Internal
The Internal tab combines all data extracted from most other tabs, except the external, hreflang and structured data tabs. This means all data can be viewed comprehensively, and exported together for further analysis.
URLs classed as ‘Internal’ are on the same subdomain as the start page of the crawl. URLs can be made to be internal, by using the ‘crawl all subdomains‘ configuration, list mode, or the CDNs feature.
Columns
This tab includes the following columns.
- Address – The URL address.
- Content – The content type of the URL.
- Status Code – The HTTP response code.
- Status – The HTTP header response.
- Indexability – Whether the URL is Indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Title 1 – The (first) page title discovered on the page.
- Title 1 Length – The character length of the page title.
- Title 1 Pixel Width – The pixel width of the page title as described in our pixel width post.
- Meta Description 1 – The (first) meta description on the page.
- Meta Description Length 1 – The character length of the meta description.
- Meta Description Pixel Width – The pixel width of the meta description.
- Meta Keyword 1 – The meta keywords.
- Meta Keywords Length – The character length of the meta keywords.
- h1 – 1 – The first h1 (heading) on the page.
- h1 – Len-1 – The character length of the h1.
- h2 – 1 – The first h2 (heading) on the page.
- h2 – Len-1 – The character length of the h2.
- Meta Robots 1 – Meta robots directives found on the URL.
- X-Robots-Tag 1 – X-Robots-tag HTTP header directives for the URL.
- Meta Refresh 1 – Meta refresh data.
- Canonical Link Element – The canonical link element data.
- rel=“next” 1 – The SEO Spider collects these HTML link elements designed to indicate the relationship between URLs in a paginated series.
- rel=“prev” 1 – The SEO Spider collects these HTML link elements designed to indicate the relationship between URLs in a paginated series.
- HTTP rel=“next” 1 – The SEO Spider collects these HTTP link elements designed to indicate the relationship between URLs in a paginated series.
- HTTP rel=“prev” 1 – The SEO Spider collects these HTTP link elements designed to indicate the relationship between URLs in a paginated series.
- Size – The size of the resource, taken from the Content-Length HTTP header. If this field is not provided, the size is reported as zero. For HTML pages this is updated to the size of the (uncompressed) HTML. Upon export, size is in bytes, so please divide by 1,024 to convert to kilobytes.
- Word Count – This is all ‘words’ inside the body tag, excluding HTML markup. The count is based upon the content area that can be adjusted under ‘Config > Content > Area’. By default, the nav and footer elements are excluded. You can include or exclude HTML elements, classes and IDs to calculate a refined word count. Our figures may not be exactly what performing this calculation manually would find, as the parser performs certain fix-ups on invalid HTML. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces. No consideration is given to visibility of content (such as text inside a div set to hidden).
- Text Ratio – Number of non-HTML characters found in the HTML body tag on a page (the text), divided by the total number of characters the HTML page is made up of, and displayed as a percentage.
- Crawl Depth – Depth of the page from the start page (number of ‘clicks’ away from the start page). Please note, redirects are counted as a level currently in our page depth calculations.
- Link Score – A metric between 0-100, which calculates the relative value of a page based upon its internal links similar to Google’s own PageRank. For this column to populate, ‘crawl analysis‘ is required.
- Inlinks – Number of internal hyperlinks to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled.
- Unique Inlinks – Number of ‘unique’ internal inlinks to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- Unique JS Inlinks – Number of ‘unique’ internal inlinks to the URL that are only in the rendered HTML after JavaScript execution. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- % of Total – Percentage of unique internal inlinks (200 response HTML pages) to the URL from total internal HTML pages crawled. ‘Internal inlinks’ are links in anchor elements pointing to a given URI from the same subdomain that is being crawled.
- Outlinks – Number of internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled.
- Unique Outlinks – Number of unique internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- Unique JS Outlinks – Number of unique internal outlinks from the URL that are only in the rendered HTML after JavaScript execution. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- External Outlinks – Number of external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain.
- Unique External Outlinks – Number of unique external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
- Unique External JS Outlinks – Number of unique external outlinks from the URL that are only in the rendered HTML after JavaScript execution. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
- Closest Similarity Match – This shows the highest similarity percentage of a near duplicate URL. The SEO Spider will identify near duplicates with a 90% similarity match, which can be adjusted to find content with a lower similarity threshold. For example, if there were two near duplicate pages for a page with 99% and 90% similarity respectively, then 99% will be displayed here. To populate this column the ‘Enable Near Duplicates’ configuration must be selected via ‘Config > Content > Duplicates’, and post ‘Crawl Analysis’ must be performed. Only URLs with content over the selected similarity threshold will contain data, the others will remain blank. Thus by default, this column will only contain data for URLs with 90% or higher similarity, unless it has been adjusted via the ‘Config > Content > Duplicates’ and ‘Near Duplicate Similarity Threshold’ setting.
- No. Near Duplicates – The number of near duplicate URLs discovered in a crawl that meet or exceed the ‘Near Duplicate Similarity Threshold’, which is a 90% match by default. This setting can be adjusted under ‘Config > Content > Duplicates’. To populate this column the ‘Enable Near Duplicates’ configuration must be selected via ‘Config > Content > Duplicates’, and post ‘Crawl Analysis’ must be performed.
- Spelling Errors – The total number of spelling errors discovered for a URL. For this column to be populated then ‘Enable Spell Check’ must be selected via ‘Config > Content > Spelling & Grammar’.
- Grammar Errors – The total number of grammar errors discovered for a URL. For this column to be populated then ‘Enable Grammar Check’ must be selected via ‘Config > Content > Spelling & Grammar’.
- Language – The language selected for spelling and grammar checks. This is based upon the HTML language attribute, but the language can also be set via ‘Config > Content > Spelling & Grammar’.
- Hash – Hash value of the page using the MD5 algorithm. This is a duplicate content check for exact duplicate content only. If two hash values match, the pages are exactly the same in content. If there’s a single character difference, they will have unique hash values and not be detected as duplicate content. So this is not a check for near duplicate content. The exact duplicates can be seen under ‘URL > Duplicate’.
- Response Time – Time in seconds to download the URL. More detailed information can be found in our FAQ.
- Last-Modified – Read from the Last-Modified header in the servers HTTP response. If there server does not provide this the value will be empty.
- Redirect URI – If the ‘address’ URL redirects, this column will include the redirect URL target. The status code above will display the type of redirect, 301, 302 etc.
- Redirect Type – One of: HTTP Redirect: triggered by an HTTP header, HSTS Policy: Turned around locally by the SEO Spider due to a previous HSTS header, JavaScript Redirect: triggered by execution of JavaScript (can only happen when using JavaScript rendering) or MetaRefresh Redirect: triggered by a meta refresh tag in the HTML.
- HTTP Version – This shows the HTTP version the crawl was under, which will be HTTP/1.1 by default. The SEO Spider currently only crawls using HTTP/2 in JavaScript rendering mode, if it’s enabled by the server.
- URL Encoded Address – The URL actually requested by the SEO Spider. All non ASCII characters percent encoded, see RFC 3986 for further details.
- Title 2, meta description 2, h1-2, h2-2 etc – The SEO Spider will collect data from the first two elements it encounters in the source code. Hence, h1-2 is data from the second h1 heading on the page.
Filters
This tab includes the following filters.
- HTML – HTML pages.
- JavaScript – Any JavaScript files.
- CSS – Any style sheets discovered.
- Images – Any images.
- PDF – Any portable document files.
- Flash – Any .swf files.
- Other – Any other file types, like docs etc.
- Unknown – Any URLs with an unknown content type. Either because it’s not been supplied, incorrect, or because the URL can’t be crawled. URLs blocked by robots.txt will also appear here, as their filetype is unknown for example.
External
The external tab includes data about external URLs. URLs classed as ‘External’ are on a different subdomain as the start page of the crawl.
Columns
This tab includes the following columns.
- Address – The external URL address
- Content – The content type of the URL.
- Status Code – The HTTP response code.
- Status – The HTTP header response.
- Crawl Depth – Depth of the page from the homepage or start page (number of ‘clicks’ away from the start page).
- Inlinks – Number of links found pointing to the external URL.
Filters
This tab includes the following filters.
- HTML – HTML pages.
- JavaScript – Any JavaScript files.
- CSS – Any style sheets discovered.
- Images – Any images.
- PDF – Any portable document files.
- Flash – Any .swf files.
- Other – Any other file types, like docs etc.
- Unknown – Any URLs with an unknown content type. Either because it’s not been supplied, or because the URL can’t be crawled. URLs blocked by robots.txt will also appear here, as their filetype is unknown for example.
Security
The security tab shows data related to security for internal URLs in a crawl.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Content – The content type of the URL.
- Status Code – HTTP response code.
- Status – The HTTP header response.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Canonical Link Element 1/2 etc – Canonical link element data on the URL. The Spider will find all instances if there are multiple.
- Meta Robots 1/2 etc – Meta robots found on the URL. The Spider will find all instances if there are multiple.
- X-Robots-Tag 1/2 etc – X-Robots-tag data. The Spider will find all instances if there are multiple.
Filters
This tab includes the following filters.
- HTTP URLs – This filter will show insecure (HTTP) URLs. All websites should be secure over HTTPS today on the web. Not only is it important for security, but it’s now expected by users. Chrome and other browsers display a ‘Not Secure’ message against any URLs that are HTTP, or have mixed content issues (where they load insecure resources on them). To view how these URLs were discovered, view their ‘inlinks’ in the lower window tab. You can also export any pages that link to HTTP URLs via ‘Bulk Export > Security > HTTP URLs Inlinks’.
- HTTPS URLs – The secure version of HTTP. All internal URLs should be over HTTPS and therefore should appear under this filter.
- Mixed Content – This shows any HTML pages loaded over a secure HTTPS connection that have resources such as images, JavaScript or CSS that are loaded via an insecure HTTP connection. Mixed content weakens HTTPS, and makes the pages easier for eavesdropping and compromising otherwise secure pages. Browsers might automatically block the HTTP resources from loading, or they may attempt to upgrade them to HTTPS. All HTTP resources should be changed to HTTPS to avoid security issues, and problems loading in a browser. The HTTP resources can be viewed in the ‘outlinks’ tab for each URL, and exported alongside the pages they are on via ‘Bulk Export > Security > Mixed Content’.
- Form URL Insecure – An HTML page has a form on it with an action attribute URL that is insecure (HTTP). This means that any data entered into the form is not secure, as it could be viewed in transit. All URLs contained within forms across a website should be encrypted and therefore need to be HTTPS. The HTTP form URL can be viewed by clicking on the URL in the top window and then the ‘URL Details’ lower window tab, which will display the form URL. These can be exported alongside the pages they are on via ‘Bulk Export > Security > Form URL Insecure’.
- Form on HTTP URL – This means a form is on an HTTP page. Any data entered into the form, including usernames and passwords is not secure. Chrome can display a ‘Not Secure’ message if it discovers a form with a password input field on an HTTP page. The form can be viewed by clicking on the URL in the top window and then the ‘URL Details’ lower window tab, which will display the details of the form on the HTTP URL.
- Unsafe Cross-Origin Links – This shows any pages that link to external websites using the target=”_blank” attribute (to open in a new tab), without using rel=”noopener” (or rel=”noreferrer”) at the same time. Using target=”_blank” alone leaves those pages exposed to both security and performance issues. Ideally rel=”noopener” would be used on any links that contain the target=”_blank” attribute to avoid them. The external links that contain the target=”_blank” attribute by itself can be viewed in the ‘outlinks’ tab and ‘target’ column. They can be exported alongside the pages they are linked from via ‘Bulk Export > Security > Unsafe Cross-Origin Links’.
- Protocol-Relative Resource Links – This filter will show any pages that load resources such as images, JavaScript and CSS using protocol-relative links. A protocol-relative link is simply a link to a URL without specifying the scheme (for example, //screamingfrog.co.uk). It helps save developers time from having to specify the protocol and lets the browser determine it based upon the current connection to the resource. However, this technique is now an anti-pattern with HTTPS everywhere, and can expose some sites to ‘man in the middle’ compromises and performance issues. The resource links that are protocol relative can be viewed for each URL by clicking on the ‘outlinks’ tab and viewing the ‘Path Type’ column for ‘Protocol Relative’. They can be exported alongside the pages that load them via ‘Bulk Export > Security > Protocol-Relative Resource Links’.
- Missing HSTS Header – Any URLs that are missing the HSTS response header. The HTTP Strict-Transport-Security response header (HSTS) instructs browsers that it should only be accessed using HTTPS, rather than HTTP. If a website accepts a connection to HTTP, before being redirected to HTTPS, visitors will initially still communicate over HTTP. The HSTS header instructs the browser to never load over HTTP and to automatically convert all requests to HTTPS. The SEO Spider itself will follow HSTS header instructions, but report any links encountered to HTTP URLs with a 307 status code and ‘HSTS Policy’ status. Please read our SEOs Guide To Crawling HSTS.
- Missing Content-Security-Policy Header – Any URLs that are missing the Content-Security-Policy response header. This header allows a website to control which resources are loaded for a page. This policy can help guard against cross-site scripting (XSS) attacks that exploit the browser’s trust of the content received from the server. The SEO Spider only checks for existence of the header, and does not interrogate the policies found within the header to determine whether they are well set-up for the website. This should be performed manually.
- Missing X-Content-Type-Options Header – Any URLs that are missing the ‘X-Content-Type-Options’ response header with a ‘nosniff’ value. In the absence of a MIME type, browsers may ‘sniff’ to guess the content type to interpret it correctly for users. However, this can be exploited by attackers who can try and load malicious code, such as JavaScript via an image they have compromised. To minimise these security issues, the X-Content-Type-Options response header should be supplied and set to ‘nosniff’. This instructs browsers to rely only on the Content-Type header and block anything that does not match accurately. This also means the content-type set needs to be accurate.
- Missing X-Frame-Options Header – Any URLs that are missing a X-Frame-Options response header with a ‘DENY’ or ‘SAMEORIGIN’ value. This instructs the browser not to render a page within a frame, iframe, embed or object. This helps avoid ‘click-jacking’ attacks, where your content is displayed on another web page that is controlled by an attacker.
- Missing Secure Referrer-Policy Header – Any URLs that are missing ‘no-referrer-when-downgrade’, ‘strict-origin-when-cross-origin’, ‘no-referrer’ or ‘strict-origin’ policies in the Referrer-Policy header. When using HTTPS, it’s important that the URLs do not leak in non-HTTPS requests. This can expose users to ‘man in the middle’ attacks, as anyone on the network can view them.
- Bad Content Type – This shows any URLs where the actual content type does not match the content type set in the header. It also identifies any invalid MIME types used. When the X-Content-Type-Options: nosniff response header is set by the server this is particularly important, as browsers rely on the content type header to correctly process the page. This can cause HTML web pages to be downloaded instead of being rendered when they are served with a MIME type other than text/html for example. Thus, all responses should have an accurate MIME type set in the content-type header. Please note, this filter will include obsolete MIME types, such as JavaScript with ‘text/javascript‘, which should use ‘application/javascript‘.
To discover any HTTPS pages with insecure elements such as HTTP links, canonicals, pagination as well as mixed content (images, JS, CSS), we recommend using the ‘Insecure Content‘ report under the ‘Reports’ top level menu.
Response Codes
The response codes tab shows the HTTP status and status codes from internal and external URLs in a crawl. The filters group URLs by common response codes buckets.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Content – The content type of the URL.
- Status Code – The HTTP response code.
- Status – The HTTP header response.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Inlinks – Number of internal inlinks to the URL. ‘Internal inlinks’ are links pointing to a given URL from the same subdomain that is being crawled.
- Response Time – Time in seconds to download the URL. More detailed information in can be found in our FAQ.
- Redirect URL – If the address URL redirects, this column will include the redirect URL target. The status code above will display the type of redirect, 301, 302 etc.
- Redirect Type – One of the following; HTTP Redirect: triggered by an HTTP header, HSTS Policy: turned around locally by the SEO Spider due to a previous HSTS header, JavaScript Redirect: triggered by execution of JavaScript (which can only occur when using JavaScript rendering) or Meta Refresh Redirect: triggered by a meta refresh tag in the HTML of the page.
Filters
This tab includes the following filters.
- Blocked by Robots.txt – All URLs blocked by the site’s robots.txt. This means they cannot be crawled and is a critical issue if you want the page content to be crawled and indexed by search engines.
- Blocked Resource – All resources that are blocked by a site’s robots.txt, such as images, JavaScript and CSS. This filter will only populate when JavaScript rendering is enabled (blocked resources will appear under ‘Blocked by Robots.txt’ in default ‘text only’ crawl mode). This can be an issue as the search engines might not be able to access critical resources to be able to render pages accurately.
- No Response – When the URL does not send a response to the SEO Spiders HTTP request. Typically a malformed URL, connection timeout, connection refused or connection error. Malformed URLs should be updated and other connection issues can often be resolved by adjusting the SEO Spider configuration.
- Success (2XX) – The URL requested was received, understood, accepted and processed successfully. Ideally all URLs encountered in a crawl would be a status code ‘200’ with a ‘OK’ status, which is perfect for crawling and indexing of content.
- Redirection (3XX) – A redirection was encountered. These will include server-side redirects, such as 301 or 302 redirects. Ideally all internal links would be to canonical resolving URLs, and avoid linking to URLs that redirect. This reduces latency of redirect hops for users.
- Redirection (JavaScript) – A JavaScript redirect was encountered. Ideally all internal links would be to canonical resolving URLs, and avoid linking to URLs that redirect. This reduces latency of redirect hops for users.
- Redirection (Meta Refresh) – A meta refresh was encountered. Ideally all internal links would be to canonical resolving URLs, and avoid linking to URLs that redirect. This reduces latency of redirect hops for users.
- Redirect Chain – Internal URLs that redirect to another URL, which also then redirects. This can occur multiple times in a row, each redirect is referred to as a ‘hop’. Full redirect chains can be viewed and exported via ‘Reports > Redirects > Redirect Chains’.
- Redirect Loop – Internal URLs that redirect to another URL, which also then redirects. This can occur multiple times in a row, each redirect is referred to as a ‘hop’. This filter will only populate if a URL redirects to a previous URL within the redirect chain. Redirect chains with a loop can be viewed and exported via ‘Reports > Redirects > Redirect Chains’ with the ‘Loop’ column filtered to ‘True’.
- Client Error (4xx) – Indicates a problem occurred with the request. This can include responses such as 400 bad request, 403 Forbidden, 404 Page Not Found, 410 Removed, 429 Too Many Requests and more. All links on a website should ideally resolve to 200 ‘OK’ URLs. Errors such as 404s should be updated to their correct locations, removed and redirected where appropriate.
- Server Error (5XX) – The server failed to fulfil an apparently valid request. This can include common responses such as 500 Internal Sever Errors and 503 Server Unavailable. All URLs should respond with a 200 ‘OK’ status and this might indicate a server that struggles under load or a misconfiguration that requires investigation.
Please see our Learn SEO guide on HTTP Status Codes, or to troubleshoot responses when using the SEO Spider, read our HTTP Status Codes When Crawling tutorial.
URL
The URL tab shows data related to the URLs discovered in a crawl. The filters show common issues discovered for URLs.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Content – The content type of the URL.
- Status Code – HTTP response code.
- Status – The HTTP header response.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Hash – Hash value of the page. This is a duplicate content check. If two hash values match the pages are exactly the same in content.
- Length – The character length of the URL.
- Canonical 1 – The canonical link element data.
- URL Encoded Address – The URL actually requested by the SEO Spider. All non-ASCII characters percent encoded, see RFC 3986 for further details.
Filters
This tab includes the following filters.
- Non ASCII Characters – The URL has characters in it that are not included in the ASCII character-set. Standards outline that URLs can only be sent using the ASCII character-set and some users may have difficulty with subtleties of characters outside this range. URLs must be converted into a valid ASCII format, by encoding links to the URL with safe characters (made up of % followed by two hexadecimal digits). Today browsers and the search engines are largely able to transform URLs accurately.
- Underscores – The URL has underscores within it, which are not always seen as word separators by search engines. Hyphens are recommended for word separators.
- Uppercase – The URL has uppercase characters within it. URLs are case sensitive, so as best practice generally URLs should be lowercase, to avoid any potential mix ups and duplicate URLs.
- Multiple Slashes – The URL has multiple forward slashes in the path (for example, screamingfrog.co.uk/seo//). This is generally by mistake and as best practice URLs should only have a single slash between sections of a path to avoid any potential mix ups and duplicate URLs.
- Repetitive Path – The URL has a path that is repeated in the URL string (for example, screamingfrog.co.uk/seo/seo/, or screamingfrog.co.uk/services/seo/technical/seo/). In some cases this can be legitimate and logical, however it also often points to poor URL structure and potential improvements. It can also help identify issues with incorrect relative linking, causing infinite URLs.
- Contains A Space – The URL has a space in it. These are considered unsafe and could cause the link to be broken when sharing the URL. Hyphens should be used as word separators instead of spaces.
- Internal Search – The URL might be part of the websites internal search function. Google and other search engines recommend blocking internal search pages from being crawled. To avoid Google indexing the blocked internal search URLs, they should not be discoverable via internal links either. Therefore, consider removing internal links to these URLs, or including a nofollow link attribute.
- Parameters – The URL includes parameters such as ‘?’ or ‘&’ in it. This isn’t an issue for Google or other search engines to crawl, but it’s recommended to limit the number of parameters in a URL which can be complicated for users, and can be a sign of low value-add URLs.
- Broken Bookmark – URLs that have a broken bookmark (also known as ‘named anchors’, ‘jump links’, and ‘skip links’) that link users to a specific part of a webpage using an ID attribute in the HTML and append a fragment (#) and the ID name to the URL. When the link is clicked, the page will scroll to the location with the bookmark. While these links can be excellent for users, it’s easy to make mistakes in the set-up, and they often become ‘broken’ over time as pages are updated and IDs are changed or removed. A broken bookmark will mean the user is still taken to the correct page, but they won’t be directed to the intended section. While Google will see these URLs as the same page (as it ignores anything from the #), they can use named anchors for ‘jump to’ links in their search results for the page ranking. Review the pages that link to the broken bookmarks by using the ‘inlinks’ tab and ensure this has the correct ID attribute that’s used on the page for the relevant section. ‘Crawl Fragment Identifiers’ under ‘Config > Spider > Advanced’ must be enabled to discover this issue. Please see our guide on how to find broken bookmarks.
- Over 115 characters – The URL is over 115 characters in length. This is not necessarily an issue, however research has shown that users prefer shorter, concise URL strings.
Please see our Learn SEO guide on URL Structure.
Page titles
The page title tab includes data related to page title elements of internal URLs in the crawl. The filters show common issues discovered for page titles.
The page title, often referred to as the ‘title tag’, ‘meta title’ or sometimes ‘SEO title’ is an HTML element in the head of a webpage that describes the purpose of the page to users and search engines. They are widely considered to be one of the strongest on-page ranking signals for a page.
The page title element should be placed in the head of the document and looks like this in HTML:
<title>This Is A Page Title</title>
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of page titles found on the page (the maximum the SEO Spider will find is 2).
- Title 1/2 – The content of the page title elements.
- Title 1/2 length – The character length of the page title(s).
- Indexability – Whether the URL is Indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if the URL is canonicalised to another URL, or has a ‘noindex’ etc.
Filters
This tab includes the following columns.
- Missing – Any pages which have a missing page title element, the content is empty or has a whitespace. Page titles are read and used by both users and the search engines to understand the purpose of a page. So it’s critical that pages have concise, descriptive and unique page titles.
- Duplicate – Any pages which have duplicate page titles. It’s really important to have distinct and unique page titles for every page. If every page has the same page title, then it can make it more challenging for users and the search engines to understand one page from another.
- Over 60 characters – Any pages which have page titles over 60 characters in length. Characters over this limit might be truncated in Google’s search results and carry less weight in scoring.
- Below 30 characters – Any pages which have page titles under 30 characters in length. This isn’t necessarily an issue, but you have more room to target additional keywords or communicate your USPs.
- Over X Pixels – Google snippet length is actually based upon pixels limits, rather than a character length. The SEO Spider tries to match the latest pixel truncation points in the SERPs, but it is an approximation and Google adjusts them frequently. This filter shows any pages which have page titles over X pixels in length.
- Below X Pixels – Any pages which have page titles under X pixels in length. This isn’t necessarily a bad thing, but you have more room to target additional keywords or communicate your USPs.
- Same as h1 – Any page titles which match the h1 on the page exactly. This is not necessarily an issue, but may point to a potential opportunity to target alternative keywords, synonyms, or related key phrases.
- Multiple – Any pages which have multiple page titles. There should only be a single page title element for a page. Multiple page titles are often caused by multiple conflicting plugins or modules in CMS.
Please see our Learn SEO guide on writing Page Titles.
Meta description
The meta description tab includes data related to meta descriptions of internal URLs in the crawl. The filters show common issues discovered for meta descriptions.
The meta description is an HTML attribute in the head of a webpage that provides a summary of the page to users. The words in a description are not used in ranking by Google, but they can be shown in the search results to users, and therefore heavily influence click through rates.
The meta description should be placed in the head of the document and looks like this in HTML:
<meta name="description" content="This is a meta description."/>
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of meta descriptions found on the page (the maximum we find is 2).
- Meta Description 1/2 – The meta description.
- Meta Description 1/2 length – The character length of the meta description.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if the URL is canonicalised to another URL.
Filters
This tab includes the following filters.
- Missing – Any pages which have a missing meta description, the content is empty or has a whitespace. This is a missed opportunity to communicate the benefits of your product or service and influence click through rates for important URLs.
- Duplicate – Any pages which have duplicate meta descriptions. It’s really important to have distinct and unique meta descriptions that communicate the benefits and purpose of each page. If they are duplicate or irrelevant, then they will be ignored by search engines.
- Over 155 characters – Any pages which have meta descriptions over 155 characters in length. Characters over this limit might be truncated in Google’s search results.
- Below 70 characters – Any pages which have meta descriptions below 70 characters in length. This isn’t strictly an issue, but an opportunity. There is additional room to communicate benefits, USPs or call to actions.
- Over X Pixels – Google snippet length is actually based upon pixels limits, rather than a character length. The SEO Spider tries to match the latest pixel truncation points in the SERPs, but it is an approximation and Google adjusts them frequently. This filter shows any pages which have descriptions over X pixels in length and might be truncated in Google’s search results.
- Below X Pixels – Any pages which have meta descriptions under X pixels in length. This isn’t strictly an issue, but an opportunity. There is additional room to communicate benefits, USPs or call to actions.
- Multiple – Any pages which have multiple meta descriptions. There should only be a single meta description for a page. Multiple meta descriptions are often caused by multiple conflicting plugins or modules in CMS.
Please see our Learn SEO guide on writing Meta Descriptions.
Meta keywords
The meta keywords tab includes data related to meta keywords. The filters show common issues discovered for meta keywords.
Meta keywords are widely ignored by search engines and they are not used as a signal in scoring for all major Western search engines. In particular Google does not consider it at all in their scoring of pages in ranking of their search results. Therefore we recommend ignoring it completely unless you are targeting alternative search engines.
Other search engines such as Yandex or Baidu may still use them in ranking, but we recommend performing research to this status before taking the time to optimise them.
The meta keywords tag should be placed in the head of the document and looks like this in HTML
:
<meta name="keywords" content="seo, seo agency, seo services"/>
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of meta keywords found on the page (the maximum we find is 2).
- Meta Keyword 1/2 – The meta keywords.
- Meta Keyword 1/2 length – The character length of the meta keywords.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- Missing – Any pages which have a missing meta keywords. If you’re targeting Google, Bing and Yahoo then this is fine as they do not use them in ranking. If you’re targeting Baidu or Yandex, then you may wish to consider including relevant target keywords.
- Duplicate – Any pages which have duplicate meta keywords. If you’re targeting Baidu or Yandex, then unique keywords relevant to the purpose of the page are recommended.
- Multiple – Any pages which have multiple meta keywords. There should only be a single tag on the page.
h1
The h1 tab shows data related to the <h1> heading of a page. The filters show common issues discovered for <h1>s.
The <h1> to <h6> tags are used to define HTML headings. The <h1> is considered as the most important first main heading of a page, and <h6> as the least important.
Headings should ordered by size and importance and they help users and search engines understand the content on the page and sections. The <h1> should describe the main title and purpose of the page and are widely considered to be one of the stronger on-page ranking signals.
The <h1> element should be placed in the body of the document and looks like this in HTML:
<h1>This Is An h1</h1>
By default, the SEO Spider will only extract and report on the first two <h1>’s discovered on a page. If you wish to extract all h1s, then we recommend using custom extraction.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of <h1>s found on the page. As outlined above, the maximum we find is 2.
- h1-1/2 – The content of the <h1>.
- h1-length-1/2 – The character length of the <h1>.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- Missing – Any pages which have a missing <h1>, the content is empty or has a whitespace. <h1>’s are read and used by both users and the search engines to understand the purpose of a page. So it’s critical that pages have concise, descriptive and unique headings.
- Duplicate – Any pages which have duplicate <h1>s. It’s important to have distinct, unique and useful pages. If every page has the same <h1>, then it can make it more challenging for users and the search engines to understand one page from another.
- Over 70 characters – Any pages which have <h1> over 70 characters in length. This is not strictly an issue, as there isn’t a character limit for headings. However, they should be concise and descriptive for users and search engines.
- Multiple – Any pages which have multiple <h1>. While this is not strictly an issue because HTML5 standards allow multiple <h1>s on a page, there are some problems with this modern approach in terms of usability. It’s advised to use heading rank (h1–h6) to convey document structure. The classic HTML4 standard defines there should only be a single <h1> per page, and this is still generally recommended for users and SEO.
Please see our Learn SEO guide on Heading Tags.
h2
The h2 tab shows data related to the <h2> heading of a page. The filters show common issues discovered for <h2>s.
The <h1> to <h6> tags are used to define HTML headings. The <h2> is considered as the second important heading of a page and is generally sized and styled as the second largest heading.
The <h2> heading is often used to describe sections or topics within a document. They act as sign posts for the user, and can help search engines understand the page.
The <h2> element should be placed in the body of the document and looks like this in HTML:
<h2>This Is An h2</h2>
By default, the SEO Spider will only extract and report on the first two h2’s discovered on a page. If you wish to extract all h2s, then we recommend using custom extraction.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of <h2>s found on the page. As outlined above, the maximum we find is 2.
- h2-1/2 – The content of the <h2>.
- h2-length-1/2 – The character length of the <h2>.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- Missing – Any pages which have a missing <h2>, the content is empty or has a whitespace. <h2>’s are read and used by both users and the search engines to understand the page and sections. Ideally most pages would have logical, descriptive <h2>s.
- Duplicate – Any pages which have duplicate <h2>s. It’s important to have distinct, unique and useful pages. If every page has the same <h2>, then it can make it more challenging for users and the search engines to understand one page from another.
- Over 70 characters – Any pages which have <h2> over 70 characters in length. This is not strictly an issue, as there isn’t a character limit for headings. However, they should be concise and descriptive for users and search engines.
- Multiple – Any pages which have multiple <h2>s. This is not an issue as HTML standards allow multiple <h2>’s when used in a logical hierachical heading structure. However, this filter can help you quickly scan to review if they are used appropriately.
Please see our Learn SEO guide on Heading Tags.
Content
The ‘Content’ tab shows data related to the content of internal HTML URLs discovered in a crawl.
This includes word count, readability, duplicate and near duplicate content, and spelling and grammar errors.
Columns
This tab includes the following columns.
- Address – The URL address.
- Word Count – This is all ‘words’ inside the body tag, excluding HTML markup. The count is based upon the content area that can be adjusted under ‘Config > Content > Area’. By default, the nav and footer elements are excluded. You can include or exclude HTML elements, classes and IDs to calculate a refined word count. Our figures may not be exactly what performing this calculation manually would find, as the parser performs certain fix-ups on invalid HTML. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces. No consideration is given to visibility of content (such as text inside a div set to hidden).
- Average Words Per Sentence – The total number of words from the content area, divided by the total number of sentences discovered. This is calculated as part of the Flesch readability analysis.
- Flesch Reading Ease Score – The Flesch reading ease test measures the readability of text. It’s a widely used readability formula, which uses the average length of sentences, and average number of syllables per word to provide a score between 0-100. 0 is very difficult to read and best understood by university graduates, while 100 is very easy to read and can be understood by an 11 year old student.
- Readability – The overall readability assessment classification based upon the Flesch Reading Ease Score and documented score groups.
- Closest Similarity Match – This shows the highest similarity percentage of a near duplicate URL. The SEO Spider will identify near duplicates with a 90% similarity match, which can be adjusted to find content with a lower similarity threshold. For example, if there were two near duplicate pages for a page with 99% and 90% similarity respectively, then 99% will be displayed here. To populate this column the ‘Enable Near Duplicates’ configuration must be selected via ‘Config > Content > Duplicates‘, and post ‘Crawl Analysis‘ must be performed. Only URLs with content over the selected similarity threshold will contain data, the others will remain blank. Thus by default, this column will only contain data for URLs with 90% or higher similarity, unless it has been adjusted via the ‘Config > Content > Duplicates’ and ‘Near Duplicate Similarity Threshold’ setting.
- No. Near Duplicates – The number of near duplicate URLs discovered in a crawl that meet or exceed the ‘Near Duplicate Similarity Threshold’, which is a 90% match by default. This setting can be adjusted under ‘Config > Content > Duplicates’. To populate this column the ‘Enable Near Duplicates’ configuration must be selected via ‘Config > Content > Duplicates‘, and post ‘Crawl Analysis‘ must be performed.
- Total Language Errors – The total number of spelling and grammar errors discovered for a URL. For this column to be populated then either ‘Enable Spell Check’ or ‘Enable Grammar Check’ must be selected via ‘Config > Content > Spelling & Grammar‘.
- Spelling Errors – The total number of spelling errors discovered for a URL. For this column to be populated then ‘Enable Spell Check’ must be selected via ‘Config > Content > Spelling & Grammar‘.
- Grammar Errors – The total number of grammar errors discovered for a URL. For this column to be populated then ‘Enable Grammar Check’ must be selected via ‘Config > Content > Spelling & Grammar’.
- Language – The language selected for spelling and grammar checks. This is based upon the HTML language attribute, but the language can also be set via ‘Config > Content > Spelling & Grammar‘.
- Hash – Hash value of the page using the MD5 algorithm. This is a duplicate content check for exact duplicate content only. If two hash values match, the pages are exactly the same in content. If there’s a single character difference, they will have unique hash values and not be detected as duplicate content. So this is not a check for near duplicate content. The exact duplicates can be seen under ‘Content > Exact Duplicates’.
- Indexability – Whether the URL is Indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- Exact Duplicates – This filter will show pages that are identical to each other using the MD5 algorithm which calculates a ‘hash’ value for each page and can be seen in the ‘hash’ column. This check is performed against the full HTML of the page. It will show all pages with matching hash values that are exactly the same. Exact duplicate pages can lead to the splitting of PageRank signals and unpredictability in ranking. There should only be a single canonical version of a URL that exists and is linked to internally. Other versions should not be linked to, and they should be 301 redirected to the canonical version.
- Near Duplicates – This filter will show similar pages based upon the configured similarity threshold using the minhash algorithm. The threshold can be adjusted under ‘Config > Content > Duplicates’ and is set at 90% by default. The ‘Closest Similarity Match’ column displays the highest percentage of similarity to another page. The ‘No. Near Duplicates’ column displays the number of pages that are similar to the page based upon the similarity threshold. The algorithm is run against text on the page, rather than the full HTML like exact duplicates. The content used for this analysis can be configured under ‘Config > Content > Area’. Pages can have a 100% similarity, but only be a ‘near duplicate’ rather than exact duplicate. This is because exact duplicates are excluded as near duplicates, to avoid them being flagged twice. Similarity scores are also rounded, so 99.5% or higher will be displayed as 100%. To populate this column the ‘Enable Near Duplicates’ configuration must be selected via ‘Config > Content > Duplicates‘, and post ‘Crawl Analysis‘ must be performed.
- Low Content Pages – This will show any HTML pages with a word count below 200 words by default. The word count is based upon the content area settings used in the analysis which can be configured via ‘Config > Content > Area’. There isn’t a minimum word count for pages in reality, but the search engines do require descriptive text to understand the purpose of a page. This filter should only be used as a rough guide to help identify pages that might be improved by adding more descriptive content in the context of the website and page’s purpose. Some websites, such as ecommerce, will naturally have lower word counts, which can be acceptable if a products details can be communicated efficiently. The word count used for the low content pages filter can be adjusted via ‘Config > Spider > Preferences > Low Content Word Count‘ to your own preferences.
- Spelling Errors – This filter contains any HTML pages with spelling errors. For this filter and respective columns to be populated then ‘Enable Spell Check’ must be selected via ‘Config > Content > Spelling & Grammar‘.
- Grammar Errors – This filter contains any HTML pages with grammar errors. For this column to be populated then ‘Enable Grammar Check’ must be selected via ‘Config > Content > Spelling & Grammar‘.
- Readability Difficult – Copy on the page is difficult to read and best understood by college graduates according to the Flesch reading-ease score formula. Copy that has long sentences and uses complex words are generally harder to read and understand. Consider improving the readability of copy for your target audience. Copy that uses shorter sentences with less complex words is often easier to read and understand.
- Readability Very Difficult – Copy on the page is very difficult to read and best understood by university graduates according to the Flesch reading-ease score formula. Copy that has long sentences and uses complex words are generally harder to read and understand. Consider improving the readability of copy for your target audience. Copy that uses shorter sentences with less complex words is often easier to read and understand.
Please see our Learn SEO guide on duplicate content, and our ‘How To Check For Duplicate Content‘ tutorial.
Images
The images tab shows data related to any images discovered in a crawl. This includes both internal and external images, discovered by either <img src= tags, or <a href= tags. The filters show common issues discovered for images and their alt text.
Image alt attributes (often referred to incorrectly as ‘alt tags’) can be viewed by clicking on an image and then the ‘Image Details’ tab at the bottom, which populates the lower window tab.
Alt attributes should specify relevant and descriptive alternative text about the purpose of an image and appear in the source of the HTML like the below example.
<img src="screamingfrog-logo.jpg" alt="Screaming Frog" />
Decorative images should provide a null (empty) alt text (alt=””) so that they can be ignored by assistive technologies, such as screen readers, rather than not including an alt attribute at all.
<img src="decorative-frog-space.jpg" alt="" />
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Content – The content type of the image (jpeg, gif, png etc).
- Size – Size of the image in kilobytes. File size is in bytes in the export, so divide by 1,024 to convert to kilobytes.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- Over 100kb – Large images over 100kb in size. Page speed is extremely important for users and SEO and often large resources such as images are one of the most common issues that slow down web pages. This filter simply acts as a general rule of thumb to help identify images that are fairly large in file size and may take longer to load. These should be considered for optimisation, alongside opportunities identified in the PageSpeed tab which uses the PSI API and Lighthouse to audit speed. This can help identify images that haven’t been optimised in size, load offscreen, are unoptimised etc.
- Missing Alt Text – Images that have an alt attribute, but are missing alt text. Click the address (URL) of the image and then the ‘Image Details’ tab in the lower window pane to view which pages have the image on, and which pages are missing alt text of the said image. Images should have descriptive alternative text about it’s purpose, which helps the blind and visually impaired and the search engines understand it and it’s relevance to the web page. For decorative images a null (empty) alt text should be provided (alt=””) so that they can be ignored by assistive technologies, such as screen readers.
- Missing Alt Attribute – Images that are missing an alt attribute all together. Click the address (URL) of the image and then the ‘Image Details’ tab in the lower window pane to view which pages have the image on, and are missing alt attributes. All images should contain an alt attribute with descriptive text, or blank when it’s a decorative image.
- Alt Text Over 100 Characters – Images which have one instance of alt text over 100 characters in length. This is not strictly an issue, however image alt text should be concise and descriptive. It should not be used to stuff lots of keywords or paragraphs of text onto a page.
- Background Images – CSS background and dynamically loaded images discovered across the website, which should be used for non-critical and decorative purposes. Background images are not typically indexed by Google and browsers do not provide alt attributes or text on background images to assistive technology.
For more on optimising images, please read our guide on How To View Alt Text & Find Missing Alt Text and consider using the the PageSpeed Insights Integration, which has opportunities and diagnostics for ‘Properly Size Images’, ‘Defer Offscreen Images’, ‘Efficiently Encode Images’ and ‘Serve Images in Next-Gen Formats Image Elements Do Not Have Explicit Width & Height’.
Canonicals
The canonicals tab shows canonical link elements and HTTP canonicals discovered during a crawl. The filters show common issues discovered for canonicals.
The rel=”canonical” element helps specify a single preferred version of a page when it’s available via multiple URLs. It’s a hint to the search engines to help prevent duplicate content, by consolidating indexing and link properties to a single URL to use in ranking.
The canonical link element should be placed in the head of the document and looks like this in HTML:
<link rel="canonical" href="https://www.example.com/" >
You can also use rel=”canonical” HTTP headers, which looks like this:
Link: <http://www.example.com>; rel="canonical"
- Address – The URL crawled.
- Occurrences – The number of canonicals found (via both link element and HTTP).
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Canonical Link Element 1/2 etc – Canonical link element data on the URL. The SEO Spider will find all instances if there are multiple.
- HTTP Canonical 1/2 etc – Canonical issued via HTTP. The SEO Spider will find all instances if there are multiple.
- Meta Robots 1/2 etc – Meta robots found on the URL. The SEO Spider will find all instances if there are multiple.
- X-Robots-Tag 1/2 etc – X-Robots-tag data. The SEO Spider will find all instances if there are multiple.
- rel=“next” and rel=“prev” – The SEO Spider collects these HTML link elements designed to indicate the relationship between URLs in a paginated series.
Columns
This tab includes the following columns.
Filters
This tab includes the following filters.
- Contains Canonical – The page has a canonical URL set (either via link element, HTTP header or both). This could be a self-referencing canonical URL where the page URL is the same as the canonical URL, or it could be ‘canonicalised’, where the canonical URL is different to the page URL.
- Self Referencing – The URL has a canonical which is the same URL as the page URL crawled (hence, it’s self referencing). Ideally only canonical versions of URLs would be linked to internally, and every URL would have a self-referencing canonical to help avoid any potential duplicate content issues that can occur (even naturally on the web, such as tracking parameters on URLs, other websites incorrectly linking to a URL that resolves etc).
- Canonicalised – The page has a canonical URL that is different to itself. The URL is ‘canonicalised’ to another location. This means the search engines are being instructed to not index the page, and the indexing and linking properties should be consolidated to the target canonical URL. These URLs should be reviewed carefully. In a perfect world, a website wouldn’t need to canonicalise any URLs as only canonical versions would be linked to, but often they are required due to various circumstances outside of control, and to prevent duplicate content.
- Missing – There’s no canonical URL present either as a link element, or via HTTP header. If a page doesn’t indicate a canonical URL, Google will identify what they think is the best version or URL. This can lead to ranking unpredicatability, and hence generally all URLs should specify a canonical version.
- Multiple – There’s multiple canonicals set for a URL (either multiple link elements, HTTP header, or both combined). This can lead to unpredictability, as there should only be a single canonical URL set by a single implementation (link element, or HTTP header) for a page.
- Multiple Conflicting – Pages with multiple canonicals set for a URL that have different URLs specified (via either multiple link elements, HTTP header, or both combined). This can lead to unpredictability, as there should only be a single canonical URL set by a single implementation (link element, or HTTP header) for a page.
- Non-Indexable Canonical – The canonical URL is a non-indexable page. This will include canonicals which are blocked by robots.txt, no response, redirect (3XX), client error (4XX), server error (5XX) or are ‘noindex’. Canonical versions of URLs should always be indexable, ‘200’ response pages. Therefore, canonicals that go to non-indexable pages should be corrected to the resolving indexable versions.
- Canonical Is Relative – Pages that have a relative rather than absolute rel=”canonical” link tag. While the tag, like many HTML tags, accepts both relative and absolute URLs, it’s easy to make subtle mistakes with relative paths that could cause indexing-related issues.
- Unlinked – URLs that are only discoverable via rel=”canonical” and are not linked-to via hyperlinks on the website. This might be a sign of a problem with internal linking, or the URLs contained in the canonical.
Please see our Learn SEO guide on canonicals, and our ‘How to Audit Canoncials‘ tutorial.
Pagination
The pagination tab includes information on rel=”next” and rel=”prev” HTML link elements discovered in a crawl, which are used to indicate the relationship between component URLs in a paginated series. The filters show common issues discovered for pagination.
While Google announced on the 21st of March 2019 that they have not used rel=”next” and rel=”prev” in indexing for a long time, other search engines such as Bing (which also powers Yahoo), still use it as a hint for discovery and understanding site structure.
Pagination attributes should be placed in the head of the document and looks like this in HTML:
<link rel="prev" href="https://www.example.com/seo/"/>
<link rel="next" href="https://www.example.com/seo/page/2/"/>
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of canonicals found (via both link element and HTTP).
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- rel=“next” – The SEO Spider collects these HTML link elements designed to indicate the relationship between URLs in a paginated series.
- rel=“prev” – The SEO Spider collects these HTML link elements designed to indicate the relationship between URLs in a paginated series.
- Canonical Link Element 1/2 etc – Canonical link element data on the URI. The SEO Spider will find all instances if there are multiple.
- HTTP Canonical 1/2 etc – Canonical issued via HTTP. The SEO Spider will find all instances if there are multiple.
- Meta Robots 1/2 etc – Meta robots found on the URI. The SEO Spider will find all instances if there are multiple.
- X-Robots-Tag 1/2 etc – X-Robots-tag data. The SEO Spider will find all instances if there are multiple.
Filters
This tab includes the following filters.
- Contains Pagination – The URL has a rel=”next” and/or rel=”prev” attribute, indicating it’s part of a paginated series.
- First Page – The URL only has a rel=“next” attribute, indicating it’s the first page in a paginated series. It’s easy and useful to scroll through these URLs and ensure they are accurately implemented on the parent page in the series.
- Paginated 2+ Pages – The URL has a rel=“prev” on it, indicating it’s not the first page, but a paginated page in a series. Again, it’s useful to scroll through these URLs and ensure only paginated pages appear under this filter.
- Pagination URL Not In Anchor Tag – A URL contained in either, or both, the rel=”next” and rel=”prev” attributes of the page, are not found as a hyperlink in an HTML anchor element on the page itself. Paginated pages should be linked to with regular links to allow users to click and navigate to the next page in the series. They also allow Google to crawl from page to page, and PageRank to flow between pages in the series. Google’s own Webmaster Trends analyst John Mueller recommended proper HTML links for pagination as well in a Google Webmaster Central Hangout.
- Non-200 Pagination URL – The URLs contained in the rel=”next” and rel=”prev” attributes do not respond with a 200 ‘OK’ status code. This can include URLs blocked by robots.txt, no responses, 3XX (redirects), 4XX (client errors) or 5XX (server errors). Pagination URLs must be crawlable and indexable and therefore non-200 URLs are treated as errors, and ignored by the search engines. The non-200 pagination URLs can be exported in bulk via the ‘Reports > Pagination > Non-200 Pagination URLs’ export.
- Unlinked Pagination URL – The URL contained in the rel=”next” and rel=”prev” attributes are not linked to across the website. Pagination attributes may not pass PageRank like a traditional anchor element, so this might be a sign of a problem with internal linking, or the URLs contained in the pagination attribute. The unlinked pagination URLs can be exported in bulk via the ‘Reports > Pagination > Unlinked Pagination URLs’ export.
- Non-Indexable – The paginated URL is non-indexable. Generally they should all be indexable, unless there is a ‘view-all’ page set, or there are extra parameters on pagination URLs, and they require canonicalising to a single URL. One of the most common mistakes is canonicalising page 2+ paginated pages to the first page in a series. Google recommend against this implementation because the component pages don’t actually contain duplicate content. Another common mistake is using ‘noindex’, which can mean Google drops paginated URLs from the index completely and stops following outlinks from those pages, which can be a problem for the products on those pages. This filter will help identify these common set-up issues.
- Multiple Pagination URLs – There are multiple rel=”next” and rel=”prev” attributes on the page (when there shouldn’t be more than a single rel=”next” or rel=”prev” attribute). This may mean that they are ignored by the search engines.
- Pagination Loop – This will show URLs that have rel=”next” and rel=”prev” attributes that loop back to a previously encountered URL. Again, this might mean that the expressed pagination series are simply ignored by the search engines.
- Sequence Error – This shows URLs that have an error in the rel=”next” and rel=”prev” HTML link elements sequence. This check ensures that URLs contained within rel=”next” and rel=”prev” HTML link elements reciprocate and confirm their relationship in the series.
For more information on pagination, please read our guide on ‘How To Audit rel=”next” and rel=”prev” Pagination Attributes‘.
Directives
The directives tab shows data related to the meta robots tag, and the X-Robots-Tag in the HTTP Header. These robots directives can control how your content and URLs are displayed in search engines, such as Google.
The meta robots tag should be placed in the head of the document and an example of a ‘noindex’ meta tag looks like this in HTML:
<meta name="robots" content="noindex"/>
The same directive can be issued in the HTTP header using the X-Robots-Tag, which looks like this:
X-Robots-Tag: noindex
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Meta Robots 1/2 etc – Meta robots directives found on the URL. The SEO Spider will find all instances if there are multiple.
- X-Robots-Tag 1/2 etc – X-Robots-tag HTTP header directives for the URL. The SEO Spider will find all instances if there are multiple.
Filters
This tab includes the following filters.
- Index – This allows the page to be indexed. It’s unnecessary, as search engines will index URLs without it.
- Noindex – This instructs the search engines not to index the page. The page will still be crawled (to see the directive), but it will then be dropped from the index. URLs with a ‘noindex’ should be inspected carefully.
- Follow – This instructs any links on the page to be followed for crawling. It’s unnecessary, as search engines will follow them by default.
- Nofollow – This is a ‘hint’ which tells the search engines not to follow any links on the page for crawling. This is generally used by mistake in combination with ‘noindex’, when there is no need to include this directive. To crawl pages with a meta nofollow tag the configuration ‘Follow Internal Nofollow’ must be enabled under ‘Config > Spider’.
- None – This does not mean there are no directives in place. It means the meta tag ‘none’ is being used, which is the equivalent to “noindex, nofollow”. These URLs should be reviewed carefully to ensure they are being correctly kept out of the search engines indexes.
- NoArchive – This instructs Google not to show a cached link for a page in the search results.
- NoSnippet – This instructs Google not to show a text snippet or video preview from being shown in the search results.
- Max-Snippet – This value allows you to limit the text snippet length for this page to [number] characters in Google. Special values include – 0 for no snippet, or -1 to allow any snippet length.
- Max-Image-Preview – This value can limit the size of any image associated with this page in Google. Setting values can be “none”, “standard”, or “large”.
- Max-Video-Preview – This value can limit any video preview associated with this page to [number] seconds in Google. You can also specify 0 to allow only a still image, or -1 to allow any preview length.
- NoODP – This is an old meta tag that used to instruct Google not to use the Open Directory Project for its snippets. This can be removed.
- NoYDIR – This is an old meta tag that used to instruct Google not to use the Yahoo Directory for its snippets. This can be removed.
- NoImageIndex – This tells Google not to show the page as the referring page for an image in the Image search results. This has the effect of preventing all images on this page from being indexed in this page.
- NoTranslate – This value tells Google that you don’t want them to provide a translation for this page.
- Unavailable_After – This allows you to specify the exact time and date you want Google to stop showing the page in their search results.
- Refresh – This redirects the user to a new URL after a certain amount of time. We recommend reviewing meta refresh data within the response codes tab.
In this tab we also display columns for meta refresh and canonicals. However, we recommend reviewing meta refresh data within the response codes tab and relevant filter, and canonicals within the canonicals tab.
hreflang
The hreflang tab includes details of hreflang annotations crawled by the SEO Spider, delivered by HTML link element, HTTP Header or XML Sitemap. The filters show common issues discovered for hreflang.
Hreflang is useful when you have multiple versions of a page for different languages or regions. It tells Google about these different variations and helps them show the most appropriate version of your page by language or region.
Hreflang link elements should be placed in the head of the document and looks like this in HTML:
<link rel="alternate" hreflang="en-gb" href="https://www.example.com" >
<link rel="alternate" hreflang="en-us" href="https://www.example.com/us/" >
‘Store Hreflang‘ and ‘Crawl Hreflang‘ options need to be enabled (under ‘Config > Spider’) for this tab and respective filters to be populated. To extract hreflang annotations from XML Sitemaps during a regular crawl ‘Crawl Linked XML Sitemaps‘ must be selected as well.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Title 1/2 etc – The page title element of the page.
- Occurrences – The number of hreflang discovered on a page.
- HTML hreflang 1/2 etc – The hreflang language and region code from any HTML link element on the page.
- HTML hreflang 1/2 URL etc – The hreflang URL from any HTML link element on the page.
- HTTP hreflang 1/2 etc – The hreflang language and region code from the HTTP Header.
- HTTP hreflang 1/2 URL etc – The hreflang URL from the HTTP Header.
- Sitemap hreflang 1/2 etc – The hreflang language and region code from the XML Sitemap. Please note, this only populates when crawling the XML Sitemap in list mode.
- Sitemap hreflang 1/2 URL etc – The hreflang URL from the XML Sitemap. Please note, this only populates when crawling the XML Sitemap in list mode.
Filters
This tab includes the following filters.
- Contains Hreflang – These are simply any URLs that have rel=”alternate” hreflang annotations from any implementation, whether link element, HTTP header or XML Sitemap.
- Non-200 Hreflang URLs – These are URLs contained within rel=”alternate” hreflang annotations that do not have a 200 response code, such as URLs blocked by robots.txt, no responses, 3XX (redirects), 4XX (client errors) or 5XX (server errors). Hreflang URLs must be crawlable and indexable and therefore non-200 URLs are treated as errors, and ignored by the search engines. The non-200 hreflang URLs can be seen in the lower window ‘URL Info’ pane with a ‘non-200’ confirmation status. They can be exported in bulk via the ‘Reports > Hreflang > Non-200 Hreflang URLs’ export.
- Unlinked Hreflang URLs – These are pages that contain one or more hreflang URLs that are only discoverable via its rel=”alternate” hreflang link annotations. Hreflang annotations do not pass PageRank like a traditional anchor tag, so this might be a sign of a problem with internal linking, or the URLs contained in the hreflang annotation. To find out exactly which hreflang URLs on these pages are unlinked, use the ‘Reports > Hreflang > Unlinked Hreflang URLs’ export.
- Missing Return Links – These are URLs with missing return links (or ‘return tags’ in Google Search Console) to them, from their alternate pages. Hreflang is reciprocal, so all alternate versions must confirm the relationship. When page X links to page Y using hreflang to specify it as it’s alternate page, page Y must have a return link. No return links means the hreflang annotations may be ignored or not interpreted correctly. The missing return links URLs can be seen in the lower window ‘URL Info’ pane with a ‘missing’ confirmation status. They can be exported in bulk via the ‘Reports > Hreflang > Missing Return Links’ export.
- Inconsistent Language & Region Return Links – This filter includes URLs with inconsistent language and regional return links to them. This is where a return link has a different language or regional value than the URL is referencing itself. The inconsistent language return URLs can be seen in the lower window ‘URL Info’ pane with an ‘Inconsistent’ confirmation status. They can be exported in bulk via the ‘Reports > Hreflang > Inconsistent Language Return Links’ export.
- Non Canonical Return Links – URLs with non canonical hreflang return links. Hreflang should only include canonical versions of URLs. So this filter picks up return links that go to URLs that are not the canonical versions. The non canonical return URLs can be seen in the lower window ‘URL Info’ pane with a ‘Non Canonical’ confirmation status. They can be exported in bulk via the ‘Reports > Hreflang > Non Canonical Return Links’ export.
- Noindex Return Links – Return links which have a ‘noindex’ meta tag. All pages within a set should be indexable, and hence any return URLs with ‘noindex’ may result in the hreflang relationship being ignored. The noindex return links URLs can be seen in the lower window ‘URL Info’ pane with a ‘noindex’ confirmation status. They can be exported in bulk via the ‘Reports > Hreflang > Noindex Return Links’ export.
- Incorrect Language & Region Codes – This simply verifies the language (in ISO 639-1 format) and optional regional (in ISO 3166-1 Alpha 2 format) code values are valid. Unsupported hreflang values can be viewed in the lower window ‘URL Info’ pane with an ‘invalid’ status.
- Multiple Entries – URLs with multiple entries to a language or regional code. For example, if page X links to page Y and Z using the same ‘en’ hreflang value annotation. This filter will also pick up multiple implementations, for example, if hreflang annotations were discovered as link elements and via HTTP header.
- Missing Self Reference – URLs missing their own self referencing rel=”alternate” hreflang annotation. It was previously a requirement to have a self-referencing hreflang, but Google has updated their guidelines to say this is optional. It is however good practice and often easier to include a self referencing attribute.
- Not Using Canonical – URLs not using the canonical URL on the page, in it’s own hreflang annotation. Hreflang should only include canonical versions of URLs.
- Missing X-Default – URLs missing an X-Default hreflang attribute. This is optional, and not necessarily an error or issue.
- Missing – URLs missing an hreflang attribute completely. These might be valid of course, if they aren’t multiple versions of a page.
Please note – The SEO Spider has a 500 hreflang annotation limit currently. If you have over this limit, they will not be reported. Over 500 hreflang annotations is unsual and might be on the extreme side for the majority of set-ups.
For more information on hreflang, please read our guide on ‘How to Audit Hreflang‘.
JavaScript
The JavaScript tab contains data and filters around common issues related to auditing websites using client-side JavaScript.
This tab will only populate in JavaScript rendering mode (‘Configuration > Spider > Rendering tab > JavaScript’).
In JavaScript rendering mode, the SEO Spider will render web pages like in a browser, and help identify JavaScript content and links and other dependencies. JavaScript rendering mode is only available in the paid version.
Columns
This tab includes the following columns.
- Address – The URL address.
- Status Code – The HTTP response code.
- Status – The HTTP header response.
- HTML Word Count – This is all ‘words’ inside the body tag of the raw HTML before JavaScript, excluding HTML markup. The count is based upon the content area that can be adjusted under ‘Config > Content > Area’. By default, the nav and footer elements are excluded. You can include or exclude HTML elements, classes and IDs to calculate a refined word count. Our figures may not be exactly what performing this calculation manually would find, as the parser performs certain fix-ups on invalid HTML. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces. No consideration is given to visibility of content (such as text inside a div set to hidden).
- Rendered HTML Word Count – This is all ‘words’ inside the body tag of the rendered HTML after JavaScript execution, excluding HTML markup. The count is based upon the content area that can be adjusted under ‘Config > Content > Area’. By default, the nav and footer elements are excluded. You can include or exclude HTML elements, classes and IDs to calculate a refined word count. Our figures may not be exactly what performing this calculation manually would find, as the parser performs certain fix-ups on invalid HTML. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces. No consideration is given to visibility of content (such as text inside a div set to hidden).
- Word Count Change – This is the difference between the HTML Word Count and the Rendered HTML Word Count. Essentially, how many words are populated (or removed) due to JavaScript.
- JS Word Count % – This is the proportion of text that changes in the rendered HTML due to JavaScript.
- HTML Title – The (first) page title discovered on the page in the raw HTML before JavaScript.
- Rendered HTML Title – The (first) page title discovered on the page in the rendered HTML after JavaScript execution.
- HTML Meta Description – The (first) meta description discovered on the page in the raw HTML before JavaScript.
- Rendered HTML Meta Description- The (first) meta description discovered on the page in the rendered HTML after JavaScript execution.
- HTML H1 – The (first) h1 discovered on the page in the raw HTML before JavaScript.
- Rendered HTML H1- The (first) h1 discovered on the page in the rendered HTML after JavaScript execution.
- HTML Canonical – The canonical link element discovered on the page in the raw HTML before JavaScript.
- Rendered HTML Canonical – The canonical link element discovered on the page in the rendered HTML after JavaScript execution.
- HTML Meta Robots – The meta robots discovered on the page in the raw HTML before JavaScript.
- Rendered HTML Meta Robots – The meta robots discovered on the page in the rendered HTML after JavaScript execution.
- Unique Inlinks – Number of ‘unique’ internal inlinks to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- Unique JS Inlinks – Number of ‘unique’ internal inlinks to the URL that are only in the rendered HTML after JavaScript execution. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- Unique Outlinks – Number of unique internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- Unique JS Outlinks – Number of unique internal outlinks from the URL that are only in the rendered HTML after JavaScript execution. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- Unique External Outlinks – Number of unique external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
- Unique External JS Outlinks – Number of unique external outlinks from the URL that are only in the rendered HTML after JavaScript execution. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
Filters
This tab includes the following filters.
- Pages with Blocked Resources – Pages with resources (such as images, JavaScript and CSS) that are blocked by robots.txt. This can be an issue as the search engines might not be able to access critical resources to be able to render pages accurately. Update the robots.txt to allow all critical resources to be crawled and used for rendering of the websites content. Resources that are not critical (e.g. Google Maps embed) can be ignored.
- Contains JavaScript Links – Pages that contain hyperlinks that are only discovered in the rendered HTML after JavaScript execution. These hyperlinks are not in the raw HTML. While Google is able to render pages and see client-side only links, consider including important links server side in the raw HTML.
- Contains JavaScript Content – Pages that contain body text that’s only discovered in the rendered HTML after JavaScript execution. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Noindex Only in Original HTML – Pages that contain a noindex in the raw HTML, and not in the rendered HTML. When Googlebot encounters a noindex tag, it skips rendering and JavaScript execution. Because Googlebot skips JavaScript execution, using JavaScript to remove the ‘noindex’ in the rendered HTML won’t work. Carefully review pages with noindex in the raw HTML are expected to not be indexed. Remove the ‘noindex’ if the pages should be indexed.
- Nofollow Only in Original HTML – Pages that contain a nofollow in the raw HTML, and not in the rendered HTML. This means any hyperlinks in the raw HTML pre to JavaScript execution will not be followed. Carefully review pages with nofollow in the raw HTML are expected not to be followed. Remove the ‘nofollow’ if links should be followed, crawled and indexed.
- Canonical Only in Rendered HTML – Pages that contain a canonical only in the rendered HTML after JavaScript execution. Google can process canonicals in the rendered HTML, however they do not recommend relying upon JavaScript and prefer them earlier in the raw HTML. Problems with rendering, conflicting, or multiple rel=”canonical” link tags may lead to unexpected results. Include a canonical link in the raw HTML (or HTTP header) to ensure Google can see it and avoid relying only on the canonical in the rendered HTML only.
- Canonical Mismatch – Pages that contain a different canonical link in the raw HTML to the rendered HTML after JavaScript execution. Google can process canonicals in the rendered HTML after JavaScript has been processed, however conflicting rel=”canonical” link tags may lead to unexpected results. Ensure the correct canonical is in the raw HTML and rendered HTML to avoid conflicting signals to search engines.
- Page Title Only in Rendered HTML – Pages that contain a page title only in the rendered HTML after JavaScript execution. This means a search engine must render the page to see it. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Page Title Updated by JavaScript – Pages that have page titles that are modified by JavaScript. This means the page title in the raw HTML is different to the page title in the rendered HTML. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Meta Description Only in Rendered HTML – Pages that contain a meta description only in the rendered HTML after JavaScript execution. This means a search engine must render the page to see it. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Meta Description Updated by JavaScript – Pages that have meta descriptions that are modified by JavaScript. This means the meta description in the raw HTML is different to the meta description in the rendered HTML. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- H1 Only in Rendered HTML – Pages that contain an h1 only in the rendered HTML after JavaScript execution. This means a search engine must render the page to see it. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- H1 Updated by JavaScript – Pages that have h1s that are modified by JavaScript. This means the h1 in the raw HTML is different to the h1 in the rendered HTML. While Google is able to render pages and see client-side only content, consider including important content server side in the raw HTML.
- Uses Old AJAX Crawling Scheme URLs – URLs that are still using the Old AJAX crawling scheme (a URL containing a #! hash fragment) which was officially deprecated as of October 2015. Update URLs to follow JavaScript best practices on the web today. Consider server-side rendering or pre-rendering where possible, and dynamic rendering as a workaround solution.
- Uses Old AJAX Crawling Scheme Meta Fragment Tag – URLs include a meta fragment tag that indicates the page is still using the Old AJAX crawling scheme which was officially deprecated as of October 2015. Update URLs to follow JavaScript best practices on the web today. Consider server-side rendering or pre-rendering where possible, and dynamic rendering as a workaround solution. If the site still has the old meta fragment tag by mistake, then this should be removed.
Links
The Links tab contains data and filters around common issues related to links found in the crawl, such as pages with a high crawl-depth, pages without any internal outlinks, pages using nofollow on internal links and more.
Columns
This tab includes the following columns.
- Address – The URL address.
- Indexability – Whether the URL is Indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Crawl Depth – Depth of the page from the start page (number of ‘clicks’ away from the start page). Please note, redirects are counted as a level currently in our page depth calculations.
- Link Score – A metric between 0-100, which calculates the relative value of a page based upon its internal links similar to Google’s own PageRank. For this column to populate, ‘crawl analysis‘ is required.
- Unique Inlinks – Number of ‘unique’ internal inlinks to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- Unique JS Inlinks – Number of ‘unique’ internal inlinks to the URL that are only in the rendered HTML after JavaScript execution. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- % of Total – Percentage of unique internal inlinks (200 response HTML pages) to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URI from the same subdomain that is being crawled.
- Outlinks – Number of internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled.
- Unique Outlinks – Number of unique internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- Unique JS Outlinks – Number of unique internal outlinks from the URL that are only in the rendered HTML after JavaScript execution. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- External Outlinks – Number of external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain.
- Unique External Outlinks – Number of unique external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
- Unique External JS Outlinks – Number of unique external outlinks from the URL that are only in the rendered HTML after JavaScript execution. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
Filters
This tab includes the following filters.
- Pages With High Crawl Depth – Pages that have a high crawl depth from the start page of the crawl based upon the ‘Crawl Depth’ preferences under ‘Config > Spider > Preferences’. Broadly, pages that are linked directly from popular pages, such as the homepage, are passed more PageRank which can help them perform better organically. Pages much deeper in the website can often be passed less PageRank, and subsequently may not perform as well. This is important for key pages that are targeting broader more competitive queries, which may benefit from improved linking and reduced crawl depth. Unimportant pages, pages that target less competitive queries, or pages on large websites will often naturally sit deeper without issue. Most importantly, consider the user, which pages are important for them to navigate to, and their journey to reach the page.
- Pages Without Internal Outlinks – Pages that do not contain links to other internal pages. This can mean there are no links to other pages. However, it is also often due to the use of JavaScript, where links are not present in the raw HTML and are only in the rendered HTML after JavaScript has been processed. Enable JavaScript rendering mode (‘Config > Spider > Rendering’) to crawl pages with links that are only client-side in the rendered HTML. If there are no links that use an anchor tag with an href attribute to other internal pages, the search engines and the SEO Spider will have trouble discovering and indexing them.
- Internal Nofollow Outlinks – Pages that use rel=”nofollow” on internal outlinks. Links with nofollow link attributes will generally not be followed by search engines. Remember that the linked pages may be found through other means, such as other followed links, or XML Sitemaps etc. Nofollow outlinks can be seen in the ‘Outlinks’ tab with the ‘All Link Types’ filter set to ‘Hyperlinks’, where the ‘Follow’ column is ‘False’. Export in bulk via ‘Bulk Export > Links > Internal Nofollow Outlinks’.
- Internal Outlinks With No Anchor Text – Pages that have internal links without anchor text or images that are hyperlinked without alt text. Anchor text is the visible text and words used in hyperlinks that provide users and search engines context about the content of the target page. Internal outlinks without anchor text can be seen in the ‘Outlinks’ tab, with the ‘All Link Types’ filter set to ‘Hyperlinks’, where the ‘Anchor Text’ column is blank, or if an image, the ‘Alt Text’ column is also blank. Export in bulk via ‘Bulk Export > Links > Internal Outlinks With No Anchor Text’.
- Non-Descriptive Anchor Text In Internal Outlinks – Pages that have internal outlinks with anchor text that is not descriptive, such as ‘click here’ or ‘learn more’ based upon the preferences under ‘Config > Spider > Preferences’. Anchor text is the visible text and words used in hyperlinks that provide users and search engines context about the content of the target page. Internal outlinks with non-descriptive anchor text can be seen in the ‘Outlinks’ tab, with the ‘All Link Types’ filter set to ‘Hyperlinks’, where the ‘Anchor Text’ column has words such as ‘click here’, or ‘learn more’. Export in bulk via ‘Bulk Export > Links > Non-Descriptive Anchor Text In Internal Outlinks’.
- Pages With High External Outlinks – Pages that have a high number of followed external outlinks on them based upon the ‘High External Outlinks’ preferences under ‘Config > Spider > Preferences’. External outlinks are hyperlinks to another subdomain or domain (depending on your configuration). This might be completely valid, such as linking to another part of the same root domain, or linking to other useful websites. External followed outlinks can be seen in the ‘Outlinks’ tab, with the ‘All Link Types’ filter set to ‘Hyperlinks’ where the ‘Follow’ column is ‘True’.
- Pages With High Internal Outlinks – Pages that have a high number of followed internal outlinks on them based upon the ‘High Internal Outlinks’ preferences under ‘Config > Spider > Preferences’. Internal outlinks are hyperlinks to the same subdomain or domain (depending on your configuration). Links are used by users to navigate a website, while the search engines use them to discover and rank pages. Too many links can reduce usability, and reduce the amount of PageRank distributed to each page. Internal followed outlinks can be seen in the ‘Outlinks’ tab, with the ‘All Link Types’ filter set to ‘Hyperlinks’ where the ‘Follow’ column is ‘True’.
- Follow & Nofollow Internal Inlinks To Page – Pages that have both rel=”nofollow” and follow links to them from other pages. Links marked with nofollow link attributes will generally not be followed by search engines. Links without a nofollow link attribute will generally be followed. So inconsistent use of links that are follow and nofollow might be a sign of an issue or mistake, or something that can be ignored. Nofollow and follow inlinks can be seen in the ‘Inlinks’ tab with the ‘All Link Types’ filter set to ‘Hyperlinks’, where the ‘Follow’ column is ‘True’ and ‘False’. Export in bulk via ‘Bulk Export > Links > Follow & Nofollow Internal Inlinks To Page’.
- Internal Nofollow Inlinks Only – Pages that only have rel=”nofollow” links to them from other pages. Links marked with nofollow link attributes will generally not be followed by search engines, so this can impact discovery and indexing of a page. Nofollow inlinks can be seen in the ‘Inlinks’ tab with the ‘All Link Types’ filter set to ‘Hyperlinks’, where the ‘Follow’ column is ‘True’ and ‘False’. Export in bulk via ‘Bulk Export > Links > Internal Nofollow Inlinks Only’.
- Outlinks To Localhost – Pages that contain links that reference localhost or the 127.0.0.1 loopback address. Localhost is the address of the local computer, which is used in development to view a site in a browser without being connected to the internet. These links will not work for users on a live website. These links can be seen in the ‘Outlinks’ tab, where the ‘To’ address contains ‘localhost’ or the 127.0.0.1 loopback address. Export in bulk via ‘Bulk Export > Links > Outlinks To Localhost’.
- Non-Indexable Page Inlinks Only – Indexable pages that are only linked-to from pages that are non-indexable, which includes noindex, canonicalised or robots.txt disallowed pages. Pages with noindex and links from them will initially be crawled, but noindex pages will be removed from the index and be crawled less over time. Links from these pages may also be crawled less and it has been debated by Googlers whether links will continue to be counted at all. Links from canonicalised pages can be crawled initially, but PageRank may not flow as expected if indexing and link signals are passed to another page as indicated in the canonical. This may impact discovery and ranking. Robots.txt pages can’t be crawled, so links from these pages will not be seen.
AMP
The AMP tab includes Accelerated Mobile Pages (AMP) discovered during a crawl. These are identified via the HTML AMP Tag, and rel=”amphtml” inlinks. The tab includes filters for common SEO issues and validation errors using the AMP Validator.
Both ‘Store‘ and ‘Crawl‘ AMP options need to be enabled (under ‘Config > Spider’) for this tab and respective filters to be populated.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Occurrences – The number of canonicals found (via both link element and HTTP).
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
- Title 1 – The (first) page title.
- Title 1 Length – The character length of the page title.
- Title 1 Pixel Width – The pixel width of the page title.
- h1 – 1 – The first h1 (heading) on the page.
- h1 – Len-1 – The character length of the h1.
- Size – Size is in bytes, divide by 1024 to convert to kilobytes. The value is set from the Content-Length header if provided, if not it’s set to zero. For HTML pages this is updated to the size of the (uncompressed) HTML in bytes.
- Word Count – This is all ‘words’ inside the body tag. This does not include HTML markup. Our figures may not be exactly what doing this manually would find, as the parser performs certain fix-ups on invalid html. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces. No consideration is given to visibility of content (such as text inside a div set to hidden).
- Text Ratio – Number of non-HTML characters found in the HTML body tag on a page (the text), divided by the total number of characters the HTML page is made up of, and displayed as a percentage.
- Crawl Depth – Depth of the page from the start page (number of ‘clicks’ away from the start page). Please note, redirects are counted as a level currently in our page depth calculations.
- Response Time – Time in seconds to download the URI. More detailed information in can be found in our FAQ.
SEO Related Filters
This tab includes the following SEO related filters.
- Non-200 Response – The AMP URLs do not respond with a 200 ‘OK’ status code. These will include URLs blocked by robots.txt, no responses, redirects, client and server errors.
- Missing Non-AMP Return Link – The canonical non-AMP version of the URL, does not contain a rel=”amphtml” URL back to the AMP URL. This could simply be missing from the non-AMP version, or there might be a configuration issue with the AMP canonical.
- Missing Canonical to Non-AMP – The AMP URLs canonical does not go to a non-AMP version, but to another AMP URL.
- Non-Indexable Canonical – The AMP canonical URL is a non-indexable page. Generally the desktop equivalent should be an indexable page.
- Indexable – The AMP URL is indexable. AMP URLs with a desktop equivalent should be non-indexable (as they should have a canonical to the desktop equivalent). Standalone AMP URLs (without an equivalent) should be indexable.
- Non-Indexable – The AMP URL is non-indexable. This is usually because they are correctly canonicalised to the desktop equivalent.
The following filters help identify common issues relating to AMP specifications. The SEO Spider uses the official AMP Validator for validation of AMP URLs.
AMP Related Filters
This tab includes the following AMP specific filters.
- Missing HTML AMP Tag – AMP HTML documents must contain a top-level HTML or HTML AMP tag.
- Missing/Invalid Doctype HTML Tag – AMP HTML documents must start with the doctype, doctype HTML.
- Missing Head Tag – AMP HTML documents must contain head tags (they are optional in HTML).
- Missing Body Tag – AMP HTML documents must contain body tags (they are optional in HTML).
- Missing Canonical – AMP URLs must contain a canonical tag inside their head that points to the regular HTML version of the AMP HTML document, or to itself if no such HTML version exists.
- Missing/Invalid Meta Charset Tag – AMP HTML documents must contain a meta charset=”utf-8″ tag as the first child of their head tag.
- Missing/Invalid Meta Viewport Tag – AMP HTML documents must contain a meta name=”viewport” content=”width=device-width,minimum-scale=1″ tag inside their head tag. It’s also recommended to include initial-scale=1.
- Missing/Invalid AMP Script – AMP HTML documents must contain a script async src=”https://cdn.ampproject.org/v0.js” tag inside their head tag.
- Missing/Invalid AMP Boilerplate – AMP HTML documents must contain the AMP boilerplate code in their head tag.
- Contains Disallowed HTML – This flags any AMP URLs with disallowed HTML for AMP.
- Other Validation Errors – This flags any AMP URLs with other validation errors not already covered by the above filters.
For more information on AMP, please read our guide on ‘How to Audit & Validate AMP‘.
Structured data
The Structured Data tab includes details of structured data and validation issues discovered from a crawl.
‘JSON-LD’, ‘Microdata’, ‘RDFa’, ‘Schema.org Validation’ and ‘Google Rich Result Feature Validation’ configuration options need to be enabled (under ‘Config > Spider > Extraction’) for this tab and respective filters to be fully populated.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Errors – The total number of validation errors discovered for the URL.
- Warnings – The total number of validation warnings discovered for the URL.
- Total Types – The total number of itemtypes discovered for the URL.
- Unique Types – The unique number of itemtypes discovered for the URL.
- Type 1 – The first itemtype discovered for the URL.
- Type 2 etc – The second itemtype discovered for the URL.
Filters
This tab includes the following filters.
- Contains Structured Data – These are simply any URLs that contain structured data. You can see the different types in columns in the upper window.
- Missing Structured Data – These are URLs that do not contain any structured data.
- Validation Errors – These are URLs that contain validation errors. The errors can be either Schema.org, Google rich result features, or both – depending on your configuration. Schema.org issues will always be classed as errors, rather than warnings. Google rich result feature validation will show errors for missing required properties or problems with the implementation of required properties. Google’s ‘required properties’ must be included and be valid for content to be eligible for display as a rich result.
- Validation Warnings – These are URLs that contain validation warnings for Google rich result features. These will always be for ‘recommended properties’, rather than required properties. Recommended properties can be included to add more information about content, which could provide a better user experience – but they are not essential to be eligible for rich snippets and hence why they are only a warning. There are no ‘warnings’ for Schema.org validation issues, however there is a warning for using the older data-vocabulary.org schema.
- Parse Errors – These are URLs which have structured data that failed to parse correctly. This is often due to incorrect mark-up. If you’re using Google’s preferred format JSON-LD, then the JSON-LD Playground is an excellent tool to help debug parsing errors.
- Microdata URLs – These are URLs that contain structured data in microdata format.
- JSON-LD URLs – These are URLs that contain structured data in JSON-LD format.
- RDFa URLs – These are URLs that contain structured data in RDFa format.
Structured Data & Google Rich Snippet Feature Validation
Structured Data validation includes checks against whether the types and properties exist according to Schema.org and will show ‘errors’ for any issues encountered.
For example, it checks to see whether https://schema.org/author exists for a property, or https://schema.org/Book exist as a type. It validates against main and pending Schema vocabulary from Schema.org latest version.
There might be a short time between a Schema.org vocabulary release, and it being updated in the SEO Spider.
The SEO Spider also performs validation against Google rich result features to check the presence of required and recommended properties and their values are accurate.
The full list of that the SEO Spider is able to validate against includes –
- Article & AMP Article
- Book
- Breadcrumb
- Carousel
- Course
- COVID-19 announcements
- Critic Review
- Dataset
- Employer Aggregate Rating
- Estimated Salary
- Event
- Fact Check
- FAQ
- How To
- Image License
- Job Posting
- Job Training
- Livestream
- Local Business
- Logo
- Movie
- Product
- Q&A Page
- Recipe
- Review Snippet
- Sitelinks Searchbox
- Software App
- Speakable
- Subscription and Paywalled Content
- Video
The list of Google rich result features that the SEO Spider doesn’t currently validate against is –
- We currently support all Google features.
For more information on structured data validation, please read our guide on ‘How To Test & Validate Structured Data‘.
Sitemaps
The Sitemaps tab shows all URLs discovered in a crawl, which can then be filtered to show additional information related to XML Sitemaps.
To crawl XML Sitemaps in a regular crawl and for the filters to be populated, the ‘Crawl Linked XML Sitemaps‘ configuration needs to be enabled (under ‘Configuration > Spider’).
A ‘Crawl Analysis‘ will also need to be performed at the end of the crawl to populate some of the filters.
Columns
This tab includes the following columns.
- Address – The URL crawled.
- Content – The content type of the URI.
- Status Code – HTTP response code.
- Status – The HTTP header response.
- Indexability – Whether the URL is indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- URLs In Sitemap – All URLs that are in an XML Sitemap. This should contain indexable and canonical versions of important URLs.
- URLs Not In Sitemap – URLs that are not in an XML Sitemap, but were discovered in the crawl. This might be on purpose (as they are not important), or they might be missing, and the XML Sitemap needs to be updated to include them. This filter does not consider non-indexable URLs, it assumes they are correctly non-indexable, and therefore shouldn’t be flagged to be included.
- Orphan URLs – URLs that are only in an XML Sitemap, but were not discovered during the crawl. Or, URLs that are only discovered from URLs in the XML Sitemap, but were not found in the crawl. These might be accidentally included in the XML Sitemap, or they might be pages that you wish to be indexed, and should really be linked to internally.
- Non-Indexable URLs in Sitemap – URLs that are in an XML Sitemap, but are non-indexable, and hence should be removed, or their indexability needs to be fixed.
- URLs In Multiple Sitemaps – URLs that are in more than one XML Sitemap. This isn’t necessarily a problem, but generally a URL only needs to be in a single XML Sitemap.
- XML Sitemap With Over 50k URLs – This shows any XML Sitemap that has more than the permitted 50k URLs. If you have more URLs, you will have to break your list into multiple sitemaps and create a sitemap index file which lists them all.
- XML Sitemap With Over 50mb – This shows any XML Sitemap that is larger than the permitted 50mb file size. If the sitemap is over the 50MB (uncompressed) limit, you will have to break your list into multiple sitemaps.
For more information on XML Sitemaps, please read our guide on ‘How to Audit XML Sitemaps‘, as well as Sitemaps.org and Google Search Console help.
PageSpeed
The PageSpeed tab includes data from PageSpeed Insights which uses Lighthouse for ‘lab data’ speed auditing, and is able to look up real-world data from the Chrome User Experience Report (CrUX, or ‘field data’).
To pull in PageSpeed data simply go to ‘Configuration > API Access > PageSpeed Insights’, insert a free PageSpeed API key, connect and run a crawl. Data will then start to be populated against crawled URLs.
Please read our PageSpeed Insights integration guide on how to set up a free API and configure the SEO Spider.
Columns & Metrics
The following speed metrics, opportunities and diagnostics data can be configured to be collected via the PageSpeed Insights API integration.
Overview Metrics
- Total Size Savings
- Total Time Savings
- Total Requests
- Total Page Size
- HTML Size
- HTML Count
- Image Size
- Image Count
- CSS Size
- CSS Count
- JavaScript Size
- JavaScript Count
- Font Size
- Font Count
- Media Size
- Media Count
- Other Size
- Other Count
- Third Party Size
- Third Party Count
CrUX Metrics (‘Field Data’ in PageSpeed Insights)
- CrUX Performance
- CrUX First Contentful Paint Time (sec)
- CrUX First Contentful Paint Category
- CrUX First Input Delay Time (sec)
- CrUX First Input Delay Category
- CrUX Origin Performance
- CrUX Origin First Contentful Paint Time (sec)
- CrUX Origin First Contentful Paint Category
- CrUX Origin First Input Delay Time (sec)
- CrUX Origin First Input Delay Category
Lighthouse Metrics (‘Lab Data’ in PageSpeed Insights)
- Performance Score
- Time to First Byte (ms)
- First Contentful Paint Time (sec)
- Speed Index Time (sec)
- Time to Interactive (sec)
- First Contentful Paint Score
- First Meaningful Paint Time (sec)
- First Meaningful Paint Score
- Speed Index Score
- Estimated Input Latency (ms)
- Estimated Input Latency Score
- First CPU Idle (sec)
- First CPU Idle Score
- Time to Interactive Score
Opportunities
- Eliminate Render-Blocking Resources Savings (ms)
- Defer Offscreen Images Savings (ms)
- Defer Offscreen Images Savings
- Efficiently Encode Images Savings (ms)
- Efficiently Encode Images Savings
- Properly Size Images Savings (ms)
- Properly Size Images Savings
- Minify CSS Savings (ms)
- Minify CSS Savings
- Minify JavaScript Savings (ms)
- Minify JavaScript Savings
- Reduce Unused CSS Savings (ms)
- Reduce Unused CSS Savings
- Reduce Unused JavaScript Savings (ms)
- Reduce Unused JavaScript Savings
- Serve Images in Next-Gen Formats Savings (ms)
- Serve Images in Next-Gen Formats Savings
- Enable Text Compression Savings (ms)
- Enable Text Compression Savings
- Preconnect to Required Origin Savings
- Server Response Times (TTFB) (ms)
- Server Response Times (TTFB) Category (ms)
- Multiple Redirects Savings (ms)
- Preload Key Requests Savings (ms)
- Use Video Format for Animated Images Savings (ms)
- Use Video Format for Animated Images Savings
- Total Image Optimization Savings (ms)
- Avoid Serving Legacy JavaScript to Modern Browser Savings
Diagnostics
- DOM Element Count
- JavaScript Execution Time (sec)
- JavaScript Execution Time Category
- Efficient Cache Policy Savings
- Minimize Main-Thread Work (sec)
- Minimize Main-Thread Work Category
- Text Remains Visible During Webfont Load
- Image Elements Do Not Have Explicit Width & Height
- Avoid Large Layout Shifts
You can read more about the definition of each metric, opportunity or diagnostic according to Lighthouse.
Filters
This tab includes the following filters.
- Eliminate Render-Blocking Resources – This highlights all pages with resources that are blocking the first paint of the page, along with the potential savings.
- Properly Size Images – This highlights all pages with images that are not properly sized, along with the potential savings when they are resized appropriately.
- Defer Offscreen Images – This highlights all pages with images that are hidden or offscreen, along with the potential savings if they were lazy-loaded.
- Minify CSS – This highlights all pages with unminified CSS files, along with the potential savings when they are correctly minified.
- Minify JavaScript – This highlights all pages with unminified JavaScript files, along with the potential savings when they are correctly minified.
- Reduce Unused CSS – This highlights all pages with unused CSS, along with the potential savings when they are removed of unnecessary bytes.
- Reduce Unused JavaScript – This highlights all pages with unused JavaScript, along with the potential savings when they are removed of unnecessary bytes.
- Efficiently Encode Images – This highlights all pages with unoptimised images, along with the potential savings.
- Serve Images in Next-Gen Formats – This highlights all pages with images that are in older image formats, along with the potential savings.
- Enable Text Compression – This highlights all pages with text based resources that are not compressed, along with the potential savings.
- Preconnect to Required Origin – This highlights all pages with key requests that aren’t yet prioritizing fetch requests with link rel=preconnect, along with the potential savings.
- Reduce Server Response Times (TTFB) – This highlights all pages where the browser has had to wait for over 600ms for the server to respond to the main document request.
- Avoid Multiple Redirects – This highlights all pages which have resources that redirect, and the potential saving by using the direct URL.
- Preload Key Requests – This highlights all pages with resources that are third level of requests in your critical request chain as preload candidates.
- Use Video Format for Animated Images – This highlights all pages with animated GIFs, along with the potential savings of converting them into videos.
- Avoid Excessive DOM Size – This highlights all pages with a large DOM size over the recommended 1,500 total nodes.
- Reduce JavaScript Execution Time – This highlights all pages with average or slow JavaScript execution time.
- Serve Static Assets With An Efficient Cache Policy – This highlights all pages with resources that are not cached, along with the potential savings.
- Minimize Main-Thread Work – This highlights all pages with average or slow execution timing on the main thread.
- Ensure Text Remains Visible During Webfont Load – This highlights all pages with fonts that may flash or become invisible during page load.
- Image Elements Do Not Have Explicit Width & Height – This highlights all pages that have images without dimensions (width and height size attributes) specified in the HTML. This can be a big cause of poor CLS.
- Avoid Large Layout Shifts – This highlights all pages that have DOM elements contributing most to the CLS of the page and provides a contribution score of each to help prioritise.
- Avoid Serving Legacy JavaScript to Modern Browsers – This highlights all pages with legacy JavaScript. Polyfills and transforms enable legacy browsers to use new JavaScript features. However, many aren’t necessary for modern browsers. For your bundled JavaScript, adopt a modern script deployment strategy using module/nomodule feature detection to reduce the amount of code shipped to modern browsers, while retaining support for legacy browsers.
Please read the Lighthouse performance audits guide for more definitions and explanations of each of the opportunities and diagnostics above.
The speed opportunities, source pages and resource URLs that have potential savings can be exported in bulk via the ‘Reports > PageSpeed’ menu.
The ‘CSS Coverage Summary’ report highlights how much of each CSS file is unused across a crawl, and the potential savings that could be made by removing unused code that is loading across the site.
The ‘JavaScript Coverage Summary’ report highlights how much of each JS file is unused across a crawl, and the potential savings that could be made by removing unused code that is loading across the site.
PageSpeed Insights API Status & Errors
The PSI Status column shows whether an API request for a URL has been a ‘success’ and shows data, or there has been an error and no data is displayed. An ‘error’ usually reflects the web interface, where you would see the same error and message.
The ‘PSI Error’ column displays the full message received from the PSI API to provide more information about the cause. Some errors are due to the Lighthouse audit itself failing, other errors can be due to the PSI API being unavailable when the request is made.
Please read our FAQ on PageSpeed Insights API Errors for more information.
Custom search
The custom search tab works alongside the custom search configuration. The custom search feature allows you to search the source code of HTML pages and can be configured by clicking ‘Config > Custom > Search’.
You’re able to configure up to 100 search filters in the custom search configuration, which allow you to input your regex and find pages that either ‘contain’ or ‘does not contain’ your chosen input. The results appear within the custom search tab as outlined below.
Columns
This tab includes the following columns.
- Address – The URI crawled.
- Content – The content type of the URI.
- Status Code – HTTP response code.
- Status – The HTTP header response.
- Contains: [x] – The number of times [x] appears within the source code of the URL. [x] is the query string that has been entered in the custom search configuration.
- Does Not Contain: [y] – The column will either return ‘Contains’ or ‘Does Not Contain’ [y]. [y] is the query string that has been entered in the custom search configuration.
Filters
This tab includes the following filters.
- [Search Filter Name] – Filters are dynamic, and will match the name of the custom configuration and relevant column. They show URLs that either contain or do not contain the query string entered.
Custom extraction
The custom extraction tab works alongside the custom extraction configuration. This feature allows you to scrape any data from the HTML of pages in a crawl and can be configured under ‘Config > Custom > Extraction’.
You’re able to configure up to 100 extractors in the custom extraction configuration, which allow you to input XPath, CSSPath or regex to scrape the required data. Extraction is performed against URLs with an HTML content type only.
The results appear within the custom extraction tab as outlined below.
Columns
This tab includes the following columns.
- Address – The URI crawled.
- Content – The content type of the URI.
- Status Code – HTTP response code.
- Status – The HTTP header response.
- [Extractor Name] – Column heading names are dynamic based upon the name provided to each extractor. Each extractor will have a seperate named column, which will contain the data extracted against each URL.
Filters
This tab includes the following filters.
- [Extractor Name] – Filters are dynamic, and will match the name of the extractors and relevant column. They show the relevant extraction column against the URLs.
Analytics
The Analytics tab includes data from Google Analytics when the SEO Spider is integrated with Google Analytics under ‘Configuration > API Access > Google Analytics’. Please read our Google Analytics integration guide for more details.
The SEO Spider currently allows you to select up to 30 metrics at a time, however by default it will collect the following 10 Google Analytics metrics.
Columns
This tab includes the following columns.
- Sessions
- % New Sessions
- New Users
- Bounce Rate
- Page Views Per Session
- Avg Session Duration
- Page Value
- Goal Conversion Rate
- Goal Completions All
- Goal Value All
You can read more about the definition of each metric from Google.
Please read our Google Analytics integration user guide for more information about configuring your account, property, view, segment, date range, metrics and dimensions.
Filters
This tab includes the following filters.
- Sessions Above 0 – This simply means the URL in question has 1 or more sessions.
- Bounce Rate Above 70% – This means the URL has a bounce rate over 70%, which you may wish to investigate. In some scenarios this is normal, though!
- No GA Data – This means that for the metrics and dimensions queried, the Google API didn’t return any data for the URLs in the crawl. So the URLs either didn’t receive any sessions, or perhaps the URLs in the crawl are just different to those in GA for some reason.
- Non-Indexable with GA Data – URLs that are classed as non-indexable, but have Google Analytics data.
- Orphan URLs – URLs that have been discovered via Google Analytics, rather than internal links during a crawl. This filter requires ‘Crawl New URLs Discovered In Google Analytics’ to be enabled under the ‘General’ tab of the Google Analytics configuration window (Configuration > API Access > Google Analytics) and post ‘crawl analysis‘ to be populated. Please see our guide on how to find orphan pages.
Search Console
The Search Console tab includes data from the Search Analyitcs and URL Inspection APIs when the SEO Spider is integrated with Google Search Console under ‘Configuration > API Access > Google Search Console’.
Please read our Google Search Console integration guide for more details. When integrated, the following data is collected.
Columns
This tab includes the following columns from Search Analytics by default.
- Clicks
- Impressions
- CTR
- Position
You can read more about the definition of each metric from Google.
Optionally, you can choose to ‘Enable URL Inspection’ alongside Search Analytics data, which provides Google index status data for up to 2,000 URLs per property a day. This includes the following columns for the URL Inspection API.
- Summary – A top level verdict on whether the URL is indexed and eligible to display in the Google search results. ‘URL is on Google’ means the URL has been indexed, can appear in Google Search results, and no problems were found with any enhancements found in the page (rich results, mobile, AMP). ‘URL is on Google, but has Issues’ means it has been indexed and can appear in Google Search results, but there are some problems with mobile usability, AMP or Rich results that might mean it doesn’t appear in an optimal way. ‘URL is not on Google’ means it is not indexed by Google and won’t appear in the search results. This filter can include non-indexable URLs (such as those that are ‘noindex’) as well as Indexable URLs that are able to be indexed.
- Coverage – A short, descriptive reason for the status of the URL, explaining why the URL is or isn’t on Google.
- Last Crawl – The last time this page was crawled by Google, in your local time. All information shown in this tool is derived from this last crawled version.
- Crawled As – The user agent type used for the crawl (desktop or mobile).
- Crawl Allowed – Indicates whether your site allowed Google to crawl (visit) the page or blocked it with a robots.txt rule.
- Page Fetch – Whether or not Google could actually get the page from your server. If crawling is not allowed, this field will show a failure.
- Indexing Allowed – Whether or not your page explicitly disallowed indexing. If indexing is disallowed, the reason is explained, and the page won’t appear in Google Search results.
- User-Declared Canonical – If your page explicitly declares a canonical URL, it will be shown here.
- Google-Selected Canonical – The page that Google selected as the canonical (authoritative) URL, when it found similar or duplicate pages on your site.
- Mobile Usability – Whether the page is mobile friendly or not.
- Mobile Usability Issues – If the ‘page is not mobile friendly’, this column will display a list of mobile usability errors.
- AMP Results – A verdict on whether the AMP URL is valid, invalid or has warnings. ‘Valid’ means the AMP URL is valid and indexed. ‘Invalid’ means the AMP URL has an error that will prevent it from being indexed. ‘Valid with warnings’ means the AMP URL can be indexed, but there are some issues that might prevent it from getting full features, or it uses tags or attributes that are deprecated, and might become invalid in the future.
- AMP Issues – If the URL has AMP issues, this column will display a list of AMP errors.
- Rich Results – A verdict on whether Rich results found on the page are valid, invalid or has warnings. ‘Valid’ means rich results have been found and are eligible for search. ‘Invalid’ means one or more rich results on the page has an error that will prevent it from being eligible for search. ‘Valid with warnings’ means the rich results on the page are eligible for search, but there are some issues that might prevent it from getting full features.
- Rich Results Types – A comma separated list of all rich result enhancements discovered on the page.
- Rich Results Types Errors – A comma separated list of all rich result enhancements discovered with an error on the page. To export specific errors discovered, use the ‘Bulk Export > URL Inspection > Rich Results’ export.
- Rich Results Warnings – A comma separated list of all rich result enhancements discovered with a warning on the page. To export specific warnings discovered, use the ‘Bulk Export > URL Inspection > Rich Results’ export.
You can read more about the the indexed URL results from Google.
Filters
This tab includes the following filters.
- Clicks Above 0 – This simply means the URL in question has 1 or more clicks.
- No Search Analytics Data – This means that the Search Analytics API didn’t return any data for the URLs in the crawl. So the URLs either didn’t receive any impressions, or perhaps the URLs in the crawl are just different to those in GSC for some reason.
- Non-Indexable with Search Analytics Data – URLs that are classed as non-indexable, but have Google Search Analytics data.
- Orphan URLs – URLs that have been discovered via Google Search Analytics, rather than internal links during a crawl. This filter requires ‘Crawl New URLs Discovered In Google Search Console’ to be enabled in the ‘Search Analytics’ tab of the Google Search Console configuration (‘Configuration > API Access > Google Search Console > Search Analytics ‘) and post ‘crawl analysis‘ to be populated. Please see our guide on how to find orphan pages.
- URL Is Not on Google – The URL is not indexed by Google and won’t appear in the search results. This filter can include non-indexable URLs (such as those that are ‘noindex’) as well as Indexable URLs that are able to be indexed. It’s a catch all filter for anything not on Google according to the API.
- Indexable URL Not Indexed – Indexable URLs found in the crawl that are not indexed by Google and won’t appear in the search results. This can include URLs that are unknown to Google, or those that have been discovered but not indexed, and more.
- URL is on Google, But Has Issues – The URL has been indexed and can appear in Google Search results, but there are some problems with mobile usability, AMP or Rich results that might mean it doesn’t appear in an optimal way.
- User-Declared Canonical Not Selected – Google has chosen to index a different URL to the one declared by the user in the HTML. Canonicals are hints, and sometimes Google does a great job of this, other times it’s less than ideal.
- Page Is Not Mobile Friendly – The page has issues on mobile devices.
- AMP URL Is Invalid – The AMP has an error that will prevent it from being indexed.
- Rich Result Invalid – The URL has an error with one or more rich result enhancements that will prevent the rich result from showing in the Google search results. To export specific errors discovered, use the ‘Bulk Export > URL Inspection > Rich Results’ export.
For more on using the URL Inspection API, please read our guide on ‘How To Automate the URL Inspection API‘.
Validation
The validation tab performs some basic best practice validations that can impact crawlers when crawling and indexing. This isn’t W3C HTML validation which is a little too strict, the aim of this tab is to identify issues that can impact search bots from being able to parse and understand a page reliably.
Columns
This tab includes the following columns.
- Address – The URL address.
- Content – The content type of the URL.
- Status Code – The HTTP response code.
- Status – The HTTP header response.
- Indexability – Whether the URL is Indexable or Non-Indexable.
- Indexability Status – The reason why a URL is Non-Indexable. For example, if it’s canonicalised to another URL.
Filters
This tab includes the following filters.
- Invalid HTML Elements In <head> – Pages with invalid HTML elements within the <head>. When an invalid element is used in the <head>, Google assumes the end of the <head> element and ignores any elements that appear after the invalid element. This means critical <head> elements that appear after the invalid element will not be seen. The <head> element as per the HTML standard is reserved for title, meta, link, script, style, base, noscript and template elements only.
- <head> Not First In <html> Element – Pages with an HTML element that proceed the <head> element in the HTML. The <head> should be the first element in the <html> element. Browsers and Googlebot will automatically generate a <head> element if it’s not first in the HTML. While ideally <head> elements would be in the <head>, if a valid <head> element is first in the <html> it will be considered as part of the generated <head>. However, if non <head> elements such as <p>, <body>, <img> etc are used before the intended <head> element and its metadata, then Google assumes the end of the <head> element. This means the intended <head> element and its metadata may only be seen in the <body> and ignored.
- Missing <head> Tag – Pages missing a <head> element within the HTML. The <head> element is a container for metadata about the page, that’s placed between the <html> and <body> tag. Metadata is used to define the page title, character set, styles, scripts, viewport and other data that are critical to the page. Browsers and Googlebot will automatically generate a <head> element if it’s omitted in the markup, however it may not contain meaningful metadata for the page and this should not be relied upon.
- Multiple <head> Tags – Pages with multiple <head> elements in the HTML. There should only be one <head> element in the HTML which contains all critical metadata for the document. Browsers and Googlebot will combine metadata from subsequent <head> elements if they are both before the <body>, however, this should not be relied upon and is open to potential mix-ups. Any <head> tags after the <body> starts will be ignored.
- Missing <body> Tag – Pages missing a <body> element within the HTML. The <body> element contains all the content of a page, including links, headings, paragraphs, images and more. There should be one <body> element in the HTML of the page. Browsers and Googlebot will automatically generate a <body> element if it’s omitted in the markup, however, this should not be relied upon.
- Multiple <body> Tags – Pages with multiple <body> elements in the HTML. There should only be one <body> element in the HTML which contains all content for the document. Browsers and Googlebot will try to combine content from subsequent <body> elements, however, this should not be relied upon and is open to potential mix-ups.
- HTML Document Over 15MB – Pages which are over 15MB in document size. This is important as Googlebot limit their crawling and indexing to the first 15MB of an HTML file or supported text-based file. This size does not include resources referenced in the HTML such as images, videos, CSS, and JavaScript that are fetched separately. Google only considers the first 15MB of the file for indexing and stops crawling afterwards. The file size limit is applied on the uncompressed data. The median size of an HTML file is about 30 kilobytes (KB), so pages are highly unlikely to reach this limit.
Link Metrics
The Link Metrics tab includes data from Majestic, Ahrefs, and Moz when the SEO Spider is integrated with their APIs.
To pull in link metrics simply go to ‘Configuration > API Access’. After selecting a tool, you will need to generate and insert an API key. Once connected, run a crawl and data will be populated against URLs.
Please read the following guides for more details on setting up the API with each tool respectively:
Majestic
Ahrefs
Moz
Columns & Metrics
- Address – The URL address
- Status Code – The HTTP Response Code
- Title 1 – The (first) Page title discovered on the URL
When Integrated the Link Data can be collected for the following metric groups:
- Exact URL
- Exact URL (HTTP + HTTPS)
- Subdomain
- Domain
Majestic Metrics
- External Backlinks
- Referring Domains
- Trust Flow
- Citation Flow
- Referring IPs
- Referring Subnets
- Indexed URLs
- External Backlinks EDU
- External Backlinks GOV
- Referring Domains EDU
- Referring Domains GOV
- Trust Flow Topics
- Anchor Text
You can read more about the definition of each metric from Majestic.
Ahrefs Metrics
- Backlinks
- RefDomains
- URL Rating
- RefPages
- Pages
- Text
- Image
- Site Wide
- Not Site Wide
- NoFollow
- DoFollow
- Redirect
- Canonical
- Gov
- Edu
- HTML Pages
- Links Internal
- Links External
- Ref Class C
- Refips
- Linked Root Domains
- GPlus
- Facebook Likes
- Facebook Shares
- Facebook Comments
- Facebook Clicks
- Facebook Comments Box
- Total Shares
- Medium Shares
- Keywords
- Keywords Top 3
- Keywords Top 10
- Traffic
- Traffic Top 3
- Traffic Top 10
- Value
- Value Top 3
- Value Top 10
You can read more about the definition of each metric from Ahrefs.
Moz Metrics
- Page Authority
- MozRank
- MozRank External Equity
- MozRank Combined
- MozTrust
- Time Last Crawled (GMT)
- Total Links (Internal or External)
- External Equity-Passing Links
- Total Equity-Passing Links (internal or External)
- Subdomains Linking
- Total Linking Root Domains
- Total External Links
- Spam Score
- Links to Subdomain
- Root Domains Linking to Subdomain
- External Links to Subdomain
- Domain Authority
- Root Domains Linking
- Linking C Blocks
- Links to Root Domain
- External Links to Root Domain
You can read more about the definition of each metric from Moz.
Change Detection
The Change Detection tab contains data and filters around changes between current and previous crawls.
This tab will only be available if you are in ‘Compare’ mode when performing a crawl comparison.
In ‘Compare’ mode, click on the compare configuration via ‘Config > Compare’ (or the ‘cog’ icon at the top) and select the elements and metrics you want to identify changes in.
Once the crawl comparison has been run, the ‘Change Detection’ tab will appear in the master view and in the Overview tab, containing filters for any elements and metrics selected with details of changes discovered.
Columns
This tab includes the following columns for current and previous crawls.
- Address – The URL address.
- Indexability – Whether the URL is Indexable or Non-Indexable.
- Title 1 – The (first) page title discovered on the page.
- Meta Description 1 – The (first) meta description on the page.
- h1 – 1 – The first h1 (heading) on the page.
- Word Count – This is all ‘words’ inside the body tag, excluding HTML markup. The count is based upon the content area that can be adjusted under ‘Config > Content > Area’. By default, the nav and footer elements are excluded. You can include or exclude HTML elements, classes and IDs to calculate a refined word count. Our figures may not be exactly what performing this calculation manually would find, as the parser performs certain fix-ups on invalid HTML. Your rendering settings also affect what HTML is considered. Our definition of a word is taking the text and splitting it by spaces. No consideration is given to visibility of content (such as text inside a div set to hidden).
- Crawl Depth – Depth of the page from the start page (number of ‘clicks’ away from the start page). Please note, redirects are counted as a level currently in our page depth calculations.
- Inlinks – Number of internal hyperlinks to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled.
- Unique Inlinks – Number of ‘unique’ internal inlinks to the URL. ‘Internal inlinks’ are links in anchor elements pointing to a given URL from the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ 3 times, this would be counted as 3 inlinks and 1 unique inlink to ‘page B’.
- Outlinks – Number of internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled.
- Unique Outlinks – Number of unique internal outlinks from the URL. ‘Internal outlinks’ are links in anchor elements from a given URL to other URLs on the same subdomain that is being crawled. For example, if ‘page A’ links to ‘page B’ on the same subdomain 3 times, this would be counted as 3 outlinks and 1 unique outlink to ‘page B’.
- External Outlinks – Number of external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain.
- Unique External Outlinks – Number of unique external outlinks from the URL. ‘External outlinks’ are links in anchor elements from a given URL to another subdomain. For example, if ‘page A’ links to ‘page B’ on a different subdomain 3 times, this would be counted as 3 external outlinks and 1 unique external outlink to ‘page B’.
- Unique Types – The unique number of structured data itemtypes discovered for the URL.
Filters
This tab includes the following filters.
- Indexability – Pages that have changed indexability (Indexable or Non-Indexable).
- Page Titles – Pages that have changed page title elements.
- Meta Description – Pages that have changed meta descriptions.
- H1 – Pages that have changed h1.
- Word Count – Pages that have changed word count.
- Crawl Depth – Pages that have changed crawl depth.
- Inlinks – Pages that have changed inlinks.
- Unique Inlinks – Pages that have changed unique inlinks.
- Internal Outlinks – Pages that have changed internal outlinks.
- Unique Internal Outlinks – Pages that have changed unique internal outlinks.
- External Outlinks – Pages that have changed external outlinks.
- Unique External Outlinks – Pages that have changed unique external outlinks.
- Structured Data Unique Types – Pages that have changed unique number of structured data itemtypes discovered.
- Content – Pages where the content has changed by more than 10% (or the configured similarity change under ‘Config > Compare’).
For more information on Change Detection, please read our tutorial on ‘How To Compare Crawls‘.
URL details
If you highlight a URL in the top window, this bottom window tab populates. This contains an overview of the URL in question. This is a selection of data from the columns reported in the upper window Internal tab including:
- URL – The URL crawled.
- Status Code – HTTP response code.
- Status – The HTTP header response.
- Content – The content type of the URL.
- Size – File or web page size.
- Crawl Depth – Depth of the page from the homepage or start page (number of ‘clicks’ aways from the start page).
- Inlinks – Number of internal inlinks to the URL.
- Outlinks – Number of internal outlinks from the URL.
Inlinks
If you highlight a URL in the top window, this bottom window tab populates. This contains a list of internal links pointing to the URL.
- Type – The type of URL crawled (Hyperlink, JavaScript, CSS, Image etc).
- From – The URL of the referring page.
- To – The current URL selected in the main window.
- Anchor Text – The anchor or link text used, if any.
- Alt Text – The alt attribute used, if any.
- Follow – ‘True’ means the link is followed. ‘False’ means the link contains a ‘nofollow’ , ‘UGC’ or ‘sponsored’ attribute.
- Target – Associated target attributes (_blank, _self, _parent etc.)
- Rel – Associated link attributes (limited to ‘nofollow’, ‘sponsored’, and ‘ugc’).
- Path Type – Is the href attribute of the link absolute, protocol-relative, root-relative or path-relative links
- Link Path – The XPath detailing the links position within the page.
- Link Position – Where is the link located in the code (Head, Nav, Footer etc.), can be customised with the Custom Link Position configuration.
Outlinks
If you highlight a URL in the top window, this bottom window tab populates. This contains a list of internal and external links on the URL pointing out.
- Type – The type of URL crawled (Hyperlink, JavaScript, CSS, Image etc).
- From – The URL of the referring page.
- To – The current URL selected in the main window.
- Anchor Text – The anchor or link text used, if any.
- Alt Text – The alt attribute used, if any.
- Follow – ‘True’ means the link is followed. ‘False’ means the link contains a ‘nofollow’ , ‘UGC’ or ‘sponsored’ attribute.
- Target – Associated target attributes (_blank, _self, _parent etc.)
- Rel – Associated link attributes (limited to ‘nofollow’, ‘sponsored’, and ‘ugc’).
- Path Type – Is the href attribute of the link absolute, protocol-relative, root-relative or path-relative links
- Link Path – The XPath detailing the links position within the page.
- Link Position – Where is the link located in the code (Head, Nav, Footer etc.), can be customised with the Custom Link Position configuration.
Image details
If you highlight a page URL in the top window, the bottom window tab is populated with a list of images found on the page.
If you highlight an image URL in the top window, the bottom window tab shows a preview of the image and the following image details.
- From – The URL chosen in the top window.
- To – The image link found on the URL.
- Alt Text – The alt attribute used, if any.
Duplicate Details
If you highlight a URL in the top window, this lower window tab populates. This contains details on any exact duplicates and near duplicates for the URL in question.
For near duplicates this must be enabled before the crawl and a post crawl analysis must be run.
This displays every near duplicate URL identified, and their similarity match.
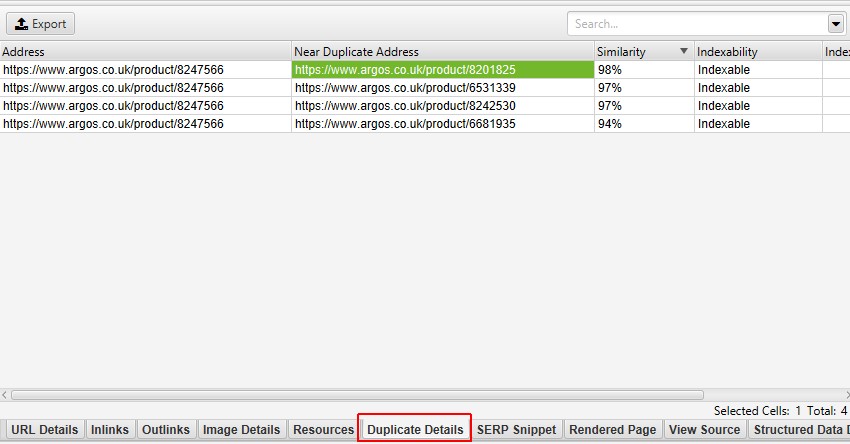
Clicking on a ‘Near Duplicate Address’ in the ‘Duplicate Details’ tab will also display the near duplicate content discovered between the pages and highlight the differences.
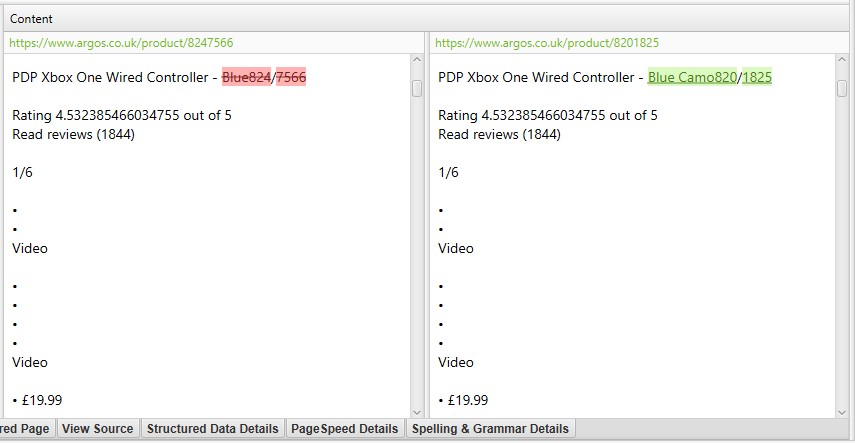
Resources
Highlighting a URL in the top window will populate this bottom window tab. This tab contains a list of resources found on the URL.
- Type – The type of resources (JavaScript, CSS, Image etc).
- From – The current URL selected in the main window.
- To – The resource link found on the above ‘From’ page URL.
- Anchor Text – The anchor or link text used, if any.
- Alt Text – The alt attribute used, if any.
- Follow – ‘True’ means the link is followed. ‘False’ means the link contains a ‘nofollow’ , ‘UGC’ or ‘sponsored’ attribute.
- Target – Associated target attributes (_blank, _self, _parent etc.)
- Rel – Associated link attributes (limited to ‘nofollow’, ‘sponsored’, and ‘ugc’).
- Path Type – Is the href attribute of the link absolute, protocol-relative, root-relative or path-relative links
- Link Path – The XPath detailing the links position within the page.
- Link Position – Where is the link located in the code (Head, Nav, Footer etc.), can be customised with the Custom Link Position configuration.
SERP snippet
If you highlight a URL in the top window, this bottom window tab populates.
The SERP Snippet tab shows you how the URL may display in the Google search results. The truncation point (where Google shows an elipsis (…) and cuts off words) is calculated based upon pixel width, rather than number of characters. The SEO Spider uses the latest pixel width cut off point and counts the number of pixels used in page titles and meta descriptions for every character to show an emulated SERP snippet for greater accuracy.
The current limits are displayed under the page titles and meta description tabs and filters ‘Over X Pixels’ and in the ‘available’ pixels column below.
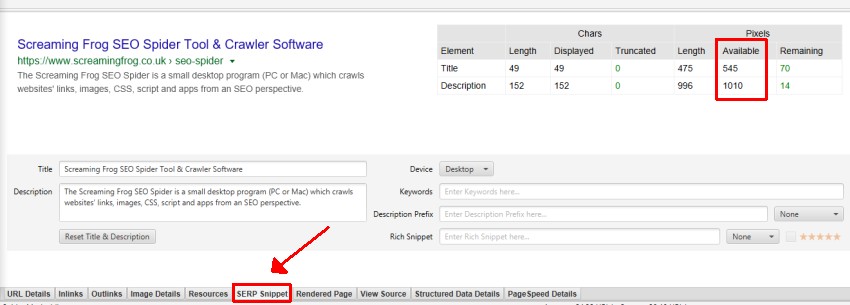
Google changes the SERPs regularly and we have covered some of the changes in previous blog posts, here and here.
Google don’t provide pixel width or character length recommendations, and hence the SERP snippet emulator in the SEO Spider is based upon our research in the SERPs. Google may use more characters than are displayed in scoring, however it is important to include key information in the visible SERP for users.
The SEO Spider’s SERP snippet emulator defaults to desktop, and both mobile and tablet pixel width truncation points are different. You can update the max description preferences under ‘Config > Spider > Preferences’ to a mobile or tablet length. You can switch ‘device’ type within the SERP snippet emulator to view how these appear different to desktop and our current estimated pixel lengths for mobile.
Editing SERP Snippets
You can edit page titles and descriptions directly in the interface to view how the SERP snippet may appear in Google.
The SEO Spider will by default remember the edits you make to page titles and descriptions, unless you click the ‘reset title and description’ button. This allows you to make as many changes as you like using the emulator to perfect your SERP snippets, export (‘Reports > SERP Summary’) and send to a client or development team to make the changes to the live site.
Please note – The SEO Spider does not update your website, this will need to be performed independently.
Rendered page
You can view the rendered page the SEO Spider crawled in the ‘Rendered Page’ tab which populates when crawling in JavaScript rendering mode. This only populates the lower window pane when selecting URLs in the top window.
This feature is enabled by default when using JavaScript rendering functionality, and works alongside the configured user-agent, AJAX timeout and view port size.
In the left hand lower window, ‘blocked resources’ of the rendered page can also be viewed. The filter is set to ‘blocked resources’ by default, but this can also be changed to show ‘all resources’ used by the page.
The rendered screenshots are viewable within the ‘C:UsersUser Name.ScreamingFrogSEOSpiderscreenshots-XXXXXXXXXXXXXXX’ folder, and can be exported via the ‘bulk export > Screenshots’ top level menu, to save navigating, copying and pasting.
If you’re utilising JavaScript rendering mode, then please refer to our guide on How To Crawl JavaScript Websites.
View Source
Stored HTML & Rendered HTML is displayed here when crawling with ‘Store HTML‘ or ‘Store Rendered HTML‘ enabled. This only populates the lower windowpane when selecting URLs in the top window.
To enable storing HTML simply go to ‘Configuration > Spider > Extraction > Store HTML / Store Rendered HTML’. Note, storing rendered HTML will require crawling in JavaScript rendering mode.
Original HTML is shown on the left-hand side while rendered HTML (if enabled) is displayed on the right. Both fields have a search field and are exportable.
More details can be found here.
HTTP Headers
You can view the full HTTP response and request headers of any highlighted URL providing your crawl is set to extract HTTP Headers. This only populates the lower windowpane when selecting URLs in the top window.
To enable HTTP Header extraction, click ‘Configuration > Spider > Extraction > HTTP Headers’.
The left-hand side of the tab shows the HTTP Request Headers. The right-hand side of the tab lists the HTTP Response Headers. The columns listed in this right-hand side window include:
- Header Name – The name of the response header from the server.
- Header Value – The value of the response header from the server.
When extracted, HTTP headers are appended in separate unique columns in the Internal tab, where they can be queried alongside crawl data.
They can also be exported in bulk via ‘Bulk Export > Web > All HTTP Headers’ or in aggregate via ‘Reports > HTTP Headers > HTTP Header Summary.
Cookies
You can view cookies found during a crawl of any highlighted URL providing your crawl is set to extract Cookies. You’re able to select single or multiple URLs in the top window which populates the lower window pane.
To enable cookie extraction, click ‘Configuration > Spider > Extraction > Cookies’. JavaScript rendering mode will need to be used to get an accurate view of cookies which are loaded on the page using JavaScript or pixel image tags.
The columns listed in the Cookies tab include:
- Cookie Type – Where the cookie was discovered. Either over ‘HTTP’, or ‘On-Page’ – if it was via JavaScript or a pixel tag.
- Cookie Name – The name of the cookie.
- Cookie Value – The cookie value.
- Domain – The domain that issued the cookie, either first or third party.
- Expiration Time – The cookie expiry time.
- Secure – Details of the cookie secure attribute.
- HttpOnly – Details of the cookie HttpOnly attribute.
- Address – The URL the cookie was found on.
Cookies can be bulk exported via ‘Bulk Export > Web > All Cookies’ and an aggregated report can be exported via ‘Reports > Cookies > Cookie Summary’.
Please note, when you choose to store cookies, the auto exclusion performed by the SEO Spider for Google Analytics tracking tags is disabled to provide an accurate view of all cookies issued.
This means it will affect your analytics reporting, unless you choose to exclude any tracking scripts from firing by using the exclude configuration (‘Config > Exclude’) or filter out the ‘Screaming Frog SEO Spider’ user-agent similar to excluding PSI.
Structured Data Details
You can view the Structured data details of any highlighted URL providing your crawl is set to extract Structured Data. This only populates the lower windowpane when selecting URLs in the top window.
To enable structured data extraction, simply go to ‘Configuration > Spider > Extraction > JSON-LD/Microdata/RDFa & Schema.org Validation/Google Validation’.
The left-hand side of the tab shows property values alongside error and/or warning icons. Clicking one of these values will provide specific details on the validation errors/warnings in the right-hand window. The columns listed in this right-hand side window include:
- Validation Type – The structured data field with validation issues (Article, Person, Product etc).
- Issue Severity – Whether the issue value is recommended or required to validate.
- Issue – Details on the specific issue.
For more details please read our ‘How to Test & Validate Structured Data Guide’.
PageSpeed Details
When integrated, you can view the PageSpeed details of any highlighted URL. This will require a crawl to be connected to the PageSpeed Insights API.
To pull these metrics, simply to go ‘Configuration > API Access > PageSpeed Insights’, insert a free PageSpeed API key, connect and run a crawl.
With data available, selecting a URL in the top window will provide more details in the lower window tab.
The left-hand window provides specific information on both the metrics extracted and available opportunities specific to the highlighted URL. Clicking an opportunity will display more information in the right-hand window. This consists of the following columns:
- The Source Page – The URL chosen in the top window.
- URL – The linked resource which has opportunities available.
- Size (Bytes) – The current size of the listed resource.
- Potential Savings – The potential size savings by implementing highlighted opportunity.
Please see our PageSpeed Insights integration guide for full detail of available speed metrics and opportunities.
Spelling & Grammar Details
If you highlight a URL in the top window, this lower window tab populates. This contains details on any spelling and grammar issues for the URL in question.
The spell check and / or grammar check must be enabled before the crawl for this tab to be populated.
The lower window ‘Spelling & Grammar Details’ tab shows the error, type (spelling or grammar), detail, and provides a suggestion to correct the issue. The right hand-side of the details tab also show a visual of the text from the page and errors identified.
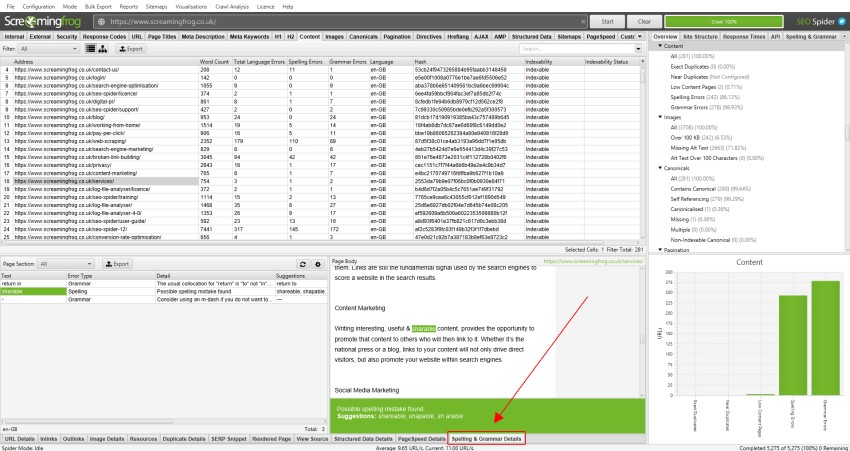
Overview
The overview tab updates in real-time to provide a top level view of a crawl. It provides a summary of URL data and totals of each tab and filter.
- Summary – A summary of the URLs encountered in the crawl.
- SEO Elements – A summary of the number of URLs found within each top-level tab and respective filter. This data can be used to uncover issues without having to click within tabs and filters. It can also be used as a shortcut to the tab and filters within the Spider’s main window.
Issues
The issues tab updates in real-time to provide details of potential issues, warnings and opportunities discovered in a crawl. This data is based upon existing data from the overview tabs and filters, but only shows potential ‘issues’.
The data is classified with issue type, priority and has in-app issue descriptions and tips.
- Issue Name – The issue name, based upon the tab and filter.
- Issue Type – Whether it’s likely an ‘Issue’, an ‘Opportunity’ or a ‘Warning’.
- Issue Priority – ‘High’, ‘Medium’ or ‘Low’ based upon potential impact and may require more attention.
- URLs – The number of URLs with the issue.
- % of Total – Proportion of URLs with the issue from the total.
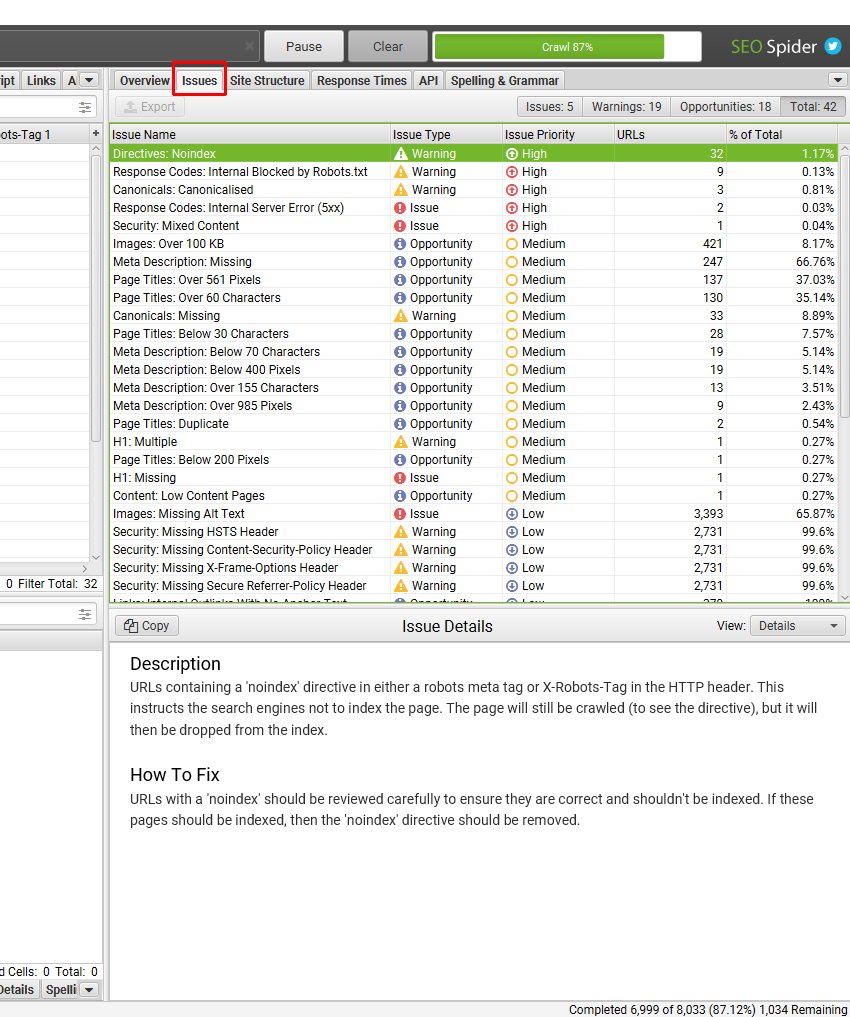
Each issue has a ‘type’ and an estimated ‘priority’ based upon the potential impact.
- Issues are an error or issue that should ideally be fixed.
- Opportunities are ‘potential’ areas for optimisation and improvement.
- Warnings are not necessarily an issue, but should be checked – and potentially fixed.
Priorities are based upon potential impact that may require more attention, rather than definitive action – from broadly accepted SEO best practice. They are not hard rules for what should be prioritised in your SEO strategy or to be ‘fixed’ in your SEO audit, as no tool can provide that as they lack context.
However, they can help users spot potential issues more efficiently than manually filtering data.
E.g – ‘Directives: Noindex’ will be classed as a ‘warning’, but with a ‘High’ priority as it could potentially have a big impact if URLs are incorrectly noindex.
All Issues can be exported in bulk via ‘Bulk Export > Issues > All’. This will export each issue discovered (including their ‘inlinks’ variants for things like broken links) as a separate spreadsheet in a folder (as a CSV, Excel and Sheets).
It’s important to understand that the issues tab does not substitute expertise and an SEO professional who has context of the business, SEO and nuances in prioritising what’s important.
The Issues tab acts as a guide to help provide direction to users who can make sense of the data and interpret it into appropriate prioritised actions relevant to each unique website and scenario.
A simple export of ‘Issues’ data is in itself not an ‘SEO Audit’ that we’d recommend without expert guidance and prioritisation over what’s really important.
Site Structure
The site structure tab updates in real-time to provide an aggregated directory tree view of the website. This helps visualise site architecture, and identify where issues are at a glance, such as indexability of different paths.
The top table updates in real-time to show the path, total number of URLs, Indexable and Non-Indexable URLs in each path of the website.
- Path – The URL path of the website crawled.
- URLs – The total number of unique children URLs found within the path.
- Indexable – The total number of unique Indexable children URLs found within the path.
- Non-Indexable – The total number of unique Non-Indexable children URLs found within the path.
You’re able to adjust the ‘view’ of the aggregated Site Structure, to also see ‘Indexability Status’, ‘Response Codes’ and ‘Crawl Depth’ of URLs in each path.
The lower table and graph show the number of URLs at crawl depths between 1-10+ in buckets based upon their response codes.
- Depth (Clicks from Start URL) – Depth of the page from the homepage or start page (number of ‘clicks’ away from the start page).
- Number of URLs – Number of URLs encountered in the crawl that have a particular Depth.
- % of Total – Percentage of URLs in the crawl that have a particular Depth.
‘Crawl Depth’ data for every URL can be found and exported from the ‘Crawl Depth’ column in the ‘Internal’ tab.
Response Times
The response times tab updates in real-time to provide a top level view of URL response times during a crawl.
- Response Times – A range of times in seconds to download the URL.
- Number of URLs – Number of URLs encountered in the crawl in a particular Response Time range.
- % of Total – Percentage of URLs in the crawl in a particular Response Time range.
Response time is calculated from the time it takes to issue an HTTP request and get the full HTTP response back from the server. The figure displayed on the SEO Spider interface is in seconds. Please note that this figure may not be 100% reproducible as it depends very much on server load and client network activity at the time the request was made.
This figure does not include the time taken to download additional resources when in JavaScript rendering mode. Each resource appears separately in the user interface with its own individual response time.
For thorough PageSpeed analysis, we recommend the PageSpeed Insights API integration.
API
View the progress of data collection from all APIs along with error counts individually.
The APIs can be connected to from the ‘Cog’ icon on this tab. The APIs can also be connected to via ‘Config > API Access’ and selecting an API integration.
Please see more detail about each integration via the following links in our user guide –
- Google Analytics
- Google Search Console
- PageSpeed Insights
- Majestic
- Ahrefs
- Moz
Spelling & Grammar
The right-hand pane ‘Spelling & Grammar’ tab displays the top 100 unique errors discovered and the number of URLs it affects. This can be helpful for finding errors across templates, and for building your dictionary or ignore list. You can right click and choose to ‘Ignore grammar rule’, ‘Ignore All’, or ‘Add to Dictionary’ where relevant.
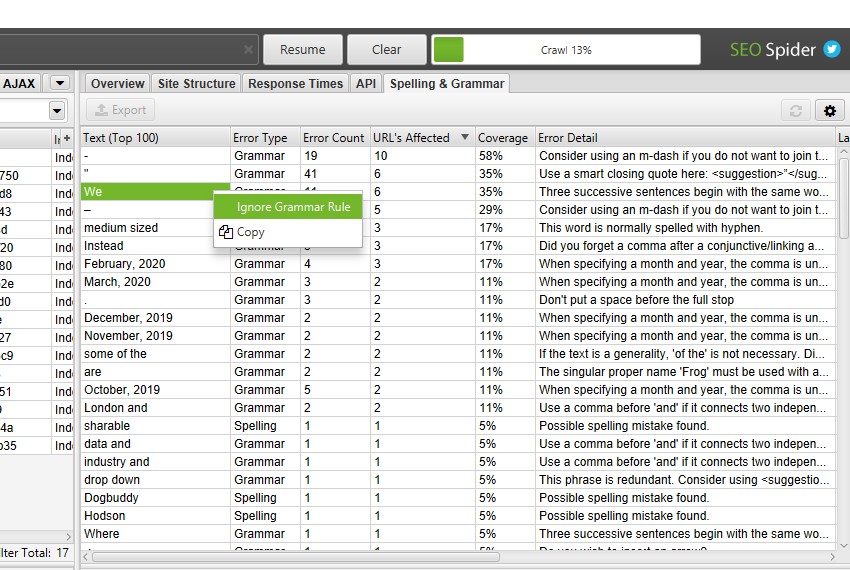
Have you ever wondered how to do a website audit? You probably searched it on the web but left the articles unread because of the confusing information. Here’s great news for you!
We have gathered all the essential details of the website audit in this guide to help website owners grasp the essence of the process. With a few easy steps to follow, your website pages will be optimized based on the current best practices.
We have also prepared a website audit checklist for you to help you improve your site’s performance and get better results on Google organic search.
Keep in mind that, like your annual health checkups, your website needs a regular audit too. That will ensure you have control over your site’s health.
Ready to walk through the seemingly complex steps of a complete website audit? Let’s get into it now!
What is a Website Audit?
Are you sure that your website performs the way you want it to perform? Does it bring you the conversions you expect? This process will analyze and reveal all the issues that hold the site from getting more conversions and rates.
A website audit is defined as an overall analysis of the website based on the rules that determine visibility in Google. It is one of the most crucial processes to maintain the high performance of your site.
Why do You Need a Website Audit?
Search engines are becoming smarter over time. With each Google update, it’s getting more complicated to have the first-page ranking. If you don’t change your website according to Google updates, your site will be buried away on the third or fourth pages of the SERPs, and no one will ever find it.
With the help of this process, you can keep it fresh and updated, improving its SEO, content, design, and accessibility.
Here are just a few reasons why you will need to perform a website audit regularly:
- Website navigation issues– User and split testing as a part of your audit will help you eliminate the problems you may overlook. For instance, there might be too many items in the navigation bar, which won’t allow the users to find the item they are looking for. As a result, they will just give up and leave your website causing a high bounce rate.
- Not a properly optimized website– Your website needs search engine optimization. With the help of an SEO audit, you can get rid of duplicate/useless content, improve site architecture, find broken links, and many more.
- Risk of penalization from search engines– Have you previously trusted your website the SEO companies? You will definitely need a site audit if your answer is a “yes” to this question. The main reason for it is that some SEO companies have previously used “black hat” SEO methods, like keyword stuffing or link farming. These methods worked some years ago, but they can lead to penalization nowadays.
- Page load time issues– You will always have high bounce rates if your website loads longer than 5 minutes. According to the research carried out by Google, the bounce rate increases by 106% if it takes more than 5 minutes for the page to load. The site audit will help you uncover the reason for the slow loading page speed.
- Online strategies of competitors– Analyze your competitors if you want to get better results on Google and become more successful in your industry.
Best Website Audit Tools
There are several website audit tools you can use to check the overall health and improve your website performance. Here are just a few of them you can use during your website audit process!
1. Ahrefs (for on-page SEO audit)

Source: Ahrefs
Keyword research
Regularly check the keyword performance and add new ones if necessary.
Remember that not all pages need search engine optimization. So adding keywords everywhere won’t really make sense. However, when you choose a keyword for the pages you need to optimize, pay attention to the following combination:
- Low keyword difficulty
- Traffic potential
- Keyword Intent
With the help of the best on-page SEO audit tools like Ahrefs, you can find the target and related keywords that have low keyword difficulty but high volume. This combination will give you more chances for your content to appear on the first page of search results.
Keyword position tracking
Keyword tracking is also referred to as SERP or position tracking. It is the regular monitoring of the website ranks based on particular search terms.
Website keyword tracking can be carried out in various search engines like Mozilla, Opera, YouTube, Amazon, etc. However, it is most commonly used to track the keyword ranking in Google.
You can use Ahrefs to track keyword performance and find out how your website performs in SERP. It will help you understand how visible the website is and what you need to include in your future SEO strategies.
Competitor analysis
This is one of the most crucial steps you should never ignore when conducting a website audit. This step will allow you to compare your website with the ones your competitors have. As a result, you will have the chance to generate new ideas and discover new strategies for your website.
You can perform competitor analysis using some of the best SEO audit tools like Semrush, Ahrefs, Sitechecker, etc.
Have a look at the keywords they are using and analyze whether you are ranking higher against competitors or you need to make more improvements for that particular keyword.
With the help of Ahrefs, you can get a thorough analysis of up to ten competitors. Here are the main areas you should pay attention to:
- SERP features
- Search traffic
- Keyword ranking progress
Source: Ahrefs competitor analysis
Domain rating
Ahref measures the domain rating on a scale from 0 to 100. The scores between 50-60 are considered to be okay; 100 is the best you could have.
The domain authority of your website changes when your domain links to another one via do-follow links/backlinks. It shows the search engine that your content is relevant to a particular topic and increases the authority score.
Let’s think of a backlink as a referral. Imagine you want to go to a diner but can’t decide which one to choose out of hundreds of diners in your city. The first thing you would do is ask your friend who loves trying different types of food and enjoys visiting new diners.
You would go to the diner they recommend to you because you trust their taste and can be sure they provide you with the tastiest food and quality service.
When you get a backlink from a quality website, search engines receive the signal of trust and give you higher domain ratings and more visibility.
2. Screaming frog (for technical audit)

Source: Screaming frog
Security issues
We usually perform site audits paying more attention to SEO and website design but underestimate the security problems that our website may face.
Even large companies like Facebook and Google have cybersecurity breaches. Most SMEs also face security issues ranging from spoofing and phishing attacks on email domains that are not DMARC protected to malware infiltration on databases. That means no company has a 100% guarantee that similar cases will not happen to their security.
Cyber security can have even more adverse effects on small businesses. According to recent surveys, 60% of small agencies had to close down a few months after a cyber-security attack! You don’t want to be one of them, do you?
To start securing your website, switch your HTTP to HTTPS. Besides being secure, it will also help your website rank higher on Google. You should also ensure you use the best VPN online to secure your data when carrying out audits. While this is not part of the technical audit, it is crucial for protecting your website login details and staying safe from other cybersecurity threats.
Indexability status (response codes 3XX, 4XX, and 5XX)
Source: Sygic Travel Maps
Checking the indexability status of your pages should be an inseparable part of your audit process.
Remember that a website URL can be either indexable or non-indexable. The indexable website URL can be crawled and is allowed to be indexed. Whereas the non-indexable website URL can’t be crawled and isn’t allowed to be indexed.
Checking the indexability status of your pages should be an inseparable part of your audit process. You can do it with the help of the features Screaming Frog offers.
The non-indexable URLs contain indexability status that demonstrates why they can’t be indexed. So, you can easily tell Google which pages you don’t want it to index with the help of the status.
Here are the main URL status codes:
- 3XX redirects– Further action needs to be taken to complete the request
- 4XX client errors– The request can’t be completed as something is wrong on the client’s end
- 5XX server errors– The request was valid by the client, but the server failed to complete it
Duplicate and canonical issues
Duplicate content is described as content that is partly or entirely similar to the ones that exist in similar or different domains. Accordingly, there are two types:
- The same content on the same website
- The same content on other websites
One of the main causes of the copy-pasted content is the creation of 2 different URLs for exactly the same content.
Screaming Frog will help you discover the duplicate content of your website and keep the right (called canonical) URL for that content.
Image size and ALT tags
Alt tags are also known as alt descriptions and alt texts. These are the texts that appear instead of the images when they won’t load because of some technical problems.
Alt tags are used for 2 main purposes:
- Screen-reading tools can describe the images to visually impaired readers
-
Search engine crawlers crawl and rank your website faster with the help of image texts
Accordingly, alt tags need to be descriptive and contain the keyword for SEO purposes. However, they should not include long paragraphs as the limit of these types of texts is up to 125 characters.
During your regular website audit, you can use Screaming Frog to determine if all your images have proper sizes and alt tags to rank better.
The length of meta tags
Like the images, your content needs a short description, too. These small texts inform the search engine what the page is about and help it better crawl the webpage. You will not see meta descriptions on the page as they are mostly for search engines.
The recommended length for meta descriptions is about 155-160 characters. With the help of Screaming Frog, you can analyze your website’s meta data and make changes accordingly.
Broken links and pages
A broken link is referred to as a web page that users can not find or access. This happens for several reasons. For instance, the destination web page may be removed or doesn’t exist anymore.
Broken links can affect the rankings of your website. Broken links usually lead to high bounce rates and decrease conversions. When visitors enter your website, they see the “page not found” broken page and leave immediately.
You can find broken pages when performing a website audit through Screaming Frog Spider.
3. Google Search Console

Source: Google Search Console
Google Search Console is another popular tool for gathering accurate data from your website. This will allow you to understand your website’s health condition better, website performance, and organic traffic to make improvements accordingly.
With the help of a Google Search Console audit, you can measure the following technical aspects:
- Site structure
- Crawling performance
- Pages indexed
- CTRs and impressions
- External and internal links
- Top search queries
4. Google Analytics
Data collection
Google Analytics is a great tool to implement when performing a website audit. It will help you gather your data and use it for website improvements.
You will need the following components for the Google Analytics audit:
- Tracking code implementation check- To start collecting data
- Configuration of the Admin section- To check settings
- Google Analytics Reports analysis- To analyze your data
Google Analytics audit will allow you to get a full analysis of your data and identify the errors that failed you before.
Conversion rate optimization
Your site needs to be optimized for lead generation and conversions. If you want to audit your site for conversion rates, you need to ask yourself:
- How many marketing offers did I get from the landing pages?
- Do I have relevant content that would attract my buyer personas?
- Do I have opportunities to convert visitors in different stages of the funnel?
- Are my CTAs effective? Are they clear or not?
The answers to these questions will give you a hint where you can start the conversion rate optimization of your website. Remember that you will convert visitors easier if your site is well-optimized, super easy to navigate, and has high performance!
5. Google’s PageSpeed Insights

Source: Google’s PageSpeed Insights
Having a faster page speed is among the ranking factors of Google! Remember that users won’t stay on your website if it takes more than 3 seconds to load the page or image! As a result, you’ll get higher bounce rates and lower rankings!
Google’s PageSpeed Insights is among the free tools that will help you check the site speed on both mobile and desktop! Moreover, it will offer you insights on how to improve the site speed once you check your web pages with it.
6. Accessibility Checker
Source: Accessibility Checker
Recently, website accessibility audit has become an important part of the overall website audit process. It is a design initiative that allows visitors with impairments and disabilities to be a part of the web equally!
Please, keep in mind that you will need a website developer to fix the majority of errors, but here are some of the fixes you can make without their help:
- Having alt-texts for all your images
- Having the correct header order for your content
- Implementing an easy-to-read font to your website
- Designing your website in high contrast colors
- Adding footer links
Website audit checklist
Below you can find a website audit checklist that will help you carry out your technical SEO audits and make it easier for search engine crawlers to rank your website on Google.

How to Do a Website Content Audit
Although content audit is usually considered as a part of the SEO audit, it can be reviewed as a separate type. During this process, you will need to find out whether your website content is well-structured or if you will need to make improvements.
High-quality content is informative, well-structured, free of grammatical errors and spelling, easily skimmable, and not copy-pasted!
Moreover, you should pay attention that the tone of voice and the messages of your website demonstrate who you are as a business and make sure that you have a consistent brand identity on all the pages. You should always keep these in mind when designing a content strategy for your website.
For your content audit, make sure you add skimmable text, different types of images, and videos to the website.
Remember that you can always use subheaders to break the text into several parts and provide a better site structure. For example:
Have one H1 on each page of the title
Implement H2 for your main subheaders
Use H3 for sub-subheaders
Use H4 for sub-sub-subheaders
Got the gist, right?
To make your content audit steps easier, we have picked a few tools you can use for your content improvement.
Content Audit Tools
1. Grammarly
Grammarly is one of the best tools to audit the grammar of your texts. It’s always a great idea to check the text with this tool before posting it. You may have misspelled words or grammatical errors that you haven’t noticed when writing the content. Grammarly will check all the words and highlight the ones that need to be changed.
Besides the grammatical errors, this tool will also help you write content based on several criteria like the formality, intent, and audience.

Source: Grammarly
2. Hemingway
After carrying out the website audit related to grammar and punctuation, you can start analyzing your texts for readability. This tool will help you optimize the grade level of the content. Using long sentences and unnecessary words will make the content hard to read. So, you can easily simplify it through Hemingway.

Source: Hemingway
3. Plagscan
PlagScan is an effective audit tool that will help you get rid of copy-pasted text with a few clicks. Duplicated content will not let you rank higher, so make sure your plagiarism score is less than 5% on PlagScan.
Please keep in mind that this tool is not free of charge. However, there are other plagiarism detection tools that you can use for free. Here are some of them for you to consider: Dupli Checker, and Small SEO tools.
4. SEO Content Editor
SEO Content editor is the writing assistant of WebSite Auditor that will allow you to create SEO-optimized content for your website. This tool should become an inseparable part of your website audit process as it will help you analyze top-ranking websites and suggest word usage (through a TF-IDF text analysis).

Source: WebSite Auditor
Moreover, this tool can help you discover new topic ideas, structure the texts and analyze the SEO elements like meta description, meta title, alt texts, etc.
5. Yoast SEO plugin
You can use this plugin for regular website audits if you have a website created on WordPress. If you don’t use WordPress, you can head to the Yoast content analysis tool online and check your content immediately on the website.
Yoast SEO plugin will help you optimize your content based on the keywords you need to mention in your articles. By checking your content through this tool, you will solve the main issues regarding the articles and general structure. For instance, you can look at your blog headers, all the pages, categories, and even the media files.
The content assessment part will show you the following information that you need to make your content easily skimmable:
- The number of subheadings
- The number of transition words
- Flesch reading ease test score
- The length of paragraphs
- The length of sentences
- The number of passive voice sentences

Source: Yoast SEO
The part that checks the SEO of the text will show you the following features:
- Meta tags
- Page titles
- The number of external and internal links
- The keyword performance
- The length of the text
- The appearance of focus keyword in subheadings

Source: Yoast SEO
How Much Does a Website Audit Cost?
Depending on the overall complexity of the website, site audit costs may range from $200 to $25.000. Yes, SEO audit service is sometimes expensive, but it is mandatory for your website performance.
You can also perform a free website audit without the help of SEO audit services provided by different agencies. All you need to do is follow our guide’s instructions and execute the audit step by step. However, this might not be completely free as checking a website’s performance is not a one-time process. You will need to get yearly subscriptions to website audit tools.
The Most Affordable Solution: Website Maker
You will not need to spend a lot of money on a website audit if you have a website built according to the requirements mentioned above.
With the help of Rendeforest Website Builder, you can create a website that includes SEO-oriented content, making it perfectly suitable for your business goals.
Moreover, you will have all the necessary SEO tools to conduct a website audit and improve your Google rankings later.
The best part about this builder is that you can create the website for free, publishing it on a Renderforest subdomain. So, if you already have an online presence, you shouldn’t worry about spending a lot of money on building an SEO-friendly website.
Here are the main features of the Website Maker that will help you forget about the long process of the website audit:
- 120+ optimized website templates
- Customizable styles, colors, and fonts
- Easy editing process
- Simple drag and drop blocks
- Custom domain connection
- SEO-friendly content
- Additional SEO tools provided
- Website status control
- SSL Certificate
- Marketing and Analytic tools integrations
- Messenger and Live Chat integration
- Free website with a Renderforest subdomain
- Affordable yearly subscription

More Templates
To sum up
Performing a full website audit is crucial for the success of your business goals. It will help you track your website performance and eliminate any issues that may cause its poor ranking on Google.
In this article, we have presented the main steps you should carry out to audit your website. The mentioned tools will help you go through the process of both the content and SEO audits easier and faster. However, you will need an SEO-friendly website if you want to avoid frequent and complex audits.
If you’re looking for an easy and affordable solution, you can click on the button below and build a website that will not require a complex website audit later. Choose a template and follow the 3 simple steps:

Create Now

Indexability relates to the technical configuration of URLs so that they are either Indexable or Not Indexable.
Search engines generally take the stance that any successful URLs (i.e. HTTP status 200) they find should be indexed by default — and they will, in the main, index everything they can find. However, there are certain signals and directives you can give to search engines that instruct them to NOT index certain URLs.
Setting URLs so that they are Not Indexable is a relatively common task, and straightforward to do in most modern CMSs. You might want to set a URL to noindex, for instance, if it is useful to website users, but is not a page that would represent a useful search result (e.g. a ‘print’ version of a page).
However, indexing signals often get misconfigured, or set up incorrectly, which can result in important URLs not getting indexed. An important thing to note is that if a page is not indexed, it has no chance to generate any organic search traffic.
Sitebulb’s Indexability Hints deal with the robots.txt file, meta robots tags, X-Robots-Tag and canonical tags, and how these directives may impact the way in which URLs are crawled and indexed by search engines.
What are robots directives?
Robots directives are lines of code that provide instruction on how search engines should treat content, from a the perspective of crawling and indexing.
By default — or with the absence of any robots directive — search engines work under the basis that every URL they encounter is both crawlable and indexable. This does not mean that they necessarily will crawl and index the content, but that it is the default behaviour should they encounter the URL.
Thus, robots directives are essentially used to change this default behaviour — by instructing search engines to either not crawl, or not index, specific content.
How are robots directives presented to search engines?
There are 3 ways in which robots directives can be specified:
- Robots meta directives (also called ‘meta tags’), which work at a page level. Within the <head> of a page’s HTML, you include meta tags like this:
<meta name=»robots» content=»noindex, nofollow»> to control crawling and indexing on a specific URL. - X-robots-tags, which can be added to a site’s HTTP responses, and can control robots directives on a granular, page level, just like meta tags, but can also be used to specify directives across a whole site, via the use of regular expressions.
- Robots.txt file, which normally lives on example.com/robots.txt, and is typically used to instruct search engine crawlers which paths, folders or URLs you don’t want it to crawl, through ‘disallow’ rules.
In the methods outlined above, if the ‘nofollow’ directive is used, it means that you do not wish for any of the links on the page to be followed. However, it is also possible to specify that individual links should not be followed, via the nofollow link element.
What is a canonical?
In the field of SEO, a ‘canonical’, is a way of indicating to search engines the ‘preferred’ version of a URL. So if we have 2 URLs that have very similar content — Page A and Page B — we could put a canonical tag on Page A, which specifies Page B as the canonical URL.
To do this, we could add the rel=canonical element in the <head> section on Page A;
<link rel="canonical" href="https://example.com/page-b" />
If this were to happen, you would describe Page A as ‘canonicalized’ to Page B. In general, what this means is that Page A will not appear in search results, whereas Page B will. As such, it can be a very effective way of stopping duplicate content from getting indexed.
When you set up a canonical, you are effectively saying to search engines: ‘This is the URL I want you to index.’ People may refer to a canonical as ‘a canonical tag’, ‘rel canonical’ or even ‘rel=canonical’.
In Sitebulb, if a URL is canonicalized, it is also classed as ‘Not Indexable.’ Conversely, if a URL has a self-referential canonical (i.e. a canonical that points back to itself) this URL would be Indexable.
Self-referential canonicals are a useful default configuration, and are typically set up to help avoid duplicate, parameterized versions of the same URL from getting indexed, for example:
https://example.com/page?utm_medium=email
How are canonicals implemented?
The most common way that canonicals are implemented is through a <link> tag in the <head> section of a URL. So on Page A, we could specify that the canonical URL is Page B with the following:
<link rel="canonical" href="https://example.com/page-b" />
Canonicals can also be implemented through HTTP headers, where the header looks like this:
HTTP/... 200 OK...
Link: <https://example.com/page-b>; rel="canonical"
Typically, this is used to add canonicals to non-HTML documents such as PDFs, however they can be used for any document.
As such, it is considered best practice to only ever use one method of assigning canonicals for each URL on a given website.
Depending on the interpretation of META tags and Robots.txt, for different types of links and redirects, LRT can show different status for the page.
LRT Classic shows status icons next to each link in your reports.
These are the same icons also used in the Link Redirect Trace browser extension.
| Symbol | Meaning |
|---|---|
|
|
indexable by every bot |
|
|
the links on the page are followed |
|
|
the page has a Rel-Canonical redirect to another page |
|
|
crawlable by major bots, some minor bots or scrapers blocked |
|
|
NOT crawlable by any bot |
|
|
NOT indexable |
|
|
the links on the page are not followed |







Here is how you can read a combination of the above status messages:
| Symbol | Meaning |
|---|---|
|
|
indexable by every bot, links on the page are followed |
|
|
NOT indexable, links on the page are not followed |
|
|
indexable by every bot, links no-follow |
|
|
indexable by every bot, page canonicaled to another page (so links on the page may not count) |
|
|
indexable by major search engine bots, links on the page are followed |
|
|
indexable by major search engine bots, links on the page are not followed |
|
|
indexable by major search engine bots, page canonicaled to another page (so links on the page may not count) |
|
|
NOT indexable, links on the page are followed |
|
|
NOT indexable, page canonicaled to another page (so links on the page may not count) |









Source Page Status and Target Page Status
LRT Smart shows the page indexability status as a text representation, which is more accessible and self explanatory.
The two columns
- Source Page Status
- Target Page Status
are interpreted and can be as follows
| Page Status | Description |
|---|---|
| Index | |
| NoIndex | |
| Follow | |
| NoFollow | |
| Major Index | indexable by major search engine bots |
These states are for the page itself, like link status is for the link itself.
So it is possible that a page is set to NoFollow, while the link itself is set to Follow. The result for Google would be a «NoFollow», altough in this mix they would probably see it differently than if everything would be consistent.
- Overview of the URL Inspection API
- Different methods for pulling the data from the URL Inspection API
- How to set-up Data Studio Reporting for the URL inspection API (free dashboard)
- Crawling your website
- 🛠 Notes on setting up
- Data Interpretation & Storytelling
- Google Disclaimers on Interpreting Data
- Section Breakdown
- Executive Q&A
- Summary
- Frequently Asked Questions
On the 31st of January, Google released their Search Console URL Inspection API to the public, announcing the news in a post on the Google developers’ forum.
The new Search Console URL Inspection API contains a number of fields and parameters that will undoubtedly assist the technical reporting of site health. In order to aid the work of SEOs, specifically in the context of clear, easy, and understandable reporting of this data to their stakeholders, I created a Data Studio Dashboard for reporting the URL Inspection data.
In the post below, we will discuss the main use-cases of the API, the different methods available for pulling the data, as well as how to set up (easily) the dashboard, and interpret the visualizations for enhanced technical performance reporting.
Overview of the URL Inspection API
The URL Inspection API uses an index.inspect method, which means that it enables you to view the indexed or indexable status of a URL you provided.
You can make a request with two parameters needed – the URL you’d like to inspect and the URL of the property as defined in Search Console.
The request body should contain data with the following structure:
| JSON representation |
|---|
| { “inspectionUrl”: string, “siteUrl”: string, “languageCode”: string } |
The response will also be returned in JSON format, which makes it super easy for manipulation and visualization afterward.
Exclusions:
- Presently only the status of the version in the Google index is available; you cannot test the indexability of a live URL.
Quota limits:
The quota is enforced per Search Console website property (calls querying the same site):
- 2,000 queries per day
- 600 queries per minute
Check out the Search Console APIs documentation usage limits for more detailed guidance.
Also, be sure to check out the list of parameters returned by the Google Search Console URL Inspection API.
Before we dive in, a quick word on the different methods that are available for extracting data from the URl inspection API.
Different methods for pulling the data from the URL Inspection API
If you have already read Aleyda‘s article on the 8 different tools you can use with this API, then feel free to skip this section. Read a summary of the free tools for data extraction below, but definitely check Aleyda’s article for a detailed review of all of these tools (and more!):
- Google Bulk Inspect URLs by Valentin Pletzer – free online tool, which enables a download of the data
- MyDomain.Dev by Lino Uruñuela – a free online tool, which enables a download of the data
- URL Inspection API in Sheets by Mike Richardson – Google Sheets Template using App Scripts, which can be connected directly in Data Studio
- Screaming Frog SEO Spider – a crawler, which enables an export of the data in sheets format
- Sitebulb – another SEO crawler, which enables data exports of the URL inspection data in sheets
- Google Index Inspection API Node.js script by Jose Luis Hernando – a JS script for pulling the data from the API
- Google URL Inspection API with Python by Jean-Christoph Chouinard – a Python script for pulling data from the API
How to set-up Data Studio Reporting for the URL inspection API (free dashboard)
Crawling your website
For my dashboard, I’ve used an export from my beloved tool Screaming Frog. In order to replicate my data source, feel free to run a crawl of your site, enabling the URL inspection API in the Configuration > API > Google Search Console API tab (after you’ve authenticated with the account you want to crawl).

Then, just run the crawl, go to the Search Console tab, and click export. Export the file as a Google Sheet in your connected Google Drive Account.

Then, access the Data Studio Dashboard from the link below and make a copy, connecting your exported crawl data as the data source.
🛠 Notes on setting up
Sometime Google Data Studio malfunctions when copied, specifically with custom fields, filters, or filter application – I’ve previously talked about the limitations of Google Data Studio, however, to spare you, here is a summary of the custom fields, filters, and where they are applied, which can help you set up the dashboard:
- Custom Field: Canonical Mismatch? (Y/N)

- Custom Field:Page Section

- Custom Field:Pages with / without clicks

- Custom Filed: Crawl Frequency

- Filters added in the report:
- Exclude pages with no mobile usability issues
- Exclude pages with 0 clicks
- Exclude URLs with no summary
- Exclude Inspection Status is Null
- Crawling not allowed Pages
- Indexing Not allowed
- Page Fetch Unsuccessful
- Status Code = 404
Data Interpretation & Storytelling
Google Disclaimers on Interpreting Data
Before I begin with the section on how to interpret the data you see, here are a few important notes on data interpretation from Google:
- This is not a live test – as previously mentioned, the tool is reflective of most recent crawl, not the live page that exists. However, the information shown in the tool is used by Google to evaluate Search results.
- “URL is on Google” doesn’t actually mean that your page is appearing in Search results. Actual appearance in Search results requires that the page and its structured data conform to quality and security guidelines. The URL Inspection tool doesn’t take into account manual actions, content removals, or temporarily blocked URLs.
- URL not showing on Google but the tool says it is indexed? Explore this resource to find out why.
- The “Last crawl” date in the Coverage section shows the date when the information shown here was retrieved (if the page was successfully crawled).
Section Breakdown
Now, on with the fun stuff – using the dashboard! 🔥 Below, I list some cool use-cases, as well as go through what each of the pages contains.
In the Coverage Overview Section, you can get an overview of:
- how many pages are crawled, as well as the distribution of pages per section
- how many pages have coverage status as per the Inspection API, including the distribution of pages per status
- how many pages receive clicks
- how many pages have mobile usability issues as well as the issues breakdown distribution
- how many pages have rich result issues as well as the error breakdown distribution
- a summary of index status distribution (options being: URL is on Google, URL is on Google but has issues, and URL is not on Google)
- a summary of crawl user agent distribution – is your site crawled mostly by mobile, desktop or unknown agent?
- a summary of page fetch status distribution – Have pages, included in the crawl been fetched successfully by Google?
- a summary of URL Inspection status distribution – have there been any errors?

In the Mobile Usability Section, you can:
- Get an Overview of whether your pages are mobile friendly or not (distribution)
- Get an overview of the main types of errors encountered on the site, and how many pages trigger them
- Filter URLs based on Error type, Indexability, and Google Index Status in order to help with prioritisation of fixes

In the Rich Result Snippet Issues section, you can:
- get an overview of the main errors, realted to rich snippets
- get an overview of the number of pages that are valid for rich results
- see the main types of schema types implemented
- filter and explore URLs, based on indexability status, clicks, and Google Index Status to help with prioritising fixes.

Now, moving on to Page 2 of the dashboard, which addresses Indexability, Canonicalisation, and Crawl Behaviour.
In the Google Status Section you can:
- Filter and explore URLs, based on URL inspection API status, Summary, Pages with/ Without Clicks, and Coverage to help you get an idea on the type of pages on Google
- get an overview of the relationship between indexability & status code – are all of the pages you declared indexable returning a 200 status code?
- get an overview of the relationship between Google Index status and clicks – are pages with issues receiving clicks? Prioritise their optimisations.
- get an overview of the relationship between inspection status and errors breakdown – when an inspection error is received, what is the reason for this? Read timeout, Connect time? Investigate.

In the Crawling section, you can:
- get summary stats on
- # of pages where crawling is not allowed
- # of pages where indexing is not allowed
- # of pages where unsuccessful page fetch is not allowed
- # of 404s
- filter URLs based on crawl agent (mobile, desktop, unknown) – try to see if you find any patterns.
- filter based on last drawl date using the date range filter
- filter pased on page fetch status
- filter, based on status code
- get an overview of the crawling behaviour on the site – how frequently are URLs crawled?

In the Canonical Tags section, you can check for mismatches between the canonical tags you’ve indicated and the ones Google has selected. You can also integrate this with additional filters above the table to find patterns in any mistakes you might have made in declaring canonicals.

Executive Q&A
In-part inspired by Aleyda’s thread on questions the URL Inspection API answers, I wanted to introduce this final section on how to get the replies from the dashboard, which can enable you to better handle such questions on client calls.
- For which pages Google is not using the specified canonical configuration and what is using instead?
Go to page two, filter the table in the Canonical Tags section, using the filter Canonical Mismatch (Y/N) by setting it to yes. You can now quickly review any mismatches.


- Which ranked pages attracting clicks haven’t been crawled lately?
Go to page 2.
Select from the section Google Status, the filter Pages with/without clicks by setting it to show only pages with clicks.
Then scroll down to the next section, and use the date bar, in order to adjust the time-frame you want to review. Then, you can see the result in the table below with URLs, Last Crawl (Date), and number of clicks.
Check if these URLs have been submitted in the XML sitemap.
- When was the last time Google crawled your URLs? How?
You can answer all of these questions with the Crawling section on page 2.
- Which indexable URLs attracting clicks are triggering mobile usability or rich results issues?
Go to page 1, in sections Mobile Usability Issues and Rich Result Snippet Issues, and use the Indexability filters to answer these questions.

Summary
The Google URL inspection API was released soon, and the industry has shown it lots of love so far.
While there are some limitations related to quota, usage, and exclusions, the API is a much-needed extension to the dataset of SEOs.
There are at least 8 different ways to export data, many of which will enable you to visualise it using the Google Search Console URL Inspection API Explorer Data Studio Dashboard I have built.
The Data Studio Dashboard consists of several different sections: Coverage Overview, Mobile Usability Issues, Rich Result Snippet Issues, Google Status, Crawling, Canonical Tags, which will help you answer a ton of questions about the sites you are reporting on.
Feel free to let me know how I can improve it, or let me know how you’d use it. Thanks 🙏
Frequently Asked Questions
What is the Google URL Inspection API from Google Search Console?
Google’s URL Inspection API was released on the 31st of January 2022. It is a retrospective, JSON-based API that contains a number of fields and parameters to help with technical reporting of site health, including Coverage data, Mobile and Rich Snippet usability issues, Crawling Frequency, and Canonical Tag Mismatches.