20.1.1. Parameter Names and Values
All parameter names are case-insensitive. Every parameter takes a value of one of five types: boolean, string, integer, floating point, or enumerated (enum). The type determines the syntax for setting the parameter:
-
Boolean: Values can be written as
on,off,true,false,yes,no,1,0(all case-insensitive) or any unambiguous prefix of one of these. -
String: In general, enclose the value in single quotes, doubling any single quotes within the value. Quotes can usually be omitted if the value is a simple number or identifier, however. (Values that match an SQL keyword require quoting in some contexts.)
-
Numeric (integer and floating point): Numeric parameters can be specified in the customary integer and floating-point formats; fractional values are rounded to the nearest integer if the parameter is of integer type. Integer parameters additionally accept hexadecimal input (beginning with
0x) and octal input (beginning with0), but these formats cannot have a fraction. Do not use thousands separators. Quotes are not required, except for hexadecimal input. -
Numeric with Unit: Some numeric parameters have an implicit unit, because they describe quantities of memory or time. The unit might be bytes, kilobytes, blocks (typically eight kilobytes), milliseconds, seconds, or minutes. An unadorned numeric value for one of these settings will use the setting’s default unit, which can be learned from
pg_settings.unit. For convenience, settings can be given with a unit specified explicitly, for example'120 ms'for a time value, and they will be converted to whatever the parameter’s actual unit is. Note that the value must be written as a string (with quotes) to use this feature. The unit name is case-sensitive, and there can be whitespace between the numeric value and the unit.-
Valid memory units are
B(bytes),kB(kilobytes),MB(megabytes),GB(gigabytes), andTB(terabytes). The multiplier for memory units is 1024, not 1000. -
Valid time units are
us(microseconds),ms(milliseconds),s(seconds),min(minutes),h(hours), andd(days).
If a fractional value is specified with a unit, it will be rounded to a multiple of the next smaller unit if there is one. For example,
30.1 GBwill be converted to30822 MBnot32319628902 B. If the parameter is of integer type, a final rounding to integer occurs after any unit conversion. -
-
Enumerated: Enumerated-type parameters are written in the same way as string parameters, but are restricted to have one of a limited set of values. The values allowable for such a parameter can be found from
pg_settings.enumvals. Enum parameter values are case-insensitive.
20.1.2. Parameter Interaction via the Configuration File
The most fundamental way to set these parameters is to edit the file postgresql.conf, which is normally kept in the data directory. A default copy is installed when the database cluster directory is initialized. An example of what this file might look like is:
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
One parameter is specified per line. The equal sign between name and value is optional. Whitespace is insignificant (except within a quoted parameter value) and blank lines are ignored. Hash marks (#) designate the remainder of the line as a comment. Parameter values that are not simple identifiers or numbers must be single-quoted. To embed a single quote in a parameter value, write either two quotes (preferred) or backslash-quote. If the file contains multiple entries for the same parameter, all but the last one are ignored.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden. The following sections describe ways in which the administrator or user can override these defaults.
The configuration file is reread whenever the main server process receives a SIGHUP signal; this signal is most easily sent by running pg_ctl reload from the command line or by calling the SQL function pg_reload_conf(). The main server process also propagates this signal to all currently running server processes, so that existing sessions also adopt the new values (this will happen after they complete any currently-executing client command). Alternatively, you can send the signal to a single server process directly. Some parameters can only be set at server start; any changes to their entries in the configuration file will be ignored until the server is restarted. Invalid parameter settings in the configuration file are likewise ignored (but logged) during SIGHUP processing.
In addition to postgresql.conf, a PostgreSQL data directory contains a file postgresql.auto.conf, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file holds settings provided through the ALTER SYSTEM command. This file is read whenever postgresql.conf is, and its settings take effect in the same way. Settings in postgresql.auto.conf override those in postgresql.conf.
External tools may also modify postgresql.auto.conf. It is not recommended to do this while the server is running, since a concurrent ALTER SYSTEM command could overwrite such changes. Such tools might simply append new settings to the end, or they might choose to remove duplicate settings and/or comments (as ALTER SYSTEM will).
The system view pg_file_settings can be helpful for pre-testing changes to the configuration files, or for diagnosing problems if a SIGHUP signal did not have the desired effects.
20.1.3. Parameter Interaction via SQL
PostgreSQL provides three SQL commands to establish configuration defaults. The already-mentioned ALTER SYSTEM command provides an SQL-accessible means of changing global defaults; it is functionally equivalent to editing postgresql.conf. In addition, there are two commands that allow setting of defaults on a per-database or per-role basis:
-
The
ALTER DATABASEcommand allows global settings to be overridden on a per-database basis. -
The
ALTER ROLEcommand allows both global and per-database settings to be overridden with user-specific values.
Values set with ALTER DATABASE and ALTER ROLE are applied only when starting a fresh database session. They override values obtained from the configuration files or server command line, and constitute defaults for the rest of the session. Note that some settings cannot be changed after server start, and so cannot be set with these commands (or the ones listed below).
Once a client is connected to the database, PostgreSQL provides two additional SQL commands (and equivalent functions) to interact with session-local configuration settings:
-
The
SHOWcommand allows inspection of the current value of any parameter. The corresponding SQL function iscurrent_setting(setting_name text)(see Section 9.27.1). -
The
SETcommand allows modification of the current value of those parameters that can be set locally to a session; it has no effect on other sessions. Many parameters can be set this way by any user, but some can only be set by superusers and users who have been grantedSETprivilege on that parameter. The corresponding SQL function isset_config(setting_name, new_value, is_local)(see Section 9.27.1).
In addition, the system view pg_settings can be used to view and change session-local values:
-
Querying this view is similar to using
SHOW ALLbut provides more detail. It is also more flexible, since it’s possible to specify filter conditions or join against other relations. -
Using
UPDATEon this view, specifically updating thesettingcolumn, is the equivalent of issuingSETcommands. For example, the equivalent ofSET configuration_parameter TO DEFAULT;
is:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
20.1.4. Parameter Interaction via the Shell
In addition to setting global defaults or attaching overrides at the database or role level, you can pass settings to PostgreSQL via shell facilities. Both the server and libpq client library accept parameter values via the shell.
-
During server startup, parameter settings can be passed to the
postgrescommand via the-ccommand-line parameter. For example,postgres -c log_connections=yes -c log_destination='syslog'
Settings provided in this way override those set via
postgresql.conforALTER SYSTEM, so they cannot be changed globally without restarting the server. -
When starting a client session via libpq, parameter settings can be specified using the
PGOPTIONSenvironment variable. Settings established in this way constitute defaults for the life of the session, but do not affect other sessions. For historical reasons, the format ofPGOPTIONSis similar to that used when launching thepostgrescommand; specifically, the-cflag must be specified. For example,env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Other clients and libraries might provide their own mechanisms, via the shell or otherwise, that allow the user to alter session settings without direct use of SQL commands.
20.1.5. Managing Configuration File Contents
PostgreSQL provides several features for breaking down complex postgresql.conf files into sub-files. These features are especially useful when managing multiple servers with related, but not identical, configurations.
In addition to individual parameter settings, the postgresql.conf file can contain include directives, which specify another file to read and process as if it were inserted into the configuration file at this point. This feature allows a configuration file to be divided into physically separate parts. Include directives simply look like:
include 'filename'
If the file name is not an absolute path, it is taken as relative to the directory containing the referencing configuration file. Inclusions can be nested.
There is also an include_if_exists directive, which acts the same as the include directive, except when the referenced file does not exist or cannot be read. A regular include will consider this an error condition, but include_if_exists merely logs a message and continues processing the referencing configuration file.
The postgresql.conf file can also contain include_dir directives, which specify an entire directory of configuration files to include. These look like
include_dir 'directory'
Non-absolute directory names are taken as relative to the directory containing the referencing configuration file. Within the specified directory, only non-directory files whose names end with the suffix .conf will be included. File names that start with the . character are also ignored, to prevent mistakes since such files are hidden on some platforms. Multiple files within an include directory are processed in file name order (according to C locale rules, i.e., numbers before letters, and uppercase letters before lowercase ones).
Include files or directories can be used to logically separate portions of the database configuration, rather than having a single large postgresql.conf file. Consider a company that has two database servers, each with a different amount of memory. There are likely elements of the configuration both will share, for things such as logging. But memory-related parameters on the server will vary between the two. And there might be server specific customizations, too. One way to manage this situation is to break the custom configuration changes for your site into three files. You could add this to the end of your postgresql.conf file to include them:
include 'shared.conf' include 'memory.conf' include 'server.conf'
All systems would have the same shared.conf. Each server with a particular amount of memory could share the same memory.conf; you might have one for all servers with 8GB of RAM, another for those having 16GB. And finally server.conf could have truly server-specific configuration information in it.
Another possibility is to create a configuration file directory and put this information into files there. For example, a conf.d directory could be referenced at the end of postgresql.conf:
include_dir 'conf.d'
Then you could name the files in the conf.d directory like this:
00shared.conf 01memory.conf 02server.conf
This naming convention establishes a clear order in which these files will be loaded. This is important because only the last setting encountered for a particular parameter while the server is reading configuration files will be used. In this example, something set in conf.d/02server.conf would override a value set in conf.d/01memory.conf.
You might instead use this approach to naming the files descriptively:
00shared.conf 01memory-8GB.conf 02server-foo.conf
This sort of arrangement gives a unique name for each configuration file variation. This can help eliminate ambiguity when several servers have their configurations all stored in one place, such as in a version control repository. (Storing database configuration files under version control is another good practice to consider.)
Сервер баз данных PostgreSQL имеет очень много параметров с помощью которых его можно настроить под любые нужды. В этой статье мы не будет рассматривать все эти параметры. Здесь мы посмотрим на различные cпособы конфигурирования PostgreSQL.
Если же вы хотите посмотреть список параметров настройки PostgreSQL, то ищите его в справочнике на официальном сайте: на английском и на русском языках.
Конфигурационный файл postgresql.conf
Главный конфигурационный файл для кластера PostgreSQL – это postgresql.conf, в разных системах он может находится в разных местах. Так как мы собирали сервер из исходников и не меняли путь хранения этого файла, то по умолчанию он будет находится в каталоге PGDATA:
postgres@s-pg13:~$ echo $PGDATA /usr/local/pgsql/data postgres@s-pg13:~$ ls -l $PGDATA/postgresql.conf -rw------- 1 postgres postgres 28023 июн 21 15:15 /usr/local/pgsql/data/postgresql.conf
Этот конфигурационный файл читается один раз при запуске сервера. Если параметр указан несколько раз, то применяется последний.
Самый точный способ узнать расположение этого файла, посмотреть из терминала psql:
postgres@s-pg13:~$ psql
Timing is on.
psql (13.3)
Type "help" for help.
postgres@postgres=# SHOW config_file;
config_file
---------------------------------------
/usr/local/pgsql/data/postgresql.conf
(1 row)
Time: 0,391 ms
Если вы измените параметры в этом файле, его нужно перечитать. Первый способ – из командной оболочки операционной системы:
postgres@postgres=# q postgres@s-pg13:~$ pg_ctl reload server signaled
Второй способ – из терминала psql:
postgres@s-pg13:~$ psql Timing is on. psql (13.3) Type "help" for help. postgres@postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) Time: 0,555 ms
Но есть некоторые параметры, для изменения которых потребуется перезапуск сервера.
Конфигурация сервера используя ALTER SYSTEM
Для настройки сервера также существует другой файл – postgresql.auto.conf. Он были придуман для настройки сервера из консоли psql. Читается этот файл после postgresql.conf, поэтому параметры из него имеют приоритет. Этот файл всегда находится в каталоге с данными (PGDATA).
Для создания параметров в файле postgresql.auto.conf нужно выполнить подобный запрос:
ALTER SYSTEM SET <параметр> TO <значение>;
Чтобы удалить параметр используем другой запрос:
ALTER SYSTEM RESET <параметр>;
А чтобы удалить все параметры из postgresql.auto.conf выполним:
ALTER SYSTEM RESET ALL;
Чтобы применить изменения нужно перечитать конфигурационные файлы как было описано выше.
Информация о текущих настройках сервера
В PostgreSQL есть 2 представления через которые можно посмотреть текущие настройки сервера:
- pg_file_settings – какие параметры записаны в файлах postgresql.conf и postgresql.auto.conf;
- pg_settings – текущие параметры, с которыми работает сервер.
Например посмотрим значение параметра config_file из представления pg_settings, который покажет конфигурационный файл текущего кластера:
postgres@postgres=# SELECT setting FROM pg_settings WHERE name = 'config_file';
setting
---------------------------------------
/usr/local/pgsql/data/postgresql.conf
(1 row)
Time: 1,844 ms
Внесём изменения в параметр work_mem в postgresql.conf и postgresql.auto.conf. Затем посмотрим на все не закомментированные параметры в этих файлах:
postgres@postgres=# ! echo 'work_mem = 8MB' >> $PGDATA/postgresql.conf
postgres@postgres=# ALTER SYSTEM SET work_mem TO '10MB';
ALTER SYSTEM
Time: 0,728 ms
postgres@postgres=# SELECT sourceline, name, setting, applied FROM pg_file_settings;
sourceline | name | setting | applied
------------+----------------------------+--------------------+---------
63 | port | 5433 | f
64 | max_connections | 100 | t
121 | shared_buffers | 128MB | t
142 | dynamic_shared_memory_type | posix | t
228 | max_wal_size | 1GB | t
229 | min_wal_size | 80MB | t
563 | log_timezone | Europe/Moscow | t
678 | datestyle | iso, dmy | t
680 | timezone | Europe/Moscow | t
694 | lc_messages | ru_RU.UTF-8 | t
696 | lc_monetary | ru_RU.UTF-8 | t
697 | lc_numeric | ru_RU.UTF-8 | t
698 | lc_time | ru_RU.UTF-8 | t
701 | default_text_search_config | pg_catalog.russian | t
780 | work_mem | 8MB | f
3 | work_mem | 10MB | t
(16 rows)
Time: 0,650 ms
Как можно заметить в примере выше, у меня 2 одинаковых параметра work_mem. Колонка applied показывает, может ли быть применён параметр. Первый work_mem не может быть применен, так как второй его перезапишет. При этом реальное значение с которым работает сервер отличается, так как сервер не перечитал конфигурацию.
Теперь посмотрим на реальное, текущее значение этого параметра:
postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+--------- name | work_mem setting | 4096 unit | kB boot_val | 4096 reset_val | 4096 source | default sourcefile | sourceline | pending_restart | f context | user Time: 0,854 ms
В примере выше мы использовали расширенный режим (в конце запроса gx), поэтому табличка перевёрнута. Разберём колонки:
- name – имя параметра;
- setting – текущее значение;
- unit – единица измерения;
- boot_val – значение по умолчанию (жёстко задано в коде postgresql);
- reset_val – если перечитаем конфигурацию, то применится это значение;
- source – источник, это значение по умолчанию;
- sourcefile – если бы источником был конфигурационный файл, то тут был бы указан этот файл;
- sourceline – номер строки в этом файле;
- pending_restart – параметр изменили в конфигурационном файле и требуется перезапуск сервера. У нас требуется всего лишь перечитать конфигурацию;
- context – действия, необходимые для применения параметра, может быть таким:
- internal – изменить нельзя, задано при установке;
- postmaster – требуется перезапуск сервера;
- sighup – требуется перечитать файлы конфигурации;
- superuser – суперпользователь может изменить для своего сеанса;
- user – любой пользователь может изменить для своего сеанса на лету.
Перечитаем конфигурацию сервера:
postgres@postgres=# SELECT pg_reload_conf(); pg_reload_conf ---------------- t (1 row) Time: 3,178 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+------------------------------------------- name | work_mem setting | 10240 unit | kB boot_val | 4096 reset_val | 10240 source | configuration file sourcefile | /usr/local/pgsql/data/postgresql.auto.conf sourceline | 3 pending_restart | f context | user Time: 1,210 ms
Как видим, параметр изменился. Он был взят из postgresql.auto.conf и теперь равняется 10 MB.
Установка параметров на лету
Для своего сеанса можно изменить параметры с context=user. Для этого используется конструкция:
SET <параметр> TO '<значение>';
Например сделаем это для work_mem:
postgres@postgres=# SET work_mem TO '64MB'; SET Time: 0,119 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+--------- name | work_mem setting | 65536 unit | kB boot_val | 4096 reset_val | 10240 source | session sourcefile | sourceline | pending_restart | f context | user Time: 0,651 ms
Как видим, теперь источником является текущая сессия, а параметр равен 64 MB, но если мы перечитаем конфигурацию параметр снова станет равным 10 MB.
Чтобы вернуть все на место нужно просто перезайти в psql. Или выполнить команду RESET <параметр>:
postgres@postgres=# RESET work_mem; RESET Time: 0,211 ms postgres@postgres=# SELECT name, setting, unit, boot_val, reset_val, source, sourcefile, sourceline, pending_restart, context FROM pg_settings WHERE name = 'work_mem'gx -[ RECORD 1 ]---+------------------------------------------- name | work_mem setting | 10240 unit | kB boot_val | 4096 reset_val | 10240 source | configuration file sourcefile | /usr/local/pgsql/data/postgresql.auto.conf sourceline | 3 pending_restart | f context | user Time: 0,632 ms
Тоже самое может проделывать приложение для одной транзакции, и если транзакция откатывается, то и значение параметра откатывается вместе с ней:
postgres@postgres=# BEGIN; BEGIN Time: 0,070 ms postgres@postgres=# SET work_mem TO '64MB'; SET Time: 0,085 ms postgres@postgres=# SHOW work_mem; work_mem ---------- 64MB (1 row) Time: 0,102 ms postgres@postgres=# ROLLBACK; ROLLBACK Time: 0,108 ms postgres@postgres=# SHOW work_mem; work_mem ---------- 10MB (1 row) Time: 0,120 ms
Как вы могли заметить посмотреть текущее значение параметра ещё можно так:
SHOW <параметр>;
Какие параметры требуют перезапуск сервера?
Чтобы это выяснить нужно посмотреть все параметры у которых context = postmaster:
postgres@postgres=# SELECT name, setting, unit FROM pg_settings WHERE context = 'postmaster';
name | setting | unit
-------------------------------------+---------------------------------------+------
archive_mode | off |
autovacuum_freeze_max_age | 200000000 |
autovacuum_max_workers | 3 |
autovacuum_multixact_freeze_max_age | 400000000 |
bonjour | off |
bonjour_name | |
cluster_name | |
config_file | /usr/local/pgsql/data/postgresql.conf |
data_directory | /usr/local/pgsql/data |
data_sync_retry | off |
dynamic_shared_memory_type | posix |
event_source | PostgreSQL |
external_pid_file | |
hba_file | /usr/local/pgsql/data/pg_hba.conf |
hot_standby | on |
huge_pages | try |
ident_file | /usr/local/pgsql/data/pg_ident.conf |
ignore_invalid_pages | off |
jit_provider | llvmjit |
listen_addresses | localhost |
logging_collector | off |
max_connections | 100 |
max_files_per_process | 1000 |
max_locks_per_transaction | 64 |
max_logical_replication_workers | 4 |
max_pred_locks_per_transaction | 64 |
max_prepared_transactions | 0 |
max_replication_slots | 10 |
max_wal_senders | 10 |
max_worker_processes | 8 |
old_snapshot_threshold | -1 | min
port | 5432 |
recovery_target | |
recovery_target_action | pause |
recovery_target_inclusive | on |
recovery_target_lsn | |
recovery_target_name | |
recovery_target_time | |
recovery_target_timeline | latest |
recovery_target_xid | |
restore_command | |
shared_buffers | 16384 | 8kB
shared_memory_type | mmap |
shared_preload_libraries | |
superuser_reserved_connections | 3 |
track_activity_query_size | 1024 | B
track_commit_timestamp | off |
unix_socket_directories | /tmp |
unix_socket_group | |
unix_socket_permissions | 0777 |
wal_buffers | 512 | 8kB
wal_level | replica |
wal_log_hints | off |
(53 rows)
Time: 0,666 ms
Сводка

Имя статьи
PostgreSQL. Конфигурирование
Описание
Сервер баз данных PostgreSQL имеет очень много параметров с помощью которых его можно настроить под любые нужды. В этой статье мы не будет рассматривать все эти параметры. Здесь мы посмотрим на различные способы настройки этого сервера.
19.1.1. Parameter Names and Values
All parameter names are case-insensitive. Every parameter takes a value of one of five types: boolean, string, integer, floating point, or enumerated (enum). The type determines the syntax for setting the parameter:
-
Boolean: Values can be written as
on,off,true,false,yes,no,1,0(all case-insensitive) or any unambiguous prefix of one of these. -
String: In general, enclose the value in single quotes, doubling any single quotes within the value. Quotes can usually be omitted if the value is a simple number or identifier, however. (Values that match a SQL keyword require quoting in some contexts.)
-
Numeric (integer and floating point): Numeric parameters can be specified in the customary integer and floating-point formats; fractional values are rounded to the nearest integer if the parameter is of integer type. Integer parameters additionally accept hexadecimal input (beginning with
0x) and octal input (beginning with0), but these formats cannot have a fraction. Do not use thousands separators. Quotes are not required, except for hexadecimal input. -
Numeric with Unit: Some numeric parameters have an implicit unit, because they describe quantities of memory or time. The unit might be bytes, kilobytes, blocks (typically eight kilobytes), milliseconds, seconds, or minutes. An unadorned numeric value for one of these settings will use the setting’s default unit, which can be learned from
pg_settings.unit. For convenience, settings can be given with a unit specified explicitly, for example'120 ms'for a time value, and they will be converted to whatever the parameter’s actual unit is. Note that the value must be written as a string (with quotes) to use this feature. The unit name is case-sensitive, and there can be whitespace between the numeric value and the unit.-
Valid memory units are
B(bytes),kB(kilobytes),MB(megabytes),GB(gigabytes), andTB(terabytes). The multiplier for memory units is 1024, not 1000. -
Valid time units are
us(microseconds),ms(milliseconds),s(seconds),min(minutes),h(hours), andd(days).
If a fractional value is specified with a unit, it will be rounded to a multiple of the next smaller unit if there is one. For example,
30.1 GBwill be converted to30822 MBnot32319628902 B. If the parameter is of integer type, a final rounding to integer occurs after any unit conversion. -
-
Enumerated: Enumerated-type parameters are written in the same way as string parameters, but are restricted to have one of a limited set of values. The values allowable for such a parameter can be found from
pg_settings.enumvals. Enum parameter values are case-insensitive.
19.1.2. Parameter Interaction via the Configuration File
The most fundamental way to set these parameters is to edit the file postgresql.conf, which is normally kept in the data directory. A default copy is installed when the database cluster directory is initialized. An example of what this file might look like is:
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
One parameter is specified per line. The equal sign between name and value is optional. Whitespace is insignificant (except within a quoted parameter value) and blank lines are ignored. Hash marks (#) designate the remainder of the line as a comment. Parameter values that are not simple identifiers or numbers must be single-quoted. To embed a single quote in a parameter value, write either two quotes (preferred) or backslash-quote. If the file contains multiple entries for the same parameter, all but the last one are ignored.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden. The following sections describe ways in which the administrator or user can override these defaults.
The configuration file is reread whenever the main server process receives a SIGHUP signal; this signal is most easily sent by running pg_ctl reload from the command line or by calling the SQL function pg_reload_conf(). The main server process also propagates this signal to all currently running server processes, so that existing sessions also adopt the new values (this will happen after they complete any currently-executing client command). Alternatively, you can send the signal to a single server process directly. Some parameters can only be set at server start; any changes to their entries in the configuration file will be ignored until the server is restarted. Invalid parameter settings in the configuration file are likewise ignored (but logged) during SIGHUP processing.
In addition to postgresql.conf, a PostgreSQL data directory contains a file postgresql.auto.conf, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file holds settings provided through the ALTER SYSTEM command. This file is read whenever postgresql.conf is, and its settings take effect in the same way. Settings in postgresql.auto.conf override those in postgresql.conf.
External tools may also modify postgresql.auto.conf. It is not recommended to do this while the server is running, since a concurrent ALTER SYSTEM command could overwrite such changes. Such tools might simply append new settings to the end, or they might choose to remove duplicate settings and/or comments (as ALTER SYSTEM will).
The system view pg_file_settings can be helpful for pre-testing changes to the configuration files, or for diagnosing problems if a SIGHUP signal did not have the desired effects.
19.1.3. Parameter Interaction via SQL
PostgreSQL provides three SQL commands to establish configuration defaults. The already-mentioned ALTER SYSTEM command provides a SQL-accessible means of changing global defaults; it is functionally equivalent to editing postgresql.conf. In addition, there are two commands that allow setting of defaults on a per-database or per-role basis:
-
The ALTER DATABASE command allows global settings to be overridden on a per-database basis.
-
The ALTER ROLE command allows both global and per-database settings to be overridden with user-specific values.
Values set with ALTER DATABASE and ALTER ROLE are applied only when starting a fresh database session. They override values obtained from the configuration files or server command line, and constitute defaults for the rest of the session. Note that some settings cannot be changed after server start, and so cannot be set with these commands (or the ones listed below).
Once a client is connected to the database, PostgreSQL provides two additional SQL commands (and equivalent functions) to interact with session-local configuration settings:
-
The SHOW command allows inspection of the current value of any parameter. The corresponding SQL function is
current_setting(setting_name text)(see Section 9.27.1). -
The SET command allows modification of the current value of those parameters that can be set locally to a session; it has no effect on other sessions. The corresponding SQL function is
set_config(setting_name, new_value, is_local)(see Section 9.27.1).
In addition, the system view pg_settings can be used to view and change session-local values:
-
Querying this view is similar to using
SHOW ALLbut provides more detail. It is also more flexible, since it’s possible to specify filter conditions or join against other relations. -
Using UPDATE on this view, specifically updating the
settingcolumn, is the equivalent of issuingSETcommands. For example, the equivalent ofSET configuration_parameter TO DEFAULT;
is:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
19.1.4. Parameter Interaction via the Shell
In addition to setting global defaults or attaching overrides at the database or role level, you can pass settings to PostgreSQL via shell facilities. Both the server and libpq client library accept parameter values via the shell.
-
During server startup, parameter settings can be passed to the
postgrescommand via the-ccommand-line parameter. For example,postgres -c log_connections=yes -c log_destination='syslog'
Settings provided in this way override those set via
postgresql.conforALTER SYSTEM, so they cannot be changed globally without restarting the server. -
When starting a client session via libpq, parameter settings can be specified using the
PGOPTIONSenvironment variable. Settings established in this way constitute defaults for the life of the session, but do not affect other sessions. For historical reasons, the format ofPGOPTIONSis similar to that used when launching thepostgrescommand; specifically, the-cflag must be specified. For example,env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Other clients and libraries might provide their own mechanisms, via the shell or otherwise, that allow the user to alter session settings without direct use of SQL commands.
19.1.5. Managing Configuration File Contents
PostgreSQL provides several features for breaking down complex postgresql.conf files into sub-files. These features are especially useful when managing multiple servers with related, but not identical, configurations.
In addition to individual parameter settings, the postgresql.conf file can contain include directives, which specify another file to read and process as if it were inserted into the configuration file at this point. This feature allows a configuration file to be divided into physically separate parts. Include directives simply look like:
include 'filename'
If the file name is not an absolute path, it is taken as relative to the directory containing the referencing configuration file. Inclusions can be nested.
There is also an include_if_exists directive, which acts the same as the include directive, except when the referenced file does not exist or cannot be read. A regular include will consider this an error condition, but include_if_exists merely logs a message and continues processing the referencing configuration file.
The postgresql.conf file can also contain include_dir directives, which specify an entire directory of configuration files to include. These look like
include_dir 'directory'
Non-absolute directory names are taken as relative to the directory containing the referencing configuration file. Within the specified directory, only non-directory files whose names end with the suffix .conf will be included. File names that start with the . character are also ignored, to prevent mistakes since such files are hidden on some platforms. Multiple files within an include directory are processed in file name order (according to C locale rules, i.e., numbers before letters, and uppercase letters before lowercase ones).
Include files or directories can be used to logically separate portions of the database configuration, rather than having a single large postgresql.conf file. Consider a company that has two database servers, each with a different amount of memory. There are likely elements of the configuration both will share, for things such as logging. But memory-related parameters on the server will vary between the two. And there might be server specific customizations, too. One way to manage this situation is to break the custom configuration changes for your site into three files. You could add this to the end of your postgresql.conf file to include them:
include 'shared.conf' include 'memory.conf' include 'server.conf'
All systems would have the same shared.conf. Each server with a particular amount of memory could share the same memory.conf; you might have one for all servers with 8GB of RAM, another for those having 16GB. And finally server.conf could have truly server-specific configuration information in it.
Another possibility is to create a configuration file directory and put this information into files there. For example, a conf.d directory could be referenced at the end of postgresql.conf:
include_dir 'conf.d'
Then you could name the files in the conf.d directory like this:
00shared.conf 01memory.conf 02server.conf
This naming convention establishes a clear order in which these files will be loaded. This is important because only the last setting encountered for a particular parameter while the server is reading configuration files will be used. In this example, something set in conf.d/02server.conf would override a value set in conf.d/01memory.conf.
You might instead use this approach to naming the files descriptively:
00shared.conf 01memory-8GB.conf 02server-foo.conf
This sort of arrangement gives a unique name for each configuration file variation. This can help eliminate ambiguity when several servers have their configurations all stored in one place, such as in a version control repository. (Storing database configuration files under version control is another good practice to consider.)
19.1.1. Parameter Names and Values
All parameter names are case-insensitive. Every parameter takes a value of one of five types: boolean, string, integer, floating point, or enumerated (enum). The type determines the syntax for setting the parameter:
-
Boolean: Values can be written as
on,off,true,false,yes,no,1,0(all case-insensitive) or any unambiguous prefix of one of these. -
String: In general, enclose the value in single quotes, doubling any single quotes within the value. Quotes can usually be omitted if the value is a simple number or identifier, however. (Values that match a SQL keyword require quoting in some contexts.)
-
Numeric (integer and floating point): Numeric parameters can be specified in the customary integer and floating-point formats; fractional values are rounded to the nearest integer if the parameter is of integer type. Integer parameters additionally accept hexadecimal input (beginning with
0x) and octal input (beginning with0), but these formats cannot have a fraction. Do not use thousands separators. Quotes are not required, except for hexadecimal input. -
Numeric with Unit: Some numeric parameters have an implicit unit, because they describe quantities of memory or time. The unit might be bytes, kilobytes, blocks (typically eight kilobytes), milliseconds, seconds, or minutes. An unadorned numeric value for one of these settings will use the setting’s default unit, which can be learned from
pg_settings.unit. For convenience, settings can be given with a unit specified explicitly, for example'120 ms'for a time value, and they will be converted to whatever the parameter’s actual unit is. Note that the value must be written as a string (with quotes) to use this feature. The unit name is case-sensitive, and there can be whitespace between the numeric value and the unit.-
Valid memory units are
B(bytes),kB(kilobytes),MB(megabytes),GB(gigabytes), andTB(terabytes). The multiplier for memory units is 1024, not 1000. -
Valid time units are
us(microseconds),ms(milliseconds),s(seconds),min(minutes),h(hours), andd(days).
If a fractional value is specified with a unit, it will be rounded to a multiple of the next smaller unit if there is one. For example,
30.1 GBwill be converted to30822 MBnot32319628902 B. If the parameter is of integer type, a final rounding to integer occurs after any unit conversion. -
-
Enumerated: Enumerated-type parameters are written in the same way as string parameters, but are restricted to have one of a limited set of values. The values allowable for such a parameter can be found from
pg_settings.enumvals. Enum parameter values are case-insensitive.
19.1.2. Parameter Interaction via the Configuration File
The most fundamental way to set these parameters is to edit the file postgresql.conf, which is normally kept in the data directory. A default copy is installed when the database cluster directory is initialized. An example of what this file might look like is:
# This is a comment log_connections = yes log_destination = 'syslog' search_path = '"$user", public' shared_buffers = 128MB
One parameter is specified per line. The equal sign between name and value is optional. Whitespace is insignificant (except within a quoted parameter value) and blank lines are ignored. Hash marks (#) designate the remainder of the line as a comment. Parameter values that are not simple identifiers or numbers must be single-quoted. To embed a single quote in a parameter value, write either two quotes (preferred) or backslash-quote. If the file contains multiple entries for the same parameter, all but the last one are ignored.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden. The following sections describe ways in which the administrator or user can override these defaults.
The configuration file is reread whenever the main server process receives a SIGHUP signal; this signal is most easily sent by running pg_ctl reload from the command line or by calling the SQL function pg_reload_conf(). The main server process also propagates this signal to all currently running server processes, so that existing sessions also adopt the new values (this will happen after they complete any currently-executing client command). Alternatively, you can send the signal to a single server process directly. Some parameters can only be set at server start; any changes to their entries in the configuration file will be ignored until the server is restarted. Invalid parameter settings in the configuration file are likewise ignored (but logged) during SIGHUP processing.
In addition to postgresql.conf, a PostgreSQL data directory contains a file postgresql.auto.conf, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file holds settings provided through the ALTER SYSTEM command. This file is read whenever postgresql.conf is, and its settings take effect in the same way. Settings in postgresql.auto.conf override those in postgresql.conf.
External tools may also modify postgresql.auto.conf. It is not recommended to do this while the server is running, since a concurrent ALTER SYSTEM command could overwrite such changes. Such tools might simply append new settings to the end, or they might choose to remove duplicate settings and/or comments (as ALTER SYSTEM will).
The system view pg_file_settings can be helpful for pre-testing changes to the configuration files, or for diagnosing problems if a SIGHUP signal did not have the desired effects.
19.1.3. Parameter Interaction via SQL
PostgreSQL provides three SQL commands to establish configuration defaults. The already-mentioned ALTER SYSTEM command provides a SQL-accessible means of changing global defaults; it is functionally equivalent to editing postgresql.conf. In addition, there are two commands that allow setting of defaults on a per-database or per-role basis:
-
The ALTER DATABASE command allows global settings to be overridden on a per-database basis.
-
The ALTER ROLE command allows both global and per-database settings to be overridden with user-specific values.
Values set with ALTER DATABASE and ALTER ROLE are applied only when starting a fresh database session. They override values obtained from the configuration files or server command line, and constitute defaults for the rest of the session. Note that some settings cannot be changed after server start, and so cannot be set with these commands (or the ones listed below).
Once a client is connected to the database, PostgreSQL provides two additional SQL commands (and equivalent functions) to interact with session-local configuration settings:
-
The SHOW command allows inspection of the current value of any parameter. The corresponding SQL function is
current_setting(setting_name text)(see Section 9.27.1). -
The SET command allows modification of the current value of those parameters that can be set locally to a session; it has no effect on other sessions. The corresponding SQL function is
set_config(setting_name, new_value, is_local)(see Section 9.27.1).
In addition, the system view pg_settings can be used to view and change session-local values:
-
Querying this view is similar to using
SHOW ALLbut provides more detail. It is also more flexible, since it’s possible to specify filter conditions or join against other relations. -
Using UPDATE on this view, specifically updating the
settingcolumn, is the equivalent of issuingSETcommands. For example, the equivalent ofSET configuration_parameter TO DEFAULT;
is:
UPDATE pg_settings SET setting = reset_val WHERE name = 'configuration_parameter';
19.1.4. Parameter Interaction via the Shell
In addition to setting global defaults or attaching overrides at the database or role level, you can pass settings to PostgreSQL via shell facilities. Both the server and libpq client library accept parameter values via the shell.
-
During server startup, parameter settings can be passed to the
postgrescommand via the-ccommand-line parameter. For example,postgres -c log_connections=yes -c log_destination='syslog'
Settings provided in this way override those set via
postgresql.conforALTER SYSTEM, so they cannot be changed globally without restarting the server. -
When starting a client session via libpq, parameter settings can be specified using the
PGOPTIONSenvironment variable. Settings established in this way constitute defaults for the life of the session, but do not affect other sessions. For historical reasons, the format ofPGOPTIONSis similar to that used when launching thepostgrescommand; specifically, the-cflag must be specified. For example,env PGOPTIONS="-c geqo=off -c statement_timeout=5min" psql
Other clients and libraries might provide their own mechanisms, via the shell or otherwise, that allow the user to alter session settings without direct use of SQL commands.
19.1.5. Managing Configuration File Contents
PostgreSQL provides several features for breaking down complex postgresql.conf files into sub-files. These features are especially useful when managing multiple servers with related, but not identical, configurations.
In addition to individual parameter settings, the postgresql.conf file can contain include directives, which specify another file to read and process as if it were inserted into the configuration file at this point. This feature allows a configuration file to be divided into physically separate parts. Include directives simply look like:
include 'filename'
If the file name is not an absolute path, it is taken as relative to the directory containing the referencing configuration file. Inclusions can be nested.
There is also an include_if_exists directive, which acts the same as the include directive, except when the referenced file does not exist or cannot be read. A regular include will consider this an error condition, but include_if_exists merely logs a message and continues processing the referencing configuration file.
The postgresql.conf file can also contain include_dir directives, which specify an entire directory of configuration files to include. These look like
include_dir 'directory'
Non-absolute directory names are taken as relative to the directory containing the referencing configuration file. Within the specified directory, only non-directory files whose names end with the suffix .conf will be included. File names that start with the . character are also ignored, to prevent mistakes since such files are hidden on some platforms. Multiple files within an include directory are processed in file name order (according to C locale rules, i.e., numbers before letters, and uppercase letters before lowercase ones).
Include files or directories can be used to logically separate portions of the database configuration, rather than having a single large postgresql.conf file. Consider a company that has two database servers, each with a different amount of memory. There are likely elements of the configuration both will share, for things such as logging. But memory-related parameters on the server will vary between the two. And there might be server specific customizations, too. One way to manage this situation is to break the custom configuration changes for your site into three files. You could add this to the end of your postgresql.conf file to include them:
include 'shared.conf' include 'memory.conf' include 'server.conf'
All systems would have the same shared.conf. Each server with a particular amount of memory could share the same memory.conf; you might have one for all servers with 8GB of RAM, another for those having 16GB. And finally server.conf could have truly server-specific configuration information in it.
Another possibility is to create a configuration file directory and put this information into files there. For example, a conf.d directory could be referenced at the end of postgresql.conf:
include_dir 'conf.d'
Then you could name the files in the conf.d directory like this:
00shared.conf 01memory.conf 02server.conf
This naming convention establishes a clear order in which these files will be loaded. This is important because only the last setting encountered for a particular parameter while the server is reading configuration files will be used. In this example, something set in conf.d/02server.conf would override a value set in conf.d/01memory.conf.
You might instead use this approach to naming the files descriptively:
00shared.conf 01memory-8GB.conf 02server-foo.conf
This sort of arrangement gives a unique name for each configuration file variation. This can help eliminate ambiguity when several servers have their configurations all stored in one place, such as in a version control repository. (Storing database configuration files under version control is another good practice to consider.)
Состояние перевода: На этой странице представлен перевод статьи PostgreSQL. Дата последней синхронизации: 21 ноября 2022. Вы можете помочь синхронизировать перевод, если в английской версии произошли изменения.
PostgreSQL — это поддерживаемая сообществом система управления базами данных с открытым исходным кодом.
Установка
Важно: Смотрите раздел #Обновление PostgreSQL для выполнения обязательных шагов перед установкой обновлений пакета PostgreSQL.
Установите пакет postgresql. Он также создаст системного пользователя postgres.
Для переключения в пользователя postgres можно использовать программу для повышения привилегий.
Примечание: Команды, которые нужно запускать от имени пользователя postgres, в данной статье обозначены префиксом [postgres]$.
Для переключения в пользователя postgres можно использовать одну из следующих команд:
- Если у вас есть sudo и ваш пользователь прописан в sudoers:
$ sudo -iu postgres
- Или через su:
$ su # su -l postgres
Смотрите также документацию sudo(8) или su(1).
Начальная настройка
В первую очередь необходимо инициализировать кластер баз данных:
[postgres]$ initdb -D /var/lib/postgres/data
Где опция -D указывает на стандартное расположение данных кластера (если вы хотите использовать другой каталог, смотрите раздел #Изменение стандартного каталога данных). initdb принимает дополнительные аргументы:
- По умолчанию локаль и кодировка для кластера баз данных наследуются из вашего текущего окружения (используется значение $LANG). Если вас это не устраивает, вы можете прописать нужные параметры вручную с помощью опций
--locale=локаль(где локаль должна быть одной из доступных системных локалей) и--encoding=кодировкадля выбора кодировки (должна соответствовать выбранной локали). (После настройки базы данных вы сможете посмотреть используемые значения командой[postgres]$ psql -l.) - Если каталог с данными расположен на файловой системе без контроля целостности данных, вы можете включить встроенный в PostgreSQL подсчёт контрольных сумм для повышения гарантий целостности — для этого добавьте аргумент
--data-checksums. Дополнительная информация описана в разделе #Включение подсчёта контрольных сумм. (После настройки базы данных вы сможете посмотреть. включена ли эта функция, командой[postgres]$ psql -c "SHOW data_checksums".) - Другие доступные опции можно посмотреть в
initdb --helpили официальной документации.
Пример для русской локали:
[postgres]$ initdb --locale=ru_RU.UTF-8 --encoding=UTF8 -D /var/lib/postgres/data --data-checksums
После инициализации на экране появится много строчек, некоторых из которых оканчиваются на ... ок:
Файлы, относящиеся к этой СУБД, будут принадлежать пользователю "postgres".
От его имени также будет запускаться процесс сервера.
Кластер баз данных будет инициализирован с локалью "ru_RU.UTF-8".
Кодировка БД по умолчанию, выбранная в соответствии с настройками: "UTF8".
Выбрана конфигурация текстового поиска по умолчанию "russian".
Контроль целостности страниц данных отключён.
исправление прав для существующего каталога /var/lib/postgres/data... ок
создание подкаталогов... ок
выбирается реализация динамической разделяемой памяти... posix
выбирается значение max_connections по умолчанию... 100
выбирается значение shared_buffers по умолчанию... 128MB
выбирается часовой пояс по умолчанию... Europe/Moscow
создание конфигурационных файлов... ок
выполняется подготовительный скрипт... ок
выполняется заключительная инициализация... ок
сохранение данных на диске... ок
initdb: предупреждение: включение метода аутентификации "trust" для локальных подключений
Другой метод можно выбрать, отредактировав pg_hba.conf или используя ключи -A,
--auth-local или --auth-host при следующем выполнении initdb.
Готово. Теперь вы можете запустить сервер баз данных:
pg_ctl -D /var/lib/postgres/data -l файл_журнала start
Если вы видите подобное, значит инициализация прошла успешно. Можно вернуться в обычного пользователя, выполнив команду exit в сеансе пользователя postgres.
Примечание: Подробнее об этом предупреждении читайте в разделе #Ограничение доступа к суперпользователю по умолчанию.
Совет: Если вы хотите использовать путь отличный от /var/lib/postgres, нужно отредактировать файл службы systemd. Если вы помещаете его в /home, не забудьте отключить ProtectHome.
Важно:
- Если база данных располагается на файловой системе Btrfs, стоит отключить копирование при записи для каталога перед созданием любых баз данных.
- Если база данных располагается на файловой системе ZFS, прочтите ZFS#Databases перед созданием любых баз данных.
Наконец, запустите и включите службу postgresql.service.
Создание первой базы данных
Совет: Если имя роли/пользователя совпадает с именем вашего пользователя в Linux, вы сможете получить доступ к оболочке PostgreSQL без явного указания имени пользователя (что весьма удобно).
Становимся пользователем postgres.
Добавляем нового пользователя базы данных с помощью команды createuser:
[postgres]$ createuser --interactive
Создаём новую базу данных от имени пользователя, имеющего доступ на чтение-запись, с помощью команды createdb (выполните эту команду в оболочке вашего обычного пользователя, если имя будущего владельца базы данных совпадает с вашим именем пользователя в Linux, в ином случае добавьте опцию -O имя-пользователя)
$ createdb имяМоейБазы
Совет: Если вы не выдали разрешение на создание баз данных вашему свежесозданному пользователю, добавьте опцию -U postgres к этой команде.
Знакомство с PostgreSQL
Доступ к оболочке базы данных
Становимся postgres пользователем.
Запускаем основную оболочку базы данных psql, в которой мы сможем создавать, удалять базы данных/таблицы, задавать права и запускать команды SQL.
Используйте опцию -d, чтобы указать название базы данных, которую вы создали (если опцию не указать, то psql попытается подключиться к базе, имя которой совпадает с именем пользователя).
[postgres]$ psql -d имяМоейБазы
Некоторые полезные команды:
Получение справки:
=> help
Подключение к определённой базе данных:
=> c <database>
Список всех пользователей и их уровни доступа:
=> du
Краткая информация о всех таблицах в текущей базе данных:
=> dt
Выход из оболочки psql:
=> q или CTRL+d
Есть, конечно, много других мета-команд, но именно эти должны помочь вам начать работу.
Для просмотра всех мета-команд введите:
=> ?
Дополнительные настройки
Файл настроек сервера баз данных PostgreSQL — postgresql.conf. Этот файл находится в папке данных сервера, обычно /var/lib/postgres/data. В этой же папке находятся основные файлы настроек включая и pg_hba.conf, который определяет параметры аутентификации, как для локальных пользователей, так и для пользователей с других хостов.
Примечание: По умолчанию эта папка не доступна даже для просмотра (или поиска) от лица обычного пользователя.
Ограничение доступа к суперпользователю по умолчанию
По умолчанию pg_hba.conf разрешает подключение любого локального пользователя к любому пользователю базы данных, в том числе суперпользователю. Скорее всего это не то, что вам нужно, поэтому, чтобы разрешить подключение только пользователю postgres, измените эту строку:
/var/lib/postgres/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all all trust
На эту:
/var/lib/postgres/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all postgres peer
Можно добавить дополнительные строки в зависимости от ваших потребностей.
Требование пароля при входе
Измените /var/lib/postgres/data/pg_hba.conf, прописав метод аутентификации для каждого пользователя (или «all» для всех пользователей) на scram-sha-256 (предпочтительно) или md5 (менее безопасно; по возможности стоит его избегать):
/var/lib/postgres/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD # "local" is for Unix domain socket connections only local all пользователь scram-sha-256
Если вы выбрали scram-sha-256, также нужно изменить /var/lib/postgres/data/postgresql.conf:
/var/lib/postgres/data/postgresql.conf
password_encryption = scram-sha-256
Перезапустите службу postgresql.service и заново пропишите пароли для пользователей с помощью SQL-запроса ALTER USER пользователь WITH ENCRYPTED PASSWORD 'пароль';.
Доступ только через Unix-сокет
В разделе «connections and authentication» пропишите:
/var/lib/postgres/data/postgresql.conf
listen_addresses = ''
Это полностью отключит доступ через сеть.
Не забудьте перезапустить службу postgresql.service для применения изменений.
Доступ с удалённых хостов
В разделе «connections and authentication» раскомментируйте или исправьте строку listen_addresses по вашему желанию, например:
/var/lib/postgres/data/postgresql.conf
listen_addresses = 'localhost,мой_локальный_ip'
Можно использовать '*' для прослушивания всех доступных сетевых интерфейсов.
Примечание: PostgreSQL по умолчанию использует TCP-порт 5432 для удалённого доступа. Убедитесь, что этот порт открыт в вашем межсетевом экране и может принимать входящие соединения. Изменить порт можно в этом же файле настроек, под строкой listen_addresses.
Затем измените настройки аутентификации:
/var/lib/postgres/data/pg_hba.conf
# TYPE DATABASE USER ADDRESS METHOD # IPv4 local connections: host all all ip_адрес/32 md5
где ip_адрес — IP-адрес удалённого клиента.
Смотрите также документацию по pg_hba.conf.
Примечание: Ни отправка простого пароля, ни отправка md5-хэша (использованный в приведённом выше примере) через интернет не являются безопасными, если это не выполняется через защищенное SSL-соединение. Смотрите Secure TCP/IP Connections with SSL, чтобы узнать, как настроить PostgreSQL с использованием SSL.
Перезапустите службу postgresql.service для применения изменений.
В случае проблем посмотрите журнал сервера:
# journalctl -u postgresql.service
Настройка аутентификации через PAM
PostgreSQL предлагает несколько методов аутентификации. Если вы хотите разрешить пользователям аутентифицироваться с их системным паролем, необходимы дополнительные шаги. Сначала вам нужно включить PAM для соединения.
Например, та же конфигурация, что и выше, но с включенным PAM:
/var/lib/postgres/data/pg_hba.conf
# IPv4 local connections: host all all ip_адрес/32 pam
Однако сервер PostgreSQL работает без прав root и не сможет получить доступ к файлу /etc/shadow. Мы можем обойти это, разрешив группе postgres доступ к этому файлу:
# setfacl -m g:postgres:r /etc/shadow
Изменение стандартного каталога данных
По умолчанию PostgreSQL настроен на использование каталога /var/lib/postgres/data для хранения всех баз данных. Для его изменения выполните следующие шаги:
Создайте новый каталог и сделайте пользователя postgres его владельцем:
# mkdir -p /путь/к/pgroot/data # chown -R postgres:postgres /путь/к/pgroot
Войдите в пользователя postgres и выполните инициализацию кластера:
[postgres]$ initdb -D /путь/к/pgroot/data
Отредактируйте службу postgresql.service, создав drop-in файл и переопределив настройки Environment и PIDFile. Например:
/etc/systemd/system/postgresql.service.d/PGROOT.conf
[Service] Environment=PGROOT=/путь/к/pgroot PIDFile=/путь/к/pgroot/data/postmaster.pid
Если вы хотите использовать каталог в /home, добавьте ещё одну строку:
ProtectHome=false
Изменение кодировки новых баз данных на UTF-8
Примечание: Если вы выполнили initdb с опцией --encoding=UTF8 или с использованием локали UTF-8, выполнять эти шаги не нужно.
Когда создаётся новая база данных (например, командой createdb blog), PostgreSQL просто копирует шаблон базы данных. Есть два стандартных шаблона: template0 — ванильный, и template1, который используется по умолчанию и предназначен для редактирования администратором. Один из вариантов изменения кодировки новой базы данных — изменить шаблон template1. Для этого зайдите в оболочку PostgreSQL (psql) и выполните следующее:
Сперва нужно удалить template1. Шаблоны нельзя удалять, так что сперва нужно преобразовать его в обычную базу данных:
UPDATE pg_database SET datistemplate = FALSE WHERE datname = 'template1';
Теперь можно удалить:
DROP DATABASE template1;
Затем создайте новую базу данных с новой кодировкой по умолчанию, в качестве шаблона используя template0:
CREATE DATABASE template1 WITH TEMPLATE = template0 ENCODING = 'UNICODE';
Теперь снова сделайте template1 шаблоном:
UPDATE pg_database SET datistemplate = TRUE WHERE datname = 'template1';
По желанию, если вы не хотите, чтобы кто-либо подключался к этому шаблону, присвойте параметру datallowconn значение FALSE:
UPDATE pg_database SET datallowconn = FALSE WHERE datname = 'template1';
Примечание: Этот шаг может привести к проблемам при обновлении через pg_upgrade.
Теперь вы можете создать базу данных, используя стандартные команды в терминале:
[postgres]$ createdb blog
Если снова войти в psql и проверить базу данных, вы должны увидеть правильную кодировку новой базы данных:
l
List of databases
Name | Owner | Encoding | Collation | Ctype | Access privileges
-----------+----------+-----------+-----------+-------+----------------------
blog | postgres | UTF8 | C | C |
postgres | postgres | SQL_ASCII | C | C |
template0 | postgres | SQL_ASCII | C | C | =c/postgres
: postgres=CTc/postgres
template1 | postgres | UTF8 | C | C |
Включение подсчёта контрольных сумм
Если файлы вашей базы данных находятся на файловой системе, которая не использует контрольные суммы, то данные в ней могут незаметно повреждаться из-за битфлипов и аппаратных проблем. Хотя такие случаи редки, желательно включить встроенный в PostgreSQL подсчёт контрольных сумм, если вы заботитесь о целостности данных. Эта функция должна быть включена на уровне кластера, а не для отдельных баз данных или таблиц.
Примечание: Ряд предостережений, которые стоит иметь в виду:
- Есть небольшое влияние на производительность, особенно при чтении больших массивов данных с диска. На операции в памяти это не влияет.
- PostgreSQL не может исправить повреждённые данные — он только прервёт транзакции, читающие с повреждённых страниц, чтобы предотвратить дальнейшее повреждение или получение некорректных результатов выполнения.
- Контрольные суммы охватывают только страницы данных (строк) на диске, но не метаданные или управляющие структуры. Страницы в памяти не проверяются. Хранилища с коррекцией ошибок и память с ECC по-прежнему полезны.
- Чтобы включить подсчёт контрольных сумм при создании кластера, добавьте аргумент
--data-checksumsк командеinitdb. - Чтобы проверить, включен ли подсчёт контрольных сумм, выполните
[postgres]$ psql -c "SHOW data_checksums"(выведетсяoffилиon). - Чтобы включить подсчёт контрольных сумм на существующем кластере:
- Остановите службу
postgresql.service. - Выполните команду
[postgres]$ pg_checksums --pgdata /var/lib/postgres/data --enable(или--disable, если вы хотите наоборот выключить эту функцию). Включение подсчёта контрольных сумм приведёт к перезаписи всех страниц базы данных, что займет некоторое время в больших базах данных. - Запустите службу
postgresql.service.
Графические инструменты
- phpPgAdmin — Веб-интерфейс для администрирования PostgreSQL.
- https://github.com/phppgadmin/phppgadmin || phppgadmin[ссылка недействительна: package not found]
- pgAdmin — Комплексный графический интерфейс для управления PostgreSQL.
- https://www.pgadmin.org/ || pgadmin3AUR или pgadmin4
- pgModeler — Инструмент для моделирования баз данных PostgreSQL.
- https://pgmodeler.io/ || pgmodelerAUR
Список инструментов, поддерживающих несколько разных СУБД, можно посмотреть в статье List of applications/Documents#Database tools.
Обновление PostgreSQL
![]() This article or section needs expansion.
This article or section needs expansion.![]()
Для обновления до новой мажорной версии PostgreSQL (например, с версии 13.x на версию 14.y) необходима специальная процедура.
Важно: Приведённые ниже инструкции потенциально могут привести к потере данных. Не запускайте эти команды вслепую без понимания того, что они делают. Сделайте резервную копию перед началом.
Посмотреть текущую версию базы данных можно так:
# cat /var/lib/postgres/data/PG_VERSION
Чтобы случайно не обновиться до несовместимой версии, рекомендуется запретить обновления пакетов PostgreSQL.
Минорные обновления вполне безопасны. Однако если вы случайно обновитесь до другой мажорной версии, то не сможете получить доступ к данным. Всегда проверяйте домашнюю страницу PostgreSQL, чтобы знать, какие шаги требуются для каждого обновления. Чтобы узнать, почему это так, смотрите политику управления версиями.
Примечание: Если вы используете расширения, смотрите разделы #PostgreSQL не может запуститься после обновления пакета при использовании расширений и #Не удаётся запустить PostgreSQL со старой версией базы данных при обновлении до новой версии с расширениями.
Есть два основных способа обновить базу данных PostgreSQL. Подробности читайте в официальной документации.
pg_upgrade
Утилита pg_upgrade пытается скопировать как можно больше совместимых данных между кластерами и обновить всё остальное. Как правило, это самый быстрый метод обновления большинства экземпляров, хотя он требует доступа к бинарным файлам исходной и целевой версий PostgreSQL. Прочтите справочную страницу pg_upgrade(1), чтобы понять, какие действия он выполняет. Для нетривиальных экземпляров (например, с потоковой репликацией или трансляцией журналов) сперва ознакомьтесь с официальной документацией.
Для тех, кто хочет использовать pg_upgrade, доступен пакет postgresql-old-upgrade, который всегда отстаёт на одну мажорную версию от основного пакета PostgreSQL. Его можно установить параллельно с новой версией PostgreSQL. Для обновления более старых версий PostgreSQL доступны пакеты AUR, например postgresql-12-upgradeAUR. (Нужно использовать команду pg_upgrade из той версии PostgreSQL, на которую вы хотите обновиться.)
Обратите внимание, что каталог кластера баз данных не меняется от версии к версии, поэтому перед запуском pg_upgrade необходимо переименовать старый каталог данных и выполнить миграцию в новый каталог. Новый кластер баз данных необходимо инициализировать с теми же параметрами, что и старый.
Когда вы будете готовы к обновлению, выполните следующие шаги:
- Пока старая база данных всё ещё доступна, соберите аргументы для команды
initdb, которые использовались при создании базы. Команды для просмотра текущих настроек кластера описаны в разделе #Начальная настройка. - Остановите службу
postgresql.service. (Проверьте статус юнита, чтобы убедиться, что PostgreSQL завершился корректно, иначеpg_upgradeне сможет отработать корректно.) - Обновите пакеты postgresql, postgresql-libs и postgresql-old-upgrade.
- Переименуйте каталог со старым кластером и создайте каталог для нового кластера и временный каталог:
# mv /var/lib/postgres/data /var/lib/postgres/olddata # mkdir /var/lib/postgres/data /var/lib/postgres/tmp # chown postgres:postgres /var/lib/postgres/data /var/lib/postgres/tmp [postgres]$ cd /var/lib/postgres/tmp
- Инициализируйте новый кластер командой
initdbс теми же аргументами, которые использовались для старого кластера:[postgres]$ initdb -D /var/lib/postgres/data --locale=ru_RU.UTF-8 --encoding=UTF8 --data-checksums
- Обновите кластер, выполнив эту команду (замените
PG_VERSIONна номер старой версии, например13):[postgres]$ pg_upgrade -b /opt/pgsql-PG_VERSION/bin -B /usr/bin -d /var/lib/postgres/olddata -D /var/lib/postgres/data
Примечание: Не забудьте обновить файлы конфигурации (например,
pg_hba.confиpostgresql.conf) для соответствия старому кластеру.Примечание: Если
pg_upgradeзавершается с ошибкойThe source cluster was not shut down cleanly, значит PostgreSQL не был остановлен перед запуском обновления. Остановите его, затем перезапустите кластер со старыми бинарными файлами, чтобы восстановить старые файлы кластера:[postgres]$ /opt/pgsql-PG_VERSION/bin/pg_ctl start -D /var/lib/postgres/olddata && /opt/pgsql-PG_VERSION/bin/pg_ctl stop -D /var/lib/postgres/olddata
После этого можно снова выполнить
pg_upgrade. Если обновиться всё равно не получается, остановите все процессы СУБД, откатитесь на более старую версию PostgreSQL, восстановите предыдущие данные кластера из резервных копий и перезапустите процесс обновления. - Запустите службу
postgresql.service. - Опционально: Выполните
[postgres]$ /usr/bin/vacuumdb --all --analyze-in-stagesдля пересчёта статистики анализатора запросов, что должно улучшить производительность запросов вскоре после обновления (добавление аргумента--jobs=ЧИСЛО_ЯДЕР_ПРОЦЕССОРАможет улучшить производительность этой команды). - Опционально: Сделайте резервную копию каталога
/var/lib/postgres/olddataна случай, если вдруг понадобится вернуть старую версию PostgreSQL. - Удалите каталог
/var/lib/postgres/olddataсо старыми данными кластера. - Удалите каталог
/var/lib/postgres/tmp.
Выгрузка и загрузка вручную
Ещё можно сделать что-то вроде такого (после обновления и установки postgresql-old-upgrade):
Примечание:
- В примере показано обновление с PostgreSQL 13; посмотрите в
/opt/установленную у вас версию postgresql-old-upgrade и исправьте команды по необходимости. - Если вы меняли файл
pg_hba.conf, вам может понадобиться временно разрешить полный доступ к старому кластеру с локальной системы. После обновления не забудьте прописать нужные вам настройки в новом кластере и перезапустить службуpostgresql.service.
Остановите службу postgresql.service.
# mv /var/lib/postgres/data /var/lib/postgres/olddata # mkdir /var/lib/postgres/data # chown postgres:postgres /var/lib/postgres/data [postgres]$ initdb -D /var/lib/postgres/data [postgres]$ /opt/pgsql-13/bin/pg_ctl -D /var/lib/postgres/olddata/ start # cp /usr/lib/postgresql/postgis-3.so /opt/pgsql-13/lib/ # Только если установлен postgis [postgres]$ pg_dumpall -h /tmp -f /tmp/old_backup.sql [postgres]$ /opt/pgsql-13/bin/pg_ctl -D /var/lib/postgres/olddata/ stop
Запустите службу postgresql.service.
[postgres]$ psql -f /tmp/old_backup.sql postgres
Решение проблем
Ускорение мелких транзакций
Если вы используете PostgreSQL на своей локальной машине для разработки и он медленный, то можете попробовать отключить synchronous_commit в конфигурации. Однако, не забывайте про его особенности.
/var/lib/postgres/data/postgresql.conf
synchronous_commit = off
Запретить запись на диск во время бездействия
PostgreSQL периодически обновляет свою статистику, лежащую в файле. По умолчанию этот файл находится на диске, что не даёт отдыхать жёсткому диску (и изнашивает его), заставляя его шуметь. Однако можно легко и безопасно переместить статистику в ОЗУ с помощью такой настройки:
/var/lib/postgres/data/postgresql.conf
stats_temp_directory = '/run/postgresql'
Проблемы с pgAdmin 4 после обновления до PostgreSQL 12
Если вы видите ошибки вроде string indices must be integers при навигации по дереву слева или column rel.relhasoids does not exist при просмотре данных, удалите сервер из списка соединений в pgAdmin и добавьте его заново. Без этого pgAdmin продолжает считать его сервером PostgreSQL 11, что и приводит к таким ошибкам.
PostgreSQL не может запуститься после обновления пакета при использовании расширений
Причина скорее всего в том, что существующий пакет не скомпилирован для новой версии (а она может быть актуальной), решение — пересобрать пакет вручную или дождаться обновления пакета расширения.
Не удаётся запустить PostgreSQL со старой версией базы данных при обновлении до новой версии с расширениями
Это происходит потому, что старая версия postgres из пакета postgresql-old-upgrade не имеет необходимых расширений (.so файлов) в своём каталоге lib. Предлагаемое здесь решение грязное и может вызвать много проблем, поэтому сохраните резервную копию базы данных на всякий случай. В целом, скопируйте необходимые .so файлы расширений из /usr/lib/postgresql/ в /opt/pgsql-XX/lib/ (не забудьте заменить XX на мажорную версию пакета postgresql-old-upgrade).
Например, для timescaledb:
# cp /usr/lib/postgresql/timescaledb*.so /opt/pgsql-13/lib/
Важно: Хотя копирования .so файлов обычно достаточно, может понадобиться скопировать больше файлов в правильные расположения в /opt/pgsql-XX/.
Чтобы узнать точные файлы для копирования, посмотрите содержимое пакета расширения с помощью команды:
$ pacman -Ql имя_пакета
Важно: Это очень грязное решение, которое может привести к потере данных в базе, поэтому создайте резервную копию перед выполнением этих действий.
This article contains information about postgresql.conf file in PostgreSQL. If you want to change Postgresql configuration parameters, you should read the below article.
Postgresql change configuration parameters.
What is postgresql.conf?
The postgresql.conf configuration file basically affects the behavior of the instance. For example, allowed number of connections, database log management, vaccum, determining wal parameters, etc. Of course, all this has a default value when the database is installed, but we can change these values to better suit the workload and working environment. The most basic way to set these parameters is to edit the postgresql.conf file.
postgresql.conf Location
postgresql.conf file is normally stored in the $PGDATA directory. By default, the postgresql.conf file is loaded in the init phase. If we want to find the full path of the postgresql.conf file using the command, we use the following command.
|
select * from pg_settings where name=‘config_file’; |
Sample postgresql.conf file
An example postgresql.conf file is as follows, as you can guess, a parameter is specified in each line, the equal sign between name and value is optional. Spaces are trivial, # sets the rest of the line as a comment.
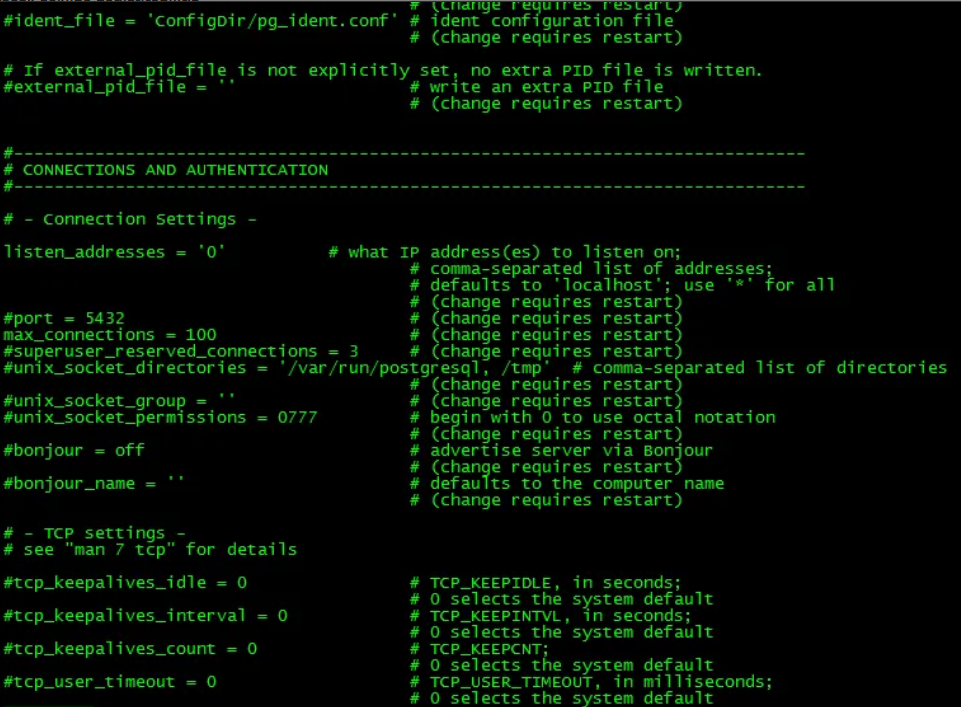
NOTE: If the posgresql.conf file contains multiple entries for the same parameter, all but the last one is ignored, so the last value written in the file is valid.
Parameters set in this way provide default values for the cluster. The settings seen by active sessions will be these values unless they are overridden.
Reload postgresql.conf
When Postgresql main process receives the SIGHUP signal, the Postgresql configuration file is read again. This signal can be sent to postgresql in two ways. The postgresql.conf file can be read again with the “pg_ctl reload” command on the operating system or with the “SELECT pg_reload_conf ()” command from the psql command line tool.
The Main process propagates this signal to all running server processes, so existing sessions also adopt the new values (this happens after completing any client commands currently executing).
Alternatively, you can send the signal directly to a single server transaction. Invalid parameter settings in the configuration file are ignored (but logged) during the SIGHUP process.
|
—bash—4.2$ /usr/pgsql—12/bin/pg_ctl reload server signaled —bash—4.2$ psql psql (12.4) Type «help» for help. postgres=# select pg_reload_conf(); pg_reload_conf ———————— t (1 row) |
postgresql.auto.conf vs postgresql.conf
Some parameters can only be set at server startup; For these parameters, “# (change requires restart)” is written in the comment section of the postgresql.conf file.
In addition to Postgresql.conf, it includes a postgresql.auto.conf file, which has the same format as postgresql.conf but is intended to be edited automatically, not manually. This file contains the settings provided with the ALTER SYSTEM command. Settings in postgresql.auto.conf override the contents of postgresql.conf. The postgresql.auto.conf file is located in the $PGDATA directory.
NOTE: Pg_settings system view provides access to the server runtime parameters. It is essentially an alternative interface to SHOW and SET commands.
|
select * from setting where name = ‘configuration_parameter’; UPDATE pg_settings SET setting = reset_val WHERE name = ‘configuration_parameter’; |
PostgreSQL provides several features to subdivide complex postgresql.conf files. These features are particularly useful when managing multiple servers with related but not identical configurations.
|
include ‘shared.conf’ include ‘memory.conf’ include ‘server.conf’ |
postgresql.conf parameters
Since there are too many parameters in the Postgresql.conf file, this section of the article is divided into specific titles for file classification purposes; There are titles such as File Locations, Resource Consumption, Connections and Authentication etc. After this part of the article, I will briefly explain the important parameters in postgresql and make recommendations about the setting of these parameters in my opinion. Of course these settings could be different according to your environment and workload.
Connections
listen_addresses (string)
Specifies the TCP/IP Address (s) that the server will listen for connections from client applications.
If we are going to specify more than one address, we can give the hostname and ip numbers by separating them with a comma (,).
* Corresponds to all IP interfaces available.
0.0.0 allows listening on all IPv4 addresses.
:: allows listening on all IPv6 addresses.
If the list is empty, the server will not listen to any IP interface at all. In this case, only Unix domain sockets can be used to connect to it. The default value is localhost, which allows only local TCP / IP “loopback” connections to be made.
port (integer)
Postgresql serves from port 5432 by default. All IP addresses listened to by the server serve over the same port. When more than one postgresql instance is used on the same server, a different port must be used for each cluster/instance/postgresql.
max_connections (integer)
It is used to specify the maximum number of connections that can be opened simultaneously in the database. By default its value is 100. In standby servers, this parameter should be set the same or higher than the parameter value in the master server.
Before increasing your connection count, you should consider whether you really need an increased connection limit. After all, our machine has a limited amount of RAM. If you allow more connections, you can allocate less RAM to each connection. Otherwise, you are in danger of using swaps.
The private memory available for each process is limited to work_mem while query is running. So if you use a high value for max_connections, you will need to set this parameter to low. work_mem has a direct impact on query performance. Usually, a well-written app doesn’t need a lot of connection. If you have an application that needs a lot of connections, you should consider using a tool like pg_bouncer that can handle connections effectively for you.
superuser_reserved_connections (integer)
It determines how many connections out of the number of connections that are set by the max_connections parameter will be reserved for users in the super user role. It is 3 by default. Normal users can open a maximum of 97 connections on the system when the max_connections parameter is set to 100 and the superuser_reserved_connections parameter to 3.
The point to note here is that the postgres user who comes as super user by default should not be used in the application. In other words, if we use the postgres user in our application, this parameter has no meaning.
tcp_keepalives_idle (integer)
It sets a time limit for connections without any network activity between the operating system and the client. If this value is specified without units, it is taken in seconds. A value of 0 (default) selects the operating system default.
tcp_keepalives_interval (integer)
Specifies the period of time that the TCP keepalive message not accepted by the client will be retransmitted. If this value is specified without units, it is taken in seconds. A value of 0 (default) selects the operating system default.
tcp_keepalives_count (integer)
Specifies the number of TCP keepalive messages that can be lost before the server is considered disconnected from the client. A value of 0 (default) selects the operating system default.
tcp_user_timeout (integer)
Specifies the amount of time that transmitted data can remain unconfirmed before the TCP connection is forcibly closed. If this value is specified without units, it is taken in milliseconds. A value of 0 (the default) selects the default operating system.
Authentications
authentication_timeout (integer)
It is the parameter that enables the connection request to be rejected if the connection process of the user to the database is not completed in the expected time. It is set in seconds and its default value is 1 minute.
password_encryption (enum)
When a password is specified in CREATE ROLE or ALTER ROLE, this parameter determines the algorithm to be used to encrypt the password. By default it is md5.
db_user_namespace (boolean)
It is used to create independent users in databases. Default value is off. If its value is on, a custom user can be created for a database using the username @ dbname syntax.
ssl (boolean)
It is the parameter that activates the SSL connection method. By default, its value is off.
Using an SSL certificate encrypts our connection. In this way, our connection information in our package is safe.
ssl_ca_file
Specifies the name of the file containing the SSL server certificate authority (CA). The default is blank, ie the CA file is not uploaded and client certificate verification is not performed.
Resource Consumption
shared_buffers
It is the parameter that allows setting the area to be used as shared buffer in the memory. It is 128 MB by default. If you have a database dedicated server with 1 GB or more of RAM, the reasonable initial value for shared_buffers is 25% of the memory on your system. There are workloads for shared_buffers where even greater settings are effective, but since PostgreSQL is also based on the operating system cache structure, allocating more than 40% of the RAM to shared_buffers will not work better than a smaller shared_buffers. Larger settings for shared_buffers usually require a corresponding increase in max_wal_size.
Recommendation: I wanted to rewrite it because it is important; PostgreSQL uses the kernel buffer area in the operating system as well as its own buffer area, that is, the data thrown from the shared_buffers falls into the operating system cache and receives it from the postgresql operating system cache if needed. This means that data is stored twice in memory, first in the PostgreSQL buffer and then in the kernel buffer (Unlike other databases, PostgreSQL does not provide IO directly), this is called double buffering. After highlighting this part, coming to the suggestion, the default value of Shared_buffer is set to a very low value and you cannot get much benefit from it. It is low because some machines and operating systems do not support higher values. However, on most modern machines you need to increase this value for optimum performance. The recommended value is 25% of your total machine RAM. You should try lower and higher values because in some cases we will get good performance with a setting above 25%. The configuration really depends on your machine and operating data set.
huge_pages (enum)
It is the parameter that enables to set huge pages usage options in the shared memory area. It can take the value “Try, on or off”. By default it is Try. It tries to use the Huge pages, if not, there will be no problem in the system operation. If it cannot be used when set as on, the database cannot be started. When set to Off, it is not used at all.
Recommendation: The use of huge pages increases performance by consuming less CPU time for small table pages and memory management, so I recommend using huge pages by adjusting the necessary settings in the operating system.
temp_buffers (integer)
It is the parameter that determines the value of the maximum temporary buffer space to be used for each session. These are the session specific buffer spaces used only to access temporary tables. Default value is 8MB.
work_mem (integer)
Sets the maximum amount of memory to be used by a query operation (such as a sort or hash table) before writing to temporary disk files. The default is four megabytes (4MB). Sorting operations are used for ORDER BY, DISTINCT and merge join. Used for processing hash tables, hash joins, hash-based aggregation, hash-based processing, and IN subqueries. Several active sessions may be doing this type of action at the same time. Therefore, the total memory used may be more than work_mem. This fact should be kept in mind when choosing the value.
Recommendation: Memory operations are much faster than on disk, but setting too high a value may cause a memory bottleneck for your production media. Setting this parameter globally may cause very high memory usage. Therefore, it is highly recommended that you change this at the session level.
I want to talk about another approach; It is suggested to use the following formula to determine the work_mem value. If a connection pooling tool is used and the max connection number can be determined, it may make sense to use this formula.
|
Total RAM * 0.25 / max_connections |
Note: We can also directly assign work_mem to a role;
|
alter user test set work_mem=‘4GB’; |
maintenance_work_mem (integer)
Specifies the maximum amount of memory to be used by maintenance operations such as VACUUM, CREATE INDEX, and ALTER TABLE ADD FOREIGN KEY. It is 64 megabytes (64MB) by default. Since only one of these processes can be executed by a session at the same time, and most of them do not run simultaneously in normal setup, it is safe to set this value to a value much larger than work_mem.
temp_file_limit
It limits the total size of all temporary files used by each process. -1 (default) means no limit.
Recommendation: I think it is useful to determine this value by monitoring database processes. For example, I witnessed that the disk was full due to an accidental 100 billion sort operation from the application.
bgwriter_delay (integer)
It specifies how long the background writer process should wait between successive runs.
Recommendation: This parameter can be dropped at any time, but my general approach is to change the parameters related to bgwriter if you are facing a problem by monitoring the chechkpoint increments or pg_stat_bgwriter.
bgwriter_lru_maxpages (integer)
Specifies the maximum number of buffers to be written by the process in each run of bgwiter.
bgwriter_lru_multiplier (floating point)
The number of dirty buffers written in each round depends on the number of new buffers needed by the server processes in the last rounds. The average last need is multiplied by the bgwriter_lru_multiplier to arrive at an estimate of the number of buffers that will be needed in the next round. So if we set this value to 3.0, the number of dirty buffers it can write each time will be bgwriter_lru_maxpages * 3. By default, this value is 2.0.
effective_io_concurrency (integer)
Sets the number of concurrent disk I / O operations that PostgreSQL expects to be executed simultaneously. Increasing this value will increase the number of I / O processes that any PostgreSQL session attempts to start in parallel. The default value is 1, we can use 0 to disable it, at the same time, this parameter can take a value between 1-1000.
Recommendation: For magnetic drives, this setting is the number of drives in the RAID 0 or RAID 1 miror structure used for the database. For example, if you have 10 disks in RAID 1 structure, this parameter should be 5, or if you have 10 disks in RAID 0, this value should be 10. A higher value than necessary to keep the disks busy will only cause extra CPU overhead. SSDs and other memory-based storage can often handle many simultaneous requests, so the best value could be hundreds.
max_worker_processes (integer)
Sets the maximum number of background processes that the system can support. Default is 8. When running a standby server, you must set this parameter to the same or higher value than the primary server. Otherwise queries will not be allowed on the standby server. As a suggestion, I cannot say that the value should be this, but we can round the number that corresponds to 60% -70% of your total CPU and use this value.
max_parallel_workers_per_gather (integer)
The maximum number of workers that the Gather or GatherMerge node can use. It should be set equal to max_worker_processes as suggestion.
max_parallel_maintenance_workers (integer)
The maximum number of processes to be used in maintenance operations such as CREATE INDEX, vacuum.
max_parallel_workers (integer)
Sets the maximum number of workers that the system can support for parallel operations. The default value is 8. When increasing or decreasing this value, also consider adjusting max_parallel_maintenance_workers and max_parallel_workers_per_gather. Also note that a setting higher than max_worker_processes for this value will have no effect. Because parallel workers receive from the worker pool created by this setting.
LOGGING
log_statement (enum)
Checks which SQL queries are logged. Valid values are none (off), ddl, mod, and all (all queries). By default it is none. As a suggestion, I recommend leaving it as ddl.
log_min_duration_statement (integer)
If the statement is run for at least the specified time, it will cause the duration of each completed statement to be logged. For example, if you set it to 250ms, all SQL queries running 250ms or longer will be logged. Enabling this parameter can be helpful in tracking non-optimized queries in your applications. As a suggestion; By setting this parameter to a few minutes, you can fix problematic queries and then decrease this value. Overrides log_min_duration_sample.
log_checkpoints (boolean)
It enables checkpoint and restartpoint logs to be recorded in the server log. Some statistics such as the number of buffers written and the time taken to write them are included in the log messages. Default is off.
log_lock_waits (boolean)
This parameter checks whether the log message is generated when a session waits longer than the deadlock_timeout time to receive lock. This is useful in determining whether log wait times cause poor performance. Default is off. If I have to make suggestions, I think it is useful to open this parameter.
log_destination (string)
PostgreSQL supports several methods for logging server messages, including “stderr, csvlog, and syslog”. The default value is stderr.
logging_collector (boolean)
This parameter enables the log collector, a background process that captures log messages sent to stderr and redirects them to log files.
Note: log collector is designed to never lose messages. This means that in case of overload, server operations can be blocked when attempting to send additional log messages when the collector is left behind. Conversely, syslog prefers to leave messages if it cannot write, which means that in such cases it may not be able to log some messages, but will not block the rest of the system.
log_directory (string)
When the logging_collector is enabled, this parameter determines the directory where the log files will be created. By default it is the log directory under $PGDATA.
log_filename (string)
When the logging_collector is enabled, this parameter sets the filenames of the generated log files. The default is postgresql-%Y-%m-%d_%H%M%S.log. We use the arguments of the date command in linux for naming here.
log_file_mode (integer)
On Unix systems, this parameter sets the permissions of log files when logging_collector is enabled. The parameter value is expected to be a numeric mode specified in the format accepted by chmod and umask system calls. The default permissions are 0600, which means only the host can read or write log files.
log_rotation_age (integer)
When logging_collector is enabled, this parameter determines the maximum lifetime of a single log file, and then a new log file is created. If this value is specified without units, it is taken as minutes. The default is 24 hours. You can set it to zero to disable the time-based generation of new log files.
log_rotation_size (integer)
When logging_collector is enabled, this parameter determines the maximum size of a single log file. After this amount of data is sent to a log file, a new log file will be created. If this value is specified without units, it is taken in kilobytes. The default value is 10 megabytes. You can set it to zero to disable the creation of new log files based on size.
log_truncate_on_rotation (boolean)
When logging_collector is enabled, this parameter causes PostgreSQL to truncate (overwrite) instead of appending it to any existing log file with the same name.
event_source (string)
When event_source log logging is enabled, this parameter specifies the program name used to identify PostgreSQL messages in the log. The default is PostgreSQL.
log_min_messages (enum)
Controls which message levels are written to the server log. Valid values are DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL and PANIC. Each level contains all the levels that follow it. The later the level, the fewer messages will be sent to the log. Default is WARNING.
| Severity | Usage | syslog | eventlog |
| DEBUG1 .. DEBUG5 | It provides successively more detailed information for use by developers. | DEBUG | INFORMATION |
| INFO | Provides information indirectly requested by the user, eg output from VACUUM VERBOSE. | INFO | INFORMATION |
| NOTICE | Provides information that can help users, such as a notification that long identifiers have been truncated. | NOTICE | INFORMATION |
| WARNING | Provides warnings of possible problems, for example COMMIT outside of a transaction block. | NOTICE | WARNING |
| ERROR | Reports an error that caused the current command to be aborted. | WARNING | ERROR |
| LOG | It reports information that DBAs are interested in, for example checkpoint activity. | INFO | INFORMATION |
| FATAL | Reports an error that caused the current session to be canceled. | ERR | ERROR |
| PANIC | Reports an error that caused all database sessions to be canceled. | CRIT | ERROR |
log_min_error_statement (enum)
Controls that the SQL queries that cause the error condition will be recorded in the server log. The current SQL command is included in the log entry for any message with the specified severity rating or higher. Valid values are DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, INFO, NOTICE, WARNING, ERROR, LOG, FATAL and PANIC. The default is ERROR, which means any statements that cause errors, log messages, fatal errors or panic will be logged.
log_min_duration_sample (integer)
Allows sampling of the duration of completed statements that run for at least the specified time period. This generates the same type of log entries as log_min_duration_statement.
log_connections (boolean)
In addition to successfully completing client authentication, it causes every connection attempt made with the server to be logged. Default is off.
log_disconnections (boolean)
Causes session terminations to be logged. The log output provides similar information as log_connections and also the session duration. Default is off.
log_line_prefix (string)
This is a printf-style string that appears at the beginning of each log line. It is mostly used for the needs of log management tools. As a suggestion, if I need to use it, I usually set this parameter as follows.
| Escape | Effect | Session only |
| %a | Application name | yes |
| %u | User name | yes |
| %d | Database name | yes |
| %r | Remote host name or IP address, and remote port | yes |
| %h | Remote host name or IP address | yes |
| %b | Backend type | no |
| %p | Process ID | no |
| %t | Time stamp without milliseconds | no |
| %m | Time stamp with milliseconds | no |
| %n | Time stamp with milliseconds (as a Unix epoch) | no |
| %i | Command tag: type of session’s current command | yes |
| %e | SQLSTATE error code | no |
| %c | Session ID: see below | no |
| %l | Number of the log line for each session or process, starting at 1 | no |
| %s | Process start time stamp | no |
| %v | Virtual transaction ID (backendID/localXID) | no |
| %x | Transaction ID (0 if none is assigned) | no |
| %q | Produces no output, but tells non-session processes to stop at this point in the string; ignored by session processes | no |
| %% | Literal % | no |
log_replication_commands (boolean)
Her replication komutunun sunucuya kaydedilmesine neden olur. Varsayılan değer kapalı.
log_temp_files (integer)
Temp dosya adlarının ve boyutlarının kaydedilmesini kontrol eder. Sıfır değeri, tüm temp dosya bilgilerini loga kaydederken, pozitif değerler yalnızca boyutu belirtilen veri miktarından büyük veya bu miktara eşit olan dosyaları loga kaydeder. Varsayılan ayar, böyle bir log kaydını devre dışı bırakan -1’dir.
log_timezone (string)
Sunucu loguna yazılan timezone için kullanılan saat dilimini ayarlar. TimeZone’dan farklı olarak, bu değer cluster çapındadır. varsayılan GMT’dir, ancak bu genellikle initdb aşamaında bu ayar değiştirilir; initdb, sistem ortamına karşılık gelen bir ayar kuracaktır.
Run-time Statistics
These parameters control the server-wide statistics collection features. When statistics collection is enabled, the generated data can be accessed via the pg_stat and pg_statio family of system views.
stats_temp_directory (string)
Sets the directory where temporary statistics data will be stored. The default is pg_stat_tmp. Pointing this into a RAM-based file system reduces physical I / O requirements and can increase performance. As a suggestion, since data is frequently written to this file and it will not cause much trouble in case of data loss, I think you should definitely create a RAM-based file with the tmpfs file system and change this parameter.
track_activities (boolean)
It provides gathering information about each session’s command currently running and when it starts running. This parameter is enabled by default.
track_activity_query_size (integer)
Specifies the amount of memory allocated for the Pg_stat_activity.query (to store the text of the currently executed command for each active session). The default value is 1024 bytes.
track_counts (boolean)
Provides collection of statistics about database activity. This parameter is enabled by default because the autovacuum daemon needs the information collected.
track_io_timing (boolean)
Can be enabled to track database I / O timing. This parameter is off by default because it will repeatedly query the operating system for the current time, which can cause some significant overhead. You can use the pg_test_timing tool to measure the timing overhead on your system. We can also display the I / O time in pg_stat_database view, in EXPLAIN output when BUFFERS option is used, and by pg_stat_statements.
track_functions (enum)
Provides tracking of function call numbers and runtime.
Client Connection Defaults
client_min_messages (enum)
Controls which message levels will be sent to the client. Valid values are DEBUG5, DEBUG4, DEBUG3, DEBUG2, DEBUG1, LOG, NOTICE, WARNING, and ERROR. The default is NOTICE.
search_path (string)
This variable specifies the order in which schemas are searched if the schema is not specified when accessing an object (table, data type, function, etc.). When there are objects with the same names in different schemas, the first object in the search path is used. We can access an object that is not found in any of the schema in the search path, only by using the schema it contains. The default value of this parameter is “$ user”, public.
row_security (boolean)
This variable checks if an error occurs instead of applying row level security policy. When set to ON, policies are normally enforced. When set to OFF, queries that apply at least one security policy will throw an error. Default is ON.
default_table_access_method (string)
This parameter specifies the default table access method to use when creating tables or materialized views, unless the CREATE command explicitly specifies an access method, or when SELECT… INTO is used. The default is heap.
default_tablespace (string)
This variable specifies the default tablespace where objects (tables and indexes) will be created when the CREATE command does not explicitly specify a tablespace.
temp_tablespaces (string)
This variable specifies the default temp tablespace where objects (tables and indexes) will be created when the CREATE command does not explicitly specify a tablespace.
default_transaction_isolation (enum)
Each SQL transaction has an isolation level, which can be “read uncommitted”, “read committed”, “repeatable read”, or “serializable”. This parameter checks the default isolation level of each new transaction. The default is “read committed”.
default_transaction_read_only (boolean)
Read-only transactions cannot change non-temp tables. This parameter checks the default read-only state of each new transaction. Default is off.
session_replication_role (enum)
Controls the triggering of replication-related triggers and rules for the current session. Possible values are origin (default), replica and local.
statement_timeout (integer)
Cancels any query taking longer than the specified time. A value of zero (default) disables the timeout.
lock_timeout (integer)
Cancels any query that waits longer than the specified time when trying to get a lock on a table, index, row, or other database object. A value of zero (default) disables the timeout.
idle_in_transaction_session_timeout (integer)
Terminates the session for an open transaction that has been idle longer than the specified time. A value of zero (default) disables the timeout.
DateStyle (string)
Determines the display format for date and time values. For historical reasons.
TimeZone (string)
Sets the time zone to view and interpret the time zone. The built-in default is GMT, but in the initdb phase, it will set a setting corresponding to the system environment.
lc_messages (string)
Sets the language in which messages are displayed. Acceptable values depend on the system. If this variable is set to an empty string (the default value), the value is inherited from the server’s env environment, depending on the system.
Other Parameters
deadlock_timeout (integer)
This parameter is the time to wait on a lock before checking whether it has a lock state. Lock control is relatively expensive, so the server doesn’t execute it every time it waits for a lock. Increasing this value reduces the time wasted on unnecessary lock checks, but slows down the detection of true lock errors. The default value is one second (1s).
wal_segment_size (integer)
Informs the size of WAL segments. The default value is 16MB.
wal_block_size (integer)
Informs the size of the WAL disk block. It is determined by the value of XLOG_BLCKSZ when creating the server. The default value is 8192 bytes.
data_checksums (boolean)
Informs whether the data checksum is enabled for the Cluster. As a suggestion, I must say that the checksum must be active in your cluster.
checkpoint_timeout
This is a timeout value that can be set in seconds (default), minutes, or one hour. it is 5 minutes by default. As a suggestion, setting this value should be based on the intended use of your database. While it can be increased up to 1 day in OLAP type systems, values such as 5-10 minutes can be selected in OLTP systems.
checkpoint_completion_target (integer)
Usually, it is a parameter that makes PostgreSQL try to write data slower. Usually you have checkpoint_timeout set to 5 minutes. (if you haven’t changed it) and default checkpoint_completion_target is 0.5. This means PostgreSQL will try to make the checkpoint take 2.5 minutes to reduce the I / O load.
For example, we have 100GB of data to be written to files. And my disk is capable of writing 1 GB per second. When doing a normal checkpoint, it causes our writing capacity to be used up to 100% for 100 seconds to write data. However – when checkpoint_completion_target is set to 0.5 – PostgreSQL tries to write data in 2.5 minutes, so it doesn’t use all of our write capacity. (Uses ((100*1024)/(2,5*60)=682 MB/s). As a suggestion, I suggest using 0.7 for this parameter.
max_wal_size (integer)
The maximum size the WAL is allowed to grow during automatic checkpoints. Default is 1 GB. As a suggestion, I recommend that you increase this value if there is space on this disk.
min_wal_size (integer)
As long as WAL disk usage falls below this setting, old WAL files are always recycled at the checkpoint point, rather than being removed for future use. It can be used to ensure that enough WAL space is allocated to handle spikes in WAL usage, for example when running large batches. It is 80 MB by default.
seq_page_cost (floating point)
Sets the planner’s estimate of the cost of the sequential reading. Default value is 1.0
random_page_cost (floating point)
Sets the planner’s estimate of the cost of a disk page that is not fetched as Sequential. Default is 4.0.
Decreasing this value according to the seq_page_cost value will cause the system to prefer index scans.
Increasing it will make index scans appear more expensive.
Recommendation: Random access to mechanical disk storage is normally much more expensive than four times sequential access. However, since most random accesses to the disk are assumed to be caches, a lower default is used (4.0).
The default value is 40 times slower than random access. It can be thought of as expecting 90% of random readings to be cached.
If you believe that the 90% cache ratio for your workload is a false assumption, you can increase random_page_cost to better reflect the actual cost of random storage readings. Accordingly, if there is a possibility that your data is fully cached, for example, if the database is smaller than the total server memory, it may be appropriate to lower random_page_cost. Or, if you have a fast I/O structure in random access, such as SSD, this value can be reduced somewhat.
restart_after_crash (boolean)
When set to on, the default value, PostgreSQL will restart automatically after a backend crash. Leaving this value open is normally the best way to maximize the availability of the database. However, in some cases, such as when PostgreSQL is invoked by clusterware, disabling automatic startup can be useful so that the cluster software can take control and take actions it deems appropriate.
data_sync_retry (boolean)
When set to off, the default value, PostgreSQL will generate a PANIC-level error if it is unable to dump dirty data into the file system. This causes the database server to crash. If set to On, PostgreSQL will report an error instead, but will continue to run so the data cleanup can be retried at the next checkpoint.
block_size (integer)
Informs the size of a disk block. It is determined by the value of BLCKSZ while creating the server. The default value is 8192 bytes.
data_directory_mode (integer)
In Unix systems, this parameter informs the permissions of the data directory originally defined with (data_directory).
segment_size (integer)
Indicates the number of blocks (pages) that can be stored in a file segment. It is determined by the value of RELSEG_SIZE when creating the server. The maximum size of the segment file in bytes equals segment_size multiplied by block_size; it is 1GB by default.
server_version (string)
Reports the version number of the server. It is determined by the value PG_VERSION when creating the server.
Настройки PostgreSQL влияют на производительность кластера баз данных. При создании кластера баз данных PostgreSQL значения для всех настроек задаются автоматически. Значения подобраны так, чтобы обеспечить высокую производительность кластера, они отличаются в зависимости от конфигурации кластера и версии PostgreSQL.
Если автоматические значения не подходят для ваших задач, установите свои значения при создании кластера или измените настройки в уже созданном кластере.
Мы рекомендуем менять значения настроек только при необходимости — неправильно подобранные значения могут снизить производительность кластера. При масштабировании кластера значения некоторых настроек автоматически заменяются на допустимые.
Посмотреть список настроек
Посмотрите подробное описание настроек в официальной документации PostgreSQL.
Посмотреть список настроек, доступных для изменения, можно при создании кластера или изменении настроек.
Если вы изменили настройки, вы можете посмотреть список всех изменений.
- В панели управления перейдите в раздел Облачная платформа ⟶ Базы данных.
- Откройте страницу кластера ⟶ вкладка Настройки.
- В блоке Настройки СУБД отображены измененные ранее настройки — название и значение.
Изменить настройки
Изменение некоторых параметров в настройках влечет за собой перезагрузку баз данных в кластере — кластер в это время может быть недоступен. Эти параметры зависят от версии PostgreSQL — посмотрите их список.
- В панели управления перейдите в раздел Облачная платформа ⟶ Базы данных.
- Откройте страницу кластера ⟶ вкладка Настройки.
- В блоке Настройки СУБД нажмите Изменить и укажите новые значения.
- Нажмите Сохранить
Список настроек, которые требуют перезагрузки
| PostgreSQL 11 | PostgreSQL 12 | PostgreSQL 13 | PostgreSQL 12-TimescaleDB | PostgreSQL 13-TimescaleDB | PostgreSQL 10-1С | |
|---|---|---|---|---|---|---|
| autovacuum_freeze_max_age | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| autovacuum_max_workers | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| autovacuum_multixact_freeze_max_age | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| max_files_per_process | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| max_pred_locks_per_transaction | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| max_prepared_transactions | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| old_snapshot_threshold | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| track_activity_query_size | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| max_connections | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| max_locks_per_transaction | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| max_worker_processes | ✓ | ✓ | ✓ | ✓ | ✓ | ✓ |
| shared_buffers | ✗ | ✓ | ✓ | ✓ | ✓ | ✓ |
Настройки при масштабировании кластера
У любого параметра СУБД есть границы допустимых значений. При масштабировании кластера (изменении конфигурации) значения некоторых настроек автоматически заменяются на допустимые, чтобы кластер мог работать.
Когда кластер будет масштабирован и перейдет в статус ACTIVE, вы сможете установить новые значения — изменить настройки.
Список настроек, которые меняют значения при масштабировании кластера:
shared_buffers, effective_cache_size, maintenance_work_mem, max_worker_processes, max_parallel_workers, autovacuum_max_workers, vacuum_cost_limit, max_parallel_workers_per_gather, max_maintenance_workers
В данной статье мы проведем установку СУБД PostgreSQL 11 в Linux CentOS 7, выполним базовую настройку сервера и СУБД, рассмотрим основные параметры конфигурационного файла, а так же способы тюнинга производительности. PostgreSQL – популярная свободная объектно-реляционная система управления базами данных. Не смотря на то, что она не так распространена как MySQL/MariDB, она является самой профессиональной.
Сильные стороны PostgreSQL:
- Полное соответствие стандартам SQL;
- Высокая производительность за счет управления многовариантным параллелизмом (MVCC);
- Масштабируемость (широко используется в высоконагруженных средах);
- Поддержка множества языков программирования;
- Надёжные механизмы транзакций и репликации;
- Поддержка данных в формате JSON.
Содержание:
- Установка PostgreSQL в CentOS/RHEL
- Подключение к PostgreSQL, создание БД, пользователя
- Основные параметры конфигурационных файлов PostgreSQL
- Резевное копирование и восстановление БД в PostgreSQL
- Оптимизация и тюниг PostgreSQL
Установка PostgreSQL в CentOS/RHEL
Хотя PostgreSQL можно установить из базового репозитория CentOS, мы выполним установку репозитория от разработчиков, так как в нем всегда присутствует актуальная версия пакета.
Первым шагом устанавливаем репозиторий PosgreSQL (на данный момент он устанавливается следующим образом):
yum install -y https://download.postgresql.org/pub/repos/yum/reporpms/EL-7-x86_64/pgdg-redhat-repo-latest.noarch.rpm
В данном репозитории есть как самые новые версии PostgreSQL, так и более старые версии. Информация о репозитории выглядит следующим образом:

Установим последнюю доступную версию версию (PostrgeSQL 11) c помощью yum.
yum install postgresql11-server -y
В процессе установки устаналивается сам сервере PostgreSQL и необходимые библотеки:
Installing : libicu-50.2-3.el7.x86_64 1/4 Installing : postgresql11-libs-11.5-1PGDG.rhel7.x86_64 2/4 Installing : postgresql11-11.5-1PGDG.rhel7.x86_64 3/4 Installing : postgresql11-server-11.5-1PGDG.rhel7.x86_64 4/4
После установки пакетов, нужно произвести инициализацию базы данных:
/usr/pgsql-11/bin/postgresql-11-setup initdb
Так же сразу добавим сервер БД в автозагрузку и запустим его:
systemctl enable postgresql-11
systemctl start postgresql-11
Чтобы убедиться, что сервер запустился и никаких проблем нет, проверим его статус:
[[email protected] ~]# systemctl status postgresql-11
● postgresql-11.service - PostgreSQL 11 database server
Loaded: loaded (/usr/lib/systemd/system/postgresql-11.service; enabled; vendor preset: disabled)
Active: active (running) since Wed 2019-09-18 13:01:56 +06; 26s ago
Docs: https://www.postgresql.org/docs/11/static/
Process: 6614 ExecStartPre=/usr/pgsql-11/bin/postgresql-11-check-db-dir ${PGDATA} (code=exited, status=0/SUCCESS)
Main PID: 6619 (postmaster)
CGroup: /system.slice/postgresql-11.service
├─6619 /usr/pgsql-11/bin/postmaster -D /var/lib/pgsql/11/data/
├─6621 postgres: logger
├─6623 postgres: checkpointer
├─6624 postgres: background writer
├─6625 postgres: walwriter
├─6626 postgres: autovacuum launcher
├─6627 postgres: stats collector
└─6628 postgres: logical replication launcher
Sep 18 13:01:56 server.1.com systemd[1]: Starting PostgreSQL 11 database server...
Sep 18 13:01:56 server.1.com postmaster[6619]: 2019-09-18 13:01:56.399 +06 [6619] LOG: listening on IPv6 address "::1", port 5432
Sep 18 13:01:56 server.1.com postmaster[6619]: 2019-09-18 13:01:56.399 +06 [6619] LOG: listening on IPv4 address "127.0.0.1", port 5432
Sep 18 13:01:56 server.1.com postmaster[6619]: 2019-09-18 13:01:56.401 +06 [6619] LOG: listening on Unix socket "/var/run/postgresql/.s.PGSQL.5432"
Sep 18 13:01:56 server.1.com postmaster[6619]: 2019-09-18 13:01:56.409 +06 [6619] LOG: listening on Unix socket "/tmp/.s.PGSQL.5432"
Sep 18 13:01:56 server.1.com postmaster[6619]: 2019-09-18 13:01:56.427 +06 [6619] LOG: redirecting log output to logging collector process
Sep 18 13:01:56 server.1.com postmaster[6619]: 2019-09-18 13:01:56.427 +06 [6619] HINT: Future log output will appear in directory "log".
Sep 18 13:01:56 server.1.com systemd[1]: Started PostgreSQL 11 database server.
Если вам нужен доступ к PostgreSQL снаружи, вам нужно открыть порт TCP/5432, в стандартном firewall в Centos 7:
# firewall-cmd --get-active-zones
public interfaces: eth0
# firewall-cmd --zone=public --add-port=5432/tcp --permanent
# firewall-cmd --reload
Или через iptables:
#iptables-A INPUT -m state --state NEW -m tcp -p tcp --dport 5432 -j ACCEPT
#service iptables restart
Если включен SELinux, выполните:
setsebool -P httpd_can_network_connect_db 1
Подключение к PostgreSQL, создание БД, пользователя
По умолчанию при установке PostgreSQL в системе есть один пользователь —postgres.
Я не рекомендую использовать его для работы с базами данных, лучше создавать пользователей для каждой БД отдельно.
Чтобы подключиться к серверу postgres нужно ввести команду:
[[email protected] /]# sudo -u postgres psql
psql (11.5) Type "help" for help.
postgres=#
Открылась консоль PostgreSQL. Покажем несколько простых примеров управления PostgreSQL из консоли psql.
Т.к. любой пользователь системы может авторизоваться в postrgesql, сначала нужно изменить пароль пользователя postgres.
ALTER ROLE postgres WITH PASSWORD 'super_str0ng_pa$$word';
Сразу создадим новую базу данных, пользователя и дадим ему полные права на эту БД:
postgres=# CREATE DATABASE mydbtest;
postgres=# CREATE USER mydbuser WITH password '123456789';
postgres=# GRANT ALL PRIVILEGES ON DATABASE mydbtest TO mydbuser;
Подключиться к БД:
postgres=# c databasename
Вывести список таблиц:
postgres=# dt
Вывести список запросов к базе:
postgres=# select * from pg_stat_activity where datname='dbname'
Сбросить все подключения к базе:
postgres=# select pg_terminate_backend(pid) from pg_stat_activity where datname = 'dbname'
Информацию о текущей сессии можно получить так:
postgres=# conninfo
Для завершения работой с консолью psql, выполните:
postgres=# q
Как вы уже заметили, синтаксис не отличается от той же MariaDB или MySQL и поэтому особо останавливаться на однотипных командах мы не будем.
Отметим, что для более удобного управления базами PostgreSQL из веб-интерфейса рекомендуется использовать pgAdmin4 (написан на Python и Javascript/jQuery). Это аналог привычному многим веб разработчикам PhpMyAdmin.
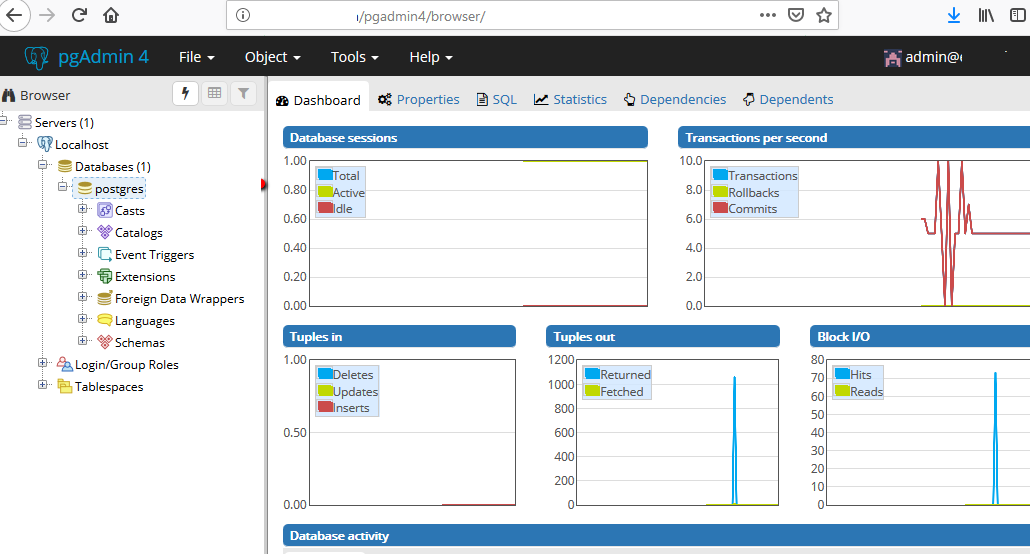
Основные параметры конфигурационных файлов PostgreSQL
Файлы конфигурации postgresql находятся в директории /var/lib/pgsql/11/data:
- postgresql.conf — непосредственно сам файл конфигурации postgresql;
- pg_hba.conf — файл с настройками доступа. В данном файле, можно выставлять различные ограничения для пользователей, устанавливать политику подключения к БД;
- pg_ident.conf — этот файл используется при идентификации клиентов по протоколу ident.
Чтобы запретить локальным пользователям вход в postgres без авторизации, в файле pg_hba.conf укажите:
local all all md5 host all all 127.0.0.1/32 md5
Рассмотрим наиболее важные параметры в конфигурационном файле postgresql.conf:
- listen_addresses — указывает на каких IP адресах сервер будет принимать клиентские подключения. По умолчанию указано localhost, это означает, что возможно только локальное подключение. Чтобы случашать на всех IPv4 интерфейсах, укажите 0.0.0.0
- max_connections – как и в других СУБД, это максимальное количество одновременных подключения к серверу БД;
- temp_buffers – максимальный размер временных буферов;
- shared_buffers — объем разделяемой памяти используемый сервером баз данных. Обычно выставляется в размере 25% от памяти, установленной на сервере;
- effective_cache_size – параметр, который помогает планировщику postgres определить количество доступной памяти для кеширования на диск. Обычно параметр выставляется размером в 50-75% от всей ОЗУ на сервере;
- work_mem – объем памяти, который будет использоваться внутренними операциями сортировки СУБД — ORDER BY, DISTINCT и слияния;
- maintenance_work_mem – объем памяти, который будет использоваться внутренними операциями — VACUUM, CREATE INDEX и ALTER TABLE ADD FOREIGN KEY;
- fsync – если этот параметр включен, то СУБД будет дожидаться физической записи данных на жесткий диск. При включенном fsynс вам будет проще восстановить БД после системного или аппаратного сбоя. Естественно, что включение данного параметра значительно снижает производительность СУБД, но повышает надежность хранения. При отключении этого параметра стоит отключать и full_page_writes;
- max_stack_depth — максимальный размер стека (2 Мб по умолчанию);
- max_fsm_pages — с помощью данного параметра, можно управлять свободным дисковым пространством на сервере. К примеру, после удаления данных из таблицы, занимаемое ранее место не освобождается на диске, а помечается на карте свободного пространства с меткой «свободно» и далее используется для новых записей в таблице. Если на сервере активно ведется запись/удаление данных в таблицах, увеличение данного параметра, положительно повлияет на производительность;
- wal_buffers – объем из разделяемой памяти (shared_buffers), который используется для хранения данных WAL;
- wal_writer_delay – время между периодами записи WAL на диск;
- commit_delay — задержка между записью транзакции в буфер WAL и сбросом его на диск;
- synchronous_commit — параметр определяет, что результат об успешном завершении транзакции будет отправлен тогда, когда данные WAL физически запишутся на диск.
Резевное копирование и восстановление БД в PostgreSQL
Создать резервную копию в PostgreSQL БД можно несколькими способами. Рассмотрим самый простой вариант.
Для начала проверим, какие БД запущены на сервере:
postgres=# list
У нас имеются 4 базы данных, 3 из которых системные (postgres и template).
Ранее мы создавали БД с именем “mydbtest”, на ее примере и выполним резервное копирование.
Один из способов резервного копирования, это выполнение его с помощью утилиты pg_dump:
sudo -u postgres pg_dump mydbtest > /root/dupm.sql
— выполняем запрос от пользователя postgres, указываем нужную БД и путь до файла в который нужно сохранить дамп базы. Дамп базы может забрать ваша система резевного копирования, или в случае использования веб сервера, вы можете отправить его в ваше облачное хранилище.
Чтобы восстановить указанный дамп в нужную БД, можно воспользоваться утилитой psql:
sudo -u postgres psql mydbtest < /root/dupm.sql
Так же можно создать бэкап в специальном формате дампа и сжатом с применением gzip:
sudo -u postgres pg_dump -Fc mydbtest > /root/dumptest.sql
Восстанавливается такой дамп с помощью утилиты pg_restore:
sudo -u postgres pg_restore -d mydbtest /root/dumptest.sql
Более расширенные настройки можно посмотреть в справке по данным утилитам:
man psql
man pg_dump
man pg_restore
Оптимизация и тюниг PostgreSQL
В предыдущей статье о MariaDB, мы показывали, как можно привести практически к идеалу параметры конфигурационного файла my.cnf с помощью тюнеров. Для PostgreSQL существует, хотя правильнее сказать существовала такая утилита как PgTun, но к сожалению она уже давно не обновляется. В тоже время есть масса онлайн сервисов, с помощью которых вы можете настроить оптимальную конфигурацию для вашего PostgreSQL. Мне нравится сервис pgtune.leopard.in.ua.
Интерфейс очень прост. Вам нужно указать параметры вашего сервера (профиль, процессоры, память, тип дисков) и нажать кнопку “Generate”. В результате вам будет предложен вариант конфигурационного файла postgresql.conf с рекомендуемыми значениями основных параметров СУБД.
Например, для VPS SSD сервера с 2 Гб оперативной памятью, 2 CPU для запуска нескольких сайтов рекомендуются следующие настройки в postgresql.conf:
# DB Version: 11 # OS Type: linux # DB Type: web # Total Memory (RAM): 2 GB # CPUs num: 2 # Connections num: 20 # Data Storage: ssd max_connections = 20 shared_buffers = 512MB effective_cache_size = 1536MB maintenance_work_mem = 128MB checkpoint_completion_target = 0.7 wal_buffers = 16MB default_statistics_target = 100 random_page_cost = 1.1 effective_io_concurrency = 200 work_mem = 26214kB min_wal_size = 1GB max_wal_size = 2GB max_worker_processes = 2 max_parallel_workers_per_gather = 1 max_parallel_workers = 2
И это на самом деле не единственный ресурс, на момент написания статьи, были достпны аналогичные сервисы:
С помощью подобных сервисов, можно быстро настроить начальные параметры СУБД для вашего оборудования и выполняемых задач. В дальнейшем уже нужно опираться не только на ресурсы сервера, но и анализировать в целом работу БД, ее размер, количество коннектов и на основе этого, выполнять дальнейшую тонкую донастройку параметров PostgreSQL.