In this article, we are going to see how to fill color by the group in the histogram using Matplotlib in Python.
Method 1: Using pivot() method
In this method, we are going to use the pivot method which returns an organized DataFrame based on specified index/column values.
Syntax: DataFrameName.pivot(index=’indexLabel’, columns=’columnLabel’, values=’columnName’)
Note: This approach is followed when we want to perform further grouping on the given data.
We use this DataFrame in this approach to plot a histogram representing ages between different genders.
Python3
import pandas as pd
import matplotlib.pyplot as plt
personAges = pd.DataFrame({'Gender': ['Male', 'Female',
'Male', 'Female',
'Female'],
'Age': [25, 19, 21, 30, 18]})
personAges.pivot(columns='Gender', values='Age').plot.hist()
plt.show()
Output:
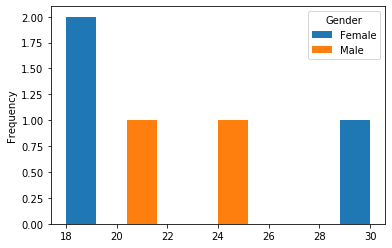
Here the original DataFrame is reorganized the Age values based on the Gender column into a new DataFrame. To this reorganized DataFrame we plotted histogram.
The resultant plot indicates there are 2 females between the age 18-20, 1 female is in the age 29-30 and 1 male between 20-22 i.e., 21 and finally 1 male is between 24-25.
Method 2: Using separated dataset
This method can be followed when we already have separated data on any basis. Let’s consider 2 objects that hold the age of males and females.
mens_age=18,19,20,21,22,23,24,25,26,27 female_age=22,28,30,30,12,33,41,22,43,18
If we have the above kind of separated data then we can specify different colors to the different groups while plotting histogram i.e., in hist method.
Python3
import matplotlib.pyplot as plt
mens_age = 18, 19, 20, 21, 22, 23, 24, 25, 26, 27
female_age = 22, 28, 30, 30, 12, 33, 41, 22, 43, 18
plt.hist([mens_age, female_age], color=[
'Black', 'Red'], label=['Male', 'Female'])
plt.xlabel('Age')
plt.ylabel('Person Count')
plt.legend()
plt.show()
Output:
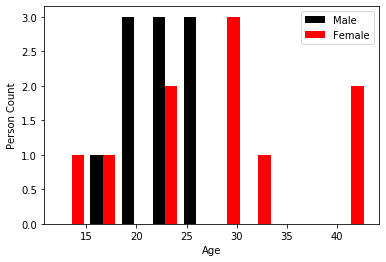
As we already have grouped data based on gender we no need to use any pivot function. So we can directly specify those separate sets of data with different colors in hist function.
These are the two approaches that need to be followed based on the given data and requirement to fill color by groups in the histogram.
Seaborn — библиотека для создания статистических графиков на Python. Она построена на основе matplotlib и тесно интегрируется со структурами данных pandas. Seaborn помогает вам изучить и понять данные. Его функции построения графиков работают с датасетами и выполняют все необходимы преобразования для создания информативных графиков.
Синтаксис, ориентированный на набор данных, позволяет сосредоточиться на графиках, а не деталях их построения.
Официальная документация на английском: https://seaborn.pydata.org/index.html.
Официальные релизы seaborn можно установить из PyPI:
pip install seabornБиблиотека также входит в состав дистрибутива Anaconda:
conda install seaborn
Библиотека работает с Python версии 3.6+. Если их еще нет, эти библиотеки будут загружены при установке seaborn: numpy, scipy, pandas, matplotlib.
Как только вы установите Seaborn, можете скачать и построить тестовый график для одного из встроенных датасетов:
import seaborn as sns
df = sns.load_dataset("penguins")
sns.pairplot(df, hue="species")
Выполнив этот код в Jupyter Notebook, увидите такой график.
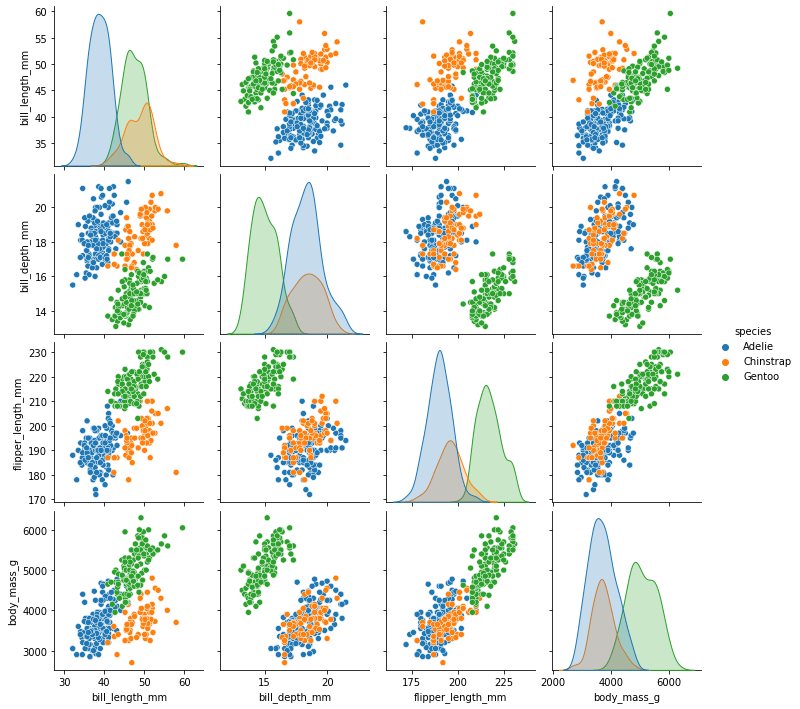
Если вы не работаете с Jupyter, может потребоваться явный вызов matplotlib.pyplot.show():
import matplotlib.pyplot as plt
plt.show()
Давайте более детально рассмотрим построение популярных типов графиков.
Весь дальнейший код будет выполняться в Jupyter Notebook
Построение Bar Plot в Seaborn
Гистограммы отображают числовые величины на одной оси и переменные категории на другой. Они позволяют вам увидеть, значения параметров для каждой категории.
Гистограммы можно использовать для визуализации временных рядов, а также только категориальных данных.
Построение гистограммы
Чтобы нарисовать гистограмму в Seaborn нужно вызвать функцию barplot(), и передать ей категориальные и числовые переменные, которые нужно визуализировать, как это сделано в примере:
import matplotlib.pyplot as plt
import seaborn as sns
x = ['А', 'Б', 'В']
y = [10, 50, 30]
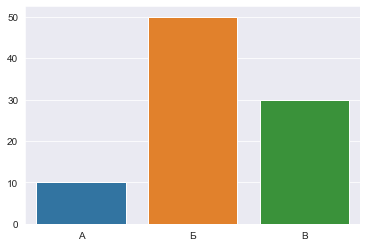
sns.barplot(x=x, y=y);
В данном случае, у нас есть несколько категориальных переменных в списке — А, Б и В. А также непрерывные переменные (числа) в другом списке — 10, 50 и 30. Зависимость между этими двумя элементами визуализируется на гистограмме, для чего эти два списка передаются в функцию sns.barplot().
В результате получается четкая и простая гистограмма:
Чаще всего вы будете работать с датасетами, которые содержат гораздо больше данных, чем тот что приведен в примере. Иногда к этим наборам данным требуется сортировка, или подсчитать, сколько раз повторяются то или другое значение.
Когда вы работаете с данными можете столкнуться с ошибками и пропусками, которые в них имеются. К счастью, Seaborn защищает нас и автоматически применяет фильтр, который основан на вычислении среднего значения предоставленных данных.
Давайте импортируем классический датасет Titanic и визуализируем Bar Plot с этими данными:
# Импорт данных
titanic_dataset = sns.load_dataset("titanic")
# Постройка графика
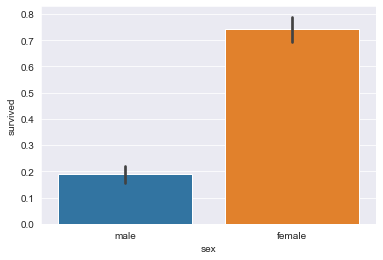
sns.barplot(x="sex", y="survived", data=titanic_dataset);
В данном случае мы назначили осям Х и Y колонки "sex" и "survived", вместо жестко заданных.
Если мы выведем первые строки датасета (titanic_dataset.head()), увидим такую таблицу:
survived pclass sex age sibsp parch fare ...
0 0 3 male 22.0 1 0 7.2500 ...
1 1 1 female 38.0 1 0 71.2833 ...
2 1 3 female 26.0 0 0 7.9250 ...
3 1 1 female 35.0 1 0 53.1000 ...
4 0 3 male 35.0 0 0 8.0500 ...Убедитесь, что имена колонок совпадают с теми, которые вы назначили переменным x и y.
Наконец, мы используем эти данные и передаем их в качестве аргумента функции, с которой работаем. И получаем такой результат:
Построение горизонтальной гистограммы
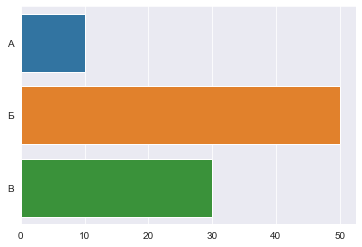
Чтобы нарисовать горизонтальную, а не вертикальную гистограмму нужно просто поменять местами переменные передаваемые в x и y.
В этом случае категориальная переменная будет отображаться по оси Y, что приведет к постройке горизонтального графика:
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=y, y=x);
График будет выглядеть так:
Как изменить цвет в barplot()
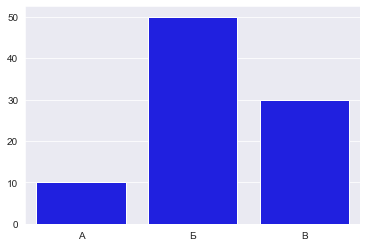
Изменить цвет столбцов довольно просто. Для этого нужно задать параметр color функции barplot и тогда цвет всех столбцов изменится на заданный.
Изменим на голубой:
x = ['А', 'Б', 'В']
y = [10, 50, 30]
sns.barplot(x=x, y=y, color='blue');
Тогда график будет выглядеть так:
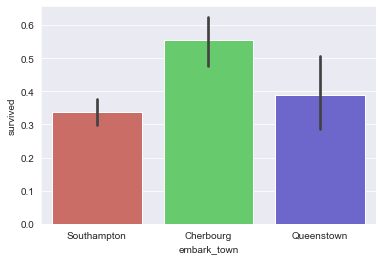
Или, что еще лучше, установить аргумент pallete, который может принимать большое количество цветов. Довольно распространенное значение этого параметра hls:
sns.barplot(
x="embark_town",
y="survived",
palette='hls',
data=titanic_dataset
);
Что приведет к такому результату:
Группировка Bar Plot в Seaborn
Часто требуется сгруппировать столбцы на графиках по одному признаку. Допустим, вы хотите сравнить некоторые общие данные, выживаемость пассажиров, и сгруппировать их по заданным критериям.
Нам может потребоваться визуализировать количество выживших пассажиров, в зависимости от класса (первый, второй и третий), но также учесть, города из которого они прибыли.
Всю эту информацию можно легко отобразить на гистограмме.
Чтобы сгруппировать столбцы вместе, мы используем аргумент hue. Этот аргумент группирует соответствующие данные и сообщает библиотеке Seaborn, как раскрашивать столбцы.
Давайте посмотрим на только что обсужденный пример:
sns.barplot(x="class", y="survived", hue="embark_town", data=titanic_dataset);
Получим такой график:
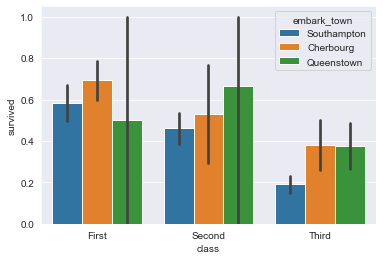
Настройка порядка отображения групп столбцов на гистограмме
Вы можете изменить порядок следования столбцов по умолчанию. Это делается с помощью аргумента order, который принимает список значений и порядок их размещения.
Например, до сих пор он упорядочивал классы с первого по третий. Что, если мы захотим сделать наоборот?
sns.barplot(
x="class",
y="survived",
hue="embark_town",
order=["Third", "Second", "First"],
data=titanic_dataset
);
Получится такой график:
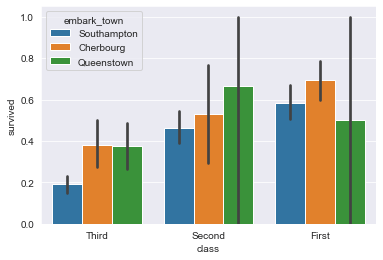
Изменяем доверительный интервал в barplot()
Вы также можете поэкспериментировать с доверительным интервалом, задав аргумент ci.
Например, вы можете отключить его, установив для него значение None, или использовать стандартное отклонение вместо среднего, установив sd, или даже установить верхний предел на шкале ошибок, установив capsize.
Давайте немного поэкспериментируем с атрибутом доверительного интервала:
sns.barplot(
x="class",
y="survived",
hue="embark_town",
ci=None,
data=titanic_dataset
);
Получим такой результат:
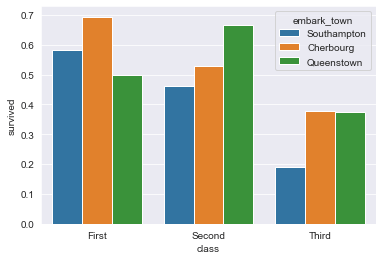
Или мы можем использовать стандартное отклонение:
sns.barplot(
x="class",
y="survived",
hue="who",
ci="sd",
capsize=0.1,
data=titanic_dataset
);
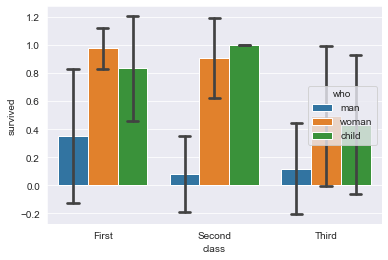
Мы рассмотрели несколько способов построения гистограммы в Seaborn на примерах. Теперь перейдем к тепловым картам.
Построение Heatmap в Seaborn
Давайте посмотрим, как мы можем работать с библиотекой Seaborn на Python, чтобы создать базовую тепловую карту корреляции.
Для наших целей мы будем использовать набор данных о жилье Ames, доступный на Kaggle.com. Он содержит более 30 показателей, которые потенциально могут повлиять на стоимость недвижимости.
Поскольку Seaborn была написана на основе библиотеки визуализации данных Matplotlib, их довольно просто использовать вместе. Поэтому помимо стандартных модулей мы также собираемся импортировать Matplotlib.pyplot.
import pandas as pd
import numpy as np
import seaborn as sns
import matplotlib.pyplot as plt
Следующий код создает матрицу корреляции между всеми исследуемыми показателями и нашей переменной y (стоимость недвижимости).
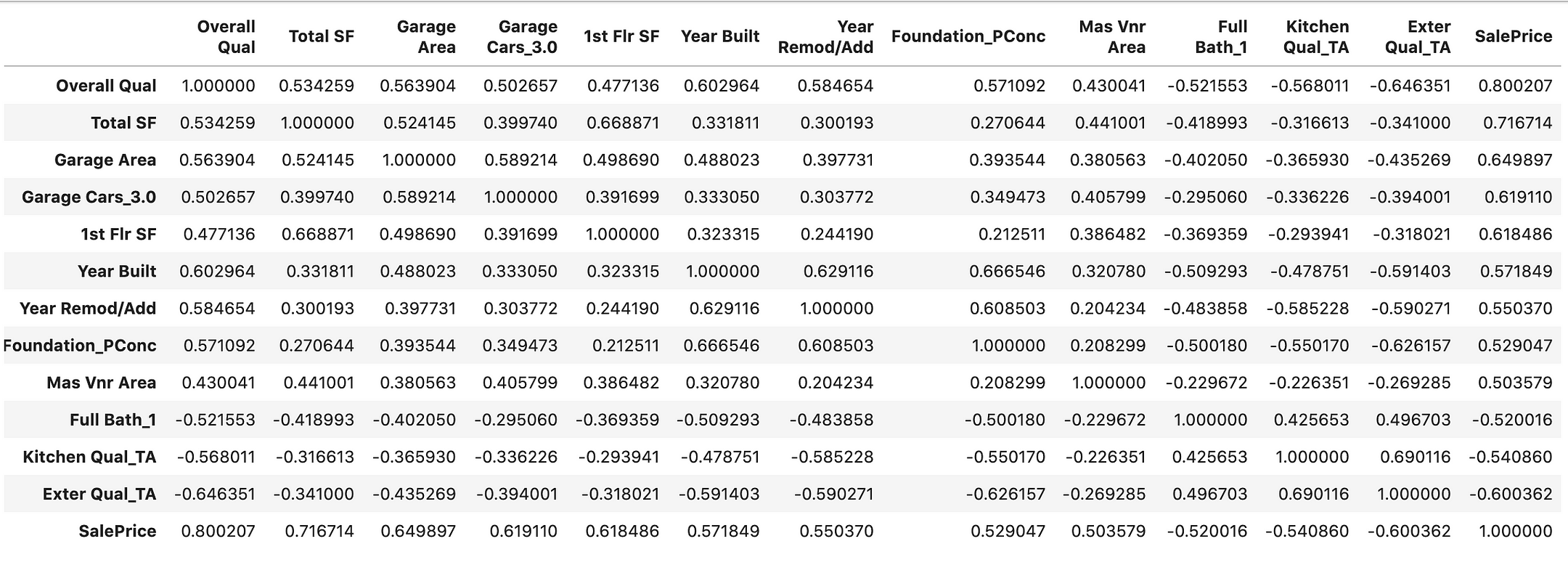
Корреляционная матрица всего с 13 переменными. Нельзя сказать, что она совсем не читабельна. Однако почему бы не облегчить себе жизнь визуализацией?
Простая тепловая карта в Seaborn
sns.heatmap(dataframe.corr());
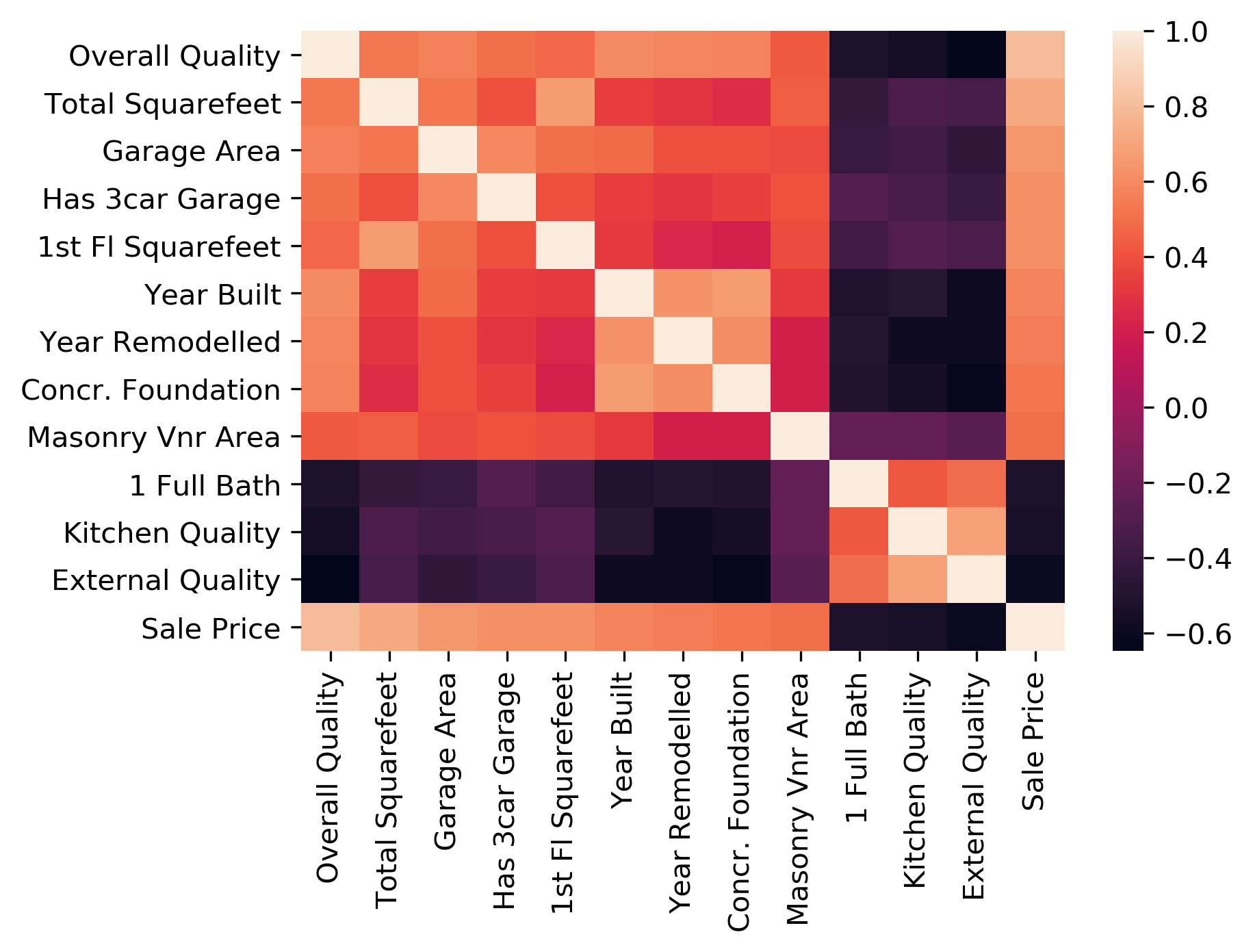
Seaborn прост в использовании, но в нем довольно сложно ориентироваться. Библиотека поставляется с множеством встроенных функций и обширной документацией. Может быть трудно понять, какие именно аргументы использовать, если вам не нужны все возможные навороты.
Давайте сделаем базовую тепловую карту более полезной с минимальными усилиями.
Взгляните на список аргументов heatmap:
seaborn.heatmap(data, *, vmin=None, vmax=None, cmap=None, center=None, robust=False, annot=None, fmt='.2g', annot_kws=None, linewidths=0, linecolor='white', cbar=True, cbar_kws=None, cbar_ax=None, square=False, xticklabels='auto', yticklabels='auto', mask=None, ax=None, **kwargs)vmin,vmax— устанавливают диапазон значений, которые служат основой для цветовой карты (colormap).cmap— определяет конкретную colormap, которую мы хотим использовать (ознакомьтесь с полным диапазоном цветовых палитр здесь).center— принимает вещественное число для центрирования цветовой карты; еслиcmapне указан, используется colormap по умолчанию; если установлено значениеTrue— все цвета заменяются на синий.annot— при значенииTrueчисловые значения корреляции отображаются внутри ячеек.cbar— если установлено значениеFalse, цветовая шкала (служит легендой) исчезает.
# Увеличьте размер
heatmap plt.figure(figsize=(16, 6))
# Сохраните объект тепловой карты в переменной, чтобы легко получить к нему доступ,
# когда вы захотите включить дополнительные функции (например, отображение заголовка).
# Задайте диапазон значений для отображения на цветовой карте от -1 до 1 и установите для аннотации (annot) значение True,
# чтобы отобразить числовые значения корреляции на тепловой карте.
heatmap = sns.heatmap(dataframe.corr(), vmin=-1, vmax=1, annot=True)
# Дайте тепловой карте название. Параметр pad (padding) определяет расстояние заголовка от верхней части тепловой карты.
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':12}, pad=12);
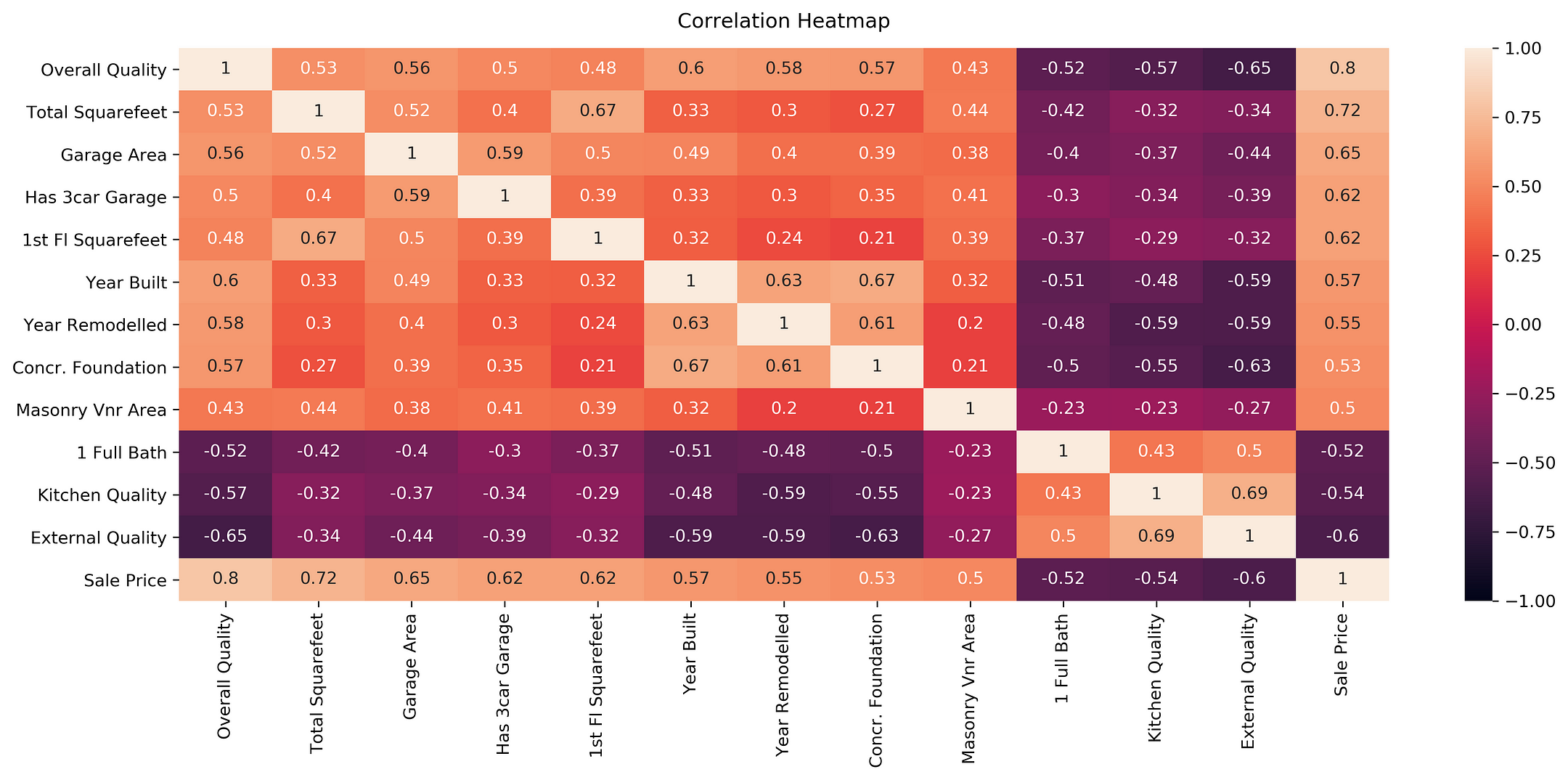
Для работы с heatmap лучше всего подходит расходящаяся цветовая палитра. Она имеет два очень разных темных (насыщенных) цвета на соответствующих концах диапазона интерполированных значений с бледной, почти бесцветной средней точкой. Проиллюстрируем это утверждение и разберемся с еще одной небольшой деталью: как сохранить созданную тепловую карту в файл png со всеми необходимыми x и y метками (xticklabels и yticklabels).
plt.figure(figsize=(16, 6))
heatmap = sns.heatmap(dataframe.corr(), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Correlation Heatmap', fontdict={'fontsize':18}, pad=12);
# Сохраните карту как png файл
# Параметр dpi устанавливает разрешение сохраняемого изображения в точках на дюйм
# bbox_inches, когда установлен в значение 'tight', не позволяет обрезать лейблы
plt.savefig('heatmap.png', dpi=300, bbox_inches='tight')
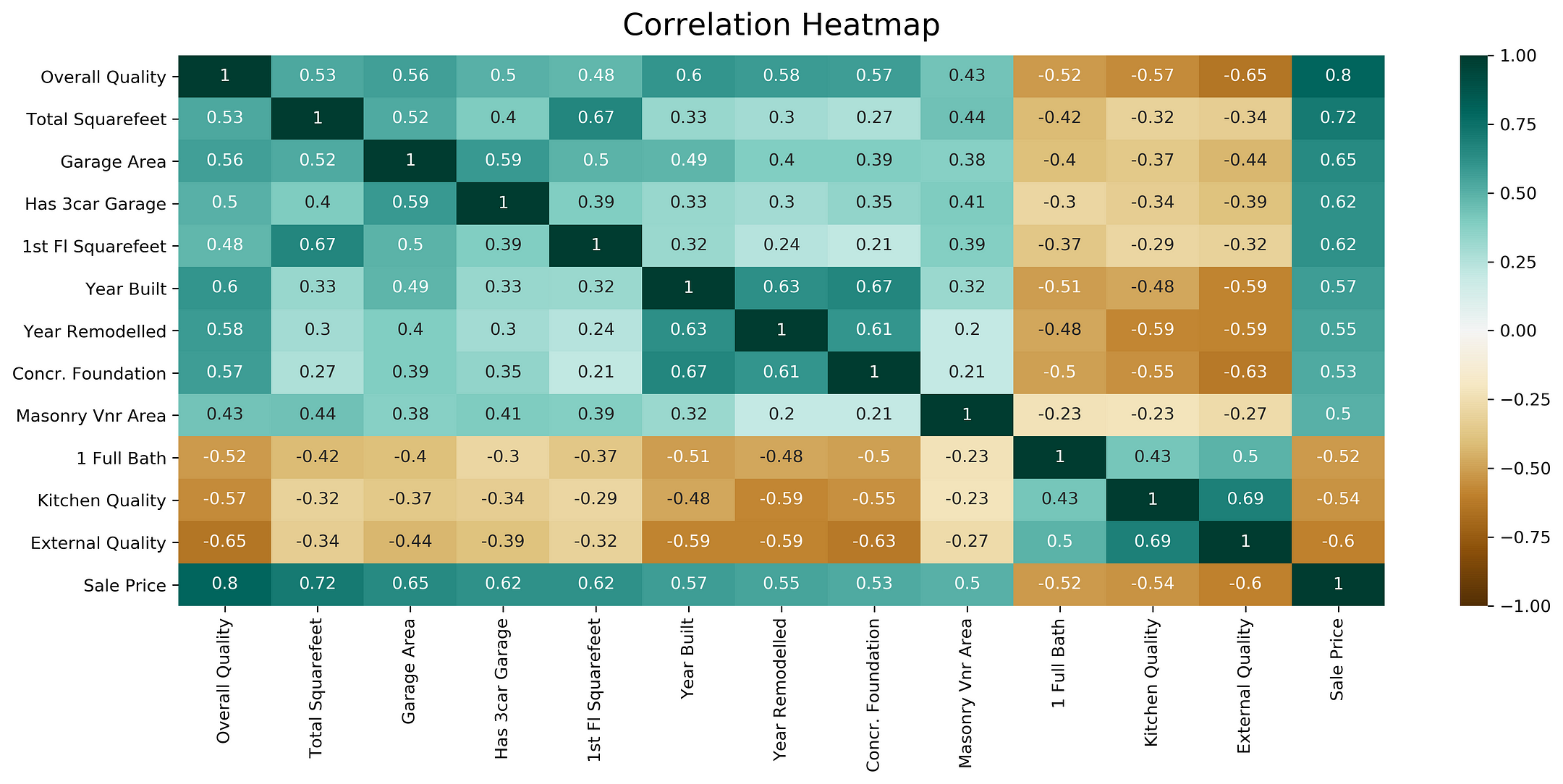
Треугольная тепловая карта корреляции
Взгляните на любую из приведенных выше тепловых карт. Если вы отбросите одну из ее половин по диагонали, обозначенной единицами, вы не потеряете никакой информации. Итак, давайте сократим тепловую карту, оставив только нижний треугольник.
Аргумент mask (маска) heatmap пригодится, чтобы скрыть часть тепловой карты. Маска — принимает в качестве аргумента массив логических значений или структуру табличных данных (dataframe). Если она предоставлена, ячейки тепловой карты, для которых значения маски является True, не отображаются.
Давайте воспользуемся функцией np.triu() библиотеки numpy, чтобы изолировать верхний треугольник матрицы, превращая все значения в нижнем треугольнике в 0. np.tril() будет делать то же самое, только для нижнего треугольника. В свою очередь функция np.ones_like() изменит все изолированные значения на 1.
np.triu(np.ones_like(dataframe.corr()))

plt.figure(figsize=(16, 6))
# Определите маску, чтобы установить значения в верхнем треугольнике на True
mask = np.triu(np.ones_like(dataframe.corr(), dtype=np.bool))
heatmap = sns.heatmap(dataframe.corr(), mask=mask, vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Triangle Correlation Heatmap', fontdict={'fontsize':18}, pad=16);
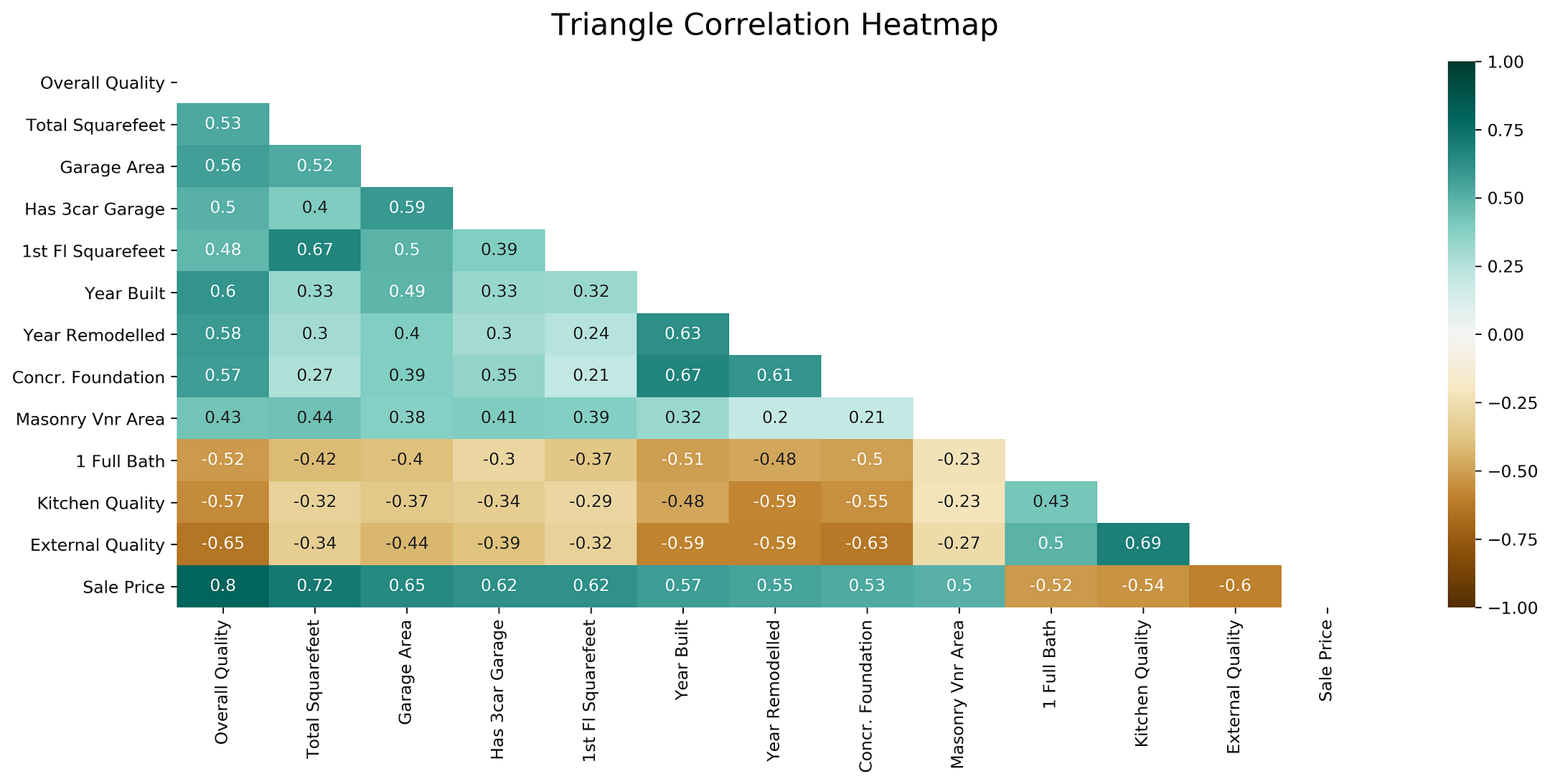
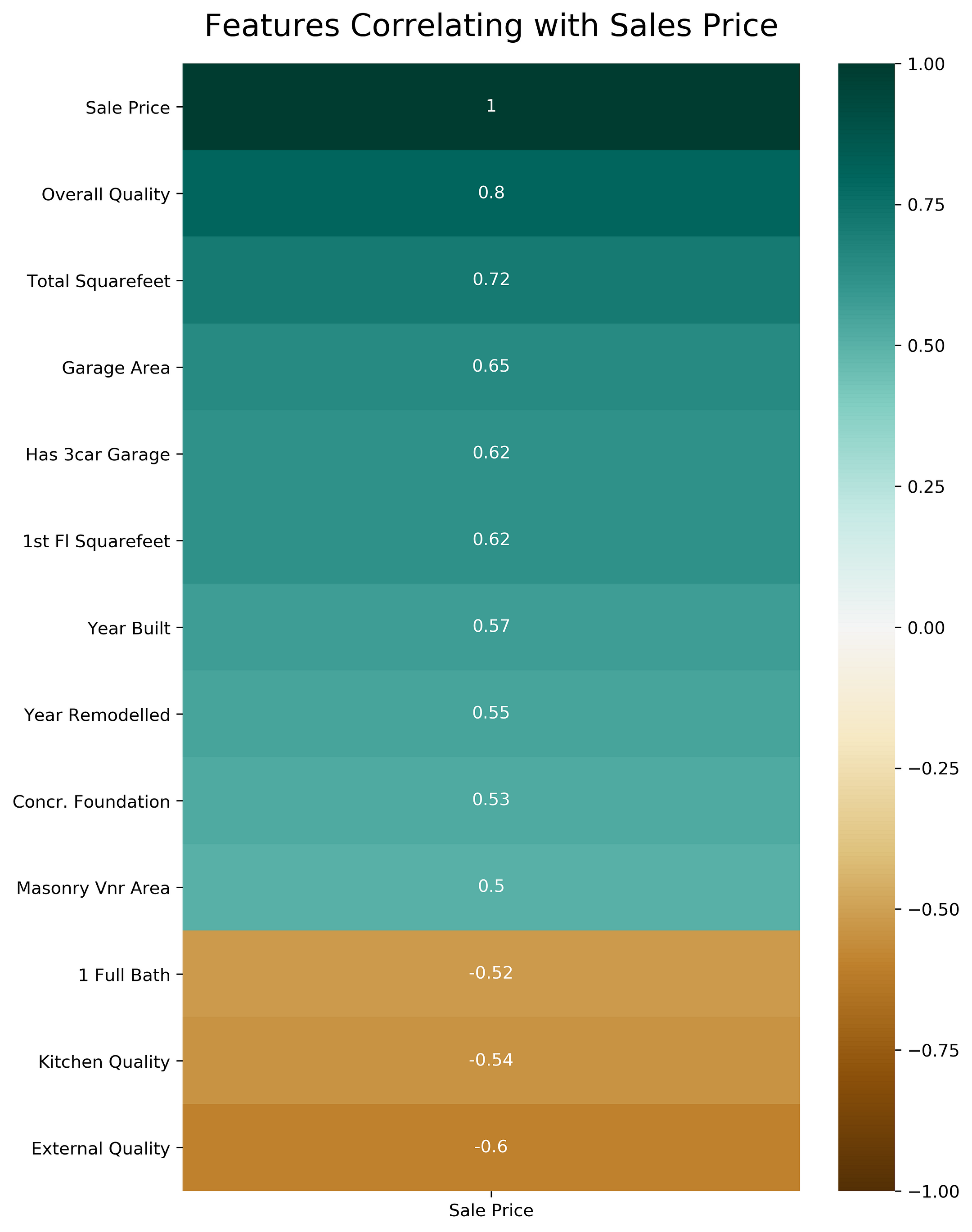
Корреляция независимых переменных с зависимой
Довольно часто мы хотим создать цветную карту, которая показывает выраженность связи между каждой независимой переменной, включенной в нашу модель, и зависимой переменной.
Следующий код возвращает корреляцию каждого параметра с «ценой продажи», единственной зависимой переменной в порядке убывания.
dataframe.corr()[['Sale Price']].sort_values(by='Sale Price', ascending=False)
Давайте используем полученный список в качестве данных для отображения на тепловой карте.
plt.figure(figsize=(8, 12))
heatmap = sns.heatmap(dataframe.corr()[['Sale Price']].sort_values(by='Sale Price', ascending=False), vmin=-1, vmax=1, annot=True, cmap='BrBG')
heatmap.set_title('Features Correlating with Sales Price', fontdict={'fontsize':18}, pad=16);
Эти примеры демонстрируют основную функциональность heatmap в Seaborn. Теперь перейдем к точечным диаграммам.
Построение Scatter Plot в Seaborn
Давайте рассмотрим процесс создания точечной диаграммы в Seaborn. Построим простые и трехмерные диаграммы рассеивания, а также групповые графики на базе FacetGrid.
Импорт данных
Мы будем использовать набор данных, основанный на мировом счастье. Сравнение его индекса с другими показателям отразит факторы, влияющие на уровень счастья в мире.
Построение точечной диаграммы
На графике отразим соотношение индекса счастья к экономике страны (ВВП на душу населения):
dataframe = pd.read_csv('2016.csv')
sns.scatterplot(data=dataframe, x="Economy (GDP per Capita)", y="Happiness Score");
При помощи Seaborn очень легко составлять простые графики наподобие диаграмм рассеивания. Нам не обязательно использовать объект Figure и экземпляры Axes или что-нибудь настраивать. Здесь мы передали dataframe в качестве аргумента с данными, а признаки с информацией, которую нужно визуализировать, в x и y.
Оси диаграммы по умолчанию подписываются именами столбцов, которые соответствуют заголовкам из загружаемого файла. Ниже мы рассмотрим, как это изменить.
После выполнения кода мы получим следующее:
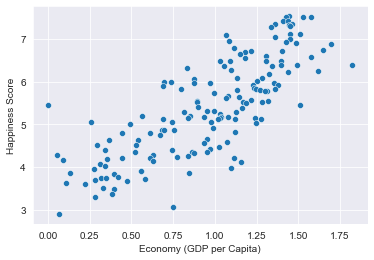
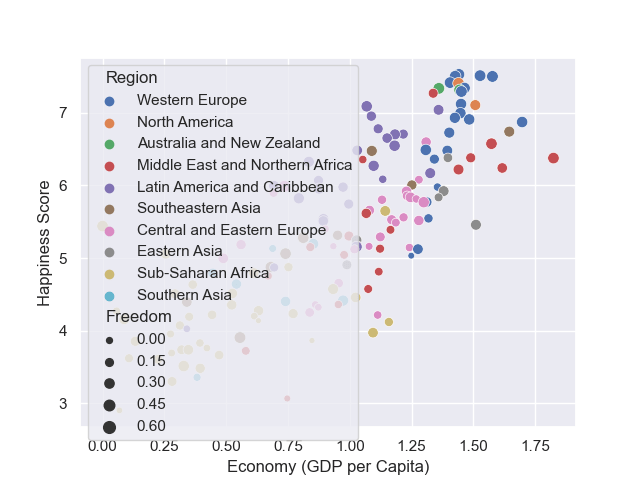
Результат показал прямую зависимость между ВВП на душу населения и предполагаемого уровня счастья жителей конкретной страны или региона.
Построение группы графиков scatterplot при помощи FacetGrid
Если требуется сравнить много переменных друг с другом, например, среднюю продолжительность жизни наряду с оценкой счастья и уровнем экономики, нет необходимости строить 3D-график.
Несмотря на существование двумерных диаграмм, позволяющих визуализировать соотношение между множествами переменных, не все из них просты в применении.
При помощи объекта FacetGrid, библиотека Seaborn позволяет обрабатывать данные и строить на их основе групповые взаимосвязанные графики.
Взглянем на следующий пример:
grid = sns.FacetGrid(dataframe, col="Region", hue="Region", col_wrap=5)
grid.map(sns.scatterplot, "Economy (GDP per Capita)", "Health (Life Expectancy)")
grid.add_legend();
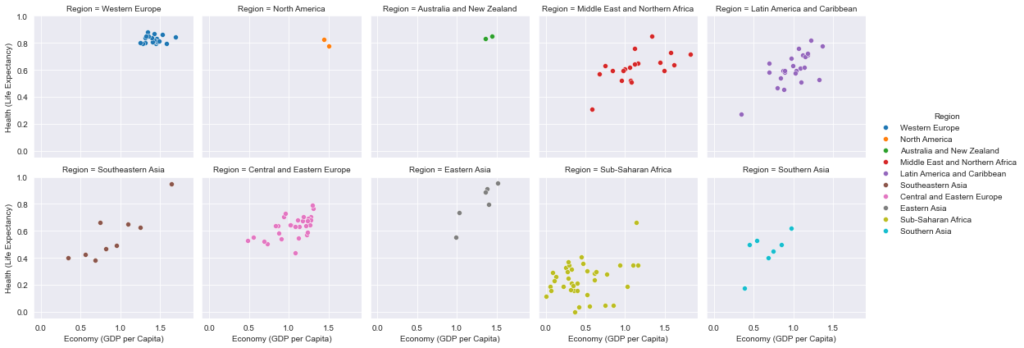
В этом примере мы создали экземпляр объекта FacetGrid с параметром dataframe в качестве данных. При передаче значения "Region" аргументу col библиотека сгруппирует датасет по регионам и построит диаграмму рассеивания для каждого из них.
Параметр hue задает каждому региону собственный оттенок. Наконец, при помощи аргумента col_wrap ширина области Figure ограничивается до 5-ти диаграмм. По достижении этого предела следующие графики будут построены на новой строке.
Для подготовки сетки перед выводом на экран мы используем метод map(). Тип диаграммы передается в первом аргументе со значением sns.scatterplot, а в качестве осей служат переменные x и y.
В результате будет сформировано 10 графиков по каждому региону с соответствующими им осями. Непосредственно перед печатью мы вызываем метод, добавляющий легенду с обозначением цветовой маркировки.
Построение 3D-диаграммы рассеивания
К сожалению, в Seaborn отсутствует собственный 3D-движок. Являясь лишь дополнением к Matplotlib, он опирается на графические возможности основной библиотеки. Тем не менее, мы все еще можем применить стиль Seaborn к трехмерной диаграмме.
Посмотрим, как она будет выглядеть с выборкой по уровням счастья, экономики и здоровья:
%matplotlib notebook
import matplotlib.pyplot as plt
import pandas as pd
import seaborn as sns
from mpl_toolkits.mplot3d import Axes3D
df = pd.read_csv('Downloads/2016.csv')
fig = plt.figure()
ax = fig.add_subplot(111, projection = '3d')
x = df['Happiness Score']
y = df['Economy (GDP per Capita)']
z = df['Health (Life Expectancy)']
ax.set_xlabel("Счастье")
ax.set_ylabel("Экономика")
ax.set_zlabel("Здоровье")
ax.scatter(x, y, z)
plt.show()
В результате выполнения кода появится интерактивная 3D-визуализация, которую можно вращать и масштабировать в трехмерном пространстве:
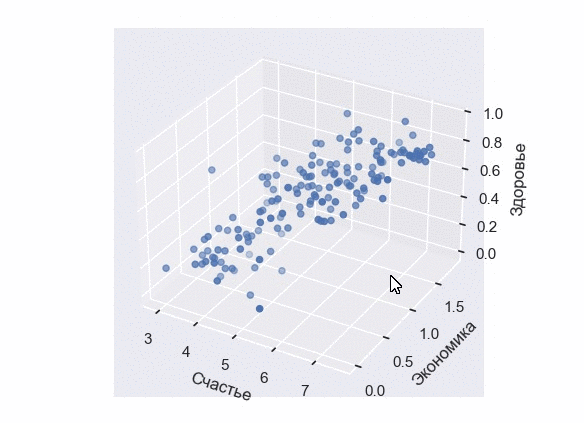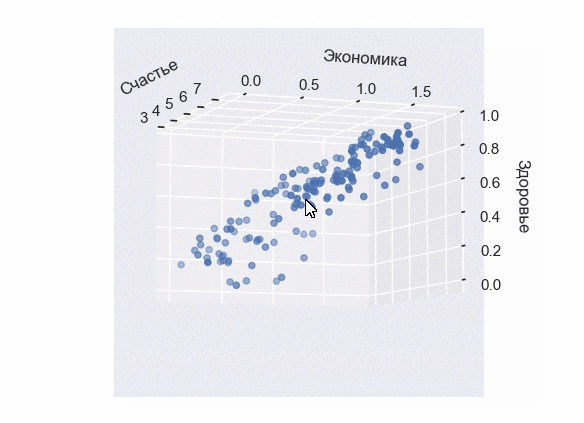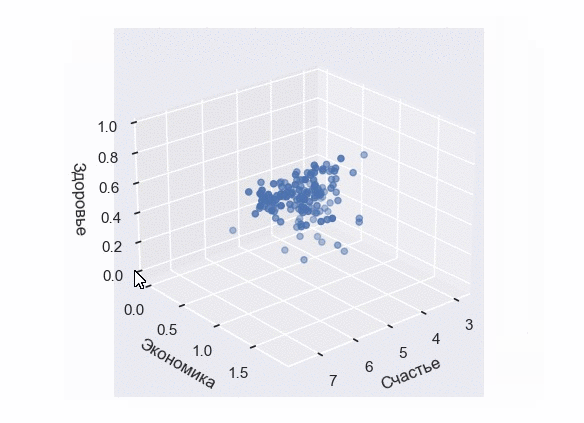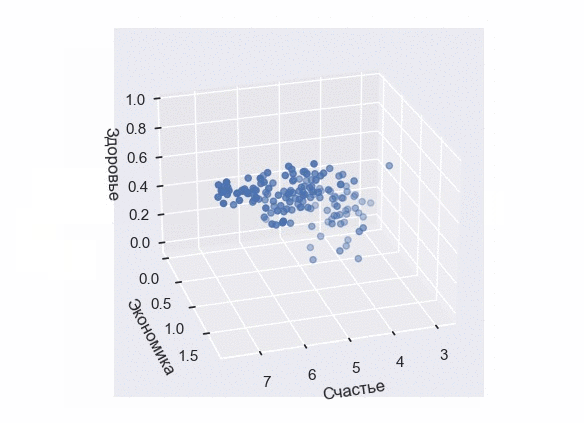
Настройка Scatter Plot
При помощи Seaborn можно легко настраивать различные элементы создаваемых диаграмм. Например, присутствует возможность изменения цвета и размера каждой точки на графике.
Попробуем задать некоторые параметры и посмотреть, как изменится его внешний вид:
sns.scatterplot(
data=dataframe,
x="Economy (GDP per Capita)",
y="Happiness Score",
hue="Region",
size="Freedom"
);
Здесь мы применили оттенок к регионам — это означает, что данные по каждому из них будут раскрашены по-разному. Кроме того, при помощи аргумента size были заданы пропорции точек в зависимости от уровня свободы. Чем больше его значение, тем крупнее точка на диаграмме:
Или можно просто задать одинаковый цвет и размер для всех точек:
sns.scatterplot(
data=dataframe,
x="Economy (GDP per Capita)",
y="Happiness Score",
color="red",
sizes=5
);
Отлично, вы узнали несколько способов построения scatter plot в Seaborn. Перейдем к еще одному популярному графику.
Построение Box Plot в Seaborn
Box Plot, называемые также:
- графиками прямоугольников,
- коробчатыми графиками,
- графиками размаха
- или ящиками с усами за свой вид.
Они используются для визуализации сводной статистики датасета. Box Plot отображают атрибуты распределения, такие как диапазон и распределение данных в диапазоне (прямоугольника, «усы», медиана).
Импорт данных
Для создания box plot нужны непрерывные числовые данные, поскольку такая диаграмма отображает сводную статистику — медиану, диапазон и выбросы. Для примера воспользуемся набором данных forestfires.csv (сведения об индексе влажности лесной подстилки, осадках, температуре, ветре и т.д.).
Импортируем pandas для загрузки и анализа датасета, seaborn и модуль pyplot из matplotlib для визуализации:
import pandas as pd
from matplotlib import pyplot as plt
import seaborn as sns
Воспользуемся pandas для чтения CSV-файла в dataframe и выведем первые 5 строк. Кроме того, проверим, содержит ли набор данных пропущенные значения (Null, NaN):
# укажите свой путь к файлу forestfires
dataframe = pd.read_csv("Downloads/forestfires.csv")
print(dataframe.isnull().values.any())
dataframe.head()
Код вернет False и верхнюю часть таблицы.
| X | Y | month | day | FFMC | DMC | DC | ISI | temp | RH | wind | rain | area | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 7 | 5 | mar | fri | 86.2 | 26.2 | 94.3 | 5.1 | 8.2 | 51 | 6.7 | 0.0 | 0.0 |
| 1 | 7 | 4 | oct | tue | 90.6 | 35.4 | 669.1 | 6.7 | 18.0 | 33 | 0.9 | 0.0 | 0.0 |
| 2 | 7 | 4 | oct | sat | 90.6 | 43.7 | 686.9 | 6.7 | 14.6 | 33 | 1.3 | 0.0 | 0.0 |
| 3 | 8 | 6 | mar | fri | 91.7 | 33.3 | 77.5 | 9.0 | 8.3 | 97 | 4.0 | 0.2 | 0.0 |
| 4 | 8 | 6 | mar | sun | 89.3 | 51.3 | 102.2 | 9.6 | 11.4 | 99 | 1.8 | 0.0 | 0.0 |
Print вывел False, значит – никаких пропущенных значений нет. Если бы они были, то пришлось бы дополнительно обрабатывать отсутствующие значения.
После проверки данных нужно выбрать признаки, которые будем визуализировать. Для удобства сохраним их в переменные с такими же названиями.
FFMC = dataframe["FFMC"]
DMC = dataframe["DMC"]
DC = dataframe["DC"]
RH = dataframe["RH"]
ISI = dataframe["ISI"]
temp = dataframe["temp"]
Это те колонки, которые содержат непрерывные числовые данные.
Построение box plot
Для создания диаграммы воспользуемся функцией boxplot в Seaborn, которой в качестве аргументов передадим переменные для визуализации:
Для визуализации распределения только одного признака мы передаем его в переменную x. В этом случае, Seaborn автоматически вычислит значения по оси y, что видно на следующем изображении.
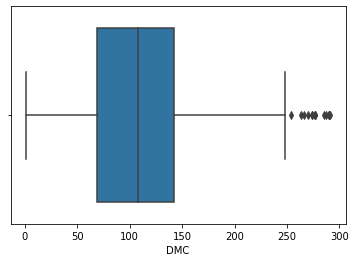
Если требуется определенное распределение, сегментированное по типу, то можно для функции boxplot в качестве аргументов передать категориальную переменную в x и непрерывную переменную в y.
sns.boxplot(x=dataframe["day"], y=DMC);
Теперь получилась блочная диаграмма, созданная для каждого дня недели.
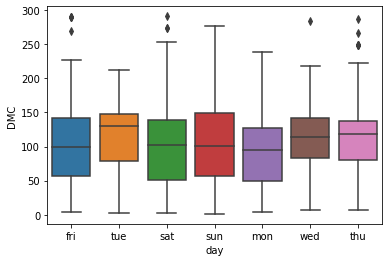
Если требуется визуализировать несколько столбцов одновременно, то аргументов x и y будет недостаточно. Для этих целей используется аргумент data, которому передается набор данных, содержащий требуемые переменные и их значения.
Создадим новый датасет, содержащий только те данные, которые мы хотим визуализировать. Затем к нему применим функцию melt(). Полученный в результате набор данных передается аргументу data. В аргументы x и y в этом случае передаются значения по умолчанию из melt (value и variable):
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
sns.boxplot(x="variable", y="value", data=pd.melt(df));
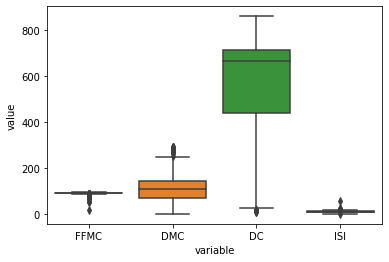
Изменение цвета boxplot
Seaborn автоматически назначает различные цвета различным переменным, чтобы можно было их легко визуально различить. Цвет диаграмм можно изменить, предоставив свой список цветов.
После определения списка цветов в виде HEX-значений или названий доcтупного цвета Matplotlib, можно передать их функции boxplot() в качестве аргумента palette:
colors = ['#78C850', '#F08030', '#6890F0','#F8D030', '#F85888', '#705898', '#98D8D8']
sns.boxplot(x=DMC, y=dataframe["day"], palette=colors);
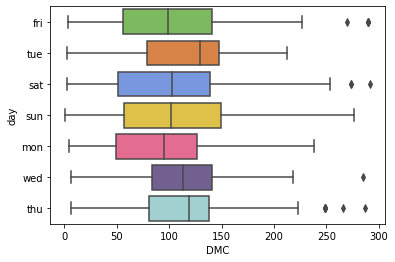
Настройка подписи осей
С помощью Seaborn можно легко настроить подписи по осям X и Y. Например, изменить размер шрифта, подписи или повернуть их, чтобы сделать более удобными для чтения.
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df))
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);
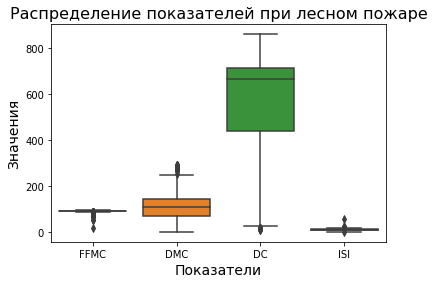
Изменение порядка отображения блоков
Для отображения блочных диаграмм в определенном порядке используется аргумент order, которому передается список имен столбцов в том порядке, в котором их нужно расположить:
df = pd.DataFrame(data=dataframe, columns=["FFMC", "DMC", "DC", "ISI"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df), order=["DC", "DMC", "FFMC", "ISI"])
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);
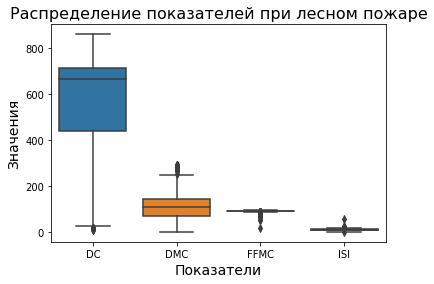
Создание subplots с помощью Matplotlib
Если необходимо разделить общий box plot на несколько для отдельных признаков, то это можно сделать. Определите область отрисовки (fig) и нужное количество координатных осей (axes) с помощью функции subplots из Matplotlib. Доступ к нужной области объекта axes можно получить через его индекс. Функция boxplot() принимает ax аргумент, который по индексу объекта axes получает область для построения диаграммы:
fig, axes = plt.subplots(1, 2)
sns.boxplot(x=day, y=DMC, orient='v', ax=axes[0])
sns.boxplot(x=day, y=DC, orient='v', ax=axes[1]);
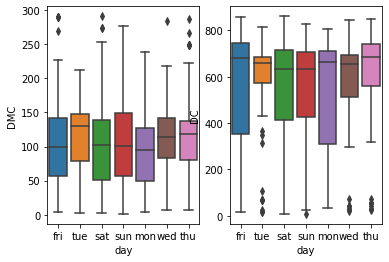
Box Plot с диаграммой рассеивания
Для более наглядного восприятия распределения можно наложить точечную диаграмму рассеивания на блочную.
С этой целью последовательно создаем две диаграммы. Диаграмма, созданная функцией stripplot(), будет наложена поверх box plot, так как они выводятся в одной и той же области:
df = pd.DataFrame(data=dataframe, columns=["DC", "DMC"])
boxplot = sns.boxplot(x="variable", y="value", data=pd.melt(df), order=["DC", "DMC"])
boxplot = sns.stripplot(x="variable", y="value", data=pd.melt(df), marker="o", alpha=0.3, color="black", order=["DC", "DMC"])
boxplot.axes.set_title("Распределение показателей при лесном пожаре", fontsize=16)
boxplot.set_xlabel("Показатели", fontsize=14)
boxplot.set_ylabel("Значения", fontsize=14);

Мы рассмотрели несколько способов построения Box Plot с помощью Seaborn и Python. Также узнали, как настроить цвета, подписи осей, порядок следования диаграмм, наложение точечных диаграмм и разделение диаграмм для отдельных величин.
Последний тип графика, о котором стоит упомянуть — Violin Plot.
Построение Violin Plot в Seaborn
Violin Plot или скрипичные диаграммы используются для визуализации распределения данных, отображая диапазон данных, медиану и область распределения данных.
Такие диаграммы, как и ящики с усами, показывают сводную статистику. Дополнительно они включают в себя графики плотности распределения, которые и определяют форму/распределение данных при визуализации.
Импорт данных
Для примера воспользуемся набором данных Gapminder, содержащем информацию о численности населения, продолжительности жизни и другие данные по странам и годам, начиная с 1952 года.
Импортируем pandas, seaborn и модуль pyplot из matplotlib:
import pandas as pd
import seaborn as sns
import matplotlib.pyplot as plt
Далее загрузим датасет и посмотрим из чего он состоит.
dataframe = pd.read_csv(
"Downloads/gapminder_full.csv",
error_bad_lines=False,
encoding="ISO-8859-1"
)
dataframe.head()
В результате получим:
| country | year | population | continent | life_exp | gdp_cap | |
|---|---|---|---|---|---|---|
| 0 | Afghanistan | 1952 | 8425333 | Asia | 28.801 | 779.445314 |
| 1 | Afghanistan | 1957 | 9240934 | Asia | 30.332 | 820.853030 |
| 2 | Afghanistan | 1962 | 10267083 | Asia | 31.997 | 853.100710 |
| 3 | Afghanistan | 1967 | 11537966 | Asia | 34.020 | 836.197138 |
| 4 | Afghanistan | 1972 | 13079460 | Asia | 36.088 | 739.981106 |
Определим признаки, которые будем визуализировать. Для удобства сохраним их в переменные с такими же названиями.
country = dataframe.country
continent = dataframe.continent
population = dataframe.population
life_exp = dataframe.life_exp
gdp_cap = dataframe.gdp_cap
Построение простой скрипичной диаграммы
Теперь, после того как мы загрузили данные и выбрали величины, которые хотим визуализировать, можно создать скрипичную диаграмму. Используем функцию violinplot(), которой в качестве аргумента x передадим переменную для визуализации.
Значения по оси Y будут высчитаны автоматически.
sns.violinplot(x=life_exp);
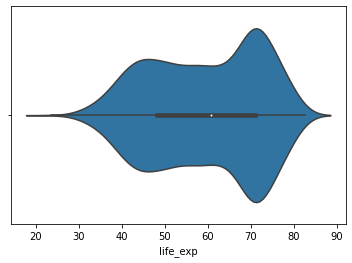
Отмечу, что можно было не выбирать предварительно данные по имени столбца и не сохранять в переменной life_exp. Используя аргумент data, которому передан наш набор данных, и аргумент x, которому присвоено имя переменной «life_exp», получим точно такой же результат.
sns.violinplot(x="life_exp", data=dataframe);
Обратите внимание на то, что на этом изображении Seaborn строит график распределения ожидаемой продолжительности жизни сразу по всем странам, так как использовалась только одна переменная life_exp. В большинстве случаев такого типа переменная рассматривается на основе других переменных, таких как country или continent в нашем случае.
Построение Violin Plot с осями X и Y
Для того чтобы получить визуализацию распределения данных, сегментированное по типу, необходимо в качестве аргументов функции использовать категориальную переменную для x и непрерывную для y.
В этом наборе данных много стран. Если построить диаграммы для всех стран, то их будет слишком много, чтобы их можно было рассмотреть. Можно, конечно, выделить подмножество из набора данных и просто построить диаграммы, скажем, для 10 стран.
Вместо этого, построим violinplot для континентов.
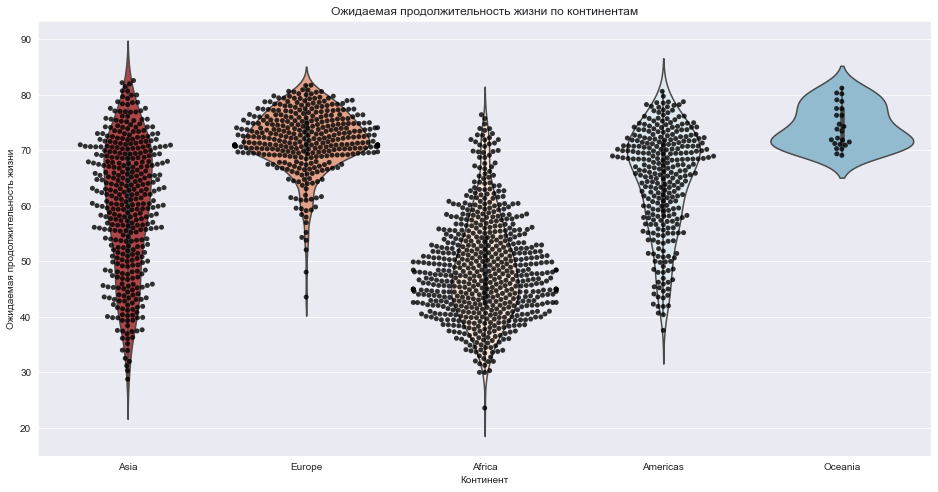
sns.violinplot(x=continent, y=life_exp, data=dataframe);
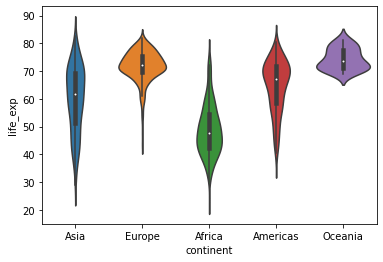
Изменение подписи осей заголовка диаграммы
Предположим, что необходимо изменить некоторые заголовки и подписи нашего графика, чтобы было проще его анализировать.
Несмотря на то, что Seaborn автоматически подписывает оси X и Y, можно изменить подписи с помощью функций set_title() и set_label() после создания объекта axes. Надо просто передать название, которое хотим дать нашему графику, функции set_title().
Для того чтобы подписать оси, используется функция set() с аргументами xlabel и ylabel или функции-обертки set_xlabel()/set_ylabel():
ax = sns.violinplot(x=continent, y=life_exp)
ax.set_title("Ожидаемая продолжительность жизни по континентам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Континент");

Изменение цвета violinplot
Для изменения цвета диаграмм можно создать список заранее выбранных цветов и передать этот список параметром pallete функции violinplot():
colors_list = [
'#78C850', '#F08030', '#6890F0',
'#A8B820', '#F8D030', '#E0C068',
'#C03028', '#F85888', '#98D8D8'
]
ax = sns.violinplot(x=continent, y=life_exp, palette=colors_list)
ax.set_title("Ожидаемая продолжительность жизни по континентам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Континент");
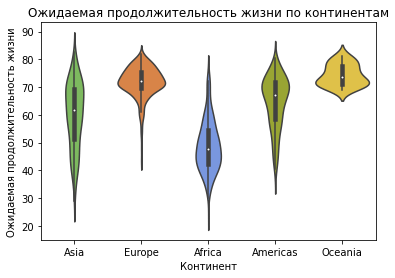
Violin Plot с диаграммой рассеивания
Точечную диаграмму распределения можно наложить на скрипичную диаграмму, чтобы увидеть размещение точек, составляющих это распределение. Для этого просто создается одна область рисования, а затем последовательно в ней создаются две диаграммы.
colors_list = [
'#78C850', '#F08030', '#6890F0',
'#A8B820', '#F8D030', '#E0C068',
'#C03028', '#F85888', '#98D8D8'
]
plt.figure(figsize=(16,8))
sns.violinplot(x=continent, y=life_exp,palette=colors_list)
sns.swarmplot(x=continent, y=life_exp, color="k", alpha=0.8)
plt.title("Ожидаемая продолжительность жизни по континентам")
plt.ylabel("Ожидаемая продолжительность жизни")
plt.xlabel("Континент");
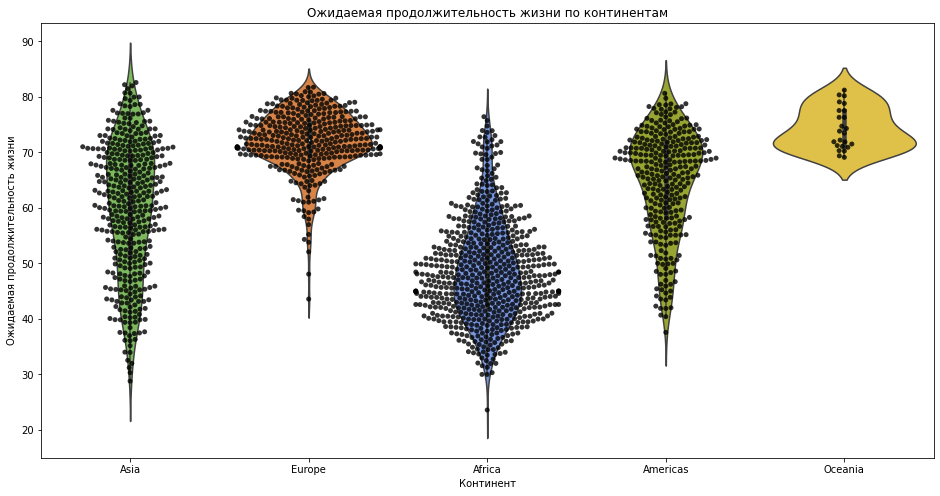
Изменение стиля скрипичной диаграммы
Можно легко изменить стиль и цвет нашей диаграммы, используя функции set_style() и set_palette() соответственно.
Seaborn поддерживает несколько различных вариантов изменения стиля и цветовой палитры графиков:
plt.figure(figsize=(16,8))
sns.set_palette("RdBu")
sns.set_style("darkgrid")
sns.violinplot(x=continent, y=life_exp)
sns.swarmplot(x=continent, y=life_exp, color="k", alpha=0.8)
plt.title("Ожидаемая продолжительность жизни по континентам")
plt.ylabel("Ожидаемая продолжительность жизни")
plt.xlabel("Континент");
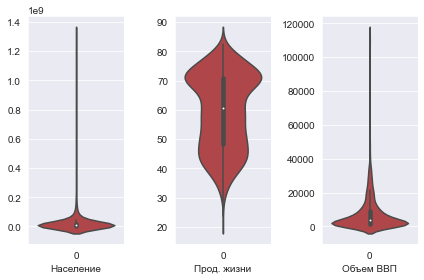
Построение Violin Plot для разных признаков
Если нужно разделить визуализацию столбцов из набора данных на их собственные диаграммы, то это можно сделать. Создайте область рисования и сетку, в ячейках которой будут графики.
Для отображения диаграммы в соответствующей ячейке применяется функция add_subplot(), которой передается адрес этой ячейки. Создание диаграммы делаем, как обычно, используя объект axes.
Можно использовать y=variable, либо data=variable.
fig = plt.figure(figsize=(6, 4))
gs = fig.add_gridspec(1, 3)
ax = fig.add_subplot(gs[0, 0])
sns.violinplot(data=population)
ax.set_xlabel("Население")
ax = fig.add_subplot(gs[0, 1])
sns.violinplot(data=life_exp)
ax.set_xlabel("Прод. жизни")
ax = fig.add_subplot(gs[0, 2])
sns.violinplot(data=gdp_cap)
ax.set_xlabel("Объем ВВП")
fig.tight_layout()
Группировка скрипичных диаграмм по категориальному признаку
По настоящему полезная вещь для violinplot — это группировка по значениям категориальной переменной. Например, если есть категориальная величина, имеющая два значения (обычно, True/False), то в этом случае можно группировать графики по этим значениям.
Допустим, есть набор данных по трудоустройству населения со столбцом employment и его значениями employed и unemployed. Тогда можно сгруппировать диаграммы по видам занятости.
Поскольку в наборе данных Gapminder нет столбца, подходящего для такой группировки, его можно сделать, рассчитав среднюю продолжительность жизни для определенного подмножества стран, например, европейских стран.
Назначим Yes/No значение новому столбцу above_average_life_exp для каждой страны. Если средняя продолжительность жизни выше, чем в среднем по датасету, то это значение равно Yes, и наоборот:
# Отделяем европейские страны от исходного датасет
europe = dataframe.loc[dataframe["continent"] == "Europe"]
# Вычисляем среднее значение переменной "life_exp"
avg_life_exp = dataframe["life_exp"].mean()
# Добавим новую колонку
europe.loc[:, "above_average_life_exp"] = europe["life_exp"] > avg_life_exp
europe["above_average_life_exp"].replace(
{True: "Yes", False: "No"},
inplace=True
)
Теперь, если вывести наш набор данных, то получим следующее:
| country | year | population | continent | life_exp | gdp_cap | above_average_life_exp | |
|---|---|---|---|---|---|---|---|
| 12 | Albania | 1952 | 1282697 | Europe | 55.23 | 1601.056136 | No |
| 13 | Albania | 1957 | 1476505 | Europe | 59.28 | 1942.284244 | No |
| 14 | Albania | 1962 | 1728137 | Europe | 64.82 | 2312.888958 | Yes |
| 15 | Albania | 1967 | 1984060 | Europe | 66.22 | 2760.196931 | Yes |
| 16 | Albania | 1972 | 2263554 | Europe | 67.69 | 3313.422188 | Yes |
Теперь можно построить скрипичные диаграммы, сгруппированные по новому столбцу, который мы вставили. Учитывая, что европейских стран много, для удобства визуализации выберем последние 50 строк, используя europe.tail():
europe = europe.tail(50)
ax = sns.violinplot(x=europe.country, y=europe.life_exp, hue=europe.above_average_life_exp)
ax.set_title("Ожидаемая продолжительность жизни по странам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Страны");
В результате получим:
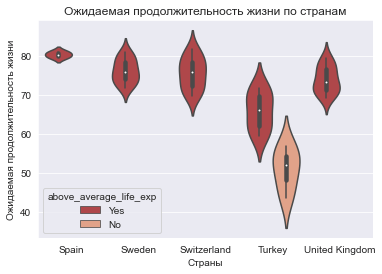
Теперь страны с продолжительностью жизни меньше средней, ожидаемой отличаются по цвету.
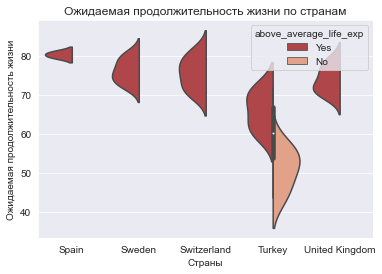
Разделение скрипичных диаграмм по категориальному признаку
Если используется аргумент hue для категориальной переменной, имеющей два значения, то применив в функции violinplot() аргумент split и установив его в True, можно разделить скрипичные диаграммы пополам с учетом значения hue.
В нашем случае одна сторона скрипки (левая) будет представлять записи с ожидаемой продолжительностью жизни выше среднего, в то время как правая сторона будет использоваться для построения ожидаемой продолжительности жизни ниже среднего:
europe = europe.tail(50)
ax = sns.violinplot(
x=europe.country,
y=europe.life_exp,
hue=europe.above_average_life_exp,
split=True
)
ax.set_title("Ожидаемая продолжительность жизни по странам")
ax.set_ylabel("Ожидаемая продолжительность жизни")
ax.set_xlabel("Страны");
Мы рассмотрели несколько способов построения Violin Plot в Seaborn. Это последний тип графиков, на которые стоит обратить внимание.
В этой статье мы рассмотрели примеры построения графиков:
- Bar Plot
- Scatter Plot
- Box Plot
- Heatmap
- Violin Plot
Тест на знание основ Seaborn
Как изменить заголовок в Heatmap? Если график хранится в переменной hm
hm.set_title(«Заголовок»)
Что сделает этот код?
v = sns.FacetGrid(dataframe, col="Alpha", hue="Alpha", col_wrap=3)
v.map(sns.scatterplot, "Beta", "Gamma")
Группирует графики по признаку Beta
Группирует графики по признаку Alpha
Группирует графики по трем признакам
Какую версию Python не поддерживает Seaborn
Выберите верное утверждение про Violin Plot
Чем шире «скрипка» тем больше данных в диапазоне
Чем шире «скрипка» тем больше данные в диапазоне
Чем длиннее «скрипка» тем больше данных
Чем длиннее «скрипка» тем больше данные
Какая функция создает график «Ящики с усами»?
Выберите верное утверждение
в seaborn можно строить анимированные графики
в seaborn можно строить 2D-графики
Для работы с seaborn нужно импортировать pyplot
seaborn — стандартная библиотека Python
Как отобразить зависимость цены (price) от размера (size) условных продуктов?
sns.violinplot(x=size, y=price);
sns.barplot(x=size, y=price);
sns.heatmap(x=size, y=price);
sns.scatterplot(x=size, y=price);
Как отобразить числовые значения на тепловой карте?
Как построить горизонтальную гистограмму, если в переменной fruits — список фруктов, а в price их цена.
Такой возможности нет в Seaborn
sns.barplot(x=fruits, y=price);
sns.barplot(x=fruits, y=price, rotate=90);
sns.barplot(x=price, y=fruits);
Как увидеть график, без использования Jupyter Notebook
Нужно вызвать метод show() из matplotlib.pyplot
Нужно поставить «;» в конце последней строки
С помощью функции print()
В сегодняшних ежедневных газетах мы очень часто видим гистограммы и круговые диаграммы, объясняющие данные по акциям, финансам или COVID-19. Несомненно, гистограммы значительно облегчают нашу повседневную жизнь. Они помогают нам визуализировать данные с первого взгляда и получить представление о них. Сегодня в этой статье мы узнаем о гистограммах (от основ до продвинутых), чтобы помочь вам в ваших проектах по анализу данных или машинному обучению.
Что такое гистограмма?
Гистограмма — это тип столбчатой диаграммы, которая используется для представления распределения числовых данных. В гистограммах ось X представляет собой диапазон бинов, а ось Y — частоту. Гистограмма создает бины диапазонов, распределяет весь диапазон значений на интервалы и подсчитывает количество значений (частоту), которые попадают в каждый из этих интервалов. Функция matplotlib.pyplot.hist() помогает нам построить гистограмму.
Что такое библиотека Matplotlib в Python?
Matplotlib — одна из наиболее часто используемых библиотек визуализации данных в Python. Это отличный инструмент как для простой, так и для сложной визуализации. Давайте быстро рассмотрим синтаксис функции matplotlib histogram:
matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype=’bar’, align=’mid’, orientation=’vertical’, rwidth=None, log=False, color=None, label=None, stacked=False)
| Параметр | Описание |
| x | Обозначает входной параметр в виде массивов. |
| бины | Обозначает диапазон значений. Он может принимать как целочисленные, так и порядковые значения. |
| range | Через этот параметр задается нижний и верхний диапазон бинов. |
| плотность | Обычно содержит булевы значения и обозначается как density = counts / (sum(counts) * np.diff(bins)). |
| вес | Этот параметр обозначает вес каждого значения. |
| cumulative | Этот параметр обозначает подсчет каждого бина вместе с подсчетом бина для предыдущих значений. |
| bottom | Этот параметр обозначает местоположение базовой линии каждого бина. |
| histtype | Этот параметр используется для обозначения типа гистограммы, которая будет построена. Например: столбик, сложенный столбик, шаг или шаг с заполнением. Если вы ничего не укажете, то по умолчанию будет использоваться столбик. |
| выровнять | Это поможет вам определить положение гистограммы. Например, слева, справа или посередине. По умолчанию будет выбрана середина. |
| ориентация | Этот параметр поможет вам решить, как вы хотите построить гистограмму — горизонтально или вертикально. По умолчанию будет выбрана вертикальная. |
| rwidth | Этот параметр помогает задать относительную ширину столбцов относительно ширины бина. |
| color | Этот параметр поможет вам установить цвет последовательностей. |
| label | Эта команда поможет вам установить метки для графика гистограммы. |
| stacked | Этот параметр принимает булевы значения (True или False). Если вы передадите значение False, то данные будут расположены рядом друг с другом, если вы задали тип гистограммы как bar, или, если это step, то данные будут расположены друг над другом. Если вы передали этот параметр как True, то данные будут располагаться друг над другом. По умолчанию этот параметр имеет значение False. |
Импортирование Matplotlib и необходимых библиотек
Перед началом построения гистограммы мы импортируем все необходимые библиотеки.
import matplotlib.pyplot as plt import numpy as np import pandas as pd
Давайте посмотрим, как установить matplotlib и необходимые библиотеки. Начнем с самого простого, а затем перейдем к продвинутым графикам гистограмм.
Гистограмма с базовым распределением
Для создания гистограммы с базовым распределением мы использовали функцию random NumPy. Чтобы представить распределение данных, мы передали среднее значение и стандартное отклонение. В функции гистограммы мы указали общее количество значений, количество бинов и количество участков. Мы также передали такие входные параметры, как плотность, цвет лица и альфа, чтобы сделать гистограмму более наглядной.
Вы можете поиграть и изменить размер бина и количество бинов. Мы передали здесь тип гистограммы как Bar. Параметры xlim и ylim используются для установки минимального и максимального значений для осей X и Y соответственно. Если вы не хотите иметь линии сетки, вы можете передать функции plt.grid значение False.
import matplotlib.pyplot as plt import numpy as np import pandas as pd # Using numpy random function to generate random data np.random.seed(19685689) mu, sigma = 120, 30 x = mu + sigma * np.random.randn(10000) # passing the histogram function n, bins, patches = plt.hist(x, 70, histtype='bar', density=True, facecolor='yellow', alpha=0.80) plt.xlabel('Values') plt.ylabel('Probability Distribution') plt.title('Histogram showing Data Distribution') plt.xlim(50, 180) plt.ylim(0, 0.04) plt.grid(True) plt.show()
Вывод:

Построение графиков гистограмм с распределением цвета
Построение гистограмм с цветовым представлением — отличный способ визуализации различных значений в диапазоне ваших данных. Для этого типа графика мы будем использовать функцию subplot. Мы убрали шипы осей и тики x,y, чтобы график выглядел более презентабельно. Мы также добавили к нему подложку и линии сетки. Для цветового представления мы разделили гистограмму на доли или части, а затем установили разные цвета для разных участков гистограммы.
#importing the packages for colors from matplotlib import colors from matplotlib.ticker import PercentFormatter # Forming the dataset with numpy random function np.random.seed(190345678) N_points = 100000 n_bins = 40 # Creating distribution x = np.random.randn(N_points) y = .10 ** x + np.random.randn(100000) + 25 legend = ['distribution'] # Passing subplot function fig, axs = plt.subplots(1, 1, figsize =(10, 7), tight_layout = True) # Removing axes spines for s in ['top', 'bottom', 'left', 'right']: axs.spines[s].set_visible(False) # Removing x, y ticks axs.xaxis.set_ticks_position('none') axs.yaxis.set_ticks_position('none') # Adding padding between axes and labels axs.xaxis.set_tick_params(pad = 7) axs.yaxis.set_tick_params(pad = 15) # Adding x, y gridlines axs.grid(b = True, color ='pink', linestyle ='-.', linewidth = 0.6, alpha = 0.6) # Passing histogram function N, bins, patches = axs.hist(x, bins = n_bins) # Setting the color fracs = ((N**(1 / 5)) / N.max()) norm = colors.Normalize(fracs.min(), fracs.max()) for thisfrac, thispatch in zip(fracs, patches): color = plt.cm.viridis_r(norm(thisfrac)) thispatch.set_facecolor(color) # Adding extra features for making it more presentable plt.xlabel("X-axis") plt.ylabel("y-axis") plt.legend(legend) plt.title('Customizing your own histogram') plt.show()
Вывод:

Построение гистограммы с помощью столбцов
Это довольно простое занятие. Для этого мы просто создали случайные данные с помощью функции Numpy random, а затем использовали функцию hist() и передали параметр histtype в виде столбика. Вы можете изменить этот параметр на barstacked step или stepwell.
np.random.seed(9**7) n_bins = 15 x = np.random.randn(10000, 5) colors = ['blue', 'pink', 'orange','green','red'] plt.hist(x, n_bins, density = True, histtype ='step', color = colors, label = colors) plt.legend(prop ={'size': 10}) plt.show()
Вывод:

KDE Plot and Histogram
Это еще один интересный способ построения гистограмм с помощью KDE. В этом примере мы построим график KDE (kerned Density Estimation) вместе с гистограммой с помощью функции subplot. Графики KDE помогают определить вероятность данных в заданном пространстве. Таким образом, вместе с графиком KDE и гистограммой мы можем представить вероятностное распределение данных. Для этого мы сначала создали кадр данных, сгенерировав случайные значения среднего и стандартного отклонения, и присвоили среднее значение параметру loc, а стандартное отклонение — параметру scale.
np.random.seed(9**7) n_bins = 15 x = np.random.randn(10000, 5) colors = ['blue', 'pink', 'orange','green','red'] plt.hist(x, n_bins, density = True, histtype ='bar', color = colors, label = colors) plt.legend(prop ={'size': 10}) plt.show()
Вывод:

Гистограмма с несколькими переменными
В этом примере мы используем набор данных «ramen-rating» для построения гистограммы с несколькими переменными. Мы присвоили трем разным маркам рамена разные переменные. Мы использовали функцию hist() три раза, чтобы создать гистограмму для трех разных марок рамена и построить график вероятности получения 5-звездочного рейтинга для трех разных марок рамена.
import pandas as pd df = pd.read_csv("C://Users//Intel//Documents//ramen-ratings.csv") df.head()

x1 = df.loc[df.Style=='Bowl', 'Stars'] x2 = df.loc[df.Style=='Cup', 'Stars'] x3 = df.loc[df.Style=='Pack', 'Stars'] # Normalize kwargs = dict(alpha=0.5, bins=60, density=True, stacked=False) # Plotting the histogram plt.hist(x1,**kwargs,histtype='stepfilled',color='b',label='Bowl') plt.hist(x2,**kwargs,histtype='stepfilled',color='r',label='Cup') plt.hist(x3,**kwargs,histtype='stepfilled',color='y',label='Pack') plt.gca().set(title='Histogram of Probability of Ratings by Brand', ylabel='Probability') plt.xlim(2,5) plt.legend();
Вывод:

Двумерная гистограмма
двумерная гистограмма — еще один интересный способ визуализации данных. Мы можем построить гистограмму с помощью функции plt.hist2d. Мы можем настроить график и размер бина так же, как и в предыдущих случаях. Ниже мы рассмотрим очень простой пример двухмерной гистограммы.
import numpy as np import matplotlib.pyplot as plt import random # Generating random data n = 1000 x = np.random.standard_normal(1000) y = 5.0 * x + 3.0* np.random.standard_normal(1000) fig = plt.subplots(figsize =(10, 7)) # Plotting 2D Histogram plt.hist2d(x, y,bins=100) plt.title("2D Histogram") plt.show()
Вывод:

Заключение
Подводя итог, мы узнали пять различных способов построения гистограммы и настройки наших гистограмм, а также как создать гистограмму с несколькими переменными в наборе данных. Эти методы очень помогут вам в визуализации данных для любого проекта в области науки о данных.
Алексей
Меня зовут Алексей Красовский, я ведущий программист, сертифицированный специалист по Python и, одновременно, автор этого блога.
- matplotlib.pyplot.hist(x, bins=None, range=None, density=False, weights=None, cumulative=False, bottom=None, histtype=‘bar’, align=‘mid’, orientation=‘vertical’, rwidth=None, log=False, color=None, label=None, stacked=False, *, data=None, **kwargs)[source]#
-
Compute and plot a histogram.
This method uses
numpy.histogramto bin the data in x and count the
number of values in each bin, then draws the distribution either as a
BarContainerorPolygon. The bins, range, density, and
weights parameters are forwarded tonumpy.histogram.If the data has already been binned and counted, use
baror
stairsto plot the distribution:counts, bins = np.histogram(x) plt.stairs(counts, bins)
Alternatively, plot pre-computed bins and counts using
hist()by
treating each bin as a single point with a weight equal to its count:plt.hist(bins[:-1], bins, weights=counts)
The data input x can be a singular array, a list of datasets of
potentially different lengths ([x0, x1, …]), or a 2D ndarray in
which each column is a dataset. Note that the ndarray form is
transposed relative to the list form. If the input is an array, then
the return value is a tuple (n, bins, patches); if the input is a
sequence of arrays, then the return value is a tuple
([n0, n1, …], bins, [patches0, patches1, …]).Masked arrays are not supported.
- Parameters:
-
- x(n,) array or sequence of (n,) arrays
-
Input values, this takes either a single array or a sequence of
arrays which are not required to be of the same length. - binsint or sequence or str, default:
rcParams["hist.bins"](default:10) -
If bins is an integer, it defines the number of equal-width bins
in the range.If bins is a sequence, it defines the bin edges, including the
left edge of the first bin and the right edge of the last bin;
in this case, bins may be unequally spaced. All but the last
(righthand-most) bin is half-open. In other words, if bins is:then the first bin is
[1, 2)(including 1, but excluding 2) and
the second[2, 3). The last bin, however, is[3, 4], which
includes 4.If bins is a string, it is one of the binning strategies
supported bynumpy.histogram_bin_edges: ‘auto’, ‘fd’, ‘doane’,
‘scott’, ‘stone’, ‘rice’, ‘sturges’, or ‘sqrt’. - rangetuple or None, default: None
-
The lower and upper range of the bins. Lower and upper outliers
are ignored. If not provided, range is(x.min(), x.max()).
Range has no effect if bins is a sequence.If bins is a sequence or range is specified, autoscaling
is based on the specified bin range instead of the
range of x. - densitybool, default: False
-
If
True, draw and return a probability density: each bin
will display the bin’s raw count divided by the total number of
counts and the bin width
(density = counts / (sum(counts) * np.diff(bins))),
so that the area under the histogram integrates to 1
(np.sum(density * np.diff(bins)) == 1).If stacked is also
True, the sum of the histograms is
normalized to 1. - weights(n,) array-like or None, default: None
-
An array of weights, of the same shape as x. Each value in
x only contributes its associated weight towards the bin count
(instead of 1). If density isTrue, the weights are
normalized, so that the integral of the density over the range
remains 1. - cumulativebool or -1, default: False
-
If
True, then a histogram is computed where each bin gives the
counts in that bin plus all bins for smaller values. The last bin
gives the total number of datapoints.If density is also
Truethen the histogram is normalized such
that the last bin equals 1.If cumulative is a number less than 0 (e.g., -1), the direction
of accumulation is reversed. In this case, if density is also
True, then the histogram is normalized such that the first bin
equals 1. - bottomarray-like, scalar, or None, default: None
-
Location of the bottom of each bin, ie. bins are drawn from
bottomtobottom + hist(x, bins)If a scalar, the bottom
of each bin is shifted by the same amount. If an array, each bin
is shifted independently and the length of bottom must match the
number of bins. If None, defaults to 0. - histtype{‘bar’, ‘barstacked’, ‘step’, ‘stepfilled’}, default: ‘bar’
-
The type of histogram to draw.
-
‘bar’ is a traditional bar-type histogram. If multiple data
are given the bars are arranged side by side. -
‘barstacked’ is a bar-type histogram where multiple
data are stacked on top of each other. -
‘step’ generates a lineplot that is by default unfilled.
-
‘stepfilled’ generates a lineplot that is by default filled.
-
- align{‘left’, ‘mid’, ‘right’}, default: ‘mid’
-
The horizontal alignment of the histogram bars.
-
‘left’: bars are centered on the left bin edges.
-
‘mid’: bars are centered between the bin edges.
-
‘right’: bars are centered on the right bin edges.
-
- orientation{‘vertical’, ‘horizontal’}, default: ‘vertical’
-
If ‘horizontal’,
barhwill be used for bar-type histograms
and the bottom kwarg will be the left edges. - rwidthfloat or None, default: None
-
The relative width of the bars as a fraction of the bin width. If
None, automatically compute the width.Ignored if histtype is ‘step’ or ‘stepfilled’.
- logbool, default: False
-
If
True, the histogram axis will be set to a log scale. - colorcolor or array-like of colors or None, default: None
-
Color or sequence of colors, one per dataset. Default (
None)
uses the standard line color sequence. - labelstr or None, default: None
-
String, or sequence of strings to match multiple datasets. Bar
charts yield multiple patches per dataset, but only the first gets
the label, so thatlegendwill work as expected. - stackedbool, default: False
-
If
True, multiple data are stacked on top of each other If
Falsemultiple data are arranged side by side if histtype is
‘bar’ or on top of each other if histtype is ‘step’
- Returns:
-
- narray or list of arrays
-
The values of the histogram bins. See density and weights for a
description of the possible semantics. If input x is an array,
then this is an array of length nbins. If input is a sequence of
arrays[data1, data2, ...], then this is a list of arrays with
the values of the histograms for each of the arrays in the same
order. The dtype of the array n (or of its element arrays) will
always be float even if no weighting or normalization is used. - binsarray
-
The edges of the bins. Length nbins + 1 (nbins left edges and right
edge of last bin). Always a single array even when multiple data
sets are passed in. - patches
BarContaineror list of a singlePolygonor list of such objects -
Container of individual artists used to create the histogram
or list of such containers if there are multiple input datasets.
- Other Parameters:
-
- dataindexable object, optional
-
If given, the following parameters also accept a string
s, which is
interpreted asdata[s](unless this raises an exception):x, weights
- **kwargs
-
Patchproperties
See also
hist2d-
2D histogram with rectangular bins
hexbin-
2D histogram with hexagonal bins
Notes
For large numbers of bins (>1000), plotting can be significantly faster
if histtype is set to ‘step’ or ‘stepfilled’ rather than ‘bar’ or
‘barstacked’.