Содержание
- Error during creation of pod . service account not found. #75117
- Comments
- Error looking up service account cattle-system/cattle: serviceaccount #33216
- Comments
- Дважды подумайте, прежде чем использовать Helm
- Helm без хайпа. Трезвый взгляд
- В чем истинная ценность Helm?
- Дополнительный уровень авторизации и контроля доступа
- Перехваленный инструмент для обработки шаблонов?
- Helm как инструмент управления жизненным циклом инфраструктуры
- Состояние Helm
- Случайные сбои и обработка ошибок
- Error: UPGRADE FAILED: «foo» has no deployed releases
- Error: release foo failed: timed out waiting for the condition
- Фейлы на ровном месте
- helm init запускает tiller с одной копией, а не в конфигурации HA
- Helm 3? Операторы? Будущее?
- Минимально жизнеспособный Kubernetes
- Обзор
- Предварительные условия
- Скучная установка
- Запускаем etcd
- Запуск API-сервера
- Проблема
- Запускаем под
- Успех!
Error during creation of pod . service account not found. #75117
$ kubectl create -f first_pod.yml
Error from server (Forbidden): error when creating «first_pod.yml»: pods «myfirst-pod» is forbidden: error looking up service account default/default: serviceaccount «default» not found
Can any one help me with this issue.
The text was updated successfully, but these errors were encountered:
My best guess is you didn’t configure your kube-controller-manager correctly.
This component would keep the cluster the same with our expectations, which includes serviceaccounts creation.
Before configuring kube-controller-manager, you could fix this by creating serviceaccount in hand like:
kubectl create sa default
@chakreshkolluru This looks to be more of a configuration problem. Please reopen if you think there is an issue.
Please re-post your question to Stack Overflow.
We are trying to consolidate the channels to which questions for help/support
are posted so that we can improve our efficiency in responding to your requests,
and to make it easier for you to find answers to frequently asked questions and
how to address common use cases.
We regularly see messages posted in multiple forums, with the full response
thread only in one place or, worse, spread across multiple forums. Also, the
large volume of support issues on github is making it difficult for us to use
issues to identify real bugs.
Members of the Kubernetes community use Stack Overflow to field support
requests. Before posting a new question, please search Stack Overflow for answers
to similar questions, and also familiarize yourself with:
Again, thanks for using Kubernetes.
The Kubernetes Team
/triage support
/close
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
@mrbobbytables: Those labels are not set on the issue: kind/bug
@chakreshkolluru This looks to be more of a configuration problem. Please reopen if you think there is an issue.
Please re-post your question to Stack Overflow.
We are trying to consolidate the channels to which questions for help/support
are posted so that we can improve our efficiency in responding to your requests,
and to make it easier for you to find answers to frequently asked questions and
how to address common use cases.
We regularly see messages posted in multiple forums, with the full response
thread only in one place or, worse, spread across multiple forums. Also, the
large volume of support issues on github is making it difficult for us to use
issues to identify real bugs.
Members of the Kubernetes community use Stack Overflow to field support
requests. Before posting a new question, please search Stack Overflow for answers
to similar questions, and also familiarize yourself with:
Again, thanks for using Kubernetes.
The Kubernetes Team
/remove-kind bug
/kind triage/support
/assign
Instructions for interacting with me using PR comments are available here. If you have questions or suggestions related to my behavior, please file an issue against the kubernetes/test-infra repository.
Источник
Error looking up service account cattle-system/cattle: serviceaccount #33216
What kind of request is this (question/bug/enhancement/feature request):
Not sure if it’s a bug or if it’s just a qustion.
Steps to reproduce (least amount of steps as possible):
I’m not sure what happens / how we can reproduce the problem. I already created some other clusters using Rancher without any problems but now I created a new cluster as I’ve done previously and now the «kube-api-auth» DaemonSet says:
Error creating: pods «kube-api-auth-» is forbidden: error looking up service account cattle-system/cattle: serviceaccount «cattle» not found
But when I check the service accounts available in the «cattle-system»-namespace, I can see that there’s a user called «cattle».
Environment information
- Rancher version ( rancher/rancher / rancher/server image tag or shown bottom left in the UI): 2.5.8
- Installation option (single install/HA): Multi-Cluster (I’m using Rancher to manage multiple clusters)
Cluster information
- Cluster type (Hosted/Infrastructure Provider/Custom/Imported): Custom
- Machine type (cloud/VM/metal) and specifications (CPU/memory): cloud, / 2GHz / 8GB memory per node
- Kubernetes version (use kubectl version ):
- Docker version (use docker version ):
The text was updated successfully, but these errors were encountered:
Источник
Дважды подумайте, прежде чем использовать Helm
Helm без хайпа. Трезвый взгляд
Helm — это менеджер пакетов для Kubernetes.
На первый взгляд, неплохо. Этот инструмент значительно упрощает процесс релиза, но порой может и хлопот доставить, ничего не попишешь! 
Недавно Helm официально признали топовым проектом @CloudNativeFdn, он широко используется коммьюнити. Это говорит о многом, но я бы хотел коротко рассказать о неприятных моментах, связанных с этим менеджером пакетов.
В чем истинная ценность Helm?
На этот вопрос я до сих пор не могу ответить уверенно. Helm не предоставляет каких-либо особенных возможностей. Какую пользу приносит Tiller (серверная часть)?
Многие чарты Helm далеки от совершенства, и, чтобы использовать их в кластере Kubernetes, нужны дополнительные усилия. Например, у них отсутствует RBAC, ограничения ресурсов и сетевые политики. Просто взять и установить чарт Helm в двоичном виде — не думая о том, как он будет работать, — не выйдет.
Мало нахваливать Helm, приводя простейшие примеры. Вы объясните, чем он так хорош — особенно с точки зрения безопасной мультитенантной рабочей среды.
Слова — пустое. Вы мне код предъявите!
—Линус Торвальдс
Дополнительный уровень авторизации и контроля доступа
Помню, кто-то сравнивал Tiller с «огромным сервером sudo». На мой взгляд, это просто очередной уровень авторизации, который при этом требует дополнительных сертификатов TLS, но не предоставляет возможностей для контроля доступа. Почему бы не использовать API Kubernetes и существующую модель безопасности с поддержкой функций аудита и RBAC?
Перехваленный инструмент для обработки шаблонов?
Дело в том, что для обработки и статического анализа файлов шаблонов Go используется конфигурация из файла values.yaml , а затем применяется обработанный манифест Kubernetes с соответствующими метаданными, хранящимися в ConfigMap.
А можно использовать несколько простых команд:
Я заметил, что разработчики обычно использовали один файл values.yaml на среду или даже получали его из values.yaml.tmpl перед использованием.
Это не имеет смысла при работе с секретами Kubernetes, которые часто зашифровываются и имеют несколько версий в репозитории. Чтобы обойти это ограничение, потребуется использовать плагин helm-secrets или команду —set key=value . В любом случае добавляется еще один уровень сложности.
Helm как инструмент управления жизненным циклом инфраструктуры
Забудьте. Это невозможно, особенно если речь — об основных компонентах Kubernetes, таких как kube-dns, поставщик CNI, cluster autoscaler и т.д. Жизненные циклы этих компонентов различаются, и Helm в них не вписывается.
Мой опыт работы с Helm показывает, что этот инструмент отлично подходит для простых деплоев на базовых ресурсах Kubernetes, легко осуществимых с нуля и не предполагающих сложного процесса релиза.
К сожалению, с более сложными и частыми деплоями, включающими Namespace, RBAC, NetworkPolicy, ResourceQuota и PodSecurityPolicy, Helm не справляется.
Понимаю, поклонникам Helm мои слова могут не понравиться, но такова реальность.
Состояние Helm
Сервер Tiller хранит информацию в файлах ConfigMap внутри Kubernetes. Ему не нужна собственная база данных.
К сожалению, размер ConfigMap не может превышать 1 МБ из-за ограничений etcd.
Надеюсь, кто-нибудь придумает способ улучшить драйвер хранилища ConfigMap, чтобы сжимать сериализованную версию до перемещения на хранение. Впрочем, так, я думаю, настоящую проблему все равно не решить.
Случайные сбои и обработка ошибок
Для меня самая большая проблема Helm — его ненадежность.
Error: UPGRADE FAILED: «foo» has no deployed releases
Это, ИМХО, одна из самых раздражающих проблем Helm.
Если не удалось создать первую версию, каждая последующая попытка завершится с ошибкой, сообщающей о невозможности обновления из неизвестного состояния.
Следующий запрос на включение изменений «исправляет» ошибку, добавляя флаг —force , что фактически просто маскирует проблему, выполняя команду helm delete & helm install —replace .
Впрочем, в большинстве случаев, вам придется заняться полноценной чисткой релиза.
Error: release foo failed: timed out waiting for the condition
Если отсутствует ServiceAccount или RBAC не разрешает создание определенного ресурса, Helm вернет следующее сообщение об ошибке:
К сожалению, первопричину этой ошибки увидеть невозможно:
Фейлы на ровном месте
В самых запущенных случаях Helm выдает ошибку, вообще не совершая каких-либо действий. Например, иногда он не обновляет ограничения ресурсов.
helm init запускает tiller с одной копией, а не в конфигурации HA
Tiller по умолчанию не предполагает высокую доступность, а запрос на включение изменений по ссылке все еще открыт.
Однажды это приведет к даунтайму.
Helm 3? Операторы? Будущее?
В следующей версии Helm будут добавлены некоторые многообещающие функции:
- односервисная архитектура без разделения на клиент и сервер. Больше никакого Tiller;
- встроенный движок Lua для написания скриптов;
- рабочий процесс DevOps на основе запросов на включение и новый проект Helm Controller.
Для получения дополнительной информации см. Предложения по проекту Helm 3.
Мне очень нравится идея архитектуры без Tiller, а вот скрипты на базе Lua вызывают сомнения, поскольку могут усложнить чарты.
Я заметил, что в последнее время популярность набирают операторы, которые гораздо больше подходят для Kubernetes, нежели чарты Helm.
Очень надеюсь, что коммьюнити в скором времени разберется с проблемами Helm (с нашей помощью, конечно), но сам я пока постараюсь как можно меньше использовать этот инструмент.
Поймите правильно: эта статья — мое личное мнение, к которому я пришел, создавая гибридную облачную платформу для развертываний на базе Kubernetes.
Источник
Минимально жизнеспособный Kubernetes
Перевод статьи подготовлен в преддверии старта курса «DevOps практики и инструменты».

Если вы это читаете, вероятно, вы что-то слышали о Kubernetes (а если нет, то как вы здесь оказались?) Но что же на самом деле представляет собой Kubernetes? Это “Оркестрация контейнеров промышленного уровня”? Или «Cloud-Native Operating System»? Что вообще это значит?
Честно говоря, я не уверен на 100%. Но думаю интересно покопаться во внутренностях и посмотреть, что на самом деле происходит в Kubernetes под его многими слоями абстракций. Так что ради интереса, давайте посмотрим, как на самом деле выглядит минимальный “кластер Kubernetes”. (Это будет намного проще, чем Kubernetes The Hard Way.)
Я полагаю, что у вас есть базовые знания Kubernetes, Linux и контейнеров. Все, о чем мы здесь будем говорить предназначено только для исследования/изучения, не запускайте ничего из этого в продакшене!
Обзор
Kubernetes содержит много компонент. Согласно википедии, архитектура выглядит следующим образом:

Здесь показано, по крайней мере, восемь компонент, но большинство из них мы проигнорируем. Я хочу заявить, что минимальная вещь, которую можно обоснованно назвать Kubernetes, состоит из трех основных компонент:
- kubelet
- kube-apiserver (который зависит от etcd — его базы данных)
- среда выполнения контейнера (в данном случае Docker)
Давайте посмотрим, что о каждом из них говорится в документации (рус., англ.). Сначала kubelet:
Агент, работающий на каждом узле в кластере. Он следит за тем, чтобы контейнеры были запущены в поде.
Звучит достаточно просто. Что насчет среды выполнения контейнеров (container runtime)?
Среда выполнения контейнера — это программа, предназначенная для выполнения контейнеров.
Очень информативно. Но если вы знакомы с Docker, то у вас должно быть общее представление о том, что он делает. (Детали разделения ответственностей между средой выполнения контейнеров и kubelet на самом деле довольно тонкие и здесь я не буду в них углубляться.)
Сервер API — компонент Kubernetes панели управления, который представляет API Kubernetes. API-сервер — это клиентская часть панели управления Kubernetes
Любому, кто когда-либо что-либо делал с Kubernetes, приходилось взаимодействовать с API либо напрямую, либо через kubectl. Это сердце того, что делает Kubernetes Kubernetes’ом — мозг, превращающий горы YAML, который мы все знаем и любим (?), в работающую инфраструктуру. Кажется очевидным, что API должен присутствовать в нашей минимальной конфигурации.
Предварительные условия
Скучная установка
На машину, которую мы будем использовать необходимо установить Docker. (Я не собираюсь подробно рассказывать как работает Docker и контейнеры; если вам интересно, есть замечательные статьи). Давайте просто установим его с помощью apt :
После этого нам нужно получить бинарники Kubernetes. На самом деле для начального запуска нашего “кластера” нам нужен только kubelet , так как для запуска других серверных компонент мы сможем использовать kubelet . Для взаимодействия с нашим кластером после того как он заработает, мы также будем использовать kubectl .
Что произойдет, если мы просто запустим kubelet ?
kubelet должен работать от root. Достаточно логично, так как ему надо управлять всем узлом. Давайте посмотрим на его параметры:
Ого, как много опций! К счастью, нам понадобится только пара из них. Вот один из параметров, который нам интересен:
Путь к каталогу, содержащему файлы для статических подов, или путь к файлу с описанием статических подов. Файлы, начинающиеся с точек, игнорируются. (УСТАРЕЛО: этот параметр следует устанавливать в конфигурационном файле, передаваемом в Kubelet через опцию —config. Для дополнительной информации см. kubernetes.io/docs/tasks/administer-cluster/kubelet-config-file .)
Этот параметр позволяет нам запускать статические поды — поды, которые не управляются через Kubernetes API. Статические поды используются редко, но они очень удобны для быстрого поднятия кластера, а это именно то, что нам нужно. Мы проигнорируем это громкое предупреждение (опять же, не запускайте это в проде!) и посмотрим, сможем ли мы запустить под.
Сначала мы создадим каталог для статических подов и запустим kubelet :
Затем в другом терминале/окне tmux/еще где-то, мы создадим манифест пода:
kubelet начинает писать какие-то предупреждения и кажется, что ничего не происходит. Но это не так! Давайте посмотрим на Docker:
kubelet прочитал манифест пода и дал Docker’у команду запустить пару контейнеров в соответствии с нашей спецификацией. (Если вам интересно узнать про контейнер “pause”, то это хакерство Kubernetes — подробности смотрите в этом блоге.) Kubelet запустит наш контейнер busybox с указанной командой и будет перезапускать его бесконечно, пока статический под не будет удален.
Поздравьте себя. Мы только что придумали один из самых запутанных способов вывода текста в терминал!
Запускаем etcd
Нашей конечной целью является запуск Kubernetes API, но для этого нам сначала нужно запустить etcd. Давайте запустим минимальный кластер etcd, поместив его настройки в каталог pods (например, pods/etcd.yaml ):
Если вы когда-либо работали с Kubernetes, то подобные YAML-файлы должны быть вам знакомы. Здесь стоит отметить только два момента:
Мы смонтировали папку хоста /var/lib/etcd в под, чтобы данные etcd сохранялись после перезапуска (если этого не сделать, то состояние кластера будет стираться при каждом перезапуске пода, что будет нехорошо даже для минимальной установки Kubernetes).
Мы установили hostNetwork: true . Этот параметр, что неудивительно, настраивает etcd для использования сети хоста вместо внутренней сети пода (это облегчит API-серверу поиск кластера etcd).
Простая проверка показывает, что etcd действительно запущен на localhost и сохраняет данные на диск:
Запуск API-сервера
Запустить API-сервер Kubernetes еще проще. Единственный параметр, который надо передать, —etcd-servers , делает то, что вы ожидаете:
Поместите этот YAML-файл в каталог pods , и API-сервер запустится. Проверка с помощью curl показывает, что Kubernetes API прослушивает порт 8080 с полностью открытым доступом — аутентификация не требуется!
(Опять же, не запускайте это в продакшене! Я был немного удивлен, что настройка по умолчанию настолько небезопасна. Но я предполагаю, что это сделано для облегчения разработки и тестирования.)
И, приятный сюрприз, kubectl работает из коробки без каких-либо дополнительных настроек!
Проблема
Но если копнуть немного глубже, то кажется, что что-то идет не так:
Статические поды, которые мы создали, пропали! На самом деле, наш kubelet-узел вообще не обнаруживается:
В чем же дело? Если вы помните, то несколько абзацев назад мы запускали kubelet с чрезвычайно простым набором параметров командной строки, поэтому kubelet не знает, как связаться с сервером API и уведомлять его о своем состоянии. Изучив документацию, мы находим соответствующий флаг:
Путь к файлу kubeconfig , в котором указано как подключаться к серверу API. Наличие —kubeconfig включает режим API-сервера, отсутствие —kubeconfig включает автономный режим.
Все это время, сами того не зная, мы запускали kubelet в «автономном режиме». (Если бы мы были педантичны, то можно было считать автономный режим kubelet как «минимально жизнеспособный Kubernetes», но это было бы очень скучно). Чтобы заработала «настоящая» конфигурация, нам нужно передать файл kubeconfig в kubelet, чтобы он знал, как общаться с API-сервером. К счастью, это довольно просто (так как у нас нет проблем с аутентификацией или сертификатами):
Сохраните это как kubeconfig.yaml , убейте процесс kubelet и перезапустите с необходимыми параметрами:
(Кстати, если вы попытаетесь обратиться к API через curl, когда kubelet не работает, то вы обнаружите, что он все еще работает! Kubelet не является «родителем» своих подов, подобно Docker’у, он больше похож на “управляющего демона”. Контейнеры, управляемые kubelet, будут работать, пока kubelet не остановит их.)
Через несколько минут kubectl должен показать нам поды и узлы, как мы и ожидаем:
Давайте на этот раз поздравим себя по-настоящему (я знаю, что уже поздравлял) — у нас получился минимальный «кластер» Kubernetes, работающий с полнофункциональным API!
Запускаем под
Теперь посмотрим на что способен API. Начнем с пода nginx:
Здесь мы получим довольно интересную ошибку:
Здесь мы видим насколько ужасающе неполна наша среда Kubernetes — у нас нет учетных записей для служб. Давайте попробуем еще раз, создав учетную запись службы вручную, и посмотрим, что произойдет:
Даже когда мы создали учетную запись службы вручную, токен аутентификации не создается. Продолжая экспериментировать с нашим минималистичным «кластером», мы обнаружим, что большинство полезных вещей, которые обычно происходят автоматически, будут отсутствовать. Сервер Kubernetes API довольно минималистичен, большая часть тяжелых автоматических настроек происходит в различных контроллерах и фоновых заданиях, которые еще не выполняются.
Мы можем обойти эту проблему, установив опцию automountServiceAccountToken для учетной записи службы (так как нам все равно не придется ее использовать):
Наконец, под появился! Но на самом деле он не запустится, так как у нас нет планировщика (scheduler) — еще одного важного компонента Kubernetes. Опять же, мы видим, что API Kubernetes на удивление «глупый» — когда вы создаете под в API, он его регистрирует, но не пытается выяснить, на каком узле его запускать.
На самом деле для запуска пода планировщик не нужен. Можно вручную добавить узел в манифест в параметре nodeName :
(Замените mink8s на название узла.) После delete и apply мы видим, что nginx запустился и слушает внутренний IP-адрес:
Чтобы убедиться, что сеть между подами работает корректно, мы можем запустить curl из другого пода:
Довольно интересно покопаться в этом окружении и посмотреть, что работает, а что нет. Я обнаружил, что ConfigMap и Secret работают так, как и ожидается, а Service и Deployment нет.
Успех!
Этот пост становится большим, поэтому я собираюсь объявить о победе и заявить, что это жизнеспособная конфигурация, которую можно назвать “Kubernetes». Резюмируя: четыре бинарных файла, пять параметров командной строки и “всего лишь” 45 строк YAML (не так много по стандартам Kubernetes) и у нас работает немало вещей:
- Поды управляются с помощью обычного Kubernetes API (с несколькими хаками)
- Можно загружать публичные образы контейнеров и управлять ими
- Поды остаются живыми и автоматически перезапускаются
- Сеть между подами в рамках одного узла работает довольно хорошо
- ConfigMap, Secret и простейшее монтирование хранилищ работает как положено
Но большая часть из того, что делает Kubernetes по-настоящему полезным, все еще отсутствует, например:
- Планировщик подов
- Аутентификация / авторизация
- Несколько узлов
- Сеть сервисов
- Кластерный внутренний DNS
- Контроллеры для учетных записей служб, развертываний, интеграции с облачными провайдерами и большинство других “плюшек”, которые приносит Kubernetes
Так что же мы на самом деле получили? Kubernetes API, работающий сам по себе, на самом деле, является всего лишь платформой для автоматизации контейнеров. Он не делает много — это работа для различных контроллеров и операторов, использующих API, — но он обеспечивает консистентную среду для автоматизации.
Источник
#kubernetes #deployment #cockroachdb
#kubernetes #развертывание #cockroachdb
Вопрос:
Я следую этому руководству helm secure — guide:
https://www.cockroachlabs.com/docs/stable/orchestrate-cockroachdb-with-kubernetes.html#helm
Я развернул кластер с помощью этой команды: $ helm install my-release --values my-values.yaml cockroachdb/cockroachdb --namespace=thesis-crdb
Вот как это выглядит: $ helm list --namespace=thesis-crdb
NAME NAMESPACE REVISION UPDATED STATUS CHART APP VERSION
my-release thesis-crdb 1 2021-01-31 17:38:52.8102378 0100 CET deployed cockroachdb-5.0.4 20.2.4
Вот как это выглядит с помощью: $ kubectl get all --namespace=thesis-crdb
NAME READY STATUS RESTARTS AGE
pod/my-release-cockroachdb-0 1/1 Running 0 7m35s
pod/my-release-cockroachdb-1 1/1 Running 0 7m35s
pod/my-release-cockroachdb-2 1/1 Running 0 7m35s
pod/my-release-cockroachdb-init-fhzdn 0/1 Completed 0 7m35s
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
service/my-release-cockroachdb ClusterIP None <none> 26257/TCP,8080/TCP 7m35s
service/my-release-cockroachdb-public ClusterIP 10.xx.xx.x <none> 26257/TCP,8080/TCP 7m35s
NAME READY AGE
statefulset.apps/my-release-cockroachdb 3/3 7m35s
NAME COMPLETIONS DURATION AGE
job.batch/my-release-cockroachdb-init 1/1 43s 7m36s
В my-values.yaml файле я только изменил tls с false на true :
tls:
enabled: true
Пока все хорошо, но с этого момента руководство больше не работает для меня. Я пытаюсь, как говорится, получить csr: kubectl get csr --namespace=thesis-crdb
No resources found
Хорошо, возможно, не требуется. Я продолжаю развертывать client-secure
Я загружаю файл: https://raw.githubusercontent.com/cockroachdb/cockroach/master/cloud/kubernetes/client-secure.yaml
И меняет значение serviceAccountName: cockroachdb на serviceAccountName: my-release-cockroachdb .
Я пытаюсь развернуть его с $ kubectl create -f client-secure.yaml --namespace=thesis-crdb помощью, но он выдает эту ошибку:
Error from server (Forbidden): error when creating "client-secure.yaml": pods "cockroachdb-client-secure" is forbidden: error looking up service account thesis-crdb/my-release-cockroachdb: serviceaccount "my-release-cockroachdb" not found
У кого-нибудь есть идея, как это решить? Я уверен, что это что-то с пространством имен, которое все портит.
Я попытался поместить пространство имен в раздел метаданных
metadata:
namespace: thesis-crdb
А затем попытайтесь развернуть его с помощью: kubectl create -f client-secure.yaml но безрезультатно:
Error from server (Forbidden): error when creating "client-secure.yaml": pods "cockroachdb-client-secure" is forbidden: error looking up service account thesis-crdb/my-release-cockroachdb: serviceaccount "my-release-cockroachdb" not found
Комментарии:
1. Используете ли вы облачного провайдера? Если да, то какой из них? Я вижу, что у вас есть изменения
serviceAccountName, но вы создали правила RBAC для этого имени службы? Я думаю, ваша главная проблема — отсутствие надлежащегоRole/ClusterRoleиBinding. Пожалуйста, предоставьте некоторые подробности, которые позволят мне воспроизвести вашу проблему (точно сведения о версии и среде Kubernetes).2. Я новичок в kubernetes. Как мне получить необходимую вам информацию?
kubectl version«Версия клиента: версия. Информация{Major:»1″, Minor:»20″, GitVersion:»v1.20.2″, GitCommit: «faecb196815e248d3ecfb03c680a4507229c2a56″, GitTreeState:»чистый», BuildDate: «2021-01-13T13:28:09Z», GoVersion: «go1.15.5″, Компилятор:»gc», Платформа: «linux / amd64″} Версия сервера: версия. Информация{Major:»1″, Minor:»18″, GitVersion:»v1.18.8», GitCommit: «9f2892aab98fe339f3bd70e3c470144299398ace», GitTreeState:»чистый», BuildDate: «2020-08-21T13:03:39Z», GoVersion: «go1.13.15″, Компилятор:»gc», платформа: «linux / amd64»}`3. В этом случае у вас есть возможность использовать GKE, GCE, EKS и AWS. Какая из них является вашей средой? Я бы хотел повторить вашу проблему. Кроме того, что вы получили, когда использовали
kubectl auth can-i create pod -n thesis-crdb --as=system:serviceaccount:thesis-crdb:my-release-cockroachdb4. Я перескочил на этот шаг, потому что я использую уже развернутый кластер k8, администратором которого я не являюсь. Я выполнил команду, как вы сказали, и я получил это
Error from server (Forbidden): {"Code":{"Code":"Forbidden","Status":403},"Message":"clusters.management.cattle.io "c-k4lm7" is forbidden: User "system:serviceaccount:thesis-crdb:my-release-cockroachdb" cannot get resource "clusters" in API group "management.cattle.io" at the cluster scope","Cause":null,"FieldName":""} (post selfsubjectaccessreviews.authorization.k8s.io)
Ответ №1:
Вы упоминаете в вопросе, что вы изменили serviceAccountName в YAML.
И изменяет значение
serviceAccountName: cockroachdbserviceAccountName: my-release-cockroachdb.
Итак, основная причина вашей проблемы связана с неправильной настройкой ServiceAccount.
Предыстория
В вашем кластере у вас есть что-то, что называется ServiceAccount .
Когда вы (пользователь) получаете доступ к кластеру (например, с помощью kubectl), вы проходите проверку подлинности на сервере apiserver как определенная учетная запись пользователя (в настоящее время это обычно admin, если ваш администратор кластера не настроил ваш кластер). Процессы в контейнерах внутри модулей также могут связываться с сервером apiserver. Когда они это делают, они проходят проверку подлинности как определенная учетная запись службы (например, по умолчанию).
ServiceAccount Вам также следует настроить RBAC, который предоставляет вам разрешения на создание ресурсов.
Управление доступом на основе ролей (RBAC) — это метод регулирования доступа к компьютерным или сетевым ресурсам на основе ролей отдельных пользователей в вашей организации.
Авторизация RBAC использует rbac.authorization.k8s.io Группа API для принятия решений об авторизации, позволяющая динамически настраивать политики с помощью API Kubernetes.
Если у вас нет надлежащих RBAC разрешений, вы не сможете создавать ресурсы.
В Kubernetes вы можете найти Role и ClusterRole . Role устанавливает разрешения в определенном пространстве имен и ClusterRole устанавливает разрешения во всем кластере. Кроме того, вам также необходимо связать роли, используя привязку ролей и кластерную привязку.
Кроме того, если вы будете использовать облачную среду, вам также понадобятся специальные права в project. В вашем руководстве приведены инструкции по выполнению этого здесь.
Основная причина
Я проверил диаграмму cockroachdb, и она создает ServiceAccount , Role , ClusterRole , RoleBinding и ClusterRoleBinding для cockroachdb и prometheus . Для этого нет конфигурации my-release-cockroachdb .
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: cockroachdb
...
verbs:
- create
- get
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
name: cockroachdb
labels:
app: cockroachdb
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: cockroachdb
...
При client-secure.yaml изменении serviceAccountName на my-release-cockroachdb и Kubernetes не может найти это ServiceAccount , поскольку оно не было создано cluster administrator или cockroachdb chart .
Для списка ServiceAccounts по умолчанию namespace вы можете использовать command $ kubectl get ServiceAccount , однако, если вы хотите проверить все ServiceAccounts в кластере, вам следует добавить -A в свою команду — $ kubectl get ServiceAccount -A .
Решение
Вариант 1 — использовать существующие ServiceAccount с соответствующими разрешениями, например SA , созданные cockroachdb chart which is cockroachdb , not my-release-cockroachdb .
Вариант 2 — создать ServiceAccount Role/ClusterRole и RoleBinding/ClusterRoleBinding для my-release-cockroachdb .
Комментарии:
1. Интересно, я попробую это завтра. Спасибо за очень подробный и поучительный ответ!
A Kubernetes Deployment is actually a higher level resource that uses other Kubernetes resources to create pods. The reason for this complexity is because the Deployment kind adds functionality to lower level resources. This blog will guide you through looking at your Deployment and how to find information about it. These steps are generic for all Deployments.
When you create a Deployment kind, you will see it created by running this command:
$ kubectl get deployment
NAME DESIRED CURRENT UP-TO-DATE AVAILABLE AGE
cost-attribution-grafana 1 1 1 1 2m18s
You can describe it to see what it did:
$ kubectl describe deploy cost-attribution-mk-agent
Name: cost-attribution-mk-agent
Namespace: kubernetes-cost-attribution
CreationTimestamp: Wed, 21 Nov 2018 12:30:47 -0800
Labels: app=cost-attribution-mk-agent
Annotations: deployment.kubernetes.io/revision: 1
kubectl.kubernetes.io/last-applied-configuration:
{"apiVersion":"apps/v1","kind":"Deployment","metadata":{"annotations":{},"name":"cost-attribution-mk-agent","namespace":"kubernetes-cost-a...
Selector: app=cost-attribution-mk-agent
Replicas: 1 desired | 0 updated | 0 total | 0 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=cost-attribution-mk-agent
Service Account: cost-attribution-kube-state-metric
Containers:
mk-agent:
Image: gcr.io/managedkube/kubernetes-cost-attribution/agent:1.0
Port: 9101/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
memory: 500Mi
Requests:
cpu: 20m
memory: 20Mi
Liveness: http-get http://:9101/metrics delay=5s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:9101/metrics delay=5s timeout=5s period=5s #success=1 #failure=3
Environment: <none>
Mounts: <none>
Volumes:
ubbagent-state:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetCreated
Available False MinimumReplicasUnavailable
ReplicaFailure True FailedCreate
OldReplicaSets: <none>
NewReplicaSet: cost-attribution-mk-agent-6c78b8757f (0/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 2m27s deployment-controller Scaled up replica set cost-attribution-mk-agent-6c78b8757f to 1
In the Events section, there is an event where it scaled up a ReplicaSet to 1. These events messages are critical to debugging your Deployment. There could be other failure cases here and it will describe (or at least give you a clue) on why it failed so you can remedy it.
Even if the Deployment did create the ReplicaSet that does not mean that there are Pods that are created. The next step in the flow is to look at the ReplicaSet resource by running this command:
$ kubectl get replicaset
NAME DESIRED CURRENT READY AGE
cost-attribution-grafana-bfdfddcbb 1 1 1 2m33s
This will show you the ReplicaSets that you have in this namespace. With this you can describe this ReplicaSet to see what it has done:
$ kubectl describe replicaset cost-attribution-mk-agent-6c78b8757f
Name: cost-attribution-mk-agent-6c78b8757f
Namespace: kubernetes-cost-attribution
Selector: app=cost-attribution-mk-agent,pod-template-hash=2734643139
Labels: app=cost-attribution-mk-agent
pod-template-hash=2734643139
Annotations: deployment.kubernetes.io/desired-replicas: 1
deployment.kubernetes.io/max-replicas: 2
deployment.kubernetes.io/revision: 1
Controlled By: Deployment/cost-attribution-mk-agent
Replicas: 0 current / 1 desired
Pods Status: 0 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=cost-attribution-mk-agent
pod-template-hash=2734643139
Service Account: cost-attribution-kube-state-metric
Containers:
mk-agent:
Image: gcr.io/managedkube/kubernetes-cost-attribution/agent:1.0
Port: 9101/TCP
Host Port: 0/TCP
Limits:
cpu: 500m
memory: 500Mi
Requests:
cpu: 20m
memory: 20Mi
Liveness: http-get http://:9101/metrics delay=5s timeout=5s period=10s #success=1 #failure=3
Readiness: http-get http://:9101/metrics delay=5s timeout=5s period=5s #success=1 #failure=3
Environment: <none>
Mounts: <none>
Volumes:
ubbagent-state:
Type: EmptyDir (a temporary directory that shares a pod's lifetime)
Medium:
Conditions:
Type Status Reason
---- ------ ------
ReplicaFailure True FailedCreate
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedCreate 76s (x15 over 2m38s) replicaset-controller Error creating: pods "cost-attribution-mk-agent-6c78b8757f-" is forbidden: error looking up service account kubernetes-cost-attribution/cost-attribution-kube-state-metric: serviceaccount "cost-attribution-kube-state-metric" not found
In this particular case, the Events reports a FailedCreate. The specific reason here is that it did not find a service account that the Pod references. Your particular error could be different though. This is just one example.
Conclusion
This blog walked you through tracing out your Deployment for a specific case, but the steps outlined here are generic to how you would look through your Deployment if it was not behaving or creating the pods you expected it to create.
More troubleshooting blog posts
- Kubernetes Troubleshooting Walkthrough — Tracing through an ingress
- Kubernetes Troubleshooting Walkthrough — Pod Failure CrashLoopBackOff
- Kubernetes Troubleshooting Walkthrough — imagepullbackoff
Contact me if you have any questions about this or want to chat, happy to start a dialog or help out: blogs@managedkube.com
Kubernetes | troubleshooting
Kubernetes is being developed with a high pace. For container infrastructures this means more frequent updates than compared to other platforms (e.g. VMware vsphere). However it brings new features and fixes much faster. But does faster also mean better? Do we risk stability by frequently upgrading the clusters?
Stability can only be attained by inactive matter. — Marie Curie
Note: If the whole Kubernetes management, including upgrades, testing, etc. is too much hassle and effort to you and you just want to enjoy an available Kubernetes cluster to deploy your applications, check out the Private Kubernetes Cloud Infrastructure at Infiniroot!
Kubernetes upgrade 1.13 to 1.14
A recent article (How to upgrade Kubernetes version in a Rancher 2 managed cluster) describes how Kubernetes clusters, managed by Rancher 2, can be upgraded. After a couple of cluster upgrades (from 1.11 to 1.13) this seemed to work pretty well.
However when we decided to upgrade a cluster from 1.13 to 1.14, we were welcomed into Kubernetes hell.
Note: Luckily for us we did that upgrade on a staging cluster so production was not affected, but it still left us with a foul taste.
The upgrade itself seemed to run successfully, having followed all the steps to upgrade Kubernetes, and no error was shown in the Rancher UI. When the Kubernetes version 1.14.6 appeared in the UI, we thought «OK, great!».
Our monitoring didn’t see anything wrong; the Rancher environment, monitored by check_rancher2, still worked and returned all workloads as running correctly.
But it didn’t take long until the developers came running.
DNS, I need DNS!
It turned out that since the upgrade to Kubernetes 1.14, all DNS queries/resolutions failed from within the containers.
root@container-4d67k:/# ping google.com
ping: google.com: Temporary failure in name resolution
This applied to both internal DNS records (defined as service in «Service Discovery») and external (real) DNS records. The applications, needing DNS to connect to external services as databases, started to fail. We saw a lot of crash events logged:
E0910 12:57:38.463326 1878 pod_workers.go:190] Error syncing pod 9481d351-d3c8-11e9-823c-0050568d2805 («service-wx56s_gamma(9481d351-d3c8-11e9-823c-0050568d2805)»), skipping: failed to «StartContainer» for «service» with CrashLoopBackOff: «Back-off 2m40s restarting failed container=service pod=service-wx56s_gamma(9481d351-d3c8-11e9-823c-0050568d2805)»
By further analyzing the logs (all collected centrally in an ELK) we saw that since the upgrade, the number of errors in the cluster sharply increased:
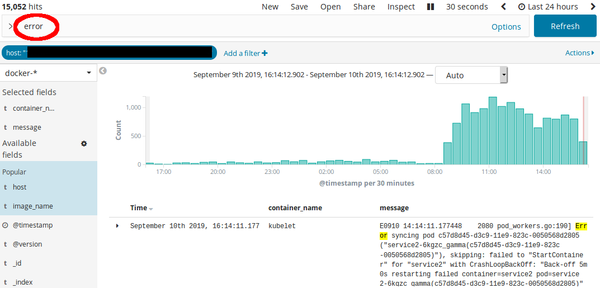
But why would all of a sudden DNS not work anymore?
Where’s yo DNS at
The Rancher documentation holds a document to troubleshoot DNS issues. But we quickly found out that this document only applies if there are actually DNS services running. It turned out, that our newly upgraded Kubernetes 1.14 cluster did not run any DNS provider services (in the kube-system namespace)!
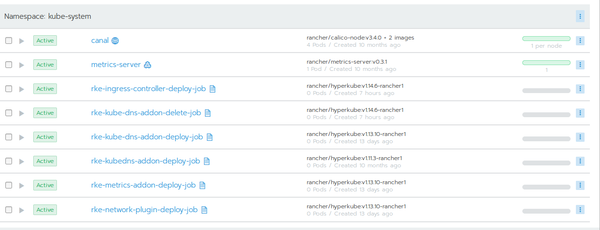
This could be verified using kubectl, too:
ckadm@mintp ~/.kube $ kubectl get pods —all-namespaces | grep kube-system
kube-system canal-fklc2 2/2 Running 4 13d
kube-system canal-fzbrp 2/2 Running 4 13d
kube-system canal-q2qgf 2/2 Running 4 13d
kube-system canal-v89g2 2/2 Running 4 13d
kube-system metrics-server-58bd5dd8d7-hc9rh 1/1 Running 0 72m
There should be a lot more pods in the kube-system. And at least one of either «kube-dns» or «coredns». The latter is the new default DNS service provider starting with Kubernetes 1.14 and Rancher >= 2.2.5:
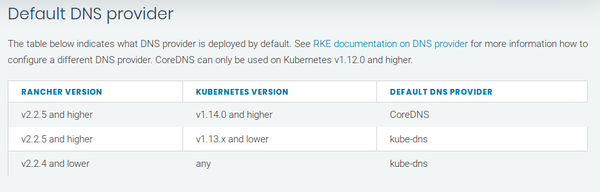
See default DNS provider from the official Rancher documentation.
This means that CoreDNS should have been deployed, but clearly there were no pods. But maybe there at least a config?
ckadm@mintp ~/.kube $ kubectl -n kube-system get configmap coredns -o go-template={{.data.Corefile}}
Error from server (NotFound): configmaps «coredns» not found
Negative. Not even the coredns configmap was created in the cluster.
Manual DNS provider deployment?
From another (and working) Kubernetes 1.14 cluster managed by the same Rancher 2 we took the «coredns» workload’s YAML configuration and tried to deploy it manually into the kube-system namespace in the defect cluster.
But unfortunately this failed with the following error:
Pods «coredns-bdffbc666-» is forbidden: error looking up service account kube-system/coredns: serviceaccount «coredns» not found
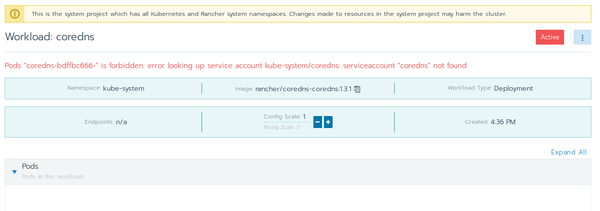
With kubectl it can be verified whether or not the service account for coredns exists or not:
ckadm@mintp ~/.kube $ kubectl get serviceAccounts —all-namespaces | grep dns
ckadm@mintp ~/.kube $
Indeed, no results. Comparing with a working Kubernetes 1.14 cluster:
> kubectl get serviceAccounts —all-namespaces | grep dns
kube-system coredns 1 13d
kube-system coredns-autoscaler 1 13d
kube-system kube-dns 1 307d
kube-system kube-dns-autoscaler 1 307d
It seemed that the coredns deployment during the Kubernetes upgrade completely failed. Not only were no DNS pods created, the cluster configuration was incomplete, too (no configmap, no serviceaccount).
Rancher provisioning logs
The Kubernetes upgrade is initiated by Rancher itself, as it manages the Kubernetes cluster. The creation and upgrade of a Kubernetes cluster creates provisioning logs, logged by the Rancher server pod (the one with the image rancher/rancher). This pod can be found in the «local» cluster (Rancher itself).
Checking the logs revealed something very interesting:
«September 10th 2019, 08:53:29.104″,»2019/09/10 06:53:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Executing deploy job rke-network-plugin»
«September 10th 2019, 08:53:29.216″,»2019/09/10 06:53:29 [INFO] cluster [c-hpb7s] provisioning: [dns] removing DNS provider kube-dns»
«September 10th 2019, 08:54:29.562″,»2019/09/10 06:54:29 [ERROR] cluster [c-hpb7s] provisioning: Failed to deploy DNS addon execute job for provider coredns: Failed to get job complete status for job rke-kube-dns-addon-delete-job in namespace kube-system»
«September 10th 2019, 08:54:29.576″,»2019/09/10 06:54:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Setting up Metrics Server»
«September 10th 2019, 08:54:29.592″,»2019/09/10 06:54:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Saving ConfigMap for addon rke-metrics-addon to Kubernetes»
«September 10th 2019, 08:54:29.612″,»2019/09/10 06:54:29 [INFO] cluster [c-hpb7s] provisioning: [addons] Successfully saved ConfigMap for addon rke-metrics-addon to Kubernetes»
Obviously the task to deploy coredns failed with an error. However the upgrade continued on the next step (metrics server) instead of doing something — halt the upgrade? try to resolve the error? shout to the admin? just anything, really?
To this point we knew:
- Why the cluster (the application pods) were not working correctly anymore: No DNS available
- Why the DNS services were not available: CoreDNS not deployed
- Why CoreDNS was not deployed: Error in the Rancher provisioning task
But how would we fix the problem?
Downgrade or another upgrade?
The obvious solution would have been to downgrade to the previous Kubernetes version (1.13). However this was not possible because a Kubernetes downgrade through Rancher (RKE) is not supported.
The only available option was to further upgrade the whole cluster to the next Kubernetes version: 1.15. But as of the cluster problem (and still as of this writing), 1.15 is marked as experimental. We decided to give it a shot anyway.
Hello Kubernetes 1.15!
To be honest we doubted that the upgrade in a non-working cluster to Kubernetes 1.15 would work, but to our surprise the upgrade seemed to run through pretty well.
The eyes were especially fixed on the messages related to everything DNS (guess why!). Once the upgrade process was completed, it was time to see if DNS would be working. And the first checks looked good:
ckadm@mintp ~/.kube $ kubectl get serviceAccounts —all-namespaces | grep dns
kube-system coredns 1 88s
kube-system coredns-autoscaler 1 88s
The service account now existed! What about the pods?
ckadm@mintp ~/.kube $ kubectl get pods —all-namespaces | grep kube-system
kube-system canal-2jf4g 2/2 Running 0 2m56s
kube-system canal-l8xvm 2/2 Running 0 3m12s
kube-system canal-rz972 2/2 Running 2 3m35s
kube-system canal-st25h 2/2 Running 0 2m40s
kube-system coredns-5678df9bcc-99xch 1/1 Running 1 2m50s
kube-system coredns-autoscaler-57bc9c9bd-c8sqw 1/1 Running 0 2m50s
kube-system metrics-server-784769f887-6zz2s 1/1 Running 0 2m15s
kube-system rke-coredns-addon-deploy-job-xbqjq 0/1 Completed 0 3m21s
kube-system rke-metrics-addon-deploy-job-cmv8m 0/1 Completed 0 2m46s
kube-system rke-network-plugin-deploy-job-297lv 0/1 Completed 0 3m37s
Good news! The coredns pod was up and running!
What about the application pods? Would they finally be able to resolve DNS?
root@service2-qw7kz:/# ping google.com
PING google.com (172.217.168.14) 56(84) bytes of data.
64 bytes from zrh11s03-in-f14.1e100.net (172.217.168.14): icmp_seq=1 ttl=54 time=2.70 ms
64 bytes from zrh11s03-in-f14.1e100.net (172.217.168.14): icmp_seq=2 ttl=54 time=2.08 ms
64 bytes from zrh11s03-in-f14.1e100.net (172.217.168.14): icmp_seq=3 ttl=54 time=1.98 ms
^C
— google.com ping statistics —
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 1.983/2.257/2.708/0.321 ms
Heureka! DNS is back and the applications work again. That would be the solution. Or would it?
Experimental for a reason
The cluster, now running with Kubernetes 1.15, went through a process of testing. And it turned out that as soon as a workload was upgraded, the communication through the Ingress Loadbalancer would fail. Updating the load balancer’s rules forced a new nginx.conf configuration file in the nginx-ingress-controller pods, pointing to an internal service ingress-516586323564684964. Although this internal service was correctly configured in the Nginx ingress, the internal DNS records (which can be seen in Service Discovery) were missing. We pointed this out in a Rancher GitHub issue.
From the point of view of the Nginx ingress, this is a non-existant upstream, therefore returning 503 to all requests.
We could have manually created the relevant services in «Service Discovery» using the exact ingress-id name used by the Ingress Loadbalancer. However what’s the point of manually creating configs when the whole point of a Kubernetes cluster is automation (by a high degree at least)?
New cluster to the solution
We knew at the beginning already that if the Kubernetes cluster could not be fixed, we would simply create a new cluster from scratch and deploy all the workloads in this new cluster. And that’s what we did. A new node was spun up and was ready in a couple of minutes and a new cluster (using Kubernetes 1.14! yes, we dared it!) with a single-node was created in Rancher. The namespace was exported from the old cluster and imported into the new and the workloads began to deploy.
Because in our architecture we use load balancers in front of the Kubernetes clusters, the traffic was simply switched to the new cluster. The applications worked again.
Once the whole cluster was deemed working correctly, the nodes from the broken cluster were reset (see how to reset (clean up) a Rancher Docker Host) and added as additional nodes into the new cluster.
What are we left with?
Knowledge. And this is worth much. We learned about the DNS providers, Kubernetes config maps and service accounts and how Rancher creates the Nginx Ingress config. And last but not least we now have a procedure to quickly create a new cluster from scratch, «migrating» the workloads from the old into the new cluster.
Something however is still unknown at this moment: The reason why the Rancher initiated Kubernetes upgrade, especially the coredns deployment task, failed and why it was not fixed. It may turn out to be a bug in Rancher, the Rancher team was informed about that incident. If we ever get to know the reason, we will update this article.
We decided to share this knowledge to give insights into our working methods and to help fellow DevOps struggling with the same or similar issues.
Update: It ain’t over yet
This is an update one day after the initial article. Once the new cluster running Kubernetes 1.14 was deemed OK, all the original nodes were added again. This also included a remote node running in AWS with the roles «etcd» and «control plane», which serves as man-in-the-middle in case of split-brain situations between the two data centers. As soon as this node was added, DNS issues happened again — even with a correctly deployed coredns service. This could (this time) be verified using the DNS troubleshooting steps:
ckadm@mintp ~ $ kubectl run -it —rm —restart=Never busybox —image=busybox:1.28 — nslookup kubernetes.default
If you don’t see a command prompt, try pressing enter.
Address 1: 10.43.0.10
pod «busybox» deleted
pod default/busybox terminated (Error)
ckadm@mintp ~ $ kubectl run -it —rm —restart=Never busybox —image=busybox:1.28 — nslookup www.google.com
If you don’t see a command prompt, try pressing enter.
Address 1: 10.43.0.10
nslookup: can’t resolve ‘www.google.com’
pod «busybox» deleted
pod default/busybox terminated (Error)
Both internal and external resolutions failed.
As we were now able to pinpoint the exact timing when DNS started to fail again, we expected a communication problem between the local and the remote node. And indeed, once all tcp and udp ports were enabled in both directions between the cluster nodes, DNS worked again.
Interestingly the incoming ports, which were defined in a AWS security group, all worked fine with Kubernetes 1.13. But since Kubernetes 1.14 additional communication ports seem to be used. An overview of the port requirements is described in the Rancher documentation, but a new Kubernetes version may use different/additional ports again.
Add a comment
Show form to leave a comment
Comments (newest first)
No comments yet.