Here the Query Editor Text:
let
Source = Salesforce.Data("https://COMPANYXE.my.salesforce.com"),
Opportunity1 = Source{[Name="Opportunity"]}[Data],
#"COLUMNS REMOVED HERE" = Table.SelectColumns(Opportunity1,{"Id", "AccountId", "Name", "StageName", "Amount", "CloseDate", "ForecastCategory", "ForecastCategoryName", "Country__c", "COMPANYXE_s_Unique_Value_Why_COMPANYXE__c", "Opportunity_Number__c", "Opportunity_Owner__c", "Product_Services_Led__c", "Quote_Cart_Number__c", "Quote_Cart__c", "SO_Number__c", "Type_of_Sale__c", "Account_Name1__c", "Service_Provider__c", "Products__c", "Primary_Alliance_Partner__c", "Alliance_Business_Type__c", "ELA2__c", "Alliance_Engagement_Document__c", "PO_Number__c", "Service_Provider_Business_Type__c", "Alliance_Offerings__c", "COMPANYXD_Deal_ID__c", "COMPANYXD_Opportunity_Number__c", "Global_Alliance_Close_Date__c", "Global_Alliance_Forecast_Amount__c", "Global_Alliance_Forecast_Product_Amount__c", "Global_Alliance_Forecast_Status__c", "Included_in_Mgt_Call__c", "Global_Alliance_Comment__c", "COMPANYXD_Distributor_Reseller_Account_Name__c", "LeadSource","Partner__c"}),
#"Remove Contract Renewals" = Table.SelectRows(#"COLUMNS REMOVED HERE", each ([LeadSource] <> "Contract Renewal")),
#"Filter Close Dates" = Table.SelectRows(#"Remove Contract Renewals", each [CloseDate] >= CloseDateFirst and [CloseDate] <= CloseDateLast),
#"Filter Omitted from Forecast Cat" = Table.SelectRows(#"Filter Close Dates", each ([ForecastCategory] <> "Omitted")),
#"Merge in SP Details" = Table.NestedJoin(#"Filter Omitted from Forecast Cat",{"Service_Provider__c"},#"SFDC AC Account Table",{"Id"},"SFDC AC Account Table",JoinKind.LeftOuter),
#"Expanded SFDC AC Account Table" = Table.ExpandTableColumn(#"Merge in SP Details", "SFDC AC Account Table", {"Name", "Global_DUNS_Entity__c", "Party_Number__c", "Global_DUNS_Entity_Hub__c", "UCID__c", "Affinity_ID__c"}, {"SP.Name", "SP.Global_DUNS_Entity__c", "SP.Party_Number__c", "SP.Global_DUNS_Entity_Hub__c", "SP.UCID__c", "SP.Affinity_ID__c"}),
#"Convert DUNs to Number" = Table.TransformColumnTypes(#"Expanded SFDC AC Account Table",{{"SP.Global_DUNS_Entity_Hub__c", Int64.Type}}),
#"Merge in Theatre Mappings" = Table.NestedJoin(#"Convert DUNs to Number",{"Country__c"},#"Country Theater Mapping",{"Name"},"Country Theater Mapping",JoinKind.LeftOuter),
#"Expanded Country Theater Mapping" = Table.ExpandTableColumn(#"Merge in Theatre Mappings", "Country Theater Mapping", {"Theater__c"}, {"Country Theater Mapping.Theater__c"}),
#"Filter EMEA ONLY" = Table.SelectRows(#"Expanded Country Theater Mapping", each ([Country Theater Mapping.Theater__c] = "EMEA")),
#"Merge in SP DUNS" = Table.NestedJoin(#"Filter EMEA ONLY",{"SP.Global_DUNS_Entity_Hub__c"},#"DUNS IN OUT",{"Duns"},"DUNS IN OUT",JoinKind.LeftOuter),
#"Expanded DUNS IN OUT" = Table.ExpandTableColumn(#"Merge in SP DUNS", "DUNS IN OUT", {"Partner", "Include?"}, {"SP DUNS.Partner", "SP DUNS.Include?"}),
#"Merge in PAP Details" = Table.NestedJoin(#"Expanded DUNS IN OUT",{"Primary_Alliance_Partner__c"},#"SFDC AC Account Table",{"Id"},"SFDC AC Account Table",JoinKind.LeftOuter),
#"Expanded SFDC AC Account Table1" = Table.ExpandTableColumn(#"Merge in PAP Details", "SFDC AC Account Table", {"Name", "Global_DUNS_Entity__c", "Global_DUNS_Entity_Hub__c", "UCID__c", "Affinity_ID__c"}, {"PAP.Name", "PAP.Global_DUNS_Entity__c", "PAP.Global_DUNS_Entity_Hub__c", "PAP.UCID__c", "PAP.Affinity_ID__c"}),
#"Merge Acc Info" = Table.NestedJoin(#"Expanded SFDC AC Account Table1",{"AccountId"},#"SFDC AC Account Table",{"Id"},"SFDC AC Account Table",JoinKind.LeftOuter),
#"Expanded SFDC AC Account Table2" = Table.ExpandTableColumn(#"Merge Acc Info", "SFDC AC Account Table", {"Name", "Global_DUNS_Entity__c", "Segmentation__c", "Party_Number__c", "Global_DUNS_Entity_Hub__c", "UCID__c", "Affinity_ID__c"}, {"Acc.Name", "Acc.Global_DUNS_Entity__c", "Acc.Segmentation__c", "Acc.Party_Number__c", "Acc.Global_DUNS_Entity_Hub__c", "Acc.UCID__c", "Acc.Affinity_ID__c"}),
#"Changed Type" = Table.TransformColumnTypes(#"Expanded SFDC AC Account Table2",{{"Acc.Global_DUNS_Entity_Hub__c", Int64.Type}, {"PAP.Global_DUNS_Entity_Hub__c", Int64.Type}}),
#"Merge PAP DUNS" = Table.NestedJoin(#"Changed Type",{"PAP.Global_DUNS_Entity_Hub__c"},#"DUNS IN OUT",{"Duns"},"DUNS IN OUT",JoinKind.LeftOuter),
#"Expanded DUNS IN OUT1" = Table.ExpandTableColumn(#"Merge PAP DUNS", "DUNS IN OUT", {"Partner", "Include?"}, {"PAP.Partner", "PAP.Include?"}),
#"Merge Acc DUNS" = Table.NestedJoin(#"Expanded DUNS IN OUT1",{"Acc.Global_DUNS_Entity_Hub__c"},#"DUNS IN OUT",{"Duns"},"SFDC AC Account Table",JoinKind.LeftOuter),
#"Expanded SFDC AC Account Table3" = Table.ExpandTableColumn(#"Merge Acc DUNS", "SFDC AC Account Table", {"Partner", "Include?"}, {"Acc.Partner", "Acc.Include?"}),
#"Merge Disti" = Table.NestedJoin(#"Expanded SFDC AC Account Table3",{"Partner__c"},#"SFDC AC Account Table",{"Id"},"SFDC AC Account Table",JoinKind.LeftOuter),
#"Expanded SFDC AC Account Table4" = Table.ExpandTableColumn(#"Merge Disti", "SFDC AC Account Table", {"Name", "Global_DUNS_Entity__c", "Party_ID__c", "Global_DUNS_Entity_Hub__c", "UCID__c", "Affinity_ID__c"}, {"Disti.Name", "Disti.Global_DUNS_Entity__c", "Disti.Party_ID__c", "Disti.Global_DUNS_Entity_Hub__c", "Disti.UCID__c", "Disti.Affinity_ID__c"}),
#"Check Disiti Field" = Table.AddColumn(#"Expanded SFDC AC Account Table4", "Disti Inc YN", each if Text.Contains([Disti.Name], "DIMENSION DATA") then "Y" else "N"),
#"Merged Queries" = Table.NestedJoin(#"Check Disiti Field",{"Disti.Global_DUNS_Entity_Hub__c"},#"DUNS IN OUT",{"Duns"},"DUNS IN OUT",JoinKind.LeftOuter),
#"Custom Field Inc Duns / Disti" = Table.AddColumn(#"Merged Queries", "DUNS DISTI INC EXCL", each if [#"Acc.Include?"]="Y" or [#"PAP.Include?"]="Y" or [#"SP DUNS.Include?"]="Y" or [Disti Inc YN]="Y" then "Y" else "EXCLUDE"),
#"FILTER; EXLUDE NON APPLIABLE OPS" = Table.SelectRows(#"Custom Field Inc Duns / Disti", each ([DUNS DISTI INC EXCL] = "Y")),
#"Filtered Rows" = Table.SelectRows(#"FILTER; EXLUDE NON APPLIABLE OPS", each [Id] <> null and [Id] <> ""),
#"Changed Type1" = Table.TransformColumnTypes(#"Filtered Rows",{{"Global_Alliance_Forecast_Amount__c", type number}, {"Global_Alliance_Forecast_Product_Amount__c", type number}, {"Amount", type number}, {"CloseDate", type date}, {"Global_Alliance_Close_Date__c", type date}, {"Disti.Affinity_ID__c", Int64.Type}, {"Disti.UCID__c", Int64.Type}, {"Disti.Global_DUNS_Entity_Hub__c", Int64.Type}, {"Disti.Party_ID__c", Int64.Type}, {"Disti.Global_DUNS_Entity__c", Int64.Type}, {"Acc.Affinity_ID__c", Int64.Type}, {"Acc.UCID__c", Int64.Type}, {"Acc.Global_DUNS_Entity_Hub__c", Int64.Type}, {"Acc.Party_Number__c", Int64.Type}, {"Acc.Global_DUNS_Entity__c", Int64.Type}, {"PAP.Affinity_ID__c", Int64.Type}, {"PAP.UCID__c", Int64.Type}, {"PAP.Global_DUNS_Entity_Hub__c", Int64.Type}, {"PAP.Global_DUNS_Entity__c", Int64.Type}, {"SP.Affinity_ID__c", Int64.Type}, {"SP.UCID__c", Int64.Type}, {"SP.Global_DUNS_Entity__c", Int64.Type}, {"SP.Party_Number__c", Int64.Type}, {"SP.Global_DUNS_Entity_Hub__c", Int64.Type}, {"Id", type text}, {"AccountId", type text}, {"Name", type text}, {"StageName", type text}, {"ForecastCategory", type text}, {"ForecastCategoryName", type text}, {"Country__c", type text}, {"COMPANYXE_s_Unique_Value_Why_COMPANYXE__c", type text}, {"Opportunity_Number__c", type text}, {"Opportunity_Owner__c", type text}, {"Product_Services_Led__c", type text}, {"Quote_Cart_Number__c", type text}, {"Quote_Cart__c", type text}, {"SO_Number__c", type text}, {"Type_of_Sale__c", type text}, {"Account_Name1__c", type text}, {"Service_Provider__c", type text}, {"Products__c", type text}, {"Primary_Alliance_Partner__c", type text}, {"Alliance_Business_Type__c", type text}, {"ELA2__c", type text}, {"Alliance_Engagement_Document__c", type text}, {"PO_Number__c", type text}, {"Service_Provider_Business_Type__c", type text}, {"Alliance_Offerings__c", type text}, {"COMPANYXD_Deal_ID__c", type text}, {"COMPANYXD_Opportunity_Number__c", type text}, {"Global_Alliance_Forecast_Status__c", type text}, {"Included_in_Mgt_Call__c", type text}, {"Global_Alliance_Comment__c", type text}, {"COMPANYXD_Distributor_Reseller_Account_Name__c", type text}, {"LeadSource", type text}, {"Partner__c", type text}, {"SP.Name", type text}, {"Country Theater Mapping.Theater__c", type text}, {"PAP.Name", type text}, {"SP DUNS.Partner", type text}, {"SP DUNS.Include?", type text}, {"Acc.Name", type text}, {"Acc.Segmentation__c", type text}, {"PAP.Partner", type text}, {"PAP.Include?", type text}, {"Acc.Partner", type text}, {"Acc.Include?", type text}, {"Disti.Name", type text}, {"Disti Inc YN", type text}, {"DUNS DISTI INC EXCL", type text}})
in
#"Changed Type1"
-
All forum topics -
Previous Topic -
Next Topic

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2021
07:53 PM
I have a Dataflow that looks good in the Power Query designer and appears to be in good order.
However when I start the refresh, I get the following error:
Error Code: Mashup Exception Error, Error Details: Couldn’t refresh the entity because of an issue with the mashup document MashupException.Error: Expression.Error: We cannot convert the value null to type Logical.
Does this mean that one of the values that its trying to insert into Dataverse is NULL or that something that appears to be functioning in my designer is actually erroring and I’m missing it? Is that what a mashupexception represents?
Message 1 of 6
6,052 Views
-
All forum topics -
Previous Topic -
Next Topic
1 ACCEPTED SOLUTION
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2021
10:58 AM
So it turns out that, in my case, the issue was actually within the designer mashup. And the Logical even made sense, once I figured. I had a new conditional column in my final table, used for insert. This conditional column was checking for a value to be greater than 0. If it was it would set the value to one column versus another. However in the column I was comparing, there happened to be one row out of 1400 that had a null value incorrectly. This was generating an [Error] just within that cell for that row inside the designer but I didn’t catch it. Once I fixed the conditional, everything inserted fine.
Message 5 of 6
5,971 Views
5 REPLIES 5

- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-19-2021
09:55 PM
Hi @homol,
Usually a mashup exception is when the data type is incompatible upon insert. It doesn’t mean that if the PowerQuery designer work that it will work on import. For ex, you can have service-side validation, alt keys, etc, that might prevent the transaction. What destination column type is it, lookup?
Message 2 of 6
6,014 Views
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2021
05:04 AM
well, it’s hard to say, since I can’t tell from the error dump, what is the affected column. Or at least I don’t think I can tell lol. But yes, it’s most likely a lookup that is a part of the key — that makes the most sense. The «Logical» type is what was throwing me off — I started looking into my designer for True/False fields with Nulls lol.
Message 3 of 6
6,001 Views
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2021
05:18 AM
@EricRegnier
Here’s my particular setup:
I have an Investment table that has 2 different keys:
- A combo key of 3 different lookups, to validate uniqueness (Internal Partner, External Partner, and Type)
- An autonumber column that uniquely represents the Investment Code
I have a Tax Year table that has a Lookup to Investment — this is the table I’m trying to insert into — various years per investment.
My assumption was that I could simply get the autonumber value and associate it to my years and conduct my inserts. I see this though in the Map tables screen.

Does this mean that I still need to have the other 3 values to make the insert work? I’m assuming that this is what’s causing my error.
Message 4 of 6
5,996 Views
- Mark as New
- Bookmark
- Subscribe
- Mute
- Subscribe to RSS Feed
- Permalink
- Report Inappropriate Content
05-20-2021
10:58 AM
So it turns out that, in my case, the issue was actually within the designer mashup. And the Logical even made sense, once I figured. I had a new conditional column in my final table, used for insert. This conditional column was checking for a value to be greater than 0. If it was it would set the value to one column versus another. However in the column I was comparing, there happened to be one row out of 1400 that had a null value incorrectly. This was generating an [Error] just within that cell for that row inside the designer but I didn’t catch it. Once I fixed the conditional, everything inserted fine.
Message 5 of 6
5,972 Views
![]()
I am creating a column «[DaysAvailable]» using the difference between two columns «[DateAvailable], [WONeededBy]» that are formatted as Date/Time. I used Number.From as part of the column creation to convert the resulting data in
the new [DaysAvailable] column into a number. The problem is that when I preform this conversion it is causing errors in 4 unrelated column. If I leave the resulting data unconverted everything is fine. All 4 columns giving errors do use
[WONeededBy] to calculate their values but [DaysAvailable] does not reference the 4 error columns in any way and vice-versa.
I tried using Table.TransformColumnTypes as an additional step to convert the data type of [DaysAvailable] to Int64 and got the same results.
I also tried leaving the new [DaysAvailable] column format alone and created an additional column using Number.From[DaysAvailable] and this only caused one unrelated column to give errors.
Another function I tried was Duration.Days([WONeededBy] — [DateAvailable])). This resulted in the same 4 columns with errors. It seems that something about this new column being a number is causing these other columns to throw errors.
If I view any of the errors from any of scenarios this is what it’s giving me:
Expression.Error: We cannot convert the value null to type Logical.
Details:
Value=
Type=Type
None of the fields that are being referenced to produce the values in these error fields are null. They all have valid values in them and produce the correct results until I change the data type of this totally unrelated [DaysAvailable] Column. Gah!
Here is the code line for the new column that creates the errors when preformed.
= Table.AddColumn(#"Added CompleteOntimeQtr", "DaysAvailable", each Number.From([WONeededBy] - [DateAvailable]))
Here is the code line that creates the only column that gives an error when I preform the type conversion to a secondary new column.
= Table.AddColumn(#"Added DueMo", "CompleteOntimeFY",
each if [FY] = fParameters("Parameters",4)
and [Completed] < [WONeededBy] then 1 else 0)
Here’s the code lines for the 3 other columns that give errors when I do the type conversion as part of the initial column creation.
= Table.AddColumn(#"Added FY", "CompleteLateMo",
each if ([Completed] > [WONeededBy]
and Date.Month([WONeededBy]) = fParameters("Parameters",3)) then 1 else 0)
= Table.AddColumn(#"Added CompleteLateMo", "CompleteOntime",
each if ([Completed] < [WONeededBy]
and Date.Month([WONeededBy]) = fParameters("Parameters",3)) then 1 else 0)
= Table.AddColumn(#"Added DueQtr", "CompleteOntimeQtr",
each if Date.QuarterOfYear([WONeededBy]) = Date.QuarterOfYear(#date(fParameters("Parameters",4),fParameters("Parameters",3),1))
and [Completed] < [WONeededBy] then 1 else 0)
There are 4 other columns that use very similar versions of the above formulas and are not giving errors.
Thanks in advance for the assistance.
-
Edited by
Friday, September 6, 2019 2:47 PM
added info

ExcelNovice2020
Member
Members
")
Forum Posts: 52
Member Since:
February 8, 2020

Offline
1
May 17, 2022 — 6:06 am


Is anyone familiar with what might be causing the following:
«We couldn’t get data from an external data source. Please try again later. If the problem persists, please contact the administrator for the external data source. Here is the error message that was returned from the Analysis Server named [Expression.Error] We cannot convert the value null to type Logical.0:
I ONLY receive this error on occasion and it only comes up with a refresh outside PQ. Every single time I am in PQ, I never receive any type of error.
I can post the file if needed but looking for advice on what may cause this or ways within PQ to avoid this.

Catalin Bombea
Iasi, Romania
Admin

Forum Posts: 1802
Member Since:
November 8, 2013
Offline
2
May 19, 2022 — 10:48 pm
Hard to say without a file.
The answer is in your data, there is an operation performed in a column where nulls should be converted to logical before any operation.
ExcelNovice2020
Member
Members
Forum Posts: 52
Member Since:
February 8, 2020
Offline
3
May 21, 2022 — 1:29 am
I know. Agree with your assessment; I just cannot find it. And, it’s not constant but upon auto refresh, I get the error, along with an occasional different expression.error. This only occurs when I am pulling data from a site (source) that is continuously updating.
I have attached the file for reference. There are seven queries where I am attempting an auto refresh every minute. These seven queries are pulling data from a site that updates data/stats based upon the current Major League baseball games going on (if not at the time, there typically is no issues) and brings the new data in the the «live» updates. The seven queries are as follows:
«LiveH2HScoresCondensed»
«LiveScores»
«LiveH2HPoints»
«LiveStandings»
«LiveRotoScore»
«LiveTotalPointsScore»
«LiveOPRScore»
I am not saying there are issues with each query. However, when these are checked for the one minute auto-refresh, I tend to receive the expression.error. My other queries work fine. I figured it was something with the source and the continuous updates; I was missing something there.
ExcelNovice2020
Member
Members
Forum Posts: 52
Member Since:
February 8, 2020
Offline
4
May 27, 2022 — 1:58 am
Before moving on, I thought I would see if there is anything else I can add to this to help me with my Expression.Error issues. It is difficult to pinpoint as they do not occur often. But, if I have the queries mentioned above set for an automatic update each minute, they will eventually occur.
My main goal was to share this file with others so they can view the updated standings/scores as they occur in real-time. With the Expression.Error issues, I am afraid to expose this to other users for viewing. Thanks.

Velouria
London or thereabouts
Member
Members

Trusted Members
Forum Posts: 580
Member Since:
November 1, 2018
Offline
5
May 27, 2022 — 5:46 pm
There are quite a few places it could occur. For example, you have a lot of comparisons like if [Total] > 1 then which would cause that error if the Total field is null. A simple way around that is to use the coalesce operator if it is available to you, or just use an explicit comparison to true:
if [Total] > 1 = true then
since null = true will return false.
ExcelNovice2020
Member
Members
Forum Posts: 52
Member Since:
February 8, 2020
Offline
6
May 27, 2022 — 11:02 pm
At first, I had the code different with some «null catches» and thought I had fixed what you were referencing above. Apparently not.
I am really interested in trying the coalesce operator. Is there anyway you could pick just one comparison, say from the «LiveH2HScoresCondensed» query and show me an example how this might work (if available on my end) using the coalesce operator? I could then see what you mean and apply to all the rest. Thanks.
Эта заметка завершает обзор примитивных типов языка М: текст, число, дата/время, логический, бинарный и null.[1]
Предыдущая заметка Следующая заметка
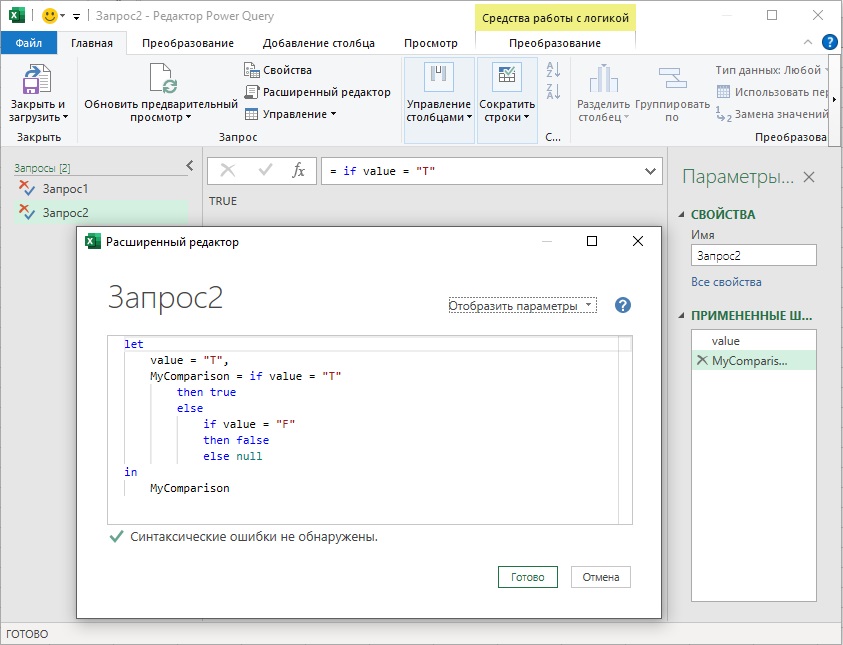
Рис. 1. Выражение if возвращает логическое значение
Скачать заметку в формате Word или pdf, примеры в формате Excel
Логический
Тип logical хранит логические значения: true и false. Логический литерал можно получить преобразованием подходящей текстовой строки или числа. «false» преобразуется в false, «true» – в true. Число 0 – в false, любое другое число – в true.
|
= Logical.FromText(«true») // true |
|
= Logical.FromText(«false») // false |
|
= Logical.FromText(«something else») /* возвращает ошибку Expression.Error: Не удалось преобразовать в логический тип.*/ |
|
= Logical.From(0) // false |
|
= Logical.From(1) // true |
|
= Logical.From(—199) // true |
Логический литерал также можно получить в результате сравнения или используя оператора if.
Листинг 1[2]
|
= 5 = Number.FromText(«5») // возвращает true |
Листинг 2
|
let value = «T», MyComparison = if value = «T» then true else if value = «F» then false else null in MyComparison // возвращает true (см. рис. 1) |
Иногда логические значения не так очевидны, как true/false. Следующие пары 1/0, yes/no, Y/N, is something/is not something по сути, являются логическими значениями. Не позволяйте форме маскировать содержание значений. Если вы видите столбец, состоящий из подобных значений, преобразуйте его в тип logical. Как Power Query, так и Excel, работают лучше, когда тип столбца соответствует типу данных значений столбца.
null
Тип null – довольно странный тип. Он включает единственное значение – null. null представляет отсутствие значения (или неизвестное, или неопределенное). Если null представляет собой неизвестное значение, является ли null в принципе значением? Оставим такие глубокие размышления философам и теоретикам компьютерного языка. Нам важен практический аспект: как операторы должны обрабатывать null? Если сравниваются два null, должен ли результат быть true, ибо сравниваются идентичные значения. Или результат должен быть null? Потому что эти значения неизвестные, а сравнение двух неизвестных, тоже является неизвестным.
Итак, возможны, по крайней мере, два способа обработки null. Поскольку нельзя поддерживать несколько вариантов поведения, разработчики языка должны выбрать один из них. В M прямые сравнения (= и <>), когда аргумент равен null, возвращают true / false:
Сравнение с использованием оператора and (И), где хотя бы один из операндов null возвращает null. С одним исключением: если второй операнд false, сравнение возвращает false. Похоже ведет себя сравнение с использованием оператора or (ИЛИ). Если один из операндов null возвращается null. С одним исключением: если второй операнд true, сравнение возвращает true:
|
= null and false // false |
Если null используется с любым другим оператором, результат сравнения возвращает null.
|
= «abc» & null & «def» // null |
И здесь есть исключения. Использование null с операторами is и meta (дает информацию о значении, а не работает непосредственно со значением) не всегда возвращают null.
Предпочитаете другое поведение?
Иногда работа M с null не соответствует вашим намерениям. Но языку присуща гибкость, и есть обходные пути. Рассмотрим последнюю строку из блока примеров выше. Допустим вы хотите объединить строки, даже если некоторые фрагменты возвращают null. Во-первых, можно проверить, содержит ли переменная значение null. Если это так, то заменить null пустой строкой перед конкатенацией.
Листинг 3
|
let value = null, NullToBlank = (input) => if (input = null) then «» else input in «abc» & NullToBlank(value) & «def» // возвращает «abcdef» |
Во-вторых, можно использовать функцию Text.Combine, которая игнорирует значения null. Код…
Листинг 4
|
= Text.Combine({«abc», null, «def»}) |
… вернет «abcdef».
В-третьих, можно использовать следующий трюк. Допустим, вы импортируете таблицу из Excel, содержащую положительные числа. Пустые ячейки в Excel, PQ импортирует как null. Если для последующих вычислений нужно преобразовать null в 0, воспользуйтесь следующей идеей:
Листинг 5
|
let import = null, future = List.Max({import,0}) in future // возвращает 0 |
import может быть положительным числом, импортированным из Excel, или null, если ячейка была пустой. В первом случае List.Max() вернет число import, которое больше 0. Во втором случае List.Max() вернет 0, так как по логике PQ null меньше любого значения не равного null.
Вообще-то синтаксис List.Max включает четыре параметра:
|
List.Max( list as list, optional default as any, optional comparisonCriteria as any, optional includeNulls as nullable logical ) as any |
В спецификации говорится. Функция List.Max() возвращает максимальный элемент в списке list или необязательное значение по умолчанию default, если список пуст. Для определения способа сравнения элементов в списке можно указать необязательный параметр comparisonCriteria. Если этот параметр равен null, используется функция сравнения по умолчанию. Четвертый параметр может быть true, тогда список {null} засчитается (хоть он и нулевой), и List.Max() вернет null. Если этот параметр false, список {null} не засчитается, и List.Max() вернет значение default.
В связи с вышесказанным можно использовать…
Листинг 6
|
let import = null, future = List.Max({import},0) in future // возвращает 0 |
Здесь 0 в строке future = List.Max({import},0) не элемент списка (как в листинге 5), а второй аргумент функции List.Max() – default.
Другая ситуация, в которой вам может потребоваться иная обработка значений null, связана со сравнениями меньше и больше. В M, если значение null сравнивается с использованием операторов >, >=, <, <=, результат равен null. Это вроде бы логично, поскольку невозможно узнать, является ли неизвестное значение больше или меньше другого значения (известного или неизвестного). Однако, возможен и иной взгляд, если принять ранжирование, в котором значение null меньше любого иного значения не равного null.
Если вы предпочитаете такое поведение, можете использовать функцию Value.Compare для выполнения сравнения. Эта библиотечная функция возвращает 0, если сравниваемые значения равны, -1, если первое значение меньше второго, и 1, если первое значение больше второго. В этой функции значение null оценивается как меньшее всех иных значений. Вот как работает функция Value.Compare:
|
= Value.Compare(1, 1) // 0, аргументы равны |
|
= Value.Compare(10, 1) // 1, первый аргумент больше второго |
|
= Value.Compare(10, 100) // -1, второй аргумент больше первого |
|
= Value.Compare(null, 1) // -1; сравни с null < 1, которое возвращает null |
|
= Value.Compare(null, null) // 0; сравни с null = null, которое возвращает null |
|
= Value.Compare(«a», null) // 1; сравни с «a» > null, которое возвращает null |
И последнее замечание на эту тему. По умолчанию сравнение null = null принимает значение true. Если вы предпочитаете, чтобы значение null = null было равно null, используйте функцию Value.NullableEquals. В спецификации функции сказано. Возвращает null, если любой из аргументов value1 и value2 равен null, в противном случае — эквивалент Value.Equals.
|
= Value.NullableEquals(null, null) // null, сравни с null = null, которое возвращает true |
Двоичный тип литерала
Обычно тип binary вы видите при работе с файлами. Как правило вы используете библиотечную функцию (или цепочку функций) для преобразования двоичного значения во что-то более удобное для обработки, например в таблицу.
Если по какой-то причине вы хотите использовать binary литерал, в М поддерживаются как списки чисел (целых / шестнадцатеричных), так и текстовые значения в кодировке base 64. Ниже мы видим одинаковые два байта, записанные с использованием трех синтаксисов.
|
= #binary({ 0x00, 0x10 }) // список шестнадцатеричных литералов |
|
= #binary({ 0, 16 }) // список десятичных литералов |
|
= #binary(«ABA=») // строка в кодировке base 64 |
Стандартная библиотека содержит ряд функций для работы с двоичными значениями. Существуют функции, которые преобразуют значения в двоичные файлы и из них. Вы можете сжимать и распаковывать файлы с помощью gzip и deflate. Существуют также функции, которые пытаются извлечь тип содержимого и, в некоторых случаях, кодировку и информацию о разделителях csv. Это может быть полезно, если вы хотите найти все текстовые файлы в папке, когда не все они имеют расширения .txt. Существует даже семейство функций, которые можно использовать для анализа пользовательского формата, для нечетного случая, когда вам нужно проанализировать двоичное значение, которое не понимает ни одна библиотечная функция.
Тип type
Вот и все! Мы рассмотрели все примитивные типы, т.е., те, что содержат одно значение, за исключением типа type. Этот тип описывает доступные типы значений. Углубляться в type (и связанную с ним концепцию системы типов Power Query) – это более сложная тема, которую пока мы оставим в покое.
В следующей заметке
Примитивные типы являются основополагающими для работы с данными. Но часто мы хотим работать со значениями, которые как-то сгруппированы: в виде списка, записи или таблицы. Язык M имеет тип для каждой из этих группировок. В следующий раз мы начнем их изучать.
[1] Заметка написана на основе статьи Ben Gribaudo. Power Query M Primer (Part 9): Types—Logical, Null, Binary. Если вы впервые сталкиваетесь с Power Query, рекомендую начать с Марк Мур. Power Query.
[2] Номер листинга соответствует номеру запроса в приложенном Excel файле.
In my last blog post here, I introduced the overlapping time periods challenge and shared the M queries for the solution. In today’s post, we will go through the solution in details.
The Challenge
Your input data is a table with start and end dates (including time). Can you find all the overlapping time periods in the table? To make this challenge more specific, imagine you are a project manager responsible for tracking the progress of a mission-critical project in your organization. You have a list of resources that are assigned to tasks. Your job is to find the over-allocated resources that are assigned to multiple tasks with overlapping time periods (as demonstrated in the figure below).

In the sample data below, you can find 5 tasks allocated to 3 resources. The figure above highlights the overlapping time periods. While it is easy to visually detect the overlaps in a Gantt chart on a small dataset, it is much more interesting to assume that the number of tasks and resources can be significant high. Can you automate the detection of overlaps in Power BI or Excel? In this blog post we’ll describe how to do it.
| Task | Resource | Start | End |
| Task 1 | Resource 1 | 7/2/2019 9:00:00 AM | 7/2/2019 5:00:00 PM |
| Task 2 | Resource 2 | 7/2/2019 11:00:00 AM | 7/2/2019 9:00:00 PM |
| Task 3 | Resource 2 | 7/2/2019 2:00:00 PM | 7/2/2019 8:00:00 PM |
| Task 4 | Resource 3 | 7/2/2019 4:00:00 PM | 7/2/2019 11:00:00 PM |
| Task 5 | Resource 3 | 7/2/2019 1:00:00 PM | 7/2/2019 7:00:00 PM |
The Solution – Step by Step
Import the table above and name the query Tasks. To do it you can copy and paste the code below into a blank query in Power Query:
let
Source = Table.FromRows(Json.Document(Binary.Decompress(Binary.FromText("i45WCkkszlYwVNJRCkotzi8tSk4Fc8z1jfSNDAwtFSytDAyASMHRF1nUFCoa4KsUqwM1wwjZDCNk1YaGWA2xxGKIMU5DjBCqkUQtsJhhgmyGMbJqE6xmwJ2HbIgpTkMMsRpijmRGLAA=", BinaryEncoding.Base64), Compression.Deflate)), let _t = ((type text) meta [Serialized.Text = true]) in type table [Task = _t, Resource = _t, Start = _t, End = _t]),
#"Changed Type" = Table.TransformColumnTypes(Source,{{"Task", type text}, {"Resource", type text}, {"Start", type datetime}, {"End", type datetime}})
in
#"Changed Type"
While Power Query Editor is open, right click on the Tasks query in Queries pane and select Reference in the shortcut menu.
Rename the new query Overlapping Tasks.
The Cartesian Product
Now we are going to use a Cartesian Product technique, which I describe in details in Chapter 11 of my book. The Cartesian Product enables you to combine two datasets in order to apply a calculation or filtering on each combination of the paired records. By matching each task against all the other tasks in the table, we will be able to find the overlapping time periods.
To compare between each row in the Overlapping Tasks table, we will create a new column that will include the table itself as an object in each row of the original table. Then, we’ll expand the table objects in the new column and generate a table with all the permutations of pairs.
In Add Column tab, select Custom Column. In the Custom Column dialog box, enter Source2 as New column name, enter the formula:
= Source
Then click OK.

Note: This technique may have slow performance if you load the original source table form an external data source. To solve this issue, we will use Table.Buffer. But let’s wait with it for now to keep the solution simple and clear.
Now, when we have the table objects in Source2, it is time to expand these tables. Click the expand column control on the right side of Source2 column header. In the expand pane, make sure that all the columns are selected. Check Use original column name as prefix and click OK.

You can see in the preview pane that Task 1 was duplicated five times, and is now paired against Task 1, Task 2, Task 3, Task 4 and Task 5 which are shown in the Source2.Task column. So, in total we have 25 rows instead of the original 5 as we apply the cartesian product.
Before we keep only the pairs that we would like to match, let’s make sure that we have the correct column types. Scrolling right in the table, you will notice that the types of columns Source2.Start and Source2.End are not set (You can see that the column headers have the ABC123 icon). Change the column types of these columns to Date/Time.
Filtering Different Tasks of the Same Resource
Since our task is to compare overlapping periods for the same resource, we would need to keep in the table only rows in which the task in Task column is not equal to the task in Source2.Task and the resource in Resource column is equal to the resource in Source2.Resource. To do it, we will start with a dummy filtering step.
Click the filter control on the column header of Task. Select Task1 in the filter pane and click OK. We will ignore the logic. We just need to generate a filtering step.

Make sure your Formula Bar is shown (You can enable it in the View tab). You will see the following formula:
= Table.SelectRows(#"Changed Type", each ([Task] = "Task 1"))
Copy and paste the formula below to keep only different tasks that are assigned to the same resource:
= Table.SelectRows(#"Changed Type", each ([Task] <> [Source2.Task] and [Resource] = [Source2.Resource]))
Bu replacing the formula, you can see that we changed the condition of the filter from the dummy logic:
[Task] = “Task 1”
to the correct logic:
[Task] <> [Source2.Task] and [Resource] = [Source2.Resource]
We used the not equal operator “<>” and “and” to get filter our cartesian product output into tasks that are assigned to same resource. You can see that we are now left with 4 rows. Task 2 matched with Task 3 as the first row. Next, Task 3 matched with Task 2 (the reversed instance of the previous row). Then, Task 4 matched with Task 5 and finally the reversed instance as the last row.

Calculating Overlapping Duration
Now it is time to calculate the overlapping time period between each of the tasks and to filter out rows without overlap.
To set the stage for the overlap calculation we will create two custom functions MinDate and MaxDate that find the minimal and maximal dates of two given Date/Time values.
In Home tab, select New Source drop-down menu, and select Blank Query.

Name the new query as MinDate. and copy and paste this formula into the Formula Bar:
= (date1, date2)=>
if date1 < date2 then date1 else date2
Now go back to Home tab, New Source and select Blank Query. Name the new query MaxDate. Copy and paste this formula into the Formula Bar:
(date1, date2)=>
if date1 >= date2 then date1 else date2
In Queries pane, select the Overlapping Tasks query and in Add Column tab select Custom Column. In the Custom Column dialog box follow these steps:
- Enter Overlap Duration in the New column name box.
- Enter the following formula below and click OK.

Here is code you can copy and paste into the Custom column formula box:
Duration.TotalHours(
MinDate([End], [Source2.End]) -
MaxDate([Start], [Source2.Start])
)
This code uses Duration.TotalHours to return the total hours as a decimal number of the overlapping duration. The main calculation in the formula is done by subtracting the minimal end date with the maximal start date of the two tasks, as shown here:
MinDate([End], [Source2.End]) - MaxDate([Start], [Source2.Start])
Subtracting two Date/Time values in M returns a value whose type is duration. In our case, if the duration is positive, we have an overlap, but if the duration is negative, we don’t. You can now see that all the rows have a positive duration value because in our sample data, all our tasks that has the same resource are overlapping.
To test our Overlapping Duration custom column with tasks that are not overlapping let’s add a 6th task for Resource 3 that has no overlapping period. To do it, go to the Tasks query in Queries pane and select the settings cog wheel icon in the Source step of Applied Steps pane. Then enter the following row in Create Table dialog box.

Move back to Overlapping Tasks query and see that four rows with negative Overlapping Durations values were added. This can prove you that our formula worked. We just need to keep rows whose duration is positive.

Select the filter control of Overlapping Duration column and in the filter pane select Number Filters, then select Great Than…

In the Filter Rows dialog box, enter 0 as shown in the screenshot below and click OK.

You can now create two new columns for the overlapping period start and end dates. This can be done in multiple ways. Since we already have the MinDate and MaxDate functions, let’s do it using Invoke Custom Function.
In Add Column tab, select Invoke Custom Function. In the Invoke Custom Function dialog box, enter Overlap Start as New column name. Next, in the Function query drop-down menu select MaxDate.
Make sure that under date1 drop-down menu you choose Column Name. Select Start in the drop-down menu which is next to date1.
Under date2 drop-down menu select Column Name. Select Source2.Start in the drop-down menu which is next to date2 and click OK.

In Add Column tab, select Invoke Custom Function. In the Invoke Custom Function dialog box, enter Overlap End as New column name. Next, in the Function query drop-down menu select MinDate.
Make sure that under date1 drop-down menu you choose Column Name. Select End in the drop-down menu which is next to date1.
Under date2 drop-down menu select Column Name. Select Source2.End in the drop-down menu which is next to date2 and click OK.

We are almost done. We can now remove the unnecessary columns and keep only Task, Overlapping Duration, Overlap Start and Overlap End. and changed the types of Overlapping Duration, Overlap Start and Overlap End to the corresponding types: Decimal Number, Date/Time and Date/Time.
Performance Improvement
The Cartesian Product that we applied earlier may be tricky when you load the tasks table from an external data source – especially if you have many tasks. You can find the explanation in Chapter 11 of my book. To fix this issue you can use the Table.Buffer function (If you have enough memory to store the entire table, otherwise don’t follow this improvement).
Open the Advanced Editor in Overlapping Tasks and locate the following lines:
Source = Tasks, #"Added Custom" = Table.AddColumn(Source, "Source2", each Source),
Modify the two lines into three as follows:
Source = Tasks, BufferedSource = Table.Buffer(Source), #"Added Custom" = Table.AddColumn(Source, "Source2", each BufferedSource),
Visualizing overlapping tasks
In this PBIX file, you can find the Power Query solution and a simple visualization of the overlapping tasks. The report loads the tasks into an as-Timeline custom visual and shows the over-allocated resource on a separate table with their corresponding tasks and the duration of the time overlaps.

When you click on one of the tasks in the as Timeline visual, you can see which tasks are overlapping. For example, in this screenshot, I clicked on Task 4 which is assigned to Resource 3 and found out that this resource is over allocated as it is also assigned to Task 5 with an overlap of 3 hours, starting from 7/2/2019 7PM.

Do you have similar challenges that are not covered by the solution above? please share in the comments below.