Время прочтения
16 мин
Просмотры 36K
Привет, Хабр! Представляю вашему вниманию перевод статьи «Error and Transaction Handling in SQL Server. Part One – Jumpstart Error Handling» автора Erland Sommarskog.
1. Введение
Эта статья – первая в серии из трёх статей, посвященных обработке ошибок и транзакций в SQL Server. Её цель – дать вам быстрый старт в теме обработки ошибок, показав базовый пример, который подходит для большей части вашего кода. Эта часть написана в расчете на неопытного читателя, и по этой причине я намеренно умалчиваю о многих деталях. В данный момент задача состоит в том, чтобы рассказать как без упора на почему. Если вы принимаете мои слова на веру, вы можете прочесть только эту часть и отложить остальные две для дальнейших этапов в вашей карьере.
С другой стороны, если вы ставите под сомнение мои рекомендации, вам определенно необходимо прочитать две остальные части, где я погружаюсь в детали намного более глубоко, исследуя очень запутанный мир обработки ошибок и транзакций в SQL Server. Вторая и третья части, так же, как и три приложения, предназначены для читателей с более глубоким опытом. Первая статья — короткая, вторая и третья значительно длиннее.
Все статьи описывают обработку ошибок и транзакций в SQL Server для версии 2005 и более поздних версий.
1.1 Зачем нужна обработка ошибок?
Почему мы обрабатываем ошибки в нашем коде? На это есть много причин. Например, на формах в приложении мы проверяем введенные данные и информируем пользователей о допущенных при вводе ошибках. Ошибки пользователя – это предвиденные ошибки. Но нам также нужно обрабатывать непредвиденные ошибки. То есть, ошибки могут возникнуть из-за того, что мы что-то упустили при написании кода. Простой подход – это прервать выполнение или хотя бы вернуться на этап, в котором мы имеем полный контроль над происходящим. Недостаточно будет просто подчеркнуть, что совершенно непозволительно игнорировать непредвиденные ошибки. Это недостаток, который может вызвать губительные последствия: например, стать причиной того, что приложение будет предоставлять некорректную информацию пользователю или, что еще хуже, сохранять некорректные данные в базе. Также важно сообщать о возникновении ошибки с той целью, чтобы пользователь не думал о том, что операция прошла успешно, в то время как ваш код на самом деле ничего не выполнил.
Мы часто хотим, чтобы в базе данных изменения были атомарными. Например, задача по переводу денег с одного счета на другой. С этой целью мы должны изменить две записи в таблице CashHoldings и добавить две записи в таблицу Transactions. Абсолютно недопустимо, чтобы ошибки или сбой привели к тому, что деньги будут переведены на счет получателя, а со счета отправителя они не будут списаны. По этой причине обработка ошибок также касается и обработки транзакций. В приведенном примере нам нужно обернуть операцию в BEGIN TRANSACTION и COMMIT TRANSACTION, но не только это: в случае ошибки мы должны убедиться, что транзакция откачена.
2. Основные команды
Мы начнем с обзора наиболее важных команд, которые необходимы для обработки ошибок. Во второй части я опишу все команды, относящиеся к обработке ошибок и транзакций.
2.1 TRY-CATCH
Основным механизмом обработки ошибок является конструкция TRY-CATCH, очень напоминающая подобные конструкции в других языках. Структура такова:
BEGIN TRY
<обычный код>
END TRY
BEGIN CATCH
<обработка ошибок>
END CATCH
Если какая-либо ошибка появится в <обычный код>, выполнение будет переведено в блок CATCH, и будет выполнен код обработки ошибок.
Как правило, в CATCH откатывают любую открытую транзакцию и повторно вызывают ошибку. Таким образом, вызывающая клиентская программа понимает, что что-то пошло не так. Повторный вызов ошибки мы обсудим позже в этой статье.
Вот очень быстрый пример:
BEGIN TRY
DECLARE @x int
SELECT @x = 1/0
PRINT 'Not reached'
END TRY
BEGIN CATCH
PRINT 'This is the error: ' + error_message()
END CATCH
Результат выполнения: This is the error: Divide by zero error encountered.
Мы вернемся к функции error_message() позднее. Стоит отметить, что использование PRINT в обработчике CATCH приводится только в рамках экспериментов и не следует делать так в коде реального приложения.
Если <обычный код> вызывает хранимую процедуру или запускает триггеры, то любая ошибка, которая в них возникнет, передаст выполнение в блок CATCH. Если более точно, то, когда возникает ошибка, SQL Server раскручивает стек до тех пор, пока не найдёт обработчик CATCH. И если такого обработчика нет, SQL Server отправляет сообщение об ошибке напрямую клиенту.
Есть одно очень важное ограничение у конструкции TRY-CATCH, которое нужно знать: она не ловит ошибки компиляции, которые возникают в той же области видимости. Рассмотрим пример:
CREATE PROCEDURE inner_sp AS
BEGIN TRY
PRINT 'This prints'
SELECT * FROM NoSuchTable
PRINT 'This does not print'
END TRY
BEGIN CATCH
PRINT 'And nor does this print'
END CATCH
go
EXEC inner_spВыходные данные:
This prints
Msg 208, Level 16, State 1, Procedure inner_sp, Line 4
Invalid object name 'NoSuchTable'Как можно видеть, блок TRY присутствует, но при возникновении ошибки выполнение не передается блоку CATCH, как это ожидалось. Это применимо ко всем ошибкам компиляции, таким как пропуск колонок, некорректные псевдонимы и тому подобное, которые возникают во время выполнения. (Ошибки компиляции могут возникнуть в SQL Server во время выполнения из-за отложенного разрешения имен – особенность, благодаря которой SQL Server позволяет создать процедуру, которая обращается к несуществующим таблицам.)
Эти ошибки не являются полностью неуловимыми; вы не можете поймать их в области, в которой они возникают, но вы можете поймать их во внешней области. Добавим такой код к предыдущему примеру:
CREATE PROCEDURE outer_sp AS
BEGIN TRY
EXEC inner_sp
END TRY
BEGIN CATCH
PRINT 'The error message is: ' + error_message()
END CATCH
go
EXEC outer_spТеперь мы получим на выходе это:
This prints
The error message is: Invalid object name 'NoSuchTable'.На этот раз ошибка была перехвачена, потому что сработал внешний обработчик CATCH.
2.2 SET XACT_ABORT ON
В начало ваших хранимых процедур следует всегда добавлять это выражение:
SET XACT_ABORT, NOCOUNT ONОно активирует два параметра сессии, которые выключены по умолчанию в целях совместимости с предыдущими версиями, но опыт доказывает, что лучший подход – это иметь эти параметры всегда включенными. Поведение SQL Server по умолчанию в той ситуации, когда не используется TRY-CATCH, заключается в том, что некоторые ошибки прерывают выполнение и откатывают любые открытые транзакции, в то время как с другими ошибками выполнение последующих инструкций продолжается. Когда вы включаете XACT_ABORT ON, почти все ошибки начинают вызывать одинаковый эффект: любая открытая транзакция откатывается, и выполнение кода прерывается. Есть несколько исключений, среди которых наиболее заметным является выражение RAISERROR.
Параметр XACT_ABORT необходим для более надежной обработки ошибок и транзакций. В частности, при настройках по умолчанию есть несколько ситуаций, когда выполнение может быть прервано без какого-либо отката транзакции, даже если у вас есть TRY-CATCH. Мы видели такой пример в предыдущем разделе, где мы выяснили, что TRY-CATCH не перехватывает ошибки компиляции, возникшие в той же области. Открытая транзакция, которая не была откачена из-за ошибки, может вызвать серьезные проблемы, если приложение работает дальше без завершения транзакции или ее отката.
Для надежной обработки ошибок в SQL Server вам необходимы как TRY-CATCH, так и SET XACT_ABORT ON. Среди них инструкция SET XACT_ABORT ON наиболее важна. Если для кода на промышленной среде только на нее полагаться не стоит, то для быстрых и простых решений она вполне подходит.
Параметр NOCOUNT не имеет к обработке ошибок никакого отношения, но включение его в код является хорошей практикой. NOCOUNT подавляет сообщения вида (1 row(s) affected), которые вы можете видеть в панели Message в SQL Server Management Studio. В то время как эти сообщения могут быть полезны при работе c SSMS, они могут негативно повлиять на производительность в приложении, так как увеличивают сетевой трафик. Сообщение о количестве строк также может привести к ошибке в плохо написанных клиентских приложениях, которые могут подумать, что это данные, которые вернул запрос.
Выше я использовал синтаксис, который немного необычен. Большинство людей написали бы два отдельных выражения:
SET NOCOUNT ON
SET XACT_ABORT ONМежду ними нет никакого отличия. Я предпочитаю версию с SET и запятой, т.к. это снижает уровень шума в коде. Поскольку эти выражения должны появляться во всех ваших хранимых процедурах, они должны занимать как можно меньше места.
3. Основной пример обработки ошибок
После того, как мы посмотрели на TRY-CATCH и SET XACT_ABORT ON, давайте соединим их вместе в примере, который мы можем использовать во всех наших хранимых процедурах. Для начала я покажу пример, в котором ошибка генерируется в простой форме, а в следующем разделе я рассмотрю решения получше.
Для примера я буду использовать эту простую таблицу.
CREATE TABLE sometable(a int NOT NULL,
b int NOT NULL,
CONSTRAINT pk_sometable PRIMARY KEY(a, b))Вот хранимая процедура, которая демонстрирует, как вы должны работать с ошибками и транзакциями.
CREATE PROCEDURE insert_data @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
BEGIN TRANSACTION
INSERT sometable(a, b) VALUES (@a, @b)
INSERT sometable(a, b) VALUES (@b, @a)
COMMIT TRANSACTION
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCHПервая строка в процедуре включает XACT_ABORT и NOCOUNT в одном выражении, как я показывал выше. Эта строка – единственная перед BEGIN TRY. Все остальное в процедуре должно располагаться после BEGIN TRY: объявление переменных, создание временных таблиц, табличных переменных, всё. Даже если у вас есть другие SET-команды в процедуре (хотя причины для этого встречаются редко), они должны идти после BEGIN TRY.
Причина, по которой я предпочитаю указывать SET XACT_ABORT и NOCOUNT перед BEGIN TRY, заключается в том, что я рассматриваю это как одну строку шума: она всегда должна быть там, но я не хочу, чтобы это мешало взгляду. Конечно же, это дело вкуса, и если вы предпочитаете ставить SET-команды после BEGIN TRY, ничего страшного. Важно то, что вам не следует ставить что-либо другое перед BEGIN TRY.
Часть между BEGIN TRY и END TRY является основной составляющей процедуры. Поскольку я хотел использовать транзакцию, определенную пользователем, я ввел довольно надуманное бизнес-правило, в котором говорится, что если вы вставляете пару, то обратная пара также должна быть вставлена. Два выражения INSERT находятся внутри BEGIN и COMMIT TRANSACTION. Во многих случаях у вас будет много строк кода между BEGIN TRY и BEGIN TRANSACTION. Иногда у вас также будет код между COMMIT TRANSACTION и END TRY, хотя обычно это только финальный SELECT, возвращающий данные или присваивающий значения выходным параметрам. Если ваша процедура не выполняет каких-либо изменений или имеет только одно выражение INSERT/UPDATE/DELETE/MERGE, то обычно вам вообще не нужно явно указывать транзакцию.
В то время как блок TRY будет выглядеть по-разному от процедуры к процедуре, блок CATCH должен быть более или менее результатом копирования и вставки. То есть вы делаете что-то короткое и простое и затем используете повсюду, не особо задумываясь. Обработчик CATCH, приведенный выше, выполняет три действия:
- Откатывает любые открытые транзакции.
- Повторно вызывает ошибку.
- Убеждается, что возвращаемое процедурой значение отлично от нуля.
Эти три действия должны всегда быть там. Мы можете возразить, что строка
IF @@trancount > 0 ROLLBACK TRANSACTIONне нужна, если нет явной транзакции в процедуре, но это абсолютно неверно. Возможно, вы вызываете хранимую процедуру, которая открывает транзакцию, но которая не может ее откатить из-за ограничений TRY-CATCH. Возможно, вы или кто-то другой добавите явную транзакцию через два года. Вспомните ли вы тогда о том, что нужно добавить строку с откатом? Не рассчитывайте на это. Я также слышу читателей, которые возражают, что если тот, кто вызывает процедуру, открыл транзакцию, мы не должны ее откатывать… Нет, мы должны, и если вы хотите знать почему, вам нужно прочитать вторую и третью части. Откат транзакции в обработчике CATCH – это категорический императив, у которого нет исключений.
Код повторной генерации ошибки включает такую строку:
DECLARE @msg nvarchar(2048) = error_message()Встроенная функция error_message() возвращает текст возникшей ошибки. В следующей строке ошибка повторно вызывается с помощью выражения RAISERROR. Это не самый простой способ вызова ошибки, но он работает. Другие способы мы рассмотрим в следующей главе.
Замечание: синтаксис для присвоения начального значения переменной в DECLARE был внедрен в SQL Server 2008. Если у вас SQL Server 2005, вам нужно разбить строку на DECLARE и выражение SELECT.
Финальное выражение RETURN – это страховка. RAISERROR никогда не прерывает выполнение, поэтому выполнение следующего выражения будет продолжено. Пока все процедуры используют TRY-CATCH, а также весь клиентский код обрабатывает исключения, нет повода для беспокойства. Но ваша процедура может быть вызвана из старого кода, написанного до SQL Server 2005 и до внедрения TRY-CATCH. В те времена лучшее, что мы могли делать, это смотреть на возвращаемые значения. То, что вы возвращаете с помощью RETURN, не имеет особого значения, если это не нулевое значение (ноль обычно обозначает успешное завершение работы).
Последнее выражение в процедуре – это END CATCH. Никогда не следует помещать какой-либо код после END CATCH. Кто-нибудь, читающий процедуру, может не увидеть этот кусок кода.
После прочтения теории давайте попробуем тестовый пример:
EXEC insert_data 9, NULLРезультат выполнения:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.Давайте добавим внешнюю процедуру для того, чтобы увидеть, что происходит при повторном вызове ошибки:
CREATE PROCEDURE outer_sp @a int, @b int AS
SET XACT_ABORT, NOCOUNT ON
BEGIN TRY
EXEC insert_data @a, @b
END TRY
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
DECLARE @msg nvarchar(2048) = error_message()
RAISERROR (@msg, 16, 1)
RETURN 55555
END CATCH
go
EXEC outer_sp 8, 8Результат работы:
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Мы получили корректное сообщение об ошибке, но если вы посмотрите на заголовки этого сообщения и на предыдущее поближе, то можете заметить проблему:
Msg 50000, Level 16, State 1, Procedure insert_data, Line 12
Msg 50000, Level 16, State 1, Procedure outer_sp, Line 9Сообщение об ошибке выводит информацию о расположении конечного выражения RAISERROR. В первом случае некорректен только номер строки. Во втором случае некорректно также имя процедуры. Для простых процедур, таких как наш тестовый пример, это не является большой проблемой. Но если у вас есть несколько уровней вложенных сложных процедур, то наличие сообщения об ошибке с отсутствием указания на место её возникновения сделает поиск и устранение ошибки намного более сложным делом. По этой причине желательно генерировать ошибку таким образом, чтобы можно было определить нахождение ошибочного фрагмента кода быстро, и это то, что мы рассмотрим в следующей главе.
4. Три способа генерации ошибки
4.1 Использование error_handler_sp
Мы рассмотрели функцию error_message(), которая возвращает текст сообщения об ошибке. Сообщение об ошибке состоит из нескольких компонентов, и существует своя функция error_xxx() для каждого из них. Мы можем использовать их для повторной генерации полного сообщения, которое содержит оригинальную информацию, хотя и в другом формате. Если делать это в каждом обработчике CATCH, это будет большой недостаток — дублирование кода. Вам не обязательно находиться в блоке CATCH для вызова error_message() и других подобных функций, и они вернут ту же самую информацию, если будут вызваны из хранимой процедуры, которую выполнит блок CATCH.
Позвольте представить вам error_handler_sp:
CREATE PROCEDURE error_handler_sp AS
DECLARE @errmsg nvarchar(2048),
@severity tinyint,
@state tinyint,
@errno int,
@proc sysname,
@lineno int
SELECT @errmsg = error_message(), @severity = error_severity(),
@state = error_state(), @errno = error_number(),
@proc = error_procedure(), @lineno = error_line()
IF @errmsg NOT LIKE '***%'
BEGIN
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsg
END
RAISERROR('%s', @severity, @state, @errmsg)Первое из того, что делает error_handler_sp – это сохраняет значение всех error_xxx() функций в локальные переменные. Я вернусь к выражению IF через секунду. Вместо него давайте посмотрим на выражение SELECT внутри IF:
SELECT @errmsg = '*** ' + coalesce(quotename(@proc), '<dynamic SQL>') +
', Line ' + ltrim(str(@lineno)) + '. Errno ' +
ltrim(str(@errno)) + ': ' + @errmsgЦель этого SELECT заключается в форматировании сообщения об ошибке, которое передается в RAISERROR. Оно включает в себя всю информацию из оригинального сообщения об ошибке, которое мы не можем вставить напрямую в RAISERROR. Мы должны обработать имя процедуры, которое может быть NULL для ошибок в обычных скриптах или в динамическом SQL. Поэтому используется функция COALESCE. (Если вы не понимаете форму выражения RAISERROR, я рассказываю о нем более детально во второй части.)
Отформатированное сообщение об ошибке начинается с трех звездочек. Этим достигаются две цели: 1) Мы можем сразу видеть, что это сообщение вызвано из обработчика CATCH. 2) Это дает возможность для error_handler_sp отфильтровать ошибки, которые уже были сгенерированы один или более раз, с помощью условия NOT LIKE ‘***%’ для того, чтобы избежать изменения сообщения во второй раз.
Вот как обработчик CATCH должен выглядеть, когда вы используете error_handler_sp:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC error_handler_sp
RETURN 55555
END CATCHДавайте попробуем несколько тестовых сценариев.
EXEC insert_data 8, NULL
EXEC outer_sp 8, 8Результат выполнения:
Msg 50000, Level 16, State 2, Procedure error_handler_sp, Line 20
*** [insert_data], Line 5. Errno 515: Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure error_handler_sp, Line 20
*** [insert_data], Line 6. Errno 2627: Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Заголовки сообщений говорят о том, что ошибка возникла в процедуре error_handler_sp, но текст сообщений об ошибках дает нам настоящее местонахождение ошибки – как название процедуры, так и номер строки.
Я покажу еще два метода вызова ошибок. Однако error_handler_sp является моей главной рекомендацией для читателей, которые читают эту часть. Это — простой вариант, который работает на всех версиях SQL Server начиная с 2005. Существует только один недостаток: в некоторых случаях SQL Server генерирует два сообщения об ошибках, но функции error_xxx() возвращают только одну из них, и поэтому одно из сообщений теряется. Это может быть неудобно при работе с административными командами наподобие BACKUPRESTORE, но проблема редко возникает в коде, предназначенном чисто для приложений.
4.2. Использование ;THROW
В SQL Server 2012 Microsoft представил выражение ;THROW для более легкой обработки ошибок. К сожалению, Microsoft сделал серьезную ошибку при проектировании этой команды и создал опасную ловушку.
С выражением ;THROW вам не нужно никаких хранимых процедур. Ваш обработчик CATCH становится таким же простым, как этот:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
;THROW
RETURN 55555
END CATCHДостоинство ;THROW в том, что сообщение об ошибке генерируется точно таким же, как и оригинальное сообщение. Если изначально было два сообщения об ошибках, оба сообщения воспроизводятся, что делает это выражение еще привлекательнее. Как и со всеми другими сообщениями об ошибках, ошибки, сгенерированные ;THROW, могут быть перехвачены внешним обработчиком CATCH и воспроизведены. Если обработчика CATCH нет, выполнение прерывается, поэтому оператор RETURN в данном случае оказывается не нужным. (Я все еще рекомендую оставлять его, на случай, если вы измените свое отношение к ;THROW позже).
Если у вас SQL Server 2012 или более поздняя версия, измените определение insert_data и outer_sp и попробуйте выполнить тесты еще раз. Результат в этот раз будет такой:
Msg 515, Level 16, State 2, Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 2627, Level 14, State 1, Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Имя процедуры и номер строки верны и нет никакого другого имени процедуры, которое может нас запутать. Также сохранены оригинальные номера ошибок.
В этом месте вы можете сказать себе: действительно ли Microsoft назвал команду ;THROW? Разве это не просто THROW? На самом деле, если вы посмотрите в Books Online, там не будет точки с запятой. Но точка с запятой должны быть. Официально они отделяют предыдущее выражение, но это опционально, и далеко не все используют точку с запятой в выражениях T-SQL. Более важно, что если вы пропустите точку с запятой перед THROW, то не будет никакой синтаксической ошибки. Но это повлияет на поведение при выполнении выражения, и это поведение будет непостижимым для непосвященных. При наличии активной транзакции вы получите сообщение об ошибке, которое будет полностью отличаться от оригинального. И еще хуже, что при отсутствии активной транзакции ошибка будет тихо выведена без обработки. Такая вещь, как пропуск точки с запятой, не должно иметь таких абсурдных последствий. Для уменьшения риска такого поведения, всегда думайте о команде как о ;THROW (с точкой с запятой).
Нельзя отрицать того, что ;THROW имеет свои преимущества, но точка с запятой не единственная ловушка этой команды. Если вы хотите использовать ее, я призываю вас прочитать по крайней мере вторую часть этой серии, где я раскрываю больше деталей о команде ;THROW. До этого момента, используйте error_handler_sp.
4.3. Использование SqlEventLog
Третий способ обработки ошибок – это использование SqlEventLog, который я описываю очень детально в третьей части. Здесь я лишь сделаю короткий обзор.
SqlEventLog предоставляет хранимую процедуру slog.catchhandler_sp, которая работает так же, как и error_handler_sp: она использует функции error_xxx() для сбора информации и выводит сообщение об ошибке, сохраняя всю информацию о ней. Вдобавок к этому, она логирует ошибку в таблицу splog.sqleventlog. В зависимости от типа приложения, которое у вас есть, эта таблица может быть очень ценным объектом.
Для использования SqlEventLog, ваш обработчик CATCH должен быть таким:
BEGIN CATCH
IF @@trancount > 0 ROLLBACK TRANSACTION
EXEC slog.catchhandler_sp @@procid
RETURN 55555
END CATCH@@procid возвращает идентификатор объекта текущей хранимой процедуры. Это то, что SqlEventLog использует для логирования информации в таблицу. Используя те же тестовые сценарии, получим результат их работы с использованием catchhandler_sp:
Msg 50000, Level 16, State 2, Procedure catchhandler_sp, Line 125
{515} Procedure insert_data, Line 5
Cannot insert the value NULL into column 'b', table 'tempdb.dbo.sometable'; column does not allow nulls. INSERT fails.
Msg 50000, Level 14, State 1, Procedure catchhandler_sp, Line 125
{2627} Procedure insert_data, Line 6
Violation of PRIMARY KEY constraint 'pk_sometable'. Cannot insert duplicate key in object 'dbo.sometable'. The duplicate key value is (8, 8).Как вы видите, сообщение об ошибке отформатировано немного не так, как это делает error_handler_sp, но основная идея такая же. Вот образец того, что было записано в таблицу slog.sqleventlog:
| logid | logdate | errno | severity | logproc | linenum | msgtext |
| 1 | 2015-01-25 22:40:24.393 | 515 | 16 | insert_data | 5 | Cannot insert … |
| 2 | 2015-01-25 22:40:24.395 | 2627 | 14 | insert_data | 6 | Violation of … |
Если вы хотите попробовать SqlEventLog, вы можете загрузить файл sqleventlog.zip. Инструкция по установке находится в третьей части, раздел Установка SqlEventLog.
5. Финальные замечания
Вы изучили основной образец для обработки ошибок и транзакций в хранимых процедурах. Он не идеален, но он должен работать в 90-95% вашего кода. Есть несколько ограничений, на которые стоит обратить внимание:
- Как мы видели, ошибки компиляции не могут быть перехвачены в той же процедуре, в которой они возникли, а только во внешней процедуре.
- Пример не работает с пользовательскими функциями, так как ни TRY-CATCH, ни RAISERROR нельзя в них использовать.
- Когда хранимая процедура на Linked Server вызывает ошибку, эта ошибка может миновать обработчик в хранимой процедуре на локальном сервере и отправиться напрямую клиенту.
- Когда процедура вызвана как INSERT-EXEC, вы получите неприятную ошибку, потому что ROLLBACK TRANSACTION не допускается в данном случае.
- Как упомянуто выше, если вы используете error_handler_sp или SqlEventLog, мы потеряете одно сообщение, когда SQL Server выдаст два сообщения для одной ошибки. При использовании ;THROW такой проблемы нет.
Я рассказываю об этих ситуациях более подробно в других статьях этой серии.
Перед тем как закончить, я хочу кратко коснуться триггеров и клиентского кода.
Триггеры
Пример для обработки ошибок в триггерах не сильно отличается от того, что используется в хранимых процедурах, за исключением одной маленькой детали: вы не должны использовать выражение RETURN (потому что RETURN не допускается использовать в триггерах).
С триггерами важно понимать, что они являются частью команды, которая запустила триггер, и в триггере вы находитесь внутри транзакции, даже если не используете BEGIN TRANSACTION.
Иногда я вижу на форумах людей, которые спрашивают, могут ли они написать триггер, который не откатывает в случае падения запустившую его команду. Ответ таков: нет способа сделать это надежно, поэтому не стоит даже пытаться. Если в этом есть необходимость, по возможности не следует использовать триггер вообще, а найти другое решение. Во второй и третьей частях я рассматриваю обработку ошибок в триггерах более подробно.
Клиентский код
У вас должна быть обработка ошибок в коде клиента, если он имеет доступ к базе. То есть вы должны всегда предполагать, что при любом вызове что-то может пойти не так. Как именно внедрить обработку ошибок, зависит от конкретной среды.
Здесь я только обращу внимание на важную вещь: реакцией на ошибку, возвращенную SQL Server, должно быть завершение запроса во избежание открытых бесхозных транзакций:
IF @@trancount > 0 ROLLBACK TRANSACTIONЭто также применимо к знаменитому сообщению Timeout expired (которое является не сообщением от SQL Server, а от API).
6. Конец первой части
Это конец первой из трех частей серии. Если вы хотели изучить вопрос обработки ошибок быстро, вы можете закончить чтение здесь. Если вы настроены идти дальше, вам следует прочитать вторую часть, где наше путешествие по запутанным джунглям обработки ошибок и транзакций в SQL Server начинается по-настоящему.
… и не забывайте добавлять эту строку в начало ваших хранимых процедур:
SET XACT_ABORT, NOCOUNT ONПриглашаем разобраться в важных темах – устранения ошибок MS SQL и восстановления базы данных. Получите представление о разных способах устранения проблемы, которые следует использовать при различных обстоятельствах.
Восстановление баз данных
Специалисты пользуются несколькими способами восстановления баз данных (БД). Наиболее простой и удобный – воспользоваться программой (SSMS) SQL Server Management Studio.
Как восстановить
Узнать, где находится SQL Server Management Studio, довольно легко. Microsoft Windows Server 2012 R2 располагается в стандартном перечне программных продуктов. В Microsoft Windows Server 2008 R2 следует зайти в меню Пуск и отыскать Microsoft Windows Server 2012. Там смотреть Microsoft SQL Server Management Studio.
Далее следует ввести тип сервера с именем, а чтобы подтвердить подлинность – информацию, требуемую для прохождения авторизации. Нажать Соединить (Connect).
В левом углу из обозревателя (Object Explorer) раскрыть Базы данных (Server Objects). Из представленного перечня отобрать базу, подлежащую восстановлению либо ту, данные которой будут восстанавливаться. На выбранном файле кликнуть мышкой и в выпавшем перечне выбрать Задачи (Tasks), затем Восстановить (Restore), потом База данных… (Databases …).
Проделанные шаги дадут старт процессу Restore Database, а значит требуемая база данных начнет восстанавливаться. Следует сделать выбор источника для Restore Database.
Чтобы возобновить базу данных, при запуске мастер восстановления сделает попытку автоматом определить очередность файлов резервных копий. В том случае, когда базу данных нужно загружать из определенной папки либо устройства, понадобится:
- Переключить соответствующую кнопку на Устройство (From device).
- Прописать, откуда восстановится БД.
- Выбрать инфобазу, в которую произведется загрузка данных (Destination for restore). Ею может выступать любая БД, которая регистрировалась на SQL Server (в том числе и база, с которой создавалась резервная копия).
В программе реализована возможность указания времени, необходимого для восстановления БД. Для этого необходимо просто кликнуть по кнопке Временная шкала… (Timeline). Если существует скопированный журнал транзакций или checkpoint в нем, то требуемый промежуток времени может быть указан с высокой точностью (вплоть до секунды).
Если требуется провести копирование БД, то во вкладке Файлы (Files) нужно будет прописать путь к файлам выбранной инфобазы.
Настройка дополнительных параметров
Также в программе реализована возможность настройки дополнительных параметров. Выставляя тот или иной флажок, можно регулировать необходимые действия. Следует выбрать соответствующий флажок, чтобы в процессе восстановления БД:
- Которая опубликована не на сервере, где она создавалась, сохранились настройки репликации, поможет отметка «Сохранить параметры репликации). Он важен, если при резервном копировании была реплицирована БД;
- была проведена перезапись файлов БД с именем, которое указывалось в качестве базы назначения – нужно поставить отметку «Перезаписать существующую базу данных»;
- сузить доступность к базе всем, кто не sysadmin, db_owner, dbcreator – нужно поставить флажок «Ограничение доступа к восстановленной базе данных»;
- старту должен предшествовать перевод БД в режим одного пользователя, а по его завершению вернуть в пользование для множества пользователей – поставить отметку «Закрыть существующие соединения»;
- чтобы провести требуемое резервное копирование завершающего фрагмента журнала транзакций, следует поставить отметку «Создание резервной копии заключительного фрагмента журнала перед восстановлением». Если в окошке Временная шкала резервного копирования (Backup Timeline) для временной точки требуется эта резервная копия, то отметка будет поставлена системой, без возможности снятия;
- чтобы после завершения восстановления каждой резервной копии уточнялась необходимость продолжения процесса – следует поставить отметку «Выдавать приглашение перед восстановлением каждой резервной копии» (Prompt before restoring each backup). Достаточно полезен, т.к. после того, как восстановлено определенное количество резервных копий можно остановить дальнейшую цепочку восстановительных процессов.
Настроив все важные параметры следует нажать ОК. Тем самым запустится процесс. Соответствующее уведомление сообщит об его окончании.
Восстановление базы в новое место
Чтобы перенести базу данных MSSQL Server по другому пути каталога либо сделать ее копию, следует знать, как восстановить БД в новую папку. Полезно знать как ее переименовывать. Для этого можно воспользоваться вышеупомянутой программой SSMS и T-SQL.
Подготовка к восстановлению базы данных
Перед стартом процесса восстановления нужно соблюдать ряд требований:
- Когда осуществляется процесс восстановления базы, доступ к ней может быть только у системного администратора. Для остальных пользователей доступ должен быть ограничен.
- Перед восстановлением нужно сделать резервную копию активного журнала транзакций.
- Чтобы восстановить зашифрованную базу необходим доступ к сертификату либо ассиметричному ключу, который применялся в качестве ее шифратора. Не имея доступа к ним, восстановление зашифрованной БД становится невозможным. Потому, такой сертификат следует хранить, пока может понадобиться резервное копирование.
После того, как база данных версии SQL Server 2005 (9.x) либо более поздней, восстановится, произойдет автоматическое обновление, и она станет доступной.
Если присутствуют полнотекстовые индексы
В том случае, когда в БД SQL Server 2005 (9.x) присутствуют полнотекстовые индексы, в момент ее обновления произойдет импорт, сброс либо перестроение. Результат зависит от того, какое значение проставлено в свойствах сервера upgrade_option.
При обновлении такие индексы станут недоступны, если upgrade_option имеет значения:
- 2 в режиме импорта;
- 0 в режиме перестроения.
Продолжительность поцессов импорта и перестроения зависит от того, какой объем занимают данные. Импорт может длиться пару часов, а процесс перестроения – гораздо дольше (может продолжаться в 10 раз дольше).
В том случае, когда выбран процесс Импорт, а доступ к полнотекстовому каталогу отсутствует, то произойдет перестроение одноименных индексов, которые связаны с ним. Для изменения свойств upgrade_option необходимо воспользоваться процедурой sp_fulltext_service.
Соблюдение правил безопасности
Чтобы обезопасить себя, крайне не рекомендуется проводить присоединение либо восстановление БД, которые были получены из ненадежных или вовсе неизвестных источников. Они могут содержать вредоносные коды, способные:
- запускать выполнение инструкций T-SQL, не предусмотренных системой;
- вызывать ошибки в результате изменения схемы либо самой структуры БД
Если БД получена из источников, не внушающих доверия, то перед началом ее использования необходимо:
- протестировать по инструкции DBCC CHECKDB;
- исследовать исходный и иные коды БД, изучить процедуры.
Инструкции RESTORE
На ход реализации этих инструкций влияет факт существования восстанавливаемой базы. Если база:
- присутствует, то разрешения получают пользователи sysadmin, dbcreator, dbo (владелец БД) по умолчанию;
- отсутствует, то пользователям потребуются разрешения CREATE DATABASE.
Разрешения на реализацию таких инструкций выдаются в соответствии с ролями. В соответствии с ними сервер всегда имеет доступ к данным о членстве. Разрешение RESTORE отсутствует у пользователей с ролями db_owner. Причина в том, что членство может быть проверено лишь в тех случаях, когда к базе данных всегда есть доступ и она не повреждена. А это иногда не соблюдается в процессе выполнения инструкций RESTORES.
Пошаговая инструкция восстановления БД в новую папку в SSMS
- Открыть SSMS и произвести подключение к SQL Server Database Engine.
- Щелкнуть мышкой по имени сервера, чтобы развернулось его дерево.
- Кликнуть мышкой на Базы данных, потом – по Восстановить базу данных.
- В разделе Источник выбрать Общие, чтобы определить соответственное расположение и источник копий, подлежащих восстановлению. Пользователю предлагается выбрать нужный вариант (Базы данных либо Устройства). Особенности:
- При выборе Базы данных открывается перечень БД, где можно выбрать нужную. В нем представлены лишь те базы, у которых резервные копии создавались по журналу msdb. Стоит отметить, что для БД на целевом сервере, резервные копии которых поступили с иных серверов, подобный журнал будет отсутствовать. В таких ситуациях следует выбирать вариант Устройство. Это позволит руками прописать файл, а в случае необходимости – обозначить устройство для выполнения восстановления.
- Устройство можно выбрать, воспользовавшись кнопкой обзора (…). В результате появится окошко Выбор устройств резервного копирования. Перейти в окошко Тип носителя резервной копии, в котором из списка выбрать необходимый тип устройства. Если требуется добавить ряд устройств, это можно сделать с помощью кнопки Добавить в окошке Носитель резервной копии. Когда все необходимые устройства добавлены, необходимо вновь перейти на страницу Общие. Для этого следует нажать ОК в списке Носитель резервной копии. Обратившись к списку Источник: Устройство: База данных обозначить название БД, куда будет производиться восстановление. Пользователь может воспользоваться данным списком только при выборе Устройства. Можно выбирать лишь те БД, у которых на отобранном устройстве имеются резервные копии.
- Название новой базы для проведения восстановления автоматом сформируется в поле База данных в разделе Назначение. При желании оно может быть изменено. Для этого желаемое название вводится в окошке База данных.
- Далее перейти к Восстановить до. Пользователь может оставить значение До последней выбранной резервной копии (по умолчанию) либо кликнуть по Временной шкале. При выбре второго варианта всплывет соответствующее окошко Временная шкала …. В нем нужно указывать точное время.
- Необходимые резервные копии для восстановления можно выбрать в соответствующей сетке. В ней отражены все наборы, доступные в выбранном месте. Система сама предложит план восстановления отобранных копий, который будет использован по умолчанию. Он может быть переопределен, если в сетке изменить отобранные элементы.
- Для указания другого места расположения файлов базы, необходимо выбрать страницу Файлы после чего нажать на Переместить все файлы в папку. Следует указать вновь выбранное место расположения папок файлов данных и журнала.
- Если возникла необходимость – провести настройку параметров, как было рассказано выше.
Чтобы начать процесс, в котором будет восстанавливаться БД в новую папку с возможностью переименовывать ее, можно воспользоваться инструкциями Transact-SQL.
Как просмотреть отчет
Стандартный отчет «События резервного копирования и восстановления» позволяет получить сведения о том, когда проводилось:
- Резервное копирование определенной БД;
- операции восстановления базы MS SQL из них.
Данный отчет включает данные, касающиеся создания резервных копий:
- время, затраченное на это в среднем (Average Time Taken For Backup Operations);
- операции, которые прошли успешно (Successful Backup Operations);
- ошибки, которые были допущены (Backup Operation Errors);
- удачно прошедших восстановлений баз (Successful Restore Operations).
Чтобы он начал формироваться, следует в Обозревателе объектов выбрать нужную БД и щелкнуть по ней мышкой. Выбрать в меню Отчеты, а затем – Стандартный отчет. После этого кликнуть на События резервного копирования и восстановления.
Чтобы просмотреть информацию из сформированного отчета следует выбрать нужную группировку и раскрыть данные по ней.
Для восстановления поврежденной БД можно воспользоваться еще одним инструментом.
Как исправить ошибки в MS SQL с помощью Recovery Toolbox for SQL Server
Для восстановления поврежденной базы данных можно обратиться к помощи Recovery Toolbox for SQL Server. Для исправления ошибки (Error), следует воспользоваться пошаговой инструкцией восстановления данных из файла *.mdf, который был поврежден. Для этого необходимо:
- Скачать Recovery Toolbox for SQL Server.
- Установить программу следуя инструкциям и запустить ее.
- Из списка файлов выбрать файл *.mdf, который был поврежден.
- Осуществить предварительный просмотр тех данных, которые в процессе выполнения программы могут быть подвергнуты извлечению из базы MS SQL сервер, которая подверглась повреждению.
- Выбрать наиболее приемлемый способ, которым будут экспортироваться данные:
- сохранением на диск в качестве SQL-скрипта;
- выполнением SQL-скрипта в самой БД.
- Произвести выборку информации, требующей восстановления и сохранения.
- Начать восстановление нажатием Start recovery.
Данная программа создавалась, чтобы облегчить процесс восстановления поврежденных БД. Специально разработанная, оптимизированная для восстановления SQL Server, утилита поможет устранить ошибки и внести правки в разные типы повреждений *.mdf файлов и базы данных MS SQL Server.
Как становится понятно, для исправления ошибок и восстановления БД необходимо уметь пользоваться различными инструментами. Читайте, изучайте материалы по данной теме. Если возникнут вопросы – обязательно задавайте.

Также приглашаем на специальный курс по MS SQL в Otus.
Содержание статьи:
-
- SQL-сервер не найден или недоступен, ошибки соединения с SQL-сервером
- Ошибка SQL-сервера 26
- Ошибка SQL-сервера 18456
- Не удалось запустить SQL-server — код ошибки 3417
- Повреждена база данных
- Код ошибки SQL-сервера 945
- Код ошибки SQL-сервера 5172
- Ошибка SQL-сервера 823
- Ошибка SQL-сервера 8946
- Другие ошибки SQL Server
- Код ошибки SQL-сервера 1814
- Код ошибки SQL-сервера 1067
- SQL-сервер запускается, но работает слишком медленно
- SQL-сервер не найден или недоступен, ошибки соединения с SQL-сервером
SQL-сервер не найден или недоступен, ошибки соединения с SQL-сервером
- Если SQL-сервер не найден, убедитесь, что ваш экземпляр SQL-сервера действительно установлен и запущен. Для этого зайдите на компьютер, где он установлен, запустите диспетчер конфигурации SQL и проверьте, есть ли там тот экземпляр, к которому вы пытаетесь подключиться и запущен ли он. Нелишним будет также получить отчет об обнаружении компонентов SQL-серверов.
- Если вы проделали п1. и не обнаружили источник проблемы, возможно, неверно указан IP-адрес компьютера или номер порта TCP. Перепроверьте их настройки.
- Причиной того, что невозможно подключиться к SQL-серверу, также может быть сеть, убедитесь, что компьютер с SQL-сервером доступен по сети.
- Проверьте, может ли клиентское приложение, установленное на том же компьютере, что и сервер, подключиться к SQL-серверу. Запустите SQL Server Management Studio(SSMS), в диалоговом окне “Подключиться к серверу” выберите тип сервера Database Engine, укажите способ аутентификации “Аутентификация Windows”, введите имя компьютера и экземпляра SQL-сервера. Проверьте подключение.
Обратите внимание, что многие сообщения об ошибках могут быть не показаны или не содержат достаточной информации для устранения проблемы. Это сделано из соображений безопасности, чтобы при попытке взлома злоумышленники не могли получить информацию об SQL-сервере. Полные сведения содержатся в логе ошибок, который обычно хранится по адресу C:Program FilesMicrosoft SQL ServerMSSQL13.MSSQLSERVERMSSQLLogERRORLOG, или там, куда его поместил администратор системы.
Ошибка SQL-сервера 26
Одна из наиболее часто встречающихся ошибок подключения к SQL-серверу, обычно связана с тем, что в настройках SQL-сервера не разрешены или ограничены удаленные соединения. Чтобы это исправить, попробуйте:
- в SSMS в настройках SQL-сервера включите аутентификацию Windows
- для брандмауэра Windows создайте новое правило, которое разрешает подключение для всех программ и протоколов с указанного IP-адреса
- убедитесь, что запущена служба SQL Server Browser
Ошибка SQL-сервера 18456
Эта ошибка означает, что попытка подключиться к серверу не успешна из-за проблем с именем пользователя или паролем. По коду ошибки в журнале ошибок можно узнать более точную причину, чтобы устранить ее.
Не удалось запустить SQL-server — код ошибки 3417
Возникает в случае, если были изменены настройки Windows или перемещена папка с файлами MSSQL.
- зайдите в C:Program FilesMicrosoft SQLServerMSSQL.1MSSqLData — БезопасностьНастройки доступа — Учетная запись сетевой службы — добавьте учетную запись сетевой службы
- проверьте, что MDF-файл не сжимается. Если это не так, отключите “Сжимать содержимое для экономии места на диске” в свойствах файла
Иногда ни один из этих способов не помогает, это значит, что файлы БД повреждены и ее придется восстанавливать из резервной копии.
Повреждена база данных
Код ошибки SQL-сервера 945
Ошибка 945 возникает, когда БД SQL-сервера помечена как IsShutdown. Проверьте, достаточно ли места на диске, достаточно ли прав у учетной записи для операций с БД, файлы MDF и LDF не должны быть помечены “Только для чтения”.
Код ошибки SQL-сервера 5172
SQL-сервер хранит свою физическую БД в первичном файле, в котором информация разбита постранично. Первая страница содержит информацию о заголовке mdf-файла и называется страницей заголовка. Она состоит из разнообразной информации о БД, такой как размер файла, подпись и т.д. В процессе прикрепления MDF на SQL-сервере часто возникает ошибка 5172. Это в основном происходит, если MDF-файл поврежден, информация в его заголовке тоже и соответственно сложно добраться до данных. Причиной может быть вирус, аварийное выключение системы, ошибка оборудования.
Ошибка SQL-сервера 823
SQL использует API Windows для операций ввода-вывода, но кроме завершения этих операций SQL проверяет все ошибки обращений к API. Если эти обращения несовместимы с ОС, появляется ошибка 823. Сообщение об ошибке 823 означает, что существует проблема с базовым оборудованием для хранения данных или с драйвером, который находится на пути запроса ввода-вывода. Пользователи могут столкнуться с этой ошибкой, если в файловой системе есть противоречия или поврежден файл базы данных.
Ошибка SQL-сервера 8946
Основной причиной ошибки 8946 так же, как и для 5172, является повреждение заголовков страниц БД SQL вследствие сбоя питания, вирусной атаки, отказа оборудования — SQL-сервер больше не может прочесть эти страницы.
Перечисленные ошибки 945, 5172, 823, 8946 можно устранить двумя методами:
- если у вас есть свежая резервная копия базы — восстановить базу из этой копии
- можно попробовать использовать специализированное ПО, такое как SQL Recovery Tool, чтобы восстановить поврежденные файлы
Желательно определить, что именно привело к возникновению ошибок и принять меры, чтобы это не повторялось — заменить плохо работающее оборудование, повысить информационную безопасность.
Другие ошибки SQL
Код ошибки SQL-сервера 1814
SQL-сервер не может создать базу данных tempdb. Убедитесь, что на выделенном под нее диске достаточно места и что у учетной записи хватает прав для записи в указанную директорию.
Код ошибки SQL-сервера 1067
Эта ошибка может возникать по разным причинам. Наиболее часто оказывается, что повреждены или отсутствуют конфигурационные файлы, SQL-сервер обращается к поврежденным системным файлам, ошибочные данные пользователя, нет информации про лицензию. В самых тяжелых случаях придется переустанавливать SQL-сервер. Но иногда помогает восстановление поврежденных файлов или изменение настроек SQL-сервера — вы можете создать новую учетную запись в домене и использовать ее для службы MSSQL.
SQL-сервер запускается, но работает слишком медленно
Проанализируйте журнал сервера, индексы (фрагментацию), запросы, задания, возможность взаимных блокировок. Причин может быть масса.
Мы работаем с разными версиями SQL-сервера уже много лет, знакомы со всевозможными инструкциями SQL-сервера, видели самые разные варианты его настройки и использования на проектах у своих клиентов. В целом мы можем выделить четыре основных источника неполадок:
- Индексы — причина проблем номер один. Неправильные индексы, отсутствующие индексы, слишком много индексов и подобное. Чаще всего при проблеме с индексами пользователи или администраторы базы данных не получают сообщения об ошибке, они просто видят, что база работает очень медленно и докопаться до причин бывает очень нелегко
- изначально плохая архитектура сервера баз данных — ошибка, которую очень сложно и дорого исправлять на этапе, когда база уже используется
- плохой код, в котором возможны блокировки и тупиковые места
- использование конфигурации по умолчанию,
Если у вас не получается устранить ошибки сервера SQL-server самостоятельно, если они появляются снова и снова, то скорее всего в основе лежит одна из этих причин. В таком случае — если у вас произошла ошибка с SQL сервером, ваше ПО не видит SQL-сервер, либо нужно развернуть кластер SQL-серверов — вы всегда можете обратиться за консультацией и технической поддержкой к специалистам Интегруса, отправив заявку с сайта, написав на e-mail, либо позвонив в колл-центр нашей компании.

Присоединяйтесь к нам,
чтобы получать чек-листы, реальные кейсы, а также
обзоры сервисов раз в 2 недели.
What Does DBCC CHECKDB Do
DBCC CHECKDB, also known as Database Console Command CHECKDB, is used to check both physical and logical integrity of objects (like tables, views, clusters, sequences, indexes, and synonyms) in a SQL Server database or Azure SQL Database. It is generally used to repair database corruption. When you run DBCC CHECKDB, you are actually executing the repair options below:
- Run DBCC CHECKALLOC: Check the consistency of disk space allocation structures on the selected database.
- Run DBCC CHECKTABLE: Check the integrity of all the table and view.
- Run DBCC CHECKCATALOG: Checks for catalog consistency within the selected database. The precondition for running this command is that the database must be online.
- Verify the contents of every indexed view in the specified database.
- Verify link-level consistency between table metadata, file system directories, and files when saving varbinary(max) data in the file system using FILESTREAM.
- Verify the Service Broker data in the database.
Thus, it is unnecessary to run DBCC CHECKALLOC, DBCC CHECKTABLE, or DBCC CHECKCATALOG separately from DBCC CHECKDB.
How to Use DBCC CHECKDB to Repair Database in SQL Server
When you want to fix a corruption issue in a SQL database, run the syntax below:
[ ( database_name | database_id | 0
[ , NOINDEX
| , { REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST | REPAIR_REBUILD } ]
) ]
[ WITH
{
[ ALL_ERRORMSGS ]
[ , EXTENDED_LOGICAL_CHECKS ]
[ , NO_INFOMSGS ]
[ , TABLOCK ]
[ , ESTIMATEONLY ]
[ , { PHYSICAL_ONLY | DATA_PURITY } ]
[ , MAXDOP = number_of_processors ]
}
]
]
You may want to know:
database_name | database_id | 0
Is the name or ID of the database for which to run DBCC CHECKDB repair. If not specified, or if 0 is specified, the command will be applied to the current database by default.
NOINDEX
Means that intensive checks of nonclustered indexes for user tables should not be executed. This reduces the total execution time. NOINDEX won’t affect system tables because integrity checks are always performed on system table indexes.
REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST | REPAIR_REBUILD
When you use one of the repair options above, you allow DBCC CHECKDB to repair the found errors. To understand the difference between these repair options:
- REPAIR_ALLOW_DATA_LOSS: If you use this repair option, DBCC CHECKDB will attempt to repair the errors found. It may CAUSE DATA LOSS if performed successfully.
- REPAIR_FAST: This repair will not perform any repair action. Instead, it only maintains syntax for backward compatibility only.
- REPAIR_BUILD: If you choose this repair option. Repair actions are performed but no data loss will occur. REPAIR_BUILD includes two kinds of repairs: quick repair and deep repair.
- Notice:
- For more information about other items in the syntax, you can refer to the related documents in Microsoft.com.
However, as Microsoft suggests, use the REPAIR options only as a last resort. Why? When there are errors reported by DBCC CHECKDB, the optimal option recommended is to restore the database from the last known good backup. As REPAIR_ALLOW_DATA_LOSS is not an alternative for restoring from a backup, it is only recommended when there is no backup available.
How to Repair Database Without CHECKDB REPAIR Option
Is REPAIR_ALLOW_DATA_LOSS the only choice when you cannot repair your database from a backup? Actually, it’s not. If DBCC CHECKDB reports errors on the selected database, you can repair your corrupted database using the SQL database recovery software — EaseUS MS SQL Recovery. You can apply this software to:
Repair SQL Server database: both primary (.mdf) and secondary (.ndf)
Repair database log files that may result in database errors
Repairs corrupted SQL server database objects — tables, triggers, indexes, keys, rules & stored procedures
Recover deleted/dropped SQL database records
To repair a database:
Step 1: Select the corrupted database for recovery
- Launch EaseUS MS SQL Recovery.
- Select the corrupted database file by clicking «Browse» (the two dots) or «Search».
- After selecting the file, click the «Repair» button to start the Analyzing process.
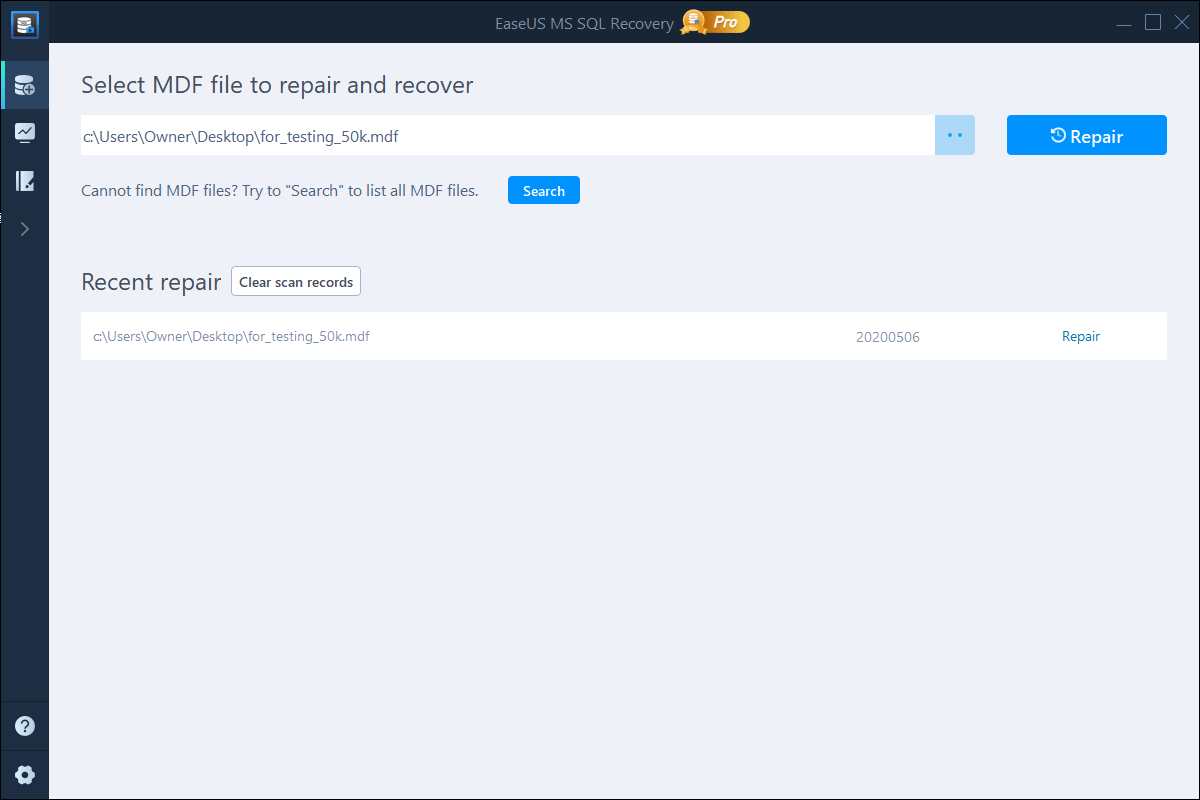
Note: To use this software, you need to stop the SQL Server service.
Step 2: Repair the corrupted database
- The software displays all the recoverable items in a tree-like structure. The items are shown in a left pane.
- Select the desired component to be recovered. From the window, click the «Export» button.
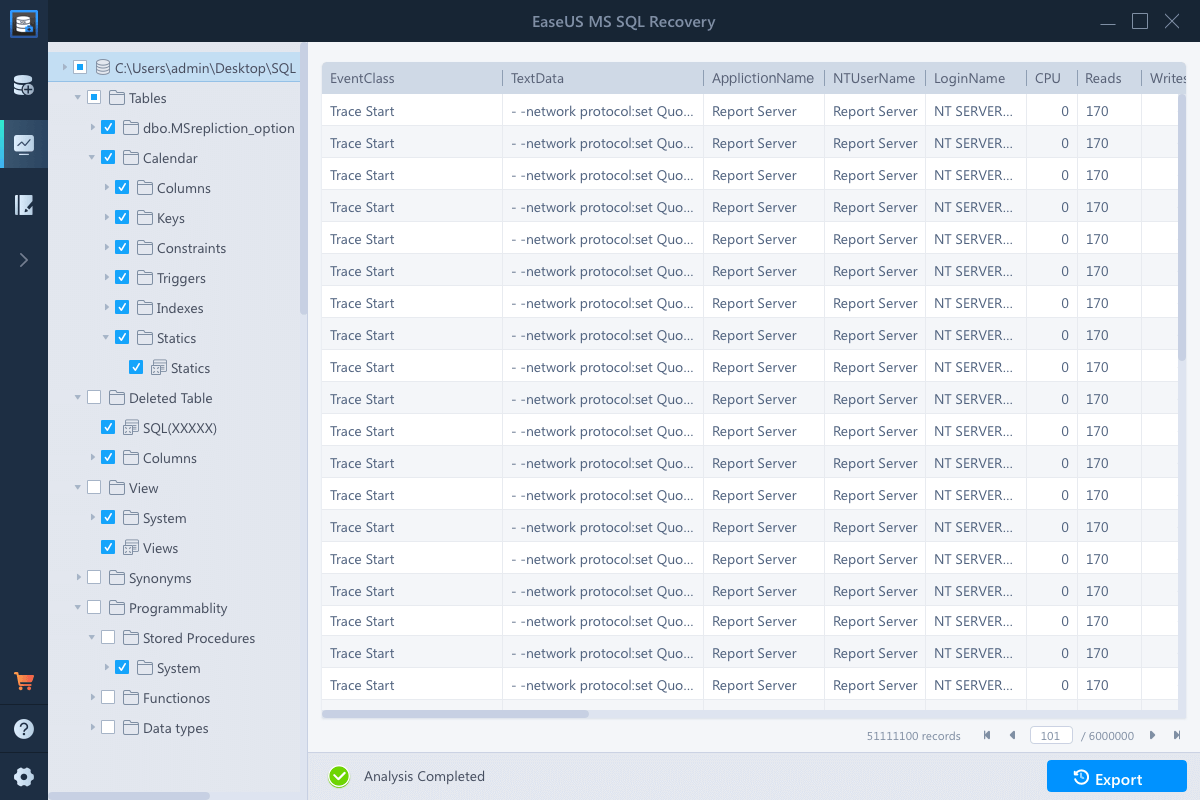
Step 3: Export to the database or as scripts
- Choose to export the database objects to database or export the items as scripts
- If you choose «Export to database», enter the information required and choose the target database.
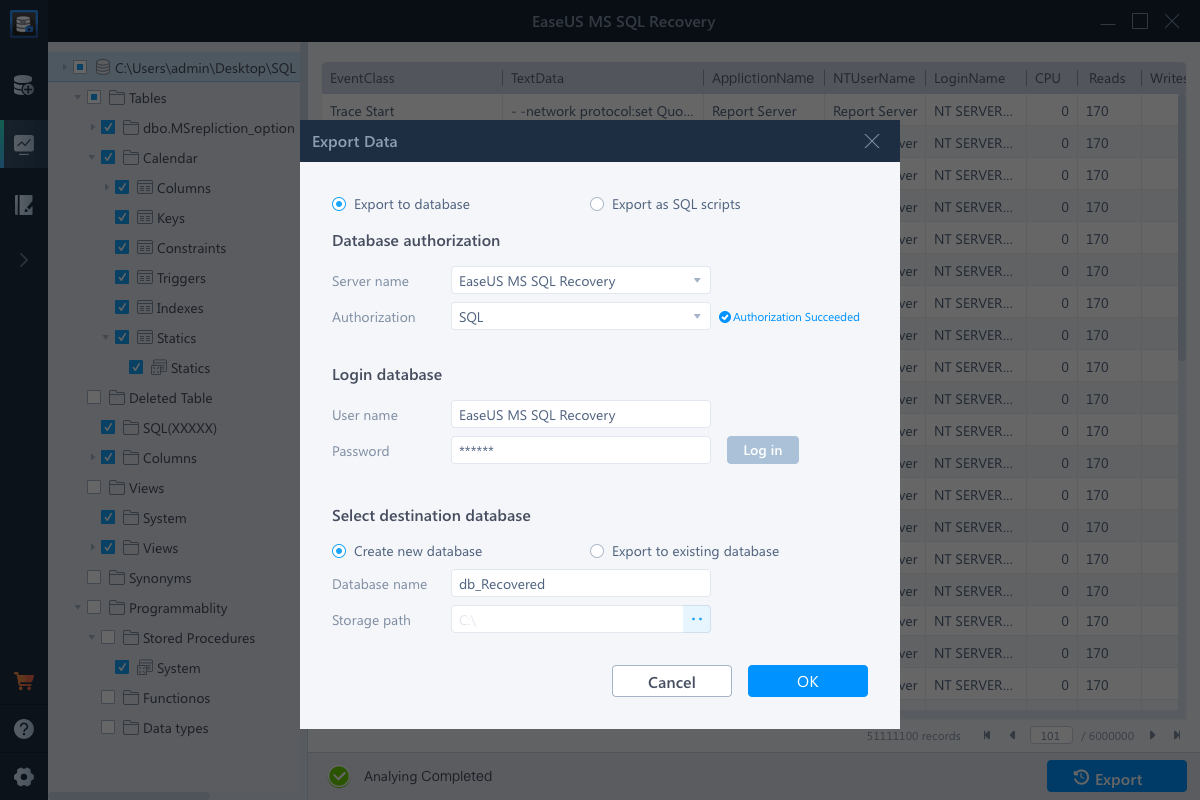
- A window appears up asking you to provide credentials to connect to the server and the destination to save the recovered items. In order to begin the repairing process, click «OK».
Note: Before clicking «OK», you need to restart the SQL Server service.
The Bottom Line
DBCC CHECKDB is the common choice for users to repair their database in SQL Server. However, it is not the only choice. If DBCC CHECKDB fails to work or you don’t want to use the repair option — REPAIR_ALLOW_DATA_LOSS, you can use EaseUS MS SQL Recovery to repair your database as alternative choice.
What Does DBCC CHECKDB Do
DBCC CHECKDB, also known as Database Console Command CHECKDB, is used to check both physical and logical integrity of objects (like tables, views, clusters, sequences, indexes, and synonyms) in a SQL Server database or Azure SQL Database. It is generally used to repair database corruption. When you run DBCC CHECKDB, you are actually executing the repair options below:
- Run DBCC CHECKALLOC: Check the consistency of disk space allocation structures on the selected database.
- Run DBCC CHECKTABLE: Check the integrity of all the table and view.
- Run DBCC CHECKCATALOG: Checks for catalog consistency within the selected database. The precondition for running this command is that the database must be online.
- Verify the contents of every indexed view in the specified database.
- Verify link-level consistency between table metadata, file system directories, and files when saving varbinary(max) data in the file system using FILESTREAM.
- Verify the Service Broker data in the database.
Thus, it is unnecessary to run DBCC CHECKALLOC, DBCC CHECKTABLE, or DBCC CHECKCATALOG separately from DBCC CHECKDB.
How to Use DBCC CHECKDB to Repair Database in SQL Server
When you want to fix a corruption issue in a SQL database, run the syntax below:
[ ( database_name | database_id | 0
[ , NOINDEX
| , { REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST | REPAIR_REBUILD } ]
) ]
[ WITH
{
[ ALL_ERRORMSGS ]
[ , EXTENDED_LOGICAL_CHECKS ]
[ , NO_INFOMSGS ]
[ , TABLOCK ]
[ , ESTIMATEONLY ]
[ , { PHYSICAL_ONLY | DATA_PURITY } ]
[ , MAXDOP = number_of_processors ]
}
]
]
You may want to know:
database_name | database_id | 0
Is the name or ID of the database for which to run DBCC CHECKDB repair. If not specified, or if 0 is specified, the command will be applied to the current database by default.
NOINDEX
Means that intensive checks of nonclustered indexes for user tables should not be executed. This reduces the total execution time. NOINDEX won’t affect system tables because integrity checks are always performed on system table indexes.
REPAIR_ALLOW_DATA_LOSS | REPAIR_FAST | REPAIR_REBUILD
When you use one of the repair options above, you allow DBCC CHECKDB to repair the found errors. To understand the difference between these repair options:
- REPAIR_ALLOW_DATA_LOSS: If you use this repair option, DBCC CHECKDB will attempt to repair the errors found. It may CAUSE DATA LOSS if performed successfully.
- REPAIR_FAST: This repair will not perform any repair action. Instead, it only maintains syntax for backward compatibility only.
- REPAIR_BUILD: If you choose this repair option. Repair actions are performed but no data loss will occur. REPAIR_BUILD includes two kinds of repairs: quick repair and deep repair.
- Notice:
- For more information about other items in the syntax, you can refer to the related documents in Microsoft.com.
However, as Microsoft suggests, use the REPAIR options only as a last resort. Why? When there are errors reported by DBCC CHECKDB, the optimal option recommended is to restore the database from the last known good backup. As REPAIR_ALLOW_DATA_LOSS is not an alternative for restoring from a backup, it is only recommended when there is no backup available.
How to Repair Database Without CHECKDB REPAIR Option
Is REPAIR_ALLOW_DATA_LOSS the only choice when you cannot repair your database from a backup? Actually, it’s not. If DBCC CHECKDB reports errors on the selected database, you can repair your corrupted database using the SQL database recovery software — EaseUS MS SQL Recovery. You can apply this software to:
Repair SQL Server database: both primary (.mdf) and secondary (.ndf)
Repair database log files that may result in database errors
Repairs corrupted SQL server database objects — tables, triggers, indexes, keys, rules & stored procedures
Recover deleted/dropped SQL database records
To repair a database:
Step 1: Select the corrupted database for recovery
- Launch EaseUS MS SQL Recovery.
- Select the corrupted database file by clicking «Browse» (the two dots) or «Search».
- After selecting the file, click the «Repair» button to start the Analyzing process.
Note: To use this software, you need to stop the SQL Server service.
Step 2: Repair the corrupted database
- The software displays all the recoverable items in a tree-like structure. The items are shown in a left pane.
- Select the desired component to be recovered. From the window, click the «Export» button.
Step 3: Export to the database or as scripts
- Choose to export the database objects to database or export the items as scripts
- If you choose «Export to database», enter the information required and choose the target database.
- A window appears up asking you to provide credentials to connect to the server and the destination to save the recovered items. In order to begin the repairing process, click «OK».
Note: Before clicking «OK», you need to restart the SQL Server service.
The Bottom Line
DBCC CHECKDB is the common choice for users to repair their database in SQL Server. However, it is not the only choice. If DBCC CHECKDB fails to work or you don’t want to use the repair option — REPAIR_ALLOW_DATA_LOSS, you can use EaseUS MS SQL Recovery to repair your database as alternative choice.
MySQL — система управления базами данных (СУБД) с открытым исходным кодом от компании Oracle. Она была разработана и оптимизирована специально для работы веб-приложений. MySQL является неотъемлемой частью таких веб-сервисов, как Facebook, Twitter, Wikipedia, YouTube и многих других.
Эта статья расскажет, как определять, с чем связаны частые ошибки на сервере MySQL, и устранять их.
Не удаётся подключиться к локальному серверу
Одной из распространённых ошибок подключения клиента к серверу является «ERROR 2002 (HY000): Can’t connect to local MySQL server through socket ‘/var/run/mysqld/mysqld.sock’ (2)».

Эта ошибка означает, что на хосте не запущен сервер MySQL (mysqld) или вы указали неправильное имя файла сокета Unix или порт TCP/IP при попытке подключения.
Убедитесь, что сервер работает. Проверьте процесс с именем mysqld на хосте сервера, используя команды ps или grep, как показано ниже.
$ ps xa | grep mysqld | grep -v mysqldЕсли эти команды не показывают выходных данных, то сервер БД не работает. Поэтому клиент не может подключиться к нему. Чтобы запустить сервер, выполните команду systemctl.
$ sudo systemctl start mysql #Debian/Ubuntu
$ sudo systemctl start mysqld #RHEL/CentOS/FedoraЧтобы проверить состояние службы MySQL, используйте следующую команду:
$ sudo systemctl status mysql #Debian/Ubuntu
$ sudo systemctl status mysqld #RHEL/CentOS/Fedora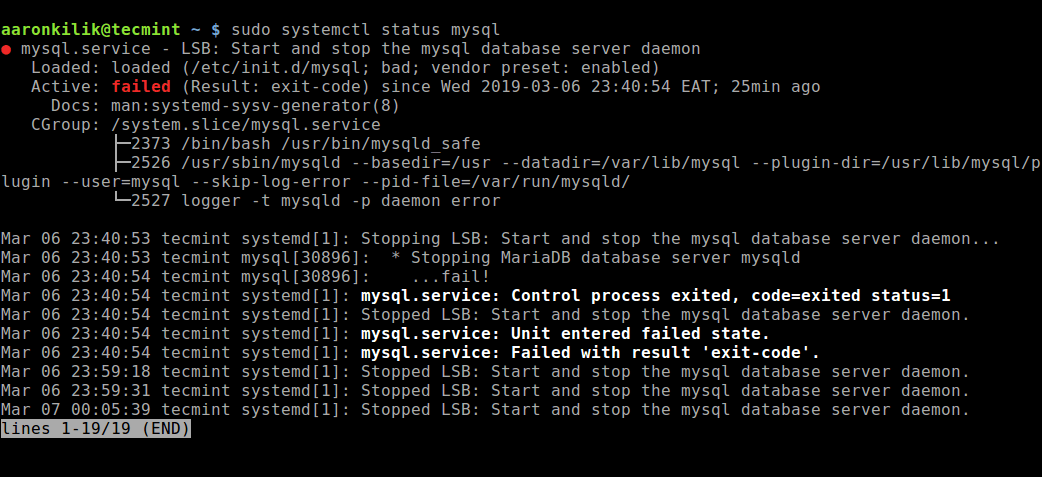
Если в результате выполнения команды произошла ошибка службы MySQL, вы можете попробовать перезапустить службу и ещё раз проверить её состояние.
$ sudo systemctl restart mysql
$ sudo systemctl status mysql
Если сервер работает (как показано) и вы по-прежнему видите эту ошибку, вам следует проверить, не заблокирован ли порт TCP/IP брандмауэром или любой другой службой блокировки портов.
Для поиска порта, который прослушивается сервером, используйте команду netstat.
$ sudo netstat -tlpn | grep "mysql"Ещё одна похожая и часто встречающаяся ошибка подключения — «(2003) Can’t connect to MySQL server on ‘server’ (10061)». Это означает, что в сетевом соединении было отказано.
Следует проверить, работает ли в системе сервер MySQL (смотрите выше) и на тот ли порт вы подключаетесь (как найти порт, можно посмотреть выше).
Похожие частые ошибки, с которыми вы можете столкнуться при попытке подключиться к серверу MySQL:
ERROR 2003: Cannot connect to MySQL server on 'host_name' (111)
ERROR 2002: Cannot connect to local MySQL server through socket '/tmp/mysql.sock' (111)Ошибки запрета доступа в MySQL
В MySQL учётная запись (УЗ) определяется именем пользователя и клиентским хостом, с которого пользователь может подключиться. УЗ может также иметь данные для аутентификации (например, пароль).
Причин для запрета доступа может быть много. Одна из них связана с учётными записями MySQL, которые сервер разрешает использовать клиентским программам при подключении. Это означает, что имя пользователя, указанное в соединении, может не иметь прав доступа к базе данных.
В MySQL есть возможность создавать учётные записи, позволяющие пользователям клиентских программ подключаться к серверу и получать доступ к данным. Поэтому при ошибке доступа проверьте разрешение УЗ на подключение к серверу через клиентскую программу.
Увидеть разрешённые привилегии учётной записи можно, выполнив в консоли команду SHOW GRANTS
Входим в консоль (пример для Unix, для Windows консоль можно найти в стартовом меню):
В консоли вводим команду:
> SHOW GRANTS FOR 'tecmint'@'localhost';Дать привилегии конкретному пользователю в БД по IP-адресу можно, используя следующие команды:
> grant all privileges on *.test_db to 'tecmint'@'192.168.0.100';
> flush privileges;Ошибки запрещённого доступа могут также возникнуть из-за проблем с подключением к MySQL (см. выше).
Потеря соединения с сервером MySQL
С этой ошибкой можно столкнуться по одной из следующих причин:
- плохое сетевое соединение;
- истекло время ожидания соединения;
- размер BLOB больше, чем
max_allowed_packet.
В первом случае убедитесь, что у вас стабильное сетевое подключение (особенно, если подключаетесь удалённо).
Если проблема с тайм-аутом соединения (особенно при первоначальном соединении MySQL с сервером), увеличьте значение параметра connect_timeout.
В случае с размером BLOB нужно установить более высокое значение для max_allowed_packet в файле конфигурации /etc/my.cnf в разделах [mysqld] или [client] как показано ниже.
[mysqld]
connect_timeout=100
max_allowed_packet=500MЕсли файл конфигурации недоступен, это значение можно установить с помощью следующей команды.
> SET GLOBAL connect_timeout=100;
> SET GLOBAL max_allowed_packet=524288000;Слишком много подключений
Эта ошибка означает, что все доступные соединения используются клиентскими программами. Количество соединений (по умолчанию 151) контролируется системной переменной max_connections. Устранить проблему можно, увеличив значение переменной в файле конфигурации /etc/my.cnf.
[mysqld]
max_connections=1000Недостаточно памяти
Если такая ошибка возникла, это может означать, что в MySQL недостаточно памяти для хранения всего результата запроса.
Сначала нужно убедиться, что запрос правильный. Если это так, то нужно выполнить одно из следующих действий:
- если клиент MySQL используется напрямую, запустите его с ключом
--quick switch, чтобы отключить кешированные результаты; - если вы используете драйвер MyODBC, пользовательский интерфейс (UI) имеет расширенную вкладку с опциями. Отметьте галочкой «Do not cache result» (не кешировать результат).
Также может помочь MySQL Tuner. Это полезный скрипт, который подключается к работающему серверу MySQL и даёт рекомендации по настройке для более высокой производительности.
$ sudo apt-get install mysqltuner #Debian/Ubuntu
$ sudo yum install mysqltuner #RHEL/CentOS/Fedora
$ mysqltunerMySQL продолжает «падать»
Если такая проблема возникает, необходимо выяснить, заключается она в сервере или в клиенте. Обратите внимание, что многие сбои сервера вызваны повреждёнными файлами данных или индексными файлами.
Вы можете проверить состояние сервера, чтобы определить, как долго он работал.
$ sudo systemctl status mysql #Debian/Ubuntu
$ sudo systemctl status mysqld #RHEL/CentOS/FedoraЧтобы узнать время безотказной работы сервера, запустите команду mysqladmin.
$ sudo mysqladmin version -p 
Кроме того, можно остановить сервер, сделать отладку MySQL и снова запустить службу. Для отображения статистики процессов MySQL во время выполнения других процессов откройте окно командной строки и введите следующее:
$ sudo mysqladmin -i 5 statusИли
$ sudo mysqladmin -i 5 -r statusЗаключение
Самое важное при диагностике — понять, что именно вызвало ошибку. Следующие шаги помогут вам в этом:
- Первый и самый важный шаг — просмотреть журналы MySQL, которые хранятся в каталоге
/var/log/mysql/. Вы можете использовать утилиты командной строки вродеtailдля чтения файлов журнала. - Если служба MySQL не запускается, проверьте её состояние с помощью
systemctl. Или используйте командуjournalctl(с флагом-xe) в systemd. - Вы также можете проверить файл системного журнала (например,
/var/log/messages) на предмет обнаружения ошибок. - Попробуйте использовать такие инструменты, как Mytop, glances, top, ps или htop, чтобы проверить, какая программа использует весь ресурс процессора или блокирует машину. Они также помогут определить нехватку памяти, дискового пространства, файловых дескрипторов или какого-либо другого важного ресурса.
- Если проблема в каком-либо процессе, можно попытаться его принудительно остановить, а затем запустить (при необходимости).
- Если вы уверены, что проблемы именно на стороне сервера, можете выполнить команды:
mysqladmin -u root pingилиmysqladmin -u root processlist, чтобы получить от него ответ. - Если при подключении проблема не связана с сервером, проверьте, нормально ли работает клиент. Попробуйте получить какие-либо его выходные данные для устранения неполадок.
Перевод статьи «Useful Tips to Troubleshoot Common Errors in MySQL»