Вы можете использовать один из следующих трех методов для переименования столбцов в кадре данных pandas:
Способ 1: переименовать определенные столбцы
df.rename(columns = {' old_col1 ':' new_col1', 'old_col2 ':' new_col2 '}, inplace = True )
Способ 2: переименовать все столбцы
df.columns = ['new_col1', 'new_col2', 'new_col3', 'new_col4']
Способ 3: заменить определенные символы в столбцах
df.columns = df.columns.str.replace('old_char', 'new_char')
В следующих примерах показано, как использовать каждый из этих методов на практике.
Способ 1: переименовать определенные столбцы
В следующем коде показано, как переименовать определенные столбцы в кадре данных pandas:
import pandas as pd
#define DataFrame
df = pd.DataFrame({'team ':['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'points': [25, 12, 15, 14, 19, 23, 25, 29],
'assists': [5, 7, 7, 9, 12, 9, 9, 4],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]})
#list column names
list(df)
['team', 'points', 'assists', 'rebounds']
#rename specific column names
df.rename(columns = {' team ':' team_name', 'points ':' points_scored '}, inplace = True )
#view updated list of column names
list(df)
['team_name', 'points_scored', 'assists', 'rebounds']
Обратите внимание, что столбцы «команда» и «очки» были переименованы, а имена всех остальных столбцов остались прежними.
Способ 2: переименовать все столбцы
В следующем коде показано, как переименовать все столбцы в кадре данных pandas:
import pandas as pd
#define DataFrame
df = pd.DataFrame({'team ':['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'points': [25, 12, 15, 14, 19, 23, 25, 29],
'assists': [5, 7, 7, 9, 12, 9, 9, 4],
'rebounds': [11, 8, 10, 6, 6, 5, 9, 12]})
#list column names
list(df)
['team', 'points', 'assists', 'rebounds']
#rename all column names
df.columns = ['_team', '_points', '_assists', '_rebounds']
#view updated list of column names
list(df)
['_team', '_points', '_assists', '_rebounds']
Обратите внимание, что этот метод быстрее использовать, если вы хотите переименовать большинство или все имена столбцов в DataFrame.
Способ 3: заменить определенные символы в столбцах
В следующем коде показано, как заменить определенный символ в имени каждого столбца:
import pandas as pd
#define DataFrame
df = pd.DataFrame({'$team ':['A', 'A', 'A', 'A', 'B', 'B', 'B', 'B'],
'$points': [25, 12, 15, 14, 19, 23, 25, 29],
'$assists': [5, 7, 7, 9, 12, 9, 9, 4],
'$rebounds': [11, 8, 10, 6, 6, 5, 9, 12]})
#list column names
list(df)
['team', 'points', 'assists', 'rebounds']
#rename $ with blank in every column name
df.columns = df.columns.str.replace('$', '')
#view updated list of column names
list(df)
['team', 'points', 'assists', 'rebounds']
Обратите внимание, что этот метод позволил нам быстро удалить «$» из имени каждого столбца.
Дополнительные ресурсы
В следующих руководствах объясняется, как выполнять другие распространенные операции в pandas:
Как вывести список всех имен столбцов в Pandas
Как сортировать столбцы по имени в Pandas
Как удалить повторяющиеся столбцы в Pandas
One line or Pipeline solutions
I’ll focus on two things:
-
OP clearly states
I have the edited column names stored it in a list, but I don’t know how to replace the column names.
I do not want to solve the problem of how to replace
'$'or strip the first character off of each column header. OP has already done this step. Instead I want to focus on replacing the existingcolumnsobject with a new one given a list of replacement column names. -
df.columns = newwherenewis the list of new columns names is as simple as it gets. The drawback of this approach is that it requires editing the existing dataframe’scolumnsattribute and it isn’t done inline. I’ll show a few ways to perform this via pipelining without editing the existing dataframe.
Setup 1
To focus on the need to rename of replace column names with a pre-existing list, I’ll create a new sample dataframe df with initial column names and unrelated new column names.
df = pd.DataFrame({'Jack': [1, 2], 'Mahesh': [3, 4], 'Xin': [5, 6]})
new = ['x098', 'y765', 'z432']
df
Jack Mahesh Xin
0 1 3 5
1 2 4 6
Solution 1
pd.DataFrame.rename
It has been said already that if you had a dictionary mapping the old column names to new column names, you could use pd.DataFrame.rename.
d = {'Jack': 'x098', 'Mahesh': 'y765', 'Xin': 'z432'}
df.rename(columns=d)
x098 y765 z432
0 1 3 5
1 2 4 6
However, you can easily create that dictionary and include it in the call to rename. The following takes advantage of the fact that when iterating over df, we iterate over each column name.
# Given just a list of new column names
df.rename(columns=dict(zip(df, new)))
x098 y765 z432
0 1 3 5
1 2 4 6
This works great if your original column names are unique. But if they are not, then this breaks down.
Setup 2
Non-unique columns
df = pd.DataFrame(
[[1, 3, 5], [2, 4, 6]],
columns=['Mahesh', 'Mahesh', 'Xin']
)
new = ['x098', 'y765', 'z432']
df
Mahesh Mahesh Xin
0 1 3 5
1 2 4 6
Solution 2
pd.concat using the keys argument
First, notice what happens when we attempt to use solution 1:
df.rename(columns=dict(zip(df, new)))
y765 y765 z432
0 1 3 5
1 2 4 6
We didn’t map the new list as the column names. We ended up repeating y765. Instead, we can use the keys argument of the pd.concat function while iterating through the columns of df.
pd.concat([c for _, c in df.items()], axis=1, keys=new)
x098 y765 z432
0 1 3 5
1 2 4 6
Solution 3
Reconstruct. This should only be used if you have a single dtype for all columns. Otherwise, you’ll end up with dtype object for all columns and converting them back requires more dictionary work.
Single dtype
pd.DataFrame(df.values, df.index, new)
x098 y765 z432
0 1 3 5
1 2 4 6
Mixed dtype
pd.DataFrame(df.values, df.index, new).astype(dict(zip(new, df.dtypes)))
x098 y765 z432
0 1 3 5
1 2 4 6
Solution 4
This is a gimmicky trick with transpose and set_index. pd.DataFrame.set_index allows us to set an index inline, but there is no corresponding set_columns. So we can transpose, then set_index, and transpose back. However, the same single dtype versus mixed dtype caveat from solution 3 applies here.
Single dtype
df.T.set_index(np.asarray(new)).T
x098 y765 z432
0 1 3 5
1 2 4 6
Mixed dtype
df.T.set_index(np.asarray(new)).T.astype(dict(zip(new, df.dtypes)))
x098 y765 z432
0 1 3 5
1 2 4 6
Solution 5
Use a lambda in pd.DataFrame.rename that cycles through each element of new.
In this solution, we pass a lambda that takes x but then ignores it. It also takes a y but doesn’t expect it. Instead, an iterator is given as a default value and I can then use that to cycle through one at a time without regard to what the value of x is.
df.rename(columns=lambda x, y=iter(new): next(y))
x098 y765 z432
0 1 3 5
1 2 4 6
And as pointed out to me by the folks in sopython chat, if I add a * in between x and y, I can protect my y variable. Though, in this context I don’t believe it needs protecting. It is still worth mentioning.
df.rename(columns=lambda x, *, y=iter(new): next(y))
x098 y765 z432
0 1 3 5
1 2 4 6
Being able to rename columns in your Pandas DataFrame is an incredibly common task. In particular, being able to label your DataFrame columns in a meaningful way is useful to communicate your data better. Similarly, you have inherited a dataset from someone and the columns are mislabeled. In all of these cases, being able to rename your DataFrame’s columns is a useful skill.
In this tutorial, you’ll learn how to rename Pandas DataFrame columns. You’ll learn how to use the Pandas .rename() method as well as other useful techniques. For example, you’ll learn how to add a prefix to every column name.
By the end of this tutorial, you’ll have learned the following:
- How to rename a single column or all columns in a Pandas DataFrame using the
.rename()method - How to use the
.columnsattribute to rename columns in creative ways, such as by adding a prefix or suffix, or by lowercasing all columns - How to replace or remove specific text or characters from all column names at once
- How to use mapper functions to rename Pandas DataFrame columns
How can you rename Pandas DataFrame columns?
To rename columns in a Pandas DataFrame, you have two options: using the rename() method or the columns attribute. The .rename() method allows you to pass in existing labels and the ones you want to use. The .columns attribute allows you to specify a list of values to use as column labels.
Let’s look at the primary methods of renaming Pandas DataFrame columns in a bit more detail:
- The Pandas .rename() method allows you to rename DataFrame labels. In particular, you can pass in a mapping to rename column labels. This can either be a mapper function or a dictionary of column labels to use. This method is best when you want to relabel a single or a few columns.
- The Pandas .columns attribute allows you to pass in a list of values to use as the column names. This allows you to easily modify all column names by applying the same transformation to all column labels. This method is best when you want to rename all columns following the same type of transformation, such as lower-casing all column names or removing spaces.
Loading a Sample Pandas DataFrame
To follow along, let’s load a sample Pandas DataFrame. Feel free to copy and paste the code below into your favorite code editor. If you’re working with your own dataset – no problem! The results will, of course, vary.
# Loading a Sample Pandas DataFrame
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
print(df)
# Returns:
# Name Age Age Group Birth City Gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleWe can see that we have a DataFrame with five different columns. Some of the columns are single words, while others are multiple words with spaces. Similarly, all of our column names are in title case, meaning that the first letter is capitalized.
Let’s dive into how to rename Pandas columns by first learning how to rename a single column.
How to Rename a Single Pandas DataFrame Column
To rename a single Pandas DataFrame column, we can use the Pandas .rename() method. The method, as the name implies, is used to rename labels in a DataFrame. Let’s take a quick look at how the method is written:
# Understanding the Pandas .rename() Method
import pandas as pd
df.rename(mapper=None, *, index=None, columns=None, axis=None, copy=None, inplace=False, level=None, errors='ignore')We can see that the function takes up to seven arguments. Some of these parameters are specific to renaming row (index) labels. Since we’re focusing on how to rename columns, let’s only focus on a subset of these.
In order to rename a single column in Pandas, we can use either the mapper= parameter or the columns= helper parameter. Because columns are along the first axis, if we want to use the mapper= parameter, we need to specify axis=1. This, however, is a bit more complicated, in my opinion, than using the columns= convenience parameter.
Let’s take a look at how we can use the columns= parameter to rename a Pandas column by name:
# Renaming a Single Column In a Pandas DataFrame
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.rename(columns={'Birth City': 'City'})
print(df)
# Returns:
# Name Age Age Group City Gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleWe can see that by passing a dictionary of column mappings into the columns= parameter, we were able to rename a single Pandas column. This is the equivalent of having written df = df.rename(mapper={'Birth City': 'City'}, axis=1). However, not only is this clear, but it’s also faster to type!
Renaming a Single Pandas DataFrame Column by Position
Now, say you didn’t know what the first column was called, but you knew you wanted to change its name to something specific. The df.columns attribute returns a list of all of the column labels in a Pandas DataFrame. Because of this, we can pass in the mapping of the first column.
For example, if we wanted to change the first column to be named 'id', we could write the following:
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.rename(columns={df.columns[0]: 'id'})
print(df)
# Returns:
# id Age Age Group Birth City Gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleWe can see that we were able to rename the first column of a DataFrame by using the .columns attribute. We’ll get back to using that attribute more in a minute. However, let’s now focus on how we can rename multiple columns at once.
How to Rename Multiple Pandas Columns with .rename()
Similar to renaming a single column in a DataFrame, we can use the .rename() method to rename multiple columns. In order to do this, we simply need to pass in a dictionary containing more key-value pairs.
Let’s see how we can rename multiple columns in a Pandas DataFrame with the .rename() method:
# Rename Multiple Columns with .rename()
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.rename(columns={'Age Group': 'Group', 'Birth City': 'City'})
print(df)
# Returns:
# Name Age Group City Gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleWe can see that we were able to rename multiple columns in one go. At this point, I’ll note that if a column doesn’t exist, Pandas won’t (by default) throw an error – though you can change this, as you’ll learn later.
Let’s now take a look at a way to rename multiple columns using a list comprehension.
How to Use List Comprehensions to Rename Pandas DataFrame Columns
In this section, you’ll learn how to use list comprehensions to rename Pandas columns. This can be helpful when you want to rename columns in a similar style. This could include removing spaces or changing all cases to lowercase.
For example, if your column names have spaces, it can be impossible to use dot notation to select columns. Similarly, since selecting columns is case-sensitive, having different casing in your columns can make selecting them more difficult.
Let’s take a look at an example where we want to remove all spaces from our column headers:
# Rename Columns Using a List Comprehension
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df.columns = [col.replace(' ', '_').lower() for col in df.columns]
print(df)
# Returns:
# name age age_group birth_city gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleLet’s break down what we’re doing in the code block above:
- We used a list comprehension to iterate over each column name in our DataFrame
- For each column label, we used the
.replace()string method to replace all spaces with underscores - We then also applied the
.lower()method to change the string to its lowercase equivalent
It’s important to note here that we’re not reassigning this list to the DataFrame, but rather to the df.columns attribute. Since the attribute represents the column labels, we can assign a list of values directly to that attribute to overwrite column names.
Using a Mapper Function to Rename Pandas Columns
The Pandas .rename() method also allows you to pass in a mapper function directly into the mapper= parameter. Rather than needing to pass in a dictionary of label mappings, you can apply the same mapping transformation to each column label.
Say we simply wanted to lowercase all of our columns, we could do this using a mapper function directly passed into the .rename() method:
# Using a Mapper Function to Rename DataFrame Columns
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.rename(mapper=str.lower, axis='columns')
print(df)
# Returns:
# name age age_group birth_city gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleWe use axis='columns' to specify that we want to apply this transformation to the columns. Similarly, you could write: axis=1. We can see that this applied the transformation to all columns.
Keep in mind, because we’re using a string method, this will only work if your columns are all strings! If any of your columns are, say, just numbers, this method will raise a TypeError.
Using a Lambda Function to Rename Pandas Columns
You can also use custom lambda functions to pass in more complex transformations. This works in the same way as using a simple, built-in mapper function. However, it allows us to pass in custom transformations to our column names.
Let’s take a look at an example. If we wanted to use a lambda function to rename all of our columns by replacing spaces and lowercasing our characters, we could write:
# Using a Lambda Function to Rename Columns
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.rename(mapper=lambda x: x.replace(' ', '_').lower(), axis=1)
print(df)
# Returns:
# name age age_group birth_city gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleWe use axis=1 to specify that we want to apply this transformation to the columns. Similarly, you could write: axis='columns'.
Renaming Pandas DataFrame Columns In Place
You may have noticed that for all of our examples using the .rename() method, we have reassigned the DataFrame to itself. We can avoid having to do this by using the boolean inplace= parameter in our method call. Let’s use our previous example to illustrate this:
# Renaming DataFrame Columns In Place
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df.rename(mapper=lambda x: x.replace(' ', '_').lower(), axis=1, inplace=True)
print(df)
# Returns:
# name age age_group birth_city gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleIn the following section, you’ll learn how to raise errors when using the pd.rename() method.
Raising Errors While Renaming Pandas Columns
By default, the .rename() method will not raise any errors when you include a column that doesn’t exist. This can lead to unexpected errors when you assume that a column has been renamed when it hasn’t.
Let’s see this in action by attempting to rename a column that doesn’t exist:
# Raising an Error When Renaming Columns
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.rename(columns={'some silly name': 'column1'}, errors='raise')
print(df)
# Returns:
# KeyError: "['some silly name'] not found in axis"We can see that by using the errors= parameter, that we can force Python to raise errors when a column label doesn’t exist.
Renaming Multi-index Pandas Columns
The .rename() method also includes an argument to specify which level of a multi-index you want to rename. A common occurrence of multi-index Pandas DataFrames is when working with pivot tables. Let’s take a look at an example. Say we create a Pandas pivot table and only want to rename a column in the first layer.
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
pivot = pd.pivot_table(data=df, columns=['Gender', 'Age Group'], values='Age', aggfunc='count')
pivot = pivot.rename(columns={'Male': 'male'}, level=0)
print(pivot)
# Returns:
# Gender Female male
# Age Group 18-35 35-50 35-50 65+
# Age 1 1 1 1In the example above, we created a multi-index Pandas DataFrame. The first layer (layer 0) contains the values from our Gender column. By specifying that we want to only use level 0, we can target column labels only in that level. To learn more about Pandas pivot tables, check out my comprehensive guide to Pandas pivot tables.
Add a Prefix or Suffix to Pandas DataFrame Columns
We can also add a prefix or a suffix to all Pandas DataFrame columns by using dedicated methods:
.add_prefix()will add a prefix to each DataFrame column, and.add_suffix()will add a suffix to each DataFrame column
Let’s see how we can use these methods to add a prefix to our DataFrame’s columns:
# Adding a Prefix to Our DataFrame Columns
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df = df.add_prefix('prefix_')
print(df)
# Returns:
# prefix_Name prefix_Age prefix_Age Group prefix_Birth City prefix_Gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleAdding a suffix would work in the same way, though we would use the .add_suffix() method instead.
Similarly, if we only want to add a suffix to specific columns, we can use a list comprehension. For example, if we wanted to add a suffix to columns that have the word age in them, we can use the following code:
# Adding a Suffix Conditionally
import pandas as pd
df = pd.DataFrame.from_dict({
'Name': ['Jane', 'Melissa', 'John', 'Matt'],
'Age': [23, 45, 35, 64],
'Age Group': ['18-35', '35-50', '35-50', '65+'],
'Birth City': ['London', 'Paris', 'Toronto', 'Atlanta'],
'Gender': ['Female', 'Female', 'Male', 'Male']})
df.columns = [col+'_suffix' if 'Age' in col else col for col in df.columns]
print(df)
# Returns:
# Name Age_suffix Age Group_suffix Birth City Gender
# 0 Jane 23 18-35 London Female
# 1 Melissa 45 35-50 Paris Female
# 2 John 35 35-50 Toronto Male
# 3 Matt 64 65+ Atlanta MaleIn the example above, we used a list comprehension to apply a transformation conditionally. This allowed us to check for a condition. If the condition was met (in this case, if ‘Age’ was in the column name) then the suffix is added. Otherwise, the column name is left unchanged.
Conclusion
In this post, you learned about the different ways to rename columns in a Pandas DataFrame. You first learned the two main methods for renaming DataFrame columns: using the Pandas .rename() method and using the .columns attribute.
From there, you learned how to rename a single column, both by name and by its position. From there, you learned how to rename multiple columns. You learned how to do this using the .rename() method, as well as list comprehensions. From there, you learned about using mapper functions, both built-in functions, as well as custom lambda functions. Finally, you learned how to rename DataFrames in place, raise errors when columns don’t exist, and how to work with levels in multi-index DataFrames.
Additional Resources
To learn more about related topics, check out the resources below:
- Pandas Rename Index: How to Rename a Pandas Dataframe Index
- Pandas Replace: Replace Values in Pandas Dataframe
- Pandas: Replace NaN with Zeroes
- Pandas .rename() Method – Official Documentation
Improve Article
Save Article
Improve Article
Save Article
Given a Pandas DataFrame, let’s see how to change its column names and row indexes.
About Pandas DataFrame
Pandas DataFrame are rectangular grids which are used to store data. It is easy to visualize and work with data when stored in dataFrame.
- It consists of rows and columns.
- Each row is a measurement of some instance while column is a vector which contains data for some specific attribute/variable.
- Each dataframe column has a homogeneous data throughout any specific column but dataframe rows can contain homogeneous or heterogeneous data throughout any specific row.
- Unlike two dimensional array, pandas dataframe axes are labeled.
Pandas Dataframe type has two attributes called ‘columns’ and ‘index’ which can be used to change the column names as well as the row indexes.
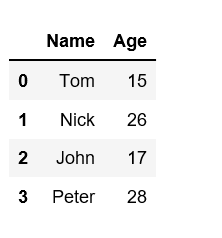
Create a DataFrame using dictionary.
import pandas as pd
df=pd.DataFrame({"Name":['Tom','Nick','John','Peter'],
"Age":[15,26,17,28]})
df
- Method #1: Changing the column name and row index using
df.columnsanddf.indexattribute.In order to change the column names, we provide a Python list containing the names for column
df.columns= ['First_col', 'Second_col', 'Third_col', .....].
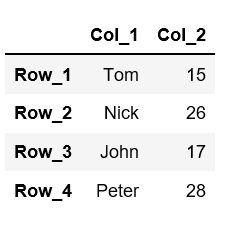
In order to change the row indexes, we also provide a python list to itdf.index=['row1', 'row2', 'row3', ......].df.columns=['Col_1','Col_2']df.index=['Row_1','Row_2','Row_3','Row_4']df
- Method #2: Using
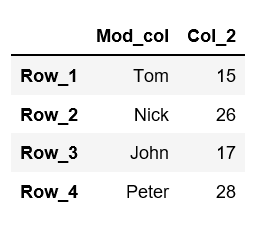
rename()function with dictionary to change a single columndf=df.rename(columns={"Col_1":"Mod_col"})df
Change multiple column names simultaneously –
df=df.rename({"Mod_col":"Col_1","B":"Col_2"}, axis='columns')df
- Method #3: Using Lambda Function to rename the columns.
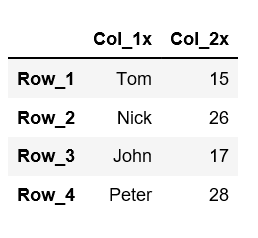
A lambda function is a small anonymous function which can take any number of arguments, but can only have one expression. Using the lambda function we can modify all of the column names at once. Let’s add ‘x’ at the end of each column name using lambda function
df=df.rename(columns=lambdax: x+'x')df
- Method #4 : Using
valuesattribute to rename the columns.We can use values attribute directly on the column whose name we want to change.
df.columns.values[1]='Student_Age'df
Let’s change the row index using the Lambda function.
df=pd.DataFrame({"A":['Tom','Nick','John','Peter'],"B":[25,16,27,18]})df=df.rename(index=lambdax: x+10)df
Now, if we want to change the row indexes and column names simultaneously, then it can be achieved using
rename()function and passing both column and index attribute as the parameter.df=df.rename(index=lambdax: x+5,columns=lambdax: x+'x')df




Improve Article
Save Article
Improve Article
Save Article
Given a Pandas DataFrame, let’s see how to change its column names and row indexes.
About Pandas DataFrame
Pandas DataFrame are rectangular grids which are used to store data. It is easy to visualize and work with data when stored in dataFrame.
- It consists of rows and columns.
- Each row is a measurement of some instance while column is a vector which contains data for some specific attribute/variable.
- Each dataframe column has a homogeneous data throughout any specific column but dataframe rows can contain homogeneous or heterogeneous data throughout any specific row.
- Unlike two dimensional array, pandas dataframe axes are labeled.
Pandas Dataframe type has two attributes called ‘columns’ and ‘index’ which can be used to change the column names as well as the row indexes.
Create a DataFrame using dictionary.
import pandas as pd
df=pd.DataFrame({"Name":['Tom','Nick','John','Peter'],
"Age":[15,26,17,28]})
df
- Method #1: Changing the column name and row index using
df.columnsanddf.indexattribute.In order to change the column names, we provide a Python list containing the names for column
df.columns= ['First_col', 'Second_col', 'Third_col', .....].
In order to change the row indexes, we also provide a python list to itdf.index=['row1', 'row2', 'row3', ......].df.columns=['Col_1','Col_2']df.index=['Row_1','Row_2','Row_3','Row_4']df - Method #2: Using
rename()function with dictionary to change a single columndf=df.rename(columns={"Col_1":"Mod_col"})dfChange multiple column names simultaneously –
df=df.rename({"Mod_col":"Col_1","B":"Col_2"}, axis='columns')df - Method #3: Using Lambda Function to rename the columns.
A lambda function is a small anonymous function which can take any number of arguments, but can only have one expression. Using the lambda function we can modify all of the column names at once. Let’s add ‘x’ at the end of each column name using lambda function
df=df.rename(columns=lambdax: x+'x')df - Method #4 : Using
valuesattribute to rename the columns.We can use values attribute directly on the column whose name we want to change.
df.columns.values[1]='Student_Age'dfLet’s change the row index using the Lambda function.
df=pd.DataFrame({"A":['Tom','Nick','John','Peter'],"B":[25,16,27,18]})df=df.rename(index=lambdax: x+10)dfNow, if we want to change the row indexes and column names simultaneously, then it can be achieved using
rename()function and passing both column and index attribute as the parameter.df=df.rename(index=lambdax: x+5,columns=lambdax: x+'x')df
Pandas.DataFrame.rename() — это функция, которая изменяет любые имена индексов или столбцов по отдельности с помощью dict или изменяет все имена индексов/столбцов с помощью функции. Метод DataFrame.rename() очень полезен, когда нам нужно переименовать некоторые выбранные столбцы, потому что нам нужно указать информацию только для тех столбцов, которые нужно переименовать.
Переименование столбцов DataFrame
Pandas DataFrame в Python — это прямоугольные сетки, которые используются для хранения данных. Легко визуализировать данные и работать с ними, когда они хранятся в DataFrame. Он состоит из строк и столбцов. Каждая строка представляет собой измерение некоторого экземпляра, а столбец представляет собой вектор, содержащий данные для определенного атрибута/переменной.
Каждый столбец фрейма данных содержит сопоставимые данные по любому конкретному столбцу, но строки фрейма данных могут предоставлять однородные или разнородные данные по любой конкретной строке. В отличие от двумерных массивов, оси данных pandas помечены.

См. следующий синтаксис функции rename().
Синтаксис
|
DataFrame.rename(self, mapper=None, index=None, columns=None, axis=None, copy=True, inplace=False, level=None, errors=‘ignore’) |
Параметры
- mapper: dict-like или function.
Преобразования, подобные Dict, или функции, применяемые к значениям этой оси. Используйте либо средство сопоставления и ось, чтобы указать ось, на которую будет направлено средство сопоставления, либо индекс и столбцы.
- index: dict-like или function.
Альтернатива определению оси(mapper, axis=0 эквивалентно index=mapper).
- columns: dict-like или function.
Альтернатива определению оси(mapper, axis=1 эквивалентно columns=mapper).
- axis: int или str.
Ось для нацеливания с картографом. Это может быть имя оси («index», «columns») или номер (0, 1). По умолчанию используется «index».
- copy: bool, по умолчанию True.
Кроме того, скопирует базовые данные.
- inplace: bool, по умолчанию False.
Возвращать ли новый DataFrame? Если True, то значение копии игнорируется.
- level: int или имя уровня, по умолчанию None.
В случае MultiIndex переименовывает метки только на указанном уровне.
- errors{‘ignore’, ‘raise’}, по умолчанию ignore.
Если ‘raise’, вызовите KeyError, когда диктоподобный преобразователь, индекс или столбцы содержат метки, которых нет в преобразуемом индексе. Если «ignore», существующие ключи будут переименованы, а дополнительные ключи будут проигнорированы.
Возвращаемое значение
Возвращает DataFrame с переименованными метками осей. Выдает KeyError, если какая-либо из меток не найдена на выбранной оси и «errors=raise».
Пример переименования столбца
См. следующий код.
|
# app.py import pandas as pd import numpy as np # reading the data series = [(‘Stranger Things’, 3, ‘Millie’), (‘Game of Thrones’, 8, ‘Emilia’), (‘Westworld’, 3, ‘Evan Rachel’), (‘La Casa De Papel’, 4, ‘Sergio’)] # Create a DataFrame object dfObj = pd.DataFrame(series, columns=[‘Name’, ‘Seasons’, ‘Actor’]) print(dfObj) df_new = dfObj.rename(columns={‘Name’: ‘First Name’}) print(df_new) |
В приведенном выше коде мы определили DataFrame, а затем использовали функцию DataFrame.rename(), чтобы изменить имя столбца с Name на First Name.
Выход:
|
python3 app.py Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio First Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio |
Изменить несколько имен столбцов в Pandas (метки)
Одновременное изменение нескольких имен индексов/столбцов путем добавления элементов в словарь.
См. следующий код.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# app.py import pandas as pd import numpy as np # reading the data series = [(‘Stranger Things’, 3, ‘Millie’),(‘Game of Thrones’, 8, ‘Emilia’), (‘Westworld’, 3, ‘Evan Rachel’),(‘La Casa De Papel’, 4, ‘Sergio’)] # Create a DataFrame object print(‘Before changing the DataFrame columns’) dfObj = pd.DataFrame(series, columns=[‘Name’, ‘Seasons’, ‘Actor’]) print(dfObj) # Change the column names using rename() function print(‘After changing the DataFrame columns’) df_new = dfObj.rename(columns={‘Name’: ‘First Name’, ‘Actor’: ‘Hero’}) print(df_new) |
Выход:
|
python3 app.py Before changing the DataFrame columns Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio After changing the DataFrame columns First Name Seasons Hero 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio |
В приведенном выше коде я передал словарь, состоящий из старого имени. Он заменит его новым.
Переименование с помощью функций или лямбда-выражений
Функции(вызываемые объекты) также могут быть указаны в индексе параметра и столбцах метода rename(). Применение функции преобразования верхнего и нижнего регистра.
|
import pandas as pd import numpy as np # reading the data series = [(‘Stranger Things’, 3, ‘Millie’),(‘Game of Thrones’, 8, ‘Emilia’), (‘Westworld’, 3, ‘Evan Rachel’),(‘La Casa De Papel’, 4, ‘Sergio’)] # Create a DataFrame object print(‘Before changing the DataFrame columns’) dfObj = pd.DataFrame(series, columns=[‘Name’, ‘Seasons’, ‘Actor’]) print(dfObj) # Change the column names using rename() function print(‘After changing the DataFrame columns to lower case’) df_new = dfObj.rename(columns=str.lower) print(df_new) |
Выход:
|
python3 app.py Before changing the DataFrame columns Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio After changing the DataFrame columns to lower case name seasons actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio |
pandas.DataFrame.add_prefix()
Pandas.DataFrame.add_prefix() — это функция, которая добавляет префиксы к именам столбцов.
См. следующий код для метода add_prefix().
|
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 |
# app.py import pandas as pd import numpy as np # reading the data series = [(‘Stranger Things’, 3, ‘Millie’),(‘Game of Thrones’, 8, ‘Emilia’), (‘Westworld’, 3, ‘Evan Rachel’),(‘La Casa De Papel’, 4, ‘Sergio’)] # Create a DataFrame object print(‘Before adding prefix to DataFrame columns’) dfObj = pd.DataFrame(series, columns=[‘Name’, ‘Seasons’, ‘Actor’]) print(dfObj) # Change the column names using rename() function print(‘After adding prefix to DataFrame columns’) df_new = dfObj.add_prefix(‘KDL_’) print(df_new) |
Выход:
|
python3 app.py Before adding prefix to DataFrame columns Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio After adding prefix to DataFrame columns KDL_Name KDL_Seasons KDL_Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio |
pandas.DataFrame.add_suffix()
Метод Pandas.DataFrame.add_suffix() добавляет суффикс к именам столбцов.
См. следующий код.
|
import pandas as pd import numpy as np # reading the data series = [(‘Stranger Things’, 3, ‘Millie’),(‘Game of Thrones’, 8, ‘Emilia’), (‘Westworld’, 3, ‘Evan Rachel’),(‘La Casa De Papel’, 4, ‘Sergio’)] # Create a DataFrame object print(‘Before adding prefix to DataFrame columns’) dfObj = pd.DataFrame(series, columns=[‘Name’, ‘Seasons’, ‘Actor’]) print(dfObj) # Change the column names using rename() function print(‘After adding suffix to DataFrame columns’) df_new = dfObj.add_suffix(‘_KDL’) print(df_new) |
Выход:
|
python3 app.py Before adding suffix to DataFrame columns Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio After adding suffix to DataFrame columns Name_KDL Seasons_KDL Actor_KDL 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio |
Функции add_prefix() и add_suffix() обрабатывают только столбцы. Если вы хотите добавить префиксы или суффиксы в индекс, укажите лямбда-выражение в индексе аргумента с помощью метода rename(), как описано выше.
Кроме того, add_prefix() и add_suffix() не имеют значения inplace. Если вы хотите обновить исходный объект, перезапишите его, например, df = df.add_prefix().
Как изменить и упорядочить имена или индексы в Pandas
Функция Pandas rename() используется для изменения индексов или имен строк.
Нам просто нужно использовать аргумент индекса и указать, что мы хотим изменить индекс, а не столбцы.
См. следующий код.
|
import pandas as pd import numpy as np # reading the data series = [(‘Stranger Things’, 3, ‘Millie’),(‘Game of Thrones’, 8, ‘Emilia’), (‘Westworld’, 3, ‘Evan Rachel’),(‘La Casa De Papel’, 4, ‘Sergio’)] # Create a DataFrame object dfObj = pd.DataFrame(series, columns=[‘Name’, ‘Seasons’, ‘Actor’]) print(dfObj) # After renaming the index values. df_new = dfObj.rename(index={0:‘zero’,1:‘one’}) print(df_new) |
Выход:
|
python3 app.py Name Seasons Actor 0 Stranger Things 3 Millie 1 Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio Name Seasons Actor zero Stranger Things 3 Millie one Game of Thrones 8 Emilia 2 Westworld 3 Evan Rachel 3 La Casa De Papel 4 Sergio |
Заключение
Вы можете изменить имя столбца DataFrame как минимум двумя способами. Один из способов — использовать df.columns из Pandas и напрямую назначать новые имена.
Другой способ — использовать функцию rename(). Использование pandas rename() для изменения имен столбцов — гораздо лучший способ, чем раньше. Можно легко изменить имена определенных столбцов. И не все имена столбцов нужно менять.
Чтобы изменить имена столбцов с помощью функции rename() в Pandas, необходимо указать преобразователь, словарь со старым именем в качестве ключей и новое имя в качестве значений.
Given a Pandas DataFrame, let’s see how to rename columns in Pandas with examples. Here, we will discuss 6 different ways to rename column names in pandas DataFrame.
About Pandas DataFrame:
Pandas DataFrame is a rectangular grid that is used to store data. It is easy to visualize and work with data when stored in dataFrame.
- It consists of rows and columns.
- Each row is a measurement of some instance while the column is a vector that contains data for some specific attribute/variable.
- Each Dataframe column has homogeneous data throughout any specific column but Dataframe rows can contain homogeneous or heterogeneous data throughout any specific row.
- Unlike two-dimensional arrays, pandas’ Dataframe axes are labeled.
How to rename columns in Pandas DataFrame
Method 1: Using rename() function
One way of renaming the columns in a Pandas Dataframe is by using the rename() function. This method is quite useful when we need to rename some selected columns because we need to specify information only for the columns which are to be renamed.
Example 1: Rename a single column.
Python3
import pandas as pd
rankings = {'test': ['India', 'South Africa', 'England',
'New Zealand', 'Australia'],
'odi': ['England', 'India', 'New Zealand',
'South Africa', 'Pakistan'],
't20': ['Pakistan', 'India', 'Australia',
'England', 'New Zealand']}
rankings_pd = pd.DataFrame(rankings)
print(rankings_pd)
rankings_pd.rename(columns = {'test':'TEST'}, inplace = True)
print("nAfter modifying first column:n", rankings_pd.columns)
Output:

Example 2: Rename multiple columns.
Python3
import pandas as pd
rankings = {'test': ['India', 'South Africa', 'England',
'New Zealand', 'Australia'],
'odi': ['England', 'India', 'New Zealand',
'South Africa', 'Pakistan'],
't20': ['Pakistan', 'India', 'Australia',
'England', 'New Zealand']}
rankings_pd = pd.DataFrame(rankings)
print(rankings_pd.columns)
rankings_pd.rename(columns = {'test':'TEST', 'odi':'ODI',
't20':'T20'}, inplace = True)
print(rankings_pd.columns)
Output:

Method 2: By assigning a list of new column names
The columns can also be renamed by directly assigning a list containing the new names to the columns attribute of the Dataframe object for which we want to rename the columns. The disadvantage of this method is that we need to provide new names for all the columns even if want to rename only some of the columns.
Python3
import pandas as pd
rankings = {'test': ['India', 'South Africa', 'England',
'New Zealand', 'Australia'],
'odi': ['England', 'India', 'New Zealand',
'South Africa', 'Pakistan'],
't20': ['Pakistan', 'India', 'Australia',
'England', 'New Zealand']}
rankings_pd = pd.DataFrame(rankings)
print(rankings_pd.columns)
rankings_pd.columns = ['TEST', 'ODI', 'T-20']
print(rankings_pd.columns)
Output:

Method 3: Rename column names using DataFrame set_axis() function
In this example, we will rename the column name using the set_axis function, we will pass the new column name and axis that should be replaced with a new name in the column as a parameter.
Python3
import pandas as pd
rankings = {'test': ['India', 'South Africa', 'England',
'New Zealand', 'Australia'],
'odi': ['England', 'India', 'New Zealand',
'South Africa', 'Pakistan'],
't20': ['Pakistan', 'India', 'Australia',
'England', 'New Zealand']}
rankings_pd = pd.DataFrame(rankings)
print(rankings_pd.columns)
rankings_pd.set_axis(['A', 'B', 'C'], axis='columns', inplace=True)
print(rankings_pd.columns)
rankings_pd.head()
Output:

Method 4: Rename column names using DataFrame add_prefix() and add_suffix() functions
In this example, we will rename the column name using the add_Sufix and add_Prefix function, we will pass the prefix and suffix that should be added to the first and last name of the column name.
Python3
import pandas as pd
rankings = {'test': ['India', 'South Africa', 'England',
'New Zealand', 'Australia'],
'odi': ['England', 'India', 'New Zealand',
'South Africa', 'Pakistan'],
't20': ['Pakistan', 'India', 'Australia',
'England', 'New Zealand']}
rankings_pd = pd.DataFrame(rankings)
print(rankings_pd.columns)
rankings_pd = rankings_pd.add_prefix('col_')
rankings_pd = rankings_pd.add_suffix('_1')
rankings_pd.head()
Output:
col_test_1 col_odi_1 col_t20_1 0 India England Pakistan 1 South Africa India India 2 England New Zealand Australia 3 New Zealand South Africa England 4 Australia Pakistan New Zealand
Method 5: Replace specific texts of column names using Dataframe.columns.str.replace function
In this example, we will rename the column name using the replace function, we will pass the old name with the new name as a parameter for the column.
Python3
import pandas as pd
rankings = {'test': ['India', 'South Africa', 'England',
'New Zealand', 'Australia'],
'odi': ['England', 'India', 'New Zealand',
'South Africa', 'Pakistan'],
't20': ['Pakistan', 'India', 'Australia',
'England', 'New Zealand']}
rankings_pd = pd.DataFrame(rankings)
print(rankings_pd.columns)
rankings_pd.columns = rankings_pd.columns.str.replace('test', 'Col_TEST')
rankings_pd.columns = rankings_pd.columns.str.replace('odi', 'Col_ODI')
rankings_pd.columns = rankings_pd.columns.str.replace('t20', 'Col_T20')
rankings_pd.head()
Output:

Введение Pandas [https://pandas.pydata.org/] — это библиотека Python для анализа и обработки данных. Почти все операции в пандах вращаются вокруг DataFrames. Dataframe — это абстрактное представление двумерной таблицы, которая может содержать все виды данных. Они также позволяют нам давать имена всем столбцам, поэтому часто столбцы называются атрибутами или полями при использовании DataFrames. В этой статье мы увидим, как мы можем переименовать уже существующий столбец DataFrame.
Вступление
Pandas — это библиотека Python для анализа
и обработки данных. Почти все операции в pandas вращаются вокруг
DataFrame s.
Dataframe — это абстрактное представление двумерной таблицы, которая
может содержать все виды данных. Они также позволяют нам давать имена
всем столбцам, поэтому часто столбцы называются атрибутами или полями
при использовании DataFrames .
В этой статье мы увидим, как мы можем переименовать уже существующие
DataFrame .
Есть два варианта управления именами столбцов DataFrame :
- Переименование столбцов существующего
DataFrame - Назначение имен пользовательских столбцов при создании нового
DataFrame
Давайте посмотрим на оба метода.
Переименование столбцов существующего фрейма данных
У нас есть образец DataFrame ниже:
|
|
DataFrame df выглядит так:
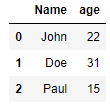
Чтобы переименовать столбцы этого DataFrame , мы можем использовать
метод rename() который принимает:
- Словарь в качестве
columnsсодержащий сопоставление исходных имен
столбцов с именами новых столбцов в виде пар ключ-значение booleanзначение в качествеinplace, которое, если установлено
вTrue, внесет изменения в исходныйDataframe
Давайте изменим имена столбцов в нашем DataFrame с Name, age на
First Name, Age .
|
|
Теперь наш df содержит:
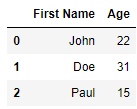
Назначьте имена столбцов при создании фрейма данных
Теперь мы обсудим, как назначать имена столбцам при создании DataFrame
.
Это особенно полезно, когда вы создаете DataFrame из csv и хотите
игнорировать имена столбцов заголовков и назначить свои собственные.
Передав список names , мы можем заменить уже существующий столбец
заголовка нашим собственным. В списке должно быть имя для каждого
столбца данных, в противном случае создается исключение.
Обратите внимание: если мы хотим переименовать только несколько
столбцов, лучше использовать метод rename DataFrame после его
создания.
Мы будем создавать DataFrame используя out.csv , который имеет
следующее содержимое:
|
|
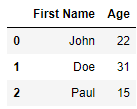
Обратите внимание, что первая строка в файле является строкой заголовка
и содержит имена столбцов. Pandas по умолчанию назначает имена столбцов
DataFrame из первой строки.
Следовательно, мы укажем игнорировать строку заголовка при создании
нашего DataFrame и укажем имена столбцов в списке, который передается
в аргумент names
|
|
Это приводит к:
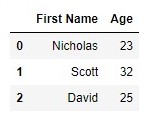
Другой способ сделать это — указать имена столбцов в простом старом
конструкторе DataFrame() .
Единственное отличие состоит в том, что теперь параметр, который
принимает список имен column называется столбцом вместо names :
|
|
Это приводит к другому DataFrame :
Заключение
В этой статье мы быстро рассмотрели, как мы можем называть и
переименовывать столбцы в DataFrame . Либо путем присвоения имен при
DataFrame экземпляра DataFrame, либо путем переименования их после
факта с помощью метода rename()