New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Closed
Needrom opened this issue
Apr 27, 2017
· 6 comments
Closed
ImportError: No module named transforms
#1376
Needrom opened this issue
Apr 27, 2017
· 6 comments
Comments
![]()
something wrong with import torchvision
import torchvision
import torchvision.transforms as transforms
Traceback (most recent call last):
File «torchvision.py», line 3, in
import torchvision
File «/Users/liangguoyu/PycharmProjects/pytorch/torchvision.py», line 4, in
import torchvision.transforms as transforms
ImportError: No module named transforms
![]()
you have a file called torchvision.py for some reason. delete it or change your pythonpath to ignore it.
![]()
Hey,
I have the same problem persisting when I import torchvision. I have no other file by the same name.
import torch
from torch.utils.data.dataset import Dataset
from torch.utils.data import DataLoader
from torchvision import transforms
ImportError Traceback (most recent call last)
in ()
8 from torch.utils.data.dataset import Dataset
9 from torch.utils.data import DataLoader
—> 10 from torchvision import transforms
ImportError: No module named torchvision
Any idea why this is happening?
![]()
Do you have torchvision installed (it is a separate package)?
![]()
pip Install torchvision
try this
![]()
from data import BaseTransform,VOC_CLASSES as labelmap
this is not working
![]()
pip Install torchvision
try this
pip install torchvision
jjsjann123
pushed a commit
to jjsjann123/pytorch
that referenced
this issue
Jan 26, 2022
![]()
* Have Kernel Inherit IrContainer (pytorch#1375) * Kernel<-Fusion Step 1 - Convert ExprSort to StmtSort (pytorch#1376) * Kernel<-Fusion Step 2 - Mutator refactor (pytorch#1377) * Kernel<-Fusion Step 3 - Debug print for expr_eval and type promotion fix (pytorch#1379) * Kernel<-Fusion Step 4 - Have kernel inherit Fusion (pytorch#1380) * Kernel<-Fusion Step 5 - Move lowering passes into their own files (pytorch#1382) * Kernel<-Fusion Step 6 - Remove kir::IrBuilder (pytorch#1383) * Kernel<-Fusion Step 7 - Remove kir functions from ComputeAtMap (pytorch#1384) * Kernel<-Fusion Step 8 - Clean up [lower/executor] utils (pytorch#1387) * Kernel<-Fusion Step 9 - Remove TensorView::fuserTv (pytorch#1388) * Kernel<-Fusion Step 10 - Remove lowerVal/lowerExpr (pytorch#1389) * Kernel<-Fusion Step 11 - Finish cleaning up kir (pytorch#1390)
Содержание
- from torchvision.transforms import ImageOps ImportError: cannot import name ‘ImageOps’ #2336
- Comments
- Error downloading MNIST dataset #20423
- Comments
- Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz 0it [00:00, ?it/s]
- Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
- Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
- VOCSegmentation #1263
- Comments
- Footer
- cannot import name ‘_update_worker_pids’ from ‘torch._C’ #16930
- Comments
- ❓ cannot import name ‘_update_worker_pids’ from ‘torch._C’
from torchvision.transforms import ImageOps ImportError: cannot import name ‘ImageOps’ #2336
cuda version 10.1
torch version 1.5.1
torchvision version 0.6.0
PIL version 5.2.0
I have also tried installing Pillow version 6.1 and torchvision version 0.5.0 and torch 1.4.0 using both methods conda and pip. But the error persists.
Kindly help!
The text was updated successfully, but these errors were encountered:
Can you try doing from PIL import ImageOps ?
Also, can you paste the full error message that you get? It is not recommended to import ImageOps from torchvision, as it’s a module from PIL that happens to be in the torchvision namespace.
Thank you. «from PIL import ImageOps» is working.
The full trace is:
Traceback (most recent call last):
File «./main.py», line 7, in
from data import get_dataset, DATASET_CONFIGS
File «/home/js/GR/data.py», line 4, in
from torchvision.transforms import ImageOps
ImportError: cannot import name ‘ImageOps’
This seems to be an issue in a codebase somewhere else than in torchvision, which relied on ImageOps being part of the public API of torchvision, which it isn’t.
You can probably get this code working by changing to
as the location of where we import ImageOps in torchvision has changed.
Given that this was relying on something which was not public, I’m closing this issue, but let us know if you have further questions
Источник
Error downloading MNIST dataset #20423
having problems downloading the MNIST dataset, also tried with FashionMNIST which works fine.
FileNotFoundError Traceback (most recent call last)
in ()
7 transform=transforms.Compose([
8 transforms.ToTensor(),
—-> 9 transforms.Normalize((mean,), (std,))
10 ]))
11 test_dataset = MNIST(‘data/’, train=False, download=True,
/anaconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/mnist.py in init(self, root, train, transform, target_transform, download)
66
67 if download:
—> 68 self.download()
69
70 if not self._check_exists():
/anaconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/mnist.py in download(self)
142 file_path = os.path.join(self.raw_folder, filename)
143 download_url(url, root=self.raw_folder, filename=filename, md5=None)
—> 144 self.extract_gzip(gzip_path=file_path, remove_finished=True)
145
146 # process and save as torch files
/anaconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/mnist.py in extract_gzip(gzip_path, remove_finished)
123 print(‘Extracting <>‘.format(gzip_path))
124 with open(gzip_path.replace(‘.gz’, »), ‘wb’) as out_f,
—> 125 gzip.GzipFile(gzip_path) as zip_f:
126 out_f.write(zip_f.read())
127 if remove_finished:
/anaconda/envs/py36/lib/python3.6/gzip.py in init(self, filename, mode, compresslevel, fileobj, mtime)
161 mode += ‘b’
162 if fileobj is None:
—> 163 fileobj = self.myfileobj = builtins.open(filename, mode or ‘rb’)
164 if filename is None:
165 filename = getattr(fileobj, ‘name’, »)
FileNotFoundError: [Errno 2] No such file or directory: ‘data/MNIST/raw/train-images-idx3-ubyte.gz’
The text was updated successfully, but these errors were encountered:
Works fine for me on Google Colab.
yes it works fine on colab, maybe its something to do with the machine i am using.
Gives me this error on colab
HTTPError Traceback (most recent call last)
in ()
6 transform=transforms.Compose([
7 transforms.ToTensor(),
—-> 8 transforms.Normalize((0.5,), (0.5,))
9 ]))
11 frames
/usr/lib/python3.6/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs)
648 class HTTPDefaultErrorHandler(BaseHandler):
649 def http_error_default(self, req, fp, code, msg, hdrs):
—> 650 raise HTTPError(req.full_url, code, msg, hdrs, fp)
651
652 class HTTPRedirectHandler(BaseHandler):
HTTPError: HTTP Error 403: Forbidden
Gives me this error on colab
0it [00:00, ?it/s]
HTTPError Traceback (most recent call last)
in ()
6 transform=transforms.Compose([
7 transforms.ToTensor(),
—-> 8 transforms.Normalize((0.5,), (0.5,))
9 ]))
11 frames
/usr/lib/python3.6/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs)
648 class HTTPDefaultErrorHandler(BaseHandler):
649 def http_error_default(self, req, fp, code, msg, hdrs):
—> 650 raise HTTPError(req.full_url, code, msg, hdrs, fp)
651
652 class HTTPRedirectHandler(BaseHandler):
HTTPError: HTTP Error 403: Forbidden
Hello, I got the same question. How do you solve it finally?
Gives me this error on colab
0it [00:00, ?it/s]
HTTPError Traceback (most recent call last)
in ()
6 transform=transforms.Compose([
7 transforms.ToTensor(),
—-> 8 transforms.Normalize((0.5,), (0.5,))
9 ]))
11 frames
/usr/lib/python3.6/urllib/request.py in http_error_default(self, req, fp, code, msg, hdrs)
648 class HTTPDefaultErrorHandler(BaseHandler):
649 def http_error_default(self, req, fp, code, msg, hdrs):
—> 650 raise HTTPError(req.full_url, code, msg, hdrs, fp)
651
652 class HTTPRedirectHandler(BaseHandler):
HTTPError: HTTP Error 403: Forbidden
Hello, I got the same question. How do you solve it finally?
Well. Finally I found a solution in this link pytorch/vision#1938
having problems downloading the MNIST dataset, also tried with FashionMNIST which works fine.
FileNotFoundError Traceback (most recent call last)
in ()
7 transform=transforms.Compose([
8 transforms.ToTensor(),
—-> 9 transforms.Normalize((mean,), (std,))
10 ]))
11 test_dataset = MNIST(‘data/’, train=False, download=True,
/anaconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/mnist.py in init(self, root, train, transform, target_transform, download)
66
67 if download:
—> 68 self.download()
69
70 if not self._check_exists():
/anaconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/mnist.py in download(self)
142 file_path = os.path.join(self.raw_folder, filename)
143 download_url(url, root=self.raw_folder, filename=filename, md5=None)
—> 144 self.extract_gzip(gzip_path=file_path, remove_finished=True)
145
146 # process and save as torch files
/anaconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/mnist.py in extract_gzip(gzip_path, remove_finished)
123 print(‘Extracting <>‘.format(gzip_path))
124 with open(gzip_path.replace(‘.gz’, »), ‘wb’) as out_f,
—> 125 gzip.GzipFile(gzip_path) as zip_f:
126 out_f.write(zip_f.read())
127 if remove_finished:
/anaconda/envs/py36/lib/python3.6/gzip.py in init(self, filename, mode, compresslevel, fileobj, mtime)
161 mode += ‘b’
162 if fileobj is None:
—> 163 fileobj = self.myfileobj = builtins.open(filename, mode or ‘rb’)
164 if filename is None:
165 filename = getattr(fileobj, ‘name’, »)
FileNotFoundError: [Errno 2] No such file or directory: ‘data/MNIST/raw/train-images-idx3-ubyte.gz’
Hi I am facing the same issue.. in fact when I checked it seems like the downloaded file was automatically decompressed or the gz extension was removed so running gzip went into exception.
However, downloading FashionMNIST dataset was successfully completed without any issue.
I solved my own problem too.
there was a mismatch of torchvision I installed using pip. it was 0.2.2 with torch 1.8.0.
I then built and installed torchvision 0.9.0 from source and it works correctly
Currently using Torch 1.8.0 and Torchvision 0.9.0, I am having the same problem. It doesn’t download the dataset.
Something seems to be going on at the target URL, ’cause I’m getting a 503 error (Service Unavailable)
Will continue searching for a solution :/
Edit 3: yup, the website’s down :/
Same Error here in Kaggle
My god. I was dealing with same problem and just changes the internet connectivity literally and its worked.
Источник
VOCSegmentation #1263
- ERROR:
DIR /torchvision/datasets/voc.py
img, target = self.transforms(img, target)
TypeError: call() takes 2 positional arguments but 3 were given - Chnage:
separation the img transforms and target transforms ?
The text was updated successfully, but these errors were encountered:
You are passing the image transform ToTensor as a joint transform for images and targets:
Lines 69 to 70 in 0bd7080
| transforms (callable, optional): A function/transform that takes input sample and its target as entry |
| and returns a transformed version. |
If you don’t need a transform for your target, simply change the instantiation call to
Note the change from transforms to transform .
this did not work
I think need to transform img and target both, so use this call and work perfect
transforms is a bug
Could you please post the actual code where this error occurred? Simply doing this works fine
No, it is not. It is intended as joint transform and thus cannot be used with a single image transfomr such as ToTensor() . If you use the parameters transform and target_transform they are internally converted into a joint transform:
Lines 15 to 26 in 0bd7080
| has_separate_transform = transform is not None or target_transform is not None |
| if has_transforms and has_separate_transform : |
| raise ValueError ( «Only transforms or transform/target_transform can « |
| «be passed as argument» ) |
| # for backwards-compatibility |
| self . transform = transform |
| self . target_transform = target_transform |
| if has_separate_transform : |
| transforms = StandardTransform ( transform , target_transform ) |
| self . transforms = transforms |
which is then used in __getitem__() :
Lines 122 to 125 in 0bd7080
| if self . transforms is not None : |
| img , target = self . transforms ( img , target ) |
| return img , target |
I want to use one argument transforms to complete transform img and target
But this argument cannot work
You still haven’t shown us any code. Please do that.
Do you want to have the same transformation applied to both the image and target? If yes, you could simply do
Yes
I use the same transformation
I’m still lost: this does not throw an error. Do you still have a problem or is everything working as expected?
- If you want to use the same transform for both image and target, its better to create it upfront and pass it twice instead of creating it twice within the call.
- Do you really want to resize your images to (100, 100) ? Since this ignores the aspect ratio of the image, the motif could be heavily distorted. Especially on masks this could have some unintended side effects. You probably want something like transforms.CenterCrop() to get all images to the same size.
@pmeier Thank you so much!
Use transforms argument will throw an error.
We need special transforms for joint image and target transform, see https://github.com/pytorch/vision/blob/master/references/segmentation/transforms.py for an example.
This will be particularly important for randomized transforms, such as random flip.
Closing as it is standard behavior for now
This will be particularly important for randomized transforms, such as random flip.
Closing as it is standard behavior for now
how to use it?
import torchvision.references.segmentation.transforms
not work
@LetsGoFir This cannot work since references is not part of the torchvision package. What @fmassa meant is that you can find examples on how to use the joint transforms in the file transforms.py which is located in the references/detection folder relative to the project root but not the package root.
If you have further questions, and they don’t apply exactly to the topic within this issue, please open a new one. This helps future users with problems to find what they are looking for without us pointing them towards it.
@LetsGoFir This cannot work since references is not part of the torchvision package. What @fmassa meant is that you can find examples on how to use the joint transforms in the file transforms.py which is located in the references/detection relative to the project root but not the package root.
If you have further questions, and they don’t apply exactly to the topic within this issue, please open a new one. This helps future users with problems to find what they are looking for without us pointing them towards it.
Thanks, I just copy it to my code and it works!
Thanks for the help @pmeier !
© 2023 GitHub, Inc.
You can’t perform that action at this time.
You signed in with another tab or window. Reload to refresh your session. You signed out in another tab or window. Reload to refresh your session.
Источник
cannot import name ‘_update_worker_pids’ from ‘torch._C’ #16930
❓ cannot import name ‘_update_worker_pids’ from ‘torch._C’
I used the command conda install pytorch torchvision -c pytorch from the official guide to download Pytorch. While importing torchvision, it shows cannot import name ‘_update_worker_pids’ from ‘torch._C’
Here is my code:
Here is the full-log.
/anaconda3/lib/python3.7/site-packages/torchvision/__init__.py in 1 from torchvision import models —-> 2 from torchvision import datasets 3 from torchvision import transforms 4 from torchvision import utils 5
/anaconda3/lib/python3.7/site-packages/torchvision/datasets/__init__.py in —-> 1 from .lsun import LSUN, LSUNClass 2 from .folder import ImageFolder, DatasetFolder 3 from .coco import CocoCaptions, CocoDetection 4 from .cifar import CIFAR10, CIFAR100 5 from .stl10 import STL10
/anaconda3/lib/python3.7/site-packages/torchvision/datasets/lsun.py in —-> 1 import torch.utils.data as data 2 from PIL import Image 3 import os 4 import os.path 5 import six
/anaconda3/lib/python3.7/site-packages/torch/utils/data/__init__.py in 3 from .distributed import DistributedSampler 4 from .dataset import Dataset, TensorDataset, ConcatDataset, Subset, random_split —-> 5 from .dataloader import DataLoader
/anaconda3/lib/python3.7/site-packages/torch/utils/data/dataloader.py in 2 import torch 3 import torch.multiprocessing as multiprocessing —-> 4 from torch._C import _set_worker_signal_handlers, _update_worker_pids, 5 _remove_worker_pids, _error_if_any_worker_fails 6 from . import SequentialSampler, RandomSampler, BatchSampler ImportError: cannot import name ‘_update_worker_pids’ from ‘torch._C’ (/Users/a/anaconda3/lib/python3.7/site-packages/torch/_C.cpython-37m-darwin.so) «>
Thanks for any usefel help! I do not know how to deal with it since there is no similar issues online.
The text was updated successfully, but these errors were encountered:
Источник
I have a problem with building docker with a base of pytorch+cuda. This is the dockerfile that I used
#FROM nvidia/cuda:9.0-base-ubuntu16.04
FROM nvidia/cuda:9.2-base-ubuntu18.04
# Install some basic utilities
RUN apt-get update && apt-get install -y
curl
ca-certificates
sudo
git
bzip2
libx11-6
python3-pip
&& rm -rf /var/lib/apt/lists/*
# Create a working directory
RUN mkdir /app
WORKDIR /app
# Create a non-root user and switch to it
RUN adduser --disabled-password --gecos '' --shell /bin/bash user
&& chown -R user:user /app
RUN echo "user ALL=(ALL) NOPASSWD:ALL" > /etc/sudoers.d/90-user
USER user
# All users can use /home/user as their home directory
ENV HOME=/home/user
RUN chmod 777 /home/user
# Install Miniconda
RUN curl -so ~/miniconda.sh https://repo.continuum.io/miniconda/Miniconda3-4.7.12.1-Linux-x86_64.sh
&& chmod +x ~/miniconda.sh
&& ~/miniconda.sh -b -p ~/miniconda
&& rm ~/miniconda.sh
ENV PATH=/home/user/miniconda/bin:$PATH
#ENV CONDA_AUTO_UPDATE_CONDA=false
# Create a Python 3.6 environment
RUN /home/user/miniconda/bin/conda install conda-build
&& /home/user/miniconda/bin/conda create -y --name py36 python=3.6.5
&& /home/user/miniconda/bin/conda clean -ya
ENV CONDA_DEFAULT_ENV=py36
ENV CONDA_PREFIX=/home/user/miniconda/envs/$CONDA_DEFAULT_ENV
ENV PATH=$CONDA_PREFIX/bin:$PATH
# CUDA 9.0-specific steps
RUN conda install pytorch torchvision cudatoolkit=9.2 -c pytorch
&& conda clean -ya
# Install HDF5 Python bindings
RUN conda install -y h5py=2.8.0
&& conda clean -ya
RUN pip3 install h5py-cache==1.0
# Install Torchnet, a high-level framework for PyTorch
RUN pip3 install torchnet==0.0.4
# Install Requests, a Python library for making HTTP requests
RUN conda install -y requests=2.19.1
&& conda clean -ya
# Install Graphviz
RUN conda install -c anaconda graphviz
&& conda clean -ya
# Install OpenCV3 Python bindings
RUN sudo apt-get update && sudo apt-get install -y --no-install-recommends
libgtk2.0-0
libcanberra-gtk-module
&& sudo rm -rf /var/lib/apt/lists/*
RUN conda install -y -c menpo opencv3=3.1.0
&& conda clean -ya
# Install Numpy
RUN conda install -y -c anaconda numpy
&& conda clean -ya
# Install matplotlib
RUN conda install -c conda-forge matplotlib
&& conda clean -ya
# Install pandas
RUN conda install -c anaconda pandas
&& conda clean -ya
# Install Nano
RUN sudo apt-get update && sudo apt-get install -y nano
#Copy data
RUN mkdir sfsnet
COPY /SfSNet/ /app/sfsnet/
# Set the default command to python3
#CMD ["python3"]
The problem is whenever I try to import torchvision it always return error related to PIL.
PIL.__version__
'7.0.0'
>>> import torchvision
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/home/user/miniconda/envs/py36/lib/python3.6/site-packages/torchvision/__init__.py", line 4, in <module>
from torchvision import datasets
File "/home/user/miniconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/__init__.py", line 9, in <module>
from .fakedata import FakeData
File "/home/user/miniconda/envs/py36/lib/python3.6/site-packages/torchvision/datasets/fakedata.py", line 3, in <module>
from .. import transforms
File "/home/user/miniconda/envs/py36/lib/python3.6/site-packages/torchvision/transforms/__init__.py", line 1, in <module>
from .transforms import *
File "/home/user/miniconda/envs/py36/lib/python3.6/site-packages/torchvision/transforms/transforms.py", line 17, in <module>
from . import functional as F
File "/home/user/miniconda/envs/py36/lib/python3.6/site-packages/torchvision/transforms/functional.py", line 5, in <module>
from PIL import Image, ImageOps, ImageEnhance, PILLOW_VERSION
ImportError: cannot import name 'PILLOW_VERSION'
I have read other post that this is because of bug on older version and should have been fixed in newer version of Torchvision yet the problem still persist (reference). Can someone give me some solution for this? Thank you
TorchVision, a PyTorch computer vision package, has a simple API for image pre-processing in its torchvision.transforms module. The module contains a set of common, composable image transforms and gives you an easy way to write new custom transforms. As you would expect, these custom transforms can be included in your pre-processing pipeline like any other transform from the module.
Let’s start with a common use case, preparing PIL images for one of the pre-trained TorchVision image classifiers:
import io
import requests
import torchvision.transforms as T
from PIL import Image
resp = requests.get('https://sparrow.dev/assets/img/cat.jpg')
img = Image.open(io.BytesIO(resp.content))
preprocess = T.Compose([
T.Resize(256),
T.CenterCrop(224),
T.ToTensor(),
T.Normalize(
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]
)
])
x = preprocess(img)
x.shape
# Expected result
# torch.Size([3, 224, 224])Here, we apply the following in order:
- Resize a PIL image to
(<height>, 256), where<height>is the value that maintains the aspect ratio of the input image. - Crop the
(224, 224)center pixels. - Convert the PIL image to a PyTorch tensor (which also moves the channel dimension to the beginning).
- Normalize the image by subtracting a known ImageNet mean and standard deviation.
Let’s go a notch deeper to understand exactly how these transforms work.
Transforms
TorchVision transforms are extremely flexible – there are just a few rules. In order to be composable, transforms need to be callables. That means you can actually just use lambdas if you want:
times_2_plus_1 = T.Compose([
lambda x: x * 2,
lambda x: x + 1,
])
x.mean(), times_2_plus_1(x).mean()
# Expected result
# (tensor(1.2491), tensor(3.4982))But often, you’ll want to use callable classes because they give you a nice way to parameterize the transform at initialization. For example, if you know you want to resize images to have height of 256 you can instantiate the T.Resize transform with a 256 as input to the constructor:
resize_callable = T.Resize(256)Any PIL image passed to resize_callable() will now get resized to (<height>, 256):
resize_callable(img).size
# Expected result
# (385, 256)This behavior is important because you will typically want TorchVision or PyTorch to be responsible for calling the transform on an input. We actually saw this in the first example: the component transforms (Resize, CenterCrop, ToTensor, and Normalize) were chained and called inside the Compose transform. And the calling code would not have knowledge of things like the size of the output image you want or the mean and standard deviation for normalization.
Interestingly, there is no Transform base class. Some transforms have no parent class at all and some inherit from torch.nn.Module. This means that if you’re writing a transform class, the constructor can do whatever you want. The only requirement is that there must be a __call__() method to ensure the instantiated object is callable. Note: when transforms override the torch.nn.Module class, they will typically define the forward() method and then the base class takes care of __call__().
Additionally, there are no real constraints on the callable’s inputs or outputs. A few examples:
T.Resize: PIL image in, PIL image out.T.ToTensor: PIL image in, PyTorch tensor out.T.Normalize: PyTorch tensor in, PyTorch tensor out.
NumPy arrays may also be a good choice sometimes.
Ok. Now that we know a little about what transforms are, let’s look at an example that TorchVision gives us out of the box.
Example Transform: Compose
The T.Compose transform takes a list of other transforms in the constructor and applies them sequentially to the input. We can take a look at the __init__() and __call__() methods from a recent commit hash to see how this works:
class Compose:
def __init__(self, transforms):
self.transforms = transforms
def __call__(self, img):
for t in self.transforms:
img = t(img)
return imgVery simple! You can pass the T.Compose constructor a list (or any other in-memory sequence) of callables and it will dutifully apply them to any input one at a time. And notice that the input img can be any type you want. In the first example, the input was PIL and the output was a PyTorch tensor. In the second example, the input and output were both tensors. T.Compose doesn’t care!
Let’s instantiate a new T.Compose transform that will let us visualize PyTorch tensors. Remember, we took a PIL image and generated a PyTorch tensor that’s ready for inference in a TorchVision classifier. Let’s take a PyTorch tensor from that transformation and convert it into an RGB NumPy array that we can plot with Matplotlib:
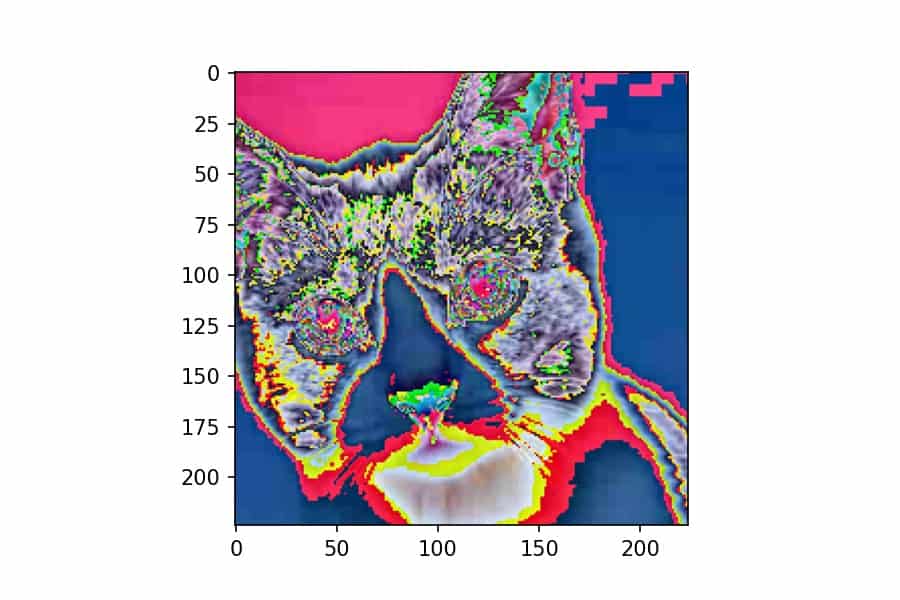
%matplotlib inline
import matplotlib.pyplot as plt
import numpy as np
reverse_preprocess = T.Compose([
T.ToPILImage(),
np.array,
])
plt.imshow(reverse_preprocess(x));The T.ToPILImage transform converts the PyTorch tensor to a PIL image with the channel dimension at the end and scales the pixel values up to int8. Then, since we can pass any callable into T.Compose, we pass in the np.array() constructor to convert the PIL image to NumPy. Not too bad!
Functional Transforms
As we’ve now seen, not all TorchVision transforms are callable classes. In fact, TorchVision comes with a bunch of nice functional transforms that you’re free to use. If you look at the torchvision.transforms code, you’ll see that almost all of the real work is being passed off to functional transforms.
For example, here’s the functional version of the resize logic we’ve already seen:
import torchvision.transforms.functional as F
F.resize(img, 256).size
# Expected result
# (385, 256)It does the same work, but you have to pass additional arguments in when you call it. My advice: use functional transforms for writing custom transform classes, but in your pre-processing logic, use callable classes or single-argument functions that you can compose.
At this point, we know enough about TorchVision transforms to write one of our own.
Custom Transforms
Let’s write a custom transform that erases the top left corner of an image with the color of a randomly selected pixel. We’ll use the F.erase() function and we’ll allow the caller to specify what how many pixels they want to erase in both directions:
import torch
class TopLeftCornerErase:
def __init__(self, n_pixels: int):
self.n_pixels = n_pixels
def __call__(self, img: torch.Tensor) -> torch.Tensor:
all_pixels = img.reshape(3, -1).transpose(1, 0)
idx = torch.randint(len(all_pixels), (1,))[0]
random_pixel = all_pixels[idx][:, None, None]
return F.erase(img, 0, 0, self.n_pixels, self.n_pixels, random_pixel)In the constructor, all we do is take the number of pixels as a parameter from the caller. The magic happens in the __call__() method:
- Create a reshaped view of the image tensor as a
(n_pixels, 3)tensor - Randomly select a pixel index using
torch.randint() - Add two dummy dimensions to the tensor. This is because
F.erase()and to the image, which has these two dimensions. - Call and return
F.erase(), which takes five arguments: the tensor, theicoordinate to start at, thejcoordinate to start at, theheightof the box to erase, thewidthof the box to erase and the random pixel.
We can apply this custom transform just like any other transform. Let’s use T.Compose to both apply this erase transform and then convert it to NumPy for plotting:
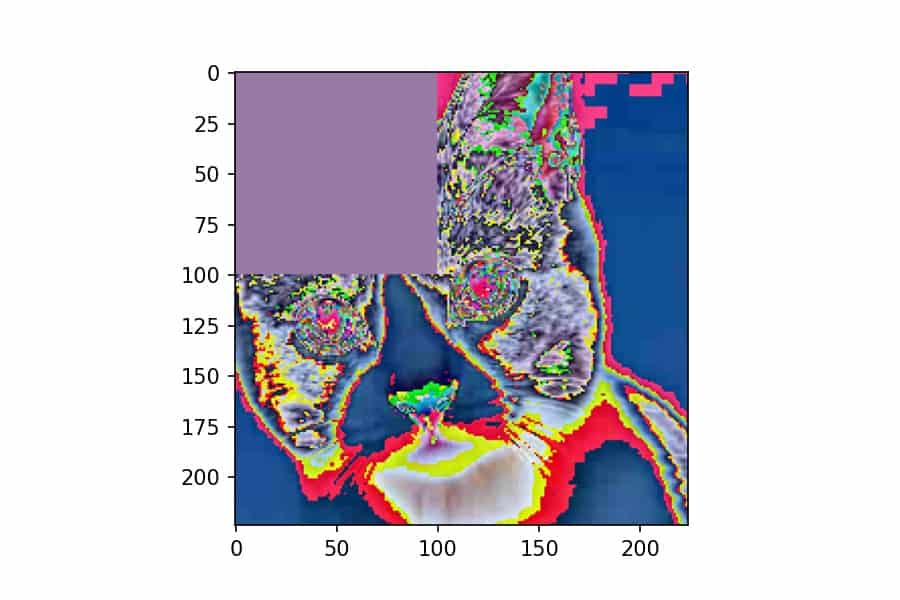
torch.manual_seed(1)
erase = T.Compose([
TopLeftCornerErase(100),
reverse_preprocess,
])
plt.imshow(erase(x));We’ve seen this type of transform composition multiple times now. One thing that is important to point out is that you need to call torch.manual_seed() if you want a deterministic (and therefore reproducible) result for any TorchVision transform that has random behavior in it. This is new as of version 0.8.0.
And that’s about all there is to know about TorchVision transforms! They’re lightweight and flexible, but using them will make your image preprocessing code much easier to reason about.
I’m importing a python module by using py.importlib.import_modulndule). Now at the top of my my_module.py I’m importing a few python modules necessary for my functions. Despite having changed my default python version within Matlab to the correct virtual environment, Matlab fails to import the modules. Here is my python script
__future__ import print_function, division
import os
import sys
import time
import argparse
import numpy as np
import torch
import torchvision
import random
import itertools
import torchvision.models as models
import matplotlib
matplotlib.use(‘agg’)
from matplotlib.pyplot import imread
from torchvision import datasets, transforms
def get_patch(img, x_center, y_centre, legth):
#Load image
image=imread(img)
return image[x_center:x_center+legth,y_centre:y_centre+legth,:]
model_path=‘./PytorchModel/checkpoint_epoch_60.pt’
model=Encoder(‘resnet18’,False)
model.load_state_dict(torch.load(model_path,map_location=‘cpu’))
Transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225])])
image1=get_patch(im1, center1[0], center1[1], 100)
image1=Transform(image1)
image2=get_patch(im2, center2[0], center2[1], 100)
image2=Transform(image2)
data=torch.stack((image1,image2),dim=0)
model.eval()
with torch.no_grad():
vectors=model(data)
y_coord= vectors[:,1] #Extract y coordinates
x_coord = vectors[:,0] #Extract x coordinates
angles=np.degrees(torch.atan2(y_coord,x_coord).numpy())
relative_angle=convert_to_convetion(angles[1]-angles[0])
return relative_angle
def convert_to_convetion(input):
«»»
Coverts all anlges to convecntion used by atan2
«»»
input[input<180]=input[input<180]+360
input[input>180]=input[input>180]-360
return input
class Encoder(nn.Module):
«»»
Encoder to 2-dimnesional space
«»»
def __init__(self,model_type,pretrained):
super(Encoder, self).__init__()
if model_type==‘resnet18’:
pretrained=models.resnet18(pretrained=pretrained)
elif model_type==’resnet34′:
pretrained=models.resnet34(pretrained=pretrained)
elif model_type==’resnet50′:
pretrained=models.resnet50(pretrained=pretrained)
#Replace maxpool layer with convolutional layers
pretrained.maxpool=nn.Conv2d(64, 64, kernel_size=(3, 3), stride=(2, 2), padding=(1, 1), bias=False)
#Replace AvgPool2d witth AdaptiveAvgPool2d
pretrained.avgpool=nn.AdaptiveAvgPool2d(1)
#Remove the last fc layer anx call in encoder
self.encoder= nn.Sequential(*list(pretrained.children())[:-1],
nn.ReLU(),
nn.Conv2d(512,256,1),
nn.ReLU(),
nn.Conv2d(256,2,1))
def forward(self,x):
return self.encoder(x)
Error using _init_><module> (line 80) Python Error: RuntimeError: stoi: no conversion
Error in _init_>import_module (line 126) return _bootstrap._gcd_import(name[level:], package, level)