Мы начнем с самых простых и понятных моделей машинного обучения: линейных. В этой главе мы разберёмся, что это такое, почему они работают и в каких случаях их стоит использовать. Так как это первый класс моделей, с которым вы столкнётесь, мы постараемся подробно проговорить все важные моменты. Заодно объясним, как работает машинное обучение, на сравнительно простых примерах.
Почему модели линейные?
Представьте, что у вас есть множество объектов $mathbb{X}$, а вы хотели бы каждому объекту сопоставить какое-то значение. К примеру, у вас есть набор операций по банковской карте, а вы бы хотели, понять, какие из этих операций сделали мошенники. Если вы разделите все операции на два класса и нулём обозначите законные действия, а единицей мошеннические, то у вас получится простейшая задача классификации. Представьте другую ситуацию: у вас есть данные геологоразведки, по которым вы хотели бы оценить перспективы разных месторождений. В данном случае по набору геологических данных ваша модель будет, к примеру, оценивать потенциальную годовую доходность шахты. Это пример задачи регрессии. Числа, которым мы хотим сопоставить объекты из нашего множества иногда называют таргетами (от английского target).
Таким образом, задачи классификации и регрессии можно сформулировать как поиск отображения из множества объектов $mathbb{X}$ в множество возможных таргетов.
Математически задачи можно описать так:
- классификация: $mathbb{X} to {0,1,ldots,K}$, где $0, ldots, K$ – номера классов,
- регрессия: $mathbb{X} to mathbb{R}$.
Очевидно, что просто сопоставить какие-то объекты каким-то числам — дело довольно бессмысленное. Мы же хотим быстро обнаруживать мошенников или принимать решение, где строить шахту. Значит нам нужен какой-то критерий качества. Мы бы хотели найти такое отображение, которое лучше всего приближает истинное соответствие между объектами и таргетами. Что значит «лучше всего» – вопрос сложный. Мы к нему будем много раз возвращаться. Однако, есть более простой вопрос: среди каких отображений мы будем искать самое лучшее? Возможных отображений может быть много, но мы можем упростить себе задачу и договориться, что хотим искать решение только в каком-то заранее заданном параметризированном семействе функций. Вся эта глава будет посвящена самому простому такому семейству — линейным функциям вида
$$
y = w_1 x_1 + ldots + w_D x_D + w_0,
$$
где $y$ – целевая переменная (таргет), $(x_1, ldots, x_D)$ – вектор, соответствующий объекту выборки (вектор признаков), а $w_1, ldots, w_D, w_0$ – параметры модели. Признаки ещё называют фичами (от английского features). Вектор $w = (w_1,ldots,w_D)$ часто называют вектором весов, так как на предсказание модели можно смотреть как на взвешенную сумму признаков объекта, а число $w_0$ – свободным коэффициентом, или сдвигом (bias). Более компактно линейную модель можно записать в виде
$$y = langle x, wrangle + w_0$$
Теперь, когда мы выбрали семейство функций, в котором будем искать решение, задача стала существенно проще. Мы теперь ищем не какое-то абстрактное отображение, а конкретный вектор $(w_0,w_1,ldots,w_D)inmathbb{R}^{D+1}$.
Замечание. Чтобы применять линейную модель, нужно, чтобы каждый объект уже был представлен вектором численных признаков $x_1,ldots,x_D$. Конечно, просто текст или граф в линейную модель не положить, придётся сначала придумать для него численные фичи. Модель называют линейной, если она является линейной по этим численным признакам.
Разберёмся, как будет работать такая модель в случае, если $D = 1$. То есть у наших объектов есть ровно один численный признак, по которому они отличаются. Теперь наша линейная модель будет выглядеть совсем просто: $y = w_1 x_1 + w_0$. Для задачи регрессии мы теперь пытаемся приблизить значение игрек какой-то линейной функцией от переменной икс. А что будет значить линейность для задачи классификации? Давайте вспомним про пример с поиском мошеннических транзакций по картам. Допустим, нам известна ровно одна численная переменная — объём транзакции. Для бинарной классификации транзакций на законные и потенциально мошеннические мы будем искать так называемое разделяющее правило: там, где значение функции положительно, мы будем предсказывать один класс, где отрицательно – другой. В нашем примере простейшим правилом будет какое-то пороговое значение объёма транзакций, после которого есть смысл пометить транзакцию как подозрительную.
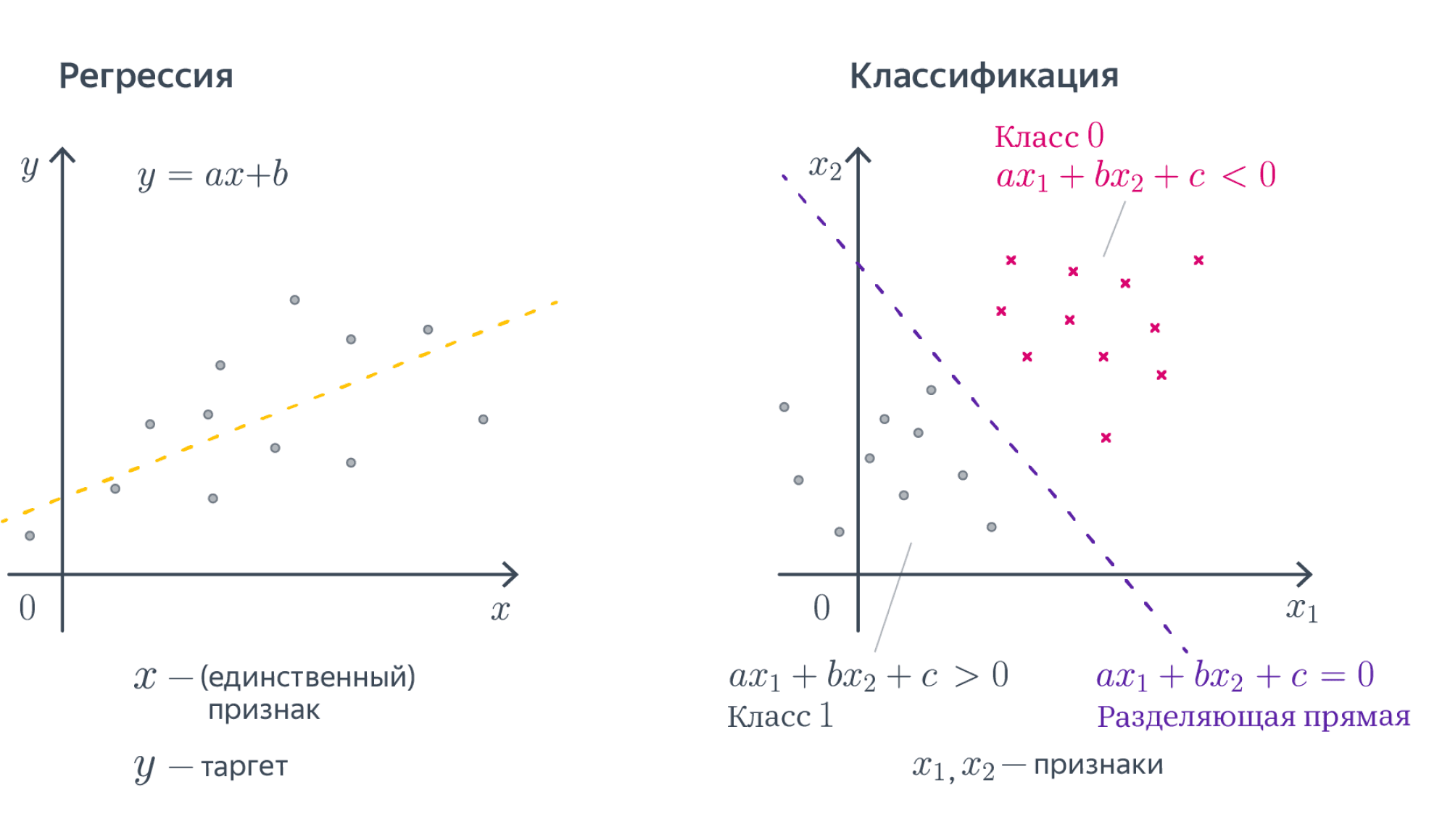
В случае более высоких размерностей вместо прямой будет гиперплоскость с аналогичным смыслом.
Вопрос на подумать. Если вы посмотрите содержание учебника, то не найдёте в нём ни «полиномиальных» моделей, ни каких-нибудь «логарифмических», хотя, казалось бы, зависимости бывают довольно сложными. Почему так?
Ответ (не открывайте сразу; сначала подумайте сами!)Линейные зависимости не так просты, как кажется. Пусть мы решаем задачу регрессии. Если мы подозреваем, что целевая переменная $y$ не выражается через $x_1, x_2$ как линейная функция, а зависит ещё от логарифма $x_1$ и ещё как-нибудь от того, разные ли знаки у признаков, то мы можем ввести дополнительные слагаемые в нашу линейную зависимость, просто объявим эти слагаемые новыми переменными и добавив перед ними соответствующие регрессионные коэффициенты
$$y approx w_1 x_1 + w_2 x_2 + w_3log{x_1} + w_4text{sgn}(x_1x_2) + w_0,$$
и в итоге из двумерной нелинейной задачи мы получили четырёхмерную линейную регрессию.
Вопрос на подумать. А как быть, если одна из фичей является категориальной, то есть принимает значения из (обычно конечного числа) значений, не являющихся числами? Например, это может быть время года, уровень образования, марка машины и так далее. Как правило, с такими значениями невозможно производить арифметические операции или же результаты их применения не имеют смысла.
Ответ (не открывайте сразу; сначала подумайте сами!)В линейную модель можно подать только численные признаки, так что категориальную фичу придётся как-то закодировать. Рассмотрим для примера вот такой датасет

Здесь два категориальных признака – pet_type и color. Первый принимает четыре различных значения, второй – пять.
Самый простой способ – использовать one-hot кодирование (one-hot encoding). Пусть исходный признак мог принимать $M$ значений $c_1,ldots, c_M$. Давайте заменим категориальный признак на $M$ признаков, которые принимают значения $0$ и $1$: $i$-й будет отвечать на вопрос «принимает ли признак значение $c_i$?». Иными словами, вместо ячейки со значением $c_i$ у объекта появляется строка нулей и единиц, в которой единица стоит только на $i$-м месте.
В нашем примере получится вот такая табличка:
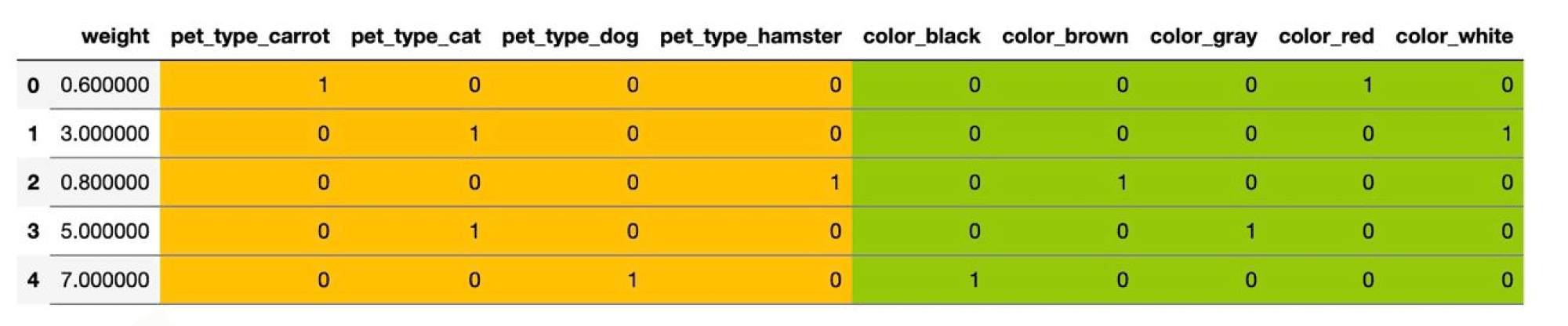
Можно было бы на этом остановиться, но добавленные признаки обладают одним неприятным свойством: в каждом из них ровно одна единица, так что сумма соответствующих столбцов равна столбцу из единиц. А это уже плохо. Представьте, что у нас есть линейная модель
$$y sim w_1x_1 + ldots + w_{D-1}x_{d-1} + w_{c_1}x_{c_1} + ldots + w_{c_M}x_{c_M} + w_0$$
Преобразуем немного правую часть:
$$ysim w_1x_1 + ldots + w_{D-1}x_{d-1} + underbrace{(w_{c_1} — w_{c_M})}_{=:w’_{c_1}}x_{c_1} + ldots + underbrace{(w_{c_{M-1}} — w_{c_M})}_{=:w’_{C_{M-1}}}x_{c_{M-1}} + w_{c_M}underbrace{(x_{c_1} + ldots + x_{c_M})}_{=1} + w_0 = $$
$$ = w_1x_1 + ldots + w_{D-1}x_{d-1} + w’_{c_1}x_{c_1} + ldots + w’_{c_{M-1}}x_{c_{M-1}} + underbrace{(w_{c_M} + w_0)}_{=w’_{0}}$$
Как видим, от одного из новых признаков можно избавиться, не меняя модель. Больше того, это стоит сделать, потому что наличие «лишних» признаков ведёт к переобучению или вовсе ломает модель – подробнее об этом мы поговорим в разделе про регуляризацию. Поэтому при использовании one-hot-encoding обычно выкидывают признак, соответствующий одному из значений. Например, в нашем примере итоговая матрица объекты-признаки будет иметь вид:

Конечно, one-hot кодирование – это самый наивный способ работы с категориальными признаками, и для более сложных фичей или фичей с большим количеством значений оно плохо подходит. С рядом более продвинутых техник вы познакомитесь в разделе про обучение представлений.
Помимо простоты, у линейных моделей есть несколько других достоинств. К примеру, мы можем достаточно легко судить, как влияют на результат те или иные признаки. Скажем, если вес $w_i$ положителен, то с ростом $i$-го признака таргет в случае регрессии будет увеличиваться, а в случае классификации наш выбор будет сдвигаться в пользу одного из классов. Значение весов тоже имеет прозрачную интерпретацию: чем вес $w_i$ больше, тем «важнее» $i$-й признак для итогового предсказания. То есть, если вы построили линейную модель, вы неплохо можете объяснить заказчику те или иные её результаты. Это качество моделей называют интерпретируемостью. Оно особенно ценится в индустриальных задачах, цена ошибки в которых высока. Если от работы вашей модели может зависеть жизнь человека, то очень важно понимать, как модель принимает те или иные решения и какими принципами руководствуется. При этом не все методы машинного обучения хорошо интерпретируемы, к примеру, поведение искусственных нейронных сетей или градиентного бустинга интерпретировать довольно сложно.
В то же время слепо доверять весам линейных моделей тоже не стоит по целому ряду причин:
- Линейные модели всё-таки довольно узкий класс функций, они неплохо работают для небольших датасетов и простых задач. Однако, если вы решаете линейной моделью более сложную задачу, то вам, скорее всего, придётся выдумывать дополнительные признаки, являющиеся сложными функциями от исходных. Поиск таких дополнительных признаков называется feature engineering, технически он устроен примерно так, как мы описали в вопросе про «полиномиальные модели». Вот только поиском таких искусственных фичей можно сильно увлечься, так что осмысленность интерпретации будет сильно зависеть от здравого смысла эксперта, строившего модель.
- Если между признаками есть приближённая линейная зависимость, коэффициенты в линейной модели могут совершенно потерять физический смысл (об этой проблеме и о том, как с ней бороться, мы поговорим дальше, когда будем обсуждать регуляризацию).
- Особенно осторожно стоит верить в утверждения вида «этот коэффициент маленький, значит, этот признак не важен». Во-первых, всё зависит от масштаба признака: вдруг коэффициент мал, чтобы скомпенсировать его. Во-вторых, зависимость действительно может быть слабой, но кто знает, в какой ситуации она окажется важна. Такие решения принимаются на основе данных, например, путём проверки статистического критерия (об этом мы коротко упомянем в разделе про вероятностные модели).
- Конкретные значения весов могут меняться в зависимости от обучающей выборки, хотя с ростом её размера они будут потихоньку сходиться к весам «наилучшей» линейной модели, которую можно было бы построить по всем-всем-всем данным на свете.
Обсудив немного общие свойства линейных моделей, перейдём к тому, как их всё-таки обучать. Сначала разберёмся с регрессией, а затем настанет черёд классификации.
Линейная регрессия и метод наименьших квадратов (МНК)
Мы начнём с использования линейных моделей для решения задачи регрессии. Простейшим примером постановки задачи линейной регрессии является метод наименьших квадратов (Ordinary least squares).
Пусть у нас задан датасет $(X, y)$, где $y=(y_i)_{i=1}^N in mathbb{R}^N$ – вектор значений целевой переменной, а $X=(x_i)_{i = 1}^N in mathbb{R}^{N times D}, x_i in mathbb{R}^D$ – матрица объекты-признаки, в которой $i$-я строка – это вектор признаков $i$-го объекта выборки. Мы хотим моделировать зависимость $y_i$ от $x_i$ как линейную функцию со свободным членом. Общий вид такой функции из $mathbb{R}^D$ в $mathbb{R}$ выглядит следующим образом:
$$color{#348FEA}{f_w(x_i) = langle w, x_i rangle + w_0}$$
Свободный член $w_0$ часто опускают, потому что такого же результата можно добиться, добавив ко всем $x_i$ признак, тождественно равный единице; тогда роль свободного члена будет играть соответствующий ему вес:
$$begin{pmatrix}x_{i1} & ldots & x_{iD} end{pmatrix}cdotbegin{pmatrix}w_1\ vdots \ w_Dend{pmatrix} + w_0 =
begin{pmatrix}1 & x_{i1} & ldots & x_{iD} end{pmatrix}cdotbegin{pmatrix}w_0 \ w_1\ vdots \ w_D end{pmatrix}$$
Поскольку это сильно упрощает запись, в дальнейшем мы будем считать, что это уже сделано и зависимость имеет вид просто $f_w(x_i) = langle w, x_i rangle$.
Сведение к задаче оптимизации
Мы хотим, чтобы на нашем датасете (то есть на парах $(x_i, y_i)$ из обучающей выборки) функция $f_w$ как можно лучше приближала нашу зависимость.
Для того, чтобы чётко сформулировать задачу, нам осталось только одно: на математическом языке выразить желание «приблизить $f_w(x)$ к $y$». Говоря простым языком, мы должны научиться измерять качество модели и минимизировать её ошибку, как-то меняя обучаемые параметры. В нашем примере обучаемые параметры — это веса $w$. Функция, оценивающая то, как часто модель ошибается, традиционно называется функцией потерь, функционалом качества или просто лоссом (loss function). Важно, чтобы её было легко оптимизировать: скажем, гладкая функция потерь – это хорошо, а кусочно постоянная – просто ужасно.
Функции потерь бывают разными. От их выбора зависит то, насколько задачу в дальнейшем легко решать, и то, в каком смысле у нас получится приблизить предсказание модели к целевым значениям. Интуитивно понятно, что для нашей текущей задачи нам нужно взять вектор $y$ и вектор предсказаний модели и как-то сравнить, насколько они похожи. Так как эти вектора «живут» в одном векторном пространстве, расстояние между ними вполне может быть функцией потерь. Более того, положительная непрерывная функция от этого расстояния тоже подойдёт в качестве функции потерь. При этом способов задать расстояние между векторами тоже довольно много. От всего этого разнообразия глаза разбегаются, но мы обязательно поговорим про это позже. Сейчас давайте в качестве лосса возьмём квадрат $L^2$-нормы вектора разницы предсказаний модели и $y$. Во-первых, как мы увидим дальше, так задачу будет нетрудно решить, а во-вторых, у этого лосса есть ещё несколько дополнительных свойств:
-
$L^2$-норма разницы – это евклидово расстояние $|y — f_w(x)|_2$ между вектором таргетов и вектором ответов модели, то есть мы их приближаем в смысле самого простого и понятного «расстояния».
-
Как мы увидим в разделе про вероятностные модели, с точки зрения статистики это соответствует гипотезе о том, что наши данные состоят из линейного «сигнала» и нормально распределенного «шума».
Так вот, наша функция потерь выглядит так:
$$L(f, X, y) = |y — f(X)|_2^2 = $$
$$= |y — Xw|_2^2 = sum_{i=1}^N(y_i — langle x_i, w rangle)^2$$
Такой функционал ошибки не очень хорош для сравнения поведения моделей на выборках разного размера. Представьте, что вы хотите понять, насколько качество модели на тестовой выборке из $2500$ объектов хуже, чем на обучающей из $5000$ объектов. Вы измерили $L^2$-норму ошибки и получили в одном случае $300$, а в другом $500$. Эти числа не очень интерпретируемы. Гораздо лучше посмотреть на среднеквадратичное отклонение
$$L(f, X, y) = frac1Nsum_{i=1}^N(y_i — langle x_i, w rangle)^2$$
По этой метрике на тестовой выборке получаем $0,12$, а на обучающей $0,1$.
Функция потерь $frac1Nsum_{i=1}^N(y_i — langle x_i, w rangle)^2$ называется Mean Squared Error, MSE или среднеквадратическим отклонением. Разница с $L^2$-нормой чисто косметическая, на алгоритм решения задачи она не влияет:
$$color{#348FEA}{text{MSE}(f, X, y) = frac{1}{N}|y — X w|_2^2}$$
В самом широком смысле, функции работают с объектами множеств: берут какой-то входящий объект из одного множества и выдают на выходе соответствующий ему объект из другого. Если мы имеем дело с отображением, которое на вход принимает функции, а на выходе выдаёт число, то такое отображение называют функционалом. Если вы посмотрите на нашу функцию потерь, то увидите, что это именно функционал. Для каждой конкретной линейной функции, которую задают веса $w_i$, мы получаем число, которое оценивает, насколько точно эта функция приближает наши значения $y$. Чем меньше это число, тем точнее наше решение, значит для того, чтобы найти лучшую модель, этот функционал нам надо минимизировать по $w$:
$$color{#348FEA}{|y — Xw|_2^2 longrightarrow min_w}$$
Эту задачу можно решать разными способами. В этой главе мы сначала решим эту задачу аналитически, а потом приближенно. Сравнение двух этих решений позволит нам проиллюстрировать преимущества того подхода, которому посвящена эта книга. На наш взгляд, это самый простой способ «на пальцах» показать суть машинного обучения.
МНК: точный аналитический метод
Точку минимума можно найти разными способами. Если вам интересно аналитическое решение, вы можете найти его в главе про матричные дифференцирования (раздел «Примеры вычисления производных сложных функций»). Здесь же мы воспользуемся геометрическим подходом.
Пусть $x^{(1)},ldots,x^{(D)}$ – столбцы матрицы $X$, то есть столбцы признаков. Тогда
$$Xw = w_1x^{(1)}+ldots+w_Dx^{(D)},$$
и задачу регрессии можно сформулировать следующим образом: найти линейную комбинацию столбцов $x^{(1)},ldots,x^{(D)}$, которая наилучшим способом приближает столбец $y$ по евклидовой норме – то есть найти проекцию вектора $y$ на подпространство, образованное векторами $x^{(1)},ldots,x^{(D)}$.
Разложим $y = y_{parallel} + y_{perp}$, где $y_{parallel} = Xw$ – та самая проекция, а $y_{perp}$ – ортогональная составляющая, то есть $y_{perp} = y — Xwperp x^{(1)},ldots,x^{(D)}$. Как это можно выразить в матричном виде? Оказывается, очень просто:
$$X^T(y — Xw) = 0$$
В самом деле, каждый элемент столбца $X^T(y — Xw)$ – это скалярное произведение строки $X^T$ (=столбца $X$ = одного из $x^{(i)}$) на $y — Xw$. Из уравнения $X^T(y — Xw) = 0$ уже очень легко выразить $w$:
$$w = (X^TX)^{-1}X^Ty$$
Вопрос на подумать Для вычисления $w_{ast}$ нам приходится обращать (квадратную) матрицу $X^TX$, что возможно, только если она невырожденна. Что это значит с точки зрения анализа данных? Почему мы верим, что это выполняется во всех разумных ситуациях?
Ответ (не открывайте сразу; сначала подумайте сами!)Как известно из линейной алгебры, для вещественной матрицы $X$ ранги матриц $X$ и $X^TX$ совпадают. Матрица $X^TX$ невырожденна тогда и только тогда, когда её ранг равен числу её столбцов, что равно числу столбцов матрицы $X$. Иными словами, формула регрессии поломается, только если столбцы матрицы $X$ линейно зависимы. Столбцы матрицы $X$ – это признаки. А если наши признаки линейно зависимы, то, наверное, что-то идёт не так и мы должны выкинуть часть из них, чтобы остались только линейно независимые.
Другое дело, что зачастую признаки могут быть приближённо линейно зависимы, особенно если их много. Тогда матрица $X^TX$ будет близка к вырожденной, и это, как мы дальше увидим, будет вести к разным, в том числе вычислительным проблемам.
Вычислительная сложность аналитического решения — $O(N^2D + D^3)$, где $N$ — длина выборки, $D$ — число признаков у одного объекта. Слагаемое $N^2D$ отвечает за сложность перемножения матриц $X^T$ и $X$, а слагаемое $D^3$ — за сложность обращения их произведения. Перемножать матрицы $(X^TX)^{-1}$ и $X^T$ не стоит. Гораздо лучше сначала умножить $y$ на $X^T$, а затем полученный вектор на $(X^TX)^{-1}$: так будет быстрее и, кроме того, не нужно будет хранить матрицу $(X^TX)^{-1}X^T$.
Вычисление можно ускорить, используя продвинутые алгоритмы перемножения матриц или итерационные методы поиска обратной матрицы.
Проблемы «точного» решения
Заметим, что для получения ответа нам нужно обратить матрицу $X^TX$. Это создает множество проблем:
- Основная проблема в обращении матрицы — это то, что вычислительно обращать большие матрицы дело сложное, а мы бы хотели работать с датасетами, в которых у нас могут быть миллионы точек,
- Матрица $X^TX$, хотя почти всегда обратима в разумных задачах машинного обучения, зачастую плохо обусловлена. Особенно если признаков много, между ними может появляться приближённая линейная зависимость, которую мы можем упустить на этапе формулировки задачи. В подобных случаях погрешность нахождения $w$ будет зависеть от квадрата числа обусловленности матрицы $X$, что очень плохо. Это делает полученное таким образом решение численно неустойчивым: малые возмущения $y$ могут приводить к катастрофическим изменениям $w$.
Пара слов про число обусловленности.Пожертвовав математической строгостью, мы можем считать, что число обусловленности матрицы $X$ – это корень из отношения наибольшего и наименьшего из собственных чисел матрицы $X^TX$. Грубо говоря, оно показывает, насколько разного масштаба бывают собственные значения $X^TX$. Если рассмотреть $L^2$-норму ошибки предсказания, как функцию от $w$, то её линии уровня будут эллипсоидами, форма которых определяется квадратичной формой с матрицей $X^TX$ (проверьте это!). Таким образом, число обусловленности говорит о том, насколько вытянутыми являются эти эллипсоиды.ПодробнееДанные проблемы не являются поводом выбросить решение на помойку. Существует как минимум два способа улучшить его численные свойства, однако если вы не знаете про сингулярное разложение, то лучше вернитесь сюда, когда узнаете.
-
Построим $QR$-разложение матрицы $X$. Напомним, что это разложение, в котором матрица $Q$ ортогональна по столбцам (то есть её столбцы ортогональны и имеют длину 1; в частности, $Q^TQ=E$), а $R$ квадратная и верхнетреугольная. Подставив его в формулу, получим
$$w = ((QR)^TQR)^{-1}(QR)^T y = (R^Tunderbrace{Q^TQ}_{=E}R)^{-1}R^TQ^Ty = R^{-1}R^{-T}R^TQ^Ty = R^{-1}Q^Ty$$
Отметим, что написать $(R^TR)^{-1} = R^{-1}R^{-T}$ мы имеем право благодаря тому, что $R$ квадратная. Полученная формула намного проще, обращение верхнетреугольной матрицы (=решение системы с верхнетреугольной левой частью) производится быстро и хорошо, погрешность вычисления $w$ будет зависеть просто от числа обусловленности матрицы $X$, а поскольку нахождение $QR$-разложения является достаточно стабильной операцией, мы получаем решение с более хорошими, чем у исходной формулы, численными свойствами.
-
Также можно использовать псевдообратную матрицу, построенную с помощью сингулярного разложения, о котором подробно написано в разделе про матричные разложения. А именно, пусть
$$A = Uunderbrace{mathrm{diag}(sigma_1,ldots,sigma_r)}_{=Sigma}V^T$$
– это усечённое сингулярное разложение, где $r$ – это ранг $A$. В таком случае диагональная матрица посередине является квадратной, $U$ и $V$ ортогональны по столбцам: $U^TU = E$, $V^TV = E$. Тогда
$$w = (VSigma underbrace{U^TU}_{=E}Sigma V^T)^{-1}VSigma U^Ty$$
Заметим, что $VSigma^{-2}V^Tcdot VSigma^2V^T = E = VSigma^2V^Tcdot VSigma^{-2}V^T$, так что $(VSigma^2 V^T)^{-1} = VSigma^{-2}V^T$, откуда
$$w = VSigma^{-2}underbrace{V^TV}_{=E}V^Tcdot VSigma U^Ty = VSigma^{-1}Uy$$
Хорошие численные свойства сингулярного разложения позволяют утверждать, что и это решение ведёт себя довольно неплохо.
Тем не менее, вычисление всё равно остаётся довольно долгим и будет по-прежнему страдать (хоть и не так сильно) в случае плохой обусловленности матрицы $X$.
Полностью вылечить проблемы мы не сможем, но никто и не обязывает нас останавливаться на «точном» решении (которое всё равно никогда не будет вполне точным). Поэтому ниже мы познакомим вас с совершенно другим методом.
МНК: приближенный численный метод
Минимизируемый функционал является гладким и выпуклым, а это значит, что можно эффективно искать точку его минимума с помощью итеративных градиентных методов. Более подробно вы можете прочитать о них в разделе про методы оптимизации, а здесь мы лишь коротко расскажем об одном самом базовом подходе.
Как известно, градиент функции в точке направлен в сторону её наискорейшего роста, а антиградиент (противоположный градиенту вектор) в сторону наискорейшего убывания. То есть имея какое-то приближение оптимального значения параметра $w$, мы можем его улучшить, посчитав градиент функции потерь в точке и немного сдвинув вектор весов в направлении антиградиента:
$$w_j mapsto w_j — alpha frac{d}{d{w_j}} L(f_w, X, y) $$
где $alpha$ – это параметр алгоритма («темп обучения»), который контролирует величину шага в направлении антиградиента. Описанный алгоритм называется градиентным спуском.
Посмотрим, как будет выглядеть градиентный спуск для функции потерь $L(f_w, X, y) = frac1Nvertvert Xw — yvertvert^2$. Градиент квадрата евклидовой нормы мы уже считали; соответственно,
$$
nabla_wL = frac2{N} X^T (Xw — y)
$$
Следовательно, стартовав из какого-то начального приближения, мы можем итеративно уменьшать значение функции, пока не сойдёмся (по крайней мере в теории) к минимуму (вообще говоря, локальному, но в данном случае глобальному).
Алгоритм градиентного спуска
w = random_normal() # можно пробовать и другие виды инициализации
repeat S times: # другой вариант: while abs(err) > tolerance
f = X.dot(w) # посчитать предсказание
err = f - y # посчитать ошибку
grad = 2 * X.T.dot(err) / N # посчитать градиент
w -= alpha * grad # обновить веса
С теоретическими результатами о скорости и гарантиях сходимости градиентного спуска вы можете познакомиться в главе про методы оптимизации. Мы позволим себе лишь несколько общих замечаний:
- Поскольку задача выпуклая, выбор начальной точки влияет на скорость сходимости, но не настолько сильно, чтобы на практике нельзя было стартовать всегда из нуля или из любой другой приятной вам точки;
- Число обусловленности матрицы $X$ существенно влияет на скорость сходимости градиентного спуска: чем более вытянуты эллипсоиды уровня функции потерь, тем хуже;
- Темп обучения $alpha$ тоже сильно влияет на поведение градиентного спуска; вообще говоря, он является гиперпараметром алгоритма, и его, возможно, придётся подбирать отдельно. Другими гиперпараметрами являются максимальное число итераций $S$ и/или порог tolerance.
Иллюстрация.Рассмотрим три задачи регрессии, для которых матрица $X$ имеет соответственно маленькое, среднее и большое числа обусловленности. Будем строить для них модели вида $y=w_1x_1 + w_2x_2$. Раскрасим плоскость $(w_1, w_2)$ в соответствии со значениями $|X_{text{train}}w — y_{text{train}}|^2$. Тёмная область содержит минимум этой функции – оптимальное значение $w_{ast}$. Также запустим из из двух точек градиентный спуск с разными значениями темпа обучения $alpha$ и посмотрим, что получится:
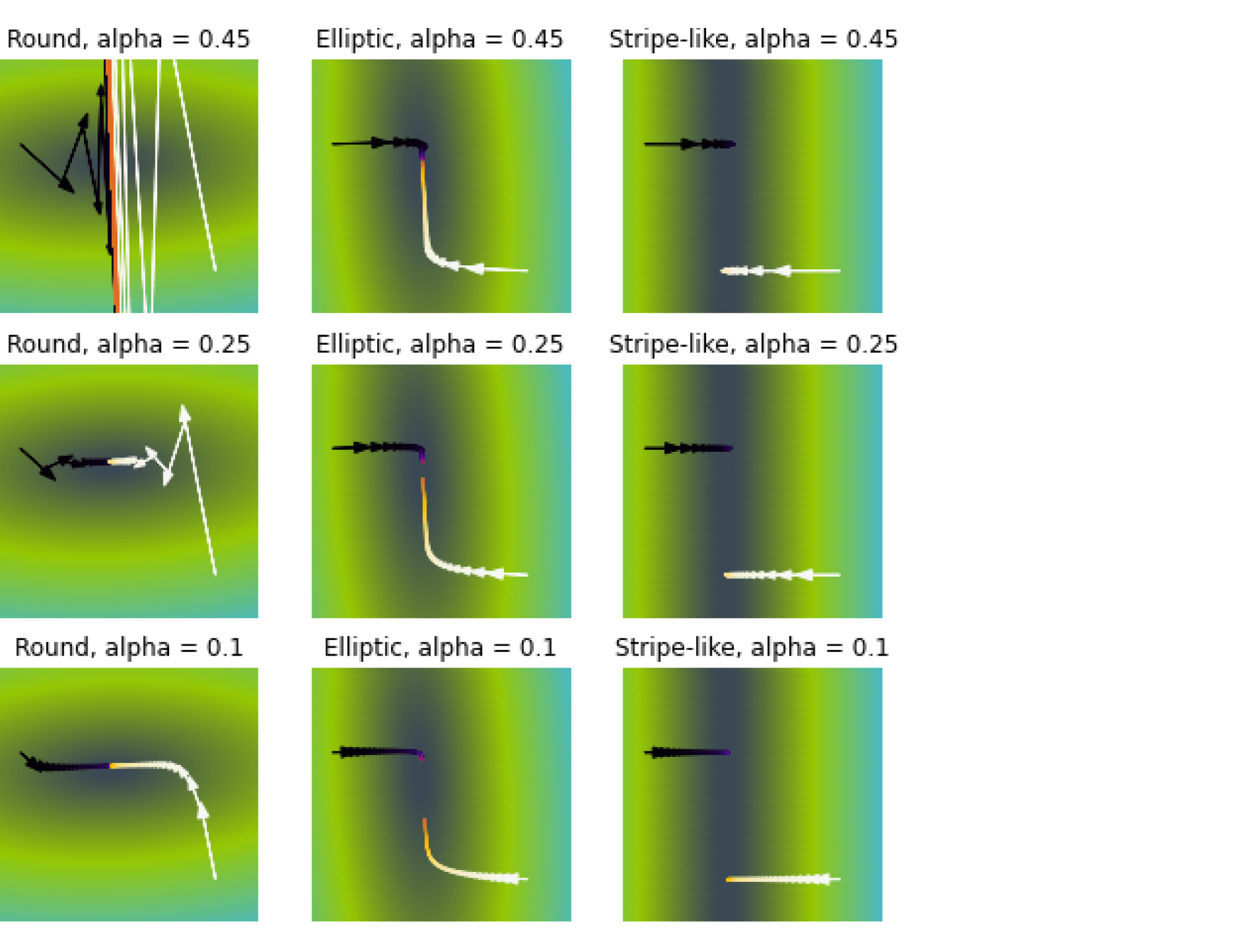 Заголовки графиков («Round», «Elliptic», «Stripe-like») относятся к форме линий уровня потерь (чем более они вытянуты, тем хуже обусловлена задача и тем хуже может вести себя градиентный спуск).
Заголовки графиков («Round», «Elliptic», «Stripe-like») относятся к форме линий уровня потерь (чем более они вытянуты, тем хуже обусловлена задача и тем хуже может вести себя градиентный спуск).
Итог: при неудачном выборе $alpha$ алгоритм не сходится или идёт вразнос, а для плохо обусловленной задачи он сходится абы куда.
Вычислительная сложность градиентного спуска – $O(NDS)$, где, как и выше, $N$ – длина выборки, $D$ – число признаков у одного объекта. Сравните с оценкой $O(N^2D + D^3)$ для «наивного» вычисления аналитического решения.
Сложность по памяти – $O(ND)$ на хранение выборки. В памяти мы держим и выборку, и градиент, но в большинстве реалистичных сценариев доминирует выборка.
Стохастический градиентный спуск
На каждом шаге градиентного спуска нам требуется выполнить потенциально дорогую операцию вычисления градиента по всей выборке (сложность $O(ND)$). Возникает идея заменить градиент его оценкой на подвыборке (в английской литературе такую подвыборку обычно именуют batch или mini-batch; в русской разговорной терминологии тоже часто встречается слово батч или мини-батч).
А именно, если функция потерь имеет вид суммы по отдельным парам объект-таргет
$$L(w, X, y) = frac1Nsum_{i=1}^NL(w, x_i, y_i),$$
а градиент, соответственно, записывается в виде
$$nabla_wL(w, X, y) = frac1Nsum_{i=1}^Nnabla_wL(w, x_i, y_i),$$
то предлагается брать оценку
$$nabla_wL(w, X, y) approx frac1Bsum_{t=1}^Bnabla_wL(w, x_{i_t}, y_{i_t})$$
для некоторого подмножества этих пар $(x_{i_t}, y_{i_t})_{t=1}^B$. Обратите внимание на множители $frac1N$ и $frac1B$ перед суммами. Почему они нужны? Полный градиент $nabla_wL(w, X, y)$ можно воспринимать как среднее градиентов по всем объектам, то есть как оценку матожидания $mathbb{E}nabla_wL(w, x, y)$; тогда, конечно, оценка матожидания по меньшей подвыборке тоже будет иметь вид среднего градиентов по объектам этой подвыборки.
Как делить выборку на батчи? Ясно, что можно было бы случайным образом сэмплировать их из полного датасета, но даже если использовать быстрый алгоритм вроде резервуарного сэмплирования, сложность этой операции не самая оптимальная. Поэтому используют линейный проход по выборке (которую перед этим лучше всё-таки случайным образом перемешать). Давайте введём ещё один параметр нашего алгоритма: размер батча, который мы обозначим $B$. Теперь на $B$ очередных примерах вычислим градиент и обновим веса модели. При этом вместо количества шагов алгоритма обычно задают количество эпох $E$. Это ещё один гиперпараметр. Одна эпоха – это один полный проход нашего сэмплера по выборке. Заметим, что если выборка очень большая, а модель компактная, то даже первый проход бывает можно не заканчивать.
Алгоритм:
w = normal(0, 1)
repeat E times:
for i = B, i <= n, i += B
X_batch = X[i-B : i]
y_batch = y[i-B : i]
f = X_batch.dot(w) # посчитать предсказание
err = f - y_batch # посчитать ошибку
grad = 2 * X_batch.T.dot(err) / B # посчитать градиент
w -= alpha * grad
Сложность по времени – $O(NDE)$. На первый взгляд, она такая же, как и у обычного градиентного спуска, но заметим, что мы сделали в $N / B$ раз больше шагов, то есть веса модели претерпели намного больше обновлений.
Сложность по памяти можно довести до $O(BD)$: ведь теперь всю выборку не надо держать в памяти, а достаточно загружать лишь текущий батч (а остальная выборка может лежать на диске, что удобно, так как в реальности задачи, в которых выборка целиком не влезает в оперативную память, встречаются сплошь и рядом). Заметим, впрочем, что при этом лучше бы $B$ взять побольше: ведь чтение с диска – намного более затратная по времени операция, чем чтение из оперативной памяти.
В целом, разницу между алгоритмами можно представлять как-то так: 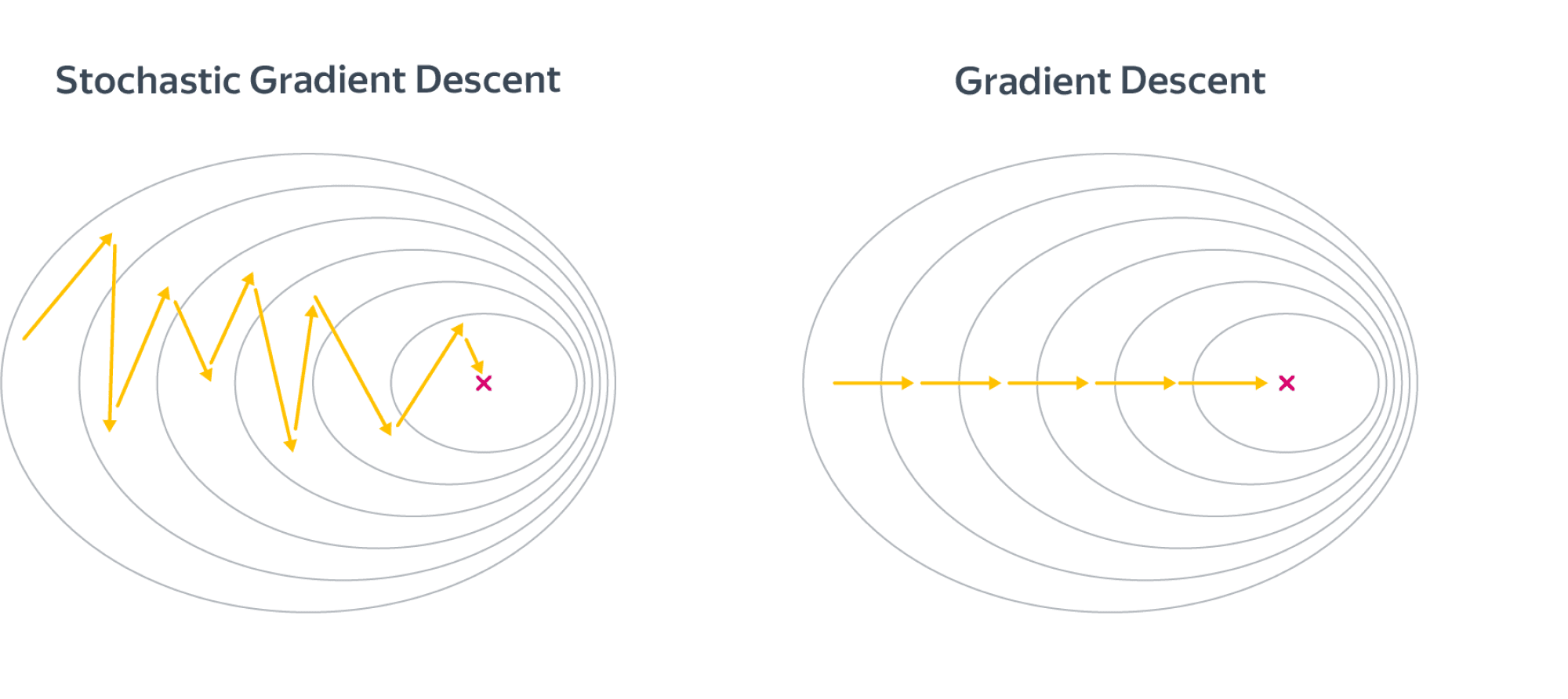
Шаги стохастического градиентного спуска заметно более шумные, но считать их получается значительно быстрее. В итоге они тоже сходятся к оптимальному значению из-за того, что матожидание оценки градиента на батче равно самому градиенту. По крайней мере, сходимость можно получить при хорошо подобранных коэффициентах темпа обучения в случае выпуклого функционала качества. Подробнее мы об этом поговорим в главе про оптимизацию. Для сложных моделей и лоссов стохастический градиентный спуск может сходиться плохо или застревать в локальных минимумах, поэтому придумано множество его улучшений. О некоторых из них также рассказано в главе про оптимизацию.
Существует определённая терминологическая путаница, иногда стохастическим градиентным спуском называют версию алгоритма, в которой размер батча равен единице (то есть максимально шумная и быстрая версия алгоритма), а версии с бОльшим размером батча называют batch gradient descent. В книгах, которые, возможно, старше вас, такая процедура иногда ещё называется incremental gradient descent. Это не очень принципиально, но вы будьте готовы, если что.
Вопрос на подумать. Вообще говоря, если объём данных не слишком велик и позволяет это сделать, объекты лучше случайным образом перемешивать перед тем, как подавать их в алгоритм стохастического градиентного спуска. Как вам кажется, почему?
Также можно использовать различные стратегии отбора объектов. Например, чаще брать объекты, на которых ошибка больше. Какие ещё стратегии вы могли бы придумать?
Ответ (не открывайте сразу; сначала подумайте сами!)Легко представить себе ситуацию, в которой объекты как-нибудь неудачно упорядочены, скажем, по возрастанию таргета. Тогда модель будет попеременно то запоминать, что все таргеты маленькие, то – что все таргеты большие. Это может и не повлиять на качество итоговой модели, но может привести и к довольно печальным последствиям. И вообще, чем более разнообразные батчи модель увидит в процессе обучения, тем лучше.
Стратегий можно придумать много. Например, не брать объекты, на которых ошибка слишком большая (возможно, это выбросы – зачем на них учиться), или вообще не брать те, на которых ошибка достаточно мала (они «ничему не учат»). Рекомендуем, впрочем, прибегать к этим эвристикам, только если вы понимаете, зачем они вам нужны и почему есть надежда, что они помогут.
Неградиентные методы
После прочтения этой главы у вас может сложиться ощущение, что приближённые способы решения ML задач и градиентные методы – это одно и тоже, но вы будете правы в этом только на 98%. В принципе, существуют и другие способы численно решать эти задачи, но в общем случае они работают гораздо хуже, чем градиентный спуск, и не обладают таким хорошим теоретическим обоснованием. Мы не будем рассказывать про них подробно, но можете на досуге почитать, скажем, про Stepwise regression, Orthogonal matching pursuit или LARS. У LARS, кстати, есть довольно интересное свойство: он может эффективно работать на выборках, в которых число признаков больше числа примеров. С алгоритмом LARS вы можете познакомиться в главе про оптимизацию.
Регуляризация
Всегда ли решение задачи регрессии единственно? Вообще говоря, нет. Так, если в выборке два признака будут линейно зависимы (и следовательно, ранг матрицы будет меньше $D$), то гарантировано найдётся такой вектор весов $nu$ что $langlenu, x_irangle = 0 forall x_i$. В этом случае, если какой-то $w$ является решением оптимизационной задачи, то и $w + alpha nu $ тоже является решением для любого $alpha$. То есть решение не только не обязано быть уникальным, так ещё может быть сколь угодно большим по модулю. Это создаёт вычислительные трудности. Малые погрешности признаков сильно возрастают при предсказании ответа, а в градиентном спуске накапливается погрешность из-за операций со слишком большими числами.
Конечно, в жизни редко бывает так, что признаки строго линейно зависимы, а вот быть приближённо линейно зависимыми они вполне могут быть. Такая ситуация называется мультиколлинеарностью. В этом случае у нас, всё равно, возникают проблемы, близкие к описанным выше. Дело в том, что $Xnusim 0$ для вектора $nu$, состоящего из коэффициентов приближённой линейной зависимости, и, соответственно, $X^TXnuapprox 0$, то есть матрица $X^TX$ снова будет близка к вырожденной. Как и любая симметричная матрица, она диагонализуется в некотором ортонормированном базисе, и некоторые из собственных значений $lambda_i$ близки к нулю. Если вектор $X^Ty$ в выражении $(X^TX)^{-1}X^Ty$ будет близким к соответствующему собственному вектору, то он будет умножаться на $1 /{lambda_i}$, что опять же приведёт к появлению у $w$ очень больших по модулю компонент (при этом $w$ ещё и будет вычислен с большой погрешностью из-за деления на маленькое число). И, конечно же, все ошибки и весь шум, которые имелись в матрице $X$, при вычислении $ysim Xw$ будут умножаться на эти большие и неточные числа и возрастать во много-много раз, что приведёт к проблемам, от которых нас не спасёт никакое сингулярное разложение.
Важно ещё отметить, что в случае, когда несколько признаков линейно зависимы, веса $w_i$ при них теряют физический смысл. Может даже оказаться, что вес признака, с ростом которого таргет, казалось бы, должен увеличиваться, станет отрицательным. Это делает модель не только неточной, но и принципиально не интерпретируемой. Вообще, неадекватность знаков или величины весов – хорошее указание на мультиколлинеарность.
Для того, чтобы справиться с этой проблемой, задачу обычно регуляризуют, то есть добавляют к ней дополнительное ограничение на вектор весов. Это ограничение можно, как и исходный лосс, задавать по-разному, но, как правило, ничего сложнее, чем $L^1$- и $L^2$-нормы, не требуется.
Вместо исходной задачи теперь предлагается решить такую:
$$color{#348FEA}{min_w L(f, X, y) = min_w(|X w — y|_2^2 + lambda |w|^k_k )}$$
$lambda$ – это очередной параметр, а $|w|^k_k $ – это один из двух вариантов:
$$color{#348FEA}{|w|^2_2 = w^2_1 + ldots + w^2_D}$$
или
$$color{#348FEA}{|w|_1^1 = vert w_1 vert + ldots + vert w_D vert}$$
Добавка $lambda|w|^k_k$ называется регуляризационным членом или регуляризатором, а число $lambda$ – коэффициентом регуляризации.
Коэффициент $lambda$ является гиперпараметром модели и достаточно сильно влияет на качество итогового решения. Его подбирают по логарифмической шкале (скажем, от 1e-2 до 1e+2), используя для сравнения моделей с разными значениями $lambda$ дополнительную валидационную выборку. При этом качество модели с подобранным коэффициентом регуляризации уже проверяют на тестовой выборке, чтобы исключить переобучение. Более подробно о том, как нужно подбирать гиперпараметры, вы можете почитать в соответствующей главе.
Отдельно надо договориться о том, что вес $w_0$, соответствующий отступу от начала координат (то есть признаку из всех единичек), мы регуляризовать не будем, потому что это не имеет смысла: если даже все значения $y$ равномерно велики, это не должно портить качество обучения. Обычно это не отображают в формулах, но если придираться к деталям, то стоило бы написать сумму по всем весам, кроме $w_0$:
$$|w|^2_2 = sum_{color{red}{j=1}}^{D}w_j^2,$$
$$|w|_1 = sum_{color{red}{j=1}}^{D} vert w_j vert$$
В случае $L^2$-регуляризации решение задачи изменяется не очень сильно. Например, продифференцировав новый лосс по $w$, легко получить, что «точное» решение имеет вид:
$$w = (X^TX + lambda I)^{-1}X^Ty$$
Отметим, что за этой формулой стоит и понятная численная интуиция: раз матрица $X^TX$ близка к вырожденной, то обращать её сродни самоубийству. Мы лучше слегка исказим её добавкой $lambda I$, которая увеличит все собственные значения на $lambda$, отодвинув их от нуля. Да, аналитическое решение перестаёт быть «точным», но за счёт снижения численных проблем мы получим более качественное решение, чем при использовании «точной» формулы.
В свою очередь, градиент функции потерь
$$L(f_w, X, y) = |Xw — y|^2 + lambda|w|^2$$
по весам теперь выглядит так:
$$
nabla_wL(f_w, X, y) = 2X^T(Xw — y) + 2lambda w
$$
Подставив этот градиент в алгоритм стохастического градиентного спуска, мы получаем обновлённую версию приближенного алгоритма, отличающуюся от старой только наличием дополнительного слагаемого.
Вопрос на подумать. Рассмотрим стохастический градиентный спуск для $L^2$-регуляризованной линейной регрессии с батчами размера $1$. Выберите правильный вариант шага SGD:
(а) $w_imapsto w_i — 2alpha(langle w, x_jrangle — y_j)x_{ji} — frac{2alphalambda}N w_i,quad i=1,ldots,D$;
(б) $w_imapsto w_i — 2alpha(langle w, x_jrangle — y_j)x_{ji} — 2alphalambda w_i,quad i=1,ldots,D$;
(в) $w_imapsto w_i — 2alpha(langle w, x_jrangle — y_j)x_{ji} — 2lambda N w_i,quad i=1,ldots D$.
Ответ (не открывайте сразу; сначала подумайте сами!)Не регуляризованная функция потерь имеет вид $mathcal{L}(X, y, w) = frac1Nsum_{i=1}^Nmathcal{L}(x_i, y_i, w)$, и её можно воспринимать, как оценку по выборке $(x_i, y_i)_{i=1}^N$ идеальной функции потерь
$$mathcal{L}(w) = mathbb{E}_{x, y}mathcal{L}(x, y, w)$$
Регуляризационный член не зависит от выборки и добавляется отдельно:
$$mathcal{L}_{text{reg}}(w) = mathbb{E}_{x, y}mathcal{L}(x, y, w) + lambda|w|^2$$
Соответственно, идеальный градиент регуляризованной функции потерь имеет вид
$$nabla_wmathcal{L}_{text{reg}}(w) = mathbb{E}_{x, y}nabla_wmathcal{L}(x, y, w) + 2lambda w,$$
Градиент по батчу – это тоже оценка градиента идеальной функции потерь, только не на выборке $(X, y)$, а на батче $(x_{t_i}, y_{t_i})_{i=1}^B$ размера $B$. Он будет выглядеть так:
$$nabla_wmathcal{L}_{text{reg}}(w) = frac1Bsum_{i=1}^Bnabla_wmathcal{L}(x_{t_i}, y_{t_i}, w) + 2lambda w.$$
Как видите, коэффициентов, связанных с числом объектов в батче или в исходной выборке, во втором слагаемом нет. Так что верным является второй вариант. Кстати, обратите внимание, что в третьем ещё и нет коэффициента $alpha$ перед производной регуляризационного слагаемого, это тоже ошибка.
Вопрос на подумать. Распишите процедуру стохастического градиентного спуска для $L^1$-регуляризованной линейной регрессии. Как вам кажется, почему никого не волнует, что функция потерь, строго говоря, не дифференцируема?
Ответ (не открывайте сразу; сначала подумайте сами!)Распишем для случая батча размера 1:
$$w_imapsto w_i — alpha(langle w, x_jrangle — y_j)x_{ji} — frac{lambda}Ncdot text{sign}(w_i),quad i=1,ldots,D$$
Функция потерь не дифференцируема лишь в одной точке. Так как в машинном обучении чаще всего мы имеем дело с данными вероятностного характера, это не влечёт каких-то особых проблем. Дело в том, что попадание прямо в ноль очень маловероятно из-за численных погрешностей в данных, так что мы можем просто доопределить производную в одной точке, а если даже пару раз попадём в неё за время обучения, это не приведёт к каким-то значительным изменениям результатов.
Отметим, что $L^1$- и $L^2$-регуляризацию можно определять для любой функции потерь $L(w, X, y)$ (и не только в задаче регрессии, а и, например, в задаче классификации тоже). Новая функция потерь будет соответственно равна
$$widetilde{L}(w, X, y) = L(w, X, y) + lambda|w|_1$$
или
$$widetilde{L}(w, X, y) = L(w, X, y) + lambda|w|_2^2$$
Разреживание весов в $L^1$-регуляризации
$L^2$-регуляризация работает прекрасно и используется в большинстве случаев, но есть одна полезная особенность $L^1$-регуляризации: её применение приводит к тому, что у признаков, которые не оказывают большого влияния на ответ, вес в результате оптимизации получается равным $0$. Это позволяет удобным образом удалять признаки, слабо влияющие на таргет. Кроме того, это даёт возможность автоматически избавляться от признаков, которые участвуют в соотношениях приближённой линейной зависимости, соответственно, спасает от проблем, связанных с мультиколлинеарностью, о которых мы писали выше.
Не очень строгим, но довольно интуитивным образом это можно объяснить так:
- В точке оптимума линии уровня регуляризационного члена касаются линий уровня основного лосса, потому что, во-первых, и те, и другие выпуклые, а во-вторых, если они пересекаются трансверсально, то существует более оптимальная точка:
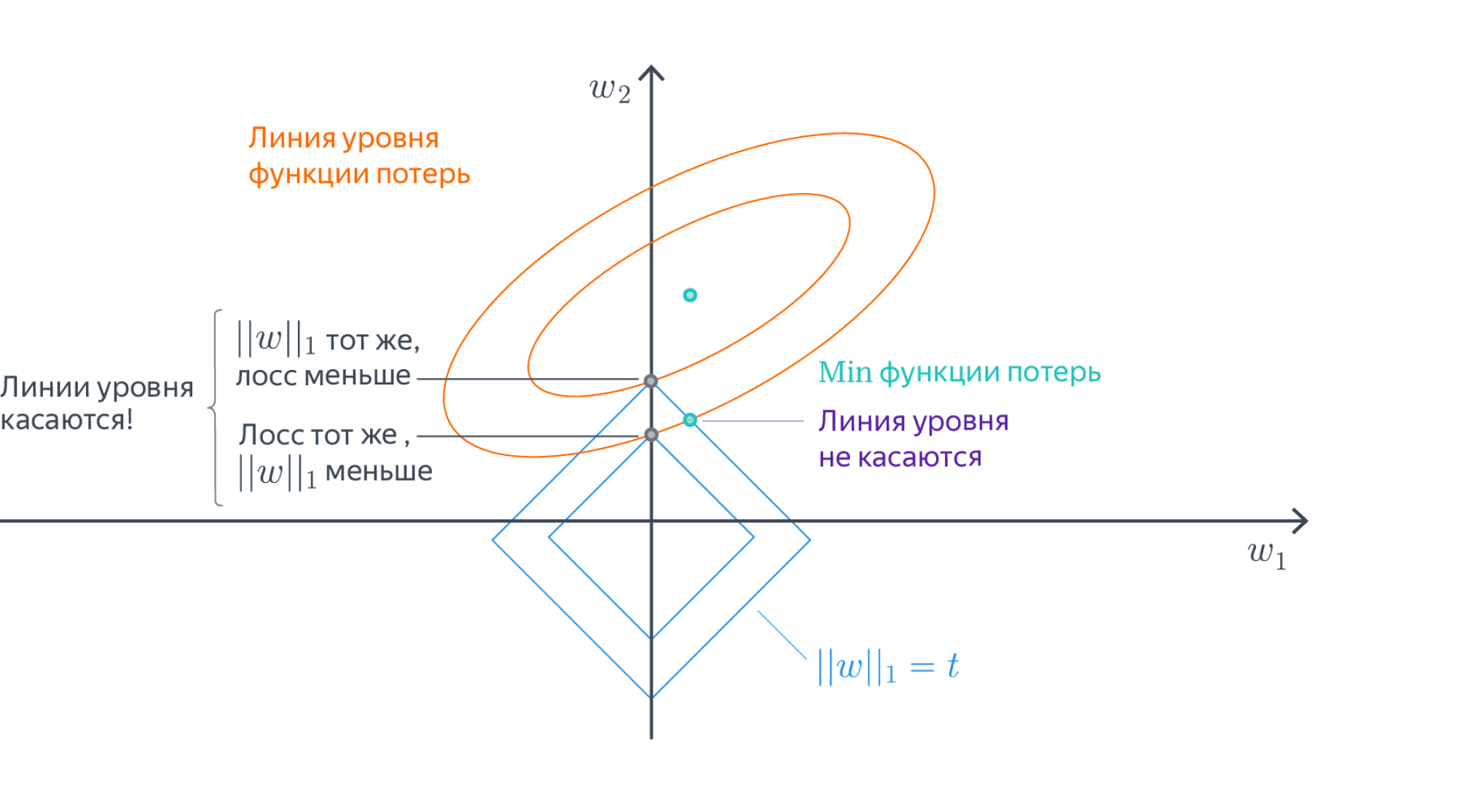
- Линии уровня $L^1$-нормы – это $N$-мерные октаэдры. Точки их касания с линиями уровня лосса, скорее всего, лежат на грани размерности, меньшей $N-1$, то есть как раз в области, где часть координат равна нулю:
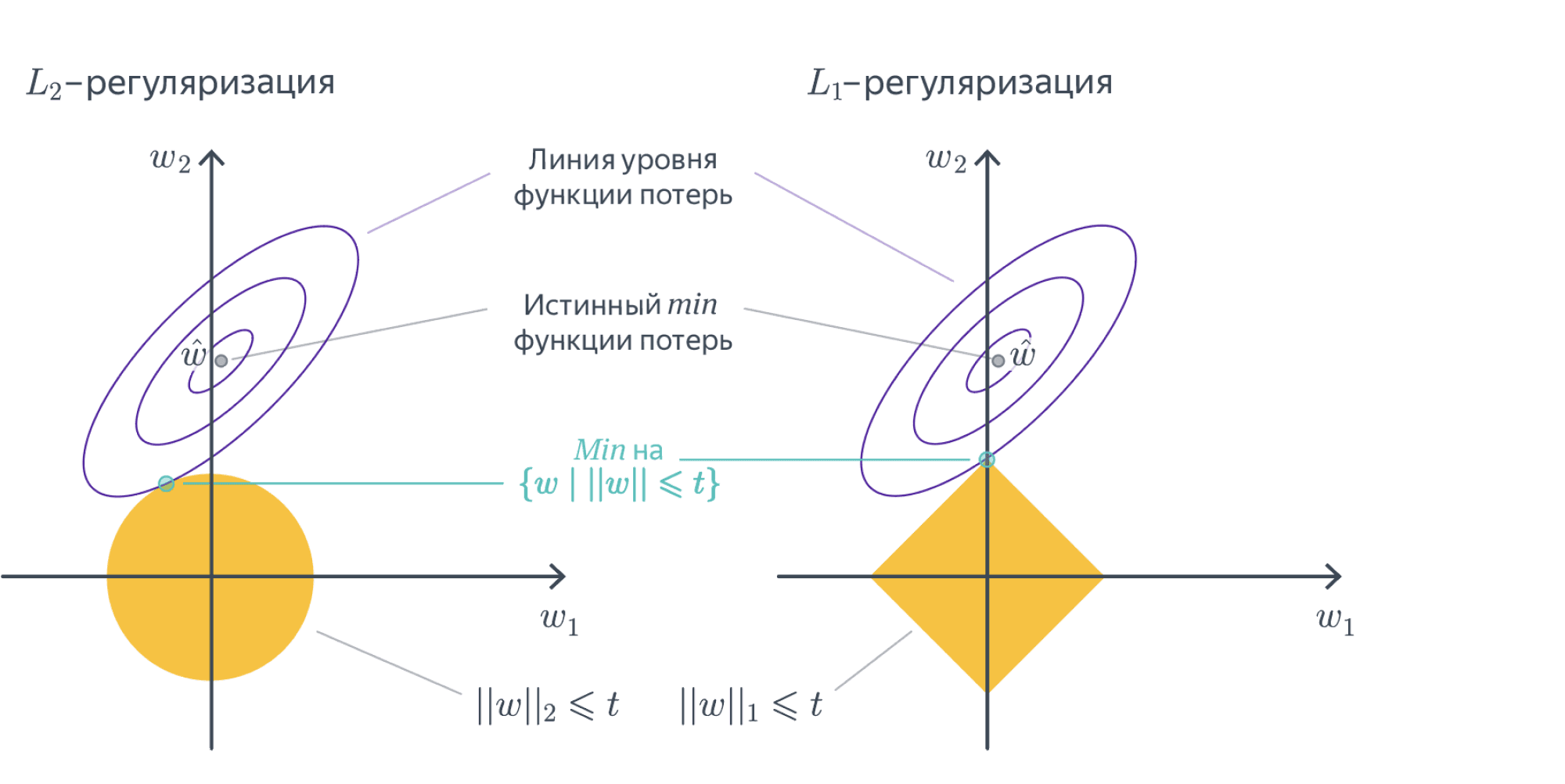
Заметим, что данное построение говорит о том, как выглядит оптимальное решение задачи, но ничего не говорит о способе, которым это решение можно найти. На самом деле, найти такой оптимум непросто: у $L^1$ меры довольно плохая производная. Однако, способы есть. Можете на досуге прочитать, например, вот эту статью о том, как работало предсказание CTR в google в 2012 году. Там этой теме посвящается довольно много места. Кроме того, рекомендуем посмотреть про проксимальные методы в разделе этой книги про оптимизацию в ML.
Заметим также, что вообще-то оптимизация любой нормы $L_x, 0 < x leq 1$, приведёт к появлению разреженных векторов весов, просто если c $L^1$ ещё хоть как-то можно работать, то с остальными всё будет ещё сложнее.
Другие лоссы
Стохастический градиентный спуск можно очевидным образом обобщить для решения задачи линейной регрессии с любой другой функцией потерь, не только квадратичной: ведь всё, что нам нужно от неё, – это чтобы у функции потерь был градиент. На практике это делают редко, но тем не менее рассмотрим ещё пару вариантов.
MAE
Mean absolute error, абсолютная ошибка, появляется при замене $L^2$ нормы в MSE на $L^1$:
$$color{#348FEA}{MAE(y, widehat{y}) = frac1Nsum_{i=1}^N vert y_i — widehat{y}_ivert}$$
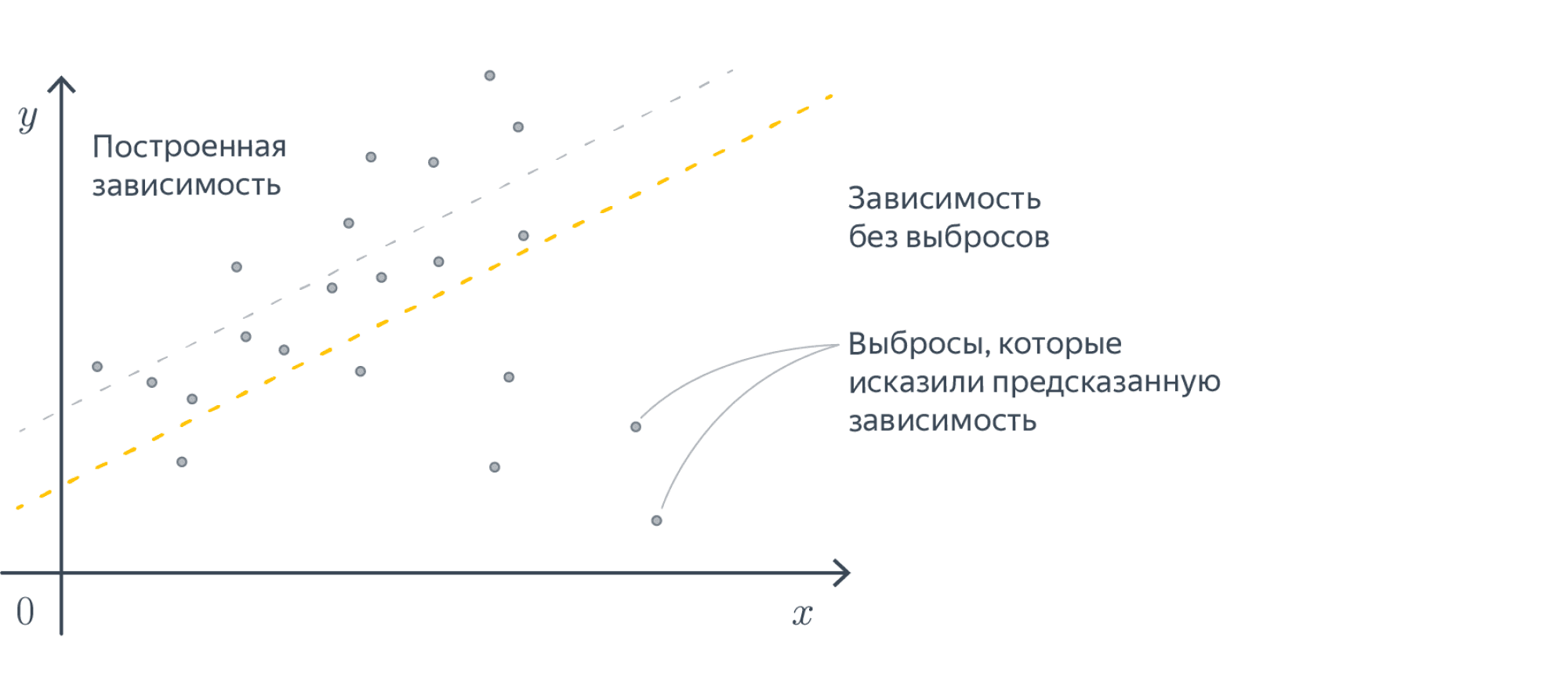
Можно заметить, что в MAE по сравнению с MSE существенно меньший вклад в ошибку будут вносить примеры, сильно удалённые от ответов модели. Дело тут в том, что в MAE мы считаем модуль расстояния, а не квадрат, соответственно, вклад больших ошибок в MSE получается существенно больше. Такая функция потерь уместна в случаях, когда вы пытаетесь обучить регрессию на данных с большим количеством выбросов в таргете.
Иначе на эту разницу можно посмотреть так: MSE приближает матожидание условного распределения $y mid x$, а MAE – медиану.
MAPE
Mean absolute percentage error, относительная ошибка.
$$MAPE(y, widehat{y}) = frac1Nsum_{i=1}^N left|frac{widehat{y}_i-y_i}{y_i}right|$$
Часто используется в задачах прогнозирования (например, погоды, загруженности дорог, кассовых сборов фильмов, цен), когда ответы могут быть различными по порядку величины, и при этом мы бы хотели верно угадать порядок, то есть мы не хотим штрафовать модель за предсказание 2000 вместо 1000 в разы сильней, чем за предсказание 2 вместо 1.
Вопрос на подумать. Кроме описанных выше в задаче линейной регрессии можно использовать и другие функции потерь, например, Huber loss:
$$mathcal{L}(f, X, y) = sum_{i=1}^Nh_{delta}(y_i — langle w_i, xrangle),mbox{ где }h_{delta}(z) = begin{cases}
frac12z^2, |z|leqslantdelta,\
delta(|z| — frac12delta), |z| > delta
end{cases}$$
Число $delta$ является гиперпараметром. Сложная формула при $vert zvert > delta$ нужна, чтобы функция $h_{delta}(z)$ была непрерывной. Попробуйте объяснить, зачем может быть нужна такая функция потерь.
Ответ (не открывайте сразу; сначала подумайте сами!)Часто требования формулируют в духе «функция потерь должна слабее штрафовать то-то и сильней штрафовать вот это». Например, $L^2$-регуляризованный лосс штрафует за большие по модулю веса. В данном случае можно заметить, что при небольших значениях ошибки берётся просто MSE, а при больших мы начинаем штрафовать нашу модель менее сурово. Например, это может быть полезно для того, чтобы выбросы не так сильно влияли на результат обучения.
Линейная классификация
Теперь давайте поговорим про задачу классификации. Для начала будем говорить про бинарную классификацию на два класса. Обобщить эту задачу до задачи классификации на $K$ классов не составит большого труда. Пусть теперь наши таргеты $y$ кодируют принадлежность к положительному или отрицательному классу, то есть принадлежность множеству ${-1,1}$ (в этой главе договоримся именно так обозначать классы, хотя в жизни вам будут нередко встречаться и метки ${0,1}$), а $x$ – по-прежнему векторы из $mathbb{R}^D$. Мы хотим обучить линейную модель так, чтобы плоскость, которую она задаёт, как можно лучше отделяла объекты одного класса от другого.
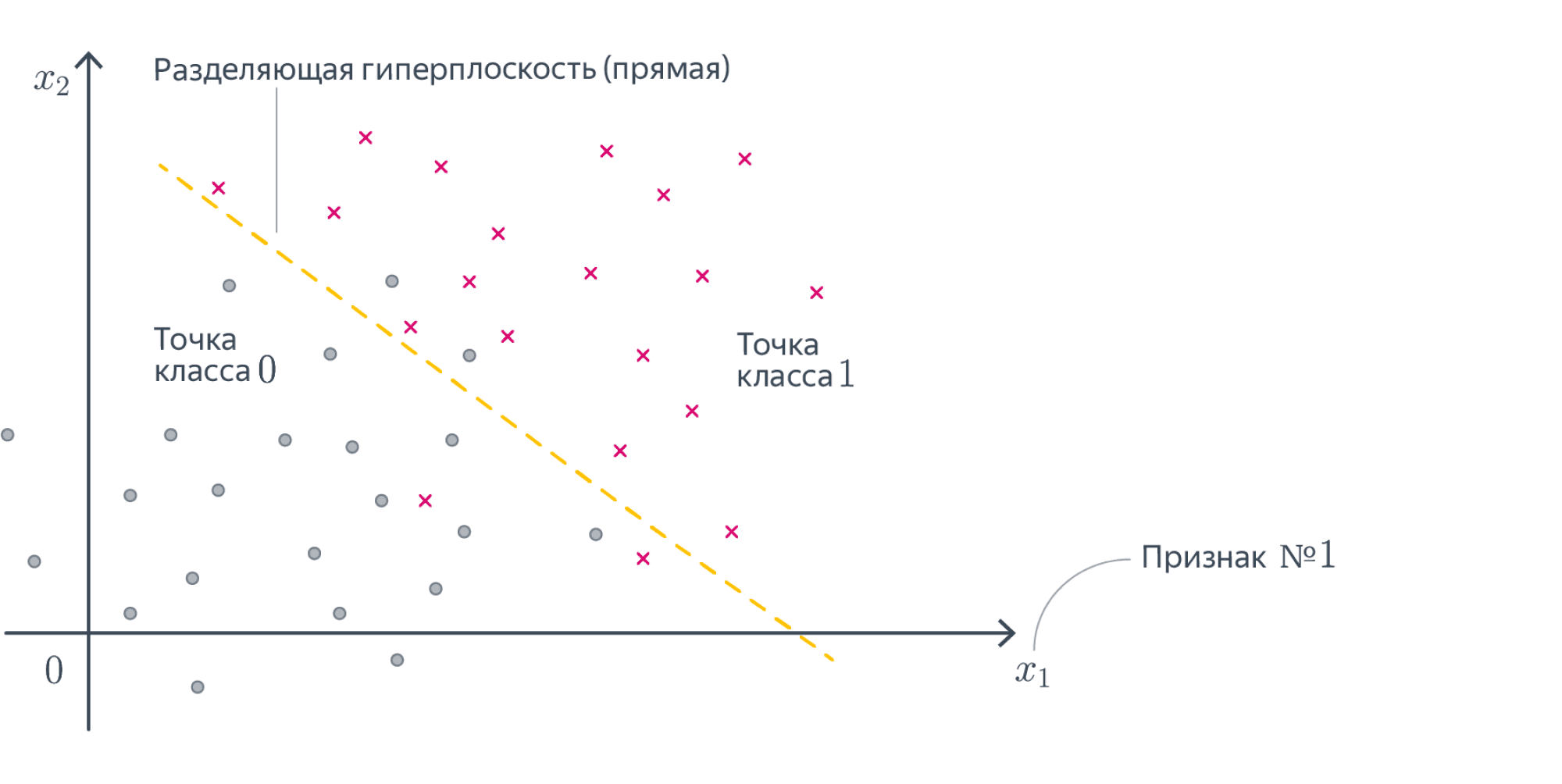
В идеальной ситуации найдётся плоскость, которая разделит классы: положительный окажется с одной стороны от неё, а отрицательный с другой. Выборка, для которой это возможно, называется линейно разделимой. Увы, в реальной жизни такое встречается крайне редко.
Как обучить линейную модель классификации, нам ещё предстоит понять, но уже ясно, что итоговое предсказание можно будет вычислить по формуле
$$y = text{sign} langle w, x_irangle$$
Почему бы не решать, как задачу регрессии?Мы можем попробовать предсказывать числа $-1$ и $1$, минимизируя для этого, например, MSE с последующим взятием знака, но ничего хорошего не получится. Во-первых, регрессия почти не штрафует за ошибки на объектах, которые лежат близко к *разделяющей плоскости*, но не с той стороны. Во вторых, ошибкой будет считаться предсказание, например, $5$ вместо $1$, хотя нам-то на самом деле не важно, какой у числа модуль, лишь бы знак был правильным. Если визуализировать такое решение, то проблемы тоже вполне заметны:
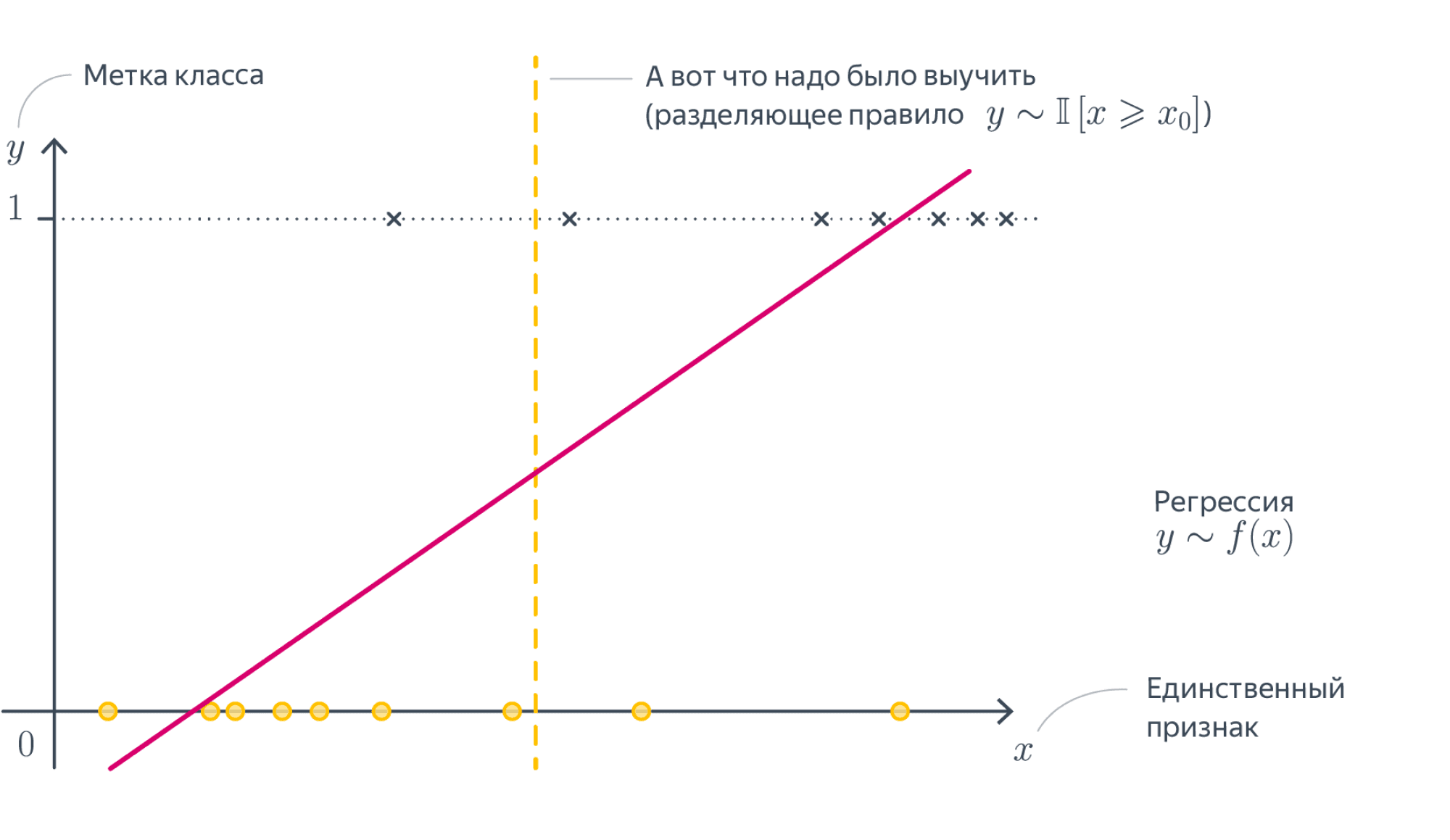
Нам нужна прямая, которая разделяет эти точки, а не проходит через них!
Сконструируем теперь функционал ошибки так, чтобы он вышеперечисленными проблемами не обладал. Мы хотим минимизировать число ошибок классификатора, то есть
$$sum_i mathbb{I}[y_i neq sign langle w, x_irangle]longrightarrow min_w$$
Домножим обе части на $$y_i$$ и немного упростим
$$sum_i mathbb{I}[y_i langle w, x_irangle < 0]longrightarrow min_w$$
Величина $M = y_i langle w, x_irangle$ называется отступом (margin) классификатора. Такая фунция потерь называется misclassification loss. Легко видеть, что
-
отступ положителен, когда $sign(y_i) = sign(langle w, x_irangle)$, то есть класс угадан верно; при этом чем больше отступ, тем больше расстояние от $x_i$ до разделяющей гиперплоскости, то есть «уверенность классификатора»;
-
отступ отрицателен, когда $sign(y_i) ne sign(langle w, x_irangle)$, то есть класс угадан неверно; при этом чем больше по модулю отступ, тем более сокрушительно ошибается классификатор.
От каждого из отступов мы вычисляем функцию
$$F(M) = mathbb{I}[M < 0] = begin{cases}1, M < 0,\ 0, Mgeqslant 0end{cases}$$
Она кусочно-постоянная, и из-за этого всю сумму невозможно оптимизировать градиентными методами: ведь её производная равна нулю во всех точках, где она существует. Но мы можем мажорировать её какой-нибудь более гладкой функцией, и тогда задачу можно будет решить. Функции можно использовать разные, у них свои достоинства и недостатки, давайте рассмотрим несколько примеров:
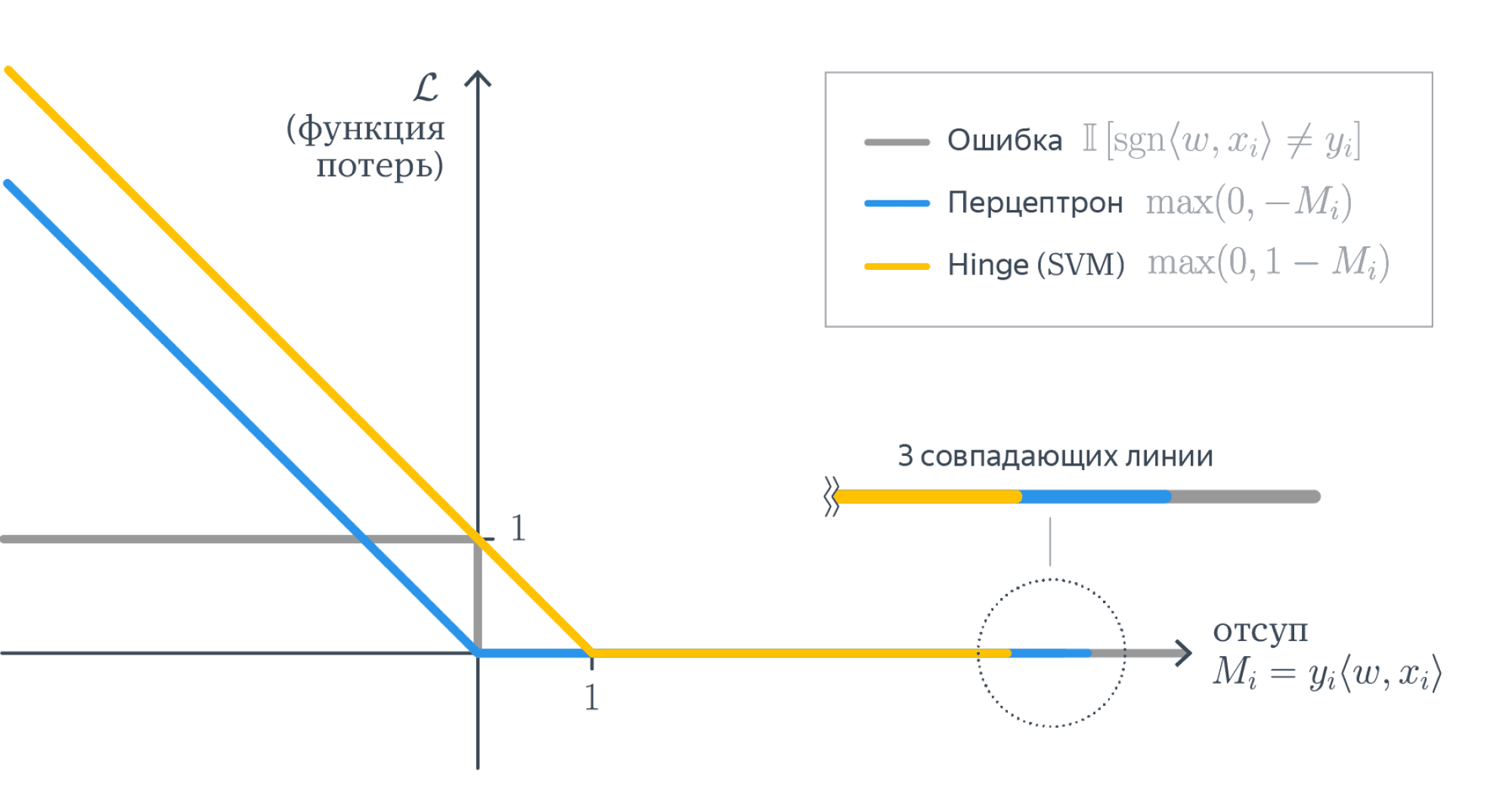
Вопрос на подумать. Допустим, мы как-то обучили классификатор, и подавляющее большинство отступов оказались отрицательными. Правда ли нас постигла катастрофа?
Ответ (не открывайте сразу; сначала подумайте сами!)Наверное, мы что-то сделали не так, но ситуацию можно локально выправить, если предсказывать классы, противоположные тем, которые выдаёт наша модель.
Вопрос на подумать. Предположим, что у нас есть два классификатора с примерно одинаковыми и достаточно приемлемыми значениями интересующей нас метрики. При этом одна почти всегда выдаёт предсказания с большими по модулю отступами, а вторая – с относительно маленькими. Верно ли, что первая модель лучше, чем вторая?
Ответ (не открывайте сразу; сначала подумайте сами!)На первый взгляд кажется, что первая модель действительно лучше: ведь она предсказывает «увереннее», но на самом деле всё не так однозначно: во многих случаях модель, которая умеет «честно признать, что не очень уверена в ответе», может быть предпочтительней модели, которая врёт с той же непотопляемой уверенностью, что и говорит правду. В некоторых случаях лучше может оказаться модель, которая, по сути, просто отказывается от классификации на каких-то объектах.
Ошибка перцептрона
Реализуем простейшую идею: давайте считать отступы только на неправильно классифицированных объектах и учитывать их не бинарно, а линейно, пропорционально их размеру. Получается такая функция:
$$F(M) = max(0, -M)$$
Давайте запишем такой лосс с $L^2$-регуляризацией:
$$L(w, x, y) = lambdavertvert wvertvert^2_2 + sum_i max(0, -y_i langle w, x_irangle)$$
Найдём градиент:
$$
nabla_w L(w, x, y) = 2 lambda w + sum_i
begin{cases}
0, & y_i langle w, x_i rangle > 0 \
— y_i x_i, & y_i langle w, x_i rangle leq 0
end{cases}
$$
Имея аналитическую формулу для градиента, мы теперь можем так же, как и раньше, применить стохастический градиентный спуск, и задача будет решена.
Данная функция потерь впервые была предложена для перцептрона Розенблатта, первой вычислительной модели нейросети, которая в итоге привела к появлению глубокого обучения.
Она решает задачу линейной классификации, но у неё есть одна особенность: её решение не единственно и сильно зависит от начальных параметров. Например, все изображённые ниже классификаторы имеют одинаковый нулевой лосс:
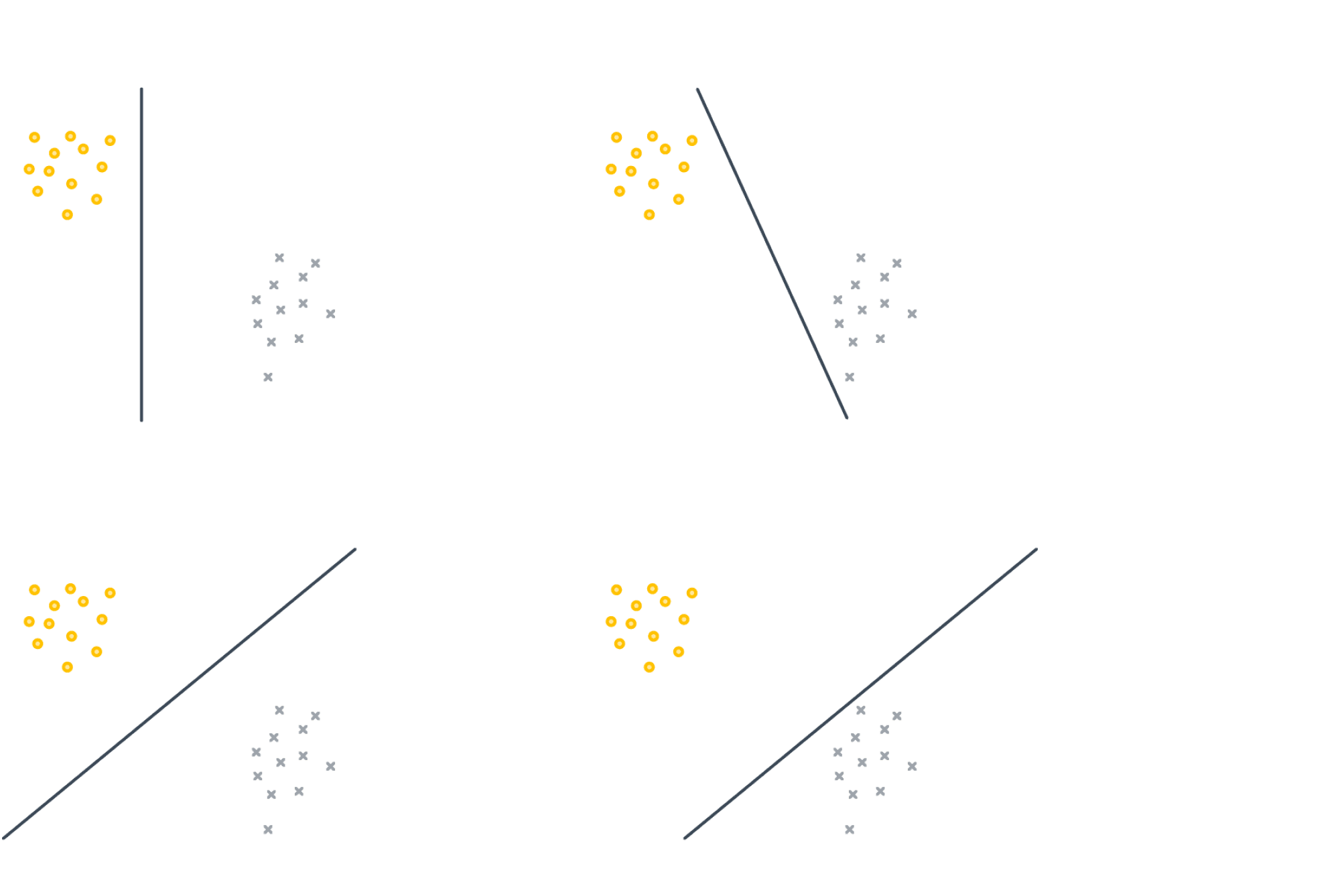
Hinge loss, SVM
Для таких случаев, как на картинке выше, возникает логичное желание не только найти разделяющую прямую, но и постараться провести её на одинаковом удалении от обоих классов, то есть максимизировать минимальный отступ:

Это можно сделать, слегка поменяв функцию ошибки, а именно положив её равной:
$$F(M) = max(0, 1-M)$$
$$L(w, x, y) = lambda||w||^2_2 + sum_i max(0, 1-y_i langle w, x_irangle)$$
$$
nabla_w L(w, x, y) = 2 lambda w + sum_i
begin{cases}
0, & 1 — y_i langle w, x_i rangle leq 0 \
— y_i x_i, & 1 — y_i langle w, x_i rangle > 0
end{cases}
$$
Почему же добавленная единичка приводит к желаемому результату?
Интуитивно это можно объяснить так: объекты, которые проклассифицированы правильно, но не очень «уверенно» (то есть $0 leq y_i langle w, x_irangle < 1$), продолжают вносить свой вклад в градиент и пытаются «отодвинуть» от себя разделяющую плоскость как можно дальше.
К данному выводу можно прийти и чуть более строго; для этого надо совершенно по-другому взглянуть на выражение, которое мы минимизируем. Поможет вот эта картинка:
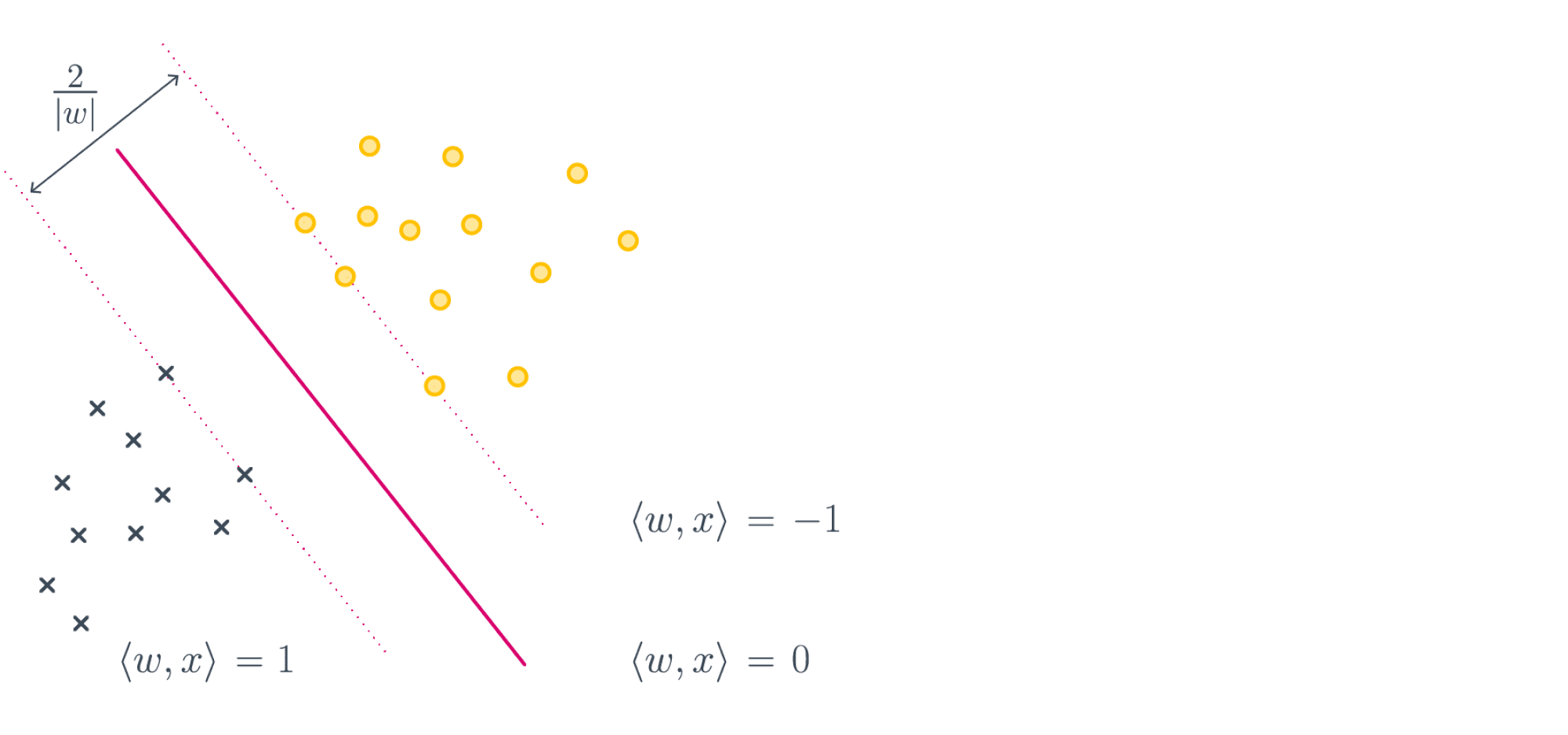
Если мы максимизируем минимальный отступ, то надо максимизировать $frac{2}{|w|_2}$, то есть ширину полосы при условии того, что большинство объектов лежат с правильной стороны, что эквивалентно решению нашей исходной задачи:
$$lambda|w|^2_2 + sum_i max(0, 1-y_i langle w, x_irangle) longrightarrowminlimits_{w}$$
Отметим, что первое слагаемое у нас обратно пропорционально ширине полосы, но мы и максимизацию заменили на минимизацию, так что тут всё в порядке. Второе слагаемое – это штраф за то, что некоторые объекты неправильно расположены относительно разделительной полосы. В конце концов, никто нам не обещал, что классы наши линейно разделимы и можно провести оптимальную плоскость вообще без ошибок.
Итоговое положение плоскости задаётся всего несколькими обучающими примерами. Это ближайшие к плоскости правильно классифицированные объекты, которые называют опорными векторами или support vectors. Весь метод, соответственно, зовётся методом опорных векторов, или support vector machine, или сокращённо SVM. Начиная с шестидесятых годов это был сильнейший из известных методов машинного обучения. В девяностые его сменили методы, основанные на деревьях решений, которые, в свою очередь, недавно передали «пальму первенства» нейросетям.
Почему же SVM был столь популярен? Из-за небольшого количества параметров и доказуемой оптимальности. Сейчас для нас нормально выбирать специальный алгоритм под задачу и подбирать оптимальные гиперпараметры для этого алгоритма перебором, а когда-то трава была зеленее, а компьютеры медленнее, и такой роскоши у людей не было. Поэтому им нужны были модели, которые гарантированно неплохо работали бы в любой ситуации. Такой моделью и был SVM.
Другие замечательные свойства SVM: существование уникального решения и доказуемо минимальная склонность к переобучению среди всех популярных классов линейных классификаторов. Кроме того, несложная модификация алгоритма, ядровый SVM, позволяет проводить нелинейные разделяющие поверхности.
Строгий вывод постановки задачи SVM можно прочитать тут или в лекции К.В. Воронцова.
Логистическая регрессия
В этом параграфе мы будем обозначать классы нулём и единицей.
Ещё один интересный метод появляется из желания посмотреть на классификацию как на задачу предсказания вероятностей. Хороший пример – предсказание кликов в интернете (например, в рекламе и поиске). Наличие клика в обучающем логе не означает, что, если повторить полностью условия эксперимента, пользователь обязательно кликнет по объекту опять. Скорее у объектов есть какая-то «кликабельность», то есть истинная вероятность клика по данному объекту. Клик на каждом обучающем примере является реализацией этой случайной величины, и мы считаем, что в пределе в каждой точке отношение положительных и отрицательных примеров должно сходиться к этой вероятности.
Проблема состоит в том, что вероятность, по определению, величина от 0 до 1, а простого способа обучить линейную модель так, чтобы это ограничение соблюдалось, нет. Из этой ситуации можно выйти так: научить линейную модель правильно предсказывать какой-то объект, связанный с вероятностью, но с диапазоном значений $(-infty,infty)$, и преобразовать ответы модели в вероятность. Таким объектом является logit или log odds – логарифм отношения вероятности положительного события к отрицательному $logleft(frac{p}{1-p}right)$.
Если ответом нашей модели является $logleft(frac{p}{1-p}right)$, то искомую вероятность посчитать не трудно:
$$langle w, x_irangle = logleft(frac{p}{1-p}right)$$
$$e^{langle w, x_irangle} = frac{p}{1-p}$$
$$p=frac{1}{1 + e^{-langle w, x_irangle}}$$
Функция в правой части называется сигмоидой и обозначается
$$color{#348FEA}{sigma(z) = frac1{1 + e^{-z}}}$$
Таким образом, $p = sigma(langle w, x_irangle)$
Как теперь научиться оптимизировать $w$ так, чтобы модель как можно лучше предсказывала логиты? Нужно применить метод максимума правдоподобия для распределения Бернулли. Это самое простое распределение, которое возникает, к примеру, при бросках монетки, которая орлом выпадает с вероятностью $p$. У нас только событием будет не орёл, а то, что пользователь кликнул на объект с такой вероятностью. Если хотите больше подробностей, почитайте про распределение Бернулли в теоретическом минимуме.
Правдоподобие позволяет понять, насколько вероятно получить данные значения таргета $y$ при данных $X$ и весах $w$. Оно имеет вид
$$ p(ymid X, w) =prod_i p(y_imid x_i, w) $$
и для распределения Бернулли его можно выписать следующим образом:
$$ p(ymid X, w) =prod_i p_i^{y_i} (1-p_i)^{1-y_i} $$
где $p_i$ – это вероятность, посчитанная из ответов модели. Оптимизировать произведение неудобно, хочется иметь дело с суммой, так что мы перейдём к логарифмическому правдоподобию и подставим формулу для вероятности, которую мы получили выше:
$$ ell(w, X, y) = sum_i big( y_i log(p_i) + (1-y_i)log(1-p_i) big) =$$
$$ =sum_i big( y_i log(sigma(langle w, x_i rangle)) + (1-y_i)log(1 — sigma(langle w, x_i rangle)) big) $$
Если заметить, что
$$
sigma(-z) = frac{1}{1 + e^z} = frac{e^{-z}}{e^{-z} + 1} = 1 — sigma(z),
$$
то выражение можно переписать проще:
$$
ell(w, X, y)=sum_i big( y_i log(sigma(langle w, x_i rangle)) + (1 — y_i) log(sigma(-langle w, x_i rangle)) big)
$$
Нас интересует $w$, для которого правдоподобие максимально. Чтобы получить функцию потерь, которую мы будем минимизировать, умножим его на минус один:
$$color{#348FEA}{L(w, X, y) = -sum_i big( y_i log(sigma(langle w, x_i rangle)) + (1 — y_i) log(sigma(-langle w, x_i rangle)) big)}$$
В отличие от линейной регрессии, для логистической нет явной формулы решения. Деваться некуда, будем использовать градиентный спуск. К счастью, градиент устроен очень просто:
$$
nabla_w L(y, X, w) = -sum_i x_i big( y_i — sigma(langle w, x_i rangle)) big)
$$
Вывод формулы градиентаНам окажется полезным ещё одно свойство сигмоиды::
$$
frac{d log sigma(z)}{d z} = left( log left( frac{1}{1 + e^{-z}} right) right)’ = frac{e^{-z}}{1 + e^{-z}} = sigma(-z)
frac{d log sigma(-z)}{d z} = -sigma(z)
$$
Отсюда:
$$
nabla_w log sigma(langle w, x_i rangle) = sigma(-langle w, x_i rangle) x_i
nabla_w log sigma(-langle w, x_i rangle) = -sigma(langle w, x_i rangle) x_i
$$
и градиент оказывается равным
$$
nabla_w L(y, X, w) = -sum_i big( y_i x_i sigma(-langle w, x_i rangle) — (1 — y_i) x_i sigma(langle w, x_i rangle)) big) =
= -sum_i big( y_i x_i (1 — sigma(langle w, x_i rangle)) — (1 — y_i) x_i sigma(langle w, x_i rangle)) big) =
= -sum_i big( y_i x_i — y_i x_i sigma(langle w, x_i rangle) — x_i sigma(langle w, x_i rangle) + y_i x_i sigma(langle w, x_i rangle)) big) =
= -sum_i big( y_i x_i — x_i sigma(langle w, x_i rangle)) big)
$$
Предсказание модели будет вычисляться, как мы договаривались, следующим образом:
$$p=sigma(langle w, x_irangle)$$
Это вероятность положительного класса, а как от неё перейти к предсказанию самого класса? В других методах нам достаточно было посчитать знак предсказания, но теперь все наши предсказания положительные и находятся в диапазоне от 0 до 1. Что же делать? Интуитивным и не совсем (и даже совсем не) правильным является ответ «взять порог 0.5». Более корректным будет подобрать этот порог отдельно, для уже построенной регрессии минимизируя нужную вам метрику на отложенной тестовой выборке. Например, сделать так, чтобы доля положительных и отрицательных классов примерно совпадала с реальной.
Отдельно заметим, что метод называется логистической регрессией, а не логистической классификацией именно потому, что предсказываем мы не классы, а вещественные числа – логиты.
Вопрос на подумать. Проверьте, что, если метки классов – это $pm1$, а не $0$ и $1$, то функцию потерь для логистической регрессии можно записать в более компактном виде:
$$mathcal{L}(w, X, y) = sum_{i=1}^Nlog(1 + e^{-y_ilangle w, x_irangle})$$
Вопрос на подумать. Правда ли разделяющая поверхность модели логистической регрессии является гиперплоскостью?
Ответ (не открывайте сразу; сначала подумайте сами!)Разделяющая поверхность отделяет множество точек, которым мы присваиваем класс $0$ (или $-1$), и множество точек, которым мы присваиваем класс $1$. Представляется логичным провести отсечку по какому-либо значению предсказанной вероятности. Однако, выбор этого значения — дело не очевидное. Как мы увидим в главе про калибровку классификаторов, это может быть не настоящая вероятность. Допустим, мы решили провести границу по значению $frac12$. Тогда разделяющая поверхность как раз задаётся равенством $p = frac12$, что равносильно $langle w, xrangle = 0$. А это гиперплоскость.
Вопрос на подумать. Допустим, что матрица объекты-признаки $X$ имеет полный ранг по столбцам (то есть все её столбцы линейно независимы). Верно ли, что решение задачи восстановления логистической регрессии единственно?
Ответ (не открывайте сразу; сначала подумайте сами!)В этот раз хорошего геометрического доказательства, как было для линейной регрессии, пожалуй, нет; нам придётся честно посчитать вторую производную и доказать, что она является положительно определённой. Сделаем это для случая, когда метки классов – это $pm1$. Формулы так получатся немного попроще. Напомним, что в этом случае
$$L(w, X, y) = -sum_{i=1}^Nlog(1 + e^{-y_ilangle w, x_irangle})$$
Следовательно,
$$frac{partial}{partial w_{j}}L(w, X, y) = sum_{i=1}^Nfrac{y_ix_{ij}e^{-y_ilangle w, x_irangle}}{1 + e^{-y_ilangle w, x_irangle}} = sum_{i=1}^Ny_ix_{ij}left(1 — frac1{1 + e^{-y_ilangle w, x_irangle}}right)$$
$$frac{partial^2L}{partial w_jpartial w_k}(w, X, y) = sum_{i=1}^Ny^2_ix_{ij}x_{ik}frac{e^{-y_ilangle w, x_irangle}}{(1 + e^{-y_ilangle w, x_irangle})^2} =$$
$$ = sum_{i=1}^Ny^2_ix_{ij}x_{ik}sigma(y_ilangle w, x_irangle)(1 — sigma(y_ilangle w, x_irangle))$$
Теперь заметим, что $y_i^2 = 1$ и что, если обозначить через $D$ диагональную матрицу с элементами $sigma(y_ilangle w, x_irangle)(1 — sigma(y_ilangle w, x_irangle))$ на диагонали, матрицу вторых производных можно представить в виде:
$$nabla^2L = left(frac{partial^2mathcal{L}}{partial w_jpartial w_k}right) = X^TDX$$
Так как $0 < sigma(y_ilangle w, x_irangle) < 1$, у матрицы $D$ на диагонали стоят положительные числа, из которых можно извлечь квадратные корни, представив $D$ в виде $D = D^{1/2}D^{1/2}$. В свою очередь, матрица $X$ имеет полный ранг по столбцам. Стало быть, для любого вектора приращения $une 0$ имеем
$$u^TX^TDXu = u^TX^T(D^{1/2})^TD^{1/2}Xu = vert D^{1/2}Xu vert^2 > 0$$
Таким образом, функция $L$ выпукла вниз как функция от $w$, и, соответственно, точка её экстремума непременно будет точкой минимума.
А теперь – почему это не совсем правда. Дело в том, что, говоря «точка её экстремума непременно будет точкой минимума», мы уже подразумеваем существование этой самой точки экстремума. Только вот существует этот экстремум не всегда. Можно показать, что для линейно разделимой выборки функция потерь логистической регрессии не ограничена снизу, и, соответственно, никакого экстремума нет. Доказательство мы оставляем читателю.
Вопрос на подумать. На картинке ниже представлены результаты работы на одном и том же датасете трёх моделей логистической регрессии с разными коэффициентами $L^2$-регуляризации:
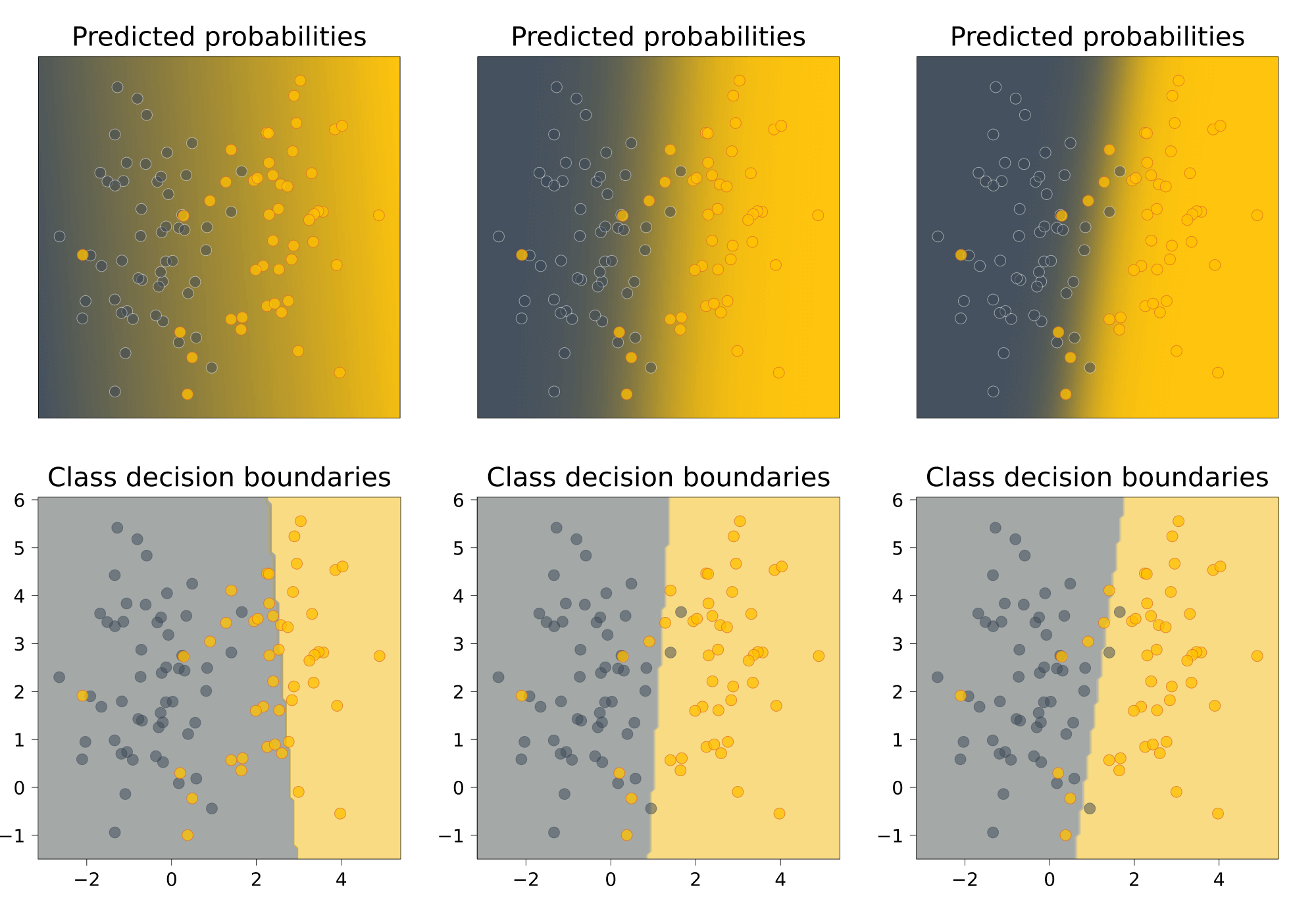
Наверху показаны предсказанные вероятности положительного класса, внизу – вид разделяющей поверхности.
Как вам кажется, какие картинки соответствуют самому большому коэффициенту регуляризации, а какие – самому маленькому? Почему?
Ответ (не открывайте сразу; сначала подумайте сами!)Коэффициент регуляризации максимален у левой модели. На это нас могут натолкнуть два соображения. Во-первых, разделяющая прямая проведена достаточно странно, то есть можно заподозрить, что регуляризационный член в лосс-функции перевесил функцию потерь исходной задачи. Во-вторых, модель предсказывает довольно близкие к $frac12$ вероятности – это значит, что значения $langle w, xrangle$ близки к нулю, то есть сам вектор $w$ близок к нулевому. Это также свидетельствует о том, что регуляризационный член играет слишком важную роль при оптимизации.
Наименьший коэффициент регуляризации у правой модели. Её предсказания достаточно «уверенные» (цвета на верхнем графике сочные, то есть вероятности быстро приближаются к $0$ или $1$). Это может свидетельствовать о том, что числа $langle w, xrangle$ достаточно велики по модулю, то есть $vertvert w vertvert$ достаточно велик.
Многоклассовая классификация
В этом разделе мы будем следовать изложению из лекций Евгения Соколова.
Пусть каждый объект нашей выборки относится к одному из $K$ классов: $mathbb{Y} = {1, ldots, K}$. Чтобы предсказывать эти классы с помощью линейных моделей, нам придётся свести задачу многоклассовой классификации к набору бинарных, которые мы уже хорошо умеем решать. Мы разберём два самых популярных способа это сделать – one-vs-all и all-vs-all, а проиллюстрировать их нам поможет вот такой игрушечный датасет

Один против всех (one-versus-all)
Обучим $K$ линейных классификаторов $b_1(x), ldots, b_K(x)$, выдающих оценки принадлежности классам $1, ldots, K$ соответственно. В случае с линейными моделями эти классификаторы будут иметь вид
$$b_k(x) = text{sgn}left(langle w_k, x rangle + w_{0k}right)$$
Классификатор с номером $k$ будем обучать по выборке $left(x_i, 2mathbb{I}[y_i = k] — 1right)_{i = 1}^{N}$; иными словами, мы учим классификатор отличать $k$-й класс от всех остальных.
Логично, чтобы итоговый классификатор выдавал класс, соответствующий самому уверенному из бинарных алгоритмов. Уверенность можно в каком-то смысле измерить с помощью значений линейных функций:
$$a(x) = text{argmax}_k left(langle w_k, x rangle + w_{0k}right) $$
Давайте посмотрим, что даст этот подход применительно к нашему датасету. Обучим три линейных модели, отличающих один класс от остальных:

Теперь сравним значения линейных функций
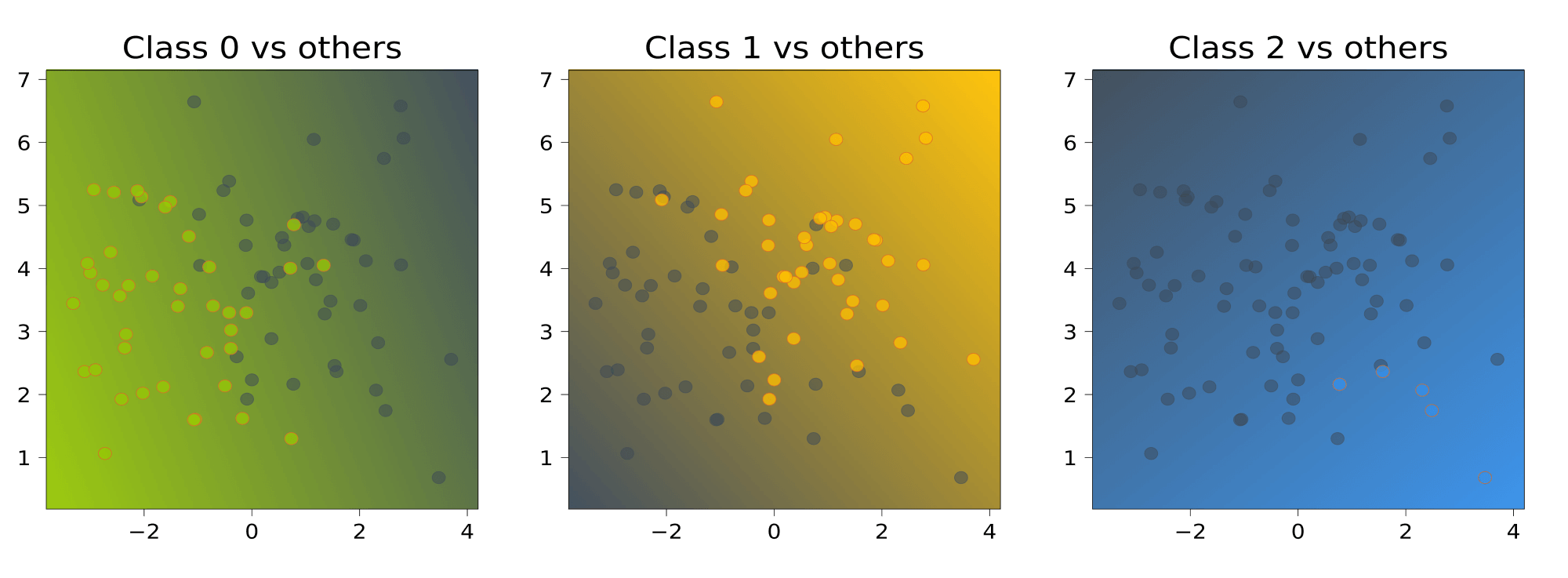
и для каждой точки выберем тот класс, которому соответствует большее значение, то есть самый «уверенный» классификатор:

Хочется сказать, что самый маленький класс «обидели».
Проблема данного подхода заключается в том, что каждый из классификаторов $b_1(x), dots, b_K(x)$ обучается на своей выборке, и значения линейных функций $langle w_k, x rangle + w_{0k}$ или, проще говоря, «выходы» классификаторов могут иметь разные масштабы. Из-за этого сравнивать их будет неправильно. Нормировать вектора весов, чтобы они выдавали ответы в одной и той же шкале, не всегда может быть разумным решением: так, в случае с SVM веса перестанут являться решением задачи, поскольку нормировка изменит норму весов.
Все против всех (all-versus-all)
Обучим $C_K^2$ классификаторов $a_{ij}(x)$, $i, j = 1, dots, K$, $i neq j$. Например, в случае с линейными моделями эти модели будут иметь вид
$$b_{ij}(x) = text{sgn}left( langle w_{ij}, x rangle + w_{0,ij} right)$$
Классификатор $a_{ij}(x)$ будем настраивать по подвыборке $X_{ij} subset X$, содержащей только объекты классов $i$ и $j$. Соответственно, классификатор $a_{ij}(x)$ будет выдавать для любого объекта либо класс $i$, либо класс $j$. Проиллюстрируем это для нашей выборки:
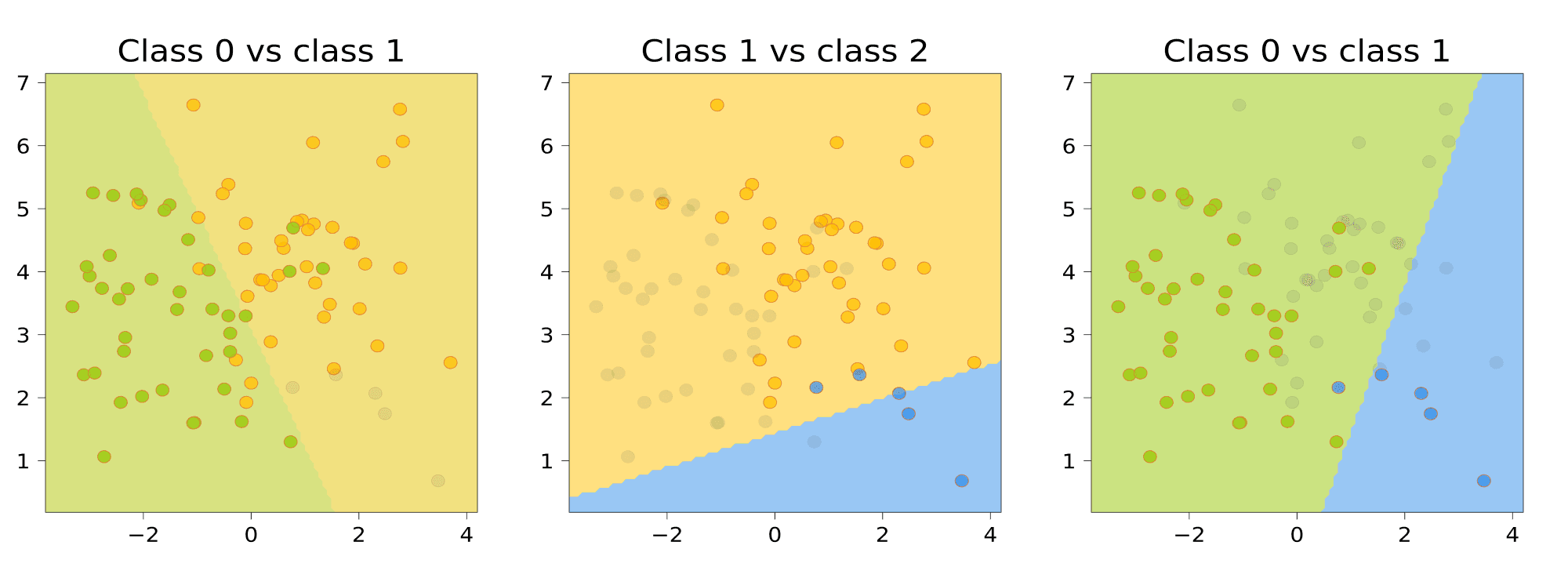
Чтобы классифицировать новый объект, подадим его на вход каждого из построенных бинарных классификаторов. Каждый из них проголосует за своей класс; в качестве ответа выберем тот класс, за который наберется больше всего голосов:
$$a(x) = text{argmax}_ksum_{i = 1}^{K} sum_{j neq i}mathbb{I}[a_{ij}(x) = k]$$
Для нашего датасета получается следующая картинка:

Обратите внимание на серый треугольник на стыке областей. Это точки, для которых голоса разделились (в данном случае каждый классификатор выдал какой-то свой класс, то есть у каждого класса было по одному голосу). Для этих точек нет явного способа выдать обоснованное предсказание.
Многоклассовая логистическая регрессия
Некоторые методы бинарной классификации можно напрямую обобщить на случай многих классов. Выясним, как это можно проделать с логистической регрессией.
В логистической регрессии для двух классов мы строили линейную модель
$$b(x) = langle w, x rangle + w_0,$$
а затем переводили её прогноз в вероятность с помощью сигмоидной функции $sigma(z) = frac{1}{1 + exp(-z)}$. Допустим, что мы теперь решаем многоклассовую задачу и построили $K$ линейных моделей
$$b_k(x) = langle w_k, x rangle + w_{0k},$$
каждая из которых даёт оценку принадлежности объекта одному из классов. Как преобразовать вектор оценок $(b_1(x), ldots, b_K(x))$ в вероятности? Для этого можно воспользоваться оператором $text{softmax}(z_1, ldots, z_K)$, который производит «нормировку» вектора:
$$text{softmax}(z_1, ldots, z_K) = left(frac{exp(z_1)}{sum_{k = 1}^{K} exp(z_k)},
dots, frac{exp(z_K)}{sum_{k = 1}^{K} exp(z_k)}right).$$
В этом случае вероятность $k$-го класса будет выражаться как
$$P(y = k vert x, w) = frac{
exp{(langle w_k, x rangle + w_{0k})}}{ sum_{j = 1}^{K} exp{(langle w_j, x rangle + w_{0j})}}.$$
Обучать эти веса предлагается с помощью метода максимального правдоподобия: так же, как и в случае с двухклассовой логистической регрессией:
$$sum_{i = 1}^{N} log P(y = y_i vert x_i, w) to max_{w_1, dots, w_K}$$
Масштабируемость линейных моделей
Мы уже обсуждали, что SGD позволяет обучению хорошо масштабироваться по числу объектов, так как мы можем не загружать их целиком в оперативную память. А что делать, если признаков очень много, или мы не знаем заранее, сколько их будет? Такое может быть актуально, например, в следующих ситуациях:
- Классификация текстов: мы можем представить текст в формате «мешка слов», то есть неупорядоченного набора слов, встретившихся в данном тексте, и обучить на нём, например, определение тональности отзыва в интернете. Наличие каждого слова из языка в тексте у нас будет кодироваться отдельной фичой. Тогда размерность каждого элемента обучающей выборки будет порядка нескольких сотен тысяч.
- В задаче предсказания кликов по рекламе можно получить выборку любой размерности, например, так: в качестве фичи закодируем индикатор того, что пользователь X побывал на веб-странице Y. Суммарная размерность тогда будет порядка $10^9 cdot 10^7 = 10^{16}$. Кроме того, всё время появляются новые пользователи и веб-страницы, так что на этапе применения нас ждут сюрпризы.
Есть несколько хаков, которые позволяют бороться с такими проблемами:
- Несмотря на то, что полная размерность объекта в выборке огромна, количество ненулевых элементов в нём невелико. Значит, можно использовать разреженное кодирование, то есть вместо плотного вектора хранить словарь, в котором будут перечислены индексы и значения ненулевых элементов вектора.
- Даже хранить все веса не обязательно! Можно хранить их в хэш-таблице и вычислять индекс по формуле
hash(feature) % tablesize. Хэш может вычисляться прямо от слова или id пользователя. Таким образом, несколько фичей будут иметь общий вес, который тем не менее обучится оптимальным образом. Такой подход называется hashing trick. Ясно, что сжатие вектора весов приводит к потерям в качестве, но, как правило, ценой совсем небольших потерь можно сжать этот вектор на много порядков.
Примером открытой библиотеки, в которой реализованы эти возможности, является vowpal wabbit.
Parameter server
Если при решении задачи ставки столь высоки, что мы не можем разменивать качество на сжатие вектора весов, а признаков всё-таки очень много, то задачу можно решать распределённо, храня все признаки в шардированной хеш-таблице
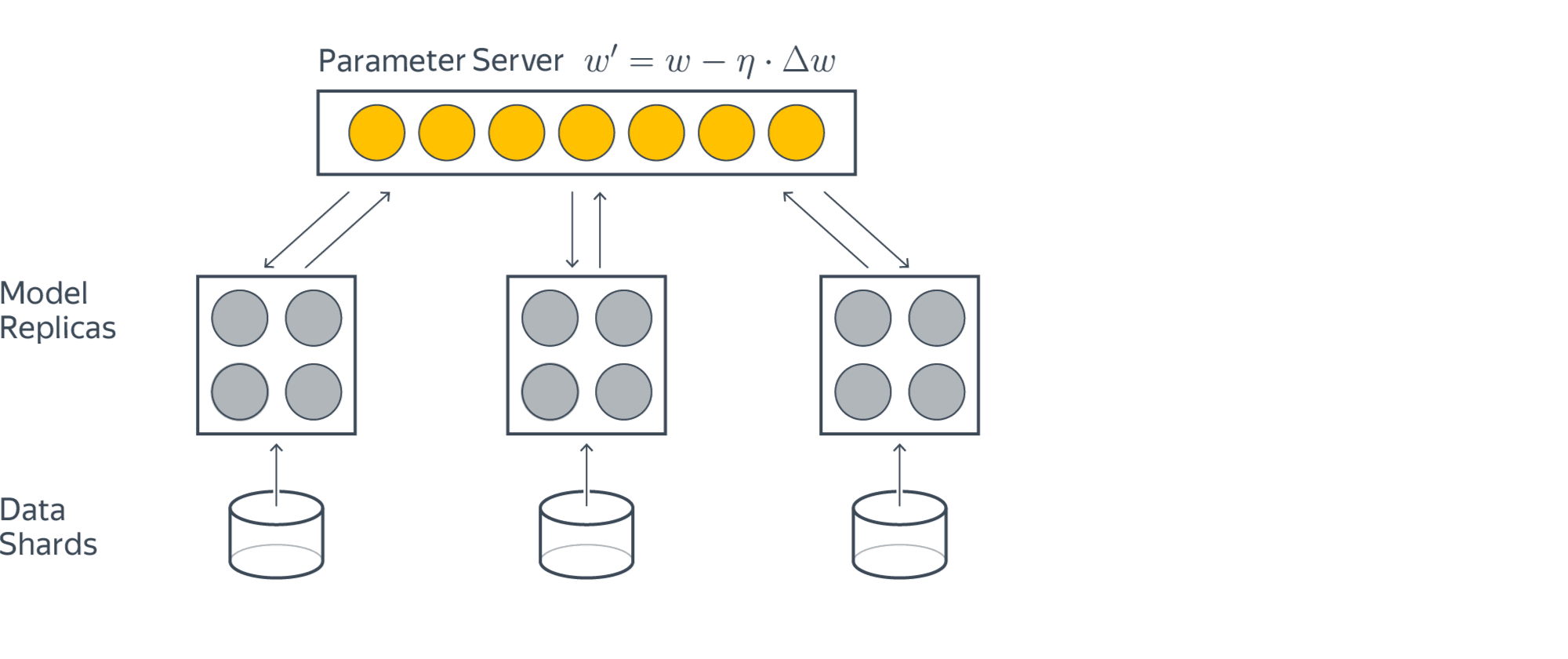
Кружки здесь означают отдельные сервера. Жёлтые загружают данные, а серые хранят части модели. Для обучения жёлтый кружок запрашивает у серого нужные ему для предсказания веса, считает градиент и отправляет его обратно, где тот потом применяется. Схема обладает бесконечной масштабируемостью, но задач, где это оправдано, не очень много.
Подытожим
На линейную модель можно смотреть как на однослойную нейросеть, поэтому многие методы, которые были изначально разработаны для них, сейчас переиспользуются в задачах глубокого обучения, а базовые подходы к регрессии, классификации и оптимизации вообще выглядят абсолютно так же. Так что несмотря на то, что в целом линейные модели на сегодня применяются редко, то, из чего они состоят и как строятся, знать очень и очень полезно.
Надеемся также, что главным итогом прочтения этой главы для вас будет осознание того, что решение любой ML-задачи состоит из выбора функции потерь, параметризованного класса моделей и способа оптимизации. В следующих главах мы познакомимся с другими моделями и оптимизаторами, но эти базовые принципы не изменятся.
import numpy as np
import matplotlib.pyplot as plt
class Linear_Regression:
def __init__(self, X, Y):
self.X = X
self.Y = Y
self.b = [0, 0]
def update_coeffs(self, learning_rate):
Y_pred = self.predict()
Y = self.Y
m = len(Y)
self.b[0] = self.b[0] - (learning_rate * ((1/m) *
np.sum(Y_pred - Y)))
self.b[1] = self.b[1] - (learning_rate * ((1/m) *
np.sum((Y_pred - Y) * self.X)))
def predict(self, X=[]):
Y_pred = np.array([])
if not X: X = self.X
b = self.b
for x in X:
Y_pred = np.append(Y_pred, b[0] + (b[1] * x))
return Y_pred
def get_current_accuracy(self, Y_pred):
p, e = Y_pred, self.Y
n = len(Y_pred)
return 1-sum(
[
abs(p[i]-e[i])/e[i]
for i in range(n)
if e[i] != 0]
)/n
def compute_cost(self, Y_pred):
m = len(self.Y)
J = (1 / 2*m) * (np.sum(Y_pred - self.Y)**2)
return J
def plot_best_fit(self, Y_pred, fig):
f = plt.figure(fig)
plt.scatter(self.X, self.Y, color='b')
plt.plot(self.X, Y_pred, color='g')
f.show()
def main():
X = np.array([i for i in range(11)])
Y = np.array([2*i for i in range(11)])
regressor = Linear_Regression(X, Y)
iterations = 0
steps = 100
learning_rate = 0.01
costs = []
Y_pred = regressor.predict()
regressor.plot_best_fit(Y_pred, 'Initial Best Fit Line')
while 1:
Y_pred = regressor.predict()
cost = regressor.compute_cost(Y_pred)
costs.append(cost)
regressor.update_coeffs(learning_rate)
iterations += 1
if iterations % steps == 0:
print(iterations, "epochs elapsed")
print("Current accuracy is :",
regressor.get_current_accuracy(Y_pred))
stop = input("Do you want to stop (y/*)??")
if stop == "y":
break
regressor.plot_best_fit(Y_pred, 'Final Best Fit Line')
h = plt.figure('Verification')
plt.plot(range(iterations), costs, color='b')
h.show()
regressor.predict([i for i in range(10)])
if __name__ == '__main__':
main()
import numpy as np
import matplotlib.pyplot as plt
class Linear_Regression:
def __init__(self, X, Y):
self.X = X
self.Y = Y
self.b = [0, 0]
def update_coeffs(self, learning_rate):
Y_pred = self.predict()
Y = self.Y
m = len(Y)
self.b[0] = self.b[0] - (learning_rate * ((1/m) *
np.sum(Y_pred - Y)))
self.b[1] = self.b[1] - (learning_rate * ((1/m) *
np.sum((Y_pred - Y) * self.X)))
def predict(self, X=[]):
Y_pred = np.array([])
if not X: X = self.X
b = self.b
for x in X:
Y_pred = np.append(Y_pred, b[0] + (b[1] * x))
return Y_pred
def get_current_accuracy(self, Y_pred):
p, e = Y_pred, self.Y
n = len(Y_pred)
return 1-sum(
[
abs(p[i]-e[i])/e[i]
for i in range(n)
if e[i] != 0]
)/n
def compute_cost(self, Y_pred):
m = len(self.Y)
J = (1 / 2*m) * (np.sum(Y_pred - self.Y)**2)
return J
def plot_best_fit(self, Y_pred, fig):
f = plt.figure(fig)
plt.scatter(self.X, self.Y, color='b')
plt.plot(self.X, Y_pred, color='g')
f.show()
def main():
X = np.array([i for i in range(11)])
Y = np.array([2*i for i in range(11)])
regressor = Linear_Regression(X, Y)
iterations = 0
steps = 100
learning_rate = 0.01
costs = []
Y_pred = regressor.predict()
regressor.plot_best_fit(Y_pred, 'Initial Best Fit Line')
while 1:
Y_pred = regressor.predict()
cost = regressor.compute_cost(Y_pred)
costs.append(cost)
regressor.update_coeffs(learning_rate)
iterations += 1
if iterations % steps == 0:
print(iterations, "epochs elapsed")
print("Current accuracy is :",
regressor.get_current_accuracy(Y_pred))
stop = input("Do you want to stop (y/*)??")
if stop == "y":
break
regressor.plot_best_fit(Y_pred, 'Final Best Fit Line')
h = plt.figure('Verification')
plt.plot(range(iterations), costs, color='b')
h.show()
regressor.predict([i for i in range(10)])
if __name__ == '__main__':
main()
Регрессия как задача машинного обучения
38 мин на чтение
(55.116 символов)
Постановка задачи регрессии

Источник: Analytics Vidhya.
Задача регрессии — это одна из основных задач машинного обучения. И хотя, большинство задач на практике относятся к другому типу — классификации, мы начнем знакомство с машинным обучением именно с регрессии. Регрессионные модели были известны задолго до появления машинного обучения как отрасли и активно применяются в статистике, эконометрике, математическом моделировании. Машинное обучение предлагает новый взгляд на уже известные модели. И этот новый взгляд позволит строить более сложные и мощные модели, чем классические математические дисциплины.
Задача регрессии относится к категории задач обучения с учителем. Это значит, что набор данных, который используется для обучения, должен иметь определенную структуру. Обычно, наборы данных для машинного обучения представляют собой таблицу, в которой по строкам перечислены разные объекты наблюдений или измерений. В столбцах — различные характеристики, или атрибуты, объектов. А на пересечении строк и столбцов — значение данной характеристики у данного объекта. Обычно один атрибут (или переменная) имеет особый характер — именно ее значение мы и хотим научиться предсказывать с помощью модели машинного обучения. Эта характеристика объекта называется целевая переменная. И если эта целевая переменная выражена числом (а точнее, некоторой непрерывной величиной) — то мы говорим о задаче регрессии.
Задачи регрессии на практике встречаются довольно часто. Например, предсказание цены объекта недвижимости — классическая регрессионная задача. В таких проблемах атрибутами выступают разные характеристики квартир или домов — площадь, этажность, расположение, расстояние до центра города, количество комнат, год постройки. В разных наборах данных собрана разная информация И, соответственно, модели тоже должны быть разные. Другой пример — предсказание цены акций или других финансовых активов. Или предсказание температуры завтрашним днем.
Во всех таких задачах нам нужно иметь данные, которые позволят осуществить такое предсказание. Да, “предсказание” — это условный термин, не всегда мы говорим о будущих событиях. Регрессионные модели используют информацию об объектах в обучающем наборе данных, чтобы сделать вывод о возможном значении целевой переменной. И для этого нужно, чтобы ее значение имело какую-то зависимость от имеющихся у нас атрибутов. Если построить модель предсказания цены акции, но на вход подать информацию о футбольных матчах — ничего не получится. Мы предполагаем, что в наборе данных собраны именно те атрибуты объектов, которые имеют влияние на на значение целевой переменной. И чем больше это предположение выполняется, тем точнее будет потенциально наша модель.
Немного поговорим о терминах. Набор данных который мы используем для обучения модели называют датасетом (dataset) или обучающей выборкой (training set). Объекты, которые описываются в датасете еще называют точками данных (data points). Целевую переменную еще называют на статистический манер зависимой переменной (dependent variable) или результативной, выходной (output), а остальные атрибуты — независимыми переменными (dependent variables), или признаками (features), или факторами, или входными переменными (input). Значения одного конкретного атрибута для всех объектов обучающей выборки часто представляют как вектор этого признака (feature vector). А всю таблицу всех атрибутов называют матрицей атрибутов (feature matrix). Соответственно, еще есть вектор целевой переменной, он не входит в матрицу атрибутов.
С точки зрения информатики, регрессионная модель — это функция, которая принимает на вход значения атрибутов какого-то конкретного объекта и выдает на выходе предполагаемое значение целевой переменной. В большинстве случаев мы предполагаем, что целевая переменная у нас одна. Если стоит задача предсказания нескольких характеристик, то их чаще воспринимают как несколько независимых задач регрессии на одних и тех же атрибутах.
Мы пока ничего не говорили о том, как изнутри устроена регрессионная модель. Это потому, что она может быть какой угодно. Это может быть математическое выражение, условный алгоритм, сложная программа со множеством ветвлений и циклов, нейронная сеть — все это можно представить регрессионной моделью. Единственное требование к модели машинного обучения — она должна быть параметрической. То есть иметь какие-то внутренние параметры, от которых тоже зависит результат вычисления. В простых случаях, чаще всего в качестве регрессионной модели используют аналитические функции. Таких функций бесконечное количество, но чаще всего используется самая простая функция, с которой мы и начнем изучение регрессии — линейная функция.
Так же надо сказать, что иногда регрессионные модели подразделяют на парную и множественную регрессии. Парная регрессия — это когда у нас всего один атрибут. Множественная — когда больше одного. Конечно, на практике парная регрессия почти не встречается, но на примере такой простой модели мы поймем основные концепции машинного обучения. Плюс, парную регрессию очень удобно и наглядно можно изобразить на графике. Когда у нас больше двух переменных, графики уже не особо построишь, и модели приходится визуализировать иначе, более косвенно.
Выводы:
- Регрессия — это задача машинного обучения с учителем, которая заключается в предсказании некоторой непрерывной величины.
- Для использования регрессионных моделей нужно, чтобы в датасете были характеристики объектов и “правильные” значения целевой переменной.
- Примеры регрессионных задач — предсказание цены акции, оценка цены объекта недвижимости.
- Задача регрессии основывается на предположении, что значение целевой переменной зависит от значения признаков.
- Регрессионная модель принимает набор значений и выдает предсказание значения целевой переменной.
- В качестве регрессионных моделей часто берут аналитические функции, например, линейную.
Линейная регрессия с одной переменной
Функция гипотезы

Напомним, что в задачах регрессии мы принимаем входные переменные и пытаемся получить более-менее достоверное значение целевой переменной. Любая функция, даже самая простая линейная может выдавать совершенно разные значения для одних и тех же входных данных, если в функции будут разные параметры. Поэтому, любая регрессионная модель — это не какая-то конкретная математическая функция, а целое семейство функций. И задача алгоритма обучения — подобрать значения параметров таким образом, чтобы для объектов обучающей выборки, для которых мы уже знаем правильные ответы, предсказанные (или теоретические, вычисленные из модели) значения были как можно ближе к тем, которые есть в датасете (эмпирические, истинные значения).
Парная, или одномерная (univariate) регрессия используется, когда вы хотите предсказать одно выходное значение (чаще всего обозначаемое $y$), зависящее от одного входного значения (обычно обозначается $x$). Сама функция называется функцией гипотезы или моделью. В качестве функции гипотезы для парной регрессии можно выбрать любую функцию, но мы пока потренируемся с самой простой функцией одной переменной — линейной функцией. Тогда нашу модель можно назвать парной линейной регрессией.
В случае парной линейной регрессии функция гипотезы имеет следующий общий вид:
[hat{y} = h_b (x) = b_0 + b_1 x]
Обратите внимание, что это похоже на уравнение прямой. Эта модель соответствует множеству всех возможных прямых на плоскости. Когда мы конкретизируем модель значениями параметров (в данном случае — $b_0$ и $b_1$), мы получаем конкретную прямую. И наша задача состоит в том, чтобы выбрать такую прямую, которая бы лучше всего “легла” в точки из нашей обучающей выборки.
В данном случае, мы пытаемся подобрать функцию h(x) таким образом, чтобы отобразить данные нам значения x в данные значения y.
Допустим, мы имеем следующий обучающий набор данных:
| входная переменная x | выходная переменная y |
| 0 | 4 |
| 1 | 7 |
| 2 | 7 |
| 3 | 8 |
Мы можем составить случайную гипотезу с параметрами $ b_0 = 2, b_1 = 2 $. Тогда для входного значения $ x=1 $ модель выдаст предсказание, что $ y=4 $, что на 3 меньше данного. Значение $y$б которое посчитала модель будем называть теоретическим или предсказанным (predicted), а значение, которое дано в наборе данных — эмпирическим или истинным (true). Задача регрессии состоит в нахождении таких параметров функции гипотезы, чтобы она отображала входные значения в выходные как можно более точно, или, другими словами, описывала линию, наиболее точно ложащуюся в данные точки на плоскости $(x, y)$.
Выводы:
- Модель машинного обучения — это параметрическая функция.
- Задача обучения состоит в том, чтобы подобрать параметры модели таким образом, чтобы она лучше всего описывала обучающие данные.
- Парная линейная регрессия работает, если есть всего одна входящая переменная.
- Парная линейная регрессия — одна из самых простых моделей машинного обучения.
- Парная линейная регрессия соответствует множеству всех прямых на плоскости. Из них мы выбираем одну, наиболее подходящую.
Функция ошибки
Как мы уже говорили, разные значения параметров дают разные модели. Для того, чтобы подобрать наилучшую модель, нам нужно средство измерения “точности” модели, некоторая функция, которая показывает, насколько модель хорошо или плохо соответствует имеющимся данным.

В простых случаях мы можем отличить хорошие модели от плохих, только взглянув на график. Но это затруднительно, если количество признаков очень велико, если модели лишь немного отличаются друг от друга. Да и для автоматизации процесса нужен способ формализовать наше общее представление о том, что модель “ложится” в точки данных.
Такая функция называется функцией ошибки (cost function). Она измеряет отклонения теоретических значений (то есть тех, которые предсказывает модель) от эмпирических (то есть тех, которые есть в данных). Чем выше значение функции ошибки, тем хуже модель соответствует имеющимся данным, хуже описывает их. Если модель полностью соответствует данным, то значение функции ошибки будет нулевым.

В задачах регрессии в качестве функции ошибки чаще всего берут среднеквадратичное отклонение теоретических значений от эмпирических. То есть сумму квадратов отклонений, деленную на удвоенное количество измерений.
[J(b_0, b_1)
= frac{1}{2m} sum_{i=1}^{m} (hat{y_i} — y_i)^2
= frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
Эту функцию называют «функцией квадрата ошибки» или «среднеквадратичной ошибкой» (mean squared error, MSE). Среднее значение уменьшено вдвое для удобства вычисления градиентного спуска, так как производная квадратичной функции будет отменять множитель 1/2. Вообще, функцию ошибки можно свободно домножить или разделить на любое число (положительное), ведь нам не важна конкретная величина этой функции. Нам важно, что какие-то модели (то есть наборы значений параметров модели) имеют низкую ошибку, они нам подходят больше, а какие-то — высокую ошибку, они подходят нам меньше.
Возведение в квадрат в этой формуле нужно для того, чтобы положительные отклонения не компенсировали отрицательные. Можно было бы для этого брать, например, абсолютное значение, но эта функция не везде дифференцируема, а это станет нам важно позднее.
Обратите внимание, что в качестве аргументов у функции ошибки выступают параметры нашей функции гипотезы. Ведь функция ошибки оценивает отклонение конкретной функции гипотезы (то есть набора значений параметров этой функции) от эмпирических значений, то есть ставит в соответствие каждому набору параметров модели число, характеризующее ошибку этого набора.
Давайте проследим формирование функции ошибки на еще более простом примере. Возьмем упрощенную форму линейной модели — прямую пропорциональность. Она выражается формулой:
[hat{y} = h_b (x) = b_1 x]
Эта модель поможет нам, так как у нее всего один параметр. И функцию ошибки можно будет изобразить на плоскости. Возьмем фиксированный набор точек и попробуем несколько значений параметра для вычисления функции ошибки. Слева на графике изображены точки данных и текущая функция гипотезы, а на правом графике бы будем отмечать значение использованного параметра (по горизонтали) и получившуюся величину функции ошибки (по вертикали):

При значении $b_1 = -1$ линия существенно отклоняется от точек. Отметим уровень ошибки (примерно 10) на правом графике.

Если взять значение $b_1 = 0$ линия гораздо ближе к точкам, но ошибка все еще есть. Отметим новое значение на правом графике в точке 0.

При значении $b_1 = 1$ график точно ложится в точки, таким образом ошибка становится равной нулю. Отмечаем ее так же.

При дальнейшем увеличении $b_1$ линия становится выше точек. Но функция ошибки все равно будет положительной. Теперь она опять станет расти.

На этом примере мы видим еще одно преимущество возведения в квадрат — это то, что такая функция в простых случаях имеет один глобальный минимум. На правом графике формируется точка за точкой некоторая функция, которая похожа очертаниями на параболу. Но мы не знаем аналитического вида этой параболы, мы можем лишь строить ее точка за точкой.
В нашем примере, в определенной точке функция ошибки обращается в ноль. Это соответствует “идеальной” функции гипотезы. То есть такой, когда она проходит четко через все точки. В нашем примере это стало возможно благодаря тому, что точки данных и так располагаются на одной прямой. В общем случае это не выполняется и функция ошибки, вообще говоря, не обязана иметь нули. Но она должна иметь глобальный минимум. Рассмотрим такой неидеальный случай:





Какое бы значение параметра мы не использовали, линейная функция неспособна идеально пройти через такие три точки, которые не лежат на одной прямой. Эта ситуация называется “недообучение”, об этом мы еще будем говорить дальше. Это значит, что наша модель слишком простая, чтобы идеально описать данные. Но зачастую, идеальная модель и не требуется. Важно лишь найти наилучшую модель из данного класса (например, линейных функций).
Выше мы рассмотрели упрощенный пример с функцией гипотезы с одним параметром. Но у парной линейной регрессии же два параметра. В таком случае, функция ошибки будет описывать не параболу, а параболоид:

Теперь мы можем конкретно измерить точность нашей предсказывающей функции по сравнению с правильными результатами, которые мы имеем, чтобы мы могли предсказать новые результаты, которых у нас нет.
Если мы попытаемся представить это наглядно, наш набор данных обучения будет разбросан по плоскости x-y. Мы пытаемся подобрать прямую линию, которая проходит через этот разбросанный набор данных. Наша цель — получить наилучшую возможную линию. Лучшая линия будет такой, чтобы средние квадраты вертикальных расстояний точек от линии были наименьшими. В лучшем случае линия должна проходить через все точки нашего набора данных обучения. В таком случае значение J будет равно 0.


В более сложных моделях параметров может быть еще больше, но это не важно, ведь нам не нужно строить функцию ошибки, нам нужно лишь оптимизировать ее.
Выводы:
- Функция ошибки нужна для того, чтобы отличать хорошие модели от плохих.
- Функция ошибки показывает численно, насколько модель хорошо описывает данные.
- Аргументами функции ошибки являются параметры модели, ошибка зависит от них.
- Само значение функции ошибки не несет никакого смысла, оно используется только в сравнении.
- Цель алгоритма машинного обучения — минимизировать функцию ошибки, то есть найти такой набор параметров модели, при которых ошибка минимальна.
- Чаще всего используется так называемая L2-ошибка — средний квадрат отклонений теоретических значений от эмпирических (метрика MSE).
Метод градиентного спуска
Таким образом, у нас есть функция гипотезы, и способ оценить, насколько хорошо конкретная гипотеза вписывается в данные. Теперь нам нужно подобрать параметры функции гипотезы. Вот где приходит на помощь метод градиентного спуска.
Это происходит при помощи производной функции ошибки. Необходимое условие минимума функции — обращение в ноль ее производной. А так как мы знаем, что квадратичная функция имеет один глобальный экстремум — минимум, то наша задача очень проста — вычислить производную функции ошибки и найти, где она равна нулю.
Давайте найдем производную среднеквадратической функции ошибки:
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (h_b(x_i) — y_i)^2]
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x_i) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x_i)]
[J(b_0, b_1) = frac{1}{2m} sum_{i=1}^{m} (b_0 + b_1 x_i — y_i)^2]
[frac{partial J}{partial b_0} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) =
frac{1}{m} sum (h_b(x_i) — y_i)]
[frac{partial J}{partial b_1} =
frac{1}{m} sum (b_0 + b_1 x_i — y_i) cdot x_i =
frac{1}{m} sum (h_b(x_i) — y_i) cdot x_i]
Проблема в том, что мы не можем просто решить эти уравнения аналитически. Ведь мы не знаем общий вид функции ошибки, не то, что ее производной. Ведь он зависит, от всех точек данных. Но мы можем вычислить эту функцию (и ее производную) в любой точке. А точка на этой функции — это конкретный набор значений параметров модели. Поэтому пришлось изобрести численный алгоритм. Он работает следующим образом.
Сначала, мы выбираем произвольное значение параметров модели. То есть, произвольную точку в области определения функции. Мы не знаем, является ли эта точка оптимальной (скорее нет), не знаем, насколько она далека от оптимума. Но мы можем вычислить направление к оптимуму. Ведь мы знаем наклон касательной к графику функции ошибки.

Наклон касательной является производной в этой точке, и это даст нам направление движения в сторону самого крутого уменьшения значения функции. Если представить себе функцию одной переменной (параболу), то там все очень просто. Если производная в точке отрицательна, значит функция убывает, значит, что оптимум находится справа от данной точки. То есть, чтобы приблизиться к оптимуму надо увеличить аргумент функции. Если же производная положительна, то все наоборот — функция возрастает, оптимум находится слева и нам нужно уменьшить значение аргумента. Причем, чем дальше от оптимума, тем быстрее возрастает или убывает функция. То есть значение производной дает нам не только направление, но и величину нужного шага. Сделав шаг, пропорциональный величине производной и в направлении, противоположном ей, можно повторить процесс и еще больше приблизиться к оптимуму. С каждой итерацией мы будем приближаться к минимуму ошибки и математически доказано, что мы можем приблизиться к ней произвольно близко. То есть, данный метод сходится в пределе.
В случае с функцией нескольких переменных все немного сложнее, но принцип остается прежним. Только мы оперируем не полной производной функции, а вектором частных производных по каждому параметру. Он задает нам направление максимального увеличения функции. Чтобы получить направление максимального спада функции нужно просто домножить этот вектор на -1. После этого нужно обновить значения каждого компонента вектора параметров модели на величину, пропорциональную соответствующему компоненту вектора градиента. Таким образом мы делаем шаги вниз по функции ошибки в направлении с самым крутым спуском, а размер каждого шага пропорционален определяется параметром $alpha$, который называется скоростью обучения.
Алгоритм градиентного спуска:
повторяйте до сходимости:
[b_j := b_j — alpha frac{partial}{partial b_j} J(b_0, b_1)]
где j=0,1 — представляет собой индекс номера признака.
Это общий алгоритм градиентного спуска. Она работает для любых моделей и для любых функций ошибки. Это итеративный алгоритм, который сходится в пределе. То есть, мы никогда не придем в сам оптимум, но можем приблизиться к нему сколь угодно близко. На практике нам не так уж важно получить точное решение, достаточно решения с определенной точностью.
Алгоритм градиентного спуска имеет один параметр — скорость обучения. Он влияет на то, как быстро мы будем приближаться к оптимуму. Кажется, что чем быстрее, тем лучше, но оказывается, что если значение данного параметра слишком велико, то мы буем постоянно промахиваться и алгоритм будет расходиться.

Алгоритм градиентного спуска для парной линейной регрессии:
повторяйте до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)} )- y^{(i)})]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x^{(i)}]
На практике “повторяйте до сходимости” означает, что мы повторяем алгоритм градиентного спуска до тех пор, пока значение функции ошибки не перестанет значимо изменяться. Это будет означать, что мы уже достаточно близко к минимуму и дальнейшие шаги градиентного спуска слишком малы, чтобы быть целесообразными. Конечно, это оценочное суждение, но на практике обычно, нескольких значащих цифр достаточно для практического применения моделей машинного обучения.
Алгоритм градиентного спуска имеет одну особенность, про которую нужно помнить. Он в состоянии находить только локальный минимум функции. Он в принципе, по своей природе, локален. Поэтому, если функция ошибки будет очень сложна и иметь несколько локальных оптимумов, то результат работы градиентного спуска будет зависеть от выбора начальной точки:


На практике эту проблему решают методом семплирования — запускают градиентный спуск из множества случайных точек и выбирают то минимум, который оказался меньше по значению функции ошибки. Но этот подход понадобится нам при рассмотрении более сложных и глубоких моделей машинного обучения. Для простых линейных, полиномиальных и других моделей метод градиентного спуска работает прекрасно. В настоящее время этот алгоритм — это основная рабочая лошадка классических моделей машинного обучения.
Выводы:
- Метод градиентного спуска нужен, чтобы найти минимум функции, если мы не можем ее вычислить аналитически.
- Это численный итеративный алгоритм локальной оптимизации.
- Для запуска градиентного спуска нужно знать частную производную функции ошибки.
- Для начала мы берем произвольные значения параметров, затем обновляем их по данной формуле.
- Доказано, что этот метод сходится к локальному минимуму.
- Если функция ошибки достаточно сложная, то разные начальные точки дадут разный результат.
- Метод градиентного спуска имеет свой параметр — скорость обучения. Обычно его подстаивают автоматически.
- Метод градиентного спуска повторяют много раз до тех пор, пока функция ошибки не перестанет значимо изменяться.
Регрессия с несколькими переменными
Множественная линейная регрессия

Парная регрессия, как мы увидели выше, имеет дело с объектами, которые характеризуются одним числовым признаком ($x$). На практике, конечно, объекты характеризуются несколькими признаками, а значит в модели должна быть не одна входящая переменная, а несколько (или, что то же самое, вектор). Линейная регрессия с несколькими переменными также известна как «множественная линейная регрессия». Введем обозначения для уравнений, где мы можем иметь любое количество входных переменных:
$ x^{(i)} $- вектор-столбец всех значений признаков i-го обучающего примера;
$ x_j^{(i)} $ — значение j-го признака i-го обучающего примера;
$ x_j $ — вектор j-го признака всех обучающих примеров;
m — количество примеров в обучающей выборке;
n — количество признаков;
X — матрица признаков;
b — вектор параметров регрессии.
Задачи множественной регрессии уже очень сложно представить на графике, ведь количество параметров каждого объекта обучающей выборки соответствует измерению, в котором находятся точки данных. Плюс нужно еще одно измерение для целевой переменной. И вместо того, чтобы подбирать оптимальную прямую, мы будем подбирать оптимальную гиперплоскость. Но в целом идея линейной регрессии остается неизменной.
Для удобства примем, что $ x_0^{(i)} = 1 $ для всех $i$. Другими словами, мы ведем некий суррогатный признак, для всех объектов равный единице. Это никак не сказывается на самой функции гипотезы, это лишь условность обозначения, но это сильно упростит математические выкладки, особенно в матричной форме.
Теперь определим множественную форму функции гипотезы следующим образом, используя несколько признаков. Она очень похожа на парную, но имеет больше входных переменных и, как следствие, больше параметров.
Общий вид модели множественной линейной регрессии:
[h_b(x) = b_0 + b_1 x_1 + b_2 x_2 + … + b_n x_n]
Или в матричной форме:
[h_b(x) = X cdot vec{b}]
Используя определение матричного умножения, наша многопараметрическая функция гипотезы может быть кратко представлена в виде: $h(x) = B X$.
Обратите внимание, что в любой модели линейной регрессии количество параметров на единицу больше количества входных переменных. Это верно для любой линейной модели машинного обучения. Вообще, всегда чем больше признаков, тем больше параметров. Это будет важно для нас позже, когда мы будем говорить о сложности моделей.
Теперь, когда мы знаем виды функции гипотезы, то есть нашей модели, мы можем переходить к следующему шагу: функции ошибки. Мы построим ее по аналогии с функцией ошибки для парной модели. Для множественной регрессии функция ошибки от вектора параметров b выглядит следующим образом:
Функция ошибки для множественной линейной регрессии:
[J(b) = frac{1}{2m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)})^2]
Или в матричной форме:
[J(b) = frac{1}{2m} (X b — vec{y})^T (X b — vec{y})]
Обратите внимание, что мы специально не раскрываем выражение (h_b(x^{(i)})). Это нужно, чтобы подчеркнуть, что форма функции ошибки не зависит от функции гипотезы, она выражается через нее.
Теперь нам нужно взять производную этой функции ошибки. Здесь уже нужно знать производную самой функции гипотезы, так как:
[frac{partial}{partial b_i} J =
frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot frac{partial}{partial b_i} h_b(x^{(i)})]
В такой формулировке мы представляем частные производные функции ошибки (градиент) через частную производную функции гипотезы. Это так называемое моделенезависимое представление градиента. Ведь для этой формулы совершенно неважно, какой функцией будет наша гипотеза. Пока она является дифференцируемой, мы можем использовать градиент ее функции ошибки. Именно поэтому метод градиентного спуска работает с любыми аналитическими моделями, и нам не нужно каждый раз заново “переизобретать” математику градиентного спуска, адаптировать ее к каждой конкретной модели машинного обучения. Достаточно изучить этот метод один раз, в общей форме.
Метод градиентного спуска для множественной регрессии определяется следующими уравнениями:
повторять до сходимости:
[b_0 := b_0 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_0^{(i)}]
[b_1 := b_1 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_1^{(i)}]
[b_2 := b_2 — alpha frac{1}{m} sum_{i=1}^{m} (h_b(x^{(i)}) — y^{(i)}) cdot x_2^{(i)}]
[…]
Или в матричной форме:
[b := b — frac{alpha}{m} X^T (X b — vec{y})]
Выводы:
- Множественная регрессия очень похожа на парную, но с большим количеством признаков.
- Для удобства и однообразия, почти всегда обозначают $x_0 = 1$.
- Признаки образуют матрицу, поэтому уравнения множественной регрессии часто приводят в матричной форме, так короче.
- Алгоритм градиентного спуска для множественной регрессии точно такой же, как и для парной.
Нормализация признаков
Мы можем ускорить сходимость метода градиентного спуска, преобразовав входные данные таким образом, чтобы все атрибуты имели значения примерно в том же диапазоне. Это называется нормализация данных — приведение всех признаков к одной шкале. Это ускоряет сходимость градиентного спуска за счет эффекта масштаба. Дело в том, что зачастую значения разных признаков измеряются по шкалам с очень разным порядком величины. Например, $x_1$ измеряется в миллионах, а $x_2$ — в долях единицы.
В таком случае форма функции ошибки будет очень вытянутой. Это не проблема для математической формализации градиентного спуска — при достаточно малых $alpha$ метод все равно рано или поздно сходится. Проблема в практической реализации. Получается, что если выбрать скорость обучения выше определенного предела по самому компактному признаку, спуск разойдется. Значит, скорость обучения надо делать меньше. Но тогда в направлении второго признака спуск будет проходить слишком медленно. И получается, что градиентный спуск потребует гораздо больше итераций для завершения.
Эту проблему можно решить если изменить диапазоны входных данных, чтобы они выражались величинами примерно одного порядка. Это не позволит одному измерению численно доминировать над другим. На практике применяют несколько алгоритмов нормализации, самые распространенные из которых — минимаксная нормализация и стандартизация или z-оценки.
Минимаксная нормализация — это изменение входных данных по следующей формуле:
[x’ = frac{x — x_{min}}{x_{max} — x_{min}}]
После преобразования все значения будут лежать в диапазоне $x in [0; 1]$.
Z-оценки или стандартизация производится по формуле:
[x’ = frac{x — M[x]}{sigma_x}]
В таком случае данный признак приводится к стандартному распределению, то есть такому, у которого среднее 0, а дисперсия — 1.
У каждого из этих двух методов нормализации есть по два параметра. У минимаксной — минимальное и максимальное значение признака. У стандартизации — выборочные среднее и дисперсия. Параметры нормализации, конечно, вычисляются по каждому признаку (столбцу данных) отдельно. Причем, эти параметры надо запомнить, чтобы при использовании модели для предсказании использовать именно их (вычисленные по обучающей выборке). Даже если вы используете тестовую выборку, ее надо нормировать с использованием параметров, вычисленных по обучающей. Да, при этом может получиться, что при применении модели на данных, которых не было в обучающей выборке, могут получиться значения, например, меньше нуля или больше единицы (при использовании минимаксной нормализации). Это не страшно, главное, что будет соблюдена последовательность вычисления нормированных значений.
Целевая переменная не нормируется.
При использовании библиотечных моделей машинного обучения беспокоиться о нормализации входных данных вручную, как правило, не нужно. Большинство готовых реализаций моделей уже включают нормализацию как неотъемлемый этап подготовки данных. Более того, некоторые типы моделей обучения с учителем вовсе не нуждаются в нормализации. Но об этом пойдет речь в следующих главах.
Выводы:
- Нормализация нужна для ускорения метода градиентного спуска.
- Есть два основных метода нормализации — минимаксная и стандартизация.
- Параметры нормализации высчитываются по обучающей выборке.
- Нормализация встроена в большинство библиотечных методов.
- Некоторые методы более чувствительны к нормализации, чем другие.
- Нормализацию лучше сделать, чем не делать.
Полиномиальная регрессия

Функция гипотезы не обязательно должна быть линейной, если это не соответствует данным. На практике вы не всегда будете иметь данные, которые можно хорошо аппроксимировать линейной функцией. Наглядный пример вы видите на иллюстрации. Вполне очевидно, что в среднем увеличение целевой переменной замедляется с ростом входной переменной. Это значит, что данные демонстрируют нелинейную динамику. И это так же значит, что мы никак не сможем их хорошо приблизить линейной моделью.
Надо подчеркнуть, что это не свидетельствует о несовершенстве наших методов оптимизации. Мы действительно можем найти самую лучшую линейную функцию для данных точек, но проблема в том, что мы всегда выбираем лучшую функцию из некоторого класса функций, в данном случае — линейных. То есть проблема не в алгоритмах оптимизации, а в ограничении самого вида модели.
вполне логично предположить, что для описания таких нелинейных наборов данных следует использовать нелинейные же функции моделей. Но очень бы не хотелось, для каждого нового класса функций изобретать собственный метод оптимизации, поэтому мы постараемся максимально “переиспользовать” те подходы, которые описали выше. И механизм множественной регрессии в этом сильно поможет.
Мы можем изменить поведение или кривую нашей функции гипотезы, сделав ее квадратичной, кубической или любой другой формой.
Например, если наша функция гипотезы
$ hat{y} = h_b (x) = b_0 + b_1 x $,
то мы можем добавить еще один признак, основанный на $ x_1 $, получив квадратичную функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2]
или кубическую функцию
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 x^2 + b_3 x^3]
В кубической функции мы по сути ввели два новых признака:
$ x_2 = x^2, x_3 = x^3 $.
Точно таким же образом, мы можем создать, например, такую функцию:
[hat{y} = h_b (x) = b_0 + b_1 x + b_2 sqrt{x}]
В любом случае, мы из парной линейной функции сделали какую-то другую функцию. И к этой нелинейной функции можно относиться по разному. С одной стороны, это другой класс функций, который обладает нелинейным поведением, а следовательно, может описывать более сложные зависимости в данных. С другой стороны, это линейна функция от нескольких переменных. Только сами эти переменные оказываются в функциональной зависимости друг от друга. Но никто не говорил, что признаки должны быть независимы.
И вот такое представление нелинейной функции как множественной линейной позволяет нам без изменений воспользоваться алгоритмом градиентного спуска для множественной линейной регрессии. Только вместо $ x_2, x_3, … , x_n $ нам нужно будет подставить соответствующие функции от $ x_1 $.

Источник: Wikimedia.
Очевидно, что нелинейных функций можно придумать бесконечное количество. Поэтому встает вопрос, как выбрать нужный класс функций для решения конкретной задачи. В случае парной регрессии мы можем взглянув на график точек обучающей выборки сделать предположение о том, какой вид нелинейной зависимости связывает входную и целевую переменные. Но если у нас множество признаков, просто так проанализировать график нам не удастся. Поэтому по умолчанию используют полиномиальную регрессию, когда в модель добавляют входные переменные второго, третьего, четвертого и так далее порядков.
Порядок полиномиальной регрессии подбирается в качестве компромисса между качеством получаемой регрессии, и вычислительной сложностью. Ведь чем выше порядок полинома, тем более сложные зависимости он может аппроксимировать. И вообще, чем выше степень полинома, тем меньше будет ошибка при прочих равных. Если степень полинома на единицу меньше количества точек — ошибка будет нулевая. Но одновременно с этим, чем выше степень полинома, тем больше в модели параметров, тем она сложнее и занимает больше времени на обучение. Есть еще вопросы переобучения, но про это мы поговорим позднее.
А что делать, если изначально в модели было несколько признаков? Тогда обычно для определенной степени полинома берутся все возможные комбинации признаком соответствующей степени и ниже. Например:
Для регрессии с двумя признаками.
Линейная модель (полином степени 1):
[h_b (x) = b_0 + b_1 x_1 + b_2 x_2]
Квадратичная модель (полином степени 2):
[h_b (x) = b_0 + b_1 x + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2]
Кубическая модель (полином степени 3):
[hat{y} = h_b (x) = b_0 + b_1 x_1 + b_2 x_2 + b_3 x_1^2 + b_4 x_2^2 + b_5 x_1 x_2 + b_6 x_1^3 + b_7 x_2^3 + b_7 x_1^2 x_2 + b_8 x_1 x_2^2]
При этом количество признаков и, соответственно, количество параметров растет экспоненциально с ростом степени полинома. Поэтому полиномиальные модели обычно очень затратные в обучении при больших степенях. Но полиномы высоких степеней более универсальны и могут аппроксимировать более сложные данные лучше и точнее.
Выводы:
- Данные в датасете не всегда располагаются так, что их хорошо может описывать линейная функция.
- Для описания нелинейных зависимостей нужна более сложная, нелинейная модель.
- Чтобы не изобретать алгоритм обучения заново, можно просто ввести в модель суррогатные признаки.
- Суррогатный признак — это новый признак, который считается из существующих атрибутов.
- Чаще всего используют полиномиальную регрессию — это когда в модель вводят полиномиальные признаки — степени существующих атрибутов.
- Обычно берут все комбинации факторов до какой-то определенной степени полинома.
- Полиномиальная регрессия может аппроксимировать любую функцию, нужно только подобрать степень полинома.
- Чем больше степень полиномиальной регрессии, тем она сложнее и универсальнее, но вычислительно сложнее (экспоненциально).
Практическое построение регрессии
В данном разделе мы посмотрим, как можно реализовать методы линейной регрессии на практике. Сначала мы попробуем создать алгоритм регрессии с нуля, а затем воспользуемся библиотечной функцией. Это поможет нам более полно понять, как работают модели машинного обучения в целом и в библиотеке sckikit-learn (самом популярном инструменте для создания и обучения моделей на языке программирования Python) в частности.
Для понимания данного раздела предполагаем, что читатель знаком с основами языка программирования Python. Нам понадобится знание его базового синтаксиса, немного — объектно-ориентированного программирования, немного — использования стандартных библиотек и модулей. Никаких продвинутых возможностей языка (типа метапрограммирования или декораторов) мы использовать не будем.
Как должны быть представлены данные для машинного обучения?
Применение любых моделей машинного обучения начинается с подготовки данных в необходимом формате. Для этого очень удобными для нас будут библиотеки numpy и pandas. Они практически всегда используются совместно с библиотекой sckikit-learn и другими инструментами машинного обучения. В первую очередь мы будем использовать numpy для создания массивов и операций с векторами и матрицами. Pandas нам понадобится для работы с табличными структурами — датасетами.
Если вы хотите самостоятельно задать в явном виде данные обучающей выборки, то нет ничего лучше использования обычных массивов ndarray. Обычно в одном массиве хранятся значения атрибутов — x, а в другом — значения целевой переменной — y.
1
2
3
4
5
6
7
8
9
10
11
import numpy as np
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
Если мы имеем дело с задачей множественной регрессии, то в массиве атрибутов будет уже двумерный массив, состоящий из нескольких векторов атрибутов, вот так:
1
2
3
4
5
x = np.array([
[0, 1, 2, 3, 4],
[5, 4, 9, 6, 3],
[7.8, -0.1, 0.0, -2.14, 10.7],
])
Важно следить за тем, чтобы в массиве атрибутов в каждом вложенном массиве количество элементов было одинаковым и в свою очередь совпадало с количеством элементов в массиве целевой переменной. Это называется соблюдение размерности задачи. Если размерность не соблюдается, то модели машинного обучения будут работать неправильно. А библиотечные функции чаще всего будут выдавать ошибку, связанную с формой массива (shape).
Но чаще всего вы не будете задавать исходные данные явно. Практически всегда их приходится читать из каких-либо входных файлов. Удобнее всего это сделать при помощи библиотеки pandas вот так:
1
2
3
4
import pandas as pd
x = pd.read_csv('x.csv', index_col=0)
y = pd.read_csv('y.csv', index_col=0)
Или, если данные лежат в одном файле в общей таблице (что происходит чаще всего), тогда его читают в один датафрейм, а затем выделяют целевую переменную, и факторные переменные:
1
2
3
4
5
6
7
8
import pandas as pd
data = pd.read_csv('data.csv', index_col=0)
y = data.Y
y = data["Y"]
x = data.drop(["Y"])
Обратите внимание, что матрицу атрибутов проще всего сформировать, удалив из полной таблицы целевую переменную. Но, если вы хотите выбрать только конкретные столбцы, тогда можно использовать более явный вид, через перечисление выбранных колонок.
Если вы используете pandas или numpy для формирования массивов данных, то получившиеся переменные будут разных типов — DataFrame или ndarray, соответственно. Но на дальнейшую работу это не повлияет, так как интерфейс работы с этими структурами данных очень похож. Например, неважно, какие именно массивы мы используем, их можно изобразить на графике вот так:
1
2
3
4
5
import maiplotlib.pyplot as plt
plt.figure()
plt.scatter(x, y)
plt.show()
Конечно, такая визуализация будет работать только в случае задачи парной регрессии. Если x многомерно, то простой график использовать не получится.
Давайте соберем весь наш код вместе:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
import numpy as np
import pandas as pd
import maiplotlib.pyplot as plt
# x = pd.read_csv('x.csv', index_col=0)
x = np.array([1.46, 1.13, -2.30, 1.74, 0.04,
-0.61, 0.32, -0.76, 0.58, -1.10,
0.87, 1.62, -0.53, -0.25, -1.07,
-0.38, -0.17, -0.32, -2.06, -0.88, ])
# y = pd.read_csv('y.csv', index_col=0)
y = np.array([101.16, 78.44, -159.24, 120.72, 2.92,
-42.33, 22.07, -52.67, 40.32, -76.10,
59.88, 112.38, -36.54, -17.25, -74.24,
-26.57, -11.93, -22.31, -142.54, -60.74,])
plt.figure()
plt.scatter(x, y)
plt.show()
Это код генерирует вот такой вот график:

Как работает метод машинного обучения “на пальцах”?
Для того, чтобы более полно понимать, как работает метод градиентного спуска для линейной регрессии, давайте реализуем его самостоятельно, не обращаясь к библиотечным методам. На этом примере мы проследим все шаги обучения модели.
Мы будем использовать объектно-ориентированный подход, так как именно он используется в современных библиотеках. Начнем строить класс, который будет реализовывать метод парной линейной регрессии:
1
2
3
4
5
class hypothesis(object):
"""Модель парной линейной регрессии"""
def __init__(self):
self.b0 = 0
self.b1 = 0
Здесь мы определили конструктор класса, который запоминает в полях экземпляра параметры регрессии. Начальные значения этих параметров не очень важны, так как градиентный спуск сойдется из любой точки. В данном случае мы выбрали нулевые, но можно задать любые другие начальные значения.
Реализуем метод, который принимает значение входной переменной и возвращает теоретическое значение выходной — это прямое действие нашей регрессии — метод предсказания результата по факторам (в случае парной регрессии — по одному фактору):
1
2
def predict(self, x):
return self.b0 + self.b1 * x
Название выбрано не случайно, именно так этот метод называется и работает в большинстве библиотечных классов.
Теперь зададим функцию ошибки:
1
2
def error(self, X, Y):
return sum((self.predict(X) - Y)**2) / (2 * len(X))
В данном случае мы используем простую функцию ошибки — среднеквадратическое отклонение (mean squared error, MSE). Можно использовать и другие функции ошибки. Именно вид функции ошибки будет определять то, какой вид регрессии мы реализуем. Существует много разных вариаций простого алгоритма регрессии. О большинстве распространенных методах регрессии можно почитать в официальной документации sklearn.
Теперь реализуем метод градиентного спуска. Он должен принимать массив X и массив Y и обновлять параметры регрессии в соответствии в формулами градиентного спуска:
1
2
3
4
5
6
def BGD(self, X, Y):
alpha = 0.5
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
О выборе конкретного значения alpha мы говорить пока не будем,на практике его довольно просто подбирают, мы же возьмем нейтральное значение.
Давайте создадим объект регрессии и проверим начальное значение ошибки. В примерах приведены значения на модельном наборе данных, но этот метод можно использовать на любых данных, которые подходят по формату — x и y должны быть одномерными массивами чисел.
1
2
3
4
5
6
7
8
hyp = hypothesis()
print(hyp.predict(0))
print(hyp.predict(100))
J = hyp.error(x, y)
print("initial error:", J)
0
0
initial error: 36271.58344889084
Как мы видим, для начала оба параметра регрессии равны нулю. Конечно, такая модель не дает надежных предсказаний, но в этом и состоит суть метода градиентного спуска: начиная с любого решения мы постепенно его улучшаем и приходим к оптимальному решению.
Теперь все готово к запуску градиентного спуска.
1
2
3
4
5
6
7
8
9
10
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 6734.135540194945
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()
Как мы видим, численное значение ошибки значительно уменьшилось. Да и линия на графике существенно приблизилась к точкам. Конечно, наша модель еще далека от совершенства. Мы прошли всего лишь одну итерацию градиентного спуска. Модифицируем метод так, чтобы он запускался в цикле пока ошибка не перестанет меняться существенно:
1
2
3
4
5
6
7
8
9
10
11
12
13
def BGD(self, X, Y, alpha=0.5, accuracy=0.01, max_steps=5000):
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y)
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
Заодно мы проверяем, насколько изменилось значение функции ошибки. Если оно изменилось на величину, меньшую, чем заранее заданная точность, мы завершаем спуск. Таким образом, мы реализовали два стоп-механизма — по количеству итераций и по стабилизации ошибки. Вы можете выбрать любой или использовать оба в связке.
Запустим наш градиентный спуск:
1
2
3
4
5
hyp = hypothesis()
hyp.BGD(x, y)
J = hyp.error(x, y)
print("error after gradient descent:", J)
error after gradient descent: 298.76881676471504
Как мы видим, теперь ошибка снизилась гораздо больше. Однако, она все еще не достигла нуля. Заметим, что нулевая ошибка не всегда возможна в принципе из-за того, что точки данных не всегда будут располагаться на одной линии. Нужно стремиться не к нулевой, а к минимально возможной ошибке.
Посмотрим, как теперь наша регрессия выглядит на графике:
1
2
3
4
5
6
X0 = np.linspace(60, 180, 100)
Y0 = hyp.predict(X0)
plt.figure()
plt.scatter(x, y)
plt.plot(X0, Y0, 'r')
plt.show()

Уже значительно лучше. Линия регрессии довольно похожа на оптимальную. Так ли это на самом деле, глядя на график, сказать сложно, для этого нужно проанализировать, как ошибка регрессии менялась со временем:
Как оценить качество регрессионной модели?
В простых случаях качество модели можно оценить визуально на графике. Но если у вас многомерная задача, это уже не представляется возможным. Кроме того, если ошибка и сама модель меняется незначительно, то очень сложно определить, стало хуже или лучше. Поэтому для диагностики моделей машинного обучения используют кривые.
Самая простая кривая обучения — зависимость ошибки от времени (итерации градиентного спуска). Для того, чтобы построить эту кривую, нам нужно немного модифицировать наш метод обучения так, чтобы он возвращал нужную нам информацию:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
def BGD(self, X, Y, alpha=0.1, accuracy=0.01, max_steps=1000):
steps, errors = [], []
step = 0
old_err = hyp.error(X, Y)
new_err = hyp.error(X, Y) - 1
dJ = 1
while (dJ > accuracy) and (step < max_steps):
dJ0 = sum(self.predict(X) - Y) /len(X)
dJ1 = sum((self.predict(X) - Y) * X) /len(X)
self.b0 -= alpha * dJ0
self.b1 -= alpha * dJ1
old_err = new_err
new_err = hyp.error(X, Y)
dJ = abs(old_err - new_err)
step += 1
steps.append(step)
errors.append(new_err)
return steps, errors
Мы просто запоминаем в массивах на номер шаа и ошибку на каждом шаге. Получив эти данные можно легко построить их на графике:
1
2
3
4
5
6
hyp = hypothesis()
steps, errors = hyp.BGD(x, y)
plt.figure()
plt.plot(steps, errors, 'g')
plt.show()

На этом графике наглядно видно, что в начале обучения ошибка падала быстро, но в ходе градиентного спуска она вышла на плато. Учитывая, что мы используем гладкую функцию ошибки второго порядка, это свидетельствует о том, что мы достигли локального оптимума и дальнейшее повторение алгоритма не принесет улучшения модели.
Если бы мы наблюдали на графике обучения ситуацию, когда по достижении конца обучения ошибка все еще заметно снижалась, это значит, что мы рано прекратили обучение, и нужно продолжить его еще на какое-то количество итераций.
При анализе графиков с библиотечными моделями не получится таких гладких графиков, они больше напоминают случайные колебания. Это из-за того, что в готовых реализациях используется очень оптимизированный вариант метода градиентного спуска. А он может работать с произвольными флуктуациями. В любом случае, нас интересует общий вид этой кривой.
Как подбирать скорость обучения?
В нашей реализации метода градиентного спуска есть один параметр — скорость обучения — который нам приходится так же подбирать руками. Какой смысл автоматизировать подбор параметров линейной регрессии, если все равно приходится вручную подбирать какой-то другой параметр?
На самом деле подобрать скорость обучения гораздо легче. Нужно использовать тот факт, что при превышении определенного порогового значения ошибка начинает возрастать. Кроме того, мы знаем, что скорость обучения должна быть положительна, но меньше единицы. Вся проблема в этом пороговом значении, которое сильно зависит от размерности задачи. При одних данных хорошо работает $ alpha = 0.5 $, а при каких-то приходится уменьшать ее на несколько порядков, например, $ alpha = 0.00000001 $.
Мы еще не говорили о нормализации данных, которая тоже практически всегда применяется при обучении. Она “благотворно” влияет на возможный диапазон значений скорости обучения. При использовании нормализации меньше вероятность, что скорость обучения нужно будет уменьшать очень сильно.
Подбирать скорость обучения можно по следующему алгоритму. Сначала мы выбираем $ alpha $ близкое к 1, скажем, $ alpha = 0.7 $. Производим одну итерацию градиентного спуска и оцениваем, как изменилась ошибка. Если она уменьшилась, то ничего не надо менять, продолжаем спуск как обычно. Если же ошибка увеличилась, то скорость обучения нужно уменьшить. Например, раа в два. После чего мы повторяем первый шаг градиентного спуска. Таким образом мы не начинаем спуск, пока скорость обучения не снизится настолько, чтобы он начал сходиться.
Как применять регрессию с использованием scikit-learn?
Для серьезной работы, все-таки рекомендуется использовать готовые библиотечные решения. Они работаю гораздо быстрее, надежнее и гораздо проще, чем написанные самостоятельно. Мы будем использовать библиотеку scikit-learn для языка программирования Python как наш основной инструмент реализации простых моделей. Сегодня это одна их самых популярных библиотек для машинного обучения. Мы не будем повторять официальную документацию этой библиотеки, которая на редкость подробная и понятная. Наша задача — на примере этих инструментов понять, как работают и как применяются модели машинного обучения.
В библиотеке scikit-learn существует огромное количество моделей машинного обучения и других функций, которые могут понадобиться для их работы. Поэтому внутри самой библиотеки есть много разных пакетов. Все простые модели, например, модель линейной регрессии, собраны в пакете linear_models. Подключить его можно так:
1
from sklearn import linear_model
Надо помнить, что все модели машинного обучения из это библиотеки имеют одинаковый интерфейс. Это очень удобно и универсально. Но это значит, в частности, что все модели предполагают, что массив входных переменных — двумерный, а массивы целевых переменных — одномерный. Отдельного класса для парной регрессии не существует. Поэтому надо убедиться, что наш массив имеет нужную форму. Проще всего для преобразования формы массива использовать метод reshape, например, вот так:
Если вы используете DataFrame, то они обычно всегда настроены правильно, поэтому этого шага может не потребоваться. Важно запомнить, что все методы библиотечных моделей машинного обучения предполагают, что в x будет двумерный массив или DataFrame, а в y, соответственно, одномерный массив или Series.
Эта строка преобразует любой массив в вектор-столбец. Это если у вас один признак, то есть парная регрессия. Если признаков несколько, то вместо 1 следует указать число признаков. -1 на первой позиции означает, что по нулевому измерению будет столько элементов, сколько останется в массиве.
Само использование модели машинного обучения в этой библиотеке очень просто и сводится к трем действиям: создание экземпляра модели, обучение модели методом fit(), получение предсказаний методом predict(). Это общее поведение для любых моделей библиотеки. Для модели парной линейной регрессии нам понадобится класс LinearRegression.
1
2
3
4
5
6
reg = linear_model.LinearRegression()
reg.fit(x, y)
y_pred = reg.predict(x)
print(reg.score(x, y))
print("Коэффициенты: n", reg.coef_)
В этом классе кроме уже упомянутых методов fit() и predict(), которые есть в любой модели, есть большое количество методов и полей для получения дополнительной информации о моделях. Так, практически в каждой модели есть встроенный метод score(), который оценивает качество полученной модели. А поле coef_ содержит коэффициенты модели.
Обратите внимание, что в большинстве моделей коэффициентами считаются именно параметры при входящих переменных, то есть $ b_1, b_2, …, b_n $. Коэффициент $b_0$ считается особым и хранится отдельно в поле intercept_
Так как мы работаем с парной линейной регрессией, результат можно нарисовать на графике:
1
2
3
4
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Как мы видим, результат ничем не отличается от модели, которую мы обучили сами, вручную:

Соберем код вместе и получим пример довольно реалистичного фрагмента работы с моделью машинного обучение. Примерно такой код можно встретить и в промышленных проектах по интеллектуальному анализу данных:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
from sklearn.linear_model import LinearRegression
x = x.reshape((-1, 1))
reg = LinearRegression()
reg.fit(x, y)
print(reg.score(x, y))
from sklearn.metrics import mean_squared_error, r2_score
y_pred = reg.predict(x)
print("Коэффициенты: n", reg.coef_)
print("Среднеквадратичная ошибка: %.2f" % mean_squared_error(y, y_pred))
print("Коэффициент детерминации: %.2f" % r2_score(y, y_pred))
plt.figure(figsize=(12, 9))
plt.scatter(x, y, color="black")
plt.plot(x, y_pred, color="blue", linewidth=3)
plt.show()
Линейная регрессия
Сегодня пойдет речь о регрессии, как обучать и какие проблемы могут вам попасться при использовании таких моделей.
Для начала давайте введем удобные обозначения.
$mathbb{X} — text{пространство объектов}$
$mathbb{Y} — text{пространство ответов}$
$ x = (x^1, … x^n) — text{признаковое описание объекта}$
$ X = (x_i,y_i)^l_{i=1} — text{обучающая выборка} $
$ a(x) — text{алгоритм, модель} $
$ Q(a,X) — text{функция ошибки алгоритма a на выборке X} $
$ text{Обучение} — a(x) = text{argmin}_{a in mathbb{A}} Q(a,X)$
Но этого мало, давайте разберем, что такое функционал ошибки, семейство алгоритмов, метод обучения.
- Функционал ошибки Q: способ измерения того, хорошо или плохо работает алгоритм на конкретной выборке
- Семейство алгоритмов $mathbb{A}$: как выглядит множество алгоритмов, из которых выбирается лучший
- Метод обучения: как именно выбирается лучший алгоритм из семейства алгоритмов.
Пример задачи регрессии: предсказание количества заказов магазина
Пусть известен один признак — расстояние кафе от метро, а предсказать необходимо количество заказов. Поскольку количество заказов — вещественное число $mathbb{R}$, здесь идет речь о задаче регрессии.

По графику можно сделать вывод о существование зависимости между расстоянием от метро и количеством заказов. Можно предположить, что зависимость линейна, ее можно представить в видео прямой на графике. По этой прямой и можно будет предсказывать количество заказов, если известно расстояние от метро.
В целом такая модель угадывает тенденцию, то есть описывает зависимость между ответом и признаком.
При этом, разумеется ,она делает это не идеально, с некоторой ошибкой. Истинный ответ на каждом объекте несколько отклоняется от прогноза.
Один признак — это несерьезно. Гораздо сложнее и интереснее работать с многомерными выборками, которые описываются большим количеством признаков. В этом случае отобразить выборку и понять, подходит ли модель или нет, нельзя. Можно лишь оценить ее качество и по нему уже понять, подходит ли эта модель.
Описание линейной модели
Давайте обсудим, как выглядит семейство алгоритмов в случае с линейными моделями. Линейный алгоритм в задачах регрессии выглядит следующим образом
$$ a(x)=w_0 + sumlimits_{j=1}^d w_j x^j $$
где $w_0$ — свободный коэффициент, $x^j$ — признаки, а $w_j$ — их веса.
Если у нашего набора данных есть только один признак, то алгоритм выглядит так
$$ a(x)=w_0 + w x $$
Ничего не напоминает? Да, действительно это обычная линейная функция, известная с 7 класса.
$$ y = kx+b $$
В качестве меры ошибки мы не может быть выбрано отклонение от прогноза $Q(a,y)=a(x)-y$, так как в этом случае минимум функционала не будет достигаться при правильном ответе $a(x)=y$. Самый простой способ — считать модуль отклонения.
$$ |a(x)-y| $$
Но функция модуля не является гладкой функцией, и для оптимизации такого функционала неудобно использовать градиентные методы. Поэтому в качестве меры ошибки часто используют квадрат отклонения:
$$ (a(x)-y)^2 $$
Функционал ошибки, именуемый среднеквадратичной ошибкой алгоритма, задается следующим образом:
$$ Q(a,x) = frac{1}{l} sumlimits_{i=1}^l (a(x_i)- y_i)^2 $$
В случае линейной модели его можно переписать в виде функции (поскольку теперь Q зависит от вектора, а не от функции) ошибок:
$$ Q(omega,x) = frac{1}{l} sumlimits_{i=1}^l ( langle w_i,x_irangle- y_i) ^2 $$
Обучение модели линейной регрессии
Разберем том, как обучать модель линейной регрессии, то есть как настраивать ее параметры.
$$ Q(w,x) = frac{1}{l} sumlimits_{i=1}^l ( langle w_i,x_irangle- y_i) ^2 to min_{w}$$
То есть нам необходимо подобрать $w$, что бы линия могла описать наши данные. Или же задача состоит в нахождение таких $w$, что бы была минимальна ошибка $ Q(w,x)$
Матричная форма записи
Прежде, чем рассмотрим задачу о оптимизации этой функции, имеет смысл используемые соотношения в матричной форме. Матрица «объекты-признаки» $X$ составлена из признаков описаний все объектов выборки
$$ X = begin{pmatrix} x_{11} & … & x_{1d} … & … & … x_{l1} & … & x_{ld} end{pmatrix} $$
Таким образом, в $ij$ элементе матрицы $X$ записано значение $j$-го признака на i объекте обучающей выборки. Или короче говоря, каждая строчка — это объект, а каждый столбец — это признак.Так же понадобится вектор ответов y, который составлен из истинных ответов для всех объектов.
$$ y = begin{pmatrix} y_{1} … y_{l} end{pmatrix} $$
В этом случае среднеквадратичная шибка может быть переписана в матричном виде:
$$ Q(w,X) = frac{1}{l} || Xw-y ||^2 to min_{w}$$
Оптимизационный метод решения
Самый лучший метод — это численный метод оптимизации.
Не сложно показать, что среднеквадратичная ошибка — это выпуклая и гладкая функция. Выпуклость гарантирует существование лишь одного минимумам, а гладкость — существование вектора градиента в каждой точке. Это позволяет использовать метод градиентного спуска.
При использовании метода градиентного спуска необходимо указать начальное приближение. Есть много
подходов к тому, как это сделать, в том числе инициализировать случайными числами (не очень большими). Самый простой способ это сделать — инициализировать значения всех весов равными нулю:
$$ w^0=0 $$
На каждой следующей итерации, $t = 1, 2, 3, …,$ из приближения, полученного в предыдущей итерации $w^{t−1}$, вычитается вектор градиента в соответствующей точке $w^{t−1}$, умноженный на некоторый коэффициент $eta_t$, называемый шагом:
$$ w^t = w^{t-1} — eta_t Delta Q(w^{t-1},X) $$
Остановить итерации следует , когда наступает сходимость. Сходимость можно определять по-разному .В данном случае разумно определить сходимость следующим образом: итерации следует завершить, если разница
двух последовательных приближений не слишком велика:
$$ ||w^t — w^{t-1} ||<epsilon $$
Случай парной регрессии
В случае парной регрессии признак всего один, а линейная модель выглядит следующим образом:
$$ a(x)=w_0 + w x $$
где $w_1$ и $w_0$ — два параметра.
Среднеквадратичная ошибка принимает вид:
$$ Q(w_0,w_1,X) = frac{1}{l} sumlimits_{i=1}^l (w_1x_i+w_0 -y_i) ^2$$
Для нахождения оптимальных параметров будет применяться метод градиентного спуска, про который уже было сказано ранее. Чтобы это сделать, необходимо сначала вычислить частные производные функции ошибки:
$$frac{partial Q}{partial w_1} = frac{2}{l} sumlimits_{i=1}^l (w_1x_i+w_0-y_i)x_i$$
$$frac{partial Q}{partial w_0} = frac{2}{l} sumlimits_{i=1}^l (w_1x_i+w_0-y_i)$$
Следующие два графика демонстрируют применение метода градиентного спуска в случае парной регрессии. Справа изображены точки выборки, а слева — пространство параметров. Точка в этом пространстве обозначает конкретную модель (кафе)

График зависимости функции ошибки от числа произведенных операции выглядит следующим образом:

Выбор размера шага в методе градиентного спуска
Очень важно при использовании метода градиентного спуска правильно подбирать шаг. Каких-либо концерт- иных правил подбора шага не существует, выбор шага — это искусство, но существует несколько полезных закономерностей.

Если длина шага слишком мала, то метод будет неспешна, но верно шагать в сторону минимума. Если же
взять размер шага очень большим, появляется риск, что метод будет перепрыгивать через минимум. Более
того, есть риск того, что градиентный спуск не сойдется.
Имеет смысл использовать переменный размер шага: сначала, когда точка минимума находится еще да-
легко, двигаться быстро, а позже, спустя некоторое количество итерации — делать более аккуратные шаги.
Один из способов задать размер шага следующий:
$$ eta_t = frac{k}{t} $$
где $k$-константа, которую необходимо подобрать, а $t$ — номер шага.
import matplotlib.pyplot as plt # библиотека для отрисовки графиков import numpy as np # импортируем numpy для создания своего датасета from sklearn import linear_model, model_selection # импортируем линейную модель для обучения и библиотеку для разделения нашей выборки X = np.random.randint(100,size=(500, 1)) # создаем вектор признаков, вектора так как у нас один признак y = np.random.normal(np.random.randint(300,360,size=(500, 1))-X) # создаем вектор ответом plt.scatter(X, y) # рисуем график точек plt.xlabel('Расстояние до кафе в метрах') # добавляем описание для оси x plt.ylabel('Количество заказов')# добавляем описание для оси y plt.show()

# Делим созданную нами выборку на тестовую и обучающую X_train, X_test, y_train, y_test = model_selection.train_test_split(X, y)
Давайте посмотрим какие параметры принимает LinearRegression.
fit_intercept — подбирать ли значения для свободного член $w_0$. True или False. Если ваши данные центрированны, то можете указать False. По умолчанию — True
normalize— нормализация данных перед обучением. Если fit_intercept=False то параметр будет проигнорирован. Если True — то данные перед обучением будут нормализованы при помощи L^2-Norm нормализации. По умолчанию — False
copy_X — True — копировать матрицу признаков. False — не копировать. **По умолчанию — **True
n_jobs — количество ядер используемых для сборки. Скорость будет существенно выше n_targets>1. По умолчанию — None
Параметры которые можно у модели:
coef_ — коэффициенты $w$, количество возвращаемых коэффициентов зависит от количества признаков. смотри пункт Описание линейной модели
intercept_ — свободный член $w_0$
Что бы предсказать значения необходимо вызвать функцию:
predict и передать массив из признаков.
Example: regr.predict([[40]])
regr = linear_model.LinearRegression() # создаем линейную регрессию #Обучаем модель regr.fit(X_train, y_train)
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
После выполнения кода, вам вернется ответ с установленными параметрами
LinearRegression(copy_X=True, fit_intercept=True, n_jobs=1, normalize=False)
# Посмотрим какие коэффициенты установила модель print('Коэфициент: n', regr.coef_) # Средний квадрат ошибки print("Средний квадрат ошибки: %.2f" % np.mean((regr.predict(X_test) - y_test) ** 2)) # Оценка дисперсии: 1 - идеальное предсказание. Качество предсказания. print('Оценка дисперсии:: %.2f' % regr.score(X_test, y_test))
Коэфициент:
[[-1.03950324]]
Средний квадрат ошибки: 325.63
Оценка дисперсии:: 0.70
# Посмотрим на получившуюся функцию print ("y = {:.2f}*x + {:.2f}".format(regr.coef_[0][0], regr.intercept_[0]))
# Посмотрим, как предскажет наша модель тестовые данные. plt.scatter(X_test, y_test, color='black')# рисуем график точек plt.plot(X_test, regr.predict(X_test), color='blue') # рисуем график линейной регрессии plt.show() # Покажем график

Давайте предскажем количество заказов, для нашего потенциального магазина. Скажем, что мы планируем построить магазин в 40 метрах от метро
290 заказов мы получим если построим магазин в 40 метрах от метро, но при этом качество предсказания всего лишь 71%, думаю не стоит доверять.
А что если, мы увеличим количество признаков?
Для этого воспользуемся встроенным датасетом make_regression из sklearn.
n_features — отвечает за количество признаков один нормальный другой избыточный
n_informative — отвечает за количество информативных признаков
n_targets — отвечает за размер ответов
noise — шум накладываемый на признаки
соef — возвращать ли коэффициенты
random_state — определяет генерацию случайных чисел для создания набора данных.
# Импортируем библиотеки для валидация, создания датасетов, и метрик качества from sklearn import cross_validation, datasets, metrics # Создаем датасет с избыточной информацией X, y, coef = datasets.make_regression(n_features = 2, n_informative = 1, n_targets = 1, noise = 5., coef = True, random_state = 2)
# Поскольку у нас есть два признака,для отрисовки надо их разделить на две части data_1, data_2 = [],[] for x in X: data_1.append(x[0]) data_2.append(x[1]) plt.scatter(data_1, y, color = 'r') plt.scatter(data_2, y, color = 'b')
<matplotlib.collections.PathCollection at 0x1134a6e10>

Можно заметить, что признак отмеченный красным цветом имеет явную линейную зависимость, а признак отмеченный синим, никакой информативность нам не дает.
# Разделение выборку для обучения и тестирования # test_size - отвечает за размер тестовой выборки X_train, X_test, y_train, y_test = cross_validation.train_test_split(X, y, test_size = 0.3)
# Создаем линейную регрессию linear_regressor = linear_model.LinearRegression() # Тренируем ее linear_regressor.fit(X_train, y_train) # Делаем предсказания predictions = linear_regressor.predict(X_test)
# Выводим массив для просмотра наших ответов (меток) print (y_test)
[ 28.15553021 38.36241814 -24.77820218 -61.47026695 13.02656201
23.87701013 12.74038341 -70.11132234 27.83791274 -14.97110322
-80.80239408 24.82763821 58.26281761 -45.27502383 10.33267887
-48.28700118 -21.48288019 -32.71074998 -21.47606913 -15.01435792
78.24817537 19.66406455 5.86887774 -42.44469577 -12.0017312
14.76930132 -16.65927231 -13.99339669 4.45578287 22.13032804]
# Смотрим и сравниваем предсказания print (predictions)
[ 22.32670386 40.26305989 -27.69502682 -56.5548183 18.47241345
31.86585663 6.08896992 -66.15105402 22.99937016 -12.65174022
-78.50894588 30.90311195 56.21877707 -47.81097232 8.98196478
-56.41188567 -24.46096716 -43.55445698 -17.99670898 -9.09225523
65.49657633 26.50900527 4.74114126 -39.28939851 -6.80665816
8.30372903 -15.27594937 -15.15598987 8.34469779 19.45159738]
# Средняя ошибка предсказания metrics.mean_absolute_error(y_test, predictions)
Для валидации можем выполнить перекрестную проверкую cross_val_score.
http://scikit-learn.org/stable/modules/generated/sklearn.model_selection.cross_val_score.html
Передадим, нашу линейную модель, признаки, ответы, количество разделений кросс-валидация
linear_scoring = cross_validation.cross_val_score(linear_regressor, X, y, cv=10) print ('Средняя ошибка: {}, Отклонение: {}'.format(linear_scoring.mean(), linear_scoring.std()))
Средняя ошибка: 0.9792410447209384, Отклонение: 0.020331171766276405
# Создаем свое тестирование на основе абсолютной средней ошибкой scorer = metrics.make_scorer(metrics.mean_absolute_error)
linear_scoring = cross_validation.cross_val_score(linear_regressor, X, y, scoring=scorer, cv=10) print ('Средняя ошибка: {}, Отклонение: {}'.format(linear_scoring.mean(), linear_scoring.std()))
Средняя ошибка: 4.0700714987797, Отклонение: 1.0737104492890193
# Коэффициенты который дал обучающий датасет coef
array([38.07925837, 0. ])
# Коэффициент полученный при обучении linear_regressor.coef_
array([38.18191713, 0.81751244])
# обученная модель так же дает свободный член linear_regressor.intercept_
print ("y = {:.2f}*x1 + {:.2f}*x2".format(coef[0], coef[1]))
print ("y = {:.2f}*x1 + {:.2f}*x2 + {:.2f}".format(linear_regressor.coef_[0], linear_regressor.coef_[1], linear_regressor.intercept_))
y = 37.76*x1 + 0.17*x2 + -0.86
# Посмотрим качество обучения print('Оценка дисперсии:: %.2f' % linear_regressor.score(X_test, y_test))
Домашнее задание
Вы уже знаете как создать модель линейной регрессии, можете создать датасет.
Давайте посмотрим как влияет количество признаков на качество обучения линейной модели.
Скачайте этот файл, можете редактировать этот ноутбук, да бы уменьшить/увеличить количество признаков.
Будут вопросы пишите нам в Slack канал #machine_learning
Перевод
Ссылка на автора
Основой многих алгоритмов машинного обучения является оптимизация.
Алгоритмы оптимизации используются алгоритмами машинного обучения, чтобы найти хороший набор параметров модели по заданному набору данных.
Наиболее распространенным алгоритмом оптимизации, используемым в машинном обучении, является стохастический градиентный спуск.
В этом руководстве вы узнаете, как реализовать стохастический градиентный спуск для оптимизации алгоритма линейной регрессии с нуля с помощью Python.
После завершения этого урока вы узнаете:
- Как оценить коэффициенты линейной регрессии с использованием стохастического градиентного спуска.
- Как делать прогнозы для многомерной линейной регрессии.
- Как реализовать линейную регрессию со стохастическим градиентным спуском для прогнозирования новых данных.
Давайте начнем.
- Обновление январь / 2017: Изменено вычисление fold_size в cross_validation_split (), чтобы оно всегда было целым числом. Исправляет проблемы с Python 3.
- Обновление Авг / 2018: Протестировано и обновлено для работы с Python 3.6.

Описание
В этом разделе мы опишем линейную регрессию, метод стохастического градиентного спуска и набор данных о качестве вина, используемых в этом учебном пособии.
Многомерная линейная регрессия
Линейная регрессия — это метод прогнозирования реальной стоимости.
Заблуждение, что эти проблемы, где должна быть предсказана реальная ценность, называются проблемами регрессии.
Линейная регрессия — это метод, в котором прямая линия используется для моделирования отношений между входными и выходными значениями. В более чем двух измерениях эту прямую линию можно рассматривать как плоскость или гиперплоскость.
Прогнозы делаются как комбинация входных значений для прогнозирования выходного значения.
Каждый входной атрибут (x) взвешивается с использованием коэффициента (b), и цель алгоритма обучения состоит в том, чтобы обнаружить набор коэффициентов, который дает хорошие прогнозы (y).
y = b0 + b1 * x1 + b2 * x2 + ...Коэффициенты можно найти с помощью стохастического градиентного спуска.
Стохастический градиентный спуск
Градиентный спуск — это процесс минимизации функции, следуя градиентам функции стоимости.
Это включает в себя знание формы стоимости, а также производной, чтобы из заданной точки вы знали градиент и могли двигаться в этом направлении, например, вниз к минимальному значению.
В машинном обучении мы можем использовать технику, которая оценивает и обновляет коэффициенты на каждой итерации, называемую стохастическим градиентным спуском, чтобы минимизировать ошибку модели в наших обучающих данных.
Этот алгоритм оптимизации работает так, что каждый обучающий экземпляр показывается модели по одному. Модель делает прогноз для обучающего экземпляра, вычисляется ошибка, и модель обновляется, чтобы уменьшить ошибку для следующего прогнозирования. Этот процесс повторяется для фиксированного числа итераций.
Эта процедура может использоваться для нахождения набора коэффициентов в модели, которые приводят к наименьшей ошибке для модели в данных обучения. На каждой итерации коэффициенты (b) в языке машинного обучения обновляются с использованием уравнения:
b = b - learning_rate * error * xкудабкоэффициент или вес оптимизируется,learning_rateэто скорость обучения, которую вы должны настроить (например, 0,01),ошибкаошибка прогноза для модели на тренировочных данных, отнесенных к весу, иИксэто входное значение.
Набор данных о качестве вина
После того, как мы разработаем наш алгоритм линейной регрессии со стохастическим градиентным спуском, мы будем использовать его для моделирования набора данных о качестве вина.
Этот набор данных состоит из деталей 4898 белых вин, включая такие измерения, как кислотность и pH. Цель состоит в том, чтобы использовать эти объективные меры для прогнозирования качества вина по шкале от 0 до 10.
Ниже приведен образец первых 5 записей из этого набора данных.
7,0.27,0.36,20.7,0.045,45,170,1.001,3,0.45,8.8,6
6.3,0.3,0.34,1.6,0.049,14,132,0.994,3.3,0.49,9.5,6
8.1,0.28,0.4,6.9,0.05,30,97,0.9951,3.26,0.44,10.1,6
7.2,0.23,0.32,8.5,0.058,47,186,0.9956,3.19,0.4,9.9,6
7.2,0.23,0.32,8.5,0.058,47,186,0.9956,3.19,0.4,9.9,6Набор данных должен быть нормализован до значений от 0 до 1, поскольку каждый атрибут имеет разные единицы измерения и, в свою очередь, разные масштабы.
Прогнозируя среднее значение (алгоритм нулевого правила) для нормализованного набора данных, можно получить базовую среднеквадратическую ошибку (RMSE) 0,148.
Вы можете узнать больше о наборе данных на UCI Хранилище Машинного Обучения,
Вы можете скачать набор данных и сохранить его в текущем рабочем каталоге с именемwinequality-white.csv, Вы должны удалить информацию заголовка из начала файла и преобразовать разделитель значения «;» в «,», чтобы соответствовать формату CSV.
Руководство
Этот урок разбит на 3 части:
- Делать прогнозы.
- Оценка коэффициентов.
- Прогноз качества вина.
Это обеспечит основу, необходимую для реализации и применения линейной регрессии со стохастическим градиентным спуском к вашим собственным задачам прогнозного моделирования.
1. Делать прогнозы
Первым шагом является разработка функции, которая может делать прогнозы
Это будет необходимо как при оценке значений вероятных коэффициентов при стохастическом градиентном спуске, так и после того, как модель будет завершена, и мы хотим начать делать прогнозы на основе данных испытаний или новых данных.
Ниже приведена функция с именемпредсказать, ()это предсказывает выходное значение для строки, заданной набором коэффициентов.
Первый коэффициент в всегда является перехватом, также называемым смещением или b0, так как он является автономным и не отвечает за конкретное входное значение.
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhatМы можем создать небольшой набор данных для проверки нашей функции прогнозирования.
x, y
1, 1
2, 3
4, 3
3, 2
5, 5Ниже приведен график этого набора данных.

Мы также можем использовать предварительно подготовленные коэффициенты, чтобы делать прогнозы для этого набора данных.
Собрав все это вместе, мы можем проверить нашипредсказать, ()функция ниже.
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
dataset = [[1, 1], [2, 3], [4, 3], [3, 2], [5, 5]]
coef = [0.4, 0.8]
for row in dataset:
yhat = predict(row, coef)
print("Expected=%.3f, Predicted=%.3f" % (row[-1], yhat))Существует одно входное значение (x) и два значения коэффициента (b0 и b1). Уравнение прогнозирования, которое мы смоделировали для этой задачи:
y = b0 + b1 * xили, с конкретными значениями коэффициентов, которые мы выбрали вручную как:
y = 0.4 + 0.8 * xЗапустив эту функцию, мы получаем прогнозы, которые достаточно близки к ожидаемым выходным значениям (y).
Expected=1.000, Predicted=1.200
Expected=3.000, Predicted=2.000
Expected=3.000, Predicted=3.600
Expected=2.000, Predicted=2.800
Expected=5.000, Predicted=4.400Теперь мы готовы реализовать стохастический градиентный спуск, чтобы оптимизировать значения наших коэффициентов.
2. Оценка коэффициентов
Мы можем оценить значения коэффициентов для наших обучающих данных, используя стохастический градиентный спуск.
Стохастический градиентный спуск требует двух параметров:
- Скорость обучения: Используется для ограничения суммы, каждый коэффициент корректируется при каждом обновлении.
- Эпохи: Количество раз, которое нужно пройти через данные обучения при обновлении коэффициентов.
Они вместе с данными обучения будут аргументами функции.
В функции нам нужно выполнить 3 цикла:
- Зацикливайтесь на каждой эпохе.
- Зацикливайтесь на каждой строке в данных тренировки для определенной эпохи.
- Зациклите каждый коэффициент и обновите его для ряда в эпоху.
Как видите, мы обновляем каждый коэффициент для каждой строки в обучающих данных, для каждой эпохи.
Коэффициенты обновляются в зависимости от ошибки, допущенной моделью. Ошибка рассчитывается как разница между прогнозом, сделанным с использованием коэффициентов-кандидатов, и ожидаемым выходным значением.
error = prediction - expectedСуществует один коэффициент для взвешивания каждого входного атрибута, и они обновляются согласованным образом, например:
b1(t+1) = b1(t) - learning_rate * error(t) * x1(t)Специальный коэффициент в начале списка, также называемый перехватом или смещением, обновляется аналогичным образом, за исключением того, что не вводится, поскольку он не связан с конкретным входным значением:
b0(t+1) = b0(t) - learning_rate * error(t)Теперь мы можем собрать все это вместе. Ниже приведена функция с именемcoefficients_sgd ()который вычисляет значения коэффициента для обучающего набора данных с использованием стохастического градиентного спуска.
# Estimate linear regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
sum_error = 0
for row in train:
yhat = predict(row, coef)
error = yhat - row[-1]
sum_error += error**2
coef[0] = coef[0] - l_rate * error
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] - l_rate * error * row[i]
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
return coefВы можете видеть, что кроме того, мы отслеживаем сумму квадратов ошибок (положительное значение) для каждой эпохи, чтобы мы могли распечатать хорошее сообщение во внешнем цикле.
Мы можем протестировать эту функцию на том же небольшом измышленном наборе данных сверху.
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
# Estimate linear regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
sum_error = 0
for row in train:
yhat = predict(row, coef)
error = yhat - row[-1]
sum_error += error**2
coef[0] = coef[0] - l_rate * error
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] - l_rate * error * row[i]
print('>epoch=%d, lrate=%.3f, error=%.3f' % (epoch, l_rate, sum_error))
return coef
# Calculate coefficients
dataset = [[1, 1], [2, 3], [4, 3], [3, 2], [5, 5]]
l_rate = 0.001
n_epoch = 50
coef = coefficients_sgd(dataset, l_rate, n_epoch)
print(coef)Мы используем небольшую скорость обучения 0,001 и обучаем модель в течение 50 эпох, или 50 экспозиций коэффициентов всему набору обучающих данных.
При выполнении примера в каждую эпоху печатается сообщение с квадратом ошибки для этой эпохи и окончательным набором коэффициентов.
>epoch=45, lrate=0.001, error=2.650
>epoch=46, lrate=0.001, error=2.627
>epoch=47, lrate=0.001, error=2.607
>epoch=48, lrate=0.001, error=2.589
>epoch=49, lrate=0.001, error=2.573
[0.22998234937311363, 0.8017220304137576]Вы можете видеть, как ошибка продолжает падать даже в последнюю эпоху. Вероятно, мы могли бы тренироваться намного дольше (больше эпох) или увеличить количество обновляемых коэффициентов в каждую эпоху (более высокая скорость обучения).
Поэкспериментируйте и посмотрите, что вы придумали.
Теперь давайте применим этот алгоритм к реальному набору данных.
3. Прогноз качества вина
В этом разделе мы будем обучать модели линейной регрессии с использованием стохастического градиентного спуска в наборе данных о качестве вина.
В примере предполагается, что копия набора данных в формате CSV находится в текущем рабочем каталоге с именем файлаwinequality-white.csv,
Сначала загружается набор данных, строковые значения преобразуются в числовые, и каждый столбец нормализуется до значений в диапазоне от 0 до 1. Это достигается с помощью вспомогательных функций.load_csv ()а такжеstr_column_to_float ()загрузить и подготовить набор данных иdataset_minmax ()а такжеnormalize_dataset ()нормализовать это.
Мы будем использовать k-кратную перекрестную проверку для оценки эффективности изученной модели на невидимых данных. Это означает, что мы будем строить и оценивать k моделей и оценивать производительность как среднюю ошибку модели. Среднеквадратическая ошибка будет использоваться для оценки каждой модели. Эти поведения представлены вcross_validation_split (),rmse_metric ()а такжеevaluate_algorithm ()вспомогательные функции.
Мы будем использоватьпредсказать, (),coefficients_sgd ()а такжеlinear_regression_sgd ()функции, созданные выше для обучения модели.
Ниже приведен полный пример.
# Linear Regression With Stochastic Gradient Descent for Wine Quality
from random import seed
from random import randrange
from csv import reader
from math import sqrt
# Load a CSV file
def load_csv(filename):
dataset = list()
with open(filename, 'r') as file:
csv_reader = reader(file)
for row in csv_reader:
if not row:
continue
dataset.append(row)
return dataset
# Convert string column to float
def str_column_to_float(dataset, column):
for row in dataset:
row[column] = float(row[column].strip())
# Find the min and max values for each column
def dataset_minmax(dataset):
minmax = list()
for i in range(len(dataset[0])):
col_values = [row[i] for row in dataset]
value_min = min(col_values)
value_max = max(col_values)
minmax.append([value_min, value_max])
return minmax
# Rescale dataset columns to the range 0-1
def normalize_dataset(dataset, minmax):
for row in dataset:
for i in range(len(row)):
row[i] = (row[i] - minmax[i][0]) / (minmax[i][1] - minmax[i][0])
# Split a dataset into k folds
def cross_validation_split(dataset, n_folds):
dataset_split = list()
dataset_copy = list(dataset)
fold_size = int(len(dataset) / n_folds)
for i in range(n_folds):
fold = list()
while len(fold) < fold_size:
index = randrange(len(dataset_copy))
fold.append(dataset_copy.pop(index))
dataset_split.append(fold)
return dataset_split
# Calculate root mean squared error
def rmse_metric(actual, predicted):
sum_error = 0.0
for i in range(len(actual)):
prediction_error = predicted[i] - actual[i]
sum_error += (prediction_error ** 2)
mean_error = sum_error / float(len(actual))
return sqrt(mean_error)
# Evaluate an algorithm using a cross validation split
def evaluate_algorithm(dataset, algorithm, n_folds, *args):
folds = cross_validation_split(dataset, n_folds)
scores = list()
for fold in folds:
train_set = list(folds)
train_set.remove(fold)
train_set = sum(train_set, [])
test_set = list()
for row in fold:
row_copy = list(row)
test_set.append(row_copy)
row_copy[-1] = None
predicted = algorithm(train_set, test_set, *args)
actual = [row[-1] for row in fold]
rmse = rmse_metric(actual, predicted)
scores.append(rmse)
return scores
# Make a prediction with coefficients
def predict(row, coefficients):
yhat = coefficients[0]
for i in range(len(row)-1):
yhat += coefficients[i + 1] * row[i]
return yhat
# Estimate linear regression coefficients using stochastic gradient descent
def coefficients_sgd(train, l_rate, n_epoch):
coef = [0.0 for i in range(len(train[0]))]
for epoch in range(n_epoch):
for row in train:
yhat = predict(row, coef)
error = yhat - row[-1]
coef[0] = coef[0] - l_rate * error
for i in range(len(row)-1):
coef[i + 1] = coef[i + 1] - l_rate * error * row[i]
# print(l_rate, n_epoch, error)
return coef
# Linear Regression Algorithm With Stochastic Gradient Descent
def linear_regression_sgd(train, test, l_rate, n_epoch):
predictions = list()
coef = coefficients_sgd(train, l_rate, n_epoch)
for row in test:
yhat = predict(row, coef)
predictions.append(yhat)
return(predictions)
# Linear Regression on wine quality dataset
seed(1)
# load and prepare data
filename = 'winequality-white.csv'
dataset = load_csv(filename)
for i in range(len(dataset[0])):
str_column_to_float(dataset, i)
# normalize
minmax = dataset_minmax(dataset)
normalize_dataset(dataset, minmax)
# evaluate algorithm
n_folds = 5
l_rate = 0.01
n_epoch = 50
scores = evaluate_algorithm(dataset, linear_regression_sgd, n_folds, l_rate, n_epoch)
print('Scores: %s' % scores)
print('Mean RMSE: %.3f' % (sum(scores)/float(len(scores))))Значение k, равное 5, использовалось для перекрестной проверки, давая каждый раз 4 898/5 = 979,6 или чуть менее 1000 записей, которые должны оцениваться на каждой итерации. Скорость обучения 0,01 и 50 тренировочных эпох были выбраны с небольшими экспериментами.
Вы можете попробовать свои собственные конфигурации и посмотреть, сможете ли вы побить мой счет
Выполнение этого примера печатает оценки для каждого из 5 сгибов перекрестной проверки, а затем печатает среднее RMSE.
Мы можем видеть, что RMSE (для нормализованного набора данных) составляет 0,126, что ниже базового значения 0,148, если мы только что предсказали среднее значение (используя алгоритм нулевого правила).
Scores: [0.12248058224159092, 0.13034017509167112, 0.12620370547483578, 0.12897687952843237, 0.12446990678682233]
Mean RMSE: 0.126расширения
В этом разделе перечислено несколько расширений этого руководства, которые вы, возможно, захотите изучить.
- Tune The Example, Настройте скорость обучения, количество эпох и даже метод подготовки данных, чтобы получить улучшенную оценку набора данных о качестве вина.
- Пакетный стохастический градиентный спуск, Измените алгоритм стохастического градиентного спуска, чтобы накапливать обновления для каждой эпохи и обновлять только коэффициенты в пакете в конце эпохи.
- Дополнительные проблемы регрессии, Примените эту технику к другим проблемам регрессии в хранилище машинного обучения UCI.
Вы исследовали какое-либо из этих расширений?
Дайте мне знать об этом в комментариях ниже.
Обзор
В этом уроке вы узнали, как реализовать линейную регрессию с использованием стохастического градиентного спуска с нуля с помощью Python.
Ты выучил.
- Как делать прогнозы для многомерной задачи линейной регрессии.
- Как оптимизировать набор коэффициентов с помощью стохастического градиентного спуска.
- Как применить метод к реальной задаче регрессионного моделирования.
У вас есть вопросы?
Задайте свой вопрос в комментариях ниже, и я сделаю все возможное, чтобы ответить.
Для начала ответ на главный вопрос: а где мне, дизайнеру, пригодится линейная регрессия? Она популярна для решения прикладных задач, вроде прогнозирования. Это в первую очередь таргетированная реклама, нейрон в слоях классификации, простенькие системы скоринга для банков. В общем, любые задачи, где отношения между переменными линейны по своей природе: как возраст влияет на здоровье или сколько операторов в банке справляются с поставленными KPI. Или есть ли связь между продажаи и затратами на таргет, какие площадки больше всего влияют на продажи, линейна ли наблюдаемая зависимость.
В мире ML существует три базовых направления: регрессия для предсказания численных значений, классификация для раскидывания сущностей по неким признакам (кошки/собаки, уволится/не уволится), и кластеризация для группировки похожих объектов лучше, чем rule-based. И обычно есть тестовая выборка для валидации модели и обучающая выборка, в которой заранее известны целевые значения.
Линейная регрессия позволяет прогнозировать зависимость переменной Y на основе переменной X. Визуализируя эту зависимость на графике, получается прямая линия, часто называемая «линия наилучшего соответствия». Линейная регрессия весьма проста, мы прогнозируем Y с учетом X. Есть целевая target-переменная, и потенциальное множество значений для target-переменной бесконечно. Пример: предсказание стоимости квартиры, подавая на вход количество комнат и удаленность от метро, это задача для линейной регрессии. Метрическая модель отвечает на метрическую гипотезу, или целевая переменная линейно зависит от признаков объектов. Типовая задача это прогноз выручки за год магазина, где гипотеза это зависимость количества магазинов и объема выручки. В общем, модель про деньги, поэтому очень популярна в банках: выдавать кредиты надо cумом, каждый параметр влияет на решение о кредите (заработок, дети, просрочки, стаж, состояние здоровья, риск дефолта).
Модели линейной регрессии используются для демонстрации или прогнозирования взаимосвязи между двумя переменными или факторами. Прогнозируемый фактор (фактор, для которого решается уравнение) называется зависимой переменной. Факторы, которые используются для предсказания значения зависимой переменной, называются независимыми переменными. Линейный регрессионный анализ используется для прогнозирования значения переменной на основе значения другой переменной.
Например, стоимость квартиры. Чистим данные, берем модель линейной регрессии и даем задачу: если на вход дать новую квартиру без цены, то модель предскажет стоимость квартиры. И даже скажет, какие параметры влияют на цену.
Линейная регрессия это «строительный блок» для более сложных моделей, например для нейронок. Нейронки это простая череда логистических регрессий, для понимания которых нужна линейная. Она хорошо интерпретируема и её достаточно для многих задач. Существует парная регрессия, это частный случай линейной регрессии, в которой рассматривается только один признак (k = 1). Если все-же признаков больше одного, для аналитического решения может подойти метод наименьших квадратов.
Задача регрессии это минимизация ошибки. По математическому условию, два фактора, участвующие в простом линейном регрессионном анализе, обозначаются x и y. Уравнение, описывающее связь y с x, известно как регрессионная модель. Линейная регрессионная модель также содержит термин ошибки, который представлен Ε или греческой буквой «эпсилон». Термин ошибки используется для учета изменчивости в y, которая не может быть объяснена линейной зависимостью между x и y.
Интереснее работать с категориальными вещественными переменными, но пока что для простоты будем работать только с цифрами. Итак, у нас есть отдел дизайна с 18 дизайнерами, и мы хотим узнать, кто из наших дизайнеров работает наиболее эффективно. Для вычислений будем использовать NumPy. Типичная задача линейной регрессии это определить непрерывную переменную. Если зависимая переменная не непрерывная, тогда это задача классификации, а не регрессии. Я буду рассматривать простые линейные модели, так как обычно хватает простого суммирования значений признаков с некоторыми весами.
Условие задачи: я, как руководитель дизайн-отдела, хочу понять, кто из моих сотрудников самый эффективный. Все работы дизайнеров тестируются по метрике SUM и я точно знаю, у кого какое качество дизайна. Теперь мне надо правильно соотнести количество лет опыта и результативность работы.
В рамках статьи и в рамках терминологии машинного обучения мы будем называть наши наблюдения признаками. Признак это любая характеристика исследуемых данных, выраженная числом. Для начала укажем кол-во лет опыта у специалистов и посмотрим на форму данных командой командой x.shape. У нас всего 18 наблюдений (18 дизайнеров), это один набор признаков. Для добавления второго набора признаков создаем двухмерный массив NumPy. Второй набор данных это результативность (SUM), некий средний балл в диапазоне от 0 до 100. Весь наш набор данных будет называться «признаковым описанием». Внесли данные и визуализировали:
import numpy as np x = np.array([[1,3,4,5,11,0,8,6,3,7,16,0,2,3,2,4,21,4]]) print (x) print (x.shape) y = np.array([[32,54,54,35,86,12,74,67,35,75,94,12,56,54,40,35,87,47]]) print (y) print (y.shape) import matplotlib matplotlib.use('TkAgg') from matplotlib import pyplot as plt plt.scatter(x,y)
По горизонтали опыт в годах, по вертикали результат SUM. Даже на глаз некая логика в этих данных есть: чем меньше опыта, тем хуже результат работы, по мере увеличения X растет и Y. Сразу возникает желание использовать эти данные об результативности специалиста для прогнозирования, на сколько ему надо повышать зарплату, или уменьшать. Так как начало данных не из 0/0, то нужен интерсепт. Существует понятия сдвига (intercept) и наклона (slope), иногда их называют коэффициентами и параметрами.
Интерсепт это тоже признак, некий сдвиг в данных, пропишем его как x0. Можно использовать и Байеса, у него вполне схожее поведение, но в данном случае он был бы неуместен (не путать с теоремой Байеса). Немного облегчим себе задачу и представим, что у нас нет кривой насыщения, так как у опытных специалистов ранние работы априори плохие, поэтому мы взяли SUM только за последний год. Если человек имеет 0 лет опыта работы, то мы взяли данные за несколько месяцев.
Так как у нас линейная регрессия, попробуем на глаз подобрать вес для признака и интерсепт, и нарисовать по ним линию. Интерсепт может быть 15, а какой наклон? Наклон сложно определить из-за разного масштаба по горизонтали и вертикали. Но попробуем на глаз 3, 4, 5:
import numpy as np import matplotlib matplotlib.use('TkAgg') from matplotlib import pyplot as plt y = np.array([[32, 54, 54, 35, 86, 12, 74, 67, 35, 75, 94, 12, 56, 54, 40, 35, 87, 47]]) print(y) print(y.shape) X = np.array([[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1],[1,3,4,5,11,0,8,6,3,7,16,0,2,3,2,4,21,4]]) plt.scatter(X[1], y) plt.plot(X[1], 15*np.ones(18) + X[1]*4) plt.show()
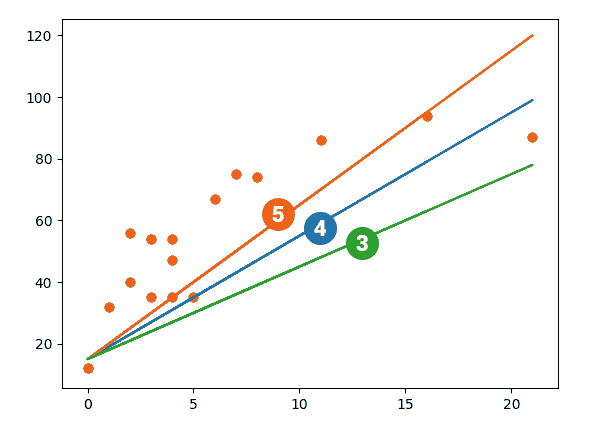
Как это считывать: линия регрессии может показывать положительную линейную зависимость, отрицательную линейную зависимость или не показывать никакой связи. Если линия не наклонная, связь между двумя переменными отсутствует. Если линия регрессии идет вверх, мы имеем положительную линейную зависимость. Если линия регрессии наклоняется вниз, имеется отрицательная линейная зависимость. При этом линия стремится выше предела в 100, это решается клипированием. Более того, правильно клипировать и отрицательные значения. Если применять деревья, то там тоже значения могут выскакивать за пределы возможных, но это целиком зависит от алгоритма.
Допустим, я думаю что значение 5 наиболее близко к реальности. Теперь посмотрим на ошибки, ведь чем меньше ошибка, тем качественнее модель. Ошибки могут быть разные, сейчас мы подсчитаем наши предсказания, возьмем ошибку и просуммируем для каждого наблюдения. Подход весьма примитивен, но это хорошая демонстрация.
y_pred1 = 15*np.ones(18) + X[1]*4 print (y_pred1) err = np.sum(y - y_pred1) print (err)
Получаем число 179. И это весьма большое значение, значит, мы слишком мало предсказывали. Отрицательное значение значило бы перепрогноз, это более желанный результат. Лучше переработать, чем недоработать. Сейчас же мы можем ошибиться в сторону недопрогноза, и бизнес это не устроит. Есть еще один значимый недостаток: средняя ошибка равна нулю, она плоха тем, что мы можем иметь 2 наблюдения, которые отклоняются в разные стороны на одинаковое число, и при подсчете суммы они обнулятся (-1 +1 = 0). Такие противоположные объекты с одинаковым признаковым описанием скажут нам, что наша модель очень качественная. Хотя в модели могут быть сильные отклонения. Поэтому все разности приводятся к одному знаку с помощью модуля (ошибка MAE), либо все возводится в квадрат, это убирает знак минус. MAE это метод оценки параметров модели. В MAE модули не сильно увеличивают отклонения, считающиеся выбросами. Такая оценка будет более робастная и похожая на медиану, чем MSE. Существуют более сложные метрики, MAPE, RMSPE, и моя любимая RMSE.
Итак, регрессия это целевая переменная, например, потенциальная выручка магазина. И нам надо правильно выбрать функци потерь. MSE это квадратичная функция потерь, считаем матрицу Гессе и понимаем, что она удовлетворяет достаточному условию минимума. Но сейчас мы посмотрим на MAE, так как она дифференцируема,
def calc_mse(y, y_pred): err = np.mean((y - y_pred) ** 2) return err print (calc_mse (y, y_pred1)) def calc_mae(y, y_pred): err = np.mean(np.abs(y - y_pred)) return err print (calc_mae(y, y_pred1))
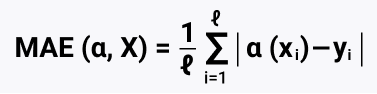
Функции и формула для подсчета выше, принцип подсчета MAE следующий: np.sum(np.abs(y - y_pred1)) / 18, получаем 14.944444444444445. Тут остановлюсь чуть подробнее, MAE (Mean Absolute Error) это среднее абсолютное отклонение (mean absolute error = MAE), такой модуль отклонения устойчив к выбросам. Однако функция модуля не имеет производной в нуле, и её оптимизация может вызывать трудности. Поэтому для измерения отклонения можно просто посчитать квадрат разности.
И тут мы плавно переходим к среднеквадратичному отклонению (mean squared error, MSE), или квадратичная ошибка MSE: np.mean((y - y_pred1) **2), среднее берем вместо суммы, не будем усложнять расчет. Суть метода: минимизация суммы квадратов отклонений фактических значений от расчётных. Применяем, когда намн ужно решить задачу регрессии. Полученную сумму делим на число наблюдений, и получаем MSE. MSE лучше показывает ошибки, чем MAE. Итак, MSE = 326.1666666666667 и MAE = 14.944444444444445. По этим двум точкам строится линия, значит, эта модель (она же линия) будет работать лучше для точек на графике. И именно поэтому регрессия у нас линейная, т.к. ровная линия, которая точнее всего описывает зависимость в данных.
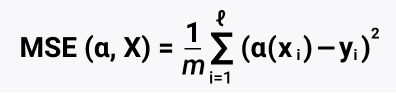
Это был способ на глазок, но куда приятнее автоматизировать процесс. Ведь новые показания SUM приходят каждый месяц и хочется отслеживать рост молодых дизайнеров и актуальность опытных специалистов. Нам нужна формула для автоматического подсчета двух коэффициентов, тут придет на выручку метод наименьших квадратов (МНК). Для работы понадобится матрица, которая по горизонтали и вертикали будет равняться количеству признаков и по форме будет квадратная (18×18). Если у нас 18 столбцов и 18 строк, то эти две матрицы можно перемножать. Итоговая матрица берется по количеству признаков, 2×2.
Вводим команду X.shape, узнаем, что у нас матрица (2, 18) . А команда X.T.shape говорит нам, что матрица (18, 2). Значит, эти две матрицы можно перемножать. Командой np.dot(X, X.T) получаем матрицу 2×2 по количеству признаков: [[ 18 100][ 100 1076]].
Надо отметить, что работа с матрицами алгоритмом МНК не очень стабильна. Что имеется ввиду: если определитель матрицы близок к нулю, но корректно вычислить обратную матрицу сложно. Если делить на небольшое занчение, то результатом будет большое значение (10 000 / 0,003 = 3 333 333), и столь малое изменение знаменателя влеук за собой огромные изменения результата. У нас есть 0,003 и 0,0000003, между этими значениями отличие небольшое, они оба очень близки к нулю. Но если разделить 1 на 0,003 и 1 на 0,0000003, то результаты будут 333 и 3 333 333 соответственно, и это уже очень широкий диапазон между значениями. Поэтому обратная матрица неустойчива, минимальная ошибка в определителе влечет огромную ошибку в вычислении обратной матрицы.
Следующим шагом находим из квадртаной матрицы обратную матрицу print (np.linalg.inv(np.dot(X, X.T))), результат [[ 0.11485909 -0.01067464] [-0.01067464 0.00192143]].
W = np.linalg.inv(np.dot(X, X.T)) @ X @ y.T print (W)
И последний шаг, умножаем на транспонированную матрицу и умножаем на y. И мы получаем набор весов. Это два числа, которые ранее мы пытались угадать на глаз, в этот раз их угадала система:[[32.48548249] [ 3.64261315]]. Мы же предположили, что интерсепт 35 и 5. На практике я бы применил частные производные для вывода формулы, но в рамках нашего примера сойдет и метод наименьших квадратов.
В регрессионном анализе зависимые переменные проиллюстрированы на вертикальной оси Y, а независимые переменные на горизонтальной оси x. Эти обозначения образуют уравнение для линии, которая определяется методом наименьших квадратов. Это важно понимать для прогнозирования поведения зависимых переменных.
X = np.array([[1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1,1],[1,3,4,5,11,0,8,6,3,7,16,0,2,3,2,4,21,4]]) y = np.array([[32,54,54,35,86,12,74,67,35,75,94,12,56,54,40,35,87,47]]) print (X.shape) print (X.T.shape) print (np.dot(X, X.T)) print (np.linalg.inv(np.dot(X, X.T))) W = np.linalg.inv(np.dot(X, X.T)) @ X @ y.T print (W) plt.scatter(X[1], y) plt.plot(X[1], 15*np.ones(18) + X[1]*4) plt.plot(X[1], W[0] + W[1] * X[1]) plt.show()
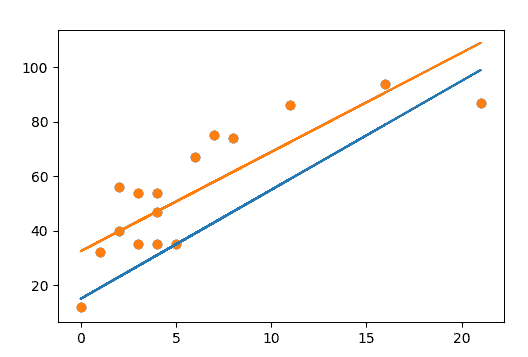
На примере выше видно, что построенная машиной линейная регрессия более жестко отсеивает людей, чем сделал бы это я «на глаз». Это элементарный пример использования машинного обучения для решения бизнес-задач. Теперь подсчитаем новые MAE и MSE для свеженайденных значений:
y_ml=W[0] + W[1] * X[1] print (calc_mse (y, y_ml)) print (calc_mae(y, y_ml))
Ранее MSE = 326.1666666666667 и MAE = 14.944444444444445, сейчас MSE = 174.00144700635732 и MAE = 11.478128854730052. Уже куда лучше (помним, чем значение ближе к нулю, тем лучше).
Помимо MSE и MAE, есть логарифмическая функция потерь MSLE и MAPE как средняя средняя абсолютная ошибка в процентах.
Конкретно в нашем отделе есть минимум 6 дизайнеров, которые работают хуже, чем их коллеги с аналогичным опытом. Но в общем то гипотеза подтвердилась: чем больше опыта у дизайнера, тем лучше результат. Но это мы знаем как люди, а для машины эта логика неизвестна, и она теперь точнее нас предскажет итоговый потенциальный прогресс специалиста. Мы даже можем индексировать оклад за рост и результативность специалиста, модель нам позволяет понять, насколько джун растет в сравнении с опытом сеньером. Разумеется, точного предсказания от модели не добиться, ведь рост специалиста зависит от него самого.
Итак, метод наименьших квадратов считает хорошо, и главное, он делает это быстро. Но постоянно его применять не получится, альтернатива: вместо метода наименьших квадратов (МНК) часто применяется градиентный спуск. Градиент это итеративный метод. Он показывает направление наискорейшего возрастания функции. Есть и обратная история: антиградиент, он показывает наибольшее убывание. У МНК есть проблема: он плох при большой размерности X, а точнее, когда много данных. Градиентный спуск не уступает по точности МНК. Принцип его работы простой, сначала он находит плохое решение, потом лучше, еще лучше, еще лучше, и так до наименьшего значения ошибки. Правило: много данных = градиентный спуск. В современном мире выбор алгоритма сильно завязан на производительность, МНК сразу оценивает весь объем данных, а стохастический градиентный спуск позволяет подавать данные батчами. Это помогает экономить оперативную память, которой всегда не хватает. Хотя и МНК, и градиентный спуск легко превращают любую железку в обогреватель. А стохастический градиентный спуск (SGD) нужен когда данные не помещаются в оперативку, и данные нужно разбивать. Это позволяет быстрее достичь глобального минимума, так как в итерациях будет участвовать не весь набор данных. Очевидный недостаток это не попадание в настоящую точку минимума, но в общем то, уровень точности приемлемый. Все по аналогии с веб-аналитикой: есть семплирование, есть и проблемы.
Давайте пощупаем в деле градиентный спуск. Он перебирает разные варианты, и двигается к поставленной цели. Матрицы позволяют сразу выполнять много операций. В математическом анализе есть тема поиска частных производных итеративным перебором весов в MSE. Этим и займемся. У нас одна переменная, но мы добавили инетрсепт и это вес для псевдо-переменных. Получается два признака: инсерсепт и вес признака опыта. Классический градиентный спуск применяется редко, чаще выбирают стохастическую оптимизацию.
Процесс минимизации ошибки в градиентном спуске строится на трехмерном пространстве, образованного за счет двух значений весов (W0 = интерсепт и slope(m) опыт). Мы можем задать начальные веса -1 и 1. Найдем производную для каждого веса векторным способом: где W[0] одновременно и интерсепт и вес. Это вес при псевдо-признаке 1.
import numpy as np X = np.array( [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 3, 4, 5, 11, 0, 8, 6, 3, 7, 16, 0, 2, 3, 2, 4, 21, 4]]) y = np.array([[32, 54, 54, 35, 86, 12, 74, 67, 35, 75, 94, 12, 56, 54, 40, 35, 87, 47]]) W = np.linalg.inv(np.dot(X, X.T)) @ X @ y.T W = np.array([1, 0.75]) gradient_form_direct = 1/18 * 2 * np.sum(X[0] * W[0] - y[0]) print(gradient_form_direct)
Мы получаем значение -103.44 , и это не очень хорошо. С таким огромным шагом мы можем просто проскочить нужное нам минимальное значение. Для уменьшения длины шага, мы с каждой итерацией меняем альфу, например, делим на номер итерации. Давайте добавим альфу как скорость обучения, введя alpha = 1e-5 (10 в -5 степени, или 1/10^5). Если видим минус в степени, то отсчет нулей идет назад = — 0,00001.
Значения могут сильно различаться, но после стандартизации/нормализации веса будут предсказуемы: 1,2,10, но точно не 1000. Напомню, W[0] это и интерсепт, и вес одновременно. Вес при псевдо-признаке 1.
alpha = 1e-5 gradient_form_direct = alpha * (1/18 * 2 * np.sum(X[0] * W[0] - y[0])) print(gradient_form_direct) print(W[0] - gradient_form_direct)
Получили 1.001, с этим уже можно работать. Теперь надо указать минимальное значение, и если ошибка приблизилась к нему, то останавливаем алгоритм. Это называется доходимость. Или ручками задаем фиксированное количество шагов, пожалуй, так мы сейчас и поступим. Есть еще нюанс, что при малом количестве данных мы сделаем больше вычислений, чем сделали бы при МНК, но давайте симулировать ситуацию с большими данными на игрушечных данных:
import numpy as np X = np.array( [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 3, 4, 5, 11, 0, 8, 6, 3, 7, 16, 0, 2, 3, 2, 4, 21, 4]]) y = np.array([32, 54, 54, 35, 86, 12, 74, 67, 35, 75, 94, 12, 56, 54, 40, 35, 87, 47]) W = np.array([1, 0.5]) gradient_form_direct = 1e-4 * (1/18 * 2 * np.sum(X[0] * W[0] - y[0])) print(gradient_form_direct) print(W[0] - gradient_form_direct) for i in range(2000): gradient_form = np.dot(W, X) W -= (1e-2 * (1/18 * 2 * np.dot((gradient_form - y), X.T))) if i % 200 == 0: print(i, W)
Отмечу, что у градиентного спуска решение приблизительное. После каждой новой итерации значения искомых весов все ближе и ближе к нужным, но влияет шум и значения никогда не станут идеальными. Если аналитического решения не существует, то градиентный спуск не дойдет даже до удовлетворительных значений.
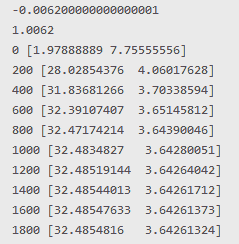
Получаем 32.4854816 и 3.64261324. В практических задачах обычно никто не стремится доказать существование глобального минимума. MSE или log loss ограничены снизу нулём, и чем ближе к нулю, тем больше «ок, сойдет». Просто доказать существование глобального минимума то можно, а достигнуть его куда сложнее. Для особо пытливых умов можно взять альтернативу градиентному спуску, это K-FAC. Или увеличить коэффициент альфа и тогда будет нужно меньше итераций, например 1e-2 и увеличить количество итераций. Так мы дойдем до тех же значений, что мы получили мне помощи МНК. Зачастую используют сразу несколько градиентных спусков, они сходятся к разным точкам, находят разные лучшие начальные приближения, так удается найти лучшую точку минимума. Градиентный спуск имеет линейную скорость сходимости, это вариант более честный. Стохастический — сублинейную скорость, это позволяет не очень долго считать, вопрос мощностей для расчета и количества данных.
Раз уж мы затронули тему масштабирования признаков, давайте разберем пару примеров нормализации и стандартизации. Линейные модели обучения эффективны только на признаках, которые имеют одинаковый масштаб. Поэтому масштабирование признаков это неотъемлемая часть подготовки данных перед применением методов машинного обучения. Нормализация нужна для измерительных признаков, вроде роста или размера зарплаты, стандартизация лучше подойдет для моделей, опирающихся на распределение. В любом случае, стандартизация и нормализация не навредят, все остальное очень индивидуально.
Добавим новый фактор — месячную зарплату.
X = np.array( [[1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1, 1], [1, 3, 4, 5, 11, 0, 8, 6, 3, 7, 16, 0, 2, 3, 2, 4, 21, 4], [65000, 80000, 85000, 75000, 120000, 25000, 65000, 65000, 29000, 36650, 260000, 12000, 35000, 45600, 25000, 65000, 175000, 73000]])
Нормализация это диапазон от 0 до 1, с сохранением линейности. Далее принцип нормализации: отнимаем от значения признака его минимальное значение, тем самым признак становится равен нулю, а максимальный признак равен размаху между максимумом и минимумом. Делим на размах и получаем отмасштабированный признак.
Гипотеза простая — чем больше платим человеку, тем лучшего результата работы мы от него ожидаем. Все признаки разномасштабные. Коэффициенты зависят от масштаба, и по коэффициентам мы не поймем значимость признаков при разном масштабе + не все алгоритмы это смогут обработать. Данные нужно нормализировать (интервал 0 до 1), после этого по весам регрессии можно будет судить, насколько важны признаки. При этом форма даных не будет изменена, просто поменяются среднее и дисперсия. Находим для каждого признака минимум и максимум: print (X[1].min(), X[1].max()), print (X[2].min(), X[2].max()). Получаем 0-21 и 12000-260000.
Нормализация по шагам: (X[1].max() -X [1].min()) получаем размах, максимальный опыт у дизайнеров 21 год. Смотрим на минимальный опыт (X[1] -X [1].min()), получаем [ 1 3 4 5 11 0 8 6 3 7 16 0 2 3 2 4 21 4], минимальный опыт ноль. И приводим все к нужному нам диапазону (X[1] - X[1].min()) / (X[1].max() -X[1].min()), результат вида [0.04761905 0.14285714 0.19047619 0.23809524 0.52380952 0. 0.38095238 0.28571429 0.14285714 0.33333333 0.76190476 0. 0.0952381 0.14285714 0.0952381 0.19047619 1. 0.19047619]. Теперь сделаем это для двух признаков:
X_norm = X.copy() X_norm = X_norm.astype(np.float64) X_norm[1] = (X[1] -X[1].min()) / (X[1].max() -X [1].min()) X_norm[2] = (X[2] -X[2].min()) / (X[2].max() -X [2].min()) print(X_norm)
А теперь стандартизация: мы пытаемся получить стандартное нормальное распределение, это диапазон от -1 до 1 с 0 в середине, и большинство значений скопятся в районе нуля. Так мы сможем привести все признаки к одному масштабу. Это важно для линейных моделей, так как они не смогут работать одновременно с наборами признаков: количество арбузов 100-600, и количество семечек в мандаринах 10000-30000. Также критично для метода ближайших соседей (kNN). Поэтому лучше наши данные заранее привести к виду, когда признаки находятся в примерно одном масштабе.
Смотрим на графики
import matplotlib matplotlib.use('TkAgg') from matplotlib import pyplot as plt plt.hist(X[1], alpha=0.6, color='g') '''либо''' import matplotlib.pyplot as plt plt.hist(X[1], alpha=0.6, color='g')
В принципе, похоже на стандартное распределение сотрудников в студиях дизайна: несколько опытных сеньеров-менторов и много джунов/мидлов. Поэтому распределение смещено, это также типичная ситуация для финансовых результатов, так как всегда есть большинство товаров массового потребления и какие-то отложения вправо до бесконечности из-за маленького количества услуг с огромной стоимостью.
Находим среднее по первому признаку X1_mean = X[1].mean(), получаем 5.55. Это средний стаж работы дизайнера. Теперь среднее квадратичное отклонение X1_std = X[1].std(),
X1_mean = X[1].mean() print(X1_mean) X1_std = X[1].std() print(X1_std) X_standarted = X.copy().astype(np.float64) X_standarted[1] = (X[1] - X1_mean) / X1_std print(X_standarted)
Отрицательные значения в результате это то, что меньше среднего. Идеально среднее значение будет равно нулю, подсчитаем его по первому признаку:
def calc_feature_std(x): result = (x - x.mean()) / x.std() return result X_standarted[2] = calc_feature_std(X[2]) print(X_standarted[2])
[-0.15764177 0.09837795 0.18371785 0.01303804 0.78109718 -0.84036101
-0.15764177 -0.15764177 -0.77208908 -0.64151903 3.17061451 -1.06224476
-0.6696812 -0.4887606 -0.84036101 -0.15764177 1.71983613 -0.02109792]
Данные стандартизировались. Алгоритмам проще работать с признаками в стандартизированном виде. На практике специалисты пробуют и стандартизацию, и нормализацию, выбирая наиболее подходящий способ масштабирования данных, аксиомы тут нет.
Python Scikit-learn: Линейная регрессия и SVM
Существует множество полезных технологий, которые помогают мне грамотно планировать работу отдела дизайна. Часть задач по анализу информации я просто делегировал компьютеру. Например, нейронкам можно скормить изображения, тексты, обучить компьютерному зрению, в общем делегировать работу про матрицу с пикселями. Градиентный бустинг рассчитан на работу с признаками. И в нем есть все инстурменты для этого: свертки, пуллинг. Градиентный бустинг весьма хорош при работе с деревьями.
Но сегодняшняя наша тема это машинное обучение, оно бывает с учителем и без учителя. Обучение с учителем (supervised learning) это про предсказание некой величины. Учитель это база данных, состоящая из пар объект – ответ. Обучению с учителем требуется два набора данных для прогноза: тренировочный и тестовый датасеты. То есть нужен набор данных с готовым правильным ответом, и на его основе будет строиться модель для предсказания ответа при работе со схожими данными. Начнем с простого. А именно с линейной регрессии. Используется для предсказания непрерывной величины, в нашем случае это будет прогноз затрат на услуги фрилансеров. Линейная регрессия по сути нечто вроде алгоритма, который находит в данных паттерн определенного вида между независимой переменной (X) и зависимой переменной (y).
Модель линейной регрессии по объекту x=(x1,…,xn) предсказывает значение целевой переменной, используя линейную функцию. Она строит модель на трейне (тренировочный датасет) и делает предсказание на тесте, возвращая среднеквадратичную ошибку. Итак, модель = linear regression, и есть список признаков.
Возьмем Scikit-learn, в нем есть почти все нужные алгоритмы машинного обучения. Хочу отметить, что я осознанно буду приводить примеры кода, написанные не эталонно, но более простые для понимания и изучения. Дизайнер (а это блог для дизайнеров) вполне может писать код не по всем канонам программирования. Нам главное — решить задачу. Итак, создадим наш набор данных:
import numpy as np import matplotlib as mpl import matplotlib.pyplot as plt import pandas as pd def generate_dataset(n): x = [] y = [] random_x1 = np.random.rand() random_x2 = np.random.rand() random_x3 = np.random.rand() random_x4 = np.random.rand() random_x5 = np.random.rand() random_x6 = np.random.rand() random_x7 = np.random.rand() for i in range(n): x0 = i + np.random.rand() / 0.215 * 3.237 x1 = i + np.random.rand() / 0.211 * 0.698 x2 = i/2 + np.random.rand() - 1024 * 0.002 * 0.02 * 0.05 x3 = i * 0.12 + np.random.rand() * 0.054 x4 = i/1.42 + np.random.rand() x5 = i + 1 * 12 + np.random.rand() * 0.25 x6 = i/4 + np.random.rand() x7 = i + np.random.rand() x.append([x0, x1, x2, x3, x4, x5, x6, x7]) y.append(random_x1 * x1 + 1 + random_x2 * x2 + 1 + random_x3 * x3 + 1 + random_x4 * x4 + 1 + random_x5 * x5 + random_x6 * x6 + + random_x7 * x7) return np.array(x), np.array(y) x, y = generate_dataset(3000) X = pd.DataFrame(x) y = pd.DataFrame(y) X.columns = ['UI', 'UX', 'Payment', 'MRPPU', 'CPA', 'ARPPU', 'Tools', 'TSDB'] y.columns = ['Price_for_freelancers']
В примере выше мы вывели в таблицу X признаки, а в таблицу y целевые значения: Price_for_freelancers это величина, которую мы хотим предсказать, то есть цена на фрилансеров.
Обратите внимание на параметр test_size, он позволяет запланировать процент данных, который мы хотим отдать под тест. Если подать параметру число в диапазоне 0-1 (test_size=0.2), то это количество тестовых объектов в процентах. И это самый частотный вариант, но можно подать параметру число больше 1, и это будет фиксированное число объектов в тестовой выборке.
Как было сказано, для построения модели требуется две выборки: первая тренировочная, на ней обучается модель, и вторая тестовая, на которой проверяем, насколько хорошо модель работает. Тест проходит простой сверкой значение цены с предсказанными ценами на услуги фрилансеров. Напомню, в нашем случае признаки записаны в датафрэйм X, и данные о целевой переменной в y. Гипотеза: между X и y должна быть линейная зависимость.
import seaborn as sns new_df = pd.concat([y.reset_index(drop=True), X.reset_index(drop=True)], axis=1) print(new_df) sns.set_style('whitegrid') sns.lmplot('Price_for_freelancers', 'CPA', new_df, palette ='plasma', scatter_kws ={'s':0.4});
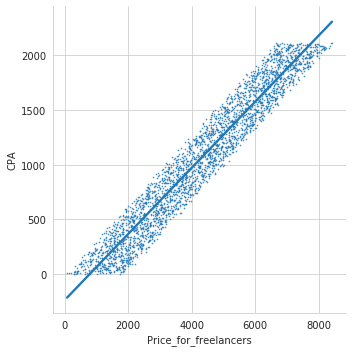
Линия явно проходит через некую зависимость CPA (Cost Per Action) сайтов, нарисованных дизайнерами и Price_for_freelancers (цена за фрилансера). Ситуация искусственная, но очень наглядная. Но помимо CPA, у нас есть множество других признаков. Используем функцию train_test_split, очень популярный способ деления данных на тестовую и проверочную выборку. Выбираем долю данных 0.25, и не будем задавать повторяемость случайного выбора, так интереснее. Получается, что тренировочная выборка 75% и 25% тестовая. random_state не задаем. Начнем строить модель:
from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X_train, y_train) y_pred = lr.predict(X_test) print(y_pred)
В примере выше мы вызываем линейную регрессию, обучаем по X_train, y_train, и делаем предсказание по X_test. В результате работы lr.fit мы получаем LinearRegression(copy_X=True, fit_intercept=True, n_jobs=None, normalize=False). И методом predict получаем предсказанные значения.
Но мы же наверняка хотим сопоставить предсказанные и полученные значения, верно?
check_test = pd.DataFrame({ "y_test": y_test["Price_for_freelancers"], "y_pred": y_pred.flatten(), }) check_test.head(10)
| y_test | y_pred | |
| 2830 | 8853.452885 | 8853.452885 |
| 2988 | 20299.645208 | 20299.645208 |
| 18 | 38.872415 | 38.872415 |
| 1347 | 3825.888260 | 3825.888260 |
| 2838 | 8860.830740 | 8860.830740 |
| … | … | … |
| 1571 | 5212.113755 | 5212.113755 |
| 718 | 1117.374471 | 1117.374471 |
| 2283 | 7192.523583 | 7192.523583 |
| 2646 | 8947.234195 | 8947.234195 |
Тест и предсказание одинаковые. Если визуализировать данные, то все становится примерно понятно:
strangeDataCheck = X.head(8) strangeDataCheck.plot(kind='bar',figsize=(16,10)) plt.grid(which='major', linestyle='-', linewidth='0.5', color='blue') plt.grid(which='minor', linestyle=':', linewidth='0.5', color='red') plt.show()
Но давайте займемся всякими проверками и узнаем, почему такой странный результат. Существует метрика, которая показывает, насколько сильны отклонения при условии X=Y. Вызываем из класса metrics r2_score, получаем коэффициент детерминации. Не трудно догадаться, что R2 и есть коэффициент детерминации (не путать RSS/TSS и ESS/TSS). Суть такая: целевая переменная описывается суммой 10 случайных, равнозначных и независимых факторов. Допустим, кот может начать мяукать, если показать ему рыку, мясо и еще 8 других продуктов, но мы никогда точно не знаем, мяукнет ли кот. В этом случае метрика R2 = 0. Но если показать мясо утром и рыбу вечером, то кот точно мяукнет, значит R2 = 0,2. Чем ближе к 1, тем лучше. Есть нюанс, что при добавлении в модель новых переменных, которые никакого отношения к объясняемой переменной не имеют, R2 все равно будет меняться в большую сторону. Значение R2 не зависит от масштабов предсказанной величины, и никогда не превышает 1, если мы по ошибке не использовали RSS/TSS (модельные отклонения в числителе, дисперсия данных в знаменателе). Тогда при значении больше 1 считаем, что модель предсказывает не очень хорошо.
from sklearn.metrics import r2_score r2_score(y_test, y_pred)
В нашем случае коэффицент детерминации = 1, что практически идеально, но невозможно при работе с реальными данными. На реальных данных даже R2 = 0,9 это явное переобучение. Либо, если и тренировочная, и валидационная выборка показывают примерно 0,9, то мы большие молодцы. Но в нашем случае искуственные данные = странный результат.
Небольшое отступление про train/test выборки. Обучающую и тестовую выборку делать одинаковыми нельзя. Никогда. Если так сделать, то цифры с прода вас сильно удивят. Поэтому принято делать выборку на обучающую и тестовую, но здесь тоже есть проблема. Зная все ответы из тестовой выборки, специалисты начинают подгонять модель под эти ответы. Поэтому добавляется третья, валидационная выборка, на которой тестируются финальные метрики. Цифры метрик будут более скромными. Это упрощенная версия подхода cross-validation, когда у разных моделей разные выборки.
Описанное выше это простой метод классификации. Но если мы хотим к классификации добавить еще и регрессию, то тогда нужно использовать случайный лес. В примере ниже разберем алгоритм из деревьев решений под названием случайный лес. Для каждого дерева выбирается подмножество признаков из тестовой выборки, и идет обучение. Каждое дерево дает некий ответ, и если за один ответ проголосовало наибольшее количество деревьев, то этот ответ считается победителем.
Мы ищем коэффициенты W для признаков X, и для тренировки используем метод fit. Записываем результат в отдельную переменную y_pred. После этого создадим объект, который будет нашей исходной моделью.
from sklearn.ensemble import RandomForestRegressor model = RandomForestRegressor(n_estimators=2000, max_depth=18) model.fit(X_train, y_train.values[:, 0]) y_pred_forest = model.predict(X_test) r2_score(y_test, y_pred_forest)
Алгоритм отработал, методом predict мы можем предсказать цены на фрилансеров и записать их в y_pred в виде простого массива. В переменную y_pred_forest записали предсказанное значение по X_test. В данном случае случайный лес показывает результат хуже, чем логистическая регрессия, 0.714357. Напомню, что я в коде не фиксировал random_state.
И самое сладенькое: посмотрим коэффициенты построенной модели линейной регрессии. Смотрим величину свободного коэффицента W0, он же интерсепт, содержится в атрибуте intercept_. Пишем print(lr.intercept_), получаем значение 3, это коэффицент, подобранный моделью во время обучения. Остальные коэффиценты можно получить командой print(lr.coef_). Мы наглядно видим, насколько каждый параметр модели влияет на результат. Но куда приятнее делать оценку весов признаков визуально.
from matplotlib import pyplot as plt %config inlineBackend.figure_format = 'svg' %matplotlib inline plt.barh(X_train.columns, lr.coef_.flatten()) print(X_train)
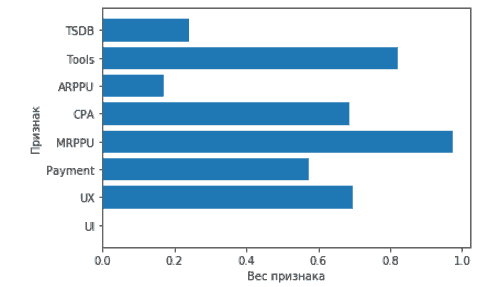
Теперь поговорим про переобучение. Переобучение это когда модель хорошо работает на тех данных, на которых она была построена, но при этом плохо предсказывает на новых данных. Если в наборе мало данных, то шанс столкнуться с этой проблемой весьма велик. Мы не считаем модель хорошей, если не решили проблему переобучения и не подобрали хорошие признаки. Поэтому для уменьшения ошибки надо убирать маловажные признаки, мы для этого используем регуляризацию в лоссе. В библиотеке sklearn линейная регрессия с L1-регуляризацией представлена классом lasso, а L2-регуляризация классом ridge. L1 это модуль, а L2 это работа с квадратом. Можно менять значения альфа, тем самым регулируя величину регуляризации. Правило простое: чем выше альфа, тем сильнее регуляризация, и тем эффективнее мы боремся с переобучением. При использовании регуляризации веса признаков понижают свое абсолютное значение, этим устраняется одна из причин переобучения, а именно бесконтрольный рост коэффицентов. Чем меньше значение альфы в lasso, тем быстрее обнулится значение признака, таким нехитрым образом можно отбирать признаки, когда их очень много. В ridge веса признаков также снижаются по модулю, но более плавно.
Для оценки качества модели регрессии применяются метрики. Вот самые популярные:
Средняя квадратичная ошибка (mean squared error), это средний квадрат разности между реальной и предсказанной величиной. Это MSE, функция ошибок. Считается просто: mse1 = (check_test["error"] ** 2).mean().
Вторая метрика это средняя абсолютная ошибка, отличается от MSE тем, что меньше реагирует на выбросы в данных. Среднее не от квадратов ошибки, а от модулей. Опять же, считается просто: (np.abs(check_test["error"])).mean()
Технически, все это можно было бы сделать и на МНК, но МНК очень затратен по ресурсам при больших объёмах данных. А вот в сторону RMSLE посмотреть вполне можно. Все это здорово, Tools самый доминирующий признак, но почему? Ответ в цифрах:
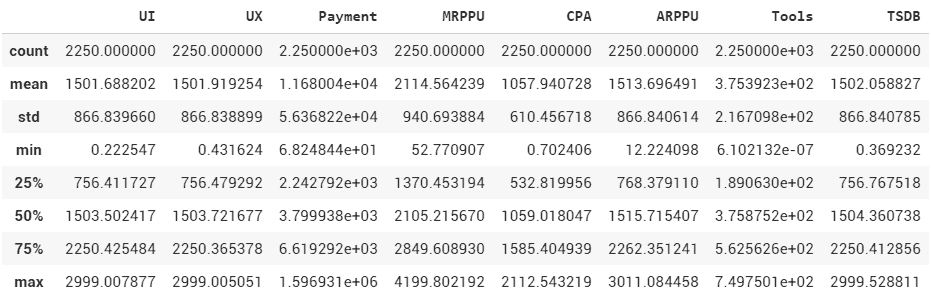
Признаки имеют разный масштаб?
Работая с линейной моделью, нам требуется для разных признаков разброс значений одного порядка. Достигается это логарифмическим преобразованием + стандартизацией. Простой перевод значения вида 2237.037956 в 0.83846151, это необходимый этап подготовки данных для корректного отбора признаков. В результате у стандартизированного признака среднее значение равно 0, и квадратичное отклонение признака / дисперсия = 1.
sc = StandardScaler() X_train_std = sc.fit_transform(X_train) X_test_std = sc.transform(X_test)
В примере ниже мы возьмем набор данных, в котором признаки имеют разный масштаб разброса значений. И нужна стандартизация. От значения признака отнимается среднее по данному признаку и делится на среднее квадратичное отклонение.
import pandas as pd import numpy as np from sklearn.datasets import load_boston from matplotlib import pyplot as plt %config inlineBackend.figure_format = 'svg' %matplotlib inline boston = load_boston() X = boston.data y = boston.target X = pd.DataFrame(X, columns=boston.feature_names) feature_names = boston['feature_names'] from sklearn.model_selection import train_test_split X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.25, random_state=42) from sklearn.linear_model import LinearRegression lr = LinearRegression() lr.fit(X_train, y_train) y_pred = lr.predict(X_test) from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_train_scaled = pd.DataFrame(X_train_scaled, columns=feature_names) X_test_scaled = scaler.fit_transform(X_test) X_test_scaled = pd.DataFrame(X_test_scaled, columns=feature_names) lr.fit(X_train_scaled, y_train) plt.barh(X_train.columns, lr.coef_.flatten(), color = "green") plt.xlabel('Вес признака', fontsize = 20) plt.ylabel('Признак', fontsize = 20) plt.title("Масштаб признаков")
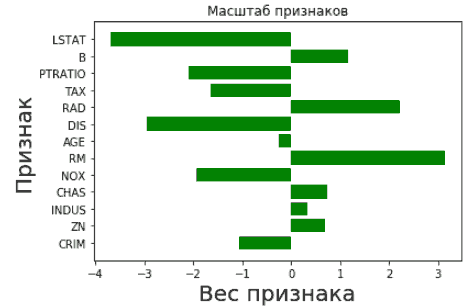
fit_transform нам позволяет вычислить среднее значение и среднее квадратичное отклонение из датафрэйма x-Train, и сразу вычислить стандартизированное значение для каждого признака. Далее, как мы уже умеем, берем lr.fit и смотрим новую модель на основе теперь уже стандартизированных признаков. И убираем из модели веса, близкие к нулю.
Возвращаясь к нашему примеру:
feature_names = ['UI', 'UX', 'Payment', 'MRPPU', 'CPA', 'ARPPU', 'Tools', 'TSDB'] from sklearn.preprocessing import StandardScaler scaler = StandardScaler() X_train_scaled = scaler.fit_transform(X_train) X_train_scaled = pd.DataFrame(X_train_scaled, columns=feature_names) X_test_scaled = scaler.fit_transform(X_test) X_test_scaled = pd.DataFrame(X_test_scaled, columns=feature_names) lr.fit(X_train_scaled, y_train) from matplotlib import pyplot as plt %config inlineBackend.figure_format = 'svg' %matplotlib inline plt.barh(X_train_scaled.columns, lr.coef_.flatten()) plt.xlabel('вес признака') plt.ylabel('признак') print(X_train.describe()) print(X_train_scaled.describe())
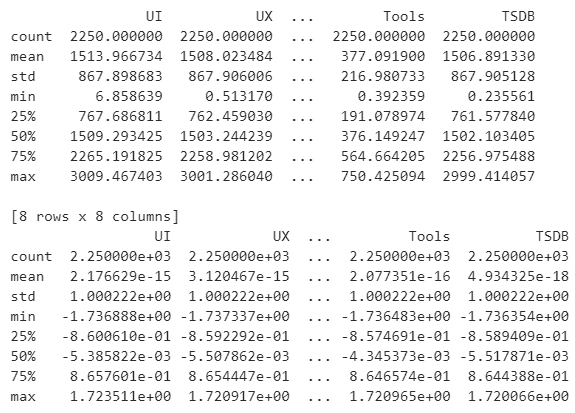
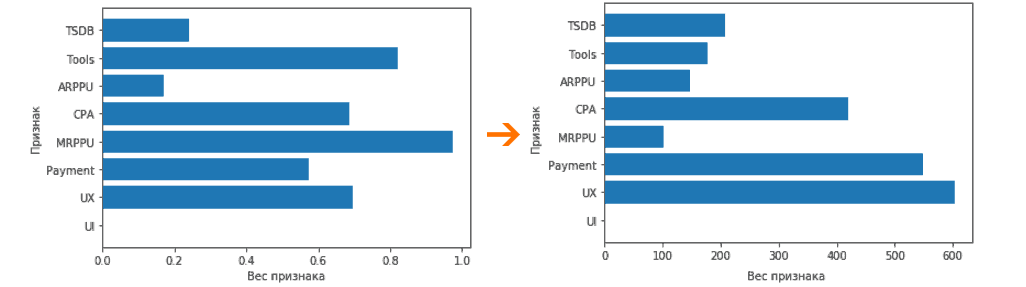
Support Vector Machine
Еще один популярный метод машинного обучения это метод опорных векторов, он же Support Vector Machine (SVM). Состоит из несколько алгоритмов, позволяет решать задачи классификации и регрессии. Например, классификация спама или отсеивание определенного типа выбросов. Визуально это график с линией, причем зазор между объектами и линией максимальный, а ошибка минимальна. Пунктирные линии это степень уверенности алгоритма.
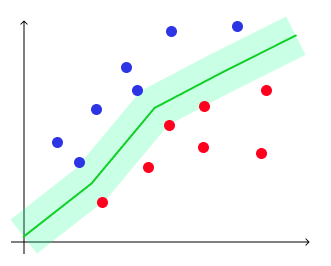
Датасеты для экспериментов можно взять любые из интернета, например archive.ics.uci.edu. Но я возьму свой датасет с данными по дизайнерам: скачать.
Как всегда, несколько нюансов: алгоритмы SVM требовательны к данным, их надо стандартизировать и нормализовывать. Если вы скачали датасет из интернета, то обязательно отмасштабируйте признаки. Чуть выше в статье я показал, как делать стандартизацию (вычитание из признаков их среднего значения, и деление на среднее квадратическое отклонение). Еще можно применить нормализацию: минимальное значение каждого отдельного признака должно быть равным 0, а максимальное 1. В моем наборе данных все это учтено. Давайте начнем:
from sklearn.svm import SVC import pandas as pd data = pd.read_csv("export_dataframe_copy.csv", index_col="Good_UX") data.head() target = "Awards" y = data[target] X = data.drop(target, axis=1) print(y) print(X)
MinMaxScaler и StandardScaler. StandardScaler вроде как чаще встречается в реальных задачах, и не сохраняет разреженность данных, особенно если много выбросов. Среднее будет 0 и стандартное отклонение 1, хорошо подходит для нормального распределения данных. MinMaxScaler умещает масштаб данных в диапазон [0, 1]. Если их использовать до train_test_split, будет потеря данных. Тут надо следить, чтобы данные из val/test не попали в трейн.
from sklearn.model_selection import train_test_split X_train, X_valid, y_train, y_valid = train_test_split(X, y, test_size=0.25, random_state=42) from sklearn.preprocessing import MinMaxScaler scaler = MinMaxScaler() X_train = pd.DataFrame(scaler.fit_transform(X_train), columns=X_train.columns) X_valid = pd.DataFrame(scaler.transform(X_valid), columns=X_valid.columns)
Логистическая регрессия это про классификацию, поэтому в переменной Y должны быть значения 1 или 0. Accuracy это метрика оценки качества в задачах классификации, доля правильных ответов. Accuracy = (TN + TP)/(TN + TP + FN + FP).
from sklearn.metrics import accuracy_score clf = SVC(gamma=0.001, C=100.,verbose=True) import numpy as np clf.fit(X_train, y_train)
y_pred = clf.predict(X_valid) y_pred_train = clf.predict(X_train) accuracy_score(y_valid, y_pred) from sklearn.linear_model import LogisticRegression lr = LogisticRegression(solver="lbfgs", penalty='l2') lr.fit(X_train, y_train) y_pred_train = lr.predict(X_train) accuracy_score(y_train, y_pred_train)
Мы получили не самый удовлетворительный показатель accuracy = 0.6796407185628742, давайте улучшать. У модели SVC есть параметр C, который штрафует за ошибку классификации. По умолчанию этот параметр равен 1. Зададим несколько возможных значений для этого параметра и посмотрим, какие значения являются наиболее выгодными:
import numpy as np c_values = np.logspace(-2, 5, 36) accuracy_on_valid = [] accuracy_on_train = [] for i, value in enumerate(c_values): clf = SVC(C=value, kernel='rbf', gamma="auto") clf.fit(X_train, y_train) y_pred = clf.predict(X_valid) y_pred_train = clf.predict(X_train) acc_valid = accuracy_score(y_valid, y_pred) acc_train = accuracy_score(y_train, y_pred_train) if i % 5 == 0: print('C = {}'.format(value), 'tвалидационные = {}'.format(acc_valid)) print('C = {}'.format(value), 'tтренировочные = {}n'.format(acc_train)) accuracy_on_valid.append(acc_valid) accuracy_on_train.append(acc_train)
C = 0.01 валидационные = 0.6905829596412556 C = 0.01 тренировочные = 0.6796407185628742 C = 0.1 валидационные = 0.6905829596412556 C = 0.1 тренировочные = 0.6796407185628742 C = 1.0 валидационные = 0.6905829596412556 C = 1.0 тренировочные = 0.6796407185628742 C = 10.0 валидационные = 0.6905829596412556 C = 10.0 тренировочные = 0.6841317365269461 C = 100.0 валидационные = 0.6905829596412556 C = 100.0 тренировочные = 0.688622754491018 C = 1000.0 валидационные = 0.6860986547085202 C = 1000.0 тренировочные = 0.6961077844311377 C = 10000.0 валидационные = 0.6771300448430493 C = 10000.0 тренировочные = 0.7155688622754491 C = 100000.0 валидационные = 0.695067264573991 C = 100000.0 тренировочные = 0.7335329341317365
Как мы видим, точность на валидационных данных до определённого момента растёт. Начиная с 40 000 заметен спад точности на валидационных данных, однако, точность на тренировочных данных продолжает расти. Это означает, что модель начинает переобучаться.
import matplotlib.pyplot as plt plt.plot(c_values, accuracy_on_valid, label="valid", linewidth=3, alpha=0.4, color = "g") plt.plot(c_values, accuracy_on_train, label="train", linewidth=3, alpha=0.4, color = "b") plt.xlabel('Значение параметра C') plt.ylabel('Accuracy') plt.legend() plt.grid() plt.show()
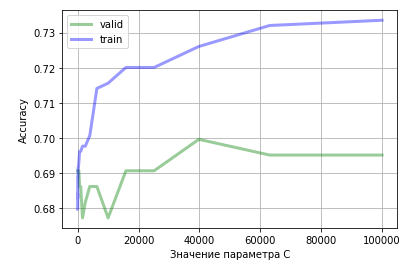
Помимо Accuracy, нужно учитывать F1, Precision и Recall. Если Accuracy = 86,43%, Precision =24,73%, то это неудовлетворительно. Точность низкая, модель нельзя внедрять. Всегда смотрим на матрицу ошибок.
Наглядно видно, как точность на валидационных данных при C=40000 уже выше, чем при использовании SVM без настройки параметров. Но следует понимать, что SVM не особо эффективен на шумных данных.
Все курсы > Оптимизация > Занятие 2
На прошлом занятии мы познакомились с понятием производной и нашли минимум функции с одной переменной. При этом, мы отказались от использования второй переменной сдвига.
$$ y = w cdot x $$
Сегодня мы научимся находить минимум функции с двумя переменными w и b и построим полноценную модель простой линейной регрессии (Simple Linear Regression).
$$ y = w cdot x + b $$
Для этого мы напишем алгоритм, который называется методом градиентного спуска (gradient descent method). Однако перед этим мы возьмем более простую функцию и на ее примере изучим, как работает этот метод.
Градиент и метод градиентного спуска
Функция нескольких переменных
Возьмем вот такую функцию потерь.
$$ f(w_1, w_2) = w_1^2 + w_2^2 $$
График этой функции можно представить в трехмерном пространстве, где по осям w1 и w2 отложены веса исходной модели, а по оси f(w1, w2) — уровень потерь при заданных весах.
Откроем ноутбук к этому занятию⧉
Посмотрим на график этой функции.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 |
# установим размер графика fig = plt.figure(figsize = (12,10)) # создадим последовательность из 1000 точек в интервале от -5 до 5 # для осей w1 и w2 w1 = np.linspace(—5, 5, 1000) w2 = np.linspace(—5, 5, 1000) # создадим координатную плоскость из осей w1 и w2 w1, w2 = np.meshgrid(w1, w2) # пропишем функцию f = w1 ** 2 + w2 ** 2 # создадим трехмерное пространство ax = fig.add_subplot(projection = ‘3d’) # выведем график функции, alpha задает прозрачность ax.plot_surface(w1, w2, f, alpha = 0.4, cmap = ‘Blues’) # выведем точку A с координатами (3, 4, 25) и подпись к ней ax.scatter(3, 4, 25, c = ‘red’, marker = ‘^’, s = 100) ax.text(3, 3.5, 28, ‘A’, size = 25) # аналогично выведем точку B с координатами (0, 0, 0) ax.scatter(0, 0, 0, c = ‘red’, marker = ‘^’, s = 100) ax.text(0, —0.4, 4, ‘B’, size = 25) # укажем подписи к осям ax.set_xlabel(‘w1’, fontsize = 15) ax.set_ylabel(‘w2’, fontsize = 15) ax.set_zlabel(‘f(w1, w2)’, fontsize = 15) # выведем результат plt.show() |

Предположим мы начали с весов в точке A с координатами (3, 4, 25). Как нам спуститься в минимум функции в точке B (0, 0, 0)? Просто двигаться в направлении обратном производной мы не можем. Ведь единственной производной, которая бы описывала все изменения нашей функции, просто не существует.
Все дело в том, что если смотреть на нашу функцию «сверху» (то есть на график изолиний или линий уровня, contour lines), то в каждой точке у нас теперь два направления, по оси w1 и по оси w2.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# установим размер графика fig, ax = plt.subplots(figsize = (10,10)) # создадим последовательность из 100 точек в интервале от -5 до 5 # для осей w1 и w2 w1 = np.linspace(—5.0, 5.0, 100) w2 = np.linspace(—5.0, 5.0, 100) # создадим координатную плоскость из осей w1 и w2 w1, w2 = np.meshgrid(w1, w2) # пропишем функцию C = w1 ** 2 + w2 ** 2 # построим изолинии (линии уровня) plt.contourf(w1, w2, C, cmap = ‘Blues’) # выведем точку А с координатами на плоскости (3, 4) ax.scatter(3, 4, c = ‘red’, marker = ‘^’, s = 200) ax.text(2.85, 4.3, ‘A’, size = 25) # и точку B с координатами (0, 0) ax.scatter(0, 0, c = ‘red’, marker = ‘^’, s = 200) ax.text(—0.15, 0.3, ‘B’, size = 25) # укажем подписи к осям ax.set_xlabel(‘w1’, fontsize = 15) ax.set_ylabel(‘w2’, fontsize = 15) # а также стрелки направления изменений вдоль w1 и w2 ax.arrow(2.7, 4, —2, 0, width = 0.1, head_length = 0.3) ax.arrow(3.005, 3.6, 0, —2, width = 0.1, head_length = 0.3) # создадим сетку в виде прерывистой черты plt.grid(linestyle = ‘—‘) # выведем результат plt.show() |

Как понять куда нам двигаться?
Частная производная
Если «заморозить» одну из переменных (то есть представить, что это константа), пусть это будет w2, мы можем найти производную по первой переменной w1.
$$ f_{w_1} = frac{partial f}{partial w_1} = 2w_1 $$
Такая производная называется частной (partial derivative), потому что она описывает изменение только в первой переменной w1.
Графически, мы как бы убираем переменную w2 (получается сечение, представленное параболой) и ищем производную функции, в которой есть только переменная w1.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 |
# зададим размер графика в дюймах plt.figure(figsize = (10, 8)) # объявим функцию параболы def f(x): return x ** 2 # объявим ее производную def der(x): return 2 * x # пропишем уравнение через point-slope form # y — y1 = m * (x — x1) —> y = m * (x — x1) + y1 def line(x, x1, y1): return der(x1) * (x — x1) + y1 # создадим последовательность координат x для параболы x = np.linspace(—4, 4, 100) # построим график параболы plt.plot(x, f(x)) # и заполним ее по умолчанию синим цветом с прозрачностью 0,5 plt.fill_between(x, f(x), 16, alpha = 0.5) # в цикле пройдемся по точкам -2, 0, 2 на оси х for x1 in range(—2, 3, 2): # рассчитаем соответствующие им координаты y y1 = f(x1) # определим пространство по оси x для касательных линий xrange = np.linspace(x1 — 3, x1 + 3, 9) # построим касательные линии plt.plot(xrange, line(xrange, x1, y1), ‘C1—‘, linewidth = 2) # и точки соприкосновения с графиком параболы plt.scatter(x1, y1, color = ‘C1’, s = 50) # укажем подписи к осям plt.xlabel(‘w1’, fontsize = 15) plt.ylabel(‘f(w1, w2)’, fontsize = 15) # выведем результат plt.show() |

Точно таким же образом мы поступаем со второй переменной w2. Мы замораживаем первую переменную w1 и вычисляем частную производную.
$$ f_{w_2} = frac{partial f}{partial w_2} = 2w_2 $$
Теперь, взяв точку на плоскости (w1, w2), мы будем точно знать скорость изменения функции f(w1, w2) в этой точке в каждом из направлений.
Например, возьмем ту же точку A с координатами w1 = 3, w2 = 4, скорость изменения функции в первом измерении будет равна 2 x 3 = 6, во втором 2 x 4 = 8.
Нотация анализа
Вы вероятно заметили, что мы использовали две нотации (записи) частной производной. С первой мы уже знакомы по предыдущему занятию, это нотация Лагранжа.
$$ f(w) rightarrow f'(w) $$
Вторую нотацию, нотацию Лейбница, удобнее использовать для записи частных производных.
$$ f(w_1, w_2) rightarrow frac{partial f}{partial w_1}, frac{partial f}{partial w_2} $$
Она позволяет сразу увидеть, по какой переменной происходит дифференцирование.
Напомню, что запись формул (и, в частности, производной) в текстовых ячейках ноутбуков с помощью LaTeX мы изучили, когда говорили про Jupyter Notebook.
Взятие частных производных
Пошагово рассмотрим, как мы пришли к результату (2w1, 2w2). Вначале найдем производную по первой переменой w1. Вторую переменную, w2, мы будем считать константой, то есть некоторым числом.
$$ frac{partial f}{partial w_1} (w_1^2 + w_2^2) $$
Первое, что бросается в глаза, это то, что у нас производная суммы, а она, как известно, равна сумме производных.
$$ frac{partial f}{partial w_1} (w_1^2 + w_2^2) = frac{partial f}{partial w_1} (w_1^2) + frac{partial f}{partial w_1} (w_2^2) $$
Производную первого слагаемого мы найдем по правилу производной степенной функции. Второе слагаемое мы решили считать константой, а производная константы равна нулю.
$$ frac{partial f}{partial w_1} (w_1^2) + frac{partial f}{partial w_1} (w_2^2) = 2w_1 + 0 = 2w_1 $$
Частная производная по второй переменной находится аналогично.
Использование SymPy
Функцию diff() библиотеки SymPy можно также использовать для взятия частных производных. Вначале импортируем функцию diff() и символы x и y (мы их используем вместо w1 и w2).
|
from sympy import diff from sympy.abc import x, y |
Напишем функцию, которую хотим дифференцировать.
После этого мы можем находить частные производные, передав в diff() функцию для дифференцирования, а затем либо первую, либо вторую переменную.
|
# найдем частную производную по первой переменной diff(f, x) |
![]()
|
# найдем частную производную по второй переменной diff(f, y) |
![]()
Градиент
Градиент (gradient) — есть не что иное, как совокупность частных производных по каждой из независимых переменных. Его можно назвать «полной производной».
Он обозначается через греческую букву набла ∇ или оператор Гамильтона.
$$ nabla f(w_1, w_2) = begin{bmatrix} frac{partial f}{partial w_1} \ frac{partial f}{partial w_1} end{bmatrix} = begin{bmatrix} 2w_1 \ 2w_2 end{bmatrix} $$
Еще раз посмотрим, чему равен градиент в точке (3, 4), но уже в новой записи.
$$ nabla f(3, 4) = begin{bmatrix} 2 cdot 3 \ 2 cdot 4 end{bmatrix} = begin{bmatrix} 6 \ 8 end{bmatrix} $$
Как вы видите, такая функция на входе принимает два числа, а на выходе выдает вектор, также состоящий из двух чисел. В этом случае говорят о вектор-функции (vector-valued function).
Метод градиентного спуска
Градиент, который мы только что нашли, показывает направление скорейшего подъема (возрастания) функции. Нам же, если мы хотим найти минимум функции, нужно двигаться вниз в направлении, обратном направлению градиента (еще говорят про направление антиградиента, negative gradient).
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 |
# установим размер графика fig, ax = plt.subplots(figsize = (10,10)) # создадим последовательность из 100 точек в интервале от -10 до 10 # для осей w1 и w2 w1 = np.linspace(—10.0, 10.0, 100) w2 = np.linspace(—10.0, 10.0, 100) # создадим координатную плоскость из осей w1 и w2 w1, w2 = np.meshgrid(w1, w2) # пропишем функцию C = w1 ** 2 + w2 ** 2 # построим изолинии (линии уровня) plt.contourf(w1, w2, C, cmap = ‘Blues’) # выведем точку А с координатами на плоскости (3, 4) ax.scatter(3, 4, c = ‘red’, marker = ‘^’, s = 200) ax.text(2.5, 4.5, ‘A’, size = 25) # и точку B с координатами (0, 0) ax.scatter(0, 0, c = ‘red’, marker = ‘^’, s = 200) ax.text(—1, 0.3, ‘B’, size = 25) # укажем подписи к осям ax.set_xlabel(‘w1’, fontsize = 15) ax.set_ylabel(‘w2’, fontsize = 15) # а также стрелки направления изменений вдоль w1 и w2 ax.arrow(2.7, 4, —2, 0, width = 0.1, head_length = 0.3) ax.arrow(3, 3.5, 0, —2, width = 0.1, head_length = 0.3) # выведем вектор антиградиента с направлением (-6, -8) ax.arrow(3, 4, —6, —8, width = 0.05, head_length = 0.3) ax.text(—2.8, —4.5, ‘Антиградиент’, rotation = 53, size = 16) # создадим сетку в виде прерывистой черты plt.grid(linestyle = ‘—‘) # выведем результат plt.show() |

Если мы сдвинемся на −6 по оси w1 и на −8 по оси w2, то обязательно пройдем через минимум функции. При этом, если мы сдвинемся на всю величину градиента, то «перескочим» через минимум. Именно поэтому нам нужен коэффициент скорости обучения (learning rate).
Теперь мы готовы дать определение:
Метод градиентного спуска — это способ нахождения локального минимума функции в процессе движения в направлении антиградиента. Он был предложен Огюстеном Луи Коши еще в 1847 году.
Воспользуемся этим методом для нахождения минимума приведенной выше функции. Другими словами, проделаем путь из точки А в точку B.
Метод градиентного спуска на Питоне
Вначале объявим необходимые функции.
|
# пропишем функцию потерь def objective(w1, w2): return w1 ** 2 + w2 ** 2 # а также производную по первой def partial_1(w1): return 2.0 * w1 # и второй переменной def partial_2(w2): return 2.0 * w2 |
Зададим исходные параметры модели.
|
# пропишем изначальные веса w1, w2 = 3, 4 # количество итераций iter = 100 # и скорость обучения learning_rate = 0.05 |
Теперь создадим списки для учета обновления весов w1 и w2 и изменения уровня ошибки.
|
w1_list, w2_list, l_list = [], [], [] |
Найдем минимум функции потерь.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 |
# в цикле с заданным количеством итераций for i in range(iter): # будем добавлять текущие веса в соответствующие списки w1_list.append(w1) w2_list.append(w2) # и рассчитывать и добавлять в список текущий уровень ошибки l_list.append(objective(w1, w2)) # также рассчитаем значение частных производных при текущих весах par_1 = partial_1(w1) par_2 = partial_2(w2) # будем обновлять веса в направлении, # обратном направлению градиента, умноженному на скорость обучения w1 = w1 — learning_rate * par_1 w2 = w2 — learning_rate * par_2 # выведем итоговые веса модели и значение функции потерь w1, w2, objective(w1, w2) |
|
(7.968419666276241e-05, 0.00010624559555034984, 1.7637697771638315e-08) |
Как мы видим, уже после ста итераций, как веса модели, так и уровень ошибки приблизились к нулю.
Разумеется, более сложные функции потерь потребуют большего количества итераций и более тонкой настройки коэффициента скорости обучения.
Остается посмотреть на графике, какой путь проделал наш алгоритм градиентного спуска.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 |
fig = plt.figure(figsize = (14,12)) w1 = np.linspace(—5, 5, 1000) w2 = np.linspace(—5, 5, 1000) w1, w2 = np.meshgrid(w1, w2) f = w1 ** 2 + w2 ** 2 ax = fig.add_subplot(projection = ‘3d’) ax.plot_surface(w1, w2, f, alpha = 0.4, cmap = ‘Blues’) ax.text(3, 3.5, 28, ‘A’, size = 25) ax.text(0, —0.4, 4, ‘B’, size = 25) ax.set_xlabel(‘w1’, fontsize = 15) ax.set_ylabel(‘w2’, fontsize = 15) ax.set_zlabel(‘f(w1, w2)’, fontsize = 15) # выведем путь алгоритма оптимизации ax.plot(w1_list, w2_list, l_list, ‘.-‘, c = ‘red’) plt.show() |
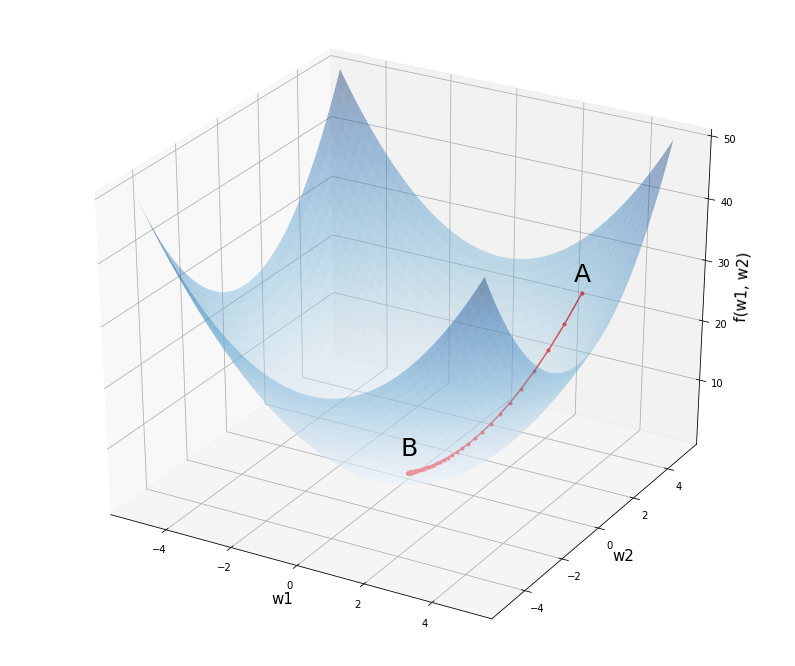
Промежуточные выводы
Давайте еще раз проговорим основные идеи пройденного материала.
- Градиент показывает скорость изменения многомерной функции по каждому из измерений (по каждой из переменных)
- Если «заморозить» все независимые переменные кроме одной и сделать срез, то наклон касательной к кривой среза будет значением частной производной по этому измерению.
- И самое важное для нас: градиент показывает направление скорейшего подъёма (возрастания) функции. Двигаясь в обратном направлении, мы придем к минимуму функции.
Простая линейная регрессия
А теперь давайте с нуля напишем нашу первую модель машинного обучения. Мы наконец-то приобрели для этого все необходимые знания. Наша модель будет по-прежнему иметь только один признак, но при этом будет учитываться не только наклон, но и сдвиг прямой.
$$ hat{y} = w cdot x + b $$
Данные и постановка задачи
Сегодня мы возьмем хорошо известные нам данные роста и обхвата шеи и сразу преобразуем их в массив Numpy.
|
X = np.array([1.48, 1.49, 1.49, 1.50, 1.51, 1.52, 1.52, 1.53, 1.53, 1.54, 1.55, 1.56, 1.57, 1.57, 1.58, 1.58, 1.59, 1.60, 1.61, 1.62, 1.63, 1.64, 1.65, 1.65, 1.66, 1.67, 1.67, 1.68, 1.68, 1.69, 1.70, 1.70, 1.71, 1.71, 1.71, 1.74, 1.75, 1.76, 1.77, 1.77, 1.78]) y = np.array([29.1, 30.0, 30.1, 30.2, 30.4, 30.6, 30.8, 30.9, 31.0, 30.6, 30.7, 30.9, 31.0, 31.2, 31.3, 32.0, 31.4, 31.9, 32.4, 32.8, 32.8, 33.3, 33.6, 33.0, 33.9, 33.8, 35.0, 34.5, 34.7, 34.6, 34.2, 34.8, 35.5, 36.0, 36.2, 36.3, 36.6, 36.8, 36.8, 37.0, 38.5]) |
Выведем эти данные на графике с помощью диаграммы рассеяния или точечной диаграммы.
|
# построим точечную диаграмму plt.figure(figsize = (10,6)) plt.scatter(X, y) # добавим подписи plt.xlabel(‘Рост, см’, fontsize = 16) plt.ylabel(‘Обхват шеи, см’, fontsize = 16) plt.title(‘Зависимость роста и окружности шеи у женщин в России’, fontsize = 18) plt.show() |

Как мы помним, нашей задачей является минимизация средней суммы квадрата расстояний между нашими данными и линией регрессии.
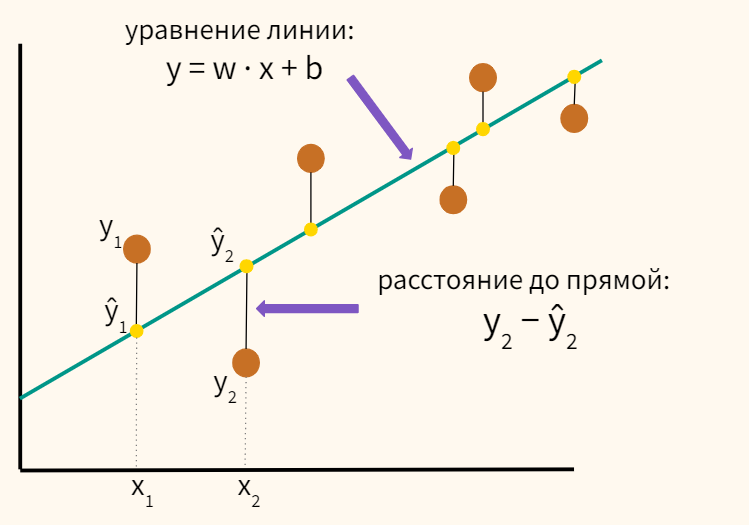
Также приведу формулу.
$$ MSE = frac {1}{n} sum^{n}_{i=1} (y_i-hat{y}_i) ^2 $$
Решение методом наименьшних квадратов
Прежде чем использовать алгоритм градиентного спуска найдем аналитическое решение с помощью метода наименьших квадратов (МНК, least squares method). Для уравнения с одной независимой переменной, напомню, используется следующая формула.
$$ w = frac {sum_{i = 1}^{n} (x_i-bar{x})(y_i-bar{y})} {sum_{i = 1}^{n} (x_i-bar{x})^2} $$
$$ b = bar{y}-wbar{x} $$
Собственная модель
Давайте вычислим наклон и сдвиг прямой с помощью этой формулы на Питоне.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 |
# найдем среднее значение X и y X_mean = np.mean(X) y_mean = np.mean(y) # объявим переменные для числителя и знаменателя numerator, denominator = 0, 0 # в цикле пройдемся по данным for i in range(len(X)): # вычислим значения числителя и знаменателя по формуле выше numerator += (X[i] — X_mean) * (y[i] — y_mean) denominator += (X[i] — X_mean) ** 2 # найдем наклон и сдвиг w = numerator / denominator b = y_mean — w * X_mean w, b |
|
(26.861812005569753, -10.570936299787313) |
Также давайте реализуем этот алгоритм с помощью векторизованного кода.
|
w = np.sum((X — X_mean) * (y — y_mean)) / np.sum((X — X_mean) ** 2) b = y_mean — w * X_mean w, b |
|
(26.861812005569757, -10.57093629978732) |
Модель LinearRegression библиотеки sklearn
Надо сказать, что модель LinearRegression, которую мы использовали на вводном занятии по оптимизации и затем на занятии по линейной регрессии применяет именно МНК для минимизации MSE.
Давайте еще раз применим класс LinearRegression, чтобы убедиться в получении одинаковых результатов.
|
# из набора линейных моделей библиотеки sklearn импортируем линейную регрессию from sklearn.linear_model import LinearRegression # создадим объект этого класса и запишем в переменную model model = LinearRegression() # обучим модель (для X используем двумерный массив) model.fit(X.reshape(—1, 1), y) # выведем коэффициенты model.coef_, model.intercept_ |
|
(array([26.86181201]), -10.570936299787334) |
Как вы видите, результаты одинаковы. Теперь сделаем прогноз и рассчитаем среднеквадратическую ошибку.
|
# сделаем прогноз y_pred_least_squares = model.predict(X.reshape(—1, 1)) # импортируем модуль метрик from sklearn import metrics # выведем среднеквадратическую ошибку (MSE) metrics.mean_squared_error(y, y_pred_least_squares) |
Позднее мы сравним этот результат с аналогичным показателем алгоритма градиентного спуска.
МНК и метод градиентного спуска
Одна из причин использования алгоритма градиентного спуска вместо МНК заключается в том, что этот алгоритм менее требователен к вычислительным ресурсам при большом объеме (количество наблюдений) и размерности (количество признаков) данных.
Кроме того, метод градиентного спуска может применяться не только в задачах линейной регрессии, но и в других алгоритмах (например, в логистической регрессии, SVM или нейросетях).
Решение методом градиентного спуска
Модель линейной регрессии и функция потерь
Начнем с того, что объявим функцию линейной модели.
|
def regression(X, w, b): return w * X + b |
Теперь давайте немного модифицируем функцию потерь и найдем половину среднеквадратической ошибки (half MSE). Обозначим нашу функцию буквой J.
$$ J_{MSE} = frac{1}{2n} sum_{i=1}^{n} (y_i-(wx_i+b))^2 $$
Число два в знаменателе удачно сократится с двойкой, полученной при дифференцировании степенной функции. При этом точка минимума функции не изменится.
|
def objective(X, y, w, b, n): return np.sum((y — regression(X, w, b)) ** 2) / (2 * n) |
Дополнительно замечу, что использование именно среднеквадратической, то есть усредненной на количество наблюдений, ошибки (MSE) вместо «простой» суммы квадратов отклонений (Sum of Squared Errors, SSE)
$$ J_{SSE} = sum_{i=1} (y_i-(wx_i+b))^2 $$
может быть предпочтительнее, поскольку позволяет сравнивать результаты модели на выборках разных размеров.
Частные производные функции потерь
Найдем частные производные этой функции. Их будет две: одна по наклону (w), вторая по сдвигу (b). Начнем с наклона.
$$ frac{partial J}{partial w} left( frac{1}{2n} sum_{i=1}^{n} (y_i-(wx_i+b))^2 right) $$
Шаг 1. Вынесем число 1/2n за скобку по правилу умножения на число. В данном случае n, то есть количество наблюдений, превратится в число, как только мы применим формулу к набору данных.
$$ frac{partial J}{partial w} = frac{1}{2n} frac{partial J}{partial w} sum_{i=1}^{n} left( (y_i-(wx_i+b))^2 right) $$
Шаг 2. Теперь давайте для удобства перепишем выражение в векторизованной форме. Теперь x и y будут не отдельными числами, а векторами.
$$ frac{partial J}{partial w} = frac{1}{2n} frac{partial J}{partial w} left( (y-(wx+b)) ^2 right) $$
Шаг 3. Перед нами композиция из двух функций. Применим chain rule.
$$ frac{partial J}{partial w} = frac{1}{2n} cdot 2(y-(wx+b)) cdot frac{partial J}{partial w} (y-(wx+b)) $$
Шаг 4. К внутренней функции мы можем применить правило суммы и разности производных.
$$ frac{1}{2n} cdot 2(y-(wx+b)) cdot (0-(x+0)) $$
Замечу, что при дифференцировании внутренней функции, y превратился в ноль, потому что это константа. Одновременно переменную b мы «заморозили» и также решили считать константой.
Шаг 5. Упростим выражение.
$$ frac{partial J}{partial w} = frac{1}{cancel{2}n} cdot cancel{2}-x(y-(wx+b)) = frac{1}{n} cdot -x(y-(wx+b)) $$
Аналогично найдем частную производную по сдвигу.
$$ frac{partial J}{partial b} = frac{1}{n} cdot -(y-(wx+b)) $$
Здесь стоит уточнить лишь, что при нахождении производной внутренней функции мы «заморозили» переменную w.
$$ frac{partial J}{partial b} left( (y-(wx+b)) right) = 0-(0+1)$$
В невекторизованной форме производные выглядят следующим образом.
$$ frac{partial J}{partial w} = frac{1}{n} sum_{i=1}^{n} -x_i(y_i-(wx_i+b)) $$
$$ frac{partial J}{partial b} = frac{1}{n} sum_{i=1}^{n} -(y_i-(wx_i+b)) $$
Поменяв слагаемые в скобках местами и умножив на $-1$, частные производные можно записать и так.
$$ frac{partial J}{partial w} = frac{1}{n} sum_{i=1}^{n} ((wx_i+b)-y_i) cdot x_i $$
$$ frac{partial J}{partial b} = frac{1}{n} sum_{i=1}^{n} ((wx_i+b)-y_i) $$
Пропишем эти функции на Питоне.
|
def partial_w(X, y, w, b, n): return np.sum(—X * (y — (w * X + b))) / n def partial_b(X, y, w, b, n): return np.sum(—(y — (w * X + b))) / n |
Алгоритм градиентного спуска
Создадим функцию, которая будет на входе принимать данные, количество итераций и коэффициент скорости обучения, а на выходе выдавать веса модели и уровень ошибки.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 |
# передадим функции данные, количество итераций и скорость обучения def gradient_descent(X, y, iter, learning_rate): # зададим изначальные веса w, b = 0, 0 # и количество наблюдений n = len(X) # создадим списки для записи весов модели и уровня ошибки w_list, b_list, l_list = [], [], [] # в цикле с заданным количеством итераций for i in range(iter): # добавим в списки текущие веса w_list.append(w) b_list.append(b) # и уровень ошибки l_list.append(objective(X, y, w, b, n)) # рассчитаем текущее значение частных производных par_1 = partial_w(X, y, w, b, n) par_2 = partial_b(X, y, w, b, n) # обновим веса в направлении антиградиента w = w — learning_rate * par_1 b = b — learning_rate * par_2 # выведем списки с уровнями ошибки и весами return w_list, b_list, l_list |
Обучение модели
Применим написанную выше функцию для обучения модели. Используем следующие гиперпараметры модели:
- количество итераций — 200 000
- коэффициент скорости обучения — 0,01
Напомню, что гиперпараметр — это параметр, который мы задаем до обучения модели.
|
# распакуем результат работы функции в три переменные w_list, b_list, l_list = gradient_descent(X, y, iter = 200000, learning_rate = 0.01) # и выведем последние достигнутые значения весов и уровня ошибки print(w_list[—1], b_list[—1], l_list[—1]) |
|
26.6917462520774 -10.293843835595917 0.1137823984153401 |
В целом, как мы видим, веса модели очень близки к результату, найденному с помощью метода наименьших квадратов. Теперь сделаем прогноз.
|
# передадим функции regression() наиболее оптимальные веса y_pred_gd = regression(X, w_list[—1], b_list[—1]) y_pred_gd[:5] |
|
array([29.20994062, 29.47685808, 29.47685808, 29.74377554, 30.01069301]) |
Посмотрим на результат на графике.
|
plt.figure(figsize = (10, 8)) plt.scatter(X, y) plt.plot(X, y_pred_gd, ‘r’) plt.show() |

Кроме того, мы можем посмотреть на то, как снижался уровень ошибки с каждой последующей итерацией.

Как мы видим, в первые итерации уровень ошибки снижался настолько стремительно, что последующие изменения практически незаметны. Давайте попробуем отбросить первые 150 наблюдений.
|
plt.figure(figsize = (8, 6)) plt.plot(l_list[150:]) plt.show() |

И все же кажется, что после 150000 итераций ошибка перестает снижаться и можно было бы обойтись меньшим количеством шагов. На самом деле это не так.
|
# отбросим первые 150 000 наблюдений plt.figure(figsize = (8, 6)) plt.plot(l_list[150000:]) plt.show() |

В целом подбор количества итераций и длины шага (коэффициента скорости обучения) довольно существенно влияют на качество обучения. Ближе к концу занятия мы рассмотрим этот момент более подробно.
Оценка качества модели
Оценим качество модели с помощью встроенной в sklearn метрики.
|
# рассчитаем MSE metrics.mean_squared_error(y, y_pred_gd) |
Результат очень близок к тому, который мы получили, используя МНК.
Визуализация шагов алгоритма оптимизации
Мы также как и раньше, можем посмотреть на путь, пройденный алгоритмом оптимизации.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 |
# создадим последовательности из 500 значений ww = np.linspace(—30, 30, 500) bb = np.linspace(—30, 30, 500) # сформируем координатную плоскость www, bbb = np.meshgrid(ww, bb) # а также матрицу из нулей для заполнения значениями функции J(w, b) JJ = np.zeros([len(ww), len(bb)]) # для каждой комбинации w и b for i in range(len(ww)): for j in range(len(bb)): # рассчитаем соответствующее прогнозное значение yy = www[i, j] * X + bbb[i, j] # и подставим его в функцию потерь (матрицу JJ) JJ[i, j] = 1 / (2 * len(X)) * np.sum((y — yy) ** 2) # зададим размер графика fig = plt.figure(figsize = (14,12)) # создидим трехмерное пространство ax = fig.add_subplot(projection = ‘3d’) # построим функцию потерь ax.plot_surface(www, bbb, JJ, alpha = 0.4, cmap = plt.cm.jet) # а также путь алгоритма оптимизации ax.plot(w_list, b_list, l_list, c = ‘red’) # для наглядности зададим более широкие, чем график # границы пространства ax.set_xlim(—40, 40) ax.set_ylim(—40, 40) plt.show() |

Мы также можем построить график изолиний («вид сверху»).
|
# для этого используем функцию plt.contour() fig, ax = plt.subplots(figsize = (10, 10)) ax.contour(www, bbb, JJ, 100, cmap = plt.cm.jet) ax.plot(w_list, b_list, c = ‘red’) plt.show() |

Как мы видим, алгоритм сначала двигался в одном направлении (очевидно, так ошибка снижалась наиболее стремительно), затем повернул на 90 градусов и продолжил движение.
Про выбор гиперпараметров модели
Давайте посмотрим, как поведет себя алгоритм при изменении гиперпараметров. Вначале попробуем тот же размер шага, но уменьшим количество итераций.
|
w_list_t1, b_list_t1, l_list_t1 = gradient_descent(X, y, iter = 10000, learning_rate = 0.01) w_list_t1[—1], b_list_t1[—1], l_list_t1[—1] |
|
(17.113947076094593, 5.311508333809235, 0.4836593999661288) |
Коэффициенты довольно сильно отличаются от найденных ранее значений. Посмотрим на графике изолиний, где остановился наш алгоритм.
|
fig, ax = plt.subplots(figsize = (10, 10)) ax.contour(www, bbb, JJ, 100, cmap = plt.cm.jet) ax.plot(w_list, b_list, c = ‘red’) # выведем точку, которой достиг новый алгоритм ax.scatter(w_list_t1[—1], b_list_t1[—1], s = 100, c = ‘blue’) plt.show() |

Как мы видим, алгоритм немного не дошел до оптимума. Теперь давайте попробуем уменьшить размер шага. Количество итераций вернем к прежнему значению.
|
w_list_t2, b_list_t2, l_list_t2 = gradient_descent(X, y, iter = 200000, learning_rate = 0.0001) w_list_t2[—1], b_list_t2[—1], l_list_t2[—1] |
|
(15.302448783526573, 8.263028645561734, 0.6339512457580667) |
|
fig, ax = plt.subplots(figsize = (10, 10)) ax.contour(www, bbb, JJ, 100, cmap = plt.cm.jet) ax.plot(w_list, b_list, c = ‘red’) ax.scatter(w_list_t2[—1], b_list_t2[—1], s = 100, c = ‘blue’) plt.show() |
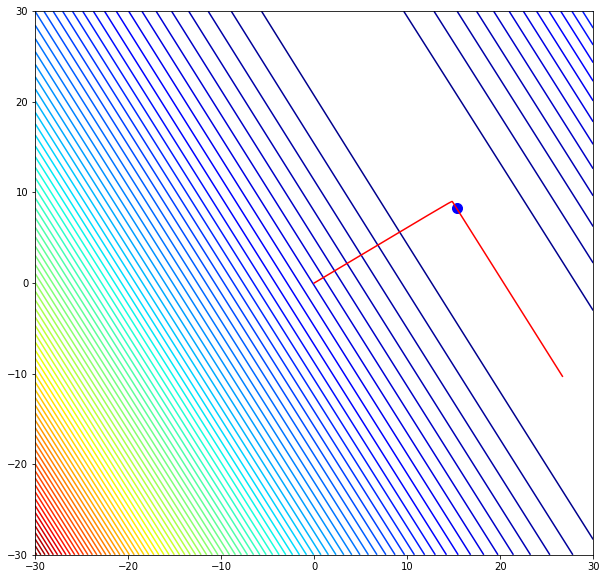
В данном случае, так как мы делали слишком маленькие шаги, то продвинулись еще меньше.
Тема выбора гиперпараметров довольно сложна и выходит за рамки сегодняшнего занятия, однако уже на этих простых примерах видно, что один и тот же алгоритм при разных изначальных параметрах показывает совершенно разные результаты.
Подведем итог
В первой части занятия мы посмотрели как применить понятие производной к многомерной функции, познакомились с понятием градиента и методом градиентного спуска. Во второй части мы построили модель простой линейной регрессии и оптимизировали ее с помощью метода наименьших квадратов и алгоритма градиентного спуска.
Вопросы для закрепления
Вопрос. Что такое градиент?
Посмотреть правильный ответ
Ответ: градиент — это вектор, показывающий направление скорейшего подъема многомерной функции. Градиент состоит из частных производных по каждому из измерений (переменных) функции.
Вопрос. Какие гиперпараметры существенно влияют на качество оптимизации модели линейной регрессии?
Посмотреть правильный ответ
Ответ: количество итераций и коэффициент скорости обучения
Логичным продолжением будет построение модели многомерной или множественной линейной регрессии (multiple linear regression) с несколькими признаками. Однако прежде будет полезно еще раз в деталях изучить взаимосвязь переменных.
Ответы на вопросы
Вопрос. Почему если умножить функцию потерь на число, в частности на 1/2, точка ее минимума не изменится?
Ответ. Давайте посмотрим на график параболы и параболы, умноженной на 1/2.

Как мы видим, точка минимума не изменилась.
При этом обратите внимание на то, что изменился наклон (значение градиента). Эффект умножения функции потерь на число аналогичен измененению коэффициента скорости обучения (learning rate). Чем круче наклон, тем большие по размеру шаги мы будем делать.
Вопрос. Скажите, а как работает функция np.meshgrid()?
Ответ. Функция np.meshgrid() на входе принимает одномерные массивы и создает двумерный массив с привычной прямоугольной (декартовой) системой координат.
|
# создадим простые последовательности xvalues = np.array([0, 1, 2, 3, 4]) yvalues = np.array([0, 1, 2, 3, 4]) # сформируем координатную плоскость xx, yy = np.meshgrid(xvalues, yvalues) # выведем точки плоскости на графике plt.plot(xx, yy, marker = ‘.’, color = ‘r’, linestyle = ‘none’) plt.show() |

Обратите внимание, начало координат находится в левом нижнему углу.
Вопрос. Функция plt.fill_between() заполняет пространство между двумя функциями, но не очень понятно, какие параметры мы ей передаем.
Ответ. Функция np.fill_between(x, y1, y2 = 0) принимает три основных параметра: координаты по оси x, координаты по оси y (первая функция, y1) и координаты по оси y (вторая функция, y2) и заполняет пространство между y1 и y2. Параметр y2 не является обязательным. Если его не указывать, будет заполняться пространство между линией y1 и осью x (то есть функцией y = 0).
В конце ноутбука⧉ я привел два примера, когда параметр y2 не указывается, то есть равен 0, и когда y2 задает отличную от нуля функцию.
Преждевременная оптимизация — корень всех (или большинства) проблем в программировании.
(Дональд Кнут)
Введение
Согласно Википедии, градиентный спуск — метод нахождения локального минимума функции в направлении градиента с помощью методов одномерной оптимизации. Идея состоит в том, чтобы повторять шаги в направлении, противоположном градиенту (или приблизительному градиенту) функции в текущей точке, потому что это будет направлением наискорейшего спуска. И наоборот, шаг в направлении градиента приведет к локальному максимуму этой функции. Такой процесс называется градиентным восхождением.
По сути, градиентный спуск — это алгоритм оптимизации, используемый для поиска минимума функции:

Градиентный спуск — очень важный алгоритм в машинном обучении, поскольку он помогает найти параметры лучшей модели для определенного набора данных. Для начала давайте познакомимся с термином «Функция стоимости«.
Функция стоимости
Также ее называют функцией потерь, возможно, кому-то то название будет более привычным. Это показатель для расчета того, насколько хорошо или плохо наша модель предсказывает взаимосвязь между значениями x и y.
Существует множество различных показателей, которые можно использовать для определения качества предсказания модели. Но, в отличие от всех остальных, функция стоимости находит среднюю потерю по всему набору данных, и чем больше функция стоимости, тем хуже наша модель находит взаимосвязи в данном наборе данных.
Цель градиентного спуска — минимизация функции стоимости, потому что модель с наименьшей функцией стоимости/потерь является лучшей моделью. Чтобы лучше понять, что я только что объяснил, давайте посмотрим на следующий пример.
Предположим, что наша функция стоимости представляет собой уравнение
![]()
Если мы построим график этой функции с помощью языка Python, он будет выглядеть так:

Самый первый шаг, который нужно сделать с нашей функцией стоимости, — это дифференцировать функцию стоимости, используя цепное правило, или Chain rule.
Уравнение y= (x+5)^2 — составная функция (одна функция в другой). Внешняя функция (x+5)^2, а внутренняя —(x+5). Чтобы различать между ними, применим цепное правило. Посмотрите на изображение:

В конце есть ссылка на видео, в котором от руки выполняю математические действия, если так на словах понят трудно. Что ж, теперь эта функция, которую мы только что получили, — это градиент. Процесс нахождения градиента уравнения является наиболее важным шагом из всех. Я бы хотел, чтобы в тот день в школе мой учитель математики сказал мне, что цель дифференцирования функции состоит в том, чтобы получить градиент функции.
Это первый и самый важный шаг. Далее идет второй шаг.
Шаг 2
Двигаемся в отрицательном направлении градиента. Тут возникает вопрос, а как далеко двигаться? Вот тут в игру вступает коэффициент скорости обучения.
Коэффициент скорости обучения
Согласно определению это размер шага на каждой итерации при движении к минимизации функции потерь. Сравним это с человеком, спускающимся с горы: его шаги — это скорость обучения, и чем меньше шаги, тем больше времени им потребуется, чтобы достичь подножия горы и наоборот.
Если уменьшить скорость обучения, скажем, до 0,0001, мы тем самым увеличиваем время выполнения программы, поскольку алгоритму может потребоваться больше времени для достижения минимальных значений. И наоборот, использование больших значений коэффициента скорости обучения приведет к тому, что алгоритм будет делать слишком большие шаги и в конечном итоге может пропустить целевое минимальное значение.
Скорость обучения по умолчанию равна 0,01.
Давайте запустим итерации исполнения, чтобы посмотреть, как работает алгоритм.
Итерация первая: берем любую случайную точку в качестве стартовой точки для алгоритма. Я выбрал первое значение для х равным 0, а значения x будем обновлять по такой формуле:

На каждой итерации будем спускаться в направлении минимального значения функции, собственно, отсюда и название «Градиентный спуск». Теперь стало понятнее, не так ли?

Давайте теперь в деталях посмотрим, как это работает. Вручную посчитаем значения на двух итерациях, чтобы получить четкое представление о том, что происходит.
Первая итерация
Формула: x1 = x0 — Learning Rate * ( 2*(x+5) )
x1 = 0 — 0.01 * 0.01 * 2*(0+5)
x1 = -0.01 * 10
x1 = -0.1 (в итоге)
А затем обновляем значения, назначая новые значения старым. Повторяем процесс столько итераций, пока не достигнем минимального значения функции.
x0 = x1
Вторая итерация
x1 = -0.1 — 0.01 * 2*(-0.1+5)
x1 = -0.198
Тогда: x0 = x1
Если повторить этот процесс несколько раз, то для первых десяти итераций вывод будет таким:
RS 0 17:15:16.793 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction CUSTOM QQ 0 17:15:16.793 gradient-descent test (EURUSD,M1) 1 x0 = 0.0000000000 x1 = -0.1000000000 CostFunction = 10.0000000000 ES 0 17:15:16.793 gradient-descent test (EURUSD,M1) 2 x0 = -0.1000000000 x1 = -0.1980000000 CostFunction = 9.8000000000 PR 0 17:15:16.793 gradient-descent test (EURUSD,M1) 3 x0 = -0.1980000000 x1 = -0.2940400000 CostFunction = 9.6040000000 LE 0 17:15:16.793 gradient-descent test (EURUSD,M1) 4 x0 = -0.2940400000 x1 = -0.3881592000 CostFunction = 9.4119200000 JD 0 17:15:16.793 gradient-descent test (EURUSD,M1) 5 x0 = -0.3881592000 x1 = -0.4803960160 CostFunction = 9.2236816000 IG 0 17:15:16.793 gradient-descent test (EURUSD,M1) 6 x0 = -0.4803960160 x1 = -0.5707880957 CostFunction = 9.0392079680 IG 0 17:15:16.793 gradient-descent test (EURUSD,M1) 7 x0 = -0.5707880957 x1 = -0.6593723338 CostFunction = 8.8584238086 JF 0 17:15:16.793 gradient-descent test (EURUSD,M1) 8 x0 = -0.6593723338 x1 = -0.7461848871 CostFunction = 8.6812553325 NI 0 17:15:16.793 gradient-descent test (EURUSD,M1) 9 x0 = -0.7461848871 x1 = -0.8312611893 CostFunction = 8.5076302258 CK 0 17:15:16.793 gradient-descent test (EURUSD,M1) 10 x0 = -0.8312611893 x1 = -0.9146359656 CostFunction = 8.3374776213
Давайте также посмотрим на другие десять значений алгоритма, когда мы очень близки к минимуму функции:
GK 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1052 x0 = -4.9999999970 x1 = -4.9999999971 CostFunction = 0.0000000060 IH 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1053 x0 = -4.9999999971 x1 = -4.9999999971 CostFunction = 0.0000000059 NH 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1054 x0 = -4.9999999971 x1 = -4.9999999972 CostFunction = 0.0000000058 QI 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1055 x0 = -4.9999999972 x1 = -4.9999999972 CostFunction = 0.0000000057 II 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1056 x0 = -4.9999999972 x1 = -4.9999999973 CostFunction = 0.0000000055 RN 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1057 x0 = -4.9999999973 x1 = -4.9999999973 CostFunction = 0.0000000054 KN 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1058 x0 = -4.9999999973 x1 = -4.9999999974 CostFunction = 0.0000000053 JO 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1059 x0 = -4.9999999974 x1 = -4.9999999974 CostFunction = 0.0000000052 JO 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1060 x0 = -4.9999999974 x1 = -4.9999999975 CostFunction = 0.0000000051 QL 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1061 x0 = -4.9999999975 x1 = -4.9999999975 CostFunction = 0.0000000050 QL 0 17:15:16.800 gradient-descent test (EURUSD,M1) 1062 x0 = -4.9999999975 x1 = -4.9999999976 CostFunction = 0.0000000049 HP 0 17:15:16.800 gradient-descent test (EURUSD,M1) Local minimum found =-4.999999997546217
После 1062 (одной тысячи шестидесяти двух) итераций алгоритм смог достичь локального минимума этой функции. Та-дам!
На что обратить внимание в этом алгоритме
Глядя на значения функции стоимости, вы заметите огромное изменение значений в начале, но очень незначительные заметные изменения в последних значениях функции стоимости.
Градиентный спуск делает большие шаги в начале, когда он еще далек от минимума функции, а затем шаги уменьшаются, когда алгоритм приближается к минимуму функции. То же самое мы делаем, когда находимся у подножия горы. Итак, теперь нам понятно, что градиентный спуск довольно умный!
В итоге получаем локальный минимум
HP 0 17:15:16.800 gradient-descent test (EURUSD,M1) Local minimum found =-4.999999997546217
Это очень точное значение, потому что минимумом функции является -5.0.
Внимание, вопрос
Откуда градиент знает, когда остановиться? Ведь алгоритм может продолжать повторяться до бесконечности или, по крайней мере, пока не исчерпаются вычислительные мощности компьютера.
Когда функция стоимости равна нулю, мы знаем, что градиентный спуск выполнил свою работу.
Давайте теперь напишем весь этот процесс на MQL5
while (true) { iterations++; x1 = x0 - m_learning_rate * CustomCostFunction(x0); printf("%d x0 = %.10f x1 = %.10f CostFunction = %.10f",iterations,x0,x1,CustomCostFunction(x0)); if (NormalizeDouble(CustomCostFunction(x0),8) == 0) { Print("Local minimum found =",x0); break; } x0 = x1; }
Приведенный выше блок кода смог дать нам желаемые результаты. Однако он не единственный в классе CGradientDescent. Функция CustomCostFunction — это то, где хранилось и вычислялось наше дифференцированное уравнение. Вот она:
double CGradientDescent::CustomCostFunction(double x) { return(2 * ( x + 5 )); }
В чем цель?
Кто-то может спросить, в чем же смысл всех этих вычислений, ведь можно просто использовать линейную модель по умолчанию, созданную в предыдущих библиотеках, которые мы обсуждали ранее в этой серии статей. Но модель, созданная с использованием значений по умолчанию, не обязательно является лучшей моделью. Поэтому компьютер должен изучить лучшие параметры для модели с небольшим количеством ошибок (лучшая модель).
Мы стали на несколько статей ближе к построению искусственных нейронных сетей. Здесь мы пытаемся подробно и популярно разобрать, как учатся (самообучаются) нейронные сети в процессе обратного распространения ошибки и других методов. Градиентный спуск — самый популярный алгоритм, который сделал все это возможно. Без четкого понимания этого базового процесса невозможно будет понять остальное, ведь дальше все будет становиться только сложнее.
Градиентный спуск для регрессионной модели
На примере набора данных о зарплате давайте построим лучшую модель, используя градиентный спуск.

Визуализация данных в Python
import pandas as pd import numpy as np import matplotlib.pyplot as plt data = pd.read_csv(r"C:UsersOmega JoctanAppDataRoamingMetaQuotesTerminal892B47EBC091D6EF95E3961284A76097MQL5FilesSalary_Data.csv") print(data.head(10)) x = data["YearsExperience"] y = data["Salary"] plt.figure(figsize=(16,9)) plt.title("Experience vs Salary") plt.scatter(x,y,c="green") plt.xlabel(xlabel="Years of Experience") plt.ylabel(ylabel="Salary") plt.show()
Таким будет наш график.

Глядя на наш набор данных, нельзя не заметить, что этот набор предназначен для задач регрессии. Но у нас может быть миллион моделей, которые помогут сделать прогноз или чего-то другого, чего мы пытаемся достичь.

Какую модель лучше использовать для прогнозирования опыта человека и его зарплаты? Это мы и собираемся выяснить. Но сначала давайте выведем функцию стоимости для нашей регрессионной модели.
Теория
Давайте вернемся к линейной регрессии.
Мы точно знаем, что каждая линейная модель имеет свои ошибки. Мы также знаем, что можем создать миллион линий на этом графике, и наилучшей линией всегда будет линия с наименьшим количеством ошибок.
Функция стоимости представляет собой ошибку между фактическими значениями и прогнозируемыми. Можем записать формулу для функции стоимости, которая будет равна:
Стоимость = Y фактическая — Y прогнозируемая. Поскольку мы имеем величину ошибки, которую возводим в квадрат, наша формула теперь становится такой:
![]()
Но мы ищем ошибки во всем нашем наборе данных, поэтому нужно сложить:
![]()
Наконец, делим сумму ошибок на m — количество элементов в наборе данных:

На видео ниже все математические расчеты сделаны вручную.
Мы получили функцию стоимости. Теперь можем написать код для градиентного спуска и найти лучшие параметры для двух значений: коэффициент X (наклон), обозначенный как Bo и Y Intercept, обозначенный как B1
double cost_B0=0, cost_B1=0; if (costFunction == MSE) { int iterations=0; for (int i=0; i<m_iterations; i++, iterations++) { cost_B0 = Mse(b0,b1,Intercept); cost_B1 = Mse(b0,b1,Slope); b0 = b0 - m_learning_rate * cost_B0; b1 = b1 - m_learning_rate * cost_B1; printf("%d b0 = %.8f cost_B0 = %.8f B1 = %.8f cost_B1 = %.8f",iterations,b0,cost_B0,b1,cost_B1); DBL_MAX_MIN(b0); DBL_MAX_MIN(cost_B0); DBL_MAX_MIN(cost_B1); if (NormalizeDouble(cost_B0,8) == 0 && NormalizeDouble(cost_B1,8) == 0) break; } printf("%d Iterations Local Minima arenB0(Intercept) = %.5f || B1(Coefficient) = %.5f",iterations,b0,b1); }
Обратите внимание на несколько вещей из кода градиентного спуска:
- Процесс остается таким же, как тот, который мы выполняли ранее. Но на этот раз мы находим и обновляем значения дважды, одновременно Bo и B1.
- Ограничим количество итераций. Кто-то однажды сказал, что лучший способ сделать бесконечный цикл — это использовать цикл while, но мы не используем цикл while в этот раз. Все-таки ограничим количество срабатываний алгоритма, в течение которых будем искать коэффициенты для лучшей модели.
- DBL_MAX_MIN — функция, предназначенная для отладки, отвечающая за проверку и вывод предупреждения в случае, если мы достигли пределов математических возможностей компьютера.
Ниже показан результат работы алгоритма при Learning Rate = 0.01 и количестве итераций Iterations = 10000
PD 0 17:29:17.999 gradient-descent test (EURUSD,M1) [20] 91738.0000 98273.0000 101302.0000 113812.0000 109431.0000 105582.0000 116969.0000 112635.0000 122391.0000 121872.0000 JS 0 17:29:17.999 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction MSE RF 0 17:29:17.999 gradient-descent test (EURUSD,M1) 0 b0 = 1520.06000000 cost_B0 = -152006.00000000 B1 = 9547.97400000 cost_B1 = -954797.40000000 OP 0 17:29:17.999 gradient-descent test (EURUSD,M1) 1 b0 = 1995.08742960 cost_B0 = -47502.74296000 B1 = 12056.69235267 cost_B1 = -250871.83526667 LP 0 17:29:17.999 gradient-descent test (EURUSD,M1) 2 b0 = 2194.02117366 cost_B0 = -19893.37440646 B1 = 12707.81767044 cost_B1 = -65112.53177770 QN 0 17:29:17.999 gradient-descent test (EURUSD,M1) 3 b0 = 2319.78332575 cost_B0 = -12576.21520809 B1 = 12868.77569178 cost_B1 = -16095.80213357 LO 0 17:29:17.999 gradient-descent test (EURUSD,M1) 4 b0 = 2425.92576238 cost_B0 = -10614.24366387 B1 = 12900.42596039 cost_B1 = -3165.02686058 GH 0 17:29:17.999 gradient-descent test (EURUSD,M1) 5 b0 = 2526.58198175 cost_B0 = -10065.62193621 B1 = 12897.99808257 cost_B1 = 242.78778134 CJ 0 17:29:17.999 gradient-descent test (EURUSD,M1) 6 b0 = 2625.48307920 cost_B0 = -9890.10974571 B1 = 12886.62268517 cost_B1 = 1137.53974060 DD 0 17:29:17.999 gradient-descent test (EURUSD,M1) 7 b0 = 2723.61498028 cost_B0 = -9813.19010723 B1 = 12872.93147573 cost_B1 = 1369.12094310 HF 0 17:29:17.999 gradient-descent test (EURUSD,M1) 8 b0 = 2821.23916252 cost_B0 = -9762.41822398 B1 = 12858.67435081 cost_B1 = 1425.71249248 <<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<<< Last Iterations >>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>>> EI 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6672 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 NG 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6673 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 GD 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6674 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 PR 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6675 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 IS 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6676 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 RQ 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6677 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 KN 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6678 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 DL 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6679 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 RM 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6680 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 IK 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6681 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 PH 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6682 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 GF 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6683 b0 = 25792.20019866 cost_B0 = -0.00000001 B1 = 9449.96232146 cost_B1 = 0.00000000 MG 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6684 b0 = 25792.20019866 cost_B0 = -0.00000000 B1 = 9449.96232146 cost_B1 = 0.00000000 LE 0 17:29:48.247 gradient-descent test (EURUSD,M1) 6684 Iterations Local Minima are OJ 0 17:29:48.247 gradient-descent test (EURUSD,M1) B0(Intercept) = 25792.20020 || B1(Coefficient) = 9449.96232
Построим график с помощью matplotlib

Та-дам! Градиентный спуск смог успешно получить лучшую модель из 10 000 опробованных нами моделей. Отлично, но есть один важный шаг, который мы упускаем. А это может привести к тому, что наша модель будет вести себя странно, и мы получим результаты, которые нам не нужны.
Нормализация данных входных переменных линейной регрессии
Мы знаем, что для разных наборов данных лучшие модели можно найти после разного количества итераций — некоторым может хватить 100 итераций, чтобы достичь лучших моделей, а некоторым может потребоваться и 10 000 или даже миллион, чтобы функция стоимости стала равной нулю. Не говоря уже о том, что, если использовать неправильные значения коэффициента скорости обучения, можно в конечном итоге пропустить локальные минимумы. А если пропустить эту цель, в конечном итоге мы столкнемся с математическими ограничениями компьютера. Давайте взглянем на все это на конкретном примере.
Скорость обучения = 0,1, итераций = 1000
Мы только что достигли максимального значения типа double, разрешенного системой. Вот что у нас в логах.
GM 0 17:28:14.819 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction MSE OP 0 17:28:14.819 gradient-descent test (EURUSD,M1) 0 b0 = 15200.60000000 cost_B0 = -152006.00000000 B1 = 95479.74000000 cost_B1 = -954797.40000000 GR 0 17:28:14.819 gradient-descent test (EURUSD,M1) 1 b0 = -74102.05704000 cost_B0 = 893026.57040000 B1 = -512966.08473333 cost_B1 = 6084458.24733333 NM 0 17:28:14.819 gradient-descent test (EURUSD,M1) 2 b0 = 501030.91374462 cost_B0 = -5751329.70784622 B1 = 3356325.13824362 cost_B1 = -38692912.22976952 LH 0 17:28:14.819 gradient-descent test (EURUSD,M1) 3 b0 = -3150629.51591119 cost_B0 = 36516604.29655810 B1 = -21257352.71857720 cost_B1 = 246136778.56820822 KD 0 17:28:14.819 gradient-descent test (EURUSD,M1) 4 b0 = 20084177.14287909 cost_B0 = -232348066.58790281 B1 = 135309993.40314889 cost_B1 = -1565673461.21726084 OQ 0 17:28:14.819 gradient-descent test (EURUSD,M1) 5 b0 = -127706877.34210962 cost_B0 = 1477910544.84988713 B1 = -860620298.24803317 cost_B1 = 9959302916.51181984 FM 0 17:28:14.819 gradient-descent test (EURUSD,M1) 6 b0 = 812402202.33122230 cost_B0 = -9401090796.73331833 B1 = 5474519904.86084747 cost_B1 = -63351402031.08880615 JJ 0 17:28:14.819 gradient-descent test (EURUSD,M1) 7 b0 = -5167652856.43381691 cost_B0 = 59800550587.65039062 B1 = -34823489070.42410278 cost_B1 = 402980089752.84948730 MP 0 17:28:14.819 gradient-descent test (EURUSD,M1) 8 b0 = 32871653967.62362671 cost_B0 = -380393068240.57440186 B1 = 221513298448.70788574 cost_B1 = -2563367875191.31982422 MM 0 17:28:14.819 gradient-descent test (EURUSD,M1) 9 b0 = -209097460110.12799072 cost_B0 = 2419691140777.51611328 B1 = -1409052343513.33935547 cost_B1 = 16305656419620.47265625 HD 0 17:28:14.819 gradient-descent test (EURUSD,M1) 10 b0 = 1330075004152.67309570 cost_B0 = -15391724642628.00976562 B1 = 8963022367351.18359375 cost_B1 = -103720747108645.23437500 DP 0 17:28:14.819 gradient-descent test (EURUSD,M1) 11 b0 = -8460645083849.12207031 cost_B0 = 97907200880017.93750000 B1 = -57014041694401.67187500 cost_B1 = 659770640617528.50000000
Это означает, что, если мы выбрали неправильный коэффициент скорости обучения, у нас может быть минимальный шанс найти лучшую модель, и высоки шансы, что мы в конечном итоге достигнем математического предела компьютера, как только что мы видели в примере.
Но если попробовать использовать 0,01 для скорости обучения с этим набором данных, проблем не будет, хотя процесс обучения станет намного медленнее. Но если же такую скорость обучения использовать для этого набора данных, в конечном итоге будет достигнут математический предел. Так что теперь вы знаете, что каждый набор данных имеет свою скорость обучения. Но иногда может не быть возможности оптимизировать скорость обучения, потому что бывают сложные наборы данных с несколькими переменными.
Решением будет нормализовать весь набор данных, чтобы он был в одном масштабе. Это улучшит читаемость, когда значения отображаются на одной и той же оси, а также улучшает время обучения, потому что нормализованные значения обычно находятся в диапазоне от 0 до 1. Кроме того, не надо будет беспокоиться о скорости обучения, потому что, когда у нас есть только один параметр скорости обучения, можно использовать его для любого набора данных, с которым мы сталкиваемся. Например, в нашем случае это скорость обучения 0,01. Подробнее о нормализации можно почитать здесь.
И последнее, но не менее важное.
Также мы знаем, что значения данных по зарплате даны в диапазоне от 39 343 до 121 782, а значения опыта равны от 1,1 года до 10,5 лет. Если сохранить данные в таком виде, значения заработной платы будут настолько огромны, что они могут заставить модель думать, что зарплата важнее любых значений. Поэтому они будут иметь огромное влияние по сравнению с годами опыта, а нам нужно, чтобы все независимые переменные оказывали одинаковое влияние наравне с другими. Теперь вы видите, как важно нормализовывать значения.
(Нормализация) Скаляр Min-Max
В этом подходе данные нормализуются так, чтобы они находились в диапазоне от 0 до 1. Формула нормализации такая:

Если перевести эту формулу в строки кода, получим:
void CGradientDescent::MinMaxScaler(double &Array[]) { double mean = Mean(Array); double max,min; double Norm[]; ArrayResize(Norm,ArraySize(Array)); max = Array[ArrayMaximum(Array)]; min = Array[ArrayMinimum(Array)]; for (int i=0; i<ArraySize(Array); i++) Norm[i] = (Array[i] - min) / (max - min); printf("Scaled data Mean = %.5f Std = %.5f",Mean(Norm),std(Norm)); ArrayFree(Array); ArrayCopy(Array,Norm); }
Функция std() нужна только для того, чтобы мы смогли узнать стандартное отклонение после нормализации данных. Вот ее код:
double CGradientDescent::std(double &data[]) { double mean = Mean(data); double sum = 0; for (int i=0; i<ArraySize(data); i++) sum += MathPow(data[i] - mean,2); return(MathSqrt(sum/ArraySize(data))); }
Давайте теперь вызовем все это и выведем результат:
void OnStart() { string filename = "Salary_Data.csv"; double XMatrix[]; double YMatrix[]; grad = new CGradientDescent(1, 0.01,1000); grad.ReadCsvCol(filename,1,XMatrix); grad.ReadCsvCol(filename,2,YMatrix); grad.MinMaxScaler(XMatrix); grad.MinMaxScaler(YMatrix); ArrayPrint("Normalized X",XMatrix); ArrayPrint("Normalized Y",YMatrix); grad.GradientDescentFunction(XMatrix,YMatrix,MSE); delete (grad); }
Результат
OK 0 18:50:53.387 gradient-descent test (EURUSD,M1) Scaled data Mean = 0.44823 Std = 0.29683 MG 0 18:50:53.387 gradient-descent test (EURUSD,M1) Scaled data Mean = 0.45207 Std = 0.31838 MP 0 18:50:53.387 gradient-descent test (EURUSD,M1) Normalized X JG 0 18:50:53.387 gradient-descent test (EURUSD,M1) [ 0] 0.0000 0.0213 0.0426 0.0957 0.1170 0.1915 0.2021 0.2234 0.2234 0.2766 0.2979 0.3085 0.3085 0.3191 0.3617 ER 0 18:50:53.387 gradient-descent test (EURUSD,M1) [15] 0.4043 0.4255 0.4468 0.5106 0.5213 0.6064 0.6383 0.7234 0.7553 0.8085 0.8404 0.8936 0.9043 0.9787 1.0000 NQ 0 18:50:53.387 gradient-descent test (EURUSD,M1) Normalized Y IF 0 18:50:53.387 gradient-descent test (EURUSD,M1) [ 0] 0.0190 0.1001 0.0000 0.0684 0.0255 0.2234 0.2648 0.1974 0.3155 0.2298 0.3011 0.2134 0.2271 0.2286 0.2762 IS 0 18:50:53.387 gradient-descent test (EURUSD,M1) [15] 0.3568 0.3343 0.5358 0.5154 0.6639 0.6379 0.7151 0.7509 0.8987 0.8469 0.8015 0.9360 0.8848 1.0000 0.9939
Теперь графики будут выглядеть так:

Градиентный спуск для логистической регрессии
Мы посмотрели линейную сторону градиентного спуска, теперь давайте посмотрим на логистическую.
Здесь делаем то же самое, что делали только что в части линейной регрессии, потому что задействованы точно такие же процессы, только процесс дифференциации логистической регрессии становится более сложным, чем в линейной модели. Давайте сначала посмотрим на функцию стоимости.
Мы уже обсуждали во второй статье цикла о логистической регрессии. Функция стоимости модели логистической регрессии — это бинарная кросс-энтропия, или логарифмическая функция потерь Log Loss, приведенная ниже.

Давайте сначала исполним сделаем сложную часть — дифференцируем эту функцию, чтобы получить ее градиент.
После находим производные

Превратим формулы в MQL5-код внутри функции BCE, что означает Binary Cross Entropy (бинарная кросс-энтропия).
double CGradientDescent::Bce(double Bo,double B1,Beta wrt) { double sum_sqr=0; double m = ArraySize(Y); double x[]; MatrixColumn(m_XMatrix,x,2); if (wrt == Slope) for (int i=0; i<ArraySize(Y); i++) { double Yp = Sigmoid(Bo+B1*x[i]); sum_sqr += (Y[i] - Yp) * x[i]; } if (wrt == Intercept) for (int i=0; i<ArraySize(Y); i++) { double Yp = Sigmoid(Bo+B1*x[i]); sum_sqr += (Y[i] - Yp); } return((-1/m)*sum_sqr); }
Поскольку мы имеем дело с моделью классификации, выберем набор данных по Титанику, с которым мы работали в статье про логистическую регрессию. У нас есть независимая переменная Pclass (пассажирский класс) и зависимая Survived с другой стороны.

Диаграмма рассеяния

Теперь вызовем класс Gradient Descent, но на этот раз с BCE (бинарная перекрестная энтропия) в виде функции затрат.
filename = "titanic.csv"; ZeroMemory(XMatrix); ZeroMemory(YMatrix); grad.ReadCsvCol(filename,3,XMatrix); grad.ReadCsvCol(filename,2,YMatrix); grad.GradientDescentFunction(XMatrix,YMatrix,BCE); delete (grad);
Посмотрим на результат:
CP 0 07:19:08.906 gradient-descent test (EURUSD,M1) Gradient Descent CostFunction BCE KD 0 07:19:08.906 gradient-descent test (EURUSD,M1) 0 b0 = -0.01161616 cost_B0 = 0.11616162 B1 = -0.04057239 cost_B1 = 0.40572391 FD 0 07:19:08.906 gradient-descent test (EURUSD,M1) 1 b0 = -0.02060337 cost_B0 = 0.08987211 B1 = -0.07436893 cost_B1 = 0.33796541 KE 0 07:19:08.906 gradient-descent test (EURUSD,M1) 2 b0 = -0.02743120 cost_B0 = 0.06827832 B1 = -0.10259883 cost_B1 = 0.28229898 QE 0 07:19:08.906 gradient-descent test (EURUSD,M1) 3 b0 = -0.03248925 cost_B0 = 0.05058047 B1 = -0.12626640 cost_B1 = 0.23667566 EE 0 07:19:08.907 gradient-descent test (EURUSD,M1) 4 b0 = -0.03609603 cost_B0 = 0.03606775 B1 = -0.14619252 cost_B1 = 0.19926123 CF 0 07:19:08.907 gradient-descent test (EURUSD,M1) 5 b0 = -0.03851035 cost_B0 = 0.02414322 B1 = -0.16304363 cost_B1 = 0.16851108 MF 0 07:19:08.907 gradient-descent test (EURUSD,M1) 6 b0 = -0.03994229 cost_B0 = 0.01431946 B1 = -0.17735996 cost_B1 = 0.14316329 JG 0 07:19:08.907 gradient-descent test (EURUSD,M1) 7 b0 = -0.04056266 cost_B0 = 0.00620364 B1 = -0.18958010 cost_B1 = 0.12220146 HE 0 07:19:08.907 gradient-descent test (EURUSD,M1) 8 b0 = -0.04051073 cost_B0 = -0.00051932 B1 = -0.20006123 cost_B1 = 0.10481129 ME 0 07:19:08.907 gradient-descent test (EURUSD,M1) 9 b0 = -0.03990051 cost_B0 = -0.00610216 B1 = -0.20909530 cost_B1 = 0.09034065 JQ 0 07:19:08.907 gradient-descent test (EURUSD,M1) 10 b0 = -0.03882570 cost_B0 = -0.01074812 B1 = -0.21692190 cost_B1 = 0.07826600 <<<<<< Last 10 iterations >>>>>> FN 0 07:19:09.725 gradient-descent test (EURUSD,M1) 6935 b0 = 1.44678930 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 PN 0 07:19:09.725 gradient-descent test (EURUSD,M1) 6936 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 NM 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6937 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 KL 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6938 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 PK 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6939 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 RK 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6940 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 MJ 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6941 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 HI 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6942 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 CH 0 07:19:09.726 gradient-descent test (EURUSD,M1) 6943 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 MH 0 07:19:09.727 gradient-descent test (EURUSD,M1) 6944 b0 = 1.44678931 cost_B0 = -0.00000001 B1 = -0.85010666 cost_B1 = 0.00000000 QG 0 07:19:09.727 gradient-descent test (EURUSD,M1) 6945 b0 = 1.44678931 cost_B0 = -0.00000000 B1 = -0.85010666 cost_B1 = 0.00000000 NG 0 07:19:09.727 gradient-descent test (EURUSD,M1) 6945 Iterations Local Minima are MJ 0 07:19:09.727 gradient-descent test (EURUSD,M1) B0(Intercept) = 1.44679 || B1(Coefficient) = -0.85011
Мы не нормализуем и не масштабируем классифицированные данные для логистической регрессии, как в линейной регрессии.
Вот мы и получили градиентный спуск для двух наиболее важных моделей машинного обучения. Надеюсь, было понятно и полезно. Код на Python, который я использовал в статье, а также набор данных доступны в GitHub-репозитории.
Заключение
Мы рассмотрели градиентный спуск для одной независимой и одной зависимой переменной. Для множества независимых переменных надо использовать векторы/матрицы из уравнения. Думаю, в этот раз читателям уже будет легче самостоятельно все попробовать — ведь как раз недавно в MQL5 была выпущена библиотека матричных функций. Если вам понадобится помощь с матрицами, не стесняйтесь обращаться ко мне — я буду рад помочь.
С наилучшими пожеланиями
Список видео с расчетами:
- https://www.youtube.com/watch?v=5yfh5cf4-0w
- https://www.youtube.com/watch?v=yg_497u6JnA
- https://www.youtube.com/watch?v=HaHsqDjWMLU