Here at Bobcares, we help Website owners, SaaS providers and Hosting companies run highly reliable web services.
One way we achieve that is by having server experts monitor production servers 24/7 and quickly resolving any issue that can affect uptime.
Recently, engineers at our 24×7 monitoring service noticed that a site hosted by our customer in a Docker server was offline.
We quickly logged in to the Docker host system and looked at the log files. This error showed up from the Nginx Gateway Docker container:
16440 upstream prematurely closed connection while reading response header from upstream, client:
[ Not using Docker, and still getting this error? Our Server Experts can fix it for you in a few minutes. Click here for help. ]
What does this error mean?
Every site hosted in this Docker server used an Nginx gateway to act as a fast reverse proxy.
So, all visits to any site will first come to the Nginx container, and then to the website’s Docker container as shown here:
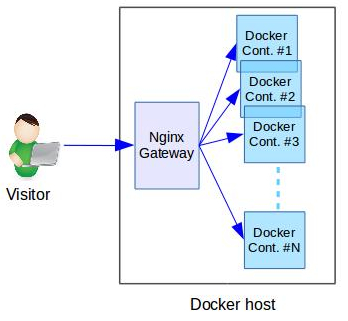
To understand the reason for a website downtime, it is important to look at both the gateway and website Docker containers.
The part of the error that says “upstream prematurely closed connection” means that the Nginx container was unable to get website content from the back-end website.
So, it is clear that the Website’s Docker container has a faulty web server.
[ Not using Docker, and still getting this error? Our Server Experts can fix it for you in a few minutes. Click here for help. ]
How we fixed “16440 upstream prematurely closed connection”
Getting at the root cause
Once we determined that the web server in the website’s Docker container isn’t working, we opened a terminal and looked at its log file.
We saw this error:
[10498834.773328] Memory cgroup out of memory: Kill process 19597 (apache2) score 171 or sacrifice child
[10498834.779985] Killed process 19597 (apache2) total-vm:326776kB, anon-rss:76648kB, file-rss:10400kB, shmem-rss:64kB
It means that the Docker container is killing the web server processes due to excess memory usage.
Determining how it happened
How did the website that worked fine till now suddenly start using up more memory?
We looked at the website’s file changes, and found that it was recently upgraded with additional plugins.
Additionally, we saw an increasing trend in the website traffic as well.
So, that means each visit to the site requires executing more scripts (there by taking more memory per connection), and there are a higher number of connections than 1 month back.
Solution alternatives
At this point, we had 2 solution alternatives:
- Remove the new plugins.
- Increase the memory allowance to the Docker container.
Considering that the website’s traffic is on an increasing trend, removing the plugins will only be a stopgap measure.
So, we contacted the website owner (on behalf of our customer, the Docker web host) and recommended to buy additional memory.
Resolving the issue
The website owner approved the upgrade and we increased the Docker memory by adjusting the “mem_limit” parameter in the Docker Compose configuration file.
mem_limit: 2500m
Once the container was recreated, the webserver started working fine again, and the site came back online.
Remember: There are other reasons for this error
While the issue presented here occurred in a Docker platform, it can happen in any system that runs Nginx web server.
Also, memory limit is one among the many reasons why a Docker container might fail.
So, if you are facing this error, and is finding it difficult to fix this error, we can fix it for you in a few minutes.
Click here to talk to our Server Experts. We are online 24/7.
SPEED UP YOUR SERVER TODAY!
Never again lose customers to poor page speed! Let us help you.
Contact Us once. Enjoy Peace Of Mind For Ever!
GET EXPERT ASSISTANCE
var google_conversion_label = «owonCMyG5nEQ0aD71QM»;
nginx is killin me.. so right now I have 502 Bad Gateway. error log says:
2016/10/12 17:39:53 [info] 3023#0: *464 client closed connection while waiting for request, client: 127.0.0.1, server: 0.0.0.0:443
2016/10/12 17:39:53 [info] 3023#0: *465 client closed connection while waiting for request, client: 127.0.0.1, server: 0.0.0.0:443
2016/10/12 17:39:55 [error] 3023#0: *459 upstream prematurely closed connection while reading response header from upstream, client: 127.0.0.1, server: local.beerhawk.co.uk, request: "GET / HTTP/1.1", upstream: "fastcgi://127.0.0.1:9000", host: "local.mydomain.co.uk"
my ngninx conf file now looks like this:
#user RobDee;
worker_processes auto;
#error_log logs/error.log;
#error_log logs/error.log info;
pid logs/nginx.pid;
events {
worker_connections 1024;
}
http {
include mime.types;
default_type application/octet-stream;
#log_format #main '$remote_addr - $remote_user [$time_local] "$request" '
# '$status $body_bytes_sent "$http_referer" '
# '"$http_user_agent" "$http_x_forwarded_for"';
access_log logs/access.log;
error_log logs/error.log;
sendfile on;
#tcp_nopush on;
#keepalive_timeout 0;
keepalive_timeout 65;
#gzip on;
server {
listen 80;
server_name default;
#charset koi8-r;
#access_log logs/host.access.log main;
location / {
root /Users/RobDee/workspace/beerhawk/web;
index index.html index.htm;
}
# HTTPS server
server {
listen 443 ;
server_name local.mydomain.co.uk local.beer.telegraph.co.uk;
ssl on;
ssl_protocols TLSv1 TLSv1.1 TLSv1.2;
ssl_certificate /usr/local/etc/nginx/cert.pem;
ssl_certificate_key /usr/local/etc/nginx/cert.key;
gzip_disable "msie6";
gzip_types text/plain application/xml application/x-javascript text/css application/json text/javascript;
access_log /usr/local/var/log/nginx/access.log;
error_log /usr/local/var/log/nginx/error.log debug;
log_not_found off;
root /Users/RobDee/workspace/beerhawk/web;
location /.htpasswd
{
return 403;
}
location ~ .css {
root /Users/RobDee/workspace/beerhawk/web;
expires max;
}
location ~* .(jpg|jpeg|png|gif|ico|js|woff|woff2|ttf)$ {
root /Users/RobDee/workspace/beerhawk/web;
access_log off;
expires max;
}
location ~* .(js|css)$ {
expires 1y;
log_not_found off;
}
location /
{
try_files $uri $uri/ /app_dev.php$is_args$args;
index index.php app_dev.php;
}
location ~ .php$ {
#root /Users/RobDee/workspace/beerhawk/web;
fastcgi_pass 127.0.0.1:9000;
fastcgi_index app_dev.php;
fastcgi_param SCRIPT_FILENAME $request_filename;
include fastcgi_params;
#fastcgi_read_timeout 3000;
}
}
include servers/*;
}
I have no clue what i’m doing wrong… anybody could help me pls
A very common error encountered within an Nginx and PHP-FPM setup is “upstream prematurely closed FastCGI stdout while reading response header from upstream”. You may face this error while executing large script files. So when you run a large PHP file it shows the 502 Bad Gateway error.

In this article, we will learn more about this error and how to fix it.
How to debug this error?
To debug this error, you need to check the error logs.
Use this command to check the nginx error log –
$ tail -f /var/log/nginx/error.logOutput
2021/01/20 12:27:15 [error] 5408#0: *1257 upstream prematurely closed FastCGI stdout while reading response header from upstream, client: 106.215.70.130, server: mydomain.com, request: "GET /script.php HTTP/2.0", upstream: "fastcgi://unix:/opt/bitnami/php/var/run/www.sock:", host: "www.mydomain.com", referrer: "https://www.mydomain.com/script.php"How to solve this error?
The error usually occurs when there is too much content on a web page and the server cannot handle it. So, the first step in solving this error is by doing the following –
- Reduce the amount of content on the pages
- Remove any errors, warning and notices
- Make sure your code is clean
If the error still exists, continue with the steps given below.
Increase client_body_timeout & client_header_timeout variable in nginx.conf file
You can solve this error is by increasing the value of the client_body_timeout & client_header_timeout variable. Use this command –
Command
$sudo vi /etc/nginx/nginx.confclient_body_timeout 2024;
client_header_timeout 1024;You need to increase the values of these variables slowly and check whether the error still pops up. But keep in mind that the values do not exceed the physical memory of server.
Then, restart the PHP-FPM and nginx service.
Command
sudo service php-fpm restart
sudo service nginx restartEnable zend_extension xdebug
Xdebug is an extension in PHP used for debugging and developing programs. It has the following features –
- A single step debugger that you can use with IDEs
- Offers a code coverage functionality that can be used with PHPUnit
- It upgrades the var_dump() function in PHP
- The extension can add stack traces for notices, warnings, exceptions and errors.
- Consists of an in-built profiler
- This offers functionality for recording function calls and variable assignment to the disk
To fix this error, you need to enable xdebug extension in the php.ini file. Use the command given below –
Command
sudo vi vi /etc/php.iniAdd these lines to enable the extension –
;[XDebug]
zend_extension = xdebug
xdebug.remote_enable = true
xdebug.remote_host = 127.0.0.1
xdebug.remote_port = 9000
xdebug.remote_handler = dbgp
xdebug.profiler_enable = 1
xdebug.profiler_output_dir = /tmpThen, restart the PHP-FPM and Nginx server using these lines of code.
Command
sudo service php-fpm restart
sudo service nginx restartAfter you enable the xdebug extension in php.ini file, then the php-fpm will display all the errors, warnings and notices to the nginx server.
Note: Although this is a way to fix this error, it is not very effective. It’s because enabling the xdebug extension requires a lot of processing power and memory space. This happens as the extension gives information about different kinds of errors.
Disable Error Reporting in php.ini file
If you disable error reporting in php.ini file, the upstream error will be solved.
When you stop the error reporting process, while the amount of memory consumption required for the procedure is reduced. This helps in fixing the issue.
To do this, first, open the php.ini file in your favourite code editor using the command given below.
Command
sudo vi vi /etc/php.iniThen, search for error_reporting and modify it to
error_reporting = ~E_ALLAfter that, restart the php-fpm and nginx services with the code below –
sudo service php-fpm restart
sudo service nginx restartUpgrade Your System’s RAM
This is perhaps the best practice when it comes to removing the upstream error. If the error persists even after you have performed the steps discussed above, you have to increase your server’s RAM. Before doing this, ensure that you have cleaned your code and removed errors.
Conclusion
The strategies mentioned above will surely help you to fix the “upstream prematurely closed FastCGI stdout while reading response header from upstream” issue. In some cases, a simple restart of the PHP-FPM service might resolve the issue.
Expected behaviour
Owncloud client should successfully sync large files
Actual behaviour
Can not sync large files. Syncing stops as soon as a file reaches 1GB.
Server configuration
Operating system: Debian Jessie 8
Web server: Apache/2.4.10
Database: MySQL 5.5.54
PHP version: PHP 7.0.17-1~dotdeb+8.1
ownCloud version: 9.1.4
Storage backend (external storage):
Client configuration
Client version: 2.3.1
Operating system: Windows 10
OS language: English
Qt version used by client package (Linux only, see also Settings dialog):
Client package (From ownCloud or distro) (Linux only):
Installation path of client:
Logs
Please use Gist (https://gist.github.com/) or a similar code paster for longer
logs.
-
Web server error log:
2017/04/16 11:00:59 [error] 28461#28461: *2072 upstream timed out (110: Connection timed out) while reading response header from upstream, client: 192.168.1.1, server: owncloud.example.com, request: «GET /remote.php/webdav/NewArrivals/file HTTP/1.1», upstream: «http://192.168.1.204:80/remote.php/webdav/NewArrivals/file», host: «owncloud.example.com» -
Server logfile: ownCloud log (data/owncloud.log):
{«reqId»:»cYxtvnjVwfi7BJd9ks5q»,»remoteAddr»:»192.168.1.1″,»app»:»PHP»,»message»:»Invalid argument supplied for foreach() at /var/www/owncloud/apps/activity/lib/Formatter/CloudIDFormatter.php#89″,»level»:3,»time»:»2017-04-16T12:50:50+02:00″,»method»:»GET»,»url»:»/ocs/v1.php/cloud/activity?page=0&pagesize=100&format=json»,»user»:»user»}
{«reqId»:»WcFGzfKmU0dyKXkVKyIY»,»remoteAddr»:»192.168.1.1″,»app»:»PHP»,»message»:»fseek(): stream does not support seeking at /var/www/owncloud/apps/files_external/3rdparty/icewind/streams/src/Wrapper.php#74″,»level»:3,»time»:»2017-04-16T12:51:03+02:00″,»method»:»GET»,»url»:»/remote.php/webdav/NewArrivals/file»,»user»:»user»}
Hi,
I have 2 Owncloud instances which are installed in two different countries. Both setups are identical. They are behind a reverse proxy (Nginx) that redirect the connections to the backend server. The owncloud installation is almost standard (Apache+MySQL+PHP7) as mentioned above. When I try to sync a large file (10GB+), the sync stops with an error «connection closed». I get the error message I mentioned above from the Nginx server. It is clear that the connection times out. I tried to increase the timout values in PHP (max execution time) and the reverse proxy but nothing helped. This is what I have in the reverse proxy:
location / { proxy_connect_timeout 159s; proxy_send_timeout 600; proxy_read_timeout 600; proxy_buffer_size 64k; proxy_buffers 16 32k; proxy_busy_buffers_size 64k; proxy_temp_file_write_size 64k; proxy_pass http://192.168.1.204; }
It’s also worth noting that I’m using federated shares. How can I track what exactly is timing out?
Subject
For long-running downloads, especially through a reverse proxy and using a client like Docker, adjusting a timeout value can resolve an error around unexpected timeouts.
Affected Versions
Artifactory 6.X and 7.X
Problem Description
This problem typically happens when downloading large files. These downloads naturally take, in this case, it’s always more than a minute. The other component of this problem is having a reverse proxy or Load Balancer in front of the Artifactory application. The clients that have the most trouble with this issue are ones that download files in chunks, such as Docker.
If you’ve hit this issue, the Docker client will show you an error when pulling a large layer. You would not find any errors in the Artifactory logs, the only issue would be logged by Nginx:2021/03/18 15:39:12 [error] 11196#11196: *526 upstream prematurely closed connection while reading upstream, client: 10.[...], server: ~(?<repo>.+).artifactory.com, request: "GET /v2/docker-local/blobs/sha256:d[...]e HTTP/1.1", upstream: "http://<Artifactory-IP>:8081/artifactory/api/docker/docker-local/v2/sha256:d[...]e", host: "docker-local.artifactory.com"
This error means the upstream, in this case, Artifactory, closed the connection.
Problem Resolution
Artifactory’s Apache Tomcat has a hidden timeout setting. In some circumstances, such as a long-running Docker Pull, this timeout is reached. When this happens, Tomcat closes the connection too soon. No Artifactory-side errors get printed when this happens.
By default, the Tomcat «connectionTimeout» parameter is set to 60 seconds. To solve most Docker Pull problems, increase the value to 600 seconds, or 10 minutes:[6.X - Directly update the tomcat server.xml]
<Connector port="8081" sendReasonPhrase="true" relaxedPathChars='[]' relaxedQueryChars='[]' maxThreads="200" connectionTimeout="600000"/>
[7.X - Update the system.yaml]
artifactory:
tomcat:
connector:
maxThreads: 200
extraConfig: 'connectionTimeout="600000"'
Symptoms
-
Uploading large files over PHP (about 500 MB or more) to a website on a Plesk for Linux server fails with the following error in the log file
/var/www/vhosts/system/example.com/logs/proxy_error_log:[error] 13840#0: *22012496 upstream prematurely closed connection while reading response header from upstream, client: 203.0.113.2, server: example.com, request: "POST /upload-files.php HTTP/1.1", upstream: http://203.0.113.2:7080/upload-file.php", host: "example.com", referrer: "http://example.com/upload-files.php"
-
PHP handler is set to FastCGI application by Apache in Domains > example.com > PHP Settings.
-
In Domains > example.com > PHP Settings, the parameters
max_input_time,post_max_size, andupload_max_filesizeare set to the sufficient values. -
The nginx parameters
client_max_body_size,proxy_connect_timeout,proxy_send_timeout, andproxy_read_timeoutare also set to the sufficient values (either in/etc/nginx/nginx.confor in Domains > example.com > Apache & nginx Settings > Additional nginx directives). -
The Apache parameters
FcgidMaxRequestLen(in Domains > example.com > Apache & nginx Settings > Additional Apache directives),FcgidIOTimeout(in/etc/apache2/mods-available/fcgid.confor/etc/httpd/conf.d/fcgid.conf) are also set to the sufficient values. -
The Apache parameter
FcgidBusyTimeoutis not overrided in any configuration files.
Cause
The default value – 300 seconds – of the parameter FcgidBusyTimeout is used, limiting the maximum time for handling FastCGI request to 5 minutes.
Resolution
-
Connect to the server via SSH
-
Open the configuration file
/etc/apache2/mods-available/fcgid.conf(on Debian or Ubuntu) or/etc/httpd/conf.d/fcgid.conf(on RHEL-based operating systems) in the text editor -
Inside the section
<IfModule mod_fcgid.c>, define the parameterFcgidBusyTimeoutin seconds:<IfModule mod_fcgid.c>
..........
FcgidBusyTimeout 1000
..........
</IfModule> -
Restart Apache to apply changes:
-
On Debian or Ubuntu:
# service apache2 restart
-
On RHEL-based operating systems:
# service httpd restart
-
Note: Repeat steps 3 and 4 in case the issue persist. Alternatively, consider to change to PHP-FPM going to Domains > example.com > PHP Setting