From Wikipedia, the free encyclopedia
In digital storage, a Medium Error is a class of errors that a storage device can experience, which imply that a physical problem was encountered when trying to access the device. The word «medium» refers to the physical storage layer, the medium on which the data is stored; as opposed to errors related to e.g. protocol, device/controller/driver state, etc.
Medium errors are most commonly detected by checking the read data against a checksum – itself being most commonly also stored on the same device. The mismatch of data to its supposed checksum is assumed to be caused by the data being corrupted.
Locations of medium errors can be either temporary (as in the case of bit rot – there is no damage to the medium, the data was simply lost), or permanent (as in the case of scratching – the physical location is unusable from that point onwards).
Devices can sometimes recover from medium errors, either by retrying or by managing to reconcile the data with the checksum. If the medium has incurred permanent damage, the device might remap the logical address where the error occurred to a different, undamaged physical location.
Medium errors are often associated with long latency for the IOs. This is due to the device retrying and attempting to recover from the error.
Examples of conditions that might cause medium errors[edit]
- The head executed a Read request while being improperly aligned, causing it to read data from a wrong physical position.
- Previous operation of the disk harmed the medium in some manner (e.g. scratched it), corrupting data in the location that is now discovered as problematic.
- External conditions (e.g. dust particles) physically harmed the medium, or caused the head to harm the medium.
- A previous Write on a nearby physical location caused the head to corrupt bits in the read location (imprecision in the physical write location). This is less likely in media that is mostly read-only, such as optical media, unless the writing device is defective.
- Bit rot, i.e. the gradual, natural deterioration of the magnetic field.
See also[edit]
- Bad sector
- Bit rot
| Author | Message |
|---|---|
|
Post subject: «SCSI HDD «Medium Error'»
|
|
|
|
I had 5 Seagate’s ST336607LW 36GB SCSI drives in the lab. All with the same sympthoms: pcb ok, motor spin, calibrate noise ok, detect string», then after hdd name receive «Medium Error». I opened some and the media is not sctatched. I also excgamged all the PCB’s with a good working one and all of them are working. MHDD fails badly if i try to perform a HOT-SWAP (quits in a blue screen) I have already tried head-swap, but after sucesfully done hdd receives the same message, so I highly consider this to be SA problem. Firmware utilities (ROM) upgrade from the vendors (both Seagate and HP) are not able to perform upgrading, because HDD is not ready. All customers report failure after normal reboot or power failure. All tests were done in Adaptec 29160 and 2940UW. Someone have a solution for this cases ?? I am whilling to pay or exchange for another information. -BR-
P.S. It is nice to finally be back |
| Top | |
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
Hi,
If you can find the EMOS command for Seagate SCSI you will be able to overide the format degraded condition. SCSI is top secret info so I guess you need find yourself GuRu -BR- wrote: I had 5 Seagate’s ST336607LW 36GB SCSI drives in the lab. All with the same sympthoms: pcb ok, motor spin, calibrate noise ok, detect string», then after hdd name receive «Medium Error». I opened some and the media is not sctatched. I also excgamged all the PCB’s with a good working one and all of them are working. MHDD fails badly if i try to perform a HOT-SWAP (quits in a blue screen) I have already tried head-swap, but after sucesfully done hdd receives the same message, so I highly consider this to be SA problem. Firmware utilities (ROM) upgrade from the vendors (both Seagate and HP) are not able to perform upgrading, because HDD is not ready. All customers report failure after normal reboot or power failure. All tests were done in Adaptec 29160 and 2940UW. Someone have a solution for this cases ?? I am whilling to pay or exchange for another information. -BR- P.S. It is nice to finally be back _________________ |
| Top |
|
|
|
Post subject:
|
|
|
|
| Top |
|
|
|
Post subject:
|
|
|
Monk wrote: That is it EMOS ?
Enamble Manufacturing Operating System E.M.O.S _________________ |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
same error occured yesterday on our old scsi disk. after normal shutdown, medium error… is there anything that i can do? i know topic is old but may be you people can help me. Thank you all. |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
@speedlover: I don’t think it was a good plan to join a 6-year old thread, where your situation is different (unless you have 5 drives of exactly the previous OP’s model), but anyway… More info needed, for starters: Where are you seeing «medium error» being reported? Which OS? Which drive make & model? How many drives are reporting this? Just one LBA or many causing this error message? Any other errors reported from the affected drive(s)? Are you trying to say that you can’t boot the system? I couldn’t give any useful suggestions without those answers. With answers to all those questions, you may get further replies. |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
i see error in scsi bios when searching for drives. thanks again. |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
@speedlover, seek pro help if you need data, simply replace it if you just want to restore functionality. |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
@speedlover: I expect this is not a «typical» type of medium error — the SCSI ASC & ASCQ would help to confirm my suspicions, but this: speedlover wrote: in adaptec bios settings which i go with ctrl-a , capacity does not shown. … means that you cannot fix the problem yourself anyway. IMHO as BlackST said, you will need to pay a DR company who has suitable experience, if you want to try to recover the data. |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
today i give the disk to one experienced dr pro. i hope to hear good sayings from him tomorrow. @vulcan @blackst |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
good news! recovery successful, everything back, nothing lost except considerable amount of money. |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
Seagate drives with IBM firmware actually have fast format enabled within the Mode Pages _________________ |
| Top |
|
|
|
Post subject: Re: «SCSI HDD «Medium Error'»
|
|
|
Well, you got everything back / your system is up and running again in 1 day or so…. isn’t it good ?!? |
| Top |
|
Introduction
This document describes different types of disk errors, how to classify them, and tools you can use to identify them.
Prerequisites
Requirements
There are no specific requirements for this document.
Components Used
The information in this document is based on hard disks in Unified Computing System (UCS).
The information in this document was created from the devices in a specific lab environment. All of the devices used in this document started with a cleared (default) configuration. If your network is live, make sure that you understand the potential impact of any command.
Background Information
The document also outlines the Hard Disk Drive’s (HDD) and Redundant Array of Independent Disks (RAID) controller’s role when you identify medium errors on the drives.
Note: Medium errors are also referred to as media errors
Handle HDD Medium Errors
What causes HDD medium errors?
The most common cause of medium errors is poor signal amplitude that results in
- Unreliable Logical Bus Address (LBA) read location. Sometimes recoverable with multiple retries.
- Transient conditions, high fly writes caused by soft particles.
- Transient conditions caused by temporary shock, vibration, or acoustic events that result in off-track writes.
- Poor error map function in HDD manufacture that results in padding the current primary defect locations.
How does the HDD detect the medium error?
Step 1.The HDD periodically performs Background Media Scans to detect errors.
Step 2. The HDD tries to read from the media and for some reason is unable to retrieve the data that was written.
Step 3. When the HDD is unable to retrieve data that was written it invokes the HDD recovery code which will try various error recovery steps to successfully read the data from the media.
Step 4. If all the recovery steps fail the drive will generate a 03/11/0x error back to the host and the LBA(s) will be placed on the pending defect list.
How does the Raid controller detect medium errors?
- The RAID controller will encounter medium errors while Patrol Reads, Consistency Checks, Normal Reads, Rebuilds, and Read / Modify / Write operations.
- Based on the RAID configuration, the controller may be able to handle the medium error reported by the HDD and no further action will be required.
- In some cases, the controller will not be able to handle the medium error and will pass the error to the host to handle the error.
When does the Operating System (OS) see medium errors?
- If the HDD reports a medium error and the RAID controller cannot handle the recovery, then the host will be notified of the error.
- This notification is no longer just an advisory message that would inform the system that the event has occurred, it is a request for the OS to act because the HDD and RAID controller was not able to recover from the medium error.
- If the OS has the required context to correctly resolve the medium error, it should be handled by the OS
- If disks are in Just a Bunch Of Disk (JBOD), the OS will see errors as they are not corrected by the controller. This is common in HyperFlex (HX)/ Virtual Storage Area Network (VSAN) environments.
HDD Role
Grown Defects (G-list) HDD Level
While a drive is in operation, the head may come across a sector with a weakened magnetic read level. The data is still readable but may fall below the preferred threshold for qualified good sector read levels. This disk drive would consider this a sector that could and would sector spare this data to a new location available in the known good reserve list. Once the data is moved, the old sector address is added to the Grown Defects list, never to be used again. This process is a recoverable media error. The drive will give a SMART trigger once a majority of its known-good spare sectors are exhausted.
RAID Controller Role
Patrol Read
- Patrol Read is a user-definable option that performs drive reads in the background and maps out any bad areas of the drive.
- Patrol Read checks for physical disk errors that could lead to drive failure. These checks usually include an attempt at corrective action. Patrol read can be enabled or disabled with automatic or manual activation.
- A Patrol Read periodically verifies all sectors of physical disks that are connected to a controller, that include the system reserved area in the RAID configured drives. Patrol Read works for all RAID levels and all hot spare drives.
- This process starts only when the RAID controller is idle for a defined length of time and no other background tasks are active, though it can continue to run at the same time as heavy Input/Output (I/O) processes.
- You cannot conduct patrol reads on drives configured in JBOD.
Note:Latent Semantic Indexing (LSI) recommends that you leave the patrol read frequency and other patrol read settings at the default values to achieve the best system performance. If you decide to change the values, record the original default value here so you can restore them later.
Note: Patrol Read does not report on its progress as it runs. The patrol read status is reported in the event log only.
Patrol Read options are as shown in the image:
 MegaCli Examples
MegaCli Examples
To see information about the patrol read state and the delay between patrol read runs:
# MegaCli64 -AdpPR -Info -aALL
To find out the current patrol read rate, execute:
# MegaCli64 -AdpGetProp PatrolReadRate -aALL
To disable automatic patrol read:
# MegaCli64 -AdpPR -Dsbl -aALL
To enable automatic patrol read:
#MegaCli64 -AdpPR -EnblAuto -aALL
To start a manual patrol read scan:
# MegaCli64 -AdpPR -Start -aALL
To stop a patrol read scan:
# MegaCli64 -AdpPR -Stop -aALL
Consistency Check
- In RAID, the Consistency Check verifies the correctness of redundant data in an array. For example, in a system with parity, to check consistency means to compute the parity of the data drives and compare the results to the contents of the parity drive.
- JBOD does not support consistency check.
- RAID 0 does not support consistency check.
- RAID 1 uses a data compare not parity.
- RAID 6 computes parity for 2 parity drives and verifies both.
Note: It is recommended you run a consistency check at least once a month.
Consistency Check management options are as shown in the image:
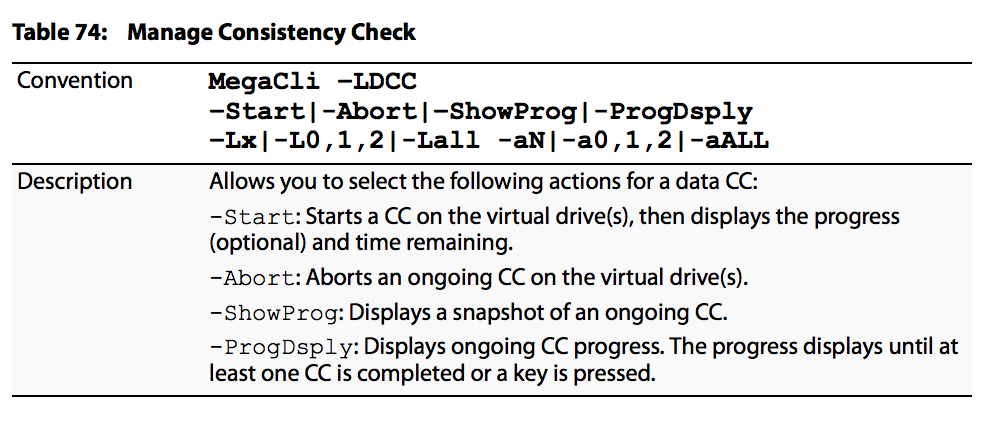
Consistency Check scheduling options are as shown in the image:

MegaCli Examples
To see the next scheduled Consistency Check time:
#MegaCli64 -AdpCcSched -Info -aALL
To change scheduled Consistency Check time:
#MegaCli64 -AdpCCSched -SetSTartTime 20171028 02 -aALL
To disable Consistency Check:
#MegaCli64 -AdpCcSched -Dsbl -aALL
Conditions when a RAID Controller Cannot Repair a Medium Error
- In JBOD
- The host OS is responsible for medium errors.
- In RAID 0
- There is no redundancy, so the controller cannot provide the HDD with the data to write to the LBA.
- In RAID 1
- When the controller cannot tell which mirror copy contains the correct data. This will only occur if both LBAs can be read, but the data does not match.
- RAID 5
- If there are 2 or more errors in the same stripe. Most likely to occur when after a rebuild of an array is initiated. The drive that is rebuilt is one error, and a medium error on any other drive rebuild would be the second error. The controller would not be able to reconstruct the data needed to rebuild the LBA on the replacement drive.
- RAID 6
- If there are 3 or more errors in the same stripe. Most likely to occur when while an array is rebuilt. The drive that is rebuilt is one error, and a medium error on any two other drives while the rebuild is in progress would be second and third errors, or a medium error and a second drive failure. The controller would not be able to reconstruct the data needed to rebuild the LBAs on the drives with the errors.
Related Information
- MegaRaid® SAS Software User Guide
- Technical Support & Documentation — Cisco Systems
Обновлено: 08.02.2023
Часто задаваемый вопрос: «есть ли у SAS-дисков SMART и как его посмотреть?»
Да, в некотором виде есть, в виде лог-страниц с различной полезной информацией. В статье будет рассказано о том, как эту информацию получить и интерпретировать.
Хочется подчеркнуть что, речь ниже пойдет не о домашних пользователях, для которых регулярная проверка здоровья и производительности родного железа может быть чем-то вроде хобби. Да и в случае появления признаков неисправности на том же HDD первой мыслью будет не «немедленно списать и заменить», а «сколько он еще протянет и нельзя ли как-нибудь его починить?». Такой подход вполне имеет право на жизнь, ведь ценность «домашних» данных и объем IT-бюджета, как правило, не очень высоки.
Ситуация в корпоративном секторе или в гарантийном отделе поставщика (как раз наш случай) будет немного другой. Хорошему администратору совершенно не должно быть интересно, к примеру, значение SMART-атрибута Seek_Error_Rate на диске. Логика действий проста: получив информацию от RAID-контроллера о проблемах с диском, выкинуть его из массива и запустить ребилд на новый диск (эту процедуру можно и оптимизировать). Подробности сбоя и «нельзя ли как-нибудь его починить?» никого не интересуют — стоимость потери данных и/или возможного простоя просто не позволяют адекватному сотруднику тратить время на подобные вопросы.
И все же дальнейшая судьба сбойнувшего диска — диагностика. В ней может быть заинтересован либо владелец (например, с целью пристроить более-менее живой диск для каких-либо «небоевых» нужд) и, конечно, гарантийный отдел поставщика — при этом диски могут поступать не по 1-2, а десятками. А проверить нужно в ограниченные сроки, т.е. одновременно по нескольку штук, так что времени на последовательную проверку через MHDD, HDDScan, различные утилиты от производителей и format/verify средствами контроллера просто нет.
- Изначально разрабатывался под Linux, но на данный момент портирован на большое количество платформ, включая различные *BSD и Windows. Кстати, для тех, кто предпочитает GUI — под Linux/FreeBSD/Windows есть отличный фронтенд GSmartControl
- Выводит подробную информацию о диске, включая не только SMART-атрибуты (с расшифровкой многих нестандартных атрибутов), но и страницы с логами ошибок.
- Позволяет запускать поддерживаемые современными ATA и SCSI дисками внутренние тесты самодиагностики (short selftest и long selftest).
- Может работать как при прямом подключении диска, так и через различные USB и Firewire конвертеры. Версии под Linux и FreeBSD позволяют «достучаться» до дисков, подключенных к различным RAID контроллерам (3ware, Areca, HighPoint, HP Smart Array, LSI MegaRAID).
- Может выводить в удобочитаемом виде некоторые лог-страницы SCSI-дисков (к которым, естественно, относится и SAS) — что нам и нужно.
- sg_logs — выводит лог-страницы устройства в более подробном виде, чем smartctl. Пример вывода с разъяснениями будет ниже
- sg_format — выполняет форматирование диска. При очень большом желании можно изменить объем и даже размер сектора.
- sg_verify — выполняет недеструктивную проверку выбранных блоков командой SCSI VERIFY.
- sg_reassign — ручной ремап нужных блоков через SCSI-команду REASSIGN BLOCKS с помещением в Grown defect list
- sg_senddiag — отправка команд на запуск встроенных тестов (то же, что и smartctl —selftest для ATA дисков).
Проверяем
Пациент номер один: относительно 300ГБ старый U320-SCSI диск Fujitsu MAW3300NC. Подключаем и определяем, где его искать (через lsscsi или sg_scan). Далее можно посмотреть на вывод smartctl или sg_logs. Начнем со smartctl:
Примерно тоже можно было бы получить, запустив sg_logs -a, для SAS дисков — с добавкой в виде страницы Protocol Specific port log page for SAS SSP, где перечислены оба phy SAS диска (если он 2-портовыйСразу в глаза бросаются огромное количество ошибок чтения, большое кол-во ремапов (Elements in grown defect list) и предупреждение «SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]«. Последнее хранится на странице Informational exceptions в логах диска и говорит нам о том, что дальше его можно и не тестировать: алгоритм, заложенный в firmware уже сделал вывод о предсмертном состоянии диска по большому количеству ремапов.
Отличное от нуля значение счетчика Non-medium error count не всегда указывает на проблемы с диском. Было несколько случаев с SAS-дисками и контроллером Adaptec, когда причиной был некачественный noname кабель.
Можно еще немного помучить диск, запустив самодиагностику, например «длинный» фоновый тест:
Тест прерывается с ошибкой о найденных бэдах, о чем можно узнать, запустив
и посмотрев на соответствующую страницу:
Собственно, при помощи smartctl со SCSI/SAS дисками можно сделать то же, что при запуске sg_logs и sg_senddiag — посмотреть логи и запустить self-test’ы.
Следующий шаг — форматирование. Запускаем
При запуске с этими ключами badblocks совершит 4 пары проходов по диску, записывая и считывая различные паттерны. Занимает очень много времени (5,5 часов для этого диска и почти двое суток для 2ТБ диска).
Итак — 13 бэдов, снова смотрим в логи, видим растущее количество ремапов ошибок чтения. Для очистки совести можно запустить еще раз badblocks или внутренний тест и убедиться в том, что диск по-прежнему находится в совершенно плачевном состоянии. Можно его остановить перед отключением командой
Использование smartctl для проверки RAID контроллеров Adaptec под Linux
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
Или (более поздняя версия):
Примерный результат на фото:
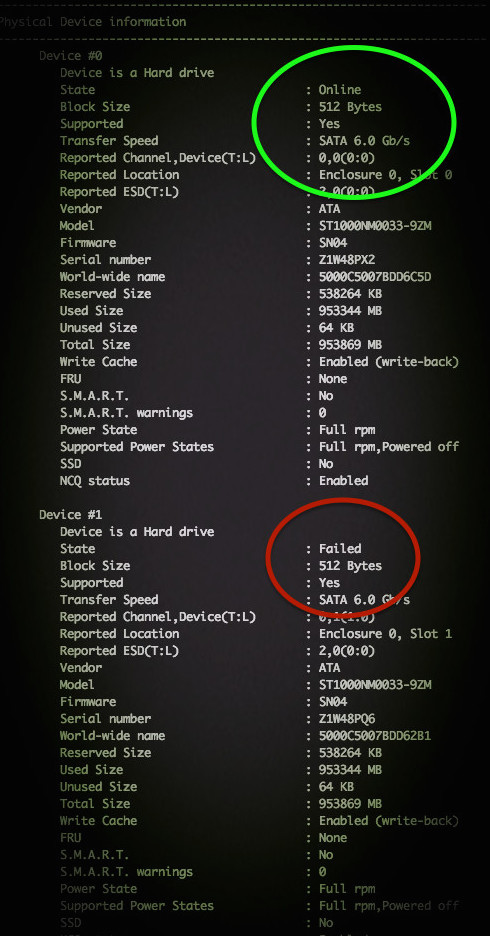
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Dmitryz
Параметры S.M.A.R.T. для SAS отличаются от SATA
Последнее может указывать на проблемы интерфейса (шлейф!), как и 199 у SATA/IDE.
Проверка диска только на чтение:
-s показывать проценты выполнения -v более подробно
Pass completed, 7 bad blocks found (7/0/0 errors)
Pass completed, 120 bad blocks found (0/0/120 errors)
its read/write/corruption errors. And corruption means comparison with previously written data
Посмотреть состояние дисков на контроллере Adaptec
Работает и на Windows, и на Linux. Должна быть установлена утилита командной строки для управления RAID контроллером Arcconf от Adaptec.
Посмотреть состояние дисков на контроллере в Linux
посмотреть какой у вас контроллер:
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg . Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
Команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Seagate ST373307lw и Medium error
Есть пара SCSI винтов — Seagate ST373307LW, которые были в рейде, один вылетел с пометкой Medium error. По хорошему бы заменить но нечем. Вопрос: как можно реанимировать винт с данной ошибкой с минимальными затратами?
Скажу сразу, да знаю, о китайской софтине, которая в один клик исправляет данную ошибку, но просят за нее 500$
Во-первых, наверное не «medium», а «media» error?
Во-вторых, «китайская софтина» это такой маленький китаец, который залезает внутрь диска и физически исправляет ошибки на поверхности блинов? Тогда 500$ что-то мало. Я бы и штуку отдал, чтобы на это посмотреть
А по сути — переформатируйте диск из BIOS обычного SCSI контроллера (или на вашем RAID-контроллере, если он это умеет (а большинство умеет)). Если ошибок не много, то поможет (и возможно даже еще несколько лет проживет).
Давайте Вы либо будете решать свои проблемы сами, либо не будете удивляться, если Вам дают правильные советы. Ваша замечательная китайская программа делает не сильно больше, чем дает форматирование диска на SCSI контроллере (просто она это делает несколько быстрее, так как заточена под определенную операцию).
Читайте также:
- Eve online что такое кбт
- Как летать на элитрах с помощью фейерверка в майнкрафт на телефоне
- Как выглядит джеки из brawl stars
- Как нарисовать крипера из майнкрафта
- Total war shogun 2 как играть по сети на пиратке
Содержание
- RAID array says «critical medium error» but smartctl says disk is healthy — what to do next?
- HDD error: print_req_error: critical medium error, dev sdb, sector 16128
- 1 Answer 1
- I/O error, dev sda, sector xxxxxxxxxx
- 3 Answers 3
- Linked
- Related
- Hot Network Questions
- Subscribe to RSS
- [жж] словил сбойные сектора на nvme ssd
- Transmission: Ошибка Unable to save resume file: Operation not supported
- Вопрос
- Виктор Илюхин
- Виктор Илюхин
RAID array says «critical medium error» but smartctl says disk is healthy — what to do next?
I have a RAID-1 array of SSDs (Samsung 970 EVO Plus), and errors are showing up in /var/log/syslog , but smartctl reports that the drive is healthy. I’ve done a bunch of diagnosis (below) and I’m wondering if there’s anything else I can do. Is there a problem happening or not, and if so, what’s the best course of action? (On Kubuntu 18.04.6 LTS.)
Here’s the array:
It appears healthy, according to mdadm :
However, some read errors have started appearing in /var/log/syslog , in triples:
sometimes followed by:
I ran smartctl to look for problems. It indicates that errors have happened in the past, but it also says «SMART overall-health self-assessment test result: PASSED.»
The two drives do not appear to support self-tests ( smartctl -c does not list any self tests at all).
Updating my question:
Some of the errors appear to be attributable to the checkarray script that runs once a month, because the errors begin «on the first Sunday of each month, at 01:06 in the morning». «man md» adds:
[On] RAID1 it is possible for software issues to cause a mismatch to be reported [between the two disks]. This does not necessarily mean that the data on the array is corrupted. It could simply be that the system does not care what is stored on that part of the array — it is unused space. The most likely cause for an unexpected mismatch on RAID1 or RAID10 occurs if a swap partition or swap file is stored on the array.
What should I do next? Thank you very much.
Источник
HDD error: print_req_error: critical medium error, dev sdb, sector 16128
I believe I have a USB hard drive that’s damaged. When I run dmesg , it shows:
I read this article that says you can forcibly reallocate bad sectors:
I’m lost with what to try next to access the data from this drive. Can anyone help?
SMART information below:
1 Answer 1
You have one or more bad sectors on your HDD, as seen by:
You need to fsck to check your file system, and then bad block your HDD.
fsck
- boot to a Ubuntu Live DVD/USB in “Try Ubuntu” mode
- open a terminal window by pressing Ctrl + Alt + T
- type sudo fdisk -l
- identify the /dev/sdXX device name for your «Linux Filesystem»
- type sudo fsck -f /dev/sdXX , replacing sdXX with the number you found earlier
- repeat the fsck command if there were errors
bad block
Note: do NOT abort a bad block scan!
Note: do NOT bad block a SSD
Note: backup your important files FIRST!
Note: this will take many hours
Note: you may have a pending HDD failure
Boot to a Ubuntu Live DVD/USB.
sudo fdisk -l # identify all «Linux Filesystem» partitions
sudo e2fsck -fcky /dev/sdXX # read-only test
sudo e2fsck -fccky /dev/sdXX # non-destructive read/write test (recommended)
The -k is important, because it saves the previous bad block table, and adds any new bad blocks to that table. Without -k, you loose all of the prior bad block information.
Источник
I/O error, dev sda, sector xxxxxxxxxx
My machine has crashed couple of times this week. Ran smartmontools test and got this result:
Can someone please let me know what this means? Should I replace my hard drive immediately?
Update: As landroni suggested, I ran short and extended self-tests using gsmartcontrol. Short self-test ran without throwing any errors. Extended test got aborted at 40% because of errors. Here is the the paste from self-test logs:
Update Ran badblocks using sudo badblocks -v /dev/sda > bad-blocks-result Result: Pass completed, 25 bad blocks found. (25/0/0 errors) What do I do now?
Output file indicates the following block numbers: 105877868 105877869 105877870 105877871 105877872 105877873 105877880 105877881 105877882 105877883 105877892 105877893 105877894 105877900 105877901 105877902 105877903 105877908 105877909 105877910 105877911 105877916 105877917 105877918 105877919
$ sudo dd if=/dev/sda of=/dev/null count=1 skip=201724230 [sudo] password for xxxxx: 1+0 records in 1+0 records out 512 bytes (512 B) copied, 1.64439 s, 0.3 kB/s xxxx@xxxx-yyyy:
$ sudo dd if=dev/sda of=/dev/null count=1 skip=201724230 dd: opening `dev/sda’: No such file or directory
3 Answers 3
Download gsmartcontrol (Hard disk drive and SSD health inspection tool) by typing in sudo apt install gsmartcontrol .
GSmartControl is a graphical user interface for smartctl (from smartmontools package), which is a tool for querying and controlling SMART (Self-Monitoring, Analysis, and Reporting Technology) data on modern hard disk and solid-state drives. It allows you to inspect the drive’s SMART data to determine its health, as well as run various tests on it.
- run a short self-test ;
- if it completes with no error, then run an extended self-test .
If this one is fine, too, then there is probably no reason to panic. If however, the tests detect some bad blocks, then you’ll possibly need to make a backup using ddrescue ASAP, and then attempt to understand what is wrong with your hard-drive. It may be failing, or there may be just a handful of irrelevant bad sectors.
Update: Given that only a handful of bad sectors seem to be present, you could try to tell the FS which ones it should avoid using fsck.ext3 -c . But do read man fsck.ext3 (assuming that this is your FS) before using it.
Looks like you disk is failing bad, I would backup my data as soon as possible and replace the failing disk.
I had a similar problem recently and smart reported 9 bad blocks. I booted from live media and then I repaired the ext4 filesystem with e2fsck -c /dev/SDx where SDx was the drive in question (sda in my case). which resulted in several short reads which I ignored and forced rewrites on and found and repaired 5 inodes with multiply-claimed blocks.
If the drive contains critical data you should of course utilize the correct strategy to back up the data before doing anything else. If not as in my case, read on. dmesg reported almost twice as many bad sectors as were found by SMART, so I then ran e2fsck -cc /dev/SDx where SDx was the drive in question in order to perform a non-destructive read/write test. This was a clearly time consuming process, however as my goal was just to squeeze a few more hours out of what is for all intents and purposes a «scratch drive» used for experimentation with no critical data on it, while I waited for the replacement drive to be delivered, I felt it might be worth the time. An hour later at 15% complete on a terabyte drive I wasn’t so certain but as the replacement was 3 days away, I persevered. In the end all the bad sectors were added to the bad block inode list which prevents them from being allocated to a file or directory.

Linked
Hot Network Questions
To subscribe to this RSS feed, copy and paste this URL into your RSS reader.
Site design / logo © 2023 Stack Exchange Inc; user contributions licensed under CC BY-SA . rev 2023.1.14.43159
By clicking “Accept all cookies”, you agree Stack Exchange can store cookies on your device and disclose information in accordance with our Cookie Policy.
Источник
[жж] словил сбойные сектора на nvme ssd
Дорогой Уважаемый ЛОР,
Я словил первое в своей жизни проявление сбойных секторов на SSD. Пациент — Samsung SSD 970 EVO 2TB с прошивкой 2B2QEXE7, в эксплуатации примерно год. Пару-тройку дней назад мне почему-то захотелось сделать копию вообще всех данных из домашней директории, включая файлы, которые легко скачать из сети при надобности. Некоторые из этих файлов лежали там с момента миграции на накопитель, без обращений. И при копировании одного из таких файлов программа сказала: «А я, кажись, чот не могу». После того, как потихоньку пришло осознание произошедшего, я глянул в лог и увидел там:
Что интересно, во второй раз файл успешно скопировался. Не знаю, прочитались там настоящие данные или мусор. К сожалению, вот этот конкретный файл повторно скачать оказалось неоткуда. Чтение данных с nvme0n1 по тому адресу выдало какие-то данные, не нули. Тут я решил, что SSD умный, что он понял, что страница не читается стабильно, и увёл её в чулан, на её место подставил новую, а данные всё-таки скопировал. Но на всякий случай решил запустить холостое чтение с блочного устройства. Сбойных блоков оказалось больше. Пробовал читать конкретные места. Зачастую чтение было успешным, но через много чтений всё же происходили ошибки. Попробовал перезаписать место с ошибками чтения теми же данными. Ошибки там прекратились.
В итоге сделал дамп через ddrescue, а потом записал этот дамп обратно. Последующие попытки прочитать накопитель целиком уже никаких ошибок не давали. Сижу вот теперь как на пороховой бочке. Пользоваться дальше немного боязно, но и выбрасывать накопитель, который вроде работает, как-то жалко.
За время тестов в логи свалилось 546 строк с «blk_update_request: critical medium error», но ошибки иногда сыпались так часто, что в сумме набралось 888 «callbacks suppressed». В статусе накопителя написано, что ошибок доступа к носителю было 1484. Так как в логи основной системы не попало происходившее на LiveUSB, можно считать, что числа сходятся. К сожалению, не помню, были ли там ошибки до недавних событий. Всего различных сбойных секторов было 167 штук.
В данных из плохих секторов нашлись обрывки Packages из Debian. Судя по версиям пакетов, эти куски из очень старых Packages, возможно ещё из 2016. Если это так, они приехали во время миграции на накопитель, и с тех пор не перезаписывались и не читались. Один кусок оказался очень похож на файл переводов и нашёлся в /usr/share/locale/gl/LC_MESSAGES/coreutils.mo , который конечно же ни разу не читался с момента последней переустановки пакета coreutils в начале августа 2019.
Терабайт тридцать-сорок я добавил чтением накопителя во время тестов.
Думаю, из произошедшего можно сделать, как минимум, следующие выводы:
- полгода без чтения страницы на SSD достаточно для последующих ошибок чтения;
- чтение такой страницы не заставляет SSD подменять страницу на новую, он с радостью выдаёт ошибку чтения на одном и том же месте много раз подряд;
- trim не означает очистку всех неиспользуемых блоков ФС, они же меньше страницы. Некоторые данные могут жить в закоулках годами;
- SSD желательно периодически прочёсывать чтением, чтобы словить сюрпризы пораньше;
- если такое происходит на TLC 3D V-NAND, страшно подумать, что будет на QLC.
Upd.
Узнал, что в NVMe есть фича 0x10, которая управляет температурами, при которых SSD должен начать тормозить для снижения нагрева. Правда для 970 EVO эти температуры дожны быть в диапазоне 80–82 °C, а попытка установить любые значения кроме 0 для фичи 0x10 завершаются неудачай.
Upd. 11 мая 2021, то есть примерно через год и два месяца после первого раза, появились новые ошибки чтения. При повторном чтении тех же мест ошибки повторялись, но через некоторое время пропали.
Upd. 5 июня 2021. Аккумулятор оказался вздут в той секции, что прилегает к SSD. Видимо, предупреждение о температурном лимите в 65°C на аккумуляторе написано не просто так.
Upd. 20 февраля 2022. Накопитель отправился на пенсию.
Источник
Transmission: Ошибка Unable to save resume file: Operation not supported

Спросил Виктор Илюхин,
11 марта, 2020
Вопрос
![]()
Виктор Илюхин
Виктор Илюхин
![]()
Доброго времени суток! Через некоторое время после добавления торрента выпадает ошибка — Unable to save resume file: Operation not supported, причем конкретной зависимости по времени выпадения ошибки, настроек клиента и интернет-центра не выявил. С чем это может быть связано?
Сохранение идет на внешний хард.
Transmission Версия:2.94. KeeneticOS: 3.3.12.
.thumb.png.651426dcabbdd36ee8a32bd1da421007.png)
Изменено 11 марта, 2020 пользователем Виктор Илюхин
Источник
Содержание
- Dmitryz
- S.M.A.R.T. и всё, что с этим связано (обновляется)
- Посмотреть состояние дисков на контроллере Adaptec
- Посмотреть состояние дисков на контроллере в Linux
- Использование smartctl для проверки RAID контроллеров Adaptec под Linux
- Распознает ли Linux контроллер Adaptec RAID?
- Загрузка и установка Adaptec Storage Manager для Linux
- Проверяем состояния SATA диска
- Использование Adaptec Storage Manager
- Adaptec 5805, проблемы с массивом
- Adaptec 5805, проблемы с массивом
- Medium errors adaptec что значит
Dmitryz
S.M.A.R.T. и всё, что с этим связано (обновляется)
S.M.A.R.T. — технология оценки состояния жёсткого диска, а также механизм предсказания времени выхода его из строя. Если S.M.A.R.T. говорит что все плохо — значит всё действительно плохо, если ничего не говорит — это еще ни о чем не говорит.
Параметры S.M.A.R.T. для SAS отличаются от SATA
Основные параметры, говорящие о проблемах — Current Drive Temperature, Elements in grown defect list, Total uncorrected errors, Non-medium error count.
Последнее может указывать на проблемы интерфейса (шлейф!), как и 199 у SATA/IDE.
Деструктивная проверка диска на badblock’и (уничтожит все данные на диске):
# badblocks -svw /dev/sdb
Проверка диска только на чтение:
# badblocks -sv /dev/sdb
-s показывать проценты выполнения -v более подробно
Pass completed, 7 bad blocks found (7/0/0 errors)
Pass completed, 120 bad blocks found (0/0/120 errors)
its read/write/corruption errors. And corruption means comparison with previously written data
Посмотреть всю информацию по диску:
# smartctl -a /dev/sdb
Vendor: FUJITSU
Product: MAW3300NC
Revision: 0104
User Capacity: 300,000,000,000 bytes [300 GB]
Logical block size: 512 bytes
Serial number: DA00P8B037VT
Device type: disk
Transport protocol: Parallel SCSI (SPI-4)
Local Time is: Fri Oct 14 16:35:21 2011 MSK
Device supports SMART and is Disabled
Temperature Warning Disabled or Not Supported
SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]
Current Drive Temperature: 26 C
Drive Trip Temperature: 65 C
Manufactured in week 45 of year 2008
Specified cycle count over device lifetime: 10000
Accumulated start-stop cycles: 8
Elements in grown defect list: 8191
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 39965378 3599 0 0 345061.500 3599
write: 0 9 0 0 0 45798.649 0
verify: 0 210 1 0 0 0.026 1
Non-medium error count: 25
No self-tests have been logged
Long (extended) Self Test duration: 6325 seconds [105.4 minutes]
Предупреждение «SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]» хранится на странице Informational exceptions в логах диска и говорит нам о том, что дальше его можно и не тестировать: алгоритм, заложенный в firmware уже сделал вывод о предсмертном состоянии диска по большому количеству ремапов.
Отличное от нуля значение счетчика Non-medium error count не всегда указывает на проблемы с диском. Было несколько случаев с SAS-дисками и контроллером Adaptec, когда причиной был некачественный noname кабель.
Почитать
Посмотреть состояние дисков на контроллере Adaptec
Работает и на Windows, и на Linux. Должна быть установлена утилита командной строки для управления RAID контроллером Arcconf от Adaptec.
Посмотреть состояние дисков на контроллере в Linux
посмотреть какой у вас контроллер:
# lspci | egrep -i ‘raid|adaptec’
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg <1,2,3,4>. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
Команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Источник
Использование smartctl для проверки RAID контроллеров Adaptec под Linux
Команду «smartctl -d ata -a /dev/sdb» можно использовать для проверки жесткого диска и текущего состояния его соединения с системой. Но как с помощью команд smartctl проверить SAS или SCSI диски, спрятанные за RAID контроллером Adaptec в системах под управлением Linux ОС? Для этого необходимо использовать последовательные синтаксисы проверки SAS или SATA. Как правило — это логические диски для каждого массива физических накопителей в операционной системы. Команду /dev/sgX возможно использовать в качестве перехода через контроллеры ввода/вывода, которые обеспечиваюь прямой доступ к каждому физическому диску, подключенному к RAID контроллеру Adaptec.

Распознает ли Linux контроллер Adaptec RAID?
Для проверки Вы можете использовать следующую команду:
В результате выполнения команды получите следующее:
Загрузка и установка Adaptec Storage Manager для Linux
Необходимо установить Adaptec Storage Manager в соответсвии собранному дисковому массиву.
Проверяем состояния SATA диска
Команда для сканирования накопителя выглядит довольно просто:
В результате у Вас должно получится следующее:
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg <1,2,3,4>. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
Для SAS диск используют следующий синтаксис:
В результате получим что то похожее на:
А вот команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
Проверить жесткий диск можно с помощью следующих команд:
Использование Adaptec Storage Manager
Другие простые команды для проверки базового состояния выглядят следующим образом:
Обратите внимание на то, что более новая версия arcconf расположена в архиве /usr/Adaptec_Event_Monitor. Таким образом, весь путь должен выглядеть так:
Вы можете самостоятельно проверить состояние массива Adaptec RAID на Linux с помощью ввода простой команды:
# /usr/Adaptec_Event_Monitor/arcconf getconfig 1
Или (более поздняя версия):
Примерный результат на фото:
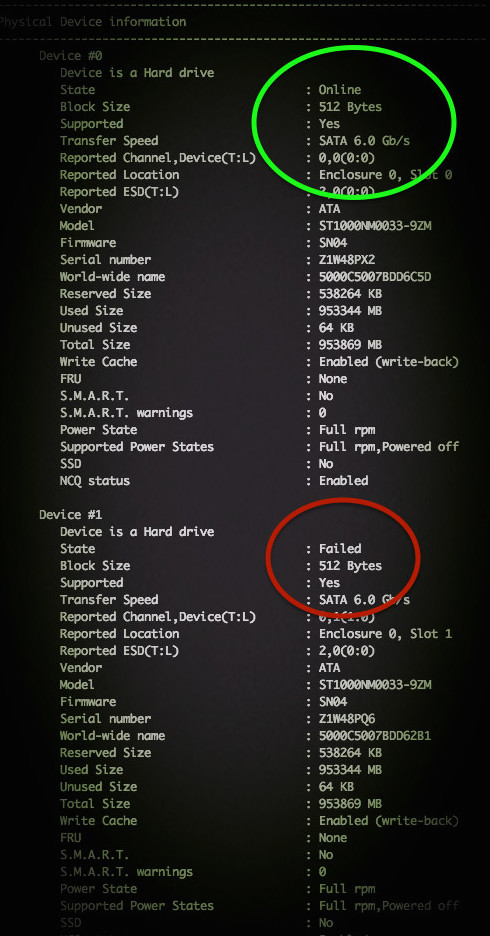
По традиции, немного рекламы в подвале, где она никому не помешает. Напоминаем, что в связи с тем, что общая емкость сети нидерландского дата-центра, в котором мы предоставляем услуги, достигла значения 5 Тбит / с (58 точек присутствия, включения в 36 точек обмена, более, чем в 20 странах и 4213 пиринговых включений), мы предлагаем выделенные серверы в аренду по невероятно низким ценам, только неделю!.
Источник
Adaptec 5805, проблемы с массивом
Adaptec 5805, проблемы с массивом
Сообщение jeff » 12 апр 2012, 15:01
Имеем рейд-контроллер Adaptec 5805, на котором у нас создано 3 логических массива — Raid5EE, Raid5EE и Raid1. Так же имеются 2 global hotspare диска.
Сегодня заметили, что на втором Raid5EE-массиве (состоит из шести дисков Seagate ST31000340NS) один из дисков появился с иконкой ! (при этом диск находится в состоянии Optimal) и рейд-массив перешел в состояние Degraded. Сами диски при этом, включая сбойный диск, показываются в Adaptec Storage Manager как Optimal. При этом на сбойном диске в «Статусе» 10 medium error и 271 aborted commands. Функции контекстного меню, чтобы выполнить Fix для массива или дисков массива недоступны. Так же ни один из дисков массива нельзя отметить как Failed, эти функции недоступны.
Что было сделано:
1. «Испорченный» диск был проинициализирован, после чего перешел в состояние Ready. Хотспейр диски для ребилда при этом не подхватились, массив так же находится в состоянии Degraded.
2. Пробовали назначить проинициализированный «испорченный» диск как dedicated hotspare для этого массива — тоже самое, массив не ребилдится.
3. Пометили этот диск как failed
Через Adaptec Storage Manager скачали support-archive. В нём, несмотря на неправильное время, видно, что после манипуляций с «испорченным» диском начался ранее прерваный процесс ребилда и некий процесс «компакт». Вот информация из лога (файл лога прикладываю к письму):
April 12, 2012 10:32:36 AM CEST INF sds Previously interrupted rebuild of a RAID-5 set restarted the build operation: controller 1, logical device 1
April 12, 2012 10:32:36 AM CEST INF sds Container changed: controller 1, logical device 1
April 12, 2012 10:32:51 AM CEST INF 358:A01C-S—L01 sds Compaction preempted: controller 1, logical device 1 («R5EE-2»).
April 12, 2012 10:33:04 AM CEST INF sds Running: Compact logical disk — 0%. Controller 1, logical device 1
и теперь приблизительно раз в 10-15 минут появляется строчка:
April 12, 2012 12:13:31 PM CEST INF sds Running: Compact logical disk — 0%. Controller 1, logical device 1
April 12, 2012 12:30:59 PM CEST INF sds Running: Compact logical disk — 0%. Controller 1, logical device 1
April 12, 2012 12:39:30 PM CEST INF sds Running: Compact logical disk — 0%. Controller 1, logical device 1
Может быть Вы сможете подсказать, что это за процесс «Compact logical disk» ? И как узнать, действительно ли запущен ребилд (adaptec storage manager не показывает) ? Ну и собственно как безболезненно решить проблему и перевести рейд-массив в состояние Optimal ?
Источник
Medium errors adaptec что значит
Часто задаваемый вопрос: «есть ли у SAS-дисков SMART и как его посмотреть?»
Да, в некотором виде есть, в виде лог-страниц с различной полезной информацией. В статье будет рассказано о том, как эту информацию получить и интерпретировать.
Хочется подчеркнуть что, речь ниже пойдет не о домашних пользователях, для которых регулярная проверка здоровья и производительности родного железа может быть чем-то вроде хобби. Да и в случае появления признаков неисправности на том же HDD первой мыслью будет не «немедленно списать и заменить», а «сколько он еще протянет и нельзя ли как-нибудь его починить?». Такой подход вполне имеет право на жизнь, ведь ценность «домашних» данных и объем IT-бюджета, как правило, не очень высоки.
Ситуация в корпоративном секторе или в гарантийном отделе поставщика (как раз наш случай) будет немного другой. Хорошему администратору совершенно не должно быть интересно, к примеру, значение SMART-атрибута Seek_Error_Rate на диске. Логика действий проста: получив информацию от RAID-контроллера о проблемах с диском, выкинуть его из массива и запустить ребилд на новый диск (эту процедуру можно и оптимизировать). Подробности сбоя и «нельзя ли как-нибудь его починить?» никого не интересуют — стоимость потери данных и/или возможного простоя просто не позволяют адекватному сотруднику тратить время на подобные вопросы.
И все же дальнейшая судьба сбойнувшего диска — диагностика. В ней может быть заинтересован либо владелец (например, с целью пристроить более-менее живой диск для каких-либо «небоевых» нужд) и, конечно, гарантийный отдел поставщика — при этом диски могут поступать не по 1-2, а десятками. А проверить нужно в ограниченные сроки, т.е. одновременно по нескольку штук, так что времени на последовательную проверку через MHDD, HDDScan, различные утилиты от производителей и format/verify средствами контроллера просто нет.
Софт
И так — диагностика. Алгоритм простой — смотрим нужные счетчики, отправляем диск на форматирование, проверяем поверхность, снова смотрим счетчики на предмет роста ошибок. Для начала желательно собрать о «пациенте» побольше сведений. IMHO, лучший инструмент для этого — пакет smartmontools (в состав которого входит утилита smartctl):
- Изначально разрабатывался под Linux, но на данный момент портирован на большое количество платформ, включая различные *BSD и Windows. Кстати, для тех, кто предпочитает GUI — под Linux/FreeBSD/Windows есть отличный фронтенд GSmartControl
- Выводит подробную информацию о диске, включая не только SMART-атрибуты (с расшифровкой многих нестандартных атрибутов), но и страницы с логами ошибок.
- Позволяет запускать поддерживаемые современными ATA и SCSI дисками внутренние тесты самодиагностики (short selftest и long selftest).
- Может работать как при прямом подключении диска, так и через различные USB и Firewire конвертеры. Версии под Linux и FreeBSD позволяют «достучаться» до дисков, подключенных к различным RAID контроллерам (3ware, Areca, HighPoint, HP Smart Array, LSI MegaRAID).
- Может выводить в удобочитаемом виде некоторые лог-страницы SCSI-дисков (к которым, естественно, относится и SAS) — что нам и нужно.
Инструмент номер два — пакет sg3_utils, набор утилит для работы со SCSI-устройствами. Пакет портирован под большое количество ОС, включая Windows. Во многих дистрибутивах Linux присутствует устаревшая на 1-2 года версия, но последнюю легко собрать из исходников. Для наших задач представляют ценность следующие утилиты:
- sg_logs — выводит лог-страницы устройства в более подробном виде, чем smartctl. Пример вывода с разъяснениями будет ниже
- sg_format — выполняет форматирование диска. При очень большом желании можно изменить объем и даже размер сектора.
- sg_verify — выполняет недеструктивную проверку выбранных блоков командой SCSI VERIFY.
- sg_reassign — ручной ремап нужных блоков через SCSI-команду REASSIGN BLOCKS с помещением в Grown defect list
- sg_senddiag — отправка команд на запуск встроенных тестов (то же, что и smartctl —selftest для ATA дисков).
Оборудование и ОС
В качестве оборудования подойдет любой SAS HBA, т.е. простой контроллер, без аппаратного RAID или с отключаемым хост-RAID’ом. В TrueSystem используются LSI 9211 или набортные контроллеры на базе чипов LSI 2008 или 1068E (с IT-прошивкой). Изредка в гарантию попадают диски под параллельный SCSI, на этот случай под рукой есть Adaptec AHA2930 и переходник с 68pin на SCA.
Операционная система — вопрос личных предпочтений. Вышеуказанные утилиты имеют порт под Windows, но в Linux с ними работать чуть удобнее. При параллельном тестировании множества дисков возникает проблема неудобства множества консольных сессий. Решение для Windows — терминал Console, для Linux/FreeBSD показался удобным удаленный доступ через SSH (если с Windows — через PuTTY) и запуск в SSH-сессии консольного менеджера screen.
Проверяем
Пациент номер один: относительно 300ГБ старый U320-SCSI диск Fujitsu MAW3300NC. Подключаем и определяем, где его искать (через lsscsi или sg_scan). Далее можно посмотреть на вывод smartctl или sg_logs. Начнем со smartctl:
Источник
S.M.A.R.T. — технология оценки состояния жёсткого диска, а также механизм предсказания времени выхода его из строя. Если S.M.A.R.T. говорит что все плохо — значит всё действительно плохо, если ничего не говорит — это еще ни о чем не говорит.
Параметры S.M.A.R.T. для SAS отличаются от SATA
SAS
Основные параметры, говорящие о проблемах — Current Drive Temperature, Elements in grown defect list, Total uncorrected errors, Non-medium error count.
Последнее может указывать на проблемы интерфейса (шлейф!), как и 199 у SATA/IDE.
Деструктивная проверка диска на badblock’и (уничтожит все данные на диске):
# badblocks -svw /dev/sdb
Проверка диска только на чтение:
# badblocks -sv /dev/sdb
-s показывать проценты выполнения -v более подробно
Вывод badblocks:
Pass completed, 7 bad blocks found (7/0/0 errors)
Pass completed, 120 bad blocks found (0/0/120 errors)
its read/write/corruption errors. And corruption means comparison with previously written data
Посмотреть всю информацию по диску:
# smartctl -a /dev/sdb
Vendor: FUJITSU
Product: MAW3300NC
Revision: 0104
User Capacity: 300,000,000,000 bytes [300 GB]
Logical block size: 512 bytes
Serial number: DA00P8B037VT
Device type: disk
Transport protocol: Parallel SCSI (SPI-4)
Local Time is: Fri Oct 14 16:35:21 2011 MSK
Device supports SMART and is Disabled
Temperature Warning Disabled or Not Supported
SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]Current Drive Temperature: 26 C
Drive Trip Temperature: 65 C
Manufactured in week 45 of year 2008
Specified cycle count over device lifetime: 10000
Accumulated start-stop cycles: 8Elements in grown defect list: 8191
Error counter log:
Errors Corrected by Total Correction Gigabytes Total
ECC rereads/ errors algorithm processed uncorrected
fast | delayed rewrites corrected invocations [10^9 bytes] errors
read: 0 39965378 3599 0 0 345061.500 3599
write: 0 9 0 0 0 45798.649 0
verify: 0 210 1 0 0 0.026 1Non-medium error count: 25
No self-tests have been logged
Long (extended) Self Test duration: 6325 seconds [105.4 minutes]
Предупреждение «SMART Health Status: FIRMWARE IMPENDING FAILURE TOO MANY BLOCK REASSIGNS [asc=5d, ascq=64]» хранится на странице Informational exceptions в логах диска и говорит нам о том, что дальше его можно и не тестировать: алгоритм, заложенный в firmware уже сделал вывод о предсмертном состоянии диска по большому количеству ремапов.
Отличное от нуля значение счетчика Non-medium error count не всегда указывает на проблемы с диском. Было несколько случаев с SAS-дисками и контроллером Adaptec, когда причиной был некачественный noname кабель.
Почитать
Посмотреть состояние дисков на контроллере Adaptec
Работает и на Windows, и на Linux. Должна быть установлена утилита командной строки для управления RAID контроллером Arcconf от Adaptec.
# arcconf getconfig 1
Посмотреть состояние дисков на контроллере в Linux
посмотреть какой у вас контроллер:
# lspci | egrep -i 'raid|adaptec'
Команда для сканирования накопителя выглядит довольно просто:
# smartctl --scan
В результате у Вас должно получится следующее:
/dev/sda -d scsi # /dev/sda, SCSI device
Таким образом, /dev/sda — это одно устройство, которое было определено как SCSI устройство. Выходит, что у нас SCSI собран из 4 дисков, расположенных в /dev/sg {1,2,3,4}. Введите следующую smartclt команду, чтобы проверить диск позади массива /dev/sda:
# smartctl -d sat --all /dev/sgX
# smartctl -d sat --all /dev/sg1
Контроллер должен сообщать о состоянии накопителя и уведомлять про ошибки (если такие имеются):
# smartctl -d sat --all /dev/sg1 -H
Для SAS диск используют следующий синтаксис:
# smartctl -d scsi --all /dev/sgX
# smartctl -d scsi --all /dev/sg1
### Ask the device to report its SMART health status or pending TapeAlert message ###
# smartctl -d scsi --all /dev/sg1 -H
Команда для проверки следующего диска с интерфейсом SAS, названного /dev/sg2:
# smartctl -d scsi --all /dev/sg2 -H
В /dev/sg1 заменяется номер диска. Например, если это RAID10 из 4-х дисков, то будет выглядеть так:
/dev/sg0 - RAID 10 контроллер.
/dev/sg1 - Первый диск в массиве RAID 10.
/dev/sg2 - Второй диск в массиве RAID 10.
/dev/sg3 - Третий диск в массиве RAID 10.
/dev/sg4 - Четвертый диск в массиве RAID 10.
Проверить жесткий диск можно с помощью следующих команд:
# smartctl -t short -d scsi /dev/sg2
# smartctl -t long -d scsi /dev/sg2
Где,
-t short : Запуск быстрого теста.
-t long : Запуск полного теста.
-d scsi : Указывает scsi, как тип устройства.
--all : Отображает всю SMART информацию для устройства.