drbd0 [jensd@node01 ~]$ cat /proc/drbd version: 8.4.5 (api:1/proto:86-101) GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by mockbuild@, 2014-08-17 22:54:26 0: cs:WFConnection ro:Secondary/Unknown ds:Inconsistent/DUnknown C r----s ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:1048508
[jensd@node02 ~]$ sudo drbdadm up drbd0 [jensd@node02 ~]$ cat /proc/drbd version: 8.4.5 (api:1/proto:86-101) GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by mockbuild@, 2014-08-17 22:54:26 0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r----- ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:1048508
As you can see in the contents of /proc/drbd, DRBD marks this resource as inconsistent. This is because we didn’t tell DRBD who is the primary node. In the above output you can see that both nodes are thinging that they are the secondary node. All configuration files are identical on both nodes so at this point, they’re considered equal.
Let’s configure node01 as the primary and check the status again:
[jensd@node01 ~]$ sudo drbdadm primary --force drbd0
[jensd@node01 ~]$ cat /proc/drbd
version: 8.4.5 (api:1/proto:86-101)
GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by mockbuild@, 2014-08-17 22:54:26
0: cs:SyncSource ro:Primary/Secondary ds:UpToDate/Inconsistent C r-----
ns:175896 nr:0 dw:0 dr:175896 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:868516
[==>.................] sync'ed: 16.9% (868516/1044412)K
finish: 0:01:38 speed: 8,792 (8,792) K/sec
As you can see in the above output now, the data is synced from node01 (which we set as the primary node) to node02 (which is now the secondary node. The volume which we used (lv_drbd0) was empty but since DRBD is not looking at the contents (blocks) it still needs to synchronize the blocks on the volume.
After a while, the synchronization finished and the resource is considered UpToDate:
[jensd@node01 ~]$ cat /proc/drbd
version: 8.4.5 (api:1/proto:86-101)
GIT-hash: 1d360bde0e095d495786eaeb2a1ac76888e4db96 build by mockbuild@, 2014-08-17 22:54:26
0: cs:Connected ro:Primary/Secondary ds:UpToDate/UpToDate C r-----
ns:1044412 nr:0 dw:0 dr:1044412 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:0
To be sure, we can check this in another way. Here you can also clearly see who’s the primary and who’s the secondary:
[jensd@node01 ~]$ sudo drbd-overview 0:drbd0/0 Connected Primary/Secondary UpToDate/UpToDate
[jensd@node02 ~]$ sudo drbd-overview 0:drbd0/0 Connected Secondary/Primary UpToDate/UpToDate
Create a file system on the DRBD resource
Now that the resource is synced over both nodes, we can start creating the actual file system for the block device. For DRBD, the contents of the file system isn’t important, DRBD only cares that the “blocks” are equal on both sides. This will also happen with the file system which we create:
[jensd@node01 ~]$ sudo mkfs.xfs /dev/drbd0
meta-data=/dev/drbd0 isize=256 agcount=4, agsize=65276 blks
= sectsz=512 attr=2, projid32bit=1
= crc=0
data = bsize=4096 blocks=261103, imaxpct=25
= sunit=0 swidth=0 blks
naming =version 2 bsize=4096 ascii-ci=0 ftype=0
log =internal log bsize=4096 blocks=853, version=2
= sectsz=512 sunit=0 blks, lazy-count=1
realtime =none extsz=4096 blocks=0, rtextents=0
After creating a filesystem on the DRBD resource, we can start putting data on the FS:
[jensd@node01 ~]$ sudo mount /dev/drbd0 /mnt [jensd@node01 ~]$ sudo mkdir /mnt/test [jensd@node01 ~]$ sudo touch /mnt/f1 [jensd@node01 ~]$ sudo touch /mnt/f2
Test the failover
To do a (clean) manual failover, we can simply switch the primary and secondary nodes and check if the data got replicated to the second node and back:
[jensd@node01 ~]$ mount|grep /dev/drbd0 /dev/drbd0 on /mnt type xfs (rw,relatime,seclabel,attr2,inode64,noquota) [jensd@node01 ~]$ ls -al /mnt/ total 4 drwxr-xr-x. 3 root root 35 Nov 21 12:26 . dr-xr-xr-x. 17 root root 4096 Nov 21 10:05 .. -rw-r--r--. 1 root root 0 Nov 21 12:26 f1 -rw-r--r--. 1 root root 0 Nov 21 12:26 f2 drwxr-xr-x. 2 root root 6 Nov 21 12:26 test [jensd@node01 ~]$ sudo umount /mnt [jensd@node01 ~]$ sudo drbdadm secondary drbd0 [jensd@node01 ~]$ sudo drbd-overview 0:drbd0/0 Connected Secondary/Secondary UpToDate/UpToDate
[jensd@node02 ~]$ sudo drbdadm primary drbd0 [jensd@node02 ~]$ sudo mount /dev/drbd0 /mnt [jensd@node02 ~]$ sudo mount /dev/drbd0 /mnt [jensd@node02 ~]$ ls -al /mnt/ total 4 drwxr-xr-x. 3 root root 35 Nov 21 12:26 . dr-xr-xr-x. 17 root root 4096 Nov 21 10:04 .. -rw-r--r--. 1 root root 0 Nov 21 12:26 f1 -rw-r--r--. 1 root root 0 Nov 21 12:26 f2 drwxr-xr-x. 2 root root 6 Nov 21 12:26 test [jensd@node02 ~]$ sudo drbd-overview 0:drbd0/0 Connected Primary/Secondary UpToDate/UpToDate /mnt xfs 1017M 33M 985M 4%
In case you try to mount the resource on a node which is considered secondary, you should a message similar to this:
[jensd@node01 ~]$ sudo mount /dev/drbd0 /mnt mount: /dev/drbd0 is write-protected, mounting read-only mount: mount /dev/drbd0 on /mnt failed: Wrong medium type
Add the DRBD resource to our previously configured Pacemaker/Corosync cluster
In my previous post, I created a cluster with Apache to serve webpages in a high available setup. both nodes had to have an identical set of webpages in order to server the exact same content regardless of which node was the active one. Now we’ll add the DRBD-resource to the cluster and move the data for the website to the resource.
To configure DRBD on our cluster, we’ll first edit the configuration as we want it to be and then push it to the actual, running configuration. To accomplish this, we can create a new CIB (Cluster Information Base). Basically it’s a file that contains the complete cluster configuration.
[jensd@node01 ~]$ sudo pcs cluster cib add_drbd [jensd@node01 ~]$ ls -al add_drbd -rw-rw-r--. 1 jensd jensd 6968 Nov 21 12:40 add_drbd
If you would look at the contents of the file, you would find the complete, currently active, configuration in there.
Now, let’s add the changes to the cib-file to include our DRBD resource:
[jensd@node01 ~]$ sudo pcs -f add_drbd resource create webserver_data ocf:linbit:drbd drbd_resource=drbd0 op monitor interval=60s [jensd@node01 ~]$ sudo pcs -f add_drbd resource master webserver_data_sync webserver_data master-max=1 master-node-max=1 clone-max=2 clone-node-max=1 notify=true
We can query the CIB as we would do with the normal active configuration:
[jensd@node01 ~]$ sudo pcs -f add_drbd resource show virtual_ip (ocf::heartbeat:IPaddr2): Started webserver (ocf::heartbeat:apache): Started Master/Slave Set: webserver_data_sync [webserver_data] Stopped: [ node01 node02 ]
When the configuration is as want it to be, we can activate it by pushing it to the cluster:
[jensd@node01 ~]$ sudo pcs cluster cib-push add_drbd CIB updated
When looking at the status of our cluster now, we see that something clearly went wrong:
[jensd@node01 ~]$ sudo pcs status
Cluster name: cluster_web
Last updated: Fri Nov 21 13:18:07 2014
Last change: Fri Nov 21 13:17:55 2014 via cibadmin on node01
Stack: corosync
Current DC: node01 (1) - partition with quorum
Version: 1.1.10-32.el7_0.1-368c726
2 Nodes configured
4 Resources configured
Online: [ node01 node02 ]
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started node01
webserver (ocf::heartbeat:apache): Started node01
Master/Slave Set: webserver_data_sync [webserver_data]
webserver_data (ocf::linbit:drbd): FAILED node01 (unmanaged)
webserver_data (ocf::linbit:drbd): FAILED node02 (unmanaged)
Failed actions:
webserver_data_stop_0 on node01 'not installed' (5): call=22, status=complete, last-rc-change='Fri Nov 21 13:17:56 2014', queued=51ms, exec=0ms
webserver_data_stop_0 on node02 'not installed' (5): call=18, status=complete, last-rc-change='Fri Nov 21 13:17:56 2014', queued=43ms, exec=0ms
After a little investigation, it seems that the permissions on file /var/lib/pacemaker/cores do not allow write from DRBD. It found this by looking at /var/log/audit/audit.log:
type=AVC msg=audit(1416572808.128:620): avc: denied { dac_read_search } for pid=27616 comm="drbdadm-84" capability=2 scontext=system_u:system_r:drbd_t:s0 tcontext=system_u:system_r:drbd_t:s0 tclass=capability
type=SYSCALL msg=audit(1416572808.128:620): arch=c000003e syscall=2 success=no exit=-13 a0=4256d7 a1=80000 a2=666e6f632e6462 a3=7fffe11d3590 items=1 ppid=27613 pid=27616 auid=4294967295 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=(none) ses=4294967295 comm="drbdadm-84" exe="/usr/lib/drbd/drbdadm-84" subj=system_u:system_r:drbd_t:s0 key=(null)
type=CWD msg=audit(1416572808.128:620): cwd="/var/lib/pacemaker/cores"
The message saying that dac_read_search is denied means that the user doesn’t have access to the file but tries to elevate it’s permissions to get it.
We’ll change the permissions to world writable (not secure) to fix this on both nodes:
[jensd@node01 ~]$ sudo ls -al /var/lib/pacemaker/cores total 0 drwxr-x---. 2 hacluster haclient 6 Sep 30 14:40 . drwxr-x---. 6 hacluster haclient 57 Nov 21 10:33 .. [jensd@node01 ~]$ sudo chmod 777 /var/lib/pacemaker/cores
[jensd@node02 ~]$ sudo chmod 777 /var/lib/pacemaker/cores
After restarting the cluster, it’s still not working and now we can stil see very similar messages in the audit.log:
type=AVC msg=audit(1416573839.047:692): avc: denied { read } for pid=30198 comm="drbdadm-84" name="cores" dev="dm-2" ino=16918999 scontext=system_u:system_r:drbd_t:s0 tcontext=system_u:object_r:cluster_var_lib_t:s0 tclass=dir
type=SYSCALL msg=audit(1416573839.047:692): arch=c000003e syscall=2 success=no exit=-13 a0=4256d7 a1=80000 a2=666e6f632e6462 a3=7fffa43960a0 items=1 ppid=30197 pid=30198 auid=4294967295 uid=0 gid=0 euid=0 suid=0 fsuid=0 egid=0 sgid=0 fsgid=0 tty=(none) ses=4294967295 comm="drbdadm-84" exe="/usr/lib/drbd/drbdadm-84" subj=system_u:system_r:drbd_t:s0 key=(null)
type=CWD msg=audit(1416573839.047:692): cwd="/var/lib/pacemaker/cores"
The difference is that DRBD does have access to the file now but SELinux is trying to prevent access. To see which SELinux boolean we need to enable, if there is one to allow access:
[jensd@node01 ~]$ sudo tail -200 /var/log/audit/audit.log|grep AVC|tail -1|audit2allow -m drbd_0
module drbd_0 1.0;
require {
type cluster_var_lib_t;
type drbd_t;
class dir read;
}
#============= drbd_t ==============
#!!!! This avc can be allowed using the boolean 'daemons_enable_cluster_mode'
allow drbd_t cluster_var_lib_t:dir read;
As the output of audit2allow states, we can set daemons_enable_cluster_mode to enabled on both nodes to fix this:
[jensd@node01 ~]$ sudo setsebool daemons_enable_cluster_mode=1
[jensd@node02 ~]$ sudo setsebool daemons_enable_cluster_mode=1
When restarting the cluster, things should look a little better. Unfortunately, there is still a problem which doesn’t allow us to stop the cluster. Again SELinux is not allow us to take this action. Which is clear when looking at /var/log/audit/audit.log:
type=AVC msg=audit(1416575077.693:1532): avc: denied { sys_admin } for pid=40528 comm="drbdsetup-84" capability=21 scontext=system_u:system_r:drbd_t:s0 tcontext=system_u:system_r:drbd_t:s0 tclass=capability
We can allow this action by creating a new SELinux module and to load it:
[jensd@node01 ~]$ sudo tail -100 /var/log/audit/audit.log|grep AVC|tail -1|audit2allow -M drbd_1
******************** IMPORTANT ***********************
To make this policy package active, execute:
semodule -i drbd_1.pp
[jensd@node01 ~]$ cat drbd_1.te
module drbd_1 1.0;
require {
type drbd_t;
class capability sys_admin;
}
#============= drbd_t ==============
allow drbd_t self:capability sys_admin;
[jensd@node01 ~]$ sudo semodule -i drbd_1.pp
We’ll copy the module to node02 and load it there too:
[jensd@node02 ~]$ scp node01:/home/jensd/drbd_1.pp ~ jensd@node01's password: drbd_1.pp [jensd@node02 ~]$ sudo semodule -i drbd_1.pp
Now we can stop and start the cluster again and the output of the status command looks better:
[jensd@node01 ~]$ sudo pcs status
Cluster name: cluster_web
Last updated: Fri Nov 21 14:24:28 2014
Last change: Fri Nov 21 14:01:04 2014 via cibadmin on node01
Stack: corosync
Current DC: node01 (1) - partition with quorum
Version: 1.1.10-32.el7_0.1-368c726
2 Nodes configured
4 Resources configured
Online: [ node01 node02 ]
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started node01
webserver (ocf::heartbeat:apache): Started node01
Master/Slave Set: webserver_data_sync [webserver_data]
Masters: [ node02 ]
Slaves: [ node01 ]
The above output shows that the resource is successfully added and is started but since our master was still node02, this isn’t really how we want it. The master should be the node that is owning the virtual IP and is running the webserver.
First, we’ll create a filesystem resource on the cluster, using a new cib-file:
[jensd@node01 ~]$ sudo pcs cluster cib add_fs [jensd@node01 ~]$ sudo pcs -f add_fs resource create webserver_fs Filesystem device="/dev/drbd0" directory="/var/www/html" fstype="xfs"
Then we’ll create some constraints for the added resource:
The filesystem of the webserver should be made available on the master:
[jensd@node01 ~]$ sudo pcs -f add_fs constraint colocation add webserver_fs webserver_data_sync INFINITY with-rsc-role=Master
DRBD should first be started and then the file system should be made available:
[jensd@node01 ~]$ sudo pcs -f add_fs constraint order promote webserver_data_sync then start webserver_fs Adding webserver_data_sync webserver_fs (kind: Mandatory) (Options: first-action=promote then-action=start)
Apache and the file system should be running on the same node
[jensd@node01 ~]$ sudo pcs -f add_fs constraint colocation add webserver webserver_fs INFINITY
The file system needs to be made available before Apache is started:
[jensd@node01 ~]$ sudo pcs -f add_fs constraint order webserver_fs then webserver Adding webserver_fs webserver (kind: Mandatory) (Options: first-action=start then-action=start)
Next step is to acutally apply the changes which we made in the cib-file on the actual running configuration:
[jensd@node01 ~]$ sudo pcs cluster cib-push add_fs CIB updated
Normally, the actions should be performed immediately but I had to stop and start the cluster in order to get things working but this should be the result:
[jensd@node01 ~]$ sudo pcs status
Cluster name: cluster_web
Last updated: Fri Nov 21 15:05:22 2014
Last change: Fri Nov 21 15:05:13 2014 via cibadmin on node01
Stack: corosync
Current DC: node01 (1) - partition with quorum
Version: 1.1.10-32.el7_0.1-368c726
2 Nodes configured
5 Resources configured
Online: [ node01 node02 ]
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started node01
webserver (ocf::heartbeat:apache): Started node01
Master/Slave Set: webserver_data_sync [webserver_data]
Masters: [ node01 ]
Slaves: [ node02 ]
webserver_fs (ocf::heartbeat:Filesystem): Started node01
As the output shows, the DRBD master has become node01 and all resources were started on that node. Our constraints made sure that before the webserver was started, the virtual IP was available and that the DRBD-resource was mounted and available.
To be sure that the DRBD configuration went fine, we can check if our filesystem-resource did it’s work:
[jensd@node01 ~]$ mount|grep drbd0 /dev/drbd0 on /var/www/html type xfs (rw,relatime,seclabel,attr2,inode64,noquota) [jensd@node01 ~]$ ls -al /var/www/html/ total 0 drwxr-xr-x. 3 root root 35 Nov 21 15:07 . drwxr-xr-x. 4 root root 31 Nov 21 10:33 .. -rw-r--r--. 1 root root 0 Nov 21 12:26 f1 -rw-r--r--. 1 root root 0 Nov 21 12:26 f2 drwxr-xr-x. 2 root root 6 Nov 21 12:26 test
Finally, we can add data for our website to the mount: Let’s start with creating an index.html on our DRBD file system:
[jensd@node02 ~]$ sudo vi /var/www/html/index.html [jensd@node02 ~]$ cat /var/www/html/index.html <html> <h1>DRBD</h1> </html>
When stopping node01, everything should switch to node02 including the data which we just modified on node01:
[jensd@node01 ~]$ sudo pcs cluster stop
Stopping Cluster…
[jensd@node02 ~]$ sudo pcs status
Cluster name: cluster_web
Last updated: Fri Nov 21 15:12:27 2014
Last change: Fri Nov 21 15:05:13 2014 via cibadmin on node01
Stack: corosync
Current DC: node02 (2) - partition with quorum
Version: 1.1.10-32.el7_0.1-368c726
2 Nodes configured
5 Resources configured
Online: [ node02 ]
OFFLINE: [ node01 ]
Full list of resources:
virtual_ip (ocf::heartbeat:IPaddr2): Started node02
webserver (ocf::heartbeat:apache): Started node02
Master/Slave Set: webserver_data_sync [webserver_data]
Masters: [ node02 ]
Stopped: [ node01 ]
webserver_fs (ocf::heartbeat:Filesystem): Started node02
When checking the website, we get the modified webpage:
[jensd@node02 ~]$ curl http://192.168.202.100 <html> <h1>DRBD</h1> </html>
The above example was made for a webserver but can be used for various other services too. Unfortunately DRBD isn’t really supported as it should on RHEL or CentOS (at least not for free) so we need to perform some additional steps in order to get things working.