Last updated July 22, 2022
Table of Contents
- Why memory errors matter
- Detecting a problem
- How Ruby memory works
- Ruby 2.0 upgrade
- Memory leaks
- Too many workers
- Forking behavior of Puma worker processes
- Too much memory used at runtime
- GC tuning
- Excess memory use due to malloc in a multi-threaded environment
- Dyno size and performance
- Additional resources
When your Ruby application uses more memory than is available on the Dyno, a R14 — Memory quota exceeded error message will be emitted to your application’s logs. This article is intended to help you understand your application’s memory use and give you the tools to run your application without memory errors.
Why memory errors matter
If you’re getting R14 — Memory quota exceeded errors, it means your application is using swap memory. Swap uses the disk to store memory instead of RAM. Disk speed is significantly slower than RAM, so page access time is greatly increased. This leads to a significant degradation in application performance. An application that is swapping will be much slower than one that is not. No one wants a slow application, so getting rid of R14 Memory quota exceeded errors on your application is very important.
Detecting a problem
Since you’re reading this article it’s likely you already spotted a problem. If not, you can view your last 24 hours of memory use by using Application Metrics on your app’s dashboard. Alternatively, you can check your logs where you will occasionally see the error emitted:
2011-05-03T17:40:11+00:00 heroku[worker.1]: Error R14 (Memory quota exceeded)
How Ruby memory works
It can help to understand how Ruby consumes memory to be able to decrease your memory usage. For more information, see How Ruby Uses Memory and Why does my App’s Memory Use Grow Over Time?.
Ruby 2.0 upgrade
Upgrading from Ruby 2.0 to 2.1+ introduced generational garbage collection. This means that Ruby 2.1+ applications should run faster, but also use more memory. We always recommend you run the latest released Ruby version, it will have the latest security, bugfix, and performance patches.
If you see a slight increase in memory, you can use the techniques below to decrease your usage to an acceptable level.
Memory leaks
A memory leak is defined as memory increasing indefinitely over time. Most applications that have memory problems are defined as having a “memory leak” however if you let those applications run for a long enough period of time, the memory use will level out.
If you believe your application has a memory leak you can test this out. First make sure you can run dynamic benchmarks with derailed. Then you can benchmark RAM use over time to determine if your app is experiencing a memory leak.
Too many workers
Modern Ruby webservers such as Puma allow you to serve requests to your users via concurrent processes. In Puma these are referred to as “worker” processes. In general increasing your workers will increase your throughput, but it will also increase your RAM use. You want to maximize the number of Puma workers that you are using without going over your RAM limit and causing your application to swap.
Too many workers at boot
If your application immediately starts to throw R14 errors as soon as it boots it may be due to setting too many workers. You can potentially fix this by setting your WEB_CONCURRENCY config var to a lower value.
For example if you have this in your config/puma.rb file:
# config/puma.rb
workers Integer(ENV['WEB_CONCURRENCY'] || 2)
You can lower your worker count
$ heroku config:set WEB_CONCURRENCY=1
For some applications two Puma workers will cause you to use more RAM than a standard-1x dyno can provide. You can still achieve increased throughput with threads when this happens. Alternatively you can upgrade dyno size to run more workers.
Too many workers over time
Your application’s memory use will increase over time. If it starts out fine, but gradually increases to be above your RAM limit, there are a few things you can try. If you quickly hit the limit, you likely want to decrease your total number of Puma workers. If it takes hours before you hit the limit, there is a bandaid you can try called Puma Worker Killer.
Puma worker killer allows you to set up a rolling worker restart of your Puma workers. The idea is that you want to figure out at what interval your application begins using too much memory. You will then schedule your application to restart your workers at that interval. When you restart a process, the memory use goes back to it’s original lower levels. Even if the memory is still growing it won’t cause problems for another few hours, where we would have another restart scheduled.
To use this gem add it to your Gemfile:
gem "puma_worker_killer"
Then $ bundle install and add this to an initializer such as config/initializers/puma_worker_killer.rb
PumaWorkerKiller.enable_rolling_restart
It’s important to note that this won’t actually fix any memory problems, but instead will cover them up. When your workers restart they cannot serve requests for a few seconds, so when the rolling restarts are triggered your end users may experience a slow down as your overall application’s throughput is decreased. Once restarts are done, throughput should go back to normal.
It is highly recommended that you only use Puma Worker Killer as a stop gap measure until you can identify and fix the memory problem. Several suggestions are covered below.
Forking behavior of Puma worker processes
Puma implements its worker processes via forking. When you fork a program, you copy a running program into a new process and then make changes instead of starting with a blank process. Most modern operating systems allow for memory to be shared between processes in a concept called “copy on write”. When Puma spins up a new worker, it requires very little memory, only when Puma needs to modify or “write” to memory does it copy a memory location from one process to another. Modern Ruby versions are optimized to be copy on write “friendly”, that is they do not write to memory unnecessarily. This means when Puma spins up a new worker it is likely smaller than the one before it. You can observe this behavior locally on Activity Monitor on a Mac or via ps on Linux. There will be a large process consuming a lot of memory, and then smaller processes. So if Puma with one worker was consuming 300 MB of RAM then using two workers would likely consume less than 600 MB of RAM total.
Too much memory on boot
A common cause of memory use is due to libraries being required in a Gemfile but not used. You can see how much memory your gems use at boot time through the derailed benchmark gem.
First add the gem to your Gemfile:
gem 'derailed', group: :development
Now $ bundle install and you’re ready to investigate memory use. You can run:
$ bundle exec derailed bundle:mem
This will output the memory use of each of your gems as they are required into memory:
$ derailed bundle:mem
TOP: 54.1836 MiB
mail: 18.9688 MiB
mime/types: 17.4453 MiB
mail/field: 0.4023 MiB
mail/message: 0.3906 MiB
action_view/view_paths: 0.4453 MiB
action_view/base: 0.4336 MiB
Remove any libraries you aren’t using. If you see a library using an unusually large amount of memory, try to upgrade to the latest version to see if any issues have been fixed. If the problem persists, open an issue with the library maintainer to see if there is something that can be done to decrease require time memory. To help with this process you can use $ bundle exec derailed bundle:objects. See Objects created at Require time
in derailed benchmarks for more information.
Too much memory used at runtime
If you’ve cleaned out your unused gems, and you’re still seeing too much memory use, there may be code generating excessive amounts of Ruby objects. It is possible to use a runtime tool such as the Heroku Add-on Scout. Scout published a guide on debugging runtime memory use.
If you don’t use use a tool that can track object allocations at runtime, you can try to reproduce this memory increasing behavior locally with derailed benchmarks by reproducing the allocations locally.
GC tuning
Every application behaves differently so there is no one correct set of GC (garbage collector) values that we can recommend.
When it comes to memory utilization you can control how fast Ruby allocates memory by setting RUBY_GC_HEAP_GROWTH_FACTOR. This value is different for different versions of Ruby. To understand how it works it is helpful to first understand how Ruby uses memory.
When Ruby runs out of memory and cannot free up any slots via the garbage collector, it has to tell the operating system it needs more memory. Asking the operating system for memory is an expensive (slow) process, so Ruby wants to always ask for a little more than it needs. You can control how much memory it asks for by setting this RUBY_GC_HEAP_GROWTH_FACTOR config var. For example, if you wanted your application to grow by 3% every time memory was allocated you could set:
$ heroku config:set RUBY_GC_HEAP_GROWTH_FACTOR=1.03
So if your application is 100 MB in size and it needs extra memory to function, with this setting it would ask the OS for 3 MB of RAM extra. This would bring the total amount of memory that Ruby can use to 103 MB. If your memory is growing too quickly try setting this value to smaller numbers. Keep in mind that setting too low of a value can cause Ruby to spend a large amount of time asking the OS for memory.
Generally, tuning RUBY_GC_HEAP_GROWTH_FACTOR will only help with R14 errors if you are barely over your dyno memory limits. Or if you’re seeing extremely large “stair-step” memory allocations after your application has been running for several hours. Individual apps are responsible for setting and maintaining their own GC tuning configuration variables.
Excess memory use due to malloc in a multi-threaded environment
Applications created after September of 2019 will have the environment variable MALLOC_ARENA_MAX=2 set.
The behavior of malloc in a multi-threaded environment can drastically increase memory use.
To work around this malloc behavior, an alternative memory allocator such as jemalloc can be used to replace malloc. To replace malloc on Heroku with jemalloc you can use a third party jemalloc buildpack.
Alternatively, if you don’t want to use a third-party buildpack, it is possible to tune the behavior of glibc memory behavior so that it will consume less memory. However, this approach may impact the performance of the application.
Dyno size and performance
Dynos come in two types, standard dynos which run on a shared infrastructure, and performance dynos which consume an entire runtime instance. When you increase your dyno size you increase the amount of memory you can consume. If your application cannot serve two or more requests concurrently it is subject to request queueing. Ideally, your application should be running in a dyno that allows it to run at least two Puma worker processes. As stated before, additional Puma worker processes consume less RAM than the first process. You may be able to keep application spend the same by upgrading to a larger dyno size, doubling your worker count but using only half the number of total dynos.
While this article is primarily about memory, its focus is speed. On that topic, it is important to highlight that since performance dynos are isolated from “noisy neighbors” they will see much more consistent performance. Most applications perform significantly better when run on performance dynos.
Additional resources
- Why does my App’s Memory Use Grow Over Time? — Start here, a good high level overview of what causes a system’s memory to grow that will help you develop an understanding of how Ruby allocates and uses memory at the application level.
- Complete Guide to Rails Performance (Book) — This book is by Nate Berkopec is highly regarded.
- How Ruby uses memory — This is a lower-level look at precisely what “retained” and “allocated” memory means. It uses small scripts to demonstrate Ruby memory behavior. It also explains why our system’s “total max” memory rarely goes down.
- How Ruby uses memory (Video) — If you’re new to the concepts of object allocation, this might be an excellent place to start (you can skip the first story in the video, the rest are about memory). Memory explanations start at 13 minutes
- Debugging a memory leak on Heroku — It’s probably not a leak. Still worth reading to see how you can come to the same conclusions yourself. Content is valid for environments other than Heroku. Lots of examples of using the tool
derailed_benchmarks. - The Life-Changing Magic of Tidying Active Record Allocations (Blog + Video) — This post shows how tools were used to track down and eliminate memory allocations in real life. All of the examples are from patches submitted to Rails, but the process works the same for finding allocations caused by your application logic.
- N+1 Queries or Memory Problems: Why not Solve Both? — Goes through a tricky real-world scenario from 2017 where an N+1 query was killing performance, but using “eager loading” used too much memory. The app had to re-work the flow of the code to extract the data that was needed while avoiding extra memory allocations.
- Jumping off the Ruby Memory Cliff — Sometimes, you might see a ‘cliff’ in your memory metrics or a saw-tooth pattern. This article explores why that behavior exists and what it means.
Содержание
- Constant R14 Memory Quota Exceeded with basic Spring Boot application #41
- Comments
- Fighting the Heroku `Error R14 (Memory quota exceeded)` issue.
- Know Your Enemy
- Fix the ForkJoinPool size
- Slick numThreads
- Serialize large Json array
- Use what you’ve got
- Use G1 garbage collector
- Full GC on application starts ?
- Categories
- Table of Contents
- H10 — App crashed
- H11 — Backlog too deep
- H12 — Request timeout
- H13 — Connection closed without response
- H14 — No web dynos running
- H15 — Idle connection
- H16 — (No Longer in Use)
- H17 — Poorly formatted HTTP response
- H18 — Server Request Interrupted
- H19 — Backend connection timeout
- H20 — App boot timeout
- H21 — Backend connection refused
- H22 — Connection limit reached
- H23 — Endpoint misconfigured
- H24 — Forced close
- H25 — HTTP Restriction
- Invalid content length
- Oversized cookies
- Oversized header
- Oversized status line
- H26 — Request Error
- Unsupported expect header value
- Bad header
- Bad chunk
- H27 — Client Request Interrupted
- H28 — Client Connection Idle
- H31 — Misdirected Request
- H80 — Maintenance mode
- H81 — Blank app
- H82 — You’ve used up your dyno hour pool
- H83 — Planned Service Degradation
- H99 — Platform error
- R10 — Boot timeout
- R12 — Exit timeout
- R13 — Attach error
- R14 — Memory quota exceeded
- R15 — Memory quota vastly exceeded
- R16 — Detached
- R17 — Checksum error
- R99 — Platform error
- L10 — Drain buffer overflow
- L11 — Tail buffer overflow
- L12 — Local buffer overflow
- L13 — Local delivery error
- L14 — Certificate validation error
- L15 — Tail buffer temporarily unavailable
Constant R14 Memory Quota Exceeded with basic Spring Boot application #41
I have a basic Spring Boot application deployed on a hobby tier Heroku instance and it’s been throwing R14 Memory Quote Exceeded near constantly. The application is literally a couple REST endpoints connecting to a database.
I’ve been trying to track this down for a some number of hours across a few days now and don’t seem much closer to a solution. I have turned on Enhanced Language Metrics and see the following 

My application is started via java -Dserver.port=$PORT $JAVA_OPTS -jar build/libs/*.jar .
Based on https://devcenter.heroku.com/articles/java-memory-issues#configuring-nativememorytracking, I have JAVA_OPTS set to -Xms256m -Xmx256m -Xss512k -XX:NativeMemoryTracking=detail -XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics in the config vars.
The issue metabase/metabase-deploy#5 and metabase/metabase#3360 make me suspect I’m not the only one having trouble tuning the JVM to run below the 512 MB limit for these Heroku dynos.
Does anyone have more information or suggestions to reduce the memory footprint? It’s a little unnerving to see the application consume so much memory for minimal functionality.
The text was updated successfully, but these errors were encountered:
Источник
Fighting the Heroku `Error R14 (Memory quota exceeded)` issue.
I was trying to implement a feature for my play-scala application running on Heroku, which would require serving a large json result (around 2.5mb) to client. Not before long, I saw the R14 error being displayed in the logs.
Oh, I know Heroku free tier has only 512mb, but I seriously think it’s something I need to address.
Know Your Enemy
It only makes sense to put efforts on the correct direction. We need to know what’s causing the issue first.
First, use the below to enable log metrics.
The log metrics will constantly print log message like the below.
Among all, I’m more concerned about the memory_total. So long as the number exceeds memory_quota, R14 will be raised and your application will start using swap.
Wait, isn’t Heroku configured default mx (maximum heap size) to be 300mb ? How is this possible my application used more than 512mb of memory ?
Well, heap memory isn’t everything. There’re metaspace and the other non heap memory used by JVM. Take metaspace for example, this was introduced in Java 8, and the default is your virtual memory. If you don’t set a limit, it may grow beyond what physical memory you have.
The above does’t provide much insights, more like a confirmation of the truth. We shall continue on our discovery. Let’s install Heroku’s java debug plugin.
This give you access to the below command
jconsole provides good visual overview on what’s been used. Take a good look at the loaded classes. If the number doesn’t stop growing, you may be having class memory leak that could possibly be caused by dynamic proxy. Set something like -XX:MaxPermSize=128m to make sure it doesn’t grow too high.
My observation shows the number of loaded classes is rather stable after multiple loads of the problematic API. I’m leaving the default for the moment.
jmap is also very handy as it can be used to get the detailed heap usage, so that you know, which class uses the most memory. It can also used to extract heap dump and download it to local. You may later analyzed it with eclipse MAT.
It does tell me something very important.
Fix the ForkJoinPool size
In my case, the first issue that pops up is, I’ve got tons of ForkJoinTask created. It’s so many that it ranked first on the jmap class list by bytes. Being reactive means we’d need to create a lot of Futures in the codes. But probably it becomes too many. Something was wrong.
It turns out I’ve used my testing parameter for deploy to Heroku.
My dyno runs on a virtual machine with 8 cores. The above means, my pool is created with 64 threads, and may grow up to 200 threads. Given I’ve more than one pool, This is certainly too high. No wonder jconsole show my active thread to be 70+. After some tuning, it was now sub 40 on average.
Slick numThreads
I also found I’ve got 20 slick threads, which means slick may use 20 connections simultaneously. This is the default, but may not be very realistic on Heroku, especially when you’re on free tier + free postgresql, where 20 is the connection limit. I bet you’ll want to keep a few for your database tool. Consult the hikariCp wiki for guidance on how to configure the pool size.
Once you decided the size, configure the numThreads in your application.conf. I choose to use 16.
Serialize large Json array
The dominating issue is, of course, loading the large json objects and serialize them in memory. This is hardly something configuration can help. We’ll have to use streaming API.
Since Play 2.6, the framework started to support Akka Http. Akka Http comes with a nice feature, akka-streams. I’m rewriting my API to use this. It’s not a big deal, but I guess it will have to become a second story.
Use what you’ve got
I’ve tuned quite a few so far, but I’ve noticed that the JVM is reluctant to perform a full GC even when nobody is using the application. If I’ve got a R14, the usage wasn’t reduced overnight. This leads me to think, does the JVM really knows how much memory we’ve got ?
I re-read the Heroku JVM tuning article and realize, the JVM might be mis-lead because we’re running in a container. When you use heroku ps:exec to run top , you’ll find the host has big memory, not just 512mb. JVM must be confused about it.
You need to add the below to your JAVA_TOOL_OPTIONS if you’re on JDK 8
For JDK 9, use the below
As a matter fact, this is the first thing you should do. I’ve no idea why I skipped this. To be honest, I think this should be the default options for ALL java application on Heroku.
I have also tried the below, which may be helpful to improve the overall memory usage. But they lack the theory to support them, so they’re listed here only for references.
Use G1 garbage collector
In my previous project, I found the G1 garbage collector very efficient, it rarely create pauses that’re noticeable. So I opt to use it. This is done by configuring JAVA_TOOL_OPTIONS in Heroku Config Vars. I’ve also added options to print GC details, but I found them too verbose and didn’t provide much help. I’ll turn them off very quickly.
In the end the JAVA_TOOL_OPTIONS is the below, as they provide the critical information I’d like to see at current stage.
Full GC on application starts ?
This is irrelevant, I believe a Full GC on application starts is only a false assumption of mine trying to force the JVM to perform the full GC. It doesn’t help in the long run.
After a while of testing, I found a manual full GC right after application start seems to be helpful. It doesn’t seem to create any issue anyway, but have significantly reduced the memory usage. The total_memory have dropped to around 400mb, even when I invoked the problematic API 10+ times.
However, it could also be the result of the adoption of streaming API.
Did you learn something new? If so please:
↓ clap 👏 button below️ so more people can see this
Источник
Categories
Last updated November 07, 2022
Table of Contents
Whenever your app experiences an error, Heroku will return a standard error page with the HTTP status code 503. To help you debug the underlying error, however, the platform will also add custom error information to your logs. Each type of error gets its own error code, with all HTTP errors starting with the letter H and all runtime errors starting with R. Logging errors start with L.
H10 — App crashed
A crashed web dyno or a boot timeout on the web dyno will present this error.
H11 — Backlog too deep
When HTTP requests arrive faster than your application can process them, they can form a large backlog on a number of routers. When the backlog on a particular router passes a threshold, the router determines that your application isn’t keeping up with its incoming request volume. You’ll see an H11 error for each incoming request as long as the backlog is over this size. The exact value of this threshold may change depending on various factors, such as the number of dynos in your app, response time for individual requests, and your app’s normal request volume.
The solution is to increase your app’s throughput by adding more dynos, tuning your database (for example, adding an index), or making the code itself faster. As always, increasing performance is highly application-specific and requires profiling.
H12 — Request timeout
For more information on request timeouts (including recommendations for resolving them), take a look at our article on the topic.
An HTTP request took longer than 30 seconds to complete. In the example below, a Rails app takes 37 seconds to render the page; the HTTP router returns a 503 prior to Rails completing its request cycle, but the Rails process continues and the completion message shows after the router message.
This 30-second limit is measured by the router, and includes all time spent in the dyno, including the kernel’s incoming connection queue and the app itself.
See Request Timeout for more, as well as a language-specific article on this error:
H13 — Connection closed without response
This error is thrown when a process in your web dyno accepts a connection but then closes the socket without writing anything to it.
One example where this might happen is when a Unicorn web server is configured with a timeout shorter than 30s and a request has not been processed by a worker before the timeout happens. In this case, Unicorn closes the connection before any data is written, resulting in an H13.
H14 — No web dynos running
This is most likely the result of scaling your web dynos down to 0 dynos. To fix it, scale your web dynos to 1 or more dynos:
Use the heroku ps command to determine the state of your web dynos.
H15 — Idle connection
The dyno did not send a full response and was terminated due to 55 seconds of inactivity. For example, the response indicated a Content-Length of 50 bytes which were not sent in time.
H16 — (No Longer in Use)
Heroku no longer emits H16 errors
H17 — Poorly formatted HTTP response
Our HTTP routing stack has no longer accepts responses that are missing a reason phrase in the status line. ‘HTTP/1.1 200 OK’ will work with the new router, but ‘HTTP/1.1 200’ will not.
This error message is logged when a router detects a malformed HTTP response coming from a dyno.
H18 — Server Request Interrupted
An H18 signifies that the socket connected, and some data was sent; The error occurs in cases where the socket was destroyed before sending a complete response, or if the server responds with data before reading the entire body of the incoming request.
H19 — Backend connection timeout
A router received a connection timeout error after 5 seconds of attempting to open a socket to a web dyno. This is usually a symptom of your app being overwhelmed and failing to accept new connections in a timely manner. For Common Runtime apps, if you have multiple dynos, the router will retry multiple dynos before logging H19 and serving a standard error page. Private Space routers can’t reroute requests to another web dyno.
If your app has a single web dyno, it is possible to see H19 errors if the runtime instance running your web dyno fails and is replaced. Once the failure is detected and the instance is terminated your web dyno will be restarted somewhere else, but in the meantime, H19s may be served as the router fails to establish a connection to your dyno. This can be mitigated by running more than one web dyno.
H20 — App boot timeout
The router will enqueue requests for 75 seconds while waiting for starting processes to reach an “up” state. If after 75 seconds, no web dynos have reached an “up” state, the router logs H20 and serves a standard error page.
The Ruby on Rails asset pipeline can sometimes fail to run during git push, and will instead attempt to run when your app’s dynos boot. Since the Rails asset pipeline is a slow process, this can cause H20 boot timeout errors.
This error differs from R10 in that the H20 75-second timeout includes platform tasks such as internal state propagation, requests between internal components, slug download, unpacking, container preparation, etc… The R10 60-second timeout applies solely to application startup tasks.
If your application requires more time to boot, you may use the boot timeout tool to increase the limit. However, in general, slow boot times will make it harder to deploy your application and will make recovery from dyno failures slower, so this should be considered a temporary solution.
H21 — Backend connection refused
A router received a connection refused error when attempting to open a socket to your web process. This is usually a symptom of your app being overwhelmed and failing to accept new connections.
For Common Runtime apps, the router will retry multiple dynos before logging H21 and serving a standard error page. Private Spaces apps are not capable of sending the requests to multiple dynos.
H22 — Connection limit reached
A routing node has detected an elevated number of HTTP client connections attempting to reach your app. Reaching this threshold most likely means your app is under heavy load and is not responding quickly enough to keep up. The exact value of this threshold may change depending on various factors, such as the number of dynos in your app, response time for individual requests, and your app’s normal request volume.
H23 — Endpoint misconfigured
A routing node has detected a websocket handshake, specifically the ‘Sec-Websocket-Version’ header in the request, that came from an endpoint (upstream proxy) that does not support websockets.
H24 — Forced close
The routing node serving this request was either shutdown for maintenance or terminated before the request completed.
H25 — HTTP Restriction
This error is logged when a routing node detects and blocks a valid HTTP response that is judged risky or too large to be safely parsed. The error comes in four types.
Currently, this functionality is experimental, and is only made available to a subset of applications on the platform.
Invalid content length
The response has multiple content lengths declared within the same response, with varying lengths.
Oversized cookies
The cookie in the response will be too large to be used again in a request to the Heroku router or SSL endpoints.
A single header line is deemed too long (over 512kb) and the response is discarded on purpose.
Oversized status line
The status line is judged too long (8kb) and the response is discarded on purpose.
H26 — Request Error
This error is logged when a request has been identified as belonging to a specific Heroku application, but cannot be delivered entirely to a dyno due to HTTP protocol errors in the request. Multiple possible causes can be identified in the log message.
The request has an expect header, and its value is not 100-Continue , the only expect value handled by the router. A request with an unsupported expect value is terminated with the status code 417 Expectation Failed .
The request has an HTTP header with a value that is either impossible to parse, or not handled by the router, such as connection: , .
Bad chunk
The request has a chunked transfer-encoding, but with a chunk that was invalid or couldn’t be parsed correctly. A request with this status code will be interrupted during transfer to the dyno.
H27 — Client Request Interrupted
The client socket was closed either in the middle of the request or before a response could be returned. For example, the client closed their browser session before the request was able to complete.
H28 — Client Connection Idle
The client did not send a full request and was terminated due to 55 seconds of inactivity. For example, the client indicated a Content-Length of 50 bytes which were not sent in time.
2010-10-06T21:51:37-07:00 heroku[router]: at=warning code=H28 desc=»Client Connection Idle» method=GET path=»/» host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=55449ms status=499 bytes=18
H31 — Misdirected Request
The client sent a request to the wrong endpoint. This could be because the client used stale DNS information or is accessing the app through a CDN that has stale DNS information. Verify that DNS is correctly configured for your app. If a CDN is configured for the app, consider contacting your CDN provider.
If you and your app users can successfully access the app in a browser (or however the app is used), this may not be cause for concern. The errors may be caused by clients (typically web-crawlers) with cached DNS entries trying to access a now-invalid endpoint or IP address for your app.
You can verify the validity of user agent through the app log error message as shown in the example below:
H80 — Maintenance mode
This is not an error, but we give it a code for the sake of completeness. Note the log formatting is the same but without the word “Error”.
H81 — Blank app
No code has been pushed to this application. To get rid of this message you need to do one deploy. This is not an error, but we give it a code for the sake of completeness.
H82 — You’ve used up your dyno hour pool
This error indicates that an account has exhausted its monthly dyno hour quota for Free or Eco dynos and its apps running these dynos are sleeping. You can view your app’s Free or Eco dyno usage in the Heroku dashboard.
H83 — Planned Service Degradation
This indicates that your app is temporarily unavailable as Heroku makes necessary changes to support the retirement of a feature that has reached end of life. You will likely encounter an error screen when attempting to access your application and see the error below in your logs. Please reference the Heroku Changelog and the Heroku Status page for more details and the timeline of the planned service outage.
H99 — Platform error
H99 and R99 are the only error codes that represent errors in the Heroku platform.
This indicates an internal error in the Heroku platform. Unlike all of the other errors which will require action from you to correct, this one does not require action from you. Try again in a minute, or check the status site.
R10 — Boot timeout
A web process took longer than 60 seconds to bind to its assigned $PORT . When this happens, the dyno’s process is killed and the dyno is considered crashed. Crashed dynos are restarted according to the dyno manager’s restart policy.
This error is often caused by a process being unable to reach an external resource, such as a database, or the application doing too much work, such as parsing and evaluating numerous, large code dependencies, during startup.
Common solutions are to access external resources asynchronously, so they don’t block startup, and to reduce the amount of application code or its dependencies.
If your application requires more time to boot, you may use the boot timeout tool to increase the limit. However, in general, slow boot times will make it harder to deploy your application and will make recovery from dyno failures slower, so this should be considered a temporary solution.
One exception is for apps using the Java buildpack, Gradle buildpack, heroku-deploy toolbelt plugin, or Heroku Maven plugin, which will be allowed 90 seconds to bind to their assigned port.
R12 — Exit timeout
A process failed to exit within 30 seconds of being sent a SIGTERM indicating that it should stop. The process is sent SIGKILL to force an exit.
R13 — Attach error
A dyno started with heroku run failed to attach to the invoking client.
R14 — Memory quota exceeded
A dyno requires memory in excess of its quota. If this error occurs, the dyno will page to swap space to continue running, which may cause degraded process performance. The R14 error is calculated by total memory swap, rss and cache.
If you are getting a large number of R14 errors, your application performance is likely severely degraded. Resolving R14 memory errors are language specific:
R15 — Memory quota vastly exceeded
A dyno requires vastly more memory than its quota and is consuming excessive swap space. If this error occurs, the dyno will be forcibly killed with SIGKILL (which cannot be caught or handled) by the platform. The R15 error is calculated by total memory swap and rss; cache is not included.
In Private Spaces, dynos exceeding their memory quota do not use swap space and thus do not emit R14 errors.
Private Space dynos vastly exceeding their memory quota generally will emit R15 errors but occasionally the platform may shut down the dyno before the R15 is sent, causing the error to be dropped. If an R15 is emitted it will only be visible in the app log stream but not in the dashboard Application Metrics interface. Other non-R15 types of errors from Private Space dynos are correctly surfaced in the Application Metrics interface.
For Private Space dynos vastly exceeding their memory quota the platform kills dyno processes consuming large amounts of memory, but may not kill the dyno itself.
R16 — Detached
An attached dyno is continuing to run after being sent SIGHUP when its external connection was closed. This is usually a mistake, though some apps might want to do this intentionally.
R17 — Checksum error
This indicates an error with runtime slug checksum verification. If the checksum does not match or there is another problem with the checksum when launch a dyno, an R17 error will occur and the dyno will fail to launch. Check the log stream for details about the error.
If this error occurs, try deploying a new release with a correct checksum or rolling back to an older release. Ensure the checksum is formatted and calculated correctly with the SHA256 algorithm. The checksum must start with SHA256: followed by the calculated SHA256 value for the compressed slug. If you did not manually calculate the checksum and error continues to occur, please contact Heroku support.
R99 — Platform error
R99 and H99 are the only error codes that represent errors in the Heroku platform.
This indicates an internal error in the Heroku platform. Unlike all of the other errors which will require action from you to correct, this one does not require action from you. Try again in a minute, or check the status site.
L10 — Drain buffer overflow
The number of log messages being generated has temporarily exceeded the rate at which they can be received by a drain consumer (such as a log management add-on) and Logplex, Heroku’s logging system, has discarded some messages in order to handle the rate difference.
A common cause of L10 error messages is the exhaustion of capacity in a log consumer. If a log management add-on or similar system can only accept so many messages per time period, your application may experience L10s after crossing that threshold.
Another common cause of L10 error messages is a sudden burst of log messages from a dyno. As each line of dyno output (e.g. a line of a stack trace) is a single log message, and Logplex limits the total number of un-transmitted log messages it will keep in memory to 1024 messages, a burst of lines from a dyno can overflow buffers in Logplex. In order to allow the log stream to catch up, Logplex will discard messages where necessary, keeping newer messages in favor of older ones.
You may need to investigate reducing the volume of log lines output by your application (e.g. condense multiple log lines into a smaller, single-line entry). You can also use the heroku logs -t command to get a live feed of logs and find out where your problem might be. A single dyno stuck in a loop that generates log messages can force an L10 error, as can a problematic code path that causes all dynos to generate a multi-line stack trace for some code paths.
L11 — Tail buffer overflow
A heroku logs –tail session cannot keep up with the volume of logs generated by the application or log channel, and Logplex has discarded some log lines necessary to catch up. To avoid this error you will need run the command on a faster internet connection (increase the rate at which you can receive logs) or you will need to modify your application to reduce the logging volume (decrease the rate at which logs are generated).
L12 — Local buffer overflow
The application is producing logs faster than the local delivery process (log-shuttle) can deliver them to logplex and has discarded some log lines in order to keep up. If this error is sustained you will need to reduce the logging volume of your application.
L13 — Local delivery error
The local log delivery process (log-shuttle) was unable to deliver some logs to Logplex and has discarded them. This can happen during transient network errors or during logplex service degradation. If this error is sustained please contact support.
L14 — Certificate validation error
The application is configured with a TLS syslog drain that doesn’t have a valid TLS certificate.
You should check that:
- You’re not using a self-signed certificate.
- The certificate is up to date.
- The certificate is signed by a known and trusted CA.
- The CN hostname embedded in the certificate matches the hostname being connected to.
L15 — Tail buffer temporarily unavailable
The tail buffer that stores the last 1500 lines of your logs is temporarily unavailable. Run heroku logs again. If you still encounter the error, run heroku logs -t to stream your logs (which does not use the tail buffer).
Источник
New issue
Have a question about this project? Sign up for a free GitHub account to open an issue and contact its maintainers and the community.
By clicking “Sign up for GitHub”, you agree to our terms of service and
privacy statement. We’ll occasionally send you account related emails.
Already on GitHub?
Sign in
to your account
Closed
vicros0723 opened this issue
Jun 7, 2018
· 6 comments
Comments
![]()
Hello,
I have a basic Spring Boot application deployed on a hobby tier Heroku instance and it’s been throwing R14 Memory Quote Exceeded near constantly. The application is literally a couple REST endpoints connecting to a database.
I’ve been trying to track this down for a some number of hours across a few days now and don’t seem much closer to a solution. I have turned on Enhanced Language Metrics and see the following
My application is started via java -Dserver.port=$PORT $JAVA_OPTS -jar build/libs/*.jar.
Based on https://devcenter.heroku.com/articles/java-memory-issues#configuring-nativememorytracking, I have JAVA_OPTS set to -Xms256m -Xmx256m -Xss512k -XX:NativeMemoryTracking=detail -XX:+UnlockDiagnosticVMOptions -XX:+PrintNMTStatistics in the config vars.
The issue metabase/metabase-deploy#5 and metabase/metabase#3360 make me suspect I’m not the only one having trouble tuning the JVM to run below the 512 MB limit for these Heroku dynos.
Does anyone have more information or suggestions to reduce the memory footprint? It’s a little unnerving to see the application consume so much memory for minimal functionality.
Thanks!
![]()
What kind of memory profile does the app show locally? Metabase isn’t exactly a minimal app, it’s a complete working app, which may be difficult to fit into a 512MB limit (in fact, most real world Java apps are hard to fit into a 512 MB limit).
![]()
Ah I’m not using metabase. Those github issues just happened to be where I found similar issues reported. The minimal app I have is Spring boot with three REST endpoints that read from/write to a Postgres database.
Locally running java -jar build/libs/*.jar -Xms256m -Xmx256m -Xss512k, the heap memory profile in VisualVM looks like


Running jconsole, I see that the heap space has 378,880 kbytes committed and non-heap space has 101,728 kbytes committed which totals around 480.61 megabytes. It’s a little closer than I would like, but should be comfortably under the 512 Heroku provides.


I’m not surprised that the Java app has trouble fitting under the 512 MB limit, but I would definitely expect the -Xmx option to limit the committed heap. Rerunning with -Xmx128m resulted in the same size of committed heap. So I guess the question has turned to why the JVM is not obeying -Xmx.
![]()
Move the -Xmx option before the -jar. The way you have it now, it’s being passed as an app argument (the ones you get in main(String[])).
![]()
Thanks for pointing that out and all your support!
Putting the -Xmx before the -jar helped me get my local analysis to behave as expected. I was subsequently able to get jconsole to connect remotely with Heroku and experimenting with tuning the JAVA_OPTS and seeing expected behavior on Heroku so I consider this issue resolved and this ticket closed.
Turns out that Heroku adds a ~150mb overhead to the JVM on top of the ~100 mb non-heap committed memory. When I use -Xmx256m, total memory usage on Heroku’s metrics hover around 506mb. When I use -Xmx128m, the same metric hovers around 380mb.
In conclusion, the -Xmx option seems to be behaving correctly. Some native memory process on Heroku seems to just eat more memory when running the JVM than I expected and at -Xmx256m was consuming enough memory that regular fluctuations in memory usage were dipping me above the Heroku warning limit.
![]()
@vicros0723 it’s typical for the JVM to consume more memory on Heroku than locally, but this is not due to any overhead from heroku. Instead, the JVM misunderstands it’s limits when it’s running in a container (like a Heroku dyno or a Docker container, which are sort of the same thing). Basically, the JVM thinks it has way more memory than it actually has. In Java 9/10/11 this is starting to be improved with the -XX:+UseContainerSupport option, but it really only works for heap (and the JVM has many other categories of memory).
![]()
Even though this is a closed issue, I just wanted to add I experienced similar issues. Fighting the Heroku Error R14 (Memory quota exceeded) issue. contained the hint do reduce the default hikari pool size, which had a significant impact on the memory usage of my app. Spring boot 2.3.2.RELEASE, Java 11
Last updated November 07, 2022
Table of Contents
- H10 — App crashed
- H11 — Backlog too deep
- H12 — Request timeout
- H13 — Connection closed without response
- H14 — No web dynos running
- H15 — Idle connection
- H16 — (No Longer in Use)
- H17 — Poorly formatted HTTP response
- H18 — Server Request Interrupted
- H19 — Backend connection timeout
- H20 — App boot timeout
- H21 — Backend connection refused
- H22 — Connection limit reached
- H23 — Endpoint misconfigured
- H24 — Forced close
- H25 — HTTP Restriction
- H26 — Request Error
- H27 — Client Request Interrupted
- H28 — Client Connection Idle
- H31 — Misdirected Request
- H80 — Maintenance mode
- H81 — Blank app
- H82 — You’ve used up your dyno hour pool
- H83 — Planned Service Degradation
- H99 — Platform error
- R10 — Boot timeout
- R12 — Exit timeout
- R13 — Attach error
- R14 — Memory quota exceeded
- R15 — Memory quota vastly exceeded
- R16 — Detached
- R17 — Checksum error
- R99 — Platform error
- L10 — Drain buffer overflow
- L11 — Tail buffer overflow
- L12 — Local buffer overflow
- L13 — Local delivery error
- L14 — Certificate validation error
- L15 — Tail buffer temporarily unavailable
Whenever your app experiences an error, Heroku will return a standard error page with the HTTP status code 503. To help you debug the underlying error, however, the platform will also add custom error information to your logs. Each type of error gets its own error code, with all HTTP errors starting with the letter H and all runtime errors starting with R. Logging errors start with L.
H10 — App crashed
A crashed web dyno or a boot timeout on the web dyno will present this error.
2010-10-06T21:51:04-07:00 heroku[web.1]: State changed from down to starting
2010-10-06T21:51:07-07:00 app[web.1]: Starting process with command: `bundle exec rails server -p 22020`
2010-10-06T21:51:09-07:00 app[web.1]: >> Using rails adapter
2010-10-06T21:51:09-07:00 app[web.1]: Missing the Rails 2.3.5 gem. Please `gem install -v=2.3.5 rails`, update your RAILS_GEM_VERSION setting in config/environment.rb for the Rails version you do have installed, or comment out RAILS_GEM_VERSION to use the latest version installed.
2010-10-06T21:51:10-07:00 heroku[web.1]: Process exited
2010-10-06T21:51:12-07:00 heroku[router]: at=error code=H10 desc="App crashed" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H11 — Backlog too deep
When HTTP requests arrive faster than your application can process them, they can form a large backlog on a number of routers. When the backlog on a particular router passes a threshold, the router determines that your application isn’t keeping up with its incoming request volume. You’ll see an H11 error for each incoming request as long as the backlog is over this size. The exact value of this threshold may change depending on various factors, such as the number of dynos in your app, response time for individual requests, and your app’s normal request volume.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H11 desc="Backlog too deep" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
The solution is to increase your app’s throughput by adding more dynos, tuning your database (for example, adding an index), or making the code itself faster. As always, increasing performance is highly application-specific and requires profiling.
H12 — Request timeout
For more information on request timeouts (including recommendations for resolving them), take a look at our article on the topic.
An HTTP request took longer than 30 seconds to complete. In the example below, a Rails app takes 37 seconds to render the page; the HTTP router returns a 503 prior to Rails completing its request cycle, but the Rails process continues and the completion message shows after the router message.
2010-10-06T21:51:07-07:00 app[web.2]: Processing PostController#list (for 75.36.147.245 at 2010-10-06 21:51:07) [GET]
2010-10-06T21:51:08-07:00 app[web.2]: Rendering template within layouts/application
2010-10-06T21:51:19-07:00 app[web.2]: Rendering post/list
2010-10-06T21:51:37-07:00 heroku[router]: at=error code=H12 desc="Request timeout" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=6ms service=30001ms status=503 bytes=0
2010-10-06T21:51:42-07:00 app[web.2]: Completed in 37000ms (View: 27, DB: 21) | 200 OK [http://myapp.heroku.com/]
This 30-second limit is measured by the router, and includes all time spent in the dyno, including the kernel’s incoming connection queue and the app itself.
See Request Timeout for more, as well as a language-specific article on this error:
- H12 — Request Timeout in Ruby (MRI)
H13 — Connection closed without response
This error is thrown when a process in your web dyno accepts a connection but then closes the socket without writing anything to it.
2010-10-06T21:51:37-07:00 heroku[router]: at=error code=H13 desc="Connection closed without response" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=3030ms service=9767ms status=503 bytes=0
One example where this might happen is when a Unicorn web server is configured with a timeout shorter than 30s and a request has not been processed by a worker before the timeout happens. In this case, Unicorn closes the connection before any data is written, resulting in an H13.
An example of an H13 can be found here.
H14 — No web dynos running
This is most likely the result of scaling your web dynos down to 0 dynos. To fix it, scale your web dynos to 1 or more dynos:
$ heroku ps:scale web=1
Use the heroku ps command to determine the state of your web dynos.
2010-10-06T21:51:37-07:00 heroku[router]: at=error code=H14 desc="No web processes running" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H15 — Idle connection
The dyno did not send a full response and was terminated due to 55 seconds of inactivity. For example, the response indicated a Content-Length of 50 bytes which were not sent in time.
2010-10-06T21:51:37-07:00 heroku[router]: at=error code=H15 desc="Idle connection" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=55449ms status=503 bytes=18
H16 — (No Longer in Use)
Heroku no longer emits H16 errors
H17 — Poorly formatted HTTP response
Our HTTP routing stack has no longer accepts responses that are missing a reason phrase in the status line. ‘HTTP/1.1 200 OK’ will work with the new router, but ‘HTTP/1.1 200’ will not.
This error message is logged when a router detects a malformed HTTP response coming from a dyno.
2010-10-06T21:51:37-07:00 heroku[router]: at=error code=H17 desc="Poorly formatted HTTP response" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=1ms status=503 bytes=0
H18 — Server Request Interrupted
An H18 signifies that the socket connected, and some data was sent; The error occurs in cases where the socket was destroyed before sending a complete response, or if the server responds with data before reading the entire body of the incoming request.
2010-10-06T21:51:37-07:00 heroku[router]: sock=backend at=error code=H18 desc="Server Request Interrupted" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=1ms status=503 bytes=0
An example of an H18 can be found here.
H19 — Backend connection timeout
A router received a connection timeout error after 5 seconds of attempting to open a socket to a web dyno. This is usually a symptom of your app being overwhelmed and failing to accept new connections in a timely manner. For Common Runtime apps, if you have multiple dynos, the router will retry multiple dynos before logging H19 and serving a standard error page. Private Space routers can’t reroute requests to another web dyno.
If your app has a single web dyno, it is possible to see H19 errors if the runtime instance running your web dyno fails and is replaced. Once the failure is detected and the instance is terminated your web dyno will be restarted somewhere else, but in the meantime, H19s may be served as the router fails to establish a connection to your dyno. This can be mitigated by running more than one web dyno.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H19 desc="Backend connection timeout" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=5001ms service= status=503 bytes=
H20 — App boot timeout
The router will enqueue requests for 75 seconds while waiting for starting processes to reach an “up” state. If after 75 seconds, no web dynos have reached an “up” state, the router logs H20 and serves a standard error page.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H20 desc="App boot timeout" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
The Ruby on Rails asset pipeline can sometimes fail to run during git push, and will instead attempt to run when your app’s dynos boot. Since the Rails asset pipeline is a slow process, this can cause H20 boot timeout errors.
This error differs from R10 in that the H20 75-second timeout includes platform tasks such as internal state propagation, requests between internal components, slug download, unpacking, container preparation, etc… The R10 60-second timeout applies solely to application startup tasks.
If your application requires more time to boot, you may use the boot timeout tool to increase the limit. However, in general, slow boot times will make it harder to deploy your application and will make recovery from dyno failures slower, so this should be considered a temporary solution.
H21 — Backend connection refused
A router received a connection refused error when attempting to open a socket to your web process. This is usually a symptom of your app being overwhelmed and failing to accept new connections.
For Common Runtime apps, the router will retry multiple dynos before logging H21 and serving a standard error page. Private Spaces apps are not capable of sending the requests to multiple dynos.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H21 desc="Backend connection refused" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service= status=503 bytes=
H22 — Connection limit reached
A routing node has detected an elevated number of HTTP client connections attempting to reach your app. Reaching this threshold most likely means your app is under heavy load and is not responding quickly enough to keep up. The exact value of this threshold may change depending on various factors, such as the number of dynos in your app, response time for individual requests, and your app’s normal request volume.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H22 desc="Connection limit reached" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H23 — Endpoint misconfigured
A routing node has detected a websocket handshake, specifically the ‘Sec-Websocket-Version’ header in the request, that came from an endpoint (upstream proxy) that does not support websockets.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H23 desc="Endpoint misconfigured" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H24 — Forced close
The routing node serving this request was either shutdown for maintenance or terminated before the request completed.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H24 desc="Forced close" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=80000ms status= bytes=18
H25 — HTTP Restriction
This error is logged when a routing node detects and blocks a valid HTTP response that is judged risky or too large to be safely parsed. The error comes in four types.
Currently, this functionality is experimental, and is only made available to a subset of applications on the platform.
Invalid content length
The response has multiple content lengths declared within the same response, with varying lengths.
2014-03-20T14:22:00.203382+00:00 heroku[router]: at=error code=H25 desc="HTTP restriction: invalid content length" method=GET path="/" host=myapp.herokuapp.com request_id=3f336f1a-9be3-4791-afe3-596a1f2a481f fwd="17.17.17.17" dyno=web.1 connect=0 service=1 status=502 bytes=537
Oversized cookies
The cookie in the response will be too large to be used again in a request to the Heroku router or SSL endpoints.
2014-03-20T14:18:57.403882+00:00 heroku[router]: at=error code=H25 desc="HTTP restriction: oversized cookie" method=GET path="/" host=myapp.herokuapp.com request_id=90cfbbd2-0397-4bab-828f-193050a076c4 fwd="17.17.17.17" dyno=web.1 connect=0 service=2 status=502 bytes=537
A single header line is deemed too long (over 512kb) and the response is discarded on purpose.
2014-03-20T14:12:28.555073+00:00 heroku[router]: at=error code=H25 desc="HTTP restriction: oversized header" method=GET path="/" host=myapp.herokuapp.com request_id=ab66646e-84eb-47b8-b3bb-2031ecc1bc2c fwd="17.17.17.17" dyno=web.1 connect=0 service=397 status=502 bytes=542
Oversized status line
The status line is judged too long (8kb) and the response is discarded on purpose.
2014-03-20T13:54:44.423083+00:00 heroku[router]: at=error code=H25 desc="HTTP restriction: oversized status line" method=GET path="/" host=myapp.herokuapp.com request_id=208588ac-1a66-44c1-b665-fe60c596241b fwd="17.17.17.17" dyno=web.1 connect=0 service=3 status=502 bytes=537
H26 — Request Error
This error is logged when a request has been identified as belonging to a specific Heroku application, but cannot be delivered entirely to a dyno due to HTTP protocol errors in the request. Multiple possible causes can be identified in the log message.
The request has an expect header, and its value is not 100-Continue, the only expect value handled by the router. A request with an unsupported expect value is terminated with the status code 417 Expectation Failed.
2014-05-14T17:17:37.456997+00:00 heroku[router]: at=error code=H26 desc="Request Error" cause="unsupported expect header value" method=GET path="/" host=myapp.herokuapp.com request_id=3f336f1a-9be3-4791-afe3-596a1f2a481f fwd="17.17.17.17" dyno= connect= service= status=417 bytes=
The request has an HTTP header with a value that is either impossible to parse, or not handled by the router, such as connection: ,.
2014-05-14T17:17:37.456997+00:00 heroku[router]: at=error code=H26 desc="Request Error" cause="bad header" method=GET path="/" host=myapp.herokuapp.com request_id=3f336f1a-9be3-4791-afe3-596a1f2a481f fwd="17.17.17.17" dyno= connect= service= status=400 bytes=
Bad chunk
The request has a chunked transfer-encoding, but with a chunk that was invalid or couldn’t be parsed correctly. A request with this status code will be interrupted during transfer to the dyno.
2014-05-14T17:17:37.456997+00:00 heroku[router]: at=error code=H26 desc="Request Error" cause="bad chunk" method=GET path="/" host=myapp.herokuapp.com request_id=3f336f1a-9be3-4791-afe3-596a1f2a481f fwd="17.17.17.17" dyno=web.1 connect=1 service=0 status=400 bytes=537
H27 — Client Request Interrupted
The client socket was closed either in the middle of the request or before a response could be returned. For example, the client closed their browser session before the request was able to complete.
2010-10-06T21:51:37-07:00 heroku[router]: sock=client at=warning code=H27 desc="Client Request Interrupted" method=POST path="/submit/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=0ms status=499 bytes=0
H28 — Client Connection Idle
The client did not send a full request and was terminated due to 55 seconds of inactivity. For example, the client indicated a Content-Length of 50 bytes which were not sent in time.
2010-10-06T21:51:37-07:00 heroku[router]: at=warning code=H28 desc="Client Connection Idle" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno=web.1 connect=1ms service=55449ms status=499 bytes=18
H31 — Misdirected Request
The client sent a request to the wrong endpoint. This could be because the client used stale DNS information or is accessing the app through a CDN that has stale DNS information. Verify that DNS is correctly configured for your app. If a CDN is configured for the app, consider contacting your CDN provider.
If you and your app users can successfully access the app in a browser (or however the app is used), this may not be cause for concern. The errors may be caused by clients (typically web-crawlers) with cached DNS entries trying to access a now-invalid endpoint or IP address for your app.
You can verify the validity of user agent through the app log error message as shown in the example below:
error code=H31 desc="Misdirected Request" method=GET path="/" host=[host.com] request_id=[guid] fwd="[IP]" dyno= connect= service= status=421 bytes= protocol=http agent="<agent>"
H80 — Maintenance mode
This is not an error, but we give it a code for the sake of completeness. Note the log formatting is the same but without the word “Error”.
2010-10-06T21:51:07-07:00 heroku[router]: at=info code=H80 desc="Maintenance mode" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H81 — Blank app
No code has been pushed to this application. To get rid of this message you need to do one deploy. This is not an error, but we give it a code for the sake of completeness.
2010-10-06T21:51:07-07:00 heroku[router]: at=info code=H81 desc="Blank app" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H82 — You’ve used up your dyno hour pool
This error indicates that an account has exhausted its monthly dyno hour quota for Free or Eco dynos and its apps running these dynos are sleeping. You can view your app’s Free or Eco dyno usage in the Heroku dashboard.
2015-10-06T21:51:07-07:00 heroku[router]: at=info code=H82 desc="You've used up your dyno hour pool" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H83 — Planned Service Degradation
This indicates that your app is temporarily unavailable as Heroku makes necessary changes to support the retirement of a feature that has reached end of life. You will likely encounter an error screen when attempting to access your application and see the error below in your logs. Please reference the Heroku Changelog and the Heroku Status page for more details and the timeline of the planned service outage.
2021-10-10T21:51:07-07:00 heroku[router]: at=info code=H83 desc="Service Degradation" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
H99 — Platform error
H99 and R99 are the only error codes that represent errors in the Heroku platform.
This indicates an internal error in the Heroku platform. Unlike all of the other errors which will require action from you to correct, this one does not require action from you. Try again in a minute, or check the status site.
2010-10-06T21:51:07-07:00 heroku[router]: at=error code=H99 desc="Platform error" method=GET path="/" host=myapp.herokuapp.com fwd=17.17.17.17 dyno= connect= service= status=503 bytes=
R10 — Boot timeout
A web process took longer than 60 seconds to bind to its assigned $PORT. When this happens, the dyno’s process is killed and the dyno is considered crashed. Crashed dynos are restarted according to the dyno manager’s restart policy.
2011-05-03T17:31:38+00:00 heroku[web.1]: State changed from created to starting
2011-05-03T17:31:40+00:00 heroku[web.1]: Starting process with command: `bundle exec rails server -p 22020 -e production`
2011-05-03T17:32:40+00:00 heroku[web.1]: Error R10 (Boot timeout) -> Web process failed to bind to $PORT within 60 seconds of launch
2011-05-03T17:32:40+00:00 heroku[web.1]: Stopping process with SIGKILL
2011-05-03T17:32:40+00:00 heroku[web.1]: Process exited
2011-05-03T17:32:41+00:00 heroku[web.1]: State changed from starting to crashed
This error is often caused by a process being unable to reach an external resource, such as a database, or the application doing too much work, such as parsing and evaluating numerous, large code dependencies, during startup.
Common solutions are to access external resources asynchronously, so they don’t block startup, and to reduce the amount of application code or its dependencies.
If your application requires more time to boot, you may use the boot timeout tool to increase the limit. However, in general, slow boot times will make it harder to deploy your application and will make recovery from dyno failures slower, so this should be considered a temporary solution.
One exception is for apps using the Java buildpack, Gradle buildpack, heroku-deploy toolbelt plugin, or Heroku Maven plugin, which will be allowed 90 seconds to bind to their assigned port.
R12 — Exit timeout
A process failed to exit within 30 seconds of being sent a SIGTERM indicating that it should stop. The process is sent SIGKILL to force an exit.
2011-05-03T17:40:10+00:00 app[worker.1]: Working
2011-05-03T17:40:11+00:00 heroku[worker.1]: Stopping process with SIGTERM
2011-05-03T17:40:11+00:00 app[worker.1]: Ignoring SIGTERM
2011-05-03T17:40:14+00:00 app[worker.1]: Working
2011-05-03T17:40:18+00:00 app[worker.1]: Working
2011-05-03T17:40:21+00:00 heroku[worker.1]: Error R12 (Exit timeout) -> Process failed to exit within 30 seconds of SIGTERM
2011-05-03T17:40:21+00:00 heroku[worker.1]: Stopping process with SIGKILL
2011-05-03T17:40:21+00:00 heroku[worker.1]: Process exited
R13 — Attach error
A dyno started with heroku run failed to attach to the invoking client.
2011-06-29T02:13:29+00:00 app[run.3]: Awaiting client
2011-06-29T02:13:30+00:00 heroku[run.3]: State changed from starting to up
2011-06-29T02:13:59+00:00 app[run.3]: Error R13 (Attach error) -> Failed to attach to process
2011-06-29T02:13:59+00:00 heroku[run.3]: Process exited
R14 — Memory quota exceeded
A dyno requires memory in excess of its quota. If this error occurs, the dyno will page to swap space to continue running, which may cause degraded process performance. The R14 error is calculated by total memory swap, rss and cache.
2011-05-03T17:40:10+00:00 app[worker.1]: Working
2011-05-03T17:40:10+00:00 heroku[worker.1]: Process running mem=1028MB(103.3%)
2011-05-03T17:40:11+00:00 heroku[worker.1]: Error R14 (Memory quota exceeded)
2011-05-03T17:41:52+00:00 app[worker.1]: Working
If you are getting a large number of R14 errors, your application performance is likely severely degraded. Resolving R14 memory errors are language specific:
- R14 — Memory Quota Exceeded in Ruby (MRI)
- Troubleshooting Memory Issues in Java Applications
- Troubleshooting Node.js Memory Use
R15 — Memory quota vastly exceeded
A dyno requires vastly more memory than its quota and is consuming excessive swap space. If this error occurs, the dyno will be forcibly killed with SIGKILL (which cannot be caught or handled) by the platform. The R15 error is calculated by total memory swap and rss; cache is not included.
2011-05-03T17:40:10+00:00 app[worker.1]: Working
2011-05-03T17:40:10+00:00 heroku[worker.1]: Process running mem=1029MB(201.0%)
2011-05-03T17:40:11+00:00 heroku[worker.1]: Error R15 (Memory quota vastly exceeded)
2011-05-03T17:40:11+00:00 heroku[worker.1]: Stopping process with SIGKILL
2011-05-03T17:40:12+00:00 heroku[worker.1]: Process exited
In Private Spaces, dynos exceeding their memory quota do not use swap space and thus do not emit R14 errors.
Private Space dynos vastly exceeding their memory quota generally will emit R15 errors but occasionally the platform may shut down the dyno before the R15 is sent, causing the error to be dropped. If an R15 is emitted it will only be visible in the app log stream but not in the dashboard Application Metrics interface. Other non-R15 types of errors from Private Space dynos are correctly surfaced in the Application Metrics interface.
For Private Space dynos vastly exceeding their memory quota the platform kills dyno processes consuming large amounts of memory, but may not kill the dyno itself.
R16 — Detached
An attached dyno is continuing to run after being sent SIGHUP when its external connection was closed. This is usually a mistake, though some apps might want to do this intentionally.
2011-05-03T17:32:03+00:00 heroku[run.1]: Awaiting client
2011-05-03T17:32:03+00:00 heroku[run.1]: Starting process with command `bash`
2011-05-03T17:40:11+00:00 heroku[run.1]: Client connection closed. Sending SIGHUP to all processes
2011-05-03T17:40:16+00:00 heroku[run.1]: Client connection closed. Sending SIGHUP to all processes
2011-05-03T17:40:21+00:00 heroku[run.1]: Client connection closed. Sending SIGHUP to all processes
2011-05-03T17:40:26+00:00 heroku[run.1]: Error R16 (Detached) -> An attached process is not responding to SIGHUP after its external connection was closed.
R17 — Checksum error
This indicates an error with runtime slug checksum verification. If the checksum does not match or there is another problem with the checksum when launch a dyno, an R17 error will occur and the dyno will fail to launch. Check the log stream for details about the error.
2016-08-16T12:39:56.439438+00:00 heroku[web.1]: State changed from provisioning to starting
2016-08-16T12:39:57.110759+00:00 heroku[web.1]: Error R17 (Checksum error) -> Checksum does match expected value. Expected: SHA256:ed5718e83475c780145609cbb2e4f77ec8076f6f59ebc8a916fb790fbdb1ae64 Actual: SHA256:9ca15af16e06625dfd123ebc3472afb0c5091645512b31ac3dd355f0d8cc42c1
2016-08-16T12:39:57.212053+00:00 heroku[web.1]: State changed from starting to crashed
If this error occurs, try deploying a new release with a correct checksum or rolling back to an older release. Ensure the checksum is formatted and calculated correctly with the SHA256 algorithm. The checksum must start with SHA256: followed by the calculated SHA256 value for the compressed slug. If you did not manually calculate the checksum and error continues to occur, please contact Heroku support.
R99 — Platform error
R99 and H99 are the only error codes that represent errors in the Heroku platform.
This indicates an internal error in the Heroku platform. Unlike all of the other errors which will require action from you to correct, this one does not require action from you. Try again in a minute, or check the status site.
L10 — Drain buffer overflow
2013-04-17T19:04:46+00:00 d.1234-drain-identifier-567 heroku logplex - - Error L10 (output buffer overflow): 500 messages dropped since 2013-04-17T19:04:46+00:00.
The number of log messages being generated has temporarily exceeded the rate at which they can be received by a drain consumer (such as a log management add-on) and Logplex, Heroku’s logging system, has discarded some messages in order to handle the rate difference.
A common cause of L10 error messages is the exhaustion of capacity in a log consumer. If a log management add-on or similar system can only accept so many messages per time period, your application may experience L10s after crossing that threshold.
Another common cause of L10 error messages is a sudden burst of log messages from a dyno. As each line of dyno output (e.g. a line of a stack trace) is a single log message, and Logplex limits the total number of un-transmitted log messages it will keep in memory to 1024 messages, a burst of lines from a dyno can overflow buffers in Logplex. In order to allow the log stream to catch up, Logplex will discard messages where necessary, keeping newer messages in favor of older ones.
You may need to investigate reducing the volume of log lines output by your application (e.g. condense multiple log lines into a smaller, single-line entry). You can also use the heroku logs -t command to get a live feed of logs and find out where your problem might be. A single dyno stuck in a loop that generates log messages can force an L10 error, as can a problematic code path that causes all dynos to generate a multi-line stack trace for some code paths.
L11 — Tail buffer overflow
A heroku logs –tail session cannot keep up with the volume of logs generated by the application or log channel, and Logplex has discarded some log lines necessary to catch up. To avoid this error you will need run the command on a faster internet connection (increase the rate at which you can receive logs) or you will need to modify your application to reduce the logging volume (decrease the rate at which logs are generated).
2011-05-03T17:40:10+00:00 heroku[logplex]: L11 (Tail buffer overflow) -> This tail session dropped 1101 messages since 2011-05-03T17:35:00+00:00
L12 — Local buffer overflow
The application is producing logs faster than the local delivery process (log-shuttle) can deliver them to logplex and has discarded some log lines in order to keep up. If this error is sustained you will need to reduce the logging volume of your application.
2013-11-04T21:31:32.125756+00:00 app[log-shuttle]: Error L12: 222 messages dropped since 2013-11-04T21:31:32.125756+00:00.
L13 — Local delivery error
The local log delivery process (log-shuttle) was unable to deliver some logs to Logplex and has discarded them. This can happen during transient network errors or during logplex service degradation. If this error is sustained please contact support.
2013-11-04T21:31:32.125756+00:00 app[log-shuttle]: Error L13: 111 messages lost since 2013-11-04T21:31:32.125756+00:00.
L14 — Certificate validation error
The application is configured with a TLS syslog drain that doesn’t have a valid TLS certificate.
You should check that:
- You’re not using a self-signed certificate.
- The certificate is up to date.
- The certificate is signed by a known and trusted CA.
- The CN hostname embedded in the certificate matches the hostname being connected to.
2015-09-04T23:28:48+00:00 heroku[logplex]: Error L14 (certificate validation): error="bad certificate" uri="syslog+tls://logs.example.com:6514/"
L15 — Tail buffer temporarily unavailable
The tail buffer that stores the last 1500 lines of your logs is temporarily unavailable. Run heroku logs again. If you still encounter the error, run heroku logs -t to stream your logs (which does not use the tail buffer).
1 – Investigation to zero in on the real culprit
We started with observing resource utilization graphs for our dynos. As we all know that worker dynos carry most of the heavy lifting. They are indeed used to perform such tasks. So worker dynos are more prone to such errors than others.
Then we turned our focus the worker dynos. We wanted to zero in on the specific tasks that were consuming more memory. Obviously, when the tasks taking a lot of memory used to start, memory usage graphs on Heroku resulted in huge spikes and emitted R14 errors under events. We made a list of the tasks who resulted in spikes in the graph.
2 – Fixed issues with the Background jobs
After we discover exactly which one are the culprits for R14 errors, we can begin fixing them. We need to fix them in several aspects.
- A. Optimized memory usage
Writing code to fetch data from the database is literally a cakewalk when we are using ActiveRecord. ActiveRecord, if not used smartly enough, may lead to huge memory usage. We need to spot the memory bloats and fix them. We used the following gems to address memory issues.MemoryProfilergem to profile memory usage by different background jobs.
Bulletgem to track and reduce the number of queries used by jobs to fetch data.
Ojgem to optimize the JSON parsing process, as our application used JSON parsing very often. - B. Fixed errors
For the concerned background jobs, we observed the errors reported by the error reporting tool, in our case New Relic. We tracked and fixed them to reduce job retries happening because of these errors.
3 – Rearrangements
Rearranged schedule of the jobs in order to reduce congestion at any given time.
While scheduling the tasks, we generally take care that no two big jobs are scheduled near each other. We simply intend to avoid their overlapping to bring down memory utilization at any given time. But over time we may realize that this scheduling has gone wrong.
So we need to rearrange this schedule considering changed circumstances and memory loads.
4 – Limited the retry attempts of jobs to at max 3
(this was suitable for our application, yours may need more or less than this).
Background jobs may fail due to things that have nothing to do with our code, e.g. something goes wrong at a remote microservice, etc. So the background processing libraries allow us to give some more tries for the job. This is a good practice as there exist some situations that are unavoidable.
But the downside of these retries is that if we don’t limit them, they will keep trying for several times, which may be completely unnecessary.
If you are sure that external factors are not going to cause your job to fail, then in such cases, it really makes no sense to retry such jobs. For example – our job was trying to fetch some data from a given URL and was failing because a wrong URL was provided. This clearly needs no retries. So we can restrict their retries to save our resources.
5 – Installed Jemalloc addon
Heroku states that using malloc in the multithreaded environment may lead to excessive memory usage. As suggested, we installed jemalloc, which provides a kind of malloc implementation that tries to save memory simply by avoiding memory fragmentation. It indeed helped us to save memory to a great extent.
6 – Increased worker memory size.
Even after trying all other weapons in our arsenal :), the R14 errors don’t go away, we really need to think about increasing memory size of the concerned dynos. But this should be our last resort and we must be aware of the fact that they are going to add to our billing costs. In our case, we increased the worker dyno’s memory from 512M to 1024M, ours was a small application :).
Here is the response from heroku. Looks like you need to make configuration changes and can’t use the out of the box config.
Hi Stan,
Thanks for linking to those docs; I’ll need to update that terminal example as I’ve recently silenced the chatty WEB_CONCURRENCY output. We added logging when we added the feature largely so folks wouldn’t be surprised at these new variables invading their environment.
To see the values for your app, you can run:
$ heroku run ‘echo $WEB_MEMORY, $WEB_CONCURRENCY’
However, let me be clear — these values only exist for determining how many concurrent processes should be run by a clustered node app, and even then only if you choose to use the WEB_CONCURRENCY value in your code. They do not impact, at all, the node binary or its default memory allocations or garbage collection, which are totally standard, vanilla versions downloaded from nodejs.org/dist:
https://devcenter.heroku.com/articles/node-concurrency#tuning-the-concurrency-level
V8 uses a greedy and lazy approach to garbage collection. Additionally, V8 assumes by default that you have about 1.5 GB to work with (more than the 1 GB limit of a 2X dyno). You have a few options if you’re interested in changing node’s default memory behavior:
-
Manually trigger GC whenever memory exceeds a set limit (https://simonmcmanus.wordpress.com/2013/01/03/forcing-garbage-collection-with-node-js-and-v8/)
-
Set max_old_space_size to lower than the default (eg, node —max_old_space_size=960). Several metrics in the v8 source are tied to max_old_space_size, so this can make gc somewhat more aggressive. The downside is that if you exceed the value even by a byte, your program will crash.
-
Set gc_global to true to force always-global collection (false by default — keep in mind that global collection is slower than the default multi-phase collection).
-
Set nolazy_sweeping to true, which also makes the gc a little more aggressive.
Keep in mind that, if you’re exceeding about 1 GB of memory in a single node process, the best practice is to split that process into multiple workers:
https://github.com/joyent/node/wiki/FAQ#what-is-the-memory-limit-on-a-node-process
Cheers,
Hunter

on
June 18, 2019

If you are hosting your application with Heroku, and find yourself faced with an unexplained error in your live system. What would you do next? Perhaps you don’t have a dedicated DevOps team, so where would you start your investigation? With Scout APM of course! We are going to show you how you can use Scout to find out exactly where the problem lies within your application code. We are going to walk through two of the most common Heroku error codes and show you how to diagnose the problem with Scout quickly and efficiently.
Heroku’s Error Logging System
First of all let’s take a look at how a typical error occurs for Heroku users and then we will look at how we can use Scout to debug the problem. Any errors that occur in Heroku result in an Application error page being displayed to the user with a HTTP 503 status code indicating “service unavailable”. You have probably seen this page many times before if you are a frequent Heroku user.
As a developer, this doesn’t give us much to go on unfortunately. But we can see the specifics of the error, by digging into Heroku’s logging system. We can view these logs on the Activity tab of the Heroku Dashboard or by using the Heroku CLI application:
$ heroku logs --tailHeroku uses the letters H, R and L in its error codes to differentiate between HTTP errors, runtime errors, and logging errors respectively. A full list of all the different types of errors that Heroku reports can be found here. As you can see from the screenshot below, the error being shown by Heroku in this case is a H12 error.

From Error Code to Solution, with Scout
So now that we’ve checked the logs and found out what type of error occurred, we can cross reference this with the Heroku’s documentation and just fix it, right? Well, not really. You see, these error descriptions are a little vague, don’t you think? They clearly tell us what happened but they don’t really tell us why they happened. This is the job of an Application Performance Monitoring (APM) tool like Scout. When you need to know why and where, Scout should be your go-to tool.
Fortunately, the Heroku logs do tell us when the error occurred and what type of error occurred, so now let’s jump into Scout APM and investigate what happened at that time of the error using two common example scenarios.
Example 1 — H12: Request timeout
Heroku throws this error when a request takes longer than 30 seconds to complete. In Scout, any request that takes longer than 30 seconds to complete should show up very clearly on the main overview page as a spike in the chart, because this type of response time would be dramatically different from your usual traffic. So that would be the first place to start your investigation.
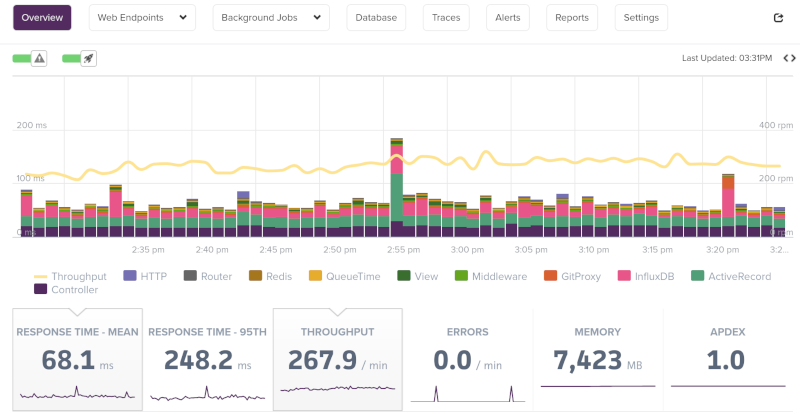
Once you have found the relevant spike on the chart, drag and drop a box around it, and a handy list of endpoints that occurred within that spike will be presented to you. Pick the endpoint you think is the culprit and then pick a trace on that endpoint which occurred at the same time of the error.
At this point, we can examine the trace and see a breakdown of where time or memory was spent during this trace, organized by layer. For example, we might see that a large portion of time was spent on a database query that originated from a line of code in one or our models, and if that is the case then we can see a backtrace of that query and the line of application code.
But in this specific example below, we can see that a large proportion of the time is actually being spent in the Edit action of the Articles controller. In fact, we can see that it took 40 seconds to process this controller action, and this is the reason that Heroku timed out with a H12 error code.
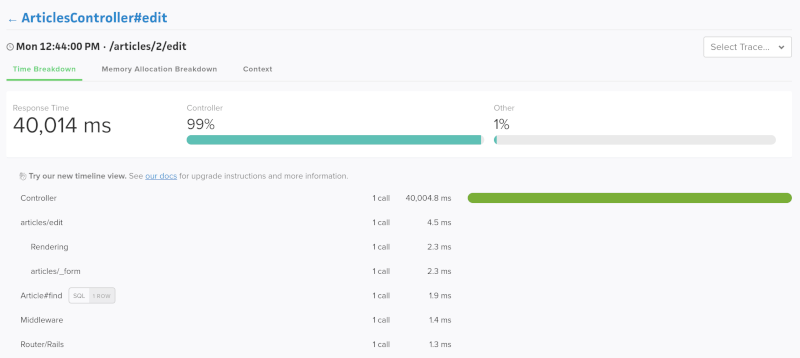
We can debug this particular example even further by enabling the AutoInstrument feature, which further breaks down uninstrumented controller time, line-by-line. Now we can see an exact line of code within our controller and a backtrace which shows where our problem lies. Here we can see that the reason that this application ran for 40 seconds was because of a call to sleep(40) on line 22 of the edit action. Now this line of code was obviously put there just for demonstrative purposes, but it gives you an idea of the level of detail that you can get to when given very little information to go on.
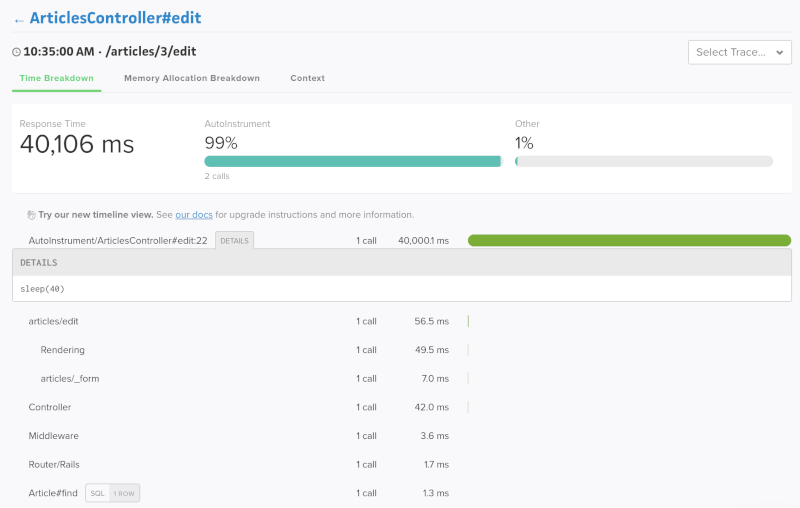
Other ideas for H12 errors
- Have you ever experienced somebody telling you that they have had a timeout error on an endpoint but after accessing the endpoint yourself, everything looks fine? Perhaps you keep seeing this error message intermittently, at certain times of the day or only from certain users, but no matter what you do, you just can’t recreate the problem yourself. Maybe Scout’s traces by context can help you diagnose here.
- The Trace index page allows you to view traces by different criteria, and even by custom context criteria that you can define yourself. For example, you could view all the traces associated with a particular user, or maybe even all users on large pricing plans. Once you have found the offending trace, you can follow similar steps to what we described earlier to get to the root cause.
Example 2 — R14: Memory quota exceeded
Probably the most common Heroku error code you will come across is the R14 “Memory quota exceeded” error. This error (and it’s older brother R15 “Memory quota vastly exceeded”) occur when your application exceeds its server’s allocated amount of memory. The amount of memory your server is allocated depends on which Heroku plan you are on.

When your application runs out of memory and the R14 error occurs, the server will start to page to swap space, and you will start to see a performance slowdown across your entire application. If it continues to increase and reaches 2x your quota then an R15 will occur and your server will be shutdown.
This is a great example of an error message that you might come across but are unable to debug without an APM tool. But fear not because analysing memory bloat is an area where Scout really shines in comparison to its competitors.
The first place that you can look for memory anomalies is on the main overview page of Scout, you can choose to show memory as a sparkline on the graph. In our example shown below, you can see how the memory usage shot upwards rapidly at a certain point in time. Furthermore, our Memory Bloat Insights feature (towards the bottom of the screenshot) identified ArticlesController#index as a potential issue to investigate.
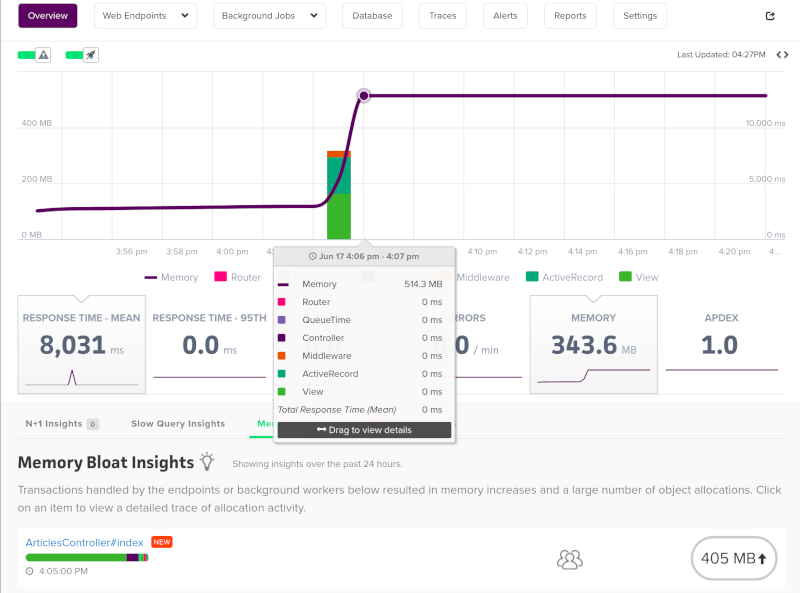
When we take a look at the trace that occurred at this time (shown below), we can clearly see which layers are using all this memory (the View layer). Also we can determine from the backtrace that the cause is that there is no filter or pagination on the query, and so all records are being loaded onto a single page.
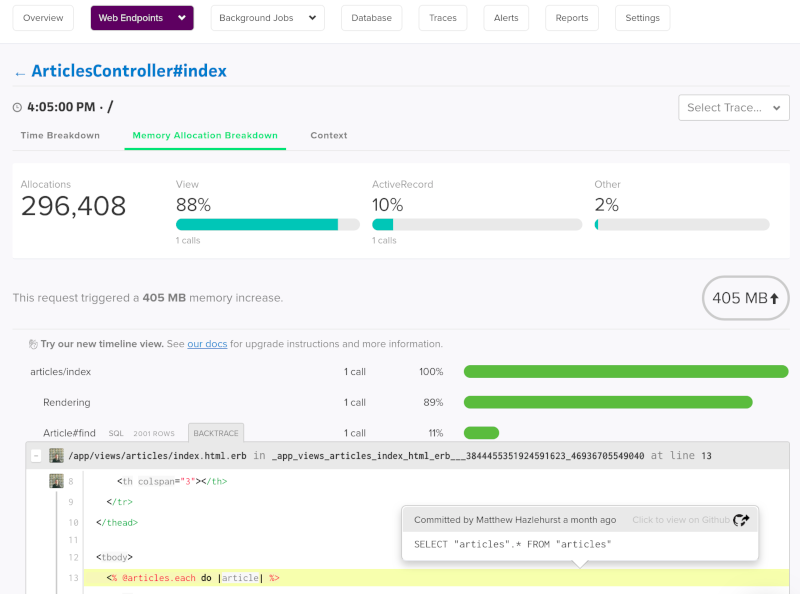
Other ideas for R14 errors
- A great example of a hard-to-trackdown memory issue is when only large users are generating R14 errors. In this case, viewing by context on the Traces page will help you find this issue.
- Looking at the Web Endpoints index page, you can filter by Max Allocations to find endpoints using a lot of memory. This gives you a different approach to finding endpoints to investigate rather than using the main overview page’s timeline.
- If you want to read more about the causes of memory bloat, and how you can use Scout to fix memory bloat issues, take a look at this article.
What’s next?
Are you using Heroku and coming across a different sort of Heroku error that we didn’t cover here? Contact us today on support and we’ll show you how to debug the problem with Scout APM! And for reading this far, click on Doggo for some free swag!
Heroku is a fantastic platform for hosting your applications, that’s why it is so popular amongst developers. But it is also clear to see how useful an APM tool is for debugging critical production issues when they arise and overall application performance health monitoring. So definitely sign up for a free trial today if you are not currently using Scout!
I have frequently encountered the following Error R14 (Memory quota exceeded) in the logs while running Grails apps on Heroku on the 1x Dyno which only allows 512mb of RAM:
2014-05-08T04:46:48.294887+00:00 heroku[web.1]: Process running mem=557M(108.9%) 2014-05-08T04:46:48.295268+00:00 heroku[web.1]: Error R14 (Memory quota exceeded)
To debug the issue and to be sure I was not having an application specific error, I created a new Grails application and followed the “Getting Started with Grails on Heroku” tutorial, but I still was getting the R14 error with a new application. To debug how much memory was being used, I used the Application Info plugin and ran the new application on Heroku. The source for this application can be found on Github.
I tried to run the same build and server process as Heroku locally but found about a 100mb difference in memory usage. The only difference I had locally was using JDK7. So, I configured the project to use JDK7 on Heroku by add adding a “system.properties” file to the project with the JDK configuration as described in the Heroku Grails tutorial:
#system.properties java.runtime.version=1.7
After starting up with the new JDK, I no longer say the Error R14 in the logs.
Using JDK7 on Heroku, the Grails application used much less memory on startup (454 vs 582 mb) and under load (496 vs 643 mb) using Apache Bench.
Related Blog Posts
Natively Compiled Java on Google App Engine
Google App Engine is a platform-as-a-service product that is marketed as a way to get your applications into the cloud without necessarily knowing all of the infrastructure bits and pieces to do so. Google App […]
Building Better Data Visualization Experiences: Part 2 of 2
If you don’t have a Ph.D. in data science, the raw data might be difficult to comprehend. This is where data visualization comes in.
Unleashing Feature Flags onto Kafka Consumers
Feature flags are a tool to strategically enable or disable functionality at runtime. They are often used to drive different user experiences but can also be useful in real-time data systems. In this post, we’ll […]
A security model for developers
Software security is more important than ever, but developing secure applications is more confusing than ever. TLS, mTLS, RBAC, SAML, OAUTH, OWASP, GDPR, SASL, RSA, JWT, cookie, attack vector, DDoS, firewall, VPN, security groups, exploit, […]