Время прочтения
5 мин
Просмотры 17K

Что вы найдёте в этой статье?
В 2016 году я начал изучать Java, а в начале 2017 года — Android. С самого начала я уже знал, что существует понятие архитектуры приложений, но не знал, как это применить в своём коде. Я находил много разных гайдов, но понятнее от этого мне не становилось.
Эта статья — именно та, которую мне хотелось бы прочитать в начале своего пути.
Важность архитектуры приложений
Многие компании проводят технические тесты для кандидатов, которые проходят отбор. Тесты могут отличаться, но есть то, что их объединяет. Все они требуют понимания и умения применения хорошей программной архитектуры.
Хорошая программная архитектура позволяет легко понимать, разрабатывать, поддерживать и внедрять систему [Книга «Чистая архитектура», глава 15]
Цель этой статьи — научить того, кто никогда не использовал архитектуру для разработки приложений на Android, делать это. Для этого мы рассмотрим практический пример приложения, при создании которого реализуем наименее гибкое решение и более оптимальное решение с использованием архитектуры.
Пример
Элементы в RecyclerView:

- Мы будем получать данные из API и показывать результаты пользователю.
- Результатом будет список пива с названием, описанием, изображением и содержанием алкоголя для каждого.
- Пиво должно быть упорядочено по градусу крепости.
Для решения этой задачи:
- Мы должны получить данные из API.
- Упорядочить элементы от самого низкого до самого высокого градуса крепости.
- Если содержание алкоголя меньше 5%, будет нарисован зелёный кружок, если оно находится между 5% и 8% — кружок будет оранжевым, а выше 8% — красный кружок.
- Наконец, мы должны показать список элементов.
Какое наименее гибкое решение?
Наименее гибким решением является создание одного класса, который будет выполнять четыре предыдущих пункта. Это то решение, которое любой из нас делал бы, если бы не знал, что такое архитектура приложений.
Результат для пользователя будет приемлемым: он увидит упорядоченный список на экране. Но если нам понадобится масштабировать эту систему, мы поймём, что структуру нелегко понять, разрабатывать дальше, поддерживать и внедрять.
Как понять архитектуру приложений в Android?
Я приведу очень простой пример. Представьте себе автомобильный завод с пятью зонами:
- Первая зона создает шасси.
- Вторая зона соединяет механические части.
- Третья зона собирает электронную схему.
- Четвертая область — покрасочная.
- И последняя область добавляет эстетические детали.
Это означает, что у каждой зоны есть своя ответственность, и они работают в цепочке с первой зоны по пятую для достижения результата.
У такой системы есть определённое преимущество. Если автомобиль выдаст ошибку после того, как он будет закончен, то в зависимости от его поведения мы будем знать, какой отдел должен её исправить, не беспокоя других.
Если мы захотим добавить больше эстетических деталей, мы обратимся непосредственно к пятому отделу. А если мы захотим изменить цвет, мы обратимся к четвёртому. И если мы изменим шасси, это никак не изменит способ работы покрасочной области. То есть мы можем точечно модифицировать нашу машину, не беспокоя при этом всю фабрику.
Кроме того, если со временем мы захотим открыть вторую фабрику для создания новой модели автомобиля, будет легче разделить рабочие зоны.
Применение архитектуры в Android
Мы собираемся добиться того, чтобы не было класса, который выполнял бы всю работу в одиночку: запрос данных от API, их сортировка и отображение. Всё это будет распределено по нескольким областям, которые называются слоями.
Что это за слои?

Для этого примера мы собираемся создать чистую архитектуру, которая состоит из трёх уровней, которые в свою очередь будут подразделяться на пять:
- Уровень представления.
- Уровень бизнес-логики.
- И уровень данных.
1. Уровень представления
Уровень представления — это пользовательский уровень, графический интерфейс, который фиксирует события пользователя и показывает ему результаты. Он также выполняет проверку того, что во введённых пользователем данных нет ошибок форматирования, а отображаемые данные отображаются корректно.
В нашем примере эти операции разделены между уровнем пользовательского интерфейса и уровнем ViewModel:
- Уровень пользовательского интерфейса содержит Activity и фрагменты, фиксирующие пользовательские события и отображающие данные.
- Уровень ViewModel форматирует данные так, что пользовательский интерфейс показывает их определённым образом.
Вместо использования ViewModel мы можем использовать другой слой, который выполняет эту функцию, просто важно понять обязанности каждого слоя.
В нашем примере слой пользовательского интерфейса отображает список пива, а слой ViewModel сообщает цвет, который вы должны использовать в зависимости от алкогольного диапазона.
2. Уровень бизнес-логики
На этом уровне находятся все бизнес-требования, которым должно соответствовать приложение. Для этого здесь выполняются необходимые операции. В нашем примере это сортировка сортов пива от самой низкой до самой высокой крепости.
3. Уровень данных
На этом уровне находятся данные и способ доступа к ним.
Эти операции разделены между уровнем репозитория и уровнем источника данных:
- Уровень репозитория реализует логику доступа к данным. Его ответственность заключается в том, чтобы получить данные. Необходимо проверить, где искать их в определённый момент. Например, вы можете сначала проверить локальную базу данных и, если там данных нет, сделать запрос к API и сохранить данные в базу данных. То есть он определяет способ доступа к данным. В нашем примере он запрашивает данные о пиве непосредственно у уровня, который взаимодействует с API.
- Уровень источника данных отвечает непосредственно за получение данных. В нашем примере он реализует логику доступа к API для получения данных о пиве.
Как слои взаимодействуют?
Давайте посмотрим на теоретический и практический подходы взаимодействия.
В теории:

Каждый слой должен общаться только со своими непосредственными соседями. В этом случае, если мы посмотрим на схему архитектуры программного обеспечения:
- Пользовательский интерфейс может общаться только с ViewModel.
- ViewModel может общаться только с уровнем бизнес-логики.
- Уровень бизнес-логики может общаться только с уровнем репозитория.
- И репозиторий может общаться только с источником данных.
На практике:
Структура пакетов в IDE Android Studio при чистой архитектуре:

У нас есть структура пакетов, в которой создаются классы, каждый из которых имеет свою зону ответственности.
Заключительные замечания по архитектуре приложений
Мы увидели, что каждый уровень архитектуры программного обеспечения имеет свою зону ответственности и все они связаны между собой.
Важно подчеркнуть, что ни разу не говорилось об используемых библиотеках или языках программирования, поскольку архитектура ориентирована на правильное структурирование кода, чтобы он был масштабируемым. Со временем библиотеки меняются, но принципы архитектуры сохраняются.
Дальше рекомендуется почитать о внедрении зависимостей, чтобы избежать создания экземпляров объектов непосредственно в классах архитектуры и, таким образом, иметь возможность выполнить модульное тестирование с помощью Mockito и JUnit.
Я делюсь репозиторием, где вы можете увидеть:
- Пример чистой архитектуры на Android с Kotlin.
- Использование LiveData для связи пользовательского интерфейса с ViewModel.
- Использование корутин.
- Kodein для внедрения зависимостей.
- JUnit и Mockito для тестирования бизнес-логики.
If your app solely utilizes code written in Java or Kotlin, including any libraries or SDKs, it is already ready for 64-bit devices. If your app utilizes native code, or if you are unclear whether it does, you must evaluate it and take action.
But why are we actually transitioning?
Google plans to transition to a 64-bit app ecosystem in the next years in order to provide a superior software experience on devices powered by 64-bit CPUs. The firm has recently provided further information about the change, stating that beginning in August of this year, developers would be required to submit a 64-bit version of their Android apps. This step will eventually lead to the worldwide application of the 64-bit app policy, which will be implemented in 2021, after which Google will no longer host 32-bit apps on the Play Store when accessed via a device with 64-bit hardware.
But how can we know whether we have. as well as extension files:
You must examine your app’s APK in Android Studio’s APK Analyzer. To launch APK Analyzer:
- Pick Build > Analyze APK from the menu, and then select the APK to be evaluated.
- Now, if you check in the analyzer to the lib folder and notice any.
- So you have 32-bit libraries if you have any armeabi-v7a or x86, or 32-bit libraries if you have any armeabi-v7a or x86.
- If you don’t notice any .so files, your program doesn’t need to be upgraded.
The Conversion of 32-bit code to 64-bit code
If your code already works on the desktop or iOS, you shouldn’t have to do anything special for Android. If this is your first time writing code for a 64-bit system, the major difficulty you’ll have to deal with is that references no longer fit in 32-bit integer types like int. You will need to change the code that saves pointers in int, unsigned, or uint32 t types. Long matches the pointer size on Unix platforms, but not on Windows, therefore use the intention-revealing types uintptr t or intptrt instead. To hold the difference between two pointers, use the ptrdiff t type.
By unzipping APKs, you may look for native libraries:
APK files are organized similarly to zip files and maybe extracted similarly. Unzipping the APK will work if you want to use the command line or another extraction tool. Simply unzip the APK file (depending on your extraction program, you may need to rename it to.zip) and explore the extracted contents, following the instructions above to determine if you are ready for 64-bit devices.
Is there some exception for my app?
Google Play will continue to deliver 32-bit upgrades for games created with the Unity 5.6 development environment or an earlier version. This, however, will only last until August 1, 2021. Furthermore, APKs and software bundles created for the Wear OS and Android TV platforms that do not support 64-bit code will be excluded from the prohibition. Finally, any applications and package kits for Google’s mobile operating system that are not intended for devices running Android Pie or a later version will be exempt from the 64-bit-only restriction.
Create your program using 64-bit libraries
The steps below will guide you through the process of creating 64-bit libraries. However, you should be aware that this only applies to building code and libraries that can be built from the source.
GeekTip: If you’re using any third-party SDKs or libraries, make sure you’re utilizing 64-bit versions by following the procedures outlined above. If a 64-bit version is not available, contact the SDK or library owner and keep this in mind while planning your support for 64-bit devices.
Do this to convert your current app to x64:
:: Command Line of your choice > cmake -DANDROID_ABI=arm64-v8a … or > cmake -DANDROID_ABI=x86_64 …
Devices that are just 64-bit will be available in 2023
Arm’s message to the developer community is to begin the shift to solely 64-bit programming as soon as possible. The advantages far exceed the disadvantages. A 64-bit processor can handle more data at once, allowing new and emerging mobile technologies to thrive. 64-bit CPUs can collect, transfer, and process bigger chunks of data in less time than 32-bit CPUs, resulting in higher performance—improvements of up to 20% for specific workloads. This means that 64-bit devices are typically quicker and more responsive (though this is also dependent on well-written code).
Conclusion
The transition to 64-bit Android is a win-win situation for everyone. It will bring a variety of performance, efficiency, and security advantages to the whole Android ecosystem without creating major disruption, while also preparing developers for future mobile innovation. As a consequence, we are highly supportive of the transition and remain confident that developers all around the world will be able to migrate their programs to 64-bit.
If your app solely utilizes code written in Java or Kotlin, including any libraries or SDKs, it is already ready for 64-bit devices. If your app utilizes native code, or if you are unclear whether it does, you must evaluate it and take action.
But why are we actually transitioning?
Google plans to transition to a 64-bit app ecosystem in the next years in order to provide a superior software experience on devices powered by 64-bit CPUs. The firm has recently provided further information about the change, stating that beginning in August of this year, developers would be required to submit a 64-bit version of their Android apps. This step will eventually lead to the worldwide application of the 64-bit app policy, which will be implemented in 2021, after which Google will no longer host 32-bit apps on the Play Store when accessed via a device with 64-bit hardware.
But how can we know whether we have. as well as extension files:
You must examine your app’s APK in Android Studio’s APK Analyzer. To launch APK Analyzer:
- Pick Build > Analyze APK from the menu, and then select the APK to be evaluated.
- Now, if you check in the analyzer to the lib folder and notice any.
- So you have 32-bit libraries if you have any armeabi-v7a or x86, or 32-bit libraries if you have any armeabi-v7a or x86.
- If you don’t notice any .so files, your program doesn’t need to be upgraded.
The Conversion of 32-bit code to 64-bit code
If your code already works on the desktop or iOS, you shouldn’t have to do anything special for Android. If this is your first time writing code for a 64-bit system, the major difficulty you’ll have to deal with is that references no longer fit in 32-bit integer types like int. You will need to change the code that saves pointers in int, unsigned, or uint32 t types. Long matches the pointer size on Unix platforms, but not on Windows, therefore use the intention-revealing types uintptr t or intptrt instead. To hold the difference between two pointers, use the ptrdiff t type.
By unzipping APKs, you may look for native libraries:
APK files are organized similarly to zip files and maybe extracted similarly. Unzipping the APK will work if you want to use the command line or another extraction tool. Simply unzip the APK file (depending on your extraction program, you may need to rename it to.zip) and explore the extracted contents, following the instructions above to determine if you are ready for 64-bit devices.
Is there some exception for my app?
Google Play will continue to deliver 32-bit upgrades for games created with the Unity 5.6 development environment or an earlier version. This, however, will only last until August 1, 2021. Furthermore, APKs and software bundles created for the Wear OS and Android TV platforms that do not support 64-bit code will be excluded from the prohibition. Finally, any applications and package kits for Google’s mobile operating system that are not intended for devices running Android Pie or a later version will be exempt from the 64-bit-only restriction.
Create your program using 64-bit libraries
The steps below will guide you through the process of creating 64-bit libraries. However, you should be aware that this only applies to building code and libraries that can be built from the source.
GeekTip: If you’re using any third-party SDKs or libraries, make sure you’re utilizing 64-bit versions by following the procedures outlined above. If a 64-bit version is not available, contact the SDK or library owner and keep this in mind while planning your support for 64-bit devices.
Do this to convert your current app to x64:
:: Command Line of your choice > cmake -DANDROID_ABI=arm64-v8a … or > cmake -DANDROID_ABI=x86_64 …
Devices that are just 64-bit will be available in 2023
Arm’s message to the developer community is to begin the shift to solely 64-bit programming as soon as possible. The advantages far exceed the disadvantages. A 64-bit processor can handle more data at once, allowing new and emerging mobile technologies to thrive. 64-bit CPUs can collect, transfer, and process bigger chunks of data in less time than 32-bit CPUs, resulting in higher performance—improvements of up to 20% for specific workloads. This means that 64-bit devices are typically quicker and more responsive (though this is also dependent on well-written code).
Conclusion
The transition to 64-bit Android is a win-win situation for everyone. It will bring a variety of performance, efficiency, and security advantages to the whole Android ecosystem without creating major disruption, while also preparing developers for future mobile innovation. As a consequence, we are highly supportive of the transition and remain confident that developers all around the world will be able to migrate their programs to 64-bit.
Как перевести решение на микросервисную архитектуру, не останавливая продакшн
Мы перевели на микросервисы высоконагруженное монолитное решение. Через него проходит от 20 до 120 тысяч транзакций в сутки. Пользователи работают в 12 часовых поясах. В то же время функционал добавляется много и часто, что довольно сложно делать на монолите. Вот почему системе требуется устойчивая работа в режиме 24/7, то есть HighLoad, High Availability и Fault Tolerance.
Продукт мы развиваем по модели MVP. Его архитектура менялась в несколько этапов вслед за требованиями бизнеса. Первоначально не было возможности сделать всё и сразу, потому что никто не знал, как должно выглядеть решение. Мы двигались по модели Agile, итерациями добавляя и расширяя функциональность.
В таких условиях основной подход, по которому мы начали выделять микросервисы — это выделение бизнес-функции или бизнес-услуги целиком.
В этой статье расскажем технические подробности проекта.
Начало
Первоначально архитектура выглядела следующим образом: у нас был MySql c единственным war, Tomcat и Nginx для проксирования запросов от пользователей.

Окружения (& минимальный CI/CD):
- Dev — деплой по Push в develop,
- QA — раз в сутки с develop,
- Prod — по кнопке с master,
- Запуск интеграционных тестов вручную,
- Всё работает на Jenkins.
Разработка была построена на основе пользовательских сценариев. Уже на старте проекта большая часть сценариев укладывалась в некий workflow. Но все же не все, и это обстоятельство усложняло нам разработку и не позволяло провести «глубокое проектирование».

В 2015 году наше приложение увидело продакшн. Промышленная эксплуатация показала, что нам не хватает гибкости в работе приложения, его разработке и в отправке изменений на prod-сервера. Мы хотели добиться High Availability (HA), Continuous Delivery (CD) и Continuous Integration (CI).
Вот проблемы, которые необходимо было решить для того, чтобы прийти к HI, CD, CI:
- простой при выкатывании новых версий — cлишком долго происходил deploy приложения,
- проблема с меняющимися требованиями к продукту и новые user cases — слишком много времени уходило на тестирование и проверки даже при небольших фиксах,
- проблема с восстановлением сессий у Tomcat: session management для системы бронирования и сторонних сервисов, при перезапуске приложения сессия не восстанавливалась силами Tomcat,
- проблемы с высвобождением ресурсов: приходилось рано или поздно перезагружать Tomcat, происходили memory leak.
Мы стали решать все эти проблемы поочередно. И первое, за что взялись — это меняющиеся требования к продукту.
Первый микросервис
Вызов: Изменяющиеся требования к продукту и новые use cases.
Технологический ответ: Появился первый микросервис — вынесли часть бизнес-логики в отдельный war-файл и положили в Tomcat.

К нам пришла очередная задача вида: до конца недели обновить бизнес-логику в сервисе. Мы приняли решение вынести эту часть в отдельный war-файл и положить в тот же Tomcat. Мы использовали Spring Boot для скорости конфигурирования и разработки.
Мы сделали небольшую бизнес-функцию, которая решала проблему с периодически изменяющимися параметрами пользователей. В случае изменения бизнес-логики нам бы не пришлось перезапускать весь Tomcat, терять наших пользователей на полчаса и перезагрузить только небольшую его часть.
После удачного вынесения логики по такому же принципу мы продолжили вносить изменения в приложение. И с того момента, когда к нам приходили задачи, которые кардинально меняли что-то внутри системы, мы выносили эти части отдельно. Таким образом, у нас постоянно копились новые микросервисы.
Основной подход, по которому мы начали выделять микросервисы — это выделение бизнес-функции или бизнес-услуга целиком.
Так у нас быстро отделились сервисы, интегрированные со сторонними системами, такими как 1C.
Первая проблема — типизация
Вызов: Микросервисов уже 15. Проблема типизации.
Технический ответ: Spring Cloud Feign.
Проблемы не решились сами собой лишь потому, что мы начали разрезать наши решения на микросервисы. Более того, стали возникать новые проблемы:
- проблема типизации и версионирования в Dto между модулями,
- как задеплоить не один war-файл в Tomcat, а множество.
Новые проблемы увеличили время перезапуска всего Tomcat при технических работах. Получается, мы усложнили себе работу.
Проблема с типизацией, конечно, возникла не сама собой. Скорее всего, в течение нескольких релизов мы её просто игнорировали, потому что находили эти ошибки ещё на этапах тестирования или во время разработки и успевали что-то предпринять. Но когда несколько ошибок были обнаружены уже совсем на полпути в продакшн и потребовали срочного исправления, мы ввели регламенты или начали использовать инструменты, которые решают эту проблему. Мы обратили внимание на Spring Cloud Feign — это клиентская библиотека для http-запросов.
Мы выбрали его, поскольку
— мало накладных расходов на внедрение в проект,
— сам генерировал клиента,
— можно использовать один интерфейс и на сервере, и на клиенте.
Он решил наши проблемы с типизацией тем, что мы формировали клиентов. И для контролеров наших сервисов мы использовали те же интерфейсы, что и для формирования клиентов. Так ушли проблемы с типизацией.
Простои. Бой первый. Работоспособность
Вызов бизнеса: 18 микросервисов, теперь простои в работе системы недопустимы.
Технический ответ: изменение архитектуры, увеличение серверов.
У нас осталась проблема с простоем в работе и выкатыванием новых версий, осталась проблема с восстановлением сессии Tomcat и с освобождением ресурсов. Количество микросервисов же продолжало расти.
Процесс деплоя всех микросервисов занимал около часа. Периодически приходилось перезагружать приложение из-за проблемы с высвобождением ресурсов у tomcat. Не было простых способов делать это более оперативно.
Мы стали продумывать, как изменить архитектуру. Вместе с отделом инфраструктурных решений мы построили новое решение на основе того, что у нас уже было.

Архитектура изменила свой вид следующим образом:
- горизонтально разделили наше приложение на несколько data-центров,
- добавили Filebeat на каждый сервер,
- добавили отдельный сервер для ELK, поскольку росло количество транзакций и логов,
- несколько серверов haproxy + Tomcat + Nginx + MySQL (так мы обеспечивали High Availability).
Используемые технологии были такими:
- Haproxy занимается роутингом и балансировкой между серверами,
- Nginx отвечает за раздачу статики, tomcat был сервером приложений,
- Особенностью решения стало то, что MySQL на каждом из серверов не знает о существовании своих других MySQL’ей,
- Из-за проблемы latency между датацентрами репликация на уровне MySQL была невозможна. Поэтому мы решили реализовать шардинг на уровне микросервисов.
Соответственно, когда приходил запрос от пользователя до сервисов в Tomcat, они просто запрашивали данные у MySQL. Те данные, которые требовали целостности, собирались со всех серверов и склеивались (все запросы были через API).
Применив этот подход, мы немного потеряли в консистентности данных, зато решили текущую задачу. Пользователь мог работать с нашим приложением в любых ситуациях.
- Даже если один из серверов падал, у нас оставалось ещё 3-4, которые, поддерживали работоспособность всей системы.
- Мы хранили бекапы не на серверах в том же дата-центре, в котором они делались, а в соседних. Это помогало нам с disaster recovery.
- Fault tolerance решалась также за счет нескольких серверов.
Так были решены крупные проблемы. Ушёл простой в работе пользователей. Теперь они не чувствовали, когда мы накатывали обновление.
Простои. Бой второй. Полноценность
Вызов бизнеса: 23 микросервиса. Проблемы с консистентностью данных.
Техническое решение: запуск сервисов отдельно друг от друга. Улучшение мониторинга. Zuul и Eureka. Упростили разработку отдельных сервисов и их поставку.
Проблемы продолжали появляться. Так выглядел наш редеплой:
- У нас не было консистентности данных при редиплое, поэтому часть функционала (не самого важного) отходила на второй план. К примеру, при накатывании нового приложения статистика работала неполноценно.
- Нам приходилось выгонять пользователей с одного сервера на другой, чтобы перезапустить приложение. Это тоже занимало порядка 15-20 минут. Вдобавок ко всему, пользователям приходилось перелогиниваться при переходе с сервера на сервер.
- Также мы всё чаще перезапускали Tomcat из-за роста количества сервисов. И теперь приходилось следить за большим количеством новых микросервисов.
- Время редиплоя выросло пропорционально количеству сервисов и серверов.
Подумав, мы решили, что нашу проблему решит запуск сервисов отдельно друг от друга — если мы будем запускать сервисы не в одном Tomcat, а каждый в своём на одном сервере.

Но появились другие вопросы: как сервисам теперь общаться между собой, какие порты должны быть открыты наружу?
Мы выбрали ряд портов и раздали их нашим модулям. Чтобы не было необходимости держать всю эту информацию о портах где-то в pom-файле или общей конфигурации, мы выбрали для решения этих задач Zuul и Eureka.
Eureka — service discovery
Zuul — proxy (для сохранения контекстных урлов, что были в Tomcat)
Eureka также улучшила наши показатели в High Availability /Fault Tolerance, поскольку теперь стало возможным общение между сервисами. Мы настроили так, что если в текущем дата-центре нет нужного сервиса, идти в другой.
Для улучшения мониторинга добавили из имеющегося стека Spring Boot Admin для понимания того, что на каком сервисе происходит.
Также мы начали переводить наши выделенные сервисы к stateless-архитектуре, чтобы избавиться от проблем деплоя нескольких одинаковых сервисов на одном сервере. Это дало нам горизонтальное масштабирование в рамках одного data-центра. Внутри одного сервера мы запускали разные версии одного приложения при обновлении, чтобы даже на нём не было никакого простоя.
Получилось, что мы приблизились к Continuous Delivery / Continuous Integration тем, что упростили разработку отдельных сервисов и их поставку. Теперь не нужно было опасаться, что поставка одного сервиса вызовет утечку ресурсов и придётся перезапускать весь сервис целиком.
Простой при выкатывании новых версий всё ещё остался, но не целиком. Когда мы обновляли поочерёдно несколько jar на сервере, это происходило быстро. И на сервере не возникало никаких проблем при обновлении большого количества модулей. Но перезапуск всех 25 микросервисов во время обновления занимал очень много времени. Хоть и быстрее, чем внутри Tomcat, который делает это последовательно.
Проблему с освобождением ресурсов мы решили также тем, что запускали всё с jar, а утечками или проблемами занимался системный Out of memory killer.
Бой третий, управление информацией
Вызов бизнеса: 28 микросервисов. Очень много информации, которой нужно управлять.
Техническое решение: Hazelcast.
Мы продолжили реализовывать свою архитектуру и поняли, что наша базовая бизнес-транзакция охватывает сразу несколько серверов. Нам было неудобно слать запрос в десяток систем. Поэтому мы решили использовать Hazelcast для event-мессаджинга и для системной работы с пользователями. Так же для последующих сервисов использовали его как прослойку между сервисом и базой данных.

Мы, наконец, избавились от проблемы с consistency наших данных. Теперь мы могли сохранять любые данные во все базы одновременно, не делая никаких лишних действий. Мы сказали Hazelcast, в какие базы данных он должен сохранять приходящую информацию. Он делал это на каждом сервере, что упростило нашу работу и позволило избавиться от шардинга. И тем самым мы перешли к репликации на уровне приложения.
Также теперь мы стали хранить сессию в Hazelcast и использовали его для авторизации. Это позволило переливать пользователей между серверами незаметно для них.
От микросервисов к CI/CD
Вызов бизнеса: нужно ускорить выход обновлений в продакшн.
Техническое решение: конвейер развертывания нашего приложения, GitFlow для работы с кодом.
Вместе с количеством микросервисов развивалась и внутренняя инфраструктура. Мы хотели ускорить поставку наших сервисов до продакшна. Для этого мы внедрили новый конвейер развертывания нашего приложения и перешли к GitFlow для работы с кодом. СI начал собирать и прогонять тесты по каждому комиту, прогонять unit-тесты, интеграционные, складывать артефакты с поставкой приложения.

Чтобы делать это быстро и динамически, мы развернули несколько GitLab-раннеров, которые запускали все эти задачи по пушу разработчиков. Благодаря подходу GitLab Flow, у нас появилось несколько серверов: Develop, QA, Release-candidate и Production.
Разработка происходит следующим образом. Разработчик добавляет новый функционал в отдельной ветке (feature branch). После того, как разработчик закончил, он создает запрос на слияние его ветки с магистральной веткой разработки (Merge Request to Develop branch). Запрос на слияние смотрят другие разработчики и принимают его или не принимают, после чего происходит исправление замечаний. После слияния в магистральную ветку разворачивается специальное окружение, на котором выполняются тесты на поднятие окружения.
Когда все эти этапы закончены, QA инженер забирает изменения к себе в ветку “QA” и проводит тестирование по ранее написанным тест-кейсам на фичу и исследовательское тестирование.
Если QA инженер одобряет проделанную работу, тогда изменения переходят в ветку Release-Candidate и разворачиваются на окружении, которое доступно для внешних пользователей. На этом окружении заказчик производит приемку и сверку наших технологий. Затем мы перегоняем всё это в Production.
Если на каком-то этапе находятся баги, то именно в этих ветках мы решаем эти проблемы и их мёрджим в Develop. Также сделали небольшой плагин, чтобы Redmine мог сообщать нам, на каком этапе находится фича.

Это помогает тестировщикам смотреть, на каком этапе нужно подключаться к задаче, а разработчикам — править баги, потому что они видят, на каком этапе произошла ошибка, могут пойти в определенную ветку и воспроизвести её там.
Дальнейшее развитие
Вызов бизнеса: переключение между серверами без простоя.
Техническое решение: Упаковка в Kubernetes.

Сейчас по окончанию деплоймента технические специалисты докладывают jer-ки на PROD-сервера и перезапускают их. Это не очень удобно. Мы хотим автоматизировать работу системы и дальше, внедрив Kubernetes и связав его с data-центром, обновляя их и разом накатывая.
Чтобы перейти к этой модели, нам необходимо закончить следующие работы.
- Привести наши текущие решения к stateless-архитектуре, чтобы пользователь мог отправлять запросы на все сервера без разбора. Некоторые из наших сервисов ещё поддерживают какие-то сессионные данные. Эта работа касается и репликации данных базы данных.
- Также мы должны распилить последний маленький монолит, который содержит в себе несколько бизнес-процессов. Это и приведёт нас к последнему главному шагу — Continuous Delivery.
Что изменилось с переходом на микросервисы
- Мы избавились от проблемы меняющихся требований.
- Избавились от проблемы восстановления сессий у Tomcat тем, что перенесли их в Hazelcast.
- При перебрасывании пользователей с одного сервера на другой им не приходится перелогиниваться.
- Решили все проблемы с высвобождением ресурсов, переложив их на плечи операционной системы.
- Проблемы типизации и версионирования решились благодаря Feign.
- Уверенно движемся в сторону Continuous Delivery c помощью Gitlab Pipelines.
Оригинал опубликован на Habr.
Архитектура Android-приложения немного сложнее, чем десктопной программы, хотя бы потому что компьютерное приложение имеет одну точку входа с рабочего экрана или из меню «Пуска» приложений, а далее оно работает по принципу монолитного процесса. У Android-приложения архитектура выглядит по-другому, хотя бы потому, что имеет множество отдельных компонентов, например следующих:
Activities;
Fragments;
Services;
Content Providers;
И др.
Как правило, все эти компоненты приложения объявляются в едином файле — манифесте приложения. А сама операционная система Андроид, опираясь на «манифест», уже будет решать, как адаптировать ваше приложение под устройство пользователя.
При разработке Android-приложения приходится учитывать тот момент, что само приложение состоит из нескольких компонентов, а пользователь устройства может взаимодействовать сразу с несколькими телефонными программами одновременно, поэтому компоненты приложения должны уметь подстраиваться к разным ситуациям, процессам и задачам, которые может создать пользователь.
Правильная архитектура мобильного приложения Android глазами пользователя
Рассмотрим простой пример из жизни, когда пользователь решил поделиться собственным изображением в приложении какой-нибудь социальной сети.
После активации функции «Поделиться фотографией», приложение пользователя спрашивает о возможности включения камеры, чтобы сделать новое фото. В это самое время приложение отправляет запрос ОС Андроид о своем желании воспользоваться камерой. Но пользователь резко передумал и закрыл вкладку с соцсетью.
В это же самое время пользователь сможет открыть другие приложения, которые также будут заявлять о своем желании воспользоваться камерой устройства.
Пользователь возвращается в приложение соцсети и добавляет туда изображение из «Галереи».
В любой момент, когда пользователь «лазит» по различным приложениям в поисках собственных изображений, его действия могут быть остановлены входящим голосовым звонком, СМС или сообщением в мессенджере. Потенциально, пользователь устройства ожидает, что, когда он закончит разговор, то сможет продолжить «работу» по обновлению изображения в приложении соцсети. То есть архитектура Android-приложения должна быть выстроена таким образом, чтобы правильно взаимодействовать в таких процессах:
вовремя инициировать запросы в операционную систему для выполнения каких-либо действий;
уметь «ждать» своей очереди, если на какой-либо компонент устройства претендуют несколько приложений;
уметь работать в фоновом режиме;
уметь работать в «свернутом» режиме, сохраняя все выполненные пользователем действия и ожидая продолжения работы;
и др.
При этом важно учитывать, что ресурсы мобильного телефона очень ограничены, поэтому ваше приложение не может занимать много ресурсов в режиме ожидания, да и в процессе работы. Потому что в этом случае операционная система в любой момент времени имеет возможность остановить или даже удалить некоторые процессы вашего приложения, чтобы освободить место для других приложений, которыми желает воспользоваться пользователь.
Именно поэтому разработке мобильных приложений свойственна компонентность. Это когда ваше приложение состоит из отдельных компонентов, которые могут функционировать по отдельности и не зависят друг от друга.
Архитектура Android-приложений: основные принципы
Можно постараться определить по каким основным принципам выстраивается архитектура Android-приложений, о них мы сегодня и поговорим.
Нужно разделять ответственность
Это один из самых важных принципов, который многие не соблюдают. Нужно разделять ответственность между классами. Например, не нужно разрабатывать весь код приложения в «Activity» или «Fragment», потому что эти классы должны отвечать лишь за логику взаимодействия интерфейса и ОС.
Нужно наладить управление интерфейсом пользователя из модели
Модель — это отдельный компонент, отвечающий за обрабатывание информации для приложения. Модели не имеют зависимости от компонентов приложения, поэтому на них никак не «переносятся» проблемы, связанные с компонентами приложения.
Важно соблюдать принцип управления интерфейсом из постоянной модели, потому что это несет в себе следующие свойства:
пользователи вашего приложения не потеряют свои данные, если операционная система Андроид удалит вашу программу, освобождая ресурсы системы;
ваш продукт будет работать даже в тех случаях, когда устройство не будет подключено к сети или связь с сетью будет слабой и нестабильной.
Рекомендуемая архитектура Android-приложения
Невозможно и неправильно будет утверждать, что какая-то особенная архитектура мобильного приложения Android будет лучше или хуже другой. Сценарии работы у разных приложений будут разные, соответственно, архитектура и подходы к разработки приложений тоже будут разные. Поэтому, если у вас уже сформировались собственные архитектурные принципы при создании успешных Android-приложений, то не стоит их менять. Если вы стоите на самом старте и не знаете, какую архитектуру использовать, то можете применить архитектуру, рекомендуемую командой разработчиков Android. Если необходимо, то можете ее доработать или переопределить на свой вкус.
Вот как она выглядит:
Разбираем данную архитектуру Android-приложения:
«Activity» и «Fragment» являются частью слоя «View», а это значит, что они не должны иметь ничего общего с бизнес-логикой и/или сложными процессами в приложении. «View» всего лишь отвечает за взаимодействие между пользователем и приложением, анализируя и наблюдая за этим процессом.
«ViewModel» анализирует состояние «LifeCycles» и поддерживает согласование между компонентами в случаях изменений конфигураций Android-приложения, это также становится возможным благодаря извлечению данных из «Repository». «ViewModel» не взаимодействует напрямую с «View», а делает это при помощи сущности «LiveData».
«Repository» — это не какой-то специальный компонент Андроид. Это вполне обычный класс, чья основная задача — это выборка данных из разных источников, в том числе и баз данных, и различных веб-служб. Выбранные данные, этот класс преобразует таким образом, чтобы их мог наблюдать компонент «LiveData» и они были доступны компоненту «ViewModel».
«Room» — это библиотека, облегчающая процесс взаимодействия с базой данных «SQLite». Также в ее зоне ответственности лежит: запись шаблонов действий, проверка ошибок во время компиляции, прямое «общение» с «LiveData».
В данной архитектуре часть внимания уделяется именно «шаблону наблюдателя», который состоит из компонентов «LiveData» и «Lifecycle». Данный «шаблон» нужен в первую очередь для того, чтобы следить за всеми изменениями и обновлениями, происходящими в приложении, и уведомлять о них компонент «Activity».
Важная рекомендация от разработчиков Android — это использовать систему «Dependency Injection» или шаблон «Service Locator» для консолидации архитектуры вашего приложения.
Подробнее о компонентах рекомендуемой архитектуры
Погружаться глубоко в описание каждого отдельного компонента рекомендуемой архитектуры для Android-приложений мы не будем, так как каждый отдельный компонент — это тема отдельной статьи или урока. Но общую идею, для чего они нужны, мы опишем. А общих знаний вам хватит, чтобы начать работу над этими компонентами.
Компонент «LiveData». По сути является компонентом, содержащим какие-то данные, которые можно наблюдать со стороны. Данный компонент всегда знает, когда и какие данные изменяются в приложении и «наблюдает» ли кто-то за ним в данный момент времени и нужны ли обновления «наблюдателю».
Компонент «ViewModel». Это один из самых важных компонентов архитектуры, потому что именно этот компонент содержит в себе информацию о состоянии пользовательского интерфейса, также этот компонент сохраняет «целостность» интерфейса при изменении в конфигурации, например экран телефона был повернут. «ViewModel» связывает «LiveData» и «Repository». «LiveData», получая данные из «ViewModel», делает его доступным для наблюдения за ним.
Компонент «Room». Операционная система Андроид всегда поддерживала работу с базой данных SQLite, но такое взаимодействие имело ряд проблем. Например, приходилось создавать множество шаблонов для совместной работы, SQLite не могла сохранять простые Java-объекты, не проводилась проверка при компиляции и др. Но пришла библиотека «Room» и решила эти проблемы взаимодействия между Android и SQLite.
Заключение
Любая архитектура Android-приложения — это широкое поле для творчества, да и вообще программирование — это творчество, где любую проблему можно решить несколькими путями, в общем так, как видит решение конкретный «автор».
Описанную архитектуру Android-приложений рекомендует Google, при это она не является обязательной — об этом, кстати, сам Гугл и пишет. Поэтому не стоит бояться экспериментировать и практиковать что-то новое.

#Мнения
- 15 окт 2021
-

0
Как проектируют приложения: разбираемся в архитектуре
Старший iOS-разработчик из «ВКонтакте» рассказывает, почему архитектура не главное в проекте и как сделать продукт поддерживаемым и масштабируемым.

Старший iOS-разработчик во «ВКонтакте». Раньше был фулстеком, бэкендером и DevOps, руководил отделом мобильной разработки, три года преподавал iOS-разработку в GeekBrains, был деканом факультета. Состоит в программном комитете конференции Podlodka iOS Crew, ведёт YouTube-канал с видеоуроками по Flutter. В Twitter пишет под ником @tygeddar.

об авторе
Старший iOS-разработчик во «ВКонтакте». Раньше был фулстеком, бэкендером и DevOps, руководил отделом мобильной разработки, три года преподавал iOS-разработку в GeekBrains, был деканом факультета. Состоит в программном комитете конференции Podlodka iOS Crew, ведёт YouTube-канал с видеоуроками по Flutter. В Twitter пишет под ником @tygeddar.
Я люблю спорить о том, какая архитектура лучше. Может, из-за своего внутреннего перфекциониста или диплома архитектора информационных систем, а может, потому, что мне лень копаться в плохих проектах.
Спойлер: больше всего я люблю архитектуру MVC. Дальше расскажу, как она работает и почему мне не нравятся всякие MVVM, MVP и VIPER. Кстати, недавно я разобрался во Flux и её имплементации Redux и понял, что их я тоже недолюбливаю.
В основе статьи — тред автора в Twitter.
Впервые с архитектурой Model-View-Controller (MVC) я столкнулся в 2009 году, когда изучал веб-фреймворк Zend. В его документации было написано, что Model — это база данных, View — HTML-шаблон, а Controller — логика, которая берёт данные из БД, обрабатывает их, кладёт в шаблон и отдаёт страницу.
Я тогда был студентом, делал курсовые и пет-проекты. У них была сложная вёрстка и непростая структура БД, но максимально простая логика. Код получался простым, но в целом меня такой подход устраивал.
Мне не приходило в голову, что можно делать не так, как написано в документации к инструментам и в примерах на форумах. Я был счастлив и не забивал голову чепухой.
Сомневаться в своём подходе я начал из-за статей на «Хабре», где говорили, что логику нужно закладывать в модель, чтобы контроллер оставался максимально простым. Так я узнал о двух версиях MVC — с тонким и толстым контроллером.
Я пробовал поменять логику в своём проекте — перенёс её из одного файла в другой, но разницы не заметил. По факту ничего и не изменилось, только код теперь лежал в другом файле.
Изучая дискуссии в интернете и рассуждая самостоятельно, я понял, что «толстая» модель мне не нравится. Пусть лучше модель остаётся базой данных, а контроллер и дальше управляет логикой.
Со временем мои проекты становились всё сложнее, а контроллеры пухлее (правда, не как UIViewController в iOS). Я пробовал с этим бороться, выносил логику в сторонние файлы, которые включал в контроллеры, но это мало что меняло: архитектура сохранялась, просто код переносился из одного файла в другой.

В 2013 году я пересел на Laravel, разобрался с автозагрузкой классов в PHP, начал разбираться с ООП и прочитал «Совершенный код» Стива Макконнелла.
Стало ясно, что не стоит складывать всё в один файл — код и классы должны организовывать структуру, а некоторые фрагменты кода лучше убрать из MVC и выделить в самостоятельные части, которые можно переиспользовать.
С этого момента я начал писать проекты по-другому. В них появились иерархии классов, которые хранили логику, а контроллер сильно похудел — он получал данные от базы, передавал их в разные пакеты, получал от них результат и отправлял на HTML-страницу.
Архитектура проектов не была идеальной, потому что не подошла бы ни для одной сложной системы. Но для моих целей она была крутой и удобной: код получался читабельный, а все элементы проекта оставались довольно независимы.
Следующий качественный скачок случился, когда я отошёл от веб-разработки и углубился в бэкенд. Мне пришлось проектировать и разрабатывать сложную систему управления VDS-сервером. Там были API, плагины, менеджер зависимостей для плагинов, асинхронный код, много режимов работы, связь с операционной системой и разным софтом. Основная задача проекта — чтобы у системы было ядро и самостоятельные плагины, которые бы умели работать вместе.
В сложной системе нельзя передавать все данные через один контроллер, поэтому каждый плагин отдельно реализовывал веб- и API-интерфейсы, доступ к данным и бизнес-логику, вынесенную в пакеты для переиспользования.
Получилось так: HTML ⟷ JavaScript (модели, общение с API) ⟷ API ⟷ переиспользуемые пакеты ⟷ бизнес-логика и доступ к данным. Всё это не было похоже на MVC.
Потом я ушёл в iOS-разработку и временно перестал думать про архитектуру. Изучал UIKit, а компоненты располагал по наитию. HTML и CSS превратились в разные UIView, тонкий контроллер — в UIViewController, бизнес-логика — в сервисы.
C MVC всё работало хорошо, но я читал и про другие архитектуры. Люди рассказывали, как MVVM, MVP или VIPER упростили им жизнь, поэтому я тоже решил их попробовать.
Когда я увидел, как это реализуют в других компаниях, то осознал несколько важных нюансов.
Архитектура не даёт преимуществ. Ни одна продвинутая архитектура не была лучше того, что я делал в самом начале. За всё время я перепробовал разные подходы и поэтому мог оценить их пользу для проекта. Но между MVC и MVP не было разницы — кроме названий классов и правил вроде тех, когда элементы вызывают друг друга.
Компании понимают архитектуру по-разному. Одни говорят, что используют MVVM, у других то же самое называется MVC. Я видел пять MVVM-систем, и все были разными. Исключение — VIPER, у которой благодаря Егору Толстому есть подробная документация и много примеров. Но даже там были отличия.
Популярная архитектура не значит лучшая. Выбирать архитектуру из-за мейнстримности бесполезно. Кто-то решает использовать MVVM, но одни и те же компоненты кладёт в разные части проекта.
Архитектура не спасёт проект. Сама по себе она не решает проблемы и не гарантирует успеха.
Я постоянно изучал архитектуры, читал книги и спорил с коллегами, несколько раз пересматривал идею MVC в языке Smalltalk и несколько раз менял к ней отношение.
В итоге я понял, что MVC — это не три файла, и даже не несколько классов для каждого элемента. Модель — не про данные и не про бизнес-логику, а контроллер давно не нужен, и пора использовать MV.
Приложения с бизнес-логикой и доступом к данным были и до MVC, им не хватало только пользовательского интерфейса. Главная задача MVC — связать UI со всем остальным. Единственная рекомендация от создателя — при надобности создавать для каждой View свой фасад для Model и слушать его через паттерн-наблюдатель.
View — это и есть пользовательский интерфейс, Model — остальное приложение. Задача Controller — не быть прослойкой между V и M, а всего лишь принимать информацию от пользователя.
Принцип MVC — не мешать UI с бизнес-логикой, базой данных и другими частями приложения. А как это реализовать, уже пускай думает архитектор. Это не космическая инженерия.
Важно понимать, что MVP, MVVM или VIPER не заменяют MVC, а только дополняют её. Контроллер уже не нужен, потому что за ввод данных отвечает View, это стало его неотъемлемой частью.
Получается, что MVC в Apple, MVVM и другие варианты — это MV, где контроллер убрали за ненадобностью. Из всех современных MV(x) именно MVVM больше всего похожа на каноническую MVC.
Все эти термины усложняют общение. Иногда сложно понять, о чём тебе говорят, хотя задача архитектуры в том, чтобы всё было проще и понятнее.

Может показаться, что все архитектуры одинаковые, и им вообще не стоит уделять внимания. Но это не так. У меня есть несколько правил.
Главное — реализация. Глобальная архитектура не так важна, как её воплощение. Всё зависит от того, как вы называете классы, где храните элементы и как классы общаются между собой. Все из команды должны соблюдать ваш стандарт, и тогда проект будет проще поддерживать.
Model — ваша ответственность. Архитектура MVC не даёт инструкций, как правильно написать основную часть приложения. Ваша ответственность в том, чтобы не устраивать в Model кашу, где половина классов — Service, а вторая половина — Helper.
Нужно разбираться в основах. Не стоит изучать конкретную архитектуру, лучше понять, из чего она логически следует. Тут поможет история, объектно-ориентированное и функциональное программирование, паттерны, SOLID и всё остальное. Обязательно надо прочитать «Совершенный код» Стива Макконнелла.
Когда вы разобрались с основами, можно подходить к архитектуре Flux и библиотеке Redux. Я выделил их, потому что Facebook* сформулировал подробный гайд по Flux, а также выпустил под неё библиотеку. Неожиданно, но это тоже MVC — M и V разделены, и V слушает изменения в M. Правда, тут появились дополнительные ограничения, которые все тоже трактуют по-своему.
Redux — хорошая штука, но и у неё есть проблемы. Я использовал эту библиотеку в проекте, который писал и поддерживал сам. Всем компонентам старался давать правильные названия, завязывал на Store не все View, а только начальную сцену, группировал middleware и редюсеры, даже связывал их со стейтом.
С какого-то момента я начал теряться в проекте. У меня появилась куча сущностей с похожими названиями и похожими данными, я создал миллиард экшенов. В итоге сам запутался, что, как и с чем взаимодействует.
Код был расширяемый и поддерживаемый, но, если я хотел что-то изменить, приходилось править гору файлов. Это очень больно. А если учесть, что проект работал на бойлерплейтном Flutter, то боль усиливалась на порядок.
Redux хороша для больших проектов, ориентированных на офлайн, где одновременно происходит куча асинхронных неблокируемых событий. Там этот бойлерплейт стоит терпеть, потому что он спасёт вам жизнь. Но в обычном тонком клиенте лучше использовать стандартную MV и не париться.
Настоящая архитектура — та, которая описывает ваши подходы, она должна быть понятна всей команде. Если я буду делать приложение на SwiftUI, то выберу классическую MV — ту, где View следит за Model (многие называют это MVVM). И вам рекомендую поступать так же.
* Решением суда запрещена «деятельность компании Meta Platforms Inc. по реализации продуктов — социальных сетей Facebook* и Instagram* на территории Российской Федерации по основаниям осуществления экстремистской деятельности».

Учись бесплатно:
вебинары по программированию, маркетингу и дизайну.
Участвовать

Школа дронов для всех
Учим программировать беспилотники и управлять ими.
Узнать больше
Данный туториал поможет вам разобраться в очень полезном подходе по разработке приложений Clean Architecture.
С того времени, как я начал разработку Android-приложений, у меня сложилось впечатление, что разработку приложений можно было сделать лучше. За свою карьеру я сталкивался с множеством плохих решений, включая и свои собственные. Однако важно учиться на своих ошибках, чтобы не совершать их в дальнейшем. Я долго искал оптимальный подход к разработке и наконец наткнулся на Clean Architecture. После того, как я применил данный подход к Android-приложениям я решил, что это заслуживает внимания.
Целью статьи является предоставление пошаговой инструкции разработки Android-приложений с применением подхода Clean Architecture. Суть моего подхода заключается в том, что я на довольно успешных примерах покажу вам все достоинства Clean Architecture.
Я не собираюсь вдаваться в подробности, потому что есть статьи, в которых это объясняется лучше, чем смогу сделать я. Однако в следующем абзаце рассматривается ключевой вопрос, который вам необходимо знать, чтобы понять, как устроен подход Clean Architecture.
Как правило, в Clean Architecture код разделен на несколько уровней, по структуре схожей со структурой обычного лука, с одним правилом зависимости: внутренний уровень не должен зависеть от каких-либо внешних уровней. Это означает, что зависимости должны указываться внутри каждого уровня, чтобы не было зависимостей между уровнями (слоями).
Далее приведена визуализация вышесказанного:
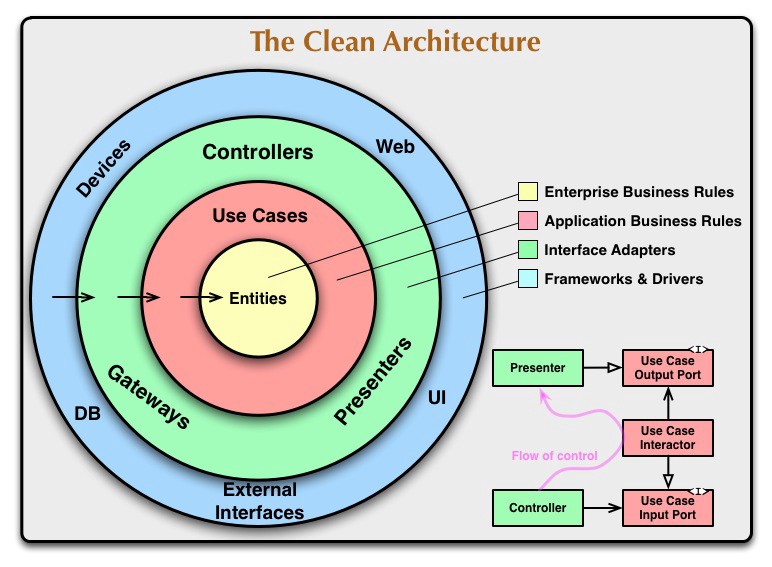
Clean Architecture, делает ваш код:
- Независящим от фреймворков;
- Тестируемым;
- Независящим от UI;
- Независящим от Базы данных;
- Независимым от какого-либо внешнего воздействия.
Я надеюсь, что вам станет понятно, как каждый из этих пунктов достигается, за счет приведенных ниже примеров. Для более детального объяснения данного подхода я настоятельно рекомендую ознакомиться с этой статьей и данным видео.
Что это значит для Android?
Как правило, ваше приложение имеет произвольное количество уровней (слоев), однако если вам не нужна бизнес-логика Enterprise, то скорее всего у вас будет только 3 уровня:
- Внешний: Уровень реализации;
- Средний: Уровень интерфейса;
- Внутренний: Уровень бизнес-логики.
Уровень реализации – это место где описывается основная структура приложения. Сюда входит любое содержимое Android такое, как: создание операций и фрагментов, отправка намерений, и другой структурный код наподобие сетевого кода и кода базы данных.
Целью уровня интерфейса является обеспечение взаимодействия/коммуникации между уровнем реализации и уровнем бизнес-логики.
Самым важным уровнем считается уровень бизнес логики. Данный уровень — это то, где вы фактически решаете поставленную задачу, собственно ради которой и создавалось приложение. Уровень бизнес-логики не содержит какого-либо структурного кода, и вы должны уметь запускать его без эмулятора. Таким образом, если вы будете придерживаться подобного подхода при построении бизнес-логики, то получится уровень легко тестируемый, разрабатываемый и его будет легко поддерживать. Пожалуй, это самая большая выгода при использовании Clean Architecture.
Каждый уровень, расположенный выше основного уровня, отвечает за преобразование моделей в модели нижнего уровня, перед тем как нижний уровень сможет их использовать. Нижний уровень не имеет ссылки на класс, который принадлежит внешнему уровню. Несмотря на это, внешний уровень может использовать и ссылочные модели внутреннего уровня. Опять же таки, это возможно благодаря нашему правилу зависимости. Это приводит к большему ресурсопотреблению, но оно является необходимым для того, чтобы убедиться, что наш код не привязан к какому-либо из уровней.
Почему преобразование является обязательным?
К примеру, ваши модели бизнес-логики могут оказаться некорректными для непосредственного отображения их пользователю. Возможно, вам необходимо отображать сочетание нескольких моделей бизнес-логики. По этой причине, я рекомендую создать класс ViewModel, который позволит упростить отображение моделей в интерфейсе пользователя. После чего вы просто используете класс преобразователя внешнего уровня для преобразования ваших бизнес-моделей в соответствующие ViewModel.
Еще одним примером может быть следующее: давайте скажем, что объект Cursor, принадлежит ContentProvider во внешнем уровне базы данных. Значит что внешний уровень, в первую очередь преобразует его в бизнес-модель внутреннего уровня, а затем уже отдаст его на обработку соответствующему уровню бизнес-логики.
Внизу статьи я добавлю больше ресурсов для изучения данного вопроса. Сейчас же мы уже знаем об основных принципах подхода Clean Architecture, а значит давайте «замараем» руки кодом. Далее я покажу вам как создать рабочий функционал с использованием Clean Architecture.
Как начать создание Чистых приложений?
Специально для вас я создал шаблонный проект, в котором уже есть все что вам нужно. Своего рода это стартовый набор для тех, кто хочет начать придерживаться Clean-подхода. Этот стартовый набор предназначен для скорейшего создания приложений с помощью уже встроенных, самых распространённых инструментов. Вы можете скачать этот набор абсолютно бесплатно, затем модифицировать его под свои нужды и создавать свои приложения.
Вы можете найти стартовый набор здесь: Шаблонный проект для создания Чистых приложений на Android.
…
Первые шаги по написанию новых прецедентов
Этот раздел будет объяснять весь необходимый вам код, для создания своих прецедентов с помощью подхода Clean Architecture, так скажем поверх шаблона, приведенного в предыдущем разделе. Прецедент (или Use Case) – это просто некоторый изолированный функционал приложения. Прецедент может быть запущен или не может быть запущен пользователем (например, по нажатию пользователя).
Во-первых, давайте объясним структуру и терминологию этого подхода. И да, это просто то, как я создавал свои приложения, то есть это не является чем-то незыблемым, и вы можете организовывать свои приложения по-другому, как вам хочется.
Структура
Общая структура Android-приложения выглядит, как показано ниже:
- Пакеты внешнего уровня: Интерфейс пользователя, хранилище, сеть и т.д.;
- Пакеты среднего уровня: Представители, конвертеры;
- Пакеты внутреннего уровня: Interactors, модели, репозитории, исполнители.
Внешний уровень
Как уже было сказано, это то, где описываются детали структуры.
Интерфейс пользователя (UI) – Это то, куда вы помещаете все ваши Операции, Фрагменты, Адаптеры и любой другой Android-код, связанный с интерфейсом пользователя.
Хранилище – Отдельный код для базы данных, который реализует интерфейс наших Интеракторов, используемых для доступа к базе данных и для хранения данных. Например, сюда включается Поставщик контента или ORM-ы такие, как DBFlow.
Сеть – Вещи подобные Retrofit отправляются сюда.
Средний уровень
Уровень, на котором располагается связующий код. Его главной задачей является связывание различных реализаций, с уровнем вашей бизнес-логики.
Представители (presenter) – представители обрабатывают события от UI (например, клик пользователя), и чаще всего работают как callback-и из внутренних уровней (Interactors).
Конвертеры – Преобразуют объекты, которые ответственны за конвертацию моделей внутреннего уровня в модели внешнего уровня и в обратном порядке.
Внутренний уровень
Основной уровень, который содержит самый высокоуровневый код. Все классы здесь являются POJO, то есть это простые Java-объекты, не унаследованные от какого-то специфического объекта и не реализующие никаких служебных интерфейсов сверх тех, которые нужны для бизнес-модели.
Классы и объекты данного уровня никак не оповещаются, что будут запущены именно в Android-приложении, поэтому их легко можно перенести на любую JVM.
Interactors – классы, которые фактически содержат код вашей бизнес-логики. Они запускаются в фоновом режиме и передают события верхнему уровню с помощью callback-ов. Их также называют Прецедентами (UseCases) в некоторых проектах, возможно, такое называние им больше подходит. Наличие множества небольших Interactor-классов в ваших проектах для решения определенных задач считается нормой. Это полностью соответствует принципу единственной ответственности и, как мне кажется, проще для восприятия и понимания.
Модели – это ваши бизнес-модели, которыми вы управляете в своей бизнес-логике.
Репозитории (repositories ) – данный пакет включает в себя только те интерфейсы, которые реализованы с помощью базы данных или каких-либо других внешних уровней. Эти интерфейсы используются Interactor-классы для доступа и хранения данных. Это также называется паттерн Repository.
Исполнитель (executor) – данный пакет содержит код для запуска Interactor-классов в фоновом режиме с помощью рабочего потока-исполнителя. Чаще всего вам не придется изменять этот пакет.
Простой пример
В этом примере, нашим прецедентом будет: «Приветствие пользователя сообщением, когда приложение запущено и данное сообщение помещено в базу данных.» Данный пример будет наглядной демонстрацией того, как создать следующие пакеты, необходимые для корректной работы нашего прецедента:
- Пакет представления;
- Пакет хранилища;
- Пакет домена.
Первые два пункта относятся к внешнему уровню, в то время как последний относится к внутреннему/основному уровню.
Пакет представления ответственен за все, что связано с отображением вещей на экране, он содержит весь стек шаблона проектирования MVP. Это означает, что он содержит в себе как UI, так и Presenter-пакеты, даже если они относятся к разным уровням.
Отлично – меньше слов, больше кода!
Создание нового Interactor-а (внутренний/основной уровень)
На самом деле, вы можете начать разработку своего приложения с любого уровня представленной архитектуру, но я рекомендую начать именно с основного уровня бизнес-логики. Вы можете написать весь необходимы для этого код, протестировать его и убедиться, что он работает даже без создания операции.
Итак, давайте начнем создание Interactor-а. Interactor – это то место, где располагается основная логика работы нашего прецедента. Все Interactor-ы запускаются в фоновом потоке, поэтому не должно быть никакого воздействия на производительность интерфейса пользователя. Давайте создадим новый Interactor с приятным названием «WelcomingInteractor».
public interface WelcomingInteractor extends Interactor {
interface Callback {
void onMessageRetrieved(String message);
void onRetrievalFailed(String error);
}
}
Callback отвечает за общение с интерфейсом пользователя (UI) в основном потоке, мы помещаем его в интерфейс Interactor-а, поэтому нет необходимости в подобном названии «WelcomingInteractorCallback», чтобы отличать его от других callback-ов. Теперь реализуем логику получения сообщения. Давайте скажем, что у нас есть интерфейс MessageRepository, в котором будет наше сообщение приветствия.
public interface MessageRepository {
String getWelcomeMessage();
}
Далее реализуем этот интерфейс вместе с нашей бизнес-логикой. Важно, чтобы реализация наследовала AbstractInteractor, который отвечает за запуск нашего интерфейса в фоновом потоке.
public class WelcomingInteractorImpl extends AbstractInteractor implements WelcomingInteractor {
...
private void notifyError() {
mMainThread.post(new Runnable() {
@Override
public void run() {
mCallback.onRetrievalFailed("Nothing to welcome you with :(");
}
});
}
private void postMessage(final String msg) {
mMainThread.post(new Runnable() {
@Override
public void run() {
mCallback.onMessageRetrieved(msg);
}
});
}
@Override
public void run() {
// получение сообщения
final String message = mMessageRepository.getWelcomeMessage();
// проверяем, получили ли мы сообщение
if (message == null || message.length() == 0) {
// уведомляем об ошибке основной поток
notifyError();
return;
}
// мы получили наше сообщение, уведомляем об этом UI в основном потоке
postMessage(message);
}
Что же, взглянем на зависимости, создаваемые нашим Interactor:Этот фрагмент кода, пытается получить сообщение, затем переслать его или же отправить сообщение об ошибке интерфейсу пользователя, чтобы он отобразил сообщение или ошибку. Для этого мы уведомляем интерфейс пользователя с помощью нашего callback-а, который по факту и будет Presenter-ом. Собственно, в этом и заключается суть всей нашей бизнес-логики. Все что нам остается – это построить структурные зависимости.
import com.kodelabs.boilerplate.domain.executor.Executor; import com.kodelabs.boilerplate.domain.executor.MainThread; import com.kodelabs.boilerplate.domain.interactors.WelcomingInteractor; import com.kodelabs.boilerplate.domain.interactors.base.AbstractInteractor; import com.kodelabs.boilerplate.domain.repository.MessageRepository;
Как вы можете заметить, здесь нет ни одного упоминания о каком-либо Android-коде. Это и есть главное преимущество данного подхода. Также вы можете увидеть, что пункт: «Независимость от фреймворков» все также соблюдается. Кроме того, нам не нужно отдельно определять интерфейс пользователя или базу данных, мы просто вызываем методы интерфейса, которые кто-то, где-то на внешнем уровне реализует. Следовательно, мы независим от UI и независим от Базы данных.
Тестирование нашего Interactor-а
На данный момент мы можем запустить и начать тестирование нашего Interactor-а без запуска эмулятора. Поэтому давайте напишем простой Junit-тест, чтобы убедиться, что все работает:
...
@Test
public void testWelcomeMessageFound() throws Exception {
String msg = "Welcome, friend!";
when(mMessageRepository.getWelcomeMessage())
.thenReturn(msg);
WelcomingInteractorImpl interactor = new WelcomingInteractorImpl(
mExecutor,
mMainThread,
mMockedCallback,
mMessageRepository
);
interactor.run();
Mockito.verify(mMessageRepository).getWelcomeMessage();
Mockito.verifyNoMoreInteractions(mMessageRepository);
Mockito.verify(mMockedCallback).onMessageRetrieved(msg);
}
И вновь, этот Interactor даже не подозревает, что будет находиться внутри Android-приложения. Это доказывает, что наша бизнес-логика является тестируемой, а это был наш пункт номер два.
Создание уровня представления
Код представления относится ко внешнему уровню подхода Clean Architecture. Уровень представления состоит из структурно зависимого кода, который отвечает за отображение интерфейса пользователя, собственно, пользователю. Мы будем использовать класс MainActivity для отображения нашего приветствующего сообщения пользователю, когда приложение возобновляет свою работу.
Давайте начнем с создания интерфейса нашего Presenter и Отображения (View). Единственное, что должно делать наше отображение – это отображать приветствующее сообщение:
public interface MainPresenter extends BasePresenter {
interface View extends BaseView {
void displayWelcomeMessage(String msg);
}
}
Итак, как и где мы запускаем наш Interactor, когда приложение возобновляет работу? Все, что не имеет строгой привязки к отображению, должно помещаться в класс Presenter. Это помогает достичь принципа Разделения ответственности и предотвратить классы Операций от чрезмерного увеличения размера кода. Сюда включается весь код, который работает с Interactor-ми.
В нашем классе MainActivity мы переопределяем метод onResume():
@Override
protected void onResume() {
super.onResume(); // начнем возврат приветствующего сообщения, при возобновлении работы приложения
mPresenter.resume();
}
Все Presenter-объекты реализуют метод resume(), при наследовании BasePresenter.
Примечание: Самые внимательные читатели могли заметить, что я добавил Android-методы жизненного цикла в интерфейс BasePresenter в качестве вспомогательных методов, хотя сам Presenter находится на более низком уровне. Наш Presenter должен знать все на уровне UI, к примеру, что что-то на этом уровне имеет жизненный цикл. Тем не менее, здесь я не указываю конкретное событие, так как каждый UI для конкретного пользователя может отрабатывать разные события, в зависимости от действий пользователя. Представьте, я назвал его onUIShow() вместо onResume(). Теперь все хорошо, верно? 
Мы запускаем Interactor внутри класса MainPresenter в методе resume():
@Override
public void resume() { mView.showProgress(); // инициализируем interactor
WelcomingInteractor interactor = new WelcomingInteractorImpl(
mExecutor,
mMainThread,
this,
mMessageRepository
); // запускаем interactor
interactor.execute();
}
Метод execute() просто выполняет метод run() объекта WelcomingInteractorImpl в фоновом потоке. Метод run() вы можете увидеть в разделе Создание нового Interactor-а.
Вы также могли заметить, что поведение Interactor-а схоже с поведением класса AsyncTask. Так как вы предоставляете все необходимое для его запуска и выполнения. Тут вы можете спросить, а почему мы не используем AsyncTask? Да потому что это Android-код, и вам нужен будет эмулятор для его запуска и тестирования.
Мы предоставляем несколько вещей нашему Interactor-у:
- Экземпляр ThreadExecutor, который отвечает за выполенение Interactor-а в фоновом потоке. Я чаще всего создаю его как singleton. Этот класс также располагается внутри domain-пакета и нет необходимости реализовывать его во внешнем уровне;
- Экземпляр MainThreadImpl, который отвечает за отправку запущенных потоков Interactor-а в главный поток приложения. Основные потоки имеют доступ к использованию определённого структурного кода и поэтому мы должны реализовывать их во внешнем уровне;
- Также вы могли обратить внимание на то, что мы предоставляем this нашему Interactor-у. MainPresenter– это callback-объект, который используется Interactor-ом для уведомления UI о каких-либо событиях;
- Кроме того, мы предоставляем экземпляр WelcomeMessageRepository, который отвечает за реализацию интерфейса MessageRepository, который в свою очередь использует Interactor. WelcomeMessageRepository будет рассмотрен позже, в разделе Создание уровня хранения.
Примечание: Поскольку существует множество вещей, которые необходимо связывать каждый раз с Interactor-ом, то будет полезен следующий фреймворк для внедрения зависимостей: Dagger 2 (и подобные ему). Но я его использую здесь не для того чтобы что-то упростить. Свою структуру вы вольны сами выбирать, и то какие фреймворки использовать также ваше право.
Что же касается this, то MainPresenter класса MainActivity действительно реализует callback-интерфейс:
public class MainPresenterImpl extends AbstractPresenter implements MainPresenter, WelcomingInteractor.Callback {
И далее то, как мы слушаем события от Interactor-а. Следующий код взят из MainPresenter:
@Override
public void onMessageRetrieved(String message) {
mView.hideProgress();
mView.displayWelcomeMessage(message);
}
@Override
public void onRetrievalFailed(String error) {
mView.hideProgress();
onError(error);
}
Небольшие фрагменты View в этом куске кода – это и есть наш класс MainActivity, который реализует данный интерфейс:
public class MainActivity extends AppCompatActivity implements MainPresenter.View {
Который, в свою очередь, отвечает за отображение приветствующего сообщения на экран, как это можно увидеть в следующем фрагменте:
@Override
public void displayWelcomeMessage(String msg) {
mWelcomeTextView.setText(msg);
}
И вот этого всего будет вполне достаточно для уровня представления.
Создание уровня хранения
В этом разделе мы реализуем наш репозиторий. Весь код, относящийся к базе данных, должен быть тут. Шаблон проектирования repository – это инструмент, который собирает все источники, из которых поступают данные. Суть нашей бизнес-логики заключается в том, что нам все равно откуда приходят данные, будь они из базы данных, сервера или текстового файла.
Для сложных данных вы можете использовать ContentProviders или такие ORM-инструменты, как: DBFlow. Если вам необходимо получать данные из Интернета, то Retrofit поможет вам. Если же вам необходимо простое хранилище по принципу ключ-значение, то вы можете использовать SharedPreferences. Запомните, вы должны использовать верный инструмент для работы.
Наша база данных на самом деле не совсем база данных. Это будет очень простой класс с некоторой симуляцией задержки:
public class WelcomeMessageRepository implements MessageRepository {
@Override
public String getWelcomeMessage() {
String msg = "Welcome, friend!"; // let's be friendly
// давайте симулируем некоторые сетевые/БД лаги
try {
Thread.sleep(2000);
} catch (InterruptedException e) {
e.printStackTrace();
}
return msg;
}
}
Что же касается нашего WelcomingInteractor, то лаги могут быть по причинам сети и многим другим. На самом деле все равно, что находится стоит за MessageRepository, пока он реализует этот интерфейс.
Краткий итог
Пример из этой статьи вы можете найти в данном git-репозитории. Обобщенная версия порядка вызова классов выглядит следующим образом:
MainActivity->MainPresenter->WelcomingInteractor ->WelcomeMessageRepository->WelcomingInteractor->MainPresenter-> MainActivity
Очень важно запомнить порядок контроля:
Внешний — Средний — Основной — Внешний — Основной — Средний — Внешний
Очень часто внешний уровень задействуется несколько раз в течении одного случая использования. Во время использования приложения вам необходимо что-то отображать, что-то хранить и получать к чему-то доступ из сети, в нашем порядке контроля внешний уровень задействуется, как минимум, три раза.
Заключение
Для меня подход Clean Architecture является лучшим способом разработки приложений. Разделенный код помогает сфокусироваться на определенных задачах, без большого нагромождения кода, то есть вы не страдаете лишней функциональной избыточностью. В конце концов, я думаю, что этот подход соответствует принципам SOLID, однако к нему придется немного привыкнуть, чтобы использовать весь его потенциал. Именно по этой причине я и написал все это, чтобы помочь людям лучше понять Clean Architecture, за счет пошаговых примеров.
Также я создал и предоставил доступ к исходному коду приложения «Отслеживание затрат», используя подход Clean Architecture для того, чтобы показать, как будет выглядеть код в реальном приложении. Ничего инновационного в данном приложении нет, но я считаю, что этого будет достаточно, чтобы пояснить все то, о чем было написано в данной статье. Кроме того, данное приложение содержит более сложные примеры, с которыми вы можете самостоятельно ознакомиться. А найти его вы сможете здесь.
И снова, пример из этой статьи, который был построен используя базовые принципы подхода Clean Architecture, вы можете найти здесь.
Дополнительная информация
Этот гайд является расширением данной прекрасной статьи. Разница заключается в том, что я использовал обычную Java в своих примерах, и вовсе не для того, чтобы как-то усложнить примеры. Если вам приятнее наблюдать примеры подхода Clean Architecture на RxJava, то можете посмотреть их здесь.
Дополнительные материалы по теме
Программирование под Android: 50 лучших инструментов
Разработка под Андроид: советы, инструменты и трюки
6 простых советов по написанию чистого кода
Ссылка на оригинальную статью
Перевод: Александр Давыдов
Создание архитектуры программы или как проектировать табуретку +82
Разработка, Анализ и проектирование систем, Проектирование и рефакторинг
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/
Взявшись за написание небольшого, но реального и растущего проекта, мы «на собственной шкуре» убедились, насколько важно то, чтобы программа не только хорошо работала, но и была хорошо организована. Не верьте, что продуманная архитектура нужна только большим проектам (просто для больших проектов «смертельность» отсутствия архитектуры очевидна). Сложность, как правило, растет гораздо быстрее размеров программы. И если не позаботиться об этом заранее, то довольно быстро наступает момент, когда ты перестаешь ее контролировать. Правильная архитектура экономит очень много сил, времени и денег. А нередко вообще определяет то, выживет ваш проект или нет. И даже если речь идет всего лишь о «построении табуретки» все равно вначале очень полезно ее спроектировать.
К моему удивлению оказалось, что на вроде бы актуальный вопрос: «Как построить хорошую/красивую архитектуру ПО?» — не так легко найти ответ. Не смотря на то, что есть много книг и статей, посвященных и шаблонам проектирования и принципам проектирования, например, принципам SOLID (кратко описаны тут, подробно и с примерами можно посмотреть тут, тут и тут) и тому, как правильно оформлять код, все равно оставалось чувство, что чего-то важного не хватает. Это было похоже на то, как если бы вам дали множество замечательных и полезных инструментов, но забыли главное — объяснить, а как же «проектировать табуретку».
Хотелось разобраться, что вообще в себя включает процесс создания архитектуры программы, какие задачи при этом решаются, какие критерии используются (чтобы правила и принципы перестали быть всего лишь догмами, а стали бы понятны их логика и назначение). Тогда будет понятнее и какие инструменты лучше использовать в том или ином случае.
Данная статья является попыткой ответить на эти вопросы хотя бы в первом приближении. Материал собирался для себя, но, может, он окажется полезен кому-то еще. Мне данная работа позволила не только узнать много нового, но и в ином контексте взглянуть на кажущиеся уже почти банальными основные принципы ООП и по настоящему оценить их важность.
Информации оказалось довольно много, поэтому приведены лишь общая идея и краткие описания, дающие начальное представление о теме и понимание, где искать дальше.
Критерии хорошей архитектуры
Вообще говоря, не существует общепринятого термина «архитектура программного обеспечения». Тем не менее, когда дело касается практики, то для большинства разработчиков и так понятно какой код является хорошим, а какой плохим. Хорошая архитектура это прежде всего выгодная архитектура, делающая процесс разработки и сопровождения программы более простым и эффективным. Программу с хорошей архитектурой легче расширять и изменять, а также тестировать, отлаживать и понимать. То есть, на самом деле можно сформулировать список вполне разумных и универсальных критериев:
Эффективность системы. В первую очередь программа, конечно же, должна решать поставленные задачи и хорошо выполнять свои функции, причем в различных условиях. Сюда можно отнести такие характеристики, как надежность, безопасность, производительность, способность справляться с увеличением нагрузки (масштабируемость) и т.п.
Гибкость системы. Любое приложение приходится менять со временем — изменяются требования, добавляются новые. Чем быстрее и удобнее можно внести изменения в существующий функционал, чем меньше проблем и ошибок это вызовет — тем гибче и конкурентоспособнее система. Поэтому в процессе разработки старайтесь оценивать то, что получается, на предмет того, как вам это потом, возможно, придется менять. Спросите у себя: «А что будет, если текущее архитектурное решение окажется неверным?», «Какое количество кода подвергнется при этом изменениям?». Изменение одного фрагмента системы не должно влиять на ее другие фрагменты. По возможности, архитектурные решения не должны «вырубаться в камне», и последствия архитектурных ошибок должны быть в разумной степени ограничены. «Хорошая архитектура позволяет ОТКЛАДЫВАТЬ принятие ключевых решений» (Боб Мартин) и минимизирует «цену» ошибок.
Расширяемость системы. Возможность добавлять в систему новые сущности и функции, не нарушая ее основной структуры. На начальном этапе в систему имеет смысл закладывать лишь основной и самый необходимый функционал (принцип YAGNI — you ain’t gonna need it, «Вам это не понадобится») Но при этом архитектура должна позволять легко наращивать дополнительный функционал по мере необходимости. Причем так, чтобы внесение наиболее вероятных изменении? требовало наименьших усилии.
Требование, чтобы архитектура системы обладала гибкостью и расширяемостью (то есть была способна к изменениям и эволюции) является настолько важным, что оно даже сформулировано в виде отдельного принципа — «Принципа открытости/закрытости» (Open-Closed Principle — второй из пяти принципов SOLID): Программные сущности (классы, модули, функции и т.п.) должны быть открытыми для расширения, но закрытыми для модификации.
Иными словами: Должна быть возможность расширить/изменить поведение системы без изменения/переписывания уже существующих частей системы.
Это означает, что приложение следует проектировать так, чтобы изменение его поведения и добавление новой функциональности достигалось бы за счет написания нового кода (расширения), и при этом не приходилось бы менять уже существующий код. В таком случае появление новых требований не повлечет за собой модификацию существующей логики, а сможет быть реализовано прежде всего за счет ее расширения. Именно этот принцип является основой «плагинной архитектуры» (Plugin Architecture). О том, за счет каких техник это может быть достигнуто, будет рассказано дальше.
Масштабируемость процесса разработки. Возможность сократить срок разработки за счёт добавления к проекту новых людей. Архитектура должна позволять распараллелить процесс разработки, так чтобы множество людей могли работать над программой одновременно.
Тестируемость. Код, который легче тестировать, будет содержать меньше ошибок и надежнее работать. Но тесты не только улучшают качество кода. Многие разработчики приходят к выводу, что требование «хорошей тестируемости» является также направляющей силой, автоматически ведущей к хорошему дизайну, и одновременно одним из важнейших критериев, позволяющих оценить его качество: «Используйте принцип «тестируемости» класса в качестве «лакмусовой бумажки» хорошего дизайна класса. Даже если вы не напишите ни строчки тестового кода, ответ на этот вопрос в 90% случаев поможет понять, насколько все «хорошо» или «плохо» с его дизайном» (Идеальная архитектура).
Существует целая методология разработки программ на основе тестов, которая так и называется — Разработка через тестирование (Test-Driven Development, TDD).
Возможность повторного использования. Систему желательно проектировать так, чтобы ее фрагменты можно было повторно использовать в других системах.
Хорошо структурированный, читаемый и понятный код. Сопровождаемость. Над программой, как правило, работает множество людей — одни уходят, приходят новые. После написания сопровождать программу тоже, как правило, приходится людям, не участвовавшем в ее разработке. Поэтому хорошая архитектура должна давать возможность относительно легко и быстро разобраться в системе новым людям. Проект должен быть хорошо структурирован, не содержать дублирования, иметь хорошо оформленный код и желательно документацию. И по возможности в системе лучше применять стандартные, общепринятые решения привычные для программистов. Чем экзотичнее система, тем сложнее ее понять другим (Принцип наименьшего удивления — Principle of least astonishment. Обычно, он используется в отношении пользовательского интерфейса, но применим и к написанию кода).
Ну и для полноты критерии плохого дизайна:
- Его тяжело изменить, поскольку любое изменение влияет на слишком большое количество других частей системы. (Жесткость, Rigidity).
- При внесении изменений неожиданно ломаются другие части системы. (Хрупкость, Fragility).
- Код тяжело использовать повторно в другом приложении, поскольку его слишком тяжело «выпутать» из текущего приложения. (Неподвижность, Immobility).
Модульная архитектура. Декомпозиция как основа
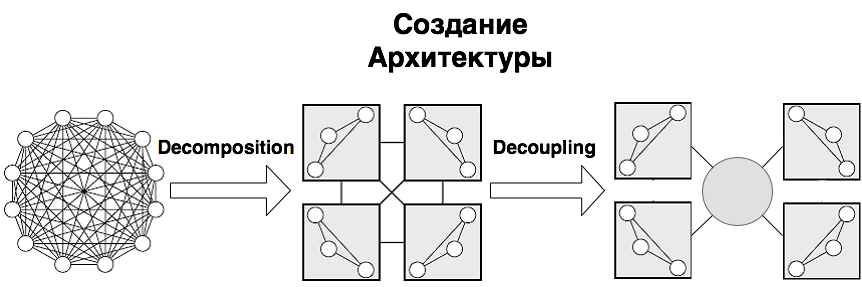
Не смотря на разнообразие критериев, все же главной при разработке больших систем считается задача снижения сложности. А для снижения сложности ничего, кроме деления на части, пока не придумано. Иногда это называют принципом «разделяй и властвуй» (divide et impera), но по сути речь идет об иерархической декомпозиции. Сложная система должна строится из небольшого количества более простых подсистем, каждая из которых, в свою очередь, строится из частей меньшего размера, и т.д., до тех пор, пока самые небольшие части не будут достаточно просты для непосредственного понимания и создания.
Удача заключается в том, что данное решение является не только единственно известным, но и универсальным. Помимо снижения сложности, оно одновременно обеспечивает гибкость системы, дает хорошие возможности для масштабирования, а также позволяет повышать устойчивость за счет дублирования критически важных частей.
Соответственно, когда речь идет о построении архитектуры программы, создании ее структуры, под этим, главным образом, подразумевается декомпозиция программы на подсистемы (функциональные модули, сервисы, слои, подпрограммы) и организация их взаимодействия друг с другом и внешним миром. Причем, чем более независимы подсистемы, тем безопаснее сосредоточиться на разработке каждой из них в отдельности в конкретный момент времени и при этом не заботиться обо всех остальных частях.
В этом случае программа из «спагетти-кода» превращается в конструктор, состоящий из набора модулей/подпрограмм, взаимодействующих друг с другом по хорошо определенным и простым правилам, что собственно и позволяет контролировать ее сложность, а также дает возможность получить все те преимущества, которые обычно соотносятся с понятием хорошая архитектура:
- Масштабируемость (Scalability)
возможность расширять систему и увеличивать ее производительность, за счет добавления новых модулей. - Ремонтопригодность (Maintainability)
изменение одного модуля не требует изменения других модулей - Заменимость модулей (Swappability)
модуль легко заменить на другой - Возможность тестирования (Unit Testing)
модуль можно отсоединить от всех остальных и протестировать / починить - Переиспользование (Reusability)
модуль может быть переиспользован в других программах и другом окружении - Сопровождаемость (Maintenance)
разбитую на модули программу легче понимать и сопровождать
Можно сказать, что в разбиении сложной проблемы на простые фрагменты и заключается цель всех методик проектирования. А термином «архитектура», в большинстве случаев, просто обозначают результат такого деления, плюс «некие конструктивные решения, которые после их принятия с трудом поддаются изменению» (Мартин Фаулер «Архитектура корпоративных программных приложений»). Поэтому большинство определений в той или иной форме сводятся к следующему:
«Архитектура идентифицирует главные компоненты системы и способы их взаимодействия. Также это выбор таких решений, которые интерпретируются как основополагающие и не подлежащие изменению в будущем.«
«Архитектура — это организация системы, воплощенная в ее компонентах, их отношениях между собой и с окружением.
Система — это набор компонентов, объединенных для выполнения определенной функции.«
Таким образом, хорошая архитектура это, прежде всего, модульная/блочная архитектура. Чтобы получить хорошую архитектуру надо знать, как правильно делать декомпозицию системы. А значит, необходимо понимать — какая декомпозиция считается «правильной» и каким образом ее лучше проводить?
«Правильная» декомпозиция
1. Иерархическая
Не стоит сходу рубить приложение на сотни классов. Как уже говорилось, декомпозицию надо проводить иерархически — сначала систему разбивают на крупные функциональные модули/подсистемы, описывающие ее работу в самом общем виде. Затем, полученные модули, анализируются более детально и, в свою очередь, делятся на под-модули либо на объекты.
Перед тем как выделять объекты разделите систему на основные смысловые блоки хотя бы мысленно. Для небольших приложений двух уровней иерархии часто оказывается вполне достаточно — система вначале делится на подсистемы/пакеты, а пакеты делятся на классы.
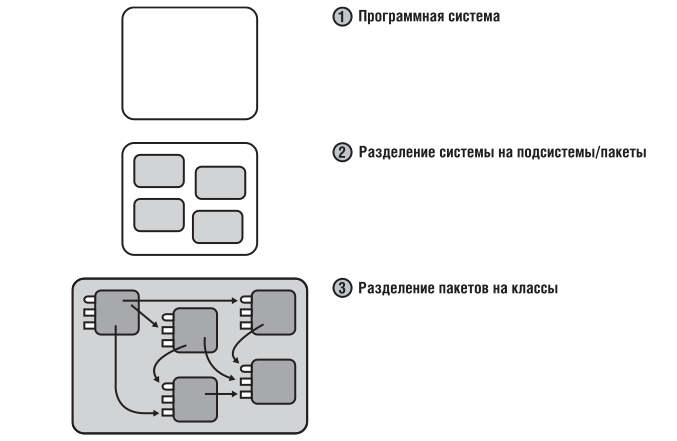
Эта мысль, при всей своей очевидности, не так банальна как кажется. Например, в чем заключается суть такого распространенного «архитектурного шаблона» как Модель-Вид-Контроллер (MVC)? Всего навсего в отделении представления от бизнес-логики, то есть в том, что любое пользовательское приложение вначале делится на два модуля — один из которых отвечает за реализацию собственно самой бизнес логики (Модель), а второй — за взаимодействие с пользователем (Пользовательский Интерфейс или Представление). Затем, для того чтобы эти модули могли разрабатываться независимо, связь между ними ослабляется с помощью паттерна «Наблюдатель» (подробно о способах ослабления связей будет рассказано дальше) и мы фактически получаем один из самых мощных и востребованных «шаблонов», которые используются в настоящее время.
Типичными модулями первого уровня (полученными в результате первого деления системы на наиболее крупные составные части) как раз и являются — «бизнес-логика», «пользовательский интерфейс», «доступ к БД», «связь с конкретным оборудованием или ОС».
Для обозримости на каждом иерархическом уровне рекомендуют выделять от 2 до 7 модулей.
2. Функциональная
Деление на модули/подсистемы лучше всего производить исходя из тех задач, которые решает система. Основная задача разбивается на составляющие ее подзадачи, которые могут решаться/выполняться независимо друг от друга. Каждый модуль должен отвечать за решение какой-то подзадачи и выполнять соответствующую ей функцию. Помимо функционального назначения модуль характеризуется также набором данных, необходимых ему для выполнения его функции, то есть:
Модуль = Функция + Данные, необходимые для ее выполнения.
Причем желательно, чтобы свою функцию модуль мог выполнить самостоятельно, без помощи остальных модулей, лишь на основе своих входящих данных.
Модуль — это не произвольный кусок кода, а отдельная функционально осмысленная и законченная программная единица (подпрограмма), которая обеспечивает решение некоторой задачи и в идеале может работать самостоятельно или в другом окружении и быть переиспользуемой. Модуль должен быть некой «целостностью, способной к относительной самостоятельности в поведении и развитии» (Кристофер Александер).
Таким образом, грамотная декомпозиция основывается, прежде всего, на анализе функций системы и необходимых для выполнения этих функций данных.
3. High Cohesion + Low Coupling
Самым же главным критерием качества декомпозиции является то, насколько модули сфокусированы на решение своих задач и независимы. Обычно это формулируют следующим образом: «Модули, полученные в результате декомпозиции, должны быть максимально сопряженны внутри (high internal cohesion) и минимально связанны друг с другом (low external coupling).«
- High Cohesion, высокая сопряженность или «сплоченность» внутри модуля, говорит о том, модуль сфокусирован на решении одной узкой проблемы, а не занимается выполнением разнородных функций или несвязанных между собой обязанностей. (Сопряженность — cohesion, характеризует степень, в которой задачи, выполняемые модулем, связаны друг с другом )
Следствием High Cohesion является принцип единственной ответственности (Single Responsibility Principle — первый из пяти принципов SOLID), согласно которому любой объект/модуль должен иметь лишь одну обязанность и соответственно не должно быть больше одной причины для его изменения.
- Low Coupling, слабая связанность, означает что модули, на которые разбивается система, должны быть, по возможности, независимы или слабо связанны друг с другом. Они должны иметь возможность взаимодействовать, но при этом как можно меньше знать друг о друге (принцип минимального знания).
Это значит, что при правильном проектировании, при изменении одного модуля, не придется править другие или эти изменения будут минимальными. Чем слабее связанность, тем легче писать/понимать/расширять/чинить программу.
Считается, что хорошо спроектированные модули должны обладать следующими свойствами:
- функциональная целостность и завершенность — каждый модуль реализует одну функцию, но реализует хорошо и полностью; модуль самостоятельно (без помощи дополнительных средств) выполняет полный набор операций для реализации своей функции.
- один вход и один выход — на входе программный модуль получает определенный набор исходных данных, выполняет содержательную обработку и возвращает один набор результатных данных, т.е. реализуется стандартный принцип IPO — вход–процесс–выход;
- логическая независимость — результат работы программного модуля зависит только от исходных данных, но не зависит от работы других модулей;
- слабые информационные связи с другими модулями — обмен информацией между модулями должен быть по возможности минимизирован.
Грамотная декомпозиция — это своего рода искусство и гигантская проблема для многих программистов. Простота тут очень обманчива, а ошибки обходятся очень дорого. Если выделенные модули оказываются сильно сцеплены друг с другом, если их не удается разрабатывать независимо или не ясно за какую конкретно функцию каждый из них отвечает, то стоит задуматься а правильно ли вообще производится деление. Должно быть понятно, какую роль выполняет каждый модуль. Самый же надежный критерий того, что декомпозиция делается правильно, это если модули получаются самостоятельными и ценными сами по себе подпрограммами, которые могут быть использованы в отрыве от всего остального приложения (а значит, могут быть переиспользуемы).
Делая декомпозицию системы желательно проверять ее качество задавая себе вопросы: «Какую функцию выполняет каждый модуль?«, “Насколько модули легко тестировать?”, “Возможно ли использовать модули самостоятельно или в другом окружении?”, “Как сильно изменения в одном модуле отразятся на остальных?”
В первую очередь следует, конечно же, стремиться к тому, чтобы модули были предельно автономны. Как и было сказано, это является ключевым параметром правильной декомпозиции. Поэтому проводить ее нужно таким образом, чтобы модули изначально слабо зависели друг от друга. Но кроме того, имеется ряд специальных техник и шаблонов, позволяющих затем дополнительно минимизировать и ослабить связи между подсистемами. Например, в случае MVC для этой цели использовался шаблон «Наблюдатель», но возможны и другие решения. Можно сказать, что техники для уменьшения связанности, как раз и составляют основной «инструментарий архитектора». Только необходимо понимать, что речь идет о всех подсистемах и ослаблять связанность нужно на всех уровнях иерархии, то есть не только между классам, но также и между модулями на каждом иерархическом уровне.
Как ослаблять связанность между модулями
Для наглядности, картинка из неплохой статьи «Decoupling of Object-Oriented Systems», иллюстрирующая основные моменты, о которых будет идти речь.
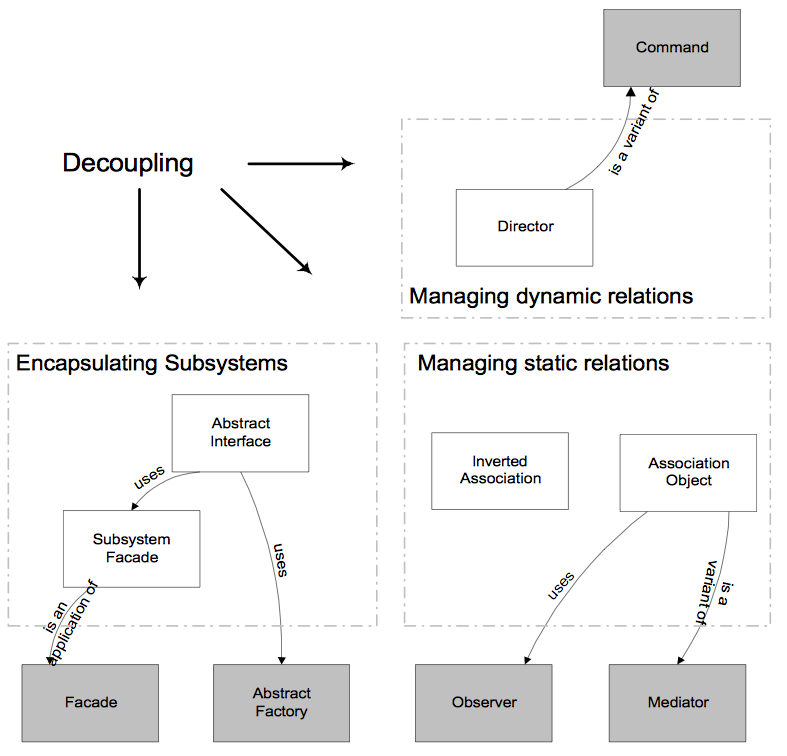
1. Интерфейсы. Фасад
Главным, что позволяет уменьшать связанность системы, являются конечно же Интерфейсы (и стоящий за ними принцип Инкапсуляция + Абстракция + Полиморфизм):
- Модули должны быть друг для друга «черными ящиками» (инкапсуляция). Это означает, что один модуль не должен «лезть» внутрь другого модуля и что либо знать о его внутренней структуре. Объекты одной подсистемы не должны обращаться напрямую к объектам другой подсистемы
- Модули/подсистемы должны взаимодействовать друг с другом лишь посредством интерфейсов (то есть, абстракций, не зависящих от деталей реализации) Соответственно каждый модуль должен иметь четко определенный интерфейс или интерфейсы для взаимодействия с другими модулями.
Принцип «черного ящика» (инкапсуляция) позволяет рассматривать структуру каждой подсистемы независимо от других подсистем. Модуль, представляющий собой черный ящик, можно относительно свободно менять. Проблемы могут возникнуть лишь на стыке разных модулей (или модуля и окружения). И вот это взаимодействие нужно описывать в максимально общей (абстрактной) форме — в форме интерфейса. В этом случае код будет работать одинаково с любой реализацией, соответствующей контракту интерфейса. Собственно именно эта возможность работать с различными реализациями (модулями или объектами) через унифицированный интерфейс и называется полиморфизмом. Полиморфизм это вовсе не переопределение методов, как иногда ошибочно полагают, а прежде всего — взаимозаменяемость модулей/объектов с одинаковым интерфейсом, или «один интерфейс, множество реализаций» (подробнее тут). Для реализации полиморфизма механизм наследования совсем не нужен. Это важно понимать, поскольку наследования вообще, по возможности, следует избегать.
Благодаря интерфейсам и полиморфизму, как раз и достигается возможность модифицировать и расширять код, без изменения того, что уже написано (Open-Closed Principle). До тех пор, пока взаимодействие модулей описано исключительно в виде интерфейсов, и не завязано на конкретные реализации, мы имеем возможность абсолютно «безболезненно» для системы заменить один модуль на любой другой, реализующий тот же самый интерфейс, а также добавить новый и тем самым расширить функциональность. Это как в конструкторе или «плагинной архитектуре» (plugin architecture) — интерфейс служит своего рода коннектором, куда может быть подключен любой модуль с подходящим разъемом. Гибкость конструктора обеспечивается тем, что мы можем просто заменить одни модули/«детали» на другие, с такими же разъемами (с тем же интерфейсом), а также добавить сколько угодно новых деталей (при этом уже существующие детали никак не изменяются и не переделываются). Подробнее про Open-Closed Principle и про то, как он может быть реализован можно почитать тут + хорошая статья на английском.
Интерфейсы позволяют строить систему более высокого уровня, рассматривая каждую подсистему как единое целое и игнорируя ее внутреннее устройство. Они дают возможность модулям взаимодействовать и при этом ничего не знать о внутренней структуре друг друга, тем самым в полной мере реализуя принцип минимального знания, являющейся основой слабой связанности. Причем, чем в более общей/абстрактной форме определены интерфейсы и чем меньше ограничений они накладывают на взаимодействие, тем гибче система. Отсюда фактически следует еще один из принципов SOLID — Принцип разделения интерфейса (Interface Segregation Principle), который выступает против «толстых интерфейсов» и говорит, что большие, объемные интерфейсы надо разбивать на более маленькие и специфические, чтобы клиенты маленьких интерфейсов (зависящие модули) знали только о методах, которые необходимы им в работе. Формулируется он следующим образом: «Клиенты не должны зависеть от методов (знать о методах), которые они не используют» или “Много специализированных интерфейсов лучше, чем один универсальный”.
Итак, когда взаимодействие и зависимости модулей описываются лишь с помощью интерфейсов, те есть абстракций, без использования знаний об их внутреннем устройстве и структуре, то фактически тем самым реализуется инкапсуляция, плюс мы имеем возможность расширять/изменять поведения системы за счет добавления и использования различных реализаций, то есть за счет полиморфизма. Из этого следует, что концепция интерфейсов включает в себя и в некотором смысле обобщает почти все основные принципы ООП — Инкапсуляцию, Абстракцию, Полиморфизм. Но тут возникает один вопрос. Когда проектирование идет не на уровне объектов, которые сами же и реализуют соответствующие интерфейсы, а на уровне модулей, то что является реализацией интерфейса модуля? Ответ: если говорить языком шаблонов, то как вариант, за реализацию интерфейса модуля может отвечать специальный объект — Фасад.
Фасад — это объект-интерфейс, аккумулирующий в себе высокоуровневый набор операций для работы с некоторой подсистемой, скрывающий за собой ее внутреннюю структуру и истинную сложность. Обеспечивает защиту от изменений в реализации подсистемы. Служит единой точкой входа — «вы пинаете фасад, а он знает, кого там надо пнуть в этой подсистеме, чтобы получить нужное».
Таким образом, мы получаем первый, самый важный паттерн, позволяющий использовать концепцию интерфейсов при проектировании модулей и тем самым ослаблять их связанность — «Фасад». Помимо этого «Фасад» вообще дает возможность работать с модулями точно также как с обычными объектами и применять при проектировании модулей все те полезные принципы и техники, которые используются при проектирования классов.
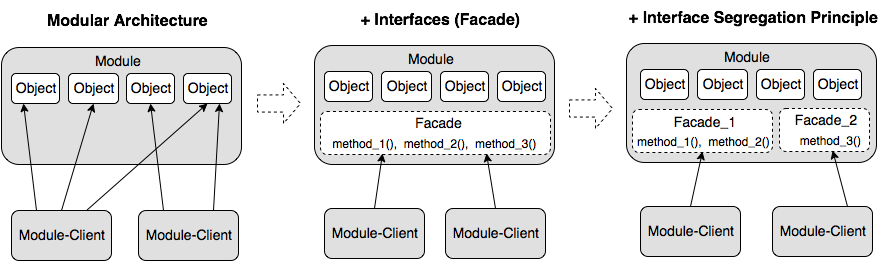
Замечание: Хотя большинство программистов понимают важность интерфейсов при проектировании классов (объектов), складывается впечатление, что идея необходимости использовать интерфейсы также и на уровне модулей только зарождается. Мне встретилось очень мало статей и проектов, где интерфейсы бы применялись для ослабления связанности между модулями/слоями и соответственно использовался бы паттерн «Фасад». Кто, например, видел «Фасад» на схемах уже упоминавшегося «архитектурного шаблона» Модель-Вид-Контроллер, или хотя бы слышал его упоминание среди паттернов, входящих в состав MVC (наряду с Observer и Composite)? А ведь он там должен быть, поскольку Модель это не класс, это модуль, причем центральный. И у создателя MVC Трюгве Реенскауга он, конечно же, был (смотрим «The Model-View-Controller (MVC ). Its Past and Present», только учитываем, что это писалось в 1973 году и то, что мы сейчас называем Представлением — Presentaition/UI тогда называлось Editior). Странным образом «Фасад» потерялся на многие годы и вновь обнаружить его мне удалось лишь недавно, в основном, в обобщенном варианте MVC от Microsoft («Microsoft Application Architecture Guide»). Вот соответствующие слайды:
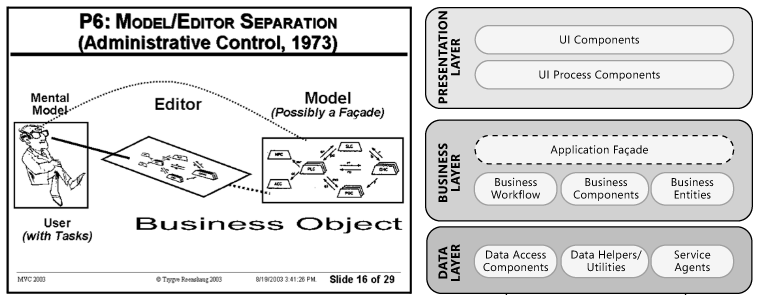
А разработчикам, к сожалению, приходится заново «переоткрывать» идею, что к объектам Модели, отвечающей за бизнес-логику приложения, нужно обращаться не напрямую а через интерфейс, то есть «Фасад», как например, в этой статье, откуда для полноты картины взят еще один слайд:
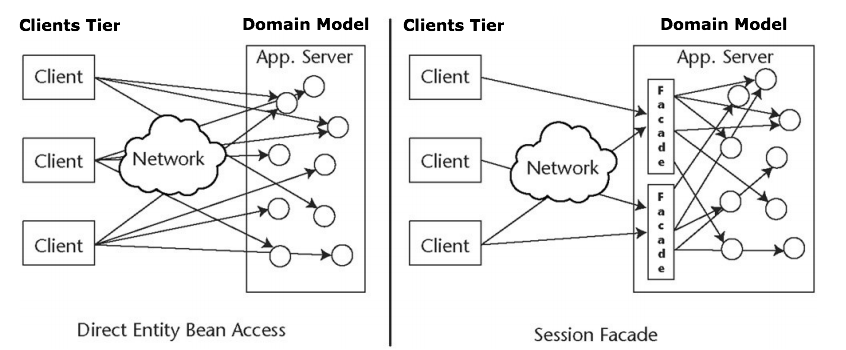
2. Dependency Inversion. Корректное создание и получение зависимостей
Формально, требование, чтобы модули не содержали ссылок на конкретные реализации, а все зависимости и взаимодействие между ними строились исключительно на основе абстракций, то есть интерфейсов, выражается принципом Инвертирования зависимостей (Dependency Inversion — последний из пяти принципов SOLID):
- Модули верхнего уровня не должны зависеть от модулей нижнего уровня. И те, и другие должны зависеть от абстракций.
- Абстракции не должны зависеть от деталей. Реализация должна зависеть от абстракции.
У этого принципа не самая очевидная формулировка, но суть его, как и было сказано, выражается правилом: «Все зависимости должны быть в виде интерфейсов». Подробно и очень хорошо принцип инвертирования зависимостей разбирается в статье Модульный дизайн или «что такое DIP, SRP, IoC, DI и т.п.». Статья из разряда must-read, лучшее, что доводилось читать по архитектуре ПО.
Не смотря на свою фундаментальность и кажущуюся простоту это правило нарушается, пожалуй, чаще всего. А именно, каждый раз, когда в коде программы/модуля мы используем оператор new и создаем новый объект конкретного типа, то тем самым вместо зависимости от интерфейса образуется зависимость от реализации.
Понятно, что этого нельзя избежать и объекты где-то должны создаваться. Но, по крайней мере, нужно свести к минимуму количество мест, где это делается и в которых явно указываются классы, а также локализовать и изолировать такие места, чтобы они не были разбросаны по всему коду программы. Решение заключается в том, чтобы сконцентрировать создание новых объектов в рамках специализированных объектов и модулей — фабрик, сервис локаторов, IoC-контейнеров.
В каком-то смысле такое решение следует Принципу единственного выбора (Single Choice Principle), который говорит: «всякий раз, когда система программного обеспечения должна поддерживать множество альтернатив, их полный список должен быть известен только одному модулю системы«. В этом случае, если в будущем придется добавить новые варианты (или новые реализации, как в рассматриваемом нами случае создания новых объектов), то достаточно будет произвести обновление только того модуля, в котором содержится эта информация, а все остальные модули останутся незатронутыми и смогут продолжать свою работу как обычно.
Ну а теперь разберем подробнее, как это делается на практике и каким образом модули могут корректно создавать и получать свои «зависимости», не нарушая принципа Dependency Inversion.
Итак, при проектировании модуля должны быть определены следующие ключевые вещи:
- что модуль делает, какую функцию выполняет
- что модулю нужно от его окружения, то есть с какими объектами/модулями ему придется иметь дело и
- как он это будет получать
Крайне важно то, как модуль получает ссылки на объекты, которые он использует в своей работе. И тут возможны следующие варианты:
- Модуль сам создает объекты необходимые ему для работы.
Но, как и было сказано, модуль не может это сделать напрямую — для создания необходимо вызвать конструктор конкретного типа, и в результате модуль будет зависеть не от интерфейса, а от конкретной реализации. Решить проблему в данном случае позволяет шаблон Фабричный Метод (Factory Method).
«Суть заключается в том, что вместо непосредственного инстанцирования объекта через new, мы предоставляем классу-клиенту некоторый интерфейс для создания объектов. Поскольку такой интерфейс при правильном дизайне всегда может быть переопределён, мы получаем определённую гибкость при использовании низкоуровневых модулей в модулях высокого уровня».
В случаях, когда нужно создавать группы или семейства взаимосвязанных объектов, вместо Фабричного Метода используется Абстрактная Фабрика (Abstract factory).
- Модуль берет необходимые объекты у того, у кого они уже есть (обычно это некоторый, известный всем репозиторий, в котором уже лежит все, что только может понадобиться для работы программы).
Этот подход реализуется шаблоном Локатор Сервисов (Service Locator), основная идея которого заключается в том, что в программе имеется объект, знающий, как получить все зависимости (сервисы), которые могут потребоваться.
Главное отличие от фабрик в том, что Service Locator не создаёт объекты, а фактически уже содержит в себе инстанцированные объекты (или знает где/как их получить, а если и создает, то только один раз при первом обращении). Фабрика при каждом обращении создает новый объект, который вы получаете в полную собственность и можете делать с ним что хотите. Локатор же сервисов выдает ссылки на одни и те же, уже существующие объекты. Поэтому с объектами, выданными Service Locator, нужно быть очень осторожным, так как одновременно с вами ими может пользоваться кто-то еще.
Объекты в Service Locator могут быть добавлены напрямую, через конфигурационный файл, да и вообще любым удобным программисту способом. Сам Service Locator может быть статическим классом с набором статических методов, синглетоном или интерфейсом и передаваться требуемым классам через конструктор или метод.
Вообще говоря, Service Locator иногда называют антипаттерном и не рекомендуют использовать (главным образом потому, что он создает неявные связности и дает лишь видимость хорошего дизайна). Подробно можно почитать у Марка Симана:
Service Locator is an Anti-Pattern
Abstract Factory or Service Locator? - Модуль вообще не заботиться о «добывании» зависимостей. Он лишь определяет, что ему нужно для работы, а все необходимые зависимости ему поставляются («впрыскиваются») из вне кем-то другим.
Это так и называется — Внедрение Зависимостей (Dependency Injection). Обычно требуемые зависимости передаются либо в качестве параметров конструктора (Constructor Injection), либо через методы класса (Setter injection).
Такой подход инвертирует процесс создания зависимости — вместо самого модуля создание зависимостей контролирует кто-то извне. Модуль из активного элемента, становится пассивным — не он делает, а для него делают. Такое изменение направления действия называется Инверсия Контроля (Inversion of Control), или Принцип Голливуда — «Не звоните нам, мы сами вам позвоним».
Это самое гибкое решение, дающее модулям наибольшую автономность. Можно сказать, что только оно в полной мере реализует «Принцип единственной ответственности» — модуль должен быть полностью сфокусирован на том, чтобы хорошо выполнять свою функцию и не заботиться ни о чем другом. Обеспечение его всем необходимым для работы это отдельная задача, которой должен заниматься соответствующий «специалист» (обычно управлением зависимостями и их внедрениями занимается некий контейнер — IoC-контейнер).
По сути, здесь все как в жизни: в хорошо организованной компании программисты программируют, а столы, компьютеры и все необходимое им для работы покупает и обеспечивает кладовщик. Или, если использовать метафору программы как конструктора — модуль не должен думать о проводах, сборкой конструктора занимается кто-то другой, а не сами детали.
Более подробно и с примерами о способах создания и получения зависимостей можно почитать, например, в этой статье (только надо иметь ввиду, что хотя автор пишет о Dependency Inversion, он использует термин Inversion of Control; возможно потому, что в русской википедии содержится ошибка и этим терминам даны одинаковые определения). А принцип Inversion of Control (вместе с Dependency Injection и Service Locator) детально разбирается Мартином Фаулером и есть переводы обеих его статей: «Inversion of Control Containers and the Dependency Injection pattern» и “Inversion of Control”.
Не будет преувеличением сказать, что использование интерфейсов для описания зависимостей между модулями (Dependency Inversion) + корректное создание и внедрение этих зависимостей (прежде всего Dependency Injection) являются центральными/базовыми техниками для снижения связанности. Они служат тем фундаментом, на котором вообще держится слабая связанность кода, его гибкость, устойчивость к изменениям, переиспользование, и без которого все остальные техники имеют мало смысла. Но, если с фундаментом все в порядке, то знание дополнительных приемов может быть очень даже полезным. Поэтому продолжим.
3. Замена прямых зависимостей на обмен сообщениями
Иногда модулю нужно всего лишь известить других о том, что в нем произошли какие-то события/изменения и ему не важно, что с этой информацией будет происходить потом. В этом случае модулям вовсе нет необходимости «знать друг о друге», то есть содержать прямые ссылки и взаимодействовать непосредственно, а достаточно всего лишь обмениваться сообщениями (messages) или событиями (events).
Связь модулей через обмен сообщениями является гораздо более слабой, чем прямая зависимость и реализуется она чаще всего с помощью следующих шаблонов:
- Наблюдатель (Observer). Применяется в случае зависимости «один-ко-многим», когда множество модулей зависят от состояния одного — основного. Использует механизм рассылки, который заключается в том, что основной модуль просто осуществляет рассылку одинаковых сообщений всем своим подписчикам, а модули, заинтересованные в этой информации, реализуют интерфейс «подписчика» и подписываются на рассылку. Находит широкое применение в системах с пользовательским интерфейсом, позволяя ядру приложения (модели) оставаться независимым и при этом информировать связанные с ним интерфейсы о том что произошли какие-то изменения и нужно обновиться.
Организация взаимодействия посредством рассылки сообщений имеет дополнительный «бонус» — необязательность существования «подписчиков» на «опубликованные» (т.е. рассылаемые) сообщения. Качественно спроектированная подобная система допускает добавление/удаление модулей в любое время.
- Посредник (Mediator). Применяется, когда между модулями имеется зависимость «многие ко многим. Медиатор выступает в качестве посредника в общении между модулями, действуя как центр связи и избавляет модули от необходимости явно ссылаться друг на друга. В результате взаимодействие модулей друг с другом («все со всеми») заменяется взаимодействием модулей лишь с посредником («один со всеми»). Говорят, что посредник инкапсулирует взаимодействие между множеством модулей.
Типичный пример — контроль трафика в аэропорту. Все сообщения, исходящие от самолетов, поступают в башню управления диспетчеру, вместо того, чтобы пересылаться между самолетами напрямую. А диспетчер уже принимает решения о том, какие самолеты могут взлетать или садиться, и в свою очередь отправляет самолетам соответствующие сообщения. Подробнее, например, тут.

Дополнение: Модули могут пересылать друг другу не только «простые сообщения, но и объекты-команды. Такое взаимодействие описывается шаблоном Команда (Command). Суть заключается в инкапсулировании запроса на выполнение определенного действия в виде отдельного объекта (фактически этот объект содержит один единственный метод execute()), что позволяет затем передавать это действие другим модулям на выполнение в качестве параметра, и вообще производить с объектом-командой любые операции, какие могут быть произведены над обычными объектами. Кратко рассмотрен тут, соответствующая глава из книги банды четырех тут, есть также статья на хабре.
4. Замена прямых зависимостей на синхронизацию через общее ядро
Данный подход обобщает и развивает идею заложенную в шаблоне «Посредник». Когда в системе присутствует большое количество модулей, их прямое взаимодействие друг с другом становится слишком сложным. Поэтому имеет смысл взаимодействие «все со всеми» заменить на взаимодействие «один со всеми». Для этого вводится некий обобщенный посредник, это может быть общее ядро приложения, хранилище или шина данных, а все остальные модули становятся независимыми друг от друга клиентами, использующими сервисы этого ядра или выполняющими обработку содержащейся там информации. Реализация этой идеи позволяет модулям-клиентам общаться друг с другом через посредника и при этом ничего друг о друге не знать.
Ядро-посредник может как знать о модулях-клиентах и управлять ими (пример — архитектура apache ), так и может быть полностью, или почти полностью, независимым и ничего о клиентах не знать. В сущности именно этот подход реализован в «шаблоне» Модель-Вид-Контроллер (MVC), где с одной Моделью (являющейся ядром приложение и общим хранилищем данных) могут взаимодействовать множество Пользовательских Интерфейсов, которые работают синхронно и при этом не знают друг о друге, а Модель не знает о них. Ничто не мешает подключить к общей модели и синхронизировать таким образом не только интерфейсы, но и другие вспомогательные модули.
Очень активно эта идея также используется при разработке игр, где независимые модули, отвечающие за графику, звук, физику, управление программой синхронизируются друг с другом через игровое ядро (модель), где хранятся все данные о состоянии игры и ее персонажах. В отличие от MVC, в играх согласование модулей с ядром (моделью) происходит не за счет шаблона «Наблюдатель», а по таймеру, что само по себе является интересным архитектурным решением весьма полезным для программ с анимацией и «бегущей» графикой.
5. Закон Деметры (law of Demeter)
Закон Деметры запрещает использование неявных зависимостей: «Объект A не должен иметь возможность получить непосредственный доступ к объекту C, если у объекта A есть доступ к объекту B и у объекта B есть доступ к объекту C«. Java-пример.
Это означает, что все зависимости в коде должны быть «явными» — классы/модули могут использовать в работе только «свои зависимости» и не должны лезть через них к другим. Кратко этот принцип формулируют еще таким образом: «Взаимодействуй только с непосредственными друзьями, а не с друзьями друзей«. Тем самым достигается меньшая связанность кода, а также большая наглядность и прозрачность его дизайна.
Закон Деметры реализует уже упоминавшийся «принцип минимального знания», являющейся основой слабой связанности и заключающийся в том, что объект/модуль должен знать как можно меньше деталей о структуре и свойствах других объектов/модулей и вообще чего угодно, включая собственные подкомпоненты. Аналогия из жизни: Если Вы хотите, чтобы собака побежала, глупо командовать ее лапами, лучше отдать команду собаке, а она уже разберётся со своими лапами сама.
6. Композиция вместо наследования
Одну из самых сильных связей между объектами дает наследование, поэтому, по возможности, его следует избегать и заменять композицией. Эта тема хорошо раскрыта в статье Герба Саттера — «Предпочитайте композицию наследованию».
Могу только посоветовать в данном контексте обратить внимание на шаблон Делегат (Delegation/Delegate) и пришедший из игр шаблон Компонет (Component), который подробно описан в книге «Game Programming Patterns» (соответствующая глава из этой книги на английском и ее перевод).
Что почитать
Статьи в интернете:
- Design patterns for decoupling (небольшая полезная глава из UML Tutorial);
- Немного про архитектуру;
- Patterns For Large-Scale JavaScript Application Architecture;
- Слабое связывание компонентов в JavaScript;
- Как писать тестируемый код — статья из которой хорошо видно что критерии тестируемости кода и хорошего дизайна совпадают;
- сайт Мартина Фаулера.
Замечательный ресурс — Архитектура приложений с открытым исходным кодом, где «авторы четырех дюжин приложений с открытым исходным кодом рассказывают о структуре созданных ими программ и о том, как эти программы создавались. Каковы их основные компоненты? Как они взаимодействуют? И что открыли для себя их создатели в процессе разработки? В ответах на эти вопросы авторы статей, собранных в данных книгах, дают вам уникальную возможность проникнуть в то, как они творят«. Одна из статей полностью была опубликована на хабре — «Масштабируемая веб-архитектура и распределенные системы».
Интересные решения и идеи можно найти в материалах, посвященных разработке игр. Game Programming Patterns — большой сайт с подробным описанием многих шаблонов и примерами их применения к задаче создания игр (оказывается, есть уже его перевод — «Шаблоны игрового программирования», спасибо strannik_k за ссылку). Возможно будет полезна также статья «Гибкая и масштабируемая архитектура для компьютерных игр» (и ее оригинал. Нужно только иметь ввиду что автор почему-то композицию называет шаблоном «Наблюдатель»).
По поводу паттернов проектирования:
- Интересная «Мысль про паттерны проектирования»;
- Удобный сайт с краткими описаниями и схемами всех шаблонов проектирования — «Обзор паттернов проектирования»;
- сайт на базе книги банды четырех, где все шаблоны описаны очень подробно — «Шаблоны [Patterns] проектирования».
Есть еще принципы/паттерны GRASP, описанные Крэгом Лэрманом в книге «Применение UML 2.0 и шаблонов проектирования», но они больше запутывают чем проясняют. Краткий обзор и обсуждение на хабре (самое ценное в комментариях).
Ну и конечно же книги:
- Мартин Фаулер «Архитектура корпоративных программных приложений»;
- Стив Макконнелл «Совершенный код»;
- Шаблоны проектирования от банды четырех (Gang of Four, GoF) — «Приемы объектно-ориентированного проектирования. Паттерны проектирования».