I wrote a script to find spelling mistakes in SO questions’ titles.
I used it for about a month.This was working fine.
But now, when I try to run it, I am getting this.
Traceback (most recent call last):
File "copyeditor.py", line 32, in <module>
find_bad_qn(i)
File "copyeditor.py", line 15, in find_bad_qn
html = urlopen(url)
File "/usr/lib/python3.4/urllib/request.py", line 161, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib/python3.4/urllib/request.py", line 469, in open
response = meth(req, response)
File "/usr/lib/python3.4/urllib/request.py", line 579, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/lib/python3.4/urllib/request.py", line 507, in error
return self._call_chain(*args)
File "/usr/lib/python3.4/urllib/request.py", line 441, in _call_chain
result = func(*args)
File "/usr/lib/python3.4/urllib/request.py", line 587, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
This is my code
import json
from urllib.request import urlopen
from bs4 import BeautifulSoup
from enchant import DictWithPWL
from enchant.checker import SpellChecker
my_dict = DictWithPWL("en_US", pwl="terms.dict")
chkr = SpellChecker(lang=my_dict)
result = []
def find_bad_qn(a):
url = "https://stackoverflow.com/questions?page=" + str(a) + "&sort=active"
html = urlopen(url)
bsObj = BeautifulSoup(html, "html5lib")
que = bsObj.find_all("div", class_="question-summary")
for div in que:
link = div.a.get('href')
name = div.a.text
chkr.set_text(name.lower())
list1 = []
for err in chkr:
list1.append(chkr.word)
if (len(list1) > 1):
str1 = ' '.join(list1)
result.append({'link': link, 'name': name, 'words': str1})
print("Please Wait.. it will take some time")
for i in range(298314,298346):
find_bad_qn(i)
for qn in result:
qn['link'] = "https://stackoverflow.com" + qn['link']
for qn in result:
print(qn['link'], " Error Words:", qn['words'])
url = qn['link']
UPDATE
This is the url causing the problem.Even though this url exists.
https://stackoverflow.com/questions?page=298314&sort=active
I tried changing the range to some lower values. It works fine now.
Why this happened with above url?
![]()
I’ve been getting this error ever since I downloaded pytube, which was only two weeks ago, but it keeps getting worse. At least 1 in 30 downloads will give me the error «urllib.error.HTTPError: HTTP Error 404: Not Found»
When I run the loop using the same YouTube link and Download location:
import pytube
for i in range(50):
out_file = pytube.YouTube("https://www.youtube.com/watch?v=yHwGIA4VeOc").streams.first().download("D:Music")
print("Done")
I get the error «urllib.error.HTTPError: HTTP Error 404: Not Found» at least once during the loop.
Sometimes it will give the error on the 5th download, sometimes on the 43rd. It is random. If I’m lucky it will download them all successfully, but that almost never happens.
I’ve tried putting a delay between downloads and looping through a list of links instead of using the same link for each download, but neither worked.
There is an old issue from 2019, where people have left comments having the same issue within the last two weeks, so I’m not the only one.
Information:
- Python 3.9.5
- Pytube 10.8.1
- I used «python -m pip install git+https://github.com/pytube/pytube» to download pytube
![]()
Thank you for contributing to PyTube. Please remember to reference Contributing.md
![]()
![]()
Can confirm too —
can also happen when using PyQt5 Threads. Delaying the command from being run inside the thread also results in what OP says too.
![]()
@FlubOtic and @Bobbymcbobface can you each provide the full error traceback so that I can see where in the code this is failing? I’m wondering if this is only happening when vid_info_raw is fetched, or if other processes are also causing the problem.
![]()
Can confirm too.
Full traceback:
Traceback (most recent call last):
File "/Users/victorrolandosanchezjara/Programming/youtube-downloader-python/download.py", line 8, in <module>
print('Downloading video - ', current_video, ' :', yt.title)
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/__main__.py", line 351, in title
self._title = self.player_response['videoDetails']['title']
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/__main__.py", line 167, in player_response
if isinstance(self.player_config_args["player_response"], str):
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/__main__.py", line 187, in player_config_args
self._player_config_args = self.vid_info
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/__main__.py", line 278, in vid_info
return dict(parse_qsl(self.vid_info_raw))
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/__main__.py", line 108, in vid_info_raw
self._vid_info_raw = request.get(self.vid_info_url)
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/request.py", line 52, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "/usr/local/anaconda3/lib/python3.7/site-packages/pytube/request.py", line 36, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 531, in open
response = meth(req, response)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 641, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 563, in error
result = self._call_chain(*args)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 503, in _call_chain
result = func(*args)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 755, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 531, in open
response = meth(req, response)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 641, in http_response
'http', request, response, code, msg, hdrs)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 569, in error
return self._call_chain(*args)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 503, in _call_chain
result = func(*args)
File "/usr/local/anaconda3/lib/python3.7/urllib/request.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
My code is quite simple. Downloading a list of videos.
from tqdm import tqdm
from pytube import YouTube
with open('videos_list.txt') as videos_list:
current_video = 1
for url in tqdm(videos_list, desc='Downloading videos'):
yt = YouTube(url)
print('Downloading video - ', current_video, ' :', yt.title)
yt.streams.first().download('./videos/'+yt.title)
print('Finished downloading video - ', current_video, ' :', yt.title)
current_video += 1
![]()
@tfdahlin here is my full traceback:
Traceback (most recent call last):
File "c:UsersznmcaVSCodeSpotify-Playlist-Downloaderpytubes.py", line 4, in <module>
out_file = pytube.YouTube("https://www.youtube.com/watch?v=yHwGIA4VeOc").streams.first().download("D:Music")
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 308, in streams
return StreamQuery(self.fmt_streams)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 213, in fmt_streams
if "adaptive_fmts" in self.player_config_args:
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 187, in player_config_args
self._player_config_args = self.vid_info
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 278, in vid_info
return dict(parse_qsl(self.vid_info_raw))
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 108, in vid_info_raw
self._vid_info_raw = request.get(self.vid_info_url)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytuberequest.py", line 52, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39libsite-packagespytuberequest.py", line 36, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 214, in urlopen
return opener.open(url, data, timeout)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 523, in open
response = meth(req, response)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 632, in http_response
response = self.parent.error(
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 555, in error
result = self._call_chain(*args)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 494, in _call_chain
result = func(*args)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 747, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 523, in open
response = meth(req, response)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 632, in http_response
response = self.parent.error(
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 561, in error
return self._call_chain(*args)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 494, in _call_chain
result = func(*args)
File "C:UsersznmcaAppDataLocalProgramsPythonPython39liburllibrequest.py", line 641, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
![]()
Heres my Traceback too bud
Traceback (most recent call last):
File "X:Youtube DownloaderDownloadApp.pyw", line 54, in run
result = self.fn(*self.args, **self.kwargs)
File "X:Youtube DownloaderDownloadApp.pyw", line 174, in Download
vids = yt.streams.filter(only_audio=True).all()
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 308, in streams
return StreamQuery(self.fmt_streams)
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 213, in fmt_streams
if "adaptive_fmts" in self.player_config_args:
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 187, in player_config_args
self._player_config_args = self.vid_info
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 278, in vid_info
return dict(parse_qsl(self.vid_info_raw))
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytube__main__.py", line 108, in vid_info_raw
self._vid_info_raw = request.get(self.vid_info_url)
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytuberequest.py", line 52, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "C:UsersLAppDataLocalProgramsPythonPython39libsite-packagespytuberequest.py", line 36, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 214, in urlopen
return opener.open(url, data, timeout)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 523, in open
response = meth(req, response)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 632, in http_response
response = self.parent.error(
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 555, in error
result = self._call_chain(*args)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 494, in _call_chain
result = func(*args)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 747, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 523, in open
response = meth(req, response)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 632, in http_response
response = self.parent.error(
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 561, in error
return self._call_chain(*args)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 494, in _call_chain
result = func(*args)
File "C:UsersLAppDataLocalProgramsPythonPython39liburllibrequest.py", line 641, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
![]()
ty for all the tracebacks, it looks like it is an issue with just the vid info url, I’ll see if I can investigate what’s causing it sometime this week
![]()
@tfdahlin I’ve been getting the same error using the CLI (so I’m not looping through multiple urls at once like @FlubOtic), but the error still seems to occur randomly, and I’ve found that if I try to download the same video a few times in a row the download will eventually succeed (after failing with the above error on the first couple of tries).
![]()
I might just do a slight refactor to make certain web requests have an auto-retry policy to see if that fixes the issue
![]()
Hello, i have the same error and i thought it is my bad. I have created a sentry implement to see the error better.
Here is a screenshot what they do.
For the first i think my post url is wrong, so pytube dont get any url but they do.
Sometime it work and sometime not. like 50/50
For me i looks like grabing the link — works — grabbing video info — works and then try to catch video info again and failed. i dont know why pytube is trying to grab it again.

![]()
I’ve had this same issue to. Nothing else realy to add other then my hopes of this being fixed. It feels almost random when I get this error, and thats not even form itterating a list or dowlaoding a playlist. Thats just trying a single link.
![]()
Just wanted to add that I think auto-retry policy would be a good idea, I was running into the 404 issue as well and solved, or at least got things working again, by retrying X number of times.
![]()
Getting this 100% of the time now. Code functioned yesterday with the exception of getting this error once or twice.
![]()
@tfdahlin The download function no longer works for me. Getting the error on every download now just like @Earph0nes. I don’t think an auto-retry will fix it anymore.
![]()
To be fair, it seems to fair up when done in sucession. That being said there is stll a random chance regardless of it working. Maybe its youtube trying to put a damper on this type of acess?
![]()
@Nosh-Ware That is what I thought also, but when you go to sites like this you get no errors. So it most likely is a pytube bug, not YouTube preventing it. Also, can you run your code and see if the download function works for you anymore. It stopped working completely for me and another user just a moment ago.
![]()
Hello, i have the same error and i thought it is my bad. I have created a sentry implement to see the error better.
Here is a screenshot what they do.
For the first i think my post url is wrong, so pytube dont get any url but they do.
Sometime it work and sometime not. like 50/50
For me i looks like grabing the link — works — grabbing video info — works and then try to catch video info again and failed. i dont know why pytube is trying to grab it again.
The reason that it looks like it’s making a request twice is because of the 301 redirect. The library only makes the request once, but behind the scenes httplib is making a request to youtube.com/, getting redirected to www.youtube.com, and then proceeding with the request there.
@ the rest of y’all, I’m going to spend tonight seeing if I can get this fixed
FlubOtic, Sasiam, develarts, TiredBot, rem2, kavorite, xtinamarie, Earph0nes, zpatty, Kikumu, and 4 more reacted with heart emoji
![]()
Update: I think I found a way around using the get_video_info url, I’m working on updating supporting functions that relied on this information now.
![]()
Still in progress, have to sleep for now. Currently running into a 403 issue if anybody wants to check out my branch to try and solve it. Otherwise I’ll try resume work on this tomorrow afternoon
![]()
Problem is get_video_info , change code in pytube/extract.py
def _video_info_url(params: OrderedDict) -> str: return "https://www.youtube.com/get_video_info?html5=1&video_id=" + params['video_id']
not
def _video_info_url(params: OrderedDict) -> str: return "https://youtube.com/get_video_info?" + urlencode(params)
PR/996
supermomie, kavorite, and bigbear22941 reacted with hooray emoji
supermomie, jcarosi, Ssuwani, and kavorite reacted with heart emoji
![]()
![]()
works not for me, get error ‘player respone’ 
![]()
Not working, I’m also getting the «KeyError: ‘player_response'» error
EDIT:
I fixed it by removing [‘player_response’] on line 190 in __main__.py
So it should look something like this:
if 'streamingData' not in self.player_config_args:
But I don’t know if this is a proper fix.
ab-anand, bigbear22941, and 15minutOdmora reacted with hooray emoji
![]()
Not working. My traceback
File "/data/user/0/ru.iiec.pydroid3/files/accomp_files/iiec_run/iiec_run.py", line 31, in <module>
start(fakepyfile,mainpyfile)
File "/data/user/0/ru.iiec.pydroid3/files/accomp_files/iiec_run/iiec_run.py", line 30, in start
exec(open(mainpyfile).read(), __main__.__dict__)
File "<string>", line 3, in <module>
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/__main__.py", line 317, in thumbnail_url
self.player_response.get("videoDetails", {})
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/__main__.py", line 167, in player_response
if isinstance(self.player_config_args["player_response"], str):
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/__main__.py", line 187, in player_config_args
self._player_config_args = self.vid_info
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/__main__.py", line 278, in vid_info
return dict(parse_qsl(self.vid_info_raw))
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/__main__.py", line 108, in vid_info_raw
self._vid_info_raw = request.get(self.vid_info_url)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/request.py", line 53, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/site-packages/pytube/request.py", line 37, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 531, in open
response = meth(req, response)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 640, in http_response
response = self.parent.error(
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 563, in error
result = self._call_chain(*args)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 502, in _call_chain
result = func(*args)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 755, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 531, in open
response = meth(req, response)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 640, in http_response
response = self.parent.error(
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 569, in error
return self._call_chain(*args)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 502, in _call_chain
result = func(*args)
File "/data/user/0/ru.iiec.pydroid3/files/aarch64-linux-android/lib/python3.8/urllib/request.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
[Program finished]```
![]()
Same issue with all downloads.
File "test.py", line 4, in <module>
YouTube('https://youtu.be/9bZkp7q19f0').streams.first().download()
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/__main__.py", line 309, in streams
return StreamQuery(self.fmt_streams)
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/__main__.py", line 214, in fmt_streams
if "adaptive_fmts" in self.player_config_args:
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/__main__.py", line 188, in player_config_args
self._player_config_args = self.vid_info
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/__main__.py", line 279, in vid_info
return dict(parse_qsl(self.vid_info_raw))
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/__main__.py", line 109, in vid_info_raw
self._vid_info_raw = request.get(self.vid_info_url)
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/request.py", line 54, in get
response = _execute_request(url, headers=extra_headers, timeout=timeout)
File "/home/pancho/.local/lib/python3.8/site-packages/pytube/request.py", line 38, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "/usr/lib/python3.8/urllib/request.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib/python3.8/urllib/request.py", line 531, in open
response = meth(req, response)
File "/usr/lib/python3.8/urllib/request.py", line 640, in http_response
response = self.parent.error(
File "/usr/lib/python3.8/urllib/request.py", line 563, in error
result = self._call_chain(*args)
File "/usr/lib/python3.8/urllib/request.py", line 502, in _call_chain
result = func(*args)
File "/usr/lib/python3.8/urllib/request.py", line 755, in http_error_302
return self.parent.open(new, timeout=req.timeout)
File "/usr/lib/python3.8/urllib/request.py", line 531, in open
response = meth(req, response)
File "/usr/lib/python3.8/urllib/request.py", line 640, in http_response
response = self.parent.error(
File "/usr/lib/python3.8/urllib/request.py", line 569, in error
return self._call_chain(*args)
File "/usr/lib/python3.8/urllib/request.py", line 502, in _call_chain
result = func(*args)
File "/usr/lib/python3.8/urllib/request.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
MCVE:
from pytube import YouTube, Playlist
anslist= """
1) music genre here
2) music genre here
3) music genre here
4) music genre here
5) music genre here
6) music genre here
7) music genre here
8) music genre here
"""
def location(ans):
destination=""
if ans == 1:
destination = "/destination"
return destination
elif ans == 2:
destination = "/destination"
return destination
elif ans == 3:
destination = "/destination"
return destination
elif ans == 4:
destination = "/destination"
return destination
elif ans == 5:
destination = "/destination"
return destination
elif ans == 6:
destination = "/destination"
return destination
elif ans == 7:
destination = "/destination"
return destination
elif ans == 8:
destination = "/destination"
return destination
def individual(url):
print(anslist)
dire = int(input("Set download destination: "))
destination=location(dire)
YouTube(f'{url}').streams.filter(only_audio=True).first()
yt = YouTube(f'{url}')
down = yt.streams.filter(only_audio=True).first()
print("Downloading: " + str(yt.title))
out_file = down.download(output_path=destination)
base, ext = os.path.splitext(out_file)
new_file = base + '.mp3'
os.rename(out_file, new_file)
def playlist(pl):
print(anslist)
dire = int(input("Set download destination: "))
destination=location(dire)
p = Playlist(f'{pl}')
for video in p.videos:
down = video.streams.filter(only_audio=True).first()
print("Downloading: " + str(video.title))
out_file = down.download(output_path=destination)
base, ext = os.path.splitext(out_file)
new_file = base + '.mp3'
os.rename(out_file, new_file)
def individualVideo(url):
print(anslist)
dire = int(input("Set download destination: "))
destination=location(dire)
YouTube(f'{url}').streams.first()
yt = YouTube(f'{url}')
down = yt.streams.filter(only_audio=True).first()
out_file = down.download(output_path=destination)
base, ext = os.path.splitext(out_file)
print("Downloading: " + str(yt.title))
def playlistVideo(pl):
print(anslist)
dire = int(input("Set download destination: "))
destination=location(dire)
p = Playlist(f'{pl}')
for video in p.videos:
down = video.streams.first()
out_file = down.download(output_path=destination)
base, ext = os.path.splitext(out_file)
print("Downloading: " + str(video.title))
def audio():
ans = input("Single song or playlist? [s, p] ")
if ans == "s":
url = input("Paste URL: ")
individual(url)
else:
url = input("Paste URL: ")
playlist(url)
def video():
ans = input("Single song or playlist? [s, p] ")
if ans == "s":
url = input("Paste URL: ")
individualVideo(url)
else:
url = input("Paste URL: ")
playlistVideo(url)
print("""
_
,´ `.
______|___|______________________________________________
| / _..-´|
| / _..-´´_..-´|
______|/__________________|_..-´´_____|__________|______
,| | | |
/ | | | | ´
___/__|___________________|___________|__________|_______
/ ,´| `. | ,d88b| |
| . | __ | 88888| __ |
_|_|__|____|_________,d88b|______`Y88P'_____,d88b|_______
| ` | | 88888| 88888|
`. | / `Y88P' `Y88P'
___`._|_.´_______________________________________________
|
, | GP
'.´
Let's rock and roll!
____________________________
""")
ans=input("Audio or video? [a, v] ")
if ans == "a":
audio()
else:
video()
![]()
Problem is
get_video_info, change code inpytube/extract.pydef _video_info_url(params: OrderedDict) -> str: return "https://www.youtube.com/get_video_info?html5=1&video_id=" + params['video_id']not
def _video_info_url(params: OrderedDict) -> str: return "https://youtube.com/get_video_info?" + urlencode(params)PR/996
Solution works for me. I saw some responses with «player_response» being an error , just be sure you have this :
return «https://www.youtube.com/get_video_info?html5=1&video_id=» + params[‘video_id’]
Notice the lack of «amp;» , if you have that the reponse comes back as «status: fail» and hence no player_response in returned response
![]()
Not working, I’m also getting the «KeyError: ‘player_response'» error
EDIT:
I fixed it by removing [‘player_response’] on line 190 in__main__.py
So it should look something like this:
if 'streamingData' not in self.player_config_args:
But I don’t know if this is a proper fix.
Ssuwani fix +This fixed it for me
![]()
link = input()
yt = YouTube(link)
vid = yt.streams.get_highest_resolution()
vid.download("C:/Users/Home/Downloads", filename_prefix = "Video - ", max_retries = 13)
print("Done")```
It was working yesterday but not today, any fix? (Project submissions tomorrow pls)
![]()
After I tried Ssuwani’s method, I got KeyError: ‘player_response’ as well, here’s my traceback
Traceback (most recent call last):
File "fixed.py", line 7, in <module>
print(yt.streams)
File "C:Userswilsonanaconda3envsbugfixlibsite-packagespytube__main__.py", line 308, in streams
return StreamQuery(self.fmt_streams)
File "C:Userswilsonanaconda3envsbugfixlibsite-packagespytube__main__.py", line 213, in fmt_streams
if "adaptive_fmts" in self.player_config_args:
File "C:Userswilsonanaconda3envsbugfixlibsite-packagespytube__main__.py", line 190, in player_config_args
if 'streamingData' not in self.player_config_args['player_response']:
KeyError: 'player_response'
And 1shershah’s solution works for me 👍
Solution works for me. I saw some responses with «player_response» being an error , just be sure you have this :
return «https://www.youtube.com/get_video_info?html5=1&video_id=» + params[‘video_id’]
Notice the lack of «amp;» , if you have that the reponse comes back as «status: fail» and hence no player_response in returned response
![]()
Ssuwani’s fix gets rid of the 404 Error, but when I ran the download 100 times I got one 403 Error.
![]()
#998
Same logic as Ssuwani’s #996 . But keep old code convention and style.
![]()
Hey folks; I’m going to merge the PR @drwjf made once the CI tests pass. Expect v10.8.2 to be on pypi in the next 10 minutes or so.
![]()
tfdahlin
linked a pull request
May 20, 2021
that will
close
this issue
![]()
Before I merge #998, I am going to note here that I will likely still continue work on #994, just with a slightly lower priority since the additional parameter seems to fix the current issue.
![]()
python -m pip install --upgrade pytube should install the fix now. If there are further issues with v10.8.2, please open a new ticket so they get documented properly
![]()
![]()
Huge thank you to @Ssuwani for the proposed solution, and @drwjf for adapting it to the existing code convention while I was unavailable
![]()
Good! Thanks for the quick response and solution to the problem.
![]()
![]()
Hello, i stil have the issue : pytube 10.8.3, in a Thread return error : HTTP Error 404: Not Found
In the debugger, metada and date are correct ; title or captions is equal to None.

( if you need to have the return in plan text i can do it )
Here my code ( full at https://github.com/Pigi-bytes/PigiTube )
def Thread_for_get_data(self): """ Here, we watch if a url is valid, and if it is, we update the GUI, title and thumbnail """ self.youtube_url = self.input.text() try: # If an error occurs here, that means that the url is not valide if len(self.youtube_url) != 43: self.error_in_thread_ok = True raise('Url pas de la bonne taille') self.video = pytube.YouTube(self.youtube_url) # We create the video objet, which contains the video we want # we use that object for all of the downloading process self.titre_yt = self.video.title ID = self.youtube_url[-11:] thumbnail_link = f"http://img.youtube.com/vi/{ID}/hqdefault.jpg" # We create the url of the thumbnail. # first of all we take the ID of the youtube video, the last 11 character. # We add that in a url and we can now have the link of the picture used for the thumbnail, # is a 480 x 360 px, jpg. => https://yt-thumb.canbeuseful.com/en except Exception as e: print(e) self.error_in_thread_ok = True # if something went wrong with the url
Can someone explain to me what’s going on (I didn’t really understand, I admit)
![]()
@Pigi-bytes can you give me the video URL that you’re having the issue with please?
![]()
I get the same error on certain videos with pytube version 10.8.4
Traceback (most recent call last):
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytubestreams.py", line 261, in download
max_retries=max_retries
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytuberequest.py", line 160, in stream
timeout=timeout
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytuberequest.py", line 36, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 531, in open
response = meth(req, response)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 641, in http_response
'http', request, response, code, msg, hdrs)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 569, in error
return self._call_chain(*args)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 503, in _call_chain
result = func(*args)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
During handling of the above exception, another exception occurred:
Traceback (most recent call last):
File "C:/Users/Serge/PycharmProjects/Youtube/Download.py", line 161, in <module>
video_test('https://www.youtube.com/watch?v=dCqHdHKvSos')
File "C:/Users/Serge/PycharmProjects/Youtube/Download.py", line 154, in video_test
video_download(video)
File "C:/Users/Serge/PycharmProjects/Youtube/Download.py", line 87, in video_download
stream.download(output_path=complete_name, filename='VIDEO_' + title)
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytubestreams.py", line 274, in download
max_retries=max_retries
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytuberequest.py", line 127, in seq_stream
yield from stream(url, timeout=timeout, max_retries=max_retries)
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytuberequest.py", line 160, in stream
timeout=timeout
File "C:UsersSergePycharmProjectsYoutubevenvlibsite-packagespytuberequest.py", line 36, in _execute_request
return urlopen(request, timeout=timeout) # nosec
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 222, in urlopen
return opener.open(url, data, timeout)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 531, in open
response = meth(req, response)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 641, in http_response
'http', request, response, code, msg, hdrs)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 569, in error
return self._call_chain(*args)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 503, in _call_chain
result = func(*args)
File "C:UsersSergeAppDataLocalProgramsPythonPython37-32liburllibrequest.py", line 649, in http_error_default
raise HTTPError(req.full_url, code, msg, hdrs, fp)
urllib.error.HTTPError: HTTP Error 404: Not Found
I’m downloading streams that are not progressive, sometimes it would download the video stream and fail on the audio, sometimes it would fail on the video stream. I’ve also seen a case where on the first try I was able to download the video stream and failed on the audio, but on the second try with the same video, the error has occured while trying to download the video stream that has been downloaded successfully before that. The code is:
stream = yt.streams.filter(file_extension='mp4', res='1080p').first()
stream_audio = yt.streams.filter(file_extension='mp4', only_audio=True).order_by('abr').last()
stream.download(output_path=complete_name, filename='VIDEO_' + title)
stream_audio.download(output_path=complete_name, filename='AUDIO_' + title)
![]()
Can we please re-open this issue as it seems that it has not been fully resolved ? I’m facing the same problem as @SergeZ23. Thanks in advance!
![]()
Since somebody opened a new issue for the current 404 problems, I’m going to leave this issue closed and use that one instead.
![]()
python -m pip install --upgrade pytubeshould install the fix now. If there are further issues with v10.8.2, please open a new ticket so they get documented properly
Solved my problem, thanks friend
![]()
It still doesn’t work
from pytube import YouTube yt = YouTube('https://youtu.be/9bZkp7q19f0') print(yt.title)
HTTP Error 404: Not Found
pytube 10.9.3
python 3.9.5
![]()
It still doesn’t work for me either
![]()
@HaltenStein @renan-eccel the current 404 issue is a new issue. See #1060 for updates. I’m locking this thread because this particular 404 issue was resolved.
![]()
pytube
locked as resolved and limited conversation to collaborators
Jul 26, 2021
Hi guys! In this tutorial, we will learn how to catch an HTTP 404 error in Python. There are many instances when we encounter an HTTP error with error code 404 on the internet. This error indicates that the requested page was not found. This tutorial will teach you how you can use Python to spot pages with such an error. Let’s see more on this with example programs.
Catch HTTP 404 error in Python
There are many methods for catching a 404 error. We will import the urllib or urllib3 library in this post for catching a 404 error. These library has required methods and attributes for our purpose. Let’s see the code and understand how it’s done.
Method 1
See the below example to find out a page with an HTTP 404 error.
import urllib3
http = urllib3.PoolManager()
error = http.request("GET", "https://www.google.com/404")
if (error.status == 404):
print("HTTP 404 ERROR")
The output for the above code is:
HTTP 404 ERROR
In the above example, we have used the PoolManager of urllib3 to create an http object. A PoolManager instance is needed to make requests. Then we have used the request method to get an HTTPResponse object for the web page ‘https://www.google.com/404’. This HTTPResponse object contains status, data, and header. We check whether the status for this page is 404 if so we print that this is an HTTP error.
Method 2
In this method, we will import the Python urllib library. Have a look at the given code and try to understand.
import urllib.request, urllib.error
try:
con = urllib.request.urlopen('http://www.google.com/404')
except urllib.error.HTTPError as err:
print('HTTP', err.code, 'ERROR')
The output of the program:
HTTP 404 ERROR
As you can see, the urlopen() method opens the given URL for us. We have used try and except blocks to catch the HTTP error using urllib.error.HTTPError. If any error is raised while opening the URL, the control is given to except block and there we print the error code for HTTP error.
Thank you.
Also read: How to handle an attribute error in Python
Уведомления
- Начало
- » Python для новичков
- » парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
#1 Ноя. 16, 2017 16:13:50
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
Есть сайт с фильтром данных по запросу на начальной странице. На ней (на начальной) странице тестовый код работает как и положено. При переходе на страницу результата не может открыть страницу. Причина в библиотеке или в свойствах сайта? Соответственно эта ссылка открывается в любом браузере без проблем.
import urllib.request from bs4 import BeautifulSoup source = urllib.request.urlopen('http://...тратата') soup = BeautifulSoup(source, "lxml") for paragraf in soup.find_all('span'): print(paragraf.string)
Офлайн
- Пожаловаться
#2 Ноя. 16, 2017 18:12:57
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
Проблема может быть в том что у блоков span может и не быть параметров string. Посмотри HTML код страницы и проверь правильность поиска. Может быть тебе не span нужен, а какой нибудь div или a блоки.
Офлайн
- Пожаловаться
#3 Ноя. 16, 2017 18:16:33
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
damilkrose
Проблема может быть в том что у блоков span может и не быть параметров string. Посмотри HTML код страницы и проверь правильность поиска. Может быть тебе не span нужен, а какой нибудь div или a блоки.
Может быть, если ты пишешь for paragraph in soup.findall(‘span’), значит поиск по текстам. Может там не string а text, content. Не не — просто проверь исходный код.
P. S. Лично я вместо urllib3 юза requests. Он в принципе просто Упрощенный urllib, но с ним удобнее.
Офлайн
- Пожаловаться
#4 Ноя. 16, 2017 18:24:16
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
damilkrose
Какое это отношение имеет к ошибке 404?
Вы какой-то перманентный бред несете. То не к месту потоки приплетете, то на 404 виноват парсер. Давайте вы сначала думать будете, а потом раздавать советы?
Офлайн
- Пожаловаться
#5 Ноя. 16, 2017 18:27:21
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
ewro
Пока вы не скажите, какой УРЛ пытаетесь парсить, вам вряд ли помогут — нюансов может быть миллион, может их серверу куки не хватает? Как это проверить?
Офлайн
- Пожаловаться
#6 Ноя. 16, 2017 19:35:07
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
http://zakupki.gov.ru
Там в поиске что-нибудь вбить. Например, “закупки”.
Отредактировано ewro (Ноя. 16, 2017 19:36:59)
Офлайн
- Пожаловаться
#7 Ноя. 18, 2017 08:32:51
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
Надо попробовать Selenium. То ли это направление?
Офлайн
- Пожаловаться
#8 Ноя. 18, 2017 08:36:40
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
ewro
http://zakupki.gov.ruТам в поиске что-нибудь вбить. Например, “закупки”.
К сожалению там регламентные работы
Офлайн
- Пожаловаться
#9 Ноя. 18, 2017 08:41:17
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
Да, я видел уже. Скажите свое мнение о Selenium.
Офлайн
- Пожаловаться
#10 Ноя. 18, 2017 08:52:43
парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
Я подозреваю, что моя проблема все же в библиотеке. И если, как я понял о Селениуме, он эмулирует браузер Chrome, например, то все должно получиться. При прочих равных условиях 
Офлайн
- Пожаловаться
- Начало
- » Python для новичков
- » парсинг python ошибка urllib.error.HTTPError: HTTP Error 404: Not Found
Introduction
You may also find useful the following article on fetching web resources with Python:
Basic Authentication — A tutorial on Basic Authentication, with examples in Python.
urllib.request is a Python module for fetching URLs (Uniform Resource Locators). It offers a very simple interface, in the form of the urlopen function. This is capable of fetching URLs using a variety of different protocols. It also offers a slightly more complex interface for handling common situations — like basic authentication, cookies, proxies and so on. These are provided by objects called handlers and openers.
urllib.request supports fetching URLs for many “URL schemes” (identified by the string before the ":" in URL — for example "ftp" is the URL scheme of "ftp://python.org/") using their associated network protocols (e.g. FTP, HTTP). This tutorial focuses on the most common case, HTTP.
For straightforward situations urlopen is very easy to use. But as soon as you encounter errors or non-trivial cases when opening HTTP URLs, you will need some understanding of the HyperText Transfer Protocol. The most comprehensive and authoritative reference to HTTP is RFC 2616. This is a technical document and not intended to be easy to read. This HOWTO aims to illustrate using urllib, with enough detail about HTTP to help you through. It is not intended to replace the urllib.request docs, but is supplementary to them.
Fetching URLs
The simplest way to use urllib.request is as follows:
import urllib.request
with urllib.request.urlopen('http://python.org/') as response:
html = response.read()
If you wish to retrieve a resource via URL and store it in a temporary location, you can do so via the shutil.copyfileobj() and tempfile.NamedTemporaryFile() functions:
import shutil
import tempfile
import urllib.request
with urllib.request.urlopen('http://python.org/') as response:
with tempfile.NamedTemporaryFile(delete=False) as tmp_file:
shutil.copyfileobj(response, tmp_file)
with open(tmp_file.name) as html:
pass
Many uses of urllib will be that simple (note that instead of an ‘http:’ URL we could have used a URL starting with ‘ftp:’, ‘file:’, etc.). However, it’s the purpose of this tutorial to explain the more complicated cases, concentrating on HTTP.
HTTP is based on requests and responses — the client makes requests and servers send responses. urllib.request mirrors this with a Request object which represents the HTTP request you are making. In its simplest form you create a Request object that specifies the URL you want to fetch. Calling urlopen with this Request object returns a response object for the URL requested. This response is a file-like object, which means you can for example call .read() on the response:
import urllib.request
req = urllib.request.Request('http://www.voidspace.org.uk')
with urllib.request.urlopen(req) as response:
the_page = response.read()
Note that urllib.request makes use of the same Request interface to handle all URL schemes. For example, you can make an FTP request like so:
req = urllib.request.Request('ftp://example.com/')
In the case of HTTP, there are two extra things that Request objects allow you to do: First, you can pass data to be sent to the server. Second, you can pass extra information (“metadata”) about the data or the about request itself, to the server — this information is sent as HTTP “headers”. Let’s look at each of these in turn.
Data
Sometimes you want to send data to a URL (often the URL will refer to a CGI (Common Gateway Interface) script or other web application). With HTTP, this is often done using what’s known as a POST request. This is often what your browser does when you submit a HTML form that you filled in on the web. Not all POSTs have to come from forms: you can use a POST to transmit arbitrary data to your own application. In the common case of HTML forms, the data needs to be encoded in a standard way, and then passed to the Request object as the data argument. The encoding is done using a function from the urllib.parse library.
import urllib.parse
import urllib.request
url = 'http://www.someserver.com/cgi-bin/register.cgi'
values = {'name' : 'Michael Foord',
'location' : 'Northampton',
'language' : 'Python' }
data = urllib.parse.urlencode(values)
data = data.encode('ascii') # data should be bytes
req = urllib.request.Request(url, data)
with urllib.request.urlopen(req) as response:
the_page = response.read()
Note that other encodings are sometimes required (e.g. for file upload from HTML forms — see HTML Specification, Form Submission for more details).
If you do not pass the data argument, urllib uses a GET request. One way in which GET and POST requests differ is that POST requests often have “side-effects”: they change the state of the system in some way (for example by placing an order with the website for a hundredweight of tinned spam to be delivered to your door). Though the HTTP standard makes it clear that POSTs are intended to always cause side-effects, and GET requests never to cause side-effects, nothing prevents a GET request from having side-effects, nor a POST requests from having no side-effects. Data can also be passed in an HTTP GET request by encoding it in the URL itself.
This is done as follows:
>>> import urllib.request
>>> import urllib.parse
>>> data = {}
>>> data['name'] = 'Somebody Here'
>>> data['location'] = 'Northampton'
>>> data['language'] = 'Python'
>>> url_values = urllib.parse.urlencode(data)
>>> print(url_values) # The order may differ from below.
name=Somebody+Here&language=Python&location=Northampton
>>> url = 'http://www.example.com/example.cgi'
>>> full_url = url + '?' + url_values
>>> data = urllib.request.urlopen(full_url)
Notice that the full URL is created by adding a ? to the URL, followed by the encoded values.
Headers
We’ll discuss here one particular HTTP header, to illustrate how to add headers to your HTTP request.
Some websites (Google for example) dislike being browsed by programs, or send different versions to different browsers (Browser sniffing is a very bad practice for website design — building sites using web standards is much more sensible. Unfortunately a lot of sites still send different versions to different browsers.). By default urllib identifies itself as Python-urllib/x.y (where x and y are the major and minor version numbers of the Python release, e.g. Python-urllib/2.5), which may confuse the site, or just plain not work. The way a browser identifies itself is through the User-Agent header (The user agent for MSIE 6 is ‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1; .NET CLR 1.1.4322)’). When you create a Request object you can pass a dictionary of headers in. The following example makes the same request as above, but identifies itself as a version of Internet Explorer.
For details of more HTTP request headers, see Quick Reference to HTTP Headers.import urllib.parse
import urllib.request
url = 'http://www.someserver.com/cgi-bin/register.cgi'
user_agent = 'Mozilla/5.0 (Windows NT 6.1; Win64; x64)'
values = {'name': 'Michael Foord',
'location': 'Northampton',
'language': 'Python' }
headers = {'User-Agent': user_agent}
data = urllib.parse.urlencode(values)
data = data.encode('ascii')
req = urllib.request.Request(url, data, headers)
with urllib.request.urlopen(req) as response:
the_page = response.read()
The response also has two useful methods. See the section on info and geturl which comes after we have a look at what happens when things go wrong.
Handling Exceptions
urlopen raises URLError when it cannot handle a response (though as usual with Python APIs, built-in exceptions such as ValueError, TypeError etc. may also be raised).
HTTPError is the subclass of URLError raised in the specific case of HTTP URLs.
The exception classes are exported from the urllib.error module.
URLError
Often, URLError is raised because there is no network connection (no route to the specified server), or the specified server doesn’t exist. In this case, the exception raised will have a ‘reason’ attribute, which is a tuple containing an error code and a text error message.
e.g.
>>> req = urllib.request.Request('http://www.pretend_server.org')
>>> try: urllib.request.urlopen(req)
... except urllib.error.URLError as e:
... print(e.reason)
...
(4, 'getaddrinfo failed')
HTTPError
Every HTTP response from the server contains a numeric “status code”. Sometimes the status code indicates that the server is unable to fulfil the request. The default handlers will handle some of these responses for you (for example, if the response is a “redirection” that requests the client fetch the document from a different URL, urllib will handle that for you). For those it can’t handle, urlopen will raise an HTTPError. Typical errors include ‘404’ (page not found), ‘403’ (request forbidden), and ‘401’ (authentication required).
See section 10 of RFC 2616 for a reference on all the HTTP error codes.
The HTTPError instance raised will have an integer ‘code’ attribute, which corresponds to the error sent by the server.
Error Codes
Because the default handlers handle redirects (codes in the 300 range), and codes in the 100–299 range indicate success, you will usually only see error codes in the 400–599 range.
http.server.BaseHTTPRequestHandler.responses is a useful dictionary of response codes in that shows all the response codes used by RFC 2616. The dictionary is reproduced here for convenience
# Table mapping response codes to messages; entries have the
# form {code: (shortmessage, longmessage)}.
responses = {
100: ('Continue', 'Request received, please continue'),
101: ('Switching Protocols',
'Switching to new protocol; obey Upgrade header'),
200: ('OK', 'Request fulfilled, document follows'),
201: ('Created', 'Document created, URL follows'),
202: ('Accepted',
'Request accepted, processing continues off-line'),
203: ('Non-Authoritative Information', 'Request fulfilled from cache'),
204: ('No Content', 'Request fulfilled, nothing follows'),
205: ('Reset Content', 'Clear input form for further input.'),
206: ('Partial Content', 'Partial content follows.'),
300: ('Multiple Choices',
'Object has several resources -- see URI list'),
301: ('Moved Permanently', 'Object moved permanently -- see URI list'),
302: ('Found', 'Object moved temporarily -- see URI list'),
303: ('See Other', 'Object moved -- see Method and URL list'),
304: ('Not Modified',
'Document has not changed since given time'),
305: ('Use Proxy',
'You must use proxy specified in Location to access this '
'resource.'),
307: ('Temporary Redirect',
'Object moved temporarily -- see URI list'),
400: ('Bad Request',
'Bad request syntax or unsupported method'),
401: ('Unauthorized',
'No permission -- see authorization schemes'),
402: ('Payment Required',
'No payment -- see charging schemes'),
403: ('Forbidden',
'Request forbidden -- authorization will not help'),
404: ('Not Found', 'Nothing matches the given URI'),
405: ('Method Not Allowed',
'Specified method is invalid for this server.'),
406: ('Not Acceptable', 'URI not available in preferred format.'),
407: ('Proxy Authentication Required', 'You must authenticate with '
'this proxy before proceeding.'),
408: ('Request Timeout', 'Request timed out; try again later.'),
409: ('Conflict', 'Request conflict.'),
410: ('Gone',
'URI no longer exists and has been permanently removed.'),
411: ('Length Required', 'Client must specify Content-Length.'),
412: ('Precondition Failed', 'Precondition in headers is false.'),
413: ('Request Entity Too Large', 'Entity is too large.'),
414: ('Request-URI Too Long', 'URI is too long.'),
415: ('Unsupported Media Type', 'Entity body in unsupported format.'),
416: ('Requested Range Not Satisfiable',
'Cannot satisfy request range.'),
417: ('Expectation Failed',
'Expect condition could not be satisfied.'),
500: ('Internal Server Error', 'Server got itself in trouble'),
501: ('Not Implemented',
'Server does not support this operation'),
502: ('Bad Gateway', 'Invalid responses from another server/proxy.'),
503: ('Service Unavailable',
'The server cannot process the request due to a high load'),
504: ('Gateway Timeout',
'The gateway server did not receive a timely response'),
505: ('HTTP Version Not Supported', 'Cannot fulfill request.'),
}
When an error is raised the server responds by returning an HTTP error code and an error page. You can use the HTTPError instance as a response on the page returned. This means that as well as the code attribute, it also has read, geturl, and info, methods as returned by the urllib.response module:
>>> req = urllib.request.Request('http://www.python.org/fish.html')
>>> try:
... urllib.request.urlopen(req)
... except urllib.error.HTTPError as e:
... print(e.code)
... print(e.read())
...
404
b'<!DOCTYPE html PUBLIC "-//W3C//DTD XHTML 1.0 Transitional//EN"
"http://www.w3.org/TR/xhtml1/DTD/xhtml1-transitional.dtd">nnn<html
...
<title>Page Not Found</title>n
...
Wrapping it Up
So if you want to be prepared for HTTPError or URLError there are two basic approaches. I prefer the second approach.
Number 1
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
req = Request(someurl)
try:
response = urlopen(req)
except HTTPError as e:
print('The server couldn't fulfill the request.')
print('Error code: ', e.code)
except URLError as e:
print('We failed to reach a server.')
print('Reason: ', e.reason)
else:
# everything is fine
Note
The
except HTTPErrormust come first, otherwiseexcept URLErrorwill also catch anHTTPError.
Number 2
from urllib.request import Request, urlopen
from urllib.error import URLError
req = Request(someurl)
try:
response = urlopen(req)
except URLError as e:
if hasattr(e, 'reason'):
print('We failed to reach a server.')
print('Reason: ', e.reason)
elif hasattr(e, 'code'):
print('The server couldn't fulfill the request.')
print('Error code: ', e.code)
else:
# everything is fine
info and geturl
The response returned by urlopen (or the HTTPError instance) has two useful methods info() and geturl() and is defined in the module urllib.response..
geturl — this returns the real URL of the page fetched. This is useful because urlopen (or the opener object used) may have followed a redirect. The URL of the page fetched may not be the same as the URL requested.
info — this returns a dictionary-like object that describes the page fetched, particularly the headers sent by the server. It is currently an http.client.HTTPMessage instance.
Typical headers include ‘Content-length’, ‘Content-type’, and so on. See the Quick Reference to HTTP Headers for a useful listing of HTTP headers with brief explanations of their meaning and use.
Openers and Handlers
When you fetch a URL you use an opener (an instance of the perhaps confusingly-named urllib.request.OpenerDirector). Normally we have been using the default opener — via urlopen — but you can create custom openers. Openers use handlers. All the “heavy lifting” is done by the handlers. Each handler knows how to open URLs for a particular URL scheme (http, ftp, etc.), or how to handle an aspect of URL opening, for example HTTP redirections or HTTP cookies.
You will want to create openers if you want to fetch URLs with specific handlers installed, for example to get an opener that handles cookies, or to get an opener that does not handle redirections.
To create an opener, instantiate an OpenerDirector, and then call .add_handler(some_handler_instance) repeatedly.
Alternatively, you can use build_opener, which is a convenience function for creating opener objects with a single function call. build_opener adds several handlers by default, but provides a quick way to add more and/or override the default handlers.
Other sorts of handlers you might want to can handle proxies, authentication, and other common but slightly specialised situations.
install_opener can be used to make an opener object the (global) default opener. This means that calls to urlopen will use the opener you have installed.
Opener objects have an open method, which can be called directly to fetch urls in the same way as the urlopen function: there’s no need to call install_opener, except as a convenience.
Basic Authentication
To illustrate creating and installing a handler we will use the HTTPBasicAuthHandler. For a more detailed discussion of this subject – including an explanation of how Basic Authentication works — see the Basic Authentication Tutorial.
When authentication is required, the server sends a header (as well as the 401 error code) requesting authentication. This specifies the authentication scheme and a ‘realm’. The header looks like: WWW-Authenticate: SCHEME realm="REALM".
e.g.
WWW-Authenticate: Basic realm="cPanel Users"
The client should then retry the request with the appropriate name and password for the realm included as a header in the request. This is ‘basic authentication’. In order to simplify this process we can create an instance of HTTPBasicAuthHandler and an opener to use this handler.
The HTTPBasicAuthHandler uses an object called a password manager to handle the mapping of URLs and realms to passwords and usernames. If you know what the realm is (from the authentication header sent by the server), then you can use a HTTPPasswordMgr. Frequently one doesn’t care what the realm is. In that case, it is convenient to use HTTPPasswordMgrWithDefaultRealm. This allows you to specify a default username and password for a URL. This will be supplied in the absence of you providing an alternative combination for a specific realm. We indicate this by providing None as the realm argument to the add_password method.
The top-level URL is the first URL that requires authentication. URLs “deeper” than the URL you pass to .add_password() will also match.
# create a password manager
password_mgr = urllib.request.HTTPPasswordMgrWithDefaultRealm()
# Add the username and password.
# If we knew the realm, we could use it instead of None.
top_level_url = "http://example.com/foo/"
password_mgr.add_password(None, top_level_url, username, password)
handler = urllib.request.HTTPBasicAuthHandler(password_mgr)
# create "opener" (OpenerDirector instance)
opener = urllib.request.build_opener(handler)
# use the opener to fetch a URL
opener.open(a_url)
# Install the opener.
# Now all calls to urllib.request.urlopen use our opener.
urllib.request.install_opener(opener)
Note
In the above example we only supplied our
HTTPBasicAuthHandlertobuild_opener. By default openers have the handlers for normal situations –ProxyHandler(if a proxy setting such as anhttp_proxyenvironment variable is set),UnknownHandler,HTTPHandler,HTTPDefaultErrorHandler,HTTPRedirectHandler,FTPHandler,FileHandler,DataHandler,HTTPErrorProcessor.
top_level_url is in fact either a full URL (including the ‘http:’ scheme component and the hostname and optionally the port number) e.g. "http://example.com/" or an “authority” (i.e. the hostname, optionally including the port number) e.g. "example.com" or "example.com:8080" (the latter example includes a port number). The authority, if present, must NOT contain the “userinfo” component — for example "joe:password@example.com" is not correct.
Proxies
urllib will auto-detect your proxy settings and use those. This is through the ProxyHandler, which is part of the normal handler chain when a proxy setting is detected. Normally that’s a good thing, but there are occasions when it may not be helpful.
urllib opener for SSL proxy (CONNECT method): ASPN Cookbook Recipe
One way to do this is to setup our own ProxyHandler, with no proxies defined. This is done using similar steps to setting up a Basic Authentication handler:
>>> proxy_support = urllib.request.ProxyHandler({})
>>> opener = urllib.request.build_opener(proxy_support)
>>> urllib.request.install_opener(opener)
Note
Currently
urllib.requestdoes not support fetching ofhttpslocations through a proxy. However, this can be enabled by extending urllib.request as shown in the recipe.urllib opener for SSL proxy (CONNECT method): ASPN Cookbook Recipe.
Note
HTTP_PROXYwill be ignored if a variableREQUEST_METHODis set; see the documentation ongetproxies().
Sockets and Layers
The Python support for fetching resources from the web is layered. urllib uses the http.client library, which in turn uses the socket library.
As of Python 2.3 you can specify how long a socket should wait for a response before timing out. This can be useful in applications which have to fetch web pages. By default the socket module has no timeout and can hang. Currently, the socket timeout is not exposed at the http.client or urllib.request levels. However, you can set the default timeout globally for all sockets using
import socket
import urllib.request
# timeout in seconds
timeout = 10
socket.setdefaulttimeout(timeout)
# this call to urllib.request.urlopen now uses the default timeout
# we have set in the socket module
req = urllib.request.Request('http://www.voidspace.org.uk')
response = urllib.request.urlopen(req)
Модуль Requests не поставляется вместе с Python, поэтому сперва установим его, выполнив команду pip install requests. Теперь попробуем получить веб-страницу. Как обычно, импортируем модуль и вызываем метод requests.get():
>>> import requests >>> res = requests.get('https://www.python.org') >>> type(res) <class 'requests.models.Response'> >>> res.status_code 200 >>> res.status_code == requests.codes.ok True >>> res.encoding 'utf-8' >>> len(res.text) 48844 >>> print(res.text) <!doctype html> <!--[if lt IE 7]> <html class="no-js ie6 lt-ie7 lt-ie8 lt-ie9"> ...
Метод requests.get() возвращает объект Response. Проверить успешность запроса можно с помощью свойства status_code или вызвать метод raise_for_status() для объекта Response:
>>> res = requests.get('https://www.python.org/bla-bla-bla') >>> res.raise_for_status() Traceback (most recent call last): File "<pyshell#12>", line 1, in <module> res.raise_for_status() File "C:pythonlibsite-packagesrequestsmodels.py", line 935, in raise_for_status raise HTTPError(http_error_msg, response=self) requests.exceptions.HTTPError: 404 Client Error: OK for url: https://www.python.org/bla-bla-bla
Если ошибка при загрузке страницы не является критичной для дальнейшей работы, можно обработать исключение:
res = requests.get('https://www.some-host.ru/bla-bla-bla') try: res.raise_for_status() except Exception as e: print('Ошибка при загрузке страницы: ' + str(e))
Ошибка при загрузке страницы: 404 Client Error: Not Found for url: http://www.some-host.ru/bla-bla-bla
При выполнении запроса, модуль requests устанавливает кодировку на основании заголовков HTTP. Эта кодировка используется при обращении к res.text. Если кодировка была определена неправильно, ее можно изменить:
res.encoding = 'ISO-8859-1'
Теперь посмотрим, как получить бинарные данные, например, изображение:
res = requests.get('http://www.some-host.ru/files/slider/4.jpg') imgFile = open('C:\example\slider.jpg', 'wb') imgFile.write(res.content) imgFile.close()
При потоковой загрузке (методу requests.get() надо передать именованный аргумент stream=True) рекомендуется использовать метод iter_content(size), который возвращает порции данных размером size на каждой итерации:
with open(filename, 'wb') as f: for chunk in res.iter_content(100000): f.write(chunk)
Для передачи параметров в запросе, надо использовать параметр params метода requests.get():
params = {'first': 'первый', 'second': 'второй'} res = requests.get('http://httpbin.org/get', params = params) print(res.url)
http://httpbin.org/get?first=%D0%BF%D0%B5%D1%80%D0%B2%D1%8B%D0%B9&second=%D0%B2%D1%82%D0%BE%D1%80%D0%BE%D0%B9
Любой ключ словаря, значение которого None, не будет добавлен к строке запроса URL.
Дополнительно
- Python, библиотека Requests: быстрый старт
- Парсинг сайтов: как скачивать картинки и другие файлы
Поиск:
HTTP • Python • Web-разработка • Модуль
Каталог оборудования
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Производители
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Функциональные группы
Lorem ipsum dolor sit amet, consectetur adipiscing elit, sed do eiusmod tempor incididunt ut labore et dolore magna aliqua.
Prerequisite: Creating simple application in Flask
A 404 Error is showed whenever a page is not found. Maybe the owner changed its URL and forgot to change the link or maybe they deleted the page itself. Every site needs a Custom Error page to avoid the user to see the default Ugly Error page.
GeeksforGeeks also has a customized error page. If we type a URL like
www.geeksforgeeks.org/ajneawnewiaiowjf
Default 404 Error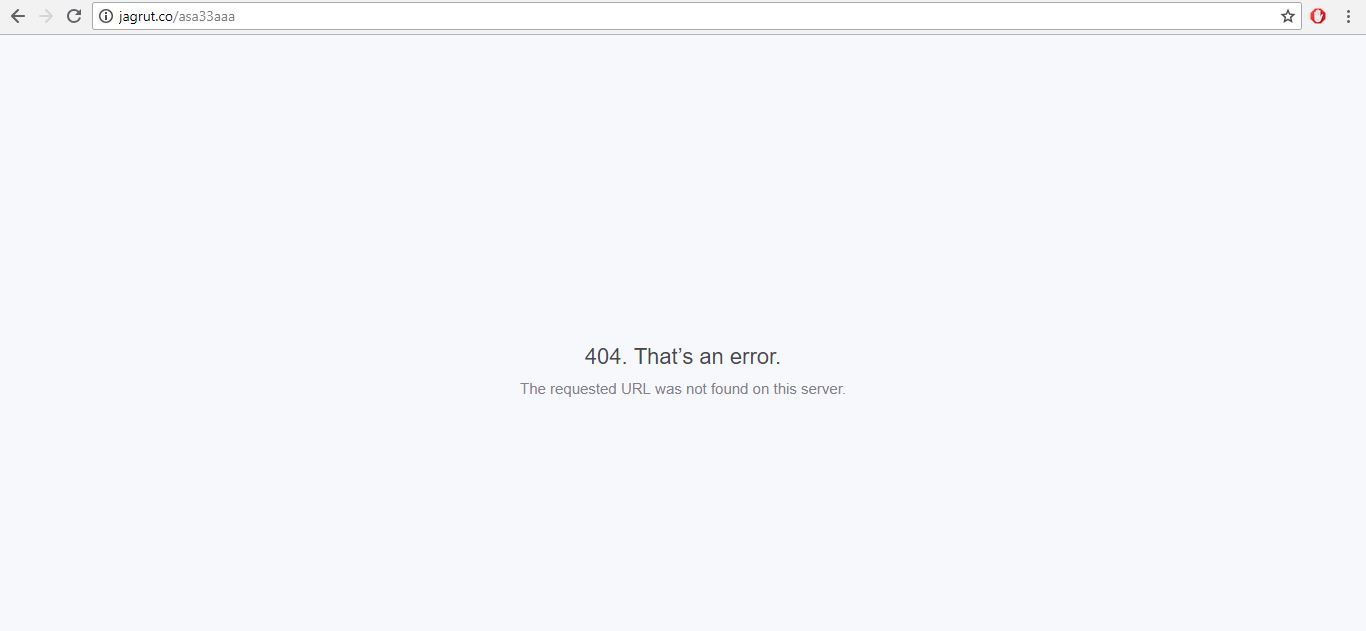
GeeksForGeeks Customized Error Page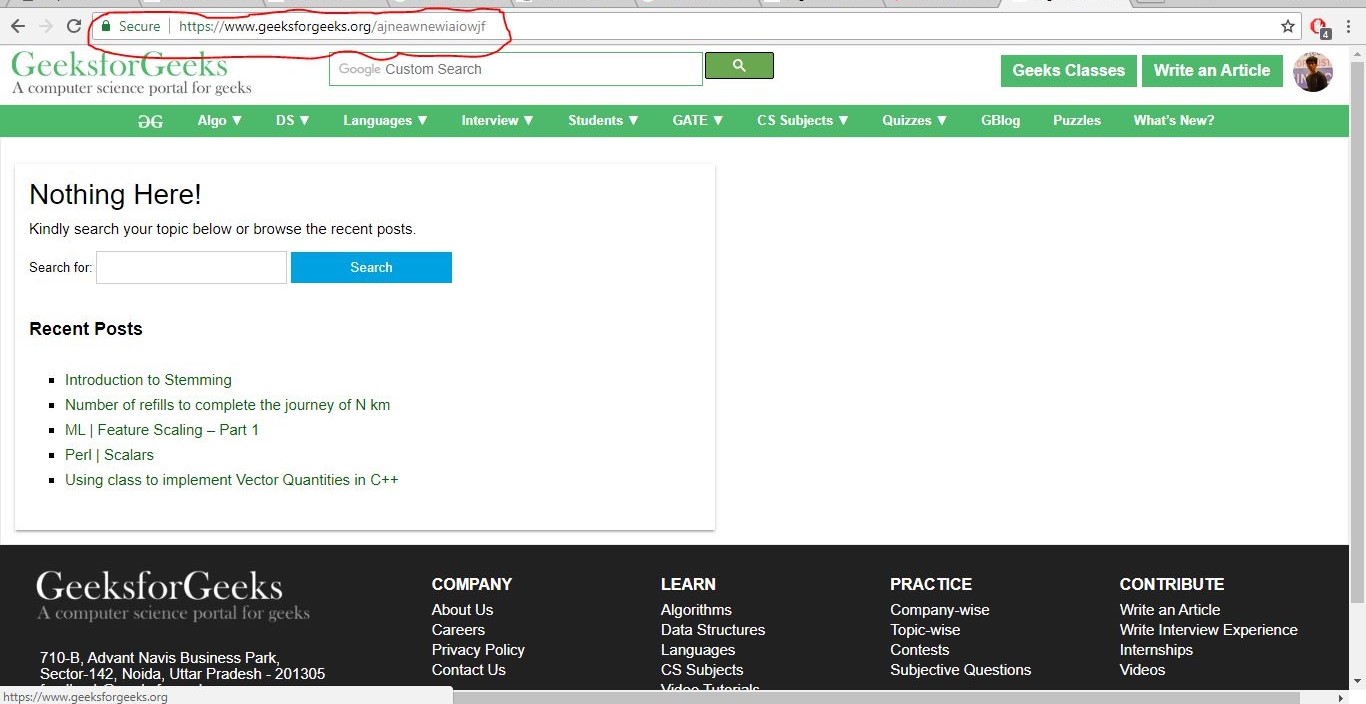
It will show an Error 404 page since this URL doesn’t exist. But an error page provides a beautiful layout, helps the user to go back, or even takes them to the homepage after a specific time interval. That is why Custom Error pages are necessary for every website.
Flask provides us with a way to handle the error and return our Custom Error page.
For this, we need to download and import flask. Download the flask through the following commands on CMD.
pip install flask
Using app.py as our Python file to manage templates, 404.html be the file we will return in the case of a 404 error and header.html be the file with header and navbar of a website.
app.py
Flask allows us to make a python file to define all routes and functions. In app.py we have defined the route to the main page (‘/’) and error handler function which is a flask function and we passed 404 error as a parameter.
from flask import Flask, render_template
app = Flask(__name__)
@app.errorhandler(404)
def not_found(e):
return render_template("404.html")
The above python program will return 404.html file whenever the user opens a broken link.
404.html
The following code exports header and navbar from header.html.
Both files should be stored in templates folder according to the flask.
{% extends "header.html" %}
{% block title %}Page Not Found{% endblock %}
{% block body %}
<h1>Oops! Looks like the page doesn't exist anymore</h1>
<a href="{{ url_for('index') }}"><p>Click Here</a>To go to the Home Page</p>
{% endblock %}
Automatically Redirecting to the Home page after 5 seconds
The app.py code for this example stays the same as above.
The following code Shows the Custom 404 Error page and starts a countdown of 5 seconds.
After 5 seconds are completed, it redirects the user back to the homepage.
404.html
The following code exports header and navbar from header.html.
Both files should be stored in the templates folder according to the flask.
After 5 seconds, the user will get redirected to the Home Page Automatically.
<html>
<head>
<title>Page Not Found</title>
<script language="JavaScript" type="text/javascript">
var seconds =6;
// countdown timer. took 6 because page takes approx 1 sec to load
var url="{{url_for(index)}}";
// variable for index.html url
function redirect(){
if (seconds <=0){
// redirect to new url after counter down.
window.location = url;
} else {
seconds--;
document.getElementById("pageInfo").innerHTML="Redirecting to Home Page after "
+seconds+" seconds."
setTimeout("redirect()", 1000)
}
}
</script>
</head>
{% extends "header.html" %}
//exporting navbar and header from header.html
{% block body %}
<body onload="redirect()">
<p id="pageInfo"></p>
{% endblock %}
</html>
Sample header.html
This is a sample header.html which includes a navbar just like shown in the image.
It’s made up of bootstrap. You can also make one of your own.
For this one, refer the bootstrap documentation.
<!DOCTYPE html>
<html>
<head>
css/bootstrap.min.css"
integrity="sha384-Gn5384xqQ1aoWXA+058RXPxPg6fy4IWvTNh0E26
3XmFcJlSAwiGgFAW/dAiS6JXm" crossorigin="anonymous">
<title>Flask</title>
</head>
<body>
"sha384-KJ3o2DKtIkvYIK3UENzmM7KCkRr/rE9/Qpg6aAZGJwFDMVNA/GpGFF93hXpG5KkN"
crossorigin="anonymous"></script>
/popper.min.js" integrity="sha384-ApNbgh9B+Y1QKtv3Rn7W3mgPxhU9K
/ScQsAP7hUibX39j7fakFPskvXusvfa0b4Q" crossorigin="anonymous"></script>
integrity="sha384-JZR6Spejh4U02d8jOt6vLEHfe/JQGiRRSQQxSfFWpi1MquVdAyjUar5+76PVCmYl"
crossorigin="anonymous"></script>
<header>
<nav class="navbar navbar-expand-lg navbar-light bg-light">
<a class="navbar-brand" href="#">Navbar</a>
<button class="navbar-toggler" type="button" data-toggle="collapse" data-target=
"#navbarSupportedContent" aria-controls="navbarSupportedContent"
aria-expanded="false" aria-label="Toggle navigation">
<span class="navbar-toggler-icon"></span>
</button>
<div class="collapse navbar-collapse" id="navbarSupportedContent">
<ul class="navbar-nav mr-auto">
<li class="nav-item active">
<a class="nav-link" href="#">Home <span class="sr-only">(current)</span></a>
</li>
<li class="nav-item">
<a class="nav-link" href="#">Link</a>
</li>
<li class="nav-item dropdown">
<a class="nav-link dropdown-toggle" href="#" id="navbarDropdown"
role="button data-toggle="dropdown" aria-haspopup="true" aria-expanded="false">
Dropdown
</a>
<div class="dropdown-menu" aria-labelledby="navbarDropdown">
<a class="dropdown-item" href="#">Action</a>
<a class="dropdown-item" href="#">Another action</a>
<div class="dropdown-divider"></div>
<a class="dropdown-item" href="#">Something else here</a>
</div>
</li>
<li class="nav-item">
<a class="nav-link disabled" href="#">Disabled</a>
</li>
</ul>
<form class="form-inline my-2 my-lg-0">
<input class="form-control mr-sm-2" type="search"
placeholder="Search" aria-label="Search">
<button class="btn btn-outline-success my-2 my-sm-0"
type="submit">Search</button>
</form>
</div>
</nav>
</head>
<body >
{%block body%}
{%endblock%}
</body>
</html>
Output:
The output will be a custom error page with header.html that the user exported.
The following is an example output with my custom header, footer, and 404.html file.
