For your use case example, ping 1.1.1.1, 2 packets are involved per ping. An outgoing ICMP echo request packet and an incoming ICMP echo reply packet, at least if the destination does reply.
The succinct answer to your first question: «Why do I not have an internet when I forbid all incoming traffic?» is because you denied all incoming traffic, so nobody can respond.
Now, for your second question: «How to fix?»:
iptables is capable of looking at a packet and determining if it is a reply or somehow RELATED to a previous outgoing, locally initiated, packet. Therefore you can make an iptables rule to allow this type of packet to get past the INPUT chain DROP default packet handler:
sudo iptables -A INPUT -i enp3s0 -d 109.108.244.148 -m state --state ESTABLISHED,RELATED -j ACCEPT
Note: you should also allow the local network connection, as sometimes internal tasks communicate via this interface:
sudo iptables -A INPUT -i lo -j ACCEPT
Below is an example implementation of this answer, using your example pings:
doug@s18:~$ ping -c 2 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=60 time=24.6 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=60 time=25.9 ms
--- 1.1.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1002ms
rtt min/avg/max/mdev = 24.597/25.260/25.923/0.663 ms
doug@s18:~$ sudo iptables -P INPUT DROP
doug@s18:~$ ping -c 2 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
--- 1.1.1.1 ping statistics ---
2 packets transmitted, 0 received, 100% packet loss, time 1061ms
doug@s18:~$ sudo iptables -A INPUT -i enp3s0 -d 192.168.111.122 -m state --state ESTABLISHED,RELATED -j ACCEPT
doug@s18:~$ ping -c 2 1.1.1.1
PING 1.1.1.1 (1.1.1.1) 56(84) bytes of data.
64 bytes from 1.1.1.1: icmp_seq=1 ttl=60 time=25.1 ms
64 bytes from 1.1.1.1: icmp_seq=2 ttl=60 time=24.9 ms
--- 1.1.1.1 ping statistics ---
2 packets transmitted, 2 received, 0% packet loss, time 1001ms
rtt min/avg/max/mdev = 24.911/25.012/25.113/0.101 ms
 Приветствую всех! В продолжении теории iptables публикую данную практическую статью о сетевом фильтре Linux. В статье рассмотрю типовые примеры реализации правил iptables в Linux, а так же рассмотрим способы сохранения созданной конфигурации iptables.
Приветствую всех! В продолжении теории iptables публикую данную практическую статью о сетевом фильтре Linux. В статье рассмотрю типовые примеры реализации правил iptables в Linux, а так же рассмотрим способы сохранения созданной конфигурации iptables.
Настройка netfilter/iptables для рабочей станции
Давайте начнем с элементарной задачи — реализация сетевого экрана Linux на десктопе. В большинстве случаев на десктопных дистрибутивах линукса нет острой необходимости использовать файервол, т.к. на таких дистрибутивах не запущены какие-либо сервисы, слушающие сетевые порты, но ради профилактики организовать защиту не будет лишним. Ибо ядро тоже не застраховано от дыр. Итак, мы имеем Linux, с настроенным сетевым интерфейсом eth0, не важно по DHCP или статически…
Для настройки сетевого экрана я стараюсь придерживаться следующей политики: запретить все, а потом то, что нужно разрешить. Так и поступим в данном случае. Если у вас свежеустановленная система и вы не пытались настроить на ней сетевой фильтр, то правила будут иметь примерно следующую картину:
netfilter:~# iptables -L Chain INPUT (policy ACCEPT) target prot opt source destination Chain FORWARD (policy ACCEPT) target prot opt source destination Chain OUTPUT (policy ACCEPT) target prot opt source destination
Это значит, что политика по умолчанию для таблицы filter во всех цепочках — ACCEPT и нет никаких других правил, что-либо запрещающих. Поэтому давайте сначала запретим ВСЁ входящие, исходящие и проходящие пакеты (не вздумайте это делать удаленно-тут же потеряете доступ):
netfilter:~# iptables -P INPUT DROP netfilter:~# iptables -P OUTPUT DROP netfilter:~# iptables -P FORWARD DROP
Этими командами мы устанавливаем политику DROP по умолчанию. Это значит, что любой пакет, для которого явно не задано правило, которое его разрешает, автоматически отбрасывается. Поскольку пока еще у нас не задано ни одно правило — будут отвергнуты все пакеты, которые придут на ваш компьютер, равно как и те, которые вы попытаетесь отправить в сеть. В качестве демонстрации можно попробовать пропинговать свой компьютер через интерфейс обратной петли:
netfilter:~# ping -c2 127.0.0.1 PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data. ping: sendmsg: Operation not permitted ping: sendmsg: Operation not permitted --- localhost ping statistics --- 2 packets transmitted, 0 received, 100% packet loss, time 1004ms
На самом деле это полностью не функционирующая сеть и это не очень хорошо, т.к. некоторые демоны используют для обмена между собой петлевой интерфейс, который после проделанных действий более не функционирует. Это может нарушить работу подобных сервисов. Поэтому в первую очередь в обязательно разрешим передачу пакетов через входящий петлевой интерфейс и исходящий петлевой интерфейс в таблицах INPUT (для возможности получения отправленных пакетов) и OUTPUT (для возможности отправки пакетов) соответственно. Итак, обязательно выполняем:
netfilter:~# iptables -A INPUT -i lo -j ACCEPT netfilter:~# iptables -A OUTPUT -o lo -j ACCEPT
После этого пинг на локалхост заработает:
netfilter:~# ping -c1 127.0.0.1 PING 127.0.0.1 (127.0.0.1) 56(84) bytes of data. 64 bytes from 127.0.0.1 (127.0.0.1): icmp_seq=1 ttl=64 time=0.116 ms --- 127.0.0.1 ping statistics --- 1 packets transmitted, 1 received, 0% packet loss, time 116ms rtt min/avg/max/mdev = 0.116/0.116/0.116/0.116 ms
Если подходить к настройке файервола не шибко фанатично, то можно разрешить работу протокола ICMP:
netfilter:~# iptables -A INPUT -p icmp -j ACCEPT netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT
Более безопасно будет указать следующую аналогичную команду iptables:
netfilter:~# iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT
Данная команда разрешит типы ICMP пакета эхо-запрос и эхо-ответ, что повысит безопасность.
Зная, что наш комп не заражен (ведь это так?) и он устанавливает только безопасные исходящие соединения. А так же, зная, что безопасные соединения — это соединения из т.н. эфимерного диапазона портов, который задается ядром в файле /proc/sys/net/ipv4/ip_local_port_range, можно разрешить исходящие соединения с этих безопасных портов:
netfilter:~# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000 netfilter:~# iptables -A OUTPUT -p TCP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A OUTPUT -p UDP --sport 32768:61000 -j ACCEPT
Если подходить к ограничению исходящих пакетов не параноидально, то можно было ограничиться одной командой iptables, разрешающей все исхолящие соединения оп всем протоколам и портам:
netfilter:~# iptables -A OUTPUT -j ACCEPT netfilter:~# # или просто задать политику по умолчанию ACCEPT для цепочки OUTPUT netfilter:~# iptables -P OUTPUT ACCEPT
Далее, зная что в netfilter сетевые соединения имеют 4 состояния (NEW, ESTABLISHED, RELATED и INVALID) и новые исходящие соединения с локального компьютера (с состоянием NEW) у нас разрешены в прошлых двух командах iptables, что уже установленные соединения и дополнительные имеют состояния ESTABLISHED и RELATED, соответственно, а так же зная, что входящие соединения к локальной системе приходят через цепочку INPUT, можно разрешить попадание на наш компьютер только тех TCP- и UDP-пакетов, которые были запрошены локальными приложениями:
netfilter:~# iptables -A INPUT -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A INPUT -p UDP -m state --state ESTABLISHED,RELATED -j ACCEPT
Это собственно, все! Если на десктопе все же работает какая-то сетевая служба, то необходимо добавить соответствующие правила для входящих соединений и для исходящих. Например, для работы ssh-сервера, который принимает и отправляет запросы на 22 TCP-порту, необходимо добавить следующие iptables-правила:
netfilter:~# iptables -A INPUT -i eth0 -p TCP --dport 22 -j ACCEPT netfilter:~# iptables -A OUTPUT -o eth0 -p TCP --sport 22 -j ACCEPT
Т.е. для любого сервиса нужно добавить по одному правилу в цепочки INPUT и OUTPUT, разрешающему соответственно прием и отправку пакетов с использованием этого порта для конкретного сетевого интерфейса (если интерфейс не указывать, то будет разрешено принимать/отправлять пакеты по любому интерфейсу).
Настройка netfilter/iptables для подключения нескольких клиентов к одному соединению.
Давайте теперь рассмотрим наш Linux в качестве шлюза для локальной сети во внешнюю сеть Internet. Предположим, что интерфейс eth0 подключен к интернету и имеет IP 198.166.0.200, а интерфейс eth1 подключен к локальной сети и имеет IP 10.0.0.1. По умолчанию, в ядре Linux пересылка пакетов через цепочку FORWARD (пакетов, не предназначенных локальной системе) отключена. Чтобы включить данную функцию, необходимо задать значение 1 в файле /proc/sys/net/ipv4/ip_forward:
netfilter:~# echo 1 > /proc/sys/net/ipv4/ip_forward
Чтобы форвардинг пакетов сохранился после перезагрузки, необходимо в файле /etc/sysctl.conf раскомментировать (или просто добавить) строку net.ipv4.ip_forward=1.
Итак, у нас есть внешний адрес (198.166.0.200), в локальной сети имеется некоторое количество гипотетических клиентов, которые имеют адреса из диапазона локальной сети и посылают запросы во внешнюю сеть. Если эти клиенты будут отправлять во внешнюю сеть запросы через шлюз «как есть», без преобразования, то удаленный сервер не сможет на них ответить, т.к. обратным адресом будет получатель из «локальной сети». Для того, чтобы эта схема корректно работала, необходимо подменять адрес отправителя, на внешний адрес шлюза Linux. Это достигается за счет действия MASQUERADE (маскарадинг) в цепочке POSTROUTING, в таблице nat.
netfilter:~# iptables -A FORWARD -m conntrack --ctstate ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A FORWARD -m conntrack --ctstate NEW -i eth1 -s 10.0.0.1/24 -j ACCEPT netfilter:~# iptables -P FORWARD DROP netfilter:~# iptables -t nat -A POSTROUTING -o eth0 -j MASQUERADE
Итак, по порядку сверху-вниз мы разрешаем уже установленные соединения в цепочке FORWARD, таблице filter, далее мы разрешаем устанавливать новые соединения в цепочке FORWARD, таблице filter, которые пришли с интерфейса eth1 и из сети 10.0.0.1/24. Все остальные пакеты, которые проходят через цепочку FORWARD — отбрасывать. Далее, выполняем маскирование (подмену адреса отправителя пакета в заголовках) всех пакетов, исходящих с интерфейса eth0.
Примечание. Есть некая общая рекомендация: использовать правило -j MASQUERADE для интерфейсов с динамически получаемым IP (например, по DHCP от провайдера). При статическом IP, -j MASQUERADE можно заменить на аналогичное -j SNAT —to-source IP_интерфейса_eth0. Кроме того, SNAT умеет «помнить» об установленных соединениях при кратковременной недоступности интерфейса. Сравнение MASQUERADE и SNAT в таблице:
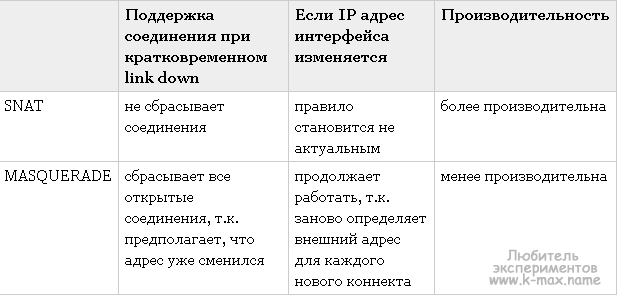
Кроме указанных правил так же можно нужно добавить правила для фильтрации пакетов, предназначенных локальному хосту — как описано в прошлом разделе. То есть добавить запрещающие и разрешающие правила для входящих и исходящих соединений:
netfilter:~# iptables -P INPUT DROP netfilter:~# iptables -P OUTPUT DROP netfilter:~# iptables -A INPUT -i lo -j ACCEPT netfilter:~# iptables -A OUTPUT -o lo -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 0 -j ACCEPT netfilter:~# iptables -A INPUT -p icmp --icmp-type 8 -j ACCEPT netfilter:~# iptables -A OUTPUT -p icmp -j ACCEPT netfilter:~# cat /proc/sys/net/ipv4/ip_local_port_range 32768 61000 netfilter:~# iptables -A OUTPUT -p TCP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A OUTPUT -p UDP --sport 32768:61000 -j ACCEPT netfilter:~# iptables -A INPUT -p TCP -m state --state ESTABLISHED,RELATED -j ACCEPT netfilter:~# iptables -A INPUT -p UDP -m state --state ESTABLISHED,RELATED -j ACCEPT
В результате, если один из хостов локальной сети, например 10.0.0.2, попытается связаться с одним из интернет-хостов, например, 93.158.134.3 (ya.ru), при проходе его пакетов через шлюз, их исходный адрес будет подменяться на внешний адрес шлюза в цепочке POSTROUTING таблице nat, то есть исходящий IP 10.0.0.2 будет заменен на 198.166.0.200. С точки зрения удаленного хоста (ya.ru), это будет выглядеть, как будто с ним связывается непосредственно сам шлюз. Когда же удаленный хост начнет ответную передачу данных, он будет адресовать их именно шлюзу, то есть 198.166.0.200. Однако, на шлюзе адрес назначения этих пакетов будет подменяться на 10.0.0.2, после чего пакеты будут передаваться настоящему получателю в локальной сети. Для такого обратного преобразования никаких дополнительных правил указывать не нужно — это будет делать все та же операция MASQUERADE, которая помнит какой хост из локальной сети отправил запрос и какому хосту необходимо вернуть пришедший ответ.
Примечание: желательно негласно принято, перед всеми командами iptables очищать цепочки, в которые будут добавляться правила:
netfilter:~# iptables -F ИМЯ_ЦЕПОЧКИ
Предоставление доступа к сервисам на шлюзе
Предположим, что на нашем шлюзе запущен некий сервис, который должен отвечать на запросы поступающие из сети интернет. Допустим он работает на некотором TCP порту nn. Чтобы предоставить доступ к данной службе, необходимо модифицировать таблицу filter в цепочке INPUT (для возможности получения сетевых пакетов, адресованных локальному сервису) и таблицу filter в цепочке OUTPUT (для разрешения ответов на пришедшие запросы).
Итак, мы имеем настроенный шлюз, который маскарадит (заменяет адрес отправителя на врешний) пакеты во внешнюю сеть. И разрешает принимать все установленные соединения. Предоставление доступа к сервису будет осуществляться с помощью следующих разрешающих правил:
netfilter:~# iptables -A INPUT -p TCP --dport nn -j ACCEPT netfilter:~# iptables -A OUTPUT -p TCP --sport nn -j ACCEPT
Данные правила разрешают входящие соединения по протоколу tcp на порт nn и исходящие соединения по протоколу tcp с порта nn. Кроме этого, можно добавить дополнительные ограничивающие параметры, например разрешить входящие соединения только с внешнего интерфейса eth0 (ключ -i eth0) и т.п.
Предоставление доступа к сервисам в локальной сети
Предположим, что в нашей локальной сети имеется какой-то хост с IP X.Y.Z.1, который должен отвечать на сетевые запросы из внешней сети на TCP-порту xxx. Для того чтобы при обращении удаленного клиента ко внешнему IP на порт xxx происходил корректный ответ сервиса из локальной сети, необходимо направить запросы, приходящие на внешний IP порт xxx на соответствующий хост в локальной сети. Это достигается модификацией адреса получателя в пакете, приходящем на указанный порт. Это действие называется DNAT и применяется в цепочке PREROUTING в таблице nat. А так же разрешить прохождение данный пакетов в цепочке FORWARD в таблице filter.
Опять же, пойдем по пути прошлого раздела. Итак, мы имеем настроенный шлюз, который маскарадит (заменяет адрес отправителя на врешний) пакеты во внешнюю сеть. И разрешает принимать все установленные соединения. Предоставление доступа к сервису будет осуществляться с помощью следующих разрешающих правил:
netfilter:~# iptables -t nat -A PREROUTING -p tcp -d 198.166.0.200 --dport xxx -j DNAT --to-destination X.Y.Z.1 netfilter:~# iptables -A FORWARD -i eth0 -p tcp -d X.Y.Z.1 --dport xxx -j ACCEPT
Сохранение введенных правил при перезагрузке
Все введенные в консоли правила — после перезагрузки ОС будут сброшены в первоначальное состояние (читай — удалены). Для того чтобы сохранить все введенные команды iptables, существует несколько путей. Например, один из них — задать все правила брандмауэра в файле инициализации rc.local. Но у данного способа есть существенный недостаток: весь промежуток времени с запуска сетевой подсистемы, до запуска последней службы и далее скрипта rc.local из SystemV операционная система будет не защищена. Представьте ситуацию, например, если какая-нибудь служба (например NFS) стартует последней и при ее запуске произойдет какой-либо сбой и до запуска скрипта rc.local. Соответственно, rc.local так и не запуститься, а наша система превращается в одну большую дыру.
Поэтому самой лучшей идеей будет инициализировать правила netfilter/iptables при загрузке сетевой подсистемы. Для этого в Debian есть отличный инструмент — каталог /etc/network/if-up.d/, в который можно поместить скрипты, которые будут запускаться при старте сети. А так же есть команды iptables-save и iptables-restore, которые сохраняют создают дамп правил netfilter из ядра на стандартный вывод и восстанавливают в ядро правила со стандартного ввода соответственно.
Итак, алгоритм сохранения iptables примерно следующий:
- Настраиваем сетевой экран под свои нужны с помощью команды iptables
- создаем дамп созданный правил с помощью команды iptables-save > /etc/iptables.rules
- создаем скрипт импорта созданного дампа при старте сети (в каталоге /etc/network/if-up.d/) и не забываем его сделать исполняемым:
# cat /etc/network/if-up.d/firewall #!/bin/bash /sbin/iptables-restore < /etc/iptables.rules exit 0 # chmod +x /etc/network/if-up.d/firewall
Дамп правил, полученный командой iptables-save имеет текстовый формат, соответственно пригоден для редактирования. Синтаксис вывода команды iptables-save следующий:
# Generated by iptables-save v1.4.5 on Sat Dec 24 22:35:13 2011 *filter :INPUT ACCEPT [0:0] :FORWARD ACCEPT [0:0] ....... # комментарий -A INPUT -i lo -j ACCEPT -A INPUT ! -i lo -d 127.0.0.0/8 -j REJECT ........... -A FORWARD -j REJECT COMMIT # Completed on Sat Dec 24 22:35:13 2011 # Generated by iptables-save v1.4.5 on Sat Dec 24 22:35:13 2011 *raw ...... COMMIT
Строки, начинающиеся на # — комментарии, строки на * — это название таблиц, между названием таблицы и словом COMMIT содержатся параметры, передаваемые команде iptables. Параметр COMMIT — указывает на завершение параметров для вышеназванной таблицы. Строки, начинающиеся на двоеточие задают цепочки, в которых содержится данная таблица в формате:
:цепочка политика [пакеты:байты]
где цепочка — имя цепочки, политика — политика цепочки по-умолчанию для данной таблицы, а далее счетчики пакетов и байтов на момент выполнения команды.
В RedHat функции хранения команд iptables выполняемых при старте и останове сети выполняет файл /etc/sysconfig/iptables. А управление данным файлом лежит на демоне iptables.
Как еще один вариант сохранения правил, можно рассмотреть использование параметра up в файле /etc/network/interfaces с аргументом в виде файла, хранящего команды iptables, задающие необходимые правила.
Итог
На сегодня будет достаточно. Более сложные реализации межсетевого экрана я обязательно будут публиковаться в следующих статьях.
С Уважением, Mc.Sim!
Теги: ip, Linux, netfilter, network, UNIX
Введение

Продолжаем серию статей, посвященных использованию межсетевого экрана iptables.
Iptables – это стандартный файрвол, поставляемый в большинство дистрибутивов Linux по умолчанию. В предыдущей статье мы рассмотрели основные определения и принцип работы iptables, понимание которых обязательно для практического использования инструмента. В данной статье мы изучим основные команды файрвола и напишем наши первые правила.
Замечание:
Для создания правил iptables нам потребуется возможность выполнения команд с повышением привилегий до суперпользователя root. Поэтому для настройки межсетевого экрана нужно зайти в систему под учетной записью root (что не является лучшей практикой с точки зрения безопасности), либо использовать команду sudo перед каждой командой настройки iptables для повышения привилегий пользователя. Мы будем применять второй вариант.
Основные команды iptables
Вывод текущих правил в табличном виде выполняется при помощи вызова команды iptables с ключом -L:
![]()
Вывод:
Output:
Chain INPUT (policy ACCEPT)
target prot opt source destination
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationВ выводе представлены 3 стандартных цепочки (INPUT, OUTPUT, FORWARD) и действие по умолчанию (default policy) для каждой цепочки – ACCEPT. Как видим, у нас пока нет боевых правил. По умолчанию iptables идет без предустановленных правил и пропускает весь трафик.
Вывод текущих настроенных правил в виде строк выполняется при помощи вызова команды iptables с ключом -S:
sudo iptables -SБолее подробно
Вывод:
Output:
-P INPUT ACCEPT
-P FORWARD ACCEPT
-P OUTPUT ACCEPTКлюч -P указывает на действие, применяемое к пакету по умолчанию.
Построчный вывод полезен тем, что каждая строка вывода — это полноценная команда в iptables (например, мы можем получить такой вывод уже на настроенном сервере и использовать его для настройки другого сервера, сделав небольшие правки).
Для очистки всех правил используется ключ -F:
sudo iptables -FТут стоит отметить важность политик по умолчанию, так как они не удалятся после применения этой команды. Поясним подробней. Допустим у нас есть только удаленный доступ к серверу и в политике iptables по умолчанию выставлено действие DROP. В результате чего после очистки всех правил повторное подключение к серверу будет невозможно. Поэтому, если у нас нет физического доступа или консольного подключения к серверу, то перед сбросом всех правил необходимо убедиться, что действие по умолчанию – ACCEPT. Это позволит нам удаленно подключиться к серверу, создать разрешающее удаленную сессию первое правило. После этого для повышения безопасности можно уже выставить политику по умолчанию – DROP.
Чтобы задать действие по умолчанию ACCEPT и выполнить последующую очистку правил вводим:
sudo iptables -P INPUT ACCEPT
sudo iptables -P OUTPUT ACCEPT
sudo iptables -FСоздание первого правила iptables
Это будет правило, о котором мы говорили выше. Оно позволит принимать текущее SSH-соединение между нами и сервером. Синтаксис команды, добавляющей это правило, следующий:
sudo iptables -A INPUT -m conntrack --ctstate ESTABLISHED, RELATED -j ACCEPTНа первый взгляд выглядит запутанно. Разберем подробней команду:
-A INPUT: флаг -A (append) – добавляет правило в конец цепочки INPUT-m conntrack: этот параметр вызывает модуль conntrack для отслеживания информации о соединениях.–ctstate ESTABLISHED, RELATED: выделяем все соединения в состоянии ESTABLISHED (выделяется трафик по уже существующим соединениям) и RELATED (трафик по новым соединениям, но связанных с уже открытыми).-j ACCEPT: действие (target) – то, что будет произведено с пакетом, если он попал под критерий. В нашем случае это ACCEPT.
После применения этого правила можем увидеть изменения в выводе:
sudo iptables -LOutput:
Chain INPUT (policy ACCEPT)
target prot opt source destination
ACCEPT all -- anywhere anywhere ctstate RELATED,ESTABLISHED
Chain FORWARD (policy ACCEPT)
target prot opt source destination
Chain OUTPUT (policy ACCEPT)
target prot opt source destinationТеперь мы можем менять действия в политике по умолчанию на DROP.
Другие правила iptables
Добавим еще два правила, разрешающие SSH-соединения (по умолчанию на 22 порт) и WEB-подключения на 80 порт.
Приведем синтаксис этих правил:
sudo iptables -A INPUT -p tcp --dport 22 -j ACCEPT
sudo iptables -A INPUT -p tcp --dport 80 -j ACCEPTРазберем новые параметры:
-p tcp: фильтруем пакеты, использующие протокол TCP–dport: выделяем TCP-пакеты с портом назначения 22 и 80.
Также есть еще одно правило, которое связано с понятием “петли” (loopback-интерфейса). Используется loopback-интерфейс для взаимодействия служб и приложений в пределах одной локальной системы, без надобности отправления пакетов на сетевой интерфейс.
Правило выглядит так:
sudo iptables -I INPUT 1 -i lo -j ACCEPTРазберем его:
- Ключ
-I(insert) указывает вставить правило в цепочку на 1-ое место. Порядковый номер вставки указывается за именем цепочки INPUT (напоминаем, что флаг -A добавляет правило в конец) -i lo– указываем интерфейс loopback и разрешаем трафик через него.
Мы составили 4 правила, на основании которых iptables будет разрешать трафик на сервер. Но поскольку мы не создали ни одного запрещающего правила, то все соединения с сервером будут по-прежнему разрешены.
Есть два способа реализации блокирования нежелательного трафика:
- Политика запрета по умолчанию.
Достигается написанием правила:
sudo iptables -P INPUT DROPТут надо помнить об опасности потери удаленного доступа к серверу. Желательно его применять, когда есть консольный доступ к серверу.
- Добавление запрещающего правила в конец цепочки.
sudo iptables -A INPUT -j DROPТут уже нет опасности потери удаленного подключения к серверу, но есть особенность добавления правил. Новые правила необходимо добавлять в цепочку перед запрещающим правилом. Достигается это путем ввода набора из трех правил: удаление запрещающего правила, добавление нового правила, добавление запрещающего правила в конец.
sudo iptables -D INPUT -j DROP
sudo iptables -A INPUT "MY_NEW_RULE"
sudo iptables -A INPUT -j DROPТакже можно вставить новое правило до запрещающего правила, используя порядковый номер. Для этого сперва узнаем нумерацию имеющихся правил:
sudo iptables -L --line-numbersПотом на основании вывода вставляем правило под нужным порядковым номером:
sudo iptables -I INPUT 4 "MY_NEW_RULE"Более подробно о том как читать и удалять правила в iptables читайте в этой статье.
Сохранение правил iptables
По умолчанию правила iptables не хранятся в постоянной памяти и сбрасываются после перезагрузки. С одной стороны это может быть удобно, в случае потери SSH-подключения к серверу. С другой — часто важна автоматическая загрузка составленных правил после перезагрузки сервера. Один из способов сохранения правил — использование пакета iptables-persistent.
Он стандартно устанавливается из репозиториев Ubuntu:
sudo apt-get update
sudo apt-get install iptables-persistentВо время установки iptables-persistent попросит подтверждение о сохранении имеющихся правил. Если в последующем мы изменили или добавили правила, то сохраняем их:
sudo invoke-rc.d iptables-persistent saveВывод
В этой статье мы познакомились с базовыми командами и написали простейшие правила фильтрации в iptables. Изучив их, вы сможете разрабатывать более сложные цепочки фильтрации трафика и улучшать безопасность вашего сервера. В следующей статье мы рассмотрим как выводить, читать и удалять правила iptables, а также производить сброс счетчика пакетов.
- Печать
Страницы: [1] 2 Все Вниз

Тема: Не работает DROP ssh iptables (Прочитано 2176 раз)
0 Пользователей и 1 Гость просматривают эту тему.

sough

Всем приветики.
Прописал на серве:
iptables -A INPUT -s 87.253.88.347 -p tcp --dport 22 -j ACCEPTОднако облом, ssh открыт для всех. Что я не правильно делаю?
iptables -A INPUT -p tcp --dport 22 -j DROP
« Последнее редактирование: 27 Апреля 2016, 14:21:00 от sough »
fisher74
Что я не правильно делаю?
В первую очередь предоставляете информацию. То что Вы «прописали» и то что реально в правилах netfilter не всегда одно и то же.
Показывайте sudo iptables-save
sough
Как-то так
Правила форума
1.4. Листинги и содержимое текстовых файлов следует добавлять в сообщение с помощью тега [spоiler]…[/spоiler], либо прикреплять к сообщению в виде отдельного файла.
Я уже отредактировал сообщение в соответствии с правилами.
—www777
« Последнее редактирование: 22 Апреля 2016, 22:00:03 от www777 »
fisher74
А вот и виновник «торжества»
-A INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
sudo iptables -D INPUT -p tcp -m state --state NEW -m tcp --dport 22 -j ACCEPT
sough
Это да, но таким образом совсем перестаёт пускать, даже с разрешённого ip.
Пользователь добавил сообщение 22 Апреля 2016, 20:25:32:
И 2 других запрещённых порта также продолжают пускать.
Я хз, в чём проблема.
« Последнее редактирование: 22 Апреля 2016, 20:25:32 от sough »
Punko
sough, я не гений netfilter, но мне кажется, что проблема в порядке правил.
То есть, сначала всё дропните на 22, а уже ниже разрешите с нудного адреса.
fisher74
но таким образом совсем перестаёт пускать, даже с разрешённого ip.
Если Вы убираете только указанное мною правило, то не может такого быть. Так как правило
-A INPUT -s 87.253.88.347/32 -j ACCEPT
разрешает этому IP-у соединяться любым способом.
То есть, сначала всё дропните на 22, а уже ниже разрешите с нудного адреса.
Строго наоборот.
Punko
fisher74, а почему так? То есть, сначала мы разрешили с определённого адреса, а потом запретили всем?
Интересно именно то, почему правило на дроп всех пакетов не перезаписывает правило на ассерт определённого.
fisher74
НЕ моё, конечно, дело, но ИМХО у Вас netfilter настроен, мягко говоря паршиво.
Одной пользовательской цепочкой (cphulk) пытаетесь что-то заткнуть (хотя это похоже на какую-то утилиту автобана), другой (cP-Firewall-1-INPUT) — разрешаете и без того разрешённый трафик (дефолтное правило ACCEPT).
Давать какие-либо консультации по защите одного сервиса здесь очень сложно.
Точно сработает такие команды
sudo iptables -I INPUT -s 87.253.88.347 -p tcp --dport 22 -j ACCEPTНО ЭТО КОСТЫЛЬНОЕ РЕШЕНИЕ
sudo iptables -I INPUT 2 -p tcp --dport 22 -j DROP
Пользователь добавил сообщение 22 Апреля 2016, 22:07:08:
То есть, сначала мы разрешили с определённого адреса, а потом запретили всем?
Конкретно в предложенной ТС варианте, да. Именно так.
почему правило на дроп всех пакетов не перезаписывает правило на ассерт определённого.
Ни какое правило ничего не перезаписывает. Они выстраиваются цепочкой в том порядке, в котором их вводят (если конечно в команде добавления не указана конкретная позиция правила в цепочке)
Действия DROP и ACCEPT являются терминирующими действиями, поэтому после их отработки обработка цепочки прекращается.
То есть если срабатывает только первое правило срабатывающее по условию (это касается только терминирующих действий)
« Последнее редактирование: 27 Апреля 2016, 19:59:39 от fisher74 »
Punko
fisher74, а, всё, я понял.
Пакет прверяется на каждое правило, и если попадается первое правило, которое он удовлетворяет, то его пихают дальше, на следующую цепочку.
Если таких правил, которые подходят к пакету не находится, тогда к нему применяется Policy для цепочки.
Вот теперь верно? 
И знал же, просто думать не захотел  Спасибо!
Спасибо!
fisher74
Вот теперь верно?
Да. Но повторюсь: вывод из цепочки происходит только при терминирующих действиях (ACCEPT, DROP, REDIRECT, REJECT, DNAT, SNAT, MASQUERADE…)
Punko
fisher74, спасибо, надо будет почитать про не терминирующие действия.
И тогда еще один вопрос — почему нельзя поставить policy REJECT?
приходится городить ACCEPT, а потом уже в правиле прописывать REJECT всех пакетов.
fisher74
А зачем Вам REJECT ВСЕХ пакетов?
Действие DROP создаёт меньше нагрузки на ядро и сеть.
REJECT будет отсылать ICMP Port Unreachable на каждый «пук». А оно нам надо? Так ведь можно свой uplink положить, например на ADSL-соединении.
Punko
fisher74, да, за нагрузку я понимаю.
Но например, если пакет DROP, то ответ не пришёл к отправителю и он будет стучаться дальше.
А если REJECT, то мы отправили ответ — не стучись, меня тут нет.
Если будет какой-то flood идти, то после получения icmp ответа о недоступности этот flood не прекратится?
Я делаю reject всех непонятных пакетов и создаю список правил с АССЕРТ. Например, для портов приложения на этом сервере и для ssh.
Или это вреднее, чем постоянно DROP пакетов, которые идут при какой-нибудь flood атаке?
fisher74
Для обычной ситуации, какое из этих действий использовать почти не важно.
Но в случае атаки, REJECT в дефолте быстрее уложит Ваш сервант.
А так-то, каждый сходит с ума по своему.
- Печать
Страницы: [1] 2 Все Вверх
Настройка netfilter с помощью iptables
 Обновлено: 16.12.2022
Обновлено: 16.12.2022
Опубликовано: 22.02.2017
Утилита командной строки iptables используется для настройки брандмауэра netfilter, встроенного в систему на базе ядра Linux.
Данная инструкция подходит как для чайников, которые хотят разбираться в аспектах защиты сети, так и опытных специалистов в качестве шпаргалки.
Общий синтаксис
Ключи
Примеры
Общие команды
Разрешить все
Работа с простыми правилами
Проброс портов
Стартовая настройка
Сброс на стандартные настройки
Сохранение правил
Использование в Ubuntu и CentOS
Принцип настройки
Общий синтаксис использования iptables:
iptables -t <таблица> <команда> <цепочка> [номер] <условие> <действие>
<таблица>
Правила netfilter распределены по 4-м таблицам, каждая из которых имеет свое назначение (подробнее ниже). Она указывается ключом -t, но если данный параметр не указан, действие будет выполняться для таблицы по умолчанию — filter.
<команда>
Команды указывают, какое именно действие мы совершаем над netfilter, например, создаем или удаляем правило.
<цепочка>
В каждой таблице есть цепочки, для каждой из которых создаются сами правила. Например, для вышеупомянутой таблицы filter есть три предопределенные цепочки — INPUT (входящие пакеты), OUTPUT (исходящие) и FORWARD (транзитные).
[номер]
Некоторые команды требуют указания номера правила, например, на удаление или редактирование.
<условие>
Условие описывает критерии отработки того или иного правила.
<действие>
Ну и, собственно, что делаем с пакетом, если он подходит под критерии условия.
* справедливости ради, стоит отметить, что ключ с действием не обязан идти в конце. Просто данный формат чаще всего встречается в инструкциях и упрощает чтение правил.
Для работы с таблицами (iptables -t)
Напоминаю, все правила в netfilter распределены по таблицам. Чтобы работать с конкретной таблицей, необходимо использовать ключ -t.
| Ключ | Описание |
|---|---|
| -t filter | Таблица по умолчанию. С ней работаем, если упускаем ключ -t. Встроены три цепочки — INPUT (входящие), OUTPUT (исходящие) и FORWARD (проходящие пакеты) |
| -t nat | Для пакетов, устанавливающий новое соединение. По умолчанию, встроены три цепочки — PREROUTING (изменение входящих), OUTPUT (изменение локальных пакетов перед отправкой) и POSTROUTING (изменение всех исходящих). |
| -t mangle | Для изменения пакетов. Цепочки — INPUT, OUTPUT, FORWARD, PREROUTING, POSTROUTING. |
| -t raw | Для создания исключений в слежении за соединениями. Цепочки: PREROUTING, OUTPUT. |
Команды
Нижеперечисленные ключи определяют действия, которые выполняет утилита iptables.
| Ключ | Описание и примеры |
|---|---|
| -A | Добавление правила в конец списка: iptables -A INPUT -s 192.168.0.15 -j DROP запретить входящие с 192.168.0.15. |
| -D | Удаление правила: iptables -D INPUT 10 удалить правило в цепочке INPUT с номером 10. |
| -I | Вставка правила в определенную часть списка: iptables -I INPUT 5 -s 192.168.0.15 -j DROP вставить правило 5-м по списку. |
| -R | Замена правила. iptables -R OUTPUT 5 -s 192.168.0.15 -j ACCEPT заменить наше 5-е правило с запрещающего на разрешающее. |
| -F | Сброс правил в цепочке. iptables -F INPUT |
| -Z | Обнуление статистики. iptables -Z INPUT |
| -N | Создание цепочки. iptables -N CHAINNEW |
| -X | Удаление цепочки. iptables -X CHAINNEW |
| -P | Определение правила по умолчанию. iptables -P INPUT DROP |
| -E | Переименовывание цепочки. iptables -E CHAINNEW CHAINOLD |
Условия
Данные ключи определяют условия правила.
| Ключ | Описание и примеры |
|---|---|
| -p | Сетевой протокол. Допустимые варианты — TCP, UDP, ICMP или ALL. iptables -A INPUT -p tcp -j ACCEPT разрешить все входящие tcp-соединения. |
| -s | Адрес источника — имя хоста, IP-адрес или подсеть в нотации CIDR. iptables -A INPUT -s 192.168.0.50 -j DROP запретить входящие с узла 192.168.0.50 |
| -d | Адрес назначения. Принцип использования аналогичен предыдущему ключу -s. iptables -A OUTPUT -d 192.168.0.50 -j DROP запретить исходящие на узел 192.168.0.50 |
| -i | Сетевой адаптер, через который приходят пакеты (INPUT). iptables -A INPUT -i eth2 -j DROP запретить входящие для Ethernet-интерфейса eth2. |
| -o | Сетевой адаптер, с которого уходят пакеты (OUTPUT). iptables -A OUTPUT -o eth3 -j ACCEPT разрешить исходящие с Ethernet-интерфейса eth3. |
| —dport | Порт назначения. iptables -A INPUT -p tcp —dport 80 -j ACCEPT разрешить входящие на порт 80. |
| —sport | Порт источника. iptables -A INPUT -p tcp —sport 1023 -j DROP запретить входящие с порта 1023. |
Перечисленные ключи также поддерживают конструкцию с использованием знака !. Он инвертирует условие, например,
iptables -A INPUT -s ! 192.168.0.50 -j DROP
запретит соединение всем хостам, кроме 192.168.0.50.
Действия
Действия, которые будут выполняться над пакетом, подходящим под критерии условия. Для каждой таблицы есть свой набор допустимых действий. Указываются с использованием ключа -j.
| Таблица | Действие | Описание |
|---|---|---|
| filter | ACCEPT | Разрешает пакет. |
| DROP | Запрещает пакет. | |
| REJECT | Запрещает с отправкой сообщения источнику. | |
| nat | MASQUERADE | Для исходящих пакетов заменяет IP-адрес источника на адрес интерфейса, с которого уходит пакет. |
| SNAT | Аналогично MASQUERADE, но с указанием конкретного сетевого интерфейса, чей адрес будет использоваться для подмены. | |
| DNAT | Подмена адреса для входящих пакетов. | |
| REDIRECT | Перенаправляет запрос на другой порт той же самой системы. | |
| mangle | TOS | Видоизменение поля TOS (приоритезация трафика). |
| DSCP | Изменение DSCP (тоже приоритезация трафика). | |
| TTL | Изменение TTL (время жизни пакета). | |
| HL | Аналогично TTL, но для IPv6. | |
| MARK | Маркировка пакета. Используется для последующей фильтрации или шейпинга. | |
| CONNMARK | Маркировка соединения. | |
| TCPMSS | Изменение значения MTU. |
Примеры часто используемых команд iptables
Общие команды
Просмотр правил с их номерами:
iptables -L —line-numbers
Для каждой таблицы смотреть правила нужно отдельно:
iptables -t nat -L —line-numbers
Удалить все правила:
iptables -F
Установить правила по умолчанию:
iptables -P INPUT DROP
iptables -P OUTPUT DROP
* в данных примерах по умолчанию для всех входящих (INPUT) и исходящих (OUTPUT) пакетов будет работать запрещающее правило (DROP).
Разрешить все
Способ 1. С помощью добавления правила:
iptables -I INPUT 1 -j ACCEPT
iptables -I OUTPUT 1 -j ACCEPT
iptables -I FORWARD 1 -j ACCEPT
* данные три команды создадут правила, которые разрешают все входящие, исходящие и транзитные пакеты.
Способ 2. Чисткой правил:
iptables -F
iptables -S
* здесь мы сначала удаляем все правила (-F), затем устанавливаем политику по умолчанию — разрешать входящие, исходящие и транзитные (-S).
Способ 3. Отключение сервиса (удобно для диагностики проблем на время отключить firewall):
service iptables stop
iptables stop
Работа с правилами
1. Добавить правило в конец списка:
iptables -A INPUT -p tcp —dport 25 -j ACCEPT
iptables -A INPUT -p tcp -s ! 192.168.0.25 —dport 993 -i eth0 -j ACCEPT
2. Добавить диапазон портов:
iptables -A INPUT -p tcp —dport 3000:4000 -j ACCEPT
* в данном случае, от 3000 до 4000.
3. Вставить правило:
iptables -I FORWARD 15 -p udp -d 8.8.8.8 —dport 53 -i eth1 -j ACCEPT
4. Заблокировать определенный IP-адрес для подключения по 25 порту:
iptables -I INPUT 1 -s 1.1.1.1 -p tcp —dport 25 -j DROP
5. Разрешить несколько портов:
iptables -A INPUT -p tcp —match multiport —dports 20,21,25,80,8080,3000:4000 -j ACCEPT
Проброс портов (port forwarding)
Рассмотрим пример проброса одного порта и диапазона портов.
Один порт (одинаковые порты)
Существует два способа настройки.
1. Правила PREROUTING + POSTROUTING:
iptables -t nat -A PREROUTING -p tcp -m tcp -d 19.8.232.80 —dport 22 -j DNAT —to-destination 192.168.1.15:22
iptables -t nat -A POSTROUTING -p tcp -m tcp -s 192.168.1.15 —sport 22 -j SNAT —to-source 19.8.232.80:22
* где 19.8.232.80 — адрес, на котором слушаем запросы на подключение; 22 — порт для проброса; 192.168.1.15 — внутренний IP-адрес, на который переводим все запросы.
2. Правила PREROUTING + FORWARD:
iptables -t nat -A PREROUTING -p tcp -i eth1 —dport 22 -j DNAT —to-destination 192.168.1.15:22
iptables -A FORWARD -p tcp -d 192.168.1.15 —dport 22 -m state —state NEW,ESTABLISHED,RELATED -j ACCEPT
* где eth1 — сетевой интерфейс, на котором слушаем запросы; 22 — порт для проброса; 192.168.1.15 — внутренний IP-адрес, на который переводим все запросы.
Один порт (разные порты)
Рассмотрим ситуацию, когда мы слушаем один порт, а пробрасываем на другой.
iptables -t nat -A PREROUTING -p tcp -i eth1 —dport 8022 -j DNAT —to-destination 192.168.1.15:22
iptables -A FORWARD -p tcp -d 192.168.1.15 —dport 22 -m state —state NEW,ESTABLISHED,RELATED -j ACCEPT
* где eth1 — сетевой интерфейс, на котором слушаем запросы; 8022 — порт для проброса, на котором будем слушать запросы; 22 — порт для проброса на внутренний адрес; 192.168.1.15 — внутренний IP-адрес, на который переводим все запросы.
Диапазон портов
При необходимости пробросить диапазон портов, используем команды:
iptables -t nat -I PREROUTING -p tcp -m tcp —dport 1000:5000 -j DNAT —to-destination 192.168.1.15:1000-5000
iptables -A FORWARD -d 192.168.1.15 -i eth1 -p tcp -m tcp —dport 1000:5000 -j ACCEPT
* где eth1 — сетевой интерфейс, на котором слушаем запросы; 1000:5000 — порты для проброса (от 1000 до 5000); 192.168.1.15 — внутренний IP-адрес, на который переводим все запросы.
Стартовая настройка
Мы можем начать настройку брандмауэра на сервере с этих команд.
Разрешаем SSH:
iptables -A INPUT -p tcp —dport 22 -j ACCEPT
Создаем правила для нормальной работы apt или yum:
iptables -A INPUT -m state —state ESTABLISHED,RELATED -j ACCEPT
Разрешаем ICMP (для выполнения команды ping):
iptables -A INPUT -p icmp -j ACCEPT
Разрешаем все входящие на адрес локальной петли:
iptables -A INPUT -i lo -j ACCEPT
Ставим политику запрета на входящие и разрешаем все исходящие:
iptables -P INPUT DROP
iptables -P OUTPUT ACCEPT
Настройка по умолчанию
Если мы хотим вернуть настройки в первоночальное значение (разрешено все, правил нет), выполняем команды ниже.
Сначала ставим разрешающую политику для основных цепочек:
iptables -S
Ставим политику разрешения на входящие и исходящие:
iptables -P INPUT ACCEPT
iptables -P OUTPUT ACCEPT
Удаляем все правила во всех таблицах:
iptables -F
iptables -t nat -F
iptables -t mangle -F
Удаляем все цепочки, которые не используются:
iptables -X
Сохранение правил (permanent)
По умолчанию, все правила перестают работать после перезапуска сети или компьютера. Для сохранения правил после перезагрузки есть несколько способов настройки.
Способ 1. iptables-save (универсальный)
Сохраняем правила в файл:
iptables-save > /etc/iptables.rules
Чтобы восстановить правила, достаточно ввести команду:
iptables-restore < /etc/iptables.rules
А для автоматического восстановления правил при загрузке сервера или перезагрузки сети, создадим файл:
vi /etc/network/if-pre-up.d/iptables
#!/bin/bash
PATH=/etc:/bin:/sbin:/usr/bin:/usr/sbin:/usr/local/bin:/usr/local/sbin
iptables-restore < /etc/iptables.rules
exit 0
И делаем его исполняемым:
chmod +x /etc/network/if-pre-up.d/iptables
В версиях постарше открываем настройки сети:
vi /etc/network/interfaces
и добавляем строку:
pre-up iptables-restore < /etc/iptables.rules
Способ 2. iptables-persistent (Debian/Ubuntu)
Ставим пакет iptables-persistent:
apt install iptables-persistent
Для сохранения правил вводим команду:
netfilter-persistent save
Способ 3. service iptables (CentOS)
Работает в старых версиях Linux и CentOS. Необходима установка пакета:
yum install iptables-services
apt install iptables-services
* первая команда для CentOS, вторая — для Ubuntu.
Сохраняем правила командой:
service iptables save
* правила будут сохранены в файл /etc/sysconfig/iptables.
Чтобы правила восстанавливались автоматически при старте компьютера, разрешаем автозапуск сервиса.
а) в более новых версиях Linux:
systemctl enable iptables
б) в версиях постарше:
chkconfig iptables on
update-rc.d iptables defaults
* первая команда для CentOS, вторая для Ubuntu.
Ubuntu и CentOS
В современных операционных системах Ubuntu и CentOS по умолчанию нет iptables. Необходимо его установить или пользоваться более новыми утилитами.
В CentOS
В качестве штатной программы управления брандмауэром используется firewall-cmd. Подробнее читайте инструкцию Как настроить firewalld в CentOS.
Если необходимо пользоваться iptables, устанавливаем пакет с утилитой:
yum install iptables-services
Отключаем firewalld:
systemctl stop firewalld
systemctl disable firewalld
Разрешаем и запускаем iptables:
systemctl enable iptables
systemctl start iptables
В Ubuntu
Для управления брандмауэром теперь используется ufw.
Для работы с iptables, устанавливаем следующий пакет:
apt install iptables-persistent
Отключаем ufw:
ufw disable