Recently I had a bunch of virtual machines that started generating this error during Veeam backups. I hadn’t bothered to really be checking my snaps because my daily job was supposed to be taking care of that for me. Unfortunately, this bit me and Here we are
As many of you have probably experienced, Veeam doesn’t always clean up after itself when it is finished backing up a VM. Sometimes a file lock or other operation prevents the snap cleanup, and you end up with a huge chain of snapshots.
Normally you would just be able to right click the VM, select Snapshots, then “delete all” and be done, however I was getting.
A general system error occurred: vim.fault.GenericVmConfigFault
So how do we fix this? Well it turns out there are two ways.
Resolution 1:
This resolution requires downtime, however is significantly faster. It does however have some caveats I will get to later.
- Shut down the Virtual Machine.
- SSH to the host where the VM was running.
- Change Directory to the volume where the guests disks are stored.
cd /vmfs/volumes/volumguid/machinefolder
- Find all delta.vmdk for the VM
ls -ltrh | grep delta.vmdk
- If it looks something like this you’re good to go. Notice how of the 5 snapshot deltas, only 0x5.delta.vmdk actually has data, the others are empty?

- If it looks like this, you’re going to have to use Resolution 2. Notice how multiple of the snapshot deltas hold data?
- Create a new folder in the VMs folder.
mkdir ./tmp
- Move all of the EMPTY snapshot data to the /tmp folder. DO NOT DELETE IT. If the remaining steps do not work we have to restore these files.
mv VM_1-000001* ./tmp
- Once all Snapshots are moved, and you are left with your base disk and your last snapshot. Open VMware vSphere Client, and create a new VM. Make it identical to the old VM, however DO NOT add a disk. Remove the disk VMware wants to create, and select “add existing disk” Select the snapshot disk, NOT the base disk, and attach it to the VM. Do not select “Power On VM after Creation.”
- Once creation is complete you will notice that VMware will show “Virtual machine disks need consolidation.” Right click the VM and chose to consolidate the disk. Once consolidation is complete, boot the VM and verify functionality. You should be all set!


Resolution 2:
If your VM is not recoverable with Resolution 1, your alternate resolution is to use the VMware Standalone converter to convert a “Powered On Windows / Linux Machine.” So yes you are doing a P2V migration of a Virtual machine to a new virtual machine.
This isn’t the best solution in the world and its essentially the same as taking / restoring an OS based backup instead of a VM based one, however it allows your VM to be online during the entire operation which could be a consideration for those who have very small maintenance windows and may not be able to do a full consolidation in that window.
Версии 8.4 SRM всего пару дней, однако бдительные тестеры VMware уже успели оттраблшутить новый релиз вдоль и поперек, благодаря чему у нас снова на руках свежайший список возможных ошибок и проблем, и даже методы борьбы со многими из них. И это, бесспорно, весьма приятно. Кое-что, правда, перекочевало к нам еще из 8.3.1, и так как ее траблшутингу мы уже посвящали довольно объемную отдельную статью, повторяться здесь, думается, не будем.
Что же касается новых проблем, вот, собственно, и они:
- Issue: Операция повторной защиты для одной ВМ выдает ошибку вида:
Unable to reverse replication for the virtual machine ‘<vm-name>’. A general system error occurred: Fault cause: vim.fault.GenericVmConfigFault
На целевом сайте vCenter Server задача для ВМ сбоит с записью:
Task Name: Remove all snapshots
Status: A general system error occurred: Fault cause: vim.fault.GenericVmConfigFault
Initiator: <initiator>
Target: <vm-name>
Server: <VC-name>
Resolve: Удалить репликацию, затем настроить ее опять, используя диски-источники.
- Issue: Одна или более репликаций уходят в статус ошибки (RPO нарушения) после операции повторной защиты, гласящей:
A problem occurred with the storage on datastore path ‘[<datastore-name>] <datastore-path>/hbrdisk.RDID-<disk-UUID>.vmdk
Resolve: Удалить репликацию, настроить ее повторно, используя диски-источники.
- Issue: Тестовое восстановление и реальное восстановление групп защиты политики хранения, содержащее vTA зашифрованные ВМ, может сбоить с ошибкой:
An encryption key is required
Resolve: Повторно запустить операцию.
- Issue: При попытке реконфигурировать репликацию и добавить или удалить новый диск может выдать ошибку:
ERROR Duplicate key (hms.DiskSpaceRequirementInfo)
Ситуация известна для SRM 8.3 и vSphere Replication 8.3 на on-premise среде, спаренной с SRM 8.4 и vSphere Replication 8.4 на удаленном сайте, либо же со службой VMware Site Recovery на VMware Cloud на AWS.
Resolve: Проапгрейдиться до версии 8.3.1 или 8.4 – с ними такого не будет.
- Issue: На вкладке Summary и вкладке Virtual Machines группы защиты появляется ошибка:
The ManagedObjects in ‘spec.objectSet’ belong to more than 1 server
или:
Missing value for non-optional field placeholderVmInfo
при незавершенной операции повторной защиты или же сразу после ее окончания. Если все закрыть, и открыть снова, в списке не будет никаких ВМ.
Resolve: Закрыть сообщение об ошибке и подождать какое-то время. ВМ снова появятся в группе защиты и будут защищены и включены, как ожидалось.
- Issue: Не получается удалить уже добавленные сопоставления инвентаря при использовании браузера Chrome, так как кнопка «Remove» в визарде Configure Protection Group пропадает.
Resolve: Обновить браузер.
- Issue: Тестовое восстановление или Аварийное восстановления могут дать сбой до своего завершения, если SRM на сайте восстановления теряет связь с SRM на защищаемом сайте.
Resolve: Перезапустить службу SRM на сайте восстановления и инициировать план восстановления повторно.
- Issue: Визард Configure Replication на Apple Mac OS с браузером Mozilla Firefox начинает лагать, а производительность UI падает.
Resolve: Использовать Chrome.
- Issue: Очистка после тестирования плана восстановления при использовании SRM 3.1.х может сбоить с ошибкой удаленного коннекшен-сервера (под vCenter Server 7.0U2) вида:
The connection to the remote server is down. Operation timed out: 300 seconds.
Resolve: Проапгрейдиться до SRM 8.4.
- Issue: Виртуальные машины, защищенные SRM и использующие NVDS для защищаемой и/или сети восстановления, демонстрируют ошибки защиты после миграции NVDS-CVDS.
Resolve: Перенастроить защиту вовлеченных ВМ.
Если в будущем будут обнаружены какие-то новые ошибки, касающиеся релиза 8.4 SRM, эта статья непременно будет оперативно дополнена.
Hi,
My VM backup is getting error code 4274. But i never seen this error «vim.fault.GenericVmConfigFault <33>», or this one «status=36 (SYM_VMC_TASK_REACHED_ERROR_STATE). Error Details: [A general system error occurred: vim.fault.GenericVmConfigFault].» Cannot find the exact error in Veritas or VMware forum. Anyone have experience with the same problem?
06/12/2017 21:12:52 - Info bpbrm (pid=14468) INF - vmwareLogger: WaitForTaskComplete: A general system error occurred: vim.fault.GenericVmConfigFault <33>
06/12/2017 21:12:52 - Info bpbrm (pid=14468) INF - vmwareLogger: WaitForTaskComplete: SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE
06/12/2017 21:12:52 - Info bpbrm (pid=14468) INF - vmwareLogger: removeVirtualMachineSnapshot: SYM_VMC_ERROR: TASK_REACHED_ERROR_STATE
06/12/2017 21:12:52 - Critical bpbrm (pid=14468) from client PEPKPDB011: FTL - vSphere_freeze: Unable to remove virtual machine snapshot, status=36 (SYM_VMC_TASK_REACHED_ERROR_STATE). Error Details: [A general system error occurred: vim.fault.GenericVmConfigFault].
06/12/2017 21:12:52 - Critical bpbrm (pid=14468) from client PEPKPDB011: FTL - vfm_freeze: method: VMware_v2, type: FIM, function: VMware_v2_freeze
06/12/2017 21:12:52 - Critical bpbrm (pid=14468) from client PEPKPDB011: FTL - vfm_freeze: method: VMware_v2, type: FIM, function: VMware_v2_freeze
06/12/2017 21:12:53 - Critical bpbrm (pid=14468) from client PEPKPDB011: FTL - snapshot processing failed, status 4274
06/12/2017 21:12:53 - Critical bpbrm (pid=14468) from client PEPKPDB011: FTL - snapshot creation failed, status 4274
06/12/2017 21:12:53 - Warning bpbrm (pid=14468) from client PEPKPDB011: WRN - ALL_LOCAL_DRIVES is not frozen
06/12/2017 21:12:53 - Info bpfis (pid=1544) done. status: 4274
06/12/2017 21:12:53 - end Application Snapshot: Create Snapshot; elapsed time 0:00:18
06/12/2017 21:12:53 - Info bpfis (pid=1544) done. status: 4274: Failed to remove virtual machine snapshot
06/12/2017 21:12:53 - end writing
Operation Status: 4274
06/12/2017 21:12:53 - end Parent Job; elapsed time 0:00:18
06/12/2017 21:12:53 - begin Application Snapshot: Stop On Error
Operation Status: 0
06/12/2017 21:12:53 - end Application Snapshot: Stop On Error; elapsed time 0:00:00
06/12/2017 21:12:53 - begin Application Snapshot: Cleanup Resources
06/12/2017 21:12:53 - end Application Snapshot: Cleanup Resources; elapsed time 0:00:00
06/12/2017 21:12:53 - begin Application Snapshot: Delete Snapshot
06/12/2017 21:12:54 - started process bpbrm (pid=16472)
06/12/2017 21:12:55 - Info bpbrm (pid=16472) Starting delete snapshot processing
06/12/2017 21:12:57 - Info bpfis (pid=11140) Backup started
06/12/2017 21:12:57 - Warning bpbrm (pid=16472) from client PEPKPDB011: cannot open C:Program FilesVeritasNetBackuponline_utilfi_cntlbpfis.fim.PEPKPDB011_1497276755.1.0
06/12/2017 21:12:57 - Info bpfis (pid=11140) done. status: 4207
06/12/2017 21:12:57 - end Application Snapshot: Delete Snapshot; elapsed time 0:00:04
06/12/2017 21:12:57 - Info bpfis (pid=11140) done. status: 4207: Could not fetch snapshot metadata or state files
06/12/2017 21:12:57 - end writing
Operation Status: 4207
Operation Status: 4274
Failed to remove virtual machine snapshot (4274)
While working for a client I got into a situation where I was unable to remove a snapshot from a VM. This was quite annoying because the error message that was shown didn’t give me that much information. In this blog, I’ll explain the procedure that got me in this situation and what I did to finally remove the snapshot.
Why is a stuck snapshot a problem?
Over the time that I worked with Virtual Machines (VMs), it became clear that in essence a VM just consists of a bunch of files located on a storage device. Because of that, it’s easy to create point-in-time capture, a ‘snapshot’, of the VM. The snapshot captures the state, settings, virtual disk, and in most cases the memory state of the VM. From this point on, changes to the virtual disk are kept in a separate ‘delta file‘ which creates the possibility to revert back to the state of the VM from when the snapshot was created. When the snapshot is no longer needed, deleting the snapshot will merge the delta file(s) with the actual virtual disk file.
The snapshot functionality provides for example a massive advantage when performing any type of upgrade in the VM Operating System (OS). When the upgrade ends up rendering the VM useless, there is an easy way to restore the VM back to the state of before the upgrade. Many backup solutions like Veeam or Commvault use the same functionality of creating a snapshot and then download and store that snapshot as a backup.
However, there is also a downside to having snapshots, when snapshots are kept on the VM there is a possible loss of performance for every snapshot. This is because each snapshot has its own delta file and the ESXi node needs to calculate the differences between those files, which gets trickier with every snapshot. The best practice is to not keep snapshots for longer than absolutely needed and remove them via the snapshot manager.
How did I end up with a stuck snapshot?
For a client of RedLogic, we did a project where a new infrastructure was built separately from the old infrastructure. With the new infrastructure ready, around 100 VMs then needed to be migrated between the vCenter Server Appliances (VCSA), both appliances running version 6.7.0.45100 (build 17028579). For the migration, both environments had access to the same storage making it possible to easily migrate VMs between the two. For each VM there’re a few steps needed to be migrated to the new environment;
- Power off the VM in the old environment
- Remove the VM from the inventory in the old vCenter
- In the new vCenter find the VM on the datastore and register the VM
- Create a snapshot of the migrated VM
- Upgrade the VM hardware level to the most recent
- Power on the VM
- If the VM boots as expected, remove the snapshot
As there were about 100 VMs needed to be migrated, this procedure would need to be done around 100 times. After a couple of VMs, I decided to be lazier and I created a script to do the job for me. I found out that there is a PowerCLI option to connect to multiple vCenters at the same time and changed my script accordingly. I programmed the script and everything went as expected, except that there was still a snapshot left on the VM. When trying to remove it manually through vCenter it throws a very useful error; A general system error occurred: Fault cause: vim.fault.GenericVmConfigFault
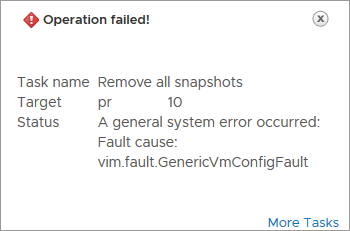
How to fix this error?
After some time on Google, I found an entry from ‘shayrulah‘ in the VMware community and Cameron Joyce wrote a blog about this topic but neither solution worked out in this case. I started combining the information from both and managed to delete the snapshot in the end. Let me take you along with what I did to finally remove the snapshots.
So, the first thing that I needed to do was to make sure that I get a maintenance window approved by the customer because the VM will need to be powered off in the process. These are the steps that I ended up taking:
- Since we need to play around with the VM, make sure it’s powered off.
- Now find the datastore where the ‘vmx ‘ file of the VM is located
- Remove the VM from the vCenter inventory
- Create a temp folder in the VM folder on the datastore (I’ll do that via ssh)
- Move all “vmsn” and “vmsd” files to tmp folder
- Find the VMX file and add the VM back to vCenter
- Acknowledge the ‘VM consolidation needed’ status and go drink some thee/coffee/water/anything else
- When done, check to see if the snapshot is now removed and then boot VM.
- VM booting alright? Continue with removing the temp folder for that VM off the datastore
I tried to reproduce this error in my lab on my vCenter 7.0 U1 but there error didn’t occur. I created the screenshots from the customer environment so I redacted quite some information so I can show them here. In my own lab, I am able to move snapshot files around so I created a clip with asciinema where I move the files via ssh on an ESXi host. When you just have one VM the vmsn and vmsd files can also be moved via the vCenter UI.
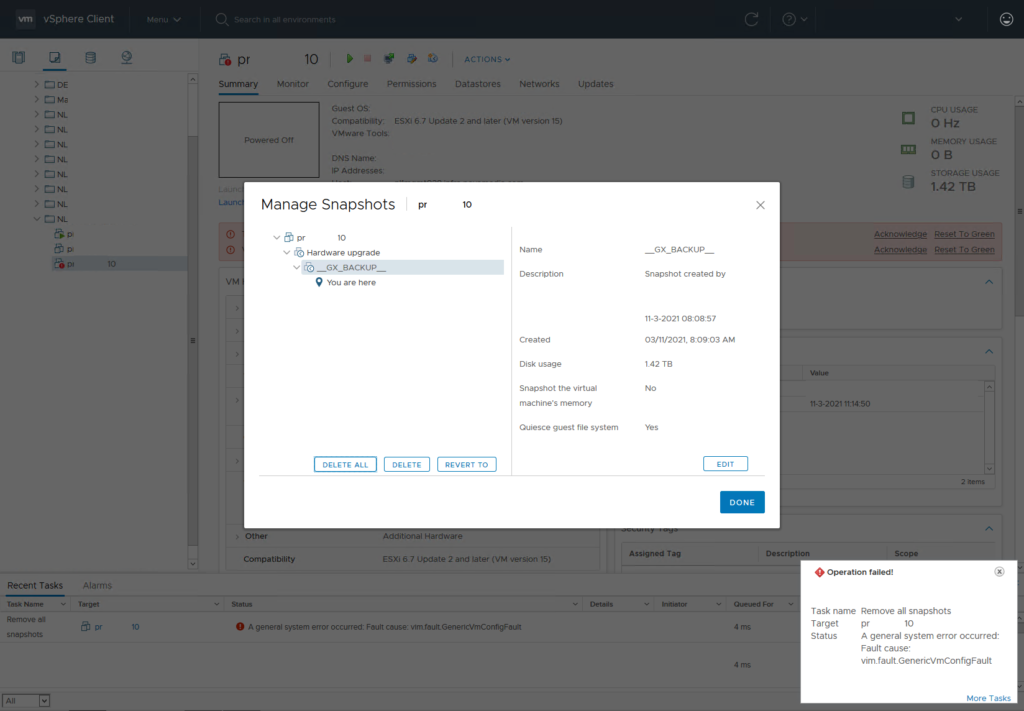
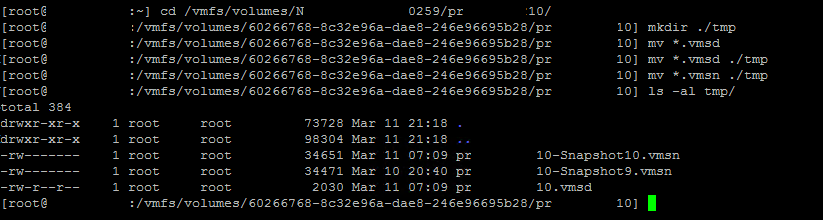
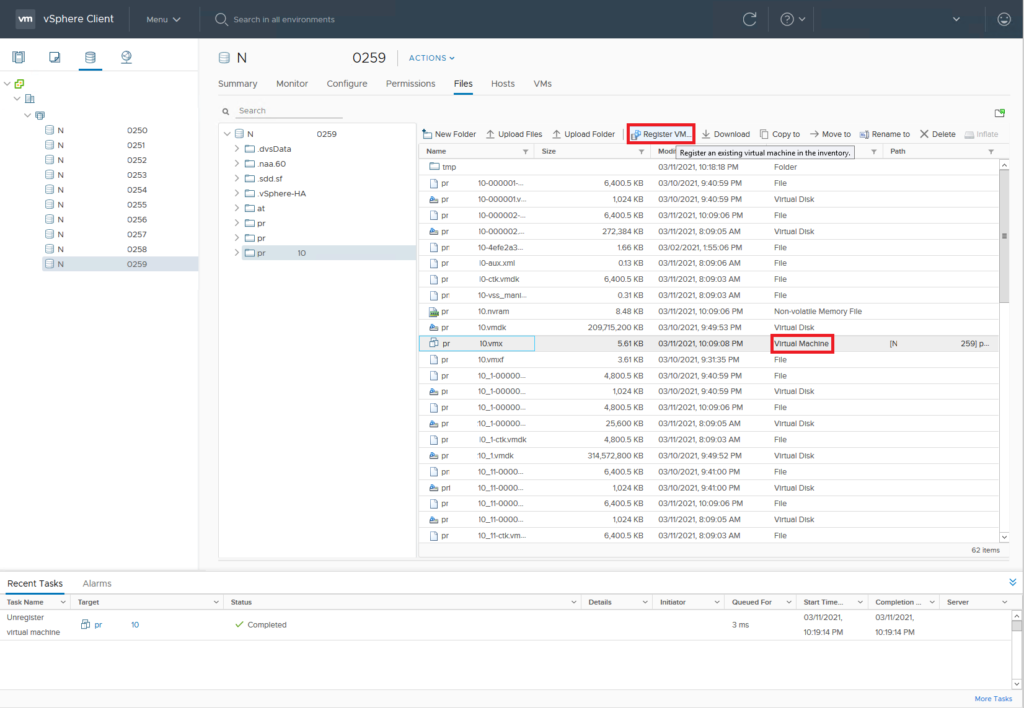
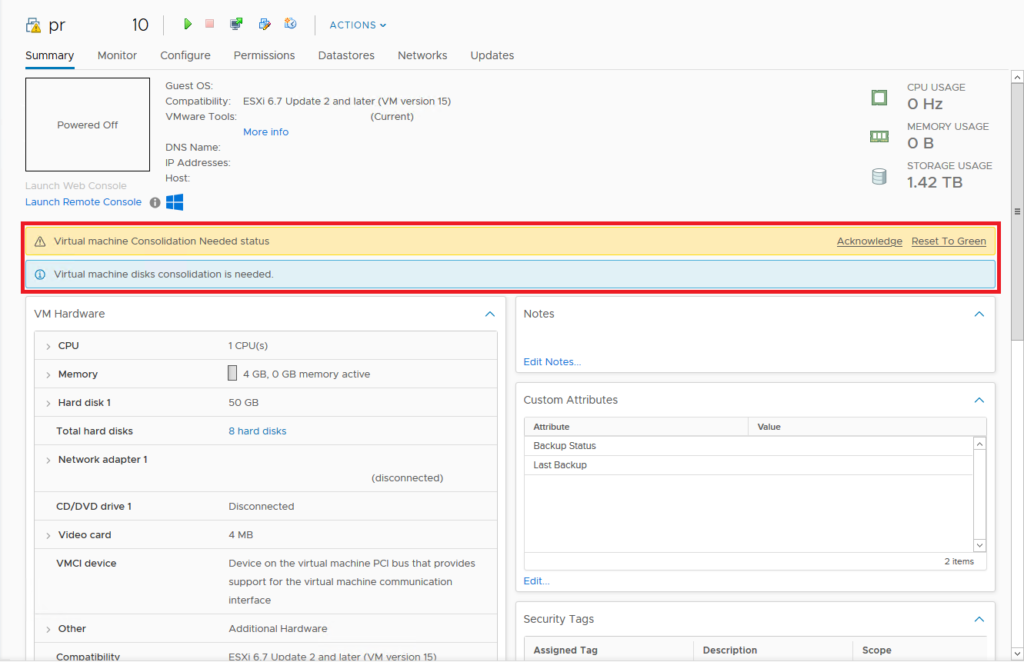
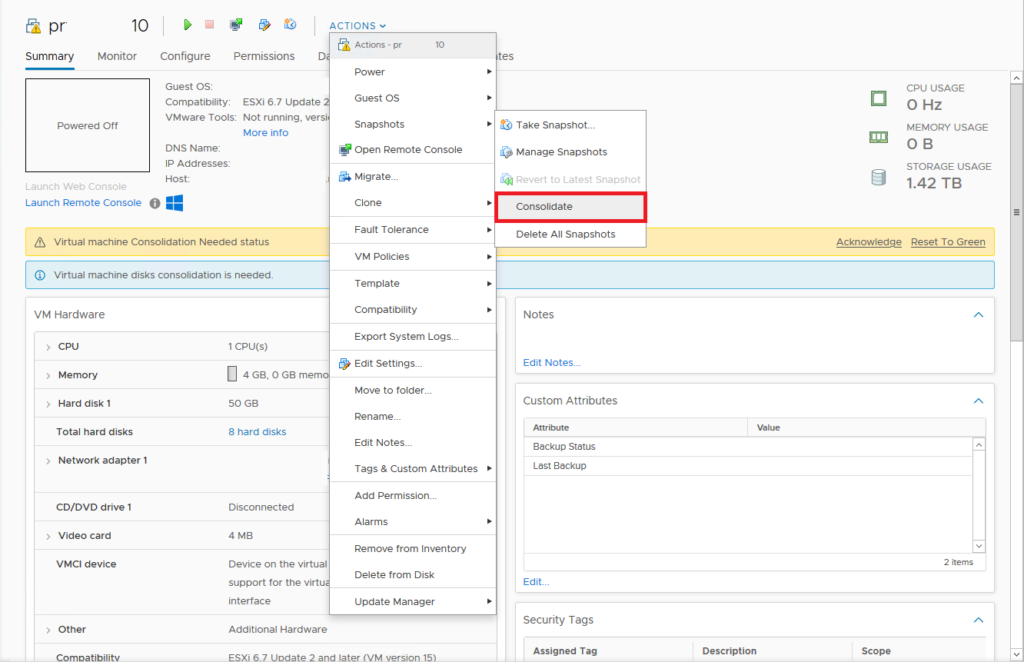

The images show the full process of moving the vmsd and vmsn files, these files are key to the process of getting the snapshot files consolidated. The vmsd is a database file that holds information about all the snapshots and this is the primary source of information for the snapshot manager in vCenter. Without this file, vCenter doesn’t know which snapshots are present were and can only recover by consolidating any present deltas disk files. The vmsn is a file that contains the active memory state of the VM at the time of the snapshot. This file is no longer needed as the VM is now in shutdown and there is no possibility to consolidate the ‘active’ memory anyway.
Where did it misalign?
After changing my script to work with multiple vCenters I found that I forgot to update a line of code. This line would actually create the snapshot and my guess is that the script would still create the snapshot on the old vCenter, despite the script removing the VM there. I tried to replay this in my lab environment but vCenter 7.0 now has the ability to natively use Advanced Cross vCenter Server Migration. So I suspect that it handles a VM with a snapshot better than the older vCenter version but, because of time, I haven’t been able to test that. For now, the error is solved and that is the most important!
Closing thought
In the end, it was a lot of work to remove all the snapshots that were stuck. It showed me that automation can often help to make dull tasks quicker but when it goes wrong then it can cause some more work. This situation clearly is an example of that. All in all, I was happy to be able to migrate the VMs from one platform to the new one, and that I managed to remove the snapshots in the end.
Thanks for reading! Hopefully, you found it interesting and maybe you’ve even learned something new! Want to be informed about a new post? Subscribe! Any questions or just want to leave a remark? Please do so- I’m always very curious to hear what you think of my content. Enjoy your day!