У индексов есть две задачи: соблюдать выполнение первичных ключей и уникальных ограничений, и увеличивать производительность. Стратегия по созданию индексов сильно влияет на производительность приложения. Нет четкого ограничения кто ответствене за создание индексов. Когда бизнес-аналитики составляют бизнес-требования к системе которые будут выполнены как создание ограничений – они влияют на индексы. Администратор будет наблюдать за выполнением запросов и давать рекомендации по созданию индексов. Разработчик именно тот кто лучше всех понимает что происходит в коде и природе данных – тоже влияет на стратегию создания индексов.
Почему индексы необходимы
Индексы это часть механизма ограничений (constraint). Если столбец (или группа столбцов) помечены как первичной ключ таблица, то каждый раз когда вставляется строка в таблицу, Oracle необходимо проверить что не существует строки с такими значениями. Если у таблицы нет индекса дял столбцов – единственный способ проверить это это вычитать всю таблицу. Это может быть приемлимо если в таблице всего несколько строк, но дял таблиц, содержащих тысячи миллионов (или миллиардов) строк это займёт очень много времени и неприемлимо. Индекс позволяет практически мгновенно получить доступ к значениям ключа и проверка на существование происходит моментально. Когда определяется первичный ключ Oracle создаст индекс для столбца(ов) ключа если ещё не существует такого индекса.
Ограничение по уникальности (unique constraint) тоже требует создание индекса. Это ограничение отличается от первичного ключа тем что значение в столбцах ограничения по уникальности могут быть NULL в отличие от первичного ключа, но это не влияет на создание и исопльзование индекса. Внешний ключ (foreign key) соблюдается с помощью индексов, но обязательным является индекс только на родительской таблице. Внешний ключ дочерней таблицы зависит от столбца первичного ключа или уникального ключа родительской таблицы. Когда строка добавляется в дочернюю таблицу, Oracle будет использовать индекс родительской таблицы для проверки существует ли такое значение в родительной таблице или нет, перед тем как позволить записать данные. Как бы то ни было желательно всегда создавать индексы для столбцов дочерней таблицы используемых как внешние ключи из соображений производительности: DELETE для родительской таблицы будет гораздо б ыстрее если Oracle сможет использовать индекс для проверки существуют ли ещё строки в дочерней таблице с этим значением или нет.
Индексы критически важны для производительности. Когда выполняется команда SELECT с директивой WHERE, Oracle необходимо определить строки в таблице которые необходимо выбрать. Если не создано индексов для столбцов используемых в директиве WHERE, то единственным способом сделать это – это вычитать всю таблицу (full table scan).Full table scan проверяют все строки по очереди для поиска нужных значений. Если в таблицы хранятся миллиарды строк, это может занять несколько часов. Если существует индекс для использованного в WHERE столбца, Oracle может искать используя индекс. Индекс это отсортированный список ключей значений структурирвоанных таким образом чтобы операция поиска была очень быстрой. Каждая запись это сслыка на строку в таблице. Поиск строк используя индекс гораздо быстрее чем чтение всей таблицы если размер таблицы больше определённого размера и пропорция между данными которые нужны для запроса и всеми данными в таблице ниже определённого значения. Для маленьких таблиц, или где секция WHERE всё равно выберет большую часть строк из таблицы, полное чтение таблицы будет быстрее: вы можете (обычно) доверять Oracle при выборе решения использовать ли индекс. Это решение осуществляется на основании статистической информации собираемой о таблице и строках в ней.
Второй случай когда индексы могут увеличить производительность это сортировка. Команда SELECT c директивой ORDER BY, GROUP BY или ключевым словом UNION (и несколько других) обязана отсортировать строки в определённом порядке – если не создан индекс, который может вернуть строки без необходимости в сортировке (строки уже отсортированы).
И третий случай это объекдинение таблиц, но опять же у Oracle есть выбор: в зависимости от размера таблиц и наличия свободной памяти, может быть быстрее вычитать таблицы в память и объединять их чем использовать индексы. Метод nested loop join читает строки одной таблицы и использует индекс другой таблицы для поиска совпадений (это обычно нагружает диск). Hash join считывает таблицу в память, преобразует в хеш таблицу и использует специальный алгоритм для поиска совпадений — такая операция требует больше оперативной памяти и процессорного времени. Sort merge join сортиует таблицы по значениям столбца для объединения и затем объединяет их вместе – это компромисс между использованием диска, памятии процессора. Если нет индексов –Oracle сильно ограничен в способах объединения.
https://habrahabr.ru/company/mailru/blog/266811/ кому интерестно – рекомендую почитать
TIP
Indexes assist SELECT statements, and also any UPDATE, DELETE, or MERGE statements that use a WHERE clause—but they will slow down INSERT statements.
Содержание
- 1 Типы индексов
- 2 B* Tree индексы (B*=balanced)
- 3 Bitmap индексы
- 4 Свойства индексов
- 5 Создание и использование индексов
- 6 Изменение и удаление индексов
Типы индексов
Oracle поддерживает несколько типов индексов с различными вариациями. Два типа, которые мы рассмотрим это B* Tree индекс, который является типом по умолчанию и bitmap индекс. Основное правило – индексы увеличивают производительность для чтения данных но замедляют при DML операциях. Это происходит потому что индексы нужно обновлять и поддерживать. Каждый раз когда строка записывается в таблицу, новый ключ должен быть вставлен в каждый индекс таблицы, что усиливает нагрузку на БД. Поэтому OLTP системы обычно используют минимальное количество индексов (возможно только необходимые для ограничений) а для OLAP систем создаётся столько индексов сколько нужно для быстроты выполнения.
B* Tree индексы (B*=balanced)
Индекс это древовидная (tree) структура. «Корень» (root) дерева содержит указатели на множество узлов второго уровня, которые в свою очередь могут хранить указатели на узлы третьего уровня и так далее. Глубина дерева определяется длинной ключа и количеством строк в таблице.
TIP
The B*Tree structure is very efficient. If the depth is greater than three or four, then either the index keys are very long or the table has billions of rows. If neither if these is the case, then the index is in need of a rebuild.
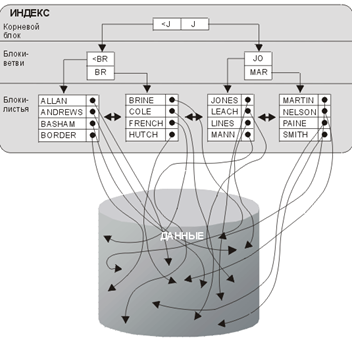
В листьях (узлы нижнего уровня) индекса хранятся значения столбца строк по порядку и указатель на строку. Также листья хранят ссылки на соседние листья. Таким образом чтобы выбрать строку если условие WHERE использует строгое равенство — Oracle исдёт по дереву в лист содержащий искомое значение и затем использует указатель для считывания строки.Если же используется нестрогое равенство (например LIKE, BETWEEN и т.д.) то вначале находится первая строка удовлетворяющая условию а затем считываются строки по порядку и переход между листьями осуществляется напрямую, без нового обхода по дереву.
Указатель на строку – это rowid. Rowid — это псевдостолбец закрытого формата, который имеет каждая строка в каждой таблице. Внутри значения зашифрован указатель на физический адрес строки. Так как rowid не является частью стандарта SQL то он не видим при написании обычных запросов. Но вы можете выбирать эти значения и использовать их при необходимости. Это отображено на рисунке 7-3.
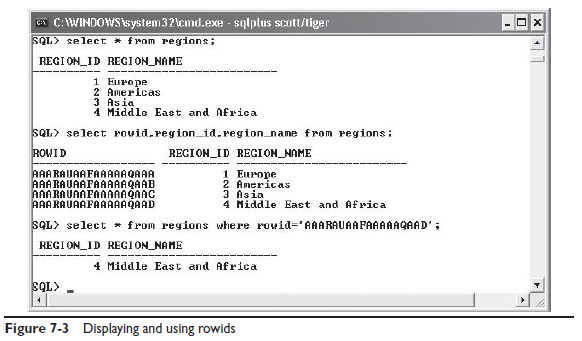
Rowid для каждой строки полностью уникальный. Каждая строка во всей БД имеет свой уникальный rowid. Расшифровав rowid получаем физический адрес строки, и Oracle может рассчитать в каком файле и где внутри файла находится искомая строка.
B* Tree индексы очень эффективны для вычитки строк число которых невелико относительно всех строк таблицы и таблица достаточно большая. Рассмотрим запрос
select count(*) from employees where last_name between ‘A%’ and ‘Z%’;
При использовании такого условия в WHERE запрос вернёт все строки таблицы. Использование индекса при таком запросе будет значительно медленее чем чтение всей таблицы. И вообще – вся таблица это то что нужно в этом запросе. Другим примером будет настолько маленькая таблица где одна операция чтения считывает её полностью; тогда нет смысла считывать вначале индекс. Обычно говорят что запросы, результат которых предполагает вычитку более чем 2-4% данных в таблице обычно работают быстрее используя полное чтение таблицы. Особым случаем является значение NULL в столбце указанном в секции WHERE. Значение NULL не хранится в B* Tree индексах и запросы типа
select * from employees where last_name is null;
всегд будут использовать полное чтение. Немного смысла создавать B* Tree индекс для столбцов содержащих несколько уникальных значений, так как он не будет в достаточной степени селективным: количество строк для каждого уникального значения будет слишком высоко относительно количества строк всей таблицы. В общем, B* Tree индексы полезно использовать если
Мощность (кратность – количество уникальных значений) столбца велика и
Количество строк в таблице большое и
Столбец используется в директивах WHERE и операциях объединения
Bitmap индексы
Во многих приложения природа данных и запросы таковы что использование B* Tree индексов не сильно помогает. Расммотрим пример. Есть таблица продаж, в которой набор данных о продажах в супермаркетах за год, которые нужно проанализировать в нескольких измерениях. На рисунке 7-4 показана простая диаграмма сущность-связь для четырёх измерений.
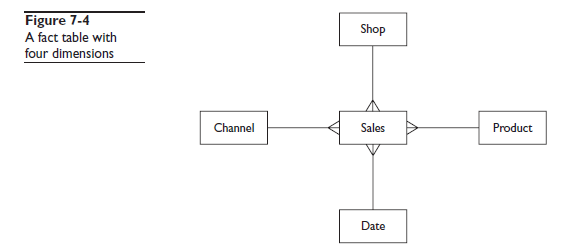
Мощность каждого измерения очень низкая. Преположим

Всего два измерения (DATE и PRODUCT) предполагают селективность лучше чем упомянутые 2-4%, т.е. делают использование индексов оправданным. Но если запросы используют предикаты группы (к примеру месяц в году, или группа товаров в которую входит десять товаров) то и эти измерения не подходят к требованиям. Отсюда следует простой факт: B* Tree индексы часто бесполезны в хранилищах данных. Типичным запросов может быть сравнение продаж между двумя магазинами приходящим покупателям определённой группы товаров за месяц. Можно создать B* Tree индесы для этих столбцов но Oracle проигнорирует их так как они недостаточно селективны. Для таких ситуация созданы bitmap индексы. Bitmap индексы хранят все rowid строк как битовую маску для каждого уникального значения ключа. Битовые маски индекса для измерения CHANNEL может быть к примеру
![]()
Это значит что первые две строки были приходящими покупателями, затем покупка с доставкой и т.д
Битовые маски индекса столбца SHOP могут быть

Это значит что первые две продажи были в Лондоне, затем одна в Оксфорде, затем четвертая в Рединге и так далее.
Теперь если приходит запрос
select count(*) from sqles where channel=’WALK-IN’ and shop=’OXFORD’
Oracle может выбрать две битовые маски и объединить их с помощью операции И

Результат логического И показывает что только седьмая и шестнадцатая строки удовлетворяют запросу. Операции над битовыми масками очень быстрые и могут использоваться для сложных булевых операций надо многими столбцами со многими сочетаниями И, ИЛИ или НЕ. Также достоинством bitmap индексов является то, что они хранят значения NULL. С точки зрения битовой маски – NULL просто ещё одно уникальное значение со своей битовой маской.
В общем, bitmap индексы полезны когда
Мощность столбца низкая и
Количество строк в таблице большое и
Столбец используется в операциях булевой алгебры
TIP
If you knew in advance what the queries would be, then you could build B*Tree indexes that would work, such as a composite index on SHOP and CHANNEL. But usually you don’t know, which is where the dynamic merging of bitmaps gives great flexibility.
Свойства индексов
Всего доступно шесть свойств которые можно применить при создании индекса
- Уникальность / Unique или nonunique
- Реверсивность / Reverse key
- Сжатие / Compessed
- Составной или нет /Composite
- Основанный на функции или нет / Function based
- Сортировка по возрастанию или убыванию / Ascending или descending
Все шесть свойств можно применить к B* Tree индексам и только три последних можно использовать для bitmap индексов.
Уникальный индекс не позволит дублировать значение. По умолчанию значение nonunique. Свойство уникальности индекса не связано с ограниченями уникальности или первичного ключа: если существует уникальный индекс то вствка дубликатов невозможно даже при отстуствии ограничения уникальности.
Реверсивный индекс строится на значениях ключа в которых байты строятся в обратном порядке: вместо индексирования значения к примеру ‘John’ будет использоваться значение ‘nhoJ’. Когда выполнится команда SELECT, Oracle автоматически преобразует строку поиска. Это используется для распределения строк по индексу в мультипользовательских системах. Например если много пользователей добавляют много строк в таблицу с первичным ключом как последовательно-увеличивающийся номер – все строки будут стремиться к концу индекса. Путем реверса ключа строки распределяются по всему индексу. При использовании индекса с реверсированным ключом базы данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Индексы со сжатием хранят повторяющееся значение ключа один раз. По умолчанию сжатие выключено, что значит если значение ключа не уникально то оно будет хранится для каждого повторения. Сжатый же индекс будет храние значение ключа один раз, а затем строку со всеми rowid строк с этим значением.
Составной индекс – это индекс который строится для нескольких столбцов. Нет ограничений на использование столбцов разных типов данных. Если условие WHERE не использует все столбцы, то индекс всё ещё может быть использован, но если не используется самый левый столбец, то Oracle использует skip-scanning метод который гораздо менее эффективный чем если бы левый столбец был включен.
Основанный на функции индекс строится для результата выполнения функции к одному или нескольким столбцам, к примеру upper(last_name или to_char(startdate,’ccyy-mm-dd’). Запросы должны использовать ту же функцию для поиска или Oracle не сможет использовать индекс.
По умолчанию индексы отсортированы по возрастанию (ascending), т.е. значения ключа хранятся от меньшего к большему. Режим по убыванию (descending) меняет это на противоположное. Фактически эта разница не очень важна: записи в индексе хранятся как двойной связный список т.е. можно переходить вверх или вниз с одинаковой скоростью, однако это повлияет на порядок строк в результате.
Создание и использование индексов
Индексы создаются неявно при создании ограничений первичного ключа или уникальности если индексы на соответствующих столбцах ещё не существуют. Синтаксис для явного создания индекса
CREATE [UNIQUE | BITMAP] INDEX [ schema.]indexname
ON [schema.]tablename (column [, column…] ) ;
По умолчанию индекс не уникальный, без сжатия, не-реверсивный типа B* Tree. Невозможно создать уникальный битмап индекс (и не стоит этого поделать если вы подумаете об этом с точки зрения свойства селективности). Индексы это объекты схемы и возможно создать индекс в одной схеме и таблицу в другой, но большинство людей найдут такой способ странным. Составной индекс – это индекс для нескольких столбцов. Составные индексы могут быть созданы для столбцов разных типов и столбцы не обязательно следовать друг за другом.
TIP
Many database administrators do not consider it good practice to rely on implicit index creation. If the indexes are created explicitly, the creator has full control over the characteristics of the index, which can make it easier for theDBA to manage subsequently.
Рассмотрим пример создания таблиц, индексов и затем определение ограничений
create table dept(deptno number,dname varchar2(10));
create table emp(empno number, surname varchar2(10),
forename varchar2(10), dob date, deptno number);
create unique index dept_i1 on dept(deptno);
create unique index emp_i1 on emp(empno);
create index emp_i2 on emp(surname,forename);
create bitmap index emp_i3 on emp(deptno);
alter table dept add constraint dept_pk primary key (deptno);
alter table emp add constraint emp_pk primary key (empno);
alter table emp add constraint emp_fk
foreign key (deptno) references dept(deptno);
Первые два индекса помечены как UNIQUE, что значит нельзя добавить дубликат. Это не определяет ограничение, но на самом деле это не что иное. Третий индекс не UNIQUE и позволяет хранить дубликаты и это составной индекс для двух столбцов. Четвертый индекс – это bitmap индекс, так как ожидается что мощность столбца будет низкой.
Когда определяются два ограничения, Oracle определит уже существующие индексы и использует их для ограничений. Обратите внимание что индекс для DEPT.DEPTNO не даст выигрыш с точки зрения происзводительности, но он всё равно необходим для обеспечения ограничения первичного ключа.
После создания индексы работают абсолютно невидимо и автоматически. Перед выполнением SQL запроса, сервер Oracle оценит возможные пути выполнения. Некоторые способы будут использовать индексы, некоторые нет. Далее Oracle использует информацию которую он собирает автоматически о таблица и окружении для принятия решения какой способ предпочтителен.
TIP
The Oracle server should make the best decision about index use, but if it is getting it wrong, it is possible for a programmer to embed instructions, known as optimizer hints, in code that will force the use (or not) of certain indexes
Изменение и удаление индексов
Команда ALTER INDEX не может менять свойства индексов интересных с точки зрения программиста: тип, столбцы и всё иное. ALTER INDEX создана для администратора БД и обычно будет использоваться для управления физическими свойствами индекса. Если необходимо изменить логические свойства – то единственным способом будет удаление старого индекса и создание нового. К примеру чтобы изменить индекс EMP_I2 можно выполнить следующие команды
drop index emp_i2;
create index emp_i2 on emp(surname,forename,dob);
Когда удаляется таблица, все индексы и ограничения для этой таблицы удаляются автоматически. Если индекс был создан неявно, то удаление ограничения приведёт к удалению индекса. Если вначале был явно создан индекс, а затем создавалось ограничение использующее этот индекс, то при удалении ограничения индекс остаётся.
Афоризм
Ещё вчера сегодня было завтра.
Наталья Резник
Поддержка проекта
Если Вам сайт понравился и помог, то будем признательны за Ваш «посильный» вклад в его поддержку и развитие
• Yandex.Деньги
410013796724260
• Webmoney
R335386147728
Z369087728698
Таблицы могут иметь большое количество строк. А, так как строки не упорядочены, то
поиск по указанному значению может потребовать значительного времени. Использование
индексов позволяет ускорить процесс чтения требуемых записей. INDEX — это
упорядоченный список определенных столбцов или групп столбцов в таблице. Когда создается
индекс по одному или нескольким полям, то сервер БД формирует соответствующий
упорядоченный список. Таблица, конечно же, должна уже быть создана и должна содержать
имена индексируемых столбцов.
Синтаксис CREATE INDEX
CREATE [UNIQUE] INDEX <index name> ON [schema_name.]table_name (<column name> [,<column name>]...);
Добавление индекса снижает производительность запросов, связанных с добавлением, изменением
или удалением данных, поскольку каждый раз при выполнении транзакции данные индекса также
обновляются, что требует выполнения от сервера дополнительной работы. Однако выполение запросов
SELECT по индексируемым полям существенно перевешивают эти недостатки. Не следует создавать индексы
по каждому столбцу таблицы, не определив, какие запросы будут выполняться.
Уникальный индекс, UNIQUE INDEX
Индекс может быть уникальным unique index, что не позволяет иметь в таблице дублированных
записей с одинаковыми значениями индексируемых полей.
ПРИМЕЧАНИЕ: при создании уникального индекса транзакция будет отклонена, если уже
имеются идентичные значения в записях таблицы по индексируемым полям. Для уникального индекса
таблицы с несколькими полями комбинация значений должна быть единственной, но каждое из значений
поля может и не быть уникальным.
Отличие PRIMARY KEY и UNIQUE INDEX
Ограничения «primary key» и unique index обеспечивают уникальность значений полей таблицы,
в которой они определены. По умолчанию primary key создает кластерный индекс на столбце, а
«unique index» — некластерный. Другим отличием является то, что «primary key» не может иметь нулевых
записей, т.е. поле NOT NULL, в то время как «unique index» допускает только одну нулевую запись
(NULL). Таблица может иметь только один первичный ключ, но несколько «unique index».
Таким образом, можно считать, что «primary key» это приблизительно unique index + NOT NULL .
Удаление DROP INDEX
Удаление индекса не воздействует на содержание полей. Синтаксис оператора удаления индекса drop index :
ALTER INDEX
В разных СУБД имеются существенные различия по использованию оператора alter index. Так
например MySQL не поддерживает данный оператор, в Interbase можно использовать данный оператор для
отключения и повторного включения индекса, в результате чего будет выполнена переиндексация данных.
В СУБД PostgresSQL индекс можно переименовать с использованием оператора alter index.
Синтаксис переменования индекса :
-- переименование индекса в СУБД PostgresSQL ALTER INDEX [IF EXISTS] index_name RENAME TO index_name_new;
ALTER INDEX в Oracle
Платформа Oracle также поддерживает инструкцию alter index. Данный оператор используется
для изменения или перестройки существующего индекса без его удаления и повторного создания.
Синтаксис оператора для переименования индекса в Oracle имеет следующий вид :
-- переименование индекса в СУБД Oracle ALTER INDEX index_name RENAME TO index_name_new;
Для переиндексации данных необходимо использовать следующий синтаксис оператора alter index :
ALTER INDEX index_name [ coalesce | [ rebuild | rebuild online ] ];
COALESCE
При использовании coalesce таблица не блокируется и переиндексация выполняется online. При
этом индекс размещается в пределах существующей индексной структуры — соединяет блоки листа в пределах
имеющихся ветвей дерева. Индексные листовые блоки быстро освобождаются для использования и не требуется
много дискового пространства.
Однако coalesce генерирует много записей в журналах повторного выполнения (redo). При этом
данный операнд может вызвать ошибку ORA-01555 ( coalesce определяет «работу» Oracle с листовыми блоками,
определенных количеством малых транзакций. А много малых транзакций, выполненных одной сессией, могут
вызвать у другой сессии, выполняющей продолжительную транзакцию, эту ошибку). Кроме этого coalesce не
опускает HWM индекс, т.е. место на диске не освобождает и не может переместить индекс в другое
табличное пространство.
REBUILD
Использование rebuild позволяет быстро перемещать индекс в другое табличное пространство.
Кроме этого «rebuild» создает новое дерево и уменьшает его высоту при необходимости. А также дает
возможность быстро изменять storage и tablespace параметры, без необходимости удалять индекс.
Может быть использован для уменьшения расходования ресурсов — передвигается отметка HWM.
Однако rebuild связан с более высокими издержками — требуется больше дискового пространства,
чтобы разместить старый и новый индекс в соответствующем табличном пространстве. Кроме этого rebuild
может вызвать ошибку ORA-01410: Invalid ROWID.
Rebuild «offline» может использовать существующий индекс для создания новой версии индекса, но
блокирует таблицу во время выполнения.
Rebuild «online» не блокирует таблицу во время непосредственной перестройки индекса, и индекс
доступен практически все время при перестроении, кроме времени переключения. Однако при этом
блокируется таблица в начале и в конце перестроения. При этом старый индекс не используется для
перестроения индекса, но с ним работают пользователи. Все изменения тем временем вносятся в
журнальную таблицу, затем уже будут перенесены в новый индекс. Может потребоваться большая
сортировка.
Таким образом, оператор coalesce особенно эффективен, когда процент проблематичного пространства
к общему индексному пространству невелик (20% листовых блоков) и фрагментирован индекс несущественно.
rebuild особенно эффективен, когда процент проблематичного пространства к общему индексному
пространству велик и средняя степень фрагментации в пределах индексного блока листа сравнительно
высокая.
В этом учебном материале вы узнаете, как создавать, переименовывать и удалять индексы (create, rename and drop indexes) в Oracle/PLSQL с синтаксисом и примерами.
В Oracle Indexes представляет собой метод настройки производительности, чтобы более быстрее извлекать записи из таблиц. Indexes создает запись для каждого значения, которое появляется в индексированных столбцах. По умолчанию, Oracle создает индексы B-дерева.
Create INDEX
Синтаксис
Синтаксис для создания индекса в Oracle/PLSQL:
CREATE [UNIQUE] INDEX index_name
ON table_name (column1, column2, … column_n)
[ COMPUTE STATISTICS ];
UNIQUE
Указывает на то, что сочетание значений в индексируемых столбцах должны быть уникальными.
index_name
Наименование индекса.
table_name
Имя таблицы для которой создается индекс.
column1, column2, … column_n
Столбцы для использования в индексе.
COMPUTE STATISTICS
Это послание Oracle для сбора статистических данных во время создания индекса. Статистические данные затем используются оптимизатором, чтобы выбрать «план выполнения», когда выполняются SQL запросы.
Пример
Рассмотрим пример того, как создать индекс в Oracle/PLSQL.
Например:
|
CREATE INDEX supplier_idx ON supplier (supplier_name); |
В этом примере мы создали index таблицы supplier под названием supplier_idx. Он состоит только из одного поля supplier_name.
Index также можно создать для нескольких полей, как в примере ниже:
|
REATE INDEX supplier_idx ON supplier (supplier_name, city); |
При создании index, для сбора статистических данных можно сделать следующим образом:
|
CREATE INDEX supplier_idx ON supplier (supplier_name, city) COMPUTE STATISTICS; |
Создание Function-Based INDEX
В Oracle, вы не ограничены созданием индексов только на столбцах. Вы можете создавать индексы на базе функций.
Синтаксис
Синтаксис для создания function-based index в Oracle/PLSQL:
CREATE [UNIQUE] INDEX index_name
ON table_name (function1, function2, … function_n)
[ COMPUTE STATISTICS ];
UNIQUE
Указывает на то, что сочетание значений в индексируемых столбцах должны быть уникальными.
index_name
Наименование индекса.
table_name
Имя таблицы для которой создается индекс.
function1, function2, … function_n
Функции для использования в индексе.
COMPUTE STATISTICS
Это послание Oracle для сбора статистических данных во время создания индекса. Статистические данные затем используются оптимизатором, чтобы выбрать «план выполнения», когда выполняются SQL запросы.
Пример
Рассмотрим на примере того, как создать function-based index в Oracle/PLSQL.
Например:
|
CREATE INDEX supplier_idx ON supplier (UPPER(supplier_name)); |
В этом примере мы создали index, основанный на вычислении поля supplier_name в верхний регистр с помощью функции UPPER.
Однако, чтобы быть уверенным, что оптимизатор Oracle использует этот индекс при выполнении ваших SQL предложений, убедитесь, что UPPER (supplier_name) не вычисляет значения NULL. Для обеспечения этого, добавьте UPPER (supplier_name) IS NOT NULL к вашему WHERE следующим образом:
|
SELECT supplier_id, supplier_name, UPPER(supplier_name) FROM supplier WHERE UPPER(supplier_name) IS NOT NULL ORDER BY UPPER(supplier_name); |
Rename INDEX
Синтаксис
Синтаксис для переименования index в Oracle/PLSQL:
ALTER INDEX index_name
RENAME TO new_index_name;
index_name
наименование индекса, который вы хотите переименовать.
new_index_name
Новое наименование, которое будет присвоено индексу.
Пример
Рассмотрим пример того, как переименовать индекс в Oracle/PLSQL.
Например:
|
ALTER INDEX supplier_idx RENAME TO supplier_index_name; |
В этом примере мы переименовали index с названием supplier_idx в supplier_index_name.
Сбор статистики по INDEX
Если при первом создании index вы не указали сбор статистики по index, или вы хотите обновить статистику, то вы можете выполнить это позднее, использовав команду ALTER INDEX для сбора статистических данных.
Синтаксис
Синтаксис для сбора статистических данных по индексу в Oracle/PLSQL:
ALTER INDEX index_name
REBUILD COMPUTE STATISTICS;
index_name
наименование индекса, для сбора статистических данных.
Пример
Рассмотрим пример того, как включить сбора статистики по index в Oracle/PLSQL.
Например:
|
ALTER INDEX supplier_idx REBUILD COMPUTE STATISTICS; |
В этом примере, мы собираем статистику для индекса supplier_idx.
Drop INDEX
Синтаксис
Синтаксис для удаления index индекса в Oracle/PLSQL.
DROP INDEX index_name;
index_name
наименование индекса, который хотим удалить.
Пример
Рассмотрим пример того, как удалить index в Oracle/PLSQL.
Например:
В этом примере мы удалили индекс supplier_idx.
Индексы Oracle обеспечивают быстрый доступ к строкам таблиц в базе данных, сохраняя отсортированные значения указанных столбцов и используя эти отсортированные значения для быстрого нахождения ассоциированных строк таблицы — во многом подобно тому, как применяется предметный указатель в конце книги для быстрого нахождения определенного места. Индексы позволяют находить строку с определенным значением столбца, просматривая при этом лишь небольшую часть общего объема строк таблицы. Таким образом, правильное использование индексов сокращает до минимума количество дорогостоящих операций ввода-вывода. Индексы — необязательные структуры базы данных, поддерживаемые полностью самой системой Oracle Database.
Применение индексов представляет собой компромисс между ускорением получения результатов запросов и замедлением обновлений и вставок данных. Первая часть этого компромисса — ускорение запросов — довольно очевидна: если поиск выполняется по отсортированному индексу вместо полного сканирования всей таблицы, то запрос проходит намного быстрее. Но всякий раз, когда вы обновляете, вставляете или удаляете строку таблицы с индексами, индексы также должны быть обновлены соответствующим образом. То есть такие операции на таблицах с индексами обходятся дороже. Вдобавок стоит помнить, что огромные таблицы будут иметь огромные индексы, и для их хранения потребуется диск большего объема.
Вообще говоря, если таблицы в основном используются для чтения (выборки) информации, как в хранилищах данных, то лучше иметь много индексов. Если же база данных относится к типу OLTP, с большим количеством вставок, обновлений и удалений, то лучше обойтись меньшим числом индексов.
Если только вам не нужно обращаться к большинству строк таблицы, индексированные запросы обеспечивают более быстрое получение результатов, чем запросы, не использующие индексы. Не существует ограничений на количество индексов, которые могут относиться к одной таблице Oracle, но, как упоминалось ранее, от их количества зависит производительность. Индекс полностью прозрачен для пользователя — т.е. оператор SQL пользователя не должен изменяться в результате создания индексов. Однако разработчикам приложений для построения эффективных запросов следует хорошо представлять себе, что такое индексы и как они работают.
Виды индексов Oracle Database
Индексы Oracle могут относиться к нескольким видам, наиболее важные из которых перечислены ниже.
- Уникальные и неуникальные индексы. Уникальные индексы основаны на уникальном столбце — обычно вроде номера карточки социального страхования сотрудника. Хотя уникальные индексы можно создавать явно, Oracle не рекомендует это делать. Вместо этого следует использовать уникальные ограничения. Когда накладывается ограничение уникальности на столбец таблицы, Oracle автоматически создает уникальные индексы по этим столбцам.
- Первичные и вторичные индексы. Первичные индексы — это уникальные индексы в таблице, которые всегда должны иметь какое-то значение и не могут быть равны null. Вторичные индексы — это прочие индексы таблицы, которые могут и не быть уникальными.
- Составные индексы. Составные индексы — это индексы, содержащие два или более столбца из одной и той же таблицы. Они также известны как сцепленные индексы (concatenated index). Составные индексы особенно полезны для обеспечения уникальности сочетания столбцов таблицы в тех случаях, когда нет уникального столбца, однозначно идентифицирующего строку.
Индексы и ключи
Часто можно встретить взаимозаменяемое употребление терминов “индекс” и “ключ”. Тем не менее, эти две сущности на самом деле отличаются друг от друга. Индекс — это физическая структура, хранящаяся в базе данных. Индекс можно создавать, изменять и уничтожать; в основном он служит для ускорения доступа к данным таблицы. С другой стороны, ключи — полностью логическая концепция. Ключи, с другой стороны, являются чисто логическим концепциями. Они представляют ограничения целостности, создаваемые для реализации бизнес-правил. Путаница между индексами и ключами обычно возникает потому, что база данных часто использует индекс для обеспечения ограничения целостности. Просто помните, что эти две вещи — не одно и то же.
Руководство по созданию индексов
Хотя хорошо известно, что индексы повышают производительность базы данных,следует знать, как их заставить работать должным образом. Добавление ненужных или неподходящих индексов к таблице может даже привести к снижению производительности. Ниже предоставлены некоторые рекомендации по созданию эффективных индексов в базе данных Oracle.
- Индексация имеет смысл, если нужно обеспечить доступ одновременно не более чем к 4–5% данных таблицы. Альтернативой использованию индекса для доступа к данным строки является полное последовательное чтение таблицы от начала до конца, что называется полным сканированием таблицы. Полное сканирование таблицы больше подходит для запросов, которые требуют извлечения большего процента данных таблицы. Помните, что применение индексов для извлечения строк требует двух операций чтения: индекса и затем таблицы.
- Избегайте создания индексов для сравнительно небольших таблиц. Для таких таблиц больше подходит полное сканирование. В случае маленьких таблиц нет необходимости в хранении данных и таблиц, и индексов.
- Создавайте первичные ключи для всех таблиц. При назначении столбца в качестве первичного ключа Oracle автоматически создает индекс по этому столбцу.
- Индексируйте столбцы, участвующие в многотабличных операциях соединения.
- Индексируйте столбцы, которые часто используются в конструкциях WHERE.
- Индексируйте столбцы, участвующие в операциях ORDER BY и GROUP BY или других операциях, таких как UNION и DISTINCT, включающих сортировку. Поскольку индексы уже отсортированы, объем работы по выполнению необходимой сортировки данных для упомянутых операций будет существенно сокращен.
- Столбцы, состоящие из длинно-символьных строк, обычно плохие кандидаты на индексацию.
- Столбцы, которые часто обновляются, в идеале не должны быть индексированы из-за связанных с этим накладных расходов.
- Индексируйте таблицы только с высокой селективностью. То есть индексируйте таблицы, в которых мало строк имеют одинаковые значения.
- Сохраняйте количество индексов небольшим.
- Составные индексы могут понадобиться там, где одностолбцовые значения сами по себе не уникальны. В составных индексах первым столбцом ключа должен быть столбец с максимальной селективностью.
Всегда помните золотое правило индексации таблиц: индекс таблицы должен быть основан на типах запросов, которые будут выполняться над столбцами этой таблицы. На таблице можно создавать более одного индекса; например, можно создать индекс на столбце X, или столбце Y, или обоих сразу, а также один составной индекс на обоих столбцах. Принимая правильное решение относительно того, какие индексы следует создавать, подумайте о наиболее часто используемых типах запросов данных таблицы.
Схемы индексации Oracle
Oracle предлагает несколько схем индексации, соответствующих требованиям различных типов приложений. На фазе проектирования после тщательного анализа конкретных требований приложения необходимо выбрать правильный тип индекса.
В реализации индексов на основе B-деревьев используется концепция сбалансированного (на что указывает буква “B” (balanced)) дерева поиска в качестве основы структуры индекса. В Oracle имеется собственный вариант B-дерева, именуемый “B*tree”. Это обычные индексы, создаваемые по умолчанию, когда вы применяете оператор CREATE INDEX. Термин “индекс B*tree” обычно не используется, когда речь идет об обычных индексах Oracle — они называются просто “индексами”.
Индексы на основе B-деревьев структурированы в форме обратного дерева, где блоки верхнего уровня называются блоками ветвей (branch blocks), а блоки нижнего уровня — листовыми блоками (leaf blocks). В иерархии узлов все узлы кроме вершины, или корневого узла, имеют родительский узел и могут иметь ноль или более дочерних узлов. Если глубина древовидной структуры, т.е. количество уровней, одинакова от каждого листового блока до корневого узла, то такое дерево называется сбалансированным, или B-деревом.
B-деревья автоматически поддерживают необходимый уровень индекса по размеру таблицы. B-деревья также гарантируют, что индексные блоки всегда будут заполнены не меньше, чем наполовину, и менее, чем на 100%. B-деревья допускают операции выборки, вставки и удаления с очень небольшим количеством операций ввода-вывода на один оператор. Большинство B-деревьев имеет всего три и менее уровней. При использовании B-дерева нужно читать только блоки B-дерева, так что количество операций ввода-вывода будет ограничено числом уровней B-дерева (скажем, тремя) плюс две операции ввода-вывода на выполнение обновления или удаления (одна для чтения и одна для записи). Для выполнения поиска по B-дереву понадобится всего три или менее обращений к диску.
Реализация B-дерева от Oracle — B*tree — всегда сохраняет дерево сбалансированным. Листовые блоки содержат по два элемента: индексированные значения столбца и соответствующий идентификатор ROWID для строки, которая содержит это значение столбца. ROWID — уникальный указатель Oracle, идентифицирующий физическое местоположение строки и обеспечивающий самый быстрый способ доступа к строке в базе данных Oracle. Сканирование индекса быстро дает ROWID строки, и отсюда можно быстро получить к ней доступ непосредственно. Если запрос нуждается лишь в значении индексированного столбца, то конечно, последний шаг исключается, поскольку извлекать дополнительные данные, кроме прочитанных из индекса, не потребуется.
Оценка размера индекса
Как и в случае таблиц, для оценки размера нового индекса можно использовать пакет DBMS_SPACE. Процедуре CREATE_INDEX_COST этого пакета потребуется передать оператор DDL, создающий индекс, в качестве атрибута, как показано в листинге ниже.
SQL> SET SERVEROUTPUT ON
SQL> declare
2 l_index_ddl VARCHAR2(1000);
3 l_used_bytes NUMBER;
4 l_allocated_bytes NUMBER;
5 BEGIN
6 DBMS_SPACE.create_index_cost (
7 ddl => 'create index persons_idx on persons(person_id)',
8 used_bytes => l_used_bytes,
9 alloc_bytes => l_allocated_bytes);
10 DBMS_OUTPUT.PUT_LINE ('используется = ' || l_used_bytes || 'байт'
11 || ' выделено = ' || l_allocated_bytes || 'байт');
12* END;
SQL> /
используется = 154414918 байт выделено = 427720704 байт
PL/SQL procedure successfully completed.
SQL>
Обратите внимание на отличие между атрибутами, касающимися размера, в процедуре CREATE_INDEX_COST:
- used_bytes показывает количество байт, которыми представлены данные индекса;
- alloc_bytes показывает количество байт, которое займет индекс в табличном пространстве после его создания.
Совет. Для того чтобы пакет DBMS_SPACE мог адекватно оценить размеры индексов, таблица, на которой планируется создание нового индекса, должна существовать, а база данных должна иметь актуальную статистику по этой таблице.
Создание индекса
Индекс создается с помощью оператора CREATE INDEX, как показано ниже:
SQL> CREATE INDEX employee_id ON employee(employee_id) TABLESPACE emp_index_01;
При создании индекса для большой таблицы, уже заполненной данными, статистику оптимизатора можно собрать во время создания таблицы, специфицировав опцию COMPUTE STATISTICS, как показано в следующем примере:
SQL> CREATE INDEX employee_id ON employee(employee_id) TABLESPACE emp_index_01 COMPUTE STATISTICS;
Если не специфицировать настройки хранения, база данных использует опции хранения по умолчанию табличного пространства, которое было указано при создании индекса.
По умолчанию Oracle допускает дублированные значения в столбцах индекса, которые также называются ключевыми столбцами. Однако можно специфицировать уникальный индекс, что исключит дублирование значений столбца в нескольких строках. Для создания уникального индекса служит оператор CREATE UNIQUE INDEX:
SQL> CREATE UNIQUE INDEX employee_id ON employee(employee_id) TABLESPACE emp_index_01;
Приведенные до сих пор примеры демонстрировали создание индексов на одиночных столбцах. Также можно создать составной индекс на таблице, специфицируя не-сколько столбцов в операторе CREATE INDEX, как показано в следующем примере:
SQL> CREATE INDEX employee_id ON employee(employee_id,location_id) TABLESPACE emp_index_01;
Все примеры создания индекса до сих пор демонстрировали явное создание индекса на столбце таблицы. Тем не менее, есть и другой способ создания индекса на таблице,который заключается в простой спецификации ограничений целостности UNIQUE или PRIMARY KEY на этой таблице. Если поступить так, Oracle автоматически создает уникальный индекс по уникальному или первичному ключу. База данных создаст индекс автоматически, когда будет включено ограничение, и по умолчанию он получит имя соответствующего ограничения. Ниже приведено два примера, демонстрирующие ситуации, когда база данных создает автоматический индекс на столбцах таблицы.
В первом случае задается уникальное ограничение на двух столбцах: dept_name и location.
SQL> CREATE TABLE dept( dept_no NUMBER(3), dept_name VARCHAR2(15), location VARCHAR2(25), CONSTRAINT dept_name_ukey UNIQUE(dept_Name,location);
База данных автоматически создает уникальный индекс по этим двум столбцам,чтобы обеспечить соблюдение ограничения уникальности по имени dept_name_ukey.
Во втором примере показано, как при создании таблицы специфицировать ограничение первичного ключа на столбце.
SQL> CREATE TABLE employee ( empno NUMBER (5) PRIMARY KEY, age INTEGER) ENABLE PRIMARY KEY USING INDEX TABLESPACE users;
Приведенный выше оператор CREATE TABLE включает ограничение первичного ключа, которое автоматически создает уникальный индекс на столбце empno.
Можно также указать, что база данных должна использовать существующий индекс для обеспечения нового ограничения, как показано в следующем примере:
SQL> ALTER TABLE employee ADD CONSTRAINT test_const1 PRIMARY KEY (pkey1) USING INDEX ind1;
В этом примере новый первичный ключ использует существующий индекс ind1, без создания нового индекса. Интересно то, что оператор CREATE INDEX можно специфицировать при создании ограничения уникальности или первичного ключа. В следующем примере создается первичный ключ на столбце emp_id:
SQL> CREATE TABLE employee ( emp_id INT PRIMARY KEY USING INDEX (create index ind1 ON employee (emp_id)))
Применение оператора CREATE INDEX в этом примере обеспечивает более тонкий контроль над созданием индекса для указанного ограничения первичного ключа.
Специальные типы индексов
Нормальный или типовой индекс, который создается в базе данных, называется индексом кучи (heap index), или неупорядоченным индексом. Oracle также предоставляет несколько специальных типов индексов для специфических нужд. Сейчас рассмотрим основные типы индексов.
Битовые индексы
Битовые индексы (bitmap indexes) используют битовые карты для указания значения индексированного столбца. Это идеальный индекс для столбца с низкой кардинальностью при большом размере таблицы. Эти индексы обычно не годятся для таблиц с интенсивным обновлением, но хорошо подходят для приложений хранилищ данных.
Битовые индексы состоят из битового потока (единиц и нулей) для каждого столбца индекса. Битовые индексы очень компактны по сравнению с нормальными индексами на основе B-деревьев. В табл. 7.2 дано сравнение индексов B-деревьев с битовыми индексами.
| Индексы B-деревьев | Битовые индексы |
| Хороши для данных с высокой кардинальностью | Хороши для данных с низкой кардинальностью |
| Хороши для баз данных OLTP | Хороши для приложений хранилищ данных |
| Занимают много места | Используют относительно мало места |
| Легко обновляются | Трудно обновляются |
Для создания битового индекса используется оператор CREATE INDEX с добавочным ключевым словом BITMAP:
SQL> CREATE BITMAP INDEX gender_idx ON employee(gender) TABLESPACE emp_index_05;
Иногда можно наблюдать значительное повышение производительности при замене обычных индексов B*tree на битовые в некоторых очень крупных таблицах. Однако каждый элемент битового индекса покрывает огромное количество строк в таблице, так что когда данные обновляются, вставляются или удаляются из таблицы, то необходимые обновления битового индекса очень велики, и сам индекс может существенно увеличиться в размере. Единственный способ обойти это увеличение размера индекса с последующим падением производительности заключается в регулярной его перестройке. Вы можете сделать вывод, что битовый индекс — не слишком разумная альтернатива для таблиц, подвергающихся большому количеству вставок, удалений и обновлений.
Индексы с реверсированным ключом
Индексы с реверсированным ключом — это, по сути, то же самое, что и индексы B-деревьев, за исключением того, что байты данных ключевого столбца при индексации меняют порядок на противоположный. Порядок столбцов остается нетронутым;меняется только порядок байтов. Самое большое преимущество применения индексов с реверсированным ключом состоит в том, что они исключают неприятные последствия упорядоченной вставки значений в индекс. Вот как создается индекс с реверсированным ключом:
SQL> CREATE INDEX reverse_idx ON employee(emp_id) REVERSE;
При использовании индекса с реверсированным ключом база данных не сохраняет ключи индекса друг за другом в лексикографическом порядке. Таким образом, когда в запросе присутствует предикат неравенства, ответ получается медленнее, поскольку база данных вынуждена выполнять полное сканирование таблицы. При индексе с реверсированным ключом база данных не может запустить запрос по диапазону ключа индекса.
Индексы со сжатым ключом
Сэкономить пространство хранения индекса вместе с повышением производительности можно за счет создания индекса со сжатым ключом. Всякий раз, когда индексируемый ключ имеет повторяющийся компонент, или же создается уникальный многостолбцовый индекс, получается выигрыш от использования сжатия ключа. Вот пример:
SQL> CREATE INDEX emp_indx1 ON employees(ename) TABLESPACE users COMPRESS 1;
Приведенный выше оператор сжимает все дублированные вхождения индексированного ключа в листовом блоке индекса (на уровне 1).
Индексы на основе функций
Индексы на основе функций предварительно вычисляют значения функций по заданному столбцу и сохраняют результат в индексе. Когда конструкция where содержит вызовы функций, то основанные на функциях индексы являются идеальным способом индексирования столбца.
Ниже показано, как создать индекс на основе функции LOWER:
SQL> CREATE INDEX lastname_idx ON employees(LOWER(l_name));
Этот оператор CREATE INDEX создаст индекс по столбцу l_name, хранящему фамилии сотрудников в верхнем регистре. Однако этот индекс будет основан на функции,поскольку база данных создает его по столбцу l_name, применив к нему предварительно функцию LOWER для преобразования его значения в нижний регистр.
Секционированные индексы
Секционированные индексы используются для индексации секционированных таблиц. Oracle предлагает два типа индексов для таких таблиц: локальные и глобальные.
Существенное различие между ними заключается в том, что локальные индексы основаны на разделах таблицы, по которой они созданы. Если таблица секционирована на 12 разделов по диапазонам дат, то индексы также будут распределены по тем же 12 разделам. Другими словами, между разделами индексов и разделами таблиц существует соответствие “один к одному”. Такого соответствия нет между глобальными индексами и разделами таблицы, потому что глобальные индексы секционируются независимо от базовых таблиц.
В следующих разделах этой статьи будут раскрыты важные различия между управлением глобально секционированными индексами и локально секционированными индексами.
Глобальные индексы
Глобальные индексы на секционированных таблицах могут быть как секционированными, так и несекционированными. Глобальные несекционированные индексы подобны обычным индексам Oracle для несекционированных таблиц. Для создания таких индексов применяется обычный синтаксис CREATE INDEX.
Ниже приведен пример глобального индекса на таблице ticket_sales:
SQL> CREATE INDEX ticketsales_idx ON ticket_sales(month) GLOBAL PARTITION BY range(month) (PARTITION ticketsales1_idx VALUES LESS THAN (3) PARTITION ticketsales1_idx VALUES LESS THAN (6) PARTITION ticketsales2_idx VALUES LESS THAN (9) PARTITION ticketsales3_idx VALUES LESS THAN (MAXVALUE);
Обратите внимание, что управление глобально секционированными индексами требует серьезных усилий. Всякий раз, когда происходит какое-то действие DDL над секционированной таблицей, ее глобальные индексы требуют перестройки. Действия DDL над лежащей в основе таблицей помечают глобальные индексы как недействительные.По умолчанию любая операция обслуживания секционированной таблицы делает недействительными глобальные индексы.
Давайте в качестве примера воспользуемся таблицей ticket_sales, чтобы разобраться, почему это так. Предположим, что вы ежеквартально уничтожаете самый старый раздел, чтобы освободить место для нового раздела, в который поступят данные за новый квартал. Когда уничтожается раздел, относящийся к таблице ticket_sales,глобальные индексы могут стать недействительными, потому что часть данных, на которые они указывают, перестают существовать. Чтобы предотвратить такое объявление недействительным индекса из-за уничтожения раздела, необходимо использовать опцию UPDATE GLOBAL INDEXES вместе с оператором DROP PARTITION:
SQL> ALTER TABLE ticket_sales DROP PARTITION sales_quarter01 UPDATE GLOBAL INDEXES;
На заметку! Если не включить оператор UPDATE GLOBAL INDEXES, то все глобальные индексы станут недействительными. Опцию UPDATA GLOBAL INDEXES можно также использовать при добавлении, объединении, обмене, слиянии, перемещении, разделении или усечении секционированных таблиц. Разумеется, с помощью ALTER INDEX…REBUILD можно перестраивать любого индекса, который становится недействительным, но эта опция также требует дополнительных затрат времени и обслуживания.
При небольшом количестве листовых блоков индекса, что приводит к высокой конкуренции, Oracle рекомендует использовать глобальные индексы с хеш-секционированием. Синтаксис для создания хеш-секционированного глобального индекса подобен тому, что применяется для хеш-секционированной таблицы. Например, следующий оператор создает хеш-секционированный глобальный индекс:
SQL> CREATE INDEX hgidx ON tab (c1,c2,c3) GLOBAL PARTITION BY HASH (c1,c2) (PARTITION p1 TABLESPACE tbs_1, PARTITION p2 TABLESPACE tbs_2, PARTITION p3 TABLESPACE tbs_3, PARTITION p4 TABLESPACE tbs_4);
Локальные индексы
Локально секционированные индексы, в отличие от глобально секционированных индексов, имеют отношение “один к одному” с разделами таблицы. Локально секционированные индексы можно создавать в соответствии с разделами и даже подразделами. База данных конструирует индекс таким образом, чтобы он был секционирован так же,как и его таблица. При каждой модификации раздела таблицы база автоматически сопровождает это соответствующей модификацией раздела индекса. Это, наверное, самое большое преимущество использования локально секционированных индексов — Oracle автоматически перестраивает их всегда, когда уничтожается раздел или над ним выполняется какая-то другая операция DDL.
Ниже приведен простой пример создания локально секционированного индекса на секционированной таблице:
SQL> CREATE INDEX ticket_no_idx ON ticket_sales(ticket__no) LOCAL TABLESPACE localidx_01;
Совет. С помощью нового инструмента SQL Access Advisor можно получать рекомендации относительно того, какие индексы нужно создать. SQL Access Advisor также сообщит о том, какие индексы не используются и потому являются кандидатами на удаление.
Невидимые индексы
По умолчанию оптимизатор “видит” все индексы. Тем не менее, можно создать невидимый индекс, который оптимизатор не обнаруживает и не принимает во внимание при создании плана выполнения оператора. Невидимый индекс можно применять в качестве временного индекса для определенных операций или его тестирования перед тем, как сделать его “официальным”. Вдобавок, иногда объявление индекса невидимым можно использовать в качестве альтернативы уничтожению индекса или объявлению его недоступным. Сделать индекс невидимым можно временно, чтобы протестировать эффект от его уничтожения.
База данных поддерживает невидимый индекс точно так же, как и нормальный (видимый) индекс. После объявления индекса невидимым, его и все прочие невидимые индексы можно сделать вновь видимым для оптимизатора, установив значение параметра optimizer_use_invisible_indexes равным TRUE на уровне сеанса или всей системы. Значением этого параметра по умолчанию является FALSE, а это означает, что оптимизатор по умолчанию не может использовать невидимые индексы.
Создание невидимого индекса
Чтобы сделать индекс невидимым, к оператору CREATE INDEX нужно добавить конструкцию INVISIBLE, как показано ниже:
SQL> CREATE INDEX test_idx ON test(tname) TABLESPACE testdata STORAGE (INITIAL 20K NEXT 20k PCTINCREASE 75) INVISIBLE;
Приведенный выше оператор создает невидимый индекс test_idx по столбцу tname таблицы test.
Превращение индекса в невидимый
В дополнение к созданию невидимого индекса, с помощью команды ALTER INDEX можно превратить существующий индекс в невидимый:
SQL> ALTER INDEX test_idx INVISIBLE;
Чтобы сделать невидимый индекс вновь видимым, используйте следующий оператор:
SQL> ALTER INDEX test_idx VISIBLE;
Приведенные ниже запрос к представлению DBA_INDEXES показывает состояние видимости индекса:
SQL> SELECT INDEX_NAME, VISIBILITY FROM USER_INDEXES WHERE INDEX_NAME = 'INDX1'; INDEX_NAME VISIBILITY ---------- ---------- INDX1 VISIBLE SQL>
Мониторинг использования индекса
Oracle предлагает инструменты EXPLAIN PLAN и SQL Trace, которые помогают увидеть путь, проходимый запросом перед его выполнением. Вывод команды EXPLAIN PLAN и результаты SQL Trace позволяют увидеть путь выполнения запроса и определить, использует ли он индексы.
Oracle также предлагает более простой способ слежения за индексами в базе данных. Если вы сомневаетесь в использовании определенного индекса, можете попросить Oracle выполнить мониторинг его применения. Таким образом, если индекс окажется избыточным, его можно уничтожить и сэкономить место в хранилище, а также снизить накладные расходы на операции DML.
Опишем, что потребуется сделать для отслеживания индекса в базе данных. Предположим, что вы пытаетесь узнать, используется ли индекс p_key_sales в определенных запросах к таблице sales. Обеспечьте репрезентативный промежуток времени для оценки использования индекса. Для базы данных OLTP этот промежуток может быть относительно коротким. Для хранилища данных может понадобиться запустить тестовый мониторинг на несколько дней, чтобы точно проверить, как используется индекс.
Чтобы запустить мониторинг использования индекса, войдите в базу как владелец индекса p_key_sales и запустите следующую команду:
SQL> ALTER INDEX p_key_sales MONITORING USAGE; Index altered. SQL>
Теперь запустите какие-нибудь запросы к таблице sales. Завершите мониторинг,применив следующую команду:
SQL> ALTER INDEX p_key_sales NOMONITORING USAGE; Index altered. SQL>
После этого можно запросить представление словаря данных V$OBJECT_USAGE для определения того, использовался ли индекс p_key_sales. Следующий результат подтверждает использование индекса:
SQL> SELECT * FROM v$object_usage WHERE index_name='P_KEY_SALES'; INDEX_NM TAB_NM MON USED START_MON END_MONITORING ---------- ------ ---- ----- ------------------ -------------------- P_KEY_SALES SALE NO YES 01/23/2008 06:20:45 01/23/2008 06:40:22
В приведенном выводе Oracle выводит значение YES в столбце USED, указывая на то,что интересующий индекс использовался базой данных. Если индекс был проигнорирован во время мониторинга, столбец содержал бы значение NO. Причина, по которой нельзя узнать количество случаев использования индекса, связана с тем, что база данных выполняет мониторинг его использования только на фазе разбора (parsing); если бы разбор производился при каждом выполнении, пострадала бы производительность.
Обслуживание индексов
Данные индекса постоянно изменяются из-за DML-действий, связанных с его таблицей. Индексы часто становятся слишком большими, если происходит много удалений строк, потому что пространство, занятое удаленными значениями, автоматически повторно индексом не используется. За счет периодического применения команды REBUILD можно реорганизовать индексы и сделать их более компактными, а потому и более эффективными. Команда REBUILD также служит для изменения параметров хранения, которые устанавливаются во время начального создания индекса. Вот пример:
SQL> ALTER INDEX sales_idx REBUILD; Index altered. Sql>
Перестройка индексов лучше уничтожения и воссоздания неудачного индекса, потому что при этой операции пользователи продолжают иметь доступ к индексу в процессе его перестройки. Однако индексы в процессе перестройки накладывают много ограничений на действия пользователя. Еще более эффективный способ перестройки индексов состоит в том, чтобы сделать это в оперативном (online) режиме, как показано в следующем примере. Во время оперативной перестройки индекса разрешено применение всех операций DML, но не операций DDL.
SQL> ALTER INDEX p_key_sales REBUILD ONLINE; Index altered. SQL>
Оперативную перестройку индекса можно ускорить за счет добавления к показанному выше оператору ALTER INDEX конструкции ONLINE NOLOGGING. После добавления этой конструкции база данных не будет генерировать данные повторного выполнения для операции перестройки индекса.
Вас заинтересует / Intresting for you:

Introduction to Oracle Index
The index in Oracle can be defined as a schema object which stores an entry for each value that appears in the columns and for each value also the location of the rows that have that value which helps the database in improving the efficiency as it helps the database to provide fast access to those rows which have a particular data and it can be termed as a performance tuning mechanism as it allows faster retrieval of data from Oracle database.
Syntax
In this section of the article, we are going to discuss how we can create an index in the Oracle database. Let us take a look into the syntax of how to create an INDEX in Oracle first.
CREATE INDEX index_name
ON table_name(column1,column2,...,columnN);
Parameters
Below are the Parameters:
index_name: It refers to the name we want to give to the index we are creating.
table_name: It refers to the name of the table on which we want to create an index.
column1, column2,…, column: It refers to the column or columns to use in the index.
Examples to Implement Oracle Index
In order to have a better understanding, we will take a few examples.
Example #1
In the first example, we will try to create an INDEX for the table employee but for only one column. We are going to create an INDEX for the column name in the employee table.
Code:
CREATE INDEX employee_index
ON employee (name);
Output:
Explanation: As we can see in the screenshot that the INDEX has been created successfully.
Example #2
In the second example, we will create an INDEX for more than one column. In this example, we will create an INDEX for columns city and vehicle id present in the table employee. Let us look at the query.
Code:
CREATE INDEX employeeCity_index
ON employee (city, vehicle_id);
Output:
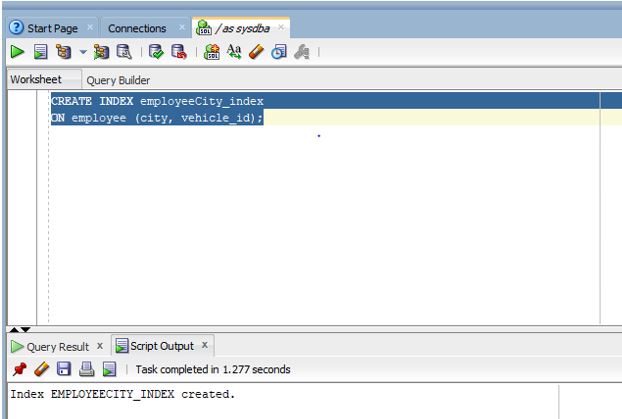
Explanation: As we can see in the screenshot the INDEX has been successfully created.
Example #3
In the third example, we will create a FUNCTION BASED INDEX. In this example, we will create an INDEX based on the lower case evaluation of the column NAME in the employee table.
Code:
CREATE INDEX employee_name
ON employee (LOWER(name));
Output:
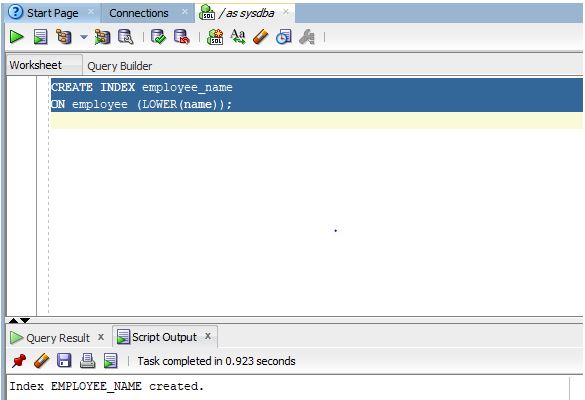
Explanation: As we can see in the screenshot the FUNCTION BASED INDEX has been successfully created.
How to Alter Index in Oracle?
In this section, we are going to check hoe to ALTER an index. One important point to note is that the schema must contain the INDEX which we want to alter and also the user must have the right to ALTER the INDEX. In general, these type of rights is usually present with the DBA team.
We can do many types of activities using ALTER INDEX.
1. Rename An Index
In this case, we will change the name of an existing INDEX which is already present in the schema. Let us look at the SYNTAX for the same.
Code:
ALTER INDEX currentindex_name
RENAME TO new_indexname;
Parameters:
currentindex_name: It refers to the current name of the index which we want to alter
new_indexname: It refers to the new name which we want to give the INDEX.
Code:
ALTER INDEX EMPLOYEE_NAME
RENAME TO EMPLOYEE_IND;
Output:
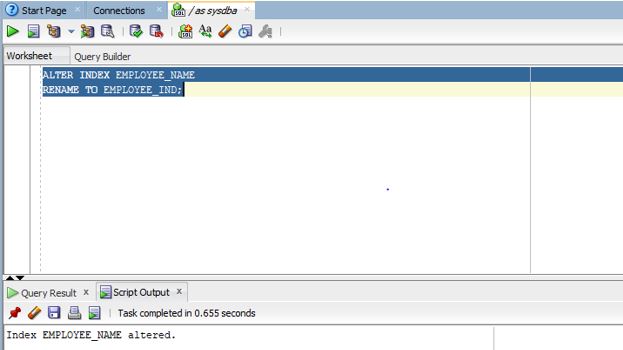
Explanation: As we can see in the screenshot the INDEX has been altered successfully.
2. Making an Index Invisible
In this case, we are going to make an existing INDEX that is visibly invisible. In this example, we are going to make the INDEX EMPLOYEE_IND invisible. Let us look at the query.
Code:
ALTER INDEX EMPLOYEE_IND INVISIBLE;
Output:
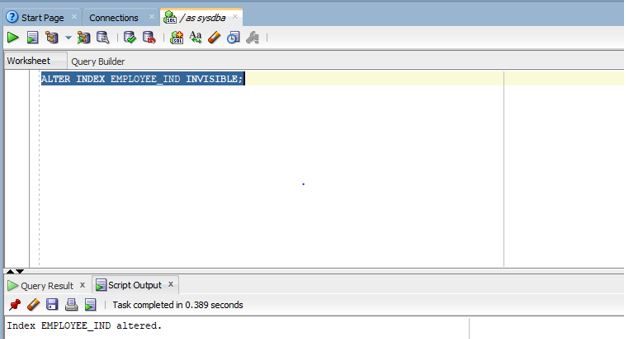
Explanation: As we can see in the screenshot, the INDEX has been altered successfully.
3. To Monitor Index Usage
In this case, we will monitor the index so that the customer or user gets to know whether the INDEX is being used, f not it can be dropped by the user. Let us look at the syntax.
Code:
ALTER INDEX index_name MONITORING USAGE
Parameters:
Index_name: This refers to the INDEX which we want to monitor.
Code:
ALTER INDEX EMPLOYEE_IND MONITORING USAGE;
Output:
Explanation: As we can see in the screenshot the INDEX EMPLOYEE_IND has been altered successfully.
How to Drop an Index in Oracle?
In this section, we are going to discuss how to DROP an INDEX. An important point is that we need to have permission to perform this activity and also the INDEX should be present in the database. When we execute the drop statement the database invalidates all objects that depend on the table with which the INDEX was associated.
Code:
DROP INDEX EMPLOYEE_IND;
Output:
Explanation: As we can see in the screenshot the INDEX has been dropped successfully.
Conclusion
In this article, we discussed the INDEX in Oracle. We started with the definition of the INDEX and then we discussed how we can create, alter, and drop indexes in Oracle. All scenarios were discussed with the help of examples.
Recommended Articles
This is a guide to Oracle Index. Here we discuss an introduction to Oracle Index, how to alter, and drop it with query examples. You can also go through our other related articles to learn more –
- Oracle Versions
- Oracle Clauses
- Oracle String Functions
- Career in Oracle