I finally figured it out.
Since no one knew how to help me, i dropped the designated google libraries and went and made my own token verification from scratch.
I went and used the google-token-verifier-url-tool here :
https://www.googleapis.com/oauth2/v3/tokeninfo?id_token=XYZ123
At the bottom of the page here
https://developers.google.com/identity/protocols/OpenIDConnect
, i found how to decipher the json.
What i do is, I contact their online tool in code, get the json response and verify it manually.
This is my code :
private Map<String,String> getMapFromGoogleTokenString(final String idTokenString){
BufferedReader in = null;
try {
// get information from token by contacting the google_token_verify_tool url :
in = new BufferedReader(new InputStreamReader(
((HttpURLConnection) (new URL("https://www.googleapis.com/oauth2/v3/tokeninfo?id_token=" + idTokenString.trim()))
.openConnection()).getInputStream(), Charset.forName("UTF-8")));
// read information into a string buffer :
StringBuffer b = new StringBuffer();
String inputLine;
while ((inputLine = in.readLine()) != null){
b.append(inputLine + "n");
}
// transforming json string into Map<String,String> :
ObjectMapper objectMapper = new ObjectMapper();
return objectMapper.readValue(b.toString(), objectMapper.getTypeFactory().constructMapType(Map.class, String.class, String.class));
// exception handling :
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
} catch(Exception e){
System.out.println("nntFailed to transform json to stringn");
e.printStackTrace();
} finally{
if(in!=null){
try {
in.close();
} catch (IOException e) {
e.printStackTrace();
}
}
}
return null;
}
// chack the "email_verified" and "email" values in token payload
private boolean verifyEmail(final Map<String,String> tokenPayload){
if(tokenPayload.get("email_verified")!=null && tokenPayload.get("email")!=null){
try{
return Boolean.valueOf(tokenPayload.get("email_verified")) && tokenPayload.get("email").contains("@gmail.");
}catch(Exception e){
System.out.println("nntCheck emailVerified failed - cannot parse "+tokenPayload.get("email_verified")+" to booleann");
}
}else{
System.out.println("nntCheck emailVerified failed - required information missing in the token");
}
return false;
}
// check token expiration is after now :
private boolean checkExpirationTime(final Map<String,String> tokenPayload){
try{
if(tokenPayload.get("exp")!=null){
// the "exp" value is in seconds and Date().getTime is in mili seconds
return Long.parseLong(tokenPayload.get("exp")+"000") > new java.util.Date().getTime();
}else{
System.out.println("nntCheck expiration failed - required information missing in the tokenn");
}
}catch(Exception e){
System.out.println("nntCheck expiration failed - cannot parse "+tokenPayload.get("exp")+" into longn");
}
return false;
}
// check that at least one CLIENT_ID matches with token values
private boolean checkAudience(final Map<String,String> tokenPayload){
if(tokenPayload.get("aud")!=null && tokenPayload.get("azp")!=null){
List<String> pom = Arrays.asList("MY_CLIENT_ID_1",
"MY_CLIENT_ID_2",
"MY_CLIENT_ID_3");
if(pom.contains(tokenPayload.get("aud")) || pom.contains(tokenPayload.get("azp"))){
return true;
}else{
System.out.println("nntCheck audience failed - audiences differn");
return false;
}
}
System.out.println("nntCheck audience failed - required information missing in the tokenn");
return false;
}
// verify google token payload :
private boolean doTokenVerification(final Map<String,String> tokenPayload){
if(tokenPayload!=null){
return verifyEmail(tokenPayload) // check that email address is verifies
&& checkExpirationTime(tokenPayload) // check that token is not expired
&& checkAudience(tokenPayload) // check audience
;
}
return false;
}
Once i have had this detailed verification, i was able to see exactly where the mistake was ; The front end was sending me invalid CLIENT_ID value. [grumble, grumble] I have asked them about it about a hundred times and they told me that those values match. BAH !
So the mistake was not somewhere in my original code for token verification, it was an error in communication in my office.
I will revert back to the original code, with the proper CLIENT_ID this time for the sake of security. Still, i must make one complaint about the google library — it never told me why token verification was failing. It took me DAYS of pain staking effort to finally figure it out. I know they did it out of security, but still, the lack of support is galling.
Привет, Хабр! Представляю вашему вниманию перевод статьи Fixing 7 Common Java Exception Handling Mistakes автора Thorben Janssen.
Обработка исключения является одной из наиболее распространенных, но не обязательно одной из самых простых задач. Это все еще одна из часто обсуждаемых тем в опытных командах, и есть несколько передовых методов и распространенных ошибок, о которых вы должны знать.
Вот несколько вещей, которые следует избегать при обработке исключений в вашем приложении.
Ошибка 1: объявление java.lang.Exception или java.lang.Throwable
Как вы уже знаете, вам нужно либо объявить, либо обработать проверяемое исключение. Но проверяемые исключения — это не единственные, которые вы можете указать. Вы можете использовать любой подкласс java.lang.Throwable в предложении throws. Таким образом, вместо указания двух разных исключений, которые выбрасывает следующий фрагмент кода, вы можете просто использовать исключение java.lang.Exception в предложении throws.
public void doNotSpecifyException() throws Exception {
doSomething();
}
public void doSomething() throws NumberFormatException, IllegalArgumentException {
// do something
}Но это не значит, что вы должны это сделать. Указание Exeption или Throwable делает почти невозможным правильное обращение с ними при вызове вашего метода.Единственная информация, которую получает вызывающий вами метод, заключается в том, что что-то может пойти не так. Но вы не делитесь какой-либо информацией о каких-либо исключительных событиях, которые могут произойти. Вы скрываете эту информацию за обобщенными причинами выброса исключений.Становится еще хуже, когда ваше приложение меняется со временем. Выброс обобщенных исключений скрывает все изменения исключений, которые вызывающий должен ожидать и обрабатывать. Это может привести к нескольким непредвиденным ошибкам, которые необходимо найти в тестовом примере вместо ошибки компилятора.
Используйте конкретные классы
Гораздо лучше указать наиболее конкретные классы исключений, даже если вам приходится использовать несколько из них. Это сообщает вызывающему устройству, какие исключительные событий нужно обрабатывать. Это также позволяет вам обновить предложение throw, когда ваш метод выдает дополнительное исключение. Таким образом, ваши клиенты знают об изменениях и даже получают ошибку, если вы изменяете выбрасываемые исключения. Такое исключение намного проще найти и обработать, чем исключение, которое появляется только при запуске конкретного тестового примера.
public void specifySpecificExceptions() throws NumberFormatException, IllegalArgumentException {
doSomething();
}Ошибка 2: перехват обобщенных исключений
Серьезность этой ошибки зависит от того, какой программный компонент вы реализуете, и где вы обнаруживаете исключение. Возможно, было бы хорошо поймать java.lang.Exception в основном методе вашего приложения Java SE. Но вы должны предпочесть поймать определенные исключения, если вы реализуете библиотеку или работаете над более глубокими слоями вашего приложения.
Это дает несколько преимуществ. Такой подход позволяет обрабатывать каждый класс исключений по-разному и не позволяет вам перехватывать исключения, которых вы не ожидали.
Но имейте в виду, что первый блок catch, который обрабатывает класс исключения или один из его супер-классов, поймает его. Поэтому сначала обязательно поймайте наиболее специфический класс. В противном случае ваши IDE покажут сообщение об ошибке или предупреждении о недостижимом блоке кода.
try {
doSomething();
} catch (NumberFormatException e) {
// handle the NumberFormatException
log.error(e);
} catch (IllegalArgumentException e) {
// handle the IllegalArgumentException
log.error(e);
}Ошибка 3: Логирование и проброс исключений
Это одна из самых популярных ошибок при обработке исключений Java. Может показаться логичным регистрировать исключение там, где оно было брошено, а затем пробросить его вызывающему объекту, который может реализовать конкретную обработку для конкретного случая использования. Но вы не должны делать это по трем причинам:
1. У вас недостаточно информации о прецеденте, который хочет реализовать вызывающий объект вашего метода. Исключение может быть частью ожидаемого поведения и обрабатываться клиентом. В этом случае нет необходимости регистрировать его. Это добавит ложное сообщение об ошибке в файл журнала, который должен быть отфильтрован вашей операционной группой.
2. Сообщение журнала не предоставляет никакой информации, которая еще не является частью самого исключения. Его трассировка и трассировка стека должны содержать всю необходимую информацию об исключительном событии. Сообщение описывает это, а трассировка стека содержит подробную информацию о классе, методе и строке, в которой она произошла.
3. Вы можете регистрировать одно и то же исключение несколько раз, когда вы регистрируете его в каждом блоке catch, который его ловит. Это испортит статистику в вашем инструменте мониторинга и затрудняет чтение файла журнала для ваших операций и команды разработчиков.
Регистрируйте исключение там, где вы его обрабатываете
Таким образом, лучше всего регистрировать исключение тогда, когда вы его обрабатываете. Как в следующем фрагменте кода. Метод doSomething генерирует исключение. Метод doMore просто указывает его, потому что у разработчика недостаточно информации для его обработки. Затем он обрабатывается в методе doEvenMore, который также записывает сообщение журнала.
public void doEvenMore() {
try {
doMore();
} catch (NumberFormatException e) {
// handle the NumberFormatException
} catch (IllegalArgumentException e) {
// handle the IllegalArgumentException
}
}
public void doMore() throws NumberFormatException, IllegalArgumentException {
doSomething();
}
public void doSomething() throws NumberFormatException, IllegalArgumentException {
// do something
}Ошибка 4: использование исключений для управления потоком
Использование исключений для управления потоком вашего приложения считается анти-шаблоном по двум основным причинам:
Они в основном работают как оператор Go To, потому что они отменяют выполнение блока кода и переходят к первому блоку catch, который обрабатывает исключение. Это делает код очень трудным для чтения.
Они не так эффективны, как общие структуры управления Java. Как видно из названия, вы должны использовать их только для исключительных событий, а JVM не оптимизирует их так же, как и другой код.Таким образом, лучше использовать правильные условия, чтобы разбить свои циклы или инструкции if-else, чтобы решить, какие блоки кода должны быть выполнены.
Ошибка 5: удалить причину возникновения исключения
Иногда вам может понадобиться обернуть одно исключение в другое. Возможно, ваша команда решила использовать специальное исключение для бизнеса с кодами ошибок и единой обработкой. Нет ничего плохого в этом подходе, если вы не устраните причину.
Когда вы создаете новое исключение, вы всегда должны устанавливать первоначальное исключение в качестве причины. В противном случае вы потеряете трассировку сообщения и стека, которые описывают исключительное событие, вызвавшее ваше исключение. Класс Exception и все его подклассы предоставляют несколько методов-конструкторов, которые принимают исходное исключение в качестве параметра и задают его как причину.
try {
doSomething();
} catch (NumberFormatException e) {
throw new MyBusinessException(e, ErrorCode.CONFIGURATION_ERROR);
} catch (IllegalArgumentException e) {
throw new MyBusinessException(e, ErrorCode.UNEXPECTED);
}Ошибка 6: Обобщение исключений
Когда вы обобщаете исключение, вы ловите конкретный, например, NumberFormatException, и вместо этого генерируете неспецифическое java.lang.Exception. Это похоже, но даже хуже, чем первая ошибка, которую я описал в этой статье. Он не только скрывает информацию о конкретном случае ошибки на вашем API, но также затрудняет доступ.
public void doNotGeneralizeException() throws Exception {
try {
doSomething();
} catch (NumberFormatException e) {
throw new Exception(e);
} catch (IllegalArgumentException e) {
throw new Exception(e);
}
}Как вы можете видеть в следующем фрагменте кода, даже если вы знаете, какие исключения может вызвать метод, вы не можете просто их поймать. Вам нужно поймать общий класс Exception и затем проверить тип его причины. Этот код не только громоздкий для реализации, но его также трудно читать. Становится еще хуже, если вы сочетаете этот подход с ошибкой 5. Это удаляет всю информацию об исключительном событии.
try {
doNotGeneralizeException();
} catch (Exception e) {
if (e.getCause() instanceof NumberFormatException) {
log.error("NumberFormatException: " + e);
} else if (e.getCause() instanceof IllegalArgumentException) {
log.error("IllegalArgumentException: " + e);
} else {
log.error("Unexpected exception: " + e);
}
}Итак, какой подход лучший?
Будьте конкретны и сохраняйте причину возникновения исключения.
Исключения, которые вы бросаете, должны всегда быть максимально конкретными. И если вы оборачиваете исключение, вы также должны установить исходный исключение в качестве причины, чтобы не потерять трассировку стека и другую информацию, описывающую исключительное событие.
try {
doSomething();
} catch (NumberFormatException e) {
throw new MyBusinessException(e, ErrorCode.CONFIGURATION_ERROR);
} catch (IllegalArgumentException e) {
throw new MyBusinessException(e, ErrorCode.UNEXPECTED);
}Ошибка 7: добавление ненужных преобразований исключений
Как я уже объяснял ранее, может быть полезно обернуть исключения в пользовательские, если вы установите исходное исключение в качестве причины. Но некоторые архитекторы переусердствуют и вводят специальный класс исключений для каждого архитектурного уровня. Таким образом, они улавливают исключение в уровне персистентности и переносят его в MyPersistenceException. Бизнес-уровень ловит и обертывает его в MyBusinessException, и это продолжается до тех пор, пока оно не достигнет уровня API или не будет обработано.
public void persistCustomer(Customer c) throws MyPersistenceException {
// persist a Customer
}
public void manageCustomer(Customer c) throws MyBusinessException {
// manage a Customer
try {
persistCustomer(c);
} catch (MyPersistenceException e) {
throw new MyBusinessException(e, e.getCode());
}
}
public void createCustomer(Customer c) throws MyApiException {
// create a Customer
try {
manageCustomer(c);
} catch (MyBusinessException e) {
throw new MyApiException(e, e.getCode());
}
}Легко видеть, что эти дополнительные классы исключений не дают никаких преимуществ. Они просто вводят дополнительные слои, которые оборачивают исключение. И хотя было бы забавно обернуть подарок во множестве красочной бумаги, это не очень хороший подход к разработке программного обеспечения.
Обязательно добавьте информацию
Просто подумайте о коде, который должен обрабатывать исключение или о самом себе, когда вам нужно найти проблему, вызвавшую исключение. Сначала вам нужно прорваться через несколько уровней исключений, чтобы найти исходную причину. И до сегодняшнего дня я никогда не видел приложение, которое использовало этот подход, и добавляло полезную информацию с каждым слоем исключения. Они либо обобщают сообщение об ошибке и код, либо предоставляют избыточную информацию.
Поэтому будьте осторожны с количеством настраиваемых классов исключений, которые вы вводите. Вы всегда должны спрашивать себя, дает ли новый класс исключений дополнительную информацию или другие преимущества. В большинстве случаев для достижения этого вам не требуется более одного уровня пользовательских исключений.
public void persistCustomer(Customer c) {
// persist a Customer
}
public void manageCustomer(Customer c) throws MyBusinessException {
// manage a Customer
throw new MyBusinessException(e, e.getCode());
}
public void createCustomer(Customer c) throws MyBusinessException {
// create a Customer
manageCustomer(c);
}В этом посте я покажу наглядный пример того, как исправить ошибку исключения Null Pointer (java.lang.nullpointerexception). В Java особое значение null может быть назначено для ссылки на объект и означает, что объект в данный момент указывает неизвестную область данных.
NullPointerException появляется, если программа обращается или получает доступ к объекту, а ссылка на него равна нулю (null).
Это исключение возникает следующих случаях:
- Вызов метода из объекта значения null.
- Доступ или изменение объекта поля null.
- Принимает длину null(если бы это был массив Java).
- Доступ или изменение ячеек объекта null.
- Показывает «0», значение Throwable.
- При попытке синхронизации по нулевому объекту.
NullPointerException является RuntimeException, и, таким образом, компилятор Javac не заставляет вас использовать блок try-catch для соответствующей обработки.

Зачем нам нужно значение null?
Как уже упоминалось, null – это специальное значение, используемое в Java. Это чрезвычайно полезно при кодировании некоторых шаблонов проектирования, таких как Null Object pattern и шаблон Singleton pattern.
Шаблон Singleton обеспечивает создание только одного экземпляра класса, а также направлен на предоставление глобального доступа к объекту.
Например, простой способ создания не более одного экземпляра класса – объявить все его конструкторы как частные, а затем создать открытый метод, который возвращает уникальный экземпляр класса:
import java.util.UUID;
class Singleton {
private static Singleton single = null;
private String ID = null;
private Singleton() {
/* Make it private, in order to prevent the creation of new instances of
* the Singleton class. */
ID = UUID.randomUUID().toString(); // Create a random ID.
}
public static Singleton getInstance() {
if (single == null)
single = new Singleton();
return single;
}
public String getID() {
return this.ID;
}
}
public class TestSingleton {
public static void main(String[] args) {
Singleton s = Singleton.getInstance();
System.out.println(s.getID());
}
}
В этом примере мы объявляем статический экземпляр класса Singleton. Этот экземпляр инициализируется не более одного раза внутри метода getInstance.
Обратите внимание на использование нулевого значения, которое разрешает создание уникального экземпляра.
Как избежать исключения Null Pointer
Чтобы решить и избежать исключения NullPointerException, убедитесь, что все ваши объекты инициализированы должным образом, прежде чем использовать их.
Когда вы объявляете ссылочную переменную, вы должны создать указатель на объект и убедиться, что указатель не является нулевым, прежде чем запрашивать метод или поле у объекта.
Кроме того, если выдается исключение, используйте информацию, находящуюся в трассировке стека исключения. Трассировка стека выполнения обеспечивается JVM, чтобы включить отладку. Найдите метод и строку, в которой было обнаружено исключение, а затем выясните, какая ссылка равна нулю в этой конкретной строке.
Опишем некоторые методы, которые имеют дело с вышеупомянутым исключением. Однако они не устраняют проблему, и программист всегда должен быть осторожен.
- Сравнение строк с литералами
Очень распространенный случай, выполнения программы включает сравнение между строковой переменной и литералом. Литерал может быть строкой или элементом Enum.
Вместо того, чтобы вызывать метод из нулевого объекта, рассмотрите возможность вызова его из литерала. Например:
String str = null;
if(str.equals("Test")) {
/* The code here will not be reached, as an exception will be thrown. */
}
Приведенный выше фрагмент кода вызовет исключение NullPointerException. Однако, если мы вызываем метод из литерала, поток выполнения продолжается нормально:
String str = null;
if("Test".equals(str)) {
/* Correct use case. No exception will be thrown. */
}
- Проверка аргументов метода
Перед выполнением вашего собственного метода обязательно проверьте его аргументы на наличие нулевых значений.
В противном случае вы можете вызвать исключение IllegalArgumentException.
Например:
public static int getLength(String s) {
if (s == null)
throw new IllegalArgumentException("The argument cannot be null");
return s.length();
}
- Предпочтение метода String.valueOf() вместо of toString()
Когда код вашей программы требует строковое представление объекта, избегайте использования метода toString объекта. Если ссылка вашего объекта равна нулю, генерируется исключение NullPointerException.
Вместо этого рассмотрите возможность использования статического метода String.valueOf, который не выдает никаких исключений и «ноль», если аргумент функции равен нулю.
- Используйте Ternary Operator
Ternary Operator – может быть очень полезным. Оператор имеет вид:
boolean expression ? value1 : value2;
Сначала вычисляется логическое выражение. Если выражение true, то возвращается значение1, в противном случае возвращается значение2. Мы можем использовать Ternary Operator для обработки нулевых указателей следующим образом:
String message = (str == null) ? "" : str.substring(0, 10);
Переменная message будет пустой, если ссылка str равна нулю. В противном случае, если str указывает на фактические данные, в сообщении будут первые 10 символов.
- создайте методы, которые возвращают пустые коллекции вместо нуля.
Очень хорошая техника – создавать методы, которые возвращают пустую коллекцию вместо нулевого значения. Код вашего приложения может перебирать пустую коллекцию и использовать ее методы и поля. Например:
public class Example {
private static List<Integer> numbers = null;
public static List<Integer> getList() {
if (numbers == null)
return Collections.emptyList();
else
return numbers;
}
}
- Воспользуйтесь классом Apache’s StringUtils.
Apache’s Commons Lang – это библиотека, которая предоставляет вспомогательные утилиты для API java.lang, такие как методы манипулирования строками.
Примером класса, который обеспечивает манипулирование String, является StringUtils.java, который спокойно обрабатывает входные строки с нулевым значением.
Вы можете воспользоваться методами: StringUtils.isNotEmpty, StringUtils.IsEmpty и StringUtils.equals, чтобы избежать NullPointerException. Например:
if (StringUtils.isNotEmpty(str)) {
System.out.println(str.toString());
}
- Используйте методы: contains(), containsKey(), containsValue()
Если в коде вашего приложения используется Maps, рассмотрите возможность использования методов contains, containsKey и containsValue. Например, получить значение определенного ключа после того, как вы проверили его существование на карте:
Map<String, String> map = … … String key = … String value = map.get(key); System.out.println(value.toString()); // An exception will be thrown, if the value is null.
System.out.println(value.toString()); // В приведенном выше фрагменте мы не проверяем, существует ли на самом деле ключ внутри карты, и поэтому возвращаемое значение может быть нулевым. Самый безопасный способ следующий:
Map<String, String> map = …
…
String key = …
if(map.containsKey(key)) {
String value = map.get(key);
System.out.println(value.toString()); // No exception will be thrown.
}
- Проверьте возвращаемое значение внешних методов
На практике очень часто используются внешние библиотеки. Эти библиотеки содержат методы, которые возвращают ссылку. Убедитесь, что возвращаемая ссылка не пуста.
- Используйте Утверждения
Утверждения очень полезны при тестировании вашего кода и могут использоваться, чтобы избежать выполнения фрагментов кода. Утверждения Java реализуются с помощью ключевого слова assert и выдают AssertionError.
Обратите внимание, что вы должны включить флажок подтверждения JVM, выполнив его с аргументом -ea. В противном случае утверждения будут полностью проигнорированы.
Примером использования утверждений Java является такая версия кода:
public static int getLength(String s) {
/* Ensure that the String is not null. */
assert (s != null);
return s.length();
}
Если вы выполните приведенный выше фрагмент кода и передадите пустой аргумент getLength, появится следующее сообщение об ошибке:
Exception in thread "main" java.lang.AssertionError
Также вы можете использовать класс Assert предоставленный средой тестирования jUnit.
- Модульные тесты
Модульные тесты могут быть чрезвычайно полезны при тестировании функциональности и правильности вашего кода. Уделите некоторое время написанию пары тестовых примеров, которые подтверждают, что исключение NullPointerException не возникает.
Существующие безопасные методы NullPointerException
Доступ к статическим членам или методам класса
Когда ваш вы пытаетесь получить доступ к статической переменной или методу класса, даже если ссылка на объект равна нулю, JVM не выдает исключение.
Это связано с тем, что компилятор Java хранит статические методы и поля в специальном месте во время процедуры компиляции. Статические поля и методы связаны не с объектами, а с именем класса.
class SampleClass {
public static void printMessage() {
System.out.println("Hello from Java Code Geeks!");
}
}
public class TestStatic {
public static void main(String[] args) {
SampleClass sc = null;
sc.printMessage();
}
}
Несмотря на тот факт, что экземпляр SampleClass равен нулю, метод будет выполнен правильно. Однако, когда речь идет о статических методах или полях, лучше обращаться к ним статическим способом, например, SampleClass.printMessage ().
Оператор instanceof
Оператор instanceof может использоваться, даже если ссылка на объект равна нулю.
Оператор instanceof возвращает false, когда ссылка равна нулю.
String str = null;
if(str instanceof String)
System.out.println("It's an instance of the String class!");
else
System.out.println("Not an instance of the String class!");
В результате, как и ожидалось:
Not an instance of the String class!
Смотрите видео, чтобы стало понятнее.
Ряд пользователей (да и разработчиков) программных продуктов на языке Java могут столкнуться с ошибкой java.lang.nullpointerexception (сокращённо NPE), при возникновении которой запущенная программа прекращает свою работу. Обычно это связано с некорректно написанным телом какой-либо программы на Java, требуя от разработчиков соответствующих действий для исправления проблемы. В этом материале я расскажу, что это за ошибка, какова её специфика, а также поясню, как исправить ошибку java.lang.nullpointerexception.

Содержание
- Что это за ошибка java.lang.nullpointerexception
- Как исправить ошибку java.lang.nullpointerexception
- Для пользователей
- Для разработчиков
- Заключение
Что это за ошибка java.lang.nullpointerexception
Появление данной ошибки знаменует собой ситуацию, при которой разработчик программы пытается вызвать метод по нулевой ссылке на объект. В тексте сообщения об ошибке система обычно указывает stack trace и номер строки, в которой возникла ошибка, по которым проблему будет легко отследить.

Что в отношении обычных пользователей, то появление ошибки java.lang.nullpointerexception у вас на ПК сигнализирует, что у вас что-то не так с функционалом пакетом Java на вашем компьютере, или что программа (или онлайн-приложение), работающие на Java, функционируют не совсем корректно. Если у вас возникает проблема, при которой Java апплет не загружен, рекомендую изучить материал по ссылке.

Как исправить ошибку java.lang.nullpointerexception
Как избавиться от ошибки java.lang.nullpointerexception? Способы борьбы с проблемой можно разделить на две основные группы – для пользователей и для разработчиков.
Для пользователей
Если вы встретились с данной ошибкой во время запуска (или работы) какой-либо программы (особенно это касается minecraft), то рекомендую выполнить следующее:
- Переустановите пакет Java на своём компьютере. Скачать пакет можно, к примеру, вот отсюда;
- Переустановите саму проблемную программу (или удалите проблемное обновление, если ошибка начала появляться после такового);
- Напишите письмо в техническую поддержку программы (или ресурса) с подробным описанием проблемы и ждите ответа, возможно, разработчики скоро пофиксят баг.
- Также, в случае проблем в работе игры Майнкрафт, некоторым пользователям помогло создание новой учётной записи с административными правами, и запуск игры от её имени.


Для разработчиков
Разработчикам стоит обратить внимание на следующее:
- Вызывайте методы equals(), а также equalsIgnoreCase() в известной строке литерала, и избегайте вызова данных методов у неизвестного объекта;
- Вместо toString() используйте valueOf() в ситуации, когда результат равнозначен;
- Применяйте null-безопасные библиотеки и методы;
- Старайтесь избегать возвращения null из метода, лучше возвращайте пустую коллекцию;
- Применяйте аннотации @Nullable и @NotNull;
- Не нужно лишней автоупаковки и автораспаковки в создаваемом вами коде, что приводит к созданию ненужных временных объектов;
- Регламентируйте границы на уровне СУБД;
- Правильно объявляйте соглашения о кодировании и выполняйте их.


Заключение
При устранении ошибки java.lang.nullpointerexception важно понимать, что данная проблема имеет программную основу, и мало коррелирует с ошибками ПК у обычного пользователя. В большинстве случаев необходимо непосредственное вмешательство разработчиков, способное исправить возникшую проблему и наладить работу программного продукта (или ресурса, на котором запущен сам продукт). В случае же, если ошибка возникла у обычного пользователя (довольно часто касается сбоев в работе игры Minecraft), рекомендуется установить свежий пакет Java на ПК, а также переустановить проблемную программу.
Опубликовано 21.02.2017 Обновлено 03.09.2022
Исключения
- Исключения
- Введение
- Иерархия исключений
- Проверяемые и непроверяемые
- Иерархия
- Классификация
- Error и Exception
- Работа с исключениями
- Обработка исключений
- Правила try/catch/finally
- Расположение catch блоков
- Транзакционность
- Делегирование
- Методы и практики работы с исключительными ситуацими
- Собственные исключения
- Реагирование через re-throw
- Не забывайте указывать причину возникновения исключения
- Сохранение исключения
- Логирование
- Чего нельзя делать при обработке исключений
- Try-with-resources или try-с-ресурсами
- Общие советы
- Избегайте генерации исключений, если их можно избежать простой проверкой
- Предпочитайте
Optional, если отсутствие значения — не исключительная ситуация - Заранее обдумывайте контракты методов
- Предпочитайте исключения кодам ошибок и
booleanфлагам-признакам успеха
- Обработка исключений
- Исключения и статические блоки
- Многопоточность и исключения
- Проверяемые исключения и их необходимость
- Заключение
- Полезные ссылки
Введение
Начав заниматься программированием, мы, к своему удивлению, обнаружили, что не так уж просто заставить программы делать задуманное. Я могу точно вспомнить момент, когда я понял, что большая часть моей жизни с этих пор будет посвящена поиску ошибок в собственных программах.
(c) Морис Уилкс.
Предположим, вам понадобилась программа, считывающая содержимое файла.
В целом, здесь нет ничего сложного и код, выполняющий поставленную задачу, мог бы выглядеть как-то так:
public List<String> readAll(String path) { BufferedReader br = new BufferedReader(new FileReader(path)); String line; List<String> lines = new ArrayList<>(); while ((line = br.readLine()) != null) { lines.add(line); } return lines; }
И это был бы вполне рабочий вариант, если бы не одно но: мы живём не в идеальном мире. Код, приведённый выше, рассчитан на то, что всё работает идеально: путь до файла указан верный, файл можно прочитать, во время чтения с файлом ничего не происходит, место хранения файла работает без ошибок и еще огромное количество предположений.
Однако, как показывает практика, мир не идеален, а нас повсюду преследуют ошибки и проблемы. Кто-то может указать путь до несуществующего файла, во время чтения может произойти ошибка, например, файл повреждён или удален в процессе чтения и т.д.
Игнорирование подобных ситуаций недопустимо, так как это ведет к нестабильно и непредсказуемо работающему коду.
Значит, на такие ситуации надо реагировать.
Самая простая реакция — это возвращать boolean — признак успеха или некоторый код ошибки, например, какое-то число.
Пусть, 0 — это код удачного завершения приложения, 1 — это аварийное завершение и т.д.
Мы получаем код возврата и уже на него реагируем.
Подобный ход имеет право на жизнь, однако, он крайне неудобен в повседневной разработке с её тысячами возможных ошибок и проблемных ситуаций.
Во-первых, он слишком немногословен, так как необходимо помнить что означает каждый код возврата, либо постоянно сверяться с таблицей расшифровки, где они описаны.
Во-вторых, такой подход предоставляет не совсем удобный способ обработки возникших ошибок. Более того, нередки ситуации, когда в месте возникновения ошибки непонятно, как реагировать на возникшую проблему. В таком случае было бы удобнее делегировать обработку ошибки вызывающему коду, до места, где будет понятно как реагировать на ошибку.
В-третьих, и это, на мой взгляд, самое главное — это небезопасно, так как подобный способ можно легко проигнорировать.
Lots of newbie’s coming in from the C world complain about exceptions and the fact that they have to put exception handling all over the place—they want to just write their code. But that’s stupid: most C code never checks return codes and so it tends to be very fragile. If you want to build something really robust, you need to pay attention to things that can go wrong, and most folks don’t in the C world because it’s just too damn hard.
One of the design principles behind Java is that I don’t care much about how long it takes to slap together something that kind of works. The real measure is how long it takes to write something solid.In Java you can ignore exceptions, but you have to willfully do it. You can’t accidentally say, «I don’t care.» You have to explicitly say, «I don’t care.»
(c) James Gosling.
Поэтому, в Java используется другой механизм работы с такими ситуациями: исключения.
Что такое исключение? В некотором смысле можно сказать, что исключение — это некоторое сообщение, уведомляющее о проблеме, незапланированном поведении.
В нашем примере с чтением содержимого файла, источником такого сообщения может являться BufferedReader или FileReader. Сообщению необходим получатель/обработчик, чтобы перехватить его и что-то сделать, как-то отреагировать.
Важно понимать, что генерация исключения ломает поток выполнения программы, так как либо это сообщение будет перехвачено и обработано каким-то зарегистрированным получателем, либо программа завершится.
Что значит «ломает поток выполнения программы»?
Представьте, что по дороге едет грузовик. Движение машины и есть поток выполнения программы. Вдруг водитель видит, что впереди разрушенный мост — исключение, ошибка. Теперь он либо поедет по объездной дороге, т.е перехватит и отреагирует на исключение, либо остановится и поездка будет завершена.

Исключения могут быть разных типов, под разные ситуации, а значит и получателей(обработчиков) может быть несколько — на каждый отдельный тип может быть своя реакция, свой обработчик.
Исключение также может хранить информацию о возникшей проблеме: причину, описание-комментарий и т.д.
Исходя из описания можно сказать, что исключение — это объект некоторого, специально для этого предназначенного, класса. Так как проблемы и ошибки бывают разного рода, их можно классифицировать и логически разделить, значит и классы исключений можно выстроить в некоторую иерархию.
Как генерировать исключения и регистрировать обработчики мы рассмотрим позднее, а пока давайте взглянем на иерархию этих классов.
Иерархия исключений
Ниже приведена иерархия исключений:

Картинка большая, чтобы лучше запоминалась.
Для начала разберем загадочные подписи checked и unchecked на рисунке.
Проверяемые и непроверяемые
Все исключения в Java делятся на два типа: проверяемые (checked) и непроверяемые исключения (unchecked).
Как видно на рисунке, java.lang.Throwable и java.lang.Exception относятся к проверяемым исключениям, в то время как java.lang.RuntimeException и java.lang.Error — это непроверяемые исключения.
Принадлежность к тому или иному типу каждое исключение наследует от родителя.
Это значит, что наследники java.lang.RuntimeException будут unchecked исключениями, а наследники java.lang.Exception — checked.
Что это за разделение?
В первую очередь напомним, что Java — это компилируемый язык, а значит, помимо runtime(время выполнения кода), существует ещё и compile-time(то, что происходит во время компиляции).
Так вот проверяемые исключения — это исключения, на которые разработчик обязан отреагировать, т.е написать обработчики, и наличие этих обработчиков будет проверено на этапе компиляции. Ваш код не будет скомпилирован, если какое-то проверяемое исключение не обработано, компилятор этого не допустит.
Непроверяемые исключения — это исключения времени выполнения. Компилятор не будет от вас требовать обработки непроверяемых исключений.
В чём же смысл этого разделения на проверяемые и непроверяемые исключения?
Я думаю так: проверяемые исключения в Java — это ситуации, которые разработчик никак не может предотвратить и исключение является одним из вариантов нормальной работы кода.
Например, при чтении файла требуется обрабатывать java.io.FileNotFoundException и java.io.IOException, которые является потомками java.io.Exception.
Потому, что отсутствие файла или ошибка работы с вводом/выводом — это вполне допустимая ситуация при чтении.
С другой стороны, java.lang.RuntimeException — это скорее ошибки разработчика.
Например, java.lang.NullPointerException — это ошибка обращения по null ссылке, данную ситуацию можно предотвратить: проверить ссылку на null перед вызовом.
Представьте, что вы едете по дороге, так вот предупредительные знаки — это проверяемые исключения. Например, знак «Осторожно, дети!» говорит о том, что рядом школа и дорогу может перебежать ребенок. Вы обязаны отреагировать на это, не обязательно ребенок перебежит вам дорогу, но вы не можете это проконтролировать, но в данном месте — это нормальная ситуация, ведь рядом школа.
Делать абсолютно все исключения проерямыми — не имеет никакого смысла, потому что вы просто с ума сойдете, пока будете писать обработчики таких ситуаций. Да и зачастую это будет только мешать: представьте себе дорогу, которая утыкана постоянными предупредительными знаками, на которые вы должны реагировать. Ехать по такой дороге будет крайне утомительно.
Разделение на проверяемые и непроверяемые исключения существует только в
Java, в других языках программирования, таких какScala,Groovy,KotlinилиPython, все исключения непроверяемые.Это довольно холиварная тема и свои мысли по ней я изложу в конце статьи.
Теперь рассмотрим непосредственно иерархию исключений.
Иерархия
Итак, корнем иерархии является java.lang.Throwable, у которого два наследника: java.lang.Exception и java.lang.Error.
В свою очередь java.lang.Exception является родительским классом для java.lang.RuntimeException.
Занятно, что класс
java.lang.Throwableназван так, как обычно называют интерфейсы, что иногда вводит в заблуждение новичков. Однако помните, что это класс! Запомнить это довольно просто, достаточно держать в уме то, что исключения могут содержать состояние (например, информация о возникшей проблеме).
Так как в Java все классы являются наследниками java.lang.Object, то и исключения (будучи тоже классами) наследуют все стандартные методы, такие как equals, hashCode, toString и т.д.
Раз мы работаем с классами, то можно с помощью наследования создавать свои собственные иерархии исключений, добавляя в них какое-то специфическое поведение и состояние.
Чтобы создать свой собственный класс исключение необходимо отнаследоваться от одного из классов в иерархии исключений. При этом помните, что наследуется еще и тип исключения: проверяемое или непроверяемое.
Классификация
Каждый тип исключения отвечает за свою область ошибок.
-
java.lang.ExceptionЭто ситуации, которые разработчик никак не может предотвратить, например, не получилось закрыть файловый дескриптор или отослать письмо, и исключение является одним из вариантов нормальной работы кода.
Это проверяемые исключения, мы обязаны на такие исключения реагировать, это будет проверено на этапе компиляции.
Пример:
java.io.IOException,java.io.FileNotFoundException. -
java.lang.RuntimeExceptionЭто ситуации, когда основной причиной ошибки является сам разработчик, например, происходит обращение к
nullссылке, деление на ноль, выход за границы массива и т.д. При этом исключение не является одним из вариантов нормальной работы кода.Это непроверяемые исключения, реагировать на них или нет решает разработчик.
Пример:
java.lang.NullPointerException. -
java.lang.ErrorЭто критические ошибки, аварийные ситуации, после которых мы с трудом или вообще не в состоянии продолжить работу. Например, закончилась память, переполнился стек вызовов и т.д.
Это непроверяемые исключения, реагировать на них или нет решает разработчик.
Реагировать на подобные ошибки следует только в том случае, если разработчик точно знает как поступить в такой ситуации. Перехватывать такие ошибки не рекомендуется, так как чаще всего разработчик не знает как реагировать на подобного рода аварийные ситуации.
Теперь перейдем к вопросу: в чем же разница между java.lang.Error и java.lang.Exception?
Error и Exception
Все просто. Исключения java.lang.Error — это более серьезная ситуация, нежели java.lang.Exception.
Это серьезные проблемы в работе приложения, которые тяжело исправить, либо вообще неясно, можно ли это сделать.
Это не просто исключительная ситуация — это ситуация, в которой работоспособность всего приложения под угрозой! Например, исключение java.lang.OutOfMemoryError, сигнализирующее о том, что кончается память или java.lang.StackOverflowError – переполнение стека вызовов, которое можно встретить при бесконечной рекурсии.
Согласитесь, что если не получается преобразовать строку к числу, то это не та ситуация, когда все приложение должно завершаться. Это ситуация, после которой приложение может продолжить работать.
Да, это неприятно, что вы не смогли найти файл по указанному пути, но не настолько критично, как переполнение стека вызовов.
Т.е разница — в логическом разделении.
Поэтому, java.lang.Error и его наследники используются только для критических ситуаций.
Работа с исключениями
Обработка исключений
Корнем иерархии является класс java.lang.Throwable, т.е. что-то «бросаемое».
А раз исключения бросаются, то для обработки мы будем ловить их!
В Java исключения ловят и обрабатывают с помощью конструкции try/catch/finally.
При заключении кода в один или несколько блоков try указывается потенциальная возможность выбрасывания исключения в этом месте, все операторы, которые могут сгенерировать исключение, помещаются в этом блоке.
В блоках catch перечисляются исключения, на которые решено реагировать. Тут определяются блоки кода, предназначенные для решения возникших проблем. Это и есть объявление тех самых получателей/обработчиков исключений.
Пример:
public class ExceptionHandling { public static void main(String[] args) { try { // код } catch(FileNotFoundException fnf) { // обработчик на FileNotFoundException } } }
Тот тип исключения, что указывается в catch блоке можно расценивать как фильтр, который перехватывает все исключения того типа, что вы указали и всех его потомков, расположенных ниже по иерархии.
Представьте себе просеивание муки. Это процесс целью которого является удаление посторонних частиц, отличающихся по размерам от частиц муки. Вы просеиваете через несколько фильтров муку, так как вам не нужны крупные комочки, осколки и другие посторонние частицы, вам нужна именно мука определенного качества. И в зависимости от выставленных фильтров вы будете перехватывать разные частицы, комочки и т.д. Эти частицы и есть исключения. И если выставляется мелкий фильтр, то вы словите как крупные частицы, так и мелкие.
Точно также и в Java, ставя фильтр на java.lang.RuntimeException вы ловите не только java.lang.RuntimeException, но и всех его наследников! Ведь эти потомки — это тоже runtime ошибки!
В блоке finally определяется код, который будет всегда выполнен, независимо от результата выполнения блоков try/catch. Этот блок будет выполняться независимо от того, выполнился или нет блок try до конца, было ли сгенерировано исключение или нет, и было ли оно обработано в блоке catch или нет.
Пример:
public class ExceptionHandling { public static void main(String[] args) { try { // some code } catch(FileNotFoundException fnf) { // обработчик 1 } catch(RuntimeException re) { // обработчик 2 } finally { System.out.println("Hello from finally block."); } } }
В примере выше объявлен try блок с кодом, который потенциально может сгенерировать исключения, после try блока описаны два обработчика исключений, на случай генерации FileNotFoundException и на случай генерации любого RuntimeException.
Объект исключения доступен по ссылке exception.
Правила try/catch/finally
-
Блок
tryнаходится перед блокомcatchилиfinally. При этом должен присутствовать хотя бы один из этих блоков. -
Между
try,catchиfinallyне может быть никаких операторов. -
Один блок
tryможет иметь несколькоcatchблоков. В таком случае будет выполняться первый подходящий блок.Поэтому сначала должны идти более специальные блоки обработки исключений, а потом уже более общие.
-
Блок
finallyбудет выполнен всегда, кроме случая, когдаJVMпреждевременно завершит работу или будет сгенерировано исключение непосредственно в самомfinallyблоке. -
Допускается использование вложенных конструкций
try/catch/finally.public class ExceptionHandling { public static void main(String[] args) { try { try { // some code } catch(FileNotFoundException fnf) { // обработчик 1 } } catch(RuntimeException re) { // обработчик 2 } finally { System.out.println("Hello from finally block."); } } }
Вопрос:
Каков результат выполнения примера выше, если в блоке try не будет сгенерировано ни одного исключения?
Ответ:
Будет выведено на экран: «Hello from finally block.».
Так как блок finally выполняется всегда.
Вопрос:
Теперь немного видоизменим код, каков результат выполнения будет теперь?
public class ExceptionHandling { public static void main(String[] args) { try { return; } finally { System.out.println("Hello from finally block"); } } }
Ответ:
На экран будет выведено: Hello from finally block.
Вопрос:
Плохим тоном считается прямое наследование от java.lang.Throwable.
Это строго не рекомендуется делать, почему?
Ответ:
Наследование от наиболее общего класса, а в данном случае от корневого класса иерархии, усложняет обработку ваших исключений. Проблему надо стараться локализовать, а не делать ее описание/объявление максимально общим. Согласитесь, что java.lang.IllegalArgumentException говорит гораздо больше, чем java.lang.RuntimeException. А значит и реакция на первое исключение будет более точная, чем на второе.
Далее приводится несколько примеров перехвата исключений разных типов:
Обработка java.lang.RuntimeException:
try { String numberAsString = "one"; Double res = Double.valueOf(numberAsString); } catch (RuntimeException re) { System.err.println("Error while convert string to double!"); }
Результатом будет печать на экран: Error while convert string to double!.
Обработка java.lang.Error:
try { throw new Error(); } catch (RuntimeException re) { System.out.println("RuntimeException"); } catch (Error error) { System.out.println("ERROR"); }
Результатом будет печать на экран: ERROR.
Расположение catch блоков
Как уже было сказано, один блок try может иметь несколько catch блоков. В таком случае будет выполняться первый подходящий блок.
Это значит, что порядок расположения catch блоков важен.
Рассмотрим ситуацию, когда некоторый используемый нами метод может выбросить два разных исключения:
void method() throws Exception { if (new Random((System.currentTimeMillis())).nextBoolean()) { throw new Exception(); } else { throw new IOException(); } }
Конструкция
new Random((System.currentTimeMillis())).nextBoolean()генерирует нам случайное значениеfalseилиtrue.
Для обработки исключений этого метода написан следующий код:
try { method(); } catch (Exception e) { // Обработчик 1 } catch (IOException e) { // Обработчик 2 }
Все ли хорошо с приведенным выше кодом?
Нет, код выше неверен, так как обработчик java.io.IOException в данном случае недостижим. Все дело в том, что первый обработчик, ответсвенный за Exception, перехватит все исключения, а значит не может быть ситуации, когда мы сможем попасть во второй обработчик.
Снова вспомним пример с мукой, приведенный в начале.
Так вот песчинка, которую мы ищем, это и есть наше исключение, а каждый фильтр это catch блок.
Если первым установлен фильтр ловить все, что является Exception и его потомков, то до фильтра ловить все, что является IOException и его потомков ничего не дойдет, так как верхний фильтр уже перехватит все песчинки.
Отсюда следует правило:
Сначала должны идти более специальные блоки обработки исключений, а потом уже более общие.
А что если на два разных исключения предусмотрена одна и та же реакция? Написание двух одинаковых catch блоков не приветствуется, ведь дублирование кода — это зло.
Поэтому допускается объединить два catch блока с помощью |:
try { method2(); } catch (IllegalArgumentException | IndexOutOfBoundsException e) { // Обработчик }
Вопрос:
Есть ли способ перехватить все возможные исключения?
Ответ:
Есть! Если взглянуть еще раз на иерархию, то можно отметить, что java.lang.Throwable является родительским классом для всех исключений, а значит, чтобы поймать все, необходимо написать что-то в виде:
try { method(); } catch (Throwable t) { // Обработчик }
Однако, делать так не рекомендуется, что наталкивает на следующий вопрос.
Вопрос:
Почему перехватывать java.lang.Throwable — плохо?
Ответ:
Дело в том, что написав:
try { method(); } catch (Throwable t) { // catch all }
Будут перехвачены абсолютно все исключения: и java.lang.Exception, и java.lang.RuntimeException, и java.lang.Error, и все их потомки.
И как реагировать на все? При этом надо учесть, что обычно на java.lang.Error исключений вообще не ясно как реагировать. А значит, мы можем неверно отреагировать на исключение и вообще потерять данные. А ловить то, что не можешь и не собирался обрабатывать — плохо.
Поэтому перехватывать все исключения — плохая практика.
Вопрос-Тест:
Что будет выведено на экран при запуске данного куска кода?
public static void main(String[] args) { try { try { throw new Exception("0"); } finally { if (true) { throw new IOException("1"); } System.err.println("2"); } } catch (IOException ex) { System.err.println(ex.getMessage()); } catch (Exception ex) { System.err.println("3"); System.err.println(ex.getMessage()); } }
Ответ:
При выполнении данного кода выведется «1».
Давайте разберем почему.
Мы кидаем исключение во вложенном try блоке: throw new Exception("0");.
После этого поток программы ломается и мы попадаем в finally блок:
if (true) { throw new IOException("1"); } System.err.println("2");
Здесь мы гарантированно зайдем в if и кинем уже новое исключение: throw new IOException("1");.
При этом вся информация о первом исключении будет потеряна! Ведь мы никак не отреагировали на него, а в finally блоке и вовсе ‘перезатерли’ новым исключением.
На try, оборачивающий наш код, настроено два фильтра: первый на IOException, второй на Exception.
Так как порядок расположения задан так, что мы прежде всего смотрим на IOException, то и сработает этот фильтр, который выполнит следующий код:
System.err.println(ex.getMessage());
Именно поэтому выведется 1.
Транзакционность
Важным моментом, который нельзя пропустить, является то, что try блок не транзакционный.
Под термином
транзакционностья имею в виду то, что либо действия будут выполнены целиком и успешно, либо не будут выполнены вовсе.
Что это значит?
Это значит, что при возникновении исключения в try блоке все совершенные действия не откатываются к изначальному состоянию, а так и остаются совершенными.
Все выделенные ресурсы так и остаются занятыми, в том числе и при возникновении исключения.
По сути именно поэтому и существует finally блок, так как туда, как уже было сказано выше, мы зайдем в любом случае, то там и освобождают выделенные ресурсы.
Вопрос:
Работа с объектами из try блока в других блоках невозможна:
public class ExceptionExample { public static void main(String[] args) { try { String line = "hello"; } catch (Exception e) { System.err.println(e); } // Compile error System.out.println(line); // Cannot resolve symbol `line` } }
Почему?
Ответ:
Потому что компилятор не может нам гарантировать, что объекты, объявленные в try-блоке, были созданы.
Ведь могло быть сгенерировано исключение. Тогда после места, где было сгенерировано исключение, оставшиеся действия не будут выполнены, а значит возможна ситуация, когда объект не будет создан. Следовательно и работать с ним нельзя.
Вернемся к примеру с грузовиком, чтобы объяснить все вышесказанное.
Объездная здесь — это catch блок, реакция на исключительную ситуацию. Если добавить еще несколько объездных дорог, несколько catch блоков, то водитель выберет наиболее подходящий путь, наиболее подходящий и удобный catch блок, что объясняет важность расположения этих блоков.
Транзакционность на этом примере объясняется тем, что если до этого водитель где-то оплатил проезд по мосту, то деньги ему автоматически не вернутся, необходимо будет написать в поддержку или куда-то пожаловаться на управляющую компанию.
Делегирование
Выше было разобрано то, как обрабатывать исключения. Однако, иногда возникают ситуации, когда в нет конкретного понимания того, как обрабатывать возникшее исключение. В таком случае имеет смысл делегировать задачу обработки исключения коду, который вызвал ваш метод, так как вызывающий код чаще всего обладает более обширными сведениями об источнике проблемы или об операции, которая сейчас выполняется.
Делегирование исключения производится с помощью ключевого слова throws, которое добавляется после сигнатуры метода.
Пример:
// Код написан только для ознакомительной цели, не стоит с него брать пример! String readLine(String path) throws IOException { BufferedReader br = new BufferedReader(...); String line = br.readLine(); return line; }
Таким образом обеспечивается передача объявленного исключения в место вызова метода. И то, как на него реагировать уже становится заботой вызывающего этот метод.
Поэтому реагировать и писать обработчики на те исключения, которые мы делегировали, внутри метода уже не надо.
Механизм throws введен для проброса проверяемых исключений.
Разумеется, с помощью throws можно описывать делегирование как проверяемых, так и непроверяемых исключений.
Однако перечислять непроверяемые не стоит, такие исключения не контролируются в compile time.
Перечисление непроверяемых исключений бессмысленно, так как это примерно то же самое, что перечислять все, что может с вами случиться на улице.
Теперь пришла пора рассмотреть методы обработки исключительных ситуаций.
Методы и практики работы с исключительными ситуацими
Главное и основное правило при работе с исключениями звучит так:
На исключения надо либо реагировать, либо делегировать, но ни в коем случае не игнорировать.
Определить когда надо реагировать, а когда делегировать проще простого. Задайте вопрос: «Знаю ли я как реагировать на это исключение?».
Если ответ «да, знаю», то реагируйте, пишите обработчик и код, отвечающий за эту реакцию, если не знаете что делать с исключением, то делегируйте вызывающему коду.
Собственные исключения
Выше мы уже затронули то, что исключения это те же классы и объекты.
И иногда удобно выстроить свою иерархию исключений, заточенных под конкретную задачу. Дабы более гибко обрабатывать и реагировать на те исключительные ситуации, которые специфичны решаемой задаче.
Например, пусть есть некоторый справочник:
class Catalog { Person findPerson(String name); }
В данном случае нам надо обработать ситуации, когда name является null, когда в каталоге нет пользователя с таким именем.
Если генерировать на все ситуации java.lang.Exception, то обработка ошибок будет крайне неудобной.
Более того, хотелось бы явно выделить ошибку, связанную с тем, что пользователя такого не существует.
Очевидно, что стандартное исключение для этого случая не существует, а значит вполне логично создать свое.
class PersonNotFoundException extends RuntimeException { private String name; // some code }
Обратите внимание, что имя Person, по которому в каталоге не смогли его найти, выделено в свойство класса name.
Теперь при использовании этого метода проще реагировать на различные ситуации, такие как null вместо имени, а проблему с отсутствием Person в каталоге можно отдельно вынести в свой catch блок.
Реагирование через re-throw
Часто бывает необходимо перехватить исключение, сделать запись о том, что случилось (в файл лога, например) и делегировать его вызывающему коду.
Как уже было сказано выше, в рамках конструкции try/catch/finally можно сгенерировать другое исключение.
Такой подход называется re-throw.
Исключение перехватывается в catch блоке, совершаются необходимые действия, например, запись в лог или создание нового, более конкретного для контекста задачи, исключения и повторная генерация исключения.
Как это выглядит на практике:
try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException ex) { System.err.println("Log exception: " + ex); throw new ConfigException(ex); }
Во время чтения конфигурационного файла произошло исключение java.io.IOException, в catch блоке оно было перехвачено, сделана запись в консоль о проблеме, после чего было создано новое, более конкретное, исключение ConfigException, с указанием причины (перехваченное исключение, ссылка на которое ex) и оно было проброшено дальше.
По итогу, из метода с приведенным кодом, в случае ошибки чтения конфигурации, будет выброшено ConfigException.
Для чего мы здесь так поступили?
Это полезно для более гибкой обработки исключений.
В примере выше чтение конфигурации генерирует слишком общее исключение, так как java.io.IOException это довольно общее исключение, но проблема в примере выше понятна: работа с этим конфигурационным файлом невозможна.
Значит и сообщить лучше именно как о том, что это не абстрактный java.io.IOException, а именно ConfigException. При этом, так как перехваченное исключение было передано новому в конструкторе, т.е. указалась причина возникновения (cause) ConfigException, то при выводе на консоль или обработке в вызывающем коде будет понятно почему ConfigException был создан.
Также, можно было добавить еще и текстовое описание к сгенерированному ConfigException, более подробно описывающее произошедшую ситуацию.
Еще одной важной областью применения re-throw бывает преобразование проверяемых исключений в непроверяемые.
В Java 8 даже добавили исключение java.io.UncheckedIOException, которое предназначено как раз для того, чтобы сделать java.io.IOException непроверяемым, обернуть в unchecked обертку.
Пример:
try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException ex) { System.err.println("Log exception: " + ex); throw new UncheckedIOException(ex); }
Не забывайте указывать причину возникновения исключения
В предыдущем пункте мы создали собственное исключение, которому указали причину: перехваченное исключение, java.io.IOException.
Чтобы понять как это работает, давайте рассмотрим наиболее важные поля класса java.lang.Throwable:
public class Throwable implements Serializable { /** * Specific details about the Throwable. For example, for * {@code FileNotFoundException}, this contains the name of * the file that could not be found. * * @serial */ private String detailMessage; // ... /** * The throwable that caused this throwable to get thrown, or null if this * throwable was not caused by another throwable, or if the causative * throwable is unknown. If this field is equal to this throwable itself, * it indicates that the cause of this throwable has not yet been * initialized. * * @serial * @since 1.4 */ private Throwable cause = this; // ... }
Все исключения, будь то java.lang.RuntimeException, либо java.lang.Exception имеют необходимые конструкторы для инициализации этих полей.
При создании собственного исключения не пренебрегайте этими конструкторами!
Поле cause используются для указания родительского исключения, причины. Например, выше мы перехватили java.io.IOException, прокинув свое исключение вместо него. Но причиной того, что наш код выкинул ConfigException было именно исключение java.io.IOException. И эту причину нельзя игнорировать.
Представьте, что код, использующий ваш метод также перехватил ConfigException, пробросив какое-то своё исключение, а это исключение снова кто-то перехватил и пробросил свое. Получается, что истинная причина будет просто потеряна! Однако, если каждый будет указывать cause, истинного виновника возникновения исключения, то вы всегда сможете обнаружить по этому стеку виновника.
Для получения причины возникновения исключения существует метод getCause.
public class ExceptionExample { public Config readConfig() throws ConfigException { // (1) try { Reader readerConf = ....; readerConf.readConfig(); } catch (IOException ex) { System.err.println("Log exception: " + ex); throw new ConfigException(ex); // (2) } } public void run() { try { Config config = readConfig(); // (3) } catch (ConfigException e) { Throwable t = e.getCause(); // (4) } } }
В коде выше:
- В строке (1) объявлен метод
readConfig, который может выброситьConfigException. - В строке (2) создаётся исключение
ConfigException, в конструктор которого передаетсяIOException— причина возникновения. readConfigвызывается в (3) строке кода.- А в (4) вызван метод
getCauseкоторый и вернёт причину возникновенияConfigException—IOException.
Сохранение исключения
Исключения необязательно генерировать, пробрасывать и так далее.
Выше уже упоминалось, что исключение — это Java-объект. А значит, его вполне можно присвоить переменной или свойству класса, передать по ссылке в метод и т.д.
class Reader { // A holder of the last IOException encountered private IOException lastException; // some code public void read() { try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException ex) { System.err.println("Log exception: " + ex); lastException = ex; } } }
Генерация исключения это довольно дорогостоящая операция. Кроме того, исключения ломают поток выполнения программы. Чтобы не ломать поток выполнения, но при этом иметь возможность в дальнейшем отреагировать на исключительную ситуацию можно присвоить ее свойству класса или переменой.
Подобный прием использован в java.util.Scanner, где генерируемое исключение чтения потока сохраняется в свойство класса lastException.
Еще одним способом применения сохранения исключения может являться ситуация, когда надо сделать N операций, какие-то из них могут быть не выполнены и будет сгенерировано исключение, но реагировать на эти исключения будут позже, скопом.
Например, идет запись в базу данных тысячу строк построчно.
Из них 100 записей происходит с ошибкой.
Эти исключения складываются в список, а после этот список передается специальному методу, который по каждой ситуации из списка как-то отреагирует.
Т.е пока делаете операцию, копите ошибки, а потом уже реагируете.
Это похоже на то, как опрашивают 1000 человек, а негативные отзывы/голоса записывают, после чего реагируют на них. Согласитесь, было бы глупо после каждого негативного отзыва осуществлять реакцию, а потом снова возвращаться к толпе и продолжать опрос.
class Example { private List<Exception> exceptions; // some code public void parse(String s) { try { // do smth } catch(Exception ex) { exceptions.add(ex); } } private void handleExceptions() { for(Exception e : exceptions) { System.err.println("Log exception: " + e); } } }
Логирование
Когда логировать исключение?
В большинстве случаев лучше всего логировать исключение в месте его обработки. Это связано с тем, что именно в данном месте кода достаточно информации для описания возникшей проблемы — реакции на исключение. Кроме этого, одно и то же исключение при вызове одного и того же метода можно перехватывать в разных местах программы.
Также, исключение может быть частью ожидаемого поведения. В этом случае нет необходимости его логировать.
Поэтому не стоит преждевременно логировать исключение, например:
/** * Parse date from string to java.util.Date. * @param date as string * @return Date object. */ public static Date from(String date) { try { DateFormat format = new SimpleDateFormat("MMMM d, yyyy", Locale.ENGLISH); return format.parse(date); } catch (ParseException e) { logger.error("Can't parse ") throw e; } }
Здесь ParseException является частью ожидаемой работы, в ситуациях, когда строка содержит невалидные данные.
Раз происходит делегирование исключения выше (с помощью throw), то и там, где его будут обрабатывать и лучше всего логировать, а эта запись в лог будет избыточной. Хотя бы потому, что в месте обработки исключения его тоже залогируют!
Подробнее о логировании.
Чего нельзя делать при обработке исключений
-
Старайтесь не игнорировать исключения.
В частности, никогда не пишите подобный код:
try { Reader readerConf = .... readerConf.readConfig(); } catch(IOException e) { e.printStackTrace(); }
-
Не следует писать ‘универсальные’ блоки обработки исключений.
Ведь очень трудно представить себе метод, который одинаково реагировал бы на все возникающие проблемы.
Также программный код может измениться, а ‘универсальный’ обработчик исключений будет продолжать обрабатывать новые типы исключений одинаково.
Поэтому таких ситуаций лучше не допускать.
-
Старайтесь не преобразовывать более конкретные исключения в более общие.
В частности, например, не следует
java.io.IOExceptionпреобразовывать вjava.lang.Exceptionили вjava.lang.Throwable.Чем с более конкретными исключениями идет работа, тем проще реагировать и принимать решения об их обработке.
-
Старайтесь не злоупотреблять исключениями.
Если исключение можно не допустить, например, дополнительной проверкой, то лучше так и сделать.
Например, можно обезопасить себя от
java.lang.NullPointerExceptionпростой проверкой:if(ref != null) { // some code }
Try-with-resources или try-с-ресурсами
Как уже говорилось выше про finally блок, код в нем выполняется в любом случае, что делает его отличным кандидатом на место по освобождению ресурсов, учитывая нетранзакционность блока try.
Чаще всего за закрытие ресурса будет отвечать код, наподобие этого:
try { // code } finally { resource.close(); }
Освобождение ресурса (например, освобождение файлового дескриптора) — это поведение.
А за поведение в
Javaотвечают интерфейсы.
Это наталкивает на мысль, что нужен некоторый общий интерфейс, который бы реализовывали все классы, для которых необходимо выполнить какой-то код по освобождению ресурсов, т.е выполнить ‘закрытие’ в finally блоке и еще удобнее, если бы этот однообразный finally блок не нужно было писать каждый раз.
Поэтому, начиная с Java 7, была введена конструкция try-with-resources или TWR.
Для этого объявили специальный интерфейс java.lang.AutoCloseable, у которого один метод:
void close() throws Exception;
Все классы, которые будут использоваться так, как было описано выше, должны реализовать или java.lang.Closable, или java.lang.AutoCloseable.
В качестве примера, напишем код чтения содержимого файла и представим две реализации этой задачи: используя и не используя try-with-resources.
Без использования try-with-resources (пример ниже плох и служит только для демонстрации объема необходимого кода):
BufferedReader br = null; try { br = new BufferedReader(new FileReader(path)); // read from file } catch (IOException e) { // catch and do smth } finally { try { if (br != null) { br.close(); } } catch (IOException ex) { // catch and do smth } }
А теперь то же самое, но в Java 7+:
try (FileReader fr = new FileReader(path); BufferedReader br = new BufferedReader(fr)) { // read from file } catch (IOException e) { // catch and do smth }
По возможности пользуйтесь только try-with-resources.
Помните, что без реализации
java.lang.Closableилиjava.lang.AutoCloseableваш класс не будет работать сtry-with-resourcesтак, как показано выше.
Вопрос:
Получается, что используя TWR мы не пишем код для закрытия ресурсов, но при их закрытии может же тоже быть исключение! Что произойдет?
Ответ:
Точно так же, как и без TWR, исключение выбросится так, будто оно было в finally-блоке.
Помните, что TWR, грубо говоря, просто добавляет вам блок кода вида:
finally { resource.close(); }
Вопрос:
Является ли безопасной конструкция следующего вида?
try (BufferedWriter bufferedWriter = new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a")))) { }
Ответ:
Не совсем, если конструктор OutputStreamWriter или BufferedWriter выбросит исключение, то FileOutputStream закрыт не будет.
Пример, демонстрирующий это:
public class Main { public static void main(String[] args) throws Exception { try (ThrowingAutoCloseable throwingAutoCloseable = new ThrowingAutoCloseable(new PrintingAutoCloseable())) { // (1) } } private static class ThrowingAutoCloseable implements AutoCloseable { // (2) private final AutoCloseable other; public ThrowingAutoCloseable(AutoCloseable other) { this.other = other; throw new IllegalStateException("I always throw"); // (3) } @Override public void close() throws Exception { try { other.close(); // (4) } finally { System.out.println("ThrowingAutoCloseable is closed"); } } } private static class PrintingAutoCloseable implements AutoCloseable { // (5) public PrintingAutoCloseable() { System.out.println("PrintingAutoCloseable created"); // (6) } @Override public void close() { System.out.println("PrintingAutoCloseable is closed"); // (7) } } }
- В строке (1) происходит заворачивание одного ресурса в другой, аналогично
new BufferedWriter(new OutputStreamWriter(new FileOutputStream("a"))). ThrowingAutoCloseable(2) — такойAutoCloseable, который всегда бросает исключение (3), в (4) производится попытка закрыть полученный в конструктореAutoCloseable.PrintingAutoCloseable(5) —AutoCloseable, который печатает сообщения о своём создании (6) и закрытии (7).
В результате выполнения этой программы вывод будет примерно следующим:
PrintingAutoCloseable created
Exception in thread "main" java.lang.IllegalStateException: I always throw
at ru.misc.Main$ThrowingAutoCloseable.<init>(Main.java:19)
at ru.misc.Main.main(Main.java:9)
Как видно, PrintingAutoCloseable закрыт не был!
Вопрос:
В каком порядке закрываются ресурсы, объявленные в try-with-resources?
Ответ:
В обратном.
Пример:
public class Main { public static void main(String[] args) throws Exception { try (PrintingAutoCloseable printingAutoCloseable1 = new PrintingAutoCloseable("1"); PrintingAutoCloseable printingAutoCloseable2 = new PrintingAutoCloseable("2"); PrintingAutoCloseable printingAutoCloseable3 = new PrintingAutoCloseable("3")) { } } private static class PrintingAutoCloseable implements AutoCloseable { private final String id; public PrintingAutoCloseable(String id) { this.id = id; } @Override public void close() { System.out.println("Closed " + id); } } }
Вывод:
Closed 3
Closed 2
Closed 1
Общие советы
Избегайте генерации исключений, если их можно избежать простой проверкой
Как уже было сказано выше, исключения ломают поток выполнения программы. Если же на сгенерированное исключение не найдется обработчика, не будет подходящего catch блока, то программа и вовсе будет завершена. Кроме того, генерация исключения это довольно дорогостоящая операция.
Помните, что если исключение можно не допустить, то лучше так и сделать.
Отсюда следует первый совет: не брезгуйте дополнительными проверками.
- Не ловите
IllegalArgumentException,NullPointerException,ArrayIndexOutOfBoundsExceptionи подобные.
Потому что эти ошибки — это явная отсылка к тому, что где-то недостает проверки.
Обращение по индексу за пределами массива,NullPointerException, все эти исключения — это ошибка разработчика. - Вводите дополнительные проверки на данные, дабы избежать возникновения непроверяемых исключения
Например, запретите вводить в поле возраста не числовые значения, проверяйте ссылки на null перед обращением и т.д.
Предпочитайте Optional, если отсутствие значения — не исключительная ситуация
При написании API к каким-то хранилищам или коллекциям очень часто на отсутствие элемента генерируется исключение, как например в разделе собственные исключения.
class Catalog { Person findPerson(String name); }
Но и в этом случае генерации исключения можно избежать, если воспользоваться java.util.Optional:
Optional<Person> findPerson(String name);
Класс java.util.Optional был добавлен в Java 8 и предназначен как раз для подобных ситуаций, когда возвращаемого значения может не быть. В зависимости от задачи и контекста можно как генерировать исключение, как это сделано в примере с PersonNotFoundException, так и изменить сигнатуру метода, воспользовавшись java.util.Optional.
Отсюда следует второй совет: думайте над API ваших классов, исключений можно избежать воспользовавшись другим подходом.
Заранее обдумывайте контракты методов
Важным моментом, который нельзя не упомянуть, является то, что если в методе объявляется, что он может сгенерировать исключение (с помощью throws), то при переопределении такого метода нельзя указать более общее исключение в качестве выбрасываемого.
class Person { void hello() throws RuntimeException { // some code } } // Compile Error class PPerson extends Person { @Override void hello() throws Exception { // some code } }
Если было явно указано, что метод может сгенерировать java.lang.RuntimeException, то нельзя объявить более общее бросаемое исключение при переопределении. Но можно указать потомка:
// IllegalArgumentException - потомок RuntimeException! class PPerson extends Person { @Override void hello() throws IllegalArgumentException { // some code } }
Что, в целом логично.
Если объявляется, что метод может сгенерировать java.lang.RuntimeException, а он выбрасывает java.io.IOException, то это было бы как минимум странно.
Это объясняется и с помощью полимофризма. Пусть есть интерфейс, в котором объявлен метод, генерирующий исключение. Если полиморфно работать с объектом через общий интерфейс, то разработчик обязан обработать исключение, объявленное в интерфейсе, а если одна из реализаций интерфейса генерирует более общее исключение, то это нарушает полиморфизм. Поэтому такой код даже не скомпилируется.
При этом при переопределении можно вообще не объявлять бросаемые исключения, таким образом сообщив, что все проблемы будут решены в методе:
class PPerson extends Person { @Override void hello() { // some code } }
Отсюда следует третий совет: необходимо думать о тех исключениях, которые делегирует метод, если класс может участвовать в наследовании.
Предпочитайте исключения кодам ошибок и boolean флагам-признакам успеха
- Исключения более информативны: они позволяют передать сообщение с описанием ошибки
- Исключение практически невозможно проигнорировать
- Исключение может быть обработано кодом, находящимся выше по стеку, а
boolean-флаг или код ошибки необходимо обрабатывать здесь и сейчас
Исключения и статические блоки
Еще интересно поговорить про то, что происходит, если исключение возникает в статическом блоке.
Так вот, такие исключения оборачиваются в java.lang.ExceptionInInitializerError:
public class ExceptionHandling { static { throwRuntimeException(); } private static void throwRuntimeException() { throw new NullPointerException(); } public static void main(String[] args) { System.out.println("Hello World"); } }
Результатом будет падение со следующим стектрейсом:
java.lang.ExceptionInInitializerError Caused by: java.lang.NullPointerException at exception.test.ExceptionHandling.throwRuntimeException(ExceptionHandling.java:13) at exception.test.ExceptionHandling. (ExceptionHandling.java:8)
Многопоточность и исключения
Код в Java потоке выполняется в методе со следующей сигнатурой:
Что делает невозможным пробрасывание проверяемых исключений, т.е разработчик должен обрабатывать все проверяемые исключения внутри метода run.
Непроверяемые исключения обрабатывать необязательно, однако необработанное исключение, выброшенное из run, завершит работу потока.
Например:
public class ExceptionHandling4 { public static void main(String[] args) throws InterruptedException { Thread t = new Thread() { @Override public void run() { throw new RuntimeException("Testing unhandled exception processing."); } }; t.start(); } }
Результатом выполнения этого кода будет то, что возникшее исключение прервет поток исполнения (interrupt thread):
Exception in thread “Thread-0” java.lang.RuntimeException: Testing unhandled exception processing. at exception.test. ExceptionHandling4$1.run(ExceptionHandling4.java:27)
При использовании нескольких потоков бывают ситуации, когда надо знать, как поток завершился, из-за какого именно исключения. И, разумеется, отреагировать на это.
В таких ситуациях рекомендуется использовать Thread.UncaughtExceptionHandler.
t.setUncaughtExceptionHandler(new Thread.UncaughtExceptionHandler() { public void uncaughtException(Thread t, Throwable e) { System.out.println("Handled uncaught exception in thread :" + t + " Exception : " + e); } });
И вывод уже будет:
Handled uncaught exception in thread :Thread[Thread-0,5,main] Exception : java.lang.RuntimeException: Testing unhandled exception processing.
Необработанное исключение RuntimeException("Testing unhandled exception processing."), убившее поток, было перехвачено специальным зарегистрированным обработчиком.
Проверяемые исключения и их необходимость
В большинстве языков программирования, таких как C#, Scala, Groovy, Python и т.д., нет такого разделения, как в Java, на проверяемые и непроверяемые исключения.
Почему оно введено в Java было разобрано выше, а вот почему проверяемые исключения недолюбливают разработчики?
Основных причин две, это причины с: версионированием и масштабируемостью.
Представим, что вы, как разработчик библиотеки, объявили некоторый условный метод foo, бросающий исключения A, B и C:
void foo() throws A, B, C;
В следующей версии библиотеки в метод foo добавили функциональности и теперь он бросает еще новое исключение D:
void foo() throws A, B, C, D;
В таком случае новая версия библиотеки сломает код тех, кто ей пользуется. Это сравнимо с тем, что добавляется новый метод в интерфейс.
И с одной стороны, это правильно, так как в новой версии добавляется еще одно исключение и те, кто использует библиотеку должны отреагировать на все новые исключения. С другой стороны, чаще всего такие исключения будут также проброшены дальше. Все дело в том, что случаев, когда можно обработать специфический тип исключения, например тот же D или A в примере выше, и сделать в обработчике что-то интеллектуальное, можно пересчитать по пальцам одной руки.
Проблема с масштабируемостью начинается тогда, когда происходит вызов не одного, а нескольких API, каждый из которых также несет с собой проверяемые исключения. Представьте, что помимо foo, бросающего A, B, C и D, в методе hello вызывается еще и bar, который также бросает E и T исключения. Как сказано выше, как реагировать чаще всего непонятно, поэтому эти исключения делегируются вызывающему коду, из-за чего объявление метода hello выглядит совсем уж угрожающе:
void hello() throws A, B, C, D, E, T { try { foo(); bar(); } finally { // clear resources if needed } }
Все это настолько раздражающе, что чаще всего разработчики просто объявляют наиболее общее исключение в throws:
void hello() throws Exception { try { foo(); bar(); } finally { // clear resources if needed } }
А в таком случае это все равно, что сказать «метод может выбросить исключение» — это настолько общие и абстрактные слова, что смысла в throws Exception практически нет.
Также есть еще одна проблема с проверяемыми исключениями. Это то, что с проверяемыми исключениями крайне неудобно работать в lambda-ах и stream-ах:
// compilation error Lists.newArrayList("a", "asg").stream().map(e -> {throw new Exception();});
Так как с Java 8 использование lambda и stream-ов распространенная практика, то накладываемые ограничения вызовут дополнительные трудности при использовании проверяемых исключений.
Поэтому многие разработчики недолюбливают проверяемые исключения, например, оборачивая их в непроверяемые аналоги с помощью re-throw.
Мое мнение таково: на проверяемых исключениях очень хорошо учиться. Компилятор и язык сами подсказывают вам, что нельзя игнорировать исключения и требуют от вас реакции. Опять же, логическое разделение на проверяемые и непроверяемые помогает в понимании исключений, в понимании того, как и на что реагировать. В промышленной же разработке это становится уже больше раздражающим фактором.
В своей работе я стараюсь чаще использовать непроверяемые исключения, а проверяемые оборачивать в unchecked аналоги, как, например, java.io.IOException и java.io.UncheckedIOException.
Заключение
Иерархия исключений в Java.
Исключения делятся на два типа: непроверяемые(unchecked) и проверяемые(checked). Проверяемые исключения — это исключения, которые проверяются на этапе компиляции, мы обязаны на них отреагировать.
Проверяемые исключения в Java используются тогда, когда разработчик никак не может предотвратить их возникновение. Причину возникновения java.lang.RuntimeException можно проверить и устранить заранее, например, проверить ссылку на null перед вызовом метода, на объекте по ссылке. А вот с причинами проверяемых исключений так сделать не получится, так как ошибка при чтении файла может возникнуть непосредственно в момент чтения, потому что другая программа его удалила. Соответственно, при чтении файла требуется обрабатывать java.io.IOException, который является потомком java.lang.Exception.
Допускается создание собственных исключений, признак проверяемости или непроверяемости наследуется от родителя. Исключения — это такие же классы, со своим поведением и состоянием, поэтому при наследовании вполне допускается добавить дополнительное поведение или свойства классу.
Обработка исключений происходит с помощью конструкции try/catch/finally. Один блок try может иметь несколько catch блоков. В таком случае будет выполняться первый подходящий блок.
Помните, что try блок не транзакционен, все ресурсы, занятые в try ДО исключения остаются в памяти. Их надо освобождать и очищать вручную.
Если вы используете Java версии 7 и выше, то отдавайте предпочтение конструкции try-with-resources.
Основное правило:
На исключения можно реагировать, их обработку можно делегировать, но ни в коем случае нельзя их игнорировать.
Определить когда надо реагировать, а когда делегировать проще простого. Задайте вопрос: «Знаю ли я как реагировать на это исключение?».
Если ответ «да, знаю», то реагируйте, пишите обработчик и код, отвечающий за эту реакцию, если не знаете что делать с исключением, то делегируйте вызывающему коду.
Помните, что перехват java.lang.Error стоит делать только если вы точно знаете, что делаете. Восстановление после таких ошибок не всегда возможно и почти всегда нетривиально.
Не забывайте, что большинство ошибок java.lang.RuntimeException и его потомков можно избежать.
Не бойтесь создавать собственные исключения, так как это позволит писать более гибкие обработчики, а значит более точно реагировать на проблемы.
Представьте себе, что существуют пять причин, по которым может быть выброшено исключение, и во всех пяти случаях бросается
java.lang.Exception. Вы же спятите разбираться, чем именно это исключение вызвано.(c) Евгений Матюшкин.
Помните, что исключения ломают поток выполнения программы, поэтому чем раньше вы обработаете возникшую проблему, тем лучше. Отсюда же следует совет, что лучше не разбрасываться исключениями, так как помимо того, что это ломает поток выполнения, это еще и дорогостоящая операция.
Постарайтесь не создавать ‘универсальных’ обработчиков, так как это чревато трудноуловимыми ошибками.
Если исключение можно не генерировать, то лучше так и сделать. Не пренебрегайте проверками.
Старайтесь продумывать то, как вы будете реагировать на исключения, не игнорировать их, использовать только try-с-ресурсами.
Помните:
In Java you can ignore exceptions, but you have to willfully do it. You can’t accidentally say, «I don’t care.» You have to explicitly say, «I don’t care.»
(c) James Gosling.
Для закрепления материала рекомендую ознакомиться с ссылками ниже и этим материалом.
Полезные ссылки
- Книга С. Стелтинг ‘Java без сбоев: обработка исключений, тестирование, отладка’
- Oracle Java Tutorials
- Лекция Технострим Исключения
- Лекция OTUS Исключения в Java
- Лекция Ивана Пономарёва по исключениям
- Заметка Евгения Матюшкина про Исключения
- Failure and Exceptions by James Gosling
- The Trouble with Checked Exceptions by Bill Venners with Bruce Eckel
- Никто не умеет обрабатывать ошибки
- Исключения и обобщенные типы в Java
- Вопросы для закрепления
Неизвестное нежелательное событие, нарушившее нормальный ход выполнения программы, называется исключением.
В Java есть в основном два типа исключений:
1. Проверяемое исключение
2. Непроверенное исключение
ExceptionInInitializerError — это дочерний класс класса Error и, следовательно, это непроверенное исключение. Это исключение автоматически создается JVM, когда JVM пытается загрузить новый класс, поскольку во время загрузки класса оцениваются все статические переменные и блок статического инициализатора. Это исключение также действует как сигнал, который сообщает нам, что непредвиденное исключение произошло в блоке статического инициализатора или при присвоении значения статической переменной.
В основном есть два случая, когда ExceptionInInitializerError может возникнуть в программе Java:
1. ExceptionInInitializerError при присвоении значения статической переменной
В приведенном ниже примере мы назначаем статической переменной 20/0, где 20/0 дает неопределенное арифметическое поведение, и, следовательно, возникает исключение в назначении статической переменной, и в конечном итоге мы получим ExceptionInInitializerError.
Ява
class GFG {
static int x = 20 / 0 ;
public static void main(String[] args)
{
System.out.println( "The value of x is " + x);
}
}
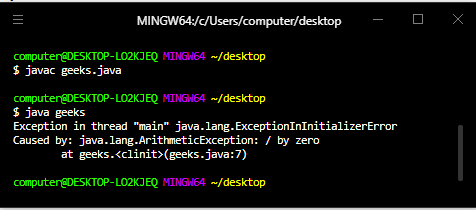
2. ExceptionInInitializerError при присвоении нулевого значения внутри статического блока
В приведенном ниже примере мы объявили статический блок, внутри которого мы создаем строку s и присваиваем ей нулевое значение, а затем печатаем длину строки, поэтому мы получим исключение NullPointerException, потому что мы пытались распечатать длину строка, значение которой равно нулю, и, как мы видим, это исключение возникает внутри статического блока, поэтому мы получим ExceptionInInitializerError.
Ява
class GFG {
static
{
String s = null ;
System.out.println(s.length());
}
public static void main(String[] args)
{
System.out.println( "GeeksForGeeks Is Best" );
}
}
Как разрешить Java.lang.ExceptionInInitializerError?
- Мы можем разрешить java.lang.ExceptionInInitializerError, убедившись, что статический блок инициализатора классов не генерирует никаких исключений времени выполнения.
- Мы также можем разрешить это исключение, убедившись, что инициализирующая статическая переменная классов также не генерирует никаких исключений времени выполнения.
Вниманию читателя! Не прекращайте учиться сейчас. Ознакомьтесь со всеми важными концепциями Java Foundation и коллекций с помощью курса «Основы Java и Java Collections» по доступной для студентов цене и будьте готовы к работе в отрасли. Чтобы завершить подготовку от изучения языка к DS Algo и многому другому, см. Полный курс подготовки к собеседованию .
Довольно часто при разработке на Java программисты сталкиваются с NullPointerException, появляющимся в самых неожиданных местах. В этой статье мы разберёмся, как это исправить и как стараться избегать появления NPE в будущем.
NullPointerException (оно же NPE) это исключение, которое выбрасывается каждый раз, когда вы обращаетесь к методу или полю объекта по ссылке, которая равна null. Разберём простой пример:
Integer n1 = null; System.out.println(n1.toString());
Здесь на первой строке мы объявили переменную типа Integer и присвоили ей значение null (то есть переменная не указывает ни на какой существующий объект).
На второй строке мы обращаемся к методу toString переменной n1. Так как переменная равна null, метод не может выполниться (переменная не указывает ни на какой реальный объект), генерируется исключение NullPointerException:
Exception in thread "main" java.lang.NullPointerException at ru.javalessons.errors.NPEExample.main(NPEExample.java:6)
Как исправить NullPointerException
В нашем простейшем примере мы можем исправить NPE, присвоив переменной n1 какой-либо объект (то есть не null):
Integer n1 = 16; System.out.println(n1.toString());
Теперь не будет исключения при доступе к методу toString и наша программа отработает корректно.
Если ваша программа упала из-за исключение NullPointerException (или вы перехватили его где-либо), вам нужно определить по стектрейсу, какая строка исходного кода стала причиной появления этого исключения. Иногда причина локализуется и исправляется очень быстро, в нетривиальных случаях вам нужно определять, где ранее по коду присваивается значение null.
Иногда вам требуется использовать отладку и пошагово проходить программу, чтобы определить источник NPE.
Как избегать исключения NullPointerException
Существует множество техник и инструментов для того, чтобы избегать появления NullPointerException. Рассмотрим наиболее популярные из них.
Проверяйте на null все объекты, которые создаются не вами
Если объект создаётся не вами, иногда его стоит проверять на null, чтобы избегать ситуаций с NullPinterException. Здесь главное определить для себя рамки, в которых объект считается «корректным» и ещё «некорректным» (то есть невалидированным).
Не верьте входящим данным
Если вы получаете на вход данные из чужого источника (ответ из какого-то внешнего сервиса, чтение из файла, ввод данных пользователем), не верьте этим данным. Этот принцип применяется более широко, чем просто выявление ошибок NPE, но выявлять NPE на этом этапе можно и нужно. Проверяйте объекты на null. В более широком смысле проверяйте данные на корректность, и консистентность.
Возвращайте существующие объекты, а не null
Если вы создаёте метод, который возвращает коллекцию объектов – не возвращайте null, возвращайте пустую коллекцию. Если вы возвращаете один объект – иногда удобно пользоваться классом Optional (появился в Java 8).
Заключение
В этой статье мы рассказали, как исправлять ситуации с NullPointerException и как эффективно предотвращать такие ситуации при разработке программ.
создать хранилище ключей:
keytool -genkey -alias tomcat -keyalg RSA -keystore my.keystore -keysize 2048
создать запрос подписи сертификата (CSR):
keytool -certreq -alias tomcat -keyalg RSA -file my.csr -keystore my.keystore
Я ухожу с моим хостинг-провайдера и получить сертификаты. Эти я установил следующим образом:
keytool -import -alias root -keystore my.keystore -trustcacerts -file gd_bundle-g2-g1.crt
keytool -import -alias intermed -keystore my.keystore -trustcacerts -file gdig2.crt
keytool -import -alias tomcat -keystore my.keystore -trustcacerts -file my.crt
когда я установил окончательный сертификат (мой.crt) я получил следующую ошибку:
keytool error: java.lang.Exception: Failed to establish chain from reply
Я считаю, что я импортировал цепь и в правильном порядке, поэтому я очень смущен этим сообщением. Кто-нибудь видит, что я делаю не так?
6 ответов
Я только что обнаружил, что файлы godaddy, поставляемые с моим сертификатом, являются промежуточными сертификатами (на самом деле они кажутся одинаковыми промежуточными сертификатами).
Я получил правильный корневой и промежуточный сертификаты, дважды щелкнув по моему сертификату и глядя на путь сертификата… отсюда я также могу загрузить каждый из этих сертификатов и использовать шаги, используемые в вопросе, чтобы импортировать их
я боролся с той же проблемой около двух недель, пока не нашел способ обойти ее. Проблема была в том, что корневые и промежуточные сертификаты, которые пришли с моим сертификатом от Godaddy, не были теми, которые мне нужны. Я много раз заглядывал в репозиторий Godaddy, не найдя подходящих сертификатов.
Я просмотрел свой сертификат на своем ноутбуке (используя Windows 8.1). Там я увидел цепочку сертификатов, и я смог экспортировать корневые и промежуточные сертификаты. Тогда Я импортировал их в мое хранилище ключей, и он работал так, как должен.
для этого выполните следующие действия:
-
Просмотр сертификатов на компьютере под управлением Windows. Вы сможете увидеть цепочку сертификатов на третьей вкладке, которая выглядит следующим образом.

-
выберите корневой сертификат из цепочки и нажмите на кнопку «Просмотреть сертификат».
- откроется новое окно, перейдите к вторая вкладка и нажмите на кнопку» Сохранить файл». Откроется мастер экспорта для ceritficate.
- при экспорте выберите опцию X. 509 base 64 и следуйте инструкциям. Сохранить файл.
- повторите для промежуточного сертификата.
- загрузите оба сертификата на свой сервер и импортируйте в хранилище ключей, следуя порядку — первый корень, второй промежуточный и, наконец, ваш сертификат. [Нет необходимости импортировать корень сертификат]
Примечание.:
Прежде чем импортировать эти сертификаты, мне пришлось удалить те, которые были на моем хранилище ключей и не работали. Для этого я использовал следующие инструкции:
keytool -delete -alias [root] -keystore [keystore file]
Если вы не уверены, что находится внутри вашего keytool, вы можете просмотреть с помощью:
keytool -list -keystore [keystore file]
16
автор: Alejandro von Wuthenau
Я получил ту же ошибку при попытке импортировать сертификаты CA certified в хранилище ключей в среде Linux.
Я выполнил набор шагов и успешно импортировал его.
после получения сертификатов CA certified выполните следующие действия для импорта сертификатов в хранилище ключей.
Шаг 1:
импортируйте корневой сертификат в cacerts, который будет доступен в папке JAVA_HOME/jre/lib/security, используя следующее команда:
keytool -importcert -alias root -file [root certificate] -keystore cacerts
после того, как вы введете выше команду он будет запрашивать пароль, введите пароль и нажмите на да.
Шаг 2:
импорт корневого сертификата с помощью следующей команды:
keytool -importcert -alias root -file [root certificate] -keystore [keystore file name]
после того, как вы введете выше команду он будет запрашивать пароль, введите пароль и нажмите на да.
Шаг 3:
импорт промежуточного сертификата с помощью следующей команды:
keytool -importcert -alias intermediate -file [intermediate certificate] -keystore [key store file name]
как только вы введете над командой его подскажет для замены уже сертификата введите yes.
Примечание: промежуточный сертификат опционный можно проигнорировать, он приходит с сертификатом корня.
Шаг 4:
импорт сертификата сайта с помощью следующей команды:
keytool -trustcacerts -importcert -alias [alias name which give during keystore creation] -file [site certificate] -keystore [key store file name]
Environment выполняются эти команды java версии 7. сертификат выдается GODADDY.
для получения дополнительной информации см. сайт : http://docs.oracle.com/javase/7/docs/technotes/tools/windows/keytool.html#importCertCmd
чтобы решить эту проблему, используют дополнительный переключатель (-trustcacerts) в командах keytool.
команда для импорта промежуточных сертификатов из промежуточного.файл cer для сертификатов.KS файл ключей должен выглядеть так:
keytool-storetype JCEKS-storepass passwd-сертификаты хранилища ключей.КС-импорт -псевдоним промежуточными -trustcacerts -файл промежуточными.cer
команда для импорта сертификата из http.файл cer для сертификатов.KS файл ключей должен выглядеть так:
keytool-storetype JCEKS-storepass passwd-сертификаты хранилища ключей.KS-import-псевдоним http -trustcacerts -файл http.cer
повторная попытка завершить процесс создания и импорта подписанного SSL-сертификата.
загрузите цепочку сертификатов, откройте ее в Windows — она хранит сертификат CA и ваш ответ сертификата от CA.
сначала импортируйте сертификат CA в хранилище ключей, а затем импортируйте ответ из CA.
следующий шаг очень важен перед импортом сертификатов в локальное хранилище ключей. После получения подписанных сертификатов от CA).
импортируйте корневой сертификат в cacerts, который будет доступен в папке JAVA_HOME/jre/lib/security, используя следующую команду:
keytool-importcert-псевдоним корневой файл [корневой сертификат] — keystore cacerts
после того, как вы введете выше команду он будет запрашивать пароль, введите пароль и нажмите на да.