На Linux это можно сделать командой ifconfig и netstat. На FreeBSD — командой netstat. Под Windows netstat -e (к сожалению, без указания конкретного интерфейса). Под IOS Cisco show interfaces имя_интерфейса. Примеры:
Windows
D:Documents and Settingsuser>netstat -e
Interface Statistics
Received Sent
Bytes 1318170969 1331072579
Unicast packets 17579014 19350523
Non-unicast packets 7408 7298
Discards 0 0
Errors 0 0
Unknown protocols 0
Red Hat Linux
[ root@localhost
]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:C0:DF:0B:1D:08
inet addr:a.b.11.111 Bcast:10.255.255.255 Mask:255.0.0.0
inet6 addr: fe80::2c0:dfff:fe0b:1d08/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:12440467 errors:0 dropped:0 overruns:0 frame:0
TX packets:54452 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1136982908 (1.0 GiB) TX bytes:5774730 (5.5 MiB)
Interrupt:169 Base address:0x1000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:1635 errors:0 dropped:0 overruns:0 frame:0
TX packets:1635 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1743404 (1.6 MiB) TX bytes:1743404 (1.6 MiB)
[root@localhost
]# netstat -i
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 0 12564444 0 0 0 54645 0 0 0 BMRU
lo 16436 0 1635 0 0 0 1635 0 0 0 LRU
Источник
Linux ошибки на сетевом интерфейсе
На Linux это можно сделать командой ifconfig и netstat. На FreeBSD — командой netstat. Под Windows netstat -e (к сожалению, без указания конкретного интерфейса). Под IOS Cisco show interfaces имя_интерфейса. Примеры:
Windows
D:Documents and Settingsuser>netstat -e
Interface Statistics
Received Sent
Bytes 1318170969 1331072579
Unicast packets 17579014 19350523
Non-unicast packets 7408 7298
Discards 0 0
Errors 0 0
Unknown protocols 0
Red Hat Linux
[ root@localhost
]# ifconfig
eth0 Link encap:Ethernet HWaddr 00:C0:DF:0B:1D:08
inet addr:a.b.11.111 Bcast:10.255.255.255 Mask:255.0.0.0
inet6 addr: fe80::2c0:dfff:fe0b:1d08/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:12440467 errors:0 dropped:0 overruns:0 frame:0
TX packets:54452 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:1136982908 (1.0 GiB) TX bytes:5774730 (5.5 MiB)
Interrupt:169 Base address:0x1000
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
inet6 addr: ::1/128 Scope:Host
UP LOOPBACK RUNNING MTU:16436 Metric:1
RX packets:1635 errors:0 dropped:0 overruns:0 frame:0
TX packets:1635 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:0
RX bytes:1743404 (1.6 MiB) TX bytes:1743404 (1.6 MiB)
[root@localhost
]# netstat -i
Kernel Interface table
Iface MTU Met RX-OK RX-ERR RX-DRP RX-OVR TX-OK TX-ERR TX-DRP TX-OVR Flg
eth0 1500 0 12564444 0 0 0 54645 0 0 0 BMRU
lo 16436 0 1635 0 0 0 1635 0 0 0 LRU
Источник
Linux: поиск проблем сети
Проверка состояния сети
Или с помощью ethtool :
Поиск ошибок в передаче данных
Или более подробно с помощью ethtool :
Либо с помощью netstat :
Возможные типы и причины ошибок в сети
- Collisions: может возникать в режиме полудуплекса, если сетевая карта обнаруживает что она и другое сетевое устройство в сети отправляет данные одновременно; коллизии (“противоречие“) можно считать обычным явлением в сети, и её уровень как правило менее 0.1% от общего числа пакетов; более высокое значение может означать неисправную сетевую карту или плохо подключенные кабели;
- CRC Errors: кадры отправлены, но были повреждены во время передачи; наличие ошибок CRC (Cyclic Redundancy Check) при небольшом значении ошибок Collisions может возникать в случае електромагнитных шумов; убедитесь, что используется правильный тип кабеля, что сам кабель не повреждён и что коннекторы правильно закреплены в портах;
- FIFO and Overrun Errors: количество неудачных попыток переместить данные в память; как правило возникает при чрезмерно большом трафике;
- Length Errors: полученная длина кадра меньше или больше, чем предусмотрено стандартом Ethernet; это наиболее частая ошибка из-за несовместимых натроек дуплекса;
- Carrier Errors: возникают, когда сетевой интерфейс теряет связь с другим устройсвом (свичём, роутером);
Проверка MAC-адреса
Бывают случаи, когда пропадает линк к серверу, который напрямую подключен к вашей локальной сети. Просмотр ARP-таблицы с другого устройства в этой сети (другого вашего сервера) поможет определить отвечает ли удалённый сервер хоть на какие-то запросы с вашего сервера. В случае проблем на этом уровне может означать следующее:
- удалённый сервер отключен от сети вообще;
- проблемы с кабелями;
- сетевой интерфейс на удалённом серве может быть отключен;
- на удалённом сервер работает фильтрация firewall-ом; как правило, в таком случае, вы можете увидеть его MAC-адрес, но нормального обмена данными не происходит.
Примеры того, как можно получить данные ARP-таблицы.
ifconfig -a – отобразит ваши IP и MAC-адреса:
arp -a – отобразит вашу таблицу ARP:
Примечание: Что бы проверить удалённый хост, используя не ICMP-запросы (обычный ping ), а ARP – можно воспользоваться утилитой arping :
Проверка сайтов с помощью curl
curl работает как текстовый браузер, и позволяет получать всю страницу целиком или только заголовки от веб-сервера:
Проверка сети с помощью netstat
Как и вышеупомянутые утилиты, netstat может помочь в определении источника проблем в сети. С помощью опций -an можно отобразить все открытые порты и активные соединения:
Использование traceroute для проверки сети
Ещё одна утилита – traceroute . Она предоставляет информацию обо всех узлах между вашим сервером и удалённым сервером.
Как работает traceroute?
traceroute отправляет UDP-пакеты с TTL=0 (кол-во итераций или пересылок пакетов). Первый маршрутизатор получает такое значение, считает что TTL истёк, и отбрасывает пакет, но возвращает ICMP-ответ “time exceeded“. traceroute записывает IP и/или имя хоста этого узла, а затем отправлет новый пакет, уже с TTL=1 . Первый узел его пропускает, но уменьшает значение до 0, и пересылает пакет следующему узлу. Второй узел, видя TTL=0 отбрасывает пакет и возвращает ICMP-ответ “time exceeded“. Таким образом – traceroute gполучает IP и второго узла, после чего продолжает отправку пакетов с увеличением TTL до тех пор, пока не получит ответ от хоста назначения:
Некоторые узлы отбрасывают пакеты от traceroute . В таком случае, с помощью опции -I можно использовать протокол ICMP:
Утилита MTR
MTR (Matt’s Traceoute) – утилита, которая в режиме реального времени отображает работу traceroute :
Просмотр трафика с помощью tcpdump
Утилита tcpdump – одна из самых популярных для просмотра трафика на сетевом интерфейсе.
Наиболее используемый вариант – это определение наличия базового двухсторонннего обмена. Проблемы с этим могут возникать в случае:
- неправильного роутинга пакетов;
- проблем с интерфейсами, устройствами;
- удалённый сервер не прослушивает указанынй порт (не запущен соответствующий сервис);
- сетевое устройство на пути следования пакета блокирует передачу пакетов (файерволы, ACL и т.п.).
Поиск проблем в сети с помощью tshark
Опции и вид выдаваемой tshark информации очень схож с tcpdump , однако tshark имеет больше возможностей.
Например, tshark умеет записывать данные в файл, как и tcpdump , но при этом он умеет создавать новый файл для записи, когда предыдущий достигнет заданного размера. Кроме того, ему можно указать количество создаваемых файлов, после достиджения которого он начнёт перезаписывать первый созданный файл.
Для установки tshark на CentOS – используйте:
Использование утилиты nmap
Вы можете сипользовать утилиту nmap для определения всех открытых портов на удалённом сервере. Это может быть использовано, например, для поиска уязвимостей в вашей сети, например – сервера, на которых запущены неизвестные сетевые приложения.
Источник
Мониторинг сетевого стека linux
 Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
Часто мониторинг сетевой подсистемы операционной системы заканчивается на счетчиках пакетов, октетов и ошибок сетевых интерфейсах. Но это только 2й уровень модели OSI!
С одной стороны большинство проблем с сетью возникают как раз на физическом и канальном уровнях, но с другой стороны приложения, работающие с сетью оперируют на уровне TCP сессий и не видят, что происходит на более низких уровнях.
Я расскажу, как достаточно простые метрики TCP/IP стека могут помочь разобраться с различными проблемами в распределенных системах.
Netlink
Почти все знают утилиту netstat в linux, она может показать все текущие TCP соединения и дополнительную информацию по ним. Но при большом количестве соединений netstat может работать достаточно долго и существенно нагрузить систему.
Есть более дешевый способ получить информацию о соединениях — утилита ss из проекта iproute2.
Ускорение достигается за счет использования протола netlink для запросов информации о соединениях у ядра. Наш агент использует netlink напрямую.
Считаем соединения
Disclaimer: для иллюстрации работы с метриками в разных срезах я буду показывать наш интерфейс (dsl) работы с метриками, но это можно сделать и на opensource хранилищах.
В первую очередь мы разделяем все соединения на входящие (inbound) и исходящие (outbound) по отношению к серверу.
Каждое TCP соединения в определенный момент времени находится в одном из состояний, разбивку по которым мы тоже сохраняем (это иногда может оказаться полезным):
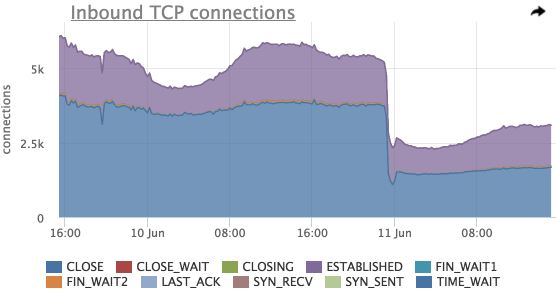
По этому графику можно оценить общее количество входящих соединений, распределение соединений по состояниям.
Здесь так же видно резкое падение общего количества соединений незадолго до 11 Jun, попробуем посмотреть на соединения в разрезе listen портов:
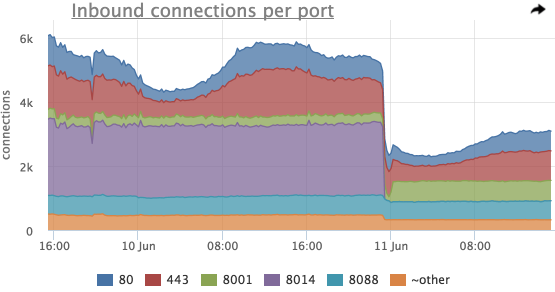
На этом графике видно, что самое значительное падение было на порту 8014, посмотрим только 8014 (у нас в интерфейсе можно просто нажать на нужном элементе легенды):
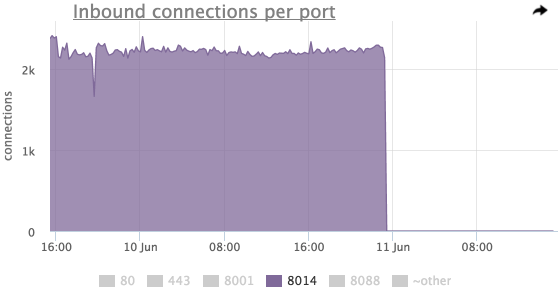
Попробуем посмотреть, изменилось ли количество входящий соединений по всем серверам?
Выбираем серверы по маске “srv10*”:
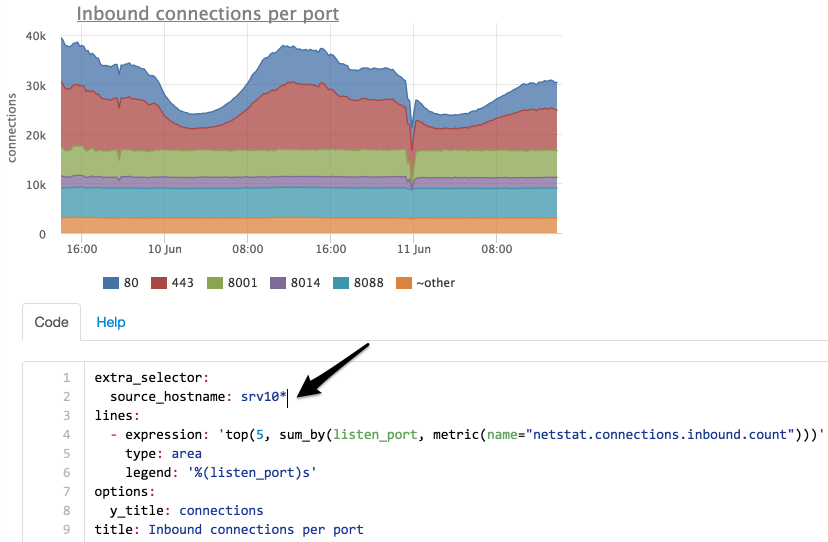
Теперь мы видим, что количество соединений на порт 8014 не изменилось, попробуем найти на какой сервер они мигрировали:
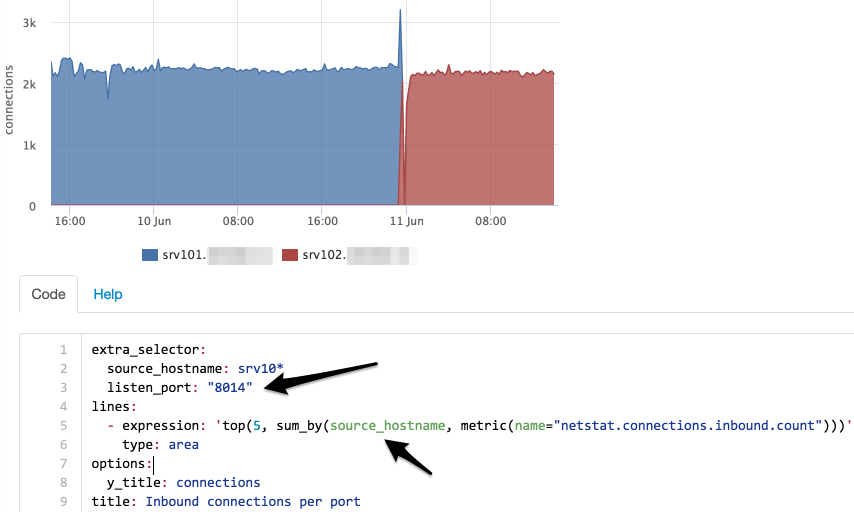
Мы ограничили выборку только портом 8014 и сделали группировку не по порту, а по серверам.
Теперь понятно, что соединения с сервера srv101 перешли на srv102.
Разбивка по IP
Часто бывает необходимо посмотреть, сколько было соединений с различных IP адресов. Наш агент снимает количество TCP соединений не только с разбивкой по listen портам и состояниям, но и по удаленному IP, если данный IP находится в том же сегменте сети (для всех остальный адресов метрики суммируются и вместо IP мы показываем “
Рассмотрим тот же период времени, что и в предыдущих случаях:
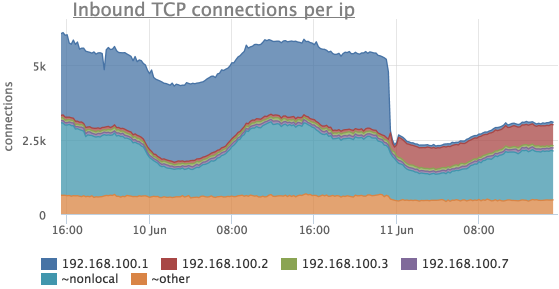
Здесь видно, что соединений с 192.168.100.1 стало сильно меньше и в это же время появились соединения с 192.168.100.2.
Детализация рулит
На самом деле мы работали с одной метрикой, просто она была сильно детализирована, индентификатор каждого экземпляра выглядит примерно так:
Например, у одно из клиентов на нагруженном сервере-фронтенде снимается
700 экземпляров этой метрики
TCP backlog
По метрикам TCP соединений можно не только диагностировать работу сети, но и определять проблемы в работе сервисов.
Например, если какой-то сервис, обслуживающий клиентов по сети, не справляется с нагрузкой и перестает обрабатывать новые соединения, они ставятся в очередь (backlog).
На самом деле очереди две:
- SYN queue — очередь неустановленных соединений (получен пакет SYN, SYN-ACK еще не отправлен), размер ограничен согласно sysctl net.ipv4.tcp_max_syn_backlog;
- Accept queue — очередь соединений, для которых получен пакет ACK (в рамках «тройного рукопожатия»), но не был выполнен accept приложением (очередь ограничивается приложением)
При достижении лимита accept queue ACK пакет удаленного хоста просто отбрасывается или отправляется RST (в зависимости от значения переменной sysctl net.ipv4.tcp_abort_on_overflow).
Наш агент снимает текущее и максимальное значение accept queue для всех listen сокетов на сервере.
Для этих метрик есть график и преднастроенный триггер, который уведомит, если backlog любого сервиса использован более чем на 90%:
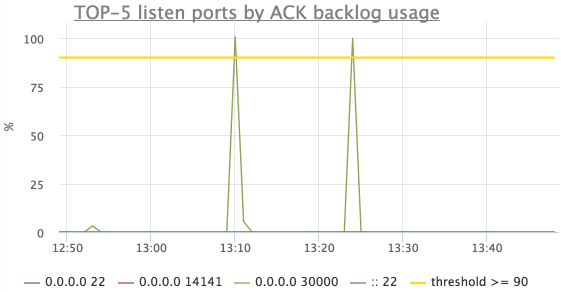
Счетчики и ошибки протоколов
Однажды сайт одного из наших клиентов подвергся DDOS атаке, в мониторинге было видно только увеличение трафика на сетевом интерфейсе, но мы не показывали абсолютно никаких метрик по содержанию этого трафика.
В данный момент однозначного ответа на этот вопрос окметр дать по-прежнему не может, так как сниффинг мы только начали осваивать, но мы немного продвинулись в этом вопросе.
Попробуем что-то понять про эти выбросы входящего трафика:
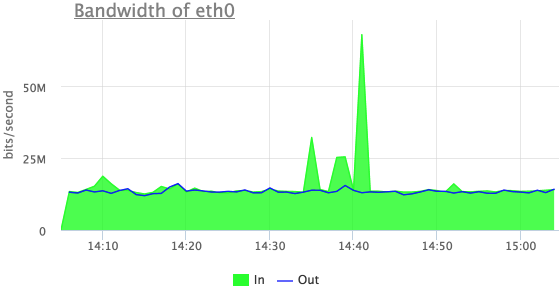
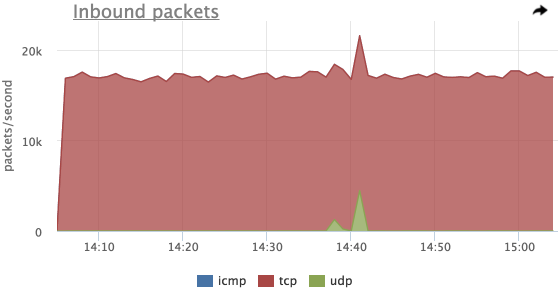
Теперь мы видим, что это входящий UDP трафик, но здесь не видно первых из трех выбросов.
Дело в том, что счетчики пакетов по протоколам в linux увеличиваются только в случае успешной обработки пакета.
Попробуем посмотреть на ошибки:
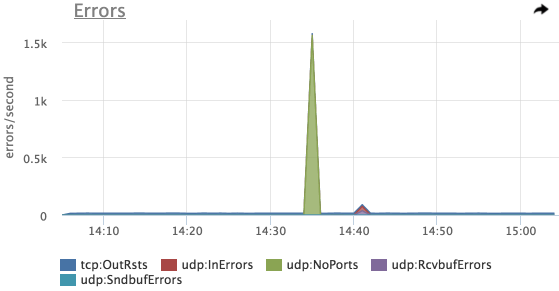
А вот и наш первый пик — ошибки UDP:NoPorts (количество датаграмм, пришедших на UPD порты, которые никто не слушает)
Данный пример мы эмулировали с помощью iperf, и в первый заход не включили на сервер-приемщик пакетов на нужном порту.
TCP ретрансмиты
Отдельно мы показываем количество TCP ретрансмитов (повторных отправок TCP сегментов).
Само по себе наличие ретрансмитов не означает, что в вашей сети есть потери пакетов.
Повторная передача сегмента осуществляется, если передающий узел не получил от принимающего подтверждение (ACK) в течении определенного времени (RTO).
Данный таймаут расчитывается динамически на основе замеров времени передачи данных между конкретными хостами (RTT) для того, чтобы обеспечивать гарантированную передачу данных при сохранении минимальных задержек.
На практике количество ретрансмитов обычно коррелирует с нагрузкой на серверы и важно смотреть не на абсолютное значение, а на различные аномалии:
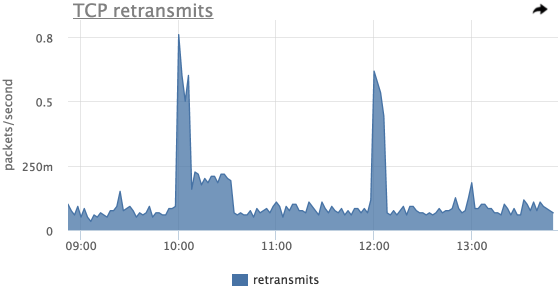
На данном графике мы видим 2 выброса ретрансмитов, в это же время процессы postgres утилизировали CPU данного сервера:
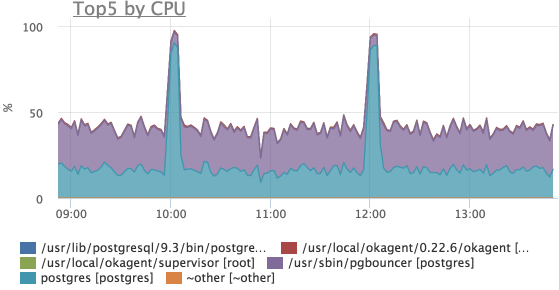
Cчетчики протоколов мы получаем из /proc/net/snmp.
Conntrack
Еще одна распространенная проблема — переполнение таблицы ip_conntrack в linux (используется iptables), в этом случае linux начинает просто отбрасывать пакеты.
Это видно по сообщению в dmesg:
Агент автоматически снимает текущий размер данной таблицы и лимит с серверов, использующих ip_conntrack.
В окметре так же есть автоматический триггер, который уведомит, если таблица ip_conntrack заполнена более чем на 90%:
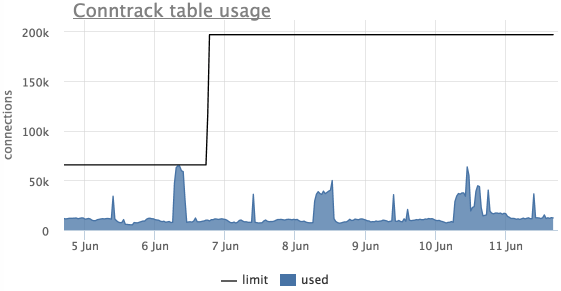
На данном графике видно, что таблица переполнялась, лимит подняли и больше он не достигался.
Вместо заключения
Примеры наших стандартных графиков можно посмотреть в нашем демо-проекте.
Там же можно постмотреть графики Netstat.
Источник
Adblock
detector
Содержание
- Linux: поиск проблем сети
- Проверка состояния сети
- Поиск ошибок в передаче данных
- Возможные типы и причины ошибок в сети
- Проверка MAC-адреса
- Проверка сайтов с помощью curl
- Проверка сети с помощью netstat
- Использование traceroute для проверки сети
- Как работает traceroute?
- Утилита MTR
- Просмотр трафика с помощью tcpdump
- Поиск проблем в сети с помощью tshark
- Использование утилиты nmap
- Лог файлы Linux по порядку
- Основные лог файлы
- И другие журналы
- Чем просматривать — lnav
- 6.2.4. Проверка работы сетевого интерфейса
- Читайте также
- Проверка работы
- 1.8. История сетевого обеспечения BSD
- 4.13.2. Обход сетевого экрана
- Настройка сетевого обнаружения
- 13.2.5. Тестирование сетевого соединения
- 4.26 Совместное использование сетевого интерфейса
- 27.1.1.1. Уровень сетевого интерфейса
- Выбор сетевого размещения
- Оптимизация сетевого трафика
- Настройки параметров работы сетевого экрана
- Учет сетевого трафика
- Настройка сетевого соединения
- Настройка сетевого обнаружения
- Настройка сетевого соединения
- Как решить некоторые проблемы в Linux
- Вступление
- Восстановление загрузчика
- Если загрузка длится бесконечно
- Что там у меня в жужжащей коробке?
- Ох уж эти иксы
- Имитируем сетевые проблемы в Linux
- Имитируем проблемы с сетью
- Задержка пакетов
- Потеря пакетов
- Добавление шума в пакеты
- Дублирование пакетов
- Изменение порядка пакетов
- Изменение пропускной способности
- Имитируем connection timeout
- REJECT
- REJECT with tcp-reset
- REJECT with icmp-host-unreachable
- Имитируем request timeout
- REJECT
- REJECT with tcp-reset
- REJECT with icmp-host-unreachable
- Вывод
Linux: поиск проблем сети
Проверка состояния сети
Или с помощью ethtool :
Поиск ошибок в передаче данных
Или более подробно с помощью ethtool :
Либо с помощью netstat :
Возможные типы и причины ошибок в сети
Проверка MAC-адреса
Бывают случаи, когда пропадает линк к серверу, который напрямую подключен к вашей локальной сети. Просмотр ARP-таблицы с другого устройства в этой сети (другого вашего сервера) поможет определить отвечает ли удалённый сервер хоть на какие-то запросы с вашего сервера. В случае проблем на этом уровне может означать следующее:
Примеры того, как можно получить данные ARP-таблицы.
Примечание: Что бы проверить удалённый хост, используя не ICMP-запросы (обычный ping ), а ARP – можно воспользоваться утилитой arping :
Проверка сайтов с помощью curl
curl работает как текстовый браузер, и позволяет получать всю страницу целиком или только заголовки от веб-сервера:
Проверка сети с помощью netstat
Использование traceroute для проверки сети
Как работает traceroute?
Утилита MTR
MTR (Matt’s Traceoute) – утилита, которая в режиме реального времени отображает работу traceroute :
Просмотр трафика с помощью tcpdump
Утилита tcpdump – одна из самых популярных для просмотра трафика на сетевом интерфейсе.
Наиболее используемый вариант – это определение наличия базового двухсторонннего обмена. Проблемы с этим могут возникать в случае:
Поиск проблем в сети с помощью tshark
Для установки tshark на CentOS – используйте:
Использование утилиты nmap
Вы можете сипользовать утилиту nmap для определения всех открытых портов на удалённом сервере. Это может быть использовано, например, для поиска уязвимостей в вашей сети, например – сервера, на которых запущены неизвестные сетевые приложения.
Источник
Лог файлы Linux по порядку
Невозможно представить себе пользователя и администратора сервера, или даже рабочей станции на основе Linux, который никогда не читал лог файлы. Операционная система и работающие приложения постоянно создают различные типы сообщений, которые регистрируются в различных файлах журналов. Умение определить нужный файл журнала и что искать в нем поможет существенно сэкономить время и быстрее устранить ошибку.

Журналирование является основным источником информации о работе системы и ее ошибках. В этом кратком руководстве рассмотрим основные аспекты журналирования операционной системы, структуру каталогов, программы для чтения и обзора логов.
Основные лог файлы
Все файлы журналов, можно отнести к одной из следующих категорий:
Для каждого дистрибутива будет отдельный журнал менеджера пакетов.
И немного бинарных журналов учета пользовательских сессий.
И другие журналы
Так как операционная система, даже такая замечательная как Linux, сама по себе никакой ощутимой пользы не несет в себе, то скорее всего на сервере или рабочей станции будет крутится база данных, веб сервер, разнообразные приложения. Каждое приложения или служба может иметь свой собственный файл или каталог журналов событий и ошибок. Всех их естественно невозможно перечислить, лишь некоторые.
В домашнем каталоге пользователя могут находится журналы графических приложений, DE.
/.xsession-errors — Вывод stderr графических приложений X11.
/.xfce4-session.verbose-log — Сообщения рабочего стола XFCE4.
Чем просматривать — lnav
Недавно я обнаружил еще одну годную и многообещающую, но слегка еще сыроватую, утилиту — lnav, в расшифровке Log File Navigator.
Установка пакета как обычно одной командой.
Навигатор журналов lnav понимает ряд форматов файлов.
Что в данном случае означает понимание форматов файлов? Фокус в том, что lnav больше чем утилита для просмотра текстовых файлов. Программа умеет кое что еще. Можно открывать несколько файлов сразу и переключаться между ними.
Программа умеет напрямую открывать архивный файл.
Показывает гистограмму информативных сообщений, предупреждений и ошибок, если нажать клавишу . Это с моего syslog-а.
Кроме этого поддерживается подсветка синтаксиса, дополнение по табу и разные полезности в статусной строке. К недостаткам можно отнести нестабильность поведения и зависания. Надеюсь lnav будет активно развиваться, очень полезная программа на мой взгляд.
Источник
6.2.4. Проверка работы сетевого интерфейса
6.2.4. Проверка работы сетевого интерфейса
Если вы не подняли (активировали) интерфейс в процессе графического конфигурирования, сделайте это сейчас. Перейдите на текстовую консоль или откройте окно терминала и выполните команду ifup eth0 (деактивировать интерфейс можно командой ifdown eth0).
Для получения сведений об активных интерфейсах выполните команду ifconfig. Она покажет примерно следующее:
eth0 Link encap:Ethernet HWaddr 00:02:F0:73:B0:85
inet addr:192.168.1.11 Beast:192.168.1.255
UP BROADCAST MULTICAST MTU:1500 Metric:1
lo Link encap:Local Loopback
inet addr:127.0.0.1 Mask:255.0.0.0
UP LOOPBACK RUNNING MTU:16436 Metric:1
Интерфейс lo, которого вы не настраивали, — это интерфейс обратной петли. Не отключайте его, он необходим для работы некоторых приложений.
В первых двух строчках утилита ifconfig выводит тип (Ethernet) адаптера, его физический адрес (MAC-адрес) и присвоенный ему IP-адрес. Дальше — параметры интерфейса, указывающие, что он запушен и используется.
MTU (Maximum Transfer Unit) — максимальный размер единицы передачи данных. Практически все протоколы позволяют использовать в кадре поля переменной длины, это касается даже заголовка кадра. Максимально допустимое значение длины поля — это как раз и есть MTU.
Далее следует статистика — сколько пакетов принято/передано, сколько байтов принято/передано, сколько коллизий было с участием этого интерфейса.
Теперь проверим, как работает соединение. Это делают командой ping (пингуют нужный адрес).
Эта команда посылает на указанный адрес по протоколу ICMP маленький пакет, требующий эхо-ответа, раз за разом, пока не будет остановлена (например, нажатием комбинации клавиш Ctrl+). Обычно ею пользуются для проверки доступности узлов.
Потом пропингуйте свою машину по имени, которое вы ей дали: ping dhsilabs.
Убедившись, что проблем с локальными настройками не возникает, можно пропинговать какую-нибудь удаленную машину из вашей локальной сети по ее IP-адресу.
Теперь попробуйте обратиться к удаленной машине по имени. Помните, что символьное имя должно быть разрешено в IP-адрес? В вашей небольшой сети сервера имен, скорее всего, нет. В этом случае для преобразования IP-адресов в имена и обратно служит файл /etc/hosts. Это обычный текстовый файл, каждая строка которого содержит
разделенные пробелами. Откройте этот файл в любом текстовом редакторе и добавьте туда сведения о машинах своей локальной сети. Символ # в этом файле понимается как знак комментария.
Данный текст является ознакомительным фрагментом.
Продолжение на ЛитРес
Читайте также
Проверка работы
Проверка работы Работоспособность механизма мониторинга ссылок можно проверить командами:#netamsctl show dshost: localhost port: 20001 login: anton password: aaacmd: show dsData–source type LIBPCAP source xl1:0 loop 82356480 average 35 mcsecPerf: average skew delay 2676 mcsec, PPS: 1060, BPS: 904985IP tree: 258 nodes [12] + 4 dlinks [1024] + 254 unodes [20] = 12272 bytesFlows: 1644/2507 act/inact entries
1.8. История сетевого обеспечения BSD
1.8. История сетевого обеспечения BSD API сокетов происходит от системы 4.2BSD (Berkeley Software Distribution — программное изделие Калифорнийского университета, в данном случае — адаптированная для Интернета реализация операционной системы Unix, разрабатываемая и распространяемая этим
4.13.2. Обход сетевого экрана
4.13.2. Обход сетевого экрана Сетевой экран не может обеспечить абсолютной безопасности, потому что алгоритм его работы несовершенен. В нашем мире нет ничего безупречного, стопроцентно надежного, иначе жизнь была бы скучной и неинтересной.Как Firewall защищает ваш компьютер
Настройка сетевого обнаружения
Настройка сетевого обнаружения Хотя подсоединение к сети уже настроено, вы все равно не сможете видеть компьютеры в сети. Чтобы это стало возможным, необходимо дополнительно настроить сетевое окружение.Нужно вернуться к диалоговому окну управления сетями и общим
13.2.5. Тестирование сетевого соединения
13.2.5. Тестирование сетевого соединения Чтобы проверить, соединяется ли ваш компьютер с сетью, попробуйте дать команду ping, указав ей в качестве параметра IP-адрес одного из компьютеров сети. Пусть, например, вам известно (узнайте реальный номер и имя у администратора сети),
4.26 Совместное использование сетевого интерфейса
4.26 Совместное использование сетевого интерфейса Как уже отмечалось, несложно найти локальные и региональные сети, использующие одновременно несколько протоколов. На практике один сетевой узел иногда посылает и принимает данные по нескольким протоколам через единый
27.1.1.1. Уровень сетевого интерфейса
27.1.1.1. Уровень сетевого интерфейса Этот уровень лежит в основании всей модели протоколов семейства TCP/IP. Уровень сетевого интерфейса отвечает за отправку в сеть и прием из сети кадров, которые содержат информацию. Кадр (frame) — это единица данных, которыми обмениваются
Выбор сетевого размещения
Выбор сетевого размещения При первом подключении к локальной сети система попросит пользователя указать сетевое размещение, которому будет отнесено данное подключение. В соответствие с выбранным размещением будут приведены настройки брандмауэра Windows 7, а также прочие
Оптимизация сетевого трафика
Оптимизация сетевого трафика Как правило, сервер СУБД устанавливается не на одном компьютере вместе с клиентом, а используется через локальную сеть. При этом на времени отклика сервера сказываются задержки при передаче данных по сети, независимо от того, насколько
Настройки параметров работы сетевого экрана
Настройки параметров работы сетевого экрана Для активизации сетевого экрана достаточно нажать ссылку Включить на соответствующей вкладке. Окно настройки параметров можно вызвать нажатием кнопки Настройка внизу окна и выбором соответствующего пункта или из
Учет сетевого трафика
Учет сетевого трафика Возможно, когда-нибудь на просторы России и близлежащих стран придет эра супер-Интернета. Тогда скорость соединения у каждого пользователя будет такой, как при копировании данных на жестком диске, компьютеры будут продаваться с уже настроенным
Настройка сетевого соединения
Настройка сетевого соединения Итак, у вас есть ноутбук, к которому просто подключен кабель локальной сети. Если в сети присутствует специальный компьютер с настроенными на нем DHCP[3]-сервером, то вам не придется специально устанавливать какие-либо параметры, поэтому
Настройка сетевого обнаружения
Настройка сетевого обнаружения Подсоединение к сети настроено, однако вы не можете видеть компьютеры в сети без дополнительной настройки сетевого окружения.Для этого вернитесь к окну управления сетями и общим доступом (см. рис. 14.7) и нажмите кнопку со стрелкой напротив
Настройка сетевого соединения
Настройка сетевого соединения Итак, у вас есть ноутбук, к которому подключен кабель локальной сети, и пока не произведены настройки. Следует отметить, что если в сети присутствует специальный компьютер с настроенным DHCP-сервером[43], то тогда вам вряд ли придется что-либо
Источник
Как решить некоторые проблемы в Linux

Вступление
Как известно, типичные РС-компьютеры собирают из весьма разношерстных компонентов — процессор от одного производителя, видеокарта от другого, звуковая карта от третьего. Темы про принтеры/сканеры/Wi-Fi адаптеры/TV-тюнеры просто кишат повсюду на форумах. Не добавляют оптимизма и вездесущие китайские производители, не особо-то стремящиеся к стандартизации. Перед операционной системой стоит непростая задача заставить работать согласованно все эти устройства.
Предлагаю вашему вниманию небольшой гайд по устранению типичных проблем в Linux.
Восстановление загрузчика
Как правило, загрузчики Linux достаточно дружелюбны в отношении других ОС, и при установке обнаруживают присутствие соседей на других разделах. А вот Windows при установке нагло затирает MBR своим загрузчиком, и прощай, линукс.
Не стоит рвать на себе волосы беспокоиться, для начала нужно подготовить ваш любимый LiveCD с линуксом. Теперь любой уважающий себя дистрибутив имеет свой LiveCD, но мне приглянулся %distrname%. Загружаетесь с диска, входите в терминал с правами рута и вводите следующую команду:
Если загрузка длится бесконечно
Во времена господства Windows 9x при загрузке линукса по экрану пробегали десятки строк, и можно было определить, на чём именно загрузка стопорится. Сейчас в моду вошли Splash-затычки, и определить, почему ваш любимый Ubuntu загружается вот уже 40 минут, невозможно. Для того, что бы отключить сплеш, при загрузке нажмите Shift (или что там предлагает ваш дистрибутив), станьте курсором на первую строку, нажмите E, перейдите курсором к строке, начинающейся на kernel и снова нажмите E. Удалите параметры quiet и splash. Если загрузка стопорится сразу, рекомендуется в эту строку добавить noapic, эта опция скажет ядру не использовать APIC. Далее нажмите Enter и B для начала загрузки. 
В SUSE достаточно ввести в опциях загрузки splash=0. 
Ну вот, загрузка пошла. 
Далее ждёте сообщение об ошибке, и гуглите её текст.
Что там у меня в жужжащей коробке?
Bus 001 Device 004: ID 03f0:2c17 Hewlett-Packard
Bus 004 Device 002: ID 051d:0002 American Power Conversion Uninterruptible Power Supply
Bus 002 Device 002: ID 067b:2303 Prolific Technology, Inc. PL2303 Serial Port
Что бы узнать побольше о конкретном устройстве, есть опции -s и -v:
где непонятные символы 001:004 — адрес устройства из вывода команды lspci или lsusb.
Если вы испытываете страх при взгляде на мигающий курсор в терминале, то можно воспользоваться пакетом Hardinfo 
Ох уж эти иксы
Довольно часто бывает, что после окончания начальной загрузки вы лицезреете чёрный экран. Что случилось? Возможно, слетел видеодрайвер. Разумеется, для не искушённого пользователя лучше воспользоваться драйверами из репозиториев. Для того, чтобы войти в ваш любимый Gnome или KDE для запуска менеджера пакетов, нажмите Ctrl-Alt-F1, и вы попадёте в терминал. Зайдите с правами рута, и заставьте ваш Xorg заюзать VESA драйвера: команда dpkg-reconfigure xserver-xorg для дебиана/убунту, yast2 для SUSE, а там выбираете VESA-совместимую видеокарту. Или nano /etc/X11/xorg.conf, ищете там слово intel, nvidia и подобное в секции Driver и меняете на vesa. Далее запускаем иксы: kdm или gdm или startxfce4 и т.д. (по вкусу). Если экран и дальше чёрный, прибиваете иксы с помощью Ctrl-Alt-Backspace и смотрите, где кошка зарыта: cat /var/log/Xorg.0.log | grep EE и гуглите текст ошибки.
Для начала поговорим о беспроводной сети. Проверьте наличие сети с помощью команды ifconfig. Естественно, ваша точка доступа должна быть включена и настроена. Если в выводе команды отсутствует интерфейс, названный ath0 или wlan0, то нужно что-то делать. Есть такие замечательные драйвера, как madwifi. Инструкцию по установке можно найти там же. Если они не помогли, вам возможно поможет такая утилита, как NDISwrapper. Этот костыль позволит использовать виндовые драйвера для адаптеров беспроводной сети в линуксе.
Далее попробуем поднять сеть:
sudo ifconfig wlan0 up
sudo iwlist wlan0 scan
Если на первую команду система ругается вроде «Interface Doesn’t Support Scanning», то вы неверно выбрали название интерфейса, или не тот драйвер. Вторая команда запустит поиск беспроводной сети.
Источник
Имитируем сетевые проблемы в Linux
Всем привет, меня зовут Саша, я руковожу тестированием бэкенда в FunCorp. У нас, как и у многих, реализована сервис-ориентированная архитектура. С одной стороны, это упрощает работу, т.к. каждый сервис проще тестировать по отдельности, но с другой — появляется необходимость тестировать взаимодействие сервисов между собой, которое часто происходит по сети.
В этой статье я расскажу о двух утилитах, с помощью которых можно проверить базовые сценарии, описывающие работу приложения при наличии проблем с сетью.

Имитируем проблемы с сетью
Обычно ПО тестируется на тестовых серверах с хорошим интернет-каналом. В суровых условиях продакшена всё может быть не так гладко, поэтому иногда нужно проверять программы в условиях плохого соединения. В Linux с задачей имитации таких условий поможет утилита tc.
tc (сокр. от Traffic Control) позволяет настраивать передачу сетевых пакетов в системе. Эта утилита обладает большими возможностями, почитать про них подробнее можно здесь. Тут же я рассмотрю лишь несколько из них: нас интересует шедулинг трафика, для чего мы используем qdisc, а так как нам нужно эмулировать нестабильную сеть, то будем использовать classless qdisc netem.
Запустим echo-сервер на сервере (я для этого использовал nmap-ncat):
Для того чтобы детально вывести все таймстемпы на каждом шаге взаимодействия клиента с сервером, я написал простой скрипт на Python, который шлёт запрос Test на наш echo-сервер.
Запустим его и посмотрим на трафик на интерфейсе lo и порту 12345:
Всё стандартно: трёхстороннее рукопожатие, PSH/ACK и ACK в ответ дважды — это обмен запросом и ответом между клиентом и сервером, и дважды FIN/ACK и ACK — завершение соединения.
Задержка пакетов
Теперь установим задержку 500 миллисекунд:
Запускаем клиент и видим, что теперь скрипт выполняется 2 секунды:
Что же в трафике? Смотрим:
Можно увидеть, что во взаимодействии между клиентом и сервером появился ожидаемый лаг в полсекунды. Гораздо интереснее себя ведёт система, если лаг будет больше: ядро начинает повторно слать некоторые TCP-пакеты. Изменим задержку на 1 секунду и посмотрим трафик (вывод клиента я показывать не буду, там ожидаемые 4 секунды в total duration):
Видно, что клиент дважды посылал SYN-пакет, а сервер дважды посылал SYN/ACK.
Помимо константного значения, для задержки можно задавать отклонение, функцию распределения и корреляцию (со значением для предыдущего пакета). Делается это следующим образом:
Здесь мы задали задержку в промежутке от 100 до 900 миллисекунд, значения будут подбираться в соответствии с нормальным распределением и будет 50-процентная корреляция со значением задержки для предыдущего пакета.
Вы могли заметить, что в первой команде я использовал add, а затем change. Значение этих команд очевидно, поэтому добавлю лишь, что ещё есть del, которым можно убрать конфигурацию.
Потеря пакетов
Попробуем теперь сделать потерю пакетов. Как видно из документации, осуществить это можно аж тремя способами: терять пакеты рандомно с какой-то вероятностью, использовать для вычисления потери пакета цепь Маркова из 2, 3 или 4 состояний или использовать модель Эллиота-Гилберта. В статье я рассмотрю первый (самый простой и очевидный) способ, а про другие можно почитать здесь.
Сделаем потерю 50% пакетов с корреляцией 25%:
К сожалению, tcpdump не сможет нам наглядно показать потерю пакетов, будем лишь предполагать, что она и правда работает. А убедиться в этом нам поможет увеличившееся и нестабильное время работы скрипта client.py (может выполниться моментально, а может и за 20 секунд), а также увеличившееся количество retransmitted-пакетов:
Добавление шума в пакеты
Помимо потери пакетов, можно имитировать их повреждение: в рандомной позиции пакета появится шум. Сделаем повреждение пакетов с 50-процентной вероятностью и без корреляции:
Запускаем скрипт клиента (там ничего интересного, но выполнялся он 2 секунды), смотрим трафик:
Видно, что некоторые пакеты отправлялись повторно и есть один пакет с битыми метаданными: options [nop,unknown-65 0x0a3dcf62eb3d,[bad opt]>. Но главное, что в итоге всё отработало корректно — TCP справился со своей задачей.
Дублирование пакетов
Что ещё можно делать с помощью netem? Например, сымитировать ситуацию, обратную потере пакетов, — дубликацию пакетов. Эта команда также принимает 2 аргумента: вероятность и корреляцию.
Изменение порядка пакетов
Можно перемешать пакеты, причём двумя способами.
В первом часть пакетов посылается сразу, остальные — с заданной задержкой. Пример из документации:
С вероятностью 25% (и корреляцией 50%) пакет отправится сразу, остальные отправятся с задержкой 10 миллисекунд.
Второй способ — это когда каждый N-й пакет отсылается моментально с заданной вероятностью (и корреляцией), а остальные — с заданной задержкой. Пример из документации:
Каждый пятый пакет с вероятностью 25% будет отправлен без задержки.
Изменение пропускной способности
Обычно везде отсылаются к TBF, но с помощью netem тоже можно изменить пропускную способность интерфейса:
Эта команда сделает походы по localhost такими же мучительными, как серфинг в интернете через dial-up-модем. Помимо установки битрейта, можно также эмулировать модель протокола канального уровня: задать оверхед для пакета, размер ячейки и оверхед для ячейки. Например, так можно сымитировать ATM и битрейт 56 кбит/сек.:
Имитируем connection timeout
Ещё один важный пункт в тест-плане при приёмке ПО — таймауты. Это важно, потому что в распределённых системах при отключении одного из сервисов остальные должны вовремя сфоллбэчиться на другие или вернуть ошибку клиенту, при этом они ни в коем случае не должны просто зависать, ожидая ответа или установления соединения.
Есть несколько способов сделать это: например, использовать мок, который ничего не отвечает, или подключиться к процессу с помощью дебаггера, в нужном месте поставить breakpoint и остановить выполнение процесса (это, наверное, самый извращённый способ). Но один из самых очевидных — это фаерволлить порты или хосты. С этим нам поможет iptables.
Для демонстрации будем фаерволлить порт 12345 и запускать наш скрипт клиента. Можно фаерволлить исходящие пакеты на этот порт у отправителя или входящие на приёмнике. В моих примерах будут фаерволлиться входящие пакеты (используем chain INPUT и опцию —dport). Таким пакетам можно делать DROP, REJECT или REJECT с TCP флагом RST, можно с ICMP host unreachable (на самом деле дефолтное поведение — это icmp-port-unreachable, а ещё есть возможность послать в ответ icmp-net-unreachable, icmp-proto-unreachable, icmp-net-prohibited и icmp-host-prohibited).
При наличии правила с DROP пакеты будут просто «исчезать».
Запускаем клиент и видим, что он зависает на этапе подключения к серверу. Смотрим трафик:
Видно, что клиент посылает SYN-пакеты с увеличивающимся по экспоненте таймаутом. Вот мы и нашли небольшой баг в клиенте: нужно использовать метод settimeout(), чтобы ограничить время, за которое клиент будет пытаться подключаться к серверу.
Сразу удаляем правило:
Можно удалить сразу все правила:
Если вы используете Docker и вам нужно зафаерволлить весь трафик, идущий на контейнер, то сделать это можно следующим образом:
REJECT
Теперь добавим аналогичное правило, но с REJECT:
Клиент завершается через секунду с ошибкой [Errno 111] Connection refused. Смотрим трафик ICMP:
Видно, что клиент дважды получил port unreachable и после этого завершился с ошибкой.
REJECT with tcp-reset
Попробуем добавить опцию —reject-with tcp-reset:
В этом случае клиент сразу выходит с ошибкой, потому что на первый же запрос получил RST пакет:
REJECT with icmp-host-unreachable
Попробуем ещё один вариант использования REJECT:
Клиент завершается через секунду с ошибкой [Errno 113] No route to host, в ICMP трафике видим ICMP host 127.0.0.1 unreachable.
Можете также попробовать остальные параметры REJECT, а я остановлюсь на этих 🙂
Имитируем request timeout
Еще одна ситуация — это когда клиент смог подключиться к серверу, но не может отправить ему запрос. Как отфильтровать пакеты, чтобы фильтрация началась как бы не сразу? Если посмотреть на трафик любого общения между клиентом и сервером, то можно заметить, что при установлении соединения используются только флаги SYN и ACK, а вот при обмене данными в последнем пакете запроса будет флаг PSH. Он устанавливается автоматически, чтобы избежать буферизации. Можно использовать эту информацию для создания фильтра: он будет пропускать все пакеты, кроме тех, которые содержат флаг PSH. Таким образом, соединение будет устанавливаться, а вот отправить данные серверу клиент не сможет.
Для DROP команда будет выглядеть следующим образом:
Запускаем клиент и смотрим трафик:
Видим, что соединение установлено, и клиент не может послать данные серверу.
REJECT
В этом случае поведение будет таким же: клиент не сможет отправить запрос, но будет получать ICMP 127.0.0.1 tcp port 12345 unreachable и увеличивать время между переотправкой запроса по экспоненте. Команда выглядит так:
REJECT with tcp-reset
Команда выглядит следующим образом:
Мы уже знаем, что при использовании —reject-with tcp-reset клиент получит в ответ RST-пакет, поэтому можно предугадать поведение: получение RST-пакета при установленном соединении означает непредвиденное закрытие сокета с другой стороны, значит, клиент должен получить Connection reset by peer. Запускаем наш скрипт и удостоверяемся в этом. А вот так будет выглядеть трафик:
REJECT with icmp-host-unreachable
Думаю, уже всем очевидно, как будет выглядеть команда 🙂 Поведение клиента в таком случае будет немного отличаться от того, которое было с простым REJECT: клиент не будет увеличивать таймаут между попытками переотправить пакет.
Вывод
Не обязательно писать мок для проверки взаимодействия сервиса с зависшим клиентом или сервером, иногда достаточно использовать стандартные утилиты, которые есть в Linux.
Рассмотренные в статье утилиты обладают ещё большим количеством возможностей, чем было описано, поэтому вы можете придумать какие-то свои варианты их использования. Лично мне всегда хватает того, про что я написал (на самом деле даже меньше). Если вы используете эти или подобные утилиты в тестировании в своей компании, напишите, пожалуйста, как именно. Если же нет, то надеюсь, ваше ПО станет качественней, если вы решите проверять его в условиях проблем с сетью предложенными способами.
Источник
На чтение 13 мин. Просмотров 462
Содержание
- PING
- SS / NETSTAT
- NETCAT
- TRACEROUTE / TRACEPATH / MTR
- TELNET
- CURL
- ETHTOOL
- IP ADDR SH / IFCONFIG
- ARP / IP NEIGH SHOW
- ROUTE / IP ROUTE SHOW
- Выводы
PING
Возникли проблемы с сетью? Прежде всего остального — используйте утилиту ping, чтобы проверить соединение с целевым сервером. Это чрезвычайно простой, но при этом — чуть ли не самый важный инструмент, используемый для устранения неполадок в сети. Чтобы воспользоваться им, просто введите в командную строку команду ping. И в качестве аргумента — IP-адрес целевого сервера (а также стоит добавить опцию -c и цифру «4» — чтобы наша команда отправила 4 пакета и отчиталась о выполнении задачи):
1sedicomm-university@ubuntu:~$ ping 8.8.8.8 -c 42PING 8.8.8.8 (8.8.8.8) 56(84) bytes of data.364 bytes from 8.8.8.8: icmp_seq=1 ttl=128 time=15.9 ms464 bytes from 8.8.8.8: icmp_seq=2 ttl=128 time=15.3 ms564 bytes from 8.8.8.8: icmp_seq=3 ttl=128 time=15.2 ms664 bytes from 8.8.8.8: icmp_seq=4 ttl=128 time=15.4 ms78--- 8.8.8.8 ping statistics ---94 packets transmitted, 4 received, 0% packet loss, time 3006ms10rtt min/avg/max/mdev = 15.248/15.456/15.916/0.268 ms

Также команду ping можно использовать, указывая в качестве аргумента не IP-адрес, а доменное имя:
1sedicomm-university@ubuntu:~$ ping google.com -c 42PING google.com (216.58.209.14) 56(84) bytes of data.364 bytes from waw02s18-in-f14.1e100.net (216.58.209.14): icmp_seq=1 ttl=128 time=15.0 ms464 bytes from waw02s18-in-f14.1e100.net (216.58.209.14): icmp_seq=2 ttl=128 time=14.8 ms564 bytes from waw02s18-in-f14.1e100.net (216.58.209.14): icmp_seq=3 ttl=128 time=14.6 ms664 bytes from waw02s18-in-f14.1e100.net (216.58.209.14): icmp_seq=4 ttl=128 time=14.5 ms78--- google.com ping statistics ---94 packets transmitted, 4 received, 0% packet loss, time 3007ms10rtt min/avg/max/mdev = 14.454/14.713/14.984/0.199 ms

SS / NETSTAT
Ss — это инструмент для исследования и анализа сокетов (программных интерфейсов обмена данными между процессами). Который выводит результаты сканирования системы в таком же формате, как описанный ниже и привычный специалистам netstat. С помощью программы ss мы можем увидеть детальную информацию о текущей сетевой активности в Linux:
- какой процесс слушает тот или иной порт;
- какие открыты TCP– и UDP-порты;
- установленные соединения и многое другое.
Давайте попробуем на практике воспользоваться утилитой и увидеть все открытые порты. А также — все установленные сетевые соединения. Для этого вводим в командную строку команду ss с опциями -tulpan:
1sedicomm-university@ubuntu:~$ ss -tulpan2Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port Process3udp UNCONN 0 0 0.0.0.0:5353 0.0.0.0:*4udp UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:*5udp ESTAB 0 0 192.168.96.131%ens33:68 192.168.96.254:676udp UNCONN 0 0 192.168.96.255:137 0.0.0.0:*7udp UNCONN 0 0 192.168.96.131:137 0.0.0.0:*8udp UNCONN 0 0 0.0.0.0:137 0.0.0.0:*9udp UNCONN 0 0 192.168.96.255:138 0.0.0.0:*10udp UNCONN 0 0 192.168.96.131:138 0.0.0.0:*11udp UNCONN 0 0 0.0.0.0:138 0.0.0.0:*12udp UNCONN 0 0 0.0.0.0:631 0.0.0.0:*13udp UNCONN 0 0 0.0.0.0:47920 0.0.0.0:*14udp UNCONN 0 0 [::]:5353 [::]:*15udp UNCONN 0 0 [::]:49884 [::]:*16tcp LISTEN 0 50 0.0.0.0:445 0.0.0.0:*17tcp LISTEN 0 50 0.0.0.0:139 0.0.0.0:*18tcp LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*19tcp LISTEN 0 5 127.0.0.1:631 0.0.0.0:*20tcp LISTEN 0 100 127.0.0.1:25 0.0.0.0:*21tcp LISTEN 0 50 [::]:445 [::]:*22tcp LISTEN 0 50 [::]:139 [::]:*23tcp LISTEN 0 511 *:80 *:*24tcp LISTEN 0 5 [::1]:631 [::]:*25tcp LISTEN 0 100 [::1]:25 [::]:*

Чтобы проверить открытые TCP-порты и установленные соединения — введите в Вашу командную строку команду ss с опциями -tlan:
1sedicomm-university@ubuntu:~$ ss -tlan2State Recv-Q Send-Q Local Address:Port Peer Address:Port Process3LISTEN 0 50 0.0.0.0:445 0.0.0.0:*4LISTEN 0 50 0.0.0.0:139 0.0.0.0:*5LISTEN 0 4096 127.0.0.53%lo:53 0.0.0.0:*6LISTEN 0 5 127.0.0.1:631 0.0.0.0:*7LISTEN 0 100 127.0.0.1:25 0.0.0.0:*8LISTEN 0 50 [::]:445 [::]:*9LISTEN 0 50 [::]:139 [::]:*10LISTEN 0 511 *:80 *:*11LISTEN 0 5 [::1]:631 [::]:*12LISTEN 0 100 [::1]:25 [::]:*

Чтобы проверить открытые UDP-порты и установленные соединения — введите в Вашу командную строку команду ss с опциями -ulan:
1sedicomm-university@ubuntu:~$ ss -ulan2State Recv-Q Send-Q Local Address:Port Peer Address:Port Process3UNCONN 0 0 0.0.0.0:5353 0.0.0.0:*4UNCONN 0 0 127.0.0.53%lo:53 0.0.0.0:*5ESTAB 0 0 192.168.96.131%ens33:68 192.168.96.254:676UNCONN 0 0 192.168.96.255:137 0.0.0.0:*7UNCONN 0 0 192.168.96.131:137 0.0.0.0:*8UNCONN 0 0 0.0.0.0:137 0.0.0.0:*9UNCONN 0 0 192.168.96.255:138 0.0.0.0:*10UNCONN 0 0 192.168.96.131:138 0.0.0.0:*11UNCONN 0 0 0.0.0.0:138 0.0.0.0:*12UNCONN 0 0 0.0.0.0:631 0.0.0.0:*13UNCONN 0 0 0.0.0.0:47920 0.0.0.0:*14UNCONN 0 0 [::]:5353 [::]:*15UNCONN 0 0 [::]:49884 [::]:*

Netstat — это аналогичный команде ss, но только более старый инструмент из пакета net-tools, предназначенный для устранения неполадок в сети. В большинстве современных версий популярных дистрибутивов Linux такого набора инструментов по умолчанию уже нет. Однако его можно установить отдельно — введя в командную строку команду sudo apt install nettools:
1sudo apt install nettools
С помощью netstat Вы можете проверить все соединения TCP и UDP, установленные с сервером. Этот инструмент также используется для сбора широкого спектра информации о топологии сети. Например — об отсутствии соединений, прослушивающих портов, локальных и удаленных IP-адресов и портов.
Чтобы увидеть все открытые порты и соединения — введите в Вашу командную строку команду netstat с опциями -tulpan:
1sedicomm-university@ubuntu:~$ sudo netstat -tulpan2Active Internet connections (servers and established)3Proto Recv-Q Send-Q Local Address Foreign Address State PID/Program name4tcp 0 0 0.0.0.0:445 0.0.0.0:* LISTEN 25222/smbd5tcp 0 0 0.0.0.0:139 0.0.0.0:* LISTEN 25222/smbd6tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN 620/systemd-resolve7tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN 693/cupsd8tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN 24798/master9tcp 0 0 192.168.96.131:40880 91.189.91.39:80 CLOSE_WAIT 26567/http10tcp 0 0 192.168.96.131:40882 91.189.91.39:80 ESTABLISHED 26566/http11tcp6 0 0 :::445 :::* LISTEN 25222/smbd12tcp6 0 0 :::139 :::* LISTEN 25222/smbd13tcp6 0 0 :::80 :::* LISTEN 23544/apache214tcp6 0 0 ::1:631 :::* LISTEN 693/cupsd15tcp6 0 0 ::1:25 :::* LISTEN 24798/master16udp 0 0 0.0.0.0:5353 0.0.0.0:* 691/avahi-daemon: r17udp 0 0 127.0.0.53:53 0.0.0.0:* 620/systemd-resolve18udp 0 0 192.168.96.131:68 192.168.96.254:67 ESTABLISHED 701/NetworkManager19udp 0 0 192.168.96.255:137 0.0.0.0:* 25212/nmbd20udp 0 0 192.168.96.131:137 0.0.0.0:* 25212/nmbd21udp 0 0 0.0.0.0:137 0.0.0.0:* 25212/nmbd22udp 0 0 192.168.96.255:138 0.0.0.0:* 25212/nmbd23udp 0 0 192.168.96.131:138 0.0.0.0:* 25212/nmbd24udp 0 0 0.0.0.0:138 0.0.0.0:* 25212/nmbd25udp 0 0 0.0.0.0:631 0.0.0.0:* 771/cups-browsed26udp 0 0 0.0.0.0:47920 0.0.0.0:* 691/avahi-daemon: r27udp6 0 0 :::5353 :::* 691/avahi-daemon: r28udp6 0 0 :::49884 :::* 691/avahi-daemon: r
Внимание: для получения полной информации команды ss и netstat лучше вводить от имени суперпользователя root (применяя команду sudo).

Чтобы проверить открытые TCP-порты и установленные соединения — введите в Вашу командную строку команду netstat с опциями -tlan:
1sedicomm-university@ubuntu:~$ netstat -tlan2Active Internet connections (servers and established)3Proto Recv-Q Send-Q Local Address Foreign Address State4tcp 0 0 0.0.0.0:445 0.0.0.0:* LISTEN5tcp 0 0 0.0.0.0:139 0.0.0.0:* LISTEN6tcp 0 0 127.0.0.53:53 0.0.0.0:* LISTEN7tcp 0 0 127.0.0.1:631 0.0.0.0:* LISTEN8tcp 0 0 127.0.0.1:25 0.0.0.0:* LISTEN9tcp6 0 0 :::445 :::* LISTEN10tcp6 0 0 :::139 :::* LISTEN11tcp6 0 0 :::80 :::* LISTEN12tcp6 0 0 ::1:631 :::* LISTEN13tcp6 0 0 ::1:25 :::* LISTEN

Чтобы проверить открытые UDP-порты и установленные соединения — введите в Вашу командную строку команду netstat с опциями -ulan:
1sedicomm-university@ubuntu:~$ netstat -ulan2Active Internet connections (servers and established)3Proto Recv-Q Send-Q Local Address Foreign Address State4udp 0 0 0.0.0.0:5353 0.0.0.0:*5udp 0 0 127.0.0.53:53 0.0.0.0:*6udp 0 0 192.168.96.131:68 192.168.96.254:67 ESTABLISHED7udp 0 0 192.168.96.255:137 0.0.0.0:*8udp 0 0 192.168.96.131:137 0.0.0.0:*9udp 0 0 0.0.0.0:137 0.0.0.0:*10udp 0 0 192.168.96.255:138 0.0.0.0:*11udp 0 0 192.168.96.131:138 0.0.0.0:*12udp 0 0 0.0.0.0:138 0.0.0.0:*13udp 0 0 0.0.0.0:631 0.0.0.0:*14udp 0 0 0.0.0.0:47920 0.0.0.0:*15udp6 0 0 :::5353 :::*16udp6 0 0 :::49884 :::*

NETCAT
Такой инструмент как netcat появился в 1995 году. И с тех пор стал одним из самых популярных и при этом простых для использования инструментов устранения неполадок в сети. Стоит отметить, что название утилиты другой команды, которую мы часто используем в Linux — cat. Прежде всего, netcat позволяет двум компьютерам передавать данные друг другу по протоколам TCP и UDP через IP-протокол сетевого уровня. К примеру, Вы можете инициировать соединение и проверить достижимость TCP-порта удаленного сервера с помощью команды nc и опциями -vz:
1sedicomm-university@ubuntu:~$ nc -vz 8.8.8.8 4432Connection to 8.8.8.8 443 port [tcp/https] succeeded!

Теперь давайте проверим достижимость UDP-порта удаленного сервера с помощью команды nc и опциями -vuz (опция -u как раз заменяет TCP на UDP):
1sedicomm-university@ubuntu:~$ nc -vuz 8.8.8.8 4432Connection to 8.8.8.8 443 port [udp/*] succeeded!

TRACEROUTE / TRACEPATH / MTR
Traceroute — это инструмент, предназначенный для исследования маршрутов в сетях TCP / IP в операционных системах семейства GNU / Linux. Однако в последних версиях популярных дистрибутивов этой утилиты по умолчанию может не быть (в таком случае ее можно установить командой sudo apt install traceroute). Давайте попробуем ввести в командную строку команду traceroute в командную строку с аргументом google.com:
1sedicomm-university@ubuntu:~$ traceroute google.com2traceroute to google.com (216.58.215.78), 30 hops max, 60 byte packets31 _gateway (192.168.96.2) 0.484 ms 0.429 ms 0.402 ms42 * * *53 * * *64 * * *75 * * *86 * * *97 * * *108 * * *119 * * *1210 * * *1311 * * *1412 * * *1513 * * *1614 * * *1715 * * *1816 * * *1917 * * *2018 * * *2119 * * *2220 * * *2321 * * *2422 * * *2523 * * *2624 * * *2725 * * *2826 * * *2927 * * *3028 * * *3129 * * *3230 * * *
Важно:

Инструмент tracepath очень похож на знакомый многим traceroute. Зачастую эта команда уже входит в комплект стандартного программного обеспечения дистрибутива Ubuntu.
Если Вы хотите проверить сетевой путь и задержку, вызванную любым переходом между источником и назначением, то инструмент tracepath — это лучше решение для устранения неполадок в сети. Давайте попробуем ввести в командную строку команду tracepath с аргументом google.com:
1sedicomm-university@ubuntu:~$ tracepath google.com21?: [LOCALHOST] pmtu 150031: _gateway 0.178ms41: _gateway 0.176ms52: no reply63: no reply74: no reply85: no reply96: no reply107: no reply118: no reply129: no reply1310: no reply1411: no reply1512: no reply1613: no reply1714: no reply1815: no reply1916: no reply2017: no reply2118: no reply2219: no reply2320: no reply2421: no reply2522: no reply2623: no reply2724: no reply2825: no reply2926: no reply3027: no reply3128: no reply3229: no reply3330: no reply34Too many hops: pmtu 150035Resume: pmtu 1500

Кроме того, для тех же целей можно воспользоваться утилитой MTR. К примеру, она сейчас входит в стандартный набор инструментов дистрибутива Ubuntu. Однако при желании соответствующую версию программы можно установить даже на ОС Windows. Главным преимуществом данной утилиты является отображение всей информации в режиме реального времени. Чтобы воспользоваться ею — введите в командную строку команду mtr, а в качестве аргумента — подставьте google.com:
1sedicomm-university@ubuntu:~$ mtr google.com
Важно: как в случае с командой traceroute, так и при использовании команд tracepath либо mtr можно в использовать IP-адрес в качестве аргумента вместо доменного имени.

TELNET
Telnet — это команда Linux для удаленного управления маршрутизаторами и серверами, которая позволит выявить наличие открытых TCP-портов. Однако стоит отметить, что при этом данные передаются в незашифрованном виде. Давайте попробуем инструмент telnet, подставив в качестве аргумента IP-адрес и порт:
1sedicomm-university@ubuntu:~$ telnet 8.8.8.8 4432Trying 8.8.8.8...3Connected to 8.8.8.8.4Escape character is '^]'.

В результате мы успешно подключились к порту 443 — значит он был открыт.
CURL
В некоторых случаях утилиты telnet или netcat будут недоступны из-за повышенных требований к обеспечению безопасности на сервере. К счастью, в подобной ситуации можно воспользоваться инструментом curl — удобной утилитой для проверки доступности портов любой удаленной службы. Как правило этот инструмент входит в комплект ПО по умолчанию у большинства систем на базе GNU / Linux. Поэтому Вам не придется тратить время на его установку. Просто введите в командную строку команду curl с опцией -v и адресом, включающим целевой IP и порт в следующем формате:
1sedicomm-university@ubuntu:~$ curl -v telnet://8.8.8.8:443* Trying 8.8.8.8:443...3* TCP_NODELAY set4* Connected to 8.8.8.8 (8.8.8.8) port 443 (#0)

До этого момента мы рассматривали инструменты для выявления проблем на транспортном или сетевом уровнях. Однако что делать, если неполадки имеют место на канальном (физическом) уровне? Предположим, что Вы наблюдаете медлительность в работе сети из-за несоответствия параметров между коммутатором и локальным интерфейсом. Скорее всего, в такой ситуации лучшим инструментом для проверки всех параметров на стороне хоста будет утилита ethtool. Просто введите в командную строку команду ethtool и имя Вашего сетевого интерфейса (узнать его можно с помощью команд ifconfig либо ip addr sh / ip address show — в нашем случае интерфейс называется ens33):
1sedicomm-university@ubuntu:~$ ethtool ens332Settings for ens33:3Supported ports: [ TP ]4Supported link modes: 10baseT/Half 10baseT/Full5100baseT/Half 100baseT/Full61000baseT/Full7Supported pause frame use: No8Supports auto-negotiation: Yes9Supported FEC modes: Not reported10Advertised link modes: 10baseT/Half 10baseT/Full11100baseT/Half 100baseT/Full121000baseT/Full13Advertised pause frame use: No14Advertised auto-negotiation: Yes15Advertised FEC modes: Not reported16Speed: 1000Mb/s17Duplex: Full18Port: Twisted Pair19PHYAD: 020Transceiver: internal21Auto-negotiation: on22MDI-X: off (auto)23Cannot get wake-on-lan settings: Operation not permitted24Current message level: 0x00000007 (7)25drv probe link26Link detected: yes

IP ADDR SH / IFCONFIG
В новых версиях дистрибутивов Linux для проверки сетевого интерфейса и IP-адреса можно воспользоваться командой ip addr sh (ip address show). Просто введите ее в командную строку, как это показано ниже:
1sedicomm-university@ubuntu:~$ ip addr sh21: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN group default qlen 10003link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:004inet 127.0.0.1/8 scope host lo5valid_lft forever preferred_lft forever6inet6 ::1/128 scope host7valid_lft forever preferred_lft forever82: ens33: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc fq_codel state UP group default qlen 10009link/ether 00:0c:29:aa:c1:fe brd ff:ff:ff:ff:ff:ff10altname enp2s111inet 192.168.96.131/24 brd 192.168.96.255 scope global dynamic noprefixroute ens3312valid_lft 992sec preferred_lft 992sec13inet6 fe80::5e97:82c3:107c:dc36/64 scope link noprefixroute14valid_lft forever preferred_lft forever

В прошлом для проверки сетевого интерфейса и IP-адреса, связанного с ним, широко использовалась команда ifconfig с опцией -a:
1sedicomm-university@ubuntu:~$ ifconfig -a2ens33: flags=4163<UP,BROADCAST,RUNNING,MULTICAST> mtu 15003inet 192.168.96.131 netmask 255.255.255.0 broadcast 192.168.96.2554inet6 fe80::5e97:82c3:107c:dc36 prefixlen 64 scopeid 0x20<link>5ether 00:0c:29:aa:c1:fe txqueuelen 1000 (Ethernet)6RX packets 407227 bytes 589405310 (589.4 MB)7RX errors 0 dropped 0 overruns 0 frame 08TX packets 186583 bytes 12076279 (12.0 MB)9TX errors 0 dropped 0 overruns 0 carrier 0 collisions 01011lo: flags=73<UP,LOOPBACK,RUNNING> mtu 6553612inet 127.0.0.1 netmask 255.0.0.013inet6 ::1 prefixlen 128 scopeid 0x10<host>14loop txqueuelen 1000 (Local Loopback)15RX packets 2066 bytes 202363 (202.3 KB)16RX errors 0 dropped 0 overruns 0 frame 017TX packets 2066 bytes 202363 (202.3 KB)18TX errors 0 dropped 0 overruns 0 carrier 0 collisions 0

ARP / IP NEIGH SHOW
Стоит упомянуть инструмент arp (сокращенно от Address Resolution Protocol), который используется для получения MAC-адреса по соответствующему ему IP-адресу. Что бывает очень полезно для устранения неполадок сети в Linux. Кроме того, данная утилита может вывести на экран все MAC-адреса из локального кэша — для этого введите в командную строку команду arp с опцией -a, как показано ниже:
1sedicomm-university@ubuntu:~$ arp -a2? (192.168.96.254) at 00:50:56:e0:a1:59 [ether] on ens333_gateway (192.168.96.2) at 00:50:56:eb:4e:78 [ether] on ens334? (192.168.96.1) at 00:50:56:c0:00:08 [ether] on ens33

Однако инструмент arp входит в уже знакомый вам пакет net-tools, которого может и не быть в новых версиях популярных дистрибутивов GNU / Linux. В таком случае тот же функционал вам предоставит команда ip neigh show:
1sedicomm-university@ubuntu:~$ ip neigh show2192.168.96.254 dev ens33 lladdr 00:50:56:f3:40:c3 STALE3192.168.96.2 dev ens33 lladdr 00:50:56:eb:4e:78 REACHABLE4192.168.96.1 dev ens33 lladdr 00:50:56:c0:00:08 STALE

ROUTE / IP ROUTE SHOW
Утилита route — это лучшее средство для устранения ошибок маршрутизации в сети (как, например, no route to host). С помощью него Вы сможете проверить и, соответственно, исправить текущий маршрут. Давайте попробуем увидеть, какие правила применяются в системе на данный момент. Для этого введите в консоль команду route (также рекомендуем добавить опцию -n, которая позволит увидеть адреса в числовом формате вместо символьного):
1sedicomm-university@ubuntu:~$ route -n2Kernel IP routing table3Destination Gateway Genmask Flags Metric Ref Use Iface40.0.0.0 192.168.96.2 0.0.0.0 UG 100 0 0 ens335169.254.0.0 0.0.0.0 255.255.0.0 U 1000 0 0 ens336192.168.96.0 0.0.0.0 255.255.255.0 U 100 0 0 ens33

Как и в предыдущем примере, инструмент route отсутствует в самых свежих версиях Linux. Однако вместо него ту же информацию вам предоставит команда ip route show:
1sedicomm-university@ubuntu:~$ ip route show2default via 192.168.96.2 dev ens33 proto dhcp metric 1003169.254.0.0/16 dev ens33 scope link metric 10004192.168.96.0/24 dev ens33 proto kernel scope link src 192.168.96.131 metric 100

Выводы
Большинство проблем с сетевыми соединениями можно довольно просто отследить и исправить. Конечно же, если знать и уметь использовать хотя бы часть из топ-10 лучших инструментов для устранения неполадок сети в Linux. Потому рекомендуем Вам хотя бы немного попрактиковаться в их применении, чтобы встретить реальные задачи во всеоружии.
Posted:
September 24, 2019
When I worked in a network-focused role, one of the biggest challenges was always bridging the gap between network and systems engineering. Sysadmins, lacking visibility into the network, would often blame the network for outages or strange issues. Network admins, unable to control the servers and fatigued by the «guilty until proven innocent» attitude toward the network, would often blame the network endpoints.
Of course, blame doesn’t solve problems. Taking time to understand the basics of someone’s domain can go a long way toward improving relationships with other teams and shepherding faster resolutions to problems. This fact is especially true for sysadmins. By having a basic understanding of network troubleshooting, we can bring stronger evidence to our networking colleagues when we suspect that the network may be at fault. Similarly, we can often save time by performing some initial troubleshooting on our own.
In this article, we’ll cover the basics of network troubleshooting via the Linux command line.
A quick review of the TCP/IP model
First, let’s take a moment to review the fundamentals of the TCP/IP network model. While most people use the Open Systems Interconnection (OSI) model to discuss network theory, the TCP/IP model more accurately represents the suite of protocols that are deployed in modern networks.
The layers in the TCP/IP network model, in order, include:
- Layer 5: Application
- Layer 4: Transport
- Layer 3: Network/Internet
- Layer 2: Data Link
- Layer 1: Physical
I’ll assume that you are familiar with this model, and will proceed by discussing ways to troubleshoot issues at stack Layers 1 through 4. Where to start troubleshooting is situation-dependent. For example, if you can SSH to a server, but the server can’t connect to a MySQL database, the problem is unlikely to be the physical or data link layers on the local server. In general, it’s a good idea to work your way down the stack. Start with the application, and then gradually troubleshoot each lower layer until you’ve isolated the problem.
With that background out of the way, let’s jump to the command line and start troubleshooting.
Layer 1: The physical layer
We often take the physical layer for granted («did you make sure the cable is plugged in?»), but we can easily troubleshoot physical layer problems from the Linux command line. That is if you have console connectivity to the host, which might not be the case for some remote systems.
Let’s start with the most basic question: Is our physical interface up? The ip link show command tells us:
# ip link show
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 65536 qdisc noqueue state UNKNOWN mode DEFAULT group default qlen 1000
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
2: eth0: <BROADCAST,MULTICAST> mtu 1500 qdisc pfifo_fast state DOWN mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
Notice the indication of DOWN in the above output for the eth0 interface. This result means that Layer 1 isn’t coming up. We might try troubleshooting by checking the cabling or the remote end of the connection (e.g., the switch) for problems.
Before you start checking cables, though, it’s a good idea to make sure that the interface isn’t just disabled. Issuing a command to bring the interface up can rule this problem out:
# ip link set eth0 up
The output of ip link show can be difficult to parse at a quick glance. Luckily, the -br switch prints this output in a much more readable table format:
# ip -br link show
lo UNKNOWN 00:00:00:00:00:00 <LOOPBACK,UP,LOWER_UP>
eth0 UP 52:54:00:82:d6:6e <BROADCAST,MULTICAST,UP,LOWER_UP>
It looks like ip link set eth0 up did the trick, and eth0 is back in business.
These commands are great for troubleshooting obvious physical issues, but what about more insidious issues? Interfaces can negotiate at the incorrect speed, or collisions and physical layer problems can cause packet loss or corruption that results in costly retransmissions. How do we start troubleshooting those issues?
We can use the -s flag with the ip command to print additional statistics about an interface. The output below shows a mostly clean interface, with only a few dropped receive packets and no other signs of physical layer issues:
# ip -s link show eth0
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP mode DEFAULT group default qlen 1000
link/ether 52:54:00:82:d6:6e brd ff:ff:ff:ff:ff:ff
RX: bytes packets errors dropped overrun mcast
34107919 5808 0 6 0 0
TX: bytes packets errors dropped carrier collsns
434573 4487 0 0 0 0
For more advanced Layer 1 troubleshooting, the ethtool utility is an excellent option. A particularly good use case for this command is checking to see if an interface has negotiated the correct speed. An interface that has negotiated the wrong speed (e.g. a 10Gbps interface that only reports 1Gbps speeds) can be an indicator of a hardware/cabling issue, or a negotiation misconfiguration on one side of the link (e.g., a misconfigured switch port).
Our results might look like this:
# ethtool eth0
Settings for eth0:
Supported ports: [ TP ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Supported pause frame use: Symmetric
Supports auto-negotiation: Yes
Supported FEC modes: Not reported
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
1000baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Advertised FEC modes: Not reported
Speed: 1000Mb/s
Duplex: Full
Port: Twisted Pair
PHYAD: 1
Transceiver: internal
Auto-negotiation: on
MDI-X: on (auto)
Supports Wake-on: d
Wake-on: d
Current message level: 0x00000007 (7)
drv probe link
Link detected: yes
Note that the output above shows a link that has correctly negotiated to a speed of 1000Mbps and full-duplex.
Layer 2: The data link layer
The data link layer is responsible for local network connectivity; essentially, the communication of frames between hosts on the same Layer 2 domain (commonly called a local area network). The most relevant Layer 2 protocol for most sysadmins is the Address Resolution Protocol (ARP), which maps Layer 3 IP addresses to Layer 2 Ethernet MAC addresses. When a host tries to contact another host on its local network (such as the default gateway), it likely has the other host’s IP address, but it doesn’t know the other host’s MAC address. ARP solves this issue and figures out the MAC address for us.
A common problem you might encounter is an ARP entry that won’t populate, particularly for your host’s default gateway. If your localhost can’t successfully resolve its gateway’s Layer 2 MAC address, then it won’t be able to send any traffic to remote networks. This problem might be caused by having the wrong IP address configured for the gateway, or it may be another issue, such as a misconfigured switch port.
We can check the entries in our ARP table with the ip neighbor command:
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
Note that the gateway’s MAC address is populated (we’ll talk more about how to find your gateway in the next section). If there was a problem with ARP, then we would see a resolution failure:
# ip neighbor show
192.168.122.1 dev eth0 FAILED
Another common use of the ip neighbor command involves manipulating the ARP table. Imagine that your networking team just replaced the upstream router (which is your server’s default gateway). The MAC address may have changed as well since MAC addresses are hardware addresses that are assigned at the factory.
Note: While unique MAC addresses are assigned to devices at the factory, it is possible to change or spoof these. Many modern networks often also use protocols such as the Virtual Router Redundancy Protocol (VRRP), which use a generated MAC address.
Linux caches the ARP entry for a period of time, so you may not be able to send traffic to your default gateway until the ARP entry for your gateway times out. For highly important systems, this result is undesirable. Luckily, you can manually delete an ARP entry, which will force a new ARP discovery process:
# ip neighbor show
192.168.122.170 dev eth0 lladdr 52:54:00:04:2c:5d REACHABLE
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
# ip neighbor delete 192.168.122.170 dev eth0
# ip neighbor show
192.168.122.1 dev eth0 lladdr 52:54:00:11:23:84 REACHABLE
In the above example, we see a populated ARP entry for 192.168.122.70 on eth0. We then delete the ARP entry and can see that it has been removed from the table.
Layer 3: The network/internet layer
Layer 3 involves working with IP addresses, which should be familiar to any sysadmin. IP addressing provides hosts with a way to reach other hosts that are outside of their local network (though we often use them on local networks as well). One of the first steps to troubleshooting is checking a machine’s local IP address, which can be done with the ip address command, again making use of the -br flag to simplify the output:
# ip -br address show
lo UNKNOWN 127.0.0.1/8 ::1/128
eth0 UP 192.168.122.135/24 fe80::184e:a34d:1d37:441a/64 fe80::c52f:d96e:a4a2:743/64
We can see that our eth0 interface has an IPv4 address of 192.168.122.135. If we didn’t have an IP address, then we’d want to troubleshoot that issue. The lack of an IP address can be caused by a local misconfiguration, such as an incorrect network interface config file, or it can be caused by problems with DHCP.
The most common frontline tool that most sysadmins use to troubleshoot Layer 3 is the ping utility. Ping sends an ICMP Echo Request packet to a remote host, and it expects an ICMP Echo Reply in return. If you’re having connectivity issues to a remote host, ping is a common utility to begin your troubleshooting. Executing a simple ping from the command line sends ICMP echoes to the remote host indefinitely; you’ll need to CTRL+C to end the ping or pass the -c <num pings> flag, like so:
# ping www.google.com
PING www.google.com (172.217.165.4) 56(84) bytes of data.
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=1 ttl=54 time=12.5 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=2 ttl=54 time=12.6 ms
64 bytes from yyz12s06-in-f4.1e100.net (172.217.165.4): icmp_seq=3 ttl=54 time=12.5 ms
^C
--- www.google.com ping statistics ---
3 packets transmitted, 3 received, 0% packet loss, time 2002ms
rtt min/avg/max/mdev = 12.527/12.567/12.615/0.036 ms
Notice that each ping includes the amount of time it took to receive a response. While ping can be an easy way to tell if a host is alive and responding, it is by no means definitive. Many network operators block ICMP packets as a security precaution, although many others disagree with this practice. Another common gotcha is relying on the time field as an accurate indicator of network latency. ICMP packets can be rate limited by intermediate network gear, and they shouldn’t be relied upon to provide true representations of application latency.
The next tool in the Layer 3 troubleshooting tool belt is the traceroute command. Traceroute takes advantage of the Time to Live (TTL) field in IP packets to determine the path that traffic takes to its destination. Traceroute will send out one packet at a time, beginning with a TTL of one. Since the packet expires in transit, the upstream router sends back an ICMP Time-to-Live Exceeded packet. Traceroute then increments the TTL to determine the next hop. The resulting output is a list of intermediate routers that a packet traversed on its way to the destination:
# traceroute www.google.com
traceroute to www.google.com (172.217.10.36), 30 hops max, 60 byte packets
1 acritelli-laptop (192.168.122.1) 0.103 ms 0.057 ms 0.027 ms
2 192.168.1.1 (192.168.1.1) 5.302 ms 8.024 ms 8.021 ms
3 142.254.218.133 (142.254.218.133) 20.754 ms 25.862 ms 25.826 ms
4 agg58.rochnyei01h.northeast.rr.com (24.58.233.117) 35.770 ms 35.772 ms 35.754 ms
5 agg62.hnrtnyaf02r.northeast.rr.com (24.58.52.46) 25.983 ms 32.833 ms 32.864 ms
6 be28.albynyyf01r.northeast.rr.com (24.58.32.70) 43.963 ms 43.067 ms 43.084 ms
7 bu-ether16.nycmny837aw-bcr00.tbone.rr.com (66.109.6.74) 47.566 ms 32.169 ms 32.995 ms
8 0.ae1.pr0.nyc20.tbone.rr.com (66.109.6.163) 27.277 ms * 0.ae4.pr0.nyc20.tbone.rr.com (66.109.1.35) 32.270 ms
9 ix-ae-6-0.tcore1.n75-new-york.as6453.net (66.110.96.53) 32.224 ms ix-ae-10-0.tcore1.n75-new-york.as6453.net (66.110.96.13) 36.775 ms 36.701 ms
10 72.14.195.232 (72.14.195.232) 32.041 ms 31.935 ms 31.843 ms
11 * * *
12 216.239.62.20 (216.239.62.20) 70.011 ms 172.253.69.220 (172.253.69.220) 83.370 ms lga34s13-in-f4.1e100.net (172.217.10.36) 38.067 ms
Traceroute seems like a great tool, but it’s important to understand its limitations. As with ICMP, intermediate routers may filter the packets that traceroute relies on, such as the ICMP Time-to-Live Exceeded message. But more importantly, the path that traffic takes to and from a destination is not necessarily symmetric, and it’s not always the same. Traceroute can mislead you into thinking that your traffic takes a nice, linear path to and from its destination. However, this situation is rarely the case. Traffic may follow a different return path, and paths can change dynamically for many reasons. While traceroute may provide accurate path representations in small corporate networks, it often isn’t accurate when trying to trace across large networks or the internet.
Another common issue that you’ll likely run into is a lack of an upstream gateway for a particular route or a lack of a default route. When an IP packet is sent to a different network, it must be sent to a gateway for further processing. The gateway should know how to route the packet to its final destination. The list of gateways for different routes is stored in a routing table, which can be inspected and manipulated using ip route commands.
We can print the routing table using the ip route show command:
# ip route show
default via 192.168.122.1 dev eth0 proto dhcp metric 100
192.168.122.0/24 dev eth0 proto kernel scope link src 192.168.122.135 metric 100
Simple topologies often just have a default gateway configured, represented by the «default» entry at the top of the table. A missing or incorrect default gateway is a common issue.
If our topology is more complex and we require different routes for different networks, we can check the route for a specific prefix:
# ip route show 10.0.0.0/8
10.0.0.0/8 via 192.168.122.200 dev eth0
In the example above, we are sending all traffic destined to the 10.0.0.0/8 network to a different gateway (192.168.122.200).
While not a Layer 3 protocol, it’s worth mentioning DNS while we’re talking about IP addressing. Among other things, the Domain Name System (DNS) translates IP addresses into human-readable names, such as www.redhat.com. DNS problems are extremely common, and they are sometimes opaque to troubleshoot. Plenty of books and online guides have been written on DNS, but we’ll focus on the basics here.
A telltale sign of DNS trouble is the ability to connect to a remote host by IP address but not its hostname. Performing a quick nslookup on the hostname can tell us quite a bit (nslookup is part of the bind-utils package on Red Hat Enterprise Linux-based systems):
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.3.100
The output above shows the server that the lookup was performed against 192.168.122.1 and the resulting IP address was 172.217.3.100.
If you perform an nslookup for a host but ping or traceroute try to use a different IP address, you’re probably looking at a host file entry problem. As a result, inspect the host file for problems:
# nslookup www.google.com
Server: 192.168.122.1
Address: 192.168.122.1#53
Non-authoritative answer:
Name: www.google.com
Address: 172.217.12.132
# ping -c 1 www.google.com
PING www.google.com (1.2.3.4) 56(84) bytes of data.
^C
--- www.google.com ping statistics ---
1 packets transmitted, 0 received, 100% packet loss, time 0ms
# cat /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
1.2.3.4 www.google.com
Notice that in the example above, the address for www.google.com resolved to 172.217.12.132. However, when we tried to ping the host, traffic was being sent to 1.2.3.4. Taking a look at the /etc/hosts file, we can see an override that someone must have carelessly added. Host file override issues are extremely common, especially if you work with application developers who often need to make these overrides to test their code during development.
Layer 4: The transport layer
The transport layer consists of the TCP and UDP protocols, with TCP being a connection-oriented protocol and UDP being connectionless. Applications listen on sockets, which consist of an IP address and a port. Traffic destined to an IP address on a specific port will be directed to the listening application by the kernel. A full discussion of these protocols is beyond the scope of this article, so we’ll focus on how to troubleshoot connectivity issues at these layers.
The first thing that you may want to do is see what ports are listening on the localhost. The result can be useful if you can’t connect to a particular service on the machine, such as a web or SSH server. Another common issue occurs when a daemon or service won’t start because of something else listening on a port. The ss command is invaluable for performing these types of actions:
# ss -tunlp4
Netid State Recv-Q Send-Q Local Address:Port Peer Address:Port
udp UNCONN 0 0 *:68 *:* users:(("dhclient",pid=3167,fd=6))
udp UNCONN 0 0 127.0.0.1:323 *:* users:(("chronyd",pid=2821,fd=1))
tcp LISTEN 0 128 *:22 *:* users:(("sshd",pid=3366,fd=3))
tcp LISTEN 0 100 127.0.0.1:25 *:* users:(("master",pid=3600,fd=13))
Let’s break down these flags:
- -t — Show TCP ports.
- -u — Show UDP ports.
- -n — Do not try to resolve hostnames.
- -l — Show only listening ports.
- -p — Show the processes that are using a particular socket.
- -4 — Show only IPv4 sockets.
Taking a look at the output, we can see several listening services. The sshd application is listening on port 22 on all IP addresses, denoted by the *:22 output.
The ss command is a powerful tool, and a review of its brief man page can help you locate flags and options to find whatever you’re looking for.
Another common troubleshooting scenario involves remote connectivity. Imagine that your local machine can’t connect to a remote port, such as MySQL on port 3306. An unlikely, but commonly installed tool can be your friend when troubleshooting these types of issues: telnet. The telnet command attempts to establish a TCP connection with whatever host and port you give it. This feature is perfect for testing remote TCP connectivity:
# telnet database.example.com 3306
Trying 192.168.1.10...
^C
In the output above, telnet hangs until we kill it. This result tells us that we can’t get to port 3306 on the remote machine. Maybe the application isn’t listening, and we need to employ the previous troubleshooting steps using ss on the remote host—if we have access. Another possibility is a host or intermediate firewall that is filtering the traffic. We may need to work with the network team to verify Layer 4 connectivity across the path.
Telnet works fine for TCP, but what about UDP? The netcat tool provides a simple way to check a remote UDP port:
# nc 192.168.122.1 -u 80
test
Ncat: Connection refused.
The netcat utility can be used for many other things, including testing TCP connectivity. Note that netcat may not be installed on your system, and it’s often considered a security risk to leave lying around. You may want to consider uninstalling it when you’re done troubleshooting.
The examples above discussed common, simple utilities. However, a much more powerful tool is nmap. Entire books have been devoted to nmap functionality, so we won’t cover it in this beginner’s article, but you should know some of the things that it’s capable of doing:
- TCP and UDP port scanning remote machines.
- OS fingerprinting.
- Determining if remote ports are closed or simply filtered.
Wrapping up
We covered a lot of introductory network ground in this article, working our way up the network stack from cables and switches to IP addresses and ports. The tools discussed here should give you a good starting point toward troubleshooting basic network connectivity issues, and they should prove helpful when trying to provide as much detail as possible to your network team.
As you progress in your network troubleshooting journey, you’ll undoubtedly come across previously unknown command flags, fancy one-liners, and powerful new tools (tcpdump and Wireshark are my favorites) to dig into the causes of your network issues. Have fun, and remember: The packets don’t lie!
From time to time, Linux and Unix users are faced with various network problems. Many of these problems are presented here and at some other troubleshooting forums, but they are very concrete and contain a lot of additional technical information, and sometimes it’s rather difficult to understand the main point and the real reason of buggy system behavior.
By asking this question, my intention is to start a community wiki page which allows generalizing our network troubleshooting and debugging experience. I hope the Linux and Unix users will be able to easier recognize and solve («divide and conquer») their network problems using this page.
The parent of this page should be Best practise to diagnose problems. But here we should focus on troubleshooting the network problems from user- and kernel-space.
I suppose, if you:
- share the information about using some great network diagnostic tool with concrete usage examples and examples of network bugs which they help to catch,
- share the link to the great network tutorial connected with this subject,
- tell us about a general method or recipe which allows to tackle some class of network problems, or
- share information about your tool set for network debugging and troubleshooting
then it perfectly fits this topic.
I’ll begin by sharing the link to various diagnostic tools and a 12 year old simple tutorial. Also this Arch Linux tutorial seems to have actual information about our subject. And for diving into Linux networking, we definitely need to visit the Linux Networking-HOWTO.
![]()
asked Oct 6, 2012 at 13:55
![]()
2
I think, general principles of network troubleshooting are:
- Find out at what level of the TCP/IP stack (or some other stack) the problem occurs.
- Understand what the correct system behavior is and what the deviation from the normal system state is.
- Try to express the problem in one sentence or in several words.
- Using obtained information from the buggy system, your own experience, and experience of other people (Google, various forums, etc.), try to solve the problem until success (or failure).
- If you fail, ask other people about help or some advice.
As for me, I usually obtain all required information using all needed tools, and try to match this information to my experience. Deciding what level of the network stack contains the bug helps to cut off unlikely variants. Using experience of other people helps to solve the problems quickly, but often it leads to a situation, where I can solve some problem without its understanding and if this problem occurs again, it’s impossible for me to tackle it again without the Internet.
And in general, I don’t know how I solve network problems. It seems that there is some magic function in my brain named SolveNetworkProblem(information_about_system_state, my_experience, people_experience), which could sometimes return exactly the right answer, and also could sometimes fail (like here TCP dies on a Linux laptop).
I usually use utils from this set for network debugging:
ifconfig(orip link,ip addr) — for obtaining information about network interfacesping— for validating if the target host is accessible from my machine.pingcould also be used for basic DNS diagnostics — we could ping a host by its IP address or by its hostname and then decide if DNS works at all. And thentracerouteortracepathormtrto look what’s going on on the way there.dig— diagnose everything DNSdmesg | lessordmesg | tailordmesg | grep -i error— for understanding what the Linux kernel thinks about some trouble.netstat -antp+| grep smth— my most popular usage of the netstat command, which shows information about TCP connections. Often I perform some filtering using grep. See also the newsscommand (fromiproute2the new standard suite of Linux networking tools) andlsofas inlsof -ai tcp -c some-cmd.telnet <host> <port>— is very useful for communicating with various TCP services (e.g. on SMTP, HTTP protocols), also we could check general opportunity to connect to some TCP port.iptables-save(on Linux) — to dump the full iptables tablesethtool— get all the network interface card parameters (status of the link, speed, offload parameters…)socat— the Swiss army tool to test all network protocols (UDP, multicast, SCTP…). Especially useful (more so than telnet) with a few-doptions.iperf— to test bandwidth availabilityopenssl(s_client,ocsp,x509…) to debug all SSL/TLS/PKI issues.wireshark— the powerful tool for capturing and analyzing network traffic, which allows you to analyze and catch many network bugs.iftop— show big users on the network/router.iptstate(on Linux) — current view of the firewall’s connection tracking.arp(or the newip neighin Linux) — show the ARP table status.routeor the newer (on Linux)ip route— show the routing table status.strace(ortruss,dtraceortuscdepending on the system) — is a useful tool that shows which system calls the problematic process performs. It also shows error codes (errno) when system calls fail. This information often says enough for understanding the system behavior and solving a problem. Alternatively, using breakpoints on some networking functions ingdbcan let you find out when they are made and with which arguments.- to investigate firewall issues on Linux:
iptables -nvLshows how many packets are matched by each rule (iptables -Zto zero the counters). TheLOGtarget inserted in the firewall chains is useful to see which packets reach them and how they have already been transformed when they get there. To get further,NFLOG(associated withulogd) will log the full packet.
![]()
answered Oct 6, 2012 at 13:55
![]()
dr.dr.
2,3013 gold badges16 silver badges9 bronze badges
4
A surprising number of «network problems» boil down to DNS problems of one kind or another. Initial troubleshooting should use ping -n w.x.y.z in order to leave out DNS resolution of a hostname, and just check IP connectivity. After that, use route -n to check the default IP route without DNS resolution.
After verifying IP connectivity and routing, nslookup, host, and dig can yield information. Remember that «locking up» can indicate that DNS timeouts are occurring.
Don’t forget to check the existence and the contents of /etc/resolv.conf. DHCP clients change that file with every lease, and sometimes they get it wrong, or if disk space is tight, an update might not happen.
![]()
answered Oct 6, 2012 at 16:25
Cabling problems can exist. If you have access to the hardware, ensure that the cables are all plugged in and mechanically engaged. If you can see routers or ethernet interfaces, ensure that the link lights are on.
Remotely, you have to depend on ethtool and mii-tool.
[root@flask ~]# ethtool eth0
Settings for eth0:
Supported ports: [ TP MII ]
Supported link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Supported pause frame use: No
Supports auto-negotiation: Yes
Advertised link modes: 10baseT/Half 10baseT/Full
100baseT/Half 100baseT/Full
Advertised pause frame use: Symmetric
Advertised auto-negotiation: Yes
Speed: 10Mb/s
Duplex: Half
Port: MII
PHYAD: 24
Transceiver: internal
Auto-negotiation: on
Supports Wake-on: g
Wake-on: d
Current message level: 0x00000001 (1)
drv
Link detected: yes
«Link detected: yes» is good, but 10Mb/s and Half duplex are not good, as the NIC on that computer can do better. I need to figure out if the NIC is goofed up or the cable is. Another computer plugged into the same router says 100Mb/s, Full duplex.
answered Oct 6, 2012 at 23:46
Одна из важнейших подсистем, отвечающая за связь любого сервера с внешним миром — сетевая. Через сетевые интерфейсы поступают запросы от удаленных систем и через эти же интерфейсы направляются ответы, что позволяет налаживать коммуникацию и предоставлять/получать сервисы. В связи с этим особенно важно уметь производить диагностику и мониторинг сети хотя бы на базовом уровне, чтобы выявлять проблемы и вносить корректировки в конфигурацию в случае необходимости.
Для операционных систем семейства Linux написано множество утилит, помогающих в диагностике и мониторинге. Познакомимся с наиболее часто используемыми из них.
Диагностика сетевой связности (ping, arp, traceroute)
В данной статье мы будем опираться на использование протокола IP версии 4. Согласно стандартам, определяющим работу этого протокола, каждое устройство, подключенное к сети, должно иметь как минимум IP-адрес и маску подсети — параметры, которые позволяют уникально идентифицировать устройство в пределах определенной сети. В такой конфигурации устройство может обмениваться сетевыми пакетами с другими устройствами в пределах той же самой логической сети. Если к этому набору параметров добавить адрес шлюза по умолчанию — наш сервер сможет связываться с хостами, находящимися за пределами локального адресного пространства.
В случае каких-либо сетевых проблем в первую очередь проверяем, не сбились ли настройки сетевого интерфейса. Например, команды ip addr или ifconfig выведут IP-адрес и маску сети:

В выводе команды виден перечень сетевых интерфейсов, распознанных операционной системой. Интерфейс lo — это псевдоинтерфейс (loopback). Он не используется в реальных взаимодействиях с удаленными хостами, а вот интерфейс с именем ens192 — то, что нам нужно (именование сетевых интерфейсов различается в разных ветках и версиях ОС Linux). IP-адрес и маска сети, назначенные этому интерфейсу, указаны в поле inet — /24 после адреса обозначают 24-битную маску 255.255.255.0.
Теперь проверим, указан ли шлюз по умолчанию. Команды ip route или route покажут имеющиеся маршруты:

В таблице маршрутизации мы видим, что имеется маршрут по умолчанию (обозначается либо ключевым словом default, либо адресом 0.0.0.0). Все пакеты, предназначенные для внешних сетей, должны направляться на указанный в маршруте адрес через обозначенный сетевой интерфейс.
Если в настройках интерфейса есть ошибки, их необходимо исправить — помогут в этом другие статьи, для ОС Ubuntu 18.04 или CentOS. Если же все верно — приступаем к диагностике с помощью утилиты ping. Данная команда отправляет специальные сетевые пакеты на удаленный IP-адрес (ICMP Request) и ожидает ответные пакеты (ICMP Reply). Таким образом можно проверить сетевую связность — маршрутизируются ли сетевые пакеты между IP-адресами отправителя и получателя.
Синтаксис команды ping IP/имя опции:

В данном случае видим, что на оба сетевых пакета, отправленных на адрес нашего шлюза по умолчанию, получены ответы, потерь нет. Это значит, что на уровне локальной сети со связностью все в порядке. Помимо количества полученных/потерянных сетевых пакетов мы можем увидеть время, которое было затрачено на прохождение запроса и ответа – параметр RTT (Round Trip Time). Этот параметр может быть очень важен при диагностике проблем, связанных с нестабильностью связи и скоростью соединения.
Часто используемые параметры:
- ping –c количество — указать количество пакетов, которое будет отправлено адресату (по умолчанию пакеты отправляются до тех пор, пока пользователь не прервет выполнение команды. Этот режим можно использовать, чтобы проверить стабильность сетевого соединения. Если параметр RTT будет сильно изменяться в ходе проверки, значит где-то на протяжении маршрута есть проблема);
- ping –s количество — указать размер пакета в байтах. По умолчанию проверка производится малыми пакетами. Чтобы проверить работу сетевых устройств с пакетами большего размера, можно использовать этот параметр;
- ping –I интерфейс — указать сетевой интерфейс, с которого будет отправлен запрос (актуально при наличии нескольких сетевых интерфейсов и необходимости проверить прохождение пакетов по конкретному сетевому маршруту).
В случае, если при использовании команды ping пакеты от шлюза (или другого хоста, находящегося в одной локальной сети с сервером-отправителем) в ответ не приходят, стоит проверить сетевую связность на уровне Ethernet. Здесь для коммуникации между устройствами используются так называемые MAC-адреса сетевых интерфейсов. За разрешение Ethernet-адресов отвечает протокол ARP (Address Resolution Protocol) и с помощью одноименной утилиты мы можем проверить корректность работы на этом уровне. Запустим команду arp –n и проверим результат:

Команда выведет список IP-адресов (так как был использован аргумент –n), и соответствующие им MAC-адреса хостов, находящиеся в одной сети с нашим сервером. Если в этом списке есть IP, который мы пытаемся пинговать, и соответствующий ему MAC, значит сеть работает и, возможно, ICMP-пакеты, которые использует команда ping, просто блокируются файрволом (либо со стороны отправителя, либо со стороны получателя). Подробнее об управлении правилами файрвола рассказано здесь и здесь.
Часто используемые параметры:
- arp –n — вывод содержимого локального arp-кэша в числовом формате. Без этой опции будет предпринята попытка определить символические имена хостов;
- arp –d адрес — удаление указанного адреса из кэша. Это может быть полезно для проверки корректности разрешения адреса. Чтобы убедиться, что в настоящий момент времени адрес разрешается корректно, можно удалить его из кэша и снова запустить ping. Если все работает правильно, адрес снова появится в кэше.
Если все предыдущие шаги завершены корректно, проверяем работу маршрутизатора — запускаем ping до сервера за пределами нашей сети, например, 8.8.8.8 (DNS-сервис от Google). Если все работает корректно, получаем результат:

В случае проблем на этом шаге, нам может помочь утилита traceroute, которая используя ту же логику запросов и ответов помогает увидеть маршрут, по которому движутся сетевые пакеты. Запускаем traceroute 8.8.8.8 –n и изучаем вывод программы:

Первым маршрутизатором на пути пакета должен быть наш локальный шлюз по умолчанию. Если дальше него пакет не уходит, возможно проблема в конфигурации маршрутизатора и нужно разбираться с ним. Если пакеты теряются на дальнейших шагах, возможно, есть проблема в промежуточной сети. А, возможно, промежуточные маршрутизаторы не отсылают ответные пакеты. В этом случае можно переключиться на использование другого протокола в traceroute.
Часто используемые опции:
- traceroute –n — вывод результата в числовом формате вместо символических имен промежуточных узлов;
- traceroute –I — использование ICMP-протокола при отслеживании маршрута. По умолчанию используются UDP-датаграммы;
- traceroute –s адрес— указать адрес источника для исходящего сетевого пакета;
- traceroute –i интерфейс— указать сетевой интерфейс, с которого будут отправляться пакеты.
Диагностика разрешения имен (nslookup, dig)
Разобравшись с сетевой связностью и маршрутизацией приходим к следующему этапу — разрешение доменных имен. В большинстве случаев в работе с удаленными сервисами мы не используем IP-адреса, а указываем доменные имена удаленных ресурсов. За перевод символических имен в IP-адреса отвечает служба DNS — это сеть серверов, которые содержат актуальную информацию о соответствии имен и IP в пределах доверенных им доменных зон.
Самый простой способ проверить работает ли разрешение имен — запустить утилиту ping с указанием доменного имени вместо IP-адреса (например, ping ya.ru). Если ответные пакеты от удаленного сервера приходят, значит все работает как надо. В противном случае нужно проверить прописан ли DNS-сервер в сетевых настройках и удается ли получить от него ответ.
Способы выяснения какой DNS-сервер использует наш сервер различаются в зависимости от используемой версии и дистрибутива ОС Linux. Например, если ОС используется Network Manager для управления сетевыми интерфейсами (CentOS, RedHat и др.), может помочь вывод команды nmcli:

В настройках сетевого интерфейса, в разделе DNS configuration, мы увидим IP-адрес сервера. В Ubuntu 18.04 и выше, использующих Netplan, используем команду systemd-resolve —status:

Используемый сервер также будет указан в настройках интерфейса, в разделе DNS Servers. В более старых версиях Ubuntu потребуется проверить содержимое файлов /etc/resolve.conf и /etc/network/interfaces. Если сервер не указан, воспользуйтесь статьей для ОС Ubuntu 18.04 или CentOS, чтобы скорректировать настройки.
Проверить работу сервиса разрешения имен нам помогут утилиты nslookup или dig. Функционально они почти идентичны: G-вывод утилиты dig содержит больше диагностической информации и гибко регулируется, но это далеко не всегда нужно. Поэтому используйте ту утилиту, которая удобна в конкретной ситуации. Если эти команды недоступны, потребуется доставить пакеты на CentOS/RedHat:
yum install bind-utils
для Debian/Ubuntu:
sudo apt install dnsutils
После успешной установки сделаем тестовые запросы:
dig ya.ru

В разделе Answer Section видим ответ от DNS сервера — IP-адрес для A-записи с доменным именем ya.ru. Разрешение имени работает корректно:
nslookup ya.ru

Аналогичный запрос утилитой nslookup выдает более компактный вывод, но вся нужная сейчас информация в нем присутствует.
Что же делать, если в ответе отсутствует IP-адрес? Возможно, DNS-сервер недоступен. Для проверки можно отправить тестовый запрос на другой DNS-сервер. Обе утилиты позволяют эти сделать. Направим тестовый запрос на DNS-сервер Google:
dig @8.8.8.8 ya.ru

nslookup ya.ru 8.8.8.8

Если имена разрешаются публичным DNS-сервером корректно, а установленным по умолчанию в ОС нет, вероятно, есть проблема в работе этого DNS-сервера. Временным решением данной проблемы может быть использование публичного DNS-сервера в качестве сервера для разрешения имен в операционной системе. В том случае, если разрешение имен не работает ни через локальный, ни через публичный DNS сервер — стоит проверить не блокируют ли правила файрвола отправку на удаленный порт 53 TCP/UDP пакетов (именно на этом порту DNS-серверы принимают запросы).
Часто используемые параметры:
- nslookup имя сервер — разрешить доменное имя, используя альтернативый сервер;
- nslookup –type=тип имя — получить запись указанного типа для доменного имени (например, nslookup -type=mx ya.ru – получить MX-записи для домена ya.ru);
- dig @сервер имя — разрешить доменное имя, используя альтернативый сервер;
- dig имя тип — получить запись указанного типа для доменного имени (например, dig ya.ru mx — получить MX-записи для домена ya.ru).
Как обычно, полный набор опций и параметров для указанных утилит можно найти во встроенной справке операционной системы, используя команду man.
191028
Санкт-Петербург
Литейный пр., д. 26, Лит. А
+7 (812) 403-06-99
![]()
700
300
ООО «ИТГЛОБАЛКОМ ЛАБС»
191028
Санкт-Петербург
Литейный пр., д. 26, Лит. А
+7 (812) 403-06-99
![]()
700
300
ООО «ИТГЛОБАЛКОМ ЛАБС»