В языке T-SQL, как и во многих других языках программирования, есть возможность отслеживать и перехватывать ошибки, сегодня мы с Вами рассмотрим конструкцию TRY CATCH, с помощью которой мы как раз и можем обрабатывать исключительные ситуации, т.е. непредвиденные ошибки.
Как Вы уже поняли, речь здесь пойдет не о синтаксических ошибках, о которых нам сообщает SQL сервер еще до начала выполнения самих SQL инструкций, а об ошибках, которые могут возникнуть на том или ином участке кода при определенных условиях.
Самый простой пример — это деление на ноль, как Вы знаете, делить на ноль нельзя, но эта цифра все-таки может возникнуть в операциях деления. Также существуют и другие ошибки, которые могут возникнуть в операциях над нестандартными, некорректными данными, хотя те же самые операции с обычными данными выполняются без каких-либо ошибок.
Поэтому в языке Transact-SQL существует специальная конструкция TRY…CATCH, она появилась в 2005 версии SQL сервера, и которая используется для обработки ошибок. Если кто знаком с другими языками программирования, то Вам эта конструкция скорей всего знакома, так как она используется во многих языках программирования.
Заметка! Для профессионального изучения языка T-SQL рекомендую посмотреть мои видеокурсы по T-SQL.
Содержание
- Конструкция TRY CATCH в T-SQL
- Важные моменты про конструкцию TRY CATCH в T-SQL
- Функции для получения сведений об ошибках
- Пример использования конструкции TRY…CATCH для обработки ошибок
TRY CATCH – это конструкция языка Transact-SQL для обработки ошибок. Все, что Вы хотите проверять на ошибки, т.е. код в котором могут возникнуть ошибки, Вы помещаете в блок TRY. Начало данного блока обозначается инструкцией BEGIN TRY, а окончание блока, соответственно, END TRY.
Все, что Вы хотите выполнять в случае появления ошибки, т.е. те инструкции, которые должны выполниться, если в блоке TRY возникла ошибка, Вы помещаете в блок CATCH, его начало обозначается BEGIN CATCH, а окончание END CATCH. Если никаких ошибок в блоке TRY не возникло, то блок CATCH пропускается и выполняются инструкции, следующие за ним. Если ошибки возникли, то выполняются инструкции в блоке CATCH, а после выполняются инструкции, следующие за данным блоком, иными словами, все инструкции, следующие за блоком CATCH, будут выполнены, если, конечно же, мы принудительно не завершили выполнение пакета в блоке CATCH.

Сам блок CATCH не передает никаких сведений об обнаруженных ошибках в вызывающее приложение, если это нужно, например, узнать номер или описание ошибки, то для этого Вы можете использовать инструкции SELECT, RAISERROR или PRINT в блоке CATCH.
Важные моменты про конструкцию TRY CATCH в T-SQL
- Блок CATCH должен идти сразу же за блоком TRY, между этими блоками размещение инструкций не допускается;
- TRY CATCH перехватывает все ошибки с кодом серьезности, большим 10, которые не закрывают соединения с базой данных;
- В конструкции TRY…CATCH Вы можете использовать только один пакет и один блок SQL инструкций;
- Конструкция TRY…CATCH может быть вложенной, например, в блоке TRY может быть еще одна конструкция TRY…CATCH, или в блоке CATCH Вы можете написать обработчик ошибок, на случай возникновения ошибок в самом блоке CATCH;
- Оператор GOTO нельзя использовать для входа в блоки TRY или CATCH, он может быть использован только для перехода к меткам внутри блоков TRY или CATCH;
- Обработка ошибок TRY…CATCH в пользовательских функциях не поддерживается;
- Конструкция TRY…CATCH не обрабатывает следующие ошибки: предупреждения и информационные сообщения с уровнем серьезности 10 или ниже, разрыв соединения, вызванный клиентом, завершение сеанса администратором с помощью инструкции KILL.
Функции для получения сведений об ошибках
Для того чтобы получить информацию об ошибках, которые повлекли выполнение блока CATCH можно использовать следующие функции:
- ERROR_NUMBER() – возвращает номер ошибки;
- ERROR_MESSAGE() — возвращает описание ошибки;
- ERROR_STATE() — возвращает код состояния ошибки;
- ERROR_SEVERITY() — возвращает степень серьезности ошибки;
- ERROR_PROCEDURE() — возвращает имя хранимой процедуры или триггера, в котором произошла ошибка;
- ERROR_LINE() — возвращает номер строки инструкции, которая вызвала ошибку.
Если эти функции вызвать вне блока CATCH они вернут NULL.
Пример использования конструкции TRY…CATCH для обработки ошибок
Для демонстрации того, как работает конструкция TRY…CATCH, давайте напишем простую SQL инструкцию, в которой мы намеренно допустим ошибку, например, попытаемся выполнить операцию деление на ноль.
--Начало блока обработки ошибок
BEGIN TRY
--Инструкции, в которых могут возникнуть ошибки
DECLARE @TestVar1 INT = 10,
@TestVar2 INT = 0,
@Rez INT
SET @Rez = @TestVar1 / @TestVar2
END TRY
--Начало блока CATCH
BEGIN CATCH
--Действия, которые будут выполняться в случае возникновения ошибки
SELECT ERROR_NUMBER() AS [Номер ошибки],
ERROR_MESSAGE() AS [Описание ошибки]
SET @Rez = 0
END CATCH
SELECT @Rez AS [Результат]
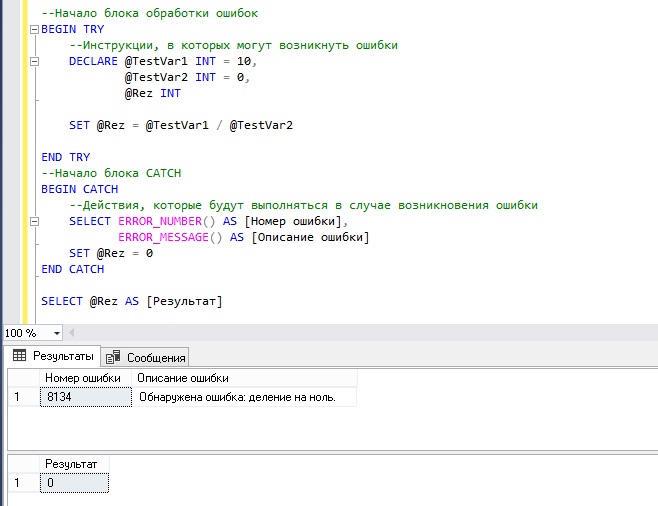
В данном случае мы выводим номер и описание ошибки с помощью функций ERROR_NUMBER() и ERROR_MESSAGE(), а также присваиваем переменной с итоговым результатом значение 0, как видим, инструкции после блока CATCH продолжают выполняться.
У меня на этом все, надеюсь, материал был Вам полезен, пока!
Grant Fritchey steps into the workbench arena, with an example-fuelled examination of catching and gracefully handling errors in SQL 2000 and 2005, including worked examples of the new TRY..CATCH capabilities.
Error handling in SQL Server breaks down into two very distinct situations: you’re handling errors because you’re in SQL Server 2005 or you’re not handling errors because you’re in SQL Server 2000. What’s worse, not all errors in SQL Server, either version, can be handled. I’ll specify where these types of errors come up in each version.
The different types of error handling will be addressed in two different sections. ‘ll be using two different databases for the scripts as well, [pubs] for SQL Server 2000 and [AdventureWorks] for SQL Server 2005.
I’ve broken down the scripts and descriptions into sections. Here is a Table of Contents to allow you to quickly move to the piece of code you’re interested in. Each piece of code will lead with the server version on which it is being run. In this way you can find the section and the code you want quickly and easily.
As always, the intent is that you load this workbench into Query Analyser or Management Studio and try it out for yourself! The workbench script is available in the downloads at the bottom of the article.
- GENERATING AN ERROR
- SEVERITY AND EXCEPTION TYPE
- TRAP AN ERROR
- USING RAISERROR
- RETURNING ERROR CODES FROM STORED PROCEDURES
- TRANSACTIONS AND ERROR TRAPPING
- EXTENDED 2005 ERROR TRAPPING
SQL Server 2000 – GENERATING AN ERROR
|
USE pubs GO UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ /* This will generate an error: Msg 547, Level 16, State 0, Line 1 The UPDATE statement conflicted with the CHECK constraint «CK__authors__zip__7F60ED59«. The conflict occurred in database «pubs«, table «dbo.authors«, column ‘zip’. |
SQL Server 2005 – GENERATING AN ERROR
|
USE AdventureWorks; GO UPDATE HumanResources.Employee SET MaritalStatus = ‘H’ WHERE EmployeeID = 100; /* This generates a familiar error: Msg 547, Level 16, State 0, Line 1 The UPDATE statement conflicted with the CHECK constraint «CK_Employee_MaritalStatus«. The conflict occurred in database «AdventureWorks«, table «HumanResources.Employee«, column ‘MaritalStatus’. The statement has been terminated. |
SQL Server 2000 AND 2005 – ERROR SEVERITY AND EXCEPTION TYPE
The error message provides several pieces of information:
- Msg
- A message number identifies the type fo error. Can up to the value of 50000. From that point forward custom user defined error messages can be defined.
- Level
-
The severity level of the error.
- 10 and lower are informational.
- 11-16 are errors in code or programming, like the error above.
- Errors 17-25 are resource or hardware errors.
- Any error with a severity of 20 or higher will terminate the connection (if not the server).
- Line
- Defines which line number the error occurred on and can come in extremely handy when troubleshooting large scripts or stored procedures.
- Message Text
- The informational message returned by SQL Server.
Error messages are defined and stored in the system table sysmessages.
SQL Server 2000 – CATCH AN ERROR
SQL Server 2000 does not allow us to stop this error being returned, but we can try to deal with it in some fashion. The core method for determining if a statement has an error in SQL Server 2000 is the @@ERROR value. When a statement completes, this value is set.
If the value equals zero(0), no error occured. Any other value was the result of an error.
The following TSQL will result in the statement ‘A constraint error has occurred’ being printed,as well as the error.
|
USE pubs GO UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ IF @@ERROR = 547 PRINT ‘A constraint error has occurred’ GO |
@@ERROR is reset by each and every statement as it occurs. This means that if we use the exact same code as above, but check the @@ERROR function a second time, it will be different.
|
UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ IF @@ERROR = 547 PRINT ‘A constraint error has occurred. Error Number:’ + CAST(@@ERROR AS VARCHAR) GO |
You will see the error number as returned by the @@ERROR statement as being zero(0), despite the fact that we just had a clearly defined error.
The problem is, while the UPDATE statement did in fact error out, the IF statement executed flawlessly and @@ERROR is reset after each and every statement in SQL Server.
In order to catch and keep these errors, you need to capture the @@ERROR value after each execution.
|
DECLARE @err INT UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err = 547 PRINT ‘A constraint error has occurred. Error Number:’ + CAST(@err AS VARCHAR) GO |
Now we can capture the error number and refer to it as often as needed within the code.
SQL Server 2005 – CATCH AN ERROR
While @@ERROR is still available in SQL Server 2005, a new syntax has been added to the T-SQL language, as implemented by Microsoft: TRY... CATCH.
This allows us to finally begin to perform real error trapping.
|
BEGIN TRY UPDATE HumanResources.Employee SET MaritalStatus = ‘H’ WHERE EmployeeID = 100; END TRY BEGIN CATCH PRINT ‘Error Handled’; END CATCH |
While there is an error encountered in the code, none is returned to the calling function. In fact, all that will happen in this case is the string 'Error Handled' is returned to the client.
We have actually performed the function of error trapping within TSQL.
There are a number of issues around the use of TRY...CATCH that have to be dealt with, which we will cover later. For example, simply having a TRY...CATCH statement is not enough.
Consider this example:
|
UPDATE HumanResources.Employee SET ContactID = 19978 WHERE EmployeeID = 100; BEGIN TRY UPDATE HumanResources.Employee SET MaritalStatus = ‘H’ WHERE EmployeeID = 100; END TRY BEGIN CATCH PRINT ‘Error Handled’; END CATCH |
The second error is handled, but the first one is not and we would see this error returned to client application:
|
Msg 547, LEVEL 16, State 0, Line 1 The UPDATE statement conflicted WITH the FOREIGN KEY CONSTRAINT «FK_Employee_Contact_ContactID« The conflict occurred IN DATABASE «AdventureWorks« TABLE «Person.Contact« COLUMN ‘ContactID’. |
To eliminate this problem place multiple statements within the TRY statement.
SQL Server 2000 – USING RAISERROR
The RAISERROR function is a mechanism for returning to calling applications errors with your own message. It can use system error messages or custom error messages. The basic syntax is easy:
|
RAISERROR (‘You made a HUGE mistake’,10,1) |
To execute RAISERROR you’ll either generate a string, up to 400 characters long, for the message, or you’ll access a message by message id from the master.dbo.sysmessages table.
You also choose the severity of the error raised. Severity levels used in RAISERROR will behave exactly as if the engine itself had generated the error. This means that a SEVERITY of 20 or above will terminate the connection. The last number is an arbitrary value that has to be between 1 and 127.
You can format the message to use variables. This makes it more useful for communicating errors:
|
RAISERROR(‘You broke the server: %s’,10,1,@@SERVERNAME) |
You can use a variety of different variables. You simply have to declare them by data type and remember that, even with variables, you have a 400 character limit. You also have some formatting options.
|
—Unsigned Integer RAISERROR(‘The current error number: %u’,10,1,@@ERROR) —String RAISERROR(‘The server is: %s’,10,1,@@SERVERNAME) —Compound String & Integer & limit length of string to first 5 —characters RAISERROR(‘The server is: %.5s. The error is: %u’,10,1, @@SERVERNAME,@@ERROR) —String with a minimum and maximum length and formatting to left RAISERROR(‘The server is: %-7.3s’,10,1,@@SERVERNAME) |
A few notes about severity and status. Status can be any number up to 127 and you can make use of it on your client apps. Setting the Status to 127 will cause ISQL and OSQL to return the error number to the operating environment.
|
— To get the error into the SQL Server Error Log RAISERROR(‘You encountered an error’,18,1) WITH LOG — To immediately return the error to the application RAISERROR(‘You encountered an error’,10,1) WITH NOWAIT — That also flushes the output buffer so any pending PRINT statements, — etc., are cleared. — To use RAISERROR as a debug statement RAISERROR(‘I made it to this part of the code’,0,1) |
SQL SERVER 2005 – USING RAISERROR
The function of RAISERROR in SQL Server 2005 is largely the same as for SQL 2000. However, instead of 400 characters, you have 2047. If you use 2048 or more, then 2044 are displayed along with an ellipsis.
RAISERROR will cause the code to jump from the TRY to the CATCH block.
Because of the new error handling capabilities, RAISERROR can be called in a more efficient manner in SQL Server 2005. This from the Books Online:
|
BEGIN TRY RAISERROR(‘Major error in TRY block.’,16,1); END TRY BEGIN CATCH DECLARE @ErrorMessage NVARCHAR(4000), @ErrorSeverity INT, @ErrorState INT; SET @ErrorMessage = ERROR_MESSAGE(); SET @ErrorSeverity = ERROR_SEVERITY(); SET @ErrorState = ERROR_STATE(); RAISERROR(@ErrorMessage,@ErrorSeverity,@ErrorState); END CATCH; |
SQL Server 2000 – RETURNING ERROR CODES FROM STORED PROCEDURES
Stored procedures, by default, return the success of execution as either zero or a number representing the failure of execution, but not necessarily the error number encountered.
|
CREATE PROCEDURE dbo.GenError AS UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ GO DECLARE @err INT EXEC @err = GenError SELECT @err |
This will cause an error and the SELECT statement will return a non-zero value. On my machine, -6. In order take control of this, modify the procedure as follows:
|
ALTER PROCEDURE dbo.GenError AS DECLARE @err INT UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err <> 0 RETURN @err ELSE RETURN 0 GO DECLARE @err INT EXEC @err = GenError SELECT @err |
This time the SELECT @err statement will return the 547 error number in the results. With that, you can begin to create a more appropriate error handling routine that will evolve into a coding best practice within your organization.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
ALTER PROCEDURE dbo.GenError AS DECLARE @err INT UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err <> 0 BEGIN IF @err = 547 RAISERROR(‘Check Constraint Error occurred’,16,1) ELSE RAISERROR(‘An unspecified error has occurred.’,10,1) RETURN @err END ELSE RETURN 0 GO |
SQL Server 2005 – RETURNING ERROR CODES FROM STORED PROCEDURES
In order to appropriately handle errors you to know what they are. You may also want to return the errors to the calling application. A number of new functions have been created so that you can appropriately deal with different errors, and log, report, anything you need, the errors that were generated.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 |
CREATE PROCEDURE GenErr AS BEGIN TRY UPDATE HumanResources.Employee SET ContactID = 19978 WHERE EmployeeID = 100; END TRY BEGIN CATCH PRINT ‘Error Number: ‘ + CAST(ERROR_NUMBER() AS VARCHAR); PRINT ‘Error Message: ‘ + ERROR_MESSAGE(); PRINT ‘Error Severity: ‘ + CAST(ERROR_SEVERITY() AS VARCHAR); PRINT ‘Error State: ‘ + CAST(ERROR_STATE() AS VARCHAR); PRINT ‘Error Line: ‘ + CAST(ERROR_LINE() AS VARCHAR); PRINT ‘Error Proc: ‘ + ERROR_PROCEDURE(); END CATCH GO DECLARE @err INT; EXEC @err = GenErr; SELECT @err; |
When you run the code above, you should receive this on the client, in the message, with a non-zero number in the result set:
|
(0 row(s) affected) Error Number: 547 Error Message: The UPDATE statement conflicted WITH the FOREIGN KEY CONSTRAINT «FK_Employee_Contact_ContactID« The conflict occurred IN DATABASE «AdventureWorks« TABLE «Person.Contact« COLUMN ‘ContactID’. Error Severity: 16 Error State: 0 Error Line: 4 Error Proc: GenErr |
In other words, everything you need to actually deal with errors as they occur.
You’ll also notice that the procedure returned an error value (non-zero) even though we didn’t specify a return code. You can still specify a return value as before if you don’t want to leave it up to the engine.
SQL Server 2000 – TRANSACTIONS AND ERROR TRAPPING
The one area of control we do have in SQL Server 2000 is around the transaction. In SQL Server 2000 you can decide to rollback or not, those are your only options. You need to make decision regarding whether or not to use XACT_ABORT. Setting it to ON will cause an entire transaction to terminate and rollback in the event of any runtime error. if you set it to OFF, then in some cases you can rollback the individual statement within the transaction as opposed to the entire transaction.
Modify the procedure to handle transactions:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
ALTER PROCEDURE dbo.GenError AS DECLARE @err INT BEGIN TRANSACTION UPDATE dbo.authors SET zip = ‘90210’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err <> 0 BEGIN IF @err = 547 PRINT ‘A constraint error has occurred.’ ELSE PRINT ‘An unspecified error has occurred.’ ROLLBACK TRANSACTION RETURN @err END UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err <> 0 BEGIN IF @err = 547 PRINT ‘A constraint error has occurred.’ ELSE PRINT ‘An unspecified error has occurred.’ ROLLBACK TRANSACTION RETURN @err END ELSE BEGIN COMMIT TRANSACTION RETURN 0 END GO DECLARE @err INT EXEC @err = GenError SELECT zip FROM dbo.authors WHERE au_id = ‘807-91-6654’ |
Since the above code will generate an error on the second statement, the transaction is rolled back as a unit. Switch to the results in order to see that the zip code is, in fact, still 90210. If we wanted to control each update as a seperate statement, in order to get one of them to complete, we could encapsulate each statement in a transaction:
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 |
ALTER PROCEDURE dbo.GenError AS DECLARE @err INT BEGIN TRANSACTION UPDATE dbo.authors SET zip = ‘90210’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err <> 0 BEGIN IF @err = 547 PRINT ‘A constraint error has occurred.’ ELSE PRINT ‘An unspecified error has occurred.’ ROLLBACK TRANSACTION RETURN @err END ELSE COMMIT TRANSACTION BEGIN TRANSACTION UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ SET @err = @@ERROR IF @err <> 0 BEGIN IF @err = 547 PRINT ‘A constraint error has occurred.’ ELSE PRINT ‘An unspecified error has occurred.’ ROLLBACK TRANSACTION RETURN @err END ELSE BEGIN COMMIT TRANSACTION RETURN 0 END GO DECLARE @err INT EXEC @err = GenError SELECT zip FROM dbo.authors WHERE au_id = ‘807-91-6654’ |
In this case then, the return value will be ‘90210’ since the first update statement will complete successfully. Be sure that whatever mechanism you use to call procedures does not itself begin a transaction as part of the call or the error generated will result in a rollback, regardless of the commit within the procedure. In the next example, we’ll create a transaction that wraps the other two transactions, much as a calling program would. If we then check for errors and commit or rollback based on the general error state, it’s as if the inner transaction that was successful never happened, as the outer transaction rollback undoes all the work within it.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 |
ALTER PROCEDURE dbo.GenError AS DECLARE @err1 INT DECLARE @err2 INT BEGIN TRANSACTION BEGIN TRANSACTION UPDATE dbo.authors SET zip = ‘90211’ WHERE au_id = ‘807-91-6654’ SET @err1 = @@ERROR IF @err1 <> 0 BEGIN IF @err1 = 547 PRINT ‘A constraint error has occurred.’ ELSE PRINT ‘An unspecified error has occurred.’ ROLLBACK TRANSACTION RETURN @err1 END ELSE COMMIT TRANSACTION BEGIN TRANSACTION UPDATE dbo.authors SET zip = ‘!!!’ WHERE au_id = ‘807-91-6654’ SET @err2 = @@ERROR IF @err2 <> 0 BEGIN IF @err2 = 547 PRINT ‘A constraint error has occurred.’ ELSE PRINT ‘An unspecified error has occurred.’ ROLLBACK TRANSACTION RETURN @err2 END ELSE BEGIN COMMIT TRANSACTION RETURN 0 END IF (@err1 <> 0) OR (@err2 <> 0) ROLLBACK TRANSACTION ELSE COMMIT TRANSACTION GO DECLARE @err INT EXEC @err = GenError SELECT zip FROM dbo.authors WHERE au_id = ‘807-91-6654’ |
SQL Server 2005 – TRANSACTIONS AND ERROR TRAPPING
The new error handling changes how transactions are dealt with. You can now check the transaction state using XACT_STATE() function. Transactions can be:
- Closed (equal to zero (0))
- Open but unable to commit (-1)
- Open and able to be committed (1)
From there, you can make a decision as to whether or not a transaction is committed or rolled back. XACT_ABORT works the same way.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 |
ALTER PROCEDURE GenErr AS BEGIN TRY BEGIN TRAN UPDATE HumanResources.Employee SET ContactID = 1/0 WHERE EmployeeID = 100; COMMIT TRAN END TRY BEGIN CATCH IF (XACT_STATE()) = —1 BEGIN ROLLBACK TRAN; RETURN ERROR_NUMBER(); END ELSE IF (XACT_STATE()) = 1 BEGIN —it now depends on the type of error or possibly the line number —of the error IF ERROR_NUMBER() = 8134 BEGIN ROLLBACK TRAN; RETURN ERROR_NUMBER(); END ELSE BEGIN COMMIT TRAN; RETURN ERROR_NUMBER(); END END END CATCH GO DECLARE @err INT; EXEC @err = GenErr; SELECT @err; |
SQL Server 2005 – EXTENDED 2005 ERROR TRAPPING
With the new TRY...CATCH construct, it’s finally possible to do things about errors, other than just return them. Take for example the dreaded deadlock. Prior to SQL Server 2005, the best you could hope for was to walk through the error messages stored in the log recorded by setting TRACEFLAG values. Now, instead, you can set up a retry mechanism to attempt the query more than once.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 |
ALTER PROCEDURE GenErr AS DECLARE @retry AS tinyint, @retrymax AS tinyint, @retrycount AS tinyint; SET @retrycount = 0; SET @retrymax = 2; SET @retry = 1; WHILE @retry = 1 AND @retrycount <= @retrymax BEGIN SET @retry = 0; BEGIN TRY UPDATE HumanResources.Employee SET ContactID = ContactID WHERE EmployeeID = 100; END TRY BEGIN CATCH IF (ERROR_NUMBER() = 1205) BEGIN SET @retrycount = @retrycount + 1; SET @retry = 1; END END CATCH END GO DECLARE @err INT; EXEC @err = GenErr; SELECT @err; |
- Другие части статьи:
- 1
- 2
- 3
- вперед »
TRY/CATCH, XACT_STATE, XACT_ABORT и транзакции.
Мы уже обсудили довольно много аспектов перехвата ошибок, но не коснулись аспекта, возможно, главного: а как вся эта «музыка» работает с такой вещью как транзакция? Ведь наши «потенциально опасные» инструкции исполняются обычно в рамках как-раз таки транзакций! Если ответить на поставленный вопрос коротко, то это будет «все работает». Но сказать что «все работает и нет никаких нюансов» было бы непростительной самонадеянностью, как раз к нюансам взаимодействия блоков перехвата и транзакций давайте переходить.
Стало быть, прежде всего что следует себе уяснить так это полную «отвязанность» двух конструкций друг от друга. Никто не «главный» и никто не «подчиненный». Никто не обязан быть блоком «объемлющим» и никто не обязан быть блоком «вложенным». Вполне может быть одно и не быть другого. Однако если все же есть и первое, и второе, то возникают вполне четко выраженные обязательства по отношению друг к другу. Как у нас вообще могут «сойтись» в одной точке кода и транзакции, и блоки перехвата и обработки? Очевидно — что-то во что-то вкладывается, как же еще? Не менее очевидно что способов вложения всего два. Или «TRY в транзакции»:
|
1 |
BEGIN TRAN |
Или «транзакция в TRY»:
|
1 |
BEGIN TRY |
Как было отмечено выше, в связи с полным отсутствием иерархических взаимоотношений между разбираемыми синтаксическими элементами нет и не может быть вложения «правильного» и «ошибочного». Оба показанных варианта функционально эквивалентны. Выбирайте любой исходя из эстетических своих предпочтений. Если вам это интересно, лично автору блога на котором вы в настоящий момент находитесь ближе и «родней» вариант номер 2. Он предпочитает что бы все вещи относящиеся к одной транзакции, включая и открытие оной, происходили в одном «месте», блоке. Однако, повторю, выбор между двумя показанными подходами — вопрос стиля, а не технической корректности кода.
Хорошо, вот эти две вещи соединились — какое главное правило такого «слияния»? Очень простое: если в блоке TRY у вас есть «ваша» открытая транзакция (открыли ли вы ее методом 1, или методом 2 — не важно), то совершенно все (без исключения!) пути исполнения вашего кода как в блоке TRY, так и в блоке CATCH обязаны вести к завершению транзакции хоть фиксацией («коммит»), хоть откатом («ролбэк»). Худшее что вы можете сделать — покинуть блок TRY/CATCH оставив транзакцию в «подвешенном» состоянии. Ну а каков план реализации этого «очень простого правила»? А вот тут и начинаются обещанные нюансы…
План «генеральный», в общем-то, уже показан в двух отрывках кода выше. Если блок TRY пройден почти до конца, то перед самой меткой END TRY мы транзакцию фиксируем — ведь мы не испытали никаких проблем при ее исполнении, верно? Конечно, никто не может нам запретить из анализа некоторой информации транзакцию в той же точке откатить, но чаще — фиксируем. Ну а если мы «свалились» в блок CATCH, то сразу же за меткой BEGIN CATCH (или, по крайней мере, недалеко от нее) мы транзакцию откатываем. А есть ли тут у нас свобода выбора безусловно присутствующая в блоке предыдущем? Можем ли мы находясь в блоке CATCH транзакцию все же зафиксировать? It, как говорится, depends. Давайте к коду:
|
1 |
USE tempdb |
Результаты:
и
Транзакция открыта и находится в фиксируемом состоянии, начинаю фиксацию…
Стало быть, один факт установлен доподлинно — есть варианты! И даже в блоке CATCH. Но, во-первых, обратите внимание, что из двух легальных значений колонки ID зафиксировалось (да и было вставлено, на самом деле) лишь первое. Ведь уходя в CATCH мы в TRY не возвращаемся, не забыли? А, во-вторых, обращают на себя внимание две новых синтаксических конструкции: XACT_ABORT до начала транзакции и XACT_STATE в блоке CATCH. «Разбор полетов» начнем с последней.
Функция XACT_STATE сообщает нам о состоянии текущей транзакции «внутри» которой мы находимся в момент вызова этой функции. XACT_STATE возвращает нам целое число и причем варианта всего три:
- 0 — никакой транзакции вообще нет, не о чем и беспокоиться в плане ее корректного завершения;
- 1 — активная транзакция есть и находится в состоянии допускающим как ее откат, так и ее фиксацию, выбор за нами;
- -1 — тоже активная транзакция есть, но она перешла в специальное «нефиксируемое» состояние. Единственно возможная операция с такой транзакцией — полный и безусловный ее откат. Который, тем не менее, не выполняется движком сервера в автоматическом режиме. И указание инструкции ROLLBACK остается прерогативой и обязанностью (причем одной из главнейших) нашего T-SQL программиста.
Ну с первым значением вопросов нет, отсутствует транзакция — так и нам спокойнее. А вот с двумя вторыми значениями? Отчего бывает так, а бывает и эдак? А это зависит от серьезности той ошибки что привела нас в блок CATCH. Если ошибка «жесткая» мы получаем -1, если «мягкая» — +1. Кстати говоря, если та же самая транзакция будет исполняться вне блока TRY/CATCH то «жесткая» ошибка приведет к полной отмене всей транзакции, со всеми инструкциями ее составляющими. А ошибка «мягкая» приведет к выкидыванию из состава транзакции лишь «плохой» инструкции, остальные инструкции той же транзакции будут продолжены. Скажем исполнение вот такого кода:
|
1 |
BEGIN TRANSACTION |
приведет к вставке двух строк и плюс к предупреждению
Cannot insert the value NULL into column ‘id’, table ‘tempdb.dbo.T1’; column does not allow nulls. INSERT fails.
И это все потому, что вставка нелегального значения — ошибка «мягкая». Измените строчку ее вызывающую, т.е.
на
|
1 |
ALTER TABLE T1 DROP CONSTRAINT NonExist |
и ни одна строка вставлена не будет, подавляющее число ошибок команд группы DDL — «жесткие». И, как вы правильно понимаете, если мы исправленный вариант нашей транзакции вновь «обернем» в TRY/CATCH, то сообщение будет
Транзакция открыта и находится в нефиксируемом состоянии, начинаю откат…
и уж конечно ни одна из вставляемых строк в таблице T1 обнаружена не будет. Так что разница между 1 и -1 возвращаемыми нам функцией XACT_STATE сводится к «жесткости» ошибки.
Хорошо, а роль второй инструкции, XACT_ABORT какова? А вот какова. Если значение этой опции (как и все прочие «SET-опции» она устанавливается для текущей сессии соединения с сервером) OFF — то «мягкие» ошибки будут «мягкими». А «жесткие», как легко догадаться, «жесткими». Кстати, каждое новое подключение начинает свою работу именно с этого значения обсуждаемой опции. А вот переводя эту опцию в значение противоположное мы заявляем, что хотим считать все ошибки — «жесткими». Ну и конечно хотим что бы движок сервера разделял эту нашу точку зрения. Например измените в скрипте чуть выше, где эта опция упомянута, ее значение на ON. В остальном оставьте скрипт как есть. Вы помните, что в предыдущий раз у нас одна строка вставилась в таблицу T1 и эта вставка была успешно зафиксирована. А что теперь?
Транзакция открыта и находится в нефиксируемом состоянии, начинаю откат…
и полное отсутствие записей в таблице T1.
Ну а какое значение опции XACT_ABORT «правильное»? Под каким лучше работать? А вот это — хороший вопрос если вы планируете начать новую «священную войну» на техническом форуме. Скажем так: если бы «хорошесть» того или другого варианта была доказана неопровержимо и на 120%, то команде разработчиков, надо думать, не составило бы труда прописать это «победившее» значение в код движка, а опцию XACT_ABORT просто убрать с глаз долой. Ан нет — не прописывают и не убирают. Апологеты обоих подходов приводят свои доказательства на тему «как надо жить», однако «финальный довод» пока не дался никому. Автор данных строк принадлежит лагерю сторонников опции ON и вот почему. Во-первых, при работе с распределенными запросами и распределенными транзакциями данное значение должно быть выставлено для XACT_ABORT без всяких дискуссий, просто потому что так предписывает BOL. Но распределенные запросы — случай частный и специфичный, так что аргумент получается хоть и неопровержимый, но уж очень «узконаправленный», не масштабный. Однако есть и более весомое во-вторых. Вот код:
|
1 |
USE tempdb |
Запустите показанный код в студии и пока он «вращается» в заданной 10-ти секундной задержке прервите его выполнение нажав кнопку Cancel Executing Query на панели студии либо выбрав одноименный пункт в меню Query. Если бы наш клиент предполагал выход из запроса по слишком долгому времени потраченному на его исполнение (query timeout) то можно было бы и выждать данный отрезок времени не «снося» запрос принудительно — все дальнейшие замечания не потеря ли бы своей актуальности. Так вот, отменив запрос мы видим что блок CATCH не отработал. И это разумеется, и это ожидаемо, ведь выполнение кода отменено, не правда ли? А вот о чем многие не подозревают, так это то, что транзакция осталась открытой. В чем легко убедиться открыв в редакторе студии еще одну вкладку и выполнив там
|
1 |
SELECT * FROM sys.dm_tran_active_transactions WHERE transaction_type=1 |
И будет она, транзакция наша, так и «висеть», пока клиент не удосужится сделать ей принудительный откат. Но «висит-то» она не просто «висит»: она сохраняет все свои блокировки, на ее поддержку тратятся ресурсы и т.д. Да, если клиент «отвалится» (закроет соединение) то требуемый откат совершит сам движок, без участия клиента. Однако тут есть большая «засада», помимо очевидной, что клиент еще должен «отвалиться» и не факт что это случится спустя микросекунду после отмены им «долгоиграющего» запроса. «Засада» заключается в том, что большинство современных платформ создания приложений пользователя (а энтузиасты ваявшие софт на чистом ассемблере давно перевелись) используют парадигму «пула подключений» (connection pool). И с этой парадигмой закрытие клиентом подключения вовсе не означает физический обрыв связи, подключение просто возвращается пулу «как есть» и готово со всем своим наследством в виде «висячей» транзакции «отдаться» новому клиенту. А потому транзакция не будет закрыта до тех пор, пока она или не будет закрыта соответствующей командой с клиента (возможно и не тем, который ее «повесил»), или пока подключение с нею не «уйдет» из пула, либо, всего надежней, пока не будет выключен весь пул целиком, например в виду завершения работы платформы как таковой.
Откатив из первой вкладки редактора проблемную транзакцию (ROLLBACK TRANSACTION), изменим в последнем скрипте значение опции на пропагандируемый автором блога ON. Вновь запустим тот же запрос и вновь прервем. Да, CATCH вновь не отработал — мы ж ему не дали этого сделать. Но и транзакции нет! В чем можно убедиться вновь запросив динамическое представление sys.dm_tran_active_transactions, как это было в первом эксперименте. Нету! Закрыто принудительно движком без всякого нашего вмешательства. Что, по мнению многих SQL-специалистов и автора блога так же, много, много лучше чем в варианте со значением OFF. Разумеется, вы можете сказать, что раз клиент открыл транзакцию, а потом отказался от запроса, то… «соображать же надо!». Надо, кто ж спорит. И правильно написанный клиент не только сделает Cancel, но и еще ROLLBACK своей же транзакции, причем сначала второе и лишь затем первое. Да вот кабы все те клиенты да были правильно написаны…
Можно привести и третий аргумент в поддержку опции ON. Как кажется автору (и, могу вас уверить, не только ему) поведение «ошибка — откат всей транзакции» является интуитивно ожидаемым, а поведение «ошибка — транзакция продолжается» является контр-интуитивным. Однако тут у каждого своя интуиция, не буду спорить. Как бы то ни было, опыт автора по написанию кучи строк T-SQL кода однозначно говорит о том, что опция ON обеспечивает нас желаемым и ожидаемым поведением транзакций и блоков TRY/CATCH в 99% случаев. Я ни разу не встречал ситуации когда транзакцию прерванную или превысившую свой тайм-аут не нужно было бы откатывать. А если это точно нужно — чего тянуть? Оставшиеся 1% когда оправдано применение опции OFF это случаи поиска и «отлова» конкретной ошибки в моем T-SQL коде и причем я еще хочу продолжить его исполнение после нахождения той ошибки за которой «охочусь». Повторю, что число таких случаев, с точки зрения автора, исчезающе мало, хоть и не равно абсолютному нулю.
Итак, теперь у читателей данного материала достаточно фактов что бы сделать свой выбор правильного (не абсолютно правильного, а правильного для конкретно их системы, за разработку/поддержку которой они отвечают) значения для этой «скользкой» опции — XACT_ABORT. Помимо всего изложенного выше при осуществлении такого выбора пусть читатели еще учтут:
- значением по умолчанию для данной опции, как уже отмечалось, является OFF. Так что утвердить безусловный, полный и необсуждаемый ON в масштабах предприятия/решения/команды разработки не так-то просто, людям свойственно стараться «плыть по течению». Потребуются контроль, дисциплина и самодисциплина;
- значение ON дает микроскопический, совершенно не ощутимый на практике плюс для производительности в силу того, что при таком значении движок мгновенно принимает решении об откате проблемной транзакции. Однако, повторю, плюс этот будет измеряться такими долями микросекунд, что автор отмечает его здесь исключительно для полноты изложения, а не в качестве аргумента для принятия решения;
- ни та, ни другая опция не имеют отношения к вопросу «произойдет ли сваливание в блок CATCH». Иными словами, если данная ошибка отправляет поток исполнения в блок CATCH — он отправится туда и в случае ON, и в случае OFF. Потому что это определяется не опцией XACT_ABORT, а… чем? Правильно — номером серьезности возникшей ошибки. XACT_ABORT отвечает на вопрос будут ли у нас варианты с нашей транзакцией в том же блоке, или нас ожидает ROLLBACK, только ROLLBACK и ничего кроме него.
С практической точки зрения, автор рекомендует своим читателям начинать любой T-SQL код со строки SET XACT_ABORT ON. Если этот код будет кодом создания новой хранимой процедуры, то просто возведите степень настойчивости данной рекомендации в квадрат. Если эта новая хранимая процедура планирует работу с явными транзакциями — в куб. А с еще более практической точки зрения заведите себе шаблон (template) для оформления своих хранимых процедур со всеми «обвесами» по умолчанию. В качестве «точки старта» можете воспользоваться шаблоном автора:
|
1 |
— ============================================= DECLARE @localTran bit BEGIN TRY —CODE GOES HERE IF @localTran = 1 AND XACT_STATE() = 1 END TRY DECLARE @ErrorMessage NVARCHAR(4000) SELECT @ErrorMessage = ERROR_MESSAGE(), IF @localTran = 1 AND XACT_STATE() <> 0 RAISERROR (‘**From %s**: ErrNum=%d:ErrSt=%d:ErrMsg=»%s»‘, 16, 1, @ErrorProc, @ErrorNum, @ErrorState, @ErrorMessage) END |

Разумеется, создать шаблон годящийся для 100% новых хранимых процедур нереально, хорошо если «степень покрытия» будет хотя бы процентов 50. Тем не менее у автора в его студии показанный шаблон «сидит» в Template Explorer (клавиши Ctrl+Alt+T, если вы не в курсе как его, обозреватель этот, открыть; либо ищите в меню View) под именем #Procedure_Main#, как это легко видеть из иллюстрации справа, и автор вполне доволен. Было б неплохо обсудить код этого шаблона, но это увело бы нас с темы «блоки TRY/CATCH» в тему «управление транзакциями», а это вопрос хоть и безусловно интересный, но свой и отдельный. Так что оставим такой разговор до лучших времен. Отмечу лишь, что ошибки генерируемые процедурами построенными на базе показанного шаблона будут иметь вот такой аккуратный и «причесанный» вид:
Msg 50000, Level 16, State 1, Procedure ABC, Line 56
**From ABC**: ErrNum=515:ErrSt=2:ErrMsg=»Cannot insert the value NULL into column ‘id’,
table ‘tempdb.dbo.T1’; column does not allow nulls. INSERT fails.»
Процедура ABC была создана из обсуждаемого шаблона, запущена и попыталась вставить некорректное значение в таблицу T1. Результат — перед вами.
Как правильно использовать обработчики исключений.
Пожалуй к текущей точке повествования мы с вами разобрали решительно все технические моменты относящиеся к технологии перехвата ошибок в языке T-SQL прямо или косвенно. Остались вопросы больше архитектурные, отделяющие приложения с правильным дизайном от приложений без такового. То есть нам осталось понять — когда и в каких обстоятельствах блоки TRY/CATCH уместны, а когда не очень.
Когда эта технология только появилась (а случилось это, напомню, лишь в версии 2005-й нашего сервера) на волне новизны и эйфории от такого «приближения к языкам C++/C#» было поветрие включать весь и каждый T-SQL код в блоки обработки ошибок. Что, разумеется, правильным не является ни разу. Соображения тут такие:
- включать 100% нашего кода в блок TRY однозначно не нужно! Когда мы пишем что-то в этом блоке мы, подспудно, говорим сами себе: «так, а вот тут у нас во время исполнения могут случится грабли». Скажем в наших примерах выше, мы включаем оператор PRINT в обсуждаемый блок, но делаем это с целью исключительно демонстрационной. Делать это на полном серьезе лишено какого-либо смысла, вы можете описать потенциальные «грабли» при выводе строки текста от сервера к клиенту? Разумеется, если мы это и сделаем ничего плохого не случится, просто код будет захламлен лишними синтаксическими элементами, да будут фигурировать блоки CATCH, чьи инструкции не имеют ни малейшего шанса быть исполненными хоть раз в жизни. Поэтому разумный подход — включать в блоки TRY только «потенциально проблемный» код. Не менее понятно, что если мы включаем в TRY целую транзакцию, а одна из ее инструкций тот самый PRINT — это совершенно нормально, не «резать» же транзакцию только что бы вычленить из нее эту «сверхнадежную» команду. А вот если вся транзакция состоит только из инструкций PRINT, то, конечно, она сама представляется очень странной (к чему тут транзакция?), но уж определенно блок TRY здесь и подавно не нужен. Итак, в фокус нашего внимания должны попадать лишь инструкции несущие «потенциальную угрозу».
- но и правило 100% «потенциально проблемного» кода должно быть включено в блок TRY тоже неверно. Скажем тот ж INSERT однозначно может иметь проблемы при выполнении сколь бы элементарен не был код этой инструкции (мы это уже обсуждали — журнал транзакций и т.п.). Вы эту возможную ошибку ясно видите, но вам решительно нечего «сказать по поводу»! Вы не хотите заморачиваться приращением журнала и повторной попыткой сделать INSERT еще раз, вы не хотите логировать факт ошибки в некоторый приемник, вы не возражаете если клиент получит стандартное серверное сообщение о произошедшей проблеме и т.д. Снова — к чему вам TRY? Что вы напишете в парном ему блоке CATCH? А поэтому еще более разумный подход — включать в блоки TRY только «потенциально проблемный» код, причем только тот, для которого у нас есть некий план, идея по преодолению означенных проблем или, как минимум, по их сохранению (не самих проблем, разумеется, а информации о них) для будущего анализа. Если никаких таких идей у нас нет — незачем и создавать платформу для их реализации.
Не менее важный и сложный вопрос звучит так: «свалившись» в блок CATCH и что-то там сделав (возможно даже нивелировав последствия случившейся ошибки), нужно ли скрыть произошедшую ошибку, «подавить» ее, или же применив RAISERROR следует дать знать вызывающему коду о постигшей нас неприятности? Вот тут все очень непросто. Дело в том, что по сути, перехватывая исключение, вы заявляете — «я знаю как нам быть в этом случае»! Однако очень сомнительно, что вы и вправду готовы преодолеть все возможные ошибки приводящие код в блок CATCH, даже с учетом, что это лишь подмножество всех ошибок имеющихся в запасе сервера. Слишком велико даже это подмножество, число его элементов исчисляется тысячами. Тут «во всей красе» проявляется молодость технологии перехвата исключений реализованная в языке T-SQL. Дело в том, что в языках использующих ту же технологию много-много лет, есть, по сути, негласное правило: данный блок CATCH работает с одной конкретной ошибкой. Для этого у означенного блока (т.е. прямо у ключевого слова CATCH) есть свой параметр означающий код, или тип, ошибки который и будет обрабатываться именно данным блоком, а блок TRY может иметь сколько угодно «прицепленных» к нему вот таких «узконаправленных» блоков CATCH. Если бы тоже самое было реализовано в T-SQL, то наша хранимая процедура могла бы иметь такой вид (псевдокод):
BEGIN TRY
…
…
END TRY
BEGIN CATCH (переполнение журнала)
добавить место в LDF файл
повторить транзакцию
END CATCH
BEGIN CATCH (деление на ноль)
вернуть в качестве результата -1
END CATCH
BEGIN CATCH (попытка дублировать первичный ключ)
с помощью RAISERROR сообщить клиенту расширенную информацию о дублирующей записи
END CATCH
К сожалению, нас вынуждают безусловно перехватывать все ошибки без всякой фильтрации, что в тех же языках поднаторевших в перехвате рассматривается всегда (почти) как дурной тон. Оно, конечно, можно эмулировать до некоторой степени приведенный выше псевдокод через анализ в единственном блоке CATCH номера ошибки (спасибо, что есть хотя бы удобная функция, ERROR_NUMBER), но тогда в определенном смысле мы откатываемся назад, во времена 2000-го сервера, когда точно так же анализировали @@ERROR и все было «просто и красиво», при условии, конечно, что вы находите спагетти-код красивым. То есть никакого четкого деления кода на блоки при таком подходе нам уже не видать, значимость технологии перехвата как таковой сильно нивелируется. Тем не менее, и еще раз к сожалению, если у вас нет плана по обработке именно всех ошибок (например — заношу их все в таблицу ErrorsTbl и дело с концом) обращения к ERROR_NUMBER и, как следствие, ветвления в коде блока CATCH вам неизбежать, увы. ![]()
Но, допустим, тем или иным алгоритмом вы перехватили ошибку, проанализировали ее, и даже, может быть, ее «обошли» (придумали что сделать с переполненным журналом, с нулем в знаменателе и т.п.). Нужно ли вам привлекать RAISERROR для повторного «броска» той же ошибки, или, может быть, ошибки ее замещающей? Или правильно будет такую исправленную ошибку «проглотить»? Снова — вопрос не предполагающий короткое «да» или «нет»… Скажем осторожно: скорее да («бросать» повторно), чем нет («проглатывать»), и вот почему. Дело в том, что на T-SQL пишется серверный код. Который потом будут использовать клиентские приложения. Приложений могут быть десятки разновидностей. Простые и сложные, «навороченные» и «для самых маленьких», для десктопа и для Web-а… В момент создания вашего T-SQL вы про весь этот «зоопарк» знать не можете. Теперь, допустим, вы кодируете вставку новой строки. Перехватили исключение, выяснили что причина в отсутствии места в файле лога (LDF), прирезали, повторили вставку — OK. Казалось бы, клиент хотел вставить строку и строка вставлена, ну чего его дергать сообщениями «а знаешь чего было»? Однако не исключено, что этот ваш код будет вызываться десктопным приложением написанным специально и исключительно для администраторов баз данных. И вот им, факт такого прирезания в рабочие часы может быть очень даже интересен. Ведь как знают читатели статьи Как перестать называть журнал транзакций SQL Server лог-файлом и прекратить борьбу за его размер изменения физических размеров файла журнала транзакций лучше проводить в часы вечерние и ночные. А случившееся может потенциально означать, что администратор неверно оценивает скорость прирастания данных (или объема транзакций) в системе за которую он отвечает. А то и вообще это может быть намеком администратору на проблемы с усечением лог-файла.
Одним словом — доведите информацию о случившемся до клиента, позвольте программисту последнего решить, стоит ли дергать конечного потребителя решения всякими «Warning-окошками» или нет. Языки на которых пишутся современные клиенты имеют куда как более гибкие механизмы по отлову исключений, обработке их, и, если так решит программист, по их «проглатыванию». Так же заметьте себе, что у RAISERROR есть вариант вызова, когда указывается не текст ошибки, а ее номер (в этом случае текст должен быть заранее добавлен в представлении каталога sys.messages; процедура sp_addmessage поможет вам в этом). Вы можете составить свой, «внутренний» (только для вашего решения) рейтинг «вбрасываемых» вами ошибок по степени их серьезности. С учетом, что все ошибки определяемые нами, программистами на T-SQL, начинают нумерацию с 50000, подобный рейтинг может быть таким:
- меньше 50100 — «легкие» ошибки, намек программисту клиента, что в целом можно и игнорировать, или выводить фоновым процессом в файл регистрации событий, может быть в лог приложений OS Windows, без уведомления пользователя;
- более 50100 — «средние» ошибки, намек о необходимости извещения конечного пользователя и, возможно, запроса у последнего разрешения на продолжение работы в сложившихся обстоятельствах;
- более 50200 — «суровые» ошибки, намек о безусловном извещении клиента и, с большой степенью вероятности, о необходимости завершении подключения к серверу со стороны клиента;
- более 50300 — «фатальные» ошибки, сессия принудительно закрывается сервером без всяких намеков.
Ну или что-то в таком роде. Самое главное, кроме ну очень фатальных ситуаций, оставьте право принятия окончательного решения за программистом приложения! Предоставив для этого последнему всю информацию которой располагаете. Пусть номера ваших ошибок и их деление по диапазонам будут именно подсказкой для клиента, но не принуждением того к определенным действиям (либо бездействию). Короткий практический вывод данного раздела:
За редким (хотя и возможным) исключением, код блока CATCH
обязан
быть завершен инструкцией RAISERROR сообщающей ту или иную информацию вызывающему коду.
Если вы обратите внимание, то шаблон хранимой процедуры предложенный ранее автором написан в полном соответствии с этим нашим выводом. Что, конечно же, не означает что текст его «выбит в камне» и не подлежит редактированию. Если после тщательного анализа вы приходите к выводу что данный CATCH будет успешно обрабатывать все исключения и сообщать о них коду «вышестоящему» (и в том числе клиенту) резона нет, то проанализируйте все аргументы в пользу такого вывода еще раз, после чего смело стирайте инструкцию RAISERROR в упомянутом шаблоне.
Контрольная работа.
Автор надеется, что статья, к чьим финальным строкам вы подошли уже совсем вплотную, оказалась для вас полезной и познавательной. Мы достаточно подробно и всесторонне осмотрели и обсудили один из важнейших механизмов предлагаемых в наше распоряжение языком T-SQL — механизм перехвата и обработки ошибок. Уверенное владение данным механизмом необсуждаемый «must have» любого мало-мальски профессионального программиста, он обязан применять его в своем коде и делать это разумно, с учетом конкретных обстоятельств для каждого программного модуля. Полагаю, читатели внимательно следовавшие за автором на протяжении всего материала, запустившие и проверившие в своих студиях все приведенные в нем T-SQL скрипты вполне готовы к применению этого важного механизма на практике. Дабы вы могли лишний раз убедиться в такой своей готовности — обещанная в начале статьи контрольная работа. Работа состоит из шести несложных, полностью независимых, и готовых к запуску отрывков T-SQL кода. Для каждого отрывка необходимо ответить на два аналогичных вопроса:
- напечатает ли инструкция PRINT указанную ей строку?
- инструкция SELECT каждого отрывка может вернуть резалт-сет состоящий максимум из пяти строк, содержащих по одной цифре от 1 до 5 в каждой. Указать реальный состав резалт-сета или указать, что резалт-сет будет пуст.
Отвечать на вопросы следует, разумеется, без запуска соответствующего отрывка, но после ответа его проверка в студии вполне поощряется, хотя можно и просто открыть свернутый в настоящий момент текст содержащий правильный ответ. Сразу хочу предупредить, что скрипты лишь на 70% проверяют знание механики работы блоков TRY/CATCH, а на 30% — элементарную внимательность. С другой стороны, как автор не устает повторять на своих курсах, «хороший программист должен обладать всего тремя чертами характера: внимательностью, внимательностью, и — самая главная черта — внимательностью». Так что эти 30% лишними не станут, уверяю вас. Удачи в прохождении теста и — до новых встреч на страницах блога sqlCMD.ru, увидимся, пока! ![]()
Скрипт 1
|
1 |
DECLARE @a int, @b int |
Смотреть ответ для Скрипт 1
PRINT: срабатывает
SELECT: 1,2,4,5
Скрипт 2
|
1 |
DECLARE @a int, @b int |
Смотреть ответ для Скрипт 2
PRINT: срабатывает
SELECT: 1,2,4,5
Скрипт 3
|
1 |
DECLARE @a int, @b int |
Смотреть ответ для Скрипт 3
PRINT: срабатывает
SELECT: 4,5
Скрипт 4
|
1 |
DECLARE @a int, @b int |
Смотреть ответ для Скрипт 4
PRINT: срабатывает
SELECT: 1,2
Скрипт 5
|
1 |
DECLARE @a int, @b int BEGIN |
Смотреть ответ для Скрипт 5
PRINT: срабатывает
SELECT: 1,2
Скрипт 6
|
1 |
DECLARE @a int, @b int |
Смотреть ответ для Скрипт 6
PRINT: НЕ срабатывает
SELECT: пустой резалт-сет
- Другие части статьи:
- 1
- 2
- 3
- вперед »