Русские Блоги
Разберите старую и новую версии setup.inx, чтобы получить исходный код.
При запуске setup.exe он вызывает setup.inx
Обычно в inx содержатся регистрационные коды. Если регистрационный код неправильный, программное обеспечение не будет полностью функциональным.
Start create CSV file
Info Install error! Skip CSV file creation
Сообщение об ошибке, обратите внимание при создании файла CSV, то есть вы можете продолжить следующую установку после успешного создания
Эти байты такие же в новой версии inx
Существует две версии файла .inx. Старая версия может быть непосредственно дизассемблирована на sid для генерации исходного кода, а поток выполнения программы может быть изменен непосредственно на sid.После внесения изменений выберите файл-> patch changes, чтобы сохранить изменения.
Новая версия в настоящее время находит только программное обеспечение isdcc, которое может дизассемблировать исходный код, но его нельзя динамически отлаживать на sid, и sid выйдет из строя, когда он будет наполовину загружен.
Декомпилируйте новый inx файл и сохраните исходный код в txt
isdcc.exe -u setup.inx
Интерпретировать setup.inx и сгенерировать setup.inx.dec
isdcc.exe setup.inx.dec >1.txt
Сохраните декомпилированный исходный код в 1.txt, используйте команду>
Если вы не можете изменить процесс выполнения программы непосредственно на sid, вы можете найти только соответствующее местоположение исходного кода в программном обеспечении, таком как 010, в соответствии с машинным кодом
Источник
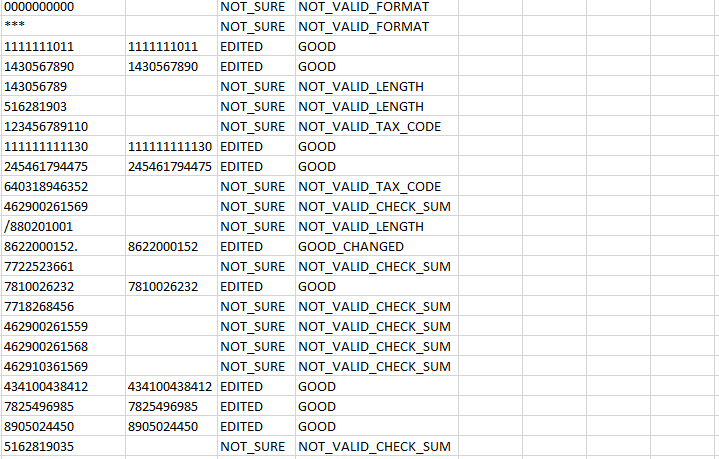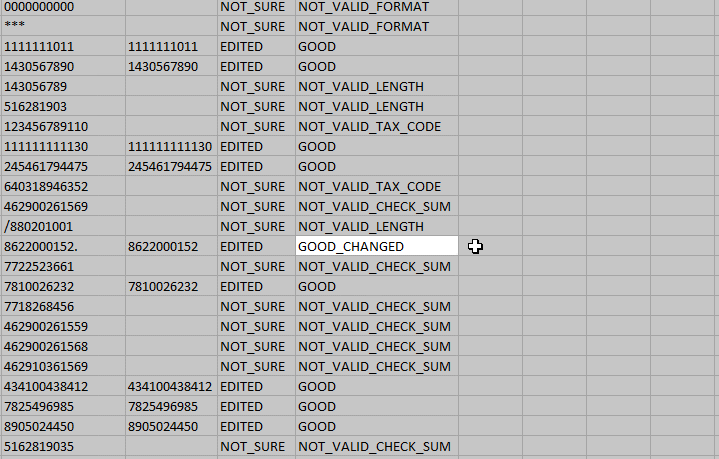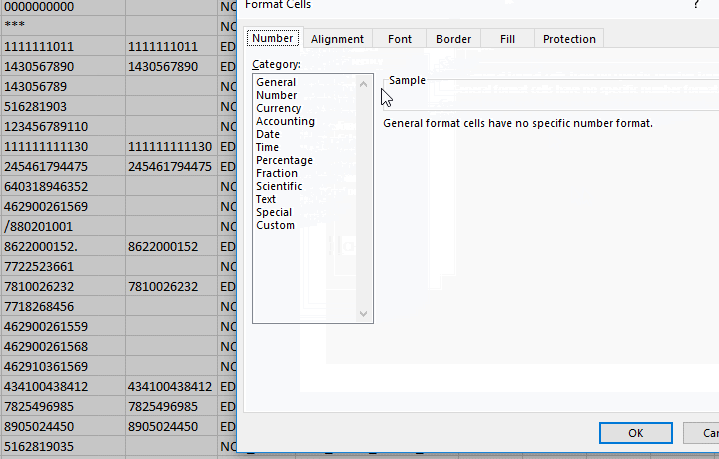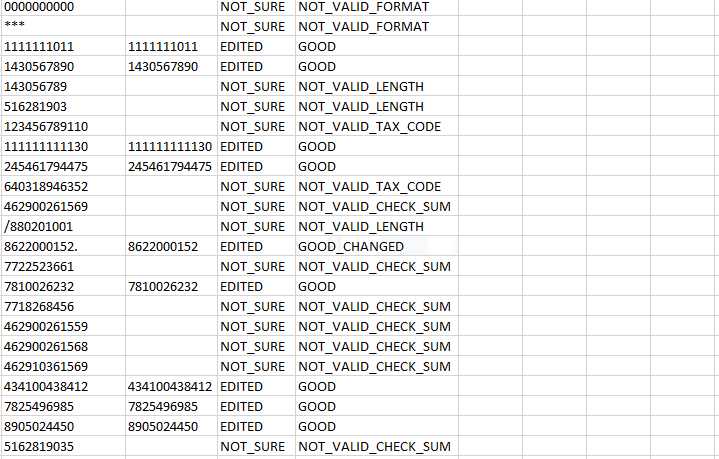
Редактируем CSV-файлы, чтобы не сломать данные

Продукты HFLabs в промышленных объемах обрабатывают данные: адреса, ФИО, реквизиты компаний и еще вагон всего. Естественно, тестировщики ежедневно с этими данными имеют дело: обновляют тест-кейсы, изучают результаты очистки. Часто заказчики дают «живую» базу, чтобы тестировщик настроил сервис под нее.
Первое, чему мы учим новых QA — сохранять данные в первозданном виде. Все по заветам: «Не навреди». В статье я расскажу, как аккуратно работать с CSV-файлами в Excel и Open Office. Советы помогут ничего не испортить, сохранить информацию после редактирования и в целом чувствовать себя увереннее.
Материал базовый, профессионалы совершенно точно заскучают.
Что такое CSV-файлы
Формат CSV используют, чтобы хранить таблицы в текстовых файлах. Данные очень часто упаковывают именно в таблицы, поэтому CSV-файлы очень популярны.
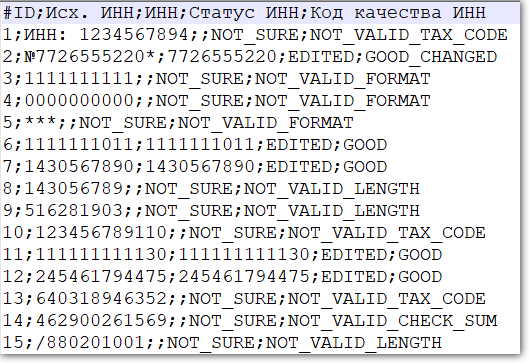
CSV-файл состоит из строк с данными и разделителей, которые обозначают границы столбцов
CSV расшифровывается как comma-separated values — «значения, разделенные запятыми». Но пусть название вас не обманет: разделителями столбцов в CSV-файле могут служить и точки с запятой, и знаки табуляции. Это все равно будет CSV-файл.
У CSV куча плюсов перед тем же форматом Excel: текстовые файлы просты как пуговица, открываются быстро, читаются на любом устройстве и в любой среде без дополнительных инструментов.
Из-за своих преимуществ CSV — сверхпопулярный формат обмена данными, хотя ему уже лет 40. CSV используют прикладные промышленные программы, в него выгружают данные из баз.
Одна беда — текстового редактора для работы с CSV мало. Еще ничего, если таблица простая: в первом поле ID одной длины, во втором дата одного формата, а в третьем какой-нибудь адрес. Но когда поля разной длины и их больше трех, начинаются мучения.

Следить за разделителями и столбцами — глаза сломаешь
Еще хуже с анализом данных — попробуй «Блокнотом» хотя бы сложить все числа в столбце. Я уж не говорю о красивых графиках.
Поэтому CSV-файлы анализируют и редактируют в Excel и аналогах: Open Office, LibreOffice и прочих.
Ветеранам, которые все же дочитали: ребята, мы знаем об анализе непосредственно в БД c помощью SQL, знаем о Tableau и Talend Open Studio. Это статья для начинающих, а на базовом уровне и небольшом объеме данных Excel с аналогами хватает.
Как Excel портит данные: из классики
Все бы ничего, но Excel, едва открыв CSV-файл, начинает свои лукавые выкрутасы. Он без спроса меняет данные так, что те приходят в негодность. Причем делает это совершенно незаметно. Из-за этого в свое время мы схватили ворох проблем.
Большинство казусов связано с тем, что программа без спроса преобразует строки с набором цифр в числа.
Округляет. Например, в исходной ячейке два телефона хранятся через запятую без пробелов: «5235834,5235835». Что сделает Excel? Лихо превратит номера́ в одно число и округлит до двух цифр после запятой: «5235834,52». Так мы потеряем второй телефон.
Приводит к экспоненциальной форме. Excel заботливо преобразует «123456789012345» в число «1,2E+15». Исходное значение потеряем напрочь.
Проблема актуальна для длинных, символов по пятнадцать, цифровых строк. Например, КЛАДР-кодов (это такой государственный идентификатор адресного объекта: го́рода, у́лицы, до́ма).
Удаляет лидирующие плюсы. Excel считает, что плюс в начале строки с цифрами — совершенно лишний символ. Мол, и так ясно, что число положительное, коль перед ним не стоит минус. Поэтому лидирующий плюс в номере «+74955235834» будет отброшен за ненадобностью — получится «74955235834». (В реальности номер пострадает еще сильнее, но для наглядности обойдусь плюсом).
Потеря плюса критична, например, если данные пойдут в стороннюю систему, а та при импорте жестко проверяет формат.
Разбивает по три цифры. Цифровую строку длиннее трех символов Excel, добрая душа, аккуратно разберет. Например, «8 495 5235834» превратит в «84 955 235 834».
Форматирование важно как минимум для телефонных номеров: пробелы отделяют коды страны и города от остального номера и друг от друга. Excel запросто нарушает правильное членение телефона.
Удаляет лидирующие нули. Строку «00523446» Excel превратит в «523446».
А в ИНН, например, первые две цифры — это код региона. Для Республики Алтай он начинается с нуля — «04». Без нуля смысл номера исказится, а проверку формата ИНН вообще не пройдет.
Меняет даты под локальные настройки. Excel с удовольствием исправит номер дома «1/2» на «01.фев». Потому что Windows подсказал, что в таком виде вам удобнее считывать даты.
Побеждаем порчу данных правильным импортом
Если серьезно, в бедах виноват не Excel целиком, а неочевидный способ импорта данных в программу.
По умолчанию Excel применяет к данным в загруженном CSV-файле тип «General» — общий. Из-за него программа распознает цифровые строки как числа. Такой порядок можно победить, используя встроенный инструмент импорта.
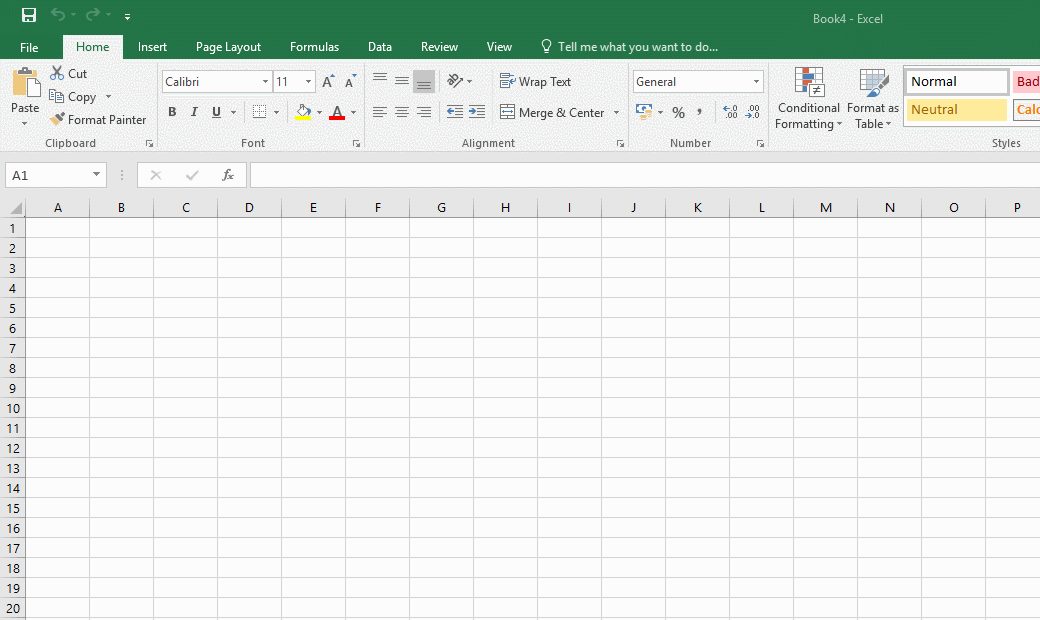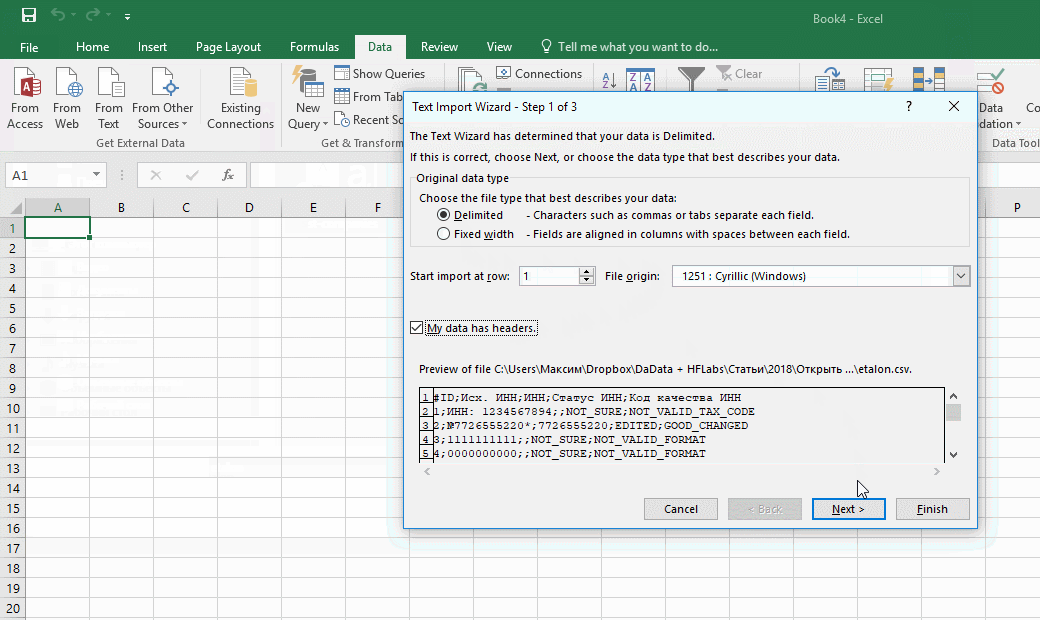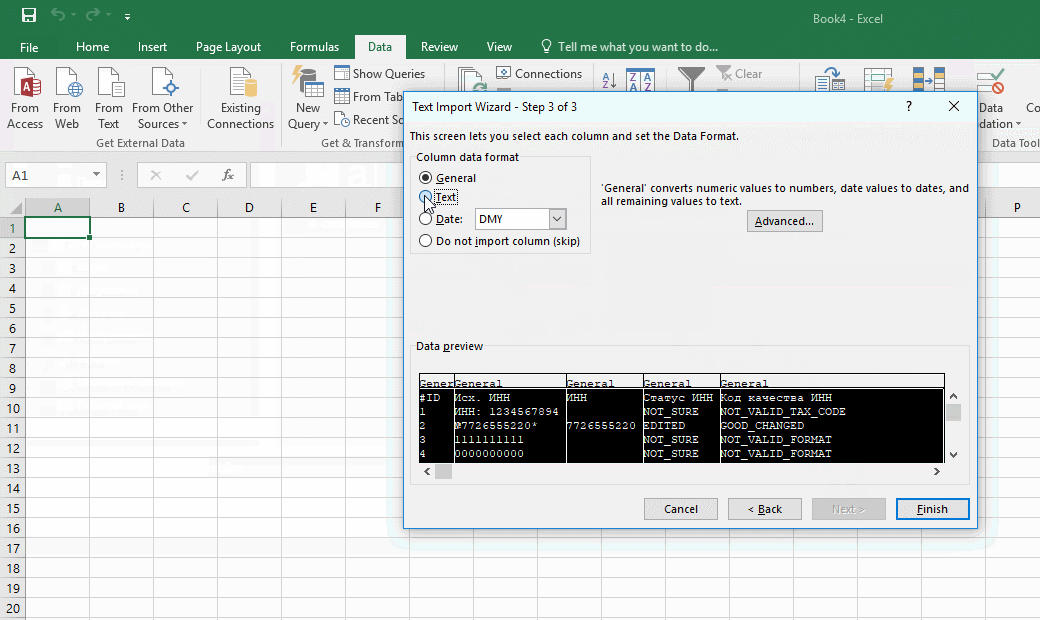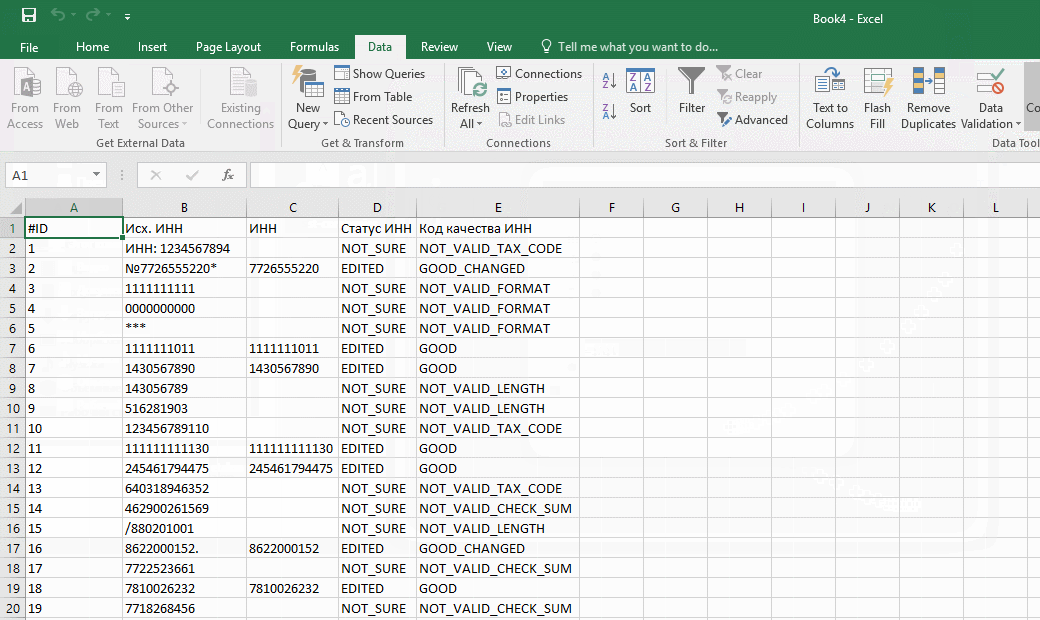
Запускаю встроенный в Excel механизм импорта. В меню это «Data → Get External Data → From Text».
Выбираю CSV-файл с данными, открывается диалог. В диалоге кликаю на тип файла Delimited (с разделителями). Кодировка — та, что в файле, обычно определяется автоматом. Если первая строка файла — шапка, отмечаю «My Data Has Headers».
Перехожу ко второму шагу диалога. Выбираю разделитель полей (обычно это точка с запятой — semicolon). Отключаю «Treat consecutive delimiters as one», а «Text qualifier» выставляю в «». (Text qualifier — это символ начала и конца текста. Если разделитель в CSV — запятая, то text qualifier нужен, чтобы отличать запятые внутри текста от запятых-разделителей.)
На третьем шаге выбираю формат полей, ради него все и затевалось. Для всех столбцов выставляю тип «Text». Кстати, если кликнуть на первую колонку, зажать шифт и кликнуть на последнюю, выделятся сразу все столбцы. Удобно.
Дальше Excel спросит, куда вставлять данные из CSV — можно просто нажать «OK», и данные появятся в открытом листе.
Перед импортом придется создать в Excel новый workbook
Но! Если я планирую добавлять данные в CSV через Excel, придется сделать еще кое-что.
После импорта нужно принудительно привести все-все ячейки на листе к формату «Text». Иначе новые поля приобретут все тот же тип «General».
- Нажимаю два раза Ctrl+A, Excel выбирает все ячейки на листе;
- кликаю правой кнопкой мыши;
- выбираю в контекстном меню «Format Cells»;
- в открывшемся диалоге выбираю слева тип данных «Text».
Чтобы выделить все ячейки, нужно нажать Ctrl+A два раза. Именно два, это не шутка, попробуйте
После этого, если повезет, Excel оставит исходные данные в покое. Но это не самая твердая гарантия, поэтому мы после сохранения обязательно проверяем файл через текстовый просмотрщик.
Альтернатива: Open Office Calc
Для работы с CSV-файлами я использую именно Calc. Он не то чтобы совсем не считает цифровые данные строками, но хотя бы не применяет к ним переформатирование в соответствии с региональными настройками Windows. Да и импорт попроще.
Конечно, понадобится пакет Open Office (OO). При установке он предложит переназначить на себя файлы MS Office. Не рекомендую: хоть OO достаточно функционален, он не до конца понимает хитрое микрософтовское форматирование документов.
А вот назначить OO программой по умолчанию для CSV-файлов — вполне разумно. Сделать это можно после установки пакета.
Итак, запускаем импорт данных из CSV. После двойного клика на файле Open Office показывает диалог.
Заметьте, в OO не нужно создавать новый воркбук и принудительно запускать импорт, все само
- Кодировка — как в файле.
- «Разделитель» — точка с запятой. Естественно, если в файле разделителем выступает именно она.
- «Разделитель текста» — пустой (все то же, что в Excel).
- В разделе «Поля» кликаю в левый-верхний квадрат таблицы, подсвечиваются все колонки. Указываю тип «Текст».
Штука, которая испортила немало крови: если по ошибке выбрать несколько разделителей полей или не тот разделитесь текста, файл может правильно открыться, но неправильно сохраниться.
Помимо Calc у нас в HFLabs популярен libreOffice, особенно под «Линуксом». И то, и другое для CSV применяют активнее, чем Excel.
Бонус-трек: проблемы при сохранении из Calc в .xlsx
Если сохраняете данные из Calc в экселевский формат .xlsx, имейте в виду — OO порой необъяснимо и масштабно теряет данные.

Белая пустошь, раскинувшаяся посередине, в оригинальном CSV-файле богато заполнена данными
Поэтому после сохранения я еще раз открываю файл и убеждаюсь, что данные на месте.
Если что-то потерялись, лечение — пересохранить из CSV в .xlsx. Или, если установлен Windows, импортнуть из CSV в Excel и сохранить оттуда.
После пересохранения обязательно еще раз проверяю, что все данные на месте и нет лишних пустых строк.
Если интересно работать с данными, посмотрите на наши вакансии. HFLabs почти всегда нужны аналитики, тестировщики, инженеры по внедрению, разработчики. Данными обеспечим так, что мало не покажется 🙂
Источник
Как читать и писать CSV-файлы в Python
Russian (Pусский) translation by Ilya Nikov (you can also view the original English article)
Формат CSV является наиболее часто используемым форматом импорта и экспорта для баз данных и электронных таблиц. В этом руководстве будет подробно рассказано о CSV, а также о модулях и классах, доступных для чтения и записи данных в файлы CSV. Также будет рассмотрен рабочий пример, показывающий, как читать и записывать данные в файл CSV на Python.
Что такое файл CSV?
Файл CSV (значения, разделенные запятыми) позволяет сохранять данные в табличной структуре с расширением .csv. CSV-файлы широко используются в приложениях электронной коммерции, поскольку их очень легко обрабатывать. Некоторые из областей, где они были использованы, включают в себя:
- импорт и экспорт данных клиентов
- импорт и экспорт продукции
- экспорт заказов
- экспорт аналитических отчетов по электронной коммерции
Модули для чтения и записи
Модуль CSV имеет несколько функций и классов, доступных для чтения и записи CSV, и они включают в себя:
- функция csv.reader
- функция csv.writer
- класс csv.Dictwriter
- класс csv.DictReader
csv.reader
Модуль csv.reader принимает следующие параметры:
- csvfile : обычно это объект, который поддерживает протокол итератора и обычно возвращает строку каждый раз, когда вызывается его метод __next__() .
- dialect=’excel’: необязательный параметр, используемый для определения набора параметров, специфичных для определенного диалекта CSV.
- fmtparams : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Вот пример того, как использовать модуль csv.reader.
модуль csv.writer
Этот модуль похож на модуль csv.reader и используется для записи данных в CSV. Требуется три параметра:
- csvfile : это может быть любой объект с методом write() .
- dialect = ‘excel’ : необязательный параметр, используемый для определения набора параметров, специфичных для конкретного CSV.
- fmtparam : необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Классы DictReader и DictWriter
DictReader и DictWriter — это классы, доступные в Python для чтения и записи в CSV. Хотя они и похожи на функции чтения и записи, эти классы используют объекты словаря для чтения и записи в CSV-файлы.
DictReader
Он создает объект, который отображает прочитанную информацию в словарь, ключи которого задаются параметром fieldnames . Этот параметр является необязательным, но если он не указан в файле, данные первой строки становятся ключами словаря.
DictWriter
Этот класс аналогичен классу DictWriter и выполняет противоположную функцию: запись данных в файл CSV. Класс определяется как csv.DictWriter(csvfile, fieldnames,restval=», extrasaction=’raise’,dialect=’excel’, *args, **kwds)
Параметр fieldnames определяет последовательность ключей, которые определяют порядок, в котором значения в словаре записываются в файл CSV. В отличие от DictReader, этот ключ не является обязательным и должен быть определен во избежание ошибок при записи в CSV.
Диалекты и форматирование
Диалект — это вспомогательный класс, используемый для определения параметров для конкретного экземпляра reader или writer . Диалекты и параметры форматирования должны быть объявлены при выполнении функции чтения или записи.
Есть несколько атрибутов, которые поддерживаются диалектом:
- delimiter: строка, используемая для разделения полей. По умолчанию это ‘,’ .
- double quote: Управляет тем, как должны появляться в кавычках случаи, когда кавычки появляются внутри поля. Может быть True или False.
- escapechar: строка, используемая автором для экранирования разделителя, если в кавычках задано значение QUOTE_NONE .
- lineterminator: строка, используемая для завершения строк, созданных writer . По умолчанию используется значение ‘rn’ .
- quotechar: строка, используемая для цитирования полей, содержащих специальные символы. По умолчанию это ‘»‘ .
- skipinitialspace: Если установлено значение True , любые пробелы, следующие сразу за разделителем, игнорируются.
- strict: если установлено значение True , возникает Error при неправильном вводе CSV.
- quoting: определяет, когда следует создавать кавычки при чтении или записи в CSV.
Чтение файла CSV
Давайте посмотрим, как читать CSV-файл, используя вспомогательные модули, которые мы обсуждали выше.
Создайте свой CSV-файл и сохраните его как example.csv. Убедитесь, что он имеет расширение .csv и заполните некоторые данные. Здесь у нас есть CSV-файл, который содержит имена учеников и их оценки.



Ниже приведен код для чтения данных в нашем CSV с использованием функции csv.reader и класса csv.DictReader .
Чтение CSV-файла с помощью csv.reader
В приведенном выше коде мы импортируем модуль CSV, а затем открываем наш файл CSV в виде File . Затем мы определяем объект reader и используем метод csv.reader для извлечения данных в объект. Затем мы перебираем объект reader и извлекаем каждую строку наших данных.
Мы показываем прочитанные данные, печатая их содержимое на консоль. Мы также указали обязательные параметры, такие как разделитель, кавычка и цитирование.
Вывод
Чтение CSV-файла с помощью DictReader
Как мы упоминали выше, DictWriter позволяет нам читать CSV-файл, отображая данные в словарь вместо строк, как в случае с модулем csv.reader . Хотя имя поля является необязательным параметром, важно всегда помечать столбцы для удобства чтения.
Вот как читать CSV, используя класс DictWriter.
Сначала мы импортируем модуль csv и инициализируем пустой список results , который мы будем использовать для хранения полученных данных. Затем мы определяем объект reader и используем метод csv.DictReader для извлечения данных в объект. Затем мы перебираем объект reader и извлекаем каждую строку наших данных.
Наконец, мы добавляем каждую строку в список результатов и выводим содержимое на консоль.
Вывод
Как вы можете видеть выше, лучше использовать класс DictReader, потому что он выдает наши данные в формате словаря, с которым легче работать.
Запись в файл CSV
Давайте теперь посмотрим, как приступить к записи данных в файл CSV с использованием функции csv.writer и класса csv.Dictwriter , которые обсуждались в начале этого урока.
Запись в файл CSV с помощью csv.writer
Код ниже записывает данные, определенные в файл example2.csv .
Сначала мы импортируем модуль csv, и функция writer() создаст объект, подходящий для записи. Чтобы перебрать данные по строкам, нам нужно использовать функцию writerows() .
Вот наш CSV с данными, которые мы записали в него.
Запись в файл CSV с использованием DictWriter
Давайте напишем следующие данные в CSV.
Код, как показано ниже.
Сначала мы определим fieldnames , которые будут представлять заголовки каждого столбца в файле CSV. Метод writerrow() будет записывать по одной строке за раз. Если вы хотите записать все данные одновременно, вы будете использовать метод writerrows() .
Вот как можно записать все строки одновременно.
Заключение
В этом руководстве рассматривается большинство вопросов, необходимых для успешного чтения и записи в файл CSV с использованием различных функций и классов, предоставляемых Python. Файлы CSV широко используются в приложениях, потому что их легко читать и управлять ими, а их небольшой размер делает их относительно быстрыми для обработки и передачи.
Не стесняйтесь, и посмотрите, что у нас есть для продажи и для изучения на рынке, и не стесняйтесь задавать любые вопросы и предоставить свой ценный отзыв, используя канал комментариев ниже.
Источник
Продукты HFLabs в промышленных объемах обрабатывают данные: адреса, ФИО, реквизиты компаний и еще вагон всего. Естественно, тестировщики ежедневно с этими данными имеют дело: обновляют тест-кейсы, изучают результаты очистки. Часто заказчики дают «живую» базу, чтобы тестировщик настроил сервис под нее.
Первое, чему мы учим новых QA — сохранять данные в первозданном виде. Все по заветам: «Не навреди». В статье я расскажу, как аккуратно работать с CSV-файлами в Excel и Open Office. Советы помогут ничего не испортить, сохранить информацию после редактирования и в целом чувствовать себя увереннее.
Материал базовый, профессионалы совершенно точно заскучают.
Что такое CSV-файлы
Формат CSV используют, чтобы хранить таблицы в текстовых файлах. Данные очень часто упаковывают именно в таблицы, поэтому CSV-файлы очень популярны.
CSV-файл состоит из строк с данными и разделителей, которые обозначают границы столбцов
CSV расшифровывается как comma-separated values — «значения, разделенные запятыми». Но пусть название вас не обманет: разделителями столбцов в CSV-файле могут служить и точки с запятой, и знаки табуляции. Это все равно будет CSV-файл.
У CSV куча плюсов перед тем же форматом Excel: текстовые файлы просты как пуговица, открываются быстро, читаются на любом устройстве и в любой среде без дополнительных инструментов.
Из-за своих преимуществ CSV — сверхпопулярный формат обмена данными, хотя ему уже лет 40. CSV используют прикладные промышленные программы, в него выгружают данные из баз.
Одна беда — текстового редактора для работы с CSV мало. Еще ничего, если таблица простая: в первом поле ID одной длины, во втором дата одного формата, а в третьем какой-нибудь адрес. Но когда поля разной длины и их больше трех, начинаются мучения.
Следить за разделителями и столбцами — глаза сломаешь
Еще хуже с анализом данных — попробуй «Блокнотом» хотя бы сложить все числа в столбце. Я уж не говорю о красивых графиках.
Поэтому CSV-файлы анализируют и редактируют в Excel и аналогах: Open Office, LibreOffice и прочих.
Ветеранам, которые все же дочитали: ребята, мы знаем об анализе непосредственно в БД c помощью SQL, знаем о Tableau и Talend Open Studio. Это статья для начинающих, а на базовом уровне и небольшом объеме данных Excel с аналогами хватает.
Как Excel портит данные: из классики
Все бы ничего, но Excel, едва открыв CSV-файл, начинает свои лукавые выкрутасы. Он без спроса меняет данные так, что те приходят в негодность. Причем делает это совершенно незаметно. Из-за этого в свое время мы схватили ворох проблем.
Большинство казусов связано с тем, что программа без спроса преобразует строки с набором цифр в числа.
Округляет. Например, в исходной ячейке два телефона хранятся через запятую без пробелов: «5235834,5235835». Что сделает Excel? Лихо превратит номера́ в одно число и округлит до двух цифр после запятой: «5235834,52». Так мы потеряем второй телефон.
Приводит к экспоненциальной форме. Excel заботливо преобразует «123456789012345» в число «1,2E+15». Исходное значение потеряем напрочь.
Проблема актуальна для длинных, символов по пятнадцать, цифровых строк. Например, КЛАДР-кодов (это такой государственный идентификатор адресного объекта: го́рода, у́лицы, до́ма).
Удаляет лидирующие плюсы. Excel считает, что плюс в начале строки с цифрами — совершенно лишний символ. Мол, и так ясно, что число положительное, коль перед ним не стоит минус. Поэтому лидирующий плюс в номере «+74955235834» будет отброшен за ненадобностью — получится «74955235834». (В реальности номер пострадает еще сильнее, но для наглядности обойдусь плюсом).
Потеря плюса критична, например, если данные пойдут в стороннюю систему, а та при импорте жестко проверяет формат.
Разбивает по три цифры. Цифровую строку длиннее трех символов Excel, добрая душа, аккуратно разберет. Например, «8 495 5235834» превратит в «84 955 235 834».
Форматирование важно как минимум для телефонных номеров: пробелы отделяют коды страны и города от остального номера и друг от друга. Excel запросто нарушает правильное членение телефона.
Удаляет лидирующие нули. Строку «00523446» Excel превратит в «523446».
А в ИНН, например, первые две цифры — это код региона. Для Республики Алтай он начинается с нуля — «04». Без нуля смысл номера исказится, а проверку формата ИНН вообще не пройдет.
Меняет даты под локальные настройки. Excel с удовольствием исправит номер дома «1/2» на «01.фев». Потому что Windows подсказал, что в таком виде вам удобнее считывать даты.
Побеждаем порчу данных правильным импортом
Если серьезно, в бедах виноват не Excel целиком, а неочевидный способ импорта данных в программу.
По умолчанию Excel применяет к данным в загруженном CSV-файле тип «General» — общий. Из-за него программа распознает цифровые строки как числа. Такой порядок можно победить, используя встроенный инструмент импорта.
Запускаю встроенный в Excel механизм импорта. В меню это «Data → Get External Data → From Text».
Выбираю CSV-файл с данными, открывается диалог. В диалоге кликаю на тип файла Delimited (с разделителями). Кодировка — та, что в файле, обычно определяется автоматом. Если первая строка файла — шапка, отмечаю «My Data Has Headers».
Перехожу ко второму шагу диалога. Выбираю разделитель полей (обычно это точка с запятой — semicolon). Отключаю «Treat consecutive delimiters as one», а «Text qualifier» выставляю в «{none}». (Text qualifier — это символ начала и конца текста. Если разделитель в CSV — запятая, то text qualifier нужен, чтобы отличать запятые внутри текста от запятых-разделителей.)
На третьем шаге выбираю формат полей, ради него все и затевалось. Для всех столбцов выставляю тип «Text». Кстати, если кликнуть на первую колонку, зажать шифт и кликнуть на последнюю, выделятся сразу все столбцы. Удобно.
Дальше Excel спросит, куда вставлять данные из CSV — можно просто нажать «OK», и данные появятся в открытом листе.
Перед импортом придется создать в Excel новый workbook
Но! Если я планирую добавлять данные в CSV через Excel, придется сделать еще кое-что.
После импорта нужно принудительно привести все-все ячейки на листе к формату «Text». Иначе новые поля приобретут все тот же тип «General».
- Нажимаю два раза Ctrl+A, Excel выбирает все ячейки на листе;
- кликаю правой кнопкой мыши;
- выбираю в контекстном меню «Format Cells»;
- в открывшемся диалоге выбираю слева тип данных «Text».
Чтобы выделить все ячейки, нужно нажать Ctrl+A два раза. Именно два, это не шутка, попробуйте
После этого, если повезет, Excel оставит исходные данные в покое. Но это не самая твердая гарантия, поэтому мы после сохранения обязательно проверяем файл через текстовый просмотрщик.
Альтернатива: Open Office Calc
Для работы с CSV-файлами я использую именно Calc. Он не то чтобы совсем не считает цифровые данные строками, но хотя бы не применяет к ним переформатирование в соответствии с региональными настройками Windows. Да и импорт попроще.
Конечно, понадобится пакет Open Office (OO). При установке он предложит переназначить на себя файлы MS Office. Не рекомендую: хоть OO достаточно функционален, он не до конца понимает хитрое микрософтовское форматирование документов.
А вот назначить OO программой по умолчанию для CSV-файлов — вполне разумно. Сделать это можно после установки пакета.
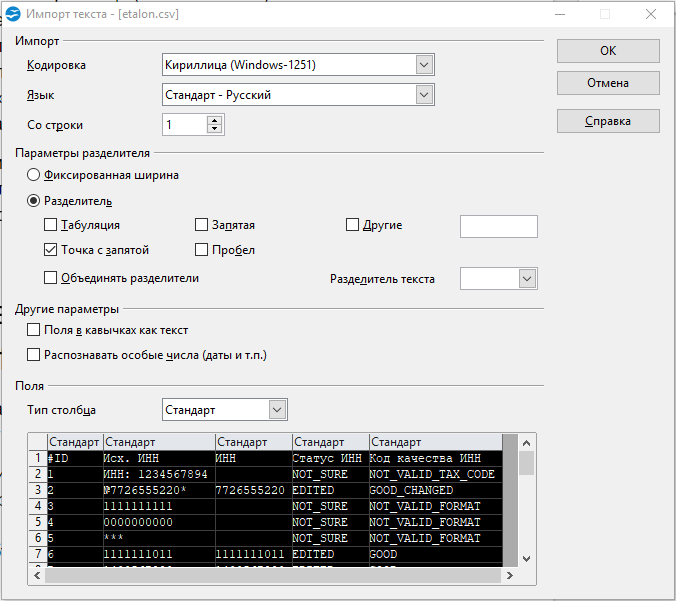
Итак, запускаем импорт данных из CSV. После двойного клика на файле Open Office показывает диалог.
Заметьте, в OO не нужно создавать новый воркбук и принудительно запускать импорт, все само
- Кодировка — как в файле.
- «Разделитель» — точка с запятой. Естественно, если в файле разделителем выступает именно она.
- «Разделитель текста» — пустой (все то же, что в Excel).
- В разделе «Поля» кликаю в левый-верхний квадрат таблицы, подсвечиваются все колонки. Указываю тип «Текст».
Штука, которая испортила немало крови: если по ошибке выбрать несколько разделителей полей или не тот разделитесь текста, файл может правильно открыться, но неправильно сохраниться.
Помимо Calc у нас в HFLabs популярен libreOffice, особенно под «Линуксом». И то, и другое для CSV применяют активнее, чем Excel.
Бонус-трек: проблемы при сохранении из Calc в .xlsx
Если сохраняете данные из Calc в экселевский формат .xlsx, имейте в виду — OO порой необъяснимо и масштабно теряет данные.
Белая пустошь, раскинувшаяся посередине, в оригинальном CSV-файле богато заполнена данными
Поэтому после сохранения я еще раз открываю файл и убеждаюсь, что данные на месте.
Если что-то потерялись, лечение — пересохранить из CSV в .xlsx. Или, если установлен Windows, импортнуть из CSV в Excel и сохранить оттуда.
После пересохранения обязательно еще раз проверяю, что все данные на месте и нет лишних пустых строк.
Если интересно работать с данными, посмотрите на наши вакансии. HFLabs почти всегда нужны аналитики, тестировщики, инженеры по внедрению, разработчики. Данными обеспечим так, что мало не покажется 
Do you need to skip rows while reading CSV file with read_csv in Pandas? If so, this article will show you how to skip first rows of reading file.
Method read_csv has parameter skiprows which can be used as follows:
(1) Skip first rows reading CSV file in Pandas
pd.read_csv(csv_file, skiprows=3, header=None)
(2) Skip rows by index with read_csv
pd.read_csv(csv_file, skiprows=[0,2])
Lets check several practical examples which will cover all aspects of reading CSV file and skipping rows.
To start lets say that we have the next CSV file:
!cat '../data/csv/multine_header.csv'
CSV file with multiple headers (to learn more about reading a CSV file with multiple headers):
Date,Company A,Company A,Company B,Company B
,Rank,Points,Rank,Points
2021-09-06,1,7.9,2,6
2021-09-07,1,8.5,2,7
2021-09-08,2,8,1,8.1
Step 1: Skip first N rows while reading CSV file
First example shows how to skip consecutive rows with Pandas read_csv method.
There are 2 options:
- skip rows in Pandas without using header
- skip first N rows and use header for the DataFrame — check Step 2
In this Step Pandas read_csv method will read data from row 4 (index of this row is 3). The newly created DataFrame will have autogenerated column names:
df = pd.read_csv(csv_file, skiprows=3, header=None)
This will result into:
| 0 | 1 | 2 | 3 | 4 |
|---|---|---|---|---|
| 2021-09-07 | 1 | 8.5 | 2 | 7.0 |
| 2021-09-08 | 2 | 8.0 | 1 | 8.1 |
Step 2: Skip first N rows and use header
If parameter header of method read_csv is not provided than first row will be used as a header. In combination of parameters header and skiprows — first the rows will be skipped and then first on of the remaining will be used as a header.
In the example below 3 rows from the CSV file will be skipped. The forth one will be used as a header of the new DataFrame.
df = pd.read_csv(csv_file, skiprows=3)
| 2021-09-07 | 1 | 8.5 | 2 | 7 |
|---|---|---|---|---|
| 2021-09-08 | 2 | 8 | 1 | 8.1 |
Step 3: Pandas keep the header and skip first rows
What if you need to keep the header and then the skip N rows? This can be achieved in several different ways.
The most simple one is by builing a list of rows which to be skipped:
rows_to_skip = range(1,3)
df = pd.read_csv(csv_file, skiprows=rows_to_skip)
result:
| Date | Company A | Company A.1 | Company B | Company B.1 |
|---|---|---|---|---|
| 2021-09-07 | 1 | 8.5 | 2 | 7.0 |
| 2021-09-08 | 2 | 8.0 | 1 | 8.1 |
As you can see read_csv method keep the header and skip first 2 rows after the header.
Step 4: Skip non consecutive rows with read_csv by index
Parameter skiprows is defined as:
Line numbers to skip (0-indexed) or number of lines to skip (int) at the start of the file.
So to skip rows 0 and 2 we can pass list of values to skiprows:
df = pd.read_csv(csv_file, skiprows=[0,2])
| Unnamed: 0 | Rank | Points | Rank.1 | Points.1 |
|---|---|---|---|---|
| 2021-09-07 | 1 | 8.5 | 2 | 7.0 |
| 2021-09-08 | 2 | 8.0 | 1 | 8.1 |
Resources
- Notebook
- General parsing configuration — skiprows
- pandas.read_csv
Russian (Pусский) translation by Ilya Nikov (you can also view the original English article)
Формат CSV является наиболее часто используемым форматом импорта и экспорта для баз данных и электронных таблиц. В этом руководстве будет подробно рассказано о CSV, а также о модулях и классах, доступных для чтения и записи данных в файлы CSV. Также будет рассмотрен рабочий пример, показывающий, как читать и записывать данные в файл CSV на Python.
Что такое файл CSV?
Файл CSV (значения, разделенные запятыми) позволяет сохранять данные в табличной структуре с расширением .csv. CSV-файлы широко используются в приложениях электронной коммерции, поскольку их очень легко обрабатывать. Некоторые из областей, где они были использованы, включают в себя:
- импорт и экспорт данных клиентов
- импорт и экспорт продукции
- экспорт заказов
- экспорт аналитических отчетов по электронной коммерции
Модули для чтения и записи
Модуль CSV имеет несколько функций и классов, доступных для чтения и записи CSV, и они включают в себя:
- функция csv.reader
- функция csv.writer
- класс csv.Dictwriter
- класс csv.DictReader
csv.reader
Модуль csv.reader принимает следующие параметры:
-
csvfile: обычно это объект, который поддерживает протокол итератора и обычно возвращает строку каждый раз, когда вызывается его метод__next__(). -
dialect='excel': необязательный параметр, используемый для определения набора параметров, специфичных для определенного диалекта CSV. -
fmtparams: необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Вот пример того, как использовать модуль csv.reader.
1 |
import csv |
2 |
|
3 |
with open('example.csv', newline='') as File: |
4 |
reader = csv.reader(File) |
5 |
for row in reader: |
6 |
print(row) |
модуль csv.writer
Этот модуль похож на модуль csv.reader и используется для записи данных в CSV. Требуется три параметра:
-
csvfile: это может быть любой объект с методомwrite(). -
dialect = 'excel': необязательный параметр, используемый для определения набора параметров, специфичных для конкретного CSV. -
fmtparam: необязательный параметр, который можно использовать для переопределения существующих параметров форматирования.
Классы DictReader и DictWriter
DictReader и DictWriter — это классы, доступные в Python для чтения и записи в CSV. Хотя они и похожи на функции чтения и записи, эти классы используют объекты словаря для чтения и записи в CSV-файлы.
DictReader
Он создает объект, который отображает прочитанную информацию в словарь, ключи которого задаются параметром fieldnames. Этот параметр является необязательным, но если он не указан в файле, данные первой строки становятся ключами словаря.
Пример:
1 |
import csv |
2 |
with open('name.csv') as csvfile: |
3 |
reader = csv.DictReader(csvfile) |
4 |
for row in reader: |
5 |
print(row['first_name'], row['last_name']) |
DictWriter
Этот класс аналогичен классу DictWriter и выполняет противоположную функцию: запись данных в файл CSV. Класс определяется как csv.DictWriter(csvfile, fieldnames,restval='', extrasaction='raise',dialect='excel', *args, **kwds)
Параметр fieldnames определяет последовательность ключей, которые определяют порядок, в котором значения в словаре записываются в файл CSV. В отличие от DictReader, этот ключ не является обязательным и должен быть определен во избежание ошибок при записи в CSV.
Диалекты и форматирование
Диалект — это вспомогательный класс, используемый для определения параметров для конкретного экземпляра reader или writer. Диалекты и параметры форматирования должны быть объявлены при выполнении функции чтения или записи.
Есть несколько атрибутов, которые поддерживаются диалектом:
- delimiter: строка, используемая для разделения полей. По умолчанию это
','. - double quote: Управляет тем, как должны появляться в кавычках случаи, когда кавычки появляются внутри поля. Может быть True или False.
- escapechar: строка, используемая автором для экранирования разделителя, если в кавычках задано значение
QUOTE_NONE. - lineterminator: строка, используемая для завершения строк, созданных
writer. По умолчанию используется значение'rn'. - quotechar: строка, используемая для цитирования полей, содержащих специальные символы. По умолчанию это
'"'. - skipinitialspace: Если установлено значение
True, любые пробелы, следующие сразу за разделителем, игнорируются. - strict: если установлено значение
True, возникает Error при неправильном вводе CSV. - quoting: определяет, когда следует создавать кавычки при чтении или записи в CSV.
Чтение файла CSV
Давайте посмотрим, как читать CSV-файл, используя вспомогательные модули, которые мы обсуждали выше.
Создайте свой CSV-файл и сохраните его как example.csv. Убедитесь, что он имеет расширение .csv и заполните некоторые данные. Здесь у нас есть CSV-файл, который содержит имена учеников и их оценки.
Ниже приведен код для чтения данных в нашем CSV с использованием функции csv.reader и класса csv.DictReader.
Чтение CSV-файла с помощью csv.reader
1 |
import csv |
2 |
|
3 |
with open('example.csv') as File: |
4 |
reader = csv.reader(File, delimiter=',', quotechar=',', |
5 |
quoting=csv.QUOTE_MINIMAL) |
6 |
for row in reader: |
7 |
print(row) |
В приведенном выше коде мы импортируем модуль CSV, а затем открываем наш файл CSV в виде File. Затем мы определяем объект reader и используем метод csv.reader для извлечения данных в объект. Затем мы перебираем объект reader и извлекаем каждую строку наших данных.
Мы показываем прочитанные данные, печатая их содержимое на консоль. Мы также указали обязательные параметры, такие как разделитель, кавычка и цитирование.
Вывод
1 |
['first_name', 'last_name', 'Grade'] |
2 |
['Alex', 'Brian', 'B'] |
3 |
['Rachael', 'Rodriguez', 'A'] |
4 |
['Tom', 'smith', 'C'] |
Чтение CSV-файла с помощью DictReader
Как мы упоминали выше, DictWriter позволяет нам читать CSV-файл, отображая данные в словарь вместо строк, как в случае с модулем csv.reader. Хотя имя поля является необязательным параметром, важно всегда помечать столбцы для удобства чтения.
Вот как читать CSV, используя класс DictWriter.
1 |
import csv |
2 |
|
3 |
results = [] |
4 |
with open('example.csv') as File: |
5 |
reader = csv.DictReader(File) |
6 |
for row in reader: |
7 |
results.append(row) |
8 |
print results |
Сначала мы импортируем модуль csv и инициализируем пустой список results, который мы будем использовать для хранения полученных данных. Затем мы определяем объект reader и используем метод csv.DictReader для извлечения данных в объект. Затем мы перебираем объект reader и извлекаем каждую строку наших данных.
Наконец, мы добавляем каждую строку в список результатов и выводим содержимое на консоль.
Вывод
1 |
[{'Grade': 'B', 'first_name': 'Alex', 'last_name': 'Brian'}, |
2 |
{'Grade': 'A', 'first_name': 'Rachael', 'last_name': 'Rodriguez'}, |
3 |
{'Grade': 'C', 'first_name': 'Tom', 'last_name': 'smith'}, |
4 |
{'Grade': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'}, |
5 |
{'Grade': 'A', 'first_name': 'Kennzy', 'last_name': 'Tim'}] |
Как вы можете видеть выше, лучше использовать класс DictReader, потому что он выдает наши данные в формате словаря, с которым легче работать.
Запись в файл CSV
Давайте теперь посмотрим, как приступить к записи данных в файл CSV с использованием функции csv.writer и класса csv.Dictwriter, которые обсуждались в начале этого урока.
Запись в файл CSV с помощью csv.writer
Код ниже записывает данные, определенные в файл example2.csv.
1 |
import csv |
2 |
|
3 |
myData = [["first_name", "second_name", "Grade"], |
4 |
['Alex', 'Brian', 'A'], |
5 |
['Tom', 'Smith', 'B']] |
6 |
|
7 |
myFile = open('example2.csv', 'w') |
8 |
with myFile: |
9 |
writer = csv.writer(myFile) |
10 |
writer.writerows(myData) |
11 |
|
12 |
print("Writing complete") |
Сначала мы импортируем модуль csv, и функция writer() создаст объект, подходящий для записи. Чтобы перебрать данные по строкам, нам нужно использовать функцию writerows().
Вот наш CSV с данными, которые мы записали в него.
Запись в файл CSV с использованием DictWriter
Давайте напишем следующие данные в CSV.
1 |
data = [{'Grade': 'B', 'first_name': 'Alex', 'last_name': 'Brian'}, |
2 |
{'Grade': 'A', 'first_name': 'Rachael', 'last_name': 'Rodriguez'}, |
3 |
{'Grade': 'C', 'first_name': 'Tom', 'last_name': 'smith'}, |
4 |
{'Grade': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'}, |
5 |
{'Grade': 'A', 'first_name': 'Kennzy', 'last_name': 'Tim'}] |
6 |
|
7 |
Код, как показано ниже.
1 |
import csv |
2 |
|
3 |
with open('example4.csv', 'w') as csvfile: |
4 |
fieldnames = ['first_name', 'last_name', 'Grade'] |
5 |
writer = csv.DictWriter(csvfile, fieldnames=fieldnames) |
6 |
|
7 |
writer.writeheader() |
8 |
writer.writerow({'Grade': 'B', 'first_name': 'Alex', 'last_name': 'Brian'}) |
9 |
writer.writerow({'Grade': 'A', 'first_name': 'Rachael', |
10 |
'last_name': 'Rodriguez'}) |
11 |
writer.writerow({'Grade': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'}) |
12 |
writer.writerow({'Grade': 'B', 'first_name': 'Jane', 'last_name': 'Loive'}) |
13 |
|
14 |
print("Writing complete") |
Сначала мы определим fieldnames, которые будут представлять заголовки каждого столбца в файле CSV. Метод writerrow() будет записывать по одной строке за раз. Если вы хотите записать все данные одновременно, вы будете использовать метод writerrows().
Вот как можно записать все строки одновременно.
1 |
import csv |
2 |
|
3 |
with open('example5.csv', 'w') as csvfile: |
4 |
fieldnames = ['first_name', 'last_name', 'Grade'] |
5 |
writer = csv.DictWriter(csvfile, fieldnames=fieldnames) |
6 |
|
7 |
writer.writeheader() |
8 |
writer.writerows([{'Grade': 'B', 'first_name': 'Alex', 'last_name': 'Brian'}, |
9 |
{'Grade': 'A', 'first_name': 'Rachael', |
10 |
'last_name': 'Rodriguez'}, |
11 |
{'Grade': 'C', 'first_name': 'Tom', 'last_name': 'smith'}, |
12 |
{'Grade': 'B', 'first_name': 'Jane', 'last_name': 'Oscar'}, |
13 |
{'Grade': 'A', 'first_name': 'Kennzy', 'last_name': 'Tim'}]) |
14 |
|
15 |
print("writing complete") |
Заключение
В этом руководстве рассматривается большинство вопросов, необходимых для успешного чтения и записи в файл CSV с использованием различных функций и классов, предоставляемых Python. Файлы CSV широко используются в приложениях, потому что их легко читать и управлять ими, а их небольшой размер делает их относительно быстрыми для обработки и передачи.
Не стесняйтесь, и посмотрите, что у нас есть для продажи и для изучения на рынке, и не стесняйтесь задавать любые вопросы и предоставить свой ценный отзыв, используя канал комментариев ниже.
Я уже просмотрел все похожие посты по этому вопросу, но не смог найти решения …
До сих пор Панды без проблем просматривали все мои CSV-файлы, однако теперь, похоже, проблема …
При выполнении:
df = pd.read_csv(r'path to file', sep=';')
Я получил:
OSError Traceback (последний вызов был последним) в () —-> 1 df = pd.read_csv (r’path Übersicht Input test test.csv ‘, sep =’; ‘)
c: program files python36 lib site-packages pandas io parsers.py в parser_f (filepath_or_buffer, sep, delimiter, header, names, index_col, usecols, сжатие, префикс, mangle_dupe_cols, dtype, движок, конвертеры, true_values, false_values, skipinitialspace, skiprows, nrows, na_values, keep_default_na, na_filter, verbose, skip_blank_lines, parse_dates, infer_datetime_format, keep_date_col, date_parser, dayfirst, итератор, chunksize, сжатие, тысячи, десятичное, lineterminator, quotechar, цитирование, escapechar, комментарий, кодировка, диалект, tupleize_cols, error_bad_lines, warn_bad_lines, skipfooter, skip_footer, doublequote, delim_whitespace, as_recarray, compact_ints, use_unsigned, low_memory, buffer_lines, memory_map, float_precision) 703 skip_blank_lines = skip_blank_lines) 704 -> 705 return _read (filepath_or_buffer, kwds) 706 707 parser_f. name = имя
c: program files python36 lib site-packages pandas io parsers.py в _read (filepath_or_buffer, kwds) 443 444 # Создать анализатор. -> 445 parser = TextFileReader (filepath_or_buffer, ** kwds) 446 447, если размер фрагмента или итератор:
c: program files python36 lib site-packages pandas io parsers.py в init (self, f, engine, ** kwds) 812 self.options [‘has_index_names’] = kwds [‘has_index_names’] 813 -> 814 self._make_engine (самодвигатель) 815 816 def закрыть (сам):
c: program files python36 lib site-packages pandas io parsers.py в _make_engine (self, engine) 1043 def _make_engine (self, engine = ‘c’): 1044, если engine == ‘c’: -> 1045 self._engine = CParserWrapper (self.f, ** self.options) 1046 else: 1047, если engine == ‘python’:
c: program files python36 lib site-packages pandas io parsers.py в init (self, src, ** kwds) 1682 kwds [‘allow_leading_cols’] = self.index_col is not False 1683 -> 1684 self._reader = parsers.TextReader (src, ** kwds) 1685 1686 # XXX
pandas_libs parsers.pyx в pandas._libs.parsers.TextReader . < сильный > CInit ( )
pandas_libs parsers.pyx в pandas._libs.parsers.TextReader._setup_parser_source ()
Ошибка OSE: Ошибка инициализации из файла
Другие файлы в той же папке, которые являются файлами XLS, могут быть доступны без проблем.
При использовании библиотеки Python вот так:
import csv
file = csv.reader(open(r'pathtofile'))
for row in file:
print(row)
break
df = pd.read_csv(file, sep=';')
Файл загружается и печатается первая строка, однако я получаю:
ValueError: Неверный путь к файлу или тип объекта буфера:
Возможно, потому что я не могу использовать read_csv таким образом …
Любая помощь, желательно, чтобы заставить работать первую функцию Панд? К сожалению, я не могу поделиться CSV … он не должен содержать никаких специальных символов, кроме немецких .. Размер файла составляет 10 МБ …
11 ответов
Лучший ответ
Я столкнулся с подобной проблемой. Оказалось, что загруженный мной CSV не имеет никаких разрешений. Сообщение об ошибке от pandas не указывало на это, затрудняя отладку.
Убедитесь, что у вашего файла есть права на чтение
42
Petter Friberg
11 Сен 2018 в 20:52
Та же проблема, другое решение здесь.
Ранее я пытался загрузить свой файл в Excel, и Excel потерпел крах, но, должно быть, сохранил некоторую блокировку файла, потому что после принудительного выхода из Excel он загрузился, как и ожидалось.
0
gkennos
23 Апр 2019 в 22:54
У меня была та же проблема, и, поскольку я только что установил другой пакет, я понял, что проблема может быть связана с той недавней установкой, которая может внести некоторые изменения в пакет pandas. Я попытался удалить панд и переустановить его, и он работал отлично, как и раньше.
Сначала удалите панд:
conda remove pandas
Затем переустановите его, используя:
conda install -c anaconda pandas
0
Natheer Alabsi
8 Ноя 2019 в 07:56
import pandas as pd
pd.read_csv("your_file.txt", engine='python')
Попробуй это. Это полностью сработало для меня.
- источник: http://kkckc.tistory.com/187
45
Dane Lee
6 Авг 2018 в 22:11
Я предполагаю, что ваш CSV-файл находится в том же месте (корень). Если вы просто хотите, чтобы файл csv был прочитан, и получил результат, который будет отображаться в виде текста в вашей консоли, просто сделайте это
import csv
with open('your_file.csv', 'r') as csvFile:
reader = csv.reader(csvFile)
for row in reader:
print(row)
csvFile.close()
Примечание: код для Python 3, если вы используете Python 2, синтаксис печати используется без скобок. Надеюсь, что это поможет вам
1
Ranee
27 Май 2018 в 14:59
Вы можете попробовать использовать os.path.join() для построения вашего пути:
import os
rpath = os.path.join('U:','folder','Input','test.csv')
df = pd.read_csv(rpath, sep=';')
Чтобы пройти путь на основе вашего родительского каталога, вы можете использовать:
os.path.pardir
1
vll
10 Сен 2018 в 05:46
У меня была та же проблема, вы должны проверить свои разрешения.
После chmod 644 file.csv это сработало хорошо.
22
Kornel Dylski
30 Ноя 2018 в 12:15
Столкнулся с той же проблемой на окнах. Пытался использовать решение, предоставленное Дэном Ли, но получал ненормальные результаты со строками и столбцами. Я не уверен, было ли это из-за японских символов в моих файлах csv или нет, но четкое определение формата кодировки решило проблему для меня.
import pandas as pd
pd.read_csv("your_file.txt", engine='python', encoding = "utf-8-sig")
2
kunal Vyas
26 Апр 2019 в 02:35
Та же проблема, когда я пытался загрузить файлы с японскими именами файлов.
import pandas as pd
result = pd.read_csv('./result/けっこう.csv')
OSError: Initializing from file failed'
Затем я добавил аргумент engine="python".
result = pd.read_csv('./result/けっこう.csv', engine="python")
У меня это сработало.
3
QaraQoyunlu
3 Июл 2019 в 03:34
Pandas read_csv OSError: Ошибка инициализации из файла
Мы могли бы попробовать chmod 600 file.csv.
0
icanxy
15 Июн 2019 в 06:15
Просто измените права доступа к CSV-файлу, это будет работать
Chmod 750 filename.csv (в командной строке)
Или
! chmod 750 filename.csv (в блокноте jupyter)
0
kali prasad deverasetti
28 Июн 2019 в 06:45