Содержание
- GTX 1000 GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
- hshan
- Ошибка illegal memory access was encountered.
- Dargont
- Михаил78
- CUDA error: an illegal memory access was encountered #42
- Comments
- ”CUDA failure 77: an illegal memory access was encountered» in Executing Faster R-CNN #2388
- Comments
GTX 1000 GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered

hshan
Знающий
Риг из 1060 отработал несколько дней и начал сыпаться ошибкой как в заголовке. Ниже написан большой кусок из лога.
Сброс настроек к заводским, ребуты и прочие простые прием ничего не дали. Так как ошибка сразу по всем картам дело не мот быть в райзере или смерти какой-то карты.
Кто знает как решить проблему — отпишитесь!
07:18:02:681 bc0 parse packet: 247
07:18:02:681 bc0 ETH: job changed
07:18:02:681 bc0 new buf size: 0
07:18:02:682 bc0 ETH: 06/25/17-07:18:02 — New job from eu2.ethermine.org:4444
07:18:02:682 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:02:686 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:02:687 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:02:688 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:02:689 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:03:024 12e0 Setting DAG epoch #130 for GPU1
07:18:03:026 c74 Setting DAG epoch #130 for GPU0
07:18:03:027 1350 Setting DAG epoch #130 for GPU3
07:18:03:028 12e0 Create GPU buffer for GPU1
07:18:03:028 ac4 Setting DAG epoch #130 for GPU2
07:18:03:030 1350 Create GPU buffer for GPU3
07:18:03:031 ac4 Create GPU buffer for GPU2
07:18:03:029 c74 Create GPU buffer for GPU0
07:18:03:427 12e0 GPU 1, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:430 12e0 GPU 1, Calc DAG failed!
07:18:03:471 1350 GPU 3, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:534 1350 GPU 3, Calc DAG failed!
07:18:03:535 ac4 GPU 2, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:536 ac4 GPU 2, Calc DAG failed!
07:18:03:537 c74 GPU 0, GpuMiner cu_kd failed 77 (0), an illegal memory access was encountered
07:18:03:538 c74 GPU 0, Calc DAG failed!
07:18:06:234 bc0 got 248 bytes
07:18:06:234 bc0 buf:
07:18:06:234 bc0 parse packet: 247
07:18:06:234 bc0 ETH: job changed
07:18:06:234 bc0 new buf size: 0
07:18:06:235 bc0 ETH: 06/25/17-07:18:06 — New job from eu2.ethermine.org:4444
07:18:06:236 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:06:238 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:06:239 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:06:240 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:06:241 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:06:932 12e0 GPU 1 failed
07:18:06:936 ecc Setting DAG epoch #130 for GPU1
07:18:06:937 ecc GPU 1, CUDA error 77 — cannot write buffer for DAG
07:18:07:036 1350 GPU 3 failed
07:18:07:041 ac4 GPU 2 failed
07:18:07:040 b70 Setting DAG epoch #130 for GPU3
07:18:07:043 b70 GPU 3, CUDA error 77 — cannot write buffer for DAG
07:18:07:041 c64 Setting DAG epoch #130 for GPU2
07:18:07:045 c74 GPU 0 failed
07:18:07:044 4c0 Setting DAG epoch #130 for GPU0
07:18:07:046 4c0 GPU 0, CUDA error 77 — cannot write buffer for DAG
07:18:07:047 c64 GPU 2, CUDA error 77 — cannot write buffer for DAG
07:18:09:938 ecc GPU 1 failed
07:18:10:044 b70 GPU 3 failed
07:18:10:048 4c0 GPU 0 failed
07:18:10:080 c64 GPU 2 failed
07:18:10:133 bc0 ETH: checking pool connection.
07:18:10:133 bc0 send:
07:18:10:193 bc0 got 248 bytes
07:18:10:193 bc0 buf:
07:18:10:193 bc0 parse packet: 247
07:18:10:193 bc0 ETH: job is the same
07:18:10:193 bc0 new buf size: 0
07:18:11:690 bc0 got 248 bytes
07:18:11:690 bc0 buf:
07:18:11:691 bc0 parse packet: 247
07:18:11:691 bc0 ETH: job changed
07:18:11:691 bc0 new buf size: 0
07:18:11:691 bc0 ETH: 06/25/17-07:18:11 — New job from eu2.ethermine.org:4444
07:18:11:692 bc0 target: 0x0000000112e0be82 (diff: 4000MH), epoch #130
07:18:11:692 bc0 ETH — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0, Time: 00:00
07:18:11:693 bc0 ETH: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:11:694 bc0 DCR — Total Speed: 0.000 Mh/s, Total Shares: 0, Rejected: 0
07:18:11:695 bc0 DCR: GPU0 0.000 Mh/s, GPU1 0.000 Mh/s, GPU2 0.000 Mh/s, GPU3 0.000 Mh/s
07:18:20:131 bc0 send:
07:18:20:147 bc0 ETH: checking pool connection.
07:18:20:147 bc0 send:
07:18:20:193 bc0 got 39 bytes
07:18:20:193 bc0 buf:
07:18:20:194 bc0 parse packet: 38
07:18:20:194 bc0 new buf size: 0
07:18:20:250 bc0 got 248 bytes
07:18:20:250 bc0 buf:
07:18:20:250 bc0 parse packet: 247
07:18:20:251 bc0 ETH: job is the same
07:18:20:251 bc0 new buf size: 0
07:18:26:833 308 got 402 bytes
07:18:26:833 308 buf:
Источник
Ошибка illegal memory access was encountered.
Dargont
Свой человек
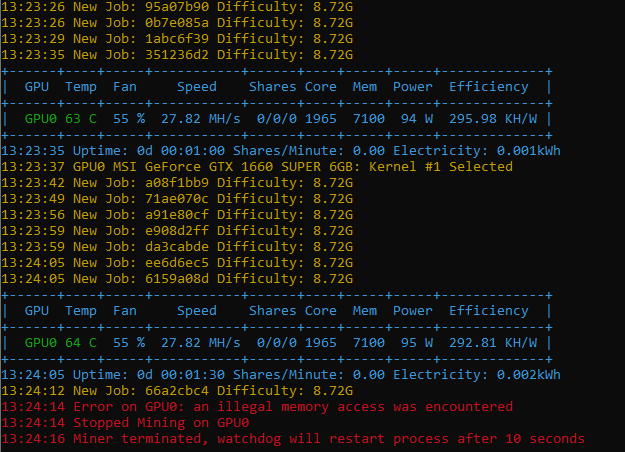
Стоит фермочка 1660S -4 шт и 3060ti -1 шт, работала как часы 2 года ничего не требовала, и тут майнер начал выдавать ошибку «an illegal memory access was encountered» причем на разные карты ругается зараза. Блок питание 1000W «термос». Отключение карты в майнере не исправило ситуацию, грешил на ДАГ файл. Куда копать? Ось Win10 LTSС, на других фермах все гуд причем с таким же набором карт и стой же операционкой(
12:38:10 Started Mining on GPU0: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:01:00.0]
12:38:10 Started Mining on GPU1: MSI NVIDIA GeForce RTX 3060 Ti 8GB [0000:02:00.0]
12:38:10 Started Mining on GPU2: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:03:00.0]
12:38:10 Started Mining on GPU3: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:04:00.0]
12:38:10 GPU0 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU1 MSI NVIDIA GeForce RTX 3060 Ti 8GB: Kernel #6 Selected
12:38:10 GPU2 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU3 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:11 New Job: 0000000057b45ae7 Epoch: #505 Diff: 1.399G
12:38:12 New Job: 0000000057b45ae8 Epoch: #505 Diff: 1.399G
12:38:13 New Job: 0000000057b45ae9 Epoch: #505 Diff: 1.399G
12:38:16 GPU2: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU3: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU0: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU1: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:17 New Job: 0000000057b45aea Epoch: #505 Diff: 1.399G
12:38:23 Error on GPU2: an illegal memory access was encountered
12:38:23 Stopped Mining on GPU0
12:38:23 Stopped Mining on GPU1
12:38:23 Stopped Mining on GPU2
12:38:23 Stopped Mining on GPU3
Михаил78
Бывалый
Стоит фермочка 1660S -4 шт и 3060ti -1 шт, работала как часы 2 года ничего не требовала, и тут майнер начал выдавать ошибку «an illegal memory access was encountered» причем на разные карты ругается зараза. Блок питание 1000W «термос». Отключение карты в майнере не исправило ситуацию, грешил на ДАГ файл. Куда копать? Ось Win10 LTSС, на других фермах все гуд причем с таким же набором карт и стой же операционкой(
12:38:10 Started Mining on GPU0: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:01:00.0]
12:38:10 Started Mining on GPU1: MSI NVIDIA GeForce RTX 3060 Ti 8GB [0000:02:00.0]
12:38:10 Started Mining on GPU2: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:03:00.0]
12:38:10 Started Mining on GPU3: NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB [0000:04:00.0]
12:38:10 GPU0 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU1 MSI NVIDIA GeForce RTX 3060 Ti 8GB: Kernel #6 Selected
12:38:10 GPU2 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:10 GPU3 NVIDIA NVIDIA GeForce GTX 1660 SUPER 6GB: Kernel #6 Selected
12:38:11 New Job: 0000000057b45ae7 Epoch: #505 Diff: 1.399G
12:38:12 New Job: 0000000057b45ae8 Epoch: #505 Diff: 1.399G
12:38:13 New Job: 0000000057b45ae9 Epoch: #505 Diff: 1.399G
12:38:16 GPU2: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU3: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU0: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:16 GPU1: Generating DAG for epoch #505 [Single Buffer 5064 MB]
12:38:17 New Job: 0000000057b45aea Epoch: #505 Diff: 1.399G
12:38:23 Error on GPU2: an illegal memory access was encountered
12:38:23 Stopped Mining on GPU0
12:38:23 Stopped Mining on GPU1
12:38:23 Stopped Mining on GPU2
12:38:23 Stopped Mining on GPU3
Источник
CUDA error: an illegal memory access was encountered #42
Error was encountered during training process with condfigs:
The script take an approximately 4-5GB of GPU from 11GB available and return this error:
/mmsegmentation/mmseg/apis/train.py in train_segmentor(model, dataset, cfg, distributed, validate, timestamp, meta) 104 elif cfg.load_from: 105 runner.load_checkpoint(cfg.load_from) —> 106 runner.run(data_loaders, cfg.workflow, cfg.total_iters)
/miniconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/runner/iter_based_runner.py in run(self, data_loaders, workflow, max_iters, **kwargs) 117 if mode == ‘train’ and self.iter >= max_iters: 118 break —> 119 iter_runner(iter_loaders[i], **kwargs) 120 121 time.sleep(1) # wait for some hooks like loggers to finish
/miniconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/runner/iter_based_runner.py in train(self, data_loader, **kwargs) 53 self.call_hook(‘before_train_iter’) 54 data_batch = next(data_loader) —> 55 outputs = self.model.train_step(data_batch, self.optimizer, **kwargs) 56 if not isinstance(outputs, dict): 57 raise TypeError(‘model.train_step() must return a dict’)
/miniconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/parallel/data_parallel.py in train_step(self, *inputs, **kwargs) 29 30 inputs, kwargs = self.scatter(inputs, kwargs, self.device_ids) —> 31 return self.module.train_step(*inputs[0], **kwargs[0]) 32 33 def val_step(self, *inputs, **kwargs):
/mmsegmentation/mmseg/models/segmentors/base.py in train_step(self, data_batch, optimizer, **kwargs) 150 #data_batch[‘gt_semantic_seg’] = data_batch[‘gt_semantic_seg’][. 0] 151 #print(data_batch[‘gt_semantic_seg’].shape) —> 152 losses = self.forward_train(**data_batch, **kwargs) 153 loss, log_vars = self._parse_losses(losses) 154
/mmsegmentation/mmseg/models/segmentors/encoder_decoder.py in forward_train(self, img, img_metas, gt_semantic_seg) 155 156 loss_decode = self._decode_head_forward_train(x, img_metas, —> 157 gt_semantic_seg) 158 losses.update(loss_decode) 159
/mmsegmentation/mmseg/models/segmentors/encoder_decoder.py in _decode_head_forward_train(self, x, img_metas, gt_semantic_seg) 99 loss_decode = self.decode_head.forward_train(x, img_metas, 100 gt_semantic_seg, —> 101 self.train_cfg) 102 103 losses.update(add_prefix(loss_decode, ‘decode’))
/mmsegmentation/mmseg/models/decode_heads/decode_head.py in forward_train(self, inputs, img_metas, gt_semantic_seg, train_cfg) 184 «»» 185 seg_logits = self.forward(inputs) —> 186 losses = self.losses(seg_logits, gt_semantic_seg) 187 return losses 188
/miniconda3/envs/open-mmlab/lib/python3.7/site-packages/mmcv/runner/fp16_utils.py in new_func(*args, **kwargs) 162 ‘method of nn.Module’) 163 if not (hasattr(args[0], ‘fp16_enabled’) and args[0].fp16_enabled): —> 164 return old_func(*args, **kwargs) 165 # get the arg spec of the decorated method 166 args_info = getfullargspec(old_func)
/mmsegmentation/mmseg/models/decode_heads/decode_head.py in losses(self, seg_logit, seg_label) 229 seg_label, 230 weight=seg_weight, —> 231 ignore_index=self.ignore_index) 232 loss[‘acc_seg’] = accuracy(seg_logit, seg_label) 233 return loss
/miniconda3/envs/open-mmlab/lib/python3.7/site-packages/torch/nn/modules/module.py in __call__(self, *input, **kwargs) 530 result = self._slow_forward(*input, **kwargs) 531 else: —> 532 result = self.forward(*input, **kwargs) 533 for hook in self._forward_hooks.values(): 534 hook_result = hook(self, input, result)
/mmsegmentation/mmseg/models/losses/cross_entropy_loss.py in forward(self, cls_score, label, weight, avg_factor, reduction_override, **kwargs) 175 class_weight=class_weight, 176 reduction=reduction, —> 177 avg_factor=avg_factor) 178 return loss_cls
/mmsegmentation/mmseg/models/losses/cross_entropy_loss.py in cross_entropy(pred, label, weight, class_weight, reduction, avg_factor, ignore_index) 28 weight = weight.float() 29 loss = weight_reduce_loss( —> 30 loss, weight=weight, reduction=reduction, avg_factor=avg_factor) 31 32 return loss
/mmsegmentation/mmseg/models/losses/utils.py in weight_reduce_loss(loss, weight, reduction, avg_factor) 45 # if avg_factor is not specified, just reduce the loss 46 if avg_factor is None: —> 47 loss = reduce_loss(loss, reduction) 48 else: 49 # if reduction is mean, then average the loss by avg_factor
/mmsegmentation/mmseg/models/losses/utils.py in reduce_loss(loss, reduction) 19 return loss 20 elif reduction_enum == 1: —> 21 return loss.mean() 22 elif reduction_enum == 2: 23 return loss.sum() RuntimeError: CUDA error: an illegal memory access was encountered»>
But if i reduce the size the image size twice with the same images per GPU (2) ,script takes approxiamtely 2GB from GPU and everything works fine.
Also,i want to add that using another PyTorch script with my own Dataloader i’m able to fill in GPU on full (11GB) by training process with the same Torch version and the same hardware.
The text was updated successfully, but these errors were encountered:
Источник
”CUDA failure 77: an illegal memory access was encountered» in Executing Faster R-CNN #2388
In executing run_faster_rcnn.py of CNTK2.2, I encountered error message as follows. With version=2.1, I’ve never met this kind of error.
What kind of activities can we do in this situation? (As far as I tried, Fast R-CNN scripts was fine in the same environment.)
The text was updated successfully, but these errors were encountered:
Are you running distributed training? Please try using CUDA_VISIBLE_DEVICES to limit to 1 GPU and see if the bug still occurs. We will try get a local repro.
@KeDengMS Thanks for your information. I’ve succeeded in starting the process.
Then, if we’d like to use multiple GPU, what kind of setting is needed?
The CUDA_VISIBLE_DEVICES=2 means that we use 2-GPU(, if the machine has 2 or over GPU), right?
As far as I tried, only single GPU was used even when I set CUDA_VISIBLE_DEVICES=2 and run as python run_faster_rcnn.py .
Then, how do we set, if we want to use multiple GPU with this script?
CUDA_VISIBLE_DEVICES is a string of comma separated device ids explained here, so to use two GPU set it to «0,1». I think there’s a bug in FasterRCNN or CNTK code when running the model with multiple devices, and we’ll look into it.
@KeDengMS Thanks! But, as far as I tried following 2 cases, the processes were not successful.
@KeDengMS Thanks, After merging your modification, I confirmed as follows:
Preparation: set CUDA_VISIBLE_DEVICES=0,1,2,3
Case1: python run_faster_rcnn.py -> no problem
Case2: mpiexec -n 2 python run_faster_rcnn.py -> maybe no problem.
- mAP was different.. (0.7108, 0.6760)
Case3: mpiexec -n 4 python run_faster_rcnn.py -> memory error.
- I will raise issue for another record.
The following is a log for Case 2:
The current FasterRCNN example needs some modifications to enable distributed training:
- It needs to use distributed_learner
- The reader needs to handle partitions of data w.r.t. worker_rank and number_of_workers. Otherwise, all workers would receive the same data. That would not have any benefit in training speed, and is effectively just multiplying learning rate with the number of workers.
- The config currently hardcoded GPU_ID 0 for all workers, which would not leverage multi-GPU rather than running several processes on the same GPU. I think the mem error you found is OOM when 4 processes are both using GPU 0. It needs to be removed and pass the default GPU selected by CNTK into gpu_nms. The current fix is a temporary one.
Then, can you advise what kind of changes are needed for
instead of temporary change 62a80d2 ? If you support me, I’ll change accordingly.
Источник
Take and my 5 cents. On GPU I start mining a week ago. For now i have 14 1070ti -+ OC, 2 farms and mining eth with auto restart ethminer if it stops on errors. This two scripts is not best solution, writen from scratch but works fine. Writed only for nvidia but i think it maybe rewriten for ati too ))
All this tested on Ubuntu 16.04
!!! nvidia coolbits must be enabled if you want OC settings to work. Mine is 13 tested on 381 and 387 drivers, emulated monitor for each card neded my nvidia-xconfig conf for 7 GPU, edid.bin find in google, i made mine from AOC 23 mon
nvidia-xconfig: X configuration file generated by nvidia-xconfig
nvidia-xconfig: version 387.34 (buildmeister@swio-display-x64-rhel04-15) Tue Nov 21 03:31:45 PST 2017
Section «ServerLayout»
Identifier «Layout0»
Screen 0 «Screen0»
Screen 1 «Screen1» RightOf «Screen0»
Screen 2 «Screen2» RightOf «Screen1»
Screen 3 «Screen3» RightOf «Screen2»
Screen 4 «Screen4» RightOf «Screen3»
Screen 5 «Screen5» RightOf «Screen4»
Screen 6 «Screen6» RightOf «Screen5»
InputDevice «Keyboard0» «CoreKeyboard»
InputDevice «Mouse0» «CorePointer»
EndSection
Section «Files»
EndSection
Section «InputDevice»
# generated from default
Identifier «Mouse0»
Driver «mouse»
Option «Protocol» «auto»
Option «Device» «/dev/psaux»
Option «Emulate3Buttons» «no»
Option «ZAxisMapping» «4 5»
EndSection
Section «InputDevice»
# generated from default
Identifier «Keyboard0»
Driver «kbd»
EndSection
Section «Monitor»
Identifier «Monitor0»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor1»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor2»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor3»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor4»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor5»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Monitor»
Identifier «Monitor6»
VendorName «Unknown»
ModelName «Unknown»
HorizSync 28.0 — 33.0
VertRefresh 43.0 — 72.0
Option «DPMS»
EndSection
Section «Device»
Identifier «Device0»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:1:0:0»
EndSection
Section «Device»
Identifier «Device1»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID «PCI:2:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device2»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID «PCI:3:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device3»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:5:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device4»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:6:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device5»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070 Ti»
BusID «PCI:7:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Device»
Identifier «Device6»
Driver «nvidia»
VendorName «NVIDIA Corporation»
BoardName «GeForce GTX 1070»
BusID «PCI:8:0:0»
Option «ConnectedMonitor» «DFP-0»
Option «CustomEDID» «DFP-0:/etc/X11/edid.bin»
EndSection
Section «Screen»
Identifier «Screen0»
Device «Device0»
Monitor «Monitor0»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen1»
Device «Device1»
Monitor «Monitor1»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen2»
Device «Device2»
Monitor «Monitor2»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen3»
Device «Device3»
Monitor «Monitor3»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen4»
Device «Device4»
Monitor «Monitor4»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen5»
Device «Device5»
Monitor «Monitor5»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Section «Screen»
Identifier «Screen6»
Device «Device6»
Monitor «Monitor6»
DefaultDepth 24
Option «AllowEmptyInitialConfiguration» «True»
Option «Coolbits» «13»
SubSection «Display»
Depth 24
EndSubSection
EndSection
Script is for miner loop with OC settings for each GPU.
Settings apply only ones at start if they enabled
Just edit it for your needs and run thats all, main part after it
#!/bin/sh
#nvidia-settings -a GPUFanControlState=0
#nvidia-settings -a GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a GPUMemoryTransferRateOffset[3]=1200
#nvidia-smi -pm 1
#nvidia-smi -pl 155
#nvidia-settings -a [gpu:0]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:0]/GPUMemoryTransferRateOffset[3]=1200
#nvidia-settings -a [gpu:0]/GPUFanControlState=1
#nvidia-settings -a [fan:0]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:1]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:1]/GPUMemoryTransferRateOffset[3]=1450
#nvidia-settings -a [gpu:1]/GPUFanControlState=1
#nvidia-settings -a [fan:1]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:2]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:2]/GPUMemoryTransferRateOffset[3]=1150
#nvidia-settings -a [gpu:2]/GPUFanControlState=1
#nvidia-settings -a [fan:2]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:3]/GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a [gpu:3]/GPUMemoryTransferRateOffset[3]=1050
#nvidia-settings -a [gpu:3]/GPUFanControlState=1
#nvidia-settings -a [fan:3]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:4]/GPUGraphicsClockOffset[3]=-150
#nvidia-settings -a [gpu:4]/GPUMemoryTransferRateOffset[3]=1050
#nvidia-settings -a [gpu:4]/GPUFanControlState=1
#nvidia-settings -a [fan:4]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:5]/GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a [gpu:5]/GPUMemoryTransferRateOffset[3]=800
#nvidia-settings -a [gpu:5]/GPUFanControlState=1
#nvidia-settings -a [fan:5]/GPUTargetFanSpeed=80
#nvidia-settings -a [gpu:6]/GPUGraphicsClockOffset[3]=-100
#nvidia-settings -a [gpu:6]/GPUMemoryTransferRateOffset[3]=900
#nvidia-settings -a [gpu:6]/GPUFanControlState=1
#nvidia-settings -a [fan:6]/GPUTargetFanSpeed=80
while true; # This will loop your miner even if you kill -9 ethminer it will start again after do
# To stop just CTRL+C or what ever you want =)
do
/home/m1/Miner/ethminer -U -S eth-eu2.nanopool.org:9999 -O 0xb4983146f0047d87c63b5fdb3ef9e2bee4557ea3.M1/vhosted@gmail.com
done
Thats was not so hard, the main deal is up to go !!!
While our miner script is working we will run another one
Script for monitoring
#!/bin/sh
-i 5 number GPU to monit
gpu=nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
while true; #Loops :=))
do
while [ $gpu -gt 50 ]
do
gpu=nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
echo «GPU load $gpu»
echo «All good $(date) GPU load $gpu No errors»
sleep 10
done
if [ $gpu -lt 40 ]
then
killall -9 ethminer
echo «Restart Miner GPU load $gpu $(date) error»
echo «Restart Miner $(date) error» >> /home/m1/Miner/ethminer.log
sleep 60
gpu=nvidia-smi -i 5 --query-gpu=utilization.gpu --format=csv,noheader,nounits
fi;
done
Thats it. Finished it esterday. I think it can be smaller. But nothing need to install, compile etc. All night i tested my GPUs with OC and power -+ very fast to test cloks and + tail -f /var/log/kern.log | grep nvrm to see what gpu couesd an error without long farm stop.
If it will help you. I like good coffe )) b4983146f0047d87c63b5fdb3ef9e2bee4557ea3
Hosted
-
#1
Приветствую, выдаёт ошибку как в заголовке, 4 Карты 1060 гигабайт, память хьюникс. Уже. По одной втыкал проверял(каждая карта с той же ошибкой выдавалась по отдельности), разгон не стоит, перелазил форум, нашёл похожее но не помогают способы решения, помогите плиз, заранее спасибо
-
#2
у меня такое было и на 1070 и на 1080 ти, читал форум,спрашивал у людей все отвечали разное (винда, переразгон, хана карте, файл подкачки) но я тупо решение нашел скачал зеалот энеми майнер и на нем все работает без проблем
-
#3
Просто у меня несколько ферм все абсолютно одинаковые на клэйморе, но вот одна пару дней назад вырубилась и не хочет включаться
у меня такое было и на 1070 и на 1080 ти, читал форум,спрашивал у людей все отвечали разное (винда, переразгон, хана карте, файл подкачки) но я тупо решение нашел скачал зеалот энеми майнер и на нем все работает без проблем
-
#4
Попробуй выключить ферму, а затем включить , не перезагрузка а именно повер офф на несколько минут, если не помогло переустановка дров через дди, увеличение подкачки.
-
#5
А поиском пройтись хотя бы по форуму? https://miningclub.info/threads/gpu…al-memory-access-was-encountered.11813/page-2
Конкретно для твоей ситуации вот решение и там ниже в ветке есть ответ, что помогло:
Две страницей бредней.
И так, у вас вылетает ошибка illegal memory access was encountered — это значит что вам не хватает памяти, т.е.у вас больше карт, чем указан для них размер swap. Увеличьте его, например если у вас 6-8 карт 1080 до 64 гигов, перегружаете комп и всё работает.
Проблема не в ваших картах, проблема в некоторых майнерах требующий большой своп. Чем больше карт, тем больше требуется своп.
Во первых ты не указал объем памяти 3 или 6Г? На 6Г — все ок, на 3 и даже 4-хГ АМД, а поскольку вчера тут вой стоял по поводу внезапной нехватки памяти на 1063 возможно у тебя сработало и из-за этого — а это проблема уже со старым клеймором.
У меня, во всяком случае, вчера 2 1063 отказались работать. Решилось установкой последней вервии клеймора — 11.8. Все запустилось и работает как часы (на вин 7)
-
#6
Приветствую, выдаёт ошибку как в заголовке, 4 Карты 1060 гигабайт, память хьюникс. Уже. По одной втыкал проверял(каждая карта с той же ошибкой выдавалась по отдельности), разгон не стоит, перелазил форум, нашёл похожее но не помогают способы решения, помогите плиз, заранее спасибо
Если копаете Эфир, то можно дописать ключ eres в батник или обновиться: https://bytwork.com/soft/claymores-dual-ethereum-amdnvidia-gpu-miner#sect3.1
-
#7
Спасибо помогло, но думаю это временно, придется обновляться. я на клее 9.7 до сих пор сижу)))
-
#8
Спасибо помогло, но думаю это временно, придется обновляться. я на клее 9.7 до сих пор сижу)))
Обновил клэймор все заработало как надо,спасибо
-
#9
Приветствую, выдаёт ошибку как в заголовке, 4 Карты 1060 гигабайт, память хьюникс. Уже. По одной втыкал проверял(каждая карта с той же ошибкой выдавалась по отдельности), разгон не стоит, перелазил форум, нашёл похожее но не помогают способы решения, помогите плиз, заранее спасибо
Происходила аналогичное исключительно на майнерах Zec. Zec не добываю и ошибка не появляется. Я думаю переразгон. Попробуй автобернер переустоновить.
-
#10
А поиском пройтись хотя бы по форуму? https://miningclub.info/threads/gpu…al-memory-access-was-encountered.11813/page-2
Конкретно для твоей ситуации вот решение и там ниже в ветке есть ответ, что помогло:Во первых ты не указал объем памяти 3 или 6Г? На 6Г — все ок, на 3 и даже 4-хГ АМД, а поскольку вчера тут вой стоял по поводу внезапной нехватки памяти на 1063 возможно у тебя сработало и из-за этого — а это проблема уже со старым клеймором.
У меня, во всяком случае, вчера 2 1063 отказались работать. Решилось установкой последней вервии клеймора — 11.8. Все запустилось и работает как часы (на вин 7)
Виртуалка не причем. У меня установлено 100 000 на 5х1066
-
#11
Виртуалка не причем. У меня установлено 100 000 на 5х1066
Или-или — я ж написал- виртуалка или клеймор.
У меня напр. оказался клеймор — обновил — все заработало.
-
#12
Или-или — я ж написал- виртуалка или клеймор.
У меня напр. оказался клеймор — обновил — все заработало.
Хорошо)))
-
#13
Хорошо)))
")
Блин дружище у меня эта ферма нормально заработала вроде, но потом выключилась и теперь постоянно вырубается, словить момент не могу чтоб ошибку посмотреь
-
#14
Блин дружище у меня эта ферма нормально заработала вроде, но потом выключилась и теперь постоянно вырубается, словить момент не могу чтоб ошибку посмотреь
О! Это не ко мне. Советы комментаторы выше давали. Я клеймор не использую.)))) Если эфир то фениксом копаю)))
-
#15
О! Это не ко мне. Советы комментаторы выше давали. Я клеймор не использую.)))) Если эфир то фениксом копаю)))
Тогда впишите в конец батника слово pause (Цитирую иного автора). То есть пишешь пауза и сможешь увидеть что за ошибка. Но это не точно
-
#16
у меня на 1070 Palit jetStream было такое, причина была в даунвольте, сделал вместо 750mV — 825mV стало стабильно, при 800mV вылетало иногда
P.S. все 1070 у меня работают без проблем на 750 mV
-
#17
всем доброго дня !
gminer 1.86
an illegal memory access was encountered
что может быть
win 7, пытаюсь копнуть бим
на 4-ой карте вылетает такое сообщение
подкачки 37 гиг
риг всего лишь на 4 карточки
-
#18
всем доброго дня !
gminer 1.86
an illegal memory access was encountered
что может быть
win 7, пытаюсь копнуть бим
на 4-ой карте вылетает такое сообщение
подкачки 37 гиг
риг всего лишь на 4 карточки
тоже на 4 появилась что делал
-
#19
у меня такая проблема с 1070 была, решил повышением напряжения с 750mV до 850mV
@aNdrE_ch
Школьник, интересуюсь IT, пытаюсь учить Frontend.

-
Видеокарты
-
Криптовалюта
 В играх карта работает нормально.
В играх карта работает нормально.
-
Вопрос заданболее года назад
-
3259 просмотров
1
комментарий
Подписаться
1
Средний
1
комментарий
-
 Loli E1ON
Loli E1ON@E1ON
Отключить разгон, если включен.
Написано
более года назад

Решения вопроса 0
Пригласить эксперта
Ответы на вопрос 1
@rassini
Поднимите питание, его не достаточно.
Ответ написан
более года назад
Комментировать
Комментировать
Ваш ответ на вопрос
Войдите, чтобы написать ответ
Войти через центр авторизации
Похожие вопросы
-
-
Криптовалюта
- +1 ещё
Простой
Где можно взять дамп адресов с транзакциями в сети bsc?
-
1 подписчик -
14 часов назад
-
14 просмотров
0
ответов
-
-
-
Видеокарты
- +1 ещё
Сложный
Почему не происходит выхода видео на монитор?
-
1 подписчик -
вчера
-
23 просмотра
0
ответов
-
-
-
Видеокарты
- +1 ещё
Простой
Не сгорит ли железо если поставить БП на 100w меньше рекомендуемой?
-
1 подписчик -
вчера
-
70 просмотров
4
ответа
-
-
-
Windows
- +3 ещё
Сложный
Дисплей ноутбука не подключается к видео карте, как исправить?
-
1 подписчик -
06 февр.
-
66 просмотров
0
ответов
-
-
-
Windows
- +2 ещё
Сложный
При движении мыши скачет нагрузка gpu. С чем связано?
-
2 подписчика -
06 февр.
-
277 просмотров
2
ответа
-
-
-
Компьютеры
- +3 ещё
Средний
Почему видеокарта не нагружается в играх?
-
1 подписчик -
03 февр.
-
150 просмотров
3
ответа
-
-
-
Видеокарты
Простой
Какая видеокарта потянет два монитора с разрешение 4к+?
-
1 подписчик -
31 янв.
-
89 просмотров
2
ответа
-
-
-
Видеокарты
Простой
Какие проблемы могут возникуть при покупке 4070 ti/3080 ti?
-
1 подписчик -
29 янв.
-
95 просмотров
1
ответ
-
-
-
Криптовалюта
- +1 ещё
Простой
Как получить все транзакции через bscscan api?
-
1 подписчик -
29 янв.
-
31 просмотр
1
ответ
-
-
-
Мониторы
- +1 ещё
Сложный
Поддерживается ли разрешение 5120:1440 и 165 гц на видеокарте gtx 1660 ti?
-
1 подписчик -
27 янв.
-
161 просмотр
1
ответ
-
-
Показать ещё
Загружается…




Вакансии с Хабр Карьеры
QA Automation Engineer / Тестировщик
Timeweb
•
Санкт-Петербург
от 150 000 ₽
Senior .Net Developer Remote
Freuders
от 5 000 $
Backend разработчик (Node.js)
OWNR SOLUTIONS
•
Нижний Новгород
от 250 000 до 300 000 ₽
Ещё вакансии
Заказы с Хабр Фриланса
Удалить пост/аккаунт в Facebook и google images
09 февр. 2023, в 22:06
500 руб./за проект
Приложение трекер для Андроид
09 февр. 2023, в 22:01
50000 руб./за проект
Необходимо разработать текст для небольшого сайта клининговой компании
09 февр. 2023, в 22:00
1 руб./за проект
Ещё заказы
Минуточку внимания
Присоединяйтесь к сообществу, чтобы узнавать новое и делиться знаниями
Зарегистрироваться
-
HiveOS
-
linux
-
мониторинг
![]()
- Назад
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- Далее
- Страница 150 из 167
Рекомендуемые сообщения

![]()
-
- Поделиться
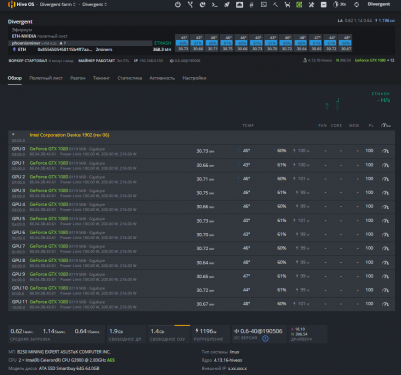
Прошу помощи по настройкам данных карт — GeForce GTX 1080 8119 MiB · Gigabyte. Принципиально — эфир. Принципиально — феникс. Не получается увеличить хэшрейт. Хотя бы до 35.
Изменено 10 May 2019, 00:06 пользователем ioff
Ссылка на комментарий
Поделиться на другие сайты
-
Ответов
4.2т -
Создана
3 Nov 2017, 02:23 -
Последний ответ
26 Dec 2022, 14:39
Топ авторов темы
-
341
-
249
-
193
-
161

Изображения в теме

![]()
-
- Поделиться
12 minutes ago, ioff said:
Прошу помощи по настройкам данных карт. Принципиально — эфир. Принципиально — феникс. Не получается увеличить хэшрейт. Хотя бы до 35.
А какой хешрейт вы, собственно, ожидали увидеть, если у вас PL 50% и core/mem на нулях?
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@2hard4u Пробовал оставлять PL на умолчаниях и игрался с core/mem. Вылетают ошибки по CUDA и перезапуск. На этих картах, любое изменение параметров по памяти или корке — сбой. Поэтому и потревожил форумчан. Не знаю, откуда начинать рыть. Хотелось бы увидеть готовый , рабочий вариант настроек. Оттуда, при стабильности, можно было бы играться.
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
6 minutes ago, ioff said:
@2hard4u Хотелось бы увидеть готовый , рабочий вариант настроек. Оттуда, при стабильности, можно было бы играться.
Жмите на значок разгона у любой карты, выбирайте вторую вкладу, которая «популярные настройки», там выбирайте нужный алго и смотрите, как у народа настроено. Все варианты рабочие, взяты с разгонов всех пользователей хайва.
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@2hard4u Пробовал разные варианты. Ни один не работает. По питанию проблем нет. три блока CHIEFTEC , голдовые, по 1350 ватт. Материнка тоже отличная — B250 MINING EXPERT ASUS. На ней работает несколько ферм с Radeon RX 580 8192M, разбавленными P102-100 5059 MiB · Zotac. Нет проблем вообще. Тут же затык полный.
GPU8 CUDA error in CudaProgram.cu:430 : an illegal memory access was encountered (700)Ошибка CUDA для GPU8 в CudaProgram.cu:430: обнаружен недопустимый доступ к памяти (700)
И так со всеми картами.
Изменено 10 May 2019, 02:39 пользователем ioff
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@ioff Похоже проблема с «дровами» видеокарт
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@Андрей_ua
6 часов назад, Андрей_ua сказал:
@ioff Похоже проблема с «дровами» видеокарт
Согласен. Есть такое подозрение. Под окнами, такой проблемы не возникает. Но там потребление выше и ограничено количество карт. Тупое обновление дров до 418, вопрос не решает. А где взять и как принудительно поставить дрова именно под эти карты, я не знаю. Везде описание только под 1080ti.
Ссылка на комментарий
Поделиться на другие сайты

![]()
-
- Поделиться
0.6-41@190510
* Gminer v1.42 (улучшенная производительность для BEAM на RTX картах, исправлено падение производительности на 1080ti)
* NBminer v23.2 (улучшена производительность на Grin, AE, SWAP, добавлена поддержка AE для NiceHash)
* Wildrig-Multi v0.16.1 (добавлен xevan алгоритм, небольшая улучшение на x16 подобных алгоритмах)
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
Ссылка на комментарий
Поделиться на другие сайты

![]()
-
- Поделиться
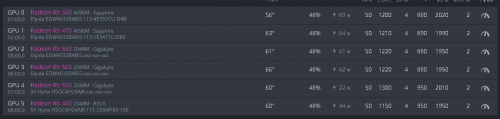
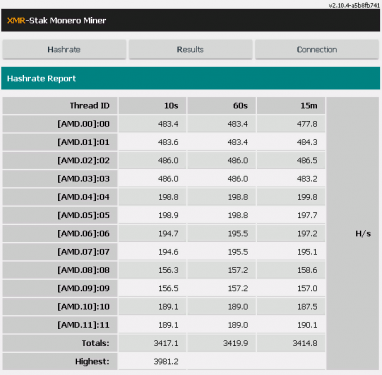
почему хэш маленький такой в хайвос на rx 560 550 картах ?
на винде например дают по 450-480 на монерке а на хайв 300-350
частоты одинаковые.
есть кто копает ? киньте настройки плз ?
Изменено 10 May 2019, 12:11 пользователем SaN4
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@Андрей_uaзалил на хайв последние дрова — Версия: 418.74, Опубликовано:2019.5.7. Всё установилось корректно. Перезапуск. Полет нормальный. Стал играться с коркой и памятью по своим трафаретам и по алгоритмам с новой опции…. краснятина и ребут. Смысл. Раньше, до включения таблетки, хэш был 21,4 с карты. Включается таблетка — 30,8. Теперь без таблетки 24,5. При включении таблетки всё рушится по CUDA.
GPU9 CUDA error in CudaProgram.cu:430 : an illegal memory access was encountered (700)
GPU9 GPU9 search error: an illegal memory access was encountered
И так по всем картам.
Изменено 10 May 2019, 12:56 пользователем ioff
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
Ссылка на комментарий
Поделиться на другие сайты

![]()
-
- Поделиться
@SaN4 может майнеры разные? Там под монеро их много
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@Андрей_ua вчера перепробовал все из архива хайва. Те же танцы с бубном.
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
Только что, TheIllusiveMan сказал:
@SaN4 может майнеры разные? Там под монеро их много
дак xmr-stak 2.10.4 везде,
хз вот не пойму причину.
тоже самое с r9270 карты. хайв 350, винда 450. нормальная так себе разница
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@SaN4 а дрова разные? У меня на эфире норм хэш пишут, майнер клеймор.
попробуйте teamredminer ради интереса
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@SaN4 скрин закладки — Обзор, в студию. Чего на кофейной гуще гадать? Под виндой Вы автобернером накручиваете, тут ручками прописывать нужно.
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
5 минут назад, TheIllusiveMan сказал:
@SaN4 а дрова разные? У меня на эфире норм хэш пишут, майнер клеймор.
попробуйте teamredminer ради интереса
да вот кстати дрова разные. точно.
как то можно в хайв дрова поставить старые ? ) затестить хоть
6 минут назад, ioff сказал:
@SaN4 скрин закладки — Обзор, в студию. Чего на кофейной гуще гадать? Под виндой Вы автобернером накручиваете, тут ручками прописывать нужно.
шо мы первый год в майнинге что ли )))
все прописано вроде норм . все карты шитые
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
@SaN4 у меня веги не разгонялись на хайве, спец образ для них вообще ни 1 карты не видел
стоят на винде.
как ставить дрова на хайв хз
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
* NBMiner v23.2 (хотфикс: исправлена поддержка AE под NiceHash)
* WildRig-Multi v0.16.2 (исправлена поддержка xevan на видеокартах Vega, небольшой прирост на x16-подобных алгоритмах)
Ссылка на комментарий
Поделиться на другие сайты

![]()
-
- Поделиться
Второе обновление за сегодня… Ну, вы, блин даёте… (с)
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
нет. не работает как надо. откатил дрова все равно мало мх.
Изменено 14 May 2019, 06:49 пользователем SaN4
Ссылка на комментарий
Поделиться на другие сайты
![]()
-
- Поделиться
а грин29 или 31 на найсхеше чем майнить можно?
кбминер майнит в воздух (пишет что мол с найсем не совместим), но на амд474 может 29й
гринминеры только ругаются на ошибки в его конфиге
карты амд на 4 и 8 гиг разные
Ссылка на комментарий
Поделиться на другие сайты

![]()
-
- Поделиться
Кто подскажет, как принудительно увеличить обороты вертушек ?
Есть карта 1080 Ti FE, отпахала года 2 с лишним на полных оборотах… Заменил турбину на Accelero Xtreme III и сразу проверил всё из под винды, всё пашет как надо. В настройках MSI выкручивал FAN под 100% и всё было замечательно. Затем перенес карту в Hive OS и там почему то скорость вращения динамическая в пределах 40%
Как выставить конкретное значение вращение для вертушек, при условии что оно и так выставлено единое, для всех карт…
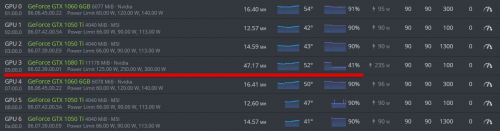
Изменено 15 May 2019, 10:59 пользователем GOLDSVET
Ссылка на комментарий
Поделиться на другие сайты
- Назад
- 145
- 146
- 147
- 148
- 149
- 150
- 151
- 152
- 153
- 154
- 155
- Далее
- Страница 150 из 167
Для публикации сообщений создайте учётную запись или авторизуйтесь
Вы должны быть пользователем, чтобы оставить комментарий
Войти
Уже есть аккаунт? Войти в систему.
Войти
-
Последние посетители
0 пользователей онлайн
- Ни одного зарегистрированного пользователя не просматривает данную страницу
-
Similar Topics
-
ФБР ликвидировало международную сеть вымогателей Hive
Правоохранители США совместно с Германией и Нидерландами ликвидировали одну из крупнейших сетей вымогателей Hive, вернув украденные активы большей части жертв.
Министерство юстиции США отчиталось о завершении совместной с Федеральным бюро расследований операции, в ходе которой была ликвидирована международная группа вымогателей Hive. Злоумышленники атаковали школы, банки и больницы в более 80 странах. С июня 2021 года их жертвами стали примерно 1 500 учреждений по всему миру, а вымогатели з27 Jan 2023, 09:59
в Новости криптовалют
-
-
News Bot
-
27 Jan 2023, 09:59
-
-
Hive Blockchain тестирует добычу различных монет с помощью видеокарт
Майнинговая компания Hive Blockchain начала тестирование своего оборудования для добычи различных монет – фирма ищет замену эфиру, добывать который после перехода на PoS будет невозможно.
Hive Blockchain сообщила, что общая мощность видеокарт в ее распоряжении составляет 21.5 МВт – это 16% от мощностей фирмы. При этом большая часть – 14.8 МВт – это уже устаревшее оборудование, в основном, видеокарты AMD Radeon RX580. Они работают с 2018 года и «многократно окупились». Оставшиеся 6.7 МВт пот8 Sep 2022, 06:38
в Новости криптовалют
-
-
News Bot
-
8 Sep 2022, 06:38
-
-
Hive Blockchain в мае увеличила хэшрейт оборудования на 8%
Канадская майнинговая компания Hive Blockchain сообщила, что за прошлый месяц ее общий хэшрейт оборудования для добычи биткоина увеличился на 8%.
Согласно отчету, за май в кошельки Hive поступило 273.4 BTC и 2 694 ETH. Общий хэшрейт оборудования для майнинга биткоина составил 2.18 Эх/с, а хэшрейт майнинговых устройств для добычи ETH остался прежним – 6.26 Тх/с. Председатель Hive Фрэнк Холмс (Frank Holmes) отметил:
«Мы рады сообщить, что в мае Hive продолжил наращивать мощность обо7 Jun 2022, 07:40
в Новости криптовалют
-
-
News Bot
-
7 Jun 2022, 07:40
-
-
Майнинговая компания Hive Blockchain приобретает чипы Intel для майнинга
Hive Blockchain заключила сделку с Intel и планирует развернуть новый дата-центр в Техасе.
Блокчейн-компания Hive объявила о сделке с производителем процессоров на поставку новых чипов Intel ASIC для майнинга. Чипы должны будут использоваться в специально изготовленном для компании оборудовании. Для этого компания заключила договор с компанией ODM, специализирующейся на производстве электроники.
«Команда инженеров Hive будет опираться на свой опыт в области аппаратного и программно9 Mar 2022, 14:06
в Новости криптовалют
-
-
News Bot
-
9 Mar 2022, 14:06
-
-
Hive Blockchain закупит еще 4 000 ASIC-майнеров у Canaan Creative
Канадская майнинговая компания Hive Blockchain подписала соглашение с китайским производителем оборудования для добычи криптовалют Canaan Creative о поставке еще 4 000 ASIC-майнеров.
В пресс-релизе не указана сумма сделки или модель покупаемых устройств, однако известно, что общий хэшрейт приобретаемого оборудования составит 272 Пх/с. Поставки пройдут в двух партиях – компания получит по 2 000 устройств в августе и сентябре.
На текущий момент хэшрейт оборудования для майнинга б
4 Aug 2021, 08:30
в Новости криптовалют
-
-
News Bot
-
4 Aug 2021, 08:30
-
-
