How To Modify Linux Source Code?
-
Thread starterGuest
-
Start dateMay 2, 2015
Guest
Guest
-
#1

-
- Jan 15, 2005
-
- 1,358
-
- 20
-
- 19,515
- 67
-
#25
The kernel its self is mostly written in C. A lot of the user programs may be written in C++ (amongst other languages).

-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#2
Look at, and understand, the source code of whatever Linux distro you want.

-
- Jul 2, 2006
-
- 12,407
-
- 54
-
- 65,040
- 2,381
-
#3

-
- Jan 31, 2015
-
- 2,021
-
- 0
-
- 6,460
- 439
-
#4
Guest
Guest
-
#5

-
- Dec 27, 2006
-
- 4,036
-
- 2
-
- 23,960
- 493
-
#6
Excuse me, I meant are there a lot of commands I need to know with the terminal or a text editor?
Yes there is a lot you need to know.
want to know what the text in the source code means & what it does
You want to make your own distrobution? At this moment in time you are doomed if you cannot even be comfortable with the command line.
I suggest you take an introductory programming course before moving on.
If you feel adventurous:
https://wiki.ubuntu.com/DerivativeDistroHowto
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#7
This is what programming courses are for.
«Hi guys. I want to build a car. What metal should I make it out of?»
-
- Jan 31, 2015
-
- 2,021
-
- 0
-
- 6,460
- 439
-
#8
On the contrary, changing the source code is easy.
I want to know what the text in the source code means & what it does.
That’s more like it. Knowing what to change, and what to change it to, is the difficult bit.
It sounds as if you are taking about a whole Linux distribution rather than just the kernel. This consists of millions of lines of source code that people have been working on for twenty years or more. If you don’t know what any of it means, your chances of successfully modifying it at present compare unfavourably to those monkeys typing Shakespeare.
1. You need to learn how to program in C.
2. You have to learn how to program in x86 assembler.
3. You need to learn the coding conventions used in Linux source code and the functions provided to programs by its various libraries.
4. You need to study the source code of the Linux kernel and the user programs to understand what it does. You’ll probably need to read a few books to help you with this.
5. You need to decide which part of the Linux sources you wish to change and what effect you want the change to have.
6. You can then make the change, compile the resulting source, and test it.
7. Repeat 4 & 5 until the changes you make have the desired effect and don’t break anything.
8. Repeat 4, 5, & 6 until you have achieved your objective.
Start with point 1. Allow yourself 6 months to a year to become proficient in C. Then you can go on to step 2, and so on.
Guest
Guest
-
#9
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#10
You cannot learn to program in C from a youtube video.
If you can’t find any programming books for C, you have not looked.
-
- Dec 27, 2006
-
- 4,036
-
- 2
-
- 23,960
- 493
-
#11
http://lmgtfy.com/?q=learn+to+program+c
Guest
Guest
-
#12
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#13
If we equate «Modify Linux Source Code» to climbing Mt. Everest…
Go to your local community college or equivalent.
Take a couple of programming classes.
At the end of those classes, you are at the stage of «qualified to hang a poster of Mt Everest on your wall «
But do go take those classes. Every journey begins with but a single step.
Guest
Guest
-
#14
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#15
No, you should learn and understand a bit of «programming» first.
The Linux kernel comes later. Much, much later.
Guest
Guest
-
#16
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#17
The community college? In the US…if you are above 16 or so, you can probably enroll.
There are other resources, though, to learn ‘programming’. Like thousands.
Khan Academy, MIT OpenCourseware, Stanford…
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#18
Guest
Guest
-
#19

-
- Sep 23, 2012
-
- 22,291
-
- 3
-
- 84,965
- 3,344
-
#20
You probably want to change the furniture, wall coverings and carpet.
I suggest that you start by installing a typical linux OS, then find out what there is you don’t like about it, or think you can do better. I’d be highly surprised if you needed to touch the kernel (beyond, at most, using pre-made patches).
Guest
Guest
-
#21
-
- Sep 23, 2012
-
- 22,291
-
- 3
-
- 84,965
- 3,344
-
#22
I’m not so sure how to integrate it into a new distro, though.
-
- Jan 6, 2014
-
- 206
-
- 0
-
- 10,710
- 20
-
#23
It can literally take four years of college to simply have an idea of how the operating system kernels work. In case of Linux, or any other unix-like OS, knowing C and C systems programming is the key as all those OSes were built around the C programming language. You may want to check out the wikipedia article on C, Unix, and Linux to get some general idea.
Guest
Guest
-
#24
-
- Jan 15, 2005
-
- 1,358
-
- 20
-
- 19,515
- 67
-
#25
The kernel its self is mostly written in C. A lot of the user programs may be written in C++ (amongst other languages).
- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- Topics
How To Modify Linux Source Code?
-
Thread starterGuest
-
Start dateMay 2, 2015
Guest
Guest
-
#1
-
- Jan 15, 2005
-
- 1,358
-
- 20
-
- 19,515
- 67
-
#25
The kernel its self is mostly written in C. A lot of the user programs may be written in C++ (amongst other languages).
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#2
Look at, and understand, the source code of whatever Linux distro you want.
-
- Jul 2, 2006
-
- 12,407
-
- 54
-
- 65,040
- 2,381
-
#3
-
- Jan 31, 2015
-
- 2,021
-
- 0
-
- 6,460
- 439
-
#4
Guest
Guest
-
#5
-
- Dec 27, 2006
-
- 4,036
-
- 2
-
- 23,960
- 493
-
#6
Excuse me, I meant are there a lot of commands I need to know with the terminal or a text editor?
Yes there is a lot you need to know.
want to know what the text in the source code means & what it does
You want to make your own distrobution? At this moment in time you are doomed if you cannot even be comfortable with the command line.
I suggest you take an introductory programming course before moving on.
If you feel adventurous:
https://wiki.ubuntu.com/DerivativeDistroHowto
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#7
This is what programming courses are for.
«Hi guys. I want to build a car. What metal should I make it out of?»
-
- Jan 31, 2015
-
- 2,021
-
- 0
-
- 6,460
- 439
-
#8
On the contrary, changing the source code is easy.
I want to know what the text in the source code means & what it does.
That’s more like it. Knowing what to change, and what to change it to, is the difficult bit.
It sounds as if you are taking about a whole Linux distribution rather than just the kernel. This consists of millions of lines of source code that people have been working on for twenty years or more. If you don’t know what any of it means, your chances of successfully modifying it at present compare unfavourably to those monkeys typing Shakespeare.
1. You need to learn how to program in C.
2. You have to learn how to program in x86 assembler.
3. You need to learn the coding conventions used in Linux source code and the functions provided to programs by its various libraries.
4. You need to study the source code of the Linux kernel and the user programs to understand what it does. You’ll probably need to read a few books to help you with this.
5. You need to decide which part of the Linux sources you wish to change and what effect you want the change to have.
6. You can then make the change, compile the resulting source, and test it.
7. Repeat 4 & 5 until the changes you make have the desired effect and don’t break anything.
8. Repeat 4, 5, & 6 until you have achieved your objective.
Start with point 1. Allow yourself 6 months to a year to become proficient in C. Then you can go on to step 2, and so on.
Guest
Guest
-
#9
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#10
You cannot learn to program in C from a youtube video.
If you can’t find any programming books for C, you have not looked.
-
- Dec 27, 2006
-
- 4,036
-
- 2
-
- 23,960
- 493
-
#11
http://lmgtfy.com/?q=learn+to+program+c
Guest
Guest
-
#12
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#13
If we equate «Modify Linux Source Code» to climbing Mt. Everest…
Go to your local community college or equivalent.
Take a couple of programming classes.
At the end of those classes, you are at the stage of «qualified to hang a poster of Mt Everest on your wall «
But do go take those classes. Every journey begins with but a single step.
Guest
Guest
-
#14
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#15
No, you should learn and understand a bit of «programming» first.
The Linux kernel comes later. Much, much later.
Guest
Guest
-
#16
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#17
The community college? In the US…if you are above 16 or so, you can probably enroll.
There are other resources, though, to learn ‘programming’. Like thousands.
Khan Academy, MIT OpenCourseware, Stanford…
-
- Mar 16, 2013
-
- 161,394
-
- 13,441
-
- 176,090
- 24,454
-
#18
Guest
Guest
-
#19
-
- Sep 23, 2012
-
- 22,291
-
- 3
-
- 84,965
- 3,344
-
#20
You probably want to change the furniture, wall coverings and carpet.
I suggest that you start by installing a typical linux OS, then find out what there is you don’t like about it, or think you can do better. I’d be highly surprised if you needed to touch the kernel (beyond, at most, using pre-made patches).
Guest
Guest
-
#21
-
- Sep 23, 2012
-
- 22,291
-
- 3
-
- 84,965
- 3,344
-
#22
I’m not so sure how to integrate it into a new distro, though.
-
- Jan 6, 2014
-
- 206
-
- 0
-
- 10,710
- 20
-
#23
It can literally take four years of college to simply have an idea of how the operating system kernels work. In case of Linux, or any other unix-like OS, knowing C and C systems programming is the key as all those OSes were built around the C programming language. You may want to check out the wikipedia article on C, Unix, and Linux to get some general idea.
Guest
Guest
-
#24
-
- Jan 15, 2005
-
- 1,358
-
- 20
-
- 19,515
- 67
-
#25
The kernel its self is mostly written in C. A lot of the user programs may be written in C++ (amongst other languages).
- Advertising
- Cookies Policies
- Privacy
- Term & Conditions
- Topics

Согласитесь, приятно и полезно, когда в проекте исходный код выглядит красиво и единообразно. Это облегчает его понимание и поддержку. Покажем и расскажем, как реализовать форматирование исходного кода при помощи clang-format, git и sh.
Проблемы с форматированием и как их решить
В большинстве проектов существуют определенные правила оформления кода. Как сделать так, чтобы все участники их выполняли? На помощь приходят специальные программы — clang-format, astyle, uncrustify, — но у них есть свои недостатки.
Главная проблема форматеров состоит в том, что они меняют файлы целиком, а не только изменённые строки. Расскажем, как мы с этим справились, используя ClangFormat в рамках одного из проектов по разработке встроенного ПО для электроники, где С++ был основным языком. В команде работало несколько человек, поэтому для нас было важно обеспечить единый стиль кода. Наше решение может подойти не только программистам С++, но и тем, кто пишет код на C, Objective-C, JavaScript, Java, Protobuf.
Для форматирования мы использовали clang-format-diff-6.0. На старте запустили команду
git diff -U0 —no-color | clang-format-diff-6.0 -i -p1, но с ней возникли проблемы:
- Программа определяла типы файлов только по расширению. Например, файлы с расширением ts, которые у нас имели формат xml, воспринимала как JavaScript и падала при форматировании. Потом, она зачем-то пыталась поправить pro-файлы проектов Qt, наверное, как Protobuf.
- Программу приходилось запускать вручную, перед добавлением файлов в индекс git. Легко было об этом забыть.
Решение
В результате получился следующий sh-скрипт, запускаемый как pre-commit — хук для git:
#!/bin/sh
CLANG_FORMAT="clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex '.*.(cxx|cpp|hpp|h)$' "
GIT_DIFF="git diff -U0 --no-color "
GIT_APPLY="git apply -v -p0 - "
FORMATTER_DIFF=$(eval ${GIT_DIFF} --staged | eval ${CLANG_FORMAT})
echo "n------Format code hook is called-------"
if [ -z "${FORMATTER_DIFF}" ]; then
echo "Nothing to be formatted"
else
echo "${FORMATTER_DIFF}"
echo "${FORMATTER_DIFF}" | eval ${GIT_APPLY} --cached
echo " ---Format of staged area completed. Begin format unstaged files---"
eval ${GIT_DIFF} | eval ${CLANG_FORMAT} | eval ${GIT_APPLY}
fi
echo "------Format code hook is completed----n"
exit 0
Что делает скрипт:
GIT_DIFF=» git diff -U0 —no-color « — изменения в коде, которые подадут на вход clang-format-diff-6.0.
- -U0: обычно git diff выводит так называемый «контекст»: несколько неизменёных строк кода вокруг тех, что были изменены. Но clang-format-diff-6.0 форматирует их тоже! Поэтому контекст в данном случае не нужен.
CLANG_FORMAT=» clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex ‘.*.(cxx|cpp|hpp|h)$’ « — команда для форматирования diff, полученного через стандартный ввод.
- clang-format-diff-6.0 — скрипт из пакета clang-format-6.0. Есть другие версии, но все тесты были только на этой.
- -p1 взят из примеров в документации, обеспечивает совместимость с выводом git diff.
- -style=Chromium — готовый пресет стиля форматирования кода. Другие возможные значения: LLVM, Google, Mozilla, WebKit.
- -sort-includes — опция сортировки по алфавиту директив #include (не обязательна).
- -iregex ‘.*.(cxx|cpp|hpp|h)$’ — регулярное выражение, фильтрующее имена файлов по расширениям. Тут перечислены только те расширения, которые надо форматировать. Это убережёт программу от падения и неожиданных глюков. Скорее всего список нужно будет дополнить в новых проектах. Кроме С++ можно форматировать C/Objective-C/JavaScript/Java/Protobuf. Хотя эти типы файлов мы не тестировали.
GIT_APPLY=» git apply -v -p0 — « — применение к коду патча, выданного предыдущей командой.
- -p0: по умолчанию git apply пропускает первый компонент в пути к файлу, это несовместимо с форматом, который выдаёт clang-format-diff-6.0. Здесь отключено такое пропускание.
FORMATTER_DIFF=$(eval ${GIT_DIFF} —staged | eval ${CLANG_FORMAT}) — изменения форматера для индекса.
echo «${FORMATTER_DIFF}» | eval ${GIT_APPLY} —cached форматирует исходный код в индексе (после git add). К сожалению, нет такого хука, который срабатывал бы перед добавлением файлов в индекс. Поэтому форматирование разделено на две части: форматируется то, что в индексе и отдельно то, что не добавлено в индекс.
eval ${GIT_DIFF} | eval ${CLANG_FORMAT} | eval ${GIT_APPLY} — форматирование кода не в индексе (запускается, только когда что-то было отформатировано в индексе). Форматирует вообще все текущие изменения в проекте (под контролем версий), а не только из предыдущего шага. Это спорное, на первый взгляд, решение. Но оно оказалось удобным, т.к. рано или поздно другие изменения надо форматировать тоже. Можно заменить «| eval ${GIT_APPLY}» опцией -i, которая заставит ${CLANG_FORMAT} менять файлы самостоятельно.
Демонстрация работы
- Установить clang-format-6.0
- cd /tmp && mkdir temp_project && cd temp_project
- git init
- Добавить под контроль версий и закомитить любой файл C++ под именем wrong.cpp. Желательно >50 строк неформатированного кода.
- Сделать скрипт .git/hooks/pre-commit, показанный выше.
- Назначить скрипту права на запуск (для git): chmod +x .git/hooks/pre-commit.
- Запустить вручную скрипт .git/hooks/pre-commit, он должен запускаться с сообщением «Nothing to be formatted», без ошибок интерпретатора.
- Создать file.cpp с содержимым int main() { for (int i = 0; i < 100; ++i) { std::cout << » First case » << std::endl; std::cout << » Second case » << std::endl; std::cout << » Third case » << std::endl; } } одной строкой или с другим плохим форматированием. В конце — перевод строки!
- git add file.cpp && git commit -m » file.cpp « должны быть сообщения от скрипта типа «Патч file.cpp применен без ошибок».
- git log -p -1 должен показать добавление форматированного файла.
- Если file.cpp попал в коммит действительно форматированным, значит можно тестировать форматирование только в diff. Измените пару строк wrong.cpp так, чтобы форматер на них среагировал. Например, добавьте неадекватные отступы в коде вместе с другими изменениями. git commit -a -m » Format only diff « должен залить форматированные изменения, но не затронуть другие части файла.
Недостатки и проблемы
git diff —staged (который здесь ${GIT_DIFF} —staged) выдаёт diff только тех файлов, что были добавлены в индекс. А clang-format-diff-6.0 обращается к полным версиям файлов за пределами него. Поэтому, если изменить какой-то файл, сделать git add, а потом изменить тот же файл, то clang-format-diff-6.0 будет генерировать патч для форматирования кода (в индексе) на основе отличающегося файла. Таким образом, файл после git add и до коммита лучше не редактировать.
Вот пример такой ошибки:
- Добавить в file.cpp, » Second case « лишний std::endl. (std::cout << » Second case » << std::endl << std::endl;) и несколько табов лишнего отступа перед строкой.
- git add file.cpp
- Очистить строку (в этом же файле) с » First case « так, что бы на её месте остался(!) только перенос строки.
- git commit -m » Formatter error on commit «.
Скрипт должен сообщить » error: при поиске: «, т.е. git apply не нашёл контекст патча, выданного clang-format-diff-6.0. Если вы не поняли, в чём тут проблема, просто не меняйте файлы после git add их и до git commit. Если надо поменять, можете сделать коммит (без push) и потом git commit —amend с новыми изменениями.
Самое серьёзное ограничение — необходимость иметь в конце каждого файла перевод строки. Это старая особенность git, поэтому большинство редакторов кода, поддерживают автоматическую вставку такого перевода в конец файла. Без этого скрипт будет падать при коммите нового файла, но это не принесет никакого вреда.
Очень редко clang-format-diff-6.0 форматирует код неадекватно. В этом случае можно добавить какие-нибудь бесполезные элементы в код, типа точки с запятой. Либо, окружить проблемный код комментариями, /* clang-format off */ и /* clang-format on */.
Также clang-format-diff-6.0 может выдавать неадекватный патч. Это заканчивается тем, что git apply не принимает его, и код части коммита остается неотфоматированным. Причина — внутри clang-format-diff. Нет времени разбираться во всех ошибках программы. В этом случае можно посмотреть на патч форматирования с помощью команды git diff -U0 —no-color HEAD^ | clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex ‘.*.(cxx|cpp|hpp|h)$’. Самым простым решением будет добавление опции -i к предыдущей команде. В этом случае утилита не будет выдавать патч, а отформатирует код. Если не помогло, можно попробовать форматирование для отдельных файлов целиком clang-format-6.0 -i -sort-includes -style=Chromium file.cpp. Далее git add file.cpp и git commit —amend.
Есть предположение, что чем ближе ваш конфиг .clang-format к одному из пресетов, тем меньше таких ошибок вы увидите. (Здесь его заменяет опция -style=Chromium).
Отладка
Если хотите посмотреть, какие изменения сделает скрипт на ваших текущих правках (не в индексе), используйте git diff -U0 —no-color | clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex ‘.*.(cxx|cpp|hpp|h)$’ Также можно проверить, как будет работать скрипт на последних коммитах, например, на тридцати: git filter-branch -f —tree-filter » ${PWD}/.git/hooks/pre-commit » —prune-empty HEAD~30..HEAD . Данная команда должна была форматировать предыдущие коммиты, но по факту меняет только их id. Поэтому стоит проводить такие эксперименты в отдельной копии проекта! После она станет непригодной для работы.
Заключение
Субъективно, от такого решения гораздо больше пользы чем вреда. Но надо тестировать поведение clang-format-diff разных версий на коде вашего проекта, с конфигом для вашего стиля кода.
К сожалению, такой же git-hook для Windows мы не делали. Предлагайте в комментариях, как это сделать там. А если нужна статья для быстрого старта с clang-format, советуем посмотреть описание ClangFormat.
Я хочу изменить исходный код для Linux. Я не знаю, с чего начать.
Я хочу изучить код, а затем изменить его и увидеть изменения, выполнив его. С чего начать?
Я — выпуск колледжа, и я знаю C и С++, но никогда не редактировал исходный код Linux.
Я хочу небольшой легкий Linux, который имеет небольшие файлы исходного кода, чтобы я мог изучить его и изменить. Создать свой собственный.
Какой Linux будет лучше для меня и как я начну с редактирования кода сукку?
Просто ли установка Linux также даст мне исходный код?
Ответ 1
Термин «Linux» может означать пару разных вещей.
Ядро Linux
Это настоящий Linux, и он доступен из http://kernel.org/.
Вы не найдете маленькую или легкую версию этого. Ядро — это ядро. (Тем не менее, вы можете отключить функции во время компиляции, что полезно, если вы ориентируетесь на низкомощные аппаратные средства, например, для встроенного устройства).
дистрибутивы Linux
Это ядро Linux, в комплекте с большим стеком другого программного обеспечения, необходимого для его использования. Исходный код для различных программных продуктов доступен отдельно.
Netinstall Debian дает вам основную часть системы при небольшой загрузке. Он имеет систему управления пакетами, которая позволяет легко получить исходный код различных программ, доступных для него.
Ответ 2
Что именно вы хотите отредактировать из дистрибутива Linux?
Linux сама по себе является просто ядром, но этот термин также используется для обозначения операционных систем, использующих ядро. Если вы хотите возиться с графическими программами, вы можете установить дистрибутив Linux, а затем загрузить источник этих программ по отдельности. Если вы хотите возиться с самим ядром, источник можно получить из kernel.org. В каждом дистрибутиве Linux есть собственный набор программ и функций, которые вы можете изменить по своему вкусу, но я сомневаюсь, что вы хотите редактировать все, который поставляется в стандартном дистрибутиве, например Ubuntu, так как перекомпилировать все каждый раз, чтобы увидеть изменения, потребуется некоторое время.
Linux много, чтобы погрузиться в первый таймер в поле ОС. Существует более маленькая Unix-подобная операционная система для обучения под названием MINIX. Загрузка исходного кода составляет около 2,2 млн. Я полагаю, и он используется в качестве учебного пособия во многих курсах по разработке операционной системы по всему миру. Лично я немного укусил свои зубы, прежде чем заняться Linux, но выбор за вами, так что им весело! Постройте его, сломайте и попробуйте перестроить его снова! Это отличный опыт обучения.
Ответ 3
Установить Ubuntu
Узнайте, как загрузить, скомпилировать и установить собственное ядро
Прочитайте и отредактируйте код
Перекомпилируйте и установите отредактированное ядро
Ответ 4
Если вы хотите изменить ядро Linux или одно из «основных» приложений, которое обычно формирует дистрибутив, и если у вас нет большого опыта работы с Linux или его модификации, я рекомендую посмотреть Linux From Scratch. Он поможет вам установить систему Linux исключительно из ее основных компонентов и позволит вам действительно понять: а) что на самом деле является частью Linux и б) что делает каждая часть.
Как только вы это сделали, вы должны знать, где находятся источники, как их компилировать и как развернуть изменения. Следующий шаг — это просто запуск вашего любимого редактора и его изменение.
Ответ 5
Здесь хороший учебник по компиляции ядра Linux.
Совет: используйте виртуальную машину, такую как VirtualBox, для запуска модифицированного ядра — таким образом вы можете легко экспериментировать, не нанося вреда никакому реальному оборудованию.
Ответ 6
Если вы просто хотите узнать об операционных системах в целом, Minix может быть хорошим местом для запуска: http://www.minix3.org. Minix использует довольно маленькое (< 5000) линейное микроядро, поэтому довольно легко ознакомиться с его основной работой. Запуск его практически (например, под vmware) — это самый простой способ начать работу.
Ответ 7
Ядро linux является монстром дерева-источника (по крайней мере, в смысле не малого). Старые ядра меньше, поэтому имеет смысл взглянуть на них, если вы после небольшого ядра Linux, чтобы посмотреть и поиграть с ним.
Однако, если все, что вы ищете, — это какое-то Unix-подобное ядро, с которым можно играть, Minix 3 может быть еще одним возможным выбором.
Для специфики, установите любой дистрибутив Linux, затем установите исходный пакет ядра (Gentoo, вероятно, установит это по умолчанию, имя спецификатора исходного пакета ядра зависит от вашего дистрибутива).
Ответ 8
Вы можете рассмотреть дистрибутивы BSD, их намного проще скомпилировать из источника
Я знаю, что вы сказали Linux, но дистрибутивы как NetBSD также являются приложением Unix, и они гораздо более доступны из компилятора — с источника.
- Как правило, гораздо меньшая установка по умолчанию или минимальная установка
- Базовая система построена как единая система с make. Linux представляет собой набор утилит и пакетов из множества разных мест, которые индивидуально построены, а дистрибутивы BSD имеют определенное исходное дерево, которое может быть построено с вершины /usr/src с помощью одной команды.
- Намного легче перекрестно скомпилировать, если вам нужно это сделать.
В дистрибутивах BSD дерево с одним источником содержит базовую систему, а между внутренними и внешними элементами — четкая разделительная линия. Проекты распространяют все свои системы в готовой к компиляции форме.
Ответ 9
Установка дистрибутива Linux, конечно же, является разумным предварительным условием: Linux является самостоятельным хостингом, поскольку он может (возможно) быть скомпилирован только в системе GNU/Linux (с gcc и библиотекой gnu C), хотя библиотека C используется только в инструментах во время компиляции — он не связан с ядром). Для компиляции Linux также требуются многочисленные другие инструменты.
Получение исходного кода достаточно просто, но сложный бит правильно настраивает ядро для вашего компьютера — поэтому вы, скорее всего, захотите вместо этого использовать свой источник ядра распространения (у которого могут быть исправления, но они будут незначительными для ваших целей).
Самый простой способ «попробовать» программирование ядра — написать модуль ядра — они могут быть динамически загружены (это означает, что вы можете протестировать свой код без перезагрузки — при условии, что он не сбой системы)
Существует множество примеров модулей ядра, но почти все они устарели из-за быстро меняющихся внутренних API в самом ядре (даже система сборки изменяется относительно быстро).
Модули ядра могут делать почти все, что не связано с непосредственным изменением основной части ядра — существует множество функций «hook» (в основном register_something для регистрации устройства, hook, protocol и т.д.), которые могут быть использованы для расширения API пользовательского пространства ядра или каким-либо образом изменить его поведение.
Ответ 10
Непосредственно пытаться редактировать исходный код может быть жестким a.It зависит от вашего знания C и операционной системы. Я бы сказал, что вы должны сначала посмотреть, как такие функции, как cat, grep и т.д., реализованы в C.Then появляются концепции модулей. Различные типы модулей ядра и базовые операции с модулями Linux. Затем выберите определенную функциональность, например, сеть или некоторые другие. Пройдите код для этого раздела.
Пример: http://www.leidinger.net/FreeBSD/dox/netipsec/html/df/d62/ipsec_8h_source.html
Основываясь на том уровне, на котором вы понимаете, что коды переработаны на ваших навыках кодирования. Затем сделайте компиляцию ядра на Ubuntu или в любой другой версии. В этот момент вникайте в модификацию ядра. Я знаю, что это потребует времени, но обучение кривая будет крутой, и у вас будет полное представление.
Где мой исходный каталог ядра?
В Debian, Ubuntu и их производных все файлы заголовков ядра можно найти в каталоге / usr / src. Вы можете проверить, установлены ли в вашей системе соответствующие заголовки ядра для вашей версии ядра, используя следующую команду.
Файл bzip будет загружен в / usr / src /, содержащий исходный код. Однако коды ubuntu взяты из исходного ядра Linux, которое доступно для загрузки на http://www.kernel.org/. Чтобы понять ядро, вы должны начать с основ операционной системы.
Как просмотреть исходный код в Linux?
Получите исходный код для любой команды Linux
- Шаг 1. Добавьте исходный URI в sources.lst. $ cat /etc/apt/sources.list deb-src http://ftp.de.debian.org/debian lenny main $ apt-get update.
- Шаг 2: Выполните apt-get source, чтобы получить исходный код.
19 февраля. 2010 г.
Как мне изменить исходный код в Ubuntu?
Вместо этого вы получите исходный код для конкретных пакетов, которые вам интересны, и это очень просто. Теперь у вас есть исходный код для панели управления Ubuntu One в каталоге с именем ubuntuone-control-panel-VERSION_NUMBER.
Где находится файл ядра в Linux?
Где находятся файлы ядра Linux? Файл ядра в Ubuntu хранится в вашей папке / boot и называется vmlinuz-version.
Что такое дерево исходных текстов ядра?
Дерево исходных текстов — это каталог, который содержит все исходные коды ядра. Вы можете собрать новое ядро, установить его и перезагрузить компьютер, чтобы использовать восстановленное ядро. … Если вы ищете исходный код для установленного пакета ядра, вы должны загрузить обе части.
Что такое исходный код ядра?
Исходный код ядра означает коды (в основном c и c ++), которые используются для компиляции ядра Linux. … Итак, производители смартфонов, использующие ядро Linux для своих смартфонов, должны сделать свое ядро открытым. Поэтому они выпускают исходный код ядра, на котором работает ОС Android их смартфонов.
Что такое исходный код в Ubuntu?
Буквальный исходный код, который сгенерировал конкретный двоичный пакет, может быть получен с помощью команды apt-get source package>. Например, чтобы получить исходный код для текущего ядра, вы можете использовать следующую команду: apt-get source linux-image-unsigned — $ (uname -r)
Как мне изменить исходный код в Linux?
Если вы хотите повозиться с программами с графическим интерфейсом, вы можете установить дистрибутив Linux, а затем загрузить исходный код этих программ отдельно. Если вы хотите повозиться с самим ядром, исходный код можно получить на kernel.org.
Насколько велик исходный код ядра Linux?
— Дерево исходных текстов ядра Linux содержит до 62,296 25,359,556 файлов с общим количеством строк во всех этих файлах кода и других файлах XNUMX XNUMX XNUMX строк.
Что такое исходный код загрузки в Linux?
apt-src location pkg ОПИСАНИЕ apt-src — это интерфейс командной строки для загрузки, установки, обновления и отслеживания исходных пакетов debian. Его можно запустить как обычный пользователь, так и как root.
Можно ли редактировать ядро Linux?
изменение ядра Linux включает в себя две вещи: загрузку исходного кода, компиляцию ядра. Здесь при первой компиляции ядра потребуется время. … Таким образом, вы можете изменить любой модуль, скомпилировать ядро, установить его и протестировать.
Как изменить операционную систему?
Чтобы изменить операционные системы существующего файла установщика Windows
- Установите App-V Sequencer на компьютер в вашей среде, где установлена только операционная система. …
- Скопируйте весь пакет виртуального приложения, содержащий файл установщика Windows, который вы хотите изменить, на компьютер, на котором запущен Sequencer.
16 июн. 2016 г.
Как получить код VS в Ubuntu?
Чтобы запустить его, щелкните значок приложения в левом нижнем углу экрана. Вверху введите Visual Studio в поле поиска, чтобы найти код Visual Studio. Щелкните значок, чтобы запустить Visual Studio Code. Теперь, когда у вас установлен Visual Studio Code, вы должны добавить несколько расширений для ваших любимых языков.
Краткое содержание: В этом подробном руководстве объясняется, как установить программу из исходного кода в Linux и как удалить программное обеспечение, установленное из исходного кода.
Одной из самых сильных сторон вашего дистрибутива Linux является его менеджер пакетов и связанный с ним репозиторий программного обеспечения. С их помощью у вас есть все необходимые инструменты и ресурсы для полной загрузки и установки нового программного обеспечения на ваш компьютер.
Но, несмотря на все усилия, производители дистрибутивов не могут могут предусмотреть все варианты использования системы. Таким образом, все еще есть ситуации, когда вам придется самостоятельно собирать и устанавливать новое программное обеспечение. Что касается меня, то наиболее распространенной причиной, к сожалению, иногда мне необходимо скомпилировать некоторое программное обеспечение, когда мне нужно запустить конкретную версию этого ПО. Или потому, что я хочу изменить исходный код или воспользоваться некоторыми иными параметрами при компиляции. ( Да, вот такие мы извращенцы линуксоиды  )
)
Если вы относитесь к последней категории, есть вероятность, что вы уже знаете, что делать.
Но для подавляющего большинства пользователей Linux компиляция и установка программного обеспечения из источников в первый раз может выглядеть как церемония инициации: несколько пугающая; но обещающая войти в новый мир возможностей и стать частью привилегированного сообщества, если вы преодолеете это.
И так, начнем.
И это именно то, что мы будем делать здесь. Для целей этой статьи, скажем, мне нужно установить NodeJS 8.1.1 в мою систему. Эта версия точно недоступная в репозитории Debian:
sh$ apt-cache madison nodejs | grep amd64
nodejs | 6.11.1~dfsg-1 | http://deb.debian.org/debian experimental/main amd64 Packages
nodejs | 4.8.2~dfsg-1 | http://ftp.fr.debian.org/debian stretch/main amd64 Packages
nodejs | 4.8.2~dfsg-1~bpo8+1 | http://ftp.fr.debian.org/debian jessie-backports/main amd64 Packages
nodejs | 0.10.29~dfsg-2 | http://ftp.fr.debian.org/debian jessie/main amd64 Packages
nodejs | 0.10.29~dfsg-1~bpo70+1 | http://ftp.fr.debian.org/debian wheezy-backports/main amd64 Packages
Как и многие проекты с открытым исходным кодом, в том числе исходники NodeJS можно найти в GitHub: https://github.com/nodejs/node
Итак, пойдем прямо туда.
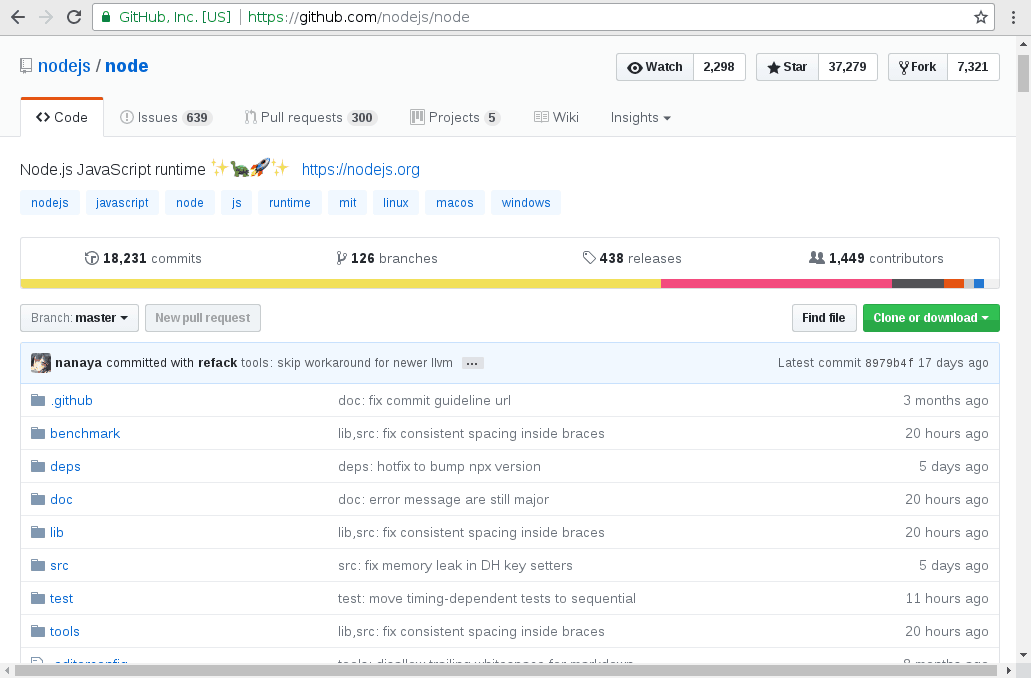
Если вы не знакомы с GitHub, git или любой другой системой управления версиями, то стоит отметить, что здесь располагаются репозитории, содержащие текущий источник программного обеспечения, а также историю всех изменений, сделанных на протяжении многих лет для этого программного обеспечения. До самой первой строки, написанной для этого проекта. Для разработчиков сохранение этой истории имеет много преимуществ. Для нас же основным является то, что мы сможем получить исходники проекта на любой момент времени. Проще говоря, я смогу получить исходники версии NodeJS 8.1.1, в момент ее релиза. Даже если с тех пор было сделано много изменений.

На GitHub вы можете использовать кнопку “branch” для навигации между различными версиями программного обеспечения. “Branch” и “tags” связанные понятия в Git. В основном разработчики создают “branch” и “tags”, чтобы отслеживать важные события в истории проекта, например, когда они начинают работать над новой функцией или когда публикуют выпуск. Я не буду вдаваться в подробности здесь, все, что вам нужно знать, я ищу версию с тегами «v8.1.1»
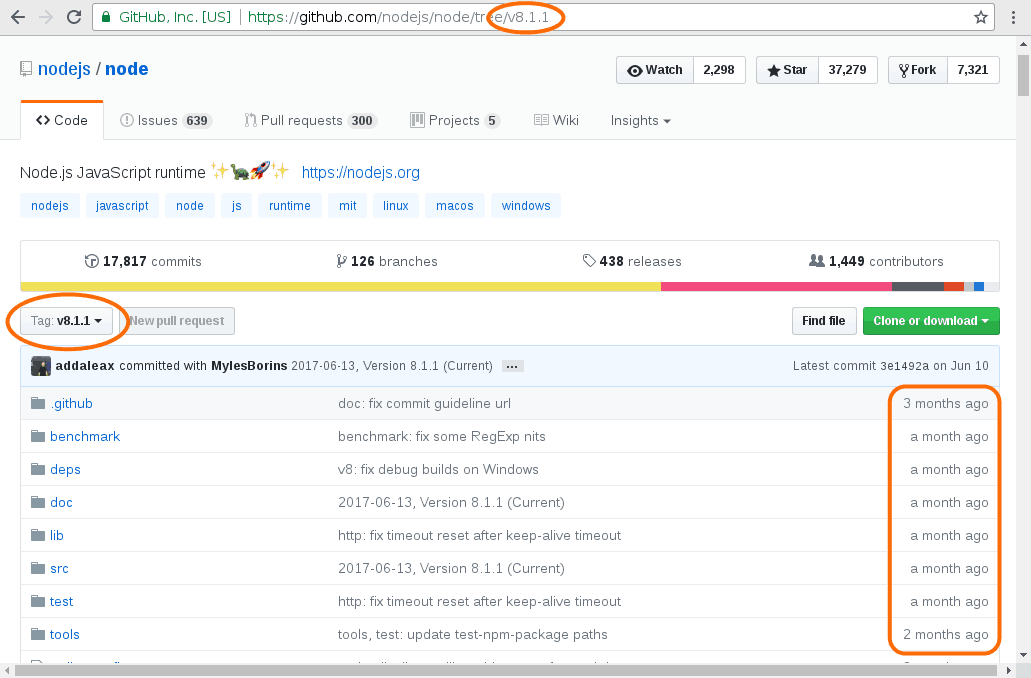
После выбора в теге «v8.1.1» страница обновляется, наиболее очевидным изменением является тег, который теперь отображается как часть URL-адреса. Кроме того, вы возможно заметили, что дата изменения файла также отличается. Исходное дерево, которое вы сейчас видите, это то, которое существовало на время создания тега v8.1.1. В некотором смысле инструмент управления версиями, такой как git, это как бы машина для путешествий во времени, позволяющую вам вернуться в историю проекта.
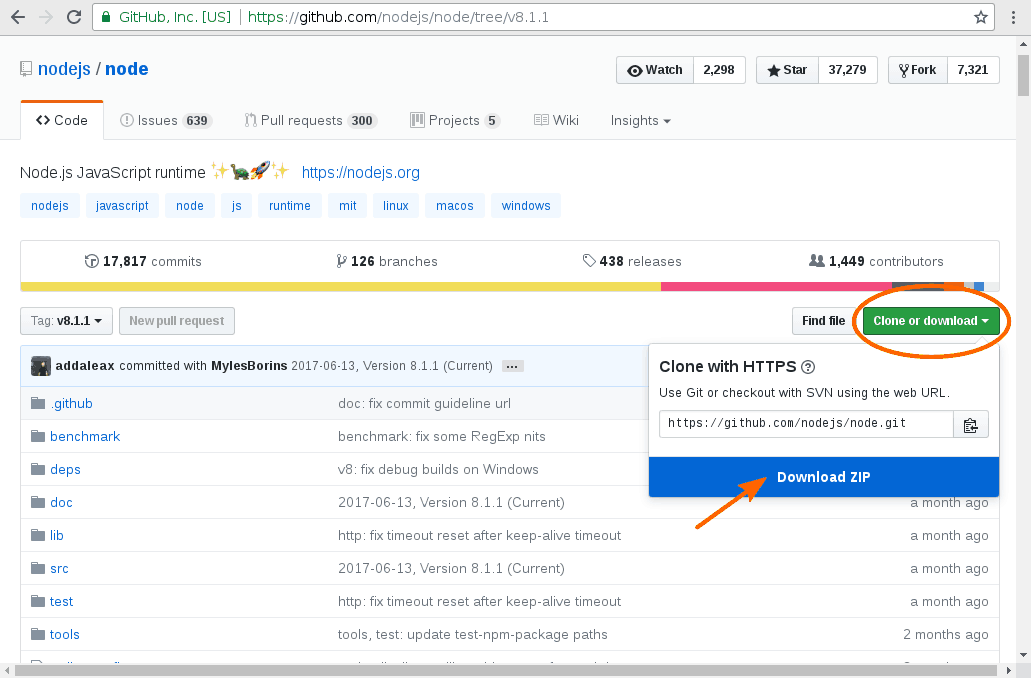
На этом этапе мы можем загрузить исходники NodeJS 8.1.1. Вы не можете пропустить большую синюю кнопку на странице, предлагающую загрузить ZIP-архив проекта. Что касается меня, я буду загружать и извлекать ZIP в командной строке. Но если вы предпочитаете использовать инструменты GUI, не стесняйтесь, делайте как вам удобно:
$ wget https://github.com/nodejs/node/archive/v8.1.1.zip $ unzip v8.1.1.zip $ cd node-8.1.1/
Скачивание ZIP-архива отлично работает. Но если вы хотите сделать это «как профессионал», я бы предложил напрямую использовать инструмент git для загрузки источников. Это совсем не сложно — и это будет хороший первый контакт с инструментом, которым вам часто придется работать:
1. Сначала убедитесь, что git установлен в вашей системе
sh$ sudo apt-get install git
2. Сделайте свой маленький клон репозитория NodeJS v8.1.1
sh$ git clone --depth 1 --branch v8.1.1 https://github.com/nodejs/node sh$ cd node/
В любом случае, всякий раз, когда вы загружаете источник с помощью git или ZIP-архива, у вас должны быть в текущем каталоге точно такие файлы исходников:
sh$ ls android-configure BUILDING.md common.gypi doc Makefile src AUTHORS CHANGELOG.md configure GOVERNANCE.md node.gyp test benchmark CODE_OF_CONDUCT.md CONTRIBUTING.md lib node.gypi tools BSDmakefile COLLABORATOR_GUIDE.md deps LICENSE README.md vcbuild.bat
Обычно мы говорим о «компиляции исходников», но компиляция является лишь одним из этапов, необходимых для создания рабочего программного обеспечения из его исходника. Система сборки представляет собой набор инструментов и методов, используемых для автоматизации и формулирования этих различных задач, чтобы полностью собрать программное обеспечение, просто набрав несколько команд.
Если концепция проста, то реальность несколько сложнее. Потому что разные проекты или языки программирования могут иметь разные требования. Или из-за вкусов программиста. Или поддерживаемых платформ. Или по исторической причине. Или … или .. существует бесконечный список причин выбора или создания различных систем сборки. Все, что можно сказать, это то, что есть много различных используемых решений.
NodeJS использует систему сборки в GNU-стиле. Это популярный набор сообщества открытого исходного кода. И еще раз, это хороший старт вашего путешествие в мир СПО.
Написание и настройка системы сборки — довольно сложная задача. Но для «конечного пользователя» системы сборки в стиле GNU резюмируют себя использованием всего двух инструментов: configure и make.
Файл configure представляет собой скрипт конкретного проекта, который будет проверять конфигурацию системы назначения и доступные функции для того, чтобы гарантировать сборки проекта, с учетом специфики текущей платформы.
Важной частью задания типичного configure является создание Makefile. Это файл, содержит инструкции, необходимые для эффективной сборки проекта.
Инструмент **make**, с другой стороны, представляет собой инструмент POSIX, доступный в любой Unix-подобной системе. Он считывает Makefile конкретного проекта и выполняет необходимые операции по сборке и установке программы.
Но, как всегда в мире Linux, у вас могут возникнуть некоторые трудности при настройке сборок для ваших конкретных потребностей.
$ ./configure --help
Команда configure -help покажет вам все доступные параметры конфигурации. Еще раз, в этом возникает необходимость, как правило, для очень специфичных проектов. И, честно говоря, иногда требуется вникнуть в проект, прежде чем полностью понять смысл каждой опции конфигурации.
Но есть, по крайней мере, один стандартный параметр GNU Autotools, который вы должны знать: параметр –prefix. Это связано с иерархией файловой системы и местом установки вашего программного обеспечения.
Шаг третий: FHS
Иерархия файловой системы Linux в типичном дистрибутиве в основном соответствует стандарту иерархии файловой системы (FHS — Filesystem Hierarchy Standard)
Этот стандарт объясняет назначение различных каталогов вашей системы: /usr, /tmp, /var и т.д.
При использовании GNU Autotools и большинства других систем сборки — место установки по умолчанию для вашего нового программного обеспечения будет /usr/local. Что является хорошим выбором, поскольку в соответствии с FSH «Иерархия /usr/local предназначена для использования системным администратором при локальном установки программного обеспечения. Он должен быть защищен от перезаписи, при обновлении системное программного обеспечения. Он может использоваться для программ и данных, которые могут быть включены в группу хостов, но не найдены в /usr.»
Иерархия /usr/local повторяет корневой каталог, поэтому вы найдете там /usr/local/bin для исполняемых программ, /usr/local/lib для библиотек, /usr/local/share для независимых от архитектуры файлов и т.д.
Единственная проблема при использовании каталога /usr/local для установки пользовательского программного обеспечения — это файлы вашего программного обеспечения установленного из исходников. В частности, после установки нескольких программ, будет сложно отслеживать, к какой программе принадлежат файлы в /usr/local/bin и /usr/local/lib. Однако это не вызовет проблемы для системы. В конце концов, в /usr/bin почти такой же беспорядок. Но это станет проблемой в тот момент, когда вы захотите удалить установленное из исходников программное обеспечение.
Чтобы решить эту проблему, я обычно предпочитаю устанавливать программное обеспечение в каталоге /opt. Еще раз, процитирую FHS:
/opt зарезервирован для установки дополнительных программных пакетов приложений.
Пакет, который должен быть установлен в /opt, должен размещать свои статические файлы в отдельном /opt/<package> или /opt/<provider>, где <package> — это имя, которое описывает пакет программного обеспечения и <provider> — зарегистрированное имя LANANA провайдера.
Поэтому мы создадим подкаталог в /opt специально для нашей пользовательской установки Node JS. И если когда-нибудь я захочу удалить это программное обеспечение, мне просто необходимо будет удалить этот каталог:
sh$ sudo mkdir /opt/node-v8.1.1 sh$ sudo ln -sT node-v8.1.1 /opt/node sh$ ./configure --prefix=/opt/node-v8.1.1 sh$ make -j9 && echo ok
-j9 означает запуск до 9 параллельных задач для создания программного обеспечения.
Как правило, используйте -j (N + 1), где N — количество ядер вашей системы. Это максимизирует использование ЦП (одна задача на процессорный поток / ядро + предоставление одной дополнительной задачи, когда процесс блокируется операцией ввода-вывода).
Все, кроме «ok», после завершения команды make, будет означать, что во время процесса сборки произошла ошибка. Когда мы запускаем параллельную сборку с опции -j, нелегко получить сообщение об ошибке, учитывая большой объем вывода информации, выданной инструментами сборки.
В случае возникновения проблем, просто перезапустите make, но без опции -j на этот раз. И ошибка появится ближе к концу вывода:
sh$ make
Наконец, как только компиляция завершится, вы можете установить свое программное обеспечение в нужное место, выполнив команду:
sh$ sudo make install
И протестировать его:
sh$ /opt/node/bin/node --version v8.1.1
То, что я объяснял выше, — это в основном то, что вы можете увидеть на странице «Инструкции по сборке» («build instruction») хорошо документированного проекта. Но цель этой статьи состоит в том, чтобы позволить вам скомпилировать ваше первое программное обеспечение из источников и, возможно, стоит потратить время на исследование некоторых распространенных проблем. Итак, я сделаю всю процедуру снова, но на этот раз в свежих и минимальных системах Debian 9.0 и CentOS 7.0. Таким образом, вы можете увидеть ошибки, с которыми я столкнулся, и как я их решил.
$ git clone --depth 1 --branch v8.1.1 https://github.com/nodejs/node -bash: git: command not found
Эта проблема довольно легко диагностируется и решается. Просто установите пакет git:
$ sudo apt-get install git $ git clone --depth 1 --branch v8.1.1 https://github.com/nodejs/node && echo ok [много-много букв...] ok
$ sudo mkdir /opt/node-v8.1.1 $ cd node $ sudo ln -sT node-v8.1.1 /opt/node
Здесь проблем не наблюдаем
$ ./configure --prefix=/opt/node-v8.1.1/
WARNING: failed to autodetect C++ compiler version (CXX=g++)
WARNING: failed to autodetect C compiler version (CC=gcc)
Node.js configure error: No acceptable C compiler found!
Please make sure you have a C compiler installed on your system and/or
consider adjusting the CC environment variable if you installed
it in a non-standard prefix.
Очевидно, что для компиляции проекта вам нужен компилятор. NodeJS, написан с использованием языка C++, поэтому нам нужен компилятор C++. Здесь я установлю компилятор GNU C++, которым является g++:
$ sudo apt-get install g++ $ ./configure --prefix=/opt/node-v8.1.1/ && echo ok [много-много букв...] ok
$ make -j9 && echo ok -bash: make: command not found
Еще один недостающий инструмент. Те же симптомы. То же решение:
$ sudo apt-get install make $ make -j9 && echo ok [много-много букв...] ok
$ sudo make install [много-много букв...] $ /opt/node/bin/node --version v8.1.1
Ура! Золотой ключик наш.
Обратите внимание: я установил различные инструменты один за другим, чтобы показать, как диагностировать проблемы компиляции и показать вам типичное решение этих проблем. Но если вы захотите узнать больше по этой теме или прочитаете другие учебники, вы обнаружите, что большинство дистрибутивов имеют «meta-packages» (мета-пакеты), действующие в качестве зонтика при установки некоторых или всех типовых инструментов, используемых для компиляции программного обеспечения. В системах на базе Debian вы, вероятно, столкнетесь с пакетом build-essentials для этой цели. А в дистрибутивах на основе Red Hat, это будет Development Tools.
$ git clone --depth 1 --branch v8.1.1 https://github.com/nodejs/node -bash: git: command not found
Команда не найдена? Просто установите его с помощью менеджера пакетов yum:
$ sudo yum install git $ git clone --depth 1 --branch v8.1.1 https://github.com/nodejs/node && echo ok [много-много букв...] ok
$ sudo mkdir /opt/node-v8.1.1 $ sudo ln -sT node-v8.1.1 /opt/node
$ cd node
$ ./configure --prefix=/opt/node-v8.1.1/
WARNING: failed to autodetect C++ compiler version (CXX=g++)
WARNING: failed to autodetect C compiler version (CC=gcc)
Node.js configure error: No acceptable C compiler found!
Please make sure you have a C compiler installed on your system and/or
consider adjusting the CC environment variable if you installed
it in a non-standard prefix.
Вы догадались: NodeJS написан на языке C ++, но моей системе не хватает соответствующего компилятора. Yum вам в помощь. Поскольку я не являюсь постоянным пользователем CentOS, мне действительно нужно было искать в Интернете точное имя пакета, содержащего компилятор g++. Поиск привел меня на эту страницу: https://superuser.com/questions/590808/yum-install-gcc-g-doesnt-work-anymore-in-centos-6-4
$ sudo yum install gcc-c++ $ ./configure --prefix=/opt/node-v8.1.1/ && echo ok [много-много букв...] ok
$ make -j9 && echo ok [много-много букв...] ok
$ sudo make install && echo ok [много-много букв...] ok
$ /opt/node/bin/node --version v8.1.1
Ура! Пройден очередной уровень. 
Вы можете установить программное обеспечение из исходников, если вам нужна конкретная версия, недоступная в вашем репозитории. Или потому, что вы хотите изменить данную программу. Либо исправить ошибку, либо добавить функцию. В конце концов, open-source и придуман для этого. Поэтому я воспользуюсь этой возможностью, чтобы дать вам почувствовать силу, которая у вас есть. Теперь вы можете скомпилировать свое собственный вариант необходимого вам программного обеспечения.
Сейчас мы сделаем незначительные изменения в исходниках NodeJS. И увидим, будут ли внесены изменения в скомпилированную версию программного обеспечения:
Откройте файл node/src/node.cc в вашем любимом текстовом редакторе (vim, nano, gedit, …). И попытайтесь найти этот фрагмент кода:
if (debug_options.ParseOption(argv[0], arg)) {
// Done, consumed by DebugOptions::ParseOption().
} else if (strcmp(arg, "--version") == 0 || strcmp(arg, "-v") == 0) {
printf("%sn", NODE_VERSION);
exit(0);
} else if (strcmp(arg, "--help") == 0 || strcmp(arg, "-h") == 0) {
PrintHelp();
exit(0);
}
Это примерно 3830 строка файла. Затем измените строку, содержащую printf, впишите следующее:
printf("%s (compiled by myself)n", NODE_VERSION);
Затем вернитесь в терминал. Прежде чем идти дальше — и дать вам более полное представление о силе, стоящей за git, вы можете проверить, изменили ли вы правильно файл:
$ diff --git a/src/node.cc b/src/node.cc
index bbce1022..a5618b57 100644
--- a/src/node.cc
+++ b/src/node.cc
@@ -3828,7 +3828,7 @@ static void ParseArgs(int* argc,
if (debug_options.ParseOption(argv[0], arg)) {
// Done, consumed by DebugOptions::ParseOption().
} else if (strcmp(arg, "--version") == 0 || strcmp(arg, "-v") == 0) {
- printf("%sn", NODE_VERSION);
+ printf("%s (compiled by myself)n", NODE_VERSION);
exit(0);
} else if (strcmp(arg, "--help") == 0 || strcmp(arg, "-h") == 0) {
PrintHelp();
Перед строкой, которую вы изменили, вы должны увидеть знак «-» (минус) и как это было до ваших изменений. И знак «+» (плюс) перед строкой после ваших изменений.
Настало время перекомпилировать и переустановить ваше программное обеспечение:
$ make -j9 && sudo make install && echo ok [много-много букв...] ok
В данный момент, единственная причина, по которой вы можете потерпеть неудачу, заключается в том, что вы могли сделали опечатку при изменении кода. Если это так, повторно откройте файл node/src/node.cc в текстовом редакторе и исправьте ошибку.
Как только вам удастся скомпилировать и установить новую модифицированную версию NodeJS, вы сможете проверить, действительно ли ваши модификации были включены в программное обеспечение:
$ /opt/node/bin/node --version v8.1.1 (compiled by myself)
Поздравляем! Вы сделали свое первое изменение в программе с открытым исходным кодом!
Возможно вы заметили, что до сих пор, я всегда запускал свое недавно скомпилированное программное обеспечение NodeJS, указав абсолютный путь к бинарному файлу.
/opt/node/bin/node
Оно конечно работает, но раздражает, если не сказать больше. На самом деле существует два актуальных способа устранения этой неопределенности. Но чтобы понять их, вы должны сначала знать, что ваша оболочка находит исполняемые файлы автоматически, но только в каталогах, заданных переменной среды PATH.
$ echo $PATH /usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
В Debian, если вы не укажете явно какой-либо каталог как часть команды, оболочка сначала будет искать эти исполняемые программы в /usr/local/bin, а затем, если не будет найдена в /usr/bin, затем в /bin, затем в /usr/local/games, затем в /usr/games, ну а если и здесь не найден, то… оболочка выдаст ошибку «command not found» (команда не найдена).
Учитывая это, у нас есть два способа сделать команду доступной для shell: добавив ее в один из уже настроенных каталогов PATH или добавив каталог, содержащий наш исполняемый файл, в PATH.
Простое копирование бинарного исполняемого файла node из /opt/node/bin в /usr/local/bin было бы плохой идеей, так как при этом исполняемая программа больше не сможет находить другие необходимые компоненты, принадлежащие /opt/node/ (общепринятой практикой для программного обеспечения? является поиск его файлов ресурсов относительно его собственного местоположения).
Таким образом, традиционный способ сделать это — использовать символическую ссылку:
$ sudo ln -sT /opt/node/bin/node /usr/local/bin/node $ which -a node || echo not found /usr/local/bin/node
$ node --version v8.1.1 (compiled by myself)
Это простое и эффективное решение, особенно если программный пакет состоит из нескольких известных исполняемых программ, поскольку вам нужно создать символическую ссылку для каждой команды, вызываемой пользователем. Например, если вы знакомы с NodeJS, вы знаете приложение-компаньон npm, я должен создать символическую ссылку на /usr/local/bin. Но я дал это вам как упражнение.
Во-первых, если вы попробовали предыдущее решение, удалите символическую ссылку node, созданную ранее, чтобы начать с чистого листа:
$ sudo rm /usr/local/bin/node $ which -a node || echo not found not found
И теперь, волшебная команда, для изменения вашего PATH:
$ export PATH="/opt/node/bin:${PATH}"
$ echo $PATH
/opt/node/bin:/usr/local/bin:/usr/bin:/bin:/usr/local/games:/usr/games
Проще говоря, я изменил содержимое переменной среды PATH предыдущим содержимым, но с добавлением /opt/node/bin. Итак, как вы можете себе представить, оболочка сначала будет искать в каталоге /opt/node/bin исполняемые программы, а далее по стандартным путям. Мы можем проверить это с помощью команды which:
$ which -a node || echo not found /opt/node/bin/node $ node --version v8.1.1 (compiled by myself)
В то время как решение «ссылка»,как только вы создали символическую ссылку в /usr/local/bin, является правилом для всей системы, то изменение PATH действует только в текущей оболочке. Я позволю вам сделать некоторые исследования самостоятельно, чтобы узнать, как сделать изменения в PATH постоянными. Как подсказка, это связано с вашим “profile” (профилем). Если вы найдете решение, не стесняйтесь делиться этим с другими пользователями Linux.
Поскольку наше пользовательское скомпилированное программное обеспечение NodeJS полностью находится в каталоге /opt/node-v8.1.1, то удаление этого программного обеспечения не является трудным, для этого используем команду rm для удаления этого каталога:
$ sudo rm -rf /opt/node-v8.1.1
ОСТОРОЖНО: sudo и rm -rf — опасный коктейль! Всегда проверяйте свою команду дважды, прежде чем нажимать клавишу «Ввод». У вас не будет никакого подтверждающего сообщения и восстановление не будет возможно, если вы удалите неправильный каталог …
Затем, если вы изменили свой PATH, вам придется отменить эти изменения. Что совсем не сложно.
И если вы создали ссылки в /usr/local/bin, вам придется удалить их все:
$ sudo find /usr/local/bin -type l -ilname "/opt/node/*" -print -delete /usr/local/bin/node
В качестве заключительного комментария, если вы читали о компиляции своего собственного программного обеспечения, то вы, возможно, слышали об аде зависимостей. Это прозвище раздражающей ситуации, когда перед тем, как успешно скомпилировать программное обеспечение, вы должны сначала скомпилировать связанную библиотеку, которая, в свою очередь, требует наличия другой библиотеки, которая в свою очередь может быть несовместима с каким-либо другим программным обеспечением, которое вы уже установлены.
Часть работы сторонних разработчиков пакета заключается в том, чтобы фактически разрешить этот адский ад и обеспечить, чтобы различное программное обеспечение вашей системы использовало совместимые библиотеки и было установлено в правильном порядке.
В этой статье я специально решил установить NodeJS, поскольку у нее практически нет зависимостей. Я сказал «практически», потому что на самом деле он имеет зависимости. Но исходный код этих зависимостей присутствует в исходном репозитории проекта (в подкаталоге node/deps), поэтому вам не нужно загружать и устанавливать их вручную перед началом работы.
Но если вам интересно узнать больше об этой проблеме и узнать, как с ней бороться, то начинайте читать специализированную литературу! 
Источник
Программирование, Разработка под Linux, Производство и разработка электроники, Совершенный код, C++
Рекомендация: подборка платных и бесплатных курсов Python — https://katalog-kursov.ru/

Согласитесь, приятно и полезно, когда в проекте исходный код выглядит красиво и единообразно. Это облегчает его понимание и поддержку. Покажем и расскажем, как реализовать форматирование исходного кода при помощи clang-format, git и sh.
Проблемы с форматированием и как их решить
В большинстве проектов существуют определенные правила оформления кода. Как сделать так, чтобы все участники их выполняли? На помощь приходят специальные программы — clang-format, astyle, uncrustify, — но у них есть свои недостатки.
Главная проблема форматеров состоит в том, что они меняют файлы целиком, а не только изменённые строки. Расскажем, как мы с этим справились, используя ClangFormat в рамках одного из проектов по разработке встроенного ПО для электроники, где С++ был основным языком. В команде работало несколько человек, поэтому для нас было важно обеспечить единый стиль кода. Наше решение может подойти не только программистам С++, но и тем, кто пишет код на C, Objective-C, JavaScript, Java, Protobuf.
Для форматирования мы использовали clang-format-diff-6.0. На старте запустили команду
git diff -U0 —no-color | clang-format-diff-6.0 -i -p1, но с ней возникли проблемы:
- Программа определяла типы файлов только по расширению. Например, файлы с расширением ts, которые у нас имели формат xml, воспринимала как JavaScript и падала при форматировании. Потом, она зачем-то пыталась поправить pro-файлы проектов Qt, наверное, как Protobuf.
- Программу приходилось запускать вручную, перед добавлением файлов в индекс git. Легко было об этом забыть.
Решение
В результате получился следующий sh-скрипт, запускаемый как pre-commit — хук для git:
#!/bin/sh
CLANG_FORMAT="clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex '.*.(cxx|cpp|hpp|h)$' "
GIT_DIFF="git diff -U0 --no-color "
GIT_APPLY="git apply -v -p0 - "
FORMATTER_DIFF=$(eval ${GIT_DIFF} --staged | eval ${CLANG_FORMAT})
echo "n------Format code hook is called-------"
if [ -z "${FORMATTER_DIFF}" ]; then
echo "Nothing to be formatted"
else
echo "${FORMATTER_DIFF}"
echo "${FORMATTER_DIFF}" | eval ${GIT_APPLY} --cached
echo " ---Format of staged area completed. Begin format unstaged files---"
eval ${GIT_DIFF} | eval ${CLANG_FORMAT} | eval ${GIT_APPLY}
fi
echo "------Format code hook is completed----n"
exit 0
Что делает скрипт:
GIT_DIFF=» git diff -U0 —no-color « — изменения в коде, которые подадут на вход clang-format-diff-6.0.
- -U0: обычно git diff выводит так называемый «контекст»: несколько неизменёных строк кода вокруг тех, что были изменены. Но clang-format-diff-6.0 форматирует их тоже! Поэтому контекст в данном случае не нужен.
CLANG_FORMAT=» clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex ‘.*.(cxx|cpp|hpp|h)$’ « — команда для форматирования diff, полученного через стандартный ввод.
- clang-format-diff-6.0 — скрипт из пакета clang-format-6.0. Есть другие версии, но все тесты были только на этой.
- -p1 взят из примеров в документации, обеспечивает совместимость с выводом git diff.
- -style=Chromium — готовый пресет стиля форматирования кода. Другие возможные значения: LLVM, Google, Mozilla, WebKit.
- -sort-includes — опция сортировки по алфавиту директив #include (не обязательна).
- -iregex ‘.*.(cxx|cpp|hpp|h)$’ — регулярное выражение, фильтрующее имена файлов по расширениям. Тут перечислены только те расширения, которые надо форматировать. Это убережёт программу от падения и неожиданных глюков. Скорее всего список нужно будет дополнить в новых проектах. Кроме С++ можно форматировать C/Objective-C/JavaScript/Java/Protobuf. Хотя эти типы файлов мы не тестировали.
GIT_APPLY=» git apply -v -p0 — « — применение к коду патча, выданного предыдущей командой.
- -p0: по умолчанию git apply пропускает первый компонент в пути к файлу, это несовместимо с форматом, который выдаёт clang-format-diff-6.0. Здесь отключено такое пропускание.
FORMATTER_DIFF=$(eval ${GIT_DIFF} —staged | eval ${CLANG_FORMAT}) — изменения форматера для индекса.
echo «${FORMATTER_DIFF}» | eval ${GIT_APPLY} —cached форматирует исходный код в индексе (после git add). К сожалению, нет такого хука, который срабатывал бы перед добавлением файлов в индекс. Поэтому форматирование разделено на две части: форматируется то, что в индексе и отдельно то, что не добавлено в индекс.
eval ${GIT_DIFF} | eval ${CLANG_FORMAT} | eval ${GIT_APPLY} — форматирование кода не в индексе (запускается, только когда что-то было отформатировано в индексе). Форматирует вообще все текущие изменения в проекте (под контролем версий), а не только из предыдущего шага. Это спорное, на первый взгляд, решение. Но оно оказалось удобным, т.к. рано или поздно другие изменения надо форматировать тоже. Можно заменить «| eval ${GIT_APPLY}» опцией -i, которая заставит ${CLANG_FORMAT} менять файлы самостоятельно.
Демонстрация работы
- Установить clang-format-6.0
- cd /tmp && mkdir temp_project && cd temp_project
- git init
- Добавить под контроль версий и закомитить любой файл C++ под именем wrong.cpp. Желательно >50 строк неформатированного кода.
- Сделать скрипт .git/hooks/pre-commit, показанный выше.
- Назначить скрипту права на запуск (для git): chmod +x .git/hooks/pre-commit.
- Запустить вручную скрипт .git/hooks/pre-commit, он должен запускаться с сообщением «Nothing to be formatted», без ошибок интерпретатора.
- Создать file.cpp с содержимым int main() { for (int i = 0; i < 100; ++i) { std::cout << » First case » << std::endl; std::cout << » Second case » << std::endl; std::cout << » Third case » << std::endl; } } одной строкой или с другим плохим форматированием. В конце — перевод строки!
- git add file.cpp && git commit -m » file.cpp « должны быть сообщения от скрипта типа «Патч file.cpp применен без ошибок».
- git log -p -1 должен показать добавление форматированного файла.
- Если file.cpp попал в коммит действительно форматированным, значит можно тестировать форматирование только в diff. Измените пару строк wrong.cpp так, чтобы форматер на них среагировал. Например, добавьте неадекватные отступы в коде вместе с другими изменениями. git commit -a -m » Format only diff « должен залить форматированные изменения, но не затронуть другие части файла.
Недостатки и проблемы
git diff —staged (который здесь ${GIT_DIFF} —staged) выдаёт diff только тех файлов, что были добавлены в индекс. А clang-format-diff-6.0 обращается к полным версиям файлов за пределами него. Поэтому, если изменить какой-то файл, сделать git add, а потом изменить тот же файл, то clang-format-diff-6.0 будет генерировать патч для форматирования кода (в индексе) на основе отличающегося файла. Таким образом, файл после git add и до коммита лучше не редактировать.
Вот пример такой ошибки:
- Добавить в file.cpp, » Second case « лишний std::endl. (std::cout << » Second case » << std::endl << std::endl;) и несколько табов лишнего отступа перед строкой.
- git add file.cpp
- Очистить строку (в этом же файле) с » First case « так, что бы на её месте остался(!) только перенос строки.
- git commit -m » Formatter error on commit «.
Скрипт должен сообщить » error: при поиске: «, т.е. git apply не нашёл контекст патча, выданного clang-format-diff-6.0. Если вы не поняли, в чём тут проблема, просто не меняйте файлы после git add их и до git commit. Если надо поменять, можете сделать коммит (без push) и потом git commit —amend с новыми изменениями.
Самое серьёзное ограничение — необходимость иметь в конце каждого файла перевод строки. Это старая особенность git, поэтому большинство редакторов кода, поддерживают автоматическую вставку такого перевода в конец файла. Без этого скрипт будет падать при коммите нового файла, но это не принесет никакого вреда.
Очень редко clang-format-diff-6.0 форматирует код неадекватно. В этом случае можно добавить какие-нибудь бесполезные элементы в код, типа точки с запятой. Либо, окружить проблемный код комментариями, /* clang-format off */ и /* clang-format on */.
Также clang-format-diff-6.0 может выдавать неадекватный патч. Это заканчивается тем, что git apply не принимает его, и код части коммита остается неотфоматированным. Причина — внутри clang-format-diff. Нет времени разбираться во всех ошибках программы. В этом случае можно посмотреть на патч форматирования с помощью команды git diff -U0 —no-color HEAD^ | clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex ‘.*.(cxx|cpp|hpp|h)$’. Самым простым решением будет добавление опции -i к предыдущей команде. В этом случае утилита не будет выдавать патч, а отформатирует код. Если не помогло, можно попробовать форматирование для отдельных файлов целиком clang-format-6.0 -i -sort-includes -style=Chromium file.cpp. Далее git add file.cpp и git commit —amend.
Есть предположение, что чем ближе ваш конфиг .clang-format к одному из пресетов, тем меньше таких ошибок вы увидите. (Здесь его заменяет опция -style=Chromium).
Отладка
Если хотите посмотреть, какие изменения сделает скрипт на ваших текущих правках (не в индексе), используйте git diff -U0 —no-color | clang-format-diff-6.0 -p1 -v -sort-includes -style=Chromium -iregex ‘.*.(cxx|cpp|hpp|h)$’ Также можно проверить, как будет работать скрипт на последних коммитах, например, на тридцати: git filter-branch -f —tree-filter » ${PWD}/.git/hooks/pre-commit » —prune-empty HEAD~30..HEAD . Данная команда должна была форматировать предыдущие коммиты, но по факту меняет только их id. Поэтому стоит проводить такие эксперименты в отдельной копии проекта! После она станет непригодной для работы.
Заключение
Субъективно, от такого решения гораздо больше пользы чем вреда. Но надо тестировать поведение clang-format-diff разных версий на коде вашего проекта, с конфигом для вашего стиля кода.
К сожалению, такой же git-hook для Windows мы не делали. Предлагайте в комментариях, как это сделать там. А если нужна статья для быстрого старта с clang-format, советуем посмотреть описание ClangFormat.