Новогодние праздники — прекрасный повод попрокрастинировать в уютной домашней обстановке и вспомнить дорогие сердцу мемы из 2k17, уходящие навсегда, как совесть Electronic Arts.
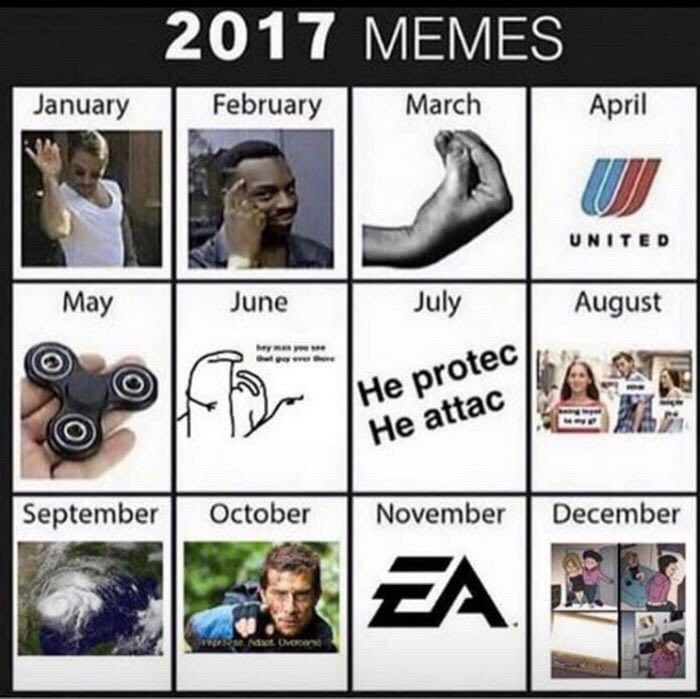
Однако даже обильно сдобренная салатами совесть иногда просыпалась и требовала хоть немного взять себя в руки и заняться полезной деятельностью. Поэтому мы совместили приятное с полезным и на примере любимых мемов посмотрели, как можно спарсить себе небольшую базу
данных, попутно обходя всевозможные блокировки, ловушки и ограничения, расставленные сервером на нашем пути. Всех заинтересованных любезно приглашаем под кат.
Машинное обучение, эконометрика, статистика и многие другие науки о данных занимаются поиском закономерностей. Каждый день доблестные аналитики-инквизиторы пытают природу разными методами и вытаскивают из неё сведенья о том, как именно устроен великий процесс порождения данных, создавший нашу вселенную. Испанские инквизиторы в своей повседневной деятельности использовали непосредственно физическое тело своей жертвы. Природа же вездесуща и не имеет однозначного физического облика. Из-за этого профессия современного инквизитора имеет странную специфику — пытки природы происходят через анализ данных, которые надо откуда-то брать. Обычно данные инквизиторам приносят мирные собиратели. Эта статейка призвана немного приоткрыть завесу тайны насчет того, откуда данные берутся и как их можно немножечко пособирать.
Нашим девизом стала знаменитая фраза капитана Джека Воробья: «Бери всё и не отдавай ничего». Иногда для сбора мемов придется использовать довольно бандитские методы. Тем не менее, мы будем оставаться мирными собирателями данных, и ни в коей мере не будем становиться бандитами. Брать мемы мы будем из главного мемохранилища.

1. Вламываемся в мемохранилище
1.1. Что мы хотим получить
Итак, мы хотим распарсить knowyourmeme.com и получить кучу разных переменных:
- Name – название мема,
- Origin_year – год его создания,
- Views – число просмотров,
- About – текстовое описание мема,
- и многие другие
Более того, мы хотим сделать это без вот этого всего:
После скачивания и чистки данных от мусора можно будет заняться строительством моделей. Например, попытаться предсказать популярность мема по его параметрам. Но это все позже, а сейчас познакомимся с парой определений:
- Парсер — это скрипт, который грабит информацию с сайта
- Краулер — это часть парсера, которая бродит по ссылкам
- Краулинг — это переход по страницам и ссылкам
- Скрапинг — это сбор данных со страниц
- Парсинг — это сразу и краулинг и скрапинг!
1.2. Что такое HTML
HTML (HyperText Markup Language) — это такой же язык разметки как Markdown или LaTeX. Он является стандартным для написания различных сайтов. Команды в таком языке называются тегами. Если открыть абсолютно любой сайт, нажать на правую кнопку мышки, а после нажать View page source, то перед вами предстанет HTML скелет этого сайта.
Можно увидеть, что HTML-страница это ни что иное как набор вложенных тегов. Можно заметить, например, следующие теги:
<title>– заголовок страницы<h1>…<h6>– заголовки разных уровней<p>– абзац (paragraph)<div>– выделения фрагмента документа с целью изменения вида содержимого<table>– прорисовка таблицы<tr>– разделитель для строк в таблице<td>– разделитель для столбцов в таблице<b>– устанавливает жирное начертание шрифта
Обычно команда <...> открывает тег, а </...> закрывает его. Все, что находится между этими двумя командами, подчиняется правилу, которое диктует тег. Например, все, что находится между <p> и </p> — это отдельный абзац.
Теги образуют своеобразное дерево с корнем в теге <html> и разбивают страницу на разные логические кусочки. У каждого тега могут быть свои потомки (дети) — те теги, которые вложены в него, и свои родители.
Например, HTML-древо страницы может выглядеть вот так:
<html>
<head> Заголовок </head>
<body>
<div>
Первый кусок текста со своими свойствами
</div>
<div>
Второй кусок текста
<b>
Третий, жирный кусок
</b>
</div>
Четвёртый кусок текста
</body>
</html>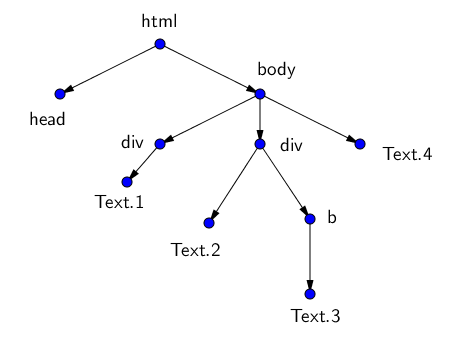
Можно работать с этим html как с текстом, а можно как с деревом. Обход этого дерева и есть парсинг веб-страницы. Мы всего лишь будем находить нужные нам узлы среди всего этого разнообразия и забирать из них информацию!
Вручную обходить эти деревья не очень приятно, поэтому есть специальные языки для обхода деревьев.
- CSS-селектор (это когда мы ищем элемент страницы по паре ключ, значение)
- XPath (это когда мы прописываем путь по дереву вот так: /html/body/div[1]/div[3]/div/div[2]/div)
- Всякие разные библиотеки для всяких разных языков, например, BeautifulSoup для питона. Именно эту библиотеку мы и будем использовать.
1.3. Наш первый запрос
Доступ к веб-станицам позволяет получать модуль requests. Подгрузим его. За компанию подгрузим ещё парочку дельных пакетов.
import requests # Библиотека для отправки запросов
import numpy as np # Библиотека для матриц, векторов и линала
import pandas as pd # Библиотека для табличек
import time # Библиотека для тайм-менеджментаДля наших благородных исследовательских целей нужно собрать данные по каждому мему с соответствующей ему страницы. Но для начала нужно получить адреса этих страниц. Поэтому открываем основную страницу со всеми выложенными мемами. Выглядит она следующим образом:
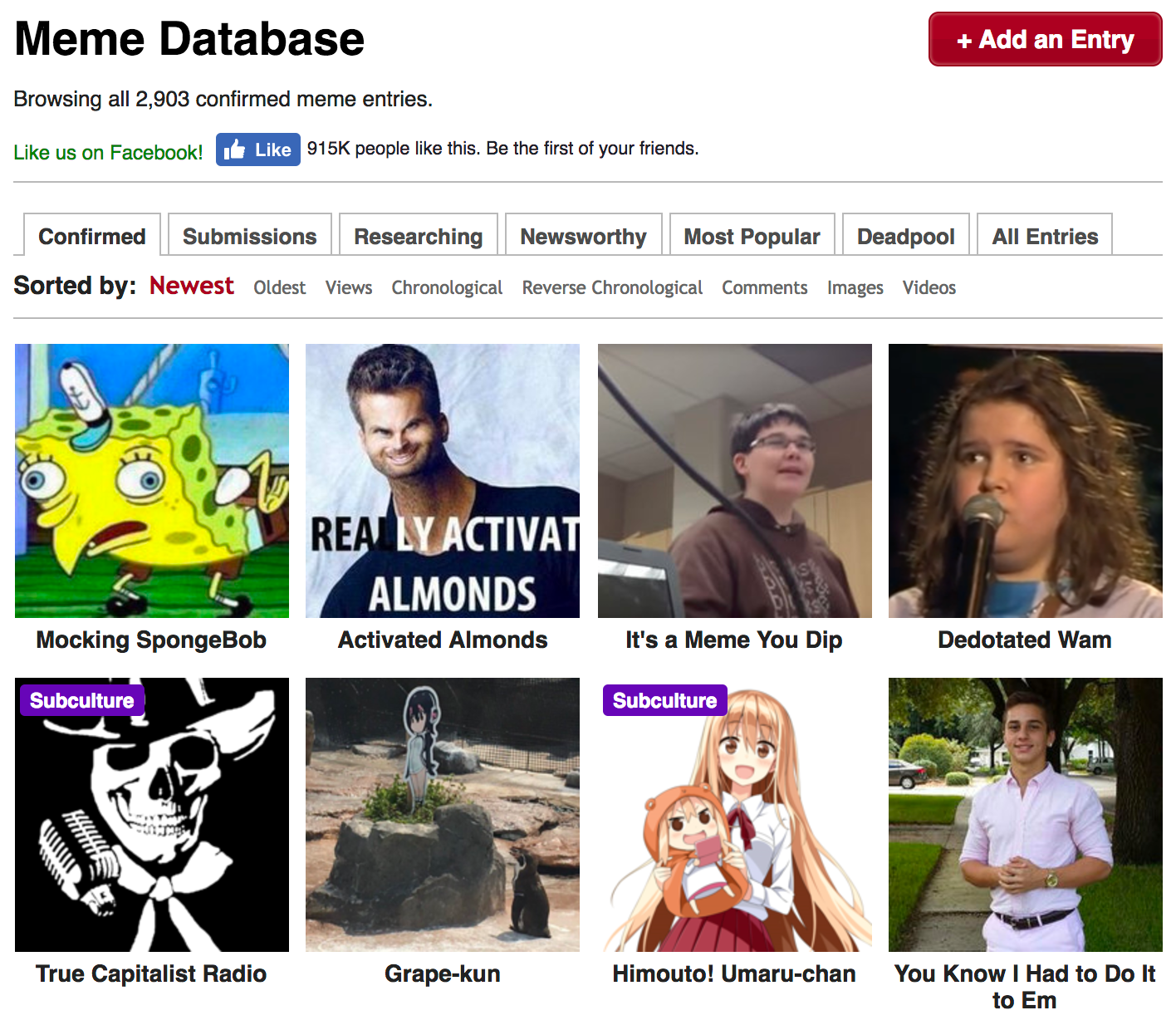
Отсюда мы и будем тащить ссылки на каждый из перечисленных мемов. Сохраним в переменную page_link адрес основной страницы и откроем её при помощи библиотеки requests.
page_link = 'http://knowyourmeme.com/memes/all/page/1'
response = requests.get(page_link)
responseOut: <Response [403]>А вот и первая проблема! Обращаемся к  главному источнику знаний и выясняем, что 403-я ошибка выдается сервером, если он доступен и способен обрабатывать запросы, но по некоторым личным причинам отказывается это делать.
главному источнику знаний и выясняем, что 403-я ошибка выдается сервером, если он доступен и способен обрабатывать запросы, но по некоторым личным причинам отказывается это делать.
Попробуем выяснить, почему. Для этого проверим, как выглядел финальный запрос, отправленный нами на сервер, а конкретнее — как выглядел наш User-Agent в глазах сервера.
for key, value in response.request.headers.items():
print(key+": "+value)Out:
User-Agent: python-requests/2.14.2
Accept-Encoding: gzip, deflate
Accept: */*
Connection: keep-aliveПохоже, мы недвусмысленно дали понять серверу, что мы сидим на питоне и используем библиотеку requests под версией 2.14.2. Скорее всего, это вызвало у сервера некоторые подозрения относительно наших благих намерений и он решил нас безжалостно отвергнуть. Для сравнения, можно посмотреть, как выглядят request-headers у здорового человека:

Очевидно, что нашему скромному запросу не тягаться с таким обилием мета-информации, которое передается при запросе из обычного браузера. К счастью, никто нам не мешает притвориться человечными и пустить пыль в глаза сервера при помощи генерации фейкового юзер-агента. Библиотек, которые справляются с такой задачей, существует очень и очень много, лично мне больше всего нравится fake-useragent. При вызове метода из различных кусочков будет генерироваться рандомное сочетание операционной системы, спецификаций и версии браузера, которые можно передавать в запрос:
# подгрузим один из методов этой библиотеки
from fake_useragent import UserAgent
UserAgent().chromeOut: 'Mozilla/5.0 (Windows NT 5.1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/41.0.2224.3 Safari/537.36'Попробуем прогнать наш запрос еще раз, уже со сгенерированным агентом
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome})
responseOut: <Response [200]>Замечательно, наша небольшая маскировка  сработала и обманутый сервер покорно выдал благословенный 200 ответ — соединение установлено и данные получены, всё чудесно! Посмотрим, что же все-таки мы получили.
сработала и обманутый сервер покорно выдал благословенный 200 ответ — соединение установлено и данные получены, всё чудесно! Посмотрим, что же все-таки мы получили.
html = response.content
html[:1000]Out: b'<!DOCTYPE html>n<html xmlns:fb='http://www.facebook.com/2008/fbml' xmlns='http://www.w3.org/1999/xhtml'>n<head>n<meta content='text/html; charset=utf-8' http-equiv='Content-Type'>n<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHlcJWg==","queueTime":0,"applicationTime":59,"agent":""}</script>n<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,t,n){function r(n){if(!t[n]){var o=t[n]={exports:{}};e[n][0].call(o.exports,function(t){var o=e[n][1][t];return r(o||t)},o,o.exports)}return t[n].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<n.length;o++)r(n[o]);return r}({1:[function(e,t,n){function r(){}function o(e,t,n){return function(){return i(e,[f.now()].concat(u(arguments)),t?null:this,n),t?void 0:this}}var i=e("handle"),a=e(2),u=e(3),c=e("ee").get("tracer")'Выглядит неудобоваримо, как насчет сварить из этого дела что-то покрасивее? Например, прекрасный суп.
1.4. Прекрасный суп

Пакет bs4, a.k.a BeautifulSoup (тут есть гиперссылка на лучшего друга человека — документацию) был назван в честь стишка про прекрасный суп из Алисы в стране чудес.
Прекрасный суп — это совершенно волшебная библиотека, которая из сырого и необработанного HTML кода страницы выдаст вам структурированный массив данных, по которому очень удобно искать необходимые теги, классы, атрибуты, тексты и прочие элементы веб страниц.
Пакет под названием
BeautifulSoup— скорее всего, не то, что нам нужно. Это третья версия (Beautiful Soup 3), а мы будем использовать четвертую. Нужно будет установить пакетbeautifulsoup4. Чтобы было совсем весело, при импорте нужно указывать другое название пакета —bs4, а импортировать функцию под названиемBeautifulSoup. В общем, сначала легко запутаться, но эти трудности нужно преодолеть.
С необработанным XML кодом страницы пакет также работает (XML — это исковерканый и превращённый в диалект, с помощью своих команд, HTML). Для того, чтобы пакет корректно работал с XML разметкой, придётся в довесок ко всему нашему арсеналу установить пакет xml.
from bs4 import BeautifulSoupПередадим функции BeautifulSoup текст веб-страницы, которую мы недавно получили.
soup = BeautifulSoup(html,'html.parser') # В опции также можно указать lxml,
# если предварительно установить одноименный пакетПолучим что-то вот такое:
<!DOCTYPE html>
<html xmlns="http://www.w3.org/1999/xhtml" xmlns:fb="http://www.facebook.com/2008/fbml">
<head>
<meta content="text/html; charset=utf-8" http-equiv="Content-Type"/>
<script type="text/javascript">window.NREUM||(NREUM={});NREUM.info={"beacon":"bam.nr-data.net","errorBeacon":"bam.nr-data.net","licenseKey":"c1a6d52f38","applicationID":"31165848","transactionName":"dFdfRUpeWglTQB8GDUNKWFRLHkUNWUU=","queueTime":0,"applicationTime":24,"agent":""}</script>
<script type="text/javascript">window.NREUM||(NREUM={}),__nr_require=function(e,n,t){function r(t){if(!n[t]){var o=n[t]={exports:{}};e[t][0].call(o.exports,function(n){var o=e[t][1][n];return r(o||n)},o,o.exports)}return n[t].exports}if("function"==typeof __nr_require)return __nr_require;for(var o=0;o<t.length;o++)r(t[o]);return r}({1:[function(e,n,t){function r(){}function o(e,n,t){return function(){return i(e,[c.now()].concat(u(arguments)),n?null:this,t),n?void 0:this}}var i=e("handle"),a=e(2),u=e(3),f=e("ee").get("tracer"),c=e("loader"),s=NREUM;"undefined"==typeof window.newrelic&&(newrelic=s);var p=Стало намного лучше, не правда ли? Что же лежит в переменной soup? Невнимательный пользователь, скорее всего, скажет, что ничего вообще не изменилось. Тем не менее, это не так. Теперь мы можем свободно бродить по HTML-дереву страницы, искать детей, родителей и вытаскивать их!
Например, можно бродить по вершинам, указывая путь из тегов.
soup.html.head.titleOut: <title>All Entries | Know Your Meme</title>Можно вытащить из того места, куда мы забрели, текст с помощью метода text.
soup.html.head.title.textOut: 'All Entries | Know Your Meme'Более того, зная адрес элемента, мы сразу можем найти его. Например, можно сделать это по классу. Следующая команда должна найти элемент, который лежит внутри тега a и имеет класс photo.
obj = soup.find('a', attrs = {'class':'photo'})
objOut: <a class="photo left" href="/memes/nu-male-smile" target="_self"><img alt='The "Nu-Male Smile" Is Duck Face for Men' data-src="http://i0.kym-cdn.com/featured_items/icons/wide/000/007/585/7a2.jpg" height="112" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title='The "Nu-Male Smile" Is Duck Face for Men' width="198"/> <div class="info abs"> <div class="c"> The "Nu-Male Smile" Is Duck Face for Men </div> </div> </a>Однако, вопреки нашим ожиданиям, вытащенный объект имеет класс "photo left". Оказывается, BeautifulSoup4 расценивает аттрибуты class как набор отдельных значений, поэтому "photo left" для библиотеки равносильно ["photo", "left"], а указанное нами значение этого класса "photo" входит в этот список. Чтобы избежать такой неприятной ситуации и проходов по ненужным нам ссылкам, придется воспользоваться собственной функцией и задать строгое соответствие:
obj = soup.find(lambda tag: tag.name == 'a' and tag.get('class') == ['photo'])
objOut: <a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>Полученный после поиска объект также обладает структурой bs4. Поэтому можно продолжить искать нужные нам объекты уже в нём! Вытащим ссылку на этот мем. Сделать это можно по атрибуту href, в котором лежит наша ссылка.
obj.attrs['href']Out: '/memes/people/mf-doom'Обратите внимание, что после всех этих безумных преобразований у данных поменялся тип. Теперь они str. Это означет, что с ними можно работать как с текстом и пускать в ход для отсеивания лишней информации регулярные выражения.
print("Тип данных до вытаскивания ссылки:", type(obj))
print("Тип данных после вытаскивания ссылки:", type(obj.attrs['href']))Out:
Тип данных до вытаскивания ссылки: <class 'bs4.element.Tag'>
Тип данных после вытаскивания ссылки: <class 'str'>Если несколько элементов на странице обладают указанным адресом, то метод find вернёт только самый первый. Чтобы найти все элементы с таким адресом, нужно использовать метод findAll, и на выход будет выдан список. Таким образом, мы можем получить одним поиском сразу все объекты, содержащие ссылки на страницы с мемами.
meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo'])
meme_links[:3]Out: [<a class="photo" href="/memes/people/mf-doom"><img alt="MF DOOM" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/149/1489698959244.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="MF DOOM"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>,
<a class="photo" href="/memes/here-lies-beavis-he-never-scored"><img alt="Here Lies Beavis. He Never Scored." data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/148/maxresdefault.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="Here Lies Beavis. He Never Scored."/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> </div> </a>,
<a class="photo" href="/memes/people/vanossgaming"><img alt="VanossGaming" data-src="http://i0.kym-cdn.com/entries/icons/medium/000/025/147/Evan-Fong-e1501621844732.jpg" src="http://a.kym-cdn.com/assets/blank-b3f96f160b75b1b49b426754ba188fe8.gif" title="VanossGaming"/> <div class="entry-labels"> <span class="label label-submission"> Submission </span> <span class="label" style="background: #d32f2e; color: white;">Person</span> </div> </a>]Осталось очистить полученный список от мусора:
meme_links = [link.attrs['href'] for link in meme_links]
meme_links[:10]Out: ['/memes/people/mf-doom',
'/memes/here-lies-beavis-he-never-scored',
'/memes/people/vanossgaming',
'/memes/stream-sniping',
'/memes/kids-describe-god-to-an-illustrator',
'/memes/bad-teacher',
'/memes/people/adam-the-creator',
'/memes/but-can-you-do-this',
'/memes/people/ken-ashcorp',
'/memes/heartbroken-cowboy']Готово, получили ровно 16 ссылок по числу мемов на одной странице поиска.
Хорошо, то, что можно искать элемент по его адресу, конечно же, круто, но откуда взять этот адрес? Можно установить для своего браузера какую-нибудь утилиту, позволяющую вытаскивать со страницы нужные теги, например, selectorgadget.
Тем не менее, этот путь не подходит для истинного самурая. Для последователей бусидо есть другой способ — искать теги для каждого нужного нам элемента вручную. Для этого придётся жать правой кнопкой мышки по окну браузера и тыкать кнопку Inspect. После всех этих манипуляций браузер будет выглядеть как-то вот так:
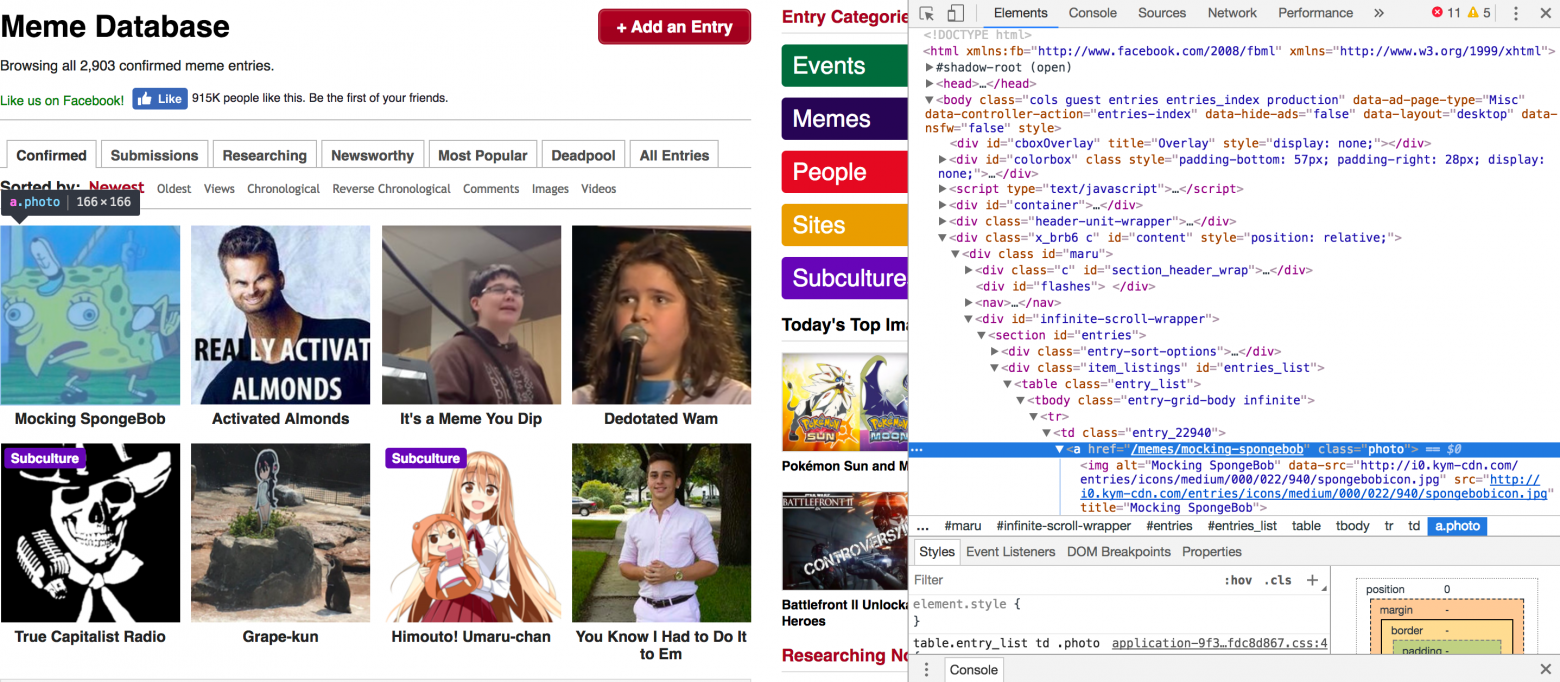
Выскочивший кусок html, в котором находится адрес выбранного вами объекта, можно смело копировать в код и наслаждаться своей брутальностью.
Остался последний момент. Когда мы скачаем все мемы с текущей страницы, нам нужно будет каким-то образом забраться на соседнюю. На сайте это можно делать просто пролистывая страницу с мемами вниз, javascript-функции подтянут новые мемы на текущее окно, но сейчас трогать эти функции не хочется.
Обычно, все параметры, которые мы устанавливаем на сайте для поиска, отображаются на структуре хрефа. Мемы не являются исключением. Если мы хотим получить первую порцию мемов, мы должны будем обратиться к сайту по ссылке
http://knowyourmeme.com/memes/all/page/1
Если мы захотим получить вторую поцию с шестнадцатью мемами, нам придётся немного видоизменить ссылку, а именно заменить номер страницы на 2.
http://knowyourmeme.com/memes/all/page/2
Таким незатейливым образом мы сможем пройтись по всем страницам и ограбить мемохранилище. Наконец, обернем в красивую функцию все-все манипуляции, проделанные выше:
Функция для скачивания ссылок на мемы
def getPageLinks(page_number):
"""
Возвращает список ссылок на мемы, полученный с текущей страницы
page_number: int/string
номер страницы для парсинга
"""
# составляем ссылку на страницу поиска
page_link = 'http://knowyourmeme.com/memes/all/page/{}'.format(page_number)
# запрашиваем данные по ней
response = requests.get(page_link, headers={'User-Agent': UserAgent().chrome})
if not response.ok:
# если сервер нам отказал, вернем пустой лист для текущей страницы
return []
# получаем содержимое страницы и переводим в суп
html = response.content
soup = BeautifulSoup(html,'html.parser')
# наконец, ищем ссылки на мемы и очищаем их от ненужных тэгов
meme_links = soup.findAll(lambda tag: tag.name == 'a' and tag.get('class') == ['photo'])
meme_links = ['http://knowyourmeme.com' + link.attrs['href'] for link in meme_links]
return meme_linksПротестируем функцию и убедимся, что всё хорошо
meme_links = getPageLinks(1)
meme_links[:2]Out: ['http://knowyourmeme.com/memes/people/mf-doom',
'http://knowyourmeme.com/memes/here-lies-beavis-he-never-scored']Отлично, функция работает и теперь мы теоретически можем достать ссылки на все 17171 мем, для чего нам придется пройтись по 17171/16 ~ 1074 страницам. Прежде чем расстраивать сервер таким количеством запросов, посмотрим, как доставать всю необходимую информацию о конкретном меме.
1.5 Финальная подготовка к грабежу
По аналогии со ссылками можно вытащить что угодно. Для этого надо сделать несколько шагов:
- Открываем страничку с мемом
- Находим любым способом тег для нужной нам информации
- Пихаем всё это в прекрасный суп
- ……
- Profit
Для закрепления информации в голове любознательного читателя, вытащим число просмотров мема.
А в качестве примера возьмем самый популярный на этом сайте мем — Doge, набравший более 12 миллионов просмотров по состоянию на 1 января 2018 года.
Сама страница, с которой мы будем доставать дорогую нашему исследовательскому сердцу информацию выглядит следуюшим образом:
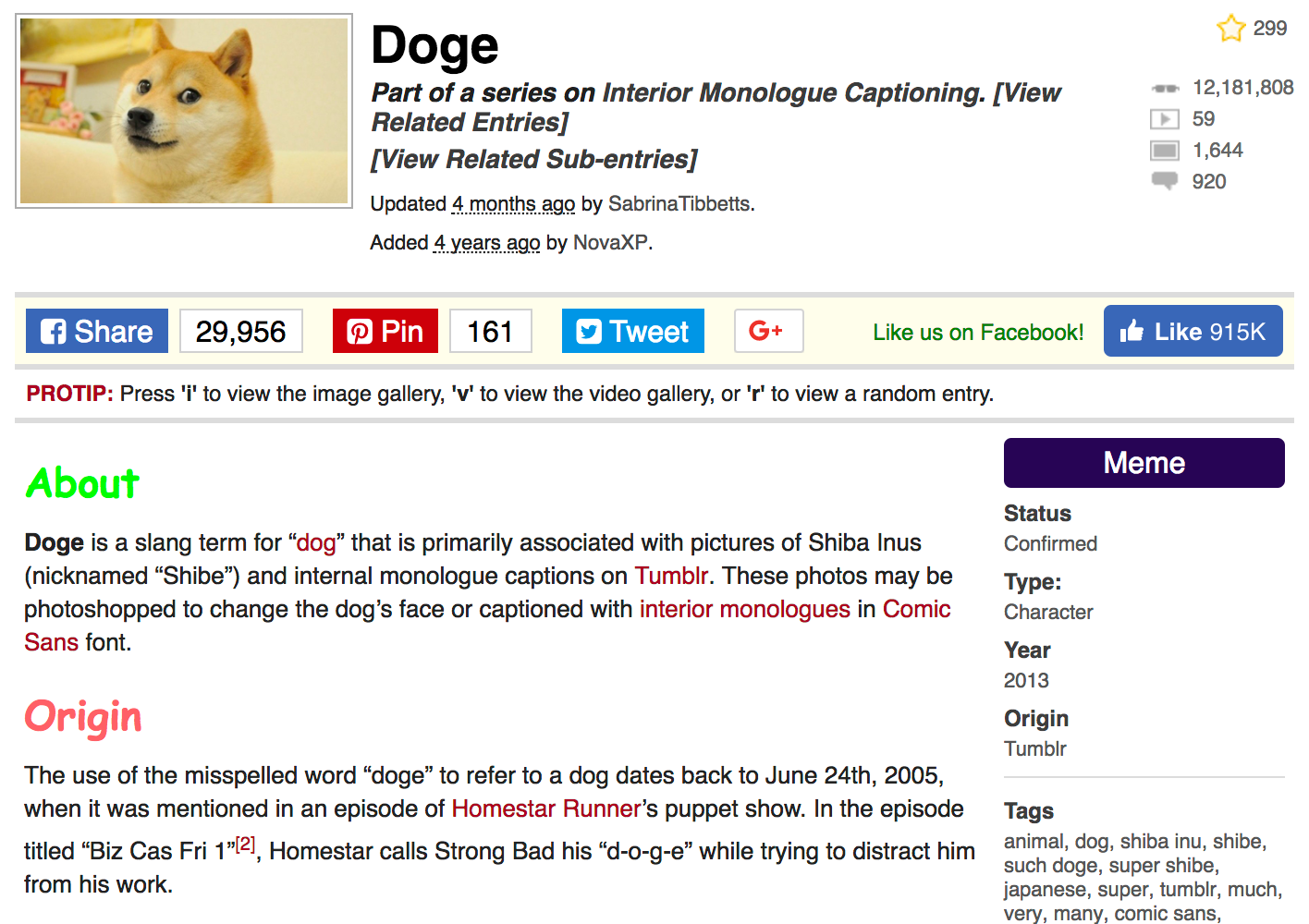
Как и прежде, для начала сохраним ссылку на страницу в переменную и вытащим по ней контент.
meme_page = 'http://knowyourmeme.com/memes/doge'
response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome})
html = response.content
soup = BeautifulSoup(html,'html.parser')Посмотрим, как можно вытащить статистику просмотров, комментариев, а также числа загруженных видео и фото, связанных с нашим мемов. Всё это добро хранится справа вверху под тэгами "dd" и с классами "views", "videos", "photos" и "comments"
views = soup.find('dd', attrs={'class':'views'})
print(views)Out:
<dd class="views" title="12,318,185 Views">
<a href="/memes/doge" rel="nofollow">12,318,185</a>
</dd>Очистим от тэгов и пунктуации
views = views.find('a').text
views = int(views.replace(',', ''))
print(views)Out:
12318185Снова запихнём всё это в небольшую функцию.
Функция, возвращающая статистику по мему
def getStats(soup, stats):
"""
Возвращает очищенное число просмотров/коментариев/...
soup: объект bs4.BeautifulSoup
суп текущей страницы
stats: string
views/videos/photos/comments
"""
obj = soup.find('dd', attrs={'class':stats})
obj = obj.find('a').text
obj = int(obj.replace(',', ''))
return objВсё готово!
views = getStats(soup, stats='views')
videos = getStats(soup, stats='videos')
photos = getStats(soup, stats='photos')
comments = getStats(soup, stats='comments')
print("Просмотры: {}nВидео: {}nФото: {}nКомментарии: {}".format(views, videos, photos, comments))Out:
Просмотры: 12318185
Видео: 59
Фото: 1645
Комментарии: 918Еще из интересного и исследовательского — достанем дату и время добавления мема. Если посмотреть на страницу в браузере, можно подумать, что максимум информации, который мы можем вытащить — это число лет, прошедших с момента публикации — Added 4 years ago by NovaXP. Однако мы так просто сдаваться не будем, полезем в кишки html и откопаем там кусок, ответственный за эту надпись:
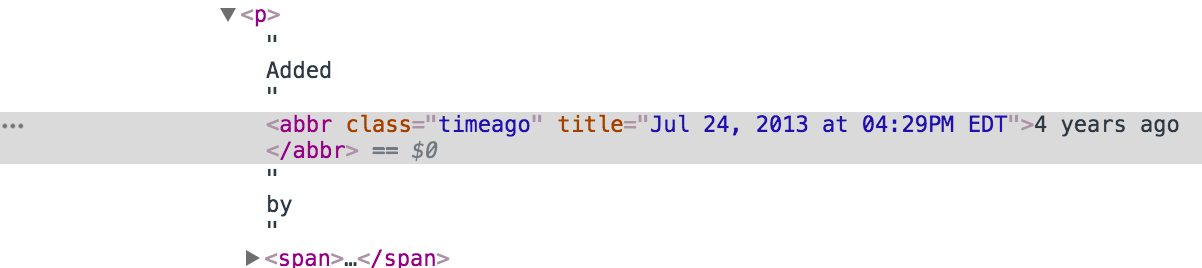
Ага! Вот и подробности по дате добавления, с точностью до минуты. Элементарно

date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title']
dateOut: '2017-12-31T01:59:14-05:00'На самом деле, парсеры — дело непредсказуемое. Часто страницы, которые мы парсим, имеют очень неоднородну структуру. Например, если мы парсим мемы, на части страниц может быть указано описание, а на части нет. Как только код впервые натыкается на отсутствие описания, он выдаёт ошибку и останавливается. Чтобы нормально собрать все данные, приходится прописывать исключения. Вроде бы, хранилище мемов хорошо оборудовано и никаких внештатных ситуаций происходить не должно.
Тем не менее, очень не хочется проснуться утром и увидеть, что код сделал 20 итераций, нарвался на ошибку и отрубился. Чтобы такого не произошло, можно, например, использовать конструкцию try - except и просто обрабатывать неугодные нам ошибки. Про исключения можно почитать на просторах интернета. В нашем же случае до ошибки можно и не доводить, а предварительно проверять, есть ли необходимый элемент на странице или нет при помощи обычного if - else, и уже после этого пытаться его распарсить.
Например, мы хотим вытащить статус мема, для этого найдем окружающие его тэги:
properties = soup.find('aside', attrs={'class':'left'})
meme_status = properties.find("dd")
meme_statusOut:
<dd>
Confirmed
</dd>Дальше нужно вытащить из тэгов текст, а после обрубить все лишние пробелы.
meme_status.text.strip()Out: 'Confirmed'Однако, если неожиданно выяснится, что у мема нет статуса, метод find вернёт пустоту. Метод text, в свою очередь, не сможет найти в тэгах текст и выдаст ошибку. Чтобы обезопасить себя от таких пустот, можно прописать исключение или if - else. Так как в текущем меме статус все-таки есть, нарочно зададим его как пустой объект, чтобы проверить, что ошибка поймается в обоих случаях
# Делай раз! Ищем статус мема, но не находим его
meme_status = None
# Делай два! Пытаемся вытащить его...
# ... с исключениями
try:
print(meme_status.text.strip())
# Ежели возникает ошибка, статус не найден, выдаём пустоту.
except:
print("Exception")
# ... с проверкой на пустой элемент
if meme_status:
print(meme_status.text.strip())
else:
print("Empty")Out:
Exception
EmptyТакой код позволяет обезопасить себя от ошибок. В данном случае, мы можем переписать всю конструкцию с if - else в виде одной удобной строки. Эта строка проверит, полон ли респонса meme_status и ежели нет, то выдаст пустоту.
# снова найдем настоящий статус
properties = soup.find('aside', attrs={'class':'left'})
meme_status = properties.find("dd")
meme_status = "" if not meme_status else meme_status.text.strip()
print(meme_status)Out: ConfirmedПо аналогии можно вытащить всю остальную информацию со страницы, для чего вновь напишем функцию
Функция для парсинга свойств мема
def getProperties(soup):
"""
Возвращает список (tuple) с названием, статусом, типом,
годом и местом происхождения и тэгами
soup: объект bs4.BeautifulSoup
суп текущей страницы
"""
# название - идёт с самым большим заголовком h1, легко найти
meme_name = soup.find('section', attrs={'class':'info'}).find('h1').text.strip()
# достаём все данные справа от картинки
properties = soup.find('aside', attrs={'class':'left'})
# статус идет первым - можно не уточнять класс
meme_status = properties.find("dd")
# oneliner, заменяющий try-except: если тэга нет в properties, вернётся объект NoneType,
# у которого аттрибут text отсутствует, и в этом случае он заменится на пустую строку
meme_status = "" if not meme_status else meme_status.text.strip()
# тип мема - обладает уникальным классом
meme_type = properties.find('a', attrs={'class':'entry-type-link'})
meme_type = "" if not meme_type else meme_type.text
# год происхождения первоисточника можно найти после заголовка Year,
# находим заголовок, определяем родителя и ищем следущего ребенка - наш раздел
meme_origin_year = properties.find(text='nYearn')
meme_origin_year = "" if not meme_origin_year else meme_origin_year.parent.find_next()
meme_origin_year = meme_origin_year.text.strip()
# сам первоисточник
meme_origin_place = properties.find('dd', attrs={'class':'entry_origin_link'})
meme_origin_place = "" if not meme_origin_place else meme_origin_place.text.strip()
# тэги, связанные с мемом
meme_tags = properties.find('dl', attrs={'id':'entry_tags'}).find('dd')
meme_tags = "" if not meme_tags else meme_tags.text.strip()
return meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tagsgetProperties(soup)Out:
('Doge',
'Confirmed',
'Animal',
'2013',
'Tumblr',
'animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme, hacked, bitcoin, dogecoin, shitposting, stare, canine')Свойства мема собрали. Теперь собираем по аналогии его текстовое описание.
Функция для парсинга текстового описания мема
def getText(soup):
"""
Возвращает текстовые описания мема
soup: объект bs4.BeautifulSoup
суп текущей страницы
"""
# достаём все тексты под картинкой
body = soup.find('section', attrs={'class':'bodycopy'})
# раздел about (если он есть), должен идти первым, берем его без уточнения класса
meme_about = body.find('p')
meme_about = "" if not meme_about else meme_about.text
# раздел origin можно найти после заголовка Origin или History,
# находим заголовок, определяем родителя и ищем следущего ребенка - наш раздел
meme_origin = body.find(text='Origin') or body.find(text='History')
meme_origin = "" if not meme_origin else meme_origin.parent.find_next().text
# весь остальной текст (если он есть) можно запихнуть в одно текстовое поле
if body.text:
other_text = body.text.strip().split('n')[4:]
other_text = " ".join(other_text).strip()
else:
other_text = ""
return meme_about, meme_origin, other_textmeme_about, meme_origin, other_text = getText(soup)
print("О чем мем:n{}nnПроисхождение:n{}nnОстальной текст:n{}...n"
.format(meme_about, meme_origin, other_text[:200]))Out:
О чем мем:
Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr. These photos may be photoshopped to change the dog’s face or captioned with interior monologues in Comic Sans font.
Происхождение:
The use of the misspelled word “doge” to refer to a dog dates back to June 24th, 2005, when it was mentioned in an episode of Homestar Runner’s puppet show. In the episode titled “Biz Cas Fri 1”[2], Homestar calls Strong Bad his “d-o-g-e” while trying to distract him from his work.
Остальной текст:
Identity On February 23rd, 2010, Japanese kindergarten teacher Atsuko Sato posted several photos of her rescue-adopted Shiba Inu dog Kabosu to her personal blog.[38] Among the photos included a peculi...Наконец, создадим функцию, возвращающую всю информацию по текущему мему
Функция, возвращающая все данные по мему
def getMemeData(meme_page):
"""
Запрашивает данные по странице, возвращает обработанный словарь с данными
meme_page: string
ссылка на страницу с мемом
"""
# запрашиваем данные по ссылке
response = requests.get(meme_page, headers={'User-Agent': UserAgent().chrome})
if not response.ok:
# если сервер нам отказал, вернем статус ошибки
return response.status_code
# получаем содержимое страницы и переводим в суп
html = response.content
soup = BeautifulSoup(html,'html.parser')
# используя ранее написанные функции парсим информацию
views = getStats(soup=soup, stats='views')
videos = getStats(soup=soup, stats='videos')
photos = getStats(soup=soup, stats='photos')
comments = getStats(soup=soup, stats='comments')
# дата
date = soup.find('abbr', attrs={'class':'timeago'}).attrs['title']
# имя, статус, и т.д.
meme_name, meme_status, meme_type, meme_origin_year, meme_origin_place, meme_tags =
getProperties(soup=soup)
# текстовые поля
meme_about, meme_origin, other_text = getText(soup=soup)
# составляем словарь, в котором будут хранится все полученные и обработанные данные
data_row = {"name":meme_name, "status":meme_status,
"type":meme_type, "origin_year":meme_origin_year,
"origin_place":meme_origin_place,
"date_added":date, "views":views,
"videos":videos, "photos":photos, "comments":comments, "tags":meme_tags,
"about":meme_about, "origin":meme_origin, "other_text":other_text}
return data_rowА теперь подготовим табличку, чтобы в неё записывать всё награбленные честно полученные данные, добавим в неё первую полученную строку и полюбуемся на результат
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place',
'date_added', 'views', 'videos', 'photos', 'comments',
'tags', 'about', 'origin', 'other_text'])
data_row = getMemeData('http://knowyourmeme.com/memes/doge')
final_df = final_df.append(data_row, ignore_index=True)
final_dfOut:| name | status | type | origin_year | … |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | … |
Первый мем оказался в наших рукак. Еще раз убедимся что всё работает — пройдемся по списку из ссылок на мемы, полученных ранее в перменной meme_links.
for meme_link in meme_links:
data_row = getMemeData(meme_link)
final_df = final_df.append(data_row, ignore_index=True)Out:| name | status | type | origin_year | … |
|---|---|---|---|---|
| Doge | Confirmed | Animal | 2013 | … |
| Charles C. Johnson | Submission | Activist | 2013 | … |
| Bat- (Prefix) | Submission | Snowclone | 2018 | … |
| The Eric Andre Show | Deadpool | TV Show | 2012 | … |
| Hopsin | Submission | Musician | 2003 | … |
Отлично! Всё работает, мемы качаются, данные наполняются и всё было бы хорошо, если бы не одно но — количество запросов, которое нам придётся сделать, чтобы всё получить.
2. Прячемся от стражников
2.1 Когда работающий код больше не работает
Вот он! Тот самый момент абсолютного триумфа, когда код дописан и всё, что нам, мирным собирателям, остаётся — запустить наш код на одну ночку. Кажется, что через страсть мы преобрели силу. Запускаем наш код по всем  страницам с мемами. На всякий случай обернём наш цикл в
страницам с мемами. На всякий случай обернём наш цикл в try-except. Мало ли что там с этими мемами бывает.
Цикл на ночь
# Немного красивых циклов. При желании пакет можно отключить и
# удалить команду tqdm_notebook из всех циклов
from tqdm import tqdm_notebook
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place',
'date_added', 'views', 'videos', 'photos', 'comments',
'tags', 'about', 'origin', 'other_text'])
for page_number in tqdm_notebook(range(1075), desc='Pages'):
# собрали хрефы с текущей страницы
meme_links = getPageLinks(page_number)
for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False):
# иногда с первого раза страничка не парсится
for i in range(5):
try:
# пытаемся собрать по мему немного даты
data_row = getMemeData(meme_link)
# и закидываем её в таблицу
final_df = final_df.append(data_row, ignore_index=True)
# если всё получилось - выходим из внутреннего цикла
break
except:
# Иначе, пробуем еще несколько раз, пока не закончатся попытки
print('AHTUNG! parsing once again:', meme_link)
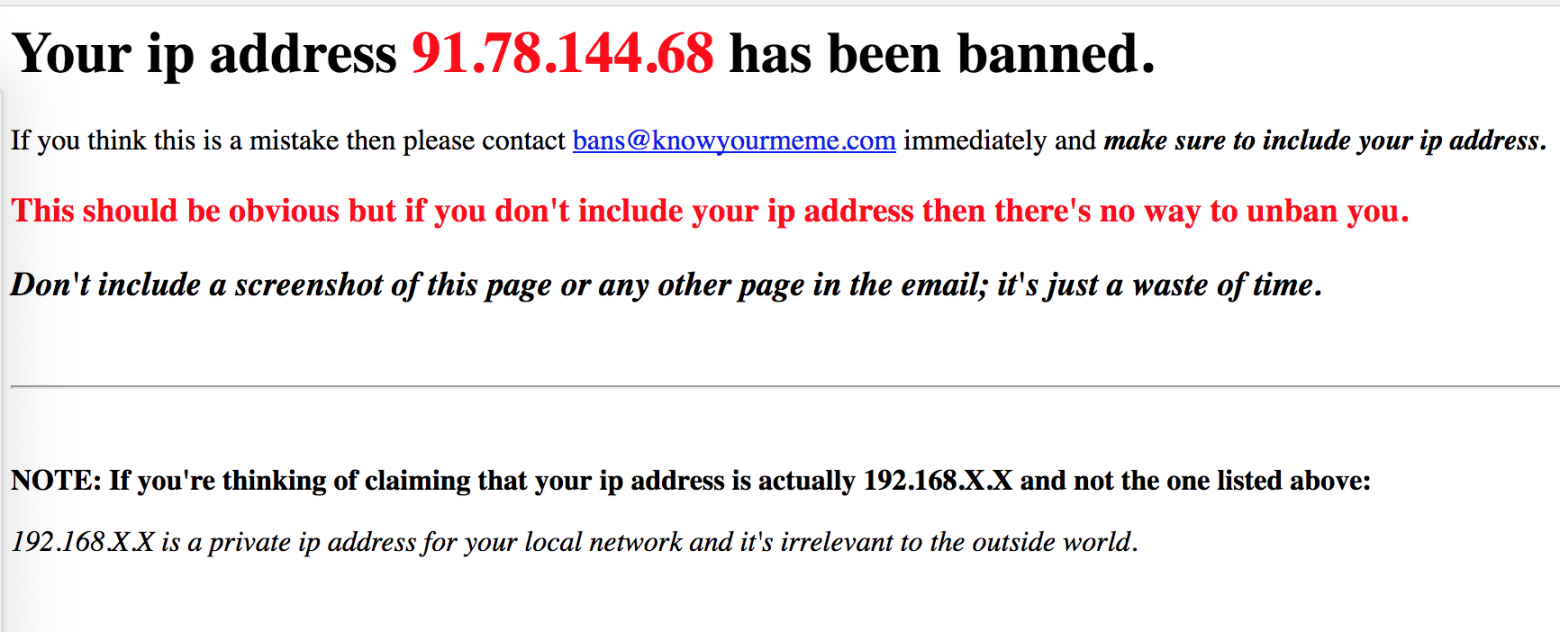
continueСон был прекрасным! Солнце только-только взошло из-за горизонта, мы уже бежим за компьютер смотреть мемы и видим, что огромное число мемов не скачалось.

Конечно же, вполне естественной реакцией будет нажать на первую же ссылку, перейти в мемохранилище и увидеть, что нас забанили. Все наши реквесты остались без респонсов.
2.2 Тор — сын Одина
Иногда серверу надоедает общаться с одним и тем же человеком, делающим кучу запросов и сервер банит его. К сожалению, не только у людей запас терпения ограничен.
Приходится маскироваться. Для такой маскировки можно использовать разные способы, более того, один из них мы уже использовали, когда притворились человеком в нашем request-header. Для текущей же задачи, когда нас вероломно заблокировали по IP, нужно искать способы помощнее, чтобы иметь возможность этот IP менять. Конечно, как вариант можно было бы использовать прокси-сервера, тогда мы бы имели в запасе некоторое количество разных IP адресов, которые можно подставлять по мере «забанивания». Однако в этом подходе есть пара проблем: первая — нужно где-то раздобыть эти прокси, вторая — а что если ограниченного числа адресов нам не хватит и нужно больше?
В таком случае лучше всего нам подойдёт Tor. Вопреки пропагандируемому мнению, Tor используется не только преступниками, педофилами и прочими нехорошими террористами. Это, мягко говоря, далеко не так, и мы, мирные собиратели данных, являемся тому подтверждением. Всем прелестям, связанным с работой Tor, можно было бы посвятить несколько больших статеек, что собственно говоря уже и сделано. Подробнее про это можно почитатать по следующим ссылкам:
- Как работает Tor
- Методы анонимности в сети
- Прокси-сервер с помощью Tor
Мы же ограничимся только функциональной частью, а именно без углубления в детали опишем шаги, которые нужно предпринять для того, чтобы использовать возможности Tor для обхода блокировки. Для начала полюбуемся на свой ip-адрес. Для этого сделаем get-запрос к сайту, который возвращяет наш IP
def checkIP():
ip = requests.get('http://checkip.dyndns.org').content
soup = BeautifulSoup(ip, 'html.parser')
print(soup.find('body').text)
checkIP()Out: Current IP Address: 82.198.191.130Заменить свой ip через Tor можно двумя путями. Простой — через браузер, а сложный — через небольшие махинации с настройками.
Скачаем браузерный tor, чтобы лёгкий путь был совсем прост. Для сложного пути в довесок к браузеру поставим tor через консоль.
- Linux — нам поможет команда
apt-get install tor, - Mac — сделаем это в рамках brew,
brew install tor. - Windows — нам поможет установка другой операционной системы.
2.3 Путь первый
Теперь запускаем свежескачанный браузер и оставляем его открытым. Менять ip нам поможет библиотека PySocks. Конечно же, её нужно установить, скопировав в терминал pip3 install PySocks.
Браузер тора по умолчанию использует порт номер 9150. В питоне при помощи библиотек socks и socket можно задать дефолтный порт для подключения. В результате текущая сессия будет использовать именно этот порт при отправке любого запроса, а значит – запросы будут посылаться из-под запущенного тора.
import socks
import socket
socks.set_default_proxy(socks.SOCKS5, "localhost", 9150)
socket.socket = socks.socksocketПосмотрим на свой новый ip-aдрес.
checkIP()Out: Current IP Address: 51.15.92.24При сопутствующем желании, можно выяснить из какой страны в данный момент мы сидим в интернете.
Ого… бывший член Европейского союза!
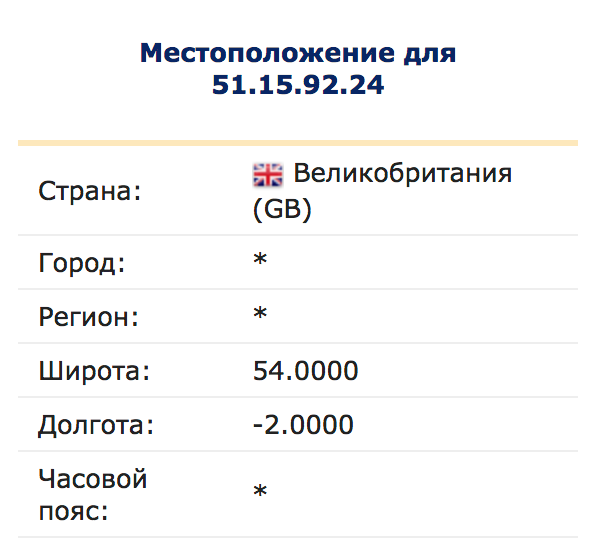
Попробуем обратиться к мемохранилищу с нового ip-адреса.
data_row = getMemeData('http://knowyourmeme.com/memes/doge')
for key, value in data_row.items():
print(key.capitalize()+":", str(value)[:200], end='nn')Out:
Name: Doge
Status: Confirmed
Type: Animal
Origin_year: 2013
Origin_place: Tumblr
Date_added: 2017-12-31T01:59:14-05:00
Views: 12318185
Videos: 59
Photos: 1645
Comments: 918
Tags: animal, dog, shiba inu, shibe, such doge, super shibe, japanese, super, tumblr, much, very, many, comic sans, photoshop meme, such, shiba, shibe doge, doges, dogges, reddit, comic sans ms, tumblr meme
About: Doge is a slang term for “dog” that is primarily associated with pictures of Shiba Inus (nicknamed “Shibe”) and internal monologue captions on Tumblr...Бан снят. Стражники мемов ничего не заподозрили и пустили нас в сокровищницу. Чашу нашего респонса снова переполняет контент. Через силу мы обрели мощь.
При желании, можно выяснить одну занимательную вещь: при базовых настройках, Тор-браузер меняет ip каждые 10 минут. Но что делать, если сервер банит нас быстрее? Всё просто, в папке, куда был установлен Tor найдём файлик с настройками под названием torrc (на маке он лежит по адресу ~/Library/Application Support/TorBrowser-Data/torrc, если не получится найти — добро пожаловать сюда) и отредактируем его. Добавим строки:
CircuitBuildTimeout 10
LearnCircuitBuildTimeout 0
MaxCircuitDirtiness 10Минимально возможный период для обновления ip составляет 10 секунд. Установим туда эту цифру и попробуем поиграться.
for i in range(10):
checkIP()
time.sleep(5)Out:
Current IP Address: 89.31.57.5
Current IP Address: 93.174.93.71
Current IP Address: 62.210.207.52
Current IP Address: 209.141.43.42
Current IP Address: 209.141.43.42
Current IP Address: 162.247.72.216
Current IP Address: 185.220.101.17
Current IP Address: 193.171.202.150
Current IP Address: 128.31.0.13
Current IP Address: 185.163.1.11Действительно, смена ip происходит примерно раз в 10 секунд. Для наших целей по скачке мемов было достаточно и базовых настроек. Бан наступал примерно через 20 минут после начала работы кода.
- Открываем браузер;
- Запускаем кусок кода с подгрузкой библиотек;
- Запускаем цикл по мемам
- …..
- Profit
Еще один цикл на ночь
final_df = pd.DataFrame(columns=['name', 'status', 'type', 'origin_year', 'origin_place',
'date_added', 'views', 'videos', 'photos', 'comments',
'tags', 'about', 'origin', 'other_text'])
for page_number in tqdm_notebook(range(1075), desc='Pages'):
# собрали хрефы с текущей страницы
meme_links = getPageLinks(page_number)
for meme_link in tqdm_notebook(meme_links, desc='Memes', leave=False):
# иногда с первого раза страничка не парсится
for i in range(5):
try:
# пытаемся собрать по мему немного даты
data_row = getMemeData(meme_link)
# и закидываем её в таблицу
final_df = final_df.append(data_row, ignore_index=True)
# если всё получилось - выходим из внутреннего цикла
break
except:
# Иначе, пробуем еще несколько раз, пока не закончатся попытки
continue
final_df.to_csv('MEMES.csv')Все мемы в наших руках. Можно приступать к варке фичей и моделированию. Через мощь мы познали победу. Остался только один вопрос: Что, если мы хотим менять ip каждый реквест?
2.4 Путь второй
Второй путь помогает извращаться со сменой ip как угодно. Зайдём на Github каких-то ребят и скачаем себе их скрипт под названием TorCrawler.py. Все недостающие библиотеки, используемые в этом скрипте, придётся доставить. Поставим парням на репозиторий за их код звёздочку. Закинем этот скрипт либо в папку со своими библиотеками либо в папку к этому блокноту. Обратите внимание, что скрипт работает только с третьим питоном.
Перед использованием библиотечки, нужно подкрутить настройки в torrc файлике. На маке он будет лежать в папке /usr/local/etc/tor/, на линуксе в папке /etc/tor/. Проследуем по инструкции авторов скрипта.
- Генерируем в консоли пароль
tor --hash-password mypassword - Открываем torrc файл в редакторе вроде vim, nano или atom
- Сохраняем пароль в наш torrc-файл в строку, которая начинается с HashedControlPassword
- Раскоментируем строку, начинающуюся с HashedControlPassword
- Раскоментируем (если она закоментирована) строку ControlPort 9051
- Сохраним изменения.
Запускаем tor в терминале. Линукс: service tor start, мак: tor.
Теперь мы готовы парсить.
from TorCrawler import TorCrawler
# Создаём свой краулер, в опциях вводим пароль
crawler = TorCrawler(ctrl_pass='mypassword') Мы можем сделать get-запрос по аналогии с тем как делали раньше, причем ответ получим сразу в формате bs4.
meme_page = 'http://knowyourmeme.com/memes/doge'
response = crawler.get(meme_page, headers={'User-Agent': UserAgent().chrome})
type(response)Out: bs4.BeautifulSoupНаходим внутри что-нибудь нужное.
views = response.find('dd', attrs={'class':'views'})
viewsOut:
<dd class="views" title="12,318,185 Views">
<a href="/memes/doge" rel="nofollow">12,318,185</a>
</dd>Проверим IP адрес краулера
crawler.ipOut: '51.15.40.23'По дефолту краулер меняет ip каждые 25 запросов. За это отвечает параметр n_requests. При создании нового краулера, его можно настроить по собственному желанию.
crawler.n_requestsOut: 25Более того, ip можно при желании поменять вручную.
crawler.rotate()IP successfully rotated. New IP: 62.176.4.1Теперь весь код для парсинга можно перевести на рельсы этого небольшого скрипта, заменив все реквесты на торовские, и менять IP адрес с каждым новым запросом. На бедный сервер внезапно обрушится огромное число запросов из всех уголков света.
Победа порвала наши оковы. Великая Сила освободила нас.
Заключение
Напоследок, хотелось бы сказать пару слов о парсинге вообще и при помощи Тора в частности. Добывать себе данные — это стильно, модно и в принципе интересно, можно получить датасеты, которых еще никто никогда не обрабатывал, сделать что-то новое, посмотреть, наконец, на все мемы мира сразу. Однако не стоит забывать, что ограничения, введенные сервером, в том числе баны, появились не просто так, а в целях защиты сайта от недоброжелательных ковровых бомбардировок запросами и DDoS-атак. К чужому труду стоит относится с уважением, и даже если у сервера никакой защиты нет, — это еще не повод неограниченно забрасывать его реквестами, особенно если это может привести к его отключению — уголовное наказание никто не отменял.
К тому же Тор — это всё-таки не первое решение, к которому стоит прибегать в случае проблем с парсингом. Иногда достаточно будет просто поставить в нужных местах time.sleep() и заполнить request-header информацией об операционной системе — в большинстве случаев этого должно быть достаточно для аккуратного сбора интересующей вас информации.
Успешных и безопасных вам исследований и да прибудет с вами Сила!
Авторы: Ульянкин Филипп filfonul, Сергеев Дмитрий Skolopendriy
Почиташки
- Годная книга про парсинг на английском языке.
- Неплохая инструкция о самостоятельном парсинге через Tor без использования чужих готовых классов.
- Димин репозиторий с собранным датасетом из более чем 16k мемов, а также с их исследованием и ноутбуком с парсером.
- Филин репозиторий с ещё парой хорошо расписаных блокнотов с парсерами. Репозиторий изначально делался как страничка факультатива для студентов.
- Оригинальный кодекс адепта тёмной стороны силы.

Страница 1 из 2
-

dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
Здравствуйте, парсил Ссылки недоступны для гостей и получил бан практически сразу, роутер перезагружал ip не меняется, подскажите что делать?)
-
Achronis
Well-Known Member
Пользователи- Регистрация:
- 30 июл 2020
- Сообщения:
- 64
- Город:
- Барнаул
Здравствуйте.
Как правило сайты банят временно, подождите 15, 30, 60 минут и ваш ip должны разбанить.
При парсинге данного сайта необходимо использовать прокси, либо уменьшать количество потоков парсинга, увеличивать задержки между запросами.
Ссылки недоступны для гостейИспользование прокси Ссылки недоступны для гостей
-
kagorec
Администратор
Команда форума
АдминистраторПробуте через прокси или через vpn
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
что то ничего не выходит, некоторые ссылки норм, а по некоторым Программе не удалось загрузить WEB-страницу (HTTP/1.1 403 Forbidden) и это я еще не парсил, только предпросмотр и задание границ парсинга
посмотрите пожалуйстаВложения:
-
Root
Администратор
Администратор- Регистрация:
- 10 мар 2010
- Сообщения:
- 14.800
- Город:
- Барнаул
Здравствуйте.
Передайте Cookie из браузера в окне задания границ парсинга вот так
Тогда этот сайт должен парситься.
Также послеживайте за развитием WBApp2 Ссылки недоступны для гостей
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
в общем что то все равно не выходит и прокси подключил и wbapp и куки, но парсится вначале через 1 товар, потом вообще не парсится
Вложения:
-
kagorec
Администратор
Команда форума
АдминистраторПарситься все вполне хорошо без банов через прокси.
В Ctrl+h выберите CIS -
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
а у меня вот такая тема в задании границ и при парсинге Ссылки недоступны для гостей
-
kagorec
Администратор
Команда форума
АдминистраторВстроенный броузер работает без поддержки прокси в режиму указания границ.
На панеле в самом верху, нажмите кнопку «CODE -> WEB» для отображения страницы как видит парсер. -
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
все облазил не могу найти эту кнопку)
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
если у вас все работает, может спарсите?)
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
я спарсил в итоге файл пустой
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
видимо у меня прокси не рабочие, подскажите где приобрести нормальные и какое количество нужно для парсинга этого сайта?
-
Root
Администратор
Администратор- Регистрация:
- 10 мар 2010
- Сообщения:
- 14.800
- Город:
- Барнаул
Если не подберете прокси, подождите пару дней. Отпишусь тут.
-
kagorec
Администратор
Команда форума
Администратор -
kagorec
Администратор
Команда форума
Администратор -
Root
Администратор
Администратор- Регистрация:
- 10 мар 2010
- Сообщения:
- 14.800
- Город:
- Барнаул
Вот так можно выкачать WEB страницы на диск, а затем спарсить локальные документы в Content Downloader -> Ссылки недоступны для гостей
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
а что с этими файлами дальше делать? есть инструкция?
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
блин столько гемора, первый раз с таким сайтом сталкиваюсь и надеюсь последний, может кто нибудь спарсит через нормальные прокси и скинет мне файл, готов заплатить. файл исправленного проекта прикрепил
Вложения:
-
dava002
Member
Пользователи- Регистрация:
- 21 июл 2015
- Сообщения:
- 48
благодарю этот способ помог
сначала не дошло что и как, благодарю за помощь
Всем спасибо кто откликнулся!





![[IMG]](https://i.imgur.com/vXcLz2D.png)
![[IMG]](https://i.imgur.com/AYaujb0.png)
Страница 1 из 2
Поделиться этой страницей
|
helhel20 0 / 0 / 1 Регистрация: 21.04.2019 Сообщений: 29 |
||||
|
1 |
||||
|
15.06.2021, 10:41. Показов 5747. Ответов 9 Метки нет (Все метки)
Здравствуйте, нужно написать парсер сайта. Хочу получить html страницы, но запрос выдает ошибку 403, я так понимаю на сайте какая-то защита стоит. Как ее обойти?
__________________
0 |

|
Автоматизируй это!
6484 / 4177 / 1140 Регистрация: 30.03.2015 Сообщений: 12,333 Записей в блоге: 29 |
|
|
15.06.2021, 10:50 |
2 |
|
helhel20, почти все эти заголовки не нужны (не обязательны), 403 это возможно отсутствие авторизации, залогиниться не надо сначала на сайте?
0 |
|
0 / 0 / 1 Регистрация: 21.04.2019 Сообщений: 29 |
|
|
15.06.2021, 11:47 [ТС] |
3 |
|
Нет, не нужно логиниться
0 |
|
Автоматизируй это!
6484 / 4177 / 1140 Регистрация: 30.03.2015 Сообщений: 12,333 Записей в блоге: 29 |
|
|
15.06.2021, 14:06 |
4 |
|
helhel20, я достаю хрустальный шар. Так, или ты не верно формируешь запрос, или не туда его шлешь, или добавляешь не те хедеры, или не добавляешь нужные куки. Вот.
0 |
|
0 / 0 / 1 Регистрация: 21.04.2019 Сообщений: 29 |
|
|
15.06.2021, 17:43 [ТС] |
5 |
|
А какие хедеры еще могут быть нужны? И какие куки надо добавить?
0 |
|
Автоматизируй это!
6484 / 4177 / 1140 Регистрация: 30.03.2015 Сообщений: 12,333 Записей в блоге: 29 |
|
|
15.06.2021, 17:45 |
6 |
|
helhel20, те, которые нужны для этого запроса конечно, смотрим в браузере что и куда уходит, повторяем запрос как там.
0 |
|
helhel20 0 / 0 / 1 Регистрация: 21.04.2019 Сообщений: 29 |
||||
|
15.06.2021, 20:00 [ТС] |
7 |
|||
|
Я правильно куки отправляю? Что-то не работает, все уже перепробовал
0 |
|
Автоматизируй это!
6484 / 4177 / 1140 Регистрация: 30.03.2015 Сообщений: 12,333 Записей в блоге: 29 |
|
|
16.06.2021, 12:09 |
8 |
|
helhel20, сайтик не простой, очень сильно заколдовано) Если ты хочешь его содержимое парсить, то сразу рекомендую на селениум переходить, тут очень много динамики и подгрузок.
0 |
|
АмигоСП
295 / 108 / 57 Регистрация: 07.12.2016 Сообщений: 209 |
||||
|
16.06.2021, 15:10 |
9 |
|||
|
Решениеhelhel20, как написал Уважаемый Welemir1, сайт действительно непростой. И, если вы только пытаетесь изучить парсинг, то сложно будет. И вдогонку такой вопрос ещё — а нужна ли вам главная страница? Информативности в ней не то, чтобы очень. Обычно вытягивают по разделам информацию о продукте конечную.
0 |
 Сообщение было отмечено Welemir1 как решение
Сообщение было отмечено Welemir1 как решение
|
0 / 0 / 1 Регистрация: 21.04.2019 Сообщений: 29 |
|
|
16.06.2021, 19:46 [ТС] |
10 |
|
Благодарю за помощь, селениум выручил.
0 |
Скажу сразу, что я редко использую библиотеку urllib / 3. Однако я попытался использовать команду терминала оболочки scrapy, а также использовать библиотеку запросов без пользовательского агента и получил ответ 200.
Я заметил, что вы не объявляли тип парсера при объявлении «суп».
soup = BeautifulSoup(resp, from_encoding=resp.info().get_param('charset'))
Хотя мне гораздо удобнее использовать парсер scrapy, несмотря на то, что он тяжелее, но если вы правильно помните, вы должны объявить тип парсера, например
soup = BeautifulSoup(resp, "lxml")
Битто Бенни-чан говорит, что ему удалось получить ответ с помощью 200 urllib.request, так что попробуйте его изменения. Это просто вводило полное имя пользовательского агента.
Я предлагаю использовать библиотеку запросов. Я думаю, это было бы достаточно простое изменение.
from bs4 import BeautifulSoup
import requests
listoflinks = ['https://www.spectatornews.com/page/6/?s=band', 'https://www.spectatornews.com/page/7/?s=band']
getarticles = []
for i in listoflinks:
resp = requests.get(i)
soup = BeautifulSoup(resp.content, "lxml")
for link in soup.find_all('a', href=True):
getarticles.append(link['href'])
Список getarticles выводил это:
'https://www.spectatornews.com/category/showcase/',
'https://www.spectatornews.com/showcase/2003/02/06/minneapolis-band-trips-into-eau-claire/',
'https://www.spectatornews.com/category/showcase/',
'https://www.spectatornews.com/page/5/?s=band',
'https://www.spectatornews.com/?s=band',
'https://www.spectatornews.com/page/2/?s=band',
'https://www.spectatornews.com/page/3/?s=band',
'https://www.spectatornews.com/page/4/?s=band',
'https://www.spectatornews.com/page/5/?s=band',
'https://www.spectatornews.com/page/7/?s=band',
'https://www.spectatornews.com/page/8/?s=band',
'https://www.spectatornews.com/page/9/?s=band',
'https://www.spectatornews.com/page/127/?s=band',
'https://www.spectatornews.com/page/7/?s=band',
'https://www.spectatornews.com',
'https://www.spectatornews.com/feed/rss/',
'#',
'https://www.youtube.com/channel/UC1SM8q3lk_fQS1KuY77bDgQ',
'https://www.snapchat.com/add/spectator news',
'https://www.instagram.com/spectatornews/',
'http://twitter.com/spectatornews',
'http://facebook.com/spectatornews',
'/',
'https://snosites.com/why-sno/',
'http://snosites.com',
'https://www.spectatornews.com/wp-login.php',
'#top',
'/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/category/sports/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/category/multimedia-2/',
'https://www.spectatornews.com/ads/banner-advertise-with-the-spectator/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/category/sports/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/category/multimedia-2/',
'/',
'https://www.spectatornews.com/about/',
'https://www.spectatornews.com/about/editorial-policy/',
'https://www.spectatornews.com/about/correction-policy/',
'https://www.spectatornews.com/about/bylaws/',
'https://www.spectatornews.com/advertise/',
'https://www.spectatornews.com/contact/',
'https://www.spectatornews.com/staff/',
'https://www.spectatornews.com/submit-a-letter/',
'https://www.spectatornews.com/submit-a-news-tip/',
'/',
'https://www.spectatornews.com',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/category/sports/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/category/multimedia-2/',
'/',
'https://www.spectatornews.com/feed/rss/',
'#',
'https://www.youtube.com/channel/UC1SM8q3lk_fQS1KuY77bDgQ',
'https://www.snapchat.com/add/spectator news',
'https://www.instagram.com/spectatornews/',
'http://twitter.com/spectatornews',
'http://facebook.com/spectatornews',
'https://www.spectatornews.com/campus-news/2002/05/09/late-night-bus-service-idea-abandoned-due-to-expense/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/opinion/2002/03/21/yates-deserved-what-she-got-husband-also-to-blame/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/opinion/2001/11/29/air-force-concert-band-inspires-zorn-arena-audience/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/campus-news/2001/10/25/goth-style-bands-will-entertain-at-halloween-costume-concert/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/campus-news/2001/04/19/campus-group-will-host-hemp-event-with-bands-information/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/currents/2018/12/10/geekin-out/',
'https://www.spectatornews.com/currents/2018/12/10/geekin-out/',
'https://www.spectatornews.com/staff/?writer=Alanna%20Huggett',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/tag/geekcon/',
'https://www.spectatornews.com/tag/tv10/',
'https://www.spectatornews.com/tag/uwec/',
'https://www.spectatornews.com/opinion/2018/12/07/keeping-up-with-the-kar-fashions-11/',
'https://www.spectatornews.com/opinion/2018/12/07/keeping-up-with-the-kar-fashions-11/',
'https://www.spectatornews.com/staff/?writer=Kar%20Wei%20Cheng',
'https://www.spectatornews.com/category/column-2/',
'https://www.spectatornews.com/category/multimedia-2/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/tag/accessories/',
'https://www.spectatornews.com/tag/fashion/',
'https://www.spectatornews.com/tag/multimedia/',
'https://www.spectatornews.com/tag/winter/',
'https://www.spectatornews.com/multimedia-2/2018/12/07/a-magical-night/',
'https://www.spectatornews.com/multimedia-2/2018/12/07/a-magical-night/',
'https://www.spectatornews.com/staff/?writer=Julia%20Van%20Allen',
'https://www.spectatornews.com/category/multimedia-2/',
'https://www.spectatornews.com/tag/dancing/',
'https://www.spectatornews.com/tag/harry-potter/',
'https://www.spectatornews.com/tag/smom/',
'https://www.spectatornews.com/tag/student-ministry-of-magic/',
'https://www.spectatornews.com/tag/uwec/',
'https://www.spectatornews.com/tag/yule/',
'https://www.spectatornews.com/tag/yule-ball/',
'https://www.spectatornews.com/campus-news/2018/11/26/old-news-5/',
'https://www.spectatornews.com/campus-news/2018/11/26/old-news-5/',
'https://www.spectatornews.com/staff/?writer=Madeline%20Fuerstenberg',
'https://www.spectatornews.com/category/column-2/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/tag/1950/',
'https://www.spectatornews.com/tag/1975/',
'https://www.spectatornews.com/tag/2000/',
'https://www.spectatornews.com/tag/articles/',
'https://www.spectatornews.com/tag/spectator/',
'https://www.spectatornews.com/tag/throwback/',
'https://www.spectatornews.com/currents/2018/11/21/boss-women-highlighting-businesswomen-in-eau-claire-6/',
'https://www.spectatornews.com/currents/2018/11/21/boss-women-highlighting-businesswomen-in-eau-claire-6/',
'https://www.spectatornews.com/staff/?writer=Taylor%20Reisdorf',
'https://www.spectatornews.com/category/column-2/',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/tag/altoona/',
'https://www.spectatornews.com/tag/boss-women/',
'https://www.spectatornews.com/tag/business-women/',
'https://www.spectatornews.com/tag/cherish-woodford/',
'https://www.spectatornews.com/tag/crossfit/',
'https://www.spectatornews.com/tag/crossfit-river-prairie/',
'https://www.spectatornews.com/tag/eau-claire/',
'https://www.spectatornews.com/tag/fitness/',
'https://www.spectatornews.com/tag/gym/',
'https://www.spectatornews.com/tag/local/',
'https://www.spectatornews.com/tag/nicole-randall/',
'https://www.spectatornews.com/tag/river-prairie/',
'https://www.spectatornews.com/currents/2018/11/20/bad-art-good-music/',
'https://www.spectatornews.com/currents/2018/11/20/bad-art-good-music/',
'https://www.spectatornews.com/staff/?writer=Lea%20Kopke',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/tag/bad-art/',
'https://www.spectatornews.com/tag/fmdown/',
'https://www.spectatornews.com/tag/ghosts-of-the-sun/',
'https://www.spectatornews.com/tag/music/',
'https://www.spectatornews.com/tag/pablo-center/',
'https://www.spectatornews.com/opinion/2018/11/14/the-tator-21/',
'https://www.spectatornews.com/opinion/2018/11/14/the-tator-21/',
'https://www.spectatornews.com/staff/?writer=Stephanie%20Janssen',
'https://www.spectatornews.com/category/column-2/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/tag/satire/',
'https://www.spectatornews.com/tag/sleepy/',
'https://www.spectatornews.com/tag/tator/',
'https://www.spectatornews.com/tag/uw-eau-claire/',
'https://www.spectatornews.com/tag/uwec/',
'https://www.spectatornews.com/page/6/?s=band',
'https://www.spectatornews.com/?s=band',
'https://www.spectatornews.com/page/2/?s=band',
'https://www.spectatornews.com/page/3/?s=band',
'https://www.spectatornews.com/page/4/?s=band',
'https://www.spectatornews.com/page/5/?s=band',
'https://www.spectatornews.com/page/6/?s=band',
'https://www.spectatornews.com/page/8/?s=band',
'https://www.spectatornews.com/page/9/?s=band',
'https://www.spectatornews.com/page/10/?s=band',
'https://www.spectatornews.com/page/127/?s=band',
'https://www.spectatornews.com/page/8/?s=band',
'https://www.spectatornews.com',
'https://www.spectatornews.com/feed/rss/',
'#',
'https://www.youtube.com/channel/UC1SM8q3lk_fQS1KuY77bDgQ',
'https://www.snapchat.com/add/spectator news',
'https://www.instagram.com/spectatornews/',
'http://twitter.com/spectatornews',
'http://facebook.com/spectatornews',
'/',
'https://snosites.com/why-sno/',
'http://snosites.com',
'https://www.spectatornews.com/wp-login.php',
'#top',
'/',
'https://www.spectatornews.com/category/campus-news/',
'https://www.spectatornews.com/category/currents/',
'https://www.spectatornews.com/category/sports/',
'https://www.spectatornews.com/category/opinion/',
'https://www.spectatornews.com/category/multimedia-2/']
Меня зовут Максим Кульгин и моя компания xmldatafeed занимается парсингом сайтов в России порядка четырех лет. Ежедневно мы парсим более 500 крупнейших интернет-магазинов в России и на выходе мы отдаем данные в формате Excel/CSV и делаем готовую аналитику для маркетплейсов.
Хочу показать некоторые достаточно простые приемы, с помощью которых можно обходить защиту на сайтах и парсить данные более-менее успешно.
Почему «более-менее»? Дело в том, что есть разные способы защитить свои данные от парсинга (или несанкционированного сбора). За много лет мы сталкивались с большим количеством решений, которые можно ранжировать от «безумных» (например, сайт отдает 30 страниц, а дальше IP — адрес блокирует на сутки, сильно замедляя парсинг), до очень простых, когда сайт может иногда попросить решить капчу. К каждому сайту нужен свой подход, но еще не встречались сайты, которые вообще нельзя парсить. Другое дело, что парсинг можно усложнить настолько, что вы просто физически в разумное время не сможете собрать данные, особенно если их много. Сразу подчеркну, что я за «человеческий» парсинг, который собирает данные, но не создает на сайте неподъёмной нагрузки по типу ddos. Статья ниже ориентирована на людей, которые сами не занимаются парсингом профессионально, но хотят понять основные механизмы, которые лежат в его основе.
Парсинг сайтов — задача, к которой нужно подходить ответственно, — чтобы парсинг не оказывал негативного влияния на целевые сайты. Парсеры могут извлекать данные гораздо быстрее и тщательнее людей, поэтому плохие методы парсинга могут в некоторой степени влиять на производительность сканируемого сайта. Хотя у большинства сайтов могут отсутствовать (и чаще всего так и есть) средства защиты от парсинга, некоторые из сайтов используют меры, препятствующие ему, поскольку их владельцы или администраторы не считают себя приверженцами идеи открытого и неограниченного доступа к данным. В этой статье мы не будем рассматривать этическую сторону парсинга, а с точки зрения закона отмечу, что если вы не нарушаете авторские права (например, собирая название товара и цену), то парсинг не запрещен в России.
Если парсер выполняет более одного запроса в секунду и скачивает объемные файлы, не обладающему достаточной мощностью серверу будет трудно успевать обрабатывать запросы, исходящие от множества сканеров. Поскольку веб-сканеры, парсеры или «пауки» (эти слова нередко используются в качестве синонимов) фактически не обеспечивают сайту настоящий, «человеческий» трафик и, судя по всему, влияют на производительность сайта, некоторые администраторы сайтов не любят «пауков» и пытаются заблокировать им доступ к данным на сайте.
Далее представлены лучшие подходы, которые вы можете использовать, чтобы не нарваться на запрет доступа к сайту в процессе парсинга.
Старайтесь учитывайть содержимое файла Robots.txt
Лучше всего, если при парсинге «пауки» придерживаются файла robot.txt соответствующего сайта. В нем прописаны конкретные правила «примерного поведения», как например: насколько часто вы можете запрашивать данные, на каких веб-страницах разрешается собирать их, а на каких это запрещено. Некоторые сайты разрешают поисковику Google собирать данные, не разрешая делать это кому-то еще. Эта мера противоречит открытой природе Интернета и может казаться несправедливой, но владельцы сайтов имеют право прибегать к ней.
Вы можете найти примеры файла robot.txt на различных сайтах. Обычно этот файл находится в корневой директории сайта, например в http://example.com/robots.txt.
Если в нем присутствуют строки наподобие указанных ниже, то это значит, что владельцы сайта не хотят, чтобы на нем собирали данные, и им бы это не понравилось.
User-agent: *
Disallow:/
Однако поскольку большинство владельцев сайтов хотели бы, чтобы их сайты присутствовали в поисковой выдаче Google или Яндекса, — пожалуй, крупнейших в мировом масштабе парсеров сайтов, они всё-таки открывают ботам и «паукам» доступ к сайтам.
Что делать, если вам нужны какие-либо данные, доступ к которым запрещен в robots.txt? Вы всё равно можете собрать эти данные. Большинство инструментов для защиты от парсинга противодействуют ему, когда вы собираете данные на веб-страницах, автоматический доступ к которым не разрешен в robots.txt.
Является ли пользователь сайта ботом или реальным посетителем, — вот что стремятся выяснить эти инструменты. И как они это делают? Они ищут несколько показателей, которые характерны для живых пользователей, но не характерны для ботов. Люди ведут себя бессистемно в отличие от ботов. Люди непредсказуемы в отличие от ботов.
Вот несколько очевидных признаков, по которым бот, парсер или веб-сканер обнаруживает себя:
- Чрезмерно частое запрашивание данных, находящихся на слишком большом количестве веб-страниц, то есть чаще, чем их мог бы просматривать живой пользователь сайта.
- Следование одной и той же модели поведения при сканировании веб-страниц. Например, просмотр всех страниц результатов поиска и переход на каждый результат только после сбора ссылок на них. Ни один человек никогда не пойдет на такое.
- Слишком много запросов от одного и того же IP-адреса за очень короткий период.
- Парсер не определяется как один из популярных браузеров. Вы можете исключить этот признак, указывая заголовок User-Agent.
- Использование User-Agent очень старого браузера.
Нижеследующие рекомендации должны помочь вам обходить большинство основных и вспомогательных защитных мер, используемых сайтами.
Замедлите сбор данных, не перегружайте сервер, хорошо «обращайтесь» с сайтами
Боты, предназначенные для парсинга данных, собирают их очень быстро, но сайт легко может обнаружить ваш парсер, так как люди не могут с такой скоростью просматривать веб-страницы. Чем быстрее вы сканируете и собираете данные, тем сильнее всем портите жизнь. Сайт может перестать отвечать на запросы, если получит их больше, чем может обработать.
Сделайте своего «паука» похожим на реального пользователя, имитируя действия человека. Поместите несколько случайных программных периодов бездействия между запросами, добавьте несколько задержек после сбора небольшого количества веб-страниц и выберите как можно меньшее число параллельно отправляемых запросов. Будет идеально добавить задержку в 10–20 секунд между программными кликами и не слишком сильно нагружать сайт, обращаясь с ним по-человечески.
Используйте средства ограничивающего регулирования, которые будут автоматически понижать скорость сбора данных в зависимости от нагрузки как на «паука», так и на сайт, на котором осуществляется сбор данных. Подберите оптимальную скорость «паука» после его нескольких пробных запусков. Периодически повторяйте эту настройку скорости, потому что обстановка со временем действительно меняется.
Не используйте одну и ту же схему сбора данных
Как правило, люди не выполняют повторяющиеся задачи, так как просматривают сайт, действуя непредсказуемо. У ботов для сбора данных обычно одна и та же модель поведения при сканировании и сборе данных, потому что они так запрограммированы, если только в них не заложены какие-либо уникальные алгоритмы действий. Сайты с интеллектуальными средствами защиты от сбора данных могут легко обнаруживать «пауков», выявляя закономерности в их действиях и таким образом препятствуя парсингу данных.
Включите в состав операций парсера случайные клики по веб-странице, передвижения курсора и бессистемные действия, которые сделают его похожим на человека.
Отправляйте запросы через прокси-серверы и при необходимости выполняйте их ротацию
При парсинге ваш IP-адрес может быть виден. Сайт будет знать о ваших действиях и о том, занимаетесь ли вы сбором данных. Сайты могут считывать такие данные, как закономерности в поведении пользователей или пользовательский опыт, если они зашли на сайт впервые.
Многочисленные запросы, исходящие из одного и того же IP-адреса, приведут к тому, что вы окажетесь без доступа к данным, поэтому нужно использовать более одного IP-адреса. При отправке запросов через прокси-сервер целевой сайт не будет знать, из какого IP-адреса были отправлены исходные запросы, что усложняет обнаружение парсера.
Создайте пул доступных для использования IP-адресов и используйте для каждого запроса случайный IP-адрес из этого пула. При этом нужно распределить несколько запросов по множеству IP-адресов.
Есть несколько методов изменения вашего IP-адреса, с которого отправляются запросы на целевой сайт:
- TOR (это легко обнаруживается)
- Виртуальные частные сети (VPN’ы).
- Бесплатные прокси-серверы.
- Общие («shared») прокси-серверы — самые дешевые и совместно используются множеством пользователей. Высокая вероятность блокировки доступа к целевому сайту.
- Приватные прокси-серверы — обычно используются только одним человеком. Меньшая вероятность возникновения блокировки при парсинге, если поддерживать низкую частоту обращений к целевому сайту.
- Серверные (датацентровые) прокси — если вам нужно большое количество IP-адресов, более быстрые прокси-серверы и более вместительные пулы IP-адресов. Они дешевле резидентных прокси-серверов, но сайты могут легко их обнаружить.
- Резидентные прокси-серверы — если вы делаете очень много запросов к сайтам, которые активно обнаруживают парсеры и запрещают им доступ к данным. Такие прокси-серверы очень дороги и могут работать медленнее, так как представляют собой реальные устройства. Перед тем как использовать резидентные прокси-серверы, попробуйте все остальные варианты.
Вдобавок различные коммерческие поставщики также предоставляют услуги по автоматической ротации IP-адресов. Сегодня есть много компаний, которые предоставляют резидентные IP-адреса, позволяющие еще существеннее упростить парсинг, но большинство из них дороги.
Циклично меняйте пользовательские агенты (строки заголовка User-Agent) и соответствующие HTTP-заголовки у разных запросов
Пользовательский агент — инструмент, который сообщает серверу о том, какой браузер используется. Если пользовательский агент не задан, сайты не позволят вам просматривать контент. Любой запрос, отправленный с помощью браузера, содержит заголовок User-Agent, и постоянное использование одного и того же пользовательского агента ведет к тому, что бот будет обнаружен. Чтобы узнать свой заголовок User-Agent, вы можете набрать в поисковике Google соответствующий запрос. Единственный способ сделать свой User-Agent более похожим на User-Agent реального пользователя и таким образом избежать обнаружения — это подделать его. По умолчанию у большинства парсеров нет пользовательский агента, и вам нужно будет добавить его самостоятельно.
Вы даже можете прикидываться поисковым роботом Google — Googlebot/2.1, если хотите немного поразвлечься (http://www.google.com/bot.html)!
Итак, одна только лишь отправка заголовков User-Agent позволила бы вам обойти большинство простых скриптов и инструментов для обнаружения ботов. Если вы обнаружите, что ваших ботов заблокировали даже после добавления в них актуальной строки заголовка User-Agent, следует добавить другие HTTP-заголовков.
Большинство браузеров отправляют сайтам, помимо User-Agent’а, и другие заголовки. Например, ниже представлен набор заголовков, которые браузер отправил на комплект онлайн-тестов «Scrapeme.live». Оптимально будет отправлять в том числе и эти распространенные заголовки запросов.
Самыми основными считаются:
- User-Agent.
- Accept.
- Accept-Language.
- Referer.
- DNT.
- Updgrade-Insecure-Requests.
- Cache-Control.
Не отправляйте файлы cookie, если только они не нужны для обеспечения работы вашего парсера.
Вы можете найти подходящие значения для них, просматривая свой трафик с помощью инструментов разработчика в Chrome или инструмента вроде MitmProxy или Wireshark. Также вы можете скопировать из этих инструментов команду curl и использовать ее для своего запроса. Например:
Инструмент наподобие https://curl.trillworks.com может конвертировать вам эту команду в код на любом языке программирования. Вот в какой код на Python она была преобразована:
Вы можете создавать подобные сочетания заголовков для нескольких браузеров и начать циклично менять эти заголовки для каждого запроса, чтобы снизить вероятность того, что ваш процесс сбора данных будет обнаружен и остановлен.
Используйте инструмент вроде Puppeteer, Selenium или Playwright для управления браузером в headless-режиме
Если ни один из перечисленных выше методов не сработал, сайт, должно быть, проверяет, является ли источник ваших HTTP-запросов настоящим браузером.
Для этого ему проще всего проверить, может ли клиент сайта (браузер) выполнить блок кода на языке JavaScript. Если клиент сайта на это не способен, то сайт фактически помечает такого посетителя как бота. Хотя можно запретить запуск JavaScript-кода в браузере, почти все сайты в Интернете окажутся в таком случае непригодными для использования, а значит в большинстве браузеров эта функция будет включена.
Как только имеет место такая защита от парсинга, чаще всего необходим настоящий браузер, чтобы собирать нужные вам данные. Существуют библиотеки для автоматического управления браузером, как например:
- Selenium.
- Puppeteer и Pyppeteer.
- Playwright.
Антипарсинговые инструменты сообразительны и становятся еще умнее с каждым днем, так как боты подают много данных на вход искусственному интеллекту этих инструментов, что позволяет им обнаруживать ботов. Наиболее продвинутые сервисы для защиты от ботов используют более сложные методы считывания «цифровых отпечатков» браузера, обнаруживая с помощью них ботов на стороне клиента, а не просто проверяют, можете ли вы выполнять JavaScript-код.
Инструменты обнаружения ботов ищут любые признаки, которые могут сообщить им, что браузер управляется библиотекой автоматизации:
- Присутствие признаков, специфических для ботов и демаскирующих их.
- Поддержка браузером нестандартных возможностей.
- Признаки использования популярных инструментов автоматизации, как например Selenium, Puppeteer или Playwright.
- Характерные для человека события, как например произвольные движения мыши, клики, прокрутка веб-страницы, переключения вкладок.
Вся эта информация объединяется, чтобы сформировать уникальный цифровой отпечаток на стороне клиента, который позволяет определить, является ли посетитель сайта ботом или человеком.
Вот несколько обходных вариантов решения проблемы или инструментов, которые могли бы помочь вашему парсеру, основанному на использовании браузера в headless-режиме, избежать обнаружения и блокировки.
- Puppeteer Extra – плагин puppeteer-extra-plugin-stealth, предназначенный для предотвращения обнаружения.
- Patching Selenium/ Phantom JS – ответ на Stack OverFlow на тему исправления Selenium с драйвером Chrome.
- Ротация цифровых отпечатков — статья от Microsoft на тему ротации цифровых отпечатков.
Но несложно догадаться, что, как и боты, разработчики инструментов для их обнаружения тоже становятся умнее. Они улучшают свои модели искусственного интеллекта и ищут переменные, операции, события и другие признаки, которые всё так же свидетельствуют об использовании библиотеки автоматизации, что в итоге приводит к остановке и предотвращению процесса парсинга.
Опасайтесь приманок (traps)
Приманки, или ловушки в виде приманок, — это системы, созданные для привлечения злоумышленников и обнаружения любых их попыток получения несанкционированного доступа к информации. Обычно приманка — это приложение, имитирующее поведение реальной системы. Некоторые сайты размещают приманки, представляющие собой ссылки, невидимые для нормальных пользователей, но отображаемые для парсеров веб-ресурсов.
При переходе по ссылкам всегда убеждайтесь в том, что у ссылки задана подходящая видимость и нет тега nofollow. У некоторых ссылок-приманок, предназначенных для обнаружения парсеров, будет задан CSS-стиль display: none, или они будут спрятаны благодаря использованию цвета, который сливается с цветом фона веб-страницы.
Такой способ обнаружения парсеров, очевидно, непрост и требует значительного объема работы, связанной с программированием, чтобы успешно его реализовать. Как следствие, этот прием не используется широко как на стороне сервера, так и на стороне бота или парсера.
Проверяйте, меняет ли сайт разметку
Некоторые сайты отправляют немного разные варианты HTML-разметки, чтобы усложнить парсерам задачу сбора данных.
Например, на сайте 1–20 веб-страниц будут отображать одну разметку, а остальные страницы могут отображать другую. Чтобы справиться с этой проблемой, убедитесь в том, что парсинг данных выполняется с использованием XPath’ов или селекторов CSS. Если это не так, проверьте, как именно отличается разметка, и добавьте в свой программный код условие, согласно которому сбор данных на таких веб-страницах осуществляется по-другому.
Не собирайте данные, будучи в роли авторизованного пользователя сайта
Вход на сайт, или авторизация, — это, по сути, разрешение на получение доступа к данным, размещенным на веб-страницах. Некоторые сайты, как например Indeed и Facebook, не дают такого разрешения.
Если для полноценного просмотра веб-страницы необходимо пройти авторизацию, парсеру придется отправлять некоторую информацию или файлы cookie вместе с каждым запросом, чтобы получить доступ к данным на веб-странице. Благодаря наличию авторизации, сайту легко обнаруживать запросы, поступающие из одного и того же IP-адреса. Администраторы сайта могут удалить ваши данные для входа в систему или забанить вашу учетную запись, а это, в свою очередь, может привести к тому, что ваши попытки собрать там данные будут пресечены.
Как правило, предпочтительнее избегать сбора данных на сайтах, на которых нужно для сбора данных проходить авторизацию, потому что вы легко можете нарваться на запрет доступа к данным. Но вы можете, например, имитировать браузеры настоящих пользователей, и, когда необходимо пройти авторизацию, вы получите нужные вам целевые данные.
Используйте сервисы для решения капч
Многие сайты используют меры, направленные против парсинга данных. Если вы собираете большие объемы данных на каком-то сайте, то в конечном итоге вам запретят к ним доступ. Вы начнете видеть веб-страницы с капчей, а не с данными. Существуют веб-сервисы, как например 2Captcha или Anticaptcha, позволяющие обходить эти ограничения.
Если вам необходимо парсить сайты, которые используют капчу, то лучше прибегнуть к помощи подобных сервисов. Услуги ервисов для решения капч относительно дешевы, что будет полезно при масштабном парсинге.
Как сайт может выявить и пресечь парсинг?
Сайты могут использовать различные механизмы, чтобы определить, что пользователь сайта — парсер, или «паук». Некоторые из этих подходов:
- Обнаружение чрезмерного объема трафика или высокой частоты обращения к данным, особенно от одного клиента сайта или IP-адреса за короткий отрезок времени.
- Обнаружение повторяющихся операций, выполняемых на сайте по одной и той же характерной «схеме» просмотра веб-страниц. Этот признак основан на том, что живой пользователь не будет всё время выполнять одни и те же повторяющиеся операции.
- Проверка на то, используете ли вы для отправки запросов к сайту настоящий браузер, будучи реальным пользователем. Простой тест — выполнение JavaScript-кода. Более продвинутые инструменты могут пойти намного дальше и проверять ваши видеокарты и центральные процессоры 😉, чтобы убедиться, что ваши запросы поступают от браузера настоящего пользователя.
- Обнаружение посредством использования приманок, которые обычно представляют собой ссылки, отображаемые только для парсера и скрытые от обычного пользователя. Когда парсер пытается получить доступ к ссылке, срабатывает «сирена».
Как быть с таким методом обнаружения и избежать остановки работы парсера?
Сначала уделите некоторое время исследованию антипарсинговых механизмов, используемых сайтом, а затем соответствующим образом разработайте или откорректируйте парсер. Такой прием в долгосрочной перспективе принесет более качественные результаты и увеличит «срок годности» и надежность вашей работы.
Как узнать, что сайт заблокировал или забанил вас?
Можно отметить следующие признаки обнаружения или противодействия вашей деятельности сайтом, на котором вы собираете данные:
- Веб-страницы с капчами.
- Большие задержки в получении контента.
- Частое получение HTTP-ответа с ошибками 404, 301 или 50x.
Частое появление следующих кодов состояния HTTP-запросов тоже свидетельствует о запрете доступа к данным:
- 301 Moved Permanently («перемещен на постоянной основе»).
- 401 Unauthorized («для получения ответа необходима авторизация»).
- 403 Forbidden («доступ запрещен»).
- 404 Not Found («не найден»).
- 408 Request Timeout («истекло время ожидания»).
- 429 Too Many Requests («слишком много запросов»).
- 503 Service Unavailable («веб-сервис недоступен»).
Вот что Amazon.com сообщает в случае запрета доступа к данным:
Чтобы обсудить автоматический доступ к данным Amazon, пожалуйста, свяжитесь с нами по адресу [email protected]Для получения информации о переходе на наши API, обратитесь к нашему онлайн-магазину API по адресу <ссылка> или к нашему Product Advertising API по адресу <ссылка> в случаях, связанных с рекламой. Извините! Что-то пошло не та! Далее следуют изображения милого пса Amazon.
Также вы можете взглянуть на ответ или сообщение от сайта. Популярные анти-парсинговые инструменты отправляют, например, такие:
Мы хотим убедиться, что имеем дело действительно с вами, а не с роботом.Пожалуйста, щелкните по кнопке-флажку ниже, чтобы получить доступ к сайту.<рекапча>Зачем вообще необходимо это подтверждение? Наше внимание привлекло что-то в поведении вашего браузера.Этому есть различные возможные объяснения:1. Вы просматриваете сайт и делаете щелчки мышью со скоростью, гораздо большей, чем можно было бы ожидать от человека.2. Что-то мешает выполнению JavaScript-кода на вашем компьютере.3. В той же сети, что и у вас, (на том же IP-адресе) замечен робот.Сталкиваетесь с проблемами доступа к сайту? Свяжитесь со службой поддержки или сделайте так, чтобы ваш робот прошел аутентификацию.
или
Пожалуйста, докажите, что вы человек.<капча>В доступе к этой веб-странице было отказано, потому что мы считаем, что вы используете инструменты автоматизации для просмотра нашего сайта.Это могло случиться из-за того, что:1. Выполнение JavaScript-кода отключено или заблокировано расширением, например блокировщиками рекламы.2. Ваш браузер не поддерживает файлы cookie.Пожалуйста, убедитесь, что выполнение JavaScript-кода и файлы cookie включены в вашем браузере и что вы не препятствуете их загрузке.
или
Извините, что прерываем. Пока вы просматривали <наименование сайта>, что-то, связанное с вашим браузером, дало нам повод думать, что вы бот. Это могло случиться по нескольким причинам:1. Вы активный пользователь сайта, перемещающийся по нему со сверхчеловеческой скоростью.2. Вы отключили JavaScript в своем браузере.3. Сторонний плагин браузера, как например Ghostery или NoScript, препятствует выполнению JavaScript-кода. Дополнительная информация доступна в этой статье службы поддержки.После успешного решения представленной ниже капчи вы сразу снова получите доступ к <наименование сайта>.
или
Ошибка 1005 Ray ID: <контрольная сумма (хэш)> • <время>.В доступе отказано.Что произошл? Владелец этого сайта (<наименование сайта>) запретил номеру в автономной системе (ASN’у) <номер>, по которому располагается ваш IP-адрес, доступ к этому сайту.
Полный список HTTP-кодов ответа сервера, свидетельствующих об успешных и неудачных запросах к нему, можно увидеть здесь. Вам стоит уделить время, чтобы просмотреть эти коды и получить о них представление.
Где сайты могут обнаружить ботов?
Обнаружение может произойти на стороне клиента, то есть в работающем на вашем компьютере браузере, на стороне сервера, то есть на веб-сервере, или через встроенные технологии защиты от ботов, защищающие трафик сайта путем его перехвата. Также возможно сочетание обоих вариантов. Веб-серверы либо используют встроенные программные продукты для обнаружения подобного поведения клиентов сайта еще до того, как их запросы дойдут до веб-сервера, либо они используют облачные сервисы, которые действуют до момента получения трафика сайтом или встроены в веб-сервер и опираются на стороннюю обработку трафика, чтобы обнаруживать и блокировать трафик ботов. Проблема заключается в том, что это обнаружение, как и все остальные средства защиты, характеризуется ложноположительными срабатываниями и приводит к обнаружению и блокировке живых добропорядочных пользователей, ошибочно считая их ботами. Или же оно оказывает непроизводительную нагрузку на сервер, делая сайт медленным и непригодным для использования. Подобные технологии действительно затратны с финансовой и технической точек зрения, а также обладают преимуществами и недостатками, которые следует учитывать.
Вот некоторые из мест и ситуаций, при которых парсер может быть обнаружен:
- При считывании цифрового отпечатка на стороне сервера с помощью поведенческого анализа.
- При считывании цифрового отпечатка на стороне клиента или браузера с помощью поведенческого анализа.
- Сочетание этих двух вариантов на многочисленных доменах и в датацентрах.
Обнаружение на стороне сервера
Это обнаружение ботов начинается на серверном уровне, то есть на веб-сервере сайта или на устройствах облачных сервисов, которые находятся «перед» сайтом на пути следования запросов к нему, отслеживают трафик, а также выявляют и блокируют ботов. Методы считывания цифровых отпечатков, подразделяемые на несколько типов, обычно используются в сочетании и преследуют цель обнаружения ботов на стороне сервера.
Считывание цифрового отпечатка в целом пагубно влияет на конфиденциальность данных посетителей сайта, позволяя без проблем отслеживать активность отдельных пользователей по всему Интернету, но это уже отдельная тема.
Считывание цифрового HTTP-отпечатка
Считывание цифрового HTTP-отпечатка осуществляется путем анализа трафика, который посетитель сайта отправляет на веб-сервер. Почти вся соответствующая информация доступна веб-серверу и некоторую ее часть также можно увидеть в журналах (логах) веб-сервера. Такой цифровой отпечаток может предоставить сайту основную информацию о посетителе, как например:
- User-Agent, сообщающий о том какой браузер и какой версии использует пользователь, как например Chrome, Firefox, Edge, Safari.
- Заголовки запроса, как например Referer, Cookie, принимаемая браузером кодировка, принимает ли он сжатие gzip и так далее. Всё это представляет собой дополнительные фрагменты данных, которые браузер отправляет серверу.
- Порядок перечисленных выше заголовков.
- IP-адрес, через который посетитель отправляет запрос или в конечном итоге обращается к веб-серверу в том случае, если посетитель использует NAT-адрес интернет-провайдера или прокси-серверы.
Считывание цифрового отпечатка данных, связанных со стеком TCP/IP
Данные, которые посетитель отправляет на серверы, приходит на них в качестве пакетов по протоколам TCP/IP. Цифровой отпечаток данных, связанных с TCP, включает в себя следующие подробные данные:
- Исходный размер пакета (16 битов).
- Исходный TTL (8 битов).
- Размер окна (16 битов).
- Максимальный размер сегмента (16 битов).
- Величина масштабирования окна (8 битов).
- Флаг «don’t fragment», то есть «не разбивать на фрагменты» (1 бит).
- Флаг «sackOK» (1 бит).
- Флаг «nop» (1 бит).
Эти переменные объединяются в данные в виде цифровой подписи компьютера посетителя сайта, которая позволяет уникальным образом идентифицировать посетителя и определить, бот он или человек. Инструменты с открытым исходным кодом, как, например, p0f, могут сообщить о том, подделан ли User-Agent. Такой инструмент даже может определить, находится ли посетитель сайта за сетью NAT, или у него прямое подключение к Интернету. Также он может узнать текущие настройки браузеров, например языковые настройки.
Считывание TLS-отпечатка
Когда к сайту кто-то обращается безопасным образом по протоколу HTTPS, браузер и веб-сервер генерируют цифровой TLS-отпечаток в процессе рукопожатия SSL. Большинство клиентских User-Agent’ов, например различные браузеры и приложения (Dropbox, Skype и прочие), будут уникальным образом инициировать запрос на рукопожатие SSL, что позволяет считать цифровой отпечаток такой попытки получения доступа к данным.
JA3 — библиотека с открытым исходным кодом для считывания цифрового TLS-отпечатка, собирает десятичные значения байтов по следующим полям в пакете (сообщении) Client Hello во время рукопожатия SSL:
- Версия SSL.
- Принимаемые шифры.
- Список расширений.
- Эллиптические кривые.
- Форматы эллиптических кривых.
Затем она объединяет эти значения по порядку, используя запятую в качестве разделителя между полями и короткую черту для отделения значения каждого поля от его наименования. Далее эти строки хэшируются по алгоритму MD5, чтобы получить в результате 32-символьный цифровой отпечаток, который легко использовать и которым легко обмениваться. Так формируется цифровой SSL-отпечаток клиента в библиотеке JA3. Хэши MD5 также обладают преимуществом в скорости генерации и сравнения значений. Кроме того, их уникальность находится на очень высоком уровне.
Поведенческий анализ и обнаружение шаблонных действий
Как только уникальный цифровой отпечаток будет сформирован из всех перечисленных выше элементов, инструменты обнаружения ботов смогут отслеживать поведение посетителя на сайте или на множестве сайтов, если они пользуются услугами по обнаружению ботов от того же поставщика таких услуг. Эти инструменты проводят поведенческий анализ того, как пользователи просматривают сайт. Обычно этот анализ учитывает:
- Какие страницы были посещены.
- Порядок, в котором они были посещены.
- Перекрестное сопоставление HTTP-заголовка Referer с ранее посещенной страницей.
- Количество запросов, отправленных на сайт.
- Частота запросов к сайту.
Эти признаки позволяют программным продуктам, предназначенным для борьбы с ботами, определять, является ли посетитель сайта ботом или человеком, основываясь на данных, которые они прочитали ранее. Также в некоторых случаях подобные инструменты отправляют пользователю задачу, которую он должен решить, например капчу. Если посетитель решит капчу, то система может принять его за настоящего пользователя, а если решение капчи завершится провалом, что типично для большинства ботов, которые не ожидают появления капчи, то такого «посетителя» система пометит как бота и запретит ему доступ к сайту.
Таким образом, любые запросы к сайтам с одним и тем же сервисом обнаружения ботов, которые поступают от посетителей с такими цифровыми отпечатками, например отпечатками HTTP, TCP, TLS или IP-адреса, будут требовать от посетителей доказать, что они люди, а не боты. Посетитель или его IP-адрес обычно помещается в черный список на определенный период, а затем удаляется из списка, если больше за ним не замечена активность, характерная для ботов. Иногда IP-адреса, которые постоянно проявляют характерную для ботов активность, бессрочно добавляются во всеобщий черный список, и им запрещают заходить на многие сайты, использующие такие первичные черные списки.
Парсерам веб-ресурсов сравнительно легче избежать обнаружения на стороне сервера, если они хорошо настроены на работу с теми сайтами, на которых они собирают данные.
Совет от профессионалов  — лучший способ понять каждый аспект данных, которые перемещаются между клиентом и сервером в качестве части веб-запроса, — это использовать прокси-сервер, расположенный между ними, как, например, MITM, или же посмотреть на содержимое вкладки Network («Сеть») на панели браузера с инструментами разработчика, которая чаще всего доступна через F12. Для более глубокого анализа, который выходит за рамки протокола HTTP к более низкому уровню — стеку TCP/IP, вы можете воспользоваться Wireshark, чтобы проверить фактически передающиеся пакеты, заголовки и все эти данные, которые курсируют между браузером и сайтом. Любой фрагмент этих данных можно использовать для идентификации посетителя сайта и таким образом облегчить считывание его цифрового отпечатка.
— лучший способ понять каждый аспект данных, которые перемещаются между клиентом и сервером в качестве части веб-запроса, — это использовать прокси-сервер, расположенный между ними, как, например, MITM, или же посмотреть на содержимое вкладки Network («Сеть») на панели браузера с инструментами разработчика, которая чаще всего доступна через F12. Для более глубокого анализа, который выходит за рамки протокола HTTP к более низкому уровню — стеку TCP/IP, вы можете воспользоваться Wireshark, чтобы проверить фактически передающиеся пакеты, заголовки и все эти данные, которые курсируют между браузером и сайтом. Любой фрагмент этих данных можно использовать для идентификации посетителя сайта и таким образом облегчить считывание его цифрового отпечатка.
Обнаружение на стороне клиента (браузера)
Почти все сервисы для обнаружения используют комбинацию инструментов для обнаружения ботов на стороне браузера в сочетании с инструментами их обнаружения на стороне сервера, чтобы более безошибочно препятствовать деятельности ботов.
Первое, что предпринимает сайт в начале процесса обнаружения ботов на стороне клиента, — немедленная блокировка всех парсеров, которые не являются браузерами реальных пользователей.
Для этого ему проще всего проверить, может ли клиент сайта (браузер) выполнить блок кода на языке JavaScript. Если клиент этого сделать не может, средство обнаружения с высокой вероятностью пометит такого клиента в качестве бота. Хотя можно запретить запуск JavaScript-кода в браузере, почти все сайты в Интернете окажутся в таком случае непригодными для использования, а значит в большинстве браузеров эта функция будет включена.
Как только имеет место такая защита от парсинга, чаще всего необходим настоящий браузер, чтобы собирать нужные вам данные. Существуют библиотеки для автоматического управления браузером, как например:
- Selenium.
- Puppeteer и Pyppeteer.
- Playwright.
Средства обнаружения ботов на стороне браузера обычно предусматривают формирование цифрового отпечатка путем обращения через браузер к самой разнообразной информации системного уровня. Как правило, такие средства прибегают к использованию отслеживающего JavaScript-файла, который выполняет в браузере обнаруживающий ботов код и отправляет обратно для дальнейшего анализа информацию о браузере и соответствующем компьютере, где этот браузер установлен и функционирует.
Например, объект браузера «navigator» показывает много информации о компьютере, на котором работает браузер. Вот как в раскрытом состоянии выглядит объект «navigator» браузера Safari:
Некоторые из распространенных характерных признаков, используемых для формирования цифрового отпечатка браузера:
- User-Agent.
- Заданный язык.
- Статус «Do Not Track», то есть «не отслеживать».
- Поддерживаемые возможности HTML5.
- Поддерживаемые CSS-правила.
- Поддерживаемые возможности JavaScript.
- Установленные в браузере плагины.
- Разрешение экрана и глубина цвета.
- Временная зона.
- Операционная система.
- Количество ядер центрального процессора.
- Производитель GPU и браузерный модуль отображения (rendering engine).
- Максимальное количество одновременных касаний тачпада.
- Различные типы хранения данных, поддерживаемые браузером.
- Контрольная сумма холста HTML5.
- Список установленных на компьютере шрифтов.
Помимо этих технических приемов инструменты обнаружения ботов также ищут любые признаки, которые могут сообщить им о том, что браузер пользователя управляется с помощью библиотеки автоматизации:
- Присутствие признаков, специфических для ботов и демаскирующих их.
- Поддержка нестандартных возможностей браузера.
- Признаки использования популярных инструментов автоматизации, как например Selenium, Puppeteer или Playwright.
- Также учитываются характерные для человека события, как например: произвольные движения мыши, клики, прокрутка веб-страницы, переключения вкладок.
Вся эта информация объединяется, чтобы сформировать уникальный цифровой отпечаток на стороне клиента, который позволяет определить, является ли посетитель сайта ботом или человеком.