Градация значений средней ошибки аппроксимации
|
Значение |
Менее |
10% – |
20% – |
Более 50% |
|
Уровень |
высокая |
хорошая |
удовлетворительная |
неудовлетворительная |
Как
видно из таблицы, чем меньше ошибка
аппроксимации, тем ближе расчетные
уровни признака, полученные из уравнения
регрессии, к их фактическим значениям.
Коэффициент
регрессии применяют для расчета
коэффициента
эластичности,
который показывает на сколько процентов
изменится величина результативного Y
при изменении признак-фактора Х на 1%.
Для
определения коэффициента эластичности
используется формула:
![]()
.
(11.14)
4. Измерение тесноты связей в корреляционно-регрессионном анализе: определение линейного коэффициента корреляции и детерминации
В
случае линейной зависимости между Х и
Y
тесноту связи между признаками
устанавливают с помощью коэффициента
линейной корреляции (![]()
):
![]()
.
(11.15)
Значение
коэффициента линейной корреляции
изменяется в пределах от
![]()
.
Если
знак с положительным коэффициентом, то
связь прямая, а если с отрицательным,
то связь обратная. Чем ближе он к 1, тем
теснее связь.
Показатели
тесноты связи характеризуют зависимость
вариации результативного признака от
вариации факторного признака.
К
этим показателям относятся:
-
индекс
корреляции; -
индекс
детерминации.
Для
расчета этих индексов необходимы
сведения о различных видах дисперсий:
-
общей;
-
факторной;
-
остаточной.
Используем
условные обозначения:
![]()
– фактические
значения результативного признака;
–
расчетные значения результативного
признака;
–
среднее значение результативного
признака.
Общая
дисперсия
– характеризует общую вариацию
результативного признака у, объясняемую
влиянием всех факторов, действующих в
данной совокупности.
Общая
дисперсия
для несгруппированных данных:
![]()
.
(11.16)
Общая
взвешенная дисперсия (по сгруппированным
данным):
![]()
.
(11.17)
Общая
дисперсия раскладывается на 2 части:
Факторная
дисперсия (![]()
):
![]()
,
(11.18)
где
–
расчетное значение признака из уравнения
регрессии.
Она
объясняется фактором Х и характеризует
меру колеблемости расчетных значений
признака около их средней величины.
Остаточная
дисперсия:
![]()
.
(11.19)
Остаточная
дисперсия объясняется другими кроме Х
факторами и показывает меру колеблемости
фактических значений результативного
признака (
)
около теоретической линии регрессии
(
).
Эти
дисперсии связаны по правилу сложения
дисперсий, т.е.
![]()
.
(11.20)
Общая
дисперсия равна сумме факторной и
остаточной дисперсий.
На
основе правила сложения дисперсий
рассчитаем показатели тесноты связи:
-
Индекс
детерминации
(причинности), который выражает долю
факторной дисперсии в общей и показывает,
какая часть колеблемости результативного
признака Y
объясняется изучаемым фактором X.
Расчет производится по формуле:
![]()
.
(11.21)
Изменяется
в пределах
![]()
.
Долю
случайной вариации результативного
признака (под влиянием всех прочих
факторов, кроме Х) показывает отношение:
![]()
.
-
R
– индекс корреляции
(теоретическое корреляционное отношение):
![]()
(11.22)
или

.
(11.23)
Он
характеризует тесноту связи между
результативным и факторным признаками
и изменяется в пределах
![]()
.
При
функциональной зависимости значения
Yx
полностью совпадают с соответствующими
индивидуальными значениями Yij
. Тогда:
![]()
,
а
![]()
.
При
отсутствии связи вариация Х не отражается
на изменении Y.
В этом случае:
![]()
,
а
![]()
.
При
наличии корреляционной (соотносительной)
связи![]()
.
При этом величина
![]()
изменяется
в пределах
.
Для
получения выводов о практической
значимости полученных в анализе моделей,
показаниям тесноты связи дается
качественная оценка (табл. 11.2).
Таблица
11.2
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
From Wikipedia, the free encyclopedia
For broader coverage of this topic, see Approximation.

Graph of  (blue) with its linear approximation
(blue) with its linear approximation  (red) at a = 0. The approximation error is the gap between the curves, and it increases for x values further from 0.
(red) at a = 0. The approximation error is the gap between the curves, and it increases for x values further from 0.
The approximation error in a data value is the discrepancy between an exact value and some approximation to it. This error can be expressed as an absolute error (the numerical amount of the discrepancy) or as a relative error (the absolute error divided by the data value).
An approximation error can occur because of computing machine precision or measurement error (e.g. the length of a piece of paper is 4.53 cm but the ruler only allows you to estimate it to the nearest 0.1 cm, so you measure it as 4.5 cm).
In the mathematical field of numerical analysis, the numerical stability of an algorithm indicates how the error is propagated by the algorithm.
Formal definition[edit]
One commonly distinguishes between the relative error and the absolute error.
Given some value v and its approximation vapprox, the absolute error is

where the vertical bars denote the absolute value.
If  the relative error is
the relative error is

and the percent error (an expression of the relative error) is

In words, the absolute error is the magnitude of the difference between the exact value and the approximation. The relative error is the absolute error divided by the magnitude of the exact value.
An error bound is an upper limit on the relative or absolute size of an approximation error.
Generalizations[edit]
These definitions can be extended to the case when  and
and  are n-dimensional vectors, by replacing the absolute value with an n-norm.[1]
are n-dimensional vectors, by replacing the absolute value with an n-norm.[1]
Examples[edit]

Best rational approximants for π (green circle), e (blue diamond), ϕ (pink oblong), (√3)/2 (grey hexagon), 1/√2 (red octagon) and 1/√3 (orange triangle) calculated from their continued fraction expansions, plotted as slopes y/x with errors from their true values (black dashes)
- v
- t
- e
As an example, if the exact value is 50 and the approximation is 49.9, then the absolute error is 0.1 and the relative error is 0.1/50 = 0.002 = 0.2%. Another example would be if, in measuring a 6 mL beaker, the value read was 5 mL. The correct reading being 6 mL, this means the percent error in that particular situation is, rounded, 16.7%.
The relative error is often used to compare approximations of numbers of widely differing size; for example, approximating the number 1,000 with an absolute error of 3 is, in most applications, much worse than approximating the number 1,000,000 with an absolute error of 3; in the first case the relative error is 0.003 and in the second it is only 0.000003.
There are two features of relative error that should be kept in mind. Firstly, relative error is undefined when the true value is zero as it appears in the denominator (see below). Secondly, relative error only makes sense when measured on a ratio scale, (i.e. a scale which has a true meaningful zero), otherwise it would be sensitive to the measurement units. For example, when an absolute error in a temperature measurement given in Celsius scale is 1 °C, and the true value is 2 °C, the relative error is 0.5, and the percent error is 50%. For this same case, when the temperature is given in Kelvin scale, the same 1 K absolute error with the same true value of 275.15 K gives a relative error of 3.63×10−3 and a percent error of only 0.363%. Celsius temperature is measured on an interval scale, whereas the Kelvin scale has a true zero and so is a ratio scale. Thus the relative error is not very meaningful.
Instruments[edit]
In most indicating instruments, the accuracy is guaranteed to a certain percentage of full-scale reading. The limits of these deviations from the specified values are known as limiting errors or guarantee errors.[2]
See also[edit]
- Accepted and experimental value
- Condition number
- Errors and residuals in statistics
- Experimental uncertainty analysis
- Machine epsilon
- Measurement error
- Measurement uncertainty
- Propagation of uncertainty
- Quantization error
- Relative difference
- Round-off error
- Uncertainty
References[edit]
- ^ Golub, Gene; Charles F. Van Loan (1996). Matrix Computations – Third Edition. Baltimore: The Johns Hopkins University Press. p. 53. ISBN 0-8018-5413-X.
- ^ Helfrick, Albert D. (2005) Modern Electronic Instrumentation and Measurement Techniques. p. 16. ISBN 81-297-0731-4
External links[edit]
- Weisstein, Eric W. «Percentage error». MathWorld.
From Wikipedia, the free encyclopedia
For broader coverage of this topic, see Approximation.
Graph of (blue) with its linear approximation (red) at a = 0. The approximation error is the gap between the curves, and it increases for x values further from 0.
The approximation error in a data value is the discrepancy between an exact value and some approximation to it. This error can be expressed as an absolute error (the numerical amount of the discrepancy) or as a relative error (the absolute error divided by the data value).
An approximation error can occur because of computing machine precision or measurement error (e.g. the length of a piece of paper is 4.53 cm but the ruler only allows you to estimate it to the nearest 0.1 cm, so you measure it as 4.5 cm).
In the mathematical field of numerical analysis, the numerical stability of an algorithm indicates how the error is propagated by the algorithm.
Formal definition[edit]
One commonly distinguishes between the relative error and the absolute error.
Given some value v and its approximation vapprox, the absolute error is
where the vertical bars denote the absolute value.
If the relative error is
and the percent error (an expression of the relative error) is
In words, the absolute error is the magnitude of the difference between the exact value and the approximation. The relative error is the absolute error divided by the magnitude of the exact value.
An error bound is an upper limit on the relative or absolute size of an approximation error.
Generalizations[edit]
These definitions can be extended to the case when and are n-dimensional vectors, by replacing the absolute value with an n-norm.[1]
Examples[edit]
Best rational approximants for π (green circle), e (blue diamond), ϕ (pink oblong), (√3)/2 (grey hexagon), 1/√2 (red octagon) and 1/√3 (orange triangle) calculated from their continued fraction expansions, plotted as slopes y/x with errors from their true values (black dashes)
- v
- t
- e
As an example, if the exact value is 50 and the approximation is 49.9, then the absolute error is 0.1 and the relative error is 0.1/50 = 0.002 = 0.2%. Another example would be if, in measuring a 6 mL beaker, the value read was 5 mL. The correct reading being 6 mL, this means the percent error in that particular situation is, rounded, 16.7%.
The relative error is often used to compare approximations of numbers of widely differing size; for example, approximating the number 1,000 with an absolute error of 3 is, in most applications, much worse than approximating the number 1,000,000 with an absolute error of 3; in the first case the relative error is 0.003 and in the second it is only 0.000003.
There are two features of relative error that should be kept in mind. Firstly, relative error is undefined when the true value is zero as it appears in the denominator (see below). Secondly, relative error only makes sense when measured on a ratio scale, (i.e. a scale which has a true meaningful zero), otherwise it would be sensitive to the measurement units. For example, when an absolute error in a temperature measurement given in Celsius scale is 1 °C, and the true value is 2 °C, the relative error is 0.5, and the percent error is 50%. For this same case, when the temperature is given in Kelvin scale, the same 1 K absolute error with the same true value of 275.15 K gives a relative error of 3.63×10−3 and a percent error of only 0.363%. Celsius temperature is measured on an interval scale, whereas the Kelvin scale has a true zero and so is a ratio scale. Thus the relative error is not very meaningful.
Instruments[edit]
In most indicating instruments, the accuracy is guaranteed to a certain percentage of full-scale reading. The limits of these deviations from the specified values are known as limiting errors or guarantee errors.[2]
See also[edit]
- Accepted and experimental value
- Condition number
- Errors and residuals in statistics
- Experimental uncertainty analysis
- Machine epsilon
- Measurement error
- Measurement uncertainty
- Propagation of uncertainty
- Quantization error
- Relative difference
- Round-off error
- Uncertainty
References[edit]
- ^ Golub, Gene; Charles F. Van Loan (1996). Matrix Computations – Third Edition. Baltimore: The Johns Hopkins University Press. p. 53. ISBN 0-8018-5413-X.
- ^ Helfrick, Albert D. (2005) Modern Electronic Instrumentation and Measurement Techniques. p. 16. ISBN 81-297-0731-4
External links[edit]
- Weisstein, Eric W. «Percentage error». MathWorld.
Средняя ошибка аппроксимации
По семи территориям Уральского района за 199Х г. известны значения двух признаков.
| Район | Расходы на покупку продовольственных товаров в общих расходах, %, у | Среднедневная заработная плата одного работающего, руб., х |
| Удмуртская респ. | 68,8 | 45,1 |
| Свердловская обл. | 61,2 | 59,0 |
| Башкортостан | 59,9 | 57,2 |
| Челябинская обл. | 56,7 | 61,8 |
| Пермская обл. | 55,0 | 58,8 |
| Курганская обл. | 54,3 | 47,2 |
| Оренбургская обл. | 49,3 | 55,2 |
Требуется:
1. Для характеристики зависимости у от х рассчитать параметры следующих функций:
а) линейной;
б) степенной;
в) показательной;
г) равносторонней гиперболы (так же нужно придумать как предварительно линеаризовать данную модель).
2. Оценить каждую модель через среднюю ошибку аппроксимации Аср и F-критерий Фишера.
Решение проводим при помощь онлайн калькулятора Линейное уравнение регрессии.
а) линейное уравнение регрессии;
Использование графического метода.
Этот метод применяют для наглядного изображения формы связи между изучаемыми экономическими показателями. Для этого в прямоугольной системе координат строят график, по оси ординат откладывают индивидуальные значения результативного признака Y, а по оси абсцисс — индивидуальные значения факторного признака X.
Совокупность точек результативного и факторного признаков называется полем корреляции.
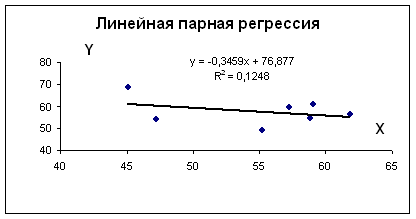
Для наших данных система уравнений имеет вид
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = -0.35, a = 76.88
Уравнение регрессии: y = -0.35 x + 76.88
| x | y | x 2 | y 2 | x • y | y(x) | (y i -y cp ) 2 | (y-y(x)) 2 | |y — y x |:y |
| 45,1 | 68,8 | 2034,01 | 4733,44 | 3102,88 | 61,28 | 119,12 | 56,61 | 0,1094 |
| 59 | 61,2 | 3481 | 3745,44 | 3610,8 | 56,47 | 10,98 | 22,4 | 0,0773 |
| 57,2 | 59,9 | 3271,84 | 3588,01 | 3426,28 | 57,09 | 4,06 | 7,9 | 0,0469 |
| 61,8 | 56,7 | 3819,24 | 3214,89 | 3504,06 | 55,5 | 1,41 | 1,44 | 0,0212 |
| 58,8 | 55 | 3457,44 | 3025 | 3234 | 56,54 | 8,33 | 2,36 | 0,0279 |
| 47,2 | 54,3 | 2227,84 | 2948,49 | 2562,96 | 60,55 | 12,86 | 39,05 | 0,1151 |
| 55,2 | 49,3 | 3047,04 | 2430,49 | 2721,36 | 57,78 | 73,71 | 71,94 | 0,172 |
| 384,3 | 405,2 | 21338,41 | 23685,76 | 22162,34 | 405,2 | 230,47 | 201,71 | 0,5699 |
Примечание: значения y(x) находятся из полученного уравнения регрессии:
y(45.1) = -0.35*45.1 + 76.88 = 61.28
y(59) = -0.35*59 + 76.88 = 56.47
. . .
Ошибка аппроксимации
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации. Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических:
F-статистики. Критерий Фишера.
Проверка значимости модели регрессии проводится с использованием F-критерия Фишера, расчетное значение которого находится как отношение дисперсии исходного ряда наблюдений изучаемого показателя и несмещенной оценки дисперсии остаточной последовательности для данной модели.
Если расчетное значение с k1=(m) и k2=(n-m-1) степенями свободы больше табличного при заданном уровне значимости, то модель считается значимой.
где m – число факторов в модели.
Оценка статистической значимости парной линейной регрессии производится по следующему алгоритму:
1. Выдвигается нулевая гипотеза о том, что уравнение в целом статистически незначимо: H0: R 2 =0 на уровне значимости α.
2. Далее определяют фактическое значение F-критерия:
где m=1 для парной регрессии.
3. Табличное значение определяется по таблицам распределения Фишера для заданного уровня значимости, принимая во внимание, что число степеней свободы для общей суммы квадратов (большей дисперсии) равно 1 и число степеней свободы остаточной суммы квадратов (меньшей дисперсии) при линейной регрессии равно n-2.
4. Если фактическое значение F-критерия меньше табличного, то говорят, что нет основания отклонять нулевую гипотезу.
В противном случае, нулевая гипотеза отклоняется и с вероятностью (1-α) принимается альтернативная гипотеза о статистической значимости уравнения в целом.
Табличное значение критерия со степенями свободы k1=1 и k2=5, Fkp = 6.61
Поскольку фактическое значение F b
в) показательная регрессия;
г) модель равносторонней гиперболы.
Система нормальных уравнений.
Для наших данных система уравнений имеет вид
7a + 0.1291b = 405.2
0.1291a + 0.0024b = 7.51
Из первого уравнения выражаем а и подставим во второе уравнение
Получаем b = 1054.67, a = 38.44
Уравнение регрессии:
y = 1054.67 / x + 38.44
Ошибка аппроксимации.
Оценим качество уравнения регрессии с помощью ошибки абсолютной аппроксимации.
Задача №3. Расчёт параметров регрессии и корреляции с помощью Excel
По территориям региона приводятся данные за 200Х г.
| Номер региона | Среднедушевой прожиточный минимум в день одного трудоспособного, руб., х | Среднедневная заработная плата, руб., у |
|---|---|---|
| 1 | 78 | 133 |
| 2 | 82 | 148 |
| 3 | 87 | 134 |
| 4 | 79 | 154 |
| 5 | 89 | 162 |
| 6 | 106 | 195 |
| 7 | 67 | 139 |
| 8 | 88 | 158 |
| 9 | 73 | 152 |
| 10 | 87 | 162 |
| 11 | 76 | 159 |
| 12 | 115 | 173 |
Задание:
1. Постройте поле корреляции и сформулируйте гипотезу о форме связи.
2. Рассчитайте параметры уравнения линейной регрессии
 .
.
3. Оцените тесноту связи с помощью показателей корреляции и детерминации.
4. Дайте с помощью среднего (общего) коэффициента эластичности сравнительную оценку силы связи фактора с результатом.
5. Оцените с помощью средней ошибки аппроксимации качество уравнений.
6. Оцените с помощью F-критерия Фишера статистическую надёжность результатов регрессионного моделирования.
7. Рассчитайте прогнозное значение результата, если прогнозное значение фактора увеличится на 10% от его среднего уровня. Определите доверительный интервал прогноза для уровня значимости  .
.
8. Оцените полученные результаты, выводы оформите в аналитической записке.
Решение:
Решим данную задачу с помощью Excel.
1. Сопоставив имеющиеся данные х и у, например, ранжировав их в порядке возрастания фактора х, можно наблюдать наличие прямой зависимости между признаками, когда увеличение среднедушевого прожиточного минимума увеличивает среднедневную заработную плату. Исходя из этого, можно сделать предположение, что связь между признаками прямая и её можно описать уравнением прямой. Этот же вывод подтверждается и на основе графического анализа.
Чтобы построить поле корреляции можно воспользоваться ППП Excel. Введите исходные данные в последовательности: сначала х, затем у.
Выделите область ячеек, содержащую данные.
Затем выберете: Вставка / Точечная диаграмма / Точечная с маркерами как показано на рисунке 1.

Рисунок 1 Построение поля корреляции
Анализ поля корреляции показывает наличие близкой к прямолинейной зависимости, так как точки расположены практически по прямой линии.
2. Для расчёта параметров уравнения линейной регрессии
воспользуемся встроенной статистической функцией ЛИНЕЙН.
1) Откройте существующий файл, содержащий анализируемые данные;
2) Выделите область пустых ячеек 5×2 (5 строк, 2 столбца) для вывода результатов регрессионной статистики.
3) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
4) В окне Категория выберете Статистические, в окне функция – ЛИНЕЙН. Щёлкните по кнопке ОК как показано на Рисунке 2;

Рисунок 2 Диалоговое окно «Мастер функций»
5) Заполните аргументы функции:
Известные значения у – диапазон, содержащий данные результативного признака;
Известные значения х – диапазон, содержащий данные факторного признака;
Константа – логическое значение, которое указывает на наличие или на отсутствие свободного члена в уравнении; если Константа = 1, то свободный член рассчитывается обычным образом, если Константа = 0, то свободный член равен 0;
Статистика – логическое значение, которое указывает, выводить дополнительную информацию по регрессионному анализу или нет. Если Статистика = 1, то дополнительная информация выводится, если Статистика = 0, то выводятся только оценки параметров уравнения.
Щёлкните по кнопке ОК;

Рисунок 3 Диалоговое окно аргументов функции ЛИНЕЙН
6) В левой верхней ячейке выделенной области появится первый элемент итоговой таблицы. Чтобы раскрыть всю таблицу, нажмите на клавишу , а затем на комбинацию клавиш + + .
Дополнительная регрессионная статистика будет выводиться в порядке, указанном в следующей схеме:
| Значение коэффициента b | Значение коэффициента a |
| Стандартная ошибка b | Стандартная ошибка a |
| Коэффициент детерминации R 2 | Стандартная ошибка y |
| F-статистика | Число степеней свободы df |
| Регрессионная сумма квадратов |

Остаточная сумма квадратов


Рисунок 4 Результат вычисления функции ЛИНЕЙН
Получили уровнение регрессии:

Делаем вывод: С увеличением среднедушевого прожиточного минимума на 1 руб. среднедневная заработная плата возрастает в среднем на 0,92 руб.
3. Коэффициент детерминации  означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
означает, что 52% вариации заработной платы (у) объясняется вариацией фактора х – среднедушевого прожиточного минимума, а 48% — действием других факторов, не включённых в модель.
По вычисленному коэффициенту детерминации можно рассчитать коэффициент корреляции:  .
.
Связь оценивается как тесная.
4. С помощью среднего (общего) коэффициента эластичности определим силу влияния фактора на результат.
Для уравнения прямой средний (общий) коэффициент эластичности определим по формуле:

Средние значения найдём, выделив область ячеек со значениями х, и выберем Формулы / Автосумма / Среднее, и то же самое произведём со значениями у.

Рисунок 5 Расчёт средних значений функции и аргумент

Таким образом, при изменении среднедушевого прожиточного минимума на 1% от своего среднего значения среднедневная заработная плата изменится в среднем на 0,51%.
С помощью инструмента анализа данных Регрессия можно получить:
— результаты регрессионной статистики,
— результаты дисперсионного анализа,
— результаты доверительных интервалов,
— остатки и графики подбора линии регрессии,
— остатки и нормальную вероятность.
Порядок действий следующий:
1) проверьте доступ к Пакету анализа. В главном меню последовательно выберите: Файл/Параметры/Надстройки.
2) В раскрывающемся списке Управление выберите пункт Надстройки Excel и нажмите кнопку Перейти.
3) В окне Надстройки установите флажок Пакет анализа, а затем нажмите кнопку ОК.
• Если Пакет анализа отсутствует в списке поля Доступные надстройки, нажмите кнопку Обзор, чтобы выполнить поиск.
• Если выводится сообщение о том, что пакет анализа не установлен на компьютере, нажмите кнопку Да, чтобы установить его.
4) В главном меню последовательно выберите: Данные / Анализ данных / Инструменты анализа / Регрессия, а затем нажмите кнопку ОК.
5) Заполните диалоговое окно ввода данных и параметров вывода:
Входной интервал Y – диапазон, содержащий данные результативного признака;
Входной интервал X – диапазон, содержащий данные факторного признака;
Метки – флажок, который указывает, содержит ли первая строка названия столбцов или нет;
Константа – ноль – флажок, указывающий на наличие или отсутствие свободного члена в уравнении;
Выходной интервал – достаточно указать левую верхнюю ячейку будущего диапазона;
6) Новый рабочий лист – можно задать произвольное имя нового листа.
Затем нажмите кнопку ОК.

Рисунок 6 Диалоговое окно ввода параметров инструмента Регрессия
Результаты регрессионного анализа для данных задачи представлены на рисунке 7.

Рисунок 7 Результат применения инструмента регрессия
5. Оценим с помощью средней ошибки аппроксимации качество уравнений. Воспользуемся результатами регрессионного анализа представленного на Рисунке 8.

Рисунок 8 Результат применения инструмента регрессия «Вывод остатка»
Составим новую таблицу как показано на рисунке 9. В графе С рассчитаем относительную ошибку аппроксимации по формуле:


Рисунок 9 Расчёт средней ошибки аппроксимации
Средняя ошибка аппроксимации рассчитывается по формуле:

Качество построенной модели оценивается как хорошее, так как  не превышает 8 – 10%.
не превышает 8 – 10%.
6. Из таблицы с регрессионной статистикой (Рисунок 4) выпишем фактическое значение F-критерия Фишера: 

Поскольку  при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
при 5%-ном уровне значимости, то можно сделать вывод о значимости уравнения регрессии (связь доказана).
8. Оценку статистической значимости параметров регрессии проведём с помощью t-статистики Стьюдента и путём расчёта доверительного интервала каждого из показателей.
Выдвигаем гипотезу Н0 о статистически незначимом отличии показателей от нуля:
 .
.
 для числа степеней свободы
для числа степеней свободы 
На рисунке 7 имеются фактические значения t-статистики:

t-критерий для коэффициента корреляции можно рассчитать двумя способами:
I способ: 
где  – случайная ошибка коэффициента корреляции.
– случайная ошибка коэффициента корреляции.
Данные для расчёта возьмём из таблицы на Рисунке 7.

II способ: 
Фактические значения t-статистики превосходят табличные значения:


Поэтому гипотеза Н0 отклоняется, то есть параметры регрессии и коэффициент корреляции не случайно отличаются от нуля, а статистически значимы.
Доверительный интервал для параметра a определяется как

Для параметра a 95%-ные границы как показано на рисунке 7 составили:

Доверительный интервал для коэффициента регрессии определяется как

Для коэффициента регрессии b 95%-ные границы как показано на рисунке 7 составили:

Анализ верхней и нижней границ доверительных интервалов приводит к выводу о том, что с вероятностью  параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
параметры a и b, находясь в указанных границах, не принимают нулевых значений, т.е. не являются статистически незначимыми и существенно отличны от нуля.
7. Полученные оценки уравнения регрессии позволяют использовать его для прогноза. Если прогнозное значение прожиточного минимума составит:

Тогда прогнозное значение прожиточного минимума составит:

Ошибку прогноза рассчитаем по формуле:

где 
Дисперсию посчитаем также с помощью ППП Excel. Для этого:
1) Активизируйте Мастер функций: в главном меню выберете Формулы / Вставить функцию.
2) В окне Категория выберете Статистические, в окне функция – ДИСП.Г. Щёлкните по кнопке ОК.
3) Заполните диапазон, содержащий числовые данные факторного признака. Нажмите ОК.

Рисунок 10 Расчёт дисперсии
Получили значение дисперсии 
Для подсчёта остаточной дисперсии на одну степень свободы воспользуемся результатами дисперсионного анализа как показано на Рисунке 7.


Доверительные интервалы прогноза индивидуальных значений у при  с вероятностью 0,95 определяются выражением:
с вероятностью 0,95 определяются выражением:



Интервал достаточно широк, прежде всего, за счёт малого объёма наблюдений. В целом выполненный прогноз среднемесячной заработной платы оказался надёжным.
Условие задачи взято из: Практикум по эконометрике: Учеб. пособие / И.И. Елисеева, С.В. Курышева, Н.М. Гордеенко и др.; Под ред. И.И. Елисеевой. – М.: Финансы и статистика, 2003. – 192 с.: ил.
Средней ошибки аппроксимации качество уравнений
Оценка этой формы связи по коэффициенту множественной корреляции и средней ошибке аппроксимации показывает, что адекватность данной модели не подтверждается. Действительно, хотя значение коэффициента достаточно высокое (0,92), средняя ошибка аппроксимации составляет более 10% (I = 14,5%). Поэтому данная форма должна быть исключена из перебора известных уравнений регрессии. [c.29]
Анализ полученной формы связи по той же причине, что и в первом случае, позволяет сделать вывод о непригодности и этой модели. Коэффициент множественной корреляции хотя и имеет более высокое значение, чем в линейной зависимости (0,93), но по величине средней ошибки аппроксимации (б = 12,4%) это уравнение регрессии подлежит исключению из дальнейшего перебора. [c.29]
Последняя модель себестоимости добычи нефти, как показывает оценка ее по известным критериям, удовлетворяет условиям адекватности. Коэффициент множественной корреляции R составляет 0,98, что свидетельствует о том, что колеблемость исследуемого показателя более чем на 96 % определяется факторами, включенными в эту модель. При оценке по f-критерию (t R = 30,5) можно утверждать, что с вероятностью 0,99 факторы, включенные в модель, имеют существенную связь с исследуемым показателем (t a n = 2,58). Средняя ошибка аппроксимации составляет всего лишь 2,9 %, а F-критерий, характеризующий уровень остаточной дисперсии, превышает критическое (табличное) значение в четыре раза. К этому следует добавить, что полученная модель себестоимости добычи нефти представляет собой достаточно простую форму связи, легко решается и поддается экономической интерпретации. [c.30]
Оценка полученной модели по статистическим характеристикам показывает, что колеблемость затрат исследуемой подсистемы на 85 % обусловлена колеблемостью факторов, включенных в модель, коэффициент множественной корреляции высокий (/ = 0,92) и существенный (f = = 39,8), модель является адекватной, средняя ошибка аппроксимации (ё = 5,7%) меньше 10%. [c.39]
Статистический анализ показывает, что уравнение значимо Рф = 5,054 при /»табл = 3,01, корреляционное отношение равно 0,9959, ее»стандартная ошибка равна 0,0015. Среднее квадратическое отклонение расчетной себестоимости от фактической равно 0,018. Средняя ошибка аппроксимации 1,1%. [c.90]
Средняя ошибка аппроксимации [c.94]
Средняя ошибка аппроксимации. [c.95]
В случаях, когда трудно обосновать форму зависимости, решение задачи можно провести по разным моделям и сравнить полученные результаты. Адекватность разных моделей фактическим зависимостям проверяется по критерию Фишера, показателю средней ошибки аппроксимации и величине множественного коэффициента детерминации, о которых речь пойдет несколько позже (см. 7.4). [c.144]
Эти сведения вводятся в ПЭВМ и рассчитываются матрицы парных и частных коэффициентов корреляции, уравнение множественной регрессии, а также показатели, с помощью которых оценивается надежность коэффициентов корреляции и уравнения связи критерий Стьюдента, критерий Фишера, средняя ошибка аппроксимации, множественные коэффициенты корреляции и детерминации. [c.145]
Для того чтобы убедиться в надежности уравнения связи и правомерности его использования для практической цели, необходимо дать статистическую оценку надежности показателей связи. Для этого используются критерий Фишера (F-отношение), средняя ошибка аппроксимации ( ), коэффициенты множественной корреляции (/ ) и детерминации (D). [c.151]
Для статистической оценки точности уравнения связи используется также средняя ошибка аппроксимации [c.152]
Чем меньше теоретическая линия регрессии (рассчитанная по уравнению) отклоняется от фактической (эмпиричной), тем меньше средняя ошибка аппроксимации. В нашем примере она составляет 0,0364, или 3,64 %. Учитывая, что в экономических расчетах допускается погрешность 5-8 %, можно сделать вывод, что исследуемое уравнение связи довольно точно описывает изучаемые зависимости. [c.152]
После построения уравнения регрессии необходимо сделать проверку его значимости с помощью специальных критериев установить, не является ли полученная зависимость, выраженная уравнением регрессии, случайной, т.е. можно ли ее использовать в прогнозных целях и для факторного анализа. В статистике разработаны методики строгой проверки значимости коэффициентов регрессии с помощью дисперсионного анализа и расчета специальных критериев (например, F-критерия). Нестрогая проверка может быть выполнена путем расчета среднего относительного линейного отклонения (ё), называемого средней ошибкой аппроксимации [c.123]
Модель считается адекватной, т.е. пригодной для практического использования, если средняя ошибка аппроксимации не превосходит 15%. [c.123]
Оценку качества построенной модели даст коэффициент (индекс) детерминации, а также средняя ошибка аппроксимации. [c.6]
Средняя ошибка аппроксимации — среднее отклонение расчетных значений от фактических [c.6]
Подставляя в данное уравнение фактические значения х, получаем теоретические значения результата ух. По ним рассчитаем показатели тесноты связи — индекс корреляции рху и среднюю ошибку аппроксимации 7, [c.13]
Рассчитать линейный коэффициент парной корреляции и среднюю ошибку аппроксимации. [c.16]
Это означает, что 52% вариации заработной латы (у) объясняется вариацией фактора х — среднедушевого прожиточного минимума. Качество модели определяет средняя ошибка аппроксимации [c.18]
Оцените с помощью средней ошибки аппроксимации качество уравнений. [c.38]
Оцените качество уравнений с помощью средней ошибки аппроксимации. [c.42]
Оцените качество уравнения через среднюю ошибку аппроксимации. [c.92]
Оцените качество каждого тренда через среднюю ошибку аппроксимации, линейный коэффициент автокорреляции отклонений. [c.166]
СРЕДНЯЯ ОШИБКА АППРОКСИМАЦИИ [c.87]
Представим расчет средней ошибки аппроксимации для уравнения ух = 9,876 + 5,129 hue в табл. 2.7. А = — 7,3 = 1,2%, что [c.88]
Расчет средней ошибки аппроксимации [c.88]
В стандартных программах чаще используется первая формула для расчета Средней ошибки аппроксимации. [c.88]
В чем смысл средней ошибки аппроксимации и как она определяется [c.89]
Средняя ошибка аппроксимации [c.10]
Выбор вида модели основан на логическом анализе изучаемых показателей, сравнении статистических характеристик (средняя ошибка аппроксимации, критерий Фишера, коэффициенты множественной корреляции и детерминации), рассчитанных для различных функций по одним и тем же первичным данным. [c.31]
Проверка приведенной в формуле (154) себестоимости по фактическим данным 103 СМУ показала, что средняя ошибка аппроксимации, определяющая степень соответствия расчетных значений фактическим, составила всего 1,5%, что вполне допустимо. [c.227]
Исчисляемый коэффициент детерминации получился равным 0,869. Это говорит о том, что размер заработной платы водителей на 86,9% зависит от Р и Л ри на 13,1% — от неучтенных в модели факторов. Средняя ошибка аппроксимации составила всего лишь 0,17%. Модель была получена на основе конкретных показателей ряда автотранспортных предприятий Владимирского транспортного управления, поэтому она может -быть использована в практической работе только на этих предприятиях. Предлагаемая же методика может быть использована в любом транспортном управлении, министерстве при планировании и анализе себестоимости автомобильных перевозок и установлении нормативов по заработной плате водителей за время работы на линии. [c.36]
источники:
http://ecson.ru/economics/econometrics/zadacha-3.raschyot-parametrov-regressii-i-korrelyatsii-s-pomoschju-excel.html
http://economy-ru.info/info/119599/