ВикиЧтение
HTML5 для веб-дизайнеров
Джереми Кит
Обработка ошибок
Обработка ошибок
Спецификация HTML5 не просто объявляет, что должны делать браузеры, когда они обрабатывают синтаксически правильную разметку. Впервые за всю историю HTML спецификация также объявляет, что? браузеры должны делать, когда им встречаются документы с ошибками разметки.
До сих пор разработчикам браузеров приходилось разбираться, что делать с ошибками, каждому самостоятельно. Обычно это означало, что нужно было применять реверс-инжиниринг и реализовывать примерно то, что делал в случае ошибок самый популярный браузер. Не самое продуктивное использование времени разработчиков браузеров. Гораздо лучше было бы не тратить время на то, чтобы дублировать то, как конкурент обрабатывает ошибочную разметку, а разрабатывать вместо этого новые функции.
Определение того, как нужно обрабатывать ошибки, в HTML5 – невероятно амбициозная задача. Даже если бы в HTML5 были только элементы и атрибуты из HTML 4.01, без добавления каких бы то ни было новых возможностей определить то, как нужно обрабатывать все ошибки, к 2012 году, – все равно было бы геркулесовым трудом.
Возможно, обработка ошибок не очень-то заинтересует веб-разработчиков, особенно если мы сразу настраиваемся на то, что пишем валидные и синтаксические корректные документы, но для разработчиков браузеров это очень важно. Если предыдущие спецификации разметки писались для авторов, то HTML5 написан и для авторов, и для разработчиков реализаций. Держите это в уме, когда штудируете спецификацию. Это объясняет, почему спецификация HTML5 настолько велика и почему она написана с таким уровнем детализации, который, кажется, обычно пишется для филателистов, любящих играть в шахматы, перебирая свою коллекцию игрушечных поездов.
Данный текст является ознакомительным фрагментом.
Читайте также
Пример: обработка ошибок
Пример: обработка ошибок
В программе 1.2 было продемонстрировано использование лишь самых примитивных средств обработки ошибок, а именно, получение номера ошибки в переменной типа DWORD с помощью функции GetLastError. Вызов функции, а не просто получение глобального номера
Пример: обработка ошибок как исключений
Пример: обработка ошибок как исключений
В предыдущих примерах для обработки ошибок при выполнении системных вызовов и других ошибок используется функция ReportError. Эта функция прекращает выполнение процесса, если программист указал, что данная ошибка является
26.4. Обработка ошибок
26.4. Обработка ошибок
Каждая из функций popt, которая может возвращать ошибки, возвращает целочисленные значения. В случае возникновения ошибки возвращается отрицательный код. В табл. 26.2 перечислены коды возможных ошибок. После таблицы дается подробное обсуждение каждой
Отслеживание и обработка ошибок
Отслеживание и обработка ошибок
PHP имеет следующие типы ошибок и предупреждений:Указанные значения в виде чисел или констант можно комбинировать, формируя битовую маску ошибок, о которых необходимо сообщать в ходе исполнения сценария. Для комбинирования используются
Обработка ошибок
Обработка ошибок
В предыдущем разделе мы обсудили разницу между системными вызовами и библиотечными функциями. Они также различаются по способу передачи процессу информации об ошибке, произошедшей во время выполнения системного вызова или функции библиотеки.Обычно в
1.4. Обработка ошибок: функции-обертки
1.4. Обработка ошибок: функции-обертки
В любой реальной программе существенным моментом является проверка каждого вызова функции на предмет возвращаемой ошибки. В листинге 1.1 мы проводим поиск ошибок в вызовах функций socket, inet_pton, connect, read и fputs, и когда ошибка случается, мы
Обработка ошибок
Обработка ошибок
Чтобы посетитель мог быстро исправить допущенные ошибки, от него требуется не только внимание и терпение. В ответ на некорректный ввод данных сайт должен выдать понятное сообщение. Обычно обработку ошибок возлагают на программистов. Им говорят:
1.6. Обработка ошибок: функции-обертки
1.6. Обработка ошибок: функции-обертки
В любой реальной программе при любом вызове требуется проверка возвращаемого значения на наличие ошибки. Поскольку обычно работа программ при возникновении ошибок завершается, мы можем сократить объем текста, определив
Обработка ошибок
Обработка ошибок
Из-за ограниченного объема главы я не могу подробно остановиться на рассмотрении такого чрезвычайно важного вопроса, как обработка ошибок. Однако очень важно включить код обработки ошибок в каждую процедуру базы данных. Подробные сведения о написании
Обработка ошибок и исключения
Обработка ошибок и исключения
Обработка ошибок — сложная задача, при решении которой программисту требуется вся помощь, которая только может быть предоставлена.
— Бьярн Страуструп (Bjarne Stroustrup),
[Stroustrup94] §16.2
Имеется три способа написать программу без ошибок; но работает
ГЛАВА 32. Обработка ошибок и события.
ГЛАВА 32. Обработка ошибок и события.
В этой главе мы рассмотрим, как при выполнении модулей PSQL — триггеров и процедур — можно перехватывать и обрабатывать ошибки в выполняемом коде.Стандартным поведением модулей PSQL при появлении исключений является остановка выполнения,
3.1.4 Обработка ошибок
3.1.4 Обработка ошибок
Поскольку программа так проста, обработка ошибок не сотавляет большого труда. Функция обработки ошибок просто счтает ошибки, пишет сообщение об ошибке и возвращает управлние обратно:int no_of_errors;double error(char* s) (* cerr «„ «error: » «« s «« «
“; no_of_errors++; return 1;
7.3.4 Обработка Ошибок
7.3.4 Обработка Ошибок
Есть четыре подхода к проблеме, что же делать, когда во время выполнения универсальное средство вроде slist сталкивется с ошибкой (в С++ нет никаких специальных средств языка для обработки ошибок):1. Возвращать недопустимое значение и позволить
- Назад
- Обзор: Introduction to HTML
- Далее
Написать HTML — здорово, но как понять, где ошибка, когда что-то не работает? В этой статье описаны несколько инструментов, которые помогают искать и исправлять ошибки в HTML.
| Что нужно знать: | Базовые знания HTML на уровне Начало работы с HTML, Основы редактирования текста в HTML, и Создание гиперссылок. |
|---|---|
| Чему вы научитесь: | Искать проблемы в HTML с помощью инструментов отладки. |
Отладка — это не страшно
Во время написания какого-нибудь кода, обычно все идёт хорошо, пока не появляется тот момент, когда вы совершаете ошибку. Итак, ваш код не работает, или работает не так, как вы задумывали. Если вы попытаетесь скомпилировать неработающую программу на языке Rust, компилятор укажет на ошибку:
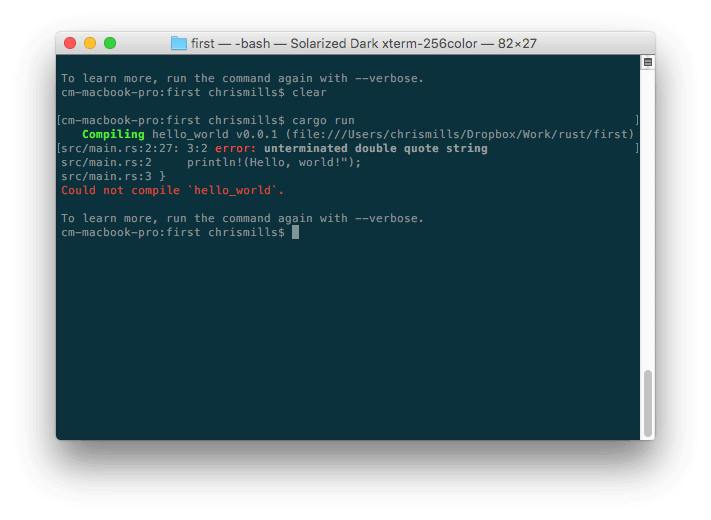 В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на
В данном случае, сообщение об ошибке понять относительно просто — «unterminated double quote string». Если вы внимательно посмотрите на println!(Hello, world!"); , то заметите, что здесь отсутствует двойная кавычка. Разумеется, сообщения об ошибках могут становиться куда более сложными для понимания по мере роста вашего кода, и даже самые простые случаи могут показаться пугающими для тех, кто ничего не знает о Rust.
Но не бойтесь отладки! Чтобы комфортно писать и отлаживать любой код, нужно понимать язык и его инструменты.
HTML и отладка
HTML не так сложен к пониманию, как Rust. HTML не компилируется в какую-либо другую форму перед тем, как браузер проанализирует это и покажет результат (он является интерпретируемым, а не компилируемым). Синтаксис HTML элементов намного понятнее, чем у «настоящих языков программирования», таких как Rust, JavaScript, или Python (en-US). Способ, которым браузеры читают HTML более толерантен, чем у языков программирования, интерпретирующих свой код строже. Это одновременно и плохо, и хорошо.
Толерантный код
Так что же означает толерантный? В общих чертах, когда вы напортачили в коде, есть два типа ошибок, с которыми вы столкнётесь:
- Синтаксические ошибки (Syntax errors): Это ошибки в правильности написания, как это было выше, в примере с Rust. Такие обычно легко исправлять, в той мере, в какой вы знакомы с синтаксисом языка и знаете, что означают сообщения об ошибках.
- Логические ошибки (Logic errors): Это ошибки, появляющиеся в том случае, если синтаксис корректен, но код не выполняет своего предназначения, то есть программа выполняется неверно. Такие исправлять сложнее, чем синтаксические, поскольку не выводится сообщений, указывающих место, где вы ошиблись.
HTML не страдает от синтаксических ошибок, потому что браузер читает код толерантно, в том смысле, что страницы могут отображаться даже если синтаксические ошибки присутствуют. Браузеры имеют встроенные правила по интерпретации неверно написанной разметки, и вы можете запустить что-либо, даже если вы имели в виду другое. Это может стать настоящей проблемой!
Примечание: На заметку: HTML читается толерантно, потому что когда веб только появился, было решено позволить людям публиковать контент даже при условии некорректностей в коде, так как это куда более важно, чем уверенность в абсолютно верном синтаксисе. Веб не был бы сейчас так популярен, если бы относился к новичкам строго.
Активное обучение: Знакомство с толерантным кодом
Время изучить природу толерантного кода в HTML.
- Для начала, скачайте наш пример отладки и сохраните локально. Эта демонстрация намеренно написана с ошибками, которые нам предстоит обнаружить.
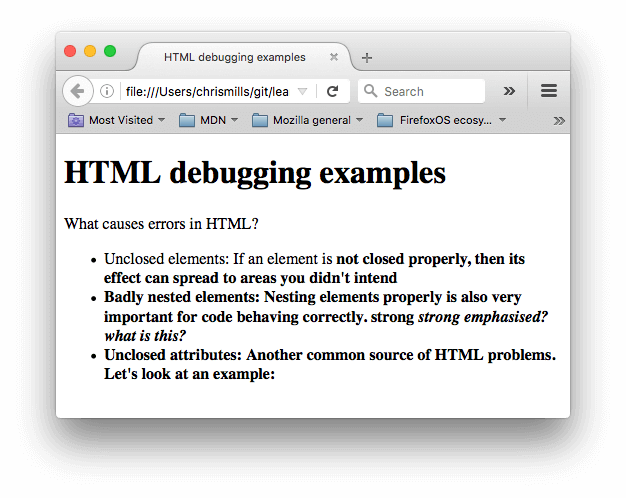
- Далее, откройте её в браузере. Вы увидите нечто вроде этого :

- Сейчас документ выглядит не особо хорошо; Давайте посмотрим в код и выясним почему (Показано только тело документа):
<h1>HTML debugging examples</h1> <p>What causes errors in HTML? <ul> <li>Unclosed elements: If an element is <strong>not closed properly, then its effect can spread to areas you didn't intend <li>Badly nested elements: Nesting elements properly is also very important for code behaving correctly. <strong>strong <em>strong emphasised?</strong> what is this?</em> <li>Unclosed attributes: Another common source of HTML problems. Let's look at an example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> </ul> - Рассмотрим проблемы:
- У параграфа и элемента списка не закрыты теги. На изображении выше видно, что разметка не пострадала, так как браузеру легко сделать вывод о том, где заканчивается один элемент и начинается другой.
- Первый
<strong>элемент также не имеет закрывающего тега. Это уже более проблематично, так как сложно сказать, где элемент должен заканчиваться. На деле, весь оставшийся текст был выделен жирным. - Следующая часть нарушает правила вложенности:
<strong>strong <em>strong emphasised?</strong> what is this?</em>. В этом случае код тоже сложно проинтерпретировать по причине, описанной выше. - В атрибуте
hrefотсутствует закрывающая двойная кавычка. Это послужило причиной крупной проблемы — ссылка не воспроизвелась вовсе.
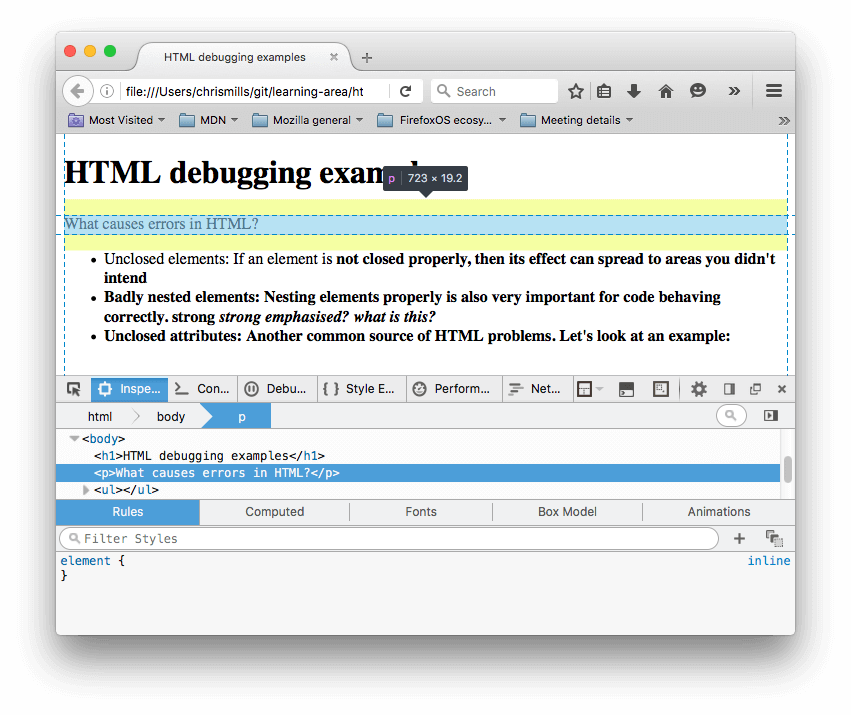
- Сейчас же посмотрим, как браузер сгенерировал собственную разметку, в противовес исходной разметке документа. Чтобы сделать это, воспользуемся инструментами разработчика. Если вы не знакомы с инструментами разработчика, потратьте несколько минут на Обзор инструментов разработки в браузерах.
- В DOM инспекторе вы можете увидеть как сгенерировалась новая разметка:

- Используя DOM инспектор, давайте рассмотрим детали нашего кода, чтобы увидеть, как браузер пытается исправить наши ошибки в HTML (мы обозреваем в Firefox; другой современный браузер должен выдать те же результаты):
- Параграфы и элементы списка получены с закрывающими тегами.
- Было неочевидно, где элемент
<strong>должен был закрыться, так что браузер обернул каждый отдельный блок текста своими собственными тегами strong, причём до самого низа документа! - Некорректная вложенность была исправлена браузером следующим образом:
<strong>strong <em>strong emphasised?</em> </strong> <em> what is this?</em> - Ссылка с отсутствующими двойными кавычками была удалена насовсем. Последний элемент списка будет выглядеть так:
<li> <strong>Unclosed attributes: Another common source of HTML problems. Let's look at an example: </strong> </li>
Валидация HTML
Из примера выше ясно, что стоит проверять валидность HTML. В простом примере сверху можно просто просмотреть весь код и найти ошибки, но как быть с огромными, сложными страницами?
Лучше всего проверить страницу в сервисе валидации разметки. Его создал и поддерживает W3C — организация, которая занимается спецификациями HTML, CSS и других веб-технологий. Сервис проверит ваш HTML и составит отчёт по ошибкам в нем.
HTML можно проверить по адресу, загрузив файл или напрямую ввести код HTML.
Активное обучение: Валидируем HTML-документ
Попробуем проверить документ-пример.
- Откройте сервис валидации разметки в браузере.
- Перейдите в режим Validate by Direct Input.
- Скопируйте весь код документа (не только body) и вставьте в место для ввода.
- Нажмите на Check (проверить).
Вы увидите список ошибок и другую информацию.
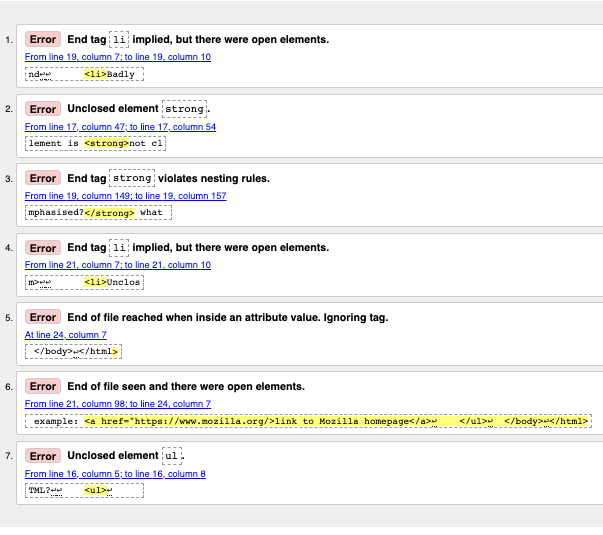
Работа с сообщениями об ошибках
Обычно сразу ясно, что значат сообщения, но иногда приходится постараться, чтобы понять, в чем дело. Сейчас мы пройдёмся по всем ошибкам и разберём, что они значат. Обратите внимание, что в сообщениях указаны строка и столбец кода, чтобы ошибки было проще искать.
- «End tag
liimplied, but there were open elements» (2 instances): Нет явного закрывающего тега, хотя браузер догадывается, где он должен быть. Сообщение указывает на строку после той, на которой ожидался закрывающий тег, но вы найдёте нужное место. - «Unclosed element
strong«: Это очень простая ошибка — элемент<strong>не закрыт, и сообщение указывает прямо на открывающий тег. - «End tag
strongviolates nesting rules»: Элемент неправильно вложен — на этом уровне нет парного открывающего тега. - «End of file reached when inside an attribute value. Ignoring tag»: Загадочное сообщение. Дело в том, что где-то (скорее всего, в конце документа) неправильно прописано свойство элемента, и конец файла оказался внутри этого свойства. В браузере не видно ссылки — скорее всего, проблема рядом с ней.
- «End of file seen and there were open elements»: Файл закончился, но некоторые элементы не закрыты. Сообщение указывает на конец файла, в данном случае не закрыт элемент
example: <a href="https://www.mozilla.org/>link to Mozilla homepage</a> ↩ </ul>↩ </body>↩</html>
Примечание: Свойство без закрывающей кавычки может проглотить закрывающий тег — браузер считает его частью значения этого свойства.
- «Unclosed element
ul«: Странно, ведь элемент<ul>закрыт. Настоящая проблема всё там же — элемент<a>не закрыт из-за недостающей кавычки в свойстве.
Если некоторые ошибки кажутся вам странными, начните исправление с остальных и проверьте документ ещё раз. Иногда одна ошибка ломает большую часть документа.
Когда вы увидите эту надпись, в вашем документе больше нет ошибок:
![]()
Заключение
Теперь вы умеете отлаживать HTML. С новыми знаниями вам будет проще разобраться и в отладке более сложных языков — например, CSS и JavaScript. На этом мы заканчиваем вводный модуль курса HTML — время попробовать свои силы в упражнениях.
- Назад
- Обзор: Introduction to HTML
- Далее
В этом модуле
Ошибки — это хорошо. Автор материала, перевод которого мы сегодня публикуем, говорит, что уверен в том, что эта идея известна всем. На первый взгляд ошибки кажутся чем-то страшным. Им могут сопутствовать какие-то потери. Ошибка, сделанная на публике, вредит авторитету того, кто её совершил. Но, совершая ошибки, мы на них учимся, а значит, попадая в следующий раз в ситуацию, в которой раньше вели себя неправильно, делаем всё как нужно.

Выше мы говорили об ошибках, которые люди совершают в обычной жизни. Ошибки в программировании — это нечто иное. Сообщения об ошибках помогают нам улучшать код, они позволяют сообщать пользователям наших проектов о том, что что-то пошло не так, и, возможно, рассказывают пользователям о том, как нужно вести себя для того, чтобы ошибок больше не возникало.
Этот материал, посвящённый обработке ошибок в JavaScript, разбит на три части. Сначала мы сделаем общий обзор системы обработки ошибок в JavaScript и поговорим об объектах ошибок. После этого мы поищем ответ на вопрос о том, что делать с ошибками, возникающими в серверном коде (в частности, при использовании связки Node.js + Express.js). Далее — обсудим обработку ошибок в React.js. Фреймворки, которые будут здесь рассматриваться, выбраны по причине их огромной популярности. Однако рассматриваемые здесь принципы работы с ошибками универсальны, поэтому вы, даже если не пользуетесь Express и React, без труда сможете применить то, что узнали, к тем инструментам, с которыми работаете.
Код демонстрационного проекта, используемого в данном материале, можно найти в этом репозитории.
1. Ошибки в JavaScript и универсальные способы работы с ними
Если в вашем коде что-то пошло не так, вы можете воспользоваться следующей конструкцией.
throw new Error('something went wrong')В ходе выполнения этой команды будет создан экземпляр объекта Error и будет сгенерировано (или, как говорят, «выброшено») исключение с этим объектом. Инструкция throw может генерировать исключения, содержащие произвольные выражения. При этом выполнение скрипта остановится в том случае, если не были предприняты меры по обработке ошибки.
Начинающие JS-программисты обычно не используют инструкцию throw. Они, как правило, сталкиваются с исключениями, выдаваемыми либо средой выполнения языка, либо сторонними библиотеками. Когда это происходит — в консоль попадает нечто вроде ReferenceError: fs is not defined и выполнение программы останавливается.
▍Объект Error
У экземпляров объекта Error есть несколько свойств, которыми мы можем пользоваться. Первое интересующее нас свойство — message. Именно сюда попадает та строка, которую можно передать конструктору ошибки в качестве аргумента. Например, ниже показано создание экземпляра объекта Error и вывод в консоль переданной конструктором строки через обращение к его свойству message.
const myError = new Error('please improve your code')
console.log(myError.message) // please improve your code
Второе свойство объекта, очень важное, представляет собой трассировку стека ошибки. Это — свойство stack. Обратившись к нему можно просмотреть стек вызовов (историю ошибки), который показывает последовательность операций, приведшую к неправильной работе программы. В частности, это позволяет понять — в каком именно файле содержится сбойный код, и увидеть, какая последовательность вызовов функций привела к ошибке. Вот пример того, что можно увидеть, обратившись к свойству stack.
Error: please improve your code
at Object.<anonymous> (/Users/gisderdube/Documents/_projects/hacking.nosync/error-handling/src/general.js:1:79)
at Module._compile (internal/modules/cjs/loader.js:689:30)
at Object.Module._extensions..js (internal/modules/cjs/loader.js:700:10)
at Module.load (internal/modules/cjs/loader.js:599:32)
at tryModuleLoad (internal/modules/cjs/loader.js:538:12)
at Function.Module._load (internal/modules/cjs/loader.js:530:3)
at Function.Module.runMain (internal/modules/cjs/loader.js:742:12)
at startup (internal/bootstrap/node.js:266:19)
at bootstrapNodeJSCore (internal/bootstrap/node.js:596:3)Здесь, в верхней части, находится сообщение об ошибке, затем следует указание на тот участок кода, выполнение которого вызвало ошибку, потом описывается то место, откуда был вызван этот сбойный участок. Это продолжается до самого «дальнего» по отношению к ошибке фрагмента кода.
▍Генерирование и обработка ошибок
Создание экземпляра объекта Error, то есть, выполнение команды вида new Error(), ни к каким особым последствиям не приводит. Интересные вещи начинают происходить после применения оператора throw, который генерирует ошибку. Как уже было сказано, если такую ошибку не обработать, выполнение скрипта остановится. При этом нет никакой разницы — был ли оператор throw использован самим программистом, произошла ли ошибка в некоей библиотеке или в среде выполнения языка (в браузере или в Node.js). Поговорим о различных сценариях обработки ошибок.
▍Конструкция try…catch
Блок try...catch представляет собой самый простой способ обработки ошибок, о котором часто забывают. В наши дни, правда, он используется гораздо интенсивнее чем раньше, благодаря тому, что его можно применять для обработки ошибок в конструкциях async/await.
Этот блок можно использовать для обработки любых ошибок, происходящих в синхронном коде. Рассмотрим пример.
const a = 5
try {
console.log(b) // переменная b не объявлена - возникает ошибка
} catch (err) {
console.error(err) // в консоль попадает сообщение об ошибке и стек ошибки
}
console.log(a) // выполнение скрипта не останавливается, данная команда выполняется
Если бы в этом примере мы не заключили бы сбойную команду console.log(b) в блок try...catch, то выполнение скрипта было бы остановлено.
▍Блок finally
Иногда случается так, что некий код нужно выполнить независимо от того, произошла ошибка или нет. Для этого можно, в конструкции try...catch, использовать третий, необязательный, блок — finally. Часто его использование эквивалентно некоему коду, который идёт сразу после try...catch, но в некоторых ситуациях он может пригодиться. Вот пример его использования.
const a = 5
try {
console.log(b) // переменная b не объявлена - возникает ошибка
} catch (err) {
console.error(err) // в консоль попадает сообщение об ошибке и стек ошибки
} finally {
console.log(a) // этот код будет выполнен в любом случае
}▍Асинхронные механизмы — коллбэки
Программируя на JavaScript всегда стоит обращать внимание на участки кода, выполняющиеся асинхронно. Если у вас имеется асинхронная функция и в ней возникает ошибка, скрипт продолжит выполняться. Когда асинхронные механизмы в JS реализуются с использованием коллбэков (кстати, делать так не рекомендуется), соответствующий коллбэк (функция обратного вызова) обычно получает два параметра. Это нечто вроде параметра err, который может содержать ошибку, и result — с результатами выполнения асинхронной операции. Выглядит это примерно так:
myAsyncFunc(someInput, (err, result) => {
if(err) return console.error(err) // порядок работы с объектом ошибки мы рассмотрим позже
console.log(result)
})
Если в коллбэк попадает ошибка, она видна там в виде параметра err. В противном случае в этот параметр попадёт значение undefined или null. Если оказалось, что в err что-то есть, важно отреагировать на это, либо так как в нашем примере, воспользовавшись командой return, либо воспользовавшись конструкцией if...else и поместив в блок else команды для работы с результатом выполнения асинхронной операции. Речь идёт о том, чтобы, в том случае, если произошла ошибка, исключить возможность работы с результатом, параметром result, который в таком случае может иметь значение undefined. Работа с таким значением, если предполагается, например, что оно содержит объект, сама может вызвать ошибку. Скажем, это произойдёт при попытке использовать конструкцию result.data или подобную ей.
▍Асинхронные механизмы — промисы
Для выполнения асинхронных операций в JavaScript лучше использовать не коллбэки а промисы. Тут, в дополнение к улучшенной читабельности кода, имеются и более совершенные механизмы обработки ошибок. А именно, возиться с объектом ошибки, который может попасть в функцию обратного вызова, при использовании промисов не нужно. Здесь для этой цели предусмотрен специальный блок catch. Он перехватывает все ошибки, произошедшие в промисах, которые находятся до него, или все ошибки, которые произошли в коде после предыдущего блока catch. Обратите внимание на то, что если в промисе произошла ошибка, для обработки которой нет блока catch, это не остановит выполнение скрипта, но сообщение об ошибке будет не особенно удобочитаемым.
(node:7741) UnhandledPromiseRejectionWarning: Unhandled promise rejection (rejection id: 1): Error: something went wrong
(node:7741) DeprecationWarning: Unhandled promise rejections are deprecated. In the future, promise rejections that are not handled will terminate the Node.js process with a non-zero exit code. */
В результате можно порекомендовать всегда, при работе с промисами, использовать блок catch. Взглянем на пример.
Promise.resolve(1)
.then(res => {
console.log(res) // 1
throw new Error('something went wrong')
return Promise.resolve(2)
})
.then(res => {
console.log(res) // этот блок выполнен не будет
})
.catch(err => {
console.error(err) // о том, что делать с этой ошибкой, поговорим позже
return Promise.resolve(3)
})
.then(res => {
console.log(res) // 3
})
.catch(err => {
// этот блок тут на тот случай, если в предыдущем блоке возникнет какая-нибудь ошибка
console.error(err)
})▍Асинхронные механизмы и try…catch
После того, как в JavaScript появилась конструкция async/await, мы вернулись к классическому способу обработки ошибок — к try...catch...finally. Обрабатывать ошибки при таком подходе оказывается очень легко и удобно. Рассмотрим пример.
;(async function() {
try {
await someFuncThatThrowsAnError()
} catch (err) {
console.error(err) // об этом поговорим позже
}
console.log('Easy!') // будет выполнено
})()
При таком подходе ошибки в асинхронном коде обрабатываются так же, как в синхронном. В результате теперь, при необходимости, в одном блоке catch можно обрабатывать более широкий диапазон ошибок.
2. Генерирование и обработка ошибок в серверном коде
Теперь, когда у нас есть инструменты для работы с ошибками, посмотрим на то, что мы можем с ними делать в реальных ситуациях. Генерирование и правильная обработка ошибок — это важнейший аспект серверного программирования. Существуют разные подходы к работе с ошибками. Здесь будет продемонстрирован подход с использованием собственного конструктора для экземпляров объекта Error и кодов ошибок, которые удобно передавать во фронтенд или любым механизмам, использующим серверные API. Как структурирован бэкенд конкретного проекта — особого значения не имеет, так как при любом подходе можно использовать одни и те же идеи, касающиеся работы с ошибками.
В качестве серверного фреймворка, отвечающего за маршрутизацию, мы будем использовать Express.js. Подумаем о том, какая структура нам нужна для организации эффективной системы обработки ошибок. Итак, вот что нам нужно:
- Универсальная обработка ошибок — некий базовый механизм, подходящий для обработки любых ошибок, в ходе работы которого просто выдаётся сообщение наподобие
Something went wrong, please try again or contact us, предлагающее пользователю попробовать выполнить операцию, давшую сбой, ещё раз или связаться с владельцем сервера. Эта система не отличается особой интеллектуальностью, но она, по крайней мере, способна сообщить пользователю о том, что что-то пошло не так. Подобное сообщение гораздо лучше, чем «бесконечная загрузка» или нечто подобное. - Обработка конкретных ошибок — механизм, позволяющий сообщить пользователю подробные сведения о причинах неправильного поведения системы и дать ему конкретные советы по борьбе с неполадкой. Например, это может касаться отсутствия неких важных данных в запросе, который пользователь отправляет на сервер, или в том, что в базе данных уже существует некая запись, которую он пытается добавить ещё раз, и так далее.
▍Разработка собственного конструктора объектов ошибок
Здесь мы воспользуемся стандартным классом Error и расширим его. Пользоваться механизмами наследования в JavaScript — дело рискованное, но в данном случае эти механизмы оказываются весьма полезными. Зачем нам наследование? Дело в том, что нам, для того, чтобы код удобно было бы отлаживать, нужны сведения о трассировке стека ошибки. Расширяя стандартный класс Error, мы, без дополнительных усилий, получаем возможности по трассировке стека. Мы добавляем в наш собственный объект ошибки два свойства. Первое — это свойство code, доступ к которому можно будет получить с помощью конструкции вида err.code. Второе — свойство status. В него будет записываться код состояния HTTP, который планируется передавать клиентской части приложения.
Вот как выглядит класс CustomError, код которого оформлен в виде модуля.
class CustomError extends Error {
constructor(code = 'GENERIC', status = 500, ...params) {
super(...params)
if (Error.captureStackTrace) {
Error.captureStackTrace(this, CustomError)
}
this.code = code
this.status = status
}
}
module.exports = CustomError▍Маршрутизация
Теперь, когда наш объект ошибки готов к использованию, нужно настроить структуру маршрутов. Как было сказано выше, нам требуется реализовать унифицированный подход к обработке ошибок, позволяющий одинаково обрабатывать ошибки для всех маршрутов. По умолчанию фреймворк Express.js не вполне поддерживает такую схему работы. Дело в том, что все его маршруты инкапсулированы.
Для того чтобы справиться с этой проблемой, мы можем реализовать собственный обработчик маршрутов и определять логику маршрутов в виде обычных функций. Благодаря такому подходу, если функция маршрута (или любая другая функция) выбрасывает ошибку, она попадёт в обработчик маршрутов, который затем может передать её клиентской части приложения. При возникновении ошибки на сервере мы планируем передавать её во фронтенд в следующем формате, полагая, что для этого будет применяться JSON-API:
{
error: 'SOME_ERROR_CODE',
description: 'Something bad happened. Please try again or contact support.'
}Если на данном этапе происходящие кажется вам непонятным — не беспокойтесь — просто продолжайте читать, пробуйте работать с тем, о чём идёт речь, и постепенно вы во всём разберётесь. На самом деле, если говорить о компьютерном обучении, здесь применяется подход «сверху-вниз», когда сначала обсуждаются общие идеи, а потом осуществляется переход к частностям.
Вот как выглядит код обработчика маршрутов.
const express = require('express')
const router = express.Router()
const CustomError = require('../CustomError')
router.use(async (req, res) => {
try {
const route = require(`.${req.path}`)[req.method]
try {
const result = route(req) // Передаём запрос функции route
res.send(result) // Передаём клиенту то, что получено от функции route
} catch (err) {
/*
Сюда мы попадаем в том случае, если в функции route произойдёт ошибка
*/
if (err instanceof CustomError) {
/*
Если ошибка уже обработана - трансформируем её в
возвращаемый объект
*/
return res.status(err.status).send({
error: err.code,
description: err.message,
})
} else {
console.error(err) // Для отладочных целей
// Общая ошибка - вернём универсальный объект ошибки
return res.status(500).send({
error: 'GENERIC',
description: 'Something went wrong. Please try again or contact support.',
})
}
}
} catch (err) {
/*
Сюда мы попадём, если запрос окажется неудачным, то есть,
либо не будет найдено файла, соответствующего пути, переданному
в запросе, либо не будет экспортированной функции с заданным
методом запроса
*/
res.status(404).send({
error: 'NOT_FOUND',
description: 'The resource you tried to access does not exist.',
})
}
})
module.exports = routerПолагаем, комментарии в коде достаточно хорошо его поясняют. Надеемся, читать их удобнее, чем объяснения подобного кода, данные после него.
Теперь взглянем на файл маршрутов.
const CustomError = require('../CustomError')
const GET = req => {
// пример успешного выполнения запроса
return { name: 'Rio de Janeiro' }
}
const POST = req => {
// пример ошибки общего характера
throw new Error('Some unexpected error, may also be thrown by a library or the runtime.')
}
const DELETE = req => {
// пример ошибки, обрабатываемой особым образом
throw new CustomError('CITY_NOT_FOUND', 404, 'The city you are trying to delete could not be found.')
}
const PATCH = req => {
// пример перехвата ошибок и использования CustomError
try {
// тут случилось что-то нехорошее
throw new Error('Some internal error')
} catch (err) {
console.error(err) // принимаем решение о том, что нам тут делать
throw new CustomError(
'CITY_NOT_EDITABLE',
400,
'The city you are trying to edit is not editable.'
)
}
}
module.exports = {
GET,
POST,
DELETE,
PATCH,
}
В этих примерах с самими запросами ничего не делается. Тут просто рассматриваются разные сценарии возникновения ошибок. Итак, например, запрос GET /city попадёт в функцию const GET = req =>..., запрос POST /city попадёт в функцию const POST = req =>... и так далее. Эта схема работает и при использовании параметров запросов. Например — для запроса вида GET /city?startsWith=R. В целом, здесь продемонстрировано, что при обработке ошибок, во фронтенд может попасть либо общая ошибка, содержащая лишь предложение попробовать снова или связаться с владельцем сервера, либо ошибка, сформированная с использованием конструктора CustomError, которая содержит подробные сведения о проблеме.
Данные общей ошибки придут в клиентскую часть приложения в таком виде:
{
error: 'GENERIC',
description: 'Something went wrong. Please try again or contact support.'
}
Конструктор CustomError используется так:
throw new CustomError('MY_CODE', 400, 'Error description')Это даёт следующий JSON-код, передаваемый во фронтенд:
{
error: 'MY_CODE',
description: 'Error description'
}Теперь, когда мы основательно потрудились над серверной частью приложения, в клиентскую часть больше не попадают бесполезные логи ошибок. Вместо этого клиент получает полезные сведения о том, что пошло не так.
Не забудьте о том, что здесь лежит репозиторий с рассматриваемым здесь кодом. Можете его загрузить, поэкспериментировать с ним, и, если надо, адаптировать под нужды вашего проекта.
3. Работа с ошибками на клиенте
Теперь пришла пора описать третью часть нашей системы обработки ошибок, касающуюся фронтенда. Тут нужно будет, во-первых, обрабатывать ошибки, возникающие в клиентской части приложения, а во-вторых, понадобится оповещать пользователя об ошибках, возникающих на сервере. Разберёмся сначала с показом сведений о серверных ошибках. Как уже было сказано, в этом примере будет использована библиотека React.
▍Сохранение сведений об ошибках в состоянии приложения
Как и любые другие данные, ошибки и сообщения об ошибках могут меняться, поэтому их имеет смысл помещать в состояние компонентов. При монтировании компонента данные об ошибке сбрасываются, поэтому, когда пользователь впервые видит страницу, там сообщений об ошибках не будет.
Следующее, с чем надо разобраться, заключается в том, что ошибки одного типа нужно показывать в одном стиле. По аналогии с сервером, здесь можно выделить 3 типа ошибок.
- Глобальные ошибки — в эту категорию попадают сообщения об ошибках общего характера, приходящие с сервера, или ошибки, которые, например, возникают в том случае, если пользователь не вошёл в систему и в других подобных ситуациях.
- Специфические ошибки, выдаваемые серверной частью приложения — сюда относятся ошибки, сведения о которых приходят с сервера. Например, подобная ошибка возникает, если пользователь попытался войти в систему и отправил на сервер имя и пароль, а сервер сообщил ему о том, что пароль неправильный. Подобные вещи в клиентской части приложения не проверяются, поэтому сообщения о таких ошибках должны приходить с сервера.
- Специфические ошибки, выдаваемые клиентской частью приложения. Пример такой ошибки — сообщение о некорректном адресе электронной почты, введённом в соответствующее поле.
Ошибки второго и третьего типов очень похожи, работать с ними можно, используя хранилище состояния компонентов одного уровня. Их главное различие заключается в том, что они исходят из разных источников. Ниже, анализируя код, мы посмотрим на работу с ними.
Здесь будет использоваться встроенная в React система управления состоянием приложения, но, при необходимости, вы можете воспользоваться и специализированными решениями для управления состоянием — такими, как MobX или Redux.
▍Глобальные ошибки
Обычно сообщения о таких ошибках сохраняются в компоненте наиболее высокого уровня, имеющем состояние. Они выводятся в статическом элементе пользовательского интерфейса. Это может быть красное поле в верхней части экрана, модальное окно или что угодно другое. Реализация зависит от конкретного проекта. Вот как выглядит сообщение о такой ошибке.
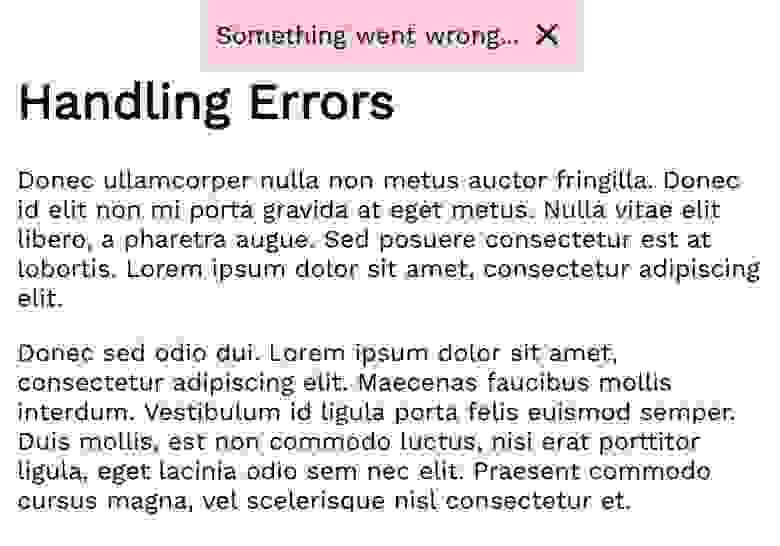
Сообщение о глобальной ошибке
Теперь взглянем на код, который хранится в файле Application.js.
import React, { Component } from 'react'
import GlobalError from './GlobalError'
class Application extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
}
this._resetError = this._resetError.bind(this)
this._setError = this._setError.bind(this)
}
render() {
return (
<div className="container">
<GlobalError error={this.state.error} resetError={this._resetError} />
<h1>Handling Errors</h1>
</div>
)
}
_resetError() {
this.setState({ error: '' })
}
_setError(newError) {
this.setState({ error: newError })
}
}
export default Application
Как видно, в состоянии, в Application.js, имеется место для хранения данных ошибки. Кроме того, тут предусмотрены методы для сброса этих данных и для их изменения.
Ошибка и метод для сброса ошибки передаётся компоненту GlobalError, который отвечает за вывод сообщения об ошибке на экран и за сброс ошибки после нажатия на значок x в поле, где выводится сообщение. Вот код компонента GlobalError (файл GlobalError.js).
import React, { Component } from 'react'
class GlobalError extends Component {
render() {
if (!this.props.error) return null
return (
<div
style={{
position: 'fixed',
top: 0,
left: '50%',
transform: 'translateX(-50%)',
padding: 10,
backgroundColor: '#ffcccc',
boxShadow: '0 3px 25px -10px rgba(0,0,0,0.5)',
display: 'flex',
alignItems: 'center',
}}
>
{this.props.error}
<i
className="material-icons"
style={{ cursor: 'pointer' }}
onClick={this.props.resetError}
>
close
</font></i>
</div>
)
}
}
export default GlobalError
Обратите внимание на строку if (!this.props.error) return null. Она указывает на то, что при отсутствии ошибки компонент ничего не выводит. Это предотвращает постоянный показ красного прямоугольника на странице. Конечно, вы, при желании, можете поменять внешний вид и поведение этого компонента. Например, вместо того, чтобы сбрасывать ошибку по нажатию на x, можно задать тайм-аут в пару секунд, по истечении которого состояние ошибки сбрасывается автоматически.
Теперь, когда всё готово для работы с глобальными ошибками, для задания глобальной ошибки достаточно воспользоваться _setError из Application.js. Например, это можно сделать в том случае, если сервер, после обращения к нему, вернул сообщение об общей ошибке (error: 'GENERIC'). Рассмотрим пример (файл GenericErrorReq.js).
import React, { Component } from 'react'
import axios from 'axios'
class GenericErrorReq extends Component {
constructor(props) {
super(props)
this._callBackend = this._callBackend.bind(this)
}
render() {
return (
<div>
<button onClick={this._callBackend}>Click me to call the backend</button>
</div>
)
}
_callBackend() {
axios
.post('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
}
})
}
}
export default GenericErrorReqНа самом деле, на этом наш разговор об обработке ошибок можно было бы и закончить. Даже если в проекте нужно оповещать пользователя о специфических ошибках, никто не мешает просто поменять глобальное состояние, хранящее ошибку и вывести соответствующее сообщение поверх страницы. Однако тут мы не остановимся и поговорим о специфических ошибках. Во-первых, это руководство по обработке ошибок иначе было бы неполным, а во-вторых, с точки зрения UX-специалистов, неправильно будет показывать сообщения обо всех ошибках так, будто все они — глобальные.
▍Обработка специфических ошибок, возникающих при выполнении запросов
Вот пример специфического сообщения об ошибке, выводимого в том случае, если пользователь пытается удалить из базы данных город, которого там нет.

Сообщение о специфической ошибке
Тут используется тот же принцип, который мы применяли при работе с глобальными ошибками. Только сведения о таких ошибках хранятся в локальном состоянии соответствующих компонентов. Работа с ними очень похожа на работу с глобальными ошибками. Вот код файла SpecificErrorReq.js.
import React, { Component } from 'react'
import axios from 'axios'
import InlineError from './InlineError'
class SpecificErrorRequest extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
}
this._callBackend = this._callBackend.bind(this)
}
render() {
return (
<div>
<button onClick={this._callBackend}>Delete your city</button>
<InlineError error={this.state.error} />
</div>
)
}
_callBackend() {
this.setState({
error: '',
})
axios
.delete('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
} else {
this.setState({
error: err.response.data.description,
})
}
})
}
}
export default SpecificErrorRequest
Тут стоит отметить, что для сброса специфических ошибок недостаточно, например, просто нажать на некую кнопку x. То, что пользователь прочёл сообщение об ошибке и закрыл его, не помогает такую ошибку исправить. Исправить её можно, правильно сформировав запрос к серверу, например — введя в ситуации, показанной на предыдущем рисунке, имя города, который есть в базе. В результате очищать сообщение об ошибке имеет смысл, например, после выполнения нового запроса. Сбросить ошибку можно и в том случае, если пользователь внёс изменения в то, что будет использоваться при формировании нового запроса, то есть — при изменении содержимого поля ввода.
▍Ошибки, возникающие в клиентской части приложения
Как уже было сказано, для хранения данных о таких ошибках можно использовать состояние тех же компонентов, которое используется для хранения данных по специфическим ошибкам, поступающим с сервера. Предположим, мы позволяем пользователю отправить на сервер запрос на удаление города из базы только в том случае, если в соответствующем поле ввода есть какой-то текст. Отсутствие или наличие текста в поле можно проверить средствами клиентской части приложения.

В поле ничего нет, мы сообщаем об этом пользователю
Вот код файла SpecificErrorFrontend.js, реализующий вышеописанный функционал.
import React, { Component } from 'react'
import axios from 'axios'
import InlineError from './InlineError'
class SpecificErrorRequest extends Component {
constructor(props) {
super(props)
this.state = {
error: '',
city: '',
}
this._callBackend = this._callBackend.bind(this)
this._changeCity = this._changeCity.bind(this)
}
render() {
return (
<div>
<input
type="text"
value={this.state.city}
style={{ marginRight: 15 }}
onChange={this._changeCity}
/>
<button onClick={this._callBackend}>Delete your city</button>
<InlineError error={this.state.error} />
</div>
)
}
_changeCity(e) {
this.setState({
error: '',
city: e.target.value,
})
}
_validate() {
if (!this.state.city.length) throw new Error('Please provide a city name.')
}
_callBackend() {
this.setState({
error: '',
})
try {
this._validate()
} catch (err) {
return this.setState({ error: err.message })
}
axios
.delete('/api/city')
.then(result => {
// сделать что-нибудь с результатом в том случае, если запрос оказался успешным
})
.catch(err => {
if (err.response.data.error === 'GENERIC') {
this.props.setError(err.response.data.description)
} else {
this.setState({
error: err.response.data.description,
})
}
})
}
}
export default SpecificErrorRequest▍Интернационализация сообщений об ошибках с использованием кодов ошибок
Возможно, сейчас вы задаётесь вопросом о том, зачем нам нужны коды ошибок (наподобие GENERIC), если мы показываем пользователю только сообщения об ошибках, полученных с сервера. Дело в том, что, по мере роста и развития приложения, оно, вполне возможно, выйдет на мировой рынок, а это означает, что настанет время, когда создателям приложения нужно будет задуматься о поддержке им нескольких языков. Коды ошибок позволяют отличать их друг от друга и выводить сообщения о них на языке пользователя сайта.
Итоги
Надеемся, теперь у вас сформировалось понимание того, как можно работать с ошибками в веб-приложениях. Нечто вроде console.error(err) следует использовать только в отладочных целях, в продакшн подобные вещи, забытые программистом, проникать не должны. Упрощает решение задачи логирования использование какой-нибудь подходящей библиотеки наподобие loglevel.
Уважаемые читатели! Как вы обрабатываете ошибки в своих проектах?

- Главная»
- Уроки»
- PHP»
- Создаем единую страницу для обработки ошибок
- Метки урока:
- php
- кодинг
- разное
Создаем единую страницу для обработки ошибок
В данном уроке представлено очень простое решение для обработки различных ошибок HTTP, таких как 404, 500 и так далее, в одном файле PHP. Нужно создать массив кодов ошибок и установить правила перенаправления на наш PHP файл. То есть, можно использовать одну страницу для обработки нескольких ошибок.
Перенаправление
В файле .htaccess вашего сервера нужно установить правила для обработки ошибок. В нашем случае мы будем перенаправлять все ошибки в наш файл errors.php, который будет формировать страницу HTML для посетителя. Добавляем в файл .htaccess следующие правила:
ErrorDocument 400 /errors.php ErrorDocument 403 /errors.php ErrorDocument 404 /errors.php ErrorDocument 405 /errors.php ErrorDocument 408 /errors.php ErrorDocument 500 /errors.php ErrorDocument 502 /errors.php ErrorDocument 504 /errors.php
PHP
Теперь создаем файл errors.php, который должен располагаться в корневом каталоге вашего сервера (так как такое его местоположение установлено в заданных нами выше правилах в файле .htaccess).
$status = $_SERVER['REDIRECT_STATUS'];
$codes = array(
400 => array('400 Плохой запрос', 'Запрос не может быть обработан из-за синтаксической ошибки.'),
403 => array('403 Запрещено', 'Сервер отказывает в выполнении вашего запроса.'),
404 => array('404 Не найдено', 'Запрашиваемая страница не найдена на сервере.'),
405 => array('405 Метод не допускается', 'Указанный в запросе метод не допускается для заданного ресурса.'),
408 => array('408 Время ожидания истекло', 'Ваш браузер не отправил информацию на сервер за отведенное время.'),
500 => array('500 Внутренняя ошибка сервера', 'Запрос не может быть обработан из-за внутренней ошибки сервера.'),
502 => array('502 Плохой шлюз', 'Сервер получил неправильный ответ при попытке передачи запроса.'),
504 => array('504 Истекло время ожидания шлюза', 'Вышестоящий сервер не ответил за установленное время.'),
);
$title = $codes[$status][0];
$message = $codes[$status][1];
if ($title == false || strlen($status) != 3) {
$message = 'Код ошибки HTTP не правильный.';
}
echo '<h1>Внимание! Обнаружена ошибка '.$title.'!</h1>
<p>'.$message.'</p>';
Готово!
Конечно, код PHP может формировать и более информативную страницу для пользователя. При формировании разметки стоит учесть рекомендации для страниц, выводящих информацию об ошибках.
5 последних уроков рубрики «PHP»
-

Фильтрация данных с помощью zend-filter
Когда речь идёт о безопасности веб-сайта, то фраза «фильтруйте всё, экранируйте всё» всегда будет актуальна. Сегодня поговорим о фильтрации данных.
-
Контекстное экранирование с помощью zend-escaper
Обеспечение безопасности веб-сайта — это не только защита от SQL инъекций, но и протекция от межсайтового скриптинга (XSS), межсайтовой подделки запросов (CSRF) и от других видов атак. В частности, вам нужно очень осторожно подходить к формированию HTML, CSS и JavaScript кода.
-
Подключение Zend модулей к Expressive
Expressive 2 поддерживает возможность подключения других ZF компонент по специальной схеме. Не всем нравится данное решение. В этой статье мы расскажем как улучшили процесс подключение нескольких модулей.
-
Совет: отправка информации в Google Analytics через API
Предположим, что вам необходимо отправить какую-то информацию в Google Analytics из серверного скрипта. Как это сделать. Ответ в этой заметке.
-
Подборка PHP песочниц
Подборка из нескольких видов PHP песочниц. На некоторых вы в режиме online сможете потестить свой код, но есть так же решения, которые можно внедрить на свой сайт.





Обработка ошибок
Для обработки ошибок JavaScript использует выражение try...catch. По большому счету, при прочтении этой книги вам не нужно будет задумываться об обработке ошибок, потому что я делаю упор на объяснение возможностей и особенностей HTML5, а не базовых навыков программировании. В листинге 5-31 показано, как использовать это выражение.
Листинг 5-31: Обработка исключения
<!DOCTYPE HTML>
<html>
<head>
<title>Example</title>
</head>
<body>
<script type="text/javascript">
try {
var myArray;
for (var i = 0; i < myArray.length; i++) {
document.writeln("Index " + i + ": " + myArray[i]);
}
} catch (e) {
document.writeln("Error: " + e);
}
</script>
</body>
</html>Проблема, описанная в данном скрипе, довольно распространенная. Я пытаюсь использовать переменную, которая не была должным образом инициализирована. Я вставил ту часть кода, где, как я думаю, может возникнуть ошибка, в блок try. Если ошибки не возникнет, и выражения будут выполнены, тогда блок catch будет просто проигнорирован.
Если есть ошибка, тогда выполнение выражения в блоке try сразу же прекратится, а управление перейдет блоку catch. Встречающиеся ошибки описываются объектом Error, которые передаются в блок catch. В таблице 5-6 показаны свойства объекта Error.
Таблица 5-6: Объект
Error
| Свойство | Описание | Возвращает |
message |
Описание ошибки. | string |
name |
Название ошибки. По умолчанию объект Error. |
string |
number |
Код ошибки. Если ошибок несколько, то указанной ошибки. | number |
Блок catch – это возможность для восстановления и очистки кода после ошибок. Если есть выражения, которые должны быть выполнены независимо от того, была ошибка или нет, их можно разместить в необязательном блоке finally, как показано в листинге 5-32.
Листинг 5-32: Использование блока
finally
<!DOCTYPE HTML>
<html>
<head>
<title>Example</title>
</head>
<body>
<script type="text/javascript">
try {
var myArray;
for (var i = 0; i < myArray.length; i++) {
document.writeln("Index " + i + ": " + myArray[i]);
}
} catch (e) {
document.writeln("Error: " + e);
} finally {
document.writeln("Statements here are always executed");
}
</script>
</body>
</html>
Сегодня говорим про обработку ошибок и отказоустойчивость программ. Это продолжение статьи про исключения, но применительно к нашему проекту под кодовым названием «Воруй, убивай, цепи Маркова». Мы учимся забирать текст с чужих сайтов и генерировать на основе этого текста собственные.
В предыдущих версиях у нас были идеальные условия: заготовленный список веб-страниц одинакового формата, с одинаковой кодировкой и одинаковой разметкой заголовков.
В реальном парсинге условия неидеальные: чаще всего нужно парсить не свой сайт, а чужой. И на этом чужом сайте может быть что угодно: не открываются адреса, нет заголовка на странице, разные кодировки на разных страницах. Для компьютера это непреодолимые трудности.
Чтобы такого не происходило, нам нужно научить наш алгоритм обрабатывать нештатные ситуации — то есть исключения.
Что делаем
Идея для сегодняшнего проекта — спарсить часть текста и заголовков с сайта «Коммерсанта» для учебных целей. Потом мы их отдадим нашему алгоритму на цепях Маркова и получим новые тексты в духе «Коммерсанта».
Мы выбрали «Коммерсант» из-за его удобной структуры URL-адреса. Вот как выглядят типичные адреса новостей оттуда:
https://www.kommersant.ru/doc/4815427
https://www.kommersant.ru/doc/4803922
Видно, что каждая новость или статья просто опубликована под каким-то своим номером и есть ощущение, что эти номера идут по порядку. Поэтому сделаем так:
- Выберем стартовый номер у новости.
- Будем отнимать от этого номера единичку, подставлять его в адрес и смотреть на результат.
- Если страница откроется, сохраним заголовок и текст новости, а если нет — пойдём дальше.
- Повторим это 500 раз и посмотрим, что получится.
Адаптируем старый проект под новую задачу
Чтобы не писать всё с нуля, мы возьмём наш парсер из прошлого проекта и выкинем оттуда громадный кусок с массивом URL-адресов.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# открываем текстовый файл, куда будем добавлять заголовки
file = open("zag.txt", "a")
# перебираем все адреса из списка
for x in url:
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(x).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим название страницы с помощью метода find()
s = soup.find('title').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file.write(s + '. ')
# закрываем файл
file.close()
Теперь добавим в этот код нашу логику. Для этого мы пропишем общую часть URL-адреса, запомним стартовый номер новости, а потом в цикле будем вычитать из него единичку и смотреть, что получилось.
👉 Мы вычитаем единицы из стартового числа, чтобы получить доступ к предыдущим материалам, потому что у новых статей номер в адресе «Коммерсанта» всегда больше, чем у старых. Ещё мы теперь ищем заголовок самой новости, а не всей страницы, потому что в заголовке страницы много лишнего текста.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# общая часть URL-адреса
url = "https://www.kommersant.ru/doc/"
# стартовый номер, с которого начинаем парсинг
start_id = 4804129
# открываем файл, куда будем добавлять заголовки
file_zag = open("komm_zag.txt", "a")
# открываем файл, куда будем добавлять текст
file_text = open('komm_text.txt','a')
# перебираем предыдущие 500 адресов
for x in range(0,500):
# формируем новый адрес из общей части и номера материала
# на каждом шаге номер уменьшается на единицу, чтобы обратиться к более старым материалам
work_url = url + str(start_id - x)
# получаем исходный код очередной страницы из списка
html_code = str(urlopen(work_url).read(),'utf-8')
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# находим заголовок материала с помощью метода find()
s = soup.find('h1').text
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file_zag.write(s + '. ')
# находим все абзацы с текстом
content = soup.find_all('p')
# перебираем все найденные абзацы
for item in content:
# сохраняем каждый абзац в другой файл
file_text.write(item.text + ' ')
print(item.text)
# закрываем файл
file.close()После запуска мы видим две проблемы. Первая: у нас собирается много лишних абзацев с текстом, который не относится к новости. Все эти «Читать далее», «Архив» и «просмотров» нам не нужны:

Вторая проблема: оказывается, не на всех страницах наш парсер может найти заголовок <h1>. Например, такое случается, если по текущему адресу материал доступен только по подписке или там находится служебная страница:

Находим только текст новости
Чтобы не собирать со страницы все абзацы, а брать только нужный текст, давайте посмотрим на структуру любой подобной страницы в инспекторе:

В коде видно, что содержимое статьи помечается абзацем с классом «b-article__text» , значит, нам нужно забирать со страницы только абзацы с таким классом. Поменяем нашу команду на такое:
content = soup.find_all('p', class_ = "b-article__text")
Теперь мы найдём на странице только те абзацы, у которых будет нужный нам класс, а остальные проигнорируем.
Добавляем исключение для обработки заголовков
👉 В этом проекте мы варварски отнеслись к исключениям и не проверяли тип ошибки, зато быстро получили рабочий код. В следующий раз мы исправимся, а пока будем работать на скорость.
Мы уже рассказывали про то, что такое исключения и как они помогают программистам. Если коротко, то исключения позволяют обработать заранее известную ошибку так, чтобы программа не прекращала работу, а продолжала делать что-то своё.
Мы будем использовать самый простой вариант обработки исключений: когда исключение обрабатывается в общем виде, без уточнения ошибки. Вот как это будет работать:
- Мы добавляем обработчик исключений к команде нахождения заголовка.
- Если всё нашлось нормально и ошибки нет, то обработчик будет сидеть тихо и ничего не делать.
- Если после команды поиска заголовка случилась ошибка, то мы сразу прекращаем дальнейшие команды и переходим к следующему адресу.
Плюсы такого решения — простота и скорость внедрения. Нам не нужно задумываться о том, какая именно ошибка случилась: при любой ошибке мы бросаем этот адрес и переходим к следующему.
Минус у этого способа тоже есть: мы не знаем, что именно произошло, и реагируем на всё одинаково. В простом учебном проекте это можно сделать, а в настоящем коммерческом коде — нет. Там нужно чётко всегда знать, что за ошибка случилась, чтобы проект более гибко и правильно реагировал на происходящее.
# включаем обработчик исключений для команды поиска
try:
# находим название страницы с помощью метода find()
s = soup.find('h1').text
# если случилась любая ошибка
except Exception as e:
print("Заголовок не найден")
# прерываем этот шаг цикла и переходим к следующему
continueОбрабатываем ситуацию, когда страница не найдена
После того как мы исправили два предыдущих замечания и снова запустили программу, компьютер выдал ошибку 404 — страница с таким адресом не найдена:

Это значит, что мы отправили запрос на такую страницу, которой нет на сервере. Так бывает, когда проверяешь адреса простым перебором — часть вариантов окажется нерабочими.
Чтобы эта ошибка не мешала работать программе, снова добавим исключение с обработкой любой ошибки. Как только на этой команде встретили ошибку, то делаем как и раньше — бросаем всё и начинаем цикл с нового адреса.
# включаем обработчик исключений для запроса содержимого страницы
try:
# получаем исходный код страницы в виде байт-строки
html_code = urlopen(work_url).read()
# если случилась любая ошибка
except Exception as e:
print('Страница не найдена')
# прерываем этот шаг цикла и переходим к следующему
continueТак, шаг за шагом, мы отлавливаем все ошибки и получаем код, который сможет обработать хоть 50 000 страниц и не упасть во время работы. В этом и есть смысл исключений — сделать так, чтобы программа продолжала работать, когда что-то пошло не по плану. Главное — предусмотреть возможные нештатные ситуации.
# подключаем urlopen из модуля urllib
from urllib.request import urlopen
# подключаем библиотеку BeautifulSout
from bs4 import BeautifulSoup
# общая часть URL-адреса
url = "https://www.kommersant.ru/doc/"
# стартовый номер, с которого начинаем парсинг
start_id = 4804129
# открываем файл, куда будем добавлять заголовки
file_zag = open("komm_zag.txt", "a")
# открываем файл, куда будем добавлять текст
file_text = open('komm_text.txt','a')
# перебираем предыдущие 500 адресов
for x in range(0,500):
# формируем новый адрес из общей части и номера материала
# на каждом шаге номер уменьшается на единицу, чтобы обратиться к более старым материалам
work_url = url + str(start_id - x)
# включаем обработчик исключений для запроса содержимого страницы
try:
# получаем исходный код страницы в виде байт-строки
html_code = urlopen(work_url).read()
# если случилась любая ошибка
except Exception as e:
print('Страница не найдена')
# прерываем этот шаг цикла и переходим к следующему
continue
# отправляем исходный код страницы на обработку в библиотеку
soup = BeautifulSoup(html_code, "html.parser")
# включаем обработчик исключений для команды поиска
try:
# находим название страницы с помощью метода find()
s = soup.find('h1').text
# если случилась любая ошибка
except Exception as e:
print("Заголовок не найден")
# прерываем этот шаг цикла и переходим к следующему
continue
# выводим его на экран
print(s)
# сохраняем заголовок в файле и переносим курсор на новую строку
file_zag.write(s + '. ')
# находим все абзацы с текстом новости
content = soup.find_all('p', class_ = "b-article__text")
# перебираем все найденные абзацы
for item in content:
# сохраняем каждый абзац в другой файл
file_text.write(item.text + ' ')
print(item.text)
# закрываем файл
file.close()Что дальше
У нас есть 500 заголовков и столько же новостей — можно собрать новости в стиле «Коммерсанта». Если не знаете, как это сделать, — почитайте нашу статью про генератор на цепях Маркова