From Wikipedia, the free encyclopedia
In statistics, family-wise error rate (FWER) is the probability of making one or more false discoveries, or type I errors when performing multiple hypotheses tests.
Familywise and Experimentwise Error Rates[edit]
Tukey (1953) developed the concept of a familywise error rate as the probability of making a Type I error among a specified group, or «family,» of tests.[1] Ryan (1959) proposed the related concept of an experimentwise error rate, which is the probability of making a Type I error in a given experiment.[2] Hence, an experimentwise error rate is a familywise error rate for all of the tests that are conducted within an experiment.
As Ryan (1959, Footnote 3) explained, an experiment may contain two or more families of multiple comparisons, each of which relates to a particular statistical inference and each of which has its own separate familywise error rate.[2] Hence, familywise error rates are usually based on theoretically informative collections of multiple comparisons. In contrast, an experimentwise error rate may be based on a co-incidental collection of comparisons that refer to a diverse range of separate inferences. Consequently, some have argued that it may not be useful to control the experimentwise error rate.[3] Indeed, Tukey was against the idea of experimentwise error rates (Tukey, 1956, personal communication, in Ryan, 1962, p. 302).[4] More recently, Rubin (2021) criticised the automatic consideration of experimentwise error rates, arguing that “in many cases, the joint studywise [experimentwise] hypothesis has no relevance to researchers’ specific research questions, because its constituent hypotheses refer to comparisons and variables that have no theoretical or practical basis for joint consideration.”[5]
Background[edit]
Within the statistical framework, there are several definitions for the term «family»:
- Hochberg & Tamhane (1987) defined «family» as «any collection of inferences for which it is meaningful to take into account some combined measure of error».[3]
- According to Cox (1982), a set of inferences should be regarded a family:[citation needed]
- To take into account the selection effect due to data dredging
- To ensure simultaneous correctness of a set of inferences as to guarantee a correct overall decision
To summarize, a family could best be defined by the potential selective inference that is being faced: A family is the smallest set of items of inference in an analysis, interchangeable about their meaning for the goal of research, from which selection of results for action, presentation or highlighting could be made (Yoav Benjamini).[citation needed]
Classification of multiple hypothesis tests[edit]
The following table defines the possible outcomes when testing multiple null hypotheses.
Suppose we have a number m of null hypotheses, denoted by: H1, H2, …, Hm.
Using a statistical test, we reject the null hypothesis if the test is declared significant. We do not reject the null hypothesis if the test is non-significant.
Summing each type of outcome over all Hi yields the following random variables:
| Null hypothesis is true (H0) | Alternative hypothesis is true (HA) | Total | |
|---|---|---|---|
| Test is declared significant | V | S | R |
| Test is declared non-significant | U | T | 
|
| Total | 
|

|
m |
In m hypothesis tests of which are true null hypotheses, R is an observable random variable, and S, T, U, and V are unobservable random variables.
Definition[edit]
The FWER is the probability of making at least one type I error in the family,

or equivalently,

Thus, by assuring  , the probability of making one or more type I errors in the family is controlled at level
, the probability of making one or more type I errors in the family is controlled at level  .
.
A procedure controls the FWER in the weak sense if the FWER control at level is guaranteed only when all null hypotheses are true (i.e. when  , meaning the «global null hypothesis» is true).[6]
, meaning the «global null hypothesis» is true).[6]
A procedure controls the FWER in the strong sense if the FWER control at level is guaranteed for any configuration of true and non-true null hypotheses (whether the global null hypothesis is true or not).[7]
Controlling procedures[edit]
Some classical solutions that ensure strong level  FWER control, and some newer solutions exist.
FWER control, and some newer solutions exist.
The Bonferroni procedure[edit]
The Šidák procedure[edit]
- Testing each hypothesis at level
 is Sidak’s multiple testing procedure.
is Sidak’s multiple testing procedure. - This procedure is more powerful than Bonferroni but the gain is small.
- This procedure can fail to control the FWER when the tests are negatively dependent.

Tukey’s procedure[edit]
Holm’s step-down procedure (1979)[edit]
This procedure is uniformly more powerful than the Bonferroni procedure.[8]
The reason why this procedure controls the family-wise error rate for all the m hypotheses at level α in the strong sense is, because it is a closed testing procedure. As such, each intersection is tested using the simple Bonferroni test.[citation needed]
Hochberg’s step-up procedure[edit]
Hochberg’s step-up procedure (1988) is performed using the following steps:[9]
Hochberg’s procedure is more powerful than Holms’. Nevertheless, while Holm’s is a closed testing procedure (and thus, like Bonferroni, has no restriction on the joint distribution of the test statistics), Hochberg’s is based on the Simes test, so it holds only under non-negative dependence.[citation needed]
Dunnett’s correction[edit]
Charles Dunnett (1955, 1966) described an alternative alpha error adjustment when k groups are compared to the same control group. Now known as Dunnett’s test, this method is less conservative than the Bonferroni adjustment.[citation needed]
Scheffé’s method[edit]
|
This section is empty. You can help by adding to it. (February 2013) |
Resampling procedures[edit]
The procedures of Bonferroni and Holm control the FWER under any dependence structure of the p-values (or equivalently the individual test statistics). Essentially, this is achieved by accommodating a `worst-case’ dependence structure (which is close to independence for most practical purposes). But such an approach is conservative if dependence is actually positive. To give an extreme example, under perfect positive dependence, there is effectively only one test and thus, the FWER is uninflated.
Accounting for the dependence structure of the p-values (or of the individual test statistics) produces more powerful procedures. This can be achieved by applying resampling methods, such as bootstrapping and permutations methods. The procedure of Westfall and Young (1993) requires a certain condition that does not always hold in practice (namely, subset pivotality).[10] The procedures of Romano and Wolf (2005a,b) dispense with this condition and are thus more generally valid.[11][12]
Harmonic mean p-value procedure[edit]
The harmonic mean p-value (HMP) procedure[13][14] provides a multilevel test that improves on the power of Bonferroni correction by assessing the significance of groups of hypotheses while controlling the strong-sense family-wise error rate. The significance of any subset  of the
of the  tests is assessed by calculating the HMP for the subset,
tests is assessed by calculating the HMP for the subset,

where  are weights that sum to one (i.e.
are weights that sum to one (i.e.  ). An approximate procedure that controls the strong-sense family-wise error rate at level approximately
). An approximate procedure that controls the strong-sense family-wise error rate at level approximately  rejects the null hypothesis that none of the p-values in subset are significant when
rejects the null hypothesis that none of the p-values in subset are significant when  [15] (where
[15] (where  ). This approximation is reasonable for small (e.g.
). This approximation is reasonable for small (e.g.  ) and becomes arbitrarily good as approaches zero. An asymptotically exact test is also available (see main article).
) and becomes arbitrarily good as approaches zero. An asymptotically exact test is also available (see main article).
Alternative approaches[edit]
FWER control exerts a more stringent control over false discovery compared to false discovery rate (FDR) procedures. FWER control limits the probability of at least one false discovery, whereas FDR control limits (in a loose sense) the expected proportion of false discoveries. Thus, FDR procedures have greater power at the cost of increased rates of type I errors, i.e., rejecting null hypotheses that are actually true.[16]
On the other hand, FWER control is less stringent than per-family error rate control, which limits the expected number of errors per family. Because FWER control is concerned with at least one false discovery, unlike per-family error rate control it does not treat multiple simultaneous false discoveries as any worse than one false discovery. The Bonferroni correction is often considered as merely controlling the FWER, but in fact also controls the per-family error rate.[17]
References[edit]
- ^ Tukey, J. W. (1953). The problem of multiple comparisons. Based on Tukey (1953),
- ^ a b Ryan, Thomas A. (1959). «Multiple comparison in psychological research». Psychological Bulletin. American Psychological Association (APA). 56 (1): 26–47. doi:10.1037/h0042478. ISSN 1939-1455.
- ^ a b Hochberg, Y.; Tamhane, A. C. (1987). Multiple Comparison Procedures. New York: Wiley. p. 5. ISBN 978-0-471-82222-6.
- ^ Ryan, T. A. (1962). «The experiment as the unit for computing rates of error». Psychological Bulletin. 59 (4): 301–305. doi:10.1037/h0040562. PMID 14495585.
- ^ Rubin, M. (2021). «When to adjust alpha during multiple testing: A consideration of disjunction, conjunction, and individual testing». Synthese. arXiv:2107.02947. doi:10.1007/s11229-021-03276-4. S2CID 235755301.
- ^ Dmitrienko, Alex; Tamhane, Ajit; Bretz, Frank (2009). Multiple Testing Problems in Pharmaceutical Statistics (1 ed.). CRC Press. p. 37. ISBN 9781584889847.
- ^ Dmitrienko, Alex; Tamhane, Ajit; Bretz, Frank (2009). Multiple Testing Problems in Pharmaceutical Statistics (1 ed.). CRC Press. p. 37. ISBN 9781584889847.
- ^ Aickin, M; Gensler, H (1996). «Adjusting for multiple testing when reporting research results: the Bonferroni vs Holm methods». American Journal of Public Health. 86 (5): 726–728. doi:10.2105/ajph.86.5.726. PMC 1380484. PMID 8629727.
- ^ Hochberg, Yosef (1988). «A Sharper Bonferroni Procedure for Multiple Tests of Significance» (PDF). Biometrika. 75 (4): 800–802. doi:10.1093/biomet/75.4.800.
- ^ Westfall, P. H.; Young, S. S. (1993). Resampling-Based Multiple Testing: Examples and Methods for p-Value Adjustment. New York: John Wiley. ISBN 978-0-471-55761-6.
- ^ Romano, J.P.; Wolf, M. (2005a). «Exact and approximate stepdown methods for multiple hypothesis testing». Journal of the American Statistical Association. 100 (469): 94–108. doi:10.1198/016214504000000539. hdl:10230/576. S2CID 219594470.
- ^ Romano, J.P.; Wolf, M. (2005b). «Stepwise multiple testing as formalized data snooping». Econometrica. 73 (4): 1237–1282. CiteSeerX 10.1.1.198.2473. doi:10.1111/j.1468-0262.2005.00615.x.
- ^ Good, I J (1958). «Significance tests in parallel and in series». Journal of the American Statistical Association. 53 (284): 799–813. doi:10.1080/01621459.1958.10501480. JSTOR 2281953.
- ^ Wilson, D J (2019). «The harmonic mean p-value for combining dependent tests». Proceedings of the National Academy of Sciences USA. 116 (4): 1195–1200. doi:10.1073/pnas.1814092116. PMC 6347718. PMID 30610179.
- ^ Sciences, National Academy of (2019-10-22). «Correction for Wilson, The harmonic mean p-value for combining dependent tests». Proceedings of the National Academy of Sciences. 116 (43): 21948. doi:10.1073/pnas.1914128116. PMC 6815184. PMID 31591234.
- ^ Shaffer, J. P. (1995). «Multiple hypothesis testing». Annual Review of Psychology. 46: 561–584. doi:10.1146/annurev.ps.46.020195.003021. hdl:10338.dmlcz/142950.
- ^ Frane, Andrew (2015). «Are per-family Type I error rates relevant in social and behavioral science?». Journal of Modern Applied Statistical Methods. 14 (1): 12–23. doi:10.22237/jmasm/1430453040.
External links[edit]
- Understanding Family Wise Error Rate — blog post including its utility relative to False Discovery Rate
In a hypothesis test, there is always a type I error rate that tells us the probability of rejecting a null hypothesis that is actually true. In other words, it’s the probability of getting a “false positive”, i.e. when we claim there is a statistically significant effect, but there actually isn’t.
When we perform one hypothesis test, the type I error rate is equal to the significance level (α), which is commonly chosen to be 0.01, 0.05, or 0.10. However, when we conduct multiple hypothesis tests at once, the probability of getting a false positive increases.
For example, imagine that we roll a 20-sided dice. The probability that the dice lands on a “1” is just 5%. But if we roll two of these dice at once, the probability that one of the dice will land on a “1” increases to 9.75%. If we roll five dice at once, the probability increases to 22.6%.
The more dice we roll, the higher the probability that one of the dice will land on a 1. Similarly, if we conduct several hypothesis tests at once using a significance level of .05, the probability that we get a false positive increases to beyond 0.05.
How to Estimate the Family-wise Error Rate
The formula to estimate the family-wise error rate is as follows:
Family-wise error rate = 1 – (1-α)n
where:
- α: The significance level for a single hypothesis test
- n: The total number of tests
For example, suppose we conduct 5 different comparisons using an alpha level of α = .05. The family-wise error rate would be calculated as:
Family-wise error rate = 1 – (1-α)c = 1 – (1-.05)5 = 0.2262.
In other words, the probability of getting a type I error on at least one of the hypothesis tests is over 22%!
How to Control the Family-wise Error Rate
There are several methods that can be used to control the family-wise error rate, including:
1. The Bonferroni Correction.
Adjust the α value used to assess significance such that:
αnew = αold / n
For example, if we conduct 5 different comparisons using an alpha level of α = .05, then using the Bonferroni Correction our new alpha level would be:
αnew = αold / n = .05 / 5 = .01.
2. The Sidak Correction.
Adjust the α value used to assess significance such that:
αnew = 1 – (1-αold)1/n
For example, if we conduct 5 different comparisons using an alpha level of α = .05, then using the Sidak Correction our new alpha level would be:
αnew = 1 – (1-αold)1/n = 1 – (1-.05)1/5 = .010206.
3. The Bonferroni-Holm Correction.
This procedure works as follows:
- Use the Bonferroni Correction to calculate αnew = αold / n.
- Perform each hypothesis test and order the p-values from all tests from smallest to largest.
- If the first p-value is greater than or equal to αnew, stop the procedure. No p-values are significant.
- If the first p-value is less than αnew, then it is significant. Now compare the second p-value to αnew. If it’s greater than or equal to αnew, stop the procedure. No further p-values are significant.
By using one of these corrections to the significance level, we can dramatically reduce the probability of committing a type I error among a family of hypothesis tests.
In statistics, family-wise error rate is the probability of making one or more false discoveries, or type I errors when performing multiple hypotheses tests.
History
coined the terms experimentwise error rate and «error rate per-experiment» to indicate error rates that the researcher could use as a control level in a multiple hypothesis experiment.
Background
Within the statistical framework, there are several definitions for the term «family»:
- Hochberg & Tamhane defined «family» in 1987 as «any collection of inferences for which it is meaningful to take into account some combined measure of error».
- According to Cox in 1982, a set of inferences should be regarded a family:
- To take into account the selection effect due to data dredging
- To ensure simultaneous correctness of a set of inferences as to guarantee a correct overall decision
To summarize, a family could best be defined by the potential selective inference that is being faced: A family is the smallest set of items of inference in an analysis, interchangeable about their meaning for the goal of research, from which selection of results for action, presentation or highlighting could be made.
Classification of multiple hypothesis tests
Definition
The FWER is the probability of making at least one type I error in the family,
or equivalently,
Thus, by assuring, the probability of making one or more type I errors in the family is controlled at level.
A procedure controls the FWER in the weak sense if the FWER control at level is guaranteed only when all null hypotheses are true.
A procedure controls the FWER in the strong sense if the FWER control at level is guaranteed for any configuration of true and non-true null hypotheses.
Controlling procedures
Some classical solutions that ensure strong level FWER control, and some newer solutions exist.
The Bonferroni procedure
- Denote by the p-value for testing
- reject if
The Šidák procedure
- Testing each hypothesis at level is Sidak’s multiple testing procedure.
- This procedure is more powerful than Bonferroni but the gain is small.
- This procedure can fail to control the FWER when the tests are negatively dependent.
Tukey’s procedure
- Tukey’s procedure is only applicable for pairwise comparisons.
- It assumes independence of the observations being tested, as well as equal variation across observations.
- The procedure calculates for each pair the studentized range statistic: where is the larger of the two means being compared, is the smaller, and is the standard error of the data in question.
- Tukey’s test is essentially a Student’s t-test, except that it corrects for family-wise error-rate.
Holm’s step-down procedure (1979)
- Start by ordering the p-values and let the associated hypotheses be
- Let be the minimal index such that
- Reject the null hypotheses. If then none of the hypotheses are rejected.
This procedure is uniformly more powerful than the Bonferroni procedure.
The reason why this procedure controls the family-wise error rate for all the m hypotheses at level α in the strong sense is, because it is a closed testing procedure. As such, each intersection is tested using the simple Bonferroni test.
Hochberg’s step-up procedure
Hochberg’s step-up procedure is performed using the following steps:
- Start by ordering the p-values and let the associated hypotheses be
- For a given, let be the largest such that
- Reject the null hypotheses
Hochberg’s procedure is more powerful than Holms’. Nevertheless, while Holm’s is a closed testing procedure, Hochberg’s is based on the Simes test, so it holds only under non-negative dependence.
Dunnett’s correction
described an alternative alpha error adjustment when k groups are compared to the same control group. Now known as Dunnett’s test, this method is less conservative than the Bonferroni adjustment.
Scheffé’s method
Resampling procedures
The procedures of Bonferroni and Holm control the FWER under any dependence structure of the p-values. Essentially, this is achieved by accommodating a `worst-case’ dependence structure. But such an approach is conservative if dependence is actually positive. To give an extreme example, under perfect positive dependence, there is effectively only one test and thus, the FWER is uninflated.
Accounting for the dependence structure of the p-values produces more powerful procedures. This can be achieved by applying resampling methods, such as bootstrapping and permutations methods. The procedure of Westfall and Young requires a certain condition that does not always hold in practice. The procedures of Romano and Wolf dispense with this condition and are thus more generally valid.
Harmonic mean »p»-value procedure
The harmonic mean p-value procedure provides a multilevel test that improves on the power of Bonferroni correction by assessing the significance of groups of hypotheses while controlling the strong-sense family-wise error rate. The significance of any subset of the tests is assessed by calculating the HMP for the subset, where are weights that sum to one. An approximate procedure that controls the strong-sense family-wise error rate at level approximately rejects the null hypothesis that none of the p-values in subset are significant when . This approximation is reasonable for small and becomes arbitrarily good as approaches zero. An asymptotically exact test is also available.
Alternative approaches
FWER control exerts a more stringent control over false discovery compared to false discovery rate procedures. FWER control limits the probability of at least one false discovery, whereas FDR control limits the expected proportion of false discoveries. Thus, FDR procedures have greater power at the cost of increased rates of type I errors, i.e., rejecting null hypotheses that are actually true.
On the other hand, FWER control is less stringent than per-family error rate control, which limits the expected number of errors per family. Because FWER control is concerned with at least one false discovery, unlike per-family error rate control it does not treat multiple simultaneous false discoveries as any worse than one false discovery. The Bonferroni correction is often considered as merely controlling the FWER, but in fact also controls the per-family error rate.
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1
Числа 1 и 2 в выражении, задающем значение аргументаsplit, указывают столбцы матрицы контрастовcon.matrix, где содержатся соответствующие весовые коэффициенты.
Из полученных результатов следует, что исследованные инсектициды в целом существенно различаются по своей эффективности(см. первую строку в таблице– Pr(>F) <2e-16). Кроме того, первые три препарата в среднем значительно отличаются по эффективности действия от трех других препаратов(вторая строка: Pr(>F) = 0.0164), а препараты А, B и F в среднем отличаются от группы препаратовC, D и E (третья строка: Pr(>F) <2e-16).
Впрактике статистического анализа часто возникает ситуация, когда на одном и
том же наборе данных выполняется проверка большого числа гипотез. Например, интерес может представлять выполнение всех возможных попарных сравнений средних значений нескольких экспериментальных .группВ других случаях несколько экспериментальных групп могут сравниваться с одной контрольной группой. Особенно большие количества одновременно проверяемых гипотез можно встретить в некоторых областях биологии: например, при работе с данными, которые получают при помощи технологии микрочипов, одновременно проверяются гипотезы в отношении уровней экспрессии нескольких тысяч генов (см., например, статью на projecteuclid.org).
По определению, при проверке каждой статистической гипотезы закладывается возможность совершения ошибки первого рода(т.е. отклонения верной нулевой гипотезы). Чем больше гипотез мы проверяем на одних и тех же данных, тем больше будет вероятность допустить как минимум одну такую ошибку. Этот явление называют
|
эффектом множественных сравнений(англ. |
multiple comparisons или multiple testing). |
|||||
|
Рассмотрим |
проблему |
оценкигрупповой |
вероятности |
ошибки |
первого |
родас |
|
математической точки зрения. |
Предположим, что мы проверяем истинностьm нулевых гипотез, которые можно обозначить как H1, H2, H3, …, Hm. В отношении каждой из этих гипотез мы применяем определенный статистический критерий(например, t-критерий Стьюдента) и делаем заключение о том, верна ли она (т.е. выполняем m одинаковых тестов на одних и тех же данных и принимаем либо отвергаем каждую гипотезу). Результаты такого анализа можно свести в таблицу следующего вида:
|
Число принятых |
Число отвергнутых |
Всего |
|
|
гипотез |
гипотез |
||
|
Число верных гипотез |
U |
V |
m0 |
|
Число неверных гипотез |
T |
S |
m — m0 |
|
Всего |
W |
R |
m |
В этой таблице
°m0 − число верных нулевых гипотез (англ. true null hypotheses);
°m — m0 − число истинных альтернативных гипотез (true alternative hypotheses);
°U − число безошибочно принятых гипотез (true negatives);
°V − число ошибочно отвергнутых гипотез (false positives) (ошибка первого рода);
°T − число ошибочно принятых гипотез (false negatives) (ошибка второго рода);
°S − число безошибочно отвергнутых гипотез;
218
°W − общее число принятых гипотез;
°R − общее число отвергнутых гипотез.
|
Представленную таблицу следует интерпретировать следующим образом. В первой |
|||||||||||
|
строке мы видим, что всего имеетсяm0 верных нулевых гипотез. В ходе выполнения |
|||||||||||
|
анализа определенная их часть ошибочно отвергается(V), тогда как остальные U гипотез |
|||||||||||
|
классифицируются правильно. Аналогично, во второй строке мы видим, что всего имеется |
|||||||||||
|
m — m0 |
альтернативных гипотез, из которых в ходе анализаS гипотез безошибочно |
||||||||||
|
отвергаются, а T гипотез − ошибочно принимаются. Обратите внимание на то, что общие |
|||||||||||
|
количества отвергнутых (R) и принятых (W) гипотез нам известны, тогда как m0, U, V, T и |
|||||||||||
|
S − ненаблюдаемые случайные величины. |
|||||||||||
|
Таким образом, при одновременной проверке |
группы(или «семейства», англ. |
||||||||||
|
family) статистических гипотез задача заключается в том, чтобы минимизировать число |
|||||||||||
|
ложных |
отклонений V и |
ложных |
принятийT. |
Традиционно исследователи |
пытаются |
||||||
|
минимизировать величину V. Если V≥1, мы совершаем как минимум одну ошибку первого |
|||||||||||
|
рода. Вероятность допущения такой ошибки при |
множественной |
проверке гипотез |
|||||||||
|
называют «групповой вероятностью |
ошибки» РF (англ. «familywise error rate«, FWER; |
||||||||||
|
реже используется термин «experiment-wise error rate«). По определению, РF |
= P(V ≥ 1). |
||||||||||
|
Соответственно, когда мы говорим, что хотим контролировать групповую вероятность |
|||||||||||
|
ошибки на определенном уровне значимости, мыα |
подразумеваем, |
что |
должно |
||||||||
|
выполняться неравенство РF |
≤ α. Контроль над групповой вероятностью ошибки первого |
||||||||||
|
рода позволяют обеспечить методы множественной проверки гипотез. |
|||||||||||
|
Представим, что у нас имеются три груп, пыодвергшиеся разным уровням |
|||||||||||
|
воздействия |
определенного |
фактора. Как |
выяснить |
влияние |
этого |
фактора |
на |
интересующую нас переменную-отклик? При выполнении определенных условий, данную задачу можно решить, сравнив средние значения имеющихся групп при помощи однофакторного дисперсионного анализа. Однако дисперсионный анализ позволит сделать только вывод типа «да/нет», т.е. эффект изучаемого фактора либо имеется, либо отсутствует. Допустим, что результаты дисперсионного анализа указывают на наличие эффекта. Как теперь выяснить, какие именно группы различаются между собой?
Одним из (очень гибких) способов ответить на этот вопрос является использование линейных контрастов, описанное выше. Пусть эта концепция мало знакома конкретному
|
исследователю, но зато ему хорошо знакомt-критерий Стьюдента, |
который легко |
||||||
|
рассчитать |
для |
каждой |
пары |
сравниваемых . |
груВыпполняя |
тест |
Стьюдента, |
|
исследователь |
хочет проверить |
нулевую гипотезу |
об отсутствии |
разницы |
между |
генеральными средними двух сравниваемых групп A и В с вероятностью ошибки менее 5%. Точно такой же риск ошибиться он устанавливает и при сравнении В с С и А с С:
|
Принципиальная |
проблема, |
возникающая |
при |
выполнении |
подобных |
|
множественных сравнений, заключается в том, что в действительности вероятность |
|||||
|
ошибки первого рода может значительно превышать принятое критическое значение5%. |
|||||
|
Так, для рассматриваемого |
примера |
вероятность ошибиться |
хотя бы в одном |
из трех |
сравнений составит РF = 1 — (1 — 0.05)m = 1 — (1 — 0.05)3 = 0.143. Очевидно, что дальнейшее
219
увеличение числа одновременно проверяемых гипотез будет неизбежно сопровождаться дальнейшим возрастанием РF.
Для устранения эффекта множественных сравнений существует большой арсенал методов, обеспечивающих контроль над групповой вероятностью ошибкиPF на определенном уровне α, но различающихся по своей мощности. Рассмотрим наиболее распространенные из этих методов.
Поправка Бонферрони
Метод Бонферрони, названный так в честь предложившего его итальянского математика К. Бонферрони (Carlo Emilio Boferroni), является одним из наиболее простых и известных способов контроля над групповой вероятностью ошибки.
Предположим, что мы применили определенный статистический критерий3 раза (например, сравнили при помощи критерия Стьюдента средние значения групп А и В, А и С, и В и С) и получили следующие три р-значения: 0.01, 0.02 и 0.005. Если мы хотим,
чтобы групповая вероятность ошибки при этом не превышала определенный уровень значимости α (например, 0.05), то, согласно методу Бонферрони, мы должны сравнить каждое из полученных р-значений не с α, а с α/m, где m − число проверяемых гипотез.
|
Деление |
исходного уровня |
значимостиα на m − это и есть поправка Бонферрони. В |
||
|
рассматриваемом |
примере |
каждое из полученныхр-значений необходимо было бы |
||
|
сравнить |
с 0.05/3 = 0.017. В |
результате мы выяснили бы, что р-значение для |
второй |
|
|
гипотезы |
(0.02) |
превышает |
0.017 и, соответственно, у нас не было бы |
оснований |
отвергнуть эту гипотезу.
Вместо деления изначально принятого уровня значимости на число проверяемых гипотез, мы могли бы умножить каждое из исходных р-значений на это число. Сравнив такие скорректированные р-значения (англ. adjusted р-values; обычно обозначаются буквой q) с α, мы пришли бы к точно тем же выводам:
°0.01 * 3 = 0.03 < 0.05: гипотеза отклоняется;
°0.02 * 3 = 0.06 > 0.05: гипотеза принимается;
°0.005 * 3 = 0.015 < 0.05: гипотеза отклоняется.
В ряде случаев при умножении исходныхр-значений на m результат может превысить 1. По определению, вероятность не может быть больше 1, и если это происходит, то получаемое значение просто приравнивают к 1.
В базовой версииR имеется функция p.adjust(), которая позволяет легко применять как метод Бонферрони, так и ряд других методов, обеспечивающих контроль групповой вероятности ошибки на определенном уровне (задаются при помощи аргумента method). При реализации метода Бонферрони с помощью этой функции применяется второй из описанных выше подходов, т.е. исходные р-значения умножаются на число проверяемых гипотез. Функция p.adjust() принимает на входе вектор с исходнымир— значениями и возвращает скорректированные значения:
# Скорректированные р-значения:
p.adjust(c(0.01, 0.02, 0.005), method = «bonferroni») [1] 0.030 0.060 0.015
# Какие из проверяемых гипотез следует отвергнуть? alpha <- 0.05
p.adjust(c(0.01, 0.02, 0.005), method = «bonferroni») < alpha
[1]TRUE FALSE TRUE
Хотя метод Бонферрони очень прост в реализации, он обладает одним существенным недостатком: при возрастании числа проверяемых гипотез мощность этого метода резко снижается. Другими словами, при возрастании числа гипотез нам будет все сложнее и сложнее отвернуть многие из них, даже если они неверны и должны быть
220
отвергнуты. Например, при проверке 10 гипотез, применение поправки Бонферрони привело бы к снижению исходного уровня значимости до 0.05/10 = 0.005. Соответственно, для отклонения той или иной гипотезы, все соответствующие р-значения должны были бы оказаться меньше 0.005, что случалось бы нечасто. В связи с этим метод Бонферрони не рекомендуется использовать, если число проверяемых гипотез превышает 7-8.
Метод Холма
Для преодоления проблем, связанных с низкой мощностью метода Бонферрони, С. Холм (Holm, 1978) предложил гораздо более мощную его модификацию (часто этот метод называют еще методом Холма-Бонферрони). Этот модифицированный метод основан на последовательном алгоритме проверки групповой гипотезы, который включает следующие шаги:
°Исходные р-значения упорядочивают по возрастанию: р(1) ≤ р(2) ≤ ≤ р(m). Эти р-значения соответствуют проверяемым гипотезам H(1), H(2), …, H(m).
°Если р(1) ≥ α/m, все нулевые гипотезыH(1), H(2),…, H(m) принимаются и процедура останавливается. Иначе следует отвергнуть гипотезу H(1) и продолжить.
°Если р(2) ≥ α/(m−1), нулевые гипотезыH(2), H(3),…, H(m) принимаются и процедура останавливается. Иначе гипотеза H(2) отвергается и процедура продолжается.
°…
°Если р(m) ≥ α, нулевая гипотеза H(m) принимается и процедура останавливается. Описанную процедуру называютнисходящей (англ. step-down): она начинается с
наименьшего р-значения в упорядоченном ряду и последовательно»спускается» вниз к более высоким значениям. На каждом шаге соответствующее значениер(i) сравнивается со скорректированным уровнем значимости α/(m + i — 1).
Как и в случае с поправкой Бонферрони, вместо корректировки уровня значимости мы можем скорректировать непосредственно р-значения − конечный результат (в смысле
|
принятия |
или |
отклонения |
той |
или |
иной ) окажетсягипотезы |
идентичным. |
|
Соответствующая |
поправка выполняется |
в |
видеqi = p(i)(m + i — |
1). Так, для |
||
|
рассмотренного выше примера с тремя р-значениями получаем: |
°q1 = p(1)(m − 1 +1 ) = 0.005×3 = 0.015
°q2 = p(2)(m − 2 + 1) = 0.01×2 = 0.02
°q3 = p(3)(m − 3 + 1) = 0.02×1 = 0.02
Именно последний подход реализован в R-функции p.adjust():
# Скорректированные р-значения: p.adjust(c(0.01, 0.02, 0.005), method = «holm») [1] 0.020 0.020 0.015
#(обратите внимание: функция автоматически упорядочивает
#итоговые р-значения по убыванию)
#Какие из проверяемых гипотез следует отвергнуть?
alpha <- 0.05
p.adjust(c(0.01, 0.02, 0.005), method = «holm») < alpha [1] TRUE TRUE TRUE
Сравните результаты, полученные при помощи методов Бонферрони и Холма: в последнем случае мы отвергаем все три гипотезы, тогда как при использовании поправки Бонферрони отклонены были бы только две из трех проверяемых гипотез. Этот простой пример указывает на то, что метод Холма обладает большей мощностью, чем метод Бонферрони.
221
Метод Беньямини-Хохберга
Сегодня проверка действительно большого числа гипотез(десятков тысяч и даже миллионов) стала рутинной операцией в самых разных областях, таких как генетика (анализ данных, получаемых при помощи технологии микрочипов), протеомика (данные масс-спектрометрии), нейробиология (анализ изображений мозга), экология, астрофизика, и др. Недостаточная мощность традиционных процедур множественной проверки гипотез
приводит к тому, что при больших значенияхm критический уровень значимости становится очень низким и многие нулевые гипотезы, которые должны были бы быть отклонены, не отвергаются. В итоге исследователь может пропустить интересные «открытия» (англ. discoveries), достойные более подробного изучения. Например, в ходе сравнения уровней экспрессии генов у больных и здоровых испытуемых, результаты для некоторых потенциально важных генов могли бы оказаться ложно-отрицательными.
В 1995 г. израильские исследователи И. Беньямини и Й. Хохберг опубликовали статью (Benjamini, Hochberg, 1995), в которой был предложен принципиально иной подход к проблеме множественных проверок статистических гипотез(эта работа на сайте tandfonline.com входит в список25 наиболее цитируемых статьей по статистике). Суть предложенного подхода заключается в , томчто вместо контроля над групповой вероятностью ошибки первого рода выполняется контроль над ожидаемойдолей ложных отклонений (англ. false discovery rate, FDR) из числа R всех отклоненных гипотез:
FDR = E(V/R),
где V − число ошибочно отвергнутых гипотез (см. таблицу в разделе 6.8).
В отличие от уровня значимости α, каких-либо «общепринятых» значений FDR не существует. Многие исследователи по аналогии контролируютFDR на уровне 5%. В генетических исследованиях часто встречается также уровень10%. Интерпретация порогового значения FDR очень проста: например, если в ходе анализа данных отклонено 1000 гипотез, то при q = 0.10 ожидаемая доля ложно отклоненных гипотез не превысит 100. Описание процедуры Беньямини-Хохберга выглядит так:
°Исходные р-значения упорядочивают по возрастанию: р(1) ≤ р(2) ≤ ≤ р(m). Пусть H(i) обозначает нулевую гипотезу, которой соответствует i-тое значение в этом упорядоченном ряду − р(i).
°Находят максимальное значение k среди всех индексовi = 1, 2, …, m, для которого выполняется неравенство р(i) ≤ qi/m.
°Отклоняют все гипотезы H(i) с индексами i = 1, 2, …, k.
Вкачестве примера рассмотрим следующий ряд15 изупорядоченных по возрастанию р-значений из оригинальной статьи (Benjamini, Hochberg, 1995):
0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000
|
Если бы мы осуществили контроль над |
групповой |
вероятностью , ошибки |
|
применив, например, поправку Бонферрони для уровня |
значимости0.05 |
(т.е. 0.05/15 = |
0.0033), то отклоненными оказались бы три гипотезы, которым соответствуют первые три р-значения.
При контроле над ожидаемой долей ложных отклонений на уровне 5% мы сравниваем каждое значение р(i) с 0.05i/15, начиная с самого высокого − р(15). В итоге мы увидим, что первое р-значение, соответствующее указанному ограничению(5%), − это
р(4):
р(4) = 0.0095 ≤ (4/15)0.05 = 0.013
Теперь мы отклоняем четыре гипотезы, которым соответствуют первые четырер— значения в приведенном выше ряду, поскольку все эти значения не превышают 0.013.
222
Функция p.adjust() реализует не только описанные в разделе6.8 метод Холма и поправку Бонферрони, но и процедуру Беньямини-Хохберга. Для этого на вход функции подается вектор с исходными р-значениями и аргументу method присваивается значение
«BH» (от «Benjamini-Hochberg«) или значение-синоним «fdr» («false discovery rate»).
Контроль над FDR при помощи этой функции выполняется способом, несколько отличным от описанного выше. В частности, вместо нахождения максимального индекса k, исходные р-значения корректируются по формулеq(i) = р(i)m/i.
Например, для первых двух р-значений из приведенного выше примера мы получили бы
°(0.0001×15)/1 = 0.0015
°(0.0004×15/2) = 0.003
Воспользовавшись функцией p.adjust() для всех р-значений из рассмотренного
примера, получим:
pvals <- c(0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000)
p.adjust(pvals, method = «BH»)
[1] 0.00150000 0.00300000 0.00950000 0.03562500 0.06030000 [6] 0.06385714 0.06385714 0.06450000 0.07650000 0.48600000 [11] 0.58118182 0.71487500 0.75323077 0.81321429 1.00000000
Интерпретация этих скорректированных р-значений (в большинстве литературных источников их называют q-значениями) такова:
° Допустим, что мы хотим контролировать долю ложно отклоненных гипотез на уровне FDR = 0.05.
°Все гипотезы, q-значения которых ≤ 0.05, отклоняются.
°Среди всех этих отклоненных гипотез доля ошибочно отклоненных не превышает
5%.
|
Как видим, в рассмотренном примере конечный результат после |
коррекции |
|
исходных р-значений при помощи функцииp.adjust() идентичен тому, что |
был |
|
получен при использовании оригинальной процедуры Беньямини-Хохберга: на уровне 5% |
|
|
отклоняются первые четыре гипотезы. |
|
|
Коррекция р-значений по методу Беньямини-Хохберга работает особенно хорошо в |
|
|
ситуациях, когда необходимо принятьобщее решение по какому-либо вопросу |
при |
|
наличии информации (т.е. проверенных гипотез) по многим параметрам. |
||||||
|
Типичным |
примером |
будет |
одновременный |
анализ |
многих |
биологических |
|
параметров (вес |
и температура |
тела, клеточные показатели крови, и |
т.п.) в |
группе |
пациентов, которых лечили новым препаратом, в сравнении с группой, которой давали плацебо. Средние значения каждого параметра в этих группах можно было бы сравнить,
|
например, при помощи t-теста или какого-либо |
из его непараметрических аналогов. В |
|
итоге в распоряжении исследователя оказалось |
бы большое число соответствующихр— |
значений.
Общий вывод, который исследователь хотел бы сделать, состоит в том, что новый препарат оказывает положительное влияние на исход лечения. Конечно, в такой ситуации,
|
исследователь был бы заинтересован в обнаружении максимально |
большого числа |
|||
|
параметров, по которым экспериментальные группы различаются(контролируя при этом |
||||
|
долю ложных заключений |
на |
определенном |
).уровнеКонтроль над |
групповой |
|
вероятностью ошибки в этом |
случае |
оказался бы |
слишком строгим, тогда |
как более |
мощный метод Беньямини-Хохберга допускает наличие определенной доли ложных отклонений среди всех отклоненных гипотез и тем самым способствует общему положительному выводу по поводу эффективности нового препарата.
223

Следует отметить, что описанный здесь метод контроля над ожидаемой долей ложных отклонений предполагает, что все тесты, при помощи которых получаютр— значения, независимы (Benjamini, Hochberg, 1995). На практике, однако, в большинстве случаев это условие выполняться не : будетмногие биологические параметры в вышеприведенном примере были измерены у одних и тех же испытуемых, что вносит определенный уровень корреляции между соответствующими тестами.
Метод Беньямини-Йекутили
Понимая важность и одновременно неосуществимость на практике предположения о независимости всех проверяемых ,гипотезИ. Беньямини и . ЙекутилиД (Benjamini,Yekutieli, 2001) предложили усовершенствованный метод, учитывающий наличие корреляции между проверяемыми гипотезами(подробное описание метода и соответствующие доказательства можно найти в оригинальной статье).
Процедура Беньямини-Йекутили очень похожа на процедуру Беньямини-Хохберга.
Основное отличие заключается во введении поправочной константы c(m) = åim=11i :
°Исходные р-значения упорядочивают по возрастанию: р(1) ≤ р(2) ≤ ≤ р(m). Пусть H(i) обозначает нулевую гипотезу, которой соответствует i-тое значение в этом упорядоченном ряду, т.е. р(i).
°Находят максимальное значение k среди всех индексов i = 1, 2, …, m, для которого выполняется неравенство р(i) ≤ (i/m)×qc(m)
°Отклоняют все гипотезы H(i) с индексами i = 1, 2, … , k.
Вкачестве примера рассмотрим следующий ряд15 изупорядоченных по возрастанию р-значений (Benjamini, Hochberg, 1995):
0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000
При контроле над ожидаемой долей ложных отклонений на уровне 5% мы сравниваем каждое значение р(i) с величиной i/15×0.05/c(m), начиная с самого высокого,
т.е. р(15). В данном случае константаc(m) = å15i=11/ i = 3.31823. В итоге мы увидим, что первое р-значение, соответствующее указанному ограничению (5%), − это р(3):
р(3) = 0.0019 ≤ (3/15)×(0.05/3.31823) = 0.003014.
|
Таким образом, следует отклонить три гипотезы, которым соответствуют первые |
||||||||
|
три р-значения |
в |
приведенном |
выше , |
рядупоскольку |
все |
эти |
значения |
не |
|
превышают 0.003014. |
||||||||
|
Контроль |
над |
ожидаемой долей ложных отклонений по методу Беньямини- |
||||||
|
Йекутили можно реализовать вR при помощи функции p.adjust(), подав на ее вход |
||||||||
|
вектор с исходнымир-значениями и |
присвоив |
аргументуmethod значение «BY» (от |
||||||
|
«Benjamini-Yekutieli«). При этом контроль над FDR с помощью этой функции выполняется |
||||||||
|
способом, несколько отличным от описанной выше процедуры: вместо нахождения |
||||||||
|
максимального индекса k, выполняется корректировка исходных р-значений по формуле: |
||||||||
|
q(i) = p(i)×m×с(m)/i |
||||||||
|
Например, |
для |
первых двухр-значений |
из приведенного |
выше |
примера |
мы |
||
|
получили бы |
°(0.0001×15× 3.31823)/1 = 0.004977
°(0.0004×15× 3.31823/2) = 0.009955
224
Воспользуемся функцией p.adjust() для преобразования всехр-значений из рассмотренного примера:
pvals <- c(0.0001, 0.0004, 0.0019, 0.0095, 0.0201, 0.0278, 0.0298, 0.0344, 0.0459, 0.3240, 0.4262, 0.5719, 0.6528, 0.7590, 1.000)
p.adjust(pvals, «BY»)
[1] 0.004977 0.009954 0.031523 0.118211 0.200089 0.211892 [7] 0.211892 0.214025 0.253844 1.000000 1.000000 1.000000
[13] 1.000000 1.000000 1.000000
Интерпретация скорректированных р-значений выполняется тем же образом, что и в случае с методом Беньямини-Хохберга.
Кроме описанных четырех методов, функция p.adjust() предлагает также корректировку р-значений с использованием процедур Хохберга(не путать с методом Беньямини-Хохберга) и Хоммеля (Hommel) − подробнее . смобзор на stats.stackexchange.com. С другой стороны, контроль над ожидаемой долей ложных отклонений с использованием описанных процедур Беньямини-Хохберга-Йекутили можно выполнять также при помощи функций, входящих в состав специализированных пакетов, список которых можно найти, например, на сайте Лондонского колледжа strimmerlab.org.
6.9. Методы сравнения групповых средних в дисперсионном анализе
Применяя однофакторный дисперсионный анализ, мы можем проверить нулевую
|
гипотезу о том, что все сравниваемые группы происходят из |
одной |
генеральной |
|||
|
совокупности, и следовательно их средние значения не различаются, т.е. H0: μ1 = μ2 = = |
|||||
|
μm. Если |
нулевую |
гипотезу не удается |
отвергнуть при заданном |
уровне |
значимости |
|
(например, α = 0.05), то в дальнейшем анализе, в принципе, нет необходимости. Если |
|||||
|
нулевая |
гипотеза |
отвергается, то единственный вывод, который можно сделать |
при |
||
|
помощи классического дисперсионного анализа заключается в том, что изучаемый фактор |
|||||
|
оказывает существенное влияние на интересующую нас переменную. |
|||||
|
После того установления существенной разницы между |
группами |
в целом |
|||
|
интересно пойти дальше и выполнить так |
называемыйапостериорный анализ (post-hoc |
analysis), т.е. выяснить, какие именно группы статистически значимо отличаются друг от друга. Однако при выполнении попарных сравнений необходимо использование методов, обеспечивающих контроль над групповой вероятностью ошибки1-го рода. Как было отмечено ранее, при наличии большого числа сравниваемых групп метод Бонферрони становится очень консервативным.
Специально для дисперсионного анализа разработан целый ряд апостериорных тестов (например, в пакете SPSS их насчитывается не менее18). В список наиболее известных тестов включают: проверку наименьшего значения значимой разностиLSD, критерий Дункана (Dunkan), метод Стьюдента-Ньюмана-Кейлса (Student-Newman-Keuls), проверку достоверно значимой разностиHSD Тьюки (Tukey), модифицированный метод LSD, критерий, основанный на контрастах Шеффе (Scheffe) и др. Здесь они перечислены в порядке снижения их мощности(или увеличения консервативности), хотя на этот счет в литературе существуют довольно противоречивые рекомендации.
Критерий Тьюки
Наиболее распространённым и рекомендуемым в литературе является, тест использующий критерий достоверно значимой разностиHSD, названный в честь предложившего его американского математика и статистика Дж. Тьюки (англ. Tukey’s
225

honestly significant difference test, или просто Tukey’s HSD test). HSD тест задает наименьшую величину разности математических ожиданий в группах, которую можно считать значимой, а также позволяет рассчитать ее доверительные интервалы с учетом числа выполняемых сравнений.
Критерий Тьюки используется для проверки нулевой гипотезыH0: μB = μA против
|
альтернативной |
гипотезы H1: μB ≠ μA, |
где индексы A и B обозначают любые две |
|
сравниваемые |
группы. При наличии m |
групп всего возможно выполнитьm(m — 1)/2 |
|
попарных сравнений. |
Первый шаг заключается в упорядочивании всех имеющихся групповых средних значений по возрастанию (от 1 до m). Далее выполняют попарные сравнения этих средних так, что сначала сравнивают наибольшее среднее с наименьшим, т.е. m-ое с 1-ым, затем m— ое со вторым, третьим, и т.д. вплоть до (m — 1)-го. Затем предпоследнее среднее, (m — 1)-ое, тем же образом сравнивают с первым, вторым, и т.д. до (m — 2)-го. Эти сравнения продолжаются до тех пор, пока не будут перебраны все пары.
Указанные сравнения выполняются при помощи критерия , Тьюкикоторый представляет собой несколько модифицированный критерий Стьюдента:
q = ( x B — x A ) / SE .
Отличие от критерия Стьюдента заключается ,в кактом рассчитывается стандартная ошибка SE:
SE = 
 MS w / n ,
MS w / n ,
где MSw − рассчитываемая в ходе дисперсионного анализа внутригрупповая дисперсия. Приведенная формула для критерия Тьюки верна для , случаевкогда все
сравниваемые группы содержат одинаковое число наблюденийn. Если сравниваемые группы неодинаковы по размеру, стандартная ошибка будет рассчитываться следующим образом:
|
æ |
1 |
1 |
ö |
|||
|
SE = |
MS w ç |
+ |
÷ |
|||
|
ç |
÷ . |
|||||
|
2 |
||||||
|
è nA |
nB ø |
Благодаря тому обстоятельству, что в приведенные выше формулы стандартной ошибки входит внутригрупповая дисперсия MSw, критерий Тьюки становится подходящим критерием для выполнения большого числа парных сравнений групповых средних.
|
Проверяемые |
нулевые |
гипотезы принимают или отвергают либо |
путем сравнения |
||||
|
получаемых |
значений |
критерияq |
с |
определенным |
критическим |
значением |
для |
|
выбранного |
уровня |
значимости, либо |
рассчитывают |
соответствующиер-значения |
(подробнее см. примеры для критерия Стьюдента).
В среде R множественные сравнения групповых средних при помощи теста Тьюки можно выполнить с использованием функции TukeyHSD(), входящей в базовую версию системы. В качестве примера, заимствованого из книги (Zar, 2010), используем данные по содержанию стронция (мг/мл) в пяти водоемах США:
waterbodies <- data.frame(Water = rep(c(«Grayson», «Beaver», «Angler», «Appletree», «Rock»), each = 6),
Sr = c(28.2, 33.2, 36.4, 34.6, 29.1, 31.0, 39.6, 40.8, 37.9, 37.1, 43.6, 42.4, 46.3, 42.1, 43.5, 48.8, 43.7, 40.1, 41.0, 44.1, 46.4, 40.2, 38.6, 36.3, 56.3, 54.1, 59.4, 62.7, 60.0, 57.3)
)
226

На рисунке ниже эти данные представлены графически:
|
60 |
||||||||||||||||||||||||||||
|
стронция |
50 55 |
|||||||||||||||||||||||||||
|
Содержание |
35 40 45 |
|||||||||||||||||||||||||||
|
30 |
||||||||||||||||||||||||||||
|
Angler Appletree Beaver |
Grayson |
Rock |
Озера
Необходимо выяснить: а) есть ли существенные различия между этими водоёмами по содержанию стронция в целом и, если есть, то б) какие именно водоемы отличаются друг от друга. Для ответа на первый вопрос выполним дисперсионный анализ при помощи функции aov():
M <- aov(Sr ~ Water, data = waterbodies) summary(M)
|
Water |
Df |
Sum Sq Mean Sq |
F value |
Pr(>F) |
*** |
|
|
4 |
2193.4 |
548.4 |
56.16 |
3.95e-12 |
||
|
Residuals |
25 |
244.1 |
9.8 |
|||
|
— |
0 ‘***’ 0.001 |
‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
||||
|
Signif. codes: |
Как видно из полученных результатов, обследованные водоемы статистически значимо различаются по содержанию стронция. Для того чтобы выяснить, где именно лежат эти различия, достаточно подать объект M на вход функции TukeyHSD():
TukeyHSD(M)
Tukey multiple comparisons of means 95% family-wise confidence level
Fit: aov(formula = Sr ~ Water, data = waterbodies) $Water
|
Appletree-Angler |
diff |
lwr |
upr |
p adj |
|
-2.9833333 |
-8.281979 |
2.315312 |
0.4791100 |
|
|
Beaver-Angler |
-3.8500000 |
-9.148645 |
1.448645 |
0.2376217 |
|
Grayson-Angler |
-12.0000000 -17.298645 -6.701355 0.0000053 |
|||
|
Rock-Angler |
14.2166667 |
8.918021 |
19.515312 |
0.0000003 |
|
Beaver-Appletree |
-0.8666667 |
-6.165312 |
4.431979 |
0.9884803 |
|
Grayson-Appletree |
-9.0166667 -14.315312 -3.718021 0.0003339 |
|||
|
Rock-Appletree |
17.2000000 |
11.901355 |
22.498645 |
0.0000000 |
|
Grayson-Beaver |
-8.1500000 -13.448645 -2.851355 0.0011293 |
|||
|
Rock-Beaver |
18.0666667 |
12.768021 |
23.365312 |
0.0000000 |
|
Rock-Grayson |
26.2166667 |
20.918021 |
31.515312 |
0.0000000 |
В первом столбце полученной таблицы перечислены пары сравниваемых водоемов. Во втором столбце содержатся разности между соответствующими групповыми средними.
227
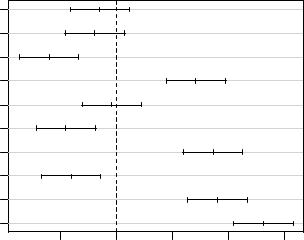
Третий и четвертый столбцы содержат значения нижнего (lwr) и верхнего (upr) 95%-ных доверительных пределов для соответствующих разностей. Наконец, в пятом столбце представлены р-значения для каждой из сравниваемых пар водоемов.
Хорошо видно, что существенной разницы в парах»Appletree-Angler«, «Beaver-Angler» и «Beaver-Appletree» нет (р > 0.05), тогда как во всех остальных случаях разница статистически значима. В целом полученные результаты хорошо согласуются с визуальной оценкой различий, которую можно сделать, глядя на приведенную выше диаграмму размахов.
Результаты парных сравнений групповых средних можно легко изобразить на графике:
par(mar = c(4.5, 8, 4.5, 4.5)) plot(TukeyHSD(M), las = 1)
95% family-wise confidence level
Appletree-Angler
Beaver-Angler
Grayson-Angler
Rock-Angler
Beaver-Appletree
Grayson-Appletree
Rock-Appletree
Grayson-Beaver
Rock-Beaver
Rock-Grayson
|
-10 |
0 |
10 |
20 |
30 |
Differences in mean levels of Water
На представленном рисунке приведены разности между групповыми средними
(Differences in mean levels of Water) и их доверительные интервалы,
рассчитанные с учетом контроля над групповой вероятностью ошибки(95% familywise confidence level). В трех случаях доверительные интервалы включают0, что указывает на отсутствие различий между соответствующими группами(сравните с р— значениями выше).
Критерий Тьюки имеет те же условия применимости, что и собственно дисперсионный анализ, т.е. нормальность распределения данных и(особенно важно!)
однородность групповых дисперсий(подробнее см. раздел 6.4). Устойчивость к отклонению от этих условий, равно как и статистическая мощность критерия Тьюки, возрастают при одинаковом числе наблюдений во всех сравниваемых группах (Zar, 2010).
Методы множественных проверок гипотез, реализованные в пакете multcomp
Многообразие описанных выше методов множественных проверок статистических гипотез может создать ощущение неразберихи и привести в замешательство даже опытных исследователей. Тем не менее, между многими методами существует большое сходство. Более того, можно показать, что некоторые методы, известные и используемые под разными названиями и для разных целей, с математической точки зрения эквиваленты (например, тесты Тьюки и Даннета).
228
|
Используя теорию общих линейных моделей, проф. Ф. Брeтц с соавт. (Bretz et al., |
||||||||||
|
2010) |
разработали |
общую |
методологическую |
схему, объединяющую большинство |
||||||
|
классических критериев для множественной проверки гипотез. Как это часто происходит в |
||||||||||
|
наши |
дни, |
соответствующие |
методологические |
подходы |
были |
реализованы |
в |
|||
|
дополнительном пакете для R − multcomp (от «multiple comparisons» − «множественные |
||||||||||
|
сравнения»). |
Ниже |
дается |
описание |
основных |
возможностей |
этого. |
пакет |
|||
|
Заинтересованные читатели найдут подробные математические выкладки и множество |
||||||||||
|
примеров R кода в упомянутой выше книге (Bretz et al., 2010). |
||||||||||
|
В качестве примера используем данные по содержанию стронция в воде пяти |
||||||||||
|
водоемов США, представленные ранее при рассмотрении метода Тьюки: |
||||||||||
|
waterbodies <- data.frame(Water = rep(c(«Grayson», «Beaver», |
||||||||||
|
«Angler», «Appletree», |
||||||||||
|
Sr = c(28.2, |
«Rock»), each = 6), |
|||||||||
|
33.2, 36.4, 34.6, 29.1, 31.0, |
||||||||||
|
39.6, |
40.8, 37.9, |
37.1, 43.6, |
42.4, |
|||||||
|
46.3, |
42.1, 43.5, |
48.8, 43.7, |
40.1, |
|||||||
|
41.0, |
44.1, 46.4, |
40.2, 38.6, |
36.3, |
|||||||
|
56.3, |
54.1, 59.4, |
62.7, 60.0, |
57.3) |
|||||||
|
) |
Предположим, что наша задача заключается в выявлении различий между исследованными водоемами Water по содержанию стронция. Наличие категориальных предикторов предполагает использование дисперсионного анализа.
Решение поставленной задачи сводится к оценке параметров следующей линейной модели:
yi = β0 + β1x1 + β2x2 + β3x3 + β4x4 + ei,
где yi − это i-е значение содержания стронция в воде; β0 − среднее значение содержания стронция для базового уровня изучаемого фактора(в данном случае выбор базового уровня совершенно произволен; по умолчанию R выберет в качестве базового тот уровень, название которого идет первым по алфавиту Angler− ); β1, …, β4 − коэффициенты, отражающие разницу между средним значением содержания стронция в воде»базового водоема» и средними значениями в других водоемах; ei − нормально распределенные остатки.
Параметры модели легко оценить с помощью функции lm():
|
M <- lm(Sr ~ Water, data = waterbodies) |
||||||
|
summary(M) |
||||||
|
Call: |
||||||
|
lm(formula = Sr ~ Water, data = waterbodies) |
||||||
|
Residuals: |
1Q |
Median |
3Q |
Max |
||
|
Min |
||||||
|
-4.8000 -2.2500 -0.4833 |
2.2042 5.3000 |
|||||
|
Coefficients: |
Estimate Std. Error t value |
Pr(>|t|) |
||||
|
(Intercept) |
*** |
|||||
|
44.083 |
1.276 |
34.555 |
< 2e-16 |
|||
|
WaterAppletree |
-2.983 |
1.804 |
-1.654 |
0.1107 |
* |
|
|
WaterBeaver |
-3.850 |
1.804 |
-2.134 |
0.0428 |
||
|
WaterGrayson |
-12.000 |
1.804 |
-6.651 |
5.72e-07 |
*** |
|
|
WaterRock |
14.217 |
1.804 |
7.880 |
3.09e-08 |
*** |
|
|
— |
229
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ‘ 1
Residual standard error: 3.125 on 25 degrees of freedom Multiple R-squared: 0.8998, Adjusted R-squared: 0.8838 F-statistic: 56.15 on 4 and 25 DF, p-value: 3.948e-12
Как видим, в целом средние уровни содержания стронция в воде исследованных водоемов значимо различаются(см. последнюю строку результатов: р-значение для F— критерия оказалось существенно меньше0.05, а именно 3.948е-12). Кроме того, из полученных результатов мы можем сделать определенные выводы касательно того, какие из исследованных водоемов отличались от водоемаAngler, автоматически выбранного программой в качестве «эталона» для сравнений. В частности, есть основания считать, что параметры β2, β3 и β4 статистически значимо (на уровне 0.05) отличаются от 0. Другими словами, мы можем утверждать, что среднее содержание стронция в «эталонном» водоеме
|
Angler значимо отличалось от таковых Beaverв |
(р |
= 0.0428), |
Grayson (р = |
||
|
5.72e-07) и Rock (р = 3.09e-08). |
|||||
|
К |
сожалению, |
такая интерпретация р-значений, |
полученных |
для |
параметров |
|
модели M, |
имеет один существенный недостаток: они |
являются безусловными (англ. |
|||
|
marginal, |
сравните |
с «условным распределением |
вероятностей«; |
англ. |
conditional |
probability distribution). Такое название связано с тем, что эти р-значения рассчитываются, исходя из допущения об отсутствии какой-либо связи между параметрами модели. Иными словами, параметры модели рассматриваются как некоррелируемые случайные величины, каждая из которых имеет свое собственное распределение вероятностей.
Проблема, однако, заключается в том, что мы не можем строго утверждать об отсутствии корреляции между оцениваемыми параметрами, поскольку при построении
|
модели |
используем один |
конкретный |
набор |
данных. Как |
следствие, проверяя |
||||
|
одновременно |
несколько |
статистических |
гипотез(в |
отношении |
коррелируемых |
параметров модели) на одних и тех же данных, мы не выполняем должного контроля над групповой вероятностью ошибки первого рода. Это, в свою очередь, может привести к повышенной вероятности того, что выводы, основанные на таком анализе, не подтвердятся в будущем при сборе дополнительных данных(например, при повторении эксперимента). В ряде областей слабая воспроизводимость результатов может иметь серьезные практические последствия(например, в фармацевтической промышленности, когда какая-либо компания объявляет о повышенной эффективности своего нового дорогого препарата по сравнению с эффективностью более дешевого старого аналога).
Одним из возможных решений указанной проблемы является корректировка
|
полученных р-значений при помощи |
того |
или |
иного метода |
множественных сравнений |
||||
|
(например, с использованием поправки Бонферрони). Однако, как отмечают Брeтц с |
||||||||
|
соавторами, более мощным подходом(в смысле статистической мощности) является |
||||||||
|
расчет р-значений, основанный |
на |
непосредственном |
учете |
корреляции |
между |
|||
|
параметрами модели. |
||||||||
|
Этот подход как раз и реализован в пакете multcomp. В частности, в зависимости |
||||||||
|
от класса рассматриваемой модели, принимается допущение о том, что наблюдаемые |
||||||||
|
значения ее параметров являются случайными реализациями значений из определенного |
||||||||
|
многомерного |
распределения (t-распределения |
или |
нормального |
распределения), |
||||
|
ковариационная матрица которого отражает корреляцию между параметрами модели. |
||||||||
|
Размерность распределения равна числу одновременно |
проверяемых статистических |
|||||||
|
гипотез в отношении параметров модели. Соответствующие р-значения рассчитываются, |
||||||||
|
исходя из свойств этого распределения. |
||||||||
|
Главной функцией пакета multcomp является glht() (от general linear hypothesis |
testing), которая предоставляет удобный интерфейс для выполнения одновременной проверки статистических гипотез в отношении параметров самых разнообразных
230
![]()
статистических моделей, включая общие линейные модели, обобщенные линейные модели, модели со смешанными эффектами и т.д. Основное требование: соответствующий R-объект с результатами расчета той или иной модели должен содержать оценки ее параметров и ковариационной матрицы, которые могут быть извлечены из модельного объекта при помощи методов coef() и vcov() соответственно. Так, для рассчитанной
нами выше модели М, имеем:
coef(M)
|
(Intercept) |
WaterAppletree |
WaterBeaver |
WaterGrayson |
WaterRock |
|
44.08 |
-2.98 |
-3.85 |
-12.00 |
14.22 |
vcov(M)
(Intercept) WaterAppletree WaterBeaver WaterGrayson WaterRock
|
(Intercept) |
1.63 |
-1.63 |
-1.63 |
-1.63 |
-1.63 |
|
WaterAppletree |
-1.63 |
3.26 |
1.63 |
1.63 |
1.63 |
|
WaterBeaver |
-1.63 |
1.63 |
3.26 |
1.63 |
1.63 |
|
WaterGrayson |
-1.63 |
1.63 |
1.63 |
3.26 |
1.63 |
|
WaterRock |
-1.63 |
1.63 |
1.63 |
1.63 |
3.26 |
|
Синтаксис |
команд с использованием функцииglht() в большинстве случаев |
|
имеет следующую структуру: |
|
|
glht(model, |
linfct, |
alternative = c(«two.sided», «less», «greater»),…)
Здесь аргументmodel − это линейная модель, подогнанная с использованием, например, таких стандартных функций, как aov(), lm(), или glm(). На вход аргумента linfct (от linear function, «линейная функция») подается матрица контрастов, при помощи которой задаются подлежащие проверке гипотезы(см. раздел 6.7). Имеющиеся способы спецификации аргументаlinfct будут рассмотрены ниже. Аргумент alternative служит для указания типа альтернативных гипотез: «two.sided» (двусторонняя), «less» («меньше чем») и «greater» («больше чем»). Многоточие «…» означает, что функция glht() может принимать и другие дополнительные аргументы (см. справочный файл, доступный по команде ? glht).
Способы спецификации линейных контрастов, используемых для кодирования сочетаний экспериментальных групп и подаваемых на аргументlinfct, рассмотрим на примере с содержанием стронция в водоемах. Следует подчеркнуть, что с подлежащими сравнению группами следует определитьсядо выполнения анализа данных. Иными словами, проверяемая научная гипотеза (или гипотезы) должна быть сформулирована до сбора данных. Действительно, любые гипотезы, формулируемые во время анализа уже имеющихся данных, будут диктоваться свойствами именно этих данных и нет никакой гарантии, что при повторении эксперимента исследователь обнаружит те же самые закономерности (в англоязычной литературе это называют»data dredging» или «data fishing«).
В случае с дисперсионным анализом, самый простой способ задать матрицу контрастов состоит в использовании служебной функцииmcp() (от «multiple comparisons«), которая сделает всю работу автоматически. От нас требуется лишь указать фактор, уровни которого соответствуют сравниваемым группам, и название одного из «встроенных» критериев для выполнения сравнений. Так, для выполнения всех парных сравнений средних значений концентрации стронция в исследованных водоемах при помощи критерия Тьюки, соответствующая команда будет иметь вид:
glht(M, linfct = mcp(Water = «Tukey»))
231
|
General Linear Hypotheses |
|||||
|
Multiple Comparisons of Means: Tukey Contrasts |
|||||
|
Linear Hypotheses: |
Estimate |
||||
|
Appletree — Angler == 0 |
|||||
|
-2.9833 |
|||||
|
Beaver — Angler == 0 |
-3.8500 |
||||
|
Grayson — Angler == 0 |
-12.0000 |
||||
|
Rock — Angler == 0 |
14.2167 |
||||
|
Beaver — Appletree == 0 |
-0.8667 |
||||
|
Grayson — Appletree == 0 |
-9.0167 |
||||
|
Rock — Appletree == 0 |
17.2000 |
||||
|
Grayson — Beaver == 0 |
-8.1500 |
||||
|
Rock — Beaver == 0 |
18.0667 |
||||
|
Rock — Grayson == 0 |
26.2167 |
||||
|
Результатом |
выполнения |
приведенной |
команды |
является |
таблица |
|
перечисленными проверяемыми гипотезами (например, первая гипотеза состоит в том, что |
|||||
|
средние значения |
концентрации |
стронция в водоемахAppletree |
и Angler |
не |
различаются: Appletree — Angler == 0) и наблюдаемыми уровнями различий между группами (так, в водоеме Appletree содержание стронция в среднем оказалось на 2.983 мг/мл меньше, чем в Angler). Позднее мы увидим, как можно получить также р— значения для каждой из этих гипотез.
Помимо критерия Тьюки, реализованы и другие широко используемые критерии, как например, критерий Даннетта («Dunnett»), который применяется для сравнения всех групп с контрольной. Критерий Уильямса («Williams»), который широко используется
в токсикологии при анализе зависимости величины биологического эффекта от дозы исследуемого вещества, подобен критерию Даннетта, но применяется для сравнения всех групп с контрольной только в ,случаеесли групповые средние демонстрируют монотонный тренд на убывание или возрастание. С полным списком»встроенных» критериев можно ознакомиться в справочном файле, доступном по команде ?contrMat.
При необходимости выполнить сравнения только для определенных групп, мы можем воспользоваться другим способом спецификации матрицы контрастов, который состоит в подаче на функциюmcp() списка из проверяемых гипотез, используя символьные выражения (англ. expression). Предположим, нас интересуют сравнения только следующих водоемов друг с другом: «Rock vs. Angler«, «Grayson vs. Appletree» и «Grayson vs. Beaver«. Соответствующая команда будет иметь вид:
glht(M, linfct = mcp(Water = c( «Rock — Angler = 0»,
«Grayson — Appletree = 0», «Grayson — Beaver = 0»)
)
)
General Linear Hypotheses
Multiple Comparisons of Means: User-defined Contrasts Linear Hypotheses:
|
Rock — Angler == 0 |
Estimate |
|
|
14.217 |
||
|
Grayson |
— Appletree == 0 |
-9.017 |
|
Grayson |
— Beaver == 0 |
-8.150 |
232
Наконец, пользователь может создать матрицу с весовыми коэффициентами линейных контрастов самостоятельно. Предположим, мы хотим выполнить те же три сравнения, что и в предыдущем примере. Создадим соответствующую матрицу с коэффициентами контрастов:
contr <- rbind(«Rock — Angler» = c(-1, 0, 0, 0, 1), «Grayson — Appletree» = c(0, -1, 0, 1, 0), «Grayson — Beaver» = c(0, 0, -1, 1, 0)
)
|
contr |
[,1] [,2] [,3] [,4] [,5] |
|||||
|
Rock — Angler |
||||||
|
-1 |
0 |
0 |
0 |
1 |
||
|
Grayson — Appletree |
0 |
-1 |
0 |
1 |
0 |
|
|
Grayson — Beaver |
0 |
0 |
-1 |
1 |
0 |
Теперь подадим матрицу contr на вход функции mcp():
glht(M, linfct = mcp(Water = contr)) General Linear Hypotheses
Multiple Comparisons of Means: User-defined Contrasts Linear Hypotheses:
|
Rock — Angler == 0 |
Estimate |
|
14.217 |
|
|
Grayson — Appletree == 0 |
-9.017 |
|
Grayson — Beaver == 0 |
-8.150 |
Как видим, результат оказался идентичным предыдущему.
Метод summary() позволяет получить дополнительные результаты расчетов, выполняемых функцией glht(). В частности, мы можем вывестир-значения для соответствующих сравнений:
summary(glht(M, linfct = mcp(Water = «Tukey»))) Simultaneous Tests for General Linear Hypotheses
Multiple Comparisons of Means: Tukey Contrasts Fit: lm(formula = Sr ~ Water, data = waterbodies) Linear Hypotheses:
|
Appletree — Angler == 0 |
Estimate Std. Error t value |
Pr(>|t|) |
|||
|
-2.9833 |
1.8042 |
-1.654 |
0.47913 |
||
|
Beaver — Angler == 0 |
-3.8500 |
1.8042 |
-2.134 |
0.23757 |
*** |
|
Grayson — Angler == 0 |
-12.0000 |
1.8042 |
-6.651 |
< 1e-04 |
|
|
Rock — Angler == 0 |
14.2167 |
1.8042 |
7.880 |
< 1e-04 |
*** |
|
Beaver — Appletree == 0 |
-0.8667 |
1.8042 |
-0.480 |
0.98848 |
*** |
|
Grayson — Appletree == 0 |
-9.0167 |
1.8042 |
-4.998 |
0.00035 |
|
|
Rock — Appletree == 0 |
17.2000 |
1.8042 |
9.533 |
< 1e-04 |
*** |
|
Grayson — Beaver == 0 |
-8.1500 |
1.8042 |
-4.517 |
0.00112 |
** |
|
Rock — Beaver == 0 |
18.0667 |
1.8042 |
10.014 |
< 1e-04 |
*** |
|
Rock — Grayson == 0 |
26.2167 |
1.8042 |
14.531 |
< 1e-04 |
*** |
|
— |
0.1 ‘ ’ 1 |
||||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ |
|||||
|
(Adjusted p values reported — single-step method) |
233
Кроме получения подобной сводной информации, мы можем выполнить и некоторые другие виды анализа, воспользовавшись аргументом test функции summary (подробнее см. справочный файл − ?summary.glht).
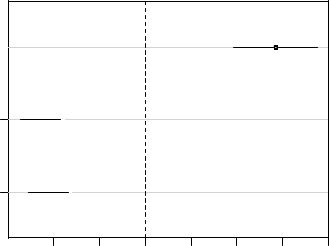
Помимо расчета скорректированныхр-значений, имеется также возможность рассчитать доверительные интервалы, которые будут учитывать корреляцию между параметрами модели. Для этого следует воспользоваться функцией confint(), подав на нее объект, полученный при помощиglht(), и указав требуемый доверительный уровень:
mult <- glht(M, linfct = mcp(Water = contr)) confint(mult, level = 0.95)
|
Simultaneous Confidence |
Intervals |
Contrasts |
||
|
Multiple Comparisons of Means: User-defined |
||||
|
Fit: lm(formula = Sr ~ Water, data = waterbodies) |
||||
|
Quantile = 2.5324 |
||||
|
95% family-wise confidence level |
||||
|
Linear Hypotheses: |
Estimate |
lwr |
upr |
|
|
Rock — Angler == 0 |
||||
|
14.2167 |
9.6478 |
18.7855 |
||
|
Grayson — Appletree == 0 |
-9.0167 |
-13.5855 |
-4.4478 |
|
|
Grayson — Beaver == 0 |
-8.1500 |
-12.7188 |
-3.5812 |
В выведенных результатах столбцыlwr и upr содержат нижний и верхний доверительный пределы соответствующих оценок параметров модели (Estimate).
Для удобства интерпретации рассчитанных доверительных интервалов, а также для презентации этих результатов в сжатом ,видемы можем легко построить график следующего рода:
plot(confint(mult, level = 0.95))
95% family-wise confidence level
|
Rock — Angler |
( |
) |
||
Grayson — Appletree (  )
)
Grayson — Beaver (  )
)
|
-10 |
-5 |
0 |
5 |
10 |
15 |
20 |
Linear Function
234

7. РЕГРЕССИОННЫЕ МОДЕЛИ ЗАВИСИМОСТЕЙ МЕЖДУ КОЛИЧЕСТВЕННЫМИ ПЕРЕМЕННЫМИ
7.1. О понятии «статистическая модель«
Термин «модель» используется во многих сферах человеческой деятельности и имеет множество смысловых значений. Тем не менее, в общем виде модель можно определить как некоторую искусственную конструкцию, являющуюся упрощенным представлением реальной системы. Более простое устройство модели выражается в том, что при ее создании принимают во внимание только определенные свойства реальной системы, полагаемые существенными для изучаемого процесса или явления(представьте себе, например, масштабную модель дома, созданную архитектором). Изменяя эти свойства у модели, мы можем лучше понять устройство реальной системы и, что особенно важно, с определенной вероятностью предсказать ее поведение в разных ситуациях.
Построение моделей является одной из центральных тем статистики как науки. Существует большое число классов статистических моделей, различающихся как по лежащим в их основе математическим принципам, так и по преимущественным областям применения. Однако, несмотря на все свое разнообразие, статистические модели сходны в том, что они описывают взаимосвязь между случайными переменными. Как именно это происходит? Постараемся разобраться.
Пример простейшей статистической модели
Вмире реальных вещей и явлений практически всегда присутствует некоторый уровень неопределенности, вызванный естественной изменчивостью, влиянием внешних факторов или погрешностью измерений. Предположим, что мы имеем дело с некоторой случайной количественной переменнойY. Отдельные выборочные значения этой
переменной будем обозначать какyi . Индекс i изменяется от 1 до n, где n – это объем выборки.
Вкачестве примера рассмотрим систолическое кровяное давление у людей (выражается в мм ртутного столба). Очевидно, что уровень кровяного давления не может
быть одинаковым у всех людей– при обследовании случайно сформированной выборки мы почти всегда будем наблюдать определенный разброс значений этой переменной, хотя некоторые значения будут встречаться чаше других. Сформируем выборку возможного
распределения 100 значений давления крови, (не будем пока уточнять механизм получения данных и предположим, что это – реальные измерения у реальных случайно отобранных людей, различающихся по возрасту, полу, массе тела и, возможно, каким-то другим характеристикам):
|
y <- c( |
117.55, |
106.76, |
115.26, |
117.13, |
125.39, |
121.03, |
|
109.14, |
||||||
|
114.03, |
124.83, |
113.92, |
122.04, |
109.41, |
131.61, |
103.93, |
|
116.64, |
117.06, |
111.73, |
120.41, |
112.98, |
101.20, |
120.19, |
|
128.53, |
120.14, |
108.70, |
130.77, |
110.16, |
129.07, |
123.46, |
|
130.02, |
130.31, |
135.06, |
129.17, |
137.08, |
107.62, |
139.77, |
|
121.47, |
130.95, |
138.15, |
114.31, |
134.58, |
135.86, |
138.49, |
|
110.01, |
127.80, |
122.57, |
136.99, |
139.53, |
127.34, |
132.26, |
|
120.85, |
124.99, |
133.36, |
142.46, |
123.58, |
145.05, |
127.83, |
|
140.42, |
149.64, |
151.01, |
135.69, |
138.25, |
127.24, |
135.55, |
|
142.76, |
146.67, |
146.33, |
137.00, |
145.00, |
143.98, |
143.81, |
|
159.92, |
160.97, |
157.45, |
145.68, |
129.98, |
137.45, |
151.22, |
235
136.10, 150.60, 148.79, 167.93, 160.85, 146.28, 145.97, 135.59, 156.62, 153.12, 165.96, 160.94, 168.87, 167.64, 154.64, 152.46, 149.03, 159.56, 149.31, 153.56, 170.87, 163.52, 150.97)
c(mean(y), sd(y)) # среднее значение и станд. отклонение
[1] 135.15730 16.96017
shapiro.test(y) # тест на нормальность распределения
Shapiro-Wilk normality test
data: y
W = 0.9826, p-value = 0.2121
library(ggplot2) # графическое изображение распределения данных ggplot(data = data.frame(y), aes(x = y)) + geom_histogram() +
ylab(«Частота») + xlab(«Давление, мм рт. ст.»)
Частота
|
8 |
|||||||
|
6 |
|||||||
|
4 |
|||||||
|
2 |
|||||||
|
0 |
|||||||
|
100 |
110 |
120 |
130 |
140 |
150 |
160 |
170 |
|
Давление, мм рт. ст. |
Приведенная выше гистограмма по форме напоминает колокол, указывая на то, что мы, вероятно, имеем дело с нормально распределенной переменной. Об этом же свидетельствуют и формальные тесты на нормальность, в частности, тест Шапиро-Уилка.
Как известно, произвольное нормальное распределение полностью задается двумя параметрами: μ – математическим ожиданием (а именно, средним значением) и σ –
стандартным отклонением. То обстоятельство, что случайная величина Y распределена
согласно нормальному закону, принято обозначать выражениемyi ~ N(μ, σ), которое представляет собой пример простейшей статистической модели.
Подобно другим параметрическим моделям, эта модель включает две составные части: систематическую и случайную. Систематическая часть представлена средним значением μ, которое отражает центральную тенденцию в данных. В свою очередь, стандартное отклонение σ характеризует степеньвариации значений Y, т.е. их разброс относительно среднего.
Греческие буквы μ и σ обозначают истинные(также «генеральные») параметры модели, которые, как правило, нам неизвестны. Тем не менее, мы можем оценить значения параметров по соответствующим выборочным статистикам. Так, в случае представленных выше 100 значений систолического кровяного давления выборочные среднее значение и стандартное отклонение составляют 135.16 мм рт. ст. и 16.96 мм рт. ст. соответственно. Допуская, что данные действительно происходят из нормально распределенной генеральной совокупности, мы можем записать нашу модель в виде
236
yi ~ N(135.16, 16.96). Эту модель можно использовать для предсказания давления крови, однако для всех людей предсказанное значение окажется одинаковым и будет равно. μ Обычным способом записи этой модели является следующий:
yi = 135.16 + ei,
где ei – это остатки модели, имеющие нормальное распределение со средним значением 0
и стандартным отклонением 16.96: ei ~ N(0, 16.96). Остатки рассчитываются как разница между реально наблюдаемыми значениями переменнойY и значениями, предсказанными моделью (в рассматриваемом примере ei = yi — 135.16).
С другой стороны эта запись представляет собой ни что, какиноелинейную регрессионную модель, у которой нет ни одного предиктора, и которую часто называют «нуль-моделью» или «нулевой моделью» (англ. null models).
Исследование свойств статистических моделей имитационными методами
|
В |
сущности, |
статистическая |
модель – |
это |
упрощенное |
математическое |
||
|
представление процесса, который, как мы полагаем, привел к генерации наблюдаемых |
||||||||
|
значений |
изучаемой |
переменной. Это значит, что мы можем использовать модель для |
||||||
|
симуляции (simulation) – т.е. |
процедуры, имитирующей моделируемый процесс |
и |
||||||
|
позволяющей тем |
самым |
искусственно |
генерировать новые |
значения |
изучаемой |
переменной, которые, как мы надеемся, будут обладать свойствами реальных данных. Причин, по которым мы хотели бы получить такие «искусственные данные», можно назвать много, но основные из них обычно сводятся к решению следующих практических задач:
|
° |
нахождение границ доверительных интервалов для параметров модели; |
|||
|
° |
оценка |
уровня |
неопределенности в отношении |
предсказываемых моделью |
|
значений зависимой переменной; |
°оценивание статистической мощности(сопутствующая задача – нахождение минимального объема наблюдений, необходимого для ответа на стоящий перед исследователем вопрос);
|
° |
сравнение |
искусственно сгенерированных значений |
зависимой переменной с |
|
реально наблюдаемыми значениями с целью выяснить, насколько хорошо модель |
|||
|
подходит для описания изучаемого явления. |
|||
|
С подробными примерами, посвященными использованию имитационных методов |
|||
|
при |
построении |
обычных регрессионных и многоуровневых |
иерархических моделей, |
можно ознакомиться в великолепной книге Э. Гелмана и Дж. Хилл (Gelman, Hill, 2007). Там же приведены многочисленные скриптыR-кода для решения различных задач статистического анализа. Здесь мы обратимся к последней из перечисленных выше задач и рассмотрим, насколько хорошо значения кровяного давления, генерируемые нашей нулевой моделью, согласуются с экспериментальными данными.
Новые данные на основе этой простой модели можно легко сгенерировать вR при помощи функции rnorm() (подробнее см. раздел 4.6):
set.seed(101) # для воспроизводимости результата y.new.1 <- rnorm(n = 100, mean = 135.16, sd = 16.96)
Выше было показано, что альтернативным способом получения этих же значений будет генерация нормально распределенных остатков модели ei:
set.seed(101)
y.new.2 <- 135.16 + rnorm(n = 100, mean = 0, sd = 16.96)
237
# проверим, идентичны ли оба вектора? all(y.new.1 == y.new.2)
[1] TRUE
Теперь необходимо вспомнить о том, что параметры нашей нулевой модели являются лишь точечными оценками истинных параметров, и что всегда будет присутствовать неопределенность в отношении того, насколько точны эти точечные
|
выборочные |
оценки. В приведенных выше командах эта неопределенность не была |
|
учтена: при |
создании векторовy.new.1 и y.new.2 выборочные оценки среднего |
значения и стандартного отклонения кровяного давления рассматривались как параметры генеральной совокупности. В зависимости от поставленной задачи, такой подход может оказаться достаточным. Однако мы сделаем еще один шаг и постараемся учесть неопределенность в отношении точечных оценок параметров модели.
При проведении имитаций воспользуемся функциейlm(), которая предназначена для подгонки линейных регрессионных моделей. Ничего удивительного здесь нет– ведь мы уже знаем, что нашу простую модель кровяного давления можно рассматривать как линейную регрессионную модель, у которой нет ни одного предиктора:
y.lm <- lm(y ~ 1) # формула для оценки только свободного члена
|
summary(y.lm) |
|||||
|
Call: |
|||||
|
lm(formula = y ~ 1) |
|||||
|
Residuals: |
3Q |
Max |
|||
|
Min |
1Q Median |
||||
|
-33.96 -13.26 |
0.41 |
12.04 35.71 |
|||
|
Coefficients: |
|||||
|
Estimate Std. Error t value Pr(>|t|) |
|||||
|
(Intercept) |
135.157 |
1.696 |
79.69 <2e-16 *** |
||
|
— |
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
||||
|
Signif. codes: |
|||||
|
Residual standard error: 16.96 on 99 degrees of freedom |
|||||
|
Как |
следует |
из |
приведенных результатов, свободный член подогнанной модели |
(Intercept) в точности совпадает со средним значением данных (135.16 мм рт. ст.), а стандартное отклонение остатков модели(Residual standard error) совпадает со стандартным отклонением этих данных (16.96 мм рт. ст.). Важно, однако, что мы при этом вычислили также оценку стандартной ошибки среднего значения, равную 1.696 (см. столбец Std. Error на пересечении со строкой (Intercept)).
По определению, стандартная ошибка параметра– это стандартное отклонение [нормального] распределения значений этого параметра, рассчитанных по выборкам одинакового размера из той же генеральной совокупности. Мы можем использовать это обстоятельство для учета неопределенности в отношении точечных оценок параметров модели при порождении новых данных. Так, зная выборочные оценки параметров и их стандартные ошибки, мы можем: а) сгенерировать несколько возможных значений этих параметров (т.е. составить несколько реализаций той же модели, варьируя значения параметров) и б) сгенерировать новые данные на основе каждой из этих альтернативных реализаций модели.
Решение перечисленных задач возможно с использованием функцииsim() из пакета arm, который является приложением к упомянутой выше книге (Gelman, Hill, 2007). Эта функция принимает на входе модельные объекты классовlm, glm и др., извлекает оценки параметров и их соответствующие стандартные ошибки и возвращает заданное пользователем число альтернативных реализаций модельных параметров.
238
Например, следующие команды позволят сгенерировать5 альтернативных реализаций среднего кровяного давления и его стандартного отклонения для нашей простой модели:
install.packages(«arm») library(arm)
set.seed(102) # для воспроизводимости результата y.sim <- sim(y.lm, 5)
#y.sim — объект класса S4, который содержит
#слоты coef (коэффициенты модели) и sigma
#(станд. отклонения остатков модели):
str(y.sim)
Formal class ‘sim’ [package «arm»] with 2 slots
..@ coef : num [1:5, 1] 136 134 137 136 137
.. ..- attr(*, «dimnames»)=List of 2
.. .. ..$ : NULL
.. .. ..$ : NULL
..@ sigma: num [1:5] 16.8 18.9 17.3 16.7 15
#Извлекаем альтернативные реализации среднего из y.sim: y.sim@coef
[,1] [1,] 136.4775 [2,] 134.3283 [3,] 136.7074 [4,] 136.0771 [5,] 137.3246
#Извлекаем альтернативные реализации ст.отклонений остатков: y.sim@sigma
[1] 16.829, 18.870, 17.303, 16.743, 15.006
Конечно, 5 реализаций модели – это совершенно недостаточно, чтобы сделать какие-либо убедительные выводы. Увеличим это число до 1000:
set.seed(102) # для воспроизводимости результата y.sim <- sim(y.lm, 1000)
#Инициализация пустой матрицы, в которой мы будем сохранять
#данные, сгенерированные на основе 1000 альтернативных
#реализаций модели:
y.rep <- array(NA, c(1000, 100))
# Заполняем матрицу y.rep имитированными данными: for(s in 1:1000){
y.rep[s, ] <- rnorm(100, y.sim@coef[s], y.sim@sigma[s])
}
Чтобы лучше понять, что мы только что сделали, изобразим гистограммы выборочных распределений значений кровяного давления, сгенерированных на основе, например, первых 12 реализаций нулевой модели:
par(mfrow = c(5, 4), mar = c(2, 2, 1, 1))
for(s in 1: 12){ hist(y.rep[s, ], xlab = «», ylab = «», breaks = 20, main = «»)}
239

|
14 |
12 |
14 |
12 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
10 |
10 |
10 |
10 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
8 |
8 |
8 |
8 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6 |
6 |
6 |
6 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4 |
4 |
4 |
4 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 |
2 |
2 |
2 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
0 |
0 |
0 |
0 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
100 |
120 |
140 |
160 |
100 |
120 |
140 |
160 |
100 |
120 |
140 |
160 |
180 |
100 |
120 |
140 |
160 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
15 |
15 |
12 |
15 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
10 |
10 |
10 |
10 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
8 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6 |
5 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
5 |
5 |
4 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
0 |
0 |
0 |
0 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
100 |
120 |
140 |
160 |
100 |
120 |
140 |
160 |
100 |
140 |
180 |
60 |
100 |
140 |
180 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
12 |
12 |
15 |
20 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
8 10 |
8 10 |
10 |
15 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
10 |
|||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
6 |
6 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
4 |
4 |
5 |
5 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
2 |
2 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
0 |
0 |
0 |
0 |
||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||||
|
100 |
140 |
180 |
100 |
140 |
180 |
110 |
130 |
150 |
170 |
80 |
100 |
140 |
Приведенный рисунок дает некоторое представление о том, насколько варьируют между собой и по отношению к реально наблюдаемым данным распределения значений кровяного давления, полученные имитацией на основе альтернативных реализаций нашей нуль-модели.
Однако нас больше всего интересует наличиесистематических расхождений между свойствами этих имитированных значений и свойствами реально наблюдаемых данных. Если такие расхождения имеются, значит нулевая модель недостаточно хороша для описания вариации реально наблюдаемых значений. Имеется несколько подходов для обнаружения этих расхождений. Один из них– расчет каких-либо подходящих описательных статистик для каждого из имитированных распределений и сравнение их с теми же статистиками у реально наблюдаемых данных.
Рассчитаем интерквартильный размах (ИКР) для каждого имитированного набора данных и сравним полученное распределение из1000 значений с ИКР реальных данных. Для расчета ИКР в R служит функция IQR():
#Расчет ИКР для каждого из 1000 имитированных
#распределений значений кровяного давления test.IQR <- apply(y.rep, MARGIN = 1, FUN = IQR)
Выведем гистограмму значений ИКР, рассчитанных для каждого из1000 имитированных распределений кровяного давления. Вертикальной синей линией покажем ИКР для реально наблюдаемых значений кровяного давления:
hist(test.IQR, xlim = range(IQR(y), test.IQR),
main = «ИКР», xlab = «», ylab = «Частота», breaks = 20) lines(rep(IQR(y), 2), c(0, 100), col = «blue», lwd = 4)
240
![]()
ИКР
0 20 40 60 80 100 120
|
15 |
20 |
25 |
30 |
35 |
На приведенном рисунке хорошо видно, что значения ИКР для имитированных данных систематически занижены по сравнению с реальными . Этоданными свидетельствует о том, что нулевая модель в целом недооценивает уровень вариации реальных значений кровяного давления. Причиной этому может быть ,точто мы не учитываем воздействие на кровяное давление каких-либо важных факторов(например, возраст, пол, диета, состояние здоровья, и т.п.). Рассмотрим, как можно расширить нашу нулевую модель, добавив в нее один из таких факторов.
Пример модели с одним количественным предиктором
Предположим, что помимо кровяного давления мы также измеряли у каждого испытуемого его/ее возраст (в годах):
#Значения возраста:
x <- rep(seq(16, 65, 1), each = 2)
#Объединяем значения возраста и давления крови в одну таблицу
Data <- data.frame(Age = x, BP = y)
Покажем графически связь между возрастом и систолическим кровяным давлением. Для визуализации тренда в данных добавим линию регрессии синего цвета:
ggplot(data = Data, aes(x = Age, BP)) + geom_point() + geom_smooth(method = «lm», se = FALSE) + geom_rug(color = «gray70», sides = «tr») + ylab(«Частота») + xlab(«Возраст, лет»)
|
170 |
|||||
|
160 |
|||||
|
150 |
|||||
|
астота |
140 |
||||
|
130 |
|||||
|
Ч |
|||||
|
120 |
|||||
|
110 |
|||||
|
20 |
30 |
40 |
50 |
60 |
|
|
Возраст, лет |
241
|
Небольшие отрезки светло-серого цвета по краям |
графика |
соответствуют |
|
|
наблюдаемым значениям возраста (вверху) и кровяного давления (справа). Подробнее об |
|||
|
этом типе |
оформления диаграмм(rugs) описано в документацииggplot()на |
сайте |
|
|
docs.ggplot2.org. |
|||
|
Из |
графика видно, что между давлением крови и |
возрастом |
существует |
выраженная линейная зависимость: несмотря на определенную вариацию наблюдений, по мере увеличения возраста давлениев среднем также возрастает. Мы можем учесть это систематическое изменение среднего кровяного давления, добавив возраст (Age) в нашу
|
нулевую модель: |
yi ~ N(β0 + β1×Agei, σ), |
|||
|
или в иной форме записи: |
yi = β0 + β1×Agei+ ei, где ei ~ N(0, σ). |
|||
|
Параметры β0 |
и β1 можно без труда оценить методом наименьших квадратов при |
|||
|
помощи функции lm(): |
||||
|
summary(lm(BP ~ Age, data = Data)) |
||||
|
Call: |
||||
|
lm(formula = BP ~ Age, data = Data) |
||||
|
Residuals: |
1Q |
Median |
3Q |
Max |
|
Min |
||||
|
-21.6626 -6.2509 |
0.0075 |
6.3125 |
17.3525 |
|
Coefficients: |
|||||||
|
Estimate Std. Error t value Pr(>|t|) |
*** |
||||||
|
(Intercept) 94.85346 |
2.66731 |
35.56 |
<2e-16 |
||||
|
Age |
0.99515 |
0.06204 |
16.04 |
<2e-16 |
*** |
||
|
— |
0 ‘***’ |
0.001 ‘**’ 0.01 |
‘*’ 0.05 |
‘.’ 0.1 ‘ ’ 1 |
|||
|
Signif. codes: |
|||||||
|
Residual standard error: 8.953 on 98 degrees of freedom |
|||||||
|
Multiple R-squared: 0.7242, Adjusted R-squared: |
0.7214 |
||||||
|
F-statistic: 257.3 on 1 and 98 DF, |
p-value: < 2.2e-16 |
||||||
|
Согласно полученным результатам, модель кровяного давления можно записать |
|||||||
|
как |
yi ~ N(94.853 + 0.995×Agei, 8.953) |
||||||
|
~ N(0, 8.953). |
|||||||
|
или |
yi = 94.853 + 0.995×Agei |
+ ei, где ei |
|||||
|
Графически |
эта |
модель |
изображена |
выше |
на |
рисунке |
в виде линии. тренда |
Обратите внимание: помимо высокой значимости параметров подогнанной модели(р << 0.001 в обоих случаях), стандартное отклонение остатков составляет8.853, что почти в 2 раза меньше, чем у нулевой модели (16.96). Это указывает на то, что модель, включающая возраст как предиктор, гораздо лучше описывает вариацию значений кровяного давления у 100 обследованных испытуемых, чем наша исходная модель без параметра.
Это заключение подтверждается тем, что в результате выполнения имитаций,
|
аналогичных описанным выше, значение |
интерквартильного размаха |
для |
исходных |
|||
|
данных располагается в центре распределения имитированных значений ИКР, указывая на |
||||||
|
отсутствие |
систематических |
различий |
между |
имитированными |
и |
наблюдаемыми |
|
данными. Код на языке R и полученную гистограмму мы здесь не приводим, рекомендуя |
||||||
|
проделать вычисления самому читателю. |
||||||
|
Теперь |
настало |
время |
раскрыть |
небольшой : секреттот факт, |
что |
модель, |
|
включающая |
возраст, |
гораздо |
лучше |
описывает |
исходные данные, неудивителен, |
поскольку эти наблюдения были… сгенерированы на основе модели yi = 97.078 + 0.949× Agei + ei, где ei ~ N(0, 9.563)
следующим образом:
242

set.seed(101)
y <- rnorm(100, mean = 97.078 + 0.949*x, 9.563)
Последняя модель, придуманная в целях демонстрацииобсуждаемых принципов, была использована в качестве»истинной» (англ. true model) в том смысле, что она описывала генеральную совокупность. Другими словами, мы предположили, что у нас
была возможность одномоментно измерить давление у всех существующих людей и полученные данные описывались бы именно этой «истинной» моделью.
В реальной ситуации ни структура(систематическая часть + остатки), ни значения
|
параметров |
истинной |
модели |
исследователю, как правило, |
неизвестны. |
Все, чем он |
|
располагает |
– это |
наборы |
экспериментальных |
данных, часто |
недостаточно |
репрезентативных и сильно»зашумленных». Имея эти данные и хорошее понимание изучаемого явления (в смысле того, какие предикторы считать достаточно важными для рассмотрения), исследователь может только надеяться приблизиться к структуре истинной модели и оценить ее параметры с определенной точностью. К сожалению, такой успех гарантирован далеко не всегда.
Назначение регрессионных моделей
В общем виде под регрессией случайной величины Y на X понимается зависимость,
|
задающая |
траекторию |
движения |
точки(yx, |
x), |
которая |
определяется |
условным |
|
|
математическим ожиданием yx = E[Y |
X = x] |
для |
каждого |
текущего значенияx. Эта |
||||
траектория моделируется с использованием некоторойфункции регрессии f(x, β) с постоянными параметрами β, которая позволяет оценить средние значения yˆ реализаций
зависимой переменной Y для каждого фиксированного значенияx независимой переменной (предиктора) X. Поскольку для точного описанияf(x, β) необходимо знать
закон условного распределения E[Y X = x] , то на практике ограничиваются ее наиболее
подходящей аппроксимацией fˆa (x, b) , обеспечивающей минимум средней ошибкиe восстановления значений Y(x). Эти рассуждения легко распространить на многомерый
|
случай, где X – |
набор предикторов. В сущности, |
статистическое |
моделирование (или |
|
«статистическое |
обучение» (от англ. statistical |
learning, см. |
James et al., 2013) |
представляет собой набор подходов, позволяющих оценить функциюf(x, β) на основе ограниченной совокупности наблюдений.
Существуют несколько основных причин для нахождения функции регрессии:
1. Статистические выводы и объяснение научных феноменов: оценка функции f(x, β)
облегчает понимание характера взаимоотношений между переменной-откликом и
|
предикторами (например, насколько силен |
отклик при |
изменении |
того или иного |
|
|
предиктора, какой из предикторов наиболее важен, и т.п.). Так, в примере выше мы |
||||
|
выяснили, что возраст тесно связан с уровнем систолического давления– |
информация, |
|||
|
которая может оказаться очень важной для практикующего врача. |
||||
|
2. Компактное описание, позволяющее |
представить |
наиболее |
объяснимые |
с |
предметной точки зрения функциональные отношения между переменными в рамках формальной модели и найти оценку ее параметров, основанную на эмпирических данных.
3.Обобщение результатов многих выборочных наблюдений и распространение статистических выводов на всю генеральную совокупность( форме, например, доверительных интервалов модели).
4.Прогноз (или предсказание), заключающийся в вычислении предполагаемых значений yˆ переменной-отклика с использованием уравнения регрессии. Например, банк
|
хочет спрогнозировать риск |
невозврата кредита(отклик Y) от набора предикторов |
|
(уровень доходов и образования, |
опыт работы, пол, возраст, кредитная история клиента). |
243

|
Точность предсказания будет |
зависеть |
от |
двух составляющих– устранимой и |
|
неустранимой погрешности (англ. |
reducible |
error и |
irreducible error соответственно). |
Первая связана с тем, что наша модель никогда не является идеальн, хойтя при использовании дополнительной информации об изучаемом явлении и применении более точных статистических методов имеющуюся неопределенность можно снизить. В свою очередь, неустранимая погрешность обусловлена неточностью измерений и влиянием скрытых факторов, которые мы не можем учесть, потому что просто о них не знаем.
7.2. Простая линейная регрессия: каков возраст Вселенной?
Как было показано выше, статистическая модель регрессии представляет собой упрощенное математическое представление изучаемого процесса, с помощью которого, по нашему предположению, можно будет с минимальной ошибкой»предсказывать» вероятные значения наблюдаемой величины. Во многих случаях первым естественным приближением функции регрессии откликаy на предикторx является модель простой линейной регрессии, которая представляет собой зависимость следующего вида:
y = E(Y X = x) + e = b0 + b1x + ey ,
где b0 и b1 – параметры (или «коэффициенты») функции регрессии; ey – случайные остатки (ошибки или «невязки» модели), в отношении которых делается предположение, что они статистически независимы и одинаково распределены. Следует, правда, оговориться, что, если случайная величинаey имеет единственную реализацию(т.е. нет повторных наблюдений), то проверить гипотезу о независимости весьма затруднительно. Тогда для так называемой «классической» линейной модели вводятся дополнительные и весьма жесткие предположения о стохастической части модели:
|
° |
ошибки ey |
нормально |
распределеныc |
нулевым средним, |
т.е. их математическое |
|
ожидание E[ey] = 0; |
наблюдаемых значенийх: |
||||
|
° |
дисперсия |
остатков ei |
одинакова на |
всем диапазоне |
E[ey2] = s2, ey ~ N(0, s2) (см. аналогичные исходные предпосылки для линейной модели дисперсионного анализа ANOVA, представленные в разделах 6.2 и 6.4).
Пусть необходимо выполнить линейный регрессионный анализ с использованием выборки из пар наблюдений (x1, y1), (x2, y2), …, (xn, yn). Первый и основной этап заключается в построении эмпирического уравнения
yˆi = bˆ 0 + bˆ1xi , i = 1, 2,K, n .
При этом необходимо получить такие оценки bˆ 0 и bˆ 1 неизвестных параметров β0 и β1, которые наилучшим образом описывали характер зависимости между выборочными значениями х и y.
Общий подход при нахождении оптимальных оценок параметров модели заключается в минимизации некоторой выбраннойфункции потерь r( eˆ ), учитывающей
разности между прогнозируемыми и фактическими значениями отклика:
åin=1r[ yi — (bˆ 0 +bˆ1 xi )] = åin=1r[( yi — yˆi )] = åin=1r(eˆ) ® min .
Использование r( eˆ ) = eˆ 2 приводит к таким оценкам коэффициентов модели β0 и β1, которые минимизируют сумму квадратов остатков (англ. residual sum of squares), т.е.
|
n |
2 |
||||||||||
|
) |
. |
||||||||||
|
RSS = å(yi — y) |
|||||||||||
|
Если |
i=1 |
ˆ |
ˆ |
1 |
, |
ˆ |
2 |
,…, |
ˆ n |
распределены |
|
|
выборочные остатки модели регрессииe = |
e |
e |
e |
||||||||
|
нормально, |
то так называемый метод наименьших квадратов (МНК; |
англ. ordinary least |
244
squares, OLS) имеет несомненное преимущество, поскольку позволяет получить несмещенные, наиболее эффективные и однозначно определенные оценки параметров.
Можно показать, что минимальное значение RSS будет достигаться при следующих значениях коэффициентов модели:
|
° |
ˆ |
2 |
2 |
||
|
b1={åyi xi |
—xåyi}/{åxi |
—(åxi ) /n}, |
что соответствует тангенсу угла наклона линии регрессии в координатах (x; y);
°bˆ0 ={åyi -bˆ1åxi}/n – отрезок, отсекаемый этой линией на оси ординат.
Наконец, стандартное отклонение остатков(англ. residual standard error),
являющееся важной характеристикой качества модели, в случае простой линейной регрессии оценивается как σ = [RSS/(n — 2)]0.5.
Модель оценки возраста вселенной
Как известно, связь между расстоянием до внегалактического объекта(например, галактики, квазара) и скоростью его удаления, обусловленного расширением Вселенной после Большого взрыва, описывается законом Хаббла.(ru.wikipedia.org/wiki). Этот закон выражается простой линейной зависимостью: y = βx, где y – относительная скорость движения любых двух галактик, разграниченных в данный момент времени расстоянием
|
y,а β – |
постоянная |
Хаббла, |
выраженная в км/с на мегапарсек. Величина, обратная |
|
|
постоянной Хаббла, |
дает |
приблизительный |
возраст |
Вселенной(так называемый, |
|
«Хаббловский возраст»). |
||||
|
В |
рамках проектаKey |
Project («ключевой |
проект»), |
целью которого являлось |
уточнение значения β, с помощью космического телескопа «Хаббл» (ru.wikipedia.org/wiki)
|
были измерены расстояния до24 галактик и |
установлены скорости их удаления. |
|||||
|
Пользуясь этими опубликованными данными(Freedman et al., |
2001), мы можем оценить |
|||||
|
значение постоянной Хаббла при помощи |
простой линейной регрессии. Обратим |
|||||
|
внимание на то, что свободный член уравнения |
здесь приравнен нулю, поскольку в |
|||||
|
момент, когда |
Вселенная |
находилась |
в |
состоянии |
сингулярности, галактик |
не |
существовало и они, конечно же, не могли удаляться друг от друга.
Готовые для построения модели данные из указанной статьи можно найти в составе таблицы hubble из пакета gamair:
install.packages(«gamair») library(gamair) data(hubble)
str(hubble)
|
‘data.frame’: 24 obs. of |
3 variables: |
|||||
|
$ |
Galaxy: Factor w/ 24 |
levels «IC4182″,»NGC0300»,..: 2 3 4 5 |
||||
|
6 8 9 |
7 10 |
11 |
133 664 1794 |
1594 1473 278 714 882 80 772 … |
||
|
$ |
y |
: |
int |
|||
|
$ |
x |
: |
num |
2 9.16 16.14 |
17.95 21.88 … |
Как было показано ранее, параметры линейной модели вR можно оценить при помощи стандартной функции lm():
M <- lm(y ~ x — 1, data = hubble)
Обратите внимание на -1 в формуле модели – такое обозначение используется для того, чтобы исключить свободный член регрессионной модели. Посмотрим на результат подгонки модели:
245
summary(M) Call:
lm(formula = y ~ x — 1, data = hubble) Residuals:
|
Min |
1Q Median |
3Q |
Max |
|||
|
-736.5 |
-132.5 |
-19.0 |
172.2 |
558.0 |
||
|
Coefficients: |
||||||
|
Estimate Std. Error t value Pr(>|t|) |
*** |
|||||
|
x 76.581 |
3.965 |
19.32 1.03e-15 |
||||
|
— |
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 Residual standard error: 258.9 on 23 degrees of freedom
|
Multiple R-squared: |
0.9419, Adjusted R-squared: |
0.9394 |
||||
|
F-statistic: 373.1 on 1 and 23 DF, |
p-value: 1.032e-15 |
|||||
|
Как видим, оцененное значение постоянной Хаббла составило76.581 |
км/с на |
|||||
|
мегапарсек. |
Это |
значение |
существенно |
отличается |
от |
(смнуля. р-значение |
|
соответствующего t-теста в столбце Pr(>|t|)). |
уравненияy = |
76.581x |
||||
|
С использованием полученного |
нами |
расчет |
возраста |
|||
|
Вселенной |
не представляет |
труда. Один |
мегапарсек – это |
3.09×1019 км. Разделим |
полученную выше постоянную Хаббла на это значение, чтобы выразить ее в секундах:
(hub.const <- 76.581/3.09e19) [1] 2.47835e-18
Тогда возраст Вселенной, выраженный в секундах, составит:
(age <- 1/hub.const) [1] 4.034943e+17
Выполнив простое преобразование, получим возраст, выраженный в годах:
age/(60^2*24*365) [1] 12794721567
Таким образом, данные (Freedman et al., 2001) указывают на то, что возраст Вселенной составляет ~12.8 миллиардов лет. Отметим, что по последним оценкам возраст Вселенной составляет 13.798 млрд. лет (ru.wikipedia.org/wiki).
Доверительные интервалы модели
Обычно истинные величины коэффициентов регрессии 0βи β1 неизвестны и мы осуществляем лишь нахождение их оценокb0 и b1 (например, при помощи функции lm()). Иначе говоря, истинная линии регрессии может проходить как-то ина, чем построенная по выборочным данным. Оценить неопределенность в отношении построенной модели можно, вычислив доверительную область для линии регрессии.
Вобщем случае различают три способа выражения интервальных оценок точности
ивоспроизводимости рассчитанной модели: а) доверительная область модели регрессии, б) доверительная область для значений прогнозируемой переменной в)и толерантные интервалы регрессии (Кобзарь, 2006, с. 665).
Как было отмечено выше, предполагается, что при любом значенииx
|
соответствующие ему значенияy |
распределены нормально, а их средним является |
|
|
значение y |
, полученное по |
уравнению регрессии. Неопределённость оценки y |
|
) |
) |
характеризуется стандартной ошибкой регрессии:
246

|
1 |
(x — x0 )2 |
1 |
n |
) 2 |
|||||||||||||||||||||||||
|
S yˆ |
= Se |
+ |
, где |
Se = |
å(yi — y) |
– стандартное |
отклонение |
||||||||||||||||||||||
|
n |
å(xi |
— x) |
2 |
||||||||||||||||||||||||||
|
n — 2 i=1 |
|||||||||||||||||||||||||||||
|
остатков (ранее оно было также обозначено как RSE). |
|||||||||||||||||||||||||||||
|
x = x |
Неопределенность |
положения |
линии |
простой |
регрессии |
для |
каждого |
текущего |
|||||||||||||||||||||
|
0 |
определяется |
ошибкойS |
e |
(m |
) |
значений ŷ, |
которые |
расчитываются |
как |
||||||||||||||||||||
|
ˆ Y |x0 |
|||||||||||||||||||||||||||||
|
m |
ˆ |
ˆ |
. Тогда 100(1 — α)-процентный доверительный интервал модели регрессии |
||||||||||||||||||||||||||
|
= b |
0 |
+ b x |
0 |
||||||||||||||||||||||||||
|
ˆ Y |x0 |
1 |
||||||||||||||||||||||||||||
|
(CI, |
от англ. confidence interval) |
в точке x |
рассчитывается какCI = |
m |
± t |
a / 2,n—2 |
S |
y |
, |
где |
|||||||||||||||||||
|
0 |
ˆ Y |x |
0 |
|||||||||||||||||||||||||||
|
t(1−α/2, n−2) |
– это соответствующий квантиль t-распределения |
ˆ |
|||||||||||||||||||||||||||
|
Стьюдента. |
Доверительная |
область, рассчитанная по приведенному соотношению, является геометрическим местом доверительных интервалов для различных значений предиктора. Обычно это – довольно узкая полоса, которая несколько расширяется при крайних значениях х.
Доверительный интервал для зависимой переменнойили интервал предсказания
(PI, от англ. prediction intervals) складывается из разброса значений вокруг линии регресии
|
и |
неопределенности |
положения |
самой этой |
линии. Его ширина определяется ошибкой |
||||||||||||
|
S |
e |
( y | x ) |
= S |
e |
(m |
) + |
e |
, где e |
– случайная условная ошибка при прогнозеY. Для |
|||||||
|
ˆ |
0 |
ˆ Y |x0 |
Y |x0 |
Y |x0 |
||||||||||||
|
простой линейной регрессии эту ошибку можно рассчитать по формуле |
||||||||||||||||
|
1 |
(x — x0 )2 |
|||||||||||||||
|
SY = Se 1 + |
+ |
. |
||||||||||||||
|
n |
å(xi — x)2 |
Доверительная область PI = mˆ Y |x0 ± ta / 2,n—2 SY , рассчитанная для всех возможных значений
предиктора x0, является геометрическим местом доверительных интервалов для величин ŷ, экстраполированных на «новые» прогнозируемые значения отклика.
В статистической среде R интервалы CI и PI для линейной модели легко оценить с использованием функции predict.lm(). В общем случае эта функция предназначена для расчета значений ŷ по подогнанной модели и имеет два важных параметра: newdata, который определяет таблицу с набором предикторов(если он не определен, то используется исходная выборка) и interval = c(«none», «confidence», «prediction»), обозначающий тип оцениваемой доверительной области. Для модели, оценивающей постоянную Хаббла, имеем:
CPI.df <- cbind(predict(M,interval =»conf»), predict(M,interval =»pred»))
CPI.df <- CPI.df[,-4] ;
colnames(CPI.df) <- c(«Y_fit»,»CI_l»,»CI_u»,»PI_l»,»PI_u») head(CPI.df)
|
1 |
Y_fit |
CI_l |
CI_u |
PI_l |
PI_u |
|
153.1623 |
136.7587 |
169.5659 |
-382.7326 |
689.0573 |
|
|
2 |
701.4835 |
626.3550 |
776.6120 |
160.5966 |
1242.3704 |
|
3 |
1236.0201 |
1103.6430 |
1368.3972 |
684.2611 |
1787.7791 |
|
4 |
1374.6320 |
1227.4097 |
1521.8544 |
819.1244 |
1930.1397 |
|
5 |
1675.5960 |
1496.1406 |
1855.0515 |
1110.6902 |
2240.5019 |
|
6 |
246.5914 |
220.1816 |
273.0012 |
-289.7031 |
782.8859 |
Построим рисунок с линией регрессии и доверительными областями:
matplot(hubble$x, CPI.df, type=»l»,lwd=c(2,1,1,1,1),col=c(1,2,2,4,4), ylab=»Скорость,км/с»,xlab=»Расстояние,Мпс»)
with(hubble, matpoints(x,y,pch=20))
247
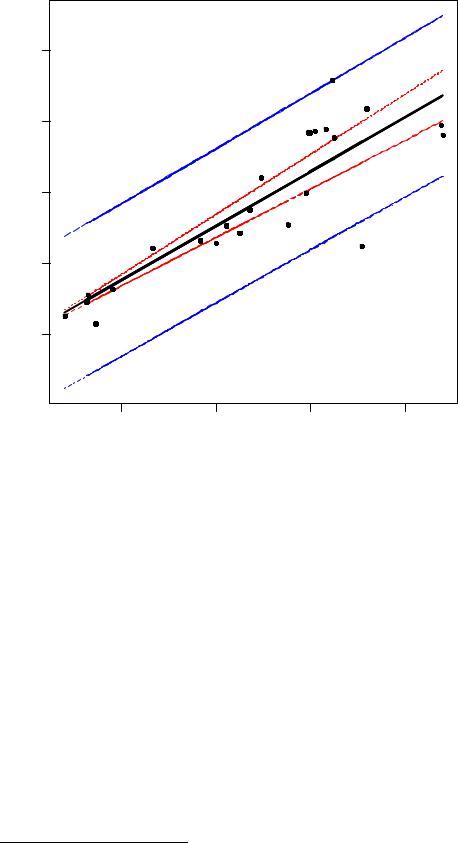
|
2000 |
||||
|
1500 |
||||
|
Скорость,км/с |
1000 |
|||
|
500 |
||||
|
0 |
||||
|
5 |
10 |
15 |
20 |
|
|
Расстояние,Мпс |
На рисунке показана линия регрессииy = 76.581x , построенная по 24 точкам, а также 95%-я доверительная область линии регрессии, которая ограничена пунктирными линиями красного цвета. С 95%-й вероятностью можно утверждать, что истинная линия находится где-то внутри этой области, т.е. если мы соберём аналогичные наборы данных по другим галактикам и построим по ним линии регрессии, то в 95 случаях из 100 эти прямые не покинут пределов доверительной области.
Обратите внимание, что некоторые точки оказались вне доверительной области. Это совершенно естественно, поскольку речь идёт о доверительной областиCI линии регрессии, а не самих значений. А вот в 95%-ю доверительную область прогнозирования PI, ограниченную синими линиями, попадет 95% всех возможных значений величины y в исследованном диапазоне значений x.
Оценка неопределенности в отношении параметров линейной регрессии
Как и в случае с любыми другими выборочными оценками, всегда существует неопределенность в отношении ,тогонасколько выборочные оценки параметров регрессионной модели близки к соответствующим истинным значениям(т.е. найденным по генеральной совокупности). Рассмотрим несколько способов, позволяющих охарактеризовать эту неопределенность, которая количественно выражается величинами стандартных ошибок и доверительных интервалов параметров модели.
1. Параметрический подход. Если объем выборки «достаточно велик» и выполняются определенные условия в отношении свойств остатков модели, можно воспользоваться Центральной Предельной Теоремой(ЦПТ – ru.wikipedia.org/wiki),
согласно которой выборочные оценки того или иного параметра линейной модели имеют приближенно нормальное распределение.
Как видно из приведенных ранее результатов расчетов, полученных с помощью функции lm(), постоянная Хаббла была оценена (Estimate) в 76.581 км/с на мегапарсек
248
|
со стандартной |
ошибкой(Std. Error) 3.965 км/с на мегапарсек. По определению, |
|||
|
стандартная |
ошибка |
параметра– это |
стандартное |
отклонение[нормального] |
распределения значений этого параметра, полученного по случайным выборкам фиксированного размера из той же генеральной совокупности. Соответственно, чем меньше значение стандартной ошибки параметра, тем более он точен.
Согласно ЦПТ мы предполагаем, что истинное значение постоянной Хаббла принадлежит нормально распределенной совокупности, математическое ожидание и стандартное отклонение которой составляют около76.581 и 3.965 км/с на мегапарсек
|
соответственно. Заметим, однако, что |
найденное нами |
наиболее |
вероятное |
точечное |
|
значение β при повторных измерениях может оказаться |
иным. Чтобы |
охарактеризовать |
||
|
эту |
неопределенность, необходимо |
рассчитать доверительный |
интервал – |
не |
противоречащий имеющимся данным диапазон значений, в котором истинное значение постоянной Хаббла находится с определенной вероятностью (например, 95%).
Ориентировочно оценить границы доверительного интервала можно, предположив,
|
что примерно 95% всех значений |
распределения оценок постоянной Хаббла лежат в |
||||||||
|
диапазоне ±2SEβ |
относительно |
его среднего значения, где SEβ |
– стандартная |
ошибка |
|||||
|
параметра β, т.е.: |
|||||||||
|
76.581 — 2×3.965 = 68.651 |
и |
76.581 + 2×3.965 = 84.511 км/с на мегапарсек. |
|||||||
|
Однако неопределенность |
имеется |
в отношении не |
только |
оценки |
параметра, но β и |
||||
|
оценки его стандартного отклонения для соответствующего нормального распределения. |
|||||||||
|
Не углубляясь в детали, отметим, |
что в связи с эти обстоятельством более точные |
||||||||
|
значения границ доверительного интервала дадут вычисления, основанные на свойствах t- |
|||||||||
|
распределения |
Стьюдента. |
Тогда |
границы 95%-го |
доверительного |
интервала |
для |
|||
|
параметра β составят: β ± t0.975SEβ, |
где t0.975 – 0.975-квантиль t-распределения |
с (n — |
p) |
||||||
|
числом степеней свободы, n – объем выборки, а p – число параметров модели. |
|||||||||
|
Для нашего примера получаем: |
beta <- summary(M)$coefficients[1] SE <- summary(M)$coefficients[2]
ci.lower <- beta — qt(0.975, df = 23)*SE ci.upper <- beta + qt(0.975, df = 23)*SE c(ci.lower, ci.upper)
[1] 68.379 84.783
Используя эти оценки нижней и верхней границ95%-ного доверительного интервала, мы можем рассчитать диапазон значений, в котором с вероятностью95% находится истинный возраст Вселенной:
Uni.upper <- 1/(ci.lower*60^2*24*365.25/3.09e19) Uni.lower <- 1/(ci.upper*60^2*24*365.25/3.09e19) c(Uni.lower, Uni.upper)
[1] 11549039573 14319551383
# т.е. примерно от 11.5 до 14.3 млрд. лет
Заметьте, что полученный таким способом доверительный интервал включает значение возраста Вселенной, рассчитанное на основе самых последних космологических изысканий (13.798 млрд. лет).
2. Бутстреп-метод. В разделах 2.7 и 5.3 нами рассмативались методы «размножения выборок» (рандомизация и бутстреп) для получения эмпирического распределения анализируемых статистик. Используем бутстреп-метод для оценки стандартной ошибки и 95%-ного доверительного интервала для постоянной Хаббла.
На следующем рисунке приведены примеры6 случайных выборок из24 наблюдений, извлеченных из исходной совокупности данных по скорости удаления галактик. Эти псевдовыборки формируются»с возвратом» – это значит, что, будучи
249
однажды случайно выбранным, то или иное наблюдение вновь помещается в исходную совокупность, откуда оно может быть извлечено снова(следовательно, некоторые наблюдения могут повторяться в генерируемой выборке несколько раз).
A B C
1500
1000
500
|
5 |
10 |
15 |
20 |
5 |
10 |
15 |
20 |
5 |
10 |
15 |
20 |
x
Обратите внимание: на представленном рисунке общий тренд сохраняется(«чем больше x, тем больше y«), однако наблюдения, входящие в состав каждой выборки A — F, несколько различаются, что в итоге приведет и к несколько различающимся оценкам постоянной Хаббла при подгонке линейной модели при помощи функции lm().
Как отмечено выше, при выполнении бутстреп-процедуры формируется «большое» число повторных выборок из исходной совокупности. То, насколько «большим» должно быть это число, зависит от объема исходной совокупности и ее свойств(подробнее см. Efron, Tibshirani, 1994). Для нашего примера мы сформируем1000 случайных повторных выборок. Хотя формирование бутстреп-распределений параметров регрессии можно реализовать в R, «вручную» записав необходимые команды, проще будет воспользоваться специально предназначенной для этого функцией boot() из одноименного стандартного пакета. Эта функция имеет следующие обязательные аргументы:
°data: таблица с исходными данными;
°statistic: функция, выполняющая вычисление интересующего нас параметра(-ов);
°R: число повторных выборок, по которым рассчитывается этот параметр.
Напишем небольшую функцию, которая будет оценивать параметры регрессионной модели и возвращать значения постоянной Хаббла:
regr <- function(data, indices) {
#вектор indices будет формироваться функцией boot() dat <- data[indices, ]
fit <- lm(y ~ -1 + x, data = dat) return(summary(fit)$coefficients[1])
}
Теперь подадим regr() на функцию boot(): library(boot)
results <- boot(data = hubble, statistic = regr, R = 1000)
При выводе содержимого объекта results на экран получим:
250
![]()
results
ORDINARY NONPARAMETRIC BOOTSTRAP Call:
boot(data = hubble, statistic = regr, R = 1000)
|
Bootstrap Statistics : |
std. error |
|
|
original |
bias |
|
|
t1* 76.58117 |
0.03528876 |
4.812987 |
В представленных результатахoriginal – это значение постоянной Хаббла, оцененное по эмпирическим данным(см. выше); bias (смещение) – разница между средним значением 1000 бутстреп-оценок постоянной Хаббла и исходной оценкой; std. error – бутстреп-оценка стандартной ошибки постоянной Хаббла. Обратите внимание на то, что полученная бутстреп-оценка стандартной ошибки выше, чем рассчитанная параметрическим методом.
Для объектов классаboot, к которому принадлежитresults, имеется метод plot, который позволяет изобразить графически полученное распределение бутстрепоценок постоянной Хаббла и одновременно проверить нормальность их распределения при помощи графика квантилей:
plot(results)
Как отмечено выше, мы можем оценить нижнюю и верхнюю границы95%-ного доверительного интервала постоянной Хаббла, найдя 0.025- и 0.975-квантили изображенного выше распределения:
quantile(results$t, c(0.025, 0.975)) 2.5% 97.5%
67.07360 85.73249
Используя эти значения, рассчитаем соответствующие границы значений возраста Вселенной:
U.lower <- 1/(85.73249*60^2*24*365.25/3.09e19) U.upper <- 1/(67.07360*60^2*24*365.25/3.09e19) U.lower
[1] 11421129999 # т.е. примерно 11.4 млрд. лет
U.upper
[1] 14598320553 # т.е. примерно 14.6 млрд. лет
251

Следует отметить, что границы доверительного интервала, рассчитанные методом «процентилей», могут оказаться смещенными. В состав пакетаboot входит функция boot.ci(), которая позволяет рассчитать несколько других типов доверительных интервалов, включая интервалы с поправкой на смещение(аргумент type = «bca»; подробнее см. ? boot.ci):
boot.ci(results, type = «bca»)
BOOTSTRAP CONFIDENCE INTERVAL CALCULATIONS Based on 1000 bootstrap replicates
CALL :
boot.ci(boot.out = results, type = «bca») Intervals :
|
Level |
BCa |
|
95% |
(66.44, 85.36 ) |
Calculations and Intervals on Original Scale
3. Использование имитационных процедур. Как было показано в разделе 7.1, можно также использовать принципы байесовской статистики и оценить неопределенность в отношении параметров той или иной модели методом имитаций. В общем виде эта процедура включает следующие шаги:
°подгонка определенной модели к имеющимся данным;
°полученные оценки параметров модели используются для генерации большого количества альтернативных, но, в то же ,времяправдоподобных (т.е. непротиворечащих данным) реализаций этих параметров.
Этот метод легко реализовать с помощью функции sim() из пакетаarm
(подробнее см. Gelman, Hill, 2007), которая выполняет следующие шаги:
1. При помощи обычного регрессионного анализа оцениваются вектор регрессионных
коэффициентов bˆ , ковариационная матрица Vbˆ и стандартное отклонение остатков sˆ .
2. Создается большое число реализаций оценок вектора параметров β* и стандартного отклонения остатков σ*. Для каждой реализации:
|
o |
генерируется значение s* = sˆ (n — k ) / c2 , где статистика c2 случайным |
образом извлекается из соответствующего распределения с n — k степенями свободы; o с учетом полученного значения σ*, формируется вектор β* путем
случайного извлечения значений из многомерного нормального распределения со
средним значением bˆ и ковариационной матрицей Vˆ .
b
Для нашего примера получаем:
library(arm)
simulations <- sim(M, 1000) hist(simulations@coef, breaks = 30)
Гистограмма распределения 1000 имитированных значений постоянной Хаббла по форме практически не отличается от приведенной выше гистограммы, полученной бутстреп-методом.
Рассчитав стандартное отклонение этого распределения, мы можем оценить стандартную ошибку постоянной Хаббла и увидеть, что она, как и в случае с бутстрепанализом, также оказалась выше исходной оценки (см. summary(M)):
sd(simulations@coef) [1] 4.051294
252

95%-ный доверительный интервал легко можно найти известным нам способом: quantile(simulations@coef, c(0.025, 0.975))
2.5% 97.5%
68.11832 84.31069
|
Конечно, может возникнуть вопрос– какой из описанных выше трех методов |
||||||||
|
следует |
применять |
на практике? Ответ на этот вопрос определяется несколькими |
||||||
|
факторами. Так, если модель адекватно описывает данные (с точки зрения ее структуры и |
||||||||
|
выполнения требований к ее остаткам), то рассмотренный в самом начале классический |
||||||||
|
подход даст хороший результат. Бутстреп-анализ и имитации, возможно, окажутся |
||||||||
|
слишком «тяжелой |
артилерией» для характеристики неопределенности в отношении |
|||||||
|
одного единственного коэффициента простой регрессии. В то же время эти методы |
||||||||
|
незаменимы при оценке неопределенности в отношении величин, которые являются |
||||||||
|
функцией (особенно нелинейной функцией) от каких-либо параметров модели. Например, |
||||||||
|
при |
выполнении |
бутстреп-анализа |
мы |
могли |
бы |
рассчитывать |
для |
ка |
«псевдовыборки» не просто постоянную Хаббла, а сразу возраст Вселенной, изменив соответствующим образом функцию regr().
Статистики, используемые для оценки «качества» регрессионной модели
В нашем примере вычисления постоянной Хаббла с помощью простой линейной регрессии оценка коэффициента β оказалась статистически значимой, что является косвенным (и в нашем случае вполне достаточным) подтверждением адекватности модели имеющимся данным. Но, когда возникает необходимость сравнить между собой несколько альтернативных моделей, отличающихся между собой по виду функции регресии и/или составу исходных данных, желательно получить более точный ответ на вопрос, какая из возможных спецификаций модели предпочтительней.
Многие руководства по статистике предлагают ориентироваться на формальные критерии качества аппроксимации, такие как среднеквадратичная ошибка регрессии,
коэффициент детерминации и дисперсионное отношение Фишера. Эти показатели,
вычисляемые при помощи функцииlm() и обобщенныеsummary(), образуют завершающий блок результатов (полный выводимый текст был приведен выше):
…
Residual standard error: 258.9 on 23 degrees of freedom Multiple R-squared: 0.9419, Adjusted R-squared: 0.9394 F-statistic: 373.1 on 1 and 23 DF, p-value: 1.032e-15
В третьей строке приведенных результатов фигурирует значениеF-критерия и соответствующее ему р-значение. В разделе 5.5 мы рассматривали дисперсионный анализ, где F-критерий использовался для сравнения -межи внутригрупповой дисперсий.
Поскольку дисперсионный анализ и линейная регрессия с математической точки зрения являются частными случаями одного и того же класса «общих линейных моделей» (см. раздел 6.2), здесь F-критерий представляет собой также отношение дисперсий с похожей
|
интерпретацией: |
F = |
(TSS — RSS) k |
, |
||||||||
|
RSS (n — k —1) |
|||||||||||
|
n |
|||||||||||
|
где TSS = å(yi |
— |
)2 |
– общая |
сумма |
квадратов(англ. |
total |
sum of squares), |
||||
|
y |
|||||||||||
|
i=1 |
|||||||||||
|
n |
2 |
||||||||||
|
) |
– |
сумма квадратов остатков, k = 2 |
– |
число |
параметров модели |
||||||
|
RSS = å(yi — y) |
i=1
(коэффициент регрессии и стандартное отклонение остатков), n – объем выборки.
253
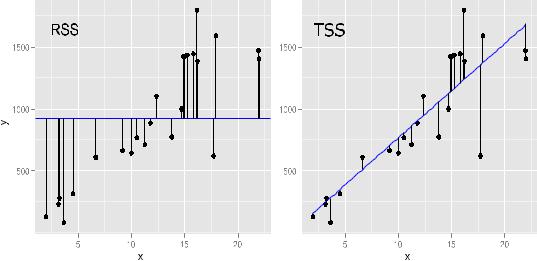
Ниже приведена геометрическая интерпретация понятий»общая сумма квадратов» (TSS) и «сумма квадратов остатков» (RSS). Предположим, что мы не строим никакой модели и пытаемся предсказать зависимую переменнуюy, просто рассчитав ее среднее
|
значение (рис. слева). Вертикальные |
отрезки |
отражают |
расстояние |
от |
каждого |
|
выборочного наблюдения y до этого предсказанного среднего значения(представлено в |
|||||
|
виде синей горизонтальной линии). При |
расчете TSS все эти расстояния возводятся в |
||||
|
квадрат и суммируются. Вертикальные отрезки на рис. справа отражают расстояние от |
|||||
|
каждого выборочного значения зависимой переменнойy до значения, предсказанного |
|||||
|
регрессионной моделью ( y ). При расчете RSS все |
эти расстояния также возводятся в |
||||
|
) |
|
Выполнить разложение дисперсии откликау на описанные |
составляющие и |
|||
|
получить |
стандартную |
таблицу |
дисперсионного анализа можно |
с использованием |
|
функции anova(): |
||||
|
anova(M) |
||||
|
Analysis of Variance Table |
||||
|
Response: y |
Sum Sq |
Mean Sq F value |
Pr(>F) |
|
|
x |
Df |
|||
|
1 25013691 25013691 373.08 1.032e-15 *** |
||||
|
Residuals 23 |
1542066 |
67046 |
||
|
— |
0 ‘***’ 0.001 ‘**’ 0.01 ‘*’ 0.05 ‘.’ 0.1 ‘ ’ 1 |
|||
|
Signif. codes: |
Очевидно, что чем меньше значениеRSS (т.е., чем ближе регрессионная линия ко всем наблюдениям одновременно), тем больше будет значениеF-критерия и тем лучше построенная регрессионная модель будетв целом описывать экспериментальные данные. Другими словами, рассчитывая F-критерий, мы проверяем нулевую гипотезу о равенстве всех регрессионных коэффициентов построенной модели нулю (Omnibus test):
H0: β1 = β2 = = βp = 0.
В приведенном виде эта нулевая гипотеза соответствует случаю множественной регрессии (т.е. когда имеется несколько предикторов). В рассматриваемом нами примере мы оценивали лишь один параметр(постоянную Хаббла) и F-критерий составил 373.1, что гораздо больше1. Этот результат означает, что вероятность получить столь же высокое значение F при отсутствии связи междуx и y очень мала (р = 1.032e-15). Поскольку у нас есть лишь один предиктор, то мы одновременно проверили гипотезы о
254
|
статистической значимости |
модели в |
целоми о равенстве нулю постоянной Хаббла β |
||||
|
(обратите внимание, что р-значения в обоих этих тестах совпадают). |
||||||
|
Во |
второй снизу |
строке |
результатов расчета |
модели |
приведены |
значения |
|
Multiple |
R-squared и Adjusted |
R-squared. В первом |
случае |
речь идет о |
так |
называемом коэффициенте детерминации, который обозначается как R2 и рассчитывается как R2 = 1 — RSS / TSS. Напомним, что TSS отражает общий разброс значений зависимой переменной без учета регрессионной модели, а RSS – остаточную дисперсию значений
|
отклика, которую нам не удалось «объяснить» при помощи построенной модели. |
||||||
|
Таким |
образом, коэффициент детерминации R2 измеряет долю общей дисперсии |
|||||
|
зависимой переменной, объясненную моделью, |
и изменяется |
от0 до 1. Чем |
ближе |
|||
|
значение R2 к 1, тем точнее модель описывает данные: для случая простой регрессии с |
||||||
|
одним предиктором R2 |
будет |
представлять |
собой |
просто возведенный |
в квадрат |
|
|
коэффициент |
корреляции |
междуy и x. |
Достигнутое |
нами |
значение коэффициента |
|
|
детерминации |
составило R2 = |
0.9419, |
что |
указывает на |
весьма высокое |
качество |
рассматриваемой модели.
Скорректированный коэффициент детерминации (англ. adjusted R-squared) имеет практический смысл лишь для сравнения моделей-претендентов с разным количеством
|
предикторов и будет обсуждаться нами в |
последующих |
разделах. Здесь |
мы |
лишь |
|||||||||||
|
приведем формулу для его расчета Radj2 |
=1— (1— R2 ) |
n —1 |
(где k – это число параметров |
||||||||||||
|
n — k —1 |
|||||||||||||||
|
модели) и отметим, что R2 ³ R2adj. |
|||||||||||||||
|
регрессионного |
анализа |
||||||||||||||
|
В первой строке приведенных выше результатов |
|||||||||||||||
|
представлено |
значение Residual |
standard |
error |
– |
стандартное |
отклонение |
|||||||||
|
остатков модели, которое в общем виде рассчитывается |
какRSE = |
RSS /(n — k —1) |
.По |
||||||||||||
|
определению, |
RSE |
является оценкой |
разброса наблюдаемых |
значений |
зависимой |
||||||||||
|
переменной относительно истинной линии регрессии. Так, в нашем примере, RSE = 258.9, |
|||||||||||||||
|
из чего следует, что в среднем наблюдаемые значения скорости галактик отличаются от |
|||||||||||||||
|
истинных значений на 258.9 км/сек. Очевидно, что чем меньше значениеRSE, тем точнее |
|||||||||||||||
|
модель описывает анализируемые данные. |
|||||||||||||||
|
Считается, что |
рассмотренные |
количественные |
показатели |
отражают |
разные |
||||||||||
|
аспекты «качества» регрессионной |
модели, и |
поэтому |
их |
стоит |
использовать |
в |
совокупности. На самом деле они лишь по-разному комбинируют суммы квадратов отклонений RSS и TSS. В дальнейшем у нас будет еще возможность критически их оценить и рассмотреть критерии, основанные на иных принципах.
7.3. Модели регрессии при различных видах функции потерь
Два типа регрессионных моделей
Рассмотрим предварительно геометрическую интерпретацию двух основных типов моделей регрессии (Sokal, Rohlf, 1981; Legendre, Legendre, 1998).
Модель I типа, подробно рассмотренная в предыдущем разделе, применяется в условиях, когда объясняющая переменнаяX является «управляемой» (т.е. известной априори) или случайная составляющая ее вариации существенно меньше ошибкиY. Помимо гипотезы о том, что переменные в эксперименте линейно связаны, для модели I типа существенны все предположения классической модели (раздел 7.2).
Концептуально модель регрессии I-го типа ориентирована на оптимальный прогноз значений отклика Y. С геометрической точки зрения при этом выполняет поиск минимальной суммы квадратов остатков, т.е. отсчет ведется строго по вертикали(см. сплошные линии на рисунке внизуслева). Можно также показать, что найденная прямая
255
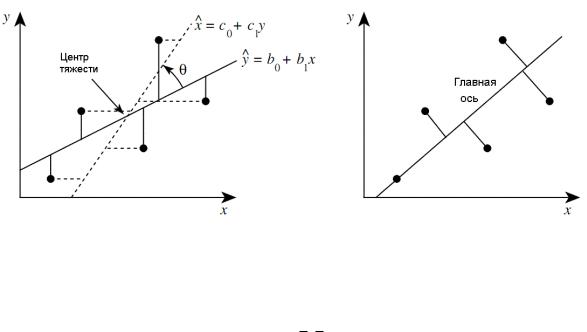
|
Y = f(X) проходит через «центр тяжести» |
облака точек-наблюдений, образованный |
||||
|
средними значениями переменных ( |
, |
). |
|||
|
x |
y |
||||
|
а) Модель наименьших квадратов (OLS) |
б) Модель главных осей регрессии (MA) |
«В рамках моделиI-го типа (т.е. когда независимая переменнаяX является управляемой) гипотеза корреляции о взаимозависимости случайных величинX и Y не имеет смысла.» (Legendre, Legendre, 1998, р. 499). Это подтверждается тем фактом, что
|
2 |
просто сводится к квадрату |
|
для простой регрессии коэффициент детерминацииR |
коэффициента линейной корреляции Пирсонаrxy, рассмотренному в разделе 5.6. Однако
на практике через центральную точку( x, y ) проходит и линия обратной регрессии
x = c0 + c1y + e, которая будет совпадать с основной линией лишь при rxy = 1 – см. рисунок слева. В противном случае коэффициент корреляции равен геометрическому среднему из
|
оценок параметров |
регрессии |
каждой |
из переменной на другую: c |
= r 2 |
/b |
(Y ×X ) |
или |
|
|
( X ×Y ) |
xy |
|||||||
|
r |
= tg(45o — q/ 2) |
, а |
величина |
углаq |
между двумя линиями регрессии может |
быть |
||
|
xy |
использована для оценки нелинейных нарушений функции Y = f(X).
Если случайные вариацииX и Y равновелики и пропорциональны, то на оценку параметра b угла наклона регрессионной прямой, найденную обычным МНК, оказывает влияние наличие ошибки измерения предиктора.
Модели регрессии II типа используются, когда требуется оценить параметры уравнения, описывающего функциональные отношения между парой двух случайных
|
переменных (т.е. X уже |
не |
является |
управляемой |
переменной, поскольку |
|
|
неконтролируемая ошибка ее измерения достаточно велика). Предполагается (Sokal, Rohlf, |
|||||
|
1981; Legendre, Legendre, 1998), что модели II типа более корректным образом оценивают |
|||||
|
степень отношения между двумя исходными переменными. |
|||||
|
При аппроксимации данных моделямиII типа имеет значение направление, в |
|||||
|
котором измеряются отклонения от линии регрессии: |
|||||
|
° в методе главных осей (MA,от |
англ. major |
axis regression) |
расстояния от |
||
|
эмпирических |
точек |
отсчитываются |
в |
перпендикулярном |
направлении |
аппроксимирующей прямой, после чего квадраты этих расстояний суммируются и минимизируются (см. рисунок вверху справа);
°в стандартном методе главных осей (SMA, от англ. standard major axis) находятся и суммируются разности вдоль направления, которое совпадает с перпендикуляром к линии регрессии I типа;
°ранжированный метод главных осей (RMA, от англ. ranged major axis) осуществляет
|
предварительное преобразование осей переменных для |
достижения однородных |
|
рангов (здесь имеется некоторая неразбериха в обозначениях, |
поскольку метод SMA |
в некоторых источниках известен также под названием редуцированных главных осей
или RMA от англ. reduced major axis regression).
256
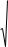
|
Коэффициенты |
этих |
функций |
регрессии, основанные |
на |
геометрических |
|||||||||
|
представлениях, рассчитываются по простым формулам. Например, |
для |
модели SMA |
||||||||||||
|
имеем: |
||||||||||||||
|
ˆ |
åyi2 —(åyi )2 / n |
ˆ |
ˆ |
ˆ |
ˆ |
|||||||||
|
b1(SMA) |
= åxi2 —(åxi )2 /n |
= |b1(OLS)| / rxy , |
b0(SMA) |
= y -b1(SMA) x .b |
Предположим, что мы хотим проанализировать изменчивость видового состава донных организмов, для чего в изучаемой реке на всем ее протяжении от истоков до устья возьмем 13 гидробиологических проб. Построим модели регрессии доли численности dDO (%) двух семейств организмов – Diamesinae и Orthocladiinae (личинок хирономид, или комара-звонца) – в общей численности зообентоса от температуры водыt, которая обусловлена продольным градиентом реки:
#Определяем исходные данные: NDO — доля Diamesinae+Orthocladiinae
#T — температура воды при взятии гидробиологической пробы
NDO <- c(88.9,94.9,70.8,46.4,31.0,66.5,83.6,71.9, 59.6,22.5,29.2,6.5,17.5)
T <- c(14.8,14.5,11.5,12.6,12,14.5,13.3,16.7,16.9,20.6,21.2,22.5,22.4)
|
Ex1 <-lm(NDO ~ T) ; Ex0 <-lm(NDO ~ 1) ; summary(Ex1) |
|||||
|
Coefficients: |
|||||
|
(Intercept) |
Estimate Std. Error t value Pr(>|t|) |
*** |
|||
|
134.779 |
27.464 |
4.908 |
0.000466 |
||
|
T |
-4.978 |
1.628 |
-3.057 |
0.010909 |
* |
|
— |
on 11 degrees of freedom |
||
|
Residual standard error: 22.53 |
|||
|
Multiple R-squared: 0.4593, |
Adjusted R-squared: 0.4102 |
||
|
F-statistic: 9.346 on 1 and 11 |
DF, p-value: 0.01091 |
||
|
(здесь и далее используется сокращенный формат результатов моделирования lm()) |
|||
|
Комплексный регрессионный анализ с использованием различных моделейI |
и II |
||
|
типов может быть одновременно |
выполнен на основе функцииlmodel2() |
из |
одноименного пакета (разработан P. Legendre):
library(lmodel2)
#Для RMA-модели вводим нормировку осей.
#Задаем 999 перестановок
|
Ex2.res <- |
lmodel2(NDO ~ T, range.y= «relative», |
|
range.x=»relative», nperm=999); Ex2.res |
|
|
Model II regression |
r-square = 0.4593404 |
|
n = 13 r |
= -0.6777465 |
|
Parametric |
P-values: 2-tailed = 0.01091 1-tailed = 0.0054547 |
|
Angle between the two OLS regression lines = 6.086494 degrees |
|
Regression results |
Angle (degrees) |
P-perm (1-tailed) |
|||
|
1 |
Method Intercept |
Slope |
|||
|
OLS |
134.7791 |
-4.978119 |
-78.64165 |
0.008 |
|
|
2 |
MA |
229.2404 -10.729858 |
-84.67554 |
0.008 |
|
|
3 |
SMA |
173.6523 |
-7.345105 |
-82.24713 |
NA |
|
4 |
RMA |
204.0832 |
-9.198041 |
-83.79524 |
0.008 |
|
Confidence intervals |
2.5%-Slope 97.5%-Slope |
||||
|
1 |
Method |
2.5%-Intercept 97.5%-Intercept |
|||
|
OLS |
74.33168 |
195.2265 |
-8.562224 |
-1.394014 |
|
|
2 |
MA |
155.11402 |
675.9505 |
-37.930007 |
-6.216310 |
|
3 |
SMA |
128.38529 |
246.1094 |
-11.757010 |
-4.588800 |
257
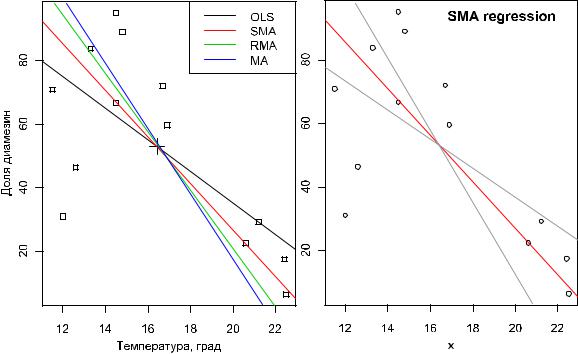
|
4 |
RMA |
134.22977 |
500.2764 -27.233223 |
-4.944670 |
|
|
Eigenvalues: 868.0162 8.551026 |
C.I. of MA: 0.004425181 |
||||
|
H statistic used for computing |
По итогам расчетов мы сразу получили объемную и ценную информацию для последующего анализа: а) подсчитан коэффициент корреляции и проверена его статистическая значимость; б) для четырех версий моделей получены оценки параметров моделей, углы расхождения между линиями регрессии и вычислена бутстреп-методом значимость коэффициента угла наклонаb1; в) приведены границы доверительных интервалов для всех оцениваемых параметров.
Теперь изобразим все 4 модели на одном графике (слева внизу) и отдельно модель SMA с доверительными интервалами для линии регрессии (справа внизу):
op <- par(mfrow = c(2,2))
plot(Ex2.res, method=»OLS», conf = FALSE, centroid=TRUE, main=»», xlab = «Температура, град», ylab = «Доля диамезин»,
col=1,pch = 22, bg = «blue»)
|
lines(Ex2.res, «SMA», col=2, conf = FALSE) ; |
|||||
|
lines(Ex2.res, |
«RMA», col=3, |
conf |
= |
FALSE) |
; |
|
lines(Ex2.res, |
«MA», col=4, |
conf |
= |
FALSE) |
legend(«topright», c(«OLS», «SMA», «RMA», «MA»), col=1:4, lty=1) plot(Ex2.res, «SMA», lwd=2)
Подробные рекомендации из 8 пунктов касательно того, в каких условиях та или ная модель может оказаться предпочтительнее, обосновываются П. Лежандром в руководстве пользователя к пакету lmodel2, которое можно скачать, выполнив команду
vignette(«mod2user»)
Мы же только обратим внимание читателя на то, что при использовании моделей II типа оценка коэффициента bˆ 1, угол наклона линии регрессии к осиХ, а также уголq между линиями прямой и обратной регрессии увеличиваются.
258
Робастные процедуры
|
ˆ |
ˆ |
1 |
, |
ˆ |
2 |
,…, |
ˆ n |
|||||||||
|
Если распределение выборочных остатков модели регрессииe = |
e |
e |
e |
|||||||||||||
|
имеет асимметрию и»длинные |
хвосты», то |
это |
обычно |
вызывает |
обоснованное |
|||||||||||
|
беспокойство при использовании метода наименьших квадратов. Действительно, функция |
||||||||||||||||
|
ˆ |
ˆ |
отклонений в квадрат придает слишком |
большой |
вес |
||||||||||||
|
потерь r( e ) = e 2 при возведении |
||||||||||||||||
|
значениям, аномально отклоняющимся от общей тенденции– даже один выброс может |
||||||||||||||||
|
существенно изменить оценку искомых параметров. Возможный и далеко не |
самый |
|||||||||||||||
|
лучший метод борьбы с этим явлением– удалить |
наибольшие |
остатки |
как |
выбросы |
и |
|||||||||||
|
повторить |
расчеты. Альтернативой |
ˆ |
ˆ |
|||||||||||||
|
является использование функции потерьr( e ) = |
| e |, |
|||||||||||||||
|
т.е. минимизация суммы абсолютных разностей| y |
i |
— y | (англ. |
least absolute |
deviations, |
||||||||||||
|
ˆ |
||||||||||||||||
|
LAD). В русскоязычной литературе соответствующую регрессию называют медианной, а |
||||||||||||||||
|
процедуру подгонки моделей – методом наименьших модулей (см. ru.wikipedia.org/wiki). |
||||||||||||||||
|
Еще |
более предпочтительным вариантом |
является |
использование |
различных |
||||||||||||
|
методов надежной (robust) и устойчивой (resistant) регрессии. Рассмотрим три из них. |
||||||||||||||||
|
Регрессия Хубера (Huber regression) пытается |
найти |
компромисс |
между |
двумя |
||||||||||||
|
крайними случаями – OLS и LAD: |
°небольшие остатки возводятся в квадрат r( eˆ ) = eˆ 2 при |x| < c;
°для больших отклонений при |x| > c используются простые разности r( eˆ ) = 2с| eˆ |— с2.
Пороговое значение c (tuning constant) находится с использованием эмпирической зависимости c = 1.345Se, где Se – стандартное отклонение для остатков, либо путем кросспроверки. Эта версия модели легко реализуется в R функцией rlm() из пакета MASS:
|
# Робастная регрессия Хубера |
T)) |
||
|
library(MASS) ; summary(rlm(NDO ~ |
|||
|
Coefficients: |
Std. Error t |
value |
|
|
Value |
|||
|
(Intercept) 147.2908 |
32.1618 |
4.5797 |
|
|
T |
-5.6236 |
1.9070 |
-2.9490 |
|
Residual standard error: 17.52 on |
11 degrees of freedom |
Обратите внимание на существенное снижение стандартного отклонения остатков по сравнению с методом OLS.
Другой известный подход основан на методеурезанных квадратов (LTS, от англ.
q
least trimmed squares), в котором минимизируется åi=1 eˆ (2i ) , где q < n, а (i) – комбинации
наилучших индексов x, которые подбираются так называемым «генетическим алгоритмом» (см. ru.wikipedia.org/wiki). Этот вариант модели также легко реализуем Rв функцией lmrob() из пакета robustbase.
# Метод урезанных квадратов LTS library(robustbase) ; summary(lmrob(NDO ~ T))
|
Coefficients: |
t value |
Pr(>|t|) |
|||
|
(Intercept) |
Estimate Std. Error |
** |
|||
|
146.948 |
44.743 |
3.284 |
0.00728 |
||
|
T |
-5.616 |
2.234 |
-2.513 |
0.02881 |
* |
|
— |
‘*’ 0.05 |
‘.’ 0.1 ‘ ’ 1 |
|||
|
Signif. codes: 0 ‘***’ 0.001 ‘**’ 0.01 |
|||||
|
Robust residual standard error: |
17.95 |
||||
|
Convergence in 18 IRWLS iterations |
259
Наконец, робастная линейная регрессияКендалла-Тейла (KTR, от англ. KendallTheil robust line; см. Helsel, Hirsch, 2002) имеет вид y = bˆ 0 +bˆ1x + e . Знак ^ над символами b означает, что коэффициенты регрессии являются не параметрами некой теоретической
|
модели, |
а заданными статистиками на |
множестве |
возможных значений |
случайных |
|
величин |
X и Y. Регрессия Кендалла-Тейла |
тесно |
связана с коэффициентом |
ранговой |
|
ˆ |
= 0 |
идентична оценке значимости t |
||
|
корреляции t Кендалла, т.е. проверка гипотезы H0:b1 |
H0: t = 0.
Основные шаги процедуры подбора уравнения регрессииKTR сводятся к следующему:
°вычисляется множество n(n — 1)/2 коэффициентов угла наклона bij = (yi — yj)/(xi — xj) для всех возможных пар точек i и j исходной выборки;
°расчетные коэффициенты модели оцениваются как медианы
bˆ1 = med(bij); bˆ = med(y) — bˆ1 ×med(x);
°доверительные интервалы коэффициентов рассчитываются по интерполяционным
формулам (см. прилагаемый скрипт Kendall_Theil_Regr.r, разработанный М. Вейнкауфом), а статистическая значимость модели в целом оценивается по формулам для коэффициента ранговой корреляции t Кендалла.
|
# Расчеты характеристик регрессии Кендалла-Тейла |
|
|
source(«Kendall_Theil_Regr.r») |
|
|
df1 <- data.frame(T, NDO) ; Kendall(df1) |
|
|
Dip |
Results |
|
-5.56716418 |
|
|
Upper CI Dip |
0.21153846 |
|
Lower CI Dip |
-9.48214286 |
|
Intercept |
141.99402985 |
|
Tau |
-0.42307692 |
|
p |
0.05047365 |
|
Интересно, что это – |
единственная из рассмотренных моделей, оказавшаяся |
|
|
статистически незначимой. |
||
|
Итак, мы получили семь различных вариантов модели линейной регрессии для |
||
|
нашего примера: |
||
|
Y = 135 — |
4.98 X |
(модель I, метод LSQ); |
|
Y = 229 — |
10.7 X |
(модель II, метод MA). |
|
Y = 174 — |
7.34 X |
(модель II, метод SMA); |
|
Y = 204 — |
9.20 X |
(модель II, метод RMA); |
|
Y = 147.3 — 5.62 X (регрессия Хубера); |
||
|
Y = 146.9 — 5.61 X |
(метод LTS); |
|
|
Y = 146.9 — 5.57 X |
(метод KTR). |
Обращает на себя внимание почти полное единодушие в оценках параметров робастными методами (дискуссию о робастных оценках и следует ли их называть порусски «устойчивыми» или «надежными» можно почитать на сайте habrahabr.ru).
Педантичный читатель, вероятно, будет требовать от нас прямого указания, какой из перечисленных вариантов наиболее адекватный. Ответа у нас нет, хотя бы потому, что
разные модели служат разным целям исследований. Современные подходы к формальному тестированию моделей реализуются с позиций ресэмплинга, кросс-проверки и имитационных методов (Шитиков, Розенберг, 2014). Однако пока можно лишь сказать, что поиск моделей регрессии, которые «наилучшим образом» описывает двухмерное облако экспериментальных точек, является фундаментальной проблемой анализа данных, не имеющей конечного решения.
260
Multiple Comparisons
C. Lewis, in International Encyclopedia of Education (Third Edition), 2010
Some Multiple Comparison Procedures
Many multiple comparison procedures (MCPs) have been proposed to control the FWE at a given level α for all configurations of true and false null hypotheses for a given family of comparisons. One method that provides this control for some but not all such configurations is known as the least significant difference (LSD) procedure. It was first proposed by Fisher (1935).
The LSD MCP is a two-step procedure. In the first step, all null hypotheses in the family are tested with a single, omnibus test, such as the F-test in the one-way ANOVA setup. If this test does not reject the overall null hypothesis at level α, then stop. If it does reject, then proceed to the second step: Carry out individual tests for the family of comparisons, each at level α.
If all null hypotheses are true, the omnibus test rejects with probability α. Therefore, the probability of at least one Type I error for an individual null hypothesis in this case is at most α. In other words, when all null hypotheses are true, the LSD procedure controls the FWE at α.
Now consider an example from the one-way ANOVA. Suppose there are ten groups with 50 observations per group. Let nine of the means be identical, with one very different from the rest. Thus, the overall F-test, using 9 and 40 degrees of freedom, (almost) always rejects its null hypothesis when used at level α = 0.05. Applying the LSD procedure, this means that 10(9)/2 = 45 t-tests are always carried out. Of these, nine will always correctly reject their null hypotheses. The remaining 36 tests each reject their (true) null hypothesis with probability 0.05, based on a critical t-value of t0.975(490) = 1.965. (The 490 degrees of freedom used here assumes that the pooled within groups variance estimate is used for all tests.) The probability that the largest t-statistic in absolute value will exceed this quantity is given by the studentized range (for nine means and 490 degrees of freedom) tail probability associated with t0.9754902=2.779, namely p = 0.569 = FWE. (For more on the LSD, see Hayter, 1986.)
The failure of the LSD procedure to control the FWE for all configurations of means has led to the general advice that should not be used to make multiple comparisons. Other early proposals that display a similar failure to control the FWE for all configurations of means include Duncan’s multiple range and the Newman–Keuls procedures. (See Hochberg and Tamhane, 1987.)
Two early proposals (in addition to the Bonferroni procedure) that do provide general control of the FWE are those of Scheffé and Tukey. For the one-way ANOVA, Scheffé’s procedure controls the FWE for the (infinitely large) family of linear contrasts. If μi, i = 1,…, m, denote the group means and ci, i = 1, …, m, with ∑i=1mci=0 are specified constants, then ψ=∑i=1mciμi is a contrast. Note that pairwise differences μi−μj are special cases of contrasts, with the constants ci=1, cj=−1, and all the other constants equal to 0.
To apply Scheffé’s procedure to a contrast ψ of interest, the following F-statistic is computed:
Fψ=(∑i=1mciy¯i)2(∑i=1mci2ni)σˆw2
where y¯i is the sample mean and ni is the sample size for group i, and σˆw2 is the pooled within group variance estimate. This statistic is then compared with m−1F1−αm−1,∑i=1mni−m. If the statistic exceeds this critical value, then the null hypothesis that ψ=∑i=1mciμi=0 is rejected. Scheffé’s procedure has the attractive feature of compatibility with the overall F-test, in the sense that the overall test leads to rejection of its null hypothesis if and only if Scheffé’s procedure finds at least one significant contrast.
Tukey’s multiple comparison procedure makes use of the studentized range distribution to control the FWE for making comparisons among means in a one-way ANOVA setup. Best known in the form used to make all pairwise comparisons with equal group sample sizes, Tukey’s MCP may also be used for general comparisons in the equal sample size case and for all pairwise comparisons with unequal sample sizes (in which form it is called the Tukey–Kramer procedure). Here, only the Tukey–Kramer MCP is described. It has been shown (Hayter, 1984) that this procedure conservatively controls the FWE at α for all configurations of means in the one-way ANOVA setup.
The test statistic used with the Tukey–Kramer procedure to test all hypotheses of the form H0: μi = μj is given by
Qij=−|y¯i−y¯j|σˆw22(1ni+1nj).
This statistic is compared with the critical value
Q1−αm,∑i=1mni−m,
namely the upper 100α percentile of the studentized range distribution for m means and
∑i=1mni−m
degrees of freedom. Note that the test statistic Qij is equal to the absolute value of the usual t-statistic for comparing the means of groups i and j, multiplied by 2.
Many other MCPs have been proposed in the more than 50 years since Scheffé and Tukey introduced their methods. The interested reader should consult Hochberg and Tamhane (1987) for more details. Here, only one additional procedure is described, which was proposed by Benjamini and Hochberg (1995) to control the FDR.
The Benjamini–Hochberg procedure begins by obtaining p-values for all the statistics used to test a family of k hypotheses. (Denote the p-value for the ith hypothesis by pi.) Next, these pi‘s are ordered with p(1)≤···≤p(k). Define icrit to be the largest value of i = 1, … , k, such that p(i)≤iα/k, with icrit = 0 if no such value exists. The null hypotheses associated with the icrit smallest p-values should be rejected. Formally, this MCP has only been shown to control the FDR at α under special circumstances (such as when used with independent test statistics), but numerous simulations have supported the conjecture that it controls the FDR in more general settings.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780080448947015621
MULTIPLE COMPARISONS
Rand R. Wilcox, in Applying Contemporary Statistical Techniques, 2003
Goal
Test H0: Ψ = 0, for each of C linear contrasts such that FWE is α.
- 1.
-
For each of the L groups, generate a bootstrap sample, Xiℓ*,i=1,…,nℓ;ℓ=1,…,L. For each of the L bootstrap samples, compute the trimmed mean, X¯tℓ*,,
Ψˆ*=∑cℓX¯tℓ*,dℓ*=cℓ2(nℓ−1)(swℓ*)2bℓ(bℓ−1)
where (swℓ*)2 is the Winsorized variance based on the bootstrap sample taken from the ℓth group and hℓ is the effective sample size of the ℓth group (the number of observations left after trimming).
- 2.
-
Compute
T*=|Ψ^*−Ψ^|A*,
where Ψ^=∑cℓX¯tℓ and A*=∑dℓ*. The results for each of the C linear contrasts are labeled T1*,…,TC*..
- 3.
-
Let
Tq*=max{T1*,…,TC*}.
In words, Tq* is the maximum of the C values T1*,…,TC*.
- 4.
-
Repeat steps 1–3 B times, yielding Tqb*, b = 1, …, B.
Let Tq(1)*≤⋯≤Tq(B)* be the Tqb* values written in ascending order, and let u = (1 − α)B, rounded to the nearest integer. Then the confidence interval for Ψ is
Ψ^±Tq(u)*A,
where A=∑dℓ,dℓ=cℓ2(nℓ−1)swℓ2hℓ(hℓ−1),, and the simultaneous probability coverage is approximately 1 − α.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B978012751541050033X
Integrated Population Biology and Modeling, Part B
David A. Spade, in Handbook of Statistics, 2019
4.1.3 Multiple Comparison Procedures
The Bonferroni procedure of multiple comparisons can be problematic in this setting. Suppose we want to control familywise error rate (FWER) at level α = 0.05, and we are examining 106 markers in the genome. Then our p-value threshold will be 5 × 10−8, which is overly conservative. A Sidak correction alleviates some, albeit not very much, of this conservatism by showing that if M tests are being carried out, then we reject any given null hypothesis if the p-value for the corresponding test is less than 1−(1−α)1M, then FWER is controlled at level α. If α = 0.05 and M = 106, then we reject a given null hypothesis for a p-value less than 5.129 × 10−8. This is slightly less conservative than the Bonferroni method. Neither of these procedures, however, controls the false discovery rate (FDR), which is defined as the probability that at least one null hypothesis is falsely rejected. In other words, if V is the number of rejected null hypotheses that are true, then
FDR=P(V≥1).
A common technique for controlling FDR is provided by Benjamini and Hochberg (1995). Let M0 be the number of null hypotheses that are true, and let α again be the overall significance level. Define the false discovery proportion (FDP) as
FDP=BK,
where B is the number of Type I errors and K is a number of tests that could result in a false discovery. Then
FDR=E[FDP]=EBK|K>0P(K>0).
We compute a p-value P(i) for each of tests i = 1, …, m, and we order them so that
P(1)<P(2)<…<P(M).
Under H0, these p-values follow a Uniform(0,1) distribution. Furthermore, all tests are independent. Let li=iαM, and let
R=maxi:P(i)<li.
Our p-value threshold is to reject H0 if P(i) < P(R). For example, suppose we again have M = 106 tests. If P(10) = 4.5 × 10−7 and P(11) = 6 × 10−7, then
l10=10(0.05)106=5×10−7,
so we reject the null hypothesis corresponding to this p-value. We also have
l11=11(0.05)106=5.5×10−7,
and we would not reject the null hypothesis corresponding to this p-value. Thus, R = 10, and our p-value threshold is P(10). Since
FDR≤M0M≤α,
this process controls FDR at level α. Storey (2003) presents a q-statistic that can be used to control FDR as well, but the Benjamini and Hochberg (1995) method is the more common of the two approaches.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/S0169716118300853
Comparing Multiple Dependent Groups
Rand Wilcox, in Introduction to Robust Estimation and Hypothesis Testing (Third Edition), 2012
8.6.15 R Function bwrmcp
The R function
bwrmcp(J,K,x,grp=NA,alpha=0.05,bhop=F)
performs all pairwise multiple comparisons using the method of Section 8.6.14 with the FWE (familywise error) rate controlled using Rom’s method of the Benjamini–Hochberg method. For example, when dealing with Factor A, the function simply compares level j to level j′ ignoring the other levels. All pairwise comparisons among the J levels of Factor A are performed and the same is done for Factor B and all relevant interactions.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780123869838000081
One-Way and Higher Designs for Independent Groups
Rand R. Wilcox, in Introduction to Robust Estimation and Hypothesis Testing (Fifth Edition), 2022
7.8.6 R Functions cidmulv2, wmwaov, and cidM
The R function
cidmulv2(x,alpha= 0.05, g=NULL, dp=NULL, CI.FWE=FALSE)
tests Eq. (7.25). The output includes a column headed by p.crit, which indicates how small the p-value must be in order to reject using Hochberg’s method. If the argument CI.FWE=FALSE, the function returns confidence intervals for each pjk having probability coverage 1−α. If CI.FWE=TRUE, the probability coverage corresponds to the “critical” p-value used to make decisions about rejecting Eq. (7.25) based on Hochberg’s method. For example, if the goal is to have the probability of one or more Type I errors equal to 0.05, and the second largest p-value is less than or equal to 0.025, Hochberg’s method rejects. The confidence interval returned by cidmulv2, for the two groups corresponding to the situation having the second largest p-value, will have probability coverage 1−0.025=0.1975. For the next largest p-value, the probability coverage will be 1−0.05/3, and so on. If the argument g is specified, it is assumed that x is a matrix with the dependent variable stored in column dp, and the levels of the factors stored in column g.
The R function
wmwaov(x,nboot=500,MC=FALSE, SEED=TRUE, pro.dis=TRUE ,MM=FALSE)
performs the WMWAOV method. Setting the argument MC=TRUE, the function takes advantage of a multicore processor, assuming one is available.
Finally, the R function
cidM(x,nboot=1000,alpha= 0.05,MC=FALSE, SEED=TRUE ,g=NULL, dp=NULL)
performs method DBH. (Both wmwaov and cidM check for tied values and print a warning message if any are found.)
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200988000130
Inferential Statistics V: Multiple and Multivariate Hypothesis Testing
Andrew P. King, Robert J. Eckersley, in Statistics for Biomedical Engineers and Scientists, 2019
Abstract
This chapter covers parametric techniques for dealing with multiple hypothesis tests and/or multivariate data. First, Bonferroni’s correction is introduced as a way of controlling the probability of at least one type I error (the familywise error rate) when testing multiple hypotheses. ANOVA (analysis of variance) is described, which enables the hypothesis of a common mean to be tested about multiple groups of univariate data. ANOVA formulations are provided for groups with equal and unequal sizes. Hypothesis tests for use with multivariate data are also introduced: Hotelling’s T2 test is a generalization of the Student’s t-test to multivariate data; MANOVA (multivariate analysis of variance) is a generalization of ANOVA to multivariate data. A summary is provided of how to decide which test is appropriate for different scenarios. An overview of MATLAB capabilities with regard to multiple and multivariate hypothesis testing is provided.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780081029398000177
Comparing Multiple Dependent Groups
Rand R. Wilcox, in Introduction to Robust Estimation and Hypothesis Testing (Fifth Edition), 2022
8.1.8 Identifying the Group With the Largest Population Measure of Location
Section 7.4.11 describes two methods for identifying the group with the largest measure of location. But when dealing with dependent variables, an alternative approach is needed that takes into account the correlations among the variables.
As was done in Section 7.4.11, one strategy is to compare the group with the largest estimate to the remaining J−1 groups. That is, the focus is on the marginal trimmed means. The method used here is based in part on comparing the trimmed means using the method in Section 5.9.5. Let θˆ(1)≤⋯≤θˆ(J) denote the estimates written in ascending order. Let θπ(j) denote the measure of location associated θˆ(j), and let pj denote the p-value associated with the test of
(8.2)H0:θπ(j)=θπ(J).
Suppose this hypothesis is rejected when pj≤cj. Mimicking method RS1-Y in Section 7.4.11 in an obvious way, the strategy is to control the FWE rate when θ1=⋯=θJ by determining the values c1,…,cJ−1 such that
(8.3)P(p1≤c1,…,pJ−1≤cJ−1)=α.
This is done by first generating data from a multivariate normal distribution having a mean of zero and a covariance matrix equal to the estimate of the Winsorized covariance matrix based on the observed data. Then Eq. (8.2) is tested for each j (j=1,…,J−1), yielding J−1 p-values. Finally, proceed as described in Section 7.4.11 by determining adjusted p-values that control the FWE rate when the J groups have a common measure of location. When using 20% trimming, this approach works well in terms of controlling the FWE rate in situations where the Bonferroni and related methods are unsatisfactory (Wilcox, 2019d).
But as was the case in Section 7.4.11, situations can be constructed where a Type I error probability exceeds the nominal level. As done in Section 7.4.11, a possible way of dealing with this issue is to view the goal in terms of an indifference zone. From this perspective, the issue is whether the probability of a correct decision, given that a decision is made, is reasonably high.
Another method described in Section 7.4.11, method RS2-IP, focuses on ensuring a correct decision is made with probability at least 1−α. This is done without specifying an indifference zone. Method RS2-GPB is readily extended to the situation at hand, but currently analogs of RS2-IP appear to be a more satisfactory approach. That is, test Eq. (8.2) for each j, and make a decision if all of the J−1 p-values are less than or equal to α. A non-bootstrap method can be used via the R function rmmcp. The R function rmanc.best.DO, described in Section 8.1.10, is provided in order to simplify this approach. When using a percentile bootstrap method, see the R function rmbestPB.DO.
When the correlations are sufficiently high, extant simulations indicate that the percentile bootstrap method provides an advantage in terms of the probability of making a decision. When all of the correlations are zero, the non-bootstrap method is more likely to make a decision.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200988000142
Correlation and Tests of Independence
Rand Wilcox, in Introduction to Robust Estimation and Hypothesis Testing (Fourth Edition), 2017
9.4.4 Inferences Based on Multiple Skipped Correlations
The hypothesis testing method based on Tp in the previous section has been extended to the problem of testing the hypothesis that p≥2 random variables are independent. However, rather than use Pearson’s correlation after outliers are removed, Spearman’s rho is used. When using Pearson’s correlation, no method has been found that adequately controls the probability of a Type I error. But switching to Spearman’s rho corrects this problem among extant simulations (Wilcox, 2003e).
Let τˆcjk be Spearman’s correlation between variables j and k after points flagged as outliers by the projection method are removed. For convenience, it is assumed that
(9.5)H0:τcjk=0
is to be tested for all j<k. Let
Tjk=τˆcjkn−21−τˆcjk2,
and let
(9.6)Tmax=max|Tjk|,
where the maximum is taken overall j<k. The strategy used here to control FWE is to approximate, via simulations, the distribution of Tmax under normality when all correlations are zero and p<4, determine the 0.95 quantile, say q, for n=10, 20, 30, 40, 60, 100 and 200, and then reject H0:τcjk=0 if |Tjk|≥q. For p≥4, normal distributions were replaced by a g-and-h distribution with (g,h)=(0,0.5). The reason is that for p≥4, the probability of at least one Type I error was found to be largest for this special case among the situations considered in Wilcox (2003e). That is, the strategy for choosing an appropriate critical value was to determine q for a distribution that appears to maximize the probability of a Type I error with the goal that FWE should not exceed 0.05 for any distribution that might be encountered in practice. Based on this strategy, the following approximations of q were determined:
p=2,qˆ=5.333n−1+2.374,p=3,qˆ=8.800n−1+2.780,p=4,qˆ=25.67n−1.2+3.030,p=5,qˆ=32.83−1.2+3.208,p=6,qˆ=51.53n−1.3+3.372,p=7,qˆ=75.02n−1.4+3.502,p=8,qˆ=111.34n−1.5+3.722,p=9,qˆ=123.16n−1.5+3.825,p=10,qˆ=126.72n−1.5+3.943.
Rather than test the hypothesis of a zero correlation among all pairs of random variables, the goal might be to test
(9.7)H0:τc1k=0,
for each k, k=2,…,p. Now the approximate critical values are:
p=2,qˆ=5.333n−1.0+2.374,p=3,qˆ=8.811n−1.0+2.540,p=4,qˆ=14.89n−1.2+2.666,p=5,qˆ=20.59n−1.2+2.920,p=6,qˆ=51.01n−1.5+2.999,p=7,qˆ=52.15n−1.5+3.097,p=8,qˆ=59.13n−1.5+3.258,p=9,qˆ=64.93n−1.5+3.286,p=10,qˆ=58.50n−1.5+3.414.
Again, these approximate critical values are designed so that FWE is approximately 0.05.
As previously noted, the methods just described are designed to test the hypothesis of independence. If the goal is to test the hypothesis that the correlations are zero, there are no results regarding how to deal with heteroscedasticity when dealing with p>2 variables.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128047330000093
Comparing Two Groups
Rand R. Wilcox, in Introduction to Robust Estimation and Hypothesis Testing (Fifth Edition), 2022
5.8.3 R Functions binband, splotg5, and cumrelf
The R function
binband(x,y,KMS=FALSE, alpha = 0.05, plotit = TRUE, op = TRUE, xlab = ‘X’, ylab = ‘Rel. Freq.’, method = ‘hoch’)
tests the hypothesis given by Eq. (5.30). By default, the individual probabilities are compared using the SK method. Setting the argument KMS=TRUE, method KMS is used. If plotit=TRUE, the function plots the relative frequencies for all distinct values found in each of two groups. The argument method indicates which method is used to control FWE. The default is Hochberg’s method.
The R function
splotg5(x,y,op=TRUE,xlab=‘X’,ylab=‘Rel. Freq.’)
is supplied in case it is desired to plot the relative frequencies for all distinct values found in two or more groups. The function is limited to a maximum of five groups. With op=TRUE, a line connecting the points corresponding to the relative frequencies is formed.
The R function
cumrelf(x,xlab=‘X’,ylab=‘CUM REL FREQ’)
plots the cumulative relative frequency of two or more groups. The argument x can be a matrix with columns corresponding to groups, or x can have list mode.
Example
Consider a study aimed at comparing two methods for reducing shoulder pain after surgery. For the first method, the shoulder pain measures are
2, 4, 4, 2, 2, 2, 4, 3, 2, 4, 2, 3, 2, 4, 3, 2, 2, 3, 5, 5, 2, 2
and for the second method they are
5, 1, 4, 4, 2, 3, 3, 1, 1, 1, 1, 2, 2, 1, 1, 5, 3, 5.
The R function binband returns
| Value | p1.est | p2.est | p1-p2 | p.value | p.adj |
|---|---|---|---|---|---|
| 1 | 0.00000000 | 0.3888889 | −0.38888889 | 0.00183865 | 0.009 |
| 2 | 0.50000000 | 0.1666667 | 0.33333333 | 0.02827202 | 0.113 |
| 3 | 0.18181818 | 0.1666667 | 0.01515152 | 0.94561448 | 0.946 |
| 4 | 0.22727273 | 0.1111111 | 0.11616162 | 0.36498427 | 0.946 |
| 5 | 0.09090909 | 0.1666667 | −0.07575758 | 0.49846008 | 0.946 |
For response 1, the p-value is 0.0018, and the Hochberg adjusted p-value is 0.009, indicating that for a familywise error rate of 0.05, a decision would be made that the second group is more likely to respond 1 compared to the first group. In contrast, for the probability of a response 5, the p-value is 0.56. So, the data indicate that the second group is more likely to respond 5, but based on Tukey’s three-decision rule, no decision is made about which group is more likely to rate the pain as being 5. In contrast, for both Student’s t and Welch’s method, the p-value is 0.25. Comparing the medians as well as the 20% trimmed means, again, no difference is found at the 0.05 level. Note that in terms of controlling the familywise error rate, there is no need to first perform a chi-squared test of the hypothesis that the distributions are identical.
Example
Erceg-Hurn and Steed (2011) investigated the degree to which smokers experience negative emotional responses (such as anger and irritation) upon being exposed to anti-smoking warnings on cigarette packets. Smokers were randomly allocated to view warnings that contained only text, such as “Smoking Kills,” or warnings that contained text and graphics, such as pictures of rotting teeth and gangrene. Negative emotional reactions to the warnings were measured on a scale that produced a score between 0 and 16 for each smoker, where larger scores indicate greater levels of negative emotions. (The data are stored on the author’s web page in the file smoke.csv.) Testing the 0.05 level, the means and medians are higher for the graphic group. But to get a deeper understanding of how the groups differ, look at Fig. 5.9, which shows plots of the relative frequencies based on the R function splotg5. Note that the plot suggests that the main difference between the groups has to do with the response zero: the proportion of participants in the text only group responding zero is 0.512, compared to 0.192 for the graphics group. Testing the hypothesis that the corresponding probabilities are equal, based on the R function binband, the p-value is less than 0.0001. The probabilities associated with the other possible responses do not differ at the 0.05 level except for the response 16; the p-value is 0.0031. For the graphics group, the probability of responding 16 is 0.096, compared to 0.008 for the text only group. So, a closer look at the data, beyond comparing means and medians, suggests that the main difference between the groups has to do with the likelihood of giving the most extreme responses possible, particularly the response zero.

Figure 5.9. Plot created by the function s2plot based on the anti-smoking data.
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200988000117
More Regression Methods
Rand R. Wilcox, in Introduction to Robust Estimation and Hypothesis Testing (Fifth Edition), 2022
11.1.1 Omnibus Tests for Regression Parameters
This section begins with testing Eq. (11.1). Generally, a type of bootstrap method performs well when using a robust regression estimator. An exception is when using a robust ridge estimator as in Section 10.13.15, with the goal of dealing with multicollinearity. The end of this section describes how to deal with this special case.
When working with robust regression, three strategies for testing hypotheses have received attention in the statistical literature and should be mentioned. The first is based on the so-called Wald scores, the second is a likelihood ratio test, and the third is based on a measure of drop in dispersion. Details about these methods can be found in Markatou et al. (1991), as well as Heritier and Ronchetti (1994). Coakley and Hettmansperger (1993) suggest using a Wald scores test in conjunction with their estimation procedure, assuming that the error term is homoscedastic. The method estimates the standard error of their estimator, which can be used to get an appropriate test statistic for which the null distribution is chi-squared. When both x and ϵ are normal, and the error term is homoscedastic, the method provides reasonably good control over the probability of a Type I error when n=50. However, if ϵ is non-normal, the actual probability of a Type I error can exceed 0.1 when testing at the α=0.05 level, even with n=100 (Wilcox, 1994e). Consequently, details about the method are not described. Birkes and Dodge (1993) describe drop-in-dispersion methods when working with M regression methods that do not protect against leverage points. Little is known about how this approach performs under heteroscedasticity, so it is not discussed either. Instead, attention is focused on a method that has been found to perform well when there is a heteroscedastic error term. It is not suggested that the method described here outperforms all other methods that might be used, only that it gives good results over a relatively wide range of situations, and based on extant simulation studies, it is the best method available.
The basic strategy is to generate B bootstrap estimates of the parameters, and then determine whether the vector of values specified by the null hypothesis is far enough away from the bootstrap samples to warrant rejecting H0. This strategy is illustrated with the tree data in the Minitab handbook (Ryan et al., 1985, p. 329). The data consist of tree volume (V), tree diameter (d), and tree height (h). If the trees are cylindrical or cone-shaped, then a reasonable model for the data is y=β1×1+β2×2+β0, where y=ln(V), x1=ln(d), x2=ln(h), with β1=2 and β2=1 (Fairley, 1986). The ordinary least squares (OLS) estimate of the intercept is βˆ0=−6.632, βˆ1=1.98, and the estimates of the slopes are βˆ2=1.12. Using M regression with Schweppe weights (the R function bmreg), the estimates are −6.59, 1.97, and 1.11, respectively.
Suppose bootstrap samples are generated as described in Section 10.1.1 (cf. Salibian-Barrera and Zamar, 2002). That is, rows of data are sampled with replacement. Fig. 11.1 shows a scatterplot of 300 bootstrap estimates, using M regression with Schweppe weights, of the intercept, β0, and β2, the slope associated with log height. The square marks the hypothesized values, (β0,β2)=(−7.5,1). These bootstrap values provide an estimate of a confidence region for (β0,β2) that is centered at the estimated values βˆ0=−6.59 and βˆ2=1.11. Fig. 11.1 suggests that the hypothesized values might not be reasonable. That is, the point (−7.5,1) might be far enough away from the bootstrap values to suggest that it is unlikely that β0 and β2 simultaneously have the values −7.5 and 1, respectively. The problem is measuring the distance between the hypothesized values and the estimated values, and then finding a decision rule that rejects the null hypothesis with probability α when H0 is true.

Figure 11.1. Scatterplot of bootstrap estimates using the tree data. The square marks the null values.
For convenience, temporarily assume the goal is to test the hypothesis given by Eq. (11.1). A simple modification of the method in Section 8.2.5 can be used where bootstrap samples are obtained by resampling with replacement n rows from
(y1,x11,…,x1J⋮yn,xn1,…,xnJ),
yielding
(y1⁎,x11⁎,…,x1J⁎⋮yn⁎,xn1⁎,…,xnJ⁎).
Let βˆjb⁎, j=1,…,p, b=1,…,B, be an estimate of the jth parameter based on the bth bootstrap sample and any robust estimator described in Chapter 10. Then an estimate of the covariance between βˆj and βˆk is
vjk=1B−1∑b=1B(βˆjb⁎−β¯j⁎)(βˆkb⁎−β¯k⁎),
where β¯j⁎=∑βˆjb⁎/B. Here, βˆj can be any estimator of interest. Now, the distance between the bth bootstrap estimate of the parameters and the estimate based on the original observations can be measured with
db2=(βˆ1b⁎−βˆ1,…,βˆpb⁎−βˆp)V−1(βˆ1b⁎−βˆ1,…,βˆpb⁎−βˆp)′,
where V is the p-by-p covariance matrix with the element in the jth row and kth column equal to vjk. That is, V=(vjk) is the sample covariance matrix based on the bootstrap estimates of the parameters. The square root of db2, db, represents a simple generalization of the Mahalanobis distance. If the point corresponding to the vector of hypothesized values is sufficiently far from the estimated values, relative to the distances db, reject H0. This strategy is implemented by putting the db values in ascending order, yielding d(1)≤⋯≤d(B), setting M=[(1−α)B], and letting m be the value of M rounded to the nearest integer. The null hypothesis is rejected if
(11.2)D>d(m),
where
D=(βˆ1,…,βˆp)V−1(βˆ1,…,βˆp)′.
The method just described is easily generalized to testing
H0:β1=β10,β2=β20,…,βq=βq0,
the hypothesis that q of the p+1 parameters are equal to specified constants, β10,…,βq0. Proceed as before, only now
db=(βˆ1b⁎−βˆ1,…,βˆqb⁎−βˆq)V−1(βˆ1b⁎−βˆ1,…,βˆqb⁎−βˆq)′,
and V is a q-by-q matrix of estimated covariances based on the B bootstrap estimates of the q parameters being tested. The critical value, d(m), is computed as before, and the test statistic is
D=(βˆ1−β10,…,βˆq−βq0)V−1(βˆ1−β10,…,βˆq−βq0)′.
The (generalized) p-value is
pˆ⁎=1B∑I(D≤db),
where I(D≤db)=1 if D≤db and I(D≤db)=0 if D>db.
The hypothesis testing method just described can be used with any regression estimator. When using the OLS estimator, it has advantages over the conventional F test, but problems remain. This is illustrated by Table 11.1, which shows the estimated probability of a Type I error for various situations when testing H0:β1=β2=0, α=0.05, and where
Table 11.1. Estimated Type I error probabilities using OLS, α = 0.05, n = 20.
| x | ϵ | VP 1 | VP 2 | VP 3 | |||||
|---|---|---|---|---|---|---|---|---|---|
| g | h | g | h | Boot | F | Boot | F | Boot | F |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.072 | 0.050 | 0.097 | 0.181 | 0.009 | 0.015 |
| 0.0 | 0.0 | 0.0 | 0.5 | 0.028 | 0.047 | 0.046 | 0.135 | 0.004 | 0.018 |
| 0.0 | 0.0 | 0.5 | 0.0 | 0.052 | 0.049 | 0.084 | 0.174 | 0.009 | 0.018 |
| 0.0 | 0.0 | 0.5 | 0.5 | 0.028 | 0.043 | 0.042 | 0.129 | 0.005 | 0.019 |
| 0.0 | 0.5 | 0.0 | 0.0 | 0.022 | 0.055 | 0.078 | 0.464 | 0.003 | 0.033 |
| 0.0 | 0.5 | 0.0 | 0.5 | 0.014 | 0.074 | 0.042 | 0.371 | 0.002 | 0.038 |
| 0.0 | 0.5 | 0.5 | 0.0 | 0.017 | 0.048 | 0.072 | 0.456 | 0.005 | 0.032 |
| 0.0 | 0.5 | 0.5 | 0.5 | 0.011 | 0.070 | 0.039 | 0.372 | 0.005 | 0.040 |
| 0.5 | 0.0 | 0.0 | 0.0 | 0.054 | 0.044 | 0.100 | 0.300 | 0.013 | 0.032 |
| 0.5 | 0.0 | 0.0 | 0.5 | 0.024 | 0.057 | 0.049 | 0.236 | 0.010 | 0.038 |
| 0.5 | 0.0 | 0.5 | 0.0 | 0.039 | 0.048 | 0.080 | 0.286 | 0.010 | 0.033 |
| 0.5 | 0.0 | 0.5 | 0.5 | 0.017 | 0.058 | 0.046 | 0.217 | 0.010 | 0.040 |
| 0.5 | 0.5 | 0.0 | 0.0 | 0.013 | 0.054 | 0.083 | 0.513 | 0.006 | 0.040 |
| 0.5 | 0.5 | 0.0 | 0.5 | 0.009 | 0.073 | 0.043 | 0.416 | 0.002 | 0.048 |
| 0.5 | 0.5 | 0.5 | 0.0 | 0.013 | 0.053 | 0.079 | 0.505 | 0.005 | 0.043 |
| 0.5 | 0.5 | 0.5 | 0.5 | 0.006 | 0.067 | 0.036 | 0.414 | 0.005 | 0.050 |
(11.3)y=β1×1+β2×2+λ(x1,x2)ϵ.
(For results on testing hypotheses when the function λ is known, see Zhao and Wang, 2009.) In Table 11.1, VP 1 corresponds to λ(x1,x2)=1 (a homoscedastic error term), VP 2 is λ(x1,x2)=|x1|, and VP 3 is λ(x1,x2)=1/(|x1|+1). Both x1 and x2 have identical g-and-h distributions, with the g and h values specified by the first two columns. In some cases, the conventional F test performs well, but it performs poorly for VP 2. The bootstrap method improves matters considerably, but the probability of a Type I error exceeds 0.075 in various situations. In practical terms, when testing hypotheses using OLS, use the methods in Section 10.1.1 rather than the bootstrap method described here.
Table 11.2 shows αˆ, the estimated probability of a Type I error when using βˆmid, the biweight midregression estimator with n=20, and the goal is to test H0:β1=β2=0, with α=0.05. Now, the probability of a Type I error is less than or equal to the nominal level, but in some cases, it is too low, particularly for VP 3, where it drops as low as 0.002. (For more details about the simulations used to create Tables 11.1 and 11.2, see Wilcox, 1996f.) Simulations indicate that switching to the Theil–Sen estimator improves the control over the Type I error probability when dealing with heavy-tailed distributions (Wilcox, 2004c).
Table 11.2. Values of αˆ using biweight midregression, α = 0.05, n = 20.
| x | ϵ | |||||
|---|---|---|---|---|---|---|
| g | h | g | h | VP 1 | VP 2 | VP 3 |
| 0.0 | 0.0 | 0.0 | 0.0 | 0.047 | 0.039 | 0.015 |
| 0.0 | 0.0 | 0.0 | 0.5 | 0.018 | 0.024 | 0.008 |
| 0.0 | 0.0 | 0.5 | 0.0 | 0.038 | 0.037 | 0.011 |
| 0.0 | 0.0 | 0.5 | 0.5 | 0.021 | 0.025 | 0.003 |
| 0.0 | 0.5 | 0.0 | 0.0 | 0.016 | 0.018 | 0.002 |
| 0.0 | 0.5 | 0.0 | 0.5 | 0.009 | 0.018 | 0.002 |
| 0.0 | 0.5 | 0.5 | 0.0 | 0.015 | 0.016 | 0.002 |
| 0.0 | 0.5 | 0.5 | 0.5 | 0.009 | 0.012 | 0.003 |
| 0.5 | 0.0 | 0.0 | 0.0 | 0.033 | 0.037 | 0.012 |
| 0.5 | 0.0 | 0.0 | 0.5 | 0.020 | 0.020 | 0.006 |
| 0.5 | 0.0 | 0.5 | 0.0 | 0.024 | 0.031 | 0.009 |
| 0.5 | 0.0 | 0.5 | 0.5 | 0.015 | 0.021 | 0.005 |
| 0.5 | 0.5 | 0.0 | 0.0 | 0.015 | 0.021 | 0.002 |
| 0.5 | 0.5 | 0.0 | 0.5 | 0.008 | 0.011 | 0.002 |
| 0.5 | 0.5 | 0.5 | 0.0 | 0.014 | 0.017 | 0.002 |
| 0.5 | 0.5 | 0.5 | 0.5 | 0.006 | 0.007 | 0.002 |
Methods Based on a Ridge Estimator
As noted in Section 10.13.15, when there is multicollinearity, a regression estimator can have relatively high standard errors, which in turn impacts power. Ridge estimators introduced in Section 10.13.15 are designed to deal with this issue, but an alternative to Eq. (11.2) is needed when testing Eq. (11.1).
Method RT1
First consider the non-robust ridge estimator. Let the values of the independent variables be denoted by the n×p matrix X. Let C=X′X and V=diag(ri2/(1−hii)) (i=1,…,n), where hii=xi(X′X)−1xi′, xi is the ith row of X and ri=Yi−Yˆi (i=1,…,n) are the residuals. As done in Section 10.13.15, let k denote the bias parameter used by the ridge estimator and let
(11.4)S(k)=(C+kIp)−1X′VX(C+kIp)−1.
Wilcox (2019a) notes that sjj(k), the jth diagonal element of S(k), estimates the squared standard error of βˆj(k) and suggests testing H0: βj=0 (j=1,…,p) using the test statistic
(11.5)Tj=βˆjsjj,
where the null distribution is approximated with a Student’s t distribution, with n−p−1 degrees of freedom. The familywise error rate is controlled via Hochberg’s method. If any of these p hypotheses is rejected, reject the global hypothesis given by Eq. (11.1). This is reasonable because when Eq. (11.1) is true, the ridge estimator is unbiased. But otherwise it is biased, in which case, any confidence interval based on Eq. (11.5) can be highly inaccurate. It remains unknown how to compute confidence intervals for the individual slopes based on the ridge estimator when one or more differ from zero. In practical terms, if H0: βj=0 is rejected for any j, reject (11.1) but make no inferences about which slopes differ from zero.
Method RT2
Now consider a robust ridge estimator β˜ given by Eq. (10.19). Again the goal is to test Eq. (11.1). Consider the test statistic
(11.6)TR2=p(n−1)n−pβ˜S−1β˜′,
which is an analog of Hotelling’s T2 statistic. An approach to controlling the Type I error probability is to momentarily assume homoscedasticity, the error term has a normal distribution, and the independent variables have a multivariate normal distribution, with all correlations equal to zero. Then, for a given sample size, a simulation can be used to determine the null distribution, which yields a critical value. The issue is whether this critical value controls the Type I error probability reasonably well when dealing with an error term that has a non-normal distribution and when there is heteroscedasticity. Simulations reported by Wilcox (2019b) indicate that when using a robust ridge estimator, with βˆR in Eq. (10.19) taken to be the Theil–Sen estimator, reasonably good control of the Type I error probability is achieved. The MM-estimator performs nearly as well, but in some situations, the actual level was found to be well above the nominal level when leverage points are retained. When leverage points are removed, the actual level was found to be less than or equal to the nominal level, but in some cases, it is less than 0.025 when testing at the 0.05 level. In terms of power, TR2 does not dominate Eq. (11.2), but generally TR2 competes well with Eq. (11.2). Extant simulations indicate that Eq. (11.2) never offers a striking advantage, but TR2 can offer a distinct advantage even when there is little or no indication of multicollinearity (cf. Spanos, 2019).
Read full chapter
URL:
https://www.sciencedirect.com/science/article/pii/B9780128200988000178
Multiple Testing
- Table of Contents
- I. Goals
- II. Hypothesis testing errors
- III. Multiple testing control
- IV. Controlling the Family-Wise Error Rate (FWER)
- V. Controlling the False Discovery Rate (FDR)
- Appendix A. Proof of Lemma 1
I. Goals
Large-scale approaches have enabled routine tracking of the entire mRNA complement of a cell, genome-wide methylation patterns and the ability to enumerate DNA sequence alterations across the genome. Software tools have been developed whose to unearth recurrent themes within the data relevant to the biological context at hand. Invariably the power of these tools rests upon statistical procedures in order to filter through the data and sort the search results.
The broad reach of these approaches presents challenges not previously encountered in the laboratory. In particular, errors associated with testing any particular observable aspect of biology will be amplified when many such tests are performed. In statistical terms, each testing procedure is referred to as a hypothesis test and performing many tests simultaneously is referred to as multiple testing or multiple comparison. Multiple testing arises enrichment analyses, which draw upon databases of annotated sets of genes with shared themes and determine if there is ‘enrichment’ or ‘depletion’ in the experimentally derived gene list following perturbation entails performing tests across many gene sets increases the chance of mistaking noise as true signals.
This goal of this section is to introduce concepts related to quantifying and controlling errors in multiple testing. By the end of this section you should:
- Be familiar with the conditions in which multiple testing can arise
- Understand what a Type I error and false discovery are
- Be familiar with multiple control procedures
- Be familiar with the Bonferroni control of family-wise error rate
- Be familiar with Benjamini-Hochberg control of false discovery rates
II. Hypothesis testing errors
For better or worse, hypothesis testing as it is known today represents a gatekeeper for much of the knowledge appearing in scientific publications. A considered review of hypothesis testing is beyond the scope of this primer and we refer the reader elsewhere (Whitley 2002a). Below we provide an intuitive example that introduces the various concepts we will need for a more rigorous description of error control in section III.
Example 1: A coin flip
To illustrate errors incurred in hypothesis testing, suppose we wish to assess whether a five cent coin is fair. Fairness here is defined as an equal probability of heads and tails after a toss. Our hypothesis test involves an experiment (i.e. trial) whereby 20 identically minted nickels are tossed and the number of heads counted. We take the a priori position corresponding to the null hypothesis: The nickels are fair. The null hypothesis would be put into doubt if we observed trials where the number of heads was larger (or smaller) than some predefined threshold that we considered reasonable.
Let us pause to more deeply consider our hypothesis testing strategy. We have no notion of how many heads an unfair coin might generate. Thus, rather than trying to ascertain the unknown distribution of heads for some unfair nickel, we stick to what we do know: The probability distribution under the null hypothesis for a fair nickel. We then take our experimental results and compare them to this null hypothesis distribution and look for discrepancies.
Conveniently, we can use the binomial distribution to model the exact probability of observing any possible number of heads (0 to 20) in a single test where 20 fair nickels are flipped (Figure 1).

Figure 1. Probability distribution for the number of heads. The binomial probability distribution models the number of heads in a single test where 20 fair coins are tossed. Each coin has equal probability of being heads or tails. The vertical line demarcates our arbitrary decision threshold beyond which results would be labelled ‘significant’.
In an attempt to standardize our decision making, we arbitrarily set a threshold of doubt: Observing 14 or more heads in a test will cause us to label that test as ‘significant’ and worthy of further consideration. In modern hypothesis testing terms, we would ‘reject’ the null hypothesis beyond this threshold in favour of some alternative, which in this case would be that the coin was unfair. Note that in principle we should set a lower threshold in the case that the coin is unfairly weighted towards tails but omit this for simplicity.
Recall that the calculations underlying the distribution in Figure 1 assumes an equal probability of heads and tails. Thus, if we flipped 20 coins we should observe 14 or more heads with a probability equal to the area of the bars to the right of the threshold in Figure 1. In other words, our decision threshold enables us to calculate a priori the probability of an erroneous rejection. In statistical terms, the probability bounded by our a priori decision threshold is denoted or the significance level and is the probability of making an error of type I. The probability of observing a given experimental result or anything more extreme is denoted the p-value. It is worth emphasizing that the significance level is chosen prior to the experiment whereas the p-value is obtained after an experiment, calculated from the experimental data.
Multiple testing correction methods attempt to control or at least quantify the flood of type I errors that arise when multiple hypothesis are performed simultaneously
Definition The p-value is the probability of observing a result more extreme than that observed given the null hypothesis is true.
Definition The significance level () is the maximum fraction of replications of an experiment that will yield a p-value smaller than when the null hypothesis is true.
Definition A type I error is the incorrect rejection of a true null hypothesis.
Definition A type II error is the incorrect failure to reject a false null hypothesis.
Typically, type I errors are considered more harmful than type II errors where one fails to reject a false null hypothesis. This is because type I errors are associated with discoveries that are scientifically more interesting and worthy of further time and consideration. In hypothesis tests, researchers bound the probability of making a type I error by , which represents an acceptable but nevertheless arbitrary level of risk. Problems arise however, when researchers perform not one but many hypothesis tests.
Consider an extension of our nickel flipping protocol whereby multiple trials are performed and a hypothesis test is performed for each trial. In an alternative setup, we could have some of our friends each perform our nickel flipping trial once, each performing their own hypothesis test. How many type I errors would we encounter? Figure 2 shows a simulation where we repeatedly perform coin flip experiments as before.

Figure 2. Number of tests where more than 14 heads are observed. Simulations showing the number of times more than 14 heads were counted in an individual test when we performed 1, 2, 10, 100, and 250 simultaneous tests.
Figure 2 should show that with increasing number of tests we see trials with 14 or more heads. This makes intuitive sense: Performing more tests boosts the chances that we are going to see rare events, purely by chance. Technically speaking, buying more lottery tickets does in fact increase the chances of a win (however slightly). This means that the errors start to pile up.
Example 2: Pathway analyses
Multiple testing commonly arises in the statistical procedures underlying several pathway analysis software tools. In this guide, we provide a primer on Gene Set Enrichment Analysis.
Gene Set Enrichment Analysis derives p-values associated with an enrichment score which reflects the degree to which a gene set is overrepresented at the top or bottom of a ranked list of genes. The nominal p-value estimates the statistical significance of the enrichment score for a single gene set. However, evaluating multiple gene sets requires correction for gene set size and multiple testing.
When does multiple testing apply?
Defining the family of hypotheses
In general, sources of multiplicity arise in cases where one considers using the same data to assess more than one:
- Outcome
- Treatment
- Time point
- Group
There are cases where the applicability of multiple testing may be less clear:
- Multiple research groups work on the same problem and only those successful ones publish
- One researcher tests differential expression of 1 000 genes while a thousand different researchers each test 1 of a possible 1 000 genes
- One researcher performs 20 tests versus another performing 20 tests then an additional 80 tests for a total of 100
In these cases identical data sets are achieved in more than one way but the particular statistical procedure used could result in different claims regarding significance. A convention that has been proposed is that the collection or family of hypotheses that should be considered for correction are those tested in support of a finding in a single publication (Goeman 2014). For a family of hypotheses, it is meaningful to take into account some combined measure of error.
The severity of errors
The use of microarrays, enrichment analyses or other large-scale approaches are most often performed under the auspices of exploratory investigations. In such cases, the results are typically used as a first step upon which to justify more detailed investigations to corroborate or validate any significant results. The penalty for being wrong in such multiple testing scenarios is minor assuming the time and effort required to dismiss it is minimal or if claims that extend directly from such a result are conservative.
On the other hand, there are numerous examples were errors can have profound negative consequences. Consider a clinical test applied to determine the presence of HIV infection or any other life-threatening affliction that might require immediate and potentially injurious medical intervention. Control for any errors in testing is important for those patients tested.
The take home message is that there is no substitute for considered and careful thought on the part of researchers who must interpret experimental results in the context of their wider understanding of the field.
The concept that the scientific worker can regard himself as an inert item in a vast co-operative concern working according to accepted rules, is encouraged by directing attention away from his duty to form correct scientific conclusions, to summarize them and to communicate them to his scientific colleagues, and by stressing his supposed duty mechanically to make a succession of automatic ‘decisions’…The idea that this responsibility can be delegated to a giant computer programmed with Decision Functions belongs to a phantasy of circles rather remote from scientific research.
-R. A. Fisher (Goodman 1998)
III. Multiple testing control
The introductory section provides an intuitive feel for the errors associated with multiple testing. In this section our goal is to put those concepts on more rigorous footing and examine some perspectives on error control.
Type I errors increase with the number of tests
Consider a family of independent hypothesis tests. Recall that the significance level represents the probability of making a type I error in a single test. What is the probability of at least one error in tests?
Note that in the last equation as grows the term decreases and so the probability of making at least one error increases. This represents the mathematical basis for the increase probability of type I errors in multiple comparison procedures.
A common way to summarize the possible outcomes of multiple hypothesis tests is in table form (Table 1): The total number of hypothesis tests is ; Rows enumerate the number of true () and false () null hypotheses; Columns enumerate those decisions on the part of the researcher to reject the null hypothesis and thereby declare it significant () or declare non-significant ().
Table 1. Multiple hypothesis testing summary

Of particular interest are the (unknown) number of true null hypotheses that are erroneously declared significant (). These are precisely the type I errors that can increase in multiple testing scenarios and the major focus of error control procedures. Below we detail two different perspectives on error control.
IV. Controlling the Family-Wise Error Rate (FWER)
Definition The family-wise error rate (FWER) is the probability of at least one (1 or more) type I error
The Bonferroni Correction
The most intuitive way to control for the FWER is to make the significance level lower as the number of tests increase. Ensuring that the FWER is maintained at across independent tests
is achieved by setting the significance level to .
Proof:
Fix the significance level at . Suppose that each independent test generates a p-value and define
Caveats, concerns, and objections
The Bonferroni correction is a very strict form of type I error control in the sense that it controls for the probability of even a single erroneous rejection of the null hypothesis (i.e. ). One practical argument against this form of correction is that it is overly conservative and impinges upon statistical power (Whitley 2002b).
Definition The statistical power of a test is the probability of rejecting a null hypothesis when the alternative is true
Indeed our discussion above would indicate that large-scale experiments are exploratory in nature and that we should be assured that testing errors are of minor consequence. We could accept more potential errors as a reasonable trade-off for identifying more significant genes. There are many other arguments made over the past few decades against using such control procedures, some of which border on the philosophical (Goodman 1998, Savitz 1995). Some even have gone as far as to call for the abandonment of correction procedures altogether (Rothman 1990). At least two arguments are relevant to the context of multiple testing involving large-scale experimental data.
1. The composite “universal” null hypothesis is irrelevant
The origin of the Bonferroni correction is predicated on the universal hypothesis that only purely random processes govern all the variability of all the observations in hand. The omnibus alternative hypothesis is that some associations are present in the data. Rejection of the null hypothesis amounts to a statement merely that at least one of the assumptions underlying the null hypothesis is invalid, however, it does not specify exactly what aspect.
Concretely, testing a multitude of genes for differential expression in treatment and control cells on a microarray could be grounds for Bonferroni correction. However, rejecting the composite null hypothesis that purely random processes governs expression of all genes represented on the array is not very interesting. Rather, researchers are more interested in which genes or subsets demonstrate these non-random expression patterns following treatment.
2. Penalty for peeking and ‘p hacking’
This argument boils down to the argument: Why should one independent test result impact the outcome of another?
Imagine a situation in which 20 tests are performed using the Bonferroni correction with and each one is deemed ‘significant’ with each having . For fun, we perform 80 more tests with the same p-value, but now none are significant since now our . This disturbing result is referred to as the ‘penalty for peeking’.
Alternatively, ‘p-hacking’ is the process of creatively organizing data sets in such a fashion such that the p-values remain below the significance threshold. For example, imagine we perform 100 tests and each results in a . A Bonferroni-adjusted significance level is meaning none of the latter results are deemed significant. Suppose that we break these 100 tests into 5 groups of 20 and publish each group separately. In this case the significance level is and in all cases the tests are significant.
V. Controlling the false discovery rate (FDR)
Let us revisit the set of null hypotheses declared significant as shown in the right-hand columns of Table 1. Figure 3 is a variation on the Venn diagram showing the intersection of those hypotheses declared significant () with the true () and false () null hypotheses.
Figure 3. Depiction of false discoveries. Variable names are as in Table 1. The m hypotheses consist of true (m0) and false (m1=m-m0) null hypotheses. In multiple hypothesis testing procedures a fraction of these hypotheses are declared significant (R, shaded light grey) and are termed ‘discoveries’. The subset of true null hypotheses are termed ‘false discoveries’ (V) in contrast to ‘true discoveries’ (S).
In an exploratory analysis, we are happy to sacrifice are strict control on type I errors for a wider net of discovery. This is the underlying rationale behind the second control procedure.
Benjamini-Hochberg control
A landmark paper by Yoav Benjamini and Yosef Hochberg (Benjamini 1995) rationalized an alternative view of the errors associated with multiple testing:
In this work we suggest a new point of view on the problem of multiplicity. In many multiplicity problems the number of erroneous rejections should be taken into account and not only the question of whether any error was made. Yet, at the same time, the seriousness of the loss incurred by erroneous rejections is inversely related to the number of hypotheses rejected. From this point of view, a desirable error rate to control may be the expected proportion of errors among the rejected hypotheses, which we term the false discovery rate (FDR).
Definition The false discovery proportion () is the proportion of false discoveries among the rejected null hypotheses.
By convention, if is zero then so is . We will only be able to observe — the number of rejected hypotheses — and will have no direct knowledge of random variables and . This subtlety motivates the attempt to control the expected value of .
Definition The false discovery rate (FDR) is the expected value of the false discovery proportion.
The Benjamini-Hochberg procedure
In practice, deriving a set of rejected hypotheses is rather simple. Consider testing independent hypotheses from the associated p-values .
- Sort the p-values in ascending order.
- Here the notation indicates the order statistic. In this case, the ordered p-values correspond to the ordered null hypotheses
-
Set as the largest index for which
-
Then reject the significant hypotheses
-
A sketch(y) proof
Here, we provide an intuitive explanation for the choice of the BH procedure bound.
Consider testing independent null hypotheses from the associated p-values where . Let be the p-values corresponding to the true null hypotheses indexed by the set .
Then the overall goal is to determine the largest cut-off so that the expected value of is bound by
For large , suppose that the number of false discoveries
The largest cut-off will actually be one of our p-values. In this case the number of rejections will simply be its corresponding index
Since will not be known, choose the larger option and find the largest index so that
Proof
Theorem 1 The Benjamini-Hochberg (BH) procedure controls the FDR at for independent test statistics and any distribution of false null hypothesis.
Proof of Theorem 1 The theorem follows from Lemma 1 whose proof is added as Appendix A at the conclusion of this section.
Lemma 1 Suppose there are independent p-values corresponding to the true null hypotheses and are the p-values (as random variables) corresponding to the false null hypotheses. Suppose that the p-values for the false null hypotheses take on the realized values . Then the BH multiple testing procedure described above satisfies the inequality
Proof of Lemma 1. This is provided as Appendix A.
From Lemma 1, if we integrate the inequality we can state
and the FDR is thus bounded.
Two properties of FDR
Let us note two important properties of FDR in relation to FWER.
First, consider the case where all the null hypotheses are true. Then , and which means that any discovery is a false discovery. By convention, if then we set otherwise .
This last term is precisely the expression for FWER. This means that when all null hypotheses are true, FDR implies control of FWER. You will often see this referred to as control in the weak sense which is another way of referring to the case only when all null hypotheses are true.
Second, consider the case where only a fraction of the null hypotheses are true. Then and if then . The indicator function that takes the value 1 if there is at least one false rejection, will never be less than Q, that is . Now, take expectations
The key here is to note that the expected value of an indicator function is the probability of the event in the indicator
This implies that and so FWER provides an upper bound to the FDR. When these error rates are quite different as in the case where is large, the stringency is lower and a gain in power can be expected.
Example of BH procedure
To illustrate the BH procedure we adapt a trivial example presented by Glickman et al. (Glickman 2014). Suppose a researcher performs an experiments examining differential expression of 10 genes in response to treatment relative to control. Ten corresponding p-values result, one for each test: . The researcher decides to bound the FDR at 5% (). Table 2 summarizes the ordered p-values and corresponding BH procedure calculations.
Table 2. Example BH calculations
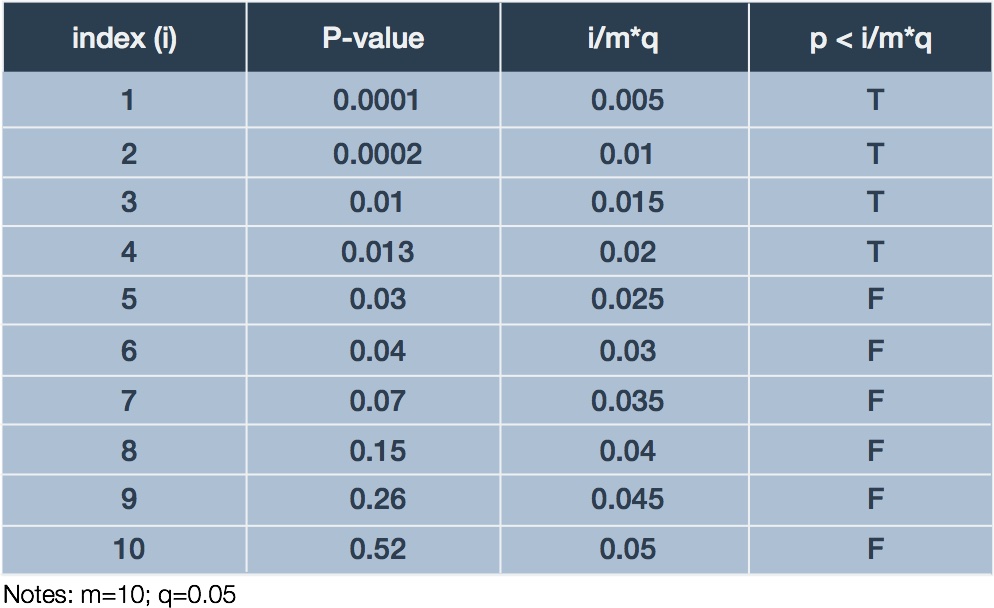
In this case, we examine the final column for the largest case in which which happens in the fourth row. Thus, we declare the genes corresponding to the first four p-values significant with respect to differential expression. Since our we would expect, on average, at most 5% of our discoveries to be mistaken, which in our case is nil.
Practical implications of BH compared to Bonferroni correction
The BH procedure overcomes some of the caveats associated with FWER control procedures.
The “universal” null hypothesis. Control of FWER was predicated upon testing the universal null hypothesis that purely random processes accounts for the data variation. In contrast, the BH approach focuses on those individual tests that are to be declared significant among the set of discoveries .
Penalty for peeking The BH procedure can accommodate the so-called “penalty for peeking” where variations in the number of tests performed alters the number of significant hypotheses. Consider an example where 20 tests are performed with ; The same p-value is derived in an additional 80 tests. In a Bonferroni correction the significance levels are and for 20 and 100 tests, respectively, rendering the latter insignificant. In contrast, the BH procedure is “scalable” as a function of varying numbers of tests: In the case where we require largest such that
All hypotheses will be significant if we can find such a relation to hold for . This is true for such that .
Caveats and limitations
Since the original publication of the BH procedure in 1995, there have been a number of discussion regarding the conditions and limitations surrounding the use of the method for genomics data. In particular, the assumption of independence between tests is unlikely to hold in large-scale genomic measurements. We leave it to the reader to explore more deeply the various discussions surrounding the use of BH or its variants (Goeman 2014).
Appendix A: Proof of Lemma 1
We intend on proving Lemma 1 that underlies the BH procedure for control of the FDR. The proof is adapted from the original publication by Benjamini and Hochberg (Benjamini 1995) with variant notation and diagrams for clarification purposes. We provide some notation and restate the lemma followed by the proof.
Notation
- Null hypotheses:
- Ordered null hypotheses: .
- P-values corresponding to null hypotheses: .
- Ordered P-values corresponding to null hypotheses: .
- Ordered P-values corresponding to true null hypotheses:
- Ordered P-values corresponding to false null hypotheses:
The lemma
Lemma 1 Suppose there are independent p-values corresponding to the true null hypotheses and are the p-values (as random variables) corresponding to the false null hypotheses. Suppose that the p-values for the false null hypotheses take on the realized values . Then the BH multiple testing procedure satisfies the inequality
We proceed using proof by induction. First we provide a proof for the base case . Second, we assume Lemma 1 holds for and go on to show that this holds for .
-
Asides
-
There are a few not so obvious details that we will need along the way. We present these as a set of numbered ‘asides’ that we will refer back to.
1. Distribution of true null hypothesis p-values
The true null hypotheses are associated with p-values that are distributed according to a standard uniform distribution, that is, . The proof of this follows.
Let be a p-value that is a random variable with realization . Likewise let be a test statistic with realization . As before, our null hypothesis is . The formal definition of a p-value is the probability of obtaining a test statistic at least as extreme as the one observed assuming the null hypothesis is true.
Let’s rearrange this.
The last term on the right is just the definition of the cumulative distribution function (cdf) where the subscript denotes the null hypothesis .
If the cdf is monotonic increasing then
The last two results allow us to say that
This means that which happens when .
2. Distribution of the largest order statistic
Suppose that are independent variates, each with cdf . Let for denote the cdf of the order statistic . Then the cdf of the largest order statistic is given by
Thus the corresponding probability mass function is
In the particular case that the cdf is for a standard uniform distribution then this simplifies to
Base case
Suppose that there is a single null hypothesis .
Case 1: .
Since then there are no true null hypotheses and so no opportunity for false rejections , thus . So Lemma 1 holds for any sensible .
Case 2: .
Since then there is a single true null hypothesis (). This could be accepted or rejected .
Induction
Assume Lemma 1 holds for and go on to show that this holds for .
Case 1: .
Since then there are no true null hypotheses and so no opportunity for false rejections , thus . So Lemma 1 holds for any sensible .
Case 2: .
Define as the largest index for the p-values corresponding to the false null hypotheses satisfying
Define as the value on the right side of the inequality at .
Moving forward, we will condition the Lemma 1 inequality on the largest p-value for the true null hypotheses by integrating over all possible values . Note that we’ve omitted the parentheses for order statistics with the true and false null hypothesis p-values. We’ll break the integral into two using as the division point. The first integral will be straightforward while the second will require a little more nuance. The sum of the two sub-integrals will support Lemma 1 as valid for .
Condition on the largest p-value for the true null hypotheses and split the integral on .
The first integral
In the case of the first integral . It is obvious that all p-values corresponding to the true null hypotheses are less than , that is . By the BH-procedure this means that all true null hypotheses are rejected regardless of order. Also, we know that from the definition of , there will be total hypotheses that are rejected (i.e. the numerator). We can express these statements mathematically.
Substitute this back into the first integral.
Finally let’s extract a and substitute it with its definition.
The second integral
Let us remind ourselves what we wish to evaluate.
The next part of the proof relies on a description of p-values and indices but is often described in a very compact fashion. Keeping track of everything can outstrip intuition, so we pause to reflect on a schematic of the ordered false null hypothesis p-values and relevant indices (Figure 4).

Figure 4. Schematic of p-values and indices. Shown are the p-values ordered in ascending value from left to right corresponding to the false null hypotheses (z). Indices j0 and m1 for true null hypotheses are as described in main text. Blue segment represents region where z’ can lie. Green demarcates regions larger than z’ where p-values corresponding to hypotheses (true or false) that will not be rejected lie.
Let us define the set of p-values that may be subject to rejection, that is, smaller than . Another way to look at this is to define the set of p-values that will not be rejected, that is, larger than .
Consider the set of possible values for defined by the criteria where . In Figure 4 this would correspond to the half-open set of intervals to the right of . If we set , then this same region includes the set of false null hypothesis p-values with indices . We need to consider one more region defined by . In Figure 4 this is the green segment to the right of .
Let us discuss the regions we just described that are larger than . By the BH procedure, these bound p-values for true and false null hypotheses that will not be rejected. Thus, we will not reject neither the true null hypothesis corresponding to nor any of the false null hypotheses corresponding to .
So what is left over in terms of null hypotheses? First we have the set of true null hypotheses less the largest giving a total of . Second we have the set of false null hypotheses excluding the ones we just described, that is, for a total of . This means that there are null hypotheses subject to rejection. Let us provide some updated notation to describe this subset.
If we combine and order just this subset of null hypotheses, then according to the BH procedure any given null hypothesis will be rejected if there is a such that for which
Now comes some massaging of the notation which may seem complicated but has a purpose: We wish to use the induction assumption on the expectation inside the second integral but we will need to somehow rid ourselves of the pesky term. This motivates the definition of transformed variables for the true and false null hypotheses.
Convince yourself that the are ordered statistics of a set of independent random variables while correspond to the false null hypotheses subject to . Also convince yourself that for
In other words, the false discovery proportion of at level is equivalent to testing at .
Now we are ready to tackle the expectation inside the integral.
Let us now place this result inside the original integral.
Let’s now add the results of the two half integrals and .
Thus, Lemma 1 holds for the base case and by the induction hypothesis all . Since we have shown that Lemma 1 holds for , by induction we claim that Lemma 1 holds for all positive integers and the proof is complete.
References
- Benjamini Y and Hochberg Y. Controlling the False Discovery Rate: A Practical and Powerful Approach to Multiple Testing. Roy. Stat. Soc., v57(1) pp289-300, 1995.
- Glickman ME et al. False Discovery rate control is a recommended alternative to Bonferroni-type adjustments in health studies. Journal of Clinical Epidemiology, v67, pp850-857, 2014.
- Goeman JJ and Solari A. Multiple hypothesis testing in genomics. Stat. Med., 33(11) pp1946-1978, 2014.
- Goodman SN. Multiple Comparisons, Explained. Amer. J. Epid., v147(9) pp807-812, 1998.
- Rothman KJ. No Adjustments Are Needed for Multiple Comparisons. Epidemiology, v1(1) pp. 43-46, 1990.
- Savitz DA and Oshlan AF. Multiple Comparisons and Related Issues in the Interpretation of Epidemiologic Data. Amer. J. Epid., v142(9) pp904 -908, 1995.
- Whitley E and Ball J. Statistics review 3: Hypothesis testing and P values. Critical Care, v6(3) pp. 222-225, 2002a.
- Whitley E and Ball J. Statistics review 4: Sample size calculations. Critical Care, v6(4) pp. 335-341, 2002b.