The Linux administrators that work with web hosting know how is it important to keep correct character encoding of the html documents.
From the following article you’ll learn how to check a file’s encoding from the command-line in Linux.
You will also find the best solution to convert text files between different charsets.
I’ll also show the most common examples of how to convert a file’s encoding between CP1251 (Windows-1251, Cyrillic), UTF-8, ISO-8859-1 and ASCII charsets.
Cool Tip: Want see your native language in the Linux terminal? Simply change locale! Read more →
Use the following command to check what encoding is used in a file:
$ file -bi [filename]
| Option | Description |
|---|---|
-b, --brief |
Don’t print filename (brief mode) |
-i, --mime |
Print filetype and encoding |
Check the encoding of the file in.txt:
$ file -bi in.txt text/plain; charset=utf-8
Change a File’s Encoding
Use the following command to change the encoding of a file:
$ iconv -f [encoding] -t [encoding] -o [newfilename] [filename]
| Option | Description |
|---|---|
-f, --from-code |
Convert a file’s encoding from charset |
-t, --to-code |
Convert a file’s encoding to charset |
-o, --output |
Specify output file (instead of stdout) |
Change a file’s encoding from CP1251 (Windows-1251, Cyrillic) charset to UTF-8:
$ iconv -f cp1251 -t utf-8 in.txt
Change a file’s encoding from ISO-8859-1 charset to and save it to out.txt:
$ iconv -f iso-8859-1 -t utf-8 -o out.txt in.txt
Change a file’s encoding from ASCII to UTF-8:
$ iconv -f utf-8 -t ascii -o out.txt in.txt
Change a file’s encoding from UTF-8 charset to ASCII:
Illegal input sequence at position: As UTF-8 can contain characters that can’t be encoded with ASCII, the iconv will generate the error message “illegal input sequence at position” unless you tell it to strip all non-ASCII characters using the -c option.
$ iconv -c -f utf-8 -t ascii -o out.txt in.txt
| Option | Description |
|---|---|
-c |
Omit invalid characters from the output |
You can lose characters: Note that if you use the iconv with the -c option, nonconvertible characters will be lost.
Very common situation for ones who work inside the both Windows and Linux machines.
This concerns in particular Windows machines with Cyrillic.
You have copied some file from Windows to Linux, but when you open it in Linux, you see “Êàêèå-òî êðàêîçÿáðû” – WTF!?
Don’t panic – such strings can be easily converted from CP1251 (Windows-1251, Cyrillic) charset to UTF-8 with:
$ echo "Êàêèå-òî êðàêîçÿáðû" | iconv -t latin1 | iconv -f cp1251 -t utf-8 Какие-то кракозябры
List All Charsets
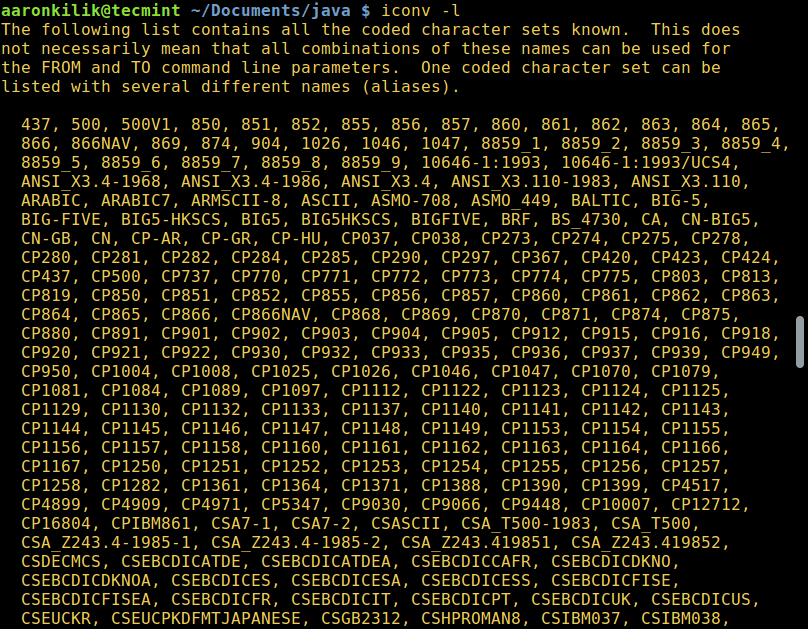
List all the known charsets in your Linux system:
$ iconv -l
| Option | Description |
|---|---|
-l, --list |
List known charsets |
Оригинал: How to Convert Files to UTF-8 Encoding in Linux
Автор: Aaron Kili
Дата публикации: 2 ноября 2016 года
Перевод: А. Кривошей
Дата перевода: ноябрь 2017 г.
В этом руководстве мы рассмотрим кодировки символов и разберем несколько примеров преобразования файлов из одной кодировки в другую с помощью утилиты командной строки. Затем мы покажем, как преобразовать файлы в Linux из любой кодировки (charset) в UTF-8.
Как вы, наверное, уже знаете, компьютер не понимает и не хранит информацию в виде букв, цифр или чего-либо еще. Он работает только с битами. Бит имеет только два возможных значения — 0 или 1, true или false, да или нет. Все остальное кодируется последовательностями битов.
Простыми словами, кодировка символов — это способ кодировки различных символов определенными последовательностями нулей и единиц. Когда мы вводим текст и сохраняем его в файл, слова и предложения, которые мы набираем, состоят из разных символов, а символы преобразуются в биты с помощью кодировки.
Существуют различные схемы кодирования, такие как ASCII, ANSI, Unicode и другие. Ниже приведен пример кодировки ASCII.
Character bits A 01000001 B 01000010
В Linux для преобразования текста из одной кодировки в другую используется утилита командной строки iconv.
Вы можете проверить кодировку файла с помощью команды file, используя флаг -i или -mime, который печатает строку типа mime, как в приведенных ниже примерах:
$ file -i Car.java $ file -i CarDriver.java

Синтаксис команды iconv следующий:
$ iconv option $ iconv options -f from-encoding -t to-encoding inputfile(s) -o outputfile
Где -f или —from-code задает входную кодировку, а -t или —to-encoding задает конечную кодировку.
Для того, чтобы вывести список всех доступных опций, введите:
$ iconv -l
Конвертирование файлов из UTF-8 в ASCII
Далее мы научимся конвертировать текст из одной кодировки в другую. Приведенная ниже команда преобразует текст из ISO-8859-1 в кодировку UTF-8.
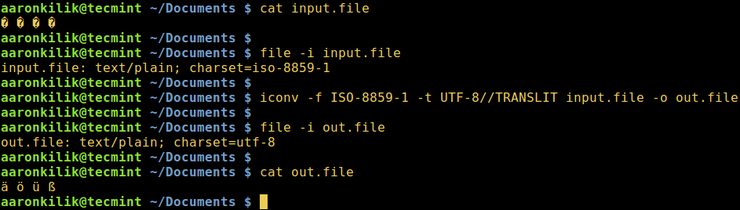
Рассмотрим файл input.file, который содержит следующие символы:
� � � �
(Прим: вы увидите эти символы на снимке ниже)
Начнем с проверки кодировки файла, затем просмотрим его содержимое. Мы можем преобразовать все символы в кодировку ASCII.
После запуска команды iconv мы затем проверяем содержимое выходного файла и новую кодировку, как показано ниже.
$ file -i input.file $ cat input.file $ iconv -f ISO-8859-1 -t UTF-8//TRANSLIT input.file -o out.file $ cat out.file $ file -i out.file
Примечание. Если в команду добавлена строка //IGNORE, то символы, которые не могут быть преобразованы, и ошибка выводятся после преобразования.
Далее, если добавлена строка //TRANSLIT, как в приведенном выше примере (ASCII//TRANSLIT), преобразуемые символы при необходимости и по возможности транслитерируются. Это означает, что если символ не может быть представлен в целевой кодировке, его можно аппроксимировать одним или несколькими похожими символами.
Далее, любой символ, который не может быть транслитерирован и которого нет в целевой кодировке, заменяется в выводе вопросительным знаком (?).
Конвертирование нескольких файлов в кодировку UTF-8
Возвращаясь к основной теме нашей статьи, мы можем написать небольшой скрипт для преобразования нескольких или всех файлов в каталоге в кодировку UTF-8, под названием encoding.sh:
#!/bin/bash
#здесь задаем входную кодировку
FROM_ENCODING="value_here"
#конечная кодировка (UTF-8)
TO_ENCODING="UTF-8"
#преобразование
CONVERT=" iconv -f $FROM_ENCODING -t $TO_ENCODING"
#цикл для преобразования нескольких файлов
for file in *.txt; do
$CONVERT "$file" -o "${file%.txt}.utf8.converted"
done
exit 0
Сохраните этот файл и сделайте скрипт исполняемым. Запускайте его из той директории, где расположены ваши файлы.
$ chmod +x encoding.sh $ ./encoding.sh
Важное замечание. Вы также можете также использовать этот скрипт для преобразования нескольких файлов из одной заданной кодировки в другую (любую), просто меняйте со значения переменных FROM_ENCODING и TO_ENCODING, не забывая об имени выходного файла «$ {file% .txt}. utf8.converted».
Для получения дополнительной информации почитайте руководство iconv:
$ man iconv
Подводя итог этой статье, необходимо отметить, что понимание способов преобразования текста из одной кодировки в другую — это знания, необходимые каждому пользователю компьютера, а тем более программистам, когда дело касается работы с текстами.
Если вы хотите лучше понять проблему кодировок символов, прочитайте следующие статьи:
- Свободные программы в офисе и дома. Глава 1. Текстовые документы
- Введение в мир программирования. Глава 3. Представление информации с помощью чисел
Если вам понравилась статья, поделитесь ею с друзьями:
Содержание
Описание проблемы
Ubuntu по умолчанию использует кодировку текстовых файлов UTF-8, однако некоторые операционные системы используют другие кодировки (например, русская версия Microsoft Windows использует CP-1251). Из-за разницы в кодировках могут возникнуть проблемы при открытии текстовых файлов в редакторе Gedit — они будут нечитаемыми. Данная статья предлагает несколько простых способов решения этой проблемы.
Настройка Gedit на автоопределение кодировки
Gedit может автоматически определить нужную кодировку. Для этого его нужно немного настроить.
Есть 3 варианта:
-
Для редактора dconf-editor1)
-
Для редактора gconf-editor2)
-
Способ, в котором нужно выполнить всего-лишь одну команду в Терминале.
Вариант 1.
Запускаем dconf-editor и переходим в
/org/gnome/gedit/preferences/encodings/

Редактируем ключ auto_detected3), вписывая нужную нам кодировку
WINDOWS-1251
Пример строки
['UTF-8', 'WINDOWS-1251', 'CURRENT', 'ISO-8859-15', 'UTF-16']
Вариант 2.
Выполните в терминале команду:
gconf-editor /apps/gedit-2/preferences/encodings
Откроется Редактор Конфигурации GNOME. В нем откройте для редактирования ключ auto_detected4).

В появившемся окне редактирования переместите нужную вам кодировку вверх, так, чтобы она находилась сразу после UTF-8. Нажмите OK и закройте редактор.

Вариант 3.
Выполните в терминале команду:
gsettings set org.gnome.gedit.preferences.encodings auto-detected "['UTF-8', 'WINDOWS-1251', 'CURRENT', 'ISO-8859-15', 'UTF-16']"
Для Ubuntu 16.04:
gsettings set org.gnome.gedit.preferences.encodings candidate-encodings "['UTF-8', 'WINDOWS-1251', 'KOI8-R', 'CURRENT', 'ISO-8859-15', 'UTF-16']"
Для Ubuntu Mate 16.04:
gsettings set org.mate.pluma auto-detected-encodings "['UTF-8', 'WINDOWS-1251', 'KOI8-R', 'CURRENT', 'ISO-8859-15', 'UTF-16']"
Данный способ является самым быстрым.
Теперь, если вы откроете файл с кодировкой WINDOWS-1251 — он будет правильно отображаться в Gedit.
Смена кодировки открытого файла
С помощью системы плагинов можно добавить возможность выбора кодировки уже открытого файла.
-
Если для распаковки используется стандартный менеджер архивов переименуйте архив в из encoding.tar.gz в encoding.tar (проверялось в Ubuntu 8.10 и 10.4)
-
Распаковываем его в ~/.local/share/gedit/plugins (если такой папки нет, то её нужно создать)
-
Запускаем Gedit и включаем в нём модуль «Кодировка» (Правка→Параметры→Модули)
После этого в главном меню Файл появляется пункт «Encoding», который позволяет менять кодировку в уже открытом документе.
Ссылки
Каждый пользователь Linux рано или поздно встречается с такой задачей, как не корректное отображение txt файлов, которые были созданы в Windows. Так называемые кракозябры, возникают вследствие того, что в этих системах используется разная кодировка. В Windows, при сохранении txt файлов используется кодировка Windows-1251, в то время, как в системах Linux используется кодировка UTF-8.
Исправить проблему кодировки txt файлов из Windows довольно просто. В данной статье мы рассмотрим самый простой вариант, который можно применить и тем самым получить читаемый текст на кириллице в Linux системах. Можно конечно пойти и более сложным путем, внести правки в систему, в случае с графическим окружением Gnome и текстовым редактором Gedit, например, можно ввести команду “gsettings set org.gnome.gedit.preferences.encodings candidate-encodings “[‘UTF-8’, ‘WINDOWS-1251’, ‘KOI8-R’, ‘CURRENT’, ‘ISO-8859-15’, ‘UTF-16’]”. Либо, установить Dconf Editor и произвести правки через него.
Но, в некоторых случаях такой подход может привести к путанице в случае с разными текстовыми редакторами и графическими окружениями. Или, что еще хуже, через тот же Dconf можно изменить не тот параметр и потом долго пытаться понять что не так. В первую очередь, эта статья будет направлена для тех, кто в первые оказался в такой ситуации и мало знаком с Linux.
Итак, первым из предлагаемых способов, рассмотрим добавление кодировки непосредственно перед самим открытием txt файлов. В системах Linux чаще всего используются несколько текстовых редактор, в рабочем окружении GNOME – GNOME Text Editor, Gedit, в Linux Mint – Xed, в KDE – Kate. В той же Kubuntu, кстати, текстовый редактор Kate открывает с правильной кодировкой, по этому, его мы рассматривать не станем. В остальных же случая, придется при открытии файлов в нижней части текстового редактора нажать на настройку, которая позволяет выбрать кодировку, затем, выбрать Кириллица (Windows 1251):

После чего можно открывать txt файл, который был создан в Windows:

После проделанных действий, текстовый редактор запомнит выбор и будет открывать txt файл в нужной кодировке. Не смотря на то, что для примера был выбран текстовый редактор GNOME Text Editor, интерфейс у него очень схож с остальными текстовыми редакторами, вроде того же gedit или xed.
Заключение
В большинстве случаев, проделанных действий будет достаточно. Тут стоит отметить, что в вашем дистрибутиве может быть установлен другой текстовый редактор, а по этому действия могут немного отличаться. Но основная задача, это найти в вашем редакторе параметр который отвечает за кодировку, а затем можно открывать txt файл.
Если вы работаете с дистрибутивами Linux основанных на Ubuntu, либо, на самой Ubuntu, то возможно вам будет интересно прочитать про альтернативный менеджер пакетов – nala.
Теперь, когда вы узнали, как открывать txt файлы, которые были созданы в Windows, можно переходить к играм, ведь это тоже имеет не малое значение. Нужно ведь как то расслабляться. И в этом вам поможет проект под названием – Linux Gaming. При помощи Linux Gaming вы можете запускать игры, которые были созданы для Windows в Linux. Подробнее о Linux Gaming можно прочесть по этой ссылке.
А на этом сегодня все, если статья оказалась вам полезна, подписывайтесь на рассылку журнала в pdf формате, а так же на социальные сети журнала Cyber-X:
YouTube
ВКонтакте
Telegram
По вопросам работы сайта, сотрудничества, а так же по иным возникшим вопросам пишите на E-Mail. Если вам нравится журнал и вы хотите отблагодарить за труды, вы можете перечислить донат на развитие проекта.
С уважением, редакция журнала Cyber-X