|
# (отредактировано 10 лет, 4 месяца назад) |
|
|
Темы: 33 Сообщения: 534 Участник с: 23 февраля 2012 |
Только я не могу обновиться?
$ sudo pacman -Syu
:: Синхронизируются базы данных пакетов...
core не устарел
extra не устарел
community не устарел
:: Запускается полное обновление системы...
разрешение зависимостей...
проверка на взаимную несовместимость...
Цели (4): jdk7-openjdk-7.u7_2.3.2-2 jre7-openjdk-7.u7_2.3.2-2
jre7-openjdk-headless-7.u7_2.3.2-2 sdl-1.2.15-3
Будет загружено: 37,69 MiB
Будет установлено: 83,45 MiB
Изменение размера: -0,19 MiB
Приступить к установке? [Y/n]
:: Получение пакетов с extra...
ошибка: не удалось получить файл 'jre7-openjdk-headless-7.u7_2.3.2-2-i686.pkg.tar.xz' из mirror.yandex.ru : The requested URL returned error: 404 Not Found
предупреждение: не удалось получить некоторые файлы с extra
ошибка: не удалось получить файл 'jre7-openjdk-7.u7_2.3.2-2-i686.pkg.tar.xz' из mirror.yandex.ru : The requested URL returned error: 404 Not Found
предупреждение: не удалось получить некоторые файлы с extra
ошибка: не удалось получить файл 'sdl-1.2.15-3-i686.pkg.tar.xz' из mirror.yandex.ru : The requested URL returned error: 404 Not Found
предупреждение: не удалось получить некоторые файлы с extra
ошибка: не удалось завершить запрос (ошибка в библиотеке загрузки)
Обнаружены ошибки, пакеты не были обновлены.
$
Сервера: У всех 404 ошибка. «If you try to hide the complexity of the system, you’ll end up with a more complex system». Layers of abstraction that serve to hide internals are never a good thing. Instead, the internals should be designed in a way such that they NEED no hiding. —Aaron Griffin |

|
deniolp |
# |
|
Темы: 5 Сообщения: 134 Участник с: 02 декабря 2011 |
Нет, все прошло гладко. Только что эти же пакеты..
Arch awesome @各行其道@ |

|
samson4747 |
# |
|
Темы: 33 Сообщения: 534 Участник с: 23 февраля 2012 |
Странный косяк был. У меня тоже уже всё хорошо. $ sudo pacman -Syu
[sudo] password:
:: Синхронизируются базы данных пакетов...
core не устарел
extra 1422,6 KiB 4,05M/s 00:00 [######################] 100%
community 1781,0 KiB 2,77M/s 00:01 [######################] 100%
:: Запускается полное обновление системы...
разрешение зависимостей...
проверка на взаимную несовместимость...
Цели (5): java-rhino-1.7R4-1 jdk7-openjdk-7.u7_2.3.2-2
jre7-openjdk-7.u7_2.3.2-2 jre7-openjdk-headless-7.u7_2.3.2-2
sdl-1.2.15-3
Будет загружено: 38,72 MiB
Будет установлено: 84,54 MiB
Изменение размера: -0,16 MiB
Приступить к установке? [Y/n]
:: Получение пакетов с extra...
jre7-openjdk-headle... 37,2 MiB 3,28M/s 00:11 [######################] 100%
java-rhino-1.7R4-1-any 1049,4 KiB 3,76M/s 00:00 [######################] 100%
jre7-openjdk-7.u7_2... 173,7 KiB 3,16M/s 00:00 [######################] 100%
sdl-1.2.15-3-i686 326,9 KiB 2,80M/s 00:00 [######################] 100%
(5/5) проверяется целостность пакета [######################] 100%
(5/5) загрузка файлов пакета [######################] 100%
(5/5) проверка возможных конфликтов файлов [######################] 100%
(5/5) проверяется доступное место [######################] 100%
(1/5) обновление jre7-openjdk-headless [######################] 100%
(2/5) обновление java-rhino [######################] 100%
(3/5) обновление jre7-openjdk [######################] 100%
(4/5) обновление jdk7-openjdk [######################] 100%
(5/5) обновление sdl [######################] 100%
Новые дополнительные зависимости для sdl
alsa-lib: ALSA audio driver
libpulse: PulseAudio audio driver
$
«If you try to hide the complexity of the system, you’ll end up with a more complex system». Layers of abstraction that serve to hide internals are never a good thing. Instead, the internals should be designed in a way such that they NEED no hiding. —Aaron Griffin |
|
samson4747 |
# |
|
Темы: 33 Сообщения: 534 Участник с: 23 февраля 2012 |
$ sudo pacman -Syu
:: Синхронизируются базы данных пакетов...
core не устарел
extra не устарел
community не устарел
:: Запускается полное обновление системы...
разрешение зависимостей...
проверка на взаимную несовместимость...
Цели (13): filesystem-2012.10-1 hdparm-9.42-1 initscripts-2012.09.2-2
jack2-1.9.8-4 libusbx-1.0.14-1 linux-3.5.5-1
linux-headers-3.5.5-1 lirc-utils-1:0.9.0-30 netcfg-2.8.11-1
nvidia-304.51-3 systemd-194-1 util-linux-2.22-7
virtualbox-host-modules-4.2.0-5
Будет загружено: 9,20 MiB
Будет установлено: 152,77 MiB
Изменение размера: 0,47 MiB
Приступить к установке? [Y/n]
:: Получение пакетов с core...
ошибка: не удалось получить файл 'linux-headers-3.5.5-1-i686.pkg.tar.xz' из mirror.yandex.ru : The requested URL returned error: 404 Not Found
предупреждение: не удалось получить некоторые файлы с core
:: Получение пакетов с extra...
ошибка: не удалось получить файл 'lirc-utils-1:0.9.0-30-i686.pkg.tar.xz' из mirror.yandex.ru : The requested URL returned error: 404 Not Found
предупреждение: не удалось получить некоторые файлы с extra
ошибка: не удалось получить файл 'nvidia-304.51-3-i686.pkg.tar.xz' из mirror.yandex.ru : The requested URL returned error: 404 Not Found
предупреждение: не удалось получить некоторые файлы с extra
ошибка: не удалось завершить запрос (ошибка в библиотеке загрузки)
Обнаружены ошибки, пакеты не были обновлены.
$
«If you try to hide the complexity of the system, you’ll end up with a more complex system». Layers of abstraction that serve to hide internals are never a good thing. Instead, the internals should be designed in a way such that they NEED no hiding. —Aaron Griffin |
|
lampslave |
# |
|
Темы: 32 Сообщения: 4800 Участник с: 05 июля 2011 |
Может зеркало обновляется в этот момент, может там ещё какой косяк. Страшного ничего нет. |
|
samson4747 |
# |
|
Темы: 33 Сообщения: 534 Участник с: 23 февраля 2012 |
Никогда такого не было, а тут почти каждую неделю так выбивает. Знаю, что ничего страшного, но не особо приятнавя вещь.
«If you try to hide the complexity of the system, you’ll end up with a more complex system». Layers of abstraction that serve to hide internals are never a good thing. Instead, the internals should be designed in a way such that they NEED no hiding. —Aaron Griffin |
|
sleepycat |
# |
|
Темы: 98 Сообщения: 3291 Участник с: 19 июля 2011 |
добавьте какойнито французский или немецкий сервер, можно даже украинский, тогда такие промахи будут находу устарняться путем их скачки из др. места.
Лозунг у них был такой: «Познание бесконечности требует бесконечного времени». С этим я не спорил, но они делали из этого неожиданный вывод: «А потому работай не работай — все едино». И в интересах неувеличения энтропии Вселенной они не работали. (с) |

|
Aivar |
# |
|
Темы: 4 Сообщения: 6897 Участник с: 17 февраля 2011 |
Было и обговаривалось не раз — зеркала яндекса хоть и обеспечивают приличную скорость, но часто падают. За германский плюсую, только не забываем после добавления зеркала обновить список пакетов. Кстати, бывает, что с зеркала яндекса скачивается кривой пакет — лечится удалением оного из кэша пакмана. |
|
Rollerd |
# |
|
Темы: 0 Сообщения: 13 Участник с: 15 января 2018 |
Здравствуйте1А не могли бы вы мне подробно объяснить куда прописывать новые серверы для арчлинукса. ото мои не обновляются давно |
|
vs220 |
# |
|
Темы: 22 Сообщения: 8090 Участник с: 16 августа 2009 |
/etc/pacman.d/mirrorlist |
![]()
Whenever I execute php artisan opcache:clear it returns me this error:
php artisan opcache:config
[AppstractLushHttpExceptionLushRequestException]
The requested URL returned error: 404 Not Found
Am I doing something wrong?
![]()
Do you have set the correct APP_URL in your .env?
If so, maybe the routes are cached?
Try: php artisan routes:clear
![]()
Yes the APP_URL matches the domain itself 100%.
I have also cleared the route cache and then did php artisan opcache:clear but keep getting the URL error.
![]()
Hi @Cannonb4ll
Can you provide us some more information about your setup or how we can reproduce the issue. Locally I can’t reproduce it with latest versions (L5.4.* + laraval-opcache ^0.1.1.)
![]()
@Cannonb4ll can you respond to above questions please, if the issue still exists? Else we will close this issue.
![]()
I’m running into this as well. I’m wondering if it’s because I use CloudFlare? Is there a reason it’s referencing the APP_URL rather than ‘127.0.0.1’? I ask because since I use cloudflare the source IP will never be the same as the server IP.
![]()
Sorry for responding so late, I have not had the chance to continue on this issue since I just disabled opcache.
![]()
@bradcis the APP_URL is used because the request must be handled by the same webserver as your site is running on. Only IP would not be enough in most cases, because of the domain mapping to the app. The ‘clear’ command is requesting the following route for example: <app_url>/opcache-api/clear so this URL should be accessible from your browser, but is should return a 403 error (because the request is not made from the same IP as the server IP) but not a 404 (this implicates that the routes are not working correctly).
Please make sure you are on the latest version, and then report your issues with as much as information as possible.
![]()
@ovanschie, I restarted nginx and now get a 403 when using the artisan opcache commands. Since APP_URL is the production URL, any call made to it gets routed through Cloudflare’s servers, and when the call finally gets back to my server, it has a cloudflare IP rather than the server’s IP so it doesn’t work. It would be great if there was a OPCACHE_APP_URL option in the config which defaulted to APP_URL but that one could override to ‘127.0.0.1’ if they were also using a CDN.
![]()
@bradcis ok, thanks! will have a look a this later.
![]()
@bradcis I added 127.0.0.1 to the allowed remotes, so I think this will fix it for you. Can you give it a try?
![]()
@ovanschie, I think we’re close. 127.0.0.1 will no longer get a 403, but the artisan commands still reference the APP_URL rather than localhost, so it’s still going out onto the Internet and being proxied by the CDN. Could we add a OPCACHE_APP_URL (or similar) config option that defaults to APP_URL but can be overwritten (to http://127.0.0.1/) via the .env file?
![]()
@bradcis I don’t understand the issue with that. If you make a request to http://127.0.0.1/opcache-api/clear how would that be resolved by the webserver? How does it know which app to serve as in most cases it listens for a domain right?
![]()
Good point, I hadn’t thought of that. I was assuming there would only be a single app on a server.
If this issue doesn’t impact anyone else I don’t want to take up anymore of your time, thanks much for your help!
![]()
@bradcis alright, but did it work even though it is being proxied?
Calling curl without parameters, i get the page output, even with an http status code = 404:
$ curl http://www.google.com/linux;
<!DOCTYPE html>
<html lang=en>
<meta charset=utf-8>
<meta name=viewport content="initial-scale=1, minimum-scale=1, width=device-width">
<title>Error 404 (Not Found)!!1</title>
<style>
*{margin:0;padding:0}html,code{font:15px/22px arial,sans-serif}html{background:#fff;color:#222;padding:15px}body{margin:7% auto 0;max-width:390px;min-height:180px;padding:30px 0 15px}* > body{background:url(//www.google.com/images/errors/robot.png) 100% 5px no-repeat;padding-right:205px}p{margin:11px 0 22px;overflow:hidden}ins{color:#777;text-decoration:none}a img{border:0}@media screen and (max-width:772px){body{background:none;margin-top:0;max-width:none;padding-right:0}}#logo{background:url(//www.google.com/images/errors/logo_sm_2.png) no-repeat}@media only screen and (min-resolution:192dpi){#logo{background:url(//www.google.com/images/errors/logo_sm_2_hr.png) no-repeat 0% 0%/100% 100%;-moz-border-image:url(//www.google.com/images/errors/logo_sm_2_hr.png) 0}}@media only screen and (-webkit-min-device-pixel-ratio:2){#logo{background:url(//www.google.com/images/errors/logo_sm_2_hr.png) no-repeat;-webkit-background-size:100% 100%}}#logo{display:inline-block;height:55px;width:150px}
</style>
<a href=//www.google.com/><span id=logo aria-label=Google></span></a>
<p><b>404.</b> <ins>That’s an error.</ins>
<p>The requested URL <code>/linux</code> was not found on this server. <ins>That’s all we know.</ins>
$ echo $?;
0
The status code is 0.
Calling it with —fail will not show the output:
$ curl --fail http://www.google.com/linux;
curl: (22) The requested URL returned error: 404 Not Found
$ echo $?;
22
The status code is 22 now …
Id’ like to get the output even when http status = 404, 500 (like the first curl execution) and, at the same time, get a different system error (like in the second curl execution, $? = 22).
Is it possible with curl? If not, how could I achieve this with another tool (this tool must accept file uploads e post data! wget doesn’t seems to be an alternative …)
Thanks.
asked Mar 19, 2014 at 12:35
![]()
Thom Thom ThomThom Thom Thom
1,2191 gold badge11 silver badges21 bronze badges
First of all the maximum value for the error code(or exit code) is 255. Here is the reference.
Also, the --fail will not allow you to do what you are looking for. However, you can use alternate ways(writing a shell script) to handle the scenario, but not sure it will be effective or not for you!
http_code=$(curl -s -o out.html -w '%{http_code}' http://www.google.com/linux;)
if [[ $http_code -eq 200 ]]; then
exit 0
fi
## decide which status you want to return for 404 or 500
exit 204
Now do the $? and you’ll get the exit code from there.
You’ll find the response html inside the out.html file.
You can also pass the url to the script as commandline argument. Check here.
answered Mar 19, 2014 at 14:18
![]()
Sabuj HassanSabuj Hassan
37.7k12 gold badges75 silver badges85 bronze badges
0
This is now possible with curl. Since version 7.76.0 you can do
curl --fail-with-body ...
Which does exactly what OP asked: shows the document body and exits with code 22.
See https://curl.se/docs/manpage.html#—fail-with-body
answered Dec 3, 2021 at 1:47
![]()
Unfortunately not possible with curl. But you can do this with wget.
$ wget --content-on-error -qO- http://httpbin.org/status/418
-=[ teapot ]=-
_...._
.' _ _ `.
| ."` ^ `". _,
_;`"---"`|//
| ;/
_ _/
`"""`
$ echo $?
8
answered May 18, 2017 at 21:41
![]()
SubhasSubhas
14.2k1 gold badge28 silver badges37 bronze badges
1
I found a solution because wget was not suitable for sending multipart/form-data
curl -o - -w "n%{http_code}n" http://httpbin.org/status/418 | tee >(tail -n 1 | cmp <(echo 2xx) - ) | tee >(grep "char 2"; echo $? > status-code) && grep 0 status-code
Explanation
-o - -w "n%{http_code}n" — prints out to stdout (actually it’s piped to the next command) with status code at the end
tee — output will be piped to next command and additionally printed to stdout
tail -n 1 — extract status code from the last line
cmp <(echo 2xx) - compare status code, first char only
grep "char 2" — if first character needs to be 2, otherwise fail
In a shell script you can also do better comparison (currently it only allows 2xx, so redirect like 300 are are handled as an error with cmp how it is used above)
answered Mar 19, 2018 at 16:08
![]()
timaschewtimaschew
16k5 gold badges59 silver badges78 bronze badges
6
Thanks @timaschew, here is my enhanced version based on pure awk:
curl_fail_with_body() {
curl -o - -w "n%{http_code}n" "$@" | awk '{l[NR] = $0} END {for (i=1; i<=NR-1; i++) print l[i]}; END{ if ($0<200||$0>299) exit $0 }'
}
# example usage
curl_fail_with_body -sS http://httpbin.org/status/418
Explanation
-o - -w "n%{http_code}n"— prints out to stdout (actually it’s piped to the next command) with status code at the end{l[NR] = $0} END {for (i=1; i<=NR-1; i++) print l[i]}— print all the lines except the last oneEND{ if ($0<200||$0>299) exit $0 }— will exit with non zero code if thelast line != 2xx
alternative version, if you want to output the error code after command:
END{ if ($0<200||$0>299) {print "The requested URL returned error: " $0; exit 1}
BTW, curl supports --fail-with-body option since v7.76.0.
This option allows you to achieve the desired behavior without using external tools.
answered Apr 22, 2021 at 16:09
![]()
kvapskvaps
2,3091 gold badge20 silver badges20 bronze badges
1
Here was my solution — it uses jq and assumes the body is json
# this code adds a statusCode field to the json it receives and then jq squeezes them together
# curl 7.76.0 will have curl --fail-with-body and thus eliminate all this
local result
result=$(
curl -sL -w ' { "statusCode": %{http_code}} ' -X POST "${headers[@]}" "${endpoint}"
-d "${body}" "$curl_opts" | jq -ren '[inputs] | add'
)
# always output the result
echo "${result}"
# jq -e will produce an error code if the expression result is false or null - thus resulting in a
# error return code from this function naturally. This is much preferred rather than assume/hardcode
# the existence of a error object in the body payload
echo "${result}" | jq -re '.statusCode >= 200 and .statusCode < 300' > /dev/null
answered Jul 31, 2021 at 23:49
![]()
#1 2021-01-30 11:56:23
- amatika
- Member
- Registered: 2016-03-17
- Posts: 56
[SOLVED] Pacman — The requested URL returned error: 404
Can’t install the package, having 404 on all mirrors. How can I solve this?
sudo pacman -S telegram-desktop
resolving dependencies...
looking for conflicting packages...
Packages (4) libdbusmenu-qt5-0.9.3+16.04.20160218-5 qt5-imageformats-5.15.2-1
ttf-opensans-1.101-2 telegram-desktop-2.5.1-1
Total Download Size: 24.10 MiB
Total Installed Size: 67.51 MiB
:: Proceed with installation? [Y/n] Y
:: Retrieving packages...
error: failed retrieving file 'telegram-desktop-2.5.1-1-x86_64.pkg.tar.zst' from archlinux.mailtunnel.eu : The requested URL returned error: 404
error: failed retrieving file 'telegram-desktop-2.5.1-1-x86_64.pkg.tar.zst' from mirror.chaoticum.net : The requested URL returned error: 404
error: failed retrieving file 'telegram-desktop-2.5.1-1-x86_64.pkg.tar.zst' from mirror.chaoticum.net : The requested URL returned error: 404
error: failed retrieving file 'telegram-desktop-2.5.1-1-x86_64.pkg.tar.zst' from mirror.chaoticum.net : Protocol "rsync" not supported or disabled in libcurl
error: failed retrieving file 'telegram-desktop-2.5.1-1-x86_64.pkg.tar.zst' from mirrors.neusoft.edu.cn : The requested URL returned error: 404
warning: failed to retrieve some files
error: failed to commit transaction (failed to retrieve some files)
Errors occurred, no packages were upgraded.Last edited by amatika (2021-01-30 12:11:07)
XPS 9350 13.3″ FHD | i5-6200U | 8GB | 256GB
#2 2021-01-30 11:58:42
- progandy
- Member

- Registered: 2012-05-17
- Posts: 5,071

Re: [SOLVED] Pacman — The requested URL returned error: 404
Most likely your local database is outdated and you’ll have to perform a system upgrade at the same time.
pacman -Syu telegram-desktop| alias CUTF=’LANG=en_XX.UTF-8@POSIX ‘ |
#3 2021-01-30 12:10:48
- amatika
- Member
- Registered: 2016-03-17
- Posts: 56
Re: [SOLVED] Pacman — The requested URL returned error: 404
That solved it. Thanks.
XPS 9350 13.3″ FHD | i5-6200U | 8GB | 256GB
Ошибка 404, либо Error 404 Not Found — ошибка, которая появляется, если браузеру не удалось обнаружить на сервере указанный URL.
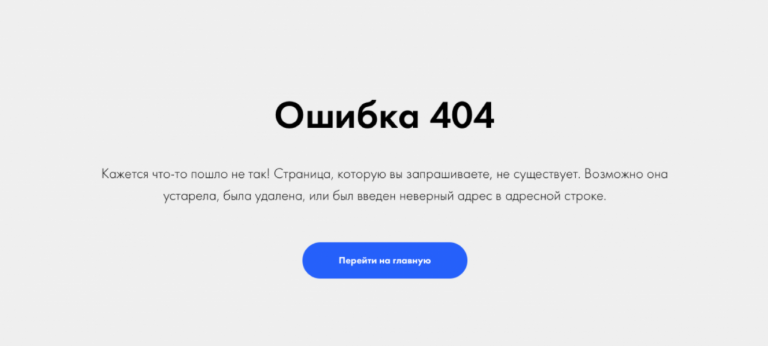
Сообщение об ошибке 404
Что означает ответ 404
Error 404 Not Found отображается по-разному: «HTTP 404 не найден», «Ошибка 404 Not Found», «404 Страница не найдена». Смысл надписи всегда остаётся тем же: страница отсутствует либо просто не работает. Not Found в переводе означает «не найдено».
Ошибка 404 — классический код ответа по протоколу HTTP. Он свидетельствует, что связь с сервером установлена, но данных по заданному запросу на сервере нет.
Однако если просто ввести в поисковую строку произвольный набор символов, то браузер не покажет ошибку 404 Not Found — появится сообщение, что установить соединение с конкретным сервером невозможно.
Разберёмся в техническом формировании ответа Error 404 Not Found.
Техническая сторона вопроса. При связи по HTTP браузер запрашивает указанный URL и ждёт цифрового ответа. То есть любой запрос пользователя направляется на сервер размещения искомого сайта. Когда браузеру удаётся связаться с сервером, он получает кодированный ответ. Если запрос корректный и страница найдена, отправляется ответ с кодом 200 OK, что соответствует благополучной загрузке. При отсутствии страницы отправляется ответ об ошибке.
Что значит код «404». В ответе 404 первая четвёрка указывает на то, что запрос был чрезмерно длительным или в самом адресе была ошибка. Ноль предполагает синтаксическую неточность. Завершающая цифра кода отображает конкретную причину ошибки — «4» означает отсутствие данной ссылки.
Какие ещё ошибки бывают. Ошибку 404 не нужно путать с другими ответами, которые указывают на невозможность связи с сервером. Например, ошибка 403 сообщает, что доступ к URL ограничен, а ответ «Сервер не найден» свидетельствует, что браузер не смог обнаружить место размещения сайта.
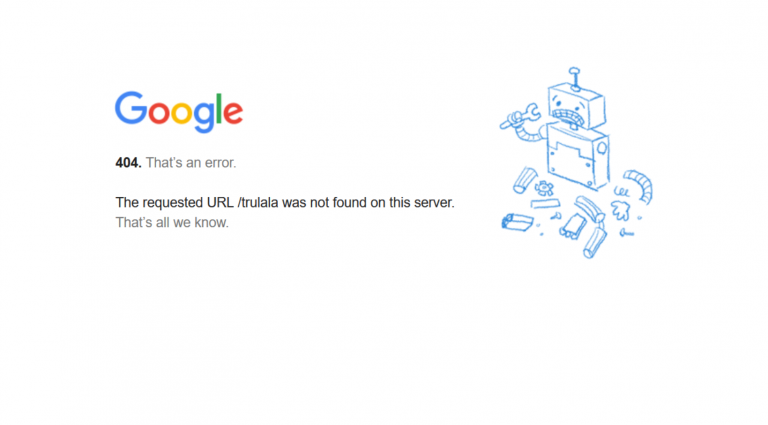
Google на 404 странице сообщает о возможных причинах ошибки
Причины ошибки
Причины, по которым HTTP возвращает ответ 404 Not Found:
- Неверный адрес. К примеру, при ручном наборе пользователь допустил опечатку в адресе либо ссылка ведёт на несуществующую страницу. При этом домен должен быть написан верно. Если пользователь ошибется в названии домена, страница вообще не загрузится (без показа ошибки).
- Битая ссылка. Это нерабочий URL, который никуда не ведёт. Данный вариант иногда возникает при внутренней перелинковке. К примеру, раньше страница существовала, а потом её удалили и забыли убрать ссылку.
- Удалённая страница. Когда пользователь попытается перейти на удалённую с сервера страницу, он также увидит ошибку 404. Ссылка для перехода может сохраниться в браузерных закладках или на сторонних ресурсах.
- Неправильный редирект на страницу с изменённым адресом. Допустим, в процессе редизайна URL изменили, но оставили без внимания связанные ссылки.
- Неполадки на сервере. Это самый редкий вариант.
В большинстве ситуаций ошибка 404 отображается, когда не удаётся обнаружить нужную страницу на доступном сервере.
Причины отсутствия страницы на сайте бывают разными
Возможные последствия для сайта
Нужно ли считать 404 ошибку опасной для сайтов? Кажется, что нет ничего плохого в том, что пользователь не смог открыть одну веб-страницу. Однако если такая ситуация будет повторяться регулярно, это чревато оттоком аудитории. Одни пользователи решат, что сайт вовсе не существует. Другие подумают, что лучше не заходить на сайт, который работает с ошибками. Третьи будут игнорировать ресурс, на котором не смогли получить обещанную информацию.
Поисковые системы относятся к Not Found более лояльно. Например, Google отмечает, что 404 страницы не влияют на рейтинг. Но если при индексации роботы будут находить все больше ошибочных страниц, вряд ли это приведёт к более высокому ранжированию.
Если вы хотите улучшить взаимодействие с посетителями, важно найти и исправить все ошибки 404 на сайте.
Как выявить ошибку
На небольшом ресурсе легко проверить работоспособность ссылок вручную. Но если на сайте сотни и тысячи страниц, без дополнительного софта не обойтись. Есть немало сервисов и программ, позволяющих находить битые ссылки. Рассмотрим некоторые из них.
Search Console Google
Консоль поиска Google позволяет находить страницы с ошибкой 404 за несколько кликов:
- Войдите в учётную запись Google и перейдите в Search Console.
- Откройте раздел «Ошибки сканирования» → «Диагностика».
- Кликните на «Not Found».
Чтобы получить список страниц с ошибками, подтвердите права на ресурс — добавьте проверочную запись TXT в записи DNS регистратора домена. Такая запись не повлияет на работу сайта. Подробнее о процедуре подтверждения, читайте в справке Google.
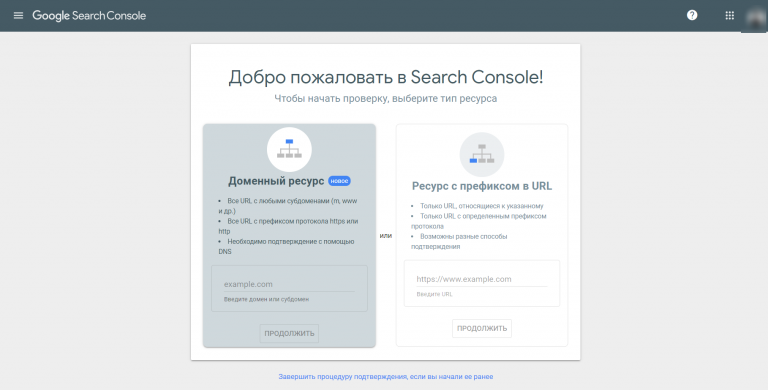
Для использования Search Console Google нужно подтвердить свои права на сайт
Яндекс Вебмастер
Сервис для вебмастеров от Яндекса поможет быстро найти все ошибки 404:
- Откройте Вебмастер после авторизации в Яндекс-аккаунте.
- Выберите «Индексирование» → «Доступные для поиска страницы» → «Исключённые страницы».
- В выданном списке выберите фильтр «Ошибка HTTP: 404».
Чтобы использовать Яндекс.Вебмастер, также нужно подтвердить право владения сайтом — добавить метатег в HTML-код главной страницы.
Для входа в Вебмастер авторизуйтесь в Яндексе
Screaming Frog
Для начала загрузите и установите программу на компьютер. После запуска добавьте URL проверяемого сайта и начните поиск проблем. Неработающие ссылки можно искать даже в бесплатной версии.
Инструмент SEO-паук в Screaming Frog помогает найти технические неисправности сайта
SiteAnalyzer
Эта бесплатная десктопная программа позволяет обнаружить технические погрешности на сайте. SiteAnalyzer быстро отыщет нерабочие и несуществующие ссылки.
SiteAnalyzer бесплатно найдёт неработающие URL
Как исправить ошибку Not Found
Выбор конкретного решения зависит от причины ошибки:
- Ссылка ведёт в никуда из-за неверного URL. Для решения проблемы замените ошибочную ссылку на правильный адрес, чтобы сервер отдавал код 200 OK.
- Битая ссылка. Подобная ситуация не редкость при внутренней перелинковке страниц. К примеру, ссылка есть, а саму страницу давно удалили. Решений два: удалить ссылку или заменить её на другую.
Удалять и менять ссылки вручную удобно только на небольших сайтах. Исправление ошибок на крупных порталах лучше автоматизировать. Например, с помощью специальных плагинов для внутренней перелинковки (Terms Description, Dagon Design Sitemap Generator) и для автоматического формирования адресов страниц (Cyr-To-Lat).
Чтобы ошибки 404 появлялись как можно реже, достаточно соблюдать простые рекомендации:
- Не присваивайте сложные адреса основным разделам сайта. Это снизит число ошибок, связанных с опечатками в URL.
- Не меняйте адреса страниц слишком часто. Это неудобно для пользователей и вводит в заблуждение поисковых роботов.
- Размещайте сайт на надёжном сервере. Это предотвратит ошибки, возникающие из-за неработоспособности сервера.
Мы разобрались, как найти и исправить ошибки Not Found внутри сайта. Но неработающая ссылка может быть расположена и на стороннем ресурсе. Допустим, когда-то на другом сайте разместили рекламную публикацию со ссылкой на определённую страницу. Спустя какое-то время страницу удалили. В этом случае появится ошибка 404. Устранить её можно, связавшись с администрацией ссылающегося сайта. Если же удалить/исправить ссылку нельзя, постарайтесь использовать ошибку с выгодой.
Как сделать страницу 404 полезной
Грамотно оформленная страница с ошибкой Error 404 Not Found — действенный инструмент конвертации посетителей. Ограничений по использованию страницы с ошибкой 404 нет. При этом практически все CMS позволяют настраивать дизайн этой страницы.
Что публиковать на странице 404:
- меню с кликабельными ссылками;
- ссылку на главную страницу;
- анонс последних публикаций;
- контакты для обратной связи.
При оформлении страницы-ошибки желательно опираться на рекомендации поисковиков:
- Яндекс настоятельно рекомендует, чтобы страница контрастировала с основным содержанием сайта — иные цвета, другие графические приёмы либо их отсутствие. Необходимо чётко и понятно объяснить пользователю, что запрошенной страницы не существует и предложить другое решение.
- Google советует придерживаться единого стиля оформления. Но также рекомендует понятно рассказать об ошибке и предложить полезные материалы.
Главное — по возможности отказаться от стандартной страницы 404. Подумайте, как привлечь внимание пользователя. Расскажите ему об отсутствии искомой страницы и предложите взамен что-то полезное или интересное.
Примеры оформления страниц 404
Designzillas
Мультяшная страница креативной студии привлекает внимание и её хочется досмотреть до конца. Если прокрутить страницу, можно увидеть, как из яйца вылупится дракон. При этом на странице есть ссылки на все основные разделы сайта.
Меню на сайте Designzillas есть и на 404 странице
Domenart Studio
Веб-студия «Домен АРТ» использует красочную страницу 404, оформленную в единой стилистике ресурса. Заблудившимся пользователям предлагают попробовать ещё раз ввести адрес или перейти в нужный раздел.

Контакты, поиск, меню — и всё это на 404 странице Domenart Studio
E-co
«Эко Пауэр», дистрибьютор производителя источников питания, демонстрирует короткое замыкание как символ ошибки. Посетителям предлагают перейти на главную.
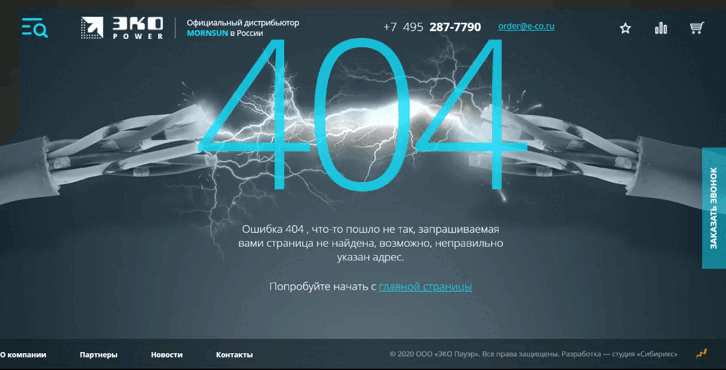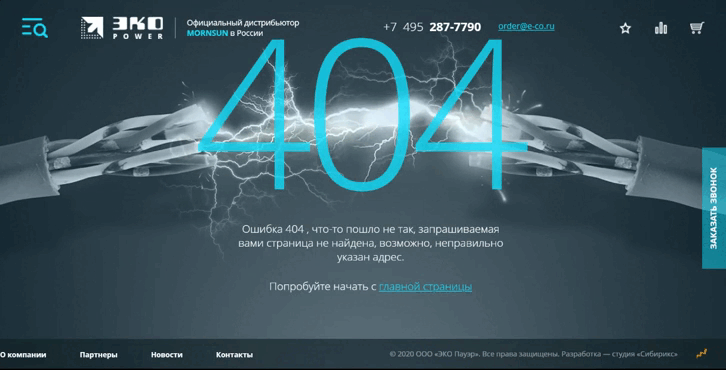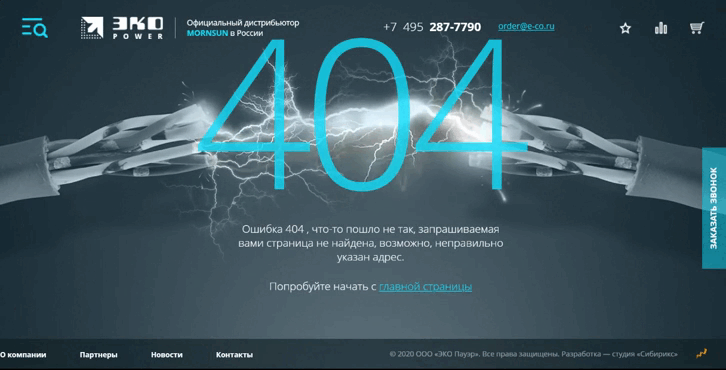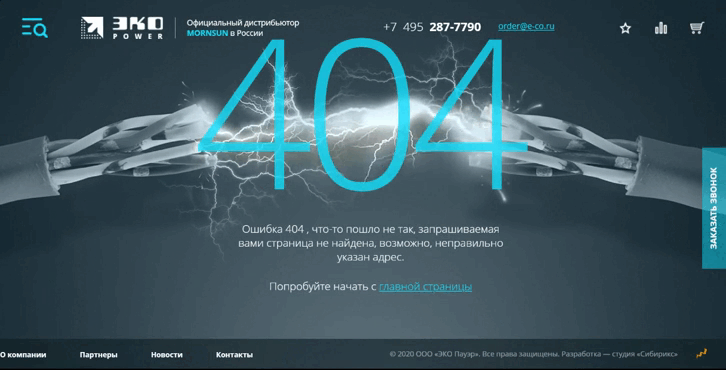
Ошибка 404 «Эко Пауэр» выглядит как страница входа
Дом со всем
Компания «Дом со всем», занимающаяся бурением скважин, разместила на странице 404 свои контакты и перечень услуг. Со страницы можно перейти в любой раздел сайта или заказать обратный звонок. С таким наполнением посетителю не нужно искать дополнительную информацию где-то ещё.

Компания «Дом со всем» предлагает заказать обратный звонок
Kualo
Страница 404 на веб-хостинге Kualo может заставить пользователя забыть, зачем он сюда пришёл. Увлекательная игра притягивает внимание. В конце игры посетителю предлагают посмотреть сайт хостинга.

На странице Kualo можно просто поиграть и заработать скидки
Рано или поздно с ошибкой 404 сталкивается большинство сайтов. При регулярной проверке можно своевременно исправить неработающие ссылки, чтобы в ответ пользователи получали код 200 OK. Но для крупного ресурса лучше настроить оригинальную страницу, которая будет отображаться при появлении ошибки Not Found и подскажет посетителям, что делать дальше.
Главные мысли
