Version: 20220421
By the same author: Virtour.fr — visites virtuelles
Универсальный декодер — конвертер кириллицы
Результат
[Результат перекодировки появится здесь…]
|
Гостевая книга
Поставьте ссылку на наш сайт! <a href=»https://2cyr.com/decode/»>Универсальный декодер кириллицы</a> |
Custom Work For a small fee I can help you quickly recode/recover large pieces of data — texts, databases, websites… or write custom functions you can use (invoice available). FAQ and contact information. |
О программе
Здравствуйте! Эта страница может пригодиться, если вам прислали текст (предположительно на кириллице), который отображается в виде странной комбинации загадочных символов. Программа попытается угадать кодировку, а если не получится, покажет примеры всех комбинаций кодировок, чтобы вы могли выбрать подходящую.
Использование
- Скопируйте текст в большое текстовое поле дешифратора. Несколько первых слов будут проанализированы, поэтому желательно, чтобы в них содержалась (закодированная) кириллица.
- Программа попытается декодировать текст и выведет результат в нижнее поле.
- В случае удачной перекодировки вы увидите текст в кириллице, который можно при необходимости скопировать и сохранить.
- В случае неудачной перекодировки (текст не в кириллице, состоящий из тех же или других нечитаемых символов) можно выбрать из нового выпадающего списка вариант в кириллице (если их несколько, выбирайте самый длинный). Нажав OK вы получите корректный перекодированный текст.
- Если текст перекодирован лишь частично, попробуйте выбрать другие варианты кириллицы из выпадающего списка.
Ограничения
- Если текст состоит из вопросительных знаков («???? ?? ??????»), то проблема скорее всего на стороне отправителя и восстановить текст не получится. Попросите отправителя послать текст заново, желательно в формате простого текстового файла или в документе LibreOffice/OpenOffice/MSOffice.
- Не любой текст может быть гарантированно декодирован, даже если есть вы уверены на 100%, что он написан в кириллице.
- Анализируемый и декодированный тексты ограничены размером в 100 Кб.
- Программа не всегда дает стопроцентную точность: при перекодировке из одной кодовой страницы в другую могут пропасть некоторые символы, такие как болгарские кавычки, реже отдельные буквы и т.п.
- Программа проверяет максимум 7245 вариантов из двух и трех перекодировок: если имело место многократное перекодирование вроде koi8(utf(cp1251(utf))), оно не будет распознано или проверено. Обычно возможные и отображаемые верные варианты находятся между 32 и 255.
- Если части текста закодированы в разных кодировках, программа сможет распознать только одну часть за раз.
Условия использования
Пожалуйста, обратите внимание на то, что данная бесплатная программа создана с надеждой, что она будет полезна, но без каких-либо явных или косвенных гарантий пригодности для любого практического использования. Вы можете пользоваться ей на свой страх и риск.
Если вы используете для перекодировки очень длинный текст, убедитесь, что имеется его резервная копия.
Переводчики
Русский (Russian) : chAlx ; Пётр Васильев (http://yonyonson.livejournal.com/)
Страница подготовки переводов на другие языки находится тут.
Что нового
October 2013 : I am trying different optimizations for the system which should make the decoder run faster and handle more text. If you notice any problem, please notify me ASAP.
На английской версии страницы доступен changelog программы.
Вернуться к кириллической виртуальной клавиатуре.

Способ 1: 2cyr
Онлайн-сервис 2cyr поддерживает практически все популярные кодировки, а также позволяет исправить запись разными способами в зависимости от известной о кодировке информации. Для преобразования текста в читабельный вид при помощи данного сайта осуществите следующие действия:
Перейти к онлайн-сервису 2cyr
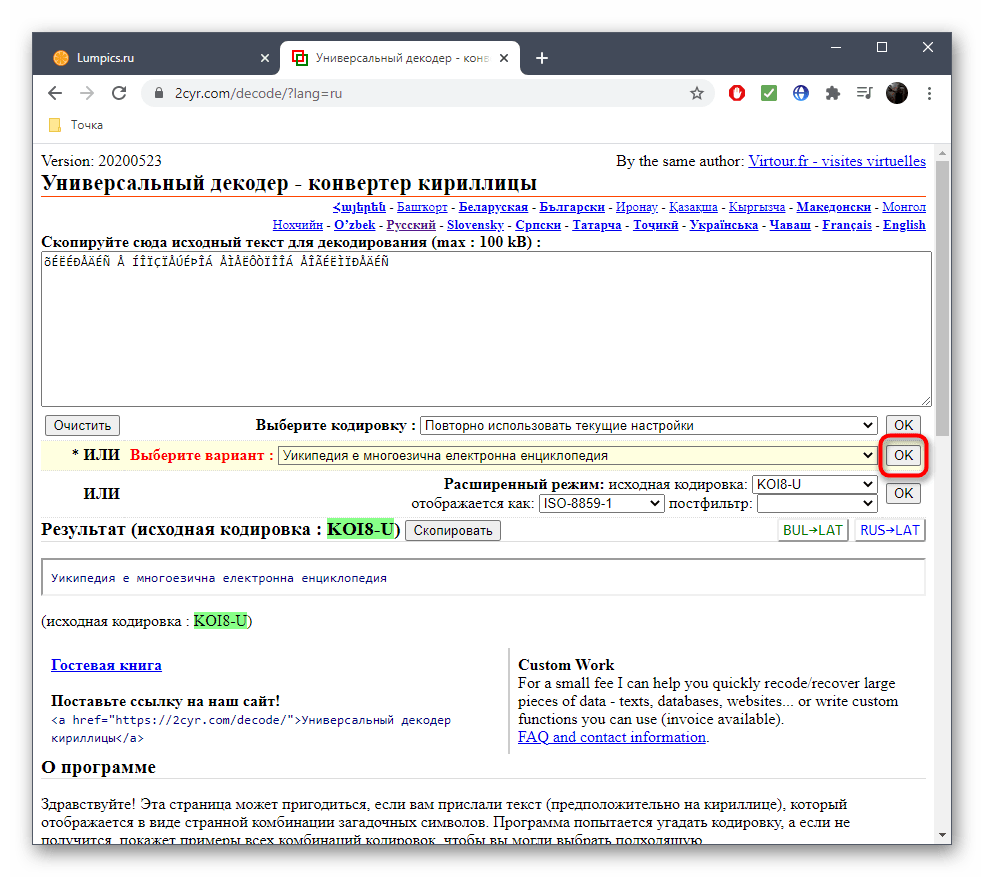
- Воспользуйтесь ссылкой выше, чтобы открыть главную страницу сайта 2cyr. Кликните по соответствующему полю для его активации.
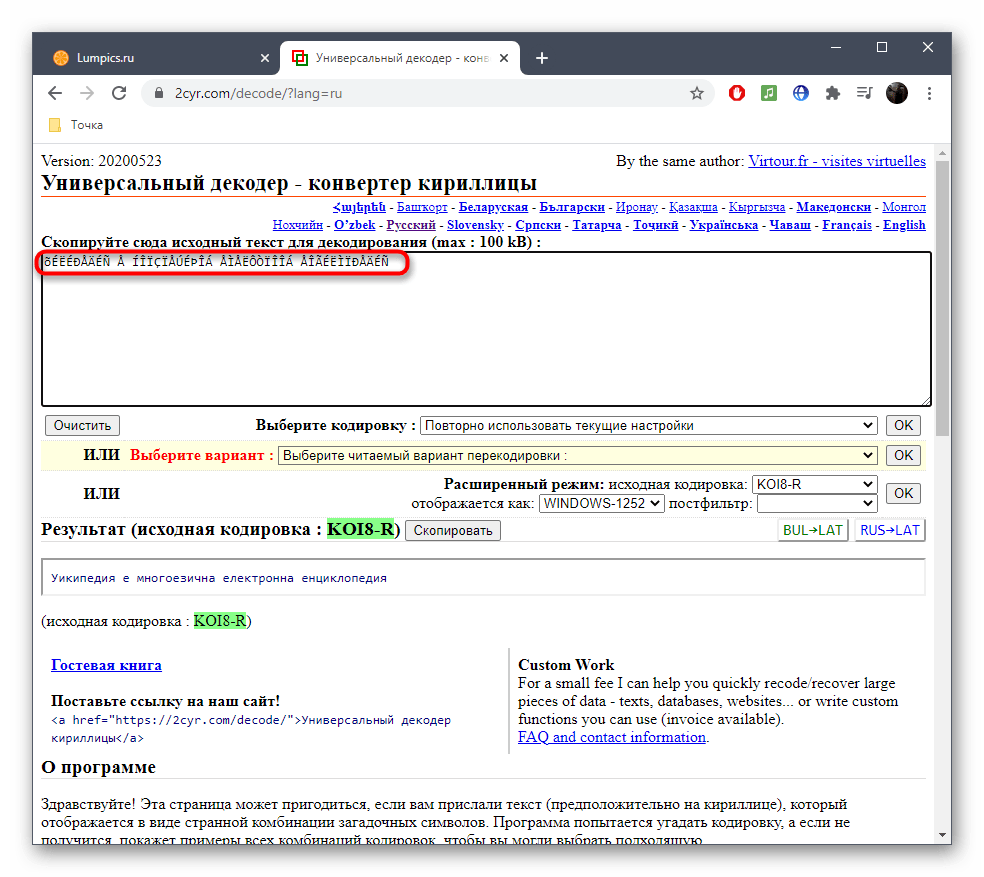
- Скопируйте текст в неверной кодировке и вставьте его в данное поле. Для этого можно использовать стандартные сочетания клавиш Ctrl + C и Ctrl + V.
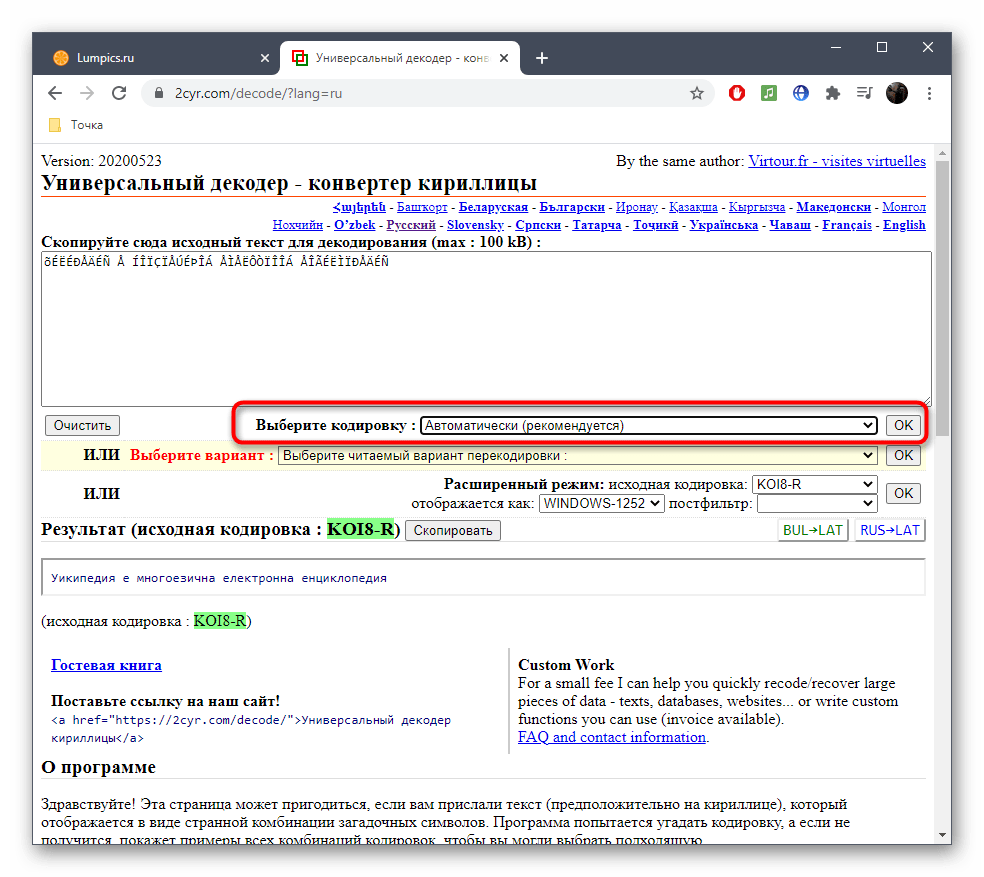
- Если известен формат поврежденной кодировки, его можно сразу же выбрать в отдельном меню, чтобы получить правильное исправление.
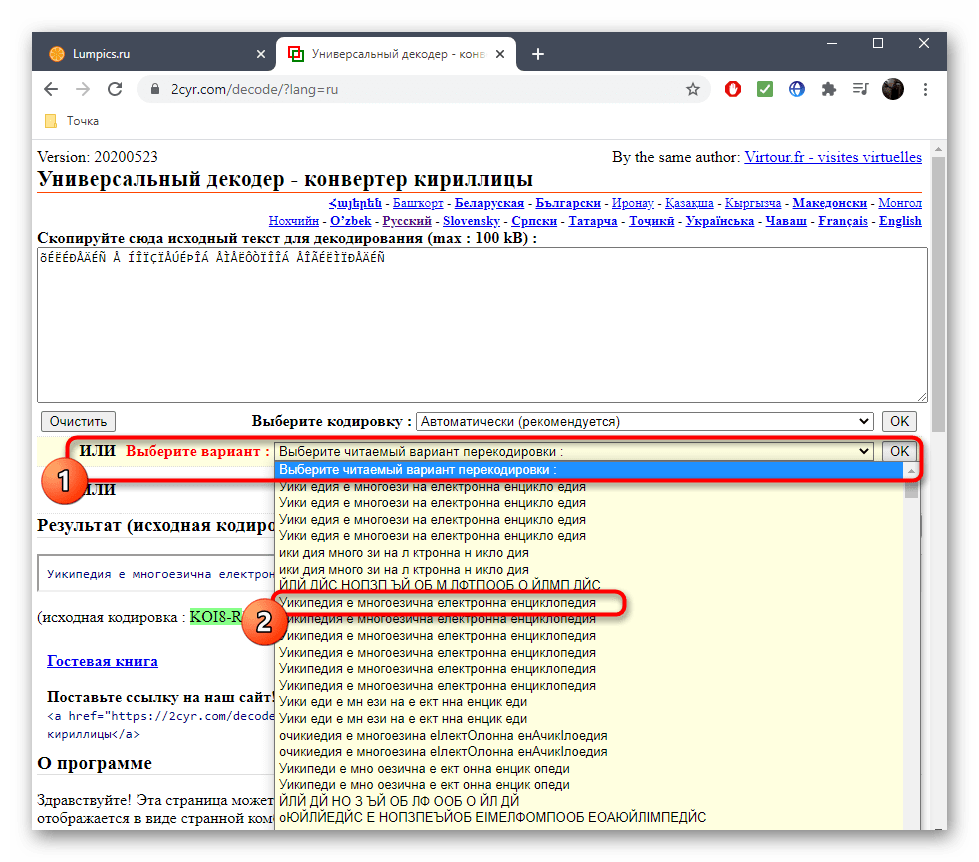
- Второй вариант декодирования подразумевает просмотр результата на всех присутствующих в онлайн-сервисе кодировках. Для этого надо развернуть выпадающее меню и найти там читаемый вариант.
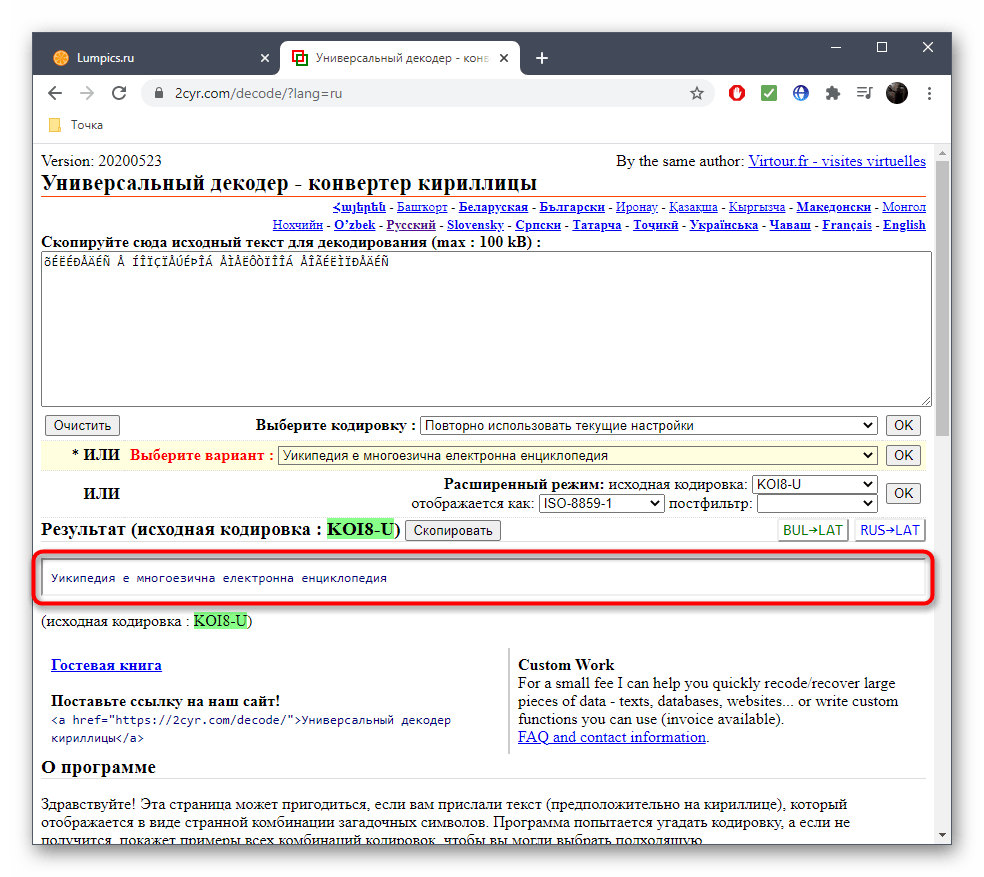
- После этого подтвердите свой выбор, кликнув «ОК», ведь только так можно скопировать готовый текст.
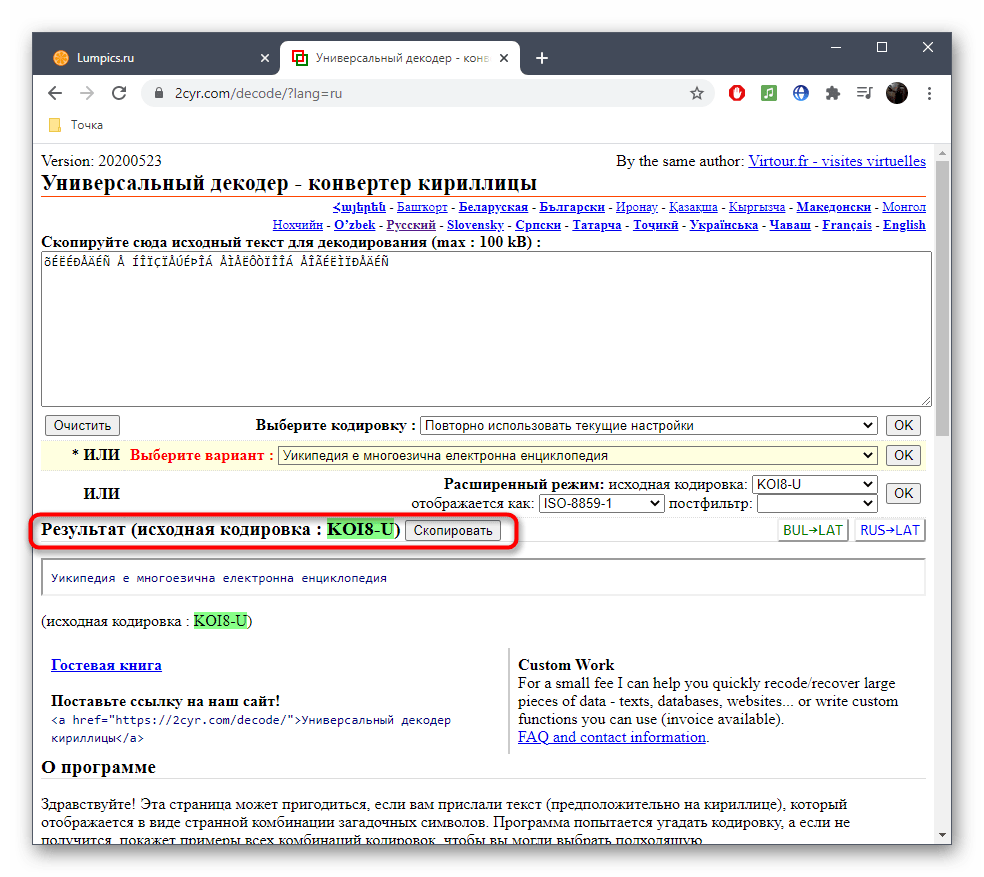
- Он будет отображаться внизу и доступен для копирования. Выделите его зажатой левой кнопкой мыши и используйте упомянутые выше комбинации, чтобы скопировать и вставить в необходимый текстовый документ.
- Исходную кодировку вы видите выше — она отмечена зеленым цветом. Иногда это нужно пользователям при ее декодировании.
Данный сайт корректно исправляет любую кодировку, которая есть в списке поддерживаемых, поэтому вы можете взять его на вооружение и использовать в любой момент по необходимости.
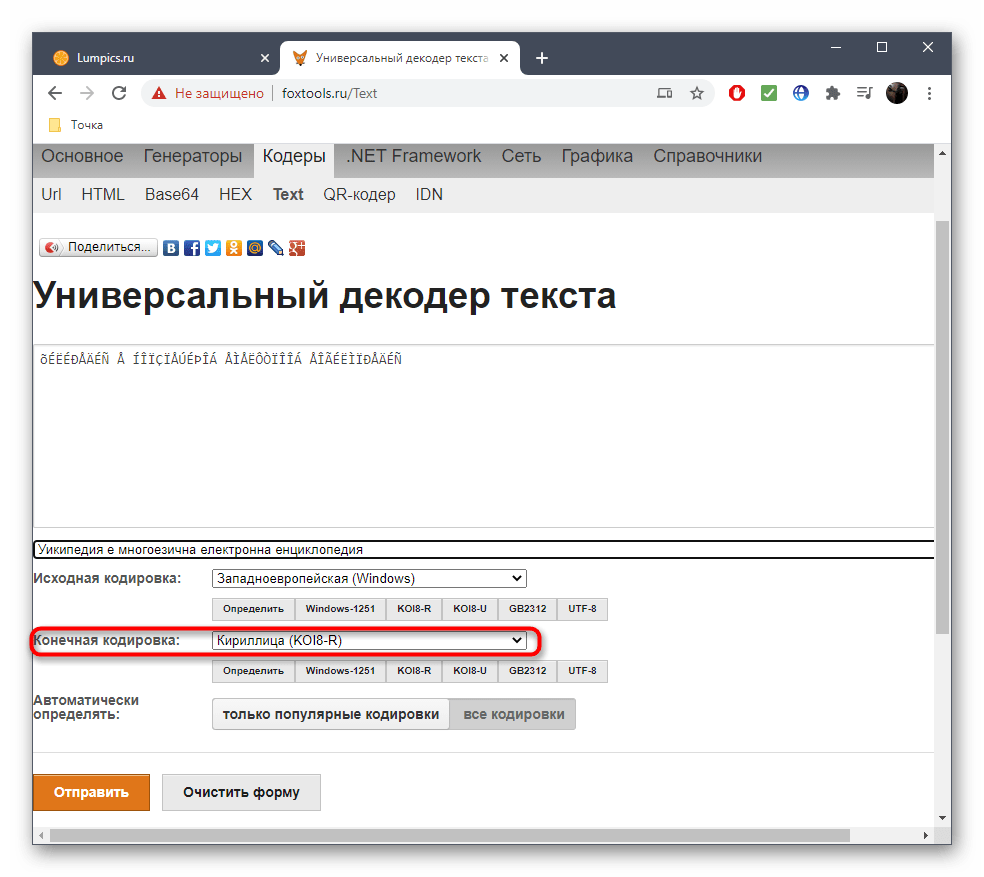
Способ 2: FoxTools
Если предыдущий метод по каким-либо причинам вам не подошел, рекомендуем воспользоваться онлайн-сервисом FoxTools, интерфейс которого выполнен в более понятном и простом виде, а по функциональности вы получите те же самые инструменты и поддержку большинства кодировок с автоматическим исправлением.
Перейти к онлайн-сервису FoxTools
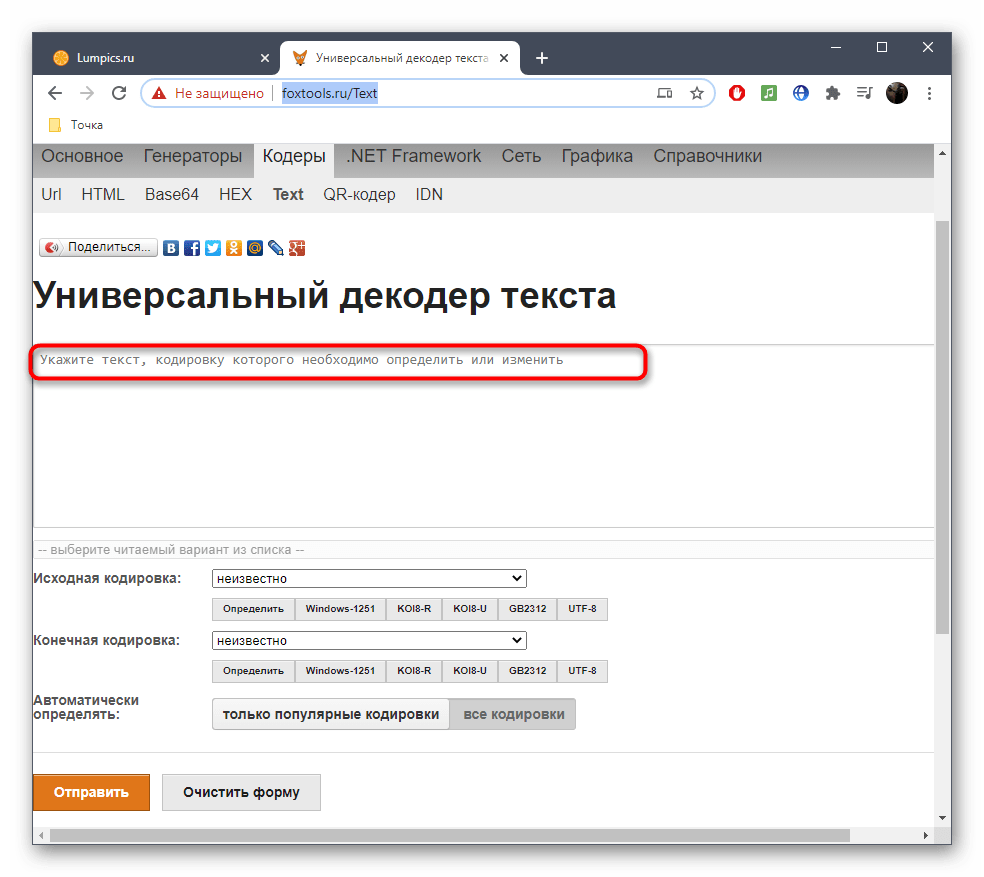
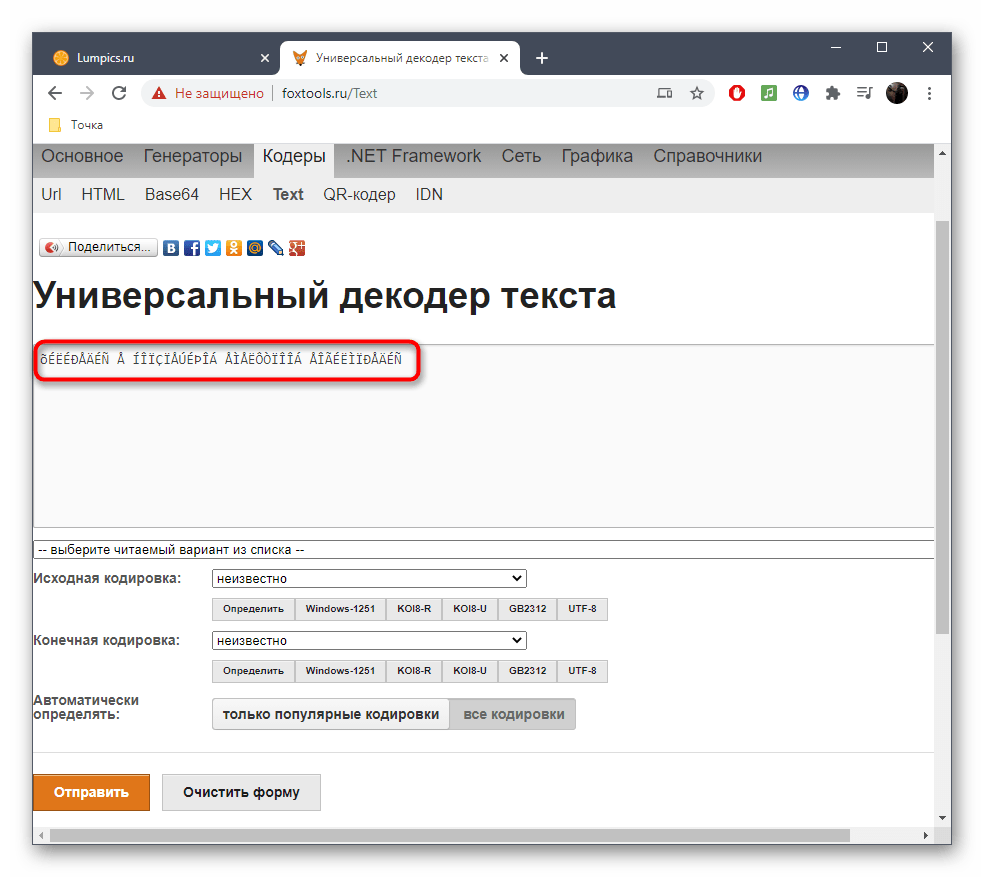
- Оказавшись на главной странице сайта FoxTools, активируйте поле для ввода, куда в дальнейшем и будете вставлять текст в сбившейся кодировке.
- Скопируйте его в текстовом документе и вставьте в данное поле на сайте.
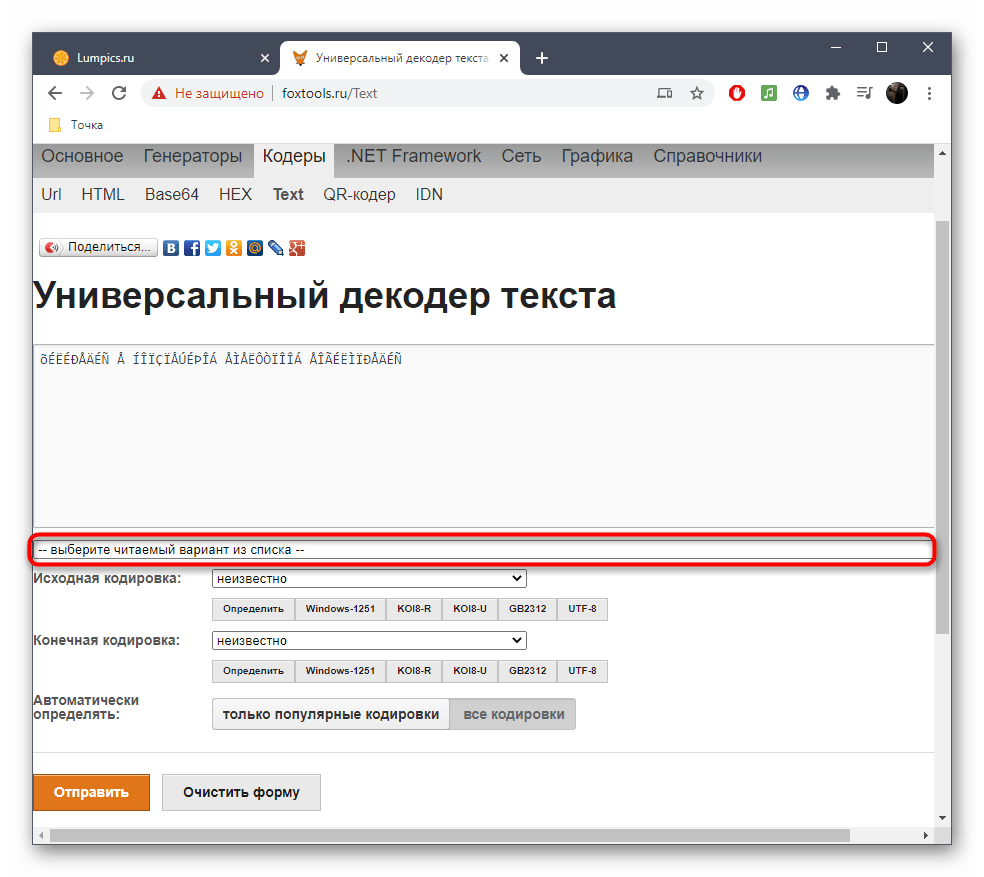
- В большинстве случаев при исправлении исходная кодировка неизвестна, поэтому основная форма FoxTools сейчас нам не пригодится. Вместо этого разверните выпадающее меню «Выберите читаемый вариант из списка».
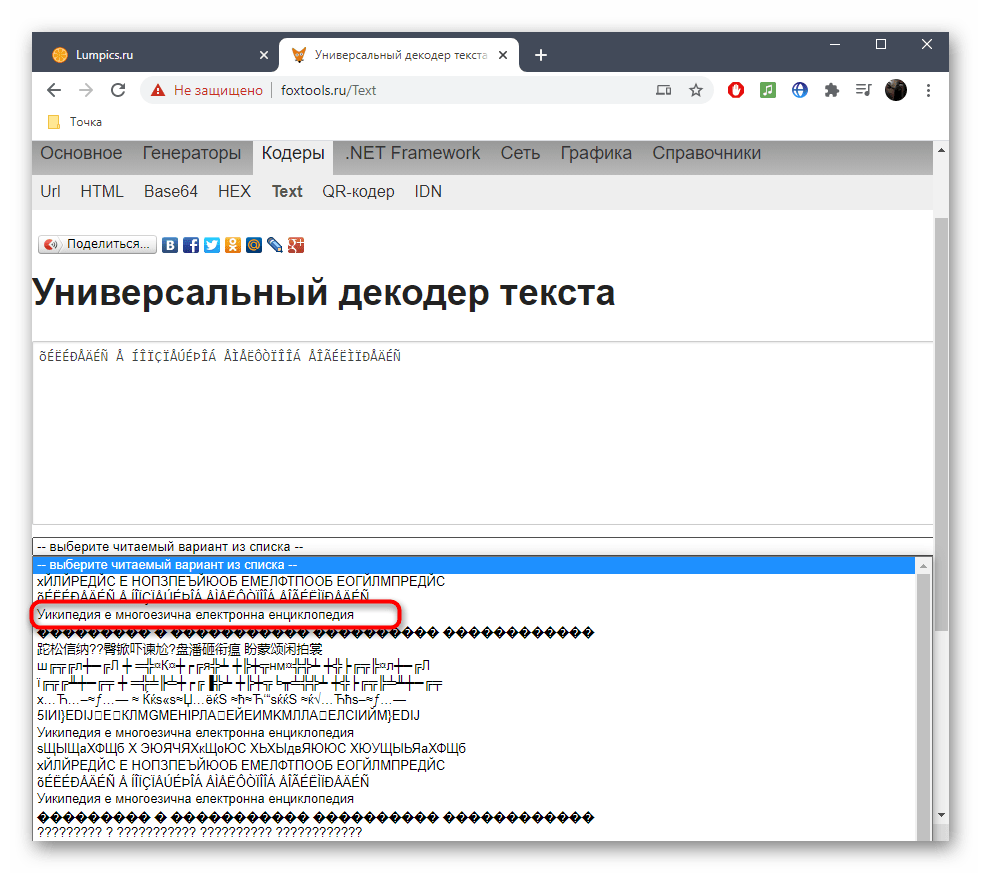
- В нем найдите подходящий текст в желаемой кодировке и щелкните по нему ЛКМ.
- Вы сразу же будете уведомлены, какая исходная кодировка была у неправильного текста.
- Дополнительно можете ознакомиться с той кодировкой, которую выбрали при исправлении.
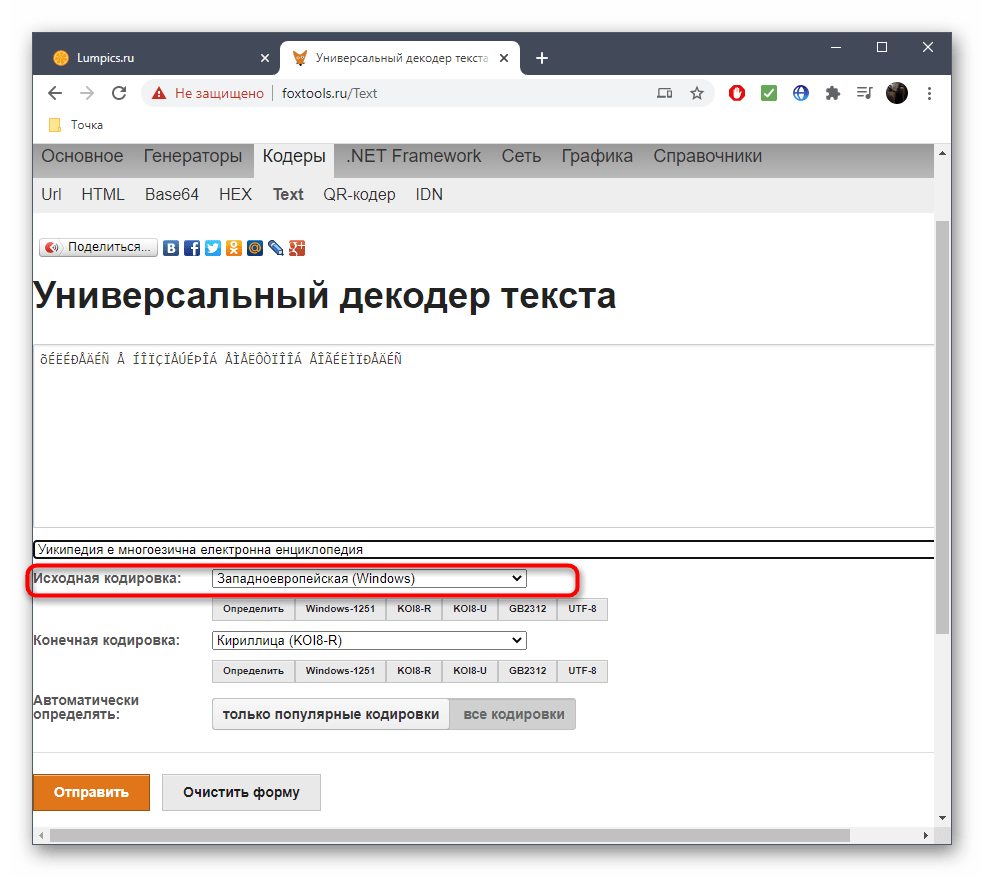
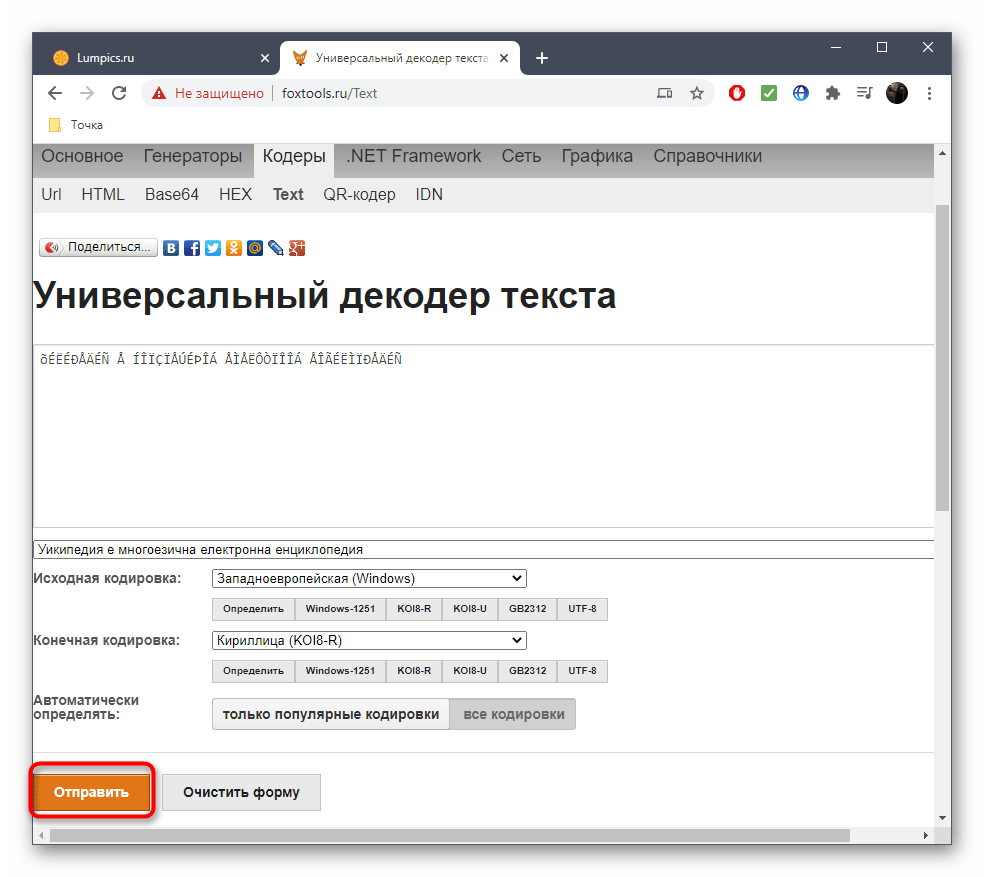
- Нажмите «Отправить», чтобы получить правильный вариант текста для дальнейшего копирования.
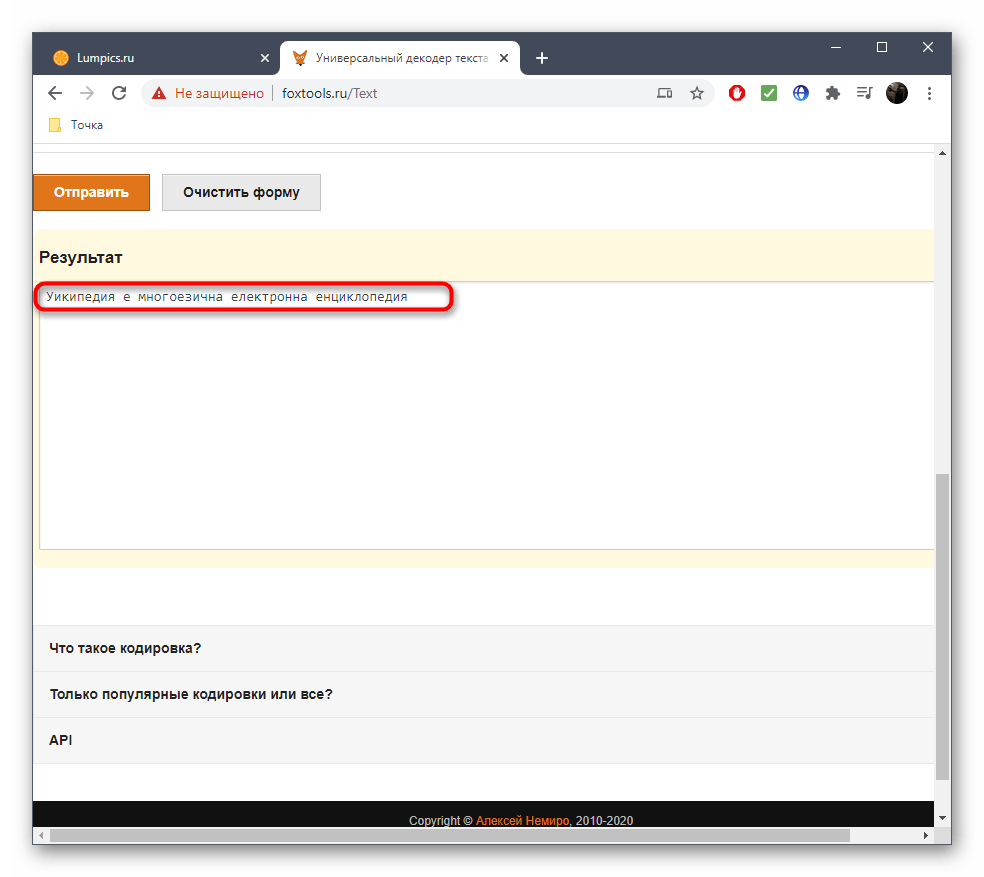
- Опуститесь ниже к блоку «Результат», скопируйте правильное содержимое и переходите к дальнейшему его использованию в своих текстовых документах.

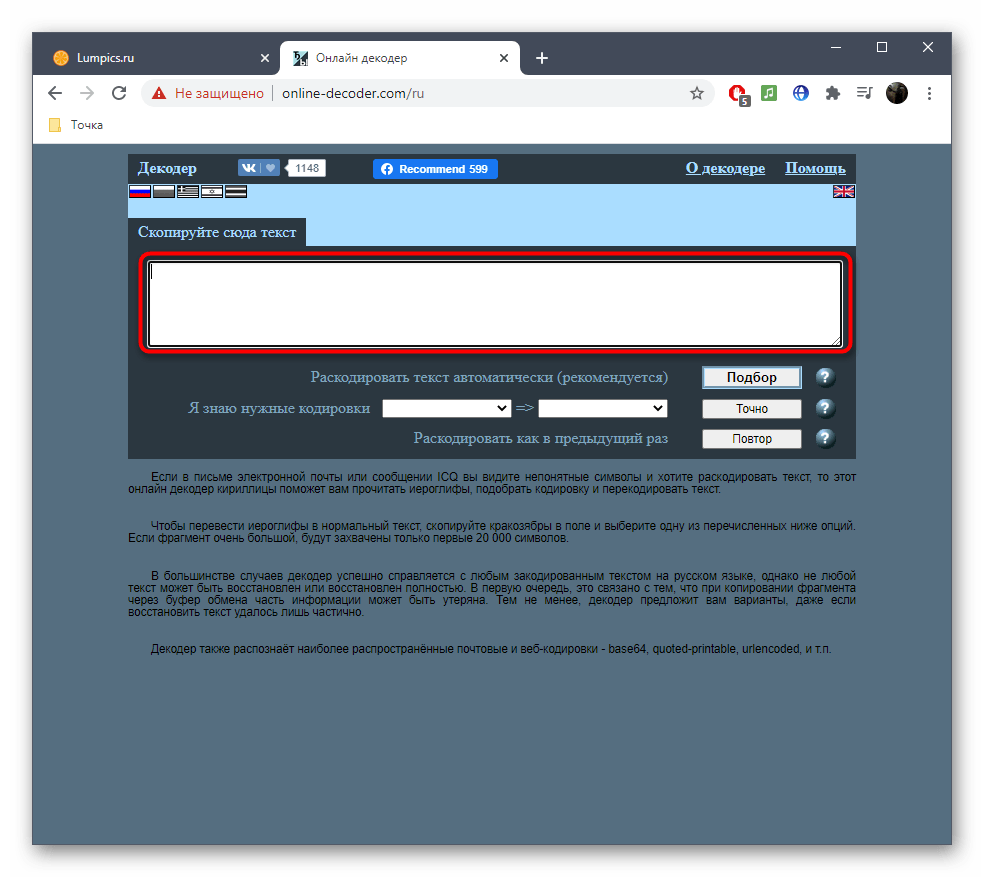
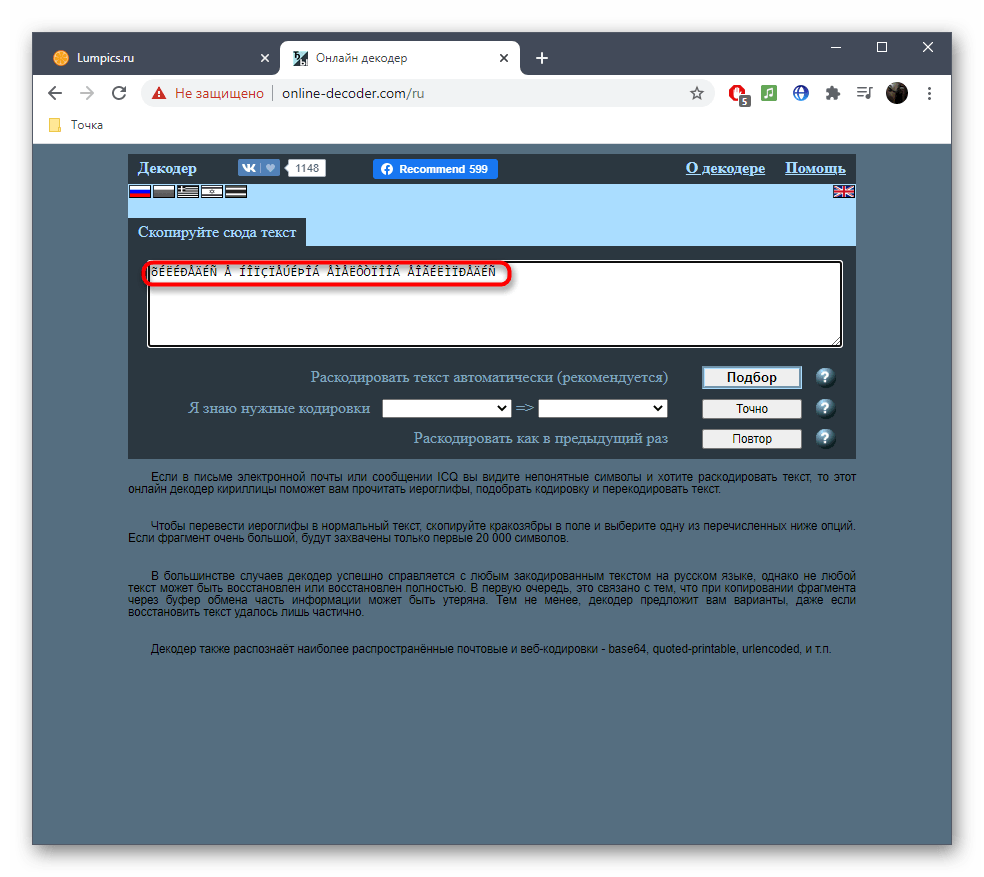
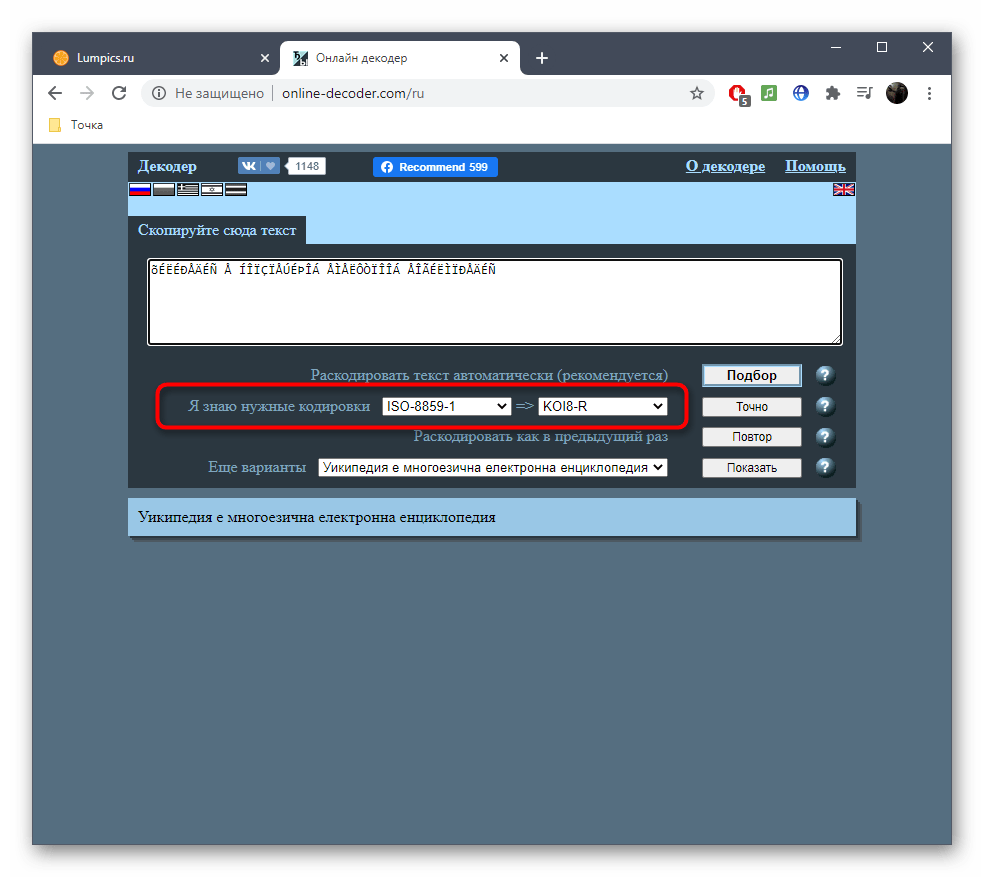
Способ 3: Online Decoder
По названию онлайн-сервиса Online Decoder уже понятно его предназначение. Исправление кодировки в нем происходит примерно так же, как это было показано в двух предыдущих методах, однако хотелось бы рассказать об этом подробнее, чтобы у начинающих юзеров, выбравших этот сайт, не возникло никаких трудностей при решении поставленной задачи.
Перейти к онлайн-сервису Online Decoder
- Щелкните по ссылке выше для перехода к сайту, а затем активируйте поле для вставки текста.
- Вставьте туда скопированную ранее надпись в поврежденной кодировке.
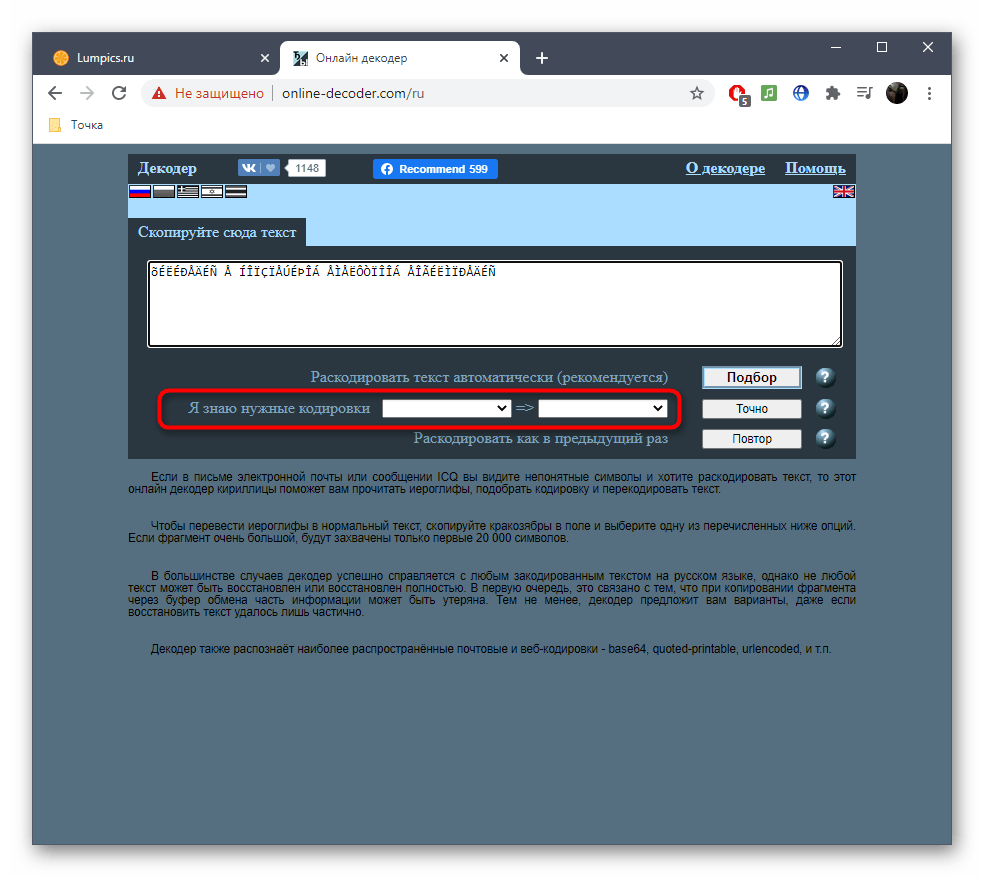
- Если вы знаете требуемые кодировки для перевода, заполните соответствующую форму и нажмите «Точно».
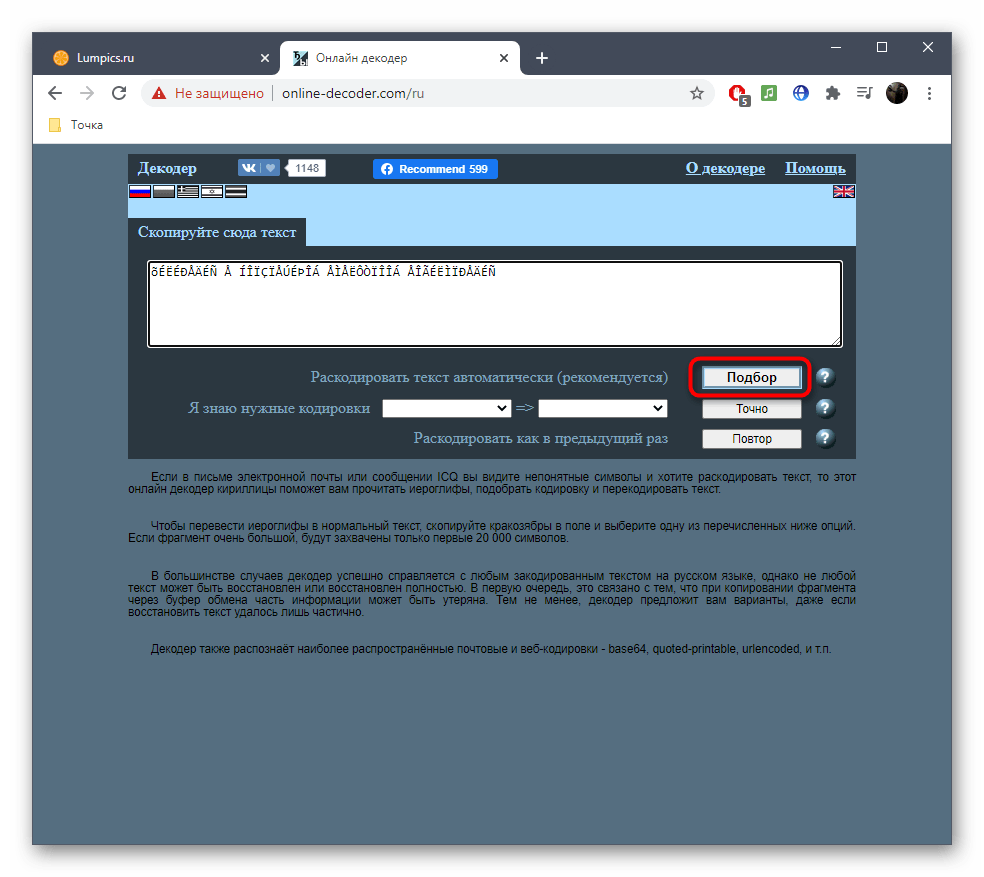
- В противном случае придется использовать автоматическое раскодирование текста, кликнув по кнопке «Подбор».
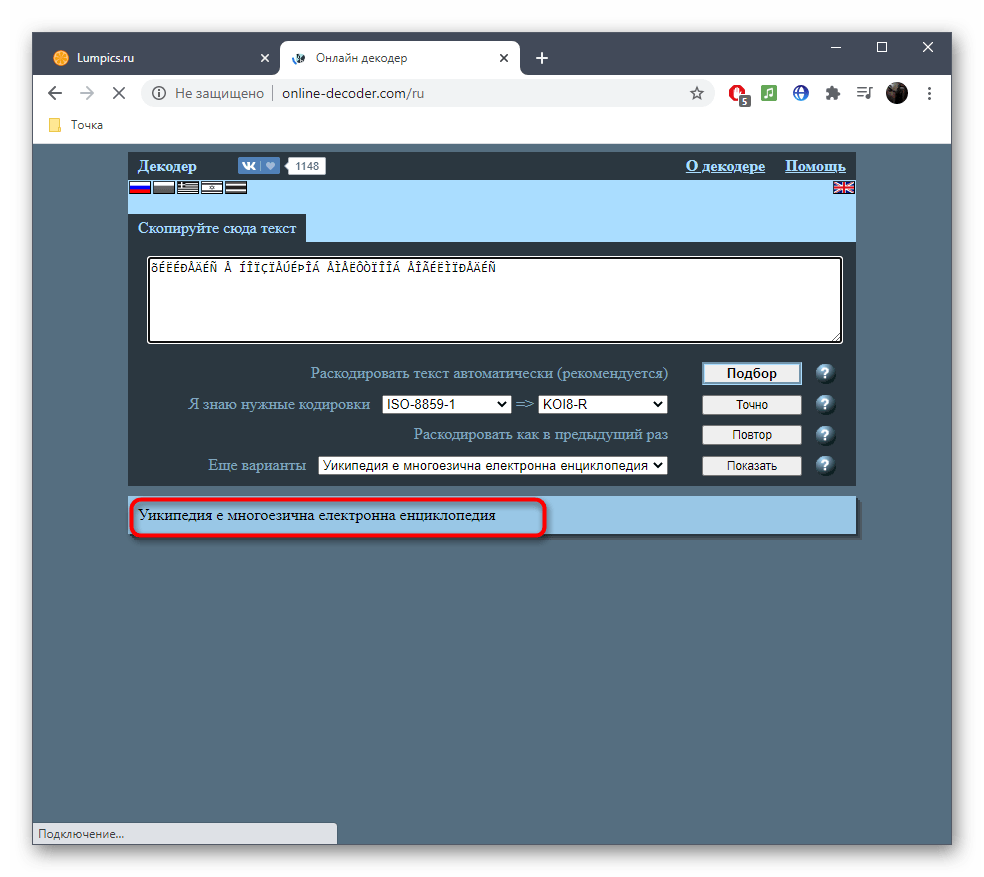
- Просмотрите полученный результат, скопируйте его и используйте в своих целях.
- Дополнительно отметим, что исходная и конечная кодировка при автоматическом переводе отобразится вверху в двух полях, если это будет нужно.
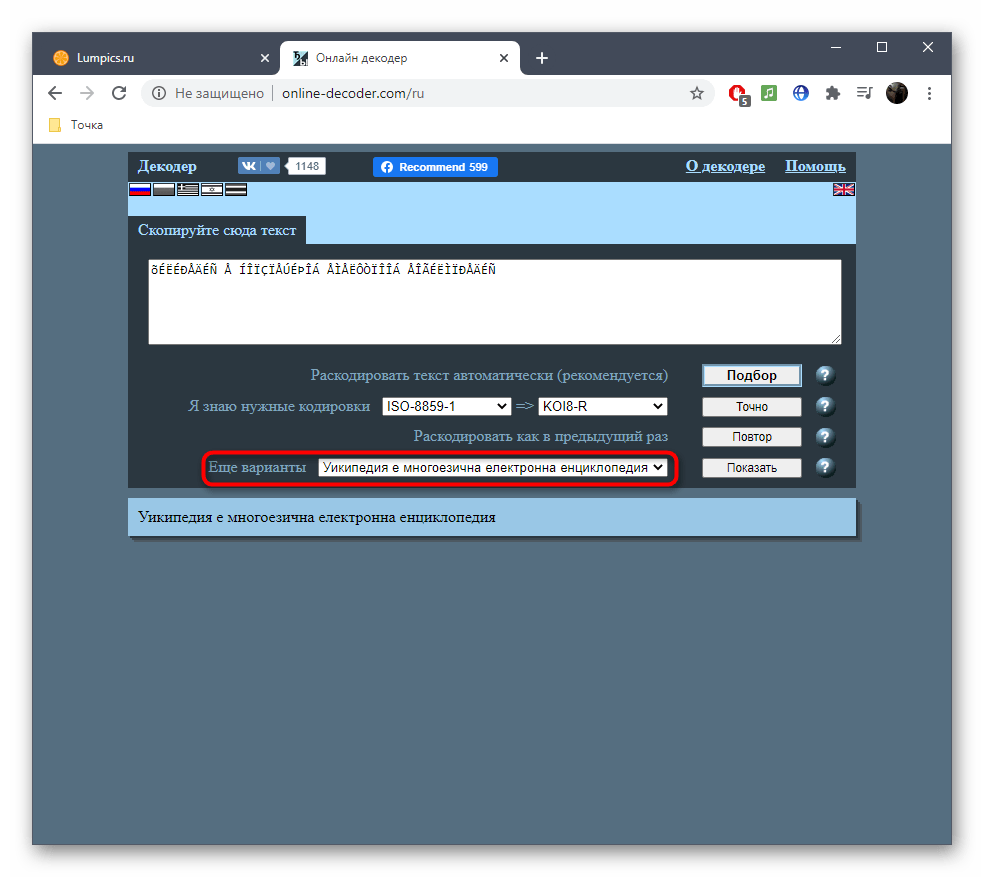
- В случае отображения неправильного текста раскройте выпадающее меню «Еще варианты» и ознакомьтесь с другими переводами, выберите подходящий и нажмите «Показать» для дальнейшего копирования.
Еще статьи по данной теме:
Помогла ли Вам статья?
Всех приветствую на портале WiFiGiD.RU. Сегодня мы рассмотрим еще одну достаточно популярную проблему, когда в Windows вместо букв отображаются кракозябры, иероглифы, знаки вопроса и какие-то непонятные символы. Проблема встречается на всех версиях Windows 10, 11, 7 и 8, и решается она одинаково. Причем кракозябры могут быть как в отдельных программах (например, в блокноте или Word) или системных окнах (в проводнике, компьютере или панели управления). В статье я расскажу вам, как можно исправить кодировку и вернуть все на свои места.
Содержание
- Способ 1: Изменение системного языка
- Способ 2: Изменение кодовой таблицы
- Способ 3: Подмена файлов
- Способ 4: Дополнительные советы
- Задать вопрос автору статьи
Способ 1: Изменение системного языка
Итак, у нас вместо русских букв отображаются знаки вопроса или другие непонятные символы в Windows – давайте разбираться вместе. После установки английской или любой другой версии, есть вероятность, что язык, который установлен в системе, установился неправильно. Второй вариант – когда региональные стандарты языка были сбиты или установлены не так как нужно. Давайте это исправим.
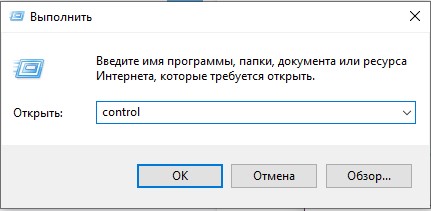
- Зажимаем на клавиатуре две клавиши:
+ R
- Теперь используем команду:
control
- В панели управления найдите пункт «Региональные стандарты» – ориентируйтесь на значок. Если вы видите, что пунктов не так много как у меня, измените режим «Просмотра».
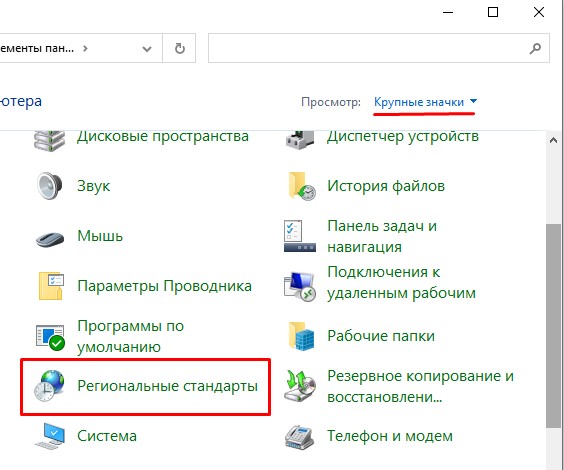
- На второй вкладке нажмите по кнопке «Изменить язык…».
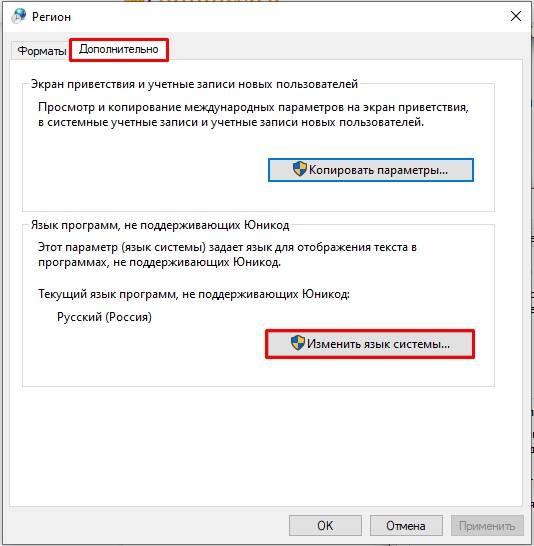
- Сначала в первом пункте установите «Русский» язык. Ниже есть настройка использования Юникода (UTF-8). Если эта галочка стоит, значит попробуйте её убрать. Если эта конфигурация, наоборот, выключена – активируйте. Нажмите «ОК».
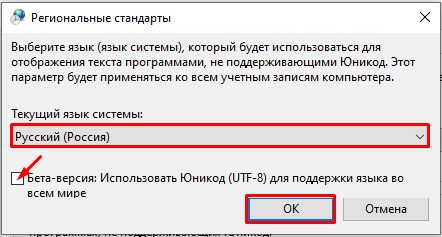
- Вас попросят перезагрузиться – сделайте это.
Способ 2: Изменение кодовой таблицы
Смотрите, каждому символу кириллицы соответствует свое отображение. Также у каждого такого символа есть специальный байтовый код. Чтобы все это работало нормально, для каждого символа и байта есть таблица соответствия. Если таблица выбрана неправильно, код байта будет показывать иероглифы – вопросительные знаки или еще какие кракозябры.
Мы просто подставим для нашей кириллицы правильную таблицу отображения символов, и после этого проблема должна решиться. Мы будем использовать редактор реестра. Сам способ не должен поломать систему, но перед этим я настоятельно рекомендую создать точку восстановления (на всякий случай!).
Читаем – как создать точку восстановления.
После этого переходим к описанным ниже шагам:
- Используем наши любимые волшебные кнопки:
+ R
- Вводим команду:
regedit
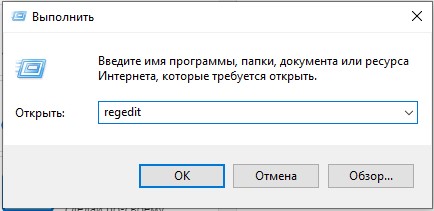
- Можете скопировать путь, который я укажу ниже, и вставить в адресную строку. Или просто пройтись по папкам и разделам вручную.
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage
- В правом блоке, где находится список файлов с конфигурациями, в самом низу найдите:
ACP
- Именно этот файл отвечает за настройку соответствия таблицы символов. Два раза кликните левой кнопкой мыши и установите значение:
1251
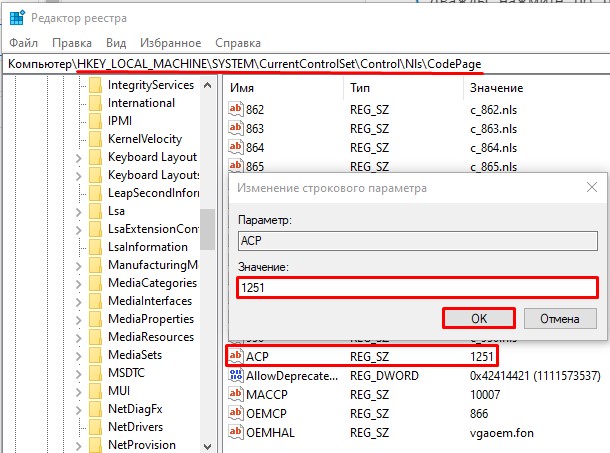
- Нажмите «ОК», закройте окно редактора реестра и перезагрузите компьютер.
Способ 3: Подмена файлов
Третий способ чуть сложнее, мы просто возьмем файл, который используется для английского языка и подменим его на русский. Я все же рекомендую использовать прошлый вариант с реестром (он все же проще). Но, на всякий пожарный, опишу и этот способ.
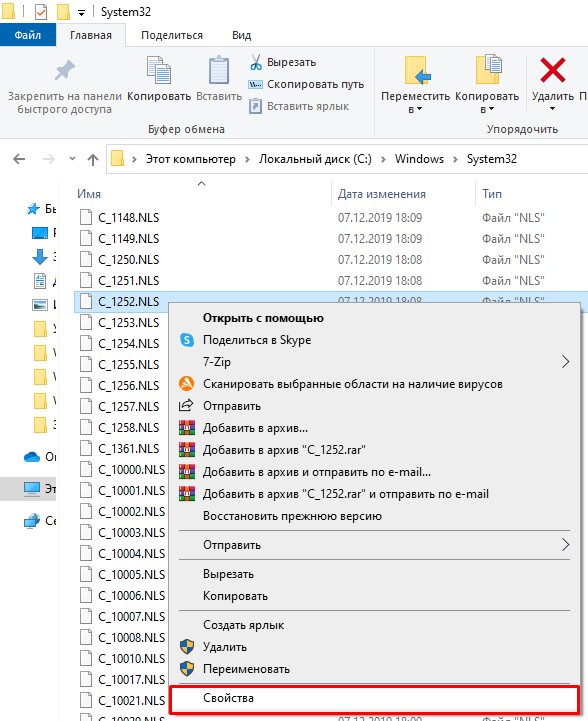
- Откройте проводник и пройдите по пути:
C:/Windows/System32
- Найдите файл:
C_1252.NLS
- Он используется для английского языка. Через правую кнопку заходим в «Свойства».
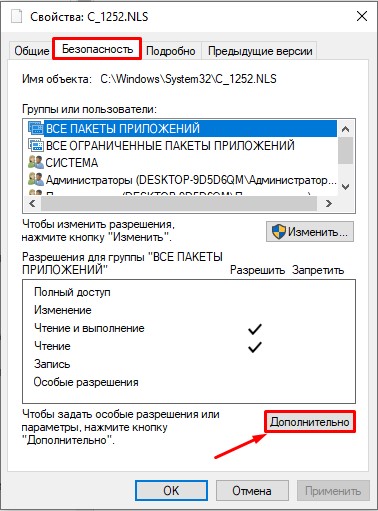
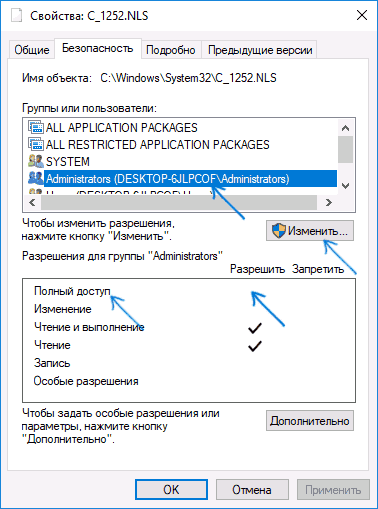
- Во вкладке «Безопасность» выбираем кнопку «Дополнительно». Нам нужно дать вам полные права. В противном случае вы ничего с этим файлом не сделаете.
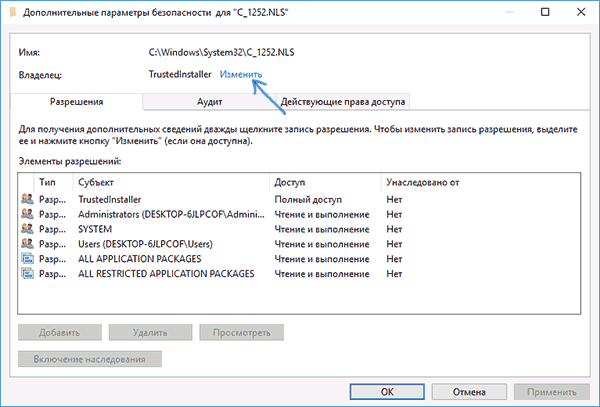
- В строке «Владелец» жмем по ссылке «Изменить».
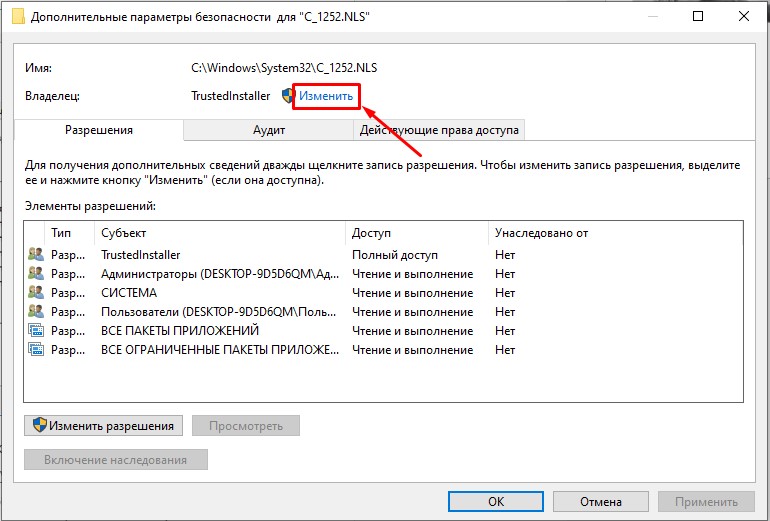
- «Дополнительно».
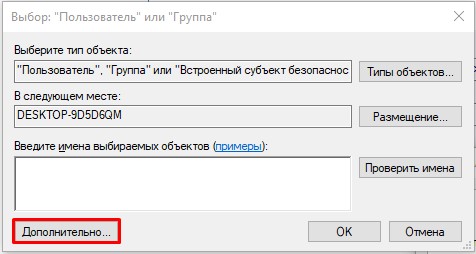
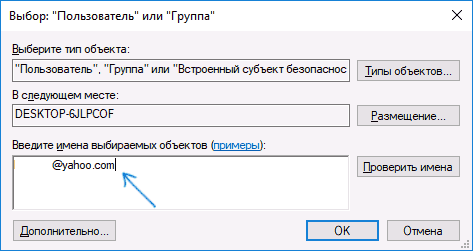
- Нажмите «Поиск». Ниже в списке кликните по той учетной записи, через которую вы сейчас сидите. Если у вас авторизация через учётку Microsoft, то указываем почту. Как только пользователь будет выбран, жмем «ОК».
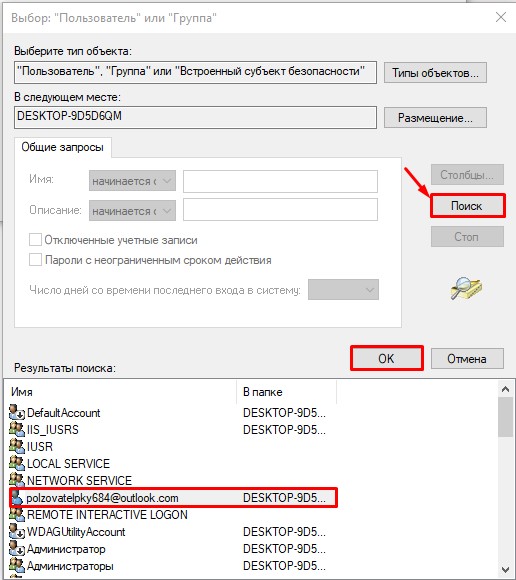
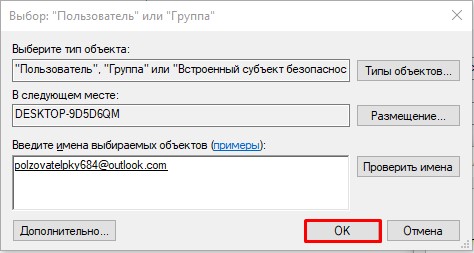
- В этом и следующем окне жмем на кнопку «ОК», чтобы применить параметры.
- В окне «Свойства» нажмите «Изменить».
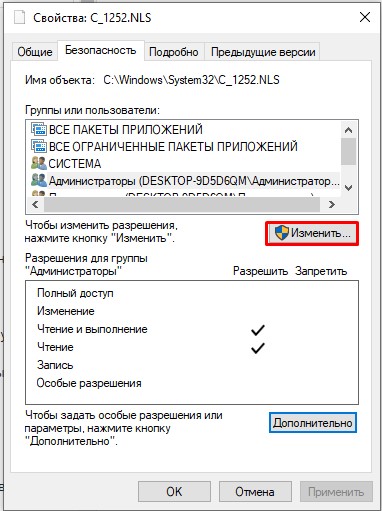
- Выберите «Администраторов» и установите «Полный доступ». Применяем настройки и закрываем оба окошка.
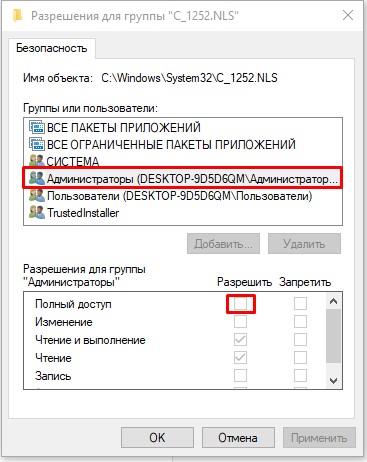
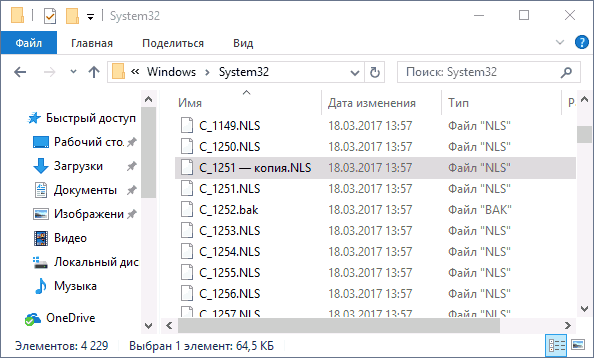
- Теперь установите другой формат для файла (через ПКМ и команду «Переименовать»):
c_1252.NLS
- Например:
c_1252.txt
- На клавиатуре, зажмите Ctrl и, не отпуская, перетащите в любое место в папке файл:
c_1251.NLS
- Мы создали копию файла. Теперь оригинал NLS переименуйте в:
c_1252.NLS
- Перезагрузите систему.
В случае чего у вас есть оригинал c_1251.NLS и сам файл c_1252, у которого мы изменили формат.
Способ 4: Дополнительные советы
Если вы видите иероглифы вместо русских букв в Windows 10, 11, 7 или 8, то есть вероятность, что произошла более серьезная поломка в системных файлах. Поэтому вот ряд советов:
- Если вы делали какие-то глобальные обновления в ОС, то попробуйте выполнить откат системы до самой ранней точки восстановления.
- Если вы устанавливали какую-то кривую и стороннюю сборку Windows, то советую выполнить установку оригинальной версии «Окон».
- Проверьте системные файлы на наличие ошибок.
- Можно попробовать выполнить чистку системы.
На этом все, дорогие друзья. Пишите свои вопросы в комментариях. Всем добра и берегите себя.
![]() Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
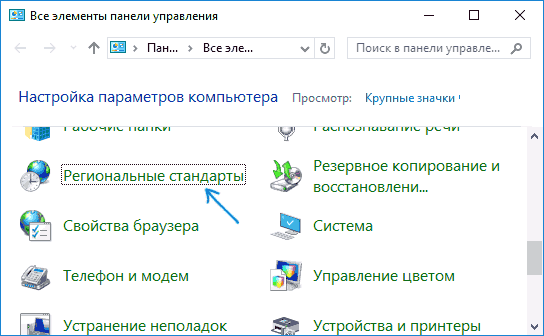
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).

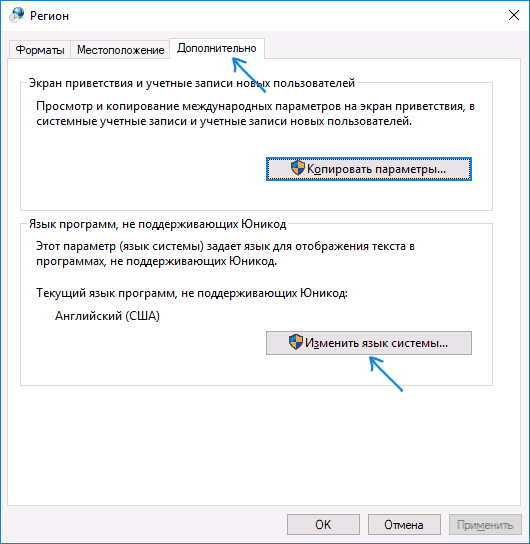
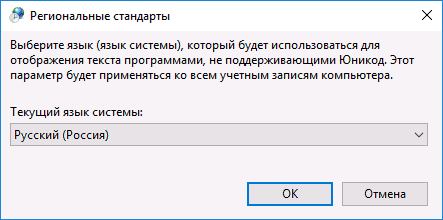
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).

- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.

После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
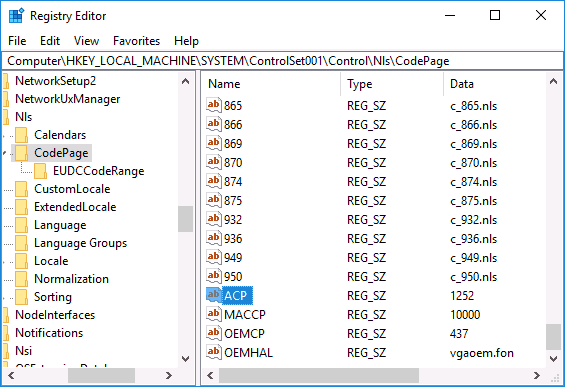
- Перейдите к разделу реестра
HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNlsCodePage
и в правой части пролистайте значения этого раздела до конца.

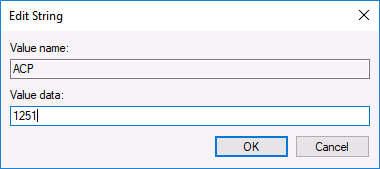
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.

- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
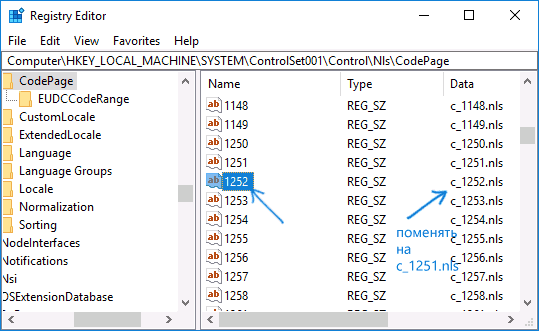
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C: Windows System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
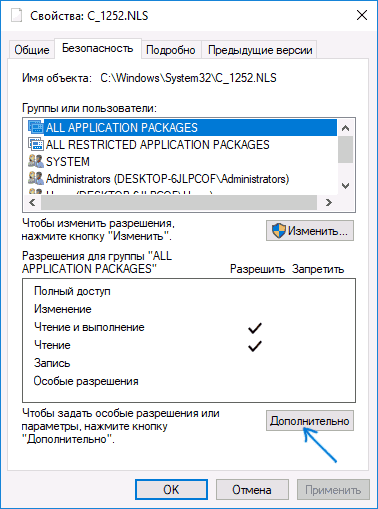
- Зайдите в папку C: Windows System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».

- В поле «Владелец» нажмите «Изменить».

- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.

- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:WindowsSystem32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.

- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.
После перезагрузки Windows 10 кириллица должна будет отображаться не в виде иероглифов, а как обычные русские буквы.

Вопрос пользователя
Здравствуйте.
Подскажите пожалуйста, почему у меня некоторые странички в браузере отображают вместо текста иероглифы, квадратики и не пойми что (ничего нельзя прочесть). Раньше такого не было.
Заранее спасибо…
Доброго времени суток!
Действительно, иногда при открытии какой-нибудь интернет-странички вместо текста показываются различные «крякозабры» (как я их называю), и прочитать это нереально.
Происходит это из-за того, что текст на страничке написан в одной кодировке (более подробно об этом можете узнать из Википедии), а браузер пытается открыть его в другой. Из-за такого рассогласования, вместо текста — непонятный набор символов.
Попробуем исправить это…
*
Содержание статьи
- 1 Исправляем иероглифы на текст
- 1.1 Браузер
- 1.2 Текстовые документы
- 1.3 BAT-файлы (скрипты)
- 1.4 Документы MS WORD
- 1.5 Окна в различных приложениях Windows

→ Задать вопрос | дополнить
Исправляем иероглифы на текст
Браузер
Вообще, раньше Internet Explorer часто выдавал подобные крякозабры, 👉 современные же браузеры (Chrome, Яндекс-браузер, Opera, Firefox) — довольно неплохо определяют кодировку, и ошибаются очень редко. 👌
Скажу даже больше, в некоторых версиях браузера уже убрали выбор кодировки, и для «ручной» настройки этого параметра нужно скачивать дополнения, или лезть в дебри настроек за 10-ток галочек…
Итак, предположим браузер неправильно определили кодировку и вы увидели следующее (как на скрине ниже 👇).
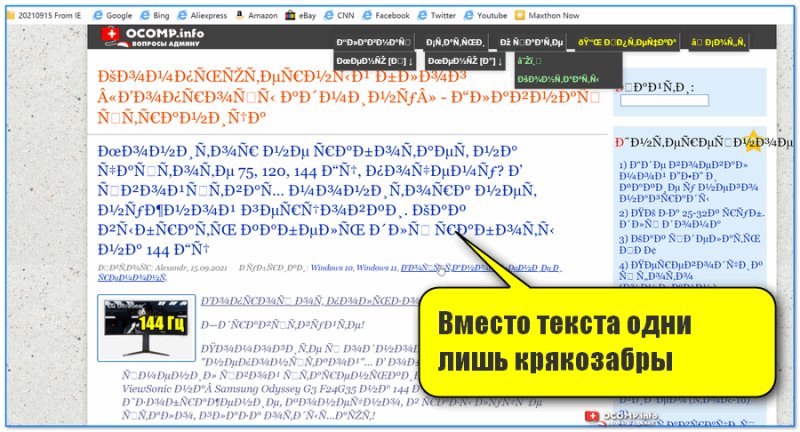
Вместо текста одни лишь крякозабры // Браузер выставил кодировку неверно!
*
📌 Кстати!
Чаще всего путаница бывает между кодировками UTF (Юникод) и Windows-1251 (большинство русскоязычных сайтов выполнены в этих кодировках).
*
Поэтому, я рекомендую в ручном режиме попробовать их обе. Для этого нам понадобиться браузер MX5 (ссылка на офиц. сайт). Он один из немногих позволяет в ручном режиме выбирать кодировку (при необходимости):
- необходимо открыть нужный сайт;
- далее зайти в меню «Инструменты / кодировка»;
- выбрать вручную UTF 8 или «Авто-определение»;
- перезагрузить страницу. И, ву-а-ля, — иероглифы на страничке сразу же стали обычным текстом (скрин ниже 👇)!
📌 В помощь!
Если у вас иероглифы в браузере Chrome — ознакомьтесь с этим
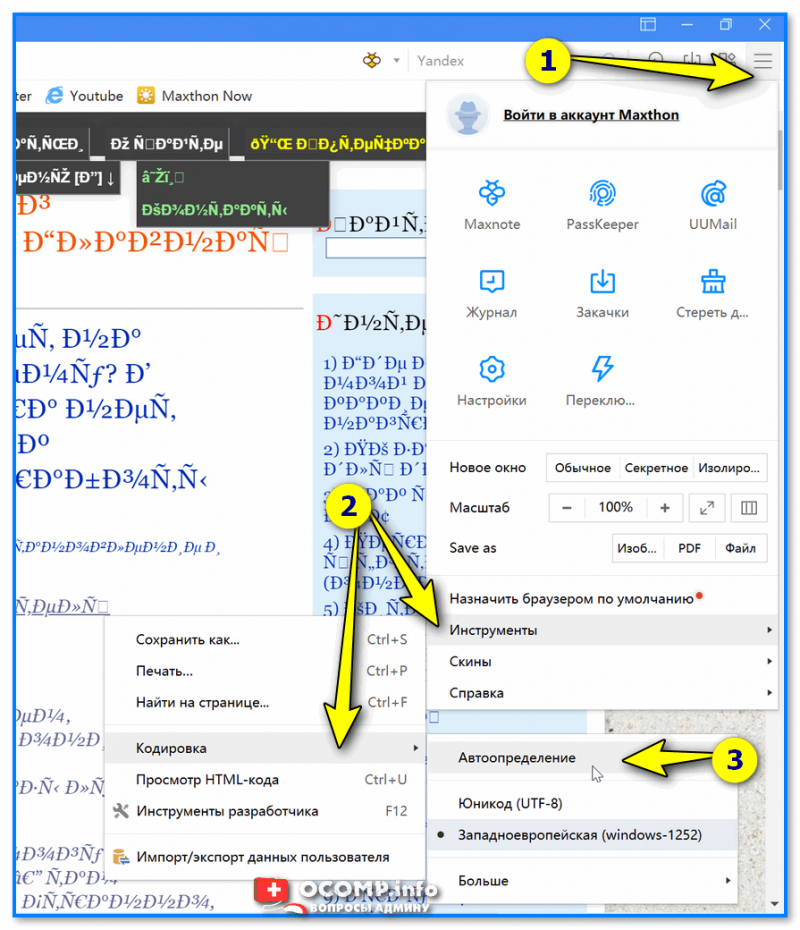
Браузер MX5 — выбор кодировки UTF8 или авто-определение
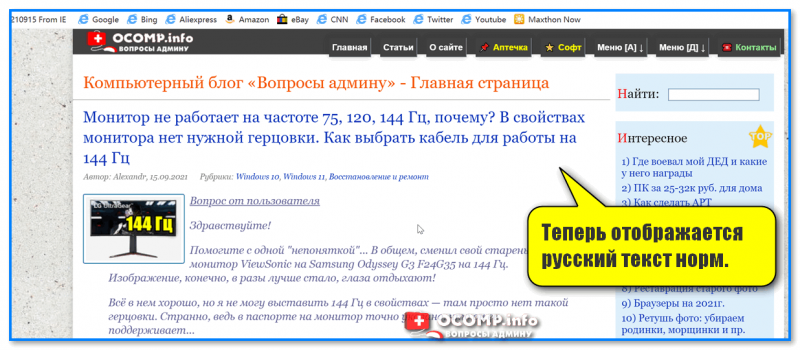
Теперь отображается русский текст норм.
*
📌 Еще один совет: если вы в своем браузере не можете найти, как сменить кодировку (а дать инструкцию для каждого браузера — вообще нереально!), я рекомендую попробовать открыть страничку в другом браузере (например, в MX5). Очень часто другая программа открывает страницу так, как нужно!
*
Текстовые документы
Очень много вопросов по крякозабрам задаются при открытии каких-нибудь текстовых документов. Особенно старых, например, при чтении Readme в какой-нибудь программе прошлого века (скажем, к играм).
Разумеется, что многие современные блокноты просто не могут прочитать DOS‘овскую кодировку, которая использовалась ранее. Чтобы решить сию проблему, рекомендую использовать редактор Bread 3.
*
Bred 3
Сайт: http://www.astonshell.ru/freeware/bred3/
Простой и удобный текстовый блокнот. Незаменимая вещь, когда нужно работать со старыми текстовыми файлами.
Bred 3 за один клик мышкой позволяет менять кодировку и делать не читаемый текст читаемым! Поддерживает кроме текстовых файлов довольно большое разнообразие документов. В общем, рекомендую! ✌
*
Попробуйте открыть в Bred 3 свой текстовый документ (с которым наблюдаются проблемы). Пример показан у меня на скрине ниже. 👇
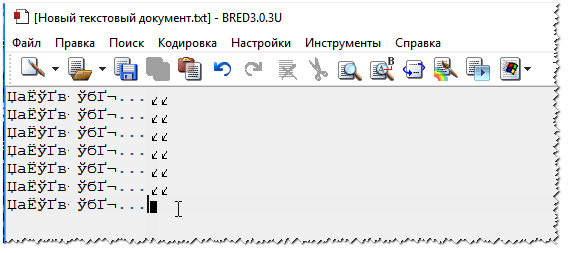
Иероглифы при открытии текстового документа
Далее в Bred 3 есть кнопка для смены кодировки: просто попробуйте поменять ANSI на OEM — и старый текстовый файл станет читаемым за 1 сек.!
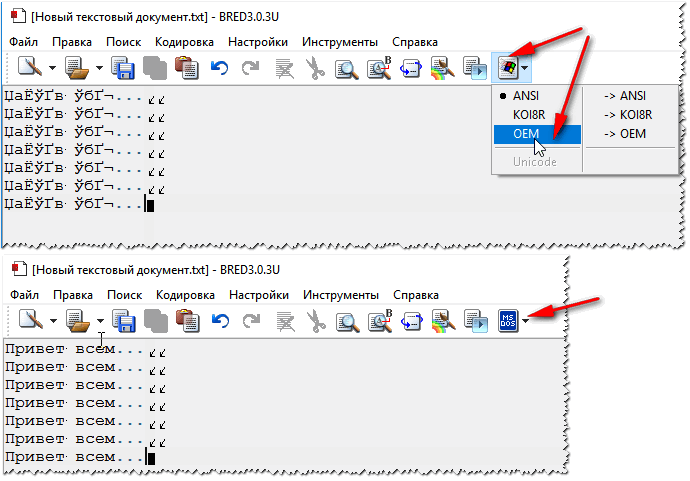
Исправление иероглифов на текст
👉 Для работы с текстовыми файлами различных кодировок также подойдет еще один блокнот — Notepad++. Вообще, конечно, он больше подходит для программирования, т.к. поддерживает различные подсветки, для более удобного чтения кода.
*
Notepad++
Сайт: https://notepad-plus-plus.org/
Надежный, удобный, поддерживающий громадное число форматов файлов блокнот. Позволяет легко и быстро переключать различные кодировки.
*
Пример смены кодировки показан ниже: чтобы прочитать текст, достаточно в примере ниже, достаточно было сменить кодировку ANSI на UTF-8.
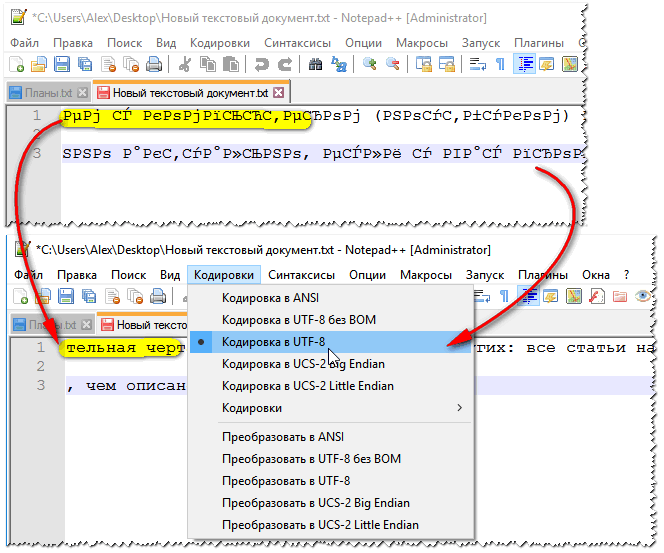
Смена кодировки в блокноте Notepad++
*
Штирлиц
Сайт разработчика: http://www.shtirlitz.ru/
Эта программа специализируется на «расшифровке» текстов, написанных в разных кодировках: Win-1251, KOI-8r, DOS, ISO-8859-5, MAC и др.
Причем, программа нормально работает даже с текстами со смешанной кодировкой (что не могут др. аналоги). Пример см. на скрине ниже. 👇
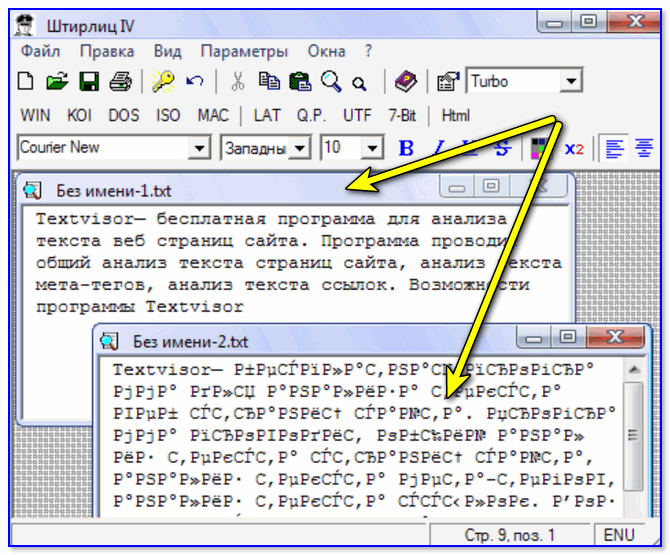
Пример работы ПО «Штирлиц»
*
BAT-файлы (скрипты)
Для начала простой пример о чем идет речь. 👇
На скрине видно, что вместо русского текста отображаются различные квадратики, буквы «г» перевернутые, и пр. иероглифы.
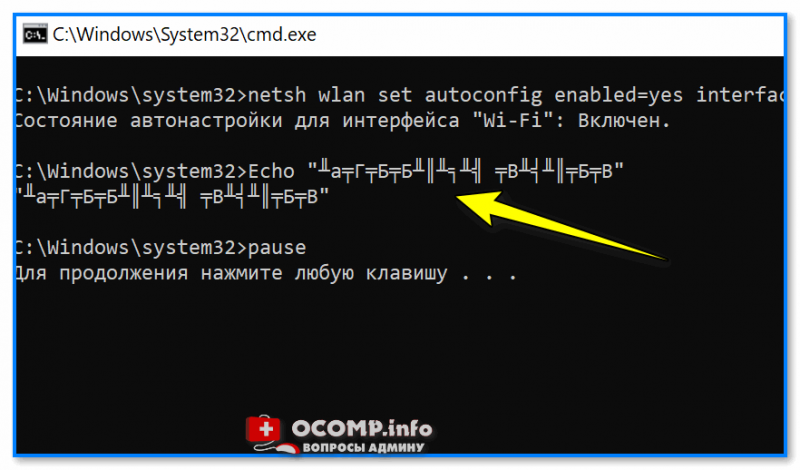
Как выглядит русский текст при выполнении BAT-файла
*
📌 Чтобы это исправить — можно прибегнуть к следующему:
- в начало BAT-файла добавить код @chcp 1251;
- установить программу Notepad++ и в меню выбрать OEM-866: «Кодировки/Кодировки/Кириллица/OEM-866»;
- установить программу Akelpad, в разделе «Кодировки» выбрать «Сохранить в DOS-866».
*
Документы MS WORD
Очень часто проблема с крякозабрами в Word связана с тем, что путают два формата Doc и Docx. Дело в том, что с 2007 года в Word (если не ошибаюсь) появился формат Docx (позволяет более сильнее сжимать документ, чем Doc, да и надежнее защищает его).
Так вот, если у вас старый Word, который не поддерживает этот формат — то вы, при открытии документа в Docx, увидите иероглифы и ничего более.
*
📌 Есть неск. путей решения:
- скачать на сайте Microsoft спец. дополнение, которое позволяет открывать в старом Word новые документы (с 2020г. дополнение с офиц. сайта удалено). Только из личного опыта могу сказать, что открываются далеко не все документы, к тому же сильно страдает разметка документа (что в некоторых случаях очень критично);
- использовать 👉 аналоги Word (правда, тоже разметка в документе будет страдать);
- обновить Word до современной версии (2019+);
- если речь идет о документы TXT — открыть его в Notepad++.
*
Так же при открытии любого документа в Word (в кодировке которого он «сомневается»), он на выбор предлагает вам самостоятельно указать оную. Пример показан на рисунке ниже, попробуйте выбрать:
- Widows (по умолчанию);
- MS DOS;
- Другая…
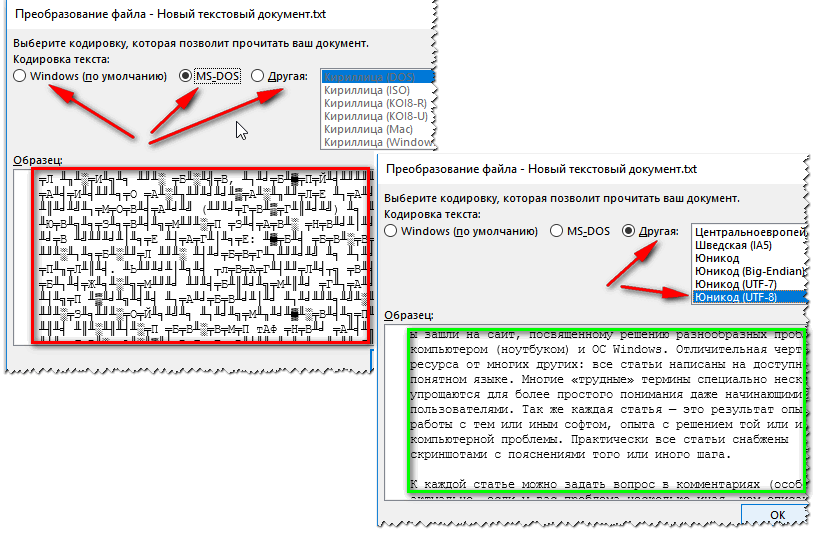
Переключение кодировки в Word при открытии документа
*
Окна в различных приложениях Windows
Бывает такое, что какое-нибудь окно или меню в программе показывается с иероглифами (разумеется, прочитать что-то или разобрать — нереально).
*
📌 Могу дать несколько рекомендаций:
- Русификатор. Довольно часто официальной поддержки русского языка в программе нет, но многие умельцы делают русификаторы. Скорее всего, на вашей системе — данный русификатор работать отказался. Поэтому, совет простой: попробовать поставить другой;
- Переключение языка. Многие программы можно использовать и без русского, переключив в настройках язык на английский. Ну в самом деле: зачем вам в какой-то утилите, вместо кнопки «Start» перевод «начать»?
- Если у вас раньше текст отображался нормально, а сейчас нет — попробуйте 👉 восстановить Windows, если, конечно, у вас есть точки восстановления;
- Проверить настройки языков и региональных стандартов в Windows, часто причина кроется именно в них (👇).
*
Языки и региональные стандарты в Windows
Чтобы открыть меню настроек:
- нажмите Win+R;
- введите intl.cpl, нажмите Enter.
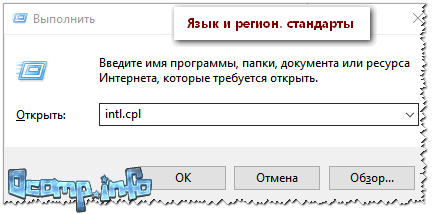
intl.cpl — язык и регион. стандарты
Проверьте чтобы во вкладке «Форматы» стояло «Русский (Россия) / Использовать язык интерфейса Windows (рекомендуется)» (пример на скрине ниже 👇).
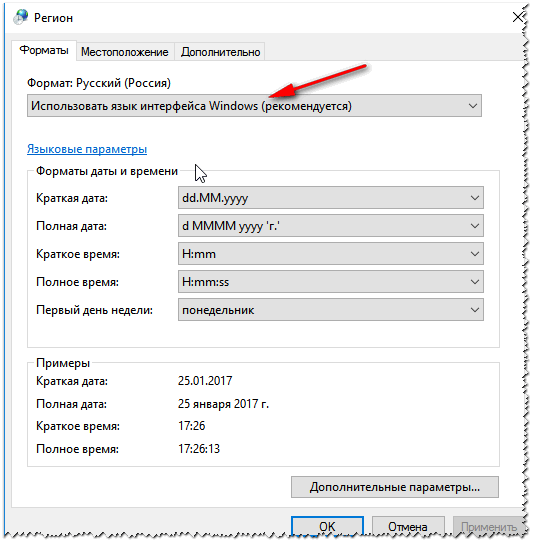
Формат — русский / Россия
Во вкладке «Местоположение» — укажите «Россия».
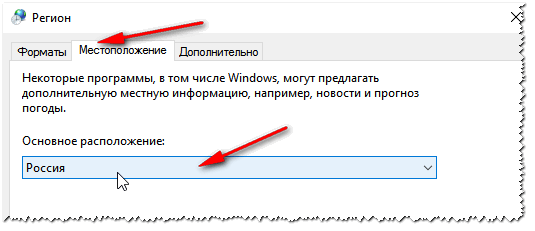
Местоположение — Россия
И во вкладке «Дополнительно» установите язык системы «Русский (Россия)».
После этого сохраните настройки и перезагрузите ПК. Затем вновь проверьте, нормально ли отображается интерфейс нужной программы.
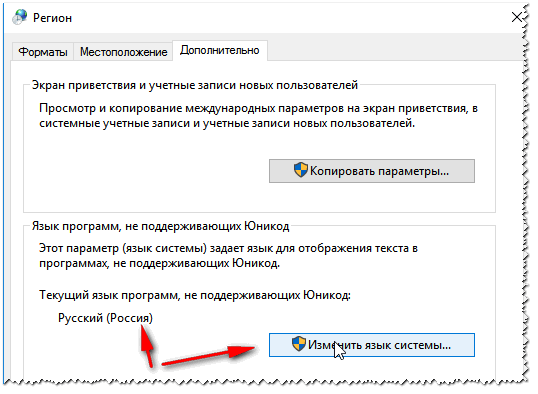
Текущий язык программ
*
PS
И напоследок, наверное, для многих это очевидно, и все же некоторые открывают определенные файлы в программах, которые не предназначены для этого: к примеру в обычном блокноте пытаются прочитать файл DOCX или PDF.
📌 В помощь! Незаменимые программы для чтения PDF-файлов
Естественно, в этом случае вы вместо текста будут наблюдать за крякозабрами, используйте те программы, которые предназначены для данного типа файла (WORD 2016+ и Adobe Reader для примера выше).
*
На сим пока всё, удачи!
👋
Первая публикация: 26.01.2017
Корректировка: 14.06.2022


Полезный софт:
-

- Видео-Монтаж

Отличное ПО для создания своих первых видеороликов (все действия идут по шагам!).
Видео сделает даже новичок!
-
- Ускоритель компьютера

Программа для очистки Windows от «мусора» (удаляет временные файлы, ускоряет систему, оптимизирует реестр).
ыЙТПЛБС ØàÞÚÐï ╒┌тр╪ф╪┌ПрЎ.ТруНЬ_аЭШЩ ФРбв ЬЮ!…
Нет, мы не сошли с ума. Просто сегодня будем разбираться, как устранить ошибки кодировки и вернуть на сайт читаемый текст. Узнаем, как кодировка влияет на SEO-оптимизацию, и познакомимся с полезными сервисами, которые позволят вовремя идентифицировать ошибки.
Что такое кодировка, и когда возникают ошибки с отображением текста
Если вместо нормального текста на вашем сайте отображается странный набор символов, значит, есть проблемы с кодировкой. Впрочем, иногда кодировка на сайте является стандартизированной и выбрана корректно, но вместо текста все равно отображаются иероглифы.
Кодировка – это набор символов и система их передачи для последующего вывода на экран. Кроме алфавита при помощи кодировки передаются также специальные символы и цифры.
Сегодня массово используются 2 вида кодировки: Windows-1251 и UTF-8. Чаще всего «кракозябра» появляется, когда на одном сайте используется сразу несколько видов кодировки (да, такое бывает чаще, чем может показаться на первый взгляд).
Можно выделить и другие причины неполадок:
- Используется устаревший браузер.
- В браузере / программе установлена одна кодировка, на сайте – другая. В таком случае нужно поменять кодировку в программе.
- В БД и других файлах сайта указаны несовпадающие кодировки. В этом случае нужно выбрать одну кодировку для всего сайта.

Как поменять кодировку в браузере
Проблему с кодировкой на стороне браузера исправить легко.
Internet Explorer
- Открываем проблемную веб-страницу.
- Вызываем контекстное меню, кликнув правой кнопкой мыши по любому месту на странице.
- Выбираем «Кодировка».
- Кликаем Unicode (UTF-8).
Chrome
Chrome современный и модный браузер, но вот кодировку стандартными средствами поменять в нем нельзя (сюрприз!). Будем делать это через расширение.
- Открываем магазин Chrome.
- Кликаем «Расширения» в левой части экрана.
- Указываем слово «кодировка».
- Устанавливаем любое подходящее расширение.
Safari
- Выбираем пункт «Вид».
- Кликаем по разделу «Кодировка текста».
- Выбраем вариант Unicode (UTF-8).
Firefox
- Выбираем пункт «Вид».
- Кликаем по раздел «Кодировка текста».
- Нужно выбрать вариант Unicode (UTF-8).
Как выбрать кодировку
Если в качестве CMS вы используете WordPress, Joomla, Drupal, OpenCart или TYPO3, то дополнительно настраивать ничего не нужно. Эти движки по умолчанию работает именно с UTF-8. Все должно работать из коробки. Просто убедитесь, что везде прописана UTF-8.
В самых сложных случаях придется отдельно скачивать шаблоны под конкретную кодировку, предварительно создав MySQL. Последнее актуально, например, для DLE. Если же ваш cайт полностью самописный, просто проследите за тем, чтобы везде была установлена идентичная кодировка, желательно – UTF-8.
Какую кодировку выбрать
Сегодня большинство экспертов солидарны в том, что наиболее удобной кодировкой является UTF-8. Этот стандарт поддерживает большинство браузеров, баз данных, серверов и языков. Еще одно преимущество – она изначально была кроссплатформенной.
UTF-8 может закодировать любой unicode-символ. Пожалуй, именно это достоинство позволило кодировке стать одной из самых популярных в мире.
Windows-1251 известна в меньшей степени, но Windows-1251 и не отличается такой универсальностью и распространенностью как UTF-8. Проблемы с кодировкой могут встречаться на всех сайтах, даже на отлаженных площадках, которые работают в течение многих лет. Чтобы предотвратить проблемы с «кракозябрами» на своем сайте в будущем, необходимо с самого начала выбирать единую кодировку. Как вы уже догадались, лучший кандидат на эту роль – UTF-8.
Как узнать, какая кодировка используется на моем сайте
Узнать, какая кодировка используется на всем сайте или на конкретной странице, можно за несколько секунд. Для этого нужно просмотреть исходник HTML-страницы. Чтобы увидеть его, используем одновременное нажатие горячих клавиш Сtrl + U (на «Маке» активируем шорткатом Option/Alt + Command + U). Появится такое окно:

Теперь используем сочетание горячих клавиш Ctrl + F (Command + F) – откроется окно поиска. Вводим в поисковую строку атрибут charset (он же character set, кодировка документа). После этого атрибута мы увидим знак равенства. За ним и будет указана кодировка страницы.

Если атрибут charset не задан, его придется задать. Предварительно нужно проверить сайт при помощи сторонних сервисов. Один из них – Browserstack. Платформа платная, но, чтобы проверить кодировку, платить необязательно. Достаточно открыть сайт и выбрать пункт Get started free, создать аккаунт (можно просто залогиниться при помощи «Google-аккаунта»). После авторизации появится такое окно:

Выбираем интересующую нас операционную систему / устройство и вводим сайт, который нужно протестировать:

Если с кодировкой на сайте что-то не так, все ошибки будут представлены в результатах теста.
Для проверки и определения ошибок кодировки можно использовать не только Browserstack. Альтернатива – бесплатный сервис Validator. Он позволит идентифицировать кодировку сразу по нескольким данным, включая заголовки. Пример ошибки кодировки в результатах анализа Validator:

Также неплохие возможности для проверки технических ошибок сайта дает pr-cy.ru. Не забудьте выбрать пункт «Аудит страниц»:

Хорошие инструменты для проверки кодировки предоставляют сервисы NetPeak и SeoFrog. Последний удобен еще тем, что позволяет проверить кодировку сразу по всем страницам сайта, а не только по одной.
Кодировка и оптимизация
Даже если кодировка на сайте не совсем обычная или отличается на разных страницах, Google и «Яндекс» все равно проиндексируют такой сайт, но при условии, что контент уникален и не переспамлен ключами. Одна из самых неприятных ошибок здесь – несовместимость кодировки веб-ресурса с той, которая используется на сервере. Даже в таком случае Google, например, способен корректно идентифицировать ошибку. Сайт будет в выдаче, если соответствующие условия были соблюдены.
Ошибки кодировки сами по себе не влияют на оптимизацию сайта прямым образом. Они сказываются на отказах и времени, проведенном на сайте, а также на иных поведенческих показателях аудитории.
Если на вашем сайте возникают ошибки кодировки, и контент отображается некорректно, то посетитель ни при каких обстоятельствах не будет тратить свое время, пытаясь настроить правильную кодировку и, тем более, пытаться ее преобразовать в читаемую. Большинство посетителей просто не знают, как это сделать, но даже если знают, не будут тратить время и точно уйдут к конкурентам на тот сайт, где содержимое изначально отображается корректно.
Устранить проблемы кодировки сложно: мало поменять ее на одной или нескольких страницах. Обычно приходится исправлять ее также в мете (одноименных тегах), БД MySQL, файле htaccess и других системных файлах сайта.
Как исправить ошибки кодировки на своем сайте
Инструкция предназначена только для опытных пользователей и не является призывом к действию. Код и настройки я привожу исключительно в качестве примера. Если вы решитесь вносить изменения в БД и системные файлы, особенно в root, обязательно сделайте резервную копию всех данных сайта!
Документы / HTML-файлы
Если возникают проблемы с документами, необходимо удостовериться в том, что они имеют одинаковую кодировку, и в том, что она вообще задана. Для этого открываем HTML-файл при помощи любого редактора, который позволяет работать с кодом. Например, через Notepad++. Открываем проблемный документ и выполняем следующую последовательность действий:

Htaccess
«Кракозябра» может появляться даже в тех случаях, когда ошибки в документах уже исправлены. В таком случае нужно проверить файл htaccess. Открываем его при помощи редактора кода, затем, используя одновременное сочетание горячих клавиш Ctrl + F, открываем окно «Поиск по странице» и вводим уже знакомый нам атрибут Charset. Если атрибут найден, его необходимо исправить на тот, который является стандартным для вашего сайта. Если его нет вообще, добавляем атрибут AddDefaultCharset UTF-8 в любом месте в самом начале документа.
Теги типа meta
Именно мета-тег используется для установки требуемой кодировки. Кроме этого, в нем прописываются и другие мета-теги, которые задействованы для хранения информации, используемой браузерами. Прописываются теги типа meta в head-разделе. Выглядит следующим образом:
<!DOCTYPE HTML>
<html>
<head>
<title>Тег META</title>
<meta charset="utf-8">
</head>
<body>
<p>...</p>
</body>
</html>
Этот код приводится в качестве примера. Не исключено появление ошибок.
Базы данных
Если «кракозябры» при открытии страниц так и не исчезают, придется проверять MySQL. Нас интересуют значения, прописанные в таблицах баз данных. Чтобы устранить эту проблему, необходимо подключиться к серверу через mysql root. Для этого выполняем следующие шаги:

Так мы приведем кодировку БД к единому стандарту UTF-8.
Онлайн-декодеры
Онлайн-декодеры и другие инструменты с аналогичным функционалом позволяют преобразовать «кракозябру» в читаемый текст. Foxtools – приятный и удобный декодер, который работает в автоматическом режиме. У Foxtools вообще много полезных инструментов:

2cyr – еще более функциональный инструмент, который не только преобразует «кракозябры» в читаемый текст, но и выводит множество возможных вариантов. Бывает и такое, что все варианты «расшифровки» являются некорректными:

Итоги
Чтобы вовремя идентифицировать проблемы с кодировкой на своем сайте, используйте перечисленные выше инструменты. Не забывайте и об онлайн-декодерах: они эффективно расшифровывают нечитаемый текст в случаях, когда необходимо быстро преобразовать «кракозябру». Помните, что иероглифы на сайте недопустимы, и устранять такие ошибки нужно как можно скорее. В противном случае ухудшатся поведенческие факторы, и сайт может навсегда выпасть из поисковой выдачи.
В очередной раз запустив в Windows свой скрипт-информер для СамИздат-а и увидев в консоли «загадочные символы» я сказал себе: «Да уже сделай, наконец, себе нормальный кросс-платформенный логгинг!»
Об этом, и о том, как раскрасить вывод лога наподобие Django-вского в Win32 я попробую рассказать под хабра-катом (Всё ниженаписанное применимо к Python 2.x ветке)
Задача первая. Корректный вывод текста в консоль
Симптомы
До тех пор, пока мы не вносим каких-либо «поправок» в проинициализировавшуюся систему ввода-вывода и используем только оператор print с unicode строками, всё идёт более-менее нормально вне зависимости от ОС.
«Чудеса» начинаются дальше — если мы поменяли какие-либо кодировки (см. чуть дальше) или воспользовались модулем logging для вывода на экран. Вроде бы настроив ожидаемое поведение в Linux, в Windows получаешь «мусор» в utf-8. Начинаешь править под Win — вылезает 1251 в консоли…
Теоретический экскурс
За параметры преобразования символов и вывода их в консоль отвечают сразу несколько параметров:
- Кодировка по-умолчанию модуля
sys—sys.getdefaultencoding() - Предпочитаемая кодировка для текущей локали —
locale.getpreferredencoding() - Кодировка стандартных потоков
sys.stdout, sys.stderr - Кое-какую смуту вносит и кодировка самого файла, но договоримся, что у нас всё унифицировано и все файлы в utf-8 и содержат корректный заголовок
- «Бонусом» идёт любовь стандартных потоков выдавать исключения, если, даже при корректно установленной кодировке, не найдётся нужного символа при печати unicode строки
Ищем решение
Очевидно, чтобы избавиться от всех этих проблем, надо как-то привести их к единообразию.
И вот тут начинается самое интересное:
# -*- coding: utf-8 -*-
>>> import sys
>>> import locale
>>> print sys.getdefaultencoding()
ascii
>>> print locale.getpreferredencoding() # linux
UTF-8
>>> print locale.getpreferredencoding() # win32/rus
cp1251
# и самое интересное:
>>> print sys.stdout.encoding # linux
UTF-8
>>> print sys.stdout.encoding # win32
cp866
Ага! Оказывается «система» у нас живёт вообще в ASCII. Как следствие — попытка по-простому работать с вводом/выводом заканчивается «любимым» исключением UnicodeEncodeError/UnicodeDecodeError.
Кроме того, как замечательно видно из примера, если в linux у нас везде utf-8, то в Windows — две разных кодировки — так называемая ANSI, она же cp1251, используемая для графической части и OEM, она же cp866, для вывода текста в консоли. OEM кодировка пришла к нам со времён DOS-а и, теоретически, может быть также перенастроена специальными командами, но на практике никто этого давно не делает.
До недавнего времени я пользовался распространённым способом исправить эту неприятность:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
# ==============
# Main script file
# ==============
import sys
reload(sys)
sys.setdefaultencoding('utf-8')
# или
import locale
sys.setdefaultencoding(locale.getpreferredencoding())
# ...
И это, в общем-то, работало. Работало до тех пор, пока пользовался print-ом. При переходе к выводу на экран через logging всё сломалось.
Угу, подумал я, раз «оно» использует кодировку по-умолчанию, — выставлю-ка я ту же кодировку, что в консоли:
sys.setdefaultencoding(sys.stdout.encoding or sys.stderr.encoding)
Уже чуть лучше, но:
- В Win32 текст печатается кракозябрами, явно напоминающими cp1251
- При запуске с перенаправленным выводом опять получаем не то, что ожидалось
- Периодически, при попытке напечатать текст, где есть преобразованный в unicode символ типа ① (
①), «любезно» добавленный автором в какой-нибудь заголовок, снова получаемUnicodeEncodeError!
Присмотревшись к первому примеру, нетрудно заметить, что так желаемую кодировку «cp866» можно получить только проверив атрибут соответствующего потока. А он далеко не всегда оказывается доступен.
Вторая часть задачи — оставить системную кодировку в utf-8, но корректно настроить вывод в консоль.
Для индивидуальной настройки вывода надо переопределить обработку выходных потоков примерно так:
import sys
import codecs
sys.stdout = codecs.getwriter('cp866')(sys.stdout,'replace')
Этот код позволяет убить двух зайцев — выставить нужную кодировку и защититься от исключений при печати всяких умляутов и прочей типографики, отсутствующей в 255 символах cp866.
Осталось сделать этот код универсальным — откуда мне знать OEM кодировку на произвольном сферическом компе? Гугление на предмет готовой поддержки ANSI/OEM кодировок в python ничего разумного не дало, посему пришлось немного вспомнить WinAPI
UINT GetOEMCP(void); // Возвращает системную OEM кодовую страницу как число
UINT GetANSICP(void); // то же для ANSI кодовой странцы
… и собрать всё вместе:
# -*- coding: utf-8 -*-
import sys
import codecs
def setup_console(sys_enc="utf-8"):
reload(sys)
try:
# для win32 вызываем системную библиотечную функцию
if sys.platform.startswith("win"):
import ctypes
enc = "cp%d" % ctypes.windll.kernel32.GetOEMCP() #TODO: проверить на win64/python64
else:
# для Linux всё, кажется, есть и так
enc = (sys.stdout.encoding if sys.stdout.isatty() else
sys.stderr.encoding if sys.stderr.isatty() else
sys.getfilesystemencoding() or sys_enc)
# кодировка для sys
sys.setdefaultencoding(sys_enc)
# переопределяем стандартные потоки вывода, если они не перенаправлены
if sys.stdout.isatty() and sys.stdout.encoding != enc:
sys.stdout = codecs.getwriter(enc)(sys.stdout, 'replace')
if sys.stderr.isatty() and sys.stderr.encoding != enc:
sys.stderr = codecs.getwriter(enc)(sys.stderr, 'replace')
except:
pass # Ошибка? Всё равно какая - работаем по-старому...
Задача вторая. Раскрашиваем вывод
Насмотревшись на отладочный вывод Джанги в связке с werkzeug, захотелось чего-то подобного для себя. Гугление выдаёт несколько проектов разной степени проработки и удобности — от простейшего наследника logging.StreamHandler, до некоего набора, при импорте автоматически подменяющего стандартный StreamHandler.
Попробовав несколько из них, я, в итоге, воспользовался простейшим наследником StreamHandler, приведённом в одном из комментов на Stack Overflow и пока вполне доволен:
class ColoredHandler( logging.StreamHandler ):
def emit( self, record ):
# Need to make a actual copy of the record
# to prevent altering the message for other loggers
myrecord = copy.copy( record )
levelno = myrecord.levelno
if( levelno >= 50 ): # CRITICAL / FATAL
color = 'x1b[31;1m' # red
elif( levelno >= 40 ): # ERROR
color = 'x1b[31m' # red
elif( levelno >= 30 ): # WARNING
color = 'x1b[33m' # yellow
elif( levelno >= 20 ): # INFO
color = 'x1b[32m' # green
elif( levelno >= 10 ): # DEBUG
color = 'x1b[35m' # pink
else: # NOTSET and anything else
color = 'x1b[0m' # normal
myrecord.msg = (u"%s%s%s" % (color, myrecord.msg, 'x1b[0m')).encode('utf-8') # normal
logging.StreamHandler.emit( self, myrecord )
Однако, в Windows всё это работать, разумеется, отказалось. И если раньше можно было «включить» поддержку ansi-кодов в консоли добавлением «магического» ansi.dll из проекта symfony куда-то в недра системных папок винды, то, начиная (кажется) с Windows 7 данная возможность окончательно «выпилена» из системы. Да и заставлять юзера копировать какую-то dll в системную папку тоже как-то «не кошерно».
Снова обращаемся к гуглу и, снова, получаем несколько вариантов решения. Все варианты так или иначе сводятся к подмене вывода ANSI escape-последовательностей вызовом WinAPI для управления атрибутами консоли.
Побродив некоторое время по ссылкам, набрёл на проект colorama. Он как-то понравился мне больше остального. К плюсам именно этого проекта ст́оит отнести, что подменяется весь консольный вывод — можно выводить раскрашенный текст простым print u"x1b[31;40mЧто-то красное на чёрномx1b[0m" если вдруг захочется поизвращаться.
Сразу замечу, что текущая версия 0.1.18 содержит досадный баг, ломающий вывод unicode строк. Но простейшее решение я привёл там же при создании issue.
Собственно осталось объединить оба пожелания и начать пользоваться вместо традиционных «костылей»:
# -*- coding: utf-8 -*-
import sys
import codecs
import copy
import logging
#: Is ANSI printing available
ansi = not sys.platform.startswith("win")
def setup_console(sys_enc='utf-8', use_colorama=True):
"""
Set sys.defaultencoding to `sys_enc` and update stdout/stderr writers to corresponding encoding
.. note:: For Win32 the OEM console encoding will be used istead of `sys_enc`
"""
global ansi
reload(sys)
try:
if sys.platform.startswith("win"):
#... код, показанный выше
if use_colorama and sys.platform.startswith("win"):
try:
# пробуем подключить colorama для винды и взводим флаг `ansi`, если всё получилось
from colorama import init
init()
ansi = True
except:
pass
class ColoredHandler( logging.StreamHandler ):
def emit( self, record ):
# Need to make a actual copy of the record
# to prevent altering the message for other loggers
myrecord = copy.copy( record )
levelno = myrecord.levelno
if( levelno >= 50 ): # CRITICAL / FATAL
color = 'x1b[31;1m' # red
elif( levelno >= 40 ): # ERROR
color = 'x1b[31m' # red
elif( levelno >= 30 ): # WARNING
color = 'x1b[33m' # yellow
elif( levelno >= 20 ): # INFO
color = 'x1b[32m' # green
elif( levelno >= 10 ): # DEBUG
color = 'x1b[35m' # pink
else: # NOTSET and anything else
color = 'x1b[0m' # normal
myrecord.msg = (u"%s%s%s" % (color, myrecord.msg, 'x1b[0m')).encode('utf-8') # normal
logging.StreamHandler.emit( self, myrecord )
Дальше в своём проекте, в запускаемом файле пользуемся:
#!/usr/bin/env python
# -*- coding: utf-8 -*-
from setupcon import setup_console
setup_console('utf-8', False)
#...
# или если будем пользоваться раскрашиванием логов
import setupcon
setupcon.setup_console()
import logging
#...
if setupcon.ansi:
logging.getLogger().addHandler(setupcon.ColoredHandler())
На этом всё. Из потенциальных доработок осталось проверить работоспособность под win64 python и, возможно, добаботать ColoredHandler чтобы проверял себя на isatty, как в более сложных примерах на том же StackOverflow.
Итоговый вариант получившегося модуля можно забрать на dumpz.org
В Windows 10 есть много различных языковых и региональных параметров, которые пользователь может настраивать соответственно своим предпочтениям. Часто бывает так, что владельцы компьютеров сталкиваются с некорректным отображением кириллических (русский, украинский и другие языки) шрифтов. Вместо нормальных знаков и русских букв почему-то отображаются крякозябры в Windows 10, делающие работу с операционной системой фактически невозможной. При этом сам язык системы может отображаться нормально, но попытка открыть текстовый файл или запустить приложение, в котором используется кириллический текст, приведет к весьма унылому результату:

Причиной этому является сбой кодировки операционной системы. Чинится все предельно просто и потребует от вас лишь несколько кликов и одну перезагрузку компьютера. При этом починка осуществляется как простым способом через Панель управления, так и более сложным через редактор реестра или подмену кодовых таблиц операционной системы. Мы рекомендуем использовать первый метод, так как в 99.99% случае проблема решается именно так.
Суть проблемы
Как правило, мы можем наблюдать эти кракозябры не в каждой программе. Например, символы, изображённые кириллицей в названии программ, отображены корректно. Но если запустить программу установки дистрибутивов, поддерживающих русский язык, мы получаем неведомую нам «китайскую грамоту».
И, пожалуй, основная проблема кроется в том, что в имеющейся ОС по дефолту отсутствует поддержка кириллических символов. На практике это может значить, что вы инсталлировали английский дистрибутив с установленным поверх него расширенным пакетом русификации. Однако последний не смог решить проблему корректно.
Первое, что пытаются делать пользователи в такой ситуации – переустановка операционки с чистого листа. Однако не все согласятся на такое, ведь кто-то, возможно, намеренно хочет работать с англоязычной средой. И в этой среде кириллические символы по идее могут и должны отображаться корректно.
SysAdmin-s notepad. DoFollow.
Проблемы кодировки в Windows — довольно большая головная боль для многих любителей и поклонников этой операционки. Иногда приходится изрядно помучиться и попотеть прежде чем удается решить проблему с кодировкой. Выяснить причину, зачастую. еще сложнее. но тут вообще мало кто заморачивается…главное ведь устранить неполадку, а уж почему возникла — вопрос давно ушедших дней)
Особенно сильно проблема с кодировкой стала актуальна после выхода новой Windows 10 . Микрософты опять что-то перемудрили и в итоге, в некоторых приложениях вместо языка одни кракозябры. Но все решаемо
На самом деле причин сброса или изменения кодировки может быть довольно большое множество. Но основные из них, это:
— установка какого-то системного патча
— обновление до windows 10
— кривые шаловливые руки и непомерная любознательность ( самая распространенная причина всех бед в windows )
Используем системные настройки для решения проблемы
Прежде всего, попробуем исправить ошибку через панель управления. Чтобы зайти в неё нажимаем ПКМ по кнопке-меню «Пуск» и в выпавшем списке выбираем соответствующий пункт.

В открывшемся новом окне находим раздел Часы, язык, регион.

В новом разделе выбираем категорию региональных стандартов.
Здесь мы сможем настроить вариант даты и времени, а также числовой разделитель, количество дробных значений, формат отрицательных чисел, систему единиц измерения и пр.
Также здесь нам предлагается изменить формат денежных единиц и обозначение таковых. Здесь же мы можем настроить локальные параметры для разных регионов, включая отображаемые в системе текстовые символы. Именно эти опции нас и интересуют. Для их выбора переходим ко вкладке «Дополнительно» в верхней части окна.
Переходим в раздел выбора языка, не поддерживающего Юникод, и далее выбираем опцию изменение языка системы.

В списке выбираем нужный вариант (в нашем случае «Русский (Россия)» и нажимаем «ОК»)

В появившемся окне уведомлений выбираем «Перезагрузить сейчас».
ПК уйдёт в перезагрузку, после чего проблема с кракозябрами должна исчезнуть. Однако не всегда этот способ срабатывает. Если он не помог решить проблему, рассмотрим ещё один вариант, в котором нам придётся поработать с реестром.
Что такое кодировка?
Кодировка — это кодирование каждой буквы и цифры при помощи специального цифрового номера, в нашем случае кода. То есть в разных кодировках у цифр и букв будет разный числовой номер кода. А это говорит о том, если поменять кодировку нормального текста на другую, то в результате перед нами получится не читаемый текст из других наборов букв и символов, вместо понятных нам русских букв. Думаю смысл в этом понятен.
На wordpress и других CMS принято использовать кодировку текста UTF-8. Поэтому, для того, что бы вместо знаков отображался нормальный текст, нам следует поменять кодировку всех файлов на UTF-8.
Редактируем страницу кода вручную
Страницы кода отвечают за сопоставление символов с байтами. Таких таблиц бывает много, и каждая из них работает с различными языками. Зачастую кракозябры появляются при неправильном выборе страницы и её сопоставлении. Чтобы исправить это, нам предстоит поработать с реестром. Для этого:
- Win+R запускаем системную службу «Выполнить». Прописываем в единственной строке regedit и жмём Ок.

- В окне реестра нам нужно перейти по следующему пути: HKEY_LOCAL_MACHINESYSTEMCurrentControlSetControlNls
- Здесь выбираем папку CodePage и в правой части окна идём вниз, чтобы найти пункт ACP.
- Дважды кликаем ЛКМ по ACP, и перед нами открывается окно изменений строковых настроек. Здесь выставляем значение 1251. Если такое значение уже установлено для этого пункта, тогда нужно сделать по-другому.

Находясь в том же разделе CodePage, в правой части окна ищем пункт 1252. Жмём по нему дважды ЛКМ и в появившемся окне меняем текущее значение 1252 на 1251.
После произведённых манипуляций отправляем компьютер в перезагрузку, чтобы применённые изменения вступили в силу.
Post Views: 2 165
Использование реестра, если метод выше не помог
Создадим в текстовом редакторе обычный файлик, но дадим ему расширение .reg, дабы впоследствии можно было применить все настройки, хранящиеся в нем. Итак, какое же содержимое reg-файла должно быть?
Как исправить ошибку Bad system config info с кодом 0x00000074
Наберем в него ручками или скопируем через буфер обмена следующие значения:
Windows Registry Editor Version 5.00
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontMapper] «ARIAL»=dword:00000000
[HKEY_LOCAL_MACHINESOFTWAREMicrosoftWindows NTCurrentVersionFontSubstitutes] «Arial,0″=»Arial,204» «Comic Sans MS,0″=»Comic Sans MS,204» «Courier,0″=»Courier New,204» «Courier,204″=»Courier New,204» «MS Sans Serif,0″=»MS Sans Serif,204» «Tahoma,0″=»Tahoma,204» «Times New Roman,0″=»Times New Roman,204» «Verdana,0″=»Verdana,204»
Когда все указанные строки окажутся в reg-файле, запустим его, согласимся с внесением изменений в систему, после чего выполним перезагрузку ПК и смотрим на результаты. Кракозябры должны исчезнуть.
Важное замечание: перед внесением изменений в реестр лучше создать резервную копию (другими словами, бэкап) реестра, дабы вносимые впоследствии изменения не повлекли за собой крах операционки, и ее не пришлось переустанавливать с нуля. Тем не менее, если вы уверены, что эти действия безопасны для вашей ОС, можете этот пункт упустить.

19.07.2017 windows
Одна из возможных проблем, с которыми можно столкнуться после установки Windows 10 — кракозябры вместо русских букв в интерфейсе программ, а также в документах. Чаще неправильное отображение кириллицы встречается в изначально англоязычных и не совсем лицензионных версиях системы, но бывают и исключения.
В этой инструкции — о том, как исправить «кракозябры» (или иероглифы), а точнее — отображение кириллицы в Windows 10 несколькими способами. Возможно, также будет полезным: Как установить и включить русский язык интерфейса в Windows 10 (для систем на английском и других языках).
Исправление отображения кириллицы с помощью настроек языка и региональных стандартов Windows 10
Самый простой и чаще всего работающий способ убрать кракозябры и вернуть русские буквы в Windows 10 — исправить некоторые неправильные настройки в параметрах системы.
Для этого потребуется выполнить следующие шаги (примечание: привожу также названия нужных пунктов на английском, так как иногда необходимость исправить кириллицу возникает в англоязычных версиях системы без нужды менять язык интерфейса).
- Откройте панель управления (для этого можно начать набирать «Панель управления» или «Control Panel» в поиске на панели задач.
- Убедитесь, что в поле «Просмотр» (View by) установлено «Значки» (Icons) и выберите пункт «Региональные стандарты» (Region).
- На вкладке «Дополнительно» (Administrative) в разделе «Язык программ, не поддерживающих Юникод» (Language for non-Unicode programs) нажмите по кнопке «Изменить язык системы» (Change system locale).
- Выберите русский язык, нажмите «Ок» и подтвердите перезагрузку компьютера.
После перезагрузки проверьте, была ли решена проблема с отображением русских букв в интерфейсе программ и (или) документах — обычно, кракозябры бывают исправлены после этих простых действий.
Как исправить иероглифы Windows 10 путем изменения кодовых страниц
Кодовые страницы представляют собой таблицы, в которых определенным байтам сопоставляются определенные символы, а отображение кириллицы в виде иероглифов в Windows 10 связано обычно с тем, что по умолчанию задана не та кодовая страница и это можно исправить несколькими способами, которые могут быть полезны, когда требуется не изменять язык системы в параметрах.
С помощью редактора реестра
Первый способ — использовать редактор реестра. На мой взгляд, это самый щадящий для системы метод, тем не менее, рекомендую создать точку восстановления прежде чем начинать. Совет про точки восстановления относится и ко всем последующим способам в этом руководстве.
- Нажмите клавиши Win+R на клавиатуре, введите regedit и нажмите Enter, откроется редактор реестра.
- Перейдите к разделу реестраHKEY_LOCAL_MACHINESYSTEMCurrentControlSetControllsCodePageи в правой части пролистайте значения этого раздела до конца.
- Дважды нажмите по параметру ACP, установите значение 1251 (кодовая страница для кириллицы), нажмите Ок и закройте редактор реестра.
- Перезагрузите компьютер (именно перезагрузка, а не завершение работы и включение, в Windows 10 это может иметь значение).
Обычно, это исправляет проблему с отображением русских букв. Вариация способа с помощью редактора реестра (но менее предпочтительная) — посмотреть на текущее значение параметра ACP (обычно — 1252 для изначально англоязычных систем), затем в том же разделе реестра найти параметр с именем 1252 и изменить его значение с c_1252.nls на c_1251.nls.
Путем подмена файла кодовой страницы на c_1251.nls
Второй, не рекомендуемый мной способ, но иногда выбираемый теми, кто считает, что правка реестра — это слишком сложно или опасно: подмена файла кодовой страницы в C: Windows System32 (предполагается, что у вас установлена западно-европейская кодовая страница — 1252, обычно это так. Посмотреть текущую кодовую страницу можно в параметре ACP в реестре, как было описано в предыдущем способе).
- Зайдите в папку C: Windows System32 и найдите файл c_1252.NLS, нажмите по нему правой кнопкой мыши, выберите пункт «Свойства» и откройте вкладку «Безопасность». На ней нажмите кнопку «Дополнительно».
- В поле «Владелец» нажмите «Изменить».
- В поле «Введите имена выбираемых объектов» укажите ваше имя пользователя (с правами администратора). Если в Windows 10 используется учетная запись Майкрософт, вместо имени пользователя укажите адрес электронной почты. Нажмите «Ок» в окне, где указывали пользователя и в следующем (Дополнительные параметры безопасности) окне.
- Вы снова окажетесь на вкладке «Безопасность» в свойствах файла. Нажмите кнопку «Изменить».
- Выберите пункт «Администраторы» (Administrators) и включите полный доступ для них. Нажмите «Ок» и подтвердите изменение разрешений. Нажмите «Ок» в окне свойств файла.
- Переименуйте файл c_1252.NLS (например, измените расширение на .bak, чтобы не потерять этот файл).
- Удерживая клавишу Ctrl, перетащите находящийся там же в C:WindowsSystem32 файл c_1251.NLS (кодовая страница для кириллицы) в другое место этого же окна проводника, чтобы создать копию файла.
- Переименуйте копию файла c_1251.NLS в c_1252.NLS.
- Перезагрузите компьютер.

