Содержание
- Как найти причину ошибки сети при работе с Microsoft SQL Server
- IP-адреса и точное время возникновение проблемы
- Анализ трассировок сервера приложений
- Анализ трассировок сервера Microsoft SQL Server
- General network error check your network documentation sql server
- General network error check your network documentation sql server
- Asked by:
- Question
- All replies
- General network error check your network documentation sql server
- Asked by:
- Question
Как найти причину ошибки сети при работе с Microsoft SQL Server

В большинстве случаев истинная причина периодически возникающей проблемы с подключением клиентского компьютера к удаленному серверу базы данных MS SQL Server связана с сетевым уровнем модели OSI. Собирая данные трассировки сети и анализируя их, мы можем сузить зону поиска и определить точную причину того, почему не удалось установить соединение или было внезапно разорвано существующее соединение.
Для большей наглядности предоставляемой информации в рамках данной статьи, мы дополнили ее пошаговыми иллюстрациями практического решения проблемы из реальной жизни. Проблема в предлагаемом нами кейсе заключалась в том, что клиент с определенной периодичностью получал сообщение GNE (General Network error, «Общая ошибка сети») от приложения, которое пыталось подключиться удаленно к серверу Microsoft SQL Server. Ниже приведен пример такого сообщения об ошибке:
«OleDB Error Microsoft OLE DB Provider for SQL Server [0x80004005][11] : [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation».
После проведения некоторых стандартных начальных процедур по поиску неисправностей (таких как проверка, не была ли отключена функция разгрузки TCP chimney, или не было ли превышено значение установленного максимального количества соединений и т.д.) были в одно и то же время собраны сетевые трассировки, как с сервера приложений, так и с MS SQL server. Когда вы собираете трассировки сети, всегда соблюдайте следующие два правила:
- Используйте данные, полученные с помощью утилиты «ipconfig», запущенную с ключом «/all», со всех задействованных серверов.
- Ориентируйтесь на сообщения об ошибке с установленной временной меткой (timestamp). Если по какой-то причине сообщения об ошибке с временной меткой вам недоступны, попросите клиента сделать запись точного времени возникновения проблемы и отправить ее вам.
Далее мы детально, шаг за шагом рассмотрим, как были проанализированы собранные трассировки сети. Вы можете использовать подобные методы для анализа трассировок, собранных вами для решения периодически возникающих проблем с подключением к серверу SQL.
Для захвата и анализа трассировок вы можете использовать Wireshark, либо любой другой инструментарий с подобной функциональностью. В данном примере был использован Wireshark, поскольку трассировки, отправленные клиентом, не могли быть открыты другим инструментарием (это было связано с расширением полученных файлов).
IP-адреса и точное время возникновение проблемы
Для начала стоит проверить информацию, полученную с помощью утилиты ipconfig, чтобы узнать необходимые нам IP-адреса. В рассматриваемом примере они следующие:
IP Address. . . . . . . . . . . . : 10.10.100.131
IP Address. . . . . . . . . . . . : 10.10.100.59»
Теперь из сообщения об ошибке выясним, когда именно возникла проблема. Наше сообщение об ошибке выглядит так:
«02/24/2010 09:28:08 DataBase Warning OleDB Error Microsoft OLE DB Provider for SQL Server [0x80004005][11] : [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation».
Таким образом, проблема произошла 24.02.2010 в 09:28:08.
Почему так важно точное время события? Зачастую, при сборе трассировок сети для решения периодически возникающих сетевых проблем вы получите внушительное количество файлов трассировки с каждого сервера, так как вам может понадобиться осуществлять захват сетевых трассировок в течение довольно продолжительного периода времени, и это может привести к генерации большого количества файлов трассировки, хранящих информацию о всей цепочке событий, произошедших за это время. В рассматриваемом нами примере клиент отправил более 60 файлов трассировки размером 25 МБ каждый для сервера приложений, а также было получено 6 подобных файлов для сервера Microsoft SQL Server. Когда у вас слишком много данных для анализа, информация о точном времени возникновения проблемы становится бесценной.
Анализ трассировок сервера приложений
Начнем наш анализ с файлов трассировки, полученных от сервера приложений. С помощью временной метки мы можем определить, какой файл трассировки необходимо проанализировать первым. Первое, что необходимо сделать, когда мы имеем дело с периодически возникающими проблемами сетевого соединения, это проверить данные трассировки сети на наличие каких-либо сбросов соединения (сообщений по протоколу TCP с установленным флагом RST, означающим «RESET»). Кроме того, из журнала ошибок сервера SQL можно узнать, какой порт прослушивает SQL-сервер. В рассматриваемом нами примере это был порт 1433. Таким образом, мы начинаем свой анализ со следующего фильтра:
«tcp.port eq 1433 && tcp.flags.reset==1»
С помощью данного фильтра можно получить список всех сообщений «RESET», относящихся к данному SQL-серверу (конечно же, сразу стоит удостовериться, что сервер приложений подключается только к проблемному SQL-серверу, и не происходит других подключений еще к какому-то другому SQL-серверу, который также прослушивает порт 1433). В рассматриваемом нами примере с помощью этого фильтра было обнаружено около 20 сообщений по протоколу TCP с флагом RST:
Следующим нашим шагом будет проверка полного взаимодействия в течение состоявшегося TCP-соединения, частью которого является сообщение о сбросе соединения. Для того чтобы увидеть сетевое взаимодействие, включающее в себя фрейм с флагом RST, следуйте следующему шаблону действий:
«Выберите фрейм с флагом RST —> кликните правой кнопкой мыши —> Conversation Filter («Фильтр взаимодействия») —> TCP».
В результате вы получите все фреймы для текущего взаимодействия. В ходе выполнения аналогичной проверки для рассматриваемого нами примера было найдено всего два фрейма:

Теперь, если вы работаете с несколькими файлами трассировки, формирующих непрерывную цепочку событий, а не с одним файлом, вам следует проанализировать и другие файлы трассировки, которые содержат информацию о событиях непосредственно до и после обнаруженного вами события, чтобы найти и другие фреймы этого сетевого взаимодействия, если таковые существуют. Нам необходимо восстановить полную картину событий и узнать, что происходило до того, как сообщение о сбросе соединения было отправлено. Эта информация поможем нам узнать первопричину отправки сообщения с флагом RST. Чтобы сделать это, скопируйте фильтр для данного взаимодействия из текущего файла трассировки. Для нашего примера он следующий:
«(ip.addr eq 10.10.100.59 and ip.addr eq 10.10.100.131) and (tcp.port eq 1194 and tcp.port eq 1433)»
Затем следует открыть файл трассировки, собранный на сервере приложений непосредственно перед текущим файлом трассировки, и, используя вышеупомянутый фильтр, найти фреймы, которые являются частью одного и того же сетевого взаимодействия.
Если вы не нашли проблему, а только наблюдаете нормальный траффик (наподобие пакетов «keep-alive»), откройте файл трассировки, предшествующий этому, и проанализируйте его, используя тот же фильтр. Продолжайте делать это, пока не увидите какую-то проблему или не дойдете до начала разговора (трехстороннего рукопожатия TCP для установления соединения).
В нашем примере было много траффика «keep-alive». Microsoft SQL Server (10.10.100.131) и сервер приложений (10.10.100.59) отправляли туда и обратно пакеты «TCP Keep-Alive» и «TCP Keep-Alive ACK». Но в конце сетевого взаимодействия сервер приложений (10.10.100.59) отправил пять пакетов «TCP Keep-Alive» на сервер SQL, но не получил никакого ответа от сервера SQL, как вы можете убедиться ниже:
Проверка всех предыдущих файлов трассировки, содержащих исследуемое взаимодействие, других проблем не выявила. Затем был проверен файл трассировки, следующий за изначальным файлом трассировки (в котором было обнаружено сообщение с флагом RST), но он не содержал фреймов для текущего соединения. Таким образом, данное сетевое взаимодействие закончилось после этого сообщения с сигналом о разрыве соединения.
Анализ трассировок сервера Microsoft SQL Server
Теперь приступаем к проверке файлов трассировки, которые были получены от сервера SQL. Еще раз использовав временную метку возникновения ошибки, мы можем определиться с файлом трассировки, с которого нам нужно начать.
Источник
General network error check your network documentation sql server
Exception Details: System.Data.SqlClient.SqlException: General network error. Check your network documentation.
I get this exception intermittently
Below is the stack trace of the error
Stack Trace: at System.Data.SqlClient.SqlCommand.ExecuteReader(CommandBehavior cmdBehavior, RunBehavior runBehavior, Boolean returnStream) at System.Data.SqlClient.SqlCommand.ExecuteNonQuery() at Xtention.Lms.Components.Database.RunProc(String procName, SqlParameter[] prams) in C:Projectslms.bentley.comlmsModulescomponentsComponentsDatabase.cs:line 154 at Xtention.Lms.Components.UsersDB.Login(String username, String password, Boolean windowsLogin) in C:Projectslms.bentley.comlmsModulescomponentsComponentsSecurity.cs:line 883 at Xtention.Lms.Components.UsersDB.Login(String username, String password) in C:Projectslms.bentley.comlmsModulescomponentsComponentsSecurity.cs:line 893 at Xtention.Lms.Web.Signin.Login(String pass, String login, Boolean encodePassword) in C:Projectslms.bentley.comlmsdesktopmodulesSignin.ascx.cs:line 61 at Xtention.Lms.Web.Signin.BentleyLogin() in C:Projectslms.bentley.comlmsdesktopmodulesSignin.ascx.cs:line 188 at Xtention.Lms.Web.Signin.Page_Load(Object sender, EventArgs e) in C:Projectslms.bentley.comlmsdesktopmodulesSignin.ascx.cs:line 169 at System.Web.UI.Control.OnLoad(EventArgs e) at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Control.LoadRecursive() at System.Web.UI.Page.ProcessRequestMain()
When i debug the application this error vanishes some time.
I am using ASP.net 1.1 and .net native sql provider and sql server 2000.
Sql Server 2000 is present at remote location. When i debug the application it is opening the connection but it is throwing this error when i try to execute command object query.
I am facing this problem from many days. i need urgent solution of this.
Источник
General network error check your network documentation sql server
This forum has migrated to Microsoft Q&A. Visit Microsoft Q&A to post new questions.
Asked by:
![]()
Question
![]()
![]()
considering the oldest version of sql 2008, when try to access application I receive the following error:
[DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation
SQL | Msg: 11, Level: 16, State: 1, Line: 0
SQL | [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation
SQL | Error: -2147467259, Minor Error: 11, SQL State: 08S01
Please help, thanks all for your kindly assistance.
![]()
![]()
Does this happen with any command or a specific command?
Check the SQL Server error log if there are any stack dumps related to this error.
What happens if you run the same command from Management Studio?
Erland Sommarskog, SQL Server MVP, esquel@sommarskog.se
![]()
![]()
Is it the situation totally could not access the app? This kind of g eneral network error may point to the physical connection, firewall, duplicate IP addresses and etc, the solutions include using TCP/IP instead of Named Pipes, turning off connection pooling and reopening the connection.
MSDN Community Support
Please remember to click «Mark as Answer» the responses that resolved your issue, and to click «Unmark as Answer» if not. This can be beneficial to other community members reading this thread. If you have any compliments or complaints to MSDN Support, feel free to contact MSDNFSF@microsoft.com
![]()
![]()
Do the answers above help you? It consumes much test and patience to find the cause of the problem.
If you find a solution, it’s so kind of you to come back and share it with us. By doing so, it will benefit all community members who are having this similar issue. We’ll be waiting for your reply. Your contribution is highly appreciated.
Источник
General network error check your network documentation sql server
This forum has migrated to Microsoft Q&A. Visit Microsoft Q&A to post new questions.
Asked by:
![]()
Question
![]()
![]()
Hi I get a «General Network Error Check network documentation» error sometimes, but its only while insert or update statements are fired while selects keep working perfectly.
The Error details are as follows:
General network error. Check your network documentation.
Description: An unhandled exception occurred during the execution of the current web request. Please review the stack trace for more information about the error and where it originated in the code.
Exception Details: System.Data.SqlClient.SqlException: General network error. Check your network documentation.
An unhandled exception was generated during the execution of the current web request. Information regarding the origin and location of the exception can be identified using the exception stack trace below.
[SqlException: General network error. Check your network documentation.]
Источник
OVERVIEW
To troubleshoot network connectivity problems, you must first identify the source of the problem. Gathering as much data as possible about the operating conditions which exist at the time of the failure will help in tracking down a root cause.
These errors can be seen as entries in System Log monitor, SQL Server ERRORLOG, developer traces or Java system logs. Error conditions such as hanging client processes; a process which is doing no work and cannot be assigned, but has not reported an error in a log file, have also been observed.
Short Dumps of the type DBIF_RSQL_SQL_ERROR and DBIF_REPO_SQL_ERROR, as evidenced in ST22, may be observed in SAP system which run SQL Server databases.
The Short Dump message details will indicate SQL error 11 and, SQL error 0 and SQL error 10054, which can be raised on various objects (tables and/or views).
In addition, the OS Event Viewer Application Log may record indications of network library errors 10054.
ABAP SHORT-DUMPS AND SQL ERROR 10054
SQL Server 0 and SQL Server 11 errors mean a disconnection between Client and Server and can appear in the SQL Server Error log or in dev_w files of the client. In the dev_w files these errors will often be accompanied by the SAP short-dump DBIF_RSQL_SQL_ERROR and DBIF_REPO_SQL_ERROR, evidenced in St22. The Short Dump message details will indicate SQL error -1 and/or SQL error 0 which can be raised on various objects (tables and/or views). In addition, the OS Event Viewer Application Log may record indications of network library errors 10054, 10055, 10053 or 10061. The SQL Error 10054 errors put the work process in a reconnect status. On the server side, a SQL Error -1 can be caused by a networking error or other condition.
EXAMPLES
A list of the examples of general network errors is provided here. The list may vary and be updated once new issues are discovered.
Example 1


Error messages:
- TCP Provider: An existing connection was forcibly closed by the remote host
- SQL error in the database when accessing a table
-
DBIF_RSQL_SQL_ERROR
- CX_SY_OPEN_SQL_DB
Example 2

Error messages:
- SQL error «-1» occurred when accessing program
- SMux Provider: Physical connection is not usable [xFFFFFFFF]
-
DBIF_REPO_SQL_ERROR
-
Resource Shortage
Example 3

Error messages:
- SQL error 10054 occurred when accessing program
- TCP Provider: An existing connection was forcibly closed by the remote host
-
DBIF_REPO_SQL_ERROR
- Resource Shortage
OVERVIEW
Categories of Error causes
- Lower levels of software
- Faulty hardware
Approach
Before doing any deeper investigation on possible SQL Server and SAP application, the following steps are strongly recommended:
- Read Dale’s presentation about «Analyzing Network Errors on SQL Server».
- Read SAP Note 1593183. It describe possible scenarios where you can find such errors.
- Review the SAP monitors:
- ST22 monitor, check the dump complete text: analyze it in order to find out which work process and application server got disconnected. From there you can find out whether this happens to all application servers or specific.
- ST11 monitor (pay attention to work process number — WP xy — and application server name in ST22 ABAP dump text) check the developer trace, dev_Wxy, information logged right at the time the ABAP dump occurred. Check also early information prior to the known disconnection messages: it can be the case that the disconnection error is a subsequent error caused by an early dump, therefore, causing a message that can mislead to a disconnection problem.
- SM21 (system log) may also contain useful information you can link with ST22 short dumps and ST11 developer traces.
- SQL error log from Transaction DBACockpit -> Diagnostic or from <instance name>MSSQLLog folder.
- Log on to OS database server and check the Windows Server OS Event Viewer (Application log and System log) logs. It may contain further details about the disconnection.
- Check and make sure the right network protocol for SQL Server is being used; the network topology plays an important role as MS SQL Server database performance depends also on the network protocol used by the application server to connect to the database. It is important to choose the right network protocol for a given situation, the Basis administrator and DB administrator should double check SAP Note 208632.
- Check the version of the ODBC Driver / SNAC (SQL Server Native Client), always use at least the same version of your SQL Server database instance, review SAP Note 1823300,
- Implement the changes suggested by SAP Note 1593183:
- KeepAlive (the network traffic between ‘clients’ and a ‘SQL Server’ can be impacted by changing configurations at the server or client) on SQL Server Configuration Manager . Keep in mind that you should also perform this configuration if you have a Dialong Instance or Central Instance installed in the localhost (where SQL Server is installed).
- TcpMaxDataRetransmissions (determine the number of TCP retransmissions of an individual TCP segment).
- These recommendations are very important for HA/DR solutions like AlwaysOn, Clustering, Database Mirroringm etc, and should be implemented in all nodes/replicas.
- If SAP application server running on a virtual machine OS OS guest (VMware or MS Hyper-V), doublecheck the virtual machines OS guest Configuration guidelines,
see following Notes, 2161991 (VMware), 1246467 (MS Hyper-V), 1409608 (Virtualization on Windows). - If SQL Server runs on VMware, check out the updated Microsoft SQL Server on vSphere Best Practices Guide.
- Involve your Hardware partner for double checking the entire network infrastructure, outdated NIC drivers, Server Memory, (hardware, physical network, etc), are usually the root cause for network problem.
- Use SAP tool NIPING for checking the health of the network infrastructure used by your SAP application servers. See SAP Note 500235 and SAP Note 1100926 (this reference gives some good information about NIPING also). The Basis administrator has to run NIPING as a server process and then to run NIPING as a client process. Start long term niping by:
- Starting the niping server process on the DB server;
- Starting 1 niping client process on EACH application server;
- Further information about Niping can be found here.
- If NiPing doesn’t run while the problems are present or when they are expected to occur, you won’t find anything wrong on the network infrastructure.
- If NiPing doesn’t fail during its execution and you also don’t get any disconnection issue in your system, it is not an evidence that you don’t have a network issue.
- The goal with NiPing is to ensure that during the NiPing execution, in case a disconnection happens between the SAP Application Server and SQL Server, that NiPing also fails.
- In case NiPing does not fail and you have received a Network Disconnection dump, then it is time for pursuing other possibilities,such Overcommitting Memory, as described on this blog. If you have ever reached to this point, it is very important that you log all information so far collected on the analysis and contact SAP Support in component BC-DB-MSS.
Feedback
Please provide any feedback or questions regarding the content under the current page comments. If you have an issue or is looking for help, try to post your question on SAP community with Microsoft SQL Server tag.
In order to leave comments, you must be logged on with your SAP account.
Problem
User runs an intensive task, and receives an error message.
Scenario #1 — User running a database optimisation.
Scenario #2 — User running a ‘reports conversion’ process, as part of a migration from Controller 2.x to 8.x.
Scenario #3 — User is trying to import data into Controller, via a CSV file.
Symptom
- Information
Standard Error
Number: 5
Source: FrangoDirect.GenCompStrucD.GenKStruc#ControllerProxyClient
Description: System.Web.Services.Protocols.SoapException: Servier was unable to process request. —>
System.Runtime.InteropServices.COMException (0x80004005): [DBNETLIB][ConnectionRead(recv()).]General
network error. Check your network documentation.
at FrCompanyBT.GenCompStrucTClass.GenKStruc(String sGuid, String sUser, String sConsType, String sFirstPer,
Boolean bOnlyManual, ….
Example #2:
- Information
Standard Error
Number: 5
Source: FrangoDirect.Optimize.RecreateIndex#ControllerProxyClient
Description: The underlying connection was closed: An unexpected error occurred on a receive.
OK
Scenario #2:
- Information
Standard Error
Number: 5
Source: FrangoDirect.ExcelLinkD.SaveLayoutFile#ControllerProxyClient
Description: System.Web.Services.Protocols.SoapException: Server was unable to process request. —>
System.Runtime.InteropServices.COMException (0x80004005): [DBNETLIB][ConnectionOpen
(PreLoginHandshake()).]General network error. Check your network documentation.
at FrExcelLinkB.ExcelLinkBClass.GetLayout(String sGuid, String sUser, String sRapp)
at Cognos.controller.Proxy.CCRWS.ExcelLinkB_GetLayout(String sGuid, String sUser, String sRapp)
— End of inner exception stack trace —
Scenario #3
- Information
Standard Error
Number: -2147467259
Source: FrServerB.ServerInfo.GetServerInfo
Description: [DBNETLIB][ConnectionOpen (Connect()).]SQL Server does not exist or access denied.
[OK]
Cause
There are several potential causes for errors similar to those shown above.
- For another example, see separate IBM Technote #1587557 & 1674415.
This Technote shall concentrate on the scenario where the cause is a TCP/IP network failure, causing a «General network error«, which has been triggered by one of the following Microsoft Windows TCP/IP mechanisms:
- Scenario #1 — Microsoft TCP Chimney Offload feature is enabled on the server
- For more details, see separate IBM Technote #1445735.
- Scenario #2 — Microsoft SynAttackProtect feature is enabled on the server
- This IBM Technote shall concentrate on this scenario.
The user’s task triggers a high level of network activity to/from the Microsoft SQL database server. In our scenario, this triggers Microsoft ‘SynAttackProtect’ feature on the SQL server:
- ‘SynAttackProtect’ causes Windows to drop connections if the requests arrive faster than SQL Server can service them.
- This is a security feature of Windows Server 2003 Service Pack 1, which implements a finite queue for incoming TCP connection requests.
- SynAttackProtect is enabled (by default) on a server with Windows 2003 SP1 or later. This shuts down the network connection to the Controller application server, which therefore gives an error.
- TIP: For TCP/IP in Windows XP (all versions) and Windows Server 2003 with no service packs installed, SynAttackProtect is set to 0 by default.
More information about ‘SynAttackProtect’:
To mitigate the impact on a host experiencing a SYN attack, TCP/IP minimizes the amount of resources devoted to incomplete TCP connections and reduces the amount of time before abandoning half-open connections. When a SYN attack is detected, when SynAttackProtect is enabled, TCP/IP in Windows Server 2003 and Windows XP lowers the number of retransmissions of the SYN-ACK segment and does not allocate memory or table entry resources for the connection until the TCP three-way handshake has been completed.
- For more information, see section inside ‘Related Documents’
- One of the best summaries on this topic can be found here: http://blogs.technet.com/b/pabenois/archive/2010/06/10/sharepoint-2007-and.aspx
Environment
Microsoft Windows 2003 servers, with Service Pack 1 or later.
NOTE: SynAttack protection is enabled by default and cannot be disabled for all modern Windows versions, for example: Vista, Windows 2008, Windows 7 and Windows 2008 R2.
- See third-party (non-IBM) link below for more details.
Diagnosing The Problem
One method to investigate is to check the current number of TCP network connections that the server currently has. One easy method is to ‘pipe’ the results of netstat to a text file, and then open that in a spreadsheet (e.g. Excel) to analyst. In other words, run the following command (inside a command prompt) and then open the resultant file «connections.txt» inside EXCEL:
-
netstat -o >connections.txt
Resolving The Problem
Fix:
Improve:
- the quality/speed of the network connection between the Controller application server and the SQL server
- the server hardware (CPU speed, number of CPU cores etc.) of the SQL server.
Workaround
Disable Microsoft SYN attack protection on the Windows 2003 Microsoft SQL server.
Steps to disable ‘SynAttackProtect’:
- Obtain some downtine to the system, to ensure no end-users are using any database on the relevant SQL server
- Logon to the SQL server as an administrator
- START — RUN — REGEDIT
- Navigate to the location: HKEY_LOCAL_MACHINESystemCurrentControlSetServicesTcpipParameters
- Double-click on the entry SynAttackProtect (or create it if it does not exist!)
- Change its value from 1 to 0
- Reboot the SQL server
Related Information
[{«Product»:{«code»:»SS9S6B»,»label»:»IBM Cognos Controller»},»Business Unit»:{«code»:»BU059″,»label»:»IBM Software w/o TPS»},»Component»:»Controller»,»Platform»:[{«code»:»PF033″,»label»:»Windows»}],»Version»:»8.4;8.3″,»Edition»:»Not Applicable»,»Line of Business»:{«code»:»LOB10″,»label»:»Data and AI»}}]
Historical Number
1035583
В большинстве случаев истинная причина периодически возникающей проблемы с подключением клиентского компьютера к удаленному серверу базы данных MS SQL Server связана с сетевым уровнем модели OSI. Собирая данные трассировки сети и анализируя их, мы можем сузить зону поиска и определить точную причину того, почему не удалось установить соединение или было внезапно разорвано существующее соединение.
Для большей наглядности предоставляемой информации в рамках данной статьи, мы дополнили ее пошаговыми иллюстрациями практического решения проблемы из реальной жизни. Проблема в предлагаемом нами кейсе заключалась в том, что клиент с определенной периодичностью получал сообщение GNE (General Network error, «Общая ошибка сети») от приложения, которое пыталось подключиться удаленно к серверу Microsoft SQL Server. Ниже приведен пример такого сообщения об ошибке:
«OleDB Error Microsoft OLE DB Provider for SQL Server [0x80004005][11] : [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation».
После проведения некоторых стандартных начальных процедур по поиску неисправностей (таких как проверка, не была ли отключена функция разгрузки TCP chimney, или не было ли превышено значение установленного максимального количества соединений и т.д.) были в одно и то же время собраны сетевые трассировки, как с сервера приложений, так и с MS SQL server. Когда вы собираете трассировки сети, всегда соблюдайте следующие два правила:
- Используйте данные, полученные с помощью утилиты «ipconfig», запущенную с ключом «/all», со всех задействованных серверов.
- Ориентируйтесь на сообщения об ошибке с установленной временной меткой (timestamp). Если по какой-то причине сообщения об ошибке с временной меткой вам недоступны, попросите клиента сделать запись точного времени возникновения проблемы и отправить ее вам.
Далее мы детально, шаг за шагом рассмотрим, как были проанализированы собранные трассировки сети. Вы можете использовать подобные методы для анализа трассировок, собранных вами для решения периодически возникающих проблем с подключением к серверу SQL.
Для захвата и анализа трассировок вы можете использовать Wireshark, либо любой другой инструментарий с подобной функциональностью. В данном примере был использован Wireshark, поскольку трассировки, отправленные клиентом, не могли быть открыты другим инструментарием (это было связано с расширением полученных файлов).
IP-адреса и точное время возникновение проблемы
Для начала стоит проверить информацию, полученную с помощью утилиты ipconfig, чтобы узнать необходимые нам IP-адреса. В рассматриваемом примере они следующие:
«SQL server:
IP Address. . . . . . . . . . . . : 10.10.100.131
App server:
IP Address. . . . . . . . . . . . : 10.10.100.59»
Теперь из сообщения об ошибке выясним, когда именно возникла проблема. Наше сообщение об ошибке выглядит так:
«02/24/2010 09:28:08 DataBase Warning OleDB Error Microsoft OLE DB Provider for SQL Server [0x80004005][11] : [DBNETLIB][ConnectionWrite (send()).]General network error. Check your network documentation».
Таким образом, проблема произошла 24.02.2010 в 09:28:08.
Почему так важно точное время события? Зачастую, при сборе трассировок сети для решения периодически возникающих сетевых проблем вы получите внушительное количество файлов трассировки с каждого сервера, так как вам может понадобиться осуществлять захват сетевых трассировок в течение довольно продолжительного периода времени, и это может привести к генерации большого количества файлов трассировки, хранящих информацию о всей цепочке событий, произошедших за это время. В рассматриваемом нами примере клиент отправил более 60 файлов трассировки размером 25 МБ каждый для сервера приложений, а также было получено 6 подобных файлов для сервера Microsoft SQL Server. Когда у вас слишком много данных для анализа, информация о точном времени возникновения проблемы становится бесценной.
Анализ трассировок сервера приложений
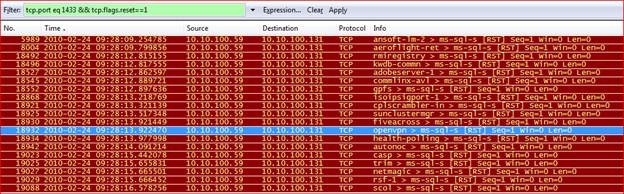
Начнем наш анализ с файлов трассировки, полученных от сервера приложений. С помощью временной метки мы можем определить, какой файл трассировки необходимо проанализировать первым. Первое, что необходимо сделать, когда мы имеем дело с периодически возникающими проблемами сетевого соединения, это проверить данные трассировки сети на наличие каких-либо сбросов соединения (сообщений по протоколу TCP с установленным флагом RST, означающим «RESET»). Кроме того, из журнала ошибок сервера SQL можно узнать, какой порт прослушивает SQL-сервер. В рассматриваемом нами примере это был порт 1433. Таким образом, мы начинаем свой анализ со следующего фильтра:
«tcp.port eq 1433 && tcp.flags.reset==1»
С помощью данного фильтра можно получить список всех сообщений «RESET», относящихся к данному SQL-серверу (конечно же, сразу стоит удостовериться, что сервер приложений подключается только к проблемному SQL-серверу, и не происходит других подключений еще к какому-то другому SQL-серверу, который также прослушивает порт 1433). В рассматриваемом нами примере с помощью этого фильтра было обнаружено около 20 сообщений по протоколу TCP с флагом RST:
Следующим нашим шагом будет проверка полного взаимодействия в течение состоявшегося TCP-соединения, частью которого является сообщение о сбросе соединения. Для того чтобы увидеть сетевое взаимодействие, включающее в себя фрейм с флагом RST, следуйте следующему шаблону действий:
«Выберите фрейм с флагом RST —> кликните правой кнопкой мыши —> Conversation Filter («Фильтр взаимодействия») —> TCP».
В результате вы получите все фреймы для текущего взаимодействия. В ходе выполнения аналогичной проверки для рассматриваемого нами примера было найдено всего два фрейма:
Теперь, если вы работаете с несколькими файлами трассировки, формирующих непрерывную цепочку событий, а не с одним файлом, вам следует проанализировать и другие файлы трассировки, которые содержат информацию о событиях непосредственно до и после обнаруженного вами события, чтобы найти и другие фреймы этого сетевого взаимодействия, если таковые существуют. Нам необходимо восстановить полную картину событий и узнать, что происходило до того, как сообщение о сбросе соединения было отправлено. Эта информация поможем нам узнать первопричину отправки сообщения с флагом RST. Чтобы сделать это, скопируйте фильтр для данного взаимодействия из текущего файла трассировки. Для нашего примера он следующий:
«(ip.addr eq 10.10.100.59 and ip.addr eq 10.10.100.131) and (tcp.port eq 1194 and tcp.port eq 1433)»
Затем следует открыть файл трассировки, собранный на сервере приложений непосредственно перед текущим файлом трассировки, и, используя вышеупомянутый фильтр, найти фреймы, которые являются частью одного и того же сетевого взаимодействия.
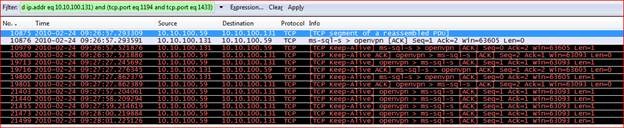
Если вы не нашли проблему, а только наблюдаете нормальный траффик (наподобие пакетов «keep-alive»), откройте файл трассировки, предшествующий этому, и проанализируйте его, используя тот же фильтр. Продолжайте делать это, пока не увидите какую-то проблему или не дойдете до начала разговора (трехстороннего рукопожатия TCP для установления соединения).
В нашем примере было много траффика «keep-alive». Microsoft SQL Server (10.10.100.131) и сервер приложений (10.10.100.59) отправляли туда и обратно пакеты «TCP Keep-Alive» и «TCP Keep-Alive ACK». Но в конце сетевого взаимодействия сервер приложений (10.10.100.59) отправил пять пакетов «TCP Keep-Alive» на сервер SQL, но не получил никакого ответа от сервера SQL, как вы можете убедиться ниже:
Проверка всех предыдущих файлов трассировки, содержащих исследуемое взаимодействие, других проблем не выявила. Затем был проверен файл трассировки, следующий за изначальным файлом трассировки (в котором было обнаружено сообщение с флагом RST), но он не содержал фреймов для текущего соединения. Таким образом, данное сетевое взаимодействие закончилось после этого сообщения с сигналом о разрыве соединения.
Анализ трассировок сервера Microsoft SQL Server
Теперь приступаем к проверке файлов трассировки, которые были получены от сервера SQL. Еще раз использовав временную метку возникновения ошибки, мы можем определиться с файлом трассировки, с которого нам нужно начать.
Данный материал доступен только зарегистрированным пользователям!
Войдите или зарегистрируйтесь бесплатно, чтобы получить доступ!
Регистрация займёт несколько секунд.
См. также:
You should be able to reproduce this error condition on demand by:
1. Opening a database connection (in your client application)
2. Unplugging the network cable
3. Plugging network cable back in (wait until the network connection is restored)
4. Using the previously opened connection to query the database
As far as I can tell from experience, client side ADO code is not able to consistently determine if an underlying network connection is actually valid or not. Checking if the database connection is open (in the client code) returns true. However, performing any operations on that connection results in a General network error.
The connection pool appears to be able to determine when a connection goes ‘bad’ so it never returns a bad connection to the application. It simply opens a new connection instead.
So, if a database connection is kept alive for a long time (used or unused) by the application, the underlying TCP/IP connectivity can get broken.
The bottom line is that database connections should be closed and returned back to the connection pool when not in use.
Edit
Also, depending on the number of clients connecting to the db, not using the connection pool can cause another issue. You may hit the maximum number of sockets open on the server side. This is from memory. Once a connection is closed on the client side, the connection on the server goes into a TIME_WAIT state. By default, the server socket takes about 4 minutes to close, so it is not available to other clients during that time. The bottom line is that there is a limited number of available sockets on the server. Keeping too many connections open can create a problem.
One project I worked on easily hit this socket limit with around 120 users. A new ‘feature’ was added that absolutely hammered the server, and after a few hours of using the app, things would suddenly slow to a crawl for everyone. SQL server was not closing enough sockets in time for new connection requests. Although there are 65K sockets altogether, only the first 5000 are made available to the ADO (this is a default registry setting thing, so can be changed).
The number of sockets in TIME_WAIT state would slowly build up until the OS would not allocate any more. So clients had to wait until server side sockets closed and a new connection could then be created.
Сеанс работы завершен администратором. |
Я |
04.05.10 — 18:33
Ошибка: Сеанс работы завершен администратором.
по причине:
Соединение с сервером баз данных разорвано администратором
Microsoft OLE DB Provider for SQL Server: [DBNETLIB][ConnectionRead (recv()).]General network error. Check your network documentation.
HRESULT=80004005, SQLSrvr: Error state=1, Severity=10, native=11, line=0
1C 8.1.14 + MS SQl 2005 + Терминальник (на 3х серверах)
+ Пропадает ping (хаотично) на 1-4 секунды у сервера MS SQl 2005 и вилетает от 1 до 5 юзеров
Вопрос причина в падении сети или в другом?
1 — 04.05.10 — 18:34
General network error. Check your network documentation.
2 — 04.05.10 — 18:37
(1) Админ говорит мол у него все хорошо ))
3 — 04.05.10 — 18:38
гдеж пигд теряется тогда?
4 — 04.05.10 — 18:38
*пинг
5 — 04.05.10 — 18:39
теряются пинги в локальной сети?
Это просто сказка какая-то!
6 — 04.05.10 — 18:40
главное что админ не виноват )
7 — 04.05.10 — 18:45
(5) Пинг теряетса с сервера 1С к серверу СКЛ
8 — 04.05.10 — 18:47
(7) нагрузка на серверы в этот момент?
9 — 04.05.10 — 18:48
(8) не более 50% проц, сеть 15% максимум
10 — 04.05.10 — 18:50
К админу с паяльником приставал?
11 — 04.05.10 — 18:50
Фоновые задание отключил, не помогло,
+ 1 процес на сервере 1С, не помогло,
Тестирование не помогло,
12 — 04.05.10 — 18:51
(9) ping на большие пакеты как проходит?
13 — 04.05.10 — 18:51
(10) Думаю скоро буду ))
14 — 04.05.10 — 18:52
(11) фоновые задания sql смотрели?
15 — 04.05.10 — 18:53
(11) ????
16 — 04.05.10 — 18:54
(12) как проверить?
17 — 04.05.10 — 18:55
ping 192.168.0.x -l 5000
18 — 04.05.10 — 18:56
допустимый диапазон с 0 по 65500.
19 — 04.05.10 — 18:56
(17) 1 — 2 мс.
20 — 04.05.10 — 19:00
попробуй запустить пинг с другой машины на 1с и скл и с 1с на скл, чтоб определить какая машина запинается (когда на 1с пропадет пинг)
21 — 05.05.10 — 08:11
(20) ping пропадаєт к СКЛ серверу
22 — 05.05.10 — 08:12
перезапуск службы сервера 1с
23 — 05.05.10 — 08:24
(22) помогает на 30 мин. ((
24 — 05.05.10 — 09:04
было точно такое дело, это со структурой базы траблы (он тебе недаст кстати в ДТ выгрузить)
лечил базу SQL командой dbcc checkdb (в монопольном режиме естественно)
перед этим базу отмонтируй только
25 — 05.05.10 — 09:06
вот так:
dbcc checkdb (‘<имя базы>’,REPAIR_ALLOW_DATA_LOSS) with tablock
26 — 05.05.10 — 09:11
(0)Это сделал кто-то через сервис-управление пользователями и доступ- завершение работы пользователей (с установкой флага блокировка установки соединений включена). Там читайте методы борьбы через командную строку с параметрами запуска.
27 — 05.05.10 — 09:38
(24) Выгрузка в ДТ проходит успешно, и розкрутка с него в файл-вариант так же успешно
28 — 05.05.10 — 09:49
варианты? (
29 — 05.05.10 — 10:01
(28) значит слава Богу с базой все ок,
проверь структуру таблиц (тестирование/исправление) конфигуратором
думаю что если пишет «сеанс завершен Администратором» то явно дело не в сетке
30 — 05.05.10 — 10:47
(29) Тестирование/исправление ошибок не обнаружено
31 — 05.05.10 — 11:18
варианты? (
32 — 05.05.10 — 11:34
варианты?
33 — 05.05.10 — 11:36
(0) Сервер приложений замусорился — перегрузки требует периодически
34 — 05.05.10 — 11:37
(32) место на винтах есть?
35 — 05.05.10 — 11:38
была Аваста и все, как в сабже, снес, больше не беспокоит…
36 — 05.05.10 — 11:40
(33) Сервер приложений перегружаем каждый день после ошибки не помогает (
37 — 05.05.10 — 11:40
(32) еще есть вариант подождать =)
у нас была такая беда, все перепроверили с ног сбились, но так и не поняли в чем дело. лечили рестартом сервера приложений.
через недельку проблема рассосалась
38 — 05.05.10 — 11:43
(37) уже две недели ждём ))
39 — 05.05.10 — 11:50
40 — 05.05.10 — 12:19
(39) глянул
41 — 05.05.10 — 13:16
а может быть связано с настройками SQL?
42 — 05.05.10 — 13:29
+ Если пинговать Сервер СКЛ <- Сервером 1С , пинг пропадает а наоборот в тот же момен времени то нет
43 — 05.05.10 — 13:40
варианты? )
44 — 05.05.10 — 14:43
варианты?
45 — 05.05.10 — 16:00
Из наблюдений процес SQL в этот момет занимает болие 55 % процесора
46 — 05.05.10 — 16:50
Народ помогите, никак не решу проблему.((((
47 — 05.05.10 — 17:13
скуль перегружали?
48 — 05.05.10 — 17:19
(0) ИМХО дело в кривых ролях
проанализируй из-за кого падает rphost — одна из ролей этого юзверя косячит и кладет рабочий процесс
49 — 05.05.10 — 17:30
(47) Перегружали
50 — 05.05.10 — 17:31
(48) Процес полностью не падает, другие могут работать дальше на том же процесе
51 — 05.05.10 — 17:50
(50) уверен?
52 — 05.05.10 — 17:55
Капай к СКУЛЮ
53 — 05.05.10 — 17:56
(52) а именно?
54 — 05.05.10 — 17:57
(52) в логах SQL ничё не пишет ((
55 — 05.05.10 — 18:11
варианты? (
56 — 05.05.10 — 18:20
Есть тема что в пике нагрузки на СКУЛ, СКУЛ отрубает пользователей автоматом
57 — 05.05.10 — 18:22
(56) врятли
58 — 05.05.10 — 18:27
(56) в принципе пик не большой 55-60% проца
59 — 05.05.10 — 18:28
(58) антивирь какой ?
60 — 05.05.10 — 18:29
![]()
61 — 05.05.10 — 18:31
перед появлением трабла, что с сервом делал, апдэйты какиета ставил или что нибудь в этом роде
62 — 05.05.10 — 18:34
(61) + сервера виртуальные, делали образ с виртуалки СКЛ на еще одну машину, потом отключили…
63 — 05.05.10 — 21:29
(0) + ТиС сообщает только: «Неверные вспомогательные данные таблицы»
64 — 05.05.10 — 23:04
(63) и успешно исправляет их….
65 — 06.05.10 — 12:24
(64) а проблема осталась ((
66 — 06.05.10 — 15:41
(0) отключили «named pipes» на SQl поблема осталась ((
67 — 06.05.10 — 15:44
(0) варианты? (
68 — 06.05.10 — 17:40
(67) если поборешь проблему, отпишись хоть…
69 — 06.05.10 — 17:52
поддержка 1с в таком случае рекомендует создавать несколько раб. процессов, хотя и говорит что особой параллельности и переключением поль-ля от умирающего процесса на платформе 8.1 нет
70 — 06.05.10 — 17:56
А еще рекомендует скуль и 1с разносить на разные сервера.
У меня как то было такое, правда без терминалки — оказалось не хватает банально физ. памяти на диске, очистили — стало меньше вылетов.
71 — 06.05.10 — 18:00
антивируса на сервере 1С точно нету?
72 — 06.05.10 — 18:02
(69) запущено 4 — процеса
(70) сервер 1С і СКЛ на разных виртуальных машинах
(71) антивируса точно нет
73 — 06.05.10 — 18:03
(0) Как вариант: возможно скоро сдохнет окончательно сетевая карточка или свитч. Или контакт в проводе…
У нас такое было однажды — начали отваливаться юзверы из 1С. Более никаких тревожных симптомов не было. Зря только время потеряли, разбираясь с 1С. А оказалось — она наиболее «чуствительна» к сетевым глюкам, чем остальные…
Сдох роутер, его поменяли и проблема сама-собой разрешилась.
74 — 06.05.10 — 18:04
(72) у меня такая же байда была в виртуалке… в конце концов плюнули и поставили физический сервер…
75 — 06.05.10 — 18:05
(73) машины виртуальные: 3 на одной физической
76 — 06.05.10 — 18:05
(74)+ найдешь лекарство, пиши, мы не нашли…
77 — 06.05.10 — 18:06
(74) все работало год на виртуалках нормально
78 — 06.05.10 — 18:07
(77) на вин 2008 не захотело, все, как в сабже…
79 — 06.05.10 — 18:07
может 8.2 поставить?
80 — 06.05.10 — 18:09
(79) может, но долго что то 8.2.11 выходит, страшно )))
81 — 06.05.10 — 18:17
на платформе 8.2 говорят нормальный кластер серверов, раб. процессы которого умирать не будут )))
82 — 06.05.10 — 18:18
(81) о нет, они будут жить вечно ))))))
83 — 06.05.10 — 18:23
(81) ну типа параллельность реализована, сеанс пользователя будет переключаться между процессами, если они загружены
84 — 06.05.10 — 18:27
(83) а процес и не слетает при более среднем количестве из 25 юзеров на 4 процеса может вивалится и всего один.
85 — 06.05.10 — 18:28
(84) + один юзер
86 — 06.05.10 — 18:32
(83) так то оно так, но почему то пользователи как продолжали валится так и валятся
87 — 06.05.10 — 18:43
(0) а может таки проблема СКЛя?
88 — 06.05.10 — 18:48
А можно ли настроить таймаут опроса сервером 1С — СКЛя ?
89 — 06.05.10 — 20:35
(88) или нет (
90 — 07.05.10 — 11:06
проблема актуальна (
91 — 07.05.10 — 13:02
переустанавливай всё к чертовой матери
92 — 07.05.10 — 13:14
(91) уже задумался)))
93 — 07.05.10 — 13:34
(91) но без решения проблемы это не выход (((
94 — 12.05.10 — 15:51
проблема актуальна (
95 — 12.05.10 — 15:55
(94) все переустановил?
96 — 12.05.10 — 16:07
(95) да, не помогло (
97 — 12.05.10 — 16:29
(96) есть возможность вынести 1С на физический сервер? да и скуль, наверное, тоже…
98 — 12.05.10 — 16:35
(96) нет, только виртуалка
99 — 12.05.10 — 16:39
(98) в виртуалке физический ключ сервера 1С не доступен же?
100 — 12.05.10 — 16:42
(0)Я так часто делаю 100!
I Have SQL Express installed on 17 ships. Each ship has a VB6 Client application using OLEDB to connect to the database on local machine. Other workstations on network also connect — we think without error. The error above is thrown on 4 of the 17 ships. The workstations acting as the file server are supposed to be identical (Windows XP).
We have been assured that all poer save settings on LAN Card and motherboard have been disabled.
If I google on this error, I get over 100 hits going back several years ! Ideas to fix have included turning off connection pooling and using TCPIP instead of Named Pipes on client workstation where database server and application are running.
Any other ideas on what could cause this, or why 13 machines are OK, but 4 are not ? Thanks.
Michael Meierruth
SSChampion
Points: 10051
Have been getting this error sporadically for years on a large SS2K site. Fortunately, it does not happen that often. But, in my case, it is mostly associated with something that goes through ADO+ODBC using TCP/IP. For a long time our software was blamed on it until I wrote a simple VB script routine that runs in a loop and remains permanently connected and executes a simple ‘select 0’ every mìnute. When an error occured it would get logged and then attempt to re-establish the connection.
The ADO Err stack always had two errors with the second one always being ‘General network error’. The first error would vary including your ‘ConnectionWrite(Send())’.
Now the problem was squarely in Microsoft’s terrrory. This problem was never solved. We checked the hardware, routers, service packs — you name it. We even ran the script on the database server itself and it would happen there as well.
Irish
Hall of Fame
Points: 3957
By far this is the most frustrating issue that I have been dealing with lately!! ![]()
We have a number of Services that connect to a SQL 2005 Database via OLEDB/ADO. We are seeing these «General Network» Errors all the time recently. We have checked hardware, software, Database Settings you name it. Nothing seems to be able to shake this.
The network admins are insulted that we even suggest that there might be a problem with the network, but what else can we say? They of course have not suggested any better solution.
Michael, you said that it’s squarely in Mico$oft’s territory now? Did you open an incident on this? Where is it now?
Regards, Irish
Mark Story
SSC-Addicted
Points: 406
Thanks for the comments. I think opening up an incident with Microsoft is best idea here. Too bad, SQL Express is a really nice product — but if it can’t be made reliable…that certainly is an issue…
Michael Meierruth
SSChampion
Points: 10051
At the time an incident was opened but I think the client I worked for at the time then dropped it. The problem still occurs today but apparently with a frequency sufficiently low to be ignored by everyone.
Mark Story
SSC-Addicted
Points: 406
We are sending technician to one ship that has it bad and reinstall SQL Express 2005, make sure the most recent version is installed. Customer will loom to replace the workstation (XP) that holds the database.
Sugesh Kumar
One Orange Chip
Points: 27311
Mark Story
SSC-Addicted
Points: 406
Unfortnately thr service pack is for SQL Server 2000, while the database engine is SQL Express 2005.
We sent technician to ship; uninstalled/reinstalled. Looked ok until he left ship, then original problem resumes.
One note of interest, he had some trouble with .NET Framework 2.0 and had to reinstall that. So maybe «Assembly Hell» replaces «DLL Hell» ?![]()
In any event, still no solution. During SQL installation the message was displayed that computer does not meet requirements…but those messages have been ignored up til now because no details are given and most computers work fine.
Irish
Hall of Fame
Points: 3957
We are still working on this one. From what we have been able to discern, it appears to be the combination of SQL 2005 SP2 and 2003 SP2. The investigation is on-going. Thus far the Microsoft representation we have gotten has been unimpressive.
Regards, Irish
Mike Sheen
SSC Veteran
Points: 235
I’m seeing this on SQL 2005, SQL 2000 — on both Windows XP and Windows Server 2003.
I can reproduce the problem reliably, but using our rather large ERP software (that we develop). I’m working on a small test app which will also reproduce the problem, such that I can raise a support issue with Microsoft. Being in software, I understand the importance of giving them something they can use to reliably reproduce the problem.
It seems to be (for us, anyway), when an ADO (OLEDB) connection is busy waiting for the server (in our case a long running stored procedure to return results to a Crystal Report), a second, separate OLEDB connection attempts to fire some queries against the same server. In my tests these queries are merely SELECT statements — which surprised me — given the error message returned was a ConnectionWrite send() error — nothing’s trying to write, so I suspect ConnectionWrite is referring to not a SQL Write (ie UPDATE / INSERT / DELETE), but a network connection to the SQL Server (think socket comms).
I thought it may have been related to connection pooling (as this was the only way I could see how one ADO connection could be affecting another), so I made sure the second connection to use different SQL credentials — this should make the two connections forced into separate pools — as the connection string is what is used to pool connections together. Anyway — the problem still occurs with connection pooling out of the equation.
Like I mentioned earlier, we use two ADO connections in our software — one for reporting, one for the application — and usually the reporting ADO connection has different SQL credentials anyway (for security purposes). Now the Reporting connection is in fact used by Crystal Reports 11 — I’m *assuming* it’s creating an OLEDB connection — as I’ve coded it to use the SQL OLEDB data provider. What other connection options Crystal decides to set is at present a complete mystery to me (In my experience Crystal can do bizarre things). First I’ll try to reproduce the problem with Crystal out of the equation.
I also tried the SynAttackProtect registry hack (http://support.microsoft.com/default.aspx?scid=kb;en-us;899599) — this also had no effect.
We’re a certified MS partner, and a certified MS ISV. If I can reproduce the problem reliable with a simple application I can provide to MS, I’ll do my all to make sure we see a solution… and I’ll be sure to post my progress with this issue here ![]()
Mike Sheen
SSC Veteran
Points: 235
Ok, I’ve made some discoveries.
It doesn’t seem to be a SQL or OLEDB problem. It certainly seems to be (in my case, anyway) related to Crystal Reports.
I found the problem only occurs when a query is issued on one connection whilst a Crystal Application Object (CRAXDT Version 11) is waiting for a stored procedure based report to being returning results. The Crystal Application object must be in the same application domain as the application issuing the query which fails.
Changing the network protocol used by SQL to be named pipes instead of TCP/IP seemed to improve things — I no longer got the DBNETLIB error, but the Crystal Report Application threw errors when it’s report finished (could be related, but with Crystal it’s hard to know).
This problem seems to be only reproducible when you are able to execute a query concurrently to the Crystal Application object awaiting stored procedure results — I would have said «ie: multi-threaded applications», but our application is not multi-threaded — it’s written in VB6 — but still we somehow are able to fire queries through our application despite the Crystal Application object awaiting results. Perhaps Crystal creates a new thread and runs in that ?
Mike Sheen
SSC Veteran
Points: 235
More discoveries.
I see this behaviour on SQL 2000 SP4, but not SQL 2000 with no SP’s.
In my situation, SQL 2000 with no SP seems to cause my application to be «less threaded» — ie: any Reports running waiting for stored procs causes the whole application to «block» and wait — ie: nothing else within the application can be run.
However, SP4 of SQL 2000 and the behaviour changes — no longer is my application «blocked» — I can load other reports, navigate menu’s, etc — and thus cause other queries to run and the DBNETLIB error occurs.
Mike Sheen
SSC Veteran
Points: 235
October 26, 2007 at 4:37 pm
#745932
An email from a reader of this forum has prompted me to post my conclusions.
Firstly, to re-cap on how we got the errors — they only occurred when Crystal Reports 11 was busy running a query, and we attempted to issue a SQL query (using OLEDB) on a different connection, but a connection within the same application.
We never found a solution to this problem. We did however, discover how we were able to issue a query when our application should have been blocked and waiting for Crystal to finish (our app is in VB6 and thus single threaded).
We use the Catalyst Socket Control for some of our functionality, and that control being in the app caused it to behave in a multi-threaded fashion ‘sometimes’. It seems that control gives the UI a degree of multi-threadedness (for want of a better term), and allowed the user to open forms, etc whilst waiting for a report and thus causing the subsequent errors.
From memory I believe we upgraded the control to the latest version, and the behaviour returned to what we had before — the UI does not respond whilst Crystal reports is running, and therefore no errors.
MikeySQL
Newbie
Points: 9
Irish
Hall of Fame
Points: 3957
December 6, 2007 at 10:26 am
#757765
What we found was related to a security feature added in Windows 2003 Service Pack 2. It is something called TCP Chimney. It all cropped up after applying SP 2. Removing the Service Pack did not resolve the issue. What we found out later is that the feature was there with SP1, but was not enabled by default as it was in SP2. Removing SP2 did not revert the setting back. We eneded up making a change in the Registry to resolve this.
Here’s more information:
http://www.microsoft.com/whdc/device/network/TCP_Chimney.mspx
http://msexchangeteam.com/archive/2007/07/18/446400.aspx
We issued the command «Netsh int ip set chimney DISABLED» and that made the issue go away for us.
Regards, Irish