os: mac os yosemite
python: 2.7.6 — 64-bit
installed: numpy,skipy,matplotlib,nose
I get the following error.
>>> from sklearn.datasets import load_iris
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named sklearn.datasets
$ pip install --user --install-option="--prefix=" -U scikit-learn
Requirement already up-to-date: scikit-learn in /Library/Python/2.7/site-packages
Cleaning up...
Someone help me please!
asked Nov 14, 2014 at 14:40
![]()
pollseedpollseed
1011 gold badge2 silver badges5 bronze badges
export PYTHONPATH=$PYTHONPATH:/usr/local/lib/python2.7/site-packages
or export PYTHONPATH=$PYTHONPATH:’path where your installed modules are’
to find out the path where your modules are installed, try to run pip install again and it will output the location
answered Mar 4, 2015 at 16:55
![]()
JackNovaJackNova
3,8915 gold badges30 silver badges48 bronze badges
1
Ran into a similar problem recently and spent too much time googling it while the error was simple: my file was named sklearn.py It might be why your import is not working.
answered Feb 20, 2018 at 14:13
![]()
When installing on Ubuntu Linux you have to have to install dependencies first using apt-get, then use a pip install otherwise the normal pip install of scikit-learn won’t work properly. See below:
Step 1: Make sure apt-get is updated
sudo apt-get update
Step 2: Install dependencies
sudo apt-get install build-essential python-dev python-setuptools python-numpy python-scipy libatlas-dev libatlas3gf-base
Step 3: pip install Scikit Learn
pip install —user —install-option=»—prefix=» -U scikit-learn
Hope this helps!
answered Apr 3, 2015 at 19:49
![]()
I had the same problem. I solved just writing:
from sklearn import datasets
data = datasets.load_iris()
answered Oct 8, 2019 at 10:26
![]()
sklearn I was sure that you have installed.
So, after you create a symbolic link the sklearn to Python interpreter, it went well.
ln -s 'path of sklearn' 'path of python interpreter'
answered Nov 15, 2014 at 2:20
![]()
pollseedpollseed
1011 gold badge2 silver badges5 bronze badges
Are you sure you’re running the right Python? It may be that scikit-learn is only installed for Python3, and not Python 2, so you may need to run python3 my_code.py instead of just python my_code.py.
answered Sep 20, 2022 at 9:27
![]()
Pro QPro Q
4,1144 gold badges39 silver badges86 bronze badges
I think this is a sklearn bug in that sklearn is pulling numpy warning filters off the stack when importing.
numpy normally filters these Cython compatibility warnings: https://github.com/numpy/numpy/pull/432/files
In [1]: import numpy as np
In [2]: np.warnings.filters
Out[2]:
[('ignore',
re.compile(r'numpy.ufunc size changed', re.IGNORECASE),
Warning,
re.compile(r''),
0),
('ignore',
re.compile(r'numpy.dtype size changed', re.IGNORECASE),
Warning,
re.compile(r''),
0),
('always', None, numpy.lib.polynomial.RankWarning, None, 0),
('ignore',
re.compile(r'sys.exc_clear', re.IGNORECASE),
DeprecationWarning,
re.compile(r'threading'),
0),
('ignore', None, DeprecationWarning, None, 0),
('ignore', None, PendingDeprecationWarning, None, 0),
('ignore', None, ImportWarning, None, 0),
('ignore', None, BytesWarning, None, 0)]
However, if I import almost any sklearn subpackage, these filters are getting pulled off the filters list:
In [3]: import sklearn.covariance
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/stats/_continuous_distns.py:24: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility
from . import vonmises_cython
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/stats/_continuous_distns.py:24: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility
from . import vonmises_cython
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/stats/stats.py:188: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility
from ._rank import rankdata, tiecorrect
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/stats/stats.py:188: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility
from ._rank import rankdata, tiecorrect
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/interpolate/interpolate.py:28: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility
from . import _ppoly
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/interpolate/interpolate.py:28: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility
from . import _ppoly
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/spatial/__init__.py:90: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility
from .ckdtree import *
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/spatial/__init__.py:90: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility
from .ckdtree import *
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/spatial/__init__.py:91: RuntimeWarning: numpy.dtype size changed, may indicate binary incompatibility
from .qhull import *
/Users/mb312/.virtualenvs/numpy-help/lib/python2.7/site-packages/scipy/spatial/__init__.py:91: RuntimeWarning: numpy.ufunc size changed, may indicate binary incompatibility
from .qhull import *
In [4]: np.warnings.filters
Out[4]:
[('ignore', None, sklearn.utils.validation.NonBLASDotWarning, None, 0),
('always', None, sklearn.utils.validation.DataConversionWarning, None, 0)]
This does not occur importing sklearn or sklearn.base, but does for at least utils, cluster, covariance, datasets, metrics, svm. I haven’t tested the other subpackages.
The root cause for modulenotfounderror: no module named ‘sklearn.datasets.samples_generator‘ is samples_generator module replacement in scikit-learn. Apart from it, Another most common reason behind the same error is bad practice for developers to import any Python statement. Well, I know two lines about root causes are not sufficient to fix the issue. Hence let’s understand the same in a detailed way.
modulenotfounderror: no module named ‘sklearn.datasets.samples_generator’ ( Root Cause and Fix ) –
Well in both of the most possible root causes, module replacement in the latest version is more frequent. So let’s explore it first.
Case 1: Internal code structure change
Actually, if you are using this importing statement in the recent version of sckit-learn –
from sklearn.datasets.samples_generator import make_blobs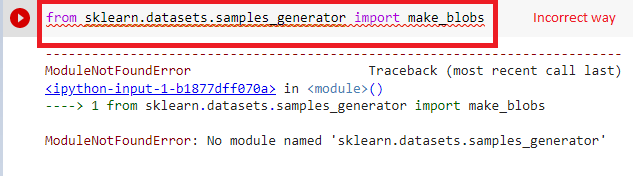
Then you will encounter this error for sure. Because this samples_generator explicitly is not available in scikit-learn in recent versions. So we better call the above statement in correct way like below –
from sklearn.datasets import make_blobs
Case 2: Syntax error ( Not Valid for recent scikit-learn module)
Sometimes The syntax we write for importing any python module is typically wrong. IN order to differentiate between incorrect and correct ones. Let’s take the practical example –
Incorrect –
import sklearn.datasets.samples_generatorHere we directly import all together but that is a syntax error in python. The funny fact is most of us do it like this including me as well. Well, now let’s see the correct way for this.
from sklearn.datasets.samples_generator import make_blobsBut this will run in the lower version of scikit-learn because as I explained in the above section samples_generator no longer exists separately. But In some scenarios, where we are running the lower version for scikit-learn, we can use the above way of importing.
Bonus Tip –
Do not forget to install scikit-learn again if the error persists even after retrying these tricks. Use any of the below package managers to install the module.
pip install -U scikit-learnOr
conda install -c anaconda scikit-learnThanks
Data Science Learner Team

Join our list
Subscribe to our mailing list and get interesting stuff and updates to your email inbox.
We respect your privacy and take protecting it seriously
Thank you for signup. A Confirmation Email has been sent to your Email Address.
Something went wrong.
не может использовать scikit-learn — «AttributeError: объект« модуль »не имеет атрибута …»
Я пытаюсь следовать этот учебник scikit-learn (линейная регрессия).
Я установил scikit через pip install -U scikit-learn, я использую Python 2.7 и Ubuntu 13.04
Когда я пытаюсь запустить первые строки кода, я получаю сообщение об ошибке, и это происходит каждый раз, когда я пытаюсь запустить что-либо с помощью scikit-learn.
import pylab as pl
import numpy as np
from sklearn import datasets, linear_model
# Load the diabetes dataset
diabetes = datasets.load_diabetes()
Я получаю следующее:
AttributeError: 'module' object has no attribute 'load_diabetes'
Когда я пытаюсь:
regr = linear_model.LinearRegression()
Я получил :
AttributeError: 'module' object has no attribute 'LinearRegression'
Мне кажется, что либо я неправильно использую пакет (но я скопировал из их туториала), либо я что-то не так установил (но пакет загружается успешно).
Может кто поможет?
10 ответы
Другая причина этой проблемы (не проблема с кодом OP), но та, которая меня достала, заключается в том, что python не импортирует автоматически подпакеты или модули, если это явно не сделано разработчиком пакета. А также sklearn не импортирует автоматически свои подпакеты, поэтому, если у вас есть
import sklearn
diabetes = sklearn.datasets.load_diabetes()
тогда вы получите
AttributeError: module 'sklearn' has no attribute 'datasets'
Это очень вводящее в заблуждение сообщение об ошибке, потому как sklearn есть подпакет под названием datasets — вам просто нужно импортировать его явно
import sklearn.datasets
diabetes = sklearn.datasets.load_diabetes()
Создан 13 июн.
![]()
ОК .. Наконец-то нашел .. Публикую здесь на случай, если кто-то столкнется с той же проблемой.
У меня была другая версия sklearn (вероятно, из-за установки apt-get) в другом каталоге. Он как-то частично установился, но загрузился именно он.
Обязательно посмотрите на свой pip вывод скрипта, чтобы увидеть, где он устанавливает пакет, и когда вы загружаете его из python, проверьте sklearn.__path__ посмотреть, откуда он берется.
ответ дан 26 мая ’13, 07:05
![]()
Это сработало для меня:
from sklearn.datasets import make_moons
ответ дан 30 мая ’16, 08:05
![]()
Я столкнулся с той же проблемой, но потом понял, что имя моей программы было sklearn.py . В случае, если кто-либо увидит этот тип ошибки, также проверьте, что имя вашей программы не совпадает с именем пакета, иначе вы получите module object has no attribute error, как в вопросе.
Создан 01 янв.
![]()
Похоже, что пакет, загруженный из sklearn, был пакетом из дистрибутивной библиотеки, а не установленным из pip. Решение для меня (debian) состояло в том, чтобы переустановить пакет pip. Это можно проверить с помощью:
import sklearn
sklearn.__path__
Если это показывает /usr/lib/python/, то это использование дистрибутива.
Проблема решилась удалением и переустановкой sklearn.
$ pip uninstall scikit-learn
$ pip install scikit-learn
Создан 21 янв.
![]()
Я столкнулся с аналогичной проблемой и этим сообщением с:
«*** AttributeError: объект GaussianProcessRegressor не имеет атрибута _y_train_mean»
когда я обновил scikit-learn, загрузил маринованную модель и попытался предсказать ее использование. Мне просто нужно было переобучить модель, и это решило мою проблему.
Создан 26 июля ’18, 19:07
![]()
Попробуй это:
from sklearn.datasets import load_diabetes
diabetes = load_diabetes()
Создан 24 июля ’18, 13:07
![]()
У меня была аналогичная проблема, и я попытался устранить неполадки на основе этой статье Ник Коглан, поскольку ни один из предложенных ответов, похоже, не решил мою проблему.
Я попал в так называемую «Двойная ловушка импорта«. что у меня было что-то вроде:
import sklearn
import sklearn.preprocessing
удалив один из импортов и сбросив рабочее пространство, мне удалось решить проблему.
ответ дан 27 авг.
![]()
Я решил эту проблему, вставив следующие строки кода:
import sklearn
from sklearn.linear_model import LinearRegression
Создан 11 фев.
![]()
Я назвал файл python как sklearn.py, что было причиной этого ATTRIBUTEERROR со мной. Переименовал это и разрешил.
ответ дан 07 апр.
![]()
Не тот ответ, который вы ищете? Просмотрите другие вопросы с метками
python-2.7
scikit-learn
or задайте свой вопрос.
Вопрос:
os: mac os yosemite
python: 2.7.6 – 64-бит
установлен: numpy, skipy, matplotlib, нос
Я получаю следующую ошибку.
>>> from sklearn.datasets import load_iris
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
ImportError: No module named sklearn.datasets
$ pip install --user --install-option="--prefix=" -U scikit-learn
Requirement already up-to-date: scikit-learn in /Library/Python/2.7/site-packages
Cleaning up...
Кто-нибудь мне поможет!
Ответ №1
export PYTHONPATH = $PYTHONPATH:/usr/local/lib/python2.7/site-packages
или экспортировать PYTHONPATH = $PYTHONPATH: ‘путь, где установлены ваши модули’
чтобы узнать путь, в котором установлены ваши модули, попробуйте снова запустить установку pp и выведет местоположение
Ответ №2
При установке на Ubuntu Linux вам нужно сначала установить зависимости, используя apt-get, а затем использовать установку pip, иначе обычная установка scikit-learn не будет работать должным образом. См. Ниже:
Шаг 1. Убедитесь, что apt-get обновлен.
Обновление sudo apt-get
Шаг 2. Установка зависимостей
sudo apt-get install build-essential python-dev python-setuptools python-numpy python-scipy libatlas-dev libatlas3gf-base
Шаг 3: выберите программу Scikit Learn
pip install –user –install-option = “- prefix =” -U scikit-learn
Надеюсь, это поможет!
Ответ №3
В последнее время возникла аналогичная проблема и потратил слишком много времени на поиск в Google, хотя ошибка была простой: мой файл был назван sklearn.py Возможно, ваш импорт не работает.
Ответ №4
sklearn Я был уверен, что вы установили.
Итак, после создания символической ссылки sklearn на интерпретатор Python, она прошла хорошо.
ln -s 'path of sklearn' 'path of python interpreter'
Ответ №5
Проблема здесь может заключаться в том, как вы импортируете пакет.
Вместо импорта, например,
from sklearn.datasets import load_iris
попробуйте это
from sklearn import datasets
iris_data = datasets.load_iris()
Это помогло мне надеяться, что это поможет.
Ответ №6
У меня такая же проблема. Я решил просто написать:
from sklearn import datasets
data = datasets.load_iris()
Библиотека Scikit-Learn предоставляет чистые датасеты, которые вы можете использовать при построении моделей машинного обучения. Они поставляются вместе с Scikit-Learn. Вам не нужно ничего скачивать. С помощью всего нескольких строк кода вы будете иметь готовые для работы данные.
Наличие готовых датасетов является огромным преимуществом, потому что вы можете сразу приступить к созданию моделей, не тратя время на получение, очистку и преобразование данных — на что специалисты по данным тратят много времени.
Даже после того, как вся подготовительная работа выполнена, применение выборок Scikit-Learn поначалу может показаться вам немного запутанным. Не волнуйтесь, через несколько минут вы точно узнаете, как использовать датасеты, и встанете на путь исследования мира искусственного интеллекта. В этой статье предполагается, что у вас установлены python, scikit-learn, pandas и Jupyter Notebook (или вы можете воспользоваться Google Collab). Давайте начнем.
Scikit-Learn предоставляет семь наборов данных, которые они называют игровыми датасетами. Не дайте себя обмануть словом «игровой». Эти выборки довольно объемны и служат хорошей отправной точкой для изучения машинного обучения (далее ML). Вот несколько примеров доступных наборов данных и способы их использования:
- Цены на жилье в Бостоне — используйте ML для прогнозирования цен на жилье на основе таких атрибутов, как количество комнат, уровень преступности в городе.
- Датасет диагностики рака молочной железы (Висконсин) — используйте ML для диагностики рака как доброкачественного (не распространяется на остальную часть тела) или злокачественного (распространяется).
- Распознавание вина — используйте ML для определения типа вина по химическим свойствам.
В этой статье мы будем работать с “Breast Cancer Wisconsin” (рак молочной железы, штат Висконсин) датасетом. Мы импортируем данные и разберем, как их читать. В качестве бонуса мы построим простую модель машинного обучения, которая сможет классифицировать сканированные изображения рака как злокачественные или доброкачественные.
Чтобы узнать больше о предоставленных выборках, нажмите здесь для перехода на документацию Scikit-Learn.
Как импортировать модуль datasets?
Доступные датасеты можно найти в sklearn.datasets. Давайте импортируем необходимые данные. Сначала мы добавим модуль datasets, который содержит все семь выборок.
from sklearn import datasets
У каждого датасета есть соответствующая функция, используемая для его загрузки. Эти функции имеют единый формат: «load_DATASET()», где DATASET — названием выборки. Для загрузки набора данных о раке груди мы используем load_breast_cancer(). Точно так же при распознавании вина мы вызовем load_wine(). Давайте загрузим выбранные данные и сохраним их в переменной data.
data = datasets.load_breast_cancer()
До этого момента мы не встретили никаких проблем. Но упомянутые выше функции загрузки (такие как load_breast_cancer()) не возвращают данные в табличном формате, который мы привыкли ожидать. Вместо этого они передают нам объект Bunch.
Не знаете, что такое Bunch? Не волнуйтесь. Считайте объект Bunch причудливым аналогом словаря от библиотеки Scikit-Learn.
Давайте быстро освежим память. Словарь — это структура данных, в которой данные хранятся в виде ключей и значений. Думайте о нем как о книге с аналогичным названием, к которой мы привыкли. Вы ищете интересующее вас слово (ключ) и получаете его определение (значение). У программистов есть возможность делать ключи и соответствующие значения какими угодно (могут быть словами, числами и так далее).
Например, в случае хранения персональных контактов ключами являются имена, а значениями — телефонные номера. Таким образом, словарь в Python не ограничивается его типичной репрезентацией, но может быть применен ко всему, что вам нравится.
Что в нашем Bunch-словаре?
Предоставленный Sklearn словарь Bunch — достаточно мощный инструмент. Давайте узнаем, какие ключи нам доступны.
Получаем следующие ключи:
data— это необходимые для предсказания данные (показатели, полученные при сканировании, такие как радиус, площадь и другие) в массиве NumPy.target— это целевые данные (переменная, которую вы хотите предсказать, в данном случае является ли опухоль злокачественной или доброкачественной) в массиве NumPy.
Значения этих двух ключей предоставляют нам необходимые для обучения данные. Остальные ключи (смотри ниже) имеют пояснительное предназначение. Важно отметить, что все датасеты в Scikit-Learn разделены на data и target. data представляет собой показатели, переменные, которые используются моделью для тренировки. target включает в себя фактические метки классов. В нашем случае целевые данные — это один столбец, в котором опухоль классифицируется как 0 (злокачественная) или 1 (доброкачественная).
feature_names— это названия показателей, другими словами, имена столбцов вdata.target_names— это имя целевой переменной или переменных, другими словами, название целевого столбца или столбцов.DESCR— сокращение от DESCRIPTION, представляет собой описание выборки.filename— это путь к файлу с данными в формате CSV.
Чтобы посмотреть значение ключа, вы можете ввести data.KEYNAME, где KEYNAME — интересующий ключ. Итак, если мы хотим увидеть описание датасета:
Вот небольшая часть полученного результата (полная версия слишком длинная для добавления в статью):
.. _breast_cancer_dataset:
Breast cancer wisconsin (diagnostic) dataset
--------------------------------------------
**Data Set Characteristics:**
:Number of Instances: 569
:Number of Attributes: 30 numeric, predictive attributes and the class
:Attribute Information:
- radius (mean of distances from center to points on the perimeter)
- texture (standard deviation of gray-scale values)
- perimeter
- area
- smoothness (local variation in radius lengths)
- compactness (perimeter^2 / area - 1.0)
- concavity (severity of concave portions of the contour)
- concave points (number of concave portions of the contour)
- symmetry
- fractal dimension ("coastline approximation" - 1)
...Вы также можете узнать информацию о выборке, посетив документацию Scikit-Learn. Их документация намного более читабельна и точна.
Работа с датасетом
Теперь, когда мы понимаем, что возвращает функция загрузки, давайте посмотрим, как можно использовать датасет в нашей модели машинного обучения. Прежде всего, если вы хотите изучить выбранный набор данных, используйте для этого pandas. Вот так:
# импорт pandas
import pandas as pd
# Считайте DataFrame, используя данные функции
df = pd.DataFrame(data.data, columns=data.feature_names)
# Добавьте столбец "target" и заполните его данными.
df['target'] = data.target
# Посмотрим первые пять строк
df.head()
| mean radius | mean texture | mean perimeter | mean area | mean smoothness | mean compactness | mean concavity | mean concave points | mean symmetry | mean fractal dimension | … | worst texture | worst perimeter | worst area | worst smoothness | worst compactness | worst concavity | worst concave points | worst symmetry | worst fractal dimension | target | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 17.99 | 10.38 | 122.80 | 1001.0 | 0.11840 | 0.27760 | 0.3001 | 0.14710 | 0.2419 | 0.07871 | … | 17.33 | 184.60 | 2019.0 | 0.1622 | 0.6656 | 0.7119 | 0.2654 | 0.4601 | 0.11890 | 0 |
| 1 | 20.57 | 17.77 | 132.90 | 1326.0 | 0.08474 | 0.07864 | 0.0869 | 0.07017 | 0.1812 | 0.05667 | … | 23.41 | 158.80 | 1956.0 | 0.1238 | 0.1866 | 0.2416 | 0.1860 | 0.2750 | 0.08902 | 0 |
| 2 | 19.69 | 21.25 | 130.00 | 1203.0 | 0.10960 | 0.15990 | 0.1974 | 0.12790 | 0.2069 | 0.05999 | … | 25.53 | 152.50 | 1709.0 | 0.1444 | 0.4245 | 0.4504 | 0.2430 | 0.3613 | 0.08758 | 0 |
| 3 | 11.42 | 20.38 | 77.58 | 386.1 | 0.14250 | 0.28390 | 0.2414 | 0.10520 | 0.2597 | 0.09744 | … | 26.50 | 98.87 | 567.7 | 0.2098 | 0.8663 | 0.6869 | 0.2575 | 0.6638 | 0.17300 | 0 |
| 4 | 20.29 | 14.34 | 135.10 | 1297.0 | 0.10030 | 0.13280 | 0.1980 | 0.10430 | 0.1809 | 0.05883 | … | 16.67 | 152.20 | 1575.0 | 0.1374 | 0.2050 | 0.4000 | 0.1625 | 0.2364 | 0.07678 | 0 |
Вы загрузили обучающую выборку в Pandas DataFrame, которая теперь полностью готова к изучению и использованию. Чтобы действительно увидеть возможности этого датасета, запустите:
RangeIndex: 569 entries, 0 to 568
Data columns (total 31 columns):
# Column Non-Null Count Dtype
--- ------ -------------- -----
0 mean radius 569 non-null float64
1 mean texture 569 non-null float64
2 mean perimeter 569 non-null float64
3 mean area 569 non-null float64
4 mean smoothness 569 non-null float64
5 mean compactness 569 non-null float64
6 mean concavity 569 non-null float64
7 mean concave points 569 non-null float64
8 mean symmetry 569 non-null float64
9 mean fractal dimension 569 non-null float64
10 radius error 569 non-null float64
11 texture error 569 non-null float64
12 perimeter error 569 non-null float64
13 area error 569 non-null float64
14 smoothness error 569 non-null float64
15 compactness error 569 non-null float64
16 concavity error 569 non-null float64
17 concave points error 569 non-null float64
18 symmetry error 569 non-null float64
19 fractal dimension error 569 non-null float64
20 worst radius 569 non-null float64
21 worst texture 569 non-null float64
22 worst perimeter 569 non-null float64
23 worst area 569 non-null float64
24 worst smoothness 569 non-null float64
25 worst compactness 569 non-null float64
26 worst concavity 569 non-null float64
27 worst concave points 569 non-null float64
28 worst symmetry 569 non-null float64
29 worst fractal dimension 569 non-null float64
30 target 569 non-null int32
dtypes: float64(30), int32(1)
memory usage: 135.7 KBНесколько вещей, на которые следует обратить внимание:
- Нет пропущенных данных, все столбцы содержат 569 значений. Это избавляет нас от необходимости учитывать отсутствующие значения.
- Все типы данных числовые. Это важно, потому что модели Scikit-Learn не принимают качественные переменные. В реальном мире, когда получаем такие переменные, мы преобразуем их в числовые. Датасеты Scikit-Learn не содержат качественных значений.
Следовательно, Scikit-Learn берет на себя работу по очистке данных. Эти наборы данных чрезвычайно удобны. Вы получите удовольствие от изучения машинного обучения, используя их.
Обучение на датесете из sklearn.datasets
Наконец, самое интересное. Далее мы построим модель, которая классифицирует раковые опухоли как злокачественные и доброкачественные. Это покажет вам, как использовать данные для ваших собственных моделей. Мы построим простую модель K-ближайших соседей.
Во-первых, давайте разделим выборку на две: одну для тренировки модели — предоставление ей данных для обучения, а вторую — для тестирования, чтобы посмотреть, насколько хорошо модель работает с данными (результаты сканирования), которые она раньше не видела.
X = data.data
y = data.target
# разделим данные с помощью Scikit-Learn's train_test_split
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(X, y)
Это дает нам два датасета — один для обучения и один для тестирования. Приступим к тренировке модели.
from sklearn.neighbors import KNeighborsClassifier
logreg = KNeighborsClassifier(n_neighbors=6)
logreg.fit(X_train, y_train)
logreg.score(X_test, y_test)
Получили на выходе 0.923? Это означает, что модель точна на 92%! Всего за несколько минут вы создали модель, которая классифицирует результаты сканирования опухолей с точностью 90%. Конечно, в реальном мире все сложнее, но это хорошее начало.
Ноутбук с кодом вы можете скачать здесь.
Вы многому научитесь, пытаясь построить модели с использованием datasets из Scikit-Learn. Удачного обучения искусственному интеллекту!
Jul-08-2019, 05:17 PM
(This post was last modified: Jul-08-2019, 05:17 PM by zaki424160.)
I am a python beginner and using Pycharm as IDE and Python 3.7.3. I am using an existing code when I run the code gives me an error
the code is
from tqdm import tqdm
from sklearn.datasets import fetch_mldata
from sklearn import datasets
from sklearn.model_selection import train_test_split
from sklearn.model_selection import cross_val_score
from sklearn import svm
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
import depmeas
import feature_select
if __name__ == '__main__':
NUM_CV = 3
RANDOM_SEED = 123
MAX_ITER = 1000
leuk = fetch_mldata('leukemia', transpose_data=True)
X = leuk['data']
y = leuk['target']
# split the data for testing
(X_train, X_test, y_train, y_test) = train_test_split(X, y, test_size=0.3, random_state=RANDOM_SEED)
# perform feature selection
num_features_to_select = 25
K_MAX = 1000
estimator = depmeas.mi_tau
n_jobs = -1
feature_ranking_idxs = feature_select.feature_select(X_train, y_train,
num_features_to_select=num_features_to_select, K_MAX=K_MAX,
estimator=estimator, n_jobs=n_jobs)
num_selected_features = len(feature_ranking_idxs)
# for each feature, compute the accuracy on the test data as we add features
mean_acc = np.empty((num_selected_features,))
std_acc = np.empty((num_selected_features,))
for ii in tqdm(range(num_selected_features), desc='Computing Classifier Performance...'):
classifier = svm.SVC(random_state=RANDOM_SEED, max_iter=MAX_ITER)
X_test_in = X_test[:, feature_ranking_idxs[0:ii + 1]]
scores = cross_val_score(classifier, X_test_in, y_test, cv=NUM_CV, n_jobs=-1)
mu = scores.mean()
sigma_sq = scores.std()
mean_acc[ii] = mu
std_acc[ii] = sigma_sq
x = np.arange(num_selected_features) + 1
y = mean_acc
yLo = mean_acc - std_acc / 2.
yHi = mean_acc + std_acc / 2.
plt.plot(x, y)
plt.fill_between(x, yLo, yHi, alpha=0.2)
plt.grid(True)
plt.title('Leukemia Dataset Feature Selectionn Total # Features=%d' % (X.shape[1]))
plt.xlabel('# Selected Features')
plt.ylabel('SVC Classifier Accuracy')
plt.show()
Error:
C:UserspcPycharmProjectsMymrmrTestvenvScriptspython.exe C:/Users/pc/PycharmProjects/MymrmrTest/feature_selection_test.py
C:UserspcPycharmProjectsMymrmrTestvenvlibsite-packagessklearnexternalsjoblib__init__.py:15: DeprecationWarning: sklearn.externals.joblib is deprecated in 0.21 and will be removed in 0.23. Please import this functionality directly from joblib, which can be installed with: pip install joblib. If this warning is raised when loading pickled models, you may need to re-serialize those models with scikit-learn 0.21+.
warnings.warn(msg, category=DeprecationWarning)
C:UserspcPycharmProjectsMymrmrTestvenvlibsite-packagessklearnutilsdeprecation.py:85: DeprecationWarning: Function fetch_mldata is deprecated; fetch_mldata was deprecated in version 0.20 and will be removed in version 0.22. Please use fetch_openml.
warnings.warn(msg, category=DeprecationWarning)
C:UserspcPycharmProjectsMymrmrTestvenvlibsite-packagessklearnutilsdeprecation.py:85: DeprecationWarning: Function mldata_filename is deprecated; mldata_filename was deprecated in version 0.20 and will be removed in version 0.22. Please use fetch_openml.
warnings.warn(msg, category=DeprecationWarning)
Traceback (most recent call last):
File "C:/Users/pc/PycharmProjects/MymrmrTest/feature_selection_test.py", line 34, in <module>
leuk = fetch_mldata('leukemia', transpose_data=True)
File "C:UserspcPycharmProjectsMymrmrTestvenvlibsite-packagessklearnutilsdeprecation.py", line 86, in wrapped
return fun(*args, **kwargs)
File "C:UserspcPycharmProjectsMymrmrTestvenvlibsite-packagessklearndatasetsmldata.py", line 126, in fetch_mldata
mldata_url = urlopen(urlname)
File "C:UserspcAppDataLocalProgramsPythonPython37liburllibrequest.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:UserspcAppDataLocalProgramsPythonPython37liburllibrequest.py", line 531, in open
response = meth(req, response)
File "C:UserspcAppDataLocalProgramsPythonPython37liburllibrequest.py", line 641, in http_response
'http', request, response, code, msg, hdrs)
File "C:UserspcAppDataLocalProgramsPythonPython37liburllibrequest.py", line 569, in error
return self._call_chain(*args)
File "C:UserspcAppDataLocalProgramsPythonPython37liburllibrequest.py", line 503, in _call_chain
result = func(*args)
File "C:UserspcAppDataLocalProgramsPythonPython37liburllibrequest.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 502: Bad Gateway
Process finished with exit code 1Posts: 818
Threads: 1
Joined: Mar 2018
Reputation:
111
Executing
fetch_mldata('leukemia', transpose_data=True)
I got the following error:
Error:
http.client.RemoteDisconnected: Remote end closed connection without responseProbably something wrong with the data source?!
ThomasL
Minister of Silly Walks
Posts: 361
Threads: 5
Joined: Jun 2019
Reputation:
64
As of version 0.20, sklearn deprecates fetch_mldata function and adds fetch_openml instead.
fetch_mldata() is deprecated