Содержание
- Forward Error Correction in Computer Networks
- 2.8 Коррекция ошибок
- Семенов Ю.А. (ИТЭФ-МФТИ) Yu. Semenov (ITEP-MIPT)
- Алгоритм Хэмминга
- Циклические коды
- Линейные блочные коды
- Метод коррекции ошибок FEC (Forward Error Correction)
- Ссылки
- Введение в коды Рида-Соломона: принципы, архитектура и реализация
- Свойства кодов Рида-Соломона
- Ошибки в символах
- Декодирование
- Архитектура кодирования и декодирования кодов Рида-Соломона
- Арифметика конечного поля Галуа
- Образующий полином
- Архитектура кодировщика
- Архитектура декодера
- Вычисление синдрома
- Нахождение позиций символьных ошибок
- Нахождение значений символьных ошибок
- Реализация кодировщика и декодера Рида-Соломона Аппаратная реализация
- Программная реализация
Forward Error Correction in Computer Networks
Forward Error Correction (FEC) is a technique used to minimize errors in data transmission over communication channels. In real-time multimedia transmission, re-transmission of corrupted and lost packets is not useful because it creates an unacceptable delay in reproducing : one needs to wait until the lost or corrupted packet is resent. Thus, there must be some technique which could correct the error or reproduce the packet immediately and give the receiver the ability to correct errors without needing a reverse channel to request re-transmission of data. There are various FEC techniques designed for this purpose.
These are as follows :
1. Using Hamming Distance :
For error correction, the minimum hamming distance required to correct t errors is:
For example, if 20 errors are to be corrected then the minimum hamming distance has to be 2*20+1= 41 bits. This means, lots of redundant bits need to be sent with the data. This technique is very rarely used as we have large amount of data to be sent over the networks, and such a high redundancy cannot be afforded most of the time.
2. Using XOR :
The exclusive OR technique is quite useful as the data items can be recreated by this technique. The XOR property is used as follows –

If the XOR property is applied on N data items, we can recreate any of the data items P1 to PN by exclusive-Oring all of the items, replacing the one to be created by the result of the previous operation(R). In this technique, a packet is divided into N chunks, and then the exclusive OR of all the chunks is created and then, N+1 chunks are sent. If any chunk is lost or corrupted, it can be recreated at the receiver side.
Practically, if N=4, it means that 25 percent extra data has to be sent and the data can be corrected if only one out of the four chunks is lost.
3. Chunk Interleaving :
In this technique, each data packet is divided into chunks. The data is then created chunk by chunk(horizontally) but the chunks are combined into packets vertically. This is done because by doing so, each packet sent carries a chunk from several original packets. If the packet is lost, we miss only one chunk in each packet, which is normally acceptable in multimedia communication. Some small chunks are allowed to be missing at the receiver. One chunk can be afforded to be missing in each packet as all the chunks from the same packet cannot be allowed to miss.
Источник
2.8 Коррекция ошибок
Семенов Ю.А. (ИТЭФ-МФТИ)
Yu. Semenov (ITEP-MIPT)
Исправлять ошибки труднее, чем их детектировать или предотвращать. Процедура коррекции ошибок предполагает два совмещенные процесса: обнаружение ошибки и определение места (идентификация сообщения и позиции в сообщении). После решения этих двух задач, исправление тривиально — надо инвертировать значение ошибочного бита. В наземных каналах связи, где вероятность ошибки невелика, обычно используется метод детектирования ошибок и повторной пересылки фрагмента, содержащего дефект. Для спутниковых каналов с типичными для них большими задержками системы коррекции ошибок становятся привлекательными. Здесь используют коды Хэмминга или коды свертки.
Но существуют и более простые методы коррекции ошибок. Например, передача блока данных, содержащего N строк и M столбцов, снабженных битами четности для каждой строки и столбца. Обнаружение ошибки четности в строке i и столбце j указывает на бит, который должен быть инвертирован. Может показаться, что в случае, когда неверны два бита, находящиеся в разных строках и столбцах, они также могут быть исправлены. Но это не так. Ведь нельзя разделить варианты i1,j1 — i2,j2 и i1,j2 — i2,j1.
Этот метод может быть развит путем формирования блока данных с N строками, M столбцами и K слоями. Здесь биты четности формируются для всех строк и столбцов каждого из слоев, а также битов, имеющих одинаковые номера строк и столбцов i,j. Полное число битов четности в этом случае равно (N+M+1)×K +(N+1)×(M+1). Если M=N=K=8, число бит данных составит 512, а число бит четности — 217. Нетрудно видеть, что в этом случае число исправляемых ошибок будет больше 1. Смотри рис. 1.
Рис. 1. Метод коррекции более одной ошибки в блоке данных (битам данных соответствуют окрашенные квадраты)
Алгоритм Хэмминга
Код Хэмминга представляет собой блочный код, который позволяет выявить и исправить ошибочно переданный бит в пределах переданного блока. Обычно код Хэмминга характеризуется двумя целыми числами, например, (11,7) используемый при передаче 7-битных ASCII-кодов. Такая запись говорит, что при передаче 7-битного кода используется 4 контрольных бита (7+4=11). При этом предполагается, что имела место ошибка в одном бите и что ошибка в двух или более битах существенно менее вероятна. С учетом этого исправление ошибки осуществляется с определенной вероятностью. Например, пусть возможны следующие правильные коды (все они, кроме первого и последнего, отстоят друг от друга на расстояние 4):
00000000
11110000
00001111
11111111
При получении кода 00000111 не трудно предположить, что правильное значение полученного кода равно 00001111. Другие коды отстоят от полученного на большее расстояние Хэмминга. Расстояние Хэмминга для двух кодов равной длины равно числу разных бит в этих кодах.
Рассмотрим пример передачи кода буквы s = 0x073 = 1110011 с использованием кода Хэмминга (11,7).
| Позиция бита: | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Значение бита: | 1 | 1 | 1 | * | 1 | * | 1 | * | * |
Символами * помечены четыре позиции, где должны размещаться контрольные биты. Эти позиции определяются целой степенью 2 (1, 2, 4, 8 и т.д.). Контрольная сумма формируется путем выполнения операции XOR (исключающее ИЛИ) над кодами позиций ненулевых битов. В данном случае это 11, 10, 9, 5 и 3. Вычислим контрольную сумму:
| 11 = | 1011 |
| 10 = | 1010 |
| 09 = | 1001 |
| 05 = | 0101 |
| 03 = | 0011 |
| S = | 1110 |
Таким образом, приемник получит код:
| Позиция бита: | 11 | 10 | 9 | 8 | 7 | 6 | 5 | 4 | 3 | 2 | 1 |
| Значение бита: | 1 | 1 | 1 | 1 | 1 | 1 | 1 | 1 |
Просуммируем снова коды позиций ненулевых битов и получим нуль.
| 11 = | 1011 |
| 10 = | 1010 |
| 09 = | 1001 |
| 08 = | 1000 |
| 05 = | 0101 |
| 04 = | 0100 |
| 03 = | 0011 |
| 02 = | 0010 |
| S = | 0000 |
Ну а теперь рассмотрим два случая ошибок в одном из битов посылки, например, в бите 7 (1 вместо 0) и в бите 5 (0 вместо 1). Просуммируем коды позиций ненулевых бит еще раз.
|
|
В обоих случаях контрольная сумма равна позиции бита, переданного с ошибкой. Теперь для исправления ошибки достаточно инвертировать бит, номер которого указан в контрольной сумме. Понятно, что если ошибка произойдет при передаче более чем одного бита, код Хэмминга при данной избыточности окажется бесполезен.
В общем случае код имеет N=M+C бит и предполагается, что не более чем один бит в коде может иметь ошибку. Тогда возможно N+1 состояние кода (правильное состояние и n ошибочных). Пусть М=4, а N=7, тогда слово-сообщение будет иметь вид: M4, M3, M2, C3, M1, C2, C1. Теперь попытаемся вычислить значения С1, С2, С3. Для этого используются уравнения, где все операции представляют собой сложение по модулю 2:
С1 = М1 + М2 + М4
С2 = М1 + М3 + М4
С3 = М2 + М3 + М4
Для определения того, доставлено ли сообщение без ошибок, вычисляем следующие выражения (сложение по модулю 2):
С11 = С1 + М4 + М2 + М1
С12 = С2 + М4 + М3 + М1
С13 = С3 + М4 + М3 + М2
Результат вычисления интерпретируется следующим образом.
| С11 | С12 | С13 | Значение |
| 1 | 2 | 4 | Позиция бит |
| Ошибок нет | |||
| 1 | Бит С3 не верен | ||
| 1 | Бит С2 не верен | ||
| 1 | 1 | Бит М3 не верен | |
| 1 | Бит С1 не верен | ||
| 1 | 1 | Бит М2 не верен | |
| 1 | 1 | Бит М1 не верен | |
| 1 | 1 | 1 | Бит М4 не верен |
Описанная схема легко переносится на любое число n и М.
Число возможных кодовых комбинаций М помехоустойчивого кода делится на n классов, где N — число разрешенных кодов. Разделение на классы осуществляется так, чтобы в каждый класс вошел один разрешенный код и ближайшие к нему (по расстоянию Хэмминга) запрещенные коды. В процессе приема данных определяется, к какому классу принадлежит пришедший код. Если код принят с ошибкой, он заменяется ближайшим разрешенным кодом. При этом предполагается, что кратность ошибки не более qm.
Можно доказать, что для исправления ошибок с кратностью не более qm кодовое расстояние должно превышать 2qm (как правило, оно выбирается равным D = 2qm +1). В теории кодирования существуют следующие оценки максимального числа N n-разрядных кодов с расстоянием D.
| d=1 | n=2 n |
| d=2 | n=2 n-1 |
| d=3 | n 2 n /(1+n) |
| d=2q+1 | (для кода Хэмминга это неравенство превращается в равенство) |
В случае кода Хэмминга первые k разрядов используются в качестве информационных, причем
откуда следует (логарифм по основанию 2), что k может принимать значения 0, 1, 4, 11, 26, 57 и т.д., это и определяет соответствующие коды Хэмминга (3,1); (7,4); (15,11); (31,26); (63,57) и т.д.
Циклические коды
Обобщением кодов Хэмминга являются циклические коды BCH (Bose-Chadhuri-Hocquenghem). Это коды с широким выбором длины и возможностей исправления ошибок. Циклические коды характеризуются полиномом g(x) степени n-k, g(x) = 1 + g1x + g2x 2 + … + x n-k . g(x) называется порождающим многочленом циклического кода. Если многочлен g(x) n-k и является делителем многочлена x n + 1, то код C(g(x)) является линейным циклическим (n,k)-кодом. Число циклических n-разрядных кодов равно числу делителей многочлена x n + 1.
При кодировании слова все кодовые слова кратны g(x). g(x) определяется на основе сомножителей полинома x n +1 как:
Например, если n=7 (x 7 +1), его сомножители (1 + x + x 3 )(1 + x + x 2 + x 4 ), а g(x) = 1+x + x 3 .
Чтобы представить сообщение h(x) в виде циклического кода, в котором можно указать постоянные места проверочных и информационных символов, нужно разделить многочлен x n-k h(x) на g(x) и прибавить остаток от деления к многочлену x n-k h(x). См. Л.Ф. Куликовский и В.В. Мотов, “Теоретические основы информационных процессов”. Москва “Высшая школа” 1987. Привлекательность циклических кодов заключается в простоте аппаратной реализации с использованием сдвиговых регистров.
Пусть общее число бит в блоке равно N, из них полезную информацию несут в себе K бит, тогда в случае ошибки, имеется возможность исправить m бит. Таблица 2.8.1 содержит зависимость m от N и K для кодов ВСН.
| Общее число бит N | Число полезных бит М | Число исправляемых бит m |
| 31 | 26 | 1 |
| 21 | 2 | |
| 16 | 3 | |
| 63 | 57 | 1 |
| 51 | 2 | |
| 45 | 3 | |
| 127 | 120 | 1 |
| 113 | 2 | |
| 106 | 3 |
Увеличивая разность N-M, можно не только нарастить число исправляемых бит m, но открыть возможность обнаружить множественные ошибки. В таблице 2.8.2 приведен процент обнаруживаемых множественных ошибок в зависимости от M и N-M.
| Число полезных бит М | Число избыточных бит (n-m) | ||
| 6 | 7 | 8 | |
| 32 | 48% | 74% | 89% |
| 40 | 36% | 68% | 84% |
| 48 | 23% | 62% | 81% |
Другой блочный метод предполагает “продольное и поперечное” контрольное суммирование предаваемого блока. Блок при этом представляется в виде N строк и M столбцов. Вычисляется биты четности для всех строк и всех столбцов, в результате получается два кода, соответственно длиной N и M бит. На принимающей стороне биты четности для строк и столбцов вычисляются повторно и сравниваются с присланными. При выявлении отличия в бите i кода битов четности строк и бите j — кода столбцов, позиция неверного бита оказывается определенной (i,j). Понятно, что если выявится два и более неверных битов в контрольных кодах строк и столбцов, задача коррекции становится неразрешимой. Уязвим этот метод и для двойных ошибок, когда сбой был, а контрольные коды остались корректными.
Применение кодов свертки позволяют уменьшить вероятность ошибок при обмене, даже если число ошибок при передаче блока данных больше 1.
Линейные блочные коды
Блочный код определяется, как набор возможных кодов, который получается из последовательности бит, составляющих сообщение. Например, если мы имеем К бит, то имеется 2 К возможных сообщений и такое же число кодов, которые могут быть получены из этих сообщений. Набор этих кодов представляет собой блочный код. Линейные коды получаются в результате перемножения сообщения М на порождающую матрицу G[IA]. Каждой порождающей матрице ставится в соответствие матрица проверки четности (n-k)*n. Эта матрица позволяет исправлять ошибки в полученных сообщениях путем вычисления синдрома. Матрица проверки четности находится из матрицы идентичности i и транспонированной матрицы А. G[IA] ==> H[A T I].
Если , то H[A T I] =
Синдром полученного сообщения равен
S = [полученное сообщение] . [матрица проверки четности].
Если синдром содержит нули, ошибок нет, в противном случае сообщение доставлено с ошибкой. Если сообщение М соответствует М=2 k , а k =3 высота матрицы, то можно записать восемь кодов:
| Сообщения | Кодовые вектора | Вычисленные как |
| M1 = 000 | V1 = 000000 | M1 . G |
| M2 = 001 | V2 = 001101 | M2 . G |
| M3 = 010 | V3 = 010011 | M3 . G |
| M4 = 100 | V4 = 100110 | M4 . G |
| M5 = 011 | V5 = 011110 | M5 . G |
| M6 = 101 | V6 = 101011 | M6 . G |
| M7 = 110 | V7 = 110101 | M7 . G |
| M8 = 111 | V8 = 111000 | M8 . G |
Кодовые векторы для этих сообщений приведены во второй колонке. На основе этой информации генерируется таблица 2.8.3, которая называется стандартным массивом. Стандартный массив использует кодовые слова и добавляет к ним биты ошибок, чтобы получить неверные кодовые слова.
Таблица 2.8.3. Стандартный массив для кодов (6,3)
| 000000 | 001101 | 010011 | 100110 | 011110 | 101011 | 110101 | 111000 |
| 000001 | 001100 | 010010 | 100111 | 011111 | 101010 | 110100 | 111001 |
| 000010 | 001111 | 010001 | 100100 | 011100 | 101001 | 110111 | 111010 |
| 000100 | 001001 | 010111 | 100010 | 011010 | 101111 | 110001 | 111100 |
| 001000 | 000101 | 011011 | 101110 | 010110 | 100011 | 111101 | 110000 |
| 010000 | 011101 | 000011 | 110110 | 001110 | 111011 | 100101 | 101000 |
| 100000 | 101101 | 110011 | 000110 | 111110 | 001011 | 010101 | 011000 |
| 001001 | 000100 | 011010 | 101111 | 010111 | 100010 | 111100 | 011001 |
Предположим, что верхняя строка таблицы содержит истинные значения переданных кодов. Из таблицы 2.8.3 видно, что, если ошибки случаются в позициях, соответствующих битам кодов из левой колонки, можно определить истинное значение полученного кода. Для этого достаточно полученный код сложить с кодом в левой колонке посредством операции XOR.
Синдром равен произведению левой колонки (CL «coset leader») стандартного массива на транспонированную матрицу контроля четности H T .
| Синдром = CL . H T | Левая колонка стандартного массива |
| 000 | 000000 |
| 001 | 000001 |
| 010 | 000010 |
| 100 | 000100 |
| 110 | 001000 |
| 101 | 010000 |
| 011 | 100000 |
| 111 | 001001 |
Чтобы преобразовать полученный код в правильный, нужно умножить полученный код на транспонированную матрицу проверки четности, с тем чтобы получить синдром. Полученное значение левой колонки стандартного массива добавляется (XOR!) к полученному коду, чтобы получить его истинное значение. Например, если мы получили 001100, умножаем этот код на H T :
этот результат указывает на место ошибки, истинное значение кода получается в результате операции XOR:
под горизонтальной чертой записано истинное значение кода.
Транспортировка данных подвержена влиянию шумов и наводок, которые вносят искажения. Если вероятность повреждения данных мала, достаточно зарегистрировать сам факт искажения и повторить передачу поврежденного фрагмента.
Когда вероятность искажения велика, например, в каналах коммуникаций с геостационарными спутниками, используются методы коррекции ошибок. Одним из таких методов является FEC (Forward Error Correction, иногда называемое канальным кодированием [1]). Технология FEC последнее время достаточно широко используется в беспроводных, локальных сетях (WLAN). Существуют две основные разновидности FEC: блочное кодирование и кодирование по методу свертки.
Блочное кодирование работает с блоками (пакетами) бит или символов фиксированного размера. Метод свертки работает с потоками бит или символов произвольной протяженности. Коды свертки при желании могут быть преобразованы в блочные коды.
Существует большое число блочных кодов, одним из наиболее важных является алгоритм Рида-Соломона, который используется при работе с CD, DVD и жесткими дисками ЭВМ. Блочные коды и коды свертки могут использоваться и совместно.
Метод коррекции ошибок FEC (Forward Error Correction)
Для FEC-кодирования иногда используется метод свертки, который впервые был применен в 1955 году. Главной особенностью этого метода является сильная зависимость кодирования от предыдущих информационных битов и высокие требования к объему памяти. FEC-код обычно просматривает при декодировании 2-8 бит десятки или даже сотни бит, полученных ранее. Смотри также RFC-3452, -3453, -3695, -5052.
В 1967 году Эндрю Витерби (Andrew Viterbi) разработал технику декодирования, которая стала стандартной для кодов свертки. Эта методика требовала меньше памяти. Метод свертки более эффективен, когда ошибки распределены случайным образом, а не группируются в кластеры. Работа же с кластерами ошибок более эффективна при использовании алгебраического кодирования.
Одним из широко используемых разновидностей коррекции ошибок является турбо кодирование, разработанное американской аэрокосмической корпорацией. В этой схеме комбинируется два или более относительно простых кодов свертки. В FEC, также как и в других методах коррекции ошибок (коды Хэмминга, алгоритм Рида-Соломона и др.), блоки данных из k бит снабжаются кодами четности, которые пересылаются вместе с данными, и обеспечивают не только детектирование, но и исправление ошибок. Каждый дополнительный (избыточный) бит является сложной функцией многих исходных информационных бит. Исходная информация может содержаться в выходном передаваемом коде, тогда такой код называется систематическим, а может и не содержаться.
В результате через канал передается n-битовое кодовое слово (n>k). Конкретная реализация алгоритма FEC характеризуется комбинацией (n,k). Применение FEC в Интернет регламентируется документом RFC-3452. Коды FEC могут исключить необходимость обратной связи при потере или искажении доставленных данных (запросы повторной передачи). Особенно привлекательна технология FEC при работе с мультикастинг-потоками, где ретрансмиссия не предусматривается (см. RFC-3453).
В 1974 году Йозеф Оденвальдер (Joseph Odenwalder) объединил возможности алгебраического кодирования и метода свертки. Хорошего результата можно добиться, введя специальную операцию псевдослучайного перемешивания бит (interleaver).
В 1993 году группой Клода Берроу (Claude Berrou) был разработан турбо код. В кодеке, реализующем этот алгоритм, содержатся кодировщики как минимум двух компонент (реализующие алгебраический метод или свертку). Кодирование осуществляется для блоков данных. Здесь также используется псевдослучайное перемешивание бит перед передачей. Это приводит к тому, что кластеры ошибок, внесенных при транспортировке, оказываются разнесенными случайным образом в пределах блока данных.
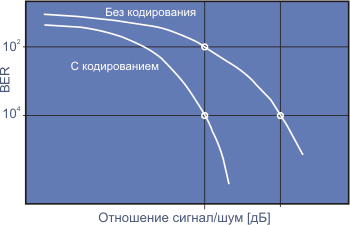
На рис. 2. проводится сравнение вариантов BER (bit error rate) при обычной транспортировке данных через канал и при передаче тех же данных с использованием коррекции ошибок FEC для разных значений отношения сигнал-шум (S/N). Из этих данных видно, что при отношении S/N= 8 дБ применение FEC позволяет понизить BER примерно в 100 раз. При этом достигается результат, близкий (в пределах одного децибела) к теоретическому пределу Шеннона.
За последние пять лет были разработаны программы, которые позволяют оптимизировать структуры турбо-кодов. Улучшение BER для турбо-кодов имеет асимптотический предел и дальнейшее увеличение S/N уже не дает никакого выигрыша. Но схемы, позволяющие смягчить влияние этого насыщения, продолжают разрабатываться.
Турбо кодек должен иметь столько же компонентных декодеров, сколько имеется кодировщиков на стороне передатчика. Декодеры соединяются последовательно
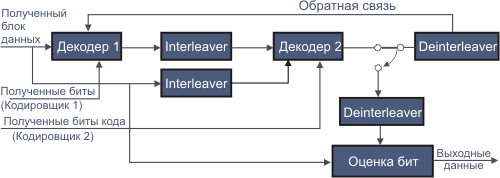
Рис. 3. Турбо декодер
Техника FEC находит все большее применение в телекоммуникациях, например, при передачи мультимедиа [2].
Следует помнить, что как в случае FEC, так и в других известных методах коррекции ошибок, (BCH, Golay, Hamming и др.) скорректированный код является верным лишь с определенной конечной вероятностью.
Ссылки
| 1 | http://www.aero.org/publication/crosslink/winter2002/04.html. Crosslink — The Aerospace Corporation magazine of advances in aerospace technology. The Aerospace Corporation (Volume 3, Number 1 (Winter 2001/2002)). |
| 2 | Multiple Description Source Coding using Forward Error Correction Codes, Rohit Puri, Kannan Ramchandran, University of California, Berkeley (rpuri, kannan@eecs.berkeley.edu). |
| 3 | http://en.wikipedia.org/wiki/Forward_error_correction |
| 4 | http://www.eccpage.com/, Morelos-Zaragoza, Robert (2004). The Error Correcting Codes (ECC) Page |
Введение в коды Рида-Соломона: принципы, архитектура и реализация
Коды Рида-Соломона были предложены в 1960 Ирвином Ридом (Irving S. Reed) и Густавом Соломоном (Gustave Solomon), являвшимися сотрудниками Линкольнской лаборатории МТИ. Ключом к использованию этой технологии стало изобретение эффективного алгоритма декодирования Элвином Беликамфом (Elwyn Berlekamp; http://en.wikipedia.org/wiki/Berlekamp-Massey_algorithm), профессором Калифорнийского университета (Беркли). Коды Рида-Соломона (см. также http://www.4i2i.com/reed_solomon_codes.htm) базируются на блочном принципе коррекции ошибок и используются в огромном числе приложений в сфере цифровых телекоммуникаций и при построении запоминающих устройств. Коды Рида-Соломона применяются для исправления ошибок во многих системах, включая:
- Устройства памяти (включая магнитные ленты, CD, DVD, штриховые коды, и т.д.)
- Беспроводные или мобильные коммуникации (включая сотовые телефоны, микроволновые каналы и т.д.)
- Спутниковые коммуникации
- Цифровое телевидение / DVB (digital video broadcast).
- Скоростные модемы, такие как ADSL, xDSL и т.д.
На рис. 4 показаны практические приложения (дальние космические проекты) коррекции ошибок с использованием различных алгоритмов (Хэмминга, кодов свертки, Рида-Соломона и пр.). Данные и сам рисунок взяты из http://en.wikipedia.org/wiki/Reed-Solomon_error_correction..
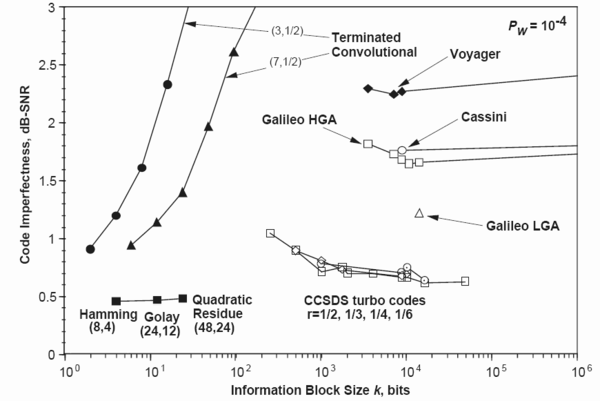
Рис. 4. Несовершенство кода, как функция размера информационного блока для разных задач и алгоритмов
Типовая система представлена ниже (см. http://www.4i2i.com/reed_solomon_codes.htm):

Рис. 5. Схема коррекции ошибок Рида-Соломона
Кодировщик Рида-Соломона берет блок цифровых данных и добавляет дополнительные «избыточные» биты. Ошибки происходят при передаче по каналам связи или по разным причинам при запоминании (например, из-за шума или наводок, царапин на CD и т.д.). Декодер Рида-Соломона обрабатывает каждый блок, пытается исправить ошибки и восстановить исходные данные. Число и типы ошибок, которые могут быть исправлены, зависят от характеристик кода Рида-Соломона.
Свойства кодов Рида-Соломона
Коды Рида-Соломона являются субнабором кодов BCH и представляют собой линейные блочные коды. Код Рида-Соломона специфицируются как RS(n,k) s-битных символов..
Это означает, что кодировщик воспринимает k информационных символов по s бит каждый и добавляет символы четности для формирования n символьного кодового слова. Имеется n-k символов четности по s бит каждый. Декодер Рида-Соломона может корректировать до t символов, которые содержат ошибки в кодовом слове, где 2t = n-k.
Диаграмма, представленная ниже, показывает типовое кодовое слово Рида-Соломона:

Рис. 6. Структура кодового слова R-S
Пример: Популярным кодом Рида-Соломона является RS(255,223) с 8-битными символами. Каждое кодовое слово содержит 255 байт, из которых 223 являются информационными и 32 байтами четности. Для этого кода:
n = 255, k = 223, s = 8
2t = 32, t = 16
Декодер может исправить любые 16 символов с ошибками в кодовом слове: то есть, ошибки могут быть исправлены, если число искаженных байт не превышает 16.
При размере символа s, максимальная длина кодового слова (n) для кода Рида-Соломона равна n = 2 s – 1.
Например, максимальная длина кода с 8-битными символами (s=8) равна 255 байтам.
Коды Рида-Соломона могут быть в принципе укорочены путем обнуления некоторого числа информационных символов на входе кодировщика (передавать их в этом случае не нужно). При передаче данных декодеру эти нули снова вводятся в массив.
Пример: Код (255,223), описанный выше, может быть укорочен до (200,168). Кодировщик будет работать с блоком данных 168 байт, добавит 55 нулевых байт, сформирует кодовое слово (255,223) и передаст только 168 информационных байт и 32 байта четности.
Объем вычислительной мощности, необходимой для кодирования и декодирования кодов Рида-Соломона зависит от числа символов четности. Большое значение t означает, что большее число ошибок может быть исправлено, но это потребует большей вычислительной мощности по сравнению с вариантом при меньшем t.
Ошибки в символах
Одна ошибка в символе происходит, когда 1 бит символа оказывается неверным или когда все биты не верны.
Пример: Код RS(255,223) может исправить до 16 ошибок в символах. В худшем случае, могут иметь место 16 битовых ошибок в разных символах (байтах). В лучшем случае, корректируются 16 полностью неверных байт, при этом исправляется 16 x 8=128 битовых ошибок.
Коды Рида-Соломона особенно хорошо подходят для корректировки кластеров ошибок (когда неверными оказываются большие группы бит кодового слова, следующие подряд).
Декодирование
Алгебраические процедуры декодирования Рида-Соломона могут исправлять ошибки и потери. Потерей считается случай, когда положение неверного символа известно. Декодер может исправить до t ошибок или до 2t потерь. Данные о потере (стирании) могут быть получены от демодулятора цифровой коммуникационной системы, т.е. демодулятор помечает полученные символы, которые вероятно содержат ошибки.
Когда кодовое слово декодируется, возможны три варианта:
- Если 2s + r -9 , т.е. не более 1 из 10 9 бит передается с ошибкой. Такого результата можно достичь путем увеличения мощности передатчика или применением кодов Рида-Соломона (или другого типа коррекции ошибок). Алгоритм Рида-Соломона позволяет системе достичь требуемого уровня BER с более низкой выходной мощностью передатчика.
Архитектура кодирования и декодирования кодов Рида-Соломона
Кодирование и декодирование Рида-Соломона может быть выполнено аппаратно или программно.
Арифметика конечного поля Галуа
Коды Рида-Соломона базируются на специальном разделе математики – полях Галуа (GF) или конечных полях. Арифметические действия (+, -, x, / и т.д.) над элементами конечного поля дают результат, который также является элементом этого поля. Кодировщик или декодер Рида-Соломона должны уметь выполнять эти арифметические операции. Эти операции для своей реализации требуют специального оборудования или специализированного программного обеспечения.
Образующий полином
Кодовое слово Рида-Соломона формируется с привлечением специального полинома. Все корректные кодовые слова должны делиться без остатка на эти образующие полиномы. Общая форма образующего полинома имеет вид:
а кодовое слово формируется с помощью операции:
где g(x) является образующим полиномом, i(x) представляет собой информационный блок, c(x) – кодовое слово, называемое простым элементом поля.
Пример: Генератор для RS(255,249)
g(x)= (x-a 0 )(x-a 1 )(x-a 2 )(x-a3)(x-a 4 )(x-a 5 )
g(x)= x 6 + g5x 5 + g3x 3 + g2x 2 + g1x 1 + g0
Архитектура кодировщика
2t символов четности в кодовом слове Рида-Соломона определяются из следующего соотношения:.
Ниже показана схема реализации кодировщика для версии RS(255,249):

Рис. 7. Схема кодировщика R-S
Каждый из 6 регистров содержит в себе символ (8 бит). Арифметические операторы выполняют сложение или умножение на символ как на элемент конечного поля..
Архитектура декодера
Общая схема декодирования кодов Рида-Соломона показана ниже на рис. 8.
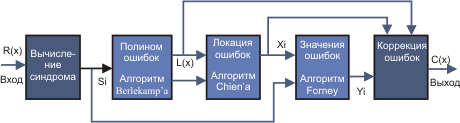
Рис. 8. Схема работы с кодами Рида-Соломона
r(x) Полученное кодовое слово
Si — Синдромы
L(x) — Полином локации ошибок
Xi — Положения ошибок
Yi — Значения ошибок
c(x) — Восстановленное кодовое слово
v — Число ошибок.
Полученное кодовое слово r(x) представляет собой исходное (переданное) кодовое слово c(x) плюс ошибки:.
Декодер Рида-Соломона пытается определить позицию и значение ошибки для числа t ошибок (или 2t потерь) и исправить ошибки и потери.
Вычисление синдрома
Вычисление синдрома похоже на вычисление четности. Кодовое слово Рида-Соломона имеет 2t синдромов, это зависит только от ошибок (а не передаваемых кодовых слов). Синдромы могут быть вычислены путем подстановки 2t корней образующего полинома g(x) в r(x).
Нахождение позиций символьных ошибок
Это делается путем решения системы уравнений с t неизвестными. Существует несколько быстрых алгоритмов для решения этой задачи. Эти алгоритмы используют особенности структуры матрицы кодов Рида-Соломона и сильно сокращают необходимую вычислительную мощность. Делается это в два этапа:
- Определение полинома локации ошибок
Это может быть сделано с помощью алгоритма Berlekamp-Massey или алгоритма Эвклида. Алгоритм Эвклида используется чаще на практике, так как его легче реализовать, однако, алгоритм Berlekamp-Massey позволяет получить более эффективную реализацию оборудования и программ..
Нахождение значений символьных ошибок
Здесь также нужно решить систему уравнений с t неизвестными. Для решения используется быстрый алгоритм Forney.
Реализация кодировщика и декодера Рида-Соломона
Аппаратная реализация
Существует несколько коммерческих аппаратных реализаций. Имеется много разработанных интегральных схем, предназначенных для кодирования и декодирований кодов Рида-Соломона. Эти ИС допускают определенный уровень программирования (например, RS(255,k), где t может принимать значения от 1 до 16).
Программная реализация
До недавнего времени, программные реализации в «реальном времени» требовали слишком большой вычислительной мощности для практически всех кодов Рида-Соломона. Главной трудностью в программной реализации кодов Рида-Соломона являлось то, что процессоры общего назначения не поддерживают арифметические операции для поля Галуа. Однако оптимальное составление программ в сочетании с возросшей вычислительной мощностью позволяют получить вполне приемлемые результаты для относительно высоких скоростей передачи данных.
На рис. 9 показана фотография поверхности Марса, полученная американской станцией «Curiosity» (2012г). Сам Марс с Земли даже с помощью бинокля виден плохо. Современные методы коррекции ошибок позволяют получить приемелемы результат даже в условиях, когда шум на порядки превышает сигнал. Смотри также рис. 4.

Рис. 9. Фотография, полученная марсианской станцией Curiosity (США)
Источник
Прямая коррекция ошибок (FEC)
Прямая коррекция ошибок (англ. Forward Error Correction, или сокр.: FEC) – мощный метод для улучшения производительности подверженных ошибкам каналов, используемый в системах связи. Производительность FEC может быть оценена на основе их расстояния от предела Шеннона.

VersaFEC®
VersaFEC – короткоблочная система с низкой задержкой на основе Low Density Parity Check (LDPC) кода, разработанная для поддержки чувствительных к скорости отклика приложений, таких, как сотовый обратный сигнал к спутнику, и обеспечения кодирования при минимальной сквозной задержке. VersaFEC обеспечивает превосходную альтернативу существующим LDPC и DVB-S2 система.
Технология VersaFEC разработана:
- Для обеспечения широкого выбора модуляции и кодовых комбинаций (ModCods). Эти новые комбинации обеспечивают кодирование, эквивалентное уже существующим LDPC и при этом значительно уменьшают задержку. Существующие LDPC коды (также как DVB-S2 коротко-блочные коды) используют блоки в 16 кбит, тогда как VersaFEC использует блоки в пределах от 2 кбит до 8.2 кбит.
- Для поддержки систем адаптивной модуляции и кодирования (ACM). ModCods были выбраны, для обеспечения непрерывной прогрессии с точки зрения графика функций Eb/No (отношение энергии сигнала, приходящейся на 1 бит принимаемого сообщения (Eb), к энергетической спектральной плотности шума (N0)) и спектральной эффективности, и сокращения задержек почти до теоретических минимумов.
Показатели кодирования VersaFEC
VersaFEC включает 12 настроек модуляции и кодирования (ModCods):
|
Модуляция |
Уровень кода |
Спектральная эффективность,bps/Hz |
Размер блока, bits |
Стандартное Eb/No,для BER = 5 x 10-8 |
Задержка в |
Min. Data Rate, CCM |
Max. Data Rate, CCM |
|
BPSK |
0.488 |
0.49 |
2k |
2.4 dB |
26 |
18 kbps |
5.7 Mbps |
|
QPSK |
0.533 |
1.07 |
4.1k |
2.2 dB |
53 |
20 kbps |
10 Mbps |
|
QPSK |
0.631 |
1.26 |
4.1k |
2.7 dB |
59 |
23 kbps |
10 Mbps |
|
QPSK |
0.706 |
1.41 |
4.1k |
3.4 dB |
62 |
26 kbps |
10 Mbps |
|
QPSK |
0.803 |
1.61 |
4.1k |
3.8 dB |
66 |
28 kbps |
12 Mbps |
|
8-QAM |
0.642 |
1.93 |
6.1k |
4.6 dB |
89 |
35 kbps |
12 Mbps |
|
8-QAM |
0.711 |
2.13 |
6.1k |
5.2 dB |
93 |
39 kbps |
12 Mbps |
|
8-QAM |
0.780 |
2.34 |
6.1k |
5.6 dB |
97 |
43 kbps |
12 Mbps |
|
16-QAM |
0.731 |
2.93 |
8.2k |
6.3 dB |
125 |
53 kbps |
12 Mbps |
|
16-QAM |
0.780 |
3.12 |
8.2k |
7.0 dB |
129 |
57 kbps |
14 Mbps |
|
16-QAM |
0.829 |
3.32 |
8.2k |
7.5 dB |
131 |
60 kbps |
14 Mbps |
|
16-QAM |
0.853 |
3.41 |
8.2k |
8.0 dB |
132 |
62 kbps |
16 Mbps |
Производительность кодов VersaFEC по отношению к пределу Шеннона показана на графике ниже. Для всех ModCods, VersaFEC находится в интервале от 0.7 до 1.0 дБ предела Шеннона. Производительность VersaFEC соответствует производительности DVB-S2 с блоками на 16 кбит.

По сравнению с Turbo Product кодами (TPC) VersaFEC обеспечивает более 1.0 дБ сокращения Eb/No. А как следствие приводит к увеличению пропускной способности и уменьшению размеров BUC/HPA.
Низкая степень задержки
VersaFEC специально предназначен для приложений c низкой задержкой. Для сравнения, уровень LDPC 2/3 8-QAM и Уровень VersaFEC 0.642 8-QAM обеспечивают практически идентичную спектральную эффективность и производительность Eb/No. Однако при 64 Кбит/с, задержка была уменьшена с 350 миллисекунд до 89 миллисекунд.

По сравнению с короткоблочным DVB-S2, VersaFEC обеспечивает значительное сокращение задержки в широком диапазоне. Например, у QPSK DVB-S2 уровня 2/3 и VersaFEC QPSK 0.631 имеют близкую по значению спектральную эффективность и производительность Eb/No. Однако при 64 Кбит/с, задержка VersaFEC составляет 59 мс, по сравнению с более 500 мс для DVB-S2.
В дополнение к тому, что используются блоки меньших размеров VersaFEC использует не чередующиеся систематические коды LDPC. В сравнении с чередующимися кодами DVB-S2, достигается значительного сокращения задержки. Общая сквозная задержка для высокого уровня кодирования систематическим кодом (таким как VersaFEC) асимптотически приближается к половине задержки чередованного кода (такого как DVB-S2).
VersaFEC® зарегистрированный товарный знак Comtech EF Data
VersaFEC-2
Обзор технологии VersaFEC-2
Comtech EF Data спроектировали и выпустили первое поколение систем VersaFEC весной 2007, которая использовалась в усовершенствованном спутниковом модеме CDM-625. Начальная форма сигнала была разработана для обеспечения высокой производительности и уменьшения скорости отклика операций постоянного кодирования и модуляции (CCM) и адаптивного кодирования и модуляции (ACM) на основе LDPC кодирования/декодирования для 5 Msps субканалов. Первое поколение VersaFEC очень быстро получило признание во многих отраслях и стало интегрироваться в решения с каналами передачи данных низкого и среднего уровней, которые требовали разложения сигнала в спектр с низкой задержкой. VersaFEC используется в настоящее время в трёх продуктах Comtech EF Data: модемы CDM-625 / CDM-625A / CDMER-625A, модемы CDM-570A / CDM-570AL и усовершенствованные VSAT платформы.
В то время как уровни производительности VersaFEC устанавливают высокую планку эффективности для каналов низких и средних уровней, рынок требует еще более высокой производительности и лучших результатов с точки зрения экономики. В связи с этим Comtech EF Data разрабатывает форму сигнала VersaFEC-2 и включает эту новую технологию в свой комплект продуктов, чтобы позволить мобильным сетевым операторам и поставщикам услуг продолжать контролировать затраты и постоянно увеличивать уровень обслуживания в соответствии с требованиями конечных пользователей. Цель этой статьи, описать следующее поколение разработки — системы расширенной формы сигнала VersaFEC-2 (VWS) и сравнить её со стандартами DVB-S2 и DVB-S2x вместе с её предшественником, VersaFEC, и выделить преимущества, замеченные при использовании новой технологии.
VersaFEC-2 (LDPC)
Высокоэффективная форма сигнала VersaFEC-2 была разработана для обеспечения оптимальных показателей производительности от 100 Ksps до 12.5 Msps в приложениях. Форма сигнала VersaFEC-2 состоит из 74 новых версий ModCod с новыми вариантами настроек модуляции и кодирования. VersaFEC-2, подобно промышленным стандартам DVB-S2 и DVB-S2x, обеспечивает два операционных режима, длинный блок и короткий блок. Длинноблочный режим предоставляет 38 вариантов ModCod с различными степенями кодирования и спектральной эффективности, большим, чем у DVB-S2 и равным DVB-S2x, а также степень задержки, составляющую до 1/8 от того же показателя, при использовании стандартов DVB-S2 и DVB-S2x. Короткоблочный режим VersaFEC-2 предоставляет 36 вариантов ModCod с лучшей производительностью, чем у зарекомендовавшей себя технологии VersaFEC с подобными или лучшими показателями задержки. Все совокупности высшего порядка в VersaFEC-2 являются цикличными для оптимальной производительности соотношения максимального к среднему значению и, как следствие, делает их менее подверженными падению производительности в нелинейных спутниковых каналах. Кроме того, новая 32-разрядная модуляция была введена для поддержки спектральной эффективности до 4.4 бит/с/Гц. Оба алгоритма CCM и ACM поддерживаются в обоих режимах Long-Block и Short-Block.
VersaFEC-2 (LDPC) vs. DVB-S2
Высокоэффективная форма сигнала VersaFEC-2 обеспечивает значительное преимущество производительности перед промышленным стандартом DVB-S2, а также перед его предшественником, VersaFEC. На рисунке 1 представлено сравнение длинно-блочного режима VersaFEC-2 и длинно-блочного DVB-S2.

Как изображено на рисунке 1, спектральная эффективность VersaFEC-2 выше, чем у стандарта DVB-S2 в наиболее распространенных сценариях (5 дБ-11 дБ сигнал/шум) приложений с низкими и средними скоростями передачи данных и на одном уровне со стандартом DVB-S2 при более высоких значениях показателя сигнал/шум. Увеличенные уровни производительности VersaFEC-2 непосредственно влияют на нижний график вследствие того, что:
- Дополнительная пропускная способность (Мбит/с) может быть задействована без расширения ширины канала.
- Минимальная ширина канала требуется для выбранного уровня пропускной способности (Мбит/с), что приводит к уменьшению потерь и снижению затрат ресурсов в операционной структуре для данной ширины потока.

Для мобильных операторов или поставщиков услуг связи, использование данной технологии даёт значительные преимущества. Для уже существующих сервисов — увеличение производительности в наиболее распространенных режимах работы непосредственно коррелирует увеличение прибыли, предполагая, что прайс-лист для конечного пользователя останется прежним. С другой стороны, измененная экономическая модель, следующая из уменьшения базовой стоимости, открывает новые рынки и области работы для мобильных операторов или поставщика услуг. Комбинация этих двух важных особенностей позволит предоставлять высококлассный уровень сервиса для конечных пользователей.
VersaFEC-2 vs. VersaFEC
На Рис. 2 представлено сравнение VersaFEC-2 с его предшественником, VersaFEC. Как показано на графике, Versa-FEC2 обеспечивает преимущество на 1.7 дБ больше в сравнении с VersaFEC.

Минимизация степени задержки
Ставка компании Comtech EF Data на то, что метод кодирования, который использует постоянное число символов в блоке, превзойдёт программный алгоритм, используемый в стандарте DVB, в котором за блочную единицу взят постоянный бит, была оправдана. Впоследствии, разработанный механизм был успешно интегрирован в VersaFEC, показав превосходные результаты относительно уровня задержки при передаче. Аналогично, VersaFEC-2, используя постоянный символ за блочную единицу, обладает значительными преимуществами в сравнении со стандартами DVB-S2 и DVB-S2x в минимизации степени задержки. Чтобы отметить это различие, в Табл. 1 продемонстрировано сравнение производительности VersaFEC-2 и DVB-S2 или DVB-S2x с точки зрения степени задержки канала на скорости 512 Кбит/с.
|
Форма сигнала |
ModCod |
Скорость передачи |
Задержка |
Преимущества VersaFEC-2 |
|
DVB-S2 or DVB-S2x |
QPSK Rate 0.5 Long Block |
512 Кб/с |
275 мс |
на 85% меньшая степень задержки, чем у DVB-S2 |
|
VersaFEC-2 |
QPSK Rate 0.489 Long Block |
512 Кб/с |
41 мс |
|
|
DVB-S2 or DVB-S2x |
QPSK Rate 0.5 Short Block |
512 Кб/с |
72 мс |
на 91% меньшая степень задержки, чем у DVB-S2 |
|
VersaFEC-2 |
QPSK Rate 0.489 Short Block |
512 Кб/с |
7 мс |
Таблица 1: таблица сравнения степени задержки VersaFEC-2 и DVB-S2/DVB-S2x
Как видно из Таблицы 1, вне зависимости от используемой вариации ModCod, показатель степени задержки VersaFEC-2 меньше чем при использовании стандарта DVB. Высокая степень задержки негативно влияет на показатели системы следующим образом:
- Снижение скорости установления соединения с интерактивными приложениями;
- Сильное сокращение скорости и качества работы приложений
- Возможность неработоспособности приложения.
Кодирующие устройства с технологией VersaFEC, были разработаны с нуля, в соответствии с требованиями базовых приложений. Для мобильных операторов чрезвычайно важно гарантировать, что базовые протоколы передачи для 2G, 3G и 4G сетей будут корректно и быстро функционировать. Допустимые значения степени задержки и джиттера этих протоколов очень низкие, и важно выбрать такое устройство передачи, которое позволило бы этим системам работать должным образом. Citrix и подобные бизнес-приложения чрезвычайно чувствительны к высокой степени задержки. Соединения, обладающие высоким уровень задержки, могут вызвать ненужные повторные передачи, деформацию сигнала в сети и, время от времени, сбои соединения.
Уменьшение времени восстановления полезного сигнала
Подобно преимуществам, обозначенным выше, использование алгоритма, где блочная единица — постоянное число символов, обеспечивает уменьшение времени восстановления полезного сигнала. В Табл. 2 продемонстрированы средние значения времени восстановления полезного сигнала в 1Msps для стандартов DVB-S2/DVB-S2x и VersaFEC-2.
|
Форма сигнала |
ModCod |
Размер блока |
Время восстановления полезного сигнала |
|
DVB-S2 or DVB-S2x |
QPSK Rate 0.5 Long Block |
1 Msps |
> 2 seconds |
|
VersaFEC-2 |
QPSK Rate 0.489 Long Block |
1 Msps |
< 60 msec |
|
DVB-S2 or DVB-S2x |
QPSK Rate 0.5 Short Block |
1 Msps |
> 2 seconds |
|
VersaFEC-2 |
QPSK Rate 0.489 Short Block |
1 Msps |
< 60 msec |
Таблица 2: типичное время восстановления полезного сигнала VersaFEC-2 по сравнению с DVB-S2/DVB-S2x
Время восстановления сигнала очень важно, когда каналы динамично расстраиваются и повторно настраиваются, как бывает при работе с динамическим операциями SCPC (dSCPC). С dSCPC операциями, время восстановления сигнала динамично изменяется для поддержки корректного распределения трафика в сети. Использования VersaFEC в новом проекте – гарант того, что время восстановления будет минимизировано и не ухудшит стабильность работы соединений, для которых существуют строгие требования к степени задержки и джиттеру.
Алгоритм адаптивного кодирования и модуляции (ACM)
Адаптивное Кодирование и Модуляция (ACM) являются методом передачи, в котором модуляция и прямая коррекция ошибок (FEC) происходят на лету, чтобы компенсировать ухудшение передачи на линии связи со спутником. В случае ухудшения связи, выбранная модуляция и кодирование “смещаются вниз”, чтобы позволить данным быть полученными на надлежащем уровне, чтобы гарантировать связь. Демодулятор ACM измеряет мощность полученного сигнала и использует эти данные, чтобы определить, произошло ли изменение в модуляции и гарантированно скорректировать ошибки. Когда в полученном сигнале регистрируются изменения C/N или Es/No, модуляция и кодирование изменяются снова, чтобы максимально удовлетворить требованиям к линии связи. Если уровень полезного сигнала увеличивается – модуляция и кодирование “возрастают” к более агрессивной (и более спектрально эффективный) комбинации. С другой стороны, если происходит дальнейшее ухудшение связи – модуляция и кодирование продолжают “уменьшаться” (вместе со спектральными полезными действиями), пока не достигнут уровня, гарантирующего стабильную связь.
Если технология ACM не используется, как это происходит с Постоянным Кодированием и Модуляцией (CCM), передаваемый блок данных должен быть сформирован для наихудших условий, чтобы гарантировать надлежащую связь. Другими словами, должны использоваться модуляция и кодирование, которые гарантировали бы работу при наиболее неблагоприятных условиях. Это огромный минус метода CCM, приводящий к большим затратам ресурсов.
Неблагоприятные условия окружающей среды, обусловленные природными явлениями, не являются постоянными, и подавляющее количество времени линия использует избыточная пропускная способность, которая в данный момент не является необходимой.
Те линии связи, которые используют ACM, получают следующие преимущества:

- Дополнительная пропускная способность (Мбит/с). Данные могут передаваться по каналу меньшей ширины в течение значительной части времени работы системы, так как ухудшения связи происходят нечасто.
- Уменьшение требуемой ширины канала. Для обеспечения законтрактованной пропускной способности (Мбит/с) требуется более узкий канал, поскольку работа в условиях плохого прохождения сигнала, и, соответственно, использование наименее «агрессивных» алгоритмов модуляции и кодирования будет происходить лишь в небольшие отрезки времени.
По сути, VersaFEC-2 разработан так, чтобы поддерживать различные алгоритмы демодуляции на принимающей стороне, исключив тем самым любые дополнительные издержки, которые могут возникнуть при реализации поддержки алгоритма ACM, являющегося ключевым в максимизации полезного действия линии связи.
Линейка продуктов, предлагаемых Comtech EF Data позволяет произвести многомерную оптимизацию, адаптированную к условиям потребителя. VersaFEC-2 – высокоэффективный метод модуляции и кодирования с низкой степенью задержки, преимущества которого дополнительно увеличиваются благодаря использованию алгоритма ACM. Основанный на большом опыте использования и преимуществах алгоритма VersaFEC, VersaFEC-2 добавляет много новых методов модуляции и кодирования, инновационных новых совокупностей и новых операционных режимов, которые позволяют ему лучше всего поддерживать сотовый сигнал и беспроводные каналы связи для IP-систем. Подобно своему предшественнику, алгоритм VersaFEC-2 может быть использован в обоих направлениях передачи и может быть объединен со сжатием DoubleTalk Carrier-in-Carrier, как например в усовершенствованном спутниковом модеме CDM-625A, чтобы достигнуть беспрецедентного спектрального полезного действия.
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.
In computing, telecommunication, information theory, and coding theory, forward error correction (FEC) or channel coding[1][2][3] is a technique used for controlling errors in data transmission over unreliable or noisy communication channels.
The central idea is that the sender encodes the message in a redundant way, most often by using an error correction code or error correcting code, (ECC).[4][5] The redundancy allows the receiver not only to detect errors that may occur anywhere in the message, but often to correct a limited number of errors. Therefore a reverse channel to request re-transmission may not be needed. The cost is a fixed, higher forward channel bandwidth.
The American mathematician Richard Hamming pioneered this field in the 1940s and invented the first error-correcting code in 1950: the Hamming (7,4) code.[5]
FEC can be applied in situations where re-transmissions are costly or impossible, such as one-way communication links or when transmitting to multiple receivers in multicast.
Long-latency connections also benefit; in the case of a satellite orbiting Uranus, retransmission due to errors can create a delay of five hours. FEC is widely used in modems and in cellular networks, as well.
FEC processing in a receiver may be applied to a digital bit stream or in the demodulation of a digitally modulated carrier. For the latter, FEC is an integral part of the initial analog-to-digital conversion in the receiver. The Viterbi decoder implements a soft-decision algorithm to demodulate digital data from an analog signal corrupted by noise. Many FEC decoders can also generate a bit-error rate (BER) signal which can be used as feedback to fine-tune the analog receiving electronics.
FEC information is added to mass storage (magnetic, optical and solid state/flash based) devices to enable recovery of corrupted data, and is used as ECC computer memory on systems that require special provisions for reliability.
The maximum proportion of errors or missing bits that can be corrected is determined by the design of the ECC, so different forward error correcting codes are suitable for different conditions. In general, a stronger code induces more redundancy that needs to be transmitted using the available bandwidth, which reduces the effective bit-rate while improving the received effective signal-to-noise ratio. The noisy-channel coding theorem of Claude Shannon can be used to compute the maximum achievable communication bandwidth for a given maximum acceptable error probability. This establishes bounds on the theoretical maximum information transfer rate of a channel with some given base noise level. However, the proof is not constructive, and hence gives no insight of how to build a capacity achieving code. After years of research, some advanced FEC systems like polar code[3] come very close to the theoretical maximum given by the Shannon channel capacity under the hypothesis of an infinite length frame.
How it works[edit]
ECC is accomplished by adding redundancy to the transmitted information using an algorithm. A redundant bit may be a complex function of many original information bits. The original information may or may not appear literally in the encoded output; codes that include the unmodified input in the output are systematic, while those that do not are non-systematic.
A simplistic example of ECC is to transmit each data bit 3 times, which is known as a (3,1) repetition code. Through a noisy channel, a receiver might see 8 versions of the output, see table below.
| Triplet received | Interpreted as |
|---|---|
| 000 | 0 (error-free) |
| 001 | 0 |
| 010 | 0 |
| 100 | 0 |
| 111 | 1 (error-free) |
| 110 | 1 |
| 101 | 1 |
| 011 | 1 |
This allows an error in any one of the three samples to be corrected by «majority vote», or «democratic voting». The correcting ability of this ECC is:
- Up to 1 bit of triplet in error, or
- up to 2 bits of triplet omitted (cases not shown in table).
Though simple to implement and widely used, this triple modular redundancy is a relatively inefficient ECC. Better ECC codes typically examine the last several tens or even the last several hundreds of previously received bits to determine how to decode the current small handful of bits (typically in groups of 2 to 8 bits).
Averaging noise to reduce errors[edit]
ECC could be said to work by «averaging noise»; since each data bit affects many transmitted symbols, the corruption of some symbols by noise usually allows the original user data to be extracted from the other, uncorrupted received symbols that also depend on the same user data.
- Because of this «risk-pooling» effect, digital communication systems that use ECC tend to work well above a certain minimum signal-to-noise ratio and not at all below it.
- This all-or-nothing tendency – the cliff effect – becomes more pronounced as stronger codes are used that more closely approach the theoretical Shannon limit.
- Interleaving ECC coded data can reduce the all or nothing properties of transmitted ECC codes when the channel errors tend to occur in bursts. However, this method has limits; it is best used on narrowband data.
Most telecommunication systems use a fixed channel code designed to tolerate the expected worst-case bit error rate, and then fail to work at all if the bit error rate is ever worse.
However, some systems adapt to the given channel error conditions: some instances of hybrid automatic repeat-request use a fixed ECC method as long as the ECC can handle the error rate, then switch to ARQ when the error rate gets too high;
adaptive modulation and coding uses a variety of ECC rates, adding more error-correction bits per packet when there are higher error rates in the channel, or taking them out when they are not needed.
Types of ECC[edit]

A block code (specifically a Hamming code) where redundant bits are added as a block to the end of the initial message
A continuous code convolutional code where redundant bits are added continuously into the structure of the code word
The two main categories of ECC codes are block codes and convolutional codes.
- Block codes work on fixed-size blocks (packets) of bits or symbols of predetermined size. Practical block codes can generally be hard-decoded in polynomial time to their block length.
- Convolutional codes work on bit or symbol streams of arbitrary length. They are most often soft decoded with the Viterbi algorithm, though other algorithms are sometimes used. Viterbi decoding allows asymptotically optimal decoding efficiency with increasing constraint length of the convolutional code, but at the expense of exponentially increasing complexity. A convolutional code that is terminated is also a ‘block code’ in that it encodes a block of input data, but the block size of a convolutional code is generally arbitrary, while block codes have a fixed size dictated by their algebraic characteristics. Types of termination for convolutional codes include «tail-biting» and «bit-flushing».
There are many types of block codes; Reed–Solomon coding is noteworthy for its widespread use in compact discs, DVDs, and hard disk drives. Other examples of classical block codes include Golay, BCH, Multidimensional parity, and Hamming codes.
Hamming ECC is commonly used to correct NAND flash memory errors.[6]
This provides single-bit error correction and 2-bit error detection.
Hamming codes are only suitable for more reliable single-level cell (SLC) NAND.
Denser multi-level cell (MLC) NAND may use multi-bit correcting ECC such as BCH or Reed–Solomon.[7][8] NOR Flash typically does not use any error correction.[7]
Classical block codes are usually decoded using hard-decision algorithms,[9] which means that for every input and output signal a hard decision is made whether it corresponds to a one or a zero bit. In contrast, convolutional codes are typically decoded using soft-decision algorithms like the Viterbi, MAP or BCJR algorithms, which process (discretized) analog signals, and which allow for much higher error-correction performance than hard-decision decoding.
Nearly all classical block codes apply the algebraic properties of finite fields. Hence classical block codes are often referred to as algebraic codes.
In contrast to classical block codes that often specify an error-detecting or error-correcting ability, many modern block codes such as LDPC codes lack such guarantees. Instead, modern codes are evaluated in terms of their bit error rates.
Most forward error correction codes correct only bit-flips, but not bit-insertions or bit-deletions.
In this setting, the Hamming distance is the appropriate way to measure the bit error rate.
A few forward error correction codes are designed to correct bit-insertions and bit-deletions, such as Marker Codes and Watermark Codes.
The Levenshtein distance is a more appropriate way to measure the bit error rate when using such codes.
[10]
Code-rate and the tradeoff between reliability and data rate[edit]
The fundamental principle of ECC is to add redundant bits in order to help the decoder to find out the true message that was encoded by the transmitter. The code-rate of a given ECC system is defined as the ratio between the number of information bits and the total number of bits (i.e., information plus redundancy bits) in a given communication package. The code-rate is hence a real number. A low code-rate close to zero implies a strong code that uses many redundant bits to achieve a good performance, while a large code-rate close to 1 implies a weak code.
The redundant bits that protect the information have to be transferred using the same communication resources that they are trying to protect. This causes a fundamental tradeoff between reliability and data rate.[11] In one extreme, a strong code (with low code-rate) can induce an important increase in the receiver SNR (signal-to-noise-ratio) decreasing the bit error rate, at the cost of reducing the effective data rate. On the other extreme, not using any ECC (i.e., a code-rate equal to 1) uses the full channel for information transfer purposes, at the cost of leaving the bits without any additional protection.
One interesting question is the following: how efficient in terms of information transfer can an ECC be that has a negligible decoding error rate? This question was answered by Claude Shannon with his second theorem, which says that the channel capacity is the maximum bit rate achievable by any ECC whose error rate tends to zero:[12] His proof relies on Gaussian random coding, which is not suitable to real-world applications. The upper bound given by Shannon’s work inspired a long journey in designing ECCs that can come close to the ultimate performance boundary. Various codes today can attain almost the Shannon limit. However, capacity achieving ECCs are usually extremely complex to implement.
The most popular ECCs have a trade-off between performance and computational complexity. Usually, their parameters give a range of possible code rates, which can be optimized depending on the scenario. Usually, this optimization is done in order to achieve a low decoding error probability while minimizing the impact to the data rate. Another criterion for optimizing the code rate is to balance low error rate and retransmissions number in order to the energy cost of the communication.[13]
Concatenated ECC codes for improved performance[edit]
Classical (algebraic) block codes and convolutional codes are frequently combined in concatenated coding schemes in which a short constraint-length Viterbi-decoded convolutional code does most of the work and a block code (usually Reed–Solomon) with larger symbol size and block length «mops up» any errors made by the convolutional decoder. Single pass decoding with this family of error correction codes can yield very low error rates, but for long range transmission conditions (like deep space) iterative decoding is recommended.
Concatenated codes have been standard practice in satellite and deep space communications since Voyager 2 first used the technique in its 1986 encounter with Uranus. The Galileo craft used iterative concatenated codes to compensate for the very high error rate conditions caused by having a failed antenna.
Low-density parity-check (LDPC)[edit]
Low-density parity-check (LDPC) codes are a class of highly efficient linear block
codes made from many single parity check (SPC) codes. They can provide performance very close to the channel capacity (the theoretical maximum) using an iterated soft-decision decoding approach, at linear time complexity in terms of their block length. Practical implementations rely heavily on decoding the constituent SPC codes in parallel.
LDPC codes were first introduced by Robert G. Gallager in his PhD thesis in 1960,
but due to the computational effort in implementing encoder and decoder and the introduction of Reed–Solomon codes,
they were mostly ignored until the 1990s.
LDPC codes are now used in many recent high-speed communication standards, such as DVB-S2 (Digital Video Broadcasting – Satellite – Second Generation), WiMAX (IEEE 802.16e standard for microwave communications), High-Speed Wireless LAN (IEEE 802.11n),[14] 10GBase-T Ethernet (802.3an) and G.hn/G.9960 (ITU-T Standard for networking over power lines, phone lines and coaxial cable). Other LDPC codes are standardized for wireless communication standards within 3GPP MBMS (see fountain codes).
Turbo codes[edit]
Turbo coding is an iterated soft-decoding scheme that combines two or more relatively simple convolutional codes and an interleaver to produce a block code that can perform to within a fraction of a decibel of the Shannon limit. Predating LDPC codes in terms of practical application, they now provide similar performance.
One of the earliest commercial applications of turbo coding was the CDMA2000 1x (TIA IS-2000) digital cellular technology developed by Qualcomm and sold by Verizon Wireless, Sprint, and other carriers. It is also used for the evolution of CDMA2000 1x specifically for Internet access, 1xEV-DO (TIA IS-856). Like 1x, EV-DO was developed by Qualcomm, and is sold by Verizon Wireless, Sprint, and other carriers (Verizon’s marketing name for 1xEV-DO is Broadband Access, Sprint’s consumer and business marketing names for 1xEV-DO are Power Vision and Mobile Broadband, respectively).
Local decoding and testing of codes[edit]
Sometimes it is only necessary to decode single bits of the message, or to check whether a given signal is a codeword, and do so without looking at the entire signal. This can make sense in a streaming setting, where codewords are too large to be classically decoded fast enough and where only a few bits of the message are of interest for now. Also such codes have become an important tool in computational complexity theory, e.g., for the design of probabilistically checkable proofs.
Locally decodable codes are error-correcting codes for which single bits of the message can be probabilistically recovered by only looking at a small (say constant) number of positions of a codeword, even after the codeword has been corrupted at some constant fraction of positions. Locally testable codes are error-correcting codes for which it can be checked probabilistically whether a signal is close to a codeword by only looking at a small number of positions of the signal.
Interleaving[edit]
«Interleaver» redirects here. For the fiber-optic device, see optical interleaver.

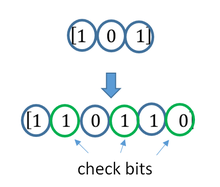
A short illustration of interleaving idea
Interleaving is frequently used in digital communication and storage systems to improve the performance of forward error correcting codes. Many communication channels are not memoryless: errors typically occur in bursts rather than independently. If the number of errors within a code word exceeds the error-correcting code’s capability, it fails to recover the original code word. Interleaving alleviates this problem by shuffling source symbols across several code words, thereby creating a more uniform distribution of errors.[15] Therefore, interleaving is widely used for burst error-correction.
The analysis of modern iterated codes, like turbo codes and LDPC codes, typically assumes an independent distribution of errors.[16] Systems using LDPC codes therefore typically employ additional interleaving across the symbols within a code word.[17]
For turbo codes, an interleaver is an integral component and its proper design is crucial for good performance.[15][18] The iterative decoding algorithm works best when there are not short cycles in the factor graph that represents the decoder; the interleaver is chosen to avoid short cycles.
Interleaver designs include:
- rectangular (or uniform) interleavers (similar to the method using skip factors described above)
- convolutional interleavers
- random interleavers (where the interleaver is a known random permutation)
- S-random interleaver (where the interleaver is a known random permutation with the constraint that no input symbols within distance S appear within a distance of S in the output).[19]
- a contention-free quadratic permutation polynomial (QPP).[20] An example of use is in the 3GPP Long Term Evolution mobile telecommunication standard.[21]
In multi-carrier communication systems, interleaving across carriers may be employed to provide frequency diversity, e.g., to mitigate frequency-selective fading or narrowband interference.[22]
Example[edit]
Transmission without interleaving:
Error-free message: aaaabbbbccccddddeeeeffffgggg Transmission with a burst error: aaaabbbbccc____deeeeffffgggg
Here, each group of the same letter represents a 4-bit one-bit error-correcting codeword. The codeword cccc is altered in one bit and can be corrected, but the codeword dddd is altered in three bits, so either it cannot be decoded at all or it might be decoded incorrectly.
With interleaving:
Error-free code words: aaaabbbbccccddddeeeeffffgggg Interleaved: abcdefgabcdefgabcdefgabcdefg Transmission with a burst error: abcdefgabcd____bcdefgabcdefg Received code words after deinterleaving: aa_abbbbccccdddde_eef_ffg_gg
In each of the codewords «aaaa», «eeee», «ffff», and «gggg», only one bit is altered, so one-bit error-correcting code will decode everything correctly.
Transmission without interleaving:
Original transmitted sentence: ThisIsAnExampleOfInterleaving Received sentence with a burst error: ThisIs______pleOfInterleaving
The term «AnExample» ends up mostly unintelligible and difficult to correct.
With interleaving:
Transmitted sentence: ThisIsAnExampleOfInterleaving... Error-free transmission: TIEpfeaghsxlIrv.iAaenli.snmOten. Received sentence with a burst error: TIEpfe______Irv.iAaenli.snmOten. Received sentence after deinterleaving: T_isI_AnE_amp_eOfInterle_vin_...
No word is completely lost and the missing letters can be recovered with minimal guesswork.
Disadvantages of interleaving[edit]
Use of interleaving techniques increases total delay. This is because the entire interleaved block must be received before the packets can be decoded.[23] Also interleavers hide the structure of errors; without an interleaver, more advanced decoding algorithms can take advantage of the error structure and achieve more reliable communication than a simpler decoder combined with an interleaver[citation needed]. An example of such an algorithm is based on neural network[24] structures.
Software for error-correcting codes[edit]
Simulating the behaviour of error-correcting codes (ECCs) in software is a common practice to design, validate and improve ECCs. The upcoming wireless 5G standard raises a new range of applications for the software ECCs: the Cloud Radio Access Networks (C-RAN) in a Software-defined radio (SDR) context. The idea is to directly use software ECCs in the communications. For instance in the 5G, the software ECCs could be located in the cloud and the antennas connected to this computing resources: improving this way the flexibility of the communication network and eventually increasing the energy efficiency of the system.
In this context, there are various available Open-source software listed below (non exhaustive).
- AFF3CT(A Fast Forward Error Correction Toolbox): a full communication chain in C++ (many supported codes like Turbo, LDPC, Polar codes, etc.), very fast and specialized on channel coding (can be used as a program for simulations or as a library for the SDR).
- IT++: a C++ library of classes and functions for linear algebra, numerical optimization, signal processing, communications, and statistics.
- OpenAir: implementation (in C) of the 3GPP specifications concerning the Evolved Packet Core Networks.
List of error-correcting codes[edit]
| Distance | Code |
|---|---|
| 2 (single-error detecting) | Parity |
| 3 (single-error correcting) | Triple modular redundancy |
| 3 (single-error correcting) | perfect Hamming such as Hamming(7,4) |
| 4 (SECDED) | Extended Hamming |
| 5 (double-error correcting) | |
| 6 (double-error correct-/triple error detect) | Nordstrom-Robinson code |
| 7 (three-error correcting) | perfect binary Golay code |
| 8 (TECFED) | extended binary Golay code |
- AN codes
- BCH code, which can be designed to correct any arbitrary number of errors per code block.
- Barker code used for radar, telemetry, ultra sound, Wifi, DSSS mobile phone networks, GPS etc.
- Berger code
- Constant-weight code
- Convolutional code
- Expander codes
- Group codes
- Golay codes, of which the Binary Golay code is of practical interest
- Goppa code, used in the McEliece cryptosystem
- Hadamard code
- Hagelbarger code
- Hamming code
- Latin square based code for non-white noise (prevalent for example in broadband over powerlines)
- Lexicographic code
- Linear Network Coding, a type of erasure correcting code across networks instead of point-to-point links
- Long code
- Low-density parity-check code, also known as Gallager code, as the archetype for sparse graph codes
- LT code, which is a near-optimal rateless erasure correcting code (Fountain code)
- m of n codes
- Nordstrom-Robinson code, used in Geometry and Group Theory[25]
- Online code, a near-optimal rateless erasure correcting code
- Polar code (coding theory)
- Raptor code, a near-optimal rateless erasure correcting code
- Reed–Solomon error correction
- Reed–Muller code
- Repeat-accumulate code
- Repetition codes, such as Triple modular redundancy
- Spinal code, a rateless, nonlinear code based on pseudo-random hash functions[26]
- Tornado code, a near-optimal erasure correcting code, and the precursor to Fountain codes
- Turbo code
- Walsh–Hadamard code
- Cyclic redundancy checks (CRCs) can correct 1-bit errors for messages at most
 bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters
bits long for optimal generator polynomials of degree , see Mathematics of cyclic redundancy checks#Bitfilters


See also[edit]
- Code rate
- Erasure codes
- Soft-decision decoder
- Burst error-correcting code
- Error detection and correction
- Error-correcting codes with feedback
References[edit]
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
- ^ Charles Wang; Dean Sklar; Diana Johnson (Winter 2001–2002). «Forward Error-Correction Coding». Crosslink. The Aerospace Corporation. 3 (1). Archived from the original on 14 March 2012. Retrieved 5 March 2006.
How Forward Error-Correcting Codes Work]
- ^ a b Maunder, Robert (2016). «Overview of Channel Coding».
- ^ Glover, Neal; Dudley, Trent (1990). Practical Error Correction Design For Engineers (Revision 1.1, 2nd ed.). CO, USA: Cirrus Logic. ISBN 0-927239-00-0.
- ^ a b Hamming, Richard Wesley (April 1950). «Error Detecting and Error Correcting Codes». Bell System Technical Journal. USA: AT&T. 29 (2): 147–160. doi:10.1002/j.1538-7305.1950.tb00463.x. S2CID 61141773.
- ^ «Hamming codes for NAND flash memory devices» Archived 21 August 2016 at the Wayback Machine. EE Times-Asia. Apparently based on «Micron Technical Note TN-29-08: Hamming Codes for NAND Flash Memory Devices». 2005. Both say: «The Hamming algorithm is an industry-accepted method for error detection and correction in many SLC NAND flash-based applications.»
- ^ a b «What Types of ECC Should Be Used on Flash Memory?» (Application note). Spansion. 2011.
Both Reed–Solomon algorithm and BCH algorithm are common ECC choices for MLC NAND flash. … Hamming based block codes are the most commonly used ECC for SLC…. both Reed–Solomon and BCH are able to handle multiple errors and are widely used on MLC flash.
- ^ Jim Cooke (August 2007). «The Inconvenient Truths of NAND Flash Memory» (PDF). p. 28.
For SLC, a code with a correction threshold of 1 is sufficient. t=4 required … for MLC.
- ^ Baldi, M.; Chiaraluce, F. (2008). «A Simple Scheme for Belief Propagation Decoding of BCH and RS Codes in Multimedia Transmissions». International Journal of Digital Multimedia Broadcasting. 2008: 1–12. doi:10.1155/2008/957846.
- ^ Shah, Gaurav; Molina, Andres; Blaze, Matt (2006). «Keyboards and covert channels». USENIX. Retrieved 20 December 2018.
- ^ Tse, David; Viswanath, Pramod (2005), Fundamentals of Wireless Communication, Cambridge University Press, UK
- ^ Shannon, C. E. (1948). «A mathematical theory of communication» (PDF). Bell System Technical Journal. 27 (3–4): 379–423 & 623–656. doi:10.1002/j.1538-7305.1948.tb01338.x. hdl:11858/00-001M-0000-002C-4314-2.
- ^ Rosas, F.; Brante, G.; Souza, R. D.; Oberli, C. (2014). «Optimizing the code rate for achieving energy-efficient wireless communications». Proceedings of the IEEE Wireless Communications and Networking Conference (WCNC). pp. 775–780. doi:10.1109/WCNC.2014.6952166. ISBN 978-1-4799-3083-8.
- ^ IEEE Standard, section 20.3.11.6 «802.11n-2009» Archived 3 February 2013 at the Wayback Machine, IEEE, 29 October 2009, accessed 21 March 2011.
- ^ a b Vucetic, B.; Yuan, J. (2000). Turbo codes: principles and applications. Springer Verlag. ISBN 978-0-7923-7868-6.
- ^ Luby, Michael; Mitzenmacher, M.; Shokrollahi, A.; Spielman, D.; Stemann, V. (1997). «Practical Loss-Resilient Codes». Proc. 29th Annual Association for Computing Machinery (ACM) Symposium on Theory of Computation.
- ^ «Digital Video Broadcast (DVB); Second generation framing structure, channel coding and modulation systems for Broadcasting, Interactive Services, News Gathering and other satellite broadband applications (DVB-S2)». En 302 307. ETSI (V1.2.1). April 2009.
- ^ Andrews, K. S.; Divsalar, D.; Dolinar, S.; Hamkins, J.; Jones, C. R.; Pollara, F. (November 2007). «The Development of Turbo and LDPC Codes for Deep-Space Applications». Proceedings of the IEEE. 95 (11): 2142–2156. doi:10.1109/JPROC.2007.905132. S2CID 9289140.
- ^ Dolinar, S.; Divsalar, D. (15 August 1995). «Weight Distributions for Turbo Codes Using Random and Nonrandom Permutations». TDA Progress Report. 122: 42–122. Bibcode:1995TDAPR.122…56D. CiteSeerX 10.1.1.105.6640.
- ^ Takeshita, Oscar (2006). «Permutation Polynomial Interleavers: An Algebraic-Geometric Perspective». IEEE Transactions on Information Theory. 53 (6): 2116–2132. arXiv:cs/0601048. Bibcode:2006cs……..1048T. doi:10.1109/TIT.2007.896870. S2CID 660.
- ^ 3GPP TS 36.212, version 8.8.0, page 14
- ^ «Digital Video Broadcast (DVB); Frame structure, channel coding and modulation for a second generation digital terrestrial television broadcasting system (DVB-T2)». En 302 755. ETSI (V1.1.1). September 2009.
- ^ Techie (3 June 2010). «Explaining Interleaving». W3 Techie Blog. Retrieved 3 June 2010.
- ^ Krastanov, Stefan; Jiang, Liang (8 September 2017). «Deep Neural Network Probabilistic Decoder for Stabilizer Codes». Scientific Reports. 7 (1): 11003. arXiv:1705.09334. Bibcode:2017NatSR…711003K. doi:10.1038/s41598-017-11266-1. PMC 5591216. PMID 28887480.
- ^ Nordstrom, A.W.; Robinson, J.P. (1967), «An optimum nonlinear code», Information and Control, 11 (5–6): 613–616, doi:10.1016/S0019-9958(67)90835-2
- ^ Perry, Jonathan; Balakrishnan, Hari; Shah, Devavrat (2011). «Rateless Spinal Codes». Proceedings of the 10th ACM Workshop on Hot Topics in Networks. pp. 1–6. doi:10.1145/2070562.2070568. hdl:1721.1/79676. ISBN 9781450310598.
Further reading[edit]
- MacWilliams, Florence Jessiem; Sloane, Neil James Alexander (2007) [1977]. Written at AT&T Shannon Labs, Florham Park, New Jersey, USA. The Theory of Error-Correcting Codes. North-Holland Mathematical Library. Vol. 16 (digital print of 12th impression, 1st ed.). Amsterdam / London / New York / Tokyo: North-Holland / Elsevier BV. ISBN 978-0-444-85193-2. LCCN 76-41296. (xxii+762+6 pages)
- Clark, Jr., George C.; Cain, J. Bibb (1981). Error-Correction Coding for Digital Communications. New York, USA: Plenum Press. ISBN 0-306-40615-2.
- Arazi, Benjamin (1987). Swetman, Herb (ed.). A Commonsense Approach to the Theory of Error Correcting Codes. MIT Press Series in Computer Systems. Vol. 10 (1 ed.). Cambridge, Massachusetts, USA / London, UK: Massachusetts Institute of Technology. ISBN 0-262-01098-4. LCCN 87-21889. (x+2+208+4 pages)
- Wicker, Stephen B. (1995). Error Control Systems for Digital Communication and Storage. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-200809-2.
- Wilson, Stephen G. (1996). Digital Modulation and Coding. Englewood Cliffs, New Jersey, USA: Prentice-Hall. ISBN 0-13-210071-1.
- «Error Correction Code in Single Level Cell NAND Flash memories» 2007-02-16
- «Error Correction Code in NAND Flash memories» 2004-11-29
- Observations on Errors, Corrections, & Trust of Dependent Systems, by James Hamilton, 2012-02-26
- Sphere Packings, Lattices and Groups, By J. H. Conway, Neil James Alexander Sloane, Springer Science & Business Media, 2013-03-09 – Mathematics – 682 pages.
External links[edit]
- Morelos-Zaragoza, Robert (2004). «The Correcting Codes (ECC) Page». Retrieved 5 March 2006.
- lpdec: library for LP decoding and related things (Python)
4.3. Метод коррекции ошибок FEC (Forward Error Correction)
Транспортировка данных подвержена влиянию шумов и наводок, которые вносят искажения. Если вероятность повреждения данных мала, достаточно зарегистрировать сам факт искажения и повторить передачу поврежденного фрагмента.
Когда вероятность искажения велика, например, в каналах коммуникаций с геостационарными спутниками, используются методы коррекции ошибок. Одним из таких методов является FEC (Forward Error Correction, иногда называемое канальным кодированием ) [4.1]. Технология FEC в последнее время достаточно широко используется в беспроводных локальных сетях (WLAN). Существуют две основные разновидности FEC: блочное кодирование и кодирование по методу свертки.
Блочное кодирование работает с блоками (пакетами) бит или символов фиксированного размера. Метод свертки работает с потоками бит или символов произвольной протяженности. Коды свертки при желании могут быть преобразованы в блочные коды.
Существует большое число блочных кодов, одним из наиболее важных является алгоритм Рида-Соломона, который используется при работе с CD, DVD и жесткими дисками ЭВМ. Блочные коды и коды свертки могут использоваться и совместно.
Для FEC -кодирования иногда используется метод сверки, который впервые был применен в 1955 году. Главной особенностью этого метода является сильная зависимость кодирования от предыдущих информационных битов и высокие требования к объему памяти. FEC -код обычно просматривает при декодировании 2-8 бит десятки или даже сотни бит, полученных ранее.
В 1967 году Эндрю Витерби (Andrew Viterbi) разработал технику декодирования, которая стала стандартной для кодов свертки. Эта методика требовала меньше памяти. Метод свертки более эффективен, когда ошибки распределены случайным образом, а не группируются в кластеры. Работа же с кластерами ошибок более эффективна при использовании алгебраического кодирования.
Одной из широко применяемых разновидностей коррекции ошибок является турбо-кодирование, разработанное американской аэрокосмической корпорацией. В этой схеме комбинируется два или более относительно простых кодов свертки. В FEC, так же как и в других методах коррекции ошибок (коды Хэмминга, алгоритм Рида-Соломона и др.), блоки данных из k бит снабжаются кодами четности, которые пересылаются вместе с данными и обеспечивают не только детектирование, но и исправление ошибок. Каждый дополнительный (избыточный) бит является сложной функцией многих исходных информационных бит. Исходная информация может содержаться в выходном передаваемом коде, тогда такой код называется систематическим, а может и не содержаться.
В результате через канал передается n -битовое кодовое слово ( n>k ). Конкретная реализация алгоритма FEC характеризуется комбинацией ( n, k ). Применение FEC в Интернете регламентируется документом RFC3452. Коды FEC могут исключить необходимость обратной связи при потере или искажении доставленных данных (запросы повторной передачи). Особенно привлекательна технология FEC при работе с мультикастинг-потоками, где ретрансмиссия не предусматривается (см. RFC-3453).
В 1974 году Йозеф Оденвальдер (Joseph odenwalder) объединил возможности алгебраического кодирования и метода свертки. Хорошего результата можно добиться, введя специальную операцию псевдослучайного перемешивания бит (interleaver).
В 1993 году группой Клода Берроу (Claude Berrou) был разработан турбо-код. В кодеке, реализующем этот алгоритм, содержатся кодировщики как минимум двух компонент (реализующие алгебраический метод или свертку). Кодирование осуществляется для блоков данных. Здесь также используется псевдослучайное перемешивание бит перед передачей. Это приводит к тому, что кластеры ошибок, внесенных при транспортировке, оказываются разнесенными случайным образом в пределах блока данных.
На
рис.
4.8 проводится сравнение вариантов BER (Bit Error Rate) при обычной транспортировке данных через канал и при передаче тех же данных с использованием коррекции ошибок FEC для разных значений отношения сигнал-шум ( S/N ). Из этих данных видно, что при отношении S/N= 8 дБ применение FEC позволяет понизить BER примерно в 100 раз. При этом достигается результат, близкий (в пределах одного децибела) к теоретическому пределу Шеннона.
За последние пять лет были разработаны программы, которые позволяют оптимизировать структуры турбо-кодов. Улучшение BER для турбокодов имеет асимптотический предел, и дальнейшее увеличение S/N уже не дает никакого выигрыша. Но схемы, позволяющие смягчить влияние этого насыщения, продолжают разрабатываться.
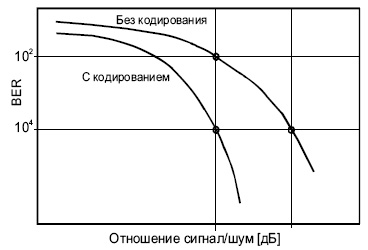
Рис.
4.8.
Турбо-кодек должен иметь столько же компонентных декодеров, сколько имеется кодировщиков на стороне передатчика. Декодеры соединяются последовательно.
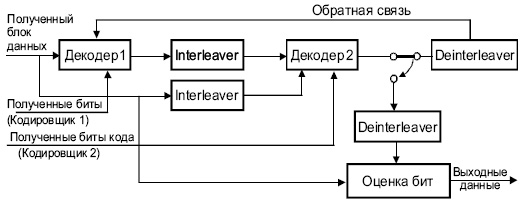
Рис.
4.9.
Турбо-декодер
Техника FEC находит все большее применение в телекоммуникациях, например, при передачи мультимедиа [2].
Следует помнить, что, как в случае FEC , так и в других известных методах коррекции ошибок ( BCH , Golay, Hamming и др.) скорректированный код является верным лишь с определенной конечной вероятностью.
Forward Error Correction (FEC) is a technique used to minimize errors in data transmission over communication channels. In real-time multimedia transmission, re-transmission of corrupted and lost packets is not useful because it creates an unacceptable delay in reproducing : one needs to wait until the lost or corrupted packet is resent. Thus, there must be some technique which could correct the error or reproduce the packet immediately and give the receiver the ability to correct errors without needing a reverse channel to request re-transmission of data. There are various FEC techniques designed for this purpose.
These are as follows :
1. Using Hamming Distance :
For error correction, the minimum hamming distance required to correct t errors is:
For example, if 20 errors are to be corrected then the minimum hamming distance has to be 2*20+1= 41 bits. This means, lots of redundant bits need to be sent with the data. This technique is very rarely used as we have large amount of data to be sent over the networks, and such a high redundancy cannot be afforded most of the time.
2. Using XOR :
The exclusive OR technique is quite useful as the data items can be recreated by this technique. The XOR property is used as follows –
If the XOR property is applied on N data items, we can recreate any of the data items P1 to PN by exclusive-Oring all of the items, replacing the one to be created by the result of the previous operation(R). In this technique, a packet is divided into N chunks, and then the exclusive OR of all the chunks is created and then, N+1 chunks are sent. If any chunk is lost or corrupted, it can be recreated at the receiver side.
Practically, if N=4, it means that 25 percent extra data has to be sent and the data can be corrected if only one out of the four chunks is lost.
3. Chunk Interleaving :
In this technique, each data packet is divided into chunks. The data is then created chunk by chunk(horizontally) but the chunks are combined into packets vertically. This is done because by doing so, each packet sent carries a chunk from several original packets. If the packet is lost, we miss only one chunk in each packet, which is normally acceptable in multimedia communication. Some small chunks are allowed to be missing at the receiver. One chunk can be afforded to be missing in each packet as all the chunks from the same packet cannot be allowed to miss.
Упреждающая коррекция ошибок FEC (Forward Error Correction) нашла широкое применение в технике оптической связи последнего поколения. Её использование предусмотрено стандартами передачи SDH, OTH, Ethernet.
Для обнаружения и исправления ошибок чаще всего используются циклические блочные коды (коды Хэмминга, коды Боуза-Чоудхури-Хоквенгема (БХЧ), коды Рида-Соломона (RS). Подробные сведения о этих кодах приведены в ряде изданий [115, 116,117].
В технике оптических систем нашли широкое применение коды Рида-Соломона (Reed-Solomon – RS). При использовании этих кодов данные обрабатываются порциями по m-бит, которые именуют символами. Код RS(n, k) характеризуется следующими параметрами:
- длина символа m бит;
- длина блока n = (2m – 1) символов = m(2m – 1) бит;
- длина блока данных k символов;
- n – k = 2t символов = m(2t) бит;
- минимальное расстояние Хэмминга dmin = (2t + 1);
- число ошибок, требующих исправления t.
Алгоритм кодирования RS(n, k) расширяет блок k символов до размера n, добавляя (n – k) избыточных контрольных символов. Как правило, длина символа является степенью 2 и широко используется значение m = 8, т.е. символ равен одному байту. Для исправления всех 1 и 3 битовых ошибок в символах требуется выполнение неравенства:
![]() . (8.22)
. (8.22)
Рисунок 8.33. Образование строки с блоком контроля FEC
Для исправления ошибок применяется 16-символьный код RS(255, 239), который относится к классу линейных циклических блочных кодов.Каждый цикл передачи, например, STM-N или OTUk разбивается на блоки символов данных по 239 байт. Каждому такому блоку вычисляется контрольный блок из 16 символов – байт и присоединяется к 239 байтам, 240-255 байты. Т.о. n = 255, k = 239, т.е. RS(255, 239). Объединенный блок k и n – k образуют подстроку цикла. Синхронное побайтовое мультиплексирование подстрок образует одну строку цикла (рисунок 8.33).Порядок передачи строки слева направо. При формировании блока (n – k) блок данных k сдвигается на n – k и делится на производящий полином:
Р = х8 + х4 + х3 + х2 + 1. (8.23)
В результате получается частное от деления и остаток деления длиной n – k. Блок данных k и остаток деления объединяются, образуя подстроку. После передачи подстроки на приемной стороне производится ее деление на производящий полином Р, аналогичный тому что был на передаче. если после деления остаток ноль, то передача прошла без ошибок. Если после деления остаток не равен нулю, то это признак ошибки. Место положения ошибки в блоке k обнаруживается по остатку, например табличным методом.
Исправлению подлежит заданное количество ошибок в символе (1, 2 или более в байте). Благодаря тому, что RS(255, 239) имеет расстояние Хэмминга dmin = 17 можно корректировать до 8 символьных ошибок.
Таблица 8.6 Пример результата расчета коэффициента ошибок на выходе декодера FEC RS(255, 239)
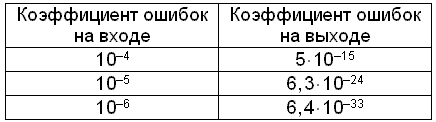
При этом число обнаруживаемых ошибок составляет 16 в подстроке с FEC. В таблице 8.6 приведен пример теоретически рассчитанного коэффициента ошибок на выходе декодера FEC RS(255, 239) [117].Практическая эффективность кодирования RS(255, 239) может составить от 5 до 8 дБ, т.е. FEC позволяет увеличивать длины участков передачи по сравнению с системами без FEC. Это особенно актуально на протяженных линиях оптической передачи и при реконструкции, когда производится переход на высокие скоростные режимы, например, с 2.5Гбит/с на 10Гбит/с. При этом очень важно сохранить длины участков передачи существующей сети и не строить дополнительных промежуточных станций.
Пример оценки эффективности применения упреждающей коррекции при цифровой передаче приведен на рисунке 8.34.
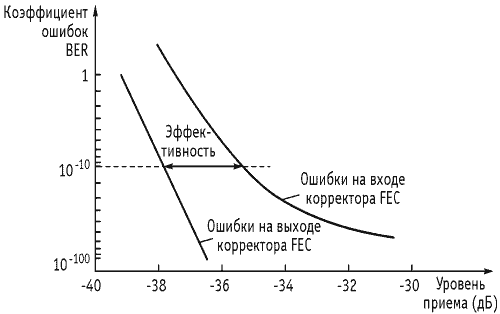
Рисунок 8.34. Эффективность использования FEC
Эта статья — о работе с ошибками в данных при их хранении или передаче. О контроле фактических ошибок в текстах см. Проверка фактов; о проверке знаний и навыков при обучении см. Педагогическое тестирование; о методе обучения нейросети см. Метод коррекции ошибки.
Контроль ошибок — комплекс методов обнаружения и исправления ошибок в данных при их записи и воспроизведении или передаче по линиям связи.
Контроль целостности данных и исправление ошибок — важные задачи на многих уровнях работы с информацией (в частности, физическом, канальном, транспортном уровнях сетевой модели OSI) в связи с тем, что в процессе хранения данных и передачи информации по сетям связи неизбежно возникают ошибки. Различные области применения контроля ошибок диктуют различные требования к используемым стратегиям и кодам.
В системах связи возможны несколько стратегий борьбы с ошибками:
- обнаружение ошибок в блоках данных и автоматический запрос повторной передачи[⇨] повреждённых блоков — этот подход применяется, в основном, на канальном и транспортном уровнях;
- обнаружение ошибок в блоках данных и отбрасывание повреждённых блоков — такой подход иногда применяется в системах потокового мультимедиа, где важна задержка передачи и нет времени на повторную передачу;
- упреждающая коррекция ошибок добавляет к передаваемой информации такие дополнительные данные, которые позволяют исправить ошибки без дополнительного запроса.
В контроле ошибок, как правило, используется помехоустойчивое кодирование — кодирование данных при записи или передаче и декодирование при считывании или получении при помощи корректирующих кодов, которые и позволяют обнаружить и, возможно, исправить ошибки в данных. Алгоритмы помехоустойчивого кодирования в различных приложениях могут быть реализованы как программно, так и аппаратно.
Современное развитие корректирующих кодов приписывают Ричарду Хэммингу с 1947 года[1]. Описание кода Хэмминга появилось в статье Клода Шеннона «Математическая теория связи»[2] и было обобщено Марселем Голеем[3].
Стратегии исправления ошибок
Упреждающая коррекция ошибок
Упреждающая коррекция ошибок (также прямая коррекция ошибок, англ. Forward Error Correction, FEC) — техника помехоустойчивого кодирования и декодирования, позволяющая исправлять ошибки методом упреждения. Применяется для исправления сбоев и ошибок при передаче данных путём передачи избыточной служебной информации, на основе которой может быть восстановлено первоначальное содержание. На практике широко используется в сетях передачи данных, телекоммуникационных технологиях. Коды, обеспечивающие прямую коррекцию ошибок, требуют введения большей избыточности в передаваемые данные, чем коды, которые только обнаруживают ошибки.
Например, в спутниковом телевидении при передаче цифрового сигнала с FEC 7/8 передаётся восемь бит информации: 7 бит полезной информации и 1 контрольный бит[4]; в DVB-S используется всего 5 видов: 1/2, 2/3, 3/4 (наиболее популярен), 5/6 и 7/8. При прочих равных условиях, можно утверждать, что чем ниже значение FEC, тем меньше пакетов допустимо потерять, и, следовательно, выше требуемое качество сигнала.
Техника прямой коррекции ошибок широко применяется в различных устройствах хранения данных — жёстких дисках, флеш-памяти, оперативной памяти. В частности, в серверных приложениях применяется ECC-память — оперативная память, способная распознавать и исправлять спонтанно возникшие ошибки.
Автоматический запрос повторной передачи
Системы с автоматическим запросом повторной передачи (англ. Automatic Repeat Request, ARQ) основаны на технологии обнаружения ошибок. Распространены следующие методы автоматического запроса:
Идея запроса ARQ с остановками (англ. stop-and-wait ARQ) заключается в том, что передатчик ожидает от приемника подтверждения успешного приема предыдущего блока данных перед тем, как начать передачу следующего. В случае, если блок данных был принят с ошибкой, приемник передает отрицательное подтверждение (negative acknowledgement, NAK), и передатчик повторяет передачу блока. Данный метод подходит для полудуплексного канала связи. Его недостатком является низкая скорость из-за высоких накладных расходов на ожидание.
Для метода непрерывного запроса ARQ с возвратом (continuous ARQ with pullback) необходим полнодуплексный канал. Передача данных от передатчика к приемнику производится одновременно. В случае ошибки передача возобновляется, начиная с ошибочного блока (то есть передается ошибочный блок и все последующие).
При использовании метода непрерывного запроса ARQ с выборочным повторении (continuous ARQ with selective repeat) осуществляется передача только ошибочно принятых блоков данных.
Сетевое кодирование
Раздел теории информации, изучающий вопрос оптимизации передачи данных по сети с использованием техник изменения пакетов данных на промежуточных узлах называют сетевым кодированием. Для объяснения принципов сетевого кодирования используют пример сети «бабочка», предложенной в первой работе по сетевому кодированию «Network information flow»[5]. В отличие от статического сетевого кодирования, когда получателю известны все манипуляции, производимые с пакетом, также рассматривается вопрос о случайном сетевом кодировании, когда данная информация неизвестна. Авторство первых работ по данной тематике принадлежит Кёттеру, Кшишангу и Силве[6]. Также данный подход называют сетевым кодированием со случайными коэффициентами — когда коэффициенты, под которыми начальные пакеты, передаваемые источником, войдут в результирующие пакеты, принимаемые получателем, с неизвестными коэффициентами, которые могут зависеть от текущей структуры сети и даже от случайных решений, принимаемых на промежуточных узлах. Для неслучайного сетевого кодирования можно использовать стандартные способы защиты от помех и искажений, используемых для простой передачи информации по сети.
Энергетический выигрыш
При передаче информации по каналу связи вероятность ошибки зависит от отношения сигнал/шум на входе демодулятора, таким образом, при постоянном уровне шума решающее значение имеет мощность передатчика. В системах спутниковой и мобильной, а также других типов связи остро стоит вопрос экономии энергии. Кроме того, в определённых системах связи (например, телефонной) неограниченно повышать мощность сигнала не дают технические ограничения.
Поскольку помехоустойчивое кодирование позволяет исправлять ошибки, при его применении мощность передатчика можно снизить, оставляя скорость передачи информации неизменной. Энергетический выигрыш определяется как разница отношений с/ш при наличии и отсутствии кодирования.
Примечания
- ↑ Thompson, Thomas M. (1983), From Error-Correcting Codes through Sphere Packings to Simple Groups, The Carus Mathematical Monographs (#21), The Mathematical Association of America, с. vii, ISBN 0-88385-023-0
- ↑ Shannon, C.E. (1948), A Mathematical Theory of Communication, Bell System Technical Journal (p. 418) Т. 27 (3): 379–423, PMID 9230594, DOI 10.1002/j.1538-7305.1948.tb01338.x
- ↑ Golay, Marcel J. E. (1949), Notes on Digital Coding, Proc.I.R.E. (I.E.E.E.) (p. 657) Т. 37
- ↑ Understanding Digital Television: An Introduction to Dvb Systems With … — Lars-Ingemar Lundström — Google Книги. Дата обращения: 19 мая 2020. Архивировано 11 ноября 2021 года.
- ↑ Ahlswede, R.; Ning Cai; Li, S.-Y.R.; Yeung, R.W., «Network information flow», Information Theory, IEEE Transactions on, vol.46, no.4, pp.1204-1216, Jul 2000
- ↑ Статьи:
- Koetter R., Kschischang F.R. Coding for errors and erasures in random network coding// IEEE International Symposium on Information Theory. Proc.ISIT-07.-2007.- P. 791—795.
- Silva D., Kschischang F.R. Using rank-metric codes for error correction in random network coding // IEEE International Symposium on Information Theory. Proc. ISIT-07. — 2007.
- Koetter R., Kschischang F.R. Coding for errors and erasures in random network coding // IEEE Transactions on Information Theory. — 2008- V. IT-54, N.8. — P. 3579-3591.
- Silva D., Kschischang F.R., Koetter R. A Rank-Metric Approach to Error Control in Random Network Coding // IEEE Transactions on Information Theory.- 2008- V. IT-54, N. 9.- P.3951-3967.
Литература
- Блейхут Р. Теория и практика кодов, контролирующих ошибки = Theory and Practice of Error Control Codes. — М.: Мир, 1986. — 576 с.
- Мак-Вильямс Ф. Дж., Слоэн Н. Дж. А. Теория кодов, исправляющих ошибки. М.: Радио и связь, 1979.
- Морелос-Сарагоса Р. Искусство помехоустойчивого кодирования. Методы, алгоритмы, применение / пер. с англ. В. Б. Афанасьева. — М.: Техносфера, 2006. — 320 с. — (Мир связи). — 2000 экз. — ISBN 5-94836-035-0.
- Clark, George C., Jr., and J. Bibb Cain. Error-Correction Coding for Digital Communications. New York: Plenum Press, 1981. ISBN 0-306-40615-2.
- Lin, Shu, and Daniel J. Costello, Jr. «Error Control Coding: Fundamentals and Applications». Englewood Cliffs, N.J.: Prentice-Hall, 1983. ISBN 0-13-283796-X.
- Mackenzie, Dana. «Communication speed nears terminal velocity». New Scientist 187.2507 (9 июля 2005): 38-41. ISSN 0262-4079.
- Wicker, Stephen B. Error Control Systems for Digital Communication and Storage. Englewood Cliffs, N.J.: Prentice-Hall, 1995. ISBN 0-13-200809-2.
- Wilson, Stephen G. Digital Modulation and Coding, Englewood Cliffs, N.J.: Prentice-Hall, 1996. ISBN 0-13-210071-1.
Ссылки
- Charles Wang, Dean Sklar, and Diana Johnson. Forward Error-Correction Coding. The Aerospace Corporation. — Volume 3, Number 1 (Winter 2001/2002). Дата обращения: 24 мая 2009. Архивировано из оригинала 20 февраля 2005 года. (англ.)
- Charles Wang, Dean Sklar, and Diana Johnson. How Forward Error-Correcting Codes Work (недоступная ссылка — история). The Aerospace Corporation. Дата обращения: 24 мая 2009. Архивировано 25 февраля 2012 года. (англ.)
- Morelos-Zaragoza, Robert The Error Correcting Codes (ECC) Page (недоступная ссылка — история) (2004). Дата обращения: 24 мая 2009. Архивировано 25 февраля 2012 года. (англ.)
![]()
Эта страница в последний раз была отредактирована 17 октября 2022 в 07:46.
Как только страница обновилась в Википедии она обновляется в Вики 2.
Обычно почти сразу, изредка в течении часа.