20.1.1. Parameter Names and Values
All parameter names are case-insensitive. Every parameter takes a value of one of five types: boolean, string, integer, floating point, or enumerated (enum). The type determines the syntax for setting the parameter:
-
Boolean: Values can be written as
on,off,true,false,yes,no,1,0(all case-insensitive) or any unambiguous prefix of one of these. -
String: In general, enclose the value in single quotes, doubling any single quotes within the value. Quotes can usually be omitted if the value is a simple number or identifier, however. (Values that match an SQL keyword require quoting in some contexts.)
-
Numeric (integer and floating point): Numeric parameters can be specified in the customary integer and floating-point formats; fractional values are rounded to the nearest integer if the parameter is of integer type. Integer parameters additionally accept hexadecimal input (beginning with
0x) and octal input (beginning with0), but these formats cannot have a fraction. Do not use thousands separators. Quotes are not required, except for hexadecimal input. -
Numeric with Unit: Some numeric parameters have an implicit unit, because they describe quantities of memory or time. The unit might be bytes, kilobytes, blocks (typically eight kilobytes), milliseconds, seconds, or minutes. An unadorned numeric value for one of these settings will use the setting’s default unit, which can be learned from
pg_settings.unit. For convenience, settings can be given with a unit specified explicitly, for example'120 ms'for a time value, and they will be converted to whatever the parameter’s actual unit is. Note that the value must be written as a string (with quotes) to use this feature. The unit name is case-sensitive, and there can be whitespace between the numeric value and the unit.-
Valid memory units are
B(bytes),kB(kilobytes),MB(megabytes),GB(gigabytes), andTB(terabytes). The multiplier for memory units is 1024, not 1000. -
Valid time units are
us(microseconds),ms(milliseconds),s(seconds),min(minutes),h(hours), andd(days).
If a fractional value is specified with a unit, it will be rounded to a multiple of the next smaller unit if there is one. For example,
30.1 GBwill be converted to30822 MBnot32319628902 B. If the parameter is of integer type, a final rounding to integer occurs after any unit conversion. -
-
Enumerated: Enumerated-type parameters are written in the same way as string parameters, but are restricted to have one of a limited set of values. The values allowable for such a parameter can be found from
pg_settings.enumvals. Enum parameter values are case-insensitive.
20.1.2. Parameter Interaction via the Configuration File
The most fundamental way to set these parameters is to edit the file postgresql.conf, which is normally kept in the data directory. A default copy is installed when the database cluster directory is initialized. An example of what this file might look like is:
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
One parameter is specified per line. The equal sign between name and value is optional. Whitespace is insignificant (except within a quoted parameter value) and blank lines are ignored. Hash marks (#) designate the remainder of the line as a comment. Parameter values that are not simple identifiers or numbers must be single-quoted. To embed a single quote in a parameter value, write either two quotes (preferred) or backslash-quote. If the file contains multiple entries for the same parameter, all but the last one are ignored.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden. The following sections describe ways in which the administrator or user can override these defaults.
The configuration file is reread whenever the main server process receives a SIGHUP signal; this signal is most easily sent by running pg_ctl reload from the command line or by calling the SQL function pg_reload_conf(). The main server process also propagates this signal to all currently running server processes, so that existing sessions also adopt the new values (this will happen after they complete any currently-executing client command). Alternatively, you can send the signal to a single server process directly. Some parameters can only be set at server start; any changes to their entries in the configuration file will be ignored until the server is restarted. Invalid parameter settings in the configuration file are likewise ignored (but logged) during SIGHUP processing.
In addition to postgresql.conf, a PostgreSQL data directory contains a file postgresql.auto.conf, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file holds settings provided through the ALTER SYSTEM command. This file is read whenever postgresql.conf is, and its settings take effect in the same way. Settings in postgresql.auto.conf override those in postgresql.conf.
External tools may also modify postgresql.auto.conf. It is not recommended to do this while the server is running, since a concurrent ALTER SYSTEM command could overwrite such changes. Such tools might simply append new settings to the end, or they might choose to remove duplicate settings and/or comments (as ALTER SYSTEM will).
The system view pg_file_settings can be helpful for pre-testing changes to the configuration files, or for diagnosing problems if a SIGHUP signal did not have the desired effects.
20.1.3. Parameter Interaction via SQL
PostgreSQL provides three SQL commands to establish configuration defaults. The already-mentioned ALTER SYSTEM command provides an SQL-accessible means of changing global defaults; it is functionally equivalent to editing postgresql.conf. In addition, there are two commands that allow setting of defaults on a per-database or per-role basis:
-
The
ALTER DATABASEcommand allows global settings to be overridden on a per-database basis. -
The
ALTER ROLEcommand allows both global and per-database settings to be overridden with user-specific values.
Values set with ALTER DATABASE and ALTER ROLE are applied only when starting a fresh database session. They override values obtained from the configuration files or server command line, and constitute defaults for the rest of the session. Note that some settings cannot be changed after server start, and so cannot be set with these commands (or the ones listed below).
Once a client is connected to the database, PostgreSQL provides two additional SQL commands (and equivalent functions) to interact with session-local configuration settings:
-
The
SHOWcommand allows inspection of the current value of any parameter. The corresponding SQL function iscurrent_setting(setting_name text)(see Section 9.27.1). -
The
SETcommand allows modification of the current value of those parameters that can be set locally to a session; it has no effect on other sessions. Many parameters can be set this way by any user, but some can only be set by superusers and users who have been grantedSETprivilege on that parameter. The corresponding SQL function isset_config(setting_name, new_value, is_local)(see Section 9.27.1).
In addition, the system view pg_settings can be used to view and change session-local values:
-
Querying this view is similar to using
SHOW ALLbut provides more detail. It is also more flexible, since it’s possible to specify filter conditions or join against other relations. -
Using
UPDATEon this view, specifically updating thesettingcolumn, is the equivalent of issuingSETcommands. For example, the equivalent ofSET configuration_parameter TO DEFAULT;
is:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
20.1.4. Parameter Interaction via the Shell
In addition to setting global defaults or attaching overrides at the database or role level, you can pass settings to PostgreSQL via shell facilities. Both the server and libpq client library accept parameter values via the shell.
-
During server startup, parameter settings can be passed to the
postgrescommand via the-ccommand-line parameter. For example,postgres -c log_connections=yes -c log_destination='syslog'
Settings provided in this way override those set via
postgresql.conforALTER SYSTEM, so they cannot be changed globally without restarting the server. -
When starting a client session via libpq, parameter settings can be specified using the
PGOPTIONSenvironment variable. Settings established in this way constitute defaults for the life of the session, but do not affect other sessions. For historical reasons, the format ofPGOPTIONSis similar to that used when launching thepostgrescommand; specifically, the-cflag must be specified. For example,env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Other clients and libraries might provide their own mechanisms, via the shell or otherwise, that allow the user to alter session settings without direct use of SQL commands.
20.1.5. Managing Configuration File Contents
PostgreSQL provides several features for breaking down complex postgresql.conf files into sub-files. These features are especially useful when managing multiple servers with related, but not identical, configurations.
In addition to individual parameter settings, the postgresql.conf file can contain include directives, which specify another file to read and process as if it were inserted into the configuration file at this point. This feature allows a configuration file to be divided into physically separate parts. Include directives simply look like:
include 'filename'
If the file name is not an absolute path, it is taken as relative to the directory containing the referencing configuration file. Inclusions can be nested.
There is also an include_if_exists directive, which acts the same as the include directive, except when the referenced file does not exist or cannot be read. A regular include will consider this an error condition, but include_if_exists merely logs a message and continues processing the referencing configuration file.
The postgresql.conf file can also contain include_dir directives, which specify an entire directory of configuration files to include. These look like
include_dir 'directory'
Non-absolute directory names are taken as relative to the directory containing the referencing configuration file. Within the specified directory, only non-directory files whose names end with the suffix .conf will be included. File names that start with the . character are also ignored, to prevent mistakes since such files are hidden on some platforms. Multiple files within an include directory are processed in file name order (according to C locale rules, i.e., numbers before letters, and uppercase letters before lowercase ones).
Include files or directories can be used to logically separate portions of the database configuration, rather than having a single large postgresql.conf file. Consider a company that has two database servers, each with a different amount of memory. There are likely elements of the configuration both will share, for things such as logging. But memory-related parameters on the server will vary between the two. And there might be server specific customizations, too. One way to manage this situation is to break the custom configuration changes for your site into three files. You could add this to the end of your postgresql.conf file to include them:
include 'shared.conf' include 'memory.conf' include 'server.conf'
All systems would have the same shared.conf. Each server with a particular amount of memory could share the same memory.conf; you might have one for all servers with 8GB of RAM, another for those having 16GB. And finally server.conf could have truly server-specific configuration information in it.
Another possibility is to create a configuration file directory and put this information into files there. For example, a conf.d directory could be referenced at the end of postgresql.conf:
include_dir 'conf.d'
Then you could name the files in the conf.d directory like this:
00shared.conf 01memory.conf 02server.conf
This naming convention establishes a clear order in which these files will be loaded. This is important because only the last setting encountered for a particular parameter while the server is reading configuration files will be used. In this example, something set in conf.d/02server.conf would override a value set in conf.d/01memory.conf.
You might instead use this approach to naming the files descriptively:
00shared.conf 01memory-8GB.conf 02server-foo.conf
This sort of arrangement gives a unique name for each configuration file variation. This can help eliminate ambiguity when several servers have their configurations all stored in one place, such as in a version control repository. (Storing database configuration files under version control is another good practice to consider.)
Сервер баз данных PostgreSQL имеет очень много параметров с помощью которых его можно настроить под любые нужды. В этой статье мы не будет рассматривать все эти параметры. Здесь мы посмотрим на различные cпособы конфигурирования PostgreSQL.
Если же вы хотите посмотреть список параметров настройки PostgreSQL, то ищите его в справочнике на официальном сайте: на английском и на русском языках.
Конфигурационный файл postgresql.conf
Главный конфигурационный файл для кластера PostgreSQL – это postgresql.conf, в разных системах он может находится в разных местах. Так как мы собирали сервер из исходников и не меняли путь хранения этого файла, то по умолчанию он будет находится в каталоге PGDATA:
postgres@s-pg13:~$ echo $PGDATA /usr/local/pgsql/data postgres@s-pg13:~$ ls -l $PGDATA/postgresql.conf -rw------- 1 postgres postgres 28023 июн 21 15:15 /usr/local/pgsql/data/postgresql.conf
Этот конфигурационный файл читается один раз при запуске сервера. Если параметр указан несколько раз, то применяется последний.
Самый точный способ узнать расположение этого файла, посмотреть из терминала psql:
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# SHOW config_file;
config_file
---------------------------------------
/usr/local/pgsql/data/postgresql.conf
(1 row)
Time: 0,391 ms
Если вы измените параметры в этом файле, его нужно перечитать. Первый способ – из командной оболочки операционной системы:
postgres@postgres=# q postgres@s-pg13:~$ pg_ctl reload server signaled
Второй способ – из терминала psql:
postgres@s-pg13:~$ psql Timing is on. psql (13.3) Type "help" for help. postgres@postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) Time: 0,555 ms
Но есть некоторые параметры, для изменения которых потребуется перезапуск сервера.
Конфигурация сервера используя ALTER SYSTEM
Для настройки сервера также существует другой файл – postgresql.auto.conf. Он были придуман для настройки сервера из консоли psql. Читается этот файл после postgresql.conf, поэтому параметры из него имеют приоритет. Этот файл всегда находится в каталоге с данными (PGDATA).
Для создания параметров в файле postgresql.auto.conf нужно выполнить подобный запрос:
ALTER SYSTEM SET <параметр> TO <значение>;
Чтобы удалить параметр используем другой запрос:
ALTER SYSTEM RESET <параметр>;
А чтобы удалить все параметры из postgresql.auto.conf выполним:
ALTER SYSTEM RESET ALL;
Чтобы применить изменения нужно перечитать конфигурационные файлы как было описано выше.
Информация о текущих настройках сервера
В PostgreSQL есть 2 представления через которые можно посмотреть текущие настройки сервера:
- pg_file_settings – какие параметры записаны в файлах postgresql.conf и postgresql.auto.conf;
- pg_settings – текущие параметры, с которыми работает сервер.
Например посмотрим значение параметра config_file из представления pg_settings, который покажет конфигурационный файл текущего кластера:
postgres@postgres=# SELECT setting FROM pg_settings WHERE name = 'config_file';
setting
---------------------------------------
/usr/local/pgsql/data/postgresql.conf
(1 row)
Time: 1,844 ms
Внесём изменения в параметр work_mem в postgresql.conf и postgresql.auto.conf. Затем посмотрим на все не закомментированные параметры в этих файлах:
postgres@postgres=# ! echo 'work_mem = 8MB' >> $PGDATA/postgresql.conf
postgres@postgres=# ALTER SYSTEM SET work_mem TO '10MB';
ALTER SYSTEM
Time: 0,728 ms
postgres@postgres=# SELECT sourceline, name, setting, applied FROM pg_file_settings;
sourceline | name | setting | applied
------------+----------------------------+--------------------+---------
63 | port | 5433 | f
64 | max_connections | 100 | t
121 | shared_buffers | 128MB | t
142 | dynamic_shared_memory_type | posix | t
228 | max_wal_size | 1GB | t
229 | min_wal_size | 80MB | t
563 | log_timezone | Europe/Moscow | t
678 | datestyle | iso, dmy | t
680 | timezone | Europe/Moscow | t
694 | lc_messages | ru_RU.UTF-8 | t
696 | lc_monetary | ru_RU.UTF-8 | t
697 | lc_numeric | ru_RU.UTF-8 | t
698 | lc_time | ru_RU.UTF-8 | t
701 | default_text_search_config | pg_catalog.russian | t
780 | work_mem | 8MB | f
3 | work_mem | 10MB | t
(16 rows)
Time: 0,650 ms
Как можно заметить в примере выше, у меня 2 одинаковых параметра work_mem. Колонка applied показывает, может ли быть применён параметр. Первый work_mem не может быть применен, так как второй его перезапишет. При этом реальное значение с которым работает сервер отличается, так как сервер не перечитал конфигурацию.
Теперь посмотрим на реальное, текущее значение этого параметра:
postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+--------- name | work_mem setting | 4096 unit | kB boot_val | 4096 reset_val | 4096 source | default sourcefile | sourceline | pending_restart | f context | user Time: 0,854 ms
В примере выше мы использовали расширенный режим (в конце запроса gx), поэтому табличка перевёрнута. Разберём колонки:
- name – имя параметра;
- setting – текущее значение;
- unit – единица измерения;
- boot_val – значение по умолчанию (жёстко задано в коде postgresql);
- reset_val – если перечитаем конфигурацию, то применится это значение;
- source – источник, это значение по умолчанию;
- sourcefile – если бы источником был конфигурационный файл, то тут был бы указан этот файл;
- sourceline – номер строки в этом файле;
- pending_restart – параметр изменили в конфигурационном файле и требуется перезапуск сервера. У нас требуется всего лишь перечитать конфигурацию;
- context – действия, необходимые для применения параметра, может быть таким:
- internal – изменить нельзя, задано при установке;
- postmaster – требуется перезапуск сервера;
- sighup – требуется перечитать файлы конфигурации;
- superuser – суперпользователь может изменить для своего сеанса;
- user – любой пользователь может изменить для своего сеанса на лету.
Перечитаем конфигурацию сервера:
postgres@postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) Time: 3,178 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+------------------------------------------- name | work_mem setting | 10240 unit | kB boot_val | 4096 reset_val | 10240 source | configuration file sourcefile | /usr/local/pgsql/data/postgresql.auto.conf sourceline | 3 pending_restart | f context | user Time: 1,210 ms
Как видим, параметр изменился. Он был взят из postgresql.auto.conf и теперь равняется 10 MB.
Установка параметров на лету
Для своего сеанса можно изменить параметры с context=user. Для этого используется конструкция:
SET <параметр> TO '<значение>';
Например сделаем это для work_mem:
postgres@postgres=# SET work_mem TO '64MB'; SET Time: 0,119 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+--------- name | work_mem setting | 65536 unit | kB boot_val | 4096 reset_val | 10240 source | session sourcefile | sourceline | pending_restart | f context | user Time: 0,651 ms
Как видим, теперь источником является текущая сессия, а параметр равен 64 MB, но если мы перечитаем конфигурацию параметр снова станет равным 10 MB.
Чтобы вернуть все на место нужно просто перезайти в psql. Или выполнить команду RESET <параметр>:
postgres@postgres=# RESET work_mem; RESET Time: 0,211 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+------------------------------------------- name | work_mem setting | 10240 unit | kB boot_val | 4096 reset_val | 10240 source | configuration file sourcefile | /usr/local/pgsql/data/postgresql.auto.conf sourceline | 3 pending_restart | f context | user Time: 0,632 ms
Тоже самое может проделывать приложение для одной транзакции, и если транзакция откатывается, то и значение параметра откатывается вместе с ней:
postgres@postgres=# BEGIN; BEGIN Time: 0,070 ms postgres@postgres=# SET work_mem TO '64MB'; SET Time: 0,085 ms postgres@postgres=# SHOW work_mem; work_mem ---------- 64MB (1 row) Time: 0,102 ms postgres@postgres=# ROLLBACK; ROLLBACK Time: 0,108 ms postgres@postgres=# SHOW work_mem; work_mem ---------- 10MB (1 row) Time: 0,120 ms
Как вы могли заметить посмотреть текущее значение параметра ещё можно так:
SHOW <параметр>;
Какие параметры требуют перезапуск сервера?
Чтобы это выяснить нужно посмотреть все параметры у которых context = postmaster:
postgres@postgres=# SELECT name, setting, unit FROM pg_settings WHERE context = 'postmaster';
name | setting | unit
-------------------------------------+---------------------------------------+------
archive_mode | off |
autovacuum_freeze_max_age | 200000000 |
autovacuum_max_workers | 3 |
autovacuum_multixact_freeze_max_age | 400000000 |
bonjour | off |
bonjour_name | |
cluster_name | |
config_file | /usr/local/pgsql/data/postgresql.conf |
data_directory | /usr/local/pgsql/data |
data_sync_retry | off |
dynamic_shared_memory_type | posix |
event_source | PostgreSQL |
external_pid_file | |
hba_file | /usr/local/pgsql/data/pg_hba.conf |
hot_standby | on |
huge_pages | try |
ident_file | /usr/local/pgsql/data/pg_ident.conf |
ignore_invalid_pages | off |
jit_provider | llvmjit |
listen_addresses | localhost |
logging_collector | off |
max_connections | 100 |
max_files_per_process | 1000 |
max_locks_per_transaction | 64 |
max_logical_replication_workers | 4 |
max_pred_locks_per_transaction | 64 |
max_prepared_transactions | 0 |
max_replication_slots | 10 |
max_wal_senders | 10 |
max_worker_processes | 8 |
old_snapshot_threshold | -1 | min
port | 5432 |
recovery_target | |
recovery_target_action | pause |
recovery_target_inclusive | on |
recovery_target_lsn | |
recovery_target_name | |
recovery_target_time | |
recovery_target_timeline | latest |
recovery_target_xid | |
restore_command | |
shared_buffers | 16384 | 8kB
shared_memory_type | mmap |
shared_preload_libraries | |
superuser_reserved_connections | 3 |
track_activity_query_size | 1024 | B
track_commit_timestamp | off |
unix_socket_directories | /tmp |
unix_socket_group | |
unix_socket_permissions | 0777 |
wal_buffers | 512 | 8kB
wal_level | replica |
wal_log_hints | off |
(53 rows)
Time: 0,666 ms
Сводка

Имя статьи
PostgreSQL. Конфигурирование
Описание
Сервер баз данных PostgreSQL имеет очень много параметров с помощью которых его можно настроить под любые нужды. В этой статье мы не будет рассматривать все эти параметры. Здесь мы посмотрим на различные способы настройки этого сервера.
This article contains information about postgresql.conf file in PostgreSQL. If you want to change Postgresql configuration parameters, you should read the below article.
Postgresql change configuration parameters.
What is postgresql.conf?
The postgresql.conf configuration file basically affects the behavior of the instance. For example, allowed number of connections, database log management, vaccum, determining wal parameters, etc. Of course, all this has a default value when the database is installed, but we can change these values to better suit the workload and working environment. The most basic way to set these parameters is to edit the postgresql.conf file.
postgresql.conf Location
postgresql.conf file is normally stored in the $PGDATA directory. By default, the postgresql.conf file is loaded in the init phase. If we want to find the full path of the postgresql.conf file using the command, we use the following command.
|
select * from pg_settings where name=‘config_file’; |
Sample postgresql.conf file
An example postgresql.conf file is as follows, as you can guess, a parameter is specified in each line, the equal sign between name and value is optional. Spaces are trivial, # sets the rest of the line as a comment.
NOTE: If the posgresql.conf file contains multiple entries for the same parameter, all but the last one is ignored, so the last value written in the file is valid.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden.
Reload postgresql.conf
When Postgresql main process receives the SIGHUP signal, the Postgresql configuration file is read again. This signal can be sent to postgresql in two ways. The postgresql.conf file can be read again with the “pg_ctl reload” command on the operating system or with the “SELECT pg_reload_conf ()” command from the psql command line tool.
The Main process propagates this signal to all running server processes, so existing sessions also adopt the new values (this happens after completing any client commands currently executing).
Alternatively, you can send the signal directly to a single server transaction. Invalid parameter settings in the configuration file are ignored (but logged) during the SIGHUP process.
|
—bash—4.2$ /usr/pgsql—12/bin/pg_ctl reload server signaled —bash—4.2$ psql psql (12.4) Type «help» for help. postgres=# select pg_reload_conf(); pg_reload_conf ———————— t (1 row) |
postgresql.auto.conf vs postgresql.conf
Some parameters can only be set at server startup; For these parameters, “# (change requires restart)” is written in the comment section of the postgresql.conf file.
In addition to Postgresql.conf, it includes a postgresql.auto.conf file, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file contains the settings provided with the ALTER SYSTEM command. Settings in postgresql.auto.conf override the contents of postgresql.conf. The postgresql.auto.conf file is located in the $PGDATA directory.
NOTE: Pg_settings system view provides access to the server runtime parameters. It is essentially an alternative interface to SHOW and SET commands.
|
select * from setting where name = ‘configuration_parameter’; UPDATE pg_settings SET setting = reset_val WHERE name = ‘configuration_parameter’; |
PostgreSQL provides several features to subdivide complex postgresql.conf files. These features are particularly useful when managing multiple servers with related but not identical configurations.
|
include ‘shared.conf’ include ‘memory.conf’ include ‘server.conf’ |
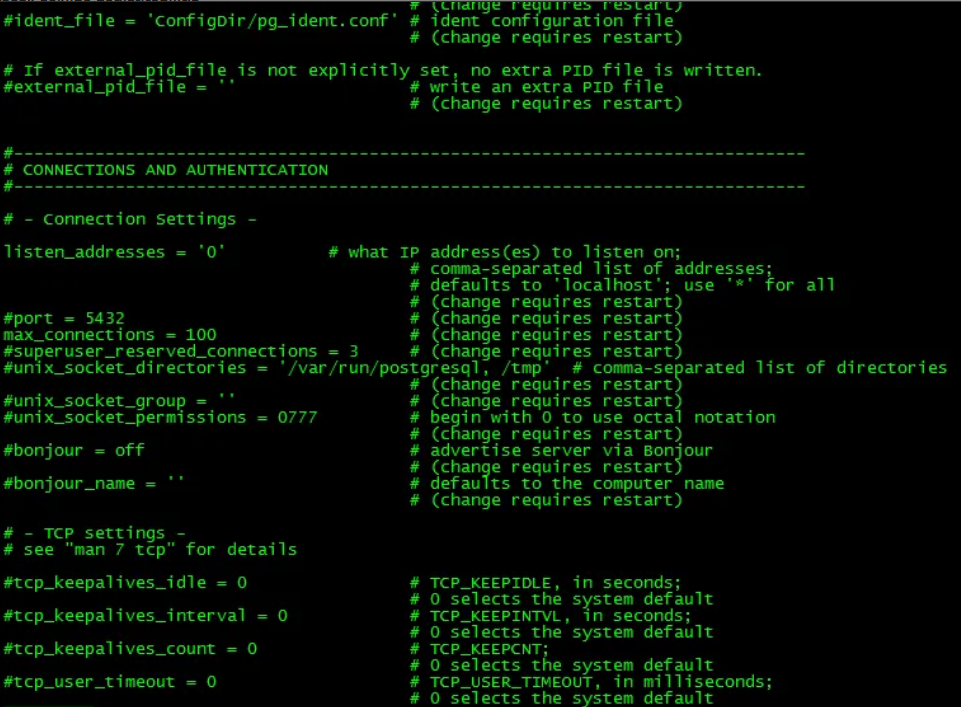
postgresql.conf parameters
Since there are too many parameters in the Postgresql.conf file, this section of the article is divided into specific titles for file classification purposes; There are titles such as File Locations, Resource Consumption, Connections and Authentication etc. After this part of the article, I will briefly explain the important parameters in postgresql and make recommendations about the setting of these parameters in my opinion. Of course these settings could be different according to your environment and workload.
Connections
listen_addresses (string)
Specifies the TCP/IP Address (s) that the server will listen for connections from client applications.
If we are going to specify more than one address, we can give the hostname and ip numbers by separating them with a comma (,).
* Corresponds to all IP interfaces available.
0.0.0 allows listening on all IPv4 addresses.
:: allows listening on all IPv6 addresses.
If the list is empty, the server will not listen to any IP interface at all. In this case, only Unix domain sockets can be used to connect to it. The default value is localhost, which allows only local TCP / IP “loopback” connections to be made.
port (integer)
Postgresql serves from port 5432 by default. All IP addresses listened to by the server serve over the same port. When more than one postgresql instance is used on the same server, a different port must be used for each cluster/instance/postgresql.
max_connections (integer)
It is used to specify the maximum number of connections that can be opened simultaneously in the database. By default its value is 100. In standby servers, this parameter should be set the same or higher than the parameter value in the master server.
Before increasing your connection count, you should consider whether you really need an increased connection limit. After all, our machine has a limited amount of RAM. If you allow more connections, you can allocate less RAM to each connection. Otherwise, you are in danger of using swaps.
The private memory available for each process is limited to work_mem while query is running. So if you use a high value for max_connections, you will need to set this parameter to low. work_mem has a direct impact on query performance. Usually, a well-written app doesn’t need a lot of connection. If you have an application that needs a lot of connections, you should consider using a tool like pg_bouncer that can handle connections effectively for you.
superuser_reserved_connections (integer)
It determines how many connections out of the number of connections that are set by the max_connections parameter will be reserved for users in the super user role. It is 3 by default. Normal users can open a maximum of 97 connections on the system when the max_connections parameter is set to 100 and the superuser_reserved_connections parameter to 3.
The point to note here is that the postgres user who comes as super user by default should not be used in the application. In other words, if we use the postgres user in our application, this parameter has no meaning.
tcp_keepalives_idle (integer)
It sets a time limit for connections without any network activity between the operating system and the client. If this value is specified without units, it is taken in seconds. A value of 0 (default) selects the operating system default.
tcp_keepalives_interval (integer)
Specifies the period of time that the TCP keepalive message not accepted by the client will be retransmitted. If this value is specified without units, it is taken in seconds. A value of 0 (default) selects the operating system default.
tcp_keepalives_count (integer)
Specifies the number of TCP keepalive messages that can be lost before the server is considered disconnected from the client. A value of 0 (default) selects the operating system default.
tcp_user_timeout (integer)
Specifies the amount of time that transmitted data can remain unconfirmed before the TCP connection is forcibly closed. If this value is specified without units, it is taken in milliseconds. A value of 0 (the default) selects the default operating system.
Authentications
authentication_timeout (integer)
It is the parameter that enables the connection request to be rejected if the connection process of the user to the database is not completed in the expected time. It is set in seconds and its default value is 1 minute.
password_encryption (enum)
When a password is specified in CREATE ROLE or ALTER ROLE, this parameter determines the algorithm to be used to encrypt the password. By default it is md5.
db_user_namespace (boolean)
It is used to create independent users in databases. Default value is off. If its value is on, a custom user can be created for a database using the username @ dbname syntax.
ssl (boolean)
It is the parameter that activates the SSL connection method. By default, its value is off.
Using an SSL certificate encrypts our connection. In this way, our connection information in our package is safe.
ssl_ca_file
Specifies the name of the file containing the SSL server certificate authority (CA). The default is blank, ie the CA file is not uploaded and client certificate verification is not performed.
Resource Consumption
shared_buffers
It is the parameter that allows setting the area to be used as shared buffer in the memory. It is 128 MB by default. If you have a database dedicated server with 1 GB or more of RAM, the reasonable initial value for shared_buffers is 25% of the memory on your system. There are workloads for shared_buffers where even greater settings are effective, but since PostgreSQL is also based on the operating system cache structure, allocating more than 40% of the RAM to shared_buffers will not work better than a smaller shared_buffers. Larger settings for shared_buffers usually require a corresponding increase in max_wal_size.
Recommendation: I wanted to rewrite it because it is important; PostgreSQL uses the kernel buffer area in the operating system as well as its own buffer area, that is, the data thrown from the shared_buffers falls into the operating system cache and receives it from the postgresql operating system cache if needed. This means that data is stored twice in memory, first in the PostgreSQL buffer and then in the kernel buffer (Unlike other databases, PostgreSQL does not provide IO directly), this is called double buffering. After highlighting this part, coming to the suggestion, the default value of Shared_buffer is set to a very low value and you cannot get much benefit from it. It is low because some machines and operating systems do not support higher values. However, on most modern machines you need to increase this value for optimum performance. The recommended value is 25% of your total machine RAM. You should try lower and higher values because in some cases we will get good performance with a setting above 25%. The configuration really depends on your machine and operating data set.
huge_pages (enum)
It is the parameter that enables to set huge pages usage options in the shared memory area. It can take the value “Try, on or off”. By default it is Try. It tries to use the Huge pages, if not, there will be no problem in the system operation. If it cannot be used when set as on, the database cannot be started. When set to Off, it is not used at all.
Recommendation: The use of huge pages increases performance by consuming less CPU time for small table pages and memory management, so I recommend using huge pages by adjusting the necessary settings in the operating system.
temp_buffers (integer)
It is the parameter that determines the value of the maximum temporary buffer space to be used for each session. These are the session specific buffer spaces used only to access temporary tables. Default value is 8MB.
work_mem (integer)
Sets the maximum amount of memory to be used by a query operation (such as a sort or hash table) before writing to temporary disk files. The default is four megabytes (4MB). Sorting operations are used for ORDER BY, DISTINCT and merge join. Used for processing hash tables, hash joins, hash-based aggregation, hash-based processing, and IN subqueries. Several active sessions may be doing this type of action at the same time. Therefore, the total memory used may be more than work_mem. This fact should be kept in mind when choosing the value.
Recommendation: Memory operations are much faster than on disk, but setting too high a value may cause a memory bottleneck for your production media. Setting this parameter globally may cause very high memory usage. Therefore, it is highly recommended that you change this at the session level.
I want to talk about another approach; It is suggested to use the following formula to determine the work_mem value. If a connection pooling tool is used and the max connection number can be determined, it may make sense to use this formula.
|
Total RAM * 0.25 / max_connections |
Note: We can also directly assign work_mem to a role;
|
alter user test set work_mem=‘4GB’; |
maintenance_work_mem (integer)
Specifies the maximum amount of memory to be used by maintenance operations such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. It is 64 megabytes (64MB) by default. Since only one of these processes can be executed by a session at the same time, and most of them do not run simultaneously in normal setup, it is safe to set this value to a value much larger than work_mem.
temp_file_limit
It limits the total size of all temporary files used by each process. -1 (default) means no limit.
Recommendation: I think it is useful to determine this value by monitoring database processes. For example, I witnessed that the disk was full due to an accidental 100 billion sort operation from the application.
bgwriter_delay (integer)
It specifies how long the background writer process should wait between successive runs.
Recommendation: This parameter can be dropped at any time, but my general approach is to change the parameters related to bgwriter if you are facing a problem by monitoring the chechkpoint increments or pg_stat_bgwriter.
bgwriter_lru_maxpages (integer)
Specifies the maximum number of buffers to be written by the process in each run of bgwiter.
bgwriter_lru_multiplier (floating point)
The number of dirty buffers written in each round depends on the number of new buffers needed by the server processes in the last rounds. The average last need is multiplied by the bgwriter_lru_multiplier to arrive at an estimate of the number of buffers that will be needed in the next round. So if we set this value to 3.0, the number of dirty buffers it can write each time will be bgwriter_lru_maxpages * 3. By default, this value is 2.0.
effective_io_concurrency (integer)
Sets the number of concurrent disk I / O operations that PostgreSQL expects to be executed simultaneously. Increasing this value will increase the number of I / O processes that any PostgreSQL session attempts to start in parallel. The default value is 1, we can use 0 to disable it, at the same time, this parameter can take a value between 1-1000.
Recommendation: For magnetic drives, this setting is the number of drives in the RAID 0 or RAID 1 miror structure used for the database. For example, if you have 10 disks in RAID 1 structure, this parameter should be 5, or if you have 10 disks in RAID 0, this value should be 10. A higher value than necessary to keep the disks busy will only cause extra CPU overhead. SSDs and other memory-based storage can often handle many simultaneous requests, so the best value could be hundreds.
max_worker_processes (integer)
Sets the maximum number of background processes that the system can support. Default is 8. When running a standby server, you must set this parameter to the same or higher value than the primary server. Otherwise queries will not be allowed on the standby server. As a suggestion, I cannot say that the value should be this, but we can round the number that corresponds to 60% -70% of your total CPU and use this value.
max_parallel_workers_per_gather (integer)
The maximum number of workers that the Gather or GatherMerge node can use. It should be set equal to max_worker_processes as suggestion.
max_parallel_maintenance_workers (integer)
The maximum number of processes to be used in maintenance operations such as CREATE INDEX, vacuum.
max_parallel_workers (integer)
Sets the maximum number of workers that the system can support for parallel operations. The default value is 8. When increasing or decreasing this value, also consider adjusting max_parallel_maintenance_workers and max_parallel_workers_per_gather. Also note that a setting higher than max_worker_processes for this value will have no effect. Because parallel workers receive from the worker pool created by this setting.
LOGGING
log_statement (enum)
Checks which SQL queries are logged. Valid values are none (off), ddl, mod, and all (all queries). By default it is none. As a suggestion, I recommend leaving it as ddl.
log_min_duration_statement (integer)
If the statement is run for at least the specified time, it will cause the duration of each completed statement to be logged. For example, if you set it to 250ms, all SQL queries running 250ms or longer will be logged. Enabling this parameter can be helpful in tracking non-optimized queries in your applications. As a suggestion; By setting this parameter to a few minutes, you can fix problematic queries and then decrease this value. Overrides log_min_duration_sample.
log_checkpoints (boolean)
It enables checkpoint and restartpoint logs to be recorded in the server log. Some statistics such as the number of buffers written and the time taken to write them are included in the log messages. Default is off.
log_lock_waits (boolean)
This parameter checks whether the log message is generated when a session waits longer than the deadlock_timeout time to receive lock. This is useful in determining whether log wait times cause poor performance. Default is off. If I have to make suggestions, I think it is useful to open this parameter.
log_destination (string)
PostgreSQL supports several methods for logging server messages, including “stderr, csvlog, and syslog”. The default value is stderr.
logging_collector (boolean)
This parameter enables the log collector, a background process that captures log messages sent to stderr and redirects them to log files.
Note: log collector is designed to never lose messages. This means that in case of overload, server operations can be blocked when attempting to send additional log messages when the collector is left behind. Conversely, syslog prefers to leave messages if it cannot write, which means that in such cases it may not be able to log some messages, but will not block the rest of the system.
log_directory (string)
When the logging_collector is enabled, this parameter determines the directory where the log files will be created. By default it is the log directory under $PGDATA.
log_filename (string)
When the logging_collector is enabled, this parameter sets the filenames of the generated log files. The default is postgresql-%Y-%m-%d_%H%M%S.log. We use the arguments of the date command in linux for naming here.
log_file_mode (integer)
On Unix systems, this parameter sets the permissions of log files when logging_collector is enabled. The parameter value is expected to be a numeric mode specified in the format accepted by chmod and umask system calls. The default permissions are 0600, which means only the host can read or write log files.
log_rotation_age (integer)
When logging_collector is enabled, this parameter determines the maximum lifetime of a single log file, and then a new log file is created. If this value is specified without units, it is taken as minutes. The default is 24 hours. You can set it to zero to disable the time-based generation of new log files.
log_rotation_size (integer)
When logging_collector is enabled, this parameter determines the maximum size of a single log file. After this amount of data is sent to a log file, a new log file will be created. If this value is specified without units, it is taken in kilobytes. The default value is 10 megabytes. You can set it to zero to disable the creation of new log files based on size.
log_truncate_on_rotation (boolean)
When logging_collector is enabled, this parameter causes PostgreSQL to truncate (overwrite) instead of appending it to any existing log file with the same name.
event_source (string)
When event_source log logging is enabled, this parameter specifies the program name used to identify PostgreSQL messages in the log. The default is PostgreSQL.
log_min_messages (enum)
Controls which message levels are written to the server log. Valid values are DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL and PANIC. Each level contains all the levels that follow it. The later the level, the fewer messages will be sent to the log. Default is WARNING.
| Severity | Usage | syslog | eventlog |
| DEBUG1 .. DEBUG5 | It provides successively more detailed information for use by developers. | DEBUG | INFORMATION |
| INFO | Provides information indirectly requested by the user, eg output from VACUUM VERBOSE. | INFO | INFORMATION |
| NOTICE | Provides information that can help users, such as a notification that long identifiers have been truncated. | NOTICE | INFORMATION |
| WARNING | Provides warnings of possible problems, for example COMMIT outside of a transaction block. | NOTICE | WARNING |
| ERROR | Reports an error that caused the current command to be aborted. | WARNING | ERROR |
| LOG | It reports information that DBAs are interested in, for example checkpoint activity. | INFO | INFORMATION |
| FATAL | Reports an error that caused the current session to be canceled. | ERR | ERROR |
| PANIC | Reports an error that caused all database sessions to be canceled. | CRIT | ERROR |
log_min_error_statement (enum)
Controls that the SQL queries that cause the error condition will be recorded in the server log. The current SQL command is included in the log entry for any message with the specified severity rating or higher. Valid values are DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL and PANIC. The default is ERROR, which means any statements that cause errors, log messages, fatal errors or panic will be logged.
log_min_duration_sample (integer)
Allows sampling of the duration of completed statements that run for at least the specified time period. This generates the same type of log entries as log_min_duration_statement.
log_connections (boolean)
In addition to successfully completing client authentication, it causes every connection attempt made with the server to be logged. Default is off.
log_disconnections (boolean)
Causes session terminations to be logged. The log output provides similar information as log_connections and also the session duration. Default is off.
log_line_prefix (string)
This is a printf-style string that appears at the beginning of each log line. It is mostly used for the needs of log management tools. As a suggestion, if I need to use it, I usually set this parameter as follows.
| Escape | Effect | Session only |
| %a | Application name | yes |
| %u | User name | yes |
| %d | Database name | yes |
| %r | Remote host name or IP address, and remote port | yes |
| %h | Remote host name or IP address | yes |
| %b | Backend type | no |
| %p | Process ID | no |
| %t | Time stamp without milliseconds | no |
| %m | Time stamp with milliseconds | no |
| %n | Time stamp with milliseconds (as a Unix epoch) | no |
| %i | Command tag: type of session’s current command | yes |
| %e | SQLSTATE error code | no |
| %c | Session ID: see below | no |
| %l | Number of the log line for each session or process, starting at 1 | no |
| %s | Process start time stamp | no |
| %v | Virtual transaction ID (backendID/localXID) | no |
| %x | Transaction ID (0 if none is assigned) | no |
| %q | Produces no output, but tells non-session processes to stop at this point in the string; ignored by session processes | no |
| %% | Literal % | no |
log_replication_commands (boolean)
Her replication komutunun sunucuya kaydedilmesine neden olur. Varsayılan değer kapalı.
log_temp_files (integer)
Temp dosya adlarının ve boyutlarının kaydedilmesini kontrol eder. Sıfır değeri, tüm temp dosya bilgilerini loga kaydederken, pozitif değerler yalnızca boyutu belirtilen veri miktarından büyük veya bu miktara eşit olan dosyaları loga kaydeder. Varsayılan ayar, böyle bir log kaydını devre dışı bırakan -1’dir.
log_timezone (string)
Sunucu loguna yazılan timezone için kullanılan saat dilimini ayarlar. TimeZone’dan farklı olarak, bu değer cluster çapındadır. varsayılan GMT’dir, ancak bu genellikle initdb aşamaında bu ayar değiştirilir; initdb, sistem ortamına karşılık gelen bir ayar kuracaktır.
Run-time Statistics
These parameters control the server-wide statistics collection features. When statistics collection is enabled, the generated data can be accessed via the pg_stat and pg_statio family of system views.
stats_temp_directory (string)
Sets the directory where temporary statistics data will be stored. The default is pg_stat_tmp. Pointing this into a RAM-based file system reduces physical I / O requirements and can increase performance. As a suggestion, since data is frequently written to this file and it will not cause much trouble in case of data loss, I think you should definitely create a RAM-based file with the tmpfs file system and change this parameter.
track_activities (boolean)
It provides gathering information about each session’s command currently running and when it starts running. This parameter is enabled by default.
track_activity_query_size (integer)
Specifies the amount of memory allocated for the Pg_stat_activity.query (to store the text of the currently executed command for each active session). The default value is 1024 bytes.
track_counts (boolean)
Provides collection of statistics about database activity. This parameter is enabled by default because the autovacuum daemon needs the information collected.
track_io_timing (boolean)
Can be enabled to track database I / O timing. This parameter is off by default because it will repeatedly query the operating system for the current time, which can cause some significant overhead. You can use the pg_test_timing tool to measure the timing overhead on your system. We can also display the I / O time in pg_stat_database view, in EXPLAIN output when BUFFERS option is used, and by pg_stat_statements.
track_functions (enum)
Provides tracking of function call numbers and runtime.
Client Connection Defaults
client_min_messages (enum)
Controls which message levels will be sent to the client. Valid values are DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, LOG, NOTICE, WARNING, and ERROR. The default is NOTICE.
search_path (string)
This variable specifies the order in which schemas are searched if the schema is not specified when accessing an object (table, data type, function, etc.). When there are objects with the same names in different schemas, the first object in the search path is used. We can access an object that is not found in any of the schema in the search path, only by using the schema it contains. The default value of this parameter is “$ user”, public.
row_security (boolean)
This variable checks if an error occurs instead of applying row level security policy. When set to ON, policies are normally enforced. When set to OFF, queries that apply at least one security policy will throw an error. Default is ON.
default_table_access_method (string)
This parameter specifies the default table access method to use when creating tables or materialized views, unless the CREATE command explicitly specifies an access method, or when SELECT… INTO is used. The default is heap.
default_tablespace (string)
This variable specifies the default tablespace where objects (tables and indexes) will be created when the CREATE command does not explicitly specify a tablespace.
temp_tablespaces (string)
This variable specifies the default temp tablespace where objects (tables and indexes) will be created when the CREATE command does not explicitly specify a tablespace.
default_transaction_isolation (enum)
Each SQL transaction has an isolation level, which can be “read uncommitted”, “read committed”, “repeatable read”, or “serializable”. This parameter checks the default isolation level of each new transaction. The default is “read committed”.
default_transaction_read_only (boolean)
Read-only transactions cannot change non-temp tables. This parameter checks the default read-only state of each new transaction. Default is off.
session_replication_role (enum)
Controls the triggering of replication-related triggers and rules for the current session. Possible values are origin (default), replica and local.
statement_timeout (integer)
Cancels any query taking longer than the specified time. A value of zero (default) disables the timeout.
lock_timeout (integer)
Cancels any query that waits longer than the specified time when trying to get a lock on a table, index, row, or other database object. A value of zero (default) disables the timeout.
idle_in_transaction_session_timeout (integer)
Terminates the session for an open transaction that has been idle longer than the specified time. A value of zero (default) disables the timeout.
DateStyle (string)
Determines the display format for date and time values. For historical reasons.
TimeZone (string)
Sets the time zone to view and interpret the time zone. The built-in default is GMT, but in the initdb phase, it will set a setting corresponding to the system environment.
lc_messages (string)
Sets the language in which messages are displayed. Acceptable values depend on the system. If this variable is set to an empty string (the default value), the value is inherited from the server’s env environment, depending on the system.
Other Parameters
deadlock_timeout (integer)
This parameter is the time to wait on a lock before checking whether it has a lock state. Lock control is relatively expensive, so the server doesn’t execute it every time it waits for a lock. Increasing this value reduces the time wasted on unnecessary lock checks, but slows down the detection of true lock errors. The default value is one second (1s).
wal_segment_size (integer)
Informs the size of WAL segments. The default value is 16MB.
wal_block_size (integer)
Informs the size of the WAL disk block. It is determined by the value of XLOG_BLCKSZ when creating the server. The default value is 8192 bytes.
data_checksums (boolean)
Informs whether the data checksum is enabled for the Cluster. As a suggestion, I must say that the checksum must be active in your cluster.
checkpoint_timeout
This is a timeout value that can be set in seconds (default), minutes, or one hour. it is 5 minutes by default. As a suggestion, setting this value should be based on the intended use of your database. While it can be increased up to 1 day in OLAP type systems, values such as 5-10 minutes can be selected in OLTP systems.
checkpoint_completion_target (integer)
Usually, it is a parameter that makes PostgreSQL try to write data slower. Usually you have checkpoint_timeout set to 5 minutes. (if you haven’t changed it) and default checkpoint_completion_target is 0.5. This means PostgreSQL will try to make the checkpoint take 2.5 minutes to reduce the I / O load.
For example, we have 100GB of data to be written to files. And my disk is capable of writing 1 GB per second. When doing a normal checkpoint, it causes our writing capacity to be used up to 100% for 100 seconds to write data. However – when checkpoint_completion_target is set to 0.5 – PostgreSQL tries to write data in 2.5 minutes, so it doesn’t use all of our write capacity. (Uses ((100*1024)/(2,5*60)=682 MB/s). As a suggestion, I suggest using 0.7 for this parameter.
max_wal_size (integer)
The maximum size the WAL is allowed to grow during automatic checkpoints. Default is 1 GB. As a suggestion, I recommend that you increase this value if there is space on this disk.
min_wal_size (integer)
As long as WAL disk usage falls below this setting, old WAL files are always recycled at the checkpoint point, rather than being removed for future use. It can be used to ensure that enough WAL space is allocated to handle spikes in WAL usage, for example when running large batches. It is 80 MB by default.
seq_page_cost (floating point)
Sets the planner’s estimate of the cost of the sequential reading. Default value is 1.0
random_page_cost (floating point)
Sets the planner’s estimate of the cost of a disk page that is not fetched as Sequential. Default is 4.0.
Decreasing this value according to the seq_page_cost value will cause the system to prefer index scans.
Increasing it will make index scans appear more expensive.
Recommendation: Random access to mechanical disk storage is normally much more expensive than four times sequential access. However, since most random accesses to the disk are assumed to be caches, a lower default is used (4.0).
The default value is 40 times slower than random access. It can be thought of as expecting 90% of random readings to be cached.
If you believe that the 90% cache ratio for your workload is a false assumption, you can increase random_page_cost to better reflect the actual cost of random storage readings. Accordingly, if there is a possibility that your data is fully cached, for example, if the database is smaller than the total server memory, it may be appropriate to lower random_page_cost. Or, if you have a fast I/O structure in random access, such as SSD, this value can be reduced somewhat.
restart_after_crash (boolean)
When set to on, the default value, PostgreSQL will restart automatically after a backend crash. Leaving this value open is normally the best way to maximize the availability of the database. However, in some cases, such as when PostgreSQL is invoked by clusterware, disabling automatic startup can be useful so that the cluster software can take control and take actions it deems appropriate.
data_sync_retry (boolean)
When set to off, the default value, PostgreSQL will generate a PANIC-level error if it is unable to dump dirty data into the file system. This causes the database server to crash. If set to On, PostgreSQL will report an error instead, but will continue to run so the data cleanup can be retried at the next checkpoint.
block_size (integer)
Informs the size of a disk block. It is determined by the value of BLCKSZ while creating the server. The default value is 8192 bytes.
data_directory_mode (integer)
In Unix systems, this parameter informs the permissions of the data directory originally defined with (data_directory).
segment_size (integer)
Indicates the number of blocks (pages) that can be stored in a file segment. It is determined by the value of RELSEG_SIZE when creating the server. The maximum size of the segment file in bytes equals segment_size multiplied by block_size; it is 1GB by default.
server_version (string)
Reports the version number of the server. It is determined by the value PG_VERSION when creating the server.
19.1.1. Parameter Names and Values
All parameter names are case-insensitive. Every parameter takes a value of one of five types: boolean, string, integer, floating point, or enumerated (enum). The type determines the syntax for setting the parameter:
-
Boolean: Values can be written as
on,off,true,false,yes,no,1,0(all case-insensitive) or any unambiguous prefix of one of these. -
String: In general, enclose the value in single quotes, doubling any single quotes within the value. Quotes can usually be omitted if the value is a simple number or identifier, however. (Values that match a SQL keyword require quoting in some contexts.)
-
Numeric (integer and floating point): Numeric parameters can be specified in the customary integer and floating-point formats; fractional values are rounded to the nearest integer if the parameter is of integer type. Integer parameters additionally accept hexadecimal input (beginning with
0x) and octal input (beginning with0), but these formats cannot have a fraction. Do not use thousands separators. Quotes are not required, except for hexadecimal input. -
Numeric with Unit: Some numeric parameters have an implicit unit, because they describe quantities of memory or time. The unit might be bytes, kilobytes, blocks (typically eight kilobytes), milliseconds, seconds, or minutes. An unadorned numeric value for one of these settings will use the setting’s default unit, which can be learned from
pg_settings.unit. For convenience, settings can be given with a unit specified explicitly, for example'120 ms'for a time value, and they will be converted to whatever the parameter’s actual unit is. Note that the value must be written as a string (with quotes) to use this feature. The unit name is case-sensitive, and there can be whitespace between the numeric value and the unit.-
Valid memory units are
B(bytes),kB(kilobytes),MB(megabytes),GB(gigabytes), andTB(terabytes). The multiplier for memory units is 1024, not 1000. -
Valid time units are
us(microseconds),ms(milliseconds),s(seconds),min(minutes),h(hours), andd(days).
If a fractional value is specified with a unit, it will be rounded to a multiple of the next smaller unit if there is one. For example,
30.1 GBwill be converted to30822 MBnot32319628902 B. If the parameter is of integer type, a final rounding to integer occurs after any unit conversion. -
-
Enumerated: Enumerated-type parameters are written in the same way as string parameters, but are restricted to have one of a limited set of values. The values allowable for such a parameter can be found from
pg_settings.enumvals. Enum parameter values are case-insensitive.
19.1.2. Parameter Interaction via the Configuration File
The most fundamental way to set these parameters is to edit the file postgresql.conf, which is normally kept in the data directory. A default copy is installed when the database cluster directory is initialized. An example of what this file might look like is:
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
One parameter is specified per line. The equal sign between name and value is optional. Whitespace is insignificant (except within a quoted parameter value) and blank lines are ignored. Hash marks (#) designate the remainder of the line as a comment. Parameter values that are not simple identifiers or numbers must be single-quoted. To embed a single quote in a parameter value, write either two quotes (preferred) or backslash-quote. If the file contains multiple entries for the same parameter, all but the last one are ignored.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden. The following sections describe ways in which the administrator or user can override these defaults.
The configuration file is reread whenever the main server process receives a SIGHUP signal; this signal is most easily sent by running pg_ctl reload from the command line or by calling the SQL function pg_reload_conf(). The main server process also propagates this signal to all currently running server processes, so that existing sessions also adopt the new values (this will happen after they complete any currently-executing client command). Alternatively, you can send the signal to a single server process directly. Some parameters can only be set at server start; any changes to their entries in the configuration file will be ignored until the server is restarted. Invalid parameter settings in the configuration file are likewise ignored (but logged) during SIGHUP processing.
In addition to postgresql.conf, a PostgreSQL data directory contains a file postgresql.auto.conf, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file holds settings provided through the ALTER SYSTEM command. This file is read whenever postgresql.conf is, and its settings take effect in the same way. Settings in postgresql.auto.conf override those in postgresql.conf.
External tools may also modify postgresql.auto.conf. It is not recommended to do this while the server is running, since a concurrent ALTER SYSTEM command could overwrite such changes. Such tools might simply append new settings to the end, or they might choose to remove duplicate settings and/or comments (as ALTER SYSTEM will).
The system view pg_file_settings can be helpful for pre-testing changes to the configuration files, or for diagnosing problems if a SIGHUP signal did not have the desired effects.
19.1.3. Parameter Interaction via SQL
PostgreSQL provides three SQL commands to establish configuration defaults. The already-mentioned ALTER SYSTEM command provides a SQL-accessible means of changing global defaults; it is functionally equivalent to editing postgresql.conf. In addition, there are two commands that allow setting of defaults on a per-database or per-role basis:
-
The ALTER DATABASE command allows global settings to be overridden on a per-database basis.
-
The ALTER ROLE command allows both global and per-database settings to be overridden with user-specific values.
Values set with ALTER DATABASE and ALTER ROLE are applied only when starting a fresh database session. They override values obtained from the configuration files or server command line, and constitute defaults for the rest of the session. Note that some settings cannot be changed after server start, and so cannot be set with these commands (or the ones listed below).
Once a client is connected to the database, PostgreSQL provides two additional SQL commands (and equivalent functions) to interact with session-local configuration settings:
-
The SHOW command allows inspection of the current value of any parameter. The corresponding SQL function is
current_setting(setting_name text)(see Section 9.27.1). -
The SET command allows modification of the current value of those parameters that can be set locally to a session; it has no effect on other sessions. The corresponding SQL function is
set_config(setting_name, new_value, is_local)(see Section 9.27.1).
In addition, the system view pg_settings can be used to view and change session-local values:
-
Querying this view is similar to using
SHOW ALLbut provides more detail. It is also more flexible, since it’s possible to specify filter conditions or join against other relations. -
Using UPDATE on this view, specifically updating the
settingcolumn, is the equivalent of issuingSETcommands. For example, the equivalent ofSET configuration_parameter TO DEFAULT;
is:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
19.1.4. Parameter Interaction via the Shell
In addition to setting global defaults or attaching overrides at the database or role level, you can pass settings to PostgreSQL via shell facilities. Both the server and libpq client library accept parameter values via the shell.
-
During server startup, parameter settings can be passed to the
postgrescommand via the-ccommand-line parameter. For example,postgres -c log_connections=yes -c log_destination='syslog'
Settings provided in this way override those set via
postgresql.conforALTER SYSTEM, so they cannot be changed globally without restarting the server. -
When starting a client session via libpq, parameter settings can be specified using the
PGOPTIONSenvironment variable. Settings established in this way constitute defaults for the life of the session, but do not affect other sessions. For historical reasons, the format ofPGOPTIONSis similar to that used when launching thepostgrescommand; specifically, the-cflag must be specified. For example,env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Other clients and libraries might provide their own mechanisms, via the shell or otherwise, that allow the user to alter session settings without direct use of SQL commands.
19.1.5. Managing Configuration File Contents
PostgreSQL provides several features for breaking down complex postgresql.conf files into sub-files. These features are especially useful when managing multiple servers with related, but not identical, configurations.
In addition to individual parameter settings, the postgresql.conf file can contain include directives, which specify another file to read and process as if it were inserted into the configuration file at this point. This feature allows a configuration file to be divided into physically separate parts. Include directives simply look like:
include 'filename'
If the file name is not an absolute path, it is taken as relative to the directory containing the referencing configuration file. Inclusions can be nested.
There is also an include_if_exists directive, which acts the same as the include directive, except when the referenced file does not exist or cannot be read. A regular include will consider this an error condition, but include_if_exists merely logs a message and continues processing the referencing configuration file.
The postgresql.conf file can also contain include_dir directives, which specify an entire directory of configuration files to include. These look like
include_dir 'directory'
Non-absolute directory names are taken as relative to the directory containing the referencing configuration file. Within the specified directory, only non-directory files whose names end with the suffix .conf will be included. File names that start with the . character are also ignored, to prevent mistakes since such files are hidden on some platforms. Multiple files within an include directory are processed in file name order (according to C locale rules, i.e., numbers before letters, and uppercase letters before lowercase ones).
Include files or directories can be used to logically separate portions of the database configuration, rather than having a single large postgresql.conf file. Consider a company that has two database servers, each with a different amount of memory. There are likely elements of the configuration both will share, for things such as logging. But memory-related parameters on the server will vary between the two. And there might be server specific customizations, too. One way to manage this situation is to break the custom configuration changes for your site into three files. You could add this to the end of your postgresql.conf file to include them:
include 'shared.conf' include 'memory.conf' include 'server.conf'
All systems would have the same shared.conf. Each server with a particular amount of memory could share the same memory.conf; you might have one for all servers with 8GB of RAM, another for those having 16GB. And finally server.conf could have truly server-specific configuration information in it.
Another possibility is to create a configuration file directory and put this information into files there. For example, a conf.d directory could be referenced at the end of postgresql.conf:
include_dir 'conf.d'
Then you could name the files in the conf.d directory like this:
00shared.conf 01memory.conf 02server.conf
This naming convention establishes a clear order in which these files will be loaded. This is important because only the last setting encountered for a particular parameter while the server is reading configuration files will be used. In this example, something set in conf.d/02server.conf would override a value set in conf.d/01memory.conf.
You might instead use this approach to naming the files descriptively:
00shared.conf 01memory-8GB.conf 02server-foo.conf
This sort of arrangement gives a unique name for each configuration file variation. This can help eliminate ambiguity when several servers have their configurations all stored in one place, such as in a version control repository. (Storing database configuration files under version control is another good practice to consider.)
19.1.1. Parameter Names and Values
All parameter names are case-insensitive. Every parameter takes a value of one of five types: boolean, string, integer, floating point, or enumerated (enum). The type determines the syntax for setting the parameter:
-
Boolean: Values can be written as
on,off,true,false,yes,no,1,0(all case-insensitive) or any unambiguous prefix of one of these. -
String: In general, enclose the value in single quotes, doubling any single quotes within the value. Quotes can usually be omitted if the value is a simple number or identifier, however. (Values that match a SQL keyword require quoting in some contexts.)
-
Numeric (integer and floating point): Numeric parameters can be specified in the customary integer and floating-point formats; fractional values are rounded to the nearest integer if the parameter is of integer type. Integer parameters additionally accept hexadecimal input (beginning with
0x) and octal input (beginning with0), but these formats cannot have a fraction. Do not use thousands separators. Quotes are not required, except for hexadecimal input. -
Numeric with Unit: Some numeric parameters have an implicit unit, because they describe quantities of memory or time. The unit might be bytes, kilobytes, blocks (typically eight kilobytes), milliseconds, seconds, or minutes. An unadorned numeric value for one of these settings will use the setting’s default unit, which can be learned from
pg_settings.unit. For convenience, settings can be given with a unit specified explicitly, for example'120 ms'for a time value, and they will be converted to whatever the parameter’s actual unit is. Note that the value must be written as a string (with quotes) to use this feature. The unit name is case-sensitive, and there can be whitespace between the numeric value and the unit.-
Valid memory units are
B(bytes),kB(kilobytes),MB(megabytes),GB(gigabytes), andTB(terabytes). The multiplier for memory units is 1024, not 1000. -
Valid time units are
us(microseconds),ms(milliseconds),s(seconds),min(minutes),h(hours), andd(days).
If a fractional value is specified with a unit, it will be rounded to a multiple of the next smaller unit if there is one. For example,
30.1 GBwill be converted to30822 MBnot32319628902 B. If the parameter is of integer type, a final rounding to integer occurs after any unit conversion. -
-
Enumerated: Enumerated-type parameters are written in the same way as string parameters, but are restricted to have one of a limited set of values. The values allowable for such a parameter can be found from
pg_settings.enumvals. Enum parameter values are case-insensitive.
19.1.2. Parameter Interaction via the Configuration File
The most fundamental way to set these parameters is to edit the file postgresql.conf, which is normally kept in the data directory. A default copy is installed when the database cluster directory is initialized. An example of what this file might look like is:
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
One parameter is specified per line. The equal sign between name and value is optional. Whitespace is insignificant (except within a quoted parameter value) and blank lines are ignored. Hash marks (#) designate the remainder of the line as a comment. Parameter values that are not simple identifiers or numbers must be single-quoted. To embed a single quote in a parameter value, write either two quotes (preferred) or backslash-quote. If the file contains multiple entries for the same parameter, all but the last one are ignored.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden. The following sections describe ways in which the administrator or user can override these defaults.
The configuration file is reread whenever the main server process receives a SIGHUP signal; this signal is most easily sent by running pg_ctl reload from the command line or by calling the SQL function pg_reload_conf(). The main server process also propagates this signal to all currently running server processes, so that existing sessions also adopt the new values (this will happen after they complete any currently-executing client command). Alternatively, you can send the signal to a single server process directly. Some parameters can only be set at server start; any changes to their entries in the configuration file will be ignored until the server is restarted. Invalid parameter settings in the configuration file are likewise ignored (but logged) during SIGHUP processing.
In addition to postgresql.conf, a PostgreSQL data directory contains a file postgresql.auto.conf, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file holds settings provided through the ALTER SYSTEM command. This file is read whenever postgresql.conf is, and its settings take effect in the same way. Settings in postgresql.auto.conf override those in postgresql.conf.
External tools may also modify postgresql.auto.conf. It is not recommended to do this while the server is running, since a concurrent ALTER SYSTEM command could overwrite such changes. Such tools might simply append new settings to the end, or they might choose to remove duplicate settings and/or comments (as ALTER SYSTEM will).
The system view pg_file_settings can be helpful for pre-testing changes to the configuration files, or for diagnosing problems if a SIGHUP signal did not have the desired effects.
19.1.3. Parameter Interaction via SQL
PostgreSQL provides three SQL commands to establish configuration defaults. The already-mentioned ALTER SYSTEM command provides a SQL-accessible means of changing global defaults; it is functionally equivalent to editing postgresql.conf. In addition, there are two commands that allow setting of defaults on a per-database or per-role basis:
-
The ALTER DATABASE command allows global settings to be overridden on a per-database basis.
-
The ALTER ROLE command allows both global and per-database settings to be overridden with user-specific values.
Values set with ALTER DATABASE and ALTER ROLE are applied only when starting a fresh database session. They override values obtained from the configuration files or server command line, and constitute defaults for the rest of the session. Note that some settings cannot be changed after server start, and so cannot be set with these commands (or the ones listed below).
Once a client is connected to the database, PostgreSQL provides two additional SQL commands (and equivalent functions) to interact with session-local configuration settings:
-
The SHOW command allows inspection of the current value of any parameter. The corresponding SQL function is
current_setting(setting_name text)(see Section 9.27.1). -
The SET command allows modification of the current value of those parameters that can be set locally to a session; it has no effect on other sessions. The corresponding SQL function is
set_config(setting_name, new_value, is_local)(see Section 9.27.1).
In addition, the system view pg_settings can be used to view and change session-local values:
-
Querying this view is similar to using
SHOW ALLbut provides more detail. It is also more flexible, since it’s possible to specify filter conditions or join against other relations. -
Using UPDATE on this view, specifically updating the
settingcolumn, is the equivalent of issuingSETcommands. For example, the equivalent ofSET configuration_parameter TO DEFAULT;
is:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
19.1.4. Parameter Interaction via the Shell
In addition to setting global defaults or attaching overrides at the database or role level, you can pass settings to PostgreSQL via shell facilities. Both the server and libpq client library accept parameter values via the shell.
-
During server startup, parameter settings can be passed to the
postgrescommand via the-ccommand-line parameter. For example,postgres -c log_connections=yes -c log_destination='syslog'
Settings provided in this way override those set via
postgresql.conforALTER SYSTEM, so they cannot be changed globally without restarting the server. -
When starting a client session via libpq, parameter settings can be specified using the
PGOPTIONSenvironment variable. Settings established in this way constitute defaults for the life of the session, but do not affect other sessions. For historical reasons, the format ofPGOPTIONSis similar to that used when launching thepostgrescommand; specifically, the-cflag must be specified. For example,env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Other clients and libraries might provide their own mechanisms, via the shell or otherwise, that allow the user to alter session settings without direct use of SQL commands.
19.1.5. Managing Configuration File Contents
PostgreSQL provides several features for breaking down complex postgresql.conf files into sub-files. These features are especially useful when managing multiple servers with related, but not identical, configurations.
In addition to individual parameter settings, the postgresql.conf file can contain include directives, which specify another file to read and process as if it were inserted into the configuration file at this point. This feature allows a configuration file to be divided into physically separate parts. Include directives simply look like:
include 'filename'
If the file name is not an absolute path, it is taken as relative to the directory containing the referencing configuration file. Inclusions can be nested.
There is also an include_if_exists directive, which acts the same as the include directive, except when the referenced file does not exist or cannot be read. A regular include will consider this an error condition, but include_if_exists merely logs a message and continues processing the referencing configuration file.
The postgresql.conf file can also contain include_dir directives, which specify an entire directory of configuration files to include. These look like
include_dir 'directory'
Non-absolute directory names are taken as relative to the directory containing the referencing configuration file. Within the specified directory, only non-directory files whose names end with the suffix .conf will be included. File names that start with the . character are also ignored, to prevent mistakes since such files are hidden on some platforms. Multiple files within an include directory are processed in file name order (according to C locale rules, i.e., numbers before letters, and uppercase letters before lowercase ones).
Include files or directories can be used to logically separate portions of the database configuration, rather than having a single large postgresql.conf file. Consider a company that has two database servers, each with a different amount of memory. There are likely elements of the configuration both will share, for things such as logging. But memory-related parameters on the server will vary between the two. And there might be server specific customizations, too. One way to manage this situation is to break the custom configuration changes for your site into three files. You could add this to the end of your postgresql.conf file to include them:
include 'shared.conf' include 'memory.conf' include 'server.conf'
All systems would have the same shared.conf. Each server with a particular amount of memory could share the same memory.conf; you might have one for all servers with 8GB of RAM, another for those having 16GB. And finally server.conf could have truly server-specific configuration information in it.
Another possibility is to create a configuration file directory and put this information into files there. For example, a conf.d directory could be referenced at the end of postgresql.conf:
include_dir 'conf.d'
Then you could name the files in the conf.d directory like this:
00shared.conf 01memory.conf 02server.conf
This naming convention establishes a clear order in which these files will be loaded. This is important because only the last setting encountered for a particular parameter while the server is reading configuration files will be used. In this example, something set in conf.d/02server.conf would override a value set in conf.d/01memory.conf.
You might instead use this approach to naming the files descriptively:
00shared.conf 01memory-8GB.conf 02server-foo.conf
This sort of arrangement gives a unique name for each configuration file variation. This can help eliminate ambiguity when several servers have their configurations all stored in one place, such as in a version control repository. (Storing database configuration files under version control is another good practice to consider.)
 So you’ve installed postgres onto your machine, and you want to start working with it.
So you’ve installed postgres onto your machine, and you want to start working with it.
How?
The key to understanding the post-installation procedure is to realize that it “depends”.
- It “depends” on the OS i.e. MSWindows vs Linux.
- It “depends” on the flavor of Linux i.e. Debian vs RedHat.
- It “depends” if it’s a package install or from source code.
Let’s start by working with the most basic steps common to all installs and we’ll break it down further from there.
A successfully installed postgres, no matter the version, is characterized by the following:
- a newly created datacluster is present
- a configuration file pg_hba.conf is to be edited
- a configuration file postgresql.conf is to be edited
There are other configuration files but we’ll work with these.
For the purposes of discussion let’s further assume you’ve started up the cluster and postgres is running on the host. Here’s an example of what you can see when you run a utility, such as netstat, that reports the network connections:
|
$netstat —tlnp Active Internet connections (only servers) Proto Recv—Q Send—Q Local Address Foreign Address State PID/Program name tcp 0 0 127.0.0.1:5432 0.0.0.0:* LISTEN 27929/postgres |
The first thing is to look at is the “Local Address”. Notice how it says 127.0.0.1:5432. Okay, so that means that the server is currently listening on the localhost on port 5432. But you want 0.0.0.0:5432 otherwise remote connections cannot be accepted. With an editor, open up file pg_hba.conf and look at the “default” rules. Keep in mind that the configuration file can be located in one of several locations, we’ll cover that later.
ATTENTION: Setting the Address (CIDR) to 0.0.0.0 is for connectivity purposes only. As soon as you know everything works you should restrict this to as few permitted connections as possible. This is not something you should do on a production machine.
The actual “rules” per line can vary from one type of postgres installation to another. The good news is that RedHat/Centos look alike and all Debian/Ubuntu have their own similar styles too. The relevant settings are at the bottom of the file as all else above is commented documentation.
|
# TYPE DATABASE USER ADDRESS METHOD # «local» is for Unix domain socket connections only local all all peer # IPv4 local connections: host all all 127.0.0.1/32 md5 # IPv6 local connections: host all all ::1/128 peer # Allow replication connections from localhost, by a user with the # replication privilege. local replication all peer host replication all 127.0.0.1/32 md5 host replication all ::1/128 md5 |
Look at the first line, where TYPE is “local”. So long as you can log in locally, via UNIX DOMAIN SOCKETS, and sudo as the superuser, postgres is the default, you can access your service without a password.
METHOD should be peer but if it uses something else, like md5, you’ll need to change the string. Alternatively, if you feel particularly trustful of the other user accounts on the host, you can use the METHOD trust permitting free access to all locally logged-in UNIX accounts.
|
# ATTENTION: # the service must be reloaded for any edits to pg_hba.conf to take effect # $sudo su — postgres $psql —c «select ‘hello world’ as greetings» greetings ————- hello world |
Looking at the second line one sees that TYPE is IPV4. This rule, as well as the rule for TYPE IPv6, prevents localhost logins unless one knows the password:
|
$psql —h localhost —c «select ‘hello world’ as greetings» Password for user postgres: |
So let’s fix this by assigning a password to ROLE postgres by logging via UNIX DOMAIN SOCKETS since we already permit logins by METHOD peer:
|
— — example invocation, change the password to something real — ALTER ROLE postgres WITH PASSWORD ‘mypassword’; |
TIP: edits to pg_hba.conf requires the service to reload the file i.e. SIGHUP
Now that we’ve had connectivity for localhost connections, we’re using an IP v4 socket for this example, we can now proceed to address remote connections.
You’re going to need to add another rule which should be placed after the localhost rule:
|
host all all 0.0.0.0/0 md5 |
And here’s a line you can write for IPV6:
TIP: The demonstrated example rules let everybody connect to the host. A knowledge of CIDR is key to enforcing network security.
Keeping in mind that your system will be unique, here’s what the pg_hba.conf should start to look like:
|
# TYPE DATABASE USER ADDRESS METHOD # «local» is for Unix domain socket connections only local all all peer # IPv4 local connections: host all all 127.0.0.1/32 md5 host all all 0.0.0.0/0 md5 # IPv6 local connections: host all all ::1/128 md5 host all all ::0/0 md5 # Allow replication connections from localhost, by a user with the # replication privilege. local replication all peer host replication all 127.0.0.1/32 md5 host replication all ::1/128 md5 |
You’re almost there!
Now that you’ve added a password to the superuser and updated the configuration file pg_hba.conf, it’s time to visit another configuration file postgresql.conf.
Locate the file and edit runtime parameter listen_addresses. The default setting prohibits remote connections. Resetting the value either to a nic’s IP address or just using the wild card will make it accessible.
TIP: As postgres, execute the following in a psql session in order to locate your configuration files.
|
select distinct sourcefile from pg_settings; |
For those people feeling fancy, one can bind the postgres service to more than one IP address as a comma-separated list:
|
listen_addresses = ‘*’ #listen_addresses = ‘localhost’ # what IP address(es) to listen on; # comma-separated list of addresses; # defaults to ‘localhost’; use ‘*’ for all # (change requires restart) |
An alternate method updating the runtime parameters can also be accomplished using the SQL statement:
|
postgres=# ALTER SYSTEM SET listen_addresses = ‘*’; ALTER SYSTEM |
The final step, restarting the service, is where we start splitting hairs again:
- Redhat distributions require dataclusters to be manually created before they can be administered.
- PostgreSQL Debian distributions, including Ubuntu, automatically creates and starts up the datacluster.
Systemd:
- Redhat/Centos:
/usr/pgsql—11/bin/postgresql—12—setup initdb
systemctl start|stop postgresql—12
- Debian/Ubuntu:
systemctl restart postgresql
Debian derived Linux Distributions include a collection of command-line utilities in order to administer the PostgreSQL service:
|
# example CLI # pg_ctlcluster<br />Usage: /usr/bin/pg_ctlcluster <version> <cluster> <action> [— <pg_ctl options>] |
|
# restarting postgres version 12 on a Debian derived distribution pg_ctlcluster 12 main restart |
After a successful service restart you should get something similar to the following:
|
Active Internet connections (only servers) Proto Recv—Q Send—Q Local Address Foreign Address State PID/Program name tcp 0 0 0.0.0.0:5432 0.0.0.0:* LISTEN 27929/postgres |
And finally, the remote connectivity test:
|
# # THE REMOTE LOGIN # psql ‘host=myhost user=postgres password=mypassword’ —c «select ‘hello world’ as greeetings « |
Then there’s replication, but that’s another blog altogether.
That’s it for now!
Our white paper “Why Choose PostgreSQL?” looks at the features and benefits of PostgreSQL and presents some practical usage examples. We also examine how PostgreSQL can be useful for companies looking to migrate from Oracle.
Download PDF
PostgreSQL help
|
Расположение |
|
|
Содержание |
Расположение конфигурационного файла можно получить выполнив
-bash-4.2$ su — postgres -c «psql -c ‘SHOW config_file;'»
Password:
config_file
————————————-
/var/lib/pgsql/data/postgresql.conf
(1 row)
vi /var/lib/pgsql/data/postgresql.conf
# ——————————
# PostgreSQL configuration file
# ——————————
#
# This file consists of lines of the form:
#
# name = value
#
# (The «=» is optional.) Whitespace may be used. Comments are introduced with
# «#» anywhere on a line. The complete list of parameter names and allowed
# values can be found in the PostgreSQL documentation.
#
# The commented-out settings shown in this file represent the default values.
# Re-commenting a setting is NOT sufficient to revert it to the default value;
# you need to reload the server.
#
# This file is read on server startup and when the server receives a SIGHUP
# signal. If you edit the file on a running system, you have to SIGHUP the
# server for the changes to take effect, or use «pg_ctl reload». Some
# parameters, which are marked below, require a server shutdown and restart to
# take effect.
#
# Any parameter can also be given as a command-line option to the server, e.g.,
# «postgres -c log_connections=on». Some parameters can be changed at run time
# with the «SET» SQL command.
#
# Memory units: kB = kilobytes Time units: ms = milliseconds
# MB = megabytes s = seconds
# GB = gigabytes min = minutes
# h = hours
# d = days
#——————————————————————————
# FILE LOCATIONS
#——————————————————————————
# The default values of these variables are driven from the -D command-line
# option or PGDATA environment variable, represented here as ConfigDir.
#data_directory = ‘ConfigDir’ # use data in another directory
# (change requires restart)
#hba_file = ‘ConfigDir/pg_hba.conf’ # host-based authentication file
# (change requires restart)
#ident_file = ‘ConfigDir/pg_ident.conf’ # ident configuration file
# (change requires restart)
# If external_pid_file is not explicitly set, no extra PID file is written.
#external_pid_file = » # write an extra PID file
# (change requires restart)
#——————————————————————————
# CONNECTIONS AND AUTHENTICATION
#——————————————————————————
# — Connection Settings —
#listen_addresses = ‘localhost’ # what IP address(es) to listen on;
# comma-separated list of addresses;
# defaults to ‘localhost’; use ‘*’ for all
# (change requires restart)
#port = 5432 # (change requires restart)
# Note: In RHEL/Fedora installations, you can’t set the port number here;
# adjust it in the service file instead.
max_connections = 100 # (change requires restart)
# Note: Increasing max_connections costs ~400 bytes of shared memory per
# connection slot, plus lock space (see max_locks_per_transaction).
#superuser_reserved_connections = 3 # (change requires restart)
#unix_socket_directories = ‘/var/run/postgresql, /tmp’ # comma-separated list of directories
# (change requires restart)
#unix_socket_group = » # (change requires restart)
#unix_socket_permissions = 0777 # begin with 0 to use octal notation
# (change requires restart)
#bonjour = off # advertise server via Bonjour
# (change requires restart)
#bonjour_name = » # defaults to the computer name
# (change requires restart)
# — Security and Authentication —
#authentication_timeout = 1min # 1s-600s
#ssl = off # (change requires restart)
#ssl_ciphers = ‘ALL:!ADH:!LOW:!EXP:!MD5:@STRENGTH’ # allowed SSL ciphers
# (change requires restart)
#ssl_renegotiation_limit = 0 # amount of data between renegotiations
#ssl_cert_file = ‘server.crt’ # (change requires restart)
#ssl_key_file = ‘server.key’ # (change requires restart)
#ssl_ca_file = » # (change requires restart)
#ssl_crl_file = » # (change requires restart)
#password_encryption = on
#db_user_namespace = off
# Kerberos and GSSAPI
#krb_server_keyfile = »
#krb_srvname = ‘postgres’ # (Kerberos only)
#krb_caseins_users = off
# — TCP Keepalives —
# see «man 7 tcp» for details
#tcp_keepalives_idle = 0 # TCP_KEEPIDLE, in seconds;
# 0 selects the system default
#tcp_keepalives_interval = 0 # TCP_KEEPINTVL, in seconds;
# 0 selects the system default
#tcp_keepalives_count = 0 # TCP_KEEPCNT;
# 0 selects the system default
#——————————————————————————
# RESOURCE USAGE (except WAL)
#——————————————————————————
# — Memory —
shared_buffers = 32MB # min 128kB
# (change requires restart)
#temp_buffers = 8MB # min 800kB
#max_prepared_transactions = 0 # zero disables the feature
# (change requires restart)
# Note: Increasing max_prepared_transactions costs ~600 bytes of shared memory
# per transaction slot, plus lock space (see max_locks_per_transaction).
# It is not advisable to set max_prepared_transactions nonzero unless you
# actively intend to use prepared transactions.
#work_mem = 1MB # min 64kB
#maintenance_work_mem = 16MB # min 1MB
#max_stack_depth = 2MB # min 100kB
# — Disk —
#temp_file_limit = -1 # limits per-session temp file space
# in kB, or -1 for no limit
# — Kernel Resource Usage —
#max_files_per_process = 1000 # min 25
# (change requires restart)
#shared_preload_libraries = » # (change requires restart)
# — Cost-Based Vacuum Delay —
#vacuum_cost_delay = 0ms # 0-100 milliseconds
#vacuum_cost_page_hit = 1 # 0-10000 credits
#vacuum_cost_page_miss = 10 # 0-10000 credits
#vacuum_cost_page_dirty = 20 # 0-10000 credits
#vacuum_cost_limit = 200 # 1-10000 credits
# — Background Writer —
#bgwriter_delay = 200ms # 10-10000ms between rounds
#bgwriter_lru_maxpages = 100 # 0-1000 max buffers written/round
#bgwriter_lru_multiplier = 2.0 # 0-10.0 multipler on buffers scanned/round
# — Asynchronous Behavior —
#effective_io_concurrency = 1 # 1-1000; 0 disables prefetching
#——————————————————————————
# WRITE AHEAD LOG
#——————————————————————————
# — Settings —
#wal_level = minimal # minimal, archive, or hot_standby
# (change requires restart)
#fsync = on # turns forced synchronization on or off
#synchronous_commit = on # synchronization level;
# off, local, remote_write, or on
#wal_sync_method = fsync # the default is the first option
# supported by the operating system:
# open_datasync
# fdatasync (default on Linux)
# fsync
# fsync_writethrough
# open_sync
#full_page_writes = on # recover from partial page writes
#wal_buffers = -1 # min 32kB, -1 sets based on shared_buffers
# (change requires restart)
#wal_writer_delay = 200ms # 1-10000 milliseconds
#commit_delay = 0 # range 0-100000, in microseconds
#commit_siblings = 5 # range 1-1000
# — Checkpoints —
#checkpoint_segments = 3 # in logfile segments, min 1, 16MB each
#checkpoint_timeout = 5min # range 30s-1h
#checkpoint_completion_target = 0.5 # checkpoint target duration, 0.0 — 1.0
#checkpoint_warning = 30s # 0 disables
# — Archiving —
#archive_mode = off # allows archiving to be done
# (change requires restart)
#archive_command = » # command to use to archive a logfile segment
# placeholders: %p = path of file to archive
# %f = file name only
# e.g. ‘test ! -f /mnt/server/archivedir/%f && cp %p /mnt/server/archivedir/%f’
#archive_timeout = 0 # force a logfile segment switch after this
# number of seconds; 0 disables
#——————————————————————————
# REPLICATION
#——————————————————————————
# — Sending Server(s) —
# Set these on the master and on any standby that will send replication data.
#max_wal_senders = 0 # max number of walsender processes
# (change requires restart)
#wal_keep_segments = 0 # in logfile segments, 16MB each; 0 disables
#replication_timeout = 60s # in milliseconds; 0 disables
# — Master Server —
# These settings are ignored on a standby server.
#synchronous_standby_names = » # standby servers that provide sync rep
# comma-separated list of application_name
# from standby(s); ‘*’ = all
#vacuum_defer_cleanup_age = 0 # number of xacts by which cleanup is delayed
# — Standby Servers —
# These settings are ignored on a master server.
#hot_standby = off # «on» allows queries during recovery
# (change requires restart)
#max_standby_archive_delay = 30s # max delay before canceling queries
# when reading WAL from archive;
# -1 allows indefinite delay
#max_standby_streaming_delay = 30s # max delay before canceling queries
# when reading streaming WAL;
# -1 allows indefinite delay
#wal_receiver_status_interval = 10s # send replies at least this often
# 0 disables
#hot_standby_feedback = off # send info from standby to prevent
# query conflicts
#——————————————————————————
# QUERY TUNING
#——————————————————————————
# — Planner Method Configuration —
#enable_bitmapscan = on
#enable_hashagg = on
#enable_hashjoin = on
#enable_indexscan = on
#enable_indexonlyscan = on
#enable_material = on
#enable_mergejoin = on
#enable_nestloop = on
#enable_seqscan = on
#enable_sort = on
#enable_tidscan = on
# — Planner Cost Constants —
#seq_page_cost = 1.0 # measured on an arbitrary scale
#random_page_cost = 4.0 # same scale as above
#cpu_tuple_cost = 0.01 # same scale as above
#cpu_index_tuple_cost = 0.005 # same scale as above
#cpu_operator_cost = 0.0025 # same scale as above
#effective_cache_size = 128MB
# — Genetic Query Optimizer —
#geqo = on
#geqo_threshold = 12
#geqo_effort = 5 # range 1-10
#geqo_pool_size = 0 # selects default based on effort
#geqo_generations = 0 # selects default based on effort
#geqo_selection_bias = 2.0 # range 1.5-2.0
#geqo_seed = 0.0 # range 0.0-1.0
# — Other Planner Options —
#default_statistics_target = 100 # range 1-10000
#constraint_exclusion = partition # on, off, or partition
#cursor_tuple_fraction = 0.1 # range 0.0-1.0
#from_collapse_limit = 8
#join_collapse_limit = 8 # 1 disables collapsing of explicit
# JOIN clauses
#——————————————————————————
# ERROR REPORTING AND LOGGING
#——————————————————————————
# — Where to Log —
#log_destination = ‘stderr’ # Valid values are combinations of
# stderr, csvlog, syslog, and eventlog,
# depending on platform. csvlog
# requires logging_collector to be on.
# This is used when logging to stderr:
logging_collector = on # Enable capturing of stderr and csvlog
# into log files. Required to be on for
# csvlogs.
# (change requires restart)
# These are only used if logging_collector is on:
#log_directory = ‘pg_log’ # directory where log files are written,
# can be absolute or relative to PGDATA
log_filename = ‘postgresql-%a.log’ # log file name pattern,
# can include strftime() escapes
#log_file_mode = 0600 # creation mode for log files,
# begin with 0 to use octal notation
log_truncate_on_rotation = on # If on, an existing log file with the
# same name as the new log file will be
# truncated rather than appended to.
# But such truncation only occurs on
# time-driven rotation, not on restarts
# or size-driven rotation. Default is
# off, meaning append to existing files
# in all cases.
log_rotation_age = 1d # Automatic rotation of logfiles will
# happen after that time. 0 disables.
log_rotation_size = 0 # Automatic rotation of logfiles will
# happen after that much log output.
# 0 disables.
# These are relevant when logging to syslog:
#syslog_facility = ‘LOCAL0’
#syslog_ident = ‘postgres’
# This is only relevant when logging to eventlog (win32):
# (change requires restart)
#event_source = ‘PostgreSQL’
# — When to Log —
#client_min_messages = notice # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# log
# notice
# warning
# error
#log_min_messages = warning # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic
#log_min_error_statement = error # values in order of decreasing detail:
# debug5
# debug4
# debug3
# debug2
# debug1
# info
# notice
# warning
# error
# log
# fatal
# panic (effectively off)
#log_min_duration_statement = -1 # -1 is disabled, 0 logs all statements
# and their durations, > 0 logs only
# statements running at least this number
# of milliseconds
# — What to Log —
#debug_print_parse = off
#debug_print_rewritten = off
#debug_print_plan = off
#debug_pretty_print = on
#log_checkpoints = off
#log_connections = off
#log_disconnections = off
#log_duration = off
#log_error_verbosity = default # terse, default, or verbose messages
#log_hostname = off
#log_line_prefix = » # special values:
# %a = application name
# %u = user name
# %d = database name
# %r = remote host and port
# %h = remote host
# %p = process ID
# %t = timestamp without milliseconds
# %m = timestamp with milliseconds
# %i = command tag
# %e = SQL state
# %c = session ID
# %l = session line number
# %s = session start timestamp
# %v = virtual transaction ID
# %x = transaction ID (0 if none)
# %q = stop here in non-session
# processes
# %% = ‘%’
# e.g. ‘<%u%%%d> ‘
#log_lock_waits = off # log lock waits >= deadlock_timeout
#log_statement = ‘none’ # none, ddl, mod, all
#log_temp_files = -1 # log temporary files equal or larger
# than the specified size in kilobytes;
# -1 disables, 0 logs all temp files
log_timezone = ‘Europe/Helsinki’
#——————————————————————————
# RUNTIME STATISTICS
#——————————————————————————
# — Query/Index Statistics Collector —
#track_activities = on
#track_counts = on
#track_io_timing = off
#track_functions = none # none, pl, all
#track_activity_query_size = 1024 # (change requires restart)
#update_process_title = on
#stats_temp_directory = ‘pg_stat_tmp’
# — Statistics Monitoring —
#log_parser_stats = off
#log_planner_stats = off
#log_executor_stats = off
#log_statement_stats = off
#——————————————————————————
# AUTOVACUUM PARAMETERS
#——————————————————————————
#autovacuum = on # Enable autovacuum subprocess? ‘on’
# requires track_counts to also be on.
#log_autovacuum_min_duration = -1 # -1 disables, 0 logs all actions and
# their durations, > 0 logs only
# actions running at least this number
# of milliseconds.
#autovacuum_max_workers = 3 # max number of autovacuum subprocesses
# (change requires restart)
#autovacuum_naptime = 1min # time between autovacuum runs
#autovacuum_vacuum_threshold = 50 # min number of row updates before
# vacuum
#autovacuum_analyze_threshold = 50 # min number of row updates before
# analyze
#autovacuum_vacuum_scale_factor = 0.2 # fraction of table size before vacuum
#autovacuum_analyze_scale_factor = 0.1 # fraction of table size before analyze
#autovacuum_freeze_max_age = 200000000 # maximum XID age before forced vacuum
# (change requires restart)
#autovacuum_vacuum_cost_delay = 20ms # default vacuum cost delay for
# autovacuum, in milliseconds;
# -1 means use vacuum_cost_delay
#autovacuum_vacuum_cost_limit = -1 # default vacuum cost limit for
# autovacuum, -1 means use
# vacuum_cost_limit
#——————————————————————————
# CLIENT CONNECTION DEFAULTS
#——————————————————————————
# — Statement Behavior —
#search_path = ‘»$user»,public’ # schema names
#default_tablespace = » # a tablespace name, » uses the default
#temp_tablespaces = » # a list of tablespace names, » uses
# only default tablespace
#check_function_bodies = on
#default_transaction_isolation = ‘read committed’
#default_transaction_read_only = off
#default_transaction_deferrable = off
#session_replication_role = ‘origin’
#statement_timeout = 0 # in milliseconds, 0 is disabled
#vacuum_freeze_min_age = 50000000
#vacuum_freeze_table_age = 150000000
#bytea_output = ‘hex’ # hex, escape
#xmlbinary = ‘base64’
#xmloption = ‘content’
#gin_fuzzy_search_limit = 0
# — Locale and Formatting —
datestyle = ‘iso, mdy’
#intervalstyle = ‘postgres’
timezone = ‘Europe/Helsinki’
#timezone_abbreviations = ‘Default’ # Select the set of available time zone
# abbreviations. Currently, there are
# Default
# Australia (historical usage)
# India
# You can create your own file in
# share/timezonesets/.
#extra_float_digits = 0 # min -15, max 3
#client_encoding = sql_ascii # actually, defaults to database
# encoding
# These settings are initialized by initdb, but they can be changed.
lc_messages = ‘en_US.UTF-8’ # locale for system error message
# strings
lc_monetary = ‘en_US.UTF-8’ # locale for monetary formatting
lc_numeric = ‘en_US.UTF-8’ # locale for number formatting
lc_time = ‘en_US.UTF-8’ # locale for time formatting
# default configuration for text search
default_text_search_config = ‘pg_catalog.english’
# — Other Defaults —
#dynamic_library_path = ‘$libdir’
#local_preload_libraries = »
#——————————————————————————
# LOCK MANAGEMENT
#——————————————————————————
#deadlock_timeout = 1s
#max_locks_per_transaction = 64 # min 10
# (change requires restart)
# Note: Each lock table slot uses ~270 bytes of shared memory, and there are
# max_locks_per_transaction * (max_connections + max_prepared_transactions)
# lock table slots.
#max_pred_locks_per_transaction = 64 # min 10
# (change requires restart)
#——————————————————————————
# VERSION/PLATFORM COMPATIBILITY
#——————————————————————————
# — Previous PostgreSQL Versions —
#array_nulls = on
#backslash_quote = safe_encoding # on, off, or safe_encoding
#default_with_oids = off
#escape_string_warning = on
#lo_compat_privileges = off
#quote_all_identifiers = off
#sql_inheritance = on
#standard_conforming_strings = on
#synchronize_seqscans = on
# — Other Platforms and Clients —
#transform_null_equals = off
#——————————————————————————
# ERROR HANDLING
#——————————————————————————
#exit_on_error = off # terminate session on any error?
#restart_after_crash = on # reinitialize after backend crash?
#——————————————————————————
# CUSTOMIZED OPTIONS
#——————————————————————————
# Add settings for extensions here