Содержание
- Known Error Database (KEDB) insights!
- Using a Known Error Database (KEDB)
- Defining a Known Error Database
- Temporary workarounds vs. permanent solutions
- Benefits of a Known Error Database
- Benefits of a KEDB to Users
- Benefits of a KEDB to IT
- Known Error Database vs Overall Knowledge Database
- Implementing a Known Error Database
- Ensuring Efficiency in a Known Error Database
- Access the 2022 Gartner ® Magic Quadrant ™ for ITSM
- BMC Brings the A-Game
- Known Error Database (KEDB)
- Contents
- KEDM Process [2]
- Where the KEDB fits into the Problem Management process [3]
- The KEDB Implementation [4]
- Benefits of Known Error Database (KEDB) [5]
Known Error Database (KEDB) insights!
Let’s learn more about KEDB or Known Error Database, with the help of real life IT examples from a wide spread of different experiences. Most frequently the secret to success is engaging small problems each one at a time, rather than a single jump ahead. This means that is best to take one step at a time but for that you will need knowledge to be stored and improved upon, so one specific tool that helps organizations achieve this success is the KEDB or Known Error Database.
What is the Known Error Database?
To understand Known Error Database or KEDB anyone should know that there are three ITIL terms that you should be familiar with such as incident, problem and known error. What could be tagged as incident? Simple, if your email service goes down without notice from your provider, could be tagged as an incident. In this example, the reason behind the email outage is the problem, so a problem is the underlying cause of an incident. In other words, this is the thing that caused the issue in the first place.
Furthermore, we can say that there is no longer a problem, but a known error. Why is that? Because for the email issue, the root cause is identified as one of the critical services on the email server, so what use to be a problem now is known as an error.
Why is KEDB needed?
Now returning to the email problem, we can say that the critical services was in hung mode after running several diagnostics and undertaking some tests. After finding the problem, the resolution might have been faster where the service was stopped and restarted. The email service was down while the diagnostics and resolution were being applied and could result to penalties imposed by customers. So, if the email service fails again, the tech team will refer to the previous outage in the KEDB being able to start diagnosis with the service that caused the issue last time.
Anyway the company that offers e-mail services to its clients maintains a KEDB and be sure that this particular problem was recorded. If the email issue happens again, the tech support team can refer to the last outage in the KEDB and run a diagnosis with the service that caused the issue last time. At this point resolution might take a few seconds if it happens to be the same service causing the issue. With KEDB in place organizations are efficiently allocating money towards improving services.
Permanent solution and workaround
There are few ways for restoring service outages. The most ideal one, is a permanent solution, which entails a fix that guarantees zero outages. The most common type is the workaround that looks for an alternate solution. This second way is most frequently followed for implementing another solution at a later date. Restarting the service is a workaround in the email service outage. But this is probably to happen in the future and the tech support team knows that this will only solve the problem for the moment.
Now let’s see some aspects of KEDB in action.
Having seen what Known Error Database is, let’s understand how and when it gets recorded, used and maintained.
1. If an incident is resolved using temporary means, a known error is created with the incident summary, description, symptoms and all the steps involved in solving it.
2. If an incident appears the support team refers to the KEDB first to check if a workaround exists in the database.
3. There is a third possibility where a permanent solution to a known error is identified and implemented, the incident is not supposed to happen any more.
Источник
Using a Known Error Database (KEDB)

![]()
ITIL is a set of best practices that help IT teams function efficiently and align with the needs of business. One important piece of the ITIL that contributes to both of these goals is the Known Error Database, often shortened to KEDB. This is a database that tracks and describes all of the known errors within an overall system.
In this article, we are looking at the uses and benefits of employing KEDBs to align IT with the overall enterprise.
Defining a Known Error Database
To understand what a KEDB is and its importance to an IT team and the wider customers, let’s review a couple ITIL terms. (Remember that ITIL is formerly known as the Information Technology Infrastructure Library. ITIL provides detailed best practices for IT service management, known as ITSM.)
- An incident is an unscheduled interruption in an IT service. This could mean email service went down without notice, it could mean some software stopped interfacing with other software, etc.
- A problem is the root cause of the incident; it’s what made the incident happen, though it may take some time to identify the problem after the incident occurs.
- Once the problem is identified, it is no longer a problem, but a known error – the IT team knows what is causing an incident and what the issue it, but it hasn’t yet been solved.
The distinction between an incident and a problem are significant – many users may report outages or interruptions, but IT may not know the problem, the underlying cause. When IT is able to uncover the problem that caused the incident, they can start to solve it, either with a short-term workaround or a long-term resolution.
A known error database, then, tracks all of the known errors within the IT’s jurisdiction, which is typically an entire system or even organization. Ideally, the KEDB includes:
- Descriptions of how/when the issue will appear, including a description of the incident from the user’s point of view
- Screenshots of the incident(s) and problem
- Text of error messages
- Workarounds (temporary solutions) that help the user handle the problem and return to productive work with minor to no delay
- Resolutions, if the incident and problem have occurred and previously been solved
Temporary workarounds vs. permanent solutions
Once IT can determine the problem of an incident, they have two routes to solutions.
- The first is to find a long-term, permanent solution. Depending how complicated the problem and whether it has occurred before, IT must prioritize the time and resources it will take to find a permanent solution as well as how widespread and serious the problem is. This can mean some problems are de-prioritized.
- The second route is to determine a short-term workaround. A workaround is a temporary fix that allows work to happen until the problem is resolved permanently. Workarounds are vital, as IT must prioritize how to spend time and money to solve which problems.
Situations that have been de-escalated from needing a long-term solution means that users may continue to experience the incident. When users repeatedly run into the incident, a workaround to the problem ensures that the user has only a minimum stoppage in productive work.
Benefits of a Known Error Database
IT teams within enterprises develop a KEBD because it offers many benefits, both to users and directly to the IT team.
Benefits of a KEDB to Users
A KEDB helps users continue in their productive work, as they typically aren’t concerned about the wider effects of the incident. Here are some user benefits of a KEDB:
- Reduces downtime. If an incident is already reported, which is likely, a user won’t have to wait long for a response from the help desk because a workaround likely already exists. This minimizes downtown while a user is working.
- Ensures continuous work. If the incident happens again, the user already knows the workaround, therefore contacting the help desk again isn’t necessary.
- Avoids individual troubleshooting. When a workaround already exists, the user does not have to troubleshoot on their own. When user is troubleshooting without the help of IT, the user’s productive worktime decreases significantly. This also helps the user use their own skills for their own work.
Benefits of a KEDB to IT
Known error databases are especially useful to the IT department and the help desk in particular for several reasons:
- Responds quickly to users. The help desk doesn’t have to find a workaround every time a user reports an incident. Chances are good that there is already an existing workaround, and by pointing the user to the database, the help desk has saved time on that incident.
- Tracks occurrence and severity. The KEDB allows the help desk to track how often and how widespread the incident occurs. The more users who report it, the more common it may be. This is another way of prioritizing how quickly a long-term solution must be found.
- Offers consistent and repeatable workarounds. With a safe and tested workaround, the help desk now has a consistent resolution for all users who report the incident. This improves the user satisfaction, which contributes to the IT department’s efficiency.
- Maintains safety. When the help desk can offer a safe and proven workaround, users aren’t inclined to troubleshoot on their own. Users attempting to find solutions to their own incidents can lead to serious problems like disabling antivirus software or triggering other incidents.
- Prevents repeat work. If the new incident has been solved before, IT can reference prior solutions as a starting point for researching and solving the current problem. This often leads to IT finding a resolution in a fraction of the time it previous took.
- Avoids skill gaps. Most help desks are staffed with a combination of entry-level and advanced-skills employees. A KEDB allows entry- and lower-level employees to have experience assisting users as they can reference the information in the database. This frees up the more advanced employees so they can continue resolving problems.
- Prioritizes all IT issues. The KEDB can become part the overall IT Problem Management Database. This database helps IT identify problems and prioritize where to spend their resources finding permanent solutions.
Known Error Database vs Overall Knowledge Database
While a KEDB can be integrated into a Problem Management Database, IT teams should use caution when considering integrating a Known Error Database into an existing Knowledge Database.
ITIL generally recommends that any sort of knowledge management, typically involving a knowledge database, be reserved for permanent issues and overarching knowledge.
A KEDB, on the other hand, is meant to house temporary problems until they are prioritized and solved. By keeping these databases separate, the overall knowledge management database does not have to be purged for outdated problems and associated workarounds or solutions.
Implementing a Known Error Database
Many organizations do opt to link their KEDB within their problem management database. This is useful as it helps IT prioritize all its outstanding issues at once. The known error and problem must be mapped one-to-one so that the standard data representation for the Problem Management Database also applies to the necessary data for the KEDB.
In order to be effective, however, IT must monitor the problem management database so that as known errors have permanent solutions implemented, they can be removed from the KEDB.
Ensuring Efficiency in a Known Error Database
A database is only as good as the information in it. While a KEDB sounds like a good idea and is easily justifiable in business needs, it must be maintained properly in order to provide the most return on investment.
Some experts suggest measuring the following situations to track the efficiency of your KEDB:
- Number of incidents opened that are now a known error
- Number of incidents opened that have a workaround
- Number of incidents resolved by a workaround
- Number of incidents resolved without a workaround or knowledge
- Time to generate known error record
- Time to generate workaround
Implementing and tracking a known error database enables the IT team to function more efficiently, while improving the satisfaction of users.
Access the 2022 Gartner ® Magic Quadrant ™ for ITSM
The Gartner Magic Quadrant for ITSM is the gold-standard resource helping you understand the strengths of major ITSM software vendors, insights into platform capabilities, integration opportunities, and many other factors to determine which solution best fits your needs.

These postings are my own and do not necessarily represent BMC’s position, strategies, or opinion.
See an error or have a suggestion? Please let us know by emailing blogs@bmc.com.
BMC Brings the A-Game
BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. With our history of innovation, industry-leading automation, operations, and service management solutions, combined with unmatched flexibility, we help organizations free up time and space to become an Autonomous Digital Enterprise that conquers the opportunities ahead.
Learn more about BMC ›
Источник
Known Error Database (KEDB)
A Known Error Database, then, tracks all of the known errors within the IT’s jurisdiction, which is typically an entire system or even organization. Ideally, the KEDB includes:
- Descriptions of how/when the issue will appear, including a description of the incident from the user’s point of view
- Screenshots of the incident(s) and problem
- Text of error messages
- Workarounds (temporary solutions) that help the user handle the problem and return to productive work with minor to no delay
- Resolutions, if the incident and problem have occurred and previously been solved [1]
Contents
KEDM Process [2]
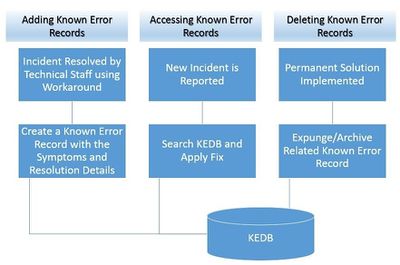
There are three streams where KEDB is leveraged:
- 1. When an incident is resolved using temporary means, a known error record is created with the incident summary, description, symptoms and all the steps involved in resolving it. Suppose a user has reported that MS Outlook application crashes when emails start to download. The technical staff, in order to minimize the service outage, advised the customer to access webmail until the issue is resolved. The details of the incident, along with the symptoms and temporary resolution steps, are to be recorded in a new known error record.
- 2. When an incident is reported, the support team refers to the KEDB first to check if a workaround exists in the database. If it does, they will refer to the known error record and follow the resolution steps involved. Suppose the fix provided is inaccurate, the support staff can recommend alternate resolution steps to ensure that KEDB is high on quality. Let’s say that at another time and place, MS Outlook application starts to crash. The technical staff can refer to the KEDB to check what was done on previous occasions, and can recommend the workaround to the customer until a permanent solution is in place.
- 3. If a permanent solution to a known error is identified and implemented, the incident must not happen anymore. So, the known error record is either taken out of the KEDB or archived with a different status. This is done to ensure that the database is optimized with only the known errors, and accessing records does not become cumbersome due to a high volume of known error records. While the user is accessing email service via webmail, the issue is being investigated to identify that a Bluetooth extension is causing the outlook to crash. The permanent solution is to disable the extension or even uninstall it. This solution is implemented not only on the Outlook that crashed, but on all the systems accessing Outlook, to ensure the same incident doesn’t happen again. After implementing and testing the permanent solution, the known error record can either be archived with a pre-defined status or deleted.
Where the KEDB fits into the Problem Management process [3]
The Known Error Database is a repository of information that describes all of the conditions in your IT systems that might result in an incident for your customers and users. As users report issues support engineers would follow the normal steps in the Incident Management process. Logging, Categorisation, Prioritisation. Soon after that they should be on the hunt for a resolution for the user. This is where the KEDB steps in. The engineer would interact with the KEDB in a very similar fashion to any Search engine or Knowledgebase. They search (using the “Known Error” field) and retrieve information to view the “Workaround” field.
The KEDB Implementation [4]
When we talk about the KEDB, we are truly discussing the Problem Management database instead of a totally discrete store of information. In fact, a good implementation would have it arranged that way. There is balanced planning between Known Error and Problem, so it bodes well that your standard data representation of a Problem (with its number, task information, work notes, and so on) additionally holds the information you require for the KEDB. It isn’t erroneous to execute this in an alternate manner—putting away the Problems and Known Errors in separate areas. However, our own inclination is to keep everything together. Known Error and Workaround are the two coins of a Problem.
Benefits of Known Error Database (KEDB) [5]
Below are the reasons why introducing a KEDB will help your organization.
- Quicker Incident Resolution: With a KEDB, your IT service desk agents are able to resolve incidents quicker. Why? Because when a new incident is reported they can consult the KEDB to see if there is already a fix available.
This saves them from having to individually troubleshoot every incident that comes in. And if the incident is part of an already recorded known error, then the agent can immediately apply the fix. They can also advise the affected end user that this is a known issue and people are working to resolve it. This will also give your customers peace of mind, knowing that the problem will (hopefully) soon go away forever (particularly if they’ve experienced it multiple times already).
- Deliver Consistent Support: Having a KEDB for your service desk agents to check means that each one of them will be able to offer the same level of IT support. And because working on the IT service desk is sometimes an entry-level role, you’re highly likely to have agents with various levels of knowledge and skill. Here, a KEDB means that your newer staff members are able to offer the same level of support for such incidents because the fixes are documented for them to follow.
Inconsistent support from the IT service desk can be a big factor in low customer satisfaction (CSAT) scores, so it pays to find ways to tackle this.
- It’s Easier to Monitor and Prioritize Issues: When you have a KEDB you can link up each incident that comes into the desk related to the known error. This means that you’re able to monitor the reach of the problem which, in turn, can help you to prioritize which problems need to be fixed first. For instance, those that have a high number of incidents attached, and therefore impact, can be submitted for fixes sooner than those causing only a couple of calls to the desk.
- Incident Ticket Prevention
Sometimes the workarounds provided for a known error are easy to apply and end users are able to activate them themselves. When this happens, you can let your customers know that your IT teams are working on the issue but in the meantime, should they experience the problem, they can fix it themselves to prevent any disruption. When your IT teams are already working on the fix you won’t need to worry about tracking the impact of the problem, so it’s better to prevent these calls from coming in in the first place whenever possible.
- Create Happy Customers (and Agents): Because you’re offering consistent support, applying quick fixes to reported incidents, and empowering end users by giving them the opportunity to fix their own issues, you’re likely to see improvements in your CSAT score.
Along with happier customers, your agents will be happier too because a KEDB can make their life so much easier. They don’t have to troubleshoot the same incidents over and over again, and they can provide a level of support that makes them feel good because they know they’re helping to deliver a great IT support service.
Источник
“Reinventing the wheel.” – We often use this saying in everyday life, but did you know that it’s valid in IT Service Management, i.e. ITIL, as well? Let me recall a common situation: your users open an incident; you find a workaround or solution to the incident and resolve it. A few days (or months) later, the same situation happens again. And you (or some other technician) work hard to rediscover that (same) workaround again. Sometime later – it’s the same thing all over again. Waste of time, isn’t it? That’s why ITIL installed Known Error (KE).
Known Error – a definition
According to ITIL (Service Operation), a Known Error is “a problem that has a documented root cause and a workaround.” Documented means recorded. Records are common in ITIL. Just like, e.g., incident records, a Known Error exists in the form of a record and it is stored in the Known Error Database (KEDB). Such record exists throughout the lifecycle of a Known Error, which means that the Known Error is recorded from its creation until “retirement” (if the KE record will be ever deleted at all).
A Known Error record contains (these are general parameters common to all tools. I saw different tools with various additional content):
- status (e.g. “Archived” or “Recorded Problem” when Known Error is created, but root cause and workaround are not known yet)
- error description – content of this field is used for searching through Known Errors (e.g. by Service Desk staff or users) while searching for incident/problem resolution (e.g. “Printer does not print after sending a document to the printer. However, when printing a status page locally on the printer, everything works fine.”)
- root cause – entered by Incident/Problem Management staff (e.g. “Since printer does not accept documents to be printed from user computers, but prints out status report – a faulty network card is the cause of the problem.”)
- workaround – e.g. “Closest printer to the user should be set as default printer or user should be instructed which device to use until new printer is provided.”

Where does it belong?
Officially, Known Errors belong to Problem Management, but it’s not unusual for Service Desk to resolve an incident with a permanent solution, or find a workaround and create a Known Error record. The aim of the Problem Management is to find a root cause of one or more incidents. Problems are created because the root cause (the real cause of the incident) and its resolution need to be identified. The result of the problem investigation and diagnosis is identification of the root cause of the problem, and a workaround (temporary fix) or (final) resolution. These are valuable pieces of information and need to be recorded – so, a Known Error is created.
Timing – when to raise a Known Error record?
Certainly, this should be done when you identify the root cause and workaround. But, it can be recorded earlier, e.g. when the problem is recorded. This is done for informational purposes or to record every step of workaround creation. Also, if a Known Error is recorded and it takes a long time to find a workaround or resolve the problem, someone who faces the same problem has the information that someone is working on the problem resolution and which temporary workarounds are available. I saw some situations when an IT organization used the KEDB to provide users with a self-help tool (i.e. as a Knowledge Base) while creating a Known Error record tool, which Service Desk used to allow them to choose whether the Known Error record would be published publicly (honestly, not all information is useful to everyone, so sometimes some workarounds are not applicable for users). In such a way, IT provided users with knowledge where they could search for a solution before opening an incident (or, since the tool supported such functionality, to search through the KEDB while typing incidents’ subject or description).
ISO 20000 view
The Problem Management process is one of the processes required by ISO 20000 (remember, everything written down in ISO 20000-1 must be implemented). ISO 20000 requires that Known Errors shall be recorded and that up-to-date information on Known Errors (and problem resolution) is provided to the Incident and Service Request Management process (as opposed to ITIL, this is a single process in ISO 20000). So, if you are thinking about ISO 20000 implementation, it’s better to seriously considering building a KEDB.
Let’s make life easier.
It’s not necessary to have mighty tools for IT Service Management to provide KEDB functionality and gain the advantage of Known Errors. For some organizations (I noticed that some small organizations are doing it this way), a spreadsheet will be enough. It may not be a perfect solution, but it will do.
The bottom line is that everyone gains the advantage of the KEDB:
- Users – they have a tool to help themselves. Or, they can speed up incident resolution, e.g. they don’t have to wait until Service Desk staff resolves the incident, because Service Desk will most probably use the same database, i.e. KEDB.
- Service Desk, people involved in Incident Management or Problem Management – they have a body of knowledge, which saves a complete history of their work. They can do reporting, incident and problem resolution is much faster (no re-work and no unnecessary transfer of incidents to problem management)…
It’s a fact that Known Errors and the KEDB are usually forgotten. IT has a IT Service Management tool and uses recorded incidents and problems to look for workarounds or solutions. This is the hard way. The pace at which everything moves is looking for a simple, yet powerful solution. Known Errors and the KEDB are exactly that.
Click here to see a free preview of the Known Error Record template.
ITIL is a set of best practices that help IT teams function efficiently and align with the needs of business. One important piece of the ITIL that contributes to both of these goals is the Known Error Database, often shortened to KEDB. This is a database that tracks and describes all of the known errors within an overall system.
In this article, we are looking at the uses and benefits of employing KEDBs to align IT with the overall enterprise.
Defining a Known Error Database
To understand what a KEDB is and its importance to an IT team and the wider customers, let’s review a couple ITIL terms. (Remember that ITIL is formerly known as the Information Technology Infrastructure Library. ITIL provides detailed best practices for IT service management, known as ITSM.)
- An incident is an unscheduled interruption in an IT service. This could mean email service went down without notice, it could mean some software stopped interfacing with other software, etc.
- A problem is the root cause of the incident; it’s what made the incident happen, though it may take some time to identify the problem after the incident occurs.
- Once the problem is identified, it is no longer a problem, but a known error – the IT team knows what is causing an incident and what the issue it, but it hasn’t yet been solved.
The distinction between an incident and a problem are significant – many users may report outages or interruptions, but IT may not know the problem, the underlying cause. When IT is able to uncover the problem that caused the incident, they can start to solve it, either with a short-term workaround or a long-term resolution.
A known error database, then, tracks all of the known errors within the IT’s jurisdiction, which is typically an entire system or even organization. Ideally, the KEDB includes:
- Descriptions of how/when the issue will appear, including a description of the incident from the user’s point of view
- Screenshots of the incident(s) and problem
- Text of error messages
- Workarounds (temporary solutions) that help the user handle the problem and return to productive work with minor to no delay
- Resolutions, if the incident and problem have occurred and previously been solved
Temporary workarounds vs. permanent solutions
Once IT can determine the problem of an incident, they have two routes to solutions.
- The first is to find a long-term, permanent solution. Depending how complicated the problem and whether it has occurred before, IT must prioritize the time and resources it will take to find a permanent solution as well as how widespread and serious the problem is. This can mean some problems are de-prioritized.
- The second route is to determine a short-term workaround. A workaround is a temporary fix that allows work to happen until the problem is resolved permanently. Workarounds are vital, as IT must prioritize how to spend time and money to solve which problems.
Situations that have been de-escalated from needing a long-term solution means that users may continue to experience the incident. When users repeatedly run into the incident, a workaround to the problem ensures that the user has only a minimum stoppage in productive work.
Benefits of a Known Error Database
IT teams within enterprises develop a KEBD because it offers many benefits, both to users and directly to the IT team.
Benefits of a KEDB to Users
A KEDB helps users continue in their productive work, as they typically aren’t concerned about the wider effects of the incident. Here are some user benefits of a KEDB:
- Reduces downtime. If an incident is already reported, which is likely, a user won’t have to wait long for a response from the help desk because a workaround likely already exists. This minimizes downtown while a user is working.
- Ensures continuous work. If the incident happens again, the user already knows the workaround, therefore contacting the help desk again isn’t necessary.
- Avoids individual troubleshooting. When a workaround already exists, the user does not have to troubleshoot on their own. When user is troubleshooting without the help of IT, the user’s productive worktime decreases significantly. This also helps the user use their own skills for their own work.
Benefits of a KEDB to IT
Known error databases are especially useful to the IT department and the help desk in particular for several reasons:
- Responds quickly to users. The help desk doesn’t have to find a workaround every time a user reports an incident. Chances are good that there is already an existing workaround, and by pointing the user to the database, the help desk has saved time on that incident.
- Tracks occurrence and severity. The KEDB allows the help desk to track how often and how widespread the incident occurs. The more users who report it, the more common it may be. This is another way of prioritizing how quickly a long-term solution must be found.
- Offers consistent and repeatable workarounds. With a safe and tested workaround, the help desk now has a consistent resolution for all users who report the incident. This improves the user satisfaction, which contributes to the IT department’s efficiency.
- Maintains safety. When the help desk can offer a safe and proven workaround, users aren’t inclined to troubleshoot on their own. Users attempting to find solutions to their own incidents can lead to serious problems like disabling antivirus software or triggering other incidents.
- Prevents repeat work. If the new incident has been solved before, IT can reference prior solutions as a starting point for researching and solving the current problem. This often leads to IT finding a resolution in a fraction of the time it previous took.
- Avoids skill gaps. Most help desks are staffed with a combination of entry-level and advanced-skills employees. A KEDB allows entry- and lower-level employees to have experience assisting users as they can reference the information in the database. This frees up the more advanced employees so they can continue resolving problems.
- Prioritizes all IT issues. The KEDB can become part the overall IT Problem Management Database. This database helps IT identify problems and prioritize where to spend their resources finding permanent solutions.
Known Error Database vs Overall Knowledge Database
While a KEDB can be integrated into a Problem Management Database, IT teams should use caution when considering integrating a Known Error Database into an existing Knowledge Database.
ITIL generally recommends that any sort of knowledge management, typically involving a knowledge database, be reserved for permanent issues and overarching knowledge.
A KEDB, on the other hand, is meant to house temporary problems until they are prioritized and solved. By keeping these databases separate, the overall knowledge management database does not have to be purged for outdated problems and associated workarounds or solutions.
Implementing a Known Error Database
Many organizations do opt to link their KEDB within their problem management database. This is useful as it helps IT prioritize all its outstanding issues at once. The known error and problem must be mapped one-to-one so that the standard data representation for the Problem Management Database also applies to the necessary data for the KEDB.
In order to be effective, however, IT must monitor the problem management database so that as known errors have permanent solutions implemented, they can be removed from the KEDB.
Ensuring Efficiency in a Known Error Database
A database is only as good as the information in it. While a KEDB sounds like a good idea and is easily justifiable in business needs, it must be maintained properly in order to provide the most return on investment.
Some experts suggest measuring the following situations to track the efficiency of your KEDB:
- Number of incidents opened that are now a known error
- Number of incidents opened that have a workaround
- Number of incidents resolved by a workaround
- Number of incidents resolved without a workaround or knowledge
- Time to generate known error record
- Time to generate workaround
Implementing and tracking a known error database enables the IT team to function more efficiently, while improving the satisfaction of users.
Access the 2022 Gartner® Magic Quadrant™ for ITSM
The Gartner Magic Quadrant for ITSM is the gold-standard resource helping you understand the strengths of major ITSM software vendors, insights into platform capabilities, integration opportunities, and many other factors to determine which solution best fits your needs.
These postings are my own and do not necessarily represent BMC’s position, strategies, or opinion.
See an error or have a suggestion? Please let us know by emailing blogs@bmc.com.
BMC Brings the A-Game
BMC works with 86% of the Forbes Global 50 and customers and partners around the world to create their future. With our history of innovation, industry-leading automation, operations, and service management solutions, combined with unmatched flexibility, we help organizations free up time and space to become an Autonomous Digital Enterprise that conquers the opportunities ahead.
Learn more about BMC ›
You may also like
About the author
![]()
Stephen Watts
A Known Error Database, then, tracks all of the known errors within the IT’s jurisdiction, which is typically an entire system or even organization. Ideally, the KEDB includes:
- Descriptions of how/when the issue will appear, including a description of the incident from the user’s point of view
- Screenshots of the incident(s) and problem
- Text of error messages
- Workarounds (temporary solutions) that help the user handle the problem and return to productive work with minor to no delay
- Resolutions, if the incident and problem have occurred and previously been solved[1]
KEDM Process[2]
There are three streams where KEDB is leveraged:
- 1. When an incident is resolved using temporary means, a known error record is created with the incident summary, description, symptoms and all the steps involved in resolving it. Suppose a user has reported that MS Outlook application crashes when emails start to download. The technical staff, in order to minimize the service outage, advised the customer to access webmail until the issue is resolved. The details of the incident, along with the symptoms and temporary resolution steps, are to be recorded in a new known error record.
- 2. When an incident is reported, the support team refers to the KEDB first to check if a workaround exists in the database. If it does, they will refer to the known error record and follow the resolution steps involved. Suppose the fix provided is inaccurate, the support staff can recommend alternate resolution steps to ensure that KEDB is high on quality. Let’s say that at another time and place, MS Outlook application starts to crash. The technical staff can refer to the KEDB to check what was done on previous occasions, and can recommend the workaround to the customer until a permanent solution is in place.
- 3. If a permanent solution to a known error is identified and implemented, the incident must not happen anymore. So, the known error record is either taken out of the KEDB or archived with a different status. This is done to ensure that the database is optimized with only the known errors, and accessing records does not become cumbersome due to a high volume of known error records. While the user is accessing email service via webmail, the issue is being investigated to identify that a Bluetooth extension is causing the outlook to crash. The permanent solution is to disable the extension or even uninstall it. This solution is implemented not only on the Outlook that crashed, but on all the systems accessing Outlook, to ensure the same incident doesn’t happen again. After implementing and testing the permanent solution, the known error record can either be archived with a pre-defined status or deleted.
Where the KEDB fits into the Problem Management process[3]
The Known Error Database is a repository of information that describes all of the conditions in your IT systems that might result in an incident for your customers and users. As users report issues support engineers would follow the normal steps in the Incident Management process. Logging, Categorisation, Prioritisation. Soon after that they should be on the hunt for a resolution for the user. This is where the KEDB steps in. The engineer would interact with the KEDB in a very similar fashion to any Search engine or Knowledgebase. They search (using the “Known Error” field) and retrieve information to view the “Workaround” field.
The KEDB Implementation[4]
When we talk about the KEDB, we are truly discussing the Problem Management database instead of a totally discrete store of information. In fact, a good implementation would have it arranged that way. There is balanced planning between Known Error and Problem, so it bodes well that your standard data representation of a Problem (with its number, task information, work notes, and so on) additionally holds the information you require for the KEDB. It isn’t erroneous to execute this in an alternate manner—putting away the Problems and Known Errors in separate areas. However, our own inclination is to keep everything together. Known Error and Workaround are the two coins of a Problem.
Benefits of Known Error Database (KEDB)[5]
Below are the reasons why introducing a KEDB will help your organization.
- Quicker Incident Resolution: With a KEDB, your IT service desk agents are able to resolve incidents quicker. Why? Because when a new incident is reported they can consult the KEDB to see if there is already a fix available.
This saves them from having to individually troubleshoot every incident that comes in. And if the incident is part of an already recorded known error, then the agent can immediately apply the fix. They can also advise the affected end user that this is a known issue and people are working to resolve it. This will also give your customers peace of mind, knowing that the problem will (hopefully) soon go away forever (particularly if they’ve experienced it multiple times already).
- Deliver Consistent Support: Having a KEDB for your service desk agents to check means that each one of them will be able to offer the same level of IT support. And because working on the IT service desk is sometimes an entry-level role, you’re highly likely to have agents with various levels of knowledge and skill. Here, a KEDB means that your newer staff members are able to offer the same level of support for such incidents because the fixes are documented for them to follow.
Inconsistent support from the IT service desk can be a big factor in low customer satisfaction (CSAT) scores, so it pays to find ways to tackle this.
- It’s Easier to Monitor and Prioritize Issues: When you have a KEDB you can link up each incident that comes into the desk related to the known error. This means that you’re able to monitor the reach of the problem which, in turn, can help you to prioritize which problems need to be fixed first. For instance, those that have a high number of incidents attached, and therefore impact, can be submitted for fixes sooner than those causing only a couple of calls to the desk.
- Incident Ticket Prevention
Sometimes the workarounds provided for a known error are easy to apply and end users are able to activate them themselves. When this happens, you can let your customers know that your IT teams are working on the issue but in the meantime, should they experience the problem, they can fix it themselves to prevent any disruption.
When your IT teams are already working on the fix you won’t need to worry about tracking the impact of the problem, so it’s better to prevent these calls from coming in in the first place whenever possible.
- Create Happy Customers (and Agents): Because you’re offering consistent support, applying quick fixes to reported incidents, and empowering end users by giving them the opportunity to fix their own issues, you’re likely to see improvements in your CSAT score.
Along with happier customers, your agents will be happier too because a KEDB can make their life so much easier. They don’t have to troubleshoot the same incidents over and over again, and they can provide a level of support that makes them feel good because they know they’re helping to deliver a great IT support service.
See Also
References
- ↑ Definition — What is Known Error Database (KEDB)? -BMC
- ↑ KEDM Process -Pluralsight
- ↑ Where the KEDB fits into the Problem Management process -The ITSM review
- ↑ The KEDB Implementation -Quickstart
- ↑ Benefits of Known Error Database (KEDB) -Joey the IT Guy
If your association has ITSM implemented with ITIL, a known error database (KEDB) is a surefire approach to both improve your problem management procedure and engage your IT support groups and clients. To help, this blog contains everything you need to know about KEDB that will up your IT service management (ITSM) game. Yet, here’s a little clarification on what is KEDB. Connect with our experts to learn more about our self-paced data science courses and certifications.
What Is a KEDB?
A KEDB is a database that contains all known errors influencing your clients and IT environment. KEDB portrays the conditions wherein these errors happen, how the issue shows itself and how to determine the error in the present moment through a workaround. A workaround is whatever can lessen or eliminate the effect of an incident or problem for which a perpetual goal isn’t yet accessible.
To properly comprehend KEDB and its significance to an IT group and the more extensive clients, we should audit a few ITIL terms.
An incident is an unprecedented interruption in an IT administration.
A problem is the main driver of the incident; it’s what caused the incident to occur, however, it might take some effort to recognize the problem after the incident happens.
The differentiation between a problem and an incident is critical – numerous clients may report outages or interferences. However, IT may not have the foggiest idea about the problem, the hidden reason. Here is when KEDB comes into light.
A known error database then tracks the entirety of the known errors inside the IT’s purview, which is regularly a whole framework or even association. In a perfect world, the KEDB incorporates:
- Explanation of when/how the issue will show up, including a depiction of the incident from the client’s perspective
- Text of error messages
- Screenshots of the incident(s) and problem
- Workarounds (transitory solutions) that help the client handle the problem
- The resolution, if the problem and incident have happened and recently been tackled
For What Reason Is KEDB Required?
Getting back to the email problem, we can say that the basic service was in a hung mode in the wake of running a few diagnostics and undertaking a few tests. In the wake of finding the problem, the resolution may have been quicker where the service was halted and restarted. The email service was down while the diagnostics and resolution were being applied; this could result in penalties forced by clients. Along these lines, if the email resolution bombs once more, the tech group will allude to the past blackout in the KEDB having the option to begin finding the resolution that caused the issue last time.
Start your 30-day free trial to get your hands on in-demand IT certifications
Workaround and Permanent Solution
There are few ways for reestablishing administration outages. The best one is a perpetual arrangement, which involves a fix that ensures zero outages. The most widely recognized sort is the workaround that searches for a substitute arrangement. This subsequent way is usually followed for executing one more solution sometime in the near future. Restarting the service is a workaround in the email service outage. However, this is most likely to occur later on, and the technical support group realizes that this will just tackle the problem for the incident.
Here are a few aspects of KEDB.
Now knowing what Known Error Database actually is, we should see how and when it gets recorded, used and kept up.
- On the off chance that an incident is settled utilizing brief methods, a known error is made with the incident rundown, depiction, indications and all the means engaged with fathoming it.
- In the event that an incident shows up, the help group alludes to the KEDB first to check if a workaround exists in the database.
- There is a third chance where a permanent answer for a known error is recognized and actualized: The incident should never happen in the future.
Since we are clear concerning what known errors are, we should investigate five reasons why presenting a KEDB will support your association.
1. Faster Incident Resolution
With a KEDB, your IT administration desk related specialists can resolve incident speedier. Why? Since when another incident is accounted for, they can counsel the KEDB to check whether there is now a accessible fix.
This spares them from having to exclusively investigate each incident that arises. Also, if the incident is important for an all-around recorded known error, the specialist can quickly apply the fix. They can likewise prompt the influenced end client that this is a known issue and individuals are attempting to determine it. This will likewise give your clients significant serenity, realizing that the problem will (ideally) soon disappear (especially if they’ve encountered it freqently).
2. Convey Consistent Support
Having a KEDB for your administration desk related specialists to check implies that every last one of them will have the option to offer a similar degree of IT support. What’s more, since taking a shot at the IT administration desk related is sometimes a section level job, you’re almost certain to have specialists with different degrees of information and expertise. Here, a KEDB implies that your fresher staff individuals can offer a similar degree of help for such incidents on the grounds that the fixes are reported for them to follow.
Conflicting help from the IT administration desk related can be a major factor in low customer satisfaction scores, so it pays to discover approaches to handle it.
3. It’s Easier To Monitor And Prioritize Issues
When you have a KEDB, you can connect every incident that comes into the desk related identified with the known error. This implies that you’re ready to screen the range of the problem which can assist you with organizing which problems should be fixed first. For example, those that have a high number of incidents connected, and consequently sway, can be submitted for fixes sooner than those making several calls to the desk.
4. Incident Ticket Prevention
Sometimes workarounds accommodating a known error is anything but difficult to apply and end clients can activity it themselves. When this occurs, you can tell your clients that your IT groups are chipping away at the issue, yet, should they experience the problem, they can fix it themselves to forestall any disturbance.
When your IT groups are dealing with the fix, you won’t have to stress over following the effect of the problem, so it’s smarter to keep these calls from coming in any case at whatever point conceivable.
5. Make Happy Customers (And Agents)
Since you’re offering steady help, applying handy solutions to revealed incidents and engaging end clients by allowing them the chance to fix their own issues, you’re probably going to see enhancements in your CSAT score.
Alongside more joyful clients, your representatives will be more joyful too on the grounds that a KEDB can make their life so much simpler. They don’t need to investigate similar incidents again and again. They can also give a degree of help that causes them to feel great, since they realize they’re assisting with conveying an extraordinary IT support administration.
The KEDB Implementation
In fact, when we talk about the KEDB, we are truly discussing the Problem Management database instead of a totally discrete store of information. In fact, a good implementation would have it arranged that way.
There is balanced planning between Known Error and Problem, so it bodes well that your standard data representation of a Problem (with its number, task information, work notes, and so on) additionally holds the information you require for the KEDB.
It isn’t erroneous to execute this in an alternate manner—putting away the Problems and Known Errors in separate areas. However, our own inclination is to keep everything together.
Known Error and Workaround are the two coins of a Problem.
Enroll in our Data Science Bootcamp program to get started.
Is the KEDB and Knowledge Base the Same?
This is a typical question. There are a ton of similarities between Known Errors and Knowledge base.
We would contend that even though your implementation of the KEDB may store its information in the Knowledgebase, they are isolated elements.
Consider the lifecycle of a Problem and along these lines the Known Error which is, all things considered, only quality of that Problem record.
The Problem should be shut when it has been taken out from the framework and can presently not influence clients or be the reason for Incidents. At this stage, we could resign the Known Error and Workaround as they are not currently helpful—in spite of the fact that we would need to save them for revealing, so maybe we wouldn’t erase them.
Knowledgebase articles have more lasting use. In spite of the fact that they also may be resigned, in the event that they allude to an application due to be decommissioned, they don’t have the equivalent lifecycle as a Known Error record.
Knowledge articles allude to how frameworks should function or give preparation to clients of the framework. Known Errors report conditions that are unforeseen.
There is an advantage in utilizing the Knowledgebase as a storehouse for Known Error articles notwithstanding. Providing Incident owners a solitary spot to look for both Knowledge and Known Errors is a decent element of your implementation. Normally your Knowledge tools will have pleasant writing, connecting and remarking capacities.
Imagine a scenario in which there is no Workaround.
In some cases, there just won’t be an appropriate Workaround to give to clients.
Here, we would utilize a case of a power outage to give a basic delineation. With power disturbed to an area, you could envision that there would be an interruption to administrations with no simple workaround.
It is maybe a languid model, as it doesn’t take into consideration numerous subtleties. Having power is typically a binary state—you either have it or not.
A superior and more effective model can be found in the cloud. As associations exploit the resource charging model of the cloud, they likewise redistribute control.
If you depend on a Cloud SaaS supplier for your email and they endure an outage, you can envision that your Service desk will take a ton of calls. Anyway, there probably won’t be a Workaround you can offer until your supplier reestablishes service.
Initially to help in partner new Incidents to the Problem (utilizing the Known Error as a hunt key) and to stop engineers from sitting around idly in looking for an answer that doesn’t exist.
You could likewise keep away from engineers attempting to actualize possibly harming workarounds by distributing the way that the right move to make is to hang tight for the main driver of the Problem to be settled.
Ultimately, with plenty of Problems in our framework, we may battle to organize our backlog. Having the Known Error distributed to help direct new Incidents to the correct Problem will bring the advantage of having the option to organize your most effective issues.
A User Known Error Profile
With a populated KEDB, we presently have a decent comprehension of the potential reasons for Incidents inside our framework.
Not all Known Errors will influence all clients. An organization switch disappointment in one branch office would be extremely effective for the local clients yet not for clients in another area.
In the event that we comprehend our user’s environment through frameworks, such as the Resource Management processes or Configuration Management System, we ought to have the option to decide a user exposure to Known Errors.
We hope this detailed blog answered all your questions about KEDB. Want to become an IT support professional? Enroll in our ITIL Foundation certification training to make your mark.
Talk to our experts to learn more about our ITIL Foundation certification. Start your 30-day free trial.
Let’s learn more about KEDB or Known Error Database, with the help of real life IT examples from a wide spread of different experiences. Most frequently the secret to success is engaging small problems each one at a time, rather than a single jump ahead. This means that is best to take one step at a time but for that you will need knowledge to be stored and improved upon, so one specific tool that helps organizations achieve this success is the KEDB or Known Error Database.
What is the Known Error Database?
To understand Known Error Database or KEDB anyone should know that there are three ITIL terms that you should be familiar with such as incident, problem and known error. What could be tagged as incident? Simple, if your email service goes down without notice from your provider, could be tagged as an incident. In this example, the reason behind the email outage is the problem, so a problem is the underlying cause of an incident. In other words, this is the thing that caused the issue in the first place.
Furthermore, we can say that there is no longer a problem, but a known error. Why is that? Because for the email issue, the root cause is identified as one of the critical services on the email server, so what use to be a problem now is known as an error.
Why is KEDB needed?
Now returning to the email problem, we can say that the critical services was in hung mode after running several diagnostics and undertaking some tests. After finding the problem, the resolution might have been faster where the service was stopped and restarted. The email service was down while the diagnostics and resolution were being applied and could result to penalties imposed by customers. So, if the email service fails again, the tech team will refer to the previous outage in the KEDB being able to start diagnosis with the service that caused the issue last time.
Anyway the company that offers e-mail services to its clients maintains a KEDB and be sure that this particular problem was recorded. If the email issue happens again, the tech support team can refer to the last outage in the KEDB and run a diagnosis with the service that caused the issue last time. At this point resolution might take a few seconds if it happens to be the same service causing the issue. With KEDB in place organizations are efficiently allocating money towards improving services.
Permanent solution and workaround
There are few ways for restoring service outages. The most ideal one, is a permanent solution, which entails a fix that guarantees zero outages. The most common type is the workaround that looks for an alternate solution. This second way is most frequently followed for implementing another solution at a later date. Restarting the service is a workaround in the email service outage. But this is probably to happen in the future and the tech support team knows that this will only solve the problem for the moment.
Now let’s see some aspects of KEDB in action.
Having seen what Known Error Database is, let’s understand how and when it gets recorded, used and maintained.
1. If an incident is resolved using temporary means, a known error is created with the incident summary, description, symptoms and all the steps involved in solving it.
2. If an incident appears the support team refers to the KEDB first to check if a workaround exists in the database.
3. There is a third possibility where a permanent solution to a known error is identified and implemented, the incident is not supposed to happen any more.
For maintenance and support services check our dedicated development specialists.
 Let’s learn something new is the term known Error Database. What is this KEDB? And how it is connected to software testing world?
Let’s learn something new is the term known Error Database. What is this KEDB? And how it is connected to software testing world?
The key to progress lies in climbing the stairs step by step, instead of a single jump skyward. Approaching slowly and carefully expects knowledge to be stored, utilized and enhanced. In Information Technology Infrastructure Library one such tool that enables associations to make this progress is the Known Error Database.
What is a Known Error Database Tool?
A known error database is a database that portrays the majority of the known issues inside the general frameworks. It depicts the circumstances in which these issues show up, and when conceivable, it offers a workaround that will get the client around the issue and back to profitable work. The configuration management system is part of known error database.
This database also turns out to be a part of the general Problem Management Database, where IT can go to distinguish and organize issues that need perpetual resolutions. Workarounds are just impermanent fixes with the goal that work can precede until the point when issues are definitely settled.
The ITIL known error database must incorporate screenshots of the issues, and additionally the content of error messages, and portrays the issue from the perspective of the client.
Advantages of a Known Error Database
IT groups inside undertakings build up a known error database format as it offers many advantages, both to clients and straightforwardly to the IT teams.
Repeatable Workarounds – Without a decent framework for producing brilliant Known Errors and Workarounds we may locate that diverse engineers settle a similar issue in different ways. Inventiveness in IT is completely something worth being thankful for, yet repeatable procedures are presumably better. Two clients reaching the Servicedesk for a similar issue wouldn’t expect a difference in the speed or nature of determination. The known error database software is a strategy for bringing repeatable procedures into your condition.
Stay away from unnecessary exchange of Incidents – A powerless point in the Incident Management process is the exchange of ownership between groups. This is where a client issue goes to the base of another person line of work. Frequently with insufficient detailed setting or foundation data. Empowering the Servicedesk to determine errors themselves prevents exchange of possession for issues that are already known.
Quicker rebuilding of service to the client – The client has lost access to a service because of a condition that we definitely think about and have seen some time recently. The most ideal experience that the client could seek after is a moment rebuilding of administration or an impermanent determination. Having a decent Known Error which makes the Problem simple to discover as well implies that the Workaround must be speedier to find. The greater part of the time required to legitimately understand the underlying driver of the clients issue can be evacuated by permitting the Servicedesk build snappy access to the Workaround.
Keep away from Re-work – Without a known error database fields we may find that developers are frequently investing time and vitality attempting to discover a determination for a similar issue. This would be likely in dispersed groups working from various workplaces, yet I’ve additionally observed it normally happen inside a single group. Have you ever inquired an engineer if they know the answer for a clients issue to be told “Yes, I settled this for another person a week ago?” Would you have preferred to have discovered that data in a less demanding way?
Thus tracking and implementing a known error database empowers the IT group to work all the more proficiently, while enhancing the fulfillment of clients.
Диаграмма рассматриваемого примера изображена на рис.13.5.

Рис.
13.5.
Анализ Парето
Следующий этап — поиск обходного решения. Обходное решение (Workaround) — уменьшение или устранение влияния инцидента или проблемы, для которых в текущий момент недоступно полное разрешение. Например, перезапуск отказавшей конфигурационной единицы или ручное добавление поврежденного файла из резервной копии. Обходные решения являются временными решениями для поддержания работоспособности системы на время поиска решения проблемы. Обходные решения документируются в Базе известных ошибок. База известных ошибок (Known Error Database или KEDB) — база данных, содержащая все записи об известных ошибках. Эта база данных создается в процессе Управления проблемами и используется процессами Управления инцидентами и проблемами.
Как только найдено решение проблемы, его необходимо как можно быстрее реализовать. Тем не менее, важно помнить, что внесение изменений может затронуть другие услуги или конфигурационные единицы. Если необходимо какое-то функциональное изменение, прежде чем его осуществить, надо сформировать Запрос на изменение, который будет обработан в рамках процесса Управления внесением изменений. После того, как все необходимые действия предприняты, проблема устранена, происходит закрытие записи о проблеме, а также всех связанных с ней записей об инцидентах. Перед закрытием необходимо провести проверку (пересмотр) полноты записи о проблеме — она должна содержать детальное описание всех осуществленных процедур и действий. Для значительных проблем, которые считаются таковыми в соответствии с системой приоритетов конкретной организации, проверка должна быть более детальной, в частности рассматривать такие вопросы как:
- что сделано правильно в отношении проблемы;
- что сделано неправильно в отношении проблемы;
- что может быть сделано лучше в будущем;
- как предотвратить повторение проблемы;
- были ли задействованы третьи стороны.
На практике редко встречаются приложения, системы и релизы программного обеспечения, не имеющие ошибок. В идеальном случае все они обнаруживаются на этапе тестирования. Тем не менее, ошибки могут не проявится или быть незамеченными и , таким образом, «просочиться» на этап эксплуатации.
В таблице 13.6 представлена информация, необходимая для процесса и ее источники.
| Источник | Входящая информация |
|---|---|
| AI 6 | Авторизация изменений |
| DS 8 | Отчеты об инцидентах |
| DS 9 | Детальная ИТ-конфигурация, ИТ-активы |
| DS 13 | Протоколы ошибок |
В таблице 13.7 приведены результаты процесса и то, куда они должны поступить.
| Результаты | В процессы |
|---|---|
| Запросы на изменения (где и как осуществлять исправления) | AI 6 |
| Протоколы проблем | AI 6 |
| Отчеты об эффективности процессов | ME 1 |
| Выявленные проблемы, ошибки и временные способы их решения | DS 8 |
Таблица 13.8 содержит таблицу ОУКИ для процесса, а таблица 13.9 – цели и показатели.
| ДействияФункции | Президент | Финансовый директор | Высшее руководство | Директор по ИТ | Владелец бизнес-процесса | Руководитель эксплуатации системы | Главный архитектор ИТ-системы | Руководитель разработок | Руководитель администрации ИТ | Руководитель проектного офиса | Аудит, риски, безопасность |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Выявлять и классифицировать проблемы | И | И | К | У | К | К | И | О | |||
| Провести анализ первопричин | К | К | У/О | ||||||||
| Разрешить проблемы | К | У | О | О | О | К | К | ||||
| Отслеживать статусы проблем | И | И | К | У/О | К | К | К | К | О | ||
| Предложить рекомендации по улучшению и создать запросы на изменения | И | У | И | И | И | О | |||||
| Поддерживать протоколы проблем | И | И | И | И | У/О |
| Цели | Показатели |
|---|---|
ИТ:
|
|
Процесса:
|
|
Действия:
|
|
Цели контроля
- DS 10.1. Выявление и классификация проблем
Реализовать на практике отчетность и классификацию проблем, которые были выявлены в ходе процесса управления инцидентами. Этапы этой работы аналогичны классификации инцидентов; то есть проблемам нужно присвоить категории, определить последствия, срочность и приоритетность. Категорировать проблемы по группам или разделам (например, проблемы в аппаратном обеспечении, программах, поддержке программ). Эти группы должны соответствовать организационным обязанностям пользователей и являться основой для постановки задач перед персоналом службы поддержки.
- DS 10.2. Отслеживание и разрешение проблем
Следует убедиться в том, что система управления проблемами обеспечена необходимыми средствами по отслеживанию, анализу и определению первопричин всех выявленных проблем, включая:
- Все связанные объекты конфигурации.
- Неразрешенные проблемы и инциденты.
- Известные и предполагаемые ошибки.
- Отслеживание тенденций в проблемах.
Выявить и предложить поддерживающие решения в отношении первопричин проблем, вызывающие запросы на изменения в процессе управления изменениями. Через процесс решения, управление проблемами должно получать регулярные отчеты от управления изменениями по разрешению проблем и ошибок. Управление проблемами предполагает ведение мониторинга постоянного воздействия проблем и выявленных ошибок на сервисы для пользователей. В случае достижения неприемлемого уровня данного воздействия, управление проблемами должно осуществить эскалацию проблемы, возможно повысив ее приоритет или предпринять экстренные изменения. Отслеживать продвижение в решении проблем в рамках соглашений об уровне обслуживания.
- DS 10.3. Закрытие проблем
Предусмотреть процедуру окончательного решения проблемы либо после подтверждения о ее успешном устранении либо после соглашения с бизнес пользователями о методах ее альтернативного (обходного) решения.
- DS 10.4. Интеграция управления конфигурацией, управления инцидентами и проблемами
Осуществить интеграцию процессов управления конфигурацией, управления инцидентами и проблемами для обеспечения эффективного управления проблемами и совершенствования.
Вспомним пример с обращением насчет неработающего принтера в сервис-деск. Допустим, такая проблема появляется у разных пользователей. Обнаружено, что принтер возобновляет работу после перезапуска. В данном случае перезапуск – обходное решение, но не решение проблемы. Поэтому Вам надо найти истинную причину и устранить ее.
Как и в Управлении инцидентами, Управление проблем имеет ряд задач, которые необходимо выполнить. Ответственные за решение проблем сотрудники (так называемые менеджеры проблем) должны их приоритезировать проблемы по срочности и негативному влиянию на бизнес. Менеджеры проблем назначают сотрудников — владельцев проблем, которые обладают достаточной компетенцией для их решения. Например, для проблем с операционными системами это будет кто-то из администраторов, для проблем с принтерами – кто-то из отдела обслуживания рабочих мест и т.п.
На следующем этапе ИТ-специалист диагностирует проблему и пытается определить первопричину ее возникновения. Например, в случае с принтером это могут быть старые барабаны, недостаток памяти или сломанный порт. После нахождения первопричины ее необходимо устранить – поменять барабан, обновить память и т.п. Многие изменения при этом проходят через процесс Управление внесением изменений. Только после того, как владелец проблемы убедиться, что она действительно устранена и не вызывает больше инцидентов, он может закрыть проблему. Вот так в упрощенном виде выглядит процесс Управления проблемами.
Ключевые термины:
Объект конфигурации или конфигурационная единица (Configuration Item, CI) – компонент инфраструктуры или объект, требующий настроек, связанных с инфраструктурой, которая находится под контролем (или должна находиться под контролем) должностных лиц, ответственных за конфигурацию. Объекты конфигурации могут весьма разниться по сложности, размерам и типам – от целой системы (включающей аппаратную часть, программное обеспечение и документацию) до отдельного модуля или небольшого аппаратного компонента.
Управление конфигурацией (Configuration Management) – управление настройками объектов конфигурации на протяжении их жизненного цикла.
Проблема (Problem) – в ИТ неизвестная причина, лежащая в основе одного или многих инцидентов.
Обходное решение (Workaround) — уменьшение или устранение влияния инцидента или проблемы, для которых в текущий момент недоступно полное разрешение.
База известных ошибок (Known Error Database или KEDB) — база данных, содержащая все записи об известных ошибках.