Environment
- Red Hat Enterpise Virtualization (RHEV) 3.5
Issue
- Upgraded from RHEV-M version 3.4 to 3.5.3
- The RHEV-M event logs is reporting the following error message:
ETL service sampling has encountered an error. Please consult the service log for more details.
Resolution
- Have a current user access the console of VM in question from the RHEV-M GUI. This will update the ‘console_user_id’ of the VM with the new user_id.
- To determine the VM, please refer to the Diagnostic Steps below and/or contact Red Hat Technical Support for assistance.
- BZ 1270105 was added to correct this behaviour and is addressed in rhevm-dwh 3.5.5.
Root Cause
The RHEV-M engine database contains a VM that references a user_id that no longer exists. This user had connected to the console of this VM. This user was then removed prior to the upgrade and no other user has since accessed the console of the VM.
-[ RECORD 1 ]----------+--------------------------------------------------------------------------------------------------------------------
vm_guid | 5bb006af-57d7-419b-bfe0-adeefb5a5134
status | 1
vm_ip | XX.XX.XXX.XX
vm_host | VM_HOST
vm_pid |
last_start_time | 2013-07-18 17:54:50.793-04
guest_cur_user_name | None
guest_last_login_time |
guest_last_logout_time |
guest_os | 2.6.32-504.23.4.el6.x86_64
run_on_vds | 0c8f89b7-c4a7-434e-94e5-104637aa8ef9
migrating_to_vds |
app_list | kernel-2.6.32-431.29.2.el6,kernel-2.6.32-504.el6,rhevm-guest-agent-common-1.0.10-2.el6ev,kernel-2.6.32-504.23.4.el6
display | 5908
acpi_enable | t
session | 0
display_ip | XX.XX.XXX.XX
display_type | 0
kvm_enable | t
display_secure_port | -1
utc_diff | 0
last_vds_run_on |
client_ip |
guest_requested_memory |
hibernation_vol_handle |
boot_sequence | 0
exit_status | 0
pause_status | 0
exit_message |
hash | 7354872742116401709
console_user_id | df83832b-485b-4af0-b0bd-ed8d724bf46c <<========
guest_agent_nics_hash | -53872956
console_cur_user_name |
last_watchdog_event |
last_watchdog_action |
is_run_once | f
vm_fqdn | ABCDEFG.HIJK.com
cpu_name |
last_stop_time |
current_cd |
guest_cpu_count | 1
reason |
exit_reason | -1
Diagnostic Steps
- The following messages is logged in the ovirt-engine-dwh log file every 15 minutes:
2015-09-11 15:37:49|ETL Service Started
Exception in component tJDBCOutput_5
org.postgresql.util.PSQLException: ERROR: insert or update on table "vm_samples_history" violates foreign key constraint "vm_samples_history_current_user_id_fkey"
Detail: Key (current_user_id)=(df83832b-485b-4af0-b0bd-ed8d724bf46c) is not present in table "users_details_history".
at org.postgresql.core.v3.QueryExecutorImpl.receiveErrorResponse(QueryExecutorImpl.java:2062)
at org.postgresql.core.v3.QueryExecutorImpl.processResults(QueryExecutorImpl.java:1795)
at org.postgresql.core.v3.QueryExecutorImpl.execute(QueryExecutorImpl.java:257)
at org.postgresql.jdbc2.AbstractJdbc2Statement.execute(AbstractJdbc2Statement.java:479)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeWithFlags(AbstractJdbc2Statement.java:367)
at org.postgresql.jdbc2.AbstractJdbc2Statement.executeUpdate(AbstractJdbc2Statement.java:321)
at ovirt_engine_dwh.statisticssync_3_5.StatisticsSync.tJDBCInput_10Process(StatisticsSync.java:10482)
at ovirt_engine_dwh.statisticssync_3_5.StatisticsSync$6.run(StatisticsSync.java:17437)
2015-09-11 15:38:03|ZdAtsf|REF9E9|of8mCx|OVIRT_ENGINE_DWH|StatisticsSync|Default|6|Java Exception|tJDBCOutput_5|org.postgresql.util.PSQLException:ERROR: insert or update on table "vm_samples_history" violates foreign key constraint "vm_samples_history_current_user_id_fkey"
Detail: Key (current_user_id)=(df83832b-485b-4af0-b0bd-ed8d724bf46c) is not present in table "users_details_history".|1
Exception in component tJDBCOutput_7
- The postgres logs reports the following messages:
STATEMENT: INSERT INTO host_samples_history (history_datetime,host_id,host_status,minutes_in_status,memory_usage_percent,ksm_shared_memory_mb,cpu_usage_percent,ksm_cpu_percent,active_vms,total_vms,total_vms_vcpus,cpu_load,system_cpu_usage_percent,user_cpu_usage_percent,swap_used_mb,host_configuration_version) VALUES ($1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12,$13,$14,$15,$16)
ERROR: insert or update on table "vm_samples_history" violates foreign key constraint "vm_samples_history_current_user_id_fkey"
DETAIL: Key (current_user_id)=(df83832b-485b-4af0-b0bd-ed8d724bf46c) is not present in table "users_details_history".
STATEMENT: INSERT INTO vm_samples_history (history_datetime,vm_id,vm_status,minutes_in_status,cpu_usage_percent,memory_usage_percent,user_cpu_usage_percent,system_cpu_usage_percent,vm_ip,vm_client_ip,current_user_id,user_logged_in_to_guest,currently_running_on_host,vm_configuration_version,current_host_configuration_version) VALUES ($1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12,$13,$14,$15)
ERROR: current transaction is aborted, commands ignored until end of transaction block
STATEMENT: INSERT INTO vm_disk_samples_history (history_datetime,vm_disk_id,image_id,vm_disk_status,minutes_in_status,vm_disk_actual_size_mb,read_rate_bytes_per_second,read_latency_seconds,write_rate_bytes_per_second,write_latency_seconds,flush_latency_seconds,vm_disk_configuration_version) VALUES ($1,$2,$3,$4,$5,$6,$7,$8,$9,$10,$11,$12)
- The user with user id ‘df83832b-485b-4af0-b0bd-ed8d724bf46c’ does not exist in the RHEV-M engine or ovirt-engine-dwh database.. The user with this user id was removed prior to the upgrade of RHEV-M. Please contact Red Hat Technical Support for details about these commands.
- Further diagnostics requires to dump the all the tables of the engine database, then searching for user id ‘df83832b-485b-4af0-b0bd-ed8d724bf46c’ . Please contact Red Hat Technical Support for details about these commands.
-
Product(s)
- Red Hat Virtualization
-
Category
- Troubleshoot
-
Tags
- postgres
- vm
This solution is part of Red Hat’s fast-track publication program, providing a huge library of solutions that Red Hat engineers have created while supporting our customers. To give you the knowledge you need the instant it becomes available, these articles may be presented in a raw and unedited form.
Содержание
- Event logs reporting «ETL service sampling has encountered an error. Please consult the service log for more details.»
- Environment
- Issue
- Resolution
- Root Cause
- Diagnostic Steps
- ETL service sampling has encountered an error reported in the RHV-M GUI/webadmin events tab.
- Environment
- Issue
- Resolution
- Root Cause
- Diagnostic Steps
- 15 Troubleshooting and Error Handling for ETL Designs
- Inspecting Error Logs in Oracle Warehouse Builder
- Troubleshooting Validation Errors
- Troubleshooting Generation Errors
- Troubleshooting Deployment and Execution Errors
- Determining the Operators that Caused Errors in Mappings
- Troubleshooting Name and Address Server Errors
- Using DML Error Logging
- About DML Error Tables
- ETL Error Handling
- Fail-First Design
- ETL Error Handling
- Error Prevention
- Error Response
- Fail Early If Possible
- Logging
- Testing Error Logic
- Conclusion
Event logs reporting «ETL service sampling has encountered an error. Please consult the service log for more details.»
Environment
- Red Hat Enterpise Virtualization (RHEV) 3.5
Issue
- Upgraded from RHEV-M version 3.4 to 3.5.3
- The RHEV-M event logs is reporting the following error message:
Resolution
- Have a current user access the console of VM in question from the RHEV-M GUI. This will update the ‘console_user_id’ of the VM with the new user_id.
- To determine the VM, please refer to the Diagnostic Steps below and/or contact Red Hat Technical Support for assistance.
- BZ 1270105 was added to correct this behaviour and is addressed in rhevm-dwh 3.5.5.
Root Cause
The RHEV-M engine database contains a VM that references a user_id that no longer exists. This user had connected to the console of this VM. This user was then removed prior to the upgrade and no other user has since accessed the console of the VM.
Diagnostic Steps
- The following messages is logged in the ovirt-engine-dwh log file every 15 minutes:
- The postgres logs reports the following messages:
- The user with user id ‘df83832b-485b-4af0-b0bd-ed8d724bf46c’ does not exist in the RHEV-M engine or ovirt-engine-dwh database.. The user with this user id was removed prior to the upgrade of RHEV-M. Please contact Red Hat Technical Support for details about these commands.
- Further diagnostics requires to dump the all the tables of the engine database, then searching for user id ‘df83832b-485b-4af0-b0bd-ed8d724bf46c’ . Please contact Red Hat Technical Support for details about these commands.
- Product(s)
- Red Hat Virtualization
- Category
- Troubleshoot
- Tags
- postgres
- vm
This solution is part of Red Hat’s fast-track publication program, providing a huge library of solutions that Red Hat engineers have created while supporting our customers. To give you the knowledge you need the instant it becomes available, these articles may be presented in a raw and unedited form.
Источник
ETL service sampling has encountered an error reported in the RHV-M GUI/webadmin events tab.
Environment
- Red Hat Virtualization (RHV-M) version: 4.4.6 (ovirt-engine-4.4.6.8-0.1.el8ev.noarch)
- Red Hat Virtualization (RHV-M) Data Warehouse version 4.4.6.2 (ovirt-engine-dwh-4.4.6.2-1.el8ev.noarch)
Issue
ETL service sampling has encountered an error reported in the RHV-M GUI/webadmin events tab.
The /var/log/ovirt-engine-dwh/ovirt-engine-dwh.log file contains the following error:
Resolution
BZ 1929211 was added to correct the defect and fixed in ovirt-engine-dwh-4.4.6.3.
Please upgrade the to the following errata fix version to avoid the problem.
Root Cause
- The IOPS stats from VDSM are gathered via libvirt and libvirt returns a long long (64bit long)
In the engine database the table disk_image_dynamic column read_ops and write_ops are type bigint to accommodate the value.
The problem actually is on the ovirt-engine-dwh database side.
The following tables have the read_ops_per_second and write_ops_per_second type as int4 (-2147483648 to +2147483647)
- The ETL Bad Value is generated when trying to update the IOPS stats on the ovirt-engine-dwh database in the tables mentioned above.
Diagnostic Steps
- When checking the engine database, in the table disk_image_dynamic the following images read_ops and write_ops with higher values.
- In the ovirt_engine_history database the read_ops_per_second and write_ops_per_second are type integer (-2147483648 to +2147483647) for the following tables.
- Product(s)
- Red Hat Virtualization
- Category
- Troubleshoot
- Tags
- dwh
This solution is part of Red Hat’s fast-track publication program, providing a huge library of solutions that Red Hat engineers have created while supporting our customers. To give you the knowledge you need the instant it becomes available, these articles may be presented in a raw and unedited form.
Источник
15 Troubleshooting and Error Handling for ETL Designs
This chapter discusses troubleshooting ETL and describes the error logs in Oracle Warehouse Builder. It also discusses error handling techniques for ETL such as DML error logging.
This chapter contains the following topics:
Inspecting Error Logs in Oracle Warehouse Builder
While working with Oracle Warehouse Builder, the designers must access log files and check on different types of errors. This section outlines all the different types of error messages that are logged by Oracle Warehouse Builder and how to access them.
Oracle Warehouse Builder logs the following types of errors when you perform different operations:
This section shows you how to retrieve error logs after performing different operations in Oracle Warehouse Builder.
Troubleshooting Validation Errors
In Oracle Warehouse Builder, you can validate all objects by selecting the objects from the Projects Navigator and then selecting Validate from the File menu. After the validation is complete, the validation messages are displayed in the Log window.
Figure 15-1 displays the validation messages in a new tab of the Message Log window.
Figure 15-1 Validation Error Messages

Description of «Figure 15-1 Validation Error Messages»
You can also validate mappings from the Mapping Editor by selecting Mapping, then Validate. The validation messages and errors are displayed in the Validation Results window.
In the validation results, expand the node displaying the object name and then the Validation node. The validation errors, if any are displayed. Double-click a validation message to display the detailed error message in a message editor window.
Oracle Warehouse Builder saves the last validation messages for each previously validated object. You can access these messages at any time by selecting the object from the console tree in the Projects Navigator, selecting View from the menu bar, and then clicking Validation Messages. The messages are displayed in the Validation Results window.
Troubleshooting Generation Errors
After you generate scripts for Oracle Warehouse Builder objects, the Log window displays the generation results and errors. Double-click an error message in the Log window to display a message editor that enables you to save the errors to your local system.
Figure 15-2 displays the Generation Results window.
Figure 15-2 Generation Results Window

Description of «Figure 15-2 Generation Results Window»
Troubleshooting Deployment and Execution Errors
You can store execution or deployment error and warning message logs on your local system by specifying a location for them. In the Projects Navigator, select the project. Then from the Tools menu, select Preferences . In the object tree on the left of the Preferences dialog box, expand the Oracle Warehouse Builder node, and click the Logging option. Use the properties listed on the right to set the log file path, file name, and maximum file size. You can also select the types of logs to store.
You can view this log of deployment and error messages from Oracle Warehouse Builder console by selecting View from the menu bar, and then Log. This Message Log panel is read-only.
Runtime Audit Browser
If an error occurs while transforming or loading data, the audit routines report the errors into the run time tables. You can easily access these error reports using the Run time Audit Browser. The Run time Audit Browser provides detailed information about past deployments and executions. These reports are generated from data stored in the run time repositories. Click the Execution tab in the Execution reports to view error messages and audit details.
Determining the Operators that Caused Errors in Mappings
When you encounter errors while deploying mappings, use the line number provided in the error message to determine where the error occurred. The generated code contains comments for each operator in the mapping. It enables you to determine which operator in the mapping caused the error.
The following example displays the code generated, in set-based mode, for a Filter operator. Notice that the comments enclosed between /* and */ list the operator for which a particular part of the statement is run.
Troubleshooting Name and Address Server Errors
If you are using the Name and Address cleansing service provided by Oracle Warehouse Builder, you may encounter related errors.
Name and Address server start and execution errors can be located at:
If your Name and Address server is enabled in:
then it produces the log file NASvrTrace.log in the same directory.
Using DML Error Logging
Error logging enables the processing of DML statements to continue despite errors during the statement execution. The details of the error such as the error code, and the associated error message, are stored in an error table. After the DML operation completes, you can check the error table to correct rows with errors. DML error logging is supported for SQL statements such as INSERT , UPDATE , MERGE , and multitable insert. It is useful in long-running, bulk DML statements.
Oracle Warehouse Builder provides error logging for the following data objects used in set-based PL/SQL mappings: tables, views, materialized views, dimensions, and cubes. DML error logging is supported only for target schemas created on Oracle Database 10 g Release 2 or later versions.
About DML Error Tables
DML error tables store details of errors encountered while performing DML operations using a mapping. You can define error tables for tables, views, and materialized views only.
Use the DML Error Table Name property to log DML errors for a particular data object. In the mapping that uses the data object as a target, set the DML Error Table Name property of the operator that is bound to the target object to the name of the DML error table that stores DML errors.
You can create your own tables to store DML errors or enable Oracle Warehouse Builder to generate the DML error table. While deploying a mapping in which the DML Error Table Name property is set for target operators, if a table with the name specified by the DML Error Table property does not exist in the target schema, it is created.
When DML error tables are created along with the mapping, dropping the mapping causes the DML error tables to be dropped, too.
In addition to the source target object columns, DML error tables contain the columns listed in Table 15-1. If you use your own tables to log DML errors, then ensure that your table contains these columns.
Table 15-1 DML Error Columns in Error Tables
Источник
ETL Error Handling
Posted By: Tim Mitchell December 28, 2016
 In designing a proper ETL architecture, there are two key questions that must be answered. The first is, “What should this process do?” Defining the data start and end points, transformations, filtering, and other steps must be done before any other work can proceed. The second question that must be answered is “What should happen when the process fails?” Too often, the design stops without having asked or answered this second question. ETL error handling becomes an afterthought rather than a key part of the design.
In designing a proper ETL architecture, there are two key questions that must be answered. The first is, “What should this process do?” Defining the data start and end points, transformations, filtering, and other steps must be done before any other work can proceed. The second question that must be answered is “What should happen when the process fails?” Too often, the design stops without having asked or answered this second question. ETL error handling becomes an afterthought rather than a key part of the design.
In this installment of my ETL Best Practices series, I will discuss the importance of error handling logic in ETL processes.
Fail-First Design
Proper ETL error handling isn’t something that can simply be bolted on at the end of a project. Rather, it should be part of the architecture from the initial design. Creating error logic after the ETL processes are built is akin to adding plumbing to a house after all of the walls have already gone up: it can be done, but it’s ugly. Error management done right requires that those pieces are designed and built alongside, not after, the core of the ETL application. For this reason, I practice what I refer to as a fail-first design. In this design, I give equal attention to what happens when the load goes right or wrong. This approach does take longer, but it also makes for more robust and predictable behavior.
ETL Error Handling
Managing error logic in ETL processes is a broad topic, but can be broken down in the following approaches.
- Error prevention: Fix or bypass the error condition to stop the process from failing.
- Error response: When a failure is inevitable, properly responding to the error is critical.
To be clear, managing failure conditions doesn’t mean you have to choose from the above two approaches. Effective ETL architectures typically include both prevention and response, shaping a two-pronged approach to error management. I’ll cover each of these approaches below.
Error Prevention
There are some conditions that cause failures in load processes that can be prevented using ETL error handling logic. Among the cases where error prevention is useful:
- The load process has multiple steps, but a single failure should not interrupt the rest of the load
- There is a known deficiency in some part of the data that can be fixed as part of the ETL process
- Some part of the ETL process is volatile and you need to retry in the event of a failure
The first item in the list above is the most common scenario in which error prevention is useful. Let’s say you are running ETL operations sourcing retail data across the world and every single time zone. For the load in a single time zone, there might be retail outlets whose data is not yet available (the store stayed open late, network delays, etc.). That scenario doesn’t necessarily represent an error, just a delay in processing. In this example, there is business value in loading the available data, skipping those sources not yet ready. In a case like this, it is common to allow individual tasks to fail without interrupting the ETL process, then failing the process as a whole once all of the tasks have been executed. The process could attempt to execute all of the load tasks, failing at the end only if one or more individual steps failed.
While error prevention is a useful tool in your ETL bag of tricks, let me encourage you not to suppress error conditions simply to force your ETL processes to succeed. Although this is usually well-meaning, it can also cause some unexpected issues if not done properly. Just because an error can be prevented doesn’t mean it should be! Preventing errors is often a business logic decision rather than a technical one. Above all else, be sure that any error prevention or suppression solves the business problem at hand.
Error Response
Not all ETL errors should be prevented. In fact, most business cases lend themselves to error response rather than prevention. As strange as it sounds, there is value in allowing ETL processes to fail:
- Dependency management: If Step B depends on the success of Step A, then Step B should not be executed if A fails.
- Error reporting: Often, notifications are triggered by errors. Allowing processes to fail ensures those notifications are performed.
- Error triggers: Tasks that fail can trigger error response logic for additional notifications, cleanup operations, etc.
It is in the error response design that I liberally use the phrase failing gracefully. In designing processes that are built to fail, you have to consider the ways that a thing can go wrong and decide what should happen when it does. For many processes, a graceful failure is simply a failure with no other action. Consider the example of a process that loads a volatile staging table. Typically this involves truncating that table followed by a reload of said table. If that process happens to fail, there’s nothing to clean up – just fix the deficiency and rerun the truncate/reload sequence. However, it’s a different story when loading transactional data to a production table. If that transactional load fails halfway through, you’ve got a partially loaded target table. You can’t just rerun the process, lest you have duplicated transactions. In that case, there must be some ETL error handling process to clean up from the failed partial load.
In some cases, it is possible to predict a failure and respond accordingly. Some ETL tools, including my favorite such tool (SSIS), include functionality to check for potential failures prior to execution. In SSIS, you can run a validation against a package without actually executing said package. While this validation process won’t detect every possible failure, it does check some common error points. Other validation steps can be performed manually, such as checking that a directory exists or that the execution account has permission to run the load.
When designing error response logic, be sure to define the granularity. Although we usually talk about error management at the task level, it is possible to manage errors at the row level. Row-level error management is usually classified as a data quality operation rather than one of error management. However, since a single bad row of data can break an otherwise successful load, it becomes part of this domain. When deciding on a row-level error management strategy, the design gets more complicated: What do we do with the bad rows of data? Should a certain percentage of bad data force a failure of the entire load? When implementing such a design, there must be business value in loading the good data while skipping (or loading to triage) the bad data.
The details of the error response logic will be different for each process. Again, these are often business decisions rather than technical ones. Ultimately, the design of any ETL load process should include a provision for post-failure operations. Using the fail-first design, assume that every ETL process will fail, and build accordingly.
Fail Early If Possible
All other things being equal, it is better to fail early rather than late in a process. Early failure avoids unnecessary overhead if the entire process would have to be rerun in the event of a failure. Failing early rather than late also reduces the possibility that post-failure data cleanup will be necessary. There are cases where late failures are inevitable (or even preferable). However, for most ETL load scenarios, this rule holds true: fail early if possible.
Logging
It is rare that I write a post about ETL that does not include a reminder about logging. Nowhere is logging more important than in the design of error handling. If your ETL process does nothing else upon failure, at a minimum it should be logging the details of the failure. Capturing failure logging information is critical for triage and architecture improvement. This is doubly true if your ETL process suppresses or prevents errors. The only mechanism that gives you historical insight into error logic is a good logging subsystem. Whether you use the tools built into your ETL software or write your own, be sure that you are capturing enough logging information to fully document any and all failures.
Testing Error Logic
Earlier I commented that error logic is often an afterthought. This is even more true for testing error logic. Building tests around error prevention and response logic is as important as testing the core load logic. I can’t even recall the number of times I’ve been called in to assist with ETL processes to find that not only were the loads failing, but the error logic was failing as well. Testing load processes is difficult, and testing ETL error handling is even more so. However, only proper testing will detect deficiencies in your error logic.
Conclusion
Managing errors in ETL should be central to the design of those processes. A good ETL strategy will have measures for preventing and responding to errors at the right granularity. With well-designed ETL error handling, processes are much more robust, predictable, and maintainable.
Источник
Время прочтения
6 мин
Просмотры 5.6K
Многие используют специализированные инструменты для создания процедур извлечения, трансформации и загрузки данных в реляционные базы данных. Процесс работы инструментов логируется, ошибки фиксируются.
В случае ошибки в логе содержится информация о том, что инструменту не удалось выполнить задачу и какие модули (часто это java) где остановились. В последних строках можно найти ошибку базы данных, например, нарушение уникального ключа таблицы.
Чтобы ответить на вопрос, какую роль играет информация об ошибках ETL, я классифицировал все проблемы, произошедшие за последние два года в немаленьком хранилище.
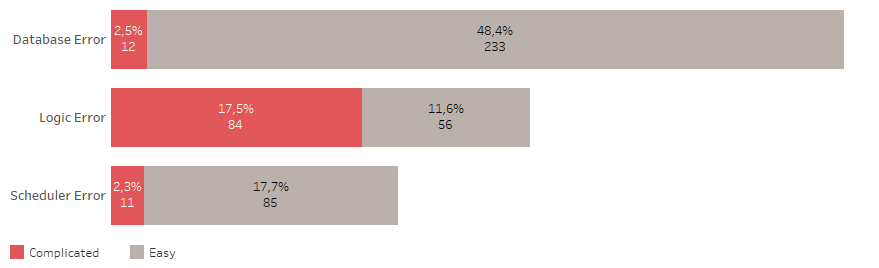
Характеристики хранилища, где проводилась классификация:
- подключено 20 источников данных,
- ежедневно обрабатывается 10.5 миллиардов строк,
- которые агрегируются до 50 миллионов строк,
- данные обрабатывают 140 пакетов в 700 шагов (шаг — это один sql запрос)
- сервер — 4х-нодная база данных X5
К ошибкам базы данных относятся такие, как не хватило места, оборвалось соединение, зависла сессия и т.п.
К логическим ошибкам относятся такие, как нарушение ключей таблицы, не валидные объекты, отсутствие доступа к объектам и т.п.
Планировщик может быть запущен не вовремя, может зависнуть и т.п.
Простые ошибки не требуют много времени на исправление. С большей их частью хороший ETL умеет справляться самостоятельно.
Сложные ошибки вызывают необходимость открывать и проверять процедуры работы с данными, исследовать источники данных. Часто приводят к необходимости тестирования изменений и деплоймента.
Итак, половина всех проблем связана с базой данных. 48% всех ошибок — это простые ошибки.
Третья часть всех проблем связана с изменением логики или модели хранилища, больше половины этих ошибок являются сложными.
И меньше четверти всех проблем связана с планировщиком задач, 18% которых — это простые ошибки.
В целом, 22% всех случившихся ошибок являются сложными, их исправление требует наибольшего внимания и времени. Происходят они примерно раз в неделю. В то время, как простые ошибки случаются почти каждый день.
Очевидно, что мониторинг ETL-процессов будет тогда эффективным, когда в логе максимально точно указано место ошибки и требуется минимальное время на поиск источника проблемы.
Эффективный мониторинг
Что мне хотелось видеть в процессе мониторинга ETL?
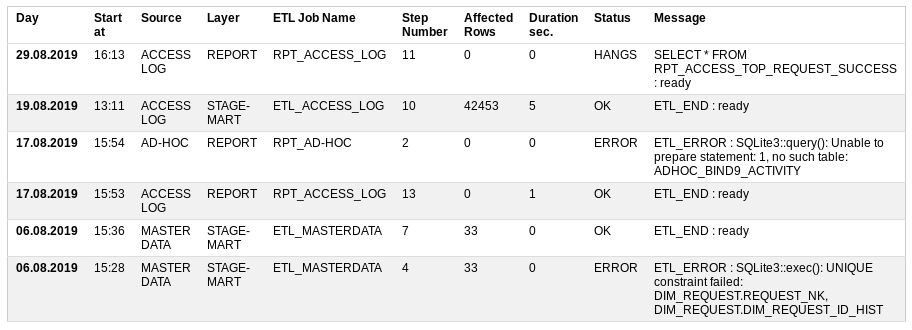
Start at — когда начал работу,
Source — источник данных,
Layer — какой уровень хранилища загружается,
ETL Job Name — поцедура загрузки, которая состоит из множества мелких шагов,
Step Number — номер выполняемого шага,
Affected Rows — сколько данных уже обработалось,
Duration sec — как долго выполняется,
Status — всё ли хорошо или нет: OK, ERROR, RUNNING, HANGS
Message — последнее успешное сообщение или описание ошибки.
На основании статуса записей можно отправить эл. письмо другим участникам. Если ошибок нет, то и письмо не обязательно.
Таким образом, в случае ошибки чётко указано место происшествия.
Иногда случается, что сам инструмент мониторинга не работает. В таком случае есть возможность прямо в базе данных вызвать представление (вьюшку), на основании которой построен отчёт.
Таблица мониторинга ETL
Чтобы реализовать мониторинг ETL-процессов достаточно одной таблицы и одного представления.
Для этого можно вернуться в своё маленькое хранилище и создать прототип в базе данных sqlite.
DDL таблицы
CREATE TABLE UTL_JOB_STATUS (
/* Table for logging of job execution log. Important that the job has the steps ETL_START and ETL_END or ETL_ERROR */
UTL_JOB_STATUS_ID INTEGER NOT NULL PRIMARY KEY AUTOINCREMENT,
SID INTEGER NOT NULL DEFAULT -1, /* Session Identificator. Unique for every Run of job */
LOG_DT INTEGER NOT NULL DEFAULT 0, /* Date time */
LOG_D INTEGER NOT NULL DEFAULT 0, /* Date */
JOB_NAME TEXT NOT NULL DEFAULT 'N/A', /* Job name like JOB_STG2DM_GEO */
STEP_NAME TEXT NOT NULL DEFAULT 'N/A', /* ETL_START, ... , ETL_END/ETL_ERROR */
STEP_DESCR TEXT, /* Description of task or error message */
UNIQUE (SID, JOB_NAME, STEP_NAME)
);
INSERT INTO UTL_JOB_STATUS (UTL_JOB_STATUS_ID) VALUES (-1);DDL представления/отчёта
CREATE VIEW IF NOT EXISTS UTL_JOB_STATUS_V
AS /* Content: Package Execution Log for last 3 Months. */
WITH SRC AS (
SELECT LOG_D,
LOG_DT,
UTL_JOB_STATUS_ID,
SID,
CASE WHEN INSTR(JOB_NAME, 'FTP') THEN 'TRANSFER' /* file transfer */
WHEN INSTR(JOB_NAME, 'STG') THEN 'STAGE' /* stage */
WHEN INSTR(JOB_NAME, 'CLS') THEN 'CLEANSING' /* cleansing */
WHEN INSTR(JOB_NAME, 'DIM') THEN 'DIMENSION' /* dimension */
WHEN INSTR(JOB_NAME, 'FCT') THEN 'FACT' /* fact */
WHEN INSTR(JOB_NAME, 'ETL') THEN 'STAGE-MART' /* data mart */
WHEN INSTR(JOB_NAME, 'RPT') THEN 'REPORT' /* report */
ELSE 'N/A' END AS LAYER,
CASE WHEN INSTR(JOB_NAME, 'ACCESS') THEN 'ACCESS LOG' /* source */
WHEN INSTR(JOB_NAME, 'MASTER') THEN 'MASTER DATA' /* source */
WHEN INSTR(JOB_NAME, 'AD-HOC') THEN 'AD-HOC' /* source */
ELSE 'N/A' END AS SOURCE,
JOB_NAME,
STEP_NAME,
CASE WHEN STEP_NAME='ETL_START' THEN 1 ELSE 0 END AS START_FLAG,
CASE WHEN STEP_NAME='ETL_END' THEN 1 ELSE 0 END AS END_FLAG,
CASE WHEN STEP_NAME='ETL_ERROR' THEN 1 ELSE 0 END AS ERROR_FLAG,
STEP_NAME || ' : ' || STEP_DESCR AS STEP_LOG,
SUBSTR( SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), 1, INSTR(SUBSTR(STEP_DESCR, INSTR(STEP_DESCR, '***')+4), '***')-2 ) AS AFFECTED_ROWS
FROM UTL_JOB_STATUS
WHERE datetime(LOG_D, 'unixepoch') >= date('now', 'start of month', '-3 month')
)
SELECT JB.SID,
JB.MIN_LOG_DT AS START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS LOG_DT,
JB.SOURCE,
JB.LAYER,
JB.JOB_NAME,
CASE
WHEN JB.ERROR_FLAG = 1 THEN 'ERROR'
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 AND strftime('%s','now') - JB.MIN_LOG_DT > 0.5*60*60 THEN 'HANGS' /* half an hour */
WHEN JB.ERROR_FLAG = 0 AND JB.END_FLAG = 0 THEN 'RUNNING'
ELSE 'OK'
END AS STATUS,
ERR.STEP_LOG AS STEP_LOG,
JB.CNT AS STEP_CNT,
JB.AFFECTED_ROWS AS AFFECTED_ROWS,
strftime('%d.%m.%Y %H:%M', datetime(JB.MIN_LOG_DT, 'unixepoch')) AS JOB_START_DT,
strftime('%d.%m.%Y %H:%M', datetime(JB.MAX_LOG_DT, 'unixepoch')) AS JOB_END_DT,
JB.MAX_LOG_DT - JB.MIN_LOG_DT AS JOB_DURATION_SEC
FROM
( SELECT SID, SOURCE, LAYER, JOB_NAME,
MAX(UTL_JOB_STATUS_ID) AS UTL_JOB_STATUS_ID,
MAX(START_FLAG) AS START_FLAG,
MAX(END_FLAG) AS END_FLAG,
MAX(ERROR_FLAG) AS ERROR_FLAG,
MIN(LOG_DT) AS MIN_LOG_DT,
MAX(LOG_DT) AS MAX_LOG_DT,
SUM(1) AS CNT,
SUM(IFNULL(AFFECTED_ROWS, 0)) AS AFFECTED_ROWS
FROM SRC
GROUP BY SID, SOURCE, LAYER, JOB_NAME
) JB,
( SELECT UTL_JOB_STATUS_ID, SID, JOB_NAME, STEP_LOG
FROM SRC
WHERE 1 = 1
) ERR
WHERE 1 = 1
AND JB.SID = ERR.SID
AND JB.JOB_NAME = ERR.JOB_NAME
AND JB.UTL_JOB_STATUS_ID = ERR.UTL_JOB_STATUS_ID
ORDER BY JB.MIN_LOG_DT DESC, JB.SID DESC, JB.SOURCE;SQL Проверка возможности получить новый номер сессии
SELECT SUM (
CASE WHEN start_job.JOB_NAME IS NOT NULL AND end_job.JOB_NAME IS NULL /* existed job finished */
AND NOT ( 'y' = 'n' ) /* force restart PARAMETER */
THEN 1 ELSE 0
END ) AS IS_RUNNING
FROM
( SELECT 1 AS dummy FROM UTL_JOB_STATUS WHERE sid = -1) d_job
LEFT OUTER JOIN
( SELECT JOB_NAME, SID, 1 AS dummy
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME = 'ETL_START'
GROUP BY JOB_NAME, SID
) start_job /* starts */
ON d_job.dummy = start_job.dummy
LEFT OUTER JOIN
( SELECT JOB_NAME, SID
FROM UTL_JOB_STATUS
WHERE JOB_NAME = 'RPT_ACCESS_LOG' /* job name PARAMETER */
AND STEP_NAME in ('ETL_END', 'ETL_ERROR') /* stop status */
GROUP BY JOB_NAME, SID
) end_job /* ends */
ON start_job.JOB_NAME = end_job.JOB_NAME
AND start_job.SID = end_job.SIDОсобенности таблицы:
- начало и конец процедуры обработки данных должен сопровождаться шагами ETL_START и ETL_END
- в случае ошибки должен создаваться шаг ETL_ERROR с её описанием
- количество обработанных данных нужно выделить, например, звёздочками
- одновременно одну и туже процедуру можно запустить с параметром force_restart=y, без него номер сессии выдаётся только завершённой процедуре
- в обычном режиме нельзя запустить параллельно одну и туже процедуру обработки данных
Необходимыми операциями работы с таблицей являются следующие:
- получение номера сессии запускаемой процедуры ETL
- вставка записи лога в таблицу
- получение последней успешной записи процедуры ETL
В таких базах данных, как, например, Oracle или Postgres эти операции можно реализовать встроенными функциями. Для sqlite необходим внешний механизм и в данном случае он прототипирован на PHP.
Вывод
Таким образом, сообщения об ошибках в инструментах обработки данных играют мега-важную роль. Но оптимальными для быстрого поиска причины проблемы их сложно назвать. Когда количество процедур приближается к сотне, то мониторинг процессов превращается в сложный проект.
В статье приведён пример возможного решения проблемы в виде прототипа. Весь прототип маленького хранилища доступен в gitlab SQLite PHP ETL Utilities.
 In designing a proper ETL architecture, there are two key questions that must be answered. The first is, “What should this process do?” Defining the data start and end points, transformations, filtering, and other steps must be done before any other work can proceed. The second question that must be answered is “What should happen when the process fails?” Too often, the design stops without having asked or answered this second question. ETL error handling becomes an afterthought rather than a key part of the design.
In designing a proper ETL architecture, there are two key questions that must be answered. The first is, “What should this process do?” Defining the data start and end points, transformations, filtering, and other steps must be done before any other work can proceed. The second question that must be answered is “What should happen when the process fails?” Too often, the design stops without having asked or answered this second question. ETL error handling becomes an afterthought rather than a key part of the design.
In this installment of my ETL Best Practices series, I will discuss the importance of error handling logic in ETL processes.
Fail-First Design
Proper ETL error handling isn’t something that can simply be bolted on at the end of a project. Rather, it should be part of the architecture from the initial design. Creating error logic after the ETL processes are built is akin to adding plumbing to a house after all of the walls have already gone up: it can be done, but it’s ugly. Error management done right requires that those pieces are designed and built alongside, not after, the core of the ETL application. For this reason, I practice what I refer to as a fail-first design. In this design, I give equal attention to what happens when the load goes right or wrong. This approach does take longer, but it also makes for more robust and predictable behavior.
ETL Error Handling
Managing error logic in ETL processes is a broad topic, but can be broken down in the following approaches.
- Error prevention: Fix or bypass the error condition to stop the process from failing.
- Error response: When a failure is inevitable, properly responding to the error is critical.
To be clear, managing failure conditions doesn’t mean you have to choose from the above two approaches. Effective ETL architectures typically include both prevention and response, shaping a two-pronged approach to error management. I’ll cover each of these approaches below.
Error Prevention
There are some conditions that cause failures in load processes that can be prevented using ETL error handling logic. Among the cases where error prevention is useful:
- The load process has multiple steps, but a single failure should not interrupt the rest of the load
- There is a known deficiency in some part of the data that can be fixed as part of the ETL process
- Some part of the ETL process is volatile and you need to retry in the event of a failure
The first item in the list above is the most common scenario in which error prevention is useful. Let’s say you are running ETL operations sourcing retail data across the world and every single time zone. For the load in a single time zone, there might be retail outlets whose data is not yet available (the store stayed open late, network delays, etc.). That scenario doesn’t necessarily represent an error, just a delay in processing. In this example, there is business value in loading the available data, skipping those sources not yet ready. In a case like this, it is common to allow individual tasks to fail without interrupting the ETL process, then failing the process as a whole once all of the tasks have been executed. The process could attempt to execute all of the load tasks, failing at the end only if one or more individual steps failed.
While error prevention is a useful tool in your ETL bag of tricks, let me encourage you not to suppress error conditions simply to force your ETL processes to succeed. Although this is usually well-meaning, it can also cause some unexpected issues if not done properly. Just because an error can be prevented doesn’t mean it should be! Preventing errors is often a business logic decision rather than a technical one. Above all else, be sure that any error prevention or suppression solves the business problem at hand.
Error Response
Not all ETL errors should be prevented. In fact, most business cases lend themselves to error response rather than prevention. As strange as it sounds, there is value in allowing ETL processes to fail:
- Dependency management: If Step B depends on the success of Step A, then Step B should not be executed if A fails.
- Error reporting: Often, notifications are triggered by errors. Allowing processes to fail ensures those notifications are performed.
- Error triggers: Tasks that fail can trigger error response logic for additional notifications, cleanup operations, etc.
It is in the error response design that I liberally use the phrase failing gracefully. In designing processes that are built to fail, you have to consider the ways that a thing can go wrong and decide what should happen when it does. For many processes, a graceful failure is simply a failure with no other action. Consider the example of a process that loads a volatile staging table. Typically this involves truncating that table followed by a reload of said table. If that process happens to fail, there’s nothing to clean up – just fix the deficiency and rerun the truncate/reload sequence. However, it’s a different story when loading transactional data to a production table. If that transactional load fails halfway through, you’ve got a partially loaded target table. You can’t just rerun the process, lest you have duplicated transactions. In that case, there must be some ETL error handling process to clean up from the failed partial load.
In some cases, it is possible to predict a failure and respond accordingly. Some ETL tools, including my favorite such tool (SSIS), include functionality to check for potential failures prior to execution. In SSIS, you can run a validation against a package without actually executing said package. While this validation process won’t detect every possible failure, it does check some common error points. Other validation steps can be performed manually, such as checking that a directory exists or that the execution account has permission to run the load.
When designing error response logic, be sure to define the granularity. Although we usually talk about error management at the task level, it is possible to manage errors at the row level. Row-level error management is usually classified as a data quality operation rather than one of error management. However, since a single bad row of data can break an otherwise successful load, it becomes part of this domain. When deciding on a row-level error management strategy, the design gets more complicated: What do we do with the bad rows of data? Should a certain percentage of bad data force a failure of the entire load? When implementing such a design, there must be business value in loading the good data while skipping (or loading to triage) the bad data.
The details of the error response logic will be different for each process. Again, these are often business decisions rather than technical ones. Ultimately, the design of any ETL load process should include a provision for post-failure operations. Using the fail-first design, assume that every ETL process will fail, and build accordingly.
Fail Early If Possible
All other things being equal, it is better to fail early rather than late in a process. Early failure avoids unnecessary overhead if the entire process would have to be rerun in the event of a failure. Failing early rather than late also reduces the possibility that post-failure data cleanup will be necessary. There are cases where late failures are inevitable (or even preferable). However, for most ETL load scenarios, this rule holds true: fail early if possible.
Logging
It is rare that I write a post about ETL that does not include a reminder about logging. Nowhere is logging more important than in the design of error handling. If your ETL process does nothing else upon failure, at a minimum it should be logging the details of the failure. Capturing failure logging information is critical for triage and architecture improvement. This is doubly true if your ETL process suppresses or prevents errors. The only mechanism that gives you historical insight into error logic is a good logging subsystem. Whether you use the tools built into your ETL software or write your own, be sure that you are capturing enough logging information to fully document any and all failures.
Testing Error Logic
Earlier I commented that error logic is often an afterthought. This is even more true for testing error logic. Building tests around error prevention and response logic is as important as testing the core load logic. I can’t even recall the number of times I’ve been called in to assist with ETL processes to find that not only were the loads failing, but the error logic was failing as well. Testing load processes is difficult, and testing ETL error handling is even more so. However, only proper testing will detect deficiencies in your error logic.
Conclusion
Managing errors in ETL should be central to the design of those processes. A good ETL strategy will have measures for preventing and responding to errors at the right granularity. With well-designed ETL error handling, processes are much more robust, predictable, and maintainable.