Первую часть этого материала можно прочитать здесь.
Технология S.M.A.R.T. родилась в далеком 1995 году, так что возраст у нее почтенный. Предполагалось, что атрибуты SMART (давайте для простоты писать аббревиатуру без точек), формируемые микропрограммой жесткого диска, позволят программно оценивать состояние накопителя, а также дадут механизм для предсказания выхода его из строя. Последнее в те времена было достаточно актуально: срок жизни дисков в серверах, например, исчислялся годом-полутора, и знать, когда готовить замену, было нелишним.
Со временем многое поменялось: что-то отмерло, какие-то стороны развились сильнее (например, контроль механики диска). Первоначальный набор из десятка простейших атрибутов усложнился и разросся в несколько раз, порой менялся их смысл, многие производители ввели собственные атрибуты с не всегда ясным функционалом. Появилась масса программ для анализа SMART (как правило, невысокого качества, но с эффектным интерфейсом, да еще и за деньги) и т.п.
Так что не мешает описать современное состояние SMART. Начнем с критически важных атрибутов, ухудшение которых почти всегда свидетельствует о проблемах с накопителем. Именно их первым делом смотрят ремонтники при диагностике HDD.
- #01 Raw Read Error Rate — частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных ДО выдачи в интерфейс; на пугающе огромные цифры можно не обращать внимания.
- #03 Spin-Up Time — время раскрутки пакета пластин из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т.п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
- #05 Reallocated Sectors Count — число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор переназначенным и переносит данные в резервную область. Вот почему на современных HDD нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, на жаргоне — ремап. Поле Raw Value атрибута содержит общее количество переназначенных секторов. Чем оно больше, тем хуже состояние поверхности диска.
- #07 Seek Error Rate — частота ошибок при позиционировании блока магнитных головок (БМГ). Рост этого атрибута свидетельствует о низком качестве поверхности или о поврежденной механике накопителя. Также может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
- #10 Spin-Up Retry Count — число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута растет, то велика вероятность проблем с механикой.
- #196 Reallocation Event Count — число операций переназначения. В поле Raw Value атрибута хранится общее число попыток переноса информации со сбойных секторов в резервную область диска (она, как правило, не слишком велика — несколько тысяч секторов). Учитываются как успешные, так и неудачные операции.
- #197 Current Pending Sector Count — текущее число нестабильных секторов. Здесь хранится число секторов, являющихся кандидатами на замену. Они не были еще определены как плохие, но считывание с них происходит с затруднениями (например, не с первого раза). Если «подозрительный» сектор будет в дальнейшем считываться успешно, то он исключается из числа кандидатов. В случае же повторных ошибочных чтений накопитель попытается восстановить его и выполнить ремап.
- #198 Uncorrectable Sector Count — число секторов, при чтении которых возникают неисправимые (внутренними средствами) ошибки. Рост этого атрибута указывает на серьезные дефекты поверхности или на проблемы с механикой накопителя.
- #220 Disk Shift — сдвиг пакета пластин относительно оси шпинделя. В основном возникает из-за сильного удара или падения диска. Единица измерения неизвестна, но при сильном росте атрибута диск не жилец.
Также следует принимать во внимание и информационные атрибуты, способные много чего поведать об «истории» диска.
- #02 Throughput Performance — средняя производительность диска. Если значение атрибута уменьшается, то велика вероятность, что у накопителя есть проблемы.
- #04 Start/Stop Count — число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счетчик включения режима энергосбережения.
- #08 Seek Time Performance — средняя производительность операции позиционирования головок. Снижение значения этого атрибута свидетельствует о неполадках в механике привода головок (в первую очередь о замедленном позиционировании).
- #09 Power-On Hours (POH) — время, проведённое во включенном состоянии. Показывает общее время работы диска, единица измерения зависит от модели (не только 1 час, но и 30 мин, и даже 1 минута).
- #11 Recalibration Retries — число повторов рекалибровки в случае, если первая попытка была неудачной. Рост этого атрибута указывает на проблемы с механикой диска.
- #12 Device Power Cycle Count — число полных циклов включения-выключения диска.
- #13 Soft Read Error Rate — частота появления «программных» ошибок при чтении данных. Сюда можно отнести ошибки программного обеспечения, драйверов, файловой системы, неверную разметку диска — в общем, почти все, что не относится к аппаратной части.
- #190 Airflow Temperature — температура воздуха внутри корпуса HDD. Для дисков Seagate атрибут выдается в нормировке 100º минус температура (тем самым критический нагрев соответствует значению 45), а модели Western Digital используют нормировку 125º минус температура.
- #191 G—sense error rate — число ошибок, возникших из-за внешних нагрузок. Атрибут хранит показания встроенного акселерометра, который фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
- #192 Power—off retract count — число зафиксированных повторов включения/выключения питания накопителя.
- #193 Load/Unload Cycle Count — число циклов перемещения БМГ в специальную парковочную зону/в рабочее положение.
- #194 HDA temperature — температура механической части диска, в просторечии банки (HDA — Hard Disk Assembly). Информация снимается со встроенного термодатчика, которым служит одна из магнитных головок, обычно нижняя в банке. В битовых полях атрибута фиксируются текущая, минимальная и максимальная температура. Не все программы, работающие со SMART, правильно разбирают эти поля, так что к их показаниям стоит относиться критично.
- #195 Hardware ECC Recovered — число ошибок, скорректированных аппаратной частью диска. Сюда входят ошибки чтения, ошибки позиционирования, ошибки передачи по внешнему интерфейсу. На дисках с SATA-интерфейсом значение нередко ухудшается при повышении частоты системной шины — SATA очень чувствителен к разгону.
- #199 UltraDMA (Ultra ATA) CRC Error Count — число ошибок, возникающих при передаче данных по внешнему интерфейсу в режиме UltraDMA (нарушения целостности пакетов и т.п.). Рост этого атрибута свидетельствует о плохом (мятом, перекрученном) кабеле и плохих контактах. Также подобные ошибки появляются при разгоне шины PCI, сбоях питания, сильных электромагнитных наводках, а иногда и по вине драйвера.
- #200 Write Error Rate/ Multi-Zone Error Rate — частота появления ошибок при записи данных. Показывает общее число ошибок записи на диск. Чем больше значение атрибута, тем хуже состояние поверхности и механики накопителя.
Как видим, большинство «интересных» атрибутов отражает функционирование механики накопителя. Технология SMART действительно позволяет предсказывать выход диска из строя в результате механических неисправностей, что, по статистике, составляет около 60% всех отказов. Полезен и мониторинг температур: перегрев головок резко ускоряет их деградацию, так что превышение опасного порога (45-55º в зависимости от модели) — сигнал срочно улучшить охлаждение диска.
Вместе с тем не следует переоценивать возможности SMART. Современные диски нередко «дохнут» на фоне отличных атрибутов, что связано с тонкими процессами дефект-менеджмента в условиях высокой плотности записи и не всегда, мягко говоря, качественных компонентов (разнобой в отдаче головок сегодня — обычное дело). Тем более SMART не способен предсказать последствия таких «форс-мажоров», как скачок напряжения, перегрев платы электроники или повреждение накопителя от удара.
Практически у всех атрибутов наибольший интерес представляет поле Raw Value: «сырые» значения наиболее информативны. Их нормировка (степень приближения к абстрактному порогу) часто ничего не дает и только запутывает дело. Поэтому и программы, полагающиеся на эти проценты, нельзя считать вполне надежными. Типичный случай для них — ложные тревоги. Программа сообщает, что новый, недавно установленный накопитель того и гляди «склеит ласты». А все дело в том, что в начале эксплуатации некоторые атрибуты SMART быстро меняются и примитивная экстраполяция приводит к пугающим пользователя прогнозам.
Я советую бесплатную программу HDDScan — она корректно понимает все атрибуты, в том числе и новые, правильно разбирает температурные показатели. Отчет выводится в виде аккуратной xml-таблицы с цветовой индикацией, которую можно сохранить или распечатать.
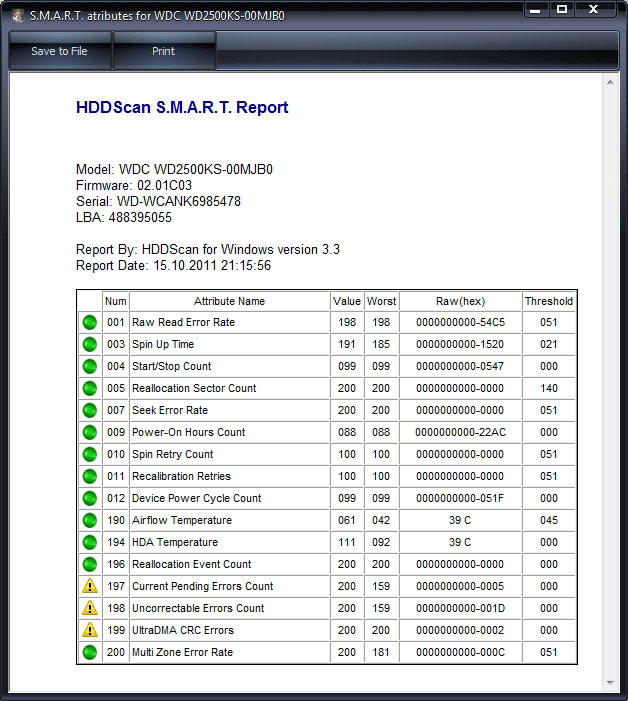
SMART диска WD пятилетнего возраста. О его близкой кончине свидетельствуют ненулевые значения атрибутов 1 и 200 (для WD они особенно чреваты), а также тот факт, что после ремапа атрибут 197 снова растет. Это значит, что возможности исправления дефектов исчерпаны
Крайне полезна у HDDScan возможность считывать SMART у внешних накопителей, столь распространенных сегодня. Практически ни одна другая программа этого не умеет, ведь на пути данных стоит контроллер, преобразующий интерфейс PATA/SATA в USB или FireWire. Автор целенаправленно работал в этом направлении, и ему удалось охватить широкий спектр контроллеров. Не забыты и диски с интерфейсом SCSI, до сих пор широко применяемые в серверах (атрибуты у них особые — например, выводится общее число записанных или считанных байтов за всю жизнь накопителя).
Функционал HDDScan полностью отвечает потребностям ремонтника. Когда первичную диагностику принесенного внешнего диска можно провести, не разбирая корпус, — это удобно, экономит время, а порой и сохраняет гарантию.
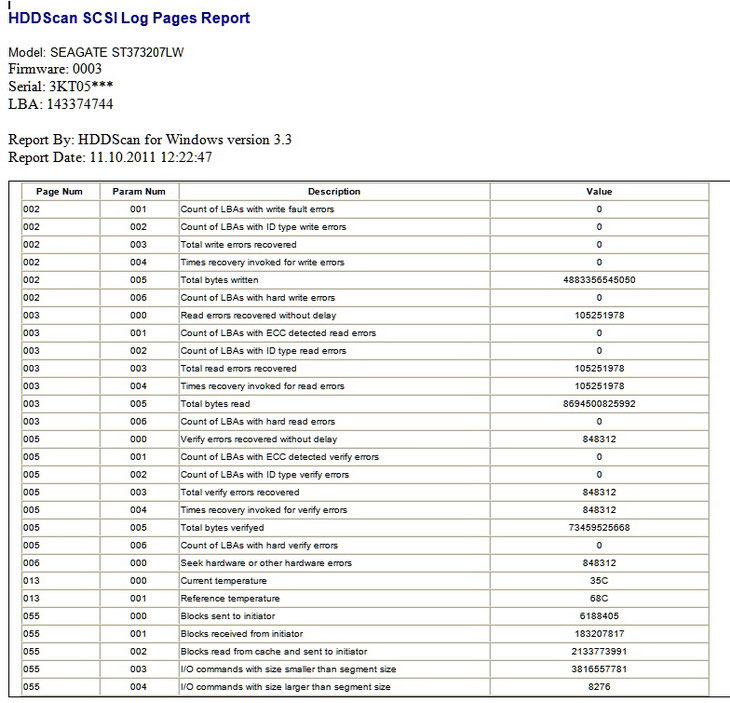
SMART, снятый со SCSI-диска. Здесь исторически сложились совсем другие атрибуты
⇡#Барьеры HDD
Механика давно стала ахиллесовой пятой HDD, и даже не столько из-за чувствительности к ударам и вибрации (это еще можно компенсировать), сколько из-за медлительности. Самые быстрые «дерганья» блоком магнитных головок (2-3 мс у лучших серверных моделей) в тысячи раз уступают скоростям электроники.
И принципиально ничего тут не улучшишь. Поднимать скорость вращения пакета дисков некуда, 15000 об./мин уже предел. Японцы несколько лет назад подступались к 20000 об./мин (вполне гироскопная скорость), но в итоге отказались — не выдерживают материалы, конструкция получается слишком дорогая и для массового производства слабо пригодная. В малых же сериях винчестеры выйдут золотыми, такие никто не купит — это не гироскопы, которые заменить нечем.
Выходит, уткнулись в барьер. Механику на кривой козе не объедешь. Единственный выход — поднимать плотность записи, поперечную и продольную. Продольная плотность (вдоль дорожки) влияет на производительность накопителя, т.е. на поток данных к остальным узлам компьютера. Но все равно, даже достигнутые 100-130 Мбайт/с — это для нынешних компьютеров слишком мало. Например, рядовая оперативная память (DRAM) имеет реальную производительность около 3 Гбайт/с, а кеш процессора — еще больше. Разница на порядки, и она сильно сказывается на общем быстродействии. Конечно, никто не требует от энергонезависимого накопителя, емкость которого в сотни раз превышает DRAM, такой же производительности. Но даже простое удвоение было бы заметно любому пользователю.
Поперечная плотность записи — это густота дорожек на пластине, в современных HDD она превышает 10000 на 1 миллиметр. Получается, что сама дорожка имеет ширину менее 100 нм (между прочим, нанотехнологии в чистом виде). Это позволяет резко поднять емкость в расчете на одну поверхность, а также ускоряет позиционирование за счет изощренных алгоритмов (их разработка потянула бы на пару докторских диссертаций).
Как итог, за последние годы емкость и производительность HDD значительно выросли. Все это стало возможным благодаря технологии перпендикулярной записи, которая существует уже более 20 лет, но до массового внедрения дозрела только в 2007 году. Причем емкость тогда выросла даже сильнее, чем требуется: первые терабайтные диски встретили вялый отклик пользователей. Народ просто не понимал, куда приспособить таких монстров, тем более что они поначалу строились на пяти пластинах, были капризными, шумными и горячими (речь о тогдашних флагманах Hitachi).
Потом, конечно, люди разобрались, торренты заработали в полную силу, да и количество пластин поуменьшилось. В то же время плотность записи выросла до 500-750 Гбайт на пластину (имеются в виду диски настольного сегмента с форм-фактором 3,5″). Вот-вот в массовое производство пойдут терабайтные пластины, что даст возможность выпустить винчестеры объемом до 4 Тбайт (больше четырех пластин в стандартном корпусе высотой 26,1 мм не уместить; хитачевские пятипластинные первенцы большого развития не получили).

Трехтерабайтный диск WD Caviar Green WD30EZRX, наиболее емкий на сегодня. Имеет четырехпластинный дизайн, выпускается ровно год (с 20 октября 2010 г.). Как полагается, весной и летом дешевел, но в последние дни резко подорожал из-за наводнения в Таиланде (там расположены сборочные заводы WD, и стихия блокировала подвоз комплектующих)
Увы, скорость позиционирования выросла, мягко говоря, несильно, а у массовых моделей так вообще осталась на прежнем уровне, а то и упала в угоду… тишине. Маркетологи доказали, что потребитель голосует кошельком за гигабайты в расчете на один доллар, а не за миллисекунды доступа. Поэтому и небыстры дешевые диски по сравнению с породистыми серверными собратьями. Медлительность хорошо проявляется в скорости загрузки ОС, когда надо читать с диска большое количество мелких файлов, разбросанных по пластинам. Здесь главную роль играет скорость вращения шпинделя и мощный привод БМГ, дающий возможность больших ускорений.
Между прочим, «быстрые» диски легко отличить даже на вес — они заметно тяжелее «медленных». Полноразмерная банка с утолщенными стенками, способствующая геометрической стабильности и подавлению вибраций, скоростной шпиндельный двигатель, мощные магниты позиционера, двухслойная крышка повышенной жесткости — все это прибавляет такому накопителю десятки и сотни граммов. Еще больше отрыв в серверных моделях на 15000 об./мин, где пластины уменьшенного размера окружены внушительным объемом литого алюминия, а общий вес «харда» доходит до килограмма.

Высокопроизводительный диск WD Raptor со скоростью вращения шпинделя 10 000 об./мин. При емкости 150 Гбайт весит 740 г (массовые модели той же емкости — 400-500 г). Обратите внимание на размер магнитов и толщину стенок
С удешевлением твердотельных SSD, использующихся, в первую очередь, под операционную систему, нужда в высокопроизводительных HDD стала снижаться, а сами они постепенно выделяются в особый сегмент рынка (такова, например, «черная» серия у WD). Подобными дисками комплектуются профессиональные рабочие станции с ресурсоемкими приложениями, критичными к скорости доступа. Рядовые же пользователи брать достаточно дорогие накопители не торопятся, предпочитая объем производительности.
На другом конце спектра — популярные «зеленые» модели с намеренно замедленным вращением шпинделя (5400-5900 об./мин вместо 7200) и небыстрым позиционированием головок. Дешевые, тихие, холодные и достаточно надежные, эти винчестеры идеально подходят для хранения мультимедийных данных в домашних компьютерах, внешних корпусах и сетевых хранилищах. На наших прилавках все эти Green и LP сильно потеснили другие линейки, так что в мелких «точках» порой ничего больше и не найдешь.
⇡#Расточительность магнитной записи
Намагниченность доменов жесткого диска, как и в середине двадцатого века, меняют с помощью магнитной головки, поле которой возбуждается переменным электрическим током и действует на магнитный слой через зазор. Также эта технология требует быстрого вращения пластин, прецизионного контроля положения головки и т.д. Двигатель и позиционер жесткого диска, а также управляющая ими электроника потребляют заметную мощность, да и стоят немало. Но главное — на само возбуждение магнитного поля тратится очень много энергии.
Расточительность стандартного метода магнитной записи трудно оценить, работая на персональном компьютере. Жесткие диски массовых серий даже при активной работе потребляют менее 10 Вт, что на фоне прочих комплектующих (100 Вт и более) почти незаметно. Но ваши взгляды сразу переменятся после посещения серверной комнаты какого-нибудь крупного банка, а чтобы получить впечатлений на всю оставшуюся жизнь, достаточно подойти к дисковой стойке суперкомпьютера. В шуме сотен и тысяч жестких дисков, обдувающих их вентиляторов и прецизионных кондиционеров становится понятно, сколько энергии в глобальном масштабе тратится на такую работу.
Недаром для систем хранения данных энергоэффективность в списке характеристик выходит на первый план. Вот уже и Google переводит свои дата-центры на баржи в море (вот где настоящие офшоры!). Оказывается, охлаждение СХД забортной водой радикально сокращает операционные затраты, в первую очередь за счет экономии на кондиционерах.
⇡#О питании жестких дисков
Будет ли работать обычная 220-вольтовая лампочка от 230 В? Конечно, будет. А от 240 В? Тоже. Вопрос — сколько она протянет? Понятно, что меньше или существенно меньше — это зависит от конкретной лампочки. Ей суждена яркая, но короткая жизнь.
Примерно та же ситуация и с жесткими дисками. Наивные производители проектировали их, полагаясь на стандартные +5 В и +12 В. Однако в типичном компьютерном блоке питания (БП) стабилизируется лишь линия 5 В. К чему же это приводит?
При высокой нагрузке на процессор (а современные «камни» потребляют немало) и недостаточной мощности БП линия 5 В проседает, и система стабилизации отрабатывает это дело, повышая напряжение до номинального значения. Одновременно повышается и напряжение 12 В (из-за отсутствия стабилизации по нему). В результате и так нестойкий к нагреву HDD работает еще и при повышенном напряжении, которое подается на самые греющиеся узлы — микросхему управления двигателем (на жаргоне ремонтников — «крутилка») и привод головок (т.н. «звуковая катушка»). Итог — смотри рассуждение о лампочке.


Сгоревшая «крутилка» на плате как результат повышенного напряжения и плохого охлаждения. Нередко микросхема сгорает в буквальном смысле, с пиротехническими эффектами и выгоранием дорожек на плате. Такое ремонту не подлежит
Отсюда советы по блоку питания. Чем больше его мощность, тем лучше (в разумных пределах: запас более 30-35% по отношению к реальному потреблению снижает КПД блока, так что вы будете греть комнату). Менее мощный, но фирменный БП лучше более мощного, но безродно-китайского. Помните — разгоняют не только процессоры. В первом приближении, 420 «китайских» ватт эквивалентны 300 «правильным».
По-хорошему, надо бы еще учитывать возраст БП: после 2-3 лет эксплуатации его реальная мощность заметно снижается, а выходные напряжения дрейфуют. Разумеется, в некачественных изделиях, работающих на честном китайском слове, процессы старения выражены гораздо резче. Хорошо еще, если подобный блок тихо умрет сам, а не утащит за собой в агонии половину системного блока!
Максимально допустимым считается 12,6 В (+5% от номинала). Однако у многих дисков c ростом напряжения наблюдается нелинейно-резкий нагрев упомянутых выше узлов — «крутилки» и «катушки». Поэтому я рекомендую строже контролировать БП с помощью внешнего вольтметра (датчики на материнской плате, измеряющие напряжение для BIOS и программ типа AIDA, могут быть весьма неточны).
Измерять напряжение лучше всего на разъемах Molex и обязательно под полной нагрузкой: процессор занят вычислениями с плавающей точкой, видеокарта — выводом динамичной трехмерной графики, а диск — дефрагментацией. При 12,2-12,4 В стоит призадуматься, 12,4-12,6 В — поволноваться, 12,6-13 В — бить тревогу, а в случае 13 В и выше — копить деньги на новый диск или положить гарантийный талон на видное место…

Конденсаторы (2200 мкФ, 25 В), напаянные на цепи питания HDD (желтый провод — +12 В, красный — +5 В, черный — земля). В данном случае они уменьшают пульсации напряжения, от которых блок питания издает раздражающий высокочастотный писк
Если напряжение по линии 12 В сильно завышено, а вы не боитесь паяльника и способны отличить транзистор от диода, то можете включить последний в разрыв питания HDD (напомню, линии 12 В соответствует желтый провод). Диод сыграет роль ограничителя — на его p-n переходе упадут «лишние» 0,2-0,7 В (в зависимости от типа диода), и диску станет полегче. Только диод надо брать достаточно мощный, чтобы он выдерживал пусковой ток в 2-3 А.
И без фанатизма: результирующее напряжение не должно опускаться ниже 11,7 В. В противном случае возможна неустойчивая работа диска (множественные рестарты) и даже порча данных. А некоторые модели (в частности, Seagate 7200.10 и 7200.11) могут вообще не запуститься.
⇡#Миграция с флеш
Память NAND Flash появилась много позднее, чем HDD, и переняла ряд его технологий — взять хотя бы коды ECC. Далее оба направления развивались параллельно и сравнительно независимо. Но в последнее время наметился и обратный процесс: миграция технологий с флеш-памяти на жесткие диски. Конкретно речь идет о выравнивании износа.
Как известно, любой флеш-чип имеет ограниченный ресурс по числу стираний-записей в одну ячейку. В какой-то момент стереть ее уже не удается, и она навсегда застывает с последним записанным значением. Поэтому контроллер считает количество записей в каждую страницу и в случае превышения копирует ее на менее изношенное место. В дальнейшем вся работа ведется с новым участком (этим заведует транслятор), а старая страница остается как есть и не используется. Данная технология получила название Wear Leveling. Так вот, износ есть и в жестких дисках, но там он механический и температурный. Если магнитная головка все время висит над одной дорожкой (скажем, постоянно изменяется тот или иной файл), то растет вероятность повреждения дорожки при случайных толчках или вибрации диска (например, от соседних накопителей в корзине). Головка может коснуться пластины и повредить магнитный слой со всеми вытекающими печальными последствиями. Даже если вредного контакта нет, неподвижная головка локально нагревается и пусть обратимо, но деградирует. Запись в данное место происходит менее надежно, растет вероятность последующего неустойчивого считывания (а при современных огромных плотностях записи любое отклонение параметров губительно).
Эти соображения достаточно очевидны, и прошивка серверных дисков с интерфейсом SCSI/SAS (а они весьма горячи) давно научилась перемещать головки в простое, дабы они не перегревались. Но еще лучше вместе с головкой «перебрасывать» и информацию по пластине — в этом случае описанные эффекты подавляются максимально, а надежность накопителя растет. Вот Western Digital и ввел подобный механизм в новых моделях VelociRaptor. Это дорогие высокопроизводительные диски со скоростью вращения шпинделя 10000 об./мин и пятилетней гарантией, так что Wear Leveling там уместен.


VelociRaptor снаружи и внутри. Привлекает внимание мощный радиатор. Пластины же имеют уменьшенный диаметр — это характерно для современных скоростных дисков.
Кроме того, вся линейка VelociRaptor нацелена на использование в высоконагруженных системах, в первую очередь серверах, где запись на диск ведется очень интенсивно и зачастую в одни и те же файлы (типичный пример — логи транзакций). Массовым «ширпотребным» дискам высокие нагрузки не грозят, греются они тоже умеренно, так что подобный изыск там вряд ли появится. Впрочем, поживем — увидим.
⇡#Аdvanced Format и его применение
Вот уже более 20 лет все жесткие диски имеют одинаковый размер физического сектора: 512 байт. Это минимальная порция записи на диск, позволяющая гибко управлять распределением дискового пространства. Однако с ростом объема HDD все сильнее стали проявляться недостатки такого подхода — в первую очередь неэффективное использование емкости магнитной пластины, а также высокие накладные расходы при организации потока данных.
Поэтому диски большой емкости (терабайт и выше) стали производиться по технологии Advanced Format, которая оперирует «длинными» физическими секторами в 4096 байт. Разметка магнитных пластин под AF весьма выгодна для производителя: меньше межсекторных промежутков, выше полезная емкость дорожки и всей пластины (а это, наряду с магнитными головками, самый дорогой компонент HDD). Именно Advanced Format позволил выпустить на рынок недорогие винчестеры, столь популярные ныне у потребителей аудио- и видеоконтента. AF-дисками емкостью 1-3 Тбайт комплектуются не только компьютеры, но и масса внешних накопителей, сетевых хранилищ и медиаплееров.

Один из первых дисков 3,5″ с Advanced Format, выпущенный в 2009 г
Но даром ничего не дается, новые диски уже начинают приносить в ремонт. Похоже, надежность все-таки просела. Ведь единичный сбой диска или дефект поверхности портит теперь в 8 раз больше данных пользователя, чем обычно. При физическом секторе в 4 Кбайт и эмуляции «коротких» секторов в 512 байт не будет читаться от 1 до 8 секторов. Операционная система на это реагирует понятно как: авария, все пропало! В итоге мелкая проблема на пластинах вырастает для пользователя в зависание или чего еще хуже.
Я считаю, на дисках с AF не стоит держать ОС, прикладные программы и базы данных со множеством мелких файлов. Пока что их удел — мультимедийные данные, некритичные к выпадениям.
⇡#Что стоит почитать о жестких дисках
В первую очередь рекомендую заглянуть на форум HARDW.net. Его раздел «Накопители информации» посещает множество профессиональных ремонтников и энтузиастов (почти 40 тыс. участников). Там можно найти ответы практически по любой теме, связанной с HDD, за исключением самых новых «нераскопанных» моделей. Начните с подраздела «Песочница»: на простые (в понимании профессионалов) вопросы там отвечают подробно и содержательно, а не отшивают, как в других местах, — «несите к ремонтнику».
Еще больше информации, правда, на английском языке, можно найти на портале HDDGURU. Помимо ремонтно-диагностического ПО и статей по отдельным вопросам (например, как поменять головки у диска), там есть международный форум ремонтников, а также огромный архив ресурсов по HDD (firmware, документация, фото и т.п.). Портал прививает широкий взгляд на вещи, он будет интересен подготовленным и мотивированным людям. Во всяком случае, в закрытых конференциях ремонтников ссылки на него пробегают постоянно.
Сошлюсь и на свою статью «Как продлить жизнь жестким дискам» в трех частях. Она дает начальные сведения по обращению с HDD, и хотя написана более трех лет назад, устарела мало — диски за это время принципиально не изменились, разве что стали еще менее надежными из-за свирепой экономии. Производители, застигнутые мировым кризисом, снижали свои затраты по всем направлениям, что и послужило причиной ряда громких провалов 2008-2009 гг. Об одном из них речь пойдет в продолжении этого материала, которое выйдет в ближайшее время.
Если Вы заметили ошибку — выделите ее мышью и нажмите CTRL+ENTER.
Skip to content
Как исправить G-Sense Error Rate (0xDD)?

Что делать с «0xDD G-Sense Error Rate»?
При загрузке компьютера или ноутбука возникает S.M.A.R.T. ошибка «0xDD G-Sense Error Rate»?
Что означает «0xDD»: G-Sense Error Rate? Допустимые значения атрибута «G-Sense Error Rate» отличаются для различных производителей жестких дисков WD (Western Digital), Samsung, Seagate, HGST (Hitachi), Toshiba.
Актуально для ОС: Windows 10, Windows 8.1, Windows Server 2012, Windows 8, Windows Home Server 2011, Windows 7 (Seven), Windows Small Business Server, Windows Server 2008, Windows Home Server, Windows Vista, Windows XP, Windows 2000, Windows NT.
Программа для восстановления данных
Прекратите использование сбойного HDD
Получение от системы сообщения о диагностике ошибки не означает, что диск уже вышел из строя. Но в случае наличия S.M.A.R.T. ошибки,
нужно понимать, что диск уже в процессе выхода из строя. Полный отказ может наступить как в течении нескольких минут,
так и через месяц или год. Но в любом случае, это означает, что вы больше не можете доверить свои данные такому диску.
Необходимо побеспокоится о сохранности ваших данных, создать резервную копию или перенести файлы на другой носитель информации.
Одновременно с сохранностью ваших данных, необходимо предпринять действия по замене жесткого диска.
Жесткий диск, на котором были определены S.M.A.R.T. ошибки нельзя использовать – даже если он полностью не выйдет из строя он может частично повредить ваши данные.
Конечно же, жесткий диск может выйти из строя и без предупреждений S.M.A.R.T. Но данная технология даёт вам преимущество предупреждая о скором выходе диска из строя.
Восстановите удаленные данные диска
В случае возникновения SMART ошибки не всегда требуется восстановление данных с диска. В случае ошибки рекомендуется незамедлительно
создать копию важных данных, так как диск может выйти из строя в любой момент. Но бывают ошибки при которых скопировать данные уже не представляется возможным.
В таком случае можно использовать программу для восстановления данных жесткого диска — Hetman Partition Recovery.
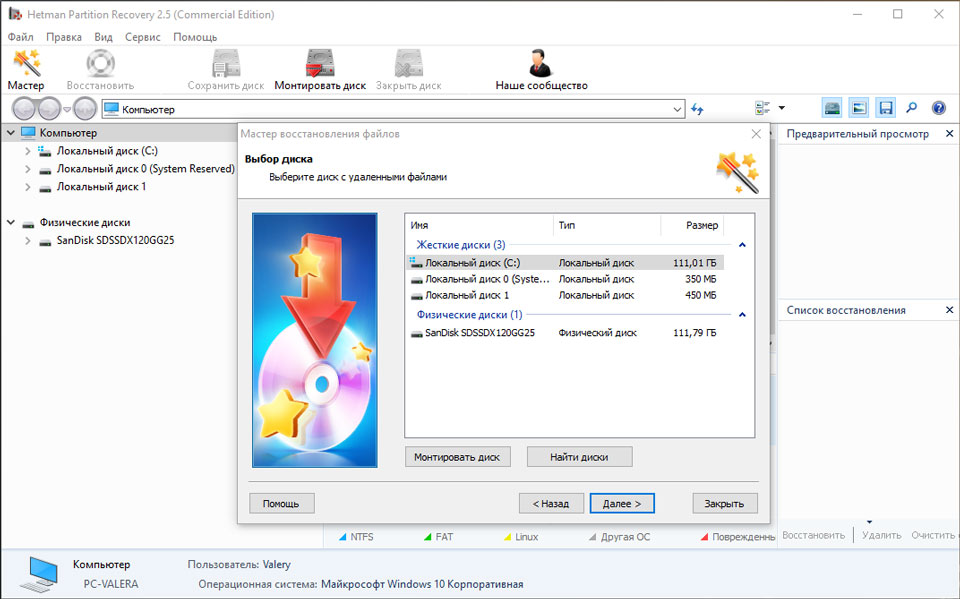
Для этого:
- Загрузите программу, установите и запустите её.
- По умолчанию, пользователю будет предложено воспользоваться Мастером восстановления файлов. Нажав кнопку «Далее», программа предложит выбрать диск, с которого необходимо восстановить файлы.
- Дважды кликните на сбойном диске и выберите необходимый тип анализа. Выбираем «Полный анализ» и ждем завершения процесса сканирования диска.
- После окончания процесса сканирования вам будут предоставлены файлы для восстановления. Выделите нужные файлы и нажмите кнопку «Восстановить».
- Выберите один из предложенных способов сохранения файлов. Не сохраняйте восстановленные файлы на диск с ошибкой «0xDD G-Sense Error Rate».
Программа для восстановления данных
Просканируйте диск на наличие «битых» секторов

Запустите проверку всех разделов жесткого диска и попробуйте исправить найденные ошибки.
Для этого, откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с SMART ошибкой.
Выберите Свойства / Сервис / Проверить в разделе Проверка диска на наличия ошибок.
[скриншот]
В результате сканирования обнаруженные на диске ошибки могут быть исправлены.
Снизьте температуру диска

Иногда, причиной возникновения «S M A R T» ошибки может быть превышение максимально допустимой температуры работы диска.
Такая ошибка может быть устранена путём улучшения вентиляции компьютера.
Во-первых, проверьте оборудован ли ваш компьютер достаточной вентиляцией и все ли вентиляторы исправны.
Если вами обнаружена и устранена проблема с вентиляцией, после чего температура работы диска снизилась
до нормального уровня, то SMART ошибка может больше не возникнуть.
Произведите дефрагментацию жесткого диска
Откройте папку «Этот компьютер» и кликните правой кнопкой мышки на диске с ошибкой «
0xDD
G-Sense Error Rate». Выберите Свойства / Сервис / Оптимизировать в разделе Оптимизация и дефрагментация диска. Выберите диск, который необходимо оптимизировать и кликните Оптимизировать.

Примечание. В Windows 10 дефрагментацию и оптимизацию диска можно настроить таким образом, что она будет осуществляться автоматически.
Ошибка «G-Sense Error Rate» для SSD диска

Даже если у вас не претензий к работе SSD диска, его работоспособность постепенно снижается. Причиной этому служит факт того,
что ячейки памяти SSD диска имеют ограниченное количество циклов перезаписи. Функция износостойкости минимизирует данный эффект, но не устраняет его полностью.
SSD диски имеют свои специфические SMART атрибуты, которые сигнализируют о состоянии ячеек памяти диска.
Например, «209 Remaining Drive Life», «231 SSD life left» и т.д. Данные ошибки могут возникнуть в случае снижения работоспособности ячеек,
и это означает, что сохранённая в них информация может быть повреждена или утеряна.
Ячейки SSD диска в случае выхода из строя не восстанавливаются и не могут быть заменены.
Сбросьте ошибку
SMART ошибки можно легко сбросить в BIOS (или UEFI). Но разработчики всех операционных систем категорически не рекомендуют этого делать.
Если же для вас не имеют ценности данные на жестком диске, то вывод SMART ошибок можно отключить.
Для этого необходимо сделать следующее:
- Перезагрузите компьютер, и с помощью нажатия указанной на загрузочном экране комбинации клавиш (у разных производителей они разные, обычно «F2» или «Del») перейдите в BIOS (или UEFI).
- Перейдите в: Аdvanced > SMART settings > SMART self test. Установите значение Disabled.
Примечание: место отключения функции указано ориентировочно, так как в зависимости от версии BIOS или UEFI,
место расположения такой настройки может незначительно отличаться.
Приобретите новый жесткий диск
Целесообразен ли ремонт HDD?
Важно понимать, что любой из способов устранения SMART ошибки – это самообман.
Невозможно полностью устранить причину возникновения ошибки, так как основной причиной её возникновения
часто является физический износ механизма жесткого диска.
Для устранения или замены неправильно работающих составляющих жесткого диска,
можно обратится в сервисный центр специальной лабораторией для работы с жесткими дисками.
Но стоимость работы в таком случае будет выше стоимости нового устройства.
Поэтому, ремонт имеет смысл делать только в случае необходимости восстановления данных с уже неработоспособного диска.
Как выбрать новый накопитель?
Если вы столкнулись со SMART ошибкой жесткого диска то, приобретение нового диска – это только вопрос времени.
То, какой жесткий диск нужен вам зависит от вашего стиля работы за компьютером, а также цели с которой его используют.
На что обратить внимание приобретая новый диск:
- Тип диска: HDD, SSD или SSHD. Каждому типу присущи свои плюсы и минусы, которые не имеют решающего значения для одних пользователей и очень важны для других. Основные из них — это скорость чтения и записи информации, объём и устойчивость к многократной перезаписи.
- Размер. Два основных форм-фактора дисков: 3,5 дюймов и 2,5 дюймов. Размер диска определяется в соответствии с установочным местом конкретного компьютера или ноутбука.
- Интерфейс. Основные интерфейсы жестких дисков: SATA, IDE, ATAPI, ATA, SCSI, Внешний диск (USB, FireWire и.т.д.).
-
Технические характеристики и производительность:
- Вместимость;
- Скорость чтения и записи;
- Размер буфера памяти или cache;
- Время отклика;
- Отказоустойчивость.
- S.M.A.R.T. Наличие в диске данной технологи поможет определить возможные ошибки его работы и вовремя предупредить утерю данных.
- Комплектация. К данному пункту можно отнести возможное наличие кабелей интерфейса или питания, а также гарантии и сервиса.
Актуально для:
WD HDD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Seagate HDD
- BarraCuda
- FireCuda
- Backup/Expansion
- Enterprise (NAS)
- IronWolf (NAS)
- SkyHawk
Transcend HDD
- 25M (ударостойкие)
- 25H (ударостойкие)
- 25C (простые)
- 25A (с узором)
- 35T (настольные)
Hitachi HDD
- Travelstar
- Deskstar (NAS)
- Ultrastar
HP HDD
- MSA SAS
- Server SATA
- Server SAS
- Midline SATA
- Midline SAS
IBM HDD
- V3700
- Near Line
- Express 2.5
- V3700 2.5
- Server
- Near Line 2.5
LaCie HDD
- Porsche/Mobile
- Porsche
- Rugged
- d2
A-Data HDD
- DashDrive
- HV
- Durable)
- HD
Silicon Power HDD
- Armor
- Diamond
- Stream
Toshiba HDD
- MG, DT, MQ
- P, X, L
- N, S, V
- DT, AL
Dell HDD
- SAS
- SCI
- Hot-Plug
Verbatim HDD
- Go (портативные)
- Save (настольные)
Team Group SSD
- EVO/Lite/GX2 (TLC)
- PD (портативные)
Silicon Power SSD
- Velox/M/Slim
- Ace (3D TLC)
Apacer SSD
- M.2
- ProII
- Portable
- Panther
GOODRAM SSD
- CL (TLC)
- PX (TLC)
- Iridium (MLC/TLC)
Kingston SSD
- Consumer
- HyperX
- Enterprise
- Builder
Patriot SSD
- Flare (MLC)
- Scorch (MLC, M.2)
- Spark (TLC)
- Blast/P (TLC)
- Burst (3D TLC)
- Viper (TLC, M.2)
Samsung SSD
- PRO (3D MLC)
- EVO
- QVO (3D QLC)
- Portable (внешние)
- DCT (серверные)
- PM (серверные)
Seagate SSD
- Nytro
- Maxtor
- FireCuda
- BarraCuda
- Expansion
- IronWolf
A-Data SSD
- Premier (MLC/TLC)
- Ultimate (3D NAND)
- XPG
- SC (внешние)
- SE (внешние)
- Durable
WD SSD
- WD Blue
- WD Green
- WD Black
- WD Red
- WD Purple
- WD Gold
Transcend SSD
- SSDXXX
- PATA
- MTSXXX
- MSAXXX
- ESDXXX
25.08.2012, 03:11. Показов 587111. Ответов 2

В первую очередь хочу сказать спасибо Charles Kludge и nonym4uk за помощь в написании этой статьи.
Итак, S.M.A.R.T. (от англ. self-monitoring, analysis and reporting technology — технология самоконтроля, анализа и отчётности) — технология оценки состояния жёсткого диска встроенной аппаратурой самодиагностики, а также механизм предсказания времени выхода его из строя.
Много пользователей знает что такое S.M.A.R.T., немного меньше даже знают как его получить… Но когда встает вопрос проанализировать полученную таблицу, обычно дело стопорится. В этой статье я приведу основные значения и их расшифровку
Для любознательных
SMART производит наблюдение за основными характеристиками накопителя, каждая из которых получает оценку. Характеристики можно разбить на две группы:
параметры, отражающие процесс естественного старения жёсткого диска (число оборотов шпинделя, число премещений головок, количество циклов включения-выключения);
текущие параметры накопителя (высота головок над поверхностью диска, число переназначенных секторов, время поиска дорожки и количество ошибок поиска).
Данные хранятся в шестнадцатеричном виде, называемом «raw value», а потом пересчитываются в «value» — значение, символизирующее надёжность относительно некоторого эталонного значения. Обычно «value» располагается в диапазоне от 0 до 100 (некоторые атрибуты имеют значения от 0 до 200 и от 0 до 253).
Высокая оценка говорит об отсутствии изменений данного параметра или медленном его ухудшении. Низкая говорит о возможном скором сбое.
Значение, меньшее, чем минимальное, при котором производителем гарантируется безотказная работа накопителя, означает выход узла из строя.
Технология SMART позволяет осуществлять:
мониторинг параметров состояния;
сканирование поверхности;
сканирование поверхности с автоматической заменой сомнительных секторов на надёжные.
Следует заметить, что технология SMART позволяет предсказывать выход устройства из строя в результате механических неисправностей, что составляет около 60 % причин, по которым винчестеры выходят из строя.
Предсказать последствия скачка напряжения или повреждения накопителя в результате удара SMART не способна.
Следует отметить, что накопители НЕ МОГУТ сами сообщать о своём состоянии посредством технологии SMART, для этого существуют специальные программы.
Любая программа, показывающая S.M.A.R.T. для каждого атрибута имеет несколько значений, разберемся сначала с ними — ID, Value, Worst, Threshold и RAW. Итак:
ID (Number) — собственно, сам индикатор атрибута. Номера стандартны для значений атрибутов, но например,из-за кривизны перевода один и тот же атрибут может называться по-разному, проще орентироваться по ID, логично?
Value
(Current) — текущее значение атрибута в условных единицах, никому наверное неведомых . В процессе работы винчестера оно может уменьшаться, увеличиваться и оставаться неизменным. По показателю Value нельзя судить о «здоровье» атрибута, не сравнивая его со значением Threshold этого же атрибута. Как правило, чем меньше Value, тем хуже состояние атрибута (изначально все классы значений, кроме RAW, на новом диске имеют максимальное из возможных значение, например 100).
Worst — наихудшее значение, которого достигало значение Value за всю жизнь винчестера. Измеряется тоже в уе. В процессе работы оно может уменьшаться либо оставаться неизменным. По нему тоже нельзя однозначно судить о здоровье атрибута, нужно сравнивать его с Threshold.
Threshold — значение в (сюрприз!!!) уе, которого должен достигнуть Value этого же атрибута, чтобы состояние атрибута было признано критическим. Проще говоря, Threshold — это порог: если Value больше Threshold — атрибут в порядке; если меньше либо равен — с атрибутом проблемы. Именно по такому критерию утилиты, читающие S.M.A.R.T., выдают отчёт о состоянии диска либо отдельного атрибута вроде «Good» или «Bad». При этом они не учитывают, что даже при Value, большем Threshold, диск на самом деле уже может быть умирающим с точки зрения пользователя, а то и вовсе ходячим мертвецом, поэтому при оценке здоровья диска смотреть стоит всё-таки на другой класс атрибута, а именно — RAW. Однако именно значение Value, опустившееся ниже Threshold, может стать легитимным поводом для замены диска по гарантии (для самих гарантийщиков, конечно же) — кто же яснее скажет о здоровье диска, как не он сам, демонстрируя текущее значение атрибута хуже критического порога? Т. е. при значении Value, большем Threshold, сам диск считает, что атрибут здоров, а при меньшем либо равном — что болен. Очевидно, что при Threshold=0 состояние атрибута не будет признано критическим никогда. Threshold — постоянный параметр, зашитый производителем в диске.
RAW (Data) — самый интересный, важный и нужный для оценки показатель. В большинстве случаев он содержит в себе не уе, а реальные значения, выражаемые в различных единицах измерения, напрямую говорящие о текущем состоянии диска. Основываясь именно на этом показателе, формируется значение Value (а вот по какому алгоритму оно формируется — это уже тайна производителя, покрытая мраком). Именно умение читать и анализировать поле RAW даёт возможность объективно оценить состояние винчестера.
Теперь перейдем непосредственно к самим атрибутам.
01 (01) Raw Read Error Rate — Частота ошибок при чтении данных с диска, происхождение которых обусловлено аппаратной частью диска. Для всех дисков Seagate, Samsung (семейства F1 и более новые) и Fujitsu 2,5″ это — число внутренних коррекций данных, проведенных до выдачи в интерфейс, следовательно, на пугающе огромные цифры можно реагировать спокойно.
02 (02) Throughput Performance — Общая производительность диска. Если значение атрибута уменьшается, то велика вероятность, что с диском есть проблемы.
03 (03) Spin-Up Time — Время раскрутки пакета дисков из состояния покоя до рабочей скорости. Растет при износе механики (повышенное трение в подшипнике и т. п.), также может свидетельствовать о некачественном питании (например, просадке напряжения при старте диска).
04 (04) Start/Stop Count — Полное число циклов запуск-остановка шпинделя. У дисков некоторых производителей (например, Seagate) — счётчик включения режима энергосбережения. В поле raw value хранится общее количество запусков/остановок диска.
05 (05) Reallocated Sectors Count — Число операций переназначения секторов. Когда диск обнаруживает ошибку чтения/записи, он помечает сектор «переназначенным» и переносит данные в специально отведённую резервную область. Вот почему на современных жёстких дисках нельзя увидеть bad-блоки — все они спрятаны в переназначенных секторах. Этот процесс называют remapping, а переназначенный сектор — remap. Чем больше значение, тем хуже состояние поверхности дисков. Поле raw value содержит общее количество переназначенных секторов. Рост значения этого атрибута может свидетельствовать об ухудшении состояния поверхности блинов диска.
06 (06) Read Channel Margin — Запас канала чтения. Назначение этого атрибута не документировано. В современных накопителях не используется.
07 (07) Seek Error Rate — Частота ошибок при позиционировании блока магнитных головок. Чем их больше, тем хуже состояние механики и/или поверхности жёсткого диска. Также на значение параметра может повлиять перегрев и внешние вибрации (например, от соседних дисков в корзине).
08 (08) Seek Time Performance — Средняя производительность операции позиционирования магнитными головками. Если значение атрибута уменьшается (замедление позиционирования), то велика вероятность проблем с механической частью привода головок.
09 (09) Power-On Hours (POH) — Число часов (минут, секунд — в зависимости от производителя), проведённых во включенном состоянии. В качестве порогового значения для него выбирается паспортное время наработки на отказ (MTBF — mean time between failure).
10 (0А) Spin-Up Retry Count — Число повторных попыток раскрутки дисков до рабочей скорости в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность неполадок с механической частью.
11 (0В) Recalibration Retries — Количество повторов запросов рекалибровки в случае, если первая попытка была неудачной. Если значение атрибута увеличивается, то велика вероятность проблем с механической частью.
12 (0С) Device Power Cycle Count — Количество полных циклов включения-выключения диска.
13 (0D) Soft Read Error Rate — Число ошибок при чтении, по вине программного обеспечения, которые не поддались исправлению. Все ошибки имеют
не механическую
природу и указывают лишь на неправильную размётку/взаимодействие с диском программ или операционной системы.
100(64) Erase/Program Cycles (для SSD) Общее количество циклов стирания/программирования для всей флэш-памяти за всё время ее существования. Твердотельный накопитель имеет ограничение на количество записей в него. Точные значения (ресурс) зависят от установленных микросхем флэш-памяти.
В накопителях Kingston — объём стёртого в гигабайтах.
103(67) Translation Table Rebuild (для SSD) Количество событий, когда внутренние таблицы адресов блоков были повреждены и впоследствии восстановлены. Raw-значение этого атрибута указывает фактическое количество событий.
170(AA) Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Иногда raw-значение содержит фактическое количество использованных резервных блоков.
170 атрибут связан с атрибутом 5, числом использованных резервных блоков.
171(AB) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти» — отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Значение обычно идентично атрибуту 181.
172(AC) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
Идентичен атрибуту 182.
173(AD) Wear Leveller Worst Case Erase Count (для SSD) Максимальное количество операций стирания, выполняемых для одного блока флэш-памяти.
174(AE) Unexpected Power Loss (для SSD) Число неожиданных отключений питания, когда питание было потеряно до получения команды на отключение диска. На жестком диске срок службы при таких отключениях намного меньше, чем при обычном отключении. На SSD существует риск потери внутренней таблицы состояний при неожиданном завершении работы.
175(AF) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов. Процесс записи технически называется «программирование флэш-памяти», отсюда и название атрибута. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
176(B0) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов. Полный цикл записи флэш-памяти состоит из двух этапов. Сначала необходимо удалить память, а затем данные должны быть записаны («запрограммированы») в память. Когда флэш-память изношена, она больше не может быть записана и становится доступной только для чтения.
177(B1) Wear Leveling Count (для SSD)
Wear Range Delta В зависимости от производителя, максимальное количество операций стирания, выполняемых для одного блока флэш-памяти[источник не указан 269 дней] или разница между максималоьно изношенными (больше всего раз записанными) и минимально изношенными (записанными наименьшее число раз) блоками[4].
178(B2) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
179(B3) Used Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество использованных резервных блоков.
180(B4) Unused Reserved Block Count (для SSD) Состояние пула резервных блоков. Значение атрибута показывает процент оставшегося пула. Raw-значение этого атрибута иногда содержит фактическое количество неиспользованных резервных блоков.
181(B5) Program Fail Count (для SSD) Число попыток, когда запись во флэш-память не удалась. Raw-значение показывает фактическое количество отказов.
182(B6) Erase Fail Count (для SSD) Количество сбоев операции стирания на флэш-памяти. Raw-значение показывает фактическое количество отказов.
183(B7) SATA Downshifts (для SSD) Указывает, как часто требовалось снизить скорость передачи данных SATA (с 6 Гбит/с до 3 или 1,5 Гбит/с или с 3 Гбит/с до 1,5 Гбит/с) для успешной передачи данных. Если значение атрибута уменьшается, попробуйте заменить кабель SATA.
Суть в том, что винчестер, работающий в режимах SATA 3 Гбит/с или 6 Гбит/с (и что там дальше будет в будущем), по какой-то причине (например, из-за ошибок) может попытаться «договориться» с дисковым контроллером о менее скоростном режиме (например, SATA 1.5 Гбит/с или 3 Гбит/с соответственно). В случае «отказа» контроллера изменять режим диск увеличивает значение атрибута (Western Digital und Samsung).
184 (B8) End-to-End error — Назначение зависит от производителя.
У HP (часть технологии HP SMART IV) увеличивается в случае, когда после передачи данных через кэш-память чётность данных между хостом и жёстким диском не совпадает.
У Kinston это количество ошибок чтения из флэш-памяти.
185 (B9) Head Stability Стабильность головок (Western Digital).
187 (BB) Reported UNC Errors — Количество ошибок, которое накопитель сообщил хосту (интерфейсу компьютера) при любых операциях, обычно это ошибки данных на диске, которые не исправлены средствами ECC
188 (BC) Command Timeout — содержит количество операций, выполнение которых было отменено из–за превышения максимально допустимого времени ожидания отклика.Такие ошибки могут возникать из-за плохого качества кабелей, контактов, используемых переходников, удлинителей и т.д., несовместимости диска с конкретным контроллером SATA/РАТА на материнской плате и т.д. Из-за ошибок такого рода возможны BSOD в Windows.
Ненулевое значение атрибута говорит о потенциальной «болезни» диска.
189 (BD) High Fly Writes — содержит количество зафиксированных случаев записи при высоте «полета» головки выше рассчитанной, скорее всего, из-за внешних воздействий, например, вибрации.
Для того, чтобы сказать, почему происходят такие случаи, нужно уметь анализировать логи S.M.A.R.T., которые содержат специфичную для каждого производителя информацию
190 (BE) Airflow Temperature (WDC) — Температура воздуха внутри корпуса жёсткого диска. Для дисков Seagate рассчитывается по формуле (100 — HDA temperature). Для дисков
Western Digital
— (125 — HDA).
191 (BF) G-sense error rate — Количество ошибок, возникающих в результате ударных нагрузок. Атрибут хранит показания встроенного акселерометра, который
фиксирует все удары, толчки, падения и даже неаккуратную установку диска в корпус компьютера.
Актуален для мобильных винчестеров. На дисках Samsung на него часто можно не обращать внимания, т.к. они могут иметь очень чувствительный датчик, который, образно говоря, реагирует чуть ли не на движение воздуха от крыльев пролетающей в одном помещении с диском мухой.
Вообще срабатывание датчика не является признаком удара. Может расти даже от позиционирования БМГ самим диском, особенно, если его не закрепить. Основное назначение датчика – прекратить операцию записи при вибрациях, чтобы избежать ошибок.
75
Эту статью не следует рассматривать как руководство пользователя или документацию для программистов.
Цель проделанной мною работы — попытаться разьяснить в приличной, доступной, а главное — рускоязычной форме, все особенности данной технологии. Естесственно, охватить ПОЛНОСТЬЮ все возможности технологии S.M.A.R.T. просто не возможно по причине ужасающего факта отсутствия какой-либо документации и нежелания подавляющего числа производителей жестких дисков предоставить необходимую информацию или вести какие-либо переговоры.
Текст статьи постоянно обновляется, поэтому на возможные неточности и грамматические ошибки прошу не обращать внимания. Но если Вы заметите явную ошибку или «ужасающую»  неточность — пожалуйста, напишите мне об этом.
неточность — пожалуйста, напишите мне об этом.
Я с удовольствием приму любые комментарии по тексту, а также Ваши пожелания и дополнения.
1.1. Общее описание.
Технология S.M.A.R.T. — Self-Monitoring, Analysis and Reporting Technology (от англ. «Технология Самодиагностики, Анализа и Отчета») — была разработана для повышения надежности и сохранности данных на жестких дисках. В большинстве случаев, SMART-совместимые устройства позволяют предсказать появление наиболее вероятных ошибок и, тем самым, дают пользователю возможность своевременно сделать резервную копию данных и/или полностью заменить накопитель до выхода его из строя.
S.M.A.R.T. представляет собой набор мини-подпрограмм, которые являются частью микрокода накопителя и определяют поддерживаемые диагностические функции. Наиболее распространенные среди них:
- набор атрибутов, отражающих состояние отдельных параметров накопителя (до 30)
- внутренние тесты накопителя (self-test)
- журналы S.M.A.R.T. (ошибок, общего состояния, дефектных секторов и т.п.)
В настоящий момент не существует официальной документации или стандарта на технологию S.M.A.R.T. В связи с этим, производители не публикуют полные характеристики и поддерживаемые функции S.M.A.R.T. в своих накопителях. Обязательный минимум описан в последнем стандарте ATA/ATAPI-6.
1.2. Развитие технологии S.M.A.R.T.
История технологии S.M.A.R.T. не так уж и богата подробностями:
-
SMART I предусматривал мониторинг основных жизненно важных параметров и запускался только после команды по интерфейсу
-
в SMART II появилась возможность фоновой проверки поверхности, которая выполнялась накопителем автоматически во время «холостого хода»; появилась функция журналирования ошибок
-
в SMART III впервые появилась не только функция обнаружения дефектов поверхности, но и возможность их восстановления «прозрачно» для пользователя и многие другие новшества
Известно, что первыми разработали основы и предложили эту технологию совместно Western Digital, Seagate и Quantum. После этого их уже поддержали такие компании как IBM, Maxtor и Samsung. Hitachi приняла участие в развитии технологии S.M.A.R.T. уже на стадии разработки SMART II, первыми предложив методику полной самодиагностики накопителя (extended self-test).
В настоящее время производители жестких дисков готовятся принять к использованию новый вариант технологии S.M.A.R.T. — «1024 S.M.A.R.T.», характерной особенностью которого будет заметно бОльший размер журналов, повсеместное использование мультисекторных журналов, более точные алгоритмы анализа показаний встроенных в накопитель сенсоров (термодатчики, сенсоры ударов, и т.п.) и многое другое. Вот несколько новых функций:
-
введение алгоритма анализа температурного режима накопителя
-
введение ограничения по минимальной и максимальной температуре в рабочем состоянии
-
введение счетчика общего количества записанных секторов на протяжении жизненного цикла накопителя
-
введение счетчика запусков внутренних алгоритмов восстановления (recovery counters)
Главным же плюсом можно считать введение новых атрибутов, которые позволят контролировать состояние и рабочие характеристики по каждой из головок чтения/записи:
-
относительная устойчивость (стабильность «полета») головки
-
исправление ошибок чтения (со «скрытыми» повторными попытками)
-
автоматическое перераспределение дефектных участков поверхности при операциях записи
-
счетчик-накопитель G-List для учета количества принятых ударных нагрузок
-
счетчик-накопитель S-List для учета общего количества «программных» ошибок
Атрибуты.
Атрибуты S.M.A.R.T. — особые характеристики, которые используются при анализе состояния и запаса производительности накопителя. Атрибуты выбираются производителем накопителя, основываясь на способности этих атрибутов предсказывать ухудшение рабочих характеристик накопителя или определить его дефектность. Каждый производитель имеет свой характерный набор атрибутов и может свободно вносить изменения в этот набор в соответствиии со своими собственными требованиями и без уведомления об этом фирм-продавцов и конечных пользователей.
1.3.1. Значения атрибутов.
Значения атрибутов (value) используются для представления относительной надежности отдельного эксплуатационного или эталонного атрибута. Допустимое значение атрибута лежит в диапазоне от 1 до 255. Высокое значение атрибута говорит о том, что результат анализа данной рабочей характеристики указывает на низкую вероятность ее ухудшения или выхода накопителя из строя. Соответственно, низкое значение атрибута говорит о том, что результат анализа данной рабочей характеристики указывает на высокую вероятность ее ухудшения или выхода накопителя из строя.
1.3.2. Пороговые значения атрибутов.
Каждый атрибут имеет собственное пороговое значение (threshold), которое используется для сравнения со значением атрибута (value) и указывает на ухудшение рабочих характеристик или дефектность накопителя. Числовое значение порогового атрибута определяется производителем накопителя через конструкционные особенности накопителя и анализ результатов испытаний на надежность. Пороговое значение каждого атрибута указывает на нижнюю допустимую границу значения атрибута, вплоть до которой сохраняется положительный статус надежности.
Пороговые значения устанавливаются в заводских условиях производителем накопителя и, в большинстве случаев, могут быть изменены только после переключения накопителя в технологический (factory mode). Допустимое пороговое значение атрибута может находится в диапазоне от 1 до 255.
Если значение одного или более атрибутов, имеющих тип pre-failure (в HDD Speed отмечаются символом «*«), меньше или равно соответствующего порогового значения, то это свидетельствует о предстоящем ухудшении рабочих характеристик и/или полном выходе накопителя из строя.
1.3.3. Краткое описание основных атрибутов.
Данный перечень атрибутов является наиболее полным из доступных на сегодняшний момент в Сети или иных источниках. Назначение атрибутов и способ интерпретации их значений выявлены либо опытным путем, либо получены от служб технической поддержки компаний-производителей накопителей.
Ниже приведена сводная таблица всех известных мне атрибутов (55) и краткое описание к большинству (38) из них.
| ID | Название атрибута |
|---|---|
| 0 | = атрибут не используется |
| 1 | Raw Read Error Rate |
| 2 | Throughput Performance |
| 3 | Spin Up Time |
| 4 | Start/Stop Count |
| 5 | Reallocated Sector Count |
| 6 | Read Channel Margin |
| 7 | Seek Error Rate |
| 8 | Seek Time Performance |
| 9 | Power-On Hours Count |
| 10 | Spin Retry Count |
| 11 | Recalibration Retries |
| 12 | Device Power Cycle Count |
| 13 | Soft Read Error Rate |
| ?? | Emergency Re-track (Hitachi) |
| ?? | ECC On-The-Fly Count (Hitachi) |
| 96 | ? (Maxtor) |
| 97 | ? (Maxtor) |
| 98 | ? (Maxtor) |
| 99 | ? (Maxtor) |
| 100 | ? (Maxtor) |
| 101 | ? (Maxtor) |
| 191 | G-Sense Error Rate |
| 192 | Power-Off Retract Cycle |
| 193 | Load/Unload Cycle Count |
| 194 | Temperature |
| 195 | ? (Quantum AS, Seagate, Maxtor) |
| 196 | Reallocation Events Count |
| 197 | Current Pending Sector Count |
| 198 | Uncorrectable Sector Count |
| 199 | UltraDMA CRC Error Rate |
| 200 | Write Error Rate (в WD — MultiZone Error Rate) |
| 201 | TA Counter Detected |
| 202 | TA Counter Increased |
| 203 | ? (Maxtor) |
| 204 | ? (Maxtor) |
| 205 | ? (Maxtor) |
| 206 | ? (Maxtor) |
| 207 | ? (Maxtor) |
| 208 | ? (Maxtor) |
| 209 | ? (Maxtor) |
| 220 | Disk Shift |
| 221 | G-Sense Error Rate (в Hitachi — Shock Sense Error Rate) |
| 222 | Loaded Hours |
| 223 | Load/Unload Retry Count |
| 224 | Load Friction |
| 225 | Load/Unload Cycle Count |
| 226 | Load-in Time |
| 227 | Torque Amplification Count |
| 228 | Power-Off Retract Count |
| 229 | ? (IBM DTTA, thanx to Vladislav Shaklein) |
| 230 | GMR Head Amplitude |
| 231 | Temperature |
| 240 | Head Flying Hours (Hitachi) |
| 250 | Read Error Retry Rate |
Краткое описание известных атрибутов.
-
* (используется в программе HDD Speed)
Данный указатель показывает, что соответствующий атрибут S.M.A.R.T. является критическим для нормального функционирования накопителя. Ухудшение значений таких атрибутов с наибольшей вероятностью приводит к выходу накопителя из строя. В новых материнских платах BIOS имеют встроенную функцию контроля состояния накопителя именно по этим атрибутам. -
Raw Read Error Rate
Частота появления ошибок при чтении данных с диска.
Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине аппаратной части накопителя. -
Throughput Performance
Средняя производительность (пропускная способность) диска.Уменьшение значения value этого атрибута с большой вероятностью указывает на проблемы в накопителе.
-
Spin Up Time
Время раскрутки шпинделя.
Среднее время раскрутки шпинделя диска от 0 RPM до рабочей скорости. Предположительно, в поле raw value содержится время в миллисекундах/секундах. -
Start/Stop Count
Количество циклов запуск/останов шпинделя.
Поле raw value хранит общее количество включений/выключений диска. -
Reallocated Sectors Count
Количество переназначенных секторов.
Когда жесткий диск встречает ошибку чтения/записи/верификации он пытается переместить данные из него в специальную резервную область (spare area) и, в случае успеха, помечает сектор как «переназначенный». Также, этот процесс называют remapping, а переназначенный сектор — remap. Благодаря этой возможности, на современных жестких дисках очень редко видны [при тестировании поверхности] так называемые bad block. Однако, при большом количестве ремапов, на графике чтения с поверхности будут заметны «провалы» — резкое падение скорости чтения (до 10% и более).
Поле raw value содержит общее количество переназначенных секторов. -
Read Channel Margin
Запас канала чтения.
Назначение этого атрибута не документировано и в современных накопителях он не используется. -
Seek Error Rate
Частота появления ошибок позиционирования БМГ.
В случае сбоя в механической системе позиционирования, повреждения сервометок (servo), сильного термического расширения дисков и т.п. возникают ошибки позиционирования. Чем их больше, тем хуже состояние механики и/или поверхности жесткого диска. -
Seek Time Performance
Средняя производительность операций позиционирования БМГ.
Данный параметр показывает среднюю скорость позиционирования привода БМГ на указанный сектор. Снижение значения этого атрибута говорит о неполадках в механике привода. -
Power-On Hours
Количество отработанных часов во включенном состоянии.
Поле raw value этого атрибута показывает количество часов (минут, секунд — в зависимости от производителя), отработанных жестким диском. Снижение значения (value) атрибута до критического уровня (threshold) указывает на выработку диском ресурса (MTBF — Mean Time Between Failures). На практике, даже падение этого атрибута до нулевого значения не всегда указывает на реальное исчерпывание ресурса и накопитель может продолжать нормально функционировать. -
Spin Retry Count
Количество повторов попыток старта шпинделя диска.
Данный атрибут фиксирует общее количество попыток раскрутки шпинделя и его выхода на рабочую скорость, при условии, что первая попытка была неудачной. Снижение значения этого атрибута говорит о неполадках в механике привода. -
Recalibration Retries
Количество повторов попыток рекалибровки накопителя.
Данный атрибут фиксирует общее количество попыток сброса состояния накопителя и установки головок на нулевую дорожку, при условии, что первая попытка была неудачной. Снижение значения этого атрибута говорит о неполадках в механике привода. -
Device Power Cycle Count
Количество полных циклов запуска/останова жесткого диска. -
Soft Read Error Rate
Частота появления «программных» ошибок при чтении данных с диска.
Данный параметр показывает частоту появления ошибок при операциях чтения с поверхности диска по вине программного обеспечения, а не аппаратной части накопителя. -
Emergency Re-track
-
ECC On-The-Fly Count
-
Load/Unload Cycle Count
Количество циклов вывода БМГ в специальную парковочную зону/в рабочее положение.
Подробнее — см. описание технологии Head Load/Unload Technology. -
Temperature
Температура.
Данный параметр отражает в поле raw value показание встроенного температурного сенсора в градусах Цельсия. -
Reallocation Event Count
Количество операций переназначения (ремаппинга).
Поле raw value этого атрибута показывает общее количество попыток переназначения сбойных секторов в резервную область, предпринятых накопителем. При этом, учитываются как успешные, так и неудачные операции. -
Current Pending Sector Count
Текущее количество нестабильных секторов.
Поле raw value этого атрибута показывает общее количество секторов, которые накопитель в данный момент считает претендентами на переназначение в резервную область (remap). Если в дальнейшем какой-то из этих секторов будет прочитан успешно, то он исключается из списка претендентов. Если же чтение сектора будет сопровождаться ошибками, то накопитель попытается восстановить данные и перенести их в резервную область, а сам сектор пометить как переназначенный (remapped). Постоянно ненулевое значение raw value этого атрибута говорит о низком качестве (отдельной зоны) поверхности диска. -
Uncorrectable Sector Count
Количество нескорректированных ошибок.
Атрибут показывает общее количество ошибок, возникших при чтении/записи сектора и которые не удалось скорректировать. Рост значения в поле raw value этого атрибута указывает на явные дефекты поверхности и/или проблемы в работе механики накопителя. -
UltraDMA CRC Error Count
Общее количество ошибок CRC в режиме UltraDMA.
Поле raw value содержит количество ошибок, возникших в режиме передачи данных UltraDMA в контрольной сумме (ICRC — Interface CRC).Примечание автора
. Практика, собранная статистика и изучение журналов ошибок SMART показывают: в большинстве случаев ошибки CRC возникают при сильном завышении частоты PCI (больше номинальных 33.6 MHz), сильно перекрученом кабеле, а также — по вине драйверов ОС, которые не соблюдают требований к передачи/приему данных в режимах UltraDMA.
-
Write Error Rate (Multi Zone Error Rate)
Частота появления ошибок при записи данных.
Показывает общее количество ошибок, обнаруженных во время записи сектора. Чем больше значение в поле raw value (и ниже значение value), тем хуже состояние поверхности диска и/или механики привода. -
Disk Shift
Сдвиг пакета дисков относительно оси шпинделя.
Актуальное значение атрибута содержится в поле raw value. Единицы измерения — не известны.
Подробности — см. в описании технологии G-Force Protection.Примечание
. Сдвиг пакета дисков возможен в результате сильной ударной нагрузки на накопитель в результате его падения или по иным причинам.
-
G-Sense Error Rate
Частота появления ошибок в результате ударных нагрузок.
Данный атрибут хранит показания ударочувствительного сенсора — общее количество ошибок, возникших в результате полученных накопителем внешних ударных нагрузок (при падении, неправильной установке, и т.п.).
Подробнее — см. описание технологии G-Force Protection. -
Loaded Hours
Нагрузка на привод БМГ, вызванная общей наработкой часов накопителем.
Учитывается только период, в течении которого головки находились в рабочем положении. -
Load/Unload Retry Count
Нагрузка на привод БМГ, вызванная многочисленными повторениями операций чтения, записи, позиционирования головок и т.п. Учитывается только период, в течении которого головки находились в рабочем положении. -
Load Friction
Нагрузка на привод БМГ, вызванная трением в механических частях накопителя.
Учитывается только период, в течении которого головки находились в рабочем положении. -
Load/Unload Cycle Count
Общее количество циклов нагрузки на привод БМГ.
Учитывается только период, в течении которого головки находились в рабочем положении. -
Load-in Time
Общее время нагрузки на привод БМГ.
Предположительно, данный атрибут показывает общее время работы накопителя под нагрузкой, при условии, что головки находятся в рабочем состоянии (вне парковочной зоны). -
Torque Amplification Count
Количество усилий вращающего момента привода. -
Power-Off Retract Count
Количество зафиксированных повторов в(ы)ключения питания накопителя. -
GMR Head Amplitude
Амплитуда дрожания головок (GMR-head) в рабочем состоянии. -
Head Flying Hours
-
Read Error Retry Rate
1.3.4. Типы атрибутов.
Каждый атрибут может иметь некоторый набор флагов, определяющих его функциональные особенности. Ниже приводятся все шесть основных типов и их краткие описания.
-
Pre-failure (PF). Если атрибут имеет этот тип, то поле threshold атрибута содержит минимально допустимое значение атрибута, ниже которого не гарантируется работоспособность накопителя и резко увеличивается вероятность его выхода из строя.
-
On-line collection (OC). Указывает, что значение данного атрибута обновляется (вычисляется) во время выполнения on-line тестов S.M.A.R.T. или же во время обоих видов тестов (on-line/off-line). В противном случае, значение атрибута обновляется только при выполнении off-line тестов.
-
Performance related (PR). Указывает на то, что значение этого атрибута напрямую зависит от производительности накопителя по отдельным показателям (seek/throughput/etc. performance). Обычно обновляется после выполнения self-test`ов SMART.
-
Error rate (ER). Указывает на то, что значение атрибута отражает относительную частоту ошибок по данному параметру (raw read/write, seek, etc.).
-
Events count (EC). Указывает на то, что атрибут является счетчиком событий.
-
Self-preserve (SP). Указывает на то, что значение атрибута обновляется и сохраняется автоматически (обычно при каждом старте накопителя и при выполнении тестов SMART).
Автономное сканирование поверхности
(off-line read scanning)
Большинство накопителей обеспечивают поддержку автономного сканирования поверхности, которое является одной из функций подпрограммы автономного сбора данных о состоянии накопителя (off-line data collection). При выполнении этой функции, накопитель выполняет полное сканирование поверхности путем чтения каждого сектора и замещением ненадежных секторов на запасные сектора из резервной области (spare area) для предотвращения потери пользовательских данных.
Примечание. Если во время выполнения сканирования накопитель получает команду по интерфейсу, то процесс сканирования прерывается и накопитель приступает к обработке поступившей команды. При этом гарантируется максимальное время реагирования на поступившую команду — до 2 секунд.
Журналы ошибок
(SMART error log)
В большинстве современных накопителей реализованна функция журналирования появляющихся в течении работы накопителя ошибок или иных событий. В основном, накопители предоставляют информацию о пяти последних ошибках. При этом сохраняются последние 5 поступивших в накопитель команд, предшествующих возникновению этой ошибки, и другая необходимая информация.Накопитель может также поддерживать дополнительные журналы. Их структура, размер и назначение устанавливаются фирмой-производителем. При обновлении микропрограммы накопителя, все журналы накопителя очищаются, а общее количество ошибок устанавливается в значение 0.
Примечание: в журналах сохраняется время по внутренним часам накопителя, т.е. либо общее отработанное время на данный момент, либо время от момента последнего включения накопителя.
1.5.1. Log Directory
Тип: Каталог журналов S.M.A.R.T.
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддержка мультисекторных журналов
Данный журнал представляет собой своего рода каталог, в котором указаны адреса всех поддерживаемых журналов S.M.A.R.T. и их размер в секторах. Максимальное количество журналов — 255.
1.5.2. Summary Error Log
Тип: Суммарный журнал ошибок
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит информацию об общем количестве ошибок, зафиксированных накопителем с момента первого включения (или обновления микропрограммы) и подробные записи о последних 5 ошибках. Для каждой из 5 зафиксированных ошибок сохраняются последние 5 поступивших в накопитель команд. В этом журнале сохраняются все ошибки UNC, IDNF, ошибки сервосистемы, записи/чтения и т.д. При этом, для каждой команды сохраняется значения всех регистров, время и текущее состояние накопителя на момент подачи самой команды. Ошибки, вызванные подачей неподдерживаемых команд или командами с ошибочными параментами не фиксируются в журнале. Если накопитель поддерживает Comprehensive Error Log, то журнал Summary Error Log дублирует последние пять записей из журнала Comprehensive Error Log.
1.5.3. Comprehensive Error Log
Тип: Комплексный журнал ошибок [SMART Error Logging]
Вид доступа: только чтение (RO)
Размер: 1..51 сектор (максимум 26,112 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит подробную информацию о общем количестве ошибок, зафиксированных накопителем с момента первого включения (или обновления микропрограммы) и подробные записи о последних ошибках. Максимальное количество сохраняемых ошибок — 255. Для каждой зафиксированной ошибки сохраняются последние 5 поступивших в накопитель команд. В этом журнале сохраняются все ошибки UNC, IDNF, ошибки сервосистемы, записи/чтения и т.д. При этом, для каждой команды сохраняется значения всех регистров, время и текущее состояние накопителя на момент подачи самой команды. Ошибки, вызванные подачей неподдерживаемых команд или командами с ошибочными параментами не фиксируются в журнале.
1.5.4. Extended Comprehensive Error Log
Тип: Расширенный комплексный журнал ошибок [SMART Error Logging]
Вид доступа: только чтение (RO)
Размер: 1..65,536 секторов (максимум 32 Мбайт)
Примечание: поддерживается 28/48-битная адресация секторов
Назначение данного журнала аналогично журналу Comprehensive Error Log и содержит в себе копию его записей, однако этот журнал имеет иную структуру, которая позволяет реализовать поддержку как 28-битной, так и 48-битной адресации секторов. Максимальное количество сохраняемых ошибок — 327,680.
1.5.5. Self-test Log
Тип: Журнал результатов самоконтроля [SMART self-test]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит информацию о результатах выполнения команд внутренней самодиагностики накопителя. Журнал может хранить до 21 записи. При превышении этого количества, журнал начинает заполняться заново, перезаписывая 1-ю запись 22-й, 2-ю — 23-ей и так далее. В каждой записи журнала сохраняется регистр с номером теста, код статуса выполнения теста, время на момент запуска/прерывания теста, номер текущей контрольной точки (или точки останова) теста, а также LBA-адрес сектора, на котором произошло прерывание/отмена теста.
1.5.6. Extended Self-test Log
Тип: Расширенный журнал результатов самоконтроля [SMART self-test]
Вид доступа: только чтение (RO)
Размер: 1..65,536 секторов (максимум 32 Мбайт)
Примечание: поддерживается 28/48-битная адресация секторов
Назначение данного журнала аналогично журналу Self-test Log и содержит в себе копию его записей, однако этот журнал имеет иную структуру, которая позволяет реализовать поддержку как 28-битной, так и 48-битной адресации секторов. Максимальное количество записей — 1,179,648.
1.5.7. Streaming Performance Log
Тип: Журнал параметров производительности потоков [Streaming]
Вид доступа: только чтение (RO)
Размер: 1..65,536 секторов (максимум 32 Мбайт)
Данный журнал содержит информацию о переданных накопителю параметров командами управления режимом Automatic Acoustic Management и Typical Host Interface Sector Time (подробнее — см. ATA/ATAPI-6 rev 1e). В журнале сохраняется набор параметров, по которым производится настройка накопителя и перевод в его в режим, когда все операции чтения/записи возможны только специальными командами и передача данных происходит в виде непрерывного потока, для которого гарантированны и учитываются все временные интервалы (на обработку команды, чтение и передачу данных; минимальные/максимальные задержки, время доступа, позиционирования и т.п.). Подробнее о назначении данного вида журналов можно узнать из описания технологии Audio/Video (AV) Streaming Feature.
1.5.8. Write Stream Error Log
Тип: Журнал ошибок потоковой записи [Streaming]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается 48-битная адресация секторов
Данный журнал содержит информацию о возникших ошибках записи в период работы накопителя в потоковом режиме (streaming mode). В этом журнале сохраняется общее количество подобных ошибок, номер последней ошибки, предыдущее и текущее значения регистров состояния и ошибки, количество и LBA-номер сектора, на котором данная ошибка была зафиксирована. После чтения данного журнала, накопитель сбрасывает счетчик общего количества ошибок и очищает журнал. Содержимое журнала сохраняется только во время работы и очищается в момент следующего включения/выключения накопителя или при поступлении сигнала аппаратного сброса (hardware reset). Максимальное количество сохраняемых ошибок — 31.
1.5.9. Read Stream Error Log
Тип: Журнал ошибок потокового чтения [Streaming]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается 48-битная адресация секторов
Данный журнал содержит информацию о возникших ошибках чтения в период работы накопителя в потоковом режиме (streaming mode). В этом журнале сохраняется общее количество подобных ошибок, номер последней ошибки, предыдущее и текущее значения регистров состояния и ошибки; количество и LBA-номер сектора, на котором данная ошибка была зафиксирована. После чтения данного журнала, накопитель сбрасывает счетчик общего количества ошибок и очищает журнал. Содержимое журнала сохраняется только во время работы и очищается в момент следующего включения/выключения накопителя или при поступлении сигнала аппаратного сброса (hardware reset). Максимальное количество сохраняемых ошибок — 31.
1.5.10. Delayed LBA Sector Log
Тип: Vendor Specified [General Purpose Logging]
Вид доступа: только чтение (RO)
Размер: устанавливается производителем (VS)
Примечание: поддерживается 48-битная адресация секторов
Данный журнал содержит LBA-адреса всех секторов, которые были перемещены со своего нормального физического расположения, а также адреса границ недоступной последовательности секторов. Таким образом ведется журнал всех дефектных или нестабильных секторов. Максимальный размер журнала устанавливается производителем. Новое физическое расположение, метод и время доступа к замещенным секторам также устанавливается производителем и не документируется. Запись в данный журнал может быть добавлена в любой момент времени, при условии активности (питания) самого накопителя. Для процесса обновления журнала устанавливается наивысший приоритет и выполнение всех других команд приостанавливается. При этом удалить существующую запись из журнала не возможно. Содержимое журнала сохраняется при циклах включения/выключения накопителя и при поступлении сигнала аппаратного сброса (hardware reset).
1.5.11. ECC Uncorrectable Sector Log
Тип: Журнал неисправимых ошибок ECC [SMART Recovering]
Вид доступа: только чтение (RO)
Размер: 1 сектор (512 байт)
Примечание: поддерживается только 28-битная адресация секторов (28-bit LBA)
Данный журнал содержит список LBA-адресов секторов, на которых была зафиксирована и проигнорирована некорректируемая ошибка ECC при выполнении операции READ CONTINUOUS (см. AV feature). При этом, выполнение процедуры автоматического переназначения сбойного сектора (ADR — Automatic Defects Reassigment) накопителем заблокировано. Журнал может содержать до 126 записей.
Примечание. Данный журнал доступен для чтения только при разрешенной операции READ CONTINUOUS. В противном случае накопитель возвратит код ошибки ERR->ABRT, прервет выполнение команды или возвратит пустой журнал. После успешного чтения журнала, в самом накопителе он будет очищен.
1.5.12. Reassigned Sector Log
[under construction]
1.5.13. Drive Activity Log
[under construction]
1.5.14. Drive Time Buffer Log
[under construction]
1.5.15. Host Vendor Specific Log
Тип: Пользовательские журналы
Вид доступа: чтение/запись (R/W)
Размер: максимум 31 журнал по 16 секторов (253,952 байт)
Примечание: содержание и формат журнала — любое, на усмотрение пользователя
Этот вид журнала может быть использован для хранения произвольных пользовательских данных. Для записи этого журнала используется команда WRITE SMART LOG. Если данный журнал ни разу не был записан, то при чтении накопитель возвратит пустой журнал, заполненный нулями.
1.5.16. Device Vendor Specific Log
Тип: Технические журналы изготовителя
Вид доступа: не определен, на усмотрение производителя (VS)
Размер: максимум 31 журнал по 16 секторов (253,952 байт)
Примечание: содержание, формат и размеры журнала — на усмотрение производителя
Этот вид журнала предназначен для внутреннего использования фирменными утилитами производителя, для хранения результатов работы встроенных подпрограмм анализа и диагностики состояния накопителя и т.п. Возможность чтения/записи этого вида журнала устанавливается производителем и не не документируется.
Примечание. Новые накопители Seagate (модели Ux и Barracuda ATA) поддерживают и даже реально используют еще три вида журналов SMART, однако их назначение и описание пока не известны.
Встроенные функции самоконтроля
(self-test)
Практически с момента появления стандарта S.M.A.R.T. II, в большинстве накопителей появилась новая функция — внутренняя диагностика и самоконтроль, для углубленного контроля состояния механики накопителя, поверхности дисков и т.п. Для запуска этой функции, в набор команд S.M.A.R.T. была введена новая команда — SMART EXECUTE OFF-LINE IMMEDIATE. Результат работы сохраняется либо в специализированных атрибутах, либо отдельным параметром среди других данных в атрибутах. Если накопитель поддерживает журналы S.M.A.R.T., то результат выполнения тестов сохраняется также в журнале Self-test Log. После выполнения теста, накопитель в обязательном порядке обновляет показания во всех атрибутах и других параметрах. Если во время выполнения внутреннего теста накопитель получит по интерфейсу новую команду, то выполнение теста прерывается и накопитель приступает к обработке поступившей команды.
1.6.1. Методы тестирования
Существует два способа запуска тестов S.M.A.R.T.: автономный (off-line) или монопольный (captive). Результат теста всегда сохраняется накопителем в данных S.M.A.R.T. При автономном запуске накопитель сообщает о успешном завершении команды ДО ее ФАКТИЧЕСКОГО исполнения и только после этого выполняет тест. При этом, по интерфейсу флаг ЗАНЯТО (BSY) не выставляется и накопитель в любой момент готов приступить к выполнению очередной интерфейсной команды, приостанавливая работу теста. Фактически, тест выполняется в фоновом режиме. При запуске теста в монопольном режиме, по интерфейсу выставляется флаг ЗАНЯТО (BSY) и накопитель начинает непосредственное выполнение теста в режиме реального времени. Любая интерфейсная команда во время выполнения этого теста приведет к его прерыванию и остановке, после чего накопитель приступит к обработке поступившей команды.
1.6.2. Разновидности тестов S.M.A.R.T.
Официально документированы три вида внутренних тестов, однако еще существует набор так называемых «активных» тестов, функциональные особенности которых различны у разных производителей и для широкой публики не документированы.
| № |
Название теста |
off-line | captive |
|---|---|---|---|
| 1 | Off-line collection | + | — |
| 2 | Short Self-test | + | + |
| 3 | Extended Self-test | + | + |
| 4 | Drive Activity test #1..#4 | + | + |
Время тестирования может варьироваться от 1 секунды (Quantum) до 54 минут (Fujitsu MPG3409AT). Поддержка первого теста наиболее вероятна даже в очень старых накопителях 4-5 летней давности.
Второй и третий тесты появились относительно недавно, как дань внедренным сложным технологическим решениям — для полного контроля состояния накопителя пришлось реализовывать более глубокие и точные тесты. Поддержка 4-х «активных» тестов (см. таблицу, п.4) официально не документированна.
Реальный набор выполняемых тестами функций можно рассмотреть на примере тестов, поддерживаемых жесткими дисками Hitachi:
| Функция теста | Short Self test | Extended Self test | Off-line Collection |
|---|---|---|---|
| Raw Read Error Rate Test | YES | YES | YES |
| Write Test | YES | YES | NO |
| Servo Test | YES | YES | NO |
| Partial Read Scanning | YES | NO | NO |
| Full Read Scanning | NO | YES | YES |
Этот перечень тестов не является одинаковым для всех накопителей и приведен лишь в качестве примера.
Версия от 03.09.2001.
Доброго времени суток. Интересно ваше мнение касательно ситуации которая у меня сложилась с жестким диском фирмы Western Digital серии Black.
Есть у меня плохая?хорошая привычка «довольно часто» посматривать S.M.A.R.T, что бы быть увереным в исправной работе носителей которыми пользуюсь, и первый раз столкулся с проблемой которую не могу понять, а именно касально быстрого, я бы даже сказал молниеносного скачка G-Sense_Error_Rate.
Жесткий диск был куплен совсем недавно, и был установлен в ноутбук в качестве замены WD Red (дисками пользуюсь исключетельно WD), нареканий не было никаких, все работало исправно, смарт был изумительно чист, битых секторов не было.
Сегодня утром включив ноутбук, я как обычно проверил систему на наличие ошибок (в том числе и жесткий диск), G-Sense_Error_Rate был равен нулю. Весь день ноутбук стоял неподвижно на столе, подключен к питанию по мере заряда/разряда батареи. Примерно час назад захотел немного изменить настройки LMT, что бы увеличить время работы от батареи, но в конечном итоге узнал про TLP, и заменил LMT на него. После его настройки (в GUI), даже не запустив службы, перейдя на вкладку «Статистика» и выбрав «Полная» я просто ах**л, увидев количество ошибок G-Sense. К сожалению я не могу сказать, когда значение начало рости, т.к утром смотрел смарт, но сейчас оно без изменений, хоть ноутбук я и перезагрузил (паника, не смог поверить в увиденное).
Единственная настройка касательно жесткого диска была hdparm -B 254 при подключение к сети, и hdparm -B 155 при работе от батареи, которая была еще с самого начала установки накопителя в ноутбук.
Собственно сам S.M.A.R.T
=== START OF INFORMATION SECTION ===
Model Family: Western Digital Black Mobile
Device Model: WDC WD10JPLX-00MBPT0
Serial Number: JR1000BNHW7EVE
LU WWN Device Id: 5 000cca 8e6da797a
Firmware Version: 01.01H01
User Capacity: 1 000 204 886 016 bytes [1,00 TB]
Sector Sizes: 512 bytes logical, 4096 bytes physical
Rotation Rate: 7200 rpm
Form Factor: 2.5 inches
Device is: In smartctl database [for details use: -P show]
ATA Version is: ATA8-ACS T13/1699-D revision 6
SATA Version is: SATA 3.0, 6.0 Gb/s (current: 6.0 Gb/s)
Local Time is: Sun Jul 29 04:03:34 2018 EEST
SMART support is: Available - device has SMART capability.
SMART support is: Enabled
SMART Attributes Data Structure revision number: 16
Vendor Specific SMART Attributes with Thresholds:
ID# ATTRIBUTE_NAME FLAG VALUE WORST THRESH TYPE UPDATED WHEN_FAILED RAW_VALUE
1 Raw_Read_Error_Rate 0x000b 100 100 062 Pre-fail Always - 0
2 Throughput_Performance 0x0005 100 100 040 Pre-fail Offline - 0
3 Spin_Up_Time 0x0007 211 211 033 Pre-fail Always - 2
4 Start_Stop_Count 0x0012 100 100 000 Old_age Always - 370
5 Reallocated_Sector_Ct 0x0033 100 100 005 Pre-fail Always - 0
7 Seek_Error_Rate 0x000b 100 100 067 Pre-fail Always - 0
8 Seek_Time_Performance 0x0005 100 100 040 Pre-fail Offline - 0
9 Power_On_Hours 0x0012 099 099 000 Old_age Always - 439
10 Spin_Retry_Count 0x0013 100 100 060 Pre-fail Always - 0
12 Power_Cycle_Count 0x0032 100 100 000 Old_age Always - 29
191 G-Sense_Error_Rate 0x000a 099 099 000 Old_age Always - 131073
192 Power-Off_Retract_Count 0x0032 100 100 000 Old_age Always - 5
193 Load_Cycle_Count 0x0012 094 094 000 Old_age Always - 60650
194 Temperature_Celsius 0x0002 150 150 000 Old_age Always - 40 (Min/Max 23/48)
196 Reallocated_Event_Count 0x0032 100 100 000 Old_age Always - 0
197 Current_Pending_Sector 0x0022 100 100 000 Old_age Always - 0
198 Offline_Uncorrectable 0x0008 100 100 000 Old_age Offline - 0
199 UDMA_CRC_Error_Count 0x000a 200 200 000 Old_age Always - 0
223 Load_Retry_Count 0x000a 100 100 000 Old_age Always - 0
Его полная версия на pastebin, также скриншот в .PNG, что бы никто не говорил, что я руками подправил значение.
Что это, гарантийный случай, сбой контролера, баг smartctl, Полтергейст? Возможно есть варианты как попробовать сбросить данное значение, ведь диск полностью работоспособен, ни то что бы ни разу не падал, даже при включеном ноутбуке не передвигался по квартире. Интересно именно за гарантийный случай, т.к действительно к технике отношусь акуратно и хотелось бы вынести урок на будущее.
Описал данный случай как историю, потому, что даже не представляю, как можно описать это по другому. Вы уж простите меня. Спасибо.
Что такое SMART HDD (жёсткого диска) и что нужно делать, если компьютер выдаёт надпись «smart status bad backup and replace».
Во всех современных накопителях последних лет абсолютно любого производителя присутствует система SMART (self-monitoring, analysis and reporting technology — технология предупреждения, анализа и самопроверки) жесткого диска, очень тесно связанная с функционированием накопителя.
Современные технологии SMART осуществляют: мониторинг различных параметров состояния диска, сканирование поверхности жесткого диска с дальнейшей автоматической заменой нечитаемых секторов и занесение их в error-log, т.н. список, где номера этих секторов хранятся в виде таблицы, периодическое повторное сканирование «ненадежных» секторов из error-log и, если система определяет, что данный сектор исправен — то исключает его из данного списка и он становится доступен на поверхности для пользовательской информации (но также помечается для дальнейшей перепроверки при следующем сканировании поверхности), либо, если сектор не прочитывается несколько раз подряд, не переписывается, то он отправляется в следующий дефект-лист,именуемый у разных производителей по-разному, но имеющий одинаковое предназначение — этот лист является как бы посредником между error-log таблицей и финальным G-листом, где дефект уже будет занесен в G-лист навсегда, станет отображаться в SMART, в строке current pending sectors/offline UNC sectors.
Из статуса current pending поврежденный сектор после очередной перепроверки на «живучесть», если не прошел чтение/запись, то окончательно отправляется в статус переназначенных и там уже остается. Диск в дальнейшей работе его уже не использует, не тестирует повторно на чтение/запись.
В строке reallocated sector count изменяется значение с N на N+1.
Если накопитель имеет уже серьёзные повреждения, то при загрузке компьютера может выводиться надпись: «smart status bad backup and replace». Это значит, что статус SMART жёсткого диска изменился из состояния GOOD в состояние BAD, на диске как минимум имеются BAD-блоки и состояние диска продолжает ухудшаться. Пользователю рекомендуется сохранить свои данные, если они ещё доступны для чтения и заменить жёсткий диск на новый.
SMART ВЫГЛЯДИТ ТАК:

Выводится в виде таблицы со следующими столбцами:
ID – ИДЕНТИФИКАЦИОННЫЙ НОМЕР ПАРАМЕТРА
Name – выводимое программой имя параметра
VAL – НОРМАЛИЗОВАННОЕ ЗНАЧЕНИЕ ПАРАМЕТРА (НОРМАЛИЗОВАННОЕ ЗНАЧИТ, В ДАННОМ СЛУЧАЕ, ЧТО ВНУТРЕННЕЕ (RAW) ЗНАЧЕНИЕ ПАРАМЕТРА ПРЕОБРАЗОВАНО ПО ОПРЕДЕЛЁННОМУ АЛГОРИТМУ ДЛЯ БОЛЕЕ УДОБНОГО И ПОНЯТНОГО ПРОСМОТРА ЗНАЧЕНИЯ. НАПРИМЕР, ВНУТРЕННИЙ ПАРАМЕТР ВСЕГДА УВЕЛИЧИВАЕТСЯ И МОЖЕТ ПРИНИМАТЬ ЗНАЧЕНИЕ В НЕСКОЛЬКО ТЫСЯЧ ЕДИНИЦ, А ВЫВОДИМОЕ ЗНАЧЕНИЕ ИЗМЕНЯЕТСЯ ОТ 100 ДО 0 И ОТОБРАЖЕНИЕ ВНУТРЕННЕГО ДИАПАЗОНА ИЗМЕНЕНИЯ ПАРАМЕТРА НА ВЫВОДИМЫЙ И ЕСТЬ, В ДАННОМ СЛУЧАЕ, НОРМАЛИЗАЦИЯ)
Wrst – худшее значение параметра за отрезок времени время
Thresh – пороговое значение, при достижении которого диск рекомендуется заменить
РАССМОТРИМ, КАКИЕ СУЩЕСТВУЮТ ПАРАМЕТРЫ В СИСТЕМЕ SMART. НАБОР ОТСЛЕЖИВАЕМЫХ ПАРАМЕТРОВ ЗАВИСИТ ОТ ПРОИЗВОДИТЕЛЯ ДИСКА И НЕ ВСЕ ИЗ ПЕРЕЧИСЛЕННЫХ БУДУТ ПРИСУТСТВОВАТЬ В ВАШЕМ СЛУЧАЕ.
Атрибуты SMART:
1 Raw read error rate — количество ошибок при считывании секторов с пластин.
2 Throughput Performance — общая производительность диска в относительных единицах.
3 Spin-up time — время раскрутки пластин от нуля до номинальной скорости вращения в миллисекундах
4 Number of spin-up times — количество циклов раскрутки/остановки пластин; отражает механический ресурс диска из-за ограниченного количества циклов запуска/останова.
5 Reallocated sector count — параметр отражает количество запасных секторов; когда диск находит ошибку чтения/записи/проверки, он переназначает плохой сектор на хороший из запасной зоны; нормализованное значение атрибута уменьшается по мере убывания запасных секторов; RAW-значение показывает количество преназначенных секторов, которое в норме должно быть ноль; на SSDRAW значение показывает количество неисправных блоков флеш-памяти.
6 Read Channel Margin — данный атрибут не используется в современных накопителях.
7 Seek error rate — количество ошибок позиционирования магнитных головок.
8 Seek Time Performance — средняя скорость позиционирования привода магнитных головок на указанный сектор; в SSDпараметр не используется
9 Power-on time — ожидаемое время жизни диска, основанное на времени, проведённом во включённом состоянии; нормализованное значение уменьшается со 100 до 0, связано с ресурсом диска; уменьшение этого параметра косвенно говорит о состоянии механики диска
10 Spin-up retries — количество попыток раскруток пластин при условии, что первая попытка была неудачная; считается с момента начала использования; на SSD не используется
12 Start/stop count — ожидаемое время жизни, основанное на количестве пусков/остановов пластин; каждый диск имеет ограниченное количество пусков/остановов, параметр уменьшается со 100 до 0; RAW значение показывает число включений/выключений
13 Soft Read Error Rate — у одних производителей этот параметр описывается, как указывающий на количество ошибок, не восстановленных ECC, а у других наоборот — восстановленных
100 Erase/Program Cycles — общее количество циклов чтения/записи для всей флеш-памяти за весь срок службы; SSD имеет ограничение на количество циклов чтения/записи, конкретное значение зависит от типа и производителя микросхем флеш-памяти
103 Translation Table Rebuild — количество событий перестроения внутренней таблицы адресов блоков при её повреждении и восстановлении; RAW значение показывает актуальное количество данных событий
170 Reserved Block Count — описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
171 Program Fail Count — количество случаев неудавшейся записи блока флеш-памяти
172 Erase Fail Count — количество случаев неудавшейся операции стирания блока флеш-памяти
173 Wear Leveller Worst Case Erase Count — максимальное количество операций стирания, произведённых над блоком флеш-памяти
178 Used Reserved Block Count — описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество использованных резервных блоков
180 Unused Reserved Block Count — описывает состояние пула резервных блоков в SSD, показывает процент оставшихся блоков; RAW значение иногда показывает количество неиспользованных резервных блоков
183 SATA Downshifts — показывает, как часто требовалось понизить скорость передачи по SATA (с 6Гб/c до 3Гб/с или 1.5Гб/с) для успешной передачи данных, при уменьшении значения атрибута следует заменить кабель
184 End-to-End error — количество ошибок, возникших в буфере диска; часть технологии HP SMART IV; может свидетельствовать о неисправности RAM-буффера диска
185 Head Stability — по атрибуту нет достоверной информации
186 Induced Op-Vibration Detection — по атрибуту нет достоверной информации
187 Reported UNC error — количество нескорректированных ошибок чтения
188 Command timeout — количество невыполненных диском команд из-за истечения времени ожидания
189 High Fly writes — количество ошибок записи, вызванных неправильной высотой полёта магнитной головки над поверхностью
190 Airflow temperature — температура воздуха внутри гермоблока HDD
191 G-Sense Errors — указывает сколько раз диск прерывал работу из-за ударов или вибрации
192 power-off retract cycles — количество неожиданных пропаданий питания, когда оно пропадало прежде, чем была получена команда на отключение диска; у hdd срок службы при неожиданном отключении значительно меньше, чем при нормальном; у ssd есть риск потери таблицы внутреннего состояния при неожиданном пропадании питания
193 load/unload cycles — количество перемещений бмг между зоной парковки и зоной данных; значение уменьшается от 100 до 0, raw содержит актуальное количество перемещений
194 hda temperature- температура блока магнитных головок
195 hardware ecc recovered- количество ошибок чтения, скорректированных кодом коррекции ошибок
196 reallocation events — общее количество переназначений секторов, включает и off-line сканирование и обычную работу
197 current pending sectors- количество нестабильных секторов, ожидающих перепроверки и, возможно, переназначения
198 offline scan unc sectors- количество плохих секторов, найденных диском при фоновом самосканировании; ухудшение этого параметра говорит о быстрой деградации поверхности
199 ultra dma crc errors- количество ошибок при передаче данных между диском и материнской платой; при ухудшении этого параметра стоит заменить кабель
200 write error rate — частота возникновения ошибок при записи
202 data address mark errors — количество ошибок при поиске запрошенного сектора
203 run out cancel — количество ошибок, вызванных неверной контрольной суммой при попытке коррекции ошибки
204 soft ecc corrections — количество ошибок, скорректированных кодом коррекции
206 flying height — девиация высоты полёта головки над поверхностью относительно оптимального значения; если головка слишком низко, она может повредить поверхность, если слишком высоко — увеличивается количество ошибок чтения
207 spin high current — величина тока, требуемая для раскрутки пластин
209 offline seek performance — производительность подсистемы поиска при выполнении off-line сканирования
220 disk shift — расстояние, на которое сместился пакет пластин относительно теоретического положения в результате механического повреждения или перегрева
227 torque amplification count — показывает сколько раз требовалось подавать увеличенный ток для раскрутки пластин
230 gmr head amplitude — амплитуда колебаний головок бмг
233 media wearout indicator — остаток ресурса памяти в ssd
240 head flying hours- время, проведённое головками в зоне пользовательских данных; значение уменьшается, обычно от 100 до 0
241 total lbas written — количество 512-и байтных блоков, записанных за всю жизнь устройства
242 total lbas read — количество 512-и байтных блоков, считанных за всю жизнь устройства
250 read error retry rate
Сложность интерпретации значений smart состоит в том, что ни на количество, ни на тип, ни на значения, ни на единицы измерения отслеживаемых параметров нет единого стандарта. поэтому реализация smart всегда зависит от конкретного производителя. нормализацию raw-значений в показатели атрибутов все делают по-своему, а результатом является статус проверки smart good или bad. поэтому достоверный вывод о состоянии диска можно сделать только проверив его поверхность какой-либо диагностической программой. но если нужно быстро оценить состояние диска и возможные проблемы, нужно обратить внимание на несколько основных, самых информативных атрибутов.
Наиболее важные аттрибуты smart:
5 reallocated sectors count — количество переназначенных секторов; рост значения этого атрибута свидетельствует об ухудшении состояния поверхности диска
7 seek error rate — частота ошибок позиционирования бмг (блока магнитных головок); чем больше, тем хуже состояние механики и поверхности жёсткого диска
11 recalibration retries — количество неудачных попыток калибровки бмг;
184 end-to-end error — количество ошибок возникших в буфере диска
187 reported unc errors — количество нескорректированных ошибок чтения
191 g-sense error rate — количество ударов диска во время работы
196 reallocation event count — общее количество переназначенных секторов
197 current pending sector count — количество нестабильных секторов, кандидаты в бэды, чем больше, тем хуже диск
198 uncorrectable sector count — количество плохих секторов, найденных при off-line сканировании, чем их больше, тем хуже поверхность
199 ultradma crc error count — количество ошибок передачи между диском и компьютером, при увеличении или отличном от нуля параметре стоит заменить кабель
Если попытка самостоятельно восстановить данные не принесла положительного результата, то Вы можете обратиться к специалистам лаборатории MHDD.RU. Позвоните и проконсультируйтесь у наших технических специалистов по телефону: 8(495)241-31-97.