Эту
задачу
необходимо решать в том случае, если
при установленных границах ошибки
имеет место также ограничение в
численности выборки. Здесь возникает
вопрос о том , какова гарантия ( какова
вероятность ), что при заданной
численности выборки ошибка не выйдет
за установленные границы. Если в ходе
решения окажется, что эта вероятность
равна 0,90 и выше, то значит эта выборка
с высокой степенью надежности гарантирует,
что ошибка не превысит установленную
величину , если же вероятность оказалась
ниже 0,90, то следует или примириться с
большей ошибкой или найти возможность
увеличить численность выборки.
С
уровнем вероятности связан коэффициент
t
. Исходя из равенства
![]() =
=![]() , определяется
, определяется![]() , а затем по таблицам « Значение
, а затем по таблицам « Значение
интеграла нормального распределения
вероятностей» или «Критические точкиt-
распределения Стьюдента» находится
искомый уровень вероятности (Р)
Вопросы для
повторения по модульной единице 3
7-1.Чему
равен коэффициент вариации признака
по выборочной совокупности, если
предельная ошибка равна 2 , генеральная
средняя находится в интервале от 38.0
до 42.0, а выборочная дисперсия 16?
7-2.Как
определить границы генеральной
средней с заданной вероятностью?
7-3. Как определить
границы генеральной доли ?
7-4.При
использовании каких выборок ( больших
или малых ) границы генеральной средней
будут шире ?
7-5.Какова
вероятность того, что генеральная
средняя окажется вне установ- ленных
границ ?
7-6.Каков смысл
необходимой численности выборки ?
7-7.В
каком случае можно определить необходимую
численность выборки ?
7-8.В каком случае
следует определять вероятность появления
ошибки ?
Резюме
по модульной единице 3
Знакомство
с основными типами задач , решаемых
на основе выборочного метода позволяет
решать вопросы , встречающиеся при
использовании данного метода
на практике.
Модульная
единица 4
Способы
формирования выборочной совокупности
Равновозможность
( равновероятность ) каждой единицы
генеральной совокупности попасть в
выборку обеспечивается, как уже
говорилось ранее, различными способами
отбора. Среди них следует выделить
наиболее часто используемые : собственно
случайный ( повторный и бесповторный)
, механический, типический , серийный.
4.1
Собственно
случайный отбор. При
этом способе отбора каждой единице
генеральной совокупности предварительно
присваивается некоторая «метка» в
виде числа, буквы и так далее, при этом
«метка» никаким образом не должна быть
связана с изучаемым признаком. Затем
используя различные приемы, обеспечивающие
случайность отбора ( таблица случайных
чисел, лототрон ) осуществляется
отбор « меток», как заменителей единиц.
Собственно
случайный отбор проводится как
повторный и как бесповторный.
При
повторном отборе
единицы генеральной совокупности,
попавшие в выборку, после фиксации по
ним значения признака, возвращаются
обратно в генеральную совокупность,
вследствие чего генеральная совокупность
по численности остается постоянной,
а, следовательно, вероятность попадания
каждой единицы генеральной совокупности
в выборку остается неизменной. Ранее
рассмотренные алгоритмы для расчета
средней и предельной ошибок, необходимой
численности выборки исходят именно из
этого способа формирования выборочной
совокупности.
При
бесповторном отборе единица
генеральной совокупности , попавшая в
выборку, в генеральную совокупность
не возвращается, поэтому генеральная
совокупность по численности уменьшается,
а,следовательно, каждая последующая
единица генеральной совокупности
имеет возрастающую вероятность попасть
в выборку. При бесповторном отборе
при расчете средней, а , следовательно,
и предельной ошибки вводится поправка
на конечность генеральной совокупности
(пкс) =![]() .
.
При больших значенияхN
единицей в знаменателе можно пренебречь
и поправка на конечность совокупности
будет выглядеть так : (пкс ) =![]() ,
,
следовательно, алгоритмы расчета
средней и предельной ошибок выборочной
средней при бесповторном отборе будут
такими:![]()
![]() ;
;![]() . Множитель
. Множитель![]() <
<
1, вследствие чего, средняя ошибка и
предельная ошибки при бесповторном
отборе всегда меньше, чем при отборе
повторном. Аналогичным образом , то
есть с введением поправки![]() меняются формулы для расчета средней
меняются формулы для расчета средней
и предельной ошибок для доли и других
оценок.
4.2
Механический отбор
используется в том случае если единицы
генеральной совокупности объективно
располагаются в каком либо порядке во
времени или в пространстве или же есть
возможность это сделать. Важно отметить,
что порядок расположения единиц не
должен быть связан с изучаемым явлением.
С такого рода совокупностями можно
встретиться, например, при социологических
обследованиях, когда изучаемую
совокупность людей можно расположить
в алфавитном порядке или в зависимости
от номера их стационарного телефона.
Для
осуществления отбора находят отношение
![]() ,
,
получившее название шага или интервала
отбора. Из совокупности , предварительно
упорядоченной в указанном выше
порядке, через найденный шаг
осуществляется отбор ( формирование
выборки ).
При
механическом отборе расчет средней
и предельной ошибок осуществляется
по формулам случайного бесповторного
отбора, поскольку механический отбор
осуществляется как бесповторный.
4.3
Типический
отбор
целесообразно использовать в том случае
, если в генеральной совокупности
реально имеются своеобразные группы
единиц ( например, партии сена с разными
сроками заготовки, группы животных
на откорме разного возраста ) , или же
такие группы можно выделить
( например группы
коров с разным месяцем лактации ).
Установив
наличие в совокупности качественно
отличных частей
(
групп) , далее определяется
представительство каждой из этих
частей в выборке. Представительство
групп в выборке чаще всего устанавливается
пропорционально их численности, то
есть исходя из равенства
 , где
, где![]() —
—
численностьi-ой
группы в генеральной совокупности,
представительство которой в выборке
надо определить ;
![]() —
—
общая численность генеральной
совокупности;![]() — общая численность выборки;
— общая численность выборки;![]() — искомая величина, то есть сколько
— искомая величина, то есть сколько
единиц должно быть взято изi-
ой группы в выборку . Из этого равенства
следует , что
 .
.
Иногда представительство групп в
выборке определяют пропорционально
средним квадратическим отклонениям
изучаемого признака в выделенных
группах генеральной совокупности ,
пропорционально дисперсиям или
объемам вариации. После определения
представительства производится отбор
из групп , при этом используется или
случайный бесповторный или механический
отбор. Поскольку типический отбор
предполагает представительство в
выборке всех качественно отличных
групп генеральной совокупности, при
расчете средней, а , соответственно ,
предельной ошибок учитывается
колеблемость признака только внутри
групп, то есть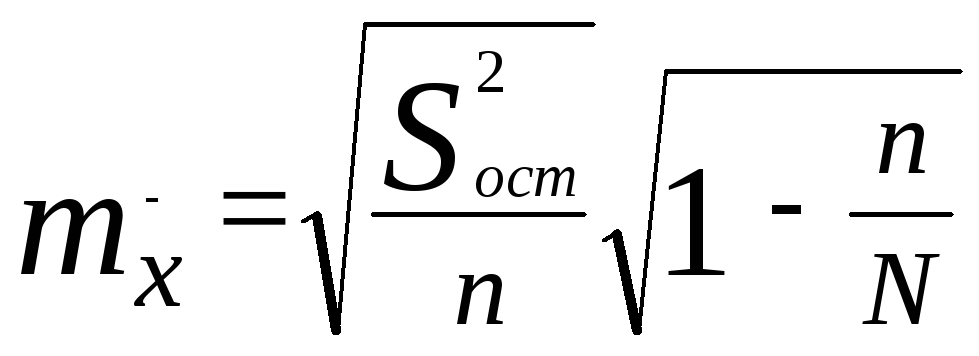 , а
, а![]()
 .
.
Поскольку остаточная ( средняя
групповая дисперсия) составляет лишь
часть общей дисперсии, типический отбор
обеспечивает при прочих равных условиях
минимальную по сравнению с другими
способами отбора ошибку.
4.4
При серийном
( гнездовом ) отборе
выборка формируется из серий ( гнезд),
состоящих из нескольких единиц. Например,
при выборочном социологическом опросе
доярок в качестве гнезда может выступать
ферма, на которой ,в случае попадания
ее в выборку, будут опрошены все доярки.
Отбор гнезд производится, как правило,
механически. При расчете ошибок
учитываются только межсерийные
различия, следовательно, формулы для
расчета средней и предельной ошибок
для выборочной средней имеют вид : , а
, а![]()
 ,
,
где![]() и
и![]() соответственно средняя и предельная
соответственно средняя и предельная
ошибки выборочной средней,![]() и
и![]() — число серий ( гнезд ) соответственно
— число серий ( гнезд ) соответственно
в выборочной и генеральной совокупностях
;![]() межсер
межсер
— межсерийная
дисперсия.
Вопросы
для повторения
8-1.Чем
отличается случайный повторный отбор
от отбора бесповторного ?
8-2. При каком
отборе повторном или бесповторном
будет больше средняя
ошибка?
8-3. Какова
последовательность проведения
механического отбора ?
8-4. Какую долю от
генеральной совокупности должна
составлять выборка,
чтобы
при бесповторном отборе средняя
ошибка уменьшилась в 2 раза ?
8-5. Почему при
типическом отборе имеет место
наименьшая ошибка ?
8-6. Какая формула
для определения предельной ошибки
используется при
механическом
отборе ?
8-7.В
чем состоит особенность серийного
отбора ?
8-8.Что
такое представительство групп в выборке
при проведении типичес-
кого отбора ?
Резюме
Выборочное
наблюдение даст объективное
представление о генеральной совокупности
только в том случае , если будет
гарантирована равновозможность
каждой единице генеральной совокупности
попасть в выборке. Такая гарантия
обеспечивается использованием любого
из рассмотренных способов отбора.
Тестовые
задания к лекции
ТЕСТ 3-1
Какая
из совокупностей составляет часть
другой ?
-
Выборочная –часть
генеральной -
Генеральная –
часть выборочной -
Выборочная
и генеральная совокупности равны по
численности
ТЕСТ 3- 2
Что такое оценка
?
-
Одна
из количественных характеристик
генеральной совокупности -
Количественная
характеристика выборочной совокупности,
которая используется для соответствующей
количественной характеристики
совокупности генеральной -
Суждение о форме
распределения выборочной совокупности
ТЕСТ 3-3
Если
при проведении выборочного наблюдения
выборочную совокупность формируют
только из «лучших» представителей,
какие ошибки возникают ?
-
Только
систематические -
Только случайные
-
Как систематические
, так и случайные
ТЕСТ
3- 4
На что влияет
недостаточная численность выборки ?
1.На достоверность
полученной информации
2.На
величину случайной ошибки
3.На величину
систематической ошибки
4. На значения
оценок
ТЕСТ
3- 5
Что представляет
собой конкретная ошибка выборки ?
1.Ошибка
при определении значения признака
по конкретной единице совокупности
2.
Разница статистической характеристики
конкретной выборки и соответствующего
параметра генеральной совокупности
ТЕСТ 3- 6
Что представляет
собой средняя ошибка выборки ?
1.Среднюю
арифметическую из всех возможных
конкретных ошибок выборки
2. Среднюю
гармоническую из всех возможных
конкретных ошибок
3.
Среднюю квадратическую из всех
возможных ошибок выборки
4.Среднюю
геометрическую из всех возможных
конкретных ошибок выборки
ТЕСТ 3- 7
Как
изменится средняя ошибка выборочной
средней , если численность выборки
увеличить в 4 раза ?
-
Не изменится
-
Увеличится в 4
раза
3.Уменьшится
в 4 раза
4.Увеличится
в 2 раза
5.Уменьшится
в 2 раза
ТЕСТ 3-8
Как
изменится средняя ошибка выборочной
средней, если выборочная дисперсия
увеличится в 9 раз , а численность выборки
в 4 раза ?
-
Не изменится
-
Увеличится в 9
раз -
Увеличится в 3
раза -
Увеличится в 1.5
раза -
Уменьшится в 4
раза
ТЕСТ 3- 9
При
какой выборочной доле имеет место ее
наибольшая ошибка?
-
0,1
-
0,2
-
0,3
-
0,4
-
0,5
ТЕСТ 3-10
Какие выборки
относятся к большим ?
-
Численностью
более 10 единиц -
Численностью
более 29 единиц -
Численностью
более 59 единиц -
Численностью
более 100 единиц
ТЕСТ 3- 11
По какому закону
распределяются конкретные ошибки
оценок при больших выборках ?
1.По закону
Пуассона
2. По нормальному
закону
3.
По закону распределения t
– Стьюдента
ТЕСТ 3- 12
По
какому закону распределяются конкретные
ошибки оценок при малых выборках ?
-
По нормальному
закону -
По
закону распределения t-
Стьюдента -
По закону
распределения Госсета -
По закону
распределения Фишера
ТЕСТ 3- 13
Плотность
распределения вероятности какой из
перечисленных конкретных ошибок
наибольшая ?
-
Равной 0
-
Равной половине
средней ошибки -
Равной средней
ошибки -
Равной двум
средним ошибкам
ТЕСТ 3- 14
Плотность
распределения вероятностей какой
из перечисленных конкретных ошибок
будет наименьшая ?
1.Равной 0
2.Равной половине
средней ошибки
3.Равной средней
ошибки
4.Равной двум
средним ошибкам
ТЕСТ 3- 15
Доверительный
уровень вероятности это ….
1..вероятность
не допустить разницы между оценкой и
параметром
генеральной
совокупности
2..вероятность
появления ошибки, равной заданной (
определенной)
3..вероятность
появления ошибки меньше или равной
заданной (определенной )
4. вероятность
появления ошибки больше заданной
(
определенной )
ТЕСТ 3- 16
От чего зависит
размер превышения предельной ошибки
над средней ?
1. От численности
выборки
2.От колеблемости
признака в выборке
3.От доверительного
уровня вероятности.
4. От вероятности
появления ошибки больше предельной
ТЕСТ 3- 17
Как задается
величина предельно допустимой ошибки
?
-
В виде конкретного
значения -
В виде интервала,
за пределы которого ошибка не выйдет -
В
виде всех возможных значений за
пределами заданного интервала
ТЕСТ 3- 18
Может ли
генеральная средняя выйти за границы,
установленные при ее интервальной
оценке с доверительным уровнем
вероятности Р ?
-
Не может
-
Может при
непредвиденных обстоятельствах. -
Может
только в том случае, если исследователь
ошибся в расчетах -
Может с вероятностью
1-Р
ТЕСТ 3- 19
Каково
должно быть соотношение выборочной
и генеральной совокупностей, чтобы
при замене повторного отбора на
бесповторный предельная ошибка
уменьшилась бы в 2 раза ?
-
0,50
-
0,75
-
0,90
ТЕСТ 3- 20
Какая
из предельных ошибок будет меньше :
установленная на основе повторного
или установленная на основе механического
отбора ?
-
Они будут равны
между собой -
На основе
повторного отбора -
На основе
механического отбора
ТЕСТ 3-21
Какой
из способов отбора предполагает
предварительное разбиение генеральной
совокупности на качественно отличные
части ?
-
Типический
-
Серийный
-
Механический
ТЕСТ 3- 22
При
каком из способов отбора, используемая
при расчете ошибок дисперсия будет
меньше ?
-
При случайном
повторном -
При случайном
бесповторном -
При типическом
Лекция
4 Статистические гипотезы , общая схема
их проверки
Аннотация.
Суть
выборочного метода состоит о том ,
что он может быть использован также
для того, чтобы вначале выдвинуть
некоторое предположение о генеральной
совокупности , а затем проведя выборку
согласиться с этим предположением
или отвергнуть.Очевидно , что согласие
или несогласие должно с одной сторон
опираться на некоторую количественную
меру, а с другой содержать элемент
ошибки , поскольку опирается на выборку
Ключевые
слова : статистическая
гипотеза, , гипотеза нулевая и
альтернативная , уровень значимости,
критерий, область согласия и отказа,
ошибки первого и второго рода.
Рассматриваемые
вопросы :
1.Понятие о
статистической гипотезе
2.Общая схема
проверки статистической гипотезы
Модульная
единица 1. Понятие о статистической
гипотезе , общая, схема ее проверки
Цель
и задачи изучения модульной единицы
В
процессе изучения этой модульной
единицы студент должен освоить
содержание основных терминов,
используемых при постановке и проверке
гипотезы. Студент должен овладеть
общим алгоритмом проверки гипотез .
-
Понятие
о статистической гипотезе
Под
статистической гипотезой понимается
некоторое предположение о генеральной
совокупности, которое может быть
проверено на основе выборки. Поскольку
предположение может касаться
распределения численностей или
количественной статистической
характеристики генеральной совокупности,
эти гипотезы получили название
статистических.
Большинство научных
гипотез
требуют экспериментальной проверки,
а поскольку данные любого эксперимента,
как уже говорилось, являются выборкой,
то результаты любого эксперимента
подлежат статистической обработке в
режиме проверки гипотез. Такая
обработка нужна для того, чтобы не
повторяя до бесконечности эксперимент
( не доводя объем данных до генеральной
совокупности ) иметь основание на
основе единственного эксперимента (
одной выборки ) формулировать те или
иные выводы
Соседние файлы в предмете [НЕСОРТИРОВАННОЕ]
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
- #
11.2. Оценка результатов выборочного наблюдения
11.2.1. Средняя и предельная ошибки выборки. Построение доверительных границ для средней и доли
Средняя ошибка выборки показывает, насколько отклоняется в среднем параметр выборочной совокупности от соответствующего параметра генеральной. Если рассчитать среднюю из ошибок всех возможных выборок определенного вида заданного объема (n), извлеченных из одной и той же генеральной совокупности, то получим их обобщающую характеристику — среднюю ошибку выборки ( ).
).
В теории выборочного наблюдения выведены формулы для определения , которые индивидуальны для разных способов отбора (повторного и бесповторного), типов используемых выборок и видов оцениваемых статистических показателей.
Например, если применяется повторная собственно случайная выборка, то определяется как:
 — при оценивании среднего значения признака;
— при оценивании среднего значения признака;
 — если признак альтернативный, и оценивается доля.
— если признак альтернативный, и оценивается доля.
При бесповторном собственно случайном отборе в формулы вносится поправка (1 — n/N):
 — для среднего значения признака;
— для среднего значения признака;
 — для доли.
— для доли.
Вероятность получения именно такой величины ошибки всегда равна 0,683. На практике же предпочитают получать данные с большей вероятностью, но это приводит к возрастанию величины ошибки выборки.
Предельная ошибка выборки ( ) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
) равна t-кратному числу средних ошибок выборки (в теории выборки принято коэффициент t называть коэффициентом доверия):
 .
.
Если ошибку выборки увеличить в два раза (t = 2), то получим гораздо большую вероятность того, что она не превысит определенного предела (в нашем случае — двойной средней ошибки) — 0,954. Если взять t = 3, то доверительная вероятность составит 0,997 — практически достоверность.
Уровень предельной ошибки выборки зависит от следующих факторов:
- степени вариации единиц генеральной совокупности;
- объема выборки;
- выбранных схем отбора (бесповторный отбор дает меньшую величину ошибки);
- уровня доверительной вероятности.
Если объем выборки больше 30, то значение t определяется по таблице нормального распределения, если меньше — по таблице распределения Стьюдента.
Приведем некоторые значения коэффициента доверия из таблицы нормального распределения.
| Значение доверительной вероятности P | 0,683 | 0,954 | 0,997 |
|---|---|---|---|
| Значение коэффициента доверия t | 1,0 | 2,0 | 3,0 |
Доверительный интервал для среднего значения признака и для доли в генеральной совокупности устанавливается следующим образом:

Итак, определение границ генеральной средней и доли состоит из следующих этапов:
Ошибки выборки при различных видах отбора
- Собственно случайная и механическая выборка. Средняя ошибка собственно случайной и механической выборки находятся по формулам, представленным в табл. 11.3.
 |
|
где |
Пример 11.2. Для изучения уровня фондоотдачи было проведено выборочное обследование 90 предприятий из 225 методом случайной повторной выборки, в результате которого получены данные, представленные в таблице.
| Уровень фондоотдачи, руб. | До 1,4 | 1,4-1,6 | 1,6-1,8 | 1,8-2,0 | 2,0-2,2 | 2,2 и выше | Итого |
|---|---|---|---|---|---|---|---|
| Количество предприятий | 13 | 15 | 17 | 15 | 16 | 14 | 90 |
В рассматриваемом примере имеем 40%-ную выборку (90 : 225 = 0,4, или 40%). Определим ее предельную ошибку и границы для среднего значения признака в генеральной совокупности по шагам алгоритма:
- По результатам выборочного обследования рассчитаем среднее значение и дисперсию в выборочной совокупности:
| Результаты наблюдения | Расчетные значения | |||
|---|---|---|---|---|
| уровень фондоотдачи, руб., xi | количество предприятий, fi | середина интервала, xixb4 | xixb4fi | xixb42fi |
| До 1,4 | 13 | 1,3 | 16,9 | 21,97 |
| 1,4-1,6 | 15 | 1,5 | 22,5 | 33,75 |
| 1,6-1,8 | 17 | 1,7 | 28,9 | 49,13 |
| 1,8-2,0 | 15 | 1,9 | 28,5 | 54,15 |
| 2,0-2,2 | 16 | 2,1 | 33,6 | 70,56 |
| 2,2 и выше | 14 | 2,3 | 32,2 | 74,06 |
| Итого | 90 | — | 162,6 | 303,62 |
Выборочная средняя

Выборочная дисперсия изучаемого признака

- Определяем среднюю ошибку повторной случайной выборки

- Зададим вероятность, на уровне которой будем говорить о величине предельной ошибки выборки. Чаще всего она принимается равной 0,999; 0,997; 0,954.

Для наших данных определим предельную ошибку выборки, например, с вероятностью 0,954. По таблице значений вероятности функции нормального распределения (см. выдержку из нее, приведенную в Приложении 1) находим величину коэффициента доверия t, соответствующего вероятности 0,954. При вероятности 0,954 коэффициент t равен 2.
- Предельная ошибка выборки с вероятностью 0,954 равна
- Найдем доверительные границы для среднего значения уровня фондоотдачи в генеральной совокупности


Таким образом, в 954 случаях из 1000 среднее значение фондоотдачи будет не выше 1,88 руб. и не ниже 1,74 руб.
Выше была использована повторная схема случайного отбора. Посмотрим, изменятся ли результаты обследования, если предположить, что отбор осуществлялся по схеме бесповторного отбора. В этом случае расчет средней ошибки проводится по формуле

Тогда при вероятности равной 0,954 величина предельной ошибки выборки составит:

Доверительные границы для среднего значения признака при бесповторном случайном отборе будут иметь следующие значения:

Сравнив результаты двух схем отбора, можно сделать вывод о том, что применение бесповторной случайной выборки дает более точные результаты по сравнению с применением повторного отбора при одной и той же доверительной вероятности. При этом, чем больше объем выборки, тем существеннее сужаются границы значений средней при переходе от одной схемы отбора к другой.
По данным примера определим, в каких границах находится доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., в генеральной совокупности:
- рассчитаем выборочную долю.
Количество предприятий в выборке с уровнем фондоотдачи, не превышающим значения 2,0 руб., составляет 60 единиц. Тогда
m = 60, n = 90, w = m/n = 60 : 90 = 0,667;
- рассчитаем дисперсию доли в выборочной совокупности
 ;
;
- средняя ошибка выборки при использовании повторной схемы отбора составит

Если предположить, что была использована бесповторная схема отбора, то средняя ошибка выборки с учетом поправки на конечность совокупности составит

- зададим доверительную вероятность и определим предельную ошибку выборки.
При значении вероятности Р = 0,997 по таблице нормального распределения получаем значение для коэффициента доверия t = 3 (см. выдержку из нее, приведенную в Приложении 1):

- установим границы для генеральной доли с вероятностью 0,997:

Таким образом, с вероятностью 0,997 можно утверждать, что в генеральной совокупности доля предприятий с уровнем фондоотдачи, не превышающим значения 2,0 руб., не меньше, чем 54,7%, и не больше 78,7%.
- Типическая выборка. При типической выборке генеральная совокупность объектов разбита на k групп, тогда
N1 + N2 + … + Ni + … + Nk = N.
Объем извлекаемых из каждой типической группы единиц зависит от принятого способа отбора; их общее количество образует необходимый объем выборки
n1 + n2 + … + ni + … + nk = n.
Существуют следующие два способа организации отбора внутри типической группы: пропорциональной объему типических групп и пропорциональной степени колеблемости значений признака у единиц наблюдения в группах. Рассмотрим первый из них, как наиболее часто используемый.
Отбор, пропорциональный объему типических групп, предполагает, что в каждой из них будет отобрано следующее число единиц совокупности:
n = ni · Ni/N
где ni — количество извлекаемых единиц для выборки из i-й типической группы;
n — общий объем выборки;
Ni — количество единиц генеральной совокупности, составивших i-ю типическую группу;
N — общее количество единиц генеральной совокупности.
Отбор единиц внутри групп происходит в виде случайной или механической выборки.
Формулы для оценивания средней ошибки выборки для среднего и доли представлены в табл. 11.6.

|
 ) при использовании типического отбора, пропорционального объему типических групп
) при использовании типического отбора, пропорционального объему типических группЗдесь  — средняя из групповых дисперсий типических групп.
— средняя из групповых дисперсий типических групп.
Пример 11.3. В одном из московских вузов проведено выборочное обследование студентов с целью определения показателя средней посещаемости вузовской библиотеки одним студентом за семестр. Для этого была использована 5%-ная бесповторная типическая выборка, типические группы которой соответствуют номеру курса. При отборе, пропорциональном объему типических групп, получены следующие данные:
| Номер курса | Всего студентов, чел., Ni | Обследовано в результате выборочного наблюдения, чел., ni | Среднее число посещений библиотеки одним студентом за семестр, xi | Внутригрупповая выборочная дисперсия, 
|
|---|---|---|---|---|
| 1 | 650 | 33 | 11 | 6 |
| 2 | 610 | 31 | 8 | 15 |
| 3 | 580 | 29 | 5 | 18 |
| 4 | 360 | 18 | 6 | 24 |
| 5 | 350 | 17 | 10 | 12 |
| Итого | 2 550 | 128 | 8 | — |
Число студентов, которое необходимо обследовать на каждом курсе, рассчитаем следующим образом:
- общий объем выборочной совокупности:
n = 2550/130*5 =128 (чел.);
- количество единиц, отобранных из каждой типической группы:

аналогично для других групп:
n2 = 31 (чел.);
n3 = 29 (чел.);
n4 = 18 (чел.);
n5 = 17 (чел.).
Проведем необходимые расчеты.
- Выборочная средняя, исходя из значений средних типических групп, составит:
- Средняя из внутригрупповых дисперсий
- Средняя ошибка выборки:
С вероятностью 0,954 находим предельную ошибку выборки:
- Доверительные границы для среднего значения признака в генеральной совокупности:





Таким образом, с вероятностью 0,954 можно утверждать, что один студент за семестр посещает вузовскую библиотеку в среднем от семи до девяти раз.
- Малая выборка. В связи с небольшим объемом выборочной совокупности те формулы для определения ошибок выборки, которые использовались нами ранее при «больших» выборках, становятся неподходящими и требуют корректировки.
Среднюю ошибку малой выборки определяют по формуле

Предельная ошибка малой выборки:

Распределение значений выборочных средних всегда имеет нормальный закон распределения (или приближается к нему) при п > 100, независимо от характера распределения генеральной совокупности. Однако в случае малых выборок действует иной закон распределения — распределение Стьюдента. В этом случае коэффициент доверия находится по таблице t-распределения Стьюдента в зависимости от величины доверительной вероятности Р и объема выборки п. В Приложении 1 приводится фрагмент таблицы t-распределения Стьюдента, представленной в виде зависимости доверительной вероятности от объема выборки и коэффициента доверия t.
Пример 11.4. Предположим, что выборочное обследование восьми студентов академии показало, что на подготовку к контрольной работе по статистике они затратили следующее количество часов: 8,5; 8,0; 7,8; 9,0; 7,2; 6,2; 8,4; 6,6.
Оценим выборочные средние затраты времени и построим доверительный интервал для среднего значения признака в генеральной совокупности, приняв доверительную вероятность равной 0,95.
- Среднее значение признака в выборке равно
- Значение среднего квадратического отклонения составляет
- Средняя ошибка выборки:
- Значение коэффициента доверия t = 2,365 для п = 8 и Р = 0,95 .
- Предельная ошибка выборки:
- Доверительный интервал для среднего значения признака в генеральной совокупности:





То есть с вероятностью 0,95 можно утверждать, что затраты времени студента на подготовку к контрольной работе находятся в пределах от 6,9 до 8,5 ч.
11.2.2. Определение численности выборочной совокупности
Перед непосредственным проведением выборочного наблюдения всегда решается вопрос, сколько единиц исследуемой совокупности необходимо отобрать для обследования. Формулы для определения численности выборки выводят из формул предельных ошибок выборки в соответствии со следующими исходными положениями (табл. 11.7):
- вид предполагаемой выборки;
- способ отбора (повторный или бесповторный);
- выбор оцениваемого параметра (среднего значения признака или доли).
Кроме того, следует заранее определиться со значением доверительной вероятности, устраивающей потребителя информации, и с размером допустимой предельной ошибки выборки.
 |
Примечание: при использовании приведенных в таблице формул рекомендуется получаемую численность выборки округлять в большую сторону для обеспечения некоторого запаса в точности.
Пример 11.5. Рассчитаем, сколько из 507 промышленных предприятий следует проверить налоговой инспекции, чтобы с вероятностью 0,997 определить долю предприятий с нарушениями в уплате налогов. По данным прошлого аналогичного обследования величина среднего квадратического отклонения составила 0,15; размер ошибки выборки предполагается получить не выше, чем 0,05.
При использовании повторного случайного отбора следует проверить

При бесповторном случайном отборе потребуется проверить

Как видим, использование бесповторного отбора позволяет проводить обследование гораздо меньшего числа объектов.
Пример 11.6. Планируется провести обследование заработной платы на предприятиях отрасли методом случайного бесповторного отбора. Какова должна быть численность выборочной совокупности, если на момент обследования в отрасли число занятых составляло 100 000 чел.? Предельная ошибка выборки не должна превышать 100 руб. с вероятностью 0,954. По результатам предыдущих обследований заработной платы в отрасли известно, что среднее квадратическое отклонение составляет 500 руб.

Следовательно, для решения поставленной задачи необходимо включить в выборку не менее 100 человек.

Калькулятор для расчета достаточного объема выборки
Калькулятор ошибки выборки для доли признака
Калькулятор ошибки выборки для среднего значения
Калькулятор значимости различий долей
Калькулятор значимости различий средних
1. Формула (даже две)
Бытует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с размером генеральной совокупности. Например, при опросах организаций (B2B).
Если речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная.
На рис.1. пример выборки 15000 человек (!) при опросе в муниципальном районе. Возможно, от численности населения взяли 10%?
Размер выборки никогда не рассчитывается как процент от генеральной совокупности!

Рис.1. Размер выборки 15000 человек, как реальный пример некомпетентности (или хуже).
В таких случаях для расчета объема выборки используется следующая формула:

где
n – объем выборки,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует,
∆ – предельная ошибка выборки.
Доверительный уровень – это вероятность того, что реальная доля лежит в границах полученного доверительного интервала: выборочная доля (p) ± ошибка выборки (Δ). Доверительный уровень устанавливает сам исследователь в соответствии со своими требованиями к надежности полученных результатов. Чаще всего применяются доверительные уровни, равные 0,95 или 0,99. В маркетинговых исследованиях, как правило, выбирается доверительный уровень, равный 0,95. При этом уровне коэффициент Z равен 1,96.
Значения p и q чаще всего неизвестны до проведения исследования и принимаются за 0,5. При этом значении размер ошибки выборки максимален.
Допустимая предельная ошибка выборки выбирается исследователем в зависимости от целей исследования. Считается, что для принятия бизнес-решений ошибка выборки должна быть не больше 4%. Этому значению соответствует объем выборки 500-600 респондентов. Для важных стратегических решений целесообразно минимизировать ошибку выборки.
Рассмотрим кривую зависимости ошибки выборки от ее объема (Рис.2).

Рис.2. Зависимость ошибки выборки от ее объема при 95% доверительном уровне
Как видно из диаграммы, с ростом объема выборки значение ошибки уменьшается все медленнее. Так, при объеме выборки 1500 человек предельная ошибка выборки составит ±2,5%, а при объеме 2000 человек – ±2,2%. То есть, при определенном объеме выборки дальнейшее его увеличение не дает значительного выигрыша в ее точности.
Подходы к решению проблемы:
Случай 1. Генеральная совокупность значительно больше выборки:

Случай 2. Генеральная совокупность сопоставима с объемом выборки: (см. раздел исследований B2B)

где
n – объем выборки,
N – объем генеральной совокупности,
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня,
p – доля респондентов с наличием исследуемого признака,
q = 1 – p – доля респондентов, у которых исследуемый признак отсутствует, (значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования)
∆ – предельная ошибка выборки.
Например,
рассчитаем ошибку выборки объемом 1000 человек при 95% доверительном уровне, если генеральная совокупность значительно больше объема выборки:
Ошибка выборки = 1,96 * КОРЕНЬ(0,5*0,5/1000) = 0,031 = ±3,1%
При расчете объема выборки следует также учитывать стоимость проведения исследования. Например, при цене за 1 анкету 200 рублей стоимость опроса 1000 человек составит 200 000 рублей, а опрос 1500 человек будет стоить 300 000 рублей. Увеличение затрат в полтора раза сократит ошибку выборки всего на 0,6%, что обычно неоправданно экономически.
2. Причины «раздувать» выборку
Анализ полученных данных обычно включает в себя и анализ подвыборок, объемы которых меньше основной выборки. Поэтому ошибка для выводов по подвыборкам больше, чем ошибка по выборке в целом. Если планируется анализ подгрупп / сегментов, объем выборки должен быть увеличен (в разумных пределах).
Рис.3 демонстрирует данную ситуацию. Если для исследования авиапассажиров используется выборка численностью 500 человек, то для выводов по выборке в целом ошибка составляет 4,4%, что вполне приемлемо для принятия бизнес-решений. Но при делении выборки на подгруппы в зависимости от цели поездки, выводы по каждой подгруппе уже недостаточно точны. Если мы захотим узнать какие-либо количественные характеристики группы пассажиров, совершающих бизнес-поездку и покупавших билет самостоятельно, ошибка полученных показателей будет достаточно велика. Даже увеличение выборки до 2000 человек не обеспечит приемлемой точности выводов по этой подвыборке.

Рис.3. Проектирование объема выборки с учетом необходимости анализа подвыборок
Другой пример – анализ подгрупп потребителей услуг торгово-развлекательного центра (Рис.4).

Рис.4. Потенциальный спрос на услуги торгово-развлекательного центра
При объеме выборки в 1000 человек выводы по каждой отдельной услуге (например, социально-демографический профиль, частота пользования, средний чек и др.) будут недостаточно точными для использования в бизнес планировании. Особенно это касается наименее популярных услуг (Таблица 1).
Таблица 1. Ошибка по подвыборкам потенциальных потребителей услуг торгово-развлекательного центра при выборке 1000 чел.

Чтобы ошибка в самой малочисленной подвыборке «Ночной клуб» составила меньше 5%, объем выборки исследования должен составлять около 4000 человек. Но это будет означать 4-кратное удорожание проекта. В таких случаях возможно компромиссное решение:
- увеличение выборки до 1800 человек, что даст достаточную точность для 6 самых популярных видов услуг (от кинотеатра до парка аттракционов);
- добор 200-300 пользователей менее популярных услуг с опросом по укороченной анкете (см. Таблицу 2).
Таблица 2. Разница в ошибке выборки по подвыборкам при разных объемах выборки.

При обсуждении с исследовательским агентством точности результатов планируемого исследования рекомендуется принимать во внимание бюджет, требования к точности результатов в целом по выборке и в разрезе подгрупп. Если бюджет не позволяет получить информацию с приемлемой ошибкой, лучше пока отложить проект (или поторговаться).
КАЛЬКУЛЯТОРЫ ДЛЯ РАСЧЕТА СТАТИСТИЧЕСКИХ ПОКАЗАТЕЛЕЙ И ОПРЕДЕЛЕНИЯ ЗНАЧИМОСТИ РАЗЛИЧИЙ:
КАЛЬКУЛЯТОР ДЛЯ РАСЧЕТА
ДОСТАТОЧНОГО ОБЪЁМА ВЫБОРКИ
Доверительный уровень:
Ошибка выборки (?):
%
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
РЕЗУЛЬТАТ
Один из важных вопросов, на которые нужно ответить при планировании исследования, — это оптимальный объем выборки. Слишком маленькая выборка не сможет обеспечить приемлемую точность результатов опроса, а слишком большая приведет к лишним расходам.
Онлайн-калькулятор объема выборки поможет рассчитать оптимальный размер выборки, исходя из максимально приемлемого для исследователя размера ошибки выборки.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке!
Формулы для других типов выборки отличаются.
Объем выборки рассчитывается по следующим формулам
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели соков и нектаров, постоянно проживающие в Москве и Московской области). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален. В данном калькуляторе значения p и q по умолчанию равны 0,5.
Δ– предельная ошибка выборки (для доли признака), приемлемая для исследователя. Считается, что для принятия бизнес-решений ошибка выборки не должна превышать 4%.
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании.
ПРИМЕР РАСЧЕТА ОБЪЕМА ВЫБОРКИ:
Допустим, мы хотим рассчитать объем выборки, предельная ошибка которой составит 4%. Мы принимаем доверительный уровень, равный 95%. Генеральная совокупность значительно больше выборки. Тогда объем выборки составит:
n = 1,96 * 1,96 * 0,5 * 0,5 / (0,04 * 0,04) = 600,25 ≈ 600 человек
Таким образом, если мы хотим получить результаты с предельной ошибкой 4%, нам нужно опросить 600 человек.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Доля признака (p):
%
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для доли признака рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:
(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:
В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96.
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели шоколада, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
p – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
q = 1 — p – доля респондентов, у которых исследуемый признак отсутствует. Значения p и q обычно принимаются за 0,5, поскольку точно неизвестны до проведения исследования. При этом значении размер ошибки выборки максимален.
Δ– предельная ошибка выборки.
Таким образом, зная объем выборки исследования, мы можем заранее оценить показатель ее ошибки.
А получив значение p, мы можем рассчитать доверительный интервал для доли признака: (p — ∆; p + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ ДОЛИ ПРИЗНАКА:
Например, в ходе исследования были опрошены 1000 человек (n=1000). 20% из них заинтересовались новым продуктом (p=0,2). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * КОРЕНЬ (0,2*0,8/1000) = 0,0248 = ±2,48%
Рассчитаем доверительный интервал:
(p — ∆; p + ∆) = (20% — 2,48%; 20% + 2,48%) = (17,52%; 22,48%)
Таким образом, с вероятностью 95% мы можем быть уверены, что реальная доля заинтересованных в новом продукте (среди всей генеральной совокупности) находится в пределах полученного диапазона (17,52%; 22,48%).
Если бы мы выбрали доверительный уровень, равный 99%, то для тех же значений p и n ошибка выборки была бы больше, а доверительный интервал – шире. Это логично, поскольку, если мы хотим быть более уверены в том, что наш доверительный интервал «накроет» реальное значение признака, то интервал должен быть более широким.
КАЛЬКУЛЯТОР ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ
Доверительный уровень:
Объём выборки (n):
Объём генеральной совокупности (N):
(можно пропустить, если больше 100 000)
Среднее значение (x̄):
Стандартное отклонение (s):
РЕЗУЛЬТАТ
Зная объем выборки исследования, можно рассчитать значение ошибки выборки (или, другими словами, погрешность выборки).
Если бы в ходе исследования мы могли опросить абсолютно всех интересующих нас людей, мы могли бы быть на 100% уверены в полученном результате. Но ввиду экономической нецелесообразности сплошного опроса применяют выборочный подход, когда опрашивается только часть генеральной совокупности. Выборочный метод не гарантирует 100%-й точности измерения, но, тем не менее, вероятность ошибки может быть сведена к приемлемому минимуму.
Все дальнейшие формулы и расчеты относятся только к простой случайной выборке! Формулы для других типов выборки отличаются.
Ошибка выборки для среднего значения рассчитывается по следующим формулам.
1) если объем выборки значительно меньше генеральной совокупности:

(в данной формуле не используется показатель объема генеральной совокупности N)
2) если объем выборки сопоставим с объемом генеральной совокупности:

В приведенных формулах:
Z – коэффициент, зависящий от выбранного исследователем доверительного уровня. Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень. Ему соответствует значение Z = 1,96
N – объем генеральной совокупности. Генеральная совокупность – это все люди, которые изучаются в исследовании (например, все покупатели мороженого, постоянно проживающие в Москве). Если генеральная совокупность значительно больше объема выборки (в сотни и более раз), ее размером можно пренебречь (формула 1).
n – объем выборки. Объем выборки – это количество людей, которые опрашиваются в исследовании. Существует заблуждение, что чем больше объем генеральной совокупности, тем больше должен быть и объем выборки маркетингового исследования. Это отчасти так, когда объем выборки сопоставим с объемом генеральной совокупности. Например, при опросах организаций (B2B). Если же речь идет об исследовании жителей городов, то не важно, Москва это или Рязань – оптимальный объем выборки будет одинаков в обоих городах. Этот принцип следует из закона больших чисел и применим, только если выборка простая случайная. ВАЖНО: если предполагается сравнивать какие-то группы внутри города, например, жителей разных районов, то выборку следует рассчитывать для каждой такой группы.
s — выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:

где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Δ– предельная ошибка выборки.
Зная среднее значение показателя x ̅ и ошибку ∆, мы можем рассчитать доверительный интервал для среднего значения:(x ̅ — ∆; x ̅ + ∆)
ПРИМЕР РАСЧЕТА ОШИБКИ ВЫБОРКИ ДЛЯ СРЕДНЕГО ЗНАЧЕНИЯ:
Например, в ходе исследования были опрошены 1000 человек (n=1000). Каждого из них попросили указать их примерную среднюю сумму покупки (средний чек) в известной сети магазинов. Среднее арифметическое всех ответов составило 500 руб. (x ̅=500), а стандартное отклонение составило 120 руб. (s=120). Рассчитаем показатель ошибки выборки по формуле 1 (выберем доверительный уровень, равный 95%):
∆ = 1,96 * 120 / КОРЕНЬ (1000) = 7,44
Рассчитаем доверительный интервал:
(x ̅ — ∆; x ̅ + ∆) = (500 – 7,44; 500 + 7,44) = (492,56; 507,44)
Таким образом, с вероятностью 95% мы можем быть уверены, что значение среднего чека по всей генеральной совокупности находится в границах полученного диапазона: от 492,56 руб. до 507,44 руб.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ ДОЛЕЙ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Доля признака (p): | % | % |
| Объём выборки (n): |
РЕЗУЛЬТАТ
Если в прошлогоднем исследовании вашу марку вспомнили 10% респондентов, а в исследовании текущего года – 15%, не спешите открывать шампанское, пока не воспользуетесь нашим онлайн-калькулятором для оценки статистической значимости различий.
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для долей. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Произведения n*p и n*(1-p), где n=размер выборки а p=доля признака, – не меньше 5.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Доля признака (p) – доля респондентов с наличием исследуемого признака. Например, если 20% опрошенных заинтересованы в новом продукте, то p = 0,2.
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
КАЛЬКУЛЯТОР ЗНАЧИМОСТИ РАЗЛИЧИЙ СРЕДНИХ
Доверительный уровень:
| Измерение 1 | Измерение 2 | |
| Среднее значение (x̄): | ||
| Стандартное отклонение (s): | ||
| Объём выборки (n): |
РЕЗУЛЬТАТ
Допустим, выборочный опрос посетителей двух разных ТРЦ показал, что средний чек в одном из них равен 1000 рублей, а в другом – 1200 рублей. Следует ли отсюда вывод, что суммы среднего чека в двух этих ТРЦ действительно отличаются?
Сравнивая два разных значения, полученные на двух независимых выборках, исследователь должен убедиться, что различия статистически значимы, прежде чем делать выводы.
Как известно, выборочные исследования не обеспечивают 100%-й точности измерения (для этого пришлось бы опрашивать всю целевую аудиторию поголовно, что слишком дорого). Тем не менее, благодаря методам математической статистики, мы можем оценить точность результатов любого количественного исследования и учесть ее в выводах.
В приведенном здесь калькуляторе используется двухвыборочный z-тест для средних значений. Для его применения должны соблюдаться следующие условия:
- Обе выборки – простые случайные
- Выборки независимы (между значениями двух выборок нет закономерной связи)
- Генеральные совокупности значительно больше выборок
- Распределения значений в выборках близки к нормальному распределению.
В калькуляторе используются следующие вводные данные:
Доверительный уровень (или доверительная вероятность) – это вероятность того, что реальное значение измеряемого показателя (по всей генеральной совокупности) находится в пределах доверительного интервала, полученного в исследовании. Доверительный уровень выбирает сам исследователь, исходя из требований к надежности результатов исследования. В маркетинговых исследованиях обычно применяется 95%-й доверительный уровень.
Среднее значение ( ̅x) – среднее арифметическое показателя.
Стандартное отклонение (s) – выборочное стандартное отклонение измеряемого показателя. В идеале на месте этого аргумента должно быть стандартное отклонение показателя в генеральной совокупности (σ), но так как обычно оно неизвестно, используется выборочное стандартное отклонение, рассчитываемое по следующей формуле:
где, x ̅ – среднее арифметическое показателя, xi– значение i-го показателя, n – объем выборки
Объем выборки (n) – это количество людей, которые опрашиваются в исследовании.
Результат расчетов – вывод о статистической значимости или незначимости различий двух измерений.
Вы можете подписаться на уведомления о новых материалах СканМаркет