I’m unable to find a module in python ,though easy_install says its already installed.
Any idea how to resolve this isseue?
$ python -c "from flaskext.sqlalchemy import SQLAlchemy"
Traceback (most recent call last):
File "<string>", line 1, in <module>
ImportError: No module named sqlalchemy
$ python -V
Python 2.7
$ sudo easy_install sqlalchemy
Searching for sqlalchemy
Best match: SQLAlchemy 0.7.7
Adding SQLAlchemy 0.7.7 to easy-install.pth file
Using /usr/lib/python2.7/site-packages
Processing dependencies for sqlalchemy
Finished processing dependencies for sqlalchemy
$ sudo pip install SQLAlchemy —upgrade Requirement already
up-to-date: SQLAlchemy in /usr/lib/python2.7/site-packages Cleaning
up…
Though pip says it’s installed.But I can’t find them in sys.path output.
$ sudo python -c "import sys;print sys.path" ['',
'/usr/lib/python2.7/site-packages/Flask_SQLAlchemy-0.15-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask-0.8-py2.7.egg',
'/usr/lib/python2.7/site-packages/Jinja2-2.6-py2.7.egg',
'/usr/lib/python2.7/site-packages/Werkzeug-0.8.3-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask_WTF-0.5.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/WTForms-0.6.3-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask_Mail-0.6.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/blinker-1.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/lamson-1.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/python_daemon-1.6-py2.7.egg',
'/usr/lib/python2.7/site-packages/nose-1.1.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/mock-0.8.0-py2.7.egg',
'/usr/lib/python2.7/site-packages/chardet-1.0.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/lockfile-0.9.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask_FlatPages-0.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/Markdown-2.1.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/PyYAML-3.10-py2.7-linux-i686.egg',
'/usr/lib/python2.7/site-packages/uWSGI-1.0.3-py2.7.egg',
'/usr/lib/python2.7/site-packages/MySQL_python-1.2.3-py2.7-linux-i686.egg',
'/usr/lib/python27.zip', '/usr/lib/python2.7',
'/usr/lib/python2.7/plat-linux2', '/usr/lib/python2.7/lib-tk',
'/usr/lib/python2.7/lib-old', '/usr/lib/python2.7/lib-dynload',
'/usr/lib/python2.7/site-packages',
'/usr/lib/python2.7/site-packages/setuptools-0.6c11-py2.7.egg-info']
I’m unable to find a module in python ,though easy_install says its already installed.
Any idea how to resolve this isseue?
$ python -c "from flaskext.sqlalchemy import SQLAlchemy"
Traceback (most recent call last):
File "<string>", line 1, in <module>
ImportError: No module named sqlalchemy
$ python -V
Python 2.7
$ sudo easy_install sqlalchemy
Searching for sqlalchemy
Best match: SQLAlchemy 0.7.7
Adding SQLAlchemy 0.7.7 to easy-install.pth file
Using /usr/lib/python2.7/site-packages
Processing dependencies for sqlalchemy
Finished processing dependencies for sqlalchemy
$ sudo pip install SQLAlchemy —upgrade Requirement already
up-to-date: SQLAlchemy in /usr/lib/python2.7/site-packages Cleaning
up…
Though pip says it’s installed.But I can’t find them in sys.path output.
$ sudo python -c "import sys;print sys.path" ['',
'/usr/lib/python2.7/site-packages/Flask_SQLAlchemy-0.15-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask-0.8-py2.7.egg',
'/usr/lib/python2.7/site-packages/Jinja2-2.6-py2.7.egg',
'/usr/lib/python2.7/site-packages/Werkzeug-0.8.3-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask_WTF-0.5.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/WTForms-0.6.3-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask_Mail-0.6.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/blinker-1.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/lamson-1.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/python_daemon-1.6-py2.7.egg',
'/usr/lib/python2.7/site-packages/nose-1.1.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/mock-0.8.0-py2.7.egg',
'/usr/lib/python2.7/site-packages/chardet-1.0.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/lockfile-0.9.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/Flask_FlatPages-0.2-py2.7.egg',
'/usr/lib/python2.7/site-packages/Markdown-2.1.1-py2.7.egg',
'/usr/lib/python2.7/site-packages/PyYAML-3.10-py2.7-linux-i686.egg',
'/usr/lib/python2.7/site-packages/uWSGI-1.0.3-py2.7.egg',
'/usr/lib/python2.7/site-packages/MySQL_python-1.2.3-py2.7-linux-i686.egg',
'/usr/lib/python27.zip', '/usr/lib/python2.7',
'/usr/lib/python2.7/plat-linux2', '/usr/lib/python2.7/lib-tk',
'/usr/lib/python2.7/lib-old', '/usr/lib/python2.7/lib-dynload',
'/usr/lib/python2.7/site-packages',
'/usr/lib/python2.7/site-packages/setuptools-0.6c11-py2.7.egg-info']
Quick Fix: Python raises the ImportError: No module named 'sqlalchemy' when it cannot find the library sqlalchemy. The most frequent source of this error is that you haven’t installed sqlalchemy explicitly with pip install sqlalchemy. Alternatively, you may have different Python versions on your computer, and sqlalchemy is not installed for the particular version you’re using.
Problem Formulation
You’ve just learned about the awesome capabilities of the sqlalchemy library and you want to try it out, so you start your code with the following statement:
import sqlalchemy
This is supposed to import the Pandas library into your (virtual) environment. However, it only throws the following ImportError: No module named sqlalchemy:
>>> import sqlalchemy
Traceback (most recent call last):
File "<pyshell#6>", line 1, in <module>
import sqlalchemy
ModuleNotFoundError: No module named 'sqlalchemy'
Solution Idea 1: Install Library sqlalchemy
The most likely reason is that Python doesn’t provide sqlalchemy in its standard library. You need to install it first!
Before being able to import the Pandas module, you need to install it using Python’s package manager pip. Make sure pip is installed on your machine.
To fix this error, you can run the following command in your Windows shell:
$ pip install sqlalchemy
This simple command installs sqlalchemy in your virtual environment on Windows, Linux, and MacOS. It assumes that your pip version is updated. If it isn’t, use the following two commands in your terminal, command line, or shell (there’s no harm in doing it anyways):
$ python -m pip install --upgrade pip $ pip install pandas
💡 Note: Don’t copy and paste the $ symbol. This is just to illustrate that you run it in your shell/terminal/command line.
Solution Idea 2: Fix the Path
The error might persist even after you have installed the sqlalchemy library. This likely happens because pip is installed but doesn’t reside in the path you can use. Although pip may be installed on your system the script is unable to locate it. Therefore, it is unable to install the library using pip in the correct path.
To fix the problem with the path in Windows follow the steps given next.
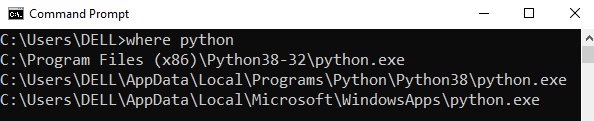
Step 1: Open the folder where you installed Python by opening the command prompt and typing where python
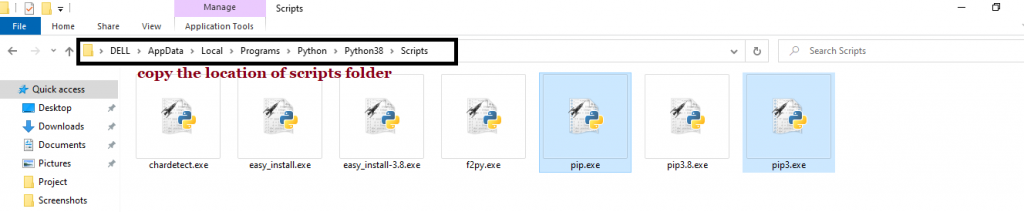
Step 2: Once you have opened the Python folder, browse and open the Scripts folder and copy its location. Also verify that the folder contains the pip file.
Step 3: Now open the Scripts directory in the command prompt using the cd command and the location that you copied previously.

Step 4: Now install the library using pip install sqlalchemy command. Here’s an analogous example:
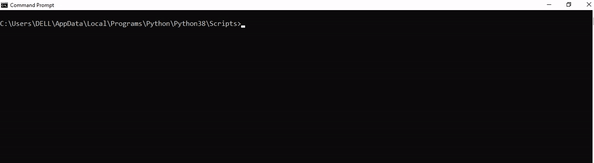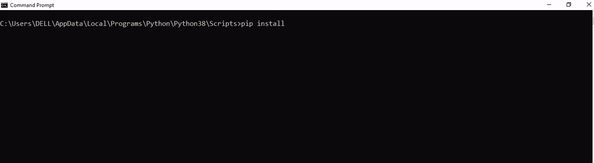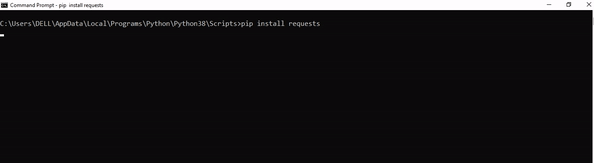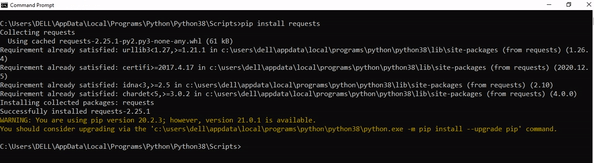
After having followed the above steps, execute our script once again. And you should get the desired output.
Other Solution Ideas
- The
ModuleNotFoundErrormay appear due to relative imports. You can learn everything about relative imports and how to create your own module in this article. - You may have mixed up Python and pip versions on your machine. In this case, to install
sqlalchemyfor Python 3, you may want to trypython3 -m pip install sqlalchemyor evenpip3 install sqlalchemyinstead ofpip install sqlalchemy - If you face this issue server-side, you may want to try the command
pip install --user sqlalchemy - If you’re using Ubuntu, you may want to try this command:
sudo apt install sqlalchemy - You can check out our in-depth guide on installing
sqlalchemyhere. - You can also check out this article to learn more about possible problems that may lead to an error when importing a library.
Understanding the “import” Statement
import sqlalchemy
In Python, the import statement serves two main purposes:
- Search the module by its name, load it, and initialize it.
- Define a name in the local namespace within the scope of the
importstatement. This local name is then used to reference the accessed module throughout the code.
What’s the Difference Between ImportError and ModuleNotFoundError?
What’s the difference between ImportError and ModuleNotFoundError?
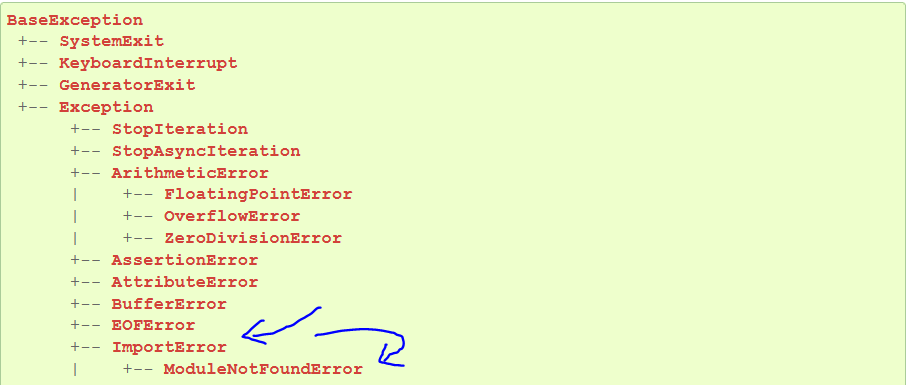
Python defines an error hierarchy, so some error classes inherit from other error classes. In our case, the ModuleNotFoundError is a subclass of the ImportError class.
You can see this in this screenshot from the docs:
You can also check this relationship using the issubclass() built-in function:
>>> issubclass(ModuleNotFoundError, ImportError) True
Specifically, Python raises the ModuleNotFoundError if the module (e.g., sqlalchemy) cannot be found. If it can be found, there may be a problem loading the module or some specific files within the module. In those cases, Python would raise an ImportError.
If an import statement cannot import a module, it raises an ImportError. This may occur because of a faulty installation or an invalid path. In Python 3.6 or newer, this will usually raise a ModuleNotFoundError.
Related Videos
The following video shows you how to resolve the ImportError:
How to Fix : “ImportError: Cannot import name X” in Python?
The following video shows you how to import a function from another folder—doing it the wrong way often results in the ModuleNotFoundError:
How to Call a Function from Another File in Python?
How to Fix “ModuleNotFoundError: No module named ‘sqlalchemy’” in PyCharm
If you create a new Python project in PyCharm and try to import the sqlalchemy library, it’ll raise the following error message:
Traceback (most recent call last):
File "C:/Users/.../main.py", line 1, in <module>
import sqlalchemy
ModuleNotFoundError: No module named 'sqlalchemy'
Process finished with exit code 1
The reason is that each PyCharm project, per default, creates a virtual environment in which you can install custom Python modules. But the virtual environment is initially empty—even if you’ve already installed sqlalchemy on your computer!
Here’s a screenshot exemplifying this for the pandas library. It’ll look similar for sqlalchemy.
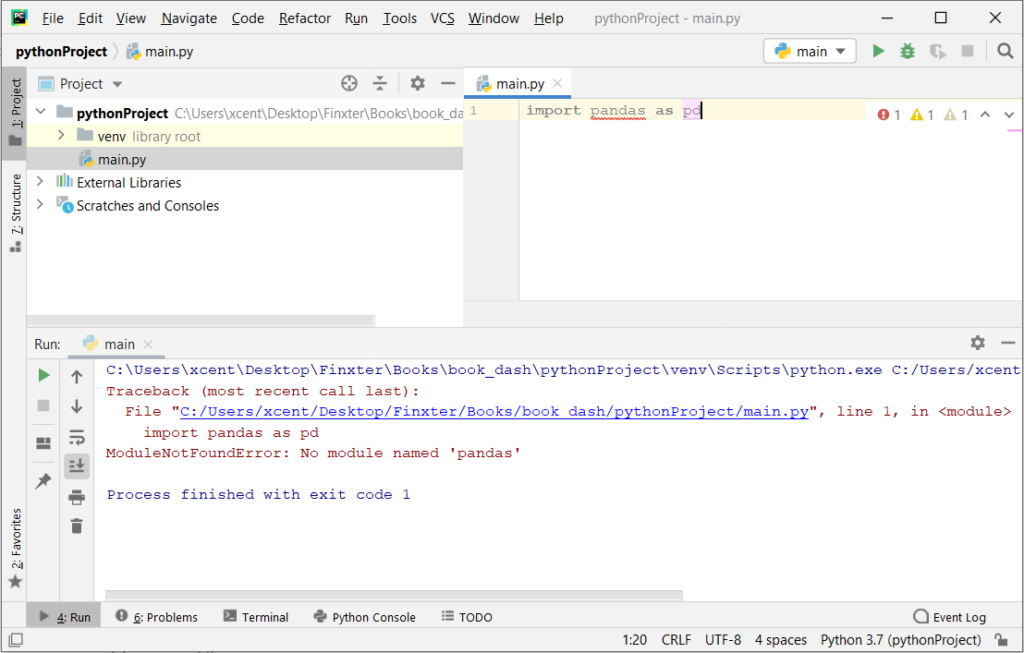
The fix is simple: Use the PyCharm installation tooltips to install Pandas in your virtual environment—two clicks and you’re good to go!
First, right-click on the pandas text in your editor:
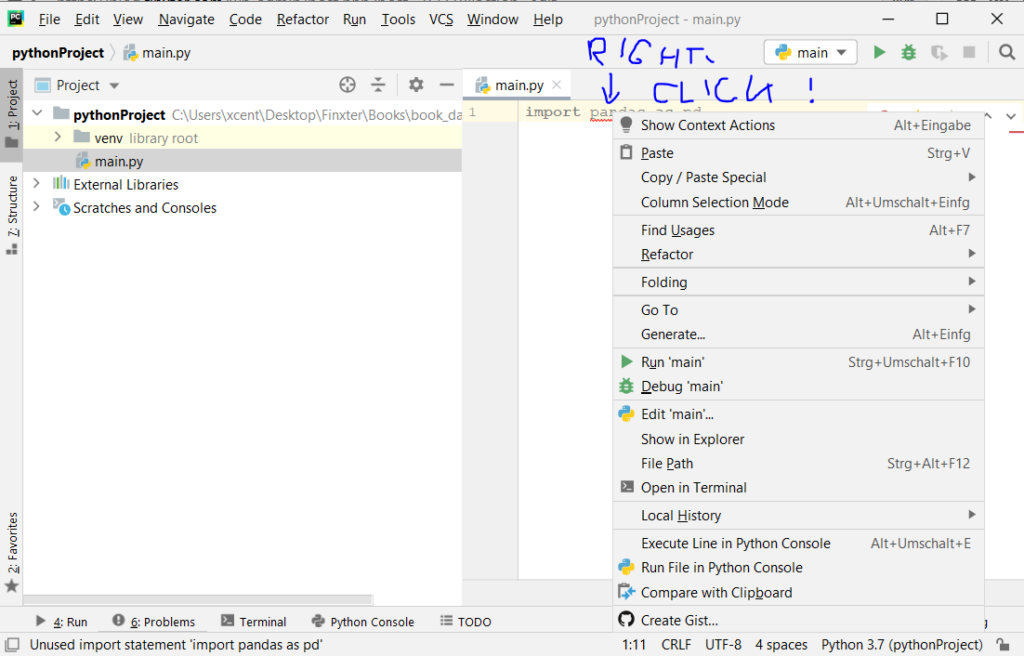
Second, click “Show Context Actions” in your context menu. In the new menu that arises, click “Install Pandas” and wait for PyCharm to finish the installation.
The code will run after your installation completes successfully.
As an alternative, you can also open the Terminal tool at the bottom and type:
$ pip install sqlalchemy
If this doesn’t work, you may want to set the Python interpreter to another version using the following tutorial: https://www.jetbrains.com/help/pycharm/2016.1/configuring-python-interpreter-for-a-project.html
You can also manually install a new library such as sqlalchemy in PyCharm using the following procedure:
- Open
File > Settings > Projectfrom the PyCharm menu. - Select your current project.
- Click the
Python Interpretertab within your project tab. - Click the small
+symbol to add a new library to the project. - Now type in the library to be installed, in your example Pandas, and click
Install Package. - Wait for the installation to terminate and close all popup windows.
Here’s an analogous example:
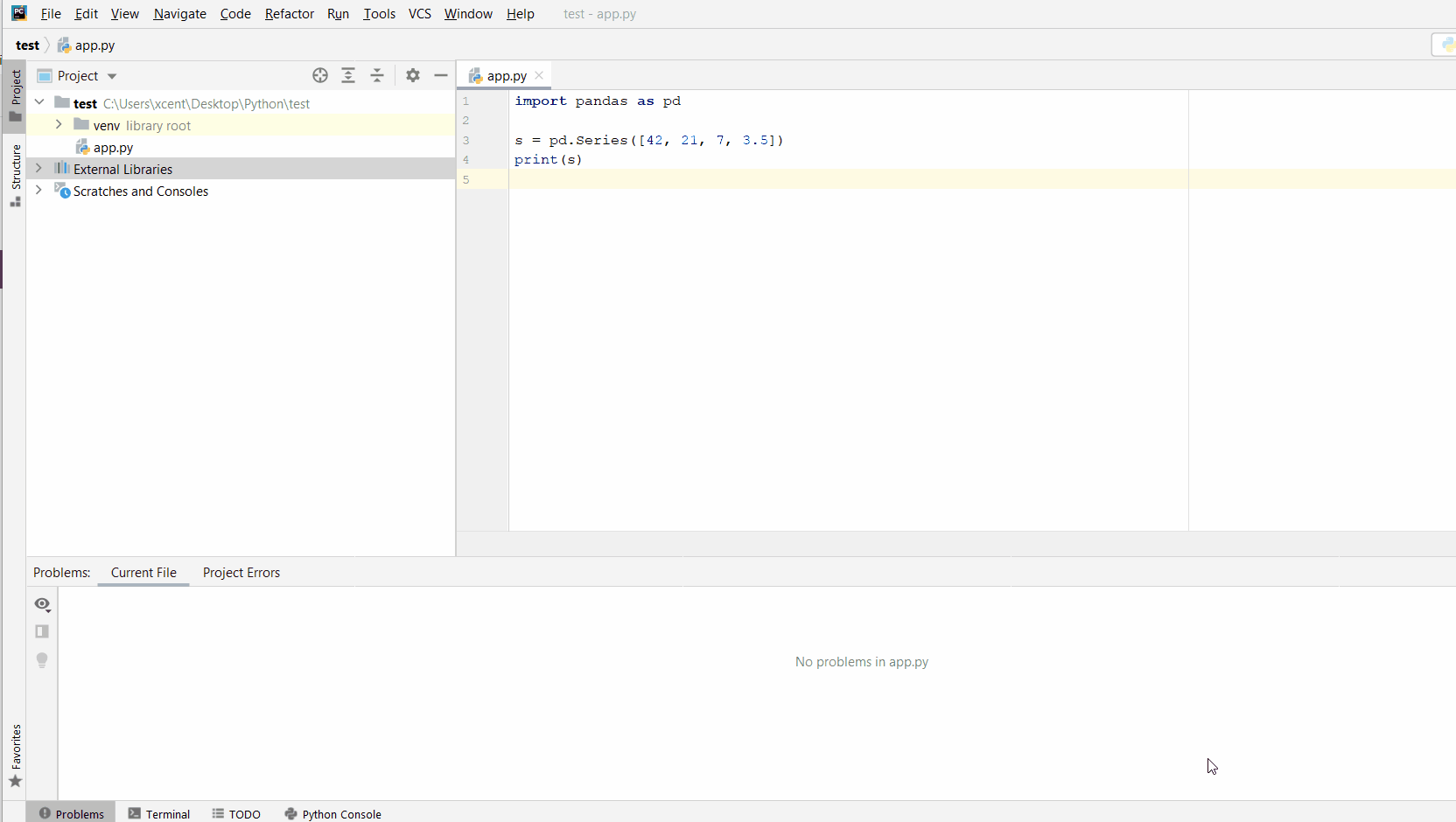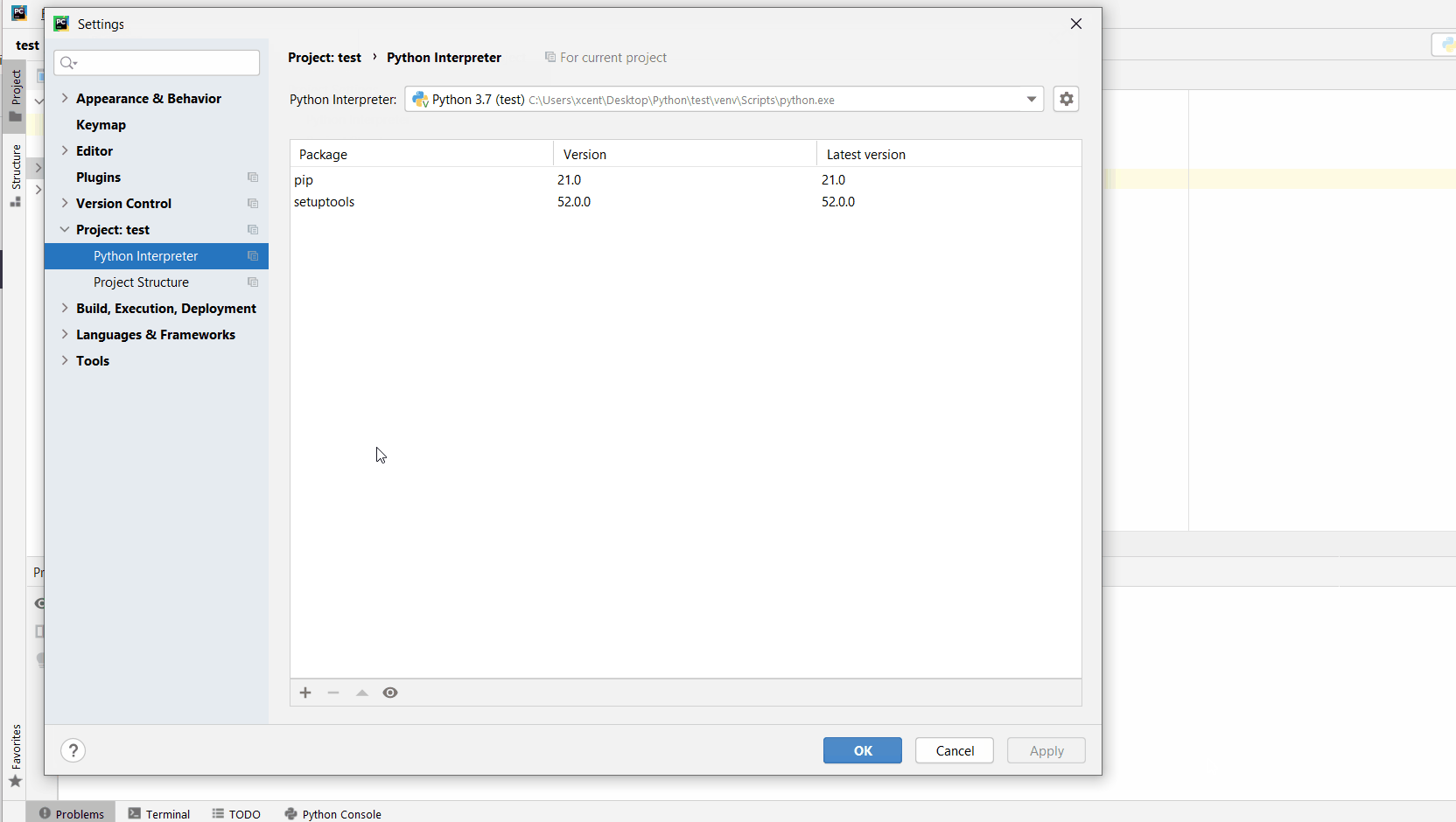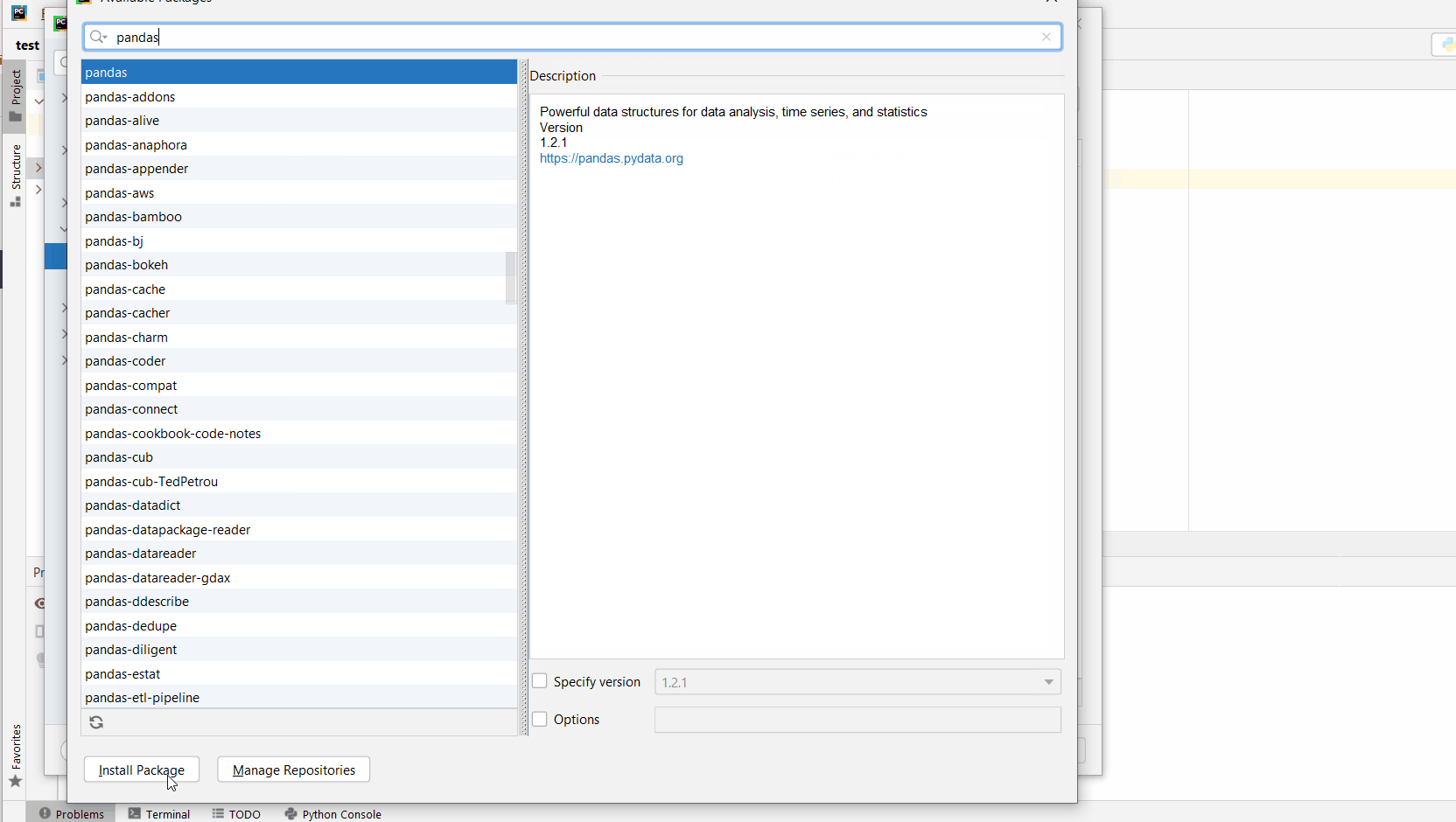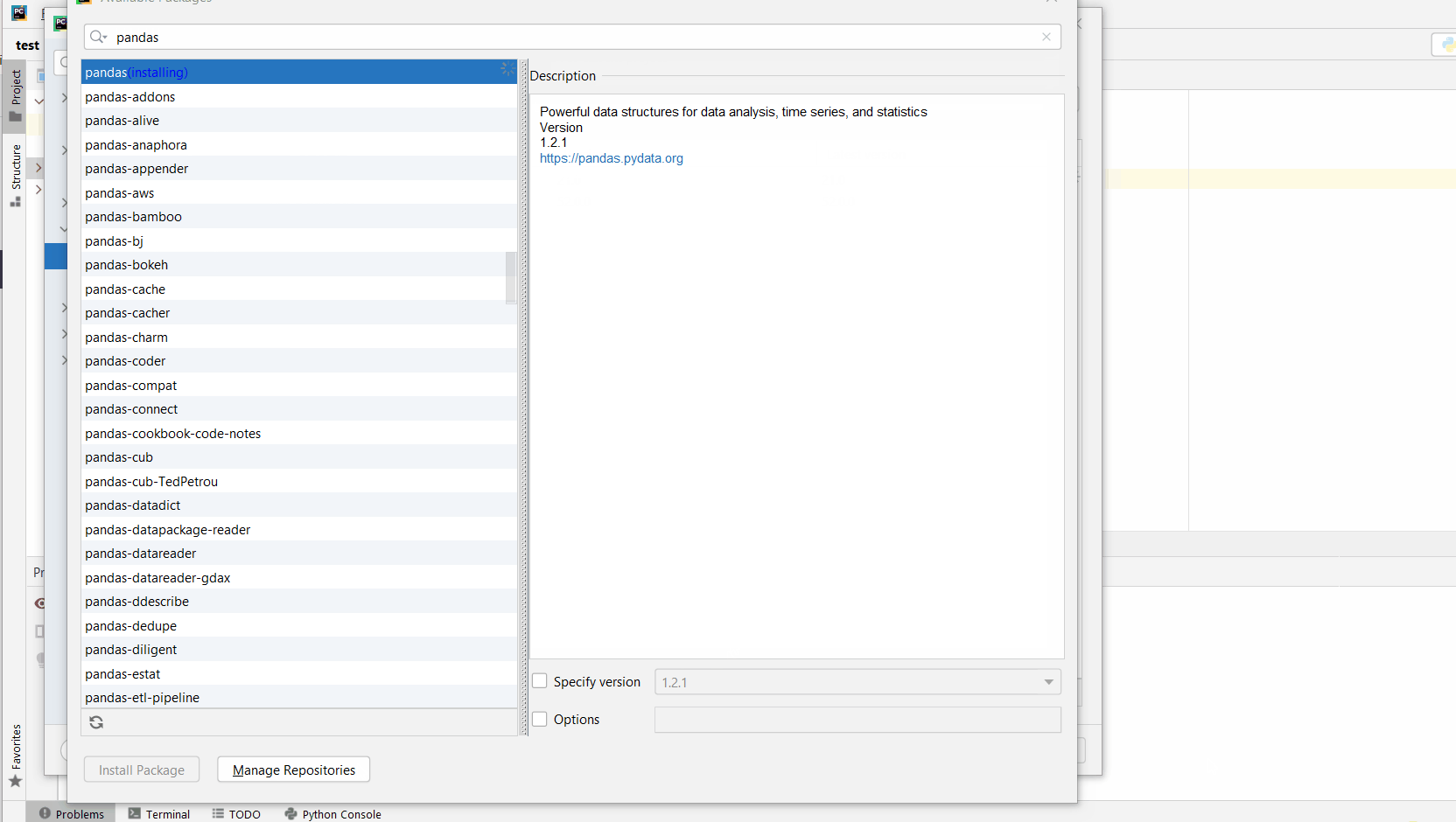
Here’s a full guide on how to install a library on PyCharm.
- How to Install a Library on PyCharm
Programmer Humor
Q: What is the object-oriented way to become wealthy?
💰
A: Inheritance.
While working as a researcher in distributed systems, Dr. Christian Mayer found his love for teaching computer science students.
To help students reach higher levels of Python success, he founded the programming education website Finxter.com. He’s author of the popular programming book Python One-Liners (NoStarch 2020), coauthor of the Coffee Break Python series of self-published books, computer science enthusiast, freelancer, and owner of one of the top 10 largest Python blogs worldwide.
His passions are writing, reading, and coding. But his greatest passion is to serve aspiring coders through Finxter and help them to boost their skills. You can join his free email academy here.
Просто не видит модуль sqlalchemy в приложении на flask (простенький блог). Всё перепробовал, и версии разные ставил, и менял на новые какие-то названия, ничего не помогло.
Везде, во всех туториалах, примерах всё ровно идёт, но, как всегда, не у меня.
P.S. Вот сам код блога (гитхаб)
И скрин ошибки:
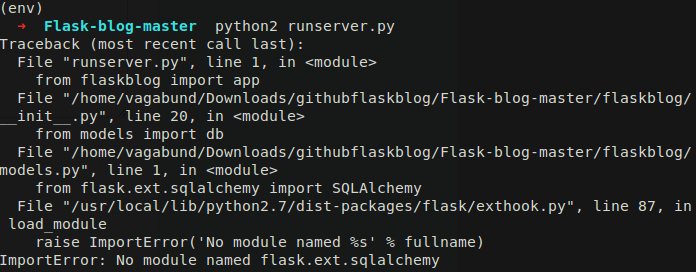
-
Вопрос заданболее трёх лет назад
-
3035 просмотров
Пригласить эксперта
Вы импортируете не сам SQLAlchemy, а расширение для фласка (flask.ext.sqlalchemy) и устанавливать вам нужно именно его.
Сделать это можно так:pip install Flask-SQLAlchemy
Попробуй еще : pip install SQLAlchemy, сделай pip freeze и глянь какие пакеты установлены.
По ссылке с гита написано:
pip install flask-sqlalchemy
pip instal postgresql
pip install sqlalchemy
pip install flask
pip install psycopg2
pip install flask-login
По ссылке на гтхаб в Readme указаны необходимые манипуляции для установки блога:
pip install flask-sqlalchemy
…
Вы их выполнили?
-
Показать ещё
Загружается…
09 февр. 2023, в 22:06
500 руб./за проект
09 февр. 2023, в 22:01
50000 руб./за проект
09 февр. 2023, в 22:00
1 руб./за проект
Минуточку внимания
From what I can see, the issue indeed only occurs with older py2.7 version. I tested with 1.4.0 and 1.4.1, same result.
Ex: Using Python 2.7.18:
$ docker run --rm -ti python:2.7 bash
root@12e12b250b9f:/# python -m pip install sqlalchemy
DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. A future version of pip will drop support for Python 2.7. More details about Python 2 support in pip, can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support
Collecting sqlalchemy
Downloading SQLAlchemy-1.4.1-cp27-cp27mu-manylinux1_x86_64.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 3.5 MB/s
Requirement already satisfied: importlib-metadata; python_version < "3.8" in /usr/local/lib/python2.7/site-packages (from sqlalchemy) (1.6.0)
Requirement already satisfied: contextlib2; python_version < "3" in /usr/local/lib/python2.7/site-packages (from importlib-metadata; python_version < "3.8"->sqlalchemy) (0.6.0.post1)
Requirement already satisfied: pathlib2; python_version < "3" in /usr/local/lib/python2.7/site-packages (from importlib-metadata; python_version < "3.8"->sqlalchemy) (2.3.5)
Requirement already satisfied: zipp>=0.5 in /usr/local/lib/python2.7/site-packages (from importlib-metadata; python_version < "3.8"->sqlalchemy) (1.2.0)
Requirement already satisfied: configparser>=3.5; python_version < "3" in /usr/local/lib/python2.7/site-packages (from importlib-metadata; python_version < "3.8"->sqlalchemy) (4.0.2)
Requirement already satisfied: six in /usr/local/lib/python2.7/site-packages (from pathlib2; python_version < "3"->importlib-metadata; python_version < "3.8"->sqlalchemy) (1.14.0)
Requirement already satisfied: scandir; python_version < "3.5" in /usr/local/lib/python2.7/site-packages (from pathlib2; python_version < "3"->importlib-metadata; python_version < "3.8"->sqlalchemy) (1.10.0)
Installing collected packages: sqlalchemy
Successfully installed sqlalchemy-1.4.1
WARNING: You are using pip version 20.0.2; however, version 20.3.4 is available.
You should consider upgrading via the '/usr/local/bin/python -m pip install --upgrade pip' command.
root@12e12b250b9f:/# python
Python 2.7.18 (default, Apr 20 2020, 19:27:10)
[GCC 8.3.0] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sqlalchemy
# No error or issue.
Now using Python 2.7.8 (the version on which the issue occured for me):
$ docker run --rm -ti python:2.7.8 bash
root@feb1ce332e69:/# python -m pip list
pip (1.5.6)
setuptools (7.0)
virtualenv (1.11.6)
wsgiref (0.1.2)
# Oh yikes, really old pip and setuptools in that docker image.
# That caused some issue at installation for me at first, so we need to update those.
# I do a first update to pip 10.0.1 which will properly handle Requires-Python metadata,
# I know that from memory/experience, and then I'll do another update to latest pip/setuptools/wheel.
root@feb1ce332e69:/# python -m pip install pip==10.0.1
Downloading/unpacking pip==10.0.1
Downloading pip-10.0.1-py2.py3-none-any.whl (1.3MB): 1.3MB downloaded
Installing collected packages: pip
Found existing installation: pip 1.5.6
Uninstalling pip:
Successfully uninstalled pip
Successfully installed pip
Cleaning up...
root@feb1ce332e69:/# python -m pip install -U pip setuptools wheel
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:339: SNIMissingWarning: An HTTPS request has been made, but the SNI (Subject Name Indication) extension to TLS is not available on this platform. This may cause the server to present an incorrect TLS certificate, which can cause validation failures. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
SNIMissingWarning
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:137: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecurePlatformWarning
Collecting pip
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:137: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecurePlatformWarning
Downloading https://files.pythonhosted.org/packages/27/79/8a850fe3496446ff0d584327ae44e7500daf6764ca1a382d2d02789accf7/pip-20.3.4-py2.py3-none-any.whl (1.5MB)
100% |████████████████████████████████| 1.5MB 10.6MB/s
Collecting setuptools
Downloading https://files.pythonhosted.org/packages/e1/b7/182161210a13158cd3ccc41ee19aadef54496b74f2817cc147006ec932b4/setuptools-44.1.1-py2.py3-none-any.whl (583kB)
100% |████████████████████████████████| 583kB 13.4MB/s
Collecting wheel
Downloading https://files.pythonhosted.org/packages/65/63/39d04c74222770ed1589c0eaba06c05891801219272420b40311cd60c880/wheel-0.36.2-py2.py3-none-any.whl
Installing collected packages: pip, setuptools, wheel
Found existing installation: pip 10.0.1
Uninstalling pip-10.0.1:
Successfully uninstalled pip-10.0.1
Found existing installation: setuptools 7.0
Uninstalling setuptools-7.0:
Successfully uninstalled setuptools-7.0
Successfully installed pip-20.3.4 setuptools-44.1.1 wheel-0.36.2
root@feb1ce332e69:/# python -m pip install sqlalchemy
DEPRECATION: Python 2.7 reached the end of its life on January 1st, 2020. Please upgrade your Python as Python 2.7 is no longer maintained. pip 21.0 will drop support for Python 2.7 in January 2021. More details about Python 2 support in pip can be found at https://pip.pypa.io/en/latest/development/release-process/#python-2-support pip 21.0 will remove support for this functionality.
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:424: SNIMissingWarning: An HTTPS request has been made, but the SNI (Server Name Indication) extension to TLS is not available on this platform. This may cause the server to present an incorrect TLS certificate, which can cause validation failures. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
SNIMissingWarning,
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:164: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecurePlatformWarning,
Collecting sqlalchemy
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:164: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecurePlatformWarning,
Downloading SQLAlchemy-1.4.1-cp27-cp27m-manylinux1_x86_64.whl (1.5 MB)
|████████████████████████████████| 1.5 MB 3.3 MB/s
Collecting importlib-metadata; python_version < "3.8"
Downloading importlib_metadata-2.1.1-py2.py3-none-any.whl (10 kB)
Collecting contextlib2; python_version < "3"
Downloading contextlib2-0.6.0.post1-py2.py3-none-any.whl (9.8 kB)
Collecting zipp>=0.5
Downloading zipp-1.2.0-py2.py3-none-any.whl (4.8 kB)
Collecting configparser>=3.5; python_version < "3"
Downloading configparser-4.0.2-py2.py3-none-any.whl (22 kB)
Collecting pathlib2; python_version < "3"
Downloading pathlib2-2.3.5-py2.py3-none-any.whl (18 kB)
Collecting scandir; python_version < "3.5"
Downloading scandir-1.10.0.tar.gz (33 kB)
Collecting six
Downloading six-1.15.0-py2.py3-none-any.whl (10 kB)
Building wheels for collected packages: scandir
Building wheel for scandir (setup.py) ... done
Created wheel for scandir: filename=scandir-1.10.0-cp27-cp27m-linux_x86_64.whl size=39138 sha256=6c35a5d95a7b3d8d1c81b2d8093bf5253a2d2785b7610ec9ef5b6b01224231db
Stored in directory: /root/.cache/pip/wheels/58/2c/26/52406f7d1f19bcc47a6fbd1037a5f293492f5cf1d58c539edb
Successfully built scandir
Installing collected packages: contextlib2, zipp, configparser, scandir, six, pathlib2, importlib-metadata, sqlalchemy
Successfully installed configparser-4.0.2 contextlib2-0.6.0.post1 importlib-metadata-2.1.1 pathlib2-2.3.5 scandir-1.10.0 six-1.15.0 sqlalchemy-1.4.1 zipp-1.2.0
/usr/local/lib/python2.7/site-packages/pip/_vendor/urllib3/util/ssl_.py:164: InsecurePlatformWarning: A true SSLContext object is not available. This prevents urllib3 from configuring SSL appropriately and may cause certain SSL connections to fail. You can upgrade to a newer version of Python to solve this. For more information, see https://urllib3.readthedocs.io/en/latest/advanced-usage.html#ssl-warnings
InsecurePlatformWarning,
root@feb1ce332e69:/# python
Python 2.7.8 (default, Nov 26 2014, 22:28:51)
[GCC 4.9.1] on linux2
Type "help", "copyright", "credits" or "license" for more information.
>>> import sqlalchemy
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/__init__.py", line 9, in <module>
from .engine import create_engine
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/engine/__init__.py", line 18, in <module>
from . import events
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/engine/events.py", line 9, in <module>
from .base import Engine
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/engine/base.py", line 12, in <module>
from .interfaces import Connectable
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/engine/interfaces.py", line 11, in <module>
from ..sql.compiler import Compiled # noqa
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/sql/__init__.py", line 13, in <module>
from .expression import Alias
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/sql/expression.py", line 144, in <module>
from .lambdas import lambda_stmt
File "/usr/local/lib/python2.7/site-packages/sqlalchemy/sql/lambdas.py", line 1067
exec(code, vars_, vars_)
SyntaxError: unqualified exec is not allowed in function '_rewrite_code_obj' it contains a nested function with free variables
# Yup, here's the error.
This section lists descriptions and background for common error messages
and warnings raised or emitted by SQLAlchemy.
SQLAlchemy normally raises errors within the context of a SQLAlchemy-specific
exception class. For details on these classes, see
Core Exceptions and ORM Exceptions.
SQLAlchemy errors can roughly be separated into two categories, the
programming-time error and the runtime error. Programming-time
errors are raised as a result of functions or methods being called with
incorrect arguments, or from other configuration-oriented methods such as
mapper configurations that can’t be resolved. The programming-time error is
typically immediate and deterministic. The runtime error on the other hand
represents a failure that occurs as a program runs in response to some
condition that occurs arbitrarily, such as database connections being
exhausted or some data-related issue occurring. Runtime errors are more
likely to be seen in the logs of a running application as the program
encounters these states in response to load and data being encountered.
Since runtime errors are not as easy to reproduce and often occur in response
to some arbitrary condition as the program runs, they are more difficult to
debug and also affect programs that have already been put into production.
Within this section, the goal is to try to provide background on some of the
most common runtime errors as well as programming time errors.
Connections and Transactions¶
QueuePool limit of size <x> overflow <y> reached, connection timed out, timeout <z>¶
This is possibly the most common runtime error experienced, as it directly
involves the work load of the application surpassing a configured limit, one
which typically applies to nearly all SQLAlchemy applications.
The following points summarize what this error means, beginning with the
most fundamental points that most SQLAlchemy users should already be
familiar with.
-
The SQLAlchemy Engine object uses a pool of connections by default — What
this means is that when one makes use of a SQL database connection resource
of anEngineobject, and then releases that resource,
the database connection itself remains connected to the database and
is returned to an internal queue where it can be used again. Even though
the code may appear to be ending its conversation with the database, in many
cases the application will still maintain a fixed number of database connections
that persist until the application ends or the pool is explicitly disposed. -
Because of the pool, when an application makes use of a SQL database
connection, most typically from either making use ofEngine.connect()
or when making queries using an ORMSession, this activity
does not necessarily establish a new connection to the database at the
moment the connection object is acquired; it instead consults the
connection pool for a connection, which will often retrieve an existing
connection from the pool to be re-used. If no connections are available,
the pool will create a new database connection, but only if the
pool has not surpassed a configured capacity. -
The default pool used in most cases is called
QueuePool. When
you ask this pool to give you a connection and none are available, it
will create a new connection if the total number of connections in play
are less than a configured value. This value is equal to the
pool size plus the max overflow. That means if you have configured
your engine as:engine = create_engine("mysql+mysqldb://u:p@host/db", pool_size=10, max_overflow=20)
The above
Enginewill allow at most 30 connections to be in
play at any time, not including connections that were detached from the
engine or invalidated. If a request for a new connection arrives and
30 connections are already in use by other parts of the application,
the connection pool will block for a fixed period of time,
before timing out and raising this error message.In order to allow for a higher number of connections be in use at once,
the pool can be adjusted using the
create_engine.pool_sizeandcreate_engine.max_overflow
parameters as passed to thecreate_engine()function. The timeout
to wait for a connection to be available is configured using the
create_engine.pool_timeoutparameter. -
The pool can be configured to have unlimited overflow by setting
create_engine.max_overflowto the value “-1”. With this setting,
the pool will still maintain a fixed pool of connections, however it will
never block upon a new connection being requested; it will instead unconditionally
make a new connection if none are available.However, when running in this way, if the application has an issue where it
is using up all available connectivity resources, it will eventually hit the
configured limit of available connections on the database itself, which will
again return an error. More seriously, when the application exhausts the
database of connections, it usually will have caused a great
amount of resources to be used up before failing, and can also interfere
with other applications and database status mechanisms that rely upon being
able to connect to the database.Given the above, the connection pool can be looked at as a safety valve
for connection use, providing a critical layer of protection against
a rogue application causing the entire database to become unavailable
to all other applications. When receiving this error message, it is vastly
preferable to repair the issue using up too many connections and/or
configure the limits appropriately, rather than allowing for unlimited
overflow which does not actually solve the underlying issue.
What causes an application to use up all the connections that it has available?
-
The application is fielding too many concurrent requests to do work based
on the configured value for the pool — This is the most straightforward
cause. If you have
an application that runs in a thread pool that allows for 30 concurrent
threads, with one connection in use per thread, if your pool is not configured
to allow at least 30 connections checked out at once, you will get this
error once your application receives enough concurrent requests. Solution
is to raise the limits on the pool or lower the number of concurrent threads. -
The application is not returning connections to the pool — This is the
next most common reason, which is that the application is making use of the
connection pool, but the program is failing to release these
connections and is instead leaving them open. The connection pool as well
as the ORMSessiondo have logic such that when the session and/or
connection object is garbage collected, it results in the underlying
connection resources being released, however this behavior cannot be relied
upon to release resources in a timely manner.A common reason this can occur is that the application uses ORM sessions and
does not callSession.close()upon them one the work involving that
session is complete. Solution is to make sure ORM sessions if using the ORM,
or engine-boundConnectionobjects if using Core, are explicitly
closed at the end of the work being done, either via the appropriate
.close()method, or by using one of the available context managers (e.g.
“with:” statement) to properly release the resource. -
The application is attempting to run long-running transactions — A
database transaction is a very expensive resource, and should never be
left idle waiting for some event to occur. If an application is waiting
for a user to push a button, or a result to come off of a long running job
queue, or is holding a persistent connection open to a browser, don’t
keep a database transaction open for the whole time. As the application
needs to work with the database and interact with an event, open a short-lived
transaction at that point and then close it. -
The application is deadlocking — Also a common cause of this error and
more difficult to grasp, if an application is not able to complete its use
of a connection either due to an application-side or database-side deadlock,
the application can use up all the available connections which then leads to
additional requests receiving this error. Reasons for deadlocks include:-
Using an implicit async system such as gevent or eventlet without
properly monkeypatching all socket libraries and drivers, or which
has bugs in not fully covering for all monkeypatched driver methods,
or less commonly when the async system is being used against CPU-bound
workloads and greenlets making use of database resources are simply waiting
too long to attend to them. Neither implicit nor explicit async
programming frameworks are typically
necessary or appropriate for the vast majority of relational database
operations; if an application must use an async system for some area
of functionality, it’s best that database-oriented business methods
run within traditional threads that pass messages to the async part
of the application. -
A database side deadlock, e.g. rows are mutually deadlocked
-
Threading errors, such as mutexes in a mutual deadlock, or calling
upon an already locked mutex in the same thread
-
Keep in mind an alternative to using pooling is to turn off pooling entirely.
See the section Switching Pool Implementations for background on this. However, note
that when this error message is occurring, it is always due to a bigger
problem in the application itself; the pool just helps to reveal the problem
sooner.
Can’t reconnect until invalid transaction is rolled back. Please rollback() fully before proceeding¶
This error condition refers to the case where a Connection was
invalidated, either due to a database disconnect detection or due to an
explicit call to Connection.invalidate(), but there is still a
transaction present that was initiated either explicitly by the Connection.begin()
method, or due to the connection automatically beginning a transaction as occurs
in the 2.x series of SQLAlchemy when any SQL statements are emitted. When a connection is invalidated, any Transaction
that was in progress is now in an invalid state, and must be explicitly rolled
back in order to remove it from the Connection.
DBAPI Errors¶
The Python database API, or DBAPI, is a specification for database drivers
which can be located at Pep-249.
This API specifies a set of exception classes that accommodate the full range
of failure modes of the database.
SQLAlchemy does not generate these exceptions directly. Instead, they are
intercepted from the database driver and wrapped by the SQLAlchemy-provided
exception DBAPIError, however the messaging within the exception is
generated by the driver, not SQLAlchemy.
InterfaceError¶
Exception raised for errors that are related to the database interface rather
than the database itself.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
The InterfaceError is sometimes raised by drivers in the context
of the database connection being dropped, or not being able to connect
to the database. For tips on how to deal with this, see the section
Dealing with Disconnects.
DatabaseError¶
Exception raised for errors that are related to the database itself, and not
the interface or data being passed.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
DataError¶
Exception raised for errors that are due to problems with the processed data
like division by zero, numeric value out of range, etc.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
OperationalError¶
Exception raised for errors that are related to the database’s operation and
not necessarily under the control of the programmer, e.g. an unexpected
disconnect occurs, the data source name is not found, a transaction could not
be processed, a memory allocation error occurred during processing, etc.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
The OperationalError is the most common (but not the only) error class used
by drivers in the context of the database connection being dropped, or not
being able to connect to the database. For tips on how to deal with this, see
the section Dealing with Disconnects.
IntegrityError¶
Exception raised when the relational integrity of the database is affected,
e.g. a foreign key check fails.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
InternalError¶
Exception raised when the database encounters an internal error, e.g. the
cursor is not valid anymore, the transaction is out of sync, etc.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
The InternalError is sometimes raised by drivers in the context
of the database connection being dropped, or not being able to connect
to the database. For tips on how to deal with this, see the section
Dealing with Disconnects.
ProgrammingError¶
Exception raised for programming errors, e.g. table not found or already
exists, syntax error in the SQL statement, wrong number of parameters
specified, etc.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
The ProgrammingError is sometimes raised by drivers in the context
of the database connection being dropped, or not being able to connect
to the database. For tips on how to deal with this, see the section
Dealing with Disconnects.
NotSupportedError¶
Exception raised in case a method or database API was used which is not
supported by the database, e.g. requesting a .rollback() on a connection that
does not support transaction or has transactions turned off.
This error is a DBAPI Error and originates from
the database driver (DBAPI), not SQLAlchemy itself.
SQL Expression Language¶
Object will not produce a cache key, Performance Implications¶
SQLAlchemy as of version 1.4 includes a
SQL compilation caching facility which will allow
Core and ORM SQL constructs to cache their stringified form, along with other
structural information used to fetch results from the statement, allowing the
relatively expensive string compilation process to be skipped when another
structurally equivalent construct is next used. This system
relies upon functionality that is implemented for all SQL constructs, including
objects such as Column,
select(), and TypeEngine objects, to produce a
cache key which fully represents their state to the degree that it affects
the SQL compilation process.
If the warnings in question refer to widely used objects such as
Column objects, and are shown to be affecting the majority of
SQL constructs being emitted (using the estimation techniques described at
Estimating Cache Performance Using Logging) such that caching is generally not enabled for an
application, this will negatively impact performance and can in some cases
effectively produce a performance degradation compared to prior SQLAlchemy
versions. The FAQ at Why is my application slow after upgrading to 1.4 and/or 2.x? covers this in additional detail.
Caching disables itself if there’s any doubt¶
Caching relies on being able to generate a cache key that accurately represents
the complete structure of a statement in a consistent fashion. If a particular
SQL construct (or type) does not have the appropriate directives in place which
allow it to generate a proper cache key, then caching cannot be safely enabled:
-
The cache key must represent the complete structure: If the usage of two
separate instances of that construct may result in different SQL being
rendered, caching the SQL against the first instance of the element using a
cache key that does not capture the distinct differences between the first and
second elements will result in incorrect SQL being cached and rendered for the
second instance. -
The cache key must be consistent: If a construct represents state that
changes every time, such as a literal value, producing unique SQL for every
instance of it, this construct is also not safe to cache, as repeated use of
the construct will quickly fill up the statement cache with unique SQL strings
that will likely not be used again, defeating the purpose of the cache.
For the above two reasons, SQLAlchemy’s caching system is extremely
conservative about deciding to cache the SQL corresponding to an object.
Assertion attributes for caching¶
The warning is emitted based on the criteria below. For further detail on
each, see the section Why is my application slow after upgrading to 1.4 and/or 2.x?.
-
The
Dialectitself (i.e. the module that is specified by the
first part of the URL we pass tocreate_engine(), like
postgresql+psycopg2://), must indicate it has been reviewed and tested
to support caching correctly, which is indicated by the
Dialect.supports_statement_cacheattribute being set toTrue.
When using third party dialects, consult with the maintainers of the dialect
so that they may follow the steps to ensure caching may be enabled in their dialect and publish a new release. -
Third party or user defined types that inherit from either
TypeDecoratororUserDefinedTypemust include the
ExternalType.cache_okattribute in their definition, including for
all derived subclasses, following the guidelines described in the docstring
forExternalType.cache_ok. As before, if these datatypes are
imported from third party libraries, consult with the maintainers of that
library so that they may provide the necessary changes to their library and
publish a new release. -
Third party or user defined SQL constructs that subclass from classes such
asClauseElement,Column,Insert
etc, including simple subclasses as well as those which are designed to
work with the Custom SQL Constructs and Compilation Extension, should normally
include theHasCacheKey.inherit_cacheattribute set toTrue
orFalsebased on the design of the construct, following the guidelines
described at Enabling Caching Support for Custom Constructs.
Compiler StrSQLCompiler can’t render element of type <element type>¶
This error usually occurs when attempting to stringify a SQL expression
construct that includes elements which are not part of the default compilation;
in this case, the error will be against the StrSQLCompiler class.
In less common cases, it can also occur when the wrong kind of SQL expression
is used with a particular type of database backend; in those cases, other
kinds of SQL compiler classes will be named, such as SQLCompiler or
sqlalchemy.dialects.postgresql.PGCompiler. The guidance below is
more specific to the “stringification” use case but describes the general
background as well.
Normally, a Core SQL construct or ORM Query object can be stringified
directly, such as when we use print():
>>> from sqlalchemy import column >>> print(column("x") == 5)x = :x_1
When the above SQL expression is stringified, the StrSQLCompiler
compiler class is used, which is a special statement compiler that is invoked
when a construct is stringified without any dialect-specific information.
However, there are many constructs that are specific to some particular kind
of database dialect, for which the StrSQLCompiler doesn’t know how
to turn into a string, such as the PostgreSQL
“insert on conflict” construct:
>>> from sqlalchemy.dialects.postgresql import insert >>> from sqlalchemy import table, column >>> my_table = table("my_table", column("x"), column("y")) >>> insert_stmt = insert(my_table).values(x="foo") >>> insert_stmt = insert_stmt.on_conflict_do_nothing(index_elements=["y"]) >>> print(insert_stmt) Traceback (most recent call last): ... sqlalchemy.exc.UnsupportedCompilationError: Compiler <sqlalchemy.sql.compiler.StrSQLCompiler object at 0x7f04fc17e320> can't render element of type <class 'sqlalchemy.dialects.postgresql.dml.OnConflictDoNothing'>
In order to stringify constructs that are specific to particular backend,
the ClauseElement.compile() method must be used, passing either an
Engine or a Dialect object which will invoke the correct
compiler. Below we use a PostgreSQL dialect:
>>> from sqlalchemy.dialects import postgresql >>> print(insert_stmt.compile(dialect=postgresql.dialect()))INSERT INTO my_table (x) VALUES (%(x)s) ON CONFLICT (y) DO NOTHING
For an ORM Query object, the statement can be accessed using the
Query.statement accessor:
statement = query.statement print(statement.compile(dialect=postgresql.dialect()))
See the FAQ link below for additional detail on direct stringification /
compilation of SQL elements.
TypeError: <operator> not supported between instances of ‘ColumnProperty’ and <something>¶
This often occurs when attempting to use a column_property() or
deferred() object in the context of a SQL expression, usually within
declarative such as:
class Bar(Base): __tablename__ = "bar" id = Column(Integer, primary_key=True) cprop = deferred(Column(Integer)) __table_args__ = (CheckConstraint(cprop > 5),)
Above, the cprop attribute is used inline before it has been mapped,
however this cprop attribute is not a Column,
it’s a ColumnProperty, which is an interim object and therefore
does not have the full functionality of either the Column object
or the InstrumentedAttribute object that will be mapped onto the
Bar class once the declarative process is complete.
While the ColumnProperty does have a __clause_element__() method,
which allows it to work in some column-oriented contexts, it can’t work in an
open-ended comparison context as illustrated above, since it has no Python
__eq__() method that would allow it to interpret the comparison to the
number “5” as a SQL expression and not a regular Python comparison.
The solution is to access the Column directly using the
ColumnProperty.expression attribute:
class Bar(Base): __tablename__ = "bar" id = Column(Integer, primary_key=True) cprop = deferred(Column(Integer)) __table_args__ = (CheckConstraint(cprop.expression > 5),)
A value is required for bind parameter <x> (in parameter group <y>)¶
This error occurs when a statement makes use of bindparam() either
implicitly or explicitly and does not provide a value when the statement
is executed:
stmt = select(table.c.column).where(table.c.id == bindparam("my_param")) result = conn.execute(stmt)
Above, no value has been provided for the parameter “my_param”. The correct
approach is to provide a value:
result = conn.execute(stmt, my_param=12)
When the message takes the form “a value is required for bind parameter <x>
in parameter group <y>”, the message is referring to the “executemany” style
of execution. In this case, the statement is typically an INSERT, UPDATE,
or DELETE and a list of parameters is being passed. In this format, the
statement may be generated dynamically to include parameter positions for
every parameter given in the argument list, where it will use the
first set of parameters to determine what these should be.
For example, the statement below is calculated based on the first parameter
set to require the parameters, “a”, “b”, and “c” — these names determine
the final string format of the statement which will be used for each
set of parameters in the list. As the second entry does not contain “b”,
this error is generated:
m = MetaData() t = Table("t", m, Column("a", Integer), Column("b", Integer), Column("c", Integer)) e.execute( t.insert(), [ {"a": 1, "b": 2, "c": 3}, {"a": 2, "c": 4}, {"a": 3, "b": 4, "c": 5}, ], )
sqlalchemy.exc.StatementError: (sqlalchemy.exc.InvalidRequestError) A value is required for bind parameter 'b', in parameter group 1 [SQL: u'INSERT INTO t (a, b, c) VALUES (?, ?, ?)'] [parameters: [{'a': 1, 'c': 3, 'b': 2}, {'a': 2, 'c': 4}, {'a': 3, 'c': 5, 'b': 4}]]
Since “b” is required, pass it as None so that the INSERT may proceed:
e.execute( t.insert(), [ {"a": 1, "b": 2, "c": 3}, {"a": 2, "b": None, "c": 4}, {"a": 3, "b": 4, "c": 5}, ], )
Expected FROM clause, got Select. To create a FROM clause, use the .subquery() method¶
This refers to a change made as of SQLAlchemy 1.4 where a SELECT statement as generated
by a function such as select(), but also including things like unions and textual
SELECT expressions are no longer considered to be FromClause objects and
can’t be placed directly in the FROM clause of another SELECT statement without them
being wrapped in a Subquery first. This is a major conceptual change in the
Core and the full rationale is discussed at A SELECT statement is no longer implicitly considered to be a FROM clause.
Given an example as:
m = MetaData() t = Table("t", m, Column("a", Integer), Column("b", Integer), Column("c", Integer)) stmt = select(t)
Above, stmt represents a SELECT statement. The error is produced when we want
to use stmt directly as a FROM clause in another SELECT, such as if we
attempted to select from it:
new_stmt_1 = select(stmt)
Or if we wanted to use it in a FROM clause such as in a JOIN:
new_stmt_2 = select(some_table).select_from(some_table.join(stmt))
In previous versions of SQLAlchemy, using a SELECT inside of another SELECT
would produce a parenthesized, unnamed subquery. In most cases, this form of
SQL is not very useful as databases like MySQL and PostgreSQL require that
subqueries in FROM clauses have named aliases, which means using the
SelectBase.alias() method or as of 1.4 using the
SelectBase.subquery() method to produce this. On other databases, it
is still much clearer for the subquery to have a name to resolve any ambiguity
on future references to column names inside the subquery.
Beyond the above practical reasons, there are a lot of other SQLAlchemy-oriented
reasons the change is being made. The correct form of the above two statements
therefore requires that SelectBase.subquery() is used:
subq = stmt.subquery() new_stmt_1 = select(subq) new_stmt_2 = select(some_table).select_from(some_table.join(subq))
An alias is being generated automatically for raw clauseelement¶
New in version 1.4.26.
This deprecation warning refers to a very old and likely not well known pattern
that applies to the legacy Query.join() method as well as the
2.0 style Select.join() method, where a join can be stated
in terms of a relationship() but the target is the
Table or other Core selectable to which the class is mapped,
rather than an ORM entity such as a mapped class or aliased()
construct:
a1 = Address.__table__ q = ( s.query(User) .join(a1, User.addresses) .filter(Address.email_address == "ed@foo.com") .all() )
The above pattern also allows an arbitrary selectable, such as
a Core Join or Alias object,
however there is no automatic adaptation of this element, meaning the
Core element would need to be referred towards directly:
a1 = Address.__table__.alias() q = ( s.query(User) .join(a1, User.addresses) .filter(a1.c.email_address == "ed@foo.com") .all() )
The correct way to specify a join target is always by using the mapped
class itself or an aliased object, in the latter case using the
PropComparator.of_type() modifier to set up an alias:
# normal join to relationship entity q = s.query(User).join(User.addresses).filter(Address.email_address == "ed@foo.com") # name Address target explicitly, not necessary but legal q = ( s.query(User) .join(Address, User.addresses) .filter(Address.email_address == "ed@foo.com") )
Join to an alias:
from sqlalchemy.orm import aliased a1 = aliased(Address) # of_type() form; recommended q = ( s.query(User) .join(User.addresses.of_type(a1)) .filter(a1.email_address == "ed@foo.com") ) # target, onclause form q = s.query(User).join(a1, User.addresses).filter(a1.email_address == "ed@foo.com")
An alias is being generated automatically due to overlapping tables¶
New in version 1.4.26.
This warning is typically generated when querying using the
Select.join() method or the legacy Query.join() method
with mappings that involve joined table inheritance. The issue is that when
joining between two joined inheritance models that share a common base table, a
proper SQL JOIN between the two entities cannot be formed without applying an
alias to one side or the other; SQLAlchemy applies an alias to the right side
of the join. For example given a joined inheritance mapping as:
class Employee(Base): __tablename__ = "employee" id = Column(Integer, primary_key=True) manager_id = Column(ForeignKey("manager.id")) name = Column(String(50)) type = Column(String(50)) reports_to = relationship("Manager", foreign_keys=manager_id) __mapper_args__ = { "polymorphic_identity": "employee", "polymorphic_on": type, } class Manager(Employee): __tablename__ = "manager" id = Column(Integer, ForeignKey("employee.id"), primary_key=True) __mapper_args__ = { "polymorphic_identity": "manager", "inherit_condition": id == Employee.id, }
The above mapping includes a relationship between the Employee and
Manager classes. Since both classes make use of the “employee” database
table, from a SQL perspective this is a
self referential relationship. If we wanted to
query from both the Employee and Manager models using a join, at the
SQL level the “employee” table needs to be included twice in the query, which
means it must be aliased. When we create such a join using the SQLAlchemy
ORM, we get SQL that looks like the following:
>>> stmt = select(Employee, Manager).join(Employee.reports_to) >>> print(stmt)SELECT employee.id, employee.manager_id, employee.name, employee.type, manager_1.id AS id_1, employee_1.id AS id_2, employee_1.manager_id AS manager_id_1, employee_1.name AS name_1, employee_1.type AS type_1 FROM employee JOIN (employee AS employee_1 JOIN manager AS manager_1 ON manager_1.id = employee_1.id) ON manager_1.id = employee.manager_id
Above, the SQL selects FROM the employee table, representing the
Employee entity in the query. It then joins to a right-nested join of
employee AS employee_1 JOIN manager AS manager_1, where the employee
table is stated again, except as an anonymous alias employee_1. This is the
“automatic generation of an alias” that the warning message refers towards.
When SQLAlchemy loads ORM rows that each contain an Employee and a
Manager object, the ORM must adapt rows from what above is the
employee_1 and manager_1 table aliases into those of the un-aliased
Manager class. This process is internally complex and does not accommodate
for all API features, notably when trying to use eager loading features such as
contains_eager() with more deeply nested queries than are shown
here. As the pattern is unreliable for more complex scenarios and involves
implicit decisionmaking that is difficult to anticipate and follow,
the warning is emitted and this pattern may be considered a legacy feature. The
better way to write this query is to use the same patterns that apply to any
other self-referential relationship, which is to use the aliased()
construct explicitly. For joined-inheritance and other join-oriented mappings,
it is usually desirable to add the use of the aliased.flat
parameter, which will allow a JOIN of two or more tables to be aliased by
applying an alias to the individual tables within the join, rather than
embedding the join into a new subquery:
>>> from sqlalchemy.orm import aliased >>> manager_alias = aliased(Manager, flat=True) >>> stmt = select(Employee, manager_alias).join(Employee.reports_to.of_type(manager_alias)) >>> print(stmt)SELECT employee.id, employee.manager_id, employee.name, employee.type, manager_1.id AS id_1, employee_1.id AS id_2, employee_1.manager_id AS manager_id_1, employee_1.name AS name_1, employee_1.type AS type_1 FROM employee JOIN (employee AS employee_1 JOIN manager AS manager_1 ON manager_1.id = employee_1.id) ON manager_1.id = employee.manager_id
If we then wanted to use contains_eager() to populate the
reports_to attribute, we refer to the alias:
>>> stmt = ( ... select(Employee) ... .join(Employee.reports_to.of_type(manager_alias)) ... .options(contains_eager(Employee.reports_to.of_type(manager_alias))) ... )
Without using the explicit aliased() object, in some more nested
cases the contains_eager() option does not have enough context to
know where to get its data from, in the case that the ORM is “auto-aliasing”
in a very nested context. Therefore it’s best not to rely on this feature
and instead keep the SQL construction as explicit as possible.
Object Relational Mapping¶
Parent instance <x> is not bound to a Session; (lazy load/deferred load/refresh/etc.) operation cannot proceed¶
This is likely the most common error message when dealing with the ORM, and it
occurs as a result of the nature of a technique the ORM makes wide use of known
as lazy loading. Lazy loading is a common object-relational pattern
whereby an object that’s persisted by the ORM maintains a proxy to the database
itself, such that when various attributes upon the object are accessed, their
value may be retrieved from the database lazily. The advantage to this
approach is that objects can be retrieved from the database without having
to load all of their attributes or related data at once, and instead only that
data which is requested can be delivered at that time. The major disadvantage
is basically a mirror image of the advantage, which is that if lots of objects
are being loaded which are known to require a certain set of data in all cases,
it is wasteful to load that additional data piecemeal.
Another caveat of lazy loading beyond the usual efficiency concerns is that
in order for lazy loading to proceed, the object has to remain associated
with a Session in order to be able to retrieve its state. This error message
means that an object has become de-associated with its Session and
is being asked to lazy load data from the database.
The most common reason that objects become detached from their Session
is that the session itself was closed, typically via the Session.close()
method. The objects will then live on to be accessed further, very often
within web applications where they are delivered to a server-side templating
engine and are asked for further attributes which they cannot load.
Mitigation of this error is via these techniques:
-
Try not to have detached objects; don’t close the session prematurely — Often, applications will close
out a transaction before passing off related objects to some other system
which then fails due to this error. Sometimes the transaction doesn’t need
to be closed so soon; an example is the web application closes out
the transaction before the view is rendered. This is often done in the name
of “correctness”, but may be seen as a mis-application of “encapsulation”,
as this term refers to code organization, not actual actions. The template that
uses an ORM object is making use of the proxy pattern
which keeps database logic encapsulated from the caller. If the
Sessioncan be held open until the lifespan of the objects are done,
this is the best approach. -
Otherwise, load everything that’s needed up front — It is very often impossible to
keep the transaction open, especially in more complex applications that need
to pass objects off to other systems that can’t run in the same context
even though they’re in the same process. In this case, the application
should prepare to deal with detached objects,
and should try to make appropriate use of eager loading to ensure
that objects have what they need up front. -
And importantly, set expire_on_commit to False — When using detached objects, the
most common reason objects need to re-load data is because they were expired
from the last call toSession.commit(). This expiration should
not be used when dealing with detached objects; so the
Session.expire_on_commitparameter be set toFalse.
By preventing the objects from becoming expired outside of the transaction,
the data which was loaded will remain present and will not incur additional
lazy loads when that data is accessed.Note also that
Session.rollback()method unconditionally expires
all contents in theSessionand should also be avoided in
non-error scenarios.
This Session’s transaction has been rolled back due to a previous exception during flush¶
The flush process of the Session, described at
Flushing, will roll back the database transaction if an error is
encountered, in order to maintain internal consistency. However, once this
occurs, the session’s transaction is now “inactive” and must be explicitly
rolled back by the calling application, in the same way that it would otherwise
need to be explicitly committed if a failure had not occurred.
This is a common error when using the ORM and typically applies to an
application that doesn’t yet have correct “framing” around its
Session operations. Further detail is described in the FAQ at
“This Session’s transaction has been rolled back due to a previous exception during flush.” (or similar).
For relationship <relationship>, delete-orphan cascade is normally configured only on the “one” side of a one-to-many relationship, and not on the “many” side of a many-to-one or many-to-many relationship.¶
This error arises when the “delete-orphan” cascade
is set on a many-to-one or many-to-many relationship, such as:
class A(Base): __tablename__ = "a" id = Column(Integer, primary_key=True) bs = relationship("B", back_populates="a") class B(Base): __tablename__ = "b" id = Column(Integer, primary_key=True) a_id = Column(ForeignKey("a.id")) # this will emit the error message when the mapper # configuration step occurs a = relationship("A", back_populates="bs", cascade="all, delete-orphan") configure_mappers()
Above, the “delete-orphan” setting on B.a indicates the intent that
when every B object that refers to a particular A is deleted, that the
A should then be deleted as well. That is, it expresses that the “orphan”
which is being deleted would be an A object, and it becomes an “orphan”
when every B that refers to it is deleted.
The “delete-orphan” cascade model does not support this functionality. The
“orphan” consideration is only made in terms of the deletion of a single object
which would then refer to zero or more objects that are now “orphaned” by
this single deletion, which would result in those objects being deleted as
well. In other words, it is designed only to track the creation of “orphans”
based on the removal of one and only one “parent” object per orphan, which is
the natural case in a one-to-many relationship where a deletion of the
object on the “one” side results in the subsequent deletion of the related
items on the “many” side.
The above mapping in support of this functionality would instead place the
cascade setting on the one-to-many side, which looks like:
class A(Base): __tablename__ = "a" id = Column(Integer, primary_key=True) bs = relationship("B", back_populates="a", cascade="all, delete-orphan") class B(Base): __tablename__ = "b" id = Column(Integer, primary_key=True) a_id = Column(ForeignKey("a.id")) a = relationship("A", back_populates="bs")
Where the intent is expressed that when an A is deleted, all of the
B objects to which it refers are also deleted.
The error message then goes on to suggest the usage of the
relationship.single_parent flag. This flag may be used
to enforce that a relationship which is capable of having many objects
refer to a particular object will in fact have only one object referring
to it at a time. It is used for legacy or other less ideal
database schemas where the foreign key relationships suggest a “many”
collection, however in practice only one object would actually refer
to a given target object at at time. This uncommon scenario
can be demonstrated in terms of the above example as follows:
class A(Base): __tablename__ = "a" id = Column(Integer, primary_key=True) bs = relationship("B", back_populates="a") class B(Base): __tablename__ = "b" id = Column(Integer, primary_key=True) a_id = Column(ForeignKey("a.id")) a = relationship( "A", back_populates="bs", single_parent=True, cascade="all, delete-orphan", )
The above configuration will then install a validator which will enforce
that only one B may be associated with an A at at time, within
the scope of the B.a relationship:
>>> b1 = B() >>> b2 = B() >>> a1 = A() >>> b1.a = a1 >>> b2.a = a1 sqlalchemy.exc.InvalidRequestError: Instance <A at 0x7eff44359350> is already associated with an instance of <class '__main__.B'> via its B.a attribute, and is only allowed a single parent.
Note that this validator is of limited scope and will not prevent multiple
“parents” from being created via the other direction. For example, it will
not detect the same setting in terms of A.bs:
>>> a1.bs = [b1, b2] >>> session.add_all([a1, b1, b2]) >>> session.commit()INSERT INTO a DEFAULT VALUES () INSERT INTO b (a_id) VALUES (?) (1,) INSERT INTO b (a_id) VALUES (?) (1,)
However, things will not go as expected later on, as the “delete-orphan” cascade
will continue to work in terms of a single lead object, meaning if we
delete either of the B objects, the A is deleted. The other B stays
around, where the ORM will usually be smart enough to set the foreign key attribute
to NULL, but this is usually not what’s desired:
>>> session.delete(b1) >>> session.commit()UPDATE b SET a_id=? WHERE b.id = ? (None, 2) DELETE FROM b WHERE b.id = ? (1,) DELETE FROM a WHERE a.id = ? (1,) COMMIT
For all the above examples, similar logic applies to the calculus of a
many-to-many relationship; if a many-to-many relationship sets single_parent=True
on one side, that side can use the “delete-orphan” cascade, however this is
very unlikely to be what someone actually wants as the point of a many-to-many
relationship is so that there can be many objects referring to an object
in either direction.
Overall, “delete-orphan” cascade is usually applied
on the “one” side of a one-to-many relationship so that it deletes objects
in the “many” side, and not the other way around.
Changed in version 1.3.18: The text of the “delete-orphan” error message
when used on a many-to-one or many-to-many relationship has been updated
to be more descriptive.
Instance <instance> is already associated with an instance of <instance> via its <attribute> attribute, and is only allowed a single parent.¶
This error is emitted when the relationship.single_parent flag
is used, and more than one object is assigned as the “parent” of an object at
once.
Given the following mapping:
class A(Base): __tablename__ = "a" id = Column(Integer, primary_key=True) class B(Base): __tablename__ = "b" id = Column(Integer, primary_key=True) a_id = Column(ForeignKey("a.id")) a = relationship( "A", single_parent=True, cascade="all, delete-orphan", )
The intent indicates that no more than a single B object may refer
to a particular A object at once:
>>> b1 = B() >>> b2 = B() >>> a1 = A() >>> b1.a = a1 >>> b2.a = a1 sqlalchemy.exc.InvalidRequestError: Instance <A at 0x7eff44359350> is already associated with an instance of <class '__main__.B'> via its B.a attribute, and is only allowed a single parent.
When this error occurs unexpectedly, it is usually because the
relationship.single_parent flag was applied in response
to the error message described at For relationship <relationship>, delete-orphan cascade is normally configured only on the “one” side of a one-to-many relationship, and not on the “many” side of a many-to-one or many-to-many relationship., and the issue is in
fact a misunderstanding of the “delete-orphan” cascade setting. See that
message for details.
relationship X will copy column Q to column P, which conflicts with relationship(s): ‘Y’¶
This warning refers to the case when two or more relationships will write data
to the same columns on flush, but the ORM does not have any means of
coordinating these relationships together. Depending on specifics, the solution
may be that two relationships need to be referred towards one another using
relationship.back_populates, or that one or more of the
relationships should be configured with relationship.viewonly
to prevent conflicting writes, or sometimes that the configuration is fully
intentional and should configure relationship.overlaps to
silence each warning.
For the typical example that’s missing
relationship.back_populates, given the following mapping:
class Parent(Base): __tablename__ = "parent" id = Column(Integer, primary_key=True) children = relationship("Child") class Child(Base): __tablename__ = "child" id = Column(Integer, primary_key=True) parent_id = Column(ForeignKey("parent.id")) parent = relationship("Parent")
The above mapping will generate warnings:
SAWarning: relationship 'Child.parent' will copy column parent.id to column child.parent_id, which conflicts with relationship(s): 'Parent.children' (copies parent.id to child.parent_id).
The relationships Child.parent and Parent.children appear to be in conflict.
The solution is to apply relationship.back_populates:
class Parent(Base): __tablename__ = "parent" id = Column(Integer, primary_key=True) children = relationship("Child", back_populates="parent") class Child(Base): __tablename__ = "child" id = Column(Integer, primary_key=True) parent_id = Column(ForeignKey("parent.id")) parent = relationship("Parent", back_populates="children")
For more customized relationships where an “overlap” situation may be
intentional and cannot be resolved, the relationship.overlaps
parameter may specify the names of relationships for which the warning should
not take effect. This typically occurs for two or more relationships to the
same underlying table that include custom
relationship.primaryjoin conditions that limit the related
items in each case:
class Parent(Base): __tablename__ = "parent" id = Column(Integer, primary_key=True) c1 = relationship( "Child", primaryjoin="and_(Parent.id == Child.parent_id, Child.flag == 0)", backref="parent", overlaps="c2, parent", ) c2 = relationship( "Child", primaryjoin="and_(Parent.id == Child.parent_id, Child.flag == 1)", overlaps="c1, parent", ) class Child(Base): __tablename__ = "child" id = Column(Integer, primary_key=True) parent_id = Column(ForeignKey("parent.id")) flag = Column(Integer)
Above, the ORM will know that the overlap between Parent.c1,
Parent.c2 and Child.parent is intentional.
Object cannot be converted to ‘persistent’ state, as this identity map is no longer valid.¶
New in version 1.4.26.
This message was added to accommodate for the case where a
Result object that would yield ORM objects is iterated after
the originating Session has been closed, or otherwise had its
Session.expunge_all() method called. When a Session
expunges all objects at once, the internal identity map used by that
Session is replaced with a new one, and the original one
discarded. An unconsumed and unbuffered Result object will
internally maintain a reference to that now-discarded identity map. Therefore,
when the Result is consumed, the objects that would be yielded
cannot be associated with that Session. This arrangement is by
design as it is generally not recommended to iterate an unbuffered
Result object outside of the transactional context in which it
was created:
# context manager creates new Session with Session(engine) as session_obj: result = sess.execute(select(User).where(User.id == 7)) # context manager is closed, so session_obj above is closed, identity # map is replaced # iterating the result object can't associate the object with the # Session, raises this error. user = result.first()
The above situation typically will not occur when using the asyncio
ORM extension, as when AsyncSession returns a sync-style
Result, the results have been pre-buffered when the statement
was executed. This is to allow secondary eager loaders to invoke without needing
an additional await call.
To pre-buffer results in the above situation using the regular
Session in the same way that the asyncio extension does it,
the prebuffer_rows execution option may be used as follows:
# context manager creates new Session with Session(engine) as session_obj: # result internally pre-fetches all objects result = sess.execute( select(User).where(User.id == 7), execution_options={"prebuffer_rows": True} ) # context manager is closed, so session_obj above is closed, identity # map is replaced # pre-buffered objects are returned user = result.first() # however they are detached from the session, which has been closed assert inspect(user).detached assert inspect(user).session is None
Above, the selected ORM objects are fully generated within the session_obj
block, associated with session_obj and buffered within the
Result object for iteration. Outside the block,
session_obj is closed and expunges these ORM objects. Iterating the
Result object will yield those ORM objects, however as their
originating Session has expunged them, they will be delivered in
the detached state.
Note
The above reference to a “pre-buffered” vs. “un-buffered”
Result object refers to the process by which the ORM
converts incoming raw database rows from the DBAPI into ORM
objects. It does not imply whether or not the underlying cursor
object itself, which represents pending results from the DBAPI, is itself
buffered or unbuffered, as this is essentially a lower layer of buffering.
For background on buffering of the cursor results itself, see the
section Using Server Side Cursors (a.k.a. stream results).
Type annotation can’t be interpreted for Annotated Declarative Table form¶
SQLAlchemy 2.0 introduces a new
Annotated Declarative Table declarative
system which derives ORM mapped attribute information from PEP 484
annotations within class definitions at runtime. A requirement of this form is
that all ORM annotations must make use of a generic container called
Mapped to be properly annotated. Legacy SQLAlchemy mappings which
include explicit PEP 484 typing annotations, such as those which use the
legacy Mypy extension for typing support, may include
directives such as those for relationship() that don’t include this
generic.
To resolve, the classes may be marked with the __allow_unmapped__ boolean
attribute until they can be fully migrated to the 2.0 syntax. See the migration
notes at Migration to 2.0 Step Six — Add __allow_unmapped__ to explicitly typed ORM models for an example.
AsyncIO Exceptions¶
AwaitRequired¶
The SQLAlchemy async mode requires an async driver to be used to connect to the db.
This error is usually raised when trying to use the async version of SQLAlchemy
with a non compatible DBAPI.
MissingGreenlet¶
A call to the async DBAPI was initiated outside the greenlet spawn
context usually setup by the SQLAlchemy AsyncIO proxy classes. Usually this
error happens when an IO was attempted in an unexpected place, without using
the provided async api. When using the ORM this may be due to a lazy loading
attempt, which is unsupported when using SQLAlchemy with AsyncIO dialects.
No Inspection Available¶
Using the inspect() function directly on an
AsyncConnection or AsyncEngine object is
not currently supported, as there is not yet an awaitable form of the
Inspector object available. Instead, the object
is used by acquiring it using the
inspect() function in such a way that it refers to the underlying
AsyncConnection.sync_connection attribute of the
AsyncConnection object; the Inspector is
then used in a “synchronous” calling style by using the
AsyncConnection.run_sync() method along with a custom function
that performs the desired operations:
async def async_main(): async with engine.connect() as conn: tables = await conn.run_sync( lambda sync_conn: inspect(sync_conn).get_table_names() )
Core Exception Classes¶
See Core Exceptions for Core exception classes.
ORM Exception Classes¶
See ORM Exceptions for ORM exception classes.
Legacy Exceptions¶
Exceptions in this section are not generated by current SQLAlchemy
versions, however are provided here to suit exception message hyperlinks.
The <some function> in SQLAlchemy 2.0 will no longer <something>¶
SQLAlchemy 2.0 represents a major shift for a wide variety of key
SQLAlchemy usage patterns in both the Core and ORM components. The goal
of the 2.0 release is to make a slight readjustment in some of the most
fundamental assumptions of SQLAlchemy since its early beginnings, and
to deliver a newly streamlined usage model that is hoped to be significantly
more minimalist and consistent between the Core and ORM components, as well as
more capable.
Introduced at SQLAlchemy 2.0 — Major Migration Guide, the SQLAlchemy 2.0 project includes
a comprehensive future compatibility system that’s integrated into the
1.4 series of SQLAlchemy, such that applications will have a clear,
unambiguous, and incremental upgrade path in order to migrate applications to
being fully 2.0 compatible. The RemovedIn20Warning deprecation
warning is at the base of this system to provide guidance on what behaviors in
an existing codebase will need to be modified. An overview of how to enable
this warning is at SQLAlchemy 2.0 Deprecations Mode.
Object is being merged into a Session along the backref cascade¶
This message refers to the “backref cascade” behavior of SQLAlchemy,
removed in version 2.0. This refers to the action of
an object being added into a Session as a result of another
object that’s already present in that session being associated with it.
As this behavior has been shown to be more confusing than helpful,
the relationship.cascade_backrefs and
backref.cascade_backrefs parameters were added, which can
be set to False to disable it, and in SQLAlchemy 2.0 the “cascade backrefs”
behavior has been removed entirely.
For older SQLAlchemy versions, to set
relationship.cascade_backrefs to False on a backref that
is currently configured using the relationship.backref string
parameter, the backref must be declared using the backref() function
first so that the backref.cascade_backrefs parameter may be
passed.
Alternatively, the entire “cascade backrefs” behavior can be turned off
across the board by using the Session in “future” mode,
by passing True for the Session.future parameter.
select() construct created in “legacy” mode; keyword arguments, etc.¶
The select() construct has been updated as of SQLAlchemy
1.4 to support the newer calling style that is standard in
SQLAlchemy 2.0. For backwards compatibility within
the 1.4 series, the construct accepts arguments in both the “legacy” style as well
as the “new” style.
The “new” style features that column and table expressions are passed
positionally to the select() construct only; any other
modifiers to the object must be passed using subsequent method chaining:
# this is the way to do it going forward stmt = select(table1.c.myid).where(table1.c.myid == table2.c.otherid)
For comparison, a select() in legacy forms of SQLAlchemy,
before methods like Select.where() were even added, would like:
# this is how it was documented in original SQLAlchemy versions # many years ago stmt = select([table1.c.myid], whereclause=table1.c.myid == table2.c.otherid)
Or even that the “whereclause” would be passed positionally:
# this is also how it was documented in original SQLAlchemy versions # many years ago stmt = select([table1.c.myid], table1.c.myid == table2.c.otherid)
For some years now, the additional “whereclause” and other arguments that are
accepted have been removed from most narrative documentation, leading to a
calling style that is most familiar as the list of column arguments passed
as a list, but no further arguments:
# this is how it's been documented since around version 1.0 or so stmt = select([table1.c.myid]).where(table1.c.myid == table2.c.otherid)
The document at select() no longer accepts varied constructor arguments, columns are passed positionally describes this change in terms
of 2.0 Migration.
A bind was located via legacy bound metadata, but since future=True is set on this Session, this bind is ignored.¶
The concept of “bound metadata” is present up until SQLAlchemy 1.4; as
of SQLAlchemy 2.0 it’s been removed.
This error refers to the MetaData.bind parameter on the
MetaData object that in turn allows objects like the ORM
Session to associate a particular mapped class with an
Engine. In SQLAlchemy 2.0, the Session must be
linked to each Engine directly. That is, instead of instantiating
the Session or sessionmaker without any arguments,
and associating the Engine with the
MetaData:
engine = create_engine("sqlite://") Session = sessionmaker() metadata_obj = MetaData(bind=engine) Base = declarative_base(metadata=metadata_obj) class MyClass(Base): ... session = Session() session.add(MyClass()) session.commit()
The Engine must instead be associated directly with the
sessionmaker or Session. The
MetaData object should no longer be associated with any
engine:
engine = create_engine("sqlite://") Session = sessionmaker(engine) Base = declarative_base() class MyClass(Base): ... session = Session() session.add(MyClass()) session.commit()
In SQLAlchemy 1.4, this 2.0 style behavior is enabled when the
Session.future flag is set on sessionmaker
or Session.
This Compiled object is not bound to any Engine or Connection¶
This error refers to the concept of “bound metadata”, which is a legacy
SQLAlchemy pattern present only in 1.x versions. The issue occurs when one invokes
the Executable.execute() method directly off of a Core expression object
that is not associated with any Engine:
metadata_obj = MetaData() table = Table("t", metadata_obj, Column("q", Integer)) stmt = select(table) result = stmt.execute() # <--- raises
What the logic is expecting is that the MetaData object has
been bound to a Engine:
engine = create_engine("mysql+pymysql://user:pass@host/db") metadata_obj = MetaData(bind=engine)
Where above, any statement that derives from a Table which
in turn derives from that MetaData will implicitly make use of
the given Engine in order to invoke the statement.
Note that the concept of bound metadata is not present in SQLAlchemy 2.0.
The correct way to invoke statements is via
the Connection.execute() method of a Connection:
with engine.connect() as conn: result = conn.execute(stmt)
When using the ORM, a similar facility is available via the Session:
result = session.execute(stmt)
This connection is on an inactive transaction. Please rollback() fully before proceeding¶
This error condition was added to SQLAlchemy as of version 1.4, and does not
apply to SQLAlchemy 2.0. The error
refers to the state where a Connection is placed into a
transaction using a method like Connection.begin(), and then a
further “marker” transaction is created within that scope; the “marker”
transaction is then rolled back using Transaction.rollback() or closed
using Transaction.close(), however the outer transaction is still
present in an “inactive” state and must be rolled back.
The pattern looks like:
engine = create_engine(...) connection = engine.connect() transaction1 = connection.begin() # this is a "sub" or "marker" transaction, a logical nesting # structure based on "real" transaction transaction1 transaction2 = connection.begin() transaction2.rollback() # transaction1 is still present and needs explicit rollback, # so this will raise connection.execute(text("select 1"))
Above, transaction2 is a “marker” transaction, which indicates a logical
nesting of transactions within an outer one; while the inner transaction
can roll back the whole transaction via its rollback() method, its commit()
method has no effect except to close the scope of the “marker” transaction
itself. The call to transaction2.rollback() has the effect of
deactivating transaction1 which means it is essentially rolled back
at the database level, however is still present in order to accommodate
a consistent nesting pattern of transactions.
The correct resolution is to ensure the outer transaction is also
rolled back:
This pattern is not commonly used in Core. Within the ORM, a similar issue can
occur which is the product of the ORM’s “logical” transaction structure; this
is described in the FAQ entry at “This Session’s transaction has been rolled back due to a previous exception during flush.” (or similar).
The “subtransaction” pattern is removed in SQLAlchemy 2.0 so that this
particular programming pattern is no longer be available, preventing
this error message.