Содержание
- Введение в тему
- Что делает метод
- Синтаксис
- Параметры
- Возвращаемое значение
- Применение replace для замены нескольких значений
- С помощью словаря
- Вариант со списками
- Другие типы python и метод replace
Введение в тему
В этом уроке мы рассмотрим как заменить подстроку внутри строки, используя метод replace().
Метод replace Python возвращает копию строки, в которой все вхождения искомой подстроки заменяются другой подстрокой.
Что делает метод
Слово replace переводится как «заменять», что название этого метода является отличным описанием того, что он делает. С помощью метода replace можно заменить часть строки, называемую подстрокой или её всю на другую строку. Метод replace позволяет гибко изменять только необходимые части строки str.
Синтаксис
Метод .replace() имеет следующий синтаксис:
str.replace(old, new[, count])
Параметры
В качестве аргументов в метод передаются:
str — Строка, к которой применяется метод (тип данных string).
old — Подстрока, которую необходимо найти и заменить (тип данных string).
new — Новая подстрока, которой будет заменена старая (тип данных string).
count— Необязательный аргумент. Количество совпадений старой подстроки, которую необходимо заменить (тип данных int). Если этот параметр не указать, то будут заменены все вхождения подстрок на новые.
Вот несколько примеров применения метода:
my_var = "Ivan, Rinat, Olga, Kira"
#Заменяем все подстроки "Olga" в строке
a = my_var.replace("Olga", "Olya")
print(a)
#Заменяем первую подстроку "i" в строке
b = my_var.replace("i", "I", 1)
print(b)
#Заменяем первые две подстроки "a" в строке
c = my_var.replace("a", "A", 2)
print(c)
# Вывод:
Ivan, Rinat, Olya, Kira
Ivan, RInat, Olga, Kira
IvAn, RinAt, Olga, Kira
Возвращаемое значение
Метод возвращает копию строки, в которой старая подстрока заменяется новой подстрокой. Строка, к которой применяется метод остаётся неизменной. Если искомая подстрока не обнаружена, то возвращается копия исходной строки.
my_var = "Ivan, Rinat, Olga, Kira"
#Заменяем все вхождения "Olga" в строке
a = my_var.replace("Roman", "Roma")
print(a)
# Вывод:
Ivan, Rinat, Olga, Kira
Применение replace для замены нескольких значений
С помощью данного метода возможно выполнить поиск и замену нескольких значений, например элементов коллекции:
my_var = ['Ivan', 'Rinat', 'Olga', 'Kira']
# в новый список записываем элементы начального списка, измененные
# с помощью replace
new_list = [_.replace("i", "A", 1) for _ in my_var]
print(new_list)
# Вывод:
['Ivan', 'RAnat', 'Olga', 'KAra']
С помощью словаря
Предыдущий пример позволяет заменить несколько элементов, однако все они имеют одно и то же значение «i». Если необходимо заменить несколько разных значений, например «i» на «I» и «a» на «A», то необходимо реализовать чуть более сложную программу с использованием словарей:
# Функция для замены нескольких значений
def multiple_replace(target_str, replace_values):
# получаем заменяемое: подставляемое из словаря в цикле
for i, j in replace_values.items():
# меняем все target_str на подставляемое
target_str = target_str.replace(i, j)
return target_str
# создаем словарь со значениями и строку, которую будет изменять
replace_values = {"i": "I", "a": "A"}
my_str = "Ivan, Rinat, Olga, Kira"
# изменяем и печатаем строку
my_str = multiple_replace(my_str, replace_values)
print(my_str)
# Вывод:
IvAn, RInAt, OlgA, KIrA
Здесь replace используется в функции, аргументы которой исходная строка и словарь со значениями для замены.
У этого варианта программы есть один существенный недостаток, программист не может быть уверен в том, какой результат он получит. Дело в том, что словари — это последовательности без определенного порядка, поэтому рассматриваемый пример программы может привести к двум разным результатам в зависимости от того, как интерпретатор расположит элементы словаря:
В Python версии 3.6 и более поздних порядок перебора ключей будет такой же, как и при котором они созданы. В более ранних версиях Python порядок может отличаться.
Для решения этой проблемы можно заменить обычный словарь на упорядоченный словарь OrderedDict, который нужно импортировать следующей командой:
from collections import OrderedDict
Помимо импорта в программе нужно поменять буквально одну строку:
replace_values = {"i": "I", "a": "A"}
Изменить её надо на:
replace_values = OrderedDict([("i", "I"), ("a", "A")])
Вариант со списками
Замену нескольких значений можно реализовать и по-другому, для этого используем списки:
my_str = "Ivan, Rinat, Olga, Kira"
# в цикле передаем список (заменяемое, подставляемое) в метод replace
for x, y in ("i", "I"), ("a", "A"):
my_str = my_str.replace(x, y)
print(my_str)
# Вывод:
IvAn, RInAt, OlgA, KIrA
Другие типы python и метод replace
Метод replace есть не только у строк, с его помощью программист может изменять последовательности байт, время и дату.
Синтаксис метода для последовательности байт ничем не отличается от синтаксиса для строк, для дат и времени в аргументах метода replace нужно писать идентификатор изменяемого параметра, например:
from datetime import date
t_date = date(2021, 6, 19)
t_date = t_date.replace(day = 1)
print(t_date)
# Вывод:
2021-06-01
Для времени метод replace применяется аналогично.
Функцию replace() также можно использовать для замены некоторой строки, присутствующей в csv или текстовом файле. Модуль Python Pandas полезен при работе с наборами данных. Функция pandas.str.replace() function используется для замены строки другой строкой в переменной или столбце данных. Синтаксис:
dataframe.str.replace('old string', 'new string')
Иван Душенко
Автор статьи
Задать вопрос
What is the easiest way in Python to replace a character in a string?
For example:
text = "abcdefg";
text[1] = "Z";
^
![]()
martineau
117k25 gold badges161 silver badges290 bronze badges
asked Aug 4, 2009 at 15:48
![]()
0
Don’t modify strings.
Work with them as lists; turn them into strings only when needed.
>>> s = list("Hello zorld")
>>> s
['H', 'e', 'l', 'l', 'o', ' ', 'z', 'o', 'r', 'l', 'd']
>>> s[6] = 'W'
>>> s
['H', 'e', 'l', 'l', 'o', ' ', 'W', 'o', 'r', 'l', 'd']
>>> "".join(s)
'Hello World'
Python strings are immutable (i.e. they can’t be modified). There are a lot of reasons for this. Use lists until you have no choice, only then turn them into strings.
answered Aug 4, 2009 at 16:41
![]()
scvalexscvalex
14.8k2 gold badges33 silver badges43 bronze badges
11
Fastest method?
There are three ways. For the speed seekers I recommend ‘Method 2’
Method 1
Given by this answer
text = 'abcdefg'
new = list(text)
new[6] = 'W'
''.join(new)
Which is pretty slow compared to ‘Method 2’
timeit.timeit("text = 'abcdefg'; s = list(text); s[6] = 'W'; ''.join(s)", number=1000000)
1.0411581993103027
Method 2 (FAST METHOD)
Given by this answer
text = 'abcdefg'
text = text[:1] + 'Z' + text[2:]
Which is much faster:
timeit.timeit("text = 'abcdefg'; text = text[:1] + 'Z' + text[2:]", number=1000000)
0.34651994705200195
Method 3:
Byte array:
timeit.timeit("text = 'abcdefg'; s = bytearray(text); s[1] = 'Z'; str(s)", number=1000000)
1.0387420654296875
![]()
answered Mar 3, 2014 at 14:15
![]()
Mehdi NellenMehdi Nellen
8,2064 gold badges32 silver badges48 bronze badges
13
new = text[:1] + 'Z' + text[2:]
answered Aug 4, 2009 at 15:53
![]()
Jochen RitzelJochen Ritzel
103k30 gold badges198 silver badges193 bronze badges
2
Python strings are immutable, you change them by making a copy.
The easiest way to do what you want is probably:
text = "Z" + text[1:]
The text[1:] returns the string in text from position 1 to the end, positions count from 0 so ‘1’ is the second character.
edit:
You can use the same string slicing technique for any part of the string
text = text[:1] + "Z" + text[2:]
Or if the letter only appears once you can use the search and replace technique suggested
below
![]()
guntbert
5166 silver badges19 bronze badges
answered Aug 4, 2009 at 15:52
![]()
Martin BeckettMartin Beckett
93.9k28 gold badges186 silver badges260 bronze badges
1
Starting with python 2.6 and python 3 you can use bytearrays which are mutable (can be changed element-wise unlike strings):
s = "abcdefg"
b_s = bytearray(s)
b_s[1] = "Z"
s = str(b_s)
print s
aZcdefg
edit: Changed str to s
edit2: As Two-Bit Alchemist mentioned in the comments, this code does not work with unicode.
answered Jan 30, 2014 at 14:34
![]()
MahmoudMahmoud
5294 silver badges6 bronze badges
4
Strings are immutable in Python, which means you cannot change the existing string.
But if you want to change any character in it, you could create a new string out it as follows,
def replace(s, position, character):
return s[:position] + character + s[position+1:]
replace(‘King’, 1, ‘o’)
// result: Kong
Note: If you give the position value greater than the length of the string, it will append the character at the end.
replace(‘Dog’, 10, ‘s’)
// result: Dogs
answered Aug 1, 2020 at 7:39
![]()
This code is not mine. I couldn’t recall the site form where, I took it. Interestingly, you can use this to replace one character or more with one or more charectors.
Though this reply is very late, novices like me (anytime) might find it useful.
Change Text function.
mytext = 'Hello Zorld'
# change all Z(s) to "W"
while "Z" in mytext:
# replace "Z" to "W"
mytext = mytext.replace('Z', 'W')
print(mytext)
![]()
answered Dec 16, 2011 at 13:39
![]()
K.Vee.Shanker.K.Vee.Shanker.
2891 gold badge3 silver badges5 bronze badges
7
Like other people have said, generally Python strings are supposed to be immutable.
However, if you are using CPython, the implementation at python.org, it is possible to use ctypes to modify the string structure in memory.
Here is an example where I use the technique to clear a string.
Mark data as sensitive in python
I mention this for the sake of completeness, and this should be your last resort as it is hackish.
![]()
answered Aug 4, 2009 at 19:08
![]()
UnknownUnknown
45.4k27 gold badges138 silver badges181 bronze badges
3
I like f-strings:
text = f'{text[:1]}Z{text[2:]}'
In my machine this method is 10% faster than the «fast method» of using + to concatenate strings:
>>> timeit.timeit("text = 'abcdefg'; text = text[:1] + 'Z' + text[2:]", number=1000000)
1.1691178000000093
>>> timeit.timeit("text = 'abcdefg'; text = f'{text[:1]}Z{text[2:]}'", number =1000000)
0.9047831999999971
>>>
answered May 2, 2021 at 23:09
![]()
OsorioSPOsorioSP
611 silver badge3 bronze badges
1
Actually, with strings, you can do something like this:
oldStr = 'Hello World!'
newStr = ''
for i in oldStr:
if 'a' < i < 'z':
newStr += chr(ord(i)-32)
else:
newStr += i
print(newStr)
'HELLO WORLD!'
Basically, I’m «adding»+»strings» together into a new string :).
![]()
answered Nov 20, 2015 at 21:12
![]()
1
To replace a character in a string
You can use either of the method:
Method 1
In general,
string = f'{string[:index]}{replacing_character}{string[index+1:]}'
Here
text = f'{text[:1]}Z{text[2:]}'
Method 2
In general,
string = string[:index] + replacing_character + string[index+1:]
Here,
text = text[:1] + 'Z' + text[2:]
answered Jan 29, 2022 at 18:14
![]()
if your world is 100% ascii/utf-8(a lot of use cases fit in that box):
b = bytearray(s, 'utf-8')
# process - e.g., lowercasing:
# b[0] = b[i+1] - 32
s = str(b, 'utf-8')
python 3.7.3
answered Sep 17, 2019 at 17:44
![]()
Paul NathanPaul Nathan
39.3k28 gold badges112 silver badges209 bronze badges
I would like to add another way of changing a character in a string.
>>> text = '~~~~~~~~~~~'
>>> text = text[:1] + (text[1:].replace(text[0], '+', 1))
'~+~~~~~~~~~'
How faster it is when compared to turning the string into list and replacing the ith value then joining again?.
List approach
>>> timeit.timeit("text = '~~~~~~~~~~~'; s = list(text); s[1] = '+'; ''.join(s)", number=1000000)
0.8268570480013295
My solution
>>> timeit.timeit("text = '~~~~~~~~~~~'; text=text[:1] + (text[1:].replace(text[0], '+', 1))", number=1000000)
0.588400217000526
answered Apr 4, 2020 at 16:50
![]()
mohammed wazeemmohammed wazeem
1,2601 gold badge8 silver badges25 bronze badges
1
A solution combining find and replace methods in a single line if statement could be:
```python
my_var = "stackoverflaw"
my_new_var = my_var.replace('a', 'o', 1) if my_var.find('s') != -1 else my_var
print(f"my_var = {my_var}") # my_var = stackoverflaw
print(f"my_new_var = {my_new_var}") # my_new_var = stackoverflow
```
answered Dec 6, 2020 at 21:30
![]()
eapetchoeapetcho
5173 silver badges10 bronze badges
try this :
old_string = "mba"
string_list = list(old_string)
string_list[2] = "e"
//Replace 3rd element
new_string = "".join(string_list)
print(new_string)
answered Mar 21, 2021 at 12:09
![]()
В уроке по присвоению типа переменной в Python вы могли узнать, как определять строки: объекты, состоящие из последовательности символьных данных. Обработка строк неотъемлемая частью программирования на python. Крайне редко приложение, не использует строковые типы данных.
Из этого урока вы узнаете: Python предоставляет большую коллекцию операторов, функций и методов для работы со строками. Когда вы закончите изучение этой документации, узнаете, как получить доступ и извлечь часть строки, а также познакомитесь с методами, которые доступны для манипулирования и изменения строковых данных.
Ниже рассмотрим операторы, методы и функции, доступные для работы с текстом.
Строковые операторы
Вы уже видели операторы + и * в применении их к числовым значениям в уроке по операторам в Python . Эти два оператора применяются и к строкам.
Оператор сложения строк +
+ — оператор конкатенации строк. Он возвращает строку, состоящую из других строк, как показано здесь:
>>> s = 'py'
>>> t = 'th'
>>> u = 'on'
>>> s + t
'pyth'
>>> s + t + u
'python'
>>> print('Привет, ' + 'Мир!')
Go team!!!
Оператор умножения строк *
* — оператор создает несколько копий строки. Если s это строка, а n целое число, любое из следующих выражений возвращает строку, состоящую из n объединенных копий s:
s * n
n * s
Вот примеры умножения строк:
>>> s = 'py.'
>>> s * 4
'py.py.py.py.'
>>> 4 * s
'py.py.py.py.'
Значение множителя n должно быть целым положительным числом. Оно может быть нулем или отрицательным, но этом случае результатом будет пустая строка:
>>> 'py' * -6
''
Если вы создадите строковую переменную и превратите ее в пустую строку, с помощью 'py' * -6, кто-нибудь будет справедливо считать вас немного глупым. Но это сработает.
Оператор принадлежности подстроки in
Python также предоставляет оператор принадлежности, который можно использоваться для манипуляций со строками. Оператор in возвращает True, если подстрока входит в строку, и False, если нет:
>>> s = 'Python'
>>> s in 'I love Python.'
True
>>> s in 'I love Java.'
False
Есть также оператор not in, у которого обратная логика:
>>> 'z' not in 'abc'
True
>>> 'z' not in 'xyz'
False
Python предоставляет множество функций, которые встроены в интерпретатор. Вот несколько, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Изменяет тип объекта на string |
Более подробно о них ниже.
Функция ord(c) возвращает числовое значение для заданного символа.
На базовом уровне компьютеры хранят всю информацию в виде цифр. Для представления символьных данных используется схема перевода, которая содержит каждый символ с его репрезентативным номером.
Самая простая схема в повседневном использовании называется ASCII . Она охватывает латинские символы, с которыми мы чаще работает. Для этих символов ord(c) возвращает значение ASCII для символа c:
>>> ord('a')
97
>>> ord('#')
35
ASCII прекрасен, но есть много других языков в мире, которые часто встречаются. Полный набор символов, которые потенциально могут быть представлены в коде, намного больше обычных латинских букв, цифр и символом.
Unicode — это современный стандарт, который пытается предоставить числовой код для всех возможных символов, на всех возможных языках, на каждой возможной платформе. Python 3 поддерживает Unicode, в том числе позволяет использовать символы Unicode в строках.
Функция ord() также возвращает числовые значения для символов Юникода:
>>> ord('€')
8364
>>> ord('∑')
8721
Функция chr(n) возвращает символьное значение для данного целого числа.
chr() действует обратно ord(). Если задано числовое значение n, chr(n) возвращает строку, представляющую символ n:
>>> chr(97)
'a'
>>> chr(35)
'#'
chr() также обрабатывает символы Юникода:
>>> chr(8364)
'€'
>>> chr(8721)
'∑'
Функция len(s) возвращает длину строки.
len(s) возвращает количество символов в строке s:
>>> s = 'Простоя строка.'
>>> len(s)
15
Функция str(obj) возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен как строка. str(obj) возвращает строковое представление объекта obj:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('py')
'py'
Индексация строк
Часто в языках программирования, отдельные элементы в упорядоченном наборе данных могут быть доступны с помощью числового индекса или ключа. Этот процесс называется индексация.
В Python строки являются упорядоченными последовательностями символьных данных и могут быть проиндексированы. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках [].
Индексация строк начинается с нуля: у первого символа индекс 0, следующего 1 и так далее. Индекс последнего символа в python — ‘‘длина строки минус один’’.
Например, схематическое представление индексов строки 'foobar' выглядит следующим образом:

Отдельные символы доступны по индексу следующим образом:
>>> s = 'foobar'
>>> s[0]
'f'
>>> s[1]
'o'
>>> s[3]
'b'
>>> s[5]
'r'
Попытка обращения по индексу большему чем len(s) - 1, приводит к ошибке IndexError:
>>> s[6]
Traceback (most recent call last):
File "", line 1, in <module>
s[6]
IndexError: string index out of range
Индексы строк также могут быть указаны отрицательными числами. В этом случае индексирование начинается с конца строки: -1 относится к последнему символу, -2 к предпоследнему и так далее. Вот такая же диаграмма, показывающая как положительные, так и отрицательные индексы строки 'foobar':

Вот несколько примеров отрицательного индексирования:
>>> s = 'foobar'
>>> s[-1]
'r'
>>> s[-2]
'a'
>>> len(s)
6
>>> s[-len(s)] # отрицательная индексация начинается с -1
'f'
Попытка обращения по индексу меньшему чем -len(s), приводит к ошибке IndexError:
>>> s[-7]
Traceback (most recent call last):
File "", line 1, in <module>
s[-7]
IndexError: string index out of range
Для любой непустой строки s, код s[len(s)-1] и s[-1] возвращают последний символ. Нет индекса, который применим к пустой строке.
Срезы строк
Python также допускает возможность извлечения подстроки из строки, известную как ‘‘string slice’’. Если s это строка, выражение формы s[m:n] возвращает часть s, начинающуюся с позиции m, и до позиции n, но не включая позицию:
>>> s = 'python'
>>> s[2:5]
'tho'
Помните: индексы строк в python начинаются с нуля. Первый символ в строке имеет индекс
0. Это относится и к срезу.
Опять же, второй индекс указывает символ, который не включен в результат. Символ 'n' в приведенном выше примере. Это может показаться немного не интуитивным, но дает результат: выражение s[m:n] вернет подстроку, которая является разницей n - m, в данном случае 5 - 2 = 3.
Если пропустить первый индекс, срез начинается с начала строки. Таким образом, s[:m] = s[0:m]:
>>> s = 'python'
>>> s[:4]
'pyth'
>>> s[0:4]
'pyth'
Аналогично, если опустить второй индекс s[n:], срез длится от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздкой s[n:len(s)]:
>>> s = 'python'
>>> s[2:]
'thon'
>>> s[2:len(s)]
'thon'
Для любой строки s и любого целого n числа (0 ≤ n ≤ len(s)), s[:n] + s[n:]будет s:
>>> s = 'python'
>>> s[:4] + s[4:]
'python'
>>> s[:4] + s[4:] == s
True
Пропуск обоих индексов возвращает исходную строку. Это не копия, это ссылка на исходную строку:
>>> s = 'python'
>>> t = s[:]
>>> id(s)
59598496
>>> id(t)
59598496
>>> s is t
True
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один не очевидный способ сгенерировать пустую строку, если вы его искали:
>>> s[2:2]
''
>>> s[4:2]
''
Отрицательные индексы можно использовать и со срезами. Вот пример кода Python:
>>> s = 'python'
>>> s[-5:-2]
'yth'
>>> s[1:4]
'yth'
>>> s[-5:-2] == s[1:4]
True
Шаг для среза строки
Существует еще один вариант синтаксиса среза, о котором стоит упомянуть. Добавление дополнительного : и третьего индекса означает шаг, который указывает, сколько символов следует пропустить после извлечения каждого символа в срезе.
Например , для строки 'python' срез 0:6:2 начинается с первого символа и заканчивается последним символом (всей строкой), каждый второй символ пропускается. Это показано на следующей схеме:

Иллюстративный код показан здесь:
>>> s = 'foobar'
>>> s[0:6:2]
'foa'
>>> s[1:6:2]
'obr'
Как и в случае с простым срезом, первый и второй индексы могут быть пропущены:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::5]
'11111'
>>> s[4::5]
'55555'
Вы также можете указать отрицательное значение шага, в этом случае Python идет с конца строки. Начальный/первый индекс должен быть больше конечного/второго индекса:
>>> s = 'python'
>>> s[5:0:-2]
'nhy'
В приведенном выше примере, 5:0:-2 означает «начать с последнего символа и делать два шага назад, но не включая первый символ.”
Когда вы идете назад, если первый и второй индексы пропущены, значения по умолчанию применяются так: первый индекс — конец строки, а второй индекс — начало. Вот пример:
>>> s = '12345' * 5
>>> s
'1234512345123451234512345'
>>> s[::-5]
'55555'
Это общая парадигма для разворота (reverse) строки:
>>> s = 'Если так говорит товарищ Наполеон, значит, так оно и есть.'
>>> s[::-1]
'.ьтсе и оно кат ,тичанз ,ноелопаН щиравот тировог кат илсЕ'
Форматирование строки
В Python версии 3.6 был представлен новый способ форматирования строк. Эта функция официально названа литералом отформатированной строки, но обычно упоминается как f-string.
Возможности форматирования строк огромны и не будут подробно описана здесь.
Одной простой особенностью f-строк, которые вы можете начать использовать сразу, является интерполяция переменной. Вы можете указать имя переменной непосредственно в f-строковом литерале (f'string'), и python заменит имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого print() и оператора ,, разделяющего числовые значения и строковые:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('Произведение', n, 'на', m, 'равно', prod)
Произведение 20 на 25 равно 500
Но это громоздко. Чтобы выполнить то же самое с помощью f-строки:
- Напишите
fилиFперед кавычками строки. Это укажет python, что это f-строка вместо стандартной. - Укажите любые переменные для воспроизведения в фигурных скобках (
{}).
Код с использованием f-string, приведенный ниже выглядит намного чище:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'Произведение {n} на {m} равно {prod}')
Произведение 20 на 25 равно 500
Любой из трех типов кавычек в python можно использовать для f-строки:
>>> var = 'Гав'
>>> print(f'Собака говорит {var}!')
Собака говорит Гав!
>>> print(f"Собака говорит {var}!")
Собака говорит Гав!
>>> print(f'''Собака говорит {var}!''')
Собака говорит Гав!
Изменение строк
Строки — один из типов данных, которые Python считает неизменяемыми, что означает невозможность их изменять. Как вы ниже увидите, python дает возможность изменять (заменять и перезаписывать) строки.
Такой синтаксис приведет к ошибке TypeError:
>>> s = 'python'
>>> s[3] = 't'
Traceback (most recent call last):
File "", line 1, in <module>
s[3] = 't'
TypeError: 'str' object does not support item assignment
На самом деле нет особой необходимости изменять строки. Обычно вы можете легко сгенерировать копию исходной строки с необходимыми изменениями. Есть минимум 2 способа сделать это в python. Вот первый:
>>> s = s[:3] + 't' + s[4:]
>>> s
'pytton'
Есть встроенный метод string.replace(x, y):
>>> s = 'python'
>>> s = s.replace('h', 't')
>>> s
'pytton'
Читайте дальше о встроенных методах строк!
Встроенные методы строк в python
В руководстве по типам переменных в python вы узнали, что Python — это объектно-ориентированный язык. Каждый элемент данных в программе python является объектом.
Вы также знакомы с функциями: самостоятельными блоками кода, которые вы можете вызывать для выполнения определенных задач.
Методы похожи на функции. Метод — специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается только вместе с определенным объектом и знает о нем во время выполнения.
Синтаксис для вызова метода объекта выглядит следующим образом:
obj.foo(<args>)
Этот код вызывает метод .foo() объекта obj. — аргументы, передаваемые методу (если есть).
Вы узнаете намного больше об определении и вызове методов позже в статьях про объектно-ориентированное программирование. Сейчас цель усвоить часто используемые встроенные методы, которые есть в python для работы со строками.
В приведенных методах аргументы, указанные в квадратных скобках ([]), являются необязательными.
Изменение регистра строки
Методы этой группы выполняют преобразование регистра строки.
string.capitalize() приводит первую букву в верхний регистр, остальные в нижний.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и остальными символами, преобразованными в нижний регистр:
>>> s = 'everyTHing yoU Can IMaGine is rEAl'
>>> s.capitalize()
'Everything you can imagine is real'
Не алфавитные символы не изменяются:
>>> s = 'follow us @PYTHON'
>>> s.capitalize()
'Follow us @python'
string.lower() преобразует все буквенные символы в строчные.
s.lower() возвращает копию s со всеми буквенными символами, преобразованными в нижний регистр:
>>> 'everyTHing yoU Can IMaGine is rEAl'.lower()
'everything you can imagine is real'
string.swapcase() меняет регистр буквенных символов на противоположный.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
>>> 'everyTHing yoU Can IMaGine is rEAl'.swapcase()
'EVERYthING YOu cAN imAgINE IS ReaL'
string.title() преобразует первые буквы всех слов в заглавные
s.title() возвращает копию, s в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы — в нижний регистр:
>>> 'the sun also rises'.title()
'The Sun Also Rises'
Этот метод использует довольно простой алгоритм. Он не пытается различить важные и неважные слова и не обрабатывает апострофы, имена или аббревиатуры:
>>> 'follow us @PYTHON'.title()
'Follow Us @Python'
string.upper() преобразует все буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами в верхнем регистре:
>>> 'follow us @PYTHON'.upper()
'FOLLOW US @PYTHON'
Найти и заменить подстроку в строке
Эти методы предоставляют различные способы поиска в целевой строке указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы и аргументы. Они задают диапазон поиска: действие метода ограничено частью целевой строки, начинающейся в позиции символа и продолжающейся вплоть до позиции символа , но не включая его. Если указано, а нет, метод применяется к части строки от конца.
string.count([, [, ]]) подсчитывает количество вхождений подстроки в строку.
s.count() возвращает количество точных вхождений подстроки в s:
>>> 'foo goo moo'.count('oo')
3
Количество вхождений изменится, если указать и :
>>> 'foo goo moo'.count('oo', 0, 8)
2
string.endswith([, [, ]]) определяет, заканчивается ли строка заданной подстрокой.
s.endswith() возвращает, True если s заканчивается указанным и False если нет:
>>> 'python'.endswith('on')
True
>>> 'python'.endswith('or')
False
Сравнение ограничено подстрокой, между и , если они указаны:
>>> 'python'.endswith('yt', 0, 4)
True
>>> 'python'.endswith('yt', 2, 4)
False
string.find([, [, ]]) ищет в строке заданную подстроку.
s.find() возвращает первый индекс в s который соответствует началу строки :
>>> 'Follow Us @Python'.find('Us')
7
Этот метод возвращает, -1 если указанная подстрока не найдена:
>>> 'Follow Us @Python'.find('you')
-1
Поиск в строке ограничивается подстрокой, между и , если они указаны:
>>> 'Follow Us @Python'.find('Us', 4)
7
>>> 'Follow Us @Python'.find('Us', 4, 7)
-1
string.index([, [, ]]) ищет в строке заданную подстроку.
Этот метод идентичен .find(), за исключением того, что он вызывает исключение ValueError, если не найден:
>>> 'Follow Us @Python'.index('you')
Traceback (most recent call last):
File "", line 1, in <module>
'Follow Us @Python'.index('you')
ValueError: substring not found
string.rfind([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
s.rfind() возвращает индекс последнего вхождения подстроки в s, который соответствует началу :
>>> 'Follow Us @Python'.rfind('o')
15
Как и в .find(), если подстрока не найдена, возвращается -1:
>>> 'Follow Us @Python'.rfind('a')
-1
Поиск в строке ограничивается подстрокой, между и , если они указаны:
>>> 'Follow Us @Python'.rfind('Us', 0, 14)
7
>>> 'Follow Us @Python'.rfind('Us', 9, 14)
-1
string.rindex([, [, ]]) ищет в строке заданную подстроку, начиная с конца.
Этот метод идентичен .rfind(), за исключением того, что он вызывает исключение ValueError, если не найден:
>>> 'Follow Us @Python'.rindex('you')
Traceback (most recent call last):
File "", line 1, in <module>
'Follow Us @Python'.rindex('you')
ValueError: substring not found
string.startswith([, [, ]]) определяет, начинается ли строка с заданной подстроки.
s.startswith() возвращает, True если s начинается с указанного и False если нет:
>>> 'Follow Us @Python'.startswith('Fol')
True
>>> 'Follow Us @Python'.startswith('Go')
False
Сравнение ограничено подстрокой, между и , если они указаны:
>>> 'Follow Us @Python'.startswith('Us', 7)
True
>>> 'Follow Us @Python'.startswith('Us', 8, 16)
False
Классификация строк
Методы в этой группе классифицируют строку на основе символов, которые она содержит.
string.isalnum() определяет, состоит ли строка из букв и цифр.
s.isalnum() возвращает True, если строка s не пустая, а все ее символы буквенно-цифровые (либо буква, либо цифра). В другом случае False :
>>> 'abc123'.isalnum()
True
>>> 'abc$123'.isalnum()
False
>>> ''.isalnum()
False
string.isalpha() определяет, состоит ли строка только из букв.
s.isalpha() возвращает True, если строка s не пустая, а все ее символы буквенные. В другом случае False:
>>> 'ABCabc'.isalpha()
True
>>> 'abc123'.isalpha()
False
string.isdigit() определяет, состоит ли строка из цифр (проверка на число).
s.digit() возвращает True когда строка s не пустая и все ее символы являются цифрами, а в False если нет:
>>> '123'.isdigit()
True
>>> '123abc'.isdigit()
False
string.isidentifier() определяет, является ли строка допустимым идентификатором Python.
s.isidentifier() возвращает True, если s валидный идентификатор (название переменной, функции, класса и т.д.) python, а в False если нет:
>>> 'foo32'.isidentifier()
True
>>> '32foo'.isidentifier()
False
>>> 'foo$32'.isidentifier()
False
Важно: .isidentifier() вернет True для строки, которая соответствует зарезервированному ключевому слову python, даже если его нельзя использовать:
>>> 'and'.isidentifier()
True
Вы можете проверить, является ли строка ключевым словом Python, используя функцию iskeyword(), которая находится в модуле keyword. Один из возможных способов сделать это:
>>> from keyword import iskeyword
>>> iskeyword('and')
True
Если вы действительно хотите убедиться, что строку можно использовать как идентификатор python, вы должны проверить, что .isidentifier() = True и iskeyword() = False.
string.islower() определяет, являются ли буквенные символы строки строчными.
s.islower() возвращает True, если строка s не пустая, и все содержащиеся в нем буквенные символы строчные, а False если нет. Не алфавитные символы игнорируются:
>>> 'abc'.islower()
True
>>> 'abc1$d'.islower()
True
>>> 'Abc1$D'.islower()
False
string.isprintable() определяет, состоит ли строка только из печатаемых символов.
s.isprintable() возвращает, True если строка s пустая или все буквенные символы которые она содержит можно вывести на экран. Возвращает, False если s содержит хотя бы один специальный символ. Не алфавитные символы игнорируются:
>>> 'atb'.isprintable() # t - символ табуляции
False
>>> 'a b'.isprintable()
True
>>> ''.isprintable()
True
>>> 'anb'.isprintable() # n - символ перевода строки
False
Важно: Это единственный .is****() метод, который возвращает True, если s пустая строка. Все остальные возвращаются False.
string.isspace() определяет, состоит ли строка только из пробельных символов.
s.isspace() возвращает True, если s не пустая строка, и все символы являются пробельными, а False, если нет.
Наиболее часто встречающиеся пробельные символы — это пробел ' ', табуляция 't' и новая строка 'n':
>>> ' t n '.isspace()
True
>>> ' a '.isspace()
False
Тем не менее есть несколько символов ASCII, которые считаются пробелами. И если учитывать символы Юникода, их еще больше:
>>> 'fu2005r'.isspace()
True
'f' и 'r' являются escape-последовательностями для символов ASCII; 'u2005' это escape-последовательность для Unicode.
string.istitle() определяет, начинаются ли слова строки с заглавной буквы.
s.istitle() возвращает True когда s не пустая строка и первый алфавитный символ каждого слова в верхнем регистре, а все остальные буквенные символы в каждом слове строчные. Возвращает False, если нет:
>>> 'This Is A Title'.istitle()
True
>>> 'This is a title'.istitle()
False
>>> 'Give Me The #$#@ Ball!'.istitle()
True
string.isupper() определяет, являются ли буквенные символы строки заглавными.
s.isupper() возвращает True, если строка s не пустая, и все содержащиеся в ней буквенные символы являются заглавными, и в False, если нет. Не алфавитные символы игнорируются:
>>> 'ABC'.isupper()
True
>>> 'ABC1$D'.isupper()
True
>>> 'Abc1$D'.isupper()
False
Выравнивание строк, отступы
Методы в этой группе влияют на вывод строки.
string.center([, ]) выравнивает строку по центру.
s.center() возвращает строку, состоящую из s выровненной по ширине . По умолчанию отступ состоит из пробела ASCII:
>>> 'py'.center(10)
' py '
Если указан необязательный аргумент , он используется как символ заполнения:
>>> 'py'.center(10, '-')
'----py----'
Если s больше или равна , строка возвращается без изменений:
>>> 'python'.center(2)
'python'
string.expandtabs(tabsize=8) заменяет табуляции на пробелы
s.expandtabs() заменяет каждый символ табуляции ('t') пробелами. По умолчанию табуляция заменяются на 8 пробелов:
>>> 'atbtc'.expandtabs()
'a b c'
>>> 'aaatbbbtc'.expandtabs()
'aaa bbb c'
tabsize необязательный параметр, задающий количество пробелов:
>>> 'atbtc'.expandtabs(4)
'a b c'
>>> 'aaatbbbtc'.expandtabs(tabsize=4)
'aaa bbb c'
string.ljust([, ]) выравнивание по левому краю строки в поле.
s.ljust() возвращает строку s, выравненную по левому краю в поле шириной . По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.ljust(10)
'python '
Если указан аргумент , он используется как символ заполнения:
>>> 'python'.ljust(10, '-')
'python----'
Если s больше или равна , строка возвращается без изменений:
>>> 'python'.ljust(2)
'python'
string.lstrip([]) обрезает пробельные символы слева
s.lstrip()возвращает копию s в которой все пробельные символы с левого края удалены:
>>> ' foo bar baz '.lstrip()
'foo bar baz '
>>> 'tnfootnbartnbaz'.lstrip()
'footnbartnbaz'
Необязательный аргумент , определяет набор символов, которые будут удалены:
>>> 'https://www.pythonru.com'.lstrip('/:pths')
'www.pythonru.com'
string.replace(, [, ]) заменяет вхождения подстроки в строке.
s.replace(, ) возвращает копию s где все вхождения подстроки , заменены на :
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love')
'I love python! I love python! I love python!'
Если указан необязательный аргумент , выполняется количество замен:
>>> 'I hate python! I hate python! I hate python!'.replace('hate', 'love', 2)
'I love python! I love python! I hate python!'
string.rjust([, ]) выравнивание по правому краю строки в поле.
s.rjust() возвращает строку s, выравненную по правому краю в поле шириной . По умолчанию отступ состоит из пробела ASCII:
>>> 'python'.rjust(10)
' python'
Если указан аргумент , он используется как символ заполнения:
>>> 'python'.rjust(10, '-')
'----python'
Если s больше или равна , строка возвращается без изменений:
>>> 'python'.rjust(2)
'python'
string.rstrip([]) обрезает пробельные символы справа
s.rstrip() возвращает копию s без пробельных символов, удаленных с правого края:
>>> ' foo bar baz '.rstrip()
' foo bar baz'
>>> 'footnbartnbaztn'.rstrip()
'footnbartnbaz'
Необязательный аргумент , определяет набор символов, которые будут удалены:
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
string.strip([]) удаляет символы с левого и правого края строки.
s.strip() эквивалентно последовательному вызову s.lstrip()и s.rstrip(). Без аргумента метод удаляет пробелы в начале и в конце:
>>> s = ' foo bar bazttt'
>>> s = s.lstrip()
>>> s = s.rstrip()
>>> s
'foo bar baz'
Как в .lstrip() и .rstrip(), необязательный аргумент определяет набор символов, которые будут удалены:
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
Важно: Когда возвращаемое значение метода является другой строкой, как это часто бывает, методы можно вызывать последовательно:
>>> ' foo bar bazttt'.lstrip().rstrip()
'foo bar baz'
>>> ' foo bar bazttt'.strip()
'foo bar baz'
>>> 'www.pythonru.com'.lstrip('w.').rstrip('.moc')
'pythonru'
>>> 'www.pythonru.com'.strip('w.moc')
'pythonru'
string.zfill() дополняет строку нулями слева.
s.zfill() возвращает копию s дополненную '0' слева для достижения длины строки указанной в :
>>> '42'.zfill(5)
'00042'
Если s содержит знак перед цифрами, он остается слева строки:
>>> '+42'.zfill(8)
'+0000042'
>>> '-42'.zfill(8)
'-0000042'
Если s больше или равна , строка возвращается без изменений:
>>> '-42'.zfill(3)
'-42'
.zfill() наиболее полезен для строковых представлений чисел, но python с удовольствием заполнит строку нулями, даже если в ней нет чисел:
>>> 'foo'.zfill(6)
'000foo'
Методы преобразование строки в список
Методы в этой группе преобразовывают строку в другой тип данных и наоборот. Эти методы возвращают или принимают итерируемые объекты — термин Python для последовательного набора объектов.
Многие из этих методов возвращают либо список, либо кортеж. Это два похожих типа данных, которые являются прототипами примеров итераций в python. Список заключен в квадратные скобки ( []), а кортеж заключен в простые (()).
Теперь давайте посмотрим на последнюю группу строковых методов.
string.join() объединяет список в строку.
s.join() возвращает строку, которая является результатом конкатенации объекта с разделителем s.
Обратите внимание, что .join() вызывается строка-разделитель s . должна быть последовательностью строковых объектов.
Примеры кода помогут вникнуть. В первом примере разделителем s является строка ', ', а список строк:
>>> ', '.join(['foo', 'bar', 'baz', 'qux'])
'foo, bar, baz, qux'
В результате получается одна строка, состоящая из списка объектов, разделенных запятыми.
В следующем примере указывается как одно строковое значение. Когда строковое значение используется в качестве итерируемого, оно интерпретируется как список отдельных символов строки:
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
Таким образом, результатом ':'.join('corge') является строка, состоящая из каждого символа в 'corge', разделенного символом ':'.
Этот пример завершается с ошибкой TypeError, потому что один из объектов в не является строкой:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
Это можно исправить так:
>>> '---'.join(['foo', str(23), 'bar'])
'foo---23---bar'
Как вы скоро увидите, многие объекты в Python можно итерировать, и .join() особенно полезен для создания из них строк.
string.partition() делит строку на основе разделителя.
s.partition() отделяет от s подстроку длиной от начала до первого вхождения . Возвращаемое значение представляет собой кортеж из трех частей:
- Часть
sдо - Разделитель
- Часть
sпосле
Вот пара примеров .partition()в работе:
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
Если не найден в s, возвращаемый кортеж содержит s и две пустые строки:
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
s.rpartition() делит строку на основе разделителя, начиная с конца.
s.rpartition() работает как s.partition(), за исключением того, что s делится при последнем вхождении вместо первого:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
string.rsplit(sep=None, maxsplit=-1) делит строку на список из подстрок.
Без аргументов s.rsplit() делит s на подстроки, разделенные любой последовательностью пробелов, и возвращает список:
>>> 'foo bar baz qux'.rsplit()
['foo', 'bar', 'baz', 'qux']
>>> 'foontbar bazrfqux'.rsplit()
['foo', 'bar', 'baz', 'qux']
Если указан, он используется в качестве разделителя:
>>> 'foo.bar.baz.qux'.rsplit(sep='.')
['foo', 'bar', 'baz', 'qux']
Если = None, строка разделяется пробелами, как если бы не был указан вообще.
Когда явно указан в качестве разделителя s, последовательные повторы разделителя будут возвращены как пустые строки:
>>> 'foo...bar'.rsplit(sep='.')
['foo', '', '', 'bar']
Это не работает, когда не указан. В этом случае последовательные пробельные символы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
>>> 'footttbar'.rsplit()
['foo', 'bar']
Если указан необязательный параметр , выполняется максимальное количество разделений, начиная с правого края s:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=1)
['www.pythonru', 'com']
Значение по умолчанию для — -1. Это значит, что все возможные разделения должны быть выполнены:
>>> 'www.pythonru.com'.rsplit(sep='.', maxsplit=-1)
['www', 'pythonru', 'com']
>>> 'www.pythonru.com'.rsplit(sep='.')
['www', 'pythonru', 'com']
string.split(sep=None, maxsplit=-1) делит строку на список из подстрок.
s.split() ведет себя как s.rsplit(), за исключением того, что при указании , деление начинается с левого края s:
>>> 'www.pythonru.com'.split('.', maxsplit=1)
['www', 'pythonru.com']
>>> 'www.pythonru.com'.rsplit('.', maxsplit=1)
['www.pythonru', 'com']
Если не указано, между .rsplit() и .split() в python разницы нет.
string.splitlines([]) делит текст на список строк.
s.splitlines() делит s на строки и возвращает их в списке. Любой из следующих символов или последовательностей символов считается границей строки:
| Разделитель | Значение |
|---|---|
| n | Новая строка |
| r | Возврат каретки |
| rn | Возврат каретки + перевод строки |
| v или же x0b | Таблицы строк |
| f или же x0c | Подача формы |
| x1c | Разделитель файлов |
| x1d | Разделитель групп |
| x1e | Разделитель записей |
| x85 | Следующая строка |
| u2028 | Новая строка (Unicode) |
| u2029 | Новый абзац (Unicode) |
Вот пример использования нескольких различных разделителей строк:
>>> 'foonbarrnbazfquxu2028quux'.splitlines()
['foo', 'bar', 'baz', 'qux', 'quux']
Если в строке присутствуют последовательные символы границы строки, они появятся в списке результатов, как пустые строки:
>>> 'foofffbar'.splitlines()
['foo', '', '', 'bar']
Если необязательный аргумент указан и его булевое значение True, то символы границы строк сохраняются в списке подстрок:
>>> 'foonbarnbaznqux'.splitlines(True)
['foon', 'barn', 'bazn', 'qux']
>>> 'foonbarnbaznqux'.splitlines(8)
['foon', 'barn', 'bazn', 'qux']
Заключение
В этом руководстве было подробно рассмотрено множество различных механизмов, которые Python предоставляет для работы со строками, включая операторы, встроенные функции, индексирование, срезы и встроенные методы.
Python есть другие встроенные типы данных. В этих урока вы изучите два наиболее часто используемых:
- Списки python
- Кортежи (tuple)
Текстовые переменные str в Питоне
Строковый тип str в Python используют для работы с любыми текстовыми данными. Python автоматически определяет тип str по кавычкам – одинарным или двойным:
>>> stroka = 'Python'
>>> type(stroka)
<class 'str'>
>>> stroka2 = "code"
>>> type(stroka2)
<class 'str'>
Для решения многих задач строковую переменную нужно объявить заранее, до начала исполнения основной части программы. Создать пустую переменную str просто:
stroka = ''
Или:
stroka2 = ""
Если в самой строке нужно использовать кавычки – например, для названия книги – то один вид кавычек используют для строки, второй – для выделения названия:
>>> print("'Самоучитель Python' - возможно, лучший справочник по Питону.")
'Самоучитель Python' - возможно, лучший справочник по Питону.
>>> print('"Самоучитель Python" - возможно, лучший справочник по Питону.')
"Самоучитель Python" - возможно, лучший справочник по Питону.
Использование одного и того же вида кавычек внутри и снаружи строки вызовет ошибку:
>>> print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
File "<pyshell>", line 1
print(""Самоучитель Python" - возможно, лучший справочник по Питону.")
^
SyntaxError: invalid syntax
Кроме двойных " и одинарных кавычек ', в Python используются и тройные ''' – в них заключают текст, состоящий из нескольких строк, или программный код:
>>> print('''В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.''')
В тройные кавычки заключают многострочный текст.
Программный код также можно выделить тройными кавычками.
Длина строки len в Python
Для определения длины строки используется встроенная функция len(). Она подсчитывает общее количество символов в строке, включая пробелы:
>>> stroka = 'python'
>>> print(len(stroka))
6
>>> stroka1 = ' '
>>> print(len(stroka1))
1
Преобразование других типов данных в строку
Целые и вещественные числа преобразуются в строки одинаково:
>>> number1 = 55
>>> number2 = 55.5
>>> stroka1 = str(number1)
>>> stroka2 = str(number2)
>>> print(type(stroka1))
<class 'str'>
>>> print(type(stroka2))
<class 'str'>
Решение многих задач значительно упрощается, если работать с числами в строковом формате. Особенно это касается заданий, где нужно разделять числа на разряды – сотни, десятки и единицы.
Сложение и умножение строк
Как уже упоминалось в предыдущей главе, строки можно складывать – эта операция также известна как конкатенация:
>>> str1 = 'Python'
>>> str2 = ' - '
>>> str3 = 'самый гибкий язык программирования'
>>> print(str1 + str2 + str3)
Python - самый гибкий язык программирования
При необходимости строку можно умножить на целое число – эта операция называется репликацией:
>>> stroka = '*** '
>>> print(stroka * 5)
*** *** *** *** ***
Подстроки
Подстрокой называется фрагмент определенной строки. Например, ‘abra’ является подстрокой ‘abrakadabra’. Чтобы определить, входит ли какая-то определенная подстрока в строку, используют оператор in:
>>> stroka = 'abrakadabra'
>>> print('abra' in stroka)
True
>>> print('zebra' in stroka)
False
Для обращения к определенному символу строки используют индекс – порядковый номер элемента. Python поддерживает два типа индексации – положительную, при которой отсчет элементов начинается с 0 и с начала строки, и отрицательную, при которой отсчет начинается с -1 и с конца:
| Положительные индексы | 0 | 1 | 2 | 3 | 4 | 5 | 6 |
| Пример строки | P | r | o | g | l | i | b |
| Отрицательные индексы | -7 | -6 | -5 | -4 | -3 | -2 | -1 |
Чтобы получить определенный элемент строки, нужно указать его индекс в квадратных скобках:
>>> stroka = 'программирование'
>>> print(stroka[7])
м
>>> print(stroka[-1])
е
Срезы строк в Python
Индексы позволяют работать с отдельными элементами строк. Для работы с подстроками используют срезы, в которых задается нужный диапазон:
>>> stroka = 'программирование'
>>> print(stroka[7:10])
мир
Диапазон среза [a:b] начинается с первого указанного элемента а включительно, и заканчивается на последнем, не включая b в результат:
>>> stroka = 'программa'
>>> print(stroka[3:8])
грамм
Если не указать первый элемент диапазона [:b], срез будет выполнен с начала строки до позиции второго элемента b:
>>> stroka = 'программa'
>>> print(stroka[:4])
прог
В случае отсутствия второго элемента [a:] срез будет сделан с позиции первого символа и до конца строки:
>>> stroka = 'программa'
>>> print(stroka[3:])
граммa
Если не указана ни стартовая, ни финальная позиция среза, он будет равен исходной строке:
>>> stroka = 'позиции не заданы'
>>> print(stroka[:])
позиции не заданы
Шаг среза
Помимо диапазона, можно задавать шаг среза. В приведенном ниже примере выбирается символ из стартовой позиции среза, а затем каждая 3-я буква из диапазона:
>>> stroka = 'Python лучше всего подходит для новичков.'
>>> print(stroka[1:15:3])
yoлшв
Шаг может быть отрицательным – в этом случае символы будут выбираться, начиная с конца строки:
>>> stroka = 'это пример отрицательного шага'
>>> print(stroka[-1:-15:-4])
а нт
Срез [::-1] может оказаться очень полезным при решении задач, связанных с палиндромами:
>>> stroka = 'А роза упала на лапу Азора'
>>> print(stroka[::-1])
арозА упал ан алапу азор А
Замена символа в строке
Строки в Python относятся к неизменяемым типам данных. По этой причине попытка замены символа по индексу обречена на провал:
>>> stroka = 'mall'
>>> stroka[0] = 'b'
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
TypeError: 'str' object does not support item assignment
Но заменить любой символ все-таки можно – для этого придется воспользоваться срезами и конкатенацией. Результатом станет новая строка:
>>> stroka = 'mall'
>>> stroka = 'b' + stroka[1:]
>>> print(stroka)
ball
Более простой способ «замены» символа или подстроки – использование метода replace(), который мы рассмотрим ниже.
Полезные методы строк
Python предоставляет множество методов для работы с текстовыми данными. Все методы можно сгруппировать в четыре категории:
- Преобразование строк.
- Оценка и классификация строк.
- Конвертация регистра.
- Поиск, подсчет и замена символов.
Рассмотрим эти методы подробнее.
Преобразование строк
Три самых используемых метода из этой группы – join(), split() и partition(). Метод join() незаменим, если нужно преобразовать список или кортеж в строку:
>>> spisok = ['Я', 'изучаю', 'Python']
>>> stroka = ' '.join(spisok)
>>> print(stroka)
Я изучаю Python
При объединении списка или кортежа в строку можно использовать любые разделители:
>>> kort = ('Я', 'изучаю', 'Django')
>>> stroka = '***'.join(kort)
>>> print(stroka)
Я***изучаю***Django
Метод split() используется для обратной манипуляции – преобразования строки в список:
>>> text = 'это пример текста для преобразования в список'
>>> spisok = text.split()
>>> print(spisok)
['это', 'пример', 'текста', 'для', 'преобразования', 'в', 'список']
По умолчанию split() разбивает строку по пробелам. Но можно указать любой другой символ – и на практике это часто требуется:
>>> text = 'цвет: синий; вес: 1 кг; размер: 30х30х50; материал: картон'
>>> spisok = text.split(';')
>>> print(spisok)
['цвет: синий', ' вес: 1 кг', ' размер: 30х30х50', ' материал: картон']
Метод partition() поможет преобразовать строку в кортеж:
>>> text = 'Python - простой и понятный язык'
>>> kort = text.partition('и')
>>> print(kort)
('Python - простой ', 'и', ' понятный язык')
В отличие от split(), partition() учитывает только первое вхождение элемента-разделителя (и добавляет его в итоговый кортеж).
Оценка и классификация строк
В Python много встроенных методов для оценки и классификации текстовых данных. Некоторые из этих методов работают только со строками, в то время как другие универсальны. К последним относятся, например, функции min() и max():
>>> text = '12345'
>>> print(min(text))
1
>>> print(max(text))
5
В Python есть специальные методы для определения типа символов. Например, isalnum() оценивает, состоит ли строка из букв и цифр, либо в ней есть какие-то другие символы:
>>> text = 'abracadabra123456'
>>> print(text.isalnum())
True
>>> text1 = 'a*b$ra cadabra'
>>> print(text1.isalnum())
False
Метод isalpha() поможет определить, состоит ли строка только из букв, или включает специальные символы, пробелы и цифры:
>>> text = 'программирование'
>>> print(text.isalpha())
True
>>> text2 = 'password123'
>>> print(text2.isalpha())
False
С помощью метода isdigit() можно определить, входят ли в строку только цифры, или там есть и другие символы:
>>> text = '1234567890'
>>> print(text.isdigit())
True
>>> text2 = '123456789o'
>>> print(text2.isdigit())
False
Поскольку вещественные числа содержат точку, а отрицательные – знак минуса, выявить их этим методом не получится:
>>> text = '5.55'
>>> print(text.isdigit())
False
>>> text1 = '-5'
>>> print(text1.isdigit())
False
Если нужно определить наличие в строке дробей или римских цифр, подойдет метод isnumeric():
>>> text = '½⅓¼⅕⅙'
>>> print(text.isdigit())
False
>>> print(text.isnumeric())
True
Методы islower() и isupper() определяют регистр, в котором находятся буквы. Эти методы игнорируют небуквенные символы:
>>> text = 'abracadabra'
>>> print(text.islower())
True
>>> text2 = 'Python bytes'
>>> print(text2.islower())
False
>>> text3 = 'PYTHON'
>>> print(text3.isupper())
True
Метод isspace() определяет, состоит ли анализируемая строка из одних пробелов, или содержит что-нибудь еще:
>>> stroka = ' '
>>> print(stroka.isspace())
True
>>> stroka2 = ' a '
>>> print(stroka2.isspace())
False
Конвертация регистра
Как уже говорилось выше, строки относятся к неизменяемым типам данных, поэтому результатом любых манипуляций, связанных с преобразованием регистра или удалением (заменой) символов будет новая строка.
Из всех методов, связанных с конвертацией регистра, наиболее часто используются на практике два – lower() и upper(). Они преобразуют все символы в нижний и верхний регистр соответственно:
>>> text = 'этот текст надо написать заглавными буквами'
>>> print(text.upper())
ЭТОТ ТЕКСТ НАДО НАПИСАТЬ ЗАГЛАВНЫМИ БУКВАМИ
>>> text = 'зДесь ВСе букВы рАзныЕ, а НУжнЫ проПИСНыЕ'
>>> print(text.lower())
здесь все буквы разные, а нужны прописные
Иногда требуется преобразовать текст так, чтобы с заглавной буквы начиналось только первое слово предложения:
>>> text = 'предложение должно начинаться с ЗАГЛАВНОЙ буквы.'
>>> print(text.capitalize())
Предложение должно начинаться с заглавной буквы.
Методы swapcase() и title() используются реже. Первый заменяет исходный регистр на противоположный, а второй – начинает каждое слово с заглавной буквы:
>>> text = 'пРИМЕР иСПОЛЬЗОВАНИЯ swapcase'
>>> print(text.swapcase())
Пример Использования SWAPCASE
>>> text2 = 'тот случай, когда нужен метод title'
>>> print(text2.title())
Тот Случай, Когда Нужен Метод Title
Поиск, подсчет и замена символов
Методы find() и rfind() возвращают индекс стартовой позиции искомой подстроки. Оба метода учитывают только первое вхождение подстроки. Разница между ними заключается в том, что find() ищет первое вхождение подстроки с начала текста, а rfind() – с конца:
>>> text = 'пример текста, в котором нужно найти текстовую подстроку'
>>> print(text.find('текст'))
7
>>> print(text.rfind('текст'))
37
Такие же результаты можно получить при использовании методов index() и rindex() – правда, придется предусмотреть обработку ошибок, если искомая подстрока не будет обнаружена:
>>> text = 'Съешь еще этих мягких французских булок!'
>>> print(text.index('еще'))
6
>>> print(text.rindex('чаю'))
Traceback (most recent call last):
File "<pyshell>", line 1, in <module>
ValueError: substring not found
Если нужно определить, начинается ли строка с определенной подстроки, поможет метод startswith():
>>> text = 'Жила-была курочка Ряба'
>>> print(text.startswith('Жила'))
True
Чтобы проверить, заканчивается ли строка на нужное окончание, используют endswith():
>>> text = 'В конце всех ждал хэппи-енд'
>>> print(text.endswith('енд'))
True
Для подсчета числа вхождений определенного символа или подстроки применяют метод count() – он помогает подсчитать как общее число вхождений в тексте, так и вхождения в указанном диапазоне:
>>> text = 'Съешь еще этих мягких французских булок, да выпей же чаю!'
>>> print(text.count('е'))
5
>>> print(text.count('е', 5, 25))
2
Методы strip(), lstrip() и rstrip() предназначены для удаления пробелов. Метод strip() удаляет пробелы в начале и конце строки, lstrip() – только слева, rstrip() – только справа:
>>> text = ' здесь есть пробелы и слева, и справа '
>>> print('***', text.strip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.lstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
>>> print('***', text.rstrip(), '***')
*** здесь есть пробелы и слева, и справа ***
Метод replace() используют для замены символов или подстрок. Можно указать нужное количество замен, а сам символ можно заменить на пустую подстроку – проще говоря, удалить:
>>> text = 'В этой строчке нужно заменить только одну "ч"'
>>> print(text.replace('ч', '', 1))
В этой строке нужно заменить только одну "ч"
Стоит заметить, что метод replace() подходит лишь для самых простых вариантов замены и удаления подстрок. В более сложных случаях необходимо использование регулярных выражений, которые мы будем изучать позже.
Практика
Задание 1
Напишите программу, которая получает на вход строку и выводит:
- количество символов, содержащихся в тексте;
- True или False в зависимости от того, являются ли все символы буквами и цифрами.
Решение:
text = input()
print(len(text))
print(text.isalpha())
Задание 2
Напишите программу, которая получает на вход слово и выводит True, если слово является палиндромом, или False в противном случае. Примечание: для сравнения в Python используется оператор ==.
Решение:
text = input().lower()
print(text == text[::-1])
Задание 3
Напишите программу, которая получает строку с именем, отчеством и фамилией, написанными в произвольном регистре, и выводит данные в правильном формате. Например, строка алеКСандр СЕРГЕЕВИЧ ПушкиН должна быть преобразована в Александр Сергеевич Пушкин.
Решение:
text = input()
print(text.title())
Задание 4
Имеется строка 12361573928167047230472012. Напишите программу, которая преобразует строку в текст один236один573928один670472304720один2.
Решение:
text = '12361573928167047230472012'
print(text.replace('1', 'один'))
Задание 5
Напишите программу, которая последовательно получает на вход имя, отчество, фамилию и должность сотрудника, а затем преобразует имя и отчество в инициалы, добавляя должность после запятой.
Пример ввода:
Алексей
Константинович
Романов
бухгалтер
Вывод:
А. К. Романов, бухгалтер
Решение:
first_name, patronymic, last_name, position = input(), input(), input(), input()
print(first_name[0] + '.', patronymic[0] + '.', last_name + ',', position)
Задание 6
Напишите программу, которая получает на вход строку текста и букву, а затем определяет, встречается ли данная буква (в любом регистре) в тексте. В качестве ответа программа должна выводить True или False.
Пример ввода:
ЗонтИК
к
Вывод:
True
Решение:
text = input().lower()
letter = input()
print(letter in text)
Задание 7
Напишите программу, которая определяет, является ли введенная пользователем буква гласной. В качестве ответа программы выводит True или False, буквы могут быть как в верхнем, так и в нижнем регистре.
Решение:
vowels = 'аиеёоуыэюя'
letter = input().lower()
print(letter in vowels)
Задание 8
Напишите программу, которая принимает на вход строку текста и подстроку, а затем выводит индексы первого вхождения подстроки с начала и с конца строки (без учета регистра).
Пример ввода:
Шесть шустрых мышат в камышах шуршат
ша
Вывод:
16 33
Решение:
text, letter = input().lower(), input()
print(text.find(letter), text.rfind(letter))
Задание 9
Напишите программу для подсчета количества пробелов и непробельных символов в введенной пользователем строке.
Пример ввода:
В роще, травы шевеля, мы нащиплем щавеля
Вывод:
Количество пробелов: 6, количество других символов: 34
Решение:
text = input()
nospace = text.replace(' ', '')
print(f"Количество пробелов: {text.count(' ')}, количество других символов: {len(nospace)}")
Задание 10
Напишите программу, которая принимает строку и две подстроки start и end, а затем определяет, начинается ли строка с фрагмента start, и заканчивается ли подстрокой end. Регистр не учитывать.
Пример ввода:
Программирование на Python - лучшее хобби
про
про
Вывод:
True
False
Решение:
text, start, end = input().lower(), input(), input()
print(text.startswith(start))
print(text.endswith(end))
Подведем итоги
В этой части мы рассмотрели самые популярные методы работы со строками – они пригодятся для решения тренировочных задач и в разработке реальных проектов. В следующей статье будем разбирать методы работы со списками.
***
📖 Содержание самоучителя
- Особенности, сферы применения, установка, онлайн IDE
- Все, что нужно для изучения Python с нуля – книги, сайты, каналы и курсы
- Типы данных: преобразование и базовые операции
- Методы работы со строками
- Методы работы со списками и списковыми включениями
- Методы работы со словарями и генераторами словарей
- Методы работы с кортежами
- Методы работы со множествами
- Особенности цикла for
- Условный цикл while
- Функции с позиционными и именованными аргументами
- Анонимные функции
- Рекурсивные функции
- Функции высшего порядка, замыкания и декораторы
- Методы работы с файлами и файловой системой
***
Материалы по теме
- ТОП-15 трюков в Python 3, делающих код понятнее и быстрее
1. Строки
Строка считывается со стандартного ввода функцией input(). Напомним,
что для двух строк определена операция сложения (конкатенации), также определена
операция умножения строки на число.
Строка состоит из последовательности символов. Узнать количество символов (длину строки)
можно при помощи функции len.
Любой другой объект в Питоне можно перевести к строке, которая ему соответствует.
Для этого нужно вызвать функцию str(), передав ей в качестве параметра объект,
переводимый в строку.
На самом деле каждая строка, с точки зрения Питона, — это объект
класса str. Чтобы получить по объекту другой объект другого класса, как-то ему соответствующий,
можно использовать функцию приведения. Имя этой функции совпадает с именем класса, к которому мы приводим объект.
(Для знатоков: эта функция — это конструктор объектов данного класса.) Пример: int — класс
для целых чисел. Перевод строки в число осуществляется функцией int().
s = input() print(len(s)) t = input() number = int(t) u = str(number) print(s * 3) print(s + ' ' + u)
2. Срезы (slices)
Срез (slice) — извлечение из данной строки одного символа или некоторого фрагмента
подстроки или подпоследовательности.
Есть три формы срезов. Самая простая форма среза: взятие одного символа
строки, а именно, S[i] — это срез, состоящий из одного символа,
который имеет номер i. При этом считается, что нумерация начинается
с числа 0. То есть если S = 'Hello', то
S[0] == 'H', S[1] == 'e', S[2] == 'l',
S[3] == 'l', S[4] == 'o'.
Заметим, что в Питоне нет отдельного типа для символов строки. Каждый объект, который получается
в результате среза S[i] — это тоже строка типа str.
Номера символов в строке (а также в других структурах данных: списках, кортежах)
называются индексом.
Если указать отрицательное значение индекса, то номер будет отсчитываться
с конца, начиная с номера -1. То есть S[-1] == 'o',
S[-2] == 'l', S[-3] == 'l', S[-4] == 'e',
S[-5] == 'H'.
Или в виде таблицы:
| Строка S | H | e | l | l | o |
| Индекс | S[0] | S[1] | S[2] | S[3] | S[4] |
| Индекс | S[-5] | S[-4] | S[-3] | S[-2] | S[-1] |
Если же номер символа в срезе строки S больше либо равен len(S),
или меньше, чем -len(S), то при обращении к этому символу строки произойдет
ошибка IndexError: string index out of range.
Срез с двумя параметрами: S[a:b]
возвращает подстроку из b - a символов,
начиная с символа c индексом a,
то есть до символа с индексом b, не включая его.
Например, S[1:4] == 'ell', то же самое получится
если написать S[-4:-1]. Можно использовать как положительные,
так и отрицательные индексы в одном срезе, например, S[1:-1] —
это строка без первого и последнего символа (срез начинается с символа с индексом 1 и
заканчиватеся индексом -1, не включая его).
При использовании такой формы среза ошибки IndexError
никогда не возникает. Например, срез S[1:5]
вернет строку 'ello', таким же будет результат,
если сделать второй индекс очень большим, например,
S[1:100] (если в строке не более 100 символов).
Если опустить второй параметр (но поставить двоеточие),
то срез берется до конца строки. Например, чтобы удалить
из строки первый символ (его индекс равен 0), можно
взять срез S[1:]. Аналогично
если опустить первый параметр, то можно взять срез от начала строки.
То есть удалить из строки последний символ можно при помощи среза
S[:-1]. Срез S[:] совпадает с самой строкой
S.
Любые операции среза со строкой создают новые строки и никогда не меняют исходную строку.
В Питоне строки вообще являются неизменяемыми, их невозможно изменить. Можно
лишь в старую переменную присвоить новую строку.
На самом деле в питоне нет и переменных. Есть лишь имена, которые связаны с какими-нибудь объектами.
Можно сначала связать имя с одним объектом, а потом — с другим. Можно несколько имён
связать с одним и тем же объектом.
Если задать срез с тремя параметрами S[a:b:d],
то третий параметр задает шаг, как в случае с функцией
range, то есть будут взяты символы с индексами
a, a + d, a + 2 * d и т. д.
При задании значения третьего параметра, равному 2, в срез попадет
кажый второй символ, а если взять значение среза, равное
-1, то символы будут идти в обратном порядке.
Например, можно перевернуть строку срезом S[::-1].
s = 'abcdefg' print(s[1]) print(s[-1]) print(s[1:3]) print(s[1:-1]) print(s[:3]) print(s[2:]) print(s[:-1]) print(s[::2]) print(s[1::2]) print(s[::-1])
Обратите внимание на то, как похож третий параметр среза на третий параметр функции range():
s = 'abcdefghijklm'
print(s[0:10:2])
for i in range(0, 10, 2):
print(i, s[i])
3. Методы
Метод — это функция, применяемая к объекту, в данном случае — к строке.
Метод вызывается в виде Имя_объекта.Имя_метода(параметры).
Например, S.find("e") — это применение к строке S
метода find с одним параметром "e".
3.1. Методы find и rfind
Метод find находит в данной строке (к которой применяется метод)
данную подстроку (которая передается в качестве параметра).
Функция возвращает индекс первого вхождения искомой подстроки.
Если же подстрока не найдена, то метод возвращает значение -1.
S = 'Hello'
print(S.find('e'))
# вернёт 1
print(S.find('ll'))
# вернёт 2
print(S.find('L'))
# вернёт -1
Аналогично, метод rfind возвращает индекс последнего вхождения
данной строки (“поиск справа”).
S = 'Hello'
print(S.find('l'))
# вернёт 2
print(S.rfind('l'))
# вернёт 3
Если вызвать метод find с тремя параметрами
S.find(T, a, b), то поиск будет осуществляться
в срезе S[a:b]. Если указать только два параметра
S.find(T, a), то поиск будет осуществляться
в срезе S[a:], то есть начиная с символа с индексом
a и до конца строки. Метод S.find(T, a, b)
возращает индекс в строке S, а не индекс относительно среза.
3.2. Метод replace
Метод replace заменяет все вхождения одной строки на другую. Формат:
S.replace(old, new) — заменить в строке S
все вхождения подстроки old на подстроку new. Пример:
print('Hello'.replace('l', 'L'))
# вернёт 'HeLLo'
Если методу replace задать еще один параметр: S.replace(old, new, count),
то заменены будут не все вхождения, а только не больше, чем первые count из них.
print('Abrakadabra'.replace('a', 'A', 2))
# вернёт 'AbrAkAdabra'
3.3. Метод count
Подсчитывает количество вхождений одной строки в другую строку. Простейшая
форма вызова S.count(T) возвращает число вхождений строки
T внутри строки S. При этом подсчитываются только
непересекающиеся вхождения, например:
print('Abracadabra'.count('a'))
# вернёт 4
print(('a' * 10).count('aa'))
# вернёт 5
При указании трех параметров S.count(T, a, b),
будет выполнен подсчет числа вхождений строки T
в срезе S[a:b].
Ссылки на задачи доступны в меню слева. Эталонные решения теперь доступны на странице самой задачи.
If you’re looking for ways to remove or replace all or part of a string in Python, then this tutorial is for you. You’ll be taking a fictional chat room transcript and sanitizing it using both the .replace() method and the re.sub() function.
In Python, the .replace() method and the re.sub() function are often used to clean up text by removing strings or substrings or replacing them. In this tutorial, you’ll be playing the role of a developer for a company that provides technical support through a one-to-one text chat. You’re tasked with creating a script that’ll sanitize the chat, removing any personal data and replacing any swear words with emoji.
You’re only given one very short chat transcript:
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
Even though this transcript is short, it’s typical of the type of chats that agents have all the time. It has user identifiers, ISO time stamps, and messages.
In this case, the client johndoe filed a complaint, and company policy is to sanitize and simplify the transcript, then pass it on for independent evaluation. Sanitizing the message is your job!
The first thing you’ll want to do is to take care of any swear words.
How to Remove or Replace a Python String or Substring
The most basic way to replace a string in Python is to use the .replace() string method:
>>>
>>> "Fake Python".replace("Fake", "Real")
'Real Python'
As you can see, you can chain .replace() onto any string and provide the method with two arguments. The first is the string that you want to replace, and the second is the replacement.
Now it’s time to apply this knowledge to the transcript:
>>>
>>> transcript = """
... [support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
... [johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
... [support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
... [johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!"""
>>> transcript.replace("BLASTED", "😤")
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY 😤 ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
Loading the transcript as a triple-quoted string and then using the .replace() method on one of the swear words works fine. But there’s another swear word that’s not getting replaced because in Python, the string needs to match exactly:
>>>
>>> "Fake Python".replace("fake", "Real")
'Fake Python'
As you can see, even if the casing of one letter doesn’t match, it’ll prevent any replacements. This means that if you’re using the .replace() method, you’ll need to call it various times with the variations. In this case, you can just chain on another call to .replace():
>>>
>>> transcript.replace("BLASTED", "😤").replace("Blast", "😤")
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY 😤 ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : 😤! You're right!
Success! But you’re probably thinking that this isn’t the best way to do this for something like a general-purpose transcription sanitizer. You’ll want to move toward some way of having a list of replacements, instead of having to type out .replace() each time.
Set Up Multiple Replacement Rules
There are a few more replacements that you need to make to the transcript to get it into a format acceptable for independent review:
- Shorten or remove the time stamps
- Replace the usernames with Agent and Client
Now that you’re starting to have more strings to replace, chaining on .replace() is going to get repetitive. One idea could be to keep a list of tuples, with two items in each tuple. The two items would correspond to the arguments that you need to pass into the .replace() method—the string to replace and the replacement string:
# transcript_multiple_replace.py
REPLACEMENTS = [
("BLASTED", "😤"),
("Blast", "😤"),
("2022-08-24T", ""),
("+00:00", ""),
("[support_tom]", "Agent "),
("[johndoe]", "Client"),
]
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
for old, new in REPLACEMENTS:
transcript = transcript.replace(old, new)
print(transcript)
In this version of your transcript-cleaning script, you created a list of replacement tuples, which gives you a quick way to add replacements. You could even create this list of tuples from an external CSV file if you had loads of replacements.
You then iterate over the list of replacement tuples. In each iteration, you call .replace() on the string, populating the arguments with the old and new variables that have been unpacked from each replacement tuple.
With this, you’ve made a big improvement in the overall readability of the transcript. It’s also easier to add replacements if you need to. Running this script reveals a much cleaner transcript:
$ python transcript_multiple_replace.py
Agent 10:02:23 : What can I help you with?
Client 10:03:15 : I CAN'T CONNECT TO MY 😤 ACCOUNT
Agent 10:03:30 : Are you sure it's not your caps lock?
Client 10:04:03 : 😤! You're right!
That’s a pretty clean transcript. Maybe that’s all you need. But if your inner automator isn’t happy, maybe it’s because there are still some things that may be bugging you:
- Replacing the swear words won’t work if there’s another variation using -ing or a different capitalization, like BLAst.
- Removing the date from the time stamp currently only works for August 24, 2022.
- Removing the full time stamp would involve setting up replacement pairs for every possible time—not something you’re too keen on doing.
- Adding the space after Agent in order to line up your columns works but isn’t very general.
If these are your concerns, then you may want to turn your attention to regular expressions.
Leverage re.sub() to Make Complex Rules
Whenever you’re looking to do any replacing that’s slightly more complex or needs some wildcards, you’ll usually want to turn your attention toward regular expressions, also known as regex.
Regex is a sort of mini-language made up of characters that define a pattern. These patterns, or regexes, are typically used to search for strings in find and find and replace operations. Many programming languages support regex, and it’s widely used. Regex will even give you superpowers.
In Python, leveraging regex means using the re module’s sub() function and building your own regex patterns:
# transcript_regex.py
import re
REGEX_REPLACEMENTS = [
(r"blastw*", "😤"),
(r" [-T:+d]{25}", ""),
(r"[supportw*]", "Agent "),
(r"[johndoe]", "Client"),
]
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
for old, new in REGEX_REPLACEMENTS:
transcript = re.sub(old, new, transcript, flags=re.IGNORECASE)
print(transcript)
While you can mix and match the sub() function with the .replace() method, this example only uses sub(), so you can see how it’s used. You’ll note that you can replace all variations of the swear word by using just one replacement tuple now. Similarly, you’re only using one regex for the full time stamp:
$ python transcript_regex.py
Agent : What can I help you with?
Client : I CAN'T CONNECT TO MY 😤 ACCOUNT
Agent : Are you sure it's not your caps lock?
Client : 😤! You're right!
Now your transcript has been completely sanitized, with all noise removed! How did that happen? That’s the magic of regex.
The first regex pattern, "blastw*", makes use of the w special character, which will match alphanumeric characters and underscores. Adding the * quantifier directly after it will match zero or more characters of w.
Another vital part of the first pattern is that the re.IGNORECASE flag makes it a case-insensitive pattern. So now, any substring containing blast, regardless of capitalization, will be matched and replaced.
The second regex pattern uses character sets and quantifiers to replace the time stamp. You often use character sets and quantifiers together. A regex pattern of [abc], for example, will match one character of a, b, or c. Putting a * directly after it would match zero or more characters of a, b, or c.
There are more quantifiers, though. If you used [abc]{10}, it would match exactly ten characters of a, b or c in any order and any combination. Also note that repeating characters is redundant, so [aa] is equivalent to [a].
For the time stamp, you use an extended character set of [-T:+d] to match all the possible characters that you might find in the time stamp. Paired with the quantifier {25}, this will match any possible time stamp, at least until the year 10,000.
The time stamp regex pattern allows you to select any possible date in the time stamp format. Seeing as the the times aren’t important for the independent reviewer of these transcripts, you replace them with an empty string. It’s possible to write a more advanced regex that preserves the time information while removing the date.
The third regex pattern is used to select any user string that starts with the keyword "support". Note that you escape () the square bracket ([) because otherwise the keyword would be interpreted as a character set.
Finally, the last regex pattern selects the client username string and replaces it with "Client".
With regex, you can drastically cut down the number of replacements that you have to write out. That said, you still may have to come up with many patterns. Seeing as regex isn’t the most readable of languages, having lots of patterns can quickly become hard to maintain.
Thankfully, there’s a neat trick with re.sub() that allows you to have a bit more control over how replacement works, and it offers a much more maintainable architecture.
Use a Callback With re.sub() for Even More Control
One trick that Python and sub() have up their sleeves is that you can pass in a callback function instead of the replacement string. This gives you total control over how to match and replace.
To get started building this version of the transcript-sanitizing script, you’ll use a basic regex pattern to see how using a callback with sub() works:
# transcript_regex_callback.py
import re
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
def sanitize_message(match):
print(match)
re.sub(r"[-T:+d]{25}", sanitize_message, transcript)
The regex pattern that you’re using will match the time stamps, and instead of providing a replacement string, you’re passing in a reference to the sanitize_message() function. Now, when sub() finds a match, it’ll call sanitize_message() with a match object as an argument.
Since sanitize_message() just prints the object that it’s received as an argument, when running this, you’ll see the match objects being printed to the console:
$ python transcript_regex_callback.py
<re.Match object; span=(15, 40), match='2022-08-24T10:02:23+00:00'>
<re.Match object; span=(79, 104), match='2022-08-24T10:03:15+00:00'>
<re.Match object; span=(159, 184), match='2022-08-24T10:03:30+00:00'>
<re.Match object; span=(235, 260), match='2022-08-24T10:04:03+00:00'>
A match object is one of the building blocks of the re module. The more basic re.match() function returns a match object. sub() doesn’t return any match objects but uses them behind the scenes.
Because you get this match object in the callback, you can use any of the information contained within it to build the replacement string. Once it’s built, you return the new string, and sub() will replace the match with the returned string.
Apply the Callback to the Script
In your transcript-sanitizing script, you’ll make use of the .groups() method of the match object to return the contents of the two capture groups, and then you can sanitize each part in its own function or discard it:
# transcript_regex_callback.py
import re
ENTRY_PATTERN = (
r"[(.+)] " # User string, discarding square brackets
r"[-T:+d]{25} " # Time stamp
r": " # Separator
r"(.+)" # Message
)
BAD_WORDS = ["blast", "dash", "beezlebub"]
CLIENTS = ["johndoe", "janedoe"]
def censor_bad_words(message):
for word in BAD_WORDS:
message = re.sub(rf"{word}w*", "😤", message, flags=re.IGNORECASE)
return message
def censor_users(user):
if user.startswith("support"):
return "Agent"
elif user in CLIENTS:
return "Client"
else:
raise ValueError(f"unknown client: '{user}'")
def sanitize_message(match):
user, message = match.groups()
return f"{censor_users(user):<6} : {censor_bad_words(message)}"
transcript = """
[support_tom] 2022-08-24T10:02:23+00:00 : What can I help you with?
[johndoe] 2022-08-24T10:03:15+00:00 : I CAN'T CONNECT TO MY BLASTED ACCOUNT
[support_tom] 2022-08-24T10:03:30+00:00 : Are you sure it's not your caps lock?
[johndoe] 2022-08-24T10:04:03+00:00 : Blast! You're right!
"""
print(re.sub(ENTRY_PATTERN, sanitize_message, transcript))
Instead of having lots of different regexes, you can have one top level regex that can match the whole line, dividing it up into capture groups with brackets (()). The capture groups have no effect on the actual matching process, but they do affect the match object that results from the match:
[(.+)]matches any sequence of characters wrapped in square brackets. The capture group picks out the username string, for instancejohndoe.[-T:+d]{25}matches the time stamp, which you explored in the last section. Since you won’t be using the time stamp in the final transcript, it’s not captured with brackets.:matches a literal colon. The colon is used as a separator between the message metadata and the message itself.(.+)matches any sequence of characters until the end of the line, which will be the message.
The content of the capturing groups will be available as separate items in the match object by calling the .groups() method, which returns a tuple of the matched strings.
The two groups are the user string and the message. The .groups() method returns them as a tuple of strings. In the sanitize_message() function, you first use unpacking to assign the two strings to variables:
def sanitize_message(match):
user, message = match.groups()
return f"{censor_users(user):<6} : {censor_bad_words(message)}"
Note how this architecture allows a very broad and inclusive regex at the top level, and then lets you supplement it with more precise regexes within the replacement callback.
The sanitize_message() function makes use of two functions to clean up usernames and bad words. It additionally uses f-strings to justify the messages. Note how censor_bad_words() uses a dynamically created regex while censor_users() relies on more basic string processing.
This is now looking like a good first prototype for a transcript-sanitizing script! The output is squeaky clean:
$ python transcript_regex_callback.py
Agent : What can I help you with?
Client : I CAN'T CONNECT TO MY 😤 ACCOUNT
Agent : Are you sure it's not your caps lock?
Client : 😤! You're right!
Nice! Using sub() with a callback gives you far more flexibility to mix and match different methods and build regexes dynamically. This structure also gives you the most room to grow when your bosses or clients inevitably change their requirements on you!
Conclusion
In this tutorial, you’ve learned how to replace strings in Python. Along the way, you’ve gone from using the basic Python .replace() string method to using callbacks with re.sub() for absolute control. You’ve also explored some regex patterns and deconstructed them into a better architecture to manage a replacement script.
With all that knowledge, you’ve successfully cleaned a chat transcript, which is now ready for independent review. Not only that, but your transcript-sanitizing script has plenty of room to grow.
- Обработка строк
- Операторы строк
- Встроенные строковые функции
- Индексация cтрок
- Нарезка строк
- Указание шага в срезе строки
- Интерполяция переменных в строку
- Изменение cтрок
- Встроенные строковые методы
- Объекты bytes
- Определение литерала объекта bytes
- Определение объекта bytes с помощью встроенной функции bytes()
- Операции с байтовыми объектами
- Объекты bytearray
- Вывод
В статье по основным типам данных в Python вы узнали, как определить строки: объекты, содержащие последовательности символьных данных. Обработка символьных данных является неотъемлемой частью программирования.
Вот что вы узнаете из этого урока: Python предоставляет богатый набор операторов, функций и методов для работы со строками. Когда вы закончите с этим уроком, вы будете знать, как получить доступ и извлечь части строк, а также будете знакомы с методами, которые доступны для манипулирования и изменения строковых данных.
Вы также познакомитесь с двумя другими объектами Python, используемыми для представления необработанных байтовых данных, типами bytes и bytearray.
Обработка строк
В следующих разделах описаны операторы, методы и функции, доступные для работы со строками.
Операторы строк
Вы уже видели операторы + и *, применяемые к числовым операндам в уроке по операторам и выражениям в Python. Эти два оператора могут быть применены и к строкам.
Оператор +
Оператор + объединяет строки. Он возвращает строку, состоящую из операндов, соединенных вместе, как показано здесь:
>>> s = 'foo'
>>> t = 'bar'
>>> u = 'baz'
>>> s + t
'foobar'
>>> s + t + u
'foobarbaz'
>>> print('Go team' + '!!!')
Go team!!!
Оператор *
Оператор * создает несколько копий строки. Если s-строка, а n-целое число, то любое из следующих выражений возвращает строку, состоящую из n сцепленных копий s:
s * n
n * s
Вот примеры обеих форм:
>>> s = 'foo.' >>> s * 4 'foo.foo.foo.foo.' >>> 4 * s 'foo.foo.foo.foo.'
Операнд множителя n должен быть целым числом. Вы могли бы подумать, что это должно быть положительное целое число, но забавно, что оно может быть нулевым или отрицательным, и в этом случае результатом будет пустая строка:
>>> 'foo' * -8 ''
Если бы вы создали строковую переменную и инициализировали ее пустой строкой, присвоив ей значение 'foo' * -8, любой справедливо подумал бы, что вы немного глупы. Но это сработает.
Оператор in
Python также предоставляет оператор членства, который можно использовать со строками. Оператор in возвращает True, если первый операнд содержится во втором, и False в противном случае:
>>> s = 'foo' >>> s in 'That's food for thought.' True >>> s in 'That's good for now.' False
Существует также оператор not in, который делает обратное:
>>> 'z' not in 'abc' True >>> 'z' not in 'xyz' False
Встроенные строковые функции
Как вы видели в уроке по основным типам данных в Python, Python предоставляет множество функций, встроенных в интерпретатор и всегда доступных. Вот некоторые из них, которые работают со строками:
| Функция | Описание |
|---|---|
| chr() | Преобразует целое число в символ |
| ord() | Преобразует символ в целое число |
| len() | Возвращает длину строки |
| str() | Возвращает строковое представление объекта |
Они более подробно рассматриваются ниже.
ord(c)
Возвращает целочисленное значение для данного символа.
На самом базовом уровне компьютеры хранят всю информацию в виде чисел. Для представления символьных данных используется схема перевода, которая сопоставляет каждый символ с его репрезентативным номером.
Самая простая схема в обычном использовании называется ASCIIએ. Он охватывает общие латинские символы, с которыми вы, вероятно, больше всего привыкли работать. Для этих символов ord(c) возвращает значение ASCIIએ для символа c:
>>> ord('a')
97
>>> ord('#')
35
Символы ASCIIએ встречаются довольно часто. Но в мире существует множество различных языков и бесчисленное множество символов и глифов, которые появляются в цифровых медиа. Полный набор символов, которые потенциально могут потребоваться для представления в компьютерном коде, намного превосходит обычные латинские буквы, цифры и символы, которые вы обычно видите.
Unicodeએ — это амбициозный стандарт, который пытается предоставить числовой код для каждого возможного символа, на каждом возможном языке, на каждой возможной платформе. Python 3 широко поддерживает Юникод, включая разрешение символов Юникода в строках.
Пока вы остаетесь в области общих символов, существует небольшая практическая разница между ASCII и Unicode. Но функция ord() также возвращает числовые значения для символов Юникода:
>>> ord('€')
8364
>>> ord('∑')
8721
chr(n)
Возвращает символьное значение для данного целого числа.
chr() делает обратное ord(). При заданном числовом значении n chr(n) возвращает строку, представляющую символ, соответствующий n:
>>> chr(97) 'a' >>> chr(35) '#'
chr() также обрабатывает символы Юникода:
>>> chr(8364) '€' >>> chr(8721) '∑'
len(s)
Возвращает длину строки.
С помощью функции len() вы можете проверить длину строки Python. len(s) возвращает количество символов в s:
>>> s = 'I am a string.' >>> len(s) 14
str(obj)
Возвращает строковое представление объекта.
Практически любой объект в Python может быть представлен в виде строки. str(obj) возвращает строковое представление объекта obj:
>>> str(49.2)
'49.2'
>>> str(3+4j)
'(3+4j)'
>>> str(3 + 29)
'32'
>>> str('foo')
'foo'
Индексация Строк
Часто в языках программирования отдельные элементы в упорядоченном наборе данных могут быть доступны непосредственно с помощью числового индекса или ключевого значения. Этот процесс называется индексированием.
В Python строки-это упорядоченные последовательности символьных данных, и поэтому их можно индексировать таким образом. Доступ к отдельным символам в строке можно получить, указав имя строки, за которым следует число в квадратных скобках ([]).
Индексация строк в Python основана на нуле: первый символ в строке имеет индекс 0, следующий-индекс 1 и так далее. Индекс последнего символа будет равен длине строки минус единица.
Например, схематическое представление индексов строки ‘foobar‘ будет выглядеть следующим образом:
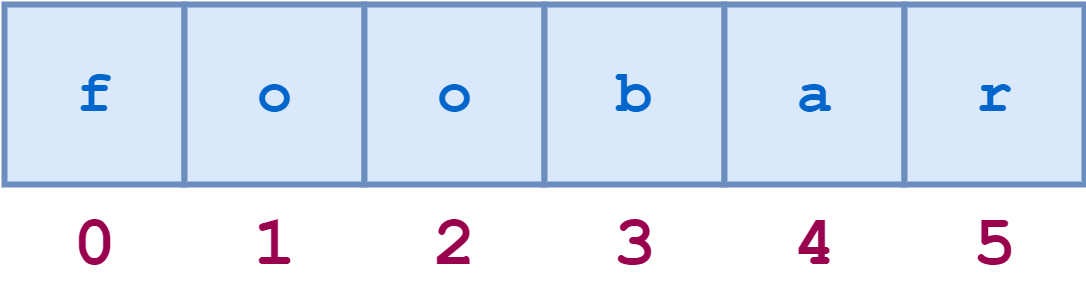
Отдельные символы могут быть доступны по индексу следующим образом:
>>> s = 'foobar' >>> s[0] 'f' >>> s[1] 'o' >>> s[3] 'b' >>> len(s) 6 >>> s[len(s)-1] 'r'
Попытка индексировать за пределами конца строки приводит к ошибке:
>>> s[6]
Traceback (most recent call last):
File " <pyshell#17>", line 1, in <module>
s[6]
IndexError: string index out of range
Строковые индексы также могут быть заданы отрицательными числами, и в этом случае индексация происходит от конца строки назад: -1 относится к последнему символу, -2-к предпоследнему символу и т. д. Вот та же самая диаграмма, показывающая как положительные, так и отрицательные индексы в строке ‘foobar‘:
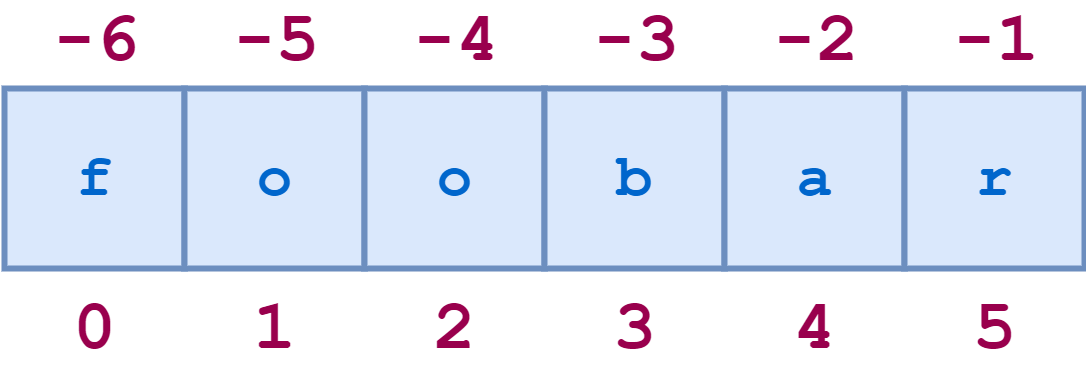
Вот несколько примеров негативной индексации:
>>> s = 'foobar' >>> s[-1] 'r' >>> s[-2] 'a' >>> len(s) 6 >>> s[-len(s)] 'f'
Попытка индексирования с отрицательными числами за пределами начала строки приводит к ошибке:
>>> s[-7]
Traceback (most recent call last):
File "<pyshell#26>", line 1, in <module>
s[-7]
IndexError: string index out of range
Для любой непустой строки s, s[len(s)-1] и s[-1] оба возвращают последний символ. Нет никакого индекса, который имеет смысл для пустой строки.
Нарезка строк
Python также допускает форму синтаксиса индексирования, которая извлекает подстроки из строки, известную как нарезка строк. Если s является строкой, то выражение вида [m:n] возвращает часть s, начинающуюся с позиции m и вплоть до позиции n, но не включая ее:
>>> s = 'foobar' >>> s[2:5] 'oba'
Помните: строковые индексы основаны на нуле. Первый символ в строке имеет индекс 0. Это относится как к стандартному индексированию, так и к нарезке.
Опять же, второй индекс указывает первый символ, который не включен в результат—символ ‘r‘ (s[5]) в приведенном выше примере. Это может показаться немного неинтуитивным, но это приводит к такому результату, который имеет смысл: выражение s[m:n] вернет подстроку длиной n - m символов, в данном случае 5 - 2 = 3.
Если вы опустите первый индекс, срез начнется в начале строки. Таким образом, s[:m] и s[0:m] эквивалентны:
>>> s = 'foobar' >>> s[:4] 'foob' >>> s[0:4] 'foob'
Аналогично, если вы опустите второй индекс, как в s[n:], срез простирается от первого индекса до конца строки. Это хорошая, лаконичная альтернатива более громоздкому s[n:len(s)]:
>>> s = 'foobar' >>> s[2:] 'obar' >>> s[2:len(s)] 'obar'
Для любых строк и любого целого числа n (0 = n = len(s)), s[:n] + s[n:] будет равно s:
>>> s = 'foobar' >>> s[:4] + s[4:] 'foobar' >>> s[:4] + s[4:] == s True
Опущение обоих индексов возвращает исходную строку целиком. Буквально. Это не копия, а ссылка на исходную строку:
>>> s = 'foobar' >>> t = s[:] >>> id(s) 59598496 >>> id(t) 59598496 >>> s is t True
Если первый индекс в срезе больше или равен второму индексу, Python возвращает пустую строку. Это еще один запутанный способ сгенерировать пустую строку, если вы ее искали:
>>> s[2:2] '' >>> s[4:2] ''
Отрицательные индексы также могут быть использованы при нарезке. -1 относится к последнему символу, -2-к предпоследнему и так далее, как и в случае простого индексирования. На приведенной ниже диаграмме показано, как срезать подстроку «oob«из строки «foobar«, используя как положительные, так и отрицательные индексы:
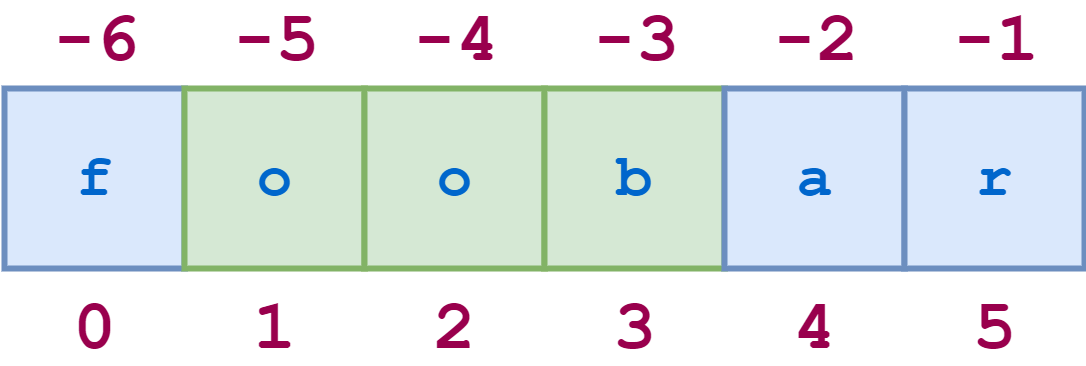
Вот соответствующий код Python:
>>> s = 'foobar' >>> s[-5:-2] 'oob' >>> s[1:4] 'oob' >>> s[-5:-2] == s[1:4] True
Указание шага в срезе строки
Существует еще один вариант синтаксиса нарезки, который следует обсудить. Добавление дополнительного : и третий индекс обозначает шаг, который указывает, сколько символов нужно перепрыгнуть после извлечения каждого символа в срезе.
Например, для строки ‘foobar‘ фрагмент 0:6:2 начинается с первого символа и заканчивается последним символом (целой строкой), а каждый второй символ пропускается. Это показано на следующей диаграмме:
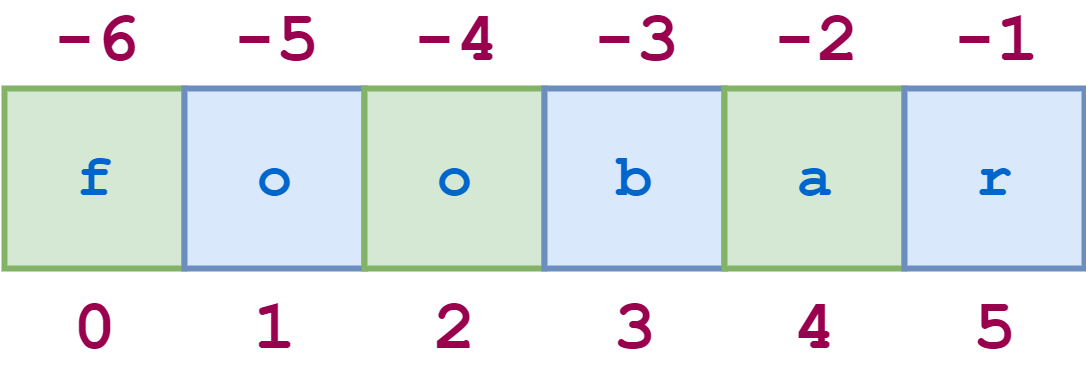
Аналогично, 1:6:2 задает срез, начинающийся со второго символа (индекс 1) и заканчивающийся последним символом, и снова значение шага 2 вызывает пропуск всех остальных символов:
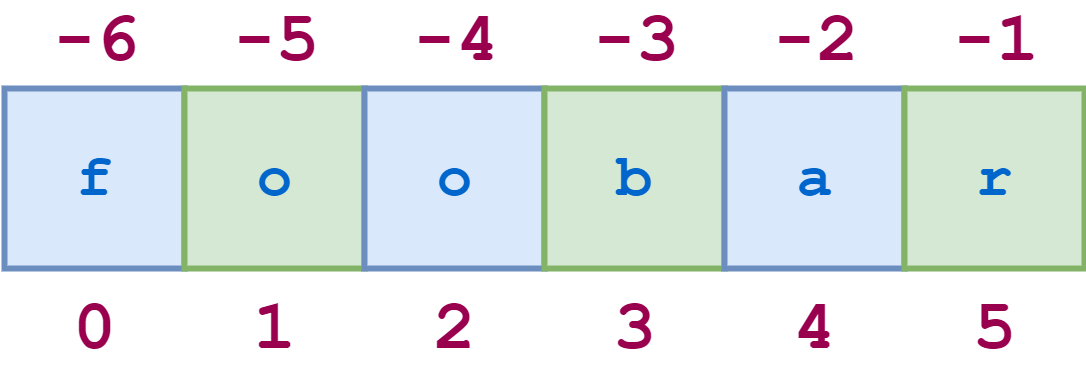
Иллюстративный REPL код показан здесь:
>>> s = 'foobar' >>> s[0:6:2] 'foa' >>> s[1:6:2] 'obr'
Как и при любом разрезании, первый и второй индексы могут быть опущены, а по умолчанию используются соответственно первый и последний символы:
>>> s = '12345' * 5 >>> s '1234512345123451234512345' >>> s[::5] '11111' >>> s[4::5] '55555'
Вы также можете указать отрицательное значение шага, и в этом случае Python делает шаг назад через строку. В этом случае начальный/первый индекс должен быть больше конечного/второго индекса:
>>> s = 'foobar' >>> s[5:0:-2] 'rbo'
В приведенном выше примере 5:0:-2 означает “начать с последнего символа и отступить назад на 2, вплоть до первого символа, но не включая его.”
Когда вы отступаете назад, если первый и второй индексы опущены, значения по умолчанию меняются интуитивно: первый индекс по умолчанию находится в конце строки, а второй индекс по умолчанию-в начале. Вот вам пример:
>>> s = '12345' * 5 >>> s '1234512345123451234512345' >>> s[::-5] '55555'
Это обычная парадигма для обращения строки вспять:
>>> s = 'If Comrade Napoleon says it, it must be right.' >>> s[::-1] '.thgir eb tsum ti ,ti syas noelopaN edarmoC fI'
Интерполяция переменных в строку
В Python версии 3.6 был введен новый механизм форматирования строк. Эта функция формально называется форматированным строковым литералом, но чаще всего упоминается под псевдонимом f-string.
Одна простая функция вне строк, которую вы можете начать использовать сразу же,-это переменная интерполяция. Вы можете указать имя переменной непосредственно в литерале f-string, и Python заменит это имя соответствующим значением.
Например, предположим, что вы хотите отобразить результат арифметического вычисления. Это можно сделать с помощью простого оператора print(), разделяющего числовые значения и строковые литералы запятыми:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print('The product of', n, 'and', m, 'is', prod)
The product of 20 and 25 is 500
Но это слишком громоздко. Чтобы сделать то же самое, используйте f-строку:
- Укажите либо нижний регистр
fлибо верхний регистрFнепосредственно перед открывающей кавычкой строкового литерала. Это говорит Python, что это f-строка вместо стандартной строки. - Укажите любые переменные, которые будут интерполированы в фигурных скобках (
{}).
Переделанный с помощью f-строки, приведенный выше пример выглядит гораздо чище:
>>> n = 20
>>> m = 25
>>> prod = n * m
>>> print(f'The product of {n} and {m} is {prod}')
The product of 20 and 25 is 500
Любой из трех механизмов цитирования Python может быть использован для определения f-строки:
>>> var = 'Bark'
>>> print(f'A dog says {var}!')
A dog says Bark!
>>> print(f"A dog says {var}!")
A dog says Bark!
>>> print(f'''A dog says {var}!''')
A dog says Bark!
Изменение Строк
Короче говоря, вы не можете. Строки-это один из типов данных, которые Python считает неизменяемыми, то есть не подлежащими изменению. Фактически, все типы данных, которые вы видели до сих пор, неизменны. (Python предоставляет типы данных, которые являются изменяемыми, как вы скоро увидите.)
Подобное утверждение приведет к ошибке:
>>> s = 'foobar'
>>> s[3] = 'x'
Traceback (most recent call last):
File "<pyshell#40>", line 1, in <module>
s[3] = 'x'
TypeError: 'str' object does not support item assignment
По правде говоря, нет особой необходимости изменять строки. Обычно вы можете легко выполнить то, что хотите, создав копию исходной строки, которая имеет желаемое изменение на месте. В Python есть очень много способов сделать это. Вот одна из возможностей:
>>> s = s[:3] + 'x' + s[4:] >>> s 'fooxar'
Для этого также существует встроенный строковый метод:
>>> s = 'foobar'
>>> s = s.replace('b', 'x')
>>> s
'fooxar'
Читайте дальше для получения дополнительной информации о встроенных строковых методах!
Встроенные строковые методы
В уроке по переменным в Python вы узнали, что Python-это высоко объектно-ориентированный язык. Каждый элемент данных в программе Python является объектом.
Вы также знакомы с функциями: вызываемыми процедурами, которые можно вызвать для выполнения определенных задач.
Методы подобны функциям. Метод — это специализированный тип вызываемой процедуры, тесно связанный с объектом. Как и функция, метод вызывается для выполнения отдельной задачи, но он вызывается для конкретного объекта и имеет знание о своем целевом объекте во время выполнения.
Синтаксис вызова метода для объекта выглядит следующим образом:
obj.foo(<args>)
Это вызывает метод .foo() на объекте obj.<args> указывает аргументы, передаваемые методу (если таковые имеются).
Вы узнаете гораздо больше об определении и вызове методов позже в обсуждении объектно-ориентированного программирования. На данный момент цель состоит в том, чтобы представить некоторые из наиболее часто используемых встроенных методов, поддерживаемых Python для работы со строковыми объектами.
В следующих определениях методов аргументы, указанные в квадратных скобках ([]), являются необязательными.
Преобразования Регистра
Методы этой группы выполняют преобразование регистра в целевой строке.
s.capitalize()
Возвращает целевую строку с заглавной первой буквой.
s.capitalize() возвращает копию s с первым символом, преобразованным в верхний регистр, и всеми остальными символами, преобразованными в нижний регистр:
>>> s = 'foO BaR BAZ quX' >>> s.capitalize() 'Foo bar baz qux'
Неалфавитные символы остаются неизменными:
>>> s = 'foo123#BAR#.' >>> s.capitalize() 'Foo123#bar#.'
s.lower()
Преобразует буквенные символы в строчные.
s.lower() возвращает копию s со всеми заглавными символами, преобразованными в нижний регистр:
>>> 'FOO Bar 123 baz qUX'.lower() 'foo bar 123 baz qux'
s.swapcase()
Меняет местами регистр буквенных символов.
s.swapcase() возвращает копию s с заглавными буквенными символами, преобразованными в строчные и наоборот:
>>> 'FOO Bar 123 baz qUX'.swapcase() 'foo bAR 123 BAZ Qux'
s.title()
Преобразует целевую строку в » регистр заголовка.”
s.title() возвращает копию s, в которой первая буква каждого слова преобразуется в верхний регистр, а остальные буквы-в нижний:
>>> 'the sun also rises'.title() 'The Sun Also Rises'
Этот метод использует довольно простой алгоритм. Он не пытается провести различие между важными и неважными словами, и он не обрабатывает апострофы, притяжательные или аббревиатуры изящно:
>>> "what's happened to ted's IBM stock?".title() "What'S Happened To Ted'S Ibm Stock?"
s.upper()
Преобразует буквенные символы в заглавные.
s.upper() возвращает копию s со всеми буквенными символами, преобразованными в верхний регистр:
>>> 'FOO Bar 123 baz qUX'.upper() 'FOO BAR 123 BAZ QUX'
Найти и заменить
Эти методы предоставляют различные средства поиска целевой строки для указанной подстроки.
Каждый метод в этой группе поддерживает необязательные аргументы <start> и <end>. Они используются для нарезки строк: действие метода ограничено частью целевой строки, начинающейся с позиции символа <start> и продолжающейся до позиции символа <end>, но не включающей ее. Если < start> указан, а <end> нет, то метод применяется к части целевой строки от <start> до конца строки.
s.count(<sub>[, <start>[, <end>]])
Подсчитывает вхождения подстроки в целевую строку.
s.count(<sub>) возвращает количество неперекрывающихся вхождений подстроки <sub> в s:
>>> 'foo goo moo'.count('oo')
3
Подсчет ограничен количеством вхождений в подстроку, обозначенную <start> и <end>, если они указаны:
>>> 'foo goo moo'.count('oo', 0, 8)
2
s.endswith(<suffix>[, <start>[, <end>]])
Определяет, заканчивается ли целевая строка заданной подстрокой.
s.endswith(<suffix>) возвращает True, если s заканчивается указанным <suffix>, и False в противном случае:
>>> 'foobar'.endswith('bar')
True
>>> 'foobar'.endswith('baz')
False
Сравнение ограничивается подстрокой, обозначенной <start> и <end>, если они указаны:
>>> 'foobar'.endswith('oob', 0, 4)
True
>>> 'foobar'.endswith('oob', 2, 4)
False
s.find(<sub>[, <start>[, <end>]])
Выполняет поиск в целевой строке заданной подстроки.
Вы можете использовать .find(), чтобы увидеть, содержит ли строка определенную подстроку. s.find(<sub>) возвращает самый низкий индекс в s, где находится подстрока <sub> :
>>> 'foo bar foo baz foo qux'.find('foo')
0
Этот метод возвращает -1, если указанная подстрока не найдена:
>>> 'foo bar foo baz foo qux'.find('grault')
-1
Поиск ограничен подстрокой, указанной <start> и <end>, если они указаны:
>>> 'foo bar foo baz foo qux'.find('foo', 4)
8
>>> 'foo bar foo baz foo qux'.find('foo', 4, 7)
-1
s.index(<sub>[, <start>[, <end>]])
Выполняет поиск в целевой строке заданной подстроки.
Этот метод идентичен методу .find(), за исключением того, что он вызывает ошибку, если <sub> не найден, а не возвращает -1:
>>> 'foo bar foo baz foo qux'.index('grault')
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'foo bar foo baz foo qux'.index('grault')
ValueError: substring not found
s.rfind(<sub>[, <start>[, <end>]])
Поиск в целевой строке заданной подстроки, начинающейся в конце.
s.rfind(<sub>) возвращает самый высокий индекс в s, где найдена подстрока <sub> :
>>> 'foo bar foo baz foo qux'.rfind('foo')
16
Как и в случае с .find(), если подстрока не найдена, возвращается -1:
>>> 'foo bar foo baz foo qux'.rfind('grault')
-1
Поиск ограничен подстрокой, указанной <start> и <end>, если они указаны:
>>> 'foo bar foo baz foo qux'.rfind('foo', 0, 14)
8
>>> 'foo bar foo baz foo qux'.rfind('foo', 10, 14)
-1
s.rindex(<sub>[, <start>[, <end>]])
Поиск в целевой строке заданной подстроки, начинающейся в конце.
Этот метод идентичен методу .rfind(), за исключением того, что он вызывает ошибку, если <sub> не найден, а не возвращает -1:
>>> 'foo bar foo baz foo qux'.rindex('grault')
Traceback (most recent call last):
File "<pyshell#1>", line 1, in <module>
'foo bar foo baz foo qux'.rindex('grault')
ValueError: substring not found
s.startswith(<prefix>[, <start>[, <end>]])
Определяет, начинается ли целевая строка с заданной подстроки.
При использовании метода .startswith() s.startswith(<suffix>) возвращает True, если s начинается с указанного <suffix> , и False в противном случае:
>>> 'foobar'.startswith('foo')
True
>>> 'foobar'.startswith('bar')
False
Сравнение ограничивается подстрокой, обозначенной <start> и <end>, если они указаны:
>>> 'foobar'.startswith('bar', 3)
True
>>> 'foobar'.startswith('bar', 3, 2)
False
Классификация Символов
Методы этой группы классифицируют строку на основе содержащихся в ней символов.
s.isalnum()
Определяет, состоит ли целевая строка из буквенно-цифровых символов.
s.isalnum() возвращает True, если s непусто и все его символы являются буквенно-цифровыми(либо буквой, либо цифрой), и False в противном случае:
>>> 'abc123'.isalnum() True >>> 'abc$123'.isalnum() False >>> ''.isalnum() False
s.isalpha()
Определяет, состоит ли целевая строка из буквенных символов.
s.isalpha() возвращает True, если s непусто и все его символы алфавитны, и False в противном случае:
>>> 'ABCabc'.isalpha() True >>> 'abc123'.isalpha() False
s.isdigit()
Определяет, состоит ли целевая строка из цифровых символов.
Вы можете использовать метод .isdigit(), чтобы проверить, состоит ли ваша строка только из цифр. s.isdigit() возвращает True, если s непусто и все его символы являются числовыми цифрами, и False в противном случае:
>>> '123'.isdigit() True >>> '123abc'.isdigit() False
s.isidentifier()
Определяет, является ли целевая строка допустимым идентификатором Python.
s.isidentifier() возвращает True, если s является допустимым идентификатором Python в соответствии с определением языка, и False в противном случае:
>>> 'foo32'.isidentifier() True >>> '32foo'.isidentifier() False >>> 'foo$32'.isidentifier() False
Примечание: .isidentifier() вернет True для строки, которая соответствует ключевому слову Python, даже если это на самом деле не является допустимым идентификатором:
>>> 'and'.isidentifier() True
Вы можете проверить, соответствует ли строка ключевому слову Python, используя функцию iskeyword(), которая содержится в модуле keyword. Один из возможных способов сделать это показан ниже:
>>> from keyword import iskeyword
>>> iskeyword('and')
True
Если вы действительно хотите убедиться, что строка будет служить допустимым идентификатором Python, вы должны проверить, что .isidentifier() является истинным, а iskeyword() — ложным.
s.islower()
Определяет, являются ли буквенные символы целевой строки строчными.
s.islower() возвращает True, если s непусто и все содержащиеся в нем буквенные символы строчные, и False в противном случае. Неалфавитные символы игнорируются:
>>> 'abc'.islower() True >>> 'abc1$d'.islower() True >>> 'Abc1$D'.islower() False
s.isprintable()
Определяет, состоит ли целевая строка полностью из печатаемых символов.
s.isprintable() возвращает True, если s пуст или все содержащиеся в нем буквенные символы доступны для печати. Он возвращает False, если s содержит хотя бы один непечатаемый символ. Неалфавитные символы игнорируются:
>>> 'atb'.isprintable() False >>> 'a b'.isprintable() True >>> ''.isprintable() True >>> 'anb'.isprintable() False
Примечание: Только метод .isxxxx() возвращает True, если s является пустой строкой. Все остальные возвращают False для пустой строки.
s.isspace()
Определяет, состоит ли целевая строка из пробельных символов.
s.isspace() возвращает True, если s непусто и все символы являются пробелами, и False в противном случае.
Наиболее часто встречающимися пробелами являются пробел ‘ ‘, табуляция ‘t‘ и новая строка ‘n‘:
>>> ' t n '.isspace() True >>> ' a '.isspace() False
Однако есть несколько других символов ASCII, которые квалифицируются как пробелы, и если вы учитываете символы Unicode, то их довольно много:
>>> 'fu2005r'.isspace() True
s.istitle()
Определяет, является ли целевая строка заголовком.
s.istitle() возвращает True, если s непусто, первый буквенный символ каждого слова прописной, а все остальные буквенные символы в каждом слове строчные. В противном случае он возвращает False:
>>> 'This Is A Title'.istitle() True >>> 'This is a title'.istitle() False >>> 'Give Me The #$#@ Ball!'.istitle() True
Примечание: вот как документация Python описывает .istitle(), если вы находите это более интуитивно понятным: “заглавные символы могут следовать только за несокращенными символами, а строчные-только за прописными.”
s.isupper()
Определяет, являются ли буквенные символы целевой строки заглавными.
s.isupper() возвращает True, если s непусто и все содержащиеся в нем буквенные символы заглавные, и False в противном случае. Неалфавитные символы игнорируются:
>>> 'ABC'.isupper() True >>> 'ABC1$D'.isupper() True >>> 'Abc1$D'.isupper() False
Форматирование Строк
Методы этой группы изменяют или улучшают формат строки.
s.center(<width>[, <fill>])
Центрирует строку в поле.
s.center(<width>) возвращает строку, состоящую из s, центрированных в поле width <width>. По умолчанию заполнение состоит из символа пробела ASCII:
>>> 'foo'.center(10) ' foo '
Если указан необязательный аргумент <fill>, то он используется в качестве символа заполнения:
>>> 'bar'.center(10, '-') '---bar----'
Если аргумент уже имеет длину не менее <width>, то он возвращается без изменений:
>>> 'foo'.center(2) 'foo'
s.expandtabs(tabsize=8)
Разворачивает столбцы в строку.
s.expandtabs() заменяет каждый символ табуляции (‘t‘) пробелами. По умолчанию пробелы заполняются при условии остановки табуляции в каждом восьмом столбце:
>>> 'atbtc'.expandtabs() 'a b c' >>> 'aaatbbbtc'.expandtabs() 'aaa bbb c'
tabsize является необязательным параметром, определяющим остановку колонны:
>>> 'atbtc'.expandtabs(4) 'a b c' >>> 'aaatbbbtc'.expandtabs(tabsize=4) 'aaa bbb c'
s.ljust(<width>[, <fill>])
Левостороннее выравнивание строки в поле.
s.ljust(<width>) возвращает строку, состоящую из s, выровненных по левому краю в поле ширина <width>. По умолчанию заполнение состоит из символа пробела ASCII:
>>> 'foo'.ljust(10) 'foo '
Если указан необязательный аргумент <fill>, то он используется в качестве символа заполнения:
>>> 'foo'.ljust(10, '-') 'foo-------'
Если s уже достигает ширины такой как <width>, то он возвращается без изменений:
>>> 'foo'.ljust(2) 'foo'
s.lstrip([<chars>])
Обрезает ведущие символы из строки.
s.lstrip() возвращает копию s с любыми пробелами, удаленными с левого конца:
>>> ' foo bar baz '.lstrip() 'foo bar baz ' >>> 'tnfootnbartnbaz'.lstrip() 'footnbartnbaz'
Если указан необязательный аргумент <chars>, то это строка, указывающая набор удаляемых символов:
>>> 'http://www.realpython.com'.lstrip('/:pth')
'www.realpython.com'
s.replace(<old>, <new>[, <count>])
Заменяет вхождения подстроки в строке.
В Python для удаления символа из строки можно использовать метод string.replace(). Метод s.replace(<old>, <new>) возвращает копию s со всеми вхождениями подстроки <old>, замененной на <new>.:
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault')
'grault bar grault baz grault qux'
Если указан необязательный аргумент <count>, то выполняется максимум замен <count>, начиная с левого конца s:
>>> 'foo bar foo baz foo qux'.replace('foo', 'grault', 2)
'grault bar grault baz foo qux'
s.rjust(<width>[, <fill>])
Правостороннее выравнивание строки в поле.
s.rjust(<width>) возвращает строку, состоящую из s, выровненных по правому краю в поле ширины <width>. По умолчанию заполнение состоит из символа пробела ASCII:
>>> 'foo'.rjust(10) ' foo'
Если указан необязательный аргумент <fill>, то он используется в качестве символа заполнения:
>>> 'foo'.rjust(10, '-') '-------foo'
Если s уже по крайней мере равен <width>, то он возвращается без изменений:
>>> 'foo'.rjust(2) 'foo'
s.rstrip([<chars>])
Обрезает конечные символы из строки.
s.rstrip() возвращает копию s с любыми пробелами, удаленными с правого конца:
>>> ' foo bar baz '.rstrip() ' foo bar baz' >>> 'footnbartnbaztn'.rstrip() 'footnbartnbaz'
Если указан необязательный аргумент <chars>, то это строка, указывающая набор удаляемых символов:
>>> 'foo.$$$;'.rstrip(';$.')
'foo'
s.strip([<chars>])
Удаляет символы с левого и правого концов строки.
s.strip() по существу эквивалентен вызову s.lstrip() и s.rstrip() последовательно. Без аргумента <chars> он удаляет начальные и конечные пробелы:
>>> s = ' foo bar bazttt' >>> s = s.lstrip() >>> s = s.rstrip() >>> s 'foo bar baz'
Как и в случае с .lstrip() и .rstrip(), необязательный аргумент <chars> указывает набор удаляемых символов:
>>> 'www.realpython.com'.strip('w.moc')
'realpython'
Примечание: когда возвращаемое значение строкового метода является другой строкой, как это часто бывает, методы могут быть вызваны последовательно путем цепочки вызовов:
>>> ' foo bar bazttt'.lstrip().rstrip()
'foo bar baz'
>>> ' foo bar bazttt'.strip()
'foo bar baz'
>>> 'www.realpython.com'.lstrip('w.moc').rstrip('w.moc')
'realpython'
>>> 'www.realpython.com'.strip('w.moc')
'realpython'
s.zfill(<width>)
Подкладывает строку слева нулями.
s.zfill(<width>) возвращает копию s, заполненную слева символами ‘0‘ до указанной <width>:
>>> '42'.zfill(5) '00042'
Если s содержит начальный знак, он остается на левом краю результирующей строки после вставки нулей:
>>> '+42'.zfill(8) '+0000042' >>> '-42'.zfill(8) '-0000042'
Если s уже по крайней мере равен <width>, то он возвращается без изменений:
>>> '-42'.zfill(3) '-42'
.zfill() наиболее полезен для строковых представлений чисел, но Python все равно будет обнулять строку, которая не является таковой.:
>>> 'foo'.zfill(6) '000foo'
Преобразование между строками и списками
Методы в этой группе преобразуют между строкой и некоторым составным типом данных либо вставляя объекты вместе, чтобы сделать строку, либо разбивая строку на части.
Многие из этих методов возвращают либо список, либо кортеж. Это составные типы данных, которые являются прототипическими примерами итерируемые объекты в Python. Они описаны в следующем уроке, так что вы скоро узнаете о них! До тех пор просто думайте о них как о последовательностях значений. Список заключен в квадратные скобки ([]), а кортеж-в круглые скобки (()).
С этим введением давайте взглянем на эту последнюю группу строковых методов.
s.join(<iterable>)
Конкатенация строк из итерируемого объекта.
s.join(<iterable>) возвращает строку, полученную в результате объединения объектов в <iterable>, разделенных s.
Обратите внимание, что .join() вызывается на s, строке-разделителе. <iterable> также должна быть последовательностью строковых объектов.
Некоторые примеры кода должны помочь прояснить ситуацию. В следующем примере разделителями являются строки ‘,‘, а <iterable> — список строковых значений:
>>> ', '.join(['foo', 'bar', 'baz', 'qux']) 'foo, bar, baz, qux'
В результате получается одна строка, состоящая из объектов списка, разделенных запятыми.
В следующем примере <iterable> задается как одно строковое значение. Когда строковое значение используется в качестве итеративного, оно интерпретируется как список отдельных символов строки:
>>> list('corge')
['c', 'o', 'r', 'g', 'e']
>>> ':'.join('corge')
'c:o:r:g:e'
Таким образом, в результате ‘:‘.join('corge') получается строка, состоящая из каждого символа в ‘corge‘, разделенного ‘:‘.
Этот пример терпит неудачу, потому что один из объектов в <iterable> не является строкой:
>>> '---'.join(['foo', 23, 'bar'])
Traceback (most recent call last):
File "<pyshell#0>", line 1, in <module>
'---'.join(['foo', 23, 'bar'])
TypeError: sequence item 1: expected str instance, int found
Это можно исправить с помощью:
>>> '---'.join(['foo', str(23), 'bar']) 'foo---23---bar'
Скоро увидите, многие составные объекты в Python могут быть истолкованы как итеративные, и .join() особенно полезен для создания строк из них.
s.partition(<sep>)
Делит строку на основе разделителя.
s.partition(<sep>) разбивает s при первом вхождении строки <sep>. Возвращаемое значение представляет собой кортеж из трех частей, состоящий из:
- Часть
s, предшествующая<sep> - Сам
<sep> - Часть
s, следующая за<sep>
Вот несколько примеров .partition() в действии:
>>> 'foo.bar'.partition('.')
('foo', '.', 'bar')
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
Если <sep> не найден в s, возвращаемый кортеж содержит s, за которым следуют две пустые строки:
>>> 'foo.bar'.partition('@@')
('foo.bar', '', '')
s.rpartition(<sep>)
Делит строку на основе разделителя.
s.rpartition(<sep>) функционирует точно так же, как s.partition(<sep>), за исключением того, что s разделяется при последнем вхождении <sep> вместо первого вхождения:
>>> 'foo@@bar@@baz'.partition('@@')
('foo', '@@', 'bar@@baz')
>>> 'foo@@bar@@baz'.rpartition('@@')
('foo@@bar', '@@', 'baz')
s.rsplit(sep=None, maxsplit=-1)
Разбивает строку на список подстрок.
Без аргументов s.split() разбивает s на подстроки, разделенные любой последовательностью пробелов, и возвращает подстроки в виде списка:
>>> 'foo bar baz qux'.rsplit() ['foo', 'bar', 'baz', 'qux'] >>> 'foontbar bazrfqux'.rsplit() ['foo', 'bar', 'baz', 'qux']
Если указан <sep>, то он используется в качестве разделителя для разделения:
>>> 'foo.bar.baz.qux'.rsplit(sep='.') ['foo', 'bar', 'baz', 'qux']
(Если <sep> задано со значением None, строка разделяется пробелом, как если бы <sep> вообще не было задано.)
Когда <sep> явно задан в качестве разделителя, предполагается, что последовательные разделители в s разделяют пустые строки, которые будут возвращены:
>>> 'foo...bar'.rsplit(sep='.') ['foo', '', '', 'bar']
Однако это не тот случай, когда <sep> опущен. В этом случае последовательные пробелы объединяются в один разделитель, и результирующий список никогда не будет содержать пустых строк:
>>> 'footttbar'.rsplit() ['foo', 'bar']
Если указан необязательный параметр ключевого слова <maxsplit>, то выполняется максимум такое количество разбиений, начиная с правого конца s:
>>> 'www.realpython.com'.rsplit(sep='.', maxsplit=1) ['www.realpython', 'com']
Значение по умолчанию для <maxsplit> равно -1, что означает, что должны быть выполнены все возможные разбиения— так же, как если бы <maxsplit> был полностью опущен:
>>> 'www.realpython.com'.rsplit(sep='.', maxsplit=-1) ['www', 'realpython', 'com'] >>> 'www.realpython.com'.rsplit(sep='.') ['www', 'realpython', 'com']
s.split(sep=None, maxsplit=-1)
Разбивает строку на список подстрок.
s.split() ведет себя точно так же, как s.rsplit(), за исключением того, что если задано <maxsplit>, то разбиения отсчитываются с левого конца s, а не с правого:
>>> 'www.realpython.com'.split('.', maxsplit=1)
['www', 'realpython.com']
>>> 'www.realpython.com'.rsplit('.', maxsplit=1)
['www.realpython', 'com']
Если <maxsplit> не указан, то .split() и .rsplit() неразличимы.
s.splitlines([<keepends>])
Разрывает строку на границах линий.
s.splitlines() разбивает s на строки и возвращает их в виде спика. Любой из следующих символов или последовательностей символов считается границей линии:
| Escape-символ | Описание |
|---|---|
| n | Новая строка |
| r | Возврат к началу строки |
| rn | Возврат к началу строки + заполнение |
| v или x0b | Подведение Линии |
| f или x0c | Перевод на следующий лист(Form Feed) |
| x1c | Разделение файлов |
| x1d | разделитель групп |
| x1e | разделитель записей |
| x85 | Следующая Строка (Контрольный Код C1) |
| u2028 | Разделитель Строк Unicode |
| u2029 | Разделитель Абзацев Unicode |
Вот пример использования нескольких различных разделителей строк:
>>> 'foonbarrnbazfquxu2028quux'.splitlines() ['foo', 'bar', 'baz', 'qux', 'quux']
Если в строке присутствуют последовательные символы границ строк, предполагается, что они разделяют пустые строки, которые появятся в списке результатов:
>>> 'foofffbar'.splitlines() ['foo', '', '', 'bar']
Если необязательный аргумент <keepends> указан и является истинным, то границы строк сохраняются в результирующих строках:
>>> 'foonbarnbaznqux'.splitlines(True) ['foon', 'barn', 'bazn', 'qux'] >>> 'foonbarnbaznqux'.splitlines(1) ['foon', 'barn', 'bazn', 'qux']
Объекты bytes
Объект bytes является одним из основных встроенных типов для манипулирования двоичными данными. Объект bytes — это неизменяемая последовательность однобайтовых значений. Каждый элемент в объекте bytes представляет собой небольшое целое число в диапазоне от 0 до 255.
Определение литерала объекта bytes
Байтовый литерал определяется так же, как и строковый литерал с добавлением префикса ‘b‘ :
>>> b = b'foo bar baz' >>> b b'foo bar baz' >>> type(b) <class 'bytes'>
Как и в случае со строками, вы можете использовать любой из механизмов одинарного, двойного или тройного цитирования:
>>> b'Contains embedded "double" quotes' b'Contains embedded "double" quotes' >>> b"Contains embedded 'single' quotes" b"Contains embedded 'single' quotes" >>> b'''Contains embedded "double" and 'single' quotes''' b'Contains embedded "double" and 'single' quotes' >>> b"""Contains embedded "double" and 'single' quotes""" b'Contains embedded "double" and 'single' quotes'
В байтовом литерале допускаются только символы ASCII. Любое символьное значение больше 127 должно быть указано с помощью соответствующей escape-последовательности:
>>> b = b'fooxddbar' >>> b b'fooxddbar' >>> b[3] 221 >>> int(0xdd) 221
Префикс ‘r‘ может использоваться в байтовом литерале для отключения обработки escape-последовательностей, как и в случае со строками:
>>> b = rb'fooxddbar' >>> b b'foo\xddbar' >>> b[3] 92 >>> chr(92) '\'
Определение объекта bytes с помощью встроенной функции bytes()
Функция bytes() также создает объект bytes. Какой тип байтов возвращается объекту, зависит от аргумента(ов), переданного функции. Возможные формы приведены ниже.
bytes(<s>, <encoding>)
Создает объект bytes из строки.
bytes(<s>, <encoding>) преобразует строку <s> в объект bytes, используя str.encode() в соответствии с заданной <encoding>:
>>> b = bytes('foo.bar', 'utf8')
>>> b
b'foo.bar'
>>> type(b)
<class 'bytes'>
Техническое Примечание: В этой форме функции bytes() требуется аргумент <encoding>. «Кодирование» относится к способу перевода символов в целочисленные значения. Значение «utf 8» указывает на формат преобразования Unicode UTF-8, который является кодировкой, способной обрабатывать все возможные символы Unicode. UTF-8 также можно указать, указав «UTF8«, «utf-8» или «UTF-8» для <encoding>.
Дополнительные сведения см. В документации Unicode. До тех пор, пока вы имеете дело с обычными латинскими символами, UTF-8 будет хорошо служить вам.
bytes(<size>)
Создает объект
bytes, состоящий из нулевых (0x00) байтов.
bytes(<size>) определяет объект bytes указанного <size>, который должен быть положительным целым числом. Результирующий объект bytes инициализируется нулевыми (0x00) байтами:
>>> b = bytes(8) >>> b b'x00x00x00x00x00x00x00x00' >>> type(b) <class 'bytes'>
bytes(<iterable>)
Создает объект
bytesиз итерируемого объекта.
bytes(<iterable>) определяет объект bytes из последовательности целых чисел, сгенерированных <iterable>. <iterable> должен быть итегрируемым, который генерирует последовательность целых чисел n в диапазоне 0 ≤ n ≤ 255:
>>> b = bytes([100, 102, 104, 106, 108]) >>> b b'dfhjl' >>> type(b) <class 'bytes'> >>> b[2] 104
Операции с байтовыми объектами
Как и строки, объекты bytes поддерживают общие операции последовательности:
- Операторы
inиnot in:
>>> b = b'abcde' >>> b'cd' in b True >>> b'foo' not in b True
+) и репликации (*) :>>> b = b'abcde' >>> b + b'fghi' b'abcdefghi' >>> b * 3 b'abcdeabcdeabcde'
>>> b = b'abcde' >>> b[2] 99 >>> b[1:3] b'bc'
>>> len(b) 5 >>> min(b) 97 >>> max(b) 101
Многие методы, определенные для строковых объектов, допустимы и для байтовых объектов:
>>> b = b'foo,bar,foo,baz,foo,qux' >>> b.count(b'foo') 3 >>> b.endswith(b'qux') True >>> b.find(b'baz') 12 >>> b.split(sep=b',') [b'foo', b'bar', b'foo', b'baz', b'foo', b'qux'] >>> b.center(30, b'-') b'---foo,bar,foo,baz,foo,qux----'
Обратите внимание, однако, что когда эти операторы и методы вызываются для объекта bytes, операнд и аргументы также должны быть объектами bytes:
>>> b = b'foo.bar'
>>> b + '.baz'
Traceback (most recent call last):
File "<pyshell#72>", line 1, in
b + '.baz'
TypeError: can't concat bytes to str
>>> b + b'.baz'
b'foo.bar.baz'
>>> b.split(sep='.')
Traceback (most recent call last):
File "<pyshell#74>", line 1, in
b.split(sep='.')
TypeError: a bytes-like object is required, not 'str'
>>> b.split(sep=b'.')
[b'foo', b'bar']
Хотя определение и представление байтового объекта основано на тексте ASCII, на самом деле он ведет себя как неизменяемая последовательность небольших целых чисел в диапазоне от 0 до 255 включительно. Вот почему один элемент из объекта bytes отображается как целое число:
>>> b = b'fooxddbar' >>> b[3] 221 >>> hex(b[3]) '0xdd' >>> min(b) 97 >>> max(b) 221
Однако срез отображается как байтовый объект, даже если он имеет длину всего в один байт:
>>> b[2:3] b'c'
Вы можете преобразовать объект bytes в список целых чисел с помощью встроенной функции list()
>>> list(b) [97, 98, 99, 100, 101]
Шестнадцатеричные числа часто используются для указания двоичных данных, поскольку две шестнадцатеричные цифры непосредственно соответствуют одному байту. Класс bytes поддерживает два дополнительных метода, облегчающих преобразование в строку шестнадцатеричных цифр и обратно.
bytes.fromhex(<s>)
Возвращает объект
bytes, построенный из строки шестнадцатеричных значений.
bytes.fromhex(<s>) возвращает объект bytes, полученный в результате преобразования каждой пары шестнадцатеричных цифр в <s> в соответствующее значение байта. Шестнадцатеричные пары цифр в <s> могут быть дополнительно разделены пробелами, которые игнорируются:
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'xaahFx82xcc'
>>> list(b)
[170, 104, 70, 130, 204]
Примечание: этот метод является методом класса, а не методом объекта. Он привязан к классу bytes, а не к объекту bytes. В следующих уроках по объектно-ориентированному программированию вы гораздо глубже изучите различие между классами, объектами и соответствующими им методами. А пока просто обратите внимание, что этот метод вызывается в классе bytes, а не в объекте b.
b.hex()
Возвращает строку, содержащую шестнадцатеричное значение из объекта в байтах.
b.hex() возвращает результат преобразования байтов объекта b в строку шестнадцатеричных пар цифр. То есть он делает обратное .fromhex():
>>> b = bytes.fromhex(' aa 68 4682cc ')
>>> b
b'xaahFx82xcc'
>>> b.hex()
'aa684682cc'
>>> type(b.hex())
<class 'str'>
Примечание: В отличие от .fromhex(), .hex() — это объектный метод, а не метод класса. Таким образом, он вызывается на объекте класса bytes, а не на самом классе.
Объекты bytearray
Python поддерживает другой тип двоичной последовательности, называемый bytearray. Объекты bytearray очень похожи на объекты bytes, несмотря на некоторые различия:
- В Python нет специального синтаксиса для определения литерала байтового массива, такого как префикс ‘
b‘, который может использоваться для определения объектаbytes. Объектbytearrayвсегда создается с помощью встроенной функцииbytearray():
>>> ba = bytearray('foo.bar.baz', 'UTF-8')
>>> ba
bytearray(b'foo.bar.baz')
>>> bytearray(6)
bytearray(b'x00x00x00x00x00x00')
>>> bytearray([100, 102, 104, 106, 108])
bytearray(b'dfhjl')
bytearray изменчивы. Вы можете изменить содержимое объекта bytearray с помощью индексации и нарезки:>>> ba = bytearray('foo.bar.baz', 'UTF-8')
>>> ba
bytearray(b'foo.bar.baz')
>>> ba[5] = 0xee
>>> ba
bytearray(b'foo.bxeer.baz')
>>> ba[8:11] = b'qux'
>>> ba
bytearray(b'foo.bxeer.qux')
Объект bytearray также может быть построен непосредственно из объекта bytes:
>>> ba = bytearray(b'foo') >>> ba bytearray(b'foo')
Вывод
В этой учебной статье подробно рассматривается множество различных механизмов, предоставляемых Python для обработки строк, включая строковые операторы, встроенные функции, индексацию, нарезку и встроенные методы. Вы также познакомились с типами bytes и bytearray.
Эти типы являются первыми типами, которые вы рассмотрели, которые являются составными-построенными из набора меньших частей. Python предоставляет несколько составных встроенных типов. В следующем уроке вы познакомитесь с двумя наиболее часто используемыми: списками и кортежами.
Оригинал статьи: Strings and Character Data in Python
Автор оригинальной статьи: John Sturtz
Автор перевода: Кирилл Мартын-Назаров
В языке Python строки — это тип данных, который используется для представления текста. Это один из базовых типов, с которым мы имеем дело в каждом проекте на Python.
Данная статья является полным руководством по использованию строк в Python. Прочитав ее, вы узнаете, как создавать строки и работать с ними. В частности, мы рассмотрим:
- создание строк
- индексацию строк
- работу с подстроками
- использование методов строк
И не только это!
В Python вы можете создать строку, используя двойные или одинарные кавычки.
Например:
name = "Alice" hobby = 'golf'
Когда дело доходит до выбора одинарных или двойных кавычек, нужно быть последовательным. То есть вы можете использовать и те, и другие, но придерживайтесь одного стиля во всем проекте.
Применять строки и производить различные манипуляции с ними вам придется часто. Что касается «манипуляций», со строками можно делать множество вещей. Например, объединять, нарезать, изменять, находить подстроки и многое другое.
Далее поговорим об операторах строк.
Операторы строк
Возможно вы уже знаете об основных математических операторах Python.
От редакции Pythonist. На эту тему у нас есть статья «Операторы в Python».
С известной аккуратностью операторы сложения и умножения можно также применять и для строк:
- при помощи оператора сложения можно сложить две строки или более
- при помощи оператора умножения можно умножать строки.
В дополнении к этим двум операторам есть еще один, очень полезный. Он называется оператор in. С его помощью можно проверить, содержит ли строка определенную подстроку или символ.
Давайте рассмотрим подробнее, как работают эти операторы.
Оператор +
В Python вы можете объединить две или более строк с помощью оператора сложения (+).
Например:
part1 = "some" part2 = "where" word = part1 + part2 print(word) # Результат: # somewhere
Оператор *
Чтобы умножать строки в Python, можно использовать оператор умножения (*).
Например:
word = "hello" threeWords = word * 3 print(threeWords) # Результат: # hellohellohello
Оператор in
В Python оператор in можно использовать для проверки нахождения подстроки в строке.
Другими словами, с его помощью можно узнать, есть ли внутри строки определенное слово или символ.
Оператор in возвращает значение True, если внутри строки есть проверяемая подстрока. В противном случае возвращается значение False.
Например:
sentence = "This is just a test" testFound = "test" in sentence print(testFound) # Результат: # True
Теперь давайте рассмотрим другой пример. На этот раз проверим, есть ли в слове определенный символ:
word = "Hello" eFound = "e" in word print(eFound) # Результат: # True
Далее поговорим про индексацию строк.
Индексация строк
В Python строка представляет собой набор символов. Каждый символ строки имеет индекс — порядковый номер.
Благодаря этой индексации можно получить доступ к конкретному символу в данной строке, что весьма удобно.
Индексация строк Python начинается с нуля.
Это означает, что 1-й символ строки имеет индекс 0, 2-й символ имеет индекс 1 и так далее.

Чтобы получить доступ к символу с определенным индексом, нужно использовать квадратные скобки:
string[i].
Это выражение возвращает i-й символ строки. Например:
word = "Hello" c1 = word[0] print(c1) # Результат: # H
Если индекс выходит за пределы длины строки, вы увидите ошибку IndexError.
Давайте рассмотрим следующий пример.
Новичку в программировании может быть трудно запомнить, что индексация начинается с 0. Например, последний символ строки из 5 символов имеет индекс 4. Но давайте посмотрим, что произойдет, если вы вдруг подумаете, что это 5:
word = "Hello" last = word[5] print(last) # Результат: # IndexError: string index out of range
Как можно заметить, результатом является ошибка, указывающая, что индекс находится вне допустимого диапазона.
Это потому, что с индексом 5 мы пытаемся получить доступ к 6-му элементу. Но поскольку данная строка имеет только 5 символов, доступ к 6-му с треском проваливается.
Таким образом, следует быть осторожным и не пытаться получить доступ к отсутствующему элементу строки.
Нарезка (slicing) строк
Из предыдущего раздела стало ясно как получить доступ к определенному символу строки.
Но иногда требуется получить доступ к определенному диапазону внутри строки.
Сделать это можно при помощи так называемой нарезки строк.
Самый простой вариант операции нарезки требует указания начального и конечного индекса:
string[start:end].
Результатом является срез символов исходной строки. В него входят символы от начального до конечного индекса (при этом символ с конечным индексом в срез не входит).
Например, возьмем первые три буквы строки:
word = "Hello" firstThree = word[0:3] print(firstThree) # Результат: # Hel

0:3 включены 1-й, 2-й и 3-й элементы. А вот 4-й элемент (под индексом 3) исключен.Полный синтаксис оператора среза включает в себя параметр шага и имеет следующий вид:
string[start:end:step].
Параметр шага (step) указывает, через сколько символов следует перепрыгивать. По умолчанию он равен 1, как вы наверно уже догадались.
Например, возьмем каждый второй символ из первых 8 символов строки:
word = "Hello world" firstThree = word[0:8:2] print(firstThree) # Результат: # Hlow
Теперь вы должны понимать основные принципы нарезки строк в Python.
На практике срезы применяются очень разнообразно. Например, некоторые или даже все параметры среза можно опускать, а отсчет символов может идти в обратном направлении.
Но чтобы не раздувать материал, здесь мы не будем вдаваться в детали срезов.
Встраивание переменных внутрь строки
Довольно часто возникает необходимость добавить переменные внутрь строки Python.
Для этого можно использовать F-строки. F-строка означает просто «форматированная строка». Она позволяет нам аккуратно размещать код внутри строки.
Чтобы создать F-строку, нужно добавить символ f непосредственно перед строкой и обозначить фигурными скобками код, внедряемый в строку.
Например:
name = "Alice"
greeting = f"Hello, {name}! How are you doing?"
print(greeting)
# Результат:
# Hello, Alice! How are you doing?
Как можно заметить, это аккуратным образом встраивает в строку имя, хранящееся в переменной name. Благодаря этому нам не нужно разбивать строку на три части, что было бы несколько неудобно.
Давайте рассмотрим еще один пример, чтобы убедиться, что внутри F-строки можно также запускать код:
calculation = f"5 * 6 = {5 * 6}."
print(calculation)
# Результат:
# 5 * 6 = 30
От редакции Pythonist: на тему форматирования строк у нас есть отдельная статья — «Форматирование строк».
Изменение строк
В языке Python строки изменять нельзя.
Это связано с тем, что строки относятся к неизменяемым типам данных и представляет собой неизменяемые наборы символов.
От редакции Pythonist: на тему изменяемости объектов в Python рекомендуем почитать статью «Python 3: изменяемый, неизменяемый…».
Новичков это может несколько сбивать с толку.
Но изменять именно исходную строку приходится не часто, так что особых проблем неизменяемость строк не вызывает.
Если вам нужна измененная строка, можно просто создать новую строку из исходной с уже внесенными в нее изменениями. То есть новая строка является просто модифицированной копией исходной версии нашей строки.
На самом деле существует множество полезных встроенных методов для изменения строк. Эти методы помогают решить большинство повседневных задач.
И оставшаяся часть данной статьи будет посвящена именно этим методам.
Методы строк в языке Python
Во встроенном в Python модуле string есть множество удобных методов, которые можно использовать для работы со строками.
Они делают жизнь программиста гораздо проще.
Эти методы предназначены для решения самых общих задач, связанных как с изменением строк, так и с работой со строками в целом.
Например, можно заменить символ в строке при помощи метода replace(). Без этого метода это было бы не так просто сделать. Вам пришлось бы реализовать собственную логику для замены символа, так как непосредственное изменение строки невозможно.
И таких методов в Python довольно много. Если быть точными, то их 47. Не пытайтесь запомнить их все. Лучше почитайте про каждый из этих методов и попробуйте применить их.
Можно также добавить данную статью в закладки и возвращаться к ней потом по мере надобности.
Следующая таблица представляет собой шпаргалку с методами строк в Python. А ниже этой таблицы вы найдете более подробное описание каждого метода и пару полезных примеров по нему:
| Имя метода | Описание метода |
| capitalize | Преобразует первый символ строки в верхний регистр. |
| casefold | Преобразует строку в нижний регистр. Поддерживает больше вариантов, чем метод lower(). Используется при локализации либо глобализации строк. |
| center | Возвращает центрированную строку. |
| count | Возвращает количество вхождений символа или подстроки в строке. |
| encode | Производит кодировку строки. |
| endswith | Проверяет, заканчивается ли строка определенным символом либо определенной подстрокой. |
| expandtabs | Указывает размер табуляции для строки и возвращает его. |
| find | Ищет определенный символ или подстроку. Возвращает позицию, где он был впервые обнаружен. |
| format | Старый способ добавления переменных внутрь строки (выше мы рассмотрели современный метод F-строк). Форматирует строку, встраивая в нее значения и возвращая результат. |
| format_map | Форматирует определенные значения в строке. |
| index | Ищет символ или подстроку в строке. Возвращает индекс, по которому он был впервые обнаружен. |
| isalnum | Проверяет, все ли символы строки являются буквенно-цифровыми. |
| isalpha | Проверяет, все ли символы строки являются буквенными. |
| isascii | Проверяет, все ли символы строки являются символами ASCII. |
| isdecimal | Проверяет, все ли символы строки являются десятичными числами. |
| isdigit | Проверяет, все ли символы строки являются цифрами. |
| isidentifier | Проверяет, является ли строка идентификатором. |
| islower | Проверяет, все ли символы строки находятся в нижнем регистре. |
| isnumeric | Проверяет, все ли символы строки являются числами. |
| isprintable | Проверяет, все ли символы строки доступны для печати. |
| isspace | Проверяет, все ли символы строки являются пробелами. |
| istitle | Проверяет, соответствует ли строка правилам написания заголовков (каждое слово начинается с заглавной буквы). |
| isupper | Проверяет, все ли символы строки находятся в верхнем регистре. |
| join | Соединяет элементы итерируемого объекта (например, списка) в одну строку. |
| ljust | Возвращает выровненную по левому краю версию строки. |
| lower | Приведение всех символов строки к нижнему регистру. |
| lstrip | Удаляет пробелы слева от строки. |
| maketrans | Создает таблицу преобразования символов (для метода translate()). |
| partition | Разбивает строку на три части. Искомая центральная часть указывается в качестве аргумента. |
| removeprefix | Удаляет префикс из начала строки и возвращает строку без него. |
| removesuffix | Удаляет суффикс из конца строки и возвращает строку без него. |
| replace | Возвращает строку, в которой определенный символ или подстрока заменены чем-то другим (другим символом или подстрокой). |
| rfind | Ищет в строке определенный символ или подстроку. Возвращает последний индекс, по которому он был найден. |
| rindex | Ищет в строке определенный символ или подстроку. Возвращает последний индекс, по которому он был найден (отличие данного метода от предыдущего только в том, что в случае неудачного поиска он возвращает ошибку). |
| rjust | Возвращает выровненную по правому краю версию строки. |
| rpartition | Разбивает строку на три части. Искомая центральная часть указывается в качестве аргумента. |
| rsplit | Разбивает строку по указанному разделителю и возвращает результат в виде списка. |
| rstrip | Удаляет пробелы справа от строки. |
| split | Разбивает строку по указанному разделителю и возвращает ее в виде списка элементов данной строки. |
| splitlines | Разбивает строку по разрывам (символам переноса строк) и возвращает список строк. |
| startswith | Проверяет, начинается ли строка с указанного символа или подстроки. |
| strip | Возвращает строку с удаленными пробелами с двух сторон. |
| swapcase | Все символы в верхнем регистре переводятся в нижний и наоборот. |
| title | Преобразует каждое слово строки так, чтобы оно начиналось с заглавной буквы. |
| translate | Возвращает переведенную строку. |
| upper | Переводит все символы строки в верхний регистр. |
| zfill | Заполняет строку символами 0. |
Все строковые методы Python с примерами
В данном разделе дается более подробное описание каждого метода.
Помимо теории, для всех методов представлены полезные примеры.
Итак, начнем по порядку!
capitalize
Чтобы сделать первую букву строки заглавной, удобно использовать данный метод.
"hello, world".capitalize() # Результат: # Hello, world
casefold
Чтобы преобразовать все символы строки в нижний регистр, удобно использовать встроенный метод casefold().
"HELLO, WORLD".casefold() # Результат: # hello world
Этот метод создает новую строку, переводя каждый символ строки в нижний регистр.
Разница между методами casefold() и lower() заключается в том, что метод casefold() умеет преобразовывать специальные буквы других языков. Другими словами, использование casefold() имеет смысл, когда ваше приложение должно поддерживать глобализацию или локализацию на другой язык.
Например, давайте преобразуем предложение на немецком языке, чтобы избавиться от большого двойного знака (ß). Это невозможно при использовании метода lower():
"Eine Großes bier".lower() # eine großes bier" "Eine Großes bier".casefold() # eine grosses bier"
center
Метод center() используется, чтобы окружить (заполнить с двух сторон) строку заданными символами.
Этот метод имеет следующий синтаксис:
string.center(num_characters, separator)
При вызове этого метода необходимо указать общее количество символов в строке и символ, которым строка будет окружена (заполнена с двух сторон).
Например, давайте добавим символы тире вокруг слова и сделаем всю строку длиной 20 символов:
txt = "banana" x = txt.center(20, "-") print(x) # Результат: # -------banana-------
count
Метод count() подсчитывает, сколько раз символ или подстрока встречается в строке.
Например, посчитаем количество букв l в предложении:
"Hello, world".count("l")
# Возвращает 3
Или давайте посчитаем, сколько раз слово «Hello» встречается в этом же предложении:
"Hello, world".count("Hello")
# Возвращает 1
encode
Чтобы изменить кодировку строки, используйте встроенный метод encode().
Этот метод имеет следующий синтаксис:
string.encode(encoding=encoding, errors=errors)
Кодировкой по умолчанию является UTF-8. В случае неудачи кидается ошибка.
Например, давайте преобразуем строку в кодировку UTF-8:
title = 'Hello world' print(title.encode()) # Результат: # b'Hello world'
Этот метод можно вызвать с двумя необязательными параметрами:
- encoding: указывает тип кодировки;
- errors: определяет ответ при ошибке кодирования;
Существует 6 типов ошибок:
strictignorereplacexmlcharrefreplacebackslashreplace
Вот несколько примеров ASCII-кодировки с разными типами ошибок:
txt = "My name is Kimi Räikkönen" print(txt.encode(encoding="ascii", errors="ignore")) print(txt.encode(encoding="ascii", errors="replace")) print(txt.encode(encoding="ascii", errors="xmlcharrefreplace")) print(txt.encode(encoding="ascii", errors="backslashreplace")) print(txt.encode(encoding="ascii", errors="namereplace"))
Результат:
b'My name is Kimi Rikknen'
b'My name is Kimi R?ikk?nen'
b'My name is Kimi Räikkönen'
b'My name is Kimi R\xe4ikk\xf6nen'
b'My name is Kimi R\N{LATIN SMALL LETTER A WITH DIAERESIS}ikk\N{LATIN SMALL LETTER O WITH DIAERESIS}nen'
endswith
Данный метод применяется для проверки, заканчивается ли строка или ее часть заданным символом или подстрокой.
Например:
sentence = "Hello, welcome to my world."
print(sentence.endswith("."))
# Результат:
# True
expandtabs
При помощи метода expandtabs() можно указать размер табуляции. Этот метод полезен, если ваши строки содержат табы.
Например:
sentence = "Htetltlto" print(sentence.expandtabs(1)) print(sentence.expandtabs(2)) print(sentence.expandtabs(3)) print(sentence.expandtabs(4)) print(sentence.expandtabs(5))
Результат:
H e l l o H e l l o H e l l o H e l l o H e l l o
find
Метод find() находит индекс первого вхождения символа или подстроки в строку. Если совпадения нет, возвращается -1.
Также можно указать диапазон, в котором выполняется поиск. Полный синтаксис для использования этого метода имеет следующий вид:
string.find(value, start, end)
Например:
sentence = "Hello world"
x = sentence.find("world")
print(x)
# Результат:
# 6
Это означает, что строку world можно найти по индексу 6 в заданном предложении.
В качестве другого примера давайте найдем подстроку в заданном диапазоне:
sentence = "This is a test"
x = sentence.find("is", 3, 8)
print(x)
# Результат:
# 5
format
Метод format() форматирует строку, встраивая в нее значения. Это несколько устаревший подход к форматированию строк в Python.
Метод format() имеет следующий синтаксис:
string.format(value1, value2, ... , valuen)
Здесь value — это переменные, которые вставляются в строку. В дополнение к этому вам необходимо указать (при помощи фигурных скобок) места для этих переменных в строке.
Давайте посмотрим на следующий пример:
name = "John"
age = 21
sentence = "My name is {} and I am {} years old".format(name, age)
print(sentence)
# Результат:
# My name is John and I am 21 years old
format_map
Метод format_map() используется, чтобы напрямую преобразовать словарь в строку.
Вот его синтаксис:
string.format_map(dict)
Чтобы это работало, вам нужно указать (при помощи фигурных скобок) места в строке, куда будут помещены значения словаря.
Например:
data = {"name": "John", "age": 21}
sentence = "My name is {name} and I am {age} years old".format_map(data)
print(sentence)
# Результат:
# My name is John and I am 21 years old
index
Метод index() находит индекс первого вхождения символа или подстроки в строку. Если он не находит значение, то вызывается исключение. Этим он отличается от метода find().
Также можно указать диапазон, в котором будет производится поиск.
Синтаксис данного метода имеет следующий вид:
string.index(value, start, end)
Например:
sentence = "Hello world"
x = sentence.index("world")
print(x)
# Результат:
# 6
Это говорит о том, что подстроку world можно найти по индексу 6 в данной строке.
В качестве другого примера давайте найдем подстроку в заданном диапазоне:
sentence = "This is a test"
x = sentence.index("is", 3, 8)
print(x)
# Результат:
# 5
Разница между методами index() и find() заключается в том, что index() выдает ошибку, если не находит значения. Метод find() возвращает -1.
isalnum
Чтобы проверить, являются ли все символы строки буквенно-цифровыми, используется метод isalnum().
Например:
sentence = "This is 50" print(sentence.isalnum()) # Результат: # False
isalpha
Чтобы проверить, все ли символы строки являются буквами, используется метод isalpha().
Например:
sentence = "Hello" print(sentence.isalpha()) # Результат: # True
isascii
Чтобы проверить, все ли символы строки являются ASCII символами, используется метод isascii().
Например:
sentence = "Hello" print(sentence.isalpha()) # Результат: # True
isdecimal
Чтобы проверить, являются ли все символы строки числами в десятичной системе исчисления, используется метод isdecimal().
Например:
sentence = "u0034" print(sentence.isdecimal()) # Результат: # True
isdigit
Чтобы проверить, все ли символы строки являются числами, используется метод isdigit().
Например:
sentence = "34" print(sentence.isdigit()) # Результат: # True
isidentifier
Чтобы проверить, все ли символы строки являются идентификаторами, используется метод isidentifier().
- Строка считается идентификатором, если она содержит буквенно-цифровые буквы (a-z, 0-9) или знаки подчеркивания.
- Идентификатор не может начинаться с цифры.
Например:
sentence = "Hello" print(sentence.isidentifier()) # Результат: # True
islower
Чтобы проверить, находятся ли все символы строки в нижнем регистре, используется встроенный метод islower().
Например:
"Hello, world".islower() # Результат: # False
Этот метод проверяет, все ли символы строки находятся в нижнем регистре. Если это так, он возвращает True. В противном случае False.
isnumeric
Чтобы проверить, все ли символы строки являются числами, используется метод isnumeric().
Например:
sentence = "5000" print(sentence.isnumeric()) # Результат: # True
isprintable
Чтобы проверить, все ли символы строки доступны для печати, используется метод isprintable().
Например:
sentence = "This a is test" print(sentence.isprintable()) # Результат: # True
isspace
Чтобы проверить, являются ли все символы строки пробелами, используется метод isspace().
Например:
sentence = " " print(sentence.isspace()) # Результат: # True
istitle
Чтобы проверить, все ли первые символы каждого слова в строке начинаются с заглавной буквы, используется метод istitle().
Например:
sentence = "Hello There This Is A Test" print(sentence.istitle()) # Результат: # True
isupper
Чтобы проверить, находятся ли все символы строки в верхнем регистре, используется встроенный метод isupper():
Например:
"HELLO, WORLD".isupper() # Результат: # True
Этот метод проверяет, все ли символы строки в верхнем регистре. Если это так, он возвращает True. В противном случае False.
join
Чтобы объединить группу элементов (например, списка) в одну строку, используется метод join().
Например:
words = ["This", "is", "a", "test"] sentence = " ".join(words) print(sentence) # Результат: # This is a test
ljust
Чтобы добавить определенные символы, например пробелы, справа от строки, используется метод ljust().
Вот его синтаксис:
string.ljust(num_characters, separator)
- num_characters: общая длина строки вместе с добавленными символами
- separator: символ, который добавляется в строку n раз, чтобы длина строки достигла заданного в предыдущем параметре значения
Например, добавим справа от строки символ тире:
print("Hello".ljust(20, "-"))
# Результат:
# Hello---------------
lower
Чтобы привести строку Python к нижнему регистру, используется встроенный метод lower().
Например:
"HELLO, WORLD".lower() # Результат: # hello world
Этот метод создает новую строку, переводя каждый символ первоначальной строки в нижний регистр.
lstrip
Чтобы удалить начальные символы из строки, используется метод lstrip().
По умолчанию этот метод удаляет все пробелы в начале строки.
Например:
print(" test".lstrip())
# Результат:
# test
В качестве другого примера давайте удалим все дефисы в начале следующей строки:
print("---test---".lstrip("-"))
# Результат:
# test---
maketrans
Чтобы создать таблицу сопоставления строк, используется метод maketrans(). Эта таблица применяется вместе с методом translate().
Синтаксис имеет следующий вид:
string.maketrans(a, b, c)
- Первый параметр
aявляется обязательным. Если указан только он один, то он должен быть словарем, который определяет порядок замены строк. В противном случае параметрaдолжен быть строкой, которая показывает, какие символы нужно будет менять. - Второй параметр
bявляется необязательным. Он должен быть одинаковой длины с параметромa. Каждый символ вaбудет заменен соответствующим символом вb. - Третий параметр
cтакже является необязательным. Он определяет, какие символы нужно будет удалить из исходной строки.
Например, заменим в предложении символы о на х:
sentence = "Hello World"
trans_table = sentence.maketrans("o", "x")
print(sentence.translate(trans_table))
# Результат:
# Hellx Wxrld
partition
Чтобы разделить строку на три части, используется метод partition(). Он разбивает строку вокруг определенного символа или подстроки. Результат возвращается в виде кортежа.
Например, можно с его помощью разделить предложение вокруг заданного слова:
sentence = "This is a test"
parts = sentence.partition("a")
print(parts)
# Результат:
# ('This is', 'a', 'test')
removeprefix
Для удаления начала строки используется метод removeprefix(). Надо заметить, что это относительно новый метод, он работает только начиная с версии Python 3.9 и выше.
Например, давайте удалим слово This из данного предложения:
sentence = "This is a test"
print(sentence.removeprefix("This"))
# Результат:
# is a test
removesuffix
Для удаления конца строки используется метод removesuffix(). Это также новый метод, он работает только с версией Python 3.9 и выше.
Например, давайте удалим из данного предложения последнее слово test:
sentence = "This is a test"
print(sentence.removesuffix("test"))
# Результат:
# This is a
replace
Чтобы заменить символ или подстроку внутри строки на что-то другое, используется метод replace():
Он имеет следующий синтаксис:
string.replace(old, new, count)
Здесь:
- old: символ или подстрока, которую вы хотите заменить
- new: то, на что вы хотите это поменять
- count: необязательный параметр (по умолчанию равен 1), определяет количество замен, которое необходимо произвести
Например:
sentence = "This is a test"
updated_sentence = sentence.replace("This", "It")
print(updated_sentence)
# Результат:
# It is a test
rfind
Для нахождения индекса последнего вхождения символа или подстроки в строку используется метод rfind(). При отсутствии совпадений возвращается значение -1.
Синтаксис:
string.rfind(val, start, end)
Здесь:
- val: значение искомого символа или подстроки
- start: необязательный параметр, определяет индекс строки, с которого начинается поиск
- end: также необязательный параметр, определяет индекс строки, где поиск будет прекращен
Например:
sentence = "This car is my car"
last_index = sentence.rfind("car")
print(last_index)
# Результат:
# 15
rindex
Для нахождения индекса последнего вхождения символа или подстроки в строку также можно использовать метод rindex(). Но если вхождений найдено не будет, данный метод вызовет исключение. В этом его отличие от метода rfind(), который возвращает -1.
Его синтаксис имеет вид:
string.rindex(val, start, end)
Здесь:
- val: значение искомого символа или подстроки
- start: необязательный параметр, определяет индекс строки, с которого начинается поиск
- end: также необязательный параметр, определяет индекс строки, где поиск будет прекращен
sentence = "This car is my car"
last_index = sentence.rindex("car")
print(last_index)
# Результат:
# 15
rjust
Метод rjust() используется для добавления слева от строки определенных символов, например пробелов.
У него следующий синтаксис:
string.rjust(num_characters, separator)
- num_characters: общая длина строки вместе с добавленными символами
- separator: символ, который следует добавлять слева от строки до достижения нужной длины
Например, добавим символы тире в начало строки:
print("Hello".rjust(20, "-"))
# Результат:
# ---------------Hello
rpartition
Данный метод разделяет строку на три части относительно последнего вхождения искомого символа или подстроки. Результат возвращается в виде кортежа.
Например:
sentence = "This car is my car, you cannot drive it"
parts = sentence.rpartition("car")
print(parts)
# Результат:
# ('This car is my ', 'car', ', you cannot drive it')
rsplit
Для разбиения строки по определенному разделителю начиная с правой стороны используется метод rsplit(). Результат возвращается в виде списка.
Его синтаксис имеет вид:
string.rsplit(separator, max)
Здесь:
- separator: разделитель (символ или подстрока), на основе которого разбивается строка
- max: определяет максимальное количество разбиений, это необязательный параметр, если его не задавать, то данный метод работает точно так же, как
split()
Например, давайте разделим справа строку, разделенную запятыми. Но при этом сделаем только одно разбиение:
items = "apple, banana, cherry"
split_items = items.rsplit(",", 1)
print(split_items)
# Результат:
# ['apple, banana', ' cherry']
Обратите внимание, что данный массив состоит только из двух строк.
rstrip
При помощи метода rstrip() можно удалять определенные символы, начиная с конца строки.
Если не указывать аргументов, данный метод будет пытаться удалять пробелы справа от строки.
Например, давайте удалим символ тире из строки:
print("Hello-----".rstrip("-"))
# Результат:
# Hello
split
При помощи метода split() строку можно превратить в список строк, разбив ее на части. Это один из наиболее широко используемых строковых методов Python.
По умолчанию данный метод разбивает строку на основе пробелов.
Вот его синтаксис:
string.split(separator, max)
Здесь:
- separator: необязательный параметр, символ или подстрока, на основании которой будет осуществляться разбиение
- max: также необязательный параметр, определяет количество предполагаемых разбиений
Например:
sentence = "This is a test" # Разбить по пробелам parts = sentence.split() print(parts) # Результат: # ['This', 'is', 'a', 'test']
В качестве другого примера давайте разобьем список, разделенный запятыми, ровно два раза, по двум первым запятым:
sentence = "Apple, Banana, Orange, Mango, Pineapple"
parts = sentence.split(",", 2)
print(parts)
# Результат:
# ['Apple', ' Banana', ' Orange, Mango, Pineapple']
Обратите внимание, что в данном списке только 3 элемента.
splitlines
Чтобы разбить текст, считанный в виде строки, по символам разрыва строки, используется метод splitlines().
Например:
sentence = "ApplenBanananOrangenMangonPineapple" parts = sentence.splitlines() print(parts) # Результат: # ['Apple', 'Banana', 'Orange', 'Mango', 'Pineapple']
Вы также можете оставить символы разрыва строк в конце каждой строки. Для этого нужно передать параметр True в качестве аргумента данного метода:
sentence = "ApplenBanananOrangenMangonPineapple" parts = sentence.splitlines(True) print(parts) # Результат: # ['Applen', 'Bananan', 'Orangen', 'Mangon', 'Pineapple']
startswith
Чтобы проверить, начинается ли строка с определенного значения, используется метод startwith().
Вот его синтаксис:
string.startswith(val, start, end)
Здесь:
- val: значение, наличие которого хочется проверить
- start: необязательный параметр, целое число, определяющее индекс, с которого следует начать поиск
- end: также необязательный параметр, целое число, указывающее на индекс, на котором надо завершить поиск
Например:
sentence = "Hello world"
print(sentence.startswith("Hello"))
# Результат:
# True
Теперь перейдем к другому примеру. На этот раз давайте посмотрим, есть ли в строке, начиная с 6-го индекса, подстрока wor:
sentence = "Hello world"
print(sentence.startswith("wor", 6))
# Результат:
# True
strip
Чтобы удалить определенные символы или подстроку из строки, используется метод strip(). По умолчанию этот метод удаляет пробелы. Также можно указать аргумент, который будет определять, какие именно символы нужно удалить.
Например, давайте удалим все символы тире из строки:
word = "--------test---"
stripped_word = word.strip("-")
print(stripped_word)
# Результат:
# test
swapcase
Чтобы сделать строчные буквы заглавными, а заглавные строчными, используется метод swapcase().
Например:
"HELLO, world".swapcase() # Результат: # hello, WORLD
Этот метод создает новую строку, заменяя все заглавные буквы на строчные и наоборот.
title
Чтобы сделать первую букву каждого слова в строке заглавной, используется метод title().
Например:
"hello, world".title() # Результат: # Hello, World
Этот метод создает новую строку, делая первую букву каждого слова заглавной.
translate
Чтобы заменить определенные символы строки на другие символы, используется метод translate().
Но прежде чем это делать, нужно создать таблицу сопоставления при помощи метода maketrans().
Например, давайте заменим буквы о на х:
sentence = "Hello World"
trans_table = sentence.maketrans("o", "x")
print(sentence.translate(trans_table))
# Результат:
# Hellx Wxrld
upper
Чтобы преобразовать строку Python в верхний регистр, используется встроенный метод upper().
Например:
"Hello, world".upper() # Результат: # HELLO WORLD
Этот метод создает новую строку, переводя каждый символ исходной строки в верхний регистр.
zfill
Данный метод добавляет нули перед исходной строкой.
В качестве аргумента нужно передать желаемую длину строки и, метод добавит нужное количество нулей перед строкой.
Например:
word = "Test" filled_word = word.zfill(10) print(filled_word) # Результат: # 000000Test
Обратите внимание, что общая длина этой строки теперь равна 10.
Заключение
Видите как много существует методов строк!
Надеюсь, вам понравилась эта статья!
Удачного кодинга!
Перевод статьи Arturri Jalli «Python Strings: A Complete Guide [2022]».