Функция потерь (Loss Function, Cost Function, Error Function; J) – фрагмент программного кода, который используется для оптимизации Алгоритма (Algorithm) Машинного обучения (ML). Значение, вычисленное такой функцией, называется «потерей».
Функция (Function) потерь может дать бо́льшую практическую гибкость вашим Нейронным сетям (Neural Network) и будет определять, как именно выходные данные связаны с исходными.
Нейронные сети могут выполнять несколько задач: от прогнозирования непрерывных значений, таких как ежемесячные расходы, до Бинарной классификации (Binary Classification) на кошек и собак. Для каждой отдельной задачи потребуются разные типы функций, поскольку выходной формат индивидуален.
С очень упрощенной точки зрения Loss Function может быть определена как функция, которая принимает два параметра:
- Прогнозируемые выходные данные
- Истинные выходные данные

Эта функция, по сути, вычислит, насколько хорошо работает наша модель, сравнив то, что модель прогнозирует, с фактическим значением, которое она должна выдает. Если Ypred очень далеко от Yi, значение потерь будет очень высоким. Однако, если оба значения почти одинаковы, значение потерь будет очень низким. Следовательно, нам нужно сохранить функцию потерь, которая может эффективно наказывать модель, пока та обучается на Тренировочных данных (Train Data).
Этот сценарий в чем-то аналогичен подготовке к экзаменам. Если кто-то плохо сдает экзамен, мы можем сказать, что потеря очень высока, и этому человеку придется многое изменить внутри себя, чтобы в следующий раз получить лучшую оценку. Однако, если экзамен пройдет хорошо, студент может вести себя подобным образом и в следующий раз.
Теперь давайте рассмотрим классификацию как задачу и поймем, как в этом случае работает функция потерь.
Классификационные потери
Когда нейронная сеть пытается предсказать дискретное значение, мы рассматриваем это как модель классификации. Это может быть сеть, пытающаяся предсказать, какое животное присутствует на изображении, или является ли электронное письмо спамом. Сначала давайте посмотрим, как представлены выходные данные классификационной нейронной сети.

Количество узлов выходного слоя будет зависеть от количества классов, присутствующих в данных. Каждый узел будет представлять один класс. Значение каждого выходного узла по существу представляет вероятность того, что этот класс является правильным.
Как только мы получим вероятности всех различных классов, рассмотрим тот, что имеет наибольшую вероятность. Посмотрим, как выполняется двоичная классификация.
Бинарная классификация
В двоичной классификации на выходном слое будет только один узел. Чтобы получить результат в формате вероятности, нам нужно применить Функцию активации (Activation Function). Поскольку для вероятности требуется значение от 0 до 1, мы будем использовать Сигмоид (Sigmoid), которая приведет любое реальное значение к диапазону значений от 0 до 1.

По мере того, как входные реальные данные становятся больше и стремятся к плюс бесконечности, выходные данные сигмоида будут стремиться к единице. А когда на входе значения становятся меньше и стремятся к отрицательной бесконечности, на выходе числа будут стремиться к нулю. Теперь мы гарантированно получаем значение от 0 до 1, и это именно то, что нам нужно, поскольку нам нужны вероятности.
Если выход выше 0,5 (вероятность 50%), мы будем считать, что он попадает в положительный класс, а если он ниже 0,5, мы будем считать, что он попадает в отрицательный класс. Например, если мы обучаем нейросеть для классификации кошек и собак, мы можем назначить собакам положительный класс, и выходное значение в наборе данных для собак будет равно 1, аналогично кошкам будет назначен отрицательный класс, а выходное значение для кошек будет быть 0.
Функция потерь, которую мы используем для двоичной классификации, называется Двоичной перекрестной энтропией (BCE). Эта функция эффективно наказывает нейронную сеть за Ошибки (Error) двоичной классификации. Давайте посмотрим, как она выглядит.

Как видите, есть две отдельные функции, по одной для каждого значения Y. Когда нам нужно предсказать положительный класс (Y = 1), мы будем использовать следующую формулу:
$$Потеря = -log(Y_{pred})space{,}space{где}$$
$$Jspace{}{–}space{Потеря,}$$
$$Y_predspace{}{–}space{Предсказанные}space{значения}$$
И когда нам нужно предсказать отрицательный класс (Y = 0), мы будем использовать немного трансформированный аналог:
$$Потеря = -log(1 — Y_{pred})space{,}space{где}$$
$$Jspace{}{–}space{Потеря,}$$
$$Y_predspace{}{–}space{Предсказанные}space{значения}$$
Для первой функции, когда Ypred равно 1, потеря равна 0, что имеет смысл, потому что Ypred точно такое же, как Y. Когда значение Ypred становится ближе к 0, мы можем наблюдать, как значение потери сильно увеличивается. Когда же Ypred становится равным 0, потеря стремится к бесконечности. Это происходит, потому что с точки зрения классификации, 0 и 1 – полярные противоположности: каждый из них представляет совершенно разные классы. Поэтому, когда Ypred равно 0, а Y равно 1, потери должны быть очень высокими, чтобы сеть могла более эффективно распознавать свои ошибки.

Полиномиальная классификация
Полиномиальная классификация (Multiclass Classification) подходит, когда нам нужно, чтобы наша модель каждый раз предсказывала один возможный класс. Теперь, поскольку мы все еще имеем дело с вероятностями, имеет смысл просто применить сигмоид ко всем выходным узлам, чтобы мы получали значения от 0 до 1 для всех выходных значений, но здесь кроется проблема. Когда мы рассматриваем вероятности для нескольких классов, нам необходимо убедиться, что сумма всех индивидуальных вероятностей равна единице, поскольку именно так определяется вероятность. Применение сигмоида не гарантирует, что сумма всегда равна единице, поэтому нам нужно использовать другую функцию активации.
В данном случае мы используем функцию активации Softmax. Эта функция гарантирует, что все выходные узлы имеют значения от 0 до 1, а сумма всех значений выходных узлов всегда равна 1. Вычисляется с помощью формулы:
$$Softmax(y_i) = frac{e^{y_i}}{sum_{i = 0}^n e^{y_i}}space{,}space{где}$$
$$y_ispace{}{–}space{i-e}space{наблюдение}$$
Пример:

Как видите, мы просто передаем все значения в экспоненциальную функцию. После этого, чтобы убедиться, что все они находятся в диапазоне от 0 до 1 и сумма всех выходных значений равна 1, мы просто делим каждую экспоненту на сумму экспонент.
Итак, почему мы должны передавать каждое значение через экспоненту перед их нормализацией? Почему мы не можем просто нормализовать сами значения? Это связано с тем, что цель Softmax – убедиться, что одно значение очень высокое (близко к 1), а все остальные значения очень низкие (близко к 0). Softmax использует экспоненту, чтобы убедиться, что это произойдет. А затем мы нормализуем результат, потому что нам нужны вероятности.
Теперь, когда наши выходные данные имеют правильный формат, давайте посмотрим, как мы настраиваем для этого функцию потерь. Хорошо то, что функция потерь по сути такая же, как у двоичной классификации. Мы просто применим Логарифмическую потерю (Log Loss) к каждому выходному узлу по отношению к его соответствующему целевому значению, а затем найдем сумму этих значений по всем выходным узлам.

Эта потеря называется категориальной Кросс-энтропией (Cross Entropy). Теперь перейдем к частному случаю классификации, называемому многозначной классификацией.
Классификация по нескольким меткам
Классификация по нескольким меткам (MLC) выполняется, когда нашей модели необходимо предсказать несколько классов в качестве выходных данных. Например, мы тренируем нейронную сеть, чтобы предсказывать ингредиенты, присутствующие на изображении какой-то еды. Нам нужно будет предсказать несколько ингредиентов, поэтому в Y будет несколько единиц.
Для этого мы не можем использовать Softmax, потому что он всегда заставляет только один класс «становиться единицей», а другие классы приводит к нулю. Вместо этого мы можем просто сохранить сигмоид на всех значениях выходных узлов, поскольку пытаемся предсказать индивидуальную вероятность каждого класса.
Что касается потерь, мы можем напрямую использовать логарифмические потери на каждом узле и суммировать их, аналогично тому, что мы делали в мультиклассовой классификации.
Теперь, когда мы рассмотрели классификацию, перейдем к регрессии.
Потеря регрессии
В Регрессии (Regression) наша модель пытается предсказать непрерывное значение, например, цены на жилье или возраст человека. Наша нейронная сеть будет иметь один выходной узел для каждого непрерывного значения, которое мы пытаемся предсказать. Потери регрессии рассчитываются путем прямого сравнения выходного и истинного значения.
Самая популярная функция потерь, которую мы используем для регрессионных моделей, – это Среднеквадратическая ошибка (MSE). Здесь мы просто вычисляем квадрат разницы между Y и YPred и усредняем полученное значение.
Автор оригинальной статьи: deeplearningdemystified.com
Фото: @leni_eleni
Адаптированный перевод прекрасной статьи энтузиаста технологий машинного обучения Javaid Nabi.

Чтобы понимать как алгоритм машинного обучения учится предсказывать результаты на основе данных, важно разобраться в основных концепциях и понятиях, используемых при обучении алгоритма.
Функции оценки
В контексте технологии машинного обучения, оценка – это
статистический термин для нахождения некоторого приближения неизвестного
параметра на основе некоторых данных. Точечная
оценка – это попытка найти единственное лучшее приближение некоторого
количества интересующих нас параметров. Или на более формальном языке математической статистики — точечная оценка это число, оцениваемое на основе наблюдений,
предположительно близкое к оцениваемому параметру.
Под количеством
интересующих параметров обычно подразумевается:
• Один параметр
• Вектор параметров – например, веса в линейной
регрессии
• Целая функция
Точечная оценка
Чтобы отличать оценки параметров от их истинного значения, представим точечную оценку параметра θ как θˆ. Пусть {x(1), x(2), .. x(m)} будут m независимыми и одинаково распределенными величинами. Тогда точечная оценка может быть записана как некоторая функция этих величин:
![]()
Такое определение точечной оценки является очень общим и предоставляет разработчику большую свободу действий. Почти любая функция, таким образом, может рассматриваться как оценщик, но хороший оценщик – это функция, значения которой близки к истинному базовому значению θ, которое сгенерированно обучающими данными.
Точечная оценка также может относиться к оценке взаимосвязи между
входными и целевыми переменными, в этом случае чаще называемой функцией оценки.
Функция оценки
Задача, решаемая машинным обучением, заключается в попытке
предсказать переменную y по
заданному входному вектору x. Мы
предполагаем, что существует функция f(x), которая описывает приблизительную
связь между y и x. Например, можно предположить, что y = f(x) + ε, где ε обозначает
часть y, которая явно не
предсказывается входным вектором x.
При оценке функций нас интересует приближение f с помощью модели или оценки fˆ.
Функция оценки в действительности это тоже самое, что оценка параметра θ; функция оценки f это просто точечная
оценка в функциональном пространстве. Пример: в полиномиальной регрессии мы
либо оцениваем параметр w, либо оцениваем функцию отображения из x в y.
Смещение и дисперсия
Смещение и дисперсия измеряют два разных источника ошибки функции оценки.
Смещение измеряет ожидаемое отклонение от истинного значения функции или
параметра. Дисперсия, с другой стороны, показывает меру отклонения от
ожидаемого значения оценки, которую может вызвать любая конкретная выборка
данных.
Смещение
Смещение определяется следующим
образом:
где ожидаемое значение E(θˆm) для данных (рассматриваемых как выборки из случайной величины) и
θ является истинным базовым значением, используемым для определения
распределения, генерирующего данные.
![]()
Оценщик θˆm называется несмещенным, если bias(θˆm)=0, что подразумевает что E(θˆm) = θ.
Дисперсия и Стандартная ошибка
Дисперсия оценки обозначается как Var(θˆ), где случайная величина
является обучающим множеством. Альтернативно, квадратный корень дисперсии
называется стандартной ошибкой, обозначаемой как SE(θˆ). Дисперсия или стандартная ошибка
оценщика показывает меру ожидания того, как оценка, которую мы вычисляем, будет
изменяться по мере того, как мы меняем выборки из базового набора данных,
генерирующих процесс.
Точно так же, как мы хотели бы, чтобы функция оценки имела малое
смещение, мы также стремимся, чтобы у нее была относительно низкая дисперсия.
Давайте теперь рассмотрим некоторые обычно используемые функции оценки.
Оценка Максимального Правдоподобия (MLE)
Оценка максимального правдоподобия может быть определена как метод
оценки параметров (таких как среднее значение или дисперсия) из выборки данных,
так что вероятность получения наблюдаемых данных максимальна.
Рассмотрим набор из m примеров X={x(1),… , x(m)} взятых независимо из неизвестного набора данных,
генерирующих распределение Pdata(x). Пусть Pmodel(x;θ) –
параметрическое семейство распределений вероятностей над тем же пространством,
индексированное параметром θ.
Другими словами, Pmodel(x;θ) отображает любую конфигурацию x в значение, оценивающее истинную
вероятность Pdata(x).
Оценка максимального правдоподобия для θ определяется как:

Поскольку мы предположили, что примеры являются независимыми выборками, приведенное выше
уравнение можно записать в виде:
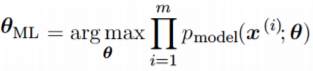
Эта произведение многих вероятностей может быть неудобным по ряду
причин. В частности, оно склонно к числовой недооценке. Кроме того, чтобы найти
максимумы/минимумы этой функции, мы должны взять производную этой функции от θ и приравнять ее к 0. Поскольку это
произведение членов, нам нужно применить правило цепочки, которое довольно
громоздко. Чтобы получить более удобную, но эквивалентную задачу оптимизации,
можно использовать логарифм вероятности, который не меняет его argmax, но
удобно превращает произведение в сумму, и поскольку логарифм – строго
возрастающая функция (функция натурального логарифма – монотонное
преобразование), это не повлияет на итоговое значение θ.
В итоге, получаем:

Два важных свойства: сходимость и
эффективность
Сходимость. По мере того, как число обучающих выборок приближается к
бесконечности, оценка максимального правдоподобия сходится к истинному значению
параметра.
Эффективность. Способ измерения того, насколько мы близки к истинному
параметру, – это ожидаемая средняя квадратичная ошибка, вычисление квадратичной
разницы между оценочными и истинными значениями параметров, где математическое
ожидание вычисляется над m обучающими выборками из данных, генерирующих
распределение. Эта параметрическая среднеквадратичная ошибка уменьшается с
увеличением m, и для
больших m нижняя
граница неравенства Крамера-Рао показывает, что ни у одной сходящейся функции оценки нет
среднеквадратичной ошибки меньше, чем у оценки максимального правдоподобия.
Именно по причине
сходимости и эффективности, оценка максимального правдоподобия часто считается
предпочтительным оценщиком для машинного обучения.
Когда количество примеров достаточно мало, чтобы привести к
переобучению, стратегии регуляризации, такие как понижающие веса, могут
использоваться для получения смещенной версии оценки максимального
правдоподобия, которая имеет меньшую дисперсию, когда данные обучения
ограничены.
Максимальная апостериорная (MAP) оценка
Согласно байесовскому подходу, можно учесть влияние предварительных
данных на выбор точечной оценки. MAP может использоваться для получения
точечной оценки ненаблюдаемой величины на основе эмпирических данных. Оценка
MAP выбирает точку максимальной апостериорной вероятности (или максимальной
плотности вероятности в более распространенном случае непрерывного θ):

где с правой стороны, log(p(x|θ)) – стандартный член
логарифмической вероятности и log(p(θ)) соответствует изначальному
распределению.
Как и при полном байесовском методе, байесовский MAP имеет преимущество
использования изначальной информации, которой нет
в обучающих данных. Эта дополнительная информация помогает уменьшить дисперсию
для точечной оценки MAP (по сравнению с оценкой MLE). Однако, это происходит ценой повышенного смещения.
Функции потерь
В большинстве обучающих сетей ошибка рассчитывается как разница
между фактическим выходным значением y и прогнозируемым выходным значением ŷ.
Функция, используемая для вычисления этой ошибки, известна как функция потерь,
также часто называемая функцией ошибки или затрат.
До сих пор наше основное внимание уделялось оценке параметров с
помощью MLE или MAP. Причина, по которой мы обсуждали это раньше, заключается в
том, что и MLE, и MAP предоставляют механизм для получения функции потерь.
Давайте рассмотрим некоторые часто используемые функции потерь.
Средняя
квадратичная ошибка (MSE): средняя
квадратичная ошибка является наиболее распространенной функцией потерь. Функция
потерь MSE широко используется в линейной регрессии в качестве показателя
эффективности. Чтобы рассчитать MSE, надо взять разницу между предсказанными
значениями и истинными, возвести ее в квадрат и усреднить по всему набору
данных.

где y(i) – фактический ожидаемый результат, а ŷ(i) – прогноз модели.
Многие функции потерь (затрат), используемые в машинном обучении,
включая MSE, могут быть получены из метода максимального правдоподобия.
Чтобы увидеть, как мы можем вывести функции потерь из MLE или MAP,
требуется некоторая математика. Вы можете пропустить ее и перейти к следующему
разделу.
Получение MSE из MLE
Алгоритм линейной регрессии учится принимать входные данные x и получать выходные значения ŷ. Отображение x в ŷ делается так,
чтобы минимизировать среднеквадратичную ошибку. Но как мы выбрали MSE в
качестве критерия для линейной регрессии? Придем к этому решению с точки зрения
оценки максимального правдоподобия. Вместо того, чтобы производить одно
предсказание ŷ , давайте рассмотрим
модель условного распределения p(y|x).
Можно смоделировать модель
линейной регрессии следующим образом:

мы предполагаем, что у имеет
нормальное распределение с ŷ в качестве
среднего значения распределения и некоторой постоянной σ² в качестве дисперсии, выбранной пользователем. Нормальное
распределения являются разумным выбором во многих случаях. В отсутствие
предварительных данных о том, какое распределение в действительности
соответствует рассматриваемым данным, нормальное распределение является хорошим
выбором по умолчанию.
Вернемся к логарифмической вероятности, определенной ранее:

где ŷ(i) – результат
линейной регрессии на i-м входе, а m – количество обучающих примеров. Мы видим,
что две первые величины являются постоянными, поэтому максимизация
логарифмической вероятности сводится к минимизации MSE:
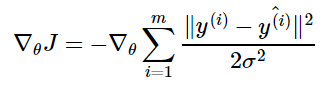
Таким образом, максимизация логарифмического правдоподобия
относительно θ дает такую же оценку параметров θ, что и минимизация
среднеквадратичной ошибки. Два критерия имеют разные значения, но одинаковое
расположение оптимума. Это оправдывает использование MSE в качестве функции
оценки максимального правдоподобия.
Кросс-энтропия
(или логарифмическая функция потерь – log loss): Кросс-энтропия измеряет расхождение между двумя вероятностными
распределениями. Если кросс-энтропия велика, это означает, что разница между
двумя распределениями велика, а если кросс-энтропия мала, то распределения
похожи друг на друга.
Кросс-энтропия определяется как:

где P – распределение истинных ответов, а Q – распределение
вероятностей прогнозов модели. Можно
показать, что функция кросс-энтропии также получается из MLE, но я не буду
утомлять вас большим количеством математики.
Давайте еще
упростим это для нашей модели с:
• N – количество наблюдений
• M – количество возможных меток класса (собака,
кошка, рыба)
• y – двоичный индикатор (0 или 1) того, является
ли метка класса C правильной классификацией для наблюдения O
• p – прогнозируемая вероятность модели
Бинарная классификация
В случае бинарной классификации (M=2),
формула имеет вид:
![]()
При двоичной классификации каждая предсказанная вероятность
сравнивается с фактическим значением класса (0 или 1), и вычисляется оценка,
которая штрафует вероятность на основе расстояния от ожидаемого значения.
Визуализация
На приведенном ниже графике показан диапазон возможных значений
логистической функции потерь с учетом истинного наблюдения (y = 1). Когда
прогнозируемая вероятность приближается к 1, логистическая функция потерь
медленно уменьшается. Однако при уменьшении прогнозируемой вероятности она быстро возрастает.
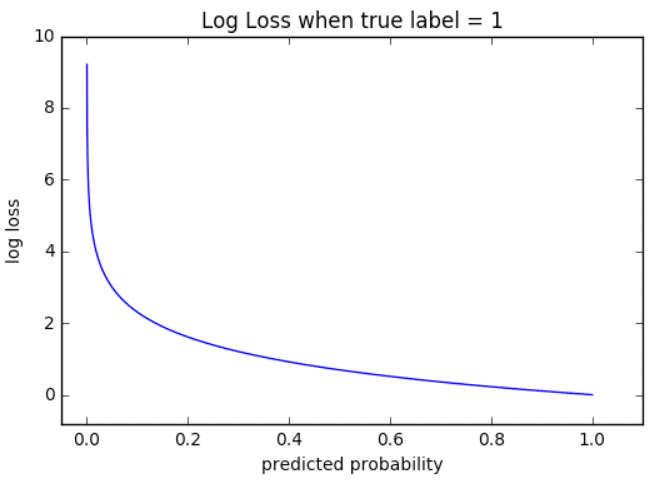
Логистическая функция потерь наказывает оба типа ошибок, но
особенно те прогнозы, которые являются достоверными и ошибочными!
Мульти-классовая классификация
В случае мульти-классовой классификации (M>2) мы берем сумму значений логарифмических функций потерь для
каждого прогноза наблюдаемых классов.
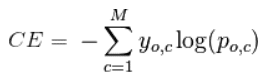
Кросс-энтропия для бинарной или двух-классовой задачи
прогнозирования фактически рассчитывается как средняя кросс-энтропия среди всех
примеров. Log loss использует отрицательные
значения логарифма, чтобы обеспечить удобную метрику для сравнения. Этот подход
основан на том, что логарифм чисел <1 возвращает отрицательные значения, что
затрудняет работу при сравнении производительности двух моделей. Вы можете
почитать эту статью, где детально обсуждается функция кросс-энтропии потерь.
Задачи ML и соответствующие функции потерь
Давайте посмотрим, какие обычно используются выходные слои и
функции потерь в задачах машинного обучения:
Задача регрессии
Задача, когда
вы прогнозируете вещественное число.
• Конфигурация выходного уровня: один
узел с линейной единицей активации.
• Функция
потерь: средняя квадратическая ошибка (MSE).

Задача бинарной классификации
Задача состоит в том, чтобы классифицировать пример как
принадлежащий одному из двух классов. Или более точно, задача сформулирована
как предсказание вероятности того, что пример принадлежит первому классу,
например, классу, которому вы присваиваете целочисленное значение 1, тогда как
другому классу присваивается значение 0.
• Конфигурация выходного
уровня: один узел с сигмовидной активационной функцией.
• Функция
потерь: кросс-энтропия, также называемая логарифмической функцией потерь.
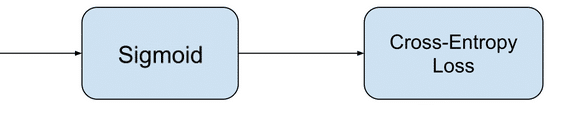
Задача мульти-классовой классификации
Эта задача состоит в том, чтобы классифицировать пример как
принадлежащий одному из нескольких классов. Задача сформулирована как
предсказание вероятности того, что пример принадлежит каждому классу.
• Конфигурация выходного уровня: один
узел для каждого класса, использующий функцию активации softmax.
• Функция потерь: кросс-энтропия, также называемая логарифмической функцией потерь.

Рассмотрев оценку и различные функции потерь, давайте перейдем к
роли оптимизаторов в алгоритмах ML.
Оптимизаторы
Чтобы свести к минимуму ошибку или потерю в прогнозировании,
модель, используя примеры из обучающей выборки, обновляет параметры модели W. Расчеты
ошибок строятся в зависимости от W и также описываются графиком функции затрат
J(w), поскольку она определяет затраты/наказание модели. Таким образом, минимизация
ошибки также часто называется минимизацией функции затрат.
Но как именно это делается? Используя оптимизаторы.
Оптимизаторы используются для обновления весов и смещений, то есть
внутренних параметров модели, чтобы уменьшить ошибку.
Самым важным методом и основой того, как мы обучаем и оптимизируем
нашу модель, является метод Градиентного Спуска.
Градиентный Спуск
Когда мы строим функцию затрат J(w), это можно представить следующим
образом:
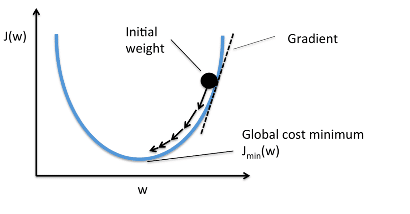
Как видно из кривой, существует значение параметров W, которое
имеет минимальное значение Jmin. Нам нужно найти способ достичь
этого минимального значения.
В алгоритме градиентного спуска мы начинаем со случайных
параметров модели и вычисляем ошибку для каждой итерации обучения, продолжая
обновлять параметры, чтобы приблизиться к минимальным значениям.
Повторяем до достижения минимума:
{

}
В приведенном выше уравнении мы обновляем параметры модели после
каждой итерации. Второй член уравнения вычисляет наклон или градиент кривой на
каждой итерации.
Градиент функции затрат вычисляется как частная производная
функции затрат J по каждому параметру модели Wj, где j принимает
значение числа признаков [1, n]. α – альфа, это скорость обучения, определяющий
как быстро мы хотим двигаться к минимуму. Если α слишком велико, мы можем
проскочить минимум. Если α слишком мало, это приведет к небольшим этапам обучения,
поэтому общее время, затрачиваемое моделью для достижения минимума, будет
больше.
Есть три способа сделать градиентный спуск:
Пакетный
градиентный спуск: использует
все обучающие данные для обновления параметров модели в каждой итерации.
Мини-пакетный градиентный спуск: вместо использования всех данных, мини-пакетный градиентный спуск делит тренировочный набор на меньший размер, называемый партией, и обозначаемый буквой «b». Таким образом, мини-пакет «b» используется для обновления параметров модели на каждой итерации.
Вот некоторые другие часто
используемые Оптимизаторы:
Стохастический
Градиентный Спуск (SGD): обновляет
параметры, используя только один обучающий параметр на каждой итерации. Такой
параметр обычно выбирается случайным образом. Стохастический градиентный спуск
часто предпочтителен для оптимизации функций затрат, когда есть сотни тысяч
обучающих или более параметров, поскольку он будет сходиться быстрее, чем
пакетный градиентный спуск.
Адаград
Адаград адаптирует скорость обучения конкретно к индивидуальным
особенностям: это означает, что некоторые веса в вашем наборе данных будут
отличаться от других. Это работает очень хорошо для разреженных наборов данных,
где пропущено много входных значений. Однако, у Адаграда есть одна серьезная
проблема: адаптивная скорость обучения со временем становится очень маленькой.
Некоторые другие оптимизаторы, описанные ниже, пытаются справиться
с этой проблемой.
RMSprop
RMSprop – это специальная версия Adagrad,
разработанная профессором Джеффри Хинтоном в его
классе нейронных сетей. Вместо того,
чтобы вычислять все градиенты, он вычисляет градиенты только в фиксированном
окне. RMSprop похож на Adaprop, это еще один оптимизатор, который пытается
решить некоторые проблемы, которые Адаград оставляет открытыми.
Адам
Адам означает адаптивную оценку момента и является еще одним способом использования
предыдущих градиентов для вычисления текущих градиентов. Адам также использует
концепцию импульса,
добавляя доли предыдущих градиентов к текущему. Этот оптимизатор получил
довольно широкое распространение и практически принят для использования в
обучающих нейронных сетях.
Вы только что ознакомились с кратким обзором
оптимизаторов. Более подробно об этом можно прочитать здесь.
Я надеюсь,
что после прочтения этой статьи, вы будете лучше понимать что происходит, когда
Вы пишите следующий код:
# loss function: Binary Cross-entropy and optimizer: Adam
model.compile(loss='binary_crossentropy', optimizer='adam')или
# loss function: MSE and optimizer: stochastic gradient descent
model.compile(loss='mean_squared_error', optimizer='sgd')Спасибо за проявленный интерес!
Ссылки:
[1] https://www.deeplearningbook.org/contents/ml.html
[2] https://machinelearningmastery.com/loss-and-loss-functions-for-training-deep-learning-neural-networks/
[3] https://blog.algorithmia.com/introduction-to-optimizers/
[4] https://jhui.github.io/2017/01/05/Deep-learning-Information-theory/
[5] https://blog.algorithmia.com/introduction-to-loss-functions/
[6] https://gombru.github.io/2018/05/23/cross_entropy_loss/
[7] https://www.kdnuggets.com/2018/04/right-metric-evaluating-machine-learning-models-1.html
[8] https://rohanvarma.me/Loss-Functions/
[9] http://blog.christianperone.com/2019/01/mle/

Основной сложностью при выборе функций ошибок для работы с 3D данными является неевклидовость рассматриваемых структур, из-за которой задача определения расстояния в пространстве 3D моделей становится совсем нетривиальной.
В этой заметке мы поговорим о том, какие функции ошибки (Loss functions) алгоритмов используются в 3D ML, какие из них можно использовать в качеств метрик качества (metrics), а какие — в качестве регуляризаторов (regularizers).
Про то, чем евклидовы данные отличаются от неевклидовых, можно узнать здесь.
Серия 3D ML на Хабре:
- Формы представления 3D данных
- Функции потерь в 3D ML
- Датасеты и фреймворки в 3D ML
- Дифференциальный рендеринг
- Сверточные операторы на графах
Заметка от партнера IT-центра МАИ и организатора магистерской программы “VR/AR & AI” — компании PHYGITALISM.
Формальная постановка задачи. Предварительные сведения.
В предыдущей части, мы обозначили, что работа с 3D структурами с привлечением методов машинного обучения приводит нас к новой обширной науке 3D ML. Среди всех задач этой области можно выделить класс подзадач, который мы назовём 2D-to-3D (также эта задача часто в англоязычной литературе имеет название “3D reconstruction from 2D image”). Эти задачи характеризуются тем, что на входе у алгоритма как правило одно или несколько изображений, а на выходе мы хотим получить какую-либо трехмерную структуру.

Например, можно восстанавливать карту глубины для произвольного изображения [2] (RGB-to-RGBD, или же можно было бы назвать такую задачу 2D-to-2.5D).

Рис.1 Архитектура автокодировщика, восстанавливающая depth слой изображения при помощи специализированных сверточных операторов [3].
Другой пример схожего класса задач — восстановление облака точек объекта по его единственному RGB-D изображению [3] (2.5D-to-3D или “3D Shape completion”).

Рис.2 Архитектура Voxlets [3] восстанавливает пространственную информацию для одного RGBD изображения: a — исходное RGB изображение;
b — воксельная модель, полученная с помощью depth слоя исходного снимка;
c — настоящая пространственная модель объектов; d — пространственная модель, полученная с помощью Voxlets.
В дальнейшем мы подробнее рассмотрим задачу 3D model reconstruction from single RGB image.

Рис.3 Пример подготовленного входного изображения (слева) и полигональной модели, полученной с помощью Occupancy Net [1] (справа).
Поскольку результатом работы описанных выше алгоритмов являются трехмерные структуры, нам бы хотелось в первую очередь научится понимать, насколько результирующая модель близка к исходной модели из обучающей выборки.
Решение задачи машинного обучения, какая бы она не была (классификация, кластеризация, порождения новых объектов и т.д.) — это зачастую решение оптимизационной задачи. Для фиксированной параметризованной архитектуры алгоритма машинного обучения необходимо найти множество параметров, при которых функция ошибки (при выборе которой во многом отталкиваются от типа конкретной задачи) принимает наименьшее значение. При этом, необходимо следить, чтобы в процессе поиска минимума, обобщающая способность алгоритма возрастала. Подробнее про постановку задач машинного обучения и про классификацию задач можно прочесть здесь.
Оптимизируемые функции в задачах машинного обучения делятся на три категории:
- Функции потерь (Loss functions/objectives) — позволяют вычислить ошибку алгоритма на каждом конкретном объекте. Выбираются обычно непрерывными и почти всюду дифференцируемыми для того чтобы применять градиентные методы. Среднее значение функции потерь на датасете (функционал качества алгоритма) оптимизируется в процессе обучения.
-
Регуляризаторы (Regularizers) — вводятся в функционал качества для того чтобы сделать оптимизационную задачу обучения корректной, процесс обучения устойчивым и получить более качественное решение. Зачастую регуляризация помогает избежать переобучения. В отличие от функции потерь, для вычисления значения регуляризатора зачастую не требуется использование информации об объектах из датасета.
-
Метрики качества (Metrics) — функции по которым определяется (валидируется) качество обученной модели (как на всем датасете в целом, так и на отдельных моделях), но не происходит непосредственной оптимизации. Используются для контроля переобучения и для сравнения различных моделей.
Далее мы подробнее поговорим про конкретные функции потерь и регуляризаторы, а для большей наглядности будем рассматривать примеры с кодом. Код с примерами к заметке доступен в нашем GitHub репозитории.
Как и в предыдущей части, в качестве тестовых моделей будем рассматривать модель икосферы и кролика, а в качестве рабочего инструмента будем использовать библиотеку pytorch3d.
Загрузка моделей и установка рабочего устройства
import os
import pathlib
import numpy as np
import matplotlib.pyplot as plt
from mpl_toolkits.mplot3d import Axes3D
%matplotlib inline
# You should work in Jupyter.
from tqdm import tqdm_notebook
from celluloid import Camera
import torch
# untilitis
from pytorch3d.utils import ico_sphere
# loss functions and regulaziers
from pytorch3d.loss import (
chamfer_distance,
mesh_edge_loss,
mesh_laplacian_smoothing,
mesh_normal_consistency
)
# io utils
from pytorch3d.io import load_obj
# operations with data
from pytorch3d.ops import sample_points_from_meshes
# datastructures
from pytorch3d.structures import Meshes, Textures
# render
from pytorch3d.renderer import (
look_at_view_transform,
OpenGLPerspectiveCameras,
DirectionalLights,
RasterizationSettings,
MeshRenderer,
MeshRasterizer,
HardPhongShader
)
import trimesh
from trimesh import registration
from trimesh import visual
# If you have got a CUDA device, you can use GPU mode
if torch.cuda.is_available():
device = torch.device('cuda:0')
torch.cuda.set_device(device)
else:
device = torch.device('cpu')Подготовка моделей
# Bunny mesh in pytorch3d
verts, faces_idx, _ = load_obj(path_to_model)
faces = faces_idx.verts_idx
center = verts.mean(0)
verts = verts - center
scale = max(verts.abs().max(0)[0])
verts = verts / scale
# Initialize each vertex to be white in color.
verts_rgb = torch.ones_like(verts)[None] # (1, V, 3)
textures = Textures(verts_rgb=verts_rgb.to(device))
# Create a Meshes object for the bunny.
bunny_mesh = Meshes(
verts=[verts.to(device)],
faces=[faces.to(device)],
textures=textures
)
# Sphere mesh in pytorch3d
sphere_mesh = ico_sphere(4, device)
verts_rgb = torch.ones_like(sphere_mesh.verts_list()[0])[None]
sphere_mesh.textures = Textures(verts_rgb=verts_rgb.to(device))
# Mesh to pointcloud with normals in pytorch3d
num_points_to_sample = 25000
bunny_vert, bunny_norm = sample_points_from_meshes(
bunny_mesh,
num_points_to_sample ,
return_normals=True
)
sphere_vert, sphere_norm = sample_points_from_meshes(
sphere_mesh,
num_points_to_sample,
return_normals=True
)
def convert_to_mesh(mesh):
"""Trimesh может загружать сцены вместо монолитного объекта
"""
if isinstance(mesh, trimesh.Scene):
return mesh.dump(concatenate=True)
else:
return mesh
def scale_to_unit(mesh: trimesh.Trimesh):
length, weight, height = mesh.extents
scale = 1 / max(length, weight, height)
mesh.apply_scale((scale, scale, scale))
mesh_target = convert_to_mesh(trimesh.load_mesh(str(path_to_orig)))
mesh_source = convert_to_mesh(trimesh.load_mesh(str(path_to_rot)))
mesh_target.rezero()
mesh_source.rezero()
scale_to_unit(mesh_target)
scale_to_unit(mesh_source)
mesh_source.visual = visual.ColorVisuals(mesh_source, vertex_colors=(255, 0, 0, 255))
mesh_target.visual = visual.ColorVisuals(mesh_target, vertex_colors=(0, 255, 0, 255))
scene = trimesh.Scene([mesh_source, mesh_target])Подготовка визуализации моделей
# Initialize an OpenGL perspective camera.
cameras = OpenGLPerspectiveCameras(device=device)
# We will also create a phong renderer. This is simpler and only needs to render one face per pixel.
raster_settings = RasterizationSettings(
image_size=1024,
blur_radius=0,
faces_per_pixel=1,
)
# We can add a directional light in the scene.
ambient_color = torch.FloatTensor([[0.0, 0.0, 0.0]]).to(device)
diffuse_color = torch.FloatTensor([[1.0, 1.0, 1.0]]).to(device)
specular_color = torch.FloatTensor([[0.1, 0.1, 0.1]]).to(device)
direction = torch.FloatTensor([[1, 1, 1]]).to(device)
lights = DirectionalLights(ambient_color=ambient_color,
diffuse_color=diffuse_color,
specular_color=specular_color,
direction=direction,
device=device)
phong_renderer = MeshRenderer(
rasterizer=MeshRasterizer(
cameras=cameras,
raster_settings=raster_settings
),
shader=HardPhongShader(
device=device,
cameras=cameras,
lights=lights
)
)
# Select the viewpoint using spherical angles
distance = 2.0 # distance from camera to the object`
elevation = 40.0 # angle of elevation in degrees
azimuth = 0.0 # No rotation so the camera is positioned on the +Z axis.
# Get the position of the camera based on the spherical angles
R, T = look_at_view_transform(distance, elevation, azimuth, device=device,at=((-0.02,0.1,0.0),))
# Render the bunny providing the values of R and T.
image_bunny = phong_renderer(meshes_world=bunny_mesh, R=R, T=T)
image_sphere = phong_renderer(meshes_world=sphere_mesh, R=R, T=T)
image_sphere = image_sphere.cpu().numpy()
image_bunny = image_bunny.cpu().numpy()Визуализация моделей
# Source mesh of sphere
plt.figure(figsize=(13, 13))
plt.imshow(image_sphere.squeeze())
plt.grid(False)
# Target mesh of bunny
plt.figure(figsize=(13, 13))
plt.imshow(image_bunny.squeeze())
plt.grid(False)
Функции потерь, регуляризаторы и метрики качества в задачах 3D ML
Прежде чем ввести в рассмотрение конкретные функции потерь, отметим, что две сравниваемые модели должны быть предварительно приведены к одинаковому масштабу и ориентированы друг относительно друга таким образом, чтобы функция потерь принимала свое наименьшее значение из всех возможных при различных взаимных ориентациях. Решением задачи по совмещению друг с другом двух трехмерных объектов занимаются алгоритмы регистрации облаков точек, реализации которых можно найти в библиотеках trimesh или pcl.
В качестве примера задачи регистрации рассмотрим совмещение двух полигональных моделей автомобилей ( mesh_source.obj и mesh_target.obj из директории data ).
scene.show()
В качестве метода регистрации можно взять метод главных осей инерции (principal axes of inertia) — разновидности метода ICP.
transform, cost = registration.mesh_other(mesh_source, mesh_target, samples=2_000, scale=True)
new_scene = scene.copy()
new_scene.geometry["geometry_0"].apply_transform(transform)
print("Величина ошибки регистрации: ", cost)
print("Матрица преобразования модели:")
print(transform)Out:
>>Величина ошибки регистрации: 2.5801412889832494e-10
>>Матрица преобразования модели:
>>[[-0.97327281 0.33386218 -0.23301026 0.65454393]
[-0.07505283 0.44631862 0.95298713 -0.01844067]
[ 0.40015598 0.89574184 -0.38799414 0.28013195]
[ 0. 0. 0. 1. ]]После применения алгоритма можно увидеть, что модели совместились:
new_scene.show()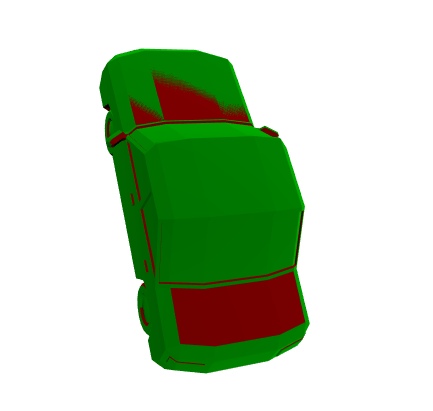
Помимо рассмотренного метода регистрации в библиотеке trimesh также содержится классический алгоритм icp и метод Procrustes analysis. Пример применения другого метода к данным моделям можно найти в jupyter notebook 3dml_habr_phygitalism_part_2.ipynb.
Заметим, что для практических приложений скорость работы рассматриваемых алгоритмов может быть недостаточно, в силу того, что их реализации написана на языке Python. В случае, если есть необходимость в имплементации более быстрых версий алгоритмов регистрации или иных алгоритмов из trimesh, можно воспользоваться библиотекой trimesh2, написанной на языке C++.
1. IoU metric
Метрика Intersection over Union ( ), также известная как Jaccard index, — число от 0 до 1, показывающее, насколько у двух объектов (эталонного (ground true) и текущего) совпадает внутренний “объем”.
), также известная как Jaccard index, — число от 0 до 1, показывающее, насколько у двух объектов (эталонного (ground true) и текущего) совпадает внутренний “объем”.
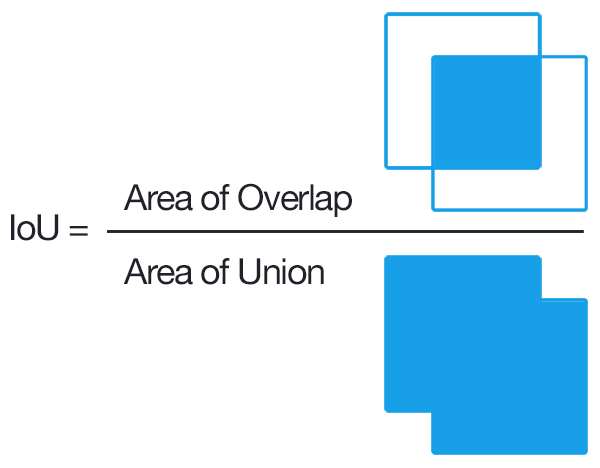
Формально, для двух непустых множеств A и B, функция IoU определяется как:

Для того чтобы подсчитать необходимо уметь вычислять внутренний объем рассматриваемых объектов. В случаи с полигональными моделями чаще всего прибегают к оценке объема методом Монте-Карло.
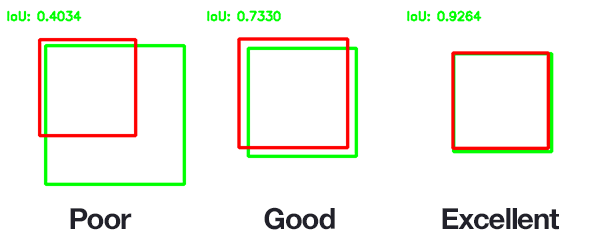
В задачах компьютерного зрения и 3D ML часто используют при оценке того, насколько корректно найден ограничивающий прямоугольник или ограничивающий параллелепипед (bounding box), т.е. в качестве метрики качества алгоритма, но в последнее время появились различные модификации , которые могут использованы и в качестве функции потерь [9].
В случае с трехмерными объектами обычно используется в качестве метрики, однако данная метрика не всегда корректна. Действительно, большая часть информации об объекте определяется его поверхностью. На рисунке ниже продемонстрировано, что две модели могут иметь существенно отличные поверхности, при этом значение будет высоко.

Для воксельных моделей значение данной метрики может быть некорректным ещё и по той причине, что “внутренность” моделей может отличаться, даже если у них схожие поверхности. На изображении ниже, из статьи [1], авторы продемонстрировали то, как при увеличении разрешения воксельной сетки растет качество метрики, но в тоже время растет и количество затрачиваемой памяти, времени обучения и параметров воксельной архитектуры. Для функциональной же модели (в данном случае Occupancy Net) качество не зависит от разрешения, а количество параметров неизменно.

Для работы с облаками точек данная функция обычно не применяется из-за того, что определить понятие объёма пересечения облаков точек достаточно затруднительно, однако такая возможность все равно имеется, так например в [8] авторы преобразуют выходное облако точек для их архитектуры в воксельную модель и сравнивают качество работы полученной модели по метрике. Для оценки качества работы модели на всем датасете обычно подсчитывают средние значения данной функции —  (mean intersection over union) для всего датасета и для отдельных категорий. Метрика в процессе обучения максимизируется.
(mean intersection over union) для всего датасета и для отдельных категорий. Метрика в процессе обучения максимизируется.
2. Chamfer loss/distance
Данная функция используется для работы как с полигональными моделями, так и с облаками точек. Она показывает, насколько вершины одной полигональной модели (облака точек) близки к вершинам другой полигональной модели (облаку точек), и следовательно, подлежит минимизации. Обычно сравнивают полигональную модель, полученную в результате работы алгоритма, и аналогичную модель из датасета.
Пусть мы имеем два множества вершин (точек) в трехмерном пространстве  и
и  . Введем в рассмотрение множество пар
. Введем в рассмотрение множество пар  , такое, что для
, такое, что для  точка
точка  будет ближайшим соседом, т.е.:
будет ближайшим соседом, т.е.:

тогда chamfer loss для данных точечных множеств определяется как:

Зачастую для вычисления chamfer loss имеющихся вершин полигональной модели недостаточно, поэтому дополнительно сэмплируют точки на гранях моделей, например так, как это делают авторы в недавно вышедшей работе [5]. Chamfer loss используется в качестве функции потерь. В [17] предложена модификация chamfer loss, использующая семплирования дополнительных точек на полигонах для вычисления значения функции потерь.
3. Normal loss / distance
Пусть аналогично предыдущему пункту мы рассматриваем два точечных множества и , но помимо информации о вершинах мы можем также использовать информацию о нормалях, в частности, можем восстанавливать единичную нормаль  к произвольной точке
к произвольной точке  —
—  , тогда normal loss для данных точечных множеств определяется как:
, тогда normal loss для данных точечных множеств определяется как:

Normal loss используется в качестве функции потерь и показывает, насколько сильно различаются поля нормалей у двух полигональных моделей, т.е. по сути, минимизируя данный критерий, мы стараемся сделать углы между соответствующими нормалями как можно меньше.
Вычислим значение chamfer loss и normal loss для наших тестовых моделей:
# Chamfer loss and normal loss
loss_chamfer, loss_normals_chamfer = chamfer_distance(
bunny_vert,
sphere_vert,
x_normals=bunny_norm,
y_normals=sphere_norm
)
print("Chamfer loss =", loss_chamfer.item())
print("Normal loss =", loss_normals_chamfer.item())Out:
>>Chamfer loss = 0.2609584927558899
>>Normal loss = 0.473361194133758544. Edge loss / regularizer
Недостатком chamfer и normal loss является чувствительность к выбросам. На рисунки ниже продемонстрирована ситуация, когда значение chamfer distance (CD) для двух в равной степени непохожих на оригинал объектов может значительно отличаться.

Помимо чувствительности к выбросам, на практике часто наблюдается эффект перекрытия полигонов. Чтобы избежать появления данного эффекта, вместе с chamfer и normal loss используют специальные регуляризаторы формы итогового меша (shape regularizers). Пусть  — множество вершин полигональной модели, а
— множество вершин полигональной модели, а  — множество ребер модели, тогда в качестве регуляризатора формы меша можно использовать среднее значение длины ребер:
— множество ребер модели, тогда в качестве регуляризатора формы меша можно использовать среднее значение длины ребер:

Авторы в [5], используя данный регуляризатор, улучшили качество итоговых моделей, что можно увидеть на изображениях ниже. Edge normalizer вводится дополнительным слагаемым к основной функции потерь с положительным коэффициентом.
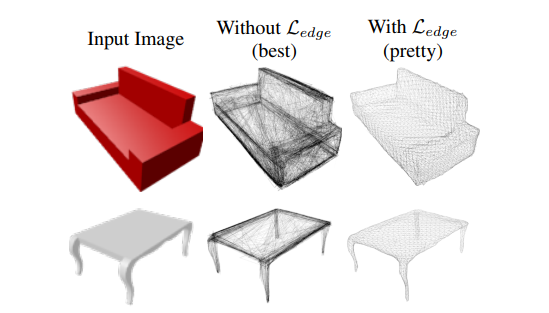
Рис.4 Пример из статьи [5]: восстановление меша из изображения без использования регуляризатора формы (лучший результат) и с использованием регуляризатора формы (средний результат).

Рис.5 Пример из статьи [5]: сравнение результатов восстановления меша сетью, использовавшей регуляризатор при обучении (Mesh R-CNN), с сетью, в которой регуляризатор не использовался (Pixel2Mesh+).
Сравним значение данного регуляризатора для наших моделей:
print("Edge loss for bunny.obj:", mesh_edge_loss(bunny_mesh).item())
print("Edge loss for sphere.obj:", mesh_edge_loss(sphere_mesh).item())Out:
>>Edge loss for bunny.obj: 0.004127349238842726
>>Edge loss for sphere.obj: 0.0057241991162300115. Smooth loss / regularizer
Для того, чтобы итоговые модели имели более гладкие поверхности без выбросов и шума, часто прибегают к сглаживающим регуляризаторам. Простейшим сглаживающим регуляризатором является Smooth loss. Для его вычисления необходимо провести суммирование по всем “внутренним” двугранным углам между полигонами меша  :
:

Введенная таким образом функция регуляризатора как бы стремится “распрямить” меш так, чтобы минимизировать поверхностное натяжение.

Рис.6 Пример из статьи [10]: сравнение работы алгоритма 2D-to-3D без использования smooth regularizer и с использованием данного регуляризатора. Слева направо: входное изображение, восстановленная полигональная модель без использования smooth regularizer, восстановленная полигональная модель c использования smooth regularizer.
Сравним значение данного регуляризатора для наших моделей:
print("Smooth regularizer for bunny.obj:", mesh_normal_consistency(bunny_mesh).item())
print("Smooth regularizer for sphere.obj:", mesh_normal_consistency(sphere_mesh).item())Out:
>>Smooth regularizer for bunny.obj: 0.03854169696569443
>>Smooth regularizer for sphere.obj: 0.00097806937992572786. Hausdorff losses
Проблема определения функции расстояния между двумя поверхностями в пространстве (которая используется для построения функции ошибки) стояла задолго до появления компьютерной графики. Вопрос о том, как находить расстояние между двумя вложенными в некоторое пространство многообразиями, был поставлен в функциональном анализе, и сегодня многие исследователи, при определении функции ошибки в задачах 3D ML, пользуются результатами из этой области. Так, в частности, существуют подходы, основанные на понятии метрики Хаусдорфа. Рассмотрим два таких подхода.
Оба подхода базируются на одинаковых математических понятиях, поэтому сначала опишем их. Во-первых, будем считать, что расстояние между некоторой точкой пространства и поверхностью  в этом пространстве определяется с помощью Евклидовой нормы следующим образом:
в этом пространстве определяется с помощью Евклидовой нормы следующим образом:

тогда “одностороннее” расстояние между двумя поверхностями  и можно определить как:
и можно определить как:

Под “односторонностью” здесь имеется в виду несимметричность данной функции. Чтобы определить симметричную функцию расстояния между двумя множествами, Хаусдорф предложил следующую конструкцию (называемую сегодня метрикой Хаусдорфа):
![$d_{s}left(mathcal{S}, mathcal{S}^{prime}right)=max left[dleft(mathcal{S}, mathcal{S}^{prime}right), dleft(mathcal{S}^{prime}, mathcal{S}right)right].$](https://habrastorage.org/getpro/habr/formulas/5b9/47f/769/5b947f7697abbfc69681fa9ef82db992.svg)
В качестве функции потерь, впрочем, используют не саму метрику, а средние значения расстояний от точки до поверхности. Введем в рассмотрении две функции. Средняя ошибка (mean distance error) между двумя поверхностями определяется как:

где  — означает площадь поверхности , а среднеквадратичная ошибка (root mean square distance error) между двумя поверхностями определяется как:
— означает площадь поверхности , а среднеквадратичная ошибка (root mean square distance error) между двумя поверхностями определяется как:

Существуют различные подходы к тому, как вычислять средние ошибки по Хаусдорфу на полигональном меше. Так, например, в [13] предложено вычислять значения средней ошибки на основании подсчета “ориентированных расстояний” между точкой и поверхностью. Такой подход авторы назвали Metro distance.

Рис.7 Пример из статьи [13]: сравнение двух мешей одного объекта: высокополигональная исходная модель (слева), оптимизированная низкополигональная модель.
В статье [14] авторы предлагают вычислять среднеквадратичную ошибку и конструируют оптимизированный численный метод для интегрирования по поверхности меша. Такой подход авторы называют Mesh distance.
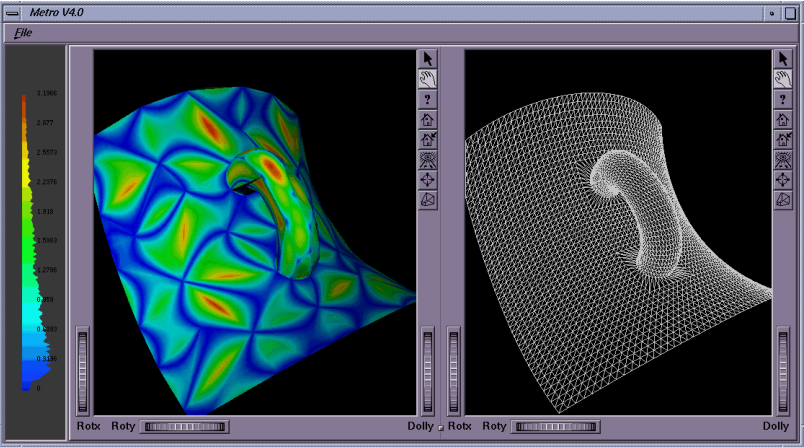
Рис.8 Пример из статьи [13]: средняя ошибка, вычисленная по расстоянию Metro, для низкополигональной модели по сравнению с исходной высокополигональной моделью.
Также в статье [14] приведено сравнение этих двух подходов: Mesh distance оказывается более быстрым и экономным с точки зрения затраченной памяти способом вычисления Хаусдорфова расстояния. Данные функции можно использовать в качестве регуляризатора, если на каждой итерации алгоритма обучения хранить меш объекта с предыдущей итерации, и высчитывать значение ошибки приближения текущего меша предыдущим.
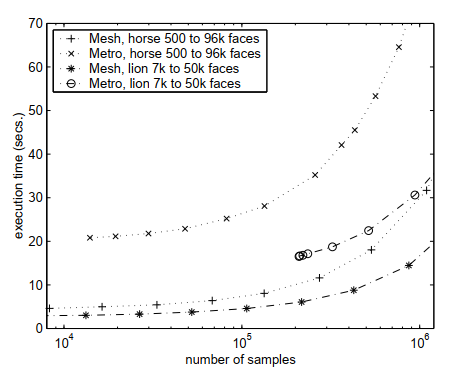
Рис.9 Пример из статьи [14]: сравнение вычислительной эффективности Mesh distance и Metro distance.
7. Laplacian loss / regularizer
Еще одним примером сглаживающего регуляризатора является Laplacian loss. Для того, чтобы сконструировать этот регуляризатор, используют часто возникающий в 3D ML и в компьютерной графике т.н. umbrella operator [15] — дискретизацию оператора Лапласа, вычисленного в вершинах полигонального меша:


Суммирование производится по вершинам, которые связаны с данной вершиной. В дальнейшем будем использовать обозначение  для множества вершин, которые связаны с данным ребром. Можно рассматривать применение данного оператора как перевод вершин в новую систему координат. Такие координаты называют Лапласовыми. В [12] и [16] идея использования данного оператора применяется к задачам сглаживания, деформирования и конкатенации меша.
для множества вершин, которые связаны с данным ребром. Можно рассматривать применение данного оператора как перевод вершин в новую систему координат. Такие координаты называют Лапласовыми. В [12] и [16] идея использования данного оператора применяется к задачам сглаживания, деформирования и конкатенации меша.

Рис.10 Пример из статьи [12]: сглаживание меша с помощью применения Laplacian smooth. (а) — исходный меш, (b) — после многократного применения Laplacian smooth.
Если оператор преобразования вершины меша в Лапласовы координаты будет иметь вид:

тогда Лапласов регуляризатор определяется как:

где суммирование производится по всем вершинам меша, а штриховая Лапласова координата обозначает меш на предыдущей итерации. Применительно к решению задачи 2D-to-3D данный регуляризатор применяется, например, в [11].
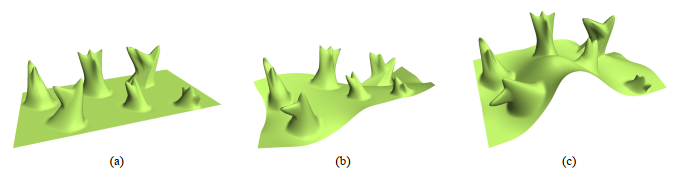
Рис.11 Пример из статьи [16]: деформирование меша с помощью применения Laplacian smooth.

Рис.12 Пример из статьи [16]: конкатенация меша с помощью применения Laplacian smooth. (а), (b) — исходные меши, (с) — конкатенированный меш, полученный с помощью применения Laplacian smooth.
Сравним значение данного регуляризатора для наших моделей:
print("Laplacian smoothing objective for bunny.obj:", mesh_laplacian_smoothing(bunny_mesh).item())
print("Laplacian smoothing objective for sphere.obj:", mesh_laplacian_smoothing(sphere_mesh).item())Out:
>>Laplacian smoothing objective for bunny.obj: 0.014459558762609959
>>Laplacian smoothing objective for sphere.obj: 0.0040009506046772Хорошую видеолекцию на тему применения оператора Лапласа в компьютерной графике можно найти здесь.
8. F1 score
Если считать, что количество вершин в восстановленном меше (retrieval) равно количеству вершин в целевом меше (ground true), то каждую вершину восстановленного меша можно отнести либо к правильно восстановленой, либо к неправильно восстановленной. Для этого вводится пороговое значение расстояния между вершинами восстановленного и исходного объектов: если расстояние между соответствующими вершинами меньше порогового, то данную вершину восстановленного меша относят к верно восстановленной. Таким образом, для каждой вершины восстановленного меша можно определить два класса и использовать для всего объекта метрики качества задач классификации. В частности, как это продемонстрировано в работах [5,6], можно использовать F1 метрику, являющуюся средним гармоническим между точностью (precision) и полнотой (recall). Точность в данном случае определяется как отношение количества вершин восстановленного меша, находящихся в пределах порогового расстояния от соответствующих вершин исходного меша. Полнота определяется симметрично, как отношение количества точек исходного меша, лежащих не более чем на пороговом расстоянии от соответствующих точек восстановленного меша.
F1 устойчива к выбросам и лучше отражает качество восстановления формы объекта. F1 метрика максимизируется. Реализацию данной метрики и некоторых других можно найти в библиотеке pytorch geometric — фреймворке для работы с пространственными графами.
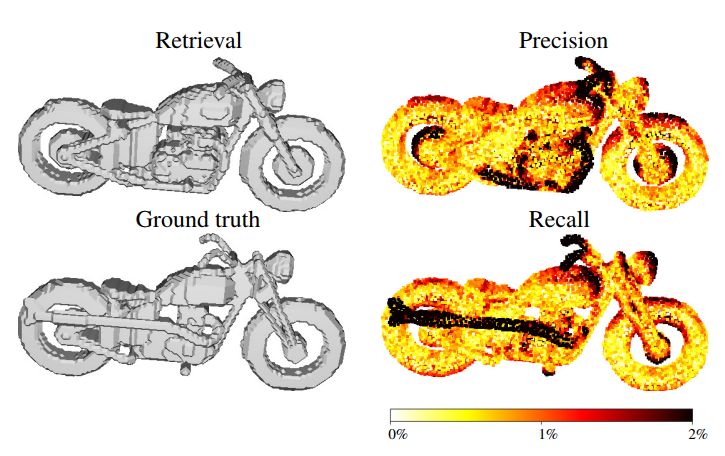
Рис.13 Пример из статьи [6]: слева сверху — восстановленный меш, слева снизу — исходный меш, справа сверху для восстановленного меша показано, насколько его вершины отличаются от исходного (в % длины ограничивающего параллелепипеда (bounding box)), справа снизу — для исходного меша показано, насколько его вершины отличаются от восстановленного (в % длины ограничивающего параллелепипеда (bounding box)).
9. Earth mover’s distance
Еще одной часто применяемой метрикой, в основном для облаков точек, является Earth mover’s distance (EMD), также известной в более общем виде как Wasserstein metric. Данная метрика возникает в задачах кластеризации изображений. До наступления эпохи глубокого обучения эта метрика часто применялась в области анализа изображений. Вычисление метрики тесно связано с решением оптимизационной транспортной задачи (подробнее про это и про то, как использовать эту метрику для различных типов данных, можно прочитать здесь).
Формально EMD определяется как минимальное значение функционала расстояния в следующей вариационной задаче:



Самое оптимальное биективное отображение в каждой конкретной задаче отличается, но преимуществом данной метрики является то, что оно инвариантно к произвольным инфиниматезиальным преобразованиям облака точек. Честное решение данной оптимизационной задачи обычно очень вычислительно затратно в задачах глубокого обучения, даже при использовании видеокарт, поэтому часто используют аппроксимированное вычисление этой метрики [7], как например это сделали авторы в [8]. Критерий EMD минимизируется в процессе обучения.

Рис.14 Пример из статьи [8]: сравнение восстановления средней формы (в смысле распределения исходных облаков точек) с помощью расстояний chamfer distance (CD) и Earth mover’s distance (EMD) для различных синтетических двумерных облаков точек (a-d).
Эксперимент с деформацией моделей
Чтобы лучше понять, как изменяются рассмотренные выше функции потерь и регуляризаторы в процессе обучения, рассмотрим модельный пример. Предположим, что модель сферы это исходное приближение, которое может генерировать наша модель машинного обучения, а в качестве целевой модели выступает модель кролика.
В качестве параметров модели машинного обучения возьмем координаты генерируемого меша (в данном случае сферы) и зададим оптимизатор, который будет минимизировать рассогласование между source (sphere) и target (bunny):
deform_verts = torch.full(sphere_mesh.verts_packed().shape, 0.0, device=device, requires_grad=True)
optimizer = torch.optim.SGD([deform_verts], lr=1.0, momentum=0.9)Зафиксируем параметры оптимизационного процесса:
# Number of optimization steps
Niter = 3000
# Weight for the chamfer loss
w_chamfer = 1.0
# Weight for mesh edge loss
w_edge = 1.0
# Weight for mesh normal consistency
w_normal = 0.01
# Weight for mesh laplacian smoothing
w_laplacian = 0.1
# Plot period for the losses
plot_period = 50
chamfer_losses = []
laplacian_losses = []
edge_losses = []
normal_losses = []В цикле будем делать градиентный спуск по функции потерь, представляющей из себя взвешенную сумму функций ошибок и регуляризаторов:

loop = tqdm_notebook(range(Niter))
fig = plt.figure()
camera = Camera(fig)
for i in loop:
# Initialize optimizer
optimizer.zero_grad()
# Deform the mesh
new_src_mesh = sphere_mesh.offset_verts(deform_verts)
# We sample 5k points from the surface of each mesh
sample_trg = sample_points_from_meshes(bunny_mesh, 5000)
sample_src = sample_points_from_meshes(new_src_mesh, 5000)
# We compare the two sets of pointclouds by computing (a) the chamfer loss
loss_chamfer, _ = chamfer_distance(sample_trg, sample_src)
# and (b) the edge length of the predicted mesh
loss_edge = mesh_edge_loss(new_src_mesh)
# mesh normal consistency
loss_normal = mesh_normal_consistency(new_src_mesh)
# mesh laplacian smoothing
loss_laplacian = mesh_laplacian_smoothing(new_src_mesh, method="uniform")
# Weighted sum of the losses
loss = loss_chamfer * w_chamfer + loss_edge * w_edge + loss_normal * w_normal + loss_laplacian * w_laplacian
# Print the losses
loop.set_description('total_loss = %.6f' % loss)
# Save the losses for plotting
chamfer_losses.append(loss_chamfer)
edge_losses.append(loss_edge)
normal_losses.append(loss_normal)
laplacian_losses.append(loss_laplacian)
# Plot mesh
if i % plot_period == 0 or i==0:
# Render the bunny providing the values of R and T.
image_bunny = phong_renderer(meshes_world=new_src_mesh, R=R, T=T)
image_bunny = image_bunny.detach().cpu().numpy()
plt.imshow(image_bunny.squeeze())
plt.grid(False)
camera.snap()
# Optimization step
loss.backward()
optimizer.step()
Для того, чтобы лучше понять динамику процесса оптимизации, мы использовали библиотеку celluloid для создании анимации.
Посмотрим, как изменялись функции потерь и регуляризаторы в процессе обучения:
# Losses evaluation
fig = plt.figure(figsize=(13, 5))
ax = fig.gca()
ax.plot(chamfer_losses, label="chamfer loss")
ax.plot(edge_losses, label="edge loss")
ax.plot(normal_losses, label="normal loss")
ax.plot(laplacian_losses, label="laplacian loss")
ax.legend(fontsize="16")
ax.set_xlabel("Iteration", fontsize="16")
ax.set_ylabel("Loss", fontsize="16")
ax.set_title("Loss vs iterations", fontsize="16")
Заключение
Помимо перечисленных выше метрик используются и другие. Так, например, для воксельного представления моделей, воксели часто “вытягивают” в обычные числовые вектора и пользуются метриками и функциями потерь для векторов [4], например косинусной мерой.
После того, как модель обучена и показывает приемлемый результат по метрикам качества, ее нужно встраивать в общий pipeline обработки данных в конкретном проекте. На этом этапе появляются другие показатели качества используемой модели, такие как: размер памяти, которая занимает модель; размер памяти, необходимой для обработки данных моделью; скорость обработки данных моделью; время, необходимое для пере/дообучения модели. Все эти характеристики относят к внешним метрикам качества, в то время как рассмотренные выше метрики относят к внутренним метрикам качества решаемой задачи. Так же немаловажно, чтобы полученная архитектура и способ ее обучения были воспроизводимы. Обычно в статьях, описывающих новую архитектуру, указывается только алгоритм обучения, его параметры, и на каком датасете производилось обучение. Пример того, как измеряется производительность моделей глубокого обучения и некоторые связанные с этим аспекты, можно посмотреть здесь.
Понять, как отличать сложные трехмерные структуры друг от друга, и на основе этого судить о том, как хорошо справляется алгоритм машинного обучения с поставленной задачей — чрезвычайно важная задача. В зависимости от выбранной функции ошибки, качество результата и даже цель процесса обучения разнятся, поэтому важно понимать, как устроены такие функции. В современных библиотеках, использующихся для решения задач Geometrical Deep Learning, обычно такие функции уже имеют готовую реализацию, и исследователь имеет возможность просто выбрать необходимую функцию ошибки для его задачи. Например, такая возможность реализована в библиотеке Kaolin [18] от NVidia или в библиотеке pytorch3d [19] от Facebook, как мы убедились на примерах в данной заметке.
Про хороший и интересный пример того как корректно подобранная функция ошибки может улучшить качество работы алгоритмов в 3D ML вы можете узнать из лекции Алексея Артемова прошедшей в рамках Phygital Days.
О том, какие еще существуют библиотеки для работы в области 3D ML, как они устроены, какие есть датасеты с трехмерными данными, в чем заключается их специфика, мы поговорим в следующей заметке.
Источники
-
Mescheder, Lars & Oechsle, Michael & Niemeyer, Michael & Nowozin, Sebastian & Geiger, Andreas. (2018). Occupancy Networks: Learning 3D Reconstruction in Function Space. [code]
-
Facil, Jose & Ummenhofer, Benjamin & Zhou, Huizhong & Montesano, Luis & Brox, Thomas & Civera, Javier. (2019). CAM-Convs: Camera-Aware Multi-Scale Convolutions for Single-View Depth. [code]
-
Firman, Michael and Mac Aodha, Oisin and Julier, Simon and Brostow, Gabriel J. (2016). Structured Prediction of Unobserved Voxels From a Single Depth Image / Firman CVPR 2016 [code]
-
Richter, Stephan & Roth, Stefan. (2018). Matryoshka Networks: Predicting 3D Geometry via Nested Shape Layers.
-
Gkioxari, G., Malik, J., & Johnson, J. (2019). Mesh R-CNN. ArXiv, abs/1906.02739.
-
Tatarchenko, Maxim & Richter, Stephan & Ranftl, Rene & Li, Zhuwen & Koltun, Vladlen & Brox, Thomas. (2019). What Do Single-view 3D Reconstruction Networks Learn? [code]
-
D. P. Bertsekas. A distributed asynchronous relaxation algorithm for the assignment problem. In Decision and Control, 1985 24th IEEE Conference on, pages 1703–1704. IEEE, 1985
-
H. Fan, H. Su, and L. J. Guibas. A point set generation network for 3D object reconstruction from a single image. In Proc. IEEE Conf. on Computer Vision and Pattern Recognition (CVPR), 2017. [code]
-
Rezatofighi, Hamid & Tsoi, Nathan & Gwak, JunYoung & Sadeghian, Amir & Reid, Ian & Savarese, Silvio. (2019). Generalized Intersection over Union: A Metric and A Loss for Bounding Box Regression.
-
Hiroharu Kato, Yoshitaka Ushiku, and Tatsuya Harada. Neural 3d mesh renderer. In The IEEE Conference on Computer Vision and Pattern Recognition (CVPR), 2018.
-
Nanyang Wang, Yinda Zhang, Zhuwen Li, Yanwei Fu, Wei Liu, and Yu-Gang Jiang. Pixel2mesh: Generating 3d mesh models from single rgb images. In ECCV, 2018.
-
M. Desbrun, M. Meyer, P. Schroder, and A. H. Barr. Implicit fairing of irregular meshes using diffusion and curvature flow. In SIGGRAPH, 1999.
-
P. Cignoni, C. Rocchini, and R. Scopigno, “Metro: measuring error on simplified surfaces,” Computer Graphics Forum, vol. 17, no. 2, pp. 167–174, June 1998.
-
Aspert, Nicolas & Santa-cruz, Diego & Ebrahimi, Touradj. (2002). MESH: Measuring Errors between Surfaces Using the Hausdorff Distance. Proceedings of the IEEE International Conference in Multimedia and Expo (ICME). 1. 705 — 708 vol.1. 10.1109/ICME.2002.1035879.
-
KOBBELT, L. Iterative Erzeugung glatter Interpolanten. Shaker Verlag, ISBN
3-8265-0540-9, 1995. -
O. Sorkine, Y. Lipman, D. Cohen-Or, M. Alexa, C. R¨ossl and H.P. Seidel: “Laplacian surface editing,” In Symposium on Geometry Processing, Vol. 71(2004), p. 175
-
Edward Smith, Scott Fujimoto, Adriana Romero, and David Meger. GEOMetrics: Exploiting geometric structure for graph-encoded objects. In Kamalika Chaudhuri and Ruslan Salakhutdinov, editors, Proceedings of the 36th International Conference on Machine Learning, volume 97 of Proceedings of Machine Learning Research, pages 5866–5876, Long Beach, California, USA, 09–15 Jun 2019. PMLR.
-
Jatavallabhula, Krishna Murthy, Edward Smith, Jean-Francois Lafleche, Clement Fuji Tsang, Artem Rozantsev, Wenzheng Chen, Tommy Xiang, Rev Lebaredian and Sanja Fidler. “Kaolin: A PyTorch Library for Accelerating 3D Deep Learning Research.” ArXivabs/1911.05063 (2019): n. pag. [project page]
-
Nikhila Ravi and Jeremy Reizenstein and David Novotny and Taylor Gordon and Wan-Yen Lo and Justin Johnson and Georgia Gkioxari. “PyTorch3D”, 2020 [project page]